Examples for using Puppeteer to do big, bold things.
Output from some of the examples:
Test lazy loading strategy by seeing CSS/JS code coverage usage across page load.

Verify all the resources you expect are being cached by a service worker for offline.

Gut check your page to make sure it renders correctly for Google Search.

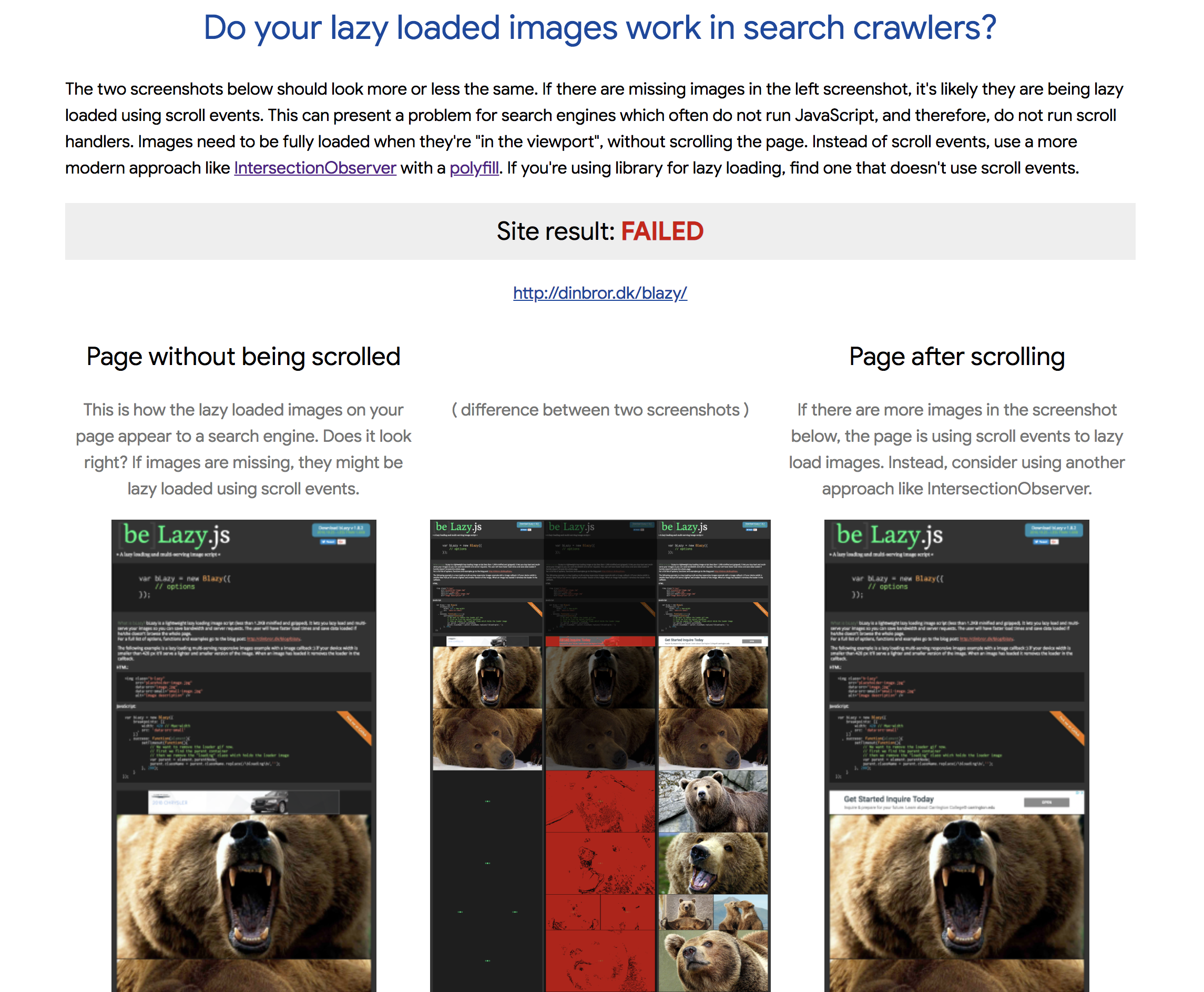
Determine if your lazy loaded images will be seen correctly by Google Search.
Make your browser talk.

Play the Google Pac-Man Doodle.

Turn a DOM element into a PDF.

Discover all the URLs on a site and visualize the subpages.

Load 2 or more pages side-by-side to visually see the difference in page load. Optional desktop viewport and throttling settings.

Apache 2.0 © 2018 Google Inc.






























































































































































































