Comments (20)
 williamSYSU
commented on May 27, 2024
williamSYSU
commented on May 27, 2024
Which NLL score do you mean? NLL_oracle or NLL_gen?
from textgan-pytorch.
 lethaiq
commented on May 27, 2024
lethaiq
commented on May 27, 2024
Which NLL score do you mean?
NLL_oracleorNLL_gen?
I meant NNL_gen for COO Image dataset.
Can you see the curve look like this one from the RelGAN paper?
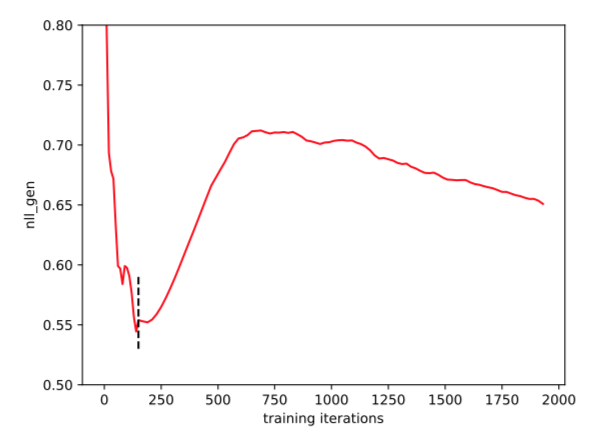
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
Actually, the curve of NLL_gen in the RelGAN paper includes pre-training and adversarial training phases, where the dashed lines represent the boundary. In my implemented codes, just like the curve you mentioned, the NLL_gen decreases during the pre-training, while continuously arises during the adversarial training.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
Actually, the curve of
NLL_genin the RelGAN paper includes pre-training and adversarial training phases, where the dashed lines represent the boundary. In my implemented codes, just like the curve you mentioned, the NLL_gen decreases during the pre-training, while continuously arises during the adversarial training.
Thanks @williamSYSU. Using your code, I can see NLL_gen decreases during pre-training (which makes sense), but during adversarial training, it continuously increases to a very high value (while in the picture the curve stop decreases after around 750 epochs (650 epochs for only adversarial training)), which shows mode-collapse. But I did not see any obvious sign of mode collapse from the generated text. Do you also observe the same?
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
Yes, I notice that. I think we can't distinguish if the generated samples are repeated based on the value of NLL_gen, and perhaps NLL_gen is not a good metric for sample diversity. From my understanding, the NLL_gen in the curve stops increasing because the temperature also increases during the adversarial training, which will make the generator generate more diverse sentences. Actually, the tendency of NLL_gen depends on the datasets and the temperature parameter. As you can see the curves of NLL_gen on synthetic data below, with the temperature=100, the NLL_gen slightly decrease after few hundreds of adversarial training epochs.
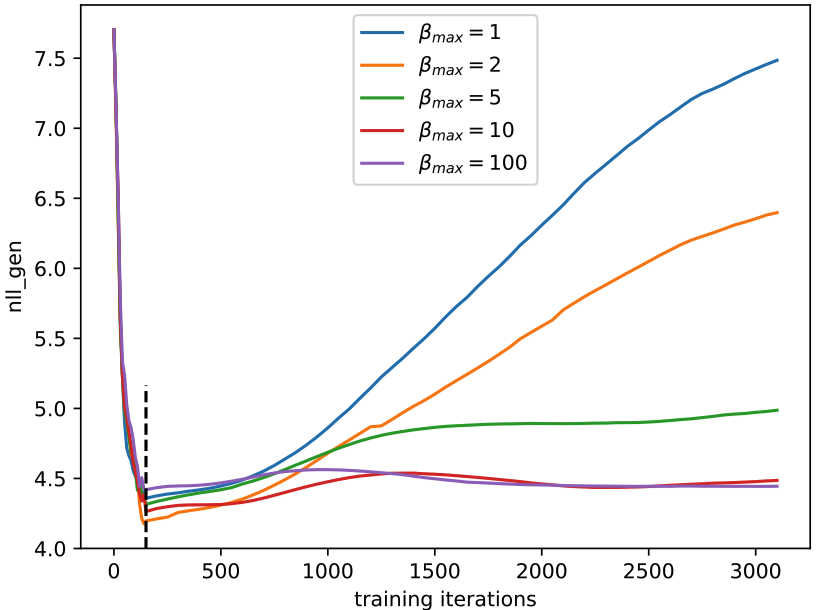
from textgan-pytorch.
lethaiq
commented on May 27, 2024
Yes, I notice that. I think we can't distinguish if the generated samples are repeated based on the value of NLL_gen, and perhaps NLL_gen is not a good metric for sample diversity. From my understanding, the NLL_gen in the curve stops increasing because the temperature also increases during the adversarial training, which will make the generator generate more diverse sentences. Actually, the tendency of NLL_gen depends on the datasets and the temperature parameter. As you can see the curves of NLL_gen on synthetic data below, with the temperature=100, the NLL_gen slightly decrease after few hundreds of adversarial training epochs.
I agree. So do you mean the current implementation is different from the original RelGAN, since the NLL_gen does not show the same behavior when tested the the same dataset and parameters? I am trying to replicate the RelGAN paper results using your code, but seems like the NLL_gen curve does not look the same. I must be doing something wrong or the current implementation has some difference with the original RelGAN's one.
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
So do you mean the current implementation is different from the original RelGAN?
Yes, I have to admit that the tendency of NLL_gen is not the same as the original paper. This problem has bothered me for a long time. I don't know if the differences between PyTorch and Tensorflow cause this divergence. If you figure out why or replicate the NLL_gen result, please let me know. Thanks!
from textgan-pytorch.
lethaiq
commented on May 27, 2024
So do you mean the current implementation is different from the original RelGAN?
Yes, I have to admit that the tendency of NLL_gen is not the same as the original paper. This problem has bothered me for a long time. I don't know if the differences between PyTorch and Tensorflow cause this divergence. If you figure out why or replicate the NLL_gen result, please let me know. Thanks!
@williamSYSU Let's figure this out together. I have been debugging for 3 days now still cannot figure that's out. Behaviors of BLEU score is pretty much the same, sometimes even better, so that's a good news.
(0) During pre-training, the NLL_gen was decreasing, similar to original implementation, yet it is slower. This can be due to difference in initialization. The pre-training loss of G formula should be exactly the same with NLL_gen, I have checked this one in your implementation and it is correct (two losses are very similar). So let's say the NLL formulation is correct for now in your implementation.
(1) In the original RelGAN, it sets a specific random seed (for initialization). This can be the case, we can test with different initialization and add this function to your code. If we test with another random initialization and the NLL_gen loss curve behaves correctly, then this is the cause. Yet I am pretty doubtful this is the case...
(2) In your RelGAN_D there are only 3 filter sizes (3,4,5) with 300 num_filter each. In original RelGAN the code has 4 filter sizes (2,3,4,5). (I know that in the paper they claim they use (3,4,5) with 300 each). I have ran both two cases with your implementation yet the NLL_gen curve still not behave correctly. You can try test this again to make sure my results are correct.
(3) In the original RelGAN code there is custom '''linear''' function, which is NOT from tf. In your code RelGAN_D, you use pytorch linear function. Can you check if these two linear functions are indeed the same? I think the two are the same expect the custom one from RelGAN original code supports spectral normalization (sn), which is set to False in the original RelGAN code. This can be irrelevant.
(4) In your get_fixed_temperature() function I remembered you did not fix N = 5000, while in the original RelGAN code it does so. However, even if I add N=5000, NLL_gen curve does not behave better. Can you please check this again?
Have you run the code with oracle (synthetic) data? Is the NLL_gen curve look like one in the RelGAN paper?
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
Behaviors of BLEU score is pretty much the same, sometimes even better, so that's a good news.
With the original RelGAN codes, the BLEU scores are better than the scores recorded in the paper. I think the RelGAN chooses the suitable BLEU scores based on a good NLL_gen score.
(2)
In RelGAN_D.py, the filter sizes are set to (2,3,4,5) actually. You may check the latest codes.
(3)
Yes, the spectral normalization is not used in the original RelGAN codes, and I got the exact results as the paper when I ran that codes.
(4)
I also notice that, and I have tried the two different settings. The results just like you said.
Have you run the code with oracle (synthetic) data? Is the NLL_gen curve look like one in the RelGAN paper?
Yes, I ran the original RelGAN codes and my codes, the NLL_gen curves is different either.
I tried to figure out why, but I have debugged for weeks and I think the two versions of codes are almost the same. Thank you for your valuable discussion. If you find any clues, please let me know.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
@williamSYSU I figured out one thing that is different in D, which can make D stronger (than expected).
In
TextGAN-PyTorch/models/RelGAN_D.py
Line 32 in 9447e57
The kernel size and stride from PyTorch documentation:

Original RelGAN code:

The kernel size and stride should be changed.
(f, self.emb_dim_single) -> (self.emb_dim_single, f)
(1, self.emb_dim_single) -> (self.emb_dim_single, 1)
This might make the D behaves very different.
Can you have a look at this?
from textgan-pytorch.
lethaiq
commented on May 27, 2024
@williamSYSU I figured out one thing that is different in D, which can make D stronger (than expected).
In
TextGAN-PyTorch/models/RelGAN_D.py
Line 32 in 9447e57
, the conv function might has different parameters from the original RelGAN code.
The kernel size and stride from PyTorch documentation:
Original RelGAN code:
The kernel size and stride should be changed.
(f, self.emb_dim_single) -> (self.emb_dim_single, f) (1, self.emb_dim_single) -> (self.emb_dim_single, 1)This might make the D behaves very different.
Can you have a look at this?
I just check, this might not be the case. your code is correct.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
@williamSYSU in the forward function of RelGAN_G, there should be no multiplication of:
out = self.temperature * out
In the original RelGAN, there is also no temperature multiplication during pretraining_loss:

I am testing this. It makes sense that there is no temperature during MLE and there is temperature during adversarial to control the trade-off between quality and diversity with gumbel-softmax. However, I wonder why the original RelGAN codes does not use temperature to calculate NLL_gen loss (it uses same loss with pretraining), or it uses temperature = 1 when calculating NLL_gen loss. I guess one can argue one way or another, and temperature is not part of the generator architecture, only a way to control the training, so it should be used when calculating NLL_gen loss. What do you think?
If this is correct, then everything makes sense. During pre-training, the code works as expected because there is no changes to temperature. At the beginning of adversarial training temperature is relatively small, around 1, so there is no big difference in NLL_gen loss. After a certain number of epochs, temperature got much larger, change the output of softmax (after multiplication with temperature), lead to changes in NLL_gen (much higher). Let's see if this hypothesis is correct or not after I test this on your code.
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
Your analysis about the NLL_gen loss is basically right, and the temperature does affects the NLL_gen loss. However, it can not explain why NLL_gen is still different on synthetic data with temperature=1. That is, NLL_gen in my codes increases much faster and higher than the original RelGAN code under all experimental settings.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
Your analysis about the NLL_gen loss is basically right, and the temperature does affects the NLL_gen loss. However, it can not explain why NLL_gen is still different on synthetic data with temperature=1. That is, NLL_gen in my codes increases much faster and higher than the original RelGAN code under all experimental settings.
@williamSYSU I am not sure if I am understanding you correctly. Can you rephrase it? I am testing on real-data and if I did not consider the temperature in calculating the NLL_gen loss, the NLL_gen seems to match the one in the original RelGAN code. I am still training to see if the NLL_gen curve will decrease at the end of the training and will let's you know, but for now it is not increase faster and higher anymore. I hope you can test this with synthetic data to see if we get a similar curve or the NLL_gen behaves any better.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
@williamSYSU one more thing I observe is the BLEU score returned from the current code fluctuates a lot, and seems to be lower compared to original RelGAN implementation. Do you observe the same? I wonder this is a pytorch versus tensorflow thing, random initialization or something else we need to figure out?
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
I have tested the program on synthetic data with temperature=1, which means the temperature doesn't change during the adversarial training. Under this condition, the calculation of NLL_gen is exactly the same as the original code. However, the NLL_gen in my code increases much faster and higher than the original code. For the Image COCO dataset, I will remove the multiplication of temperature in forward and run more experiments to verify if the performances can be better. Thanks for your valuable advise!
Speaking of the performance of BLEU scores in my codes, the BLEU-[4, 5] are lower than the values mentioned in the paper. Perhaps like you said, this is caused by the differences between PyTorch and Tensorflow.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
I have tested the program on synthetic data with temperature=1, which means the temperature doesn't change during the adversarial training. Under this condition, the calculation of NLL_gen is exactly the same as the original code. However, the NLL_gen in my code increases much faster and higher than the original code. For the Image COCO dataset, I will remove the multiplication of temperature in
forwardand run more experiments to verify if the performances can be better. Thanks for your valuable advise!Speaking of the performance of BLEU scores in my codes, the BLEU-[4, 5] are lower than the values mentioned in the paper. Perhaps like you said, this is caused by the differences between PyTorch and Tensorflow.
@williamSYSU , so from my understanding, we should still keep updating the temperature during adversarial training, yet ONLY with calculation of NLL_gen we set temperature = 1. Or I am missing something cause I have not looked at your code for the synthetic part yet.
I guess the values in the paper is averaged from different runs with pre-selected random seeds, then the current code BLEU-2 is good. Do you know why RelGAN does not use the RMC with attention and only use with vanilla model?
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
Correct, the update of the temperature is a key balance between the quality and the diversity in the RelGAN paper. To keep the code exactly the same as the original code, we better set temperature=1 while calculating the NLL_gen (remove the multiplication of the temperature in forward).
I guess the values in the paper is averaged from different runs with pre-selected random seeds, then the current code BLEU-2 is good.
It's possible, and I need to run more experiments with the original code.
Do you know why RelGAN does not use the RMC with attention and only use with vanilla model?
I haven't run the original code with attention RMC. From my understanding, the RMC with attention and the vanilla RMC may have similar performances or the RMC with attention is slightly better than the vanilla RMC, yet these thoughts haven't been proved. After all, the vanilla RMC have achieved the same performances the paper claimed.
from textgan-pytorch.
lethaiq
commented on May 27, 2024
Correct, the update of the temperature is a key balance between the quality and the diversity in the RelGAN paper. To keep the code exactly the same as the original code, we better set temperature=1 while calculating the NLL_gen (remove the multiplication of the temperature in
forward).I guess the values in the paper is averaged from different runs with pre-selected random seeds, then the current code BLEU-2 is good.
It's possible, and I need to run more experiments with the original code.
Do you know why RelGAN does not use the RMC with attention and only use with vanilla model?
I haven't run the original code with attention RMC. From my understanding, the RMC with attention and the vanilla RMC may have similar performances or the RMC with attention is slightly better than the vanilla RMC, yet these thoughts haven't been proved. After all, the vanilla RMC have achieved the same performances the paper claimed.
@williamSYSU I just ran a test training on COO image and confirm that the loss and BLEU score behaves correctly now. Thank you so much for good implementations!
from textgan-pytorch.
williamSYSU
commented on May 27, 2024
Perfect! If you run with the synthetic data and get the same curve, please let me know!
from textgan-pytorch.
Related Issues (20)
- Sentigan generates repetitive samples HOT 2
- Can you tell me the GPU model and running time when running CatGaN?
- How to generate samples from the trained SeqGan Model?
- AttributeError: 'MaliGANInstructor' object has no attribute 'train_data' HOT 3
- Some questions about the evaluation metrics
- Senti-GAN loss function -ve sign
- Execution in CPU-only Mode HOT 3
- Question about the onehot encoding
- Description data
- Runtime Error when running LeakGAN HOT 1
- How does seqgan train on real data? HOT 2
- SentiGAN reproducible results?
- question about seqgan rollout code
- Cite as and citations for datasets
- catGAN real dataset
- Training catGAN with a custom dataset: AttributeError: 'CatGANInstructor' object has no attribute 'train_samples_list'
- Question about the executable parameter of subprocess.call
- Gradient problem
- save
- Hello teacher
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from textgan-pytorch.