autonomousvision / unimatch Goto Github PK
View Code? Open in Web Editor NEW[TPAMI'23] Unifying Flow, Stereo and Depth Estimation
Home Page: https://haofeixu.github.io/unimatch/
License: MIT License
[TPAMI'23] Unifying Flow, Stereo and Depth Estimation
Home Page: https://haofeixu.github.io/unimatch/
License: MIT License
Very nice results! Is it possible to generate depth information from an image sequence which has no pose information at all?
I want to train on my custom dataset, how do I pre-processing it?
Hi guys.
Do I need to generate Intrinsic and pose files in some external software in order to use "main_depth.py" with my own images? If so, can I use colmap for that?
I am trying to evaluate the Middlebury dataset with these parameters:
main_stereo.py --eval --resume pretrained/gmstereo-scale2-regrefine3-resumeflowthings-middleburyfthighres-a82bec03.pth --val_dataset middlebury --middlebury_resolution F --padding_factor 32 --upsample_factor 4 --num_scales 2 --attn_type self_swin2d_cross_swin1d --attn_splits_list 2 8 --corr_radius_list -1 4 --prop_radius_list -1 1 --reg_refine --num_reg_refine 3
I am getting this out of memory error:
File "/hal/pytorch/unimatch/unimatch/attention.py", line 85, in single_head_split_window_attention scores = torch.matmul(q.view(b_new, -1, c), k.view(b_new, -1, c).permute(0, 2, 1) torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 14.85 GiB (GPU 0; 31.75 GiB total capacity; 23.68 GiB already allocated; 4.12 GiB free; 25.24 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
My GPU has 32GB of memory, do I need more memory or is there an error in the input parameters?
If I include the parameter "--inference_size 1024 1536", as in the demo script, I don't get the error.
Hi,
Would you be interested in incorporating unimatch into kornia library?
We have sota image matching like LoFTR and now are looking for some good optical flow & stereo method.
https://github.com/kornia/kornia
Best, Dmytro
Hi,
I am using this work to finetune on some depth images and make prediction.
However, I encountered some difficulty when trying to compute pose.txt for images. In your code, it seems that you are using colmap to get the pose.txt file for each image. I referred to colmap but couldn't figure out how to do that (issue in colmap). Could you provide some details/scripts on that?
BTW, I wonder if there will be an approach to directly predict depth from monocular images? It seems that current inference code needs consecutive images from one scene evaluate_depth.py#L338.
Thank you!
Thanks for sharing such a Nice Work!!!
I use "gmflow-scale2-regrefine6-mixdata-train320x576-4e7b215d.pth" for inferencing the optical flow. My purpose is to use the optical flow as my ground truth for single image depth estimation. However, I found that different resolution will make huge difference.
Input

resolution 1888*1015

half resolution 944*507

1/4 resolution 472*253

1/8 236*126

Does that make sense? I tried the stereo matching, but I didn't encounter the same situation. Maybe the best resolution for inferencing optical flow is as close as the training size? Or how do I get the best quality of optical flow with large resolution?
Hello
I wonder whether the min_depth and max_depth should be reversed because "min_depth" here is the inverse depth.
depth_up_pad = self.upsample_flow(depth_pad, feature0,
is_depth=True).clamp(min=min_depth, max=max_depth)
BR
Hai
Did anyone try to run UniMatch in Windows?
I modified conda_environment.yml to include more channels (conda-forge) and removed some required versions. It solved some of the problems but it still miss 18 packages which seems to be available only for other OS.
Is there an easy way around it?
ResolvePackageNotFound: (sorted =)
- _openmp_mutex=5.1
- dbus
- gmp
- gnutls=3.6.15
- gst-plugins-base=1.14.0
- ld_impl_linux-64=2.38
- libgcc-ng
- libgfortran5
- libgfortran-ng
- libgomp=11.2.0
- libidn2=2.3.2
- libstdcxx-ng
- libtasn1=4.16.0
- libunistring
- libuuid=1.41.5
- ncurses
- nettle=3.7.3
- readline=8.2
It looks looks you're resetting the hidden-state during each RAFT-based refinement step. Is this done on purpose?
Lines 317 to 322 in 0dfa361
Hello, may I ask if you can provide the sintel-gmflow-scale2-regrefine6.pth
Hello!
I am currently trying to integrate ROS system and unimatch, but the time required for stereo matching is taking more than 3 seconds and does not run as smoothly as the demo video.
My input image is 1920x1080 in size and I tried reducing the resolution, but it takes about the same amount of time.
Is there any point to increase the frame rate?
I was just wondering what script (or outside repo?) I could use to replicate the baselines in Table 1 (i.e. cost volume + conv and conv + softmax). Thanks!
Hi.
After performing inference, the obtained optical flow is an RGB image with three channels. If my objective is to utilize this RGB optical flow image for video action recognition and I need to decode it back to its original form (rescaled back to its original range) to extract motion information, could you kindly guide me on how to accomplish this?
Thank you very much!
How to generate files for depth estimation:
demo/depth-scannet/intrinsic/intrinsic_depth.txt
demo/depth-scannet/pose/*
Where are any instructions? How to do this?
How to generate files for depth estimation:
demo/depth-scannet/intrinsic/intrinsic_depth.txt
demo/depth-scannet/pose/*
Is there any instructions? Maybe Colmap?
[GMflow] I see that if stage=sintel, train_dataset = 100 * sintel_clean + 100 * sintel_final + 200 * kitti + 5 * hd1k + things. '100,200,5' , What do these coefficients mean?
According to the name of the pretrained weight, my guess is:
Is this correct?
Thanks for sharing this terrific work!
I see there's an example to generate a depth map for an image pair(not stereo), but is there example code that takes a video or full image sequence as input and outputs multiple depth maps so we can see the temporal consistency? Thanks!
Very good job! Could you provide a loss curve from a regular training session? I'm using the same model on another dataset, but the EPE is decreasing slowly.
Dear Professor:
The link "https://github.com/castacks/tartanair_tools/blob/master/download_training_zipfiles.txt" and other similar url seems not available in Tartanair project.
"wget -c https://tartanair.blob.core.windows.net/tartanair-release1/*/*/depth_left.zip" returns an Error
Warning: wildcards not supported in HTTP.
--2023-06-11 14:58:29-- https://tartanair.blob.core.windows.net/tartanair-release1/*/*/depth_left.zip
Resolving tartanair.blob.core.windows.net (tartanair.blob.core.windows.net)... 52.239.169.4
Connecting to tartanair.blob.core.windows.net (tartanair.blob.core.windows.net)|52.239.169.4|:443... connected.
HTTP request sent, awaiting response... 403 The specified account is disabled.
2023-06-11 14:58:30 ERROR 403: The specified account is disabled..
How could you solve this problem?
Hello, thanks for your excellent work! I am just a little confused about the meaning of your pre-trained model. For instance, what is the meaning of the pretrained model 'gmstereo-scale2-regrefine3-resumeflowthings-sceneflow-f724fee6.pth'? Is it trained on both the flowthings dataset and sceneflow dataset, or trained on flowthings dataset and finetune on sceneflow dataset? How about the 'gmstereo-scale2-resumeflowthings-sceneflow-48020649.pth' pretrained model? Thank you.
"Hello, while executing gmstereo_scale1_train.sh, I switched the training set to kitti15mix and used only kitti15 for the evaluation set. However, after 100,000 iterations, the results were not very good. I did not modify any parameters. Could this be the reason for the suboptimal performance? I look forward to your reply and guidance. Thank you."
Hi, thank you very much for your great work!
I'm trying to fine-train your GMstereo in my dataset.
I figured out that you don't upscale disparity during training step as is_depth=task == 'depth'.
I was expecting that disparity (which is in pixel) should be scaled according to the image resolution.
Also, I didn't find any down-scale from disparity label side.
# upsample to the original resolution for supervison at training time only
if self.training:
flow_bilinear = self.upsample_flow(flow, None, bilinear=True, upsample_factor=upsample_factor,
is_depth=task == 'depth')
flow_preds.append(flow_bilinear)
I really appreciate if you can elaborate on this!
Thanks for sharing the model and weights. It's working efficiently. Inference accuracy and speed are good. However, I want to deploy it on Jetson Orin, it's working with good accuracy, however FPS is not so good. So I want to optimize the pretraineed model with TorchScript or TensorRT. Is there any work going on or guideline how to deploy the "unimatch" for edge devices?
Hi, thank you very much for your great work!
I have a question about model and model_without_ddp in main_*.py scripts.
(I'm new to pytorch and distributed data parallel.)
I'm trying to train your network with new dataset, and my setting has --resume some_path and --distributed False.
When I follow your main_depth.py script, I found that model is initialized, and model_without_ddp loads the checkpoint from resume. So something like below,
model = Unimatch(...)
model_without_ddp = model
optimizer = torch.optim.AdamW(model_without_ddp.parameters(), ...)
model_without_ddp.load_state_dict(resume ...)
Then, it seems that during epochs, model_without_ddp is actually trained because optimizer is initialized with model_without_ddp.
My question is why do we have two models (model and model_without_ddp) in this case? How do they sync to each other? Is the assignment actually pointer?
Thanks!
Hi, thanks for your great work. Is there possible ways to extract multi-level features in the optical flow estimation task? I notice there is a hyperparameter ' num_scales', but when I try to set it to 4, it seems it has correlation with the hyperparameter 'attn_splits_list', 'corr_radius_list' and 'prop_radius_list'. Could you show me how to adjust these three parameters if I would like to extract the 4 level upsample features? Thank you!
I follow the other issues and install COLORMAP to run python imgs2poses.py ../scenedir3/ and sussess. then I got sparse folder with have some *bin file and some *txt *db *npy file ,so how can I got the intrinsic and pose file after that ? I am new to this , look forward your answer.thanks.
I knowed that tartan air dataset's depth map is not disparity but, there is no changing disparity code to depth in the dataset build code.
Would you plz what is the right sense?
Hi,
Thanks for the great work!
I am trying to finetune the depth estimation model on some other datasets. But I encountered errors preparing the downloaded datasets when I tried to train on the depth dataset you provided. Below are error information.
Thank you!
$ python prepare_demon_train.py
Converting rgbd_bugfix_10_to_20_3d_train.h5 ...
Processing sequence 0/1237
prepare_demon_train.py:67: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning disappear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly.
img = imageio.imread(img.tobytes())
Traceback (most recent call last):
File "prepare_demon_train.py", line 119, in <module>
preparedata()
File "prepare_demon_train.py", line 96, in preparedata
dump_example(scene)
File "prepare_demon_train.py", line 67, in dump_example
img = imageio.imread(img.tobytes())
File ".../lib/python3.8/site-packages/imageio/__init__.py", line 97, in imread
return imread_v2(uri, format=format, **kwargs)
File ".../lib/python3.8/site-packages/imageio/v2.py", line 226, in imread
with imopen(uri, "ri", **imopen_args) as file:
File ".../lib/python3.8/site-packages/imageio/core/imopen.py", line 303, in imopen
raise err_type(err_msg)
ValueError: Could not find a backend to open `<bytes>`` with iomode `ri`.
In the Unimatch code, I've observed that the 'self.ids' of labeled data are extended to match the length of the unlabeled data. Consequently, within the same epoch, the number of iterations for the supervised model and Unimatch differ significantly. This leads to discrepancies in the optimizer's step count for the model. What would the results be if the iterations were identical?
Hello, I am trying to reproduce the results in the training set, but I am obtaining slightly worse results

I am using these parameters
main_stereo.py --submission --resume pretrained/gmstereo-scale2-regrefine3-resumeflowthings-middleburyfthighres-a82bec03.pth --inference_size 1024 1536 --val_dataset middlebury --middlebury_resolution F --middlebury_submission_mode training --output_path /hal/pytorch/MiddEval3/trainingF --padding_factor 32 --upsample_factor 4 --num_scales 2 --attn_type self_swin2d_cross_swin1d --attn_splits_list 2 8 --corr_radius_list -1 4 --prop_radius_list -1 1 --reg_refine --num_reg_refine 3
Could you please tell me if I am doing something wrong with the parameters?
I have images from different cameras with different intrinsics that I would like the calculate the depth from.
I already have the intrinsics for each and the relative pose between them, but this code base doesn't support this currently (e.g. see matching.py line 260 and 265 which explicitly assumes the intrinsics are the same for both cameras.
Cheers,
Jonathon
I wanted to turn training in depth, so I tried to turn it by typing this bash in gmflow_scale1_train.sh in colab as an example.
!CHECKPOINT_DIR=checkpoints_flow/chairs-gmflow-scale1 && \ mkdir -p ${CHECKPOINT_DIR} && \python3 -m torch.distributed.launch --nproc_per_node=4 --master_port=9989 main_depth.py --launcher pytorch --checkpoint_dir ${CHECKPOINT_DIR} --resume pretrained/gmflow-scale1-things-e9887eda.pth --no_resume_optimizer --dataset scannet --val_dataset scannet --image_size 480 640 --batch_size 8 --lr 4e-4 --summary_freq 100 --val_freq 5000 --save_ckpt_freq 5000 --num_steps 100000 2>&1 | tee -a
Result:
main_depth.py: error: unrecognized arguments: --local-rank=3
usage: main_depth.py [-h] [--checkpoint_dir CHECKPOINT_DIR]
[--dataset DATASET]
[--val_dataset VAL_DATASET [VAL_DATASET ...]]
[--image_size IMAGE_SIZE [IMAGE_SIZE ...]]
[--padding_factor PADDING_FACTOR] [--eval]
[--demon_split DEMON_SPLIT]
[--eval_min_depth EVAL_MIN_DEPTH]
[--eval_max_depth EVAL_MAX_DEPTH] [--save_vis_depth]
[--count_time] [--lr LR] [--batch_size BATCH_SIZE]
[--weight_decay WEIGHT_DECAY] [--workers WORKERS]
[--seed SEED] [--summary_freq SUMMARY_FREQ]
[--save_ckpt_freq SAVE_CKPT_FREQ]
[--save_latest_ckpt_freq SAVE_LATEST_CKPT_FREQ]
[--val_freq VAL_FREQ] [--num_steps NUM_STEPS]
[--resume RESUME] [--strict_resume]
[--no_resume_optimizer] [--task TASK]
[--num_scales NUM_SCALES]
[--feature_channels FEATURE_CHANNELS]
[--upsample_factor UPSAMPLE_FACTOR] [--num_head NUM_HEAD]
[--ffn_dim_expansion FFN_DIM_EXPANSION]
[--num_transformer_layers NUM_TRANSFORMER_LAYERS]
[--reg_refine] [--attn_type ATTN_TYPE]
[--attn_splits_list ATTN_SPLITS_LIST [ATTN_SPLITS_LIST ...]]
[--min_depth MIN_DEPTH] [--max_depth MAX_DEPTH]
[--num_depth_candidates NUM_DEPTH_CANDIDATES]
[--prop_radius_list PROP_RADIUS_LIST [PROP_RADIUS_LIST ...]]
[--num_reg_refine NUM_REG_REFINE]
[--depth_loss_weight DEPTH_LOSS_WEIGHT]
[--depth_grad_loss_weight DEPTH_GRAD_LOSS_WEIGHT]
[--inference_dir INFERENCE_DIR]
[--inference_size INFERENCE_SIZE [INFERENCE_SIZE ...]]
[--output_path OUTPUT_PATH] [--depth_from_argmax]
[--pred_bidir_depth] [--distributed]
[--local_rank LOCAL_RANK] [--launcher LAUNCHER]
[--gpu_ids GPU_IDS [GPU_IDS ...]] [--debug]
main_depth.py: error: unrecognized arguments: --local-rank=1
usage: main_depth.py [-h] [--checkpoint_dir CHECKPOINT_DIR]
[--dataset DATASET]
[--val_dataset VAL_DATASET [VAL_DATASET ...]]
[--image_size IMAGE_SIZE [IMAGE_SIZE ...]]
[--padding_factor PADDING_FACTOR] [--eval]
[--demon_split DEMON_SPLIT]
[--eval_min_depth EVAL_MIN_DEPTH]
[--eval_max_depth EVAL_MAX_DEPTH] [--save_vis_depth]
[--count_time] [--lr LR] [--batch_size BATCH_SIZE]
[--weight_decay WEIGHT_DECAY] [--workers WORKERS]
[--seed SEED] [--summary_freq SUMMARY_FREQ]
[--save_ckpt_freq SAVE_CKPT_FREQ]
[--save_latest_ckpt_freq SAVE_LATEST_CKPT_FREQ]
[--val_freq VAL_FREQ] [--num_steps NUM_STEPS]
[--resume RESUME] [--strict_resume]
[--no_resume_optimizer] [--task TASK]
[--num_scales NUM_SCALES]
[--feature_channels FEATURE_CHANNELS]
[--upsample_factor UPSAMPLE_FACTOR] [--num_head NUM_HEAD]
[--ffn_dim_expansion FFN_DIM_EXPANSION]
[--num_transformer_layers NUM_TRANSFORMER_LAYERS]
[--reg_refine] [--attn_type ATTN_TYPE]
[--attn_splits_list ATTN_SPLITS_LIST [ATTN_SPLITS_LIST ...]]
[--min_depth MIN_DEPTH] [--max_depth MAX_DEPTH]
[--num_depth_candidates NUM_DEPTH_CANDIDATES]
[--prop_radius_list PROP_RADIUS_LIST [PROP_RADIUS_LIST ...]]
[--num_reg_refine NUM_REG_REFINE]
[--depth_loss_weight DEPTH_LOSS_WEIGHT]
[--depth_grad_loss_weight DEPTH_GRAD_LOSS_WEIGHT]
[--inference_dir INFERENCE_DIR]
[--inference_size INFERENCE_SIZE [INFERENCE_SIZE ...]]
[--output_path OUTPUT_PATH] [--depth_from_argmax]
[--pred_bidir_depth] [--distributed]
[--local_rank LOCAL_RANK] [--launcher LAUNCHER]
[--gpu_ids GPU_IDS [GPU_IDS ...]] [--debug]
main_depth.py: error: unrecognized arguments: --local-rank=0
usage: main_depth.py [-h] [--checkpoint_dir CHECKPOINT_DIR]
[--dataset DATASET]
[--val_dataset VAL_DATASET [VAL_DATASET ...]]
[--image_size IMAGE_SIZE [IMAGE_SIZE ...]]
[--padding_factor PADDING_FACTOR] [--eval]
[--demon_split DEMON_SPLIT]
[--eval_min_depth EVAL_MIN_DEPTH]
[--eval_max_depth EVAL_MAX_DEPTH] [--save_vis_depth]
[--count_time] [--lr LR] [--batch_size BATCH_SIZE]
[--weight_decay WEIGHT_DECAY] [--workers WORKERS]
[--seed SEED] [--summary_freq SUMMARY_FREQ]
[--save_ckpt_freq SAVE_CKPT_FREQ]
[--save_latest_ckpt_freq SAVE_LATEST_CKPT_FREQ]
[--val_freq VAL_FREQ] [--num_steps NUM_STEPS]
[--resume RESUME] [--strict_resume]
[--no_resume_optimizer] [--task TASK]
[--num_scales NUM_SCALES]
[--feature_channels FEATURE_CHANNELS]
[--upsample_factor UPSAMPLE_FACTOR] [--num_head NUM_HEAD]
[--ffn_dim_expansion FFN_DIM_EXPANSION]
[--num_transformer_layers NUM_TRANSFORMER_LAYERS]
[--reg_refine] [--attn_type ATTN_TYPE]
[--attn_splits_list ATTN_SPLITS_LIST [ATTN_SPLITS_LIST ...]]
[--min_depth MIN_DEPTH] [--max_depth MAX_DEPTH]
[--num_depth_candidates NUM_DEPTH_CANDIDATES]
[--prop_radius_list PROP_RADIUS_LIST [PROP_RADIUS_LIST ...]]
[--num_reg_refine NUM_REG_REFINE]
[--depth_loss_weight DEPTH_LOSS_WEIGHT]
[--depth_grad_loss_weight DEPTH_GRAD_LOSS_WEIGHT]
[--inference_dir INFERENCE_DIR]
[--inference_size INFERENCE_SIZE [INFERENCE_SIZE ...]]
[--output_path OUTPUT_PATH] [--depth_from_argmax]
[--pred_bidir_depth] [--distributed]
[--local_rank LOCAL_RANK] [--launcher LAUNCHER]
[--gpu_ids GPU_IDS [GPU_IDS ...]] [--debug]
main_depth.py: error: unrecognized arguments: --local-rank=2
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 2) local_rank: 0 (pid: 8007) of binary: /usr/bin/python3
Traceback (most recent call last):
File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launch.py", line 196, in <module>
main()
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launch.py", line 192, in main
launch(args)
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launch.py", line 177, in launch
run(args)
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/run.py", line 785, in run
elastic_launch(
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 250, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
main_depth.py FAILED
But this error came out. How can we solve this?
Plz be my hero:)
Hi, I wanted to ask what the Accuracy /Speed tradeoff is between gm_stereo_scale1 vs gm_stereo_scale2?
perfect work guys,and,do you plan to make a live camera estimation?maybe with gui window
The gmflow/unimatch sintel model performs very well in 3D animation. Btw, the Spring optical flow dataset was recently released at CVPR2023. Do you have any plans to finetune or train a new model on Spring?
I think when training unimatch begining at chairs(optical flow) dataset, we don't need a pretrained model.
But in your gmflow_scale2_regrefine6_train.sh, you add "resume" in the script, and the resume target gmflow-scale2-chairs-020cc9be.pth can't be found in model_zoo. Can you explain why?
Thks.
Thanks for your amazing work! For testing optical flow result, I input a pair of left/right image and split the x and y flow.
x flow result

y flow result

I think the x flow should be like disparity, so the y flow is unclear really make sense. But why the value in close region is smaller than the far region in x flow image. Do I misunderstand something?
PS: The purpose of doing this is to make my own dataset for training a model for relative depth map. I think the opticalflow is the best performance.
Hi @haofeixu , what is the scale of depth in scannet demo? I want to convert the estimated depth to point cloud while have no idea what the scale is.
Thanks for the great work! A question I have is about fine-tuning on driving stereo dataset. Do you use the sparse GT directly for training or you preprocess the GT to get a dense map for training? Thanks!
I predicted the optical flow very well at a resolution of 960x520, but the prediction effect was very poor at a resolution of 1920x1080. Do you have any solutions。
Thanks
Very nice work!
There are a few questions that confuse me. As far as I know, disparity and depth can be converted into each other. So, for the depth estimation, many works estimate disparity first and then convert it to depth.
(1) May I ask if the unimatch can be used to get depth in this way (estimating disparity to get depth)?
(2) And in comparison, does the plane-sweep stereo method have unique advantages?
(3) Under what circumstances can these two tasks be treated differently, and under what circumstances can they be treated equally?
I hope you forgive my ignorance, and I eagerly await your reply.
Hi,
I tried https://github.com/fyusion/llff#1-recover-camera-poses, and got poses_bounds.npy for each pair of frames from video. There are 17 pose parameters for each image, but it seems that there are 4 * 4 parameters in each pose.txt file.
I would appreciate it if you could provide the scripts used to extract the pose from poses_bounds.npy.
Computation of 17 pose parameters.

Loading of pose.txt in unimatch
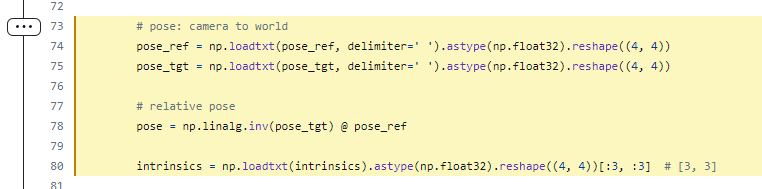
Hi, I try to export your model to onnx.
Did you try to do something like this?
Now I`m stuck with "RuntimeError: Expected a sequence type, but received a non-iterable type in graph output index 0". Is this because flow_preds is a dic, or can it be related to something else?
Hi, there. Thanks for your great work!
I am new to optical flow estimation, and I want to integrate optical flow into my own project as an out-of-the-box tool.
I run the script below on my own video, but I found that many frames in the optical flow video look like meaningless random noise.
# inference on video
# script from: https://github.com/autonomousvision/unimatch/blob/master/scripts/gmflow_demo.sh
CUDA_VISIBLE_DEVICES='1' python main_flow.py \
--inference_video video_path \
--resume pretrained/gmflow-scale2-regrefine6-mixdata-train320x576-4e7b215d.pth \
--output_path result_dir \
--padding_factor 32 \
--upsample_factor 4 \
--num_scales 2 \
--attn_splits_list 2 8 \
--corr_radius_list -1 4 \
--prop_radius_list -1 1 \
--reg_refine \
--num_reg_refine 6 \
--save_video #\
# --concat_flow_imgThen, I calculate the optical flow between two identical images and found that the result also seems like random noise. (Shouldn’t it be an all-white picture?) I guess the above problem may be caused by this, because some scenes in my video are static.
Because I know little about optical flow, I would like to ask if this phenomenon is normal? If not, how to solve it?

Thanks a lot.
Thanks for your excellent work, I use your code for stereo disparity estimate, but just find there is a gap betweent unimatch and disparity computing from sgbm as well as hitnet. In hitnet there is a param called png_disparity_factor, which can convert disparity to the same scale as sgbm. So is there a disparity factor too ? Thx.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.