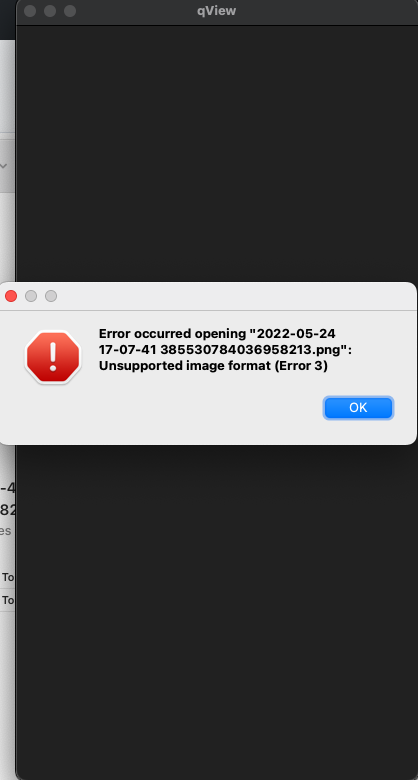
The application crashed and provided me with an error and instructions as I'm sure you know because you programmed it. Here is the error. I'm not sure what extra information I can provide. I was using previously downloaded files from .2 and tried the new update old download folder option. Let me know if you need more information.
Traceback (most recent call last):
File "urllib3\connectionpool.py", line 703, in urlopen
File "urllib3\connectionpool.py", line 398, in _make_request
File "urllib3\connection.py", line 239, in request
File "http\client.py", line 1282, in request
File "http\client.py", line 1328, in _send_request
File "http\client.py", line 1277, in endheaders
File "http\client.py", line 1037, in _send_output
File "http\client.py", line 998, in send
File "ssl.py", line 1236, in sendall
File "ssl.py", line 1205, in send
ssl.SSLEOFError: EOF occurred in violation of protocol (_ssl.c:2384)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "requests\adapters.py", line 440, in send
File "urllib3\connectionpool.py", line 785, in urlopen
File "urllib3\util\retry.py", line 592, in increment
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='cdn2.fansly.com', port=443): Max retries exceeded with url (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:2384)')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "fansly_scraper.py", line 304, in <module>
File "requests\sessions.py", line 542, in get
File "requests\sessions.py", line 529, in request
File "requests\sessions.py", line 645, in send
File "requests\adapters.py", line 517, in send
requests.exceptions.SSLError: HTTPSConnectionPool(host='cdn2.fansly.com', port=443): Max retries exceeded with url (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:2384)')))