benjamn / brigade Goto Github PK
View Code? Open in Web Editor NEWBucket brigade for bundling browser modules
Bucket brigade for bundling browser modules







Module resolution, transformation, and bundling are now more configurable than ever!
My command-line parser https://github.com/visionmedia/commander.js doesn't appear capable of parsing the argument syntax --config -.
In practice, it turns out that a schema tree can be repetitive and awkward to write down.
Suppose we specified the tree as a list of roots instead:
['a', 'b', 'c']
What I mean to capture here is that any subset of the bundle root modules in the list could be included on a given page (including the empty set), but (because the order of bundles is not important) the order in which they appear will always follow the listed order.
Here's how we might have expressed this set of possibilities as a schema tree:
{
"a": {
"b": {
"c": {}
},
"c": {}
},
"b": {
"c": {}
},
"c": {}
}
I claim that schema trees always need to have such a structure for maximum flexibility, and so a list of roots should be sufficient to express all desired schema trees.
The only drawback is that the schema tree gets large with many roots. How large? For 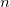

Now that we generate pure CommonJS module files during build (see #21), some users of Brigade may not be interested in the bundles or bundle tree output.
I've noticed seemingly identical bundles getting written multiple times. This kind of thing is prevented from run to run by the file existence check in BundleWriter.writeP, but might not be adequately guarded against during the same run.
For backwards compatibility, the install("module/id",function(require,exports,module){...}) syntax has to remain the default, but it makes it much easier to interface with other build tools if that default can be overridden.
Plan: add a --wrapper option to the CLI interface that names a module that module.exports = some function that takes the id and source of each module as arguments.
Ideally this would be smarter than just a wrapper around bin/brigade, and would use require("fs").watch to trigger partial rebuilds.
Minification (the main use case for bundle-level transformation) is provided automatically by the tool, and ever since cc326f0 it likely makes more sense to apply build steps to individual modules whenever possible.
Please comment here if you have any reason for opposing the removal of require("brigade").bundle.
As described here:
http://gruntjs.com/creating-tasks
http://gruntjs.com/creating-plugins
For instance, instead of bundling tests/login as 76bfa5a904beec3d69a3f942d7e534bfaaad8b4d.js, call it something like
tests_login.76bfa5a904beec3d69a3f942d7e534bfaaad8b4d.js
The hex digest part will still disambiguate the file perfectly well, and the new filenames won't be any more guessable than the pure hex filenames.
It's just really annoying to have to guess which bundle is which when you're inspecting the DOM.
fs.open with 0_EXCL seems like a good candidate for making this bullet-proof:
Exclusive mode (O_EXCL) ensures that path is newly created. fs.open() fails if a file by that name already exists. On POSIX systems, symlinks are not followed. Exclusive mode may or may not work with network file systems.
http://nodejs.org/api/fs.html#fs_fs_open_path_flags_mode_callback
Need a way to specify build steps for both modules and bundles.
A module might have a special directive in a comment that specifies some unique identifier for the module in the global module namespace, for example.
I have a prototype implementation of this that uses https://github.com/benjamn/less.js.
It would be great if this could be expressed as a build step, but I suspect it will require modifications to the module search logic in the ModuleReader.
This will allow clients to configure dependency scanning as they see fit.
A default implementation will obviously be provided (but extra steps can be inserted before/after).
Otherwise introducing a new root bundle will require restarting the tool.
Sometimes a module will not be found because the require statement that indicated it as a dependency appeared in a comment or some dead code.
There should be a warning when this happens, and a dummy module should be installed, but this kind of error should not be fatal.
A bundle can end up empty if its ancestors have already included everything the empty bundle needed.
It should be possible to avoid making a request for an empty bundle. The tree entry for the empty bundle should probably have an "empty": True property. If the consumer of the tree chooses to ignore it, it's not the end of the world.
We don't currently know whether UglifyJS is going to be used when modules are wrapped, so it's not trivial to wrap them differently.
There may be a way to cope with require mangling, but it would probably require cooperation with the install module.
Preserving require seems like the simplest approach for now.
Right now we avoid rebuilding bundles that already exist, but we don't make any effort to avoid unnecessary rebuilding of individual modules.
Right now exceptions require the program to be manually restarted.
These files should be compatible with Node's require function, and consumable by require.js or whatever else.
For simplicity, the module root should just be the same directory provided by --output-dir.
Should it be possible to suppress the bundle output if all you want is the directory structure of modules?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.