Comments (28)
 fabiospampinato
commented on June 14, 2024
1
fabiospampinato
commented on June 14, 2024
1
Apparently the current size of that Polish dictionary is closer to 3MB, but still pretty good, maybe they just added more words to it https://github.com/morfologik/morfologik-stemming/blob/master/morfologik-polish/src/main/resources/morfologik/stemming/polish/polish.dict
from spylls.
fabiospampinato
commented on June 14, 2024
1
can't promise I'll investigate the PyPy one, but broken dictionaries shouldn't be
No worries, that doesn't actually matter to me, I'd be happy to leave this running overnight or something, I care much more about it working well.
Just to be in sync: where did you take the dictionaries from? (So I'll be testing on the exact same ones)
I'm using the dictionaries listed here: https://github.com/wooorm/dictionaries
from spylls.
fabiospampinato
commented on June 14, 2024
1
About dictionary parsing (hmm, it would be cool to split this ticket into several discussions actually... Maybe we can go with a private repo for your project with me as a contributor, so I can see/answer issues and discussions there? Or WDYT?):
Sure, I'll open up a repo for this tomorrow.
In the meantime I'll close this issue as I would consider the original request addressed.
Regarding the throwing dictionaries:
es-DO: Now I'm not getting the error anymore, but strangely I don't recall updating Spylls. Interestingly Spylls made me a 6.5MB file while Hunspell made me a 11.6MB file, I'm not sure what the reason behind that difference is.cs-CZ: It works after the patch.hy-AM: It works after the patch.
I don't believe it is the right way, and not sure I have a resource to do it. If you want to try approaching this yourself, I might help with some advice; if you'll go the preprocessing way (try split, then see if it is a proper compound; which I believe is more promising), I can be of some advice, too.
I think I'll put this on hold for now, as all the possible paths seem complicated and I can't dedicate too much time to this at the moment, I'll probably get back to this in a couple of months or so, or if a simpler path materializes. In the meantime I'll ship what I've got and see how it behaves in practice.
from spylls.
 zverok
commented on June 14, 2024
zverok
commented on June 14, 2024
Hey!
Thanks for your kind words about my work.
The question of linearizing the dictionary (Hunspell and its predecessors call this "unmunching" for some reason) is a quirky one.
Basically, if we ignore word compounding, it is more or less trivial: look at word flags, see which suffixes and prefixes it might have, produce all valid combinations". Here is proof-of-concept Spylls-based script for doing so: https://gist.github.com/zverok/c574b7a9c42cc17bdc2aa396e3edd21a
I haven't tested it extensively, but it seems to work and produce valid results, so you can try to use it for your idea!
The problem is, this script can be made universal to handle any possible dictionary because of word compounding. In languages with word compounding, the "potentially possible" words list is incredibly huge. (The topic is covered in this article).
For example, in nb_NO (one of two variants of Norwegian) dictionary, there are 11k words with COMPOUNDFLAG. This means that "theoretically possible" is any combination of those 11k words (not only every pair but also three, four, ... in a row). The dictionary contains enough information to tell "whether this is the valid compound word", but not enough to produce all really existing/used compounds (see example in the article I've linked: “røykfritt” (“smoke-free” = “non-smoking”) and “frittrøyk” are both "valid" for Hunspell, but the second one is actually not an existing word... But I assume some poet might use it, and Norvegian readers might understand what they mean in the context.)
That's why "unmunching" the list of words for languages with compounding is impossible—so, to have just a list of "all actually existing Norwegian words" Hunspell's dictionary is useless.
Another curious example: English dictionary have "compounding rules" used to check numerals, like "11th is valid, and 10000011th is valid, but 10000011nd is not". Attempt to produce "all possible" combinations from this rule will obviously lead to an infinite loop :)
As far as I understand, that's the biggest obstacle for "full list"-based spellcheckers: AFAIK, LanguageTool grammar checking project uses morfologik spellchecker which encodes word lists with FSA very efficiently but falls back to Hunspell for languages like German or Norwegian due to compounding.
from spylls.
fabiospampinato
commented on June 14, 2024
Here is proof-of-concept Spylls-based script for doing so: gist.github.com/zverok/c574b7a9c42cc17bdc2aa396e3edd21a
Awesome! Thanks a lot.
In languages with word compounding, the "potentially possible" words list is incredibly huge.
English dictionary have "compounding rules" used to check numerals, like "11th is valid, and 10000011th is valid, but 10000011nd is not". Attempt to produce "all possible" combinations from this rule will obviously lead to an infinite loop :)
That's indeed a big problem 🤔 Thanks for pointing that out.
Potentially that could be solved by taking a hybrid approach, using a FSA for regular words and using some dynamic logic for accounting for compounding, however with an hybrid approach now I can't just ignore Hunspell's logic entirely, I can't just throw away all the flags after parsing, and accounting for compounding will most probably be tough at best.
I'll have to think more about this.
from spylls.
zverok
commented on June 14, 2024
Potentially that could be solved by taking a hybrid approach
Yes, that's what comes to mind:
- "unmunch" should preserve flags (maybe recoding it into more obvious format) like "onlyincompound", "compoundflag", "comboundbegin" etc
- Then, at least the part of Hunspell's algorithms that calculates compounding by flags should be ported (compound_by_flags, but instead of calling
affix_formsit should just look in the unmunched word list and deduce whether compound is good) - But looking closer to it, unmunching should be quite smart to understand also "compoundforbid" (this affix should never be for compound word) and "compoundpermit" (this affix can even be in the middle of the compound), and tagging the unmunched words appropriately (this particular form is ok in any compound... this is not)
- Mechanism of compounding by rules seem to be used (in all dictionaries I saw it) only for numerals producing, so I believe it is more productive to hardcode it somehow in more simple form
In general, it all looks bearable, yet not a small amount of work. If you'll take this road and will need more info on how this mad mechanism works, feel free to ping me (here or by email), I spent a lot of intimate moments with it and will be glad if my acquired knowledge, if incomplete, would be of some use.
from spylls.
fabiospampinato
commented on June 14, 2024
In general, it all looks bearable, yet not a small amount of work.
Yeah, another problem is that I don't really have a clue about how to make a serialized DA-FSA that can be worked with directly without requiring it to be deserialized first, there's some somewhat approachable material on ~serializing a Trie, but the compression ratios would be much better with a DA-FSA, and for that I've only been able to find some papers that talk about it and some probably buggy implementations nobody seems to use.
If you'll take this road and will need more info on how this mad mechanism works, feel free to ping me (here or by email), I spent a lot of intimate moments with it and will be glad if my acquired knowledge, if incomplete, would be of some use.
Thank you, the knowledge you've distilled in what you posted online has already been very useful to me. I'll let you know if I'll actually end up working on that, for now I'm thinking it would probably be unwise for me to dedicate that much time to it. I think the next step for me should be to check what the performance characteristics of a WASM port of Hunspell are, I probably overlooked a few things the first time I looked into that, if memory usage with that isn't insane like it is with nspell I'll probably just use that for now, but even in that scenario I'll still very much be interested in making something better for my use case.
I'm potentially open to look into alternative approaches, but I care about memory usage and startup time, and for that working with a succinct DA-FSA seems optimal really (just load a compressed string into memory and that's it).
from spylls.
zverok
commented on June 14, 2024
I don't really have a clue about how to make a serialized DA-FSA that can be worked with directly without requiring it to be deserialized first
You might be interested in morfologik, BTW. They solve exactly this problem. I actually did a port of the algorithm to Ruby (you might notice repeating motive in my activities 😂); even the naive implementation in a "known to be slow" language is quite effective. But that reimplementation was "blind" (I just ported Java to Ruby, cleaned up, and debugged it to work exactly like Java), so I don't have a deep understanding, but I assume on the top level it layouted like this:
1. Assume we have words to encode: "aardvark", "abacus", "abbot", "abbreviation", ...
2. In FSA, it would be coded (logical) this way:
a -> a -> rdvark
b -> a -> cus
b -> o -> t
r -> eviation
3. Phisically, it would be layouted like this:
<start point>
<address to "A" as a first letter>
<address to "B" as a first letter>
....
A-as-a-first-letter point
<address to "A" as a second letter>
<address to "B" as a second letter>
....
A-as-a-second-letter point
<address to "A" as a third letter...>
So, when we want to check "aardvark", we do this:
- go to starting address (known from FSA header)
- iterating over adjacent data position to find one pointing at "jump here for A"
- there, iterates over adjacent data positions to find one pointing at "jump here for the second A"
- ...and this way, all the way till the data position saying "it corresponds to K, being at the end of the word", so you have an AARDVARK coded there (plus additional metadata for this word)
Something like that
from spylls.
fabiospampinato
commented on June 14, 2024
I'll look into morfologik, thanks for the pointer.
The way you explained it seems fairly approachable, perhaps I should try implementing something like that.
However there might be a couple of problematic details with that:
- Given the words you picked there are no suffixes to deduplicate, but when deduplicating suffixes constructing the FSA could be significantly more difficult, but not that difficult probably, I haven't thought much about this but I guess one could just keep track of terminal nodes and walk the ~tree backwards from each of them basically to find suffixes that can be deduplicated.
- The data structure you described I think may work for my use case, but I don't think that would be succinct because it is encoding both the content of nodes and the pointers to them basically, by doing this succinctly one could get rid of the pointers completely, which in your data structure I guess would consume most of the memory actually:
- each node for a 32-letters alphabet would need 5 bits of information, with a succinct data structure we wouldn't need many more bits than this basically.
- with your data structure one needs to encode pointers too though, and for a 2mb string (which could be an optimistic estimation for most dictionaries) all pointers pointing at nodes located after the first mb would be encoding indexes above 1 million, that's at minimum 20 bits of information just for each of those pointers.
- also maybe in your data structure one would need to use extra bits in order to mark where a node ends and a pointer begins, you don't really need that when doing this succinctly.
The best documentation I've found so far about this is this lecture, but it stops at encoding Tries not full-blown DA-FSAs.
from spylls.
fabiospampinato
commented on June 14, 2024
that's at minimum 20 bits of information just for each of those pointers.
Well I guess each pointer rather than encoding the distance from the start could be encoding the instance from itself, saving a good amount of memory, but as in theory one doesn't need to encode this information at all perhaps it'd be better just to try to implement the more optimal data structure.
from spylls.
zverok
commented on June 14, 2024
You should consider I retold "how it works" from the memory of a loose reimplementation I did 2 years ago :)
But I know that morfologik's encoding is quite efficient:
Example: for Polish, the 3.5 million word list becomes less than 1MB file in the FSA format.
from spylls.
fabiospampinato
commented on June 14, 2024
Interesting, perhaps then it would be pretty good for my use case 🤔 I definitely have to look into that.
from spylls.
fabiospampinato
commented on June 14, 2024
I've started dedicating some time to this. Some random thoughts:
- Overall I'm pleasantly surprised by Spylls/Python's speed, it takes just over a second to extract the words from the en-US dictionary on my machine, that's certainly good enough for me especially considering that I don't expect to extract words from the same dictionaries many times over, it's more of a one-time thing really.
- It'd still be useful if somehow the whole process could be made significantly faster with very little effort, I'm not familiar with Python but I tried running the unmunch script through PyPy and I got the following error, I don't know if that could be easily fixable or if using PyPy to begin with could make sense:
Traceback (most recent call last):
File "src/unmunch.py", line 32, in <module>
from spylls.hunspell.dictionary import Dictionary
File "/usr/local/Cellar/pypy3/7.3.3/libexec/site-packages/spylls/hunspell/__init__.py", line 1, in <module>
from .dictionary import Dictionary
File "/usr/local/Cellar/pypy3/7.3.3/libexec/site-packages/spylls/hunspell/dictionary.py", line 11, in <module>
from spylls.hunspell.algo import lookup, suggest
File "/usr/local/Cellar/pypy3/7.3.3/libexec/site-packages/spylls/hunspell/algo/lookup.py", line 37, in <module>
import spylls.hunspell.algo.permutations as pmt
AttributeError: module 'spylls' has no attribute 'hunspell'
- The libraries I had found that said they could encode succinctly a DA-FSA turns out they either only use the DA-FSA for the in-memory structure and encode succinctly only a Trie, or use pointers for encoding a DA-FSA, and the literature that talks about how to properly encode succinctly a DA-FSA goes way over my head, so I'll just go with a succinct Trie which should be much easier to implement while possibly still using an acceptable amount of memory.
- The
vi-VNdictionary seems utterly useless, the whole thing weighs like 40kb and just over 6000 words get extracted from it, there's no way that's complete by any means, removing it from my app would probably be better than using this dictionary just because I'd imagine the false negatives would be through the roof. - The
rw-RWdictionary looks really weird, its aff file weighs ~38MB and its dic file weighs just half a kilobyte, weird, I don't know what's the deal with that. - There might be lots of words unaccounted for because of compound rules, the unmunch script extracted just over half a million words from the
fr-FRdictionary, but I think I was getting millions of words extracted from it bynspell, so maybe a lot of them are encoded via compound rules, ornspellwas just doing something wrong, I'll have to check how many words hunspell's own unmunch command can extract. - The
hu-HUdictionary (ironically), takes forever to process, I let it run for over half an hour and it still wasn't done, it just kept consuming more and more memory, there might be an endless loop in there somewhere. I'll have to check what the size of the stdout buffer was, but I'm guess it was well over 5GB, which would be unworkable for my approach anyway.

- Processing the
es-DOdictionary leads to the following error:
Traceback (most recent call last):
File "/Users/fabio/Desktop/notable-spellchecker/src/unmunch.py", line 34, in <module>
dictionary = Dictionary.from_files(sys.argv[1])
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/dictionary.py", line 141, in from_files
aff, context = readers.read_aff(FileReader(path + '.aff'))
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 105, in read_aff
dir_value = read_directive(source, line, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 161, in read_directive
value = read_value(source, name, *arguments, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 251, in read_value
for line in _read_array(int(count))
- Processing the
hy-AMdictionary leads to the following error:
Traceback (most recent call last):
File "/Users/fabio/Desktop/notable-spellchecker/src/unmunch.py", line 34, in <module>
dictionary = Dictionary.from_files(sys.argv[1])
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/dictionary.py", line 141, in from_files
aff, context = readers.read_aff(FileReader(path + '.aff'))
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 105, in read_aff
dir_value = read_directive(source, line, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 161, in read_directive
value = read_value(source, name, *arguments, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 251, in read_value
for line in _read_array(int(count))
ValueError: invalid literal for int() with base 10: 'ցվեցին/CH'
- Processing the
cs-CZdictionary leads to the following error:
Traceback (most recent call last):
File "/Users/fabio/Desktop/notable-spellchecker/src/unmunch.py", line 34, in <module>
dictionary = Dictionary.from_files(sys.argv[1])
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/dictionary.py", line 141, in from_files
aff, context = readers.read_aff(FileReader(path + '.aff'))
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 105, in read_aff
dir_value = read_directive(source, line, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 161, in read_directive
value = read_value(source, name, *arguments, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 249, in read_value
return [
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 250, in <listcomp>
make_affix(directive, flag, crossproduct, *line, context=context)
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/readers/aff.py", line 294, in make_affix
return kind_class(
File "<string>", line 9, in __init__
File "/usr/local/lib/python3.9/site-packages/spylls/hunspell/data/aff.py", line 266, in __post_init__
self.cond_regexp = re.compile(self.condition.replace('-', '\\-') + '$')
File "/usr/local/Cellar/[email protected]/3.9.2_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/re.py", line 252, in compile
return _compile(pattern, flags)
File "/usr/local/Cellar/[email protected]/3.9.2_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/re.py", line 304, in _compile
p = sre_compile.compile(pattern, flags)
File "/usr/local/Cellar/[email protected]/3.9.2_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_compile.py", line 764, in compile
p = sre_parse.parse(p, flags)
File "/usr/local/Cellar/[email protected]/3.9.2_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py", line 948, in parse
p = _parse_sub(source, state, flags & SRE_FLAG_VERBOSE, 0)
File "/usr/local/Cellar/[email protected]/3.9.2_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py", line 443, in _parse_sub
itemsappend(_parse(source, state, verbose, nested + 1,
File "/usr/local/Cellar/[email protected]/3.9.2_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py", line 549, in _parse
raise source.error("unterminated character set",
re.error: unterminated character set at position 36
from spylls.
fabiospampinato
commented on June 14, 2024
- The
eu-ESdictionary also takes forever to process.
from spylls.
fabiospampinato
commented on June 14, 2024
he-ILtakes forever too.
from spylls.
fabiospampinato
commented on June 14, 2024
ko-KRtakes forever too.
from spylls.
fabiospampinato
commented on June 14, 2024
Short summary:
- 3 dictionaries throw errors:
es-DO,hy-AM,cs-CZ, hopefully those can all be fixed in Spylls as they seem errors related to encoding. - 5 dictionaries take forever to complete:
eu-ES,he-IL,hu-HU,ko-KR,rw-RW, I don't know if they just produce gigabytes-level words lists or if there's an infinite loop somewhere, I killed the process after a while. Whatever the culprit is it'd be good if Spylls could somehow fix it or ignore the flags that cause the combinatorics to explode. I should try runninghunspell's ownunmunchover them too. - Almost all produced words lists are under 100MB, most of them are under 20MB.
- Most dictionaries take less than 1m to get processed, many of them take less than 10s.
- So far 260MB worth of dictionaries ballooned into 5GB worth of words lists.
Overall the unmunch script seems to have worked pretty well, I'd say the next steps are:
- Crafting an initial FSA implementation, I definitely have enough data to play with for that.
- Fixing all the issues that prevented words lists to be generated from those 8 dictionaries.
- Lastly figuring out how to best handle compound rules, which is probably going to be the hard part.
- I think potentially the only option here is extracting the portions of the dictionaries that have to do with compound rules, extracting the portion of the code in Spylls that deals with them and converting that to JS (which is what I need), then use that in combination with the FSA.
- It'd be good if the unmunch script could be updated to output compound words only, up to a limit, and potentially breadth-first too. Because right now I don't really have a sense of what the situation is with compound words across dictionaries, maybe most dictionaries make very light use of them, maybe most of the rules related to them are stuff regarding numbers that I can jut hard-code, maybe for some dictionaries that use them the produced list of compound words is actually not immense and I can just use the FSA for them too. Without a better understanding of the situation it's hard for me to tell what the best approach here would be.
from spylls.
fabiospampinato
commented on June 14, 2024
Here's the result of running Hunspell's unmunch over the problematic dictionaries:
es-DO: it made an 11MB words list.hy-AM: it gave me a segmentation fault.cs-CZ: it made a 45MB words list.eu-ES: it gave me a segmentation fault.he-IL: it made a huge 1.3GB words list.hu-HU: after a looong time it I had to stop it because I was running out of disk space, in the meantime it wrote me a gigantic 22GB words list to disk, I guess that's one of the languages that makes heavy use of compound rules.ko-KR: it gave me a gazillion errors and a segmentation fault.rw-RW: after a while it made a 2MB words list, weird.
Better than nothing I guess, it'd be great if I could regenerate these words lists with Spylls though, disabling compound rules entirely as I'll handle them specially.
from spylls.
zverok
commented on June 14, 2024
@fabiospampinato Interesting investigation!
I'll definitely dive into fixing/investigating all problems somewhere upcoming week (can't promise I'll investigate the PyPy one, but broken dictionaries shouldn't be).
Just to be in sync: where did you take the dictionaries from? (So I'll be testing on the exact same ones)
from spylls.
fabiospampinato
commented on June 14, 2024
Update on the progress with the succinct trie:
- How this thing works finally clicked with me, I have it basically working correctly (I think) right now, but I still need to encode all the data strings in a memory efficient way, which could be a bit tricky but probably not particularly so.
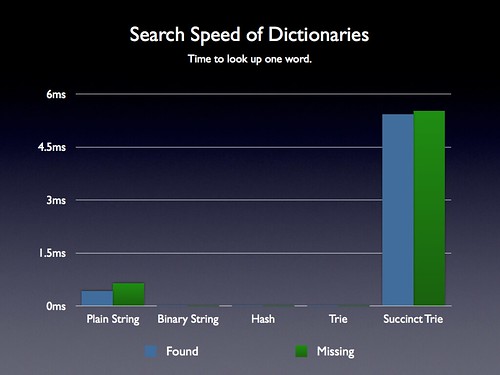
- The performance is unbelievably good, considering that I'm executing JS. I can add the ~3.5 million words in the polish dictionary to the regular trie in ~3 seconds, encode the whole trie (non memory-efficiently yet) in ~4 seconds (it takes much longer to do that with other implementations I found, they didn't know about a kind of obscure performance cliff in v8), parse the encoded trie in ~200ms (I've cut some corners to get this up and running, this figure should become ~0ms soon) and lookup each of those ~3.5 million words with the encoded trie in ~3 seconds, which is the same lookup performance I'm getting with the regular Trie which is INSANE, this figure may go up a bit when I'll trade some things for much lower memory usage though, but lookup performance so far is much better than what you might have seen in charts like this one from John Resig's blog post, he must have overlooked a few interesting optimizations. That's roughly 0.0009ms per lookup call, also known as no time at all 😂.
- The gzip size of the encoded trie seems really good as well, even considering that I'm encoding the trie very inefficiently still. The gzipped encoded trie for the polish dictionary currently takes about 4MB, which I can work with. I care about this because I need to download these dictionaries on demand over the internet when needed.
- Startup-time is really good even considering that I'm doing things I can eliminate entirely, 200ms for millions of words in theory would already be good enough for me already.
- Memory usage currently is terrible, but most of that comes from doing something (computing a lookup table for each possible input of the select-0 function) that I should be able to eliminate almost entirely, which makes the potential final memory usage really promising.
{kind=link}
Basically I'm kind of ecstatic, this data structure is amazing.
I'm just hoping the situation regarding compound words has a reasonably simple solution, because potentially until I get that working I can't ship this.
from spylls.
fabiospampinato
commented on June 14, 2024
A little analysis of alphabets as extracted from words lists ordered by frequencies:
bg-BG- Alphabet:
аиеотнрвялспзкдмъугбщхчшцжйфюьКСМБДПТВГАРНЛХИЧЕЗЦОФШЯЙЖУЮЩЪ - Length: 59
- Alphabet:
br-FR- Alphabet:
eanoi'rthdluzmsgcpjkfvùbñMDPTNwyCXIêVLüGKB’âFZASEWRHJOYéqïUë-áôûxíóåà QèÅÂãç10 - Length: 78
- Alphabet:
ca-ES- Alphabet:
es-alinortum'cdgphvbfqxzjyDàïAEL·íSéòèçIOHóüUkúCMBPÀTGRVwFNÈÒÍÉKJāXWÚZáQöY1ūšīñžōÓşčäǧ935µâłḤøΩ42ṭṣŏýḥČåēëı7680śãîŠęôǦḫŭķ³²êŽÅÁ+ţŌńÖÇûǎŚŁĀìřù₂ăṬḍźżĒØÑÆṇňėćḗǒőṛ - Length: 159
- Alphabet:
ca-ES- Alphabet:
es-alinortum'cdgphvbfqxzjyDàïAEL·íSòéèçIOHóüUkúCMBPÀTGRVwFNÈÒÍÉKJāXWÚZáQöY1ūšīñžōÓşčäǧ3µâ9ł5ḤøΩ4ṭ2ṣŏýḥČåēëıśã76îŠęôǦḫ80ŭķ³²êŽÅÁ+ţŌńÖÇûǎŚŁĀìřù₂ăṬḍźżĒØÑÆṇňėćḗǒőṛ - Length: 159
- Alphabet:
cs-CZ- Alphabet:
noeavtimlrsíupkájcdhzěšyřýbčéžfgůňťKxúBHPSMVóďŠLDRJTCFAZNGOČwEŽIUWŘüöqÚĎäYXÁÍľQĽÓ; - Length: 82
- Alphabet:
da-DK- Alphabet:
esrntdliaogkmuvbpføyhæjSNåc'M’VØ-zAwBéHKTL.xERGFDCJPIOqUWZüYÅö"XQ óèáÆäúłßíðëęśđńÖ3μ6Áܵï2ωψχφυτσςρποξνλκιθηζεδγβαΩΨΧΦΥΤΣΡΠΟΞΝΜΛΚΙΘΗΖΕΔΓΒΑ85ÞôñêçÓàãšîć,1ʻžŽÒÍýòÿőğșż/90 - Length: 168
- Alphabet:
de-AT- Alphabet:
enrstialhugc-dmobkfpzwväüISöABKßyEPVGMTFDxRHWjLZNUqCOJÜQÄéÖ. YXñêâ92180:63à_,>@<¶Ã)(7 - Length: 85
- Alphabet:
de-CH- Alphabet:
enrstialhugc-dmobkfpzwväüISöABKßyEPVGMTFDxRHWjLZNUqCOJÜQÄéÖ. YXñêâ92180:63à_,>@<¶Ã)(7 - Length: 85
- Alphabet:
de-DE- Alphabet:
enrstialhugc-dmobkfpzwväüISöABKßyEPVGMTFDxRHWjLZNUqCOJÜQÄéÖ. YXñêâ92180:63à_,>@<¶Ã)(7 - Length: 85
- Alphabet:
el-GR- Alphabet:
αοετνισρμκυπλςηόγωδίέθάύφχζώήβξψϊΑΚΜΣΠϋΒΤΛΐΓΕΝΔΦΙΧΡΟΘΆΖΗΰΈΊΌΥΞΨΩΉΎ - Length: 66
- Alphabet:
en-AU- Alphabet:
seiarntolcd'ugpmhbyfkvwxzMSCqAjBPTLHDGREKNFWJOIVUYZQX3219876540 - Length: 63
- Alphabet:
en-CA- Alphabet:
seiarntolcd'ugpmhbyfkvwzxMSCAqjBPTLHDGRENKFWJOIVUYZQX3219876540 - Length: 63
- Alphabet:
en-GB- Alphabet:
seiarntolcd'ugpmhbyfkvwxzMSCqAjBPTLHDGRENKFWJOIVUYZQX3219876540 - Length: 63
- Alphabet:
en-PH- Alphabet:
aersoinctldmubpágízfvhéjqóñxyCúPTAMSüBGHLkVRNIOJEDYFQUZwXKWÁÑ-ÚÉÓ.Í/ _ - Length: 71
- Alphabet:
en-US- Alphabet:
seiarntolcd'ugpmhbyfkvwzxMSCAqjBPTLHDGREKNFWJOIVUYZQX3219876540 - Length: 63
- Alphabet:
en-ZA- Alphabet:
esianrtolcdumgp'hbyfvkw-zxSMqjBCATRNLGKDWHPEOFVIJUéZYQ.èXêñâç!üïôóöáàä31û4ë5Åîã862 - Length: 82
- Alphabet:
es-AR- Alphabet:
aersionctldmubpágízfvhéjqóñxyúükCAMSwBGPLTEDIRNJVHFOUYKQZWÁ./ÓÑÍX - Length: 66
- Alphabet:
es-BO- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükMCSwABGIEPTNDVRHLJFUYOKÁZWQ/.ÓÍX - Length: 65
- Alphabet:
es-CL- Alphabet:
aersonicltdmupbágfzívhjéqóñxyúükCMPwASLBTGINEHDRVFJQUOKYÑÁZW/.ÓÍX - Length: 66
- Alphabet:
es-CO- Alphabet:
aersonictldmubpágífzvhjéqóñxyúCPMüASTGBkRVLNEDJIHFOUYwQZKÁWÚÓÑÍÉ/X. - Length: 69
- Alphabet:
es-CR- Alphabet:
aersonictldmupbágzfívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 64
- Alphabet:
es-DO- Alphabet:
aesornlitdcmáupbgéífvzhjqóxñyúS|/ükwMACGBEINDPJLFV RHTUOKYÁZW.X ÓÍ - Length: 66
- Alphabet:
es-EC- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 64
- Alphabet:
es-ES- Alphabet:
aersoinctdlmubpágífzvhéjqóñxyúükAMCSPBGwVRLTEINDJFHOUÁZKYWÉ/.ÚÓÍX - Length: 66
- Alphabet:
es-GT- Alphabet:
aersonictldmupbágzfívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-HN- Alphabet:
aersonictldmupbágzfívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-MX- Alphabet:
aersonictldmubpágífzvhjéqóñxyúTCüAkMSPHNIBJEGLZODYwRVXFUQKÁW/.ÓÑÍ - Length: 67
- Alphabet:
es-NI- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 64
- Alphabet:
es-PA- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-PE- Alphabet:
aersonictldmupbágífzvhjéqóñxyúCükPAMSHTLBIVRwOJYNQGEUDFKZ-ÁW/.ÓÑÍX _ - Length: 69
- Alphabet:
es-PR- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-PY- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-SV- Alphabet:
aersonictldmupbágzfívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-US- Alphabet:
aersionctldmubpágízfvhéjqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 64
- Alphabet:
es-UY- Alphabet:
aersonictldmupbágfzívhjéqóñxyúükwMSACGBEINDPJLRFVHTUOKÁYZW/.ÓÍX - Length: 65
- Alphabet:
es-VE- Alphabet:
aersonictldmubpágífzvhjéqóñxyúükMCASGwBPTEILRDNVFJUHOZKYÁW/Q.ÓÍX - Length: 66
- Alphabet:
et-EE- Alphabet:
iatesuklnmgrvodphjõäbüöfðþz-yAxCcBLID.MEKRGTSFHUOPNVÜWXw - Length: 56
- Alphabet:
fa-IR- Alphabet:
اینرتهمدوشسبلکگزفخپجعقآحچصغطذضژثظئٔءأُؤًِةَّ - Length: 45
- Alphabet:
fo-FO- Alphabet:
anrisultkgmeðvdobfpjøóyháíúæýSHEKTMBAGJVNF-RcDÁOLwz.PIxÍCUÚØÓYéWÆ/Qå+ü761qZ#83 - Length: 78
- Alphabet:
fr-FR- Alphabet:
esiarntolucémdp'gbhfvqz-yâLDQxèCAOjSHk₂MBNPFI₃TîçRG₄EêwïVKû₁JWô₆₅ÉœUYZ₇₈₀à₉XëöüæᵉóŒá231íµÎ4ÀùΩℓΩˢʳÆ976ɴꜱć0ÈÂᵈñ85äÅωψχφυτσρποξνμλκιθηζεδγβαΔܳ²ãńśÿᴀᴍᴏšÔÊōˡåúᵛᵐᵍ_ⁿ - Length: 161
- Alphabet:
fy-NL- Alphabet:
esntriaklodjfpgbmhuwcyûAOUzúvâôê-'.SBëHGïWNFMTKJRELDPIäöYxéqCèVü341QX6520åàZ8 - Length: 77
- Alphabet:
ga-IE- Alphabet:
ahinrtceoldsímgbfáó'uéúp-CASBMIGvFTPDEyOLRHNUkÉwzVKÚXÁWJxÍÓjZQqYüöèñćëâêãùäìěòîçğà - Length: 82
- Alphabet:
gd-GB- Alphabet:
ahin-esrcdgltbomufà'pòìùèéóACSMBIEGFTDPLáONRUykvÈÉÀHÌwzÒxÙWVKqJjY.XZ‑Qñíōüā1öäëÁūÓ,úłđ⁊âôçŌćĐÅē=ïęøãīıễîŷʻğŭŏăşåþ - Length: 113
- Alphabet:
gl-ES- Alphabet:
elsoanrcmávidthubpéígfzxóñqúïükAySCMBP.RTLjGDEHKNJFIVw-OWZYUXаиQ'норöōелвèëсšткοςçãÁдäАαÉмłàιйū/ρčνÖôчяěıλâ1уêðşηøВžτгСśМσКő2ь3κεŽğРДυδПфř0ФИпāЛГòбΑίŞхάåÓæÆНЕμܵŠŌİБýćīέзшγΩ4πΆÍªăТΝόÇ+ω9βÅЯОÞňîΔφìť5ΣΠώĐ Čõ8ἈіήĽØ´ďùþżюΕύÚęÑ6ա́ΜθЮЗыёΛΚΓχńû7Θξē:ХъΡΙΒđė@Οϊßəţ|アորբэцΧΦΤζǺºů’ǧ伯ラのეկЭЦУЙΖŻÐÂÀ²ʿ][ạșąǎ™亞亚ドーハブἌიაՎնմԱШЖџжῑΈŚŁÌijịảț–ĉ&이아友千道罕拉东台中ッキインルベムナ海しἸთქნਨਮիգտեՀհЧєІΥȘŘŐĀÙÕÒÎűʻ⁺ệ¡ģọẩṭ₂ǫũề),ǽ$찬해지함라브市走網叉夜犬島路淡毅正クジ社会式株政李之励方狼場戦内寺利実族氏尼安川野吉门厦隠神尋と北子未來當当九丹视电央国ザオバカシウュ・へユチニァヴスャエヌワトィデぎふΩ€‰”“ῊἩϐỈᒃᓗᑖᖅᑭᕿვლდღობრუზมัดาอ්මදආਘੰਿਸਹੋमहार्बअսՊՅյւձռփўїқљЁϋῖȣᾱῐἀὕἰΉƏŬźĪĢĒứộỗẹĆÊÈȳ°¥£′ʾṢṣḤḇửỳÝ‘…ļ_ɘṛ!ờưņḥķĭǔᵥữŏœểŕ%` - Length: 586
- Alphabet:
he-IL- Alphabet:
וכשי"מלתבהנרםפקןאחסטדעגצךז'ףץ - Length: 29
- Alphabet:
hr-HR- Alphabet:
aionerjmtsuvklpdgzčbšchćžfđASB-KMPTLHJEDVGNIRFCZOŠČUwŽyĐxéëXYĆQW: - Length: 65
- Alphabet:
is-IS- Alphabet:
anrisultgemkfðödvjbhóápoæíyúþýéxHSABEGFVÁKMJÞR-DLNTÍIPc.ÓÚOUÖCWqzYwÆÝZ - Length: 71
- Alphabet:
it-IT- Alphabet:
leiatn'ocrsmugvdAIpbzfqhDEQCOBSNULMTVòàéìHxkyPwRGFù èjZ/0KW2JY,.1":-)(3;><654Xçôâ7 - Length: 82
- Alphabet:
ka-GE- Alphabet:
აიესნბრმოლდვთუგცკტშხზქფპწყღძჩჯჭჰჟ- ietosanTEOIrRNAShl,dcf#bHuLpgwFCmDMWGyPUY/B.v):("VKjx_kX40 - Length: 93
- Alphabet:
lb-LU- Alphabet:
enrtsialohcugmpdkfébzwäëvSKBPGAFMyDHREVTxWLIjONCZüqUJËèÄöQ-ÉêûôîçYÖXâÜñ'ïàí&/320Šó!51 - Length: 85
- Alphabet:
lt-LT- Alphabet:
iseanuotmjrbkpdlvėčšgyžąįųūzęfchPKSGBVMADLRJTŠNEŽUZIČOFCHŪĄYĖĮwxWXQq - Length: 68
- Alphabet:
lv-LV- Alphabet:
aieānsojmtkupšrēzldīvgbcķūļņžfčģhA.MSVDLKBIERGJTZPHNOFUCĀŠĶŽĢĒČŅ-Ī)(ĻŪ3ōyżW2/w:XYx - Length: 82
- Alphabet:
mk-MK- Alphabet:
аеоинвтрслпкудмзбчгјшцњжфхќџѓљѕ-АК’СМБПИТВЕГДШРНЛХФЈЦУОЗ!Ч.ЃѐЖѝЊЉ - Length: 65
- Alphabet:
mn-MN- Alphabet:
агэлдйхүуниросчтөцмвбшзжыяекьпфёъюБКМАСГЛДХПТФНВРЭОУШИЧЖЦЗЯЮӨЕЙщҮЁ - Length: 66
- Alphabet:
nb-NO- Alphabet:
ensrtialkogdmpuvfbjhøyåæc-éSzwABTVMFHELOKNGxDRPIC.ôèJUqWØÅYZüQäçêöòXëÆÄ - Length: 71
- Alphabet:
ne-NP- Alphabet: ्ाि
नरकसेलुहमदछोतयइँपबगटथीखौैएचभजउडवधअफूघझठङशढणषईआओञृंऊऔ१९८७६५४३२०ऐ ः-ऋ24,#/:31)(ळ5 - Length: 85
- Alphabet: ्ाि
nl-BE- Alphabet:
enrsatioldgkpumhbcv-fwjijz'ySBHMxAKLëRDWVGTENCPOJFqIJZIïé.UèöYXQüêç6130245áäóûàîúôñ+í 8â97/Å - Length: 90
- Alphabet:
nn-NO- Alphabet:
earnstilkogdmupvfbjøyhåæc-SzBwéHêTAMKFNGVELRxDôO.PòCèIJUWqØÅóYQZçüäXÄÆë - Length: 71
- Alphabet:
pl-PL- Alphabet:
iaeonyzwrcmsktpuldjłbghąśężfóńćSKźPMB-WGCDRALTJZNOFHvEŁIŚUŻxVqYXQĆ'éŹ. - Length: 70
- Alphabet:
pt-BR- Alphabet:
aesor-inmltcdhuvpbgfzájqíçãxõéóêôâMCBASPúIGTELNRFJUVDXHy.kZOQwKÁW'Í üèÉöàʺªÂëYÚÓïµñîøØÒ³²åÔ - Length: 93
- Alphabet:
pt-PT- Alphabet:
aers-iolmntcdhuvápgbfzíãjqçxêéóõúâCAMPôSBTELGRkFVDNHIJOwyUKZWQXÁàYÍÉ .ÓèÂîÚü?;:,)("! - Length: 84
- Alphabet:
ro-RO- Alphabet:
eiranotlucăsdm-pzțșgbfvâhîjxkCwBySMPADGTRLVIFqNHOEȘJUZKWȚXQYöüÎ/éíş82ţáÂè6543 - Length: 77
- Alphabet:
ru-RU- Alphabet:
оаеивнрстмлпукяшыдюзгбйчхьщжцфэъ-АКВМСБПГЛНДТИРЕФОЗЭХШУЯЧЖЮЦЙЩё - Length: 63
- Alphabet:
rw-RW- Alphabet:
anir|XS/tkeyumbghozcsdwfpvj - Length: 27
- Alphabet:
sk-SK- Alphabet:
enoaivrtjmksšlupcdhzáíbčyýúéťžľgfňóäxôďŕĺ-MBSKPwATLHVDGNRJŠOFZEICUČŽöĽqWXÁQYĎÚÍüŤ ÓěÉêÝŇĹàëÖ - Length: 92
- Alphabet:
sl-SI- Alphabet:
aienormvtkljsčpduzgšhbcžSfPMKBVLGDRTŠCJćZHAIONČŽFXEUywWxüqYöĐQđ.Ć - Length: 65
- Alphabet:
sr-Cy- Alphabet:
аиоенртусмвклпдјзгбшчцћњхљжфђСМБКџПВАДЈРТНЛГХИЕОФШЗЂЧЦУЖЉЋЏЊ - Length: 60
- Alphabet:
sr-La- Alphabet:
aioenrtulsjmvkpdzgbščcćhžfđSMBKPVADJRTLNGHIEOFŠĐZČCUŽĆ - Length: 54
- Alphabet:
sv-FI- Alphabet:
snraetilokgdmpubväföhåyjcx-SzéBHwMKLTAVRGFNEPDCOIJ:ÖUWÅ qÄ.YZü3241èáQ7X860ç5'ćóíê,9łøôâàæńšëñžşúûãřÉωψχφυτσρποξνμλκιθηζεδγβαΩΔęňāčğ㜌źŁµőï - Length: 139
- Alphabet:
sv-SE- Alphabet:
snraetilokgdmpubväföhåyjcx-SzéBHwMKLTAVRGFNEPDCIOJ:ÖUWÅ qÄ.YZü3241èáQ7X860ç5'ćóíê,9łøôâàæńšëñžşúûãřÉωψχφυτσρποξνμλκιθηζεδγβαΩΔęňāčğ㜌źŁµőï - Length: 139
- Alphabet:
tk-TM- Alphabet:
aylirdemngkýňtzsşbäjouüpçwhö-fžAGMSOHBNKcRPJTDIÝÇUÖ ZLvYEŞ - Length: 58
- Alphabet:
tr-TR- Alphabet:
aeilrnımdktysuzşobüğcgçpvhöf'jAKSTBMEİHDGYÖONRFUŞPCÇVÜILZJ.âWĞw - Length: 63
- Alphabet:
uk-UA- Alphabet:
оанивіретсмкулпьдзягйбюшчхцжєфїщ-'КСБПМГВДЛАТРНґОЗШФЧІХЯЖУЄЕЦЮҐЩЙЇИ - Length: 67
- Alphabet:
vi-VN- Alphabet:
nhgticmuorpalbkáđyxưsvdạàếảốêệóớấúộqắéôụíơồềậeọợờâùịòẹèầãặăỏứìổẩủểẻựỉằởừửẫễũỡỗõĩẽẳữýỵẵỷỳNIVTHCỹPURDLMGAQFSBwEJĐK - Length: 112
- Alphabet:
from spylls.
fabiospampinato
commented on June 14, 2024
Interestingly all alphabets but one seem to have <= 256 letters, which should allow me to use at most 1 byte per letter to store them. One should probably be able to pack more than one letter in one byte for languages with very short alphabets, I'll have to investigate that.
That language with more than 256 letters may be a bit of an issue encoding-wise 🤔
from spylls.
fabiospampinato
commented on June 14, 2024
Update on the encoded trie, which is largely done and so far has the following characteristics:
- It takes ~9MB (both on disk and in memory, which for JS isn't obvious) for encoding all the ~3.5 million words in
pl-PL, which zipped goes down to ~4MB. This should be ok for my use case, butmorfologikseems to get ~2.7MB and ~1.8MB respectively, which is a lot better, I guess deduplicating suffixes too is really worth it (I don't know if their dictionary is case-insensitive though, some implementations I've seen just ignore casing). I'd like to try to encode a FSA eventually too, but that's too complicated for me for now. - Lookup performance is 3x slower than what I'm getting with the non-encoded trie, meaning it takes ~0.0025ms per unique lookup on average, so really good for my use case. That's with memoizing a function though, which will increase runtime memory usage over time, but very reasonably so IMHO because that scales with the percentage of the encoded words queried, no way people are going to need to look up all ~3.5 million words, and even if they do memory usage won't skyrocket too much.
- Encoding the trie is still pretty fast, at about 1 million words per second.
I'll put the finishing touches on this thing, and then I'll try to understand what the situation is regarding compound words, any guidance on that would be greatly appreciated.
Mainly I'd say I'd like to have a way to extract compound words up to a limit just to gauge the situation across dictionaries, then I can think about how to address it.
from spylls.
fabiospampinato
commented on June 14, 2024
Two random thoughts:
- The packed italian dictionary takes 100MB, and zipping it brings that figure down to ~12MB, there's a lot of redundancy left in this encoding, using tries just can't squeeze these words lists as much as an FSA could.
- A handful of rules seem to generate a huge amount of words, and it may be better to hard-code those rules rather than to evaluate them at compile time, for example the rule that capitalizes words seems super noisy. Would it be possible to somehow detect these rules and/or turn them off manually? I guess for that rule specifically I could also code something on my end, removing the capitalization before inserting words in the trie.
- Using tries for that rule essentially doubles the number of nodes because the very first node in the prefix is different between the capitalized and uncapitalized versions of the word and pretty much every word I'd image can be capitalized, at least in some languages. With an FSA I guess instead of duplicating the trie you'd only have a node for each capitalized letter and then a pointer to some other existing structure, which would be waaaay more compact, but also much more difficult to work with.
from spylls.
zverok
commented on June 14, 2024
NB: I follow your comments, but during the weekdays have only an ability to spend a shallow attention on them, probably will read more deeply on weekend. But two things that you might found interesting that I know about morfologik's approach:
- They seem to encode data byte-by-byte, so the format "knows" nothing about encoding (e.g. UTF string "мама" will be put in the FSA as a sequence of bytes
[208, 188, 208, 176, 208, 188, 208, 176]). It is probably harder to debug, but easier for memory layouting, so the encoder/decoder can be absolutely "dumb". - They seem to store only "canonical" capitalization, so only "gatto" (cat) can be found in FSA, but not "Gatto" or "GATTO", and only "Parigi" (Paris), but not "PARIS".
(I still suspect that digging in their code/links/docs could be fruitful for your tasks, too.)
I'll investigate dictionary bugs in the next few days, and I'll hopefully be able to provide some guidance for compounding, when the time comes.
from spylls.
zverok
commented on June 14, 2024
This might be a good starting point for their approach to FSA building: https://github.com/morfologik/morfologik-stemming/blob/master/morfologik-fsa-builders/src/main/java/morfologik/fsa/builders/FSABuilder.java
from spylls.
fabiospampinato
commented on June 14, 2024
Sorry I'm dumping too many words in this thread 😅.
An update/summary:
- Overall the unmunch script worked pretty well, except for a handful of languages for which it threw errors.
- Encoding-wise I'm done with my ~succinct trie implementation, overall it works really well for most languages (~0ms startup time, ~10MB of memory usage for Italian which has a pretty heavy words list, ~1200 words looked up per millisecond).
- Spell-checking-wise I've got something that gets me to ~83% accuracy in a little benchmark I've made from this, which is comparable to what I was getting before with
nspell, but it's ~20x faster. I could just throw more compute at this, and/or walk the trie smartly perhaps rather than computing edit distances blinding, but for now that's good enough for me. - Encoding an FSA ~succinctly is too complicated for me currently, I've looked into
morfologik's code a bit but I didn't really learn a lot, I would need to spend much more time on this to really understand it. - Storing the canonical version of words and performing some post-processing on the generated words lists helped a lot with trimming those lists down significantly for some languages.
- Most languages don't seem to be using compound words heavily, or at all, so I think I can just ship this new experimental spell-checker to taste the water, it should be good enough.
- The finnish dictionary might be badly done, I think it contained something like 200k common replacements, either the dictionary is kind of terrible or the language itself is, maybe both.
- The main standing issue for me is that of compound words, I would still like to better support languages like German. It'd be great if you could update the unmunch script to extract compound words up to a limit, possibly searching breadth first, I have a feeling that just extracting a few million compound words at maximum for each language would get me 90% there already really quickly, then I can think how to fix this properly.
- Spylls' code and documentation has been pretty useful to me, the code feels very approachable and clean to me and I've learned a lot from it.
from spylls.
zverok
commented on June 14, 2024
About dictionary parsing (hmm, it would be cool to split this ticket into several discussions actually... Maybe we can go with a private repo for your project with me as a contributor, so I can see/answer issues and discussions there? Or WDYT?):
- es-DO works fine for me; but maybe it is because I fixed one bug in the recent version of Spylls, try it?
- cs has a bug in .aff-file (this line — unclosed character class; if you add
]at the end manually,unmunch.pyworks fine) - hy has a big in this line, should say 172 (otherwise the last suffix of the list is treated as a new suffix group), if you fix it manually, works fine.
I'll investigate "forever to complete" (infinite loops or too long lists) dictionaries next.
PS: About this one:
It'd be great if you could update the unmunch script to extract compound words
I don't believe it is the right way, and not sure I have a resource to do it. If you want to try approaching this yourself, I might help with some advice; if you'll go the preprocessing way (try split, then see if it is a proper compound; which I believe is more promising), I can be of some advice, too.
from spylls.
Related Issues (17)
- MIT license certainly isn't compatible with Hunspell's license HOT 1
- ValueError: invalid literal for int() with base 10: HOT 1
- It takes too long time to return an answer on a corner case HOT 1
- Knob to fix word-case HOT 2
- aff-regex HOT 6
- .dic and .aff content by param. HOT 7
- ask for the Stemming feature HOT 1
- Infinite loop when suggesting HOT 2
- Generating dictionary wordforms/unmunch HOT 12
- Question: Does hunspell/spylls have facility to change the root of the word? HOT 1
- Spelling mistake in example code on spylls.readthedocs.io HOT 1
- TypeError: '<' not supported between instances of 'Word' and 'Word' HOT 8
- Upgrade the package HOT 2
- Integrate Black for formatting HOT 2
- spylls fails to load Dutch dictionary HOT 3
- Using spylls to clean-up text file HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from spylls.