连续获取一个或多个微博关键词搜索结果,并将结果写入文件(可选)、数据库(可选)等。所谓微博关键词搜索即:搜索正文中包含指定关键词的微博,可以指定搜索的时间范围。
举个栗子,比如你可以搜索包含关键词“迪丽热巴”且发布日期在2020-03-01和2020-03-16之间的微博。搜索结果数量巨大,对于非常热门的关键词,在一天的指定时间范围,可以获得1000万以上的搜索结果。注意这里的一天指的是时间筛选范围,具体多长时间将这1000万微博下载到本地还要看获取的速度。1000万只是一天时间范围可获取的微博数量,如果想获取更多微博,可以加大时间范围,比如10天,最多可以获得1000万X10=1亿条搜索结果,当然你也可以再加大时间范围。对于大多数关键词,微博一天产生的相关搜索结果应该低于1000万,因此可以说本程序可以获取指定关键词的全部或近似全部的搜索结果。本程序可以获得几乎全部的微博信息,如微博正文、发布者等,详情见输出部分。支持输出多种文件类型,具体如下:
- 写入csv文件(默认)
- 写入MySQL数据库(可选)
- 写入MongoDB数据库(可选)
- 下载微博中的图片(可选)
- 下载微博中的视频(可选)
- 微博id:微博的id,为一串数字形式
- 微博bid:微博的bid
- 微博内容:微博正文
- 头条文章url:微博中头条文章的url,若某微博中不存在头条文章,则该值为''
- 原始图片url:原创微博图片和转发微博转发理由中图片的url,若某条微博存在多张图片,则每个url以英文逗号分隔,若没有图片则值为''
- 视频url: 微博中的视频url和Live Photo中的视频url,若某条微博存在多个视频,则每个url以英文分号分隔,若没有视频则值为''
- 微博发布位置:位置微博中的发布位置
- 微博发布时间:微博发布时的时间,精确到天
- 点赞数:微博被赞的数量
- 转发数:微博被转发的数量
- 评论数:微博被评论的数量
- 微博发布工具:微博的发布工具,如iPhone客户端、HUAWEI Mate 20 Pro等,若没有则值为''
- 话题:微博话题,即两个#中的内容,若存在多个话题,每个url以英文逗号分隔,若没有则值为''
- @用户:微博@的用户,若存在多个@用户,每个url以英文逗号分隔,若没有则值为''
- 原始微博id:为转发微博所特有,是转发微博中那条被转发微博的id,那条被转发的微博也会存储,字段和原创微博一样,只是它的本字段为空
- 结果文件:保存在当前目录“结果文件”文件夹下以关键词为名的文件夹里
- 微博图片:微博中的图片,保存在以关键词为名的文件夹下的images文件夹里
- 微博视频:微博中的视频,保存在以关键词为名的文件夹下的videos文件夹里
- user_authentication:微博用户类型,值分别是
蓝v,黄v,红v,金v和普通用户
本程序的所有配置都在setting.py文件中完成,该文件位于“weibo-search\weibo\settings.py”。
$ git clone https://github.com/dataabc/weibo-search.git本程序依赖Scrapy,要想运行程序,需要安装Scrapy。如果系统中没有安装Scrapy,请根据自己的系统安装Scrapy,以Ubuntu为例,可以使用如下命令:
$ pip install scrapy$ pip install -r requirements.txt
DEFAULT_REQUEST_HEADERS中的cookie是我们需要填的值,如何获取cookie详见如何获取cookie,获取后将"your cookie"替换成真实的cookie即可。
修改setting.py文件夹中的KEYWORD_LIST参数。 如果你想搜索一个关键词,如“迪丽热巴”:
KEYWORD_LIST = ['迪丽热巴']
如果你想分别搜索多个关键词,如想要分别获得“迪丽热巴”和“杨幂”的搜索结果:
KEYWORD_LIST = ['迪丽热巴', '杨幂']
如果你想搜索同时包含多个关键词的微博,如同时包含“迪丽热巴”和“杨幂”微博的搜索结果:
KEYWORD_LIST = ['迪丽热巴 杨幂']
如果你想搜索微博话题,即包含#的内容,如“#迪丽热巴#”:
KEYWORD_LIST = ['#迪丽热巴#']
也可以把关键词写进txt文件里,然后将txt文件路径赋值给KEYWORD_LIST,如:
KEYWORD_LIST = 'keyword_list.txt'
txt文件中每个关键词占一行。
START_DATE代表搜索的起始日期,END_DATE代表搜索的结束日期,值为“yyyy-mm-dd”形式,程序会搜索包含关键词且发布时间在起始日期和结束日期之间的微博(包含边界)。比如我想筛选发布时间在2020-06-01到2020-06-02这两天的微博:
START_DATE = '2020-06-01'
END_DATE = '2020-06-02'
FURTHER_THRESHOLD是程序是否进一步搜索的阈值。一般情况下,如果在某个搜索条件下,搜索结果很多,则搜索结果应该有50页微博,多于50页不显示。当总页数等于50时,程序认为搜索结果可能没有显示完全,所以会继续细分。比如,若当前是按天搜索的,程序会把当前的1个搜索分成24个搜索,每个搜索条件粒度是小时。这样就能获取在天粒度下无法获取完全的微博。同理,如果小时粒度下总页数仍然是50,会继续细分,以此类推。然而,有一些关键词,搜索结果即便很多,也只显示40多页。所以此时如果FURTHER_THRESHOLD是50,程序会认为只有这么多微博,不再继续细分,导致很多微博没有获取。因此为了获取更多微博,FURTHER_THRESHOLD应该是小于50的数字。但是如果设置的特别小,如1,这样即便结果真的只有几页,程序也会细分,这些没有必要的细分会使程序速度降低。因此,建议FURTHER_THRESHOLD的值设置在40与46之间:
FURTHER_THRESHOLD = 46
ITEM_PIPELINES是我们可选的结果保存类型,第一个代表去重,第二个代表写入csv文件,第三个代表写入MySQL数据库,第四个代表写入MongDB数据库,第五个代表下载图片,第六个代表下载视频。后面的数字代表执行的顺序,数字越小优先级越高。如果你只要写入部分类型,可以把不需要的类型用“#”注释掉,以节省资源;如果你想写入数据库,需要在setting.py填写相关数据库的配置。
DOWNLOAD_DELAY代表访问完一个页面再访问下一个时需要等待的时间,默认为10秒。如我想设置等待15秒左右,可以修改setting.py文件的DOWNLOAD_DELAY参数:
DOWNLOAD_DELAY = 15
WEIBO_TYPE筛选要搜索的微博类型,0代表搜索全部微博,1代表搜索全部原创微博,2代表热门微博,3代表关注人微博,4代表认证用户微博,5代表媒体微博,6代表观点微博。比如我想要搜索全部原创微博,修改setting.py文件的WEIBO_TYPE参数:
WEIBO_TYPE = 1
CONTAIN_TYPE筛选结果微博中必需包含的内容,0代表不筛选,获取全部微博,1代表搜索包含图片的微博,2代表包含视频的微博,3代表包含音乐的微博,4代表包含短链接的微博。比如我想筛选包含图片的微博,修改setting.py文件的CONTAIN_TYPE参数:
CONTAIN_TYPE = 1
REGION筛选微博的发布地区,精确到省或直辖市,值不应包含“省”或“市”等字,如想筛选北京市的微博请用“北京”而不是“北京市”,想要筛选安徽省的微博请用“安徽”而不是“安徽省”,可以写多个地区,具体支持的地名见region.py文件,注意只支持省或直辖市的名字,省下面的市名及直辖市下面的区县名不支持,不筛选请用”全部“。比如我想要筛选发布地在山东省的微博:
REGION = ['山东']
MONGO_URI是MongoDB数据库的配置;
MYSQL开头的是MySQL数据库的配置。
$ scrapy crawl search -s JOBDIR=crawls/search其实只运行“scrapy crawl search”也可以,只是上述方式在结束时可以保存进度,下次运行时会在程序上次的地方继续获取。注意,如果想要保存进度,请使用“Ctrl + C”一次,注意是一次。按下“Ctrl + C”一次后,程序会继续运行一会,主要用来保存获取的数据、保存进度等操作,请耐心等待。下次再运行时,只要再运行上面的指令就可以恢复上次的进度。如果再次运行没有结果,可能是进度没有正确保存,可以先删除crawls文件夹内的进度文件,再运行上述命令。
- 用Chrome打开 https://weibo.com/
- 点击"立即登录", 完成私信验证或手机验证码验证, 进入新版微博. 如下图所示:

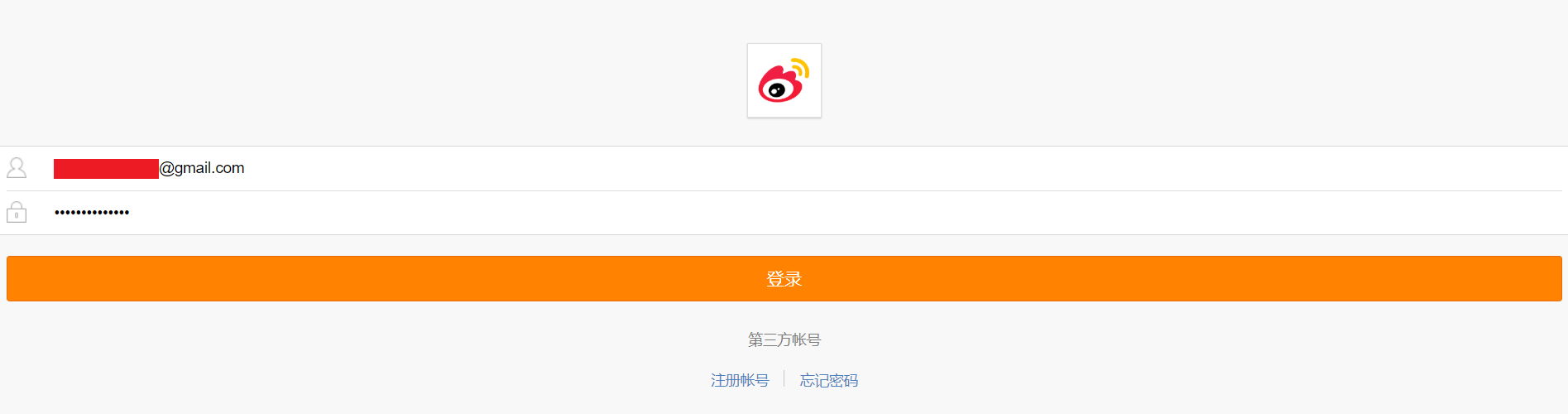
1.用Chrome打开https://passport.weibo.cn/signin/login;
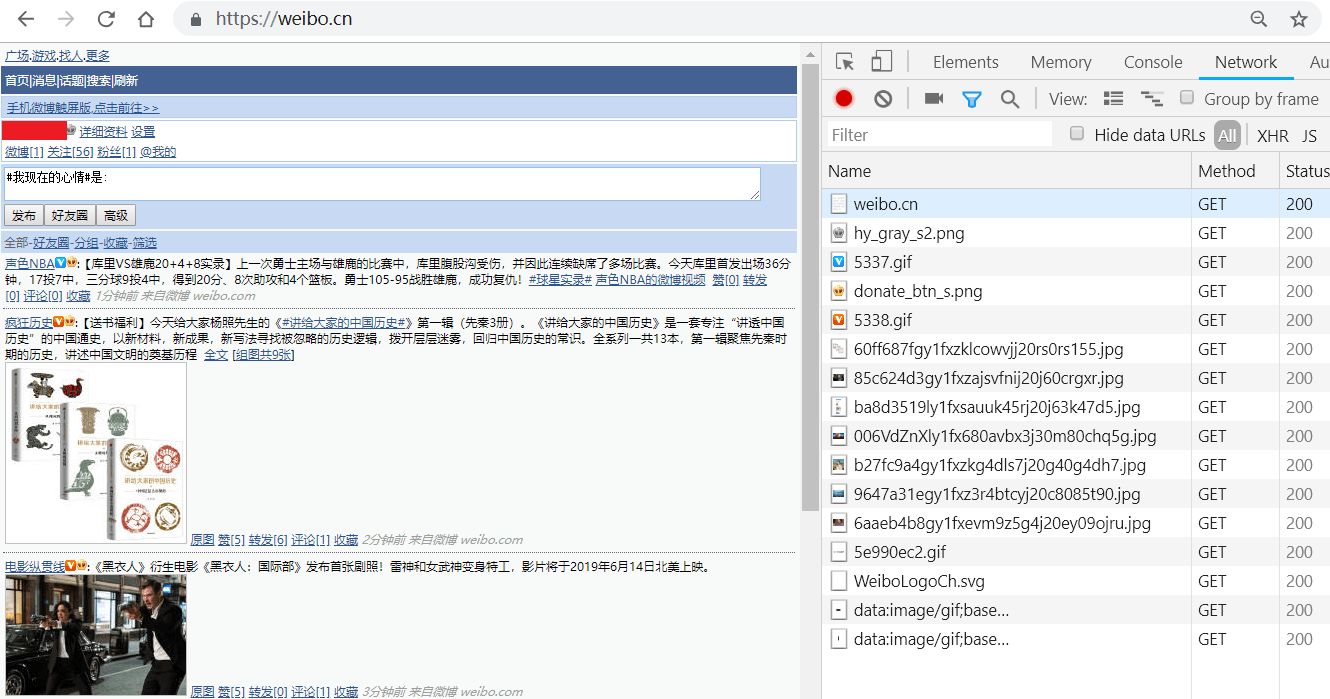
2.输入微博的用户名、密码,登录,如图所示:登录成功后会跳转到https://m.weibo.cn;
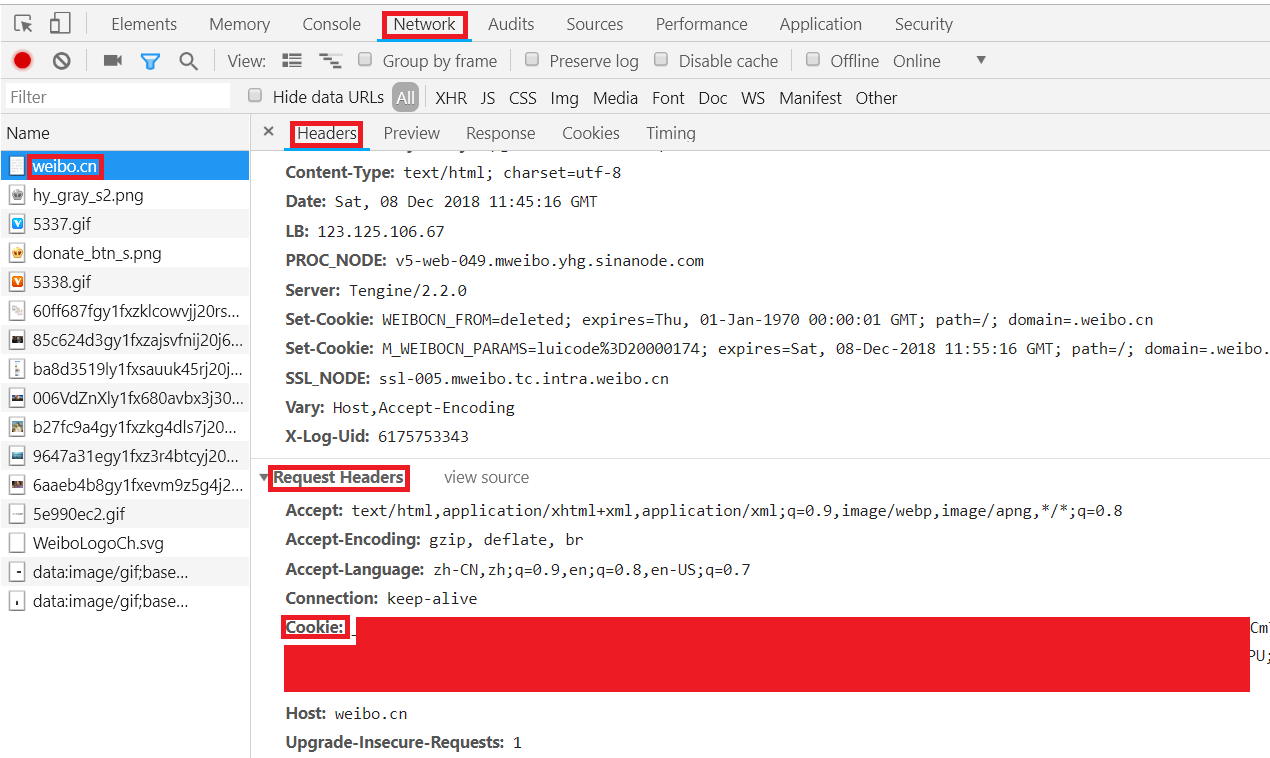
3.按F12键打开Chrome开发者工具,在地址栏输入并跳转到https://weibo.cn,跳转后会显示如下类似界面:4.依此点击Chrome开发者工具中的Network->Name中的weibo.cn->Headers->Request Headers,"Cookie:"后的值即为我们要找的cookie值,复制即可,如图所示: