说明文档英文版请点击英文版
该项目是以Python为基础,旨在为教育工作者提供一系列常用的处理功能——如词频统计,字符云等,减少教育研究者使用Python的难度。计划V1.0版本维护时间为1年。
作者:李坦(北京师范大学教育技术学院博士生) Email:[email protected]
该类用于处理所有涉及到文件的操作
该函数用于读取文件并返回出文件内的结果
完整结构
readfile(filename)- filename: 您的文件路径, 并且文件路径以utf-8编码.
from oset import File
data = File.readfile('C:\\Users\\Administrator\\Desktop\\dict.txt')
for word in data:
print(word)
>>> 这是一个测试文本该函数主要是为了将一个文件夹内所有的文件名读取出来
完整结构
readfilesname(filename)- filename: 文件路径
from oset import File
filelist = File.readfilesname('C:\\Users\\Administrator\\Desktop\\images')
for fl in filelist:
print(fl)
该函数用于合并某一个文件夹下所有的子文件内容,并输出到指定位置
完整结构
combfile(filepath,**outpath)- filepath:文件夹路径
- outpath:合并文件输出位置(可选,若不选则输出到读取文件的位置)
from oset import File
File.combfile('C:\\Users\\Administrator\\Desktop\\test')test文件下存在三个子文件:one.txt,TJNU.txt,two.txt。自动合并产生一个文件名为“combfile_Fin.txt”的文件,该文件中已经上上述子文件内容合并进来。

该函数是替换文件中内容 完整结构
repfilecont(filepath,content,replacecontent)- filepath:文件路径
- content:需要替换的内容
- replacecontent:被替换内容
更详细说明参见:[解决方案]Python批量替换文件中的内容
from oset import File
File.repfilecont('C:\\Users\\Administrator\\Desktop\\test','天津师范大学','天师大')该函数是批量替换文件夹中所有子文件中的内容 完整结构
repbatfilecont(filepath,content,replacecontent)- filepath:文件夹路径
- content:需要替换的内容
- replacecontent:被替换内容
更详细说明参见:[解决方案]Python批量替换文件中的内容
from oset import File
File.repbatfilecont('C:\\Users\\Administrator\\Desktop\\test','天津师范大学','天师大')
该类主要用于处理所有涉及到简体中文的任务,如分词,词频统计,字符云等。
这个函数可以切分出文本中的中文词汇。在这个函数中,该函数已经内嵌了停用词表和教育领域专业分词词表。主要目的是减少研究人员在分词时的难度。(停用词表,如:'我','是','这'...;专业词汇表,如:'课程论','导师制','双轨制'...)
完整结构
cutword(sentence)- sentence: is the sentence that need to cut
from oset import Chineseword
s = "天津师范大学教育学部教育技术研究所"
c = Chineseword.cutword(s)
print(c)
>>>[' 天津师范大学', ' 教育学部', ' 教育技术研究所']该函数用于将文档通过字符云的方式进行可视化展示,可以自动对单个文档或者多个文档进行字符云绘制。
wordcloud(filepath)- filepath: 文件地址(可以是单个文件地址,也可以是存储多个文件的文件夹地址)
文件夹下有如下文件
#仅仅对单个txt文件进行可视化
from oset import Chineseword
Chineseword.wordcloud('C:\\Users\\Administrator\\Desktop\\test\\教育学部.txt')
#对某个文件夹下所有文件进行批量可视化展示
from oset import Chineseword
Chineseword.wordcloud('C:\\Users\\Administrator\\Desktop\\test')
该函数用于对文本中词频进行统计,既可以对单个文件进行词频统计,也可以对多个文件进行词频统计。
wordcount(filepath)- filepath: 文件地址(可以是单个文件地址,也可以是存储多个文件的文件夹地址)
文件夹下有如下结构:
#对单个文件进行词频统计
from oset import Chineseword
Chineseword.wordcount('C:\\Users\\Administrator\\Desktop\\test\\教育学部.txt')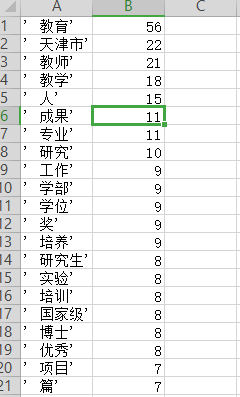
#对多个文件进行词频统计
from oset import Chineseword
Chineseword.wordcount('C:\\Users\\Administrator\\Desktop\\test')