Comments (9)
 jonycgn
commented on June 11, 2024
jonycgn
commented on June 11, 2024
Hi Jillian,
I'm not sure why you think that mean squared error must be averaged across the RGB channels. The current code treats the RGB information as a colorspace. The computed mean squared error is then the squared Euclidean distance in this 3-dimensional colorspace, averaged across pixels. I can't see anything fundamentally wrong with that, it is simply a different convention (which makes sense for other colorspaces as well).
When you set lambda to a very small number, eventually, the bit rate should end up collapsing to 0 bpp, and the distortion will be very large. This should be expected. Have you tried raising lambda? What is the smallest bpp that you can successfully train?
from compression.
 Jillian2017
commented on June 11, 2024
Jillian2017
commented on June 11, 2024
Hi, Johannes:
Thanks for your explanation.
Yes, I agree with that this is not fundamentally error, and I think this make little difference in training. In my opinion, the mean squared error should be averaged across points instead of RGB channels. Suppose input and output are not images with 3 channels, they are arrays that are made up of some elements, then the MSE should be the average value across all these points.
For the problem of convergence, I have tried to train the model with lambda equals 0.001, the trend of the RD curve is downward actually, after certain iteration(maybe a hundred thousand) the MSE value oscillates between 150 and 600, and it will not converge even the last_step is very high(1e7). My training data contains about 2 thousand patches, the learning rate is the same. Is data augmentation needed for small bitrate? As for higher lambda, such as 0.1, it does not oscillate a lot.
Best regards.
from compression.
jonycgn
commented on June 11, 2024
Hi!
While it doesn't matter fundamentally how you compute MSE and is a matter of preference (it's just off by a factor of 3), I realized that almost all publications (including my own) have been using the way of computing MSE that you prefer. So, to make things consistent, I changed it in commit 164bc19. This should also resolve some issues where people reported not being able to reproduce results in the papers.
Thanks for reporting this!
Next, I'm going to try to reproduce your problem at low bitrates. I'll report back soon.
from compression.
Jillian2017
commented on June 11, 2024
Hi, Johannes:
Thanks a lot. Very appreciate your reply and look forward to your report.
Best regards.
from compression.
jonycgn
commented on June 11, 2024
Jillian,
I was able to train models at quite low bitrates just fine (lambda=0.001 and lambda=0.00025). I don't see any oscillation happening, or any other problems with convergence.
From what dataset did you gather your image patches for training?
Could you check out the latest code, try again, and see if the problem is still happening?
from compression.
Jillian2017
commented on June 11, 2024
Johannes:
Thanks a lot for your timely reply. I have changed the way of reading images, in my side, 256*256 patches are randomly cropped from high resolution images. What's more, my dataset contains less than 3 thousand high resolution images which are made up of DIV2K, CLIC's training images. So, is it possible that there are not much images in dataset. There are many high resolution in website, but most of them are in lossy format, such as jpeg, I think they are not good candidates for image compression. Do you have any suggestion for data augment based on these lossy images?
What's more I will download your lastest code and train again.
Best regards.
from compression.
jonycgn
commented on June 11, 2024
~3000 images should be more than enough to train a model. These image compression models are generally in underfitting regime (meaning it's very hard for them to "memorize" the data).
However, you should know that the resolution of images can have a big effect on the performance. If you are evaluating on Kodak, for example, you should train with images that have a similar resolution (or if you use high resolution images, downsample them for training).
The latest change also contains some improvements to the input pipeline, so it's possible that fixes it. Please try again and let me know.
from compression.
Jillian2017
commented on June 11, 2024
Hi, Johannes:
I haved downloaded your latest code and run it again, but the result seems not improve. My training dataset contains almost 3000 thousands images in png format, lambda is 0.001, patch size is 256*256, and number filters is 192. After 526144 steps, the loss still oscillates, attached is the screenshot from tensorboard.
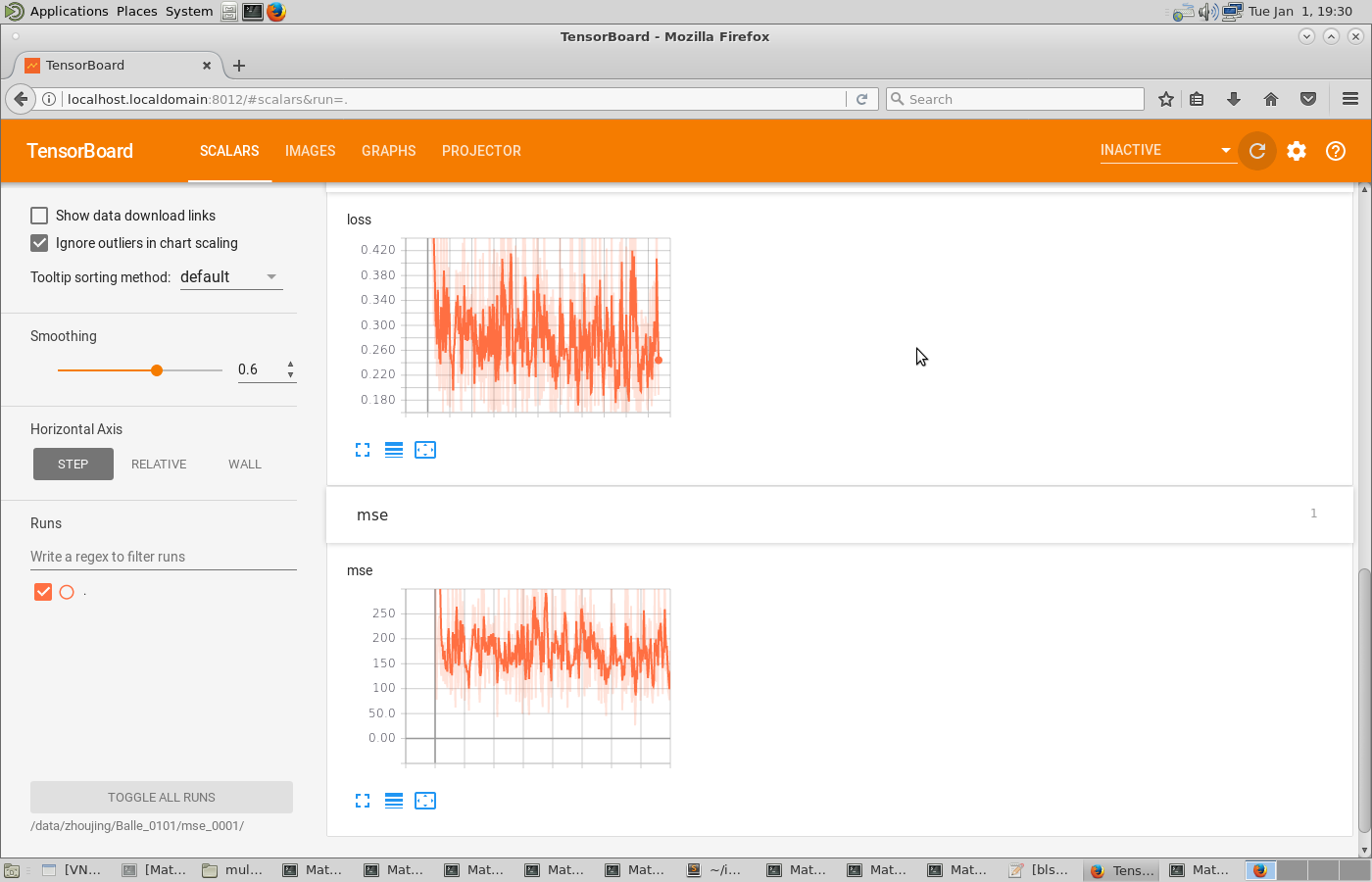
Wish your advice. Best regards.
from compression.
jonycgn
commented on June 11, 2024
Hi, these curves look completely normal. What you are seeing is the natural fluctuation of the loss due to stochastic gradients. Try running the model on one of the Kodak images (with "python bls2017.py -v compress") and compare the results to the corresponding plot in the appendix of this paper. You should get something matching the Balle 2017 curve quite closely.
I'm closing the bug for now. If your results are way off, and you still think there is a bug in the library, you can reopen it. If you need tips for tweaking the dataset/training, please post to the Google group.
Again, thanks for pointing out the MSE inconsistency!
from compression.
Related Issues (20)
- what's .tfci file and how to get the real codewords of an image HOT 1
- metagraphs link is outdated HOT 2
- Metagraph error while performing compression HOT 1
- libcudart.so.11.0 file
- Regarding GPU and tf compatibility HOT 1
- INVALID_ARGUMENT error during decompression on GPU HOT 1
- tfc-2.9.1 import error HOT 6
- Use tensorflow compression with tensorflow federated on apple silicon HOT 4
- Running all tests fail in Colab Pro+, Premium, High-Ram environment (A100-SXM4-40GB) HOT 5
- tfci.py recognizing, but not using GPUs HOT 2
- TypeError: pack() missing 1 required positional argument: 'arrays' HOT 1
- The memory size of the compressed and decompressed image has become larger? HOT 4
- How to compress an image by the trained model
- How to build tensorflow-compression package for aarch64?
- Unable to save model
- module 'tensorflow_compression' has no attribute 'SignalConv2D'
- Binaries for MacOs only available for X86 platform and not Apple Silicon
- 安卓
- Could not find variable conv1/gdn_0/reparam_gamma
- will not run on GPU on COLAB
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from compression.