ddangelov / top2vec Goto Github PK
View Code? Open in Web Editor NEWTop2Vec learns jointly embedded topic, document and word vectors.
License: BSD 3-Clause "New" or "Revised" License
Top2Vec learns jointly embedded topic, document and word vectors.
License: BSD 3-Clause "New" or "Revised" License











































































































































In CORD-19_top2vec.ipynb, the attribute 'has_full_text' has been renamed:
E.g. from meatadata.readme:
has_pdf_parse and full_text_filepdf_json_files, which now stores the relative paths to theHi there. I'm trying to use this module on some tweets. I found the word clouds generating from each topic almost has the same elements.
Is there any way to make each topic more distinguishable from the others?
Thanks in advance.
RuntimeError: you must first build vocabulary before training the model
when run
model = Top2Vec(documents=newsgroups.data, speed="learn", workers=8)
gives an error.

Is this possible to be forked and trained with a GPU?
In code documentation it is mentioned that we can use pretrained model using embedding_model but it is not recognized. I have updated the library as well
Why the same model create different topics every time I run it?
Would be good to has a rgument to set a random_state, to ensure that the model will give the same topics every time is runned.
Hi,
thanks for sharing your work! I am fairly new to NLP and were able to use it. However, I am not sure if I am doing it right.
I have a domain specific German dataset with ~11k documents. The number of words in a document range from 10 to 900, mean is 67. Documents are cased, contain some domain specific abbreviations and terms as well as spelling mistakes, numbers and special characters (data gathered from actual usage, sloppy language). I used your code (doc2vec, learn) without any text preprocessing and the results look promising!
One document consists of n sentences with k words per sentence:
print(documents[0])
Word1-1 word1-2 Word1-3 Wrd1-4abbreviated. 123 (word1-5) word1-6.
word2-1 word2-2abbreviated. word2-3 WORD2-4 WORD2-5 word2-6/word2-7 word2-8...
Is this correct or should I have only words/tokens without sentences and punctuation?
How does your code detect the beginning and the end of a sentence, especially if the sentence contains a misspelled or domain-specific abbreviation?
What preprocessing would you recommend?
Let's say I want to compare different models with each other and only use the best model for your REST API:
model_doc2vec_learn = Top2Vec(documents, 'learn')
model_doc2vec_deeplearn = Top2Vec(documents, 'deep-learn')
model_universal-sentence-encoder-multilingual = Top2Vec(documents, embedding_model='universal-sentence-encoder')
model_distiluse-base-multilingual-cased = Top2Vec(documents, embedding_model='distiluse-base-multilingual-cased')
etc.
What metrics should I use and how can this be achieved with your implementation?
"For large data sets and data sets with very unique vocabulary doc2vec could produce better results... The universal sentence encoder options are suggested for smaller data sets. "
Is my dataset (11k documents) large? It has a rather unique vocabulary... What pretrained models would you recommend?
Do I have to use sentence encoders or can I use pretrained transformers such as the following as well?
https://huggingface.co/bert-base-german-cased
First, thanks for great work.
There is some prevention to integrate a fasttext language model?
I think it may work better than Doc2Vec for some corpuses.
Is there any parameter to enable faster training of model in 'deep-learn' mode using a GPU?
My model took around 8 hours to run in collab and was utilizing only CPU while training.
does increasing the number of workers (8 used in sample script) has an effect in accuracy or it just aids in speeding up the training time.
I used deep-learn as method and use_corpus=True. I think that the suggested documents are wrong as it is not related to the keywords or the topic at all.
Training:
model = Top2Vec(documents=new_products, speed="deep-learn", workers=16, verbose=True, use_corpus_file=True)
But finding similar words and topics seem to work.
Created word cloud

Documents related to Topic 1799 (WRONG)

Documents related to bicycle (wrong)

Topics related to bicycle (correct)

This is actually extremely cool. I've worked on similar problems - but this is one of my favorite open source examples of using text embeddings, high quality dimensionality reduction and clustering together to create a very effective semantic search system.
Hope they're paying you well wherever you work.
Firstly, thanks for the awesome work.
What I tried:
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=['email'], num_topics=2)
for topic in topic_nums:
model.generate_topic_wordcloud(topic, background_color='white')
The error:
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-201-39f22daabb42> in <module>
2 topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=['email'], num_topics=2)
3 for topic in topic_nums:
----> 4 model.generate_topic_wordcloud(topic, background_color='white')
~/.local/lib/python3.8/site-packages/top2vec/Top2Vec.py in generate_topic_wordcloud(self, topic_num, background_color, reduced)
1201 plt.axis("off")
1202 plt.imshow(
-> 1203 WordCloud(width=1600,
1204 height=400,
1205 background_color=background_color).generate_from_frequencies(word_score_dict))
~/.local/lib/python3.8/site-packages/wordcloud/wordcloud.py in generate_from_frequencies(self, frequencies, max_font_size)
499 font, orientation=orientation)
500 # get size of resulting text
--> 501 box_size = draw.textsize(word, font=transposed_font)
502 # find possible places using integral image:
503 result = occupancy.sample_position(box_size[1] + self.margin,
/usr/lib/python3/dist-packages/PIL/ImageDraw.py in textsize(self, text, font, spacing, direction, features, language, stroke_width)
426 if font is None:
427 font = self.getfont()
--> 428 return font.getsize(text, direction, features, language, stroke_width)
429
430 def multiline_textsize(
/usr/lib/python3/dist-packages/PIL/ImageFont.py in getsize(self, text, *args, **kwargs)
562
563 def getsize(self, text, *args, **kwargs):
--> 564 w, h = self.font.getsize(text)
565 if self.orientation in (Image.ROTATE_90, Image.ROTATE_270):
566 return h, w
/usr/lib/python3/dist-packages/PIL/ImageFont.py in getsize(self, text, direction, features, language, stroke_width)
254 :return: (width, height)
255 """
--> 256 size, offset = self.font.getsize(text, direction, features, language)
257 return (
258 size[0] + stroke_width * 2 + offset[0],
OSError: raster overflow
When I tried to train the model, I get the message "raise RuntimeError("you must first build vocabulary before training the model")", I change min_count to 10, and 1, same problem, I input a large corpus(100000 texts), the problem still appears. what's the reason to make the problem and how to fix it?
RuntimeError: you must first build vocabulary before training the model
After document(list of string) is passed the respective runtime error arrives.
Also top2vec is imported.
Hi,
I am getting this Error when running pip install top2vec:
ERROR: numba 0.51.2 has requirement llvmlite<0.35,>=0.34.0.dev0, but you'll have llvmlite 0.31.0 which is incompatible.
Running this example then fails

Do you know a way to fix this? Thanks a lot in advance!
Hi guys,
Hope you are all well !
I was wondering if it is possible to use the latest arXiv dataset available here with top2vec.
In a nutshell, I would like to extract topics from abstracts.
gsutil ls gs://arxiv-dataset/metadata-v5/
gsutil cp gs://arxiv-dataset/metadata-v5/arxiv-metadata-oai.json .
Is it possible to index this dataset quickly as there is an update every week ?
Thanks in advance for your insights and inputs.
Cheers,
X
Hi Dimo,
thank you for this wonderful new tool for topic modeling.
I have tried out and used fastText embeddings and some simple additions for document vectors for my usage.
It works very well.
Could you also provide some examples for the evaluating information gain?
Thank you!
Hey, I've been playing around with the new stuff. Really exciting.
One question though. Under the method get_document_topics, I added print statements to look at the stuffs as shown in the snippet below.

The results are shown in the snippet below here. I'm trying to understand why are the two lengths len(documents) and len(doc_top) or len(doc_top_reduced)` unequal?

Down here, I have hierarchically reduced the number of topics to 10.
The project is awesome and the API is well documented! Top2Vec would automatically identity the number of topics since it uses HDBSCAN. In my application 1970 topics are generated are this is really too much to interpret. Then I go for using hierarchical topic reduction but then the choice of number of topics to reduced is not intuitive to decide. So I would like to ask if a dendrogram plot feature can be added?
Read your paper, really interesting insights and information gained!
Would like to know if there is any way to get the total information gained (mutual info) after training the model? :)
Is there an inference function to search what topics a document is when we use the add_document() function?'
Something like search_topic_by_documents?
hi @ddangelov great work 👍
when will be Inferring topics on unseen documents (getting cosine similarity based on the query and doc) and adding it to the model be done?
as in current approach it seems like we need to train on whole corpus from scratch just for sake of adding 2-3 new documents.
Hi,
Thanks for the great work.
What would be the simplest way to extract the learned vocabulary from the model? I would like to avoid the error regarding the word not being known by the model.
Carlos
After doing an add_documents for a list of documents, I want to do a get_documents_topic. However, get_documents_topic requires me to input doc_id as its argument. Without giving the documents an id in the beginning, is there an easier way to search document id? Such as a get_documents_id function?
Something like
def get_document_id(self, document):
if self.documents is not None:
document_id = self.documents.tolist().index(document)
return document_id
Hello,
With new version, where you added possibility of make hierarchy, number of topics could strangely collapsed to few only topics.
Here an example. I create corpus with two type of documents from different domains, 'computer vision' and 'genomics', each set of documents contains around 3000 documents. The code is bellow
def lemma(docs):
lemmatizer = WordNetLemmatizer()
docs = [[lemmatizer.lemmatize(token) for token in doc] for doc in docs]
return docs
path = "../data"
f_in = join(path,"cv.txt")
f_ig = join(path,"gn.txt")
# Corpus =================
docs = []
print('Loading docs ...')
with open(f_in, 'r') as fin:
for doc in fin:
docs.append([dc.strip('\r\n') for dc in doc.split(' ')])
with open(f_ig, 'r') as fin:
for doc in fin:
docs.append([dc.strip('\r\n') for dc in doc.split(' ')])
# Lemmatize the documents.
docs = lemma(docs)
texts = [' '.join(doc) for doc in docs]
# Model ======================
model = Top2Vec(documents=texts, speed='deep-learn',workers=8) When I use previous version it finds 59 topics as expected as single domain set gives around 30 topics. If I use new version with hierarchy, it gives only 2 topics. All topics collapsed to high level clusters.
Hi Dimo,
I tried to write the evaluation script, something isn't quite right, since I get the value only 0.3, but the topic words look really nice, please have a look, thanks
def pwi(topic):
topic_document_indexes = np.where(model.doc_top == topic)[0]
topic_document_indexes_ordered = np.flip(np.argsort(model.doc_dist[topic_document_indexes]))
doc_indexes = topic_document_indexes[topic_document_indexes_ordered]
doc_scores = model.doc_dist[doc_indexes]
doc_ids = model._get_document_ids(doc_indexes)
documents = model.documents[doc_indexes]
len_doc = len(documents)
print(len_doc)
topic_words = model.topic_words[0][:10]
d_in_t =[]
total_unique_word_d = len(list(set(chain.from_iterable(documents))))
for d in documents:
print('document:', d)
words_in_t = []
for word in topic_words:
print('word:==========', word)
count_d_w = sum([1 for x in d if word==x])
p_wd = round(count_d_w/total_unique_word_d, 6)
p_w = word_prob[word]
p_d = round(1/LEN,6)
print(p_wd, p_w, p_d)
pmi = np.log(p_wd)- np.log(p_w) - np.log(p_d)
# p(d|w)
p_d_on_w = p_wd * p_w
p_dw_pwi = p_d_on_w * pmi
words_in_t.append(p_dw_pwi)
arr_words = np.array(words_in_t)
arr_words_ = arr_words[~np.isnan(arr_words)]
print(arr_words_)
d_in_t.append(arr_words_.sum())
return sum(d_in_t)
Is there an API or any way to add new documents?
How does the code adapt new incoming documents?
Can you please add code lines for umap and hdbscan visualization?
I am trying the below code for umap but not sure what should I put in fit_transform(?).
import umap
import time
umap_embeddings = umap.UMAP(n_neighbors=15,
n_components=5,
min_dist=0.0,
metric='cosine',
random_state=42).fit_transform(?)
I'm using a set of text documents (pdf documents converted into text) for topic modeling. While training the model I'm getting this error.
It's a great help if someone can help me to sort this out.
C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\umap\umap_.py:1678: UserWarning: n_neighbors is larger than the dataset size; truncating to X.shape[0] - 1
warn(
C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\scipy\sparse\linalg\eigen\arpack\arpack.py:1590: RuntimeWarning: k >= N for N * N square matrix. Attempting to use scipy.linalg.eigh instead.
warnings.warn("k >= N for N * N square matrix. "
Traceback (most recent call last):
File "c:/Users/prabo/Desktop/Topic modeling pipeline/test.py", line 27, in
model = Top2Vec(documents=df.text, speed="learn", workers=8)
File "C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\top2vec\Top2Vec.py", line 222, in init
umap_model = umap.UMAP(n_neighbors=15,
File "C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\umap\umap_.py", line 1965, in fit
self.embedding_ = simplicial_set_embedding(
File "C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\umap\umap_.py", line 1033, in simplicial_set_embedding
initialisation = spectral_layout(
File "C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\umap\spectral.py", line 324, in spectral_layout
eigenvalues, eigenvectors = scipy.sparse.linalg.eigsh(
File "C:\Users\prabo\Desktop\Topic modeling pipeline.venv\lib\site-packages\scipy\sparse\linalg\eigen\arpack\arpack.py", line 1595, in eigsh
raise TypeError("Cannot use scipy.linalg.eigh for sparse A with "
TypeError: Cannot use scipy.linalg.eigh for sparse A with k >= N. Use scipy.linalg.eigh(A.toarray()) or reduce k.
I set documents to around 1000 strings each is a subject of research paper (less than 10 words), but model generates topics either only contains stop words or empty, anything I may did wrong?

Some questions:
Do I need to add all my documents into the model and use the model like a database for querying?
If I have a new document, how do I get its topic using the model and find the nearest documents, topics, etc without inserting it to the model?
from top2vec import Top2Vec
from sklearn.datasets import fetch_20newsgroups
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
model = Top2Vec(documents=newsgroups.data, speed="learn", workers=8)
Error:
Traceback (most recent call last):
File "checkThis.py", line 13, in <module>
model = Top2Vec(documents=allSents, speed="learn", workers=8)
File "/workspace/Top2Vec/top2vec/Top2Vec.py", line 234, in __init__
self._create_topic_vectors(cluster.labels_)
File "/workspace/Top2Vec/top2vec/Top2Vec.py", line 260, in _create_topic_vectors
self.topic_vectors = np.vstack([self.model.docvecs.vectors_docs[np.where(cluster_labels == label)[0]]
File "<__array_function__ internals>", line 5, in vstack
File "/workspace/.pip-modules/lib/python3.8/site-packages/numpy/core/shape_base.py", line 283, in vstack
return _nx.concatenate(arrs, 0)
File "<__array_function__ internals>", line 5, in concatenate
ValueError: need at least one array to concatenate
My NumPy version : '1.19.0'
Hi!
First of all: great work! I'm testing this approach with great results!
I would like to suggest an option to use pretrained word2vec embeddings using the embedding_model_path param, so that we can pass customized embeddings to our model.
Also, I would like to know if universal-sentence-encoder-multilingual-large model was tested or will be an option in the future.
Right now we need to train the Top2Vec model from a large corpus, but in many problems we only have small corpus
Would you plan to release any pre-trained Top2Vec models? I believe it could greatly benefit more users especially those who are facing small data issue
When I sent a list of string into Top2vec, I get such a message.
What's the reason that causes the problem?
Is it because the corpus is too small, or I should change the min_count of word2vec?
or I must call model.build_vocab by hand?
Thanks!
Hello! First, thanks a lot, this is a really nice package to play with! Is there a clean and easy way to get all topics a document is associated to? It can ofc be achieved by iterating over all topics by search_documents_by_topic. Perhaps I overlooked some methods?
Edit: Giving a second thought. Maybe it is not even possible that a document belongs to more than one topic.
Hi!
topic_words (and topic_words_reduced as well) is not reordered when add_documents() is called with a large number of documents.
Probably the problem with this method.
I solved it in my code (without editing you package) in the following way:
index_start = model.documents.shape[0]
doc_top_reduced_old = model.doc_top_reduced[:index_start]
model.add_documents(documents)
doc_top_reduced_new = model.doc_top_reduced[:index_start]
topic_new_to_old = dict(zip(doc_top_reduced_new, doc_top_reduced_old))
index = [topic_new_to_old[i] for i in range(len(topic_new_to_old))]
model.topic_words_reduced = model.topic_words_reduced[index]
By the way, Great tool! :)
Hi, this looks very interesting, I would love to apply it to a dataset, however it's in german. Any ideas / tips how to make this work on german documents?
Best regards
Thanks a lot for your word, I think you're building something great!
Just a few questions:
Given an unseen document, it is possible to know which are the topic related to it?
It is possible to assign a name to a topic to retrieve just its name instead of the main words?
Using the function add_documents is like "fine-tuning" the model?
Thanks
I was training top2vec model on own documents but it is throwing an error: Documents is not a list of strings but I checked my preprocessed documents which looks like list of strings even then it is throwing an error..
@ddangelov @gclen Please help me in this ...
Here is glimpse of some documents on which I wanna train this model..
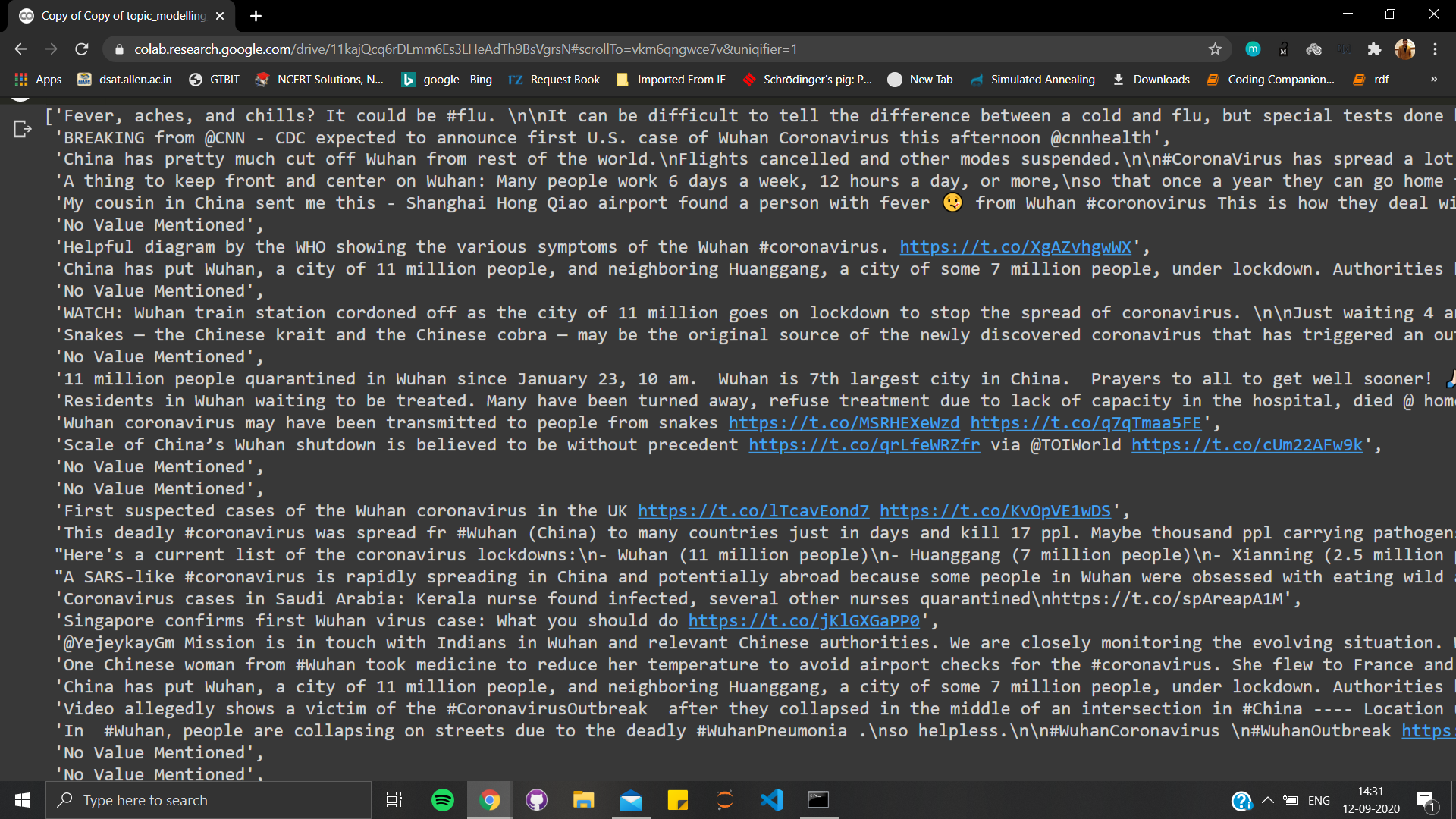
How should I arrange these cleaned documents?
Thanks!
The top2vec is a good tool, but can it process chinese?
I found it. Thanks!
I have windows 10, python 3.6, x64
I get following error when I do 'pip install top2vec'
ERROR: Could not find a version that satisfies the requirement tensorflow-text (from top2vec) (from versions: none)
ERROR: No matching distribution found for tensorflow-text (from top2vec)
Is there any way of training the top2vec model on a corpus which you cannot fit in memory? For example, I have a corpus of 10 million documents and it is about 500GB, and I have RAM = 128GB, how would I get the top2vec model trained on this dataset?
I would like to know if it is possible to get the allocation of the documents to the clusters calculated by hdbscan and then plot them as you did in readme point 3? I could already get the document vectors through Top2Vec.model.docvecs.vectors_docs
Hi, great work for Top2Vec, I am trying to apply it to my dataset which has 1.6million instances. I successfully trained Doc2vec inside Top2vec. with 300 dimensions as the default. but I run out of memory on the Umap procedure in 2 minutes. BTW I have a 32g memory. I also try low_memory=True. The same oom.
So, I wonder that how many memory UMAP gonna take for 2m points with 300 dimensions? For precaution, how many more memory HDBScan gonna cost?
Thank you!
hi @ddangelov,
could you please provide this additional feature on searching via keywords, as in current scenario its accepting only single tokenized keyword.
(example: search via "machine learning" instead of "machine" or "learning" )
also while searching via tokens with special characters like "C#" or "C++" or "C" its unable to find any documents and throws an error saying "model has not learnt those words during training", but those words are clearly present in the corpus.
Thank you for nice end elegant approach to topic modeling. I would propose to implement few features.
Good luck and thank you again!
I encountered this error when trying to fit the model. It was fixed by [1]. Replace
import umap
with
import umap.umap_ as umap
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.