Open Source browsing application for Wordnet database
- Ruby 2.1.10
- PostgreSQL 9
- Neo4J 2
- MySQL (for WordnetSQL import)
# Load wordnet database to MySQL
rbenv install 2.1.10
rbenv use 2.1.10
bundle install
bin/rake db:create db:migrate
bin/rake wordnet:import
Video: https://www.youtube.com/watch?v=kJVyO9I173o.
- Create hosting account (e.g. digitalocean)
- Create user with sudo permissions
- Remember to
ssh-copy-idyour public key to this new user account - Add your public key to
data/playbook.yml - Ensure ansible is installed on your machine
- Run
bin/setup-host USER@HOST:PORTcommand to setup your server. It installs:- common tools
- ruby, java
- mysql, postgresql, neo4j
- deployment framework
ssh wordnet@HOST -p PORTand run./deployscript- download mysql database to server
- import database to mysql via
mysql -D wordnet < wordnet.sql - go to current deployment location (cd production/current) and run:
RAILS_ENV=production bin/rake wordnet:import(imports mysql to postgresql)RAILS_ENV=production bin/rake wordnet:export(exports postgresql to neo4j)RAILS_ENV=production bin/rake wordnet:translations(generates translations)RAILS_ENV=production bin/rake wordnet:stats(generates statistics)
- to change url prefix of application:
- add
URL_ROOT=/wordnetto.envfile in application's deployment directory - touch tmp/restart.txt to restart an application
- add
Słowosieć is a Polish equivalent of Princeton Wordnet, a lexical database of word senses and relations between them.
The purpose of this document is to describe a successful effort of making the web interface of Polish Wordnet more performant and user-friendly. In particular we'll elaborate on developed architecture, used components, and database designs.
The front-end and back-end of application were rebuilt from scratch. As as result the browsing latency dropped from 30 seconds in some cases to 110ms on average.
Following decisions has been made:
- Data is stored in normalised form using relational database
- Data is indexed and queried using graph database
- Data is rendered on client-side using templates
- Data is loaded through a well-crafted API endpoint
Given multiple issues with MySQL database and performance issues with handling UUIDs, the PostgreSQL were chosen as relational database backend. This has an additional advantage of storing data in Hstore and Array types (where sensible), avoiding unnecessary JOIN statements for data retrieval.
Neo4J has been chosen as relational database backend. The main reasons included being open-source, mature, and reliable graph store. Neo4J is one of the few graph databases providing declarative way of querying data, using Cypher language (similar in some ways to SQL).
On front-end an Angular.js framework is used. It is relatively new, but popular product developed and maintained by Google. It allows for easy decoupling of application logic and template rendering using unique concepts of directives, services, and controllers.
Rails 4 web-framework is used for both API endpoint, and serving front-end. Rails is mature software, allowing for robust development of modern web applications. Made in Ruby, allows us to use use tens of thousands of Ruby Gems, significantly boosting the development.
API allows for disjoint development of front-end and back-end.
Experience made us choose following set of tool for application development:
- CoffeeScript replacing plain JavaScript
- SASS replacing plain CSS stylesheets
- SLIM for rendering front-end HTML markup
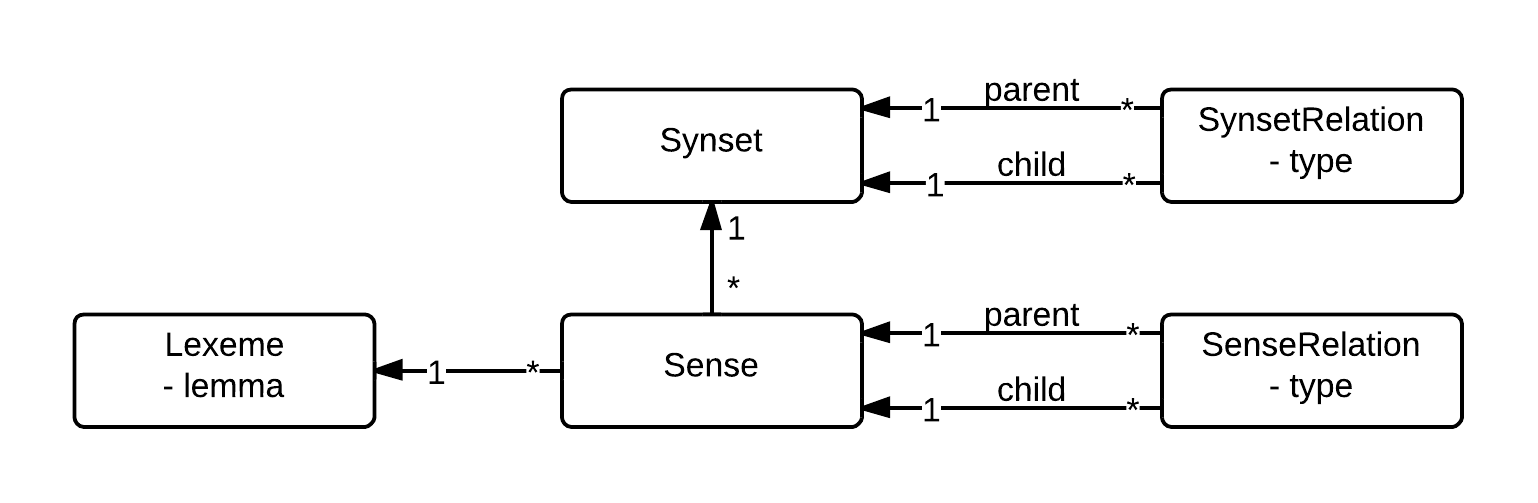
- Lexeme - unit of lexical meaning that exists regardless of the number of inflectional endings it may have or the number of words it may contain (e.g. run, ran, runs)
- Lemma - particular form of a lexeme that is chosen by convention to represent a canonical form of a lexeme (e.g. run)
- Sense - a Lexeme associated with particular meaning. Each Lexeme can have multiple Senses. In Wordnet each Sense is associated with number to easily distinguish (e.g. I can write
run 4meaning an unbroken series of events, orrun 5meaning the act of running) - Synset - a set of Senses (not Lexemes) with similar meaning, i.e. synonyms (e.g.
run 2forms Synset with following Senses:bunk 3,escape 6, turntail 1). - Sense Relation - a relationship between two Senses, i.e. relationship between two particular meanings of words (e.g.
big 1is antonym oflittle 1) - Synset Relation - a relationship between two Synsets, i.e. relationship between two groups of Senses (e.g.
Synset { act 10, play 25 }is hyponym ofSynset { overact 1, overplay 1 }). - Relation Type - each SenseRelation and SynsetRelation has its type, it can be among others: antonym, hyponym, hyperonym, meronym, ...
In summary: Each Lexeme is represented by Lemma. Each Lexeme has multiple Senses. Each Sense forms Synset with other Senses. Each Sense can be in SenseRelation to other Senses. Each Synset can be in SynsetRelation to other Synsets. Each Relation has its own RelationType.
Above concepts of Wordnet are modelled in application in following way:
Introducing Relational Database as primary store had two purposes:
- Reliably and economically storing data in normalised form
- Ability to use de-normalised graph database as index
The data is imported to normalised form from Polish Wordnet, but the process allows for importing arbitrary Wordnet-alike database.
Non-conventionally the primary keys of database tables are UUIDs, instead of auto-incrementing values. It has few advantages:
- Plays well with graph databases, each node has its own unique ID
- UUIDs for records can be generated by application code what makes inserting interconnected data into the database easier & performant.
- Makes replication of relational database trivial
- Allows for easy merging of two databases with same schema
The overall schema closely reassembles concepts described earlier:
id: The UUID identifiersynset_id: The UUID of connected Synsetexternal_id: The ID from external database, used for importinglemma: The lemma of Lexeme that Sense belongs to (e.g. car)sense_index: The index of sense in context of its Synset (e.g. 1)comment: The short comment, used in UI (e.g. transporting machine)language: Currently can been_GBorpl_PLpart_of_speech: The part of speech of Sense (noun etc.)domain_id: The ID of the Domain of Sense (not used yet)
id: The UUID identifierexternal_id: The ID from external database, used for importingcomment: The short comment by Słowosieć, used in UIdefinition: The short comment by Princeton Wordnet, used in UIexamples: The examples of usage of synset from Princeton Wordnet
name: Name of the relationreverse_relation: Name of reverse relation (see: normalisation)parent_id: Name of parent RelationType (inheritance-like)priority: It is used for sorting relation types in UI (lower-better)description: Description of the relation (not used yet)
parent_id: UUID of base sense (or synset)child_id: UUID of of related sense (or synset)relation_id: UUID of relation in which child is toward parent (e.g. UUID hyponymy relation means child is hyponym of parent)
Imported relations are normalised in few ways:
- For reverse relation types we leave only one relation type (by convention the one where where are more children than parents, e.g. hyponymes, not hyperonymes).
- The name of removed reverse relation is assigned to reverse_name
- Name and reverse_name are in plural form for for UI purposes
- Even name has it’s parent, the name describes full relation type name (for example “Meronymes (place)”, not “place”)

 Graph database has slightly different structure than relational database. Most importantly Sense and Synset nodes don’t contain any data except their IDs. The relationships of type
Graph database has slightly different structure than relational database. Most importantly Sense and Synset nodes don’t contain any data except their IDs. The relationships of type relation exist only between Synset and Senses. All data displayed in UI columns is hold in Data nodes.
Each Synset and each Sense is represented by connected Data node in UI.
Data node holds following data from Sense model:
- lemma
- sense_index
- comment
- language
- part_of_speech
- domain_id
Wordnet uses internal, normalised representation of database. The normalised structure is defined in Relational Database section.
The data mapping is done by 5 classes inherited from Importer class:
- WordnetPl::RelationType
- WordnetPl::Sense
- WordnetPl::Synset
- WordnetPl::SenseRelation
- WordnetPl::SynsetRelation
Each class is responsible for importing data to corresponding models.
Importer class processes data in batches for performance reasons. It handles progress bar rendering, parallelising import process, and synchronising writes. It expects following methods to be defined in descendants:
total_count: The total count of items to be importedload_entities(limit, offset): This method should loadlimitrecords from external database with givenoffsetand return hash consumed later byprocess_entities!methodprocess_entities!(entities): This method is responsible for processing data returned fromload_entitesand passing them topersist_entities!method described below
persist_entities!(table_name, collection, unique_attributes) uses Upsert method to insert or update data in database in performant way. It accepts table in database where the record should be inserted/updated, the actual collection of records as array of hashes where keys are column names (see relational database schema) and values are row values. The unique_attributes is an array of column names that upsert method will use for selecting data to merge (usually “id”, but can be for example [“parent_id”, “child_id”] for relations.
Import process can be triggered by issuing command:
bin/rake wordnet:import
The source database defaults to mysql2://root@localhost/wordnet, but you can change it by passing SOURCE_URL environment variable.
The same way importer classes inherit from Importer, exporter classes inherit from Exporter. The are only 4 exporter classes:
- Neo4J::Sense
- Neo4J::Synset
- Neo4J::SenseRelation
- Neo4J::SynsetRelation
Each exporter is supposed to define 2 methods:
export_index!: that ensures at the beginning of export that proper indexes are present in Neo4J databaseprocess_batch(entities): method that accepts array of entity hashes, just likeprocess_entities!and returns array of queries to execute in batch request by Neography gem.
Export process can be triggered by issuing command:
bin/rake wordnet:export
The destination defaults to http://127.0.0.1:7474, but you can change it by passing NEO4J_URL environment variable.
Application is supposed to be run on at least 3 servers:
- Application server
- PostgreSQL server
- Neo4J server
On application server the Rails application should be deployed, using any method. At least Node.js, Ruby 2.0, and development libraries of Postgresql and Mysql are required to be installed on system.
The addresses of PostgreSQL database and Neo4J database are passed by NEO4J_URL environment variable, and database information is configured in config/database.yml.
The assets need to be precompiled before deploying app on production:
RAILS_ENV=production bin/rake assets:precompile
The server can be started by hand with:
RAILS_ENV=production bin/rails server --port 80
Or by tool you choose (Capistrano or other).
Wordnet is released under the MIT License.




