blog's People
Contributors

Stargazers




















Watchers




blog's Issues
简单讲解一下 http2 多路复用
简单讲解一下 http2 多路复用
多路复用是 http2 提供的一个功能,在同一个 tcp 连接中客户端和服务端都可以同时发送多个请求或回应。而且两端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
帧和流
HTTP/2 是一个二进制协议, 每一个请求和响应都有一个唯一的 id,叫做流 id。每个请求和响应的数据会被划分为帧。帧是二进制数据块,流id用于标识一个帧属于哪个请求或响应。流是具有相同流id的帧的集合。
要发出HTTP请求,客户端首先将请求划分为二进制帧,并将请求的流ID分配给帧。然后,它与服务端建立TCP连接。连接成功后客户端开始向服务端发送帧数据。一旦服务端准备好响应,它就将响应划分为帧,并为响应帧提供相同的响应流id。服务端以帧的形式发送响应。
在 HTTP/2 中给请求流和响应流分配唯一 id 是必须的,因为多个不同的请求会使用同一个 TCP 连接发送。所以流 id 可以标识出一个帧属于哪个请求或响应。这样就能同步的发送多个 http 请求而不造成阻塞。
多路复用
一个 TCP 连接只能向同一个源发送 HTTP 请求,对于多个源需要建立多个 TCP 连接。
一旦建立了 TCP 连接,对该源所有的请求都将通过这个 TCP 连接完成。多个 HTTP/2 的请求会被划分成帧,并分配它们各自的流 ID。来自客户端多个请求流的帧是异步发送到,服务端的响应也是异步发送的。因此如果一个响应会花费大量的时间,其他的响应并不会被阻塞。客户端通过流 id 来区分和排列帧。
请求和响应都是并行的。当客户端发送请求的帧时,服务端同时也会返回响应的帧。
对特定源的所有请求完成后,TCP 连接将保持打开一段时间,然后关闭。
帧中的其他信息
流(或请求)可以具有优先级值。使用优先级值 server 决定需要为请求分配多少内存、CPU 时间和带宽。默认情况下,服务器不按任何顺序异步发送多个请求的帧,并并行处理它们。但是在请求时带上额外的 priority 信息可以强制服务器在其他响应之前发送响应的帧。
什么是防抖和节流?有什么区别?如何实现?
防抖(debounce)
定义
在事件被触发 n 秒后再执行回调,如果在这 n 秒内又被触发,则重新计时。
应用场景
- 搜索框输入发送AJAX请求
- 窗口缩放,每次resize/scroll触发事件
用例
比如有一个关键词搜索的input框,用户输入后触发keyup事件向后端发送一个请求:
<div>
<input id="input" type="text">
</div>
<script>
const input = document.getElementById('input')
input.addEventListener('keyup', (e) => {
console.log(e.target.value)
})
</script>测试后可以发现,每次输入都会有打印结果,如果是请求后端接口,那么不仅会造成极大的浪费,而且实际应用中,用户也是输出完整的字符后,才会请求。下面我们优化一下:
function debounce(fn, delay) {
let timer = null
return function(...args) {
const context = this
if(timer) {
clearTimeout(timer)
}
const _agrs = args.join(',')
timer = setTimeout(fn.bind(context, _agrs), delay)
}
}
const consoleDebounce = debounce(console.log, 500)
const input = document.getElementById('input')
input.addEventListener('keyup', (e) => {
consoleDebounce(e.target.value)
})在运行一次后可以看到,当在频繁的输入时,并不会打印结果,只有当你在指定间隔内没有输入时,才会执行函数。如果停止输入但是在指定间隔内又输入,会重新触发计时。
完整实现一个通用防抖函数
function debounce(fn, delay = 500, immediate = false) {
let timer = null
return function(...args) {
const context = this
// 是否立即执行一次
if (immediate && !timer) {
fn.apply(context, args)
}
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.apply(context, args)
}, delay)
}
}节流(throttle)
定义:
指连续触发事件但是在 n 秒中只执行一次函数。 节流会稀释函数的执行频率
应用场景
- DOM 元素的拖拽功能实现(mousemove)
- 计算鼠标移动的距离(mousemove)
- 监听滚动事件判断是否到页面底部自动加载更多内容
- 按钮点击事件(多次点击 n 秒内只生效一次)
用例
一个 button 按钮,每次点击�需要提交表单。
<div>
<button id="button">提交</button>
</div>
<script>
const button = document.getElementById('button')
button.addEventListener('click', (e) => {
console.log('click')
})
</script>上面代码的问题是,当我们快速点击 button 时,每次点击都会打印 'click',下面用节流函数优化一下。
const conThrottle = throttle(console.log, 2000)
const button = document.getElementById('button')
button.addEventListener('click', (e) => {
conThrottle(1)
})
function throttle(fn, time) {
let timer = null
let flag = true
return function(...args) {
let context = this
if (flag) {
fn.apply(context, args)
flag = false
timer = null
}
if (!timer) {
timer = setTimeout(() => {
flag = true
}, time)
}
}
}再次测试,可以发现不管我们点击的速度多么快,在每 2 秒内,函数只会执行 1 次。
完整实现时间戳版本 throttle 函数
function throttle(fn, time) {
let startTime = 0
return function(...args) {
let context = this
let endTime = Date.now()
if (endTime - startTime >= time) {
fn.apply(context, args)
startTime = endTime
}
}
}JavaScript中的执行上下文和堆栈是什么
JavaScript中的执行上下文和堆栈是什么
在这篇文章中,将深入研究JavaScript最基本的部分之一,即执行上下文。在这篇文章的最后,你应该更清楚地理解解释器要做什么,为什么在声明一些函数/变量之前可以使用它们,以及它们的值是如何确定的。
什么是执行上下文
当JavaScript代码运行时,执行代码的环境是相当重要的。一般有以下三种情况:
- 全局代码 -- 代码首次开始执行的默认环境
- 函数代码 -- 每当进入一个函数内部
- Eval代码 -- eval内部代码执行时
把执行上下文看作是当前代码正在执行的环境/作用域
// global context
var sayHello = 'sayHello'
function person() {
var first = 'webb'
var last = 'wang'
function firstName() {
return first
}
function lastName() {
return last
}
console.log(sayHello + firstName() + '' + lastName())
}以上代码没什么特别的地方,它包括1个全局上下文和3个不同的函数上下文,全局上下文可以被程序中的其它任何上下文访问。
你可以有任意数量的函数上下文,每个函数被调用的时候都会创建一个新的上下文。每个下文都有一个不能被外部函数直接访问到的内部变量的私有作用域。在上面代码的例子中,一个函数可以访问当前上下文外部声明的变量,但是一个外部上下文不可以访问函数内部声明的变量。
执行上下文堆栈
浏览器中的JavaScript解释器是作为一个单线程实现的,这实际上意味着,在浏览器中,一次只能发生一件事,其他操作或事件将排队在所谓的执行堆栈中。
当浏览器开始执行脚本时,首先会默认进入全局执行上下文,如果在全局代码中调用了函数,程序会按照顺序进入被调用函数,创建一个新的执行上下文,并推入到执行栈的栈顶。
如果你在当前执行的函数中,调用了另外的函数,代码的执行流将会进入函数内部,并创建一个新的执行上下文推入到执行栈顶。浏览器总是会先执行栈顶的代码,并且一旦函数完成执行当前执行上下文,他就会从栈顶弹出,将控制权返回到当前堆栈中的上下文。
关于执行堆栈有以下关键点
- 单线程
- 同步执行
- 1个全局上下文
- 每个函数调用都会创建一个新的执行上下文,即使调用它自身。
深入理解执行上下文
现在我们知道每当有函数被调用时,都会创建一个新的执行上下文。在js内部,每个执行上文创建都要经历下面2个阶段
1.创建阶段(函数被调用,但还没有执行内部代码)
- 创建作用域链
- 创建变量和参数
- 决定this指向
2.代码执行阶段
- 变量赋值,执行代码
可以将每个执行上下文概念上表示为一个具有3个属性的对象:
executionContextObj = {
'scopeChain': { /* variableObject + all parent execution context's variableObject */ },
'variableObject': { /* function arguments / parameters, inner variable and function declarations */ },
'this': {}
}活动对象/变量对象(AO/VO)
当函数被调用时,在创建阶段解释器会创建包含有函数内部变量,参数的一个变量对象
下面是解释器如何评估代码的概述
- 扫描被调用函数中的代码
- 在代码执行前,创建执行上文
- 进入创建阶段
- 初始化作用域链
- 创建变量对象
- 创建arguments对象,检查参数上下文,初始化名称和值,并创建引用副本
- 扫描上下文中函数的声明
- 对于找到的每个函数,在变量对象中创建一个属性,该属性是确切的函数名,该函数在内存中有一个指向该函数的引用指针
- 如果函数名已经存在,指针将会被覆盖
- 扫描变量的声明
- 对于找到的每个变量,在变量对象中创建一个属性,该属性是确切的变量名,该变量的值是undefined
- 如果变量名已经存在,将不会做任何处理继续�执行
- 决定this的值
- 代码执行阶段
- 变量赋值,按顺序执行代码
声明提升
你可以在网上找到许多用JavaScript定义术语提升的资源,解释变量和函数声明被提升到函数作用域的顶部。但是,没有人详细解释为什么会发生这种情况,而且有了解释器如何创建激活对象的新知识,就很容易理解为什么会发生这种情况。以下面的代码为例:
(function() {
console.log(typeof foo); // function pointer
console.log(typeof bar); // undefined
var foo = 'hello',
bar = function() {
return 'world';
};
function foo() {
return 'hello';
}
}());为什么在变量声明之前可以访问到foo
如果我们遵循创建阶段,我们就知道在代码执行阶段之前已经创建了变量。因此,当函数流开始执行时,foo已经在活动对象中定义。
Foo声明了两次,为什么Foo是函数而不是未定义或字符串?
尽管foo声明了两次,但从创建阶段我们就知道函数是在变量之前在变量对象上创建的,如果变量对象上的属性名已经存在,那么我们只需绕过。
因此,首先在变量对象上创建对函数foo()的引用,当解释器到达var foo时,我们已经看到了属性名foo的存在,所以代码什么也不做,继续执行
为什么bar是undefined
bar实际上是一个具有函数赋值的变量,我们知道这些变量是在创建阶段创建的,但是它们是用undefined值初始化的。
总结
希望现在你已经很好地理解了JavaScript解释器是如何执行代码的。理解执行上下文和堆栈可以让你了解代码没有按照预期执行的原因
Node.js && JavaScript 面试常用的设计模式
Node.js && JavaScript 面试常用的设计模式
设计模式是任何软件开发人员日常工作的一部分,不管他们是否意识到这一点。
在本文中,我们将研究如何识别这些设计模式,以及如何在自己的项目中开始使用它们。
什么是设计模式
简单地说,设计模式就是一种可以让你以某种方式更好的组织代码的方法,从而获得一些好处。比如更快的开发速度、代码的可重用性等等。
所有模式都很容易采用OOP范式。尽管考虑到JavaScript的灵活性,你也可以在非OOP项目中实现这些概念。事实上,每年都会有新的设计模式被创建,有太多的设计模式无法在一篇文章中涵盖,本文将重点介绍和实现几种常见的设计模式。
立即执行函数表达式(IIFE)
我要展示的第一个是允许同时定义和调用函数的模式。由于JavaScript作用域的工作方式,使用IIFE可以很好地模拟类中的私有属性之类的东西。事实上,这个特定的模式有时被用作其他更复杂需求的一部分。我们待会再看。
IIFE常见例子
在我们深入研究用例和它背后的机制之前,让我快速地看一下它到底是什么样子的:
(function() {
const x = 20
const y = 20
const answer = x + y
console.log(answer)
})()通过将上述代码粘贴到浏览器的控制台,你将立即得到结果,因为正如其名所示,一旦定义了函数,就会立即执行它。
IIFE由一个匿名函数声明组成,在一组括号内(括号将定义转换为函数表达式),然后在它的尾部有一组调用括号。像这样:
(function(/*received parameters*/) {
//your code here
})(/*parameters*/)用例
模拟静态变量
还记得静态变量吗? 例如在C或c#中。使用静态变量的好处是,如果你在一个函数中定义一个静态变量,不管你调用它多少次,这个变量对函数的所有实例都是通用的。一个简单的例子是像下面这样的:
function autoIncrement() {
static let number = 0
number++
return number
}上面的函数每次调用都会返回一个新的数字(当然,假设静态关键字在JS中可用)。我们可以在JS中来实现它,你可以像这样模拟一个静态变量:
let autoIncrement = (function() {
let number = 0
return function () {
number++
return number
}
})()立即函数执行后返回一个新函数(闭包),该函数内部引用了number变量。由于JS闭包机制,立即函数执行完毕后,number变量不会立即被垃圾回收掉,所以autoIncrement每次执行总是可以访问number变量(就像它是一个全局变量一样)。
模拟私有变量
ES6类将每个成员都视为公共的,这意味着没有私有属性或方法。但是多亏了IIFE,如果你想的话,你可以模拟它。
const autoIncrementer = (function() {
let value = 0
return {
incr() {
value++
},
get value() {
return value
}
}
})()
> autoIncrementer.incr()
undefined
> autoIncrementer.incr()
undefined
> autoIncrementer.value
2
> autoIncrementer.value = 3
3
> autoIncrementer.value
2上面的代码展示了一种创建私有变量的方法,立即函数执行后,返回一个object赋值给变量autoIncrementer,在外部只能通过value方法和incr方法获取和修改value的值。
工厂方法模式
这个模式是我最喜欢的模式之一,因为它可以让代码变动清楚简洁。
工厂模式是用来创建对象的一种最常用的设计模式。我们不暴露创建对象的具体逻辑,而是将逻辑封装在一个函数中,那么这个函数就可以被视为一个工厂。
这可能听起来并不是那么有用,但请看下面这个简单例子就会明白。
( _ => {
let factory = new MyEmployeeFactory()
let types = ["fulltime", "parttime", "contractor"]
let employees = [];
for(let i = 0; i < 100; i++) {
employees.push(factory.createEmployee({type: types[Math.floor( (Math.random(2) * 2) )]}) )}
//....
employees.forEach( e => {
console.log(e.speak())
})
})()上面的代码的关键点是通过factory.createEmployee添加了多个对象到employees数组中,所有这些对象都共享相同的接口(他们有相同的一组方法),也有自己特有的属性,但是你真的不需要关心对象创建的细节和什么时候创建。
下面我们具体看一下构造函数MyEmployeeFactory的实现
class Employee {
speak() {
return "Hi, I'm a " + this.type + " employee"
}
}
class FullTimeEmployee extends Employee{
constructor(data) {
super()
this.type = "full time"
//....
}
}
class PartTimeEmployee extends Employee{
constructor(data) {
super()
this.type = "part time"
//....
}
}
class ContractorEmployee extends Employee{
constructor(data) {
super()
this.type = "contractor"
//....
}
}
class MyEmployeeFactory {
createEmployee(data) {
if(data.type == 'fulltime') return new FullTimeEmployee(data)
if(data.type == 'parttime') return new PartTimeEmployee(data)
if(data.type == 'contractor') return new ContractorEmployee(data)
}
}用例
前面的代码已经显示了一个通用用例,但是如果我们想更具体一些,接下来使用这个模式的来处理错误对象的创建。
假设有一个大约有10个端点的Express应用程序,其中每个端点都需要根据用户输入返回2到3个错误,假设我们有30个语句大概像这样:
if(err) {
res.json({error: true, message: “Error message here”})
}如果突然需要给error对象新加一个属性,那么需要修改30个位置,这是非常麻烦的。可以过将错误对象定义到一个简单的类中解决这个问题。如果有多种类型的错误对象,这个时候就可以创建一个工厂函数来决定实例化那个错误对象。
如果你要集中创建错误对象的逻辑,那么你在整个代码中要做的就是:
if(err) {
res.json(ErrorFactory.getError(err))
}单例模式
这是另一个老的但很好用的设计模式。注意,这是一个非常简单的模式,但是它可以帮助你跟踪正在实例化的类的实例数量。实际上,它可以帮助你一直保持这个数字为1。单例模式允许实例化一个对象一次,然后当每次需要时都使用它,而不是创建一个新的对象。这样可以更好的追踪对这个对象的引用。
通常,其他语言使用一个静态属性实现此模式,一旦实例存在,它们将存储该实例。这里的问题是,正如我之前提到的,我们无法访问JS中的静态变量。我们可以用两种方式实现,一种是使用IIFE而不是类。
另一种方法是使用ES6模块,并让我们的单例类使用本地全局变量来存储实例。通过这样做,类本身被导出到模块之外,但是全局变量仍然是模块的本地变量。
这听起来比看起来要复杂得多:
let instance = null
class SingletonClass {
constructor() {
this.value = Math.random(100)
}
printValue() {
console.log(this.value)
}
static getInstance() {
if(!instance) {
instance = new SingletonClass()
}
return instance
}
}
module.exports = SingletonClass你可以像下面这样使用:
const Singleton = require(“./singleton”)
const obj = Singleton.getInstance()
const obj2 = Singleton.getInstance()
obj.printValue()
obj2.printValue()
console.log("Equals:", obj === obj2)上面的代码输出:
0.5035326348000628
0.5035326348000628
Equals:: true确实,我们只实例化对象一次,并返回现有实例。
用例
在决定是否需要类似于单例的实现时,需要考虑以下问题:你真正需要多少类实例?如果答案是2或更多,那么这不是你的模式。
但是当处理数据库连接时,你可能需要考虑它。
考虑一下,一旦连接到数据库,在整个代码中保持连接活动和可访问性是一个好主意。注意,这可以用很多不同的方法来解决,但是单例模式确实是其中之一。
利用上面的例子,我们可以把它写成这样:
const driver = require("...")
let instance = null
class DBClass {
constructor(props) {
this.properties = props
this._conn = null
}
connect() {
this._conn = driver.connect(this.props)
}
get conn() {
return this._conn
}
static getInstance() {
if(!instance) {
instance = new DBClass()
}
return instance
}
}
module.exports = DBClass现在,可以确定,无论在哪里使用getInstance方法,都将返回惟一的活动连接(如果有的话)。
结论
上面几种是我们写代码时常用的设计模式,下一篇我们将重点深入理解观察者模式和职责链模式
关注作者github,第一时间获得更新。
['1', '2', '3'].map(parseInt)` what & why ?
output
[1, NaN, NaN]分析
map
- map 方法创建一个新数组,其结果是该数组中的每个元素都调用一个提供的 callback 后返回的结果。
- map 函数接受 2 个参数,callback 和 thisArg。
- callback 函数自动接受 3 个参数,分别是数组当前正在处理的元素、数组当前正在处理元素索引和数组本身。
- callback 没有指定参数时,默认自动传入上述 3 个参数。
- thisArg 参数指定 callback 执行时 this 的指向。 没有指定时默认指向 window。
parseInt
- parseInt 函数接受 2 个参数, 要被解析的值和基数,基数不存在时,默认10进制解析。
结论
parseInt 作为 callback 参数传入map函数后,由于 parseInt 可以接受 2 个参数,所以会收到元素值和元素索引 2 个参数。
所以实际执行的 callback 如下:
parseInt(1,0) // 1
parseInt(2,1) // NaN
parseInt(3,2) // NaN优化网站性能最佳实践
优化网站性能最佳实践
HTTP 方面
-
减少 HTTP 请求
- 合并文件
- CSS Sprites: 减少 image 的请求,将多个背景图片合并到一张图片,然后使用 CSS backgroud-image 和 backgroud-position 属性来展示这个大背景图片的一部分
- 内联图片: 使用 data: URL scheme 形式的图片格式,这样虽然增加减少了一次 http� 请求,但是也增加了 html 文档的体积。把内联图片加到 css 文件中然后缓存 css 文件,这样既不会增加页面的体积,也可以减少 http 请求
-
缓存 http response
- server response 加入 Expires 或者 Cache-Control Header: 对于静态的不经常变的内容(如:jquery等)可以使用 Expires 然后设置一个较长时间的值。对于经常变更的内容,可以使用 Cache-Control header 配合 etag 和 last-modified 等字段实现缓存和更新
-
减少 http response 体积,加快响应速度
- Gzip 压缩 response 内容: HTTP/1.1 开始 web 客户端支持在 HTTP request中加入 Accept-Encoding� Header 来表明客户端支持的压缩方式。
Accept-Encoding: gzip, deflate
- 如果 web �Server 发现客户端 request Header 中有这个字段,server 可以使用客户端提供的压缩方式压缩 response,并且在 response Header 中告诉客户端使用的压缩方式
Content-Encoding: gzip
代码层面
css js
-
css 放到最上面: 浏览器从上到下加载和执行代码,我们希望浏览器能可能快的展示出内容给用户。当我们的网站有大量的内容而且用户的信号不好时,能尽快给用户视觉上的反馈是极其重要的。当把 css 放到文档底部会禁止浏览器渐进式渲染。这些浏览器会阻止页面呈现以避免在样式发生变化时重新绘制整个页面,会给用户呈现一个白屏状态直到 css 加载完成。
-
避免使用 css 表达式
-
使用外链的方式加载 css 和 js,充分利用 HTTP 的缓存。
-
js 放到文档底部: js 加载和执行会阻塞页面的渲染,js 放到底部可以页面渲染完成后在加载和执行。
-
js 文件加入 defer: js文件可以并行的加载和执行而不阻塞页面的渲染,当 js 文件加载完成后,在 DOMContentLoaded 事件之前执行。
-
当 js css 文件有很多时,放到不同的域名下。
content
-
减少 dom 的数量
-
缓存 dom 节点
-
使用事件代理
-
减少图片体积
预加载
-
prefetch: 是一种告诉浏览器获取一项可能被下一页访问所需要的资源方式。这意味着资源将以较低优先级地获取。这意味着 prefetch 的主要用途是加速下一页访问速度,而不是当前页面的速度。
-
preload: 最基本的使用方式是提前加载较晚发现的资源而不阻塞页面的渲染。比如字体文件等。
懒加载
- 利用 webpack 实现懒加载或者按需加载
JavaScript中的数据结构
JavaScript中的数据结构
Intruduction
随着业务逻辑越来越多的从后端转向前端,专业的前端工程知识变的更加关键。作为前端的工程师,我们依赖像React这样的库来开发view层,同时又依赖Redux这样的库来管理数据状态,两者组合起来作为响应式编程,当数据动态变化时,UI层可以实时的更新。渐渐地,后端可以专注于api的开发,仅仅提供数据的检索和更新。这样实际上,后端只是将数据库转发到前端,前端工程师处理所有的逻辑,微服务和graphql的日益增长证明了这个趋势。
如今,前端工程师不仅要精通html和css,也要精通JavaScript。随着客户端的数据存储成为服务器端数据库的“副本”,熟悉惯用数据结构就变得至关重要。事实上,工程师的经验水平可以从他/她区分何时以及为什么使用特定数据结构的能力中推断出来。
Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
— Linus Torvalds, Creator of Linux and Git
在高等级上,有3中类型的数据结构, 栈和队列是类数组的结构,它们只是在插入和删除数据上有所不同。链表、树和图是拥有节点的结构,并且节点有对其他节点的指针。哈希表依赖哈希函数保存和定位数据。
就复杂性而言,队列和栈是最简单的,可以由链表构造,树和图是最复杂的,因为它们在链表的结构上进行了扩展。哈希表需要利用这些数据结构来可靠地执行。就效率而言,链表最适合记录和存储数据,哈希表最适合检索数据。
下文将解释并说明应该在何时使用这些数据结构。
Stack
可以说JavaScript中最重要的堆栈是调用堆栈,每当函数执行时,会把函数的作用域推入栈中。在编程方式上而言,栈只是一个包含pop和push操作的数组结构,Push增加元素到数组的顶端,Pop移除数组元素在相同的位置,换句话说,栈结构遵循“后进先出”的原则(LIFO)。
class Stack {
constructor() {
this.list = []
}
push(...item) {
this.list.push(...item)
}
pop() {
this.list.pop()
}
}Queue
JavaScript是一种事件驱动的编程语言,它支持非阻塞操作。在浏览器内部,只有一个线程来运行所有的JavaScript代码,使用事件循环来注册事件,为了支持单线程环境中的异步性(为了节省CPU资源和增强web体验),回调函数只有在调用堆栈为空时才会退出队列并执行。Promise依赖于这个事件驱动的体系结构,允许异步代码的“同步风格”执行,而不会阻塞其他操作。
在编程方式上而言,队列是只包含一个unshift和pop操作的数组结构,Unshift将数据项加入队列的末尾,Pop从数组的顶部将元素出列,换句话说,队列遵循“先进先出”的原则(FIFO)。
class Queue {
constructor() {
this.list = []
}
enqueue(...item) {
this.list.unshift(...item)
}
dequeue() {
this.list.pop()
}
}Linked List
与数组相似,链表按顺序存储数据元素。链表不保存索引,而是保存指向其他数据项的指针。第一个节点成为头节点,最后一个节点成为尾节点。在单链表中,每个节点只有指向下一个节点的指针,头部是每次检索开始的地方,在双链表中,每个节点还有指向前一个节点的指针,因此双链表可以从尾部开始向前检索。
链表在插入和删除元素时有固定的时间,因为可以改变指针。但是在数组中执行相同的操作需要线性时间,因为后续需要移位。此外,只要有空间,链表就可以增长。然而,即使是自动调整大小的“动态”数组也可能变得异常昂贵。但是要查找或编辑链表中的元素,我们可能需要遍历整个长度,这等于线性时间。然而,对于数组索引来说,这样的操作是微不足道的。
与数组一样,单链表也可以作为堆栈来操作,只要让头部成为唯一可以插入和移除元素的地方。双链表可以作为队列来操作,只要在尾部插入元素,在头部移除元素。对于大量的数据来说,这种实现队列的方法比数组性能更好,因为数组的shift和unshift操作需要线性的时间在后续重新索引每个元素。
链表结构在客户端和服务端都是常用的。在客户端,像Rudex这样的状态管理库以链表的方式构建其中间件逻辑。当action被dispatch后,它们从一个中间件到另外一个中间件直到到达ruducer。在服务端,像Express这样的web框架也以类似的方式构造它的中间件逻辑,当一个request到达时,它会按顺序从一个中间件到另一个中间件,直到发出响应。
单链表的简单实现
class LinkList {
constructor() {
this.head = null
}
find(value) {
let curNode = this.head
while (curNode.value !== value) {
curNode = curNode.next
}
return curNode
}
findPrev(value) {
let curNode = this.head
while (curNode.next!==null && curNode.next.value !== value) {
curNode = curNode.next
}
return curNode
}
insert(newValue, value) {
const newNode = new Node(newValue)
const curNode = this.find(value)
newNode.next = curNode.next
curNode.next = newNode
}
delete(value) {
const preNode = this.findPrev(value)
const curNode = preNode.next
preNode.next = preNode.next.next
return curNode
}
}
class Node {
constructor(value, next) {
this.value = value
this.next = null
}
}Hash Table
哈希表类似于字典结构,由键值对组成。每个对在内存中的地址有一个哈希函数确定,该函数接受一个key作为参数,并返回一个检索该对的内存地址。如果两个或者多个key转为相同的地址,则可能会发送冲突。为了健壮性,getter和setter应该预测这些事件,以确保所有数据都可以恢复,并且没有覆盖任何数据。
如果已经知道的地址是整数序列,可以简单地使用数组来存储键值对。对于更复杂的映射,我们可以使用maps或者objects, 哈希表的插入和查找元素的时间平均为常数,如果key表示地址,就不需要散列,一个简单的对象就足够了。哈希表实现键和值之间的简单对应,键和地址之间的简单关联,但是牺牲了数据之间的关系。所以,哈希表在存储数据方面不是最优的。
如果一个应用倾向于检索而不是存储数据,那么在查找、插入和删除方面,没有其他数据结构能够与哈希表的速度相匹配。因此哈希表被广泛应用也就不足为奇了。从数据库到服务端,再到客户端,哈希表尤其是哈希函数对应用程序的性能和安全方面是至关重要的。数据库的查询速度很大程度上依赖于指向记录的索引按顺序保存。这样,二进制搜索就可以在对数时间内完成,特别是对于大的数据来说,这是一个巨大的性能优势。
在客户端和服务端,许多流行的库都用缓存来最大程度提升性能。通过在哈希表中保存输入和输出的记录,对于相同的输入,函数仅运行一次。流行的Reselect库使用这种缓存策略来优化启动了Redux应用程序的mapStateToProps函数。实际上,JavaScript引擎还利用名为调用栈的哈希表存储所有我们创建的变量。这些变量可以通过调用栈上的指针被访问到。
互联网本身也依赖于哈希算法来安全运行。互联网的结构是这样的:任何计算机都可以通过互相连接的web设备与其他计算机通信。每当一个设备登录到互联网上,它也可以成为一个路由器,数据流可以通过它进行传输。然而这是一把双刃剑。分散式架构意味着网络中的任何设备都可以监听并篡改它帮助转发的数据包。MD5和SHA256等哈希函数在防止中间人攻击方面发挥着关键作用。HTTPS上的电子商务之所以安全,只是因为使用了这些散列函数。
受Internet的启发,区块链技术通过使用哈希函数对每个区块的数据创建一个不可变的“指纹”,本质上建立了一个可以在web上被公开的完整数据库,任何人都可以查看和贡献。从结构上看,区块链就是加密散列的二叉树单链表。哈希非常神秘,任何人都可以创建和更新一个财务交易数据库。曾经只有政府和**银行才能做到的事情,现在任何人都可以安全地创造自己的货币!
随着越来越多的数据库走向开放,要求前端工程师可以抽象出所有底层密码的复杂性。在未来,应用程序主要的区别将是用户体验。
一个简单的不做冲突处理的哈希表
class HashTable {
constructor(size) {
this.table = new Array(size)
}
hash(key) { // hash函数
// 将字符串中的每个字符的ASCLL码值相加,再对数组的长度取余
let total = 0
for (let i = 0; i < key.length; k++) {
total += key.charCodeAt(i)
}
return total % this.table
}
insert(key, value) {
const hashKey = this.hash(key)
this.table[hashKey] = value
}
get(key) {
const hashKey = this.hash(key)
if (!this.table[hashKey]) {
return null
}
return this.table[hashKey]
}
getAll() {
const table = []
for (let i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
table.push(this.table[i])
}
}
return table
}
}总结
这些数据结构可以在任何地方被找到,从数据库到服务端再到前端,甚至JavaScript引擎自身。随着逻辑层越来越多的从后端移向前端,前端的数据层变得至关重要。对这一层的恰当的管理需要掌握逻辑所依赖的数据结构。没有一种数据结构适合所有情况,因为对一个属性进行优化总是会影响另外的属性。一些数据结构对于存储数据是非常高效的,然而另外的数据结构对于搜索元素来说更加高效。在一种极端情况下,链表是存储的最佳选择,可以被分成堆栈和队列(线性时间)。另一方面,没有其他结构可以匹配哈希表的搜索速度(常数时间)。树的结构性能位于两者之间(对数时间),图表可以描述自然界最复杂的结构。
编写一个程序将数组扁平化去并除其中重复部分数据,最终得到一个升序且不重复的数组
已知数组
var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10]解法一
function flat(arr) {
return [...new Set(arr.flat(Infinity).sort((a,b) => a - b))]
}解法二
function flat(arr) {
return [...new Set(arr.toString().split(',').sort((a,b) => a-b))]
}解法三(使用递归实现 flat 函数)
function flat(arr) {
const flatArr = arr.reduce((res, next) => Array.isArray(next) ? res.concat(flat(next)) : res.concat(next),[])
return [...new Set(flatArr.sort((a,b) => a - b))]
}解法四(非递归实现 flat 函数)
// 使用 栈 来实现
// 由于栈后进先出的特点,先把原数组倒序
function flat(arr) {
let stack = []
let res = []
for (let i = arr.length - 1; i >= 0; i--) {
stack.push(arr[i])
}
while (stack.length) {
const item = stack.pop()
if (Array.isArray(item)) {
for (let i = item.length - 1; i >= 0; i--) {
stack.push(item[i])
}
} else {
res.push(item)
}
}
return [...new Set(res)].sort((a,b) => a - b)
}Git switch 和 restore 命令
对于经常使用 git 的人来说,很少有机会发现关于 git 的新东西。我最近发现在高级命令列表中增加了 2 个新功能:
- git restore
- git switch
为了理解为什么新增这两个命令,我们先回顾一下经常使用的 git checkout 这个命令。
Git checkout
有些新手刚开始使用 git checkout 时会感到困惑。这是因为它造成的结果依赖于传入的参数。
下面我们看一下 git checkout 的几个使用场景
-
切换本地分支,更准确的说法是,切换 HEAD 指针指向的分支,比如,你可以从 develop 分支切换到 main 分支:
git checkout main
-
切换 HEAD 指针指向一个特定的 Commit
git checkout f8c540805b7e16753c65619ca3d7514178353f39
-
恢复文件到上次提交的状态
如果输入的参数是一个文件名而不是分支名或者 commit,它将丢弃你对这个文件的修改并重置到上一次的 commit 版本状态。
git checkout test.text
看到这上面几种行为,你可能会认为它没有任何意义,为什么一个命令做两个不同的动作?如果我们查看 git 文档,我们可以看到命令有一个额外的参数,通常被忽略:
git checkout <tree-ish> -- <pathspec>什么是 ?它可以表示很多不同的东西,但最常见的是表示提交 commit 值或分支名称。默认情况下,它被认为是当前分支,但它可以是任何其他分支或 commit。例如,如果你在 develops 分支,想要将 test.txt 文件更改为来自 main 分支的版本,你可以这样做:
git checkout main -- test.txt看到这里,也许事情开始变得有意义了。当你为 git checkout 提供一个分支或 commit 参数时,它会将你的所有文件更改为相应版本中的状态,但如果你也指定了一个文件名,它只会更改该文件的状态以匹配指定的版本。
新增的命令
即使我们现在知道了 git checkout 的多种用法,我们必须承认,它对于新手仍然是困惑的。这就是为什么在 git 的 2.23 版本中,引入了两个新命令来取代旧的 git checkout(它仍然可用,但新使用 git 的人最好从这些命令开始)。它们分别实现了 git 的多种行为中的一种。
Switch
可以使用这个命令来在分支或 commit 之间切换
git switch develop不同于 git checkout 切换 commit 直接提供 commit hash, 使用 switch 切换 commit 时需要加 -d 标志
git switch -d f8c540805b7e16753c65619ca3d7514178353f39同时切换并新增一个本地分支时需要加 -c 标志
git checkout -b new_branch
git switch -c new_branchRestore
可以将文件的状态恢复到指定的 git 版本 (默认为当前分支)
git restore -- test.txt总结
相比较于 git checkout,这两个命令更加的清晰。
关于这两个命令的更多细节可以在 git 文档中找到:
为什么使用v-for时必须添加唯一的key?
vue视图更新机制
- 状态变更,重新渲染一个完整的Virtual DOM对象。
- 新旧Virtual Dom对比,记录两棵树的差异。
- 对差异的地方进行真正的DOM操作。
- 新的Virtual Dom对象替换旧的Virtual Dom。
Virtual Dom对比算法(Diff 算法)
-
基于两个基本假设:
- 两个相同的组件产生类似的DOM结构,不同的组件产生不同的DOM结构。
- 同一层级的一组节点,他们可以通过唯一的id进行区分。基于以上这两点假设,使得虚拟DOM的Diff算法的复杂度从O(n^3)降到了O(n)。
-
仅在同级的vnode间做diff,递归地进行同级vnode的diff,最终实现整个DOM树的更新
结论
-
在渲染一组同级的VNode时,也遵循上述规则。所以当有key,在进行新旧VNode对比时可以很快的计算出那些项是没有变动的,没变动的这些可以复用旧VNode的数据。在真正的更新DOM时只更新变动的部分。让更新更加高效。
-
用Index做可以不推荐的原因比如有如下数据:
<ul>
<li v-for="(item, index) in a" :key="index">{{a}}</li>
<ul>
data() {
return {
a: [1,2,3]
}
}上面的VNode可以表示为:
// VNode
[
{ tagName: 'li', key: 0, children: [1] },
{ tagName: 'li', key: 1, children: [2] }
{ tagName: 'li', key: 2, children: [3] }
]如果在 a 数组 1 和 2 之间插入数字 4,此时的 a = [1,4,2,3], VNode如下:
// VNode
[
{ tagName: 'li', key: 0, children: [1] },
{ tagName: 'li', key: 1, children: [4] },
{ tagName: 'li', key: 2, children: [2] }
{ tagName: 'li', key: 3, children: [3] }
]可以看到除了key=0可以复用外,其他项都不可复用,但是数据和之前是一样的。所以建议用Id作为key会更加高效。
setTimeout、Promise、Async/Await 的区别
JavaScript 单线程语言
众所周知 JavaScript 是单线程语言,也就是说,同一时间只能做一件事。JavaScrpt之所以设计成单线程语言,是与它的用途有关, JavaScript 被设计之初的主要用途是操作 DOM, 假设如果有两个线程,一个线程在某个节点上添加元素,另外一个线程删除了这个节点,这时,浏览器该以哪个线程为准呢。所以为了避免这一问题, JavaScript 诞生之初就是单线程。
这样就可能导致的问题是,所有的任务都需要排队,只有前一个任务结束,才会执行后一个任务,如果前一个任务耗时太长,后一个任务就只能等着,如 IO 操作(AJAX请求等),在数据返回之前,CPU 一直是空闲状态,就大大浪费了时间和资源。所以 JavaScript 通过时间循环来解决这个问题。
Event Loop
JavaScript 中所有任务分为两种,一种是同步任务,另一种是异步任务。同步任务是指,在主线程上排队的任务,只有前一个任务执行完毕,才会执行后一个任务。异步任务是指,不进入主线程,而是进入“任务队列”,只有“任务队列”通知主线程,某个异步任务可以执行了。该任务的回调函数才会进入主线程执行。异步任务又分为宏任务和微任务
具体来说,异步执行的运行机制如下。
- JavaScript 中有一个主执行栈,所有同步任务都在主执行栈上执行。
- 主执行栈之外,还存在一个“任务队列”,只有异步任务有了运行结果,就把回调函数放到”任务队列“之中。
- 一旦“执行栈”中的所有同步任务执行完毕,接下来会先执行微任务, 然后系统就会读取“任务队列”,看看里面有那些事件,把执行完成的事件回调函数放入主执行栈,开始执行。
- 主线程不断重复上面的第三步(1-3称为事件循环的一个 Tick)。
这个过程就是 Event Loop。
下面从一个例子来看 setTimeout、Promise、Async/Await 的区别
console.log('script start')
setTimeout(() => {
console.log('setTimeout')
},0)
new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise1 end')
}).then(function () {
console.log('promise2')
})
async function foo() {
console.log('foo start')
await bar()
console.log('foo end')
}
async function bar() {
console.log('bar start')
}
foo()
console.log('script end')
// output: script start -> promise1 -> promise1 end -> foo start -> bar start -> script end -> promise2 -> foo end -> settimeout上面的代码执行过程如下
- 主执行栈开始依次执行同步任务 console.log('script start')
- 调用 setTimeout 函数,并将回调函数放入到任务队列中
- Promise 本身是一个同步的立即执行函数,当执行 resolve 或者 reject的时候,此时是异步操作。把 then 或者 catch 中的函数放到微任务队列中。
- 执行 foo 函数,async 函数返回一个 Promise 对象,遇到 await 关键字就先执行 bar 函数,等待异步操作完成后在执行函数体后面的语句。同样将函数体后的语句放入到微任务队列中
- 执行 bar 函数
- 执行 console.log('script end') 此时,同步任务执行完毕。
- 主线程先从微任务队列中从头部开始依次取出回调函数执行,先执行 promise2, 然后执行 foo end
- 当前 Tick 执行完成,从任务队列中查看是否有事件完成,将回调函数放入主执行栈中执行 console.log('setTimeout')
前端必须知道的 HTTP 安全头配置
在本文中,我将介绍常用的安全头信息设置,并对每个响应头设置给出一个示例。
Content-Security-Policy
内容安全策略(CSP)常用来通过指定允许加载哪些资源来防止跨站点脚本攻击。在接下来所介绍的所有安全头信息中,CSP 可能是创建和维护花费时间最多的而且也是最容易出问题的。在配置你的网站 CSP 过程中,要小心彻底地测试它,因为阻止某些资源有可能会破坏你的网站的功能。
功能
CSP 的主要目标是减少和报告 XSS 攻击, XSS 攻击利用了浏览器对于从服务器所获取的内容的信任。使得恶意脚本有可能在用户的浏览器中执行,因为浏览器信任其内容来源,即使有时候这些脚本并非来自该站点的服务器当中。
CSP 通过指定允许浏览器加载和执行那些资源,使服务器管理者有能力减少或消除 XSS 攻击的可能性。 一个 CSP 兼容的浏览器将会仅执行从白名单域获取得到的脚本文件,忽略所有其他的脚本(包括内联脚本)。
示例
一个最佳的 CSP 可能是下面这样(注释按照配置值的顺序),在站点包含的每一部分资源请求相关都加入域名限制。
# 所有的内容(比如: JavaScript,image,css,fonts,ajax request, frams, html5 Media等)均来自和站点的同一个源(不包括其子域名)
# 允许加载当前源的图片和特定源图片
# 不允许 objects(比如 Flash 和 Java)
# 仅允许当前源的脚本下载和执行
# 仅允许当前源的 CSS 文件下载和执行
# 仅允许当前源的 frames
# 限制 <base> 标签中的 URL 与当前站点同源
# 仅允许表单提交到当前站点
Content-Security-Policy: default-src 'self'; img-src 'self' https://img.com; object-src 'none'; script-src 'self'; style-src 'self'; frame-ancestors 'self'; base-uri 'self'; form-action 'self';关于 CSP 更加详细的介绍可以看 https://content-security-policy.com/
Strict-Transport-Security
Strict-Transport-Security(HSTS) 告诉浏览器该站点只能通过 HTTPS 访问,如果使用了子域,也建议对任何该站点的子域强制执行此操作。
功能
一个站点如果接受了一个 HTTP 请求,然后跳转到 HTTPS,用户可能在开始跳转前,通过没有加密的方式和服务器对话。这样就存在中间人攻击的潜在威胁,跳转过程可能被恶意网站利用来直接接触用户信息,而不是原来的加密信息。
网站通过HTTP Strict Transport Security通知浏览器,这个网站禁止使用HTTP方式加载,浏览器应该自动把所有尝试使用HTTP的请求自动替换为HTTPS请求。
示例
# 浏览器接受到这个请求后的 3600 秒内的时间,凡是访问这个域名下的请求都是用https请求
# 指定 includeSubDomains 此规则适用该站点下的所有子域名
Strict-Transport-Security: max-age=3600; includeSubDomainsX-Content-Type-Options
X-Content-Type-Options 响应头相当于一个提示标志,被服务器用户提示浏览器一定要遵循 Content-Type 头中 MIME 类型的设定,而不能对其进行修改。
功能
它减少了浏览器可能“猜测”某些内容不正确的意外应用程序行为,例如当开发人员将一个页面标记为“HTML”,但浏览器认为它看起来像JavaScript并试图将其呈现为JavaScript时。这个头将确保浏览器始终按照服务器设置的MIME类型来解析。
示例
X-Content-Type-Options: nosniffCache-Control
Cache-Control 通用消息头字段,被用于在 http 请求和响应中,通过指定指令来实现缓存机制。缓存指令是单向的,这意味着在请求中设置的指令,不一定被包含在响应中。
功能
这一个比其他的稍微复杂一些,因为你可能需要针对不同的内容类型使用不同的缓存策略。
任何包含有敏感信息的网页,例如用户个人信息页面或客户结帐页面,都应该设置为 no-cache。原因是防止共享计算机上的某人按下后退按钮或浏览历史并查看个人信息。
示例
Cache-Control: no-cacheX-Frame-Options
X-Frame-Options 响应头是用来给浏览器指示允许一个页面可否在 , <iframe>, 或者 中展现的标记。站点可以通过确保网站没有被嵌入到别人的站点里面,从而避免点击劫持攻击。
功能
如果恶意的站点将你的网页嵌入到 iframe 标签中, 在你不知道的情况下打开并点击恶意网站的某个按钮,恶意网站能够执行一个攻击通过运行一些 JavaScript 将捕获点击事件到 iframe 中,然后代表你与网站交互。
将 X-Frame-Options 设置为 deny 可以禁止该页面在任何域中的 ifram 标签中展示。
X-Frame-Options 设置可以由 CSP 的 frame-ancestors 配置所代替。
示例
X-Frame-Options: DENY # 表示该页面不允许在 frame 中展示,即便是在相同域名的页面中嵌套也不允许。
X-Frame-Options: SAMEORIGIN # 表示该页面可以在相同域名页面的 frame 中展示。
X-Frame-Options: ALLOW-FROM uri # 表示该页面可以在指定来源的 frame 中展示。Access-Control-Allow-Origin
Access-Control-Allow-Origin 响应头指定了该响应的资源是否被允许与给定的 origin 共享。
功能
可以被用来可解决浏览器的跨域请求。
比如一个站点 A 页面中发起一个 AJAX 请求到 站点 B, A B 不同源。正常情况下因为浏览器的同源策略将不会把 B 的响应结果返回给 A, 除非 B 在响应头中设置允许 A 站点发起请求。
示例
Access-Control-Allow-Origin: * # 允许所有域请求
Access-Control-Allow-Origin: http://someone.com # 允许特定域请求Set-Cookie
Set-Cookie 响应头被用来由服务器端向客户端发送 cookie。
示例
# domain: 指定 cookie 可以送达的域名,默认为当前域名(不包含子域名)
# Secure: 只有在 https 协议时才会被发送到服务端。然而,保密或敏感信息永远不要在 HTTP cookie 中存储或传输,因为整个机制从本质上来说都是不安全的
# HttpOnly: cookie 不能使用 JavaScript代码获取到
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>; Secure; HttpOnlyX-XSS-Protection
X-XSS-Protection 响应头是Internet Explorer,Chrome和Safari的一个功能,当检测到跨站脚本攻击 (XSS)时,浏览器将停止加载页面。
示例
X-XSS-Protection: 1; mode=block # 启用XSS过滤。如果检测到 XSS 攻击,浏览器将不会清除页面,而是阻止页面加载。总结
设置 HTTP 头信息是相对快速和简单的对于网站的数据保护、XSS 攻击和点击劫持等攻击。有针对性的设置这些头信息,你的网站的安全性将会有不错的提高。
ES5/ES6 的继承除了写法以外还有什么区别?
ES6 继承
ES6 通过 class 关键字实现类,类与类之间通过 extends 关键字实现继承。
class Super {
constructor(x,y) {
this.x = x
this.y = y
}
print() {
console.log(this.x, this.y)
}
}
class Sub extends Super {
constructor(x,y) {
super(x,y)
}
}
const sub = new Sub(1,2)
sub.print() // 1,2上面代码中,子类 Sub 的 constructor 方法中出现了 super 关键字, 它在这里表示父类构造函数,用来新建父类的 this 对象
子类必须在 constructor 方法中调用 super 方法,否则新建实例时会报错。这是因为子类自己的 this 对象,必须先通过父类的构造函数完成塑造,得到与父类同样的实例属性和方法,然后再对其进行加工,加上子类自己的实例属性和方法。如果不调用 super 方法,子类就得不到 this 对象。
ES5 继承
ES5 没有 class关键字,通过修改原型链实现继承
function Super() {
this.name = 'super'
}
Super.prototype.print = function() {
console.log(this.name, this.x, this.y)
}
function Sub(x,y) {
this.x = x
this.y = y
}
Sub.prototype = new Super()
Sub.prototype.constructor = Sub
const sub = new Sub(1, 2)
sub.print() // super 1 2当试图访问一个对象的属性或者方法时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索,直到找到一个名字匹配的属性或到达原型链的末尾。
上面的代码中, 子类 Sub 的 prototype 属性指向了 Super 的实例,也就是把 Sub 的原型指向了 Super 的一个实例, 每个实例对象内部都有一个 proto 属性,指向构造函数的原型对象,这样,通过 proto 属性的指向,形成了原型链,用代码将上述关系可以表示为:
Sub.prototype.__proto__ === Super.prototype // true
sub.__proto__ === Sub.prototype // true当我们调用 sub 实例的 print 方法时,首先在 sub 对象自身上查找,发现没有这个方法,就回去 sub 的构造函数原型上去查找,也就是看 Sub.prototype 对象是否存在 print 方法, 发现也没有,最后再去查询 Sub.prototype 的原型,即 Super.prototype上调用这个方法。
总结
- Class 声明变量会进入暂时性死区, 也就是必须先声明,再使用。
- Class 通过 extends 关键字实现继承。 ES5 通过修改原型链实现继承
- Class 内部定义的所有方法都不可枚举,这在 ES5 中默认是可枚举的
- Class 内部默认使用严格模式
- 最重要的一点不同是: ES5 是先创建子类实例对象的this,然后将父类方法赋到这个this上。Class 是先在子类构造函数中用 super 创建父类实例的 this,再在构造函数中进行修改它,这个差别使得 ES6 可以继承内置对象。。
- Class 的子类,通过 proto 属性可以直接访问到父类 如:
function Super() {
this.name = 'super'
}
Super.prototype.print = function() {
console.log(this.name, this.x, this.y)
}
function Sub(x,y) {
this.x = x
this.y = y
}
Sub.prototype = new Super()
Sub.prototype.constructor = Sub
const sub = new Sub(1, 2)
Sub.__proto__ === Function.prototype // true
class Super {}
class Sub extends Super {}
Sub.__proto__ === Super // true介绍下深度优先遍历和广度优先遍历,如何实现?
介绍下深度优先遍历和广度优先遍历,如何实现?
深度优先遍历
定义
以二叉树为例,从根节点 V 出发,首先访问根节点,然后依次从它的各个未被访问的邻接节点出发深度优先搜索,直至二叉树中所有和 V 相通的节点都被访问到。
实现
<div id="root">
<div>
<div></div>
</div>
<div>
<div>
<div></div>
</div>
</div>
</div>假设有如上 dom 结构,深度优先遍历出 root 下面的所有子孙节点。
// 递归实现
function dfs(node,nodeList = []) {
if (node) {
nodeList.push(node)
const children = node.children
children.forEach(i => {
dfs(i, nodeList)
})
}
return nodeList
}
// 非递归实现(利用栈)
funtion dfs(node) {
let nodes = []
let stack = [] // 利用栈元素后进先出的特性
stack.push(node)
while (stack.length) {
const item = stack.pop()
nodes.push(item)
const children = item.children
if (children.length) {
for(let i = children.length - 1; i >= 0; i--) {
stack.push(children(i))
}
}
}
return node
}广度优先遍历
定义
以二叉树为例,从根节点 V 出发,首先访问根节点,然后依次访问它的邻接节点,再分别从这些邻接节点出发依次访问它们各自的邻接节点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至二叉树中所有已被访问的节点的邻接点都被访问到。
实现
还是以上面的 dom 结构为例,使用广度优先遍历 root 节点下的所有子孙节点
// 递归实现
function bfs(node, nodeList = [], count = 0) {
if (node) {
if (!nodeList.length) {
nodeList.push(node)
} else {
let children = node.children
if (children.length) {
nodeList = nodeList.concat(children)
}
}
bfs(nodeList[count], nodeList, count++)
}
return nodeList
}
// 利用队列实现
function bfs(node) {
let nodes = []
let queue = []
queue.push(node)
while (queue.length) {
const item = queue.shift()
nodes.push(item)
const children = item.children
if (children.length) {
queue.concat(children)
}
}
return nodes
}深度优先搜索和广度优先遍历实现深拷贝
// 深度优先遍历
function dfs(entry) {
if (typeof entry !== 'object') {
return entry
}
if (type(entry) === '[object Array]') {
let output = []
for (let i of entry) {
output.push(dfs(i, arr))
}
return output
}
if (type(entry) === '[object Object]') {
let output = {}
Object.keys(entry).forEach(key => {
output[key] = dfs(entry[key])
})
return output
}
}
function type(v) {
return Object.prototype.toString.call(v)
}// 广度优先遍历
function deepCopyBFS(origin){
let queue = []
let target = getEmpty(origin)
if(target !== origin){
queue.push([origin, target])
}
while(queue.length){
let [ori, tar] = queue.shift();
for(let key in ori){
tar[key] = getEmpty(ori[key]);
if(tar[key] !== ori[key]){
queue.push([ori[key], tar[key]]);
}
}
}
return target;
}
function getEmpty(o){
if(Object.prototype.toString.call(o) === '[object Object]'){
return {};
}
if(Object.prototype.toString.call(o) === '[object Array]'){
return [];
}
return o;
}从零实现支持洋葱模型中间件的 vuex
前言
刚开始看 redux 时候,reducer、store、dispatch、middleware 这些名词都比较难以理解,后面接触了 vuex 就比较好理解了。本章会从零开始实现一个简单版本的状态管理器。方便大家今后理解 vuex 和 redux 的状态管理库的源码
什么是状态管理器
一个状态管理器的核心**是将之前放权到各个组件的修改数据层的 controller 代码收归一处,统一管理,组件需要修改数据层的话需要去触发特定的预先定义好的 dispatcher,然后 dispatcher 将 action 应用到 model 上,实现数据层的修改。然后数据层的修改会应用到视图上,形成一个单向的数据流。
简单的状态管理器
本文会一步步的编写一个 Store 类,实现状态的同步更新、异步更新、中间件等方法。
首先,我们编写一个 Store 类。
class Store {
constructor({ state, mutations, actions }) {
this._state = state
this._mutations = {}
this._actions = {}
this._callbacks = []
}
}state 中存放所有需要的数据, mutaition 是更改 state 的唯一方法。 action 类似于 mutation, 不同在于,action 通过提交 mutation 来更改 state,action 可以包含任意的异步操作。 这和 vuex 是一样的。 当我们更改 state 时,需要通知到订阅者。这里可以实现发布-订阅模式来完成。callbacks 用来存放订阅者的回调函数。下面我们来一一实现这些方法。
Mutation
更改 Store 中 state 的唯一方法是提交 mutation,每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。这个回调函数就是我们实际进行状态更改的地方,并且它会接受 state 作为第一个参数,然后对 state 进行一些更改:
const state = {
name: 'webb',
age: 20,
data: {}
}
const mutations = {
changeAge(state, data) {
state.age = data
},
changeData(state, data) {
state.data = data
}
}接下来我们实现把 state 作为第一个参数传递给 mutation
function initMutation(state, mutations, store) {
const keys = Object.keys(mutations)
keys.forEach(key => {
registerMutation(key, mutations[key], state, store)
})
}
function registerMutation(key, handle, state, store) {
// 提交 mutation 时 实际执行 store._mutations[key]函数,这个函数接受一个 data 参数
// 并且实现了把 state 作为第一个参数传入回调函数中
store._mutations[key] = function(data) {
handle.call(store, state, data)
}
}改造一下 Store 类
class Store {
constructor({ state, mutations, actions }) {
this._state = state
this._mutations = {}
this._actions = {}
this._callbacks = []
}
}
Store.prototype._init = function (state, mutations, actions) {
initMutation(this, mutations, state)
}
Store.prototype.commit = function(type, payload) {
const mutation = this._mutations[type]
mutation(payload)
}
// 获取最新 state
Store.prototype.getState = function() {
return this._state
}
const store = new Store({
state,
mutations
})通过 commit 一个 mutation 来更新 state
console.log(store.getState()) // {name: 'webb', age: 20, data: {}}
store.commit('changeAge', 21)
console.log(store.getState()) // {name: 'webb', age: 21, data: {}}到这里我们实现了当提交 mutation 的时候,会修改 state 的值,现在有一个问题摆在我们面前,如果直接通过 this._state.xx = xx 也是可以修改 state的值的。我们应该避免直接修改state的值。那么我们可以在修改 state 的时候做一层拦截,如果不是 mutation 修改的,就抛出错。现在我们尝试用 es6 proxy 来解决这个问题。
class Store {
constructor({ state, mutations, actions }) {
this._committing = false // 用来判断是否是 commit mutation 触发更新
this._mutations = {}
this._init(state, mutations, actions)
}
}
Store.prototype._init = function (state, mutations, actions) {
this._state = initProxy(this, state)
}
Store.prototype.commit = function(type, payload) {
const mutation = this._mutations[type]
this._committing = true
mutation(payload)
this._committing = false
}
// 对 state 的操作加入拦截,如果不是 commit mutation 就抛出错误
function initProxy(store,state) {
return new Proxy(state, handle(store))
}
function handle(store) {
return {
get: function (target, key) {
return Reflect.get(target, key)
},
set: function (target, key, value) {
if (!store._committing) {
throw new Error('只能通过 mutation 更改 state')
}
return Reflect.set(target, key, value)
}
}
}Subscribe
上面我们完成了对 state 数据的修改。接下来我们实现,当 state 数据更新后,通知到相关 state 的使用者。
// 收集订阅者
Store.prototype.subscribe = function (callback) {
this._callbacks.push(callback)
}
// 修改 state 后, 触发订阅者的回调函数,并把旧的 state 和新的 state 作为参数传递
Store.prototype.commit = function (mutationName, payload) {
const mutation = this._mutations[mutationName]
const state = deepClone(this.getStatus())
this._committing = true
mutation(payload)
this._committing = false
this._callbacks.forEach(callback => {
callback(state, this._state)
})
}
const store = new Store({
state,
mutations
})
store.subscribe(function (oldState, newState) {
console.log('old', oldState)
console.log('new', newState)
})
store.commit('changeAge', 21)
// old: { name: 'webb', age: 20, data: {} }
// new: { name: 'webb', age: 21, data: {} }上面代码中我们使用发布-订阅模式,通过 subscribe 函数订阅 state 的变化,在 mutation 执行完成后,调用订阅者的回调函数,并把之前的 state 的 最新的 state 作为参数返回。
actions
vuex 文档中提到
一条重要的原则就是要记住 mutation 必须是同步函数 为什么?请参考下面的例子:
mutations: {
someMutation (state) {
api.callAsyncMethod(() => {
state.count++
})
}
}现在想象,我们正在 debug 一个 app 并且观察 devtool 中的 mutation 日志。每一条 mutation 被记录,devtools 都需要捕捉到前一状态和后一状态的快照。然而,在上面的例子中 mutation 中的异步函数中的回调让这不可能完成:因为当 mutation 触发的时候,回调函数还没有被调用,devtools 不知道什么时候回调函数实际上被调用——实质上任何在回调函数中进行的状态的改变都是不可追踪的
所以为了处理异步操作,我们需要实现 action。
const mutations = {
changeData(state, data) {
state.data = data
}
}
const actions = {
async getData({ commit }) {
const data = await axios.get('http://ip-api.com/json')
commit('changeData', data.data.status)
}
}
function initAction(store, actions) {
const keys = Object.keys(actions)
keys.forEach(key => {
registerAction(key, store, actions[key])
})
}
function registerAction(key, store, handle) {
store._actions[key] = function (data) {
// 把 commit 和 state 作为参数传递给 action 的回调函数,当异步任务执行完成后,可以 commit 一个 mutation 来更新 state
let res = handle.call(store, { commit: store.commit.bind(store), state: store._state }, data)
return res
}
}
// action 通过 dispatch 来触发, 并把更新后的 state 作为 promise 的结果返回
Store.prototype.dispatch = function (actionName, payload) {
return new Promise((resolve, reject) => {
const action = this._actions[actionName]
const self = this
// action 异步操作返回 promise,当 promise 有结果时,获取最新的 state 返回。
action(payload).then(() => {
resolve(this._state)
})
})
}
store.dispatch('getData').then(state => {
console.log('dispatch success', state)
})到这里我们已经实现了一个基本的状态管理器。
中间件 middleware
现在有一个需求,在每次修改 state 的时候,记录下来修改前的 state ,为什么修改了,以及修改后的 state。
这里我们模仿 koa 的洋葱模型中间件来实现。
// 首先定义一个 middleware 类
class Middleware {
constructor() {
this.middlewares = []
this.index = 0
}
use(middleware) {
this.middlewares.push(middleware)
}
exec() {
this.next()
}
next() {
if (this.index < this.middlewares.length) {
const middleware = this.middlewares[this.index]
this.index++
middleware.call(this, this.next.bind(this))
} else {
this.index = 0
}
}
}
// 每次 commit 的时候去执行中间件
Store.prototype.commit = function (mutationName, payload) {
const mutation = this._mutations[mutationName]
const state = deepClone(this.getStatus())
execMiddleware(this) // 执行中间件
this._committing = true
mutation(payload)
this._committing = false
this._callbacks.forEach(callback => {
callback(state, this._state)
})
}
// 注册中间件
store.$middlewares.use(async next => {
console.log('start middleware', store.getStatus())
await next()
console.log('end middleware', store.getStatus())
})
store.commit('changeAge', 21)
// start middleware { name: 'webb', age: 20, data: {} }
// end middleware { name: 'webb', age: 20, data: {} }中间件的完整代码可以查看 github
总结
好了,到这里一个支持中间件模式的微型状态管理库已经实现了。当然 vuex 的源码比这要复杂很多,希望通过本文能让你更好的阅读理解 vuex 的源码。
介绍下 Set、Map、WeakSet 和 WeakMap 的区别?
Set
定义
Set在其他语言中又叫做集合,是由一堆无序的、相关联的,且不重复的内存结构组成的组合。
根据定义可以得出几个关键点:
- 集合中的元素无序且唯一
- 集合中的元素可以是任何类型,无论是原始值还是对象引用
Set 的实例属性和方法
-
size: 返回集合中所包含的元素的数量
-
add(value): 向集合中添加一个新的项
-
delete(value): 从集合中删除一个值
-
has(value): 如果值在集合中存在,返回ture, 否则返回false
-
clear(): 移除集合中的所有项
-
keys(): 返回键名的遍历器
-
values(): 返回键值的遍历器 (由于 Set 没有键名只有键值,所有 keys 和 values 效果一致)
-
entries(): 返回键值对的遍历器
-
forEach(): 使用回调函数遍历每个成员
Set 的基本用法
Set 本身是一个构造函数,用来生成Set结构
const s = new Set()
[1,2,3,4,4].forEach(i => s.add(i))
for(let i of s) {
console.log(i)
}
// output: 1 2 3 4
// Set不会添加重复元素上面代码可以看出 Set 用途之一是可以去除数组中的重复元素
Set 构造函数还可以接受一个数组(或具有 iterable 接口的其他数据结构)作为参数,用来初始化一个集合。
// 例 1
const s = new Set([1,2,3,4,5,5,4,'5'])
[...s] // [1,2,3,4,5,'5']
// 注意 向 Set 中加入值的时候不会发生类型转换, Set内部用 (===) 来判断两个值是否相等
// 例 2
const m = new Map()
m.set('a', 1)
m.set('a', 2)
const s = new Set(m)
[...s] // [['a', 1], ['b', 2]]
Array.from(s) // [['a', 1], ['b', 2]] Array.from方法可以将 Set 转为数组WeakSet
定义
WeakSet 结构与 Set 类似,也是不重复的值的集合
与 Set 的区别
- WeakSet 中的元素只能是对象,不能是其他类型的值
- WeakSet 中的对象都是弱引用,即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果该对象不在被其他变量引用,那么垃圾回收机制就会自动回收该对象所占用内存,所以只要 WeakSet 成员对象在外部消失,它们在 WeakSet 里面的引用就会自动消失。
- 由于 WeakSet 内部有多少个成员,取决于垃圾回收机制有没有运行,运行前后很可能成员个数是不一样的,而垃圾回收机制何时运行是不可预测的,因此 ES6 规定 WeakSet 不可遍历。
Map
定义
类似于对象,也是键值对的集合
与对象(Object)的区别:
- 对象的键只能是字符串,Map 的键可以是任意类型
Map 的实例属性和方法
-
size: 返回 Map 结构的元素总数
-
set(key, value): 向 Map 中加入或更新键值对
-
get(key): 读取 key 对用的值,如果没有,返回 undefined
-
has(key): 某个键是否在 Map 对象中,在返回 true 否则返回 false
-
delete(key): 删除某个键,返回 true, 如果删除失败返回 false
-
clear(): 删除所有元素
-
keys():返回键名的遍历器
-
values():返回键值的遍历器
-
entries():返回所有成员的遍历器
-
forEach():遍历 Map 的所有成员
Map 基本用法
const m = new Map()
m.set('a', 1)
m.set(1: 'a')
m.get('a') // 1
m.has(1) // true
m.size() // 2const map = new Map([
['F', 'no'],
['T', 'yes'],
])
for (let key of map.keys()) {
console.log(key)
}
// "F"
// "T"
for (let value of map.values()) {
console.log(value)
}
// "no"
// "yes"
for (let [key, value] of map) {
console.log(key, value)
}
// "F" "no"
// "T" "yes"
[...map] // [['F', 'no'], ['T', 'yes']]WeakMap
定义
WeakMap 结构与 Map 结构类似,也是用于生成键值对的集合。
WeakMap 和 Map 区别
- WeakMap 只接受对象作为键名(不包括null)
- WeakMap 键名所指向的对象,不计入垃圾回收机制(同 WeakSet)
结论
- Set、Map、WeakSet、WeakMap、都是一种集合的数据结构
- Set 和 WeakSet 是一种值-值的集合,且元素唯一不重复
- Map 和 WeakMap 是一种键-值对的集合,Map 的键可以是任意类型,WeakMap 的键只能是对象类型。
- Set 和 Map可遍历,WeakSet 和 WeakMap不可遍历
- WeakSet 和 WeakMap 键名所指向的对象,不计入垃圾回收机制
JavaScript中的算法(附10道面试常见算法题解决方法和思路)
Introduction
面试过程通常从最初的电话面试开始,然后是现场面试,检查编程技能和文化契合度。几乎毫无例外,最终的决定因素是还是编码能力。通常上,不仅仅要求能得到正确的答案,更重要的是要有清晰的思维过程。写代码中就像在生活中一样,正确的答案并不总是清晰的,但是好的推理通常就足够了。有效推理的能力预示着学习、适应和进化的潜力。好的工程师一直是在成长的,好的公司总是在创新的。
算法挑战是有用的,因为解决它们的方法不止一种。这为决策的制定和决策的计算提供了可能性。在解决算法问题时,我们应该挑战自己从多个角度来看待问题的定义,然后权衡各种方法的优缺点。通过足够的尝试后,我们甚至可能看到一个普遍的真理:不存在“完美”的解决方案。
要真正掌握算法,就必须了解它们与数据结构的关系。数据结构和算法就像阴阳、水杯和水一样密不可分。没有杯子,水就不能被容纳。没有数据结构,我们就没有对象来应用逻辑。没有水,杯子是空的,没有营养。没有算法,对象就不能被转换或“消费”。
要了解和分析JavaScript中的数据结构,请看JavaScript中的数据结构
Primer
在JavaScript中,算法只是一个函数,它将某个确定的数据结构输入转换为某个确定的数据结构输出。函数内部的逻辑决定了怎么转换。首先,输入和输出应该清楚地提前定义。这需要我们充分理解手上的问题,因为对问题的全面分析可以很自然地提出解决方案,而不需要编写任何代码。
一旦完全理解了问题,就可以开始对解决方案进行思考,需要那些变量? 有几种循环? 有那些JavaScript内置方法可以提供帮助?需要考虑那些边缘情况?复杂或者重复的逻辑会导致代码十分的难以阅读和理解,可以考虑能否提出抽象成多个函数?一个算法通常上需要可扩展的。随着输入size的增加,函数将如何执行? 是否应该有某种缓存机制吗? 通常上,需要牺牲内存优化(空间)来换取性能提升(时间)。
为了使问题更加具体,画图表!
当解决方案的具体结构开始出现时,伪代码就可以开始了。为了给面试官留下深刻印象,请提前寻找重构和重用代码的机会。有时,行为相似的函数可以组合成一个更通用的函数,该函数接受一个额外的参数。其他时候,函数柯里的效果更好。保证函数功能的纯粹方便测试和维护也是非常重要的。换句话说,在做出解决问题的决策时需要考虑到架构和设计模式。
Big O(复杂度)
为了计算出算法运行时的复杂性,我们需要将算法的输入大小外推到无穷大,从而近似得出算法的复杂度。最优算法有一个恒定的时间复杂度和空间复杂度。这意味着它不关心输入的数量增长多少,其次是对数时间复杂度或空间复杂度,然后是线性、二次和指数。最糟糕的是阶乘时间复杂度或空间复杂度。算法复杂度可用以下符号表示:
- Constabt: O(1)
- Logarithmic: O(log n)
- Linear: O(n)
- Linearithmic: O(n log n)
- Quadratic: O(n^2)
- Expontential: O(2^n)
- Factorial: O(n!)
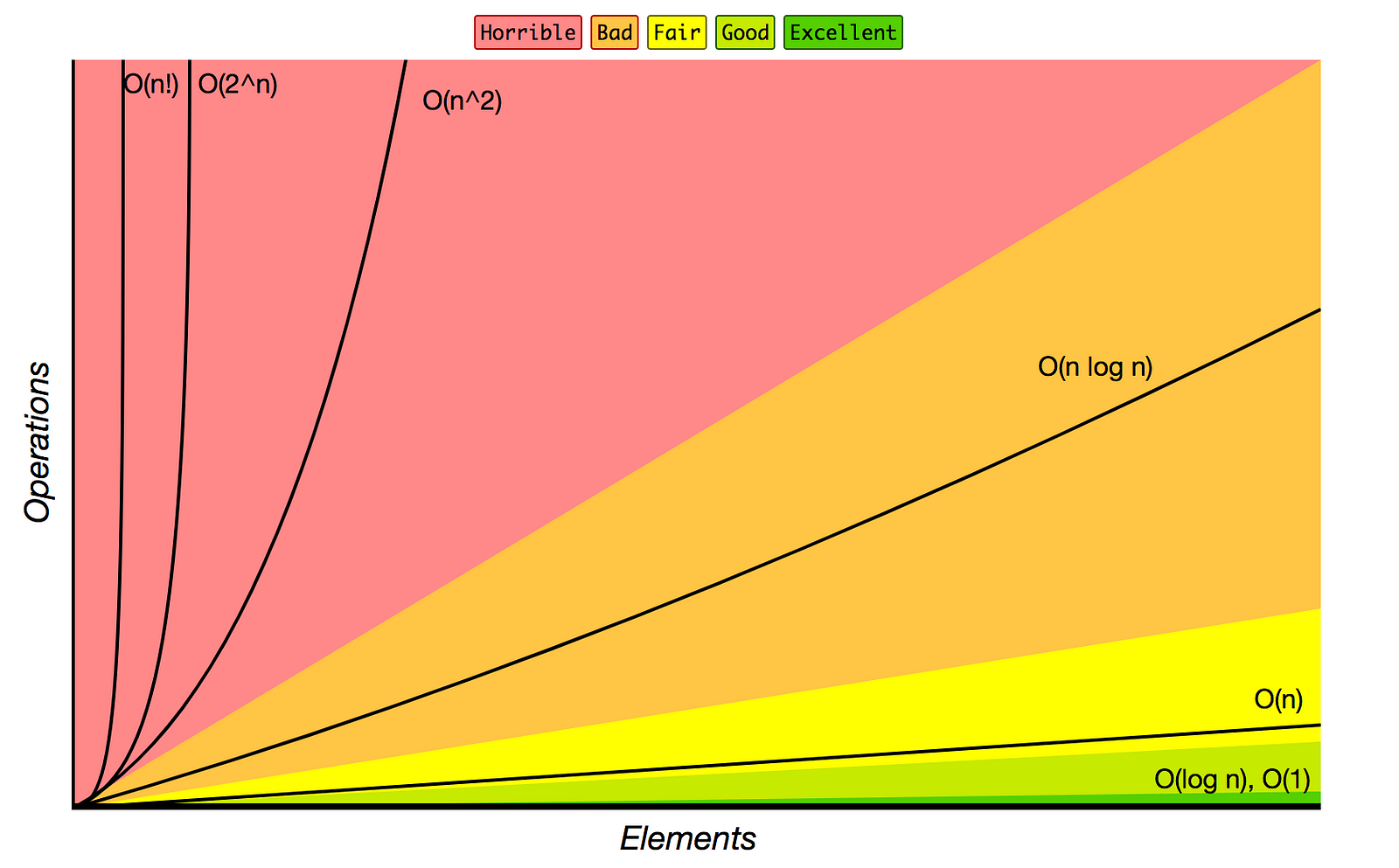
在设计算法的结构和逻辑时,时间复杂度和空间复杂度的优化和权衡是一个重要的步骤。
Arrays
一个最优的算法通常上会利用语言里固有的标准对象实现。可以说,在计算机科学中最重要的是数组。在JavaScript中,没有其他对象比数组拥有更多的实用方法。值得记住的数组方法有:sort、reverse、slice和splice。数组元素从第0个索引开始插入,所以最后一个元素的索引是 array.length-1。数组在push元素有很好的性能,但是在数组中间插入,删除和查找元素上性能却不是很优,JavaScript中的数组的大小是可以动态增长的。
数组的各种操作复杂度
- Push: O(1)
- Insert: O(n)
- Delet: O(n)
- Searching: O(n)
- Optimized Searching: O(log n)
Map 和 Set是和数组相似的数据结构。set中的元素都是不重复的,在map中,每个Item由键和值组成。当然,对象也可以用来存储键值对,但是键必须是字符串。
Iterations
与数组密切相关的是使用循环遍历它们。在JavaScript中,有5种最常用的遍历方法,使用最多的是for循环,for循环可以用任何顺序遍历数组的索引。如果无法确定迭代的次数,我们可以使用while和do while循环,直到满足某个条件。对于任何Object, 我们可以使用 for in 和 for of循环遍历它的keys 和values。为了同时获取key和value我们可以使用 entries()。我们也可以在任何时候使用break语句终止循环,或者使用continue语句跳出本次循环进入下一次循环。
原生数组提供了如下迭代方法:indexOf,lastIndexOf,includes,fill,join。 另外我们可以提供一个回调函数在如下方法中:findIndex,find,filter,forEach,map,some,every,reduce。
Recursions
在一篇开创性的论文中,Church-Turing论文证明了任何迭代函数都可以用递归函数来复制,反之亦然。有时候,递归方法更简洁、更清晰、更优雅。以这个迭代阶乘函数为例:
const factorial = number => {
let product = 1
for (let i = 2; i <= number; i++) {
product *= i
}
return product
}如果使用递归,仅仅需要一行代码
const _factorial = number => {
return number < 2 ? 1 : number * _factorial(number - 1)
}所有的递归函数都有相同的模式。它们由创建一个调用自身的递归部分和一个不调用自身的基本部分组成。任何时候一个函数调用它自身都会创建一个新的执行上下文并推入执行栈顶直。这种情况会一直持续到直到满足了基本情况为止。然后执行栈会一个接一个的将栈顶元素推出。因此,对递归的滥用可能导致堆栈溢出的错误。
最后,我们一起来思考一些常见算法题!
1. 字符串反转
一个函数接受一个字符串作为参数,返回反转后的字符串
describe("String Reversal", () => {
it("Should reverse string", () => {
assert.equal(reverse("Hello World!"), "!dlroW olleH");
})
})思考
这道题的关键点是我们可以使用数组自带的reverse方法。首先我们使用 split方法将字符串转为数组,然后使用reverse反转字符串,最后使用join方法转为字符串。另外也可以使用数组的reduce方法
给定一个字符串,每个字符需要访问一次。虽然这种情况发生了很多次,但是时间复杂度会正常化为线性。由于没有单独的内部数据结构,空间复杂度是恒定的。
const reverse = string => string.split('').reverse().join('')
const _reverse = string => string.split('').reduce((res,char) => char + res)2. 回文
回文是一个单词或短语,它的读法是前后一致的。写一个函数来检查。
describe("Palindrome", () => {
it("Should return true", () => {
assert.equal(isPalindrome("Cigar? Toss it in a can. It is so tragic"), true);
})
it("Should return false", () => {
assert.equal(isPalindrome("sit ad est love"), false);
})
})思考
函数只需要简单地判断输入的单词或短语反转之后是否和原输入相同,完全可以参考第一题的解决方案。我们可以使用数组的 every 方法检查第i个字符和第array.length-i个字符是否匹配。但是这个方法会使每个字符检查2次,这是没必要的。那么,我们可以使用reduce方法。和第1题一样,时间复杂度和空间复杂度是相同的。
const isPalindrome = string => {
const validCharacters = "abcdefghijklmnopqrstuvwxyz".split("")
const stringCharacters = string // 过滤掉特殊符号
.toLowerCase()
.split("")
.reduce(
(characters, character) =>
validCharacters.indexOf(character) > -1
? characters.concat(character)
: characters,
[]
);
return stringCharacters.join("") === stringCharacters.reverse().join("")3. 整数反转
给定一个整数,反转数字的顺序。
describe("Integer Reversal", () => {
it("Should reverse integer", () => {
assert.equal(reverse(1234), 4321);
assert.equal(reverse(-1200), -21);
})
})思考
把number类型使用toString方法换成字符串,然后就可以按照字符串反转的步骤来做。反转完成之后,使用parseInt方法转回number类型,然后使用Math.sign加入符号,只需一行代码便可完成。
由于我们重用了字符串反转的逻辑,因此该算法在空间和时间上也具有相同的复杂度。
const revserInteger = integer => parseInt(number
.toString()
.split('')
.reverse()
.join('')) * Math.sign(integer)4. 出现次数最多的字符
给定一个字符串,返回出现次数最多的字符
describe("Max Character", () => {
it("Should return max character", () => {
assert.equal(max("Hello World!"), "l");
})
})思考
可以创建一个对象,然后遍历字符串,字符串的每个字符作为对象的key,value是对应该字符出现的次数。然后我们可以遍历这个对象,找出value最大的key。
虽然我们使用两个单独的循环来迭代两个不同的输入(字符串和字符映射),但是时间复杂度仍然是线性的。它可能来自字符串,但最终,字符映射的大小将达到一个极限,因为在任何语言中只有有限数量的字符。空间复杂度是恒定的。
const maxCharacter = (str) => {
const obj = {}
let max = 0
let character = ''
for (let index in str) {
obj[str[index]] = obj[str[index]] + 1 || 1
}
for (let i in obj) {
if (obj[i] > max) {
max = obj[i]
character = i
}
}
return character
}5.找出string中元音字母出现的个数
给定一个单词或者短语,统计出元音字母出现的次数
describe("Vowels", () => {
it("Should count vowels", () => {
assert.equal(vowels("hello world"), 3);
})
})思考
最简单的解决办法是利用正则表达式提取所有的元音,然后统计。如果不允许使用正则表达式,我们可以简单的迭代每个字符并检查是否属于元音字母,首先应该把输入的参数转为小写。
这两种方法都具有线性的时间复杂度和恒定的空间复杂度,因为每个字符都需要检查,临时基元可以忽略不计。
const vowels = str => {
const choices = ['a', 'e', 'i', 'o', 'u']
let count = 0
for (let character in str) {
if (choices.includes(str[character])) {
count ++
}
}
return count
}
const vowelsRegs = str => {
const match = str.match(/[aeiou]/gi)
return match ? match.length : 0
}6.数组分隔
给定数组和大小,将数组项拆分为具有给定大小的数组列表。
describe("Array Chunking", () => {
it("Should implement array chunking", () => {
assert.deepEqual(chunk([1, 2, 3, 4], 2), [[1, 2], [3, 4]]);
assert.deepEqual(chunk([1, 2, 3, 4], 3), [[1, 2, 3], [4]]);
assert.deepEqual(chunk([1, 2, 3, 4], 5), [[1, 2, 3, 4]]);
})
})一个好的解决方案是使用内置的slice方法。这样就能生成更干净的代码。可通过while循环或for循环来实现,它们按给定大小的步骤递增。
这些算法都具有线性时间复杂度,因为每个数组项都需要访问一次。它们还具有线性空间复杂度,因为保留了一个内部的“块”数组,它与输入数组成比例地增长。
const chunk = (array, size) => {
const chunks = []
let index = 0
while(index < array.length) {
chunks.push(array.slice(index, index + size))
index += size
}
return chunks
}7.words反转
给定一个短语,按照顺序反转每一个单词
describe("Reverse Words", () => {
it("Should reverse words", () => {
assert.equal(reverseWords("I love JavaScript!"), "I evol !tpircSavaJ");
})
})思考
可以使用split方法创建单个单词数组。然后对于每一个单词,可以复用之前反转string的逻辑。
因为每一个字符都需要被访问,而且所需的临时变量与输入的短语成比例增长,所以时间复杂度和空间复杂度是线性的。
const reverseWords = string => string
.split(' ')
.map(word => word
.split('')
.reverse()
.join('')
).join(' ')8.首字母大写
给定一个短语,每个首字母变为大写。
describe("Capitalization", () => {
it("Should capitalize phrase", () => {
assert.equal(capitalize("hello world"), "Hello World");
})
})思考
一种简洁的方法是将输入字符串拆分为单词数组。然后,我们可以循环遍历这个数组并将第一个字符大写,然后再将这些单词重新连接在一起。出于不变的相同原因,我们需要在内存中保存一个包含适当大写字母的临时数组。
因为每一个字符都需要被访问,而且所需的临时变量与输入的短语成比例增长,所以时间复杂度和空间复杂度是线性的。
const capitalize = str => {
return str.split(' ').map(word => word[0].toUpperCase() + word.slice(1)).join(' ')
}9.凯撒密码
给定一个短语,通过在字母表中上下移动一个给定的整数来替换每个字符。如果有必要,这种转换应该回到字母表的开头或结尾。
describe("Caesar Cipher", () => {
it("Should shift to the right", () => {
assert.equal(caesarCipher("I love JavaScript!", 100), "E hkra FwrwOynelp!")
})
it("Should shift to the left", () => {
assert.equal(caesarCipher("I love JavaScript!", -100), "M pszi NezeWgvmtx!");
})
})思考
首先我们需要一个包含所有字母的数组,这意味着我们需要把给定的字符串转为小写,然后遍历整个字符串,给每个字符增加或减少给定的整数位置,最后判断大小写即可。
由于需要访问输入字符串中的每个字符,并且需要从中创建一个新的字符串,因此该算法具有线性的时间和空间复杂度。
const caesarCipher = (str, number) => {
const alphabet = "abcdefghijklmnopqrstuvwxyz".split("")
const string = str.toLowerCase()
const remainder = number % 26
let outPut = ''
for (let i = 0; i < string.length; i++) {
const letter = string[i]
if (!alphabet.includes(letter)) {
outPut += letter
} else {
let index = alphabet.indexOf(letter) + remainder
if (index > 25) {
index -= 26
}
if (index < 0) {
index += 26
}
outPut += str[i] === str[i].toUpperCase() ? alphabet[index].toUpperCase() : alphabet[index]
}
}
return outPut
}10.找出从0开始到给定整数的所有质数
describe("Sieve of Eratosthenes", () => {
it("Should return all prime numbers", () => {
assert.deepEqual(primes(10), [2, 3, 5, 7])
})
})思考
最简单的方法是我们循环从0开始到给定整数的每个整数,并创建一个方法检查它是否是质数。
const isPrime = n => {
if (n > 1 && n <= 3) {
return true
} else {
for(let i = 2;i <= Math.sqrt(n);i++){
if (n % i == 0) {
return false
}
}
return true
}
}
const prime = number => {
const primes = []
for (let i = 2; i < number; i++) {
if (isPrime(i)) {
primes.push(i)
}
}
return primes
}自己动手实现一个高效的斐波那契队列
describe("Fibonacci", () => {
it("Should implement fibonacci", () => {
assert.equal(fibonacci(1), 1);
assert.equal(fibonacci(2), 1);
assert.equal(fibonacci(3), 2);
assert.equal(fibonacci(6), 8);
assert.equal(fibonacci(10), 55);
})
})彻底理解 JavaScript 中的类型转换
类型转换是将值从一种类型转换为另一种类型的过程(比如字符串转数字,对象转布尔值等)。任何类型不论是原始类型还是对象类型都可以进行类型转换,JavaScript 的原始类型有:number, string, boolean, null, undefined, Symbol。
本文将通过 17 道题目来深入的了解 JS 中的类型转换,通过阅读本文之后,你将能自信的回答出下面题目的答案,并且能够理解背后的原理。在文章的最后,我讲写出答案并解释。在看答案之前,你可以把答案写下来,最后再对照一下,便于找出理解有误的地方。
true + false
12 / "6"
"number" + 15 + 3
15 + 3 + "number"
[1] > null
"foo" + + "bar"
"true" == true
false == "false"
null == ""
!!"false" == !!"true"
["x"] == "x"
[] + null + 1
[1,2,3] == [1,2,3]
{} + [] + {} + [1]
! + [] + [] + ![]
new Date(0) - 0
new Date(0) + 0类似于上面的这些问题大概率也会在 JS 面试中被问到, 所以继续往下读。
隐式 vs 显式类型转换
类型转换可以分为隐式类型转换和显式类型转换。
当开发人员通过编写适当的代码(如Number(value))用于在类型之间进行转换时,就称为显式类型强制转换(或强制类型转换)。
然而 JavaScript 是弱类型语言,在某些操作下,值可以在两种类型之间自动的转换,这叫做隐式类型转换。在对不同类型的值使用运算符时通常会发生隐式类型转换。比如 1 == null, 2 / "5", null + new Date()。当值被 if 语句包裹时也有可能发生,比如 if(value) {} 会将 value 转换为 boolean类型。
严格相等运算符(===)不会触发类型隐式转换,所以它可以用来比较值和类型是否都相等。
隐式类型转换是一把双刃剑,使用它虽然可以写更少的代码但有时候会出现难以被发现的bug。
三种类型转换
我们需要知道的第一个规则是:在 JS 中只有 3 种类型的转换
- to string
- to boolean
- to number
第二,类型转换的逻辑在原始类型和对象类型上是不同的,但是他们都只会转换成上面 3 种类型之一。
我们首先分析一下原始类型转换。
String 类型转换
String() 方法可以用来显式将值转为字符串,隐式转换通常在有 + 运算符并且有一个操作数是 string 类型时被触发,如:
String(123) // 显式类型转换
123 + '' // 隐式类型转换所有原始类型转 String 类型
String(123) // '123'
String(-12.3) // '-12.3'
String(null) // 'null'
String(undefined) // 'undefined'
String(true) // 'true'Symbol 类型转 String 类型是比较严格的,它只能被显式的转换
String(Symbol('symbol')) // 'Symbol(symbol)'
'' + Symbol('symbol') // TypeError is thrownBoolean 类型转换
Boolean() 方法可以用来显式将值转换成 boolean 型。
隐式类型转换通常在逻辑判断或者有逻辑运算符时被触发(|| && !)。
Boolean(2) // 显示类型转换
if(2) {} // 逻辑判断触发隐式类型转换
!!2 // 逻辑运算符触发隐式类型转换
2 || 'hello' // 逻辑运算符触发隐式类型转换注意: 逻辑运算符(比如 || 和 &&)是在内部做了 boolean 类型转换,但实际上返回的是原始操作数的值,即使他们都不是 boolean 类型。
// 返回 number 类型 123,而不是 boolean 型 true
// 'hello' 和 '123' 仍然在内部会转换成 boolean 型来计算表达式
let x = 'hello' && 123 // x === 123boolean 类型转换只会有 true 或者 false 两种结果。
Boolean('') // false
Boolean(0) // false
Boolean(-0) // false
Boolean(NaN) // false
Boolean(null) // false
Boolean(undefined) // false
Boolean(false) // false任何不在上面列表中的值都会转换为 true, 包括 object, function, Array, Date 等,Symbol 类型是真值,空对象和空数组也是真值。
Boolean({}) // true
Boolean([]) // true
Boolean(Symbol()) // true
!!Symbol() // true
Boolean(function() {}) // trueNumber 类型转换
和 Boolean()、String() 方法一样, Number() 方法可以用来显式将值转换成 number 类型。
number 的隐式类型转换是比较复杂的,因为它可以在下面多种情况下被触发。
- 比较操作(>, <, <=, >=)
- 按位操作(| & ^ ~)
- 算数操作(- + * / %), 注意,当 + 操作存在任意的操作数是 string 类型时,不会触发 number 类型的隐式转换
- 一 元 + 操作
- 非严格相等操作(== 或者 !== ),注意,== 操作两个操作数都是 string 类型时,不会发生 number 类型的隐式转换
Number('123') // 显示类型转换
+ '123' // 隐式类型转换
123 != "456" // 隐式类型转换
4 > "5" // 隐式类型转换
5 / null // 隐式类型转换
true | 0 // 隐式类型转换接下来看一下原始类型显示转换 number 类型会发生什么
Number(null) // 0
Number(undefined) // NaN
Number(true) // 1
Number(false) // 0
Number(" 12 ") // 12
Number("-12.34") // -12.34
Number("\n") // 0
Number(" 12s ") // NaN
Number(123) // 123当将一个字符串转换为一个数字时,引擎首先删除前尾空格、\n、\t 字符,如果被修剪的字符串不成为一个有效的数字,则返回 NaN。如果字符串为空,则返回 0。
Number() 方法对于 null 和 undefined 的处理是不同的, null 会转换为 0, undefined 会转换为 NaN
不管是显式还是隐式转换都不能将 Symbol 类型转为 number 类型,当试图这样操作时,会抛出错误。
Number(Symbol('my symbol')) // TypeError is thrown
+Symbol('123') // TypeError is thrown这里有 2 个特殊的规则需要记住:
- 当将 == 应用于 null 或 undefined 时,不会发生数值转换。null 只等于 null 或 undefined,不等于其他任何值。
null == 0 // false, null is not converted to 0
null == null // true
undefined == undefined // true
null == undefined // true
undefined == 0 // false- NaN 不等于任何值,包括它自己
NaN === NaN // false
if(value !== value) { console.log('the value is NaN') }object 类型转换
到这里我们已经深入了解了原始类型的转换,接下来我们来看一下 object 类型的转换。
当涉及到对象的操作比如:[1] + [2,3],引擎首先会尝试将 object 类型转为原始类型,然后在将原始类型转为最终需要的类型,而且仍然只有 3 种类型的转换:number, string, boolean
最简单的情况是 boolean 类型的转换,任何非原始类型总是会转换成 true,无论对象或数组是否为空。
对象通过内部 [[ToPrimitive]] 方法转换为原始类型,该方法负责数字和字符串转换。
[[ToPrimitive]] 方法接受两个参数一个输入值和一个需要转换的类型(Numer or String)
number 和 string的转换都使用了对象的两个方法: valueOf 和 toString。这两个方法都在 Object.prototype 上被声明,因此可用于任何派生类,比如 Date, Array等。
通常上 [[ToPrimitive]] 算法如下:
- �如果输入的值已经是原始类型,直接返回这个值。
- 输入的值调用 toString() 方法,如果结果是原始类型,则返回。
- 输入的值调用 valueOf() 方法,如果结果是原始类型,则返回。
- 如果上面 3 个步骤之后,转换后的值仍然不是原始类型,则抛出 TypeError 错误。
number 类型的转换首先会调用 valueOf() 方法,如果不是�原始值�在调用 toString() 方法。 string 类型的转换则相反。
大多数 JS 内置对象类型的 valueOf() 返回这个对象本身,其�结果经常被忽略,因为它不是一个原始类型。所以大多数情况下当 object 需要转换成 number 或 string 类型时最终都调��用了 toString() 方法。
当运算符不同时,[[ToPrimitive]] 方法接受的转换类型参数也不相同。当存在 == 或者 + 运算符时一般会��先触发 number 类型的转换再触发 string 类型转换。
在 JS 中你可以通过重写对象的 toString 和 valueOf 方法来修改对象到�原始类型转换的逻辑。
答案解析
接下来我们按照之前的转换逻辑来解释一下每一道题,看一下是否和你的答案一样。
true + false // 1'+' 运算符会��触发 number 类型转换对于 true 和 false
12 / '6' // 2算数运算符会把字符串 ‘6’ 转为 number 类型
"number" + 15 + 3 // "number153"'+' 运算符按从左到右的顺序的执行,所以优先执行 “number” + 15, 把 15 转为 string 类型,得到 “number15” 然后同理执行 “number15” + 3
15 + 3 + "number" // "18number"15 + 3 先执行,�运算符两边都是 number 类型 ,不用转换,然后执行 18 + “number” 最终得到 “18number”
[1] > null // true
==> '1' > 0
==> 1 > 0
==> true比较运算符 > 执行 number 类型隐式转换。
"foo" + + "bar" // "fooNaN"
==> "foo" + (+"bar")
==> "foo" + NaN
==> "fooNaN"一元 + 运算符比二元 + 运算符具有更高的优先级。所以 + bar表达式先求值。一元加号执行字符串“bar” 的 number 类型转换。因为字符串不代表一个有效的数字,所以结果是NaN。在第二步中,计算表达式'foo' + NaN。
'true' == true // false
==> NaN == 1
==> false
'false' == false // false
==> NaN == 0
==> false== 运算符执行 number 类型转换,'true' 转换为 NaN, boolean 类型 true 转换为 1
null == '' // falsenull 不等于任何值除了 null 和 undefined
!!"false" == !!"true" // true
==> true == true
==> true!! 运算符将字符串 'true' 和 'false' 转为 boolean 类型 true, 因为不是空字符串,然后两边都是 boolean 型不在执行隐式转换操作。
['x'] == 'x' // true== 运算符对数组类型执行 number 转换,先调用对象的 valueOf() 方法,结果是数组本身,不是原始类型值,所以执行对象的 toString() 方法,得到字符串 'x'
[] + null + 1 // 'null1'
==> '' + null + 1
==> 'null' + 1
==> 'null1''+' 运算符执行 number 类型转换,先调用对象的 valueOf() 方法,结果是数组本身,不是原始类型值,所以执行对象的 toString() 方法,得到字符串 '', 接下来执行表达式 '' + null + 1。
0 || "0" && {} // {}
==> (0 || '0') && {}
==> (false || true) && true
==> true && true
==> true逻辑运算符 || 和 && 将值转为 boolean 型,但是会返回原始值(不是 boolean)。
[1,2,3] == [1,2,3] // false当运算符两边类型相同时,不会执行类型转换,两个数组的内存地址不一样,所以返回 false
{} + [] + {} + [1] // '0[object Object]1'
==> +[] + {} + [1]
==> 0 + {} + [1]
==> 0 + '[object Object]' + '1'
==> '0[object Object]1'所有的操作数都不是原始类型,所以会按照从左到右的顺序执行 number 类型的隐式转换, object 和 array 类型的 valueOf() 方法返回它们本身,所以直接忽略,执行 toString() 方法。 这里的技巧是,第一个 {} 不被视为 object,而是块声明语句,因此它被忽略。计算从 +[] 表达式开始,该表达式通过toString()方法转换为空字符串,然后转换为0。
! + [] + [] + ![] // 'truefalse'
==> !(+[]) + [] + (![])
==> !0 + [] + false
==> true + [] + false
==> true + '' + false
==> 'truefalse'一元运算符优先执行,+[] 转为 number 类型 0,![] 转为 boolean 型 false。
new Date(0) - 0 // 0
==> 0 - 0
==> 0'-' 运算符执行 number 类型隐式转换对于 Date 型的值,Date.valueOf() 返回到毫秒的时间戳。
new Date(0) + 0
==> 'Thu Jan 01 1970 02:00:00 GMT+0200 (EET)' + 0
==> 'Thu Jan 01 1970 02:00:00 GMT+0200 (EET)0''+' 运算符触发默认转换,因此使用 toString() 方法,而不是 valueOf()。
Git switch 和 restore 命令
对于经常使用 git 的人来说,很少有机会发现关于 git 的新东西。我最近发现在高级命令列表中增加了 2 个新功能:
- git restore
- git switch
为了理解为什么新增这两个命令,我们先回顾一下经常使用的 git checkout 这个命令。
Git checkout
有些新手刚开始使用 git checkout 时会感到困惑。这是因为它造成的结果依赖于传入的参数。
下面我们看一下 git checkout 的几个使用场景
-
切换本地分支,更准确的说法是,切换 HEAD 指针指向的分支,比如,你可以从 develop 分支切换到 main 分支:
git checkout main
-
切换 HEAD 指针指向一个特定的 Commit
git checkout f8c540805b7e16753c65619ca3d7514178353f39
-
恢复文件到上次提交的状态
如果输入的参数是一个文件名而不是分支名或者 commit,它将丢弃你对这个文件的修改并重置到上一次的 commit 版本状态。
git checkout test.text
看到这上面几种行为,你可能会认为它没有任何意义,为什么一个命令做两个不同的动作?如果我们查看 git 文档,我们可以看到命令有一个额外的参数,通常被忽略:
git checkout <tree-ish> -- <pathspec>什么是 ?它可以表示很多不同的东西,但最常见的是表示提交 commit 值或分支名称。默认情况下,它被认为是当前分支,但它可以是任何其他分支或 commit。例如,如果你在 develops 分支,想要将 test.txt 文件更改为来自 main 分支的版本,你可以这样做:
git checkout main -- test.txt看到这里,也许事情开始变得有意义了。当你为 git checkout 提供一个分支或 commit 参数时,它会将你的所有文件更改为相应版本中的状态,但如果你也指定了一个文件名,它只会更改该文件的状态以匹配指定的版本。
新增的命令
即使我们现在知道了 git checkout 的多种用法,我们必须承认,它对于新手仍然是困惑的。这就是为什么在 git 的 2.23 版本中,引入了两个新命令来取代旧的 git checkout(它仍然可用,但新使用 git 的人最好从这些命令开始)。它们分别实现了 git 的多种行为中的一种。
Switch
可以使用这个命令来在分支或 commit 之间切换
git switch develop不同于 git checkout 切换 commit 直接提供 commit hash, 使用 switch 切换 commit 时需要加 -d 标志
git switch -d f8c540805b7e16753c65619ca3d7514178353f39同时切换并新增一个本地分支时需要加 -c 标志
git checkout -b new_branch
git switch -c new_branchRestore
可以将文件的状态恢复到指定的 git 版本 (默认为当前分支)
git restore -- test.txt总结
相比较于 git checkout,这两个命令更加的清晰。
关于这两个命令的更多细节可以在 git 文档中找到:
记 mysql 并发更新时的表锁问题
记 mysql 并发更新时的表锁问题
最近在做一个 nodejs 项目时遇到的一个基础的 mysql 问题,下面记录一下。
问题
当对数据表中的数据做更新操作时,如果并发的对同一条数据进行更新,那么后面触发的会有一定概率更新失败。
原因
mysql innodb 的行锁基于索引的,当我们执行下面这条更新语句时,会触发 mysql 的排它锁,如果更新还没完成,其他对于 id=1 的更新操作会执行失败
update tableName set field = newField where id=1解决
通过用事务的方式来执行这种高并发的语句,可以解决这个问题。
数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的"独立"环境执行。
当前一个事务没有执行完成时,下面的只能等待当前事务完成,才会执行。
sequelize 代码
await sequelize.transaction({}, async (transaction) => {
const instance = await model.findOne({
where: {
id: 1,
},
transaction,
})
await instance.update({
field: newField,
}, {
transaction,
})
})Node.js && JavaScript 面试常用的设计模式二
观察者模式
这是一个非常有趣的模式,它允许你通过对某个输入作出反应来响应,而不是主动地检查是否提供了输入。换句话说,使用此模式,可以指定你正在等待的输入类型,并被动地等待,直到提供该输入才执行代码。
在这里,观察者是一个对象,它们知道想要接收的输入类型和要响应的操作,这些对象的作用是“观察”另一个对象并等待它与它们通信。
另一方面,可观察对象将让观察者知道何时有新的输入可用,以便他们可以对它做出反应(如果适用的话)。如果这听起来很熟悉,那是因为Node.js中处理事件的任何东西都是这种模式。
下面的代码是一段HTTP Server的实现
const http = require('http');
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Your own server here');
})
server.on('error', err => {
console.log(“Error:: “, err)
})
server.listen(3000, '127.0.0.1', () => {
console.log('Server up and running');
})在上面的代码中隐藏了观察者模式。服务器对象将充当可观察对象,而回调函数是实际的观察者。你可以看到,这种模式非常适合这种HTTP异步调用。这种模式的另一个广泛使用的用例是触发特定事件。这种模式可以在任何容易异步触发事件(例如错误或状态更新)的模块上找到。例如数据库驱动程序,甚至套接字。io,它允许你在自己代码之外触发的特定事件上设置观察者。
下面我们简单的实现一个EventEmitter类来实现观察者模式:
class eventEmitter {
constructor() {
this.eventObj = {}
}
on(evName, fn) {
this.eventObj[evName] = this.eventObj[evName] ? this.eventObj[evName].concat(fn) : [fn]
}
emit(evName, ...params) {
for (let fn of this.eventObj[evName]) {
fn.apply(null, params)
}
}
}const event = new eventEmitter()
event.on('error', err => {
console.log(err, 1)
})
event.on('error', err => {
console.log(err, 2)
})
event.emit('error')上面的例子中,error事件作为一个被观察对象,回调函数是观察者,当触发on事件时,观察者会被加入到一个队列中,当error事件触发时,回调函数(观察者)会受到通知,并且依次被调用。
职责链模式
职责链模式是Node.js世界中很多人使用过的一种模式,他们甚至没有意识到这一点。
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
下面是一个非常基本的实现这个模式,你可以看到在底部,我们有四个可能的值需要处理,但是我们不在乎谁来处理它们,我们只需要,至少,一个函数来使用它们,因此我们只是寄给链,让链中的每一个函数决定他们是否应该使用它或忽略它。
function processRequest(r, chain) {
let lastResult = null
let i = 0
do {
lastResult = chain[i](r)
i++
} while(lastResult != null && i < chain.length)
if(lastResult != null) {
console.log("Error: request could not be fulfilled")
}
}
let chain = [
function (r) {
if(typeof r == 'number') {
console.log("It's a number: ", r)
return null
}
return r
},
function (r) {
if(typeof r == 'string') {
console.log("It's a string: ", r)
return null
}
return r
},
function (r) {
if(Array.isArray(r)) {
console.log("It's an array of length: ", r.length)
return null
}
return r
}
]
processRequest(1, chain)
processRequest([1,2,3], chain)
processRequest('[1,2,3]', chain)
processRequest({}, chain)输出的结果是:
It's a number: 1
It's an array of length: 3
It's a string: [1,2,3]
Error: request could not be fulfilled使用例子
在我们经常使用的开发库中,这种模式最明显的例子是ExpressJS的中间件。使用该模式,实际上是在设置一系列函数(中间件),这些函数计算请求对象并决定对其运行一个函数或者忽略它。可以将该模式看作上面示例的异步版本,在这个版本中,不是检查函数是否返回值,而是检查将哪些值传递给它们调用的下一个回调。
var app = express();
app.use(function (req, res, next) {
console.log('Time:', Date.now())
next(); //call the next function on the chain
})中间件是这种模式的一种特殊实现,因为可以认为所有中间件都可以完成请求,而不是链中的一个成员。然而,其背后的原理是一样的。
下面我们来自己简单实现一个中间件函数
class App {
constructor() {
this.middleware = []
this.index = 0
}
use(fn) {
this.middleware.push(fn)
}
exec() {
this.next()
}
next() {
if (this.index < this.middleware.length) {
const fn = this.middleware[this.index]
this.index++
fn.call(this, this.next.bind(this))
}
}
}
const app = new App()
app.use(function (next) {
console.log(1)
next()
})
app.use(function (next) {
console.log(2)
})
app.exec()输出结果
1,2当使用use函数时,在中间件队列中加入回调函数,在执行时,可以调用next()来进入下一个中间件。
上一篇我们深入理解IIFE和工厂模式还有单例模式
关注作者github,第一时间获得更新。
两种敏捷开发方式的工作流
两种敏捷开发方式的工作流
敏捷开发时当今很流行的一种开发软件方式,接下来主要介绍一下两种主要的敏捷开发方式的工作流
Scrum flow
项目计划从定义backlog开始,即交付完成的产品时应该完成的用户需求列表。
- 产品 backlog - 列出团队主要的 “To Do” list。 产品的代办事项列表应该包括全部的特性和 bug 修复。以便在项目结束时确认已经完成。产品的代办列表需要在工作中按照新的需求或者发现的错误持续的更新。产品的负责人负责待办事项,使其与客户的反馈和建议以及团队的工作进度同步。一些Item的优先级应该被提升或下降,一些item应该根据需求的变化增加或者减少。
- Sprint backlog - 包含在特定sprint中要完成的任务。sprint backlog的项目被选择为在sprint结束时交付一个完成的特性或组件。虽然sprint backlog也允许一定的灵活性和修改,但是sprint的目标应该保持不变,并且变更应该保持在最小。
- Sprint goal or increment - 作为sprint结果交付的可用产品。通常,sprint以展示完成的特性或组件的演示结束。在这方面,一个重要的概念是“done”的定义,它指的是要将每个用户工作视为完整的。“done”的定义可能会根据用户的情况而有所不同:它可能包含多个任务,例如开发、测试、设计、文档和表示,还可能涉及不同的团队成员。
每个sprint都从一个计划阶段开始,在下一个sprint中选择任务。对于计划阶段,整个团队通常都会到场,包括产品负责人和Scrum Master。团队决定在sprint结束时可以交付什么,并从产品backlog中选择相应的用户工作。通过这种方式,他们将sprint backlog放在一起。
在sprint期间,团队每天开会进行“每日scrum”,讨论他们的进展以及可能遇到的任何障碍。每日scrum的目的是尽早发现问题,并快速找到解决方案,以免中断sprint流程。
在sprint之后,涉众将审查完成的特性。在sprint评审期间,团队有机会收到关于他们工作的反馈,以及变更建议(如果有的话)。
与此同时,团队开会进行sprint回顾,分析他们刚刚完成的sprint,并找到可以改进的地方。回顾之后,流程被重置,新的sprint从计划阶段开始。

Kanban flow
在 Kanban中,没有要求需要在一个确定的时间点完成一定数量的工作。相反,Kanban专注于平衡团队的当前正在进行的工作的能力。
一个 Kanban 项目流程从一般的backlog开始,包含所有的应该完成的任务。每个团队成员从backlog中为自己挑选一个任务,并集中精力完成它。当任务完成时,成员选择下一个任务,以此类推,直到所有任务完成为止。待办事项列表的优先级是将最紧急的任务放在顶部,由团队首先处理。
在Kanban中,重要的是在项目期间的任何时候,正在进行的工作量都不能超过团队的能力。为此目的,有可能根据现有的能力为任何类型的工作定一个限度。
产品负责人可以尽可能频繁地设置和更改backlog中的优先级,因为backlog管理对团队的性能没有影响。团队只关心正在进行的工作,只有在当前任务完成后才返回到backlog。
每个任务都沿着“To Do”—“Work in Progress”—“Done”路线进行。当然,Kanban也支持“完成”定义的概念,这是每个任务接受的标准。
总而言之,我们可以说Scrum的主要区别在于它试图在指定的时间内完成预定的工作,而Kanban确保正在进行的工作永远不会超过设定的限制。
如何选择
如果你一直在等待这个问题的最终答案,我们可能会让你失望。到目前为止,我们希望已经成功地证明了这两种方法都有它们的优点,并且都可以帮助建立敏捷开发过程。然而,我们提供了一些指导方针,可以帮助您选择最适合您的团队的方法。
使用 Scrim
- 你可以相对容易地将工作划分为逻辑块,这些逻辑块可以在两周内完成。
- 你需要对整个项目有高度的可预测性。Scrum专注于将sprint中的变更保持在最小。
- 你的团队里有很多新成员。使用Scrum,如果需要的话,他们会更容易理解团队纪律并做出改进。
使用 Kanban
- 你期望项目中有很多频繁的变更。
- 很难隔离能够在两周内交付的产品组件。
- 你的团队纪律严明,可以信任他们会在没有严格截止日期的情况下安排他们的活动。
彻底理解Node.js中的Buffer
彻底理解Node.js中的Buffer
每当在Node.js中遇到Buffer,Stream和binary data之类的单词时,是否总是像我一样感到困惑? 认为它们并不是常用的,而只适合Node.js专家和包开发人员去使用。
实际上,这些单词是非常重要的,尤其对于用Node.js进行web开发而没有任何CS学位的人员。
当然,如果你选择继续做一个普通的Node.js开发人员,你可能永远不会直接使用它们。但是如果你想对Node.js的理解提升到下一个级别,那么你确实需要更深入地了解Node的许多核心特性。比如Buffer。这正是我写这篇文章的目的——帮助我们揭开其中一些特性的神秘面纱,并将Node.js的学习带到下一个层次。
在开始前,先看一下Node.js官方文档对Buffer的说明
… mechanism for reading or manipulating streams of binary data. The Buffer class was introduced as part of the Node.js API to make it possible to interact with octet streams in the context of things like TCP streams and file system operations.
让我们用简单易懂的语言来重新描述它:
Buffer类作为Node.js API的一部分引入,使操作二进制数据流或与之交互成为可能。
接下来我们更深入的去了解Buffer,streams,binary data。
什么是二进制数据
你可能已经知道计算机以二进制文件存储和表示数据。二进制就是1和0的集合。例如,下面是5个不同的二进制文件,5组不同的1和0:
10, 01, 001, 1110, 00101011
二进制中每个1和0都称为Bit,这是二进制数字的一种简短形式。
为了存储或表示一段数据,计算机需要将该数据转换为二进制表示。例如,要存储数字12,计算机需要将12转换成二进制表示,即1100。
但是在工作中,number并不是唯一的数据类型。通常上还会有string,images,videos。计算机知道如何用二进制表示所有的数据类型。比如计算机如何用二进制表示string类型的“L”呢?要将任何字符存储在二进制文件中,计算机首先将该字符转换为数字,然后将该数字转换为二进制表示形式。对于字符串“L”,计算机首先将L转换成表示L的数字。
打开浏览器控制台,输入“L”. charcodeat(0)。这时控制台会显示出数字76,这是字符“L”的数字表示。但是计算机又是如何知道每个字符表示的确切数字呢?它怎么知道用76来表示L?
字符集
字符集已经定义好的表示每个字符的确切数字的规则。我们对这些规则有不同的定义,最流行的包括Unicode和ASCII。JavaScript可以很好地处理Unicode字符集。所以,浏览器中的Unicode规定76应该表示L。
我们已经看到计算机是如何用数字表示字符的。转换成数字之后计算机再把76转换它的二进制表示。
字符编码
正如有一些字符集规则定义数字应该怎么样表示字符一样,也有一些规则定义了数字应该如何在二进制文件中表示。具体来说,就是用多少位来表示数字。这叫做字符编码。
字符编码的一个规则是UTF-8。UTF-8声明字符应该以bytes编码。一个byte是8位(bit)的集合 —— 8个1和0。因此,UTF-8规定应该使用8个1和0来表示二进制中任何字符。
之前的例子提到,数字12用二进制表示为 1100,但是用UTF-8表示应该是8位才对。所以UTF-8规定,计算机需要在不满8位的二进制数字左边添加更多的位,以使其成为一个字节。所以12应该存储为00001100。
因此 76 在UTF-8规则下存储表示为:01001100
这就是计算机在二进制文件中存储字符串或字符的方式。同样,计算机也规定了图片和视频应该如何转换、编码和存储在二进制文件中的规则。计算机将所有数据类型存储在二进制文件中。
现在我们了解了什么是二进制数据,接下来我们介绍一下什么是二进制数据流。
流
js中的Stream只是表示随着时间的推移从一个点移动到另一个点的数据序列。整个概念是,你有大量的数据要处理,但是你不需要等到所有的数据都可用后才开始处理它。基本上,这个大数据被分解并以块的形式发送。因此,从Buffer的原始定义来看,这仅仅意味着二进制数据正在文件系统中移动。例如,将存储在file1.txt中的文本移动到file2.txt。
但是Buffer究竟如何帮助我们在流与二进制数据进行交互或操作呢?Buffer到底是什么?
Buffer
我们已经提到,数据流是数据从一个点移动到另一个点,但是它们究竟是如何移动的呢?
通常数据的移动是为了处理或读取数据,并根据数据做出决策。在这个过程中,可能需要数据到达一个最小量或者最大量才能进行处理。因此,如果数据到达的速度快于进程消耗数据的速度,那么多余的数据需要在某个地方的等待来处理。另一方面,如果进程消耗数据的速度快于数据到达的速度,那么早到达的少数数据需要等待一定数量的数据到达,然后再发送出去进行处理。
那个“等候区”就是Buffer!它是计算机中的一个小物理位置,通常位于RAM中,数据在RAM中被临时收集、等待,并最终发在流过程中送出去进行处理。
我们可以把整个stream和buffer过程看做一个汽车站。在某个汽车站,汽车直到有一定数量的乘客或者是一个特殊的时间才可以发车。此外,乘客可能在不同的时间以不同的速度到达。无论是旅客还是汽车站都不能控制旅客到达车站的时间。提前到达的乘客需要等汽车发车。当有些乘客到达时,乘客已经满员或者汽车已经离开,需要等待下一辆汽车。
无论什么情况,总有一个等待的地方。这就是Node.js的Buffer! js不能控制数据到达的速度或时间,也不能控制流的速度。它只能决定何时发送数据。如果还没有到时间,Node.js将把它们放在buffer中,即RAM中的一个小位置,直到将它们发送出去进行处理为止。
一个典型的例子是,当你在观看流媒体视频时,可以看到buffer在工作。如果你的互联网连接足够快,流的速度将足够快,可以立即填满Buffer并发送出去进行处理,然后再填入另一个Buffer,然后发送出去,再发送一个,再发送一个,直到流完成为止。
但是如果你的连接很慢,在处理了第一组到达的数据后,视频会被卡主,这意味着程序正在收集更多的数据,或者等待更多的数据到达。当buffer被填满并处理后,播放器会继续播放视频。在播放的同时,更多的数据将继续到达并在buffer中等待。
与Buffer交互
Node.js在处理流期间会自动创建buffer,我们也可以通过Nodejs提供的API自己创建buffer。根据你的需求,这里有几种不同的方法可以创建buffer。
// Create an empty buffer of size 10.
// A buffer that only can accommodate 10 bytes
const buf1 = Buffer.alloc(10)
// Create a buffer with content
const buf2 = Buffer.from("hello buffer")当创建成功buffer后,你就可以开始和它进行交互了。
// 查看buffer的结构
buf1.toJSON()
// { type: 'Buffer', data: [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] }
buf2.toJSON()
//{ type: 'Buffer',data: [ 104, 101, 108, 108, 111, 32, 98, 117, 102, 102, 101, 114 ]}
buf1.length // 10
buf2.length // 12
// 写操作
buf1.write("Buffer really rocks!")
// decode
buf1.toString() // 'Buffer rea'
// 因为buf1创建时只分配了10byte的空间。超过的将不会被存储。更多的交互API,可以查看官方文档,
希望这篇介绍能帮助您更好地理解Node.js Buffer。
Nodejs Docker 镜像体积优化实践
Node.js docker 镜像体积优化实践
你讨厌部署你的应用程序花费很长时间吗? 对于单个容器来说,超过gb并不是最佳实践。每次部署新版本时都要处理数十亿字节,这对我们来说并不太合适。
本文将通过Nodejs程序展示如何优化Docker镜像的几个简单步骤,使它们更小、更快、更适合生产环境。
简单的一段Node.js项目
首先写一段基于express的简单web服务器程序
// package.json
{
"name": "docker-test",
"version": "1.0.0",
"description": "",
"main": "app.js",
"scripts": {
"start": "node app"
},
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.16.4"
},
"devDependencies": {
"eslint": "^5.16.0"
}
}// app.js
const express = require('express')
const app = express()
app.get('/', function(req, res){
res.send('hello world')
})
app.listen(3000)在根目录下新建Dockerfile并写入以下代码
# Dockerfile
FROM node
COPY . /home/app
RUN cd /home/app && npm install
WORKDIR /home/app
CMD ['npm', 'start']执行
- docker build -t myapp .
- docker images

可以看到这段最简单的nodejs程序有920MB,请不要这样做。接下来我们将逐步的减少这个镜像的体积。
优化docker生产环境镜像
-
使用Node.js Alpine 镜像
大幅减小镜像体积的最简单和最快的方法是选择一个小得多的基本镜像。Alpine是一个很小的Linux发行版,可以完成这项工作。只要选择Node.js的Alpine版本,就会有很大的改进。
FROM node:alpine COPY . /home/app RUN cd /home/app && npm install WORKDIR /home/app CMD ['npm', 'start']
build之后
可以看到整整减少了800MB,这是一个非常大的优化。
-
生成环境下不打包开发的依赖包
但我们还能继续优化。我们正在安装所有依赖项,即使我们最终只需要生成环境下的依赖包。如果只打包生产环境的以来不会怎么样,继续改进一下。
FROM node:alpine COPY . /home/app RUN cd /home/app && npm install --production WORKDIR /home/app CMD ['npm', 'start']
build之后
我们又减少了6MB,因为我们目前只有一个开发依赖,可以想象在一个正常的项目中这也将是非常大的优化。
-
使用基础版本的 Alpine 镜像组合Nodejs
如果我们使用基础版本的 Alpine 镜像,然后自己安装Nodejs结果会怎么样呢?
FROM alpine:latest RUN apk add --no-cache --update nodejs nodejs-npm COPY . /home/app RUN cd /home/app && npm install --production WORKDIR /home/app CMD ['npm', 'start']
build之后
现在只剩下了65MB,相比刚开始已经减少了10倍多。
-
多阶段构建
-
Docker镜像是分层的,Dockerfile中的每个指令都会创建一个新的镜像层,镜像层可以被复用和缓存。当Dockerfile的指令修改了,复制的文件变化了,或者构建镜像时指定的变量不同了,对应的镜像层缓存就会失效,某一层的镜像缓存失效之后,它之后的镜像层缓存都会失效。
-
因此我们还可以将RUN指令合并,但是需要记住的是,我们只能将变化频率一致的指令合并。
-
我们应该把变化最少的部分放在Dockerfile的前面,这样可以充分利用镜像缓存。
-
通过最小化镜像层的数量,我们可以得到更小的镜像。
-



上述示例中,源代码会经常变化,则每次构建镜像时都需要重新安装NPM模块,这显然不是我们希望看到的。因此我们可以先拷贝package.json,然后安装NPM模块,最后才拷贝其余的源代码。这样的话,即使源代码变化,也不需要重新安装NPM模块。
FROM alpine AS builder
WORKDIR /home/app
RUN apk add --no-cache --update nodejs nodejs-npm
COPY package.json package-lock.json ./
RUN npm install --production
FROM alpine
WORKDIR /home/app
RUN apk add --no-cache --update nodejs nodejs-npm
COPY --from=builder /usr/src/app/node_modules ./node_modules
COPY . .
CMD [ 'npm', 'start' ]
最终的镜像只有51MB,比最开始大概减少了17倍!并且后续的 build 速度也大大提升。
每一条 FROM 指令都是一个构建阶段,多条 FROM 就是多阶段构建,虽然最后生成的镜像只能是最后一个阶段的结果,但是,能够将前置阶段中的文件拷贝到后边的阶段中,这就是多阶段构建的最大意义。
在上面的Dockerfile文件中,我们先 copy 了package.json,然后 npm install,在第二阶段构建时,我们直接 copy 了第一阶段已经下载好的node_moduls,在下一次 build 时,如果没有新增依赖,docker将使用缓存中的node_modules,这样就减少了部署的时间。
使用 docker inspect imageId命令 我们可以看到,虽然我们有多个指令,但是最终的镜像也只有5层,这就是层的共享机制。
使用多阶段构建可以充分利用Docker镜像的缓存,大大减少最终部署到生产环境的时间。
结论
在实际生产环境中,没有任何理由使用gb大小的镜像,如果你确实需要提高部署速度,并且被缓慢的CI/CD所困扰,那么多阶段构建将会是一个非常有帮助的方法
希望这篇简短的文章对考虑使用Docker进行基于Node.js的应用程序开发或部署的人有些许帮助。
如何实现一个 new
new 做了什么
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例。new 关键字会进行如下操作:
- 创建一个空对象
- 设置该空对象的原型为构造函数的原型({}.protp = constructor.prototype)
- 执行构造函数,将 this 指向新创建的空对象
- 如果构造函数没有返回值或返回的不是一个对象,则返回步骤 1 新创建的对象
实现一个 new
根据以上步骤,用原生 js 实现一个 new
function _new(fn, args) {
let obj = Object.create(fn.prototype) // 1. 创建了一个新对象,2. 新对象的 __proto__ 指向 fn.prototype
const ret = fn.call(obj, args) // 3. 执行构造函数,并且 this 指向新对象
return ret instanceof Object ? ret : obj // 4. 如果构造函数返回不是对象,则返回新对象
}扩展
上面的代码用到了 Object.create() 和 instanceof 下面我们具体在了解一下这两个方法
Object.create
Object.create 方法创建一个新对象,并且使用参数中的对象作为新创建对象的 proto
Object.create 方法接受 2 个参数
- proto: 新创建对象的原型对象
- propertiesObject: 如果没有指定为 undefined,则是要添加到新创建对象的可枚举属性(即其自身定义的属性,而不是其原型链上的枚举属性)对象的属性描述符以及相应的属性名称。这些属性对应Object.defineProperties()的第二个参数。
那么用 Object.create 方法创建的对象,和直接用 {} 创建的对象有什么区别呢?
首先来看
let obj = {}在 chrome 控制台中输入以上代码可以看到打印出了 obj 变量, 它有 proto 属性,这个属性指向的对象中有 toString() valueOf() 等方法
再看
let obj = Object.create({})同样在 chrome 控制台查看, 发现它几乎和直接使用字面量创建的对象一样,不同的是,多了一层 proto 嵌套。 这是因为 Object.create 创建的对象的 proto 属性指向了参数的第一个对象。
当我们把代码修改成
let obj = Object.create({}.__proto__)这时,obj 就和直接使用字面量形式创建的对象一样了。
我们在像 vue.js 这样的库中,经常看到 Object.create(null) 这样的代码,这是因为 null 没有 proto 属性,所有这样创建出来的对象高度干净且可定制。
instanceof
instanceof 运算符用于检测构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。所以也可用来判断一个对象是否在另一个对象的原型链中。
需要注意的是,如果表达式 obj instanceof Foo 返回true,则并不意味着该表达式会永远返回true,因为Foo.prototype属性的值有可能会改变,改变之后的值很有可能不存在于obj的原型链上,这时原表达式的值就会成为false。
SSL或TLS握手的概述
SSL或TLS握手的概述
SSL或TLS握手建立了用于客户端和服务端通信的秘钥。
客户端和服务端SSL或TLS能够相互通信的基本步骤:
- 确认使用协议的版本
- 选择加密算法
- 通过交换和验证数字证书对彼此进行身份验证
- 使用非对称加密技术生成共享密钥,避免了密钥分发问题。然后SSL或TLS使用共享密钥对消息进行对称加密解密,这比非对称加密更快
综上所述SSL握手的步骤如下:
- SSL或TLS客户端先向服务端发送一个加密通信请求,叫做ClientHello请求。该请求包含以下信息:
- 客户端支持的SSL或者TLS版本
- 客户端生成的随机数,用于生成后续通信的随机字符串("对话密钥")
- 客户端支持的加密算法
- SSL或TLS服务端收到客户端请求后,向客户端发出响应,叫做ServerHello。该响应包含以下信息:
- 服务端从客户端提供的SSL或TLS列表中选择的版本
- Sesstion ID 和 另外生成的随机数
- 服务端的数字证书(如果服务端需要用于客户端身份验证的数字证书,则服务端发送一个客户端证书请求,其中包含受支持的证书类型列表和可接受的认证机构(CAs)的专有名称。)
- 确认使用的加密算法
- 客户端收到服务端响应后,首先校验服务端发来的数字证书决定是否继续通信。
- 证书校验通过,会像服务端发送以下信息:
- 生成一个随机数,并对这个随机数用从服务端数字证书中取出的公钥加密(用与生成后续通信的“随机密钥”)
- 如果服务端发送了一个客户端证书请求,客户端将会发送一个用客户端私钥加密的随机字符串和客户端的数字证书,或者没有数字证书的警告。在某些强制客户端证书的实现中,如果客户端没有数字证书责握手会失败
- 服务端接受并验证客户端证书
- 服务端用之前的3个随机数和商定好的加密方法计算生成会话密钥,之后双方用这个会话密钥通信。
- 客户端向服务端发送一条完成的消息,该消息使用密钥加密,表示握手的客户端部分已经完成。
- 服务端向客户端发送一条完成的消息,该消息使用密钥加密,表示握手的服务端部分已经完成
- 在SSL或TLS会话期间,服务端和客户端现在可以交换使用共享密钥对称加密的消息
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.