chemdemo / chemdemo.github.io Goto Github PK
View Code? Open in Web Editor NEWdmyang blog
dmyang blog






































































































































































































React以一种全新的编程范式定义了前端开发约束,它为视图开发带来了一种全新的心智模型:
UI = F(DATA),这里的F需要负责对输入数据进行加工、并对数据的变更做出响应F在React里抽象成组件,React是以组件(Component-Based)为粒度编排应用的,组件是代码复用的最小单元props属性来接收外部的数据,使用state属性来管理组件自身产生的数据(状态),而为了实现(运行时)对数据变更做出响应需要,React采用基于类(Class)的组件设计!这就是React组件设计的理论基础,我们最熟悉的React组件一般长这样:
// React基于Class设计组件
class MyConponent extends React.Component {
// 组件自身产生的数据
state = {
counts: 0
}
// 响应数据变更
clickHandle = () => {
this.setState({ counts: this.state.counts++ });
if (this.props.onClick) this.props.onClick();
}
// lifecycle API
componentWillUnmount() {
console.log('Will mouned!');
}
// lifecycle API
componentDidMount() {
console.log('Did mouned!');
}
// 接收外来数据(或加工处理),并编排数据在视觉上的呈现
render(props) {
return (
<>
<div>Input content: {props.content}, btn click counts: {this.state.counts}</div>
<button onClick={this.clickHandle}>Add</button>
</>
);
}
}组件并不是单纯的信息孤岛,组件之间是可能会产生联系的,一方面是数据的共享,另一个是功能的复用:
Render Props和Higher Order Component,直到再后来的Function Component+ Hooks设计,React团队对于组件复用的探索一直没有停止HOC使用(老生常谈)的问题:
Render Props:
this.props属性,不能像HOC那样访问this.props.childrenClass的缺陷1、this的指向(语言缺陷)
class People extends Component {
state = {
name: 'dm',
age: 18,
}
handleClick(e) {
// 报错!
console.log(this.state);
}
render() {
const { name, age } = this.state;
return (<div onClick={this.handleClick}>My name is {name}, i am {age} years old.</div>);
}
}createClass不需要处理this的指向,到了Class Component稍微不慎就会出现因this的指向报错。
2、编译size(还有性能)问题:
// Class Component
class App extends Component {
state = {
count: 0
}
componentDidMount() {
console.log('Did mount!');
}
increaseCount = () => {
this.setState({ count: this.state.count + 1 });
}
decreaseCount = () => {
this.setState({ count: this.state.count - 1 });
}
render() {
return (
<>
<h1>Counter</h1>
<div>Current count: {this.state.count}</div>
<p>
<button onClick={this.increaseCount}>Increase</button>
<button onClick={this.decreaseCount}>Decrease</button>
</p>
</>
);
}
}
// Function Component
function App() {
const [ count, setCount ] = useState(0);
const increaseCount = () => setCount(count + 1);
const decreaseCount = () => setCount(count - 1);
useEffect(() => {
console.log('Did mount!');
}, []);
return (
<>
<h1>Counter</h1>
<div>Current count: {count}</div>
<p>
<button onClick={increaseCount}>Increase</button>
<button onClick={decreaseCount}>Decrease</button>
</p>
</>
);
}Class Component编译结果(Webpack):
var App_App = function (_Component) {
Object(inherits["a"])(App, _Component);
function App() {
var _getPrototypeOf2;
var _this;
Object(classCallCheck["a"])(this, App);
for (var _len = arguments.length, args = new Array(_len), _key = 0; _key < _len; _key++) {
args[_key] = arguments[_key];
}
_this = Object(possibleConstructorReturn["a"])(this, (_getPrototypeOf2 = Object(getPrototypeOf["a"])(App)).call.apply(_getPrototypeOf2, [this].concat(args)));
_this.state = {
count: 0
};
_this.increaseCount = function () {
_this.setState({
count: _this.state.count + 1
});
};
_this.decreaseCount = function () {
_this.setState({
count: _this.state.count - 1
});
};
return _this;
}
Object(createClass["a"])(App, [{
key: "componentDidMount",
value: function componentDidMount() {
console.log('Did mount!');
}
}, {
key: "render",
value: function render() {
return react_default.a.createElement(/*...*/);
}
}]);
return App;
}(react["Component"]);Function Component编译结果(Webpack):
function App() {
var _useState = Object(react["useState"])(0),
_useState2 = Object(slicedToArray["a" /* default */ ])(_useState, 2),
count = _useState2[0],
setCount = _useState2[1];
var increaseCount = function increaseCount() {
return setCount(count + 1);
};
var decreaseCount = function decreaseCount() {
return setCount(count - 1);
};
Object(react["useEffect"])(function () {
console.log('Did mount!');
}, []);
return react_default.a.createElement();
}Function类来处理的🤔问题:React是如何识别纯函数组件和类组件的?
不是所有组件都需要处理生命周期,在React发布之初Function Component被设计了出来,用于简化只有render时Class Component的写法。
function Child(props) {
const handleClick = () => {
this.props.setCounts(this.props.counts);
};
// UI的变更只能通过Parent Component更新props来做到!!
return (
<>
<div>{this.props.counts}</div>
<button onClick={handleClick}>increase counts</button>
</>
);
}
class Parent extends Component() {
// 状态管理还是得依赖Class Component
counts = 0
render () {
const counts = this.state.counts;
return (
<>
<div>sth...</div>
<Child counts={counts} setCounts={(x) => this.setState({counts: counts++})} />
</>
);
}
}所以,Function Comonent是否能脱离Class Component独立存在,关键在于让Function Comonent自身具备状态处理能力,即在组件首次render之后,“组件自身能够通过某种机制再触发状态的变更并且引起re-render”,而这种“机制”就是Hooks!
Hooks的出现弥补了Function Component相对于Class Component的不足,让Function Component取代Class Component成为可能。
1、功能相对独立、和render无关的部分,可以直接抽离到hook实现,比如请求库、登录态、用户核身、埋点等等,理论上装饰器都可以改用hook实现(如react-use,提供了大量从UI、动画、事件等常用功能的hook实现)。
case:Popup组件依赖视窗宽度适配自身显示宽度、相册组件依赖视窗宽度做单/多栏布局适配
🤔:请自行脑补使用Class Component来如何实现
function useWinSize() {
const html = document.documentElement;
const [ size, setSize ] = useState({ width: html.clientWidth, height: html.clientHeight });
useEffect(() => {
const onSize = e => {
setSize({ width: html.clientWidth, height: html.clientHeight });
};
window.addEventListener('resize', onSize);
return () => {
window.removeEventListener('resize', onSize);
};
}, [ html ]);
return size;
}
// 依赖win宽度,适配图片布局
function Article(props) {
const { width } = useWinSize();
const cls = `layout-${width >= 540 ? 'muti' : 'single'}`;
return (
<>
<article>{props.content}<article>
<div className={cls}>recommended thumb list</div>
</>
);
}
// 弹层宽度根据win宽高做适配
function Popup(props) {
const { width, height } = useWinSize();
const style = {
width: width - 200,
height: height - 300,
};
return (<div style={style}>{props.content}</div>);
}2、有render相关的也可以对UI和功能(状态)做分离,将功能放到hook实现,将状态和UI分离
case:表单验证
function App() {
const { waiting, errText, name, onChange } = useName();
const handleSubmit = e => {
console.log(`current name: ${name}`);
};
return (
<form onSubmit={handleSubmit}>
<>
Name: <input onChange={onChange} />
<span>{waiting ? "waiting..." : errText || ""}</span>
</>
<p>
<button>submit</button>
</p>
</form>
);
}useState<S>(initialState: (() => S) | S): [S, Dispatch<BasicStateAction<S>>]作用:返回一个状态以及能修改这个状态的setter,在其他语言称为元组(tuple),一旦mount之后只能通过这个setter修改这个状态。
思考🤔:useState为啥不返回object而是返回tuple?
Hooks API的默认实现:
function throwInvalidHookError() {
invariant(false, 'Invalid hook call. Hooks can only be called inside of the body of a function component. This could happen for one of the following reasons:\n1. You might have mismatching versions of React and the renderer (such as React DOM)\n2. You might be breaking the Rules of Hooks\n3. You might have more than one copy of React in the same app\nSee https://fb.me/react-invalid-hook-call for tips about how to debug and fix this problem.');
}
var ContextOnlyDispatcher = {
...
useEffect: throwInvalidHookError,
useState: throwInvalidHookError,
...
};当在Function Component调用Hook:
function renderWithHooks(current, workInProgress, Component, props, refOrContext, nextRenderExpirationTime) {
currentlyRenderingFiber$1 = workInProgress; // 指针指向当前正在render的fiber节点
....
if (nextCurrentHook !== null) {
// 数据更新
ReactCurrentDispatcher$1.current = HooksDispatcherOnUpdateInDEV;
} else {
// 首次render
ReactCurrentDispatcher$1.current = HooksDispatcherOnMountInDEV;
}
}
/// hook api的实现
HooksDispatcherOnMountInDEV = {
...
useState: function (initialState) {
currentHookNameInDev = 'useState';
...
return mountState(initialState);
},
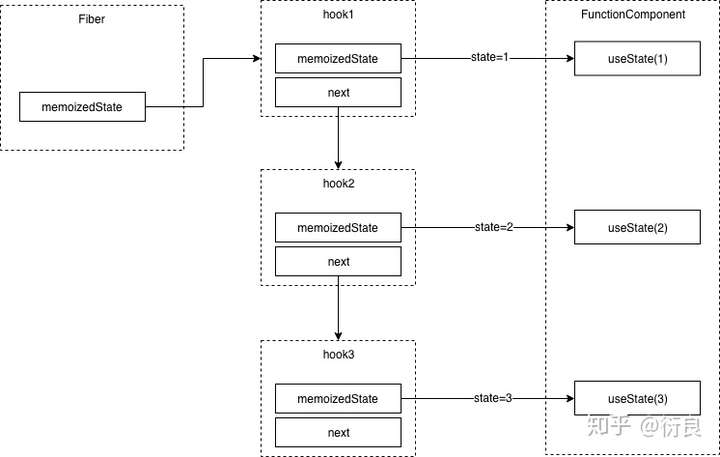
};在类组件中,state就是一个对象,对应FiberNode的memoizedState属性,在类组件中当调用setState()时更新memoizedState即可。但是在函数组件中,memoizedState被设计成一个链表(Hook对象):
// Hook类型定义
type Hook = {
memoizedState: any, // 存储最新的state
baseState: any,
baseUpdate: Update<any, any> | null,
queue: UpdateQueue<any, any> | null, // 更新队列
next: Hook | null, // 下一个hook
}
// 定义一次更新
type Update<S, A> = {
...
action: A,
eagerReducer: ((S, A) => S) | null,
eagerState: S | null, // 待更新状态值
next: Update<S, A> | null,
...
};
// 待更新队列定义
type UpdateQueue<S, A> = {
last: Update<S, A> | null, // 最后一次更新操作
dispatch: (A => mixed) | null,
lastRenderedReducer: ((S, A) => S) | null, // 最新处理处理state的reducer
lastRenderedState: S | null, // 最新渲染后状态
};示例:
function App() {
const [ n1, setN1 ] = useState(1);
const [ n2, setN2 ] = useState(2);
// if (sth) {
// const [ n4, setN4 ] = useState(4);
// } else {
// const [ n5, setN5 ] = useState(5);
// }
const [ n3, setN3 ] = useState(3);
}Hook存储(链表)结构:
useState(5)分支,相反useState(4)则不会执行到,导致useState(5)返回的值其实是4,因为首次render之后,只能通过useState返回的dispatch修改对应Hook的memoizedState,因此必须要保证Hooks的顺序不变,所以不能在分支调用Hooks,只有在顶层调用才能保证各个Hooks的执行顺序!useState() mount阶段(部分)源码实现:
// useState() 首次render时执行mountState
function mountState(initialState) {
// 从当前Fiber生成一个新的hook对象,将此hook挂载到Fiber的hook链尾,并返回这个hook
var hook = mountWorkInProgressHook();
hook.memoizedState = hook.baseState = initialState;
var queue = hook.queue = {
last: null,
dispatch: null,
lastRenderedReducer: (state, action) => isFn(state) ? action(state) : action,
lastRenderedState: initialState
};
// currentlyRenderingFiber$1保存当前正在渲染的Fiber节点
// 将返回的dispatch和调用hook的节点建立起了连接,同时在dispatch里边可以访问queue对象
var dispatch = queue.dispatch = dispatchAction.bind(null, currentlyRenderingFiber$1, queue);
return [hook.memoizedState, dispatch];
}
//// 功能相当于setState!
function dispatchAction(fiber, queue, action) {
...
var update = {
action, // 接受普通值,也可以是函数
next: null,
};
var last = queue.last;
if (last === null) {
update.next = update;
} else {
last.next = update;
}
// 略去计算update的state过程
queue.last = update;
...
// 触发React的更新调度,scheduleWork是schedule阶段的起点
scheduleWork(fiber, expirationTime);
}dispatchAction函数是更新state的关键,它会生成一个update挂载到Hooks队列上面,并提交一个React更新调度,后续的工作和类组件一致。useState更新数据和setState不同的是,前者会与old state做merge,我们只需把更改的部分传进去,但是useState则是直接覆盖!schedule阶段介于reconcile和commit阶段之间,schedule的起点方法是scheduleWork。 ReactDOM.render, setState,forceUpdate, React Hooks的dispatchAction都要经过scheduleWork。
Ref:https://zhuanlan.zhihu.com/p/54042084
update阶段(state改变、父组件re-render等都会引起组件状态更新)useState()更新状态:
function updateState(initialState) {
var hook = updateWorkInProgressHook();
var queue = hook.queue;
var newState;
var update;
if (numberOfReRenders > 0) {
// 组件自己re-render
newState = hook.memoizedState;
// renderPhaseUpdates是一个全局变量,是一个的HashMap结构:HashMap<(Queue: Update)>
update = renderPhaseUpdates.get(queue);
} else {
// update
newState = hook.baseState;
update = hook.baseUpdate || queue.last;
}
do {
newState = update.action; // action可能是函数,这里略去了细节
update = update.next;
} while(update !== null)
hook.memoizedState = newState;
return [hook.memoizedState, queue.dispatch];
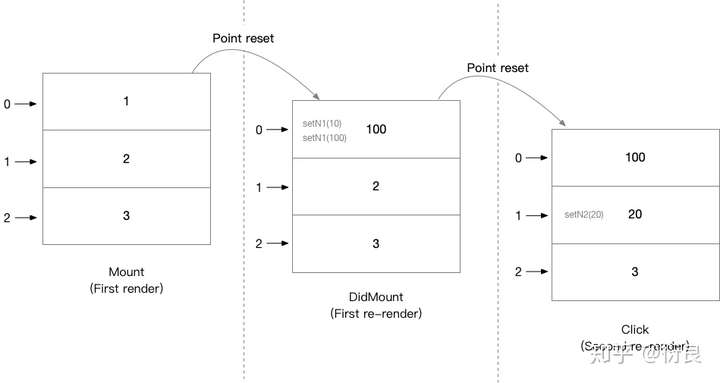
}function App() {
const [n1, setN1] = useState(1);
const [n2, setN2] = useState(2);
const [n3, setN3] = useState(3);
useEffect(() => {
setN1(10);
setN1(100);
}, []);
return (<button onClick={() => setN2(20)}>click</button>);
}图解更新过程:
useEffect(effect: React.EffectCallback, deps?: ReadonlyArray<any> | undefined)作用:处理函数组件中的副作用,如异步操作、延迟操作等,可以替代Class Component的componentDidMount、componentDidUpdate、componentWillUnmount等生命周期。
HooksDispatcherOnMountInDEV = {
useEffect: function() {
currentHookNameInDev = 'useEffect';
...
return mountEffectImpl(Update | Passive, UnmountPassive | MountPassive, create, deps);
},
};
function mountEffectImpl(fiberEffectTag, hookEffectTag, create, deps) {
var hook = mountWorkInProgressHook();
var nextDeps = deps === undefined ? null : deps;
return hook.memoizedState = pushEffect(hookEffectTag, create, undefined, nextDeps);
}
function pushEffect(tag, create, destroy, deps) {
var effect = {
tag: tag,
create: create, // 存储useEffect传入的callback
destroy: destroy, // 存储useEffect传入的callback的返回函数,用于effect清理
deps: deps,
next: null
};
.....
componentUpdateQueue = createFunctionComponentUpdateQueue();
componentUpdateQueue.lastEffect = effect.next = effect;
....
return effect;
}
function renderWithHooks() {
...
currentlyRenderingFiber$1.updateQueue = componentUpdateQueue;
....
}effect对象,effect对象最终会被挂载到Fiber节点的updateQueue队列(当Fiber节点都渲染到页面上后,就会开始执行Fiber节点中的updateQueue中所保存的函数)下面一段很常见的代码,🤔有什么问题?运行demo
// 用Hook写
function App() {
const [data, setData] = useState('');
useEffect(() => {
setTimeout(() => {
setData(`current data: ${Date.now()}`);
}, 3000);
});
return <div>{data}</div>;
}
// 等价代码
class App extends Component {
state = {data = ''}
componentDidMount() {
setTimeout(() => {
this.setState({ data: `current data: ${Date.now()}` });
}, 3000);
}
render() {
return <div>{this.state.data}</div>;
}
}deps,用于在re-render时判断是否重新执行callback,所以deps必须要按照实际依赖传入,不能少传也不要多传!Hook接受useEffect传入的callback返回一个函数,在Fiber的清理阶段将会执行这个函数,从而达到清理effect的效果:
function App() {
useEffect(() => {
const timer = setTimeout(() => {
console.log('print log after 1s!');
}, 1000);
window.addEventListener('load', loadHandle);
return () => window.removeEventListener('load', loadHandle); // 执行清理
}, []);
}
// 同等实现
class App extends Component {
componentDidMount() {
const timer = setTimeout(() => {
console.log('print log after 1s!');
}, 1000);
window.addEventListener('load', loadHandle);
}
componentDidUnmount() {
window.removeEventListener('load', loadHandle);
}
}对于组件之间的状态共享,在类组件里边官方提供了Context相关的API:
React.createContext API创建Context,由于支持在组件外部调用,因此可以实现状态共享Context.Provider API在上层组件挂载状态Context.Consumer API为具体的组件提供状态或者通过contextType属性指定组件对Context的引用在消费context提供的状态时必须要使用contextType属性指定Context引用或者用<Context.Consumer>包裹组件,在使用起来很不方便(参见React Context官方示例)。
React团队为函数组件提供了useContext Hook API,用于在函数组件内部获取Context存储的状态:
useContext<T>(Context: ReactContext<T>, unstable_observedBits: void | number | boolean): TuseContext的实现比较简单,只是读取挂载在context对象上的_currentValue值并返回:
function useContext(content, observedBits) {
// 处理observedBits,暂时
// 只有在React Native里边isPrimaryRenderer才会是false
return isPrimaryRenderer ? context._currentValue : context._currentValue2;
}理解useContext的实现,首先要对Context源码实现有所了解,推荐《React 源码系列 | React Context 详解》
useContext极大地简化了消费Context的过程,为组件之间状态共享提供了一种可能,事实上,社区目前存在大量的基于Hooks的状态管理方案很大一部分是基于useContext API来实现的(另一种是useState),关于状态管理方案的探索我们放在后面的文章介绍。
useReducer<S, I, A>(reducer: (S, A) => S, initialArg: I, init?: I => S, ): [S, Dispatch<A>]作用:用于管理复杂的数据结构(useState一般用于管理扁平结构的状态),基本实现了redux的核心功能,事实上,基于Hooks Api可以很容易地实现一个useReducer Hook:
const useReducer = (reducer, initialArg, init) => {
const [state, setState] = useState(
init ? () => init(initialArg) : initialArg,
);
const dispatch = useCallback(
action => setState(prev => reducer(prev, action)),
[reducer],
);
return useMemo(() => [state, dispatch], [state, dispatch]);
};reducer提供了一种可以在组件外重新编排state的能力,而useReducer返回的dispatch对象又是“性能安全的”,可以直接放心地传递给子组件而不会引起子组件re-render。
function reducer(state, action) {
// 这里能够拿到组件的全部state!!
switch (action.type) {
case "increment":
return {
...state,
count: state.count + state.step,
};
...
}
}
function App() {
const [state, dispatch] = useReducer(reducer, {count: initialCount, step: 10});
return (
<>
<div>{state.count}</div>
// redux like diaptch
<button onClick={() => dispatch({type: 'increment'})}>+</button>
<button onClick={() => dispatch({type: 'decrement'})}>-</button>
<ChildComponent dispatch={dispatch} />
</>
);
} useCallback<T>(callback: T, deps: Array<mixed> | void | null): T由于javascript函数的特殊性,当函数签名被作为deps传入useEffect时,还是会引起re-render(即使函数体没有改变),这种现象在类组件里边也存在:
// 当Parent组件re-render时,Child组件也会re-render
class Parent extends Component {
render() {
const someFn = () => {}; // re-render时,someFn函数会重新实例化
return (
<>
<Child someFn={someFn} />
<Other />
</>
);
}
}
class Child extends Component {
componentShouldUpdate(prevProps, nextProps) {
return prevProps.someFn !== nextProps.someFn; // 函数比较将永远返回false
}
}Function Component(查看demo):
function App() {
const [count, setCount] = useState(0);
const [list, setList] = useState([]);
const fetchData = async () => {
setTimeout(() => {
setList(initList);
}, 3000);
};
useEffect(() => {
fetchData();
}, [fetchData]);
return (
<>
<div>click {count} times</div>
<button onClick={() => setCount(count + 1)}>Add count</button>
<List list={list} />
</>
);
}解决方案:
useEffect内部useEffect内部(如需要传递给子组件),可以使用useCallback API包裹函数,useCallback的本质是对函数进行依赖分析,依赖变更时才重新执行useMemo<T>(create: () => T, deps: Array<mixed> | void | null): TuseMemo用于缓存一些耗时的计算结果,只有当依赖参数改变时才重新执行计算:
function App(props) {
const start = props.start;
const list = props.list;
const fibValue = useMemo(() => fibonacci(start), [start]); // 缓存耗时操作
const MemoList = useMemo(() => <List list={list} />, [list]);
return (
<>
<div>Do some expensive calculation: {fibValue}</div>
{MemoList}
<Other />
</>
);
}简单理解:
useCallback(fn, deps) === useMemo(() => fn, deps)
在函数组件中,React提供了一个和类组件中和PureComponent相同功能的API React.memo,会在自身re-render时,对每一个 props 项进行浅对比,如果引用没有变化,就不会触发重渲染。
// 只有列表项改变时组件才会re-render
const MemoList = React.memo(({ list }) => {
return (
<ul>
{list.map(item => (
<li key={item.id}>{item.content}</li>
))}
</ul>
);
});相比React.memo,useMemo在组件内部调用,可以访问组件的props和state,所以它拥有更细粒度的依赖控制。
关于useRef其实官方文档已经说得很详细了,useRef Hook返回一个ref对象的可变引用,但useRef的用途比ref更广泛,它可以存储任意javascript值而不仅仅是DOM引用。
useRef的实现比较简单:
// mount阶段
function mountRef(initialValue) {
var hook = mountWorkInProgressHook();
var ref = { current: initialValue };
{
Object.seal(ref);
}
hook.memoizedState = ref;
return ref;
}
// update阶段
function updateRef(initialValue) {
var hook = updateWorkInProgressHook();
return hook.memoizedState;
}useRef是比较特殊:
Capture Values特性1、useState具有capture values,查看demo
2、useEffect具有capture values
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
// 连续点击三次button,页面的title将依次改为1、2、3,而不是3、3、3
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>Click me</button>
</div>
);
}3、event handle具有capture values,查看demo
4、。。。所有的Hooks API都具有capture values特性,除了useRef,查看demo(setTimeout始终能拿到state最新值),state是Immutable的,ref是mutable的。
function mountRef(initialValue) {
var hook = mountWorkInProgressHook();
var ref = { current: initialValue }; // ref就是一个普通object的引用,没有闭包
{
Object.seal(ref);
}
hook.memoizedState = ref;
return ref;
}非useRef相关的Hook API,本质上都形成了闭包,闭包有自己独立的状态,这就是Capture Values的本质。
// mount结束
const onMount = function useDidMount(effect) => {
useEffect(effect, []);
};// render结束,可以执行DOM操作
const onUpdate = function useDomDidMount(effect) => {
useLayoutEffect(effect, []);
};const unMount = function useWillUnMount(effect) => {
useEffect(() => effect, []);
};// 使用React.memo包裹组件
const MyComponent = React.memo(() => {
return <Child prop={prop} />
}, [prop]);
// or
function A({ a, b }) {
const B = useMemo(() => <B1 a={a} />, [a]);
const C = useMemo(() => <C1 b={b} />, [b]);
return (
<>
{B}
{C}
</>
);
}1、Hooks能解决组件功能复用,但没有很好地解决JSX的复用问题,比如(1.4)表单验证的case:
function App() {
const { waiting, errText, name, onChange } = useName();
// ...
return (
<form>
<div>{name}</div>
<input onChange={onChange} />
{waiting && <div>waiting<div>}
{errText && <div>{errText}<div>}
</form>
);
}虽能够将用户的输入、校验等逻辑封装到useName hook,但DOM部分还是有耦合,这不利于组件的复用,期待React团队拿出有效的解决方案来。
2、React Hooks模糊了(或者说是抛弃了)生命周期的概念,但也带来了更高门槛的学习心智(如Hooks生命周期的理解、Hooks Rules的理解、useEffect依赖项的判断等),相比Vue3.0即将推出的Hooks有较高的使用门槛。
3、类拥有比函数更丰富的表达能力(OOP),React采用Hooks+Function Component(函数式)的方式其实是一种无奈的选择,试想一个挂载了十几个方法或属性的Class Component,用Function Component来写如何组织代码使得逻辑清晰?这背后其实是函数式编程与面向对象编程两种设计模式的权衡。
原文: https://medium.com/react-ecosystem/react-components-lifecycle-ce09239010df#.j7h6w8ccc
在先前的文章里我们涵盖了React基本原理和如何构建更加复杂的交互组件。此篇文章我们将会继续探索React组件的特性,特别是生命周期。
稍微思考一下React组件所做的事,首先想到的是一点是:React描述了如何去渲染(DOM)。我们已经知道React使用render()方法来达到这个目的。然而仅有render()方法可能不一定都能满足我们的需求。如果在组件rendered之前或之后我们需要做些额外的事情该怎么做呢?我们需要做些什么以避免重复渲染(re-render)呢?
看起来我们需要对组件(运行)的各个阶段进行控制,组件运行所有涉及的各个阶段叫做组件的生命周期,并且每一个React组件都会经历这些阶段。React提供了一些方法并在组件处于相应的阶段时通知我们。这些方法叫做React组件的生命周期方法且会根据特定并可预测的顺序被调用。
基本上所有的React组件的生命周期方法都可以被分割成四个阶段:初始化、挂载阶段(mounting)、更新阶段、卸载阶段(unmounting)。让我们来近距离分别研究下各个阶段。
初始化阶段就是我们分别通过getDefaultProps()和getInitialState()方法定义this.props默认值和this.state初始值的阶段。
getDefaultProps()方法被调用一次并缓存起来——在多个类实例之间共享。在组件的任何实例被创建之前,我们(的代码逻辑)不能依赖这里的this.props。这个方法返回一个对象并且属性如果没有通过父组件传入的话相应的属性会挂载到this.props对象上。
getInitialState()方法也只会被调用一次,(调用时机)刚好是mounting阶段开始之前。返回值将会被当成this.state的初始值,且必须是一个对象。
现在我们来证明上面的猜想,实现一个显示的值可以被增加和减少的组件,基本上就是一个拥有“+”和“-”按钮的计数器。
var Counter = React.createClass({
getDefaultProps: function() {
console.log('getDefaultProps');
return {
title: 'Basic counter!!!'
}
},
getInitialState: function() {
console.log('getInitialState');
return {
count: 0
}
},
render: function() {
console.log('render');
return (
<div>
<h1>{this.props.title}</h1>
<div>{this.state.count}</div>
<input type='button' value='+' onClick={this.handleIncrement} />
<input type='button' value='-' onClick={this.handleDecrement} />
</div>
);
},
handleIncrement: function() {
var newCount = this.state.count + 1;
this.setState({count: newCount});
},
handleDecrement: function() {
var newCount = this.state.count - 1;
this.setState({count: newCount});
},
propTypes: {
title: React.PropTypes.string
}
});
ReactDOM.render(
React.createElement(Counter),
document.getElementById('app-container')
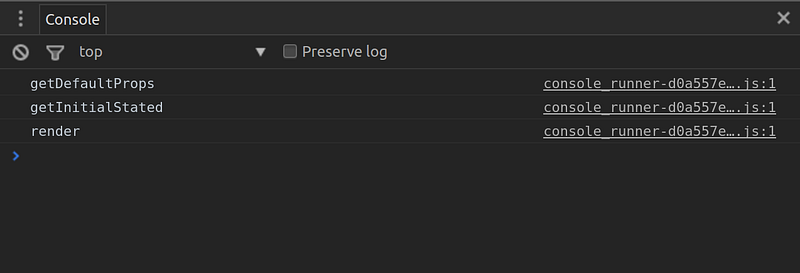
);我们通过getDefaultProps()方法配置一个“title”属性,如果没有传入则提供一个默认值。然后通过getInitialState()为组件设置一个初始state值“{count: 0}”。如果运行这段代码你将会看到控制台输出如下结果:
现在我们想要让Counter组件可以设置this.state.count初始值和增加/减少的步长值,但依然提供一个默认值:
var Component = React.createClass({
getDefaultProps: function() {
console.log('getDefaultProps');
return {
title: "Basic counter!!!",
step: 1
}
},
getInitialState: function() {
console.log('getInitialState');
return {
count: (this.props.initialCount || 0)
};
},
render: function() {
console.log('render');
var step = this.props.step;
return (
<div>
<h1>{this.props.title}</h1>
<div>{this.state.count}</div>
<input type='button' value='+' onClick={this.updateCounter.bind(this, step)} />
<input type='button' value='-' onClick={this.updateCounter.bind(this, -step)} />
</div>
);
},
updateCounter: function(value) {
var newCount = this.state.count + value;
this.setState({count: newCount});
},
propTypes: {
title: React.PropTypes.string,
initialCount: React.PropTypes.number,
step: React.PropTypes.number
}
});
ReactDOM.render(
React.createElement(Component, {initialCount: 5, step: 2}),
document.getElementById('app-container')
);这里通过Function.prototype.bind使用偏函数应用(Partial Application)来达到复用代码的目的。
现在我们拥有了一个可定制化的组件。
Mounting阶段发生在组件即将被插入到DOM之前。这个阶段有两个方法可以用:componentWillMount()和componentDidMount()。
componentWillMount()方法是这个阶段最先调用的,它只在刚好初始渲染(initial rendering)发生之前被调用一次,也就是React在DOM插入组件之前。需要注意的是在此处调用this.setState()方法将不会触发重复渲染(re-render)。如果添加下面的代码到计数器组件我们将会看到此方法在getInitialState()之后且render()之前被调用。
getInitialState: function() {...},
componentWillMount: function() {
console.log('componentWillMount');
},componentDidMount()是这个阶段第二个被调用的方法,刚好发生在React插入组件到DOM之后,且也只被调用一次。现在可以更新DOM元素了,这意味着这个方法是初始化其他需要访问DOM或操作数据的第三方库的最佳时机。
假设我们想要通过API拉取数据来初始化组件。我们应该直接在计数器组件的componentDidMount()方法拉取数据,但是这让组件看起来有太多逻辑了,更可取的方案是使用容器组件来做:
var Container = React.createClass({
getInitialState: function() {
return {
data: null,
fetching: false,
error: null
};
},
render: function() {
if (this.props.fetching) {
return <div>Loading...</div>;
}
if (this.props.error) {
return (
<div className='error'>
{this.state.error.message}
</div>
);
}
return <Counter {...data} />
},
componentDidMount: function() {
this.setState({fetching: true});
Axios.get(this.props.url).then(function(res) {
this.setState({data: res.data, fetching: false});
}).catch(function(res) {
this.setState({error: res.data, fetching: false});
});
}
});Axios是一个基于priomise的跨浏览器和Node.js的HTTP客户端。
当组件的属性或者状态更新时也需要一些方法来供我们执行代码,这些方法也是组件更新阶段的一部分且按照以下的顺序被调用:
当从父组件接收到新的属性时:
当通过this.setState()改变状态时:
此阶段React组件已经被插入DOM了,因此这些方法将不会在首次render时被调用。
最先被调用的方法是componentWillReceiveProps(),当组件接收到新属性时被调用。我们可以利用此方法为React组件提供一个在render之前修改state的机会。在此方法内调用this.setState()将不会导致重复render,然后可以通过this.props访问旧的属性。例如计数器组件,如果我们想要在任何时候父组件传入“initialCount”时更新状态,可以这样做:
...
componentWillReceiveProps: function(newProps) {
this.setState({count: newProps.initialCount});
},
...shouldComponentUpdate()方法允许我们自行决定下一个state更新时是否触发重复render。此方法返回一个布尔值,且默认是true。但是我们也可以返回false,这样下面的(生命周期)方法将不会被调用:
当有性能瓶颈时也可以使用shouldComponentUpdate()方法(来优化)。尤其是数百个组件一起时重新render的代价将会十分昂贵。为了证明这个猜想我们来看一个例子:
var TextComponent = React.createClass({
shouldComponentUpdate: function(nextProps, nextState) {
if (this.props.text === nextProps.text) return false;
return true;
},
render: function() {
return <textarea value={this.props.text} />;
}
});此例中无论何时父组件传入一个“text”属性到TextComponent并且text属性等于当前的“text”属性时,组件将会不会重复render。
当接收到新的属性或者state时在render之前会立刻调用componentWillUpdate()方法。可以利用此时机来为更新做一些准备工作,虽然这个阶段不能调用this.setState()方法:
...
componentWillUpdate: function(nextProps, nextState) {
console.log('componentWillUpdate', nextProps, nextState);
},
...componentDidUpdate()方法在React更新DOM之后立刻被调用。可以在此方法里操作被更新过的DOM或者执行一些后置动作(action)。此方法有两个参数:
这个方法的一个常见使用场景是当我们使用需要操作更新后的DOM才能工作的第三方库——如jQuery插件的时候。在componentDidMount()方法内初始化第三方库,但是在属性或state更新触发DOM更新之后也需要同步更新第三方库来保持接口一致,这些必须在componentDidUpdate()方法内来完成。为了验证这一点,让我们看看如何开发一个Select2库包裹(wrapper)React组件:
var Select2 = React.createClass({
componentDidMount: function() {
$(this._ref).select2({data: this.props.items});
},
render: function() {
return (
<select
ref={
function(input) {
this._ref = input;
}.bind(this)
}>
</select>
);
},
componentDidUpdate: function() {
$(this._ref).select2('destroy');
$(this._ref).select2({data: this.props.items});
}
});此阶段React只提供了一个方法:
它将在组件从DOM卸载之前被调用。可以在内部执行任何可能需要的清理工作,如无效的计数器或者清理一些在componentDidMount()/componentDidUpdate()内创建的DOM。比如在Select2组件里边我们可以这样子:
...
componetWillUnmount: function(){
$(this._ref).select2('destroy');
},
...React为我们提供了一种在创建组件时申明一些将会在组件生命周期的特定时机被自动调用的方法的可能。现在我们很清晰的理解了每一个组件生命周期方法所扮演的角色以及他们被调用的顺序。这使我们有机会在组件创建和销毁时执行一些操作。也允许我们在当属性和状态变化时做出相应的反应从而更容易的整合第三方库和追踪性能问题。
希望您觉得此文对您有用,如果是这样,请推荐之!!!
本篇谈谈Node.js捕获异常的一些探索。
采用事件轮询、异步IO等机制使得Node.js能够从容应对无阻塞高并发场景,令工程师很困扰的几个理解Node.js的地方除了它的事件(回调)机制,还有一个同样头痛的是异常代码的捕获。
一般情况下,我们会将有可能出错的代码放到try/catch块里。但是到了Node.js,由于try/catch无法捕捉异步回调里的异常,Node.js原生提供uncaughtException事件挂到process对象上,用于捕获所有未处理的异常:
process.on('uncaughtException', function(err) {
console.error('Error caught in uncaughtException event:', err);
});
try {
process.nextTick(function() {
fs.readFile('non_existent.js', function(err, str) {
if(err) throw err;
else console.log(str);
});
});
} catch(e) {
console.error('Error caught by catch block:', e);
}执行的结果是代码进到了uncaughtException的回调里而不是catch块。
uncaughtException虽然能够捕获异常,但是此时错误的上下文已经丢失,即使看到错误也不知道哪儿报的错,定位问题非常的不利。而且一旦uncaughtException事件触发,整个node进程将crash掉,如果不做一些善后处理的话会导致整个服务挂掉,这对于线上的服务来说将是非常不好的。
随Node.js v0.8版本发布了一个domain(域)模块,专门用于处理异步回调的异常,使用domain我们将很轻松的捕获异步异常:
process.on('uncaughtException', function(err) {
console.error('Error caught in uncaughtException event:', err);
});
var d = domain.create();
d.on('error', function(err) {
console.error('Error caught by domain:', err);
});
d.run(function() {
process.nextTick(function() {
fs.readFile('non_existent.js', function(err, str) {
if(err) throw err;
else console.log(str);
});
});
});运行上面的代码,我们会看到错误被domain捕获到,并且uncaughtException回调并不会执行,事情似乎变得稍微容易些了。
但是如果研究domain模块的API很快我们会发现,domain提供了好几个方法,理解起来似乎不是那么直观(其实为啥这个模块叫“域(domain)”呢,总感觉些许别扭),这里简单解释下:
首先,关于domain模块,我们看到它的稳定性是2,也就是不稳定,API可能会变更。
默认情况下,domain模块是不被引入的,当domain.create()创建一个domain之后,调用enter()方法即可“激活”这个domain,具体表现为全局的进程(process)对象上会有一个domain属性指向之前创建的这个的domain实例,同时,domain模块上有个active属性也指向这个的domain实例。
结合should断言库测试下上面说的:
// domain was not exists by default
should.not.exist(process.domain);
var d = domain.create();
d.on('error', function(err) {
console.log(err);
});
d.enter(); // makes d the current domain
process.domain.should.be.an.Object;
process.domain.should.equal(domain.active);
d.exit(); // makes d inactive
should.not.exist(process.domain);执行之后发现几个断言都能pass。exit()方法的意思是退出当前“域”,将会影响到后续异步异常的捕获,后面会提到。
enter和exit组合调用这样会使代码有些混乱,尤其是当多个domain混合、嵌套使用时比较难理解。
这时候可以使用run()方法,run()其实就是对enter和exit以及回调的简单封装,即:run() -- callback() -- exit()这样,就像上面例子中的run()一样。
还有两个方法,bind()和intercept():
bind:
fs.readFile('non_existent.js', d.bind(function(err, buf) {
if(err) throw err;
else res.end(buf.toString());
}));intercept:
fs.readFile('non_existent.js', d.intercept(function(buf) {
console.log(buf);
}));用法差不多,只是intercept拦截了异步回调,如果抛出异常就自己处理掉了。
domain主要会影响timers模块(包括setTimeout, setInterval, setImmediate), 事件循环process.nextTick,还有就是event。
实现的思路都差不多,都是通过注入domain代码到timer、nextTick、event模块中,在创建的时候检查当前有没有激活(active)的domain,有则记录下,如果是timer和nextTick,当在事件循环中执行回调的时候,把process.domain设置为之前记录的domain并把错误交给它处理。如果是event,多一步判断,先会把异常交给event自己定义的error事件处理。
这里要注意,如果这个domain没有绑定error事件的话,node会直接抛出错误,即使uncaughtException绑定了也没有用:
var d = domain.create();
process.on('uncaughtException', function(err) {
console.error('Error caught in uncaughtException event:', err);
});
d.run(function() {
process.nextTick(function() {
fs.readFile('non_existent.js', function(err, str) {
if(err) throw err;
else console.log(str);
});
});
});在这个例子里面,使用了domain捕获异常但是没有监听domain的error事件,监听了uncaughtException,但是还是抛出了异常,个人觉得觉得这里是个bug,domain没有errorHandle应该把异常交给全局的uncaughtException,后面有例子验证这一点。
还有一个小问题,同时监听了uncaughtException和domain的error事件,在node v0.8里有个bug,uncaughtException和domain都能捕获异常,0.10+已经修复。
上面没有提到的两个API是add()和remove(),add作用是把domain创建之前创建的(EventEmitter实例)对象添加到这个domain里边,然后这个对象即可使用domain捕捉异常了,remove则相反。domain对象上有个numbers队列专门用于管理add后的对象。
这里可参考官方示例。
我们看node源码有这么一行:
// do this good and early, since it handles errors.
startup.processFatal();processFatal里边调用process._fatalException(),先判断是否存在process.domain,尝试把错误交给process.domain处理,如果不存在才交给uncaughtException处理,所以domain捕获异常的关键代码在node.js#L219。
这里尝试修改下上面的例子,在抛出异常前把process.domain设为null:
d.run(function() {
process.domain = null;
process.nextTick(function() {
fs.readFile('non_existent.js', function(err, str) {
if(err) throw err;
else console.log(str);
});
});
});这下uncaughtException将捕获异常!
当上面提到的异常都没被捕获,进程将直接退出node.js#L280:
// if someone handled it, then great. otherwise, die in C++ land
// since that means that we'll exit the process, emit the 'exit' event
...
process.emit('exit', 1);另外关于domain如何在多个不同的事件循环中传递,可以参考下这篇文章。
值得关注的是,并不是所有在domain域下创建的事件分发器(EventEmitter)上面的异步异常都能捕获:
var d = domain.create();
var msg;
var Msg = function() {
events.EventEmitter.call(this);
this.on('msg', function(msg) {
console.log(msg);
});
this.send = function(msg) {
this.emit('msg', msg);
};
this.read = function(file) {
var root = this;
fs.readFile(file, function(err, buf) {
if(err) throw err;
else root.send(buf.toString());
});
};
};
require('util').inherits(Msg, events.EventEmitter);
d.on('error', function(err) {
console.error('Error caught by domain:', err);
});
d.run(function() {
msg = new Msg();
});
msg.read('non_existent.js');这个例子中,msg对象虽然是在domain中实例化,但是msg.send里边fs.readFile在执行回调的时候,process.domain是undefined。
我们稍微改造下,把readFile的回调绑定到domain上,或者把msg.send()的调用放到d.run()包裹,结果可预知,能正常捕获抛出的异常。为了验证,尝试改造下readFile:
fs.readFile(file, function(err, buf) {
process.domain = d;
if(err) throw err;
else root.send(buf.toString());
});这样亦可捕获异常,不过实际中不要这样写,还是要采用domain提供的方法。
其实上,更推荐的做法是,如果在活动domain里面创建了事件分发器(EventEmitter)实例,我们应该尽可能的给它注册error事件,把错误都抛给这个EventEmitter实例处理,就像上面的例子,我们改造下,绑定error事件并把readFile的错误交给Msg实例处理:
this.on('error', function(err) {
throw err;
});
this.read = function(file) {
var root = this;
fs.readFile(file, function(err, buf) {
if(err) root.emit('error', err);
else root.send(buf.toString());
});
};在书写Node.js代码的时候,对于事件分发器,应该养成先绑定(on()或addEventListener())后触发(emit())的习惯。在执行事件回调的时候,对于有可能抛异常的情况,应该把emit放到domain里去:
var d = domain.create();
var e = new events.EventEmitter();
d.on('error', function(err) {
console.error('Error caught by domain:', err);
});
e.on('data', function(err) {
if(err) throw err;
});
if(Math.random() > 0.5) {
d.run(function() {
e.emit('data', new Error('Error in domain runtime.'));
});
} else {
e.emit('data', new Error('Error without domain.'));
}根据domain#L187可知,run会把传进去的函数包装成另一个函数返回,并在这个返回的函数上设置domain:
b.domain = this;events模块events.js#L85有这么一行:
if (this.domain && this !== process) this.domain.enter();当调用e.emit()的时候,如果回调函数上挂有domain,则将这个domain激活,进而可以捕获异常。
有了domain,似乎异步异常捕捉已经不再是难事。Node.js允许创建多个domain实例,并允许使用add添加多个事件分发器给domain管理,,而且domain之间可以相互嵌套,而创建domain,是有一定的性能耗损的,这样带来了一个棘手的问题是:多个domain如何合理的创建与销毁,domain的运行期应该如何维护?
还有一点,domain并不能捕捉所有的异常,看这里。
关于使用domain到集群环境,推荐都看看官方的说明:Warning: Don't Ignore Errors!。把每一个网络请求都包在一个domain里边,捕获到异常时,不要立即退出进程,应该保证进程中其他连接正常退出之后再exit,官方推荐的是设一个定时器,过3min后退出进程,接下去做善后处理,然后应该返回应该有的错误(如500)给客户端。
对于connect或者express创建的web服务,有一个domain-middleware中间件可以直接用,它会把next包装到一个已经定制好的domain里边。
在具体应用场景,应该uncaughtException事件配合domain来用。
本篇完,欢迎补充指正,所有用到的例子都在这里。
参考资料:
本篇记录MongoDB高可用模式部署步骤,其他部署方式见上一篇。
首先准备机器,我这里是在公司云平台创建了三台DB server,ip分别是10.199.144.84,10.199.144.89,10.199.144.90。
分别安装mongodb最新稳定版本:
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.12.tgz
tar -xzvf mongodb-linux-x86_64-2.4.12.tgz
mv mongodb-linux-x86_64-2.4.12 /usr/lib做个软连接或者按照官方的做法把mongo shell都添加到环境变量:
ln -s /usr/lib/mongodb-linux-x86_64-2.4.12/bin/mongo /usr/bin/mongo
ln -s /usr/lib/mongodb-linux-x86_64-2.4.12/bin/mongos /usr/bin/mongos
ln -s /usr/lib/mongodb-linux-x86_64-2.4.12/bin/mongod /usr/bin/mongod分别创建存储数据的目录:
mkdir -p /data/mongodb && cd /data/mongodb/ && mkdir -p conf/data conf/log mongos/log shard{1..3}/data shard{1..3}/log分别配置启动config服务器:
mongod --configsvr --dbpath /data/mongodb/conf/data --port 27100 --logpath /data/mongodb/conf/confdb.log --fork --directoryperdb确保config服务都启动之后,启动路由服务器(mongos):
mongos --configdb 10.199.144.84:27100,10.199.144.89:27100,10.199.144.90:27100 --port 27000 --logpath /data/mongodb/mongos/mongos.log --fork分别配置启动各个分片副本集,这里副本集名分别叫shard1,shard2,shard3:
mongod --shardsvr --replSet shard1 --port 27001 --dbpath /data/mongodb/shard1/data --logpath /data/mongodb/shard1/log/shard1.log --directoryperdb --fork
mongod --shardsvr --replSet shard2 --port 27002 --dbpath /data/mongodb/shard2/data --logpath /data/mongodb/shard2/log/shard2.log --directoryperdb --fork
mongod --shardsvr --replSet shard3 --port 27003 --dbpath /data/mongodb/shard3/data --logpath /data/mongodb/shard3/log/shard3.log --directoryperdb --fork接下来配置副本集,假设使用如下的架构,每台物理机都有一个主节点,一个副本节点和一个仲裁节点:
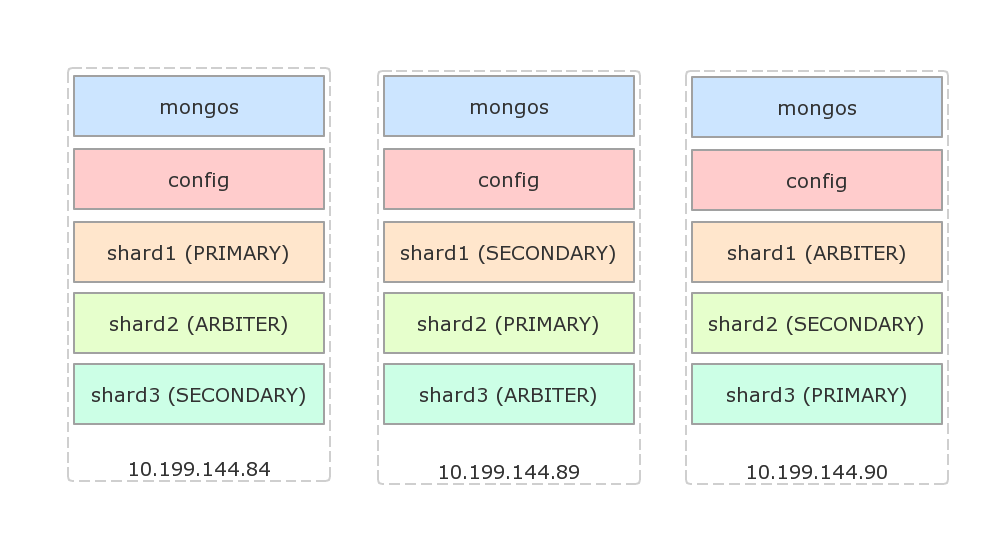
配置shard1(登陆84,没有显式指定主节点时,会选择登陆的机器为主节点):
mongo --port 27001
use admin
rs.initiate({
_id: 'shard1',
members: [
{_id: 84, host: '10.199.144.84:27001'},
{_id: 89, host: '10.199.144.89:27001'},
{_id: 90, host: '10.199.144.90:27001', arbiterOnly: true}
]
});配置shard2(登陆89):
mongo --port 27001
use admin
rs.initiate({
_id: 'shard2',
members: [
{_id: 84, host: '10.199.144.84:27002', arbiterOnly: true},
{_id: 89, host: '10.199.144.89:27002'},
{_id: 90, host: '10.199.144.90:27002'}
]
});配置shard3(登陆90):
mongo --port 27001
use admin
rs.initiate({
_id: 'shard3',
members: [
{_id: 84, host: '10.199.144.84:27002'},
{_id: 89, host: '10.199.144.89:27002', arbiterOnly: true},
{_id: 90, host: '10.199.144.90:27002'}
]
});下面设置路由到分片集群配置,随便登陆一台机器,假设是84:
mongo --port 27000
use admin
db.runCommand({addShard: 'shard1/10.199.144.84:27001,10.199.144.89:27001,10.199.144.90:27001'});
db.runCommand({addShard: 'shard2/10.199.144.84:27002,10.199.144.89:27002,10.199.144.90:27002'});
db.runCommand({addShard: 'shard3/10.199.144.84:27003,10.199.144.89:27003,10.199.144.90:27003'});查看配置好的shard:
mongo --port 27000
use admin
db.runCommand({listshards: 1});结果:
{
"shards" : [
{
"_id" : "shard1",
"host" : "shard1/10.199.144.84:27001,10.199.144.89:27001"
},
{
"_id" : "shard2",
"host" : "shard2/10.199.144.89:27002,10.199.144.90:27002"
},
{
"_id" : "shard3",
"host" : "shard3/10.199.144.90:27003,10.199.144.84:27003"
}
],
"ok" : 1
}其中仲裁(ARBITER)节点没有列出来。
下面测试分片:
mongo --port 27000
use admin
db.runCommand({enablesharding: 'dbtest'});
db.runCommand({shardcollection: 'dbtest.coll1', key: {id: 1}});
use dbtest;
for(var i=0; i<10000; i++) db.coll1.insert({id: i, s: 'str_' + i});如果dbtest已经存在,需要确保它已经以id建立了索引!
过上一段时间之后,运行db.coll1.stats()显式分片状态:
{
"sharded" : true,
"ns" : "dbtest.coll1",
"count" : 10000,
...
"shards" : {
"shard1" : {
"ns" : "dbtest.coll1",
"count" : 0,
"size" : 0,
...
},
"shard2" : {
"ns" : "dbtest.coll1",
"count" : 10000,
"size" : 559200,
...
}
}
...
}可以看到,这里分片已经生效,只是分配不均匀,所有的数据都存在了shard2中了。分片key的选择策略可以参考官方文档。在2.4版本中,使用hashed shard key算法保证文档均匀分布:
mongo --port 27000
use admin
sh.shardCollection('dbtest.coll1', {id: 'hashed'});使用hashed算法之后,做同样的测试,插入的数据基本均匀分布:
{
"sharded" : true,
"ns" : "dbtest.coll1",
"count" : 10000,
...
"shards" : {
"shard1" : {
"ns" : "dbtest.coll1",
"count" : 3285,
"size" : 183672,
...
},
"shard2" : {
"ns" : "dbtest.coll1",
"count" : 3349,
"size" : 187360,
...
},
"shard3" : {
"ns" : "dbtest.coll1",
"count" : 3366,
"size" : 188168,
...
}
}
}更多资料,请参考MongoDB Sharding。
在应用程序里,使用MongoClient创建db连接:
MongoClient.connect('mongodb://10.199.144.84:27000,10.199.144.89:27000,10.199.144.90:27000/dbtest?w=1', function(err, db) {
;
});原文 Webpack—The Confusing Parts
Webpack是目前基于React和Redux开发的应用的主要打包工具。我想使用Angular 2或其他框架开发的应用也有很多在使用Webpack。
当我第一次看到Webpack的配置文件时,它看起来非常的陌生,我非常的疑惑。经过一段时间的尝试之后我认为这是因为Webpack只是使用了比较特别的语法和引入了新的原理,因此会让使用者感到疑惑。这些也是导致Webpack不被人熟悉的原因。
因为刚开始使用Webpack很让人疑惑,我觉得有必要写几篇介绍Webpack的功能和特性的文章以帮助初学者快速理解。此文是最开始的一篇。
Webpack的两个最核心的原理分别是:
require('myJSfile.js')亦可以require('myCSSfile.css')。这意味着我们可以将事物(业务)分割成更小的易于管理的片段,从而达到重复利用等的目的。bundle.js文件。但是在真实的app里边,“bundle.js”文件可能有10M到15M之大可能会导致应用一直处于加载中状态。因此Webpack使用许多特性来分割代码然后生成多个“bundle”文件,而且异步加载部分代码以实现按需加载。好了,下面来看看那些令人困惑的部分吧。
首先要知道的是Webpack有许许多多的特性,一些是”开发模式“下才有的,一些是”生产模式“下才有的,还有一些是两种模式下都有的。
通常使用到Webpack如此多特性的项目都会有两个比较大的Webpack配置文件
为了生成bundles文件你可能在package.json文件加入如下的scripts项:
"scripts": {
// 运行npm run build 来编译生成生产模式下的bundles
"build": "webpack --config webpack.config.prod.js",
// 运行npm run dev来生成开发模式下的bundles以及启动本地server
"dev": "webpack-dev-server"
}值得注意的是,Webpack作为模块打包工具,提供两种用户交互接口:
这种方式可以从命令行获取参数也可以从配置文件(默认叫webpack.config.js)获取,将获取到的参数传入Webpack来打包。
当然你也可以从命令行(CLI)开始学习Webpack,以后你可能主要在生产模式下使用到它。
用法:
方式1:
// 全局模式安装webpack
npm install webpack --g
// 在终端输入
$ webpack // <--使用webpack.config.js生成bundle
方式 2 :
// 费全局模式安装webpack然后添加到package.json依赖里边
npm install webpack --save
// 添加build命令到package.json的scripts配置项
"scripts": {
"build": "webpack --config webpack.config.prod.js -p",
...
}
// 用法:
"npm run build"这是一个基于Express.js框架开发的web server,默认监听8080端口。server内部调用Webpack,这样做的好处是提供了额外的功能如热更新“Live Reload”以及热替换“Hot Module Replacement”(即HMR)。
用法:
方式 1:
// 全局安装
npm install webpack-dev-server --save
// 终端输入
$ webpack-dev-server --inline --hot
用法 2:
// 添加到package.json scripts
"scripts": {
"start": "webpack-dev-server --inline --hot",
...
}
// 运行:
$ npm start
// 浏览器预览:
http://localhost:8080注意像inline和hot这些选项是Webpack-dev-server特有的,而另外的如hide-modules则是CLI模式特有的选项。
另外值得注意的是你可以通过以下两种方式向webpack-dev-server传入参数:
// 通过CLI传参
webpack-dev-server --hot --inline
// 通过webpack.config.js传参
devServer: {
inline: true,
hot:true
}我发现有时devServer配置项(hot: true 和inline: true)不生效,我更偏向使用如下的方式向CLI传递参数:
// package.json
{
"scripts": "webpack-dev-server --hot --inline"
}注意:确定你没有同时传入
hot:true和-hot
“inline”选项会为入口页面添加“热加载”功能,“hot”选项则开启“热替换(Hot Module Reloading)”,即尝试重新加载组件改变的部分(而不是重新加载整个页面)。如果两个参数都传入,当资源改变时,webpack-dev-server将会先尝试HRM(即热替换),如果失败则重新加载整个入口页面。
// 当资源发生改变,以下三种方式都会生成新的bundle,但是又有区别:
// 1. 不会刷新浏览器
$ webpack-dev-server
//2. 刷新浏览器
$ webpack-dev-server --inline
//3. 重新加载改变的部分,HRM失败则刷新页面
$ webpack-dev-server --inline --hotEnter配置项告诉Webpack应用的根模块或起始点在哪里,它的值可以是字符串、数组或对象。这看起来可能令人困惑,因为不同类型的值有着不同的目的。
像绝大多数app一样,倘若你的应用只有一个单一的入口,enter项的值你可以使用任意类型,最终输出的结果都是一样的。
但是,如果你想添加多个彼此不互相依赖的文件,你可以使用数组格式的值。
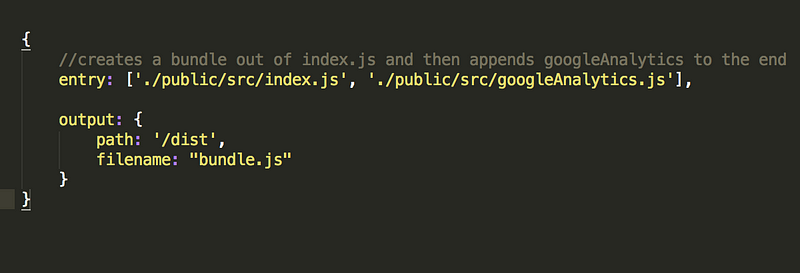
例如,你可能在html文件里引用了“googleAnalytics.js”文件,可以告诉Webpack将其加到bundle.js的最后。
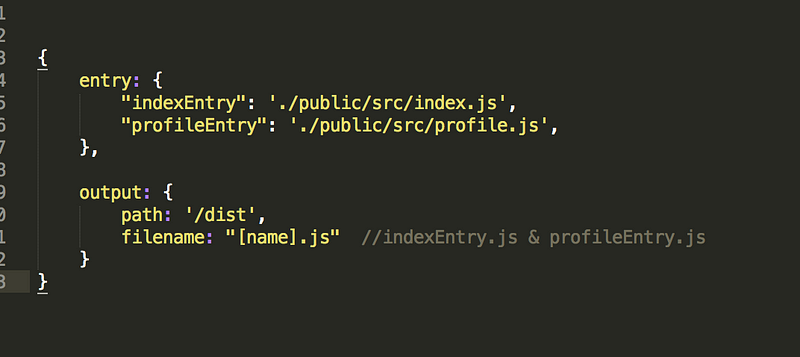
现在,假设你的应用是多页面的(multi-page application)而不是SPA,有多个html文件(index.html和profile.html)。然后你通过一个对象告诉Webpack为每一个html生成一个bundle文件。
以下的配置将会生成两个js文件:indexEntry.js和profileEntry.js分别会在index.html和profile.html中被引用。
用法:
//profile.html
<script src=”dist/profileEntry.js”></script>
//index.html
<script src=”dist/indexEntry.js”></script>注意:文件名取自“entry”对象的键名。
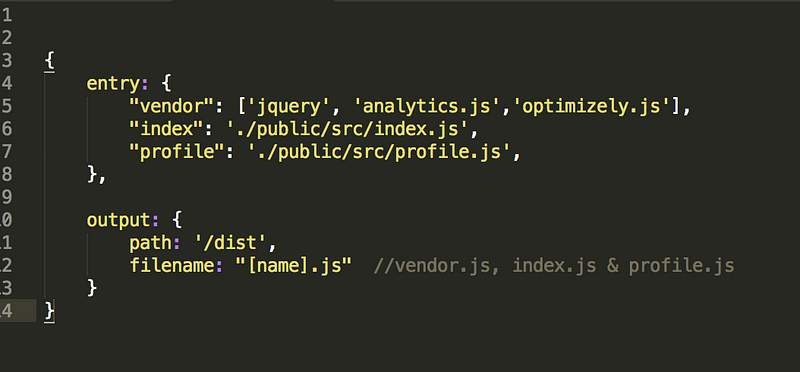
你也可以在enter对象里使用数组类型,例如下面的配置将会生成3个文件:vender.js(包含三个文件),index.js和profile.js文件。
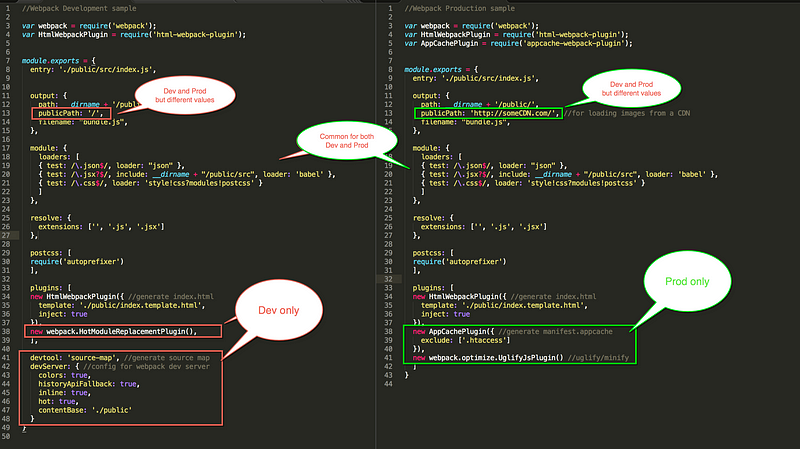
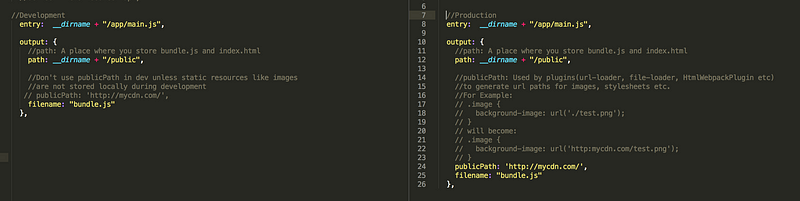
output项告诉webpack怎样存储输出结果以及存储到哪里。output的两个配置项“path”和“publicPath”可能会造成困惑。
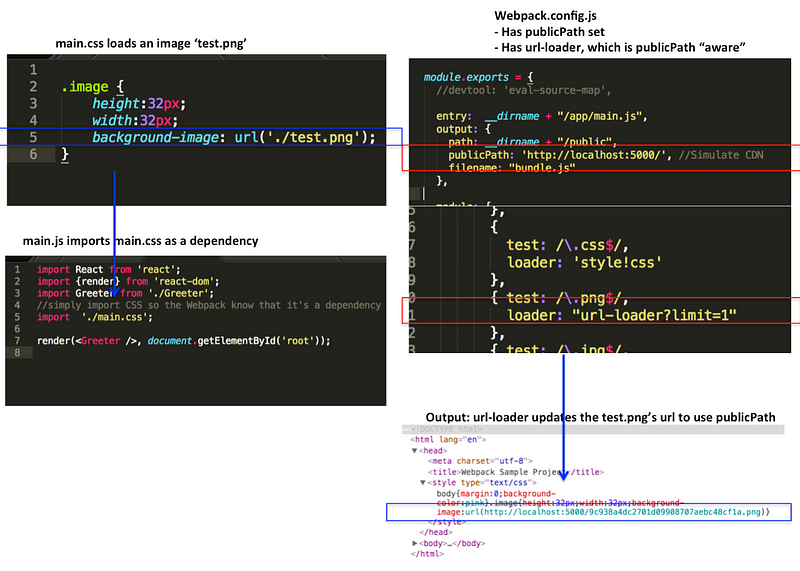
“path”仅仅告诉Webpack结果存储在哪里,然而“publicPath”项则被许多Webpack的插件用于在生产模式下更新内嵌到css、html文件里的url值。
例如,在localhost(译者注:即本地开发模式)里的css文件中边你可能用“./test.png”这样的url来加载图片,但是在生产模式下“test.png”文件可能会定位到CDN上并且你的Node.js服务器可能是运行在HeroKu上边的。这就意味着在生产环境你必须手动更新所有文件里的url为CDN的路径。
然而你也可以使用Webpack的“publicPath”选项和一些插件来在生产模式下编译输出文件时自动更新这些url。
// 开发环境:Server和图片都是在localhost(域名)下
.image {
background-image: url('./test.png');
}
// 生产环境:Server部署下HeroKu但是图片在CDN上
.image {
background-image: url('https://someCDN/test.png');
}模块加载器是可自由添加的Node模块,用于将不同类型的文件“load”或“import”并转换成浏览器可以识别的类型,如js、Stylesheet等。更高级的模块加载器甚至可以支持使用ES6里边的“require”或“import”引入模块。
例如,你可以使用babel-loader来将使用ES6语法写成的文件转换成ES5:
module: {
loaders: [{
test: /\.js$/, // 匹配.js文件,如果通过则使用下面的loader
exclude: /node_modules/, // 排除node_modules文件夹
loader: 'babel' // 使用babel(babel-loader的简写)作为loader
}]多个loader可以用在同一个文件上并且被链式调用。链式调用时从右到左执行且loader之间用“!”来分割。
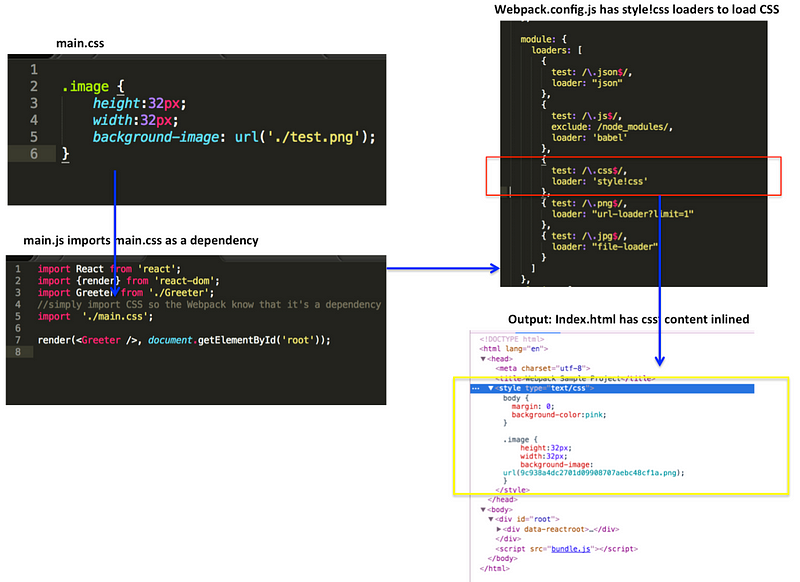
例如,假设我们有一个名为“myCssFile.css”的css文件,然后我们想将它的内容使用style标签内联到最终输出的html里边。我们可以使用css-loader和style-loader两个loader来达到目的。
module: {
loaders: [{
test: /\.css$/,
loader: 'style!css' //(short for style-loader!css-loader)
}]这里展示它是如何工作的:
模块加载器(loader)自身可以根据传入不同的参数进行配置。
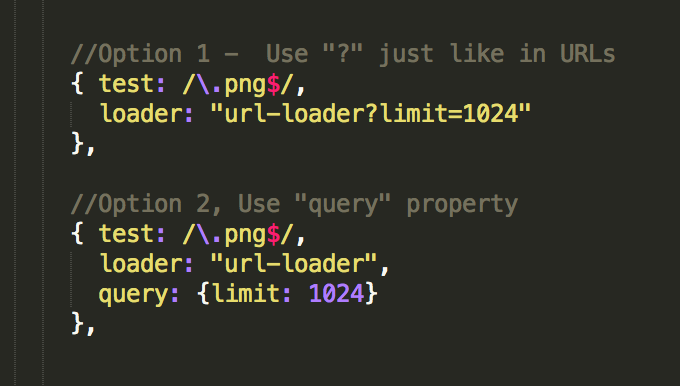
在下面的例子中,我们可以配置url-loader来将小于1024字节的图片使用DataUrl替换而大于1024字节的图片使用url,我们可以用如下两种方式通过传入“limit“参数来实现这一目的:
babal-loader使用”presets“配置项来标识如何将ES6语法转成ES5以及如何转换React的JSX成js文件。我们可以用如下的方式使用”query“参数传入配置:
module: {
loaders: [
{
test: /\.jsx?$/,
exclude: /(node_modules|bower_components)/,
loader: 'babel',
query: {
presets: ['react', 'es2015']
}
}
]
}然而在很多项目里babel的配置可能比较大,因此你可以把babel-loader的配置项单独保存在一个名为”.babelrc“的文件中,在执行时babel-loader将会自动加载.babelrc文件。
所以在很多例子里,你可能会看到:
//webpack.config.js
module: {
loaders: [
{
test: /\.jsx?$/,
exclude: /(node_modules|bower_components)/,
loader: 'babel'
}
]
}
//.bablerc
{
presets: ['react', 'es2015']
}插件一般都是用于输出bundle的node模块。
例如,uglifyJSPlugin获取bundle.js然后压缩和混淆内容以减小文件体积。
类似的extract-text-webpack-plugin内部使用css-loader和style-loader来收集所有的css到一个地方最终将结果提取结果到一个独立的”styles.css“文件,并且在html里边引用style.css文件。
//webpack.config.js
// 获取所有的.css文件,合并它们的内容然后提取css内容到一个独立的”styles.css“里
var ETP = require("extract-text-webpack-plugin");
module: {
loaders: [
{test: /\.css$/, loader:ETP.extract("style-loader","css-loader") }
]
},
plugins: [
new ExtractTextPlugin("styles.css") //Extract to styles.css file
]
}注意:如果你只是想把css使用style标签内联到html里,你不必使用extract-text-webpack-plugin,仅仅使用css loader和style loader即可:
module: {
loaders: [{
test: /\.css$/,
loader: 'style!css' // (short for style-loader!css-loader)
}]你可能已经意识到了,Loader处理单独的文件级别并且通常作用于包生成之前或生成的过程中。
而插件则是处理包(bundle)或者chunk级别,且通常是bundle生成的最后阶段。一些插件如commonschunkplugin甚至更直接修改bundle的生成方式。
很多Webpack的配置文件都有一个resolve属性,然后就像下面代码所示有一个空字符串的值。空字符串在此是为了resolve一些在import文件时不带文件扩展名的表达式,如require('./myJSFile')或者import myJSFile from './myJSFile'(译者注:实际就是自动添加后缀,默认是当成js文件来查找路径)
{
resolve: {
extensions: ['', '.js', '.jsx']
}
}就这么多。
数据类型:
Undefined, Null, Bollean, Number, StringObject、ArrayDate、RegExptypeof输出(以下六个值之一):
undefinedvar x;
typeof(x); // "undefined"booleanvar x = false;
typeof x; // "boolean"stringvar x = '';
typeof x; // "string"numbervar x = NaN;
typeof x; // "number"objectvar x = {};
var y = [];
var z = null;
typeof x; // "object"
typeof y; // "object"
typeof z; // "object"functionvar x = function() {};
typeof x; // "function"'1'-0; // 0, equal to Number(1)var n = 5;
console.log(n.toString(2)); // 快速进制转换对象 -> 简单类型(参考JavaScript 类型转换)
valueOf、再 toString(Date 在 + 和 == 时优先转化为字串):[] + 1; // 1valueOf,再toString(),都不存在则返回NaN:Number({}); // NaNvalueOf(),再取valueOf(),都不存在则抛异常:String({}); // [object Object]createElement, createTextNode, createDocumentFragment, appendChildremoveChild, removeNodegetElementById, getElementsByTagName, getElementsByClassName, querySelector, querySelectorAll, parentNode, firstChild, lastChild, nextSibling, previousSibling, childNodesreplaceChild, insertBeforegetAttribute, setAttribute, data-x, jQuery.attr(), jQuery().prop(), jQuery().data(), classList, innerHTML, innerText, textContent事件绑定与解绑:addEventListener(type, handler, flag), attechEvent('on' + type, handler), removeEventListener(type, handler), detechEvent('on' + type, handler)
事件流:
function handler(e) {
var e = e || window.event;
var target = e.target || e.srcElement;
// e.currentTarget 指的是绑定事件的元素,不一定和target是同一个
}比较(参考 全面理解面向对象的 JavaScript)
Class的面向对象,对象由类Class产生:如Java、C#prototype的OOP,对象由构造器(构造函数)constructor利用原型prototype产生生成js对象:
var Preson = {
name: 'xiaoming',
age: 15
};this.city,在内存里生成了多次var Person = function(name, age) {
// 全部标记为私有成员
this.name = name;
this.age = age;
this.city = 'shen zhen';
};
var xm = new Person('xiaoming', 15);
var xl = new Person('xiaoli', 20);prototype模式:每次实例化只增加私有的对象属性(或方法)到实例中,所有实例的公有属性(或方法)指向同一个内存地址var Person = function(name, age) {
// 对象的私有成员
this.name = name;
this.age = age;
};
Person.prototype.city = 'shen zhen';// 共有成员对象的继承
非构造函数的继承:继承可以简单使用对象之间的深、浅拷贝
构造函数的继承:大多是基于原型的继承,但是阅读性差,也不利于扩展
function A(name) {
this.name = name;
}
function B(name, age) {
A.apply(this, arguments);
this.age = age;
}function A() {}
A.prototype.propA = 'a';
A.prototype.propB = 'b';
function B() {}
B.prototype = A.prototype; // 原型链引用,改成B.prototype = new A();可以解决引用的问题
B.prototype.propB = 'B'; // 函数重载
B.prototype.constructor = B;
var b = new B();A、B的prototype引用同一个地址,实时上A的prototype.constructor已经被改成了B
function extend(sub, sup) {
var _f = function() {};
_f.prototype = sup.prototype;
sub.prototype = new _f();
sub.prototype.constructor = sub;
sub.super = sup.prototype;// 保存原构造函数
_f = null;
}
A.prototype.propA = 'a';
A.prototype.propB = 'b';
function B() {}
extend(B, A);构造函数的继承,重要的是理解原型链prototype chain,继承基本就是原型链的拷贝或者引用。
理解原型链prototype chain:
function A() {}
function B() {}
B.prototype = new A();
function C(x, y) {}
C.prototype = new B();
var c = new C();
c.__proto__ === C.prototype;// true
B.prototype.__proto__ === A.prototype;// true
B.__proto__ === B.prototype;// true
A.__proto__ === Function.prototype;// true
A.prototype.__proto__ === Object.prototype;// true_proto属性_:对象的__proto__指向Object.prototype,Function对象的__proto__指向构造函数的prototype。
类式继承:本质上还是使用构造函数的prototype,封装成类,典型的例子是jQuery之父_John Resig_的Simple JavaScript Inheritance,其他类库也有各自的实现
var Person = Class.extend({
init: function(gender) {
this.gender = gender;
}
});
var Teacher = Person.extend({
init: funciton(gender, name) {
this._super(gender);
this.name = name;
},
role: 'teacher',
speek: function() {
console.log('Hello, i am a %s.', this.role);
}
});
var Student = Person.extend({
init: funciton(gender, name) {
this._super(gender);
this.name = name;
},
role: 'student',
speek: function() {
console.log('Hello, i am a %s.', this.role);
}
});foo(1, 2);
function foo(a, b, c) {
console.log(arguments.length);//2 实际传入的参数
console.log(foo.length);//3 期望传入的参数
}function foo() {} // 函数申明
var foor = function foo() {};// 函数表达式执行顺序:解析器会率先读取函数声明,所以在任何代码执行前函数申明可用
fn(2); // 4
function fn(n) {console.log(n);}
fn(2); // 4
function fn(n) {console.log(n*n);} //重载
fn(2); // 4
var fn = function(n) {console.log(++n);};// 函数表达式,按照申明的顺序执行
fn(2); // 3arguments, callee, caller, apply, call
arguments,类数组,类似的还有NodeList、classList等对象arguments.callee,返回正在执行的Function对象的一个引用function foo(n) {
console.log(arguments.callee.arguments.length);
console.log(arguments.callee.length);
}
foo(1, 2, 3);// 分别打出3,1arguments.caller,返回调用这个Function对象的Function对象的引用apply和call,传参不同,功能相同,都是把Function对象绑定到另外一个对象上去执行,其内的this指向这个对象作用域
var声明的变量var申明的变量,会自动升级为全局变量挂到window上var申明的变量是window对象的一个属性闭包
function foo() {
var x = 1;
return function fn() { // closure
return x;
}
}
var bar = foo();
console.log(bar()); // get the local variables in foothis:函数中的this始终指向函数的调用者
function foo(x) {
this.x = x;
}
foo(1); // 调用者是window,也可以window.foo()
console.log(window.x); // 1
var o = {};
o.foo = foo;
o.foo(2); // 调用者是o
console.log(o.x); // 2
console.log(window.x); // 1这里有一篇详细的例子
xhr.open()xhr.send()xhr.abort()HTML的就绪状态:xhr.readyStatexhr.responseTextPOST, GET, PUT, DELETE
postMessage跨域通讯可阅读yuanyan同学的jQuery编程实践
html结构:SEO友好,利于维护html结构:嵌套过复杂的结构会导致浏览器构建DOM树缓慢html最小化:html大小直接关系到下载速度,移除内联的css,javascript,甚至模板片,有条件的话尽可能压缩html,去除注释、空行等无用文本img、link、script、iframe元素的src或href属性被设置了,但是属性却为空):部分浏览器依然会去请求空地址@import引入样式表:IE低版本浏览器会再页面构建好之后再去加载import的样式表,会导致白屏head里,脚本延后引入\*=, |=, ^=, $=, ~=):正则表达式匹配比基于类别的匹配慢.box {margin-top: 10px; margin-left: 5px; margin-bottom: 15px;} /* bad */
.box {margin: 10px 0 15px 5px;} /* better */DocumentFragement批量修改,最后再插入文档images, links, forms, document.getElementsByTagName):childNodes, firstChild不区分元素节点和其他类型节点,但大部分情况下只需要访问元素节点_引自《高性能JavaScript》_):
children代替childNodeschildElementCount代替childNodes.lengthfirstElementChild代替firstChildx = box.offsetLeft; // read
box.offsetLeft = '100px'; // write
y = box.offsetTop; // read
box.offsetTop = '100px'; // write这个过程造成了两次的layout,可做如下改造:
x = box.offsetLeft; // read
y = box.offsetTop; // read
box.offsetLeft = '100px'; // write
box.offsetTop = '100px'; // writerepeat):box.style.width = '100px';
box.style.heihgt = '50px;';
box.style.left = '200px';三个操作都会重新计算元素的几何结构,在部分浏览器可能会导致3次重排,可做如下改写:
var css = 'width: 100px; height: 50px; left: 200px;';
box.style.cssText += css;var a = $('#box .a');
var b = $('#box .b');可以缓存$('#box')到临时变量:
var box = $('#box');
var a = box.find('.a');
var b = box.find('.b');var $P = Jx().UI.Pager.create();// 同样可以先缓存结果Expires信息Web Worker$('#box'); // document.getElementById | document.querySelector
$('div'); // document.getElementsByTagNamequerySelector的浏览器很慢$('input[checked="checked"]'); // 比较快
$('input:checked'); // 较慢$.fn.find查找子元素,因为find之前的选择器并没有使用 jQuery 自带的 Sizzle 选择器引擎,而是使用原生API查找元素$('#parent').find('.child'); // 最快
$('.child', $('#parent')); // 较快,内部会转换成第一条语句的形式,性能有一定损耗
$('#parent .child'); // 不如上一个语句块$('div.foo .bar'); // slow
$('.foo div.bar'); // faster$('.foo .bar .baz');
$('.foo div.baz'); // betterdocument.getElementById('el')比$('#el')块$('div').click(function(e) {
// 生成了个jQuery对象
var id = $(this).attr('id');
// 这样更直接
var id = this.id;
});<div id="user" class="none">
<p class="name"></p>
<p class="city"></p>
</div>$('#user')
.find('.name').html('zhangsan').end()
.find('.city').html('shenzhen').end()
.removeClass('none');var box = $('.box');
box.find('> .cls1');
box.find('> .cls2');var $el = $('.box').detach();
var $p = $el.parent();
// do some stuff with $el...
$p.append($el);// 性能差
$.each(arr, function(i, el) {
$('.box').prepend($(el));
});
// 较好的做法
var frag = document.createDocumentFragment();
$.each(arr, function(i, el) {
flag.appendChild(el);
});
$('.box')[0].appendChild(flag);$('ul li').on('click', fn);
// better
$('ul').on('click', 'li', fn);使用事件代理(委托),当有新元素添加进来的时候,不需要再为它绑定事件,这里有demo可以查看效果。
keep-alive本篇主要介绍webpack的基本原理以及基于webpack搭建前端项目工程化解决方案的思路。
下篇(还没写)探讨下对于Node.js作为后端的项目工程化、模块化、前后端共享代码、自动化部署的做法。
下面是百科关于“软件工程”的名词解释:
软件工程是一门研究用工程化方法构建和维护有效的、实用的和高质量的软件的学科。
其中,工程化是方法,是将软件研发的各个链路串接起来的工具。
对于软件“工程化”,个人以为至少应当有如下特点:
广泛意义上讲,前端也属于软件工程的范畴。
但前端没有Eclipse、Visual Studio等为特定语言量身打造的IDE。因为前端不需要编译,即改即生效,在开发和调试时足够方便,只需要打开个浏览器即可完成,所以前端一般不会扯到“工程”这个概念。
在很长一段时间里,前端很简单,比如下面简单的几行代码就能够成一个可运行前端应用:
<!DOCTYPE html>
<html>
<head>
<title>webapp</title>
<link rel="stylesheet" href="app.css">
</head>
<body>
<h1>app title</h1>
<script src="app.js"></script>
</body>
</html>但随着webapp的复杂程度不断在增加,前端也在变得很庞大和复杂,按照传统的开发方式会让前端失控:代码庞大难以维护、性能优化难做、开发成本变高。
感谢Node.js,使得JavaScript这门前端的主力语言突破了浏览器环境的限制可以独立运行在OS之上,这让JavaScript拥有了文件IO、网络IO的能力,前端可以根据需要任意定制研发辅助工具。
一时间出现了以Grunt、Gulp为代表的一批前端构建工具,“前端工程”这个概念逐渐被强调和重视。但是由于前端的复杂性和特殊性,前端工程化一直很难做,构建工具有太多局限性。
诚如 张云龙@fouber 所言:
前端是一种特殊的GUI软件,它有两个特殊性:一是前端由三种编程语言组成,二是前端代码在用户端运行时增量安装。
html、css和js的配合才能保证webapp的运行,增量安装是按需加载的需要。开发完成后输出三种以上不同格式的静态资源,静态资源之间有可能存在互相依赖关系,最终构成一个复杂的资源依赖树(甚至网)。
所以,前端工程,最起码需要解决以下问题:
其中,资源管理是前端最需要也是最难做的一个环节。
注:个人以为,与前端工程化对应的另一个重要的领域是前端组件化,前者属于工具,解决研发效率问题,后者属于前端生态,解决代码复用的问题,本篇对于后者不做深入。
在此以开发一个多页面型webapp为例,给出上面所提出的问题的解决方案。
- webapp/ # webapp根目录
- src/ # 开发目录
+ css/ # css资源目录
+ img/ # webapp图片资源目录
- js/ # webapp js&jsx资源目录
- components/ # 标准组件存放目录
- foo/ # 组件foo
+ css/ # 组件foo的样式
+ js/ # 组件foo的逻辑
+ tmpl/ # 组件foo的模板
index.js # 组件foo的入口
+ bar/ # 组件bar
+ lib/ # 第三方纯js库
... # 根据项目需要任意添加的代码目录
+ tmpl/ # webapp前端模板资源目录
a.html # webapp入口文件a
b.html # webapp入口文件b
- assets/ # 编译输出目录,即发布目录
+ js/ # 编译输出的js目录
+ img/ # 编译输出的图片目录
+ css/ # 编译输出的css目录
a.html # 编译输出的入口a
b.html # 编译处理后的入口b
+ mock/ # 假数据目录
app.js # 本地server入口
routes.js # 本地路由配置
webpack.config.js # webpack配置文件
gulpfile.js # gulp任务配置
package.json # 项目配置
README.md # 项目说明这是个经典的前端项目目录结构,项目目结构在一定程度上约定了开发规范。业务开发的同学只需关注src目录即可,开发时尽可能最小化模块粒度,这是异步加载的需要。assets是整个工程的产出,无需关注里边的内容是什么,至于怎么打包和解决资源依赖的,往下看。
我们使用开源web框架搭建一个webserver,便于本地开发和调试,以及灵活地处理前端路由,以koa为例,主要代码如下:
// app.js
var http = require('http');
var koa = require('koa');
var serve = require('koa-static');
var app = koa();
var debug = process.env.NODE_ENV !== 'production';
// 开发环境和生产环境对应不同的目录
var viewDir = debug ? 'src' : 'assets';
// 处理静态资源和入口文件
app.use(serve(path.resolve(__dirname, viewDir), {
maxage: 0
}));
app = http.createServer(app.callback());
app.listen(3005, '0.0.0.0', function() {
console.log('app listen success.');
});运行node app启动本地server,浏览器输入http://localhost:8080/a.html即可看到页面内容,最基本的环境就算搭建完成。
如果只是处理静态资源请求,可以有很多的替代方案,如Fiddler替换文件、本地起Nginx服务器等等。搭建一个Web服务器,个性化地定制开发环境用于提升开发效率,如处理动态请求、dnsproxy(多用于解决移动端配置host的问题)等,总之local webserver拥有无限的可能。
我们的local server是localhost域,在ajax请求时为了突破前端同源策略的限制,本地server需支持代理其他域下的api的功能,即proxy。同时还要支持对未完成的api进行mock的功能。
// app.js
var router = require('koa-router')();
var routes = require('./routes');
routes(router, app);
app.use(router.routes());// routes.js
var proxy = require('koa-proxy');
var list = require('./mock/list');
module.exports = function(router, app) {
// mock api
// 可以根据需要任意定制接口的返回
router.get('/api/list', function*() {
var query = this.query || {};
var offset = query.offset || 0;
var limit = query.limit || 10;
var diff = limit - list.length;
if(diff <= 0) {
this.body = {code: 0, data: list.slice(0, limit)};
} else {
var arr = list.slice(0, list.length);
var i = 0;
while(diff--) arr.push(arr[i++]);
this.body = {code: 0, data: arr};
}
});
// proxy api
router.get('/api/foo/bar', proxy({url: 'http://foo.bar.com'}));
}ECMAScript 6之前,前端的模块化一直没有统一的标准,仅前端包管理系统就有好几个。所以任何一个库实现的loader都不得不去兼容基于多种模块化标准开发的模块。
webpack同时提供了对CommonJS、AMD和ES6模块化标准的支持,对于非前三种标准开发的模块,webpack提供了shimming modules的功能。
受Node.js的影响,越来越多的前端开发者开始采用CommonJS作为模块开发标准,npm已经逐渐成为前端模块的托管平台,这大大降低了前后端模块复用的难度。
在webpack配置项里,可以把node_modules路径添加到resolve search root列表里边,这样就可以直接load npm模块了:
// webpack.config.js
resolve: {
root: [process.cwd() + '/src', process.cwd() + '/node_modules'],
alias: {},
extensions: ['', '.js', '.css', '.scss', '.ejs', '.png', '.jpg']
},$ npm install jquery react --save// page-x.js
import $ from 'jquery';
import React from 'react';根据webpack的设计理念,所有资源都是“模块”,webpack内部实现了一套资源加载机制,这与Requirejs、Sea.js、Browserify等实现有所不同,除了借助插件体系加载不同类型的资源文件之外,webpack还对输出结果提供了非常精细的控制能力,开发者只需要根据需要调整参数即可:
// webpack.config.js
// webpack loaders的配置示例
...
loaders: [
{
test: /\.(jpe?g|png|gif|svg)$/i,
loaders: [
'image?{bypassOnDebug: true, progressive:true, \
optimizationLevel: 3, pngquant:{quality: "65-80"}}',
'url?limit=10000&name=img/[hash:8].[name].[ext]',
]
},
{
test: /\.(woff|eot|ttf)$/i,
loader: 'url?limit=10000&name=fonts/[hash:8].[name].[ext]'
},
{test: /\.(tpl|ejs)$/, loader: 'ejs'},
{test: /\.js$/, loader: 'jsx'},
{test: /\.css$/, loader: 'style!css'},
{test: /\.scss$/, loader: 'style!css!scss'},
]
...简单解释下上面的代码,test项表示匹配的资源类型,loader或loaders项表示用来加载这种类型的资源的loader,loader的使用可以参考using loaders,更多的loader可以参考list of loaders。
对于开发者来说,使用loader很简单,最好先配置好特定类型的资源对应的loaders,在业务代码直接使用webpack提供的require(source path)接口即可:
// a.js
// 加载css资源
require('../css/a.css');
// 加载其他js资源
var foo = require('./widgets/foo');
var bar = require('./widgets/bar');
// 加载图片资源
var loadingImg = require('../img/loading.png');
var img = document.createElement('img');
img.src = loadingImg;注意,require()还支持在资源path前面指定loader,即require(![loaders list]![source path])形式:
require("!style!css!less!bootstrap/less/bootstrap.less");
// “bootstrap.less”这个资源会先被"less-loader"处理,
// 其结果又会被"css-loader"处理,接着是"style-loader"
// 可类比pipe操作require()时指定的loader会覆盖配置文件里对应的loader配置项。
通过loader机制,可以不需要做额外的转换即可加载浏览器不直接支持的资源类型,如.scss、.less、.json、.ejs等。
但是对于css、js和图片,采用webpack加载和直接采用标签引用加载,有何不同呢?
运行webpack的打包命令,可以得到a.js的输出的结果:
webpackJsonp([0], {
/***/0:
/***/function(module, exports, __webpack_require__) {
__webpack_require__(6);
var foo = __webpack_require__(25);
var bar = __webpack_require__(26);
var loadingImg = __webpack_require__(24);
var img = document.createElement('img');
img.src = loadingImg;
},
/***/6:
/***/function(module, exports, __webpack_require__) {
...
},
/***/7:
/***/function(module, exports, __webpack_require__) {
...
},
/***/24:
/***/function(module, exports) {
...
},
/***/25:
/***/function(module, exports) {
...
},
/***/26:
/***/function(module, exports) {
...
}
});从输出结果可以看到,webpack内部实现了一个全局的webpackJsonp()用于加载处理后的资源,并且webpack把资源进行重新编号,每一个资源成为一个模块,对应一个id,后边是模块的内部实现,而这些操作都是webpack内部处理的,使用者无需关心内部细节甚至输出结果。
上面的输出代码,因篇幅限制删除了其他模块的内部实现细节,完整的输出请看a.out.js,来看看图片的输出:
/***/24:
/***/function(module, exports) {
module.exports = "data:image/png;base64,...";
/***/
}注意到图片资源的loader配置:
{
test: /\.(jpe?g|png|gif|svg)$/i,
loaders: [
'image?...',
'url?limit=10000&name=img/[hash:8].[name].[ext]',
]
}意思是,图片资源在加载时先压缩,然后当内容size小于~10KB时,会自动转成base64的方式内嵌进去,这样可以减少一个HTTP的请求。当图片大于10KB时,则会在img/下生成压缩后的图片,命名是[hash:8].[name].[ext]的形式。hash:8的意思是取图片内容hashsum值的前8位,这样做能够保证引用的是图片资源的最新修改版本,保证浏览器端能够即时更新。
对于css文件,默认情况下webpack会把css content内嵌到js里边,运行时会使用style标签内联。如果希望将css使用link标签引入,可以使用ExtractTextPlugin插件进行提取。
webpack的三个概念:模块(module)、入口文件(entry)、分块(chunk)。
其中,module指各种资源文件,如js、css、图片、svg、scss、less等等,一切资源皆被当做模块。
webpack编译输出的文件包括以下2种:
下面是一段entry和output项的配置示例:
entry: {
a: './src/js/a.js'
},
output: {
path: path.resolve(debug ? '__build' : './assets/'),
filename: debug ? '[name].js' : 'js/[chunkhash:8].[name].min.js',
chunkFilename: debug ? '[chunkhash:8].chunk.js' : 'js/[chunkhash:8].chunk.min.js',
publicPath: debug ? '/__build/' : ''
}其中entry项是入口文件路径映射表,output项是对输出文件路径和名称的配置,占位符如[id]、[chunkhash]、[name]等分别代表编译后的模块id、chunk的hashnum值、chunk名等,可以任意组合决定最终输出的资源格式。hashnum的做法,基本上弱化了版本号的概念,版本迭代的时候chunk是否更新只取决于chnuk的内容是否发生变化。
细心的同学可能会有疑问,entry表示入口文件,需要手动指定,那么chunk到底是什么,chunk是怎么生成的?
在开发webapp时,总会有一些功能是使用过程中才会用到的,出于性能优化的需要,对于这部分资源我们希望做成异步加载,所以这部分的代码一般不用打包到入口文件里边。
对于这一点,webpack提供了非常好的支持,即code splitting,即使用require.ensure()作为代码分割的标识。
例如某个需求场景,根据url参数,加载不同的两个UI组件,示例代码如下:
var component = getUrlQuery('component');
if('dialog' === component) {
require.ensure([], function(require) {
var dialog = require('./components/dialog');
// todo ...
});
}
if('toast' === component) {
require.ensure([], function(require) {
var toast = require('./components/toast');
// todo ...
});
}url分别输入不同的参数后得到瀑布图:
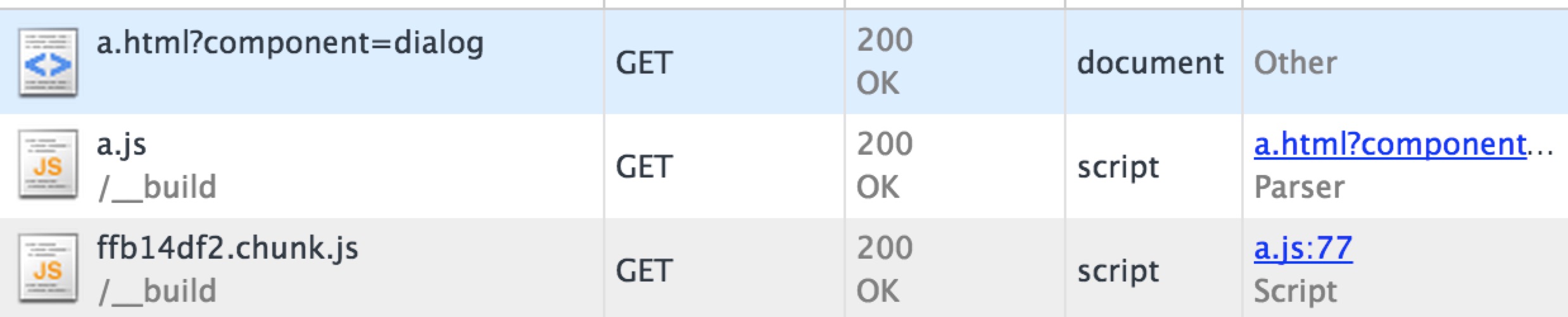
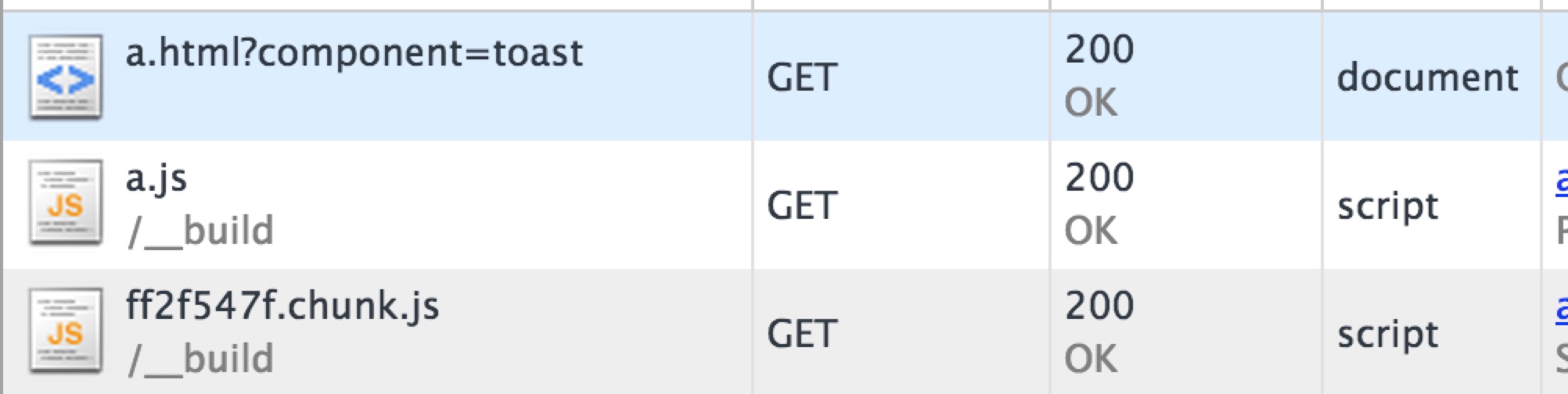
webpack将require.ensure()包裹的部分单独打包了,即图中看到的[hash].chunk.js,既解决了异步加载的问题,又保证了加载到的是最新的chunk的内容。
假设app还有一个入口页面b.html,那麽就需要相应的再增加一个入口文件b.js,直接在entry项配置即可。多个入口文件之间可能公用一个模块,可以使用CommonsChunkPlugin插件对指定的chunks进行公共模块的提取,下面代码示例演示提取所有入口文件公用的模块,将其独立打包:
var chunks = Object.keys(entries);
plugins: [
new CommonsChunkPlugin({
name: 'vendors', // 将公共模块提取,生成名为`vendors`的chunk
chunks: chunks,
minChunks: chunks.length // 提取所有entry共同依赖的模块
})
],引用模块,webpack提供了require()API(也可以通过添加bable插件来支持ES6的import语法)。但是在开发阶段不可能改一次编译一次,webpack提供了强大的热更新支持,即HMR(hot module replace)。
HMR简单说就是webpack启动一个本地webserver(webpack-dev-server),负责处理由webpack生成的静态资源请求。注意webpack-dev-server是把所有资源存储在内存的,所以你会发现在本地没有生成对应的chunk访问却正常。
下面这张来自webpack官网的图片,可以很清晰地说明module、entry、chunk三者的关系以及webpack如何实现热更新的:
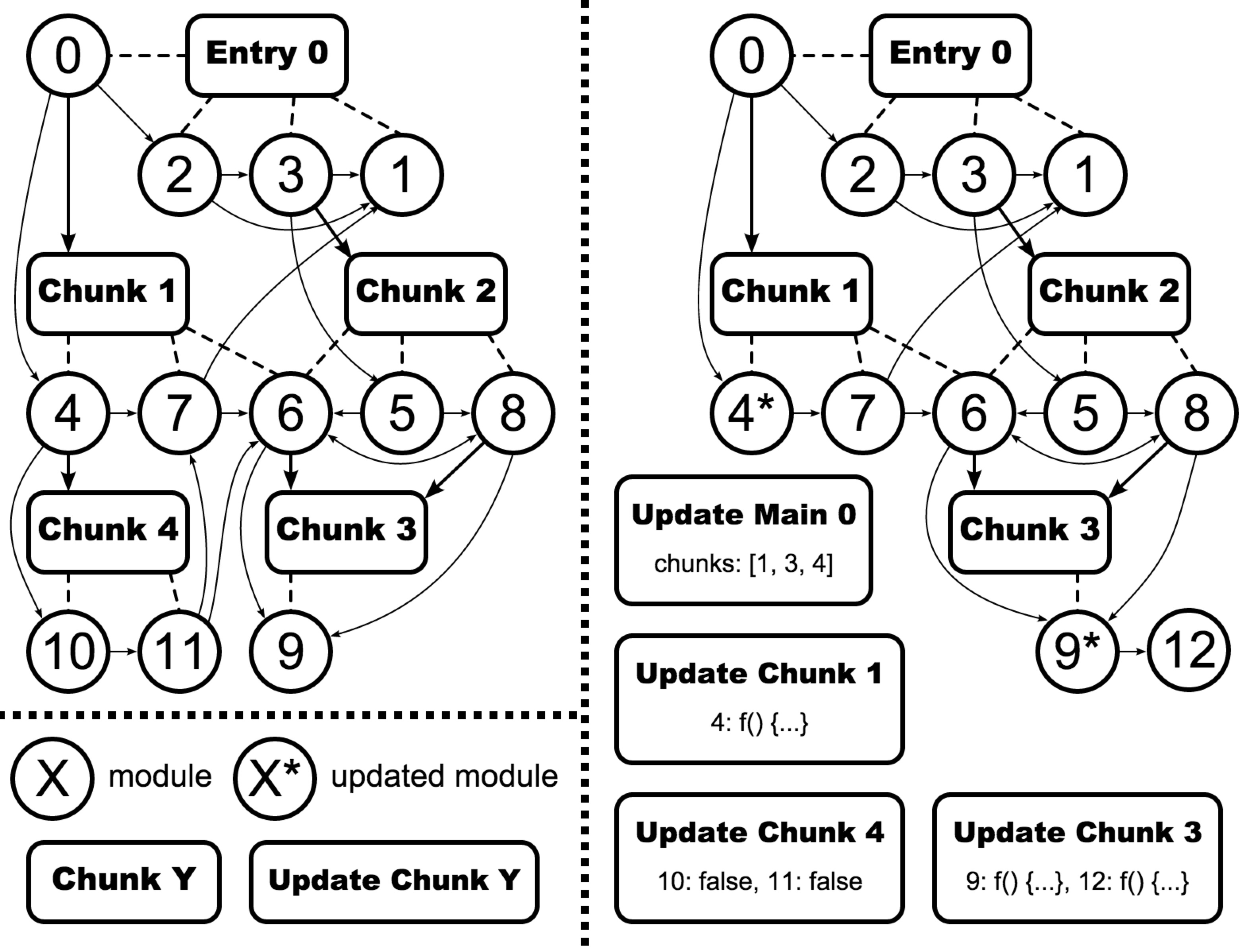
enter0表示入口文件,chunk1~4分别是提取公共模块所生成的资源块,当模块4和9发生改变时,因为模块4被打包在chunk1中,模块9打包在chunk3中,所以HMR runtime会将变更部分同步到chunk1和chunk3中对应的模块,从而达到hot replace。
webpack-dev-server的启动很简单,配置完成之后可以通过cli启动,然后在页面引入入口文件时添加webpack-dev-server的host即可将HMR集成到已有服务器:
...
<body>
...
<script src="http://localhost:8080/__build/vendors.js"></script>
<script src="http://localhost:8080/__build/a.js"></script>
</body>
...因为我们的local server就是基于Node.js的webserver,这里可以更进一步,将webpack开发服务器以中间件的形式集成到local webserver,不需要cli方式启动(少开一个cmd tab):
// app.js
var webpackDevMiddleware = require('koa-webpack-dev-middleware');
var webpack = require('webpack');
var webpackConf = require('./webpack.config');
app.use(webpackDevMiddleware(webpack(webpackConf), {
contentBase: webpackConf.output.path,
publicPath: webpackConf.output.publicPath,
hot: true,
stats: webpackConf.devServer.stats
}));启动HMR之后,每次保存都会重新编译生成新的chnuk,通过控制台的log,可以很直观地看到这一过程:
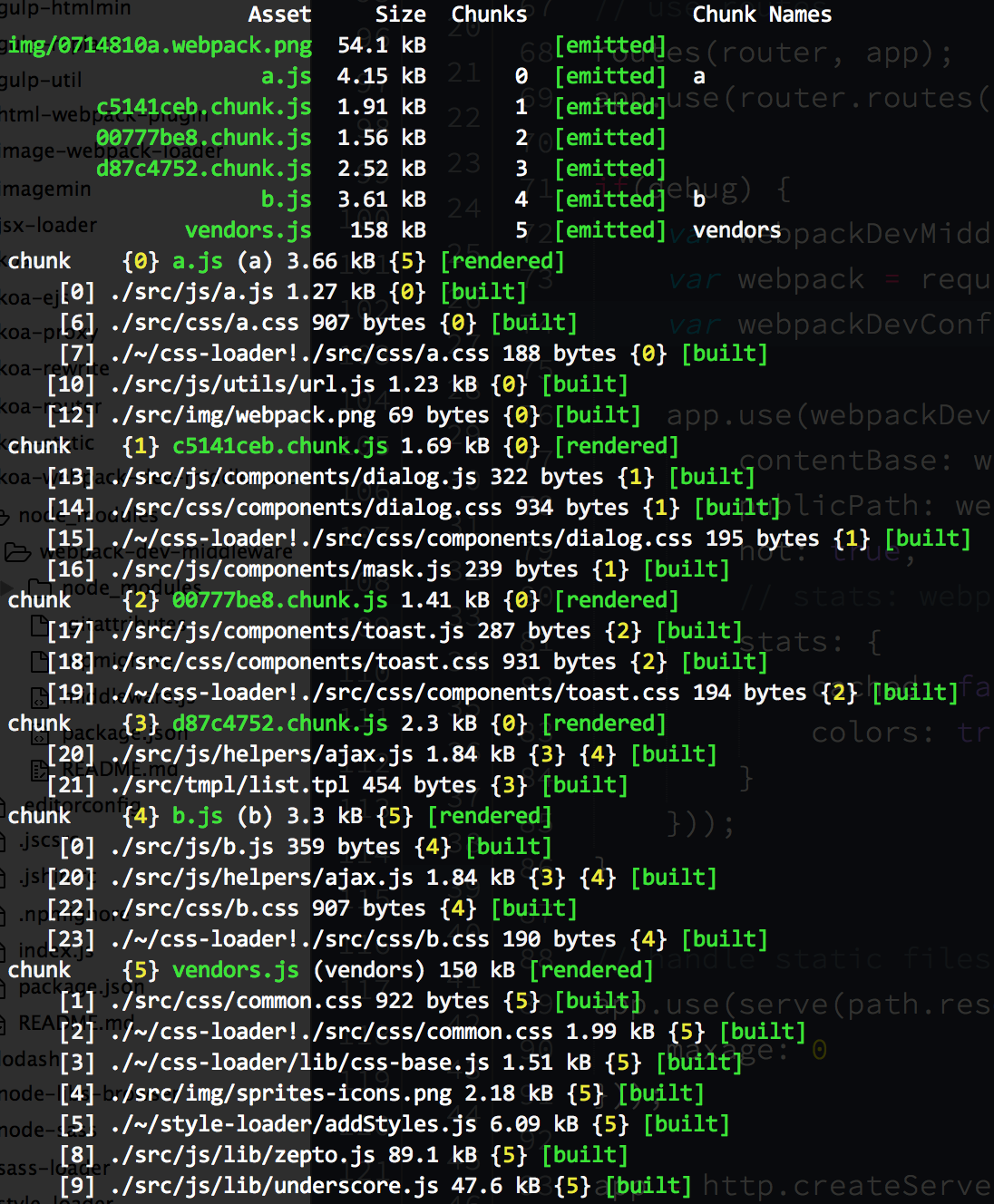
webpack解决了资源依赖的问题,这使得封装组件变得很容易,例如:
// js/components/component-x.js
require('./component-x.css');
// @see https://github.com/okonet/ejs-loader
var template = require('./component-x.ejs');
var str = template({foo: 'bar'});
function someMethod() {}
exports.someMethod = someMethod;使用:
// js/a.js
import {someMethod} from "./components/component-x";
someMethod();正如开头所说,将三种语言、多种资源合并成js来管理,大大降低了维护成本。
对于新开发的组件或library,建议推送到npm仓库进行共享。如果需要支持其他加载方式(如RequireJS或标签直接引入),可以参考webpack提供的externals项。
由于入口文件是手动使用script引入的,在webpack编译之后入口文件的名称和路径一般会改变,即开发环境和生产环境引用的路径不同:
// 开发环境
// a.html
<script src="/__build/vendors.js"></script>
<script src="/__build/a.js"></script>// 生产环境
// a.html
<script src="http://cdn.site.com/js/460de4b8.vendors.min.js"></script>
<script src="http://cdn.site.com/js/e7d20340.a.min.js"></script>webpack提供了HtmlWebpackPlugin插件来解决这个问题,HtmlWebpackPlugin支持从模板生成html文件,生成的html里边可以正确解决js打包之后的路径、文件名问题,配置示例:
// webpack.config.js
plugins: [
new HtmlWebpackPlugin({
template: './src/a.html',
filename: 'a',
inject: 'body',
chunks: ['vendors', 'a']
})
]这里资源根路径的配置在output项:
// webpack.config.js
output: {
...
publicPath: debug ? '/__build/' : 'http://cdn.site.com/'
}其他入口html文件采用类似处理方式。
local server解决本地开发环境的问题,webpack解决开发和生产环境资源依赖管理的问题。在项目开发中,可能会有许多额外的任务需要完成,比如对于使用compass生成sprites的项目,因目前webpack还不直接支持sprites,所以还需要compass watch,再比如工程的远程部署等,所以需要使用一些构建工具或者脚本的配合,打通研发的链路。
因为每个团队在部署代码、单元测试、自动化测试、发布等方面做法都不同,前端需要遵循公司的标准进行自动化的整合,这部分不深入了。
前端工程化的建设,早期的做法是使用Grunt、Gulp等构建工具。但本质上它们只是一个任务调度器,将功能独立的任务拆解出来,按需组合运行任务。如果要完成前端工程化,这两者配置门槛很高,每一个任务都需要开发者自行使用插件解决,而且对于资源的依赖管理能力太弱。
在国内,百度出品的fis也是一种不错的工程化工具的选择,fis内部也解决了资源依赖管理的问题。因笔者没有在项目中实践过fis,所以不进行更多的评价。
webpack以一种非常优雅的方式解决了前端资源依赖管理的问题,它在内部已经集成了许多资源依赖处理的细节,但是对于使用者而言只需要做少量的配置,再结合构建工具,很容易搭建一套前端工程解决方案。
基于webpack的前端自动化工具,可以自由组合各种开源技术栈(Koa/Express/其他web框架、webpack、Sass/Less/Stylus、Gulp/Grunt等),没有复杂的资源依赖配置,工程结构也相对简单和灵活。
附上笔者根据本篇的理论所完成的一个前端自动化解决方案项目模板:
webpack-bootstrap
(完)。
Grunt很强大,但也很复杂,往后的文章会逐渐分享下grunt的一些配置经验。本篇是对grunt官方插件——JST的一点点改进。
对于设计良好的Web App来说,数据(Model)和模板(View)分离几乎是标配,但当逻辑比较复杂的时候,模板管理是个让人头疼的事情。
以往的做法是把模板放到一个script标签里,设置一个id,在用到的时候取这个script节点的innerHTML。这有个问题就是不同page之间模板不能复用,还有就是整洁的html页面里乱入了一些里边是一坨非js的script节点这对于有代码洁癖的童靴来说是很受不的。
还有一种很流行的做法是使用requirejs动态加载html模板,但是并非所有的项目都用到了requirejs。
对于使用grunt作为项目管理的项目来说,可以尝试使用grunt官方提供的grunt-contrib-jst插件,将html模板编译成js文件,编译出来的js文件其实就是调用underscore的模板对html文件进行预编译,生成几个函数。配置项这里不赘述,参考官方示例即可。至于模板,一般都是同一个页面所需的模板编译成一个js,根据文件名进行区分。
假设有如下html模板tmpl-list.html:
<ul>
<% list.forEach(function(item) { %>
<li><%= item.name %><strong><%= item.price %></strong></li>
<% }); %>
</ul>编译生成如下js文件listTmpl.js(名称可配置):
this["JST"]["tmplList"] = function(obj) {
var __t, __p = '', __e = _.escape, __j = Array.prototype.join;
// template string here...
};ok,到了这里就算完成模板编译。
细心的童靴可能会发现预编译出来的这个js,它引用了_.escape,换句话说就是它还是依赖underscore或者lodash,或者要把用到的几个方法单独拷贝出来插到其他脚本里。
这里提供了一种方法,就是把模板所用到的额外的函数或者变量,统统塞到编译成的js文件里头,使得生成的js能够独立运行。在这里,我们给jst插件添加个参数prepend(借鉴jQuery的api),在jst的task文件加这么几行:
if(options.prepend) {
var prepend = options.prepend;
if(typeof prepend === 'function') prepend = prepend();
if(options.prettify) prepend = prepend.replace(/(^\s+|\s+$)/gm, '');
output.unshift(prepend);
}prepend即支持string也支持传入函数,用法如下:
jst: {
compile: {
options: {
prepend: function() {
var vars = function() {
var _ = {};
_.escape = function(string) {
var escapeMap = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
"'": '''
};
var escapeRegexe = new RegExp('[' + Object.keys(escapeMap).join('') + ']', 'g');
if (string == null) return '';
return ('' + string).replace(escapeRegexe, function(match) {
return escapeMap[match];
});
};
};
var entire = vars.toString();
// entire = entire.replace(/(^\s+|\s+$)/gm, '');
return entire.slice(entire.indexOf('{') + 1, entire.lastIndexOf('}'));
},
}
}
}ok,其实就这么点内容,很简单的一个问题竟然用了这么大篇幅,罪过罪过。。
关于Hybrid模式开发app的好处,网络上已有很多文章阐述了,这里不展开。
本文将从以下几个方面阐述Hybrid app架构设计的一些经验和思考。
作为一种跨语言开发模式,通讯层是Hybrid架构首先应该考虑和设计的,往后所有的逻辑都是基于通讯层展开。
Native(以Android为例)和H5通讯,基本原理:
loadUrl方法可以直接执行js代码,类似浏览器地址栏输入一段js一样的效果webview.loadUrl("javascript: alert('hello world')");var ifm = document.createElement('iframe');
ifm.src = 'jsbridge://namespace.method?[...args]';JSBridge即我们通常说的桥协议,基本的通讯原理很简单,接下来就是桥协议具体实现。
P.S:注册私有协议的做法很常见,我们经常遇到的在网页里拉起一个系统app就是采用私有协议实现的。app在安装完成之后会注册私有协议到OS,浏览器发现自身不能识别的协议(http、https、file等)时,会将链接抛给OS,OS会寻找可识别此协议的app并用该app处理链接。比如在网页里以itunes://开头的链接是Apple Store的私有协议,点击后可以启动Apple Store并且跳转到相应的界面。国内软件开发商也经常这么做,比如支付宝的私有协议alipay://,腾讯的tencent://等等。
由于JavaScript语言自身的特殊性(单进程),为了不阻塞主进程并且保证H5调用的有序性,与Native通讯时对于需要获取结果的接口(GET类),采用类似于JSONP的设计理念:
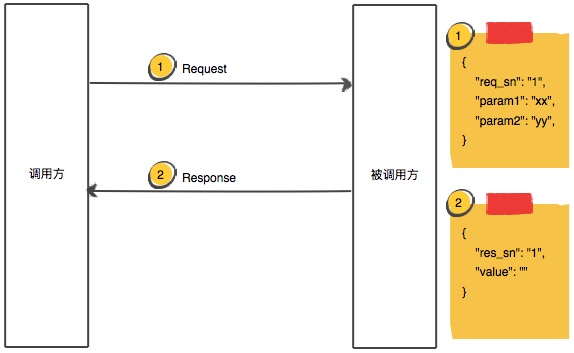
类比HTTP的request和response对象,调用方会将调用的api、参数、以及请求签名(由调用方生成)带上传给被调用方,被调用方处理完之后会吧结果以及请求签名回传调用方,调用方再根据请求签名找到本次请求对应的回调函数并执行,至此完成了一次通讯闭环。
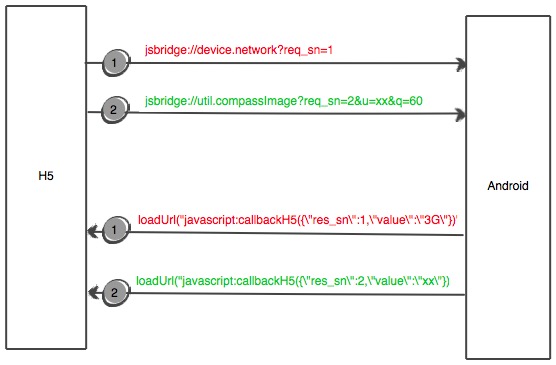
H5调用Native(以Android为例)示意图:
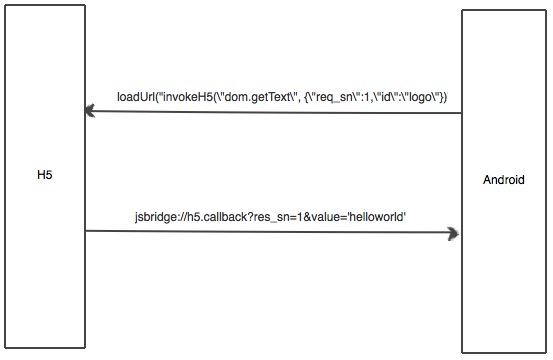
Native(以Android为例)调用H5示意图:
jsbridge作为一种通用私有协议,一般会在团队级或者公司级产品进行共享,所以需要和业务层进行解耦,将jsbridge的内部细节进行封装,对外暴露平台级的API。
以下是笔者剥离公司业务代码后抽象出的一份HybridApi js部分的实现,项目地址:
另外,对于Native提供的各种接口,也可以简单封装下,使之更贴近前端工程师的使用习惯:
// /lib/jsbridge/core.js
function assignAPI(name, callback) {
var names = name.split(/\./);
var ns = names.shift();
var fnName = names.pop();
var root = createNamespace(JSBridge[ns], names);
if(fnName) root[fnName] = callback || function() {};
}增加api:
// /lib/jsbridge/api.js
var assign = require('./core.js').assignAPI;
...
assign('util.compassImage', function(path, callback, quality, width, height) {
JSBridge.invokeApp('os.getInfo', {
path: path,
quality: quality || 80,
width: width || 'auto',
height: height || 'auto',
callback: callback
});
});H5上层应用调用:
// h5/music/index.js
JSBridge.util.compassImage('http://cdn.foo.com/images/bar.png', function(r) {
console.log(r.value); // => base64 data
});本质上,Native和H5都能完成界面开发。几乎所有hybrid的开发模式都会碰到同样的一个问题:哪些由Native负责哪些由H5负责?
这个回到原始的问题上来:我们为什么要采用hybrid模式开发?简而言之就是同时利用H5的跨平台、快速迭代能力以及Native的流畅性、系统API调用能力。
根据这个原则,为了充分利用二者的优势,应该尽可能地将app内容使用H5来呈现,而对于js语言本身的缺陷,应该使用Native语言来弥补,如转场动画、多线程作业(密集型任务)、IO性能等。即总的原则是H5提供内容,Native提供容器,在有可能的条件下对Android原生webview进行优化和改造(参考阿里Hybrid容器的JSM),提升H5的渲染效率。
但是,在实际的项目中,将整个app所有界面都使用H5来开发也有不妥之处,根据经验,以下情形还是使用Native界面为好:
因H5比较容易被恶意攻击,对于安全性要求比较高的界面,如注册界面、登陆、支付等界面,会采用Native来取代H5开发,保证数据的安全性,这些页面通常UI变更的频率也不高。
对于这些界面,降级的方案也有,就是HTTPS。但是想说的是在国内的若网络环境下,HTTPS的体验实在是不咋地(主要是慢),而且只能走现网不能走离线通道。
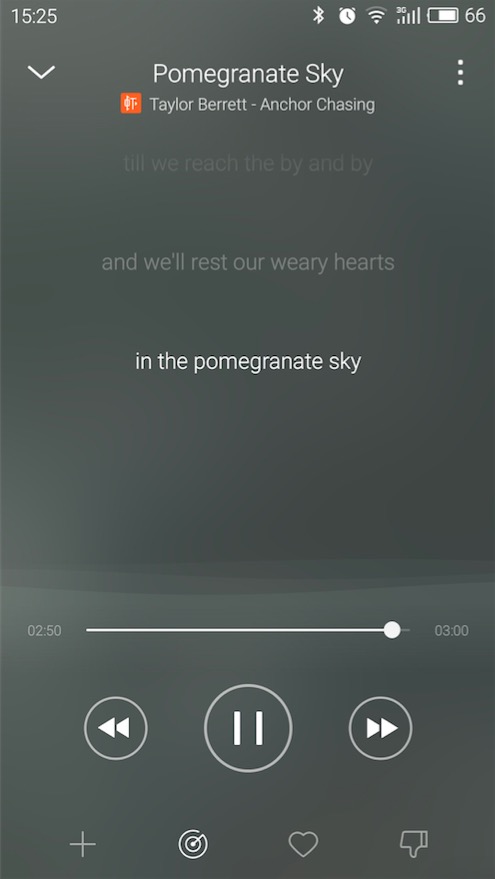
另外,H5本身的动画开发成本比较高,在低端机器上可能有些绕不过的性能坎,原生js对于手势的支持也比较弱,因此对于这些类型的界面,可以选择使用Native来实现,这也是Native本身的优势不是。比如要实现下面这个音乐播放界面,用H5开发门槛不小吧,留意下中间的波浪线背景,手指左右滑动可以切换动画。
导航组件,就是页面的头组件,左上角一般都是一个back键,中间一般都是界面的标题,右边的话有时是一个隐藏的悬浮菜单触发按钮有时则什么也没有。
移动端有一个特性就是界面下拉有个回弹效果,头不动body部分跟着滑动,这种效果H5比较难实现。
再者,也是最重要的一点,如果整个界面都是H5的,在H5加载过程中界面将是白屏,在弱网络下用户可能会很疑惑。
所以基于这两点,打开的界面都是Native的导航组件+webview来组成,这样即使H5加载失败或者太慢用户可以选择直接关闭。
在API层面,会相应的有一个接口来实现这一逻辑(例如叫JSBridge.layout.setHeader),下面代码演示定制一个只有back键和标题的导航组件:
// /h5/pages/index.js
JSBridge.layout.setHeader({
background: {
color: '#00FF00',
opacity: 0.8
},
buttons: [
// 默认只有back键,并且back键的默认点击处理函数就是back()
{
icon: '../images/back.png',
width: 16,
height: 16,
onClick: function() {
// todo...
JSBridge.back();
}
},
{
text: '音乐首页',
color: '#00FF00',
fontSize: 14,
left: 10
}
]
});上面的接口,可以满足绝大多数的需求,但是还有一些特殊的界面,通过H5代码控制生成导航组件这种方式达不到需求:
如上图所示,界面含有tab,且可以左右滑动切换,tab标题的下划线会跟着手势左右滑动。大多见于app的首页(mainActivity)或者分频道首页,这种界面一般采用定制webview的做法:定制的导航组件和内容框架(为了支持左右滑动手势),H5打开此类界面一般也是开特殊的API:
// /h5/pages/index.js
// 开打音乐频道下“我的音乐”tab
JSBridge.view.openMusic({'tab': 'personal'});这种打开特殊的界面的API之所以特殊,是因为它内部要么是纯Native实现,要么是和某个约定的html文件绑定,调用时打开指定的html。假设这个例子中,tab内容是H5的,如果H5是SPA架构的那么openMusic({'tab': 'personal'})则对应/music.html#personal这个url,反之多页面的则可能对应/mucic-personal.html。
至于一般的打开新界面,则有两种可能:
app内H5界面
指的是由app开发者开发的H5页面,也即是app的功能界面,一般互相跳转需要转场动画,打开方式是采用Native提供的接口打开,例如:
JSBridge.view.openUrl({
url: '/music-list.html',
title: '音乐列表'
});再配合下面即将提到的离线访问方式,基本可以做到模拟Native界面的效果。
第三方H5页面
指的是app内嵌的第三方页面,一般由a标签直接打开,没有转场动画,但是要求打开webview默认的历史列表,以免打开多个链接后点回退直接回到Native主界面。
基于以下原因,一些通用的UI组件,如alert、toast等将采用Native来实现:
下面代码演示H5调用Native提供的UI组件:
JSBridge.ui.toast('Hello world!');由于H5是在H5容器里进行加载和渲染,所以Native很容易对H5页面的行为进行监控,包括进度条、loading动画、404监控、5xx监控、网络诊断等,并且在H5加载异常时提供默认界面供用户操作,防止APP“假死”。
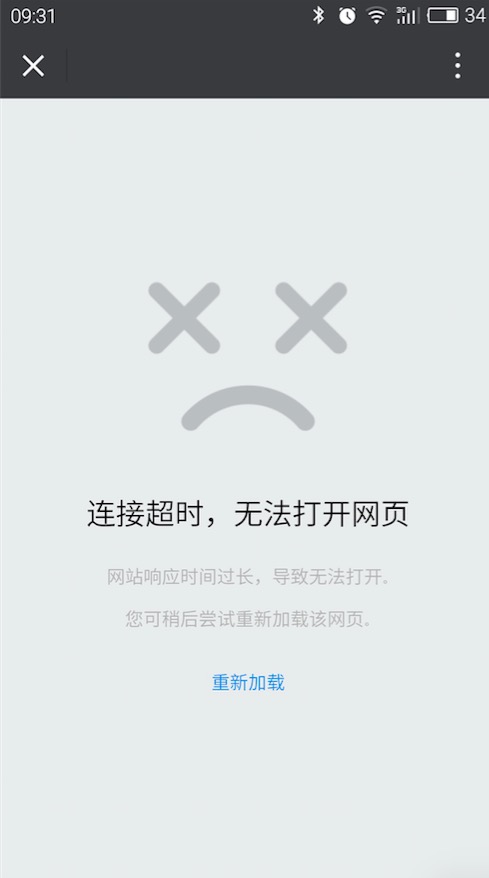
下面是微信的5xx界面示意:
Native除了负责部分界面开发和公共UI组件设计之外,作为H5的runtime,H5容器是hybrid架构的核心部分,为了让H5运行更快速稳定和健壮,还应当提供并但不局限于下面几方面。
之所以选择hybrid方式来开发,其中一个原因就是要解决webapp访问慢的问题。即使我们的H5性能优化做的再好服务器在牛逼,碰到蜗牛一样的运营商网络你也没辙,有时候还会碰到流氓运营商再给webapp插点广告。。。哎说多了都是泪。
离线访问,顾名思义就是将H5预先放到用户手机,这样访问时就不会再走网络从而做到看起来和Native APP一样的快了。
但是离线机制绝不是把H5打包解压到手机sd卡这么简单粗暴,应该解决以下几个问题:
H5应该有线上版本
作为访问离线资源的降级方案,当本地资源不存在的时候应该走现网去拉取对应资源,保证H5可用。另外就是,对于H5,我们不会把所有页面都使用离线访问,例如活动页面,这类快速上线又快速下线的页面,设计离线访问方式开发周期比较高,也有可能是页面完全是动态的,不同的用户在不同的时间看到的页面不一样,没法落地成静态页面,还有一类就是一些说明类的静态页面,更新频率很小的,也没必要做成离线占用手机存储空间。
开发调试&抓包
我们知道,基于file协议开发是完全基于开发机的,代码必须存放于物理机器,这意味着修改代码需要push到sd卡再看效果,虽然可以通过假链接访问开发机本地server发布时移除的方式,但是个人觉得还是太麻烦易出错。
为了实现同一资源的线上和离线访问,Native需要对H5的静态资源请求进行拦截判断,将静态资源“映射”到sd卡资源,即实现一个处理H5资源的本地路由,实现这一逻辑的模块暂且称之为Local Url Router,具体实现细节在文章后面。
将H5资源放置到本地离线访问,最大的挑战就是本地资源的动态更新如何设计,这部分可以说是最复杂的了,因为这同时涉及到H5、Native和服务器三方,覆盖式离线更新示意图如下:
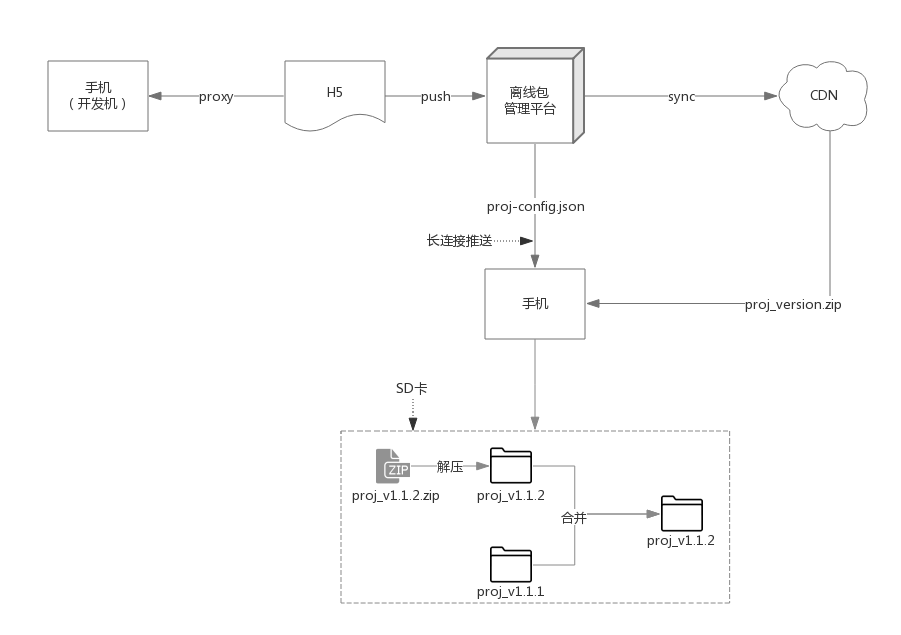
解释下上图,开发阶段H5代码可以通过手机设置HTTP代理方式直接访问开发机。完成开发之后,将H5代码推送到管理平台进行构建、打包,然后管理平台再通过事先设计好的长连接通道将H5新版本信息推送给客户端,客户端收到更新指令后开始下载新包、对包进行完整性校验、merge回本地对应的包,更新结束。
其中,管理平台推送给客户端的信息主要包括项目名(包名)、版本号、更新策略(增量or全量)、包CDN地址、MD5等。
通常来说,H5资源分为两种,经常更新的业务代码和不经常更新的框架、库代码和公用组件代码,为了实现离线资源的共享,在H5打包时可以采用分包的策略,将公用部分单独打包,在本地也是单独存放,分包及合并示意图:
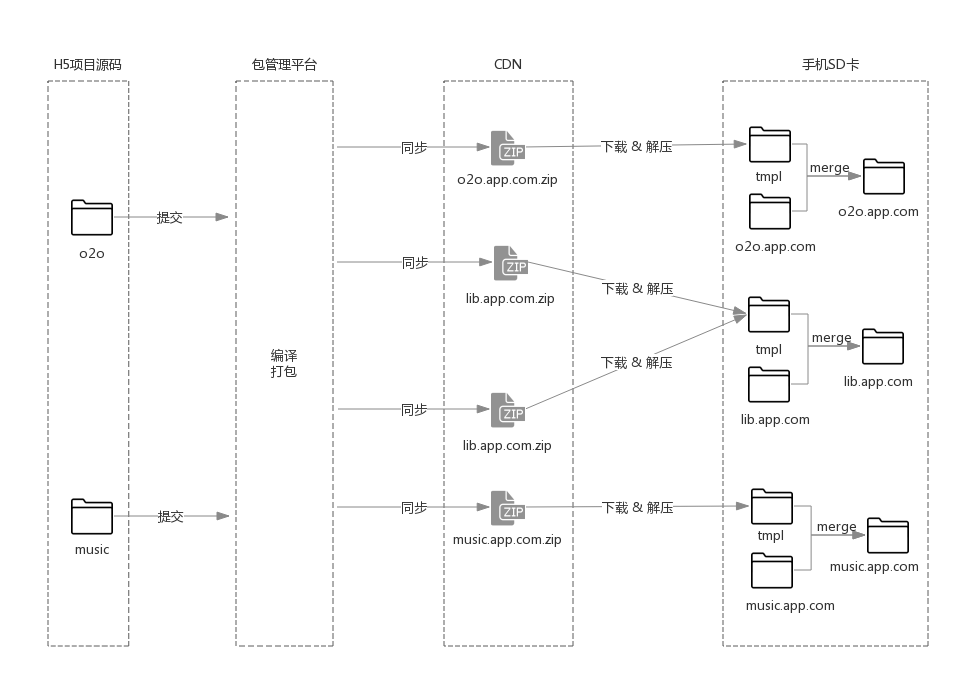
离线资源更新的问题解决了,剩下的就是如何使用离线资源了。
上面已经提到,对于H5的请求,线上和离线采用相同的url访问,这就需要H5容器对H5的资源请求进行拦截“映射”到本地,即Local Url Router。
Local Url Router主要负责H5静态资源请求的分发(线上资源到sd卡资源的映射),但是不管是白名单还是过滤静态文件类型,Native拦截规则和映射规则将变得比较复杂。这里,阿里去啊app的思路就比较赞,我们借鉴一下,将映射规则交给H5去生成:H5开发完成之后会扫描H5项目然后生成一份线上资源和离线资源路径的映射表(souce-router.json),H5容器只需负责解析这个映射表即可。
H5资源包解压之后在本地的目录结构类似:
$ cd h5 && tree
.
├── js/
├── css/
├── img/
├── pages
│ ├── index.html
│ └── list.html
└── souce-router.jsonsouce-router.json的数据结构类似:
{
"protocol": "http",
"host": "o2o.xx.com",
"localRoot": "[/storage/0/data/h5/o2o/]",
"localFolder": "o2o.xx.com",
"rules": {
"/index.html": "pages/index.html",
"/js/": "js/"
}
}H5容器拦截到静态资源请求时,如果本地有对应的文件则直接读取本地文件返回,否则发起HTTP请求获取线上资源,如果设计完整一点还可以考虑同时开启新线程去下载这个资源到本地,下次就走离线了。
下图演示资源在app内部的访问流程图:
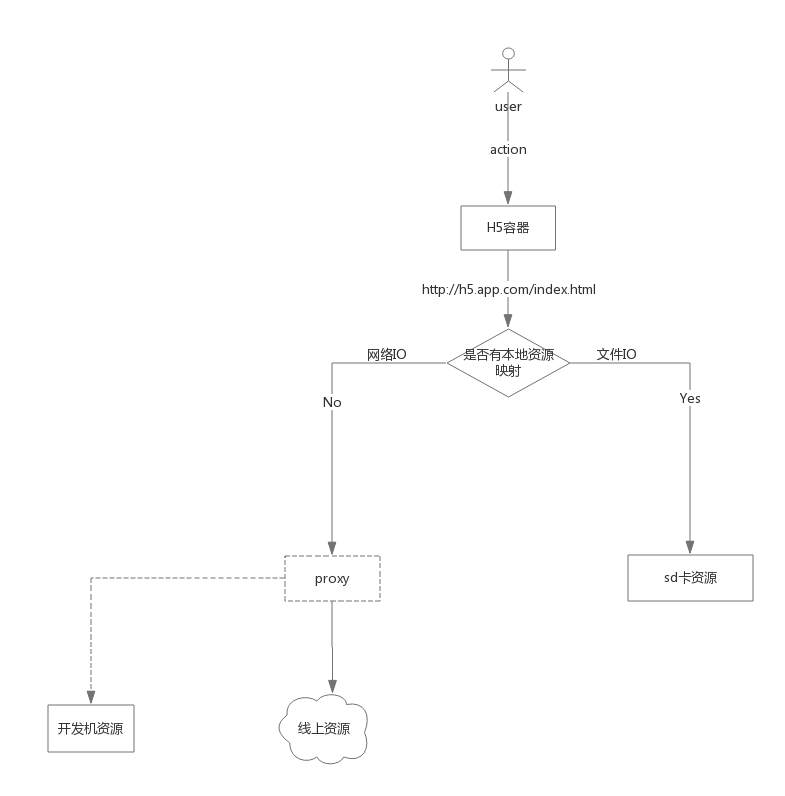
其中proxy指的是开发时手机设置代理http代理到开发机。
上报
由于界面由H5和Native共同完成,界面上的用户交互埋点数据最好由H5容器统一采集、上报,还有,由页面跳转产生的浏览轨迹(转化漏斗),也由H5容器记录和上报
ajax代理
因ajax受同源策略限制,可以在hybridApi层对ajax进行统一封装,同时兼容H5容器和浏览器runtime,采用更高效的通讯通道加速H5的数据传输
主要指扩展H5的硬件接口调用能力,比如屏幕旋转、摄像头、麦克风、位置服务等等,将Native的能力通过接口的形式提供给H5。
最后来张图总结下,hybrid客户端整体架构图:
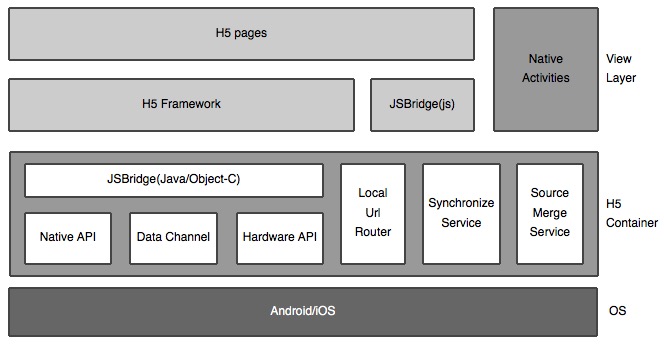
其中的Synchronize Service模块表示和服务器的长连接通信模块,用于接受服务器端各种推送,包括离线包等。Source Merge Service模块表示对解压后的H5资源进行更新,包括增加文件、以旧换新以及删除过期文件等。
可以看到,hybrid模式的app架构,最核心和最难的部分都是H5容器的设计。
注:(摘自《鸟哥的Linux私房菜》)
一般模式 --i|o(新增一行)|a(插入)|R(替换)--> 编辑模式 --ESC--> 一般模式
一般模式 --:|/|?--> 命令行模式 --ESC--> 一般模式
| 按键 | 说明 |
|---|---|
| h或← | 光标左移一个字符。如果是30h,表示左移30个字符,下同 |
| j或↓ | 光标下移一个字符 |
| k或↑ | 光标上移一个字符 |
| l或→ | 光标右移一个字符 |
| [Ctrl]+[f] | 屏幕向下移动一页 |
| [Ctrl]+[b] | 屏幕向上移动一页 |
| 0或[Home] | 移动到此行最前面字符处 |
| H | 光标移到当前屏幕最上方行的第一个字符 |
| M | 光标移到当前屏幕最中间行的第一个字符 |
| L | 光标移到当前屏幕最下方行第一个字符 |
| G | 到此文件最后一行 |
| nG | 移动到第n行 |
| gg | 相当于1G,即到行首 |
| n[Enter] | 光标下移n行 |
| /word | 向下查找单词“word” |
| ?word | 向上查找单词“word” |
| n | 英文按键,表示重复前一个查找操作 |
| N | 与n相反 |
| :n1,n2s/word1/word2/g | 在n1到n2行查找word1替换成word2 |
| :1,$s/word1/word2/g | 在1到最后一行查找word1替换成word2 |
| :1,$s/word1/word2/gc | 同上,在替换前confirm用户是否替换 |
| x | 向后删除一个字符 |
| nx | 向后删除n个字符 |
| X | 向前删除一个字符 |
| dd | 删除光标所在行 |
| ndd | 删除光标所在行以下n行 |
| d1G | 删除光标所在行到第一行所有数据 |
| dG | 删除光标所在行到最后一行所有数据 |
| d$ | 删除光标所在处到同行最后一个字符 |
| d0 | 删除光标所在处到同行第一个字符 |
| yy | 复制光标所在行 |
| nyy | 复制光标所在向下n行 |
| y1G | 复制光标所在行到第一行所有数据 |
| yG | 复制光标所在行到最后一行所有数据 |
| y$ | 复制光标所在处到同行最后一个字符 |
| y0 | 复制光标所在处到同行第一个字符 |
| p | 将已复制的数据粘贴到光标所在下一行 |
| P | 同上,粘贴到上一行 |
| u | 复原前一个操作 |
| [Ctrl]+r | 重做上一个操作 |
| . | 重复前一个操作 |
| 按键 | 说明 |
|---|---|
| i | 从光标所在处插入 |
| l | 在所在行第一个非空白字符处插入 |
| a | 从光标所在下一个字符处插入 |
| A | 从光标所在行最后一个字符处插入 |
| o | 在光标所在处下一行插入新的一行 |
| O | 在光标所在处上一行插入新的一行 |
| r | 替换光标所在处字符一次 |
| R | 一直替换光标所在处文字知道Esc |
| 按键 | 说明 |
|---|---|
| :w[filename] | 另存为filename |
| :r[filename] | 读取filename到光标所在行后面 |
| :n1,n2 w[filename] | 将n1到n2行另存为filename |
| :! command | 临时切换到命令行模式下执行command,如::! ls /tmp |
| :set nu | 显示行号 |
| :set nonu | 取消显示行号 |
| 按键 | 说明 |
|---|---|
| V | 开始块选择,光标移过的行将会被选择 |
| [Ctrl]+v | 块选择,开始选择矩形区域 |
| y | 将所选区域复制 |
| d | 将所选区域删除 |
使用vim file1 file2开始多文件编辑
| 按键 | 说明 |
|---|---|
| :n | 编辑下一个文件 |
| :N | 编辑上一个文件 |
| :files | 列出打开的所有文件 |
在命令行模式输入:sp[filename]即可打开多个窗口,输入filename则会打开另一个文件,否则只是切割当前文件。
| 按键 | 说明 |
|---|---|
| [ctrl]+w+j或[ctrl]+w+↓ | 光标移到下方窗口 |
| [ctrl]+w+k或[ctrl]+w+↑ | 光标移到上方窗口 |
| [ctrl]+w+q | 上下切换窗口 |
注:这里所有的组合键都是先按住ctrl再按w然后再按下最后一个。
配置文件:vim ~/.vimrc
详细配置后续补上。
折腾Node.js有些日子了,下面将陆陆续续记录下使用Node.js的一些细节。
熟悉Node.js的童鞋都知道,Node.js作为服务器端的javascript运行环境,它使用npm作为通用的包管理工具,npm遵循CommonJS规范定义了一套用于Node.js模块的约定,关于npm实现Node.js模块的更多细节请细读深入Node.js的模块机制,这里简单讲下书写Node.js代码时module.exports与exorts的区别。
在浏览器端js里面,为了解决各模块变量冲突等问题,往往借助于js的闭包把所有模块相关的代码都包装在一个匿名函数里。而Node.js编写模块相当的自由,开发者只需要关注require,exports,module等几个变量就足够,而为了保持模块的可读性,很推荐把不同功能的代码块都写成独立模块,减少各模块耦合。开发者可以在“全局”环境下任意使用var申明变量(不用写到闭包里了),通过exports暴露接口给调用者。
我们经常看到类似export.xxx = yyy或者module.exports = xx这样的代码,可实际在通过require函数引入模块时会出现报错的情况,这是什么原因导致的呢?
Node.js在模块编译的过程中会对模块进行包装,最终会返回类似下面的代码:
(function (exports, require, module, __filename, __dirname) {
// module code...
});其中,module就是这个模块本身,require是对Node.js实现查找模块的模块Module._load实例的引用,__filename和__dirname是Node.js在查找该模块后找到的模块名称和模块绝对路径,这就是官方API里头这两个全局变量的来历。
关于module.exports与exorts的区别,了解了下面几点之后应该就完全明白:
模块内部大概是这样:
exports = module.exports = {};exports.xxx,相当于在导出对象上挂属性,该属性对调用模块直接可见exports =相当于给exports对象重新赋值,调用模块不能访问exports对象及其属性module.exports,这样调用者就是一个类构造器,可以直接new实例客官如果看明白咋回事儿了下面的内容可以忽略:)
假如有模块a.js代码如下:
exports.str = 'a';
exports.fn = function() {};对a模块的调用:
var a = require('./a');
console.log(a.str);
console.log(a.fn());这样用是对的,如果改造a如下:
exports.str = 'a';
exports = function fn() {};在调用a模块时自然没用fn属性了。
再改造下a模块:
exports.str = 'a';
module.exports = function fn() {};这时a模块其实就是fn函数的引用,也就是说可以require('./a')()这样使用,而同时不再有str属性了。
下面直接导出一个类:
module.exports = function A() {};调用:
var A = require('./a');
var a = new A();总结下,有两点:
exports对象上module.exports对象上,不要和导出属性值混在一起最后,不用再纠结module.exports与exorts什么时候该用哪个了吧~
本篇,主要普及promise的用法。
一直以来,JavaScript处理异步都是以callback的方式,在前端开发领域callback机制几乎深入人心。在设计API的时候,不管是浏览器厂商还是SDK开发商亦或是各种类库的作者,基本上都已经遵循着callback的套路。
近几年随着JavaScript开发模式的逐渐成熟,CommonJS规范顺势而生,其中就包括提出了Promise规范,Promise完全改变了js异步编程的写法,让异步编程变得十分的易于理解。
在callback的模型里边,我们假设需要执行一个异步队列,代码看起来可能像这样:
loadImg('a.jpg', function() {
loadImg('b.jpg', function() {
loadImg('c.jpg', function() {
console.log('all done!');
});
});
});这也就是我们常说的回调金字塔,当异步的任务很多的时候,维护大量的callback将是一场灾难。当今Node.js大热,好像很多团队都要用它来做点东西以沾沾“洋气”,曾经跟一个运维的同学聊天,他们也是打算使用Node.js做一些事情,可是一想到js的层层回调就望而却步。
好,扯淡完毕,下面进入正题。
Promise可能大家都不陌生,因为Promise规范已经出来好一段时间了,同时Promise也已经纳入了ES6,而且高版本的chrome、firefox浏览器都已经原生实现了Promise,只不过和现如今流行的类Promise类库相比少些API。
所谓Promise,字面上可以理解为“承诺”,就是说A调用B,B返回一个“承诺”给A,然后A就可以在写计划的时候这么写:当B返回结果给我的时候,A执行方案S1,反之如果B因为什么原因没有给到A想要的结果,那么A执行应急方案S2,这样一来,所有的潜在风险都在A的可控范围之内了。
上面这句话,翻译成代码类似:
var resB = B();
var runA = function() {
resB.then(execS1, execS2);
};
runA();只看上面这行代码,好像看不出什么特别之处。但现实情况可能比这个复杂许多,A要完成一件事,可能要依赖不止B一个人的响应,可能需要同时向多个人询问,当收到所有的应答之后再执行下一步的方案。最终翻译成代码可能像这样:
var resB = B();
var resC = C();
...
var runA = function() {
reqB
.then(resC, execS2)
.then(resD, execS3)
.then(resE, execS4)
...
.then(execS1);
};
runA();在这里,当每一个被询问者做出不符合预期的应答时都用了不同的处理机制。事实上,Promise规范没有要求这样做,你甚至可以不做任何的处理(即不传入then的第二个参数)或者统一处理。
好了,下面我们来认识下Promise/A+规范:
then方法(可以说,then就是promise的核心),而且then必须返回一个promise,同一个promise的then可以调用多次,并且回调的执行顺序跟它们被定义时的顺序一致可以看到,Promise规范的内容并不算多,大家可以试着自己实现以下Promise。
以下是笔者自己在参考许多类Promise库之后简单实现的一个Promise,代码请移步promiseA。
简单分析下思路:
构造函数Promise接受一个函数resolver,可以理解为传入一个异步任务,resolver接受两个参数,一个是成功时的回调,一个是失败时的回调,这两参数和通过then传入的参数是对等的。
其次是then的实现,由于Promise要求then必须返回一个promise,所以在then调用的时候会新生成一个promise,挂在当前promise的_next上,同一个promise多次调用都只会返回之前生成的_next。
由于then方法接受的两个参数都是可选的,而且类型也没限制,可以是函数,也可以是一个具体的值,还可以是另一个promise。下面是then的具体实现:
Promise.prototype.then = function(resolve, reject) {
var next = this._next || (this._next = Promise());
var status = this.status;
var x;
if('pending' === status) {
isFn(resolve) && this._resolves.push(resolve);
isFn(reject) && this._rejects.push(reject);
return next;
}
if('resolved' === status) {
if(!isFn(resolve)) {
next.resolve(resolve);
} else {
try {
x = resolve(this.value);
resolveX(next, x);
} catch(e) {
this.reject(e);
}
}
return next;
}
if('rejected' === status) {
if(!isFn(reject)) {
next.reject(reject);
} else {
try {
x = reject(this.reason);
resolveX(next, x);
} catch(e) {
this.reject(e);
}
}
return next;
}
};这里,then做了简化,其他promise类库的实现比这个要复杂得多,同时功能也更多,比如还有第三个参数——notify,表示promise当前的进度,这在设计文件上传等时很有用。对then的各种参数的处理是最复杂的部分,有兴趣的同学可以参看其他类Promise库的实现。
在then的基础上,应该还需要至少两个方法,分别是完成promise的状态从pending到resolved或rejected的转换,同时执行相应的回调队列,即resolve()和reject()方法。
到此,一个简单的promise就设计完成了,下面简单实现下两个promise化的函数:
function sleep(ms) {
return function(v) {
var p = Promise();
setTimeout(function() {
p.resolve(v);
});
return p;
};
};
function getImg(url) {
var p = Promise();
var img = new Image();
img.onload = function() {
p.resolve(this);
};
img.onerror = function(err) {
p.reject(err);
};
img.url = url;
return p;
};由于Promise构造函数接受一个异步任务作为参数,所以getImg还可以这样调用:
function getImg(url) {
return Promise(function(resolve, reject) {
var img = new Image();
img.onload = function() {
resolve(this);
};
img.onerror = function(err) {
reject(err);
};
img.url = url;
});
};接下来(见证奇迹的时刻),假设有一个BT的需求要这么实现:异步获取一个json配置,解析json数据拿到里边的图片,然后按顺序队列加载图片,没张图片加载时给个loading效果
function addImg(img) {
$('#list').find('> li:last-child').html('').append(img);
};
function prepend() {
$('<li>')
.html('loading...')
.appendTo($('#list'));
};
function run() {
$('#done').hide();
getData('map.json')
.then(function(data) {
$('h4').html(data.name);
return data.list.reduce(function(promise, item) {
return promise
.then(prepend)
.then(sleep(1000))
.then(function() {
return getImg(item.url);
})
.then(addImg);
}, Promise.resolve());
})
.then(sleep(300))
.then(function() {
$('#done').show();
});
};
$('#run').on('click', run);这里的sleep只是为了看效果加的,可猛击查看demo!当然,Node.js的例子可查看这里。
在这里,Promise.resolve(v)静态方法只是简单返回一个以v为肯定结果的promise,v可不传入,也可以是一个函数或者是一个包含then方法的对象或函数(即thenable)。
类似的静态方法还有Promise.cast(promise),生成一个以promise为肯定结果的promise;
Promise.reject(reason),生成一个以reason为否定结果的promise。
我们实际的使用场景可能很复杂,往往需要多个异步的任务穿插执行,并行或者串行同在。这时候,可以对Promise进行各种扩展,比如实现Promise.all(),接受promises队列并等待他们完成再继续,再比如Promise.any(),promises队列中有任何一个处于完成态时即触发下一步操作。
可参考html5rocks的这篇文章JavaScript Promises,目前高级浏览器如chrome、firefox都已经内置了Promise对象,提供更多的操作接口,比如Promise.all(),支持传入一个promises数组,当所有promises都完成时执行then,还有就是更加友好强大的异常捕获,应对日常的异步编程,应该足够了。
现今流行的各大js库,几乎都不同程度的实现了Promise,如dojo,jQuery、Zepto、when.js、Q等,只是暴露出来的大都是Deferred对象,以jQuery(Zepto类似)为例,实现上面的getImg():
function getImg(url) {
var def = $.Deferred();
var img = new Image();
img.onload = function() {
def.resolve(this);
};
img.onerror = function(err) {
def.reject(err);
};
img.src = url;
return def.promise();
};当然,jQuery中,很多的操作都返回的是Deferred或promise,如animate、ajax:
// animate
$('.box')
.animate({'opacity': 0}, 1000)
.promise()
.then(function() {
console.log('done');
});
// ajax
$.ajax(options).then(success, fail);
$.ajax(options).done(success).fail(fail);
// ajax queue
$.when($.ajax(options1), $.ajax(options2))
.then(function() {
console.log('all done.');
}, function() {
console.error('There something wrong.');
});jQuery还实现了done()和fail()方法,其实都是then方法的shortcut。
处理promises队列,jQuery实现的是$.when()方法,用法和Promise.all()类似。
其他类库,这里值得一提的是when.js,本身代码不多,完整实现Promise,同时支持browser和Node.js,而且提供更加丰富的API,是个不错的选择。这里限于篇幅,不再展开。
我们看到,不管Promise实现怎么复杂,但是它的用法却很简单,组织的代码很清晰,从此不用再受callback的折磨了。
最后,Promise是如此的优雅!但Promise也只是解决了回调的深层嵌套的问题,真正简化JavaScript异步编程的还是Generator,在Node.js端,建议考虑Generator。
下一篇,研究下Generator。
前些日子在开发一个Node.js项目的时候,请求量什么的需要上报公司统一的monitor。已有的接口是C++写成的,也有编译好的二进制文件可以直接用shell命令调用,如果简单使用的话可能只需调用nodejschild_process模块执行命令行即可,但是感觉这种方法比较蹩脚,每一个前端请求都需要创建一个子进程,开销太大。于是决定使用C++库编译node扩展。
编译node扩展,本来官方文档说的已经很清晰了,按照文档一步步来即可,这里大概记录下编译过程和所碰到的问题。
1.新建attrlib.cc C++原文件,添加V8头文件、引入lib头文件:
#include <node.h>
#include <v8.h>
#include "Attr_API.h"
using namespace v8;2.封装接口,完成对C++ lib api所需参数的类型、个数什么的做检查,对暴露的js接口进行容错,这里因之前完全没接触过C++,对它的各种数据类型的检查和转换花了不少的时间。
针对Attr_API.h头文件里的api接口(这里做为例子,其他接口省去了):
int adv_attr_set(int attr_id , size_t len , char* pvalue);具体的封装:
Handle<Value> AdvAttrSet(const Arguments& args) {
HandleScope scope;
if(args.Length() < 3) {
ThrowException(Exception::TypeError(String::New("Wrong number of arguments")));
return scope.Close(Undefined());
}
v8::String::Utf8Value pVal(args[2]->ToString());
Local<Integer> iRet = Integer::New(adv_attr_set(
args[0]->Int32Value(),
args[1]->IntegerValue(),
(char*) *pVal
));
return scope.Close(iRet);
}3.暴露js接口:
void init(Handle<Object> exports) {
exports->Set(String::NewSymbol("advAttrSet"),
FunctionTemplate::New(AdvAttrSet)->GetFunction());
}
NODE_MODULE(AttrLib, init);接下来编写binding.gyp,它就是一个json格式的配置文件(node低版本使用wscript文件进行编译,高版本都采用binding.gyp),接着使用node-gyp模块进行自动编译。
{
"targets": [
{
"target_name": "AttrLib",
"sources": [ "attrlib.cc" ],
"libraries": [ "/data/nodejs/modules/base/tools/attrapi/attrapi.a" ]
}
]
}这里简单说下,如果C++ lib使用了静态(.a文件)或者动态链接库(.so文件),只需要在libraries这一项里指出该库的路劲即可,笔者一开始因为没引入静态链接库,编译出来的.node文件在调用的时候会报错:node: symbol lookup error: /data/nodejs/modules/base/test/attr_api/build/Release/attr_api.node: undefined symbol: Attr_API。
接下来又开始编译,再一次报错:6_64_32 against `.rodata' can not be used when making a shared object; recompile with -fPIC /data/nodejs/modules/base/tools/attrapi/attrapi.a: could not read symbols: Bad value collect2: ld returned 1 exit status
问了google才知道是个很常见的C++编译错误,即需要指定-fPIC参数。但是看了binding.gyp似乎没这个配置,于是请教后台同学,恰好有人碰到过这个错误,发现是静态链接库不完整导致。
接下来开始编译,cd到binding.gyp所在路径,运行:node-gyp configure build,会生成一个build文件夹,进去之后会发现很多的文件,其中就有大家熟悉的Makefile,猜想node-gyp应该是通过配置生成Makefile,然后再运行make。
最后就是编写测试用例,逐个去跑了。
总体来说,编译node C++扩展扩展很简单,但是碰到抛异常的话,对于jser来说还是很蛋疼。
MongoDB安装和配置很简单,下载解压完成之后,使用mongod --help查看启动配置项,即可简单快速启动MongoDB。
MongoDB的部署,简单总结了下有四种:
启动:
mongod --dbpath [path/to/db] --logpath [path/to/log/xx.log] --logappend --directoryperdb --fork其中,directoryperdb表示每个数据库的文件存放在一个文件夹,推荐这样做,便于管理。
fork表示启动后一直在后台运行,如果只是简单调试就不需要fork参数。
一般来说,配置参数较多的进程我们都推荐采用配置文件启动,假如配置文件存放在/etc/mongodb.conf,即可这样启动:
mongod -f /etc/mongodb.conf注意,生产环境永远不要用单机模式部署。
主从模式,顾名思义,主机+从机模式,至少需要两台机器(同一台机器不同端口也行)。
主节点的启动:跟单机启动差不多,只不过加上master参数
mongod ... --master从节点启动:
mongod ... --slave --source [master节点host:master节点端口]原则上,从节点的数量是不限制的,很方便横向扩展。
主从模式可用性提高了些,不过这种模式有很多缺陷:
基于种种原因,MongoDB官方已经不推荐采用主从模式了。
副本集群即主节点-副本节点模式,主节点负责写入,副本节点负责读。
下面是副本集群方式的部署:
先准备多太机器,我在里用的是两台物理机器,其中一台使用两个端口(官方说副本集数量最好是奇数)。
在机器192.168.44.171上建立数据存放目录:
mkdir -p /db/mongodb/replset/mongo1/data /db/mongodb/replset/mongo2/data命令行分别启动副本:
mongod --port 27020 --dbpath /db/mongodb/replset/mongo1/data --logpath=/db/mongodb/replset/mongo1/mongo1.log --replSet mstats --directoryperdb --logappend --fork
mongod --port 27021 --dbpath /db/mongodb/replset/mongo2/data --logpath=/db/mongodb/replset/mongo2/mongo2.log --replSet mstats --directoryperdb --logappend --fork这里,replSet参数是副本集群的标志,给这个副本集群起个名字叫mstats。
在机器192.168.42.14上启动:
mkdir -p /db/mongodb/replset/mongo1/data
mongod --port 27020 --dbpath /db/mongodb/replset/mongo1/data --logpath=/db/mongodb/replset/mongo1/mongo1.log --replSet mstats --directoryperdb --logappend --fork下面是配置集群:
假设我们想要192.168.44.171的27020端口作为主节点,那登录到192.168.44.171机器,进行以下配置:
mongo --port 27020会发现跟单机模式一样,终端只显示>输入标志。接着运行以下命令进行配置:
use admin;
conf = {
_id: "mstats",
members: [
{
_id: 0,
host: "192.168.44.171:27020",
},
{
_id: 1,
host: "192.168.44.171:27021",
},
{
_id: 2,
host: "192.168.42.14:27020",
}
]
}
rs.initiate(conf);过上一段时间,终端显示
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}则表示配置成功,如果没有则检查下配置是否写错。
接着运行rs.status()则可以查看副本集状态:
mstats:PRIMARY> rs.status()输出:
{
"set" : "mstats",
"date" : ISODate("2014-09-18T15:13:39Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "192.168.44.171:27020",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1616,
"optime" : Timestamp(1411053004, 1),
"optimeDate" : ISODate("2014-09-18T15:10:04Z"),
"electionTime" : Timestamp(1411052557, 1),
"electionDate" : ISODate("2014-09-18T15:02:37Z"),
"self" : true
},
{
"_id" : 1,
"name" : "192.168.44.171:27021",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 670,
"optime" : Timestamp(1411053004, 1),
"optimeDate" : ISODate("2014-09-18T15:10:04Z"),
"lastHeartbeat" : ISODate("2014-09-18T15:13:38Z"),
"lastHeartbeatRecv" : ISODate("2014-09-18T15:13:39Z"),
"pingMs" : 0,
"syncingTo" : "192.168.44.171:27020"
},
{
"_id" : 2,
"name" : "192.168.42.14:27020",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 670,
"optime" : Timestamp(1411053004, 1),
"optimeDate" : ISODate("2014-09-18T15:10:04Z"),
"lastHeartbeat" : ISODate("2014-09-18T15:13:37Z"),
"lastHeartbeatRecv" : ISODate("2014-09-18T15:13:37Z"),
"pingMs" : 0,
"syncingTo" : "192.168.44.171:27020"
}
],
"ok" : 1
}查看副本集:
mongod --port 27021这时候我们将看到终端显示mstats:SECONDARY>,表示当前登陆的是mstats副本集的副本节点,插入数据试试:
use test;
db.testtable.insert({'foo': 'bar'});在命令行将看到错误信息WriteResult({ "writeError" : { "code" : undefined, "errmsg" : "not master" } }),说明副本集是不能写入的。
切换到主机后插入一条测试数据:
use test;
db.testtable.insert({'foo': 'bar'});再切到副本集读数据:
use test;
db.testtable.find();这时候又看到报错error: { "$err" : "not master and slaveOk=false", "code" : 13435 },显示需要开启副本集可写,运行:
db.getMongo().setSlaveOk();这时候再查询就ok了。
副本集具有故障转移的功能,即主机不可用时,副本集内部会采用选举机制选出新的主节点,解决了主节点的自动切换问题。
副本集群的同步机制:
查看副本集群内部local数据库中,发现会有一个oplog.rs表:
use local;
show collections;输出:
me
oplog.rs
replset.minvalid
startup_log
system.indexes
system.replsetoplog.rs表存放本机的所有操作记录,方便和主服务器进行对比数据是否同步还可以用于错误恢复。oplog是一个固定大小的集合,新数据加入超过集合的大小会覆盖。当落后的数据超过了oplog大小,就会触发集群间数据同步,所以需要设置合理的oplog大小避免在生产环境全量复制。
可以通过启动参数--oplogSize设置oplogoplogSize,oplogSize默认为剩余磁盘空间的5%。新节点的加入,会全量同步数据库,但同步也并非只能从主节点同步,可以从就近的副本集同步。
副本集的选举机制,采用Bully算法,这里有文章介绍。
至此,副本集群解决了以下问题:
但是,集群怎么做到自动扩容呢?
答案是有的,就是分片模式。这里限于篇幅,不再继续,下一篇实践下分片。
目前ReactNative只支持Mac平台,iOS的开发环境比较简单,基本上只需要一个xcode即可。
Android开发环境需要装很多软件,而且问题比较多,本篇记录下。
Android Studio
没啥好说的,翻墙从官网下载最新的安装包并安装。
SDK及其他
启动Android Studio,选择"Tools"-->"Android"-->"SDK Manager",勾选以下项目:
这一步也需要翻墙,经过漫长的等待之后,成功安装。
设置环境变量
模拟器
手头没Android设备,所以需要装个Android模拟器。
回到SDK Manager界面,勾选并安装“Inter x86 Emulator Accelerator(HAXM installer)”,完成之后似乎还不能启动AVD创建界面,手动安装HAXM:在android sdk目录下找到extras文件夹,依次点进去"intel"-->"Hardware_Accelerated_Execution_Manager",双击“IntelHAXM_1.1.4.dmg”安装。
安装上HAXM之后即可启动AVD Manager界面,然后创建模拟器:
Android环境设置
全局环境变量设置:
$ vim ~/.bash_profile
$ export ANDROID_HOME="/Users/[your name]/Library/Android/sdk/android-sdk_r24.2" # 以实际位置为准
$ source ~/.bash_profile # 立即生效或者在初始化的项目中android目录下新建文件local.properties,内容是:
sdk.dir=/Users/[your name]/Library/Android/sdk/android-sdk_r24.2Node.js以及React命令行模块
从官网下载最新的Node.js并安装,过程略。
安装cli模块:
$ npm install -g react-native-cli安装watchman
watchman是mac平台的一个用于监听文件变化的软件,热更新的时候需要它。
$ brew install watchman安装flow
flow是mac平台下一个FTP + SFTP客户端。
$ brew install flow$ react-native init [appname]这一步也很慢,失败之后重试几遍。成功后会在当前目录生成以appname为名的项目文件夹,结构如下:
$ cd [appname]
$ ll
total 24
drwxr-xr-x 12 dmyang staff 408B 9 20 16:09 android
drwxr-xr-x 2 dmyang staff 68B 9 23 17:48 app
-rw-r--r-- 1 dmyang staff 1.0K 10 10 14:48 index.android.js
-rw-r--r-- 1 dmyang staff 1.0K 9 18 23:35 index.ios.js
drwxr-xr-x 7 dmyang staff 238B 9 19 19:34 ios
drwxr-xr-x 4 dmyang staff 136B 9 18 23:35 node_modules
-rw-r--r-- 1 dmyang staff 202B 9 18 23:35 package.json对于iOS,比较简单,进入ios/目录下,双击[appname].xcodeproj文件即可运行。
对于Android,需要编译成apk安装包模拟器里边,运行:
直到“BUILD SUCCESSFUL”
$ react-native run-android
Starting JS server...
Building and installing the app on the device (cd android && ./gradlew installDebug)...
:app:preBuild UP-TO-DATE
:app:preDebugBuild UP-TO-DATE
:app:checkDebugManifest
:app:preReleaseBuild UP-TO-DATE
:app:prepareComAndroidSupportAppcompatV72300Library UP-TO-DATE
:app:prepareComAndroidSupportSupportV42300Library UP-TO-DATE
:app:prepareComFacebookFrescoDrawee061Library UP-TO-DATE
:app:prepareComFacebookFrescoFbcore061Library UP-TO-DATE
:app:prepareComFacebookFrescoFresco061Library UP-TO-DATE
:app:prepareComFacebookFrescoImagepipeline061Library UP-TO-DATE
:app:prepareComFacebookFrescoImagepipelineOkhttp061Library UP-TO-DATE
:app:prepareComFacebookReactReactNative0110Library UP-TO-DATE
:app:prepareOrgWebkitAndroidJscR174650Library UP-TO-DATE
:app:prepareDebugDependencies
:app:compileDebugAidl UP-TO-DATE
:app:compileDebugRenderscript UP-TO-DATE
:app:generateDebugBuildConfig UP-TO-DATE
:app:generateDebugAssets UP-TO-DATE
:app:mergeDebugAssets UP-TO-DATE
:app:generateDebugResValues UP-TO-DATE
:app:generateDebugResources UP-TO-DATE
:app:mergeDebugResources UP-TO-DATE
:app:processDebugManifest UP-TO-DATE
:app:processDebugResources UP-TO-DATE
:app:generateDebugSources UP-TO-DATE
:app:processDebugJavaRes UP-TO-DATE
:app:compileDebugJavaWithJavac UP-TO-DATE
:app:compileDebugNdk UP-TO-DATE
:app:compileDebugSources UP-TO-DATE
:app:preDexDebug UP-TO-DATE
:app:dexDebug UP-TO-DATE
:app:validateDebugSigning
:app:packageDebug UP-TO-DATE
:app:zipalignDebug UP-TO-DATE
:app:assembleDebug UP-TO-DATE
:app:installDebug
Installing APK 'app-debug.apk' on 'reactnative(AVD) - 6.0'
Installed on 1 device.
BUILD SUCCESSFUL
Total time: 20.947 secs直到“BUILD SUCCESSFUL”。
这一步是问题最多的,务必确认android/app/src/build.gradle里的sdk和build tool版本已经(在SDK Manager)安装。
笔者碰到的问题是“unable to download js bundle”,如下图:
经过几番折腾,发现是watchman版本问题,更新下即可:
$ brew update && brew upgrade watchman编译安装好apk之后,就可以在模拟器启动app:
app只需要编译一遍,安装到模拟器里边之后,以后的开发只需要打开app+刷新app即可看到更新的效果。
Android版本是通过Fn+F2来刷新,iOS是通过control+r来刷新。
通过以下命令来监听文件的改变以达到实时刷新:
$ react-native start致此,开发环境算是搭建起来的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.