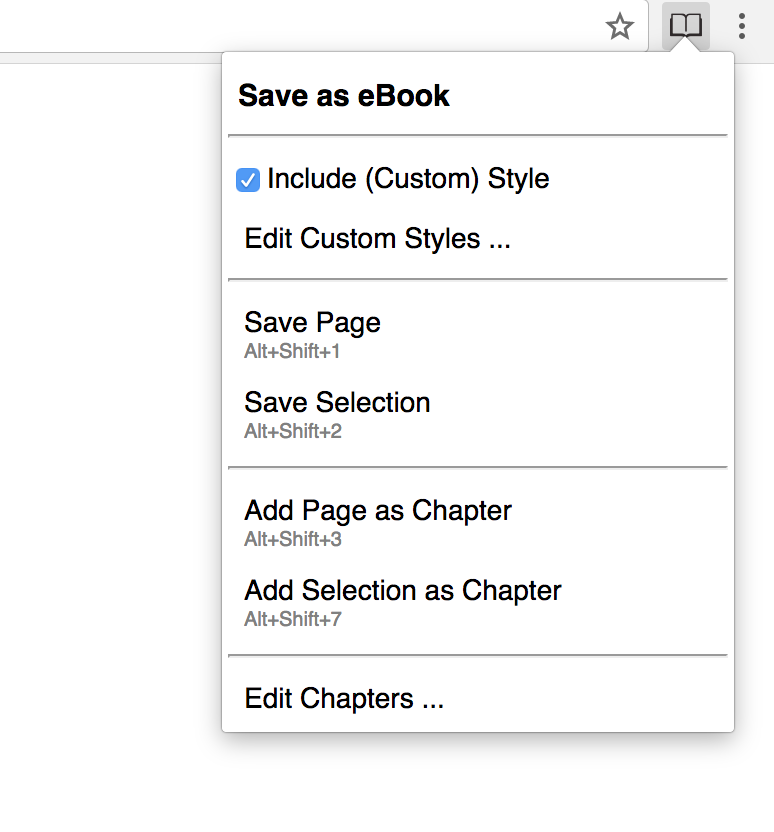
Save a web page/selection as an eBook (.epub format) - a Chrome/Firefox/Opera Web Extension

From Chrome Web Store
or manually (tested on v. 52.0.2743.116)
1. Navigate to chrome://extensions/
2. Load unpacked extension ...
3. Select the extension's directory
From Firefox Add-ons
or manually (tested on v. 50.0a2)
1. Navigate to about:debugging
2. Load temporary add-on ...
3. Select the extension's directory
1. Navigate to opera:extensions
2. Load unpacked extension ...
3. Select the extension's directory
sudo apt-get install calibre
ebook-convert "book.epub" "book.mobi"
NOTE These shortcuts are not fixed and the browser will assign a different shortcut if the default one is taken
| Shortcut | Description |
|---|---|
| Alt + Shift + 1 | Save current page as eBook |
| Alt + Shift + 2 | Save current selection as eBook |
| Alt + Shift + 3 | Add current page as chapter |
| Alt + Shift + 4 | Add current selection as chapter |
in Chrome:
1. Navigate to chrome://extensions/
2. Scroll down
3. Click on Keyboard shortcuts
- Added MIME type to the generated .epub file
- Remove unnecessary permissions
- Detect image type if the URL doesn't have a file extension (jpg, gif, png)
- Reset the Busy indicator on errors
- Remove hidden elements when style is not included
- Replace iframes with divs
- Smaller ebook file size
- Fix for #37 - custom styles not applied
- Fix for #36 - br tag missing from pre blocks
- Fix for #31 - hanging in Busy state
- Other misc bug fixes
- Fix for MathML - the rendered expression is too large (Issue #26)
- Add translation in Russian (thanks to @ Emil Khalikov) & Brazilian Portuguese (thanks to @welksonramos)
- Keyboard shortcuts
- Simplified tool bar menu
- Misc bug fixes
- fixed & & issue in title; Issue # 10
- support for hr/br html tags
- BETA: Support for CSS
- BETA: Create / edit custom Styles
- No errors from EPUB Validator (http://validator.idpf.org/) + this should fix the Google Play upload issue
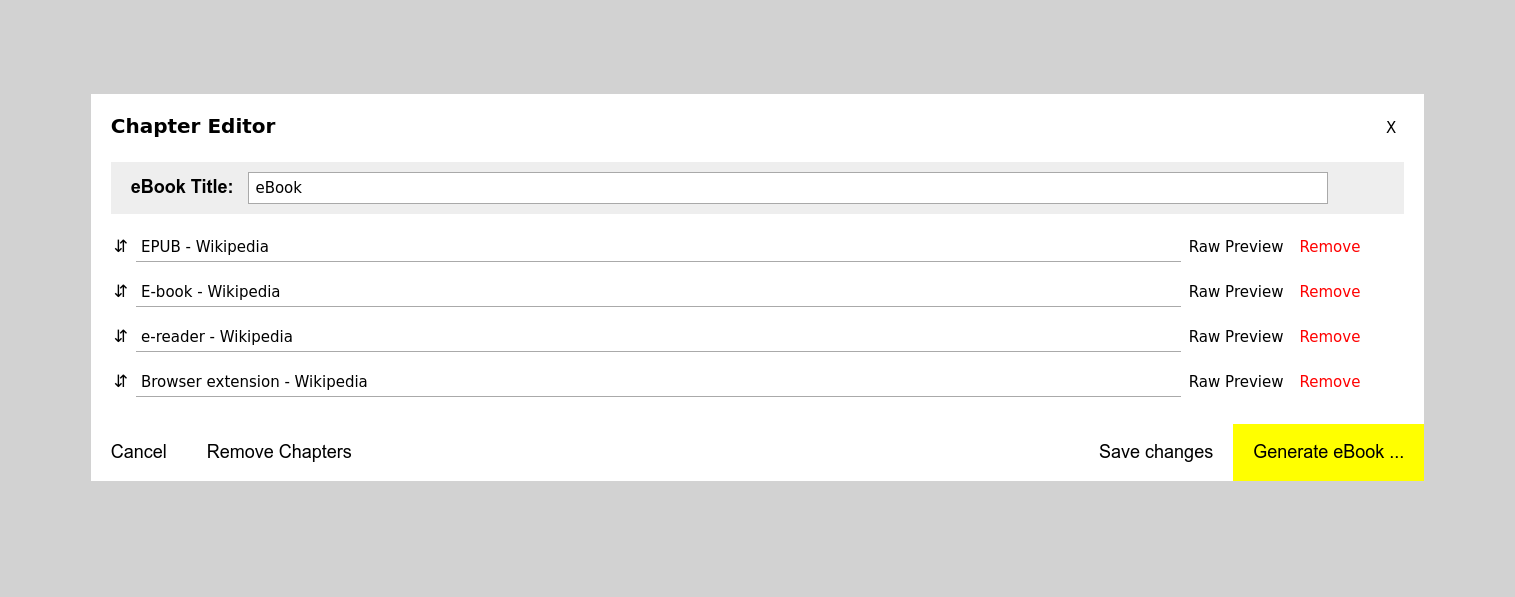
- Chapter Editor: option to save changes
- Chapter Editor: option to remove all chapters
- persist Chapter Editor changes & chapters after generating an eBook or after a browser restart
- make the Custom Style Editor more user friendly
- support backup / restore for Custom Styles
- DONE fix all 'epubcheck' errors (https://github.com/IDPF/epubcheck)
- clean & optimize code
- create tests
- support other formats (mobi, pdf etc.)
- show confirmations (ui/ux)
- display errors (ui/ux)
- DONE support custom style
- add 'remove from ebook' right click menu action
cd tests
yarn install # install puppeteer
node test/index.js # should start a chrome instance with Save as eBook loaded
# it will generate and save the ebook in ./tmp-downloads
....
- http://ebooks.stackexchange.com/questions/1183/what-is-the-minimum-required-content-for-a-valid-epub
- https://github.com/blowsie/Pure-JavaScript-HTML5-Parser
- https://stuk.github.io/jszip/
- http://johnny.github.io/jquery-sortable/
- https://github.com/eligrey/FileSaver.js/
- https://www.iconfinder.com/icons/753890/book_books_education_library_study_icon#size=128
- Thanks to pumpk0n and Francois Bocquet for helping me with the French translation








































































































































