ccforward / cc Goto Github PK
View Code? Open in Web Editor NEWCode & Blog
Code & Blog






































































































































































































类似数组,但是成员都是唯一的没有重复值。
Set本身是一个构造函数用来生成Set类型的数据
Set可以接受一个数组或者类数组的对象作为参数来初始化
var s = new Set([1,2,3,3,3,4,5])
s.size // 5
[...s] // [1,2,3,4,5]
var ss = new Set([...document.querySelectorAll('div')]);
ss.size // div的个数
// 相当于
[...document.querySelectorAll('div')].forEach(div => ss.add(div))使用 Set 数组去重 [...new Set(array)]
使用 Set 加入值时不会转换类型 5 和 '5' 是两个不同的值。虽然 NaN === NaN 返回 false, 但是在 Set 内部 NaN 是等于自身的。
var set = new Set();
var a = NaN;
var b = NaN;
set.add(a);
set.add(b);
set.size // 1 Set 内部 两个 NaN 是相等的但是两个对象总是不等的
var set = new Set();
set.add({});
set.add({});
set.size // 2Set.prototype.constroctor 构造函数Set.prototype.size Set 实例的成员总数Array.from 可以将 Set 结构转为数组
var s = new Set([1,2,3,4]);
var arr = Array.from(s);
arr // [1, 2, 3, 4]数组去重的另一种方法
var unique = function(arr){
return Array.from(new Set(arr))
}
unique([1,2,2,3,3,4]);Set 遍历的顺序就是插入顺序。如果使用Set保存一个回调函数的列表,调用时就能按照添加的顺序来调用。
key()、values()、entries()返回的都是遍历器对象。因为 Set 没有键名(或者键名和键值是同一个值),所以key()和value()的行为完全一致。
var set = new Set(['aa', 'bb', 'cc']);
for (var item of set.keys()) {
console.log(item);
}
// aa
// bb
// cc
for (var item of set.values()) {
console.log(item);
}
// aa
// bb
// cc
for (var item of set.entries()) {
console.log(item);
}
// ["aa", "aa"]
// ["bb", "bb"]
// ["cc", "cc"]Set 结构的实例默认可以遍历 它的默认遍历器生成函数就是它的 values 方法
Set.prototype[Symbol.iterator] === Set.prototype.values
那么就可以直接用 for...of 来遍历Set。省略 values 方法。
var set = new Set(['aa', 'bb', 'cc']);
for(s of set) {
console.log(s);
}
// aa
// bb
// ccvar set = new Set(['aa', 'bb', 'cc']);
set.forEach((val,key) => console.log(val + ' - sss'))扩展运算符 (...) 内部使用 for...of 循环,所以也可以是用 Set 结构。
var set = new Set(['a', 'b', 'c']);
var arr = [...set];
// ['a', 'b', 'c']数组的 map filter 方法也可用于 Set
var set = new Set([1, 2, 3]);
set = new Set([...set].map(x => x*2));
// Set {2, 4, 6}
var set = new Set([1, 2, 3, 4, 5]);
set = new Set([...set].filter(x => (x%2) ==0 ));
// Set {2, 4}Set 很容易实现并集(Union)、交集(Intersect)和差集(Difference)
var a = new Set([1,2,3]);
var b = new Set([2,3,4]);
var union = new Set([...a, ...b]);
// Set {1, 2, 3, 4}
var intersect = new Set([...a].filter(x => b.has(x) ));
// Set {2, 3}
var diff = new Set([...a].filter(x => !b.has(x) ));
// Set {1}与 Set 区别
var ws = new WeakSet();
ws.add(1); // Uncaught TypeError: Invalid value used in weak set
ws.add(Symbol()); // Uncaught TypeError: Invalid value used in weak setvar a = [[1,2], [3,4]];
var ws = new WeakSet(a);上面代码中 a 数组的成员成为 WeakSet 的成员,而不是 a 数组本身。因此数组的成员只能是对象。
WeakSet 没有 size forEach 属性,没有办法遍历它的成员。
WeakSet不能遍历,是因为成员都是弱引用,随时可能消失,遍历机制无法保证成员的存在,很可能刚刚遍历结束,成员就取不到了。WeakSet的一个用处,是储存DOM节点,而不用担心这些节点从文档移除时,会引发内存泄漏。
对象(Object) 本质上是键值对的集合(Hash结构), 但是只能用字符串当键(字符串 - 值)。
Map 数据结构中各种类型的值(包括对象)都可以当作键(值 - 值)。
var m = new Map();
var o = {a: 'abcd'};
m.set(o, 'content');
m.get(o); // 'content'
m.has(o); // true
m.delete(o); // true
m.has(o); // falseMap也可以接受一个数组作为参数。该数组的成员是一个个表示键值对的数组。
var m = new Map([
['name1', 'a'],
['name2', 'b']
]);
m.size // 2
m.has('name1') // truetrue 和 字符串 'true' 在 Map 表示两个值
var m = new Map([
[true, 'a'],
['true', 'b']
]);
m.get(true) // 'a'
m.get('true') // 'b'重复赋值会覆盖
var m = new Map();
m
.set('a', 'a')
.set('a', 'b')
m.get('a') // 'b'读取一个未知的键,则返回undefined new Map().get('abc')
只有对用一个对象的引用 Map 才会视为同一个键
var m = new Map();
m.set(['a'], 123);
m.get(['a']) // undefined
var map = new Map();
var k1 = ['a'];
var k2 = ['a'];
map
.set(k1, 111)
.set(k2, 222);
map.get(k1) // 111
map.get(k2) // 222
// 变量k1和k2的值是一样的,但是它们在Map结构中被视为两个键所以说,Map 的键是和内存地址绑定的,内存地址不同,就视为两个键。这样就解决了同名属性的问题。
在 Map 中 NaN 视为同一个键 0与 -0 也是同一个键,因为 0 === -0
Map的遍历顺序就是插入顺序。
let map = new Map([
['F', 'no'],
['T', 'yes'],
]);
[...map.values()]
// ["no", "yes"]
[...map.keys()]
// ["F", "T"]
for (let item of map.entries()) {
console.log(item[0], item[1]);
}
// 或者
for (let [key, value] of map.entries()) {
console.log(key, value);
}
// F no
//T yes使用扩展运算符(...)Map结构可转为数组结构
var map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
]);
[...map.entries()]
// [[1,'one'], [2, 'two'], [3, 'three']]
[...map]
// [[1,'one'], [2, 'two'], [3, 'three']]结合数组的map方法、filter方法,可以实现Map的遍历和过滤(Map本身没有map和filter方法)
var map0 = new Map()
.set(1, 'a')
.set(2, 'b')
.set(3, 'c');
var map1 = new Map(
[...map0].filter(([k, v]) => k < 3)
);
// 产生Map结构 {1 => 'a', 2 => 'b'}
var map2 = new Map(
[...map0].map(([k, v]) => [k * 2, '_' + v])
);
// 产生Map结构 {2 => '_a', 4 => '_b', 6 => '_c'}Map转为数组
使用扩展运算符
var m = new Map().set(true, 7).set({foo: 3}, ['abc']);
[...m]
// [ [ true, 7 ], [ { foo: 3 }, [ 'abc' ] ] ]数组转为Map
数组直接放入Map的构造函数
var m = new Map([ [ true, 7 ], [ { foo: 3 }, [ 'abc' ] ] ]);
m
// Map {true => 7, Object {foo: 3} => ["abc"]}Map转为对象
所有的键为字符串的Map可转换为数组
function strMapToObj(map) {
let obj = Object.create(null);
for(let [k,v] of map){
obj[k] = v;
}
return obj;
}
var m = new Map().set('a', 'a1a2a3').set('true', true);
strMapToObj(m);
// Object {a: "a1a2a3", true: true}对象转为Map
function objToStrMap(obj){
let m = new Map();
for(let [k,v] of obj){
m.set(k,v)
}
return m
}Map转为JSON
Map的键名都是字符串,可以直接转为JSON
function mapToJson(map){
return JSON.stringify(strMapToObj(map));
}
var m = new Map().set('yes', true).set('no', false);
strMapToJson(m)
// '{"yes":true,"no":false}'Map的键名如果有非字符串,可选择转为数组JSON
function mapToArrayJson(m){
return JSON.stringify([...m])
}
var mm = new Map().set(true, 7).set({foo: 3}, ['abc']);
mapToArrayJson(mm)
// "[[true,7],[{"foo":3},["abc"]]]"JSON转为Map
正常情况下所有键名都是字符串
function jsonToStrMap(json){
return objToStrMap(json);
}
jsonToStrMap('{"yes":true,"no":false}')
// Map {'yes' => true, 'no' => false}有一种特殊情况 整个 JSON 是一个数组,每个数组成员本身又是一个有两个成员的数组,这时课一一对应的转为Map
function jsonToMap(jsonStr) {
return new Map(JSON.parse(jsonStr));
}
jsonToMap('[[true,7],[{"foo":3},["abc"]]]')
// Map {true => 7, Object {foo: 3} => ["abc"]}WeakMap 与 Map 类似,只接受对象作为键名(null 除外),而且键名所指向的对象,不计入垃圾回收机制。
WeakMap 的设计目的在于,键名是对象的弱引用(垃圾回收机制不将该引用考虑在内),所以其所对应的对象可能会被自动回收。当对象被回收后,WeakMap 自动移除对应的键值对。典型应用是,一个对应 DOM 元素的WeakMap 结构,当某个 DOM 元素被清除,其所对应的 WeakMap 记录就会自动被移除。基本上,WeakMap 的专用场合就是,它的键所对应的对象,可能会在将来消失。WeakMap结构有助于防止内存泄漏。
var wm = new WeakMap();
var element = document.querySelector(".element");
wm.set(element, "Original");
wm.get(element) // "Original"
element.parentNode.removeChild(element);
element = null;
wm.get(element) // undefinedWeakMap 没有遍历操作,无法清空,只有四个方法可用:get()、set()、has()、delete()
WeakMap 应用的典型场合就是 DOM 节点作为键名。
let myElement = document.getElementById('logo');
let myWeakmap = new WeakMap();
myWeakmap.set(myElement, {timesClicked: 0});
myElement.addEventListener('click', function() {
let logoData = myWeakmap.get(myElement);
logoData.timesClicked++;
myWeakmap.set(myElement, logoData);
}, false);myElement 是一个 DOM 节点,每当发生 click 事件,就更新一下状态。我们将这个状态作为键值放在 WeakMap 里,对应的键名就是 myElement 。一旦这个 DOM 节点删除,该状态就会自动消失,不存在内存泄漏风险。
WeakMap的另一个用处是部署私有属性。
let _counter = new WeakMap();
let _action = new WeakMap();
class Countdown {
constructor(counter, action) {
_counter.set(this, counter);
_action.set(this, action);
}
dec() {
let counter = _counter.get(this);
if (counter < 1) return;
counter--;
_counter.set(this, counter);
if (counter === 0) {
_action.get(this)();
}
}
}
let c = new Countdown(2, () => console.log('DONE'));
c.dec()
c.dec()Countdown 类的两个内部属性 _counter 和 _action ,是实例的弱引用,所以如果删除实例,它们也就随之消失,不会造成内存泄漏。
其实很简单:
text-decoration: underline
或者
a[href] {
border-bottom: 1px solid #333;
text-decoration: none;
}虽然用 border-bottom 模拟下划线可以对颜色、线宽、线型进行控制,但是明显这些下划线和文本之间的间距太大。如图:
当然可以给a标签加一个 display:inline-block; 再制定一个小一点的 line-height:
display: inline-block;
border-bottom: 1px solid #333;
line-height: .9;但是一旦换行就悲剧了,阻止了正常的文本换行:
其实还可以用一层内嵌的 box-shadow: 0 -1px #333 inset让鲜花县李文本近一些,但是微乎其微只是近了线宽那么一点的距离,不明显。
最佳的解决方案是用意想不到的 background-image
background: linear-gradient(#f00, #f00) repeat-x;
background-size: 100% 1px;
background-position: 0 1em;这样就显得很优雅柔和了
不过还有问题,字母 p 和 y 被下划线穿过了,如果遇到字母能自动避开会更好,所以,加入背景是一片实色,即可以设置两层与背景色相同的 text-shadow 来模拟这种效果
background: linear-gradient(#f00, #f00) repeat-x;
background-size: 100% 1px;
background-position: 0 1em;
text-shadow: .05em 0 #fff, -.05em 0 #fff;使用背景渐变来实现下划线可以做到相当灵活的转换:
比如一条绿色虚线下划线
background: linear-gradient(90deg, #f00 70%, transparent 0) repeat-x;
background-size: .2em 2px;
background-position: 0 1em;
text-shadow: .05em 0 #fff, -.05em 0 #fff;通过色标的百分比调整虚线的虚实比例, 用 background-size 来调整虚线的疏密。
把页面的数据爬下来难道还是自己再重新拼接数据的嘛
<meta charset="utf-8"><html lang="zh-cmn-Hans"><html lang="zh-cmn-Hant"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /><meta name="renderer" content="webkit"><meta http-equiv="Cache-Control" content="no-siteapp" />经常写:
<meta name ="viewport" content ="width=device-width, initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no">
content参数:
iPhone 6 和 iPhone 6+ :
<meta name="viewport" content="width=375">
<meta name="viewport" content="width=414">
<meta name="apple-mobile-web-app-title" content="标题"><meta name="apple-mobile-web-app-capable" content="yes" /><meta name="apple-mobile-web-app-status-bar-style" content="black-translucent" /><meta name="format-detection" content="telephone=no" />link标签,rel 参数: apple-touch-icon 图片自动处理成圆角和高光等效果。
apple-touch-icon-precomposed 禁止系统自动添加效果,直接显示设计原图。
<link rel="apple-touch-icon-precomposed" href="/apple-touch-icon-57x57-precomposed.png" /><link rel="apple-touch-icon-precomposed" sizes="72x72" href="/apple-touch-icon-72x72-precomposed.png" /><link rel="apple-touch-icon-precomposed" sizes="114x114" href="/apple-touch-icon-114x114-precomposed.png" /><link rel="apple-touch-icon-precomposed" sizes="144x144" href="/apple-touch-icon-144x144-precomposed.png" /><link rel="apple-touch-icon-precomposed" sizes="180x180" href="retinahd_icon.png">Apple的文档 链接
iPad启动画面不包括状态栏区域
<link rel="apple-touch-startup-image" sizes="768x1004" href="/splash-screen-768x1004.png" />iPhone 和 iPod touch 的启动画面是包含状态栏区域的
<link rel="apple-touch-startup-image" href="/splash-screen-320x480.png" /><link rel="apple-touch-startup-image" href="launch6.png" media="(device-width: 375px)"><link rel="apple-touch-startup-image" href="launch6plus.png" media="(device-width: 414px)"><meta name="apple-itunes-app" content="app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL">Android Lollipop 中的 Chrome 39 增加 theme-color meta 标签,用来控制选项卡颜色。
<meta name="theme-color" content="#db5945">
<meta name="msapplication-TileColor" content="#000"/><meta name="msapplication-TileImage" content="icon.png"/>添加RSS订阅
<link rel="alternate" type="application/rss+xml" title="RSS" href="/rss.xml" />
<!DOCTYPE html> <!-- 使用 HTML5 doctype,不区分大小写 -->
<html lang="zh-cmn-Hans"> <!-- 更加标准的 lang 属性写法 http://zhi.hu/XyIa -->
<head>
<!-- 声明文档使用的字符编码 -->
<meta charset='utf-8'>
<!-- 优先使用 IE 最新版本和 Chrome -->
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/>
<!-- 页面描述 -->
<meta name="description" content="不超过150个字符"/>
<!-- 页面关键词 -->
<meta name="keywords" content=""/>
<!-- 网页作者 -->
<meta name="author" content="name, [email protected]"/>
<!-- 搜索引擎抓取 -->
<meta name="robots" content="index,follow"/>
<!-- 为移动设备添加 viewport -->
<meta name="viewport" content="initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no">
<!-- width=device-width 会导致 iPhone 5 添加到主屏后以 WebApp 全屏模式打开页面时出现黑边 http://bigc.at/ios-webapp-viewport-meta.orz -->
<!-- iOS 设备 begin -->
<meta name="apple-mobile-web-app-title" content="标题">
<!-- 添加到主屏后的标题(iOS 6 新增) -->
<meta name="apple-mobile-web-app-capable" content="yes"/>
<!-- 是否启用 WebApp 全屏模式,删除苹果默认的工具栏和菜单栏 -->
<meta name="apple-itunes-app" content="app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL">
<!-- 添加智能 App 广告条 Smart App Banner(iOS 6+ Safari) -->
<meta name="apple-mobile-web-app-status-bar-style" content="black"/>
<!-- 设置苹果工具栏颜色 -->
<meta name="format-detection" content="telphone=no, email=no"/>
<!-- 忽略页面中的数字识别为电话,忽略email识别 -->
<!-- 启用360浏览器的极速模式(webkit) -->
<meta name="renderer" content="webkit">
<!-- 避免IE使用兼容模式 -->
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<!-- 针对手持设备优化,主要是针对一些老的不识别viewport的浏览器,比如黑莓 -->
<meta name="HandheldFriendly" content="true">
<!-- 微软的老式浏览器 -->
<meta name="MobileOptimized" content="320">
<!-- uc强制竖屏 -->
<meta name="screen-orientation" content="portrait">
<!-- QQ强制竖屏 -->
<meta name="x5-orientation" content="portrait">
<!-- UC强制全屏 -->
<meta name="full-screen" content="yes">
<!-- QQ强制全屏 -->
<meta name="x5-fullscreen" content="true">
<!-- UC应用模式 -->
<meta name="browsermode" content="application">
<!-- QQ应用模式 -->
<meta name="x5-page-mode" content="app">
<!-- windows phone 点击无高光 -->
<meta name="msapplication-tap-highlight" content="no">
<!-- iOS 图标 begin -->
<link rel="apple-touch-icon-precomposed" href="/apple-touch-icon-57x57-precomposed.png"/>
<!-- iPhone 和 iTouch,默认 57x57 像素,必须有 -->
<link rel="apple-touch-icon-precomposed" sizes="114x114" href="/apple-touch-icon-114x114-precomposed.png"/>
<!-- Retina iPhone 和 Retina iTouch,114x114 像素,可以没有,但推荐有 -->
<link rel="apple-touch-icon-precomposed" sizes="144x144" href="/apple-touch-icon-144x144-precomposed.png"/>
<!-- Retina iPad,144x144 像素,可以没有,但推荐有 -->
<!-- iOS 图标 end -->
<!-- iOS 启动画面 begin -->
<link rel="apple-touch-startup-image" sizes="768x1004" href="/splash-screen-768x1004.png"/>
<!-- iPad 竖屏 768 x 1004(标准分辨率) -->
<link rel="apple-touch-startup-image" sizes="1536x2008" href="/splash-screen-1536x2008.png"/>
<!-- iPad 竖屏 1536x2008(Retina) -->
<link rel="apple-touch-startup-image" sizes="1024x748" href="/Default-Portrait-1024x748.png"/>
<!-- iPad 横屏 1024x748(标准分辨率) -->
<link rel="apple-touch-startup-image" sizes="2048x1496" href="/splash-screen-2048x1496.png"/>
<!-- iPad 横屏 2048x1496(Retina) -->
<link rel="apple-touch-startup-image" href="/splash-screen-320x480.png"/>
<!-- iPhone/iPod Touch 竖屏 320x480 (标准分辨率) -->
<link rel="apple-touch-startup-image" sizes="640x960" href="/splash-screen-640x960.png"/>
<!-- iPhone/iPod Touch 竖屏 640x960 (Retina) -->
<link rel="apple-touch-startup-image" sizes="640x1136" href="/splash-screen-640x1136.png"/>
<!-- iPhone 5/iPod Touch 5 竖屏 640x1136 (Retina) -->
<!-- iOS 启动画面 end -->
<!-- iOS 设备 end -->
<meta name="msapplication-TileColor" content="#000"/>
<!-- Windows 8 磁贴颜色 -->
<meta name="msapplication-TileImage" content="icon.png"/>
<!-- Windows 8 磁贴图标 -->
<link rel="alternate" type="application/rss+xml" title="RSS" href="/rss.xml"/>
<!-- 添加 RSS 订阅 -->
<link rel="shortcut icon" type="image/ico" href="/favicon.ico"/>
<!-- 添加 favicon icon -->
<title>标题</title>
</head>就像这样,隔行换背景色(这种情况在页面中显示源码情况下比较常见)

斑马线、条纹图案用css的背景线性渐变就能实现
div {
/* 水平条纹 */
background: linear-gradient(#f06 50%, #fff 0);
background-size: 100% 30px;
}
div {
/* 垂直条纹 */
background: linear-gradient(to right, #f06 50%, #fff 0);
background-size: 30px 100%;
}上面代码 linear-gradient(#f06 50%, #fff 0) 中,第二个色标的位置值为 0 ,那它的位置就会被浏览器调整为前一个色标的位置值。
三种颜色的条纹,也很简单:
div {
/* 三种颜色 */
background: linear-gradient(#f06 33.3%, #9c0 0, #9c0 66.6%, #58a 0);
}直接看demo:
其实,把每行文本放入一个 div 中,用 :nth-child() 来实现斑马条纹也可以,但是 DOM 过多明显会拖累页面性能。
所以按照第一步,画出条纹背景,并用 em 单位来设定背景尺寸,这样背景就可以自适应font-size的变化了;并且它的 background-size 为 line-height 的两倍(因为每条背景要覆盖两行文本)
pre {
width: 100%;
padding: .5em 0;
line-height: 1.5;
background: #f5f5f5;
background-image: linear-gradient(rgba(0,0,120,.1) 50%, transparent 0);
background-size: auto 3em;
color: #333;
font-size: 16px;
}
如上图,有两个问题:
设置 background-origin: content-box; 让浏览器在解析 background-origin 时候以 content box 的外沿为基准,而不是默认的 padding box。
这个简单,因为源码中用的 tab 不是空格,所以浏览器会把缩进的tab默认显示为 8 个字符
只需要加入css3的新特性
pre {
tab-size: 2; // tab为2个字符
}[].forEach.call($$("*"),function(a){a.style.outline="1px solid #"+(~~(Math.random()*(1<<24))).toString(16)})
使用 document.querySelectorAll
[].forEach.call(document.querySelectorAll("*"),function(a){a.style.outline="1px solid #"+(~~(Math.random()*(1<<24))).toString(16)})
使用hsl颜色
for(i=0;A=$$("*")[i++];)A.style.outline="solid hsl("+(A+A).length*9+",99%,50%)1px"
代码先转成三行
[].forEach.call($$("*"),function(a){
a.style.outline="1px solid #"+(~~(Math.random()*(1<<24))).toString(16)
})
函数$$();在现代浏览器的API中几乎都有支持,等价于 document.querySelectorAll();
$$('_')将所有DOM元素转成NodeList对象,但这并不是一个JS数组,所以不能用$$('_').forEach()方法来迭代,所以使用call或者apply方法来使用foreach
[].forEach.call 等价于 Array.prototype.forEach.call 不过前者字节更少
首先,为什么使用outline 而不是 border?
因为border是在元素的CSS盒模型之内,outline在CSS盒模型之外,所以添加outline之后不会影响布局。
然后最有趣的部分:随机生成颜色函数
(~~(Math.random()*(1<<24))).toString(16)
我们使用十六进制的的颜色 0~ffffff
并且 parseInt('ffffff',16) == 16777215 == 2^24-1
位运算 1>>24 == 16777216
Math.random()*(1<<24) 返回 (0,16777216)之间的 _浮点数, 等于十六进制的 0~ffffff
使用~取反,~~连续取反可以去掉浮点数的小数部分,所以~~等价于parseInt()
~12.3 == -13
~~12.3 == 12
~-12.98 == 11
~~12.98 == 12
使用toString(16)转换成16进制数(颜色)
这篇原文下面的评论也很有意思,歪果仁写了更多版本的代码。
最近在研究 web 性能优化的问题,看了来自Google的文章《FLIP your animations》
这篇文章提供了一种优化动画性能的方法,但是实现起来略微复杂,不过前端界本来就是各种 Hack 大行其道,所以简单了解了下其原理:
通过在100ms的动画响应延迟窗口期内计算动画初始与终止的属性差值,把动画尽量转换为只变化transform或opacity这类只触发重组不会触发重绘与重排的属性。
关于什么是动画响应的延迟时间,为什么会是100ms?100ms可以说是人类大脑的时间常量值,如果一个动作在触发后立即执行,视觉上就会有一种违和的感觉,而延迟100ms才响应的体验是让人感到最舒服的,关于100ms延迟具体细节可以查看人机交互领域大师的这几篇文章:
PS: 上面文章之前同事有推荐过,但是具体内容我没有细看。
整个动画过程的实现代码大概如下:
// 1. 获取开始位置的状态
var first = el.getBoundingClientRect();
// 2. 通过添加样式类设置元素为最终位置的状态
el.classList.add('at-the-end');
// 3. 获取最终位置的状态
var last = el.getBoundingClientRect();
// 4. 计算初始与终止位置状态的差值,这里只计算top属性为例,通常需计算以下属性差值:left、top、width、height、scaleX、scaleY、opactiy
var difference = first.top - last.top;
// 5. 通过transform设置位置偏移
el.style.transform = 'translateY(' + difference + 'px)';
// 6. 等待下一帧生效,确保第5步已经生效
requestAnimationFrame(function() {
// 7. 添加样式类,让动画跑起来
el.classList.add('animatable');
// 8. 重置transform
el.style.transform = '';
});
// 9. 动画结束后移除添加的类
el.addEventListener('transitionend', function transitionend() {
el.classList.remove('animatable');
el.removeEventListener('transitionend', transitionend)
});关于 requestAnimationFrame 的使用,写了一段兼容代码:
requestAnimationFrame.js
其中 animatable 样式规则如下,transition-property 设置为 tranform 与 opacity , transition-duration 与 transition-timing-function 可按需求自定义设置:
.animatable {
transition: transform 1s linear, opacity 1s linear;
}
我个人认为,无论何时,性能优化总是不能达到极限,所以性能优化要一直持续下去。
在以前,(是以前!) 梯形确实不太好画出来啊。。。
在三维的世界中旋转一个矩形,因为透视关系,最终看到的二维图像就是一个梯形啦
transform: perspective(.5em) rotateX(5deg);
但是因为对整个元素进行了3D变形,所以里面的文字也变形了。有一点值得注意:对元素使用了3D变形后,内部的变形效应是『不可逆转』的。 但是2D变形体系下内部的逆向变形是可以抵消外部的变形效应的。
所以唯一的方法就是把变形效果作用在 伪元素 上。如图:

div {
position: relative;
width: 100px;
height: 50px;
margin: 20px auto;
padding: .5em 1em .35em;
text-align: center;
color: #fff;
}
div:before {
content: '';
position: absolute;
top: 0;
bottom: 0;
left: 0;
right: 0;
z-index: -1;
background: #f60;
transform: perspective(.5em) rotateX(5deg);
}虽然已经实现了一个梯形,当我们没有设置 transform-origin 属性时,变形效果会让这个元素以它自身中心线为轴进行空间上的旋转。
从上面的gif图也能看出,它的宽度会增加,位置会下移,高度上也会有减小,这样会在设计上比较难控制。
所以添加 transform-origin: bottom, 当它在 3D 空间旋转时可以把它的底边固定住。

但是这样高度会有明显的缩水,以为现在整个元素是转离屏幕前观众的;之前元素上半部分转向屏幕后面,下半部分转出屏幕。相比之下,3D空间中,之前的元素总体上里观众更近了。
所以解决方案是:通过变形属性改变尺寸。 试验后得知一个 magic number:scaleY(1.3) 来弥补高度上的缩水。
.trap3:before {
transform: perspective(.5em) rotateX(5deg) scaleY(1.3);
transform-origin: bottom;
}效果明显
只需要把 transform-origin 改为 bottom left 或者 bottom right 即可
.trap4:before {
transform: perspective(.5em) rotateX(5deg) scaleY(1.3);
transform-origin: bottom left;
}
.trap5:before {
transform: perspective(.5em) rotateX(5deg) scaleY(1.3);
transform-origin: bottom right;
}http://ccforward.github.io/css-secrets/trapezoid/index.html
人们经常抱怨HTTPS内容不能被浏览器缓存,因为从安全角度看(缓存)很敏感。实际上,HTTPS缓存可以像HTTP一样使用响应头来控制。
Fiddler的开发者Eric Lawrence在他的博客里做了简单的介绍:
令很多人吃惊的是,默认情况下,所有版本的IE浏览器都会缓存HTTPS内容直到缓存失效。例如,如果一个资源发送时带的请求头中包含了
Cache-Control:max-age=600,那么,IE会将该资源缓存10分钟。HTTPS的使用对于IE的资源缓存策略没有影响。(非IE浏览器对于HTTPS内容的默认缓存行为不一样,与用户使用的浏览器版本有关)。
值得注意的一个小点是Firefox默认只会将HTTPS资源缓存在内存中。如果想将缓存放到硬盘上,需要增加Cache-Control:Public响应头。
下面的截屏展示了Firefox磁盘缓存的内容,以及在HttpWatch中看到的
Cache-Control:Public响应头。
随便逛逛就会发现10美元一年的SSL证书或者和一个.com域名一年的注册成本差不多。
最便宜的证书和比较贵的公司验证的选项不在一个级别,但是能够在几乎所有主流浏览器上使用。
随着IPv4地址池的耗尽,需要考虑这个问题,而且确实一个IP地址只能有一个SSL证书。然而,如果有wildcard SSL证书(通配符SSL证书)大约125美元一年,一个IP地址可以按照喜好来配置多个子域名。例如:httpwatch的官网在同一个公共IP地址上就有https://www.httpwatch.com,http://www.httpwatch.com和https://store.httpwatch.com这几个域名。
在IIS7上有一个小技巧。在添加证书后,需要查找证书,然后在证书管理器中重命名,名字以*开头。如果不这样做的话就不能为一个HTTPS绑定编辑域名:
更新:UCC(Unified Coummunications Certificate,统一通信证书)支持单个SSL证书上有多个域名,可以用于需要为多个站点而不是子域名提供HTTPS支持的情况。
更新2:SNI(Server Name Indication——服务器名称指示)允许在相同IP地址的主机上有多个不同证书的不同域名。服务器端:Apache和Nginx支持该配置,IIS不行。客户端:原文有误,实际上与浏览器版本无关,而是与系统有关。例如维基百科上提到的,windows xp系统不支持SNI。
可以使用ssldb并且禁用web服务器上较旧加密方法来测试网站对HTTPS的支持。
HTTPS Everywhere工具也可以用来收集网站升级到HTTPS的详情。
购买证书包括下列步骤:
设计这些步骤是为了确保证书能够安全的传输到web服务器,避免有人通过劫持邮件或者下载第2步包含的证书来使用证书。
因此不能在其他web服务器上使用第2步的文件。如果想要那样做,需要将证书以其他格式导出。
在IIS中可以创建一个有密码保护而且可传输的.pfx文件:
然后可以通过密码来将该文件导入其他web服务器。
使用HTTPS并不能为网站加速(实际上可以——看下面的内容),但是通过遵守HTTPS Performance Tuning——HTTPS性能调整博客中的建议可以避免大部分开销。
通过压缩文本内容可以减少用于加密数据的CPU资源,而且在使用现代CPU的服务器上,这些开销也不是特别显著。
为了保证HTTPS连接的安全,在TCP连接时会有额外的延迟(round-trips),发送和接受也要带上一些附加数据。不过,可以在httpwatch中看到在HTTPS连接建立以后这样的开销很小:
首次访问HTTPS站点比HTTP要慢,因为建立SSL连接需要的时间更长。下面是张使用httpwatch看到得一个HTTP站点页面加载的时间图:
以及使用HTTPS访问相同站点的时间图:
更长的连接时间使得首次页面加载速度慢了约10%。然而,浏览器建立了活跃的keep-alive HTTPS连接后,后续的页面刷新和HTTP差别非常小。
首先,使用HTTP刷新页面:
然后使用HTTPS刷新:
有可能一些用户会发现HTTPS版本的站点比HTTP站点快。如果用户开启了公司代理,在代理拦截、检查以及记录Web流量的情况下会发生这种情况。HTTPS连接通常会通过代理使用简单的TCP连接来发送,因为HTTPS流量不能被拦截。这样的安全绕过(bypassing)可以提升性能。
更新:F5的一篇博客文章挑战了认为SSL的CPU开销不再显著的说法,但是其中的大部分论据都在这篇文章被反驳了。
虽然黑客不能劫持用户在网络上的HTTP流量,或者直接读取他们的cookie和查询字符串(query string),仍然需要确保cookie和query string不能被轻易地预测到。
例如,有一家英国的银行网站使用数值计数器作为会话的ID值:
黑客可以使用一个假账号来查看cookie的使用,并且找到其最近的值。然后尝试在浏览器中修改cookie值来劫持临近ID的会话。
查询字符串也可以通过HTTP来保护,但是仍然有其他方式来泄露它们的值。细节请查看这篇文章How Secure Are Query Strings Over HTTPS——HTTPS查询字符串有多安全。
这是比较普遍的观点。它所基于的理论是HTTPS会在登陆时保护用户的密码,但是登陆完成后就不再需要HTTPS了。
Firefox Firesheep扩展可以展示这种观点的谬误,以及劫持Twitter和Facebook的用户会话有多么轻松。
咖啡店的免费公共WiFi是理想的会话劫持环境,因为:
有许多关于这种安全方法的实例。例如,默认Twitter的登陆页面使用了HTTPS,但是在建立会话cookie后,又切换回了HTTP:
HttpWatch会警告这些cookie是在HTTPS上建立的,但是没有使用secure标记来防止它们在HTTP上使用。
咖啡店里的人可以使用Firesheep来劫持twitter会话cookie,然后代替你发推特消息。
英文原文--Top 7 Mythis about HTTPS
SNI--Server Name Indication
RFC4366--TLS Extension
SNI在概念上类似HTTP1.1的虚拟主机,它指定了在TLS握手过程开始时客户端尝试连接的主机名。SNI是一种TLS协议扩展。SNI需要客户端的支持。
SSL握手延迟以及HTTPS优化——SSL Handshaek Latency and HTTPS Optimizations
hybrid)模式这篇文章介绍不通过全站HTTPS来增强安全的方法,即使用非加密的Cookie加上加密Cookie来实现安全。
文章标题为
slaying firesheep(屠杀firesheep),实际上firesheep可以通过修改安全脚本来防止重定向,从而使得文章所提到的安全建议失效。而且实际上这篇文章提到的建议专业术语称为security through obscurity,是最不被推崇的安全建议之一。因为其本质只是增加信息收集的难度,系统仍然是有弱点的(vulnerable)的。
支持太大——Dispelling the new ssl myth
支持不大——Still Inexpensive
总结一下,认为开销大的原因:
针锋相对的这篇文章写得很漂亮,而且一阵见血指出了,F5其实是家卖SSL硬件的公司,它们的文章其实是在搞市场营销。呵呵。
新配置的云服务器(CentOS 7)安装了 lnmp 之后,要开启Mysql的远程连接,和部分端口连接:
flush privileges;
grant all PRIVILEGES on *.* to root@'10.101.100.88' identified by 'password';这样,所有的ip地址都可以通过设置的root账户密码进行连接
首先 firewall-cmd --state 查看防火墙状态
没有开启防火墙,执行systemctl start firewalld开启
开启 3306 端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --reload设置完毕后发现网站和ip都不能访问,查了下是 80 端口没开启,重开:
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --reload首先引入文件模块 var fs = require('fs');
function copy(src, target) {
console.log(target);
fs.writeFileSync(target, fs.readFileSync(src));
}
function copy(src, target) {
var rs = fs.createReadStream(src),
ws = fs.createWriteStream(target);
fs.on('data', function(chunk) {
console.log('read');
ws.write(chunk, function() {
console.log('write');
})
})
fs.on('end', function() {
ws.end();
})
}根据 Method 2 改进
function copy(src, target) {
var rs = fs.createReadStream(src),
ws = fs.createWriteStream(target);
fs.on('data', function(chunk) {
console.log('read');
if (ws.write(chunk, function() {
console.log('write');
}) === false) {
rs.pause();
} else {
rs.resume();
}
})
fs.on('end', function() {
ws.end();
})
}node中支持pipe方法,类似于管道,将读出来的内容通过管道写入到目标文件中
function copy(src, target) {
fs.createReadStream(src).pipe(fs.createWriteStream(target));
}1.64G 的文件用了20秒复制完毕,没有内存溢出
- EventLoop 事件循环
- global 和 process
- EventEmitter 事件
- Stream 和 Buffer
- Cluster 集群
- 异步Error
- C++ 插件
事件循环算是Node的一个核心了,即使进程中不断有I/O调用也能处理其他任务。正因为阻塞I/O代价太高所以就凸显了Node的高效。

ps: keynote做的图,不会PS,太麻烦。。。
在 Python 这样来实现一个延迟处理
import time
print "Step 1"
print "Step 2"
time.sleep(2)
print "Step 3"Node或JavaScript 通过异步回调的方式来实现
console.log('Step 1');
setTimeout(function () {
console.log('Step 3');
}, 2000)
console.log('Step 2');可以事件循环想象成一个for或while循环,只有在现在或将来没有任务要执行的时候才会停下来。

在等待I/O任务完成之前就可以做更多事情,事件循环因此让系统更加高效。

Node也让我们从死锁中解放,因为根本没有锁。
PS:我们仍然可以写出阻塞的代码
var start = Date.now();
for (var i = 1; i<1000000000; i++) {}
var end = Date.now();
console.log(end-start);这次的阻塞在我的机器上花了3400多毫秒。不过我们多数情况下不会跑一个空循环。
而且fs模块提供了同步(阻塞)和异步(非阻塞)两套处理方法(区别于方法名后是否有Sync)
如下阻塞方式的代码:
var fs = require('fs');
var con1 = fs.readFileSync('1.txt','utf8');
console.log(con1);
console.log('read 1.txt');
var con2 = fs.readFileSync('2.txt','utf8');
console.log(con2);
console.log('read 2.txt');结果就是
content1->read 1.txt->content2->read 2.txt
非阻塞方式的代码:
var fs = require('fs');
fs.readFile('1.txt','utf8', function(err, contents){
console.log(contents);
});
console.log('read 1.txt');
fs.readFile('2.txt','utf8', function(err, contents){
console.log(contents);
});
console.log("read 2.txt");代码执行后因为要花时间执行 读 的操作,所以会在最后的回调函数中打印出文件内容。当读取操作结束后事件循环就会拿到内容
read 1.txt->read 2.txt->content1->content2
事件循环的概念对前端工程师比较好理解,关键就是异步、非阻塞I\O。
从浏览器端切换到Node端就会出现几个问题
有一个 global 对象,顾名思义就是全局的,它的属性很多
在命令行里执行一次 global 一切就都懂了。
通过process对象获取和控制Node自身进程的各种信息。另外process是一个全局对象,在任何地方都可以直接使用。
部分属性
部分方法
Events == Node Observer Pattern
异步处理写多了就会出现callbackhell(回调地狱),还有人专门做了叫 callbackhell 的网站。
EventEmitter 就是可以触发任何可监听的事件,callbackhell可以通过事件监听和触发来避免。
var events = require('events');
var emitter = new events.EventEmitter();添加事件监听和事件触发
emitter.on('eat', function() {
console.log('eating...');
});
emitter.on('eat', function() {
console.log('still eating...');
});
emitter.emit('eat');
假设我们有一个已经继承了 EventEmitter 的类,能每周、每天的处理邮件任务,而且这个类具有足够的可扩展性能够自定义最后的输出内容,换言之就是每个使用这个类的人都能够在任务结束时增加自定义的方法和函数。
如下图,我们继承了 EventEmitter 模块创建了一个Class: Job,然后通过事件监听器 done 来实现Job的自定义处理方式。

我们需要做的只是在进程结束的时候触发 done 事件:
// job.js
var util = require('util');
var Job = function() {
var job = this;
job.process = function() {
job.emit('done', { completeTime: new Date() })
}
}
util.inherits(Job, require('events').EventEmitter);
module.exports = Job;我们的目的是在 Job 任务结束时执行自定义的函数方法,因此我们可以监听 done 事件然后添加回调:
var Job = require('./job.js')
var job = new Job()
job.on('done', function(data){
console.log('Job completed at', data.completeTime)
job.removeAllListeners()
})
job.process()关于 emitter 还有这些常用方法
用Node处理比较大的数据时可能会出现些问题:
用Stream就会解决。因为Node的 Stream 是对连续数据进行分块后的一个抽象,也就是不需要等待资源完全加载后再操作。
标准Buffer的处理方式:

只有整个Buffer加载完后才能进行下一步操作,看图对比下Node的Stream,只要拿到数据的第一个 chunk 就可以进行处理了

Node中有四种数据流:
Stream在Node中很常见:
process.stdin 是一个标准输入流,数据一般来自于键盘输入,用它来实现一个可读流的例子。
我们使用 data 和 end 事件从 stdin 中读取数据。其中 data 事件的回调函数的参数就是 chunk 。
process.stdin.resume()
process.stdin.setEncoding('utf8')
process.stdin.on('data', function (chunk) {
console.log('chunk: ', chunk)
})
process.stdin.on('end', function () {
console.log('--- END ---')
})PS: stdin 默认是处于pause状态的,要想读取数据首先要将其 resume()
可读流还有一个 同步 的 read() 方法,当流读取完后会返回 chunk或null ,课这样来用:
var readable = getReadableStreamMethod()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})
我们在Node中要尽可能写异步代码避免阻塞线程,不过好在 chunk 都很小所以不用担心同步的 read() 方法把线程阻塞
我们用 process.stdin 对应的 process.stdout 方法来实现个例子
process.stdout.write('this is stdout data');
把数据写入标准输出后是在命令行中可见的,就像用 console.log()
就像自来水要有自来水管一样,Stream 需要传送 也需要 Pipe。
下面的代码就是从文件中读数据,然后GZip压缩,再把数据写入文件
const r = fs.createReadStream('file.txt')
const z = zlib.createGzip()
const w = fs.createWriteStream('file.txt.gz')
r.pipe(z).pipe(w)readable.pipe() 方法从可读流中拉取所有数据,并写入到目标流中,同时返回目标流,因此可以链式调用(也可以叫导流链)。
PS:该方法能自动控制流量以避免目标流被快速读取的可读流所淹没。
web应用最常见了,HTTP 流用的也最多。
request 和 response 是继承自Event Emitter的可读可写流。下面的代码在各种教程中就很常见了:
const http = require('http')
var server = http.createServer( (req, res) => {
var body = '';
req.setEncoding('utf8');
req.on('data', (chunk) => {
body += chunk;
})
req.on('end', () => {
var data = JSON.parse(body);
res.write(typeof data);
res.end();
})
})
server.listen(5502)之前还写过一篇关于 Stream 和 Pipe 的文章:Node.js 使用 fs 模块做文件 copy 的四种方法 能清楚的比较出使用Stream后能更快的获取到数据。
浏览器中的JS没有二进制类型的数据(ES6中ArrayBuffer是二进制),但是Node里面有,就是 Buffer。 Buffer是个全局对象,可直接使用来创建二进制数据:
官方API中有最全的方法。
标准的Buffer数据比较难看懂,一般用 toString() 来转换成人类可读的数据
let buf = Buffer.alloc(26)
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log(buf); // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a>
buf.toString('utf8'); // abcdefghijklmnopqrstuvwxyz
buf.toString('ascii'); // abcdefghijklmnopqrstuvwxyz
// 截取
buf.toString('utf8', 0, 5); // abcde
buf.toString(undefined, 0, 5); // abcde 编码默认是 utf8fs 模块的 readFile 方法回调中的data就是个Buffer
fs.readFile('file-path', function (err, data) {
if (err) return console.error(err);
console.log(data);
});单个 Node 实例运行在单个线程中。要发挥多核系统的能力,就需要启动一个 Node 进程集群来处理负载。核心模块 cluster 可以让一台机器的所有 CPU 都用起来,这样就能纵向的来扩展我们的Node程序。
var cluster = require('cluster');
var numCPUs = 4; // 我的 MacBook Air 是4核的
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
} else if (cluster.isWorker) {
console.log('worker')
}上面的代码比较简单,引入模块创建一个 master 多个 worker,不过 numCPUs 并一定非得是一台电脑的核心数,这个可以根据自己需求想要多少都行。
worker 和 master 可以监听相同的端口,worker通过事件和master通信。master也能监听事件并根据需要重启集群。
pm2优点很多:
pm2 启动很简单:
$ pm2 start server.js -i 4 -l ./log.txt
pm2 启动后自动到后台执行 通过 $ pm2 list 可以查看正在跑着那些进程。
更多内容直接看官网: http://pm2.keymetrics.io/
child_process.spawn() vs child_process.fork() vs child_process.exec()
Node中有如上三种方式创建一个外部进程,而且都来自于核心模块 child_process
require('child_process').spawn() 用于比较大的数据,支持流,可以与任何命令(bash python ruby 以及其他脚本)一起使用,并且不创建一个新的V8实例
官网的例子就是执行了一个bash命令
require('child_process').fork() 创建一个新的V8实例,实例出多个worker
和spawn不同的的是 fork 只执行 node 命令
require('child_process').exec() 使用Buffer,这使得它不适合比较大的数据和Stream,异步调用,并在回调一次性拿到所有数据
exec()用的不是事件模式,而是在回调中返回 stdout stderr
处理异常一般都用 try/catch ,尤其是在同步代码非常好用,但是在异步执行中就会出现问题
try {
setTimeout(function () {
throw new Error('Fail!')
}, 1000)
} catch (e) {
console.log(e.message)
}这种异步的回调里面情况肯定catch不到错误,当然把try/catch放入回调函数肯定没问题,但这并不是个好办法。
所以Node里面标准的回调函数的第一个参数都是 error ,于是就有了这样的代码
if (error) return callback(error)一般处理异步异常的方法如下:
uncaughtException是一种很简单粗暴的机制,当一个异常冒泡到事件循环中就会触发这个事件,不过这个不建议使用。
process.on('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
})domain自身其实是一个EventEmitter对象,它通过事件的方式来传递捕获的异常。
进程抛出了异常,没有被任何的try catch捕获到,这时候将会触发整个process的processFatal,此时如果在domain包裹之中,将会在domain上触发error事件,反之,将会在process上触发uncaughtException事件。
用法:
var domain = require('domain').create()
d.on('error', function(e) {
console.log(e)
})
d.run(function() {
setTimeout(function () {
throw new Error('Failed!')
}, 1000)
});从 4.0 开始Node已经不建议使用了,以后也会被剥离出核心模块
日志不仅仅能记录异常信息
Node.js在硬件、IoT领域开始流行就是因为能和 C/C++ 代码合体使用。
官方提供了很多C++插件的例子:https://github.com/nodejs/node-addon-examples
以第一个HelloWorld为例:
创建 hello.cc 文件,这个代码比较好理解
#include <node.h>
namespace demo {
using v8::FunctionCallbackInfo;
using v8::HandleScope;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "Hello World C++ addon")); // 输出Hello World
}
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method); // Exporting
}
NODE_MODULE(addon, init)
} 创建binding.gyp文件 内容一看就懂
{
"targets": [
{
"target_name": "addon",
"sources": [ "hello.cc" ]
}
]
}依次执行两个命令
$ node-gyp configure
$ node-gyp build
编译完成后在 build/Release/ 下面会有一个 addon.node 文件
然后就简单了创建 h.js
var addon = require('./build/Release/addon')
console.log(addon.hello())
执行 $ node hello.js 打印出了 Hello World C++ addon
OVER....
PS: 文中图片都是用keynote制作的
PS: 部分参考和翻译自:
// 创建XMLHttpRequest对象
function xhr(){
var xhr;
try {
xhr = new XMLHttpRequest();
}catch(e){
try{
xhr = new ActiceXObject('Msxml2.XMLHTTP');
}catch(e){
try{
xhr = new ActiveXObject('Microsoft.XMLHTTP');
}catch(e){
alert('不支持 ajax');
return fasle;
}
}
}
return xhr;
}
/** 发送Ajax请求
* url:请求地址
* methodType: GET,POST,HEAD 请求方式
* sycn: true,false 同步或异步
* callback 回调
* obj 回调中要处理的对象
*/
function ajaxRequest(url,methodType,sycn,callback,obj){
var xhr = xhr();
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
if(xhr.status == 200){
obj.result = xhr.responseText;
console.log(xhr);
callback(obj);
}
}
}
xhr.open(methodType,url,sycn);
xhr.send(null);
}
<a href="googlechrome:www.taobao.com">taobao</a><a href="intent://www.taobao.com#Intent;scheme=http;package=com.android.chrome;end">taobao</a>这些meta标签在开发无线页面尤其是webAPP时作用很大
<meta content="yes" name="apple-mobile-web-app-capable"/>
<meta content="yes" name="apple-touch-fullscreen"/>
safari私有的标签,表示允许全屏
<meta content="telephone=no,email=no" name="format-detection"/>
忽略将页面的数字识别为电话号码
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no"/>
强制让文档的宽度与设备的宽度保持1:1,并且文档最大的宽度比例是1.0
并且文档最大的宽度比例是1.0,且不允许用户点击屏幕放大浏览
<meta name="data-spm" content="a.b"> 埋点PS:content里的属性要用分号+空格来分开
保存网页到桌面上时使用的图标,没有设置则显示网页截图
<link rel="apple-touch-icon-precomposed" href="../icon_114.png" />
<link rel="apple-touch-icon-precomposed" sizes="72x72" href="../_icon_72.png" />
<link rel="apple-touch-icon-precomposed" sizes="114x114" href="../icon_114.png" />启动画面的图片,没有设置就显示白屏
<link rel="apple-touch-startup-image" href="../start.png" />
其中还有个专门针对iOS的meta标签
<meta name="apple-mobile-web-app-status-bar-style" content="black" />
用来设置顶部的bar(状态栏)颜色,Apple有个官方的说明 iOS的meta标签
估计已经有人翻译了,不过没找到中文版
safari有隐私模式,但是 ’localStorage’ in window 依然返回true,就需要使用try catch来捕获错误
try{
if('localStorage' in window){
//localstorage可用
}else{
//localstorage不可用
}
}catch(e){
// 隐私模式localstorage不可用
}答案来自这里 stackoverflow
function touchHandlerDummy(e){
e.preventDefault();
return false;
}
document.addEventListener("touchstart", touchHandlerDummy, false);
document.addEventListener("touchmove", touchHandlerDummy, false);
document.addEventListener("touchend", touchHandlerDummy, false);alert(navigator.standalone);
$('.dom').on('touchmove', function(){
// 处理逻辑
})如果处理逻辑的代码非常复杂,那就会使fps下降,可以添加一个setTimeout
$('.dom').on('touchmove', function(){
setTimeout(function(){
// 处理逻辑
},0);
})像这种写法 <input type="number"> 是可以输入其他字符的
So,我们这样来搞定: <input type="text" pattern="\d*"> 实现纯数字输入
还有种九宫格数字键盘: <input type="tel"> 可以输入 +*# 等电话字符
input标签这玩意儿还挺好玩的 可以看下Apple的官方文档
-webkit-user-select:none-webkit-touch-callout:noneinput::-webkit-input-speech-button {display: none}overflow-x: hidden;后滑动时,页面会不流畅,出现卡顿,这时候就需要-webkit-overflow-scrolling来hack一下*{-webkit-overflow-scrolling: touch;}html,body{ overflow-x: hidden;}1、旋转事件 onorientationchange
window.onorientationchange = function() {
switch(window.orientation) {
case 0:
alert("正常屏幕");
break;
case -90:
alert("屏幕左转”);
break;
case 90:
alert("屏幕右转");
break;
case 180:
alert("屏幕倒转”);
break;
}
};
旋转屏幕后字体大小会发生改变,阻止:
html, body, form, fieldset, p,
div, h1, h2, h3, h4, h5, h6
{-webkit-text-size-adjust:none;}
2、click事件
绑定了click后会出现点击后闪一下的情况,可以给绑定元素添加
-webkit-tap-highlight-color: rgba(0,0,0,0);
3、hover
使用touchstart和touchend模拟hover
$('.link').on('touchstart',function(){$(this).addClass('hover')});
$('.link').on('touchend',function(){$(this).removeClass('hover')});
.link:hover,.link.hover{ color:#fff }
4、active伪类
使active伪类生效,只需要在touchstart或touchend上添加空的匿名函数
$('a').on('touchend',function(){});
5、输入
input输入框 type=“date” 时添加placeholder的hack:
<input type="date" id="J_Date" placeholder="选择日期">
$('#J_Date').on('focus', function(){
$(this).attr('type','date')
});
同理,type的值为moonth week time时候一样处理 (不过week在iOS7上不支持)
忽略输入框自动大写和修正单词
<input type="text" autocapitalize="off" autocorrect="off" />
iOS上打电话 发短信的a标签
<a href="tel:18688886666">Call Me</a>
<a href="sms:18688886666">Send Msg</a>
document.implementation.hasFeature("http:// www.w3.org/TR/SVG11/feature#Image", "1.1")
先看最经典的 Fisher-Yates 的洗牌算法
这里有一个该算法的可视化实现
其算法**就是 从原始数组中随机抽取一个新的元素到新数组中
按步骤一步一步来就很简单的实现
function shuffle(arr){
var result = [],
random;
while(arr.length>0){
random = Math.floor(Math.random() * arr.length);
result.push(arr[random])
arr.splice(random, 1)
}
return result;
}这种算法要去除原数组 arr 中的元素,所以时间复杂度为 O(n2)
Fisher-Yates 洗牌算法的一个变种是 Knuth Shuffle
每次从未处理的数组中随机取一个元素,然后把该元素放到数组的尾部,即数组的尾部放的就是已经处理过的元素,这是一种原地打乱的算法,每个元素随机概率也相等,时间复杂度从 Fisher 算法的 O(n2)提升到了 O(n)
function shuffle(arr){
var length = arr.length,
temp,
random;
while(0 != length){
random = Math.floor(Math.random() * length)
length--;
// swap
temp = arr[length];
arr[length] = arr[random];
arr[random] = temp;
}
return arr;
}Durstenfeld Shuffle的算法是从数组第一个开始,和Knuth的区别是遍历的方向不同
利用Array的sort方法可以更简洁的实现打乱,对于数量小的数组来说足够。因为随着数组元素增加,随机性会变差。
[1,2,3,4,5,6].sort(function(){
return .5 - Math.random();
})Knuth-Durstenfeld shuffle 的 ES6 实现,代码更简洁
function shuffle(arr){
let n = arr.length, random;
while(0!=n){
random = (Math.random() * n--) >>> 0; // 无符号右移位运算符向下取整
[arr[n], arr[random]] = [arr[random], arr[n]] // ES6的结构赋值实现变量互换
}
return arr;
}EventFire仓库地址: https://github.com/ccforward/EventFire
事件的管理主要有三点:绑定(on)、触发(fire)、销毁(off);所以写一个自定义的事件库就从这三点出发。
下面一步一步来写
就像在各种js库里面监听DOM事件一样,会有下面几种方式:
event.on('someEvent', callback)
// 绑定多个事件
event.on(['someEventA', 'someEventB'], callback)
// 绑定一次
event.once('someEvent', callback)
// .... 其他PS: 触发的函数名可以是 trigger 或者 emmit,个人感觉 fire 像游戏一样,听起来更爽。
event.fire('someEvent')
// 触发时绑定数据
event.fire('someEvent', {weapon: 'machine gun'})
// 触发多个事件
event.fire(['someEventA', 'someEventB'], callback)
// .... 其他销毁肯定和事件绑定是对应关系
event.off('someEvent', callback)
event.off('someEvent')
event.off(['someEventA', 'someEventB'], callback)
// .... 其他一个简单的事件库应该有如下的方法:
on 事件绑定once 绑定一次off 事件解绑fire 触发事件offAll 解绑所有事件listeners 返回某一事件上的监听器enable 事件绑定和触发-可用disable 事件绑定和触发-暂停destory 解绑实例上的事件,并完全销毁这个实例(不能再继续绑定和触发事件)最开始时已经有了两个基本的用法,思考后想到一些新的传参方式来支持更加灵活的事件绑定:
字符串参数,单个事件
on('event', callback, {once: true})
数组参数,事件集合
on(['event1', 'event2'], callback, {once: true})
事件和回调的键值对
on({
event1: function(){},
event2: function(){}
}, {once: true});绑定到所有事件上
on(function(){}, {once: true})函数监听器的名字也应该能支持正则
on(/^event/)
on(/event\d+/)最后一个可选参数是考虑到 once 方法后来添加的,对于 on 方法直接单次的事件绑定会更灵活些
on 最后还应该返回 this 来支持链式调用
在 on 方法上添加了 {once: true} 这个可选参数后,这个方法就仅仅是 on 方法的一个变形了,不再多说。
once 可以和最后提到的 scope 统一放在配置项中
off 很好理解, 它设计肯定和 on 是对应的,不过会多一种调用方式:
off('eventName') 解绑 eventName 事件
fire 也是和 on 相对应的:
参数 data 可以用在回调函数中,用来传递状态、自定义数据等消息
这里需要创建三个内部变量,用来存储回调函数,从而在解绑的时候能够找到已经绑定的函数
on(function(){})所以解绑所有事件就是把上面三个变量置为空
PS: 这个方法也可直接用在构造器中,初始化上面三个内部变量
listeners(eventName) 返回一个绑定在 eventName 上的所有函数的数组
这两个方法最开始考虑叫 pause 和 goon 但只是个构思,后来看了其他的事件库后发现暂停绑定事件的执行是个很大的需求才改为更通用的名字
同样这里也需要引入一个内部变量 _enabled 来对应两个方法设置为 true 和 false
这个方法实现起来最简单粗暴,三步:
null 或 falseFunction.prototype函数在绑定的时候可以添加一个作用域,类似添加 {once: true} 一样, 添加一个名为 scope 的配置来替代 this
on('event1', fn1, {scope: {hello: 'world'}})
on('event2', fn2, {scope: {hello: 'world'}, once: true})fire 方法的最后一个参数 data, 但是在 fire 的时候需要传递数据,因此一个 data 变量就是个刚需了。
e.on('event', function(ev){
console.log(ev.data)
});
e.fire('event', {a: 123});最后添加 commonjs 和 AMD 规范的兼容,具体的代码在 index.js 最后
技术水平有限,只是从前端角度和部分个人经验来浅显的分析了 https://tower.im 站点的性能。
今天升级了到了 OS X 10.10.5, 然后在PHP CLI里出现了下面错误
$ php
dyld: Library not loaded: /usr/lib/libnetsnmp.25.dylib
Referenced from: /usr/bin/php
Reason: image not found
Trace/BPT trap: 5然后检查了/usr/lib 文件夹目录,发现 Net-SNMP libraries 最近的一些更新
$ ls -la /usr/lib/libnetsnmp.*
-rwxr-xr-x 1 root wheel 1106528 9 10 2014 /usr/lib/libnetsnmp.15.1.2.dylib
-rwxr-xr-x 1 root wheel 1241136 7 9 15:38 /usr/lib/libnetsnmp.30.dylib
-rwxr-xr-x 1 root wheel 476848 9 10 2014 /usr/lib/libnetsnmp.5.2.1.dylib
lrwxr-xr-x 1 root wheel 22 4 28 19:13 /usr/lib/libnetsnmp.5.dylib -> libnetsnmp.5.2.1.dylib
lrwxr-xr-x 1 root wheel 19 7 20 10:07 /usr/lib/libnetsnmp.dylib -> libnetsnmp.30.dylib把 libnetsnmp.25.dylib 软连接到最新版本的 libnetsnmp.dylib
$ sudo ln -s /usr/lib/libnetsnmp.dylib /usr/lib/libnetsnmp.25.dylib
很奇怪为什么php没有跟随系统升级到最新...
然后就好用了
$ php -v
PHP 5.5.24 (cli) (built: May 19 2015 10:10:05)
Copyright (c) 1997-2015 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2015 Zend Technologies
先看代码(Babel配置如下)
Babel Version 6.9.1
presets: ['es2015', 'es2015-loose', 'stage-2'],
ES6 代码如下:
let foo = 'outer';
function bar(func = x => foo){
let foo = 'inner';
console.log(func());
}
bar(); // outerBabel 编译后的代码:
'use strict';
var foo = 'outer';
function bar() {
var func = arguments.length <= 0 || arguments[0] === undefined ? function (x) {
return foo;
} : arguments[0];
var foo = 'inner';
console.log(func());
}
bar(); // inner
ES6规定复杂参数的表达式是不能看到函数体内的声明的变量的,但是Babel转换后的代码把默认参数在bar函数作用域中做了计算。
对于这个bug他们早在今年3月就出现了,可现在线上的6.9.1依然有问题。
let foo = 'outer';
function bar(a, b, func = x => [foo, a, b, func]) {
let foo = 'inner';
var omg = 4;
console.log(func()); // outer
}
bar();
未来的Babel编译结果
let foo = 'outer';
function bar(_a, _b) {
var a, b, func;
{
var _func = arguments.length <= 0 || arguments[0] === undefined ? function (x) {
return [foo, _a, _b, _func];
} : arguments[0];
[a, b, func] = [_a, _b, _func];
}
{
let omg;
let foo = 'inner';
omg = 4;
console.log(func()); // outer
}
}
bar();所以说 Babel 对于ES6的很多特性尤其是新特性转换起来非常的二逼。。。
问题出自这里 函数参数默认值
理解事件循环系列第一步 浅析和总览
多数的网站不需要大量计算,程序花费的时间主要集中在磁盘 I/O 和网络 I/O 上面
SSD读取很快,但和CPU处理指令的速度比起来也不在一个数量级上,而且网络上一个数据包来回的时间更慢:
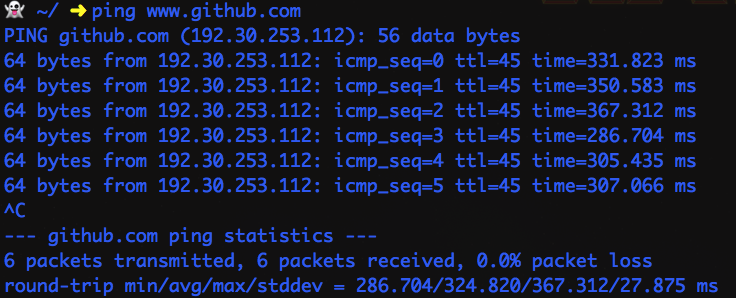
一个数据包来回的延迟平均320ms(我网速慢,ping国内网站会更快),这段时间内一个普通 cpu 执行几千万个周期应该没问题
因此异步IO就要发挥作用了,比如用多线程,如果用 Java 去读一个文件,这是一个阻塞的操作,在等待数据返回的过程中什么也干不了,因此就开一个新的线程来处理文件读取,读取操作结束后再去通知主线程。
这样虽然行得通,但是代码写起来比较麻烦。像 Node.js V8 这种无法开一个线程的怎么办?
先看下面函数执行过程
当我们调用一个函数,它的地址、参数、局部变量都会压入到一个 stack 中
function fire() {
const result = sumSqrt(3, 4)
console.log(result);
}
function sumSqrt(x, y) {
const s1 = square(x)
const s2 = square(y)
const sum = s1 + s2;
return Math.sqrt(sum)
}
function square(x) {
return x * x;
}
fire()下面的图都是用 keynote 做的 keynote地址
函数 fire 首先被调用
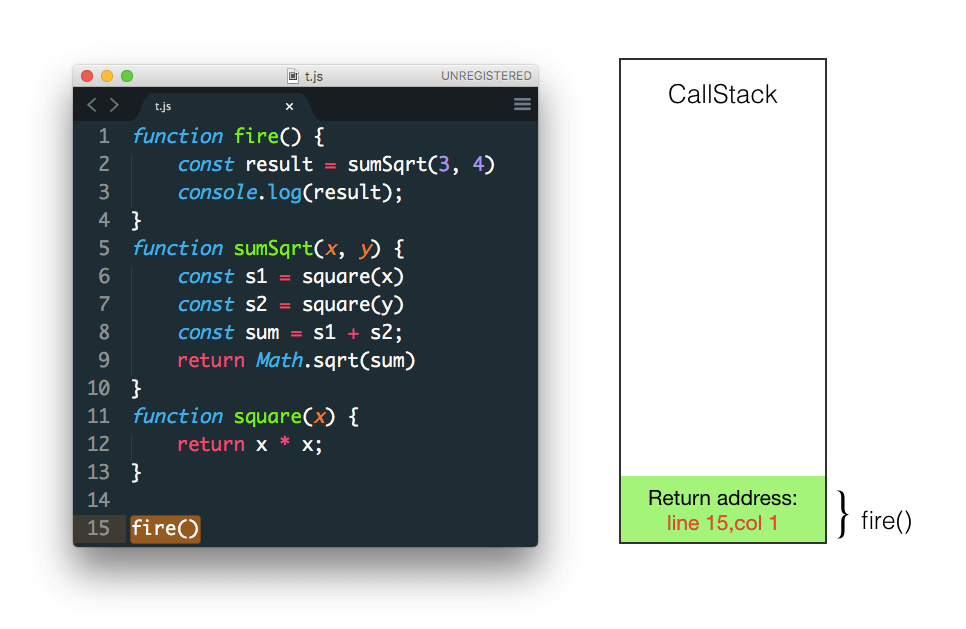
fire 调用 sumSqrt 函数 参数为3和4

之后调用 square 参数为 x, x==3

当 square 执行结束返回时,从 stack 中弹出,并将返回值赋值给 s1
s1加入到 sumSqrt 的 stack frame 中

以同样的方式调用下一个 square 函数


在下一行的表达式中计算出 s1+s2 并赋值给 sum

之后调用 Math.sqrt 参数为sum

现在就剩下 sumSqrt 函数返回计算结果了

返回值赋值给 result
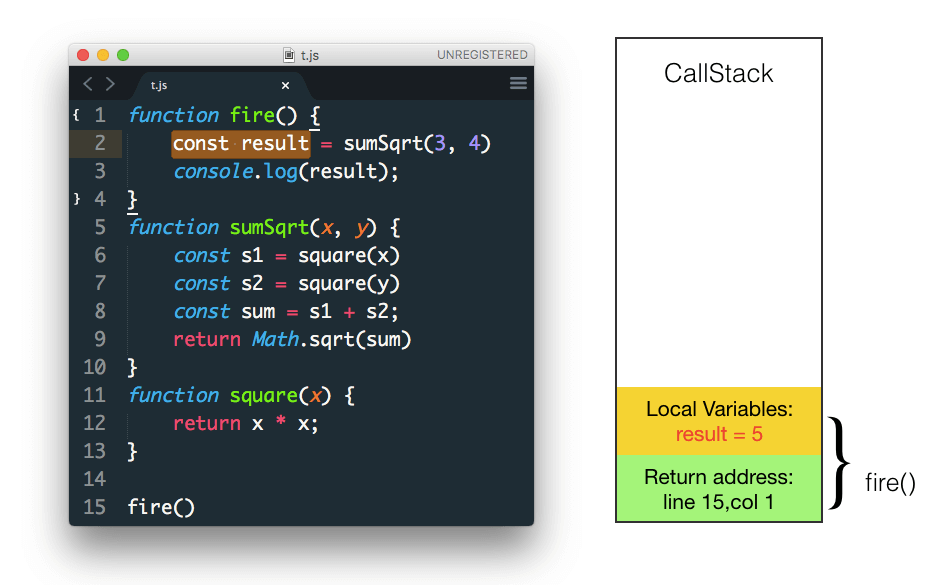
在 console 中打印出 result

最终 fire 没有任何返回值 从stack中弹出 stack也清空了
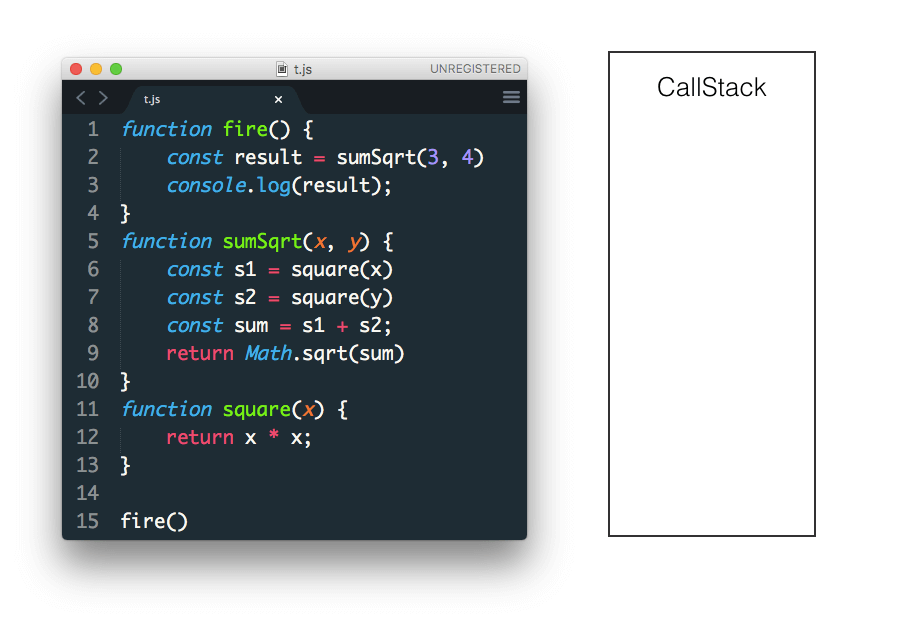
当函数执行完毕后本地变量会从 stack 中弹出,这只有在使用 numbers string boolean 这种基本数据类型时才会发生。而对象、数组的值是存在于 heap(堆) 中的,stack 只存放了他们对应的指针。
当函数之行结束从 stack 中弹出来时,只有对象的指针被弹出,而真正的值依然存在 heap 中,然后由垃圾回收器自动的清理回收。
通过一个例子来了解函数的执行顺序
'use strict'
const express = require('express')
const superagent = require('superagent')
const app = express()
app.get('/', getArticle)
function getArticle(req, res) {
fetchArticle(req, res)
print()
}
const aids = [4564824, 4506868, 4767667, 4856099, 7456996];
function fetchArticle(req, res) {
const aid = aids[Math.floor(Math.random() * aids.length)]
superagent.get(`http://news-at.zhihu.com/api/4/news/${aid}`)
.end((err, res) => {
if(err) {
console.log('error ......');
return res.status(500).send('an error ......')
}
const article = res.body
res.send(article)
console.log('Got an article')
})
console.log('Now is fetching an article')
}
function print(){
console.log('Print something')
}
app.listen('5000')请求 http://localhost:5000/ 后打印出
Now is fetching an article
Print something
Got an article
虽然 V8 是单线程的,但底层的 C++ API 却不是。这意味着当我们执行一些非阻塞的操作,Node会调用一些代码,与引擎里的js代码同时执行。一旦这个隐藏的线程收到了等待的返回值或者抛出一个异常,之前提供的回调函数就会执行。
上面的说的Node调用的一些代码其实就是 libuv,一个开源的跨平台的异步 I/O 。最初就是为 Node.js 开发的,现在很多项目都在用
javascript 是单线程事件驱动的语言,那我们可以给时间添加监听器,当事件触发时,监听器就能执行回调函数。
当我们去调用 setTimeout http.get fs.readFile, Node.js 会把这些定时器、http、IO操作发送给另一个线程以保证V8继续执行我们的代码。
然而我们只有一个主线程和一个 call-stack ,这样当一个读取文件的操作还在执行时,有一个网络请求request过来,那这时他的回调就需要等stack变空才能执行。
回调函数正在等待轮到自己执行所排的队就被称为任务队列(或者事件队列、消息队列)。每当主线程完成前一个任务,回调函数就会在一个无限循环圈里被调用,因此这个圈被称为事件循环。
我们前面那个获取文章的例子的执行顺序就会如下:
request 事件触发getArticlegetArticle 压入(push) stackfetchArticle 被调用 同时压入 stackMath.floor 和 Math.random 被调用压入 stack 然后再 弹出(pop), 从 aids 里面取出的一个值被赋值给变量 aidsuperagent.get 被执行,参数为 'http://news-at.zhihu.com/api/4/news/${aid}' ,并且回调函数注册给了 end 事件http://news-at.zhihu.com/api/4/news/${aid} 的HTTP请求被发送到后台线程,然后函数继续往下执行'Now is fetching an article' 打印在 console 中。 函数 fetchArticle 返回print 函数被调用, 'Print something' 打印在 console 中getArticle 返回,并从 stack 中弹出, stack 为空http://news-at.zhihu.com/api/4/news/${aid} 发送相应信息end 事件被触发end 事件的匿名回调函数被执行,这个匿名函数和他闭包中的所有变量压入 stack,这意味着这个匿名函数可以访问并修改 express, superagent, app, aids, req, res, aid 的值以及之前所有已经定义的函数res.send() 伴随着 200 或 500 的状态码被执行,但同时又被放入到后台线程中,因此 响应流 不会阻塞我们函数的执行。匿名函数也被 pop 出 stack。任务队列不止一个,还有 microtasks 和 macrotasks
microtasks:
macrotasks:
这两个的详细区别下一篇再写,先看一段代码
console.log('start')
const interval = setInterval(() => {
console.log('setInterval')
}, 0)
setTimeout(() => {
console.log('setTimeout 1')
Promise.resolve()
.then(() => {
console.log('promise 3')
})
.then(() => {
console.log('promise 4')
})
.then(() => {
setTimeout(() => {
console.log('setTimeout 2')
Promise.resolve()
.then(() => {
console.log('promise 5')
})
.then(() => {
console.log('promise 6')
})
.then(() => {
clearInterval(interval)
})
}, 0)
})
}, 0)
Promise.resolve()
.then(() => {
console.log('promise 1')
})
.then(() => {
console.log('promise 2')
})理解了node的事件循环还是比较容易得出答案的:
start
promise 1
promise 2
setInterval
setTimeout 1
promise 3
promise 4
setInterval
setTimeout 2
promise 5
promise 6
根据 WHATVG 的说明,在一个事件循环的周期(cycle)中一个 (macro)task 应该从 macrotask 队列开始执行。当这个 macrotask 结束后,所有的 microtasks 将在同一个 cycle 中执行。在 microtasks 执行时还可以加入更多的 microtask,然后一个一个的执行,直到 microtask 队列清空。
规范理解起来有点晦涩,来看下上面的例子
1) setInterval 被列为 task
2) setTimeout 1 被列为 task
3) Promise.resolve 1 中两个 then 被列为 microtask
4) stack 清空 microtasks 执行
任务队列: setInterval setTimeout 1
5) microtasks 队列清空 setInteval 的回调可以执行。另一个 setInterval 被列为 task , 位于 setTimeout 1 后面
任务队列: setTimeout 1 setInterval
6) microtask 队列清空,setTimeout 1 的回调可以执行,promise 3 和 promise 4 被列为 microtasks
7) promise 3 和 promise 4 执行。 setTimeout 2 被列为 task
任务队列 setInterval setTimeout 2
8) microtask 队列清空 setInteval 的回调可以执行。然后另一个 setInterval 被列为 task ,位于 setTimeout 2 后面
任务队列: setTimeout 2 setInterval
9) setTimeout 2 的回调执行, promise 5 和 promise 6 被列为 microtasks
现在 promise 5 和 promise 6 的回调应该执行,并且 clear 掉 interval。 但有的时候不知道为什么 setInterval 还会在执行一遍,变成下面结果
...
setTimeout 2
setInterval
promise 5
promise 6
但是把上面的代码放入 chrome console 中执行却没有问题。这一点还要再根据不同的 node版本 查一下。
这篇只是对 事件循环 的浅析和总览,后面再继续深入的研究。
在手机上使用CSS动画时很多时候会感到卡顿,然后网上很多教程说开启GPU加速 transform: translate3d(0,0,0); 可解决,但是为什么开启GPU加速就能让动画顺滑呢?
JS是单线程的,但是浏览器可以开启多个线程,渲染一个网页需要两个重要的线程来共同完成:
我们知道如果长时间的执行 JS 会阻塞主线程,页面就会出现各种的卡顿。
而绘制线程会尽量的去响应用户的交互,页面发生变化时,绘制线程会以每秒60帧(60fps是最适合人眼的交互,30fps以下的动画,让人感觉到明显的卡顿)的间隔不断重绘页面。
GPU 在如下方面很快:
但是在将位图加载到GPU内存中有点慢
_PS: 橙色方框的操作比较耗时,绿色方框的操作比较快速_
div {
height: 100px;
transition: height 1s linear;
}
div:hover {
height: 200px;
}一个从 height: 100px 到 height: 200px 的动画按照下面的流程图来执行各种操作

图中有那么多的橙色方框,浏览器会做大量的计算,动画就会卡顿。
因为每一帧的变化浏览器都在进行布局、绘制、把新的位图交给 GPU 内存(这恰好是我们上面提到的GPU的短板)
虽然只改变元素高度但是很可能要同步改变他的子元素的大小,那浏览器就要重新计算布局,计算完后主线程再来重新生成该元素的位图。
div {
transform: scale(0.5);
transition: transform 1s linear;
}
div:hover {
transform: scale(1.0);
}流程图如下
![]()
很明显,这么少的橙色方框,动画肯定会流畅。
因为 transform 属性不会改变自己和他周围元素的布局,他会对元素的整体产生影响。
因此,浏览器只需要一次生成这个元素的位图,然后动画开始时候交给 GPU 来处理他最擅长的位移、旋转、缩放等操作。这就解放了浏览器不再去做各种的布局、绘制等操作。
把上面的demo代码在浏览器中执行下看下效果,demo地址:
http://ccforward.github.io/demos/css/animation.html

同样是改变大小的 scale 动画
![]()
参考信息:
http://blogs.adobe.com/webplatform/2014/03/18/css-animations-and-transitions-performance/
WebRTC是Web Real-Time Communication(网页实时通信)。WebRTC 包含有三个组件:
分别对应三个API接口:
最新支持成都可在 caniuse.com 上查询
function hasGetUserMedia() {
return !!(navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia);
}navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.moZGetUserMedia || navigator.msGetUserMedia;
var video = document.querySelector('video');
navigator.getUserMedia({
audio : true,
video : true
}, function (stream) {
video.src = window.URL.creatObjectURL(stream);
}, function (error) {
console.log(error);
});这样就可以通过video标签成功将视频流输出到页面上。
var video = document.querySelector('video');
var canvas = document.querySelector('canvas');
var ctx = canvas.getContext('2d');
navigator.getUserMedia({
audio: true,
video: true
}, function(stream) {
video.src = window.URL.creatObjectURL(stream);
}, function(error) {
console.log(error);
});
video.addEventListener('click', function() {
ctx.drawImage(video, 0, 0);
var img = new Image();
img.src = canvas.toDataURL('image/png');
document.appendChild(img);
}, false)var imgData = ctx.getImageData();
var filter = {
// 灰度效果
grayscale: function(pixels) {
var d = pixels.data;
for (var i = 0, len = d.length; i < len; i += 4) {
var r = d[i],
g = d[i + 1],
b = d[i + 2];
d[i] = d[i + 1] = d[i + 2] = (r + g + b) / 3;
}
return pixels;
},
// 复古效果
sepia: function(pixels) {
var d = pixels.data;
for (var i = 0, len = d.length; i < len; i += 4) {
var r = d[i],
g = d[i + 1],
b = d[i + 2];
d[i] = (r * 0.393) + (g * 0.769) + (b * 0.189);
d[i + 1] = (r * 0.349) + (g * 0.686) + (b * 0.168);
d[i + 2] = (r * 0.272) + (g * 0.534) + (b * 0.131);
}
return pixels;
},
// 红色蒙版效果
red: function(pixels) {
var d = pixels.data;
for (var i = 0, len = d.length; i < len; i += 4) {
var r = d[i],
g = d[i + 1],
b = d[i + 2];
d[i] = (r + g + b) / 3;
d[i + 1] = d[i + 2] = 0;
}
return pixels;
},
// 反转效果
invert: function(pixels) {
var d = pixels.data;
for (var i = 0, len = d.length; i < len; i += 4) {
var r = d[i],
g = d[i + 1],
b = d[i + 2];
d[i] = 255 - r;
d[i + 1] = 255 - g;
d[i + 2] = 255 - b;
}
return pixels;
}
};
ctx.putImageData(filter[type](imgData));var range = document.querySelector('input');
window.AudioContext = window.AudioContext || window.webkitAudioContext;
var audioCtx = new AudioContext();
navigator.getUserMedia({
audio: true
}, function(stream) {
// 创建音频流
var source = audioCtx.createMediaStreamSource(stream);
// 双二阶滤波器
var biquadFilter = audioCtx.createBiquadFilter();
biquadFilter.type = 'lowshelf';
biquadFilter.frequenc.value = 1000;
biquadFilter.gain.value = range.value;
source.connect(biquadFilter);
biquadFilter.connect(audioCtx.destination);
}, function(error) {
console.log(error);
});RTCPeerConnection,用于peer跟peer之间呼叫和建立连接以便传输音视频数据流;
WebRTC是实现peer to peer的实时通信(可以两个或多个peer之间),在能够通信前peer跟peer之间必须建立连接,这是RTCPeerConnection的任务,为此需要借助一个信令服务器(signaling server)来进行,信令包括3种类型的信息:
var PeerConnection = window.RTCPeerConnection || window.mozRTCPeerConnection || window.webkitRTCPeerConnection;
navigator.getUserMedia = navigator.getUserMedia ? "getUserMedia" :
navigator.mozGetUserMedia ? "mozGetUserMedia" :
navigator.webkitGetUserMedia ? "webkitGetUserMedia" : "getUserMedia";
var v = document.createElement("video");
// 创建信令
var pc = new PeerConnection();
pc.addStream(video);
pc.createOffer(function(desc) {
pc.setLocalDescription(desc, function() {
// send the offer to a server that can negotiate with a remote client
});
})
// 创建回复
var pc = new PeerConnection();
pc.setRemoteDescription(new RTCSessionDescription(offer), function() {
pc.createAnswer(function(answer) {
pc.setLocalDescription(answer, function() {
// send the answer to the remote connection
});
});
})
peer跟peer之间一旦建立连接就可以直接传输音视频数据流,并不需要借助第三方服务器中转。
具体文档可以查看:https://developer.mozilla.org/en-US/docs/Web/API/RTCPeerConnection。
RTCDataChannel可以建立浏览器之间的点对点通讯。常用的通讯方式有webSocket, ajax和 Server Sent Events等方式,websocket虽然是双向通讯,但是无论是websocket还是ajax都是客户端和服务器之间的通讯,这就意味着你必须配置服务器才可以进行通讯。而RTCDATAChannel采用另外一种实现方式
WebRTC并未规定使用何种信令机制和消息协议,象SIP、XMPP、XHR、WebSocket这些技术都可以用作WebRTC的信令通信。
除了信令服务器,peer跟peer建立连接还需要借助另一种服务器(称为STUN server)实现NAT/Firewall穿越,因为很多peer是处于私有局域网中,使用私有IP地址,必须转换为公有IP地址才能相互之间传输数据。这其中涉及到一些专业术语包括STUN、TURN、ICE等,其实我对这些概念也不是很理解。网上找到的WebRTC demo好象都用的是Google提供的STUN server。
参考文章:http://www.html5rocks.com/en/tutorials/webrtc/datachannels/?redirect_from_locale=zh
https://developer.mozilla.org/en-US/docs/Web/API/RTCDataChannel
WebRTC的目的是为了简化基于浏览器的实时数据通信的开发工作量,但实际应用编程还是有点复杂,尤其调用RTCPeerConnection必须对如何建立连接、交换信令的流程和细节有较深入的理解。因此我们可以使用已经封装好的WebRTC库,这些WebRTC库对原生的webRTC的API进行进一步的封装,包装成更简单的API接口。同时屏蔽了不同浏览器之间的差异。
目前网上主要有两种WebRTC的封装库:
最后是用WebRTC写的一个小demo:https://ccforward.github.io/demos/webrtc/index.html
关于 WebRTC 的相关文章推荐:http://www.html5rocks.com/en/tutorials/webrtc/basics/
服务器上本来有多个版本的PHP,因为误操作把一个老版本的PHP给误删,只好重装。
因为好久没装过环境了,有些生疏,所以把编译安装过程简单记下来
因为历史原因,一些老的服务必须依赖 PHP-5.3.27 所以以此版本为例
tar -zxvf php-5.3.27.tar.gz./configure --prefix=/usr/local/php-5.3.27 \
--with-mysql=mysqlnd \
--with-mysqli=mysqlnd \
--with-pdo-mysql=mysqlnd \
--with-iconv-dir=/usr/local \
--with-freetype-dir \
--with-jpeg-dir \
--with-png-dir \
--with-zlib \
--with-libxml-dir \
--enable-xml \
--enable-pdo \
--disable-rpath \
--enable-bcmath \
--enable-shmop \
--enable-sysvsem \
--enable-inline-optimization \
--with-curl \
--with-mcrypt \
--with-curlwrappers \
--enable-mbregex \
--enable-fpm \
--enable-mbstring \
--with-gd \
--enable-gd-native-ttf \
--with-openssl \
--with-mhash \
--enable-pcntl \
--enable-sockets \
--with-xmlrpc \
--enable-zip \
--enable-soap \
--with-pear \
--with-bz2 \
make
make install
复制配置文件 php.ini
cp php.ini-development /usr/local/php-5.3.27/lib/php.ini
PS: 这个版本的 php.ini 文件要放在bin目录下,之前一直按照 php5.6 放在etc目录下,导致出现各种问题,看了 ./php -i | grep ini 后才发现
Configuration File (php.ini) Path => /usr/local/php-5.3.27/lib
配置 php-fpm
因为用了 nginx 做为服务器,所以用 php-fpm 做个 FastCGI 管理器
cp php-fpm.conf.default php-fpm.confpid = run/php-fpm.pidphp-fpm.conf user=www group=www 和 listen = 127.0.0.1:9527cp /etc/init.d/php-fpm /etc/init.d/php-fpm5327./php-fpm5327 start是 memcached 不是 memcache
wget http://launchpad.net/libmemcached/1.0/0.42/+download/libmemcached-0.42.tar.gztar -zxvf libmemcached-0.42.tar.gzcd libmemcached-0.42./configure --prefix=/usr/local/libmemcached --with-memcachedmake && make install/usr/local/php-5.3.27/bin/phpize./configure --with-php-config=/usr/local/php-5.3.27/bin/php-config --with-libmemcached-dir=/usr/local/libmemcachedmake && make install/usr/local/php-5.3.27/bin/phpize./configure --with-php-config=/usr/local/php-5.3.27/bin/php-configmake && make install./usr/local/php-5.3.27/bin/phpize./configure -with-php-config=/usr/local/php-5.3.27/bin/php-config -with-pdo-mysql=/usr/local/mysqlmake && make install根据需要安装完各种扩展后 重启 fpm 即可:
/etc/init.d/php-fpm5327 restart
基本用法
{
let a = 10;
var b= 1;
}
console.log(a) // error
console.log(b) // 1let 很适合用在 for 循环中的计数器
不存在变量提升
console.log(foo); // ReferenceError
let foo = 10;
// typeof 将不再是一个百分百安全的操作
typeof x ; // ReferenceError
let x;暂时性死区 (TDZ temporal dead zone)
只要块级作用域内存在 let 命令,它所声明的变量就 "绑定" 这个区域,不再受外部的影响
var tmp = 123;
if(true){
// TDZ 开始
tmp = 'abc'; // ReferenceError
console.log(tmp); // ReferenceError
let tmp; // TDZ 结束
}不允许重复声明
let 不允许在相同作用域内重复声明同一个变量
// 报错
function() {
var a = 10;
let a = 10;
}
// 报错
function() {
let b = 10;
let b = 10;
}
// 报错
function(arg) {
let arg ;
}
// 不报错
function(arg) {
{
let arg ;
}
}块级作用域的出现让广泛应用的 IIFE 不再必要了
// IIFE 写法
(function(){
var tmp = '';
....
})()
// 块级作用域写法
{
let tmp = '';
....
}块级作用域外部无法调用块级作用域内部的函数
{
let a = 'aaa';
function f() {
return a;
}
}
f() // 报错这样来处理
let f;
{
let a = 'aaa';
f = function() {
return a;
}
}
f() // 'aaa'声明常量
const一旦声明就必须立即初始化,不能留到以后赋值。
const foo;
// SyntaxError: missing = in const declarationconst 复合型变量
变量名不指向数据,而是指向数据所在的地址。
const foo = {};
foo.prop = 123;
foo.prop; // 123
foo = {}; // 报错 read-only真想冻结对象 可用 freeze 方法
const foo = Object.freeze({});
const声明的常量只在当前代码块有效。如下方法来跨模块:
//constants.js 模块
export const A = 1;
export const B = 2;
export const C = 3;
// test1.js 模块
import * as constants from './constants';
console.log(constants.A); // 1
console.log(constants.B); // 2
// test2.js 模块
import {A, B} from './constants';
console.log(A); // 1
console.log(B); // 2ES6中规定
var a = 1;
window.a; // 1
let b = 1;
window.b; // undefined按照一定模式,从数组和对象中提取值,对变量进行赋值。
用法
var [a, b, c] = [1, 2, 3];
let [foo, [[bar], baz]] = [1, [[2], 3]];
let [head, ...tail] = [1, 2, 3, 4, 5];
// head 1
// tail [2, 3, 4, 5]
const [x, y, ...z] = ['a'];
// x 'a'
// y undefined
// z []结构不成功, 变量的值就是 undefind
如果等号的右边不是 可遍历结构 ,那将会报错
// 全部报错
var [foo] = 1;
var [foo] = false;
let [foo] = NaN;
let [foo] = undefined;
let [foo] = null;
let [foo] = {};因为上面等号右边的值, 幺妹转为对象后不具备 Iterator 接口(前5个),要么本身就不具备 Iterator 接口(最后一个)。
Set 结构, 也可以使用数组的解构赋值
let [x, y, z] = new Set(['a', 'b', 'c']);默认值
ES6中使用 === 判断哪一个位置是否有值。所以,一个数组成员不严格等于 undefined ,默认值是不会生效的
var [x = 1] = [undefined];
// x 1
var [x = 1] = [null];
// x null
// 因为 null !== undefined --> true和数组的不同点
数组的元素是有次序的,变量的取值由他的位置决定;而对象的属性没有次序,变量必须与属性同名,才能取到正确的值。
var {bar, foo} = { foo: "aaa", bar: "bbb"};
foo // "aaa"
bar // "bbb"
var {baz} = {foo:"aaa", bar: "bbb"}
baz // undefined如果变量名与属性名不一致
var {foo: baz} = {foo: "aaa", bar: "bbb"};
baz // "aaa"
foo // error: foo is not define实际上,对象的解构赋值是以下形式的简写
var {foo: foo, bar: bar} = {foo: "aaa", bar: "bbb"};真正赋值的是后者 不是前者
其他
var {foo: {bar}} = {baz: "baz"}
// 报错此时 foo 的属性对应一个子对象。该子对象的bar属性结构时会报错。因为 foo 现在为undefined。
var x;
{x} = {x: 1}
// SyntaxError: syntax error对于已经声明的变量用于解构赋值必须很小心。因为上面的代码 js 引擎会把 {x} 理解成一个代码块,发生语法错误。正确的写法:
({x} = {x:1});圆括号与解构赋值的关系
解构赋值允许等号左边的模式中不放置任何变量名。于是写出很古怪的表达式
({} = [true, false]);
({} = 'abc');
({} = []);上面的表达式毫无意义 但是语法是合法可以执行的。
对象的解构赋值可以很方便的将现有对象的方法赋值到某个变量。
let { log, sin, cos } = Math
字符串被转换成一个类似数组的对象
const [a, b, c, d, e] = 'hello';
a // "h"
b // "e"
c // "e"
d // "l"
e // "o"类似数组的对象都有 length 属性,因此可以对这个属性解构赋值
let {length: len} = 'hello';
len // 5解构赋值时,如果等号右边是数值或布尔值,则会 先转为对象 。
let {toString: s} = 123
s === Number.prototype.toString // true
let {toString: b} = true
b === Boolean.prototype.toString // true上面代码中 数值 和 布尔值 的包装对象都有 toString 属性,因此 s 都能取到值。
解构赋值的规则是,只要等号右边的值不是对象,就现将其转为对象。 由于 undefined 和 null 无法转为对象,所以对他们进行解构赋值都会报错。
let {prop: x} = undefined; // TypeError
let {prop: y} = null; // TypeError
// 转为 ES5 的代码 一目了然
var x = undefined.prop;
var _ref = null;
var y = _ref.prop;function add([x,y]){
return x + y;
}
add([1,2]) //3上面的代码,函数的参数不是一个数组,而是通过解构得到的变量 x 和 y
function move({x=0, y=0} = {}){
return [x, y];
}
move({x:3, y:8}) // [3, 8]
move({x:3}) // [3, 0]
move({}) // [0, 0]
move() // [0 ,0]上面的代码,函数 move 的参数是一个对象,通过对这个对象进行解构,得到变量 x y 的值。 解构失败,则等于x y等于默认值。
function move({x, y} = {x:0, y:0}){
return [x, y];
}
move({x:3, y:8}) // [3, 8]
move({x:3}) // [3, undefined]
move({}) // [undefined, undefined]
move() // [0 ,0]上面的代码视为函数 move 的参数指定默认值,而不是为 x y 指定默认值,所以结果不同。
一个式子是模式还是表达式,没有办法一开始就知道,必须解析到或解析不到等号才知道。
ES6的规则是,只要有可能导致解构歧义,就不得使用圆括号。
变量声明语句中,模式不能带有圆括号
// 全部报错
var [(1)] = [1];
var {x: (c)} = {};
var {o: ({p:p})} = {o: {p:2}}函数参数中,模式不能带有圆括号
函数参数也属于声明变量
不能将整个模式或嵌套模式的一层放在圆括号中
// 全部报错
({p:a}) = {p: 1};
([a]) = [5];
[({p: a}), {x: y}] = [{p: 1}, {x: 2}];只有一种情况:赋值语句的非模式部分可以使用后圆括号
[(b)] = [1]; // 模式是取数组的第一个成员
({p: (a)} = {p: 1}); // 模式是p 而不是a
([parseInt.prop]) = [1]; // 同第一个因为上面语句都是赋值语句,不是声明语句;他们的圆括号都不属于模式的一部分
[x, y] = [y, x]; // 交换 x y 的值babel转换后
"use strict";
var _ref = [y, x];
x = _ref[0];
y = _ref[1];
_ref;函数只能返回一个值,想要多个就只能放在数组或对象中返回了。
// 返回一个数组
function example(){
return [1,2,3]
}
var [a,b,c] = example()
// 返回一个对象
function example(){
return {
foo: 1,
bar: 2
}
}
var {foo, bar} = example();很方便的将一组参数和变量对应起来
// 参数是一组有次序的值
function f([x,y,z]){
...
}
f([1,2,3])
// 无次序
function f({x,y,z}){
...
}
f({z:3, y:2, x:1})十分有用
var jsonData = {
id: 1,
status: 'OK',
data: [12,13]
}
let {id, status, data: number} = jsonData;
console.log(id, status, number)jQuery.ajax = function(url,{
async = true,
beforeSend = function(){},
cache = true,
complete = function(){},
crossDomain = false,
global = true
....
}){
....
}可以避免在函数内部再写 var foo = config.foo || 'defaule foo';
任何部署了 Iterator 接口的对象,都可以用 for...of 循环再遍历。Map原生支持 Iterator 接口,使用变量的解构赋值获取 key value 很方便。
var map = new Map();
map.set('first', 'hello');
map.set('second', 'world');
for(let [key, value] of map){
console.log(key, value);
}
// 只获取键
let [key] of map
// 只获取值
let [,value] of map加载模块时候,往往需要指定哪些方法。
const {parseURL, util} = require('base');
转成 ES5
'use strict';
var _require = require('base');
var parseURL = _require.parseURL;
var util = _require.util;* * * * * command3,15 * * * * command3,15 8-11 * * * command3,15 8-11 */2 * * command3,15 8-11 * * 1 command30 21 * * * command45 4 1,10,22 * * command10 1 * * 6,0 command0,30 18-23 * * * command0 23 * * 6 command* */1 * * ** 23-7/1 * * *0 11 4 * mon-wed0 4 1 jan *01 * * * * root run-parts /etc/cron.hourly手动可执行任务,但无法自动执行,需要注意环境变量
cat start_cbp.sh
#!/bin/sh
source /etc/profile
export RUN_CONF=/home/d139/conf/platform/cbp/cbp_jboss.conf
/usr/local/jboss-4.0.5/bin/run.sh -c mev &
清理系统用户的邮件日志
新创建的cron job,不会马上执行,至少要过2分钟才执行。如果重启cron则马上执行。
当crontab突然失效时,可以尝试/etc/init.d/crond restart解决问题。或者查看日志看某个job有没有执行/报错tail -f /var/log/cron。
重新开始看Javascript基础知识,记录知识点关键字
Any application that can be written in JavaScript, will eventually be written in JavaScript.
利用多行注释生成多行字符串
(function () { /*
line 1
line 2
line 3
*/}).toString().split('\n').slice(1,-1).join('\n')
'hello'[1]; //e
base64转码
window.btoa("Hello World")
// "SGVsbG8gV29ybGQ="
window.atob("SGVsbG8gV29ybGQ=")
// "Hello World"
这是stackoverflow上的一个老问题,却有个干货答案,但是扩展的信息量很大,我只在此抛个砖。
Not jQuery. Not YUI. Not 等等…
js的框架的确很有用,但是它们却常常把一些js的丑陋细节和DOM原理给你隐藏了。如果你的目标是做一个精通javascript的工程师,那花大把的时间放在框架上可能恰恰背道而驰了。
下面就有javascript这门语言的一些特性,你应该知道并且深谙此道,但是很多人可能还并不清楚。
1、对象属性,object.prop和object['prop']是一回事(所以你能停止使用eval了吗?!3KU);对象的属性多是String类型(有些也是数组Array);for…in是什么情况下使用,什么情况慎用?
方括号可以通过变量来访问属性
person.name;
person['name'];
var propertyName = 'name';
person[propertyName]; // name当属性是带空格的string时就只能用方括号了:person['first name'];
for…in 循环输出的属性名顺序不可预测,使用之前先检测对象是否为null 或者 undefined
2、属性检测;undefined和null;为什么鲜为人知的in运算符非常有用,以及它和typeof、undefined的区别;hasOwnProperty;delete作用
undefined好理解一般用来表示未定义,而且不能用delete来删除它。
null 表示一个空对象指针 所以 typeof null返回 object
undefined派生自null alert(null == undefined) 返回true; 但alert(null === undefined)就返回false了
关于hasOwnProperty和Object:
hasOwnProperty是js中唯一一个处理属性但是不查找原型链的函数
Object.prototype.prop = 'propsss';
var obj = {und:undefined};
obj.prop; // propsss
'und' in obj; // true
obj.hasOwnProperty('prop'); // false
obj.hasOwnProperty('und'); // true
//只有hasOwnProperty可以给出正确和期望的结果,尤其在遍历一个对象时
//除了hasOwnProperty外,没有其他方法可以排除原型链上的属性(不是定义在对象自身上的属性)
//如果hasOwnProperty被占用呢?来看:
var obj = {
hasOwnProperty: function(){
return false;
},
prop: 'this is bad...'
};
obj.hasOwnProperty('prop'); // 总是返回false
//这样解决:
<del>{}.hasOwnProperty.call(obj,'prop');</del>
Object.hasOwnProperty.call(obj,'prop'); // 返回truevar o =new Object();
Object的每个实例都具有下列属性方法:
3、Number类型就是浮点类型(64位浮点数);使用浮点数会遇到语言无关性的问题;避免使用parseInt时的八进制陷阱
ECMAScript5不具有解析八进制的能力,ES3和ES5之间存在分歧
javascript中的乘法问题:
一般可以用 10000 作为基数
31.12 * 10000 * 9.7 / 10000
4、嵌套函数作用域;避免全局变量导致的意外而使用var的必要性;闭包的作用域如何结合使用;在循环与闭包的问题
作用域和var关键字的面试题
function(){
var a=b=10;
}
console.log(a);
console.log(b);循环中使用闭包
function createFunctions(){
var result = new Array();
for(var i=0;i<10;i++){
result[i] = fucntion(){
return i;
}
}
return result;
}
//每个函数的作用域链中都保存着createFunctions()函数的活动对象,所以他们引用的都是同一个变量i。
//当createFunctions()返回后 变量i的值是10
//所以可以这样写
for(var i=0;i<10;i++){
result[i] = function(num){
return function(){
return num;
};
}(i);
}之前写过的闭包的理解关于闭包
5、全局变量和window对象的属性产生冲突怎么办(它们其实是一回事);全局变量和DOM元素在IE中的冲突;在全局作用域中使用var来避免这些问题
6、 function语句在解析时会被提升(不管function被放置在哪里,它都会被移动到定义时所在作用域的顶层) 函数声明和函数表达式;为什么命名函数表达式不应该使用
关于函数声明提升:
解析器会执行一个函数声明提升(function decalaration hoisting)的过程,读取并将函数声明添加到执行环境中。
对代码求值时js引擎在第一遍会声明函数并将它们放到源代码树的顶部。
alert(sum(10,10))
function sum(n1,n2){
return n1+n2;
}
//单独使用下面代码时,函数表达式会出错:
alert(sum(10,10));
var sum = function (n1,n2){
return n1+n2;
}关于命名函数表达式:
1、命名函数表达式即被认为是函数声明也被认为是函数表达式
typeof g; // "function"
var f = function g(){};
//上面这个例子论证了 jScript 是如何把一个命名函数表达式处理成一个函数声明的
//在函数声明发生之前就把 g 给解析了 【在IE中检测】2、命名函数表达式还能创建两个不同的函数对象—-这是js的bug
var f = function g(){};
f === g; //false
f.prop = 'a prop';
g.prop; // undefined 【在IE中检测】竟然创建了两个对象,他们之间还不是引用的关系,是不是很有趣。。。我只能说:呵呵 interesting……
3、在条件语句中命名函数表达的声明式仍然会被解析
var f = function g(){
return 1;
};
if(false){
f= function g(){
return 100;
};
}
g(); //猜猜返回什么 【在IE中检测】
//还有arguments也中枪了
var f = function g(){
return [
arguments.callee == f,
arguments.callee == g
];
};
console.log(f()); // [true, false]
console.log(g()); // [false, true] 【在IE中检测】注:上面的3条准确的说应该是算是jScript的bug
7、构造函数;prototype属性;new运算符的运行机制;利用这些方法实现一个类-子类-实例的系统;在何时应该考虑使基于闭包的对象来替代原型设计
8、this是在函数调用时才被确定的而不是定义的时候;把函数当做参数传入时不像其他语言那样执行;如何使用闭包或者Function.prototype.bind来解决这些问题呢
关于this的调用,直接上代码:
var Dog = {
toString: function() { return 'dog';},
fn: function() { alert(this);},
};
var Cat = {
toString: function() { return 'cat';}
};
Dog.fn(); // dog
Dog['fn']() // dog
Cat.fn = Dog.fn;
Cat.fn(); // cat
var func = Dog.fn;
func(); // window上面代码很简单 请自行补脑……
Obj.method = function() {
var self = this;
function test() {
//this 被设置为全局对象(window)
//self 指向 Obj 对象
}
}
//想到了arguments做个低耦合的递归求阶乘
function factorial(num) {
if(num<=1)
return 1;
else
return num*arguments.callee(num-1);
}
//callee指向拥有这个arguments对象的函数关于Function.prototype.bind(thisArg [, arg1 [, arg2, …]]):
这是ECMAScript 5中的方法看看Opera的对它的介绍吧
简单翻译就是:
Function.prototype.bind 返回一个新的函数对象,该对象的 this 绑定到了thisArg参数上。本质就是:这允许你在其他对象链中执行一个函数
但是很多浏览器不支持,通过一个js的hack看看原理吧:
if(!Object.bind){
Function.prototype.bind = function(owner){
var self = this;
var args = Array.prototype.slice.call(arguments,1);
return function() {
return self.allpy(
args.length===0 ? arguments : arguments.length===0? args:
args.contact(Array.prototype.slice.call(arguments,0))
);
};
};
}9、其他的ES5新特性如indexOf 、 forEach 以及Array使用函数式编程;旧浏览器如何兼容这些新的方法;使用匿名函数调用这些方法来使代码更加紧致具有可读性
Array.prototype.indexOf(searchString ,position)
var data = [1,3,5,7,9];
console.log(data.indexOf(5)); //2
console.log(data.indexOf(5,4)); //-1 从4号位开始搜索
console.log(data.indexOf('7')); //-1 7!== '7'
Array.prototype.lastIndexOf //从末尾开始查找
Array.prototype.some //某些条件符合
var arr = [1,2,3,4,11];
function larger(item){
return item> 10
}
console.log(arr.some(larger)?'ok':'no...');
//注:只要有一条符合 即返回true 不再执行
Array.prototype.every // all符合 和some相比就是返回的 true 和 false 调换一下
Array.prototype.forEach //类似jQ里的each
[1, 2 ,3, 4].forEach(alert);
[1, 2 ,3, 4].forEach(console.log);//FF下运行 不知为什么chrome不行。。。。。
Array.prototype.map //映射 类似forEach 把原数组映射成新数组
var arr = [1,3,5,7];
var result = arr.map(function(item){
return item * item;
});
console.log(result); //求各项平方
Array.prototype.filter //筛选
var filter = [0,2,3,0,undefined].filter(function(item){
return item;
});
console.log(filter);
//filter的callback函数需要返回值为 true 或 false。若为false则过滤掉
Array.prototype.reduce //不是减少 是一种迭代
var sum = [1,2,3,4,5].reduce(function(pre,current,index,array) {
return pre + current;
});
console.log(sum); //15
Array.prototype.reduceRight //right 自然是从数组末未开始这些都是 ES5 中 Array 对象的扩展方法
PS:还是点此自行补脑,我也在研究中…..后续会再补充
10、浏览器和js代码之间控制流程的原理;同步和异步执行;事件在运行时触发和事件在控制返回时触发的区别;调用同步执行的方法如alert而引起控制流重新进入的潜在问题(翻译不通,请自行补脑)。
11、跨window脚本对instanceof的影响 在不同的DOM中跨window脚本对控制流的影响;postMessage怎么解决这个问题
postMessage就是HTML5解决跨域问题引入的API,使得多个iframe/window实现跨域通信。
写了个postMessage跨域通信的demo: 点此查看
最重要的是,你需要批判的去看待javascript,承认因为种种历史原因而导致各种不完美(甚至比其他语言还要糟糕),并要避免各种陷阱。Crockford在这方面的研究很值得学习(虽然我不完全认同他的《javascript语言精粹》)
完(水平有限,欢迎指正)。
七牛的10G 免费云存储 一直没用,正好现在拿这个做自己的cdn图床。(其实现在付费cdn的存储和流量都超便宜)
chrome扩展就是在图片上右键上传img标签里的图片,本地和远程图片都可上传。

新版本的七牛上传 node-sdk 比以前简化了很多代码,更好用了
代码 在这 也就20几行,很简单。
这一步也简单,直接 http.createServer 来提供一个接口获取图片的地址,然后重点就是下一步,上传图片。
这里要判断是远程线上图片还是本地在浏览器打开的图片
对于本地的图片地址要做 decodeURI(url.replace('file://','')) ,不然node找不到文件(这里被坑了一下)
本地图片获取文件大小和格式
var localURL = decodeURI(url.replace('file://','')),
size = fs.statSync(localURL).size / (1024*1024),
format = path.extname(localURL).split('.').pop();文件格式只是从路径中读取,可能会出问题,暂时先这样用。
有个类似插件之前就在公司内部用过,现在把最基本功能挪出来。
先做一个简单版本,只添加了图片右键监听,点击后发送一个ajax请求到第2步中HTTP提供的接口里,异步调用上传接口。
chrome.contextMenus.create({
"type": "normal",
"title": "上传这张图片(向我曾经的cdn插件致敬)",
"contexts": ["image"],
"onclick": evt
});一个稍微复杂点的例子**https://github.com/ccforward/cc/blob/master/promise/example-new.js**
_ES6规范确认以前,写过一个Promise的简单实现_
Promise就是一个容器,里面保存着某个未来才会结束的事件(一个异步操作)的结果。作为一个对象,从Promise可以获取异步操作的消息。
Pending(进行中) Resolved(已完成 Fullfilled) Rejected(已失败)。通过Promise对象就可以将异步操作以同步操作的流程表达出来,避免嵌套层层回调的地狱。
var getJSON = function(url){
var promise = new Promise(function(){
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onreadystatechange = hanlder;
xhr.responseType = 'json';
xhr.setRequestHeader('Accept', 'application/json');
xhr.send();
function hanlder(){
if(this.readyState !== 4){
return;
}
if(this.status == 200){
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
});
return promise;
}如果调用 resolve 或者 reject 函数时带有参数,那么这些参数会传递给回调函数。 reject的参数通常是 Error 对象的实例,表示跑出的错误。
then 方法是为 Promise 实例添加状态改变时的回调函数。then方法的第一个参数是 Resolved 状态的回调函数,第二个参数(可选)是 Rejected 状态的回调函数。
then方法返回的是一个新的Promise实例(不是原来那个),可采用链式写法。如下:
getJSON("a.json").then(function(res){
return getJSON(res.dataURL)
}).then(function fnA(data){
console.log('Resolved: ' + data);
}, function fnB(err){
console.log('Rejected: ' + err);
});第一个then方法指定的回调函数返回的是一个新的 Promise 对象。这时,第二个then方法指定的回调函数就等待这个新的 Promise 对象发生变化来调用A或B函数
上面的代码改为箭头函数更简洁:
getJSON("a.json").then(
res => getJSON(res.dataURL)
).then(
data => console.log('Resolved: ' + data),
err => console.log('Rejected: ' + err)
);Promise.prototype.catch 是 .then(null, rejection) 的别名。
如果异步操作抛出错误,状态就会变为 Rejected, 就会调用catch方法指定的回调函数处理这个错误。
一般来说,不要再then方法中定义 Rejected 状态的回调函数(then的第二个参数),而应该总是使用 catch 方法。
//bad
promise
.then(function(data){
// success
},function(err){
// error
})
// good
promise
.then(function(data){ //回调函数
// success
})
.catch(function(err){
// error
})跟传统的 try/catch 不同,如果没有使用catch方法指定错误处理的回调函数, Promise对象抛出的错误不会传递到外层代码,即不会有任何反应。
catch 返回的还是一个 Promise 对象,因此后面可以继续调用 then 方法。
var someAsync = function(){
return new Promise(function(resolve, reject){
// x没声明 报错
resolve(x+2);
});
}
comAsync()
.catch(function(err){
console.log('error: ' + err)
})
.then(function(){
console.log('go on')
});
// error: [ReferenceError: x is not defined]
// go on 接着运行then方法Promise.all 用于将多个 Promise 实例包装成一个新的 Promise 实例。
var p = Promise.all([p1, p2, p3]);p的状态由 p1 p2 p3 决定
Promise.race 也是将多个 Promise 实例包装成一个新的 Promise 实例。
var p = Promise.race([p1, p2, p3]);只要 p1 p2 p3 中有一个实例率先改变状态,p的状态就跟着改变
var p = Promise.race([
fetch('/data.json'),
new Promise(function (resolve, reject) {
setTimeout(() => reject(new Error('request timeout')), 5000)
})
])
p.then(response => console.log(response))
p.catch(error => console.log(error))如果5秒之内fetch方法无法返回结果,变量p的状态就会变为rejected,从而触发catch方法指定的回调函数。
Promise.resolve方法将现有对象转为Promise对象。
Promise.resolve($.ajax('/whatever.json'));
把 jQuery 生成的 deferred 对象转为新的 Promise 对象
Promise.resolve('foo')
// 等价于
new Promise(resolve => resolve('foo'))如果resolve方法的参数是一个不具有then方法的对象,则Promise.resolve方法返回一个新的Promise对象,状态为Resolved。
var p = Promise.resolve('Hello');
p.then(function (s){
console.log(s)
});字符串Hello不属于异步操作(判断方法是它不是具有then方法的对象),返回Promise实例的状态从一生成就是Resolved,所以回调函数会立即执行。
Promise.resolve方法允许调用时不带参数,直接调用Promise.resolve可以获得一个 Promise 对象。
var p = Promise.resolve();
p.then(function () {
// ...
});Promise.reject() 方法也会返回一个新的Promise实例,且状态为rejected。
它的参数用法与Promise.resolve方法完全一致。
var p = Promise.reject('出错了');
// 等同于
var p = new Promise((resolve, reject) => reject('出错了'))
p.then(null, function (s){
console.log(s)
});
// 出错了Promise.prototype.done = function (onFulfilled, onRejected) {
this.then(onFulfilled, onRejected)
.catch(function (reason) {
// 抛出一个全局错误
setTimeout(() => { throw reason }, 0);
});
};Promise.prototype.finally = function (callback) {
let P = this.constructor;
return this.then(
value => P.resolve(callback()).then(() => value),
reason => P.resolve(callback()).then(() => { throw reason })
);
};sticky从iOS6开始支持,Android4.4版本还不支持
其实这个css3属性很简单,只是做个兼容的demo来演示下
demo地址(扫码查看): css-sticky
HTTP/2是基于Google的SPDY协议为基础开发的新的web协议。HTTP/2算是从1991年以来HTTP的第一次重大升级。
Yahoo 旗下的 Flickr 貌似在2016年7月开始用上了HTTP2,如图

虽然 HTTP/2 是基于 SPDY 协议开发的,但是两者还是有不同点的:
HTTP2的优势:
因为我们基于node实现的h2用的是spdy模块,所以必须建立在https的基础上,先生成自签名的证书
$ mkdir h2-node
$ cd h2-node
$ openssl genrsa -des3 -passout pass:x -out server.pass.key 2048
$ openssl rsa -passin pass:x -in server.pass.key -out server.key
$ openssl req -new -key server.key -out server.csr
# ...
# 输入证书相关信息(随意填写)
# ...
$ openssl x509 -req -sha256 -days 365 -in server.csr -signkey server.key -out server.crt
$ rm server.pass.key初始化 package.json 文件并添加 spdy 和 express 模块
npm init
npm i express spdy --save
新建一个 index.js 文件作为应用入口
const spdy = require('spdy');
const express = require('express');
const path = require('path');
const fs = require('fs');添加 express 并配置路由
const port = 3000;
const app = express();
app.get('*', (req, res) => {
res
.status(200)
.json({error: 0, msg: "http2 OK"});
})加载https的证书
const options = {
key: fs.readFileSync(__dirname + '/server.key'),
cert: fs.readFileSync(__dirname + '/server.crt')
}最后 spdy创建服务器,并加载 ssl 配置和 express 实例
spdy
.createServer(options, app)
.listen(port, (error) => {
if (error) {
console.error(error)
return process.exit(1)
} else {
console.log('Listening on port: ' + port + '.')
}
})执行 node index.js 然后访问
因为浏览器默认情况下不信任自签名的证书,所以这里点击 继续前往localhost(不安全) 即可
原文地址
发现已经有人翻译过了。。。。
http://weizhifeng.net/javascript-the-core.html
- 对象
- 原型链
- 构造函数
- 执行上下文栈
- 执行上下文
- 变量对象
- 活动对象
- 作用域链
- 闭包
- this
- 结论
这篇文章是“深入理解ECMA-262-3”的一个总览和概要,每个章节都有对应的详细的链接。
ECMAScript作为一个高度抽象的面向对象语言,是通过对象来做数据传递的。当然也有一些基本数据类型,但通常也会被转换为对象来处理。
一个对象就是一组属性的集合,并拥有一个独立的prototype对象,这个prototype可以是个对象也可以是个null
举个简单例子,对象的 prototype 是以内部的[[Prototype]]属性来引用的。但是我们在图表中使用 __<internal-property>__下划线标记来代替双括号,尤其是prototype对象:__proto__
代码如下:
var foo = {
x: 10,
y: 20
};
于是就有这个结构:两个显式的自身属性和一个隐式属性__proto__,这个隐式属性就是对 foo 原型对象的引用
为什么需要这些prototype?那我们就以原型链 (prototype chain) 的概念来回答这个问题。
原型对象也是简单对象,并且也有自己的原型。如果一个原型对象的原型有一个非空(not null)的引用,那么以此类推,这就叫做原型链。
原型链是一个可以实现继承和对象共享的有限对象链
假设我们有两个对象,其中只有一小部分不同,其他绝大部分相同。很明显,对于一个有良好设计的系统,我们会复用相似的函数和代码。在基于类的系统中,代码复用风格叫做类继承class-based inheritance —— 把一组相似的功能放入Class A,然后Class B和C继承Class A,并又有独自的小改动。
ECMAScript中没有类的概念。但是代码复用的风格并没有多大的不同(尽管从某些方面来说这种方式比累积成要更灵活)并且通过原型链来实现。这种集成被称作委托继承(delegation based inheritance)(或者用ECMAScript的范式来说就叫做原型继承)。
类似子上面例子中的类A、B、C,在ECMAScript中创建对象a、b、c。那么在a中存储b、c通用的部分,b、c只存储自己额外属性和方法。
代码如下:
var a = {
x: 10,
calculate: function (z) {
return this.x + this.y + z;
}
};
var b = {
y: 20,
__proto__: a
};
var c = {
y: 30,
__proto__: a
};
// call the inherited method
b.calculate(30); // 60
c.calculate(40); // 80
足够简单,对吧。b和c调用了a中的calculate方法,这就叫做原型链继承。
规则很简单:一个属性或一个方法没有在对象自身中找到(即对象自身没有那个属性),然后就尝试在原型中查找这个属性或者方法,如果原型中没有找到,就会继续查找原型的原型,以此来遍历整个原型链(当然这在基于类继承中是一样的,调用继承方法时会遍历真个Class链)第一个被查找到的同名属性/方法会被使用。因此,一个被查找到的属性叫作_继承_属性。如果在遍历了整个原型链之后还是没有查找到这个属性的话,返回undefined值。
规则很简单:如果一个属性或者一个方法在对象_自身_中无法找到(也就是对象自身没有一个那样的属性),然后它会尝试在原型链中寻找这个属性/方法。如果这个属性在原型中没有查找到,那么将会查找这个原型的原型,以此类推,遍历整个原型链(当然这在类继承中也是一样的,当解析一个继承的_方法_的时候-我们遍历_class链_( class chain))。第一个被查找到的同名属性/方法会被使用。因此,一个被查找到的属性叫作_继承_属性。如果在遍历了整个原型链之后还是没有查找到这个属性的话,返回undefined值。
注意,继承方法中所使用的this的值被设置为_原始_对象,而并不是在其中查找到这个方法的(原型)对象。也就是,在上面的例子中this.y取的是b和c中的值,而不是a中的值。但是,this.x是取的是a中的值,并且又一次通过_原型链_机制完成。
如果没有明确为一个对象指定原型,那么它将会使用__proto__的默认值-Object.prototype。Object.prototype对象自身也有一个__proto__属性,这是原型链的_终点_并且值为null。
下一张图展示了对象a,b,c之间的继承层级:
注意:
ES5标准化了一个实现原型继承的可选方法,即使用Object.create函数:
var b = Object.create(a, {y: {value: 20}});
var c = Object.create(a, {y: {value: 30}});
你可以在对应的章节获取到更多关于ES5新API的信息。
ES6标准化了 __proto__属性,并且可以在对象初始化的时候使用它。
通常情况下需要对象拥有_相同或者相似的状态结构_(也就是相同的属性集合),赋以不同的_状态值_。在这个情况下我们可能需要使用_构造函数_(constructor function),其以_指定的模式_来创造对象。
除了以指定模式创建对象之外,构造函数_也做了另一个有用的事情-它_自动地为新创建的对象设置一个原型对象。这个原型对象存储在ConstructorFunction.prototype属性中。
换句话说,我们可以使用构造函数来重写上一个拥有对象b和对象c的例子。因此,对象a(一个原型对象)的角色由Foo.prototype来扮演:
// a constructor function
function Foo(y) {
// which may create objects
// by specified pattern: they have after
// creation own "y" property
this.y = y;
}
// also "Foo.prototype" stores reference
// to the prototype of newly created objects,
// so we may use it to define shared/inherited
// properties or methods, so the same as in
// previous example we have:
// inherited property "x"
Foo.prototype.x = 10;
// and inherited method "calculate"
Foo.prototype.calculate = function (z) {
return this.x + this.y + z;
};
// now create our "b" and "c"
// objects using "pattern" Foo
var b = new Foo(20);
var c = new Foo(30);
// call the inherited method
b.calculate(30); // 60
c.calculate(40); // 80
// let's show that we reference
// properties we expect
console.log(
b.__proto__ === Foo.prototype, // true
c.__proto__ === Foo.prototype, // true
// also "Foo.prototype" automatically creates
// a special property "constructor", which is a
// reference to the constructor function itself;
// instances "b" and "c" may found it via
// delegation and use to check their constructor
b.constructor === Foo, // true
c.constructor === Foo, // true
Foo.prototype.constructor === Foo // true
b.calculate === b.__proto__.calculate, // true
b.__proto__.calculate === Foo.prototype.calculate // true
);
这个代码可以表示为如下关系:
这张图又一次说明了每个对象都有一个原型。构造函数Foo也有自己的__proto__,值为Function.prototype,Function.prototype也通过其__proto__属性关联到Object.prototype。因此,重申一下,Foo.prototype就是Foo的一个明确的属性,指向对象b和对象c的原型。
正式来说,如果思考一下_分类_的概念(并且我们已经对Foo进行了_分类_),那么构造函数和原型对象合在一起可以叫作「类」。实际上,举个例子,Python的_第一级_(first-class)动态类(dynamic classes)显然是以同样的属性/方法处理方案来实现的。从这个角度来说,Python中的类就是ECMAScript使用的委托继承的一个语法糖。
注意: 在ES6中「类」的概念被标准化了,并且实际上以一种构建在构造函数上面的语法糖来实现,就像上面描述的一样。从这个角度来看原型链成为了类继承的一种具体实现方式:
// ES6
class Foo {
constructor(name) {
this._name = name;
}
getName() {
return this._name;
}
}
class Bar extends Foo {
getName() {
return super.getName() + ' Doe';
}
}
var bar = new Bar('John');
console.log(bar.getName()); // John Doe
有关这个主题的完整、详细的解释可以在ES3系列的第七章找到。分为两个部分:7.1 面向对象.基本理论,在那里你将会找到对各种面向对象范例、风格的描述以及它们和ECMAScript之间的对比,然后在7.2 面向对象.ECMAScript实现,是对ECMAScript中面向对象的介绍。
现在,在我们知道了对象的基础之后,让我们看看_运行时程序的执行_(runtime program execution)在ECMAScript中是如何实现的。这叫作_执行上下文栈_(execution context stack),其中的每个元素也可以抽象成为一个对象。是的,ECMAScript几乎在任何地方都和对象的概念打交道;)
这里有三种类型的ECMAScript代码:_全局_代码、函数_代码和_eval_代码。每个代码是在其_执行上下文(execution context)中被求值的。这里只有一个全局上下文,可能有多个函数执行上下文以及_eval_执行上下文。对一个函数的每次调用,会进入到函数执行上下文中,并对函数代码类型进行求值。每次对eval函数进行调用,会进入_eval_执行上下文并对其代码进行求值。
注意,一个函数可能会创建无数的上下文,因为对函数的每次调用(即使这个函数递归的调用自己)都会生成一个具有新状态的上下文:
function foo(bar) {}
// call the same function,
// generate three different
// contexts in each call, with
// different context state (e.g. value
// of the "bar" argument)
foo(10);
foo(20);
foo(30);
一个执行上下文可能会触发另一个上下文,比如,一个函数调用另一个函数(或者在全局上下文中调用一个全局函数),等等。从逻辑上来说,这是以栈的形式实现的,它叫作_执行上下文栈_。
一个触发其他上下文的上下文叫作_caller_。被触发的上下文叫作_callee_。callee在同一时间可能是一些其他callee的caller(比如,一个在全局上下文中被调用的函数,之后调用了一些内部函数)。
当一个caller触发(调用)了一个callee,这个caller会暂缓自身的执行,然后把控制权传递给callee。这个callee被push到栈中,并成为一个_运行中_(活动的)执行上下文。在callee的上下文结束后,它会把控制权返回给caller,然后caller的上下文继续执行(它可能触发其他上下文)直到它结束,以此类推。callee可能简单的_返回_或者由于_异常_而退出。一个抛出的但是没有被捕获的异常可能退出(从栈中pop)一个或者多个上下文。
换句话说,所有ECMAScript_程序的运行时_可以用_执行上下文(EC)栈_来表示,栈顶_是当前_活跃(active)上下文:
当程序开始的时候它会进入_全局执行上下文_,此上下文位于_栈底_并且是栈中的_第一个_元素。然后全局代码进行一些初始化,创建需要的对象和函数。在全局上下文的执行过程中,它的代码可能触发其他(已经创建完成的)函数,这些函数将会进入它们自己的执行上下文,向栈中push新的元素,以此类推。当初始化完成之后,运行时系统(runtime system)就会等待一些_事件_(比如,用户鼠标点击),这些事件将会触发一些函数,从而进入新的执行上下文中。
在下个图中,拥有一些函数上下文EC1和全局上下文Global EC,当EC1进入和退出全局上下文的时候下面的栈将会发生变化:
这就是ECMAScript的运行时系统如何真正地管理代码执行的。
更多有关ECMAScript中执行上下文的信息可以在对应的第一章 执行上下文中获取。
像我们所说的,栈中的每个执行上下文都可以用一个对象来表示。让我们来看看它的结构以及一个上下文到底需要什么_状态_(什么属性)来执行它的代码。
一个执行上下文可以抽象的表示为一个简单的对象。每一个执行上下文拥有一些属性(可以叫作_上下文状态_)用来跟踪和它相关的代码的执行过程。在下图中展示了一个上下文的结构:
除了这三个必需的属性(一个_变量对象_(variable objec),一个_this值以及一个_作用域链(scope chain))之外,执行上下文可以拥有任何附加的状态,这取决于实现。
让我们详细看看上下文中的这些重要的属性。
变量对象是与执行上下文相关的数据作用域。它是一个与上下文相关的特殊对象,其中存储了在上下文中定义的变量和函数声明。
注意,函数表达式(与_函数声明_相对)_不包含_在变量对象之中。
变量对象是一个抽象概念。对于不同的上下文类型,在物理上,是使用不同的对象。比如,在全局上下文中变量对象就是_全局对象本身_(这就是为什么我们可以通过全局对象的属性名来关联全局变量)。
让我们在全局执行上下文中考虑下面这个例子:
var foo = 10;
function bar() {} // function declaration, FD
(function baz() {}); // function expression, FE
console.log(
this.foo == foo, // true
window.bar == bar // true
);
console.log(baz); // ReferenceError, "baz" is not defined
之后,全局上下文的变量对象(variable objec,简称VO)将会拥有如下属性:
再看一遍,函数baz是一个_函数表达式_,没有被包含在变量对象之中。这就是为什么当我们想要在函数自身之外访问它的时候会出现ReferenceError。
注意,与其他语言(比如C/C++)相比,在ECMAScript中_只有函数_可以创建一个新的作用域。在函数作用域中所定义的变量和内部函数在函数外边是不能直接访问到的,而且并不会污染全局变量对象。
使用eval我们也会进入一个新的(eval类型)执行上下文。无论如何,eval使用全局的变量对象或者使用caller(比如eval被调用时所在的函数)的变量对象。
那么函数和它的变量对象是怎么样的?在函数上下文中,变量对象是以_活动对象_(activation object)来表示的。
当一个函数被caller所_触发_(被调用),一个特殊的对象,叫作_活动对象_(activation object)将会被创建。这个对象中包含_形参_和那个特殊的arguments对象(是对形参的一个映射,但是值是通过索引来获取)。_活动对象_之后会做为函数上下文的_变量对象_来使用。
换句话说,函数的变量对象也是一个同样简单的变量对象,但是除了变量和函数声明之外,它还存储了形参和arguments对象,并叫作_活动对象_。
考虑如下例子:
function foo(x, y) {
var z = 30;
function bar() {} // FD
(function baz() {}); // FE
}
foo(10, 20);
我们看下函数foo的上下文中的活动对象(activation object,简称AO):
并且_函数表达式_baz还是没有被包含在变量/活动对象中。
关于这个主题所有细节方面(像变量和函数声明的_提升问题_(hoisting))的完整描述可以在同名的章节第二章 变量对象中找到。
注意,在ES5中_变量对象_和_活动对象_被并入了_词法环境_模型(lexical environments model),详细的描述可以在对应的章节找到。
然后我们向下一个部分前进。众所周知,在ECMAScript中我们可以使用_内部函数_,然后在这些内部函数我们可以引用_父_函数的变量或者_全局_上下文中的变量。当我们把变量对象命名为上下文的_作用域对象_,与上面讨论的原型链相似,这里有一个叫作_作用域链_的东西。
作用域链是一个对象列表,上下文代码中出现的标识符在这个列表中进行查找。
这个规则还是与原型链同样简单以及相似:如果一个变量在函数自身的作用域(在自身的变量/活动对象)中没有找到,那么将会查找它父函数(外层函数)的变量对象,以此类推。
就上下文而言,标识符指的是:变量_名称_,函数声明,形参,等等。当一个函数在其代码中引用一个不是局部变量(或者局部函数或者一个形参)的标识符,那么这个标识符就叫_作自由变量_。搜索这些自由变量(free variables)正好就要用到_作用域链_。
在通常情况下,作用域链_是一个包含所有_父(函数)变量对象__加上(在作用域链头部的)函数_自身变量/活动对象_的一个列表。但是,这个作用域链也可以包含任何其他对象,比如,在上下文执行过程中动态加入到作用域链中的对象-像_with对象_或者特殊的_catch从句_(catch-clauses)对象。
当_解析_(查找)一个标识符的时候,会从作用域链中的活动对象开始查找,然后(如果这个标识符在函数自身的活动对象中没有被查找到)向作用域链的上一层查找-重复这个过程,就和原型链一样。
var x = 10;
(function foo() {
var y = 20;
(function bar() {
var z = 30;
// "x" and "y" are "free variables"
// and are found in the next (after
// bar's activation object) object
// of the bar's scope chain
console.log(x + y + z);
})();
})();
我们可以假设通过隐式的__parent__属性来和作用域链对象进行关联,这个属性指向作用域链中的下一个对象。这个方案可能在真实的Rhino代码中经过了测试,并且这个技术很明确得被用于ES5的词法环境中(在那里被叫作outer连接)。作用域链的另一个表现方式可以是一个简单的数组。利用__parent__概念,我们可以用下面的图来表现上面的例子(并且父变量对象存储在函数的[[Scope]]属性中):
在代码执行过程中,作用域链可以通过使用with语句和catch从句对象来增强。并且由于这些对象是简单的对象,它们可以拥有原型(和原型链)。这个事实导致作用域链查找变为_两个维度_:(1)首先是作用域链连接,然后(2)在每个作用域链连接上-深入作用域链连接的原型链(如果此连接拥有原型)。
对于这个例子:
Object.prototype.x = 10;
var w = 20;
var y = 30;
// in SpiderMonkey global object
// i.e. variable object of the global
// context inherits from "Object.prototype",
// so we may refer "not defined global
// variable x", which is found in
// the prototype chain
console.log(x); // 10
(function foo() {
// "foo" local variables
var w = 40;
var x = 100;
// "x" is found in the
// "Object.prototype", because
// {z: 50} inherits from it
with ({z: 50}) {
console.log(w, x, y , z); // 40, 10, 30, 50
}
// after "with" object is removed
// from the scope chain, "x" is
// again found in the AO of "foo" context;
// variable "w" is also local
console.log(x, w); // 100, 40
// and that's how we may refer
// shadowed global "w" variable in
// the browser host environment
console.log(window.w); // 20
})();
我们可以给出如下的结构(确切的说,在我们查找__parent__连接之前,首先查找__proto__链):
注意,不是在所有的实现中全局对象都是继承自Object.prototype。上图中描述的行为(从全局上下文中引用「未定义」的变量x)可以在诸如SpiderMonkey引擎中进行测试。
由于所有父变量对象都存在,所以在内部函数中获取父函数中的数据没有什么特别-我们就是遍历作用域链去解析(搜寻)需要的变量。就像我们上边提及的,在一个上下文结束之后,它所有的状态和它自身都会被_销毁_。在同一时间父函数可能会_返回_一个_内部函数_。而且,这个返回的函数之后可能在另一个上下文中被调用。如果自由变量的上下文已经「消失」了,那么这样的调用将会发生什么?通常来说,有一个概念可以帮助我们解决这个问题,叫作_(词法)闭包_,其在ECMAScript中就是和_作用域链_的概念紧密相关的。
在ECMAScript中,函数是_第一级_(first-class)对象。这个术语意味着函数可以做为参数传递给其他函数(在那种情况下,这些参数叫作「函数类型参数」(funargs,是"functional arguments"的简称))。接收「函数类型参数」的函数叫作_高阶函数_或者,贴近数学一些,叫作高阶_操作符_。同样函数也可以从其他函数中返回。返回其他函数的函数叫作_以函数为值_(function valued)的函数(或者叫作拥有_函数类值_的函数(functions with functional value))。
这有两个在概念上与「函数类型参数(funargs)」和「函数类型值(functional values)」相关的问题。并且这两个子问题在_"Funarg problem"(或者叫作"functional argument"问题)中很普遍。为了解决_整个"funarg problem",闭包(closure)的概念被创造了出来。我们详细的描述一下这两个子问题(我们将会看到这两个问题在ECMAScript中都是使用图中所提到的函数的[[Scope]]属性来解决的)。
「funarg问题」的第一个子问题是_「向上funarg问题」(upward funarg problem)。它会在当一个函数从另一个函数向上返回(到外层)并且使用上面所提到的_自由变量_的时候出现。为了在_即使父函数上下文结束_的情况下也能访问其中的变量,内部函数在_被创建的时候_会在它的[[Scope]]属性中保存父函数的_作用域链。所以当函数被_调用_的时候,它上下文的作用域链会被格式化成活动对象与[[Scope]]属性的和(实际上就是我们刚刚在上图中所看到的):
Scope chain = Activation object + [[Scope]]
再次注意这个关键点-确切的说在_创建时刻_-函数会保存_父函数的_作用域链,因为确切的说这个_保存下来的作用域链_将会在未来的函数调用时用来查找变量。
function foo() {
var x = 10;
return function bar() {
console.log(x);
};
}
// "foo" returns also a function
// and this returned function uses
// free variable "x"
var returnedFunction = foo();
// global variable "x"
var x = 20;
// execution of the returned function
returnedFunction(); // 10, but not 20
这个类型的作用域叫作_静态(或者词法)作用域_。我们看到变量x在返回的bar函数的[[Scope]]属性中被找到。通常来说,也存在_动态作用域_,那么上面例子中的变量x将会被解析成20,而不是10。但是,动态作用域在ECMAScript中没有被使用。
「funarg问题」的第二个部分是_「向下funarg问题」_。这种情况下可能会存在一个父上下文,但是在解析标识符的时候可能会模糊不清。问题是:标识符该使用_哪个作用域_的值-以静态的方式存储在函数创建时刻的还是在执行过程中以动态方式生成的(比如_caller_的作用域)?为了避免这种模棱两可的情况并形成闭包,_静态作用域_被采用:
// global "x"
var x = 10;
// global function
function foo() {
console.log(x);
}
(function (funArg) {
// local "x"
var x = 20;
// there is no ambiguity,
// because we use global "x",
// which was statically saved in
// [[Scope]] of the "foo" function,
// but not the "x" of the caller's scope,
// which activates the "funArg"
funArg(); // 10, but not 20
})(foo); // pass "down" foo as a "funarg"
我们可以断定_静态作用域_是一门语言拥有_闭包的必需条件_。但是,一些语言可能会同时提供动态和静态作用域,允许程序员做选择-什么应该包含(closure)在内和什么不应包含在内。由于在ECMAScript中只使用了静态作用域(比如我们对于funarg问题的两个子问题都有解决方案),所以结论是:ECMAScript完全支持闭包,技术上是通过函数的[[Scope]]属性实现的。现在我们可以给闭包下一个准确的定义:
闭包是一个代码块(在ECMAScript是一个函数)和以静态方式/词法方式进行存储的所有父作用域的一个集合体。所以,通过这些存储的作用域,函数可以很容易的找到自由变量。
注意,由于_每个_(标准的)函数都在创建的时候保存了[[Scope]],所以理论上来讲,ECMAScript中的_所有函数_都是_闭包_。
另一个需要注意的重要事情是,多个函数可能拥有_相同的父作用域_(这是很常见的情况,比如当我们拥有两个内部/全局函数的时候)。在这种情况下,[[Scope]]属性中存储的变量是在拥有相同父作用域链的_所有函数之间共享_的。一个闭包对变量进行的修改会_体现_在另一个闭包对这些变量的读取上:
function baz() {
var x = 1;
return {
foo: function foo() { return ++x; },
bar: function bar() { return --x; }
};
}
var closures = baz();
console.log(
closures.foo(), // 2
closures.bar() // 1
);
以上代码可以通过下图进行说明:
确切来说这个特性在循环中创建多个函数的时候会使人非常困惑。在创建的函数中使用循环计数器的时候,一些程序员经常会得到非预期的结果,所有函数中的计数器都是_同样_的值。现在是到了该揭开谜底的时候了-因为所有这些函数拥有同一个[[Scope]],这个属性中的循环计数器的值是最后一次所赋的值。
var data = [];
for (var k = 0; k < 3; k++) {
data[k] = function () {
alert(k);
};
}
data[0](); // 3, but not 0
data[1](); // 3, but not 1
data[2](); // 3, but not 2
这里有几种技术可以解决这个问题。其中一种是在作用域链中提供一个额外的对象-比如,使用额外函数:
var data = [];
for (var k = 0; k < 3; k++) {
data[k] = (function (x) {
return function () {
alert(x);
};
})(k); // pass "k" value
}
// now it is correct
data[0](); // 0
data[1](); // 1
data[2](); // 2
对闭包理论和它们的实际应用感兴趣的同学可以在第六章 闭包中找到额外的信息。如果想获取更多关于作用域链的信息,可以看一下同名的第四章 作用域链。
然后我们移动到下个部分,考虑一下执行上下文的最后一个属性。这就是关于this值的概念。
this是一个与执行上下文相关的特殊对象。因此,它可以叫作上下文对象(也就是用来指明执行上下文是在哪个上下文中被触发的对象)。
_任何对象_都可以做为上下文中的this的值。我想再一次澄清,在一些对ECMAScript执行上下文和部分this的描述中的所产生误解。this经常被_错误的_描述成是变量对象的一个属性。这类错误存在于比如像这本书中(即使如此,这本书的相关章节还是十分不错的)。再重复一次:
this是执行上下文的一个属性,而不是变量对象的一个属性
这个特性非常重要,因为_与变量相反_,this从不会参与到标识符解析过程。换句话说,在代码中当访问this的时候,它的值是_直接_从执行上下文中获取的,并_不需要任何作用域链查找_。this的值只在_进入上下文_的时候进行_一次_确定。
顺便说一下,与ECMAScript相反,比如,Python的方法都会拥有一个被当作简单变量的self参数,这个变量的值在各个方法中是相同的的并且在执行过程中可以被更改成其他值。在ECMAScript中,给this赋一个新值是_不可能的_,因为,再重复一遍,它不是一个变量并且不存在于变量对象中。
在全局上下文中,this就等于_全局对象本身_(这意味着,这里的this等于_变量对象_):
var x = 10;
console.log(
x, // 10
this.x, // 10
window.x // 10
);
在函数上下文的情况下,对_函数的每次调用_,其中的this值可能是_不同的_。这个this值是通过_函数调用表达式_(也就是函数被调用的方式)的形式由_caller_所提供的。举个例子,下面的函数foo是一个_callee_,在全局上下文中被调用,此上下文为caller。让我们通过例子看一下,对于一个代码相同的函数,this值是如何在不同的调用中(函数触发的不同方式),由caller给出_不同的_结果的:
// the code of the "foo" function
// never changes, but the "this" value
// differs in every activation
function foo() {
alert(this);
}
// caller activates "foo" (callee) and
// provides "this" for the callee
foo(); // global object
foo.prototype.constructor(); // foo.prototype
var bar = {
baz: foo
};
bar.baz(); // bar
(bar.baz)(); // also bar
(bar.baz = bar.baz)(); // but here is global object
(bar.baz, bar.baz)(); // also global object
(false || bar.baz)(); // also global object
var otherFoo = bar.baz;
otherFoo(); // again global object
为了深入理解this为什么(并且更本质一些-如何)在每个函数调用中可能会发生变化,你可以阅读第三章 This。在那里,上面所提到的情况都会有详细的讨论。
#!/bin/bash
#
# CRM .bash_profile Time-stamp: "2008-12-07 19:42"
#
source ~/.profile # Get the paths
source ~/.bashrc # get aliases
#
#- end原文:all this
习惯了高级语言的你或许觉得JavaScript中的this跟Java这些面向对象语言相似,保存了实体属性的一些值。其实不然。将它视作幻影魔神比较恰当,手提一个装满未知符文的灵龛。
以下内容我希望广大同行们能够了解。下面都是满满的干货,其中很多花费了我很多时间才掌握。
this浏览器宿主的全局环境中,this指的是window对象。
<script type="text/javascript">
console.log(this === window); //true
</script>浏览器中在全局环境下,使用var声明变量其实就是赋值给this或window。
<script type="text/javascript">
var foo = "bar";
console.log(this.foo); //logs "bar"
console.log(window.foo); //logs "bar"
</script>任何情况下,创建变量时没有使用var或者let(ECMAScript 6),也是在操作全局this。
<script type="text/javascript">
foo = "bar";
function testThis() {
foo = "foo";
}
console.log(this.foo); //logs "bar"
testThis();
console.log(this.foo); //logs "foo"
</script>Node命令行(REPL)中,this是全局命名空间。可以通过global来访问。
> this
{ ArrayBuffer: [Function: ArrayBuffer],
Int8Array: { [Function: Int8Array] BYTES_PER_ELEMENT: 1 },
Uint8Array: { [Function: Uint8Array] BYTES_PER_ELEMENT: 1 },
...
> global === this
true在Node环境里执行的JS脚本中,this其实是个空对象,有别于global。
console.log(this);
console.log(this === global);$ node test.js
{}
false当尝试在Node中执行JS脚本时,脚本中全局作用域中的var并不会将变量赋值给全局this,这与在浏览器中是不一样的。
var foo = "bar";
console.log(this.foo);$ node test.js
undefined...但在命令行里进行求值却会赋值到this身上。
> var foo = "bar";
> this.foo
bar
> global.foo
bar在Node里执行的脚本中,创建变量时没带var或let关键字,会赋值给全局的global但不是this(译注:上面已经提到this和global不是同一个对象,所以这里就不奇怪了)。
foo = "bar";
console.log(this.foo);
console.log(global.foo);
命令行执行:
$ node test.js
> undefined
> bar但在Node命令行里,就会赋值给两者了。
注意:* Node脚本中global和this是区别对待的,而Node命令行中,两者可等效为同一对象。*
this除了DOM的事件回调或者提供了执行上下文(后面会提到)的情况,函数正常被调用(不带new)时,里面的this指向的是全局作用域。
<script type="text/javascript">
foo = "bar";
function testThis() {
this.foo = "foo";
}
console.log(this.foo); //logs "bar"
testThis();
console.log(this.foo); //logs "foo"
</script>foo = "bar";
function testThis () {
this.foo = "foo";
}
console.log(global.foo);
testThis();
console.log(global.foo);$ node test.js
bar
foo还有个例外,就是使用了"use strict";。此时this是undefined。
<script type="text/javascript">
foo = "bar";
function testThis() {
"use strict";
this.foo = "foo";
}
console.log(this.foo); //logs "bar"
testThis(); //Uncaught TypeError: Cannot set property 'foo' of undefined
</script>当用调用函数时使用了new关键字,此刻this指代一个新的上下文,不再指向全局this。
<script type="text/javascript">
foo = "bar";
function testThis() {
this.foo = "foo";
}
console.log(this.foo); //logs "bar"
new testThis();
console.log(this.foo); //logs "bar"
console.log(new testThis().foo); //logs "foo"
</script>通常我将这个新的上下文称作实例。
this函数创建后其实以一个函数对象的形式存在着。既然是对象,则自动获得了一个叫做prototype的属性,可以自由地对这个属性进行赋值。当配合new关键字来调用一个函数创建实例后,此刻便能直接访问到原型身上的值。
function Thing() {
console.log(this.foo);
}
Thing.prototype.foo = "bar";
var thing = new Thing(); //logs "bar"
console.log(thing.foo); //logs "bar"当通过new的方式创建了多个实例后,他们会共用一个原型。比如,每个实例的this.foo都返回相同的值,直到this.foo被重写。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
Thing.prototype.setFoo = function (newFoo) {
this.foo = newFoo;
}
var thing1 = new Thing();
var thing2 = new Thing();
thing1.logFoo(); //logs "bar"
thing2.logFoo(); //logs "bar"
thing1.setFoo("foo");
thing1.logFoo(); //logs "foo";
thing2.logFoo(); //logs "bar";
thing2.foo = "foobar";
thing1.logFoo(); //logs "foo";Demo
thing2.logFoo(); //logs "foobar";在实例中,this是个特殊的对象,而this自身其实只是个关键字。你可以把this想象成在实例中获取原型值的一种途径,同时对this赋值又会覆盖原型上的值。完全可以将新增的值从原型中删除从而将原型还原为初始状态。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
Thing.prototype.setFoo = function (newFoo) {
this.foo = newFoo;
}
Thing.prototype.deleteFoo = function () {
delete this.foo;
}
var thing = new Thing();
thing.setFoo("foo");
thing.logFoo(); //logs "foo";
thing.deleteFoo();
thing.logFoo(); //logs "bar";
thing.foo = "foobar";
thing.logFoo(); //logs "foobar";
delete thing.foo;
thing.logFoo(); //logs "bar";...或者不通过实例,直接操作函数的原型。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo, Thing.prototype.foo);
}
var thing = new Thing();
thing.foo = "foo";
thing.logFoo(); //logs "foo bar";同一函数创建的所有实例均共享一个原型。如果你给原型赋值了一个数组,那么所有实例都能获取到这个数组。除非你在某个实例中对其进行了重写,事实上是进行了覆盖。
function Thing() {
}
Thing.prototype.things = [];
var thing1 = new Thing();
var thing2 = new Thing();
thing1.things.push("foo");
console.log(thing2.things); //logs ["foo"]通常上面的做法是不正确的(译注:改变thing1的同时也影响了thing2)。如果你想每个实例互不影响,那么请在函数里创建这些值,而不是在原型上。
function Thing() {
this.things = [];
}
var thing1 = new Thing();
var thing2 = new Thing();
thing1.things.push("foo");
console.log(thing1.things); //logs ["foo"]
console.log(thing2.things); //logs []多个函数可以形成原型链,这样this便会在原型链上逐步往上找直到找到你想引用的值。
function Thing1() {
}
Thing1.prototype.foo = "bar";
function Thing2() {
}
Thing2.prototype = new Thing1();
var thing = new Thing2();
console.log(thing.foo); //logs "bar"很多人便是利用这个特性在JS中模拟经典的对象继承。
注意原型链底层函数中对this的操作会覆盖上层的值。
function Thing1() {
}
Thing1.prototype.foo = "bar";
function Thing2() {
this.foo = "foo";
}
Thing2.prototype = new Thing1();
function Thing3() {
}
Thing3.prototype = new Thing2();
var thing = new Thing3();
console.log(thing.foo); //logs "foo"我习惯将赋值到原型上的函数称作方法。上面某些地方便使用了方法这样的字眼,比如logFoo方法。这些方法中的this同样具有在原型链上查找引用的魔力。通常将最初用来创建实例的函数称作构造函数。
原型链方法中的this是从实例中的this开始住上查找整个原型链的。也就是说,如果原型链中某个地方直接对this进行赋值覆盖了某个变量,那么我们拿到 的是覆盖后的值。
function Thing1() {
}
Thing1.prototype.foo = "bar";
Thing1.prototype.logFoo = function () {
console.log(this.foo);
}
function Thing2() {
this.foo = "foo";
}
Thing2.prototype = new Thing1();
var thing = new Thing2();
thing.logFoo(); //logs "foo";在JavaScript中,函数可以嵌套函数,也就是你可以在函数里面继续定义函数。但内层函数是通过闭包获取外层函数里定义的变量值的,而不是直接继承this。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
var info = "attempting to log this.foo:";
function doIt() {
console.log(info, this.foo);
}
doIt();
}
var thing = new Thing();
thing.logFoo(); //logs "attempting to log this.foo: undefined"上面Demo中,doIt 函数中的this指代是全局作用域或者是undefined如果使用了"use strict";声明的话。对于很多新手来说,理解这点是非常头疼的。
还有更奇葩的。把实例的方法作为参数传递时,实例是不会跟着过去的。也就是说,此时方法中的this在调用时指向的是全局this或者是undefined在声明了"use strict";时。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
function doIt(method) {
method();
}
var thing = new Thing();
thing.logFoo(); //logs "bar"
doIt(thing.logFoo); //logs undefined所以很多人习惯将this缓存起来,用个叫self或者其他什么的变量来保存,以将外层与内层的this区分开来。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
var self = this;
var info = "attempting to log this.foo:";
function doIt() {
console.log(info, self.foo);
}
doIt();
}
var thing = new Thing();
thing.logFoo(); //logs "attempting to log this.foo: bar"...但上面的方式不是万能的,在将方法做为参数传递时,就不起作用了。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
var self = this;
function doIt() {
console.log(self.foo);
}
doIt();
}
function doItIndirectly(method) {
method();
}
var thing = new Thing();
thing.logFoo(); //logs "bar"
doItIndirectly(thing.logFoo); //logs undefined
解决方法就是传递的时候使用bind方法显示指明上下文,bind方法是所有函数或方法都具有的。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
function doIt(method) {
method();
}
var thing = new Thing();
doIt(thing.logFoo.bind(thing)); //logs bar同时也可以使用apply或call 来调用该方法或函数,让它在一个新的上下文中执行。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
function doIt() {
console.log(this.foo);
}
doIt.apply(this);
}
function doItIndirectly(method) {
method();
}
var thing = new Thing();
doItIndirectly(thing.logFoo.bind(thing)); //logs bar使用bind可以任意改变函数或方法的执行上下文,即使它没有被绑定到一个实例的原型上。
function Thing() {
}
Thing.prototype.foo = "bar";
function logFoo(aStr) {
console.log(aStr, this.foo);
}
var thing = new Thing();
logFoo.bind(thing)("using bind"); //logs "using bind bar"
logFoo.apply(thing, ["using apply"]); //logs "using apply bar"
logFoo.call(thing, "using call"); //logs "using call bar"
logFoo("using nothing"); //logs "using nothing undefined"避免在构造函数中返回作何东西,因为返回的东西可能覆盖本来该返回的实例。
function Thing() {
return {};
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
var thing = new Thing();
thing.logFoo(); //Uncaught TypeError: undefined is not a function但,如果你在构造函数里返回的是个原始值比如字符串或者数字什么的,上面的错误就不会发生了,返回语句将被忽略。所以最好别在一个将要通过new来调用的构造函数中返回作何东西,即使你是清醒的。如果你想实现工厂模式,那么请用一个函数来创建实例,并且不通过new来调用。当然这只是个人建议。
当然,你也可以使用Object.create从而避免使用new。这样也能创建一个实例。
function Thing() {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
var thing = Object.create(Thing.prototype);
thing.logFoo(); //logs "bar"这种方式不会调用该构造函数。
function Thing() {
this.foo = "foo";
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
console.log(this.foo);
}
var thing = Object.create(Thing.prototype);
thing.logFoo(); //logs "bar"正因为Object.create没有调用构造函数,这在当你想实现一个继承时是非常有用的,随后你可能想要重写构造函数。
function Thing1() {
this.foo = "foo";
}
Thing1.prototype.foo = "bar";
function Thing2() {
this.logFoo(); //logs "bar"
Thing1.apply(this);
this.logFoo(); //logs "foo"
}
Thing2.prototype = Object.create(Thing1.prototype);
Thing2.prototype.logFoo = function () {
console.log(this.foo);
}
var thing = new Thing2();this可以在对象的任何方法中使用this来访问该对象的属性。这与用new得到的实例是不一样的。
var obj = {
foo: "bar",
logFoo: function () {
console.log(this.foo);
}
};
obj.logFoo(); //logs "bar"注意这里并没有使用new,也没有用Object.create,更没有函数的调用来创建对象。也可以将函数绑定到对象,就好像这个对象是一个实例一样。
var obj = {
foo: "bar"
};
function logFoo() {
console.log(this.foo);
}
logFoo.apply(obj); //logs "bar"此时使用this没有向上查找原型链的复杂工序。通过this所拿到的只是该对象身上的属性而以。
var obj = {
foo: "bar",
deeper: {
logFoo: function () {
console.log(this.foo);
}
}
};
obj.deeper.logFoo(); //logs undefined也可以不通过this,直接访问对象的属性。
var obj = {
foo: "bar",
deeper: {
logFoo: function () {
console.log(obj.foo);
}
}
};
obj.deeper.logFoo(); //logs "bar"this在DOM事件的处理函数中,this指代的是被绑定该事件的DOM元素。
function Listener() {
document.getElementById("foo").addEventListener("click",
this.handleClick);
}
Listener.prototype.handleClick = function (event) {
console.log(this); //logs "<div id="foo"></div>"
}
var listener = new Listener();
document.getElementById("foo").click();...除非你通过bind人为改变了事件处理器的执行上下文。
function Listener() {
document.getElementById("foo").addEventListener("click",
this.handleClick.bind(this));
}
Listener.prototype.handleClick = function (event) {
console.log(this); //logs Listener {handleClick: function}
}
var listener = new Listener();
document.getElementById("foo").click();thisHTML标签的属性中是可能写JS的,这种情况下this指代该HTML元素。
<div id="foo" onclick="console.log(this);"></div>
<script type="text/javascript">
document.getElementById("foo").click(); //logs <div id="foo"...
</script>this无法重写this,因为它是一个关键字。
function test () {
var this = {}; // Uncaught SyntaxError: Unexpected token this
}eval中的thiseval 中也可以正确获取当前的 this。
function Thing () {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
eval("console.log(this.foo)"); //logs "bar"
}
var thing = new Thing();
thing.logFoo();这里存在安全隐患。最好的办法就是避免使用eval。
使用Function关键字创建的函数也可以获取this:
function Thing () {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = new Function("console.log(this.foo);");
var thing = new Thing();
thing.logFoo(); //logs "bar"with时的this使用with可以将this人为添加到当前执行环境中而不需要显示地引用this。
function Thing () {
}
Thing.prototype.foo = "bar";
Thing.prototype.logFoo = function () {
with (this) {
console.log(foo);
foo = "foo";
}
}
var thing = new Thing();
thing.logFoo(); // logs "bar"
console.log(thing.foo); // logs "foo"正如很多人认为的那样,使用with是不好的,因为会产生歧义。
this一如HTML DOM元素的事件回调,jQuery库中大多地方的this也是指代的DOM元素。页面上的事件回调和一些便利的静态方法比如$.each 都是这样的。
<div class="foo bar1"></div>
<div class="foo bar2"></div>
<script type="text/javascript">
$(".foo").each(function () {
console.log(this); //logs <div class="foo...
});
$(".foo").on("click", function () {
console.log(this); //logs <div class="foo...
});
$(".foo").each(function () {
this.click();
});
</script>this如果你用过underscore.js或者lo-dash你便知道,这两个库中很多方法你可以传递一个参数来显示指定执行的上下文。比如_.each。自ECMAScript 5 标准后,一些原生的JS方法也允许传递上下文,比如forEach。事实上,上文提到的bind,apply还有call 已经给我们手动指定函数执行上下文的能力了。
function Thing(type) {
this.type = type;
}
Thing.prototype.log = function (thing) {
console.log(this.type, thing);
}
Thing.prototype.logThings = function (arr) {
arr.forEach(this.log, this); // logs "fruit apples..."
_.each(arr, this.log, this); //logs "fruit apples..."
}
var thing = new Thing("fruit");
thing.logThings(["apples", "oranges", "strawberries", "bananas"]);这样可以使得代码简洁些,不用层层嵌套bind,也不用不断地缓存this。
一些编程语言上手很简单,比如Go语言手册可以被快速读完。然后你差不多就掌握这门语言了,只是在实战时会有些小的问题或陷阱在等着你。
而JavaScript不是这样的。手册难读。非常多缺陷在里面,以至于人们抽离出了它好的部分(The Good Parts)。最好的文档可能是MDN上的了。所以我建议你看看他上面关于this的介绍,并且始终在搜索JS相关问题时加上"mdn" 来获得最好的文档资料。静态代码检查也是个不错的工具,比如jshint。
这些都是在做的、在学的和准备做的知识点。以概念为主,每一点拿出来都可以做很深的扩展。
主要还是透过lodash学习下函数式编程
主要还是以Vue为主,工作中用的比较多;
React 全家桶太多,处于不断学习的状态,把所有的API都用过,以个人项目、公司小项目使用为主;
Angular还是在2013年时候用过,现在基本忘光了,暂时也不打算放精力在上面。
关于工程化,后面再单独写篇文章,总结下自己的实践、汇总下其他的方案。
爬取了从 20150519 以来所有的文章、点赞数、评论数和部分评论内容
感觉数据挺多,简单的统计了下,还挺有趣的。
具体的数据统计和分析移步到我在知乎上的回答
Node.js + Vue.js + MongoDB
首页
顶部是每天最新数据,点赞大于 1000 的做了高亮标红处理
下面是历史每日数据

文章详情页 - 下面是2015年评论 TOP 1 的文章

文章的部分评论也爬了下来
在页面最底部点开

按日期查看每日历史文章
可以查看历史每一天的所有文章,主要用在统计页面上,后面做个日历入口方便跳转,链接如下:
http://zhihu.ccforward.net/#/date?dtime=20161001
PS: 知乎日报第一篇文章
基本用法
function log(x, y='Worlds'){
console.log(x,y)
}
log('Hello'); // Hello, World
function Poin(x=0,y=0){
this.x = x;
this.y = y;
}
var p = new Point();
p // {x:0, y:0}参数变量是默认声明的,不能用 let const 再次声明
function foo(x = 1){
let x = 2; // error
const x = 3; // error
}与解构赋值默认值结合使用
function fetch(url, {method='GET'}={}){
console.log(method)
}
fetch('/index.html') // 'GET'
function m({x=0,y=0}={}){
console.log([x,y])
}
m() // [0,0]
m({x:1, y:2}) // [1,2]
m({x:3}) // [3,0]
m({}) // [0,0]
m({xx:1}) // [0,0]参数默认值位置
通常把函数的尾参数作为有默认值的参数。因为这样比较容易看出到底忽略那些参数。
function f(x,y=1,z){
console.log([x,y,z])
}
f() // [undefined, 1, undefined]
f(1) // [1, 1, undefined]
f(1,,2) // 出错
f(1,undefined,3) // [1, 1, 3]上面的函数,有默认值的参数不是尾参数,因此无法省略该参数而不省略其后的参数,除非显式的输入 undefined
函数length属性
指定了默认值后函数的 length 属性将返回没有指定默认值的参数个数
(function(a){}).length // 1
(function(a,b,c=1){}).length //2PS: rest参数不会计入 length 属性
作用域
如果参数默认值是一个变量,则该变量所处的作用域与其它变量的作用域规则是一样的,即先是当前函数的作用域,然后才是全局作用域。
var x = 1;
function f(x, y=x){
console.log(y)
}
f(2) // 2由于函数作用域内部的变量 x 已经生成所以 y 等于参数 x 而不是全局变量x。
let x = 1;
function f(y=x){
let x= 2;
console.log(y)
}
f() // 1上述代码函数调用时 y 的默认值变量 x 尚未在函数内部生成,所以 x 指向全局变量。
如果函数A的默认值是函数B
那么由于函数的作用域是其声明时的作用域,函数B的作用域就不是函数A,而是全局作用域。如下:
let foo = 'outer';
function bar(func = x => foo){
let foo = 'inner';
console.log(func());
}
bar(); // outer上述代码等同于
let foo = 'outer';
let f = x => foo;
function bar(func = f) {
let foo = 'inner';
console.log(func());
}
bar(); // outer应用
可指定函数某一个参数不得省略,省略就会抛出错误
function throwIfMissing() {
throw new Error('Missing parameter');
}
function foo(mustBeProvided = throwIfMissing()) {
return mustBeProvided;
}
foo()
// Error: Missing parameter上述代码可知参数 mustBeProvided 的默认值等于 throwIfMissing 函数的运行结果。这说明函数参数的默认值不是在定义时执行,而是在运行时执行。
如果把函数参数默认值设置为 undefined 则表示这个参数是可以省略的。
rest参数("...变量名"),用于获取函数的多余参数。rest参数搭配的变量是一个数组,该变量将多余的参数放入其中。
function push(array, ...items){
items.forEach(item => {
array.push(item);
})
}
var a = [];
push(a,1,2,3)rest 参数只能作为最后一参数。
函数的 length 属性不包括 rest 参数。
(function(...a){}).length // 0
(function(a, ...b){}).length // 1含义
扩展运算符(spread)是三个点(...)。它好比rest参数的逆运算,将一个数组转为用逗号分隔的参数序列。
console.log(...[1,2,3])
// 1 2 3
console.log(1, ...[2,3,4], 5)
// 1 2 3 4 5该运算符主要用于函数的调用
function add(x,y){
console.log(x+y);
}
var arr = [1,10];
add(...arr); // 11 ...运算符把arr数组变为参数序列替代数组的 apply 方法
由于扩展运算符可以展开数组,所以不需要apply将数组转为函数的参数了。
// ES5
function f(x,y,z){}
var args = [1,2,3];
f.apply(null, args)// ES6
function f(x,y,z){}
var args = [1,2,3];
f(...args)使用 Math.max 求数组最大元素
// ES5
Math.max.apply(null, [1,2,3,4])// ES6
Math.max(null, ...[1,2,3,4])通过 push 将一个数组添加到另一数组尾部
// ES5
var arr1 = [0,1,2];
var arr2 = [3,4,5];
Array.prototype.push.apply(arr1,arr2)// ES6
var arr1 = [0,1,2];
var arr2 = [3,4,5];
arr1.push(...arr2)扩展运算符的应用
合并数组
//ES5
[1,2].concat(more);
arr1.concat(arr2,arr3)
//ES6
[1,2, ...more]
[...arr1, ...arr2, ...arr3)与解构赋值结合生成数组
// ES5
a = list[0], rest = list.slice(1)
// ES6
[a, ...rest] = list
const [first, ...rest] = [1, 2, 3, 4, 5];
first // 1
rest // [2, 3, 4, 5]
const [first, ...rest] = [];
first // undefined
rest // []:
const [first, ...rest] = ["foo"];
first // "foo"
rest // []如果将扩展运算符用于数组赋值,只能放在参数的最后一位
字符串
将字符串转为真正的数组
[...'hello']
// [ "h", "e", "l", "l", "o" ]还有一个好处是 能够正确识别32位的Unicode字符
其中Unicode字符如: 'x\uD83D\uDE80y' 也就是 "x🚀y"
'x\uD83D\uDE80y'.length // 4
[...'x\uD83D\uDE80y'].length // 3JavaScript会将32位Unicode字符,识别为2个字符,采用扩展运算符就没有这个问题。因此可以这样来写:
function length(str) {
return [...str].length;
}
length('x\uD83D\uDE80y') // 3凡是涉及到操作32位Unicode字符的函数,都有这个问题。因此,最好都用扩展运算符改写。
let str = 'x\uD83D\uDE80y';
str.split('').reverse().join('')
// 'y\uDE80\uD83Dx'
[...str].reverse().join('')
// 'y\uD83D\uDE80x'类似数组的对象
任何类似数组的对象都可以用扩展运算符转为真正的数组
[...document.quertSelectorAll('div')];
// [<div>, <div>, <div>]Map和Set结构,Generator函数
扩展运算符内部调用的是数据结构的Iterator接口,因此只要具有Iterator接口的对象,都可以使用扩展运算符。
let map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
]);
let arr = [...map.keys()]; // [1, 2, 3]Generator函数运行后,返回一个遍历器对象,因此也可以使用扩展运算符。
name属性返回该函数的函数名
匿名函数:
var fn = function(){}
//ES5
fn.name // ""
//ES6
fn.name // fnFunction构造函数返回的函数实例,name属性的值为“anonymous”。
(new Function).name // "anonymous"bind返回的函数,name属性值会加上“bound ”前缀。
function foo() {};
foo.bind({}).name // "bound foo"
(function(){}).bind({}).name // "bound "基本用法
var f = v => v;
var f = function(v){
return v;
}由于大括号被解释为代码块,所以如果箭头函数要返回一个对象,必须在对象外面加上括号。
var getTempItem = id => ({ id: id, name: "Temp" });与解构赋值一起使用:
const full = ({first, last}) => first + ',' + last;
//等同于
function full(person){
return person.first + person.last;
}简化回调函数:
[1,2,3,4].map(x => x * x);
//等同于
[1,2,3,4].map(function(x){
return x * x;
});
var result = values.sort((a,b) => a-b);
//等同于
var result = values.sort(function(a,b){
return a - b;
})结合rest参数使用
const numbers = (...nums) => nums;
numbers(1,2,3,4,5)
// [1,2,3,4,5]
headAndTail(1, 2, 3, 4, 5);
// [1,[2,3,4,5]]注意点
第一条尤其重要。this对象的指向是可变的,但是在箭头函数内部是固定的。
function foo(){
setTimeout(() => {
console.log("id:" + this.id)
},1000)
}
foo.call({id:11})
//转为ES5代码
function foo() {
var _this = this;
setTimeout(function () {
console.log("id:" + _this.id);
}, 1000);
}如果是个普通函数,执行的this应该指向 window 对象,但是箭头函数导致this对象总是指向函数所在的对象。
再比如:
function Timer(){
this.seconds = 0;
setInterval(()=>this.seconds++,1000)
}
var t = new Timer();
setTimeout(()=>console.log(t.seconds), 3100);
// 3Timer函数内的 setInterval 调用了 this.seconds 属性,通过箭头函数让this总是指向Timer的实例对象。否则输出0 而不是3.
this 指向的固定化,并不是因为箭头函数内部有绑定this的机制,实际原因是箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。正因为没有this,所以不能用作构造函数。
除了this,arguments super new.target 这三个变量在箭头函数中也是不存在的,分别指向外层函数对应的变量。
function foo() {
setTimeout(() => {
console.log('args:', arguments);
}, 100);
}
foo(2, 4, 6, 8)
// args: [2, 4, 6, 8]箭头函数内部的变量 arguments 其实是函数 foo 的 arguments 变量。
由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向。
(function() {
return [
(() => this.x).bind({ x: 'inner' })()
];
}).call({ x: 'outer' });
// outer上面的代码中箭头函数没有自己的 this,所以 bind 无效,内部的 this 指向外部的 this。
函数绑定
ES7提出了『函数绑定』运算符用来取代 call apply bind 调用。
函数绑定运算符是并排的双冒号 :: ,昨天冒号绑定一个对象,右边是一个函数。会自动将左边的对象作为上下文环境(this对象)绑定到右边的函数上。
foo::bar;
bar.bind(foo);
foo::bar(...arguments);
bar.apply(foo, arguments);
var foo = {ss: 112}
var bar = function(){console.log(this.ss)};
foo::bar(); // 112双冒号运算符返回的还是原对象,因此可以采用链式写法
let { find, html } = jake;
document.querySelectorAll("div.classA")
::find("p")
::html("this is p");判断一个元素是否在数组中,代码很简单,也就一个 if 判断了事
var t = {val:2};
if([1,2,3,4,5].indexOf(t.val) >= 0){
alert('Yes');
}PS:indexOf 来自 ES5 ,IE9一下不支持
使用 ~ 符号却能简化判断语句,如下:
if( ~[1,2,3,4,5].indexOf(t.val) ){
// other things
}如果一个元素存在于数组中,indexOf() 则返回它的索引;不存在,返回 -1。
细节怎么的不重要,因为 ~ 就是个位操作符(按位非),反转操作数的比特位,只有-1才会返回0。
整数在 js 中是被符号化的,意味着最左侧的一个bit用来表示符号位;也就是一个表示帧数负数的标记,1开始表示为负数,32位表示如下
1 : 00000000000000000000000000000001
2 : 00000000000000000000000000000010
3 : 00000000000000000000000000000011
15: 00000000000000000000000000001111对应的负数:
-1 : 11111111111111111111111111111111
-2 : 11111111111111111111111111111110
-3 : 11111111111111111111111111111101
-15: 11111111111111111111111111110001二进制中正负数原码 反码不必多说。
下面简单的二进制计算 来展示 -1 + +1 是如何运算的
00000000000000000000000000000001 +1
+ 11111111111111111111111111111111 -1
-------------------------------------------
= 00000000000000000000000000000000 0以及 -15 + +15
00000000000000000000000000001111 +15
+ 11111111111111111111111111110001 -15
--------------------------------------------
= 00000000000000000000000000000000 0从最右侧开始相加,1+1=2 也就是 10 把1向前借位,然后一直循环到最左侧,直到最后一个借位的 1 无处可去,于是就 溢出 overflow 了,然后就丢失了,我们只剩下一堆的 0 ,结果于是就是 0
-1 这个数是为一个其二进制码全是 1 的数字,因此使用 ~ 这个按位取反符号后,它的所有二进制数位全部反转。
所以这大段的文其实就只是解释了 按位取反后只有-1才会返回0。
https://ccforward.github.io/css-secrets/frosted-glass/index.html
background-attachment: fixed 处理起来容易些,非固定背景的情况比较麻烦主要代码:
main {
position: relative
}
main::before {
content: '';
position: absolute;
top: 0;
left: 0;
bottom: 0;
right: 0;
z-index: -1; /* 伪元素置于最下面 */
background: rgba(255, 0, 0, .5); /* 添加背景色做测试 */
}效果:
然后就把红色背景替换掉 开始进行模糊处理
添加代码:
body, main::before {
background: url(//gw.alicdn.com/tps/i1/TB1Zc6qHpXXXXb3XFXXeowVVXXX-1200-800.jpg) 0 / cover fixed;
}
main {
background: hsla(0, 0%, 100%, .2) border-box;
}
main::before {
-webkit-filter: blur(15px);
filter: blur(15px);
}现在的效果其实已经很接近毛玻璃了,但是有个问题,就是边缘处的模糊效果会逐渐的削弱并突出出去(显得有点脏玻璃的感觉),换成红色背景来看就很明显:
所以解决方案就是:
main::before {
margin: -30px;
}main {
overflow: hidden;
}最终效果就出来了
上一篇 理解事件循环一(浅析) 用例子简单理解了下 macrotask 和 microtask
这里再详细的总结下两者的区别和使用
一个事件循环(EventLoop)中会有一个正在执行的任务(Task),而这个任务就是从 macrotask 队列中来的。在whatwg规范中有 queue 就是任务队列。当这个 macrotask 执行结束后所有可用的 microtask 将会在同一个事件循环中执行,当这些 microtask 执行结束后还能继续添加 microtask 一直到真个 microtask 队列执行结束。
基本来说,当我们想以同步的方式来处理异步任务时候就用 microtask(比如我们需要直接在某段代码后就去执行某个任务,就像Promise一样)。
其他情况就直接用 macrotask。
whatwg规范:https://html.spec.whatwg.org/multipage/webappapis.html#task-queue
再来回顾下事件循环如何执行一个任务的流程
当执行栈(call stack)为空的时候,开始依次执行:
上面就算是一个简单的 event-loop 执行模型
再简单点可以总结为:
插入SD卡,使用 df 查看当前已经挂载的卷
$ df
Filesystem 512-blocks Used Available Capacity iused ifree %iused Mounted on
/dev/disk1 233269248 218788512 13968736 94% 27412562 1746092 94% /
devfs 374 374 0 100% 648 0 100% /dev
map -hosts 0 0 0 100% 0 0 100% /net
map auto_home 0 0 0 100% 0 0 100% /home
/dev/disk2s1 31100416 4992 31095424 1% 0 0 100% /Volumes/Pi
因为已经命名了SD卡为 Pi ,所以SD卡的分区对应的设备文件为:/dev/disk2s1
使用diskutil unmount卸载
$ diskutil unmount /dev/disk2s1
Volume Pi on disk2s1 unmounted
diskutil list 确认设备 我买的是16G的卡
$ diskutil list
/dev/disk2
#: TYPE NAME SIZE IDENTIFIER
0: FDisk_partition_scheme *15.9 GB disk2
1: DOS_FAT_32 Pi 15.9 GB disk2s1
使用dd命令将系统镜像写入
PS /dev/disk2s1是分区,/dev/disk2是块设备,/dev/rdisk2是原始字符设备
$ dd bs=4m if=pi.img of=/dev/rdisk2
781+1 records in
781+1 records out
3276800000 bytes transferred in 194.134151 secs (16879050 bytes/sec)
至此,SD卡上已经刷入了 Raspbian 系统
再用diskutil unmountDisk卸载设备
$ diskutil unmountDisk /dev/disk2
Unmount of all volumes on disk2 was successful
把SD卡插入树莓派,连上网线,因为不知道树莓派的ip,所以在网上随便找了个扫描ip的软件(Free IP Scanner),然后在一台windows电脑上扫描了局域网内的所有ip,其中端口为22的ip就是我们的树莓派了。
然后就是 ssh 登录树莓派 用户名 pi 密码 raspberry
如果执行 ssh 命令返回
connection refused, 则需要开启 sshd 服务
service sshd restartSSH 服务启动成功
$ ssh [email protected]
[email protected]'s password:
Linux raspberrypi 3.18.11-v7+ #781 SMP PREEMPT Tue Apr 21 18:07:59 BST 2015 armv7l
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Fri Sep 11 11:16:12 2015 from c.local
NOTICE: the software on this Raspberry Pi has not been fully configured. Please run 'sudo raspi-config'
执行 sudo raspi-config
选择第一项 Expand Filesystem 扩展 SD 卡上可用的空间,不然以后安装大软件会提示空间不足
执行 df -h
pi@raspberrypi ~ $ df -h
Filesystem Size Used Avail Use% Mounted on
rootfs 2.9G 2.4G 335M 88% /
/dev/root 2.9G 2.4G 335M 88% /
devtmpfs 460M 0 460M 0% /dev
tmpfs 93M 224K 93M 1% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 186M 0 186M 0% /run/shm
/dev/mmcblk0p1 56M 19M 37M 34% /boot
先把自带的难用的vim删掉 重新安装
删除 sudo apt-get remove vim-common
安装 sudo apt-get install vim
然后就是 linux 下 vim 的配置,不再多说。
由于前端触及的领域越来越宽,而且每条业务线的开发都有相同和不行痛的部分,所以通过公司业务实践和思考,从整体的角度对前端的体系做下总结。
目前的技术体系(正在用和正在开发的)包括这几个方面:
如下图所示:
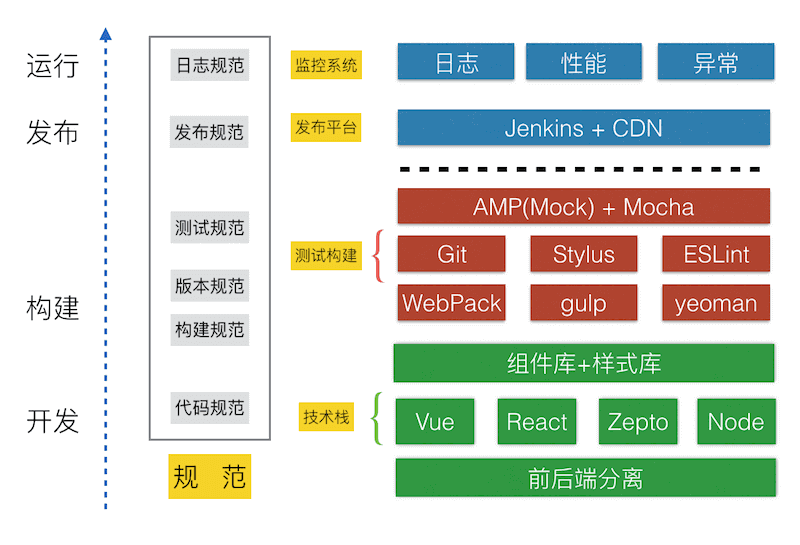
js 基于 ES6 开发,用 stylus 做预处理器来提升 css 代码的可维护性(sass也是其他项目的可选项),gulp/webpack+babel 做构建工具
固定项目的目录结构,方便统一构建的方式。
用 git 做版本控制,每次新需求都从 master 分支 checkout 出来,用 ESLint 静态检查做强制约束,通过 git 的 hook 保证 ESLint 不通过 git 就不能提交代码。
直接通过 git 发布当亲开发分支的静态代码,每次发布打版本 tag ,通过服务器的脚本自动将分支合并到master。
前后端分离
Vue.js zepto stylus React 都可选,根据业务的不同选择最优方案。同时用 Yeoman 开发出对应的脚手架工具,通过脚手架快速进行项目的而搭建和组件的开发
前端技术栈更新太快,所以技术栈的更新也配合开发构建工具的更新,这就像业务一样是个不断发展的过程。
根据构建需求开发 webpack 和 gulp 的插件来适应技术栈的更新和业务的需求。
因为用的都是开源的模块和框架,所以用 NPM 作为团队统一的包管理工具。如果后期内部的组件和模块丰富了,可以搭建一套内部的 NPM 来做包管理。
前后端开发不可能同步,所以开发一个 API Mock 平台来模拟 api 返回的数据,好处如下:
PS:这个 API Mock 平台正在开发中,简称 AMP(API Mock Platform)
痛点:
所以基于前端 TDD (Test-Driven Development 测试驱动开发) 能省时省力
有了 APM 平台也能快速的做接口的单元测试
关于 TDD 后面专门开一篇文章做总结
代码做过rview 并通过测试后进入发布流程
现在的统计监控是基于公司的一套上报系统来做的,后端已经相对完整,只需要前端做数据的上报即可。
但是现在的数据只是收集,还需要搭建一套通知系统,保证出现线上故障能够快速的修复
var fs = require("fs");
var http = require('http');
fs.readFile('img.txt', 'UTF-8', function(err, data){
if(!err){
var con = data.split('\n');
var i=0,
len=con.length;
function down(file){
http.get(file, function(res){
var imgData = '';
res.setEncoding('binary');
res.on('data', function(chunk){
imgData+=chunk;
});
res.on('end', function(){
fs.writeFile(i+'.jpg', imgData, 'binary', function(err){
if(err){
console.log('fail: ' + file);
}
i++;
if(i<len){
down(con[i]);
}
console.log('download over')
});
});
});
}
down(con[0]);
}else {
console.log(err);
}
});关于 Node 这段代码最初文件写入用的 for 循环,没有把 down 函数抽取出来做递归,于是每次做文件写操作时候会覆盖上一个文件,是因为 javascript 是单线程的,先执行完整个循环的同步内容之后才去执行其中的异步操作。get 函数里的匿名函数就是一个异步回调。
处于闭包原则,该函数会保留 for 循环最后一次循环的i变量,才会导致只保存了一个文件。
所以写 node 时候尽可能的多用递归。
但是因为异步所以会按顺序依次下载,速度并不是很快,依次如下:
在 for 循环中如果使用自执行函数 (function(i,file){})(i,con[i]) 就可以那个避免上述问题。
更重要的是,异步回调速度很快,因为不会产生阻塞,可以同步的下载图片,所以最终我选择的代码如下:
var fs = require("fs");
var http = require('http');
fs.readFile('img.txt', 'UTF-8', function(err, data){
if(!err){
var con = data.split('\n');
for(var i=0,len=con.length;i<len;i++){
(function(i, file){
http.get(file, function(res){
var imgData = '';
res.setEncoding('binary');
res.on('data', function(chunk){
imgData+=chunk;
});
res.on('end', function(){
fs.writeFile(i+'.jpg', imgData, 'binary', function(err){
if(err){
console.log('fail: ' + con[0]);
}
console.log('download over')
});
});
});
})(i, con[i]);
}
}else {
console.log(err);
}
});最近看了点 Ruby 的代码,实现相同功能只需要17行,简单暴力
还没有研究 Ruby 是否可以做异步回调
require 'net/http'
require 'open-uri'
con = Array.new
File.open("img.txt", "r") do |file|
while line = file.gets
con.push(line)
end
end
name = 0
for i in con do
data = open(i){|f|f.read}
open(name.to_s + '.jpg', 'wb'){|f|f.write(data)}
name = name +1
print name
end文章
在 javascript 代码中,因为各浏览器之间的行为的差异,我们经常会在函数中包含了大量的 if 语句,以检查浏览器特性,解决不同浏览器的兼容问题。
例如,我们最常见的为 dom 节点添加事件的函数:
function addEvent (type, element, fun) {
if (element.addEventListener) {
element.addEventListener(type, fun, false);
}
else if(element.attachEvent){
element.attachEvent('on' + type, fun);
}
else{
element['on' + type] = fun;
}
}每次调用 addEvent 函数的时候,它都要对浏览器所支持的能力进行检查,首先检查是否支持 addEventListener 方法,如果不支持,再检查是否支持 attachEvent 方法,如果还不支持,就用 dom 0 级的方法添加事件。
这个过程,在 addEvent 函数每次调用的时候都要走一遍,其实,如果浏览器支持其中的一种方法,那么他就会一直支持了,就没有必要再进行其他分支的检测了,
也就是说,if 语句不必每次都执行,代码可以运行的更快一些。
解决的方案就是称之为惰性载入的技巧。
所谓惰性载入,就是说函数的if分支只会执行一次,之后调用函数时,直接进入所支持的分支代码。
有两种实现惰性载入的方式,第一种事函数在第一次调用时,对函数本身进行二次处理,该函数会被覆盖为符合分支条件的函数,这样对原函数的调用就不用再经过执行的分支了,
我们可以用下面的方式使用惰性载入重写 addEvent()。
function addEvent (type, element, fun) {
if (element.addEventListener) {
addEvent = function (type, element, fun) {
element.addEventListener(type, fun, false);
}
}
else if(element.attachEvent){
addEvent = function (type, element, fun) {
element.attachEvent('on' + type, fun);
}
}
else{
addEvent = function (type, element, fun) {
element['on' + type] = fun;
}
}
return addEvent(type, element, fun);
}在这个惰性载入的 addEvent() 中,if 语句的每个分支都会为 addEvent 变量赋值,有效覆盖了原函数。
最后一步便是调用了新赋函数。下一次调用 addEvent() 的时候,便会直接调用新赋值的函数,这样就不用再执行 if 语句了。
第二种实现惰性载入的方式是在声明函数时就指定适当的函数。
这样在第一次调用函数时就不会损失性能了,只在代码加载时会损失一点性能。
一下就是按照这一思路重写的 addEvent()。
var addEvent = (function () {
if (document.addEventListener) {
return function (type, element, fun) {
element.addEventListener(type, fun, false);
}
}
else if (document.attachEvent) {
return function (type, element, fun) {
element.attachEvent('on' + type, fun);
}
}
else {
return function (type, element, fun) {
element['on' + type] = fun;
}
}
})();这个例子中使用的技巧是创建一个匿名的自执行函数,通过不同的分支以确定应该使用那个函数实现,实际的逻辑都一样,
不一样的地方就是使用了函数表达式(使用了 var 定义函数)和新增了一个匿名函数,另外每个分支都返回一个正确的函数,并立即将其赋值给变量 addEvent。
惰性载入函数的优点只执行一次 if 分支,避免了函数每次执行时候都要执行 if 分支和不必要的代码,因此提升了代码性能。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.










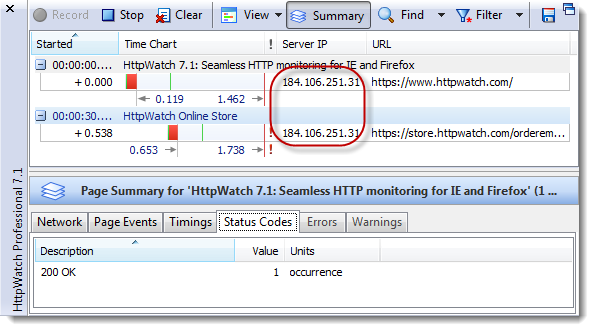
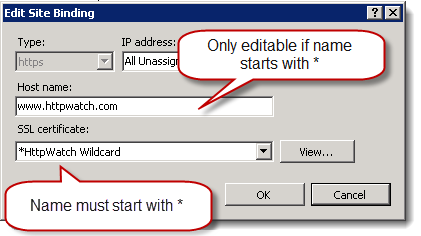
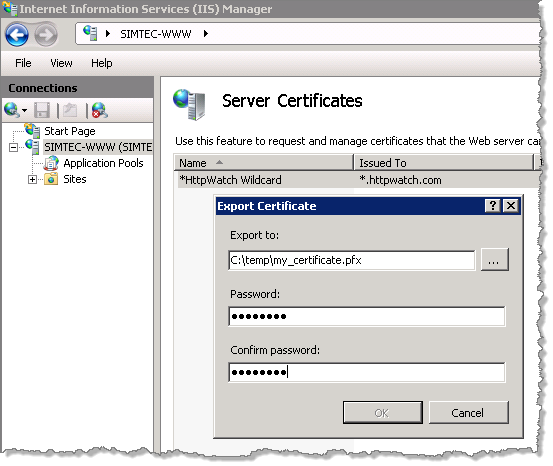
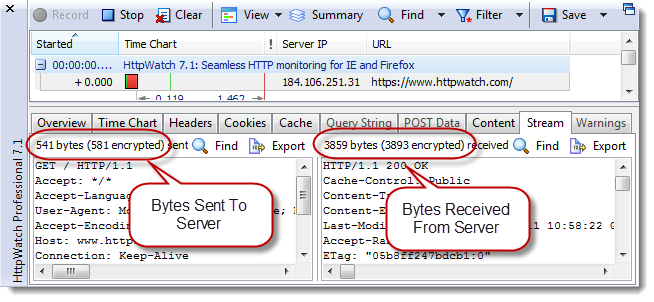
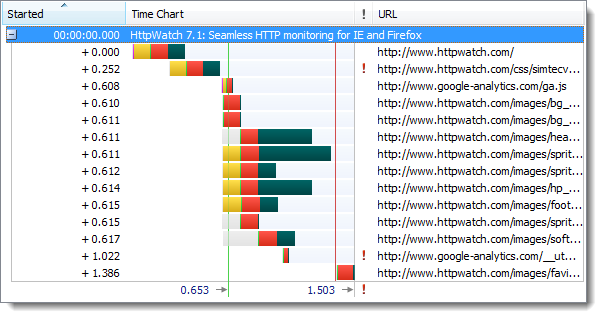
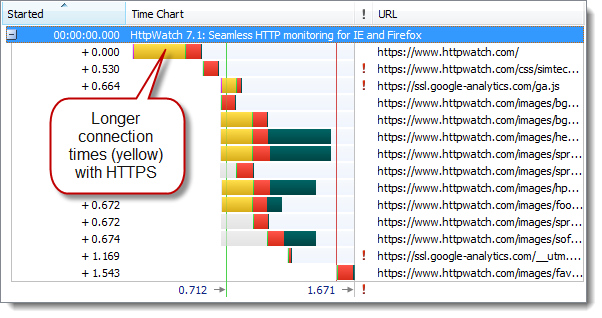
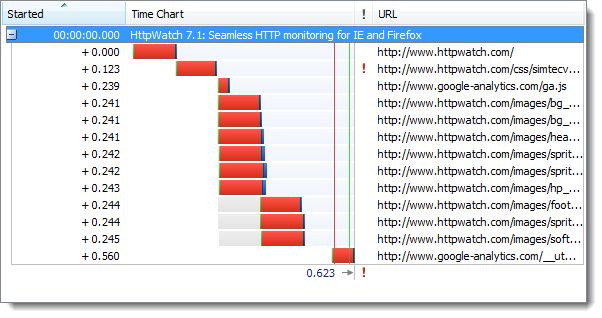
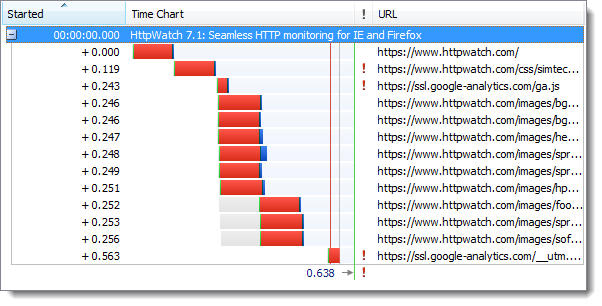

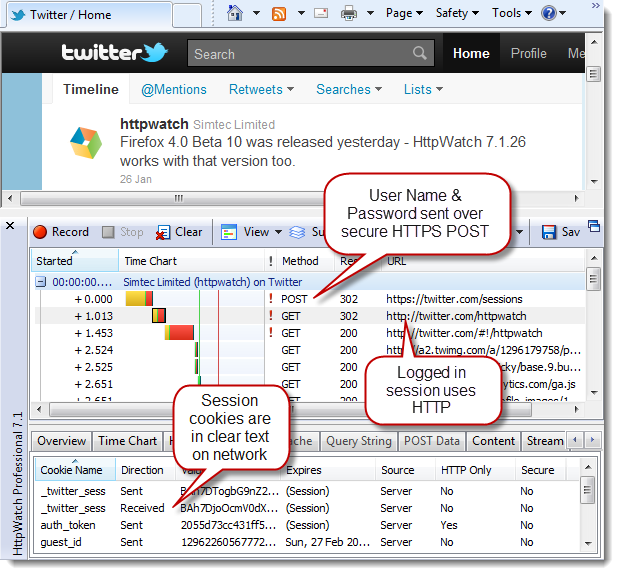
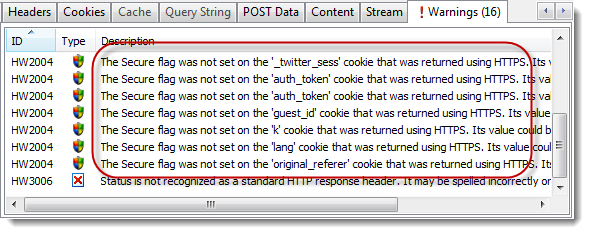

























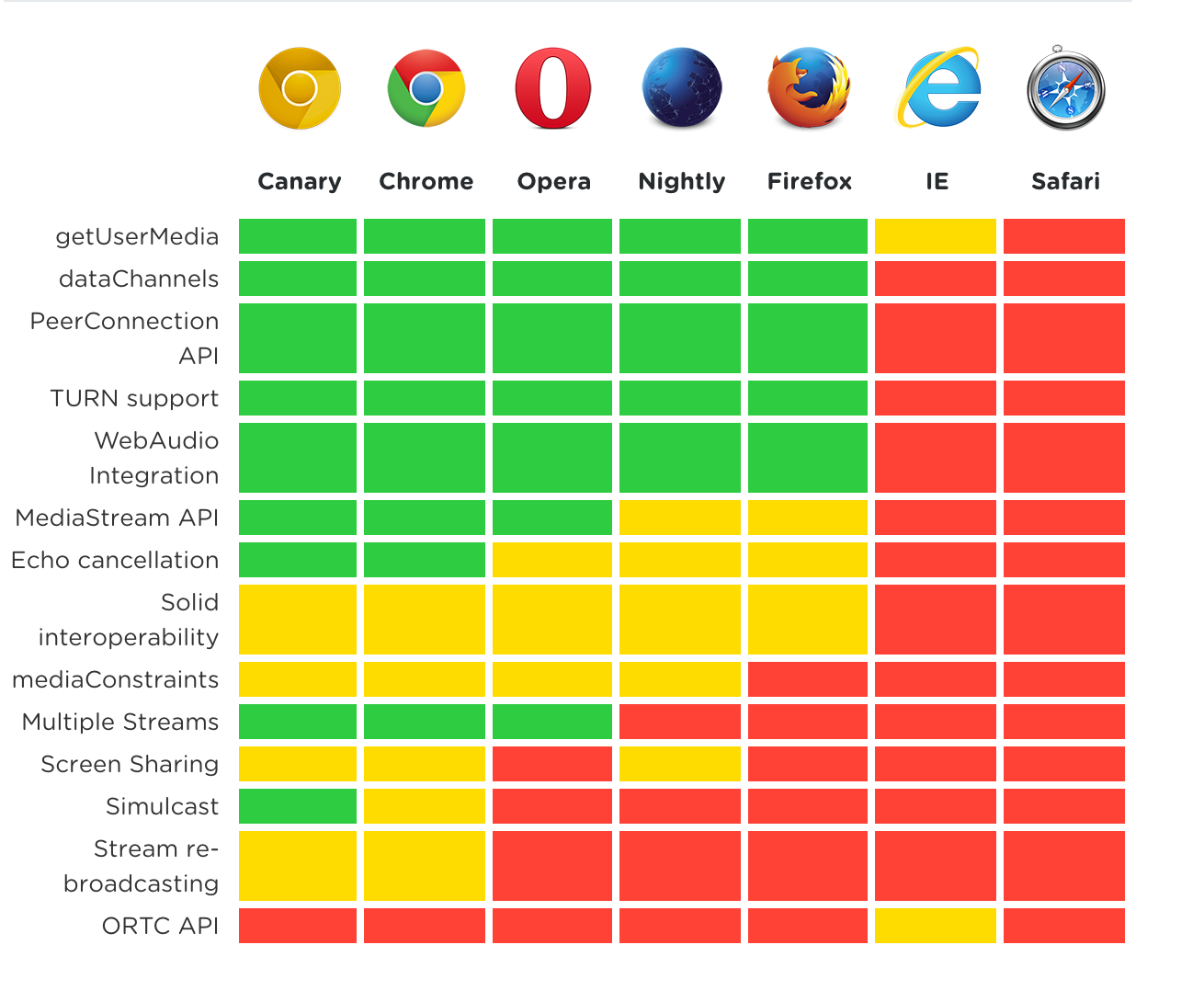{kind=link}
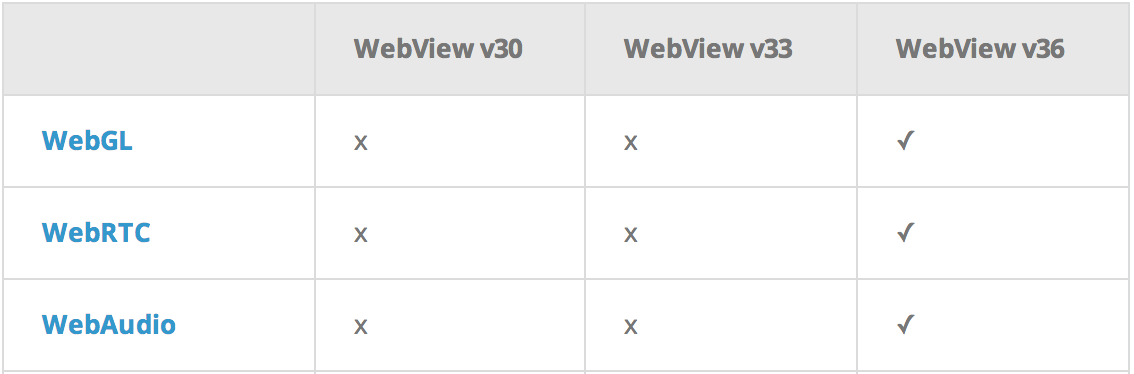{kind=link}