ccsbook's People
Contributors




Stargazers





Watchers
ccsbook's Issues
typo's susan
Herin (p. iv)
Etablished (p. 2)
distinghuished (p. 3)
genuinly (p. 3)
Instace (p. 3)
specically (p. 3)
To some extend (p. 4)
as a social scientists (p. 4)
compuational (p. 4)
partiuclar (p. 4)
predcited (p. 3)
Knowledge (p. 6)
gradutate (p. 7)
T:his chapter (p .13)
ususally (p. 15)
more close (p. 16)
It it (p. 20)
your are (p. 20)
you own (p. 30)
It goes beyon this chapter to (p. 117)
ch7 .copy() vs df2=df1
Incorporate in chapter 7 (data wrangling) the difference between
df2 = df1 and df2 = df1.copy() and explain why the former can bite you.
In relation to that, mention that many pandas dataframe methods have an inplace = True argument
Anaconda vs native (Ch 3)
In Chapter 3, we now first explain how to install Python and R and then suddenly say: you could have installed anaconda instead. That's too late; people will already have installed. We need to decide whether we want to recommend anaconda or not, and if so, move it up.
escaping backslashes in R
e.g. in https://cssbook.net/chapter09.html#tab:regexample, for R all backslashes would need to be doubled. This is explained earlier but should probably be included in a footnote to the table?
ch9 make sure that algo's such as random forest set a seed
example 12.3: typo in code
- example 12.3 starts with
i=300but it should bei=0. Of course it works as well, but it's a bit weird to skip the first 300 results ;-)
ch7 and elsewhere: move import statements to top of code examples
trouble with geopandas in chapter 2
Problem
The problem I mean is that installing geopandas can be a nightmare on Windows, involving the need to have a C-compiler etc
We came up with a workaround (https://github.com/uvacw/teaching-bdaca/blob/main/12ec-course/week01/exercises.md#on-the-installation-of-geopandas-andor-wordcloud ) but even that did not work painlessly for all students
Solvable, but annoying if it's literally the first exercise students do...
Solution
We can just drop the maps, or add them at the end as bonus content with a warning that it can cause troubles installing on windows
ch8 mention SVD when explaining PCA
(esecially performance aspect)
Which example datasets?
We discussed before that it would be a good idea to have re-occuring example datasets in the book. Any suggestions/preferences for specific ones until know?
`stanza` as NLP package?
https://stanfordnlp.github.io/stanza/
Stanza - A Python NLP Library for Many Human Languages
About
Stanza is a Python natural language analysis package. It contains tools, which can be used in a pipeline, to convert a string containing human language text into lists of sentences and words, to generate base forms of those words, their parts of speech and morphological features, to give a syntactic structure dependency parse, and to recognize named entities. The toolkit is designed to be parallel among more than 70 languages, using the Universal Dependencies formalism.
Stanza is built with highly accurate neural network components that also enable efficient training and evaluation with your own annotated data. The modules are built on top of the PyTorch library. You will get much faster performance if you run this system on a GPU-enabled machine.
In addition, Stanza includes a Python interface to the CoreNLP Java package and inherits additonal functionality from there, such as constituency parsing, coreference resolution, and linguistic pattern matching.
To summarize, Stanza features:
Native Python implementation requiring minimal efforts to set up;
Full neural network pipeline for robust text analytics, including tokenization, multi-word token (MWT) expansion, lemmatization, part-of-speech (POS) and morphological features tagging, dependency parsing, and named entity recognition;
Pretrained neural models supporting 66 (human) languages;
A stable, officially maintained Python interface to CoreNLP.
Below is an overview of Stanza’s neural network NLP pipeline:
Getting Started
We strongly recommend installing Stanza with pip, which is as simple as:
To see Stanza’s neural pipeline in action, you can launch the Python interactive interpreter, and try the following commands:
import stanza
stanza.download('en') # download English model
nlp = stanza.Pipeline('en') # initialize English neural pipeline
doc = nlp("Barack Obama was born in Hawaii.") # run annotation over a sentence
You should be able to see all the annotations in the example by running the following commands:
print(doc)
print(doc.entities)
For more details on how to use the neural network pipeline, please see our Getting Started Guide and Tutorials.
Aside from the neural pipeline, Stanza also provides the official Python wrapper for accessing the Java Stanford CoreNLP package. For more details, please see Stanford CoreNLP Client.
Note:
If you run into issues during installation or when you run the example scripts, please check out this FAQ page. If you cannot find your issue there, please report it to us via GitHub Issues.
License
Stanza is licensed under the Apache License, Version 2.0 (the “License”), you may not use the software package except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Main Contributors
The PyTorch implementation of Stanza’s neural pipeline is due to Peng Qi, Yuhao Zhang, and Yuhui Zhang, with help from Jason Bolton and Tim Dozat.
The CoreNLP client is mostly written by Arun Chaganty, and Jason Bolton spearheaded merging the two projects together.
We are also grateful to community contributors for their help in improving Stanza.
Citing Stanza in papers
If you use Stanza in your work, please cite this paper:
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton and Christopher D. Manning. 2020. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv preprint arXiv:2003.07082. [pdf]
If you use Stanford CoreNLP through the Stanza python client, please also follow the instructions here to cite the proper publications.
Links
GitHub
PyPI
Stanford CoreNLP
enable processing of cells with multiple elements and pictures
.... so that we can revert this ugly hack:
Several references to non-existing section 6.2)
Several references to Unicode/encoding section and to the JSON/file formats section throughout the book (6.2, 6.2.2 etc.) , but per
aa6ef49
chapter has been removed (b/c of duplicates).
Change references and make sure relevant info is still somewhere
Feedback by Dmitry Bogdanov (student Damian) on Chapter 3.2 and 3.3
Canvas. Hopefully you will find it useful.
The reference to bytes objects on pages 23-24 is unclear. What are they, why would we need them? If they only become relevant much later, maybe it would be a good idea to introduce them later as well?
I have to admit that going back and forth between Python and R confuses me quite a bit, especially since I don’t know R, and I don’t expect it to be relevant for this particular course. As someone who is quite new to programming, I would prefer to focus on ideas and underlying concepts, not on syntax differences between the languages.
It probably should be mentioned that the last element of the slice range is not included in Python (p.29), which I believe is different from how slicing vectors works in R? I.e. my_list[0:2] only returns elements with indices 0 and 1, but not 2.
Some examples that include print statements do not have corresponding output blocks, while others do (e.g. compare “Lists and tuples in Python” block on p.29 and “The (for many unexpected) behavior of mutable objects” block on p.30). If space is a concern, maybe you could add expected output as #comments?
“Just as the elements of a list can be of any type, and you can have lists of lists, you can also nest dictionaries to get dicts of dicts.” (p.33). This may lead readers to believe that it is possible to have dictionaries as keys within other dictionaries, but as far as I know it is not possible, since only immutable data types can be used as keys, whereas dictionaries can only be used as values. https://docs.python.org/3/tutorial/datastructures.html
Some concepts are used in examples before being introduced in text. For example the code block on page 34 uses function arguments and importing modules before either of those concepts are introduced
“Print the string “What a surprise!” if it is exactly 44 characers” (p.40) - the example actually prints “What a coincidence!", a different string.
Example 3.9 (p. 41) actually produces a different output for me (see screenshot). Probably because all the headlines satisfy either the if or elif conditions, so ‘NaN’ never gets printed
Example on p.43 shows the result of 6*0.6 as 3.5999999999999996. Floating point precision is a very confusing topic for novices (I know it was for me!), so maybe you should either give some kind of explanation, or choose a different number as an example to keep things simple.
I ignored spelling mistakes and typos (e.g. “betwee” instead of “between”, “python” instead of “Python” etc.) but I can include those, if we need to review any other chapters in the future.
ch7 consider adding venn diagrams for joins
next to illustrations in chapter 7
baseR vs tidyverse: check consistency
I think that we agreed before that we will basically use tidyverse in the book, but we need some guideline on how far that goes. Do we always use tidyverse? Are there some things where we use base R instead? Or do we sometimes mention both?
For instance, data.frame is something that we need to introduce (after all, they will find it everywhere when googling or reading other materials), but do we then need to switch to using tibbles instead (https://cran.r-project.org/web/packages/tibble/vignettes/tibble.html )?
feedback SML chapter
Lastly, as you mentioned in the first class that you are writing a new textbook and any suggestions will be valuable, I do have some suggestions on the SML part.
I think it'll be better (at least for me) to understand the concepts if you can add mathematical models and definitions to it.
I feel like some terms will need more definitions to better-understand. For example, the ROC-AUC curve. The definition of FPR and TPR are lacking, but I think some math models can certainly help the students to understand the curve a little better.
TPR = P(Y_predicted = 1 | Y = 1); FPR = 1- P(Y_predicted = 0 | Y = 0)I think it's also good to include why AUC curve is sometimes a better measurement for a predicted model rather than accuracy of F1 score. From my research and understanding, the AUC curve is better because its assumptions are all Y, not Y_pred. Therefore, it's more accurate than accuracy and F1-score (because precision is partly based on Y_pred).
I hope these suggestions help and thank you for your advice in advance!
Best,
Chih-Hsuan (Ian) Lee
check new missing value types pandas 1.0
pandas 1.0 has now a different handling of missing values and new missing value types. check that out and adapt in (at least) chapter 8 (when referring to np.nan)
maybe extra visualization precision/recall
by dmitry:
I think it would be really helpful to illustrate your description of confusion matrices and the concepts of precision, recall, and accuracy with either a circular diagram like the one you used in the slides, or a table like this:
https://2.bp.blogspot.com/-EvSXDotTOwc/XMfeOGZ-CVI/AAAAAAAAEiE/oePFfvhfOQM11dgRn9FkPxlegCXbgOF4QCLcBGAs/s1600/confusionMatrxiUpdated.jpg
I
found the latter illustration particularly helpful, as it includes all of those concepts, and neatly shows how they correspond to the Type I and Type II errors in traditional statistics.
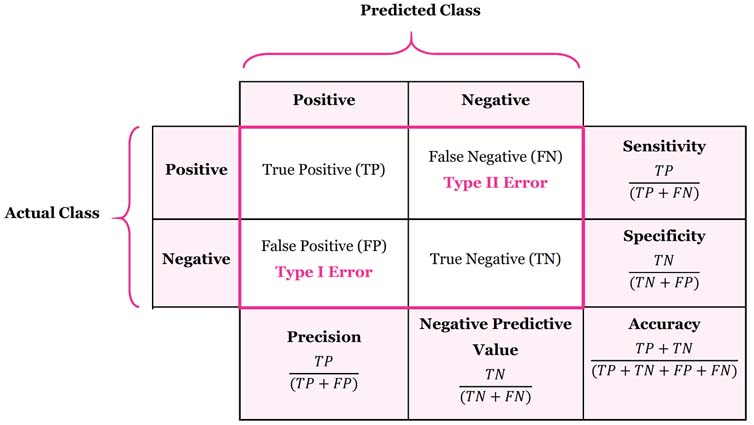{kind=link}
incorporate feedback student carlos ch 9 and 11
@damian0604 will do that
section on recoding data
Feedback from Lotte Schrijver:
The current chapter on data wrangling deals with mutate, but does not really explain how to recode data with e.g. ifelse, recode, and case_when. It would be nice to have a new section on this :D
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.