A collection of kubernetes knowledge

- Traditional deployment era
- organizations ran applications on physical servers
- caused resource allocation issues
- scale by add more physical server but expensive for organizations to maintain many physical servers
- Virtualized deployment era
- it allows you to run multiple Virtual Machines (VMs) on a single physical server’s CPU
- with virtualization you can present a set of physical resources as a cluster of disposable virtual machines
- full machine running all the components, including its own operating system
- Container deployment era
- containers are similar to VMs, but they have relaxed isolation properties to share the Operating System (OS) among the applications
- Service discovery and load balancing
- Storage orchestration
- Automated rollouts and rollbacks
- Automatic bin packing
- You tell Kubernetes how much CPU and memory (RAM) each container needs. Kubernetes can fit containers onto your nodes to make the best use of your resources.
- Self-healing
- Secret and configuration management
- Lets you store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys. You can deploy and update secrets and application configuration without rebuilding your container images, and without exposing secrets in your stack configuration
When you deploy Kubernetes, you get a cluster
A cluster has at least one worker node and at least one master node
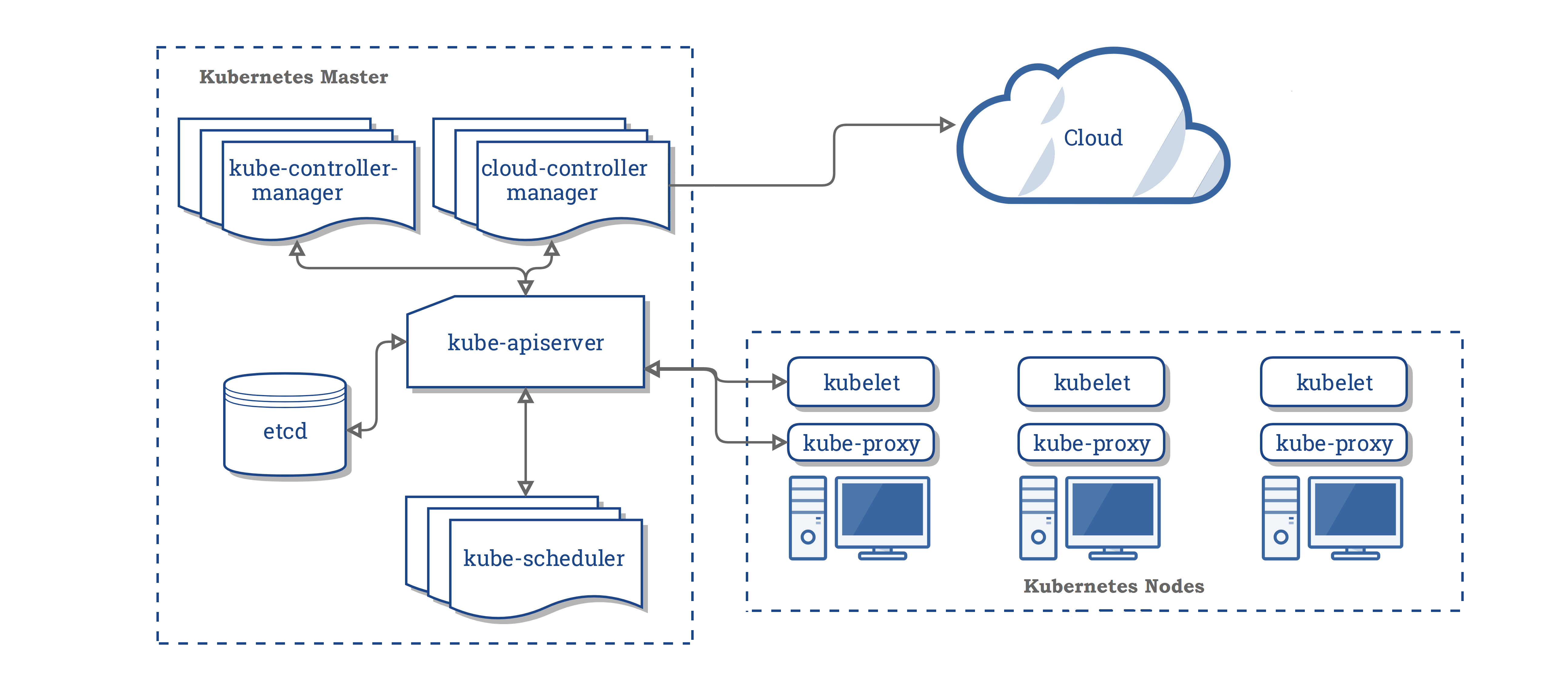
- kube-apiserver
- Exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane.
- etcd
- Consistent and highly-available key value store used as Kubernetes’ backing store for all cluster data
- kube-scheduler
- Watches newly created pods that have no node assigned, and selects a node for them to run on
- kube-controller-manager
- Logical
- Node Controller: Responsible for noticing and responding when nodes go down
- Replication Controller: Responsible for maintaining the correct number of pods for every replication controller object in the system
- Endpoints Controller: Populates the Endpoints object (that is, joins Services & Pods)
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces
- Logical
- cloud-controller-manager
- runs controllers that interact with the underlying cloud providers
- allows the cloud vendor’s code and the Kubernetes code to evolve independently of each other
- kubelet
- An agent that runs on each node in the cluster. It makes sure that containers are running in a pod
- kube-proxy
- a network proxy that runs on each node in your cluster to maintains network rules on nodes
- These network rules allow network communication to your Pods from network sessions inside or outside of your cluster
- Container Runtime
- The container runtime is the software that is responsible for running containers
- Read more
A Kubernetes object is a “record of intent”–once you create the object, the Kubernetes system will constantly work to ensure that object exists. By creating an object, you’re effectively telling the Kubernetes system what you want your cluster’s workload to look like; this is your cluster’s desired state
To work with Kubernetes objects–whether to create, modify, or delete them–you’ll need to use the Kubernetes API
Kubernetes object includes two nested object fields
- object spec
- which you must provide, describes your desired state for the object–the characteristics that you want the object to have
- object status
- describes the actual state of the object, and is supplied and updated by the Kubernetes system
Most often, you provide the information to kubectl in a .yaml file. kubectl converts the information to JSON when making the API request
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Each object in your cluster has a Name that is unique for that type of resource. Every Kubernetes object also has a UID that is unique across your whole cluster
Namespaces are intended for use in environments with many users spread across multiple teams, or projects. For clusters with a few to tens of users, you should not need to create or think about namespaces at all
Labels are key/value pairs that are attached to objects, such as pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
With label selector, the client/user can identify a set of objects. The label selector is the core grouping primitive in Kubernetes
"selector": {
"component" : "redis",
}
Labels can be used to select objects and to find collections of objects that satisfy certain conditions. In contrast, annotations are not used to identify and select objects.
Annotations allow you to add non-identifying metadata to Kubernetes objects. Examples include phone numbers of persons responsible for the object or tool information for debugging purposes
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
Field selectors let you select Kubernetes resources based on the value of one or more resource fields
kubectl get pods --field-selector status.phase=Running
Shared labels and annotations share a common prefix: app.kubernetes.io. Labels without a prefix are private to users. The shared prefix ensures that shared labels do not interfere with custom user labels
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm

A Pod represents a unit of deployment: a single instance of an application in Kubernetes, which might consist of either a single container or a small number of containers that are tightly coupled and that share resources.

- Pending
- The Pod accepted by the K8s system, but one or more of the container images not ready yet
- Running
- The Pod bound to a node, and all of the containers created
- Succeeded
- All Containers in the Pod have terminated in success
- Failed
- All Containers in the Pod have terminated, and at least one Container has terminated in failure
- Unknown
- For some reason the state of the Pod could not be obtained
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods
A ReplicationController ensures that a specified number of pod replicas are running at any one time. In other words, a ReplicationController makes sure that a pod or a homogeneous set of pods is always up and available
A Deployment that configures a ReplicaSet is now the recommended way to set up replication.
A Deployment provides declarative updates for Pods and ReplicaSets.
is a Kubernetes abstraction meant to decouple environment-dependent application-configuration-data from containerized applications, allowing them to remain portable across environments
is an object that contains a small amount of sensitive data such as a password, a token, or a key. Putting such sensitive information in a secret allows for more control over how it is used and reduces the risk of accidental exposure
is the workload API object used to manage stateful applications.require a Headless Service to be responsible for the network identity of the Pods.
Advantage
- Stable, unique network identifiers.
- Stable, persistent storage. (using volumeClaimTemplates field it will provide stable storage using PersistentVolumes provisioned)
- Ordered, graceful deployment and scaling.
- Ordered, automated rolling updates.
Naming
- Hostname
-
$(statefulset name)-$ (ordinal)
-
- DNS
- DNS
-
$(service name).$ (namespace).svc.cluster.local
-
- subdomain DNS
-
$(podname).$ (governing service domain) from serviceName field
-
- DNS
Use cases
- Database cluster (zookeeper,etc.)
Every replica of a stateful set will have its own state, and each of the pods will be creating its own PVC(Persistent Volume Claim). So a statefulset with 3 replicas will create 3 pods, each having its own Volume, so total 3 PVCs
ensures that all (or some) Nodes run a copy of a Pod
Typical uses of a DaemonSet
- a daemon for cluster storage on each node
- glusterd
- ceph
- a daemon for logs collections on each node
- fluentd
- logstash
- a daemon for node monitoring on ever node
- collectd
Normal Pods waiting to be scheduled are created and in Pending state, but DaemonSet pods are not created in Pending state but it will focus on Pod preemption
- DaemonSet controller
- Specific by .spec.nodeName
- Deafult scheduler
- Specific by .nodeAffinity
Taints and tolerations work together to ensure that pods are not scheduled onto inappropriate nodes
Example
kubectl taint nodes node1 key=value:NoSchedule
places a taint on node node1. The taint has key key, value value, and taint effect NoSchedule. This means that no pod will be able to schedule onto node1 unless it has a matching toleration.
- spec.template.spec.nodeSelector
- used to run on only a subset of the nodes that match the selector
- spec.template.spec.affinity
- can be used to run on only a subset of the nodes that match the affinity
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: simple-daemonset
labels:
app: simple-daemonset
spec:
selector:
matchLabels:
app: simple-daemonset
template:
metadata:
labels:
app: simple-daemonset
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: busybox
image: busybox
args:
- sleep
- "10000"
spec.selctor a selector for pods managed by the DaemonSet spec.template a pod definition for the pod you’d like to run on all nodes spec.template.spec.nodeSelector can be used to run on only a subset of the nodes that match the selector spec.template.spec.affinity can be used to run on only a subset of the nodes that match the affinity
- PersistentVolume (PV)
- storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes
- PersistentVolumeClaim (PVC)
- a request for storage by a user
Persistent Volumes are provisioned in two ways, Statically or Dynamically
- Static Volumes
- A static PV simply means that some k8s administrator provisioned a persistent volume in the cluster
- In other word, we will create Persistent Volumes (PV) and Persistent Volumes Calim (PVC)
- Dynamic Volumes
- In some circumstances a pod could require a persistent volume that doesn’t exist
- In other word, we only need to have Persistent Volumes Calim (PVC)
- Retain
- When the claim is deleted, the volume remains
- Recycle
- When the claim is deleted the volume remains but in a state where the data can be manually recovered
- Delete
- The persistent volume is deleted when the claim is deleted
is an abstract way to expose an application running on a set of Pods as a network service. Since the IP address of a pod is not a reliable way to access business functionality offered by the pod. The recommendation to access the pod outside the cluster is use Ingress nginx with loadbalancer of Cloud provider like GKE or EKS
is a service with a service IP but instead of load-balancing it will return the IPs of our associated Pods. This allows us to interact directly with the Pods instead of a proxy.By set ClusterIP to NONE (Normally, you will interact with ClusterIP service that help you to redirect between Pods)
Endpoints track the IP Addresses of the objects the service send traffic to. In normal cases, when we're using services object with selector so it will know how to send traffic to that endpoint but without selector it won't have endpoint to send the traffic to so that is a part we can use endpoint object to redirect traffic to anywhere depend on endpoint mapping manually
Every node in a Kubernetes cluster runs a kube-proxy. kube-proxy is responsible for implementing a form of virtual IP for Services of type other than ExternalName
Kube-proxy is the closest to the reverse proxy model
As a reverse proxy, kube-proxy is responsible for watching client requests to some IP:port and forwarding/proxying them to the corresponding service/application on the private network
Kube-Proxy have 3 models
- User space proxy mode
- watches the Kubernetes master for the addition and removal of Service and Endpoint objects
- For each Service it opens a port (randomly chosen) on the local node. Any connections to this “proxy port” is proxied to one of the Service’s backend Pods (as reported via Endpoints)
- 4 Steps
- watches addition or removal
- opens a random port on the node
- installs iptables rules that intercept traffic to the Service’s VIP and Service Port and redirect that traffic to the host port opened
- kube-proxy works as a load balancer distributing traffic across the backend Pods
- must frequently switch context between userspace and kernelspace when it interacts with iptables and does load balancing
- iptables proxy mode
- watches the Kubernetes control plane for the addition and removal of Service and Endpoint objects
- For each Service, it installs iptables rules, which capture traffic to the Service’s clusterIP and port, and redirect that traffic to one of the Service’s backend sets
- iptables have lower traffic no need to switch between user space and kernel space
- Prevent traffic sent to a Pod that’s known to have failed
- IPVS proxy mode
- watches Kubernetes Services and Endpoints
- netlink interface to create IPVS rules accordingly and synchronizes IPVS rules with Kubernetes Services and Endpoints periodically
- based on netfilter hook function that is similar to iptables mode, but uses hash table as the underlying data structure and works in the kernel space not user space
- lower latency than kube-proxy in iptables mode
Kubernetes DNS schedules a DNS Pod and Service on the cluster, and configures the kubelets to tell individual containers to use the DNS Service’s IP to resolve DNS names
kubelet sets each new pod’s /etc/resolv.conf nameserver option to the cluster IP of the kube-dns service, with appropriate search options to allow for shorter hostnames to be used
nameserver 10.32.0.10
search namespace.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
- A record Service
service.namespace.svc.cluster.local
Pod
actual-IP-address.namespace.pod.cluster.local
- SRV record
_my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster-domain.example
Currently when a pod is created, its hostname is the Pod’s metadata.name value.
Pod spec has an optional
- hostname
- When specified, it takes precedence over the Pod’s name
- subdomain
- which can be used to specify its subdomain
Additional Configuration Options
- dnsConfig option
- with dnsPolicy set to "None"
apiVersion: v1
kind: Pod
metadata:
namespace: example
name: custom-dns
spec:
containers:
- name: example
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 203.0.113.44
searches:
- custom.dns.local
this config will rewrite a pod’s resolv.conf to enable the changes
- Sidecar pattern
- sidecar attached to a motorcycle
- the sidecar is attached to a parent application and provides supporting features for the application. The sidecar also shares the same lifecycle as the parent application, being created and retired alongside the parent
Logging containers is to write to the standard output (stdout) and standard error (stderr) streams
When a container running on Kubernetes writes its logs to stdout or stderr streams, the container engine streams them to the logging driver configured in Kubernetes
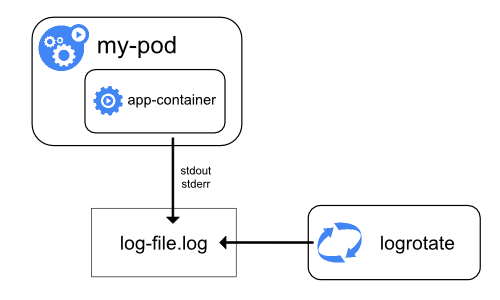
- node-level logging is implementing log rotation, so that logs don’t consume all available storage on the node
two types of system components
- run in a container
- The Kubernetes scheduler and kube-proxy run in a container
- not run in a container
- The kubelet and container runtime
Most case write to .log files in the /var/log directory
Kubernetes does not provide a native solution for cluster-level logging but we can implement cluster-level logging by including a node-level logging agent on each node
Three options that we can manage cluster-level logging
- Use a node-level logging agent that runs on every node.
- Include a dedicated sidecar container for logging in an application pod.
- Push logs directly to a backend from within an application
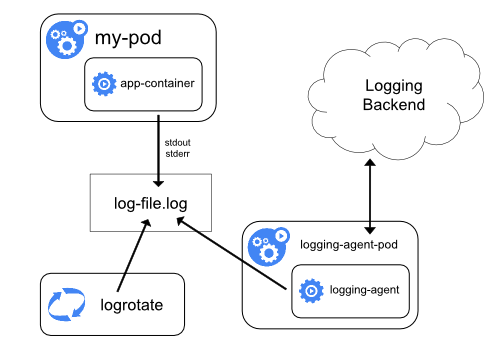
By including a node-level logging agent on each node implement it as DaemonSet replica
Two optional logging agents are packaged with the Kubernetes release
- Stackdriver Logging
- for use with Google Cloud Platform
- Elasticsearch
Both use fluentd with custom configuration as an agent on the node
- The sidecar container streams application logs to its own stdout
- The sidecar container runs a logging agent, which is configured to pick up logs from an application container
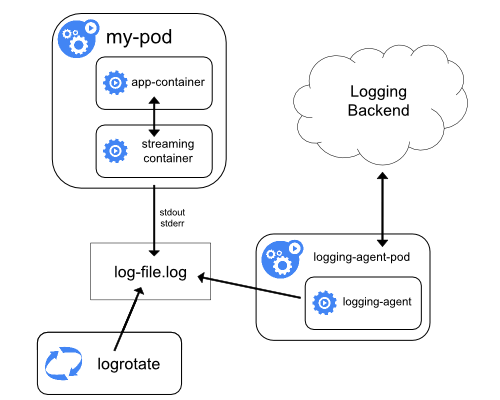
allows you to separate several log streams from different parts of your application, some of which can lack support for writing to stdout or stderr
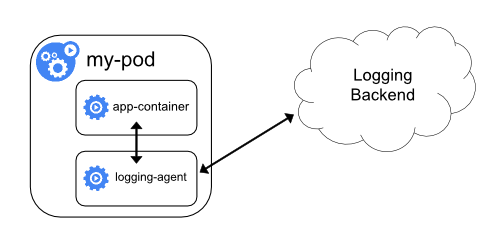
Using a logging agent in a sidecar container can lead to significant resource consumption. Moreover, you won’t be able to access those logs using kubectl logs command, because they are not controlled by the kubelet.
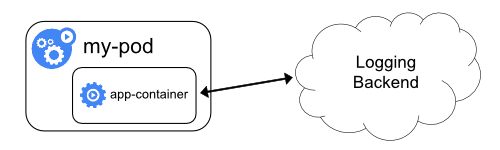
pushing logs directly from every application
