anshiii / blog Goto Github PK
View Code? Open in Web Editor NEWblog
blog







")
ECMAScript 2015 中引入的 JavaScript 类实质上是 JavaScript 现有的基于原型的继承的语法糖。类语法不会为JavaScript引入新的面向对象的继承模型。
我们知道 js 并没有类的概念,所谓的类是在原型链的基础之上。例如我们通常所使用的 function 实际上是继承于 Function 类的对象。
function fool(a, b) {
return a + b
}
var fool = new Function("a, b", "return a+b");两者所做的事情是相同的,函数 fool 其实是 Function 的一个实例,也就是说 fool.__proto__ === Function.prototype的返回值是 true。
于是问题来了,Function 的构造函数是如何生成的呢?
同时我们知道 Function 并不是这一条原型链的终点,Function 是继承于 Object 的。
那么问题又来了 Object 的构造函数是如何生成的呢?
ECMA中关于 Object 的构造函数是这么描述的:
是内置对象 %Object%,同样的 Function 的 constructor 也是内置对象 %Function%,事实上这个问题也不重要。我们只需要知道 这两个 constructor 都不是 Function 的实例即可。
有对象的概念,就会有子类的概念。在 ES2015 中,新增了 关键字 extends。
class ChildClass extends ParentClass { ... }我们只知道 extends 的作用相当于从 ChildClass 的原型链上可以获取 ParentClass 的原型对象,但是具体做了什么事情呢?
首先我们要明白,如何创建子类。
核心内容: B的实例继承自B.prototype,后者同样也要继承自A.prototype。
我们知道 B.prototype 和 A.prototype 究其根本 都是 对象(Object),那对象的继承概念是什么?
于是我们自然而然的写下两行代码,
B.prototype = new A();
B.prototype.constructor = B;此时我们开始起草我们的 继承方法 inherit。
function inherit(SuperClass, ChildClass) {
ChildClass.prototype = new SuperClass();
ChildClass.prototype.constructor = ChildClass;
return ChildClass
}我们再看看 babel 里对 extends 的实现:
function _inherits(subClass, superClass) {
if (typeof superClass !== "function" && superClass !== null) {
throw new TypeError("Super expression must either be null or a function, not " + typeof superClass);
}
subClass.prototype = Object.create(superClass && superClass.prototype, {
constructor: {
value: subClass,
enumerable: false,
writable: true,
configurable: true
}
});
if (superClass) Object.setPrototypeOf ? Object.setPrototypeOf(subClass, superClass)
:
subClass.__proto__ = superClass;
}这里使用了Object.create方法。
这里其实和以下代码类似,只不过回避了对父类构造函数的调用(父类构造函数内如果有生成实例属性的话,也将在原型链继承了)不至于产生多余的属性。
let obj = new superClass();
obj.constructor = subClass
subClass.prototype = obj如果要在继承时回避对父类构造函数的调用又不使用 Object.create 方法,可以使用过桥函数,如下代码。
function inherit2(SuperClass, ChildClass) {
function F() {
}
F.prototype = SuperClass.prototype;
ChildClass.prototype = new F();
ChildClass.prototype.constructor = ChildClass;
return ChildClass;
}总结: 其实构造函数的 prototype 就是个普通的对象,只不过他具有特殊意义,同时这个对象 有个 constructor 属性(不是必须的),这个属性指向构造函数本身。
对象的
__proto__属性是 非标准 但许多浏览器实现了的用于访问对象原型的属性,现在可以通过Object.getPrototypeOf()和Object.setPrototypeOf()访问器来访问。
设备①PIxel 2XL 2017年发布
设备②Redmi K50 Ultra 2022年发布
云设备③iPhone 6 2014年发布
设备④MacBook Pro 2023 14inch 2023年发售
unit: ms
| 设备编号 | 平台 | 单Key读取A2 | 多Key读取B2 | 单Key写入A1 | 多Key写入B1 |
|---|---|---|---|---|---|
| 设备① | chrome | 351.63 | 186.27 | 803.97 | 1896.62 |
| 设备② | chrome | 157.15 | 117.33 | 428.224 | 416.44 |
| 设备③ | safari | 599.50 | 661.60 | 3613.80 | 1380.90 |
| 设备④ | chrome | 35.62 | 22.53 | 86.23 | 151.44 |
| 设备④ | safari | 36.98 | 43.72 | 150.50 | 119.82 |
假设1 在低端设备读写 50MB 数据的耗时会大于1秒。
结论:部分正确:在读取数据时,即使是 设备③ ,B2为 661.60 ms,小于 1 秒;但是写入数据时 设备①采用多 key 写入,以及 设备③ 任意方式写入都会大于 1 秒,其中设备③的 A1 值为 3613.80,远大于 1 秒。
假设2 从多个 Key 读取总量 50MB 的数据比从单个 Key 读取总量 50MB 的数据所花费的时间更少。
结论:与平台有关,在 chrome 平台,多 Key 读取速度更快;在 safari 平台,单 key 读取速度更快;
建议:有 redux 的实践后再来看相关的文章。你需要先知道 redux 能让你做什么,才会激起对源码的欲望。
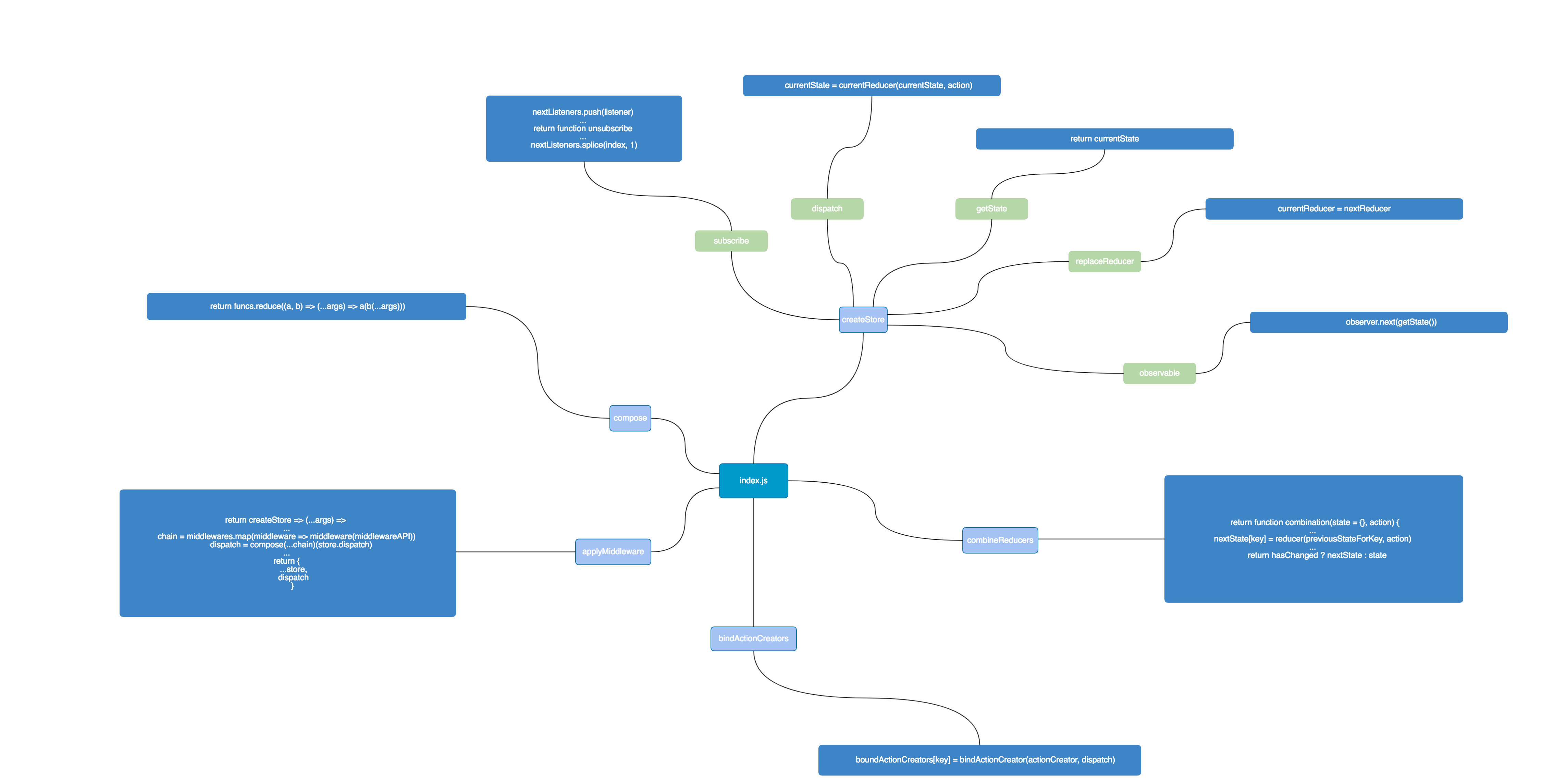
redux 的源码内容并不多,可以说很少,相比 koa.js 会多一点 (笑)。源码结构如下图:
index.js入口文件主要做了两件事,
判断生成环境的条件如下;
if (
process.env.NODE_ENV !== 'production' &&
typeof isCrushed.name === 'string' &&
isCrushed.name !== 'isCrushed'
)process.env.NODE_ENV可能大家都见过但是没有深究,浏览器下是没有 process 这个变量的,只有 node 环境才有, process.env 返回一个包含运行环境参数的对象,但是我没有在文档内看到对 NODE_ENV 这个变量有任何的提及...然后我稍微搜索了一下,这个变量似乎是因为 express 而流行起来的,常见的值有 development, staging, production, testing。
至于在哪里设置,相信朋友们常在 package.json 看见有 script 带着 NODE_ENV=sth这样的参数吧,例如redux源码的打包脚本之一。
"build:commonjs": "cross-env NODE_ENV=cjs rollup -c -o lib/redux.js",
我们看第二个条件
typeof isCrushed.name === 'string'
isCrushed是一个空函数,官方也有注释,这里声明这个函数就是为了判断函数名是否被压缩,如果被压缩化了且 NODE_ENV 的值不是 production,那就警告用户。
createStore.js读源码之前我们再次熟悉这个 api 用于处理什么事务。回顾一下使用 createStore的地方,
let store = Redux.createStore(aReducer,initState);
emm,接受 reducer 函数 和 一个初始的 state对象作为参数,返回一个 store 对象。回顾一下 reducer 和 state的关系,大概知道 reducer 会对 preState 做一些改动,然后返回 newState,那么肯定会有类似 newState = reducer(preState)这样代码的实现。
我们看看源码:
export default function createStore(reducer, preloadedState, enhancer) {
...
第三个参数 enhancer 官方有注释,这是用于拓展 store 的参数,并不是必须的。有什么作用呢?
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState)
}
嗯,可以预计 enhancer 内部应该是长这样的,最终返回值估计也是 store 对象。
function enhancer (createStore) {
...
return function (reducer,preloadedState){
...
}
}
那没有 enhancer 是如何走下来的呢?
返回的对象就是反复提到的 store了,其中的 $$observable 是?
import $$observable from 'symbol-observable'
姑且先认为这就是一个普通的 symbol 类型的变量吧。
我们以返回对象的key的陈列顺序翻看对应的函数,
dispatchredux 约定改变 state 的操作只能是 dispatch 一个 action,而 reducer 是改变 state 的直接函数,可以预计,这个函数内应该还有 state = reducer(action) 之类的操作。源码注释说道,为了方便,dispatch 将返回参数 action,但是这可能被一些第三方中间件所更改。进入函数后,首当其冲的就是两个判断,符合判断条件就抛出异常。
if (!isPlainObject(action)) {
...
if (typeof action.type === 'undefined') {
...
第二个判断用意很明显,action 是一个必须带有 type 属性的对象。isPlainObject的函数内部如下
export default function isPlainObject(obj) {
if (typeof obj !== 'object' || obj === null) return false
let proto = obj
while (Object.getPrototypeOf(proto) !== null) {
proto = Object.getPrototypeOf(proto)
}
return Object.getPrototypeOf(obj) === proto
}
typeof 的值为 object 的类型有 数组,对象和 null;getPrototypeOf顾名思义是获取对象的原型,while循环下 proto 的值是 obj 的顶级原型,函数最终返回值Object.getPrototypeOf(obj) === proto即 obj 的上一级原型和顶级原型的是否相等的布尔值。我们知道 JS 万物皆对象(误),数组的上一级原型是 Array,再上一级才是 Object,也就是说存在多级原型链的对象都会返回 false,比如 Promise。只有家事清白的 obj 才能返回 true。(笑)
再往下是一把锁 if (isDispatching) ,变量是声明在当前函数外createStore 函数内的局部变量(下 currentState,currentReducer 同),默认值为 false,这是场景的锁的设置方式,因为不允许异步操作,逻辑也变得很简单(不禁令人在意如果是异步该如何加锁)。
接着就是 dispatch 主要内容了,这里不赘述了,用意明显。
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
再之后是调用监听器,返回参数 action。dispacth的逻辑的到此结束了。
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
subscribe

slice用于获取数组指定区间的浅拷贝,这里没有参数,就是整个数组的一份浅拷贝。这里的用意应该是 subscribe 的调用必定会引起 nextListeners 的变化,但是 push 方法不会改变原来变量的内存地址,所以需要手动的 new 一块新的内存来存放变化后的 nextListeners。
卸载监听器的逻辑也比较简单,逻辑也与外部函数类似,就不赘述了,值得注意的是这里是 splice 不是 slice,前者是直接在调用对象上操作的。
注:这里的 isSubscribed 是 subscribe 内生命的变量,初始值为 true。
getState
此函数名如其码不过多赘述。
replaceReducer
注释直译:用于替换当前 store 计算 state 所使用的reducer。这是一个高级 API。只有在你需要实现代码分隔,而且需要动态加载一些 reducer 的时候才可能会用到它。在实现 Redux 热加载机制的时候也可能会用到。
ActionTypes 是其他模块导入的对象,代码如下,是不是觉得摸不着头脑,可以看看这个。
const ActionTypes = {
INIT:
'@@redux/INIT' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.'),
REPLACE:
'@@redux/REPLACE' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
}
observable{subscribe:fun,[$$observable]:fun},function observable() {
//subscribe 是之前提到的函数之一
const outerSubscribe = subscribe
return {
subscribe(observer) {
if (typeof observer !== 'object') {
throw new TypeError('Expected the observer to be an object.')
}
function observeState() {
if (observer.next) {
observer.next(getState())
}
}
observeState()
//这里的 outerSubscribe 就是之前提到的 subscribe,该函数执行返回的是卸载订阅器的函数,并赋给了 unsubscribe
const unsubscribe = outerSubscribe(observeState)
return { unsubscribe }
},
[$$observable]() {
return this
}
}
}
这一块还并不能明白有何用意, observer.next 类似于 node 中的 event.emit,当然并不是完全一样,此处如果调用 observable 内返回的 subscribe,就订阅了 state 树的变化事件,你调用 subscribe 时使用的参数,可以做一些对应的操作。
到此, createStore.js 的源码到此就结束了。
然而并没有...,在返回对象之前,函数内部还立即分发了一个 action,这个actionTypes 有在上文出现过,就不赘述了。
---end ಠ౪ಠ
在页面加载前后如果连续多次调用原生的方法,会遇到回调参数未被调用的情况。
// 多次调用如下函数, 部分 callback 将不会被调用
window.WebViewJavascriptBridge.callHandler(api, parameter, callback);在页面加载时通过jsBridge和原生进行10次以上的数据交换。
在多篇文章(1,2)中看到是因为 jsBridge 使用 iframe 的 src 变化 和 shouldOverrideUrlLoading 来实现原生与js的沟通导致的问题,而刷新 iframe 并不能保证 shouldOverrideUrlLoading 会被调用。
于是我们以此为假设进行验证
验证1: jsBridge 是否使用 iframe.src 的变化来进行js与原生的通讯
我们可以直接看看进行一次完整的通讯的调用过程。
//依据调用链
window.WebViewJavascriptBridge.callHandler(api, parameter, callback);
function callHandler(handlerName, data, responseCallback) {
_doSend(
{
handlerName: handlerName,
data: data
},
responseCallback
);
}
function _doSend(message, responseCallback) {
if (responseCallback) {
var callbackId = "cb_" + uniqueId++ + "_" + new Date().getTime();
responseCallbacks[callbackId] = responseCallback;
message.callbackId = callbackId;
}
sendMessageQueue.push(message);
//改变html内的iframe的src
messagingIframe.src = CUSTOM_PROTOCOL_SCHEME + "://" + QUEUE_HAS_MESSAGE;
}
// 此时步骤转到原生层面// shouldOverrideUrlLoading 将在 iframe.src 改变时被调用
public boolean shouldOverrideUrlLoading(WebView view, String urlString) {
super.shouldOverrideUrlLoading(view, urlString);
if (PhoneUtil.INSTANCE.startTelActivity(getActivity(), urlString)) return true;
if (mWebViewHelper.shouldOverrideUrlLoading(view, urlString)) return true;
return false;
}
//父类的 shouldOverrideUrlLoading
public boolean shouldOverrideUrlLoading(WebView view, String url) {
try {
url = URLDecoder.decode(url, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 根据 url 的内容,区分是哪种类型的操作
// 事实上 只有 YY_RETURN_DATA 和 YY_OVERRIDE_SCHEMA 两种
// YY_RETURN_DATA 根据 url 的 参数,返回数据,即原生备好数据后调用 js 原生方法(js 的回调函数)
// YY_OVERRIDE_SCHEMA 则注入脚本到 webview 调用 js 原生方法 _fetchQueue
if (url.startsWith(BridgeUtil.YY_RETURN_DATA)) {
webView.handlerReturnData(url);
return true;
} else if (url.startsWith(BridgeUtil.YY_OVERRIDE_SCHEMA)) { //
webView.flushMessageQueue();
return true;
} else {
return super.shouldOverrideUrlLoading(view, url);
}
}
//通讯结束 // YY_OVERRIDE_SCHEMA 类型通讯所调用的原生方法
function _fetchQueue() {
var messageQueueString = JSON.stringify(sendMessageQueue);
console.warn(++count, "-", messageQueueString);
sendMessageQueue = [];
//android can't read directly the return data,
//so we can reload iframe src to communicate with java
messagingIframe.src =
CUSTOM_PROTOCOL_SCHEME +
"://return/_fetchQueue/" +
encodeURIComponent(messageQueueString);
}从源码可以看出,一个完整的通讯过程,将改变两次 src,也就是说 shouldOverrideUrlLoading 会被调用两次(预计)。@q说来 jsBridge 设计也奇怪,为什么不设计成一次 src,完成一次通讯。
验证1证实完毕。
验证2:iframe 改变 src 是否与 shouldOverrideUrlLoading 调用次数一致。
我在 WebViewJavascriptBridge.js 中对 ifram.src 的变化 和 BasewebviewFragment.java 的 shouldOverrideUrlLoading 调用进行计数,发现两边的次数确实不一致。
| 通讯状态 | iframe 的 src 改变次数 | shouldOverrideUrlLoading 被调用次数 |
|---|---|---|
| 预计 | 18 | 18 |
| T | 13 | 9 |
| T | 17 | 14 |
| T | 13 | 6 |
| F | 17 | 18 |
| F | 6 | 3 |
| T | 11 | 8 |
验证2 证实完毕。
同时我们也得知,就算二者调用次数不一致,也不影响 js 与 native 的通讯,几次通讯成功的情况二者的次数都不一致,甚至我们可以初步预测,二者的次数根本不需要一致就能实现通讯。
@q 那么通讯成功的充分必要条件是什么呢?
回顾我们之前所做的验证1,一个完整的通讯过程,其调用时序图如下:
回顾我们最初遇到的问题,多次调用 callHandler 后,部分 callback 没有被调用,导致通讯失败。
根据流程图逆行推理, callback 未被调用 => 表示携带该callback 的 respMessage 未被传递过来,也就是说 yy://return/ ${resp} 缺失了 => _fetchQueue 传递的数据有缺失
function _fetchQueue() {
var messageQueueString = JSON.stringify(sendMessageQueue);
// ATENTION 这里在将 string 化后立即清空了当前的 messageQueue
sendMessageQueue = [];
messagingIframe.src =
CUSTOM_PROTOCOL_SCHEME +
"://return/_fetchQueue/" +
encodeURIComponent(messageQueueString);
}从 _fetchQueue 的源码中,发现在将 message 传递后就立马清空了,实际上这并不准确,因为连续N次改变 iframe 的 src ,shouldOverrideUrlLoading 的实际调用次数为 M(M<N),且将后一次调用时的参数为准。
上述图示是一次失败通讯的日志,可以看到,前6次调用为 _doSend 的调用,即改变了 6次 iframe 的 src,但实际上只有两次生效了,第一次生效的通讯调用了 _fetchQueue ,传递前 6 次的 message 给 native,但是由于清空了 message 队列,紧跟的第二次 _fetchQueue 执行时传递空数组给 native ,又因为两次 _fetchQueue 的调用间隔太短,实际上只有第二次 _fetchQueue 的调用传递给了 native ,此时 native 只收到一个 空数组的 通讯,自然没有了后续的操作。
所以我们最初 callHandler 里的 callback,都没人再调用了...
原因已经明了,当前的问题是如何解决。切入点有以下几个,
鉴于1的实施难度对我这个切图仔来说有点大,优先考虑后续两个解决方法。
function _fetchQueue() {
if (sendMessageQueue.length === 0 || fetchingQueueLength > 0) {
return;
}
// 记录当前等待 native 响应的个数
fetchingQueueLength += sendMessageQueue.length;
var messageQueueString = JSON.stringify(sendMessageQueue);
sendMessageQueue = [];
//android can't read directly the return data, so we can reload iframe src to communicate with java
bizMessagingIframe.src = CUSTOM_PROTOCOL_SCHEME + '://return/_fetchQueue/' + encodeURIComponent(messageQueueString);
}
/* ... */
function _dispatchMessageFromNative(messageJSON) {
setTimeout(function() {
var message = JSON.parse(messageJSON);
fetchingQueueLength--;
// 如果通讯完毕,清理被阻塞的 message
if (fetchingQueueLength === 0) {
// 使用 sto,在当前的通讯结束后再 _fetchQueue
setTimeout(function() {
_fetchQueue();
});
}
...以私有变量 fetchingQueueLength 记录等待响应的 message 数量,但是存在队首阻塞的问题,甚至因为没保证所以没采用。
既然是因为 _fetchQueue 调用间隔太短,所以就采用了切图仔常用的节流方案。
var lastCallTime = 0;
var stoId = null;
var FETCH_QUEUE = 20;
function _fetchQueue() {
// 空数组直接返回
if (sendMessageQueue.length === 0) {
return;
}
if (new Date().getTime() - lastCallTime < FETCH_QUEUE) {
if (!stoId) {
stoId = setTimeout(_fetchQueue, FETCH_QUEUE);
}
return;
}
lastCallTime = new Date().getTime();
stoId = null;
var messageQueueString = JSON.stringify(sendMessageQueue);
sendMessageQueue = [];
//android can't read directly the return data, so we can reload iframe src to communicate with java
bizMessagingIframe.src = CUSTOM_PROTOCOL_SCHEME + '://return/_fetchQueue/' + encodeURIComponent(messageQueueString);
}这个 20 ms,其实我是有些随意的定义的,从 200 开始向下试验,20 是我觉得比较稳定一个数字… 。20 ms 内连续的调用 _fetchQueue 将只有一次生效,回顾之前通讯流程的同学应该知道 _fetchQueue 的触发是依靠 native 的调用的,所以 _fetchQueue 的触发对 _doSend 来说是异步的,所以并不需要一一对应,_doSend 只是往 sendMessageQueue 里添加任务,而 _fetchQueue 只负责将 sendMessageQueue 里的任务清空,只要保证至少有一个 _fetchQueue 晚于 _doSend 执行即可。
但是这里改动 WebViewJavascriptBridge.js 是需要重新发包的。
这个其实有点难处理,因为是在 js 层面,这里解决的点仍然是 2. 中的 _fetchQueue 调用频繁的问题,从这个角度切入有点隔山打牛的意味。但是因为改动只在页面,不依赖原生发包,所以在某些场景也适用。
这里的**类似,封装 callHandler 函数,节流或者串行均可,当然串行就会有阻塞的可能,节流,这里的节流是想让 _fetchQueue 的调用节流,但是 _fetchQueue 的触发毕竟是异步,而且掌控在原生代码那边,所有其实不太推荐适用这个方案。
纵观整个通讯过程,其实就是一个网络协议的缩影。最开始考虑部分通讯失败的问题时,想的这是不是就是网络里的丢包,想想 TCP 怎么解决丢包的,好像是记录字节序 + 定时器,但是这里响应体只包含通讯内容,光是标记请求就有点麻烦了,再加上定时器...如果要改就是大重构了…算了;后来开始针对 _fetchQueue ,要不就考虑学 HTTP 一来一回吧,但是这样效率太低了,js 单线程也没有并发,而且还有队首阻塞的问题… 后来转而一想,既然 fetchQueue 间隔短,那我控制间隔不就好了吗…于是引入了节流的方案… 变动小代码简单易懂…虽然这个 20ms 不太具有事实依据性。
总的来说解决问题并不难,难得是找到问题的核心,为了这个我甚至找了原生开发小哥 copy 一份源码…,好在之前有过 RN 调试经验… 不至于卡在配置 android studio 上….当然我的方案不是最好的,如果你有更好的方案,欢迎留言。
建议:有 redux 的实践后再来看相关的文章。你需要先知道 redux 能让你做什么,才会激起对源码的欲望。
redux 的源码内容并不多,可以说很少,相比 koa.js 会多一点 (笑)。源码结构如下图:
combineReducers的大致结构如下
回忆我们使用 combineReducers 的时候
//a.reducer
const aR = function(state = initialState, action) {
switch (action.type) {
case ...
default:
return state;
}
}
//b.reducer
const bR = function(state = initialState, action) {
switch (action.type) {
case ...
default:
return state;
}
}
export default combineReducers({aR,bR});
对应到源码,就不难理解使用时的一些“要求”。(比如 接受的参数对象 的 key 要与对应的 state 对应。)
代码先对 参数 reducers 进行一次遍历查空,值非空且为 function 的键值对组成最终的 recuder。题外话:现在遍历对象还是得靠 Object.keys 吗?
//assertReducerShape
const reducerKeys = Object.keys(reducers)
const finalReducers = {}
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
按部就班下来,finalReducers 就是我们刚才得到的新对象,去往 assertReducerShape 内部,可以发现该函数内并没有做影响外部的事情,也没有返回值,该函数的用意应该是试探性的运行当前的 reducer,确定 reducer 被调用后没有返回 undefined ..而且还进行了两次判断...@todo 暂时还未明白为何要两次判断
let shapeAssertionError
try {
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
combineReducers 的返回值仍然是函数,毕竟我们只是将多个 reducer 函数合并成一个函数;核心逻辑代码如下,可以看出 进入 combineReducers 的 reducers 的 key 是需要和 state 下对应 key 一致的;赋值给 nextState 前还需要判断非 undefined ,同时只要任一的 reducer 改变了 state,hasChanged 的值都为true,都将返回新的 state。
let hasChanged = false
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
return hasChanged ? nextState : state
其实核心逻辑的代码量可能还不如判空,判 undefined ,输出警告等行为的代码量,但是一个优秀的插件,对不合理的值应该有合适的处理而不是等着运行环境给我们报错,这是很多新手前端(比如我)会忽视的内容,日常可能还得靠各种报错一点点累计经验...以至于不会重视报错,认为有错改一下就好了。
这个函数我们经常用...但你可能并不太了解他的作用:
const mapStateToProps = state => {
return {
stateKey: state.stateKey
};
};
const mapDispatchToProps = dispatch =>
bindActionCreators(
{
oneAction
},
dispatch
);
export default connect(mapStateToProps, mapDispatchToProps)(Component);以前的认知就是执行了这些,就可以在组件下直接 this.props.oneActionCreator(actionParam)来发起一个 action,而不是 this.store.dispatch(oneActionCreator(actionParam))。
我们先从源码的返回值 开始看,如下图。
函数返回 boundActionCreators 我们再追溯的看这个变量如何赋值的。
const boundActionCreators = {}
for (let i = 0; i < keys.length; i++) {
const key = keys[i]
const actionCreator = actionCreators[key]
if (typeof actionCreator === 'function') {
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
可以大致得知,函数主要做了这样的操作。
那关键步骤就是bindActionCreator 了,而其也十分简单...
function bindActionCreator(actionCreator, dispatch) {
return function() {
return dispatch(actionCreator.apply(this, arguments))
}
}
朋友们还记得 dispatch 做了什么吗~ 分发action!没错,bindActionCreator直接帮你在创建 action 时 dispatch 这个 action。
综述,bindActionCreators.js 的处理过程如下图。
可是这里为什么要使用 apply 呢?为什么不直接 return dispatch(actionCreator(arguments)) ?我们知道以函数形式调用的函数的 this 的值是全局对象 ( javascript 权威指南第八章),使用 apply 后间接等于方法调用,这里形如 this. actionCreator(arguments),方法形式调用的函数其上下文 (this) 为调用的对象。所以这里的 this 是打算将调用 bindActionCreator 内部函数的上下文传递给 actionCreator 使用。
该模块返回函数 applyMiddleware ,参数 ...middlewares 类似于用 arguments 来接受一系列参数。函数内部返回值仍然是函数。注意 返回的值 是用于 createStore 的第三个参数 enhancer。
return createStore => (...args) => {
const store = createStore(...args)
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
箭头函数真的不太适合阅读...(可能是我不太习惯)
return function (createStore) {
return function (...args) {
const store = createStore(...args)
...
}
}
符合 enhancer 在 createStore 的逻辑enhancer(createStore)(reducer, preloadedState)
观察函数的返回值,可以得知函数内部只改动了 dispatch 方法,再看源码。
dispatch = compose(...chain)(store.dispatch)
compose 方法是另一个文件导入的,源码也不多,比较关键的一句是 return funcs.reduce((a, b) => (...args) => a(b(...args))),但是这一句让不熟悉函数式编程的我思考了很久......
compose(...chain),输出这一句的执行结果
function (...args){
return a( b(...args) )
}
看起来只是个普通的函数,只是这里的 a ,b 是谁呢?ಥ_ಥ
我们知道 reduce 返回值是最后一次累加计算的结果,compose(...chain) 的返回值仍然是个函数,函数内的 a 就是上一次累加返回的结果,b 是当前项,也就是 chain 的最后一项;上一次累加结果仍然是 这个普通的函数,只不是此时的 b 是 chain 的倒数第二项,a 是再上一次的累加返回结果...
dispatch = compose(...chain)(store.dispatch)
此时再看这一句,其实就是:先以参数,运行了 chain 的最后一项函数,返回值做为参数被 a 调用,a是上一次的返回值,再次跳回 2 行,此时的 b 是 chain 的倒数第二项...以此类推,到chain 的第二项时(reduce 没有 设置初始值时,accumulator 的默认值为调用数组的第一项,同时从第二项开始累加计算),以 chain 第三项运行的返回值做为参数,调用 第二项,其后的返回值,做为参数 调用 chain 的第一项,然后 执行 3行,再次跳回3 行 ... 返回值 赋给 dispatch。
// funcs 是该函数的参数数组。
return funcs.reduce((a, b) => (...args) => a(b(...args)))
//可以转换成
0 return funcs.reduce( function (a,b) {
1 return function (...args){
2 return a( b(...args) )
3 }
4 })
总结下来就是...
假设数组 chain 是 [ fun1, fun2, fun3],相当于最后以
fun1(fun2(fun3(store.dispatch)))这样的形式调用了。
写到这里时我并不是十分了解中间件的作用,不过从此处的代码可以推断,中间件需要接受一个形如 middlewareAPI 的参数,且返回值仍然是函数,返回值很有可能仍然是 store.dispatch...
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
也就是说中间件主要对 store.dispatch 进行一些改造,同时也拿了 getState 方法做一些事情。
此时在看 applyMiddleware 的用法,至少不会觉得茫然吧...(大概 ಠ౪ಠ)
const enhancer = applyMiddleware(
thunk,
createLogger()
);
const store = createStore(rootReducer, initialState, enhancer);
初学 redux 我觉得最困难的就是记很多名词,很多规矩,redux 规定了很多东西,让我摸不着头脑。为此我送上一份源码脉络梳理图。
最后送上一份源码脉络梳理图,画的有些粗略... 本意就是希望看到图还能回忆起各个函数大概做了些什么事情...
为了协调事件,用户交互,脚本,渲染,网络等,用户代理必须使用本节所述的事件循环。有两种事件循环:browsing contexts 和 workers。
每一个用户代理至少有一个 browsing contexts 事件循环,而一个 browsing contexts 事件循环至少有一个 browsing contexts,二者相互依存,一个 browsing contexts 总是有一个事件循环来协调其活动。 worker 事件循环也是类似的,并且 worker 进程模型管理其事件循环的生命周期。
一个事件循环有一至多个任务队列(task queues),而一个任务队列是一个有序的任务列表。
任务的算法如下:
一个事件循环有一个 当前正运行的任务(currently running task),初始值为 null。
一个事件循环也有一个 微任务执行检查点(performing a microtask checkpoint flag) ,初始值为 false,
一个事件循环有一个微任务队列。
1.在一个事件循环的一个任务队列中选出最旧(最先进队列)的任务,如果没有,则跳入 Microtasks 步骤。
2.将上一步选择的任务设置为事件循环当前正运行的任务。(flag)
3.运行选择的任务。
4.事件循环当前正运行的任务设置回 null。
5.将刚才选择的任务从任务队列中移除。
6.Microtasks 步骤:执行一个微任务(Microtasks)检查点。
7.更新渲染的内容:不同的事件循环有不同的副步骤。
8.返回第一步。
如果 检查点的值为 false,
1.令检查点的值为 true。
2.处理微任务队列:如果微任务队列为空,则跳转到 完成(Done) 步骤
3.选择队列中最旧的微任务。
4.设置事件循环的 当前运行任务 为 上一步选择的任务。
5.运行选择的任务。
6.设置事件循环的 当前运行任务 为 null。
7.从微任务队列中移除该任务,回到 处理微任务队列步骤(2)。
8.完成(Done):
9.清理索引数据库。
10.令检查点的值为 false。
规范说明有两种微任务:孤立回调微任务(solitary callback microtasks)和复合微任务(compound microtasks)。(但是规范并没指出哪些任务是微任务)
note: 执行
promise相关的 enqueuejob 会产生一个微任务。
根据以上的内容可以绘出如下 event loop 大致概念图:
此图当前的状态是正在执行任务队列1中的任务1的微任务1。
需要注意的是规范里没有明说哪些是微任务哪些属于任务,但是通常的认知如下(出处,尽管该文章也没有写明出处):
task——setTimeout、setInterval、setImmediate、I/O、UI rendering
microtask——process.nextTick、promise、Object.observe、MutationObserver
现有如下代码,思考输出的内容。
console.log('start')
setTimeout( function () {
console.log('setTimeout')
}, 0 )
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('end')首先你要知道,我们默认以上代码是以 script 标签嵌入在 html 内的,相当于 Using a resource ,也就是处理 script 标签内的代码相当于处理一个任务;当然你也可以说我给 script 的属性 async设为 true,那么之后处理该脚本时相当于回调 Callbacks,仍然是 处理一个任务。
处理该任务前的主执行栈应该是空的,如果不是空的,那应该先执行完主执行栈的内容才会去获取 event loop 内的任务;
回顾上文提到的 “事件循环的运行步骤”,先选出任务队列中最旧的任务,也就是上述的 script 脚本解析任务,设置为当前运行任务。
于是此时的 event loop 应该是这样的;
然后是 步骤3.运行选择的任务
于是我们逐行解析 script 脚本内的内容:
//进入主执行栈
console.log('start')
//做为 task 进入到 event loop
setTimeout( function () {
console.log('setTimeout')
}, 0 )
//做为 microtask 进入到 event loop
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
//进入主执行栈
console.log('end')解释完毕后,步骤4.设置当前运行任务为 null、5.将刚才选择的任务从任务队列中移除。
此时的事件循环如下(这里的微任务列表的 promise 可以理解为执行一次微任务解一层异步...):
接着步骤 6.执行一个微任务(Microtasks)检查点 >>> 去往微任务检查点步骤:
步骤1 - 5 :设置检查点的值、处理微任务队列、选择最旧的微任务、运行:
先解释队列中最旧的任务 > console.log('promise1'),然后执行下一个微任务
// 向微任务队列添加新内容
.then(function() {
console.log('promise2');
})然后 再执行下一个微任务 > console.log('promise2');
此时微任务队列已空,令微任务检查点的值为 false,回到事件循环步骤7.更新渲染的内容(如果执行的js代码中有渲染内容的变更),返回第一步,选出任务队列中最旧的任务,也就是
console.log('setTimeout'),依次往下,直至任务队列和微任务队列均为空,本次事件循环结束。
此时控制台的输出内容如下
// start
// end
// promise1
// promise2
// setTimeout那么以下代码的输出内容又是怎样的顺序?可以尝试绘制一下几个过程的 事件循环 图... 能正确得出结果就算理解了,结果我就不码了,浏览器里跑一下就知道了...
Promise.resolve().then(function promise1 () {
console.log('promise1');
})
setTimeout(function setTimeout1 (){
console.log('setTimeout1')
Promise.resolve().then(function promise2 () {
console.log('promise2');
})
}, 0)
setTimeout(function setTimeout2 (){
console.log('setTimeout2')
}, 0)参考文章:
event-loops
Philip Roberts: What the heck is the event loop anyway? | JSConf EU 2014
从event loop规范探究javaScript异步及浏览器更新渲染时机
推荐阅读:
不要混淆nodejs和浏览器中的event loop
由于 js 的传参方式有时会遇到这样的场景:
function setTime(data) {
let result = {};
result.obj = data.obj || {};
result.obj.time = Date.now();
return result
}
let data = {
title:'loooook!',
obj: {
name: 'keo',
age: '12'
}
}
let res = setTime(data);
console.log('res',res);
//res { obj: { name: 'keo', age: '12', time: 1533625350183 } }
console.log('data',data);
//data { title: 'loooook!', obj: { name: 'keo', age: '12', time: 1533625350183 } }我只是想继承参数的部分数据,并在此基础添加一些东西,但是参数 data 的源数据也被我改动了,如果之后有其他人想要从data获取数据,他可能还需要注意是否有像 setTime 这样的函数调用它。
function setTime(data) {
let result = {};
result.obj = {};
Object.assign(result.obj,data.obj)
result.obj.time = Date.now();
return result
}嗯,或者你也可以用 for...in,注意下二者的不同。
我们知道 Object.assign 只是浅拷贝,如果 data.obj 的属性值仍然有引用类型的话,那么还是会遇见同样的问题。
那要怎么办?难道要遍历data下每个属性的值?一个个复制过来?我们看看 lodash 是怎么做的
你猜的没错,的确是要深度遍历的。
在 baseClone方法内,拿到要拷贝的对象 value 后,先检查其类型,然后由对应的 handler 来处理,比如value是数组类型,则使 result 为同样长度的数据,然后对每一项都递归调用 baseClone,直到 value 是非引用类型,返回 value的值;如果是普通对象类型,则使 result 为空数组,然后拿取value的key,对每个key的赋值也是递归调用baseClone。
难道我深拷贝一个变量还要引入 lodash 这么麻烦吗 ?没有简单点的办法吗?
JSON.parse(JSON.stringify(param))嗯,可能有点不是那么酷炫,但是他确实可以满足要求,而且也无须引入其他的库。但如果它真的这么完美,为什么 lodash 不这么写呢?
的确,它的缺点还挺多的,这里取几个我觉得比较重要的:
{}是啊,毕竟JSON的两个方法本身就只是用来转换 js 内的对象为 JSON 格式的,上述几点甚至都不是缺点,是我们想借用其他方法做深拷贝时遇到的问题。
既然是问题那应该可以解决吧,比如第一条和第二条,在 stringify 时判断类型,转化成 带类型标识符的对象字符串如:Set [1,2,3,4,5],然后在parse的时候对字符串进行解析,特别的类型调用对应的构造函数... 听起来变得更麻烦了,没关系,忍忍把各个类型的处理都写了;针对第三条,抛错了?没关系,我 try catch 包起来...,什么?循环引用?
function parse (param){
return JSON.parse(JSON.stringify(param))
}
var a = {}
var b = {}
a['b'] = b
b['a'] = a
console.log(parse(a))
//TypeError: Converting circular structure to JSON at JSON.stringify如上代码, 变量a 和 b 互相引用对方,此时如果借用 JSON 的方法来进行深拷贝的话,会报循环结构转换转换 JSON 错误。这个问题怎么解决呢?我们再翻出 lodash 的源码看看...
// Check for circular references and return its corresponding clone.
stack || (stack = new Stack);
var stacked = stack.get(value);
if (stacked) {
return stacked;
}
stack.set(value, result);这里的 value 和 result 分别是是一次遍历中 要拷贝的值 和 拷贝的结果。stack 是一个用来储存每次对应的 value 和 result 的对象, stack下有一块用于储存的数组结构,该数组的每一项记录了单次遍历中的 value 和 result,后二者再次以数组的形式存储,以 value 做为下标 0 的项,result 为下标 1 的项(这里不用对象的 key-value 形式可能是因为循环引用的变量无法使用 JSON.stringify 转换成字符串,只能 toString 转成 object Object);stack 是做为参数贯穿整个遍历过程的,每次遍历时都会以当前的 value 值进行查找(这里的查找直接是判断内存地址相等),如果能在 stack 中查到到对应的结果,则直接返回记录中的result,不再继续递归。
好了,循环引用的问题我们解决了,鼓掌!但是我也放弃使用 JSON 方法了...还有没有其他直接点的方法呢?
结构化克隆算法是由HTML5规范定义的用于复制复杂JavaScript对象的算法,它通过递归输入对象来构建克隆,同时保持先前访问过的引用的映射,以避免无限遍历循环。
怎么用?
emmm... 它还不能直接使用,你得依靠一些其他的 API ,间接的使用它。
postMessage()function StructuredClone(param) {
return new Promise(function (res, rej) {
const {port1, port2} = new MessageChannel();
port2.onmessage = ev => res(ev.data);
port1.postMessage(param);
})
}
StructuredClone(objects).then(result => console.log(result))什么??还是异步的... 不,我希望能使用同步的方法使用它。
history()function structuralClone(obj) {
const oldState = history.state;
history.replaceState(obj, document.title);
const copy = history.state;
history.replaceState(oldState, document.title);
return copy;
}
const clone = structuralClone(objects);如你所见,我们要借用一下 history.replaceState 这个方法,但是我们不能改变 history 原有的状态,所以用完就要恢复原状,当无事发生过。
至少,这是个同步的方法...,如果是同步的场景可以考虑一下...
这里的测试代码是使用的 [Deep-copying in JavaScript] (https://dassur.ma/things/deep-copy/) 一文中的,并再次基础做了一些修改。
单位 μs (缪斯),计算时间的用的接口是 performance.now()结果精确到5微秒。
chrome
safari
...em...Safari浏览器在调用完 postMessage 方法后就...没有然后了...表格都没刷出来...等了 40 s 终于刷出第一栏...
注释完 postMessage 又发现不能频繁的调用 history 。
就结果而言好像看不出什么区别,可能是我的数据不好,大家可以去看看原文,有展示阅读性更好的图表,尽管没有 lodash 就是了。
回到我们最初的问题,我们只是想深拷贝一个 js 对象,如果只是一个比较"普通"的对象,用JSON的方法简单又快捷,但是如果这个对象有些“复杂”,似乎使用 lodash 的方法是比较好的选择,而且 lodash 连 Structured Clone 算法忽视的 symbol 类型 和 Function 也考虑其中,兼容性也没问题,也不会在不同的浏览器发生意外的状况...
lodash **!lol!!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

























