
数据结构可以分为 队列、树、堆、数组、栈、链表、图、散列表。
概念:链表由一系列结点(链表中每一个元素称为结点)组成,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个(上一个)结点地址的指针域。

上图是双链表,代表着节点中有2个指针,一个指向前一个元素,另外一个指向后一个元素。链表其实可以分类为单链表和双链表,双链表比单链表多了一个指向前一个元素的指针而已,相信很好理解。
- 插入和删除只需修改指针,不需要移动其他元素,效率高,为O(1);
- 不要求连续空间,空间利用率高;
- 查找元素的效率低,比如要查找位置为99的元素,需要从第1个开始查找到99,效率非常低
以上就是关于链表的概念,相信大家可以很好的理解。知道了链表的优缺点,在我们日常开发中需要对数据进行频繁插入和删除的就可以使用链表。
链表在java中的实现类为LinkedList,这个类
首先java使用一个静态内部类来代表链表的节点:
private static class Node<E> {
E item;// 数据
Node<E> next;// 前一个节点
Node<E> prev;// 后一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}非常简单粗暴,很好理解。像我们日常使用最常用的方法肯定是:add,remove,get,set。
public boolean add(E e) {
linkLast(e);
return true;
}
//首先是add方法,里面调用了linkLast方法,方法名的意思是连接最后一个
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
//last记录的是链表中最后一个元素,当列表为空时last为null,这段代码简单,首先new一个节点,头指针指向当前链表节点中的最后一个,尾指针是指向null。然后,如果last为空就说明链表还是空的,那么这个新增的节点就是头节点。再来看remove方法,remove方法有3个重载,remove()删除的是第一个节点,remove(int index)删除的是指定位置节点,remove(Object o)删除的是节点数据为o的节点,其实只需要知道remove(Object o)就行,其余2个重载的方法都使用的是相同的方法。
public E remove(int index) {
checkElementIndex(index);// 检查index是否为0或是否越界
return unlink(node(index));
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//上述代码中最关键的就是unlink(node(index)),node方法会根据index查找到对应节点,unlink方法则是删除指定节点
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//这里的size >> 1其实就是size/2,这段代码很巧妙的已链表大小的一半来查询,是为了增加查询的效率。如果index小于size/2,则从链表的第一个节点开始遍历到index然后返回节点;如果index大于size/2,则从链表最后一个节点开始倒叙遍历到index然后返回节点。其实这里就很明显的体现出了链表的缺点了,因为必须要从链表的第一个节点开始查询,且要遍历index次才能找到对应节点。
//node方法找到了对应index的节点,然后unlink则负责断开该节点。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
//首先判断该节点是不是头节点,如果是,记录下一个节点作为头节点;如果不是,则让前一个节点的尾指针指向后一个节点。然后再判断是不是尾节点,如果是,记录前一个节点为尾节点;如果不是,让后一个节点的头指针指向前一个节点。这段代码很好理解,完全可以不用看解析。
//然后在来看remove(Object o)
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//很简单粗暴,遍历链表,查看是否有节点数据为o,有,则调用unlink方法删除。这里要注意的一点是,链表的节点数据是允许为null的。再来看一下get方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//还是熟悉的味道和配方,关键的node方法,找到对应节点并返回数据。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//set方法同样使用的是node方法,不再详述了提到哈希表,必然提一下哈希碰撞问题,哈希碰撞两个不同的原始值在经过哈希运算后得到同样的结果,这样就是哈希碰撞。
大家写Map可能绝大部分情况下都是使用HashMap。HashMap底层是通过数组加链表(Java1.8新加了红黑树)来实现。为什么要搞这么复杂呢?又是数组又是链表又是树的?其实还是为了提高效率。上面的把键值对封装成Data,加到List中。get效率跟HashMap比就会非常惨了。因为get只能一个个去遍历,但是HashMap就可以通过key的hashcode非常高效的get数据。
看名字就知道多了个Linked,意思就是排序。LinkedHashMap本身就是继承自HashMap,所以增删改查方面和HashMap基本是一致的。区别主要就是通过entrySet遍历了。LinkedHashMap会保存元素的添加顺序然后按顺序遍历,但HashMap就是无序了。
TreeMap内部是个红黑树。从使用角度来看,它跟LinkedHashMap主要区别就LinkedHashMap保存的是元素的插入顺序,而TreeMap则是对key排序。遍历可以得到一个按key排序的结果。
内部是个链表,另外就是线程同步。
ArrayMap内部也是使用数组。查找数据会通过二分法来提高效率,Google推荐用ArrayMap来代替HashMap。
SparseArray内部依然是使用数组来实现。但是限制了key只能int,而且没有装箱,HashMap的key只能是Integer。所以Sparse性能会更好,它内部做了数据压缩,来稀疏数组的数据,节省内存。
主要讲的是对于数据结构的基本认识和链表的了解,可能对于我们实际开发并不会有很大的实质性帮助,但是这只是数据结构和算法知识的一小部分,我相信当我们对数据结构和算法有一个比较全面的了解和理解的时候,对于我们的实质编码肯定是会有帮助的,加油吧!
String[] arr1 = new String[3];// 创建一个大小为3的数组
arr1[0] = "0";
arr1[1] = "1";
arr1[2] = "2";
String[] arr2 = new String[]{"0", "1", "2"};// 创建一个大小为3的数据并赋值上述代码,实际开发中,像这样使用数组的地方并不多,我们更多的使用的是像ArrayList这样的数组,其实用容器来形容ArrayList更贴切,在他的内部维护着一个数组,我们可以非常方便的增删查改一个ArrayList就是因为容器中已经提供了大量的方法供我们使用且不需要我们自己维护,可以说是非常棒了。
数组分配在一块连续的数组空间上,所以在给他分配空间时要确定它的大小,像我们上面两种声明数组的方式都是确定了大小。但是链表却不同,它时一块动态空间,可以随意的改变长短,所以初始化时不需要确定大小。
- 访问、查找元素的效率很高。
- 由于空间是固定的,所以插入和删除元素效率会很低
ArrayList我们使用的非常多,里面有很多方法都非常的好用,我们就通过这些方法来理解数组以及数组容器,形成数据结构的思想。
transient Object[] elementData;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}这里有一个elementData,它就是一个数组,transient修饰符是用来描述序列化相关的,这里我们不关心,这个数组在我们初始化ArrayList就被创建了,容器的用处就是来为维护这个数组方便我们使用。
再来看一下另一个构造方法,此构造方法的参数就是数组的初始化大小:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
}还有另一个,此构造方法是把另外一个数组的内容复制到这个新的数组中,这里有一个Array.copyOf()方法,Arrays是一个专门用来操作数组的类,里面提供了大量调用底层C的方法。
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}总共2行代码,第2行就是一个简单的数组赋值操作,把添加新来的元素加入到elementData中并使数组的size加1,还记得我前面讲过的数组的大小是再初始化的时候固定的吗,如果一个大小为1的数组,那么怎么才能往它里面加第二个元素呢,所以我们就可以想到第一行的ensureCapacityInternal方法肯定使用了某种方法增大了原数组的大小。
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}这段代码先会判断elementData的内容是否为空,如果是就会给数组设置一个最小容量,这个最小容量是默认大小(10)和当前数组当前大小+1的最大值。确定这个大小之后,剩下的就是给数组扩容了,我们继续看下去:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}如果数组的新容量是大于数组当前大小就增容,grow(生长)方法名字也取得相当到位
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}这里还会修正一次容量大小,当数组元素较少,大概为个位数的时候,容量会增到到10,当元素较多,像20个以上时容量会以1.5倍增大,最后一行又用到了Arrays中的方法,同样的是一个复制数组元素的方法。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}这个add方法是向指定位置插入元素,首先同样的会给数组扩容,因为想一个入组中的某一个位置插入元素,假设这个位置是数组的中间,那么就意味着从数组中间+1位置的元素到最后一个元素都要后移,但是我们知道数组是不具备这个功能的,所以还是用到了System.arraycopy方法来复制数组,这个方法其实就是Arrays.copy()的底层方法。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);src代表数据源,srcPos代表复制的位置,dest代表要复制的结果数据源,destPos,结果数据源的复制位置,length代表复制长度。代入之后就是从elementData中,复制从index到size - index这段元素,然后替换位置从index + 1开始,长度为size - index这段元素,最后给位置为index的地方赋值。看图:

看了以上两个add方法后,addAll方法的流程其实也是相同的,第一步:扩容,第二步:复制数组。
public E get(int index) {
rangeCheck(index);//检验是否越界
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}get方法就这么点。。。所以说数组查询元素很简单嘛,是不是
public E remove(int index) {
rangeCheck(index);//检验是否越界
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work 将最后一位变成空,让系统GC
return oldValue;
}这里的大多数方法和内容都多么的似曾相似,见图,不多说了:

然后,remove(Object o)流程也是相似的
把ArrayList中的一系列方法都过了一遍之后,我们可以总结出如下内容:
-
查询数组中的元素效率非常高。
-
插入和删除数组中的元素需要复制数组中的元素,效率是很低的。
-
ArrayList作为一个容器动态的帮我们维护了数组的大小和内容,我们只需要关心怎么使用即可。
-
Arrays中有大量操作数组的方法
-
文章上述的内容更多的是想让大家理解数组以及数组容器而不是源码,希望大家有所收获。
队列稍有耳闻的同学肯定会知道它有一个特点:先进先出。正是这个特点使得队列在处理一些对于顺序要求很高的需求时有很好的效果,就像网络请求的排序,队列大概是这样的:

上图可以看出队列是一个很明显的先进先出的结构,中间的元素是不允许修改的。
java中使用Queue(队列)来描述队列,它里面有一系列方法:
- offer方法,向队列尾部入列一个元素;
- poll方法,把队列的第一个元素出列;
- peek方法,查看队列的第一个元素,但是不出列;
除了上面3个方法,其实还有3个方法:add,remove,element与上面3个方法对应,唯一的区别就是这3个方法会抛出异常,这不是我们关注的重点。
java种关于Queue的实现结构如下:

其中:
-priorityQueue虽然是Queue的实现类,但是它的实现与队列的“先进先出”特点是有些出入的,因为它会对每次进入队列的元素进行排序,也就是说当使用peek方法取出的元素可能不会是第一个进入队列的元素,而是整个队列最小的元素。
-Deque是一个继承了Queue的接口,它在Queue的基础上增加了几个方法,使它成为了一个双端队列的结构,可以通过这些方法来操作队列两端的元素
-ArrayDeque是Deque的一个典型实现
-LinkedList,当时是把它当作做链表来讲解,其实它还实现了Deque,也就是说它还可以当做双端队列来使用。
既然java没有给我们提供一个规范的队列实现,我们就自己动手来写一个遵循”先进先出“规则的简单队列,毕竟我们学习数据结构更多的是理解这些数据结构的特点,而不是过多的关心它的实现。
public class Queue<E> {
private Object[] data = null;// 队列
private int front;// 队列头,允许删除
private int rear;// 队列尾,允许插入
public Queue() {
this(10);// 默认队列的大小为10
}
public Queue(int initialSize) {
data = new Object[initialSize];
front = rear = 0;
}
// 入列一个元素
public void offer(E e) {
data[rear++] = e;
}
// 返回队首元素,但不删除
public E peek() {
return (E) data[front];
}
// 出队排在最前面的一个元素
public E poll() {
E value = (E) data[front];// 保留队列的front端的元素的值
data[front++] = null;// 释放队列的front端的元素
return value;
}
}来测试一下:
Queue<String> queue = new Queue<>();
queue.offer("1");
queue.offer("2");
queue.offer("3");
queue.offer("4");
System.out.println("当前第一个元素: " + queue.peek());// 取队列第一个元素
System.out.println("出列第一个元素: " + queue.poll());// 出列第一个元素
System.out.println("当前第一个元素: " + queue.peek());// 取队列第一个元素
//结果如下:
当前第一个元素: 1
出列第一个元素: 1
当前第一个元素: 2代码很简单,没有做异常处理和各种边界处理,但是遵循了“先进先出的原理”。
栈的特性是:先进后出。它的性质和队列有些相似,都可以通过他们的特性在某些场景发挥很好的作用:

在java中使用Stack这个类来描述栈。
public class Stack<E> extends Vector<E> {
...
}可以看到Stack是继承自Vector同ArrayList一样,是一个比较古老的类,它是线程安全的。Stack中大部份方法都是直接调用Vector的,所以也是线程安全的。
Stack中有几个常用的方法:
public E push(E item)// 入栈一个元素
public synchronized E pop()// 出栈一个元素
public synchronized E peek()// 查看栈顶元素
public boolean empty()// 判断是否为空
public synchronized int search(Object o)// 到栈中查找一个元素这几个方法都言简意赅,至于源码的流程,Vector中的方法实现与ArrayList基本相同。
实现流程:
- 新建一个空栈
- 读入字符串,如遇到开放符号,则入栈,开放符号为:”{“、”(“、”[“,这种。
- 如果遇到关闭符号,就出栈当前栈顶元素,把出栈的元素与这个关闭符号进行匹配,像”{“对应的是”}”,如果匹配是正确的就说明符号是对应的,如果匹配是不正确的,就说明编码有问题。
- 如果传入的字符串是正确的,程序按照上述3步运行下来,栈应该还是空的。如果栈非空,说明编码有问题
把上面4步转换成代码,可以得到以下程序:
public static boolean test(String code) {
Stack<String> stack = new Stack<>();
char[] chars = code.toCharArray();// 把输入的字符串拆分成char一个一个读取
for (char aChar : chars) {
String s = String.valueOf(aChar);// char转String
if ("{".equals(s) || "[".equals(s) || "(".equals(s)) {
stack.push(String.valueOf(aChar));// 如果是开放符号就入栈
}
if (stack.isEmpty()) {
// 如果栈是空的,就说明有关闭符号缺少相应的开放符号
System.out.println("您的代码中有符号不对应");
return false;
}
// 如果是关闭符号,则出栈最上层的元素进行比较
// 如果是配对的符号,就说明是正确的;如果不是配对的符号,就说明是错误的
switch (s) {
case "}":
if (!"{".equals(stack.pop())) {
System.out.println("您的代码中有符号不对应");
return false;
}
break;
case "]":
if (!"[".equals(stack.pop())) {
System.out.println("您的代码中有符号不对应");
return false;
}
break;
case ")":
if (!"(".equals(stack.pop())) {
System.out.println("您的代码中有符号不对应");
return false;
}
break;
}
}
if (!stack.isEmpty()) {
System.out.println("您的代码中缺少闭合符号");
return false;
}
return true;
}代码的注释写的很详细,流程也很清晰,我们来测试一下几种情况:
// 以下模拟了4种情况:
System.out.println(test("{[]}"));// 正确
System.out.println("————————————————————————————————");
System.out.println(test("{[{}{}]"));// 缺少结尾"}"
System.out.println("————————————————————————————————");
System.out.println(test("{[{}{}]}}"));// 结尾多了一个"}"
System.out.println("————————————————————————————————");
System.out.println(test("{[{}{(}]}"));// 中间多了一个"("输出结果为:
true
————————————————————————————————
您的代码中缺少闭合符号
false
————————————————————————————————
您的代码中有符号不对应
false
————————————————————————————————
您的代码中有符号不对应
false可以看到我还判断了出错的大概原因,利用栈结构就很好的完成了编码检查这个工作,像这种思想还可以运用到我们的实际开发中,希望大家都能有所体会。
进程是资源分配的最小单位,运行一个进程需要,CPU,内存,磁盘IO;线程是CPU调度的最小单位;线程必须依赖于进程存在。(模块化,异步化,简单化),Linux是开启的线程不能超过1000个,每个开启一个线程都要分配一个栈空间。
public class OnlyMain{
public static void main(String[] args){
//Java 虚拟机线程系统的管理接口
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的monitor 和 synchronizer信息,仅仅获取线程和线程堆信息
ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false,false);
//遍历线程信息,仅打印线程ID和线程名称信息
for(ThreadInfo threadInfo: threadInfos){
System.out.println("["+threadInfo.getThreadId()+"]"
+threadInfo.getThreadName());
}
}
}新开启线程的方式位两种(官方JDK标注的)!
Thread是java语言对线程的抽象,Runnable是对任务的抽象。

规范定义:死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或者系统产生了死锁。
让出CPU执行权(让出的时间不能设定),让出后,仍然还是会被选中。(不会让出锁,只是让出执行权)
不会释放锁
这个并不是线程的运行方法,只是等于调用了内部方法,真正执行的是主线程;
这个是调用线程运行的方法,将线程变成就绪状态,当线程拿到执行权的时候,才是真正的运行状态。
类似于插队,面试题中会问到,怎么让线程顺序执行,可以利用join()方法,会让线程变成一个串型执行。
推荐使用这个方法来停止线程
对象调用wait方法后,他会把他持有的锁给释放掉。
不会释放锁,只会唤醒一个等待线程。
不会释放锁,会唤醒所有的等待线程。
!!! 为什么不建议用stop停止线程,因为他会导致线程所占用的资源不会正常的释放
!!! JDK线程是协作式的,不是抢占式
!!! 处于死锁状态,是不会理会中断的
!!!守护线程Run方法里finally不一定会执行
文件标识符
大概需要20000CPU周期
实际上是一起执行
实际上是交替的运行,在讨论并发的时候一定不能脱离时间单位,比如说单位时间内并发量是多少。(比如说咖啡机一分钟能4个人通过,那么就说这个并发量是一分钟4个);
(Compare And Swap)比较并且交换,原子操作就是不可再分。自旋:就是等于死循环。
实现原子操作可以使用锁,锁机制,满足基本的需求是没有问题的了,但是有的时候我们的需求并非这么简单,我们需要更有效,更加灵活的机制,synchronized关键字是基于阻塞的锁机制,也就是说当一个线程拥有锁的时候,访问同一资源的其它线程需要等待,直到该线程释放锁,
这里会有些问题:首先,如果被阻塞的线程优先级很高很重要怎么办?其次,如果获得锁的线程一直不释放锁怎么办?(这种情况是非常糟糕的)。还有一种情况,如果有大量的线程来竞争资源,那CPU将会花费大量的时间和资源来处理这些竞争,同时,还有可能出现一些例如死锁之类的情况,最后,其实锁机制是一种比较粗糙,粒度比较大的机制,相对于像计数器这样的需求有点儿过于笨重。
CAS的原理:利用了现代处理器都支持的CAS的指令,循环这个指令,直到成功为止。

CAS的问题
**1.ABA问题。**解决办法就是带上一个版本戳 AtomicMarkableReference(关心这个值有没有人动过),AtomicStampedReference(关心这个有没有人动过,还关心被人动过几次)这两个类
**2.开销问题。**自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
**3.只能保证一个共享变量的原子操作。**解决办法AtomicReference,把要修改的值打包到一个类里面去修改
同步工具类的内部(继承AQS),要求使用 模板方法的设计模式
/**
* 类说明:抽象蛋糕
*/
public abstract class AbstractCake{
protected abstract void shape();//造型
protected abstract void apply();//涂抹
protected abstract void brake();//烤制
public final void run(){
this.shape();
this.apply();
this.brake();
}
}AQS的基本思想是CLH队列锁,AQS自旋锁不会一直自旋,自旋到一定次数就会挂起阻塞等待唤醒,每一个等拿锁的线程打包成一个节点,挂到一个链表上,每个线程不断检测前面一个线程是否释放锁,释放了就拿锁。state成员变量,靠改变这个成员变量来检测拿锁
线程时稀缺又昂贵的资源。经常创建和销毁线程会造成严重的资源浪费
//7个参数
public ThreadPoolExecutor(
int corePoolSize,//线程池的核心线程数
int maximumPoolSize,//可使用的最大线程数
long keepAliveTime,//控制空闲线程的醋存活时间,如果超过时间会销毁空闲的线程
TimeUnit unit,//时间单位
BlockingQueue<Runnable> workQueue,//阻塞队列,如果要工作的线程超过了maximumPoolSize,就会放到阻塞队列里面来,尽量配置成有界的
ThreadFactory threadFactory,//线程工厂。可以创建线程时微调
RejectedExecutionHandler handler//拒绝策略
) {
}流程:如果线程池是空的时间,工作线程进来会在corePool里面,当超过了corePoolSize以后,线程会放到workQueue阻塞队列里面去,当workQueue放满以后,线程会在maximumPool里创建,但是不能超过maximumPoolSize数量,一但超过,RejectedExecutionHandler拒绝策略就会起作用。
!!!JDK为我们提供了4种拒绝策略:
- DiscardOldestPolicy:直接丢弃最老的那一个
- AbortPolicy:直接抛出异常,默认策略
- CallerRunsPolicy:让调用者线程执行任务,谁调用谁执行
- DiscardPolicy:把最新提交的任务直接扔了
- shutdown:尝试关闭线程池,所有当前没有执行的线程进行中断
- shutdowNow:不管有没有执行,都会尝试进行中断
- CPU密集型:从内存中取数进行机算,maximumPoolSize配置的时候不要超过CPU核心数 + 1。(cpu+1是为了解决cpu页缺失状态)
- IO密集型:读取磁盘,网络通讯,线程数:maximumPoolSize配置的时候机器得cpu核心数*2
- 混合型,综合上面
概念、生产者消费性模式,平衡性能问题
常用阻塞队列:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。实现是一个堆
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。支持元素的延迟获取
- SynchronousQueue:一个不存储元素的阻塞队列。里面不存在任何元素,都在内存里,解决耦合问题
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。transfer()方法,如果有消费者在等待拿东西,生产者直接给消费者,不再放进阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
锁的4中状态:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态(级别从低到高)
(原子操作)锁的是对象,注意锁的对象不能变化。
使用monitorenter 和 monitorexit 指令实现的
- monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处。
- 每个monitorenter 必须有对应的monitorexit 与之配对
- 任何对象都有一个monitor 与之关联
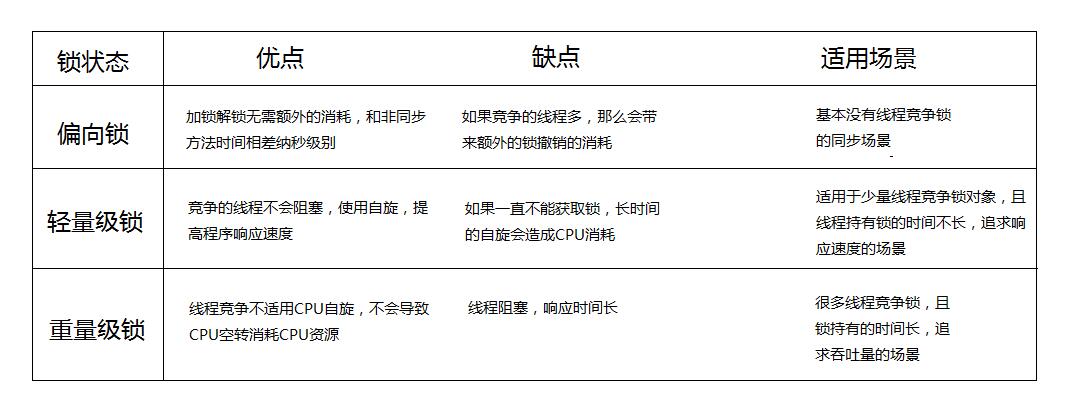
其实锁的还是一个对象,不过锁的是每一个类里面在虚拟机里仅有的一个对象。
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
优点:所有的线程都能得到资源,不会饿死在队列中。 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。 非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。 缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。 我举个例子给他家通俗易懂的讲一下的,想了好几天终于在前天跟三歪去肯德基买早餐排队的时候发现了怎么举例了。
现在是早餐时间,敖丙想去kfc搞个早餐,发现有很多人了,一过去没多想,就乖乖到队尾排队,这样大家都觉得很公平,先到先得,所以这是公平锁咯。
最轻量的同步机制,保证的是可见性(并不保证原子性),加了volatile之后,子线程就可以看到主线程的成员变量的修改。
一写多读的情况下适合使用volatile。
volatile只是强制读的时候在堆内存(主内存)读,并且强制更新回去。
有volatile变量修饰的共享变量进行写操作的时候会使用CPU提供的Lock前缀指令。
- 将当前处理器缓存行的数据写回到系统内存。
- 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
!!!面试题要点 i++ 但是会返回新的内存地址,因为实现的时候其实是返回了一个new integer()
为每一个线程提供了一个变量副本,实现了线程的隔离。
每个线程里都有一个ThreadlocalMap ,以Threadlocal是Key,obj为Value。默认大小为16;

remove里面会调用expungeStaleEntry()方法做清除。
无论如果都不会被回收。
只有在内存不足的时候才会被回收。
只要被GC扫描到了,就会被回收到。
体现了分而治之,算法中属于分而治之的有 归并排序,快速排序,二分查找
大问题--》分割 相同的小问题,小问题之间无关联
答:synchronized 主要是靠monitorenter 指令来实现, ReentrantLock拿锁的动作可以中断,可以实现可重入。synchronized 是非公平锁,ReentrantLock可以实现公平锁 和 非公平锁。
答:为了提升性能,JDK以入了偏向锁,自旋锁(轻量级锁),重量级锁。
答:虚拟机加载机制,虚拟器会加锁,保证同一时间只有一个线程可以执行类加载机制。
答:可以的,所以才会实现sleep方法的时候要时候try
答:是线程的本地变量,特殊变量。TheadLocal为每个线程实现的本地的变量副本。
!!!静态内部类跟外面的类没有任何关系,可以理解为一个独立的类
序列化的概念:将数据结构或对象转换成二进制串的过程。
反序列化:将序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
持久化:把数据结构或对象,存储起来。
标识:tags
1.通过IO对硬盘操作,速度较慢
2.大小不受限制
3.大量使用反射,产生内存碎片
objectOutput
objectStreamClass:描述一个对象的结构
1.直接在内存操作,效率高,性能好
2.一般不能超过1m,修改内核也只能4m
链式调用
//起点
Observable.just(String) //内部会分发 //todo 2
// 订阅 起点 和 终点 订阅起来
.map(new Function<String,Bitmap>()){
@override
public Bitmap apply(String s){
//todo 3 卡片式拦截
return null;
}
})
.subscribeOn(Schedulers.io())//给上面的代码分配异步线程
.observeOn(AndroidSchedulers.mainThread())//给下面观察者分配主线程
.subscribe(
//终点
new observer<String>(){
//订阅开启
@override
public void onSubscribe(Disposable d){
//todo 1
}
//拿到事件
@override
public void onNext(String s){
//todo 4
}
//错误事件
@override
public void onError(Throwable e){
}
//完成事件
@override
public void onComplete()){
//todo 5
}
}
)发送一条信息,向下发送多条
RxJavaPlugins.onAssembly()全部操作符都有这个,全局
public static <T> Observable<T> onAssembly(@NonNull Observable<T> source){
//默认情况下 f == null
Function<? super Observable,? extends Observable> f = onObservableAssembly;
if( f != null){
return apply(f,source);
}
return source;
}Observable创建过程时,ObservableCreate传的是我们自定义source
字节流:就是一个一个字节的读。
字符流:就是一串一串的读。
成员方法:
seek(int index);可以将指针移动到某个位置开始读写
setLength(long len);给写入文件预留空间;
Java解释执行是栈(操作数栈),C是寄存器(硬件)运算
JVM只是一个翻译
JRE提供了基础类库
JDK提供了工具
解释执行:解释一行,翻译一行
Java Virtual Machine java程序 通常.java后缀
\|/
翻译 java字节码 通常.class .jar 等
\|/
JVM
\|/
从跨平台到跨语言 操作系统函数 Linux,window,maxos定义:Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。
有 方法区 、 堆 、虚拟机栈、本地方法栈、程序计数器。其中 虚拟机栈、本地方法栈、程序计数器 是线程私有的, 线程共享的有 方法区 、堆
指向当前线程正在执行的字节码指令的地址,唯一不会OOM。
存储当前线程运行方法所需的数据、指令、返回地址。先进后出
-
局部变量表
-
操作数栈
-
动态连接
-
完成出口
本地方法栈保存得是native方法得信息。
当一个JVM创建的线程调用native方法后,JVM不再为其在虚拟机栈中创建栈帧,JVM只是简单地动态链接并直接调用native方法。
- 类信息
- 常量
- 静态变量
- 即时编译期编译后的代码
- 对象实例(几乎所有)
- 数组
- 申请内存
- 类加载--.class进入方法区
- 以栈帧得方式存储方式方法调用的过程,并存储方法调用过程中基本数据类型的变量(int、short、long、byte、float、double,Boolean、char)以及对象的引用变量,其内存分配在栈上,变量出了作用域就会自动释放;
- 而堆内存用来存储Java中的对象,无论市成员变量,局部变量,还是类变量,他们指向的对象都存储在堆内存中;
- 栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成线程的私有内存。
- 堆内存中的对象对所有线程可见。堆内存中的对象可以被所有线程访问。
栈的内存要远远小于堆内存,栈的深度市有限制的,可能发生stackOverFlowError问题。
- 栈溢出
- 堆溢出
- 方法区溢出
- 本机直接内存溢出(堆外内存)
运行时的常量池(字符串部份--放入堆)。静态(Class)---方法区
方法区:类,类会在那个时候卸载、回收?
- 类--所有的实例。都要回收掉。
- 加载的该类的classload已经被回收。
- 该类,java.lang.class对象,没有任何地方被引用。无法通过反射访问该类的方法。
—— 类加载
失败 /|\ \|/
—— 检查加载
\|/
分配内存 划分内存:指针碰撞、空闲列表
并发安全问题:CAS加失败重试,本地线程分配缓冲
\|/
内存空间初始化 ———— 设置 —————— 对象初始化 |——哈希码
|——GC分代年龄
|——锁状态标识
|——线程持有的锁
|——偏向线程ID
|—— 存储对象自身的运行数据 |——偏向时间戳
|—— 对象头 ——|—— 类型指针
| |—— 若为对象数组,还应有记录数组长度的数据
对象 —— |—— 实例数据
|
|—— 对齐填充(非必须),因为在存储的时候规定格式大小
- 引用计数算法
- 可达性分析
新生代和老年代,默认比例为1:2,可修改。
- 对象优先在Eden分配 ;新生代比例 eden from to 8:1:1
- 空间分配担保
- 大对象直接进入老年代
- 长期存活得对象进入老年代;经过15次垃圾回收后还存活进入
- 动态对象年龄判定
- 逃逸分析 (虚拟机栈 )
- 本地线程分配缓冲(TLAB)
- 新生代:复制算法;
- 老年代:标记清除算法,标记整理算法;
- 实现简单、运行高效
- 内存复制、没有内存碎片
- 利用率只有一半
- 执行效率不稳定
- 内存碎片导致提前GC
- 对象移动
- 引用更新
- 用户线程暂停
- 没有内存碎片
ANDROID 给每个 APP 分配一个 JVM,让 APP 运行在 DALVIK 上,这样即时 APP 崩溃也不会影响到系统。系统给 JVM 分配了一定的内存大小,APP 可以申请使用的内存大小不能超过此硬性逻辑限制,就算物理内存富余,如果应用超出 JVM 最大内存,就会出现内存溢出。
由程序控制操作的内存空间在 heap 上,分 JAVA heapsize 和 native heapsize
Java 申请的内存在 JVM heap 上,所以如果 java 申请的内存大小超过 JVM 的逻辑内存限制,就会出现内存溢出的异常。
native 层内存申请不受其限制,native 层受 native process 对内存大小的限制。
Android应用程序运行在Dalvik / Art虚拟机,并且每一个应用程序对应有一个单独的Dalvik虚拟机实例。Dalvik虚拟机实则也算是一个Java虚拟机,只不过它执行的不是class文件,而是dex文件。
Dalvik虚拟机与Java虚拟机共享有差不多的特性,差别在于两者执行的指令集是不一样的,前者的指令集是基本寄存器的,而后者的指令集是基于堆栈的。
对于基于栈的虚拟机来说,每一个运行时的线程,都有一个独立的栈,栈中记录了方法的调用的历史,每有一次方法调用,栈中便会多一个栈帧。最顶部的栈帧称作当前栈帧,其代表着当前执行的方法。基于栈的虚拟机通过操作数栈进行所有操作。
寄存器是CPU的组成部分。寄存器是有限存储容量的高速存储部件,它们可用来暂存指令、数据和位址。
基于寄存器的虚拟机中没有操作数栈,但是有跟多虚拟寄存器。其实和操作数栈相同,这些寄存器野存放在运行是栈中,本质上就是一个数组。与JVM相似,在Dalvik VM中每个线程都有自己PC和调用栈,方法调用的活动记录以帧为单位保存在调用栈上。
Dalvik虚拟机执行的是dex字节码,解释执行。从Android2.2版本开始,支持JIT即时编译(Just in Time)在程序运行的过程中进行选择热点代码(机场执行的代码)进行编译或者优化。
而ART(Android Runtime)是在Android4.4中引入的一个开发者选项,也是Android5.0及更高版本的默认Android运行时。ART虚拟机执行的是本地机器码。Android的运行时从Dalvik虚拟机替换成ART虚拟机,并不要求开发者将自己的应用直接编译成目标机器码,Apk仍然是一个包含dex字节码的文件。
责任链设计模式
PathClassLoader --》父类 --》BootClassLoader
var hh = "123" //可以修改
val ii = "123" //不可以修改
//可变参数(可变长、参数函数)
lenMethod(1,2,3,4,5)
fun lenMethod(vararg value:Int){
for(i in value){
prinln(i)
}
}
//从 1到9
for (i:int in 1..9){
prinln(i)
}
//从大到小
for (i :Int in 9 downTo 1){
}
//数组
val numbers = arrayof(1,2,3)
for (number in numbers){
}
//标签
ttt@ for (i in 1..20){
for (j in 1..20){
break@ttt //i循环给break
}
}
//lateinit 懒加载
lateinit var name :String
//数据类 == java实体类
data class User(val id:int,val name:String,val sex: char)
//只实例一次 == 单例
object my{
}
//派生操作
class NetManager{
companion object{
//全部都是 相当于 java static
}
}
//内部类
inner class Sub2{
}
作用域函数是Kotlin比较重要的一个特性,共分为以下5种:let、run、with、apply 以及 also;
Kotlin 标准库包含几个函数,它们的唯一目的是在对象的上下文中执行代码块。当对一个对象调用这样的函数并提供一个 lambda 表达式时,它会形成一个临时作用域。在此作用域中,可以访问该对象而无需其名称。这些函数称为作用域函数。
public inline fun <T, R> T.let(block: (T) -> R): R let函数是参数化类型 T 的扩展函数。在let块内可以通过 it 指代该对象。返回值为let块的最后一行或指定return表达式。
我们以一个Book对象为例,类中包含Book的name和price,如下:
class Book() {
var name = "《数据结构》"
var price = 60
fun displayInfo() = print("Book name : $name and price : $price")
}
fun main(args: Array<String>) {
val book = Book().let {
it.name = "《计算机网络》"
"This book is ${it.name}"
}
print(book)
}
控制台输出:
This book is 《计算机网络》在上面案例中,我们对Book对象使用let作用域函数,在函数块的最后一句添加了一行字符串代码,并且对Book对象进行打印,我们可以看到最后控制台输出的结果为字符串“This book is 《计算机网络》”。
按照我们的编程思想,打印一个对象,输出必定是对象,但是使用let函数后,输出为最后一句字符串。这是由于let函数的特性导致。因为在Kotlin中,如果let块中的最后一条语句是非赋值语句,则默认情况下它是返回语句。
那如果我们将let块中最后一条语句修改为赋值语句,会发生什么变化?
fun main(args: Array<String>) {
val book = Book().let {
it.name = "《计算机网络》"
}
print(book)
}
控制台输出:
kotlin.Unit可以看到我们将Book对象的name值进行了赋值操作,同样对Book对象进行打印,但是最后控制台的输出结果为“kotlin.Unit”,这是因为在let函数块的最后一句是赋值语句,print则将其当做是一个函数来看待。
这是let角色设定的第一点
let块中的最后一条语句如果是非赋值语句,则默认情况下它是返回语句,反之,则返回的是一个Unit类型。
我们来看let的第二点
let可用于空安全检查。
如需对非空对象执行操作,可对其使用安全调用操作符 ?. 并调用let在lambda表达式中执行操作。如下案例
var name: String? = null
fun main(args: Array<String>) {
val nameLength = name?.let {
it.length
} ?: "name为空时的值"
print(nameLength)
}我们设置name为一个可空字符串,利用name?.let来进行空判断,只有当name不为空时,逻辑才能走进let函数块中。在这里,我们可能还看不出来let空判断的优势,但是当你有大量name的属性需要编写的时候,就能发现let的快速和简洁。
let的第三点
let可对调用链的结果进行操作。
关于这一点,官方教程给出了一个案例,在这里就直接使用:
fun main(args: Array<String>) {
val numbers = mutableListOf("One","Two","Three","Four","Five")
val resultsList = numbers.map { it.length }.filter { it > 3 }
print(resultsList)
}
//我们的目的是获取数组列表中长度大于3的值。因为我们必须打印结果,所以我们将结果存储在一个单独的变量中,然后打印它。但是使用“let”操作符,我们可以将代码修改为:
fun main(args: Array<String>) {
val numbers = mutableListOf("One","Two","Three","Four","Five")
numbers.map { it.length }.filter { it > 3 }.let {
print(it)
}
}使用let后可以直接对数组列表中长度大于3的值进行打印,去掉了变量赋值这一步。
inline fun <T, R> T.run(block: T.() -> R): Rrun函数以“this”作为上下文对象,且它的调用方式与let一致。
另外,第一点:当 lambda 表达式同时包含对象初始化和返回值的计算时,run更适合。
这句话是什么意思?我们还是用案例来说话:
fun main(args: Array<String>) {
Book().run {
name = "《计算机网络》"
price = 30
displayInfo()
}
}
控制台输出:
Book name : 《计算机网络》 and price : 30inline fun <T, R> with(receiver: T, block: T.() -> R): R with属于非扩展函数,直接输入一个对象receiver,当输入receiver后,便可以更改receiver的属性,同时,它也与run做着同样的事情。
fun main(args: Array<String>) {
val book = Book()
with(book) {
name = "《计算机网络》"
price = 40
}
print(book)
}上面为例,with(T)类型传入了一个参数book,则可以在with的代码块中访问book的name和price属性,并做更改。
with使用的是非null的对象,当函数块中不需要返回值时,可以使用with。
inline fun <T> T.apply(block: T.() -> Unit): Tapply是 T 的扩展函数,与run函数有些相似,它将对象的上下文引用为“this”而不是“it”,并且提供空安全检查,不同的是,apply不接受函数块中的返回值,返回的是自己的T类型对象。
fun main(args: Array<String>) {
Book().apply {
name = "《计算机网络》"
price = 40
}
print(book)
}
控制台输出:
com.fuusy.kotlintest.Book@61bbe9ba前面看到的 let、with 和 run 函数返回的值都是 R。但是,apply 和下面查看的 also 返回 T。例如,在 let 中,没有在函数块中返回的值,最终会成为 Unit 类型,但在 apply 中,最后返回对象本身 (T) 时,它成为 Book 类型。
apply函数主要用于初始化或更改对象,因为它用于在不使用对象的函数的情况下返回自身。
inline fun <T> T.also(block: (T) -> Unit): T also是 T 的扩展函数,返回值与apply一致,直接返回T。also函数的用法类似于let函数,将对象的上下文引用为“it”而不是“this”以及提供空安全检查方面。
fun main(args: Array<String>) {
val book = Book().also {
it.name = "《计算机网络》"
it.price = 40
}
print(book)
}
控制台输出:
com.fuusy.kotlintest.Book@61bbe9ba- 用于初始化对象或更改对象属性,可使用apply
- 如果将数据指派给接收对象的属性之前验证对象,可使用also
- 如果将对象进行空检查并访问或修改其属性,可使用let
- 如果是非null的对象并且当函数块中不需要返回值时,可使用with
- 如果想要计算某个值,或者限制多个本地变量的范围,则使用run
Kotlin 是一门仅在标准库中提供最基本底层 API 以便各种其他库能够利用协程的语言。与许多其他具有类似功能的语言不同,async 与 await 在 Kotlin 中并不是关键字,甚至都不是标准库的一部分。此外,Kotlin 的 挂起函数 概念为异步操作提供了比 future 与 promise 更安全、更不易出错的抽象。
import kotlinx.coroutines.*
fun main() {
GlobalScope.launch { // 在后台启动一个新的协程并继续
delay(1000L) // 非阻塞的等待 1 秒钟(默认时间单位是毫秒)
println("World!") // 在延迟后打印输出
}
println("Hello,") // 协程已在等待时主线程还在继续
Thread.sleep(2000L) // 阻塞主线程 2 秒钟来保证 JVM 存活
}
Hello,
World!本质上,协程是轻量级的线程。 它们在某些 CoroutineScope 上下文中与 launch 协程构建器 一起启动。 这里我们在 GlobalScope 中启动了一个新的协程,这意味着新协程的生命周期只受整个应用程序的生命周期限制。
可以将 GlobalScope.launch { …… } 替换为 thread { …… },并将 delay(……) 替换为 Thread.sleep(……) 达到同样目的。 试试看(不要忘记导入 kotlin.concurrent.thread)。
如果你首先将 GlobalScope.launch 替换为 thread,编译器会报以下错误:这是因为 delay()是一个特殊的 挂起函数 ,它不会造成线程阻塞,但是会 挂起 协程,并且只能在协程中使用。
第一个示例在同一段代码中混用了 非阻塞的 delay(……) 与 阻塞的 Thread.sleep(……)。 这容易让我们记混哪个是阻塞的、哪个是非阻塞的。 让我们显式使用 runBlocking 协程构建器来阻塞:
import kotlinx.coroutines.*
fun main() {
GlobalScope.launch { // 在后台启动一个新的协程并继续
delay(1000L)
println("World!")
}
println("Hello,") // 主线程中的代码会立即执行
runBlocking { // 但是这个表达式阻塞了主线程
delay(2000L) // ……我们延迟 2 秒来保证 JVM 的存活
}
}结果是相似的,但是这些代码只使用了非阻塞的函数 delay。 调用了 runBlocking 的主线程会一直 阻塞 直到 runBlocking 内部的协程执行完毕。
这个示例可以使用更合乎惯用法的方式重写,使用 runBlocking 来包装 main 函数的执行:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> { // 开始执行主协程
GlobalScope.launch { // 在后台启动一个新的协程并继续
delay(1000L)
println("World!")
}
println("Hello,") // 主协程在这里会立即执行
delay(2000L) // 延迟 2 秒来保证 JVM 存活
}这里的 runBlocking<Unit> { …… } 作为用来启动顶层主协程的适配器。 我们显式指定了其返回类型 Unit,因为在 Kotlin 中 main 函数必须返回 Unit 类型。
这也是为挂起函数编写单元测试的一种方式:
class MyTest {
@Test
fun testMySuspendingFunction() = runBlocking<Unit> {
// 这里我们可以使用任何喜欢的断言风格来使用挂起函数
}
}协程的实际使用还有一些需要改进的地方。 当我们使用 GlobalScope.launch 时,我们会创建一个顶层协程。虽然它很轻量,但它运行时仍会消耗一些内存资源。如果我们忘记保持对新启动的协程的引用,它还会继续运行。如果协程中的代码挂起了会怎么样(例如,我们错误地延迟了太长时间),如果我们启动了太多的协程并导致内存不足会怎么样? 必须手动保持对所有已启动协程的引用并 join 之很容易出错。
有一个更好的解决办法。我们可以在代码中使用结构化并发。 我们可以在执行操作所在的指定作用域内启动协程, 而不是像通常使用线程(线程总是全局的)那样在 GlobalScope 中启动。
在我们的示例中,我们使用 runBlocking 协程构建器将 main 函数转换为协程。 包括 runBlocking 在内的每个协程构建器都将 CoroutineScope 的实例添加到其代码块所在的作用域中。 我们可以在这个作用域中启动协程而无需显式 join 之,因为外部协程(示例中的 runBlocking)直到在其作用域中启动的所有协程都执行完毕后才会结束。因此,可以将我们的示例简化为:
import kotlinx.coroutines.*
fun main() = runBlocking { // this: CoroutineScope
launch { // 在 runBlocking 作用域中启动一个新协程
delay(1000L)
println("World!")
}
println("Hello,")
}除了由不同的构建器提供协程作用域之外,还可以使用 coroutineScope 构建器声明自己的作用域。它会创建一个协程作用域并且在所有已启动子协程执行完毕之前不会结束。
runBlocking 与 coroutineScope 可能看起来很类似,因为它们都会等待其协程体以及所有子协程结束。 主要区别在于,runBlocking 方法会阻塞当前线程来等待, 而 coroutineScope 只是挂起,会释放底层线程用于其他用途。 由于存在这点差异,runBlocking 是常规函数,而 coroutineScope 是挂起函数。
可以通过以下示例来演示:
import kotlinx.coroutines.*
fun main() = runBlocking { // this: CoroutineScope
launch {
delay(200L)
println("Task from runBlocking")
}
coroutineScope { // 创建一个协程作用域
launch {
delay(500L)
println("Task from nested launch")
}
delay(100L)
println("Task from coroutine scope") // 这一行会在内嵌 launch 之前输出
}
println("Coroutine scope is over") // 这一行在内嵌 launch 执行完毕后才输出
}请注意,(当等待内嵌 launch 时)紧挨“Task from coroutine scope”消息之后, 就会执行并输出“Task from runBlocking”——尽管 coroutineScope 尚未结束。
我们来将 launch { …… } 内部的代码块提取到独立的函数中。当你对这段代码执行“提取函数”重构时,你会得到一个带有 suspend 修饰符的新函数。 这是你的第一个挂起函数。在协程内部可以像普通函数一样使用挂起函数, 不过其额外特性是,同样可以使用其他挂起函数(如本例中的 delay)来挂起协程的执行。
import kotlinx.coroutines.*
fun main() = runBlocking {
launch { doWorld() }
println("Hello,")
}
// 这是你的第一个挂起函数
suspend fun doWorld() {
delay(1000L)
println("World!")
}以下代码在 GlobalScope 中启动了一个长期运行的协程,该协程每秒输出“I'm sleeping”两次,之后在主函数中延迟一段时间后返回。
import kotlinx.coroutines.*
fun main() = runBlocking {
GlobalScope.launch {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // 在延迟后退出
}你可以运行这个程序并看到它输出了以下三行后终止:
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
在 GlobalScope 中启动的活动协程并不会使进程保活。它们就像守护线程。
这一部分包含了协程的取消与超时。
在一个长时间运行的应用程序中,你也许需要对你的后台协程进行细粒度的控制。 比如说,一个用户也许关闭了一个启动了协程的界面,那么现在协程的执行结果已经不再被需要了,这时,它应该是可以被取消的。 该 launch 函数返回了一个可以被用来取消运行中的协程的 Job:
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // 延迟一段时间
println("main: I'm tired of waiting!")
job.cancel() // 取消该作业
job.join() // 等待作业执行结束
println("main: Now I can quit.")程序执行后的输出如下:
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.
一旦 main 函数调用了 job.cancel,我们在其它的协程中就看不到任何输出,因为它被取消了。 这里也有一个可以使 Job 挂起的函数 cancelAndJoin 它合并了对 cancel 以及 join 的调用。
协程的取消是 协作 的。一段协程代码必须协作才能被取消。 所有 kotlinx.coroutines 中的挂起函数都是 可被取消的 。它们检查协程的取消, 并在取消时抛出 CancellationException。 然而,如果协程正在执行计算任务,并且没有检查取消的话,那么它是不能被取消的,就如如下示例代码所示:
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (i < 5) { // 一个执行计算的循环,只是为了占用 CPU
// 每秒打印消息两次
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // 等待一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消一个作业并且等待它结束
println("main: Now I can quit.")
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
job: I'm sleeping 3 ...
job: I'm sleeping 4 ...
main: Now I can quit.运行示例代码,并且我们可以看到它连续打印出了“I'm sleeping”,甚至在调用取消后, 作业仍然执行了五次循环迭代并运行到了它结束为止。
我们有两种方法来使执行计算的代码可以被取消。第一种方法是定期调用挂起函数来检查取消。对于这种目的 yield 是一个好的选择。 另一种方法是显式的检查取消状态。让我们试试第二种方法。
将前一个示例中的 while (i < 5) 替换为 while (isActive) 并重新运行它。
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (isActive) { // 可以被取消的计算循环
// 每秒打印消息两次
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // 等待一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消该作业并等待它结束
println("main: Now I can quit.")
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.你可以看到,现在循环被取消了。isActive 是一个可以被使用在 CoroutineScope 中的扩展属性。
我们通常使用如下的方法处理在被取消时抛出 CancellationException 的可被取消的挂起函数。比如说,try {……} finally {……} 表达式以及 Kotlin 的 use 函数一般在协程被取消的时候执行它们的终结动作:
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
println("job: I'm running finally")
}
}
delay(1300L) // 延迟一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消该作业并且等待它结束
println("main: Now I can quit.")
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
job: I'm running finally
main: Now I can quit.在前一个例子中任何尝试在 finally 块中调用挂起函数的行为都会抛出 CancellationException,因为这里持续运行的代码是可以被取消的。通常,这并不是一个问题,所有良好的关闭操作(关闭一个文件、取消一个作业、或是关闭任何一种通信通道)通常都是非阻塞的,并且不会调用任何挂起函数。然而,在真实的案例中,当你需要挂起一个被取消的协程,你可以将相应的代码包装在 withContext(NonCancellable) {……} 中,并使用 withContext 函数以及 NonCancellable 上下文,见如下示例所示:
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
withContext(NonCancellable) {
println("job: I'm running finally")
delay(1000L)
println("job: And I've just delayed for 1 sec because I'm non-cancellable")
}
}
}
delay(1300L) // 延迟一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消该作业并等待它结束
println("main: Now I can quit.")
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
job: I'm running finally
job: And I've just delayed for 1 sec because I'm non-cancellable
main: Now I can quit.本节介绍了将挂起函数组合的各种方法。
假设我们在不同的地方定义了两个进行某种调用远程服务或者进行计算的挂起函数。我们只假设它们都是有用的,但是实际上它们在这个示例中只是为了该目的而延迟了一秒钟:
suspend fun doSomethingUsefulOne(): Int {
delay(1000L) // 假设我们在这里做了一些有用的事
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L) // 假设我们在这里也做了一些有用的事
return 29
}
如果需要按 顺序 调用它们,我们接下来会做什么——首先调用 doSomethingUsefulOne 接下来 调用 doSomethingUsefulTwo,并且计算它们结果的和吗? 实际上,如果我们要根据第一个函数的结果来决定是否我们需要调用第二个函数或者决定如何调用它时,我们就会这样做。
我们使用普通的顺序来进行调用,因为这些代码是运行在协程中的,只要像常规的代码一样 顺序 都是默认的。下面的示例展示了测量执行两个挂起函数所需要的总时间:
val time = measureTimeMillis {
val one = doSomethingUsefulOne()
val two = doSomethingUsefulTwo()
println("The answer is ${one + two}")
}
println("Completed in $time ms")
The answer is 42
Completed in 2007 ms如果 doSomethingUsefulOne 与 doSomethingUsefulTwo 之间没有依赖,并且我们想更快的得到结果,让它们进行 并发 吗?这就是 async 可以帮助我们的地方。
在概念上,async 就类似于 launch。它启动了一个单独的协程,这是一个轻量级的线程并与其它所有的协程一起并发的工作。不同之处在于 launch 返回一个 Job 并且不附带任何结果值,而 async 返回一个 Deferred —— 一个轻量级的非阻塞 future, 这代表了一个将会在稍后提供结果的 promise。你可以使用 .await() 在一个延期的值上得到它的最终结果, 但是 Deferred 也是一个 Job,所以如果需要的话,你可以取消它。
val time = measureTimeMillis {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
The answer is 42
Completed in 1017 ms这里快了两倍,因为两个协程并发执行。 请注意,使用协程进行并发总是显式的。
可选的,async 可以通过将 start 参数设置为 CoroutineStart.LAZY 而变为惰性的。 在这个模式下,只有结果通过 await 获取的时候协程才会启动,或者在 Job 的 start 函数调用的时候。运行下面的示例:
val time = measureTimeMillis {
val one = async(start = CoroutineStart.LAZY) { doSomethingUsefulOne() }
val two = async(start = CoroutineStart.LAZY) { doSomethingUsefulTwo() }
// 执行一些计算
one.start() // 启动第一个
two.start() // 启动第二个
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")它的打印输出如下:
The answer is 42
Completed in 1017 ms
因此,在先前的例子中这里定义的两个协程没有执行,但是控制权在于程序员准确的在开始执行时调用 start。我们首先 调用 one,然后调用 two,接下来等待这个协程执行完毕。
注意,如果我们只是在 println 中调用 await,而没有在单独的协程中调用 start,这将会导致顺序行为,直到 await 启动该协程 执行并等待至它结束,这并不是惰性的预期用例。 在计算一个值涉及挂起函数时,这个 async(start = CoroutineStart.LAZY) 的用例用于替代标准库中的 lazy 函数。
我们可以定义异步风格的函数来 异步 的调用 doSomethingUsefulOne 和 doSomethingUsefulTwo 并使用 async 协程建造器并带有一个显式的 GlobalScope 引用。 我们给这样的函数的名称中加上“……Async”后缀来突出表明:事实上,它们只做异步计算并且需要使用延期的值来获得结果。
// somethingUsefulOneAsync 函数的返回值类型是 Deferred<Int>
fun somethingUsefulOneAsync() = GlobalScope.async {
doSomethingUsefulOne()
}
// somethingUsefulTwoAsync 函数的返回值类型是 Deferred<Int>
fun somethingUsefulTwoAsync() = GlobalScope.async {
doSomethingUsefulTwo()
}
//注意,这些 xxxAsync 函数不是 挂起 函数。它们可以在任何地方使用。 然而,它们总是在调用它们的代码中意味着异步(这里的意思是 并发 )执行。
//下面的例子展示了它们在协程的外面是如何使用的:
// 注意,在这个示例中我们在 `main` 函数的右边没有加上 `runBlocking`
fun main() {
val time = measureTimeMillis {
// 我们可以在协程外面启动异步执行
val one = somethingUsefulOneAsync()
val two = somethingUsefulTwoAsync()
// 但是等待结果必须调用其它的挂起或者阻塞
// 当我们等待结果的时候,这里我们使用 `runBlocking { …… }` 来阻塞主线程
runBlocking {
println("The answer is ${one.await() + two.await()}")
}
}
println("Completed in $time ms")
}
The answer is 42
Completed in 1118 ms这种带有异步函数的编程风格仅供参考,因为这在其它编程语言中是一种受欢迎的风格。在 Kotlin 的协程中使用这种风格是强烈不推荐的, 原因如下所述。
考虑一下如果 val one = somethingUsefulOneAsync() 这一行和 one.await() 表达式这里在代码中有逻辑错误, 并且程序抛出了异常以及程序在操作的过程中中止,将会发生什么。 通常情况下,一个全局的异常处理者会捕获这个异常,将异常打印成日记并报告给开发者,但是反之该程序将会继续执行其它操作。但是这里我们的 somethingUsefulOneAsync 仍然在后台执行, 尽管如此,启动它的那次操作也会被终止。这个程序将不会进行结构化并发,如下一小节所示。
让我们使用使用 async 的并发这一小节的例子并且提取出一个函数并发的调用 doSomethingUsefulOne 与 doSomethingUsefulTwo 并且返回它们两个的结果之和。 由于 async 被定义为了 CoroutineScope 上的扩展,我们需要将它写在作用域内,并且这是 coroutineScope 函数所提供的:
suspend fun concurrentSum(): Int = coroutineScope {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
one.await() + two.await()
}
//这种情况下,如果在 concurrentSum 函数内部发生了错误,并且它抛出了一个异常, 所有在作用域中启动的协程都会被取消。
val time = measureTimeMillis {
println("The answer is ${concurrentSum()}")
}
println("Completed in $time ms")
The answer is 42
Completed in 1022 ms取消始终通过协程的层次结构来进行传递:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
try {
failedConcurrentSum()
} catch(e: ArithmeticException) {
println("Computation failed with ArithmeticException")
}
}
suspend fun failedConcurrentSum(): Int = coroutineScope {
val one = async<Int> {
try {
delay(Long.MAX_VALUE) // 模拟一个长时间的运算
42
} finally {
println("First child was cancelled")
}
}
val two = async<Int> {
println("Second child throws an exception")
throw ArithmeticException()
}
one.await() + two.await()
}
//请注意,如果其中一个子协程(即 two)失败,第一个 async 以及等待中的父协程都会被取消:
Second child throws an exception
First child was cancelled
Computation failed with ArithmeticException协程总是运行在一些以 CoroutineContext 类型为代表的上下文中,它们被定义在了 Kotlin 的标准库里。
协程上下文是各种不同元素的集合。其中主元素是协程中的 Job, 我们在前面的文档中见过它以及它的调度器,而本文将对它进行介绍。
协程上下文包含一个 协程调度器 (参见 CoroutineDispatcher)它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。
所有的协程构建器诸如 launch 和 async 接收一个可选的 CoroutineContext 参数,它可以被用来显式的为一个新协程或其它上下文元素指定一个调度器。
尝试下面的示例:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
launch { // 运行在父协程的上下文中,即 runBlocking 主协程
println("main runBlocking : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Unconfined) { // 不受限的——将工作在主线程中
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Default) { // 将会获取默认调度器
println("Default : I'm working in thread ${Thread.currentThread().name}")
}
launch(newSingleThreadContext("MyOwnThread")) { // 将使它获得一个新的线程
println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}")
}
}它执行后得到了如下输出(也许顺序会有所不同):
Unconfined : I'm working in thread main
Default : I'm working in thread DefaultDispatcher-worker-1
newSingleThreadContext: I'm working in thread MyOwnThread
main runBlocking : I'm working in thread main
当调用 launch { …… } 时不传参数,它从启动了它的 CoroutineScope 中承袭了上下文(以及调度器)。在这个案例中,它从 main 线程中的 runBlocking 主协程承袭了上下文。
Dispatchers.Unconfined 是一个特殊的调度器且似乎也运行在 main 线程中,但实际上, 它是一种不同的机制,这会在后文中讲到。
当协程在 GlobalScope 中启动时,使用的是由 Dispatchers.Default 代表的默认调度器。 默认调度器使用共享的后台线程池。 所以 launch(Dispatchers.Default) { …… } 与 GlobalScope.launch { …… } 使用相同的调度器。
newSingleThreadContext 为协程的运行启动了一个线程。 一个专用的线程是一种非常昂贵的资源。 在真实的应用程序中两者都必须被释放,当不再需要的时候,使用 close 函数,或存储在一个顶层变量中使它在整个应用程序中被重用。
Dispatchers.Unconfined 协程调度器在调用它的线程启动了一个协程,但它仅仅只是运行到第一个挂起点。挂起后,它恢复线程中的协程,而这完全由被调用的挂起函数来决定。非受限的调度器非常适用于执行不消耗 CPU 时间的任务,以及不更新局限于特定线程的任何共享数据(如UI)的协程。
另一方面,该调度器默认继承了外部的 CoroutineScope。 runBlocking 协程的默认调度器,特别是, 当它被限制在了调用者线程时,继承自它将会有效地限制协程在该线程运行并且具有可预测的 FIFO 调度。
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
launch(Dispatchers.Unconfined) { // 非受限的——将和主线程一起工作
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
delay(500)
println("Unconfined : After delay in thread ${Thread.currentThread().name}")
}
launch { // 父协程的上下文,主 runBlocking 协程
println("main runBlocking: I'm working in thread ${Thread.currentThread().name}")
delay(1000)
println("main runBlocking: After delay in thread ${Thread.currentThread().name}")
}
}执行后的输出:
Unconfined : I'm working in thread main
main runBlocking: I'm working in thread main
Unconfined : After delay in thread kotlinx.coroutines.DefaultExecutor
main runBlocking: After delay in thread main
所以,该协程的上下文继承自 runBlocking {...} 协程并在 main 线程中运行,当 delay 函数调用的时候,非受限的那个协程在默认的执行者线程中恢复执行。
非受限的调度器是一种高级机制,可以在某些极端情况下提供帮助而不需要调度协程以便稍后执行或产生不希望的副作用, 因为某些操作必须立即在协程中执行。 非受限调度器不应该在通常的代码中使用。
协程可以在一个线程上挂起并在其它线程上恢复。 如果没有特殊工具,甚至对于一个单线程的调度器也是难以弄清楚协程在何时何地正在做什么事情。
Kotlin 插件的协程调试器简化了 IntelliJ IDEA 中的协程调试.
调试适用于 1.3.8 或更高版本的
kotlinx-coroutines-core。
调试工具窗口包含 Coroutines 标签。在这个标签中,你可以同时找到运行中与已挂起的协程的相关信息。 这些协程以它们所运行的调度器进行分组。

使用协程调试器,你可以:
- 检查每个协程的状态。
- 查看正在运行的与挂起的的协程的局部变量以及捕获变量的值。
- 查看完整的协程创建栈以及协程内部的调用栈。栈包含所有带有变量的栈帧,甚至包含那些在标准调试期间会丢失的栈帧。
- 获取包含每个协程的状态以及栈信息的完整报告。要获取它,请右键单击 Coroutines 选项卡,然后点击 Get Coroutines Dump。
要开始协程调试,你只需要设置断点并在调试模式下运行应用程序即可。
在这篇教程中学习更多的协程调试知识。
另一种调试线程应用程序而不使用协程调试器的方法是让线程在每一个日志文件的日志声明中打印线程的名字。这种特性在日志框架中是普遍受支持的。但是在使用协程时,单独的线程名称不会给出很多协程上下文信息,所以 kotlinx.coroutines 包含了调试工具来让它更简单。
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码:
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking<Unit> {
val a = async {
log("I'm computing a piece of the answer")
6
}
val b = async {
log("I'm computing another piece of the answer")
7
}
log("The answer is ${a.await() * b.await()}")
}这里有三个协程,包括 runBlocking 内的主协程 (#1) , 以及计算延期的值的另外两个协程 a (#2) 和 b (#3)。 它们都在 runBlocking 上下文中执行并且被限制在了主线程内。 这段代码的输出如下:
[main @coroutine#2] I'm computing a piece of the answer
[main @coroutine#3] I'm computing another piece of the answer
[main @coroutine#1] The answer is 42
这个 log 函数在方括号种打印了线程的名字,并且你可以看到它是 main 线程,并且附带了当前正在其上执行的协程的标识符。这个标识符在调试模式开启时,将连续分配给所有创建的协程。
当 JVM 以
-ea参数配置运行时,调试模式也会开启。 你可以在 DEBUG_PROPERTY_NAME 属性的文档中阅读有关调试工具的更多信息。
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() {
newSingleThreadContext("Ctx1").use { ctx1 ->
newSingleThreadContext("Ctx2").use { ctx2 ->
runBlocking(ctx1) {
log("Started in ctx1")
withContext(ctx2) {
log("Working in ctx2")
}
log("Back to ctx1")
}
}
}
}它演示了一些新技术。其中一个使用 runBlocking 来显式指定了一个上下文,并且另一个使用 withContext 函数来改变协程的上下文,而仍然驻留在相同的协程中,正如可以在下面的输出中所见到的:
[Ctx1 @coroutine#1] Started in ctx1
[Ctx2 @coroutine#1] Working in ctx2
[Ctx1 @coroutine#1] Back to ctx1
注意,在这个例子中,当我们不再需要某个在 newSingleThreadContext 中创建的线程的时候, 它使用了 Kotlin 标准库中的 use 函数来释放该线程。
协程的 Job 是上下文的一部分,并且可以使用 coroutineContext [Job] 表达式在上下文中检索它:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
println("My job is ${coroutineContext[Job]}")
}在调试模式下,它将输出如下这些信息:
My job is "coroutine#1":BlockingCoroutine{Active}@6d311334
请注意,CoroutineScope 中的 isActive 只是 coroutineContext[Job]?.isActive == true 的一种方便的快捷方式。
当一个协程被其它协程在 CoroutineScope 中启动的时候, 它将通过 CoroutineScope.coroutineContext 来承袭上下文,并且这个新协程的 Job 将会成为父协程作业的 子 作业。当一个父协程被取消的时候,所有它的子协程也会被递归的取消。
然而,当使用 GlobalScope 来启动一个协程时,则新协程的作业没有父作业。 因此它与这个启动的作用域无关且独立运作。
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
// 启动一个协程来处理某种传入请求(request)
val request = launch {
// 孵化了两个子作业, 其中一个通过 GlobalScope 启动
GlobalScope.launch {
println("job1: I run in GlobalScope and execute independently!")
delay(1000)
println("job1: I am not affected by cancellation of the request")
}
// 另一个则承袭了父协程的上下文
launch {
delay(100)
println("job2: I am a child of the request coroutine")
delay(1000)
println("job2: I will not execute this line if my parent request is cancelled")
}
}
delay(500)
request.cancel() // 取消请求(request)的执行
delay(1000) // 延迟一秒钟来看看发生了什么
println("main: Who has survived request cancellation?")
}这段代码的输出如下:
job1: I run in GlobalScope and execute independently!
job2: I am a child of the request coroutine
job1: I am not affected by cancellation of the request
main: Who has survived request cancellation?
一个父协程总是等待所有的子协程执行结束。父协程并不显式的跟踪所有子协程的启动,并且不必使用 Job.join 在最后的时候等待它们:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
// 启动一个协程来处理某种传入请求(request)
val request = launch {
repeat(3) { i -> // 启动少量的子作业
launch {
delay((i + 1) * 200L) // 延迟 200 毫秒、400 毫秒、600 毫秒的时间
println("Coroutine $i is done")
}
}
println("request: I'm done and I don't explicitly join my children that are still active")
}
request.join() // 等待请求的完成,包括其所有子协程
println("Now processing of the request is complete")
}结果如下所示:
request: I'm done and I don't explicitly join my children that are still active
Coroutine 0 is done
Coroutine 1 is done
Coroutine 2 is done
Now processing of the request is complete
当协程经常打印日志并且你只需要关联来自同一个协程的日志记录时, 则自动分配的 id 是非常好的。然而,当一个协程与特定请求的处理相关联时或做一些特定的后台任务,最好将其明确命名以用于调试目的。 CoroutineName 上下文元素与线程名具有相同的目的。当调试模式开启时,它被包含在正在执行此协程的线程名中。
下面的例子演示了这一概念:
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking(CoroutineName("main")) {
log("Started main coroutine")
// 运行两个后台值计算
val v1 = async(CoroutineName("v1coroutine")) {
delay(500)
log("Computing v1")
252
}
val v2 = async(CoroutineName("v2coroutine")) {
delay(1000)
log("Computing v2")
6
}
log("The answer for v1 / v2 = ${v1.await() / v2.await()}")
}程序执行使用了 -Dkotlinx.coroutines.debug JVM 参数,输出如下所示:
[main @main#1] Started main coroutine
[main @v1coroutine#2] Computing v1
[main @v2coroutine#3] Computing v2
[main @main#1] The answer for v1 / v2 = 42
有时我们需要在协程上下文中定义多个元素。我们可以使用 + 操作符来实现。 比如说,我们可以显式指定一个调度器来启动协程并且同时显式指定一个命名:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
launch(Dispatchers.Default + CoroutineName("test")) {
println("I'm working in thread ${Thread.currentThread().name}")
}
}这段代码使用了 -Dkotlinx.coroutines.debug JVM 参数,输出如下所示:
I'm working in thread DefaultDispatcher-worker-1 @test#2
让我们将关于上下文,子协程以及作业的知识综合在一起。假设我们的应用程序拥有一个具有生命周期的对象,但这个对象并不是一个协程。举例来说,我们编写了一个 Android 应用程序并在 Android 的 activity 上下文中启动了一组协程来使用异步操作拉取并更新数据以及执行动画等等。所有这些协程必须在这个 activity 销毁的时候取消以避免内存泄漏。当然,我们也可以手动操作上下文与作业,以结合 activity 的生命周期与它的协程,但是 kotlinx.coroutines 提供了一个封装:CoroutineScope 的抽象。 你应该已经熟悉了协程作用域,因为所有的协程构建器都声明为在它之上的扩展。
我们通过创建一个 CoroutineScope 实例来管理协程的生命周期,并使它与 activity 的生命周期相关联。CoroutineScope 可以通过 CoroutineScope() 创建或者通过MainScope() 工厂函数。前者创建了一个通用作用域,而后者为使用 Dispatchers.Main 作为默认调度器的 UI 应用程序 创建作用域:
class Activity {
private val mainScope = MainScope()
fun destroy() {
mainScope.cancel()
}
// 继续运行……现在,我们可以使用定义的 scope 在这个 Activity 的作用域内启动协程。 对于该示例,我们启动了十个协程,它们会延迟不同的时间:
// 在 Activity 类中
fun doSomething() {
// 在示例中启动了 10 个协程,且每个都工作了不同的时长
repeat(10) { i ->
mainScope.launch {
delay((i + 1) * 200L) // 延迟 200 毫秒、400 毫秒、600 毫秒等等不同的时间
println("Coroutine $i is done")
}
}
}
} // Activity 类结束在 main 函数中我们创建 activity,调用测试函数 doSomething,并且在 500 毫秒后销毁这个 activity。 这取消了从 doSomething 启动的所有协程。我们可以观察到这些是由于在销毁之后, 即使我们再等一会儿,activity 也不再打印消息。
import kotlinx.coroutines.*
class Activity {
private val mainScope = CoroutineScope(Dispatchers.Default) // use Default for test purposes
fun destroy() {
mainScope.cancel()
}
fun doSomething() {
// 在示例中启动了 10 个协程,且每个都工作了不同的时长
repeat(10) { i ->
mainScope.launch {
delay((i + 1) * 200L) // 延迟 200 毫秒、400 毫秒、600 毫秒等等不同的时间
println("Coroutine $i is done")
}
}
}
} // Activity 类结束
fun main() = runBlocking<Unit> {
val activity = Activity()
activity.doSomething() // 运行测试函数
println("Launched coroutines")
delay(500L) // 延迟半秒钟
println("Destroying activity!")
activity.destroy() // 取消所有的协程
delay(1000) // 为了在视觉上确认它们没有工作
}这个示例的输出如下所示:
Launched coroutines
Coroutine 0 is done
Coroutine 1 is done
Destroying activity!
你可以看到,只有前两个协程打印了消息,而另一个协程在 Activity.destroy() 中单次调用了 job.cancel()。
注意,Android 在所有具有生命周期的实体中都对协程作用域提供了一等的支持。 请查看相关文档。
有时,能够将一些线程局部数据传递到协程与协程之间是很方便的。 然而,由于它们不受任何特定线程的约束,如果手动完成,可能会导致出现样板代码。
ThreadLocal, asContextElement 扩展函数在这里会充当救兵。它创建了额外的上下文元素, 且保留给定 ThreadLocal 的值,并在每次协程切换其上下文时恢复它。
它很容易在下面的代码中演示
import kotlinx.coroutines.*
val threadLocal = ThreadLocal<String?>() // 声明线程局部变量
fun main() = runBlocking<Unit> {
threadLocal.set("main")
println("Pre-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
val job = launch(Dispatchers.Default + threadLocal.asContextElement(value = "launch")) {
println("Launch start, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
yield()
println("After yield, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
}
job.join()
println("Post-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
}在这个例子中我们使用 Dispatchers.Default 在后台线程池中启动了一个新的协程,所以它工作在线程池中的不同线程中,但它仍然具有线程局部变量的值, 我们指定使用 threadLocal.asContextElement(value = "launch"), 无论协程执行在哪个线程中都是没有问题的。 因此,其输出如(调试)所示:
Pre-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
Launch start, current thread: Thread[DefaultDispatcher-worker-1 @coroutine#2,5,main], thread local value: 'launch'
After yield, current thread: Thread[DefaultDispatcher-worker-2 @coroutine#2,5,main], thread local value: 'launch'
Post-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
这很容易忘记去设置相应的上下文元素。如果运行协程的线程不同, 在协程中访问的线程局部变量则可能会产生意外的值。 为了避免这种情况,建议使用 ensurePresent 方法并且在不正确的使用时快速失败。
ThreadLocal 具有一流的支持,可以与任何 kotlinx.coroutines 提供的原语一起使用。 但它有一个关键限制,即:当一个线程局部变量变化时,则这个新值不会传播给协程调用者(因为上下文元素无法追踪所有 ThreadLocal 对象访问),并且下次挂起时更新的值将丢失。 使用 withContext 在协程中更新线程局部变量,详见 asContextElement。
另外,一个值可以存储在一个可变的域中,例如 class Counter(var i: Int),是的,反过来, 可以存储在线程局部的变量中。然而,在这个案例中你完全有责任来进行同步可能的对这个可变的域进行的并发的修改。
对于高级的使用,例如,那些在内部使用线程局部传递数据的用于与日志记录 MDC 集成,以及事务上下文或任何其它库,请参见需要实现的 ThreadContextElement 接口的文档。
自定义view 包含什么?布局 显示 时间分发
布局:onLayout onMeausre / layout:ViewGroup
显示:onDraw : canvas paint matrix clip rect animation path(别塞尔曲线)
交互:onTouchEvennt :组合的viewgroup
ViewGroup 先度量孩子,再度量自己
在没有现成的View,需要自己 实现的时候,就使用自定义View,一般继承自View,SurfaceView或其他View。
自定义ViewGroup一般是利用现有的组件根据特定的布局方法来组成新的组件,大多继承自ViewGroup或各种Layout。
高两位:用来表示mode UNSPECIFIED 不对View大小左限制,系统使用;EXACTLY 确切得大小,如100dp;AT_MOST 大小不可超过某数值,如:matchParent,最大不能超过你爸爸。
低30位:表示size
事件分发流程 Activity # dispatchTouchEvent()
\|/
PhoneWindow # SuperDispatchTouchEvent()
\|/
DecorView # SuperDispatchTouchEvent()
\|/
ViewGroup # dispatchTouchEvent()
\|/
处理事件 View # dispatchTouchEvent()
\|/
View # onTouchEvent()会的!当onTouch 返回 true 的时候 onClick会被拦截了。
外部拦截法 父View去处理
内部拦截法 子view去处理
- 判断事件是否拦截
- 分发或者处理(拦截:相当于你是最后一个)down事件才会分发
一般来说是直接交给Down事件处理对象。
Handler 通信实现的方案实际上是内存共享的方案。
(子线程)handler--》sendMessage(发出消息)--》messageQueue.enqueueMessage(把消息放到消息队列)--》Looper.loop(循环拿出消息池里的信息)--》messageQueue.next()--》(主线程)handler.dispatchMessage()-->handler.handleMessage(拿到消息)
数据结构:由单链表实现的优先级队列
排序算法?插入算法!
先进,先出
永远都是取第一个:所以是一个优先级队列。
Looper源码核心? 构造函数 loop方法 threadLocal
MessageQueue伴随着looper一起创建,只有一个
享元设计模式(内存复用)为什么Handler 会有Activity对象,因为内部类持有外部类对象(JAVA思想)
刷新UI
HandlerThread 是 Thread 的子类,就是一个线程,只是它在自己的线程里面帮我们创建了Looper。
HandlerThread存在的意义如下
- 方便使用,方便初始化,方便获取线程Looper
- 保证了线程安全
因为有 ThreadLocal()的存在,ThreadLocalMap里保存了loop对象。
线程 -》 ThreadLocalMap -》 <唯一的ThreadLocal,value>
有N个,可以一直New
一个,因为有stheardLocal,保存了一份Looper对象。
内部类持有外部类的对象!其他类是生命周期的问题 Handler持有activity对象,根据可达性分析回收不到。
new Thread(Runnable){
Looper.prepare();
//再发送消息
handler.sendMessage();
Looper.loop();
}子线程没有消息一定要调用,mQueue.quit();
两个方面:
- message 不到时间 (自动唤醒)
- messageQueue为空,(无限等待),当sendMessage的时候会nativeWake()方法唤醒。
应用退出(mQueue.quit()...
- 进程间的通信机制
- 驱动设备
- binder.java -->实现 Ibinder 接口
- 每个进程里面 都有自己的内存空间 和 内核内存空间
自己创建得进程:webview, 视频播放,音乐,推送
管道,信号量,socket,共享内存
优点:
- 内存
- 风险隔离
- 性能小于共享内存,优与其他方法 IPC(进程间通信)

Linux通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(menory mapping)。
- 通过用户空间得虚拟内存大小---分配一块内核的虚拟内存
- 分配了一块物理内存
- 把这块物理内存分别映射到 用户空间的虚拟内存和内核的虚拟内存
虚拟内存--地球仪
物理内存--地球
BInder 初始化主要做以下的事:
- 分配内存
- 初始化设备
- 放入链表( binder_devices )
- 创建binder_proc对象
- 当前进程的信息,proc
- filp->private_data = proc
- 添加到binder_procs链表中
- 通过用户空间的虚拟内存大小--分配一块内核的虚拟内存
- 分配了一块物理内存---4kb(一叶)
- 把这块物理内存分别映射到---用户空间的虚拟内存 和 内核的虚拟内存
struct vm_struct * area;---内核的虚拟内存
vma ---- 进程的虚拟内存 ----4M驱动定的,1M-8k ---intent 里面使用了binder 所以传输数据大小不能超过1M
虚拟内存 放入一个东西
用户空间 == 虚拟内存地址 + 偏移量
分配4kb的物理内存 --- 内核的虚拟空间(默认同步)
- 读写操作---BINDER_WRITE_READ---ioctl(BINDER_WRITE_READ )
binder 的 jni 注册 目的:java 和 native 能够互相调用--系统帮我们注册了
Java Object life Cycle
Created创建--》In use应用--》invisible不可见--》Unreachable--》不可达--》Collected收集--》Finalize终结--》Dealucateated--》对象空间重新分配
Android:
Dalvik:
Linear Alloc:匿名共享内存
zygote space:
Alloc space:每个进程独占
ART:
Non Moving Space:
Zygote Space:
Image Space:预加载的类信息
Large OBJ Space:大对象 bitmap 可以查看app后台分配数字,如果数字越大,回收的时候越容易被回收。
- 内存抖动
- 内存泄漏
- 内存溢出
内存波动图形呈锯齿状、GC导致卡顿。
在当前应用周期内不再使用的对象被GC Roots引用,导致不能回收,使实际可使用内存变少。
即OOM,OOM时会导致程序异常。Android设备出长以后,java虚拟机对单个应用的最大内存分配就确定下来了,超出这个值就会OOM。
- JAVA堆内存溢出
- 没有足够的连续内存空间
- FD数量超出限制
- 线程数量超出限制
- 虚拟内存不足
#include <stdio.h>
- <>寻找系统得资源
- "" 寻找我们自己写的资源
- .h .hpp (声明文件 头文件)
- .c .cpp (实现文件)
#include <stdio.h>
//基本数据类型
int main(){
int i = 100;
double d = 200.21;
float f = 200;
long l = 100;
short s = 100;
char c = 'd';
//字符串
char * str = "Karson";
//不是随便打印,需要占位
printf("i的值是:%d\n",i);
printf("d的值是:%lf\n",d);
printf("f的值是:%f\n",f);
printf("l的值是:%d\n",l);
printf("s的值是:%d\n",s);
printf("c的值是:%c\n",c);
printf("str的值是:%s\n",str);
//& 等于取出这个值的地址
//* 等于取出这个地址所对应的值
//指针永远存放内存地址
/*
* 内存地址 == 指针
* 指针 == 内存地址
* int * int类型的指针
* 指针别名,指针变量 == 就是一个变量而已,只不过是指针变量
*/
int num = 99;
int * num_p = #//取出num的内存地址给num_p 一级指针
int ** num_p_p = &num_p;//取出num_p的内存地址给num_p_P 二级指针
//定义数组
int arr[] = {1,2,3,4};
//数组的内存地址 == 第一个元素的内存地址
//数组是连续的内存空间
//规范写法
int i = 0;
for(i = 0;i < 4; ++i ){
}
return 0;
}基本数据类型占多少个字节,不同系统不同!!
int == 4字节
double == 8字节
char == 1字节
#include<stdio.h>
void change(int i);//先声明
//
int main(){
return 0;
}
//再实现
void change(int i){
}指针占用的内存大小是?4个字节,不同操作系统不同,32位是4 ,64是8
指针有什么用,既然都是4?数组每次挪动都是4!类型规定的好处
//函数指针
void add(int num1,int num2){
}
void opreate(void(*method)(int,int),int num1,int num2){
//函数的上面已经声明就是 函数的指针,所以可以省略*
method(num1,num2);
}
//把函数当成指针
int main(){
opreate(10,10);
return 0;
}函数指针升级用法
#include<stdio.h>
//进栈
void staticAction(){
int arr[5];//静态开辟 栈区
int i = 0;
for (i = 0;i < 5; ++i ){
arr[i] = i;
printf("%d,%p \n",*(arr + 1),arr + 1);
}
}
//malloc 在堆区开辟的内存空间(动态的范畴)
void dynamicAction(){
//void * 可以任意转变 int * double *
int * arr = malloc(1 * 1024 * 1024);
//必须释放
free(arr);
arr = NULL;
}//此函数弹栈后,不会释放堆区成员。
//动态开辟之 realloc
//面试题 为什么传入arr指针,和总大小长度,因为有可能系统占用了资源,新开辟空间
int main(){
int num;
printf("i请输入数的个数");
scanf("%d",&num);
int * arr = (int *)malloc(sizeof(int) * num);
int new_num;
scanf("%d",&new_num);
int * new_arr = (int *)realloc(arr,sizeof(int) * (num + new_num));
}
void callBackMethod(char * fileName,int current,int total){
}
//压缩的方法
//定义函数指针:返回值(*名称)(int,double)
void compress(char * fileName,void(*callBack)(char * ,int,int)){
callBack(fileName,5,10);//回调给外界 压缩的进度情况
}
//C语言 boolean 不是0就是true!!
//栈区:占用内存大小 最大值:2M 平台有关系的
int main(){
void(* call) (char*,int,int) = callBackMethod;//这个写法不规范
//先定义再赋值
void (* call)(char *,int,int);
call = callBackMethod;
//使用
compress("karson",call);
}
//字符串
void string(){
char str[] = {'k','a','r','s','o','n'};
str[2] = 'z';
printf("第一种方式%s\n",str);//printf 必须遇到 \0才结束。
char * str2 = "karson";//隐式添加 karson\0
str2[2] = 'z';//这个会崩溃
}
int getlen(char * string){
int count = 0;
while(*string){// stirng != \0
count++;
}
return count;
}
/**
* 字符串转换
*/
void changeStr(){
char * num = "1";
int result = atoi(num);
if(result){
//转换成功 ,非0就是ture
}else{
//转换失败
}
}
void len(){
char * pop = "karson";
char * text = "l am karson";
//求取位置
int index = pop - text;
printf("%s第一次出现的位置是:%d\n",pop,index);
}
//转换成小写
void lower(char * dest,char * name){
while(*name){
*dest = tolower(*name);
name++;//挪动指针
dest++;//挪动指针
}
*dest = '\0';//避免打印系统值
}// 第一种写法
struct Dog{
//成员
char name[10];//这个需要strcpy进去
int age;
char sex;
};
//第二种
struct Person{
//成员
char * name;
int age;
char sex;
} ppp = {"karson",33,'M'},
ppp2,
ppp3,
ppp5;
//第三种
struct Study{
char * studyContent;//学习内容
};
struct Student{
//成员
char * name;
int age;
char sex;
Study study;//vs 的写法
struct Study study;//Clion 工具写法
struct Wan{
char * wanContent;//玩的内容
} wan;
};
int main(){
struct Dog dog;//这样写完,成员是没有任何初始化的,成员默认值为系统值
//赋值操作
strcpy(dog.name,"旺财");
dog.age = 3;
dog.sex = 'g';
// ppp.name = karson
ppp.name = "karson"
ppp.age = 3;
ppp.sex = 'g';
//3
struct Student student ={"mm",88,'g',{"学习C"},{"王者荣耀"}};
return 0;
}struct Cat{
char name[10];
int age;
}
//结构体与 结构体别名
typedef struct Cat;//给结构体取别名 为什么要做 typedef 因为要做兼容
typedef Cat * cat;//给结构体指针取别名
//匿名结构体的别名
typedef struct {
char name[10];
int age;
} AV ;//AV 是这个匿名结构体的别名
int main(){
//定义了别名
// VS CLion 一样的写法了
Cat * cat2 = malloc(sizeof(Cat));//就可以这样写了
//============================================
//栈区
//结构体
struct Cat cat = {"jumao",2};
struct Cat * catp = &cat;
catp->age = 3;
strcpy(catp->name,"hahahaha");
//堆区
struct Cat * cat2 = malloc(sizeof(struct Cat));
//栈区
//结构体数组
struct cat cat[10] ={
{"cat1",1},
{"cat2",2}
}
struct Cat cat9 = {"cat9",9};
cat[9] = cat9;
//堆区
struct Cat * cat = malloc(sizeof(struct Cat) * 10);
//默认第一个
strcpy(cat->name,"cat1");
cat->age = 1;
//给第八个赋值
cat += 7;
strcpy(cat->name,"cat1");
cat ->age = 1;
}enum CommentType{
TEXT = 10,
TEXT_IMAGRE,
IAMGE
};
//创建的时候已经有别名
enum CommentType{
TEXT = 10,
TEXT_IMAGRE,
IAMGE
}AV;
int main(){
//CLion 写法
enum CommentType commentType = TEXT;
//VS
CommentType commentType = TEXT;
return 0;
}#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
//fopen 打开文件的意思(参数1 文件路径,参数2 模式(r)读(w)写 (rb)作为二进制的读,(wb)作为二进制的写) 返回值是结构体
///=================打开文件========================
//文件路径
char * fileName = "filePath";
File * file = fopen(fileName,"r");
if(!file){
exit(0);//退出程序
}
///=================读读读========================
char bufferp[10];
while(fgets(buffer,10,file)){
printf("%s",buffer);
}
//关闭文件
fclose(file);
return 0;
}#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
//fopen 打开文件的意思(参数1 文件路径,参数2 模式(r)读(w)写 (rb)作为二进制的读,(wb)作为二进制的写) 返回值是结构体
char * fileNameStr = "D:.....";
//既然是使用了w,他会自动生成文件
FILE * file(fileNameStr,"w");
if(!file){
exit(0);
}
fputs("karson Success run..",file);
//关闭文件
fclose(file);
return 0;
} #include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
char * fileNameStrFrom = "D:.....";//来源
char * fileNameStrTo = "C:....."; //到哪里去
//rb 读取二进制数据
FILE * file = fopen(fileNameStrFrom,"rb");
//rw 写入二进制数据
FILE * fileCopy = fopen(fileNameStrTo,"wb");
if(!file || !fileCopy){
exit(0);
}
///=================读读读========================
char buffer[514]; //514 * 4个字节
int len;//每次读取的长度
//fread: 参数1:容器buffer , 参数2 :每次偏移多少, 参数3 :容器大小
while((len = fread(buffer,sizeof(int),sizeof(buffer) / sizeof(int) ,file)) != 0){
fwrite(buffer,sizeof(int),len,fileCopy);
}
//关闭文件
fclose(file);
fclose(fileCopy);
return 0;
}#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
char * fileNameStr = "D:.....";//来源
File * file = fopen(fileName,"rb");
if(!file){
exit(0);
}
SEEK_CUR()
// SEEK_SET(开头) SEEK_CUR(当前)
fseek(file,0,SEEK_END);//挪动文件指针
long file_size = ftell(file);
printf("文件字节的大小: %d",file_size);
//关闭文件
fclose(file);
return 0;
}#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//================加密=================================
int main(){
char * fileNameStr = "D:.....";//来源
char * fileNameStrEncode = "D:.....";//加密后的目标文件
File * file = fopen(fileName,"rb");// r 必须提前准备好文件
File * fileEncode = fopen(fileNameStrEncode,"wb");// w 创建一个0kb文件
if(!file || !fileEncode){
exit(0);
}
// 【加密 和 解密 的 思路】
// 加密 === 破坏文件
// 解密 === 还原文件
int c;//接受读取的值
while((c = fgetc(file)) != EOF){
//加密操作
fputc(c ^ 5,fileEncode);//写入 到 fileEncode
}
//关闭文件
fclose(file);
fclose(fileEncode);
return 0;
}
//==============解密=======================================
int main(){
char * fileNameStrEncode = "D:.....";//来源
char * fileNameStr = "D:.....";//解密后的目标文件
File * file = fopen(fileName,"rb");// r 必须提前准备好文件
File * fileEncode = fopen(fileNameStr,"wb");// w 创建一个0kb文件
if(!file || !fileEncode){
exit(0);
}
// 【加密 和 解密 的 思路】
// 加密 === 破坏文件
// 解密 === 还原文件
int c;//接受读取的值
while((c = fgetc(file)) != EOF){
//加密操作
fputc(c ^ 5,fileEncode);//写入 到 fileEncode
}
//关闭文件
fclose(file);
fclose(fileEncode);
return 0;
}C++ 语言面向对象
c语言面向过程
void numberChange2(int & number1,int & number2){
//如果采用了引用 那两个函数的内存地址是一样的
int temp = 0;
tmep = number1;
number1 = number2;
number2 = temp;
}
int main(){
int number1 = 10;
int number2 = 20;
numberChange2(number1,number2);
return 0;
}#include<iostream>
//声明std 我们的main函数就可以直接使用
using namespace std;
typedef struct{
char name[20];
int age;
}Student;
//常量引用:Student 不准你改
//插入数据库
void insertStudent(const Student & student){
//只能读 不能修改
}
int main(){
Student student = {"karson","18"};
insertStudent(student);
//—> 调用一级指针的成员
return 0;
}
//默认行参赋值
int add(bool isOk = 0){
}
//系统源码大量使用
void add(char * logText,int ,int ,int){
}#include<iostream>
//声明std 我们的main函数就可以直接使用
using namespace std;
class Student{
public:
//空参数构造函数
Student(){
count << "123" << endl;
}
//系统源码
Student(char * name):name(name){
count << "一个参数构造函数" << endl;
}
//如果想一个构造函数调用两个构造喊出
//先调用两个构造函数,再调用一个构造函数
Student(char * name):Student(name,18){
count << "一个参数构造函数" << endl;
}
Student(char * name,int age){
count << "两个个参数构造函数" << endl;
}
//析构函数 Student 对象的,临终遗言,Student对象被回收了,你做一些释放工作
//delete stu 的时候,我们的析构函数一定会执行
//free 不会执行
~Student(){
}
//拷贝构造函数,它默认有,我们看不到,一旦我们写拷贝构造函数,会覆盖它
//对象1 = 对象2
//覆盖拷贝构造函数
Student(const Student & student){//常量引用: 只读的
cout << "拷贝构造函数" << endl;
//要自己来处理 可以自己来控制
this-name = student.name;
this->age = student.age;
}
private:
char * name;
int age;
public:
void setName(char * name){
this->name = name;
}
char * getName(){
return this->name;
}
};
int main(){
//栈区空间
Student stu;
stu.setName("123");
//堆区
Student * stu = new Student("karson",26);
delete stu;
return 0;
}!!!new / delete 是一套 会调用构造函数 与 析构函数【C++标准规范】
!!!malloc / free 是一套 不会调用构造函数 与 析构函数【C语言范畴】
#include<iostream>
struct Person{
int age;
char * name;
}
int main{
Person person1 = {100,"sss"};
// = 你看起来,没什么特殊,但是有隐式的代码
//寻求p1 地址的对应成员的值 -》 寻求p2地址的对应成员赋值给给他们
//这样会调用自己定义的构造函数
Person person2 = person1;
cout << preson2.name << "," << person2.age << endl;
Person person2
person2 = person1;//这样不会调用自己定义的拷贝构造函数,但是会调用默认的拷贝构造函数
return 0;
}
int main(){
int number = 9;
int number2 = 8;
//常量指针
const int * numberP1 = &number;
*numberP1 = 100;//报错 不允许去修改【常量指针】存放地址所对应的值
numberP1 = &number2;//ok,允许重新指向【常量指针】存放的地址
//指针常量
int * const numberP2 = &number;
*numberP2 = 100;//ok 允许去修改【常量指针】存放地址所对应的值
numberP2 = &number2;//报错,不允许重新指向【常量指针】存放的地址
//常量指针常量
//指针常量
const int * const numberP3 = &number;
*numberP3 = 100;//报错 不允许去修改【常量指针】存放地址所对应的值
numberP3 = &number2;//报错,不允许重新指向【常量指针】存放的地址
return 0;
}1、执行速度
从执行速度来看 StringBuilder > StringBuffer > String
2、一个特殊例子
String str = “This is only a” + “ simple” + “ test”; StringBuffer builder = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
你会很惊讶的发现,生成str对象的速度简直太快了,而这个时候StringBuffer居然速度上根本一点都不占优势。其实这是JVM的一个把戏,实际上:
String str = “This is only a” + “ simple” + “test”;
其实就是:
String str = “This is only a simple test”;
所以不需要太多的时间了。但大家这里要注意的是,如果你的字符串是来自另外的String对象的话,速度就没那么快了,例如:
String str2 = “This is only a”;
String str3 = “ simple”;
String str4 = “ test”;
String str1 = str2 +str3 + str4;
这时候JVM会规规矩矩的按照原来的方式去做。
3、StringBuilder与 StringBuffer
StringBuilder:线程非安全的
StringBuffer:线程安全的
当我们在字符串缓冲去被多个线程使用是,JVM不能保证StringBuilder的操作是安全的,虽然他的速度最快,但是可以保证StringBuffer是可以正确操作的。当然大多数情况下就是我们是在单线程下进行的操作,所以大多数情况下是建议用StringBuilder而不用StringBuffer的,就是速度的原因。
4、StringBuffer对象和String对象之间的互转
StringBuffer和String属于不同的类型,也不能直接进行强制类型转换 StringBuffer对象和String对象之间的互转的代码如下:
String s = “abc”; StringBuffer sb1 = new StringBuffer(“123”); StringBuffer sb2 = new StringBuffer(s); //String转换为StringBuffer String s1 = sb1.toString(); //StringBuffer转换为String
5、 对于三者使用的总结:
1.如果要操作少量的数据用 String
2.单线程操作字符串缓冲区 下操作大量数据用StringBuilder
3.多线程操作字符串缓冲区 下操作大量数据 用StringBuffer
1.AndroidManifest没有设置configChanges属性 竖屏启动:
onCreate -->onStart-->onResume
切换横屏:
onPause -->onSaveInstanceState -->onStop -->onDestroy -->onCreate-->onStart -->
onRestoreInstanceState-->onResume -->onPause -->onStop -->onDestroy
(Android 6.0 Android 7.0 Android 8.0) 横屏启动:
onCreate -->onStart-->onResume
切换竖屏:
onPause -->onSaveInstanceState -->onStop -->onDestroy -->onCreate-->onStart -->
onRestoreInstanceState-->onResume -->onPause -->onStop -->onDestroy
(Android 6.0 Android 7.0 Android 8.0)
总结:没有设置configChanges属性Android 6.0 7.0 8.0 系统手机 表现都是一样的,当前的界面调用onSaveInstanceState走一遍流程,然后重启调用onRestoreInstanceState再走一遍完整流程,最终destory。
2.AndroidManifest设置了configChanges android:configChanges="orientation" 竖屏启动:
onCreate -->onStart-->onResume
切换横屏:
onPause -->onSaveInstanceState -->onStop -->onDestroy -->onCreate-->onStart -->
onRestoreInstanceState-->onResume -->onPause -->onStop -->onDestroy
(Android 6.0)
onConfigurationChanged-->onPause -->onSaveInstanceState -->onStop -->onDestroy --> onCreate-->onStart -->onRestoreInstanceState-->onResume -->onPause -->onStop -->onDestroy
(Android 7.0)
onConfigurationChanged
(Android 8.0)
横屏启动:
onCreate -->onStart-->onResume
切换竖屏:
onPause -->onSaveInstanceState -->onStop -->onDestroy -->onCreate-->onStart -->
onRestoreInstanceState--> onResume -->onPause -->onStop -->onDestroy
(Android 6.0 )
onConfigurationChanged-->onPause -->onSaveInstanceState -->onStop -->onDestroy --> onCreate-->onStart -->onRestoreInstanceState-->onResume -->onPause -->onStop -->onDestroy
(Android 7.0)
onConfigurationChanged
(Android 8.0)
总结:设置了configChanges属性为orientation之后,Android6.0 同没有设置configChanges情况相同,完整的走完了两个生命周期,调用了onSaveInstanceState和onRestoreInstanceState方法;Android 7.0则会先回调onConfigurationChanged方法,剩下的流程跟Android 6.0 保持一致;Android 8.0 系统更是简单, 只是回调了onConfigurationChanged方法,并没有走Activity的生命周期方法。
*3.AndroidManifest设置了configChanges **
android:configChanges="orientation|keyboardHidden|screenSize"
竖(横)屏启动:onCreate -->onStart-->onResume
切换横(竖)屏:onConfigurationChanged (Android 6.0 Android 7.0 Android 8.0)
总结:设置android:configChanges="orientation|keyboardHidden|screenSize" 则都不会调用Activity的其他生命周期方法,只会调用onConfigurationChanged方法。
**4.AndroidManifest设置了configChanges ** android:configChanges="orientation|screenSize" 竖(横)屏启动:onCreate -->onStart-->onResume 切换横(竖)屏:onConfigurationChanged (Android 6.0 Android 7.0 Android 8.0)
总结:没有了keyboardHidden跟3是相同的,orientation代表横竖屏切换 screenSize代表屏幕大小发生了改变, 设置了这两项就不会回调Activity的生命周期的方法,只会回调onConfigurationChanged 。
5.AndroidManifest设置了configChanges
android:configChanges="orientation|keyboardHidden"
总结:跟只设置了orientation属性相同,Android6.0 Android7.0会回调生命周期的方法,Android8.0则只回调onConfigurationChanged。说明如果设置了orientation 和 screenSize 都不会走生命周期的方法,keyboardHidden不影响。
1.不设置configChanges属性不会回调onConfigurationChanged,且切屏的时候会回调生命周期方法。 2.只有设置了orientation 和 screenSize 才会保证都不会走生命周期,且切屏只回调onConfigurationChanged。 3.设置orientation,没有设置screenSize,切屏会回调onConfigurationChanged,但是还会走生命周期方法。
另: 代码动态设置横竖屏状态(onConfigurationChanged当屏幕发生变化的时候回调) setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_LANDSCAPE); setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_PORTRAIT);
获取屏幕状态(int ORIENTATION_PORTRAIT = 1; 竖屏 int ORIENTATION_LANDSCAPE = 2; 横屏) int screenNum = getResources().getConfiguration().orientation;
configChanges属性
- orientation 屏幕在纵向和横向间旋转 2.keyboardHidden 键盘显示或隐藏 3.screenSize 屏幕大小改变了 4.fontScale 用户变更了首选的字体大小 5.locale 用户选择了不同的语言设定 6.keyboard 键盘类型变更,例如手机从12键盘切换到全键盘 7.touchscreen或navigation 键盘或导航方式变化,一般不会发生这样的事件 常用的包括:orientation keyboardHidden screenSize,设置这三项界面不会走Activity的生命周期,只会回调onConfigurationChanged方法。
screenOrientation属性 1.unspecified 默认值,由系统判断状态自动切换 2.landscape 横屏
- portrait 竖屏 4.user 用户当前设置的orientation值
- behind 下一个要显示的Activity的orientation值
- sensor 使用传感器 传感器的方向
- nosensor 不使用传感器 基本等同于unspecified 仅landscape和portrait常用,代表界面默认是横屏或者竖屏,还可以再代码中更改。
1.standard:标准模式:如果在mainfest中不设置就默认standard;standard就是新建一个Activity就在栈中新建一个activity实例; 2.singleTop:栈顶复用模式:与standard相比栈顶复用可以有效减少activity重复创建对资源的消耗,但是这要根据具体情况而定,不能一概而论; 3.singleTask:栈内单例模式,栈内只有一个activity实例,栈内已存activity实例,在其他activity中start这个activity,Android直接把这个实例上面其他activity实例踢出栈GC掉; 4.singleInstance :堆内单例:整个手机操作系统里面只有一个实例存在就是内存单例;
在singleTop、singleTask、singleInstance 中如果在应用内存在Activity实例,并且再次发生startActivity(Intent intent)回到Activity后,由于并不是重新创建Activity而是复用栈中的实例,因此Activity再获取焦点后并没调用onCreate、onStart,而是直接调用了onNewIntent(Intent intent)函数;
二、Activity四种启动模式常见使用场景: 这也是面试中最为长见的面试题;当然也是个人工作经验和借鉴网友博文,如有错误纰漏尽请诸位批评指正;
| LauchMode | Instance |
|---|---|
| standard | 邮件、mainfest中没有配置就默认标准模式 |
| singleTop | 登录页面、WXPayEntryActivity、WXEntryActivity 、推送通知栏 |
| singleTask | 程序模块逻辑入口:主页面(Fragment的containerActivity)、WebView页面、扫一扫页面、电商中:购物界面,确认订单界面,付款界面 |
| singleInstance | 系统Launcher、锁屏键、来电显示等系统应用 |
大纲里面有
大纲里面有