bramblexu / knowledge-graph-learning Goto Github PK
View Code? Open in Web Editor NEWA curated list of awesome knowledge graph tutorials, projects and communities.
License: MIT License
A curated list of awesome knowledge graph tutorials, projects and communities.
License: MIT License














































































































































precise link prediction的问题有两个:ill-posed algebraic system, the over-strict geometric form
本文的原创点在于把翻译模型的原则改为了manifold function,以此来解决上面两个问题。
通过显性的关键词和隐形的关系来推测话语的连贯性
关键词:
一句话总结:
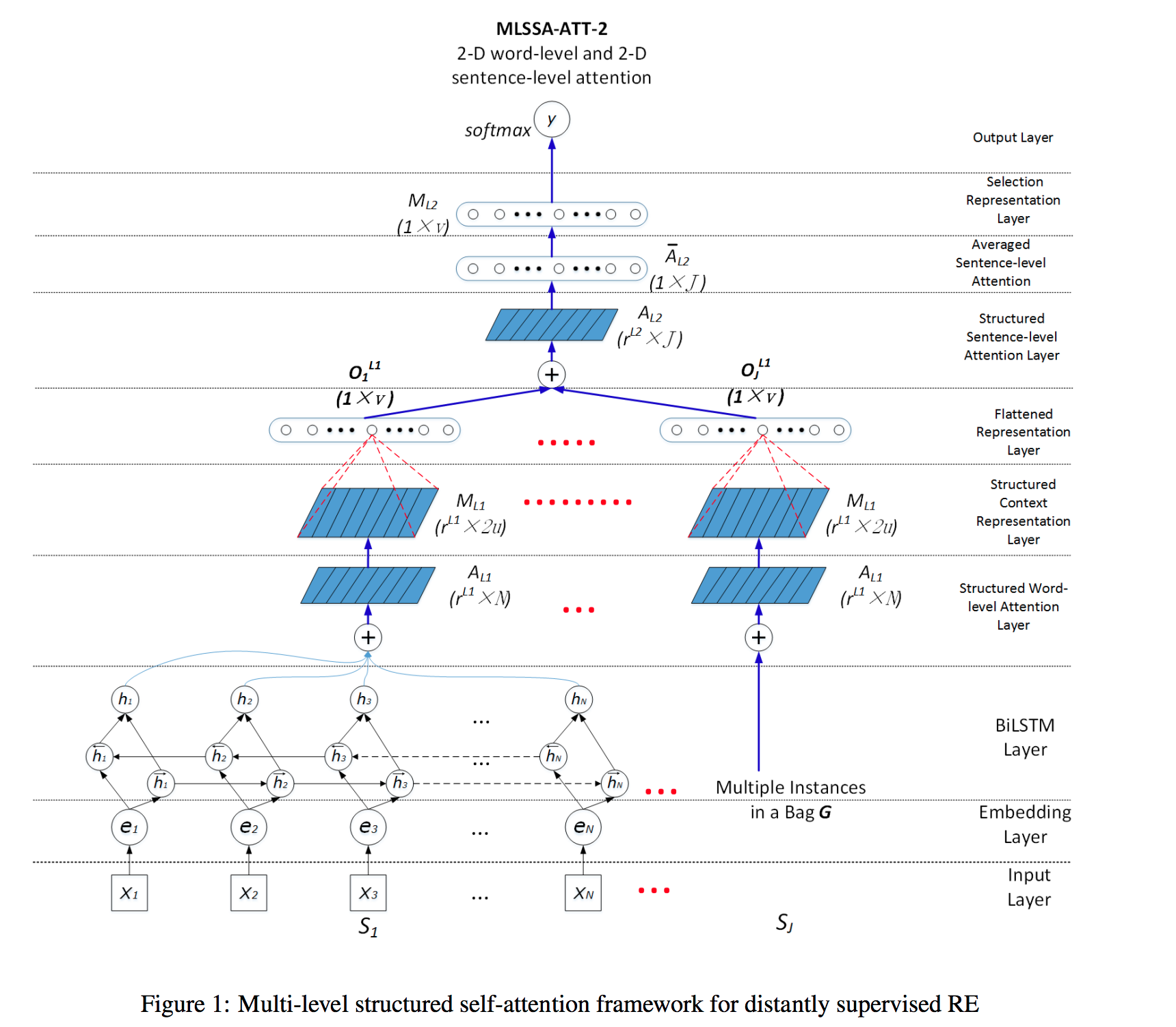
通过2-D matrix-based word-level attention mechanism来解决表达context word的问题,通过2-D sentence-level attention mechanism 解决 mul-tiple instance learning的问题,即选择正确的instance。
资源:
关键字:
笔记:
Here are two important representation learning problems in DNN-based distantly supervised RE: (1) Problem I : entity pair-targeted context representation learn-ing from an instance; and (2)Problem II : valid in-stance selection representation learning over mul-tiple instances.
基于DNN的DS RE方法有两个问题:
The former can use a word-level attention mechanism to learn a weight distribu-tion on words and then a weighted sentence rep-resentation regarding two entities; the latter canemploy a sentence-level attention mechanism to 2217 learn a weight distribution on multiple instances so that valid sentences with higher weights can be fo-cused and selected, and noisy instances with lower weights are suppressed.
前者通过attention给entity的word赋予更大的权重,而后者可以通过一个sentence level的attention模型来给valid sentence赋予更大的权重。(这不还是需要标注吗?得知道哪些是wrong label才行啊)
之前的研究是通过RNN来学习 1-D vectors 。而本工作则是基于structured self-attentive sen-tence embedding in Lin et al. (2017b ), 提出了一个multi-level structured (2-D ) self-attention mechanism (MLSSA) in a bidirectional LSTM-based (BiLSTM) 。
针对问题1:2-D matrix-based word-level attention mechanism, which contains mul-tiple vectors, each focusing on different aspects of the sentence for better context representation learning.
针对问题2:propose a 2-D sentence-level attention mechanism for mul-tiple instance learning, where it contains multi-ple vectors, each focusing on different valid in-stances for a better sentence selection.
4.2 Word Embeddings and Relative Position Features
模型图:
结果:
早期DL在RE方面的研究就是把RE当做了一个多分类问题。
把问题变为Multi-instance learning问题,这样我们可以通过远程监督来构建更大的训练集。Multi-instance learning是distant supervision的一种,含义是一个label有一群instance,而不是单单的一个instance。
在RE这个问题上,每个entity pair定义一个bag,这个bag包含涉及到entity pair的所有句子。然后我们把一个relation label标记给整个bag,而不是单单一个instance。
5.1 Piecewise Convolutional Neural Networks (Zeng et al., 2015)
5.2 Selective Attention over Instances (Lin et al., 2016)
效果币PCNN好
5.3 Multi-instance Multi-label CNNs (Jiang et al., 2016)
深度模型普遍比不深的好。attention + PCNN是效果最好的。奇怪的是没有LSTM在RE方面的工作。
Relation Extraction : A Survey
为了防止Graph在split的时候丢失信息,提出了Graph State LSTM模型。
关键词:
对于corss-sentence的关系抽取人物,通常把输入变为graph,然后把这个graph split为两个DAG,然后通过DAG-structured LSTM来分别对两个DAG进行学习。
但是在split的时候,容易丢失信息。于是本工作提出了graph-state LSTM模型。
基于GloVe学习样本中的relation,得到embedding。这种relation embedding对于RE或者relation similarity这样的任务很有帮助。
一句话总结:
不使用hard label, 而是用KGE中的t-h来代替relation label。提高RE的效果
资源:
关键字:
笔记:
假设:noisy in DS这个问题主要是没有充分使用KG信息导致的。
办法:通过relation embedding (t- h) 以及entity type来代表label,而不是hard relation labels.
针对wrong label的问题,解决办法大致分为下面几种。
这篇文章主要是想避免 hard relation labels。 因为只要是hard labels,就不可避免引入一些noisy。所以想通过t-h的embedding来表示label. (但是这还是有问题啊,同样的t-h可能表达不同的realtionship,embedding学出来的效果还是会有noisy存在)
Our assumption is that each relation r in a KG has one or more sentence patterns that can describe the meaning of r .
左边的句子里Ankara和Turkey是captial的关系,而右边Mexcio和Guadalajara则是contains的关系。这二者如果直接去学的话,关系不一样(这里captial的关系属于noisy,我们想要的是contains的关系,而captial是contains的一个子关系)。但是如果通过t-h的话,这二者的关系,能更接近contain的关系,而不是capital的关系。
有两种embedding:
We use typical KG embedding models such as TransE to pre-train the embedding of entities and
relations. We intend to supervise the learning by t - h instead of hard relation label r
Word Embeddings and Attentions
Instead of encoding sentences directly, we first replace the entity mentions e in the sentences with corresponding entity types type e in the KG, such as PERSON, PLACE, ORGANIZATION, etc. We then pre-train the word embedding by word2vec.
Position embedding
还是用的 #13 的方式。
模型图:


结果:


通过autoencoder对KB进行embedding,可以做到降维的效果,得到的embedding对于KBC任务的MR指标有显著提升。
关键词:
(Finding Nemo, country_of_film, ?).通过KB embedding来学习关系,但是这种方法有太多的参数学要学习,所以要reduce dimensionality of relations. 而且,两个关系的合成,可以得到第三个关系。$M_1 + M_2 = M_3$这里的M是代表relation的矩阵。这样的话说明满足 compositional constraints,
以前的 reduce dimensionality of relations手法是imposing pre-designed hard con-straints on the parameter space. 但是这种方法对于compositinoal constraints并不好。很难通过两种关系合成第三种关系。
所以本文的方法是 training relation parameters jointly with an autoencoder。
结果方法,模型的提升主要在Mean Rank (MR)这个指标上
参考了这个Tim Dettmers, Minervini Pasquale, Stenetorp Pon-tus, and Sebastian Riedel. 2018. Convolutional 2d knowledge graph embeddings. In Proceedings of the 32th AAAI Conference on Artificial Intelligence
For an incomplete triplehh;r;?iin the test, ifh is OOV, we replace it with the most frequent entity that has ever appeared as a head of relationr in the training data. If the gold tail entity is OOV, we use the zero vector for computing the score and the rank of the gold entity.
简单来说就是拿r里最常见的entity来取代head entity或tail entity。另外,在WUN18RR这个数据集上因为有6.7%的triples有OOV,作者把这部分entity全都删除了。
这是一篇关于如何构建垂直领域知识图谱的文章,这里的垂直领域是航空风险领域。主要分为以下几步:
The knowledge graph can be divided into general field and vertical field according
to its knowledge range.
空难事件受很多因素影响,飞机状况,乘务员状态,天气,地理因素等等。这些因素和时间本身狗冲了一个非常复杂的网络,每个事件都是一个很大的知识网络系统,所以用KG比较好描述这些复杂的关系。
这篇文章结合了两点,一个是空难领域的特征,一个是这个领域的知识图谱构建方法。
构建的过程包括以下几点,domain ontology modeling, instance-toontology mapping, visualization analysis and application maintenance.

根据这个构建过程,这篇文章可以分为三个部分:知识表示,数据映射,知识图谱的管理和应用
The knowledge representation method based on ontology: M. Zhao, Y. Du, H. She, J. Zhang, H. Wang, Y. Chen. Transactions of the Chinese Society for Agricultural Machinery, 47(9), 278(2016)
这篇文章构建了一个空难领域的knowledge ontology framework(知识本体框架)。

Figure 2 shows a partial of the aviation risk event ontology model.
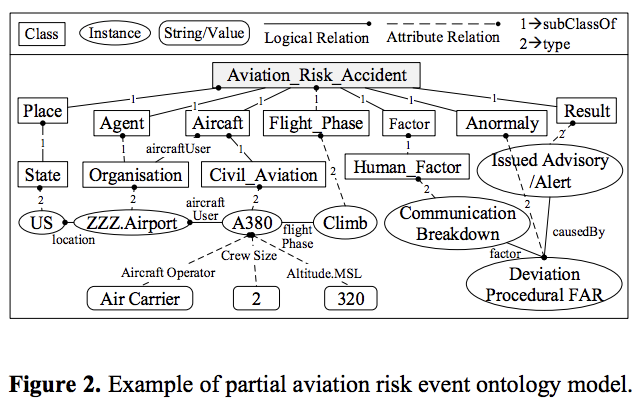
构建完ontology model之后,接下来就是把知识存储到数据库中。In this paper, we use Jena, a ontology parsing java toolkit, to transform the ontology metadata into the resource description framework RDF [20], then store and query knowledge in the form of .
知识来源是结构数据,来自ASRS,数据质量比较高。本文使用pattern-based data mapping mechanism来完成结构数据的转换,即RDB2RDF data conversion process.
W3C介绍过两种营业语言的标准(2012年):Direch 和 R2RML。
R2RML映射设计了一个逻辑表格,可以从关系数据库中提取数据。We will define a SQL query of table in relational database as a logical table. Each logical table is converted into RDF data by a triples map, that is, each row of instance data in the logical table is mapped to several RDF triples. R2RML mapping mechanism expression is:

R2RML mapping有一个mapping文档,包括一系列RDF三元组,可以表示为:

R2RML映射文档基于上面的表达式,可以用下图表示

The RDF storage pattern includes two types of tuple from the ontology mapping and data mapping. We extract the and as entities in the knowledge graph, and extract , , and as the attribute and the association in the knowledge graph, so we can construct the knowledge graph.
通常的知识图谱构建需要进行知识融合,但是在空难领域,是不需要的。因为数据来源已经是被处理过的结构化数据了。所以当数据增加的时候,本论文可以使用data-driven incremental ontology 建模技术来扩增concepts和instances。concept指的是a class with the same entities. 因为concept的改变并不多,所以主要是instance的自动更新。
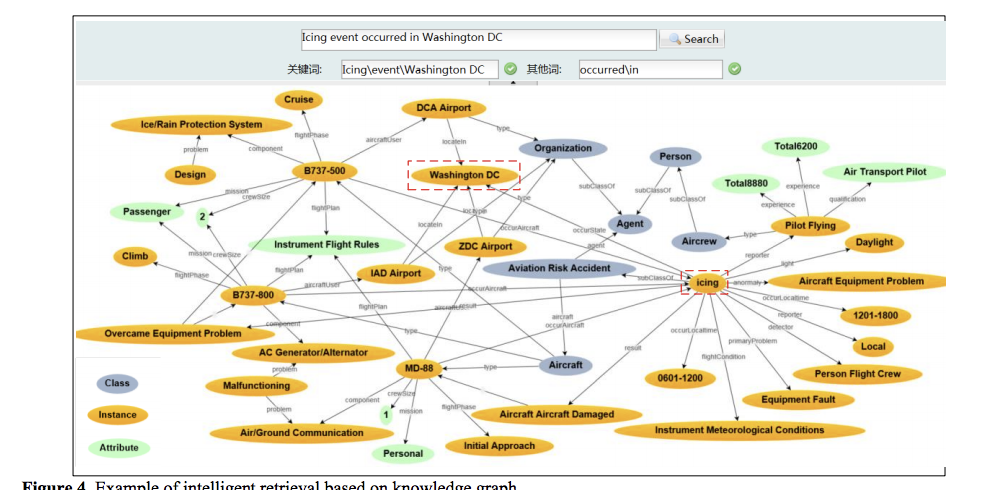
知识图谱在空难领域的应用:1 智能语义检索。2 决策支持。
在构建图谱的过程中,一些实际的构建技巧。
Qian Zhao1, Qing Li1 and Jingqian Wen2
1 School of Mechanical Engineering and Automation, Beihang University, Beijing 100191, China
2 School of Mechanical Engineering, Beijing Institute of Technology, Beijing 100081, China
2018/02/21
2017 Asia Conference on Mechanical and Aerospace Engineering (ACMAE 2017)
非常ground-truth的一篇论文,并不是算法模型的创新,而是工程实践的一篇总结,主要是选择在了空难这个垂直领域,针对这个领域设计了一个新的ontology框架。剩下的就是一些工程实现了。
通过把二元关系变为一元关系,来捕捉文本里的implicit relation, 来提高KBP(KB构建)任务的效果。
IBM Research AI: 这篇论文的introduciton写得很好,推荐阅读。但是图画得真不敢恭维。最后的评价指标也优点微妙。但是点子不错,话说之前没有人做过这方面的尝试?
关键词:
本研究只考虑提供的triple是正确的情况。当前的问题是text中出现的关系很多都是implicit的,即没有明确的语法关系可以判断entity之间的relation,这导致了KBP关系抽取的大部分方法的recall比较低。因为这些方法大部分是依靠判断两个entity之间的 词法-句法(lexical-syntactic)来确认relation的。
目标关系是presidentOf, 两个entity是TRUMP and UNITED_STATES.
第一个句子里的两个entity有explicit relation
第二个句子里虽然也表达的同样的关系,但是是implicity,需要一些背景知识才能推测。而且 UNITED_STATES压根没有出现。
The state-of-the-art systems are affected by very low performance, close to 16.6% F1, as shown in the latest TAC-KBP evaluation cam-paigns and in the open KBP evaluation bench-mark1 .
为了从文本中识别implicit relation,本研究把 identifying binary re-lations problem变为a much larger set of simpler unary relations problm. 下面举个例子:
For example, to build a Knowl-edge Base (KB) about presidents in the G8 countries, thepresidentOf relation can be expanded to presidentOf:UNITEDSTATES, pres-identOf:GERMANY, presidentOf:JAPAN , and so on. For all these unary relations, we train a multi-class (and in other cases, multi-label) classifier from all the available training data. This classifier takes textual evidence where only one entity is identified (e.g. ANGELA_MERKEL ) and predicts a confidence score for each unary relation In this way, ANGELA_MERKELwill be assigned to the unary relation presidentOf:GERMANY , which in turn generates the triple (ANGELA_MERKEL, presidentOf:GERMANY) .
把不同的总统按国家来预先区分,即把presidentOf->which country 变为``president(country)`,也就是说少了一步推理的步骤,关系变为了一元关系。文本中得到的只能有一个entity,然后判断这个entity属于哪个关系。当做多关系任务来训练。
Baseline 是 Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances.
接下来的研究计划:
KBP's goal is to improve re-call by identifying implicit information from texts
提出了一个新的数据集,既可以用作 关系分类,又可以用于做few-shot learning的验证。
DS带来的noisy,通过few-shot的方法来进行减少。然后用几个sota的few-shot learning方法,来做关系分类。结果显示与人类的判断还是有较大差距的。
关键词:
DS得来的数据数量比较少,一旦样本数下降,模型效果也会下降很快。比如NYT-10这个数据集,其中有58%的数据都是少于100 instances。DS得来的数据集中有很多noisy,模型苦于wrong labeling problem久已。因此,通过少量数据来训练RC模型是有必要的。
制作过程
we remove relations with fewer than 1000 instances, and randomly keep 1000 instances for the rest of
the relations. As a result, we get a candidate set of 122 relations and 122, 000 instances.
通过Amazon MTurk. Then the annotator is asked to judge whether the relation could be deduced only from the sentence semantics. We also ask the annotator to mark an instance as negative if the sentence is not complete, or the mention is falsely linked with the entity.
After the annotation, we remove relations with fewer than 700 positive instances. For the remaining 105 relations, we calculate the inter-annotator agreement for each relation using the free-marginal multirater kappa (Randolph, 2005), and keep the top 100 relations.
也就是说,每个relation起码都有700个instance啊。
The final FewRel dataset consists of 100 relations, each has 700 instances. A full list of relations, including their names and descriptions, is provided in Appendix A.2. The average number of tokens in each sentence is 24.99, and there are 124, 577 unique tokens in total

Table 2 provides a comparison of our FewRel dataset to two other popular few-shot classification datasets, Omniglot and mini-ImageNet. Table 3 provides a comparison of FewRel to the previous RC datasets
就relation数量来说,fewrel是最多的。
一句话总结:
这个工作的主要创新点是结合了attention模型和position information。并提出了一个新的数据集。
#147 #148
资源:
关键字:
笔记:
按照上面标注手册里的内容, 2015年slot filling task,一共有41个relation。然后tacred添加了一个新的no_relation标称了42个。从TACRED dataset官网可以看到,relation的分布是非常不均匀的,因为其中79.5%都是no_relation. 恐怕这也是为什么相比于其他NYT,SemEval等数据集,tacred SOTA f1才只有70%
有41个relation和1个no_relation,其中41个relaiton主要是分为per slot和org slot两种。而且tacred并不能用于DS noise方面的研究,应为数据集是通过经过人工编辑过后得到的,没有noise。而且主要是用于slot filling这方面研究的。基于noise的研究,主要是用NYT数据集来进行的。而long tail研究的话,主要是FewRel这个数据集,但是这个数据集没有annotation guide相关的文件,只知道有100个relation,每个relation有700个instance,而且每个relation只有编号,没有对应的解释,无法直观进行理解,而且数据只有head和tail的位置信息,其他什么都没有。而如果研究long tail+DS noise的话,用NYT数据集。
下面是论文里的内容
This task involves en-tity recognition, mention coreference and/or entity linking, and relation extraction。而这个工作则是关注 most challenging “slot filling” task of filling in the relations between entities in the text. 说是slot filling,其实就是RC。
We believe machine learning approaches have suf-fered from two key problems: (1) the models used have been insufficiently tailored to relation extrac-tion, and (2) there has been insufficient annotated data available to satisfy the training of data-hungry models, such as deep learning models.
两个问题:
This work addresses both of these problems. We propose a new, effective neural network se-quence model for relation classification. Its ar-chitecture is better customized for the slot fill-ing task: the word representations are augmented by extra distributed representations of word posi-tion relative to the subject and object of the puta-tive relation. This means that the neural attention model can effectively exploit the combination of semantic similarity-based attention and position-based attention.
Secondly, we markedly improve the availability of supervised training data by us-ing Mechanical Turk crowd annotation to pro-duce a large supervised training dataset (Table 1 ), suitable for the common relations between peo-ple, organizations and locations which are used in the TAC KBP evaluations. We name this dataset theTAC RelationExtractionD ataset (TACRED), and will make it available through the Linguistic Data Consortium (LDC) in order to respect copy-rights on the underlying text
这部分首先diss了一下 #13 以及其他两篇文章,这些工作都是在关于与CNN,RNN以及他们的一些结合上。这些工作在测试的数据及上效果可以,但是对于longer sentences的数据库来说,效果不好。
现在模型的结构有两个问题
所以我们提出了position-aware attention mechanism over an LSTM network to tackle these challenges. 这个模型的优点:
具体对position的建模:

每个entity有一个non-overlapping consecutive spans。受到了 #13 以及 Natural language processing (almost) from scratch这两篇文章对于position encoding的启发,define a position sequence relative to the subject entity

其中的P_{i}^{s}定义如下:

其中s1和s2是subject的starting and ending indices. 所以P_{i}^{s}可以看作是每个token x_i到subject entity之间的相对距离。同样的道理,可以得到P_{i}^{o},即到object entities的相对距离。


这个attention把h_i, q, p_i^s,p_i^o都放在一起了。但是q本来就是h_i的集合体。如果不是因为效果不好的话,可能不会这样设计。

计算出a_i之后,每个句子的表示是a_i*h_i。
Here the summary vector (q) helps the model to base this selection on the semantic information of the entire sentence (rather than on each word only), while the position vectors (p_i^s and p_i^o) provides important spatial information between each word and the entities. 为什么上面的公式要这么设计? q用来考虑整个sentence information, 而p_i^s and p_i^o则用来引入spatial information.
模型图:

结果:




后续基于tacred的结果:
注意,上面是单一模型的效果,如果是多模型的话,C-GCN已经能做到68.2了

提出了一个模型,能在各种不同类型的RC数据集上有不错的表现。并比较了不同模型在6个数据集上的表现,查看模型的泛化效果。
关键词:
这篇论文出彩的地方在于可视化以及实验部分。
当前针对RC的研究,针对的数据集范围比较小(比如只在一个或两个数据集上进行比较,然后就说自己是SOTA),所以怀疑在其他类型的数据集上的表现如何。本工作对6中不同类型的RC数据集进行了调查,并提出了一个multi-channel LSTM模型(+CNN)来利用liguistic and architectural feature. 这个模型在两个数据集上有SOTA的表现。
简单介绍了自动问答系统的构造

这篇文章里以知识来源对QA进行了分为了两类:KBQA 基于知识库的问答 & DBQA 基于文档的问答 (SQuAD).
类比推理能捕捉语言规律。
Analogy questions can be automatically solved via vector computation, e.g.“apples - apple + car �= cars”for morphological regularities and “king -man + woman� = queen” for semantic regularities.
根据语言的不同,语言规律也会有很大的不同。而中文是一个典型的 分析型语言。
贡献:
propose a Chinese ana-logical reasoning task based on 68 morphological relations and 28 semantic relations
This is a test issue for IssueHunt
一句话总结:
通过GNN学习Dependency Trees的特征来提高RE效果。
资源:
关键字:
笔记:
这个工作主要是和dependency-based neural models进行对比的。
传统的feature-based模型可以把dependency information表示为overlapping path along the trees. 但是这些模型面临两个问题:sparse feature spaces and are brittle to lexical variations.
More recent neural models address this problem with distributed representations built from their computation graphs formed along parse trees. 于是一些基于nerual的模型试图解决这个问题。在parse trees构成的graph上用graph representation。
这种基于graph的表示通常有两种做法:
第一种做法的模型很难做到并行计算,because aligning trees for efficient batch training is usually non-trivial.
第二种做法的模型简化了假设,models based on the shortest dependency path between the subject and object are computationally more efficient, but this simplifying assumption has major limitations as well
本工作提出了一个针对RE特化的GNN模型,能encode dependency structure. 另外还使用了a novel path-centric pruning technique to remove irrelevant information from the tree while maximally keeping relevant content。

Contextualized GCN (C-GCN) model, where the input word vectors are first fed into a bi-directional long short-term memory (LSTM) network to generate contextualized representations, which are then used as h (0) in the original model. This BiLSTM contextualization layer is trained jointly with the rest of the network
普通的GCN模型并不会考虑contextual information. 而且GCN对于parse tree的依赖性很强(如果parse效果不好的话,效果也会变差)。这里提出的C-GCN,先把word vector输入到bi-LSTM里,生成contextuallized representations, 即模型图中的 h(0). bi-LSTM是和网络一起进行联合学习的。
下面这部分其实和我设计的sdp+rdp1的想法是一样的

这部分把RE的模型分成了两类,第一类是Dependency-based models,第二类是Neural sequence model。后者就是(PA-LSTM) #50 .
模型图:

结果:
这篇论文的模型叫做Contextualized GCN (C-GCN)。可以看到

一篇调查类论文。测试了不同knowledge base embedding方法对于relation prediction和relation extraction的效果。
大部分工作都是用于预测missing entites或者找到missing triple,很少有预测关系的。因为预测关系相对于预测实体简单,因为实体的数量比关系要多很多。
https://arxiv.org/abs/1802.02114
2018/06/06
比较了三种模型:TransE, DistMult, and ComplEx
KBE模型在relation prediction上表现都不错,但是在relation extraction上效果并不好。

构建了一个用于判断语义关系(同义、反义关系,上下位,和整体的关系)的模型。不同的语义关系需要特殊的向量来表示。
关键词:
判断单词之间的语义关系,synonymy, antonymy, hypernymy, and meronymy(同义、反义关系,上下位,和整体的关系)
The STM architecture is based on the hypothesis that different specializations of input distributional vectors are needed for predicting dif-ferent lexico-semantic relations.
embedding entities and relationships of multi-relational data in low-dimensional vector spaces.
Multi-relational data 指的是directed graphs,其中地node与entities和edges相关。
应用场景
本文的工作是从KB(wordnet freebase)中建模,目的是自动添加new fact,即自动添加各种关系。
Modeling multi-relational data
对于single-relaitonal data,用一些描述性分析也能做很多预测,而relational data的难点在于locality(局部)可能会涉及多个关系,多个实体,而且种类会不一样。我们需要一个更普通的方法来考虑各种模式,对multi-relaional data进行建模,来同时捕捉所有的heterogeneous relationships(异质关系)。
Relationships as translations in the embedding space
relationships are represented as translations in the embedding space: (h, l, t)
这个模型的契机有两点。一是hierarchical relationship在了KB中很常见。比如对于一个tree结构的node进行表示,其emebdding应该接近于它的相邻node。第二点是word2vec模型的出现。
数据:Freebase containing 1M entities, 25k relationships and more than 17M training samples.
将三元组embedding


Wordnet synsets 同义词集. We considered the data version used in [2], which wedenote WN in the following. Examples of triplets are (scoreNN1,hypernym,evaluationNN1)or (scoreNN2,haspart,musicalnotationNN1
WN is composed of senses, its entities are denoted by the concatenation of a word, its part-of-speech tagand a digit indicating which sense it refers to i.e.scoreNN1encodes the first meaning of the noun “score”
relationship根据head和tail分为四种类:1-TO-1, 1-TO-MANY, MANY-TO-1, MANY-TO-MANY.
We obtained that FB15k has 26.2% of 1-TO-1relationships, 22.7% of 1-TO-MANY, 28.3% of MANY-TO-1, and 22.8% of MANY-TO-MANY.


对KB中不同的数据类型进行embedding,来实现更好的KBC效果。
关键词:
资源
为了方便human fact checker,在进行事实判断的时候,提供相关的事实和规律有助于盘算。这里的事实就是在从source 到 target 之间的各种path(relation)。
通过遍历KG,来找到truthfulness。遍历方式有:randome walks (PRA), path enumeration (PredPath), shortest paths (knowledge linker), learning from multi-relational data (RESCAL, TransE 已经TransE的各种变种), 或者使用link prediction in social networks.
In this paper, we propose Knowledge Stream (KS), an unsupervised approach for fact-checking triples based on the idea of treating a KG as a flow network. There are three motivations for this idea:
不仅和sota进行比较,还能产生对于预测结果的解释。
具体例子
(David and Goliath (book), author,Malcolm Gladwell). 这里的set of path 被称为 stream of knowledge.

Triple(s,p,o), we view knowledge as a certainamount of an abstract commodity that needs to be movedfrom the subject entitysto the object entityoacross thenetwork.
也就是说这里的并不重要,主要是找到s和o之间的的各种path。而p作为target predicate p, p`则是各种找到的和p相关的path。
https://arxiv.org/abs/1708.07239
https://github.com/shiralkarprashant/knowledgestream
2017/08/24
通过提供多个path,即relation的方式来提供更多的信息,让fact checker进行判断。
一个创新点是计算不同relation之间的相似度。



在金融方面的应用,可以找到两个公司之间的深层关系。比如上面伯克希尔和巴菲特之间通常只有一个简单的关系,但是却可以找到更多的信息。
只不过这样的话从现有的图数据库里加工还好,有很多现成的关系可以用。如果是构建垂直领域的KG,必须要添加足够多的realtion才能做到path挖掘。
虽然和知识图谱没什么关系。。
这是一篇综述文章,讲了一些用于NLP任务的Bootstrapping Techniques。
https://www.eecis.udel.edu/~vijay/fall13/snlp/lit-survey/Bootstrapping.pdf
找不到时间,但是引用的都是2003年之前的,可能就是2003年的文章吧
为什么看这篇文章?因为想把auto-label功能装到doccano上,但是active learning的效果似乎并不好(https://arxiv.org/pdf/1807.04801.pdf)。所以想找auto-label,就是随着人工标记的样本越多,模型能自动学习标记的数据,然后预测其他未标记的文本。
通过调查发现在NLP领域,这种auto-label的方法,叫做Bootstrapping。
虽然根据NLP的任务不同,Bootstrapping方法也会不一样,但是基本遵循一定的套路:
Bootstrapping Algorithms
While there is great variation between implementations, bootstrapping approaches in natural language processing all follow the same general format:
The core feature of a bootstrapping algorithm is that each iteration is fed the same type of data as its input that it produces as its output. The output of the first iteration is used as the input of the second iteration, and so on. It should not be surprising that choosing the initial set of data (the seeds) from which all other data is “grown” is a critical factor (arguably the most critical factor) in the performance of the algorithm.
上一轮迭代的结果作为下一轮的输入,这种**到时和RNN挺像的。
第一步的list of things: Usually words or phrases, but it can be any representation of language (such as regular expressions, tuples, etc.)
Knowledge Representation Learning (KRL) / Knowledge Embedding (KE)
This is the note of Chapter 5 from Deep Learning in Natural Language Processing
Goal: Embedding the entities and relations in KG.
Recent studies reveal that translation-based representation learning methods are efficient and effective to encode relational facts in KG with low-dimensional representations of both entities and relations, which can alleviate the issue of data sparsity and be further employed to knowledge acquisition, fusion, and inference
Translation-based representation learning methods:
TransE只考虑direct relations between entities.于是有了下面考虑不同relation path的方法
Relation-path-based methods:
上面这些值考虑structure information in KG, 忽视了rich multisource information such as textual information, type information, and visual information.
Goal: automatically finding unknown relational facts
Relation extraction (RE): Relation extraction aims at extracting relational data from plaintexts. In recent years, as the development of deep learning (Bengio 2009) techniques, neural relation extraction adopts an end-to-end neural network to model the relation extraction task.
The framework of neural relation extraction includes a sentence encoder to capture the semantic meaning of the input sentence and represents it as a sentence vector, and a relation extractor to generate the probability distribution of extracted relations according to sentence vectors.
Neural relation extraction (NRE) has two main tasks including sentence-level NRE and document-level NRE
Sentence-level NRE aims at predicting the semantic relations between the entity (or nominal) pair in a sentence.
三个部分
这里介绍了四种embedding:
New York is a city of United States, the relative distance from the word city to New York is 3 and United States is −2.>>> dog = wn.synset('dog.n.01')
>>> dog.hypernyms()
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]sentence encoder负责把输入的embedding变为一个向量来表示一个句子。
上面的一些方法总是受限于不足的训练样本。为了解决这个问题,研究者提出了distant supervision假设,通过KG来自动生成训练样本。
The intuition of distant supervision assumption is that all sentences that contain two entities will express their relations in KGs. For example, (New York, city of, United States) is a relational fact in KGs. Distant supervision assumption will regard all sentences that contain these two entities as valid instances for relation city of. It offers a natural way to utilize information from multiple sentences (document-level) rather than single sentence (sentence-level) to decide if a relation holds between two entities.
Therefore, document-level NRE aims to predict the semantic relations between an entity pair using all involved sentences. 其实就是multi-instance learning的另一种说法。
Document-Level NRE有四个部分:
The document encodes all sentence vectors into either single vector S.
实体链接就是研究如何将指代词链接到知识库。比如Jobs leaves Apple这个句子,我们的KB里已经有Steve Jobs这个实体了,如果把"Jobs"链接到"Steve Jobs",其实也是在消除歧义。
The main challenges for entity linking are the name ambiguity problem(实体歧义) and the name variation problem(实体变化).
这部分是传统的EL流程,没有涉及深度学习。
Given a document d and a Knowledge Graph K B, an entity linking system links the name mentions in the document as follows. 下面分几个步骤
Name Mention Identification
Candidate Entity Selection
Local Compatibility Computation
One main problem of EL is the name ambiguity problem, thus, the key challenge is how to compute the compatibility between a name mention and an entity by effectively using contextual evidences.
The name ambiguity problem is related to the fact that a name may refer to different entities in different contexts. For example, the name Apple can refer to more than 20 entities in Wikipedia, such as fruit Apple, the IT company Apple Inc., and the Apple Bank.
现在的EL很大程度上依赖于local compatibility model。即用一些手工制作的特征来表达不同的contextual evidenes. 但是这些feature-engineering-based approaches有缺点:
为了解决这些缺点,提出了基于DL的方法。
NN的一个强项在于对input能有一个很好的表达,比如词向量。
By encoding all contextual evidences in the continuous vector space which are suitable for entity linking, neural networks avoid the need of designing handcrafted features. In following, we introduce how to represent different types of contextual evidences in detail.
但是这种平均的方法没有考虑到单词的位置关系(这个很重要)。
An EL system needs to take all different types of contextual evidences into consideration。如何利用好更多的背景证据。
Generally, two strategies have been used to model the semantic interactions between different contextual evidences:
学习局部相容条件,要有一个对应的局部相容指标。
We can see that mention’s evidence and entity’s evidence will be first encoded into a continuous feature space using contextual evidence representation neural networks, then compatibility signals between mention and entity will be com-puted using semantic interaction modeling neural networks, and finally, all these signals will be summarized into the local compatibility score.
主要是针对一个句子中出现多个entity,多种relation的情况。通过把RE问题当做graph问题来处理。
关键词:
大部分RE模型假设一个句子里只有一种relation,但是一个句子的entity之间可能会包含多种关系。
这句话里有三个entity,toefting和teammates之间通过with可以知道是PER-SOC的关系,而teammates和capital之间通过in可以知道是PHYS的关系。然后可以通过这两个关系推测出toefting和captial之间也是PHYS的关系。
本文的工作是在一个entity graph上构建RE模型,entity mentions包括nodes和directed edges。
However, for relation extraction from a sentence, related pairs are not predefined and consequently all entity pairs need to be considered to extract relations. In addition, state-of-the-art RE models sometimes depend on external syntactic tools to build the shortest depen-dency path (SDP) between two entities in a sen-tence (Xu et al., 2015; Miwa and Bansal, 2016 ). This dependence on external tools leads to domain dependent models.
其实就是把RE问题中的多个relation问题,当做 graph里寻找两个node之间的shortest path问题。
公布了一个中文的数据集用来做关系分类。模型方面tree-based structure regularization令SDP更短,提升了效果。
关键词
汉语的文学作品里有很多隐含意义和作者的感受,但这些很难被识别。文学作品里的语法信息噪音很大,所以提出了结构正则化的方法来对这种文本进行关系分类。
一句话总结:
第一次把AT以正则化的用法,用于joint task。
资源:
关键字:
dataset: ACE04, ADE, CoNLL04, DREC. 看着数据集应该主要是抽取name
Adversarial training (AT)
entity recognition
relation extraction
jointly ex-tracting entities and relations
on sev-eral datasets in different contexts, and for dif-ferent languages (English and Dutch)
笔记:
Goodfellow et al.(2015 ) proposed adversarial training (AT) (for image recognition) as a regularization method which uses a mixture of clean and adversarial examples to enhance the robustness of the model. Goodfellow提出可以用AT作为正则化方法,来提高模型的robustness。
模型图:
结果:

接下来要看的论文:
提出了一个新任务:relation summarizatoin。通过query focused method来判断句子中是否表达了relationships.
关键词:
这个新任务的应用场景
一个例子:
What is the relation-ship between “Advanced Integrated Systems” and“United Arab Emirates” in the Paradise Papers?
在一篇文章里,询问两个entity的关系?和QA有点像啊。
原来还有现行研究:summarizing relationships (Falke and Gurevych, 2017a ),
Tobias Falke and Iryna Gurevych. 2017a. Bringing structure into summaries: Crowdsourcing a bench-mark corpus of concept maps. InEMNLP .
本文的工作,answering user queries about the connec-tions between two particular terms, without referencing a knowledge graph。(这种通过KG来回答关系的研究也有人做过了,Nikos Voskarides, Edgar Meij, Manos Tsagkias, Maarten De Rijke, and Wouter Weerkamp. 2015. Learning to explain entity relationships in knowl-edge graphs. InACL )
下面是两个task的解释
假设:
The relational summarization problem is some-what different: we begin with a pair of query terms,(t1)and(t2) , and we wish to learn the nature of their relationship. Therefore, any state-ment which coherently describes any relationship between the two query terms is potentially of in-terest, even if it does not match prior expectations of what constitutes a relation.
We approach the candidate set generation task as a specialized form of sentence compres-sion: we attempt to predict if a sentence from the text can be coherently compressed to the form (t1)r(t2). Table 2 shows examples of sentences which can and cannot be shortened to this form
如何找到具有关系的句子呢?这里的创新点是把这个问题变为了sentence compression问题。如果一个句子可以被压缩成 t1, r, t2的形式,那么就认为这个句子包含了t1和t2之间的关系。(这种方法能用在DS上来减少噪音吗?)
看下面效果似乎不错。
实体的细节不看了,有必要的时候再回顾。
这篇论文挺有启发性的,具体的method不用看,有必要之后再回顾。下面是两个点子:
KDD 2018 best paper in the ADS (Applied Data Science) Track.
通过SVM的Tree Kernel学习 问题文 的句法信息,然后把这个信息注入到NN模型里。注入的方式是用SVM标记没有标签的大量数据,然后用NN去学习,再拿有标签的数据去fine-tune
这是一个增强远程监督关系抽取任务的工作,通过DRL来将false positive sample变为negtive samples。
关键词:
knowledge graph construciton is the downstream applications of relation extraction.
data sparsity issue—It is extremely expensive, and almost impossible for human annotators to go through a large corpus of millions of sentences to provide a large amount of labeled training in-stances.
因为人力标注上亿语料(数据分散问题)是不可能的,所以distant supervision relation extraction 才流行。
正因为选择出的sentence是noisy的,所以才有很多研究解决这个问题。
但是本文反对这种做法,因为这种方法只会选择出一个exaple。这种方法不是最优的。(额,反对的理由太少了)为了增强robutness, 需要一个更系统的解决方案来利用更多的instance,即removing false positives and placing them in the right place.
本文的目标就是想构建一个动态的选择策略,来移除或保留 disntantly supervised candidate instance. 而这个选择策略,是通过RL来实现的。agent通过移除false positives了最大化classification accuracy.
另外RL的方法可以当做一个component组合到任意的RE模型,比如下面的图片里。即通过RL来boost其他模型。
4.4 关于False Positive Samples的影响
Zeng et al. (2015) and Lin et al. (2016) are both the robust models to solve wrong labeling problem of distant supervision relation extraction.
这两个模型都是为了解决 错误标注 问题的。但是false positive phenomenon also in-cludes the case that all the sentences of one en-tity pair are wrong。
也就是说,从distant 方法选来的样本里,本来没有entity,但是却被当做有entity pair被选中了,结果被当做表示了entity pair relation的句子。
而RL agent做的就是把这些false positive的样本,移动到negtive样本里,不让这些样本祸害模型的学习。
一句话总结:
通过学习全局的信息来对relation embdding,解决DS中样本的noisy问题。
资源:
关键字:
笔记:
embedding textual relations ,defined as the shortest dependency path1 between two entities in the dependency graph of a sentence, to improve relation extraction. 这里所谓的textual relation指的是两个实体之间的依赖关系图。
已经有人尝试过在DS上进行embedding,但是因为noisy的缘故,embedding的质量不好。传统的embedding方法是基于局部信息的(应该指的是windows),而本工作的假设则是,global statistics is more robust to noise than local statistics.
传统的embedding method是基于local statistics, 比如figure 1中左边的部分。而本文则认为,针对DS的noisy,global statistic比local statistics更健壮。通过收集global co-occurrence statistics of textual and KB relation, we will have a more comprehensive view of relation semantics: The semantics of a textual relation can then be represented by its co-occurrence distribution of KB relations
感觉对于global statistics的解释很牵强啊。
果然要有一个编故事的能力啊。说是global,其实指的是document层面(DL in KG 第五章里的分类方法,docuemnt层面指的是从DS中得到的所有instances)。因为multi-instance里有正确和false positive的例子,所以都对这些instance学习的话,自然能学到正确的关系情报。
模型图:

结果:

The pre-cision of the top 1,000 relational facts discovered by the model is improved from 83.9% to 89.3%, a 33.5% decrease in error rate. The results suggest that relation embedding with global statistics can capture complementary information to existing lo-cal statistics based models
感觉这篇论文和其他一些论文都能结合起来做一些工作。这里提到了能直接学到全局的信息,但即使这样,语料里毕竟还是包含了false positive,所以可以考虑之前那个query-based模型来提高instance质量,再去进行embedding的学习。不过只是简单结合一下,创新点有点少。(编故事?)
第一个使用了word embedding,以及positional mebdding,并把CNN用于RE任务上的工作。
此前的RE模型都是基于统计模型的,效果的好坏很大程度上取决于抽取的特征。如果特征抽取不好的话,误差也会被传递下去。
如何提取好的特征是一个问题?
通过DNN来lexical和sentence level的特征。
下面是这篇论文里和context相关的内容摘抄
用到了lexical level feature 和 sentence level features 两种特征。
Lexical Level Feature是对relation最直接的暗示。传统的lexical level feature通常会包含两个entity自己,以及这些entity的类型(应该是说POS之类吧), 以及两个entity之间的word sequence, 这些信息对于现在NLP工具的依赖非常强。为了简化可能产生噪音,这篇文章使用word embeding作为最基本的feature。表格1列出的L1~L4都是使用word embeding. 而L5的wordnet hypernyms则使用了MVRNN模型。通过MVRNN得到entity对应的hypernyms,然后再使用hypernyms的word embedding。最后把这些不同的word embedding全部concatenate起来。
其中sentence level features是通过Window Processing之后,得到了word feature和position feature 。
主要有三个部分:Word Representation, Feature Extraction and Output.
Our experiments directly utilize the trained embeddings provided by Turian et al.(2010).
这个embedding找不到了
We select the word embeddings of marked nouns and the context tokens. Moreover, the WordNet hypernyms 4 are adopted as MVRNN (Socher et al., 2012). All of these features are concatenated into our lexical level features vector
用max-pooled CNN抽取特征。
一对entity对应一个label y。window size是3.
structure features (e.g., the shortest dependency path between nominals) 是一个很有用的feautre,可以包含两个entity之间的依赖信息。但是这种特征无法通过上面的CNN提取到,所以PF被提出来了。
比如上面的例子,moving到People和downtown的距离是3, -3。而且这个相对距离会被映射到一个$d_e$维的向量。于是得到$\rm PF=[\mathbf{d}_1, \mathbf{d}_2] $.
W1是权重,X是window process输出的结果。
最后从每个句子抽取,得到一个n1维的向量(代表关系),这样就和句子长度无关了。
为了学习更复杂的特征,这里用了tanh作为非线性激活函数。
这里说经过激活函数后得到的结果代表更高维的特征,比如代表整个句子
输入是句子s,经过window processing之后,得到了X。N是word embedding. 输出是每个relation的概率。
我们的目的是最大化这个目标函数。
优化方法使用SGD。N,W,X都是随机初始化的,X是通过embedding得到的。
SemEval-2010 Task 8 dataset
macro-averaged F1-scores
position features (PF) are successfully proposed to specify the pairs of nominals to which we expect to assign relation labels. The system obtains a significant improvement when PF are added.
把Distant Supervision问题当做multi-instance问题就解决错误标注的情况。并引入PCNN提取segment更细节的information。
对于RE任务,distant supervision有两个问题。
针对RE,一个挑战是如何产生足够的训练数据。而distant supervision被提出来了。
但是这种方式有两个很大的缺点
Figure 3 shows our neural network architecture for distant supervised relation extraction. It illustrates the procedure that handles one instance of a bag. 这个过程包含四个部分: Vector Representation, Convolution, Piecewise Max Pooling and Softmax Output. We describe these parts in detail below.
与之前面的#13 使用的embedding不同,这里用了word2vec
为什么选择son作为中点呢?是因为son、表示关系吗?如果句子里没有这个表示关系的词的话,怎么办?
卷积的说明
Convolution is an operation between a vector of weights, w, and a vector of inputs that is treated as a sequence q
将卷积的结果做Piecewise Max Pooling,根据两个entity的位置分别做 Max Pooling。具体可以看图容易理解。每一个filter的结果通过Piecewise Max Pooling得到一个3位的向量,然后把这个向量与其他filter通过Piecewise Max Pooling的结果结合起来。
最后得到的向量维度与原来的句子长度无关。
最后一步通过softmax输出的结果$o_i$表是对每个$relaiton_i$的概率。
在倒数第二层用一个dropout来进行正则化。具体的**就是用一个masking操作来屏蔽掉一些神经元。
测试的时候不能使用dropout,即关闭masking。
为了解决第一个问题,使用multi-instance learning for PCNN。还记得刚才说的吗?通过设计一个更有效的目标函数来考虑bag里的没有标签的实例。
因为之前的目标函数是针对instance的,所以这里要把目标函数改为针对bag的。等等。
整个算法流程为:
传统的反向传递是根据所有训练实例的,但是multi-instance learning则是基于bag的。因为一个bag里有标注错误的句子,所以我们基于bag训练的结果,自然也把这种错误的信息学了进去。
训练好PCNN之后,用于预测的时候,只有当一个bag里起码有一个实例被标记为正标签的时候,这个bag才会被标记为正标签。
We evaluate our method on a widely used dataset 4 that was developed by (Riedel et al., 2010) and has also been used by (Hoffmann et al., 2011; Surdeanu et al., 2012). This dataset was generated by aligning Freebase relations with the NYT corpus, with sentences from the years 2005-2006 used as the training corpus and sentences from 2007 used as the testing corpus.
word2vec,每个单词50维。
Half of the Freebase relations are used for testing.
MIML is a multi-instance multilabel model that was proposed by (Surdeanu et al., 2012).PCNNs+MIL denotes our method
Thus, the held-out evaluation suffers from false negatives in Freebase. We perform a manual evaluation to eliminate these problems. For the manual evaluation, we choose the entity pairs for which at least one participating entity is not present in Freebase as a candidate. This means that there is no overlap between the held-out and manual candidates.
Both CNNs+MIL and PCNNs+MIL outperform their counterparts CNNs and PCNNs, respectively, thereby demonstrating that incorporation of multi-instance learning into our neural network was successful in solving the wrong label problem.
一句话总结:
这篇survey比之前 #10 那篇要更详细一些,有点长51页。
资源:
关键字:
笔记:
第2章里全是基于feautre和kernel的监督式学习方法。但是如何事前没有标记好的POS,NER之类的标签的话,错误是会累计的。比如先预测NER出错,再判断relation仍然会出错。为了防止这种情况,于是把Entities and Relations的抽取任务结合起来处理。
Major motivation behind designing semi-supervised techniques is two-fold: i) to reduce the manual efforts required to create labelled data; and ii) exploit the unlabelled data which is generally easily available without investing much efforts.
Distant Supervision, proposed by Mintz et al. [75], is an alternative paradigm which does not require labelled data. The idea is to use a large semantic database for automatically obtaining relation type labels. Such labels may be noisy, but the huge amount of training data is expected to offset this noise.
There have been several techniques for joint modelling of entity and relation extraction. However, the best reported F-measure on ACE 2004 dataset when gold-standard entities are not given, is still very low at around 48%. This almost 30% lower than the F-measure achieved when gold-standard entity information is assumed. Hence, there is still some scope of improvement here with more sophisticated models.
There has been little work for extracting n-ary relations, i.e. relations involving more than two entity mentions. There is a scope for more useful and principled approaches for this.
Most of the RE research has been carried out for English, followed by Chinese and Arabic, as ACE program released the datasets for these 3 languages. It would be interesting to analyse how effective and language independent are the existing RE techniques. More systematic study is required for languages with poor resources (lack of good NLP pre-processing tools like POS taggers, parsers) and free word order, e.g. Indian languages.
Depth of the NLP processing used in most of the RE techniques, is mainly limited to lexical and syntax (constituency and dependency parsing) and few techniques use light semantic processing. It would be quite fruitful to analyse whether deeper NLP processing such as semantics and discourse level can help in improving RE performance.
模型图:
结果:
接下来要看的论文:
通过释义将复合名词里隐含的关系变为明显的关系。
关键字:
复合名词里包含了一些隐含的语义关系,比如‘birthday cake’ is a cakeeaten on a birthday, while ‘apple cake’ is a cakemade of apples. 而当前一些 复合名词释义 的工作是基于corpus co-occurrences的,这个corpus里包含有复合名词成分中的explicit relation。但这种方法有问题,gen-eralize for unseen noun-compounds。
本文提出了一个半监督模型用来对复合名词释义。we train the model to predict ei-ther a paraphrase expressing the semantic rela-tion of a noun-compound (predicting ‘[w2 ] made of [w1 ]’ given ‘apple cake’), or a missing con-stituent given a combination of paraphrase and noun-compound (predicting ‘apple’ given ‘cake made of [w1 ]’).
给定apple cake, 然后输出 [w2 ] made of [w1 ]这样的释义(paraphrase), 或者给定一个释义 cake made of [w1 ], 然后预测w1是'apple'.
这种预测模型可以在一定程度上解决没有见过的复合名词,吗?()
一句话总结:
DS noisy中大部分模型没有考虑relation之间的内在关系。通过考虑Relation之间的Hierarchical Relation,利用attention-based模型给每个句子与不同relation的关系打分,对于 long-tail relations得到了不错的效果。
资源:
关键字:
笔记:
现在解决DS中wrong label problem的方法中,都是独立看待relation的,对于每一种relation,用一个单独的模型从noisy data中来选择出与这个relation相关的instance,而没有考虑relation之间的语义关系,而这些语义关系以hierarchy的形式存在。
以KG Freebase为例,其中地relaiton是以hierarchical structures的形式被标记的。比如一个relation /location/province/capital,表示的是provicen和capital之间的关系,属于locantion这个分支下。在这个分支下面,还有其他一些relations,比如/location/location/contains and /location/country/capital. 这些relation之间的关系是很接近的,可以用hierarchical来表示。
为了利用好这些信息,这里提出了一个hier-archical attention scheme. 不是直接把hierarchi-cal information 当做feature,而是基于attention模型,对每一个instance,计算它和corresponding relation之间的重要度 score。如下图所示,这个多层注意力模型是基于relation hierarchies来计算score的,比如针对包含同样head, tail entity的instance, 计算每个instance在不同realtion下的score。
这个模型的优点,对于 those long-tail relations效果比较好。
模型图:

结果:

一句话总结:
通过MRT作为global loss来对NER以及RE进行joint learning。
资源:
论文信息:
笔记:
一般的joint settting是把NER和RE分为两个模型来处理的,忽视了二者之间的联系(NER的提高能提升RE的效果?)。比如NER的时候无视了relation annotation,而这些对于辨别name entity是有用的的。比如ORG-AFF这样的关系,那么NER模型给实体赋予ORG和AFF就可以了。(有问题啊,大部分RE里的relation,都不是这样定义的)
模型图:
结果:
接下来要看的论文:
一句话总结:
提出了triplet其实有很多类型,大家都没有注意到overlop的问题。为了解决这个问题,基于Zheng et al. (2017 ) 的工作,通过copy的方式来解决triplet overlap问题。模型方面是用seq2seq,可以直接同时提取 entity和relation
问题:
提案:
具体做法:
效果:
资源:
论文信息:
笔记:
Recently, with the success of deep learning on many NLP tasks, it is also applied on relation-al facts extraction. Zeng et al. (2014); Xu et al. (2015a,b ) employed CNN or RNN on relation classification. Miwa and Bansal (2016); Gupta et al. (2016); Zhang et al. (2017 ) treated relation extraction task as an end-to-end (end2end) table-filling problem. Zheng et al. (2017 ) proposed a novel tagging schema and employed a Recurrent Neural Networks (RNN) based sequence labeling model to jointly extract entities and relations
Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. 2017. Joint extrac-tion of entities and relations based on a novel tagging scheme. InProceedings of ACL, pages 1227–1236.
这篇文章似乎有必要读一读

(具体解释一下怎么个overlap problem。这个主要是根据relation类型进行分类的。第一种normal case没什么讲的。第二种EntityPairOverlap例子,即Sudan和Khartoum这两个entity之间有不止一个relation, 所以叫EntityPairOverlap。第三种情况下只有Aarhus有两种relation,所以叫做SingleEntityOverlap)
而大部分研究都只针对normal case,比如 #203 虽然做到了joint,减少了NER的误差。但是这个model只能对一个word赋予一个tag,即一个word只能存在于最多一个triplet里。(也就是说无法同时预测出多个relation)
模型方面,使用了seq2seq。The encoder converts a natural language sentence (the source sentence) into a fixed length semantic vector. Then, the decoder reads in this vector and generates triplets directly.
To generate a triplet,
模型图:

结果:

(。。数据太小了)

(但是NovelTagging的值有点小啊)
直接与 #203 进行比较。
4.5 Detailed Results on Different Sentence Types
We divide the sentences in NYT test set into 5 subclasses. Each class contains sentences that has 1,2,3,4 or >= 5 triplets. The results are shown in Figure 5.

接下来要看的论文:
为了消除Distant supervision dataset的噪音,训练一个GAN的生成器,利用GAN来从nosiy data里判别正样本和false positive样本,提高数据的质量。
这个和之前那个利用强化学习的那篇文章类似,目的是选出更好的training samples,可以和其他模型混用。
#23
关键词:
However, they overlook the case that all sentences of an entity pair are false positive, which is also the common phenomenon in distant supervision datasets. Un-der this consideration, an independent and accu-ratesentence-level noise reduction strategy is the better choice
DS对于RE有用,但是有noise labeling problem. 现在的一些基于DS的研究忽视了false positive样本。所以本文的工作就是利用GAN对noisy dataset进行判断,选出positive samples,false positive sample放到negtive smaple里。
Given the discriminator that possesses the decision boundary of DS dataset (the brown decision boundary in Figure 1 ), the generator tries to generate true positive samples from DS posi-tive dataset; Then, we assign the generated sam-ples with negative label and the rest samples with positive label to challenge the discriminator. Un-der this adversarial setting, if the generated sam-ple set includes more true positive samples and more false positive samples are left in the rest set, the classification ability of the discriminator will drop faster
针对NEL任务,通过把entity之间的relation变为latent variable来进行学习,来让NEL的识别程度摆脱专门的领域知识和标签。
关键词:
创建了一个新的科学文献数据集,将Identification of Entities, Relations, and Coreference三个task通过multi-task的学习方式,提高了cross-sentence的抽取效果。
关键词:
资源:
将学术信息变为结构化的KG需要IE方法来判断entity以及relationship。但有一些挑战:
大部分工作都是把extracting scientific entities, relations, and coreference resolution.这三个任务进行分别处理的,但是本文提出了一个统一的学习模型,来把这些模型作为整体来处理。这个模型是multi=task的,在low-level task上share parameters,然后利用不同文本之间的coreference link了预测。本文是基于之前的工作(end-to-end coreference resolution system),(Lee et al., 2017; He et al., 2018 ). 与一般的taggin系统不一样,本文的系统能李举出所有可能的)span(即使是overlapped span),这样可以防止不同task之间训练时错误传递,统一给all span, span-span建模。
新数据集SCIERC,包括了scientific terms, relation categories and co-reference links。最后还构建了KG,来实际查看效果如何。
手动创建一个三元组(triple)的成本大约在 2 到 6 美元左右,而自动创建知识图谱的成本要降低 15 到 250 倍(即一个三元组 1 美分到 15 美分)。
triple: (subject, relation, object). For example, "(cats, play with, yarn)"
这篇文章很短,大致估计了一下创建每条三元组的成本。
用于比较的知识图谱数据库有两大类型,人工创建和自动创建。人工创建指的是通过人力来制作三元组 。自动创建是通过编写代码,通过代码自动从数据中提取三元组。
人工创建(通过投资或时薪来估算)
cost per assertion = total cost / number of assertions 自动创建(通过每小时的lines of code (LOC)和时薪来估算)
另外不仅要看成本,还要看数据的质量
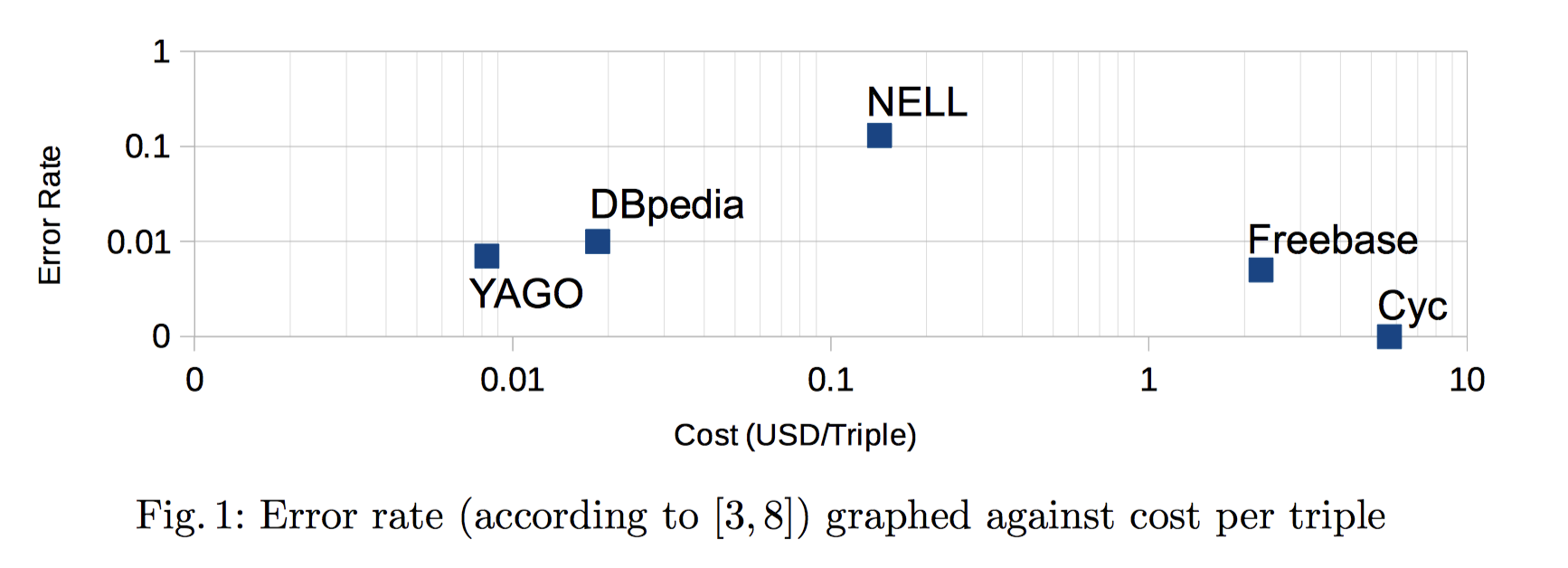
可以看到人工创建的错误率普遍较低。
一句话总结:
不同的NLP任务中对于relation的标注和设计都不同,这种换了task整个标注数据就无法复用的设计太差了。于是本文提出了一个通用式的标注框架,用这个框架能对在不同NLP任务中,表达relation。
资源:
关键字:
笔记:
这篇论文主要是设计SRL任务,和RE关系不太。而且还是做event extraction。
模型图:

但这个框架是基于XML的,从趋势来看,还是JSON会更好一些
结果:
接下来要看的论文:
把Seed选择和降噪这两个任务当做排序任务来处理。
Bootstrapping for relation extraction: initial-ized by a small set of example instances called seeds , to represent a particular semantic relation, the bootstrapping system operates iteratively to ac-quire new instances of a target relation. Selecting “good ” seeds is one of the most important steps to reduce semantic drift , which is a typical phe-nomenon of the bootstrapping process。对每种关系选择一组seed example来代表这种关系。而如何选择good seed则是非常关键的。毕竟选得不好,训练出来效果自然不怎么样。
distant supervision:does not require any la-bels on the text. The assumption of DS is that if two entities participate in a known Freebase rela-tion, any sentence that contains those two entities might express that relation. However, this tech-nique often introduces noise to the generated train-ing data. As a result, DS is still limited by the quality of training data, and noise existing in pos-itively labeled data may affect the performance of supervised learning。说白了就是DS默认只要一句话里包含两个entity,就默认这句话里有这两个entity的固定关系,可在现实中,即使两个entity同时出现,二者的关系也可能会变化,所以DS会引入噪音,即标签本身就不对。
本文提出了能自动选择seed,以及nosie reduction的方案,即根据ranking criteria把这些任务当做ranking problem。启发来自于HITS算法。
**Hub页面(枢纽页面)和Authority页面(权威页面)是HITS算法最基本的两个定义**。所谓“Authority”页面,是指与某个领域或者某个话题相关的高质量网页,比如搜索引擎领域,Google和百度首页即该领域的高质量网页,比如视频领域,优酷和土豆首页即该领域的高质量网页。
所谓“Hub”页面,指的是包含了很多指向高质量“Authority”页面链接的网页,比如hao123首页可以认为是一个典型的高质量“Hub”网页。
图1给出了一个“Hub”页面实例,这个网页是斯坦福大学计算语言学研究组维护的页面,这个网页收集了与统计自然语言处理相关的高质量资源,包括一些著名的开源软件包及语料库等,并通过链接的方式指向这些资源页面。这个页面可以认为是“自然语言处理”这个领域的“Hub”页面,相应的,被这个页面指向的资源页面,大部分是高质量的“Authority”页面。
算法基本**:相互增强关系
基本假设1:一个好的“Authority”页面会被很多好的“Hub”页面指向;
基本假设2:一个好的“Hub”页面会指向很多好的“Authority”页面;
简单来说就是另一个用于计算网页权重的方法,和pagerank一类。
Formulation as Ranking Tasks: As we can see from the task definitions above, both seed selec-tion and noise reduction are the task of selecting triples from a given collection. Indeed, the two tasks essentially have a similar goal in terms of the ranking-based perspective. We thus formulate them as the task of ranking instances (in seed se-lection) or triples (in noise reduction), given a set of (possibly noisy) triples. In the seed selection task, we use thek highest ranked instances as the seeds for bootstrapping RE. Likewise, in noise re-duction for DS, we only use thek highest ranked triples from the DS-generated data to train a clas-sifier. Note that the value ofk in noise reduction may be much larger than in seed selection.
调查active learning对于NLP任务标注是否真得有用的文章。
https://arxiv.org/abs/1807.04801
12 Jul 2018
active learning是通过A模型挑选出一些”值得“标注的样本,然后再用其他的S模型进行训练。A模型是使用了score function的。
总体来说,即使直接随机挑选样本给S模型训练,效果可能都比用A模型挑选样本给S模型训练来得好。所以active learning的有效性值得怀疑。
对于Lifelong learning in Relation Extraction这个新问题,提出了一个alignment model用来减轻emebdding space在学习过程中的变形。解决Lifelong learning中的forgetting prpblem.
关键词:
主要问题:
当前的RE都是在给定relation的情况下进行抽取的。但是这种情况对于真实的使用场景来说不方便。因为现实中relation是不断增加的。
所以需要一个能不断学习动态数据的进化系统,这就是Lifelong learning、continual learning的背景(这不就是online-learning嘛)。一个learning agent从一系列tasks中学习,每个task包含不同的relation数据。
但是很难把新数据和旧数据整合在一起,然后对combined数据进行再训练。
Lifelong learning:
Learn the tasks incrementally. 以递增的方式学习tasks,同时还要防止catastrophic forgetting. 因为模型在对new task学习的时候,会忘记之前的知识。
解决办法:
但是本工作尝试了上面的两种方法,效果不好。
当前的LL方法只对model parameter space或者gradient space进行限制,而没有对feature or embedding space进行限制。所以在训练新task的时候,embedding空间会变形。
所以我们的假设是,这种变形会让模型忘记之前学习的知识。
为了解决这个问题,本工作提出了an alignment model,用来固定sentence embedding。Specifically, the alignment model treats the saved data from previous tasks as anchor points and minimizes the distortion of the anchor points in the embedding space in the lifelong relation extraction.
The aligned embedding space is then utilized for relation extraction.
贡献:
相关论文:EMNLP-2018-FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation #37
当前针对RE任务,bootstrapping方法基于entity-pair-centered学到的extractor是很noisy的,为了减少噪音,同时利用entity-pair和tempate-centered方法来同时学习extractor,提高了正样本的数量,提高了extractor的置信度。
关键词:
下面第一段直接拿过来了,对于bootstraping解释得很清楚。
bootstrap是一种半监督的RE方法,首先从corpus中找到positive seed的entity pairs,然后转换成extraction pattern。这里的extractor(提取器)是从corpus里生成的一个聚类样本集。所以要选取好的seed是非常重要的,如果seed选的不好,生成的聚类样本集质量也会差,污染了训练数据。
所以对extractor进行评价,提高confidence才能让输出的质量也变高。本文提出了oint Boot-strapping Machine1 (JBM)。至今为止的研究都是entity-pair-centered boosttrappng for RE, 而JBM则能同时利用entity-pair和tempate-centered方法来同时学习extractor,学习样本里出现的entity pair以及template seeds。
模型的目标(效果):提高extractor的置信度, improving the scores fornon-noisy-low-confidence extractors, resulting in higherrecall .
通过将relation变为三个层级(Relation clusters, relations and sub-relations),来增强普通的KGE方法(transE, TransH, Dist-Mult)对于relation的学习能力。
关键词:
一句话总结:
利用CNN和Transformer构建的模型,学习长文本里的entity之间的关系。
用了transformer。jointly solve for NER and RE tasks using cross-entropy loss.
资源:
关键字:
笔记:
问题背景:一般的RE是在一个很短的句子上,并且句子里只有一对entity pair,预测是否存在relation。但是这种方法无视了不同mentions之间的内在联系,也无视了不同entity在不同句子中的关系(有点像是指代的问题)。
比如在Biocreative V CDR dataset这个数据集里,30%以上的relaiton,都是across sentnce boundaries.
尽管二者没有出现在一个句子里,但是我们还是能看出来,azathioprine can cause the side effect fibrosis。
To facilitate efficient full-abstract relation ex-traction from biological text, we propose Bi-affine Relation Attention Networks (BRANs), a combi-nation of network architecture, multi-instance and multi-task learning designed to extract relations be-tween entities in biological text without requiring explicit mention-level annotation.
BRANs:NN网络,multi-instance and multi-task learning
We synthesize convolutions and self-attention, a modification of the Transformer encoder introduced by Vaswani et al. (2017 ), over sub-word tokens to efficiently incorporate into token representations rich context between distant mention pairs across the entire ab-stract.
把CNN和一个Transformaer的变种结合起来,并在sub-word level上学习embedding。
模型图:
结果:
后续研究: #99
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.