Comments (8)
 smp
commented on June 4, 2024
1
smp
commented on June 4, 2024
1
@Ajonp - if you add the API to your amplify video resource it will deploy an appsync API that you can use for uploads and content access URLs. This database does not store data for the content processing pipeline and isn't required for Amplify Video VOD to function (though this might change down the line).
We are working on documentation in the wiki now (feel free to add anything you see fit), but if you want to see it in action, the best place to look is within our companion workshop UnicornFlix that uses Amplify Video VOD in context of an application.
We welcome and feedback you have on the implementation so please let us know what you think is missing or
from amplify-video.
smp
commented on June 4, 2024
@wizage - You mentioned 3 users that you talked to can you add any specific feedback you've gotten from users on this? I'm curious about...
-
dynamic encoding profile selection i.e. if a user uploads a SD file, you wouldn't want to encode/upscale it to HD. You would want the encoding optimized based on input info.
-
dynamic workflow configuration i.e. maybe i want to add a custom pre-process or post-process step to the file transcoding process. Custom filters, metadata twiddling, qc tools, image extractors, other stuff that mediaconvert doesn't have natively.
-
API Design What API experience would developers want? We could do something super basic where we return playback urls for encoded content as they become available and/or we could have a subscription feed of content and/or we could provide playback URLs to content that hasn't even been encoded yet and dynamically process the content based on requesting client. Commonly referred to as just-in-time-encoding (JITE), this would be complex, but innovative, and has been implemented by services like mux because it's a great experience for users and it lowers backend costs.
For reference, we have an existing VOD solution that could serve as a good starting point architectually. It doesn't do JITE, but a similar design could allow for more complex workflows: https://aws.amazon.com/solutions/video-on-demand-on-aws/
from amplify-video.
 davekiss
commented on June 4, 2024
davekiss
commented on June 4, 2024
As a fullstack dev with a video production background pursuing OTT/VOD, I'm very interested in this featureset. I've already gone through the VOD workshop (S3->MediaConvert->CloudWatch->Lambda->DynamoDB) and have everything set up and working as expected. Here's some input from my perspective:
dynamic encoding profile selection i.e. if a user uploads a SD file, you wouldn't want to encode/upscale it to HD. You would want the encoding optimized based on input info.
This would be a huge improvement. I'd love to see some layer implemented within the lambda that watches S3 to dynamically propose job settings without any input on my end that would cover 95% of OTT customers/use case. To me, that'd be a qVBR job with DASH, HLS, and potentially MP4 outputs, with resolutions being determined based on source video metadata and/or preferred delivery devices ie. const outputs = ['phone', 'tablet', 'laptop', 'desktop', 'tv']
dynamic workflow configuration i.e. maybe i want to add a custom pre-process or post-process step to the file transcoding process. Custom filters, metadata twiddling, qc tools, image extractors, other stuff that mediaconvert doesn't have natively.
This would introduce welcomed flexibility, but is not the primary use case for OTT in general. Typically, my end users wouldn't want any modification to their source files as all of those decisions have been made prior to uploading the video. Some of these choices might be cool to apply within a client-side library after the initial transcoding, like previewing/applying filters after the initial transcoding.
API Design What API experience would developers want? We could do something super basic where we return playback urls for encoded content as they become available
Right now I have a lambda set up that updates the related dynamodb record with playback urls when job completed, not sure if that's the approach you had in mind but it seems to work well as the transcoding jobs could take a while.
we could have a subscription feed of content
@smp I'd love to hear more about what you have in mind here.
we could provide playback URLs to content that hasn't even been encoded yet and dynamically process the content based on requesting client. Commonly referred to as just-in-time-encoding (JITE), this would be complex, but innovative, and has been implemented by services like mux because it's a great experience for users and it lowers backend costs.
Complex, yes. Awesome, yes.
Most of the painpoints with my experience are related to determining job settings based on source media. Mux promotes Per Title Encoding which analyzes incoming videos using deep learning and determines, in seconds, the right video encoding settings. This might be moot when considering qVBR outputs, but it'd likely be worth getting some input from video encoding pros re: the dev approach on this.
Some work towards thumbnail generation presets (preview strips, GIFs, overlay play icon etc.) might also be worth discussing.
Looking forward to your efforts!
from amplify-video.
 wizage
commented on June 4, 2024
wizage
commented on June 4, 2024
Design docs:
Ingestion
Ingestion should be done from S3. The S3 ingestion would require the user to upload the RAW untranscoded files to S3 to trigger a lambda job to create a new MediaPackage job. The Lambda function will be only triggered off of a successful Put on S3. A delete will do the opposite and delete all content related to the RAW film (this can be turned on or off maybe).
MediaConvert Config
The MediaConvert will be configure based on the input file provided and the specs provide in the CLI. This means that if you see a file that is only 720p it will transcode from 720->down. You can specify what your min and max transcode job is or use defaults like [Mobile, Web, 4k, etc.].
Storage of meta
Meta data should be stored in a DynamoDB database (more design docs coming soon on how the table will look). The database will contain the raw file location, the transcoded file locations, available transcodings of the file (e.g. DASH, HLS) and any other info provide by the user. (We might need to have way to provide info to this table).
Providing data back
Accessing of the content will need to have either a secure option or a non-secure option. This means either using signed-urls for S3 or CloudFront. To return the URLs and to access other meta data including title, actors, etc. will be done through the API Layer. The API layer is still open to utilizing either AppSync or API Gateway.
API Gateway (Rest)
API Gateway will be designed with a simple access patterns including: GetItemMeta, GetList, GetFilm. Extra fields would have to be added manually and would require extra configuration outside of Amplify which is a huge downside of API Gateway for this model. But a huge upside is that everyone knows how Rest works.
AppSync (GraphQL)
AppSync will be designed with direct access to the meta data DynamoDB table. This will allow access straight to the data so you can change what your frontend needs and allows you to add more fields without extra configuration outside of Amplify. This can take in power of codegen as well for Amplify. Downside is we need to create a Lambda resolver for the signed URL portion to return back the right info, and knowledge of GraphQL is not as widely known. Upside allows users to quickly add new meta data to the table as they see fit.
Attached is the first draft of the proposed architecture.
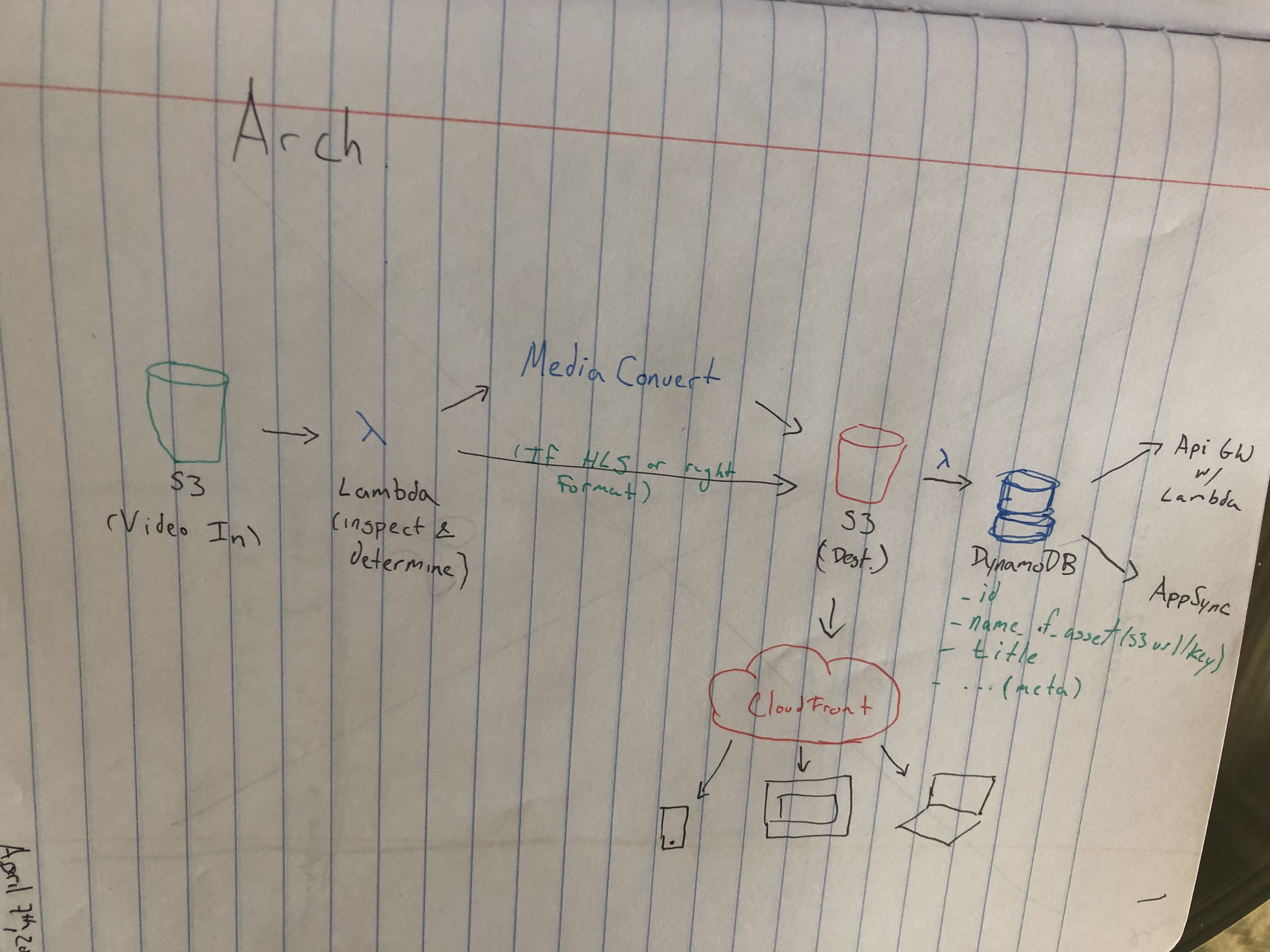
from amplify-video.
smp
commented on June 4, 2024
Meeting 7/29
- Creating GraphQL "Video Transformer" instead of a GraphQL model
- @wizage working on cfn implementation
- @axptwig working on encoding lambda function
- @smp updage diagram doc (sync with sam at tech summit)
from amplify-video.
 codercatdev
commented on June 4, 2024
codercatdev
commented on June 4, 2024
I was hoping to dive in and help out, but I might be a little behind on where the project sits. I ran through the amplify video add for VOD. I uploaded to the input S3, it converts and then drops off to the output S3. So is there still work to be done on the upload of metadata back to Dynamo?
from amplify-video.
wizage
commented on June 4, 2024
Video on Demand is officially marked good for Release. Closing this issue.
Diagrams can be found on the wiki of the final implementations:
https://github.com/awslabs/amplify-video/wiki/VOD-Concepts
API is in beta as we wait for the Amplify CLI to add headless support for API (GraphQL)
Docs are still being written and improved but core docs can be found on our wiki as we continue to improve this!
from amplify-video.
 rahulynot
commented on June 4, 2024
rahulynot
commented on June 4, 2024
What's the suggested way to get the content url in CMS dynamodb? Considering there are different resolution content m38u files generated, how to get them in CMS to fetch them using Appsync APIs?
I'm new to the topic, so apologies if I missed something. I can't find any documentation in the wiki for CMS.
from amplify-video.
Related Issues (20)
- Getting 403 Forbidden when trying to upload video to the input s3 bucket as an authenticated user HOT 9
- Output bucket not granting Public Read permission when filename contains spaces HOT 1
- Video player fails to play signed urls HOT 8
- Video object lost when VodAsset json is parsed into VodAsset object HOT 1
- Deployment Failed when Deploying from Admin UI After Adding Amplify Video to Schema HOT 4
- HLS Video with Credentials (signed url) cannot be played on iOS/Safari HOT 11
- Surface Ivs Start/Stop channel events to a SNS queue
- Audio-Only Pipeline Guide in Wiki Fails to Output Audio HLS
- Cannot Add New Environment with Video Plugin
- Can not push to amplify when updating to v3.9.2 HOT 1
- Template error: instance of Fn::GetAtt references undefined resource videoResource HOT 2
- Provide Audio-On-Demand (AOD) option
- Failed compiling GraphQL schema: Your GraphQL Schema is using "@connection" directive from an older version of the GraphQL Transformer. HOT 3
- Adding amplify video with a Signed URL option fails because of permissions (even with an IAM user with Admin access)
- React video code for both Dash and HLS? HOT 1
- `AccessDeniedException` when invoking lambda function to convert video from input to output bucket HOT 1
- amplify video add command not found HOT 1
- Amplify will not Push after adding Video
- Generated GraphQL schema contains @connection HOT 1
- amplify video add (video on demand) no longer working with away amplify updated cli. HOT 11
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from amplify-video.