alibaba / graphscope Goto Github PK
View Code? Open in Web Editor NEW🔨 🍇 💻 🚀 GraphScope: A One-Stop Large-Scale Graph Computing System from Alibaba | 一站式图计算系统
Home Page: https://graphscope.io
License: Apache License 2.0
🔨 🍇 💻 🚀 GraphScope: A One-Stop Large-Scale Graph Computing System from Alibaba | 一站式图计算系统
Home Page: https://graphscope.io
License: Apache License 2.0
original issue title: a publicly available k8s cluster on aliyun as playground for tutorials and quick start
As titled. Let's provide a cluster as a playground for beginners.
Since the original issue will be solved via #65, and a question posed as below, the title changed to "Is k8s is a necessity for GraphScope"
We plan to gradually enable GraphScope with such abilities. We setup this master issue to track the progress.
Is your feature request related to a problem? Please describe.
Describe the solution you'd like
Describe alternatives you've considered
A clear and concise description of any alternative solutions or features you've considered.
Additional context
Add any other context or screenshots about the feature request here.
Is your feature request related to a problem? Please describe.
The show_log parameters between different sessions will affect each other.
Describe the solution you'd like
Deprecated show_log, log_level params in the session, instead,It is better to define as global configuration of graphscope.
import graphscope
graphscope.set_option("show_log", True)
graphscope.get_option("show_log")Describe the bug
GraphScope can't create pods (such as GraphManager pod and gremlin server pod) in the namespace with ResourceQuota limit.
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "2"
requests.memory: 2Gi
limits.cpu: "2"
limits.memory: 2GiError from server (Forbidden): : pods "xxxx" is forbidden: failed quota: mem-cpu-demo: must specify limits.cpu,limits.memory,requests.cpu,requests.memoryWe plan to release GraphScope 0.3.0 in March 2021.
Graph Visualization
Performance Enhancement
Kubernetes Releated
Integration with Mars
Improve the compatibility with NetworkX
Cloud service integration
Run GraphScope locally without K8s/Docker
Improve graph manipulation APIs
User-friendly API improvements
Built-in app extension
Describe the bug
The show_log=True parameter has been removed in #42 but there are still many occurrences in our codebase.
Expected behavior
Don't use removed parameter.
Provide colab-like notebook as playground.
Refs:
Currently the compatibility of NetworkX API is in preview.
We will make it solid in these aspects:
./scripts/prepare_env.sh script to check compatibility.
Is your feature request related to a problem? Please describe.
Session has a param called show_log which controls whether print backend logs to stdout / stderr, which is great. But when we run a session with show_log=False since we don't want to be distracted by logs, and occasionally session launched failed, we can't get much useful information about why it failed and how to fix it, usually we need to rerun the session with show_log=True.
Describe the solution you'd like
Print logs when session failed, even when show_log=False.
Is your feature request related to a problem? Please describe.
The NodePort service type cannot meet the k8s cluster deployed on the cloud, while the LoadBalancer service type meets this requirement.
Describe the solution you'd like
Add a session param named k8s_service_type, valid options are NodePort, and LoadBalancer. Defaults to NodePort.
sess = graphscope.session(k8s_service_type='LoadBalancer')Is your feature request related to a problem? Please describe.
Too many services exposed by GraphScope to the client in one instance, such as vineyard RPC service、gremlin service、GLE train server service.
Describe the solution you'd like
It would be great if we can proxy all traffic from the client in one coordinator service.
Refs
Look forward to any helpful information.
Support load and write to AWS S3 stroage.
Most cloud storages are compatible with S3.
Interactive engine already supports submit a script to query the remote graph, which syntax is like:
interactive.execute("g.V().count()").result().one().
However, there is also another bytecode-based style to query a graph, which should also be supported, as follows:
g.V().count().toList().
We should support bytecode-based style as it's the recommended style by Tinkerpop.
Is your feature request related to a problem? Please describe.
When I needed to connect to a remote k8s cluster, I found that GS had no configurable parameters to do so
In the script session.py, at line 572:
api_client = kube_config.new_client_from_config()Let's look at thenew_client_from_config function:
def new_client_from_config(
config_file=None,
context=None,
persist_config=True):
"""
Loads configuration the same as load_kube_config but returns an ApiClient
to be used with any API object. This will allow the caller to concurrently
talk with multiple clusters.
"""
client_config = type.__call__(Configuration)
load_kube_config(config_file=config_file, context=context,
client_configuration=client_config,
persist_config=persist_config)
client_config.verify_ssl = False
return ApiClient(configuration=client_config)k8s allows developers to pass in the config_file parameter, but GS hides this parameter.
Describe the solution you'd like
I think the parameters of the functionnew_client_from_config can be configured by the developer in the Session class, just like:
api_client = kube_config.new_client_from_config(config_file=None, context=None, persist_config=persist_config)
or
api_client = kube_config.new_client_from_config(kw.pop('k8s_client_config'))This allows us to easily load the k8s configuration:
sess = graphscope.session(kw = {config_file=None, context=None, persist_config=True})
or
sess = graphscope.session(kw ={"k8s_client_config" : {config_file=None, context=None, persist_config=True}})Describe alternatives you've considered
Additional context
My current solution is to configure the environment variables as follows:
os.environ.setdefault(
"KUBECONFIG", os.path.join(Config.BASE_DIR, "config/kube_inner_config")
)
import graphscopeThis way of writing causes that environment variables must be declared before the graphscope is imported, which is very inelegant.
Currently the analytical engine only supports user-defined algorithms in cpp or python(via cython).
We are planning to support Java API on the analytical engine, which enables:
Is your feature request related to a problem? Please describe.
As titled.
# 2021-01-05 15:53:20,693 [WARNING][rpc:75]: Grpc call 'send_heartbeat' failed: StatusCode.UNAVAILABLE: failed to connect to all addresses
In [19]: sess
Out[19]: {'status': 'active', 'type': 'k8s', 'engine_hosts': 'gs-engine-tttqih-dpfkm,gs-engine-tttqih-tb2lg', 'namespace': 'gs-zcwihz', 'num_workers': 2, 'coordinator_endpoint': 'xxxx:xxxx', 'engine_config': {'experimental': 'ON', 'vineyard_socket': '/tmp/vineyard_workspace/vineyard.sock', 'vineyard_rpc_endpoint': xxxx:xxxx', 'vineyard_service_name': 'gs-vineyard-service-wtnaep'}}Add k-shell algorithm.
You may find its descriptions here: https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.core.k_shell.html#networkx.algorithms.core.k_shell
Please provide its verification (comparing the correctness with networkx) to CI together with the algorithm.
Is your feature request related to a problem? Please describe.
Currently, the documentation of PIE and Pregel, as well as its code sample, are not very intuitive to new users.
https://graphscope.io/docs/analytics_engine.html#writing-your-own-algorithms-in-pie
Describe the solution you'd like
context, frag, message, and vd_type, md_type for the pregel.graphscope.Vertex, and what does graphscope.declare do?2 in e.get_int(2)?src for context.get_config(b"src")?ret = my_app(g, source="0"), where source and src doesn't correspond. for v_label_id in range(v_label_num):
iv = frag.inner_nodes(v_label_id)
for v in iv:
v_dist = context.get_node_value(v)
for e_label_id in range(e_label_num):
es = frag.get_outgoing_edges(v, e_label_id)
for e in es:
u = e.neighbor()
u_dist = v_dist + e.get_int(2)
if context.get_node_value(u) > u_dist:
context.set_node_value(u, u_dist)Is your feature request related to a problem? Please describe.
Mount ${GS_TEST_DIR} to /testingdata is bad, and usually confused users. we should parameterize it as a session param.
combine prepare_env.sh and prepare_env_wsl.sh into one script would help user easily to prepare the environment of GraphScope.
clean up dependencies of unused modules to make the code base more concise.
Describe the bug
An internal error occurred while I was loading the diagram
Expected behavior
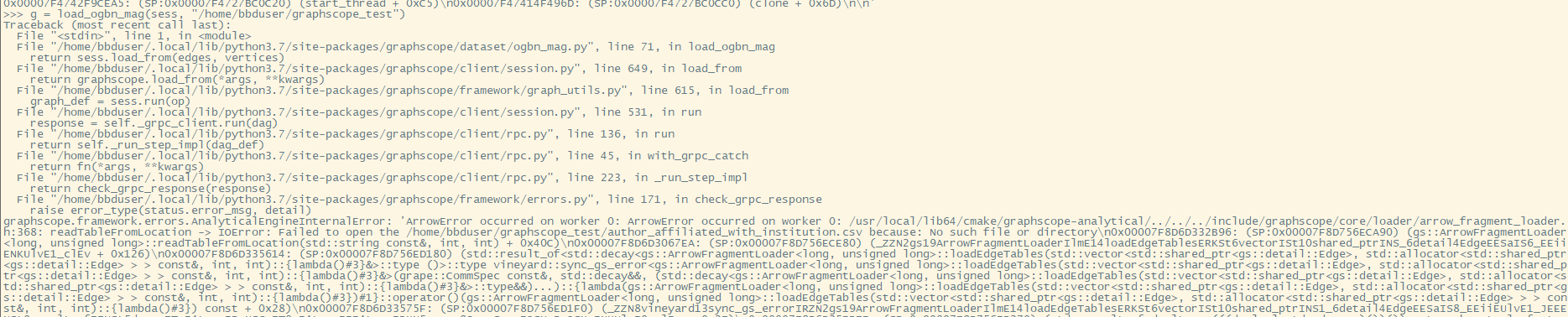
g = load_ogbn_mag(sess, "/home/bbduser/graphscope_test") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/dataset/ogbn_mag.py", line 71, in load_ogbn_mag return sess.load_from(edges, vertices) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/client/session.py", line 649, in load_from return graphscope.load_from(*args, **kwargs) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/framework/graph_utils.py", line 615, in load_from graph_def = sess.run(op) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/client/session.py", line 531, in run response = self._grpc_client.run(dag) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/client/rpc.py", line 136, in run return self._run_step_impl(dag_def) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/client/rpc.py", line 45, in with_grpc_catch return fn(*args, **kwargs) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/client/rpc.py", line 223, in _run_step_impl return check_grpc_response(response) File "/home/bbduser/.local/lib/python3.7/site-packages/graphscope/framework/errors.py", line 171, in check_grpc_response raise error_type(status.error_msg, detail) graphscope.framework.errors.AnalyticalEngineInternalError: 'ArrowError occurred on worker 0: ArrowError occurred on worker 0: /usr/local/lib64/cmake/graphscope-analytical/../../../include/graphscope/core/loader/arrow_fragment_loader.h:368: readTableFromLocation -> IOError: Failed to open the /home/bbduser/graphscope_test/author_affiliated_with_institution.csv because: No such file or directory
this file is exists
Screenshots
Environment (please complete the following information):
Additional context
Add any other context about the problem here.
样例的papers = interactive.execute("g.V().has('author', 'id', 2).out('writes').where(__.in('writes').has('id', 4307)).count()").one()
能够执行,统计节点数与边数也可以
但执行这句sub_graph = interactive.subgraph("g.V().has('year', inside(2014, 2020)).outE('cites')")
时报错
RuntimeError: [json.exception.type_error.302] type must be number, but is string
Describe the bug
A clear and concise description of what the bug is.
tensorflow :2.2.0
run node_classification_on_citation.ipynb :
config = {"class_num": 349, # output dimension
"features_num": 130, # 128 dimension + kcore + triangle count
"batch_size": 500,
"val_batch_size": 100,
"test_batch_size":100,
"categorical_attrs_desc": "",
"hidden_dim": 256,
"in_drop_rate": 0.5,
"hops_num": 2,
"neighs_num": [5, 10],
"full_graph_mode": False,
"agg_type": "gcn", # mean, sum
"learning_algo": "adam",
"learning_rate": 0.0005,
"weight_decay": 0.000005,
"epoch": 20,
"node_type": "paper",
"edge_type": "cites"}
train(config, lg)
AttributeError Traceback (most recent call last)
in
18 "edge_type": "cites"}
19
---> 20 train(config, lg)
in train(config, graph)
27 config["learning_algo"],
28 config["learning_rate"],
---> 29 config["weight_decay"]))
30 trainer.train_and_evaluate()
~/anaconda3/envs/graphscope/lib/python3.7/site-packages/graphscope/learning/graphlearn/python/model/tf/trainer.py in init(self, model_func, epoch, optimizer)
161 epoch,
162 optimizer)
--> 163 self.model = self._model_func()
164
165 def init(self, **kwargs):
in model_fn()
21 node_type=config["node_type"],
22 edge_type=config["edge_type"],
---> 23 full_graph_mode=config["full_graph_mode"])
24 trainer = LocalTFTrainer(model_fn,
25 epoch=config["epoch"],
~/anaconda3/envs/graphscope/lib/python3.7/site-packages/graphscope/learning/examples/tf/gcn/gcn.py in init(self, graph, output_dim, features_num, batch_size, val_batch_size, test_batch_size, categorical_attrs_desc, hidden_dim, in_drop_rate, hops_num, neighs_num, full_graph_mode, node_type, edge_type)
88 self.src_ego_spec = gl.EgoSpec(src_spec, hops_spec=[hop_spec] * self.hops_num)
89 # encoders.
---> 90 self.encoders = self._encoders()
91
92 def _sample_seed(self):
~/anaconda3/envs/graphscope/lib/python3.7/site-packages/graphscope/learning/examples/tf/gcn/gcn.py in _encoders(self)
128
129 depth = self.hops_num
--> 130 feature_encoders = [gl.encoders.IdentityEncoder()] * (depth + 1)
131 conv_layers = []
132 for i in range(depth):
AttributeError: module 'graphlearn' has no attribute 'encoders'
Environment (please complete the following information):
Additional context
Add any other context about the problem here.
Is your feature request related to a problem? Please describe.
We have Graph.project_to_simple which select an edge + a vertice and a property to project a property fragment as a simple fragment. But we cannot obtain a subset of the original graph as a new property graph. The implementation should be straightforward.
Describe the solution you'd like
Implements Graph.project(elabels: Map[string, List[string]], vlabels: Map[string, List[string]]) -> Graph.
session.g() to return a Graph.remove related syntax and docs.project and project_to_simpleadd_column works by checking individual vertex label's signature, not by graph object id.Provisioning k8s cluster on amazon and aliyun, with configurations like accessId and accessSecrets.
Is your feature request related to a problem? Please describe.
Vineyard can be install using helm:
helm repo add vineyard https://dl.bintray.com/libvineyard/charts/
helm install vineyard vineyard/vineyard
GraphScope should depend on a publicly available vineyard distribution.
Is your feature request related to a problem? Please describe.
Describe the solution you'd like
Describe alternatives you've considered
A clear and concise description of any alternative solutions or features you've considered.
Additional context
Add any other context or screenshots about the feature request here.
Hi,
I'm puzzled at how can I launch the GraphScope's k8s ,just after using the prepare_env.sh shell to pull all the needed docker images like graphscope, zookeeper, etcd...then how can i launch and arrange the pods,is it should be launched and be set manually separately?? which means , I should start the GraphScope as a pod firstly , and then start the etcd or zookeeper as another pod ...?
Or, are these works all done by the graphscope's Session?
Is your feature request related to a problem? Please describe.
Add more rich types to ArrowPropertyFragment.
Describe alternatives you've considered
Marshal as a fixed-size binary type.
Additional context
For applications like GNN training, split a tensor to a set of arrays is bad for user side API as well as for performance.
Is your feature request related to a problem? Please describe.
The logs is still doesn't every helpful when error occurs. Could we print something like (when show_logs=True):
Launching coordinator...
Coordinator service is ready.
Launching graphscope engines... (or, `Waiting graphscope engines....`)
Graphscope engines are ready.
I mean, we should let user know what we are doing or waiting for, in a detailed manner, when show_logs is True.
Additional context
I just think log in comments #3 (comment) is quite confusing. The word "ready" combined with no extra logs deliver a sense of "we are ready", but actually things are not ready, and users are confused about what they are waiting for and why it doesn't return or raise.
Is your feature request related to a problem? Please describe.
For support jupyterhub.
We can get current namespace from the k8s context (such as ~/.kube/config) when missing k8s_namespace params, rather than create a new namespace with random str (gs-djdjch). So, we also can limit resources for the namespace.
Describe the bug
Set k8s_etcd_mem to a customed number in graphscope.session() doesn't take effect.
To Reproduce
Steps to reproduce the behavior:
run sess = graphscope.session(k8s_etcd_mem='512Mi').
describe the pod you will see the limits is still 128Mi.
Expected behavior
The etcd pod's memory limit set to 512Mi.
Environment (please complete the following information):
Is your feature request related to a problem? Please describe.
Graph visualization is an essential part for a graph computing platform.
As the first step, we may want a module to visualize the graph data.
Describe the solution you'd like
/python/jupyterdraw functions are invoked.draw APIs:# assume the g is a Graph in GraphScope.
# draw the whole graph. (maybe cascaded if the graph is huge.)
g.draw()
# draw selected vertices and their induced subgraph
g.draw(vertices=[1,2,3,4])
# draw induced subgraph with hop extension
g.draw(vertices=[1, 2 ,3, 4], hop=2)
# draw a subgraph with selected labels.
g.draw(vlabel=“students”, elabel=“friends”)
# draw the graph with captions
# label.e, label.v, label
# id.e, id.v, id
# prop.XXX
# e.g.,
g.draw(caption=“label:e”)
g.draw(caption="prop.name")
# pass the args with a dict.
g.draw(config=Dict())Describe alternatives you've considered
A clear and concise description of any alternative solutions or features you've considered.
Additional context
Add any other context or screenshots about the feature request here.
Describe the bug
The "persist" happens in the Seal operation of GlobalPGStreamBuilder, which is unnecessary, and might be wrong.
Additional context
N/A
Add Chinese documentation to better serve Chinese-speaking users
Currently the help of module itself does not produce very useful information. I think it is a good idea to improve the doc there, following the example of pandas for example
>>> help(graphscope)
Help on package graphscope:
NAME
graphscope
DESCRIPTION
# -*- coding: utf-8 -*-
#
# Copyright 2020 Alibaba Group Holding Limited. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
PACKAGE CONTENTS
analytical (package)
client (package)
config
dataset (package)
deploy (package)
experimental (package)
framework (package)
interactive (package)
learning (package)
proto (package)
version
DATA
Vertex = Vertex
VERSION
0.1.1
FILE
/opt/conda/lib/python3.8/site-packages/graphscope/__init__.py
Add authentication and encryption to make it ready for production use.
GraphScope differs from many existing graph systems. I think it is a good idea to have a FAQ section in the docs to help users quickly getting started.
Ref: #16
Is your feature request related to a problem? Please describe.
Currently the "Prerequisites" section in README is a bit confusion, e.g., do we advertise that kind is OK as well for Mac? AFAIK we haven't test it yet.
And the codepath for minikube to get the service endpoint on Mac, as well as the k8s_minikube_vm_driver parameter in graphscope.session is a bit hacky.
Describe the solution you'd like
If kind works better we could deprecate the support for minikube and use kind everywhere in our codebase and documentation.
Additional context
N/A
We provided the details about how we conduct the experiments of benchmarking on:
In addition, to help users reproduce the results easier, we are going to provide a snapshot on aliyun, with GraphScope installed and a script to run the benchmark suite.
Is your feature request related to a problem? Please describe.
mars is a distributed tensor-based computation engine. The intermediate data/results of GraphScope in the format of dataframe should be enabled to process in mars, as a part of the workflow pipeline.
Describe the bug
GraphScope will raise if the existing protobuf package version is too low:
AttributeError: module 'google.protobuf.descriptor' has no attribute '_internal_create_key'
That is because we didn't specify the version range of protobuf in requirements.txt. That is bad when raising during import graphscope, and without a clear error message to tell the users how to fix that.
Expected behavior
Declare which version that we could accept in requirements.txt.
Additional context
N/A.
Describe the bug
./scripts/prepare_env.sh
During running this script will delete my existing docker instance, without warning or checking if docker exists.
Really confused.
Is your feature request related to a problem? Please describe.
Support serialize/deserialize a graph loaded in a session, for fast loading in the future.
Describe the solution you'd like
functions in the python to support serialize/deserialize graph. e.g.,
g1 =sess.load_from(HUGE_CONFIG)
g1.serialize("hdfs://LOCATION")
sess.close()
# next time to analysis the same graph maybe a few days later.
g2 = another_sess.deserialize_from("hdfs://LOCATION")This may save huge time, because:
Describe alternatives you've considered
A clear and concise description of any alternative solutions or features you've considered.
Additional context
Add any other context or screenshots about the feature request here.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.