alibaba / alicemind Goto Github PK
View Code? Open in Web Editor NEWALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
License: Apache License 2.0
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
License: Apache License 2.0
























































































































































This is an advance subject of ASoC 2022 and #44 .
Supplementing the implementation of common downstream tasks such as regression/multi-label classification/sequence labeling/machine reading comprehension of StructBERT.
Design and implement regression/multi-label classification/sequence labeling/machine reading comprehension code of StructBERT.
Normal
Wei Wang (@wangwei7175878 )([email protected])
这是一个阿里巴巴编程之夏 2022 的基础课题 #44
补充StructBERT在回归/多标签分类/序列标注/机器阅读理解等常见下游任务的代码实现。
补充StructBERT在回归/多标签分类/序列标注/机器阅读理解等常见下游任务的代码实现。
正常
Wei Wang(@wangwei7175878 )([email protected])
StructuralLM, 如何定义cell box
对于ocr 通过给出的是一整行信息,或者说key:value 靠的很近,请问这算一个cell吗?还是算两个?
layoutlmv2 related work

structralral related work

Hi,
Link for downloading structvbert.en.base model does not work (http://119608.oss-cn-hangzhou-zmf.aliyuncs.com/structvbert/pretrained_model.tar.gz). Could you please fix?
Thank you
I found StructBERT + CLEVER in the GLUE benchmark. Is that a technology about the pertaining or fine-tuning? Can you provide more information about CLEVER? Thanks a lot.

您好,感谢您的工作,有一点小问题,文章中汇报的TNEWS结果为什么跟CLUE原文中汇报的差距这么大,CLUE原文汇报的测试接上的Accuracy大概在56-58之间,而在本文中普遍在67-68之间
Hi, do you have plans for deploying the demo of SDCUP on https://alicemind.aliyuncs.com? Really looking forward to it! Many thanks.
I tried to finetune StructuralLM on DocVQA dataset using the released weights, but I only get 76.85 ANLS on the test set.
Can the finetuning code on DocVQA be open-sourced ?
I want to infer the SDCUP model, and get the sql code to execute, could you tell me how to deal?
Hi, I'm wondering if the code for E2E-VLP would be published?
Could you tell me where is the code implement of cross-attention in the paper VECO?
Hi,
I downloaded the structbert.en.large through the given link (https://alice-open.oss-cn-zhangjiakou.aliyuncs.com/StructBERT/en_model), but the below error occured during running.
RuntimeError: Error(s) in loading state_dict for BertForSequenceClassificationMultiTask:
Missing key(s) in state_dict: "classifier.0.weight", "classifier.0.bias".
Unexpected key(s) in state_dict: "lm_bias", "linear.weight", "linear.bias", "LayerNorm.gamma", "LayerNorm.beta", "classifier.weight", "classifier.bias".
Do you have any idea why this happen? Thank you very much.
跑LatticeBERT里面fine-tuning a AFQMC classification model的样例,参数也没动,标注数据集,迭代几次就loss NaN?
Hi,
I'm trying to transfer the labert model to pytorch, I used the code online :
path="./chinese_labert-base-std-512/"
tf_checkpoint_path = path + "model.ckpt/"#自己BERT模型文件夹下的ckpt文件(共3个一组)
bert_config_file = path + "labert_config.json" #自己BERT模型文件夹下的config
pytorch_dump_path = path + "pytorch_model.bin"
def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, bert_config_file, pytorch_dump_path):
# Initialise PyTorch model
config = BertConfig.from_json_file(bert_config_file)
print(f"Building PyTorch model from configuration: {config}")
model = BertForPreTraining(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print(f"Save PyTorch model to {pytorch_dump_path}")
torch.save(model.state_dict(), pytorch_dump_path)
convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, bert_config_file, pytorch_dump_path)
But I got this:

Does anyone know if there's a way to make it work?Thanks a lot!!
Hello, where can I download the teacher model?
hello~ 我这边使用train_xnli.sh的默认参数进行了训练,最终得到平均acc为78.63%,和论文中的79.9%的结果有些出入,且看上去应该是每种语言的acc都低了一点。请问下可能是什么原因导致的呢?非常感谢。
我这边是用的单核GPU,采用Tesla M40 24GB卡,Driver Version: 440.64,CUDA Version: 10.2
我从和论文中的fine-tune参数对比上看。
一个是sh代码里面使用的epoch=2,论文中是用的3/5/10选的
另一个是这里TOTAL_BATCH_SIZE=64,BATCH_SIZE=2,论文中是16/32/64选的
会不会是这两个超参导致的出入呢?
非常感谢~
Hi,你们在clue上提交的通义模型对应的是PLUG吗?
The link for downloading mplug.en.large.v2 is down.
Could you help to check and update the link?
Thanks!
Thanks a lot for all the details you provide in Appendix B for reproducibility! However, I still encounter some difficulties in reproducing the experiment.
I noticed that you apply grid search. Could you please provide the specific ,
and learning rate for each task?
It's a bit suffering to use your model like StructBert.
There are some minor code modifications compared with huggingface's bert.
So i won't say it's safe to directly use huggingface's from_pretrained api on your released model checkpoint, while it could be inconvenient to use your modeling code where the BertModel are not inherited with huggingface's PreTrainedModel.
Any advice?
StructuralLM源码里my_layer.py的layer_norm为什么用batch_norm来实现?
想使用跨模态模型做文生图的工作,目前的文生图工作尚不能适应下游任务。(比如装置艺术、环境设计等)
我有相关的专业数据集。
Hi, Author
Thanks for your great contribution.
But I can't download the pretrained model and data whose link starts with
http://119608.oss-cn-hangzhou-zmf.aliyuncs.com
For example, the links as follows can not be downloaded:
http://119608.oss-cn-hangzhou-zmf.aliyuncs.com/structvbert/pretrained_model.tar.gz
http://119608.oss-cn-hangzhou-zmf.aliyuncs.com/structvbert/data.tar.gz
Any advice is appreciated! Thanks.
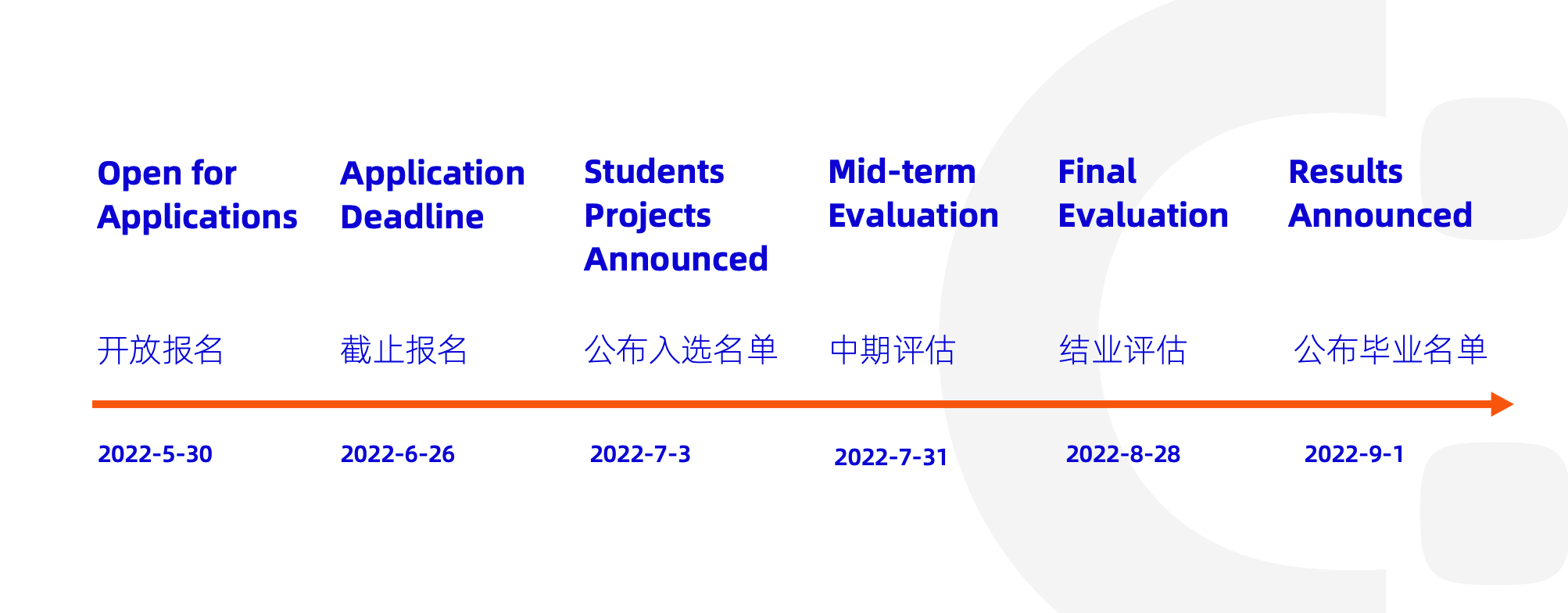
Welcome to the open source world! If you haven't planned how to spend this summer, come to the Alibaba Summer of Code and code with us! 💻
Alibaba Summer of Code is a global program focused on engaging students directly in open source software development. Under the guidance of the mentor in the Alibaba open source project, students can experience software development in the real world. Alibaba Summer of code will begin from May 30th to September 1st. Students can use the summertime to participate in the open source project and work with the core members of the project.
This is a master issue to track the progress and result of Alibaba Summer of Code 2022.
On this exclusive developer journey, students will have the opportunity to:
Wei Wang (@wangwei7175878 ), ASoC Mentor, Core member of AliceMind
Chuanqi Tan (@Chuanqi1992 ), ASoC Mentor, Core member of AliceMind
Chenliang Li (@lcl6679292 ), ASoC Mentor, Core member of AliceMind
Browse open idea list here:
阿里巴巴开源之夏: StructBERT下游任务代码实现:
Difficulty: Normal
#41
阿里巴巴开源之夏:基于PALM实现图片生成模型
Difficulty: Normal
#43
阿里巴巴开源之夏:基于AliceMind模型的稀疏算法实现
Difficulty: Hard
#42
Upload your CV and project proposal via ASOC 2022 official website
If you have any questions, visit the event website: https://opensource.alibaba.com/asoc2022
Email address: [email protected]
This is an advance subject of ASoC 2022 and #44 .
At present, SOFA cannot support the sparse algorithm. It is necessary to refer to the previous work to implement common sparse metrics (e.g. MaP and MvP) and sparse patterns (e.g. unstructured pruning, block-wise pruning).
The implementation of common sparse metrics (e.g. MaP and MvP) and sparse patterns (e.g. unstructured pruning, block-wise pruning).
Hard
Chuanqi Tan (@Chuanqi1992 )([email protected])
这是一个阿里巴巴编程之夏 2022 的基础课题 #44
AliceMind-SOFA框架不支持稀疏算法,需要参考先有工作实现MaP、MvP、L0等稀疏Metric和随机稀疏、block稀疏等稀疏Pattern。
实现MaP、MvP、L0等稀疏Metric和随机稀疏、block稀疏等稀疏Pattern。
高
Chuanqi Tan (@Chuanqi1992 )([email protected])
import igraph
File "/data2/anaconda3/envs/LatticeBERT/lib/python3.6/site-packages/igraph/init.py", line 8, in
raise DeprecationWarning("To avoid name collision with the igraph project, "
DeprecationWarning: To avoid name collision with the igraph project, this visualization library has been renamed to 'jgraph'. Please upgrade when convenient.
requirements.txt need to modify.
For CLUEWSC2020 data, how did you manage the inputs? As was demonstrated in the Lattice-BERT paper, the coreference resolution task was also treated as a classification task in which the representation corresponding to [CLS] was used as the feature vector. I just wonder how you distinguished the different spans in the input.
i'm struggling how to annotate bertindex_knowledge and header_knowledge, can you explain them? thanks
请问在哪能看到这篇论文 Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
Hi, I'm trying to code StructBERT from scratch. But I couldn't find any code examples pre-training about StructBERT.
In the repository I've found codes for fine-tuning based on various datasets.
Are you planning to share pre-training model's code for StructBert such as BertForPretraining in Transformers library ?
Thanks in advance 🙂
may i use a bert-like model to load params of pre-train sdcup, then add some head top for task of table qa?
when i look into pre-train sdcup, can i ignore params like: "mlp_action1.linear.weight", "mlp_action1.linear.bias", "mlp_action2.linear.weight", "mlp_action2.linear.bias", "mlp_column1.linear.weight", "mlp_column1.linear.bias", "mlp_column2.linear.weight", "mlp_column2.linear.bias", "mlp_column1_single.linear.weight", "mlp_column1_single.linear.bias", "mlp_column2_single.linear.weight", "mlp_column2_single.linear.bias", "layer_norm_1.gamma", "layer_norm_1.beta", "layer_norm_2.gamma", "layer_norm_2.beta", "layer_norm_3.gamma", "layer_norm_3.beta". are these useful for fine-tune?
can sdcup models be called by transformers interface? such as TapasForQuestionAnswering, thanks
Hi, I can not reproduce the result reported in the paper by the code example:
python run_classifier_multi_task.py \
--task_name STS-B \
--do_train \
--do_eval \
--do_test \
--lr_decay_factor 1 \
--dropout 0.1 \
--do_lower_case \
--detach_index -1 \
--core_encoder bert \
--data_dir data \
--vocab_file config/vocab.txt \
--bert_config_file config/large_bert_config.json \
--init_checkpoint model/en_model \
--max_seq_length 128 \
--train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--fast_train \
--gradient_accumulation_steps 1 \
--output_dir output \
--amp_type O1
Are there any hyper-params I set wrong?
(https://github.com/alibaba/AliceMind/tree/main/SOFA/sofa/models)/__init__.py /
为什么这里只有三个,roberta没有init呢?
同样README.md里面也没有roberta的相关结果,所以roberta暂时还不能实现是么?
那么如果我需要加入其他模型(如GPT-2)需要如何做呢?
Hi, I notice that there is a Chinese version of mPLUG in modelscope, could you please tell me some details about this model? Such as pretrained dataset, many thanks
This is an advance subject of ASoC 2022 and #44 .
At present, PALM cannot support image generation. The code for image generation needs to be developed based on the PALM model and you can refer to public models such as DALLE, etc.
Design and implement image generation code for training and inference.
Normal
Chenliang Li (@lcl6679292)([email protected])
这是一个阿里巴巴编程之夏 2022 的基础课题 #44
AliceMind-PALM模型不支持图片生成任务。需要参考现有图片生成模型如DALLE,为PALM补充下游图片生成的代码
设计并实现图片生成代码的训练和推理
正常
Chenliang Li (@lcl6679292)([email protected])
I cannot find UED that was mentioned in the PR article.
Could you please give the paper link?
Thanks.
Hi,
I want to reproduce the experiment of Child-Tuning, I saw "We report the averaged results over 10 random seeds" In the paper 3.2, could you display the seed sequence?
Thank you,looking forward to your reply.
https://github.com/alibaba/AliceMind/blob/main/StructuralLM/run_seq_labeling.py#L386
Why append pad_index to input_mask and segment_ids? This will make the input_mask all 1, and segment_ids begins with 0 and ends with 1.
Currently, only the pretrained weights before fine-tuning on downstream tasks for mPLUG are released. Is it possible to release the pretrained weights for downstream tasks after fine-tuning, like visual question answering and image captioning?
Thanks!
In the origin paper, PALM-base has 6 encoder layers and 6 decoder layers. However, when I run the given code with the given base checkpoint, it prints 12 encoder layers and 12 decoder layers. Am I wrong?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.