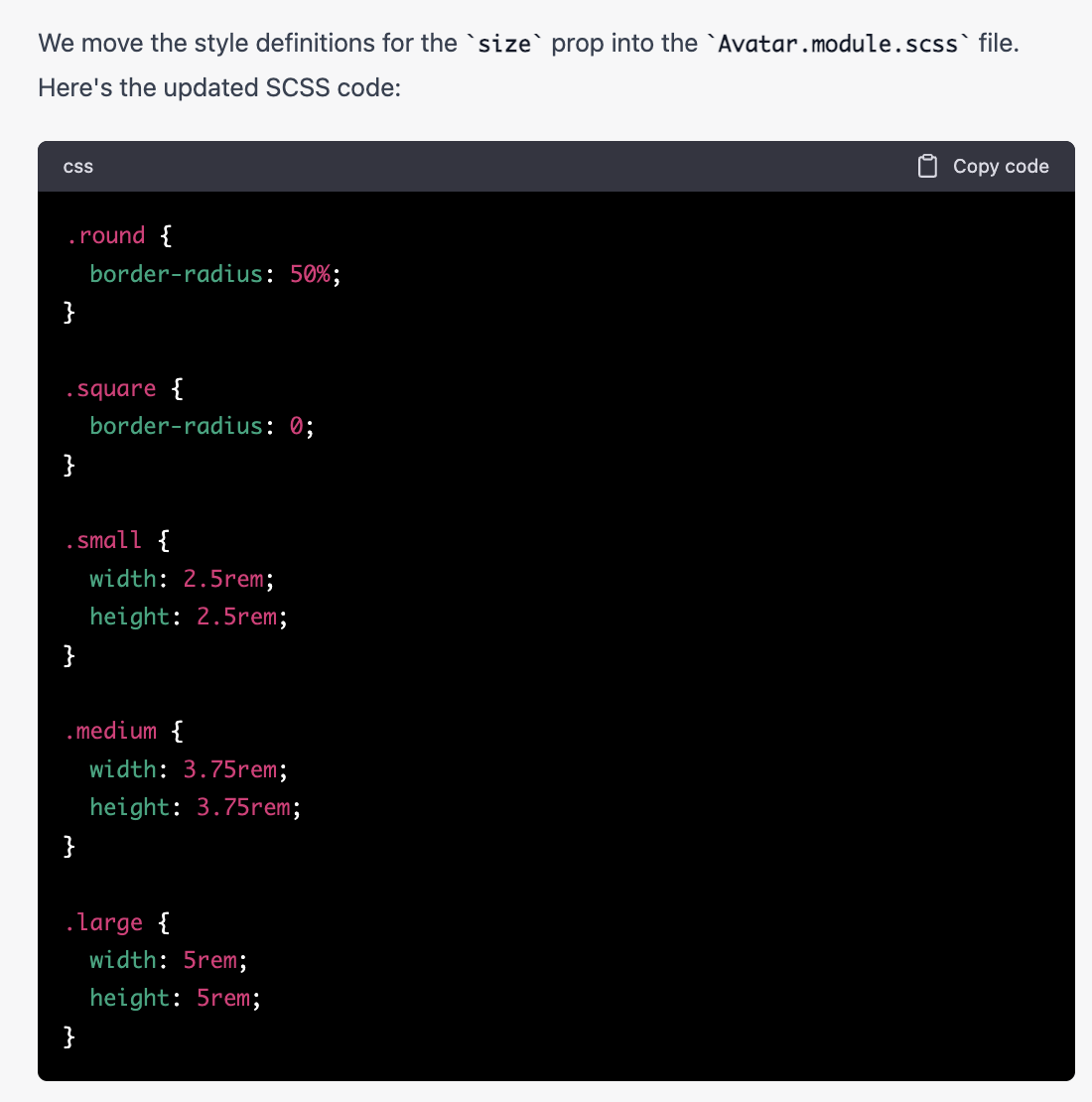
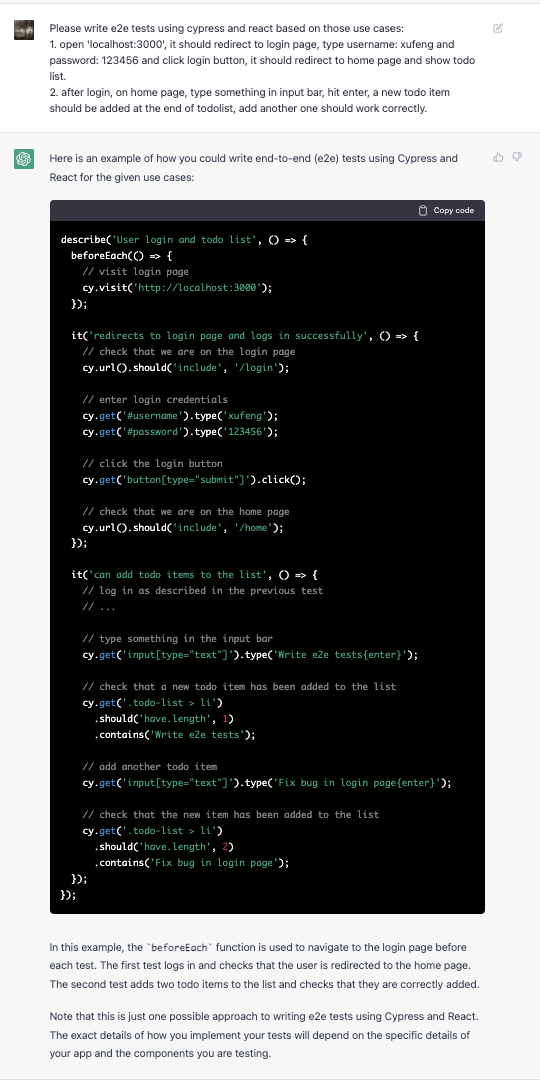
What is React Server Component(RSC)?
React Server Component is a new feature of React that allows the server and the client(browser) to collaborate in rendering React applications. Simply put, it moves part of the rendering process to the server to improve the overall performance.
Typical Construction Flow of React Element Tree
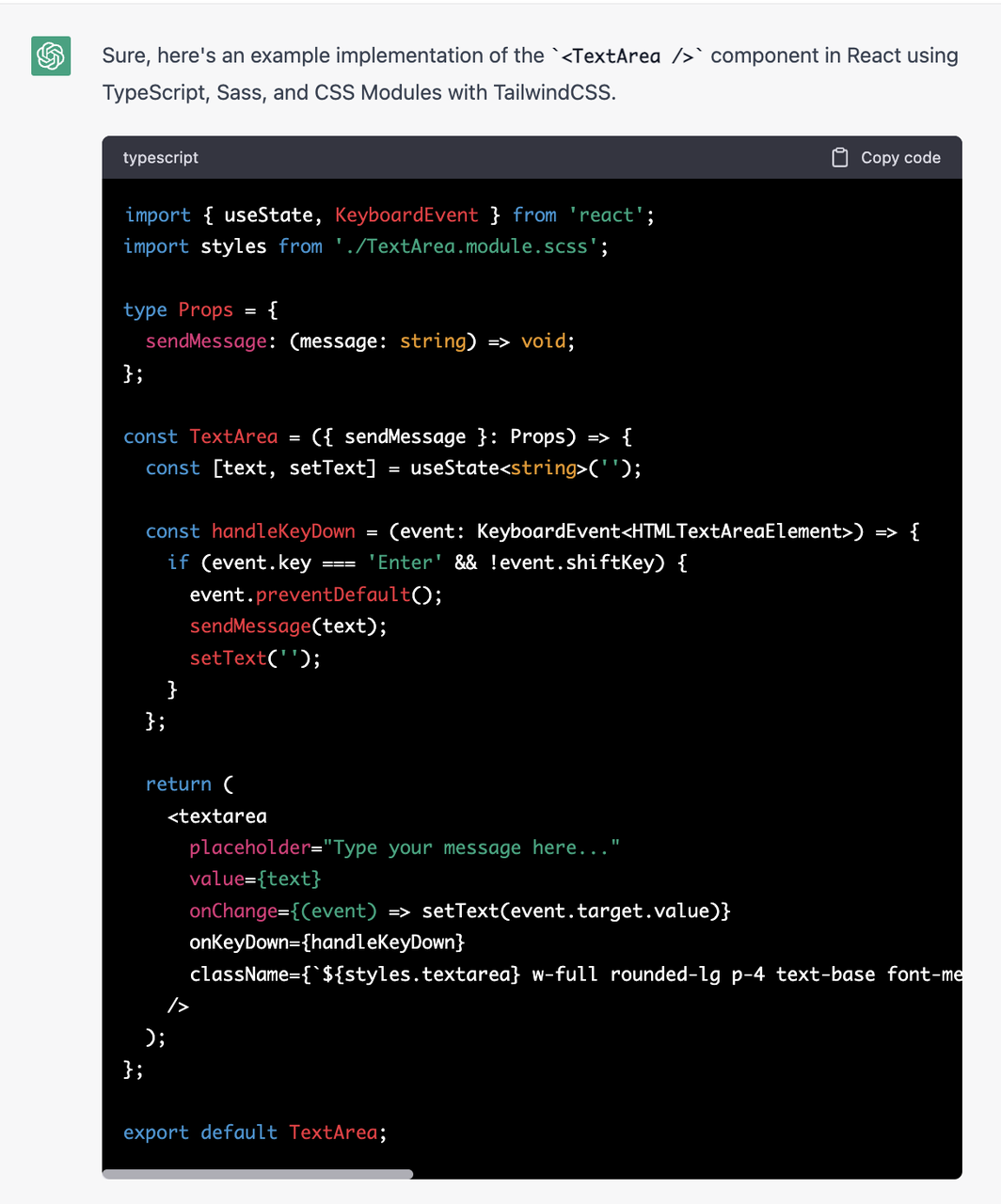
To better understand why we need to move the rendering process to the server, let's look at how the client-side render method renders a react element tree(JSX):
// App Component
function App() {
return (
<div>
<ComponentA />
<ComponentB />
</div>
);
}
// ComponentA
function ComponentA() {
return <h1 onClick={() => alert("cool!")}>Hello from Component A</h1>;
}
// ComponentB
function ComponentB() {
const data = await fetchDataApi();
return <div>{data} fetched from Component B</div>;
}The above Components will be transformed into Virtual DOM(react element tree) after we use React.createElement to render it:
const App = {
$$typeof: Symbol(react.element),
type: "div",
props: {
children: [
{
$$typeof: Symbol(react.element),
type: ComponentA,
props: {
children: [
$$typeof: Symbol(react.element),
type: "h1",
props: {
onClick: () => alert("cool!")
},
]
},
},
{
$$typeof: Symbol(react.element),
type: ComponentB,
props: {
children: [
// ...
]
},
}
]
},
}Then ReactDOM.render will render this react element tree into HTML format and attach it to HTML.
Two things to notice here are:
- The whole tree construction process is done in the browser: This means that if one of your components has heavy logic like
ComponentB's fetchData, it will slow down the tree construction and occupy the resource of the browser.
- There are function existed in this tree(type, onClick prop): This makes the Serialization(Turn the tree to a JSON string) infeasible.
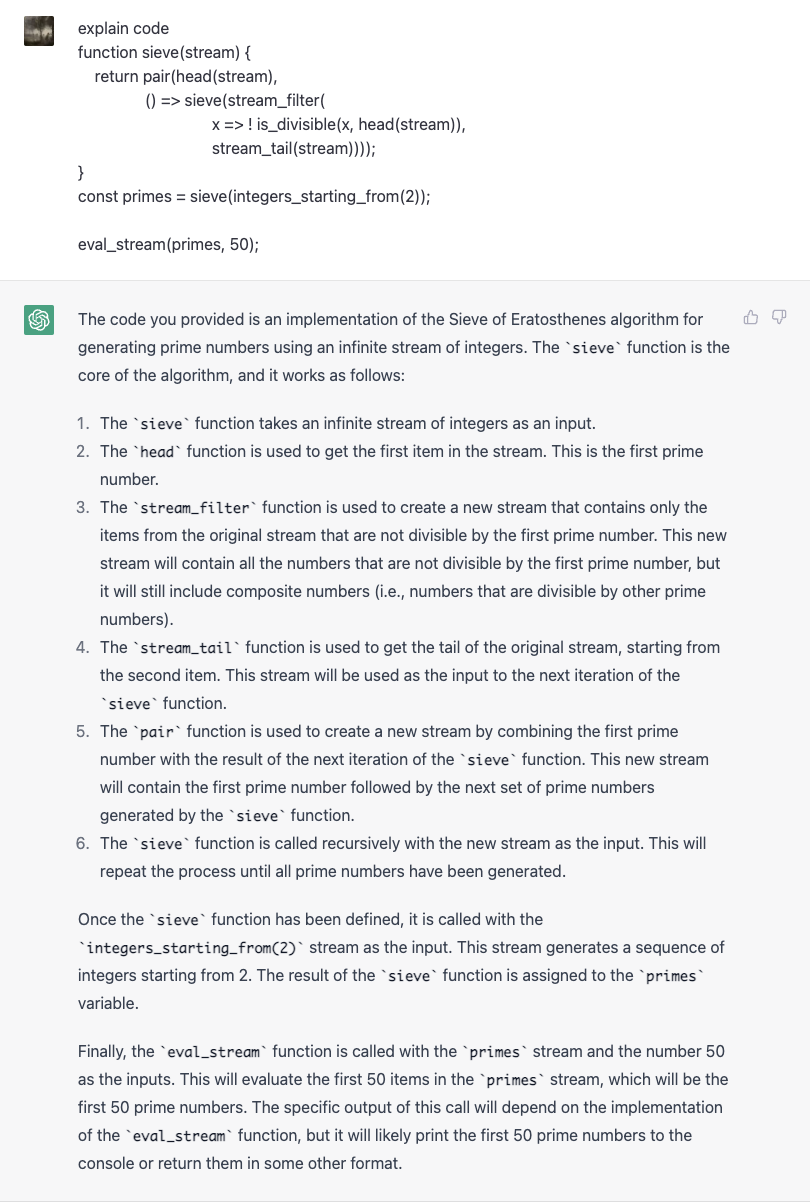
RSC Construction Flow of React Element Tree
RSC improves the performance via separating those calculation-intense components rendered as server components, while those components that create interactive logic are handled by the client as client components.
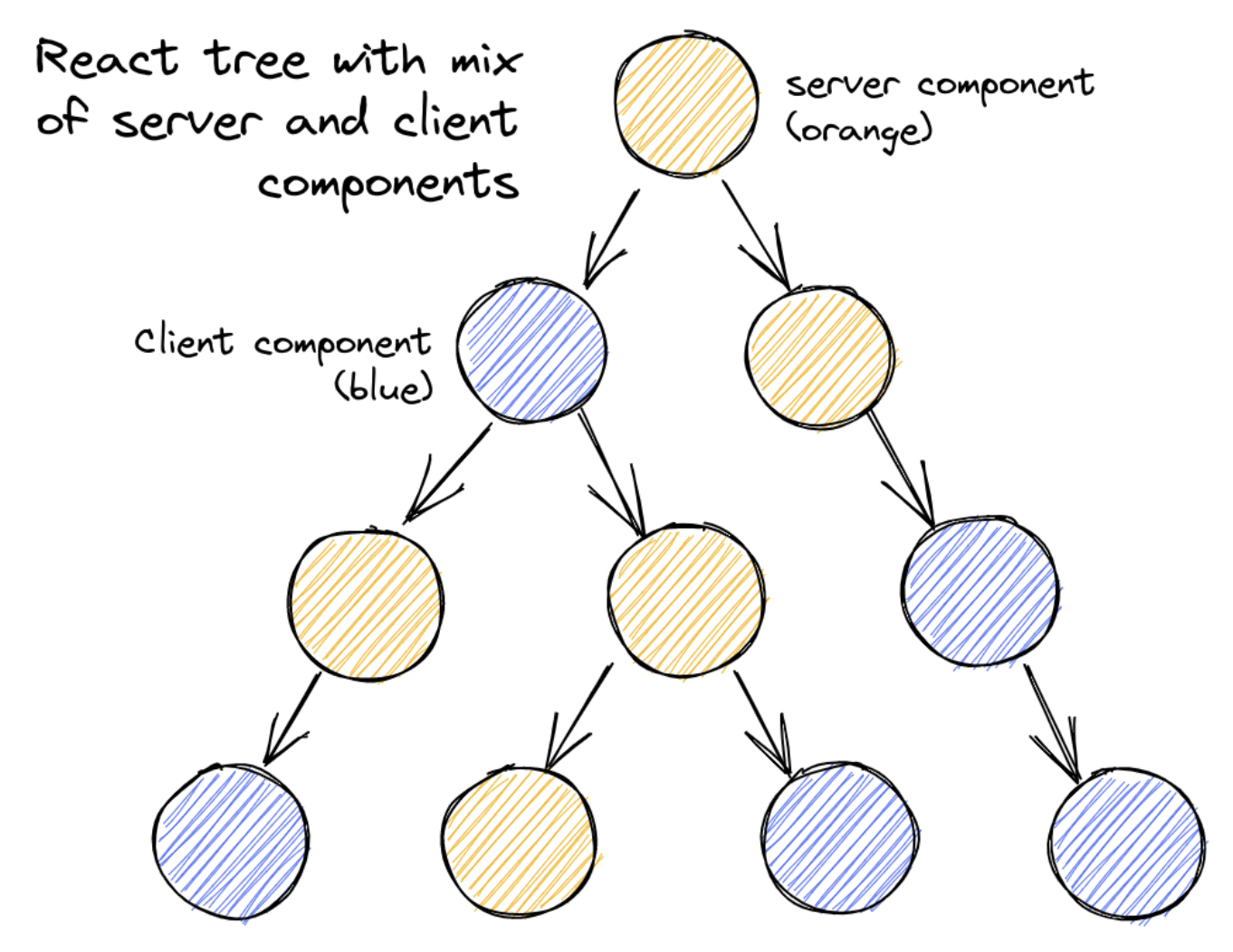
When a client requires a server component, the server side will first construct the react element tree by parsing all server components on the tree skipping all client components, and leaving a placeholder with an instruction to tell the client side to fill it up in a browser(We will walk through the detail implementation later).
So when user open a page build with rsc, they will typically see server components are rendered, and then the components with interactive logic are rendered.
What's the differences between RSC and SSR?
There is another concept that is easy to mix with RSC, which is SSR(server-side rendering). Though they all doing some jobs in server side, they are quite different.
The main difference is granularity. SSR renders a page on server side each request, while the RSC render a component each request, and it request the client side to fill up all the placeholder inside the component to finish.
In other word, SSR's output is a HTML, and RSC's output is a react element tree.
In SSR, after client side gets the HTML, it will use (hydrate(reactNode, domNode, callback?)[https://react.dev/reference/react-dom/hydrate] to attach the html with react node, so that the react can take care of DOM(enabling interactive events). And RSC doesn't require hydrate process because client components are rendered in browser.
Why RSC?
So what is the benefits of RSC? The browser is a good place for this, because it allows your React application to be interactive — you can install event handlers, keep track of state, mutate your React tree in response to events, and update the DOM efficiently. But in these use cases, react server components could be a better choice:
- Rendering a slice of data(fetching a lot of data): Rendering the component in server side can allow you directly access the data, you don't need to hop through different public API endpoint. And if your component only require a small slice of data, this can reduce the bundle size of client request because it only return the data that it needs.
- Access sensitive logic and data: server component is stored and ran in server, which means that you don't need to expose your data and logic to public, this increases safety.
- Loading heavy code module: When other people try hard to think about how to use limited resource of browser to load heavy code module(like using service worker), you put the code in server instead, the server is more scalable and stable with much more resource than browser.
Components
Without further ado, let's start introducing how react(and other frameworks) implement RSC. To control the complexity, we will separate the RSC system into several components, simplified them and build them one by one.
Serialization
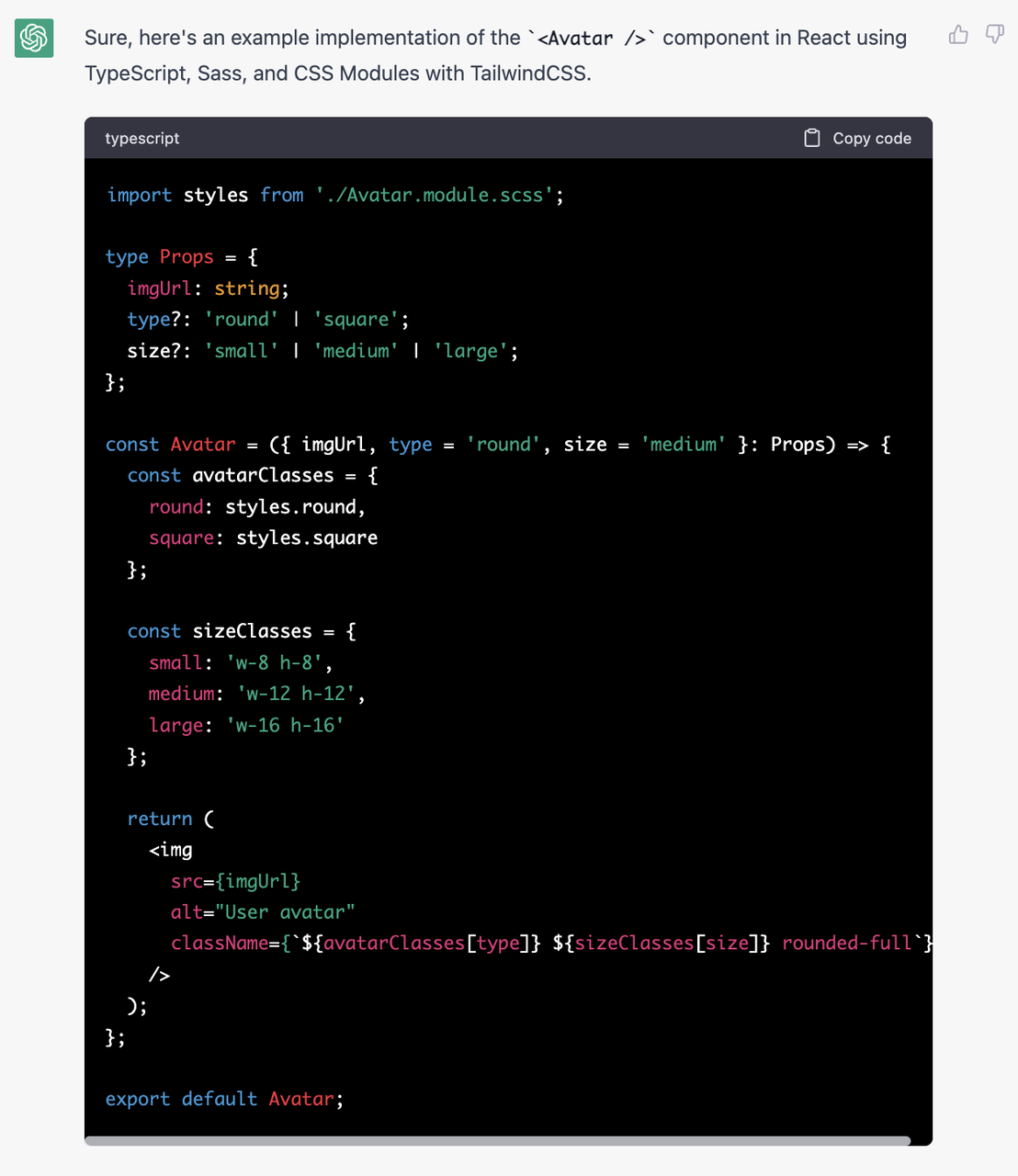
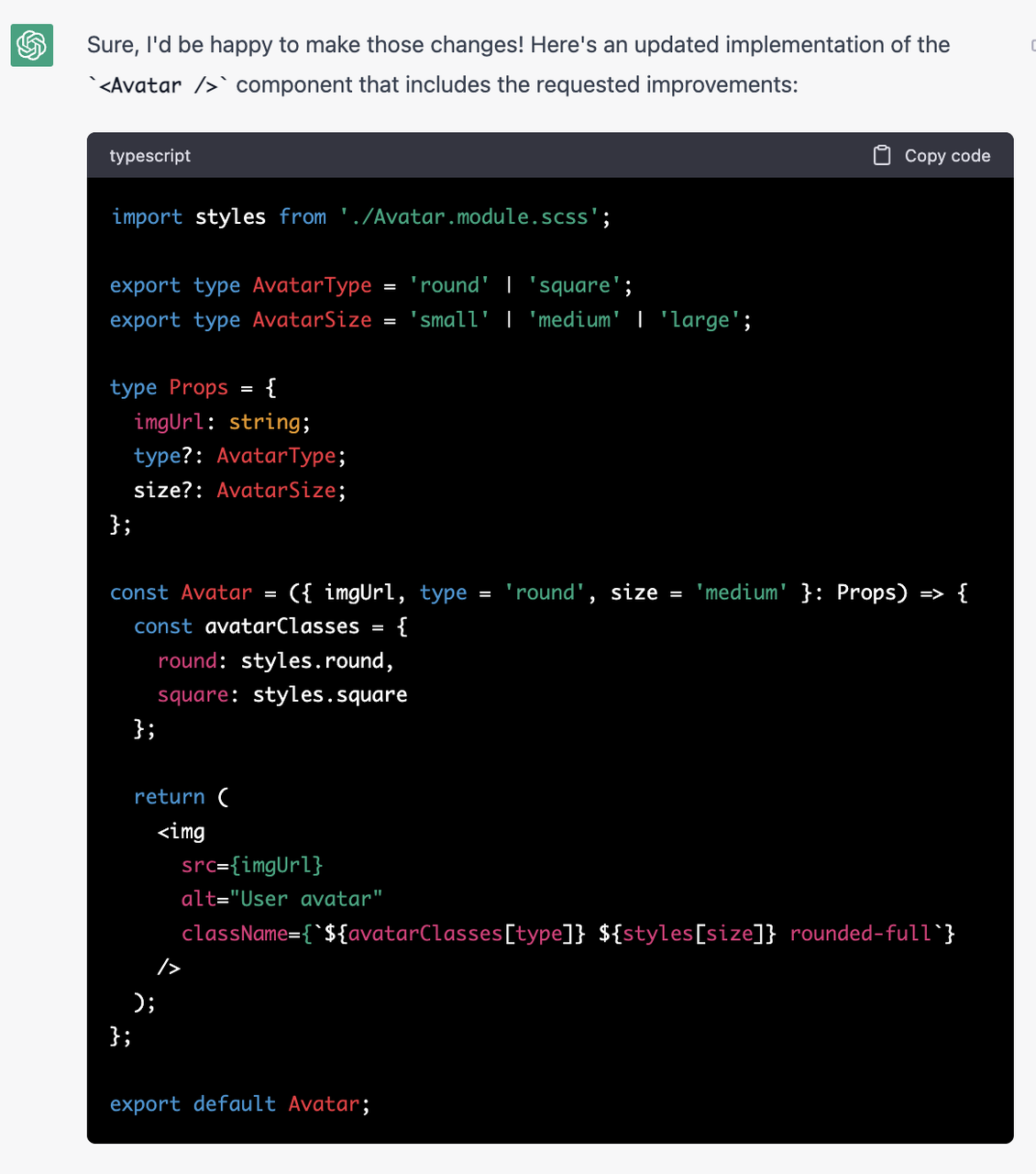
The life of a page using RSC always starts at the server, server will render an incomplete serializable react element tree and send to client, let the client to fill up the tree and render as HTML. Let's start by looking at how server render an serializable react element tree in this section.
- Separate server component from client component: In order to handle the component correctly, we need a way to separate server/client component. React team defines this based on the extension of the file:
.server.jsx and .client.jsx. This Definition is easy for humans and bundlers to tell them apart.
We modify our previous example a bit using RSC like this:
// App.server.jsx
function App() {
return (
<div>
<ComponentA />
<ComponentB />
</div>
);
}
// ComponentA.client.jsx
function ComponentA() {
return <h1 onClick={() => alert("cool!")}>Hello from Component A</h1>;
}
// ComponentB.server.jsx
function ComponentB() {
const data = await fetchDataApi();
return <div>{data} fetched from Component B</div>;
}The serialization output is like this:
const App = {
$$typeof: Symbol(react.element),
type: "div",
props: {
children: [
// ComponentA client component
{
$$typeof: Symbol(react.element),
type: ComponentA,
props: {
children: [
$$typeof: Symbol(react.element),
type: "h1",
props: {
onClick: () => alert("cool!")
},
]
},
},
// ComponentB server component
{
$$typeof: Symbol(react.element),
type: ComponentB,
props: {
children: [
// ...
]
},
}
]
},
}There are two things that it is not available to serialize here:
- The
type field: type field is a function when it is a react component, which is not JSON-serializable.(It is coupling with memory.)
- The props of client component: client component may contain
onClick: () => alert("cool!") function, which is also not JSON-serializable.
To JSON-stringify everything, react passes a replacer function to JSON.stringify, to deal with the type function reference and replace client component with a placeholder. Check out the source code (resolveModelToJSON)[https://github.com/facebook/react/blob/42c30e8b122841d7fe72e28e36848a6de1363b0c/packages/react-server/src/ReactFlightServer.js#L368].
Here I create a simplified version to help you understand:
// value is the react model we pass
// this is in server side so we have request context
export function resolveModelToJSON(request, parent, key, value) {
while (
typeof value === 'object' &&
value !== null &&
value.$$typeof === REACT_ELEMENT_TYPE
) {
const element: React$Element<any> = value;
// server component or plain html element
try {
value = attemptResolveElement(
element.type,
element.key,
element.ref,
element.props,
);
}
}
// client side component
if (isModuleReference(value)) {
// get file path like "./src/ClientComponent.client.js"
// name is the file export, e.g. name: "default" -> ClientComponent is the default export...
const moduleMetaData: ModuleMetaData = resolveModuleMetaData(
request.bundlerConfig,
moduleReference,
);
// placeholder++
request.pendingChunks++;
// assign an ID for this module
const moduleId = request.nextChunkId++;
// add module meta data to chunk
emitModuleChunk(request, moduleId, moduleMetaData);
// cache
writtenModules.set(moduleKey, moduleId);
// return id as a reference
return serializeByValueID(moduleId);
}
}
function attemptResolveElement(
type: any,
key: null | React$Key,
ref: mixed,
props: any,
): ReactModel {
// ...
if (typeof type === 'function') {
// This is a server-side component.
// render it directly using props and return the result
return type(props);
} else if (typeof type === 'string') {
// This is a host element. E.g. HTML.
// It is already serializable, return it directly
return [REACT_ELEMENT_TYPE, type, key, props];
}
// client component, leave it here
// This might be a built-in React component. We'll let the client decide.
// Any built-in works as long as its props are serializable.
return [REACT_ELEMENT_TYPE, type, key, props];
// ...
}
type ModuleMetaData = {
id: string,
name: string,
};
function resolveModuleMetaData() {
// ...
return {
id: moduleReference.filepath,
name: moduleReference.name,
};
}The output of client component is like this:
{
$$typeof: Symbol(react.element),
// The type field now has a reference object,
// instead of the actual component function
type: {
$$typeof: Symbol(react.module.reference),
// ClientComponent is the default export...
name: "default",
// from this file!
filename: "./src/ClientComponent.client.js"
},
props: { children: "oh my" },
}This whole process happens during bundling. React has a official react-server-dom-webpack loader which can match *.client.jsx and turn them to moduleReference object.
At the end of the serialization process, we send a JSON that represent this serializable React tree to client like this:
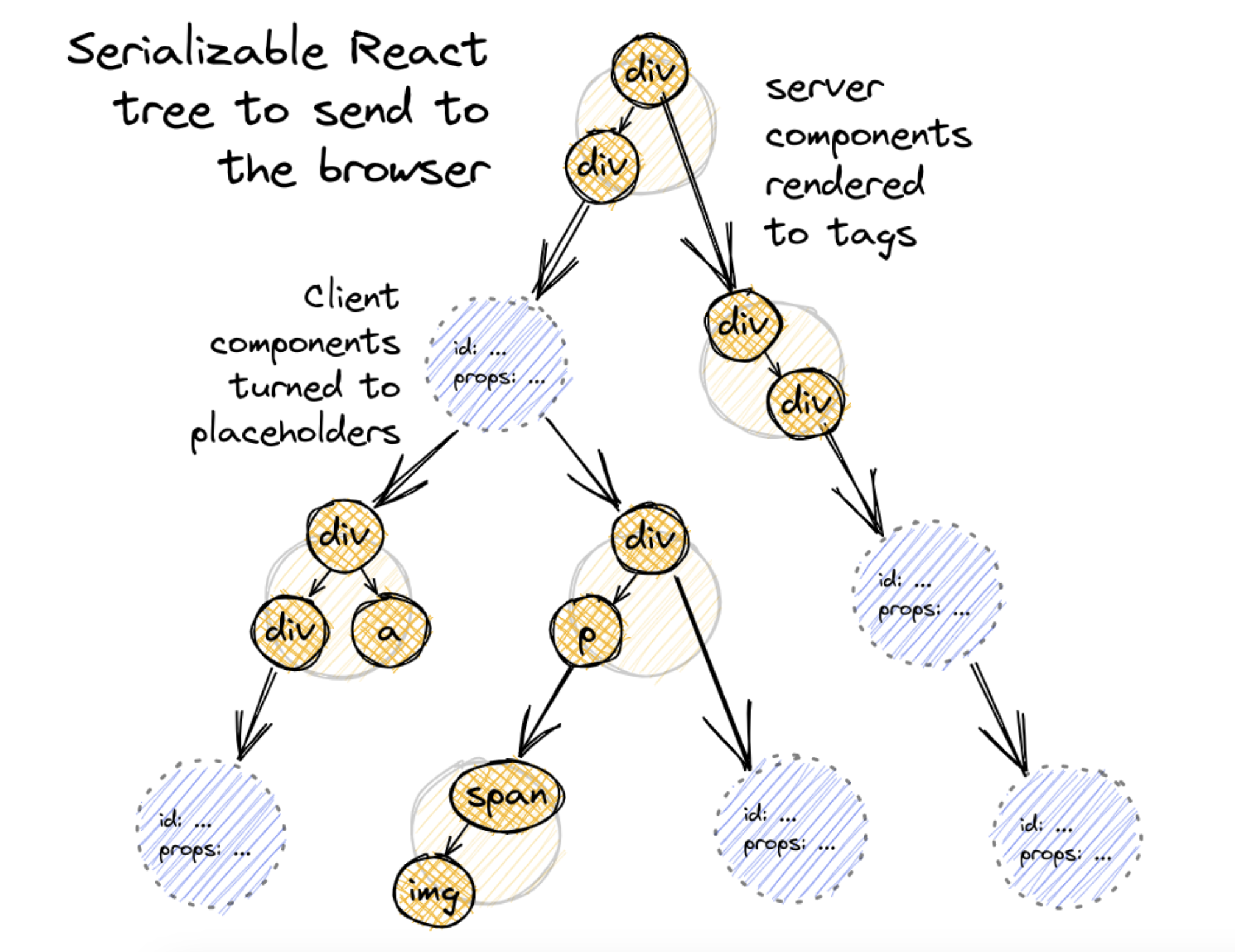
Three things happened:
- html tags keep the same.
- server components rendered.
- client components became
moduleReference object.
Suspense(Streaming)
Now we managed to separate part of work to server, so that we can expect a better performance when rendering. Because the output is serializable, we can do even more. Now client side needs to wait until the whole react element tree is received from server side, there are a lot of time is wasted in client side. We can apply streaming concept to make this process progressively. Streaming means that server side will send the react element tree slice by slice during the construction process, instead of sending the whole tree until the construction is done. The Suspense feature in react plays an important role to implement this.
// The Suspense component allows us to wait for the DataFetchingComponent to load
// while showing some fallback content.
// When the DataFetchingComponent is loaded, it will replace the fallback content.
function DataFetchingComponent() {
const [data, setData] = useState(null);
// Fetch data on component mount
useEffect(() => {
fetchData().then(data => setData(data));
}, []);
// If data is not yet fetched, return null
if (!data) return null;
return <div>{data}</div>;
}
function App() {
return (
// Wrap the data fetching component inside the Suspense component
<Suspense fallback={<div>Loading...</div>}>
<DataFetchingComponent />
</Suspense>
);
}There are two places that RSC will use suspense feature to optimaze performance:
- Server component rendering
Server component utilizes this feature to output a suspense placeholder(promise) when the server component is fetching data, or doing heavy calculation before finishing rendering. Once the rendering is finished, it will push a completed component chunk to client side and ask it to fill up the tree.
Here is the simple implementation:
export function resolveModelToJSON(
request: Request,
parent: {+[key: string | number]: ReactModel} | $ReadOnlyArray<ReactModel>,
key: string,
value: ReactModel,
): ReactJSONValue {
// Resolve server components.
while (
typeof value === 'object' &&
value !== null &&
value.$$typeof === REACT_ELEMENT_TYPE
) {
// TODO: Concatenate keys of parents onto children.
const element: React$Element<any> = (value: any);
try {
// Attempt to render the server component.
value = attemptResolveElement(
element.type,
element.key,
element.ref,
element.props,
);
} catch (x) {
if (typeof x === 'object' && x !== null && typeof x.then === 'function') {
// Something suspended, we'll need to create a new segment and resolve it later.
request.pendingChunks++;
const newSegment = createSegment(request, value);
const ping = newSegment.ping;
// when x promise is finished, push completed chunk to client side
x.then(ping, ping);
return serializeByRefID(newSegment.id);
}
}
}
}
- Client component rendering
Remember when server sends react element tree to client side, client components are still yet to render, so they will suspense first until the client renders them.
This suspense and stream feature enable the browser too incrementally render the data as they become available.
You might wonder how can a react element tree(JSON) become a stream, react server component use a simple format to make this possible. The format is like this:
M1:{"id":"./src/ClientComponent.client.js","chunks":["client1"],"name":""}
J0:["$","@1",null,{"children":["$","span",null,{"children":"Hello from server land"}]}]The lines that start with M defines a client component module reference, with the information needed to look up the component function in the client bundles.
The line starting with J defines an actual React element tree, with things like @1 referencing client components defined by the M lines.
This format is very streamable — Given that each row is a module/component, as soon as the client has read a whole row, it can parse a snippet of JSON and make some progress.
// Tweets.server.js
import { fetch } from 'react-fetch' // React's Suspense-aware fetch()
import Tweet from './Tweet.client'
export default function Tweets() {
const tweets = fetch(`/tweets`).json()
return (
<ul>
{tweets.slice(0, 2).map((tweet) => (
<li>
<Tweet tweet={tweet} />
</li>
))}
</ul>
)
}
// Tweet.client.js
export default function Tweet({ tweet }) {
return <div onClick={() => alert(`Written by ${tweet.username}`)}>{tweet.body}</div>
}
// OuterServerComponent.server.js
export default function OuterServerComponent() {
return (
<ClientComponent>
<ServerComponent />
<Suspense fallback={'Loading tweets...'}>
<Tweets />
</Suspense>
</ClientComponent>
)
}The output stream is like this:
M1:{"id":"./src/ClientComponent.client.js","chunks":["client1"],"name":""}
S2:"react.suspense"
J0:["$","@1",null,{"children":[["$","span",null,{"children":"Hello from server land"}],["$","$2",null,{"fallback":"Loading tweets...","children":"@3"}]]}]
M4:{"id":"./src/Tweet.client.js","chunks":["client8"],"name":""}
J3:["$","ul",null,{"children":[["$","li",null,{"children":["$","@4",null,{"tweet":{...}}}]}],["$","li",null,{"children":["$","@4",null,{"tweet":{...}}}]}]]}]J0 now has a suspense boundary, and inside the boundary, there is a @3 that has not finished rendering and pushed to the stream. RSC continue push M4 to the stream and when @3 is ready, it is push to the stream as J3.
Client Reconstructs the React Tree
When client receives the React Tree stream, it will start reconstructing the completed React tree and render to HTML progressively.
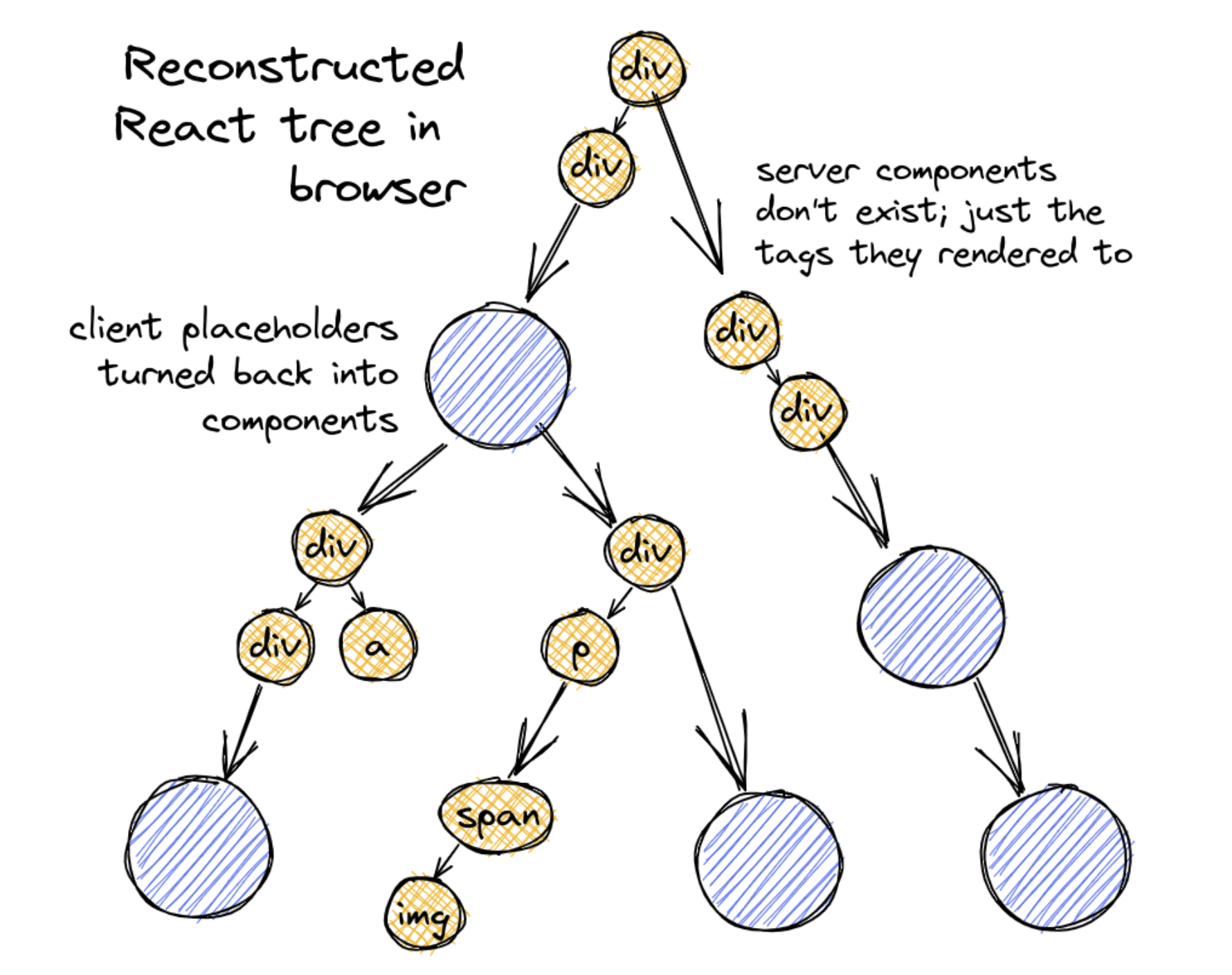
React provides a method called createFromFetch in react-server-dom-webpack to render RSC. The basic usage is like this:
import { createFromFetch } from 'react-server-dom-webpack'
function ClientRootComponent() {
// fetch() from our RSC API endpoint. react-server-dom-webpack
// can then take the fetch result and reconstruct the React
// element tree
const response = createFromFetch(fetch('/rsc?...'))
return <Suspense fallback={null}>{response.readRoot() /* Returns a React element! */}</Suspense>
}response.readRoot() read the stream from /rsc?... and update the react element progressively.