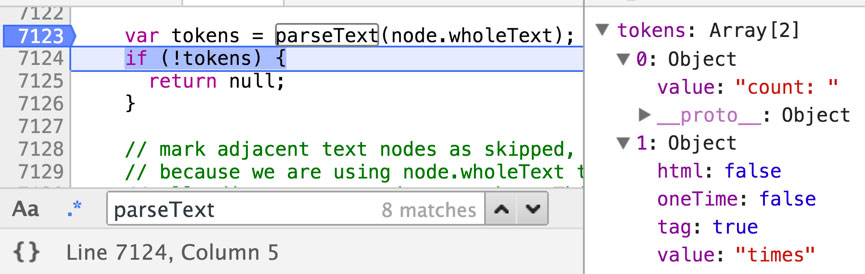
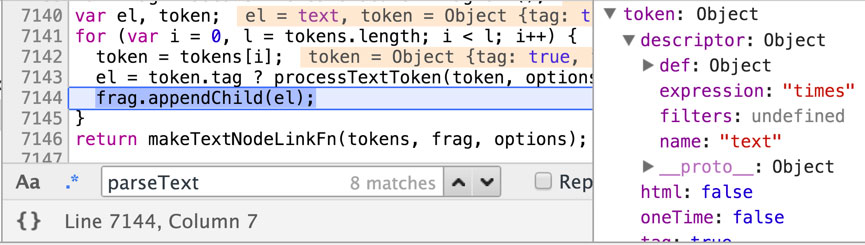
ddfe / ddfe-blog Goto Github PK
View Code? Open in Web Editor NEW:clap: welcome to DDFE's blog
License: MIT License
:clap: welcome to DDFE's blog
License: MIT License









































































































































































































可写流是对数据写入“目的地”的一种抽象,可作为可读流的一种消费者。数据源可能多种多样,如果使用了可写流来完成数据的消费,那么就有可写流的内部机制来控制数据在生产及消费过程中的各状态的扭转等。

首先来看下可写流内部几个比较关键的状态:
function WritableState(options, stream) {
options = options || {};
// Duplex streams are both readable and writable, but share
// the same options object.
// However, some cases require setting options to different
// values for the readable and the writable sides of the duplex stream.
// These options can be provided separately as readableXXX and writableXXX.
var isDuplex = stream instanceof Stream.Duplex;
// object stream flag to indicate whether or not this stream
// contains buffers or objects.
this.objectMode = !!options.objectMode;
if (isDuplex)
this.objectMode = this.objectMode || !!options.writableObjectMode;
// the point at which write() starts returning false
// Note: 0 is a valid value, means that we always return false if
// the entire buffer is not flushed immediately on write()
var hwm = options.highWaterMark;
var writableHwm = options.writableHighWaterMark;
var defaultHwm = this.objectMode ? 16 : 16 * 1024;
if (hwm || hwm === 0)
this.highWaterMark = hwm;
else if (isDuplex && (writableHwm || writableHwm === 0))
this.highWaterMark = writableHwm;
else
this.highWaterMark = defaultHwm;
// cast to ints.
this.highWaterMark = Math.floor(this.highWaterMark);
// if _final has been called
this.finalCalled = false;
// drain event flag.
this.needDrain = false;
// at the start of calling end()
this.ending = false;
// when end() has been called, and returned
this.ended = false;
// when 'finish' is emitted
this.finished = false;
// has it been destroyed
this.destroyed = false;
// should we decode strings into buffers before passing to _write?
// this is here so that some node-core streams can optimize string
// handling at a lower level.
var noDecode = options.decodeStrings === false;
this.decodeStrings = !noDecode;
// Crypto is kind of old and crusty. Historically, its default string
// encoding is 'binary' so we have to make this configurable.
// Everything else in the universe uses 'utf8', though.
this.defaultEncoding = options.defaultEncoding || 'utf8';
// not an actual buffer we keep track of, but a measurement
// of how much we're waiting to get pushed to some underlying
// socket or file.
// 不是真实buffer的长度,而是等待被写入文件或者socket等的数据的长度
this.length = 0;
// a flag to see when we're in the middle of a write.
this.writing = false;
// when true all writes will be buffered until .uncork() call
this.corked = 0;
// a flag to be able to tell if the onwrite cb is called immediately,
// or on a later tick. We set this to true at first, because any
// actions that shouldn't happen until "later" should generally also
// not happen before the first write call.
this.sync = true;
// a flag to know if we're processing previously buffered items, which
// may call the _write() callback in the same tick, so that we don't
// end up in an overlapped onwrite situation.
this.bufferProcessing = false;
// the callback that's passed to _write(chunk,cb)
// onwrite偏函数,stream始终作为一个参数
this.onwrite = onwrite.bind(undefined, stream);
// the callback that the user supplies to write(chunk,encoding,cb)
this.writecb = null;
// the amount that is being written when _write is called.
this.writelen = 0;
// 缓存池中的头结点
this.bufferedRequest = null;
// 缓存池中的尾结点
this.lastBufferedRequest = null;
// number of pending user-supplied write callbacks
// this must be 0 before 'finish' can be emitted
this.pendingcb = 0;
// emit prefinish if the only thing we're waiting for is _write cbs
// This is relevant for synchronous Transform streams
this.prefinished = false;
// True if the error was already emitted and should not be thrown again
this.errorEmitted = false;
// count buffered requests
this.bufferedRequestCount = 0;
// allocate the first CorkedRequest, there is always
// one allocated and free to use, and we maintain at most two
var corkReq = { next: null, entry: null, finish: undefined };
corkReq.finish = onCorkedFinish.bind(undefined, corkReq, this);
this.corkedRequestsFree = corkReq;
}在实现的可写流当中必须要定义一个write方法,在可写流内部,这个方法会被赋值给一个内部_write方法,主要是在数据被消费的时候调用:
const { Writable } = require('stream')
const ws = new Writable({
write (chunk, encoding, cb) {
// chunk 即要被消费的数据
// encoding为编码方式
// cb为内部实现的一个onwrite方法,上面说的状态定义里面有关于这个说明,主要是在完成一次消费后需要手动调用这个cb方法来扭转内部状态,下面会专门讲解这个方法
}
})可写流对开发者暴露了一个write方法,这个方法用于接收数据源的数据,同时来完成数据向消费者的传递或者是将数据暂存于缓冲区当中。
让我们来看下一个简单的例子:
function writeOneMillionTimes(writer, data, encoding, callback) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
i--;
if (i === 0) {
// 最后 一次
writer.write(data, encoding, callback);
} else {
// 检查是否可以继续写入。
// 这里不要传递 callback, 因为写入还没有结束!
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// 不得不提前停下!
// 当 'drain' 事件触发后继续写入
writer.once('drain', write);
}
}
}
const { Writable } = require('stream')
const ws = new Writable({
write (chunk, encoding, cb) {
// do something to consume the chunk
}
})
writeOneMillionTimes(ws, 'aaaaaa', 'utf8', function () {
console.log('this is Writable')
})程序开始后,首先可写流调用writer.write方法,将数据data传入到可写流当中,然后可写流内部来判断将数据是直接提供给数据消费者还是暂时先存放到缓冲区。
Writable.prototype.write = function (data, encoding, callback) {
var state = this._writableState;
// 是否可向可写流当中继续写入数据
var ret = false;
var isBuf = !state.objectMode && Stream._isUint8Array(chunk);
// 转化成buffer
if (isBuf && Object.getPrototypeOf(chunk) !== Buffer.prototype) {
chunk = Stream._uint8ArrayToBuffer(chunk);
}
// 对于可选参数的处理
if (typeof encoding === 'function') {
cb = encoding;
encoding = null;
}
// 编码
if (isBuf)
encoding = 'buffer';
else if (!encoding)
encoding = state.defaultEncoding;
if (typeof cb !== 'function')
cb = nop;
// 如果已经停止了向数据消费者继续提供数据
if (state.ended)
writeAfterEnd(this, cb);
else if (isBuf || validChunk(this, state, chunk, cb)) {
state.pendingcb++;
// 是将数据直接提供给消费者还是暂时存放到缓冲区
ret = writeOrBuffer(this, state, isBuf, chunk, encoding, cb);
}
return ret;
}
function writeOrBuffer (stream, state, isBuf, chunk, encoding, cb) {
...
var len = state.objectMode ? 1 : chunk.length;
state.length += len;
var ret = state.length < state.highWaterMark;
// we must ensure that previous needDrain will not be reset to false.
// 如果state.length长度大于hwm,将needDrain置为true,需要触发drain事件,开发者通过监听这个事件可以重新恢复可写流对于数据源的获取
if (!ret)
state.needDrain = true;
// state.writing 代表现在可写流正处于将数据传递给消费者使用的状态
// 或 当前处于corked状态时,就将数据写入buffer缓冲区内
// writeable的buffer缓冲区也是链表结构
if (state.writing || state.corked) {
var last = state.lastBufferedRequest;
state.lastBufferedRequest = {
chunk,
encoding,
isBuf,
callback: cb,
next: null
};
if (last) {
last.next = state.lastBufferedRequest;
} else {
state.bufferedRequest = state.lastBufferedRequest;
}
state.bufferedRequestCount += 1;
} else {
// 将数据写入底层数据即传递给消费者
doWrite(stream, state, false, len, chunk, encoding, cb);
}
return ret;
}
function doWrite(stream, state, writev, len, chunk, encoding, cb) {
// chunk的数据长度
state.writelen = len;
// chunk传递给消费者后的回调函数
state.writecb = cb;
// 可写流正在将数据传递给消费者的状态
state.writing = true;
// 同步态
state.sync = true;
// 如果定义了writev批量写入数据数据的就调用此方法
if (writev)
stream._writev(chunk, state.onwrite);
else
// 这个方法即完成将数据传递给消费者,并传入onwrite回调,这个onwrite函数必须要调用来告知写数据是完成还是失败
// 这3个参数也对应着上面提到的在自定义实现可写流时需要定义的write方法所接受的3个参数
// 可写流向消费者提供数据是同步的,但是消费者拿到数据后同步可写流的状态可能是同步,也可能是异步的
stream._write(chunk, encoding, state.onwrite);
state.sync = false;
}在doWrite方法中调用了开发者定义的write方法来完成数据的消费,即stream._write(),同时也提到了关于当数据被消费完了后需要调用state.onwrite这个方法来同步可写流的状态。接下来就来看下这个方法的内部实现:
// 完成一次_write方法后,更新相关的state状态
function onwriteStateUpdate(state) {
state.writing = false; // 已经写完数据
state.writecb = null; // 回调
state.length -= state.writelen;
state.writelen = 0; // 需要被写入数据的长度
}
// 数据被写入底层资源后必须要调用这个callback,其中stream是被作为预设函数,可参数上面Writeable中关于onwrite的定义
function onwrite(stream, er) {
var state = stream._writableState;
var sync = state.sync;
var cb = state.writecb;
// 首先更新可写流的状态
onwriteStateUpdate(state);
if (er)
onwriteError(stream, state, sync, er, cb);
else {
// Check if we're actually ready to finish, but don't emit yet
// 检验是否要结束这个writeable的流
var finished = needFinish(state);
// 每次写完一次数据后都需要检验
// 如果finished代表可写流里面还保存着有数据,那么需要调用clearBuffer,将可写流的缓冲区的数据提供给消费者
if (!finished &&
!state.corked &&
!state.bufferProcessing &&
state.bufferedRequest) {
clearBuffer(stream, state);
}
// 始终是异步的调用afterWrite方法
if (sync) {
process.nextTick(afterWrite, stream, state, finished, cb);
} else {
afterWrite(stream, state, finished, cb);
}
}
}
function afterWrite(stream, state, finished, cb) {
if (!finished)
onwriteDrain(stream, state);
state.pendingcb--;
cb();
finishMaybe(stream, state);
}
// 是否要结束这个writeable的流,需要将内部缓冲区的数据全部写入底层资源池
function needFinish(state) {
return (state.ending &&
state.length === 0 &&
state.bufferedRequest === null &&
!state.finished &&
!state.writing);
}
// if there's something in the buffer waiting, then process it
// 内部递归调用doWrite方法来完成将数据从缓冲区传递给消费者
function clearBuffer(stream, state) {
// 这个字段代表正在处理缓冲区buffer
state.bufferProcessing = true;
var entry = state.bufferedRequest;
// 在定义了writev方法的情况下才可能调用,批量将数据传递给消费者
if (stream._writev && entry && entry.next) {
// Fast case, write everything using _writev()
...
} else {
// Slow case, write chunks one-by-one
// 一个一个将数据传递给消费者
while (entry) {
var chunk = entry.chunk;
var encoding = entry.encoding;
var cb = entry.callback;
var len = state.objectMode ? 1 : chunk.length;
// 继续将缓冲区的数据提供给消费者
doWrite(stream, state, false, len, chunk, encoding, cb);
entry = entry.next;
state.bufferedRequestCount--;
// if we didn't call the onwrite immediately, then
// it means that we need to wait until it does.
// also, that means that the chunk and cb are currently
// being processed, so move the buffer counter past them.
if (state.writing) {
break;
}
}
if (entry === null)
state.lastBufferedRequest = null;
}
state.bufferedRequest = entry;
// 缓冲区buffer已经处理完
state.bufferProcessing = false;
}每次调用onWrite方法时,首先都会调用onwriteStateUpdate方法来更新这个可写流的状态,具体见上面的方法定义。同时需要对这个可写流进行判断,是否要关闭这个可写流。同时还进行判断buffer是否还有可供消费者使用的数据。如果有那么就调用clearBuffer方法用以将缓冲区的数据提供给消费者来使用。
当数据源提供给可写流的数据过快的时候有可能出现背压的情况,这个时候数据源不再提供数据给可写流,是否出现背压的情况,可通过可写流的write方法的返回值来进行判断,如果返回的是false,那么就出现的了背压。
参见这个例子在实现的write方法中通过setTimeout来延迟一段时间调用onwrite方法,这个时候每次数据消费者都拿到了数据,但是因为这个地方延迟了更新可写流的状态,但是从数据源向可写流中还是同步的写入数据,因此可能会出现在可写流的缓冲区保存的数据大于hmw的情况。
在writeOrBuffer方法中有关于可写流缓冲区保存的数据长度和hwm的比较:
var ret = state.length < state.highWaterMark;
// we must ensure that previous needDrain will not be reset to false.
// 如果state.length长度大于hwm,将needDrain置为true,可能需要触发drain事件,
if (!ret)
state.needDrain = true;将needDrain置为true。出现背压后,数据源不再提供数据给可写流,这个时候只有等可写流将缓冲区的所有完成全部提供给消费者消耗,同时更新完可写流的状态后,会触发一个drain事件。
function onwrite(stream, er) {
...
if (er)
...
else {
...
if (sync) {
process.nextTick(afterWrite, stream, state, finished, cb);
} else {
afterWrite(stream, state, finished, cb);
}
}
}
function afterWrite(stream, state, finished, cb) {
if (!finished)
onwriteDrain(stream, state);
state.pendingcb--;
cb();
finishMaybe(stream, state);
}
// 缓冲区的数据已经全部提供给消费者,同时needDrain被置为了true 触发drain事件
function onwriteDrain(stream, state) {
if (state.length === 0 && state.needDrain) {
state.needDrain = false;
stream.emit('drain');
}
}这个时候如果你的程序提前定义的监听drain事件的方法,那么可以在回调里面再次调用可写流的write方法来让数据源继续提供数据给可写流。
webpack 的特点之一是一切皆模块,我们可以将逻辑拆分到不同的文件中,然后通过模块化 API 进行导出和引入。现在 ES6 的 Module 则是大家最常用的模块化方案。所以你一定写过 import './xxx' 或者 import 'something-in-nodemodules' 再或者 import '@/xxx'(@ 符号通过 webpack 配置中 alias 设置)。webpack 处理这些模块引入 import 的时候,有一个重要的步骤,就是如何正确的找到 './xxx'、'something-in-nodemodules' 或者 '@/xxx' 等等对应的是哪个文件。这个步骤就是 resolve 的部分需要处理的逻辑。
其实不仅是针对源码中的模块需要 resolve,包括 loader 在内,webpack 的整体处理过程中,涉及到文件路径的,都离不开 resolve 的过程。
同时 webpack 在配置文件中有一个 resolve 的配置,可以对 resolve 的过程进行适当的配置,比如设置文件扩展名,查找搜索的目录等(更多的参考官方介绍)。
下面,将主要介绍针对普通文件的 resolve 流程 和 loader 的 resolve 主流程。
首先先准备一个简单的 demo
import { A } from './a.js'然后针对这个 demo 来看主流程。在 webpack 系列之一总览 文章中有一个 webpack 编译总流程图,图中可以看到在 webpack 处理每一个文件开始之前都会有一个 resolve 的过程,找到完整的文件路径信息。

webpack 源码中 resolve 流程开始的入口在 factory 阶段,
factory 事件会触发 NormalModuleFactory 中的函数。先放一张粗略的总体流程图,在深入源码前现有一个大概的框架图

接下来我们就从 NormalModuleFactory.js 文件中开始看起
this.hooks.factory.tap("NormalModuleFactory", () => (result, callback) => {
// 首先得到 resolver
let resolver = this.hooks.resolver.call(null);
// Ignored
if (!resolver) return callback();
// 执行
resolver(result, (err, data) => {
if (err) return callback(err);
// Ignored
if (!data) return callback();
// direct module
if (typeof data.source === "function") return callback(null, data);
this.hooks.afterResolve.callAsync(data, (err, result) => {
//... resolve结束后流程,此处省略
});
});
});第一步获得 resolver 逻辑比较简单,触发 resolver 事件(SyncWaterfallHook类型的Hook,关于Hook的类型,可以参考webpack系列之二Tapable),同时 NormalModuleFactory 中注册了 resolver 事件。下面是 resolver 事件的代码,可以看到返回了一个函数。
this.hooks.resolver.tap("NormalModuleFactory", () => (data, callback) => {
//...先展示省略具体内容,后面会详细解释。
})因此 this.hooks.resolver.call(null); 结束后,将得到一个函数。然后接下来就是执行该函数获得 resolver 结果。
resolver 函数中,从整体看分为两大主要流程 loader 和 文件。
loader流程
import Styles from 'style-loader!css-loader?modules!./styles.css';会从中解析出 style-loader 和 css-loader。由于此步骤只是为了解析出路径,所以对于 loader 的配置部分并不关心。
得到 loader 类型的 resolver 处理实例,即 const loaderResolver = this.getResolver("loader");
对每一个 loader 用 loaderResolver 依次处理,得到执行文件的路径。
文件流程
得到普通文件的 resolver 处理实例,即代码 const normalResolver = this.getResolver("normal", data.resolveOptions);
用 normalResolver 处理文件,得到最终文件绝对路径
下面是具体的 resolver 代码:
this.hooks.resolver.tap("NormalModuleFactory", () => (data, callback) => {
const contextInfo = data.contextInfo;
const context = data.context;
const request = data.request;
// ... 省略部分和 loader 处理相关的代码
// 处理 inline loaders,拿到 loader request 部分(loader 的名称或者 loader 的路径,由于这里不关系 loader 的配置等其他细节,所以直接将开头的 -!, 和 ! 直接替换掉,将多个 ! 替换成一个,方便后面处理)
let elements = request
.replace(/^-?!+/, "")
.replace(/!!+/g, "!")
.split("!");
let resource = elements.pop();
// 提取出具体的 loader
elements = elements.map(identToLoaderRequest);
const loaderResolver = this.getResolver("loader");
const normalResolver = this.getResolver("normal", data.resolveOptions);
asyncLib.parallel(
[
callback =>
this.resolveRequestArray(
contextInfo,
context,
elements,
loaderResolver,
callback
),
callback => {
if (resource === "" || resource[0] === "?") {
return callback(null, {
resource
});
}
normalResolver.resolve(
contextInfo,
context,
resource,
{},
(err, resource, resourceResolveData) => {
if (err) return callback(err);
callback(null, {
resourceResolveData,
resource
});
}
);
}
],
(err, results) => {
// ... reslover callback
})
)
})
结合上面的步骤和代码看,其实 loader 类和普通文件类型(后面称为 normal 类),大致流程是相似的。我们先看获取不同类型的 resolver 实例部分。
getResolver 函数,会调用到 webpack/lib/ResolverFactory.js 中的 get 方法。该方法中获取 resolver 实例的具体流程如下图。

上图中,首先根据不同 type 获取 options 。那么这些 options 配置都存在哪里呢?
webpack中options配置
webpack 直接对外暴露的 resolve 的配置,在配置文件中 resolve 和 resolveLoader 部分,详细的字段见官网。但是其内部会有一个默认的配置,在 webpack.js 入口处理函数中,初始化了所有的默认配置
// ...
if (Array.isArray(options)) {
compiler = new MultiCompiler(options.map(options => webpack(options)));
} else if (typeof options === "object") {
options = new WebpackOptionsDefaulter().process(options);
compiler = new Compiler(options.context);
compiler.options = options;
// ...在 WebpackOptionsDefaulter() 中,配置了很多关于 resolve 和 resolveLoader 的配置。process 方法将我们写的 webpack 的配置 和默认的配置合并。
// WebpackOptionsDefaulter.js 文件
//...
this.set("resolve", "call", value => Object.assign({}, value));
this.set("resolve.unsafeCache", true); // 默认开启缓存
this.set("resolve.modules", ["node_modules"]); // 默认从 node_modules 中查找
// ...webpack.js 中,接下来有一句
new WebpackOptionsApply().process(options, compiler);其中 process 过程里会注入关于 normal/context/loader 的默认配置的获取函数。
compiler.resolverFactory.hooks.resolveOptions
.for("normal")
.tap("WebpackOptionsApply", resolveOptions => {
return Object.assign(
{
fileSystem: compiler.inputFileSystem
},
options.resolve,
resolveOptions
);
});
compiler.resolverFactory.hooks.resolveOptions
.for("context")
.tap("WebpackOptionsApply", resolveOptions => {
return Object.assign(
{
fileSystem: compiler.inputFileSystem,
resolveToContext: true
},
options.resolve,
resolveOptions
);
});
compiler.resolverFactory.hooks.resolveOptions
.for("loader")
.tap("WebpackOptionsApply", resolveOptions => {
return Object.assign(
{
fileSystem: compiler.inputFileSystem
},
options.resolveLoader,
resolveOptions
);
});options 介绍到此先结束,我们继续沿着上面流程图往下看。当获取到 resolver 实例后,就开始 resolver 的过程:根据类型的不同,会有 normalResolver 和 loaderResolver,同时在 normalResolver 中会区分文件和 module。
webpack 中有很多针对路径的配置,例如 alias, extensions, modules 等等,node.js 中的 require 已经无法满足 webpack 对路径的解析的要求。因此,webpack 封装出一个单独的库 enhanced-resolve,专门用来处理各种路径的解析,仍然采用了 webpack 的插件模式来组织代码。
接下来会深入到这个库中,依次介绍普通文件、module 和 loader 的处理过程(webpack 中还有一个 context 的 resolve 过程,由于其过程没太多特别之处,放在 module 过程中一起介绍)。先看普通文件的处理过程。
普通文件 resolver 处理入口为 webpack 中 normalResolver.resolve 方法,而整个 resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。

将这些事件一个一个串联起来的关键部分在 doResolve 和每个事件的处理函数中。这里以 doResolve 和调用的 UnsafePlugin 为例,看一下衔接的过程。
// 第一个参数 hook,函数中用到的 hook 是通过参数传进来的。
doResolve(hook, request, message, resolveContext, callback) {
// ...
// 生成 context 栈。
const stackLine = hook.name + ": (" + request.path + ") " +
(request.request || "") + (request.query || "") +
(request.directory ? " directory" : "") +
(request.module ? " module" : "");
let newStack;
if(resolveContext.stack) {
newStack = new Set(resolveContext.stack);
if(resolveContext.stack.has(stackLine)) {
// Prevent recursion
const recursionError = new Error("Recursion in resolving\nStack:\n " + Array.from(newStack).join("\n "));
recursionError.recursion = true;
if(resolveContext.log) resolveContext.log("abort resolving because of recursion");
return callback(recursionError);
}
newStack.add(stackLine);
} else {
newStack = new Set([stackLine]);
}
// 简单的demo中这里没有事件注册,先忽略
this.hooks.resolveStep.call(hook, request);
// 如果该hook有注册过事件,则调触发该 hook
if(hook.isUsed()) {
const innerContext = createInnerContext({
log: resolveContext.log,
missing: resolveContext.missing,
stack: newStack
}, message);
return hook.callAsync(request, innerContext, (err, result) => {
if(err) return callback(err);
if(result) return callback(null, result);
callback();
});
} else {
callback();
}
}调用到 hook.callAsync 时,进入 UnsafeCachePlugin,然后看 UnsafeCachePlugin 中部分实现:
class UnsafeCachePlugin {
constructor(source, filterPredicate, cache, withContext, target) {
this.source = source;
// ... 省略部分
this.target = target;
}
apply(resolver) {
// ensureHook 主要逻辑:如果 resolver 已经有对应的 hook 则返回;如果没有,则会给 resolver 增加一个 this.target 类型的 hook
const target = resolver.ensureHook(this.target);
// getHook 会根据 this.source 字符串获取对应的 hook
resolver.getHook(this.source).tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {
//... 先省略 UnsafeCache 中其他逻辑,只看衔接部分
// 继续调用 doResolve,但是注意这里的 target
resolver.doResolve(target, request, null, resolveContext, (err, result) => {
if(err) return callback(err);
if(result) return callback(null, this.cache[cacheId] = result);
callback();
});
});
}
}UnsafeCachePlugin 分为两部分:事件注册(new 和 执行apply) 和事件执行(resolver.getHook(this.source).tapAsync 的回调部分)。事件注册阶段发在 webpack 获取不同类型 resolve 处理实例时(前面获取不同类型 resolver 处理实例小节中,getResolver 的时候),这时会传入一个 source 值(字符串类型)和一个 target 值(字符串类型),代码如下
// source 值为 resolve,target 值为 new-resolve
new UnsafeCachePlugin("resolve", cachePredicate, unsafeCache, cacheWithContext, "new-resolve")`
//...然后会调用 apply 方法在 apply 中,将 UnsafeCachePlugin 的处理逻辑注册为 source 事件的回调,同时确保 target 事件的存在(如果没有则注册一个)。
事件执行阶段,完成 UnsafeCachePlugin 本身的逻辑之后,递归调用 resolver.doResolve(target, ...),这时第一个参数为 UnsafeCachePlugin 中的 target 事件。如此,再进入到 doResolve 之后,再触发 target 的事件,这样就形成了事件流。而整体的调用过程,简化来看整体逻辑就是:
doResolve(target1)
-> target1 事件(srouce:target1, target: target2)
-> 递归调用doResolve(target2)
-> target2 事件(srouce:target2, target: target3)
-> 递归调用doResolve(target3)
-> target3 事件(srouce:target3, target: target4)
...
->遇到递归结束标识,结束递归
通过对 doResolve 的递归调用,事件之间就衔接了起来,形成完整的处事件流,最终得到 resolve 结果。在 ResolverFactory.js 文件的 createResolver 方法中各个 plugin 的注册方法,决定了整个 resolve 的事件流。
exports.createResolver = function(options) {
// ...
// 根据 options 中条件的不同,加入各种 plugin
if(unsafeCache) {
plugins.push(new UnsafeCachePlugin("resolve", cachePredicate, unsafeCache, cacheWithContext, "new-resolve"));
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
// ... plugin 加入的代码
plugins.forEach(plugin => {
plugin.apply(resolver);
});
// ...上面代码整理一下,可以得到完整的事件流图(下图为简化版本,完成版本见附件)

结合上面的图和 demo,我们来一步一步看这个事件流中每一环都做了什么。(ps:下面步骤中,会涉及到 request 参数,这个参数贯穿所有事件处理逻辑,保存了整个 resolve 的信息)
增加一层缓存,由于 webpack 处理打包的过程中,涉及到大量的 resolve 过程。所以需要增加一层缓存,提高效率。webpack 默认会启用 UnsafeCache。
ParsePlugin
初步解析路径,判断是否为 module/directory/file,结果保存到 request 参数中。
DescriptionFilePlugin 和 NextPlugin
DescriptionFilePlugin 中会寻找描述文件,默认会寻找 package.json。首先会在 request.path 这个目录下寻找,如果没有则按照路径一层一层往上寻找。最后读取到 package.json 的信息和其所在的目录/路径信息,存入 request 中。我们在 demo 的根目录有 package.json 文件,所以这里会获取到根目录的文件。
NextPlugin 起一个衔接的作用,内部逻辑就是直接调用 doResolve,然后触发下一个事件。当 DescriptionFilePlugin 中未找到 package.json 文件时,会进入 NextPlugin,然后让事件流继续。
AliasPlugin/AliasFieldPlugin
这一步开始处理别名,由于 AliasFieldPlugin 中依赖于 package.json 的配置,所以这一步放在了 DescriptionFilePlugin 之后。
除了我们在配置文件中写一些别名外,webpack 还会有一些自带的 alias;每一个 alias 配置,都会注册一个函数。这一步将执行所有的函数,一一对比。
若命中某一 alias 的配置或者 aliasField,那么就会进入上图红色虚线的分支。用新的别名替换 request 参数内容,然后再次开始 resolve 过程。
没有命中,则进入下一个处理函数 ModuleKindPlugin
根据 request.module 的值走不同的分支。如果是 module,则后续进入 rawModule 的逻辑。前面 ParsePlugin 中得到的结果中 request.module 为 false,所以这里返回 undefined,继续进入下一个处理函数。
将 request 中 path 和 request 合并起来,将 request 中 relativePath 和 request 合并起来,得到两个完整的路径。在这个 demo 中会得到 /Users/didi/dist/webpackdemo/webpack-demos/demo01/a.js 和 ./demo01/a.js
这时会再次进入 DescriptionFilePlugin 。不过与第一次进入时不同之处在于,此时的 request.path 变成了 /dir/demo/a.js`。由于 path 改变了,所以需要再次查找一下 package.json
随后触发 describedRelative 事件,进入下一个流程
判断是否为一个 directory,如果是则返回 undefined, 进入下一个 tryNextPlugin,这时会进入 directory 的分支。否则,则表明是一个文件,进入 rawFile 事件。我们的 demo 中,这里将走向 rawFile 分支。
由于 webpack 中默认的 enforceExtension 值为 true,所以这里会进入 TryNextPlugin,同时 enableConcord 为 false,不会有 ConcordExtensionsPlugin。
TryNextPlugin 和 NextPlugin 类似,起一个衔接的作用,内部逻辑就是直接调用 doResolve,然后触发下一个事件。所以在这个阶段会直接走到触发 file 事件的分支。
当 TryNextPlugin 有返回,且返回为 undefined 。这时意味着没有找到 request.path 所对应的文件,那么会继续执行后续的 AppendPlugin。
AppendPlugin 主要逻辑:webpack 会设置 resolve.extensions 参数(配置中设置或者使用 webpack 默认的),AppendPlugin 会给 request.path 和 request.relativePath 逐一添加这些后缀,然后进入 file 分支,继续事件流程。
这时会再次进入到 Alias 的处理逻辑,注意在此步中 webpack 内部自带的很多 Alias 不会再有。
与前面相同,这里依然没有 ConcorModulesPlugin
SymlinkPlugin 用来处理路径中存在 link 的情况。由于 webpack 默认是按照真实的路径来解析的,所以这里会检查路径中每一段,如果遇到 link,则替换为真实路径。由于 path 改变了,所以会再回到 relative 阶段。
若路径中没有 link,则进入 FileExistsPlugin
读取 request.path 所在的文件,看文件是否存在。文件存在则进入到 existingFile 事件。
通过 NextPlugin 衔接,再进入 Resolved 事件。然后执行 ResultPlugin,到此 resolve 整个流程就结束了,request 保存了 resolve 的结果。
在 webpack 中,我们除了会 import 一个文件以外,还会 import 一个模块,比如 import Vue from 'vue'。那么这时候,webpack 就需要正确找到 vue 所对应的入口文件在哪里。针对 vue,ParsePlugin 结果中 request.module = true,随后在 ModuleKindPlugin 就会进入上面图中 rawModule 的分支。我们就以 import Vue from 'vue' 为 demo,看一下 rawModule 分支流程。
ModuleAppendPlugin 和上面的 AppendPlugin 类似,添加后缀。
TryNextPlugin 进入 module 事件
ModulesInHierachicDirectoriesPlugin 中会依次在 request.path 的每一层目录中寻找 node_modules。例如 request.path = 'dir/demo'
那么寻找 node_modules 的过程为:
dir/demo/node_modules
dir/node_modules
/node_modules如果 dir/demo/node_modules 存在,则修改 request.path 和 request.request
const obj = Object.assign({}, request, {
path: addr, // node_module 所在的路径
request: "./" + request.request
});对于 ModulesInRootPlugin,则默认为在根目录下寻找,直接进行替换
const obj = Object.assign({}, request, {
path: this.path,
request: "./" + request.request
});随后,由于改变了 request.path 和 request.request,所以重新回到 resolve 开始的阶段。但是这时 request.request 从一个 module 变成了一个普通文件类型./vue。
按照普通文件的方式查找 dir/demo/node_module/vue 的过程与前文中普通文件 resolve 过程类似,经历上一节中 1-7 的步骤,然后触发 describedRelative 事件(这个事件下注册了两个函数 FileKindPlugin 和 TryNextPlugin)。 首先进入 FileKindPlugin 的逻辑,由于 dir/demo/node_module/vue 不是一个文件地址,所以在第 8 步 FileKindPlugin 中最终会返回 undefined。 这时候会进入下一个处理事件 TryNextPlugin,然后触发 directory 事件,把 dir/demo/node_module/vue 按照文件夹的方式来解析。
确认 dir/demo/node_module/vue 是否存在。(ps: 针对 context 的 resolve 过程,到这里如果文件夹存在,则就结束了。)
webpack 默认的 mainField 为 ['browser', 'module', 'main']。这里会按照顺序,在 dir/demo/node_module/vue/package.json 中找对应字段。
vue 的 package.json 中定义了
{
"module": "dist/vue.runtime.esm.js"
}所以找到该字段后,会将 request.request 的值替换为 ./dist/vue.runtime.esm.js。之后又回到 resolve 节点,开始新一轮,寻找一个普通文件 ./dist/vue.runtime.esm.js 的过程。
当 MainFieldPlugin 执行完,都没有结果时,会进入 UseFilePlugin
当我们 package.json 中没有写 browser、module、main 时,webpack 会自动去找目录下的 index 文件,request 变成如下
{
//...省略其他部分
relativePath: "./index",
path: 'dir/demo/node_modules/vue/index'
}然后触发 undescribedRawFile 事件
针对新的 request.path ,重新寻找描述文件,即 package.json
依次为 'dir/demo/node_modules/vue/index' 添加后缀名,然后寻找该文件是否存在。与前文中 file 之后的流程相同。直到最后找到存在的文件,整个针对 module 的 resolve 过程就结束了。
loader 的 resolve 过程和 module 的过程类似,我们以 url-loader 为例,入口在 NormalModuleFactory.js 中 resolveRequestArray 函数。这里会执行 resolver.resolve,这里的 resolver 为之前得到的 loaderResolver,resolve 过程开始时 request 参数如下:
{
context: {
compiler: undefined,
issuer: "/dir/demos/main.js"
},
path: "/dir/demos"
request: "url-loader"
}在 ParsePlugin 中,request: "url-loader" 会被解析为 module。随后过程中整个和 module 执行流程相同。
到此 webpack 中关于 resolve 流程就结束了。除此之外 webpack 还有不少的细节处理,鉴于篇幅有限这里就不展开细细讨论了,大家可以结合文章看 webpack 代码时去细细品味。
webpack 中每涉及到一个文件,就会经过 resolve 的过程。而 resolve 过程中其中针对一些不确定的因素,比如后缀名,node_modules 路径等,会存在探索的过程,从而使得整个 resolve 的链条很长。很多针对 webpack 的优化,都会提到利用 resolve 配置来减少文件搜索范围:
我们日常开发项目中,常常会存在类似 common 这样的目录,common 目录下的文件,会被经常引用。比如 'common/index.js'。如果我们针对 common 目录建立一个 alias 的话,在所有用到 'common/index.js' 的文件中,可以写 import xx from 'common/index.js'。 由于 UnsafeCachePlugin 的存在,当 webpack 再次解析到 'common/index.js' 时,就可以直接使用缓存。同时如果在 alias 配置中将 common 设置为绝对目录的话,整体解析 'common/index.js' 的事件链条也会变短。
resolve.modules 的默认值为 ['node_modules'],所以在对 module 的 resolve 过程中,会依次查找 ./node_modules、../node_modules、../../node_modules 等,即沿着路径一层一层往上找,直到找到 node_modules。可以直接设置
resolve.modules:[path.resolve(__dirname, 'node_modules')]如此会进入 ModulesInRootPlugin 而不是 ModulesInHierachicDirectoriesPlugin,避免了层层寻找 node_modules 的开销。
对第三方的 module 进行 resolve 过程中,除了上面提到的 node_modules 目录查找过程,还会涉及到对 package.json 中配置的解析等。可以直接为其设置 alias 为执行文件,来简化整个 resolve 过程,如下:
resolve.alias: {
'vue': path.resolve(__dirname, './node_modules/vue/dist/vue.common.js')
}当我们的文件没有后缀时,AppendPlugin 会根据 resolve.extensions 中的值,依次添加后缀然后查找文件。为了减少文件查找,我们可以直接将文件后缀写上,或者设置 resolve.extensions 中的值,列表值尽量少,频率高的文件类型的后缀写在前面。
明白了 resolve 的细节之后,再来看这些优化策略,便可以更好的了解其原因,做到“知其然知其所以然”。
我们在使用 webpack 的时候可以通过 webpack 这个命令配合一些参数来执行我们打包编译的任务。我们想探究它的源码,从这个命令入手能够比较容易让我们了解整个代码的运行过程。那么在执行这个命令的时候究竟发生了什么呢?
注:本文中的 webpack 源码版本为1.13.3。本文中的源码分析主要关注的是代码的整体流程,因此一些我认为不是很重要的细节都会省略,以使得读者不要陷入到细节中而 get 不到整体。按照官方文档,
webpack.config.js会通过 module.exports 暴露一个对象,下文中我们统一把这个对象称为 webpack 编译对象(Webpack compiler object)。
bin/webpack.js// bin/webpack.js
// 引入 nodejs 的 path 模块
var path = require ("path") ;
// 获取 /bin/webpack.js 的绝对路径
try {
var localWebpack = require.resolve (path.join (process.cwd (), "node_modules", "webpack", "bin", "webpack.js")) ;
if (__filename !== localWebpack) {}
} catch (e) {}
// 引入第三方命令行解析库 optimist
// 解析 webpack 指令后面追加的与输出显示相关的参数(Display options)
var optimist = require ("optimist").usage ((("webpack " + require ("../package.json").version) + "\n") + "Usage: https://webpack.github.io/docs/cli.html") ;
require ("./config-optimist") (optimist) ;
optimist
.boolean ("json").alias ("json", "j").describe ("json")
.boolean ("colors").alias ("colors", "c")... ;
// 获取解析后的参数并转换格式
var argv = optimist.argv ;
var options = require ("./convert-argv") (optimist, argv) ;
// 判断是否符合 argv 里的参数,并执行该参数的回调
function ifArg (name, fn, init) {...}
// 处理输出相关(output)的配置参数,并执行编译函数
function processOptions (options) {...}
// 执行
processOptions (options) ;小结1.1:从上面的分析中我们可以比较清晰地看到执行
webpack命令时会做什么处理,主要就是解析命令行参数以及执行编译。其中 processOptions 这个函数是整个/bin/webpack.js里的核心函数。下面我们来仔细看一下这个函数:
function processOptions (options) {
// 支持 Promise 风格的异步回调
if ((typeof options.then) === "function") {...}
// 处理传入一个 webpack 编译对象是数组时的情况
var firstOptions = (Array.isArray (options)) ? options[0]: options;
// 设置输出 options
var outputOptions = Object.create ((options.stats || firstOptions.stats) || ({}));
// 设置输出的上下文 context
if ((typeof outputOptions.context) === "undefined") outputOptions.context = firstOptions.context ;
// 处理各种显示相关的参数,从略
ifArg ("json",
function (bool){...}
);
...
// 引入主入口模块 lib/webpack.js
var webpack = require ("../lib/webpack.js") ;
// 设置错误堆栈追踪上限
Error.stackTraceLimit = 30 ;
var lastHash = null ;
// 执行编译
var compiler = webpack (options) ;
// 编译结束后的回调函数
function compilerCallback (err, stats) {...}
// 是否在编译完成后继续 watch 文件变更
if (options.watch) {...}
else
// 执行编译后的回调函数
compiler.run (compilerCallback) ;
}小结1.2:从 processOptions 中我们看到,最核心的编译一步,是使用的入口模块 lib/webpack.js 暴露处理的方法,所以我们的数据流接下来要从
bin/webpack.js来到lib/webpack.js了,接下来我们看看lib/webpack.js里将会发生什么。
lib/webpack.js 中的方法开始编译// lib/webpack.js
// 引入 Compiler 模块
var Compiler = require ("./Compiler") ;
// 引入 MultiCompiler 模块,处理多个 webpack 配置文件的情况
var MultiCompiler = require ("./MultiCompiler") ;
// 引入 node 环境插件
var NodeEnvironmentPlugin = require ("./node/NodeEnvironmentPlugin") ;
// 引入 WebpackOptionsApply 模块,应用 webpack 配置文件
var WebpackOptionsApply = require ("./WebpackOptionsApply") ;
// 引入 WebpackOptionsDefaulter 模块,应用 webpack 默认配置
var WebpackOptionsDefaulter = require ("./WebpackOptionsDefaulter") ;
// 核心函数,也是 ./bin/webpack.js 中引用的核心方法
function webpack (options, callback) {...}
exports = module.exports = webpack ;
// 在 webpack 对象上设置一些常用属性
webpack.WebpackOptionsDefaulter = WebpackOptionsDefaulter ;
webpack.WebpackOptionsApply = WebpackOptionsApply ;
webpack.Compiler = Compiler ;
webpack.MultiCompiler = MultiCompiler ;
webpack.NodeEnvironmentPlugin = NodeEnvironmentPlugin ;
// 暴露一些插件
function exportPlugins (exports, path, plugins) {...}
exportPlugins (exports, ".", ["DefinePlugin", "NormalModuleReplacementPlugin", ...]) ;小结2.1:
lib/webpack.js文件里的代码比较清晰,核心函数就是我们期待已久的 webpack,我们在 webpack.config.js 里面引入的 webpack 模块就是这个文件,下面我们再来仔细看看这个函数。
function webpack (options, callback) {
var compiler ;
if (Array.isArray (options)) {
// 如果传入了数组类型的 webpack 编译对象,则实例化一个 MultiCompiler 来处理
compiler = new MultiCompiler (options.map(function (options) {
return webpack (options) ; // 递归调用 webpack 函数
})) ;
} else if ((typeof options) === "object") {
// 如果传入了一个对象类型的 webpack 编译对象
// 实例化一个 WebpackOptionsDefaulter 来处理默认配置项
new WebpackOptionsDefaulter ().process (options) ;
// 实例化一个 Compiler,Compiler 会继承一个 Tapable 插件框架
// Compiler 实例化后会继承到 apply、plugin 等调用和绑定插件的方法
compiler = new Compiler () ;
// 实例化一个 WebpackOptionsApply 来编译处理 webpack 编译对象
compiler.options = options ; // 疑惑:为何两次赋值 compiler.options?
compiler.options = new WebpackOptionsApply ().process (options, compiler) ;
// 应用 node 环境插件
new NodeEnvironmentPlugin ().apply (compiler) ;
compiler.applyPlugins ("environment") ;
compiler.applyPlugins ("after-environment") ;
} else {
// 抛出错误
throw new Error ("Invalid argument: options") ;
}
}小结2.2:
webpack函数里面有两个地方值得关注一下。
一是
Compiler,实例化它会继承 Tapable ,这个 Tapable 是一个插件框架,通过继承它的一系列方法来实现注册和调用插件,我们可以看到在 webpack 的源码中,存在大量的 compiler.apply、compiler.applyPlugins、compiler.plugin 等Tapable方法的调用。Webpack 的 plugin 注册和调用方式,都是源自 Tapable 。Webpack 通过 plugin 的 apply 方法安装该 plugin,同时传入一个 webpack 编译对象(Webpack compiler object)。
二是
WebpackOptionsApply的实例方法process (options, compiler),这个方法将会针对我们传进去的webpack 编译对象进行逐一编译,接下来我们再来仔细看看这个模块。
lib/WebpackOptionsApply.js 模块的 process 方法来逐一编译 webpack 编译对象的各项// lib/WebpackOptionsApply.js
// ...此处省略一堆依赖引入
// 创建构造器函数 WebpackOptionsApply
function WebpackOptionsApply () {
OptionsApply.call (this) ;
}
// 将构造器暴露
module.exports = WebpackOptionsApply ;
// 修改构造器的原型属性指向
WebpackOptionsApply.prototype = Object.create (OptionsApply.prototype) ;
// 创建 WebpackOptionsApply 的实例方法 process
WebpackOptionsApply.prototype.process = function (options, compiler) {
// 处理 context 属性,根目录
compiler.context = options.context ;
// 处理 plugins 属性
if (options.plugins && (Array.isArray (options.plugins))) {...}
// 缓存输入输出的目录地址等
compiler.outputPath = options.output.path ;
compiler.recordsInputPath = options.recordsInputPath || options.recordsPath ;
compiler.recordsOutputPath = options.recordsOutputPath || options.recordsPath ;
compiler.name = options.name ;
// 处理 target 属性,该属性决定包 (bundle) 应该运行的环境
if ((typeof options.target) === "string") {...}
else if (options.target !== false) {...}
else {...}
// 处理 output.library 属性,该属性决定导出库 (exported library) 的名称
if (options.output.library || (options.output.libraryTarget !== "var")) {...}
// 处理 externals 属性,告诉 webpack 不要遵循/打包这些模块,而是在运行时从环境中请求他们
if (options.externals) {...}
// 处理 hot 属性,它决定 webpack 了如何使用热替换
if (options.hot) {...}
// 处理 devtool 属性,它决定了 webpack 的 sourceMap 模式
if (options.devtool && (((options.devtool.indexOf ("sourcemap")) >= 0) || ((options.devtool.indexOf ("source-map")) >= 0))) {...}
else if (options.devtool && ((options.devtool.indexOf ("eval")) >= 0)) {...}
// 以下是安装并调用各种插件 plugin,由于功能众多个人阅历有限,不能面面俱到
compiler.apply (new EntryOptionPlugin ()) ; // 调用处理入口 entry 的插件
compiler.applyPluginsBailResult ("entry-option", options.context, options.entry) ;
if (options.prefetch) {...}
compiler.apply (new CompatibilityPlugin (),
new LoaderPlugin (), // 调用 loader 的插件
new NodeStuffPlugin (options.node), // 调用 nodejs 环境相关的插件
new RequireJsStuffPlugin (), // 调用 RequireJs 的插件
new APIPlugin (), // 调用变量名的替换,webpack 编译后的文件里随处可见的 __webpack_require__ 变量名就是在此处理
new ConstPlugin (), // 调用一些 if 条件语句、三元运算符等语法相关的插件
new RequireIncludePlugin (), // 调用 require.include 函数的插件
new RequireEnsurePlugin (), // 调用 require.ensure 函数的插件
new RequireContextPlugin(options.resolve.modulesDirectories, options.resolve.extensions),
new AMDPlugin (options.module, options.amd || ({})), // 调用处理符合 AMD 规范的插件
new CommonJsPlugin (options.module)) ; // 调用处理符合 CommonJs 规范的插件
compiler.apply (new RemoveParentModulesPlugin (), // 调用移除父 Modules 的插件
new RemoveEmptyChunksPlugin (), // 调用移除空 chunk 的插件
new MergeDuplicateChunksPlugin (), // 调用合并重复多余 chunk 的插件
new FlagIncludedChunksPlugin ()) ; //
compiler.apply (new TemplatedPathPlugin ()) ;
compiler.apply (new RecordIdsPlugin ()) ; // 调用记录 Modules 的 Id 的插件
compiler.apply (new WarnCaseSensitiveModulesPlugin ()) ; // 调用警告大小写敏感的插件
// 处理 webpack.optimize 属性下的几个方法
if (options.optimize && options.optimize.occurenceOrder) {...} // 调用 OccurrenceOrderPlugin 插件
if (options.optimize && options.optimize.minChunkSize) {...} // 调用 MinChunkSizePlugin 插件
if (options.optimize && options.optimize.maxChunks) {...} // 调用 LimitChunkCountPlugin 插件
if (options.optimize.minimize) {...} // 调用 UglifyJsPlugin 插件
// 处理cache属性(缓存),该属性在watch的模式下默认开启缓存
if ((options.cache === undefined) ? options.watch: options.cache) {...}
// 处理 provide 属性,如果有则调用 ProvidePlugin 插件,这个插件可以让一个 module 赋值为一个变量,从而能在每个 module 中以变量名访问它
if ((typeof options.provide) === "object") {...}
// 处理define属性,如果有这个属性则调用 DefinePlugin 插件,这个插件可以定义全局的常量
if (options.define) {...}
// 处理 defineDebug 属性,调用并开启 DefinePlugin 插件的 debug 模式?
if (options.defineDebug !== false) compiler.apply (new DefinePlugin ({...})) ; // 处理定义插件的
// 调用一些编译完后的处理插件
compiler.applyPlugins ("after-plugins", compiler) ;
compiler.resolvers.normal.apply (new UnsafeCachePlugin (options.resolve.unsafeCache)...) ;
compiler.resolvers.context.apply (new UnsafeCachePlugin (options.resolve.unsafeCache)...) ;
compiler.resolvers.loader.apply (new UnsafeCachePlugin (options.resolve.unsafeCache)...) ;
compiler.applyPlugins ("after-resolvers", compiler) ;
// 最后把处理过的 webpack 编译对象返回
return options;
};小结3.1:我们可以在上面的代码中看到 webpack 文档中 Configuration 中介绍的各个属性,同时看到了这些属性对应的处理插件都是谁。我个人看完这里之后,熟悉了好几个平常不怎么用到,但是感觉还是很有用的东西,例如 externals 和 define 属性。
由于插件繁多,切每个插件都有不同的细节,我们这里选择一个大家可能比较熟悉的插件
UglifyJsPlugin.js(压缩代码插件)来理解 webpack 的流程。
// lib/optimize/UglifyJsPlugin.js
// 引入一些依赖,主要是与压缩代码、sourceMap 相关
var SourceMapConsumer = require("webpack-core/lib/source-map").SourceMapConsumer;
var SourceMapSource = require("webpack-core/lib/SourceMapSource");
var RawSource = require("webpack-core/lib/RawSource");
var RequestShortener = require("../RequestShortener");
var ModuleFilenameHelpers = require("../ModuleFilenameHelpers");
var uglify = require("uglify-js");
// 定义构造器函数
function UglifyJsPlugin(options) {
...
}
// 将构造器暴露出去
module.exports = UglifyJsPlugin;
// 按照 Tapable 风格编写插件
UglifyJsPlugin.prototype.apply = function(compiler) {
...
// 编译器开始编译
compiler.plugin("compilation", function(compilation) {
...
// 编译器开始调用 "optimize-chunk-assets" 插件编译
compilation.plugin("optimize-chunk-assets", function(chunks, callback) {
var files = [];
...
files.forEach(function(file) {
...
try {
var asset = compilation.assets[file];
if(asset.__UglifyJsPlugin) {
compilation.assets[file] = asset.__UglifyJsPlugin;
return;
}
if(options.sourceMap !== false) {
// 需要 sourceMap 时要做的一些操作...
} else {
// 获取读取到的源文件
var input = asset.source();
...
}
// base54 编码重置
uglify.base54.reset();
// 将源文件生成语法树
var ast = uglify.parse(input, {
filename: file
});
// 语法树转换为压缩后的代码
if(options.compress !== false) {
ast.figure_out_scope();
var compress = uglify.Compressor(options.compress); // eslint-disable-line new-cap
ast = ast.transform(compress);
}
// 处理混淆变量名
if(options.mangle !== false) {
ast.figure_out_scope();
ast.compute_char_frequency(options.mangle || {});
ast.mangle_names(options.mangle || {});
if(options.mangle && options.mangle.props) {
uglify.mangle_properties(ast, options.mangle.props);
}
}
// 定义输出变量名
var output = {};
// 处理输出的注释
output.comments = Object.prototype.hasOwnProperty.call(options, "comments") ? options.comments : /^\**!|@preserve|@license/;
// 处理输出的美化
output.beautify = options.beautify;
for(var k in options.output) {
output[k] = options.output[k];
}
// 处理输出的 sourceMap
if(options.sourceMap !== false) {
var map = uglify.SourceMap({ // eslint-disable-line new-cap
file: file,
root: ""
});
output.source_map = map; // eslint-disable-line camelcase
}
// 将压缩后的数据输出
var stream = uglify.OutputStream(output); // eslint-disable-line new-cap
ast.print(stream);
if(map) map = map + "";
stream = stream + "";
asset.__UglifyJsPlugin = compilation.assets[file] = (map ?
new SourceMapSource(stream, file, JSON.parse(map), input, inputSourceMap) :
new RawSource(stream));
if(warnings.length > 0) {
compilation.warnings.push(new Error(file + " from UglifyJs\n" + warnings.join("\n")));
}
} catch(err) {
// 处理异常
...
} finally {
...
}
});
// 回调函数
callback();
});
compilation.plugin("normal-module-loader", function(context) {
context.minimize = true;
});
});
};
小结4.1:从这个插件的源码分析,我们可以基本看到 webpack 编译时的读写过程大致是怎么样的:实例化插件(如 UglifyJsPlugin )--> 读取源文件 --> 编译并输出
现在我们回过头来再看看整体流程,当我们在命令行输入 webpack 命令,按下回车时都发生了什么:
Compiler,继承 Tapable 插件框架,实现注册和调用一系列插件。/WebpackOptionsApply.js 模块的 process 方法,使用各种各样的插件来逐一编译 webpack 编译对象的各项。作为 Vue 的使用者我们对于 vue-cli 都很熟悉,但是对它的 webpack 配置我们可能关注甚少,今天我们为大家带来 vue-cli#2.0 的 webpack 配置分析
vue-cli 的简介、安装我们不在这里赘述,对它还不熟悉的同学可以直接访问 vue-cli 查看
.
├── README.md
├── build
│ ├── build.js
│ ├── check-versions.js
│ ├── dev-client.js
│ ├── dev-server.js
│ ├── utils.js
│ ├── webpack.base.conf.js
│ ├── webpack.dev.conf.js
│ └── webpack.prod.conf.js
├── config
│ ├── dev.env.js
│ ├── index.js
│ └── prod.env.js
├── index.html
├── package.json
├── src
│ ├── App.vue
│ ├── assets
│ │ └── logo.png
│ ├── components
│ │ └── Hello.vue
│ └── main.js
└── static本篇文章的主要关注点在
build - 编译任务的代码
config - webpack 的配置文件
package.json - 项目的基本信息
从 package.json 中我们可以看到
"scripts": {
"dev": "node build/dev-server.js",
"build": "node build/build.js",
"lint": "eslint --ext .js,.vue src"
}当我们执行 npm run dev / npm run build 时运行的是 node build/dev-server.js 或 node build/build.js
让我们先从 build/dev-server.js 入手
require('./check-versions')() // 检查 Node 和 npm 版本
var config = require('../config') // 获取 config/index.js 的默认配置
/*
** 如果 Node 的环境无法判断当前是 dev / product 环境
** 使用 config.dev.env.NODE_ENV 作为当前的环境
*/
if (!process.env.NODE_ENV) process.env.NODE_ENV = JSON.parse(config.dev.env.NODE_ENV)
var path = require('path') // 使用 NodeJS 自带的文件路径工具
var express = require('express') // 使用 express
var webpack = require('webpack') // 使用 webpack
var opn = require('opn') // 一个可以强制打开浏览器并跳转到指定 url 的插件
var proxyMiddleware = require('http-proxy-middleware') // 使用 proxyTable
var webpackConfig = require('./webpack.dev.conf') // 使用 dev 环境的 webpack 配置
/* 如果没有指定运行端口,使用 config.dev.port 作为运行端口 */
var port = process.env.PORT || config.dev.port
/* 使用 config.dev.proxyTable 的配置作为 proxyTable 的代理配置 */
/* 项目参考 https://github.com/chimurai/http-proxy-middleware */
var proxyTable = config.dev.proxyTable
/* 使用 express 启动一个服务 */
var app = express()
var compiler = webpack(webpackConfig) // 启动 webpack 进行编译
/* 启动 webpack-dev-middleware,将 编译后的文件暂存到内存中 */
var devMiddleware = require('webpack-dev-middleware')(compiler, {
publicPath: webpackConfig.output.publicPath,
stats: {
colors: true,
chunks: false
}
})
/* 启动 webpack-hot-middleware,也就是我们常说的 Hot-reload */
var hotMiddleware = require('webpack-hot-middleware')(compiler)
/* 当 html-webpack-plugin 模板更新的时候强制刷新页面 */
compiler.plugin('compilation', function (compilation) {
compilation.plugin('html-webpack-plugin-after-emit', function (data, cb) {
hotMiddleware.publish({ action: 'reload' })
cb()
})
})
// 将 proxyTable 中的请求配置挂在到启动的 express 服务上
Object.keys(proxyTable).forEach(function (context) {
var options = proxyTable[context]
if (typeof options === 'string') {
options = { target: options }
}
app.use(proxyMiddleware(context, options))
})
// 使用 connect-history-api-fallback 匹配资源,如果不匹配就可以重定向到指定地址
app.use(require('connect-history-api-fallback')())
// 将暂存到内存中的 webpack 编译后的文件挂在到 express 服务上
app.use(devMiddleware)
// 将 Hot-reload 挂在到 express 服务上并且输出相关的状态、错误
app.use(hotMiddleware)
// 拼接 static 文件夹的静态资源路径
var staticPath = path.posix.join(config.dev.assetsPublicPath, config.dev.assetsSubDirectory)
// 为静态资源提供响应服务
app.use(staticPath, express.static('./static'))
// 让我们这个 express 服务监听 port 的请求,并且将此服务作为 dev-server.js 的接口暴露
module.exports = app.listen(port, function (err) {
if (err) {
console.log(err)
return
}
var uri = 'http://localhost:' + port
console.log('Listening at ' + uri + '\n')
// 如果不是测试环境,自动打开浏览器并跳到我们的开发地址
if (process.env.NODE_ENV !== 'testing') {
opn(uri)
}
})刚刚我们在 dev-server.js 中用到了 webpack.dev.conf.js 和 index.js,我们先来看一下 webpack.dev.conf.js
var config = require('../config') // 同样的使用了 config/index.js
var webpack = require('webpack') // 使用 webpack
var merge = require('webpack-merge') // 使用 webpack 配置合并插件
var utils = require('./utils') // 使用一些小工具
var baseWebpackConfig = require('./webpack.base.conf') // 加载 webpack.base.conf
/* 使用 html-webpack-plugin 插件,这个插件可以帮我们自动生成 html 并且注入到 .html 文件中 */
var HtmlWebpackPlugin = require('html-webpack-plugin')
// 将 Hol-reload 相对路径添加到 webpack.base.conf 的 对应 entry 前
Object.keys(baseWebpackConfig.entry).forEach(function (name) {
baseWebpackConfig.entry[name] = ['./build/dev-client'].concat(baseWebpackConfig.entry[name])
})
/* 将我们 webpack.dev.conf.js 的配置和 webpack.base.conf.js 的配置合并 */
module.exports = merge(baseWebpackConfig, {
module: {
// 使用 styleLoaders
loaders: utils.styleLoaders({ sourceMap: config.dev.cssSourceMap })
},
// 使用 #eval-source-map 模式作为开发工具,此配置可参考 DDFE 往期文章详细了解
devtool: '#eval-source-map',
plugins: [
/* definePlugin 接收字符串插入到代码当中, 所以你需要的话可以写上 JS 的字符串 */
new webpack.DefinePlugin({
'process.env': config.dev.env
}),
// 参考项目 https://github.com/glenjamin/webpack-hot-middleware#installation--usage
new webpack.optimize.OccurenceOrderPlugin(),
/* HotModule 插件在页面进行变更的时候只会重回对应的页面模块,不会重绘整个 html 文件 */
new webpack.HotModuleReplacementPlugin(),
/* 使用了 NoErrorsPlugin 后页面中的报错不会阻塞,但是会在编译结束后报错 */
new webpack.NoErrorsPlugin(),
// 参考项目 https://github.com/ampedandwired/html-webpack-plugin
/* 将 index.html 作为入口,注入 html 代码后生成 index.html文件 */
new HtmlWebpackPlugin({
filename: 'index.html',
template: 'index.html',
inject: true
})
]
})我们看到在 webpack.dev.conf.js 中又引入了 webpack.base.conf.js, 它看起来很重要的样子,所以我们只能在下一章来看看 config/index.js 了 (摊手)
var path = require('path') // 使用 NodeJS 自带的文件路径插件
var config = require('../config') // 引入 config/index.js
var utils = require('./utils') // 引入一些小工具
var projectRoot = path.resolve(__dirname, '../') // 拼接我们的工作区路径为一个绝对路径
/* 将 NodeJS 环境作为我们的编译环境 */
var env = process.env.NODE_ENV
/* 是否在 dev 环境下开启 cssSourceMap ,在 config/index.js 中可配置 */
var cssSourceMapDev = (env === 'development' && config.dev.cssSourceMap)
/* 是否在 production 环境下开启 cssSourceMap ,在 config/index.js 中可配置 */
var cssSourceMapProd = (env === 'production' && config.build.productionSourceMap)
/* 最终是否使用 cssSourceMap */
var useCssSourceMap = cssSourceMapDev || cssSourceMapProd
module.exports = {
entry: {
app: './src/main.js' // 编译文件入口
},
output: {
path: config.build.assetsRoot, // 编译输出的静态资源根路径
publicPath: process.env.NODE_ENV === 'production' ? config.build.assetsPublicPath : config.dev.assetsPublicPath, // 正式发布环境下编译输出的上线路径的根路径
filename: '[name].js' // 编译输出的文件名
},
resolve: {
// 自动补全的扩展名
extensions: ['', '.js', '.vue'],
// 不进行自动补全或处理的文件或者文件夹
fallback: [path.join(__dirname, '../node_modules')],
alias: {
// 默认路径代理,例如 import Vue from 'vue',会自动到 'vue/dist/vue.common.js'中寻找
'vue$': 'vue/dist/vue.common.js',
'src': path.resolve(__dirname, '../src'),
'assets': path.resolve(__dirname, '../src/assets'),
'components': path.resolve(__dirname, '../src/components')
}
},
resolveLoader: {
fallback: [path.join(__dirname, '../node_modules')]
},
module: {
preLoaders: [
// 预处理的文件及使用的 loader
{
test: /\.vue$/,
loader: 'eslint',
include: projectRoot,
exclude: /node_modules/
},
{
test: /\.js$/,
loader: 'eslint',
include: projectRoot,
exclude: /node_modules/
}
],
loaders: [
// 需要处理的文件及使用的 loader
{
test: /\.vue$/,
loader: 'vue'
},
{
test: /\.js$/,
loader: 'babel',
include: projectRoot,
exclude: /node_modules/
},
{
test: /\.json$/,
loader: 'json'
},
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
loader: 'url',
query: {
limit: 10000,
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
loader: 'url',
query: {
limit: 10000,
name: utils.assetsPath('fonts/[name].[hash:7].[ext]')
}
}
]
},
eslint: {
// eslint 代码检查配置工具
formatter: require('eslint-friendly-formatter')
},
vue: {
// .vue 文件配置 loader 及工具 (autoprefixer)
loaders: utils.cssLoaders({ sourceMap: useCssSourceMap }),
postcss: [
require('autoprefixer')({
browsers: ['last 2 versions']
})
]
}
}终于分析完了 webpack.base.conf.js,来让我们看一下 config/index.js
index.js 中有 dev 和 production 两种环境的配置
var path = require('path')
module.exports = {
build: { // production 环境
env: require('./prod.env'), // 使用 config/prod.env.js 中定义的编译环境
index: path.resolve(__dirname, '../dist/index.html'), // 编译输入的 index.html 文件
assetsRoot: path.resolve(__dirname, '../dist'), // 编译输出的静态资源路径
assetsSubDirectory: 'static', // 编译输出的二级目录
assetsPublicPath: '/', // 编译发布的根目录,可配置为资源服务器域名或 CDN 域名
productionSourceMap: true, // 是否开启 cssSourceMap
// Gzip off by default as many popular static hosts such as
// Surge or Netlify already gzip all static assets for you.
// Before setting to `true`, make sure to:
// npm install --save-dev compression-webpack-plugin
productionGzip: false, // 是否开启 gzip
productionGzipExtensions: ['js', 'css'] // 需要使用 gzip 压缩的文件扩展名
},
dev: { // dev 环境
env: require('./dev.env'), // 使用 config/dev.env.js 中定义的编译环境
port: 8080, // 运行测试页面的端口
assetsSubDirectory: 'static', // 编译输出的二级目录
assetsPublicPath: '/', // 编译发布的根目录,可配置为资源服务器域名或 CDN 域名
proxyTable: {}, // 需要 proxyTable 代理的接口(可跨域)
cssSourceMap: false // 是否开启 cssSourceMap(因为一些 bug 此选项默认关闭,详情可参考 https://github.com/webpack/css-loader#sourcemaps)
}
}至此,我们的 npm run dev 命令就讲解完毕,下面让我们来看一看执行 npm run build 命令时发生了什么 ~
require('./check-versions')() // 检查 Node 和 npm 版本
require('shelljs/global') // 使用了 shelljs 插件,可以让我们在 node 环境的 js 中使用 shell
env.NODE_ENV = 'production'
var path = require('path') // 不再赘述
var config = require('../config') // 加载 config.js
var ora = require('ora') // 一个很好看的 loading 插件
var webpack = require('webpack') // 加载 webpack
var webpackConfig = require('./webpack.prod.conf') // 加载 webpack.prod.conf
console.log( // 输出提示信息 ~ 提示用户请在 http 服务下查看本页面,否则为空白页
' Tip:\n' +
' Built files are meant to be served over an HTTP server.\n' +
' Opening index.html over file:// won\'t work.\n'
)
var spinner = ora('building for production...') // 使用 ora 打印出 loading + log
spinner.start() // 开始 loading 动画
/* 拼接编译输出文件路径 */
var assetsPath = path.join(config.build.assetsRoot, config.build.assetsSubDirectory)
/* 删除这个文件夹 (递归删除) */
rm('-rf', assetsPath)
/* 创建此文件夹 */
mkdir('-p', assetsPath)
/* 复制 static 文件夹到我们的编译输出目录 */
cp('-R', 'static/*', assetsPath)
// 开始 webpack 的编译
webpack(webpackConfig, function (err, stats) {
// 编译成功的回调函数
spinner.stop()
if (err) throw err
process.stdout.write(stats.toString({
colors: true,
modules: false,
children: false,
chunks: false,
chunkModules: false
}) + '\n')
})var path = require('path')
var config = require('../config') // 加载 confi.index.js
var utils = require('./utils') // 使用一些小工具
var webpack = require('webpack') // 加载 webpack
var merge = require('webpack-merge') // 加载 webpack 配置合并工具
var baseWebpackConfig = require('./webpack.base.conf') // 加载 webpack.base.conf.js
/* 一个 webpack 扩展,可以提取一些代码并且将它们和文件分离开 */
/* 如果我们想将 webpack 打包成一个文件 css js 分离开,那我们需要这个插件 */
var ExtractTextPlugin = require('extract-text-webpack-plugin')
/* 一个可以插入 html 并且创建新的 .html 文件的插件 */
var HtmlWebpackPlugin = require('html-webpack-plugin')
var env = config.build.env
/* 合并 webpack.base.conf.js */
var webpackConfig = merge(baseWebpackConfig, {
module: {
/* 使用的 loader */
loaders: utils.styleLoaders({ sourceMap: config.build.productionSourceMap, extract: true })
},
/* 是否使用 #source-map 开发工具,更多信息可以查看 DDFE 往期文章 */
devtool: config.build.productionSourceMap ? '#source-map' : false,
output: {
/* 编译输出目录 */
path: config.build.assetsRoot,
/* 编译输出文件名 */
filename: utils.assetsPath('js/[name].[chunkhash].js'), // 我们可以在 hash 后加 :6 决定使用几位 hash 值
// 没有指定输出名的文件输出的文件名
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js')
},
vue: {
/* 编译 .vue 文件时使用的 loader */
loaders: utils.cssLoaders({
sourceMap: config.build.productionSourceMap,
extract: true
})
},
plugins: [
/* 使用的插件 */
/* definePlugin 接收字符串插入到代码当中, 所以你需要的话可以写上 JS 的字符串 */
new webpack.DefinePlugin({
'process.env': env
}),
/* 压缩 js (同样可以压缩 css) */
new webpack.optimize.UglifyJsPlugin({
compress: {
warnings: false
}
}),
new webpack.optimize.OccurrenceOrderPlugin(),
/* 将 css 文件分离出来 */
new ExtractTextPlugin(utils.assetsPath('css/[name].[contenthash].css')),
/* 构建要输出的 index.html 文件, HtmlWebpackPlugin 可以生成一个 html 并且在其中插入你构建生成的资源 */
new HtmlWebpackPlugin({
filename: config.build.index, // 生成的 html 文件名
template: 'index.html', // 使用的模板
inject: true, // 是否注入 html (有多重注入方式,可以选择注入的位置)
minify: { // 压缩的方式
removeComments: true,
collapseWhitespace: true,
removeAttributeQuotes: true
// 更多参数可查看 https://github.com/kangax/html-minifier#options-quick-reference
},
chunksSortMode: 'dependency'
}),
// 此处增加 @OYsun 童鞋补充
// CommonsChunkPlugin用于生成在入口点之间共享的公共模块(比如jquery,vue)的块并将它们分成独立的包。而为什么要new两次这个插件,这是一个很经典的bug的解决方案,在webpack的一个issues有过深入的讨论webpack/webpack#1315 .----为了将项目中的第三方依赖代码抽离出来,官方文档上推荐使用这个插件,当我们在项目里实际使用之后,发现一旦更改了 app.js 内的代码,vendor.js 的 hash 也会改变,那么下次上线时,用户仍然需要重新下载 vendor.js 与 app.js
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: function (module, count) {
// 依赖的 node_modules 文件会被提取到 vendor 中
return (
module.resource &&
/\.js$/.test(module.resource) &&
module.resource.indexOf(
path.join(__dirname, '../node_modules')
) === 0
)
}
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
chunks: ['vendor']
})
]
})
/* 开启 gzip 的情况下使用下方的配置 */
if (config.build.productionGzip) {
/* 加载 compression-webpack-plugin 插件 */
var CompressionWebpackPlugin = require('compression-webpack-plugin')
/* 向webpackconfig.plugins中加入下方的插件 */
webpackConfig.plugins.push(
/* 使用 compression-webpack-plugin 插件进行压缩 */
new CompressionWebpackPlugin({
asset: '[path].gz[query]',
algorithm: 'gzip',
test: new RegExp(
'\\.(' +
config.build.productionGzipExtensions.join('|') +
')$'
),
threshold: 10240,
minRatio: 0.8
})
)
}
module.exports = webpackConfig至此 ~ 我们的 vue-cli#2.0 webpack 配置分析文件就讲解完毕 ~
对于一些插件的详细 options 我们没有进行讲解,感兴趣的同学可以去 npm 商店搜索对应插件查看 options ~
本篇来分析下 webpack loader 详细的分析部分,由于涉及内容比较多,所以总共分成三篇文章来分析:
webpack 对于一个 module 所使用的 loader 对开发者提供了2种使用方式:
// webpack.config.js
module.exports = {
...
module: {
rules: [{
test: /.vue$/,
loader: 'vue-loader'
}, {
test: /.scss$/,
use: [
'vue-style-loader',
'css-loader',
{
loader: 'sass-loader',
options: {
data: '$color: red;'
}
}
]
}]
}
...
}// module
import a from 'raw-loader!../../utils.js'2 种不同的配置形式,在 webpack 内部有着不同的解析方式。此外,不同的配置方式也决定了最终在实际加载 module 过程中不同 loader 之间相互的执行顺序等。
在讲 loader 的匹配过程之前,首先从整体上了解下 loader 在整个 webpack 的 workflow 过程中出现的时机。

在一个 module 构建过程中,首先根据 module 的依赖类型(例如 NormalModuleFactory)调用对应的构造函数来创建对应的模块。在创建模块的过程中(new NormalModuleFactory()),会根据开发者的 webpack.config 当中的 rules 以及 webpack 内置的 rules 规则实例化 RuleSet 匹配实例,这个 RuleSet 实例在 loader 的匹配过滤过程中非常的关键,具体的源码解析可参见Webpack Loader Ruleset 匹配规则解析。实例化 RuleSet 后,还会注册2个钩子函数:
class NormalModuleFactory {
...
// 内部嵌套 resolver 的钩子,完成相关的解析后,创建这个 normalModule
this.hooks.factory.tap('NormalModuleFactory', () => (result, callback) => { ... })
// 在 hooks.factory 的钩子内部进行调用,实际的作用为解析构建一共 module 所需要的 loaders 及这个 module 的相关构建信息(例如获取 module 的 packge.json等)
this.hooks.resolver.tap('NormalModuleFactory', () => (result, callback) => { ... })
...
}当 NormalModuleFactory 实例化完成后,并在 compilation 内部调用这个实例的 create 方法开始真实开始创建这个 normalModule。首先调用hooks.factory获取对应的钩子函数,接下来就调用 resolver 钩子(hooks.resolver)进入到了 resolve 的阶段,在真正开始 resolve loader 之前,首先就是需要匹配过滤找到构建这个 module 所需要使用的所有的 loaders。首先进行的是对于 inline loaders 的处理:
// NormalModuleFactory.js
// 是否忽略 preLoader 以及 normalLoader
const noPreAutoLoaders = requestWithoutMatchResource.startsWith("-!");
// 是否忽略 normalLoader
const noAutoLoaders =
noPreAutoLoaders || requestWithoutMatchResource.startsWith("!");
// 忽略所有的 preLoader / normalLoader / postLoader
const noPrePostAutoLoaders = requestWithoutMatchResource.startsWith("!!");
// 首先解析出所需要的 loader,这种 loader 为内联的 loader
let elements = requestWithoutMatchResource
.replace(/^-?!+/, "")
.replace(/!!+/g, "!")
.split("!");
let resource = elements.pop(); // 获取资源的路径
elements = elements.map(identToLoaderRequest); // 获取每个loader及对应的options配置(将inline loader的写法变更为module.rule的写法)首先是根据模块的路径规则,例如模块的路径是以这些符号开头的 ! / -! / !! 来判断这个模块是否只是使用 inline loader,或者剔除掉 preLoader, postLoader 等规则:
! 忽略 webpack.config 配置当中符合规则的 normalLoader-! 忽略 webpack.config 配置当中符合规则的 preLoader/normalLoader!! 忽略 webpack.config 配置当中符合规则的 postLoader/preLoader/normalLoader这几个匹配规则主要适用于在 webpack.config 已经配置了对应模块使用的 loader,但是针对一些特殊的 module,你可能需要单独的定制化的 loader 去处理,而不是走常规的配置,因此可以使用这些规则来进行处理。
接下来将所有的 inline loader 转化为数组的形式,例如:
import 'style-loader!css-loader!stylus-loader?a=b!../../common.styl'最终 inline loader 统一格式输出为:
[{
loader: 'style-loader',
options: undefined
}, {
loader: 'css-lodaer',
options: undefined
}, {
loader: 'stylus-loader',
options: '?a=b'
}]对于 inline loader 的处理便是直接对其进行 resolve,获取对应 loader 的相关信息:
asyncLib.parallel([
callback =>
this.resolveRequestArray(
contextInfo,
context,
elements,
loaderResolver,
callback
),
callback => {
// 对这个 module 进行 resolve
...
callack(null, {
resouceResolveData, // 模块的基础信息,包含 descriptionFilePath / descriptionFileData 等(即 package.json 等信息)
resource // 模块的绝对路径
})
}
], (err, results) => {
const loaders = results[0] // 所有内联的 loaders
const resourceResolveData = results[1].resourceResolveData; // 获取模块的基本信息
resource = results[1].resource; // 模块的绝对路径
...
// 接下来就要开始根据引入模块的路径开始匹配对应的 loaders
let resourcePath =
matchResource !== undefined ? matchResource : resource;
let resourceQuery = "";
const queryIndex = resourcePath.indexOf("?");
if (queryIndex >= 0) {
resourceQuery = resourcePath.substr(queryIndex);
resourcePath = resourcePath.substr(0, queryIndex);
}
// 获取符合条件配置的 loader,具体的 ruleset 是如何匹配的请参见 ruleset 解析(https://github.com/CommanderXL/Biu-blog/issues/30)
const result = this.ruleSet.exec({
resource: resourcePath, // module 的绝对路径
realResource:
matchResource !== undefined
? resource.replace(/\?.*/, "")
: resourcePath,
resourceQuery, // module 路径上所带的 query 参数
issuer: contextInfo.issuer, // 所解析的 module 的发布者
compiler: contextInfo.compiler
});
// result 为最终根据 module 的路径及相关匹配规则过滤后得到的 loaders,为 webpack.config 进行配置的
// 输出的数据格式为:
/* [{
type: 'use',
value: {
loader: 'vue-style-loader',
options: {}
},
enforce: undefined // 可选值还有 pre/post 分别为 pre-loader 和 post-loader
}, {
type: 'use',
value: {
loader: 'css-loader',
options: {}
},
enforce: undefined
}, {
type: 'use',
value: {
loader: 'stylus-loader',
options: {
data: '$color red'
}
},
enforce: undefined
}] */
const settings = {};
const useLoadersPost = []; // post loader
const useLoaders = []; // normal loader
const useLoadersPre = []; // pre loader
for (const r of result) {
if (r.type === "use") {
// postLoader
if (r.enforce === "post" && !noPrePostAutoLoaders) {
useLoadersPost.push(r.value);
} else if (
r.enforce === "pre" &&
!noPreAutoLoaders &&
!noPrePostAutoLoaders
) {
// preLoader
useLoadersPre.push(r.value);
} else if (
!r.enforce &&
!noAutoLoaders &&
!noPrePostAutoLoaders
) {
// normal loader
useLoaders.push(r.value);
}
} else if (
typeof r.value === "object" &&
r.value !== null &&
typeof settings[r.type] === "object" &&
settings[r.type] !== null
) {
settings[r.type] = cachedMerge(settings[r.type], r.value);
} else {
settings[r.type] = r.value;
}
// 当获取到 webpack.config 当中配置的 loader 后,再根据 loader 的类型进行分组(enforce 配置类型)
// postLoader 存储到 useLoaders 内部
// preLoader 存储到 usePreLoaders 内部
// normalLoader 存储到 useLoaders 内部
// 这些分组最终会决定加载一个 module 时不同 loader 之间的调用顺序
// 当分组过程进行完之后,即开始 loader 模块的 resolve 过程
asyncLib.parallel([
[
// resolve postLoader
this.resolveRequestArray.bind(
this,
contextInfo,
this.context,
useLoadersPost,
loaderResolver
),
// resove normal loaders
this.resolveRequestArray.bind(
this,
contextInfo,
this.context,
useLoaders,
loaderResolver
),
// resolve preLoader
this.resolveRequestArray.bind(
this,
contextInfo,
this.context,
useLoadersPre,
loaderResolver
)
],
(err, results) => {
...
// results[0] -> postLoader
// results[1] -> normalLoader
// results[2] -> preLoader
// 这里将构建 module 需要的所有类型的 loaders 按照一定顺序组合起来,对应于:
// [postLoader, inlineLoader, normalLoader, preLoader]
// 最终 loader 所执行的顺序对应为: preLoader -> normalLoader -> inlineLoader -> postLoader
// 不同类型 loader 上的 pitch 方法执行的顺序为: postLoader.pitch -> inlineLoader.pitch -> normalLoader.pitch -> preLoader.pitch (具体loader内部执行的机制后文会单独讲解)
loaders = results[0].concat(loaders, results[1], results[2]);
process.nextTick(() => {
...
// 执行回调,创建 module
})
}
])
}
})简单总结下匹配的流程就是:
首先处理 inlineLoaders,对其进行解析,获取对应的 loader 模块的信息,接下来利用 ruleset 实例上的匹配过滤方法对 webpack.config 中配置的相关 loaders 进行匹配过滤,获取构建这个 module 所需要的配置的的 loaders,并进行解析,这个过程完成后,便进行所有 loaders 的拼装工作,并传入创建 module 的回调中。
黄轶,前端技术专家,现就职于滴滴出行公共FE团队,前端技术专家。计算机专业硕士,2012年毕业于北京科技大学,曾任职百度。擅长前端自动化、工程化,前端架构等方向。业余时间喜欢写点H5小游戏,偶尔造造轮子。喜欢关注业界一些新技术,乐于分享,热爱开源。对代码有洁癖,追求高质量的代码。
本文为滴滴公共FE团队在WebApp方向的一些实践经验总结,主要内容包括:WebApp首页技术架构、前端工程化在WebApp的实践、通用地图JS库的设计和实践、 统一登录SDK的设计、通用客户端JSBridge的封装、在公共部门做通用服务的一些感悟、个人成长总结。
这里是github地址,欢迎star和follow~
(1)滴滴多条业务线在一个 WebApp 页面里运行,业务线之间互不影响。
(2)业务线发单流程基本一致,部分业务线支持自定义化。
(3)业务线可以独立自主迭代上线,不需要公共团队的参与。
(4)新业务线可以快速接入首页。
(1)每个业务线提供自已的 biz.js,首页加载的时候会异步请求这些 JS 文件。
(2)公共提供全局的 dd.registerBiz(option) 方法,供业务线 biz.js 调用,同时在 option 里提供 init、onEnter、onExit、orderRecover 等钩子函数,业务线的代码通过调用 dd.registerBiz 方法完成接入。
(3)把页面拆分成多个区块,有一些公共区块如一级导航菜单和地址选择区块;也有一些业务线区块如 ETA 区块、发单区块、自定义区块等。公共会在业务线区块下根据 registerBiz 注册的业务线动态创建业务线独立的子区块,业务线可以填充这些子区块的 DOM,公共这边提供通用的样式。创建业务线区块的时候完毕会调用 init 钩子函数,业务线可以在这个函数里做一些初始化操作。
(4)公共负责管理业务线的切换,来控制每个业务线子区块的 show 和 hide,这些细节业务线不用关心。在切入的时候会调用 onEnter 钩子函数,切出的时候会调用 onExit 钩子函数。
(5)公共会提供业务线一些公共方法调用,比如统一的 sendOrder 发单方法。还会通过事件机制和业务线通讯,比如当公共定位完成会调用 events.emit('location.suceess',posInfo) 派发事件,业务线可以监听该事件拿到定位信息。
(6)公共会提供一些封装好的通用组件,供业务线调用。
(7)业务线的 biz.js 地址是通过服务端渲染前端模板的时候通过变量传到模板里的,这个 JS 地址业务线可以自主配置,达到业务线自主上线的目的。
(8)新业务线的接入只需要提供业务线 biz.js,实现 dd.registerBiz 接口。公共不用关心具体接入的业务线,与业务线这边完全解耦。公共这边还提供了一套完整的 wiki,方便业务线接入。
(1)scrat 完成模块化 + 构建。
(2)zepto + gmu 实现组件化。
(3)前端模板 handlebar。
(4)combo 服务。
业务线接入的 biz.js 示例如下:
dd.registerBiz({
id: 123,
_tpl: {
// ...
},
init: function (ids) {
// ...
},
onEnter: function () {
// ...
},
onExit: function() {
// ...
}
});(1)支持模块化开发,包括 JS 和 CSS。
(2)组件化开发。一个组件的 JS、CSS、模板放在一个目录,方便维护。
(3)多个项目按项目名称 + 版本部署,采用非覆盖式发布。
(4)允许第三方引用项目公共模块。
(5)要支持 CSS 预处理器,前端模板。
(6)与公司的 jenkins 发布平台配合,上线方便。
(7)前后端分离,前端可以独立自主上线。
(1)使用 scrat 做前端工程化工具,完美支持上述的 1-5 需求。
(2)每个项目用一个 git 的 repo 维护,然后有专门上线的2个 repo,一个存储静态资源,另一个存储页面模板。每个项目有一个shell脚本,脚本通过 scrat 编译当前项目,把编译后的结果分别 push 到上线的 repo。然后上线的 2 个 repo 关联公司的 jenkis 平台发布上线。
(3)每个项目迭代上线前修改版本号,所有静态资源都会增量发布。上线过程先全量上线静态资源,线上模板仍然指向旧的资源,不会有任何问题。然后再上线模板,先上到预发布环境让 qa 回归,回归完后再全量上线模板,完成整个上线流程。
一个WebApp项目的目录结构如下:
project
|- component_modules(生态模块)
|- components (工程模块)
|- views (非模块资源)
|- component.json (模块化资源描述文件)
|- fis-conf.js (构建工具配置文件)
|- package.json (项目描述文件)
|- index.html
|- …
一个组件的目录结构如下:
components
|- header
|- header.js
|- header.styl
|- header.tpl
|- logo.png
按项目名称 + 版本发布的 fis-conf.js 配置规则如下:
var meta = require('./package.json');
fis.config.set('name', meta.name);
fis.config.set('version', meta.version);
// 自定义发布规则
var userRoadMap = [
{
reg: /^\/components\/(.*\.tpl)$/i,
isHtmlLike: true,
release: '/pages/c/${name}/${version}/$1'
},
{
reg: /^\/pages\/(.*\.tpl)$/,
useCache: false,
isViews: true,
isHtmlLike: true,
release: '/pages/${name}/${version}/$1'
},
{
reg: /^\/pages\/boot\.js$/,
useOptimizer: false,
},
{
reg: /^\/pages\/(.*\.(?:js))$/,
useCache: false,
isViews: true,
url: '/${name}/${version}/$1',
release: '/public/${name}/${version}/$1'
},
{
reg: /^\/pages\/(.*\.(?:html))$/,
useCache: false,
useOptimizer: false,
isViews: true,
release: '$1'
},
{
reg: /^\/pages\/(.*)$/,
useSprite: true,
isViews: true,
url: '/${name}/${version}/$1',
release: '/public/${name}/${version}/$1'
}
];
var defaultRoadmap = fis.config.get('roadmap.path');
fis.config.set('roadmap.path', userRoadMap.concat(defaultRoadmap));编译后部署的目录结构如下:
|-public (生成的静态资源目录)
|- c
|- project
|-1.0.0
|- header
|- header.css
|- header.css.js
|- header.js
|- home
...
|- project
|- 1.0.0
|- lib
|- index.html
|-views (模板目录)
|- …
(1)支持多种地图、多种地图场景的开发。
(2)屏蔽底层地图库(高德、腾讯)的接口差异。
(3)实现小车平滑移动。
(1)底层对腾讯地图和高德地图分别封装(不会在源码中出现 if(qq){} 风格的代码),依据 webpack 动态打包成 2 个 JS文件,上游根据需求异步加载 JS ,对外提供同一套编程接口。
(2)抽象地图场景的概念,可以通过接口注册一个场景类,在场景中可以操作各种封装好的地图组件和方法,编写业务逻辑,实现需求。
(3)小车的平滑移动通过封装地图 sdk 提供的底层 marker,轮询小车坐标点,实现小车平滑移动(css3),并把“移动 + 转向 + 移动...”一系列操作抽象出动画队列的概念。
(1)原生 js
(2)webpack 打包
行程分享这个场景中,有等待接驾、行程中、行程结束等状态,有轨迹,小车平滑移动等功能。我们要做的就是利用通用地图 JS 库暴露的接口去编写行程分享的逻辑。
贴一下部分代码,看一下如何去使用封装好的地图 JS 库。
我们可以先去写一个行程分享的场景:tripShare.js
var Map = window.map;
var _ = Map.utils._;
var inherit = Map.utils.inherit;
var api = Map.utils.api;
var config = Map.utils.config;
var EventEmitter = Map.utils.EventEmitter;
var Car = Map.component.Car;
var StartPoint = Map.component.StartPoint;
var EndPoint = Map.component.EndPoint;
var TrackControl = Map.control.TrackControl;
var TrafficControl = Map.control.TrafficControl;
var TrafficLayer = Map.layer.TrafficLayer;
var Polyline = Map.Polyline;
function TripShare(map, options) {
TripShare._super.call(this);
// ...
}
inherit(TripShare, EventEmitter);
TripShare.prototype.begin = function () {
// ...
};
// ...然后我们这样去注册场景。
var Map = window.map;
var fromlat = 31.17626;
var fromlng = 121.425;
var tolat = 31.20425;
var tolng = 121.40398;
Map.ready(function (mapInstance) {
var map = mapInstance.createMap('container', {});
var TripShare = require('./tripShare');
var scene = map.scene.register(TripShare, {
orderStatus: 1,
url: 'xxxx',
oid: 'aaaa',
pathUrl: 'xxxx'
fromlat: fromlat,
fromlng: fromlng,
tolat: tolat,
tolng: tolng,
usePath: true
});
scene.begin();
scene.on('path.badCase', function(badCase) {
// do anything
});
});我们可以调用场景的方法,又由于场景继承了 EventEmitter 事件中心,它会通过 trigger 派发事件,我们可以监听这些事件,去做一些事情。
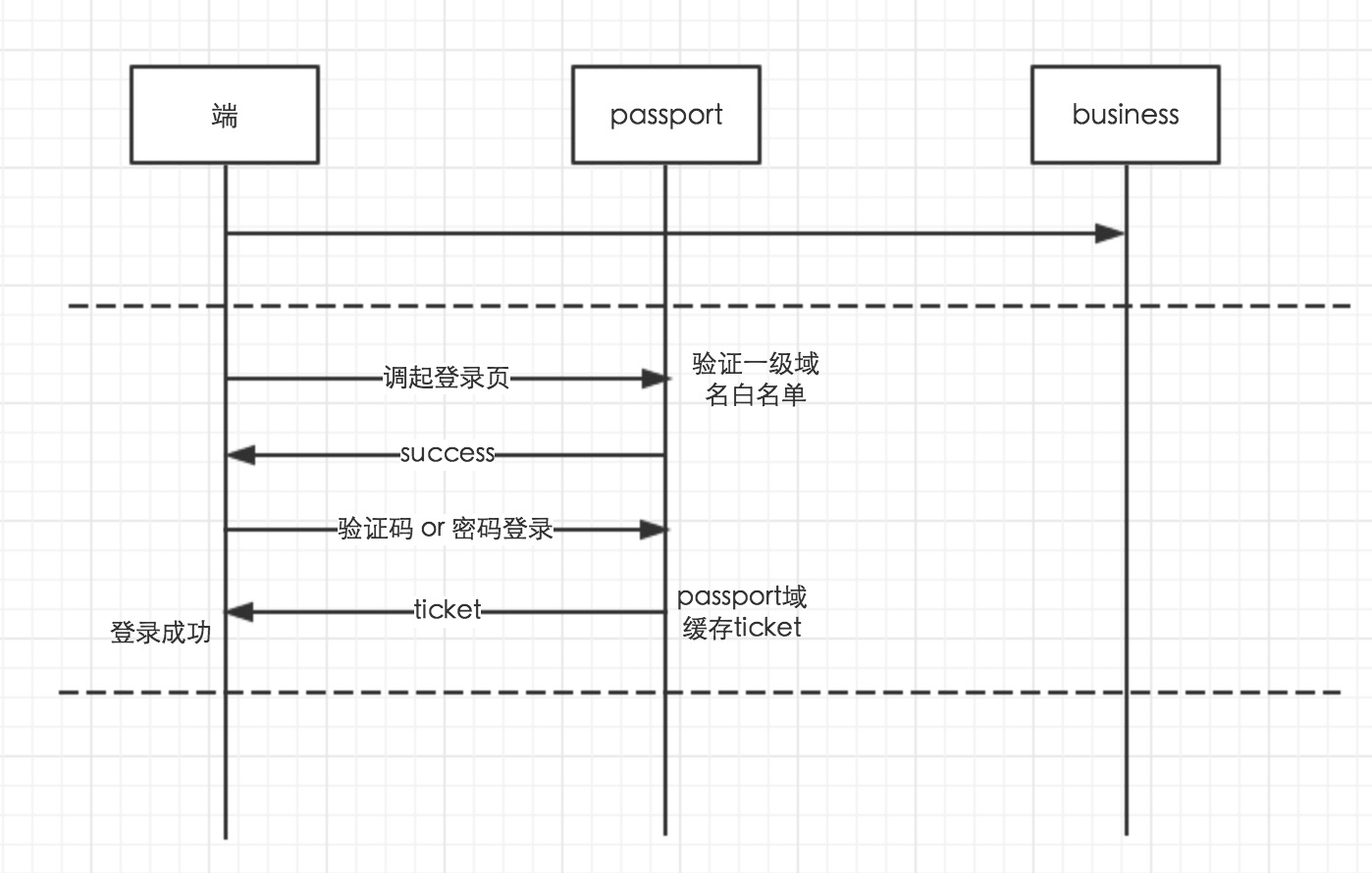
(1)滴滴有众多业务线,每个业务线都有独立的域名,需要打通各个WebApp域名的登录态。
(2)方便新老业务线、运营活动等页面接入登录。
(3)提供简单、友好的接口。
(1)与帐号部门合作,通过跨域方式访问 passport 域名下的接口。跨域方案是通过 iframe passport 域名下的页面,利用 postmessage 进行通信。登录成功后会在 passport 域名下利用种下 ticket。后端提供判断是否登录的接口,前端请求这个接口的时候会从 passport 域名下读取 ticket 并把它作为请求的参数传给后端,这样一旦用户在 a 域名下登录成功,那么在 b 域名下调用是否登录接口,返回的就是登录成功的结果,这样就打通了多个域名的登录态。
(2)封装复杂的登录交互细节,对外提供简单的交互接口。
(3)提供完善 wiki 文档,建立专门的钉钉服务交流群。
(1)原生 js
(2)webpack 打包
(1)内嵌在滴滴 app 端里的页面,需要通过 JSBrigde 的方式获取端的一些能力。
(2)屏蔽 IOS 端和 Android 端的一些底层通讯差异。
(3)提供简单、友好的接口。
(1)对 IOS 和 Anroid 的交互接口进一层封装,所有需要与端通讯的接口封装成 DDBridge.funcName(options,callback) 的方式。
(2)对端的一些具象接口,比如分享微信、分享微博等做更高级封装,提供share接口,通过参数指定分享到不同的渠道。
(3)提供完善 wiki 文档,建立专门的钉钉服务交流群。
(1)es6 + eslint
(2)webpack 打包
export function initGlobalAPI(DDBridge) {
each(config.api, (conf, name) => {
DDBridge[name] = makeBridgeFn(conf);
DDBridge[name].support = conf.support;
});
initSupport(DDBridge);
initVersion(DDBridge);
initShare(DDBridge);
initPay(DDBridge);
};
export function makeBridgeFn(conf) {
return function (param = '', callback = noop) {
if (arguments.length === 1 && isFn(param)) {
callback = param;
param = '';
}
let fn = conf.fn;
if (supportPrompt) {
promptSend(fn, param, callback);
} else {
bridgeReady((bridge) => {
bridge.callHandler(fn, param, (data) => {
if (isStr(data)) {
data = JSON.parse(data);
}
callback(data);
});
});
}
};
};
入职滴滴一年,造了不少公司级别的“轮子”,不少轮子已经在业务线跑起来了,运行状况还算可以。我自己也总结了做通用服务要注意的几点:
1.一定要好用,用起来要简单。
这是我一直贯彻的理念,如果你写的通用服务不好用,那一定会受到质疑和吐槽。同样我们用开源的框架,也一定会选简单好用的,当年 jQuery,prototype,tangram 等 JS 库百家争鸣的时候,jQuery笑到了最后,为什么呢,很简单的一点,jQuery好用啊,一个 $(xxx) 搞定一切。相比 tangram 那种 Baidu.T.createDom() 的方式,高下立判。
我们在设计通用 JS 库的时候,一定要站在更高的角度去对需求做抽象。比如我在设计统一登录 SDK,首先要想的不是复杂的交互逻辑、如何去实现、有哪些技术难点,而是去想,别人怎么用这个库,怎么用起来爽。登录的需求就是用户触发一个登录动作,登录完成能拿到用户一些信息,所以我就设计一个login(callback)接口,那么使用方只需要简单调用这个方法,就可以完成登录需求,而不用去关心登录各种复杂的细节。
2.该做封装的地方要封装,对外暴露的接口越少越好。
封装很重要,举个通俗的例子,有一天我去洗手,发现水龙头的开关把手没了,把原始的开关暴露给我了,也能用,但是体验就会很不好。水龙头的开关把手就是对原始开关的封装。我在做 JSBridge 库 的时候,也是一样的道理,如果让用户直接调用 IOS 和 Andrid 提供的原生 bridge 接口的,也能 work,但是非常难用,需要判断 IOS 和 Android 接口的差异,还需要考虑 bridge ready 事件后才能执行方法等,这些都是我原本不需要关心的细节。所以我们的库就是帮助用户封装掉这些“脏活”,对外提供简单的 DDBridge.funcName(options,callback) 接口,优化使用体验。
为什么说对外暴露的接口越少越好,因为接口越多,则说明用户的学习成本越高,比如如火如荼的 Vue.js,1.x 版本很多接口的功能大同小异,所以在 2.0 版本的 Vue 就干掉了很多接口,减少了用户的学习成本。同样的,我们在做 JSBridge 分享接口相关的时候,也通过一个share接口封装了端提供的微信分享、支付宝分享、微博分享等接口。
3.先思考再动手,设计合理的代码组织方式。
我们在写代码之前,一定要先思考清楚,切忌上来就写代码,那样很容易写成一波流代码。合理的代码组织方式,有利于代码的扩展和维护,最基本的就是模块化。这里没有银弹,需要大量的实践和总结,学会抽象的看问题,看一些设计模式相关多书籍,多看优秀的开源的代码,可以先从模仿开始。
由于我们写的是通用服务,用户也可能会提出各种需求,当我们遇到这个问题的时候,不能上来就写代码去实现甚至hack,而是先思考这个需求是不是可以抽象成通用的需求,如果不能抽象,我们如何更优雅的实现,之前的设计是不是有问题。总之,要多想多思考,也可以和小伙伴讨论,争取做到是在设计代码而不是堆代码。
4.追求体验极致。
现在很多前端都在玩 node,玩构建工具,玩 mvvm 框架,玩 es6,好像感觉学会了这些就可以提高身价。其实,这些大部分都是工具、服务我们平时工作的,不要忘了我们的本行还是前端,还是需要写页面的。其实前端有些组件和效果如果想要追求体验极致的话,也不容易。如果能做到极致,身价也不会低。举个例子,我在写 mofang 移动端组件的时候,有个筛选器组件 picker,类似 IOS 原生 UIPickerView 的东东,我当时拿到需求的时候,也从 github 上搜索过,没有满意的,体验都很一般,于是我就对比 IOS 原生的 UIPickerView的体验,思考它的实现、一点点细节的调试,最终也撸出来体验几乎一致的移动端 h5 picker 组件。举这个例子其实想说明,我们在做通用服务的时候,要多花心思,如果能做出一些极致体验的东东,不仅对用户来说他们很乐意使用,对自己也是一种锻炼。
5.一定要写 wiki
要写 wiki!要写 wiki!要写 wiki!重要的事情说 3 遍。由于我们做通用服务,免不了和用户打交道,wiki 就尤为重要了。我们需要把通用服务的接口,使用方式,常见问题等都写清楚,。好的文档可以很好的指导用户如何使用我们的服务,这样可以大大的减少沟通成本,节约我们自身和用户的时间。
6.要学会销售。
有些人可能会觉得写通用服务似乎比做业务的同学更高大上,其实不然,本质上我们都是在为公司打工,都是在输出自己的价值,只是做事的重心不同。那么做公共的同学的价值在哪里,就是让自己写的通用服务被更多的人用,去提升他们的工作效率。所以,我们要学会销售自己的服务,而不是写完一个的服务摆出一副你爱用不用的态度。如果你写出来的东西没人用,就算它再牛逼,对公司的价值也是 0。另外,我们还要学会从业务中去沉淀服务,要去发现业务中的痛点,可以提升效率的地方,然后用技术的手段和工具去解决它。
7.一颗服务的心。
做公共的同学一定要有颗服务的心。我们售卖的是自己的服务,那么也一定要做好售后服务,除了 wiki,各种沟通钉钉微信沟通群也要积极响应,耐心的去帮助用户解决问题,其实很多时候,都是靠着用户去帮我们去发现 bug ,完善功能和优化体验的。
我入前端这行已经4年了,在学校的时候我是玩 .net 的,喜欢折腾。毕业后当然和大部分应届生一样,渴望进 BAT 这样的大公司,不过 BAT 几乎不招 .net 的岗位。由于我读研的时候做过一些网站方向的开发,所以就投了百度的一个相近的职位,web前端开发。这里我要特别感谢我百度的mentor张袁炜,他是一个对技术要求很高的人,受他的影响,我也成为一个对技术有追求的人。四年的工作经历,我写过页面,写过网页游戏、写过chrome插件、写过框架、写过组件、写过服务,由于一直在做不同的东西,每一年我都有所收获。
兴趣导向,有的时候我感觉写代码和玩游戏是一样爽的事情,我也很喜欢看优秀的开源作品,看看他们的代码设计、技术细节,会吸收一些不错的东西到自己平时的工作中。
前端这几年发展很快,新技术层出不穷,有的时候,我们要跳出自己的舒适圈,接纳一些新事物,新技术,去让自己不断学习,而不是满足于自己已掌握的那些技术。这里我不是去倡导滥用新技术,而是要保持一颗学习的心态,一颗包容的心态。
对于 webpack 来说每个文件都是一个 module,这篇文章带你来看 webpack 如何从配置中 entry 的定义开始,顺藤摸瓜找到全部的文件,并转化为 module。
webpack 入口 entry,entry 参数是单入口字符串、单入口数组、多入口对象还是动态函数,无论是什么都会调用 compilation.addEntry 方法,这个方法会执行 _addModuleChain,将入口文件加入需要编译的队列中。然后队列中的文件被一个一个处理,文件中的 import 引入了其他的文件又会通过 addModuleDependencies 加入到编译队列中。最终当这个编译队列中的内容完成被处理完时,就完成了文件到 module 的转化。

上面是一个粗略的轮廓,接下来我们将细节一一补充进这个轮廓中。首先看编译的总流程控制——编译队列的控制
_addModuleChain 和 addModuleDependencies 函数中都会调用 this.semaphore.acquire 这个函数的具体实现在 lib/util/Semaphore.js 文件中。看一下具体的实现
class Semaphore {
constructor(available) {
// available 为最大的并发数量
this.available = available;
this.waiters = [];
this._continue = this._continue.bind(this);
}
acquire(callback) {
if (this.available > 0) {
this.available--;
callback();
} else {
this.waiters.push(callback);
}
}
release() {
this.available++;
if (this.waiters.length > 0) {
process.nextTick(this._continue);
}
}
_continue() {
if (this.available > 0) {
if (this.waiters.length > 0) {
this.available--;
const callback = this.waiters.pop();
callback();
}
}
}
}对外暴露的只有两个个方法:
这个 Semaphore 类借鉴了在多线程环境中,对使用资源进行控制的 Semaphore(信号量)的概念。其中并发个数通过 available 来定义,那么默认值是多少呢?在 Compilation.js 中可以找到
this.semaphore = new Semaphore(options.parallelism || 100);默认的并发数是 100,注意这里说的并发只是代码设计中的并发,不要和js的单线程特性搞混了。总的来看编译流程如下图

webpack 官网配置指南中 entry 可以有下面几种形式:
{
entry: './demo.js'
}{
entry: ['./demo1.js', './demo2.js']
}{
entry: {
app: './demo.js'
}
}{
entry: () => './demo.js'
}
// 或者
{
entry: () => new Promise((resolve) => resolve('./demo.js'))
}这些是哪里处理的呢?
webpack 的启动文件 webpack.js 中, 会先对 options 进行处理,有如下一句
compiler.options = new WebpackOptionsApply().process(options, compiler);在 process 的过程中会对 entry 的配置做处理
// WebpackOptionsApply.js 文件中
new EntryOptionPlugin().apply(compiler);
compiler.hooks.entryOption.call(options.context, options.entry);先看 EntryOptionsPlugin 做了什么
const SingleEntryPlugin = require("./SingleEntryPlugin");
const MultiEntryPlugin = require("./MultiEntryPlugin");
const DynamicEntryPlugin = require("./DynamicEntryPlugin");
const itemToPlugin = (context, item, name) => {
if (Array.isArray(item)) {
return new MultiEntryPlugin(context, item, name);
}
return new SingleEntryPlugin(context, item, name);
};
module.exports = class EntryOptionPlugin {
apply(compiler) {
compiler.hooks.entryOption.tap("EntryOptionPlugin", (context, entry) => {
// string 类型则为 new SingleEntryPlugin
// array 类型则为 new MultiEntryPlugin
if (typeof entry === "string" || Array.isArray(entry)) {
itemToPlugin(context, entry, "main").apply(compiler);
} else if (typeof entry === "object") {
// 对于 object 类型,遍历其中每一项
for (const name of Object.keys(entry)) {
itemToPlugin(context, entry[name], name).apply(compiler);
}
} else if (typeof entry === "function") {
// function 类型则为 DynamicEntryPlugin
new DynamicEntryPlugin(context, entry).apply(compiler);
}
return true;
});
}
};在 EntryOptionsPlugin 中注册了 entryOption 的事件处理函数,根据 entry 值的不同类型(string/array/object中每一项/functioin)实例化和执行不同的 EntryPlugin:string 对应 SingleEntryPlugin; array 对应 MultiEntryPlugin;function 对应 DynamicEntryPlugin。而对于 object 类型来说遍历其中的每一个 key,将每一个 key 当做一个入口,并根据类型 string/array 的不同选择 SingleEntryPlugin 或 MultiEntryPlugin。下面我们主要分析:SingleEntryPlugin,MultiEntryPlugin,DynamicEntryPlugin
横向对比一下这三个 Plugin,都做了两件事:
dependencyFactoriescompiler.hooks.compilation.tap('xxEntryPlugin', (compilation, { normalModuleFactory }) => {
//...
compilation.dependencyFactories.set(...)
})_addModuleChain 进入正式的编译阶段。compiler.hooks.make.tapAsync('xxEntryPlugin',(compilation, callback) => {
// ...
compilation.addEntry(...)
})结合 webpack 的打包流程,我们从 Compiler.js 中的 compile 方法开始,看一下 compilation 事件和 make 事件回调起了什么作用

xxxEntryPlugin 在 compilation 事件中回调用来设置compilation.dependencyFactories,保证在后面 _addModuleChain 回调阶段可以根据 dependency 获取到对应的 moduleFactory。
make 事件回调中根据不同的 entry 配置,生成 dependency,然后调用addEntry,并将 dependency 传入。
在 _addModuleChain 回调中根据不同 dependency 类型,然后执行 multiModuleFactory.create 或者 normalModuleFacotry.create。
上面的步骤中不停的提到 dependency,在接下来的文章中将会出现各种 dependency。可见,dependency 是 webpack 中一个很关键的东西,在 webpack/lib/dependencies 文件夹下,你会看到各种各样的 dependency。dependency 和 module 的关系结构如下:
module: {
denpendencies: [
dependency: {
//...
module: // 依赖的 module,也可能为 null
}
]
}
}webpack 中将入口文件也当成入口的依赖来处理,所以上面 xxEntryPlugin 中生成的是 xxEntryDependency。module 中的 dependency 保存了这个 module 对其他文件的依赖信息、自身 export 出去的内容等。后面的文章中,你会看到在生成 chunk 时会依靠 dependency 来得到依赖关系图,生成最终文件时会依赖 dependency 中方法和保存的信息将源文件中的 import 等语句替换成最终输出的可执行的 js 语句。
看完了各个 entryPlugin 的共同点之后,我们纵向深入每个 plugin,对比一下不同之处。
SingleEntryPlugin
SingleEntryPlugin 逻辑很简单:将 SingleEntryDependency 和 normalModuleFactory 关联起来,所以后续的 create 方法会执行 normalModuleFactory.create 方法。
apply(compiler) {
compiler.hooks.compilation.tap(
"SingleEntryPlugin",
(compilation, { normalModuleFactory }) => {
// SingleEntryDependency 对应的是 normalModuleFactory
compilation.dependencyFactories.set(
SingleEntryDependency,
normalModuleFactory
);
}
);
compiler.hooks.make.tapAsync(
"SingleEntryPlugin",
(compilation, callback) => {
const { entry, name, context } = this;
const dep = SingleEntryPlugin.createDependency(entry, name);
// dep 的 constructor 为 SingleEntryDependency
compilation.addEntry(context, dep, name, callback);
}
);
}
static createDependency(entry, name) {
const dep = new SingleEntryDependency(entry);
dep.loc = name;
return dep;
}MultiEntryPlugin
与上面 SingleEntryPlugin 相比,
MultiEntryDependency: multiModuleFactory
SingleEntryDependency: normalModuleFactorystatic createDependency(entries, name) {
return new MultiEntryDependency(
entries.map((e, idx) => {
const dep = new SingleEntryDependency(e);
// Because entrypoints are not dependencies found in an
// existing module, we give it a synthetic id
dep.loc = `${name}:${100000 + idx}`;
return dep;
}),
name
);
}3.multiModuleFactory.create
在第二步中,由 MultiEntryPlugin.createDependency 生成的 dep,结构如下:
{
dependencies:[]
module: MultiModule
//...
}dependencies 是一个数组,包含多个 SingleEntryDependency。这个 dep 会当做参数传给 multiModuleFactory.create 方法,即下面代码中 data.dependencies[0]
// multiModuleFactory.create
create(data, callback) {
const dependency = data.dependencies[0];
callback(
null,
new MultiModule(data.context, dependency.dependencies, dependency.name)
);
}create 中生成了 new MultiModule,在 callback 中会执行 MultiModule 中 build 方法,
build(options, compilation, resolver, fs, callback) {
this.built = true; // 标记编译已经完成
this.buildMeta = {};
this.buildInfo = {};
return callback();
}这个方法中将编译是否完成的变量值设置为 true,然后直接进入的成功的回调。此时,入口已经完成了编译被转化为一个 module, 并且是一个只有 dependencies 的 module。由于在 createDependency 中每一项都作为一个 SingleEntryDependency 处理,所以 dependencies 中每一项都是一个 SingleEntryDependency。随后进入对这个 module 的依赖处理阶段,我们配置在 entry 中的多个文件就被当做依赖加入到编译链中,被作为 SingleEntryDependency 处理。
总的来看,对于多文件的入口,可以简单理解为 webpack 内部先把入口转化为一个下面的形式:
import './demo1.js'
import './demo2.js'然后对其做处理。
DynamicEntryPlugin
动态的 entry 配置中同时支持同步方式和返回值为 Promise 类型的异步方式,所以在处理 addEntry 的时候首先调用 entry 函数,然后根据返回的结果类型的不同,进入 string/array/object 的逻辑。
compiler.hooks.make.tapAsync(
"DynamicEntryPlugin",
(compilation, callback) => {
const addEntry = (entry, name) => {
const dep = DynamicEntryPlugin.createDependency(entry, name);
return new Promise((resolve, reject) => {
compilation.addEntry(this.context, dep, name, err => {
if (err) return reject(err);
resolve();
});
});
};
Promise.resolve(this.entry()).then(entry => {
if (typeof entry === "string" || Array.isArray(entry)) {
addEntry(entry, "main").then(() => callback(), callback);
} else if (typeof entry === "object") {
Promise.all(
Object.keys(entry).map(name => {
return addEntry(entry[name], name);
})
).then(() => callback(), callback);
}
});
}
);所以动态入口与其他的差别仅在于多了一层函数的调用。
入口找到了之后,就是将文件转为 module 了。接下来的一篇文章中,将详细介绍转 module 的过程。
Vue版本: 2.3.2
首先让我们从最简单的一个实例Vue入手:
const app = new Vue({
// options 传入一个选项obj.这个obj即对于这个vue实例的初始化
})通过查阅文档,我们可以知道这个options可以接受:
具体未展开的内容请自行查阅相关文档,接下来让我们来看看传入的选项/数据是如何管理数据之间的相互依赖的。
const app = new Vue({
el: '#app',
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
},
data: {
msg1: 'Hello world!',
arr: {
arr1: 1
}
},
watch: {
a (newVal, oldVal) {
console.log(newVal, oldVal)
}
},
methods: {
go () {
console.log('This is simple demo')
}
}
})我们使用Vue这个构造函数去实例化了一个vue实例app。传入了props, data, watch, methods等属性。在实例化的过程中,Vue提供的构造函数就使用我们传入的options去完成数据的依赖管理,初始化的过程只有一次,但是在你自己的程序当中,数据的依赖管理的次数不止一次。
那Vue的构造函数到底是怎么实现的呢?Vue
// 构造函数
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}
// 对Vue这个class进行mixin,即在原型上添加方法
// Vue.prototype.* = function () {}
initMixin(Vue)
stateMixin(Vue)
eventsMixin(Vue)
lifecycleMixin(Vue)
renderMixin(Vue)当我们调用new Vue的时候,事实上就调用的Vue原型上的_init方法.
// 原型上提供_init方法,新建一个vue实例并传入options参数
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// a uid
vm._uid = uid++
let startTag, endTag
// a flag to avoid this being observed
vm._isVue = true
// merge options
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
// 将传入的这些options选项挂载到vm.$options属性上
vm.$options = mergeOptions(
// components/filter/directive
resolveConstructorOptions(vm.constructor),
// this._init()传入的options
options || {},
vm
)
}
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
initProxy(vm)
} else {
vm._renderProxy = vm
}
// expose real self
vm._self = vm // 自身的实例
// 接下来所有的操作都是在这个实例上添加方法
initLifecycle(vm) // lifecycle初始化
initEvents(vm) // events初始化 vm._events, 主要是提供vm实例上的$on/$emit/$off/$off等方法
initRender(vm) // 初始化渲染函数,在vm上绑定$createElement方法
callHook(vm, 'beforeCreate') // 钩子函数的执行, beforeCreate
initInjections(vm) // resolve injections before data/props
initState(vm) // Observe data添加对data的监听, 将data转化为getters/setters
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created') // 钩子函数的执行, created
// vm挂载的根元素
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}
}其中在this._init()方法中调用initState(vm),完成对vm这个实例的数据的监听,也是本文所要展开说的具体内容。
export function initState (vm: Component) {
// 首先在vm上初始化一个_watchers数组,缓存这个vm上的所有watcher
vm._watchers = []
// 获取options,包括在new Vue传入的,同时还包括了Vue所继承的options
const opts = vm.$options
// 初始化props属性
if (opts.props) initProps(vm, opts.props)
// 初始化methods属性
if (opts.methods) initMethods(vm, opts.methods)
// 初始化data属性
if (opts.data) {
initData(vm)
} else {
observe(vm._data = {}, true /* asRootData */)
}
// 初始化computed属性
if (opts.computed) initComputed(vm, opts.computed)
// 初始化watch属性
if (opts.watch) initWatch(vm, opts.watch)
}我们在实例化app的时候,在构造函数里面传入的options中有props属性:
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
}function initProps (vm: Component, propsOptions: Object) {
// propsData主要是为了方便测试使用
const propsData = vm.$options.propsData || {}
// 新建vm._props对象,可以通过app实例去访问
const props = vm._props = {}
// cache prop keys so that future props updates can iterate using Array
// instead of dynamic object key enumeration.
// 缓存的prop key
const keys = vm.$options._propKeys = []
const isRoot = !vm.$parent
// root instance props should be converted
observerState.shouldConvert = isRoot
for (const key in propsOptions) {
// this._init传入的options中的props属性
keys.push(key)
// 注意这个validateProp方法,不仅完成了prop属性类型验证的,同时将prop的值都转化为了getter/setter,并返回一个observer
const value = validateProp(key, propsOptions, propsData, vm)
// 将这个key对应的值转化为getter/setter
defineReactive(props, key, value)
// static props are already proxied on the component's prototype
// during Vue.extend(). We only need to proxy props defined at
// instantiation here.
// 如果在vm这个实例上没有key属性,那么就通过proxy转化为proxyGetter/proxySetter, 并挂载到vm实例上,可以通过app._props[key]这种形式去访问
if (!(key in vm)) {
proxy(vm, `_props`, key)
}
}
observerState.shouldConvert = true
}接下来看下validateProp(key, propsOptions, propsData, vm)方法内部到底发生了什么。
export function validateProp (
key: string,
propOptions: Object, // $options.props属性
propsData: Object, // $options.propsData属性
vm?: Component
): any {
const prop = propOptions[key]
// 如果在propsData测试props上没有缓存的key
const absent = !hasOwn(propsData, key)
let value = propsData[key]
// 处理boolean类型的数据
// handle boolean props
if (isType(Boolean, prop.type)) {
if (absent && !hasOwn(prop, 'default')) {
value = false
} else if (!isType(String, prop.type) && (value === '' || value === hyphenate(key))) {
value = true
}
}
// check default value
if (value === undefined) {
// default属性值,是基本类型还是function
// getPropsDefaultValue见下面第一段代码
value = getPropDefaultValue(vm, prop, key)
// since the default value is a fresh copy,
// make sure to observe it.
const prevShouldConvert = observerState.shouldConvert
observerState.shouldConvert = true
// 将value的所有属性转化为getter/setter形式
// 并添加value的依赖
// observe方法的分析见下面第二段代码
observe(value)
observerState.shouldConvert = prevShouldConvert
}
if (process.env.NODE_ENV !== 'production') {
assertProp(prop, key, value, vm, absent)
}
return value
}// 获取prop的默认值
function getPropDefaultValue (vm: ?Component, prop: PropOptions, key: string): any {
// no default, return undefined
// 如果没有default属性的话,那么就返回undefined
if (!hasOwn(prop, 'default')) {
return undefined
}
const def = prop.default
// the raw prop value was also undefined from previous render,
// return previous default value to avoid unnecessary watcher trigger
if (vm && vm.$options.propsData &&
vm.$options.propsData[key] === undefined &&
vm._props[key] !== undefined) {
return vm._props[key]
}
// call factory function for non-Function types
// a value is Function if its prototype is function even across different execution context
// 如果是function 则调用def.call(vm)
// 否则就返回default属性对应的值
return typeof def === 'function' && getType(prop.type) !== 'Function'
? def.call(vm)
: def
}Vue提供了一个observe方法,在其内部实例化了一个Observer类,并返回Observer的实例。每一个Observer实例对应记录了props中这个的default value的所有依赖(仅限object类型),这个Observer实际上就是一个观察者,它维护了一个数组this.subs = []用以收集相关的subs(订阅者)(即这个观察者的依赖)。通过将default value转化为getter/setter形式,同时添加一个自定义__ob__属性,这个属性就对应Observer实例。
说起来有点绕,还是让我们看看我们给的demo里传入的options配置:
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
}在往上数的第二段代码里面的方法obervse(value),即对{key1: 'a', key2: {a: 'b'}}进行依赖的管理,同时将这个obj所有的属性值都转化为getter/setter形式。此外,Vue还会将props属性都代理到vm实例上,通过vm.a就可以访问到这个属性。
此外,还需要了解下在Vue中管理依赖的一个非常重要的类: Dep
export default class Dep {
constructor () {
this.id = uid++
this.subs = []
}
addSub () {...} // 添加订阅者(依赖)
removeSub () {...} // 删除订阅者(依赖)
depend () {...} // 检查当前Dep.target是否存在以及判断这个watcher已经被添加到了相应的依赖当中,如果没有则添加订阅者(依赖),如果已经被添加了那么就不做处理
notify () {...} // 通知订阅者(依赖)更新
}在Vue的整个生命周期当中,你所定义的响应式的数据上都会绑定一个Dep实例去管理其依赖。它实际上就是观察者和订阅者联系的一个桥梁。
刚才谈到了对于依赖的管理,它的核心之一就是观察者Observer这个类:
export class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that has this object as root $data
constructor (value: any) {
this.value = value
// dep记录了和这个value值的相关依赖
this.dep = new Dep()
this.vmCount = 0
// value其实就是vm._data, 即在vm._data上添加__ob__属性
def(value, '__ob__', this)
// 如果是数组
if (Array.isArray(value)) {
// 首先判断是否能使用__proto__属性
const augment = hasProto
? protoAugment
: copyAugment
augment(value, arrayMethods, arrayKeys)
// 遍历数组,并将obj类型的属性改为getter/setter实现
this.observeArray(value)
} else {
// 遍历obj上的属性,将每个属性改为getter/setter实现
this.walk(value)
}
}
/**
* Walk through each property and convert them into
* getter/setters. This method should only be called when
* value type is Object.
*/
// 将每个property对应的属性都转化为getter/setters,只能是当这个value的类型为Object时
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i], obj[keys[i]])
}
}
/**
* Observe a list of Array items.
*/
// 监听array中的item
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}walk方法里面调用defineReactive方法:通过遍历这个object的key,并将对应的value转化为getter/setter形式,通过闭包维护一个dep,在getter方法当中定义了这个key是如何进行依赖的收集,在setter方法中定义了当这个key对应的值改变后,如何完成相关依赖数据的更新。但是从源码当中,我们却发现当getter函数被调用的时候并非就一定会完成依赖的收集,其中还有一层判断,就是Dep.target是否存在。
/**
* Define a reactive property on an Object.
*/
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: Function
) {
// 每个属性新建一个dep实例,管理这个属性的依赖
const dep = new Dep()
// 或者属性描述符
const property = Object.getOwnPropertyDescriptor(obj, key)
// 如果这个属性是不可配的,即无法更改
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
const getter = property && property.get
const setter = property && property.set
// 递归去将val转化为getter/setter
// childOb将子属性也转化为Observer
let childOb = observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
// 定义getter -->> reactiveGetter
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
// 定义相应的依赖
if (Dep.target) {
// Dep.target.addDep(this)
// 即添加watch函数
// dep.depend()及调用了dep.addSub()只不过中间需要判断是否这个id的dep已经被包含在内了
dep.depend()
// childOb也添加依赖
if (childOb) {
childOb.dep.depend()
}
if (Array.isArray(value)) {
dependArray(value)
}
}
return value
},
// 定义setter -->> reactiveSetter
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
// 对得到的新值进行observe
childOb = observe(newVal)
// 相应的依赖进行更新
dep.notify()
}
})
}在上文中提到了Dep类是链接观察者和订阅者的桥梁。同时在Dep的实现当中还有一个非常重要的属性就是Dep.target,它事实就上就是一个订阅者,只有当Dep.target(订阅者)存在的时候,调用属性的getter函数的时候才能完成依赖的收集工作。
Dep.target = null
const targetStack = []
export function pushTarget (_target: Watcher) {
if (Dep.target) targetStack.push(Dep.target)
Dep.target = _target
}
export function popTarget () {
Dep.target = targetStack.pop()
}那么Vue是如何来实现订阅者的呢?Vue里面定义了一个类: Watcher,在Vue的整个生命周期当中,会有4类地方会实例化Watcher:
Vue实例化的过程中有watch选项Vue实例化的过程中有computed计算属性选项Vue原型上有挂载$watch方法: Vue.prototype.$watch,可以直接通过实例调用this.$watch方法Vue生成了render函数,更新视图时constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: Object
) {
// 缓存这个实例vm
this.vm = vm
// vm实例中的_watchers中添加这个watcher
vm._watchers.push(this)
// options
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy
this.sync = !!options.sync
} else {
this.deep = this.user = this.lazy = this.sync = false
}
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
....
// parse expression for getter
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = function () {}
}
}
// 通过get方法去获取最新的值
// 如果lazy为true, 初始化的时候为undefined
this.value = this.lazy
? undefined
: this.get()
}
get () {...}
addDep () {...}
update () {...}
run () {...}
evaluate () {...}
run () {...}Watcher接收的参数当中expOrFn定义了用以获取watcher的getter函数。expOrFn可以有2种类型:string或function.若为string类型,首先会通过parsePath方法去对string进行分割(仅支持.号形式的对象访问)。在除了computed选项外,其他几种实例化watcher的方式都是在实例化过程中完成求值及依赖的收集工作:this.value = this.lazy ? undefined : this.get().在Watcher的get方法中:
!!!前方高能
get () {
// pushTarget即设置当前的需要被执行的watcher
pushTarget(this)
let value
const vm = this.vm
if (this.user) {
try {
// $watch(function () {})
// 调用this.getter的时候,触发了属性的getter函数
// 在getter中进行了依赖的管理
value = this.getter.call(vm, vm)
console.log(value)
} catch (e) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
}
} else {
// 如果是新建模板函数,则会动态计算模板与data中绑定的变量,这个时候就调用了getter函数,那么就完成了dep的收集
// 调用getter函数,则同时会调用函数内部的getter的函数,进行dep收集工作
value = this.getter.call(vm, vm)
}
// "touch" every property so they are all tracked as
// dependencies for deep watching
// 让每个属性都被作为dependencies而tracked, 这样是为了deep watching
if (this.deep) {
traverse(value)
}
popTarget()
this.cleanupDeps()
return value
}一进入get方法,首先进行pushTarget(this)的操作,此时Vue当中Dep.target = 当前这个watcher,接下来进行value = this.getter.call(vm, vm)操作,在这个操作中就完成了依赖的收集工作。还是拿文章一开始的demo来说,在vue实例化的时候传入了watch选项:
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
},
watch: {
a (newVal, oldVal) {
console.log(newVal, oldVal)
}
}, 在Vue的initState()开始执行后,首先会初始化props的属性为getter/setter函数,然后在进行initWatch初始化的时候,这个时候初始化watcher实例,并调用get()方法,设置Dep.target = 当前这个watcher实例,进而到value = this.getter.call(vm, vm)的操作。在调用this.getter.call(vm, vm)的方法中,便会访问props选项中的a属性即其getter函数。在a属性的getter函数执行过程中,因为Dep.target已经存在,那么就进入了依赖收集的过程:
if (Dep.target) {
// Dep.target.addDep(this)
// 即添加watch函数
// dep.depend()及调用了dep.addSub()只不过中间需要判断是否这个id的dep已经被包含在内了
dep.depend()
// childOb也添加依赖
if (childOb) {
childOb.dep.depend()
}
if (Array.isArray(value)) {
dependArray(value)
}
}dep是一开始初始化的过程中,这个属性上的dep属性。调用dep.depend()函数:
depend () {
if (Dep.target) {
// Dep.target为一个watcher
Dep.target.addDep(this)
}
}Dep.target也就刚才的那个watcher实例,这里也就相当于调用了watcher实例的addDep方法: watcher.addDep(this),并将dep观察者传入。在addDep方法中完成依赖收集:
addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}这个时候依赖完成了收集,当你去修改a属性的值时,会调用a属性的setter函数,里面会执行dep.notify(),它会遍历所有的订阅者,然后调用订阅者上的update函数。
initData过程和initProps类似,具体可参见源码。
以上就是在initProps过程中Vue是如何进行依赖收集的,initData的过程和initProps类似,下来再来看看initComputed的过程.
在computed属性初始化的过程当中,会为每个属性实例化一个watcher:
const computedWatcherOptions = { lazy: true }
function initComputed (vm: Component, computed: Object) {
// 新建_computedWatchers属性
const watchers = vm._computedWatchers = Object.create(null)
for (const key in computed) {
const userDef = computed[key]
// 如果computed为funtion,即取这个function为getter函数
// 如果computed为非function.则可以单独为这个属性定义getter/setter属性
let getter = typeof userDef === 'function' ? userDef : userDef.get
// create internal watcher for the computed property.
// lazy属性为true
// 注意这个地方传入的getter参数
// 实例化的过程当中不去完成依赖的收集工作
watchers[key] = new Watcher(vm, getter, noop, computedWatcherOptions)
// component-defined computed properties are already defined on the
// component prototype. We only need to define computed properties defined
// at instantiation here.
if (!(key in vm)) {
defineComputed(vm, key, userDef)
}
}
}但是这个watcher在实例化的过程中,由于传入了{lazy: true}的配置选项,那么一开始是不会进行求值与依赖收集的: this.value = this.lazy ? undefined : this.get().在initComputed的过程中,Vue会将computed属性定义到vm实例上,同时将这个属性定义为getter/setter。当你访问computed属性的时候调用getter函数:
function createComputedGetter (key) {
return function computedGetter () {
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
// 是否需要重新计算
if (watcher.dirty) {
watcher.evaluate()
}
// 管理依赖
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
}
}在watcher存在的情况下,首先判断watcher.dirty属性,这个属性主要是用于判断这个computed属性是否需要重新求值,因为在上一轮的依赖收集的过程当中,观察者已经将这个watcher添加到依赖数组当中了,如果观察者发生了变化,就会dep.notify(),通知所有的watcher,而对于computed的watcher接收到变化的请求后,会将watcher.dirty = true即表明观察者发生了变化,当再次调用computed属性的getter函数的时候便会重新计算,否则还是使用之前缓存的值。
initWatch的过程中其实就是实例化new Watcher完成观察者的依赖收集的过程,在内部的实现当中是调用了原型上的Vue.prototype.$watch方法。这个方法也适用于vm实例,即在vm实例内部调用this.$watch方法去实例化watcher,完成依赖的收集,同时监听expOrFn的变化。
总结:
以上就是在Vue实例初始化的过程中实现依赖管理的分析。大致的总结下就是:
initState的过程中,将props,computed,data等属性通过Object.defineProperty来改造其getter/setter属性,并为每一个响应式属性实例化一个observer观察者。这个observer内部dep记录了这个响应式属性的所有依赖。setter函数时,通过dep.notify()方法去遍历所有的依赖,调用watcher.update()去完成数据的动态响应。这篇文章主要从初始化的数据层面上分析了Vue是如何管理依赖来到达数据的动态响应。下一篇文章来分析下Vue中模板中的指令和响应式数据是如何关联来实现由数据驱动视图,以及数据是如何响应视图变化的。
作者:崔静
在上一篇 module生成1中我们已经分析了 webpack 是如何根据 entry 配置找到对应的文件的,接下来就是将文件转为 module 了。这个长长的过程,可以分成下面几个阶段
后面会以一个简单的 js 文件为例,看整个主流程
// a.js
export const A = 'a'
// demo.js,webpack 入口文件
import { A } from './a.js'
function test() {
const tmp = 'something'
return tmp + A
}
const r = test()_addModuleChain 之后就是文件的 create 阶段,正式进入文件处理环节。上面一节我们介绍 MultipleEntryPlugin 中曾简单提到过:_addModuleChain 的回调中执行的是 moduleFactory.create。对于上面例子来说这里 create 方法,其实执行是 nromalModuleFactory.create 方法,代码主逻辑如下:
create(data, callback) {
//...省略部分逻辑
this.hooks.beforeResolve.callAsync(
{
contextInfo,
resolveOptions,
context,
request,
dependencies
},
(err, result) => {
//...
// 触发 normalModuleFactory 中的 factory 事件。
const factory = this.hooks.factory.call(null);
// Ignored
if (!factory) return callback();
factory(result, (err, module) => {
//...
callback(null, module);
});
}
);
}单独看 create 内部逻辑:

到此已经得到了一个 module 实例。为了方便,后文我们将这个 module 实例称为 demo module。
得到 demo module 之后,需要将其保存到全局的 Compilation.modules 数组中和 _modules 对象中。
这个过程中还会为 demo module 添加 reason ,即哪个 module 中依赖了 demo module。由于是 demo.js 是入口文件,所以这个 reason 自然就是 SingleEntryDependency。
并且对于入口文件来说,还会被添加到 Compilation.entries 中。
// moduleFactory.create 的 callback 函数
(err, module) => {
//...
let afterFactory;
//...
// addModule 会执行 this._modules.set(identifier, module); 其中 identifier 对于 normalModule 来说就是 module.request,即文件的绝对路径
// 和 this.modules.push(module);
const addModuleResult = this.addModule(module);
module = addModuleResult.module;
// 对于入口文件来说,这里会执行 this.entries.push(module);
onModule(module);
dependency.module = module;
module.addReason(null, dependency);
//... 开始 build 阶段
}这个阶段可以认为是 add 阶段,将 module 的所有信息保存到 Compilation 中,以便于在最后打包成 chunk 的时候使用。随后在这个回调函数中,会调用 this.buildModule 进入 build 阶段。
demo module 是 NormalModule 的实例,所以 Compilation.buildModule 中调用的 module.build 方法实际为 NormalModule.build 方法。build 方法主逻辑如下:
// NormalModule.build 方法
build(options, compilation, resolver, fs, callback) {
//...
return this.doBuild(options, compilation, resolver, fs, err => {
//...
try {
// 这里会将 source 转为 AST,分析出所有的依赖
const result = this.parser.parse(/*参数*/);
if (result !== undefined) {
// parse is sync
handleParseResult(result);
}
} catch (e) {
handleParseError(e);
}
})
}
// NormalModule.doBuild 方法
doBuild(options, compilation, resolver, fs, callback) {
//...
// 执行各种 loader
runLoaders(
{
resource: this.resource,
loaders: this.loaders,
context: loaderContext,
readResource: fs.readFile.bind(fs)
},
(err, result) => {
//...
// createSource 会将 runLoader 得到的结果转为字符串以便后续处理
this._source = this.createSource(
this.binary ? asBuffer(source) : asString(source),
resourceBuffer,
sourceMap
);
//...
}
);
}build 分成两大块: doBuild 和 doBuild 的回调。
在 doBuild 之前,我们实际上只得到了文件的路径,并没有获取到文件的真正内容,而在这一环节在 doBuild 的 runLoader 方法中会根据这个路径得到读取文件的内容,然后经过各种 loader 处理,得到最终结果,这部分已经在 loader 中分析过,参见 webpack系列之四loader详解2。
上一步得到了文件的 source 是 demo.js 的字符串形式,如何从这个字符串中得到 demo.js 的依赖呢?这就需要对这个字符串进行处理了,this.parser.parse 方法被执行。
接下来我们详细看一下 parse 的过程,具体的代码在 lib/Parser.js 中。代码如下:
parse(source, initialState) {
let ast;
let comments;
if (typeof source === "object" && source !== null) {
ast = source;
comments = source.comments;
} else {
comments = [];
ast = Parser.parse(source, {
sourceType: this.sourceType,
onComment: comments
});
}
const oldScope = this.scope;
const oldState = this.state;
const oldComments = this.comments;
// 设置 scope,可以理解为和代码中个作用域是一致的
this.scope = {
topLevelScope: true,
inTry: false,
inShorthand: false,
isStrict: false,
definitions: new StackedSetMap(),
renames: new StackedSetMap()
};
const state = (this.state = initialState || {});
this.comments = comments;
// 遍历 AST,找到所有依赖
if (this.hooks.program.call(ast, comments) === undefined) {
this.detectStrictMode(ast.body);
this.prewalkStatements(ast.body);
this.walkStatements(ast.body);
}
this.scope = oldScope;
this.state = oldState;
this.comments = oldComments;
return state;
}在 parse 方法中,source 参数可能会有两种形式:ast 对象或者 string。为什么会有 ast 对象呢?要解释这个问题,我们先看一个参数 source 从哪里来的。回到 runLoaders 的回调中看一下
runLoaders({...}, (err, result) => {
//...省略其他内容
const source = result.result[0];
const sourceMap = result.result.length >= 1 ? result.result[1] : null;
const extraInfo = result.result.length >= 2 ? result.result[2] : null;
//...
this._ast =
typeof extraInfo === "object" &&
extraInfo !== null &&
extraInfo.webpackAST !== undefined
? extraInfo.webpackAST
: null;
})runLoader 结果是一个数组: [source, sourceMap, extraInfo], extraInfo.webpackAST 如果存在,则会被保存到 module._ast 中。也就是说,loader 除了返回处理完了 source 之后,还可以返回一个 AST 对象。在 doBuild 的回调中会优先使用 module._ast 。
const result = this.parser.parse(
this._ast || this._source.source(),
//...
)这时传入 parse 方法中的就是 loader 处理之后,返回的 extraInfo.webpackAST,类型是 AST 对象。这么做的好处是什么呢?如果 loader 处理过程中已经执行过将文件转化为 AST 了,那么这个 AST 对象保存到 extraInfo.webpackAST 中,在这一步就可以直接复用,以避免重复生成 AST,提升性能。
回到正题 parse 方法中,如果 source 是字符串,那么会经过 Parser.parse 之后被转化为 AST(webpack 中使用的是 acorn)。到这里 demo.js 中的源码会被解析成一个树状结构,大概结构如下图

接下来就是对这个树进行遍历了,流程为: program事件 -> detectStrictMode -> prewalkStatements -> walkStatements。这个过程中会给 module 增加很多 dependency 实例。每个 dependency 类都会有一个 template 方法,并且保存了原来代码中的字符位置 range,在最后生成打包后的文件时,会用 template 的结果替换 range 部分的内容。所以最终得到的 dependency 不仅包含了文件中所有的依赖信息,还被用于最终生成打包代码时对原始内容的修改和替换,例如将 return 'sssss' + A 替换为 return 'sssss' + _a_js__WEBPACK_IMPORTED_MODULE_0__["A"]
program 事件
program 事件中,会触发两个 plugin 的回调:HarmonyDetectionParserPlugin 和 UseStrictPlugin
HarmonyDetectionParserPlugin 中,如果代码中有 import 或者 export 或者类型为 javascript/esm,那么会增加了两个依赖:HarmonyCompatibilityDependency, HarmonyInitDependency 依赖。
UseStrictPlugin 用来检测文件是否有 use strict,如果有,则增加一个 ConstDependency 依赖。这里估计大家会有一个疑问:文件中已经有了,为什么还有增加一个这样的依赖呢?在 UseStrictPlugin.js 的源码中有一句注释
Remove "use strict" expression. It will be added later by the renderer again.
This is necessary in order to not break the strict mode when webpack prepends code.
意识是说,webpack 在处理我们的代码的时候,可能会在开头增加一些代码,这样会导致我们原本写在代码第一行的 "use strict" 不在第一行。所以 UseStrictPlugin 中通过增加 ConstDependency 依赖,来放置一个“占位符”,在最后生成打包文件的时候将其再转为 "use strict"。
总的来说,program 事件中,会根据情况给 demo module 增加依赖。
detectStrictMode
检测当前执行块是否有 use strict,并设置 this.scope.isStrict = true
prewalkStatements
prewalk 阶段负责处理变量。结合上面的 demo AST ,我们看 prewalk 代码怎么处理变量的。
首先进入 prewalkStatements 函数,该函数,对 demo AST 中第一层包含的三个结点分别调用 prewalkStatement
prewalkStatements(statements) {
for (let index = 0, len = statements.length; index < len; index++) {
const statement = statements[index];
this.prewalkStatement(statement);
}
}prewalkStatement 函数是一个巨大的 switch 方法,根据 statement.type 的不同,调用不同的处理函数。
prewalkStatement(statement) {
switch (statement.type) {
case "BlockStatement":
this.prewalkBlockStatement(statement);
break;
//...
}
}第一个节点的 type 是 importDeclaration,所以会进入 prewalkImportDeclaration 方法。
prewalkImportDeclaration(statement) {
// source 值为 './a.js'
const source = statement.source.value;
this.hooks.import.call(statement, source);
// 如果原始代码为 import x, {y} from './a.js',则 statement.specifiers 包含 x 和 { y } ,也就是我们导入的值
for (const specifier of statement.specifiers) {
const name = specifier.local.name; // 这里是 import { A } from './a.js' 中的 A
// 将 A 写入 renames 和 definitions
this.scope.renames.set(name, null);
this.scope.definitions.add(name);
switch (specifier.type) {
case "ImportDefaultSpecifier":
this.hooks.importSpecifier.call(statement, source, "default", name);
break;
case "ImportSpecifier":
this.hooks.importSpecifier.call(
statement,
source,
specifier.imported.name,
name
);
break;
case "ImportNamespaceSpecifier":
this.hooks.importSpecifier.call(statement, source, null, name);
break;
}
}
}涉及到的几个插件:
import 事件会触发 HarmonyImportDependencyParserPlugin,增加 ConstDependency 和 HarmonyImportSideEffectDependency。
importSpecifier 事件触发 HarmonyImportDependencyParserPlugin,这个插件中会在 rename 中设置 A 的值为 'imported var'
parser.hooks.importSpecifier.tap(
"HarmonyImportDependencyParserPlugin",
(statement, source, id, name) => {
// 删除 A
parser.scope.definitions.delete(name);
// 然后将 A 设置为 import var
parser.scope.renames.set(name, "imported var");
if (!parser.state.harmonySpecifier)
parser.state.harmonySpecifier = new Map();
parser.state.harmonySpecifier.set(name, {
source,
id,
sourceOrder: parser.state.lastHarmonyImportOrder
});
return true;
}
);第一个节结束后,继续第二个节点,进入 prewalkFunctionDeclaration。这里只会处理函数名称,并不会深入函数内容进行处理。
prewalkFunctionDeclaration(statement) {
if (statement.id) {
// 将 function 的名字,test 添加到 renames 和 definitions 中
this.scope.renames.set(statement.id.name, null);
this.scope.definitions.add(statement.id.name);
}
}其余的这里不一一介绍了,prewalkStatements 过程中会处理当前作用域下的变量,将其写入 scope.renames 中,同时为 import 语句增加相关的依赖。

walkStatements
上一步中 prewalkStatements 只负责处理当前作用域下的变量,如果遇到函数并不会深入内部。而在 walk 这一步则主要负责深入函数内部。对于 demo 的 AST 会深入第二个节点 FunctionDeclaration。
walkFunctionDeclaration(statement) {
const wasTopLevel = this.scope.topLevelScope;
this.scope.topLevelScope = false;
for (const param of statement.params) this.walkPattern(param);
// inScope 方法会生成一个新的 scope,用于对函数的遍历。在这个新的 scope 中会将函数的参数名 和 this 记录到 renames 中。
this.inScope(statement.params, () => {
if (statement.body.type === "BlockStatement") {
this.detectStrictMode(statement.body.body);
this.prewalkStatement(statement.body);
this.walkStatement(statement.body);
} else {
this.walkExpression(statement.body);
}
});
this.scope.topLevelScope = wasTopLevel;
}在遍历之前会先调用 inScope 方法,生成一个新的 scope,然后对于 function(){} 的方法,继续 detectStrictMode -> prewalkStatement -> walkStatement。这个过程和遍历 body 类似,我们这里跳过一下,直接看 return temp + A 中的 A,即 AST 中 BinaryExpression.right 叶子节点。因为其中的 A 是我们引入的变量, 所以会有所不同,代码如下
walkIdentifier(expression) {
// expression.name = A
if (!this.scope.definitions.has(expression.name)) {
const hook = this.hooks.expression.get(
this.scope.renames.get(expression.name) || expression.name
);
if (hook !== undefined) {
const result = hook.call(expression);
if (result === true) return;
}
}
}在 prewalk 中针对 A 变量有一个处理,重新设置会将其从 definitions 中删除掉(HarmonyImportDependencyParserPlugin 插件中逻辑)。
// 删除 A
parser.scope.definitions.delete(name);
// 然后将 A 设置为 import var
parser.scope.renames.set(name, "imported var");所以这里会进入到 if 逻辑中,同时this.scope.renames.get(expression.name) 这个值的结果就是 'import var'。同样是在 HarmonyImportDependencyParserPlugin 插件中,还注册了一个 'import var' 的 expression 事件:
parser.hooks.expression
.for("imported var")
.tap("HarmonyImportDependencyParserPlugin", expr => {
const name = expr.name;// A
// parser.state.harmonySpecifier 会在 prewalk 阶段写入
const settings = parser.state.harmonySpecifier.get(name);
// 增加一个 HarmonyImportSpecifierDependency 依赖
const dep = new HarmonyImportSpecifierDependency(
settings.source,
parser.state.module,
settings.sourceOrder,
parser.state.harmonyParserScope,
settings.id,
name,
expr.range,
this.strictExportPresence
);
dep.shorthand = parser.scope.inShorthand;
dep.directImport = true;
dep.loc = expr.loc;
parser.state.module.addDependency(dep);
return true;
});因此在 walkIdentifier 方法中通过 this.hooks.expression.get 获取到这个事件的 hook,然后执行。执行结束后,会给 module 增加一个 HarmonyImportSpecifierDependency 依赖,同样的,这个依赖同时也是一个占位符,在最终生成打包文件的时候会对 return tmp + A 中的 A 进行替换。

parse总结
整个 parse 的过程关于依赖的部分,我们总结一下:
所有的依赖都被保存在 module.dependencies 中,一共有下面4个
HarmonyCompatibilityDependency
HarmonyInitDependency
ConstDependency
HarmonyImportSideEffectDependency
HarmonyImportSpecifierDependency到此 build 阶段就结束了,回到 module.build 的回调函数。接下来就是对依赖的处理
首先回到的是 module.build 回调中,源码位于 Compilation.js 的 buildModule 中。对 dependencies 按照代码在文件中出现的先后顺序排序,然后执行 callback,继续返回,回到 buildModule 方法的回调中,调用 afterBuild。
const afterBuild = () => {
if (currentProfile) {
const afterBuilding = Date.now();
currentProfile.building = afterBuilding - afterFactory;
}
// 如果有依赖,则进入 processModuleDependencies
if (addModuleResult.dependencies) {
this.processModuleDependencies(module, err => {
if (err) return callback(err);
callback(null, module);
});
} else {
return callback(null, module);
}
};这时我们有4个依赖,所以会进入 processModuleDependencies。
processModuleDependencies(module, callback) {
const dependencies = new Map();
// 整理 dependency
const addDependency = dep => {
const resourceIdent = dep.getResourceIdentifier();
// 过滤掉没有 ident 的,例如 constDependency 这些只用在最后打包文件生成的依赖
if (resourceIdent) {
// dependencyFactories 中记录了各个 dependency 对应的 ModuleFactory。
// 还记得前一篇文章中介绍的处理入口的 xxxEntryPlugin 吗?
// 在 compilation 事的回调中会执行 `compilation.dependencyFactories.set` 方法。
// 类似的,ImportPlugin,ConstPlugin 等等,也会在 compilation 事件回调中执行 set 操作,
// 将 dependency 与用来处理这个 dependency 的 moduleFactory 对应起来。
const factory = this.dependencyFactories.get(dep.constructor);
if (factory === undefined)
throw new Error(
`No module factory available for dependency type: ${
dep.constructor.name
}`
);
let innerMap = dependencies.get(factory);
if (innerMap === undefined)
dependencies.set(factory, (innerMap = new Map()));
let list = innerMap.get(resourceIdent);
if (list === undefined) innerMap.set(resourceIdent, (list = []));
list.push(dep);
}
};
const addDependenciesBlock = block => {
if (block.dependencies) {
iterationOfArrayCallback(block.dependencies, addDependency);
}
if (block.blocks) {
iterationOfArrayCallback(block.blocks, addDependenciesBlock);
}
if (block.variables) {
iterationBlockVariable(block.variables, addDependency);
}
};
try {
addDependenciesBlock(module);
} catch (e) {
callback(e);
}
const sortedDependencies = [];
// 将上面的结果转为数组形式
for (const pair1 of dependencies) {
for (const pair2 of pair1[1]) {
sortedDependencies.push({
factory: pair1[0],
dependencies: pair2[1]
});
}
}
this.addModuleDependencies(/*参数*/);
}block, variable 哪里来的?
build 阶段得到的 dependency 在这一步都会进入 addDependency 逻辑。我们 demo 中得到的全部都是 dependency,但是除此之外还有 block 和 variable 两种类型。
block 依赖
当我们使用 webpack 的懒加载时 import('xx.js').then() 的写法,在 parse 阶段,解析到这一句时会执行
//...省略其他逻辑
else if (expression.callee.type === "Import") {
result = this.hooks.importCall.call(expression);
//...
}
//...这时会进入到 ImportParserPlugin 中,这个插件中默认是 lazy 模式,即懒加载。在该模式下,会生成一个 ImportDependenciesBlock 类型的依赖,并加入到 module.block 中。
// ImportParserPlugin
const depBlock = new ImportDependenciesBlock(
param.string,
expr.range,
Object.assign(groupOptions, {
name: chunkName
}),
parser.state.module,
expr.loc,
parser.state.module
);
// parser.state.current 为当前处理的 module
parser.state.current.addBlock(depBlock);ImportDependenciesBlock 是一个单独的 chunk ,它自己也会有 dependency, block, variable 类型的依赖。
variables 依赖
如果我们使用到了 webpack 内置的模块变量 __resourceQuery ,例如下面的代码
// main.js
require('./a.js?test')
// a.js
const a = __resourceQuery
console.log(a)a.js 的模块中 module.variables 中就会存在一个 __resourceQuery 。variables 依赖用来存放 webpack 内全局变量(测试的时候暂时只发现 __resourceQuery 会存入 variables 中),一般情况下也很少用到(在最新的 webpack5 处理模块依赖中关于 variables 的部分已经被去掉了)。
回到我们的 demo 中,前面我们得到的 4 个 dependency 中,有一些是纯粹用作“占位符”(HarmonyCompatibilityDependency,HarmonyInitDependency,ConstDependency),addDependency 中第一步dep.getResourceIdentifier(); 逻辑则会将这些依赖都过滤掉,然后再将剩下的 dependency 按照所对应的 moduleFactory 和 dependency 的 ident 归类,最终得到下面的结构:
dependencies = {
NormalModuleFactory: {
"module./a.js": [
HarmonyImportSideEffectDependency,
HarmonyImportSpecifierDependency
]
}
}之后再转化为数组形式
sortedDependencies = [
{
factory: NormalModuleFactory,
dependencies: [
HarmonyImportSideEffectDependency,
HarmonyImportSpecifierDependency
]
}
]然后在 addModuleDependencies 方法中会对 sortedDependencies 数组中的每一项执行相同的处理,将其加入到编译链条中。细看一下 addModuleDependencies 中处理依赖的代码
// addModuleDependencies
addModuleDependencies(
module,
dependencies,
bail,
cacheGroup,
recursive,
callback
) {
//...
asyncLib.forEach(
dependencies,
(item, callback) => {
const dependencies = item.dependencies;
//...
semaphore.acquire(() => {
const factory = item.factory;
// create 阶段
factory.create(
{/*参数*/},
(err, dependentModule) => {
let afterFactory;
const isOptional = () => {
return dependencies.every(d => d.optional);
};
//...
// addModule 阶段
const iterationDependencies = depend => {
for (let index = 0; index < depend.length; index++) {
const dep = depend[index];
dep.module = dependentModule;
dependentModule.addReason(module, dep);
}
};
const addModuleResult = this.addModule(
dependentModule,
cacheGroup
);
dependentModule = addModuleResult.module;
// 将 module 信息写入依赖中
iterationDependencies(dependencies);
// build 阶段
const afterBuild = () => {
//...
// build 阶段结束后有依赖的话继续处理依赖
if (recursive && addModuleResult.dependencies) {
this.processModuleDependencies(dependentModule, callback);
} else {
return callback();
}
};
//...
if (addModuleResult.build) {
this.buildModule(/*参数*/);
} else {
//...
}
}
);
});
},
err => {
//...
}
);
}上面代码可以看到,对于所有的依赖再次经过 create->build->add->processDep。如此递归下去,最终我们所有的文件就都转化为了 module,并且会得到一个 module 和 dependencies 的关系结构
_preparedEntrypoints:
\
module: demo.js module
|\
| HarmonyImportSideEffectDependency
| module: a.js module
\
HarmonyImportSpecifierDependency
module: a.ja module这个结构会交给后续的 chunck 和 生成打包文件代码使用。 module 生成的过程结束之后,最终会回到 Compiler.js 中的 compile 方法的 make 事件回调中:
compile(callback) {
const params = this.newCompilationParams();
this.hooks.beforeCompile.callAsync(params, err => {
//...
this.hooks.make.callAsync(compilation, err => {
// 回到这个回调中
if (err) return callback(err);
compilation.finish();
compilation.seal(err => {
if (err) return callback(err);
this.hooks.afterCompile.callAsync(compilation, err => {
if (err) return callback(err);
return callback(null, compilation);
});
});
});
});回调的 seal 方法中,将运用这些 module 以及 module 的 dependencies 信息整合出最终的 chunck(具体过程,我们会在下一篇文章《webpack 系列之chunk生成》中介绍)。
到此,module 生成的过程就结束了,我们以一张流程图来整体总结一下 module 生成的过程:

作者:肖磊
这篇文章主要是通过源码去探索下 webpack 是如何通过在编译环节创建的 module graph 来生成对应的 chunk graph。
首先来了解一些概念及其相互之间的关系:
我们都知道 webpack 打包构建时会根据你的具体业务代码和 webpack 相关配置来决定输出的最终文件,具体的文件的名和文件数量也与此相关。而这些文件就被称为 chunk。例如在你的业务当中使用了异步分包的 API:
import('./foo.js').then(bar => bar())在最终输出的文件当中,foo.js会被单独输出一个 chunk 文件。
又或者在你的 webpack 配置当中,进行了有关 optimization 优化 chunk 生成的配置:
module.exports = {
optimization: {
runtimeChunk: {
name: 'runtime-chunk'
}
}
}最终 webpack 会将 webpack runtime chunk 单独抽离成一个 chunk 后再输出成一个名为runtime-chunk.js的文件。
而这些生成的 chunk 文件当中即是由相关的 module 模块所构成的。
接下来我们就看下 webpack 在工作流当中是如何生成 chunk 的,首先我们先来看下示例:
// a.js (webpack config 入口文件)
import add from './b.js'
add(1, 2)
import('./c').then(del => del(1, 2))
-----
// b.js
import mod from './d.js'
export default function add(n1, n2) {
return n1 + n2
}
mod(100, 11)
-----
// c.js
import mod from './d.js'
mod(100, 11)
import('./b.js').then(add => add(1, 2))
export default function del(n1, n2) {
return n1 - n2
}
-----
// d.js
export default function mod(n1, n2) {
return n1 % n2
}webpack 相关的配置:
// webpack.config.js
module.exports = {
entry: {
app: 'a.js'
},
output: {
filename: '[name].[chunkhash].js',
chunkFilename: '[name].bundle.[chunkhash:8].js',
publicPath: '/'
},
optimization: {
runtimeChunk: {
name: 'bundle'
}
},
}其中 a.js 为 webpack config 当中配置的 entry 入口文件,a.js 依赖 b.js/c.js,而 b.js 依赖 d.js,c.js 依赖 d.js/b.js。最终通过 webpack 编译后,将会生成3个 chunk 文件,其中:
接下来我们就通过源码来看下 webpack 内部是通过什么样的策略去完成 chunk 的生成的。
在 webpack 的工作流程当中,当所有的 module 都被编译完成后,进入到 seal 阶段会开始生成 chunk 的相关的工作:
// compilation.js
class Compilation {
...
seal () {
...
this.hooks.beforeChunks.call();
// 根据 addEntry 方法中收集到入口文件组成的 _preparedEntrypoints 数组
for (const preparedEntrypoint of this._preparedEntrypoints) {
const module = preparedEntrypoint.module;
const name = preparedEntrypoint.name;
const chunk = this.addChunk(name); // 入口 chunk 且为 runtimeChunk
const entrypoint = new Entrypoint(name); // 每一个 entryPoint 就是一个 chunkGroup
entrypoint.setRuntimeChunk(chunk); // 设置 runtime chunk
entrypoint.addOrigin(null, name, preparedEntrypoint.request);
this.namedChunkGroups.set(name, entrypoint); // 设置 chunkGroups 的内容
this.entrypoints.set(name, entrypoint);
this.chunkGroups.push(entrypoint);
// 建立起 chunkGroup 和 chunk 之间的关系
GraphHelpers.connectChunkGroupAndChunk(entrypoint, chunk);
// 建立起 chunk 和 module 之间的关系
GraphHelpers.connectChunkAndModule(chunk, module);
chunk.entryModule = module;
chunk.name = name;
this.assignDepth(module);
}
this.processDependenciesBlocksForChunkGroups(this.chunkGroups.slice());
// 对 module 进行排序
this.sortModules(this.modules);
// 创建完 chunk 之后的 hook
this.hooks.afterChunks.call(this.chunks);
//
this.hooks.optimize.call();
while (
this.hooks.optimizeModulesBasic.call(this.modules) ||
this.hooks.optimizeModules.call(this.modules) ||
this.hooks.optimizeModulesAdvanced.call(this.modules)
) {
/* empty */
}
// 优化 module 之后的 hook
this.hooks.afterOptimizeModules.call(this.modules);
while (
this.hooks.optimizeChunksBasic.call(this.chunks, this.chunkGroups) ||
this.hooks.optimizeChunks.call(this.chunks, this.chunkGroups) ||
// 主要涉及到 webpack config 当中的有关 optimization 配置的相关内容
this.hooks.optimizeChunksAdvanced.call(this.chunks, this.chunkGroups)
) {
/* empty */
}
// 优化 chunk 之后的 hook
this.hooks.afterOptimizeChunks.call(this.chunks, this.chunkGroups);
...
}
...
}在这个过程当中首先遍历 webpack config 当中配置的入口 module,每个入口 module 都会通过addChunk方法去创建一个 chunk,而这个新建的 chunk 为一个空的 chunk,即不包含任何与之相关联的 module。之后实例化一个 entryPoint,而这个 entryPoint 为一个 chunkGroup,每个 chunkGroup 可以包含多的 chunk,同时内部会有个比较特殊的 runtimeChunk(当 webpack 最终编译完成后包含的 webpack runtime 代码最终会注入到 runtimeChunk 当中)。到此仅仅是分别创建了 chunk 以及 chunkGroup,接下来便调用GraphHelpers模块提供的connectChunkGroupAndChunk及connectChunkAndModule方法来建立起 chunkGroup 和 chunk 之间的联系,以及 chunk 和 入口 module 之间(这里还未涉及到依赖 module)的联系:
// GraphHelpers.js
/**
* @param {ChunkGroup} chunkGroup the ChunkGroup to connect
* @param {Chunk} chunk chunk to tie to ChunkGroup
* @returns {void}
*/
GraphHelpers.connectChunkGroupAndChunk = (chunkGroup, chunk) => {
if (chunkGroup.pushChunk(chunk)) {
chunk.addGroup(chunkGroup);
}
};
/**
* @param {Chunk} chunk Chunk to connect to Module
* @param {Module} module Module to connect to Chunk
* @returns {void}
*/
GraphHelpers.connectChunkAndModule = (chunk, module) => {
if (module.addChunk(chunk)) {
chunk.addModule(module);
}
};例如在示例当中,入口 module 只配置了一个,那么在处理 entryPoints 阶段时会生成一个 chunkGroup 以及一个 chunk,这个 chunk 目前仅仅只包含了入口 module。我们都知道 webpack 输出的 chunk 当中都会包含与之相关的 module,在编译环节进行到上面这一步仅仅建立起了 chunk 和入口 module 之间的联系,那么 chunk 是如何与其他的 module 也建立起联系呢?接下来我们就看下 webpack 在生成 chunk 的过程当中是如何与其依赖的 module 进行关联的。
与此相关的便是 compilation 实例提供的processDependenciesBlocksForChunkGroups方法。这个方法内部细节较为复杂,它包含了两个核心的处理流程:
我们先通过一个整体的流程图来大致了解下这个方法内部的处理过程:

在第一个步骤中,首先对这次 compliation 收集到的 modules 进行一次遍历,在遍历 module 的过程中,会对这个 module 的 dependencies 依赖进行处理,获取这个 module 的依赖模块,同时还会处理这个 module 的 blocks(即在你的代码通过异步 API 加载的模块),每个异步 block 都会被加入到遍历的过程当中,被当做一个 module 来处理。因此在这次遍历的过程结束后会建立起基本的 module graph,包含普通的 module 及异步 module(block),最终存储到一个 map 表(blockInfoMap)当中:
const iteratorBlockPrepare = b => {
blockInfoBlocks.push(b);
// 将 block 加入到 blockQueue 当中,从而进入到下一次的遍历过程当中
blockQueue.push(b);
};
// 这次 compilation 包含的所有的 module
for (const modules of this.modules) {
blockQueue = [module];
currentModule = module;
while (blockQueue.length > 0) {
block = blockQueue.pop(); // 当前正在被遍历的 module
blockInfoModules = new Set(); // module 依赖的同步的 module
blockInfoBlocks = []; // module 依赖的异步 module(block)
if (block.variables) {
iterationBlockVariable(block.variables, iteratorDependency);
}
// 在 blockInfoModules 数据集(set)当中添加 dependencies 中的普通 module
if (block.dependencies) {
iterationOfArrayCallback(block.dependencies, iteratorDependency);
}
// 在 blockInfoBlocks 和 blockQueue 数组当中添加异步 module(block),这样这些被加入到 blockQueue当中的
// module 也会进入到遍历的环节,去获取异步 module(block)的依赖
if (block.blocks) {
iterationOfArrayCallback(block.blocks, iteratorBlockPrepare);
}
const blockInfo = {
modules: Array.from(blockInfoModules),
blocks: blockInfoBlocks
};
// blockInfoMap 上保存了每个 module 依赖的同步 module 及 异步 blocks
blockInfoMap.set(block, blockInfo);
}
}在我们的实例当中生成的 module graph 即为:

当基础的 module graph (即blockInfoMap)生成后,接下来开始根据 module graph 去生成 basic chunk graph。刚开始仍然是数据的处理,将传入的 entryPoint(chunkGroup) 转化为一个新的 queue,queue 数组当中每一项包含了:
在我们提供的示例当中,因为是单入口的,因此这里 queue 初始化后只有一项。
{
action: ENTER_MODULE,
block: a.js,
module: a.js,
chunk,
chunkGroup: entryPoint
}接下来进入到 queue 的遍历环节
// 创建异步的 block
// For each async Block in graph
/**
* @param {AsyncDependenciesBlock} b iterating over each Async DepBlock
* @returns {void}
*/
const iteratorBlock = b => {
// 1. We create a chunk for this Block
// but only once (blockChunkGroups map)
let c = blockChunkGroups.get(b);
if (c === undefined) {
c = this.namedChunkGroups.get(b.chunkName);
if (c && c.isInitial()) {
this.errors.push(
new AsyncDependencyToInitialChunkError(b.chunkName, module, b.loc)
);
c = chunkGroup;
} else {
// 通过 addChunkInGroup 方法创建新的 chunkGroup 及 chunk,并返回这个 chunkGroup
c = this.addChunkInGroup(
b.groupOptions || b.chunkName,
module, // 这个 block 所属的 module
b.loc,
b.request
);
chunkGroupCounters.set(c, { index: 0, index2: 0 });
blockChunkGroups.set(b, c);
allCreatedChunkGroups.add(c);
}
} else {
// TODO webpack 5 remove addOptions check
if (c.addOptions) c.addOptions(b.groupOptions);
c.addOrigin(module, b.loc, b.request);
}
// 2. We store the Block+Chunk mapping as dependency for the chunk
let deps = chunkDependencies.get(chunkGroup);
if (!deps) chunkDependencies.set(chunkGroup, (deps = []));
// 当前 chunkGroup 所依赖的 block 及 chunkGroup
deps.push({
block: b,
chunkGroup: c,
couldBeFiltered: true
});
// 异步的 block 使用创建的新的 chunkGroup
// 3. We enqueue the DependenciesBlock for traversal
queueDelayed.push({
action: PROCESS_BLOCK,
block: b,
module: module,
chunk: c.chunks[0], // 获取新创建的 chunkGroup 当中的第一个 chunk,即 block 需要被加入的 chunk
chunkGroup: c // 异步 block 使用新创建的 chunkGroup
});
};
...
const ADD_AND_ENTER_MODULE = 0;
const ENTER_MODULE = 1;
const PROCESS_BLOCK = 2;
const LEAVE_MODULE = 3;
...
const chunkGroupToQueueItem = chunkGroup => ({
action: ENTER_MODULE,
block: chunkGroup.chunks[0].entryModule,
module: chunkGroup.chunks[0].entryModule,
chunk: chunkGroup.chunks[0],
chunkGroup
});
let queue = inputChunkGroups.map(chunkGroupToQueueItem).reverse()
while (queue.length) { // 外层 queue 遍历
while (queue.length) { // 内层 queue 遍历
const queueItem = queue.pop();
module = queueItem.module;
block = queueItem.block;
chunk = queueItem.chunk;
chunkGroup = queueItem.chunkGroup;
switch (queueItem.action) {
case ADD_AND_ENTER_MODULE: {
// 添加 module 至 chunk 当中
// We connect Module and Chunk when not already done
if (chunk.addModule(module)) {
module.addChunk(chunk);
} else {
// already connected, skip it
break;
}
}
// fallthrough
case ENTER_MODULE: {
...
queue.push({
action: LEAVE_MODULE,
block,
module,
chunk,
chunkGroup
});
}
// fallthrough
case PROCESS_BLOCK: {
// get prepared block info
const blockInfo = blockInfoMap.get(block);
// Traverse all referenced modules
for (let i = blockInfo.modules.length - 1; i >= 0; i--) {
const refModule = blockInfo.modules[i];
if (chunk.containsModule(refModule)) {
// skip early if already connected
continue;
}
// enqueue the add and enter to enter in the correct order
// this is relevant with circular dependencies
queue.push({
action: ADD_AND_ENTER_MODULE,
block: refModule, // 依赖 module
module: refModule, // 依赖 module
chunk, // module 所属的 chunk
chunkGroup // module 所属的 chunkGroup
});
}
// 开始创建异步的 chunk
// Traverse all Blocks
iterationOfArrayCallback(blockInfo.blocks, iteratorBlock);
if (blockInfo.blocks.length > 0 && module !== block) {
blocksWithNestedBlocks.add(block);
}
break;
}
case LEAVE_MODULE: {
...
break;
}
}
}
const tempQueue = queue;
queue = queueDelayed.reverse();
queueDelayed = tempQueue;
}通过源码我们发现对于 queue 的处理进行了2次遍历的操作(内层和外层),具体为什么会需要进行2次遍历操作后文会说明。首先我们来看下内层的遍历操作,首先根据 action 的类型进入到对应的处理流程当中:
首先进入到 ENTRY_MODULE 的阶段,会在 queue 中新增一个 action 为 LEAVE_MODULE 的项会在后面遍历的流程当中使用,当 ENTRY_MODULE 的阶段进行完后,立即进入到了 PROCESS_BLOCK 阶段:
在这个阶段当中根据 module graph 依赖图保存的模块映射 blockInfoMap 获取这个 module(称为A) 的同步依赖 modules 及异步依赖 blocks。
接下来遍历 modules 当中的包含的 module(称为B),判断当前这个 module(A) 所属的 chunk 当中是否包含了其依赖 modules 当中的 module(B),如果不包含的话,那么会在 queue 当中加入新的项,新加入的项目的 action 为 ADD_AND_ENTER_MODULE,即这个新增项在下次遍历的时候,首先会进入到 ADD_AND_ENTER_MODULE 阶段。
当新项被 push 至 queue 当中后,即这个 module 依赖的还未被处理的 module(A) 被加入到 queue 当中后,接下来开始调用iteratorBlock方法来处理这个 module(A) 依赖的所有的异步 blocks,在这个方法内部主要完成的工作是:
调用addChunkInGroup为这个异步的 block 新建一个 chunk 以及 chunkGroup,同时调用 GraphHelpers 模块提供的 connectChunkGroupAndChunk 建立起这个新建的 chunk 和 chunkGroup 之间的联系。这里新建的 chunk 也就是在你的代码当中使用异步API 加载模块时,webpack 最终会单独给这个模块输出一个 chunk,但是此时这个 chunk 为一个空的 chunk,没有加入任何依赖的 module;
建立起当前 module 所属的 chunkGroup 和 block 以及这个 block 所属的 chunkGroup 之间的依赖关系,并存储至 chunkDependencies Map 表中,这个 Map 表主要用于后面优化 chunk graph;
向 queueDelayed 中添加一个 action 类型为 PROCESS_BLOCK,module 为当前所属的 module,block 为当前 module 依赖的异步模块,chunk(chunkGroup 当中的第一个 chunk) 及 chunkGroup 都是处理异步模块生成的新项,而这里向 queueDelayed 数据集当中添加的新项主要就是用于 queue 的外层遍历。
在 ENTRY_MODULE 阶段即完成了将 entry module 的依赖 module 加入到 queue 当中,这个阶段结束后即进入到了 queue 内层第二轮的遍历的环节:
在对 queue 的内层遍历过程当中,我们主要关注 queue 当中每项 action 类型为 ADD_AND_ENTER_MODULE 的项,在进行实际的处理时,进入到 ADD_AND_ENTER_MODULE 阶段,这个阶段完成的主要工作就是判断 chunk 所依赖的 module 是否已经添加到 chunk 内部(chunk.addModule方法),如果没有的话,那么便会将 module 加入到 chunk,并进入到 ENTRY_MODULE 阶段,进入到后面的流程(见上文),如果已经添加过了,那么则会跳过这次遍历。
当对 queue 这一轮的内层的遍历完成后(每一轮的内层遍历都对应于同一个 chunkGroup,即每一轮内层的遍历都是对这个 chunkGroup 当中所包含的所有的 module 进行处理),开始进入到外层的遍历当中,即对 queueDelayed 数据集进行处理。
以上是在processDependenciesBlocksForChunkGroups方法内部对于 module graph 和 chunk graph 的初步处理,最终的结果就是根据 module graph 建立起了 chunk graph,将原本空的 chunk 里面加入其对应的 module 依赖。
entryPoint 包含了 a, b, d 3个 module,而 a 的异步依赖模块 c 以及 c 的同步依赖模块 d 同属于新创建的 chunkGroup2,chunkGroup2 中只有一个 chunk,而 c 的异步模块 b 属于新创建的 chunkGroup3。

接下来进入到第二个步骤,遍历 chunk graph,通过和依赖的 module 之间的使用关系来建立起不同 chunkGroup 之间的父子关系,同时剔除一些没有建立起联系的 chunk。
/**
* Helper function to check if all modules of a chunk are available
*
* @param {ChunkGroup} chunkGroup the chunkGroup to scan
* @param {Set<Module>} availableModules the comparitor set
* @returns {boolean} return true if all modules of a chunk are available
*/
// 判断chunkGroup当中是否已经包含了所有的 availableModules
const areModulesAvailable = (chunkGroup, availableModules) => {
for (const chunk of chunkGroup.chunks) {
for (const module of chunk.modulesIterable) {
// 如果在 availableModules 存在没有的 module,那么返回 false
if (!availableModules.has(module)) return false;
}
}
return true;
};
// For each edge in the basic chunk graph
/**
* @param {TODO} dep the dependency used for filtering
* @returns {boolean} used to filter "edges" (aka Dependencies) that were pointing
* to modules that are already available. Also filters circular dependencies in the chunks graph
*/
const filterFn = dep => {
const depChunkGroup = dep.chunkGroup;
if (!dep.couldBeFiltered) return true;
if (blocksWithNestedBlocks.has(dep.block)) return true;
if (areModulesAvailable(depChunkGroup, newAvailableModules)) {
return false; // break, all modules are already available
}
dep.couldBeFiltered = false;
return true;
};
/** @type {Map<ChunkGroup, ChunkGroupInfo>} */
const chunkGroupInfoMap = new Map();
/** @type {Queue<ChunkGroup>} */
const queue2 = new Queue(inputChunkGroups);
for (const chunkGroup of inputChunkGroups) {
chunkGroupInfoMap.set(chunkGroup, {
minAvailableModules: undefined,
availableModulesToBeMerged: [new Set()]
});
}
...
while (queue2.length) {
chunkGroup = queue2.dequeue();
const info = chunkGroupInfoMap.get(chunkGroup);
const availableModulesToBeMerged = info.availableModulesToBeMerged;
let minAvailableModules = info.minAvailableModules;
...
}
...首先还是完成一些数据的初始化工作,chunkGroupInfoMap 存放了不同 chunkGroup 相关信息:
/** @type {Map<ChunkGroup, ChunkGroupInfo>} */
const chunkGroupInfoMap = new Map();
/** @type {Queue<ChunkGroup>} */
const queue2 = new Queue(inputChunkGroups);
for (const chunkGroup of inputChunkGroups) {
chunkGroupInfoMap.set(chunkGroup, {
minAvailableModules: undefined,
availableModulesToBeMerged: [new Set()]
});
}完成之后,遍历 queue2,其中的每一项都是 chunkGroup,初始为 entry 对应的 chunkGroup,在我们的示例中由于存在动态加载的模块c,所以也会加入到queue2队列中当做一个“独立”的 entry 处理,但是是存在父子关系的,它依托于入口 entry 所对应的 chunkGroup。
while (queue2.length) {
chunkGroup = queue2.dequeue();
const info = chunkGroupInfoMap.get(chunkGroup);
const availableModulesToBeMerged = info.availableModulesToBeMerged;
let minAvailableModules = info.minAvailableModules;
// 1. Get minimal available modules
// It doesn't make sense to traverse a chunk again with more available modules.
// This step calculates the minimal available modules and skips traversal when
// the list didn't shrink.
availableModulesToBeMerged.sort(bySetSize);
let changed = false;
for (const availableModules of availableModulesToBeMerged) {
if (minAvailableModules === undefined) {
minAvailableModules = new Set(availableModules);
info.minAvailableModules = minAvailableModules;
changed = true;
} else {
for (const m of minAvailableModules) {
if (!availableModules.has(m)) {
minAvailableModules.delete(m);
changed = true;
}
}
}
}
availableModulesToBeMerged.length = 0;
if (!changed) continue;
// 获取这个 chunkGroup 的 deps 数组,包含异步的 block 及 对应的 chunkGroup
// 2. Get the edges at this point of the graph
const deps = chunkDependencies.get(chunkGroup);
if (!deps) continue;
if (deps.length === 0) continue;
// 根据之前的 minAvailableModules 创建一个新的 newAvailableModules 数据集
// 即之前所有遍历过的 chunk 当中的 module 都会保存到这个数据集当中,不停的累加
// 3. Create a new Set of available modules at this points
newAvailableModules = new Set(minAvailableModules);
for (const chunk of chunkGroup.chunks) {
for (const m of chunk.modulesIterable) { // 这个 chunk 当中所包含的 module
newAvailableModules.add(m);
}
}
// 边界条件,及异步的 block 所在的 chunkGroup
// 4. Foreach remaining edge
const nextChunkGroups = new Set();
// 异步 block 依赖
for (let i = 0; i < deps.length; i++) {
const dep = deps[i];
// Filter inline, rather than creating a new array from `.filter()`
if (!filterFn(dep)) {
continue;
}
// 这个 block 所属的 chunkGroup,在 iteratorBlock 方法内部创建的
const depChunkGroup = dep.chunkGroup;
const depBlock = dep.block;
// 开始建立 block 和 chunkGroup 之间的关系
// 在为 block 创建新的 chunk 时,仅仅建立起了 chunkGroup 和 chunk 之间的关系,
// 5. Connect block with chunk
GraphHelpers.connectDependenciesBlockAndChunkGroup(
depBlock,
depChunkGroup
);
// 建立起新创建的 chunkGroup 和此前的 chunkGroup 之间的相互联系
// 6. Connect chunk with parent
GraphHelpers.connectChunkGroupParentAndChild(chunkGroup, depChunkGroup);
nextChunkGroups.add(depChunkGroup);
}
// 7. Enqueue further traversal
for (const nextChunkGroup of nextChunkGroups) {
...
// As queue deduplicates enqueued items this makes sure that a ChunkGroup
// is not enqueued twice
queue2.enqueue(nextChunkGroup);
}
}获取在第一阶段的 chunkDependencies 当中缓存的 chunkGroup 的 deps 数组依赖,chunkDependencies 中保存了不同 chunkGroup 所依赖的异步 block,以及同这个 block 一同创建的 chunkGroup(目前二者仅仅是存于一个 map 结构当中,还未建立起 chunkGroup 和 block 之间的依赖关系)。
如果 deps 数据不存在或者长度为0,那么会跳过遍历 deps 当中的 chunkGroup 流程,否则会为这个 chunkGroup 创建一个新的 available module 数据集 newAvailableModules,开始遍历这个 chunkGroup 当中所有的 chunk 所包含的 module,并加入到 newAvailableModules 这一数据集当中。并开始遍历这个 chunkGroup 的 deps 数组依赖,这个阶段主要完成的工作就是:
connectDependenciesBlockAndChunkGroup建立起 deps 依赖中的异步 block 和 chunkGroup 的依赖关系;connectChunkGroupParentAndChild建立起 chunkGroup 和 deps 依赖中的 chunkGroup 之间的依赖关系 (这个依赖关系也决定了在 webpack 编译完成后输出的文件当中是否会有 deps 依赖中的 chunkGroup 所包含的 chunk);那么在我们给出的示例当中,经过在上面提到的这些步骤,第一阶段处理 entryPoint(chunkGroup),以及其包含的所有的 module,在处理过程中发现这个 entryPoint 依赖异步 block c,它包含在了 blocksWithNestedBlocks 数据集当中,依据对应的过滤规则,是需要继续遍历异步 block c 所在的 chunkGroup2。接下来在处理 chunkGroup2 的过程当中,它依赖 chunkGroup3,且这个 chunkGroup3 包含异步 block d,因为在第一阶段处理 entryPoint 过程中完成了一轮 module 集的收集,其中就包含了同步的 module d,这里可以想象得到的是同步的 module d 和异步 block d 最终只可能输出一个,且同步的 module d 要比异步的 block d 的优先级更高。因此最终模块 d 的代码会以同步的 module d 的形式被输出到 entryPoint 所包含的 chunk 当中,这样包含异步 block d 的 chunkGroup3 也就相应的不会再被输出,即会被从 chunk graph 当中剔除掉。
最终会生成的 chunk 依赖图为:

以上就是通过源码分析了 webpack 是如何构建 module graph,以及是如何通过 module graph 去生成 chunk graph 的,当你读完这篇文章后应该就大致了解了在你每次构建完成后,你的项目应用中目标输出文件夹出现的不同的 chunk 文件是经过哪些过程而产生的。
webpack 对于每个前端儿来说都不陌生,它将每个静态文件当成一个模块,经过一系列的处理为我们整合出最后的需要的 js、css、图片、字体等文件。来自官网的图很形象的阐述了 webpack 的功能 —— bundle js / css / ... (打包全世界ヾ(◍°∇°◍)ノ゙)

在阅读一个东西的源码之前,首先需要了解这个东西是什么,怎么用。这样在阅读源码过程中才能在大脑中形成一副整体的认知。所以,先了解一下 webpack 打包前后代码发生了什么?找一个简单的例子
入口文件为 main.js, 在其中引入了 a.js, b.js
// main.js
import { A } from './a'
import B from './b'
console.log(A)
B()// a.js
export const A = 'a'// b.js
export default function () {
console.log('b')
}经过 webpack 的一番蹂躏,最后变成了一个文件:bundle.js。先忽略细节,看最外面的代码结构
(function(modules){
...(webpack的函数)
return __webpack_require__(__webpack_require__.s = "./demo01/main.js");
})(
{
"./demo01/a.js": (function(){...}),
"./demo01/b.js": (function(){...}),
"./demo01/main.js": (function(){...}),
}
)最外层是一个立即执行函数,参数是 modules。 a.js、b.js 和 main.js 最后被编译成三个函数(下文将这三个函数称为 module 函数),key 是文件的相对路径。bundle.js 会执行到 __webpack_require__(__webpack_require__.s = "./demo01/main.js"); 即通过 __webpack_require__('./demo01/main.js') 开始主入口函数的执行。
通过 bundle.js 的主接口可以清晰的看出,对于 webpack 每个文件就是一个 module。 我们写的 import 'xxx',则最终为 __webpack_require__ 函数执行。更多的时候我们使用的是 import A from 'xxx' 或者 import { B } from 'xxx' ,可以猜想一下,这个 __webpack_require__ 函数中除了找到对应的 'xxx' 来执行,还需要一个返回 'xxx' 中 export 出来的内容。
function __webpack_require__(moduleId) {
// Check if module is in cache
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache)
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
module.l = true;
// Return the exports of the module
return module.exports;
}调用每一个 module 函数时,参数为 module、module.exports、__webpack_require__。 module.exports 用来收集 module 中所有的 export xxx 。看 ”./demo/a.js“ 的 module
(function(module, __webpack_exports__, __webpack_require__) {
...
__webpack_require__.d(__webpack_exports__, "A", function() { return A; });
const A = 'a'
/***/ })
...
__webpack_require__.d = function(exports, name, getter) {
if(!__webpack_require__.o(exports, name)) {
Object.defineProperty(exports, name, {
configurable: false,
enumerable: true,
get: getter
});
}
};
// Object.prototype.hasOwnProperty.call
__webpack_require__.o = function(object, property) {
return Object.prototype.hasOwnProperty.call(object, property);
};
...__webpack_require__.d(__webpack_exports__, "A", function() { return A; }); 简单理解就是
__webpack_exports__.A = A而 __webpack_exports__ 实际为上面的 __webpack_require__ 中传入的 moule.exports, 如此,就将 A 变量收集到了 module.exports 中。如此我们的
import { A } from './a.js'
console.log(A)就编译为
var _a__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./demo/a.js");
console.log(_a__WEBPACK_IMPORTED_MODULE_0__["A"])对于 b.js 我们使用的是 export default,webpack 处理后,会在 module.exports 中增加一个 default 属性。
__webpack_exports__["default"] = (function () {
console.log('b')
});
最后 import B from './b.js 编译为
var _b__WEBPACK_IMPORTED_MODULE_1__ = __webpack_require__("./demo/b.js")
Object(_b__WEBPACK_IMPORTED_MODULE_1__["default"])()简单的 demo 入手
// c.js
export default {
key: 'something'
}// main.js
import('./c').then(test => {
console.log(test)
})打包结果,异步加载的 c.js,最后打包在一个单独的文件 0.js 中
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([[0],{
"./demo/c.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
__webpack_exports__["default"] = ({
key2: 'key2'
});
})
}]);简化一下,执行的就是
var t = window["webpackJsonp"] = window["webpackJonsp"] || [])
t.push([[0], {function(){...}}])执行 import('./c.js') 时,实际上通过在 HTML 中插入一个 script 标签加载 0.js。 0.js 加载后会执行 window["webpackJsonp"].push 方法。
在 main.js 在还有一段:
var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
jsonpArray.push = webpackJsonpCallback;这里篡改了一下, window["webpackJsonp"] 的 push 方法,将 push 方法外包装了一层 webpackJonspCallback 的逻辑。当 0.js 加载后,会执行 window["webpackJsonp"].push ,这时便会进入 webpackJsonpCallback 的执行逻辑。
function webpackJsonpCallback(data) {
var chunkIds = data[0];
var moreModules = data[1];
// add "moreModules" to the modules object,
// then flag all "chunkIds" as loaded and fire callback
var moduleId, chunkId, i = 0, resolves = [];
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
if(parentJsonpFunction) parentJsonpFunction(data);
while(resolves.length) {
resolves.shift()();
}
};在 webpackJsonpCallback 中会将 0.js 中的 chunks 和 modules 保存到全局的 modules 变量中,并设置 installedChunks 的标志位。
有两点需要详细说明的:
在加载 0.js 之前会在全局 installedChunks 中先存入了一个 promise 对象
installedChunks[chunkId] = [resolve, reject, promise]
resolve 这个值在 webpackJsonpCallback 中会被用到,这时就会进入到我们写的 import('./c.js').then() 的 then 语句中了。
jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
...
jsonpArray = jsonpArray.slice();
for(var i = 0; i < jsonpArray.length; i++) webpackJsonpCallback(jsonpArray[i]);
var parentJsonpFunction = oldJsonpFunction;也就是说如果之前已经存在全局的 window["webpackJsonp"] 那么在替换其 push 函数之前会将原有的 push 方法保存为 oldJsonpFunction,同时将已存在于 window["webpackJsonp"] 中的内容,一一执行 webpackJsonpCallback 。并且在 webpackJsonpCallback 中也将异步加载的内容也会在 parentJsonpFunction 中同样执行一次
if(parentJsonpFunction) parentJsonpFunction(data);这样的同步意义何在?试想下面的场景,webpack 中多入口情况下,例如如下配置
{
entry: {
bundle1: 'bundle1.js',
bundle2: 'bundle2.js'
}
}并且 bundle1 和 bundle2 中都用到了异步加载了 0.js。而且在同一个页面中同时加载了 bundle1 和 bundle2。那么由于上面的逻辑,执行的流程如下图:

通过上图可以看到,这样设计对于多入口的地方,可以将 bundle1.js 和 bundle2.js 中异步模块进行同步,这样不仅保证了 0.js 可以同时在两个文件中被引用,而且不会重复加载。
异步加载中,有两个需要注意的地方:
promise
在 webpack 异步加载使用了 promise。要兼容低版本的安卓,比如4.x 的代码来说,需要有全局的 promise polyfill。
window["webpackJsonp"]
如果一个 HTML 页面中,会加载多个 webpack 独立打包出来的文件。那么这些文件异步加载的回调函数,默认都叫 "webpackJonsp",会相互冲突。需要通过 output.jsonpFunction 配置修改这个默认的函数名称。
知道上面的产出,根据产出看 webpack 的总流程。这里我们暂时不考虑 webpack 的缓存、错误处理、watch 等逻辑,只看主流程。
首先会有一个入口文件写在配置文件中,确定 webpack 从哪个文件开始处理。
step1 webpack 配置文件处理
我们在写配置文件中 entry 的时候,肯定写过 ./main.js 这时一个相对目录,所以会有一个将相对目录变成绝对目录的处理
step2 文件位置解析
webpack 需要从入口文件开始,顺藤摸瓜找到所有的文件。那么会有一个
step3 加载文件
step4 文件解析
step5 从解析结果中找到文件引入的其他文件
在加载文件的时候,我们会在 webpack 中配置很多的 loaders 来处理 js 文件的 babel 转化等等,还应该有文件对应的 loader 解析,loader 执行。
step3.1 找到所有对应的 loader,然后逐个执行
处理完整入口文件之后,得到依赖的其他文件,递归进行处理。最后得到了所有文件的 module 。最终输出的是打包完成的 bundle 文件。所以会有
step4 module 合并成 chunk 中
输出最终文件
根据 webpack 的使用和结果,我们猜测了一下 webpack 中大概的流程。然后看一下 webpack 的源码,并和我们脑中的流程对比一下。实际的 webpack 流程图如下:

对整体框架和流程有了大致的概念之后,我们可以将源码拆分为一部分一部分来详细阅读。后续会通过一系列文章一一介绍:
底层 Tapable 介绍 已更新,点击查看
webpack 的底层使用的 Tapable 用来处理各种类型的 hook。这部分主要介绍 Tabpable 原理。
reslove 过程 已更新,点击查看
webpack 中我们所写的各种相对路径/绝对路径,alias 等是如何被处理,最终找到正确的执行文件的。
loaders 处理 webpack系列之四loader详解1,webpack系列之四loader详解2,webpack系列之四loader详解3
写在 webpack 配置中,各种 loaders 如何被加载、解析
module 生成 webpack系列之五module生成1, webpack系列之五module生成2
js文件如何被解析,分析出依赖,同时递归处理所有的依赖
chunk 生成 已更新,点击查看
项目中各个文件之间的依赖图的生成,以及根据定义的规则,module 最终如何聚合为 chunk。
最终文件的生成 已更新,点击查看
经历了上面的所有过程后,内存中保存了生成文件的各种信息,这些信息如何整合吐出最终真正执行的所有文件。
在上篇中介绍了 vue-router 的整体流程,但是具体的 history 部分没有具体分析,本文就具体分析下和 history 相关的细节。
通过整体流程可以知道在路由实例化的时候会根据当前 mode 模式来选择实例化对应的History类,这里再来回顾下,在 src/index.js 中:
// ...
import { HashHistory, getHash } from './history/hash'
import { HTML5History, getLocation } from './history/html5'
import { AbstractHistory } from './history/abstract'
// ...
export default class VueRouter {
// ...
constructor (options: RouterOptions = {}) {
// ...
// 默认模式是 hash
let mode = options.mode || 'hash'
// 如果设置的是 history 但是如果浏览器不支持的话
// 强制退回到 hash
this.fallback = mode === 'history' && !supportsHistory
if (this.fallback) {
mode = 'hash'
}
// 不在浏览器中 强制 abstract 模式
if (!inBrowser) {
mode = 'abstract'
}
this.mode = mode
// 根据不同模式选择实例化对应的 History 类
switch (mode) {
case 'history':
this.history = new HTML5History(this, options.base)
break
case 'hash':
// 细节 传入了 fallback
this.history = new HashHistory(this, options.base, this.fallback)
break
case 'abstract':
this.history = new AbstractHistory(this)
break
default:
assert(false, `invalid mode: ${mode}`)
}
}
// ...可以看到 vue-router 提供了三种模式:hash(默认)、history 以及 abstract 模式,还不了解具体区别的可以在文档 中查看,有很详细的解释。下面就这三种模式初始化一一来进行分析。
首先就看默认的 hash 模式,也应该是用的最多的模式,对应的源码在 src/history/hash.js 中:
// ...
import { History } from './base'
import { getLocation } from './html5'
import { cleanPath } from '../util/path'
// 继承 History 基类
export class HashHistory extends History {
constructor (router: VueRouter, base: ?string, fallback: boolean) {
// 调用基类构造器
super(router, base)
// 如果说是从 history 模式降级来的
// 需要做降级检查
if (fallback && this.checkFallback()) {
// 如果降级 且 做了降级处理 则什么也不需要做
return
}
// 保证 hash 是以 / 开头
ensureSlash()
}
checkFallback () {
// 得到除去 base 的真正的 location 值
const location = getLocation(this.base)
if (!/^\/#/.test(location)) {
// 如果说此时的地址不是以 /# 开头的
// 需要做一次降级处理 降级为 hash 模式下应有的 /# 开头
window.location.replace(
cleanPath(this.base + '/#' + location)
)
return true
}
}
// ...
}
// 保证 hash 以 / 开头
function ensureSlash (): boolean {
// 得到 hash 值
const path = getHash()
// 如果说是以 / 开头的 直接返回即可
if (path.charAt(0) === '/') {
return true
}
// 不是的话 需要手工保证一次 替换 hash 值
replaceHash('/' + path)
return false
}
export function getHash (): string {
// 因为兼容性问题 这里没有直接使用 window.location.hash
// 因为 Firefox decode hash 值
const href = window.location.href
const index = href.indexOf('#')
// 如果此时没有 # 则返回 ''
// 否则 取得 # 后的所有内容
return index === -1 ? '' : href.slice(index + 1)
}可以看到在实例化过程中主要做两件事情:针对于不支持 history api 的降级处理,以及保证默认进入的时候对应的 hash 值是以 / 开头的,如果不是则替换。值得注意的是这里并没有监听 hashchange 事件来响应对应的逻辑,这部分逻辑在上篇的 router.init 中包含的,主要是为了解决 vuejs/vue-router#725,在对应的回调中则调用了 onHashChange 方法,后边具体分析。
HTML5History 则是利用 history.pushState/repaceState API 来完成 URL 跳转而无须重新加载页面,页面地址和正常地址无异;源码在 src/history/html5.js 中:
// ...
import { cleanPath } from '../util/path'
import { History } from './base'
// 记录滚动位置工具函数
import {
saveScrollPosition,
getScrollPosition,
isValidPosition,
normalizePosition,
getElementPosition
} from '../util/scroll-position'
// 生成唯一 key 作为位置相关缓存 key
const genKey = () => String(Date.now())
let _key: string = genKey()
export class HTML5History extends History {
constructor (router: VueRouter, base: ?string) {
// 基类构造函数
super(router, base)
// 定义滚动行为 option
const expectScroll = router.options.scrollBehavior
// 监听 popstate 事件 也就是
// 浏览器历史记录发生改变的时候(点击浏览器前进后退 或者调用 history api )
window.addEventListener('popstate', e => {
// ...
})
if (expectScroll) {
// 需要记录滚动行为 监听滚动事件 记录位置
window.addEventListener('scroll', () => {
saveScrollPosition(_key)
})
}
}
// ...
}
// ...可以看到在这种模式下,初始化作的工作相比 hash 模式少了很多,只是调用基类构造函数以及初始化监听事件,不需要再做额外的工作。
理论上来说这种模式是用于 Node.js 环境的,一般场景也就是在做测试的时候。但是在实际项目中其实还可以使用的,利用这种特性还是可以很方便的做很多事情的。由于它和浏览器无关,所以代码上来说也是最简单的,在 src/history/abstract.js 中:
// ...
import { History } from './base'
export class AbstractHistory extends History {
index: number;
stack: Array<Route>;
constructor (router: VueRouter) {
super(router)
// 初始化模拟记录栈
this.stack = []
// 当前活动的栈的位置
this.index = -1
}
// ...
}可以看出在抽象模式下,所做的仅仅是用一个数组当做栈来模拟浏览器历史记录,拿一个变量来标示当前处于哪个位置。
三种模式的初始化的部分已经完成了,但是这只是刚刚开始,继续往后看。
history 改变可以有两种,一种是用户点击链接元素,一种是更新浏览器本身的前进后退导航来更新。
先来说浏览器导航发生变化的时候会触发对应的事件:对于 hash 模式而言触发 window 的 hashchange 事件,对于 history 模式而言则触发 window 的 popstate 事件。
先说 hash 模式,当触发改变的时候会调用 HashHistory 实例的 onHashChange:
onHashChange () {
// 不是 / 开头
if (!ensureSlash()) {
return
}
// 调用 transitionTo
this.transitionTo(getHash(), route => {
// 替换 hash
replaceHash(route.fullPath)
})
}对于 history 模式则是:
window.addEventListener('popstate', e => {
// 取得 state 中保存的 key
_key = e.state && e.state.key
// 保存当前的先
const current = this.current
// 调用 transitionTo
this.transitionTo(getLocation(this.base), next => {
if (expectScroll) {
// 处理滚动
this.handleScroll(next, current, true)
}
})
})上边的 transitionTo 以及 replaceHash、getLocation、handleScroll 后边统一分析。
再看用户点击链接交互,即点击了 <router-link>,回顾下这个组件在渲染的时候做的事情:
// ...
render (h: Function) {
// ...
// 事件绑定
const on = {
click: (e) => {
// 忽略带有功能键的点击
if (e.metaKey || e.ctrlKey || e.shiftKey) return
// 已阻止的返回
if (e.defaultPrevented) return
// 右击
if (e.button !== 0) return
// `target="_blank"` 忽略
const target = e.target.getAttribute('target')
if (/\b_blank\b/i.test(target)) return
// 阻止默认行为 防止跳转
e.preventDefault()
if (this.replace) {
// replace 逻辑
router.replace(to)
} else {
// push 逻辑
router.push(to)
}
}
}
// 创建元素需要附加的数据们
const data: any = {
class: classes
}
if (this.tag === 'a') {
data.on = on
data.attrs = { href }
} else {
// 找到第一个 <a> 给予这个元素事件绑定和href属性
const a = findAnchor(this.$slots.default)
if (a) {
// in case the <a> is a static node
a.isStatic = false
const extend = _Vue.util.extend
const aData = a.data = extend({}, a.data)
aData.on = on
const aAttrs = a.data.attrs = extend({}, a.data.attrs)
aAttrs.href = href
} else {
// 没有 <a> 的话就给当前元素自身绑定时间
data.on = on
}
}
// 创建元素
return h(this.tag, data, this.$slots.default)
}
// ...这里一个关键就是绑定了元素的 click 事件,当用户触发后,会调用 router 的 push 或 replace 方法来更新路由。下边就来看看这两个方法定义,在 src/index.js 中:
push (location: RawLocation) {
this.history.push(location)
}
replace (location: RawLocation) {
this.history.replace(location)
}可以看到其实他们只是代理而已,真正做事情的还是 history 来做,下面就分别把 history 的三种模式下的这两个方法进行分析。
直接看代码:
// ...
push (location: RawLocation) {
// 调用 transitionTo
this.transitionTo(location, route => {
// ...
})
}
replace (location: RawLocation) {
// 调用 transitionTo
this.transitionTo(location, route => {
// ...
})
}
// ...操作是类似的,主要就是调用基类的 transitionTo 方法来过渡这次历史的变化,在完成后更新当前浏览器的 hash 值。上篇中大概分析了 transitionTo 方法,但是一些细节并没细说,这里来看下遗漏的细节:
transitionTo (location: RawLocation, cb?: Function) {
// 调用 match 得到匹配的 route 对象
const route = this.router.match(location, this.current)
// 确认过渡
this.confirmTransition(route, () => {
// 更新当前 route 对象
this.updateRoute(route)
cb && cb(route)
// 子类实现的更新url地址
// 对于 hash 模式的话 就是更新 hash 的值
// 对于 history 模式的话 就是利用 pushstate / replacestate 来更新
// 浏览器地址
this.ensureURL()
})
}
// 确认过渡
confirmTransition (route: Route, cb: Function) {
const current = this.current
// 如果是相同 直接返回
if (isSameRoute(route, current)) {
this.ensureURL()
return
}
const {
deactivated,
activated
} = resolveQueue(this.current.matched, route.matched)
// 整个切换周期的队列
const queue: Array<?NavigationGuard> = [].concat(
// leave 的钩子
extractLeaveGuards(deactivated),
// 全局 router before hooks
this.router.beforeHooks,
// 将要更新的路由的 beforeEnter 钩子
activated.map(m => m.beforeEnter),
// 异步组件
resolveAsyncComponents(activated)
)
this.pending = route
// 每一个队列执行的 iterator 函数
const iterator = (hook: NavigationGuard, next) => {
// ...
}
// 执行队列 leave 和 beforeEnter 相关钩子
runQueue(queue, iterator, () => {
//...
})
}这里有一个很关键的路由对象的 matched 实例,从上次的分析中可以知道它就是匹配到的路由记录的合集;这里从执行顺序上来看有这些 resolveQueue、extractLeaveGuards、resolveAsyncComponents、runQueue 关键方法。
首先来看 resolveQueue:
function resolveQueue (
current: Array<RouteRecord>,
next: Array<RouteRecord>
): {
activated: Array<RouteRecord>,
deactivated: Array<RouteRecord>
} {
let i
// 取得最大深度
const max = Math.max(current.length, next.length)
// 从根开始对比 一旦不一样的话 就可以停止了
for (i = 0; i < max; i++) {
if (current[i] !== next[i]) {
break
}
}
// 舍掉相同的部分 只保留不同的
return {
activated: next.slice(i),
deactivated: current.slice(i)
}
}可以看出 resolveQueue 就是交叉比对当前路由的路由记录和现在的这个路由的路由记录来决定调用哪些路由记录的钩子函数。
继续来看 extractLeaveGuards:
// 取得 leave 的组件的 beforeRouteLeave 钩子函数们
function extractLeaveGuards (matched: Array<RouteRecord>): Array<?Function> {
// 打平组件的 beforeRouteLeave 钩子函数们 按照顺序得到 然后再 reverse
// 因为 leave 的过程是从内层组件到外层组件的过程
return flatten(flatMapComponents(matched, (def, instance) => {
const guard = extractGuard(def, 'beforeRouteLeave')
if (guard) {
return Array.isArray(guard)
? guard.map(guard => wrapLeaveGuard(guard, instance))
: wrapLeaveGuard(guard, instance)
}
}).reverse())
}
// ...
// 将一个二维数组(伪)转换成按顺序转换成一维数组
// [[1], [2, 3], 4] -> [1, 2, 3, 4]
function flatten (arr) {
return Array.prototype.concat.apply([], arr)
}可以看到在执行 extractLeaveGuards 的时候首先需要调用 flatMapComponents 函数,下面来看看这个函数具体定义:
// 将匹配到的组件们根据fn得到的钩子函数们打平
function flatMapComponents (
matched: Array<RouteRecord>,
fn: Function
): Array<?Function> {
// 遍历匹配到的路由记录
return flatten(matched.map(m => {
// 遍历 components 配置的组件们
//// 对于默认视图模式下,会包含 default (也就是实例化路由的时候传入的 component 的值)
//// 如果说多个命名视图的话 就是配置的对应的 components 的值
// 调用 fn 得到 guard 钩子函数的值
// 注意此时传入的值分别是:视图对应的组件类,对应的组件实例,路由记录,当前 key 值 (命名视图 name 值)
return Object.keys(m.components).map(key => fn(
m.components[key],
m.instances[key],
m, key
))
}))
}此时需要仔细看下调用 flatMapComponents 时传入的 fn:
flatMapComponents(matched, (def, instance) => {
// 组件配置的 beforeRouteLeave 钩子
const guard = extractGuard(def, 'beforeRouteLeave')
// 存在的话 返回
if (guard) {
// 每一个钩子函数需要再包裹一次
return Array.isArray(guard)
? guard.map(guard => wrapLeaveGuard(guard, instance))
: wrapLeaveGuard(guard, instance)
}
// 这里没有返回值 默认调用的结果是 undefined
})先来看 extractGuard 的定义:
// 取得指定组件的 key 值
function extractGuard (
def: Object | Function,
key: string
): NavigationGuard | Array<NavigationGuard> {
if (typeof def !== 'function') {
// 对象的话 为了应用上全局的 mixins 这里 extend 下
// 赋值 def 为 Vue “子类”
def = _Vue.extend(def)
}
// 取得 options 上的 key 值
return def.options[key]
}很简答就是取得组件定义时的 key 配置项的值。
再来看看具体的 wrapLeaveGuard 是干啥用的:
function wrapLeaveGuard (
guard: NavigationGuard,
instance: _Vue
): NavigationGuard {
// 返回函数 执行的时候 用于保证上下文 是当前的组件实例 instance
return function routeLeaveGuard () {
return guard.apply(instance, arguments)
}
}其实这个函数还可以这样写:
function wrapLeaveGuard (
guard: NavigationGuard,
instance: _Vue
): NavigationGuard {
return _Vue.util.bind(guard, instance)
}这样整个的 extractLeaveGuards 就分析完了,这部分还是比较绕的,需要好好理解下。但是目的是明确的就是得到将要离开的组件们按照由深到浅的顺序组合的 beforeRouteLeave 钩子函数们。
再来看一个关键的函数 resolveAsyncComponents,一看名字就知道这个是用来解决异步组件问题的:
function resolveAsyncComponents (matched: Array<RouteRecord>): Array<?Function> {
// 依旧调用 flatMapComponents 只是此时传入的 fn 是这样的:
return flatMapComponents(matched, (def, _, match, key) => {
// 这里假定说路由上定义的组件 是函数 但是没有 options
// 就认为他是一个异步组件。
// 这里并没有使用 Vue 默认的异步机制的原因是我们希望在得到真正的异步组件之前
// 整个的路由导航是一直处于挂起状态
if (typeof def === 'function' && !def.options) {
// 返回“异步”钩子函数
return (to, from, next) => {
// ...
}
}
})
}下面继续看,最后一个关键的 runQueue 函数,它的定义在 src/util/async.js 中:
// 执行队列
export function runQueue (queue: Array<?NavigationGuard>, fn: Function, cb: Function) {
// 内部迭代函数
const step = index => {
// 如果说当前的 index 值和整个队列的长度值齐平了 说明队列已经执行完成
if (index >= queue.length) {
// 执行队列执行完成的回调函数
cb()
} else {
if (queue[index]) {
// 如果存在的话 调用传入的迭代函数执行
fn(queue[index], () => {
// 第二个参数是一个函数 当调用的时候才继续处理队列的下一个位置
step(index + 1)
})
} else {
// 当前队列位置的值为假 继续队列下一个位置
step(index + 1)
}
}
}
// 从队列起始位置开始迭代
step(0)
}可以看出就是一个执行一个函数队列中的每一项,但是考虑了异步场景,只有上一个队列中的项显式调用回调的时候才会继续调用队列的下一个函数。
在切换路由过程中调用的逻辑是这样的:
// 每一个队列执行的 iterator 函数
const iterator = (hook: NavigationGuard, next) => {
// 确保期间还是当前路由
if (this.pending !== route) return
// 调用钩子
hook(route, current, (to: any) => {
// 如果说钩子函数在调用第三个参数(函数)` 时传入了 false
// 则意味着要终止本次的路由切换
if (to === false) {
// next(false) -> abort navigation, ensure current URL
// 重新保证当前 url 是正确的
this.ensureURL(true)
} else if (typeof to === 'string' || typeof to === 'object') {
// next('/') or next({ path: '/' }) -> redirect
// 如果传入的是字符串 或者对象的话 认为是一个重定向操作
// 直接调用 push 走你
this.push(to)
} else {
// confirm transition and pass on the value
// 其他情况 意味着此次路由切换没有问题 继续队列下一个
// 且把值传入了
// 传入的这个值 在此时的 leave 的情况下是没用的
// 注意:这是为了后边 enter 的时候在处理 beforeRouteEnter 钩子的时候
// 可以传入一个函数 用于获得组件实例
next(to)
}
})
}
// 执行队列 leave 和 beforeEnter 相关钩子
runQueue(queue, iterator, () => {
// ...
})而 queue 是上边定义的一个切换周期的各种钩子函数以及处理异步组件的“异步”钩子函数所组成队列,在执行完后就会调用队列执行完成后毁掉函数,下面来看这个函数做的事情:
runQueue(queue, iterator, () => {
// enter 后的回调函数们 用于组件实例化后需要执行的一些回调
const postEnterCbs = []
// leave 完了后 就要进入 enter 阶段了
const enterGuards = extractEnterGuards(activated, postEnterCbs, () => {
return this.current === route
})
// enter 的回调钩子们依旧有可能是异步的 不仅仅是异步组件场景
runQueue(enterGuards, iterator, () => {
// ...
})
})仔细看看这个 extractEnterGuards,从调用参数上来看还是和之前的 extractLeaveGuards 是不同的:
function extractEnterGuards (
matched: Array<RouteRecord>,
cbs: Array<Function>,
isValid: () => boolean
): Array<?Function> {
// 依旧是调用 flatMapComponents
return flatten(flatMapComponents(matched, (def, _, match, key) => {
// 调用 extractGuard 得到组件上的 beforeRouteEnter 钩子
const guard = extractGuard(def, 'beforeRouteEnter')
if (guard) {
// 特殊处理 依旧进行包装
return Array.isArray(guard)
? guard.map(guard => wrapEnterGuard(guard, cbs, match, key, isValid))
: wrapEnterGuard(guard, cbs, match, key, isValid)
}
}))
}
function wrapEnterGuard (
guard: NavigationGuard,
cbs: Array<Function>,
match: RouteRecord,
key: string,
isValid: () => boolean
): NavigationGuard {
// 代理 路由 enter 的钩子函数
return function routeEnterGuard (to, from, next) {
// ...
}
}可以看出此时整体的思路还是和 extractLeaveGuards 的差不多的,只是多了 cbs 回调数组 和 isValid 校验函数,截止到现在还不知道他们的具体作用,继续往下看此时调用的 runQueue:
// enter 的钩子们
runQueue(enterGuards, iterator, () => {
// ...
})可以看到此时执行 enterGuards 队列的迭代函数依旧是上边定义的 iterator,在迭代过程中就会调用 wrapEnterGuard 返回的 routeEnterGuard 函数:
function wrapEnterGuard (
guard: NavigationGuard,
cbs: Array<Function>,
match: RouteRecord,
key: string,
isValid: () => boolean
): NavigationGuard {
// 代理 路由 enter 的钩子函数
return function routeEnterGuard (to, from, next) {
// 调用用户设置的钩子函数
return guard(to, from, cb => {
// 此时如果说调用第三个参数的时候传入了回调函数
// 认为是在组件 enter 后有了组件实例对象之后执行的回调函数
// 依旧把参数传递过去 因为有可能传入的是
// false 或者 字符串 或者 对象
// 继续走原有逻辑
next(cb)
if (typeof cb === 'function') {
// 加入到 cbs 数组中
// 只是这里没有直接 push 进去 而是做了额外处理
cbs.push(() => {
// 主要是为了修复 #750 的bug
// 如果说 router-view 被一个 out-in transition 过渡包含的话
// 此时的实例不一定是注册了的(因为需要做完动画) 所以需要轮训判断
// 直至 current route 的值不再有效
poll(cb, match.instances, key, isValid)
})
}
})
}
}这个 poll 又是做什么事情呢?
function poll (
cb: any, // somehow flow cannot infer this is a function
instances: Object,
key: string,
isValid: () => boolean
) {
// 如果实例上有 key
// 也就意味着有 key 为名的命名视图实例了
if (instances[key]) {
// 执行回调
cb(instances[key])
} else if (isValid()) {
// 轮训的前提是当前 cuurent route 是有效的
setTimeout(() => {
poll(cb, instances, key, isValid)
}, 16)
}
}isValid 的定义就是很简单了,通过在调用 extractEnterGuards 的时候传入的:
const enterGuards = extractEnterGuards(activated, postEnterCbs, () => {
// 判断当前 route 是和 enter 的 route 是同一个
return this.current === route
})回到执行 enter 进入时的钩子函数队列的地方,在执行完所有队列中函数后会调用传入 runQueue 的回调:
runQueue(enterGuards, iterator, () => {
// 确保当前的 pending 中的路由是和要激活的是同一个路由对象
// 以防在执行钩子过程中又一次的切换路由
if (this.pending === route) {
this.pending = null
// 执行传入 confirmTransition 的回调
cb(route)
// 在 nextTick 时执行 postEnterCbs 中保存的回调
this.router.app.$nextTick(() => {
postEnterCbs.forEach(cb => cb())
})
}
})
通过上篇分析可以知道 confirmTransition 的回调做的事情:
this.confirmTransition(route, () => {
// 更新当前 route 对象
this.updateRoute(route)
// 执行回调 也就是 transitionTo 传入的回调
cb && cb(route)
// 子类实现的更新url地址
// 对于 hash 模式的话 就是更新 hash 的值
// 对于 history 模式的话 就是利用 pushstate / replacestate 来更新
// 浏览器地址
this.ensureURL()
})针对于 HashHistory 来说,调用 transitionTo 的回调就是:
// ...
push (location: RawLocation) {
// 调用 transitionTo
this.transitionTo(location, route => {
// 完成后 pushHash
pushHash(route.fullPath)
})
}
replace (location: RawLocation) {
// 调用 transitionTo
this.transitionTo(location, route => {
// 完成后 replaceHash
replaceHash(route.fullPath)
})
}
// ...
function pushHash (path) {
window.location.hash = path
}
function replaceHash (path) {
const i = window.location.href.indexOf('#')
// 直接调用 replace 强制替换 以避免产生“多余”的历史记录
// 主要是用户初次跳入 且hash值不是以 / 开头的时候直接替换
// 其余时候和push没啥区别 浏览器总是记录hash记录
window.location.replace(
window.location.href.slice(0, i >= 0 ? i : 0) + '#' + path
)
}其实就是更新浏览器的 hash 值,push 和 replace 的场景下都是一个效果。
回到 confirmTransition 的回调,最后还做了一件事情 ensureURL:
ensureURL (push?: boolean) {
const current = this.current.fullPath
if (getHash() !== current) {
push ? pushHash(current) : replaceHash(current)
}
}此时 push 为 undefined,所以调用 replaceHash 更新浏览器 hash 值。
整个的流程和 HashHistory 是类似的,不同的只是一些具体的逻辑处理以及特性,所以这里呢就直接来看整个的 HTML5History:
export class HTML5History extends History {
// ...
go (n: number) {
window.history.go(n)
}
push (location: RawLocation) {
const current = this.current
// 依旧调用基类 transitionTo
this.transitionTo(location, route => {
// 调用 pushState 但是 url 是 base 值加上当前 fullPath
// 因为 fullPath 是不带 base 部分得
pushState(cleanPath(this.base + route.fullPath))
// 处理滚动
this.handleScroll(route, current, false)
})
}
replace (location: RawLocation) {
const current = this.current
// 依旧调用基类 transitionTo
this.transitionTo(location, route => {
// 调用 replaceState
replaceState(cleanPath(this.base + route.fullPath))
// 滚动
this.handleScroll(route, current, false)
})
}
// 保证 location 地址是同步的
ensureURL (push?: boolean) {
if (getLocation(this.base) !== this.current.fullPath) {
const current = cleanPath(this.base + this.current.fullPath)
push ? pushState(current) : replaceState(current)
}
}
// 处理滚动
handleScroll (to: Route, from: Route, isPop: boolean) {
const router = this.router
if (!router.app) {
return
}
// 自定义滚动行为
const behavior = router.options.scrollBehavior
if (!behavior) {
// 不存在直接返回了
return
}
assert(typeof behavior === 'function', `scrollBehavior must be a function`)
// 等待下重新渲染逻辑
router.app.$nextTick(() => {
// 得到key对应位置
let position = getScrollPosition(_key)
// 根据自定义滚动行为函数来判断是否应该滚动
const shouldScroll = behavior(to, from, isPop ? position : null)
if (!shouldScroll) {
return
}
// 应该滚动
const isObject = typeof shouldScroll === 'object'
if (isObject && typeof shouldScroll.selector === 'string') {
// 带有 selector 得到该元素
const el = document.querySelector(shouldScroll.selector)
if (el) {
// 得到该元素位置
position = getElementPosition(el)
} else if (isValidPosition(shouldScroll)) {
// 元素不存在 降级下
position = normalizePosition(shouldScroll)
}
} else if (isObject && isValidPosition(shouldScroll)) {
// 对象 且是合法位置 统一格式
position = normalizePosition(shouldScroll)
}
if (position) {
// 滚动到指定位置
window.scrollTo(position.x, position.y)
}
})
}
}
// 得到 不带 base 值的 location
export function getLocation (base: string): string {
let path = window.location.pathname
if (base && path.indexOf(base) === 0) {
path = path.slice(base.length)
}
// 是包含 search 和 hash 的
return (path || '/') + window.location.search + window.location.hash
}
function pushState (url: string, replace?: boolean) {
// 加了 try...catch 是因为 Safari 有调用 pushState 100 次限制
// 一旦达到就会抛出 DOM Exception 18 错误
const history = window.history
try {
// 如果是 replace 则调用 history 的 replaceState 操作
// 否则则调用 pushState
if (replace) {
// replace 的话 key 还是当前的 key 没必要生成新的
// 因为被替换的页面是进入不了的
history.replaceState({ key: _key }, '', url)
} else {
// 重新生成 key
_key = genKey()
// 带入新的 key 值
history.pushState({ key: _key }, '', url)
}
// 保存 key 对应的位置
saveScrollPosition(_key)
} catch (e) {
// 达到限制了 则重新指定新的地址
window.location[replace ? 'assign' : 'replace'](url)
}
}
// 直接调用 pushState 传入 replace 为 true
function replaceState (url: string) {
pushState(url, true)
}这样可以看出和 HashHistory 中不同的是这里增加了滚动位置特性以及当历史发生变化时改变浏览器地址的行为是不一样的,这里使用了新的 history api 来更新。
抽象模式是属于最简单的处理了,因为不涉及和浏览器地址相关记录关联在一起;整体流程依旧和 HashHistory 是一样的,只是这里通过数组来模拟浏览器历史记录堆栈信息。
// ...
import { History } from './base'
export class AbstractHistory extends History {
index: number;
stack: Array<Route>;
// ...
push (location: RawLocation) {
this.transitionTo(location, route => {
// 更新历史堆栈信息
this.stack = this.stack.slice(0, this.index + 1).concat(route)
// 更新当前所处位置
this.index++
})
}
replace (location: RawLocation) {
this.transitionTo(location, route => {
// 更新历史堆栈信息 位置则不用更新 因为是 replace 操作
// 在堆栈中也是直接 replace 掉的
this.stack = this.stack.slice(0, this.index).concat(route)
})
}
// 对于 go 的模拟
go (n: number) {
// 新的历史记录位置
const targetIndex = this.index + n
// 超出返回了
if (targetIndex < 0 || targetIndex >= this.stack.length) {
return
}
// 取得新的 route 对象
// 因为是和浏览器无关的 这里得到的一定是已经访问过的
const route = this.stack[targetIndex]
// 所以这里直接调用 confirmTransition 了
// 而不是调用 transitionTo 还要走一遍 match 逻辑
this.confirmTransition(route, () => {
// 更新
this.index = targetIndex
this.updateRoute(route)
})
}
ensureURL () {
// noop
}
}整个的和 history 相关的代码到这里已经分析完毕了,虽然有三种模式,但是整体执行过程还是一样的,唯一差异的就是在处理location更新时的具体逻辑不同。
欢迎拍砖。
作者:肖磊
[email protected] 是一个全新的 Vue 项目脚手架。不同于 1.x/2.x 基于模板的脚手架,[email protected] 采用了一套基于插件的架构,它将部分核心功能收敛至 CLI 内部,同时对开发者暴露可拓展的 API 以供开发者对 CLI 的功能进行灵活的拓展和配置。接下来我们就通过 [email protected] 的源码来看下这套插件架构是如何设计的。
整个插件系统当中包含2个重要的组成部分:
vue create创建一个新的项目;当你使用 vue create <project-name>创建一个新的 Vue 项目,你会发现生成的项目相较于 1.x/2.x 初始化一个项目时从远程拉取的模板发生了很大的变化,其中关于 webpack 相关的配置以及 npm script 都没有在模板里面直接暴露出来,而是提供了新的 npm script:
// package.json
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint"
}前 2 个脚本命令是项目本地安装的 @vue/cli-service 所提供的基于 webpack 及相关的插件进行封装的本地开发/构建的服务。@vue/cli-service 将 webpack 及相关插件提供的功能都收敛到 @vue/cli-service 内部来实现。
这 2 个命令对应于 node_modules/@vue/cli-service/lib/commands 下的 serve.js 和 build/index.js。
在 serve.js 和 build/index.js 的内部分别暴露了一个函数及一个 defaultModes 属性供外部来使用。事实上这两者都是作为 built-in(内置)插件来供 vue-cli-service 来使用的。
说到这里那么就来看看 @vue/cli-service 内部是如何搭建整个插件系统的。就拿执行npm run serve启动本地开发服务来说,大概流程是这样的:
首先来看下 @vue/cli-service 提供的 cli 启动入口服务(@vue/cli-service/bin/vue-cli-service.js):
#!/usr/bin/env node
const semver = require('semver')
const { error } = require('@vue/cli-shared-utils')
const Service = require('../lib/Service') // 引入 Service 基类
const service = new Service(process.env.VUE_CLI_CONTEXT || process.cwd()) // 实例化 service
const rawArgv = process.argv.slice(2)
const args = require('minimist')(rawArgv)
const command = args._[0]
service.run(command, args, rawArgv).catch(err => { // 开始执行对应的 service 服务
error(err)
process.exit(1)
})看到这里你会发现在 bin 里面并未提供和本地开发 serve 相关的服务,事实上在项目当中本地安装的 @vue/cli-service 提供的不管是内置的还是插件提供的服务都是动态的去完成相关 CLI 服务的注册。
在 lib/Service.js 内部定义了一个核心的类 Service,它作为 @vue/cli 的运行时的服务而存在。在执行npm run serve后,首先完成 Service 的实例化工作:
class Service {
constructor(context) {
...
this.webpackChainFns = [] // 数组内部每项为一个fn
this.webpackRawConfigFns = [] // 数组内部每项为一个 fn 或 webpack 对象字面量配置项
this.devServerConfigFns = []
this.commands = {} // 缓存动态注册 CLI 命令
...
this.plugins = this.resolvePlugins(plugins, useBuiltIn) // 完成插件的加载
this.modes = this.plugins.reduce((modes, { apply: { defaultModes }}) => { // 缓存不同 CLI 命令执行时所对应的mode值
return Object.assign(modes, defaultModes)
}, {})
}
}在实例化 Service 的过程当中完成了两个比较重要的工作:
当 Service 实例化完成后,调用实例上的 run 方法来启动对应的 CLI 命令所提供的服务。
async run (name, args = {}, rawArgv = []) {
const mode = args.mode || (name === 'build' && args.watch ? 'development' : this.modes[name])
// load env variables, load user config, apply plugins
// 执行所有被加载进来的插件
this.init(mode)
...
const { fn } = command
return fn(args, rawArgv) // 开始执行对应的 cli 命令服务
}
init (mode = process.env.VUE_CLI_MODE) {
...
// 执行plugins
// apply plugins.
this.plugins.forEach(({ id, apply }) => {
// 传入一个实例化的PluginAPI实例,插件名作为插件的id标识,在插件内部完成注册 cli 命令服务和 webpack 配置的更新的工作
apply(new PluginAPI(id, this), this.projectOptions)
})
...
// apply webpack configs from project config file
if (this.projectOptions.chainWebpack) {
this.webpackChainFns.push(this.projectOptions.chainWebpack)
}
if (this.projectOptions.configureWebpack) {
this.webpackRawConfigFns.push(this.projectOptions.configureWebpack)
}
}接下来我们先看下 @vue/cli-service 当中的 Service 实例化的过程:通过 resolvePlugins 方法去完成插件的加载工作:
resolvePlugins(inlinePlugins, useBuiltIn) {
const idToPlugin = id => ({
id: id.replace(/^.\//, 'built-in:'),
apply: require(id) // 加载对应的插件
})
let plugins
// @vue/cli-service内部提供的插件
const builtInPlugins = [
'./commands/serve',
'./commands/build',
'./commands/inspect',
'./commands/help',
// config plugins are order sensitive
'./config/base',
'./config/css',
'./config/dev',
'./config/prod',
'./config/app'
].map(idToPlugin)
if (inlinePlugins) {
plugins = useBuiltIn !== false
? builtInPlugins.concat(inlinePlugins)
: inlinePlugins
} else {
// 加载项目当中使用的插件
const projectPlugins = Object.keys(this.pkg.devDependencies || {})
.concat(Object.keys(this.pkg.dependencies || {}))
.filter(isPlugin)
.map(idToPlugin)
plugins = builtInPlugins.concat(projectPlugins)
}
// Local plugins
if (this.pkg.vuePlugins && this.pkg.vuePlugins.service) {
const files = this.pkg.vuePlugins.service
if (!Array.isArray(files)) {
throw new Error(`Invalid type for option 'vuePlugins.service', expected 'array' but got ${typeof files}.`)
}
plugins = plugins.concat(files.map(file => ({
id: `local:${file}`,
apply: loadModule(file, this.pkgContext)
})))
}
return plugins
}在这个 resolvePlugins 方法当中,主要完成了对于 @vue/cli-service 内部提供的插件以及项目应用(package.json)当中需要使用的插件的加载,并将对应的插件进行缓存。在其提供的内部插件当中又分为两类:
'./commands/serve'
'./commands/build'
'./commands/inspect'
'./commands/help'这一类插件在内部动态注册新的 CLI 命令,开发者即可通过 npm script 的形式去启动对应的 CLI 命令服务。
'./config/base'
'./config/css'
'./config/dev'
'./config/prod'
'./config/app'这一类插件主要是完成 webpack 本地编译构建时的各种相关的配置。@vue/cli-service 将 webpack 的开发构建功能收敛到内部来完成。
插件加载完成,开始调用 service.run 方法,在这个方法内部开始执行所有被加载的插件:
this.plugins.forEach(({ id, apply }) => {
apply(new PluginAPI(id, this), this.projectOptions)
})在每个插件执行的过程中,接收到的第一个参数都是 PluginAPI 的实例,PluginAPI 也是整个 @vue/cli-service 服务当中一个核心的基类:
class PluginAPI {
constructor (id, service) {
this.id = id // 对应这个插件名
this.service = service // 对应 Service 类的实例(单例)
}
...
registerCommand (name, opts, fn) { // 注册自定义 cli 命令
if (typeof opts === 'function') {
fn = opts
opts = null
}
this.service.commands[name] = { fn, opts: opts || {}}
}
chainWebpack (fn) { // 缓存变更的 webpack 配置
this.service.webpackChainFns.push(fn)
}
configureWebpack (fn) { // 缓存变更的 webpack 配置
this.service.webpackRawConfigFns.push(fn)
}
...
}每个由 PluginAPI 实例化的 api 实例都提供了:
api.registerCommand)api.chainWebpack)api.configureWebpack),与api.chainWebpack提供的链式 api 操作 webpack 配置的方式不同,api.configureWebpack可接受raw式的配置形式,并通过 webpack-merge 对 webpack 配置进行合并。api.resolveWebpackConfig),调用之前通过 chainWebpack 和 configureWebpack 上完成的对于 webpack 配置的改造,并生成最终的 webpack 配置首先我们来看下 @vue/cli-service 提供的关于动态注册 CLI 服务的插件,拿 serve 服务(./commands/serve)来说:
// commands/serve
module.exports = (api, options) => {
api.registerCommand(
'serve',
{
description: 'start development server',
usage: 'vue-cli-service serve [options] [entry]',
options: {
'--open': `open browser on server start`,
'--copy': `copy url to clipboard on server start`,
'--mode': `specify env mode (default: development)`,
'--host': `specify host (default: ${defaults.host})`,
'--port': `specify port (default: ${defaults.port})`,
'--https': `use https (default: ${defaults.https})`,
'--public': `specify the public network URL for the HMR client`
}
},
async function serve(args) {
// do something
}
)
}./commands/serve 对外暴露一个函数,接收到的第一个参数 PluginAPI 的实例 api,并通过 api 提供的 registerCommand 方法来完成 CLI 命令(即 serve 服务)的注册。
再来看下 @vue/cli-service 内部提供的关于 webpack 配置的插件(./config/base):
module.exports = (api, options) => {
api.chainWebpack(webpackConfig => {
webpackConfig.module
.rule('vue')
.test(/\.vue$/)
.use('cache-loader')
.loader('cache-loader')
.options(vueLoaderCacheConfig)
.end()
.use('vue-loader')
.loader('vue-loader')
.options(
Object.assign(
{
compilerOptions: {
preserveWhitespace: false
}
},
vueLoaderCacheConfig
)
)
})
}这个插件完成了 webpack 的基本配置内容,例如 entry、output、加载不同文件类型的 loader 的配置。不同于之前使用的配置式的 webpack 使用方式,@vue/cli-service 默认使用 webpack-chain(链接请戳我) 来完成 webpack 配置的修改。这种方式也使得 webpack 的配置更加灵活,当你的项目迁移至 @vue/[email protected],使用的 webpack 插件也必须要使用 API 式的配置,同时插件不仅仅要提供插件自身的功能,同时也需要帮助调用方完成插件的注册等工作。
@vue/cli-service 将基于 webpack 的本地开发构建配置收敛至内部来实现,当你没有特殊的开发构建需求的时候,内部配置可以开箱即用,不用开发者去关心一些细节。当然在实际团队开发当中,内部配置肯定是无法满足的,得益于 @vue-cli@3.0 的插件构建设计,开发者不需要将内部的配置进行 Eject,而是直接使用 @vue/cli-service 暴露出来的 API 去完成对于特殊的开发构建需求。
以上介绍了 @vue/cli-service 插件系统当中几个核心的模块,即:
Service.js 提供服务的基类,它提供了 @vue/cli 生态当中本地开发构建时:插件加载(包括内部插件和项目应用插件)、插件的初始化,它的单例被所有的插件所共享,插件使用它的单例去完成 webpack 的更新。
PluginAPI.js 提供供插件使用的对象接口,它和插件是一一对应的关系。所有供 @vue/cli-service 使用的本地开发构建的插件接收的第一个参数都是 PluginAPI 的实例(api),插件使用这个实例去完成 CLI 命令的注册及对应服务的执行、webpack 配置的更新等。
以上就是 @vue/cli-service 插件系统简单的分析,感兴趣的同学可以深入阅读相关源码(链接请戳我)进行学习。
不同于之前 1.x/2.x 的 vue-cli 工具都是基于远程模板去完成项目的初始化的工作,它属于那种大而全的方式,当你需要完成自定义的脚手架工具时,你可能要对 vue-cli 进行源码级别的改造,或者是在远程模板里面帮开发者将所有的配置文件初始化完成好。而 @vue/[email protected] 主要是基于插件的 generator 去完成项目的初始化的工作,它将原来的大而全的模板拆解为现在基于插件系统的工作方式,每个插件完成自己所要对于项目应用的模板拓展工作。
@vue/cli 提供了终端里面的 vue 命令,例如:
vue create <project> 创建一个新的 vue 项目vue ui 打开 vue-cli 的可视化配置当你需要对 vue-cli 进行改造,自定义符合自己开发要求的脚手架的时候,那么你需要通过开发 vue-cli 插件来对 vue-cli 提供的服务进行拓展来满足相关的要求。vue-cli 插件始终包含一个 Service 插件作为其主要导出,且可选的包含一个 Generator 和一个 Prompt 文件。这里不细讲如何去开发一个 vue-cli 插件了,大家感兴趣的可以阅读vue-cli-plugin-eslint
这里主要是来看下 vue-cli 是如何设计整个插件系统以及整个插件系统是如何工作的。
@vue/[email protected] 提供的插件安装方式为一个 cli 服务:vue add <plugin>:
install a plugin and invoke its generator in an already created project
执行这条命令后,@vue/cli 会帮你完成插件的下载,安装以及执行插件所提供的 generator。整个流程的执行顺序可通过如下的流程图去概括:
我们来看下具体的代码逻辑:
// @vue/cli/lib/add.js
async function add (pluginName, options = {}, context = process.cwd()) {
...
const packageManager = loadOptions().packageManager || (hasProjectYarn(context) ? 'yarn' : 'npm')
// 开始安装这个插件
await installPackage(context, packageManager, null, packageName)
log(`${chalk.green('✔')} Successfully installed plugin: ${chalk.cyan(packageName)}`)
log()
// 判断插件是否提供了 generator
const generatorPath = resolveModule(`${packageName}/generator`, context)
if (generatorPath) {
invoke(pluginName, options, context)
} else {
log(`Plugin ${packageName} does not have a generator to invoke`)
}
}首先 cli 内部会安装这个插件,并判断这个插件是否提供了 generator,若提供了那么去执行对应的 generator。
// @vue/cli/lib/invoke.js
async function invoke (pluginName, options = {}, context = process.cwd()) {
const pkg = getPkg(context)
...
// 从项目应用package.json中获取插件名
const id = findPlugin(pkg.devDependencies) || findPlugin(pkg.dependencies)
...
// 加载对应插件提供的generator方法
const pluginGenerator = loadModule(`${id}/generator`, context)
...
const plugin = {
id,
apply: pluginGenerator,
options
}
// 开始执行generator方法
await runGenerator(context, plugin, pkg)
}
async function runGenerator (context, plugin, pkg = getPkg(context)) {
...
// 实例化一个Generator实例
const generator = new Generator(context, {
pkg
plugins: [plugin], // 插件提供的generator方法
files: await readFiles(context), // 将项目当中的文件读取为字符串的形式保存到内存当中,被读取的文件规则具体见readFiles方法
completeCbs: createCompleteCbs,
invoking: true
})
...
// resolveFiles 将内存当中的所有缓存的 files 输出到文件当中
await generator.generate({
extractConfigFiles: true,
checkExisting: true
})
}和 @vue/cli-service 类似,在 @vue/cli 内部也有一个核心的类Generator,每个@vue/cli的插件对应一个Generator的实例。在实例化Generator方法的过程当中,完成插件提供的 generator 的执行。
// @vue/cli/lib/Generator.js
module.exports = class Generator {
constructor (context, {
pkg = {},
plugins = [],
completeCbs = [],
files = {},
invoking = false
} = {}) {
this.context = context
this.plugins = plugins
this.originalPkg = pkg
this.pkg = Object.assign({}, pkg)
this.imports = {}
this.rootOptions = {}
...
this.invoking = invoking
// for conflict resolution
this.depSources = {}
// virtual file tree
this.files = files
this.fileMiddlewares = []
this.postProcessFilesCbs = []
...
const cliService = plugins.find(p => p.id === '@vue/cli-service')
const rootOptions = cliService
? cliService.options
: inferRootOptions(pkg)
// apply generators from plugins
// 每个插件对应生成一个 GeneratorAPI 实例,并将实例 api 传入插件暴露出来的 generator 函数
plugins.forEach(({ id, apply, options }) => {
const api = new GeneratorAPI(id, this, options, rootOptions)
apply(api, options, rootOptions, invoking)
})
}
}和 @vue/cli-service 所使用的插件类似,@vue/cli 插件所提供的 generator 也是向外暴露一个函数,接收的第一个参数 api,然后通过该 api 提供的方法去完成应用的拓展工作。
开发者利用这个 api 实例去完成项目应用的拓展工作,这个 api 实例提供了:
api.extendPackage)api.render)api.onCreateComplete)import语法的方法(api.injectImports)例如 @vue/cli-plugin-eslint 插件的 generator 方法主要是完成了:vue-cli-service cli lint 服务命令的添加、相关 lint 标准库的依赖添加等工作:
module.exports = (api, { config, lintOn = [] }, _, invoking) => {
if (typeof lintOn === 'string') {
lintOn = lintOn.split(',')
}
const eslintConfig = require('./eslintOptions').config(api)
const pkg = {
scripts: {
lint: 'vue-cli-service lint'
},
eslintConfig,
devDependencies: {}
}
if (config === 'airbnb') {
eslintConfig.extends.push('@vue/airbnb')
Object.assign(pkg.devDependencies, {
'@vue/eslint-config-airbnb': '^3.0.0-rc.10'
})
} else if (config === 'standard') {
eslintConfig.extends.push('@vue/standard')
Object.assign(pkg.devDependencies, {
'@vue/eslint-config-standard': '^3.0.0-rc.10'
})
} else if (config === 'prettier') {
eslintConfig.extends.push('@vue/prettier')
Object.assign(pkg.devDependencies, {
'@vue/eslint-config-prettier': '^3.0.0-rc.10'
})
} else {
// default
eslintConfig.extends.push('eslint:recommended')
}
...
api.extendPackage(pkg)
...
// lint & fix after create to ensure files adhere to chosen config
if (config && config !== 'base') {
api.onCreateComplete(() => {
require('./lint')({ silent: true }, api)
})
}
}以上介绍了 @vue/cli 和插件系统相关的几个核心的模块,即:
add.js 提供了插件下载的 cli 命令服务和安装的功能;
invoke.js 完成插件所提供的 generator 方法的加载和执行,同时将项目当中的文件转化为字符串缓存到内存当中;
Generator.js 和插件进行桥接,@vue/cli 每次 add 一个插件时,都会实例化一个 Generator 实例与之对应;
GeneratorAPI.js 和插件一一对应,是 @vue/cli 暴露给插件的 api 对象,提供了很多项目应用的拓展工作。
以上是对 [email protected] 的插件系统当中两个主要部分:@vue/cli 和 @vue/cli-service 简析。
vue create <projectName>、vue add <pluginName>前者主要完成了对于插件的依赖管理,项目模板的拓展等,后者主要是提供了在运行时本地开发构建的服务,同时后者也作为 @vue/cli 整个插件系统当中的内部核心插件而存在。在插件系统内部也对核心功能进行了插件化的拆解,例如 @vue/cli-service 内置的基础 webpack 配置,npm script 命令等。二者使用约定式的方式向开发者提供插件的拓展能力,具体到如何开发 @vue/cli 的插件,请参考官方文档。
滴滴的 webapp 是运行在微信、支付宝、手 Q 以及其它第三方渠道的打车软件。借着产品层面的功能和视觉升级,我们用 Vue 2.0 对它进行了一次技术重构。
MVVM框架: Vue 2.0
源码:es6
代码风格检查:eslint
构建工具:webpack
前端路由:vue-router
状态管理:vuex
服务端通讯:vue-resource
滴滴 webapp 是一个大的 SPA 应用么?
滴滴 webapp 包含众多业务线,每个业务线都有独立的一套的发单流程逻辑。那么问题来了,这些业务逻辑都是在一个单页中完成的么?
如何实现组件化?
滴滴 webapp 5.0 的设计思路就是组件化,设计提供了很多组件,每个页面都是由组件拼接而成。那么问题来了,如何区分基础组件和业务组件,并把基础组件抽象成一个公共组件库?
一个代码仓库多条业务线,如何很好的做到多人同时开发和持续集成?
滴滴有多条业务线,每条业务线会有一位前端同学开发代码。那么问题来了,如何模块化的组织代码,如何尽可能的减少开发的冲突以及做好持续集成?
有部分业务线需要异步加载,这部分业务线如何开发?
滴滴目前会把类专车业务线的代码放在一个仓库里,但是部分业务线,如顺风车的代码是不在这个仓库里的。那么问题来了,这部分代码如何开发,如何使用 Vue,Vuex,store,以及一些公用方法和组件?
异步加载的业务线组件,如何动态注册?
我们需要异步加载业务线的 JS 代码,这些业务线实现的是一个 Vue component。那么问题来了,如何优雅地动态注册这些组件呢?
异步加载的业务线如何动态注册路由?
我们在使用 Vue-router 初始化路由的时候,通常都会写一个路由映射表。那么问题来了,这些异步加载的业务线,如果也想使用路由,那么如何动态注册呢?
如何在测试环境下与后端接口交互?
我们在开发阶段,通常都是在本地调试,本地起的服务域名通常是 localhost:端口号。那么问题来了,这样会和 ajax 请求产生跨域问题,而我们也不能要求服务端把所有 ajax 请求接口都开跨域,如何解决呢?
如何部署到线下测试环境?
我们在本地开发完代码后,需要把代码提测。通常测试拿到代码后,需要部署和测试,那么问题来了,我们如何把本地代码部署到我们的开发机测试环境中呢?
滴滴 webapp 是一个大的 SPA 应用么?
滴滴 webapp 包含众多业务线,每个业务线都有独立的一套的发单 -> 接驾 -> 行程中 -> 订单完成的流程逻辑。试想一下,如果整体是一个 SPA 应用,最终打包的 JS 会变的很大,虽然可以通过 code spliting 技术异步加载,但也不可避免会增加代码量,而且非常不利于维护。
因此,我们把发单和后续的业务逻辑拆开,拆成发单首页和后续流程页面,每个业务线都有自己独立的发单后的流程页面。这样滴滴的 webapp 相当于多个 SPA 应用构成,页面间跳转的数据传递通过 url 传参即可。
如何实现组件化?
组件化现在几乎成为 webapp 开发的标准,滴滴从设计角度就已经是组件化的思路了。但是设计只会把页面拆成一个个组件,我们作为开发者,需要从这些众多组件中提取出哪些是基础组件,哪些是业务组件,哪些组件可被复用等等。
基础组件主要指那些本身不包含任何业务逻辑、可以被轻松复用的组件,例如 picker、timepicker、toast、dialog、actionsheet 等等...我们基于 Vue 2.0 实现了一套移动端的基础组件库,打包了所有基础组件,并托管在 npm 私服上,使用非常方便。基础组件的通讯基本就是往组件传入 prop,并监听组件 $emit 的事件。
业务组件主要指那些包含业务逻辑,包括一些与后端接口通讯的逻辑。业务组件会包含若干个基础组件,通常我们会把一些业务逻辑的数据通过 Vuex 管理起来,然后组件内部读取数据和提交对数据修改的动作。这里需要说明一点,当我们使用 Vuex 的时候,并不是所有和后端通讯的请求都需要提交一个 action,如果这个请求并不会修改我们 store 里的数据,可以在组件内部消化。举个实际的例子,我们在开发 suggest 组件的时候,每次输入字符检索相关的地址的时候,这个请求由组件内部发起,并且把请求的数据渲染到组件的列表即可,因为它并没有修改 store 里的数据。
基础组件通常都是可复用的,部分业务组件同样可复用,它们的 UI 和业务逻辑相似。我们会把单个可复用的业务组件单独发布到 npm 私服上,需要使用的业务线依赖即可。注意,业务组件我们是不建议使用 Vuex,需要考虑到不同的使用方对 Vuex 内部变量的定义和使用是不相同的。
一个代码仓库多条业务线,如何很好的做到多人同时开发和持续集成?
滴滴的 webapp 首页有多条业务线,每条业务线都有一个开发人员,为了保证尽量减少代码的冲突,我们按业务线对代码进行了模块划分。由于 Vuex 支持modules,我们很自然地按业务线拆分了 modules,每个 modules 维护自己的 getters、actions、mutaions 和 state,而一些公共数据如经纬度、上下车信息、用户登录状态等作为 root state,被所有业务线共享。同样,components 里也按业务线做了更细致的划分,每个业务线独立的业务组件放在各自的目录里,彼此之前不会有冲突。
仅仅做到目录拆分还是不够的,我们还要考虑到持续集成,跟着产品的版本迭代节奏发布上线。那么每个版本的需求,每个业务线都会参与开发,我们用 gitlab 管理代码,如果每个开发同学都拉一个分支,那么会面临着分支太多,功能联调麻烦等问题。因此,我们约定了一套 git 的管理规范,每个大需求版本,我们会约定以 "dev +上线时间日期" 作为分支名创建开发分支,所有人在这个分支上开发,开发完成让 QA 测试该分支,上线前才会将分支合入主干发布。在两个版本发布期间如果有 bug fix,则约定以 "bugfix + 功能描述" 为分支名创建 bugfix 分支,修复完成后合入主干上线。每次上线前,我们都会运行脚本新增版本号,编译打包,保证前端资源的增量发布。
有部分业务线需要异步加载,这部分业务线如何开发?
滴滴目前会把一些业务线的代码放在一个仓库里,但是部分业务线,如顺风车的代码是不在这个仓库里的。首页通过异步加载 JS 去加载这部分业务线的代码,这部分业务线很显然也是需要用 Vue 开发的,但是他们不可以再去单独引入 Vue.js。
我们的解决方案是在 window 上注册一个 XXApp 对象,把 Vue、Vuex 以及一些公共组件和方法等挂载到这个对象上,那么这些异步加载的业务线就可以通过 window.XXApp 访问到了,代码如下:
window.XXApp = {
Vue,
Vuex,
store, // 全局store
saveCurrentBiz, // 公共方法
Location // 公共组件
// 其它一些公共方法和组件
}
业务线可以访问到这些对象后,接下来需要实现的就是一个 Vue component。
异步加载的业务线组件,如何动态注册?
Vue.js 官网提供的异步组件的解决方案大多是基于 webpack 的 require.ensure 去异步加载组件的,但很显然这并不适用滴滴的业务场景,因为我们的代码并不在一个仓库下。我们需要一种类似 amd 的解决方案,这些异步业务线需要实现的是一个 Vue component,我们该如何优雅地动态注册这个 component 呢?
我们知道 Vue 提供了动态注册组件的 api,通过 Vue.component('async-example',function(resolve){ //... }) 的方式在工厂函数里通过 resolve 方法动态注册组件。注意,这个工厂函数的执行时机是组件实际需要渲染时,那我们渲染这些异步组件的时机就是当我们切换顶部导航栏到该业务线的时候。
首先,每一条业务线对应着一个独立的组件,业务线有各自的 id,因此,我们先用一个对象去维护这样的映射关系,代码如下:
const modules = {
业务线id: Taxi, // 出租车
// 其它同步业务线组件
}
这个对象初始化的都是同步业务线组件,对于异步加载的业务线组件,我们需要动态注册。首先我们在全局的 config.js 里维护一个业务线的配置关系表,异步加载的业务线会多一个 src 属性,代码如下:
bizConf: {
异步业务线id: {
name: 'alift', // 业务线名称
src: xxx // 加载异步业务线的 js 地址
},
同步业务线 id: {
name: 'taxi'
}
// 其它业务线配置
接下来我们遍历这个对象,代码如下:
// 获取 bizConf 对象
const bizJSConf = config.get('bizConf')
for (let id in bizJSConf) {
let conf = bizJSConf[id]
if (conf.src) {
modules[id] = conf.name
Vue.component(conf.name, (resolve, reject) => {
loadScript(conf.src).then(() => {
resolve(modules[id])
}).catch(() => {
reject()
})
})
}
}
可以看到,对于异步业务线,我们会把它的 name 添加到 modules 对象的映射关系中,并按这个 name 注册一个异步组件,注意,这个时候注册组件的工厂函数并不会执行。
我们之前说到了渲染这些异步组件的时机就是当我们切换顶部导航栏到该业务线的时候,我们来看看切换顶部导航栏的时候执行了什么逻辑,关键代码如下:
this.currentView = modules[productid]
这个 currentView 我们是在 App.vue 的 data 里初始化的,映射到 template 的代码如下:
<component :is="currentView"></component>
没错,这里我们又用到一个 Vue 的高级用法,动态组件。我们的业务线组件对应的就是这个动态组件。官网文档介绍的动态组件是绑定到一个组件对象上的,这对于我们的同步组件,当然是没有问题的,modules 映射的就是一个组件对象;但是对于异步组件,我们映射的是组件的名称,它是一个字符串,当 currentView 指向这个字符串的时候,注册异步组件的工厂函数执行了,回顾之前的代码,这个时候它会去加载异步业务线的 js,加载完成的回调函数里,执行 resolve(modules[id])。
等等,看到这里,有人不禁会问,这里 modules[id] 是什么,还是异步组件的名称吗?当然不是了,这里的 modules[id] 对应的是异步业务线的组件对象。那么,它是怎么被赋值成组件对象的呢?我们来看代码:
window.XXApp = {
// ...
// 一些公共方法和组件
registerBiz(id, component) {
modules[id] = component
}
}
我们在 window.XXApp 下又添加了一个 registerBiz 的方法,当我们异步加载完业务线的 JS 后,异步业务线调用这个方法真正的把自己实现的 Vue component 注册到我们的 modules 里,所以我们 resolve 的就是这个组件对象,是不是很优雅?至此,我们完成了异步业务线组件的动态注册。
异步加载的业务线如何动态注册路由?
再接着上述问题继续发散,我们在使用 Vue-router 初始化路由的时候,通常都会写一个路由映射表。对于同步业务线这些已知的组件,路由的映射是没有问题的,那么这些异步加载的业务线,如果它的某些子组件也想使用路由该怎么办?
我们需要一套动态注册路由的方案,而官网文档提供的路由懒加载的方案并不能满足我们的需求,因此我们想到了另一种变通方案。我们在路由配置如下:
{
path: 'pathA' //这里的命名只是示意
component: componentA
},
{
path: 'pathB',
component: componentB
},
//...
{
path: '/:name', // 动态匹配
component: Dynamic // 已知组件
}
可以看到,我们在定义了一系列常规的路由后,最后定义了一个动态匹配路由,也就是任意 name 的一级 path,只要没有命中之前的 path,都会映射到这个我们定义好的 Dynamic 组件上。我们来看看这个 Dynamic 组件的实现,先看一下模板:
<template>
<transition :name="transitionName">
<component :is="currentRouter"></component>
</transition>
</template>
本质上,Dynamic 组件还是利用了 Vue 的动态组件,通过修改 currentRouter 这个变量,可以改变当前渲染的组件。我们来看一下这个 currentRouter 修改的逻辑:
created() {
this.setCurrent()
},
methods: {
setCurrent() {
const name = this.$route.params.name
const component = this.routes[name]
if (component) {
this.currentRouter = component
}
}
}
在组件创建的钩子函数里,我们会调用 this.setCurrent() ,该方法首先通过路由参数拿到 name,然后从 this.routes[name] 拿到对应的组件,并赋给 this.currentRouter 。那么 this.routes 变的尤为重要了。我们实际上是把 routes 存储到了 Vuex 的 store 里, 然后通过 Vuex 的 mapGetters 获取的:
computed: {
...mapGetters([
'routes'
])
},
既然通过 Vuex 的方法可以获取 this.routes ,我们一定会有写的逻辑,而这个存的逻辑实际上就是我们提供给这些异步业务线提供了一个 api 接口实现的:
window.XXApp = {
// ...
// 一些公共方法和组件
registerRouter(name, component) {
Vue.component(name, component)
store.commit('ADD_ROUTES', {
name,
component
})
}
}
我们提供了 registerRouter 接口,参数就是路由的名称和对应的组件实例,我们首先通过 Vue.component 全局注册这个组件,然后通过 Vuex 提供的 commit 接口提交了一个 ADD_ROUTES 的 mutation,来看一下这个 mutation 的定义:
[types.ADD_ROUTES](state, data) {
state.routes = Object.assign({}, state.routes, {
[data.name]: data.component
})
},
至此,我们就完成了 routes 的存取逻辑,整个动态路由方案也就完成了, 异步业务线想使用动态路由,只需要调用我们提供的 registerRouter 接口,是不是很方便呢~
如何在测试环境下与后端接口交互?
我们在开发阶段,通常都是在本地调试,本地起的服务域名通常是 localhost:端口号。这样会产生一些接口的跨域问题,除了常规的一些跨域方案,我们实际上可以借助 node.js 服务帮我们代理这些接口。
我们借助 vue-cli 脚手架帮我们生成一些初始化代码。在 config/index.js 文件中,我们修改 dev 下 proxyTable 的配置,代码如下:
proxyTable: {
'/xxxservice': {
target: 'http://xxx.com.cn', //你的目标域名
changeOrigin: true
},
//...
}
实际上,它就是利用了 node.js 帮我们做了一层服务的转发,这样就可以解决开发阶段的跨域问题了。
如何部署到线下测试环境?
我们在本地开发完代码后,需要把代码提测。通常测试拿到代码后,需要部署和测试,为此我们写了一个 deploy 的脚本。原理其实很简单,就是利用一个 scp2 的 node 包上传代码,它的执行时机是在 webpack 编译完成后,代码如下:
var client = require('scp2')
//...
webpack(webpackConfig, function (err, stats) {
// ...
client.scp('deploy/home.html', {
host,
username,
password,
path
}, function (err) {
if (err) {
console.log(err)
} else {
console.log('Finished, the page url is xxx')
}
})
})
技术的重构总伴随着产品的升级,从这次大重构中,我们对 Vue 有了更深入的理解和掌握。对于它的周边插件如 Vuex 和 Vue-router,我们团队的小伙伴也有了较深入的研究,产出几篇文章也在这里和大家分享:
Vuex 2.0 源码分析
vue-router源码分析-整体流程
vue-router 源码分析-history
以上,欢迎拍砖~
前2篇文章:webpack loader详解1和webpack loader详解2主要通过源码分析了 loader 的配置,匹配和加载,执行等内容,这篇文章会通过具体的实例来学习下如何去实现一个 loader。
这里我们来看下 vue-loader(v15) 内部的相关内容,这里会讲解下有关 vue-loader 的大致处理流程,不会深入特别细节的地方。
git clone [email protected]:vuejs/vue-loader.git我们使用 vue-loader 官方仓库当中的 example 目录的内容作为整篇文章的示例。
首先我们都知道 vue-loader 配合 webpack 给我们开发 Vue 应用提供了非常大的便利性,允许我们在 SFC(single file component) 中去写我们的 template/script/style,同时 v15 版本的 vue-loader 还允许开发在 SFC 当中写 custom block。最终一个 Vue SFC 通过 vue-loader 的处理,会将 template/script/style/custom block 拆解为独立的 block,每个 block 还可以再交给对应的 loader 去做进一步的处理,例如你的 template 是使用 pug 来书写的,那么首先使用 vue-loader 获取一个 SFC 内部 pug 模板的内容,然后再交给 pug 相关的 loader 处理,可以说 vue-loader 对于 Vue SFC 来说是一个入口处理器。
在实际运用过程中,我们先来看下有关 Vue 的 webpack 配置:
const VueloaderPlugin = require('vue-loader/lib/plugin')
module.exports = {
...
module: {
rules: [
...
{
test: /\.vue$/,
loader: 'vue-loader'
}
]
}
plugins: [
new VueloaderPlugin()
]
...
}一个就是 module.rules 有关的配置,如果处理的 module 路径是以.vue形式结尾的,那么会交给 vue-loader 来处理,同时在 v15 版本必须要使用 vue-loader 内部提供的一个 plugin,它的职责是将你定义过的其它规则复制并应用到 .vue 文件里相应语言的块。例如,如果你有一条匹配 /\.js$/ 的规则,那么它会应用到 .vue 文件里的 <script> 块,说到这里我们就一起先来看看这个 plugin 里面到底做了哪些工作。
我们都清楚 webpack plugin 的装载过程是在整个 webpack 编译周期中初始阶段,我们先来看下 VueLoaderPlugin 内部源码的实现:
// vue-loader/lib/plugin.js
class VueLoaderPlugin {
apply() {
...
// use webpack's RuleSet utility to normalize user rules
const rawRules = compiler.options.module.rules
const { rules } = new RuleSet(rawRules)
// find the rule that applies to vue files
// 判断是否有给`.vue`或`.vue.html`进行 module.rule 的配置
let vueRuleIndex = rawRules.findIndex(createMatcher(`foo.vue`))
if (vueRuleIndex < 0) {
vueRuleIndex = rawRules.findIndex(createMatcher(`foo.vue.html`))
}
const vueRule = rules[vueRuleIndex]
...
// 判断对于`.vue`或`.vue.html`配置的 module.rule 是否有 vue-loader
// get the normlized "use" for vue files
const vueUse = vueRule.use
// get vue-loader options
const vueLoaderUseIndex = vueUse.findIndex(u => {
return /^vue-loader|(\/|\\|@)vue-loader/.test(u.loader)
})
...
// 创建 pitcher loader 的配置
const pitcher = {
loader: require.resolve('./loaders/pitcher'),
resourceQuery: query => {
const parsed = qs.parse(query.slice(1))
return parsed.vue != null
},
options: {
cacheDirectory: vueLoaderUse.options.cacheDirectory,
cacheIdentifier: vueLoaderUse.options.cacheIdentifier
}
}
// 拓展开发者的 module.rule 配置,加入 vue-loader 内部提供的 pitcher loader
// replace original rules
compiler.options.module.rules = [
pitcher,
...clonedRules,
...rules
]
}
}这个 plugin 主要完成了以下三部分的工作:
.vue或.vue.html进行 module.rule 的配置;.vue或.vue.html配置的 module.rule 是否有 vue-loader;我们看到有关 pitcher loader 的 rule 匹配条件是通过resourceQuery方法来进行判断的,即判断 module path 上的 query 参数是否存在 vue,例如:
// 这种类型的 module path 就会匹配上
'./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&'如果存在的话,那么就需要将这个 loader 加入到构建这个 module 的 loaders 数组当中。以上就是 VueLoaderPlugin 所做的工作,其中涉及到拓展后的 module rule 里面加入的 pitcher loader 具体做的工作后文会分析。
接下来我们看下 vue-loader 的内部实现。首先来看下入口文件的相关内容:
// vue-loader/lib/index.js
...
const { parse } = require('@vue/component-compiler-utils')
function loadTemplateCompiler () {
try {
return require('vue-template-compiler')
} catch (e) {
throw new Error(
`[vue-loader] vue-template-compiler must be installed as a peer dependency, ` +
`or a compatible compiler implementation must be passed via options.`
)
}
}
module.exports = function(source) {
const loaderContext = this // 获取 loaderContext 对象
// 从 loaderContext 获取相关参数
const {
target, // webpack 构建目标,默认为 web
request, // module request 路径(由 path 和 query 组成)
minimize, // 构建模式
sourceMap, // 是否开启 sourceMap
rootContext, // 项目的根路径
resourcePath, // module 的 path 路径
resourceQuery // module 的 query 参数
} = loaderContext
// 接下来就是一系列对于参数和路径的处理
const rawQuery = resourceQuery.slice(1)
const inheritQuery = `&${rawQuery}`
const incomingQuery = qs.parse(rawQuery)
const options = loaderUtils.getOptions(loaderContext) || {}
...
// 开始解析 sfc,根据不同的 block 来拆解对应的内容
const descriptor = parse({
source,
compiler: options.compiler || loadTemplateCompiler(),
filename,
sourceRoot,
needMap: sourceMap
})
// 如果 query 参数上带了 block 的 type 类型,那么会直接返回对应 block 的内容
// 例如: foo.vue?vue&type=template,那么会直接返回 template 的文本内容
if (incomingQuery.type) {
return selectBlock(
descriptor,
loaderContext,
incomingQuery,
!!options.appendExtension
)
}
...
// template
let templateImport = `var render, staticRenderFns`
let templateRequest
if (descriptor.template) {
const src = descriptor.template.src || resourcePath
const idQuery = `&id=${id}`
const scopedQuery = hasScoped ? `&scoped=true` : ``
const attrsQuery = attrsToQuery(descriptor.template.attrs)
const query = `?vue&type=template${idQuery}${scopedQuery}${attrsQuery}${inheritQuery}`
const request = templateRequest = stringifyRequest(src + query)
templateImport = `import { render, staticRenderFns } from ${request}`
}
// script
let scriptImport = `var script = {}`
if (descriptor.script) {
const src = descriptor.script.src || resourcePath
const attrsQuery = attrsToQuery(descriptor.script.attrs, 'js')
const query = `?vue&type=script${attrsQuery}${inheritQuery}`
const request = stringifyRequest(src + query)
scriptImport = (
`import script from ${request}\n` +
`export * from ${request}` // support named exports
)
}
// styles
let stylesCode = ``
if (descriptor.styles.length) {
stylesCode = genStylesCode(
loaderContext,
descriptor.styles,
id,
resourcePath,
stringifyRequest,
needsHotReload,
isServer || isShadow // needs explicit injection?
)
}
let code = `
${templateImport}
${scriptImport}
${stylesCode}
/* normalize component */
import normalizer from ${stringifyRequest(`!${componentNormalizerPath}`)}
var component = normalizer(
script,
render,
staticRenderFns,
${hasFunctional ? `true` : `false`},
${/injectStyles/.test(stylesCode) ? `injectStyles` : `null`},
${hasScoped ? JSON.stringify(id) : `null`},
${isServer ? JSON.stringify(hash(request)) : `null`}
${isShadow ? `,true` : ``}
)
`.trim() + `\n`
if (descriptor.customBlocks && descriptor.customBlocks.length) {
code += genCustomBlocksCode(
descriptor.customBlocks,
resourcePath,
resourceQuery,
stringifyRequest
)
}
...
// Expose filename. This is used by the devtools and Vue runtime warnings.
code += `\ncomponent.options.__file = ${
isProduction
// For security reasons, only expose the file's basename in production.
? JSON.stringify(filename)
// Expose the file's full path in development, so that it can be opened
// from the devtools.
: JSON.stringify(rawShortFilePath.replace(/\\/g, '/'))
}`
code += `\nexport default component.exports`
return code
}以上就是 vue-loader 的入口文件(index.js)主要做的工作:对于 request 上不带 type 类型的 Vue SFC 进行 parse,获取每个 block 的相关内容,将不同类型的 block 组件的 Vue SFC 转化成 js module 字符串,具体的内容如下:
import { render, staticRenderFns } from "./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&"
import script from "./source.vue?vue&type=script&lang=js&"
export * from "./source.vue?vue&type=script&lang=js&"
import style0 from "./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&"
/* normalize component */
import normalizer from "!../lib/runtime/componentNormalizer.js"
var component = normalizer(
script,
render,
staticRenderFns,
false,
null,
"27e4e96e",
null
)
/* custom blocks */
import block0 from "./source.vue?vue&type=custom&index=0&blockType=foo"
if (typeof block0 === 'function') block0(component)
// 省略了有关 hotReload 的代码
component.options.__file = "example/source.vue"
export default component.exports从生成的 js module 字符串来看:将由 source.vue 提供 render函数/staticRenderFns,js script,style样式,并交由 normalizer 进行统一的格式化,最终导出 component.exports。
这样 vue-loader 处理的第一个阶段结束了,vue-loader 在这一阶段将 Vue SFC 转化为 js module 后,接下来进入到第二阶段,将新生成的 js module 加入到 webpack 的编译环节,即对这个 js module 进行 AST 的解析以及相关依赖的收集过程,这里我用每个 request 去标记每个被收集的 module(这里只说明和 Vue SFC 相关的模块内容):
[
'./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&',
'./source.vue?vue&type=script&lang=js&',
'./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&',
'./source.vue?vue&type=custom&index=0&blockType=foo'
]我们看到通过 vue-loader 处理到得到的 module path 上的 query 参数都带有 vue 字段。这里便涉及到了我们在文章开篇提到的 VueLoaderPlugin 加入的 pitcher loader。如果遇到了 query 参数上带有 vue 字段的 module path,那么就会把 pitcher loader 加入到处理这个 module 的 loaders 数组当中。因此这个 module 最终也会经过 pitcher loader 的处理。此外在 loader 的配置顺序上,pitcher loader 为第一个,因此在处理 Vue SFC 模块的时候,最先也是交由 pitcher loader 来处理。
事实上对一个 Vue SFC 处理的第二阶段就是刚才提到的,Vue SFC 会经由 pitcher loader 来做进一步的处理。那么我们就来看下 vue-loader 内部提供的 pitcher loader 主要是做了哪些工作呢:
// vue-loader/lib/loaders/pitcher.js
module.export = code => code
module.pitch = function () {
...
const query = qs.parse(this.resourceQuery.slice(1))
let loaders = this.loaders
// 剔除 eslint loader
// if this is a language block request, eslint-loader may get matched
// multiple times
if (query.type) {
// if this is an inline block, since the whole file itself is being linted,
// remove eslint-loader to avoid duplicate linting.
if (/\.vue$/.test(this.resourcePath)) {
loaders = loaders.filter(l => !isESLintLoader(l))
} else {
// This is a src import. Just make sure there's not more than 1 instance
// of eslint present.
loaders = dedupeESLintLoader(loaders)
}
}
// 剔除 pitcher loader 自身
// remove self
loaders = loaders.filter(isPitcher)
if (query.type === 'style') {
const cssLoaderIndex = loaders.findIndex(isCSSLoader)
if (cssLoaderIndex > -1) {
const afterLoaders = loaders.slice(0, cssLoaderIndex + 1)
const beforeLoaders = loaders.slice(cssLoaderIndex + 1)
const request = genRequest([
...afterLoaders,
stylePostLoaderPath,
...beforeLoaders
])
return `import mod from ${request}; export default mod; export * from ${request}`
}
}
if (query.type === 'template') {
const path = require('path')
const cacheLoader = cacheDirectory && cacheIdentifier
? [`cache-loader?${JSON.stringify({
// For some reason, webpack fails to generate consistent hash if we
// use absolute paths here, even though the path is only used in a
// comment. For now we have to ensure cacheDirectory is a relative path.
cacheDirectory: path.isAbsolute(cacheDirectory)
? path.relative(process.cwd(), cacheDirectory)
: cacheDirectory,
cacheIdentifier: hash(cacheIdentifier) + '-vue-loader-template'
})}`]
: []
const request = genRequest([
...cacheLoader,
templateLoaderPath + `??vue-loader-options`,
...loaders
])
// the template compiler uses esm exports
return `export * from ${request}`
}
// if a custom block has no other matching loader other than vue-loader itself,
// we should ignore it
if (query.type === `custom` &&
loaders.length === 1 &&
loaders[0].path === selfPath) {
return ``
}
// When the user defines a rule that has only resourceQuery but no test,
// both that rule and the cloned rule will match, resulting in duplicated
// loaders. Therefore it is necessary to perform a dedupe here.
const request = genRequest(loaders)
return `import mod from ${request}; export default mod; export * from ${request}`
}对于 style block 的处理,首先判断是否有 css-loader,如果有的话就重新生成一个新的 request,这个 request 包含了 vue-loader 内部提供的 stylePostLoader,并返回一个 js module,根据 pitch 函数的规则,pitcher loader 后面的 loader 都会被跳过,这个时候开始编译这个返回的 js module。相关的内容为:
import mod from "-!../node_modules/vue-style-loader/index.js!../node_modules/css-loader/index.js!../lib/loaders/stylePostLoader.js!../lib/index.js??vue-loader-options!./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&"
export default mod
export * from "-!../node_modules/vue-style-loader/index.js!../node_modules/css-loader/index.js!../lib/loaders/stylePostLoader.js!../lib/index.js??vue-loader-options!./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&" 对于 template block 的处理流程类似,生成一个新的 request,这个 request 包含了 vue-loader 内部提供的 templateLoader,并返回一个 js module,并跳过后面的 loader,然后开始编译返回的 js module。相关的内容为:
export * from "-!../lib/loaders/templateLoader.js??vue-loader-options!../node_modules/pug-plain-loader/index.js!../lib/index.js??vue-loader-options!./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&"这样对于一个 Vue SFC 处理的第二阶段也就结束了,通过 pitcher loader 去拦截不同类型的 block,并返回新的 js module,跳过后面的 loader 的执行,同时在内部会剔除掉 pitcher loader,这样在进入到下一个处理阶段的时候,pitcher loader 不在使用的 loader 范围之内,因此下一阶段 Vue SFC 便不会经由 pitcher loader 来处理。
接下来进入到第三个阶段,编译返回的新的 js module,完成 AST 的解析和依赖收集工作,并开始处理不同类型的 block 的编译转换工作。就拿 Vue SFC 当中的 style / template block 来举例,
style block 会经过以下的流程处理:
source.vue?vue&type=style -> vue-loader(抽离 style block) -> stylePostLoader(处理作用域 scoped css) -> css-loader(处理相关资源引入路径) -> vue-style-loader(动态创建 style 标签插入 css)

template block 会经过以下的流程处理:
source.vue?vue&type=template -> vue-loader(抽离 template block ) -> pug-plain-loader(将 pug 模块转化为 html 字符串) -> templateLoader(编译 html 模板字符串,生成 render/staticRenderFns 函数并暴露出去)

我们看到经过 vue-loader 处理时,会根据不同 module path 的类型(query 参数上的 type 字段)来抽离 SFC 当中不同类型的 block。这也是 vue-loader 内部定义的相关规则:
// vue-loader/lib/index.js
const qs = require('querystring')
const selectBlock = require('./select')
...
module.exports = function (source) {
...
const rawQuery = resourceQuery.slice(1)
const inheritQuery = `&${rawQuery}`
const incomingQuery = qs.parse(rawQuery)
...
const descriptor = parse({
source,
compiler: options.compiler || loadTemplateCompiler(),
filename,
sourceRoot,
needMap: sourceMap
})
// if the query has a type field, this is a language block request
// e.g. foo.vue?type=template&id=xxxxx
// and we will return early
if (incomingQuery.type) {
return selectBlock(
descriptor,
loaderContext,
incomingQuery,
!!options.appendExtension
)
}
...
}当 module path 上的 query 参数带有 type 字段,那么会直接调用 selectBlock 方法去获取 type 对应类型的 block 内容,跳过 vue-loader 后面的处理流程(这也是与 vue-loader 第一次处理这个 module时流程不一样的地方),并进入到下一个 loader 的处理流程中,selectBlock 方法内部主要就是根据不同的 type 类型(template/script/style/custom),来获取 descriptor 上对应类型的 content 内容并传入到下一个 loader 处理:
module.exports = function selectBlock (
descriptor,
loaderContext,
query,
appendExtension
) {
// template
if (query.type === `template`) {
if (appendExtension) {
loaderContext.resourcePath += '.' + (descriptor.template.lang || 'html')
}
loaderContext.callback(
null,
descriptor.template.content,
descriptor.template.map
)
return
}
// script
if (query.type === `script`) {
if (appendExtension) {
loaderContext.resourcePath += '.' + (descriptor.script.lang || 'js')
}
loaderContext.callback(
null,
descriptor.script.content,
descriptor.script.map
)
return
}
// styles
if (query.type === `style` && query.index != null) {
const style = descriptor.styles[query.index]
if (appendExtension) {
loaderContext.resourcePath += '.' + (style.lang || 'css')
}
loaderContext.callback(
null,
style.content,
style.map
)
return
}
// custom
if (query.type === 'custom' && query.index != null) {
const block = descriptor.customBlocks[query.index]
loaderContext.callback(
null,
block.content,
block.map
)
return
}
}通过 vue-loader 的源码我们看到一个 Vue SFC 在整个编译构建环节是怎么样一步一步处理的,这也是得益于 webpack 给开发这提供了这样一种 loader 的机制,使得开发者通过这样一种方式去对项目源码做对应的转换工作以满足相关的开发需求。结合之前的2篇有关 webpack loader 源码的分析,大家应该对 loader 有了更加深入的理解,也希望大家活学活用,利用 loader 机制去完成更多贴合实际需求的开发工作。
杜欢,滴滴平台产品中心技术总监。2015 年加入滴滴,负责公司公共业务、客户端/前端架构和新业务孵化,致力于用技术手段解决业务痛点和提升研发效率,曾作为技术负责人主导公司技术架构升级以支撑公司业务快速迭代的需求。在加入滴滴前有长达五年的创业经历,具有丰富的团队管理经验,熟悉移动互联网应用的整个技术栈。
去年我们做了一次非常大的重构。上面图中是今天要讲的大纲,我会从问题本身出发,回顾一下整个过程,包括如何发现问题、分析问题和解决方案。最后,我也会提出一些想法,如何规避重蹈这样的覆辙。
首先,我们看一下挑战在哪里。滴滴在出行领域是非常独特的公司,它的独特不在于业务模式多复杂,而在于它的发展非常快。滴滴的成立时间是2012年的6月,到现在为止才经过了四年的时间。
滴滴的成长速度十分惊人,到今天它的估值已经超过260亿美元,融资轮次非常多。如果不是因为竞争非常恶劣,滴滴也不会一直用融资的方法为自己开路。在这样的压力之下,滴滴所有的动作可能都会走形,所有的想法可能因为现在一些短期利益不得不进行一些权衡。
同时,公司的业务也在爆炸式地增长。如果滴滴只做一个业务,原本可以做得非常深入。滴滴从2014年开始加入了专车业务,2015年业务数量增加到七条,2016年已经超过十条。业务急速发展之中大家会思考,到底怎么做才能使这些还不稳定或者还没有想清楚的业务很好地迭代起来。
想到最简单的方法是,如果新业务跟某个旧业务非常类似但又不完全一样,我们就把旧业务的旧代码复制并修改,这样新业务就做出来了。之前,这种情况经常发生,就造成了很大的问题。
在2015年上半年,滴滴整个系统已经积累了很多问题,分布在乘客App、服务端、Web App之中。特别值得一提的是,服务端的问题并不是性能,而是在于巨大的耦合导致数据紊乱和迭代速度越来越慢。
滴滴的独特性迫使我们独立思考这些问题,所有的解法都要针对滴滴现状,而不是看哪个大公司是怎么做的,然后直接复制过来。
在解决问题之前,我们需要了解现状是怎样的。如图所示,在2015年下半年,滴滴的系统架构分为四层。最顶层是用户应用,每一个用户应用就是一个端,也就是用户所能看到的入口。然后是接入层,这是非常传统的结构,我们用了Nginx,还专门做了TCP接入层。
在业务层,Web是非常大的集群,有非常大的代码量,我们只对业务做了分割,有策略引擎、司机调度。在数据层,有KV集群、MySQL集群、任务队列、特征存储。这是任何一个初创公司应该有的架构,我们对这个架构并没有做特殊的策划,仅仅在这个技术体系里面把业务逻辑实现出来。
上面这张图可能会比较有趣。右边这个红色的球,代表的是重构之前App依赖的关系。当时我很想梳理一下App在模块之间是如何进行依赖的,然后我就写了一个脚本运行了一下,得到的结果让我很惊讶。我用蓝色的线表示正常的依赖,就是模块A依赖于模块B,A是B的上一层,B不会反过来依赖A,用红色的线表示异常的依赖,即A依赖B、B通过各种手段反过来依赖A,最后发现基本上都是红色的。
做任何模块的拆分,发现不得不面临这样的问题:把任何一个模块取出来就等于把所有模块都取出来,实际上没有做拆分。所以,关键是需要解耦模块结果。这是iOS的情况。安卓的情况更糟糕。
对于Web App来讲,最大的问题在于耦合性。以前滴滴只有出租车这个业务,最开始的Web App只有出租车,后来专车上线了,就在出租车里面加了专车入口,只是业务名不同界面会有小区别,后来加入了快车、代驾,都跟出租车差不多,没遇到太大问题。
再后来有了顺风车,顺风车跟其他功能不一样,整体界面是预约型的,有乘客和车主两种模式。如果在老首页里面开发顺风车成本太大了,需要和出租车业务线的人一起开发业务模块,如果未来做迭代,这种开发模式将非常痛苦。老首页的模块也没有做拆分,代码散落各地,只是通过打包工具拼接在一起,没有做模块化,所以整体情况也比较糟糕。
相比端,API稍好一点的是,API至少在业务维度上是分开的,出租车与专车、快车是分开的两个系统,放在两个仓库里面。不过API也有一个很大的问题,业务代码没有做服务化拆分,没有model 封装,业务所有的API和后台MIS都在一个仓库里,这对系统来说是非常大的一个隐患。
现状看上去很糟糕,要仔细思考才能入手。最基本的思路是把所有事情分类,就像整理自己家里一样,无论多乱,我们要做的事情就是将东西分门别类放好。因此,最关键的是要了解到底哪些东西应该放在一起,我们用颜色来比喻模块或者代码的归属,核心问题就变成这些模块到底是什么颜色。
我们的思路是,先从前面,也就是从用户入口进行拆分,要先保证所有的模块是足够内聚的,由统一的团队负责。比如,出租车业务线可以完全控制自己的代码,能够写自己的客户端,也能够写自己的Web App,最终只是通过一些工程构建手段将多个业务整合起来变成一个完整的端。
做到这一点之后,所有的业务迭代问题就迎刃而解了,因为业务间已经没有依赖和耦合了。这一步完成之后做的就是重新梳理业务,让业务根据自己模型特点进行一些重构。
最开始的时候,我们考虑的是怎么做代码治理和模块下沉。代码治理本质上就是把各种模块进行染色、再把它们归类的过程。代码治理最难的事情在于消除错综复杂的依赖。到底怎么做才对呢?
首先,一定要把不同模块的代码放在不同仓库里面,使得模块能够物理上隔离。特别是Java、Obj-C这些静态编译的语言,一旦把代码仓库隔离就完全没有办法直接对其他模块产生依赖,至少绝对不会再出现循环依赖。
再者,就看如何把循环依赖通过一些间接层隔离开,比如通过抽象接口隔离开,一点一点把代码拆到不同仓库。
最后,有了这样一个简单的拆分之后,就需要考虑怎么让模块能独立的开发、测试、上线。独立的流程一旦独立起来,就意味着拆分基本上成功了。
模块下沉与代码治理息息相关。如果只是要求把所有代码拆分,而没有合适的拆分方法,这件事情是无法推进下去的。对于程序员来说,他们内心总有一种冲动想做有意思的事情,比如封装一个很有意思的模块给更多程序员用。大家并非不想做封装,只是如果封装并共享出来的代价太大,就会影响大家的热情。
模块下沉是一种机制,一方面我们应该鼓励,另一方面还应该让大家发现这是一件不得不做的事情。如果仅仅对内公开模块列表让大家自由选择,达不到模块下沉的目的。因为人都很懒,不想思考太多,只想尽快把事情完成,大家往往倾向于复制粘贴,也不愿意额外花时间做下沉。
怎么办呢?我们会给所有业务提供一个统一的SDK,里面包含所有能用的组件,大家必须使用它进行开发。如果业务模块稳定了并且比较通用,我们有工具和相应的简单机制把业务模块下沉下来,变成SDK的一部分,长期下去SDK会越来越大,只要SDK里做好分类和规划,上层就会越来越轻,我们可以真正专注于业务逻辑开发。
除了上面这些,最核心的一点在于,一定要把所有业务都做到“无状态”和“异步化”。
“无状态”这个概念在服务端比较容易理解。一般我们倾向于把各种业务做到无状态,这样容易做水平扩展。在客户端也是一个道理,也要考虑横向扩展性。一个简单的框架往往提供一些最基础的控件,比如按纽、列表,这些都不会耦合任何业务逻辑,所以很容易使用。
但是当业务做起来,大家习惯将一些状态放到业务控件里面,这在一定程度上方便了,但是一旦需要将业务进行重构或者进行模块化下沉的时候,就造成了非常大的困难。例如,一个模块如果大量通过全局变量或单例跟上下游耦合,那么这个模块就很难复用和重构,这些全局变量或单例就是状态。
所以,我们在客户端也提出使用“无状态”的方式,把存储的信息都放到外面。后面我会提到到底应该怎么样去做。
“异步化”也是解耦的方式。服务端的RPC类似于函数调用,如果参数变了,实现和调用的双方都要做改变,这很不透明,也不能够渐进式上线。我们用订阅/发布的模式对 RPC进行解耦,要求所有接口都要异步返回。
在客户端也是这样,比如做数据的缓存,想优化网络,我们不能够期待这个函数是一个同步函数,一定用回调的方式接受所有参数。所以做设计的时候,只要是有可能发生网络请求或者访问磁盘,在客户端也尽量异步请求数据。
刚刚讲的都是相对比较抽象的内容,接下来会说一下滴滴的业务形态本身。
滴滴是一个出行的平台,涵盖的是整个出行领域所有的出行需求。大家出行到底想要什么?就是到达自己想去的地方。实际上,我们的模型可以做得非常抽象和简单。比如,我想要打快车去机场,我就是一个需求方,我的需求会发到很多服务者那里去,服务者会根据特征进行一些匹配。
最基本的特征是服务能力,如果服务者能够开快车并通过了能力验证,这个需求就有可能发给他。如果开出租车的也有能力开快车,但是他还没有在平台上验证这个能力,就只能开出租车。一个人可以验证很多服务,白天可以开快车,晚上可以做代驾,做不同的事。
服务和需求的匹配是通过计价模型和匹配策略来实现的。发送需求的时候需要选择计价模型和车的类型。快车和专车服务过程大同小异,但是价格差别很明显,专车价格会贵很多。通过匹配策略可以实现各种需求的匹配。
例如,选择了拼车,这个需求会尽量匹配已经有拼友和顺路的车。如果选择专车,可以要求这辆车在指定时间来接人,这时候匹配策略会优化倾向这种方式。
滴滴所有的业务基本上都是以这种模式运转的,所有功能都是核心主干或者旁路,只要把业务模型抽象出来,基本上就能够满足大部分的业务了。
基于这样的想法,我们就思考如何设计真正高度抽象的工具。简单起见,我们把滴滴出行的过程抽象成一个框架(见上图),这并不是完整的框架。有颜色的地方表示出租车、快车、专车、代驾共同的流程,只要组合各种流程就可以实现整个业务形态的能力。在这个框架里可以定制所有业务形态的车标、提示语、匹配的模型、计价模型等功能。
当时梳理这个抽象的时候,我们感觉非常兴奋,因为这意味着在这个基础之上就可以简易扩展出滴滴未来的业务形态。只要滴滴还是在做需求和服务的匹配,基本上就离不开这样一种套路。
然后我们开始落实到具体该怎么拆的问题。
**首先就是客户端,最重要的是需要将业务拆出来。**以前所有业务放在同一个仓库里,如果不小心提交了一段错误代码就会带来灾难性的后果,所有业务工作可能都会受到影响。以前编译速度也很糟糕,大家可以想象,每次下载代码都会有几个头文件发生改变,由于循环依赖的缘故几乎所有文件都要重编,二三十分钟后才能重新调试,这个过程让人极度崩溃。
对于iOS,我们用cocoapods把业务拆到不同的pod里面;对于安卓,我们把业务拆分打包并用Maven管理起来。我们拆分方法如下图所示,其中虚线框部分展示的是公共框架,最开始没有很细致分割,只是把它放在一个独立仓库里,保证依赖关系充分清楚,后面就可以随时把代码独立出来,使其变成单独的模块。
同时,我们也在开发构建系统。原生的构建系统使用起来会有很多问题,它并不支持多人并行开发,如果要实现一个舒适的工作流就需要定制。我们还做了网络和日志的封装,将其放在下层。还有一个业务整合的基础框架,包括滴滴出行的App界面框架、首页导航栏,各种业务可以注册自己的入口,并在导航栏里进行切换。
业务之间没有任何代码耦合,比如出租车和专车业务没有关联性,那么代码也没有任何相关的地方,这意味着开发出租车业务的时候,完全没有必要实时更新专车代码,集成的时候也不会因为专车代码而造成问题。
最顶层的One Travel可以通过简单的配置分业务包,比如可以输出只有出租车业务的包,在这上面开发测试速度比较快,整体也会比较灵活。One Travel里面只有极少的代码,未来会改成没有代码、通过脚本就可以生成的项目。
怎么做页面的解耦?上图中是一种类似数据库缓存的设计。从客户端角度来看,如果把服务器当做一个数据库,最终状态存储在服务器,而客户端里存着的是跟服务器同步过的最新状态的缓存。客户端不太可能做到精确的数据同步,一定是每隔一段时间同步一次,或者是在关键节点上靠服务器推送得到订单状态变化。
客户端的业务代码其实不关心究竟是如何同步状态的,所以我们专门写了一个缓存服务器状态的Store层,它是热数据。如果不需要最新状态的数据,业务读取Store时可以读到上次同步的数据,假设此时Store从未同步过状态就会自动读取最新状态;如果业务一定要最新状态的数据,那么就显示要求缓存失效,这样Store就会再读取一次获取最新的信息。
Store还可以自动设置失效时间长度,这个机制跟跟做数据库缓存是一样的,为了性能的平衡,要保证读出准确的数据,同时性能也要最优。同时,Store也有责任负责数据更新,当客户端变化可能会让服务器状态变化时,Store可以自动让相关状态失效,这也是管理缓存的一般做法。
做了这样一些解耦之后,令人惊喜的是,我们发现所有界面是可以随意跳转的,虽然没有从发单直接跳到评价的必要性,但实际上只要有这个架构,就可以从界面A跳到界面B,不会有任何问题。
如果跳到另外一个界面,没有发现必要的数据,就从服务器读取,它自己也会报错,整个逻辑非常清晰。如果需要在流程A和流程B之间再增加一个流程C,我们可以把流程C直接加进去,流程C没有破坏A和B之间的依赖,因为原本A和B之间也没有什么依赖。
我们也做一些App的组件化,把从服务端API到客户端逻辑打包在一起,引用客户端组件就可以实现完整功能。实际封装方法略微有点复杂(注:可以阅读另外一篇文章支撑滴滴高速发展的引擎:滴滴的组件化实践与优化)。
图中所示是做平滑移动组件,地图上有很多车在移动,这些车就是地图上的额外信息,把这些车挂在地图上。如果这个控件不存在,地图上就没有车,控件存在,地图上就有车,只要在上面启动控件就好了。
App集成也采用了异步和无障碍的做法,每个业务只需要在仓库里面测试完之后直接打tag,之后就能自动生成整个所有业务的ipa/apk包。
接下来讲Web App的拆解,这实际上是纯工程的解耦。
首先,我们需要实现一个简单的公共框架,这跟业务是无关的。我们使用scrat和webpack来实现工程化,将首页拆分成了许多组件,所有的业务可以根据不同配置选择使用哪些组件,同时也保证页面风格的统一、功能的稳定。
如果网络比较糟糕,我们会做一系列的降级,首先出来的会是一些统一的控件,比如上车地点、目的地、广告等,之后会根据定位的结果得到当前开通的业务线列表,并加载业务代码,然后默认选择当前业务线的逻辑。
如果业务线代码加载好了就开始渲染,如果业务加载出错或代码执行出错,业务就会被隐藏。业务线之间也是完全解耦的,大家可以通过公共框架提供的事件机制来通信,但不允许业务之间直接通信。线上的Web App就是如上图所看到的,每个业务线都有一段独立js代码,第一次加载相对较慢,会看到很多请求,如果业务线代码没有更新,下次打开就完全不走网络请求。
我们也做了很多控件,这是内网发布的一些控件(见上图),每个业务只要关注自己的业务逻辑即可,公共的功能都可以使用控件。特别是选择地址的控件,它把前端界面交互和后端API都打包在一起,和客户端一样,只要引用它,就可以直接在Web App使用,无需任何服务端的开发。
关于服务器API的拆分,我们最开始希望一次性实现理想方案,但是这个理想方案遇到一些问题。
我先来谈谈理想方案是什么。首先,滴滴业务一般都是基于订单流转推动各种业务动作。为什么会发生订单流转?是因为对乘客和司机做了一些操作,如果想象成一个客户端系统,就有点类似于触发各种用户事件。客户端动作根本上决定了信息该如何流转,所有事情都应该在客户端触发,触发之后来到了组件这一层,所有动作进行消费,然后进行下一步操作。
比如,用户提出一个需求,发单对需求进行过滤,判断是哪种需求,然后进行一些检查。快车有拼车和不拼车两种,发单的时候就可以知道是拼车还是不拼车,对于统一订单系统来说这就是个标志。无论拼不拼,这个单对用户都一样,无非就是消耗多少人民币、消耗几个座位还是消耗整辆车的问题。
之后分单系统会进行订单的匹配。一旦匹配成功,客户端有很多动作,司机确认接单,乘客可以看到确认。如果直接做成消息,客户端和服务端用一条总线连接,问题就解决了。
这里有一个很大的优点——可拼接,所有东西都组件化了。但是最大的问题在于抽象程度非常高。这是函数式的**,要求所有的Worker都是纯函数,纯函数是非常高的要求,上下文状态必须要通过参数才行。我们发现很难做到这一点,因为所有系统必须有状态,一旦这样这个纯函数就不是纯函数了,要依赖外部的变量。
与面向对象设计的思路差异非常大,做函数式设计时很容易陷入一些抉择当中,如何定义输入、输出,如何划分流程。有一些流程划分成三段式,中间的流程异步调出去,又异步调回来继续后续流程,这种设计让人很纠结。
函数很依赖异步化,异步化会让数据流变得复杂。我们思考数据流的流向,以及每次数据流在流转的时候都需要设置的输入、输出。最终,这个方案并没有实施,虽然我们开发了接近半年的时间。
2016年,我们又重新思考了这个问题,这次是比较简单和现实的方法。首先我们进行了一些代码的隔离,把代码分开,之后对系统按照刚才讲的模块进行面向对象的抽象,比如发单就是单独的系统,订单也是一个单独的系统,支付的收银体系是一个系统,评价体系是一个系统。每一个系统变得很简单,互相之间用RPC调用关联起来。
这会有什么缺点呢?长期来讲缺点还是比较明显的,就是不容易扩展。现在我们设计的模型是来源于当前业务现状,如果业务发生改变,比如多了一种车型,就会遇到该如何扩展的抉择:应该提供更多API接口满足新的业务功能,还是在原有API修改上提供更多参数。
两种方法看起来都可以,但是本质上我认为无论用哪种方案都会使模块本身变得越来越臃肿,其实都是把很多种东西融合在一起,并不是很理想。当一个服务臃肿到一定程度之后又会出现以前的问题,又要再次做拆分和重构,甚至整个RPC调用流程都会发生很大震动。
从项目整体实施效果上来讲,这次重构最主要是解决了开发迭代的问题,能够让迭代速度更快。让我们比较意外的情况是,重构前客户端crash率非常高,重构中我们对代码进行了非常多的修改,同时还在用户体验上做了很多优化,但最终crash率反而大幅下降,从以前1%降低到0.3%。
重构后各个业务团队的开发模式发生了根本的变化,以前是各个业务各耦合在一起进行开发,现在各个业务都能独立开发,互不干扰,同时平台还会不断产出更多的公共组件。
最后提一下如何重蹈覆辙。我认为,所有的设计应该是自上而下,先从产品层面上规划核心业务的模式,然后考虑如何让产品技术实现它。如果把业务模式描述成如图所示的核心循环,会非常清楚。我们不仅要考虑现在,还要考虑未来。如果让整个架构保持健康,就要考虑什么功能是真正紧密相关的。
比如在服务端,直觉上感觉各种不同的发单应该是在一起的,但实际上并不是这样。不同车型的发单接口互相之间并没有什么联系,每一种发单都会有独特的个性化定制,这些定制才是真正应该跟发单紧耦合的东西。
所以我们应该从产品角度上考虑,把一种发单所调用的所有相关API放在一起,服务端发生变化,调用的组件也会发生变化,做到发单闭环。刚刚提到的今年服务端的重构的方法,实际上并没有让各个子系统打通,这是一件很遗憾的事。未来如果开发一些新需求,肯定还会涉及多个模块、团队,避免不了一些沟通成本。
webpack 整个编译过程中暴露出来大量的 Hook 供内部/外部插件使用,同时支持扩展各种插件,而内部处理的代码,也依赖于 Hook 和插件。webpack 的整体执行过程,总的来看就是被事件驱动的。从一个事件,走向下一个事件。Tapable 用来提供各种类型的 Hook。我们通过下面一个直观的使用例子,初步认识一下 Tapable:
const {
SyncHook
} = require('tapable')
// 创建一个同步 Hook,指定参数
const hook = new SyncHook(['arg1', 'arg2'])
// 注册
hook.tap('a', function (arg1, arg2) {
console.log('a')
})
hook.tap('b', function (arg1, arg2) {
console.log('b')
})
hook.call(1, 2)看起来起来功能和 EventEmit 类似,先注册事件,然后触发事件。不过 Tapable 的功能要比 EventEmit 强大。从官方介绍中,可以看到 Tapable 提供了很多类型的 Hook,分为同步和异步两个大类(异步中又区分异步并行和异步串行),而根据事件执行的终止条件的不同,由衍生出 Bail/Waterfall/Loop 类型。
下图展示了每种类型的作用:


BasicHook: 执行每一个,不关心函数的返回值,有 SyncHook、AsyncParallelHook、AsyncSeriesHook。
我们平常使用的 eventEmit 类型中,这种类型的钩子是很常见的。
BailHook: 顺序执行 Hook,遇到第一个结果 result !== undefined 则返回,不再继续执行。有:SyncBailHook、AsyncSeriseBailHook, AsyncParallelBailHook。
什么样的场景下会使用到 BailHook 呢?设想如下一个例子:假设我们有一个模块 M,如果它满足 A 或者 B 或者 C 三者任何一个条件,就将其打包为一个单独的。这里的 A、B、C 不存在先后顺序,那么就可以使用 AsyncParallelBailHook 来解决:
x.hooks.拆分模块的Hook.tap('A', () => {
if (A 判断条件满足) {
return true
}
})
x.hooks.拆分模块的Hook.tap('B', () => {
if (B 判断条件满足) {
return true
}
})
x.hooks.拆分模块的Hook.tap('C', () => {
if (C 判断条件满足) {
return true
}
})如果 A 中返回为 true,那么就无须再去判断 B 和 C。
但是当 A、B、C 的校验,需要严格遵循先后顺序时,就需要使用有顺序的 SyncBailHook(A、B、C 是同步函数时使用) 或者 AsyncSeriseBailHook(A、B、C 是异步函数时使用)。
WaterfallHook: 类似于 reduce,如果前一个 Hook 函数的结果 result !== undefined,则 result 会作为后一个 Hook 函数的第一个参数。既然是顺序执行,那么就只有 Sync 和 AsyncSeries 类中提供这个Hook:SyncWaterfallHook,AsyncSeriesWaterfallHook
当一个数据,需要经过 A,B,C 三个阶段的处理得到最终结果,并且 A 中如果满足条件 a 就处理,否则不处理,B 和 C 同样,那么可以使用如下
x.hooks.tap('A', (data) => {
if (满足 A 需要处理的条件) {
// 处理数据 data
return data
} else {
return
}
})
x.hooks.tap('B', (data) => {
if (满足B需要处理的条件) {
// 处理数据 data
return data
} else {
return
}
})
x.hooks.tap('C', (data) => {
if (满足 C 需要处理的条件) {
// 处理数据 data
return data
} else {
return
}
})LoopHook: 不停的循环执行 Hook,直到所有函数结果 result === undefined。同样的,由于对串行性有依赖,所以只有 SyncLoopHook 和 AsyncSeriseLoopHook(PS:暂时没看到具体使用 Case)
我们先给出 Tapable 代码的主脉络:
hook 事件注册 ——> hook 触发 ——> 生成 hook 执行代码 ——> 执行
hook 类关系图很简单,各种 hook 都继承自一个基本的 Hook 抽象类,同时内部包含了一个 xxxCodeFactory 类,会在生成 hook 执行代码中用到。

Tapable 基本逻辑是,先通过类实例的 tap 方法注册对应 Hook 的处理函数:

Tapable 提供了 tap/tapAsync/tapPromise 这三个注册事件的方法(实现逻辑在 Hook 基类中),分别针对同步(tap)/异步(tapAsync/tapPromise),对要 push 到 taps 中的内容赋给不一样的 type 值,如上图所示。
对于 SyncHook, SyncBailHook, SyncLoopHook, SyncWaterfallHook 这四个同步类型的 Hook, 则会覆写基类中 tapAsync 和 tapPromise 方法,防止使用者在同步 Hook 中误用异步方法。
tapAsync() {
throw new Error("tapAsync is not supported on a SyncHook");
}
tapPromise() {
throw new Error("tapPromise is not supported on a SyncHook");
}与 tap/tapAsync/tapPromise 相对应的,Tapable 中提供了三种触发事件的方法 call/callAsync/promise。这三这方法也位于基类 Hook 中,具体逻辑如下
this.call = this._call = this._createCompileDelegate("call", "sync");
this.promise = this._promise = this._createCompileDelegate("promise", "promise");
this.callAsync = this._callAsync = this._createCompileDelegate("callAsync", "async");
// ...
_createCall(type) {
return this.compile({
taps: this.taps,
interceptors: this.interceptors,
args: this._args,
type: type
});
}
_createCompileDelegate(name, type) {
const lazyCompileHook = (...args) => {
this[name] = this._createCall(type);
return this[name](...args);
};
return lazyCompileHook;
}无论是 call, 还是 callAsync 和 promise,最终都会调用到 compile 方法,再此之前,其区别就是 compile 中所传入的 type 值的不同。而 compile 根据不同的 type 类型生成了一个可执行函数,然后执行该函数。
注意上面代码中有一个变量名称 lazyCompileHook,懒编译。当我们 new Hook 的时候,其实会先生成了 promise, call, callAsync 对应的 CompileDelegate 代码,其实际的结构是
this.call = (...args) => {
this[name] = this._createCall('sync');
return this['call'](...args);
}
this.promise = (...args) => {
this[name] = this._createCall('promise');
return this['promise'](...args);
}
this.callAsync = (...args) => {
this[name] = this._createCall('async');
return this['callAsync'](...args);
}当在触发 hook 时,比如执行 xxhook.call() 时,才会编译出对应的执行函数。这个过程就是所谓的“懒编译”,即用的时候才编译。
接下来我们主要看 compile 的逻辑,这块也是 Tapable 中大部分的逻辑所在。
在看源码之前,我们可以先写几个简单的 demo,看一下 Tapable 最终生成了什么样的执行代码,来直观感受一下:

上图分别是 SyncHook.call, AsyncSeriesHook.callAsync 和 AsyncSeriesHook.promise 生成的代码。_x 中保存了注册的事件函数,_fn${index} 则是每一个函数的执行,而生成的代码中根据不同的 Hook 以及以不同的调用方式, _fn${index} 会有不同的执行方式。这些差异是如何通过代码生成的呢?我们来细看 compile 方法。
compile 这个方法在基类中并没有实现,其实现位于派生出来的各个类中。以 SyncHook 为例,看一下
class SyncHookCodeFactory extends HookCodeFactory {
content({ onError, onResult, onDone, rethrowIfPossible }) {
return this.callTapsSeries({
onError: (i, err) => onError(err),
onDone,
rethrowIfPossible
});
}
}
const factory = new SyncHookCodeFactory();
class SyncHook extends Hook {
// ... 省略其他代码
compile(options) {
factory.setup(this, options);
return factory.create(options);
}
}这里生成可执行代码使用了工厂模式:HookCodeFactory 是一个用来生成代码的工厂基类,每一个 Hook 中派生出一个子类。所有的 Hook 中 compile 都调用到了 create 方法。先来看一下这个 create 方法做了什么。
create(options) {
this.init(options);
switch(this.options.type) {
case "sync":
return new Function(this.args(), "\"use strict\";\n" + this.header() + this.content({
onError: err => `throw ${err};\n`,
onResult: result => `return ${result};\n`,
onDone: () => "",
rethrowIfPossible: true
}));
case "async":
return new Function(this.args({
after: "_callback"
}), "\"use strict\";\n" + this.header() + this.content({
onError: err => `_callback(${err});\n`,
onResult: result => `_callback(null, ${result});\n`,
onDone: () => "_callback();\n"
}));
case "promise":
let code = "";
code += "\"use strict\";\n";
code += "return new Promise((_resolve, _reject) => {\n";
code += "var _sync = true;\n";
code += this.header();
code += this.content({
onError: err => {
let code = "";
code += "if(_sync)\n";
code += `_resolve(Promise.resolve().then(() => { throw ${err}; }));\n`;
code += "else\n";
code += `_reject(${err});\n`;
return code;
},
onResult: result => `_resolve(${result});\n`,
onDone: () => "_resolve();\n"
});
code += "_sync = false;\n";
code += "});\n";
return new Function(this.args(), code);
}
}乍一看代码有点多,简化一下,画个图,就是下面的流程:

由此可以看到,create 中只实现了代码的主模板,实现了公共的部分(函数参数和函数一开始的公共参数),然后留出差异的部分 content,交给各个子类来实现。然后横向对比一下各个 Hook 中继承自 HookCodeFactory 的子 CodeFactory,看一下 content 的实现差异:
//syncHook
class SyncHookCodeFactory extends HookCodeFactory {
content({ onError, onResult, onDone, rethrowIfPossible }) {
return this.callTapsSeries({
onError: (i, err) => onError(err),
onDone,
rethrowIfPossible
});
}
}
//syncBailHook
content({ onError, onResult, onDone, rethrowIfPossible }) {
return this.callTapsSeries({
onError: (i, err) => onError(err),
onResult: (i, result, next) => `if(${result} !== undefined) {\n${onResult(result)};\n} else {\n${next()}}\n`,
onDone,
rethrowIfPossible
});
}
//AsyncSeriesLoopHook
class AsyncSeriesLoopHookCodeFactory extends HookCodeFactory {
content({ onError, onDone }) {
return this.callTapsLooping({
onError: (i, err, next, doneBreak) => onError(err) + doneBreak(true),
onDone
});
}
}
// 其他的结构都类似,便不在这里贴代码了可以看到,在所有的子类中,都实现了 content 方法,根据不同钩子执行流程的不同,调用了 callTapsSeries/callTapsParallel/callTapsLooping 并且会有 onError, onResult, onDone, rethrowIfPossible 这四中情况下的代码片段。
callTapsSeries/callTapsParallel/callTapsLooping 都在基类的方法中,这三个方法中都会走到一个 callTap 的方法。先看一下 callTap 方法。代码比较长,不想看代码的可以直接看后面的图。
callTap(tapIndex, { onError, onResult, onDone, rethrowIfPossible }) {
let code = "";
let hasTapCached = false;
// 这里的 interceptors 先忽略
for(let i = 0; i < this.options.interceptors.length; i++) {
const interceptor = this.options.interceptors[i];
if(interceptor.tap) {
if(!hasTapCached) {
code += `var _tap${tapIndex} = ${this.getTap(tapIndex)};\n`;
hasTapCached = true;
}
code += `${this.getInterceptor(i)}.tap(${interceptor.context ? "_context, " : ""}_tap${tapIndex});\n`;
}
}
code += `var _fn${tapIndex} = ${this.getTapFn(tapIndex)};\n`;
const tap = this.options.taps[tapIndex];
switch(tap.type) {
case "sync":
if(!rethrowIfPossible) {
code += `var _hasError${tapIndex} = false;\n`;
code += "try {\n";
}
if(onResult) {
code += `var _result${tapIndex} = _fn${tapIndex}(${this.args({
before: tap.context ? "_context" : undefined
})});\n`;
} else {
code += `_fn${tapIndex}(${this.args({
before: tap.context ? "_context" : undefined
})});\n`;
}
if(!rethrowIfPossible) {
code += "} catch(_err) {\n";
code += `_hasError${tapIndex} = true;\n`;
code += onError("_err");
code += "}\n";
code += `if(!_hasError${tapIndex}) {\n`;
}
if(onResult) {
code += onResult(`_result${tapIndex}`);
}
if(onDone) {
code += onDone();
}
if(!rethrowIfPossible) {
code += "}\n";
}
break;
case "async":
let cbCode = "";
if(onResult)
cbCode += `(_err${tapIndex}, _result${tapIndex}) => {\n`;
else
cbCode += `_err${tapIndex} => {\n`;
cbCode += `if(_err${tapIndex}) {\n`;
cbCode += onError(`_err${tapIndex}`);
cbCode += "} else {\n";
if(onResult) {
cbCode += onResult(`_result${tapIndex}`);
}
if(onDone) {
cbCode += onDone();
}
cbCode += "}\n";
cbCode += "}";
code += `_fn${tapIndex}(${this.args({
before: tap.context ? "_context" : undefined,
after: cbCode
})});\n`;
break;
case "promise":
code += `var _hasResult${tapIndex} = false;\n`;
code += `_fn${tapIndex}(${this.args({
before: tap.context ? "_context" : undefined
})}).then(_result${tapIndex} => {\n`;
code += `_hasResult${tapIndex} = true;\n`;
if(onResult) {
code += onResult(`_result${tapIndex}`);
}
if(onDone) {
code += onDone();
}
code += `}, _err${tapIndex} => {\n`;
code += `if(_hasResult${tapIndex}) throw _err${tapIndex};\n`;
code += onError(`_err${tapIndex}`);
code += "});\n";
break;
}
return code;
}也是对应的分成 sync/async/promise ,上面代码翻译成图,如下



总的来看, callTap 内是一次函数执行的模板,也是根据调用方式的不同,分为 sync/async/promise 三种。
然后看 callTapsSeries 方法,
callTapsSeries({ onError, onResult, onDone, rethrowIfPossible }) {
if(this.options.taps.length === 0)
return onDone();
const firstAsync = this.options.taps.findIndex(t => t.type !== "sync");
const next = i => {
if(i >= this.options.taps.length) {
return onDone();
}
const done = () => next(i + 1);
const doneBreak = (skipDone) => {
if(skipDone) return "";
return onDone();
}
return this.callTap(i, {
onError: error => onError(i, error, done, doneBreak),
// onResult 和 onDone 的判断条件,就是说有 onResult 或者 onDone
onResult: onResult && ((result) => {
return onResult(i, result, done, doneBreak);
}),
onDone: !onResult && (() => {
return done();
}),
rethrowIfPossible: rethrowIfPossible && (firstAsync < 0 || i < firstAsync)
});
};
return next(0);
}注意看 this.callTap 中 onResult 和 onDone 的条件,就是说要么执行 onResult, 要么执行 onDone。先看简单的直接走 onDone 的逻辑。那么结合上面 callTap 的流程,以 sync 为例,可以得到下面的图:

对于这种情况,callTapsSeries 的结果是递归的生成每一次的调用 code,直到最后一个时,直接调用外部传入的 onDone 方法得到结束的 code, 递归结束。而对于执行 onResult 的流程,看一下 onResult 代码: return onResult(i, result, done, doneBreak)。简单理解,和上面图中流程一样的,只不过在 done 的外面用 onResult 包裹了一层关于 onResult 的逻辑。
接着我们看 callTapsLooping 的代码:
callTapsLooping({ onError, onDone, rethrowIfPossible }) {
if(this.options.taps.length === 0)
return onDone();
const syncOnly = this.options.taps.every(t => t.type === "sync");
let code = "";
if(!syncOnly) {
code += "var _looper = () => {\n";
code += "var _loopAsync = false;\n";
}
// 在代码开始前加入 do 的逻辑
code += "var _loop;\n";
code += "do {\n";
code += "_loop = false;\n";
// interceptors 先忽略,只看主要部分
for(let i = 0; i < this.options.interceptors.length; i++) {
const interceptor = this.options.interceptors[i];
if(interceptor.loop) {
code += `${this.getInterceptor(i)}.loop(${this.args({
before: interceptor.context ? "_context" : undefined
})});\n`;
}
}
code += this.callTapsSeries({
onError,
onResult: (i, result, next, doneBreak) => {
let code = "";
code += `if(${result} !== undefined) {\n`;
code += "_loop = true;\n";
if(!syncOnly)
code += "if(_loopAsync) _looper();\n";
code += doneBreak(true);
code += `} else {\n`;
code += next();
code += `}\n`;
return code;
},
onDone: onDone && (() => {
let code = "";
code += "if(!_loop) {\n";
code += onDone();
code += "}\n";
return code;
}),
rethrowIfPossible: rethrowIfPossible && syncOnly
})
code += "} while(_loop);\n";
if(!syncOnly) {
code += "_loopAsync = true;\n";
code += "};\n";
code += "_looper();\n";
}
return code;
}先简化到最简单的逻辑就是下面这段,很简单的 do/while 逻辑。
var _loop
do {
_loop = false
// callTapsSeries 生成中间部分代码
} while(_loop)
code += "var _loop;\n";callTapsSeries 前面了解了其代码,这里调用 callTapsSeries 时,有 onResult 逻辑,也就是说中间部分会生成类似下面的代码(仍是以 sync 为例)
var _fn${tapIndex} = _x[${tapIndex}];
var _hasError${tapIndex} = false;
try {
fn1(${this.args({
before: tap.context ? "_context" : undefined
})});
} catch(_err) {
_hasError${tapIndex} = true;
onError("_err");
}
if(!_hasError${tapIndex}) {
// onResult 中生成的代码
if(${result} !== undefined) {
_loop = true;
// doneBreak 位于 callTapsSeries 代码中
//(skipDone) => {
// if(skipDone) return "";
// return onDone();
// }
doneBreak(true); // 实际为空语句
} else {
next()
}
}通过在 onResult 中控制函数执行完成后到执行下一个函数之间,生成代码的不同,就从 callTapsSeries 中衍生出了 LoopHook 的逻辑。
然后我们看 callTapsParallel
callTapsParallel({ onError, onResult, onDone, rethrowIfPossible, onTap = (i, run) => run() }) {
if(this.options.taps.length <= 1) {
return this.callTapsSeries({ onError, onResult, onDone, rethrowIfPossible })
}
let code = "";
code += "do {\n";
code += `var _counter = ${this.options.taps.length};\n`;
if(onDone) {
code += "var _done = () => {\n";
code += onDone();
code += "};\n";
}
for(let i = 0; i < this.options.taps.length; i++) {
const done = () => {
if(onDone)
return "if(--_counter === 0) _done();\n";
else
return "--_counter;";
};
const doneBreak = (skipDone) => {
if(skipDone || !onDone)
return "_counter = 0;\n";
else
return "_counter = 0;\n_done();\n";
}
code += "if(_counter <= 0) break;\n";
code += onTap(i, () => this.callTap(i, {
onError: error => {
let code = "";
code += "if(_counter > 0) {\n";
code += onError(i, error, done, doneBreak);
code += "}\n";
return code;
},
onResult: onResult && ((result) => {
let code = "";
code += "if(_counter > 0) {\n";
code += onResult(i, result, done, doneBreak);
code += "}\n";
return code;
}),
onDone: !onResult && (() => {
return done();
}),
rethrowIfPossible
}), done, doneBreak);
}
code += "} while(false);\n";
return code;
}由于 callTapsParallel 最终生成的代码是并发执行的,那么代码流程就和两个差异较大。上面代码看起来较多,捋一下主要结构,其实就是下面的图(仍是以 sync 为例)

总结一下 callTap 中实现了 sync/promise/async 三种基本的一次函数执行的模板,同时将涉及函数执行流程的代码 onError/onDone/onResult 部分留出来。而 callTapsSeries/callTapsLooping/callTapsParallel 中,通过传入不同的 onError/onDone/onResult 实现出不同流程的模板。不过 callTapsParallel 由于差异较大,通过在 callTap 外包裹一层 onTap 函数,对生成的结果进行再次加工。
到此,我们得到了 series/looping/parallel 三大类基础模板。我们注意到,callTapsSeries/callTapsLooping/callTapsParallel 中同时也暴露出了自己的 onError, onResult, onDone, rethrowIfPossible, onTap,由此来实现每个子 Hook 根据不同情况对基础模板进行定制。以 SyncBailHook 为例,它和 callTapsSeries 得到的基础模板的主要区别在于函数执行结束时机不同。因此对于 SyncBailHook 来说,修改 onResult 即可达到目的:
class SyncBailHookCodeFactory extends HookCodeFactory {
content({ onError, onResult, onDone, rethrowIfPossible }) {
return this.callTapsSeries({
onError: (i, err) => onError(err),
// 修改一下 onResult,如果 函数执行得到的 result 不为 undefined 则直接返回结果,否则继续执行下一个函数
onResult: (i, result, next) => `if(${result} !== undefined) {\n${onResult(result)};\n} else {\n${next()}}\n`,
onDone,
rethrowIfPossible
});
}
}
最后我们来用一张图,整体的总结一下 compile 部分生成最终执行代码的思路:总结出通用的代码模板,将差异化部分拆分到函数中并且暴露给外部来实现。

相比于简单的 EventEmit 来说,Tapable 作为 webpack 底层事件流库,提供了丰富的事件。而最终事件触发后的执行,是先动态生成执行的 code,然后通过 new Function 来执行。相比于我们平时直接遍历或者递归的调用每一个事件来说,这种执行方法效率上来说相对更高效。虽然平时写代码时,对于一个循环,是拆开来写每一个还是直接 for 循环,在效率上来说看不出什么,但是对 webpack 来说,由于其整体是由事件机制推动,内部存在大量这样的逻辑。那么这种拆开来直接执行每一个函数的方式,便可看出其优势所在。
最近将内部测试框架的底层库从mocha迁移到了AVA,迁移的原因之一是因为AVA提供了更好的流程控制。
我们从一个例子开始入手:
有A,B,C,D4个case,我要实现A -->> B -->> (C | D),A最先执行,B等待A执行完再执行,最后是(C | D)并发执行,使用ava提供的API来完成case就是:
const ava = require('ava')
ava.serial('A', async () => {
// do something
})
ava.serial('B', async () => {
// do something
})
ava('C', async () => {
// do something
})
ava('D', async () => {
// do something
})接下来我们就来具体看下AVA内部是如何实现流程控制的:
在AVA内实现了一个Sequence类:
class Sequence {
constructor (runnables) {
this.runnables = runnables
}
run() {
// do something
}
}这个Sequence类可以理解成集合的概念,这个集合内部包含的每一个元素可以是由一个case组成,也可以是由多个case组成。这个类的实例当中runnables属性(数组)保存了需要串行执行的case或case组。一个case可以当做一个组(runnables),多个case也可以当做一组,AVA用Sequence这个类来保证在runnables中保存的不同元素的顺序执行。
顺序执行了解后,我们再看下AVA内部实现的另外一个控制case并行执行的类:Concurrent:
class Concurrent {
constructor (runnables) {
this.runnables = runnables
}
run () {
// do something
}
}可以将Concurrent可以理解为组的概念,实例当中的runnables属性(数组)保存了这个组中所有待执行的case。这个Concurrent和上面提到的Sequence组都部署了run方法,用以runnables的执行,不同的地方在于,这个组内的case都是并行执行的。
具体到我们提供的实例当中:A -->> B -->> (C | D),AVA是如何从这2个类来实现他们之间的按序执行的呢?
在你定义case的时候:
ava.serial('A', async () => {
// do something
})
ava.serial('B', async () => {
// do something
})
ava('C', async () => {
// do something
})
ava('D', async () => {
// do something
})在ava内部便会维护一个serial数组用以保存顺序执行的case,concurrent数组用以保存并行执行的case:
const serial = ['A', 'B'];
const concurrent = ['C', 'D']然后用这2个数组,分别实例化一个Sequence和Concurrent实例:
const serialTests = new Sequence(serial)
const concurrentTests = new Concurrent(concurrent)这样保证了serialTests内部的case是顺序执行的,concurrentTests内部的case是并行执行的。但是如何保证这2个实例(serialTests和concurrentTests)之间的顺序执行呢?即serialTests内部case顺序执行完后,再进行concurrentTests的并行执行。
同样是使用Sequence这个类,实例化一个Sequence实例:
const allTests = new Sequence([serialTests, concurrentTests])之前我们就提到过Sequence实例的runnables属性中就维护了串行执行的case,所以在这里的具体体现就是,serialTests和concurrentTests之间是串行执行的,这也对应着:A -->> B -->> (C | D)。
接下来,我们就具体看下对应具体的流程实现:
allTests是所有这些case的集合,Sequence类上部署了run方法,因此调用:
allTests.run()开始case的执行。在Sequence类的run方法当中:
class Sequence {
constructor (runnables) {
this.runnables = runnables
}
run () {
// 首先获取runnables的迭代器对象,runnables数组保存了顺序执行的case
const iterator = this.runnables[Symbol.iterator]()
let activeRunnable
// 定义runNext方法,主要是用于保证case执行的顺序
// 因为ava支持同步和异步的case,这里也着重分析下异步case的执行顺序
const runNext = () => {
// 每次调用runNext方法都初始化一个新变量,用以保存异步case返回的promise
let promise
// 通过迭代器指针去遍历需要串行执行的case
for (let next = iterator.next(); !next.done; next = iterator.next()) {
// activeRunnable即每一个case或者是case的集合
activeRunnable = next.value
// 调用case的run方法,或者case集合的run方法,如果activeRunnable是一个case,那么就会执行这个case,而如果是case集合,调用run方法后,还是对应于sequence的run方法
// 因此在调用allTests.run()的时候,第一个activeRunnable就是'A',‘B’2个case的集合(sequence实例)。
const passedOrPromise = activeRunnable.run()
// passedOrPromise如果返回为false,即代表这个同步的case执行失败
if (!passedOrPromise) {
// do something
} else if (passedOrPromise !== true) { // !!!注意这里,如果passedOrPromise是个promise,那么会调用break来跳出这个for循环,进行到下面的步骤,这也是sequence类保证case顺序执行的关键。
promise = passedOrPromise
break;
}
}
if (!promise) {
return this.finish()
}
// !!!通过then方法,保证上一个promise被resolve后(即case执行完后),再进行后面的步骤,如果then接受passed参数为真,那么继续调用runNext()方法。再次调用runNext方法后,通过迭代器访问的数组:iterator迭代器的内部指针就不会从这个数组的一开始的起始位置开始访问,而是从上一次for循环结束的地方开始。这样也就保证了异步case的顺序执行
return promise.then(passed => {
if (!passed) {
// do something
}
return runNext()
})
}
return runNext()
}
}具体到我们提供的例子当中:
allTests这个Sequence实例的runnables属性保存了一个Sequence实例(A和B)和一个Concurrent实例(C和D)。
在调用allTests.run()后,在对allTesets的runnables的迭代器对象进行遍历的时候,首先调用包含A和B的Sequence实例的run方法,在run内部递归调用runNext方法,用以确保异步case的顺序执行。
具体的实现主要还是使用了Promise迭代链来完成异步任务的顺序执行:每次进行异步case时,这个异步的case会返回一个promise,这个时候停止迭代器对象的遍历,而是通过在promise的then方法中递归调用runNext(),来保证顺序执行。
return promise.then(passed => {
if (!passed) {
// do something
}
return runNext()
})当A和B组成的Sequence执行完成后,才会继续执行由C和D组成的Conccurent,接下来我们看下并发执行case的内部实现:同样在Concurrent类上也部署了run方法,用以开始需要并发执行的case:
class Concurrent {
constructor(runnables, bail) {
if (!Array.isArray(runnables)) {
throw new TypeError('Expected an array of runnables');
}
this.runnables = runnables;
}
run () {
// 所有的case是否通过
let allPassed = true;
let pending;
let rejectPending;
let resolvePending;
// 维护一个promise数组
const allPromises = [];
const handlePromise = promise => {
// 初始化一个pending的promise
if (!pending) {
pending = new Promise((resolve, reject) => {
rejectPending = reject;
resolvePending = resolve;
});
}
// 如果每个case都返回的是一个promise,那么首先调用then方法添加对于这个promise被resolve或者reject的处理函数,(这个添加被reject的处理,主要是用于下面Promise.all方法来处理所有被resolve的case)同时将这个promise推入到allPromises数组当中
allPromises.push(promise.then(passed => {
if (!passed) {
allPassed = false;
if (this.bail) {
// Stop if the test failed and bail mode is on.
resolvePending();
}
}
}, rejectPending));
};
// 通过for循环遍历runnables中保存的case。
for (const runnable of this.runnables) {
// 调用每个case的run方法
const passedOrPromise = runnable.run();
// 如果是同步的case,且执行失败了
if (!passedOrPromise) {
if (this.bail) {
// Stop if the test failed and bail mode is on.
return false;
}
allPassed = false;
} else if (passedOrPromise !== true) { // !!!如果返回的是一个promise
handlePromise(passedOrPromise);
}
}
if (pending) {
// 使用Promise.all去处理allPromises当中的promise。当所有的promise被resolve后才会调用resolvePending,因为resolvePending对应于pending这个promise的resolve方法,也就是pending这个promise也被resolve,最后调用pending的then方法中添加的对于promise被resolve的方法。
Promise.all(allPromises).then(resolvePending);
// 返回一个处于pending态的promise,但是它的then方法中添加了这个promise被resolve后的处理函数,即返回allPassed
return pending.then(() => allPassed);
}
// 如果是同步的测试
return allPassed;
}
}
}具体到我们的例子当中:Concurrent实例的runnables属性中保存了C和D2个case,调用实例的run方法后,C和D2个case即开始并发执行,不同于Sequence内部通过iterator遍历器来实现的case的顺序执行,Concurrent内部直接只用for循环来启动case的执行,然后通过维护一个promise数组,并调用Promise.all来处理promise数组的状态。
以上就是通过一个简单的例子介绍了AVA内部的流程控制模型。简单的总结下:
在AVA内部使用Promise来进行整个的流程控制(这里指的异步的case)。
串行:
Sequence类来保证case的串行执行,在需要串行运行的case当中,调用Sequence实例的runNext方法开始case的执行,通过获取case数组的iterator对象来手动对case(或case的集合)进行遍历执行,因为每个异步的case内部都返回了一个promise,这个时候会跳出对iterator的遍历,通过在这个promise的then方法中递归调用runNext方法,这样就保证了case的串行执行。
并行:
Concurrent类来保证case的并行执行,遇到需要并行运行的case时,同样是使用for循环,但是不是通过获取数组iterator迭代器对象去手动遍历,而是并发去执行,同时通过一个数组去收集这些并发执行的case返回的promise,最后通过Promise.all方法去处理这些未被resolve的promise,当然这里面也有一些小技巧,我在上面的分析中也指出了,这里不再赘述。
关于文中提到的Promise进行异步流程控制具体的应用,可以看下这2篇文章:
在现在单页应用这么火爆的年代,路由已经成为了我们开发应用必不可少的利器;而纵观各大框架,都会有对应的强大路由支持。Vue.js 因其性能、通用、易用、体积、学习成本低等特点已经成为了广大前端们的新宠,而其对应的路由 vue-router 也是设计的简单好用,功能强大。本文就从源码来分析下 Vue.js 官方路由 vue-router 的整体流程。
本文主要以 vue-router 的 2.0.3 版本来进行分析。
首先来张整体的图:
先对整体有个大概的印象,下边就以官方仓库下 examples/basic 基础例子来一点点具体分析整个流程。
先来看看整体的目录结构:
和流程相关的主要需要关注点的就是 components、history 目录以及 create-matcher.js、create-route-map.js、index.js、install.js。下面就从 basic 应用入口开始来分析 vue-router 的整个流程。
首先看应用入口的代码部分:
import Vue from 'vue'
import VueRouter from 'vue-router'
// 1. 插件
// 安装 <router-view> and <router-link> 组件
// 且给当前应用下所有的组件都注入 $router and $route 对象
Vue.use(VueRouter)
// 2. 定义各个路由下使用的组件,简称路由组件
const Home = { template: '<div>home</div>' }
const Foo = { template: '<div>foo</div>' }
const Bar = { template: '<div>bar</div>' }
// 3. 创建 VueRouter 实例 router
const router = new VueRouter({
mode: 'history',
base: __dirname,
routes: [
{ path: '/', component: Home },
{ path: '/foo', component: Foo },
{ path: '/bar', component: Bar }
]
})
// 4. 创建 启动应用
// 一定要确认注入了 router
// 在 <router-view> 中将会渲染路由组件
new Vue({
router,
template: `
<div id="app">
<h1>Basic</h1>
<ul>
<li><router-link to="/">/</router-link></li>
<li><router-link to="/foo">/foo</router-link></li>
<li><router-link to="/bar">/bar</router-link></li>
<router-link tag="li" to="/bar">/bar</router-link>
</ul>
<router-view class="view"></router-view>
</div>
`
}).$mount('#app')上边代码中关键的第 1 步,利用 Vue.js 提供的插件机制 .use(plugin) 来安装 VueRouter,而这个插件机制则会调用该 plugin 对象的 install 方法(当然如果该 plugin 没有该方法的话会把 plugin 自身作为函数来调用);下边来看下 vue-router 这个插件具体的实现部分。
VueRouter 对象是在 src/index.js 中暴露出来的,这个对象有一个静态的 install 方法:
/* @flow */
// 导入 install 模块
import { install } from './install'
// ...
import { inBrowser, supportsHistory } from './util/dom'
// ...
export default class VueRouter {
// ...
}
// 赋值 install
VueRouter.install = install
// 自动使用插件
if (inBrowser && window.Vue) {
window.Vue.use(VueRouter)
}可以看到这是一个 Vue.js 插件的经典写法,给插件对象增加 install 方法用来安装插件具体逻辑,同时在最后判断下如果是在浏览器环境且存在 window.Vue 的话就会自动使用插件。
install 在这里是一个单独的模块,继续来看同级下的 src/install.js 的主要逻辑:
// router-view router-link 组件
import View from './components/view'
import Link from './components/link'
// export 一个 Vue 引用
export let _Vue
// 安装函数
export function install (Vue) {
if (install.installed) return
install.installed = true
// 赋值私有 Vue 引用
_Vue = Vue
// 注入 $router $route
Object.defineProperty(Vue.prototype, '$router', {
get () { return this.$root._router }
})
Object.defineProperty(Vue.prototype, '$route', {
get () { return this.$root._route }
})
// beforeCreate mixin
Vue.mixin({
beforeCreate () {
// 判断是否有 router
if (this.$options.router) {
// 赋值 _router
this._router = this.$options.router
// 初始化 init
this._router.init(this)
// 定义响应式的 _route 对象
Vue.util.defineReactive(this, '_route', this._router.history.current)
}
}
})
// 注册组件
Vue.component('router-view', View)
Vue.component('router-link', Link)
// ...
}这里就会有一些疑问了?
插件在打包的时候是肯定不希望把 vue 作为一个依赖包打进去的,但是呢又希望使用
Vue对象本身的一些方法,此时就可以采用上边类似的做法,在install的时候把这个变量赋值Vue,这样就可以在其他地方使用Vue的一些方法而不必引入 vue 依赖包(前提是保证install后才会使用)。
Vue.prototype 定义 $router、$route 属性就可以把他们注入到所有组件中吗?在 Vue.js 中所有的组件都是被扩展的 Vue 实例,也就意味着所有的组件都可以访问到这个实例原型上定义的属性。
beforeCreate mixin 这个在后边创建 Vue 实例的时候再细说。
VueRouter在入口文件中,首先要实例化一个 VueRouter ,然后将其传入 Vue 实例的 options 中。现在继续来看在 src/index.js 中暴露出来的 VueRouter 类:
// ...
import { createMatcher } from './create-matcher'
// ...
export default class VueRouter {
// ...
constructor (options: RouterOptions = {}) {
this.app = null
this.options = options
this.beforeHooks = []
this.afterHooks = []
// 创建 match 匹配函数
this.match = createMatcher(options.routes || [])
// 根据 mode 实例化具体的 History
let mode = options.mode || 'hash'
this.fallback = mode === 'history' && !supportsHistory
if (this.fallback) {
mode = 'hash'
}
if (!inBrowser) {
mode = 'abstract'
}
this.mode = mode
switch (mode) {
case 'history':
this.history = new HTML5History(this, options.base)
break
case 'hash':
this.history = new HashHistory(this, options.base, this.fallback)
break
case 'abstract':
this.history = new AbstractHistory(this)
break
default:
assert(false, `invalid mode: ${mode}`)
}
}
// ...
}里边包含了重要的一步:创建 match 匹配函数。
match 匹配函数匹配函数是由 src/create-matcher.js 中的 createMatcher 创建的:
/* @flow */
import Regexp from 'path-to-regexp'
// ...
import { createRouteMap } from './create-route-map'
// ...
export function createMatcher (routes: Array<RouteConfig>): Matcher {
// 创建路由 map
const { pathMap, nameMap } = createRouteMap(routes)
// 匹配函数
function match (
raw: RawLocation,
currentRoute?: Route,
redirectedFrom?: Location
): Route {
// ...
}
function redirect (
record: RouteRecord,
location: Location
): Route {
// ...
}
function alias (
record: RouteRecord,
location: Location,
matchAs: string
): Route {
// ...
}
function _createRoute (
record: ?RouteRecord,
location: Location,
redirectedFrom?: Location
): Route {
if (record && record.redirect) {
return redirect(record, redirectedFrom || location)
}
if (record && record.matchAs) {
return alias(record, location, record.matchAs)
}
return createRoute(record, location, redirectedFrom)
}
// 返回
return match
}
// ...具体逻辑后续再具体分析,现在只需要理解为根据传入的 routes 配置生成对应的路由 map,然后直接返回了 match 匹配函数。
继续来看 src/create-route-map.js 中的 createRouteMap 函数:
/* @flow */
import { assert, warn } from './util/warn'
import { cleanPath } from './util/path'
// 创建路由 map
export function createRouteMap (routes: Array<RouteConfig>): {
pathMap: Dictionary<RouteRecord>,
nameMap: Dictionary<RouteRecord>
} {
// path 路由 map
const pathMap: Dictionary<RouteRecord> = Object.create(null)
// name 路由 map
const nameMap: Dictionary<RouteRecord> = Object.create(null)
// 遍历路由配置对象 增加 路由记录
routes.forEach(route => {
addRouteRecord(pathMap, nameMap, route)
})
return {
pathMap,
nameMap
}
}
// 增加 路由记录 函数
function addRouteRecord (
pathMap: Dictionary<RouteRecord>,
nameMap: Dictionary<RouteRecord>,
route: RouteConfig,
parent?: RouteRecord,
matchAs?: string
) {
// 获取 path 、name
const { path, name } = route
assert(path != null, `"path" is required in a route configuration.`)
// 路由记录 对象
const record: RouteRecord = {
path: normalizePath(path, parent),
components: route.components || { default: route.component },
instances: {},
name,
parent,
matchAs,
redirect: route.redirect,
beforeEnter: route.beforeEnter,
meta: route.meta || {}
}
// 嵌套子路由 则递归增加 记录
if (route.children) {
// ...
route.children.forEach(child => {
addRouteRecord(pathMap, nameMap, child, record)
})
}
// 处理别名 alias 逻辑 增加对应的 记录
if (route.alias !== undefined) {
if (Array.isArray(route.alias)) {
route.alias.forEach(alias => {
addRouteRecord(pathMap, nameMap, { path: alias }, parent, record.path)
})
} else {
addRouteRecord(pathMap, nameMap, { path: route.alias }, parent, record.path)
}
}
// 更新 path map
pathMap[record.path] = record
// 更新 name map
if (name) {
if (!nameMap[name]) {
nameMap[name] = record
} else {
warn(false, `Duplicate named routes definition: { name: "${name}", path: "${record.path}" }`)
}
}
}
function normalizePath (path: string, parent?: RouteRecord): string {
path = path.replace(/\/$/, '')
if (path[0] === '/') return path
if (parent == null) return path
return cleanPath(`${parent.path}/${path}`)
}可以看出主要做的事情就是根据用户路由配置对象生成普通的根据 path 来对应的路由记录以及根据 name 来对应的路由记录的 map,方便后续匹配对应。
这也是很重要的一步,所有的 History 类都是在 src/history/ 目录下,现在呢不需要关心具体的每种 History 的具体实现上差异,只需要知道他们都是继承自 src/history/base.js 中的 History 类的:
/* @flow */
// ...
import { inBrowser } from '../util/dom'
import { runQueue } from '../util/async'
import { START, isSameRoute } from '../util/route'
// 这里从之前分析过的 install.js 中 export _Vue
import { _Vue } from '../install'
export class History {
// ...
constructor (router: VueRouter, base: ?string) {
this.router = router
this.base = normalizeBase(base)
// start with a route object that stands for "nowhere"
this.current = START
this.pending = null
}
// ...
}
// 得到 base 值
function normalizeBase (base: ?string): string {
if (!base) {
if (inBrowser) {
// respect <base> tag
const baseEl = document.querySelector('base')
base = baseEl ? baseEl.getAttribute('href') : '/'
} else {
base = '/'
}
}
// make sure there's the starting slash
if (base.charAt(0) !== '/') {
base = '/' + base
}
// remove trailing slash
return base.replace(/\/$/, '')
}
// ...实例化完了 VueRouter,下边就该看看 Vue 实例了。
Vue实例化很简单:
new Vue({
router,
template: `
<div id="app">
<h1>Basic</h1>
<ul>
<li><router-link to="/">/</router-link></li>
<li><router-link to="/foo">/foo</router-link></li>
<li><router-link to="/bar">/bar</router-link></li>
<router-link tag="li" to="/bar">/bar</router-link>
</ul>
<router-view class="view"></router-view>
</div>
`
}).$mount('#app')options 中传入了 router,以及模板;还记得上边没具体分析的 beforeCreate mixin 吗,此时创建一个 Vue 实例,对应的 beforeCreate 钩子就会被调用:
// ...
Vue.mixin({
beforeCreate () {
// 判断是否有 router
if (this.$options.router) {
// 赋值 _router
this._router = this.$options.router
// 初始化 init
this._router.init(this)
// 定义响应式的 _route 对象
Vue.util.defineReactive(this, '_route', this._router.history.current)
}
}
})具体来说,首先判断实例化时 options 是否包含 router,如果包含也就意味着是一个带有路由配置的实例被创建了,此时才有必要继续初始化路由相关逻辑。然后给当前实例赋值 _router,这样在访问原型上的 $router 的时候就可以得到 router 了。
下边来看里边两个关键:router.init 和 定义响应式的 _route 对象。
然后来看 router 的 init 方法就干了哪些事情,依旧是在 src/index.js 中:
/* @flow */
import { install } from './install'
import { createMatcher } from './create-matcher'
import { HashHistory, getHash } from './history/hash'
import { HTML5History, getLocation } from './history/html5'
import { AbstractHistory } from './history/abstract'
import { inBrowser, supportsHistory } from './util/dom'
import { assert } from './util/warn'
export default class VueRouter {
// ...
init (app: any /* Vue component instance */) {
// ...
this.app = app
const history = this.history
if (history instanceof HTML5History) {
history.transitionTo(getLocation(history.base))
} else if (history instanceof HashHistory) {
history.transitionTo(getHash(), () => {
window.addEventListener('hashchange', () => {
history.onHashChange()
})
})
}
history.listen(route => {
this.app._route = route
})
}
// ...
}
// ...可以看到初始化主要就是给 app 赋值,针对于 HTML5History 和 HashHistory 特殊处理,因为在这两种模式下才有可能存在进入时候的不是默认页,需要根据当前浏览器地址栏里的 path 或者 hash 来激活对应的路由,此时就是通过调用 transitionTo 来达到目的;而且此时还有个注意点是针对于 HashHistory 有特殊处理,为什么不直接在初始化 HashHistory 的时候监听 hashchange 事件呢?这个是为了修复vuejs/vue-router#725这个 bug 而这样做的,简要来说就是说如果在 beforeEnter 这样的钩子函数中是异步的话,beforeEnter 钩子就会被触发两次,原因是因为在初始化的时候如果此时的 hash 值不是以 / 开头的话就会补上 #/,这个过程会触发 hashchange 事件,所以会再走一次生命周期钩子,也就意味着会再次调用 beforeEnter 钩子函数。
来看看这个具体的 transitionTo 方法的大概逻辑,在 src/history/base.js 中:
/* @flow */
import type VueRouter from '../index'
import { warn } from '../util/warn'
import { inBrowser } from '../util/dom'
import { runQueue } from '../util/async'
import { START, isSameRoute } from '../util/route'
import { _Vue } from '../install'
export class History {
// ...
transitionTo (location: RawLocation, cb?: Function) {
// 调用 match 得到匹配的 route 对象
const route = this.router.match(location, this.current)
// 确认过渡
this.confirmTransition(route, () => {
// 更新当前 route 对象
this.updateRoute(route)
cb && cb(route)
// 子类实现的更新url地址
// 对于 hash 模式的话 就是更新 hash 的值
// 对于 history 模式的话 就是利用 pushstate / replacestate 来更新
// 浏览器地址
this.ensureURL()
})
}
// 确认过渡
confirmTransition (route: Route, cb: Function) {
const current = this.current
// 如果是相同 直接返回
if (isSameRoute(route, current)) {
this.ensureURL()
return
}
// 交叉比对当前路由的路由记录和现在的这个路由的路由记录
// 以便能准确得到父子路由更新的情况下可以确切的知道
// 哪些组件需要更新 哪些不需要更新
const {
deactivated,
activated
} = resolveQueue(this.current.matched, route.matched)
// 整个切换周期的队列
const queue: Array<?NavigationGuard> = [].concat(
// leave 的钩子
extractLeaveGuards(deactivated),
// 全局 router before hooks
this.router.beforeHooks,
// 将要更新的路由的 beforeEnter 钩子
activated.map(m => m.beforeEnter),
// 异步组件
resolveAsyncComponents(activated)
)
this.pending = route
每一个队列执行的 iterator 函数
const iterator = (hook: NavigationGuard, next) => {
// 确保期间还是当前路由
if (this.pending !== route) return
hook(route, current, (to: any) => {
if (to === false) {
// next(false) -> abort navigation, ensure current URL
this.ensureURL(true)
} else if (typeof to === 'string' || typeof to === 'object') {
// next('/') or next({ path: '/' }) -> redirect
this.push(to)
} else {
// confirm transition and pass on the value
next(to)
}
})
}
// 执行队列
runQueue(queue, iterator, () => {
const postEnterCbs = []
// 组件内的钩子
const enterGuards = extractEnterGuards(activated, postEnterCbs, () => {
return this.current === route
})
// 在上次的队列执行完成后再执行组件内的钩子
// 因为需要等异步组件以及是OK的情况下才能执行
runQueue(enterGuards, iterator, () => {
// 确保期间还是当前路由
if (this.pending === route) {
this.pending = null
cb(route)
this.router.app.$nextTick(() => {
postEnterCbs.forEach(cb => cb())
})
}
})
})
}
// 更新当前 route 对象
updateRoute (route: Route) {
const prev = this.current
this.current = route
// 注意 cb 的值
// 每次更新都会调用 下边需要用到!
this.cb && this.cb(route)
// 执行 after hooks 回调
this.router.afterHooks.forEach(hook => {
hook && hook(route, prev)
})
}
}
// ...可以看到整个过程就是执行约定的各种钩子以及处理异步组件问题,这里有一些具体函数具体细节被忽略掉了(后续会具体分析)但是不影响具体理解这个流程。但是需要注意一个概念:路由记录,每一个路由 route 对象都对应有一个 matched 属性,它对应的就是路由记录,他的具体含义在调用 match() 中有处理;通过之前的分析可以知道这个 match 是在 src/create-matcher.js 中的:
// ...
import { createRoute } from './util/route'
import { createRouteMap } from './create-route-map'
// ...
export function createMatcher (routes: Array<RouteConfig>): Matcher {
const { pathMap, nameMap } = createRouteMap(routes)
// 关键的 match
function match (
raw: RawLocation,
currentRoute?: Route,
redirectedFrom?: Location
): Route {
const location = normalizeLocation(raw, currentRoute)
const { name } = location
// 命名路由处理
if (name) {
// nameMap[name] = 路由记录
const record = nameMap[name]
const paramNames = getParams(record.path)
// ...
if (record) {
location.path = fillParams(record.path, location.params, `named route "${name}"`)
// 创建 route
return _createRoute(record, location, redirectedFrom)
}
} else if (location.path) {
// 普通路由处理
location.params = {}
for (const path in pathMap) {
if (matchRoute(path, location.params, location.path)) {
// 匹配成功 创建route
// pathMap[path] = 路由记录
return _createRoute(pathMap[path], location, redirectedFrom)
}
}
}
// no match
return _createRoute(null, location)
}
// ...
// 创建路由
function _createRoute (
record: ?RouteRecord,
location: Location,
redirectedFrom?: Location
): Route {
// 重定向和别名逻辑
if (record && record.redirect) {
return redirect(record, redirectedFrom || location)
}
if (record && record.matchAs) {
return alias(record, location, record.matchAs)
}
// 创建路由对象
return createRoute(record, location, redirectedFrom)
}
return match
}
// ...路由记录在分析 match 匹配函数那里以及分析过了,这里还需要了解下创建路由对象的 createRoute,存在于 src/util/route.js 中:
// ...
export function createRoute (
record: ?RouteRecord,
location: Location,
redirectedFrom?: Location
): Route {
// 可以看到就是一个被冻结的普通对象
const route: Route = {
name: location.name || (record && record.name),
meta: (record && record.meta) || {},
path: location.path || '/',
hash: location.hash || '',
query: location.query || {},
params: location.params || {},
fullPath: getFullPath(location),
// 根据记录层级的得到所有匹配的 路由记录
matched: record ? formatMatch(record) : []
}
if (redirectedFrom) {
route.redirectedFrom = getFullPath(redirectedFrom)
}
return Object.freeze(route)
}
// ...
function formatMatch (record: ?RouteRecord): Array<RouteRecord> {
const res = []
while (record) {
res.unshift(record)
record = record.parent
}
return res
}
// ...回到之前看的 init,最后调用了 history.listen 方法:
history.listen(route => {
this.app._route = route
})listen 方法很简单就是设置下当前历史对象的 cb 的值, 在之前分析 transitionTo 的时候已经知道在 history 更新完毕的时候调用下这个 cb。然后看这里设置的这个函数的作用就是更新下当前应用实例的 _route 的值,更新这个有什么用呢?请看下段落的分析。
继续回到 beforeCreate 钩子函数中,在最后通过 Vue 的工具方法给当前应用实例定义了一个响应式的 _route 属性,值就是获取的 this._router.history.current,也就是当前 history 实例的当前活动路由对象。给应用实例定义了这么一个响应式的属性值也就意味着如果该属性值发生了变化,就会触发更新机制,继而调用应用实例的 render 重新渲染。还记得上一段结尾留下的疑问,也就是 history 每次更新成功后都会去更新应用实例的 _route 的值,也就意味着一旦 history 发生改变就会触发更新机制调用应用实例的 render 方法进行重新渲染。
回到实例化应用实例的地方:
new Vue({
router,
template: `
<div id="app">
<h1>Basic</h1>
<ul>
<li><router-link to="/">/</router-link></li>
<li><router-link to="/foo">/foo</router-link></li>
<li><router-link to="/bar">/bar</router-link></li>
<router-link tag="li" to="/bar">/bar</router-link>
</ul>
<router-view class="view"></router-view>
</div>
`
}).$mount('#app')可以看到这个实例的 template 中包含了两个自定义组件:router-link 和 router-view。
router-view 组件比较简单,所以这里就先来分析它,他是在源码的 src/components/view.js 中定义的:
export default {
name: 'router-view',
functional: true, // 功能组件 纯粹渲染
props: {
name: {
type: String,
default: 'default' // 默认default 默认命名视图的name
}
},
render (h, { props, children, parent, data }) {
// 解决嵌套深度问题
data.routerView = true
// route 对象
const route = parent.$route
// 缓存
const cache = parent._routerViewCache || (parent._routerViewCache = {})
let depth = 0
let inactive = false
// 当前组件的深度
while (parent) {
if (parent.$vnode && parent.$vnode.data.routerView) {
depth++
}
处理 keepalive 逻辑
if (parent._inactive) {
inactive = true
}
parent = parent.$parent
}
data.routerViewDepth = depth
// 得到相匹配的当前组件层级的 路由记录
const matched = route.matched[depth]
if (!matched) {
return h()
}
// 得到要渲染组件
const name = props.name
const component = inactive
? cache[name]
: (cache[name] = matched.components[name])
if (!inactive) {
// 非 keepalive 模式下 每次都需要设置钩子
// 进而更新(赋值&销毁)匹配了的实例元素
const hooks = data.hook || (data.hook = {})
hooks.init = vnode => {
matched.instances[name] = vnode.child
}
hooks.prepatch = (oldVnode, vnode) => {
matched.instances[name] = vnode.child
}
hooks.destroy = vnode => {
if (matched.instances[name] === vnode.child) {
matched.instances[name] = undefined
}
}
}
// 调用 createElement 函数 渲染匹配的组件
return h(component, data, children)
}
}可以看到逻辑还是比较简单的,拿到匹配的组件进行渲染就可以了。
再来看看导航链接组件,他在源码的 src/components/link.js 中定义的:
// ...
import { createRoute, isSameRoute, isIncludedRoute } from '../util/route'
// ...
export default {
name: 'router-link',
props: {
// 传入的组件属性们
to: { // 目标路由的链接
type: toTypes,
required: true
},
// 创建的html标签
tag: {
type: String,
default: 'a'
},
// 完整模式,如果为 true 那么也就意味着
// 绝对相等的路由才会增加 activeClass
// 否则是包含关系
exact: Boolean,
// 在当前(相对)路径附加路径
append: Boolean,
// 如果为 true 则调用 router.replace() 做替换历史操作
replace: Boolean,
// 链接激活时使用的 CSS 类名
activeClass: String
},
render (h: Function) {
// 得到 router 实例以及当前激活的 route 对象
const router = this.$router
const current = this.$route
const to = normalizeLocation(this.to, current, this.append)
// 根据当前目标链接和当前激活的 route匹配结果
const resolved = router.match(to, current)
const fullPath = resolved.redirectedFrom || resolved.fullPath
const base = router.history.base
// 创建的 href
const href = createHref(base, fullPath, router.mode)
const classes = {}
// 激活class 优先当前组件上获取 要么就是 router 配置的 linkActiveClass
// 默认 router-link-active
const activeClass = this.activeClass || router.options.linkActiveClass || 'router-link-active'
// 相比较目标
// 因为有命名路由 所有不一定有path
const compareTarget = to.path ? createRoute(null, to) : resolved
// 如果严格模式的话 就判断是否是相同路由(path query params hash)
// 否则就走包含逻辑(path包含,query包含 hash为空或者相同)
classes[activeClass] = this.exact
? isSameRoute(current, compareTarget)
: isIncludedRoute(current, compareTarget)
// 事件绑定
const on = {
click: (e) => {
// 忽略带有功能键的点击
if (e.metaKey || e.ctrlKey || e.shiftKey) return
// 已阻止的返回
if (e.defaultPrevented) return
// 右击
if (e.button !== 0) return
// `target="_blank"` 忽略
const target = e.target.getAttribute('target')
if (/\b_blank\b/i.test(target)) return
// 阻止默认行为 防止跳转
e.preventDefault()
if (this.replace) {
// replace 逻辑
router.replace(to)
} else {
// push 逻辑
router.push(to)
}
}
}
// 创建元素需要附加的数据们
const data: any = {
class: classes
}
if (this.tag === 'a') {
data.on = on
data.attrs = { href }
} else {
// 找到第一个 <a> 给予这个元素事件绑定和href属性
const a = findAnchor(this.$slots.default)
if (a) {
// in case the <a> is a static node
a.isStatic = false
const extend = _Vue.util.extend
const aData = a.data = extend({}, a.data)
aData.on = on
const aAttrs = a.data.attrs = extend({}, a.data.attrs)
aAttrs.href = href
} else {
// 没有 <a> 的话就给当前元素自身绑定时间
data.on = on
}
}
// 创建元素
return h(this.tag, data, this.$slots.default)
}
}
function findAnchor (children) {
if (children) {
let child
for (let i = 0; i < children.length; i++) {
child = children[i]
if (child.tag === 'a') {
return child
}
if (child.children && (child = findAnchor(child.children))) {
return child
}
}
}
}
function createHref (base, fullPath, mode) {
var path = mode === 'hash' ? '/#' + fullPath : fullPath
return base ? cleanPath(base + path) : path
}可以看出 router-link 组件就是在其点击的时候根据设置的 to 的值去调用 router 的 push 或者 replace 来更新路由的,同时呢,会检查自身是否和当前路由匹配(严格匹配和包含匹配)来决定自身的 activeClass 是否添加。
整个流程的代码到这里已经分析的差不多了,再来回顾下:
相信整体看完后和最开始的时候看到这张图的感觉是不一样的,且对于 vue-router 的整体的流程了解的比较清楚了。当然由于篇幅有限,这里还有很多细节的地方没有细细分析,后续会根据模块来进行具体的分析。
去年 6 月初,我在慕课网上线了一门 Vue.js 2.0 的高级实战课程音乐 WebApp 课程,教同学们如何去开发基础组件和业务组件。在一般大公司的实际项目中,并不会为每一个项目都去开发基础组件,他们往往会把基础组件收敛成一个组件库,供各个项目复用。滴滴也是如此,我们在去年初使用 Vue.js 去重构了我们的打车 WebApp,也抽象出了一套移动端组件库,在经过一年多的业务考验后,我们决定做开源,一方面是想把好的东西分享出去,并通过社区的反馈去完善我们的组件库;另一方面也是想让大家了解滴滴的前端,能吸引一些优秀的人才加入滴滴。于是在去年的 11 月份,我们团队开源了 cube-ui,到现在为止收到的反馈还算不错,也陆续有一些同学在生产环境也开始使用。
cube-ui 和其它同类型的开源组件库有一个很大的不同,它内部了使用了一个我们团队玩出来的“后编译”技术,它能帮我们玩出很多花样,比如减少组件包体积、支持 rem、支持自定义组件颜色等等,但带来好处的同时也会有一些不便(webpack 的配置会略显复杂),因此我们团队也为 cube-ui 在 vue-cli 的基础上扩展了一套脚手架,方便大家开箱即用。
其实相对于 PC 端的组件库,移动端组件库有一个比较大的不同就是定制化要求较高。比如做 PC 端的 MIS 类的项目,如果使用 Vue 技术栈,大家往往会选择 element 或者是 iview,几乎都是拿来即用,最多换一下主题,很少会抠组件的细节,因为 MIS 类的项目是 to b 的,很多也是内部人员使用,所以对一些细节的要求并不高。而对于移动端项目,往往都是 to c 的,都有专门的 UI 设计,很少有完全符合要求的现成组件库能拿来用,所以 cube-ui 尽量提供一些通用性强的组件,并提供了自定义组件颜色的能力、和组件扩展能力,目的是让使用方 cube-ui 的基础上做二次开发,去满足自己的定制化需求。
因为毕竟 cube-ui 是从滴滴的业务中抽象出来的,在做滴滴相关业务的时候,这些组件都能很好的满足需求,但是换成一个新的项目,cube-ui 好不好用呢,于是我想到了我的音乐课程项目,它有一些基础组件是可以从 cube-ui 里拿的,但是整体的配色风格和 cube-ui 的默认配色又完全不一样,正好可以来检验一波,接下来我分享一下 cube-ui 重构音乐课程项目的经验。
由于我们是现有项目,并不能使用脚手架去初始化项目,所以我们需要根据官网的文档去做 webpack 的相关配置。这里我要稍微提醒一些同学,在使用一个开源项目的时候,最好的方式就是阅读它的文档,遇到问题首先想的是查看它的 issue。那么 cube-ui 的文档在这里,我们来看一下快速上手部分。
首先需要安装 cube-ui,这块很简单,直接运行命令就好了。
npm install cube-ui --save后编译简单的理解就是把编译工作交给应用来完成,也就是使用 cube-ui 的项目vue-music 来完成编译。由于是现成的项目,我们不能用脚手架初始化项目,那么所有的后编译相关的 webpack 配置都需要自己来动手,接下来我会一边教大家配置,一边来解释这些配置的作用。
{
// webpack-post-compile-plugin 依赖 compileDependencies
"compileDependencies": ["cube-ui"],
"devDependencies": {
"babel-plugin-transform-modules": "^0.1.0",
// 新增 stylus 相关依赖
"stylus": "^0.54.5",
"stylus-loader": "^2.1.1",
"webpack-post-compile-plugin": "^0.1.2"
}
}
首先需要修改的是 package.json 文件,我们需要在 devDependencies 添加几个插件,先简单对它们做一些介绍。
babel-plugin-transform-modules
babel-plugin-transform-modules 是从 babel-transform-imports fork 来的,加上了对 style 的支持,为了解决组件按需引入的问题。
stylus & stylus-loader
stylus 和 stylus-loader 是为了编译 stylus 文件用的,因为 cube-ui 源码的 css 部分使用了 stylus 预处理器。
webpack-post-compile-plugin 是为了解决后编译嵌套问题编写的 webpack 插件,因为在默认情况下,webpack 是不会编译 node_modules目录下的模块的,而我们的 cube-ui 是安装在 node_modules 下的,为了编译它,需要在 webpack 配置文件中显示地声明 include 指向 node_modules 下的 cube-ui,例如:
module: {
rules: [
{
test: /\.js$/,
loader: 'babel-loader',
include: [resolve('src'), resolve('node_modules/cube-ui')]
},
// ...
]
}
但这里会有一个问题,如果 cube-ui 一旦也后编译依赖其它模块,作为编译的应用方也需要把它们显示地写进 include 里,但这显然是不合理的,因为应用不应该知道 cube-ui 依赖的模块,每个模块只应该声明它自身的后编译依赖即可。那么 webpack-post-compile-plugin 就是来解决这个问题的,它会读取每个模块 package.json 文件中声明的 compileDependencies,并递归去查找后编译依赖,然后添加到应用 webpack 配置的 include 中,所以在我们应用项目中的 package.json 文件中,我们指定了 compileDependencies 为 [cube-ui]。
{
"plugins": [
["transform-modules", {
"cube-ui": {
// 注意: 这里的路径需要修改到 src/modules 下
"transform": "cube-ui/src/modules/${member}",
"kebabCase": true
}
}]
]
}
这个配置项是为了配合 babel-plugin-transform-modules 使用的,给按需引入提供了一个语法糖。举个例子,当我们在代码中按需引入 cube-ui 的组件,如:
import { Button } from 'cube-ui'
相当于:
import Button from 'cube-ui/src/modules/button'
因为是引入源码,所以 import 的路径指向了 src 目录,显然前者的写法比后者优雅了很多,并且一旦我们不用后编译,也不用去修改源码的 import 方式,只需要修改 .babelrc 文件即可。
var PostCompilePlugin = require('webpack-post-compile-plugin')
module.exports = {
// ...
plugins: [
// ...
new PostCompilePlugin()
]
// ...
}
这里就是对 webpack-post-compile-plugin 插件的应用,把它添加到 plugins 中即可。
exports.cssLoaders 函数exports.cssLoaders = function (options) {
// ...
const stylusOptions = {
'resolve url': true
}
// https://vue-loader.vuejs.org/en/configurations/extract-css.html
return {
css: generateLoaders(),
postcss: generateLoaders(),
less: generateLoaders('less'),
sass: generateLoaders('sass', { indentedSyntax: true }),
scss: generateLoaders('sass'),
stylus: generateLoaders('stylus', stylusOptions),
styl: generateLoaders('stylus', stylusOptions)
}
}
这里了一个 stylus 的配置项 'resovle url':true,目的是为了解决被引入的 stylus 文件再去引入资源的相对路径的问题,参考官方文档。
module.exports = {
loaders: utils.cssLoaders({
sourceMap: sourceMapEnabled,
extract: false
}),
// ...
}
这里需要强制指定 css-loader 的选项 extract 为 false,否则我们通过 npm run build 编译后的项目异步加载 vue 组件会有问题。
那么到这里,后编译的 webpack 配置就告一段落了,核心**就是让我们的应用引入 cube-ui 的源码,并且接管 cube-ui 的编译工作。
这篇文章我不会把所有代码的修改都 forEach 一遍,那样太浪费时间,我会挑重点的地方讲,具体的修改都可以在项目代码的 use-cube-ui 分支里看到。这里我想强调一下,我的项目代码托管在 GitHub 私仓,并不开源,只有购买正版课程的学生才能访问,那些不知道从哪些途径搞到我项目初始代码还开源大肆宣传的人,你们不尊重我的劳动成果看盗版视频也就罢了,拿这个骗 star,不害臊吗?
BTW,官方正版的项目代码是一直维护的,并且修复了 70+ issue,如果真心想学知识的同学,花几百块钱买正版课程一定是物超所值。
接下来就是修改我们项目的源码,我们会用到 cube-ui 的基础样式、Scroll 滚动组件、Slide 轮播图组件、IndexList 索引列表组件以及 createAPI 模块去把我们已有的 Confirm 组件变成 API 式的调用。我们会在 main.js 里引用这些组件和模块:
import {
Style,
IndexList,
Scroll,
Slide,
createAPI
} from 'cube-ui'
import Confirm from 'base/confirm/confirm.vue'
Vue.use(IndexList)
Vue.use(Scroll)
Vue.use(Slide)
createAPI(Vue, Confirm, ['confirm', 'click'], true)
这里我们会 import Style,它的作用是引入 cube-ui 提供的一些 reset 样式、基础样式和字体图标样式,那么对于我们的项目,就可以把 reset 样式移除了。
对于组件的引用我们会使用 Vue.use 注册插件的方式,它内部会调用 Vue.component 全局注册组件,这样我们就可以在任何组件内部里使用这些组件了。
createAPI 是把我们之前声明式的组件使用方式改变成 API 式的调用,这块儿稍后我们会详细说明。
音乐 App 的歌手页面有一个歌手列表,如下图所示:
它恰好可以使用 cube-ui 提供的 IndexList 组件,在我的教学课程中,我也是把它单独抽象出来的一个基础组件,所以替换就变的很容易了。
学会使用一个组件,最好的方式就是看它的文档。cube-ui 提供的 IndexList 样式如下:
可以看到相对于 cube-ui 的 IndexList,我们的歌手页面的背景颜色、列表的样式都有所不同,幸好 cube-ui 支持自定义组件颜色和 IndexList 的插槽功能,我们可以很好的解决这两个问题。
IndexList 组件的颜色cube-ui 提供了自定义组件颜色的能力,我们打开它的文档,实际上只需要做两件事情。
首先在 src 目录下新建 theme.styl 文件,然后填入如下代码:
@import "./common/stylus/variable.styl"
// index-list
$index-list-bgc := $color-background
$index-list-anchor-color := $color-text-l
$index-list-anchor-bgc := $color-highlight-background
$index-list-nav-color := $color-text-l
$index-list-nav-active-color := $color-theme
这里我们用到了 stylus 的一个条件赋值的语法,它会先判断有没有对这个变量赋值,如果已经赋值了,则不会去覆盖这个变量的值。那么这里我们引入了 vue-music 项目中对于颜色定义的一些变量,把它赋值给了 cube-ui 关于 IndexList 组件所引用的一些颜色变量。
接下来配置 webpack,修改 build/utils.js 里的 exports.cssLoaders 函数中的 stylusOptions
const stylusOptions = {
'resolve url': true,
// 这里 新增 import 配置项,指向自定义主题文件
import: [path.resolve(__dirname, '../src/theme')]
}
这里通过配置 stylus 选项,新增 import 配置项指向我们刚才创建的 theme.styl 文件,可以达到的效果是在 stylus 的编译过程中,对每一个 .styl 文件以及 .vue 中的 stylus 部分都优先 import 这个主题文件,这样就实现了组件颜色的自定义,会优先使用我们在 theme.styl 文件中的颜色。
IndexList 的插槽由于我们的列表项是图文混排的布局,和默认的样式不一样,因此我们需要用到插槽来自定义列表项布局,参考文档,我们对模板代码的修改如下:
<template>
<div class="singer" ref="singer">
<cube-index-list :data="singers" ref="list">
<cube-index-list-group v-for="(group, index) in singers" :key="index" :group="group" class="list-group">
<cube-index-list-item v-for="(item, index) in group.items" :key="index" :item="item" @select="selectSinger" class="list-group-item">
<img class="avatar" v-lazy="item.avatar">
<span class="name">{{item.name}}</span>
</cube-index-list-item>
</cube-index-list-group>
</cube-index-list>
<router-view></router-view>
</div>
</template>
我们使用 cube-ui 提供的 cube-index-list-group 和 cube-index-list-item 做二重循环,因为是组件的循环,所以循环的过程中需要设置 key。这里有个地方需要注意一下,我们给 IndexList 组件传的数据是 singers,而 singers 的数据结构是有要求的,它本身是一个数组,对于数组的每一项,它有组名 name 和数据项 items。这个字段名和我们项目之前定义的略微不同,所以我们在处理从服务端拿到的歌手数据的时候,需要构造符合 IndexList 约定的数据结构。
最后还有一处细节的修改,我们项目中的每一组的标题样式和 cube-ui 的 IndexList 略微不同,可以通过覆盖 CSS 的方式对样式做修改。
.singer
.cube-index-list-anchor
padding: 8px 0 8px 20px
这里要注意的是,一旦我们要覆盖某个子组件的样式,那么引用该子组件的父组件(在我们这个 case 是 Singer 组件)样式部分就不能使用 scoped 特性,因为如果设置了 scoped,Vue 在初始化的过程中会给组件的样式加上属性 id,那么就不能够覆盖 cube-ui 中的组件样式了。
音乐 App 的推荐页面用到了轮播图,如下图所示:
在我们的项目中已经封装了轮播图组件,它恰好可以使用 cube-ui 的 Slide 组件无缝替换,同样的我们来看一下 Slide 组件 的文档,修改代码如下:
<cube-slide ref="slider">
<cube-slide-item v-for="(item,index) in recommends" :key="index">
<a :href="item.linkUrl">
<img @load="loadImage" :src="item.picUrl">
</a>
</cube-slide-item>
<template slot="dots" slot-scope="props">
<span class="dot" :class="{active: props.current === index}" v-for="(item, index) in props.dots"></span>
</template>
</cube-slide>
对于 Slide 组件内部的元素,我们用 cube-slide-item 组件来做循环,由于底部的 dots 样式很不一样,我们使用了作用域插槽,因为需要根据子组件的 current 来决定它渲染的 active 样式;并且我们想让 dots 的位置向上偏移,所以我们依然采用覆盖 CSS 的方式:
.recommend
.cube-slide-dots
bottom: 12px
同样,我们也需要把 Recommend 组件 stylus 部分的 scoped 移除。
音乐 App 项目在 better-scroll 的基础上插件封装了 Scroll 组件,并在项目中大量应用,比如推荐页面、歌手详情页、搜索页面、歌曲列表、甚至是歌词列表。cube-ui 中也基于 better-scroll 封装了 Scroll 组件,它的功能更完善,所以我们决定替换 Scroll 组件。
Scroll 组件在项目中应用的地方非常多,这里我挑一个比较有代表性的场景,就是搜索页面的 Suggest 组件,如下所图所示:
Suggest 组件下方的列表是根据检索的关键词动态渲染的,它不仅可以局部滚动,还有一个上拉加载的功能,它就是移动端场景下分页功能的实现。我们完全可以用 cube-ui 的 Scroll 组件来实现它,同样我们也是先去阅读它的文档,然后做如下代码的修改:
<cube-scroll ref="suggest"
:data="result"
:options="scrollOptions"
@pulling-up="searchMore"
>
<ul class="suggest-list">
<li @click="selectItem(item)" class="suggest-item" v-for="item in result">
<div class="icon">
<i :class="getIconCls(item)"></i>
</div>
<div class="name">
<p class="text" v-html="getDisplayName(item)"></p>
</div>
</li>
</ul>
</cube-scroll>
<script type="text/ecmascript-6">
// ...
export default {
data() {
return {
// ...
scrollOptions: {
pullUpLoad: {
threshold: 0,
txt: ''
}
}
}
},
methods: {
searchMore() {
if (!this.hasMore) {
this.$refs.suggest.forceUpdate()
return
}
this.page++
search(this.query, this.page, this.showSinger, perpage).then((res) => {
if (res.code === ERR_OK) {
this.result = this.result.concat(this._genResult(res.data))
this._checkMore(res.data)
} else {
this.$refs.suggest.forceUpdate()
}
}).catch(() => {
this.$refs.suggest.forceUpdate()
})
}
// ...
}
// ...
}
</script>
这里需要注意两个地方,一个是 scrollOptions,另一个是 pullingUp 事件的回调函数 searchMore。
scrollOptions
这个参数是 better-scroll 的 options 配置,由于我们使用了上拉加载的功能,所以需要配置 pullUpLoad,这里我们指定了 threshold 为 0,也就是刚到底部就触发 pullingUp 事件,txt 设置为空因为在我们的项目中上拉加载不需要任何文案。
searchMore
这个回调函数的作用就是根据条件去加载新的数据,如果没有更多数据了,我们直接调用 this.$refs.suggest.forceUpdate() 通知 Scroll 组件结束上拉的过程,另外单次加载数据发生任何异常的时候我们也都应该调用一次 this.$refs.suggest.forceUpdate()。
Scroll 组件在其它地方都可以直接替换,另外除了有上拉加载和下拉刷新的场景,我们可以不给 Scroll 组件传 data 了,因为 1.5+ 版本的 better-scroll 已经有了根据 DOM 变化在合适时机自动 refresh 的能力了。
createAPI 的应用前面我们简单地提到了 createAPI 的作用是把我们之前声明式的组件使用方式改变成 API 式的调用,为什么会有这样的需求呢?我们知道 Vue 推荐的就是声明式的组件使用方式,比如在使用一个组件 xxx,我们简单在使用的地方声明它就好了,就像这样:
<tempalte>
<xxx/>
</tempalte>
对于一般组件,这样使用并没有问题,但对于全屏类的弹窗组件,如果在一个层级嵌套很深的子组件中使用,仍然通过声明式的方式,很可能它的样式会受到父元素某些 CSS 的影响导致渲染不符合预期。这类组件最好的使用方式就是挂载到 body 下,但是我们如果是声明式地把这些组件挂载到最外层,对它们的控制也非常不灵活。其实最理想的方式是动态把这类组件挂载到 body 下,createAPI 就是干这个事情的。
先来看一下 createAPI 的文档,它可以把任何组件变成 API 式的调用。在我们的项目中有一个 Confirm 组件,它就是一个弹窗类型的组件。cube-ui 提供了所有弹窗类组件的基类组件 Popup,如果是新增一个弹窗类组件,推荐基于 Popup 做二次开发,不过我们的项目已经实现了全屏 Confirm 组件,目前需要实现的是调用它的使用可以动态挂载到 body 下,首先我们使用 createAPI 包装一下它:
createAPI(Vue, Confirm, ['confirm', 'click'], true)
接着我们就可以在组件内部通过 this.$createConfirm 的方式调用它,我们在 Search 组件中改变一下 Confirm 组件的调用方式:
methods: {
showConfirm() {
this.$createConfirm({
text: '是否清空所有搜索历史',
confirmBtnText: '清空',
onConfirm: () => {
this.clearSearchHistory()
}
}).show()
},
}
当执行 .show 的时候,cube-ui 内部会把 Confirm 组件动态挂载到 body 下。
到此这篇文章的主体内容就介绍完了,看似简单,但实际上我在重构的过程中还是发现了一些问题,顺便也对 cube-ui 和 better-scroll 做了一些优化。希望我的学生在看完这篇文章后能真正自己尝试着做一遍重构,因为很多细节的问题只有你去尝试做了才能发现,只有发现并解决问题你才能积累更多的经验;重构的过程中务必要看文档,遇到问题一定要自己先思考一遍,实在解决不了再求助。另外我也希望大家也多多使用 cube-ui,哪怕 cube-ui 能帮你解决一个小小的需求,那么我们觉得开源这件事情都是非常有意义的。如果大家在使用的过程中遇到一些问题,欢迎给我们提 issue & pr,帮助我们一起共建 cube-ui,也可以加 qq 群与我们交流,二维码如下:

如果 cube-ui 对你有帮助,也不要吝啬你的 star。
另附上 vue-music 项目的线上地址,扫下方二维码体验:
如果想跟着我学习这门 Vue.js 的进阶课程,真心想学到知识,请务必购买正版课程,你一定不会失望。
在我们日常的移动端项目开发中,处理滚动列表是再常见不过的需求了。 以滴滴为例,可以是这样竖向滚动的列表,如图所示:
也可以是横向滚动的导航栏,如图所示:
可以打开“微信 —> 钱包—>滴滴出行”体验效果。
我们在实现这类滚动功能的时候,会用到我写的第三方库,better-scroll。
better-scroll 是一个移动端滚动的解决方案,它是基于 iscroll 的重写,它和 iscroll 的主要区别在这里。better-scroll 也很强大,不仅可以做普通的滚动列表,还可以做轮播图、picker 等等。
不少同学可能用过 better-scroll,我收到反馈最多的问题是:
我的 better-scroll 初始化了, 但是没法滚动。
不能滚动是现象,我们得搞清楚这其中的根本原因。在这之前,我们先来看一下浏览器的滚动原理:
浏览器的滚动条大家都会遇到,当页面内容的高度超过视口高度的时候,会出现纵向滚动条;当页面内容的宽度超过视口宽度的时候,会出现横向滚动条。也就是当我们的视口展示不下内容的时候,会通过滚动条的方式让用户滚动屏幕看到剩余的内容。
那么对于 better-scroll 也是一样的道理,我们先来看一下 better-scroll 常见的 html 结构:
<div class="wrapper">
<ul class="content">
<li>...</li>
<li>...</li>
...
</ul>
</div>为了更加直观,我们再来看一张图:
绿色部分为 wrapper,也就是父容器,它会有固定的高度。黄色部分为 content,它是父容器的第一个子元素,它的高度会随着内容的大小而撑高。那么,当 content 的高度不超过父容器的高度,是不能滚动的,而它一旦超过了父容器的高度,我们就可以滚动内容区了,这就是 better-scroll 的滚动原理。
那么,我们怎么初始化 better-scroll 呢,如果是上述 html 结构,那么初始化代码如下:
import BScroll from 'better-scroll'
let wrapper = document.querySelector('.wrapper')
let scroll = new BScroll(wrapper, {})better-scroll 对外暴露了一个 BScroll 的类,我们初始化只需要 new 一个类的实例即可。第一个参数就是我们 wrapper 的 DOM 对象,第二个是一些配置参数,具体参考 better-scroll 的文档。
better-scroll 的初始化时机很重要,因为它在初始化的时候,会计算父元素和子元素的高度和宽度,来决定是否可以纵向和横向滚动。因此,我们在初始化它的时候,必须确保父元素和子元素的内容已经正确渲染了。如果子元素或者父元素 DOM 结构发生改变的时候,必须重新调用 scroll.refresh() 方法重新计算来确保滚动效果的正常。所以同学们反馈的 better-scroll 不能滚动的原因多半是初始化 better-scroll 的时机不对,或者是当 DOM 结构发送变化的时候并没有重新计算 better-scroll。
相信很多同学对 Vue.js 都不陌生,当 better-scroll 遇见 Vue,会擦出怎样的火花呢?
很多同学开始接触使用 better-scroll 都是受到了我的一门教学课程——《Vue.js高仿饿了么外卖App》 的影响。在那门课程中,我们把 better-scroll 和 Vue 做了结合,实现了很多列表滚动的效果。在 Vue 中的使用方法如下:
<template>
<div class="wrapper" ref="wrapper">
<ul class="content">
<li>...</li>
<li>...</li>
...
</ul>
</div>
</template>
<script>
import BScroll from 'better-scroll'
export default {
mounted() {
this.$nextTick(() => {
this.scroll = new Bscroll(this.$refs.wrapper, {})
})
}
}
</script>
Vue.js 提供了我们一个获取 DOM 对象的接口—— vm.$refs。在这里,我们通过了 this.$refs.wrapper 访问到了这个 DOM 对象,并且我们在 mounted 这个钩子函数里,this.$nextTick 的回调函数中初始化 better-scroll 。因为这个时候,wrapper 的 DOM 已经渲染了,我们可以正确计算它以及它内层 content 的高度,以确保滚动正常。
这里的 this.$nextTick 是一个异步函数,为了确保 DOM 已经渲染,感兴趣的同学可以了解一下它的内部实现细节,底层用到了 MutationObserver 或者是 setTimeout(fn, 0)。其实我们在这里把 this.$nextTick 替换成 setTimeout(fn, 20) 也是可以的(20 ms 是一个经验值,每一个 Tick 约为 17 ms),对用户体验而言都是无感知的。
在我们的实际工作中,列表的数据往往都是异步获取的,因此我们初始化 better-scroll 的时机需要在数据获取后,代码如下:
<template>
<div class="wrapper" ref="wrapper">
<ul class="content">
<li v-for="item in data">{{item}}</li>
</ul>
</div>
</template>
<script>
import BScroll from 'better-scroll'
export default {
data() {
return {
data: []
}
},
created() {
requestData().then((res) => {
this.data = res.data
this.$nextTick(() => {
this.scroll = new Bscroll(this.$refs.wrapper, {})
})
})
}
}
</script>
这里的 requestData 是伪代码,作用就是发起一个 http 请求从服务端获取数据,并且这个函数返回的是一个 promise(实际项目中我们可能会用 axios 或者 vue-resource)。我们获取到数据的后,需要通过异步的方式再去初始化 better-scroll,因为 Vue 是数据驱动的, Vue 数据发生变化(this.data = res.data)到页面重新渲染是一个异步的过程,我们的初始化时机是要在 DOM 重新渲染后,所以这里用到了 this.$nextTick,当然替换成 setTimeout(fn, 20) 也是可以的。
为什么这里在 created 这个钩子函数里请求数据而不是放到 mounted 的钩子函数里?因为 requestData 是发送一个网络请求,这是一个异步过程,当拿到响应数据的时候,Vue 的 DOM 早就已经渲染好了,但是数据改变 —> DOM 重新渲染仍然是一个异步过程,所以即使在我们拿到数据后,也要异步初始化 better-scroll。
我们在实际开发中,除了数据异步获取,还有一些场景可以动态更新列表中的数据,比如常见的下拉加载,上拉刷新等。比如我们用 better-scroll 配合 Vue 实现下拉加载功能,代码如下:
<template>
<div class="wrapper" ref="wrapper">
<ul class="content">
<li v-for="item in data">{{item}}</li>
</ul>
<div class="loading-wrapper"></div>
</div>
</template>
<script>
import BScroll from 'better-scroll'
export default {
data() {
return {
data: []
}
},
created() {
this.loadData()
},
methods: {
loadData() {
requestData().then((res) => {
this.data = res.data.concat(this.data)
this.$nextTick(() => {
if (!this.scroll) {
this.scroll = new Bscroll(this.$refs.wrapper, {})
this.scroll.on('touchend', (pos) => {
// 下拉动作
if (pos.y > 50) {
this.loadData()
}
})
} else {
this.scroll.refresh()
}
})
})
}
}
}
</script>
这段代码比之前稍微复杂一些, 当我们在滑动列表松开手指时候, better-scroll 会对外派发一个 touchend 事件,我们监听了这个事件,并且判断了 pos.y > 50(我们把这个行为定义成一次下拉的动作)。如果是下拉的话我们会重新请求数据,并且把新的数据和之前的 data 做一次 concat,也就更新了列表的数据,那么数据的改变就会映射到 DOM 的变化。需要注意的一点,这里我们对 this.scroll 做了判断,如果没有初始化过我们会通过 new BScroll 初始化,并且绑定一些事件,否则我们会调用 this.scroll.refresh 方法重新计算,来确保滚动效果的正常。
这里,我们就通过 better-scroll 配合 Vue,实现了列表的下拉刷新功能,上拉加载也是类似的套路,一切看上去都是 ok 的。但是,我们发现这里写了大量命令式的代码(这一点不是 Vue.js 推荐的),如果有很多类似滚动的组件,我们就需要写很多类似的命令式且重复性的代码,而且我们把数据请求和 better-scroll 也做了强耦合,这些对于一个追求编程逼格的人来说,就不 ok 了。
因此,我们有强烈的需求抽象出来一个 scroll 组件,类似小程序的 scroll-view 组件,方便开发者的使用。
首先,我们要考虑的是 scroll 组件本质上就是一个可以滚动的列表组件,至于列表的 DOM 结构,只需要满足 better-scroll 的 DOM 结构规范即可,具体用什么标签,有哪些辅助节点(比如下拉刷新上拉加载的 loading 层),这些都不是 scroll 组件需要关心的。因此, scroll 组件的 DOM 结构十分简单,如下所示:
<template>
<div ref="wrapper">
<slot></slot>
</div>
</template>
这里我们用到了 Vue 的特殊元素—— slot 插槽,它可以满足我们灵活定制列表 DOM 结构的需求。接下来我们来看看 JS 部分:
<script type="text/ecmascript-6">
import BScroll from 'better-scroll'
export default {
props: {
/**
* 1 滚动的时候会派发scroll事件,会截流。
* 2 滚动的时候实时派发scroll事件,不会截流。
* 3 除了实时派发scroll事件,在swipe的情况下仍然能实时派发scroll事件
*/
probeType: {
type: Number,
default: 1
},
/**
* 点击列表是否派发click事件
*/
click: {
type: Boolean,
default: true
},
/**
* 是否开启横向滚动
*/
scrollX: {
type: Boolean,
default: false
},
/**
* 是否派发滚动事件
*/
listenScroll: {
type: Boolean,
default: false
},
/**
* 列表的数据
*/
data: {
type: Array,
default: null
},
/**
* 是否派发滚动到底部的事件,用于上拉加载
*/
pullup: {
type: Boolean,
default: false
},
/**
* 是否派发顶部下拉的事件,用于下拉刷新
*/
pulldown: {
type: Boolean,
default: false
},
/**
* 是否派发列表滚动开始的事件
*/
beforeScroll: {
type: Boolean,
default: false
},
/**
* 当数据更新后,刷新scroll的延时。
*/
refreshDelay: {
type: Number,
default: 20
}
},
mounted() {
// 保证在DOM渲染完毕后初始化better-scroll
setTimeout(() => {
this._initScroll()
}, 20)
},
methods: {
_initScroll() {
if (!this.$refs.wrapper) {
return
}
// better-scroll的初始化
this.scroll = new BScroll(this.$refs.wrapper, {
probeType: this.probeType,
click: this.click,
scrollX: this.scrollX
})
// 是否派发滚动事件
if (this.listenScroll) {
this.scroll.on('scroll', (pos) => {
this.$emit('scroll', pos)
})
}
// 是否派发滚动到底部事件,用于上拉加载
if (this.pullup) {
this.scroll.on('scrollEnd', () => {
// 滚动到底部
if (this.scroll.y <= (this.scroll.maxScrollY + 50)) {
this.$emit('scrollToEnd')
}
})
}
// 是否派发顶部下拉事件,用于下拉刷新
if (this.pulldown) {
this.scroll.on('touchend', (pos) => {
// 下拉动作
if (pos.y > 50) {
this.$emit('pulldown')
}
})
}
// 是否派发列表滚动开始的事件
if (this.beforeScroll) {
this.scroll.on('beforeScrollStart', () => {
this.$emit('beforeScroll')
})
}
},
disable() {
// 代理better-scroll的disable方法
this.scroll && this.scroll.disable()
},
enable() {
// 代理better-scroll的enable方法
this.scroll && this.scroll.enable()
},
refresh() {
// 代理better-scroll的refresh方法
this.scroll && this.scroll.refresh()
},
scrollTo() {
// 代理better-scroll的scrollTo方法
this.scroll && this.scroll.scrollTo.apply(this.scroll, arguments)
},
scrollToElement() {
// 代理better-scroll的scrollToElement方法
this.scroll && this.scroll.scrollToElement.apply(this.scroll, arguments)
}
},
watch: {
// 监听数据的变化,延时refreshDelay时间后调用refresh方法重新计算,保证滚动效果正常
data() {
setTimeout(() => {
this.refresh()
}, this.refreshDelay)
}
}
}
</script>
JS 部分实际上就是对 better-scroll 做一层 Vue 的封装,通过 props 的形式,把一些对 better-scroll 定制化的控制权交给父组件;通过 methods 暴露的一些方法对 better-scroll 的方法做一层代理;通过 watch 传入的 data,当 data 发生改变的时候,在适当的时机调用 refresh 方法重新计算 better-scroll 确保滚动效果正常,这里之所以要有一个 refreshDelay 的设置是考虑到如果我们对列表操作用到了 transition-group 做动画效果,那么 DOM 的渲染完毕时间就是在动画完成之后。
有了这一层 scroll 组件的封装,我们来修改刚刚最复杂的代码(假设我们已经全局注册了 scroll 组件)。
<template>
<scroll class="wrapper"
:data="data"
:pulldown="pulldown"
@pulldown="loadData">
<ul class="content">
<li v-for="item in data">{{item}}</li>
</ul>
<div class="loading-wrapper"></div>
</scroll>
</template>
<script>
import BScroll from 'better-scroll'
export default {
data() {
return {
data: [],
pulldown: true
}
},
created() {
this.loadData()
},
methods: {
loadData() {
requestData().then((res) => {
this.data = res.data.concat(this.data)
})
}
}
}
</script>
可以很明显的看到我们的 JS 部分精简了非常多的代码,没有对 better-scroll 再做命令式的操作了,同时把数据请求和 better-scroll 也做了剥离,父组件只需要把数据 data 通过 prop 传给 scroll 组件,就可以保证 scroll 组件的滚动效果。同时,如果想实现下拉刷新的功能,只需要通过 prop 把 pulldown 设置为 true,并且监听 pulldown 的事件去做一些数据获取并更新的动作即可,整个逻辑也是非常清晰的。
这篇文章我不仅仅是要教会大家封装一个 scroll 组件,还想传递一些把第三方插件(原生 JS 实现)Vue 化的思考过程。很多学习 Vue.js 的同学可能还停留在 “XX 效果如何用 Vue.js 实现” 的程度,其实把插件 Vue 化有两点很关键,一个是对插件本身的实现原理很了解,另一个是对 Vue.js 的特性很了解。对插件本身的实现原理了解需要的是一个思考和钻研的过程,这个过程可能困难,但是收获也是巨大的;而对 Vue.js 的特性的了解,是需要大家对 Vue.js 多多使用,学会从平时的项目中积累和总结,也要善于查阅 Vue.js 的官方文档,关注一些 Vue.js 的升级等。
所以,我们拒绝伸手党,但也不是鼓励大家什么时候都要去造轮子,当我们在使用一些现成插件的同时,也希望大家能多多思考,去探索一下现象背后的本质,把 “XX 效果如何用 Vue.js 实现” 这句话从问号变成句号。
最近上线了一门 Vue.js 的高级课程,想在 Vue.js 和移动端开发方向进阶的同学可以关注一波~
目前大家使用最多也是最广泛的应用打包工具就是 webpack 了,除去 webpack 本身已经提供的优化能力(例如,Tree Shaking、Code Splitting 等)之外,我们还能做哪些事情呢,本篇主要就为大家介绍下滴滴 WebApp 团队在这条路上的一些探索。
现在越来越多的项目都使用 ES2015+ 开发,并且搭配 webpack + babel 作为工程化基础,并通过 NPM 去加载第三方依赖库。同时为了达到代码复用的目的,我们会把一些自己开发的组件库或者是 JSSDK 抽成独立的仓库维护,并通过 NPM 去加载。
大部分人已经习惯了这样的开发方式,并且觉得非常方便实用。但在方便的背后,却隐藏了两个问题:
代码冗余
一般来说,这些 NPM 包也是基于 ES2015+ 开发的,每个包都需要经过 babel 编译发布后才能被主应用使用,而这个编译过程往往会附加很多“编译代码”;每个包都会有一些相同的编译代码,这就造成大量代码的冗余,并且这部分冗余代码是不能通过 Tree Shaking 等技术去除掉的。
非必要的依赖
考虑到组件库的场景,通常我们为了方便一股脑引入了所有组件;但实际情况下对于一个应用而言可能只是用到了部分组件,此时如果全部引入,也会造成代码冗余。
代码的冗余会造成静态资源包加载时间变长、执行时间也会变长,进而很直接的影响性能和体验。既然我们已经认识到有此类问题,那么接下来看看如何解决这两个问题。
我们对于上述的 2 个问题,核心的解决优化方案是:后编译和按需引入。
先来看下滴滴车票项目(用票人)优化前后的数据(非 gzip,压缩后整个项目的大小):
最终减少了约 80 KB,优化效果还是相当可观的。
上边的数据主要是对组件库和一些内部通用 JSSDK 采用后编译和按需引入策略后的效果,需要注意的是按需引入的效果是要视项目情况而定的,这里的数据仅供参考。
下面就分别来看看这两个点的具体细节。
先来解释下:
后编译:指的是应用依赖的 NPM 包并不需要在发布前编译,而是随着应用编译打包的时候一块编译。
后编译的核心在于把编译依赖包的时机延后,并且统一编译;先来看看它的 webpack 配置。
对具体项目应用而言,做到后编译,其实不需要做太多,只需要在 webpack 的配置文件中,包含需要我们去后编译的依赖包即可(webpack 2+):
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
// ...
{
test: /\.js$/,
loader: 'babel-loader',
// 注意这里的 include
// 除了 src 还包含了额外的 node_modules 下的两个包
include: [
resolve('src'),
resolve('node_modules/A'),
resolve('node_modules/B')
]
},
// ...
]
},
// ...
}我们只需要把后编译的模块 A 和 B 通过 webpack 的 include 配置包含进来即可。
但是这里会存在一些问题,举个例子,如下图:
上述所示的应用中依赖了需要后编译的包 A 和 B,而 A 又依赖了需要后编译的包 C 和 D,B 依赖了不需要后编译的包 E;重点来看依赖包 A 的情况:A 本身需要后编译,然后 A 的依赖包 C 和 D 也需要后编译,这种场景我们可以称之为嵌套后编译,此时如果依旧通过上边的 webpack 配置方式的话,还必须要显示的去 include 包 C 和 D,但对于应用而言,它只知道自身需要后编译的包 A 和 B,并不知道 A 也会有需要后编译的包 C 和 D,所以应用不应该显示的去 include 包 C 和 D,而是应该由 A 显示的去声明自己需要哪些后编译模块。
为了解决上述嵌套后编译问题,我们开发了一个 webpack 插件 webpack-post-compile-plugin,用于自动收集后编译的依赖包以及其嵌套依赖;来看下这个插件的核心代码:
var util = require('./util')
function PostCompilePlugin (options) {
// ...
}
PostCompilePlugin.prototype.apply = function (compiler) {
var that = this
compiler.plugin(['before-run', 'watch-run'], function (compiler, callback) {
// ...
var dependencies = that._collectCompileDependencies(compiler)
if (dependencies.length) {
var rules = compiler.options.module.rules
rules && rules.forEach(function (rule) {
if (rule.include) {
if (!Array.isArray(rule.include)) {
rule.include = [rule.include]
}
rule.include = rule.include.concat(dependencies)
}
})
}
callback()
})
}原理就是在 webpack compiler 的 before-run 和 watch-run 事件钩子中去收集依赖然后附加到 webpack module.rule 的 include 上;收集的规则就是查找应用或者依赖包的 package.json 中声明的 compileDependencies 作为后编译依赖。
所以对于上述应用的情况,使用 webpack-post-compile-plugin 插件的 webpack 配置:
var PostCompilePlugin = require('webpack-post-compile-plugin')
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
// ...
{
test: /\.js$/,
loader: 'babel-loader',
include: [
resolve('src')
]
},
// ...
]
},
// ...
plugins: [
new PostCompilePlugin()
]
}当前项目的 package.json 中添加 compileDependencies 字段来指定后编译依赖包:
// app package.json
{
// ...
"compileDependencies": ["A", "B"]
// ...
}A 还有后编译依赖,所以需要在包 A 的 package.json 中指定 compileDependencies:
// A package.json
{
// ...
"compileDependencies": ["C", "D"]
// ...
}PS: 关于 babel-plugin-transform-runtime 和 babel-polyfill 的选择问题,对于应用而言,我们建议的是采用 babel-polyfill。因为一些第三方包的依赖会判断全局是否支持某些特性,而不去做 polyfill 处理。例如:vuex 会检查是否支持 Promise,如果不支持则会报错;或者说在代码中有类似 "foobar".includes("foo") 的代码的话 babel-plugin-transform-runtime 也是不能正确处理的。
当然,后编译的技术方案肯定不是完美无瑕的,它也会有一些缺点。
虽然有一些缺点,但是综合考虑到成本/收益,目前来看采用后编译仍不失为一种不错的选择。
后编译主要解决的问题是代码冗余,而按需引入主要是用来解决非必要的依赖的问题。
按需引入针对的场景主要是组件库、工具类依赖包。因为不管是组件库还是依赖包,往往都是“大而全”的,而在开发应用的时候,我们可能只是使用了其一部分能力,如果全部引入的话,会有很多资源浪费。
为了解决这个问题,我们需要按需引入。目前主流组件库或者工具包也都是提供按需引入能力的,但是基本都是提供对编译后模块引入。
而我们推荐的是对源码的按需引入,配合后编译的打包方案 。
但是实际上我们可能会遇到一些向后兼容问题,不能一竿子打死,例如之前已经创建的项目,目前没有人力或者时间去做对应的升级改造,那么我们对内的一些组件库或者工具包目前需要做一点牺牲:提供两个入口,一个编译后的入口,一个源码入口。
这里涉及到一个 NPM 包有两个入口的问题,不过还好这个问题 webpack 2+ 或者 rollup 已经帮我们处理了,即编译后入口依旧使用 package.json 中的 main 字段,然后源码的入口使用 module 字段,可以参见 rollup pkg.module wiki。这样我们就能实现两个入口共享,既能保证向后兼容,又可以保证使用 webpack 2+ 或者 rollup 的入口直接指向的就是源码,在这样的基础上可以很直接的利用后编译了。
后编译和按需引入一个最最典型的场景就是我们的组件库,这里分享下我们对于组件库(基于 Vue)的实践经验。
按需引入,在没有后编译的时候,其实我们已经实现了在编译发布的时候直接做到自动根据各模块分别编译,这样使用方就可以直接引入对应目录的入口文件。这个原理很简单:遍历源码目录下的模块目录,得到各个入口,动态修改了组件库 webpack 配置的入口。而这个过程在__后编译__场景中就不存在了,可以直接引入到源码所对应的模块入口,因为后编译不需要依赖包自己编译,只需要应用去编译就好了。
对于组件而言,如果是前编译的话,一般我们会编译出入口 JS 文件,以及样式 CSS 文件,这样如果来实现按需引入的话,可能是这样的:
import Dialog from 'cube-ui/lib/dialog'
import 'cube-ui/lib/dialog/style.css'即使是在后编译场景下,虽然不需要处理样式问题了,但是还是会遇到按需引入的时候,路径不够优雅:
import Dialog from 'cube-ui/src/modules/dialog'以上不管是哪种,总是不够优雅,幸好有一个 babel 插件 babel-plugin-transform-imports 来帮助我们优雅的按需引入。但是对于我们编译后的场景,还需要引入样式,为此,我们对其做了统一,在 babel-plugin-transform-imports 上做了增强的 babel-plugin-transform-modules 插件,增设了 style 配置项。
所以不管是不是使用了后编译,我们想要做到按需引入,只需要:
import { Dialog } form 'cube-ui'这样写就可以了,如果你是使用的后编译,直接引入的是源码,那么只需要在 .babelrc 文件中增加如下配置:
"plugins": [
["transform-modules", {
"cube-ui": {
"transform": "cube-ui/src/modules/${member}",
"preventFullImport": true,
"kebabCase": true
}
}]
]而如果是 webpack 1 或者说使用的组件库是已经编译后的,那只需要增设 style 配置项即可:
"plugins": [
["transform-modules", {
"cube-ui": {
"transform": "cube-ui/lib/${member}",
"preventFullImport": true,
"kebabCase": true,
"style": true
}
}]
]这样我们就通过一个插件实现了优雅的按需引入,不管是不是使用了后编译,对于开发者而言只需要修改下 babel 的配置即可,而不需要大肆去修改源码中的引入路径。
以上就是我们基于 webpack 的编译优化的一点探索,这里可以总结下使用 webpack 做应用编译打包的“最佳实践”:
后编译 + 按需引入
再搭配上 babel-preset-env, babel-plugin-transform-modules 开发体验以及收益效果更好。
Vue.component(conf.name, (resolve, reject) => {
loadScript(conf.src).then(() => {
resolve(modules[id])
}).catch(() => {
reject()
})
})
问题:
(1)loadScript 函数的实现 是用的npm库,还是如何实现的,猜想你里面应该是promise的写法去动态创建scsript标签,插入异步业务线的 js 地址(单独基于webpack打包的),
(2)业务线代码仓库下的 JS开发 是直接编写vue格式文件的全局组件定义方式吗?
(3)这个组件的开发,他所依赖的npm包 在那里安装了?
建议给个例子!
Originally posted by @wwb568109135 in #13 (comment)
webapp
设计它的初衷其实在第一场分享中也已经提到了,我们可以再回顾一下:
痛点:
每一个系统 UI、交互规范、组件依赖底层技术都不一样,复用性低,依赖第三方开源但技术支持不到位,遇到问题没人服务。
技术选型:
定位: PC 很清晰:就是内外 Mis 系统
组件需求:
简单举例:
目前我们 PC 组件提供 2 套:
1、Angular
技术底层选型:
基于这 2 点,我们第一期的组件库包含:
按钮、表格、下拉框、日历框、多选框、弹窗等等。
部分展示:
组件简介:
<didi-list
data="data"
resource-url="resourceUrl"
resource-index="resourceIndex"
pagination-options="paginationOptions"
grid-options="gridOptions"
></didi-list>
<script>
var app = angular.module('List', ['bn.list']);
app.controller('listController', ['$scope', function ($scope) {
var listInterface = 'http://xxx.json';
var options = {
resourceUrl: listInterface,
resourceIndex: 'id',
gridOptions: {
fields: [
{
title: '活动名称',
align: 'center',
field: 'name'
},
......
]
}
};
angular.extend($scope, options);
}]);
angular.bootstrap(document, ['List']);
</script>
部分配置项说明:
resource-url 配置列表的数据接口请求地址
resource-index 列表内置支持 RESTful 方式的增删改查,所以对应的就是主键、默认是id,可以不用配置
grid-options 配置列表项相关信息
pagination-options 配置分页相关信息
search-options 配置和列表绑定的搜索表单信息
param-obj 配置列表请求接口时在 url 中所带参数
event-hooks 事件钩子对象,onloadbefore钩子在服务端数据返回来之后可以对原始数据进 行加工格式化;ongetbefore钩子可以在请求发送之前进行字段校验等操作, 返回 false 时不会发送请求data,很多时候不需要自动发送 http请求来获取数据,而是直接设置
魔方 pc 组件项目源码目录结构如下:
mofang-pc-angular
|- app(生态模块)
|- dist (目标模块)
|- node-modules(依赖模块)
|- src (代码模块)
|- common (公共代码)
|- componets (组件)
|- vendor(angular 相关依赖)
|- webpack.config.js (测试环境配置)
|- webpack.min.js (上线环境配置)
|- gulpfile.js (打包环境配置)
|- package.json
打包方式
webpack
入口文件为 mofang.js,我们为 pc 组件库准备了两个配置文件,分别是测试环境和生产环境。我们通过 package.json 的 version 控制组件的版本迭代,由于我们想单独导出 css 文件,我们使用 ExtractTextPlugin 插件,我们采用读取配置文件的方式动态加载模块,最后通过 gulp 配置文件将文件压缩为zip包,以便上传 cdn。配置文件如下
var version = require('./package.json').version;
module.exports = {
entry: {
mofang-widget: './src/mofang.js'
},
output: {
publicPath: __dirname + '/dist/mofang-widget/' + version,
filename: '[name].min.js',
library: 'mofang',
libraryTarget: 'umd'
},
module: {
loaders: [
{
test: /\.css$/,
loader: ExtractTextPlugin.extract("style-loader", "css-loader!sass-loader!prepend-loader?data=" + sassData)
},
{
test: /\.js$/,
loader: 'callback'
}
…….
]
},
callbackLoader: {
dynamicRequireModule: function () {
var requireStr = '';
modules.forEach(function (moduleName) {
.....
});
return requireStr;
}
},
plugins: [
new ExtractTextPlugin("[name].css"),
new webpack.optimize.UglifyJsPlugin({
compress: {
warnings: false
}
})
...
]
}
组件设计
1) 需求调研,了解现有的同类组件都实现哪些功能, 我们的业务都需要组件提供功能
2) 可拓展性,基础组件和业务组件分开
3) 使用和配置简便
4) 文档要全
didi-list 设计
需求分析:
1)搜索功能,我们依托配置类型,遍历生成对应的类型组件,包含select、 input、 radio、checkbox、日期等。
2)操作按钮(搜索、清空、刷新、导出、用户自定义按钮)
3)列表展示,操作列支持用户增删改查、排序,,是否全选,默认序列号等功能,意味着我们要提供 modal 组件,
4)分页功能
5)支持数据动态拉取和直接灌入
5)钩子函数,发送请求前、获取数据时等等
所需组件:
<didi-searchform>
<didi-input>
<didi-datetimepicker>
<didi-select>
....
<didi-grid>
<didi-pagination>
功能设计:
didi-list 组件是由其它底层组件共同协助,搜索控件将表单中内容与paramObj结合后,提供给列表组件进行数据的请求,返回的数据渲染自身展示外,同时传给分页组件,更新分页组件. 此外对于组件的http请求,我们扩展angular的$resource,对其进行封装,使其可以非常方便的同支持restful的服务单进行数据交互。
2、React
考虑到公司级组件库的初衷,也看到有部分业务还是喜欢 React,我们也快速封闭开发,去铺 React 版本。
组件需求:
react组件提供与pc端相同的功能
组件使用方式
<didi-list
paginationOptions={paginationOptions}
gridOptions={gridOptions}
data={data}
paramObj={paramObj}
resourceUrl={resourceUrl}
/>
目录结构
mofang-pc-react
|- dist ()
|- node_modules
|- src
|- components (组件)
|- utils (工具方法)
|- mofang.js (主入口)
|- package.json
|- webpack.config.js
|- webpack.min.js
组件开发
我们所有的组件是基于 ES6,所有的结构都是固定的,而且通过脚手架创建:
'use strict';
import React, { Component, PropTypes } from 'react';
import classnames from 'classnames';
class Button extends Component {
constructor (props) {
super(props);
this.state = {
disabled: props.disabled
};
this.handleClick = this.handleClick.bind(this);
}
handleClick() { ... }
render() {
.....
return (
<button onClick={this.handleClick}
{...this.props}
disabled={this.state.disabled}
className={className}
>
{ this.props.children }
</button>
);
}
}
Button.propTypes = {
disabled: PropTypes.bool,
onClick: PropTypes.func,
...
};
module.exports = Button;
打包方式
react组件开发我们依然采用webpack的方式对文件进行打包,使用ES6进行编写,将react和react-dom从主文件中抽离,针对不同的加载环境进行不同的配置。
配置文件:
var path = require('path');
var version = require('./package.json').version;
var webpack = require('webpack');
module.exports = {
entry: {
mofang: './src/mofang.js'
},
output: {
publicPath: '/assets/',
path: __dirname + '/build',
filename: '[name].js',
library: '',
libraryTarget: 'umd'
},
externals: [
{
'react': {
root: 'React',
commonjs2: 'react',
commonjs: 'react',
amd: 'react'
}
}...
],
module: {
loaders: [
{test: /\.js$/, loader: 'babel'}
]
}
......
};
因为使用externals配置,打包后库文件可以在 AMD、CMD和全局环境下使用,但这几种环境中我们依赖的 react 和 react DOM 模块名不同,如:
AMD下 define(['react'], function (){})
全局使用时 window.React
CMD下 require('react')
配置external后 webpack编译结果:
注意:我们使用es2015-loose将ES6代码转译成ES5代码。在使用 ES6 解构 rest 属性时,需要安装 babel-plugin-transform-object-rest-spread 插件
例如下面代码的解析:
const { id, text, ...itemParams } = item
安装
npm install babel-plugin-transform-object-rest-spread
在 .babelrc 中配置
{
"presets": ["react", "es2015-loose"],
"plugins": ["transform-object-rest-spread"]
}
组件设计
我们组件是采用组件组合的开发方式,将组件做到最小颗粒化,每个组件实现单一的功能,使组件运用起来更加灵活。公共组件由每个功能单一的组件拼合而成。组件开发依赖state,通过componentwillreciveprops生命周期函数接受props更新state,来使view更新。
技术选型:
定位: 移动端h5页面
组件需求:
技术栈
1) webpack
2) zepto + gmu + stylus + handlebar
目录结构:
mofang-webapp
|- app(生态模块)
|- dist (目标模块)
|- node-modules(依赖模块)
|- helpers (handlebar.helper)
|- src (代码模块)
|- common (公共代码)
|- componets (组件)
|- carchoose
|- carchoose.js
|- carchoose.html
|- carchoose.hanlebar
|- color.handlebar
|- type.handlebar
|- brand.handlebar
|- shortcut.handlebar.
|- city
|- dialog
…
|- vendor(angular 相关依赖)
|- webpack.config.js (测试环境配置)
|- webpack.min.js (生产环境配置)
|- webpack.module.js (生产环境配置)
|- gulpfile.js (打包环境配置)
最终目录结构为:
|- mofang-webapp()
|- 0.1.21 (版本号)
|- mofang.min.js
|- mofang.min.css
|- module(模块)
|-0.1.21
|- carchoose.min.js
|- city.min.js
|- dialog.min.js
组件使用方式:
我们以 carchoose 组件为例,来看一下它是如何被使用的:
var $carchoose = $('#carchoose');
$carchoose.carchoose({
onselect: function(obj){
...
}
});
如代码所示,我们的组件是绑定在元素上,组件内容全部通过配置参数来控制。
组件设计
我们以carchoose为例,该组件主要是用来展示品牌车型的,其中包括车辆品牌、车辆型号、车辆颜色。分别通过点击事件依次从右侧划入屏幕。
组件如图:
1)功能拆分
将组件分为三块部分(品牌、型号、颜色),品牌中再分为热门、缩略、列表。
2)参数定义
brandsURL: '',
typesURL: '',
colorsURL: '',
hotcarbrands: [],
onselect:fuction(){},
onCloseSelector: function(){},
onrenderBefore: function(type){}
从功能上看,我们有三种主要数据需要渲染,数据通过请求方式获取,数据量太大一次性读取数据还是很耗时的,而且用户不会频繁操作该组件。但是不能因为用户不会频繁操作,而忽略这个问题。我们采取将用户获取数据进行缓存,当用户再次点击,我们只需用缓存数据进行渲染即可。热门品牌以及钩子函数是必须的。
3)技术实现
动画效果采用css3实现
列表展示采用bscroll组件
加载效果采用lodaing组件
(其中bscroll为滴滴内部研发类似iscroll,性能优于iscroll的组件)
痛点:
我们没有一套滴滴定制化的可视化控件,每个设计师设计的图标各不相同, 而且代码没有可复用性,每次都要重新开发,浪费资源。加上目前流行的可视化组件配置项比较复杂,所以我们基于 canvas API 封装了一套基础图表组件。
技术选型:
定位:pc 端数据可视化图表
组件需求:
折线图 & 饼状图 & 柱状图 & 雷达图
两套皮肤
组件使用方式:
以折线图为例:
<canvas mofang-line chart-data="data"></canvas>
<script>
angular
.module( 'myModule', [ 'mofang.chart' ])
.controller( 'myController', function( $scope ) {
$scope.data = {
theme:'warm',
fill: true,
labels: ["11.01", "11.02", "11.03", "11.04"],
datasets: [{
label: "图例1",
data: [13, 24, 89, 65]
}, {
label: "图例2",
data: [25, 98, 87, 65],
}]
};
});
</script>
参数说明:
theme 皮肤,支持 2 套配色皮肤['warm','cold'],默认:warm
fill 是否填充颜色,支持 [true,false],默认:false
labels 配置横轴内容[数组格式]
datasets 配置线数据,包含两个字段:label是图例名称,data 是数据[数组格式]
$broadcast("update") 更新图表数据
现有可视化库:
组件设计:
我们的可视化组件是在 chartjs 的基础上,保留原有 chartjs 的基本框架结构,对内部的组件canvs画图方式以及组件间数据传递进行改造,以达到滴滴定制可视化组件的效果,为避免用户调用过于复杂,又鉴于MIS系统都是基于angularjs组件库开发的,就将可视化组件用angular封装,只对用户暴露简单的数据接口。
我们发现只解决了 UI 交互组件化、规范化,针对日益繁多的 MIS 项目,还是缺少点什么:
配置化:
现在很多人的做法:
把很多配置信息比如请求的 url 都放到一个 js 里面
// Action.js
var URLS = {
AJAXS: {
BUS_LIST: '*****'
},
LOGS: {
},
SCHEMAS: {
}
}
我们搭建了 MIS 配置平台,可以配置很多类似的东西:
各个 MIS 系统的用户权限,菜单配置
MIS 配置平台都是基于angular组件开发的系统,每个子系统配置不同的用户角色,每个角色针对应不同的权限。系统的左侧菜单也是通过配置平台,这样可以方便的控制每个角色对页面访问权限,同时我们还会记录每个用户的操作行为,方便回溯问题根源。配置平台中项目的环境有三套,一套针对内网环境,一套针对外网环境,一套测试环境。平台配置分别分别记录每个项目在相应机器中的端口号,以及域名,统一查询和维护。
由于项目组这边经常要协助其它组开发 MIS 系统相关的开发,我们创建了支持 angular、react及vue开发的脚手架,方便快速开发项目,只关注项目的逻辑功能,减少对环境的搭建。
mofang angular-demo
选择 PC 后:
然后我们会在当前目录下:
创建一定模板规则的目录,配置好依赖和构建脚本
通用组件:底层组件,提供基础功能、可扩展性
业务组件:在通用组件基础上做拼接、定制
业务组件与通用组件是密切相关的,正如一句话“用的人多了,就会变成通用组件啦”, 业务组件是在通用组件的基础上做的拼接与定制。通用组件适用的业务场景比较广泛,业务组件业务场景比较单一。当好多业务场景下,都使用了相同组件时,我们就要考虑是否将业务组件提取成公共组件,方便大家使用,节约开发成本。
大多数技术人员在开发项目过程中都会遇到这样,产品经理提出的需求总是要在公共组件的基础上来点特殊的定制化业务逻辑,以使他的产品更加炫酷。如果满足这种需求,往往我们需要给公共组件加各种补丁,或者把组件拿过来自己再重新封装一下。遇到这种情况我们应该怎么办?
在以往的工作中,在完成一个系统开发的时候,无论后端语言是php、java, 常见开发模式分两种情况:
第一种:前后端代码共同维护在一个项目中,前端开发完全依赖后端同学,我们需要后端同学给我们搭建一套测试环境,创建一个目录发布专属前端的代码,既麻烦又费事,还有可能可能出现代码冲突。
第二种:前后端同学各自维护项目,但是页面在后端系统中维护,前端只提供脚本文件。第二种方式其实稍好于第一种,只是这样都没有完全实现全后端代码的分离。比如说前端在业务开发的时候发现还需要引用另外的脚本文件,页面在后端项目中,他没有权限,他只能找后端同学帮他在页面加上相应脚本。
我们在开发MIS项目时使用DNode服务,所有的前端代码我们都由自己维护,我们只需要后端给我们提供 API 接口,前端自己启服务,搭建测试环境,真正的实现前后端分离,可以随心所欲的开发。
目前我们的做法:
1)为了防止恶意攻击,我们将所有与后端api的请求都做一层转发,并在请求之前对请求来源做验证,如果不是来自我们域名下的请求, 我们将其视为无效请求,并告知其请求无效,代码示例如下:
getProvinces: function(req,res){
res.header('Access-Control-Allow-Origin', '***.com');
res.header('Access-Control-Allow-Methods', 'GET');
res.header('Access-Control-Allow-Headers', 'Content-Type');
var util = sails.services.util;
var cookies = cookie.parse(req.headers.cookie);
if(req.headers.referer && req.headers.referer.indexOf(util.Referer')>=0) {
request.get(util , function (error, response, body){
res.json(JSON.parse(body));
});
} else {
res.json({
error: 10000,
data: [],
errormsg: '非法请求'
});
}
}
2)创建 DNode Auth 服务接入权限系统
var Q = require('q');
var request = require('request');
var defaults = {
url: 'xxx/xxx/xxx/xxx/index'
};
var sso = {
getUser: function (key) {
var deferred = Q.defer();
//...
request.post(obj, function(err,httpResponse,body) {
....
});
return deferred.promise;
}
};
我们内建了很多服务和 SDK,下面简单以 Mock Server 为例:
这里面的方案业界比较多,我们分 2 类:
1、JSON Editor + CDN 化
这种接口应用场景:
用来配置线上数据的,而且公网能访问,还是依托我们第一场分享中的 TMS
2、JSON Server + JSON schema + DSwagger Doc UI
这种接口应用场景:
用来构建按规则的假数据,不依赖 DB,一般都是 json 文件,然后加上类似 Swagger 的那种 UI 输出给相关协同开发
目前前端的状况:
编辑器差异化还好,但构建类工具和预编译类工具都各种各样
我们团队 IDE 为例:
构建工具:
而且我们发现编辑器越来越强大,很多插件化的东西都可以安装进编辑器里面,所以我们有一个目标:
搭建一个在线编辑器:
好处:
屏蔽各种本地安装带来的问题,专注于业务开发
继承了现有的工具:git、脚手架等
展示:
技术演变:
Ace:基于 web 的开源代码编辑器,star 数目 13000+
C9:内置命令行、各种语言工具的在线编辑器,目前已经发布到 3.* 版本了
C9 的功能非常强大,我们也自定义和开发了很多相关插件。
由于编辑器比较庞大,如果对编辑器感兴趣的,我们可以私下在联系。
致谢:
感谢领导的信任与栽培,感谢一路陪伴、一起奋斗的滴滴小伙伴,感谢infoq提供分享平台。
cube-ui 是滴滴去年底开源的一款基于 Vue.js 2.0 的移动端组件库,主要核心目标是做到体验极致、灵活性强、易扩展以及提供良好的周边生态—后编译。
自 17 年 11 月开源至今已有 5 个月,在这个过程中 cube-ui 受到了不少的关注,同时从社区中也收到了很多很好的反馈和建议。我们也一直在迭代更新,从最初的 1.0 版本到最近发布的 1.7 的版本,除了对原有组件做一些增强优化,我们也提供了很多新的组件。此外,周边后编译技术生态也做了很多优化,满足于更多场景需求,官网也做了一次升级。
接下来就重点介绍下 cube-ui 在这个过程中的有哪些成果以及一些设计细节。
cube-ui 的组件数已经从最初的 14 个增长了 28 个,足足翻了一倍,已有的组件生态:
扫码体验:
除了上述的组件外,cube-ui 还对外暴露了三个模块:
而且 cube-ui 也已经支持了如下特性:
此外,cube-ui 的周边生态也有了进一步丰富:
针对于上边所介绍的关键成果,我们来聊聊具体设计上的细节。
滚动 & Picker 类组件
在移动端,由于手机尺寸以及交互特性,我们需要处理很多滚动类需求:下拉刷新、上拉更多、轮播等以及 Picker 选择等场景。cube-ui 底层滚动类组件以及 Picker 类依赖于我们团队的移动端利器 better-scroll 实现,基于其出色的体验进而保证了我们上层封装的滚动类、Picker 类组件的出色的交互体验。
弹出层类组件
在实际开发中我们会遇到很多弹出层类组件,因为我们设计了一个基础弹出层组件 Popup,它主要解决移动端最为常见的居中(Tip:文本换行位置也很重要哦)、置底以及是否有蒙层效果,借助于它来实现绝大多数的弹出层组件。
另一个常见的痛点就是由于弹出类组件往往是全屏的状态,如果我们按照 Vue 推荐的声明式的语法在子组件里使用弹出层组件,由于嵌套层级问题,很容易受到父级元素的样式影响。为此我们单独开发了 create-api 模块,通过 API 的形式将实例化的弹出层组件动态挂载到 Body 元素下,因此摆脱了父级元素样式的影响,同时会随着使用它的组件的销毁而自动销毁,且为了降低开销成本,根据需要有些弹出层类组件都被设计成了单例模式。它是一个很通用的能力,我们把这样的一个便捷的 API 对外暴露出去,开发者也可以根据实际场景将自己开发的组件通过 createAPI 进行注册,进而也可解决上述痛点。
表单类组件
表单类需求往往特应性比较大,交互也很难做到统一,但是仍然可以有主流的表单设计交互,在 cube-ui 中表单可以设置 layout 来决定样式甚至是交互,满足日常场景需求。在表单设计中有两个很重要的组件:Validator 和 Form。Validator 成为独立的组件主要基于校验场景不确定性,同时还需要满足各种形式的校验,所以 Validator 就只做了两件核心的事情,对数据源进行校验以及对应的错误信息的展示。考虑到开发者开发表单的便利性,我们参考 vue-form-generator 的设计,把表单设计成了根据 Schema 配置自动生成表单,这样开发表单的成本就降低了很多;同时为了兼顾灵活性,也支持通过插槽来自定义开发者需要的结构交互。
后编译是 cube-ui 的一个重要的生态,借助于后编译,整个的 web 应用的开发都可以直接基于 ES2015+ 进行开发,而项目依赖的一些 NPM 包也是可以直接使用 ES2015+ 进行开发,并且无需编译可直接发布到 NPM 平台上(也可以是自己 NPM 私服)。这样,这些组件库或者工具就可以有更多的想象空间、可以做更多有意思的事情。
cube-ui 支持的两个特性自定义主题以及 rem 布局都是基于我们主推的后编译技术实现。
接下来一起来看下这两个特性实现的细节。
一般而言,组件库都是有默认主题的,而往往还会搭配有多套主题(PC 类组件库比较常见)。现在借助于 CSS 预处理器,我们可以给组件定义一些变量(一般都是颜色值),然后在组件对应的样式中使用。
对于自定义主题这种需求,主流的做法有:样式覆盖和修改变量。
样式覆盖
样式覆盖是最古老的做法,但是缺点也很明显,第一就是样式冗余问题,默认主题样式是一直存在的;第二就是开发者需要确切的知道样式对应的优先级去覆盖,要么是同级的优先级样式后置,要么就是提升自身覆盖的样式优先级。
当然,样式覆盖的做法也是有优点的,那就是对于多主题同时存在,自由切换场景会比较合适。
修改变量
现在有很多的 CSS 预处理器可以选择,每一种 CSS 预处理器都提供了变量功能,借助于变量,我们可以很容易创建一个主题文件,里边包含组件依赖的变量定义。要实现自定义主题,开发者需要在自己项目下创建一个单独的样式文件,定义赋值变量,同时引入组件库自身源码下的主题文件。
本质上也是一种后编译做法,这个编译是利用 CSS 预处理器自身的变量能力达到目的。对于 Vue 组件库而言,主流的也是推荐的做法是把样式写在 .vue 文件中,这样便于维护,比较符合组件化开发思维;但是为了方便的使用预处理器实现自定义主题,通常都会把样式单独拿出来,一般的做法是创建一个样式文件夹,里边包含所有组件样式,而在 .vue 文件中则是没有样式的。
cube-ui 做法
核心点就是借助于后编译,我们可以按照原有我们习惯的方式去书写组件,即在 .vue 文件中包含模板、脚本和样式。如果需要自定义主题,就在自己项目下创建一个主题文件,里边定义变量,这个做法和一般的修改变量做法一样,但是不需要引入所有样式入口文件,因为也不存在这样的一个文件;同时借助于 webpack,我们完全可以做到在不侵入源码的情况下,做到主题定制。
接下来就看下具体做法,如果是新创建的项目,那么推荐使用 Vue-cli + cube-template 模板生成;而如果是现成的项目,则具体参考官方文档 - 主题 中配置。主要有两个核心点:
theme.styl,一般放在 src/ 目录下import 字段用于依赖自定义主题文件接下来就看一个简单项目演示,假设创建了一个 demo 的项目,这个项目默认跑起来是这样的:
如果我们想要把项目中使用的按钮的背景色该换掉,那么可以修改 theme.styl 的文件内容:
// 如果你需要使用 cube-ui 自带的颜色值 需要 require 进来
@require "~cube-ui/src/common/stylus/var/color.styl"
// button
$btn-bgc := #409eff
$btn-bdc := #409eff
$btn-active-bgc := #66b1ff
$btn-active-bdc := #66b1ff配合我们的 webpack 配置,刷新后的样子为:
这样我们就可以轻松做自己想要的主题定制,所要做的就是修改 cube-ui 已经定义好的变量值即可。对于 cube-ui 组件库自身,则不会有任何修改,且对于应用开发者而言,用不用自定义主题,本身的源代码不用修改,只需要创建一个主题文件(无需手工引入)配合 webpack 插件配置即可。
其实对于主题定制,还可以更进一步,未来 cube-ui 会考虑借助于 CSS 自身支持的变量(自定义属性)达到主题定制的目的,例如可以把处理器变量改为原生的变量,编译的话可以通过 post-css-variables 插件把默认变量值做替换,可以实现和现有编译后功能相同的效果,同时在后编译的情况下不失原生 CSS 变量的动态优势。这样,不仅可以做到主题定制,也可以做到多主题的自由切换,因为 CSS 原生变量可以直接修改变量值而不需要通过事先写死然后切换 class 覆盖的方式做多主题切换。
在移动端还是有很多设计师、产品或者开发者偏爱用缩放来达到不同尺寸屏幕适配目的,而缩放的实现一般都是采用 rem 进行布局,业内比较出名的方案就是手机淘宝前端团队开源的 lib-flexible。
现在其实是不推荐使用 rem 进行布局的,如果真的要缩放的效果,可以考虑 vw vh 等 CSS 单位来实现。
rem 布局有两个核心的点:
font-size 的值对于组件库而言,如果想要同时做到即支持普适的 px 又支持 rem 这种方式的话,社区貌似还没见到。和后编译搭配,则比较容易实现,在 cube-ui 中,已经提供了 rem 支持,主要采取的方案:
这其实是对组件库本身有了一定要求,和尺寸相关的尽量要用样式控制,这样才能通过处理工具 postcss-px2rem 将 px 单位处理成 rem 单位,进而实现动态缩放需求。
来看下 cube-ui 使用 rem 的效果,默认 iPhone 5 尺寸效果:
当尺寸变大,例如为 iPhone 6 Plus 尺寸时效果:
可以看出整体的效果,当尺寸较小时,Button 和 Toast 都是比较小的,而当尺寸比较大时,相对应的都会更大,达到了缩放的目的。
这里上层扩展主要是指基于组件库进行二次封装,例如在滴滴内部,我们的很多业务组件库就是在开源的 cube-ui 组件库之上做增强而来的。
这个能力是非常重要的,因为移动端组件库和 PC 组件库最大的区别是移动端多是 to C 的业务场景,不同的业务场景下的设计是不一样的,所以 cube-ui 专注于通用组件和基础能力的建设,并不会在布局和业务组件方面大做文章;而 PC 组件库一般都是用于 to B 的场景,如内部 MIS 类的系统,对于设计的要求并没有特别苛刻,所以基础的样式,组件都是可以统一的。因此 cube-ui 的定位并不是要提供一个“大而全”的组件库,而是提供了二次扩展的能力,目标是任何移动端的业务场景都可以基于 cube-ui 提供的能力做二次扩展。
以我们的快速上手教程为例,我们要开发如下图的弹窗组件。
我们基于 cube-ui 提供的能力开发它就非常方便了。首先可以基于 Popup 组件开发一个 subscribe-dialog.vue 组件:
<template>
<div class="subscribe-dialog-view">
<cube-popup ref="popup" @mask-click="hide">
<div class="subscribe-dialog-wrapper">
<span class="close" @click="hide"><i class="cubeic-close"></i></span>
<div class="title">开启推送通知</div>
<img src="./subscribe.png">
<p class="desc">第一时间获取最新鲜出炉的新闻攻略、赛事咨询、数据专题、精彩视频</p>
<cube-button class="button" @click="start">现在开启</cube-button>
</div>
</cube-popup>
</div>
</template>
<script>
export default {
name: 'subscribe-dialog',
methods: {
show () {
this.$refs.popup.show()
this.$emit('show')
},
hide () {
this.$refs.popup.hide()
this.$emit('hide')
},
// ...
}
}
</script>接着使用 createAPI 模块把它变成一个 API 式的组件:
import SubscribeDialog from './components/subscribe-dialog/subscribe-dialog'
createAPI(Vue, SubscribeDialog, [], true)然后调用它就非常方便了:
this.subscribeDialog = this.$createSubscribeDialog()
this.subscribeDialog.show()
周边生态有两个核心:后编译 + 按需引入。为此,我们开发了两个 webpack 的插件来帮助我们更好的去使用、开发。
这个插件主要是读取应用 package.json 中的 compileDependencies 字段的值(用于指定应用需要后编译哪些依赖包),而且还能解决嵌套后编译包的问题,因为开发者只需要关注自己依赖需要后编译的包,而不需要关注依赖的依赖包,这样就能构成一条生态链。
为什么不是一个 NPM 包自己声明需不需要后编译,而是由使用者去声明?
主要考虑整个 NPM 生态,例如 lodash-es 并不在我们控制范围之内,为了更好的使用整个 NPM 生态圈的包,我们决定由使用者去声明需要后编译的 NPM 包。
这个插件主要解决更方便、友好地使用按需引入的问题,为了更好的统一应用使用后编译和不使用的情况,我们在原本 babel-transform-imports 的基础上做了升级优化产出了 babel-plugin-transform-modules 插件,但是和后编译的场景类似,这个是不能解决后编译场景下 NPM 包嵌套按需引入的问题的,为此才开发了 webpack-transform-modules-plugin 这个插件,和 compileDependencies 字段类似,我们新增了 transformModules 字段来声明按需引入的 NPM 包的的转换规则,例如:
"transformModules": {
"cube-ui": {
"transform": "cube-ui/src/modules/${member}",
"kebabCase": true
}
}当然在后编译的场景下,我们借助于 webpack 4 Tree shaking 中新增的 side-effects 也可以达到目的,这个是未来我们去优化的方向。
任何的技术都是有成本的,我们新增了 webpack 插件,也有一些需要配合的改动,所以为了降低开发者成本,我们提供了适用于 vue-cli 脚手架的模板 cube-template,当然对应的也会新增一些配置项,感兴趣的可以了解下cube-template wiki。
同时为了初次使用 cube-ui 的开发者快速上手,我们还有一个简单的上手教程 cube-application-guide。
cube-ui 目前还处于初步的阶段,还缺少很多组件,但是我们一直在努力,希望在很快的未来可以提供更多更好用的组件。不仅如此,我们希望的是除去组件库本身,额外还会丰富周边的整个生态建设,给开发者一个良好的生态环境,进一步提升开发体验,提升应用性能等。当然,我们也希望社区的小伙伴也能参与进来,一块共同建设,共同进步。
未来 cube-ui 会朝着如下方面继续前行:
希望感兴趣的同学可以一起共建或者加入我们团队,一起玩技术!
this.scroll.refresh()
//Unresolved function or method refresh() (编辑器显示)
||代码如下:
methods: {
loadData() {
this.$http.get('/api/dinners').then((response) => {
this.data = response.body.data.concat(this.data)
this.$nextTick(() => {
let wrapper = document.querySelector('.wrapper')
let scroll = new Bscroll(wrapper, {})
if (!this.scroll) {
this.scroll = new Bscroll(this.$refs.wrapper, {})
probeType: 3,
this.scroll.on('touchend', (pos) => {
// 下拉动作
if (pos.y > 50) {
this.loadData()
}
})
} else {
this.scroll.refresh();
}
})
})
}}
原文链接:https://github.com/tank0317/unit-test-demo#unit-test-demo
为什么做单元测试?测试可以验证代码的正确性,当然手工也可以测试,但是这是一次性的事情,下次测试还需要从头来过,效率不能得到保证。通过编写测试用例,可以做到一次编写,多次运行。
单元测试是什么?意义?不是我们今天想讨论的重点,今天只是聊一聊怎么做单元测试。如果你最近也对单元测试是怎么做的感兴趣,这篇文章可能是你需要的。
该文章通过五个环节一步一步介绍了如何给项目添加单元测试。文章中会涉及到 Mocha, Chai, Karma, Travis-CI, Istanbul, Codecov 等,如果你还不知道这些名词是什么,或者还不知道他们是如何配合起来工作的,你可以通过以下几个环节逐步了解。
以上的每一个环节与项目中的 Commit 一一对应,项目地址。
同时,该项目是渐进增强的,每个环节会给项目添加新的能力,又都是独立可运行的完整示例。 每个环节都有对应的 README 介绍该环节执行的结果是什么以及是如何做到的。你也可以借助 Git 查看每个环节具体修改了哪些地方。
如果在 Github 上你可以直接通过 Tags 进入对应的环节,如下图所示。项目地址
如果已经将项目克隆到本地,你可以通过 git checkout Chapter* 检出你想要查看的环节。
如果你跟我一样一开始并不了解单元测试,推荐将项目克隆到本地,检出每个环节对应的 Commit ,直观查看执行的结果。只有程序都跑通了,我们再谈是怎么做到的。项目地址
对于前两个环节你可以直接在本地运行命令查看结果,但是对于第三和第四个环节,需要 Push 代码到 Github 才能看到效果。所以你可以fork 项目到自己的 Github,基于第二个环节对应的 Commit 新建一个分支,在新的分支上进行操作,然后 Push 代码到自己的仓库,查看是否有预期效果。
通过该文章你不仅仅能够学会如何给项目添加单元测试,同时能够了解到:
BetterScroll 是一款重点解决移动端各种滚动场景需求的开源插件(GitHub地址),适用于滚动列表、选择器、轮播图、索引列表、开屏引导等应用场景。
为了满足这些场景,它不仅支持惯性滚动、边界回弹、滚动条淡入淡出等效果的灵活配置,让滚动更加流畅,同时还提供了很多 API 方法和事件,以便我们更快地实现滚动场景下的需求,如下拉刷新、上拉加载。
由于它基于原生 JavaScript 实现,不依赖任何框架,所以既可以原生 JavaScript 引用,也可以与目前前端 MVVM 框架结合使用,比如,其官网上的示例就是与 Vue 的结合。
首先,让我们来看一下它是怎样让滚动更流畅的吧。
在移动端,如果你使用过 overflow: scroll 生成一个滚动容器,会发现它的滚动是比较卡顿,呆滞的。为什么会出现这种情况呢?
因为我们早已习惯了目前的主流操作系统和浏览器视窗的滚动体验,比如滚动到边缘会有回弹,手指停止滑动以后还会按惯性继续滚动一会,手指快速滑动时页面也会快速滚动。而这种原生滚动容器却没有,就会让人感到卡顿。
试一试 BetterScroll 的滚动体验吧。体验地址
可以发现,在增加惯性滚动,边缘回弹等效果之后,明显流畅、舒服了很多。那么,这些效果是怎么实现的呢?
BetterScroll 在用户滑动操作结束时,还会继续惯性滚动一段。首先看一下源码中的 BScroll.prototype._end 函数,这是 touchend、mouseup、touchcancel、mousecancel 事件的处理函数,也就是用户滚动操作结束时的逻辑。
BScroll.prototype._end = function (e) {
...
if (this.options.momentum && duration < this.options.momentumLimitTime && (absDistY > this.options.momentumLimitDistance || absDistX > this.options.momentumLimitDistance)) {
let momentumX = this.hasHorizontalScroll ? momentum(this.x, this.startX, duration, this.maxScrollX, this.options.bounce ? this.wrapperWidth : 0, this.options)
: {destination: newX, duration: 0}
let momentumY = this.hasVerticalScroll ? momentum(this.y, this.startY, duration, this.maxScrollY, this.options.bounce ? this.wrapperHeight : 0, this.options)
: {destination: newY, duration: 0}
newX = momentumX.destination
newY = momentumY.destination
time = Math.max(momentumX.duration, momentumY.duration)
this.isInTransition = 1
}
...
}以上代码的作用是,在用户滑动操作结束时,如果需要开启了惯性滚动,用 momentum 函数计算惯性滚动距离和时间。该函数,根据用户滑动操作的速度和 deceleration选项 ——惯性减速来计算滚动距离,至于滚动时间,也是一个可配置的选项。
function momentum(current, start, time, lowerMargin, wrapperSize, options) {
...
let distance = current - start
let speed = Math.abs(distance) / time
...
let duration = swipeTime
let destination = current + speed / deceleration * (distance < 0 ? -1 : 1)
...
}超过边缘时的回弹,有两个处理步骤,第一步是滚动到超过边界时速度要变慢,第二步是回弹到边界。其中,第一步是在源码的 BScroll.prototype._move 函数,这是 touchmove 和 mousemove 事件的处理函数,也就是在用户滑动操作过程中的逻辑。
// Slow down or stop if outside of the boundaries
if (newY > 0 || newY < this.maxScrollY) {
if (this.options.bounce) {
newY = this.y + deltaY / 3
} else {
newY = newY > 0 ? 0 : this.maxScrollY
}
}第二步是调用BScroll.prototype.resetPosition函数,回弹到边界。
BScroll.prototype.resetPosition = function (time = 0, easeing = ease.bounce) {
...
let y = this.y
if (!this.hasVerticalScroll || y > 0) {
y = 0
} else if (y < this.maxScrollY) {
y = this.maxScrollY
}
...
this.scrollTo(x, y, time, easeing)
...
}流畅的滚动仅仅是基础,BetterScoll 真正的能力在于:提供了大量通用 / 定制的 option 选项 、 API 方法和事件,让各种滚动需求实现起来更高效。
下面,以结合 Vue 的使用为例,说一下 BetterScroll 在各种场景下的姿势。
比如,有如下列表:
<div ref="wrapper" class="list-wrapper">
<ul class="list-content">
<li @click="clickItem($event,item)" class="list-item" v-for="item in data">{{item}}</li>
</ul>
</div>我们想要让它垂直滚动,只需要对该容器进行简单的初始化。
import BScroll from 'better-scroll'
const options = {
scrollY: true // 因为scrollY默认为true,其实可以省略
}
this.scroll = new BScroll(this.$refs.wrapper, options)对于 Vue 中使用 BetterScroll,有一个需要注意的点是,因为在 Vue 模板中列表渲染还没完成时,是没有生成列表 DOM 元素的,所以需要在确保列表渲染完成以后,才能创建 BScroll 实例,因此在 Vue 中,初始化 BScroll 的最佳时机是 mouted 的 nextTick。
// 在 Vue 中,保证列表渲染完成时,初始化 BScroll
mounted() {
setTimeout(() => {
this.scroll = new BScroll(this.$refs.wrapper, options)
}, 20)
},初始化之后,这个 wrapper 容器就能够优雅地滚动了,并且可以通过 BScroll 实例this.scroll使用其提供的 API 方法和事件。
下面介绍几个常用的选项、方法和事件。
scrollbar选项,用来配置滚动条,默认为 false。当设置为 true 或者是一个 Object,开启滚动条。还可以通过 fade 属性,配置滚动条是随着滚动操作淡入淡出,还是一直显示。
// fade 默认为 true,滚动条淡入淡出
options.scrollbar = true
// 滚动条一直显示
options.scrollbar = {
fade: false
}
this.scroll = new BScroll(this.$refs.wrapper, options)具体效果可见普通滚动列表-示例。
pullDownRefresh选项,用来配置下拉刷新功能。当设置为 true 或者是一个 Object 的时候,开启下拉刷新,可以配置顶部下拉的距离(threshold)来决定刷新时机,以及回弹停留的距离(stop)
options.pullDownRefresh = {
threshold: 50, // 当下拉到超过顶部 50px 时,触发 pullingDown 事件
stop: 20 // 刷新数据的过程中,回弹停留在距离顶部还有 20px 的位置
}
this.scroll = new BScroll(this.$refs.wrapper, options)监听 pullingDown 事件,刷新数据。并在刷新数据完成之后,调用 finishPullDown() 方法,回弹到顶部边界
this.scroll.on('pullingDown', () => {
// 刷新数据的过程中,回弹停留在距离顶部还有20px的位置
RefreshData()
.then((newData) => {
this.data = newData
// 在刷新数据完成之后,调用 finishPullDown 方法,回弹到顶部
this.scroll.finishPullDown()
})
})具体效果可见普通滚动列表-示例。
pullUpLoad选项,用来配置上拉加载功能。当设置为 true 或者是一个 Object 的时候,可以开启上拉加载,可以配置离底部距离阈值(threshold)来决定开始加载的时机
options.pullUpLoad = {
threshold: -20 // 在上拉到超过底部 20px 时,触发 pullingUp 事件
}
this.scroll = new BScroll(this.$refs.wrapper, options)监听 pullingUp 事件,加载新数据。
this.scroll.on('pullingDown', () => {
loadData()
.then((newData) => {
this.data.push(newData)
})
})具体效果可见普通滚动列表-示例。
wheel选项,用于开启并配置选择器。可配置选择器当前选择的索引(selectedIndex),列表的弯曲弧度(rotate),以及切换选择项的调整时间(adjustTime)。
options.wheel = {
selectedIndex: 0,
rotate: 25,
adjustTime: 400
}
// 初始化选择器的每一列
this.wheels[i] = new BScroll(wheelWrapper.children[i], options)具体效果可见选择器 - 示例。
其中联动选择器,需要监听每个选择列表的选择,来改变其他选择列表。
data() {
return {
tempIndex: [0, 0, 0]
}
},
...
// 监听每个选择列表的选择
this.wheels[i].on('scrollEnd', () => {
this.tempIndex.splice(i, 1, this.wheels[i].getSelectedIndex())
})
...
// 根据当前选择项,确定其他选择列表的内容
computed: {
linkageData() {
const provinces = provinceList
const cities = cityList[provinces[this.tempIndex[0]].value]
const areas = areaList[cities[this.tempIndex[1]].value]
return [provinces, cities, areas]
}
},具体效果可见选择器 - 示例中的联动选择器。
snap选项,用于开启并配置轮播图。可配置轮播图是否循环播放(loop),每页的宽度(stepX)和高度(stepY),切换阈值(threshold),以及切换速度(speed)。
options = {
scrollX: true,
snap: {
loop: true, // 开启循环播放
stepX: 200, // 每页宽度为 200px
stepY: 100, // 每页高度为 100px
threshold: 0.3, // 滚动距离超过宽度/高度的 30% 时切换图片
speed: 400 // 切换动画时长 400ms
}
}
this.slide = BScroll(this.$refs.slide, options)具体效果可见轮播图 - 示例。
除了普通滚动列表、选择器、轮播图等基础滚动场景,还可以利用 BetterScroll 提供的能力,做一些特殊场景。
索引列表,首先需要在滚动过程中实时监听滚动到哪个索引的区域了,来更新当前索引。在这种场景下,我们可以使用probeType选项,当此选项设置为 3 时,会在整个滚动过程中实时派发 scroll 事件。从而获取滚动过程中的位置。
options.probeType = 3
this.scroll = new BScroll(this.$refs.wrapper, options)
this.scroll.on('scroll', (pos) => {
const y = pos.y
for (let i = 0; i < listHeight.length - 1; i++) {
let height1 = listHeight[i]
let height2 = listHeight[i + 1]
if (-y >= height1 && -y < height2) {
this.currentIndex = i
}
}
})当点击索引时,使用scrollToElement()方法滚动到该索引区域。
scrollTo(index) {
this.$refs.indexList.scrollToElement(this.$refs.listGroup[index], 0)
}具体效果可见索引列表 - 示例。
开屏引导,其实就是一种不自动循环播放的横向滚动轮播图而已。
options = {
scrollX: true,
snap: {
loop: false
}
}
this.slide = BScroll(this.$refs.slide, options)具体效果可见开屏引导 - 示例。因为此需求场景一般只有移动端才有,所以最好在手机模式下看效果。
freeScroll选项,用于开启自由滚动,允许横向和纵向同时滚动,而不限制在某个方向。
options.freeScroll = true另外需要注意的是,此选项在 eventPassthrough 设置了保持原生滚动时无效。
具体效果可见自由滚动-示例。
BetterScroll 可以用于几乎所有滚动场景,本文仅介绍了在一些典型场景下的使用姿势。
作为一款旨在解决移动端滚动需求的插件,BetterScroll 开放的众多选项、方法和事件,其实,就是提供了一种让我们更加快捷、灵活、精准时机地处理滚动的能力。
经过前几篇文章我们介绍了 webpack 如何从配置文件的入口开始,将每一个文件转变为内部的 module,然后再由 module 整合成一个一个的 chunk。这篇文章我们来看一下最后一步 —— chunk 如何转变为最终的 js 文件。
上篇文章主要是梳理了在 seal 阶段的开始, webpack 内部是如何将有依赖关系的 module 统一组织到一个 chunk 当中的。现在继续来看 seal 阶段,chunk 生成之后的部分,我们从 optimizeTree.callAsync 看起
seal(callback) {
// 优化 dependence 的 hook
// 生成 chunk
// 优化 modules 的 hook,提供给插件修改 modules 的能力
// 优化 chunk 的 hook,提供给插件修改 chunk 的能力
this.hooks.optimizeTree.callAsync(this.chunks, this.modules, err => {
//... 优化 chunk 和 module
//... record 为记录相关的,不是主流程,这里先忽略
//... 优化顺序
// 生成 module id
this.hooks.beforeModuleIds.call(this.modules);
this.hooks.moduleIds.call(this.modules);
this.applyModuleIds();
//... optimize
// 排序
this.sortItemsWithModuleIds();
// 生成 chunk id
//...
this.hooks.optimizeChunkOrder.call(this.chunks);
this.hooks.beforeChunkIds.call(this.chunks);
this.applyChunkIds();
//... optimize
// 排序
this.sortItemsWithChunkIds();
//...省略 recode 相关代码
// 生成 hash
this.hooks.beforeHash.call();
this.createHash();
this.hooks.afterHash.call();
//...
// 生成最终输出静态文件的内容
this.hooks.beforeModuleAssets.call();
this.createModuleAssets();
if (this.hooks.shouldGenerateChunkAssets.call() !== false) {
this.hooks.beforeChunkAssets.call();
this.createChunkAssets();
}
this.hooks.additionalChunkAssets.call(this.chunks);
this.summarizeDependencies();
//...
// 增加 webpack 需要的额外代码
this.hooks.additionalAssets.callAsync(err => {
//...
});
});
}上面代码中,按照从上往下的顺序依次看,经历的主流程如下:

主要步骤为:生成 moduleId,生成 chunkId,生成 hash,然后生成最终输出文件的内容,同时每一步之间都会暴露 hook , 提供给插件修改的机会。接下来我们一一看一下核心逻辑:id 生成,hash 生成,文件内容生成
webpack 会对 module 和 chunk 分别生成id,这二者在逻辑上基本相同。我们先以 module id 为例来看 id 生成的过程(在 webpack 为 module 生成 id 的逻辑位于 applyModuleIds 方法中),代码如下
applyModuleIds() {
const unusedIds = [];
let nextFreeModuleId = 0;
const usedIds = new Set();
if (this.usedModuleIds) {
for (const id of this.usedModuleIds) {
usedIds.add(id);
}
}
const modules1 = this.modules;
for (let indexModule1 = 0; indexModule1 < modules1.length; indexModule1++) {
const module1 = modules1[indexModule1];
if (module1.id !== null) {
usedIds.add(module1.id);
}
}
if (usedIds.size > 0) {
let usedIdMax = -1;
for (const usedIdKey of usedIds) {
if (typeof usedIdKey !== "number") {
continue;
}
usedIdMax = Math.max(usedIdMax, usedIdKey);
}
let lengthFreeModules = (nextFreeModuleId = usedIdMax + 1);
while (lengthFreeModules--) {
if (!usedIds.has(lengthFreeModules)) {
unusedIds.push(lengthFreeModules);
}
}
}
// 为 module 设置 id
const modules2 = this.modules;
for (let indexModule2 = 0; indexModule2 < modules2.length; indexModule2++) {
const module2 = modules2[indexModule2];
if (module2.id === null) {
if (unusedIds.length > 0) module2.id = unusedIds.pop();
else module2.id = nextFreeModuleId++;
}
}
}可以看到设置 id 的流程主要分两步:
找到当前未使用的 id 和 已经使用的最大的 id。举个例子:如果已经使用的 id 是 [3, 6, 7 ,8],那么经过第一步处理后,nextFreeModuleId = 9, unusedIds = [0, 1, 2, 4, 5]。
给没有 id 的 module 设置 id。设置 id 时,优先使用 unusedIds 中的值。
在设置 id 的时候,有一个判断 module2.id === null,也就是说若在这一步之前,已经被设置过 id 值,那么这里便直接忽略。在设置 id 之前,会触发两个钩子:
this.hooks.beforeModuleIds.call(this.modules);
this.hooks.moduleIds.call(this.modules);我们可在这两个钩子中,操作 module,设置自己的 id。webpack 内部 NamedModulesPlugin 就是注册在 beforeModuleIds 钩子上,将 module 的相对路径设置为 id。在开发环境下,便于我们调试和分析代码,webpack 默认会使用这个插件。
设置完 id 之后,会对 this.modules 中的 module 和 chunks 中的 module 按照 id 来排序。同时还会对 module 中的 reason 和 usedExports 排序。
chunk id 的生成逻辑与 module id 类似,同样的,在设置完 id 后,按照 id 进行排序。
在 webpack 生成最后文件的时候,我们经常会设置文件名称为 [name].[hash].js 的模式,给文件名称增加一个 hash 值。凭着直觉,这里的 hash 值和文件内容相关,但是具体是怎么来的呢?答案就位于 Compilation.js 的 createHash 方法中:
createHash() {
const outputOptions = this.outputOptions;
const hashFunction = outputOptions.hashFunction;
const hashDigest = outputOptions.hashDigest;
const hashDigestLength = outputOptions.hashDigestLength;
const hash = createHash(hashFunction);
//... update hash
// module hash
const modules = this.modules;
for (let i = 0; i < modules.length; i++) {
const module = modules[i];
const moduleHash = createHash(hashFunction);
module.updateHash(moduleHash);
module.hash = moduleHash.digest(hashDigest);
module.renderedHash = module.hash.substr(0, hashDigestLength);
}
// clone needed as sort below is inplace mutation
const chunks = this.chunks.slice();
/**
* sort here will bring all "falsy" values to the beginning
* this is needed as the "hasRuntime()" chunks are dependent on the
* hashes of the non-runtime chunks.
*/
chunks.sort((a, b) => {
const aEntry = a.hasRuntime();
const bEntry = b.hasRuntime();
if (aEntry && !bEntry) return 1;
if (!aEntry && bEntry) return -1;
return byId(a, b);
});
// chunck hash
for (let i = 0; i < chunks.length; i++) {
const chunk = chunks[i];
const chunkHash = createHash(hashFunction);
if (outputOptions.hashSalt) chunkHash.update(outputOptions.hashSalt);
chunk.updateHash(chunkHash);
const template = chunk.hasRuntime()
? this.mainTemplate
: this.chunkTemplate;
template.updateHashForChunk(chunkHash, chunk);
this.hooks.chunkHash.call(chunk, chunkHash);
chunk.hash = chunkHash.digest(hashDigest);
hash.update(chunk.hash);
chunk.renderedHash = chunk.hash.substr(0, hashDigestLength);
this.hooks.contentHash.call(chunk);
}
this.fullHash = hash.digest(hashDigest);
this.hash = this.fullHash.substr(0, hashDigestLength);
}主结构其实就是两部分:
webpack 中计算 hash 值底层所使用的是 Node.js 中的 crypto, 主要用到了两个方法:
hash.update 可以简单认为是增加用于生成 hash 的原始内容(以下统一简称为 hash 源)digest 方法用来得到最终 hash 值。下面我们先看 module hash 生成过程。
module hash 生成的代码逻辑如下:
createHash() {
//...省略其他逻辑
const modules = this.modules;
for (let i = 0; i < modules.length; i++) {
const module = modules[i];
const moduleHash = createHash(hashFunction);
module.updateHash(moduleHash);
module.hash = moduleHash.digest(hashDigest);
module.renderedHash = module.hash.substr(0, hashDigestLength);
}
//...省略其他逻辑
}其中关键的 updateHash 方法,封装在每个 module 类的实现中,调用关系如下:

上面图可以看到,module hash 内容包括:
每个 module 中自己特有的需要写入 hash 中的信息
而对于 NormalModule 来说,这个方法具体为:
updateHash(hash) {
this.updateHashWithSource(hash);
this.updateHashWithMeta(hash);
super.updateHash(hash);
}也就说会包含 souce 内容和生成文件相关的元信息 buildMeta。
module id 和 被使用到的 exports 信息
依赖的信息
各个依赖具体有哪些信息要写入 hash 源,由 xxxDependency.js 中 updateHash 方法决定。例如下面的代码
// 打包的入口 main.js
import { A } from './a.js'
import B from './b.js'
import 'test-module'
console.log(A)
B()转化为 module 后(module 生成的流程请回忆webpack系列之五module生成2),三个 import 会得到三个 HarmonyImportSideEffectDependency。这里就以该依赖为例,看一下 hash 内容原始内容中写入依赖信息的过程,如下图

上面图可以看出,依赖的 module 会影响当前 module 的 hash,如果我们修改顺序或者其他的操作造成依赖 module 的 id 改变了,那么当前 module 得到的 hash 也会改变。
所以 module 的 hash 内容不仅包含了源码,还包含了和其打包构建相关的内容。因为当我们修改了 webpack 的相关配置时,最终得到的代码很有可能会改变,将这些会影响最终代码生成的配置写入生成 hash 的 buffer 中可以保证,当我们仅修改 webpack 的打包配置,比如改变 module id 生成方式等,也可以得到一个 hash 值不同的文件名。
在生成 chunk hash 之前,会先对 chunck 进行排序(为什么要排序,这个问题先放一下,在我们看完 chunk 生成之后再来解答)。
chunck hash 生成,第一步是 chunk.updateHash(chunkHash);,具体代码如下(位于 Chunck.js 中):
updateHash(hash) {
hash.update(`${this.id} `);
hash.update(this.ids ? this.ids.join(",") : "");
hash.update(`${this.name || ""} `);
for (const m of this._modules) {
hash.update(m.hash);
}
}这部分逻辑很简单,将 id,ids,name 和其包含的所有 module 的 hash 信息写入。然后写入生成 chunck 的模板信息: template.updateHashForChunk(chunkHash, chunk)。webpack 将 template 分为两种:mainTemplate 最终会生成包含 runtime 的代码 和 chunkTemplate,也就是我们在第一篇文章里看到的通过 webpackJsonp 加载的 chunck 代码模板。
我们主要看 mainTemplate 的 updateHashForChunk 方法
updateHashForChunk(hash, chunk) {
this.updateHash(hash);
this.hooks.hashForChunk.call(hash, chunk);
}
updateHash(hash) {
hash.update("maintemplate");
hash.update("3");
hash.update(this.outputOptions.publicPath + "");
this.hooks.hash.call(hash);
}这里会将 template 类型 "maintemplate" 和 我们配置的 publicPath 写入。然后触发 的 hash 事件和 hashForChunk 事件会将一些文件的输出信息写入。例如:加载 chunck 所使用的 jsonp 方式,是通过 JsonpMainTemplatePlugin 实现的。在 hash hooks 中会触发其回调,将 jsonp 的相关信息写入 hash,例如:jsonp 回调函数的名称等。将相关信息都存入 hash 的 buffer 之后,调用 digest 方法生成最终的 hash,然后从中截取出需要的长度,chunk 的 hash 就得到了。
总的来看,chunk hash 依赖于其内部所有 module 的 hash,并且还依赖于我们配置的各种输出 chunk 相关的信息。和 module hash 类似,这样才能保证当我们修改了 webpack 的相关配置导致代码改变后会得到不同的 hash 值。
到此还遗留了一个问题,为什么在生成 chunk hash 时候要排序?
在 updateHashForChunk 过程中,插件 TemplatePathPlugin 会在 hashForChunk hook 时被触发并执行一段下面的逻辑
// TemplatePathPlugin.js
mainTemplate.hooks.hashForChunk.tap(
"TemplatedPathPlugin",
(hash, chunk) => {
const outputOptions = mainTemplate.outputOptions;
const chunkFilename =
outputOptions.chunkFilename || outputOptions.filename;
// 文件名带 chunkhash
if (REGEXP_CHUNKHASH_FOR_TEST.test(chunkFilename))
hash.update(JSON.stringify(chunk.getChunkMaps(true).hash));
// 文件名带 contenthash
if (REGEXP_CONTENTHASH_FOR_TEST.test(chunkFilename)) {
hash.update(
JSON.stringify(
chunk.getChunkMaps(true).contentHash.javascript || {}
)
);
}
// 文件名带 name
if (REGEXP_NAME_FOR_TEST.test(chunkFilename))
hash.update(JSON.stringify(chunk.getChunkMaps(true).name));
}
);如果我们在 webpack.config.js 中设置输出文件名称带有 chunkhash 的时候,比如: filename: [name].[chunkhash].js,会查找当前所有 chunk 的 hash,得到一个下面的结构:
{
hash: { // chunkHashMap
0: 'chunk 0 的 hash',
...
},
name: nameHashMap,
contentHash: { // chunkContentHashMap
javascript: {
0: 'chunk 0 的 contentHash',
...
}
}
}然后将上面结果中 hash 内容转为字符串写入 hash buffer 中。所以说对于有 runtime 的 chunk 这一步依赖于所有不含 runtime 的 chunk 的 hash 值。因此在计算 chunk hash 之前会有一段排序的逻辑。再深入思考一步,为什么要依赖不含 runtime 的 chunk 的 hash 值呢?对于需要被异步加载的 chunk (即不含 runtime 的 chunk)在用到时会通过 script 标签加载,这时 src 中便是其文件名称,因此这个文件的名称需要被保存在含有 runtime 的 chunk 中。当文件名称包含 hash 值时,含 runtime 的 chunk 文件的内容会因为其他 chunk 的 hash 值的不同而不同,从而生成的 hash 值也应该随之改变。
hash 值生成之后,会调用 createChunkAssets 方法来决定最终输出到每个 chunk 当中对应的文本内容是什么。
// Compilation.js
class Compilation extends Tapable {
...
createChunkAssets() {
for (let i = 0; i < this.chunks.length; i++) {
const chunk = this.chunks[i]
try {
const template = chunk.hasRuntime()
? this.mainTemplate
: this.chunkTemplate;
const manifest = template.getRenderManifest({
chunk,
hash: this.hash, // 这次 compilation 的 hash 值
fullHash: this.fullHash, // 这次 compilation 未被截断的 hash 值
outputOptions,
moduleTemplates: this.moduleTemplates,
dependencyTemplates: this.dependencyTemplates
}); // [{ render(), filenameTemplate, pathOptions, identifier, hash }]
for (const fileManifest of manifest) {
...
source = fileManifeset.render() // 渲染生成每个 chunk 最终输出的代码
...
this.assets[file] = source;
...
}
}
....
}
}
...
}主要步骤:
在 createChunkAssets 方法内部会对最终需要输出的 chunk 进行遍历,根据这个 chunk 是否包含有 webpack runtime 代码来决定使用的渲染模板(mainTemplate/chunkTemplate)。其中 mainTemplate 主要用于包含 webpack runtime bootstrap 的 chunk 代码渲染生成工作,chunkTemplate 主要用于普通 chunk 的代码渲染工作。
mainTemplate 和 chunkTemplate 分别有自己的 getRenderManifest 方法,在这个方法中会生成 render 代码需要的所有信息,包括文件名称格式、对应的 render 函数,哈希值等。
我们首先来看下包含有 webpack runtime 代码的 chunk 是如何输出最终的 chunk 文本内容的。
这种情况下使用的 mainTemplate,调用实例上的 getRenderManifest 方法获取 manifest 配置数组,其中每项包含的字段内容为:
// MainTemplate.js
class MainTemplate extends Tapable {
...
getRenderManifest(options) {
const result = [];
this.hooks.renderManifest.call(result, options);
return result;
}
...
}接下来会判断这个 chunk 是否有被之前已经输出过(输出过的 chunk 是会被缓存起来的)。如果没有的话,那么就会调用 render 方法去完成这个 chunk 的文本输出工作,即:compilation.mainTemplate.render方法。
// MainTemplate.js
module.exports = class MainTemplate extends Tapable {
...
constructor() {
// 注册 render 钩子函数
this.hooks.render.tap(
"MainTemplate",
(bootstrapSource, chunk, hash, moduleTemplate, dependencyTemplates) => {
const source = new ConcatSource();
source.add("/******/ (function(modules) { // webpackBootstrap\n");
source.add(new PrefixSource("/******/", bootstrapSource));
source.add("/******/ })\n");
source.add(
"/************************************************************************/\n"
);
source.add("/******/ (");
source.add(
// 调用 modules 钩子函数,用以渲染 runtime chunk 当中所需要被渲染的 module
this.hooks.modules.call(
new RawSource(""),
chunk,
hash,
moduleTemplate,
dependencyTemplates
)
);
source.add(")");
return source;
}
);
}
...
/**
* @param {string} hash hash to be used for render call
* @param {Chunk} chunk Chunk instance
* @param {ModuleTemplate} moduleTemplate ModuleTemplate instance for render
* @param {Map<Function, DependencyTemplate>} dependencyTemplates dependency templates
* @returns {ConcatSource} the newly generated source from rendering
*/
render(hash, chunk, moduleTemplate, dependencyTemplates) {
// 生成 webpack runtime bootstrap 代码
const buf = this.renderBootstrap(
hash,
chunk,
moduleTemplate,
dependencyTemplates
);
// 调用 render 钩子函数
let source = this.hooks.render.call(
new OriginalSource(
Template.prefix(buf, " \t") + "\n",
"webpack/bootstrap"
),
chunk,
hash,
moduleTemplate,
dependencyTemplates
);
if (chunk.hasEntryModule()) {
source = this.hooks.renderWithEntry.call(source, chunk, hash);
}
if (!source) {
throw new Error(
"Compiler error: MainTemplate plugin 'render' should return something"
);
}
chunk.rendered = true;
return new ConcatSource(source, ";");
}
...
}这个方法内部首先调用 renderBootstrap 方法完成 webpack runtime bootstrap 代码的拼接工作,接下来调用 render hook,这个 render hook 是在 MainTemplate 的构造函数里面就完成了注册。
我们可以看到这个 hook 内部,主要是在 runtime bootstrap 代码外面完成了一层包装,然后调用 modules hook 开始进行这个 runtime chunk 当中需要渲染的 module 的生成工作(具体每个 module 如何去完成代码的拼接渲染工作后文会讲)。
render hook 调用完后,即得到了包含 webpack runtime bootstrap 代码的 chunk 代码,最终返回一个 ConcatSource 类型实例。
简化一下,大概如下图:

最终的代码会被保存在一个 ConcatSource 类的 children 中,而每个 module 的最终代码在一个 ReplaceSource 的类中,这个类包含一个 replacements 的数组,里面存放了对源码转化的操作,数组中每个元素结构如下:
[替换源码的起始位置,替换源码的终止位置,替换的最终内容,优先级]
也就是说在 render 的过程中,其实不会真的去改变源码字符串,而是将要更改的内容保存在了一个数组中,在最后输出静态文件的时候根据这个数组和源码来生成最终代码。这样保证了整个过程中,我们可以追溯对源码做了那些改变,并且在一些 hook 中,我们可以灵活的修改这些操作。
runtime chunk
webpack config 提供了一个代码优化配置选项:是否将 runtime chunk 单独抽离成一个 chunk 并输出到最终的文件当中。这也决定了最终在 render hook 生成 runtime chunk 代码时最终所包含的内容。首先我们来看下相关配置信息:
// webpack.config.js
module.exports = {
...
optimization: {
runtimeChunk: {
name: 'bundle'
}
}
...
}通过进行 optimization 字段的配置,可以出发 RuntimeChunkPlugin 插件的注册相关的事件。
module.exports = class RuntimeChunkPlugin {
constructor(options) {
this.options = Object.assign(
{
name: entrypoint => `runtime~${entrypoint.name}`
},
options
);
}
apply(compiler) {
compiler.hooks.thisCompilation.tap("RuntimeChunkPlugin", compilation => {
// 在 seal 阶段,生成最终的 chunk graph 后触发这个钩子函数,用以生成新的 runtime chunk
compilation.hooks.optimizeChunksAdvanced.tap("RuntimeChunkPlugin", () => {
// 遍历所有的 entrypoints(chunkGroup)
for (const entrypoint of compilation.entrypoints.values()) {
// 获取每个 entrypoints 的 runtimeChunk(chunk)
const chunk = entrypoint.getRuntimeChunk();
// 最终需要生成的 runtimeChunk 的文件名
let name = this.options.name;
if (typeof name === "function") {
name = name(entrypoint);
}
if (
chunk.getNumberOfModules() > 0 ||
!chunk.preventIntegration ||
chunk.name !== name
) {
// 新建一个 runtime 的 chunk,在 compilation.chunks 中也会新增这一个 chunk。
// 这样在最终生成的 chunk 当中会包含一个 runtime chunk
const newChunk = compilation.addChunk(name);
newChunk.preventIntegration = true;
// 将这个新的 chunk 添加至 entrypoint(chunk) 当中,那么 entrypoint 也就多了一个新的 chunk
entrypoint.unshiftChunk(newChunk);
newChunk.addGroup(entrypoint);
// 将这个新生成的 chunk 设置为这个 entrypoint 的 runtimeChunk
entrypoint.setRuntimeChunk(newChunk);
}
}
});
});
}
};这样便通过 RuntimeChunkPlugin 这个插件将 webpack runtime bootstrap 单独抽离至一个 chunk 当中输出。最终这个 runtime chunk 仅仅只包含了 webpack bootstrap 相关的代码,不会包含其他需要输出的 module 代码。当然,如果你不想将 runtime chunk 单独抽离出来,那么这部分 runtime 代码最终会被打包进入到包含 runtime chunk 的 chunk 当中,这个 chunk 最终输出文件内容就不仅仅需要包含这个 chunk 当中依赖的不同 module 的最终代码,同时也需要包含 webpack bootstrap 代码。
var window = window || {}
// webpackBootstrap
(function(modules) {
// 包含了 webpack bootstrap 的代码
})([
/* 0 */ // module 0 的最终代码
(function(module, __webpack_exports__, __webpack_require__) {
}),
/* 1 */ // module 1 的最终代码
(function(module, __webpack_exports__, __webpack_require__) {
})
])
module.exports = window['webpackJsonp']以上就是有关使用 MainTemplate 去渲染完成 runtime chunk 的有关内容。
接下来我们看下不包含 webpack runtime 代码的 chunk (使用 chunkTemplate 渲染模板)是如何输出得到最终的内容的。
首先调用 ChunkTemplate 类上提供的 getRenderManifest 方法来获取 chunk manifest 相关的内容。
// ChunkTemplate.js
class ChunkTemplate {
...
getRenderManifest(options) {
const result = []
// 触发 ChunkTemplate renderManifest 钩子函数
this.hooks.renderManifest.call(result, options)
return result
}
...
}
// JavascriptModulesPlugin.js
class JavascriptModulesPlugin {
apply(compiler) {
compiler.hooks.compilation.tap('JavascriptModulesPlugin', (compilation, { normalModuleFactory }) => {
...
// ChunkTemplate hooks.manifest 钩子函数
compilation.chunkTemplate.hooks.renderManifest.tap('JavascriptModulesPlugin', (result, options) => {
...
result.push({
render: () =>
// 每个 chunk 代码的生成即调用 JavascriptModulesPlugin 提供的 renderJavascript 方法来进行生成
this.renderJavascript(
compilation.chunkTemplate, // chunk模板
chunk, // 需要生成的 chunk 实例
moduleTemplates.javascript, // 模块类型
dependencyTemplates // 不同依赖所对应的渲染模板
),
filenameTemplate,
pathOptions: {
chunk,
contentHashType: 'javascript'
},
identifier: `chunk${chunk.id}`,
hash: chunk.hash
})
...
})
...
})
}
renderJavascript(chunkTemplate, chunk, moduleTemplate, dependencyTemplates) {
const moduleSources = Template.renderChunkModules(
chunk,
m => typeof m.source === "function",
moduleTemplate,
dependencyTemplates
)
const core = chunkTemplate.hooks.modules.call(
moduleSources,
chunk,
moduleTemplate,
dependencyTemplates
)
let source = chunkTemplate.hooks.render.call(
core,
chunk,
moduleTemplate,
dependencyTemplates
)
if (chunk.hasEntryModule()) {
source = chunkTemplate.hooks.renderWithEntry.call(source, chunk)
}
chunk.rendered = true
return new ConcatSource(source, ";")
}
}这样通过触发 renderManifest hook 获取到了渲染这个 chunk manifest 配置项。和 MainTemplate 获取到的 manifest 数组不同的主要地方就在于其中的 render 函数,这里可以看到的就是渲染每个 chunk 是调用的 JavascriptModulesPlugin 这个插件上提供的 render 函数。
获取到了 chunk 渲染所需的 manifest 配置项后,即开始调用 render 函数开始渲染这个 chunk 最终的输出内容了,即对应于 JavascriptModulesPlugin 上的 renderJavascript 方法。

renderChunkModules——生成每个module的代码
在 webpack 总览中,我们介绍过 webpack 打包之后的常见代码结构:
(function(modules){
...(webpack的函数)
return __webpack_require__(__webpack_require__.s = "./demo01/main.js");
})(
{
"./a.js": (function(){...}),
"./b.js": (function(){...}),
"./main.js": (function(){...}),
}
)一个立即执行函数,函数的参数是各个 module 组成的对象(某些时候是数组)。这里函数的参数就是 renderChunkModules 这个函数得到的:通过 moduleTemplate.render 方法得到每个 module 的代码,然后将其封装为数组的形式: [/*module a.js*/, /*module b.js*/] 或者对象的形式: {'a.js':function, 'b.js': function} 的形式,作为参数添加到立即执行函数中。
renderChunkModules 方法代码如下:
class Template {
static renderChunkModules(
chunk,
filterFn,
moduleTemplate,
dependencyTemplates,
prefix = ""
) {
const source = new ConcatSource();
const modules = chunk.getModules().filter(filterFn); // 获取这个 chunk 所依赖的模块
let removedModules;
if (chunk instanceof HotUpdateChunk) {
removedModules = chunk.removedModules;
}
// 如果这个 chunk 没有依赖的模块,且 removedModules 不存在,那么立即返回,代码不再继续向下执行
if (
modules.length === 0 &&
(!removedModules || removedModules.length === 0)
) {
source.add("[]");
return source;
}
// 遍历所有依赖的 module,每个 module 通过使用 moduleTemplate.render 方法进行渲染得到最终这个 module 需要输出的内容
/** @type {{id: string|number, source: Source|string}[]} */
const allModules = modules.map(module => {
return {
id: module.id, // 每个 module 的 id
source: moduleTemplate.render(module, dependencyTemplates, { // 渲染每个 module
chunk
})
};
});
// 判断这个 chunk 所依赖的 module 的 id 是否存在边界值,如果存在边界值,那么这些 modules 将会放置于一个以边界数组最大最小值作为索引的数组当中;
// 如果没有边界值,那么 modules 将会被放置于一个以 module.id 作为 key,module 实际渲染内容作为 value 的对象当中
const bounds = Template.getModulesArrayBounds(allModules);
if (bounds) {
// Render a spare array
const minId = bounds[0];
const maxId = bounds[1];
if (minId !== 0) {
source.add(`Array(${minId}).concat(`);
}
source.add("[\n");
/** @type {Map<string|number, {id: string|number, source: Source|string}>} */
const modules = new Map();
for (const module of allModules) {
modules.set(module.id, module);
}
for (let idx = minId; idx <= maxId; idx++) {
const module = modules.get(idx);
if (idx !== minId) {
source.add(",\n");
}
source.add(`/* ${idx} */`);
if (module) {
source.add("\n");
source.add(module.source); // 添加每个 module 最终输出的代码
}
}
source.add("\n" + prefix + "]");
if (minId !== 0) {
source.add(")");
}
} else {
// Render an object
source.add("{\n");
allModules.sort(stringifyIdSortPredicate).forEach((module, idx) => {
if (idx !== 0) {
source.add(",\n");
}
source.add(`\n/***/ ${JSON.stringify(module.id)}:\n`);
source.add(module.source);
});
source.add(`\n\n${prefix}}`);
}
return source
}
}我们来看下在 chunk 渲染过程中,如何对每个所依赖的 module 进行渲染拼接代码的,即在 Template 类当中提供的 renderChunkModules 方法中,遍历这个 chunk 当中所有依赖的 module 过程中,调用 moduleTemplate.render 完成每个 module 的代码渲染拼接工作。
首先我们来了解下3个和输出 module 代码相关的模板:
RuntimeTemplate
顾名思义,这个模板类主要是提供了和 module 运行时相关的代码输出方法,例如你的 module 使用的是 esModule 类型,那么导出的代码模块会带有__esModule标识,而通过 import 语法引入的外部模块都会通过/* harmony import */注释来进行标识。
dependencyTemplates
dependencyTemplates 模板数组主要是保存了每个 module 不同依赖的模板,在输出最终代码的时候会通过 dependencyTemplates 来完成模板代码的替换工作。
ModuleTemplate
ModuleTemplate 模板类主要是对外暴露了 render 方法,通过调用 moduleTemplate 实例上的 render 方法,即完成每个 module 的代码渲染工作,这也是每个 module 输出最终代码的入口方法。
现在我们从 ModuleTemplate 模板开始:
// ModuleTemplate.js
module.exports = class ModuleTemplate extends Tapable {
constructor(runtimeTemplate, type) {
this.runtimeTemplate = runtimeTemplate
this.type = type
this.hooks = {
content: new SyncWaterfallHook([]),
module: new SyncWaterfallHook([]),
render: new SyncWaterfallHook([]),
package: new SyncWaterfallHook([]),
hash: new SyncHook([])
}
}
render(module, dependencyTemplates, options) {
try {
// replaceSource
const moduleSource = module.source(
dependencyTemplates,
this.runtimeTemplate,
this.type
);
const moduleSourcePostContent = this.hooks.content.call(
moduleSource,
module,
options,
dependencyTemplates
);
const moduleSourcePostModule = this.hooks.module.call(
moduleSourcePostContent,
module,
options,
dependencyTemplates
);
// 添加编译 module 外层包裹的函数
const moduleSourcePostRender = this.hooks.render.call(
moduleSourcePostModule,
module,
options,
dependencyTemplates
);
return this.hooks.package.call(
moduleSourcePostRender,
module,
options,
dependencyTemplates
);
} catch (e) {
e.message = `${module.identifier()}\n${e.message}`;
throw e;
}
}
}
首先调用 module.source 方法,传入 dependencyTemplates, runtimeTemplate,以及渲染类型 type(默认为 javascript)。 module.source 方法执行完成后会返回一个 ReplaceSource 类,其中包含源码和一个 replacement 数组。其中 replacement 数组中保存了对源码处理操作。
FunctionModuleTemplatePlugin 会在 render hook 阶段被调用,将我们写在文件中的代码封装为一个函数
children:[
'/***/ (function(module, __webpack_exports__, __webpack_require__) {↵↵'
'"use strict";↵'
CachedSource // 1,2 步骤中得到的结果
'↵↵/***/ })'
]最终打包,触发 package hook。FunctionModuleTemplatePlugin 会在这个阶段为我们的最终代码增加一些注释,方便我们查看代码。
source——代码装换
现在我们要深入 module.source,即在每个 module 上定义的 source 方法:
// NormalModule.js
class NormalModule extends Module {
...
source(dependencyTemplates, runtimeTemplate, type = "javascript") {
const hashDigest = this.getHashDigest(dependencyTemplates);
const cacheEntry = this._cachedSources.get(type);
if (cacheEntry !== undefined && cacheEntry.hash === hashDigest) {
// We can reuse the cached source
return cacheEntry.source;
}
// JavascriptGenerator
const source = this.generator.generate(
this,
dependencyTemplates, // 依赖的模板
runtimeTemplate,
type
);
const cachedSource = new CachedSource(source);
this._cachedSources.set(type, {
source: cachedSource,
hash: hashDigest
});
return cachedSource;
}
...
}我们看到在 module.source 方法内部调用了 generator.generate 方法,那么这个 generator 又是从哪里来的呢?事实上在通过 NormalModuleFactory 创建 NormalModule 的过程即完成了 generator 的创建,以用来生成每个 module 最终渲染的 javascript 代码。

所以 module.source 中 generator.generate 的执行代码在 JavascriptGenerator.js 中
// JavascriptGenerator.js
class JavascriptGenerator {
generate(module, dependencyTemplates, runtimeTemplate) {
const originalSource = module.originalSource(); // 获取这个 module 的 originSource
if (!originalSource) {
return new RawSource("throw new Error('No source available');");
}
// 创建一个 ReplaceSource 类型的 source 实例
const source = new ReplaceSource(originalSource);
this.sourceBlock(
module,
module,
[],
dependencyTemplates,
source,
runtimeTemplate
);
return source;
}
sourceBlock(
module,
block,
availableVars,
dependencyTemplates,
source,
runtimeTemplate
) {
// 处理这个 module 的 dependency 的渲染模板内容
for (const dependency of block.dependencies) {
this.sourceDependency(
dependency,
dependencyTemplates,
source,
runtimeTemplate
);
}
...
for (const childBlock of block.blocks) {
this.sourceBlock(
module,
childBlock,
availableVars.concat(vars),
dependencyTemplates,
source,
runtimeTemplate
);
}
}
// 获取对应的 template 方法并执行,完成依赖的渲染工作
sourceDependency(dependency, dependencyTemplates, source, runtimeTemplate) {
const template = dependencyTemplates.get(dependency.constructor);
if (!template) {
throw new Error(
"No template for dependency: " + dependency.constructor.name
);
}
template.apply(dependency, source, runtimeTemplate, dependencyTemplates);
}
}在 JavascriptGenerator 提供的 generate 方法主要流程如下:
完成对源码转换的大部分操作在上面第二步中,这个过程就是调用每个依赖对应的 dependencyTemplate 的 apply 方法。webpack 中所有的 xxDependency 类中会有一个静态的 Template 方法,这个方法便是该 dependency 对应的生成最终代码的方法(相关的可参考 #49 )。
我们用下面一个简单的例子,详细看一下源码转换的过程。demo 如下
// 打包的入口 main.js
import { A } from './a.js'
console.log(A)
// a.ja
export const A = 'a'
export const B = 'B'前面几篇文章我们介绍过,经过 webpack 中文件 make 的过程之后会得到所有文件的 module,同时每个文件中 import/export 会转化为一个 dependency。如下

所以 main.js 模块,在执行 generate 方法中 for (const dependency of block.dependencies) 这一步时,会遇到有 5 类 dependency,一个一个来看
HarmonyCompatibilityDependency
它的 Template 代码如下:
HarmonyCompatibilityDependency.Template = class HarmonyExportDependencyTemplate {
apply(dep, source, runtime) {
const usedExports = dep.originModule.usedExports;
if (usedExports !== false && !Array.isArray(usedExports)) {
const content = runtime.defineEsModuleFlagStatement({
exportsArgument: dep.originModule.exportsArgument
});
source.insert(-10, content);
}
}
};这里 usedExport 变量中保存了 module 中被其他 module 使用过的 export。对于每个 chunk 的入口模块来说比较特殊,这个值会被直接赋为 true,而对于有 export default 语句的模块来说,这个值是 default,这两种情况在这里都生成一句如下的代码:
__webpack_require__.r(__webpack_exports__);__webpack_require__.r 方法会为 __webpack_exports__ 对象增加一个 __esModule 属性,将其标识为一个 es module。webpack 会将我们代码中暴露出的 export 都转化为 module.exports 的属性,对于有 __esModule 标识的模块,当我们通过 import x from 'xx' 引入时,x 是 module.exports.default 的内容,否则的话会被当成为 CommonJs module 的规范,引入的是整个 module.exports。
HarmonyInitDependency
和 HarmonyCompatibilityDependency 依赖一起出现的还有 HarmonyInitDependency。这个 Template 方法中会遍历 module 下的所有依赖,如果依赖有 harmonyInit,则会执行。
for (const dependency of module.dependencies) {
const template = dependencyTemplates.get(dependency.constructor);
if (
template &&
typeof template.harmonyInit === "function" &&
typeof template.getHarmonyInitOrder === "function"
) {
//...
}
}harmonyInit 方法这里需要解释一下:当我们在源码中使用到 import 和 export 时 , webpack 为处理这些引用的逻辑,需要在我们源码的最开始有针对性的插入一些代码,可以认为是初始化的代码。例如我们在 webpack 生成的代码中常见到的
__webpack_exports__["default"] = /*...*/
或者
__webpack_require__.d(__webpack_exports__, "A", function() { return A; });这些代码的生成逻辑就保存在对应的 dependency 的 harmonyInit 方法中,而在处理 HarmonyInitDependency 阶段会被执行。到这里,你也会更加明白我们曾在讲 module 生成中 parse 阶段的时候提到过,如果检测到源码中有 import 或者 export 的时候,会增加一个 HarmonyInitDependency 依赖的原因。
main.js 的 HarmonyImportSideEffectDependency 和 HarmonyImportSpecifierDependency 中的 harmonyInit 方法,都会在这里被调用,分别生成下面的代码
"/* harmony import */ var _a_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);↵" // 对应:import { A } from './a.js'ConstDepedency 和 HarmonyImportSideEffectDependency
import { A } from './a.js' 为例:
/* harmony import */ var _a_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);HarmonyImportSpecifierDependency
在处理 console.log(A) 中的 A 的时候被加入这个依赖,在这里会生成下面一个变量名称:
_a_js__WEBPACK_IMPORTED_MODULE_0__[/* A */ "a"]并用这个名称替换源码中的 A,最终将 A 对应到 a.js 中暴露出来的 A 变量上。
当 main.js 所有依赖处理完之后,会得到下面的数据
//ReplaceSource
replacements:[
[-10, -11, "__webpack_require__.r(__webpack_exports__);↵", 0],
[-1, -2, "/* harmony import */ var _a_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);↵", 1],
[0, 25, "", 2], // 0-25 对应源码:import { A } from './a.js'
[39, 39, "_a_js__WEBPACK_IMPORTED_MODULE_0__[/* A */ "a"]", 7], // 84-84 对应源码:console.log(A) 中的 A
]对照一下源码,把源码中对应位置的代码替换成 ReplaceSource 中的内容:
__webpack_require__.r(__webpack_exports__);
/* harmony import */ var _a_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./a.js */ "./demo01/a.js");
console.log(_a_js__WEBPACK_IMPORTED_MODULE_0__["A"])进行 webpack 处理后,我们的 main.js 就会变成上面这样的代码。
下面我们再看一下 a.js:
a.js 中有 4 类 dependency:HarmonyCompatibilityDependency、HarmonyInitDependency、HarmonyExportHeaderDependency、HarmonyExportSpecifierDependency。
HarmonyInitDependency
前面在 main.js 中已经介绍过这个 dependency,它会遍历所有的 dependency。在这个过程中 a.js 代码 export const A 和 export const B 所对应的 HarmonyExportSpecifierDependency 中的 template.harmonyInit 方法将会在这时执行,然后得到下面两句
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "a", function() { return A; });
/* unused harmony export B */这样在最终的代码中 const A 就被注册到了 a.js 对应的 module 的 exports 上。而 const B 由于没被其他代码所引用,所以会被 webpack 的 tree-shaking 逻辑探测到,在这里只是转化为一句注释
HarmonyExportHeaderDependency
它对源码的处理很简单,代码如下:
HarmonyExportHeaderDependency.Template = class HarmonyExportDependencyTemplate {
apply(dep, source) {
const content = "";
const replaceUntil = dep.range
? dep.range[0] - 1
: dep.rangeStatement[1] - 1;
source.replace(dep.rangeStatement[0], replaceUntil, content);
}
};由于前面在 HarmonyInitDependency 的逻辑中已经完成了对 export 变量的处理,所以这里将 export const A = 'a' 和 export const B = 'b' 语句中的 export 替换为空字符串。
HarmonyExportSpecifierDependency
本身的 Template.apply 是空函数,所以这个依赖主要在 HarmonyInitDependency 时发挥作用。
完成对 a.js 中所有 dependency 的处理后,会得到下面的一个结果:
// ReplaceSource
children:[
[-1, -2, "/* harmony export (binding) */ __webpack_require__…", "a", function() { return A; });↵", 0],
[-1, -2, "/* unused harmony export B */↵", 1],
[0, 6, "", 2], // 0-6 对应源码:'export '
[21, 27, "", 3], // 21-27 对应源码:'export '
]同样的,如果把 a.js 源码中对应位置的代码替换一下,a.js 的源码就变成了下面这样:
__webpack_require__.r(__webpack_exports__);
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "A", function() { return A; });
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "B", function() { return B; });
const A = 'a'
const B = 'B'generate.render 这一步完成了对源码内容的转换,之后回到 ModuleTemplate.js 的 render 方法中,继续将独立的 module 整合成最终的可执行函数。
content、module、render、package——代码包裹
generate.render 完成之后,接下来触发 hooks.content 、 hooks.module 这2个钩子函数,主要是用来对于 module 完成依赖代码替换后的代码处理工作,开发者可以通过注册相关的钩子完成对于 module 代码的改造,因为这个时候得到代码还没有在外层包裹 webpack runtime 的代码,因此在这2个钩子函数对于 module 代码做改造最合适。
当上面2个 hooks 都执行完后,开始触发 hooks.render 钩子:
// FunctionModuleTemplatePlugin.js
class FunctionModuleTemplatePlugin {
apply(moduleTemplate) {
moduleTemplate.hooks.render.tap(
"FunctionModuleTemplatePlugin",
(moduleSource, module) => {
const source = new ConcatSource();
const args = [module.moduleArgument]; // module
// TODO remove HACK checking type for javascript
if (module.type && module.type.startsWith("javascript")) {
args.push(module.exportsArgument); // __webpack_exports__
if (module.hasDependencies(d => d.requireWebpackRequire !== false)) {
// 判断这个模块内部是否使用了被引入的其他模块,如果有的话,那么就需要加入 __webpack_require__
args.push("__webpack_require__"); // __webpack_require__
}
} else if (module.type && module.type.startsWith("json")) {
// no additional arguments needed
} else {
args.push(module.exportsArgument, "__webpack_require__");
}
source.add("/***/ (function(" + args.join(", ") + ") {\n\n");
if (module.buildInfo.strict) source.add('"use strict";\n'); // harmony module 会使用 use strict; 严格模式
// 将 moduleSource 代码包裹至这个函数当中
source.add(moduleSource);
source.add("\n\n/***/ })");
return source;
}
)
}
}这个钩子函数主要的工作就是完成对上面已经完成的 module 代码进行一层包裹,包裹的内容主要是 webpack 自身的一套模块加载系统,包括模块导入,导出等,每个 module 代码最终生成的形式为:
/***/ (function(module, __webpack_exports__, __webpack_require__) {
// module 最终生成的代码被包裹在这个函数内部
// __webpack_exports__ / __webpack_require__ 相关的功能可以阅读 webpack runtime bootstrap 代码去了解
/***/ })当 hooks.render 钩子触发后完成 module 代码的包裹后,触发 hooks.package 钩子,这个主要是用于在 module 代码中添加注释的功能,就不展开说了,具体查阅FunctionModuleTemplatePlugin.js。
到这里就完成了对于一个 module 的代码的渲染工作,最终在每个 chunk 当中的每一个 module 代码也就是在此生成。
module 代码生成之后便返回到上文JavascriptModulePlugin.renderJavascript方法当中,继续后面生成每个 chunk 最终代码的过程中了。
整合成可执行函数
接下来触发 chunkTemplate.hooks.modules 钩子函数,如果你需要对于 chunk 代码有所修改,那么在这里可以通过 plugin 注册 hooks.modules 钩子函数来完成相关的工作。这个钩子触发后,继续触发 chunkTemplate.hooks.render 钩子函数,在JsonpChunkTemplatePlugin这个插件当中注册了对应的钩子函数:
class JsonpChunkTemplatePlugin {
/**
* @param {ChunkTemplate} chunkTemplate the chunk template
* @returns {void}
*/
apply(chunkTemplate) {
chunkTemplate.hooks.render.tap(
"JsonpChunkTemplatePlugin",
(modules, chunk) => {
const jsonpFunction = chunkTemplate.outputOptions.jsonpFunction;
const globalObject = chunkTemplate.outputOptions.globalObject;
const source = new ConcatSource();
const prefetchChunks = chunk.getChildIdsByOrders().prefetch;
source.add(
`(${globalObject}[${JSON.stringify(
jsonpFunction
)}] = ${globalObject}[${JSON.stringify(
jsonpFunction
)}] || []).push([${JSON.stringify(chunk.ids)},`
);
source.add(modules);
const entries = getEntryInfo(chunk);
if (entries.length > 0) {
source.add(`,${JSON.stringify(entries)}`);
} else if (prefetchChunks && prefetchChunks.length) {
source.add(`,0`);
}
if (prefetchChunks && prefetchChunks.length) {
source.add(`,${JSON.stringify(prefetchChunks)}`);
}
source.add("])");
return source;
}
)
}
}这个钩子函数主要完成的工作就是将这个 chunk 当中所有已经渲染好的 module 的代码再一次进行包裹组装,生成这个 chunk 最终的代码,也就是最终会被写入到文件当中的代码。与此相关的是 JsonpTemplatePlugin,这个插件内部注册了 chunkTemplate.hooks.render 的钩子函数,在这个函数里面完成了 chunk 代码外层的包裹工作。我们来看个通过这个钩子函数处理后生成的 chunk 代码的例子:
// a.js
import { add } from './add.js'
add(1, 2)
-------
// 在 webpack config 配置环节将 webpack runtime bootstrap 代码单独打包成一个 chunk,那么最终 a.js 所在的 chunk输出的代码是:
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([[1],[
/* 0 */
/***/ (function(module, __webpack_exports__, __webpack_require__) {
// module id 为0的 module 输出代码,即 a.js 最终输出的代码
/***/ }),
/* 1 */
/***/ (function(module, __webpack_exports__, __webpack_require__) {
// module id 为1的 module 输出代码,即 add.js 最终输出的代码
/***/ })
],[[0,0]]]);到此为止,有关 renderJavascript 方法的流程已经梳理完毕了,这也是非 runtime bootstrap chunk 代码最终的输出时的处理流程。
以上就是有关 chunk 代码生成的流程分析即 createChunkAssets,当这个流程进行完后,所有需要生成到文件的 chunk 最终会保存至 compilation 的一个 key/value 结构当中:
compilation.assets = {
[输出文件路径名]: ConcatSource(最终 chunk 输出的代码)
}接下来针对保存在内容当中的这些 assets 资源做相关的优化工作,同时会暴露出一些钩子供开发者对于这些资源做相关的操作,例如可以使用 compilation.optimizeChunkAssets 钩子函数去往 chunk 内添加代码等等,有关这些钩子的说明具体可以查阅webpack文档上有关assets优化的内容。
经历了上面所有的阶段之后,所有的最终代码信息已经保存在了 Compilation 的 assets 中。然后代码片段会被拼合起来,并且上一步 generator.generate 得到的 ReplaceSource 结果中,会遍历 replacement 中的操作,按照要替换的源码的先后位置(同一位置的话,按照 replacement 中的最后一个参数优先级先后)来一一对源码进行替换,然后代码最终代码。
webpack 配置中可以配置一些优化,例如压缩,所以在得到代码后会进行一些优化。
当 assets 资源相关的优化工作结束后,seal 阶段也就结束了。这时候执行 seal 函数接受到 callback,进入到 webpack 后续的流程。具体内容可查阅 compiler 编译器对象提供的 run 方法。这个 callback 方法内容会执行到 compiler.emitAssets 方法:
// Compiler.js
class Compiler extends Tapable {
...
emitAssets(compilation, callback) {
let outputPath;
const emitFiles = err => {
if (err) return callback(err);
asyncLib.forEach(
compilation.assets,
(source, file, callback) => {
let targetFile = file;
const queryStringIdx = targetFile.indexOf("?");
if (queryStringIdx >= 0) {
targetFile = targetFile.substr(0, queryStringIdx);
}
const writeOut = err => {
if (err) return callback(err);
const targetPath = this.outputFileSystem.join(
outputPath,
targetFile
);
if (source.existsAt === targetPath) {
source.emitted = false;
return callback();
}
let content = source.source();
if (!Buffer.isBuffer(content)) {
content = Buffer.from(content, "utf8");
}
source.existsAt = targetPath;
source.emitted = true;
this.outputFileSystem.writeFile(targetPath, content, callback);
};
if (targetFile.match(/\/|\\/)) {
const dir = path.dirname(targetFile);
this.outputFileSystem.mkdirp(
this.outputFileSystem.join(outputPath, dir),
writeOut
);
} else {
writeOut();
}
},
err => {
if (err) return callback(err);
this.hooks.afterEmit.callAsync(compilation, err => {
if (err) return callback(err);
return callback();
});
}
);
};
this.hooks.emit.callAsync(compilation, err => {
if (err) return callback(err);
outputPath = compilation.getPath(this.outputPath);
this.outputFileSystem.mkdirp(outputPath, emitFiles);
});
}
...
}在这个方法当中首先触发 hooks.emit 钩子函数,即将进行写文件的流程。接下来开始创建目标输出文件夹,并执行 emitFiles 方法,将内存当中保存的 assets 资源输出到目标文件夹当中,这样就完成了内存中保存的 chunk 代码写入至最终的文件。最终有关 emit assets 输出最终 chunk 文件的流程图见下:

一开始仿照better-scroll+vue使用的probeType为1,上拉加载的时候,依次提示“上拉加载更多”、“释放刷新”、“数据加载完成”,文字切换正常;
后面应为要实现固定头行和头列的滚动table,必须probeType为3,实时计算头行和头列的移动距离保持其在页面上的位置不变,但是文字提示就没办法正常了。原因是一直触发“scroll”事件,scroll事件中提示文案是“释放刷新”。所以,不管怎么滚动提示文字都是“释放刷新”,但其实它是有依次切换文案了,因为看不到变化的过程,且最后都是“释放刷新”。
有遇到类似的问题吗?或者说说probeType为3时触发频率是咋样的?
webpack 对于不同依赖模块的模板处理都有单独的依赖模块类型文件来进行处理。例如,在你写的源代码当中,使用的是ES Module,那么最终会由 HarmonyModulesPlugin 里面使用的依赖进行处理,再例如你写的源码中模块使用的是符合 CommonJS Module 规范,那么最终会有 CommonJsPlugin 里面使用的依赖进行处理。除此外,webpack 还对于其他类型的模块依赖语法也做了处理:
// WebpackOptionsApply.js
const LoaderPlugin = require("./dependencies/LoaderPlugin");
const CommonJsPlugin = require("./dependencies/CommonJsPlugin");
const HarmonyModulesPlugin = require("./dependencies/HarmonyModulesPlugin");
const SystemPlugin = require("./dependencies/SystemPlugin");
const ImportPlugin = require("./dependencies/ImportPlugin");
const AMDPlugin = require("./dependencies/AMDPlugin");
const RequireContextPlugin = require("./dependencies/RequireContextPlugin");
const RequireEnsurePlugin = require("./dependencies/RequireEnsurePlugin");
const RequireIncludePlugin = require("./dependencies/RequireIncludePlugin");
class WebpackOptionsApply extends OptionsApply {
constructor() {
super()
}
process(options, compiler) {
...
new HarmonyModulesPlugin(options.module).apply(compiler);
new AMDPlugin(options.module, options.amd || {}).apply(compiler);
new CommonJsPlugin(options.module).apply(compiler);
new LoaderPlugin().apply(compiler);
new RequireIncludePlugin().apply(compiler);
new RequireEnsurePlugin().apply(compiler);
new RequireContextPlugin(
options.resolve.modules,
options.resolve.extensions,
options.resolve.mainFiles
).apply(compiler);
new ImportPlugin(options.module).apply(compiler);
new SystemPlugin(options.module).apply(compiler);
...
}
}模块依赖语法的处理对于 webpack 生成最终的文件内容非常的重要。这些针对不同依赖加载语法的处理插件在 webpack 初始化创建 compiler 的时候就完成了加载及初始化过程。这里我们可以来看下模块遵循 ES Module 所使用的相关的依赖依赖模板的处理是如何进行的,即 HarmonyModulesPlugin 这个插件内部主要完成的工作。
// part 1: 引入的主要是 ES Module 当中使用的不同语法的依赖类型
const HarmonyCompatibilityDependency = require("./HarmonyCompatibilityDependency");
const HarmonyInitDependency = require("./HarmonyInitDependency");
const HarmonyImportSpecifierDependency = require("./HarmonyImportSpecifierDependency");
const HarmonyImportSideEffectDependency = require("./HarmonyImportSideEffectDependency");
const HarmonyExportHeaderDependency = require("./HarmonyExportHeaderDependency");
const HarmonyExportExpressionDependency = require("./HarmonyExportExpressionDependency");
const HarmonyExportSpecifierDependency = require("./HarmonyExportSpecifierDependency");
const HarmonyExportImportedSpecifierDependency = require("./HarmonyExportImportedSpecifierDependency");
const HarmonyAcceptDependency = require("./HarmonyAcceptDependency");
const HarmonyAcceptImportDependency = require("./HarmonyAcceptImportDependency");
const NullFactory = require("../NullFactory");
// part 2: 引入的主要是 ES Module 使用的不同的语法,在编译过程中需要挂载的 hooks,方便做依赖收集
const HarmonyDetectionParserPlugin = require("./HarmonyDetectionParserPlugin");
const HarmonyImportDependencyParserPlugin = require("./HarmonyImportDependencyParserPlugin");
const HarmonyExportDependencyParserPlugin = require("./HarmonyExportDependencyParserPlugin");
const HarmonyTopLevelThisParserPlugin = require("./HarmonyTopLevelThisParserPlugin");
class HarmonyModulesPlugin {
constructor(options) {
this.options = options;
}
apply(compiler) {
compiler.hooks.compilation.tap(
"HarmonyModulesPlugin",
(compilation, { normalModuleFactory }) => {
compilation.dependencyFactories.set(
HarmonyCompatibilityDependency,
new NullFactory()
);
// 设置对应的依赖渲染所需要的模板
compilation.dependencyTemplates.set(
HarmonyCompatibilityDependency,
new HarmonyCompatibilityDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyInitDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyInitDependency,
new HarmonyInitDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyImportSideEffectDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyImportSideEffectDependency,
new HarmonyImportSideEffectDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyImportSpecifierDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyImportSpecifierDependency,
new HarmonyImportSpecifierDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportHeaderDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyExportHeaderDependency,
new HarmonyExportHeaderDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportExpressionDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyExportExpressionDependency,
new HarmonyExportExpressionDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportSpecifierDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyExportSpecifierDependency,
new HarmonyExportSpecifierDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportImportedSpecifierDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyExportImportedSpecifierDependency,
new HarmonyExportImportedSpecifierDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyAcceptDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyAcceptDependency,
new HarmonyAcceptDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyAcceptImportDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyAcceptImportDependency,
new HarmonyAcceptImportDependency.Template()
);
const handler = (parser, parserOptions) => {
if (parserOptions.harmony !== undefined && !parserOptions.harmony)
return;
new HarmonyDetectionParserPlugin().apply(parser);
new HarmonyImportDependencyParserPlugin(this.options).apply(parser);
new HarmonyExportDependencyParserPlugin(this.options).apply(parser);
new HarmonyTopLevelThisParserPlugin().apply(parser);
};
normalModuleFactory.hooks.parser
.for("javascript/auto")
.tap("HarmonyModulesPlugin", handler);
normalModuleFactory.hooks.parser
.for("javascript/esm")
.tap("HarmonyModulesPlugin", handler);
}
);
}
}
module.exports = HarmonyModulesPlugin;在 HarmonyModulesPlugin 引入的文件当中主要是分为了2部分:
当 webpack 创建新的 compilation 对象后,便执行compiler.hooks.compilation注册的钩子内部的方法。其中主要完成了以下几项工作:
1.设置不同依赖类型的 moduleFactory,例如设置HarmonyImportSpecifierDependency依赖类型的 moduleFactory 为normalModuleFactory;
2.设置不同依赖类型的 dependencyTemplate,例如设置HarmonyImportSpecifierDependency依赖类型的模板为new HarmonyImportSpecifierDependency.Template()实例;
3.注册 normalModuleFactory.hooks.parser 钩子函数。每当新建一个 normalModule 时这个钩子函数都会被执行,即触发 handler 函数的执行。handler 函数内部去初始化各种 plugin,注册相关的 hooks。
我们首先来看下 handler 函数内部初始化的几个 plugin 里面注册的和 parser 编译相关的插件。
// HarmonyDetectionParserPlugin.js
const HarmonyCompatibilityDependency = require("./HarmonyCompatibilityDependency");
const HarmonyInitDependency = require("./HarmonyInitDependency");
module.exports = class HarmonyDetectionParserPlugin {
apply(parser) {
parser.hooks.program.tap("HarmonyDetectionParserPlugin", ast => {
const isStrictHarmony = parser.state.module.type === "javascript/esm";
const isHarmony =
isStrictHarmony ||
ast.body.some(statement => {
return /^(Import|Export).*Declaration$/.test(statement.type);
});
if (isHarmony) {
// 获取当前的正在编译的 module
const module = parser.state.module;
const compatDep = new HarmonyCompatibilityDependency(module);
compatDep.loc = {
start: {
line: -1,
column: 0
},
end: {
line: -1,
column: 0
},
index: -3
};
// 给这个 module 添加一个 compatDep 依赖
module.addDependency(compatDep);
const initDep = new HarmonyInitDependency(module);
initDep.loc = {
start: {
line: -1,
column: 0
},
end: {
line: -1,
column: 0
},
index: -2
};
// 给这个 module 添加一个 initDep 依赖
module.addDependency(initDep);
parser.state.harmonyParserScope = parser.state.harmonyParserScope || {};
parser.scope.isStrict = true;
// 初始化这个 module 最终被编译生成的 meta 元信息,
module.buildMeta.exportsType = "namespace";
module.buildInfo.strict = true;
module.buildInfo.exportsArgument = "__webpack_exports__";
if (isStrictHarmony) {
module.buildMeta.strictHarmonyModule = true;
module.buildInfo.moduleArgument = "__webpack_module__";
}
}
});
...
}
};在每个 module 开始编译的时候便会触发这个 plugin 上注册的 hooks。通过 AST 的节点类型来判断这个 module 是否是 ES Module,如果是的话,首先会实例化一个HarmonyCompatibilityDependency依赖的实例,并记录依赖需要替换的位置,然后将这个实例加入到 module 的依赖中,接下来实例化一个HarmonyInitDependency依赖的实例,并记录依赖需要替换的位置,然后将实例加入到 module 的依赖当中。然后会设定当前被 parser 处理的 module 最终被渲染时的一些构建信息,例如exportsArgument可能会使用__webpack_exports__,即这个模块输出挂载变量使用__webpack_exports__。
其中HarmonyCompatibilityDependency依赖的 Template 主要是:
HarmonyCompatibilityDependency.Template = class HarmonyExportDependencyTemplate {
apply(dep, source, runtime) {
const usedExports = dep.originModule.usedExports;
if (usedExports !== false && !Array.isArray(usedExports)) {
// 定义 module 的 export 类型
const content = runtime.defineEsModuleFlagStatement({
exportsArgument: dep.originModule.exportsArgument
});
source.insert(-10, content);
}
}
}调用 RuntimeTemplate 实例上提供的 defineEsModuleFlagStatement 方法在当前模块最终生成的代码内插入代码:
__webpack_require__.r(__webpack_exports__) // 用以在 __webpack_exports__ 上定义一个 __esModule 属性,用以标识当前 module 是一个 ES Module而在HarmonyInitDependency依赖的 Template 中主要完成的工作是:
HarmonyInitDependency.Template = class HarmonyInitDependencyTemplate {
apply(dep, source, runtime, dependencyTemplates) {
const module = dep.originModule;
const list = [];
// 遍历这个依赖的所属的 module 的所有依赖
for (const dependency of module.dependencies) {
// 获取不同依赖所使用的 template
const template = dependencyTemplates.get(dependency.constructor);
// 部分 template 并不是在 generator 调用 generate 方法立即执行相关模板依赖的替换工作的
// 而是将相关的操作置于 harmonyInit 函数当中,在这个会被加入到一个数组当中
if (
template &&
typeof template.harmonyInit === "function" &&
typeof template.getHarmonyInitOrder === "function"
) {
const order = template.getHarmonyInitOrder(dependency);
if (!isNaN(order)) {
list.push({
order,
listOrder: list.length,
dependency,
template
});
}
}
}
// 对模板依赖数组进行排序
list.sort((a, b) => {
const x = a.order - b.order;
if (x) return x;
return a.listOrder - b.listOrder;
});
// 依次执行模板依赖上的 harmonyInit 方法,这个时候开始相关模板的替换工作
for (const item of list) {
item.template.harmonyInit(
item.dependency,
source,
runtime,
dependencyTemplates
);
}
}
}接下来我们再来看 HarmonyModulesPlugin 插件里面初始化的第二个插件HarmonyImportDependencyParserPlugin,这个插件主要完成的工作是和 ES Module 当中使用 import 语法相关:
module.exports = class HarmonyImportDependencyParserPlugin {
constructor() {
...
}
apply(parser) {
...
parser.hooks.import.tap('HarmonyImportDependencyParserPlugin', (statement, source) => {
...
const sideEffectDep = new HarmonyImportSideEffectDependency({ ... })
parser.state.module.addDependency(sideEffectDep);
...
})
parser.hooks.importSpecifier.tap('HarmonyImportDependencyParserPlugin', (statement, source, id, name) => {
...
// 设置引入模块名的映射关系
parser.state.harmonySpecifier.set(name, {
source,
id,
sourceOrder: parser.state.lastHarmonyImportOrder
});
...
})
parser.hooks.expression
.for('imported var')
.tap('HarmonyImportDependencyParserPlugin', expr => {
...
const dep = new HarmonyImportSpecifierDependency({ ... });
parser.state.module.addDependency(dep);
...
})
parser.hooks.call
.for('imported var')
.tap('HarmonyImportDependencyParserPlugin', expr => {
...
const dep = new HarmonyImportSpecifierDependency({ ... })
parser.state.module.addDependency(dep);
...
})
}
}在这个插件里面主要是注册了在模块通过 parser 编译的过程中,遇到不同 tokens 触发的 hooks。例如hooks.importSpecifier主要是用于你通过import语法加载其他模块时所申明的变量名,会通过一个 map 结构记录这个变量名。当你在源代码中使用了这个变量名,例如作为一个函数去调用(对应触发hooks.call钩子),或者是作为一个表达式去访问(对应触发hooks.express钩子),那么它们都会新建一个HarmonyImportSpecifierDependency依赖的实例,并进入到当前被编译的 module 当中。
这个HarmonyImportSpecifierDependency模板依赖主要完成的工作就是:
HarmonyImportSpecifierDependency.Template = class HarmonyImportSpecifierDependencyTemplate extends HarmonyImportDependency.Template {
apply(dep, source, runtime) {
super.apply(dep, source, runtime);
const content = this.getContent(dep, runtime);
source.replace(dep.range[0], dep.range[1] - 1, content);
}
getContent(dep, runtime) {
const exportExpr = runtime.exportFromImport({
module: dep._module,
request: dep.request,
exportName: dep._id,
originModule: dep.originModule,
asiSafe: dep.shorthand,
isCall: dep.call,
callContext: !dep.directImport,
importVar: dep.getImportVar()
});
return dep.shorthand ? `${dep.name}: ${exportExpr}` : exportExpr;
}
};将源码中引入的其他模块的依赖变量名进行字符串的替换,具体可以查阅RuntimeTemplate.exportFromImport方法。
我们来看个例子:
// 在 parse 编译过程中,触发 hooks.importSpecifier 钩子,通过 map 记录对应变量名
import { add } from './add.js'
// 触发 hooks.call 钩子,给 module 加入 HarmonyImportSpecifierDependency 依赖
add(1, 2)
---
// 最终生成的代码为:
/* harmony import */ var _add__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);
Object(_b__WEBPACK_IMPORTED_MODULE_0__["add"])(1, 2);这个插件主要完成的是和 ES Module 当中使用 export 语法相关的工作:
module.exports = class HarmonyExportDependencyParserPlugin {
constructor(moduleOptions) {
this.strictExportPresence = moduleOptions.strictExportPresence;
}
apply(parser) {
parser.hooks.export.tap(
"HarmonyExportDependencyParserPlugin",
statement => {
...
const dep = new HarmonyExportHeaderDependency(...);
...
parser.state.current.addDependency(dep);
return true;
}
);
parser.hooks.exportImport.tap(
"HarmonyExportDependencyParserPlugin",
(statement, source) => {
...
const sideEffectDep = new HarmonyImportSideEffectDependency(...);
...
parser.state.current.addDependency(sideEffectDep);
return true;
}
);
parser.hooks.exportExpression.tap(
"HarmonyExportDependencyParserPlugin",
(statement, expr) => {
...
const dep = new HarmonyExportExpressionDependency(...);
...
parser.state.current.addDependency(dep);
return true;
}
);
parser.hooks.exportDeclaration.tap(
"HarmonyExportDependencyParserPlugin",
statement => {}
);
parser.hooks.exportSpecifier.tap(
"HarmonyExportDependencyParserPlugin",
(statement, id, name, idx) => {
...
if (rename === "imported var") {
const settings = parser.state.harmonySpecifier.get(id);
dep = new HarmonyExportImportedSpecifierDependency(...);
} else {
dep = new HarmonyExportSpecifierDependency(...);
}
parser.state.current.addDependency(dep);
return true;
}
);
parser.hooks.exportImportSpecifier.tap(
"HarmonyExportDependencyParserPlugin",
(statement, source, id, name, idx) => {
...
const dep = new HarmonyExportImportedSpecifierDependency(...);
...
parser.state.current.addDependency(dep);
return true;
}
);
}
};parse 在编译源码过程中,根据你使用的不同的 ES Module export 语法去触发不通过的 hooks,然后给当前编译的 module 加入对应的依赖 module。还是通过2个例子来看:
// export 一个 add 标识符,在 parse 环节会触发 hooks.exportSpecifier 钩子,会在当前 module 加入一个 HarmonyExportSpecifierDependency 依赖
export function add() {}
---
// 最终在输出文件当中输出的内容为
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "add", function() { return add; });
function add() {}// export 从 add.js 模块加载的 add 标识符,在 parse 环节会触发 hooks.exportImportSpecifier 钩子,会在当前 module 加入一个 HarmonyExportImportedSpecifierDependency 依赖
export { add } from './add'
---
// 最终在输出文件当中输出的内容为
/* harmony import */ var _add__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);
/* harmony reexport (safe) */ __webpack_require__.d(__webpack_exports__, "add", function() { return _add__WEBPACK_IMPORTED_MODULE_0__["add"]; });具体替换的工作可以查阅HarmonyExportSpecifierDependency.Template和HarmonyExportImportedSpecifierDependency.Template提供的依赖模板函数。
作者:tank0317
我们都很熟悉的,通过 npm run script-name 可以执行 package.json 中 scripts 对象配置的脚本。但是,你或许不知道下面这些知识。
下文中 npm-scirpt 指 package.json
scripts中配置的脚本命令。name-scirpt 指代某一个名字为 name 的脚本命令。
当我们使用命令 npm start 时,npm 会尝试执行 package.json scripts 中配置的 start 脚本命令。start-script 的默认配置为 "start": "node server.js"。所以如果项目根目录下有 server.js 文件,那么通过 npm start 会直接运行 server.js 中的代码。
除了 start-script ,当使用 npm start 命令时,npm 同样会尝试在 package.json scripts 中查找是否配置了 prestart,poststart 脚本命令。如果都配置了,npm 会按照以下顺序执行脚本。
类似的,npm test, npm restart, npm stop 都会按照以上的方式执行 scripts 中配置的对应脚本。同时 npm 会通过 npm_lifecycle_event 环境变量标识当前处于哪一阶段(所谓的生命周期)。比如,在 prestart-script 脚本执行阶段 npm_lifecycle_event 的值为 "prestart",start-script 阶段,值为 "start",即 package.json scripts 对象配置的脚本名字。
以上是 npm 内置命令对应的脚本执行逻辑,对于我们平时最熟悉的自定义脚本,以上逻辑同样适用。比如我们配置了 "build": "webpack --mode=production",同时配置了 prebuild 以及 postbuild 脚本,当使用 npm run build 时,同样会依次执行 prebuild-script、build-script、postbuild-script。
我们配置的脚本命令,如 "start": "node server.js",node server.js 会当做一行代码传递给系统的 SHELL 去解释执行。实际使用的 SHELL 可能会根据系统平台而不同,类 UNIX 系统里,如 macOS 或 linux 中指代的是 /bin/sh, 在 windows 中使用的是 cmd.exe。
既然是交给 SHELL 去解释执行的,说明配置的脚本可以是任意能够在 SHELL 中运行的命令,而不仅仅是 node 脚本或者 js 程序。即如果你的系统里安装了 python(或者说系统变量 PATH 里能找到 python 命令),你也可以将 scripts 配置为 "myscript": "python xxx.py"
上面提到了在使用 npm run script-name 命令时,npm 会设置一个环境变量 npm_lifecycle_event。实际上 npm 还会设置很多环境变量,通过内置命令 npm run env 可以查看 npm 为脚本运行时设置的所有环境变量。 其中 package.json 中设置的所有字段,都会被设置为 npm_package_ 开头的环境变量。如果你的 packge.json 设置如下
{
"name": "npm-demo",
"version": "1.0.0",
"script": {
"build": "webpack --mode=production"
},
"files": ["src"]
}则可以得到 npm_package_name、npm_package_version、npm_package_script_build、npm_package_files_0 等变量。注意上面 package.json 中对象和数组中每个字段都会有对应的环境变量。
不止 package.json,npm 相关的所有配置也会有 npm_config_ 开头的环境变量。
另外,需要注意的是,即使在子目录下使用 npm run 命令,脚本也会在项目的根目录下运行。如果你想要区分在哪里使用的 npm run 命令,可以使用 INIT_CWD 环境变量,该变量保存了 npm run 命令运行时目录的绝对路径。
如何使用这些环境变量?如果你的脚本是 shell 脚本,可以直接通过对应的环境变量名获取变量值,如果是 node 脚本,可以通过 nodejs 中的全局变量 process.env 获取,比如获取项目版本号可以使用 process.env.npm_package_version。
上面提到了 npm-script 执行前会设置一些环境变量,其中很重要的一个环境变量是 PATH。npm 会将项目 node_modules/.bin 的绝对路径添加到环境变量 PATH 中。因此我们可以在 npm-script 中使用项目本地安装的一些命令行工具。如上面设置的 build 脚本: "build": "webpack --mode=production"。
只要我们本地安装了 webpack,就可以在项目的 node_modules/.bin 路径下看到 webpack 可执行文件。又因为 node_modules/.bin 路径已经添加到 PATH 中,所以脚本运行时能够在 PATH 中找到 webpack 命令,从而顺利执行。
最后,为什么 webpack 安装后,能够在 node_modules/.bin 路径下找到对应的可执行文件?可以查看 https://docs.npmjs.com/files/package.json.html#bin
https://docs.npmjs.com/cli/run-script.html
上篇文章主要讲了 loader 的配置,匹配相关的机制。这篇主要会讲当一个 module 被创建之后,使用 loader 去处理这个 module 内容的流程机制。首先我们来总体的看下整个的流程:

在 module 一开始构建的过程中,首先会创建一个 loaderContext 对象,它和这个 module 是一一对应的关系,而这个 module 所使用的所有 loaders 都会共享这个 loaderContext 对象,每个 loader 执行的时候上下文就是这个 loaderContext 对象,所以可以在我们写的 loader 里面通过 this 来访问。
// NormalModule.js
const { runLoaders } = require('loader-runner')
class NormalModule extends Module {
...
createLoaderContext(resolver, options, compilation, fs) {
const requestShortener = compilation.runtimeTemplate.requestShortener;
// 初始化 loaderContext 对象,这些初始字段的具体内容解释在文档上有具体的解释(https://webpack.docschina.org/api/loaders/#this-data)
const loaderContext = {
version: 2,
emitWarning: warning => {...},
emitError: error => {...},
exec: (code, filename) => {...},
resolve(context, request, callback) {...},
getResolve(options) {...},
emitFile: (name, content, sourceMap) => {...},
rootContext: options.context, // 项目的根路径
webpack: true,
sourceMap: !!this.useSourceMap,
_module: this,
_compilation: compilation,
_compiler: compilation.compiler,
fs: fs
};
// 触发 normalModuleLoader 的钩子函数,开发者可以利用这个钩子来对 loaderContext 进行拓展
compilation.hooks.normalModuleLoader.call(loaderContext, this);
if (options.loader) {
Object.assign(loaderContext, options.loader);
}
return loaderContext;
}
doBuild(options, compilation, resolver, fs, callback) {
// 创建 loaderContext 上下文
const loaderContext = this.createLoaderContext(
resolver,
options,
compilation,
fs
)
runLoaders(
{
resource: this.resource, // 这个模块的路径
loaders: this.loaders, // 模块所使用的 loaders
context: loaderContext, // loaderContext 上下文
readResource: fs.readFile.bind(fs) // 读取文件的 node api
},
(err, result) => {
// do something
}
)
}
...
}当 loaderContext 初始化完成后,开始调用 runLoaders 方法,这个时候进入到了 loaders 的执行阶段。runLoaders 方法是由loader-runner这个独立的 NPM 包提供的方法,那我们就一起来看下 runLoaders 方法内部是如何运行的。
首先根据传入的参数完成进一步的处理,同时对于 loaderContext 对象上的属性做进一步的拓展:
exports.runLoaders = function runLoaders(options, callback) {
// read options
var resource = options.resource || ""; // 模块的路径
var loaders = options.loaders || []; // 模块所需要使用的 loaders
var loaderContext = options.context || {}; // 在 normalModule 里面创建的 loaderContext
var readResource = options.readResource || readFile;
var splittedResource = resource && splitQuery(resource);
var resourcePath = splittedResource ? splittedResource[0] : undefined; // 模块实际路径
var resourceQuery = splittedResource ? splittedResource[1] : undefined; // 模块路径 query 参数
var contextDirectory = resourcePath ? dirname(resourcePath) : null; // 模块的父路径
// execution state
var requestCacheable = true;
var fileDependencies = [];
var contextDependencies = [];
// prepare loader objects
loaders = loaders.map(createLoaderObject); // 处理 loaders
// 拓展 loaderContext 的属性
loaderContext.context = contextDirectory;
loaderContext.loaderIndex = 0; // 当前正在执行的 loader 索引
loaderContext.loaders = loaders;
loaderContext.resourcePath = resourcePath;
loaderContext.resourceQuery = resourceQuery;
loaderContext.async = null; // 异步 loader
loaderContext.callback = null;
...
// 需要被构建的模块路径,将 loaderContext.resource -> getter/setter
// 例如 /abc/resource.js?rrr
Object.defineProperty(loaderContext, "resource", {
enumerable: true,
get: function() {
if(loaderContext.resourcePath === undefined)
return undefined;
return loaderContext.resourcePath + loaderContext.resourceQuery;
},
set: function(value) {
var splittedResource = value && splitQuery(value);
loaderContext.resourcePath = splittedResource ? splittedResource[0] : undefined;
loaderContext.resourceQuery = splittedResource ? splittedResource[1] : undefined;
}
});
// 构建这个 module 所有的 loader 及这个模块的 resouce 所组成的 request 字符串
// 例如:/abc/loader1.js?xyz!/abc/node_modules/loader2/index.js!/abc/resource.js?rrr
Object.defineProperty(loaderContext, "request", {
enumerable: true,
get: function() {
return loaderContext.loaders.map(function(o) {
return o.request;
}).concat(loaderContext.resource || "").join("!");
}
});
// 在执行 loader 提供的 pitch 函数阶段传入的参数之一,剩下还未被调用的 loader.pitch 所组成的 request 字符串
Object.defineProperty(loaderContext, "remainingRequest", {
enumerable: true,
get: function() {
if(loaderContext.loaderIndex >= loaderContext.loaders.length - 1 && !loaderContext.resource)
return "";
return loaderContext.loaders.slice(loaderContext.loaderIndex + 1).map(function(o) {
return o.request;
}).concat(loaderContext.resource || "").join("!");
}
});
// 在执行 loader 提供的 pitch 函数阶段传入的参数之一,包含当前 loader.pitch 所组成的 request 字符串
Object.defineProperty(loaderContext, "currentRequest", {
enumerable: true,
get: function() {
return loaderContext.loaders.slice(loaderContext.loaderIndex).map(function(o) {
return o.request;
}).concat(loaderContext.resource || "").join("!");
}
});
// 在执行 loader 提供的 pitch 函数阶段传入的参数之一,包含已经被执行的 loader.pitch 所组成的 request 字符串
Object.defineProperty(loaderContext, "previousRequest", {
enumerable: true,
get: function() {
return loaderContext.loaders.slice(0, loaderContext.loaderIndex).map(function(o) {
return o.request;
}).join("!");
}
});
// 获取当前正在执行的 loader 的query参数
// 如果这个 loader 配置了 options 对象的话,this.query 就指向这个 option 对象
// 如果 loader 中没有 options,而是以 query 字符串作为参数调用时,this.query 就是一个以 ? 开头的字符串
Object.defineProperty(loaderContext, "query", {
enumerable: true,
get: function() {
var entry = loaderContext.loaders[loaderContext.loaderIndex];
return entry.options && typeof entry.options === "object" ? entry.options : entry.query;
}
});
// 每个 loader 在 pitch 阶段和正常执行阶段都可以共享的 data 数据
Object.defineProperty(loaderContext, "data", {
enumerable: true,
get: function() {
return loaderContext.loaders[loaderContext.loaderIndex].data;
}
});
var processOptions = {
resourceBuffer: null, // module 的内容 buffer
readResource: readResource
};
// 开始执行每个 loader 上的 pitch 函数
iteratePitchingLoaders(processOptions, loaderContext, function(err, result) {
// do something...
});
}这里稍微总结下就是在 runLoaders 方法的初期会对相关参数进行初始化的操作,特别是将 loaderContext 上的部分属性改写为 getter/setter 函数,这样在不同的 loader 执行的阶段可以动态的获取一些参数。
接下来开始调用 iteratePitchingLoaders 方法执行每个 loader 上提供的 pitch 函数。大家写过 loader 的话应该都清楚,每个 loader 可以挂载一个 pitch 函数,每个 loader 提供的 pitch 方法和 loader 实际的执行顺序正好相反。这块的内容在 webpack 文档上也有详细的说明(请戳我)。
这些 pitch 函数并不是用来实际处理 module 的内容的,主要是可以利用 module 的 request,来做一些拦截处理的工作,从而达到在 loader 处理流程当中的一些定制化的处理需要,有关 pitch 函数具体的实战可以参见下一篇文档[Webpack 高手进阶-loader 实战] TODO: 链接
function iteratePitchingLoaders() {
// abort after last loader
if(loaderContext.loaderIndex >= loaderContext.loaders.length)
return processResource(options, loaderContext, callback);
// 根据 loaderIndex 来获取当前需要执行的 loader
var currentLoaderObject = loaderContext.loaders[loaderContext.loaderIndex];
// iterate
// 如果被执行过,那么直接跳过这个 loader 的 pitch 函数
if(currentLoaderObject.pitchExecuted) {
loaderContext.loaderIndex++;
return iteratePitchingLoaders(options, loaderContext, callback);
}
// 加载 loader 模块
// load loader module
loadLoader(currentLoaderObject, function(err) {
// do something ...
});
}每次执行 pitch 函数前,首先根据 loaderIndex 来获取当前需要执行的 loader (currentLoaderObject),调用 loadLoader 函数来加载这个 loader,loadLoader 内部兼容了 SystemJS,ES Module,CommonJs 这些模块定义,最终会将 loader 提供的 pitch 方法和普通方法赋值到 currentLoaderObject 上:
// loadLoader.js
module.exports = function (loader, callback) {
...
var module = require(loader.path)
...
loader.normal = module
loader.pitch = module.pitch
loader.raw = module.raw
callback()
...
}当 loader 加载完后,开始执行 loadLoader 的回调:
loadLoader(currentLoaderObject, function(err) {
var fn = currentLoaderObject.pitch; // 获取 pitch 函数
currentLoaderObject.pitchExecuted = true;
if(!fn) return iteratePitchingLoaders(options, loaderContext, callback); // 如果这个 loader 没有提供 pitch 函数,那么直接跳过
// 开始执行 pitch 函数
runSyncOrAsync(
fn,
loaderContext, [loaderContext.remainingRequest, loaderContext.previousRequest, currentLoaderObject.data = {}],
function(err) {
if(err) return callback(err);
var args = Array.prototype.slice.call(arguments, 1);
// Determine whether to continue the pitching process based on
// argument values (as opposed to argument presence) in order
// to support synchronous and asynchronous usages.
// 根据是否有参数返回来判断是否向下继续进行 pitch 函数的执行
var hasArg = args.some(function(value) {
return value !== undefined;
});
if(hasArg) {
loaderContext.loaderIndex--;
iterateNormalLoaders(options, loaderContext, args, callback);
} else {
iteratePitchingLoaders(options, loaderContext, callback);
}
}
);
})这里出现了一个 runSyncOrAsync 方法,放到后文去讲,开始执行 pitch 函数,当 pitch 函数执行完后,执行传入的回调函数。我们看到回调函数里面会判断接收到的参数的个数,除了第一个 err 参数外,如果还有其他的参数(这些参数是 pitch 函数执行完后传入回调函数的),那么会直接进入 loader 的 normal 方法执行阶段,并且会直接跳过后面的 loader 执行阶段。如果 pitch 函数没有返回值的话,那么进入到下一个 loader 的 pitch 函数的执行阶段。让我们再回到 iteratePitchingLoaders 方法内部,当所有 loader 上面的 pitch 函数都执行完后,即 loaderIndex 索引值 >= loader 数组长度的时候:
function iteratePitchingLoaders () {
...
if(loaderContext.loaderIndex >= loaderContext.loaders.length)
return processResource(options, loaderContext, callback);
...
}
function processResource(options, loaderContext, callback) {
// set loader index to last loader
loaderContext.loaderIndex = loaderContext.loaders.length - 1;
var resourcePath = loaderContext.resourcePath;
if(resourcePath) {
loaderContext.addDependency(resourcePath); // 添加依赖
options.readResource(resourcePath, function(err, buffer) {
if(err) return callback(err);
options.resourceBuffer = buffer;
iterateNormalLoaders(options, loaderContext, [buffer], callback);
});
} else {
iterateNormalLoaders(options, loaderContext, [null], callback);
}
}在 processResouce 方法内部调用 node API readResouce 读取 module 对应路径的文本内容,调用 iterateNormalLoaders 方法,开始进入 loader normal 方法的执行阶段。
function iterateNormalLoaders () {
if(loaderContext.loaderIndex < 0)
return callback(null, args);
var currentLoaderObject = loaderContext.loaders[loaderContext.loaderIndex];
// iterate
if(currentLoaderObject.normalExecuted) {
loaderContext.loaderIndex--;
return iterateNormalLoaders(options, loaderContext, args, callback);
}
var fn = currentLoaderObject.normal;
currentLoaderObject.normalExecuted = true;
if(!fn) {
return iterateNormalLoaders(options, loaderContext, args, callback);
}
// buffer 和 utf8 string 之间的转化
convertArgs(args, currentLoaderObject.raw);
runSyncOrAsync(fn, loaderContext, args, function(err) {
if(err) return callback(err);
var args = Array.prototype.slice.call(arguments, 1);
iterateNormalLoaders(options, loaderContext, args, callback);
});
}在 iterateNormalLoaders 方法内部就是依照从右到左的顺序(正好与 pitch 方法执行顺序相反)依次执行每个 loader 上的 normal 方法。loader 不管是 pitch 方法还是 normal 方法的执行可为同步的,也可设为异步的。这里说下 normal 方法的,一般如果你写的 loader 里面可能涉及到计算量较大的情况时,可将你的 loader 异步化,在你 loader 方法里面调用this.async方法,返回异步的回调函数,当你 loader 内部实际的内容执行完后,可调用这个异步的回调来进入下一个 loader 的执行。
module.exports = function (content) {
const callback = this.async()
someAsyncOperation(content, function(err, result) {
if (err) return callback(err);
callback(null, result);
});
}除了调用 this.async 来异步化 loader 之外,还有一种方式就是在你的 loader 里面去返回一个 promise,只有当这个 promise 被 resolve 之后,才会调用下一个 loader(具体实现机制见下文):
module.exports = function (content) {
return new Promise(resolve => {
someAsyncOpertion(content, function(err, result) {
if (err) resolve(err)
resolve(null, result)
})
})
}这里还有一个地方需要注意的就是,上下游 loader 之间的数据传递过程中,如果下游的 loader 接收到的参数为一个,那么可以在上一个 loader 执行结束后,如果是同步就直接 return 出去:
module.exports = function (content) {
// do something
return content
}如果是异步就直接调用异步回调传递下去(参见上面 loader 异步化)。如果下游 loader 接收的参数多于一个,那么上一个 loader 执行结束后,如果是同步那么就需要调用 loaderContext 提供的 callback 函数:
module.exports = function (content) {
// do something
this.callback(null, content, argA, argB)
}如果是异步的还是继续调用异步回调函数传递下去(参见上面 loader 异步化)。具体的执行机制涉及到上文还没讲到的 runSyncOrAsync 方法,它提供了上下游 loader 调用的接口:
function runSyncOrAsync(fn, context, args, callback) {
var isSync = true; // 是否为同步
var isDone = false;
var isError = false; // internal error
var reportedError = false;
// 给 loaderContext 上下文赋值 async 函数,用以将 loader 异步化,并返回异步回调
context.async = function async() {
if(isDone) {
if(reportedError) return; // ignore
throw new Error("async(): The callback was already called.");
}
isSync = false; // 同步标志位置为 false
return innerCallback;
};
// callback 的形式可以向下一个 loader 多个参数
var innerCallback = context.callback = function() {
if(isDone) {
if(reportedError) return; // ignore
throw new Error("callback(): The callback was already called.");
}
isDone = true;
isSync = false;
try {
callback.apply(null, arguments);
} catch(e) {
isError = true;
throw e;
}
};
try {
// 开始执行 loader
var result = (function LOADER_EXECUTION() {
return fn.apply(context, args);
}());
// 如果为同步的执行
if(isSync) {
isDone = true;
// 如果 loader 执行后没有返回值,执行 callback 开始下一个 loader 执行
if(result === undefined)
return callback();
// loader 返回值为一个 promise 实例,待这个实例被resolve或者reject后执行下一个 loader。这也是 loader 异步化的一种方式
if(result && typeof result === "object" && typeof result.then === "function") {
return result.catch(callback).then(function(r) {
callback(null, r);
});
}
// 如果 loader 执行后有返回值,执行 callback 开始下一个 loader 执行
return callback(null, result);
}
} catch(e) {
// do something
}
}以上就是对于 module 在构建过程中 loader 执行流程的源码分析。可能平时在使用 webpack 过程了解相关的 loader 执行规则和策略,再配合这篇对于内部机制的分析,应该会对 webpack loader 的使用有更加深刻的印象。
Readable Stream是对数据源的一种抽象。它提供了从数据源获取数据并缓存,以及将数据提供给数据消费者的能力。
接下来分别通过Readable Stream的2种模式来学习下可读流是如何获取数据以及将数据提供给消费者的。

在flowing模式下,可读流自动从系统的底层读取数据,并通过EventEmitter接口的事件提供给消费者。如果不是开发者需要自己去实现可读流,大家可使用最为简单的readable.pipe()方法去消费数据。
接下来我们就通过一个简单的实例去具体分析下flowing模式下,可读流是如何工作的。
const { Readable } = require('stream')
let c = 97 - 1
// 实例化一个可读流
const rs = new Readable({
read () {
if (c >= 'z'.charCodeAt(0)) return rs.push(null)
setTimeout(() => {
// 向可读流中推送数据
rs.push(String.fromCharCode(++c))
}, 100)
}
})
// 将可读流的数据pipe到标准输出并打印出来
rs.pipe(process.stdout)
process.on('exit', () => {
console.error('\n_read() called ' + (c - 97) + ' times')
})首先我们先来看下Readable构造函数的实现:
function Readable(options) {
if (!(this instanceof Readable))
return new Readable(options);
// _readableState里面保存了关于可读流的不同阶段的状态值,下面会具体的分析
this._readableState = new ReadableState(options, this);
// legacy
this.readable = true;
if (options) {
// 重写内部的_read方法,用以自定义从数据源获取数据
if (typeof options.read === 'function')
this._read = options.read;
if (typeof options.destroy === 'function')
// 重写内部的_destory方法
this._destroy = options.destroy;
}
Stream.call(this);
}在我们创建可读流实例时,传入了一个read方法,用以自定义从数据源获取数据的方法,如果是开发者需要自己去实现可读流,那么这个方法一定需要去自定义,否则在程序的运行过程中会报错。ReadableState构造函数中定义了很多关于可读流的不同阶段的状态值:
function ReadableState(options, stream) {
options = options || {};
...
// object stream flag. Used to make read(n) ignore n and to
// make all the buffer merging and length checks go away
// 是否为对象模式,如果是的话,那么从缓冲区获得的数据为对象
this.objectMode = !!options.objectMode;
if (isDuplex)
this.objectMode = this.objectMode || !!options.readableObjectMode;
// the point at which it stops calling _read() to fill the buffer
// Note: 0 is a valid value, means "don't call _read preemptively ever"
// 高水位线,一旦buffer缓冲区的数据量大于hwm时,就会停止调用从数据源再获取数据
var hwm = options.highWaterMark;
var readableHwm = options.readableHighWaterMark;
var defaultHwm = this.objectMode ? 16 : 16 * 1024; // 默认值
if (hwm || hwm === 0)
this.highWaterMark = hwm;
else if (isDuplex && (readableHwm || readableHwm === 0))
this.highWaterMark = readableHwm;
else
this.highWaterMark = defaultHwm;
// cast to ints.
this.highWaterMark = Math.floor(this.highWaterMark);
// A linked list is used to store data chunks instead of an array because the
// linked list can remove elements from the beginning faster than
// array.shift()
// readable可读流内部的缓冲区
this.buffer = new BufferList();
// 缓冲区数据长度
this.length = 0;
this.pipes = null;
this.pipesCount = 0;
// flowing模式的初始值
this.flowing = null;
// 是否已将源数据全部读取完毕
this.ended = false;
// 是否触发了end事件
this.endEmitted = false;
// 是否正在从源数据处读取数据到缓冲区
this.reading = false;
// a flag to be able to tell if the event 'readable'/'data' is emitted
// immediately, or on a later tick. We set this to true at first, because
// any actions that shouldn't happen until "later" should generally also
// not happen before the first read call.
this.sync = true;
// whenever we return null, then we set a flag to say
// that we're awaiting a 'readable' event emission.
this.needReadable = false;
this.emittedReadable = false;
this.readableListening = false;
this.resumeScheduled = false;
// has it been destroyed
this.destroyed = false;
// Crypto is kind of old and crusty. Historically, its default string
// encoding is 'binary' so we have to make this configurable.
// Everything else in the universe uses 'utf8', though.
// 编码方式
this.defaultEncoding = options.defaultEncoding || 'utf8';
// 在pipe管道当中正在等待drain事件的写入流
// the number of writers that are awaiting a drain event in .pipe()s
this.awaitDrain = 0;
// if true, a maybeReadMore has been scheduled
this.readingMore = false;
this.decoder = null;
this.encoding = null;
if (options.encoding) {
if (!StringDecoder)
StringDecoder = require('string_decoder').StringDecoder;
this.decoder = new StringDecoder(options.encoding);
this.encoding = options.encoding;
}
}在上面的例子中,当实例化一个可读流rs后,调用可读流实例的pipe方法。这正式开始了可读流在flowing模式下从数据源开始获取数据,以及process.stdout对数据的消费。
Readable.prototype.pipe = function (dest, pipeOpts) {
var src = this
var state = this._readableState
...
// 可读流实例监听data,可读流会从数据源获取数据,同时数据被传递到了消费者
src.on('data', ondata)
function ondata (chunk) {
...
var ret = dest.write(chunk)
...
}
...
}Node提供的可读流有3种方式可以将初始态flowing = null的可读流转化为flowing = true:
data事件stream.resume()方法stream.pipe()方法事实上这3种方式都回归到了一种方式上:strean.resume(),通过调用这个方法,将可读流的模式改变为flowing态。继续回到上面的例子当中,在调用了rs.pipe()方法后,实际上内部是调用了src.on('data', ondata)监听data事件,那么我们就来看下这个方法当中做了哪些工作。
Readable.prototype.on = function (ev, fn) {
...
// 监听data事件
if (ev === 'data') {
// 可读流一开始的flowing状态是null
// Start flowing on next tick if stream isn't explicitly paused
if (this._readableState.flowing !== false)
this.resume();
} else if (ev === 'readable') {
...
}
return res;
}可读流监听data事件,并调用resume方法:
Readable.prototype.resume = function() {
var state = this._readableState;
if (!state.flowing) {
debug('resume');
// 置为flowing状态
state.flowing = true;
resume(this, state);
}
return this;
};
function resume(stream, state) {
if (!state.resumeScheduled) {
state.resumeScheduled = true;
process.nextTick(resume_, stream, state);
}
}
function resume_(stream, state) {
if (!state.reading) {
debug('resume read 0');
// 开始从数据源中获取数据
stream.read(0);
}
state.resumeScheduled = false;
// 如果是flowing状态的话,那么将awaitDrain置为0
state.awaitDrain = 0;
stream.emit('resume');
flow(stream);
if (state.flowing && !state.reading)
stream.read(0);
}resume方法会判断这个可读流是否处于flowing模式下,同时在内部调用stream.read(0)开始从数据源中获取数据(其中stream.read()方法根据所接受到的参数会有不同的行为):
TODO: 这个地方可说明stream.read(size)方法接收到的不同的参数
Readable.prototype.read = function (n) {
...
if (n === 0 &&
state.needReadable &&
(state.length >= state.highWaterMark || state.ended)) {
debug('read: emitReadable', state.length, state.ended);
// 如果缓存中没有数据且处于end状态
if (state.length === 0 && state.ended)
// 流状态结束
endReadable(this);
else
// 触发readable事件
emitReadable(this);
return null;
}
...
// 从缓存中可以读取的数据
n = howMuchToRead(n, state);
// 判断是否应该从数据源中获取数据
// if we need a readable event, then we need to do some reading.
var doRead = state.needReadable;
debug('need readable', doRead);
// if we currently have less than the highWaterMark, then also read some
// 如果buffer的长度为0或者buffer的长度减去需要读取的数据的长度 < hwm 的时候,那么这个时候还需要继续读取数据
// state.length - n 即表示当前buffer已有的数据长度减去需要读取的数据长度后,如果还小于hwm话,那么doRead仍然置为true
if (state.length === 0 || state.length - n < state.highWaterMark) {
// 继续read数据
doRead = true;
debug('length less than watermark', doRead);
}
// however, if we've ended, then there's no point, and if we're already
// reading, then it's unnecessary.
// 如果数据已经读取完毕,或者处于正在读取的状态,那么doRead置为false表明不需要读取数据
if (state.ended || state.reading) {
doRead = false;
debug('reading or ended', doRead);
} else if (doRead) {
debug('do read');
state.reading = true;
state.sync = true;
// if the length is currently zero, then we *need* a readable event.
// 如果当前缓冲区的长度为0,首先将needReadable置为true,那么再当缓冲区有数据的时候就触发readable事件
if (state.length === 0)
state.needReadable = true;
// call internal read method
// 从数据源获取数据,可能是同步也可能是异步的状态,这个取决于自定义_read方法的内部实现,可参见study里面的示例代码
this._read(state.highWaterMark);
state.sync = false;
// If _read pushed data synchronously, then `reading` will be false,
// and we need to re-evaluate how much data we can return to the user.
// 如果_read方法是同步,那么reading字段将会为false。这个时候需要重新计算有多少数据需要重新返回给消费者
if (!state.reading)
n = howMuchToRead(nOrig, state);
}
// ret为输出给消费者的数据
var ret;
if (n > 0)
ret = fromList(n, state);
else
ret = null;
if (ret === null) {
state.needReadable = true;
n = 0;
} else {
state.length -= n;
}
if (state.length === 0) {
// If we have nothing in the buffer, then we want to know
// as soon as we *do* get something into the buffer.
if (!state.ended)
state.needReadable = true;
// If we tried to read() past the EOF, then emit end on the next tick.
if (nOrig !== n && state.ended)
endReadable(this);
}
// 只要从数据源获取的数据不为null,即未EOF时,那么每次读取数据都会触发data事件
if (ret !== null)
this.emit('data', ret);
return ret;
}这个时候可读流从数据源开始获取数据,调用this._read(state.highWaterMark)方法,对应着例子当中实现的read()方法:
const rs = new Readable({
read () {
if (c >= 'z'.charCodeAt(0)) return rs.push(null)
setTimeout(() => {
// 向可读流中推送数据
rs.push(String.fromCharCode(++c))
}, 100)
}
})在read方法当中有一个非常中的方法需要开发者自己去调用,就是stream.push方法,这个方法即完成从数据源获取数据,并供消费者去调用。
Readable.prototype.push = function (chunk, encoding) {
....
// 对从数据源拿到的数据做处理
return readableAddChunk(this, chunk, encoding, false, skipChunkCheck);
}
function readableAddChunk (stream, chunk, encoding, addToFront, skipChunkCheck) {
...
// 是否添加数据到头部
if (addToFront) {
// 如果不能在写入数据
if (state.endEmitted)
stream.emit('error',
new errors.Error('ERR_STREAM_UNSHIFT_AFTER_END_EVENT'));
else
addChunk(stream, state, chunk, true);
} else if (state.ended) { // 已经EOF,但是仍然还在推送数据,这个时候会报错
stream.emit('error', new errors.Error('ERR_STREAM_PUSH_AFTER_EOF'));
} else {
// 完成一次读取后,立即将reading的状态置为false
state.reading = false;
if (state.decoder && !encoding) {
chunk = state.decoder.write(chunk);
if (state.objectMode || chunk.length !== 0)
// 添加数据到尾部
addChunk(stream, state, chunk, false);
else
maybeReadMore(stream, state);
} else {
// 添加数据到尾部
addChunk(stream, state, chunk, false);
}
}
...
return needMoreData(state);
}
// 根据stream的状态来对数据做处理
function addChunk(stream, state, chunk, addToFront) {
// flowing为readable stream的状态,length为buffer的长度
// flowing模式下且为异步读取数据的过程时,可读流的缓冲区并不保存数据,而是直接获取数据后触发data事件供消费者使用
if (state.flowing && state.length === 0 && !state.sync) {
// 对于flowing模式的Reabable,可读流自动从系统底层读取数据,直接触发data事件,且继续从数据源读取数据stream.read(0)
stream.emit('data', chunk);
// 继续从缓存池中获取数据
stream.read(0);
} else {
// update the buffer info.
// 数据的长度
state.length += state.objectMode ? 1 : chunk.length;
// 将数据添加到头部
if (addToFront)
state.buffer.unshift(chunk);
else
// 将数据添加到尾部
state.buffer.push(chunk);
// 触发readable事件,即通知缓存当中现在有数据可读
if (state.needReadable)
emitReadable(stream);
}
maybeReadMore(stream, state);
}在addChunk方法中完成对数据的处理,这里需要注意的就是,在flowing态下,数据被消耗的途径可能还不一样:
这2种情况到底使用哪一种还要看开发者的是同步还是异步的去调用push方法,对应着state.sync的状态值。
当push方法被异步调用时,即state.sync为false:这个时候对于从数据源获取到的数据是直接通过触发data事件以供消费者来使用,而不用存放到缓冲区。然后调用stream.read(0)方法重复读取数据并供消费者使用。
当push方法是同步时,即state.sync为true:这个时候从数据源获取数据后,就不是直接通过触发data事件来供消费者直接使用,而是首先上数据缓冲到可读流的缓冲区。这个时候你看代码可能会疑惑,将数据缓存起来后,那么在flowing模式下,是如何流动起来的呢?事实上在一开始调用resume_方法时:
function resume_() {
...
//
flow(stream);
if (state.flowing && !state.reading)
stream.read(0); // 继续从数据源获取数据
}
function flow(stream) {
...
// 如果处理flowing状态,那么调用stream.read()方法用以从stream的缓冲区中获取数据并供消费者来使用
while (state.flowing && stream.read() !== null);
}在flow方法内部调用stream.read()方法取出可读流缓冲区的数据供消费者使用,同时继续调用stream.read(0)来继续从数据源获取数据。
以上就是在flowing模式下,可读流是如何完成从数据源获取数据并提供给消费者使用的大致流程。
在pasued模式下,消费者如果要获取数据需要手动调用stream.read()方法去获取数据。
举个例子:
const { Readable } = require('stream')
let c = 97 - 1
const rs = new Readable({
highWaterMark: 3,
read () {
if (c >= 'f'.charCodeAt(0)) return rs.push(null)
setTimeout(() => {
rs.push(String.fromCharCode(++c))
}, 1000)
}
})
rs.setEncoding('utf8')
rs.on('readable', () => {
// console.log(rs._readableState.length)
console.log('get the data from readable: ', rs.read())
})通过监听readable事件,开始出发可读流从数据源获取数据。
Readable.prototype.on = function (env) {
if (env === 'data') {
...
} else if (env === 'readable') {
// 监听readable事件
const state = this._readableState;
if (!state.endEmitted && !state.readableListening) {
state.readableListening = state.needReadable = true;
state.emittedReadable = false;
if (!state.reading) {
process.nextTick(nReadingNextTick, this);
} else if (state.length) {
emitReadable(this);
}
}
}
}
function nReadingNextTick(self) {
debug('readable nexttick read 0');
// 开始从数据源获取数据
self.read(0);
}在nReadingNextTick当中调用self.read(0)方法后,后面的流程和上面分析的flowing模式的可读流从数据源获取数据的流程相似,最后都要调用addChunk方法,将数据获取到后推入可读流的缓冲区:
function addChunk(stream, state, chunk, addToFront) {
if (state.flowing && state.length === 0 && !state.sync) {
...
} else {
// update the buffer info.
// 数据的长度
state.length += state.objectMode ? 1 : chunk.length;
// 将数据添加到头部
if (addToFront)
state.buffer.unshift(chunk);
else
// 将数据添加到尾部
state.buffer.push(chunk);
// 触发readable事件,即通知缓存当中现在有数据可读
if (state.needReadable)
emitReadable(stream);
}
maybeReadMore(stream, state);
}一旦有数据被加入到了缓冲区,且needReadable(这个字段表示是否需要触发readable事件用以通知消费者来消费数据)为true,这个时候会触发readable告诉消费者有新的数据被push进了可读流的缓冲区。此外还会调用maybeReadMore方法,异步的从数据源获取更多的数据:
function maybeReadMore(stream, state) {
if (!state.readingMore) {
state.readingMore = true;
process.nextTick(maybeReadMore_, stream, state);
}
}
function maybeReadMore_(stream, state) {
var len = state.length;
// 在非flowing的模式下,且缓冲区的数据长度小于hwm
while (!state.reading && !state.flowing && !state.ended &&
state.length < state.highWaterMark) {
debug('maybeReadMore read 0');
stream.read(0);
// 获取不到数据后
if (len === state.length)
// didn't get any data, stop spinning.
break;
else
len = state.length;
}
state.readingMore = false;
}每当可读流有新的数据被推进缓冲区,触发readable事件后,消费者通过调用stream.read()方法来从可读流中获取数据。
当数据消费消费数据的速度慢于可写流提供给消费者的数据后会产生背压。
还是通过pipe管道来看:
Readable.prototype.pipe = function () {
...
// 监听drain事件
var ondrain = pipeOnDrain(src);
dest.on('drain', ondrain);
...
src.on('data', ondata)
function ondata () {
increasedAwaitDrain = false;
// 向writable中写入数据
var ret = dest.write(chunk);
if (false === ret && !increasedAwaitDrain) {
...
src.pause();
}
}
...
}
function pipeOnDrain(src) {
return function() {
var state = src._readableState;
debug('pipeOnDrain', state.awaitDrain);
// 减少pipes中awaitDrain的数量
if (state.awaitDrain)
state.awaitDrain--;
// 如果awaitDrain的数量为0,且readable上绑定了data事件时(EE.listenerCount返回绑定的事件回调数量)
if (state.awaitDrain === 0 && EE.listenerCount(src, 'data')) {
// 重新开启flowing模式
state.flowing = true;
flow(src);
}
};
}当dest.write(chunk)返回false的时候,即代表可读流给可写流提供的数据过快,这个时候调用src.pause方法,暂停flowing状态,同步也暂停可写流从数据源获取数据以及向可写流输入数据。这个时候只有当可写流触发drain事件时,会调用ondrain来恢复flowing,同时可读流继续向可写流输入数据。关于可写流的背压可参见关于Writable_stream的源码分析。
以上就是通过可读流的2种模式分析了下可读流的内部工作机制。当然还有一些细节处大家有兴趣的话可以阅读相关的源码。
本文并不打算讲官网已有的内容,而会通过源码分析的方式,让同学们从另外一个角度认识和理解 Vuex 2.0。
当我们用 Vue.js 开发一个中到大型的单页应用时,经常会遇到如下问题:
通常,在项目不是很复杂的时候,我们会利用全局事件总线 (global event bus)解决,但是随着复杂度的提升,这些代码将变的难以维护。因此,我们需要一种更加好用的解决方案,于是,Vuex 诞生了。
本文并不是 Vuex 的科普文章,对于还不了解 Vuex 的同学,建议先移步 Vuex 官方文档;看英文文档吃力的同学,可以看 Vuex 的中文文档。
Vuex 的设计**受到了 Flux,Redux 和 The Elm Architecture 的启发,它的实现又十分巧妙,和 Vue.js 配合相得益彰,下面就让我们一起来看它的实现吧。
Vuex 的源码托管在 github,我们首先通过 git 把代码 clone 到本地,选一款适合自己的 IDE 打开源码,展开 src 目录,如下图所示:
src 目录下的文件并不多,包含几个 js 文件和 plugins 目录, plugins 目录里面包含 2 个 Vuex 的内置插件,整个源码加起来不过 500-600 行,可谓非常轻巧的一个库。
麻雀虽小,五脏俱全,我们先直观的感受一下源码的结构,接下来看一下其中的实现细节。
本文的源码分析过程不会是自上而下的给代码加注释,我更倾向于是从 Vuex 提供的 API 和我们的使用方法等维度去分析。Vuex 的源码是基于 es6 的语法编写的,对于不了解 es6 的同学,建议还是先学习一下 es6。
看源码一般是从入口开始,Vuex 源码的入口是 src/index.js,先来打开这个文件。
我们首先看这个库的 export ,在 index.js 代码最后。
export default {
Store,
install,
mapState,
mapMutations,
mapGetters,
mapActions
}这里可以一目了然地看到 Vuex 对外暴露的 API。其中, Store 是 Vuex 提供的状态存储类,通常我们使用 Vuex 就是通过创建 Store 的实例,稍后我们会详细介绍。接着是 install 方法,这个方法通常是我们编写第三方 Vue 插件的“套路”,先来看一下“套路”代码:
function install (_Vue) {
if (Vue) {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
return
}
Vue = _Vue
applyMixin(Vue)
}
// auto install in dist mode
if (typeof window !== 'undefined' && window.Vue) {
install(window.Vue)
}我们实现了一个 install 方法,这个方法当我们全局引用 Vue ,也就是 window 上有 Vue 对象的时候,会手动调用 install 方法,并传入 Vue 的引用;当 Vue 通过 npm 安装到项目中的时候,我们在代码中引入第三方 Vue 插件通常会编写如下代码:
import Vue from 'vue'
import Vuex from 'vuex'
...
Vue.use(Vuex)当我们执行 Vue.use(Vuex) 这句代码的时候,实际上就是调用了 install 的方法并传入 Vue 的引用。install 方法顾名思义,现在让我们来看看它的实现。它接受了一个参数 _Vue,函数体首先判断 Vue ,这个变量的定义在 index.js 文件的开头部分:
let Vue // bind on install对 Vue 的判断主要是保证 install 方法只执行一次,这里把 install 方法的参数 _Vue 对象赋值给 Vue 变量,这样我们就可以在 index.js 文件的其它地方使用 Vue 这个变量了。install 方法的最后调用了 applyMixin 方法,我们顺便来看一下这个方法的实现,在 src/mixin.js 文件里定义:
export default function (Vue) {
const version = Number(Vue.version.split('.')[0])
if (version >= 2) {
const usesInit = Vue.config._lifecycleHooks.indexOf('init') > -1
Vue.mixin(usesInit ? { init: vuexInit } : { beforeCreate: vuexInit })
} else {
// override init and inject vuex init procedure
// for 1.x backwards compatibility.
const _init = Vue.prototype._init
Vue.prototype._init = function (options = {}) {
options.init = options.init
? [vuexInit].concat(options.init)
: vuexInit
_init.call(this, options)
}
}
/**
* Vuex init hook, injected into each instances init hooks list.
*/
function vuexInit () {
const options = this.$options
// store injection
if (options.store) {
this.$store = options.store
} else if (options.parent && options.parent.$store) {
this.$store = options.parent.$store
}
}
}这段代码的作用就是在 Vue 的生命周期中的初始化(1.0 版本是 init,2.0 版本是 beforeCreated)钩子前插入一段 Vuex 初始化代码。这里做的事情很简单——给 Vue 的实例注入一个 $store 的属性,这也就是为什么我们在 Vue 的组件中可以通过 this.$store.xxx 访问到 Vuex 的各种数据和状态。
我们在使用 Vuex 的时候,通常会实例化 Store 类,然后传入一个对象,包括我们定义好的 actions、getters、mutations、state等,甚至当我们有多个子模块的时候,我们可以添加一个 modules 对象。那么实例化的时候,到底做了哪些事情呢?带着这个疑问,让我们回到 index.js 文件,重点看一下 Store 类的定义。Store 类定义的代码略长,我不会一下就贴上所有代码,我们来拆解分析它,首先看一下构造函数的实现:
class Store {
constructor (options = {}) {
assert(Vue, `must call Vue.use(Vuex) before creating a store instance.`)
assert(typeof Promise !== 'undefined', `vuex requires a Promise polyfill in this browser.`)
const {
state = {},
plugins = [],
strict = false
} = options
// store internal state
this._options = options
this._committing = false
this._actions = Object.create(null)
this._mutations = Object.create(null)
this._wrappedGetters = Object.create(null)
this._runtimeModules = Object.create(null)
this._subscribers = []
this._watcherVM = new Vue()
// bind commit and dispatch to self
const store = this
const { dispatch, commit } = this
this.dispatch = function boundDispatch (type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit (type, payload, options) {
return commit.call(store, type, payload, options)
}
// strict mode
this.strict = strict
// init root module.
// this also recursively registers all sub-modules
// and collects all module getters inside this._wrappedGetters
installModule(this, state, [], options)
// initialize the store vm, which is responsible for the reactivity
// (also registers _wrappedGetters as computed properties)
resetStoreVM(this, state)
// apply plugins
plugins.concat(devtoolPlugin).forEach(plugin => plugin(this))
}
...
} 构造函数的一开始就用了“断言函数”,来判断是否满足一些条件。
assert(Vue, `must call Vue.use(Vuex) before creating a store instance.`)这行代码的目的是确保 Vue 的存在,也就是在我们实例化 Store 之前,必须要保证之前的 install 方法已经执行了。
assert(typeof Promise !== 'undefined', `vuex requires a Promise polyfill in this browser.`)这行代码的目的是为了确保 Promsie 可以使用的,因为 Vuex 的源码是依赖 Promise 的。Promise 是 es6 提供新的 API,由于现在的浏览器并不是都支持 es6 语法的,所以通常我们会用 babel 编译我们的代码,如果想使用 Promise 这个 特性,我们需要在 package.json 中添加对 babel-polyfill 的依赖并在代码的入口加上 import 'babel-polyfill' 这段代码。
再来看看 assert 这个函数,它并不是浏览器原生支持的,它的实现在 src/util.js 里,代码如下:
export function assert (condition, msg) {
if (!condition) throw new Error(`[vuex] ${msg}`)
}非常简单,对 condition 判断,如果不不为真,则抛出异常。这个函数虽然简单,但这种编程方式值得我们学习。
再来看构造函数接下来的代码:
const {
state = {},
plugins = [],
strict = false
} = options这里就是利用 es6 的解构赋值拿到 options 里的 state,plugins 和 strict。state 表示 rootState,plugins 表示应用的插件、strict 表示是否开启严格模式。
接着往下看:
// store internal state
this._options = options
this._committing = false
this._actions = Object.create(null)
this._mutations = Object.create(null)
this._wrappedGetters = Object.create(null)
this._runtimeModules = Object.create(null)
this._subscribers = []
this._watcherVM = new Vue()这里主要是创建一些内部的属性:
this._options 存储参数 options。
this._committing 标志一个提交状态,作用是保证对 Vuex 中 state 的修改只能在 mutation 的回调函数中,而不能在外部随意修改 state。
this._actions 用来存储用户定义的所有的 actions。
this._mutations 用来存储用户定义所有的 mutatins。
this._wrappedGetters 用来存储用户定义的所有 getters 。
this._runtimeModules 用来存储所有的运行时的 modules。
this._subscribers 用来存储所有对 mutation 变化的订阅者。
this._watcherVM 是一个 Vue 对象的实例,主要是利用 Vue 实例方法 $watch 来观测变化的。
继续往下看:
// bind commit and dispatch to self
const store = this
const { dispatch, commit } = this
this.dispatch = function boundDispatch (type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit (type, payload, options) {
return commit.call(store, type, payload, options)
}
// strict mode
this.strict = strict这里的代码也不难理解,把 Store 类的 dispatch 和 commit 的方法的 this 指针指向当前 store 的实例上,dispatch 和 commit 的实现我们稍后会分析。this.strict 表示是否开启严格模式,在严格模式下会观测所有的 state 的变化,建议在开发环境时开启严格模式,线上环境要关闭严格模式,否则会有一定的性能开销。
我们接着往下看:
// init root module.
// this also recursively registers all sub-modules
// and collects all module getters inside this._wrappedGetters
installModule(this, state, [], options)
// initialize the store vm, which is responsible for the reactivity
// (also registers _wrappedGetters as computed properties)
resetStoreVM(this, state)
// apply plugins
plugins.concat(devtoolPlugin).forEach(plugin => plugin(this))这段代码是 Vuex 的初始化的核心,其中,installModule 方法是把我们通过 options 传入的各种属性模块注册和安装;resetStoreVM 方法是初始化 store._vm,观测 state 和 getters 的变化;最后是应用传入的插件。
下面,我们先来看一下 installModule 的实现:
function installModule (store, rootState, path, module, hot) {
const isRoot = !path.length
const {
state,
actions,
mutations,
getters,
modules
} = module
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, state || {})
})
}
if (mutations) {
Object.keys(mutations).forEach(key => {
registerMutation(store, key, mutations[key], path)
})
}
if (actions) {
Object.keys(actions).forEach(key => {
registerAction(store, key, actions[key], path)
})
}
if (getters) {
wrapGetters(store, getters, path)
}
if (modules) {
Object.keys(modules).forEach(key => {
installModule(store, rootState, path.concat(key), modules[key], hot)
})
}
}installModule 函数可接收5个参数,store、rootState、path、module、hot,store 表示当前 Store 实例,rootState 表示根 state,path 表示当前嵌套模块的路径数组,module 表示当前安装的模块,hot 当动态改变 modules 或者热更新的时候为 true。
先来看这部分代码:
const isRoot = !path.length
const {
state,
actions,
mutations,
getters,
modules
} = module代码首先通过 path 数组的长度判断是否为根。我们在构造函数调用的时候是 installModule(this, state, [], options),所以这里 isRoot 为 true。module 为传入的 options,我们拿到了 module 下的 state、actions、mutations、getters 以及嵌套的 modules。
接着看下面的代码:
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, state || {})
})
}这里判断当不为根且非热更新的情况,然后设置级联状态,这里乍一看不好理解,我们先放一放,稍后来回顾。
再往下看代码:
if (mutations) {
Object.keys(mutations).forEach(key => {
registerMutation(store, key, mutations[key], path)
})
}
if (actions) {
Object.keys(actions).forEach(key => {
registerAction(store, key, actions[key], path)
})
}
if (getters) {
wrapGetters(store, getters, path)
}这里分别是对 mutations、actions、getters 进行注册,如果我们实例化 Store 的时候通过 options 传入这些对象,那么会分别进行注册,我稍后再去介绍注册的具体实现。那么到这,如果 Vuex 没有 module ,这个 installModule 方法可以说已经做完了。但是 Vuex 巧妙了设计了 module 这个概念,因为 Vuex 本身是单一状态树,应用的所有状态都包含在一个大对象内,随着我们应用规模的不断增长,这个 Store 变得非常臃肿。为了解决这个问题,Vuex 允许我们把 store 分 module(模块)。每一个模块包含各自的 state、mutations、actions 和 getters,甚至是嵌套模块。所以,接下来还有一行代码:
if (modules) {
Object.keys(modules).forEach(key => {
installModule(store, rootState, path.concat(key), modules[key], hot)
})
}这里通过遍历 modules,递归调用 installModule 去安装子模块。这里传入了 store、rootState、path.concat(key)、和 modules[key],和刚才不同的是,path 不为空,module 对应为子模块,那么我们回到刚才那段代码:
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, state || {})
})
}当递归初始化子模块的时候,isRoot 为 false,注意这里有个方法getNestedState(rootState, path),来看一下 getNestedState 函数的定义:
function getNestedState (state, path) {
return path.length
? path.reduce((state, key) => state[key], state)
: state
}这个方法很简单,就是根据 path 查找 state 上的嵌套 state。在这里就是传入 rootState 和 path,计算出当前模块的父模块的 state,由于模块的 path 是根据模块的名称 concat 连接的,所以 path 的最后一个元素就是当前模块的模块名,最后调用
store._withCommit(() => {
Vue.set(parentState, moduleName, state || {})
}) 把当前模块的 state 添加到 parentState 中。
这里注意一下我们用了 store._withCommit 方法,来看一下这个方法的定义:
_withCommit (fn) {
const committing = this._committing
this._committing = true
fn()
this._committing = committing
}由于我们是在修改 state,Vuex 中所有对 state 的修改都会用 _withCommit 函数包装,保证在同步修改 state 的过程中 this._committing 的值始终为true。这样当我们观测 state 的变化时,如果 this._committing 的值不为 true,则能检查到这个状态修改是有问题的。
看到这里,有些同学可能会有点困惑,举个例子来直观感受一下,以 Vuex 源码中的 example/shopping-cart 为例,打开 store/index.js,有这么一段代码:
export default new Vuex.Store({
actions,
getters,
modules: {
cart,
products
},
strict: debug,
plugins: debug ? [createLogger()] : []
})这里有两个子 module,cart 和 products,我们打开 store/modules/cart.js,看一下 cart 模块中的 state 定义,代码如下:
const state = {
added: [],
checkoutStatus: null
}我们运行这个项目,打开浏览器,利用 Vue 的调试工具来看一下 Vuex 中的状态,如下图所示:
可以看到,在 rootState 下,分别有 cart 和 products 2个属性,key 根据模块名称而来,value 就是在每个模块文件中定义的 state,这就把模块 state 挂载到 rootState 上了。
我们了解完嵌套模块 state 是怎么一回事后,我们回过头来看一下 installModule 过程中的其它 3 个重要方法:registerMutation、registerAction 和 wrapGetters。顾名思义,这 3 个方法分别处理 mutations、actions 和 getters。我们先来看一下 registerMutation 的定义:
function registerMutation (store, type, handler, path = []) {
const entry = store._mutations[type] || (store._mutations[type] = [])
entry.push(function wrappedMutationHandler (payload) {
handler(getNestedState(store.state, path), payload)
})
}registerMutation 是对 store 的 mutation 的初始化,它接受 4 个参数,store为当前 Store 实例,type为 mutation 的 key,handler 为 mutation 执行的回调函数,path 为当前模块的路径。mutation 的作用就是同步修改当前模块的 state ,函数首先通过 type 拿到对应的 mutation 对象数组, 然后把一个 mutation 的包装函数 push 到这个数组中,这个函数接收一个参数 payload,这个就是我们在定义 mutation 的时候接收的额外参数。这个函数执行的时候会调用 mutation 的回调函数,并通过 getNestedState(store.state, path) 方法得到当前模块的 state,和 playload 一起作为回调函数的参数。举个例子:
// ...
mutations: {
increment (state, n) {
state.count += n
}
}这里我们定义了一个 mutation,通过刚才的 registerMutation 方法,我们注册了这个 mutation,这里的 state 对应的就是当前模块的 state,n 就是额外参数 payload,接下来我们会从源码分析的角度来介绍这个 mutation 的回调是何时被调用的,参数是如何传递的。
我们有必要知道 mutation 的回调函数的调用时机,在 Vuex 中,mutation 的调用是通过 store 实例的 API 接口 commit 来调用的,来看一下 commit 函数的定义:
commit (type, payload, options) {
// check object-style commit
if (isObject(type) && type.type) {
options = payload
payload = type
type = type.type
}
const mutation = { type, payload }
const entry = this._mutations[type]
if (!entry) {
console.error(`[vuex] unknown mutation type: ${type}`)
return
}
this._withCommit(() => {
entry.forEach(function commitIterator (handler) {
handler(payload)
})
})
if (!options || !options.silent) {
this._subscribers.forEach(sub => sub(mutation, this.state))
}
}commit 支持 3 个参数,type 表示 mutation 的类型,payload 表示额外的参数,options 表示一些配置,比如 silent 等,稍后会用到。commit 函数首先对 type 的类型做了判断,处理了 type 为 object 的情况,接着根据 type 去查找对应的 mutation,如果找不到,则输出一条错误信息,否则遍历这个 type 对应的 mutation 对象数组,执行 handler(payload) 方法,这个方法就是之前定义的 wrappedMutationHandler(handler),执行它就相当于执行了 registerMutation 注册的回调函数,并把当前模块的 state 和 额外参数 payload 作为参数传入。注意这里我们依然使用了 this._withCommit 的方法提交 mutation。commit 函数的最后,判断如果不是静默模式,则遍历 this._subscribers,调用回调函数,并把 mutation 和当前的根 state 作为参数传入。那么这个 this._subscribers 是什么呢?原来 Vuex 的 Store 实例提供了 subscribe API 接口,它的作用是订阅(注册监听) store 的 mutation。先来看一下它的实现:
subscribe (fn) {
const subs = this._subscribers
if (subs.indexOf(fn) < 0) {
subs.push(fn)
}
return () => {
const i = subs.indexOf(fn)
if (i > -1) {
subs.splice(i, 1)
}
}
}subscribe 方法很简单,他接受的参数是一个回调函数,会把这个回调函数保存到 this._subscribers 上,并返回一个函数,当我们调用这个返回的函数,就可以解除当前函数对 store 的 mutation 的监听。其实,Vuex 的内置 logger 插件就是基于 subscribe 接口实现对 store 的 muation的监听,稍后我们会详细介绍这个插件。
在了解完 registerMutation,我们再来看一下 registerAction 的定义:
function registerAction (store, type, handler, path = []) {
const entry = store._actions[type] || (store._actions[type] = [])
const { dispatch, commit } = store
entry.push(function wrappedActionHandler (payload, cb) {
let res = handler({
dispatch,
commit,
getters: store.getters,
state: getNestedState(store.state, path),
rootState: store.state
}, payload, cb)
if (!isPromise(res)) {
res = Promise.resolve(res)
}
if (store._devtoolHook) {
return res.catch(err => {
store._devtoolHook.emit('vuex:error', err)
throw err
})
} else {
return res
}
})
}registerAction 是对 store 的 action 的初始化,它和 registerMutation 的参数一致,和 mutation 不同一点,mutation 是同步修改当前模块的 state,而 action 是可以异步去修改 state,这里不要误会,在 action 的回调中并不会直接修改 state ,仍然是通过提交一个 mutation 去修改 state(在 Vuex 中,mutation 是修改 state 的唯一途径)。那我们就来看看 action 是如何做到这一点的。
函数首先也是通过 type 拿到对应 action 的对象数组,然后把一个 action 的包装函数 push 到这个数组中,这个函数接收 2 个参数,payload 表示额外参数 ,cb 表示回调函数(实际上我们并没有使用它)。这个函数执行的时候会调用 action 的回调函数,传入一个 context 对象,这个对象包括了 store 的 commit 和 dispatch 方法、getter、当前模块的 state 和 rootState 等等。接着对这个函数的返回值做判断,如果不是一个 Promise 对象,则调用 Promise.resolve(res) 给res 包装成了一个 Promise 对象。这里也就解释了为何 Vuex 的源码依赖 Promise,这里对 Promise 的判断也和简单,参考代码 src/util.js,对 isPromise 的判断如下:
export function isPromise (val) {
return val && typeof val.then === 'function'
}其实就是简单的检查对象的 then 方法,如果包含说明就是一个 Promise 对象。
接着判断 store._devtoolHook,这个只有当用到 Vuex devtools 开启的时候,我们才能捕获 promise 的过程中的 。 action 的包装函数最后返回 res ,它就是一个地地道道的 Promise 对象。来看个例子:
actions: {
checkout ({ commit, state }, payload) {
// 把当前购物车的商品备份起来
const savedCartItems = [...state.cart.added]
// 发送结帐请求,并愉快地清空购物车
commit(types.CHECKOUT_REQUEST)
// 购物 API 接收一个成功回调和一个失败回调
shop.buyProducts(
products,
// 成功操作
() => commit(types.CHECKOUT_SUCCESS),
// 失败操作
() => commit(types.CHECKOUT_FAILURE, savedCartItems)
)
}
}这里我们定义了一个 action,通过刚才的 registerAction 方法,我们注册了这个 action,这里的 commit 就是 store 的 API 接口,可以通过它在 action 里提交一个 mutation。state 对应的就是当前模块的 state,我们在这个 action 里即可以同步提交 mutation,也可以异步提交。接下来我们会从源码分析的角度来介绍这个 action 的回调是何时被调用的,参数是如何传递的。
我们有必要知道 action 的回调函数的调用时机,在 Vuex 中,action 的调用是通过 store 实例的 API 接口 dispatch 来调用的,来看一下 dispatch 函数的定义:
dispatch (type, payload) {
// check object-style dispatch
if (isObject(type) && type.type) {
payload = type
type = type.type
}
const entry = this._actions[type]
if (!entry) {
console.error(`[vuex] unknown action type: ${type}`)
return
}
return entry.length > 1
? Promise.all(entry.map(handler => handler(payload)))
: entry[0](payload)
}dispatch 支持2个参数,type 表示 action 的类型,payload 表示额外的参数。前面几行代码和 commit 接口非常类似,都是找到对应 type 下的 action 对象数组,唯一和 commit 不同的地方是最后部分,它对 action 的对象数组长度做判断,如果长度为 1 则直接调用 entry[0](payload), 这个方法就是之前定义的 wrappedActionHandler(payload, cb),执行它就相当于执行了 registerAction 注册的回调函数,并把当前模块的 context 和 额外参数 payload 作为参数传入。所以我们在 action 的回调函数里,可以拿到当前模块的上下文包括 store 的 commit 和 dispatch 方法、getter、当前模块的 state 和 rootState,可见 action 是非常灵活的。
了解完 registerAction 后,我们来看看 wrapGetters的定义:
function wrapGetters (store, moduleGetters, modulePath) {
Object.keys(moduleGetters).forEach(getterKey => {
const rawGetter = moduleGetters[getterKey]
if (store._wrappedGetters[getterKey]) {
console.error(`[vuex] duplicate getter key: ${getterKey}`)
return
}
store._wrappedGetters[getterKey] = function wrappedGetter (store) {
return rawGetter(
getNestedState(store.state, modulePath), // local state
store.getters, // getters
store.state // root state
)
}
})
}wrapGetters 是对 store 的 getters 初始化,它接受 3个 参数, store 表示当前 Store 实例,moduleGetters 表示当前模块下的所有 getters, modulePath 对应模块的路径。细心的同学会发现,和刚才的 registerMutation 以及 registerAction 不同,这里对 getters 的循环遍历是放在了函数体内,并且 getters 和它们的一个区别是不允许 getter 的 key 有重复。
这个函数做的事情就是遍历 moduleGetters,把每一个 getter 包装成一个方法,添加到 store._wrappedGetters 对象中,注意 getter 的 key 是不允许重复的。在这个包装的方法里,会执行 getter 的回调函数,并把当前模块的 state,store 的 getters 和 store 的 rootState 作为它参数。来看一个例子:
export const cartProducts = state => {
return state.cart.added.map(({ id, quantity }) => {
const product = state.products.all.find(p => p.id === id)
return {
title: product.title,
price: product.price,
quantity
}
})
}这里我们定义了一个 getter,通过刚才的 wrapGetters 方法,我们把这个 getter 添加到 store._wrappedGetters 对象里,这和回调函数的参数 state 对应的就是当前模块的 state,接下来我们从源码的角度分析这个函数是如何被调用,参数是如何传递的。
我们有必要知道 getter 的回调函数的调用时机,在 Vuex 中,我们知道当我们在组件中通过 this.$store.getters.xxxgetters 可以访问到对应的 getter 的回调函数,那么我们需要把对应 getter 的包装函数的执行结果绑定到 ````this.$store``` 上。这部分的逻辑就在 resetStoreVM 函数里。我们在 Store 的构造函数中,在执行完 installModule 方法后,就会执行 resetStoreVM 方法。来看一下它的定义:
function resetStoreVM (store, state) {
const oldVm = store._vm
// bind store public getters
store.getters = {}
const wrappedGetters = store._wrappedGetters
const computed = {}
Object.keys(wrappedGetters).forEach(key => {
const fn = wrappedGetters[key]
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key]
})
})
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: { state },
computed
})
Vue.config.silent = silent
// enable strict mode for new vm
if (store.strict) {
enableStrictMode(store)
}
if (oldVm) {
// dispatch changes in all subscribed watchers
// to force getter re-evaluation.
store._withCommit(() => {
oldVm.state = null
})
Vue.nextTick(() => oldVm.$destroy())
}
}这个方法主要是重置一个私有的 _vm 对象,它是一个 Vue 的实例。这个 _vm 对象会保留我们的 state 树,以及用计算属性的方式存储了 store 的 getters。来具体看看它的实现过程。我们把这个函数拆成几个部分来分析:
const oldVm = store._vm
// bind store public getters
store.getters = {}
const wrappedGetters = store._wrappedGetters
const computed = {}
Object.keys(wrappedGetters).forEach(key => {
const fn = wrappedGetters[key]
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key]
})
})这部分留了现有的 store._vm 对象,接着遍历 store._wrappedGetters 对象,在遍历过程中,依次拿到每个 getter 的包装函数,并把这个包装函数执行的结果用 computed 临时变量保存。接着用 es5 的 Object.defineProperty 方法为 store.getters 定义了 get 方法,也就是当我们在组件中调用this.$store.getters.xxxgetters 这个方法的时候,会访问 store._vm[xxxgetters]。我们接着往下看:
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: { state },
computed
})
Vue.config.silent = silent
// enable strict mode for new vm
if (store.strict) {
enableStrictMode(store)
}这部分的代码首先先拿全局 Vue.config.silent 的配置,然后临时把这个配置设成 true,接着实例化一个 Vue 的实例,把 store 的状态树 state 作为 data 传入,把我们刚才的临时变量 computed 作为计算属性传入。然后再把之前的 silent 配置重置。设置 silent 为 true 的目的是为了取消这个 _vm 的所有日志和警告。把 computed 对象作为 _vm 的 computed 属性,这样就完成了 getters 的注册。因为当我们在组件中访问 this.$store.getters.xxxgetters 的时候,就相当于访问 store._vm[xxxgetters],也就是在访问 computed[xxxgetters],这样就访问到了 xxxgetters 对应的回调函数了。这段代码最后判断 strict 属性决定是否开启严格模式,我们来看看严格模式都干了什么:
function enableStrictMode (store) {
store._vm.$watch('state', () => {
assert(store._committing, `Do not mutate vuex store state outside mutation handlers.`)
}, { deep: true, sync: true })
}严格模式做的事情很简单,监测 store._vm.state 的变化,看看 state 的变化是否通过执行 mutation 的回调函数改变,如果是外部直接修改 state,那么 store._committing 的值为 false,这样就抛出一条错误。再次强调一下,Vuex 中对 state 的修改只能在 mutation 的回调函数里。
回到 resetStoreVM 函数,我们来看一下最后一部分:
if (oldVm) {
// dispatch changes in all subscribed watchers
// to force getter re-evaluation.
store._withCommit(() => {
oldVm.state = null
})
Vue.nextTick(() => oldVm.$destroy())
}这里的逻辑很简单,由于这个函数每次都会创建新的 Vue 实例并赋值到 store._vm 上,那么旧的 _vm 对象的状态设置为 null,并调用 $destroy 方法销毁这个旧的 _vm 对象。
那么到这里,Vuex 的初始化基本告一段落了,初始化核心就是 installModule 和
resetStoreVM 函数。通过对 mutations 、actions 和 getters 的注册,我们了解到 state 的是按模块划分的,按模块的嵌套形成一颗状态树。而 actions、mutations 和 getters 的全局的,其中 actions 和 mutations 的 key 允许重复,但 getters 的 key 是不允许重复的。官方推荐我们给这些全局的对象在定义的时候加一个名称空间来避免命名冲突。
从源码的角度介绍完 Vuex 的初始化的玩法,我们再从 Vuex 提供的 API 方向来分析其中的源码,看看这些 API 是如何实现的。
Vuex 常见的 API 如 dispatch、commit 、subscribe �我们前面已经介绍过了,这里就不再赘述了,下面介绍的一些 Store 的 API,虽然不常用,�但是了解一下也不错。�
watch 作用是响应式的监测一个 getter 方法的返回值,当值改变时调用回调。getter 接收 store 的 state 作为唯一参数。来看一下它的实现:
watch (getter, cb, options) {
assert(typeof getter === 'function', `store.watch only accepts a function.`)
return this._watcherVM.$watch(() => getter(this.state), cb, options)
}函数首先断言 watch 的 getter 必须是一个方法,接着利用了内部一个 Vue 的实例对象 ````this._watcherVM ``` 的 $watch 方法,观测 getter 方法返回值的变化,如果有变化则调用 cb 函数,回调函数的参数为新值和旧值。watch 方法返回的是一个方法,调用它则取消观测。
registerModule 的作用是注册一个动态模块,有的时候当我们异步加载一些业务的时候,可以通过这个 API 接口去动态注册模块,来看一下它的实现:
registerModule (path, module) {
if (typeof path === 'string') path = [path]
assert(Array.isArray(path), `module path must be a string or an Array.`)
this._runtimeModules[path.join('.')] = module
installModule(this, this.state, path, module)
// reset store to update getters...
resetStoreVM(this, this.state)
}函数首先对 path 判断,如果 path 是一个 string 则把 path 转换成一个 Array。接着把 module 对象缓存到 this._runtimeModules 这个对象里,path 用点连接作为该对象的 key。接着和初始化 Store 的逻辑一样,调用 installModule 和 resetStoreVm 方法安装一遍动态注入的 module。
和 registerModule 方法相对的就是 unregisterModule 方法,它的作用是注销一个动态模块,来看一下它的实现:
unregisterModule (path) {
if (typeof path === 'string') path = [path]
assert(Array.isArray(path), `module path must be a string or an Array.`)
delete this._runtimeModules[path.join('.')]
this._withCommit(() => {
const parentState = getNestedState(this.state, path.slice(0, -1))
Vue.delete(parentState, path[path.length - 1])
})
resetStore(this)
}函数首先还是对 path 的类型做了判断,这部分逻辑和注册是一样的。接着从 this._runtimeModules 里删掉以 path 点连接的 key 对应的模块。接着通过 this._withCommit 方法把当前模块的 state 对象从父 state 上删除。最后调用 resetStore(this) 方法,来看一下这个方法的定义:
function resetStore (store) {
store._actions = Object.create(null)
store._mutations = Object.create(null)
store._wrappedGetters = Object.create(null)
const state = store.state
// init root module
installModule(store, state, [], store._options, true)
// init all runtime modules
Object.keys(store._runtimeModules).forEach(key => {
installModule(store, state, key.split('.'), store._runtimeModules[key], true)
})
// reset vm
resetStoreVM(store, state)
}这个方法作用就是重置 store 对象,重置 store 的 _actions、_mutations、_wrappedGetters 等等属性。然后再次调用 installModules 去重新安装一遍 Module 对应的这些属性,注意这里我们的最后一个参数 hot 为true,表示它是一次热更新。这样在 installModule 这个方法体类,如下这段逻辑就不会执行
function installModule (store, rootState, path, module, hot) {
...
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, state || {})
})
}
...
}由于 hot 始终为 true,这里我们就不会重新对状态树做设置,我们的 state 保持不变。因为我们已经明确的删除了对应 path 下的 state 了,要做的事情只不过就是重新注册一遍 muations、actions 以及 getters。
回调 resetStore 方法,接下来遍历 this._runtimeModules 模块,重新安装所有剩余的 runtime Moudles。最后还是调用 resetStoreVM 方法去重置 Store 的 _vm 对象。
hotUpdate 的作用是热加载新的 action 和 mutation。 来看一下它的实现:
hotUpdate (newOptions) {
updateModule(this._options, newOptions)
resetStore(this)
}函数首先调用 updateModule 方法去更新状态,其中当前 Store 的 opition 配置和要更新的 newOptions 会作为参数。来看一下这个函数的实现:
function updateModule (targetModule, newModule) {
if (newModule.actions) {
targetModule.actions = newModule.actions
}
if (newModule.mutations) {
targetModule.mutations = newModule.mutations
}
if (newModule.getters) {
targetModule.getters = newModule.getters
}
if (newModule.modules) {
for (const key in newModule.modules) {
if (!(targetModule.modules && targetModule.modules[key])) {
console.warn(
`[vuex] trying to add a new module '${key}' on hot reloading, ` +
'manual reload is needed'
)
return
}
updateModule(targetModule.modules[key], newModule.modules[key])
}
}
}首先我们对 newOptions 对象的 actions、mutations 以及 getters 做了判断,如果有这些属性的话则替换 targetModule(当前 Store 的 options)对应的属性。最后判断如果 newOptions 包含 modules 这个 key,则遍历这个 modules 对象,如果 modules 对应的 key 不在之前的 modules 中,则报一条警告,因为这是添加一个新的 module ,需要手动重新加载。如果 key 在之前的 modules,则递归调用 updateModule,热更新子模块。
调用完 updateModule 后,回到 hotUpdate 函数,接着调用 resetStore 方法重新设置 store,刚刚我们已经介绍过了。
replaceState的作用是替换整个 rootState,一般在用于调试,来看一下它的实现:
replaceState (state) {
this._withCommit(() => {
this._vm.state = state
})
}函数非常简单,就是调用 this._withCommit 方法修改 Store 的 rootState,之所以提供这个 API 是由于在我们是不能在 muations 的回调函数外部去改变 state。
到此为止,API 部分介绍完了,其实整个 Vuex 源码下的 src/index.js 文件里的代码基本都过了一遍。
Vuex 除了提供我们 Store 对象外,还对外提供了一系列的辅助函数,方便我们在代码中使用 Vuex,提供了操作 store 的各种属性的一系列语法糖,下面我们来一起看一下:
mapState 工具函数会将 store 中的 state 映射到局部计算属性中。为了更好理解它的实现,先来看一下它的使用示例:
// vuex 提供了独立的构建工具函数 Vuex.mapState
import { mapState } from 'vuex'
export default {
// ...
computed: mapState({
// 箭头函数可以让代码非常简洁
count: state => state.count,
// 传入字符串 'count' 等同于 `state => state.count`
countAlias: 'count',
// 想访问局部状态,就必须借助于一个普通函数,函数中使用 `this` 获取局部状态
countPlusLocalState (state) {
return state.count + this.localCount
}
})
}当计算属性名称和状态子树名称对应相同时,我们可以向 mapState 工具函数传入一个字符串数组。
computed: mapState([
// 映射 this.count 到 this.$store.state.count
'count'
])通过例子我们可以直观的看到,mapState 函数可以接受一个对象,也可以接收一个数组,那它底层到底干了什么事呢,我们一起来看一下源码这个函数的定义:
export function mapState (states) {
const res = {}
normalizeMap(states).forEach(({ key, val }) => {
res[key] = function mappedState () {
return typeof val === 'function'
? val.call(this, this.$store.state, this.$store.getters)
: this.$store.state[val]
}
})
return res
}函数首先对传入的参数调用 normalizeMap 方法,我们来看一下这个函数的定义:
function normalizeMap (map) {
return Array.isArray(map)
? map.map(key => ({ key, val: key }))
: Object.keys(map).map(key => ({ key, val: map[key] }))
}这个方法判断参数 map 是否为数组,如果是数组,则调用数组的 map 方法,把数组的每个元素转换成一个 {key, val: key}的对象;否则传入的 map 就是一个对象(从 mapState 的使用场景来看,传入的参数不是数组就是对象),我们调用 Object.keys 方法遍历这个 map 对象的 key,把数组的每个 key 都转换成一个 {key, val: map[key]}的对象。最后我们把这个对象数组作为 normalizeMap 的返回值。
回到 mapState 函数,在调用了 normalizeMap 函数后,把传入的 states 转换成由 {key, val} 对象构成的数组,接着调用 forEach 方法遍历这个数组,构造一个新的对象,这个新对象每个元素都返回一个新的函数 mappedState,函数对 val 的类型判断,如果 val 是一个函数,则直接调用这个 val 函数,把当前 store 上的 state 和 getters 作为参数,返回值作为 mappedState 的返回值;否则直接把 this.$store.state[val] 作为 mappedState 的返回值。
那么为何 mapState 函数的返回值是这样一个对象呢,因为 mapState 的作用是把全局的 state 和 getters 映射到当前组件的 computed 计算属性中,我们知道在 Vue 中 每个计算属性都是一个函数。
为了更加直观地说明,回到刚才的例子:
import { mapState } from 'vuex'
export default {
// ...
computed: mapState({
// 箭头函数可以让代码非常简洁
count: state => state.count,
// 传入字符串 'count' 等同于 `state => state.count`
countAlias: 'count',
// 想访问局部状态,就必须借助于一个普通函数,函数中使用 `this` 获取局部状态
countPlusLocalState (state) {
return state.count + this.localCount
}
})
}经过 mapState 函数调用后的结果,如下所示:
import { mapState } from 'vuex'
export default {
// ...
computed: {
count() {
return this.$store.state.count
},
countAlias() {
return this.$store.state['count']
},
countPlusLocalState() {
return this.$store.state.count + this.localCount
}
}
}我们再看一下 mapState 参数为数组的例子:
computed: mapState([
// 映射 this.count 到 this.$store.state.count
'count'
])经过 mapState 函数调用后的结果,如下所示:
computed: {
count() {
return this.$store.state['count']
}
}mapGetters 工具函数会将 store 中的 getter 映射到局部计算属性中。它的功能和 mapState 非常类似,我们来直接看它的实现:
export function mapGetters (getters) {
const res = {}
normalizeMap(getters).forEach(({ key, val }) => {
res[key] = function mappedGetter () {
if (!(val in this.$store.getters)) {
console.error(`[vuex] unknown getter: ${val}`)
}
return this.$store.getters[val]
}
})
return res
}mapGetters 的实现也和 mapState 很类似,不同的是它的 val 不能是函数,只能是一个字符串,而且会检查 val in this.$store.getters 的值,如果为 false 会输出一条错误日志。为了更直观地理解,我们来看一个简单的例子:
import { mapGetters } from 'vuex'
export default {
// ...
computed: {
// 使用对象扩展操作符把 getter 混入到 computed 中
...mapGetters([
'doneTodosCount',
'anotherGetter',
// ...
])
}
}经过 mapGetters 函数调用后的结果,如下所示:
import { mapGetters } from 'vuex'
export default {
// ...
computed: {
doneTodosCount() {
return this.$store.getters['doneTodosCount']
},
anotherGetter() {
return this.$store.getters['anotherGetter']
}
}
}再看一个参数 mapGetters 参数是对象的例子:
computed: mapGetters({
// 映射 this.doneCount 到 store.getters.doneTodosCount
doneCount: 'doneTodosCount'
})经过 mapGetters 函数调用后的结果,如下所示:
computed: {
doneCount() {
return this.$store.getters['doneTodosCount']
}
}mapActions 工具函数会将 store 中的 dispatch 方法映射到组件的 methods 中。和 mapState、mapGetters 也类似,只不过它映射的地方不是计算属性,而是组件的 methods 对象上。我们来直接看它的实现:
export function mapActions (actions) {
const res = {}
normalizeMap(actions).forEach(({ key, val }) => {
res[key] = function mappedAction (...args) {
return this.$store.dispatch.apply(this.$store, [val].concat(args))
}
})
return res
}可以看到,函数的实现套路和 mapState、mapGetters 差不多,甚至更简单一些, 实际上就是做了一层函数包装。为了更直观地理解,我们来看一个简单的例子:
import { mapActions } from 'vuex'
export default {
// ...
methods: {
...mapActions([
'increment' // 映射 this.increment() 到 this.$store.dispatch('increment')
]),
...mapActions({
add: 'increment' // 映射 this.add() to this.$store.dispatch('increment')
})
}
}经过 mapActions 函数调用后的结果,如下所示:
import { mapActions } from 'vuex'
export default {
// ...
methods: {
increment(...args) {
return this.$store.dispatch.apply(this.$store, ['increment'].concat(args))
}
add(...args) {
return this.$store.dispatch.apply(this.$store, ['increment'].concat(args))
}
}
}mapMutations 工具函数会将 store 中的 commit 方法映射到组件的 methods 中。和 mapActions 的功能几乎一样,我们来直接看它的实现:
export function mapMutations (mutations) {
const res = {}
normalizeMap(mutations).forEach(({ key, val }) => {
res[key] = function mappedMutation (...args) {
return this.$store.commit.apply(this.$store, [val].concat(args))
}
})
return res
}函数的实现几乎也和 mapActions 一样,唯一差别就是映射的是 store 的 commit 方法。为了更直观地理解,我们来看一个简单的例子:
import { mapMutations } from 'vuex'
export default {
// ...
methods: {
...mapMutations([
'increment' // 映射 this.increment() 到 this.$store.commit('increment')
]),
...mapMutations({
add: 'increment' // 映射 this.add() 到 this.$store.commit('increment')
})
}
}经过 mapMutations 函数调用后的结果,如下所示:
import { mapActions } from 'vuex'
export default {
// ...
methods: {
increment(...args) {
return this.$store.commit.apply(this.$store, ['increment'].concat(args))
}
add(...args) {
return this.$store.commit.apply(this.$store, ['increment'].concat(args))
}
}
}Vuex 的 store 接收 plugins 选项,一个 Vuex 的插件就是一个简单的方法,接收 store 作为唯一参数。插件作用通常是用来监听每次 mutation 的变化,来做一些事情。
在 store 的构造函数的最后,我们通过如下代码调用插件:
import devtoolPlugin from './plugins/devtool'
// apply plugins
plugins.concat(devtoolPlugin).forEach(plugin => plugin(this))我们通常实例化 store 的时候,还会调用 logger 插件,代码如下:
import Vue from 'vue'
import Vuex from 'vuex'
import createLogger from 'vuex/dist/logger'
Vue.use(Vuex)
const debug = process.env.NODE_ENV !== 'production'
export default new Vuex.Store({
...
plugins: debug ? [createLogger()] : []
})在上述 2 个例子中,我们分别调用了 devtoolPlugin 和 createLogger() 2 个插件,它们是 Vuex 内置插件,我们接下来分别看一下他们的实现。
devtoolPlugin 主要功能是利用 Vue 的开发者工具和 Vuex 做配合,通过开发者工具的面板展示 Vuex 的状态。它的源码在 src/plugins/devtool.js 中,来看一下这个插件到底做了哪些事情。
const devtoolHook =
typeof window !== 'undefined' &&
window.__VUE_DEVTOOLS_GLOBAL_HOOK__
export default function devtoolPlugin (store) {
if (!devtoolHook) return
store._devtoolHook = devtoolHook
devtoolHook.emit('vuex:init', store)
devtoolHook.on('vuex:travel-to-state', targetState => {
store.replaceState(targetState)
})
store.subscribe((mutation, state) => {
devtoolHook.emit('vuex:mutation', mutation, state)
})
}我们直接从对外暴露的 devtoolPlugin 函数看起,函数首先判断了devtoolHook 的值,如果我们浏览器装了 Vue 开发者工具,那么在 window 上就会有一个 __VUE_DEVTOOLS_GLOBAL_HOOK__ 的引用, 那么这个 devtoolHook 就指向这个引用。
接下来通过 devtoolHook.emit('vuex:init', store) 派发一个 Vuex 初始化的事件,这样开发者工具就能拿到当前这个 store 实例。
接下来通过 devtoolHook.on('vuex:travel-to-state', targetState => { store.replaceState(targetState) })监听 Vuex 的 traval-to-state 的事件,把当前的状态树替换成目标状态树,这个功能也是利用 Vue 开发者工具替换 Vuex 的状态。
最后通过 store.subscribe((mutation, state) => { devtoolHook.emit('vuex:mutation', mutation, state) }) 方法订阅 store 的 state 的变化,当 store 的 mutation 提交了 state 的变化, 会触发回调函数——通过 devtoolHook 派发一个 Vuex mutation 的事件,mutation 和 rootState 作为参数,这样开发者工具就可以观测到 Vuex state 的实时变化,在面板上展示最新的状态树。
通常在开发环境中,我们希望实时把 mutation 的动作以及 store 的 state 的变化实时输出,那么我们可以用 loggerPlugin 帮我们做这个事情。它的源码在 src/plugins/logger.js 中,来看一下这个插件到底做了哪些事情。
// Credits: borrowed code from fcomb/redux-logger
import { deepCopy } from '../util'
export default function createLogger ({
collapsed = true,
transformer = state => state,
mutationTransformer = mut => mut
} = {}) {
return store => {
let prevState = deepCopy(store.state)
store.subscribe((mutation, state) => {
if (typeof console === 'undefined') {
return
}
const nextState = deepCopy(state)
const time = new Date()
const formattedTime = ` @ ${pad(time.getHours(), 2)}:${pad(time.getMinutes(), 2)}:${pad(time.getSeconds(), 2)}.${pad(time.getMilliseconds(), 3)}`
const formattedMutation = mutationTransformer(mutation)
const message = `mutation ${mutation.type}${formattedTime}`
const startMessage = collapsed
? console.groupCollapsed
: console.group
// render
try {
startMessage.call(console, message)
} catch (e) {
console.log(message)
}
console.log('%c prev state', 'color: #9E9E9E; font-weight: bold', transformer(prevState))
console.log('%c mutation', 'color: #03A9F4; font-weight: bold', formattedMutation)
console.log('%c next state', 'color: #4CAF50; font-weight: bold', transformer(nextState))
try {
console.groupEnd()
} catch (e) {
console.log('—— log end ——')
}
prevState = nextState
})
}
}
function repeat (str, times) {
return (new Array(times + 1)).join(str)
}
function pad (num, maxLength) {
return repeat('0', maxLength - num.toString().length) + num
}插件对外暴露的是 createLogger 方法,它实际上接受 3 个参数,它们都有默认值,通常我们用默认值就可以。createLogger 的返回的是一个函数,当我执行 logger 插件的时候,实际上执行的是这个函数,下面来看一下这个函数做了哪些事情。
函数首先执行了 let prevState = deepCopy(store.state) 深拷贝当前 store 的 rootState。这里为什么要深拷贝,因为如果是单纯的引用,那么 store.state 的任何变化都会影响这个引用,这样就无法记录上一个状态了。我们来了解一下 deepCopy 的实现,在 src/util.js 里定义:
function find (list, f) {
return list.filter(f)[0]
}
export function deepCopy (obj, cache = []) {
// just return if obj is immutable value
if (obj === null || typeof obj !== 'object') {
return obj
}
// if obj is hit, it is in circular structure
const hit = find(cache, c => c.original === obj)
if (hit) {
return hit.copy
}
const copy = Array.isArray(obj) ? [] : {}
// put the copy into cache at first
// because we want to refer it in recursive deepCopy
cache.push({
original: obj,
copy
})
Object.keys(obj).forEach(key => {
copy[key] = deepCopy(obj[key], cache)
})
return copy
}deepCopy 并不陌生,很多开源库如 loadash、jQuery 都有类似的实现,原理也不难理解,主要是构造一个新的对象,遍历原对象或者数组,递归调用 deepCopy。不过这里的实现有一个有意思的地方,在每次执行 deepCopy 的时候,会用 cache 数组缓存当前嵌套的对象,以及执行 deepCopy 返回的 copy。如果在 deepCopy 的过程中通过 find(cache, c => c.original === obj) 发现有循环引用的时候,直接返回 cache 中对应的 copy,这样就避免了无限循环的情况。
回到 loggerPlugin 函数,通过 deepCopy 拷贝了当前 state 的副本并用 prevState 变量保存,接下来调用 store.subscribe 方法订阅 store 的 state 的变。 在回调函数中,也是先通过 deepCopy 方法拿到当前的 state 的副本,并用 nextState 变量保存。接下来获取当前格式化时间已经格式化的 mutation 变化的字符串,然后利用 console.group 以及 console.log 分组输出 prevState、mutation以及 nextState,这里可以通过我们 createLogger 的参数 collapsed、transformer 以及 mutationTransformer 来控制我们最终 log 的显示效果。在函数的最后,我们把 nextState 赋值给 prevState,便于下一次 mutation。
Vuex 2.0 的源码分析到这就告一段落了,最后我再分享一下看源码的小心得:对于一个库或者框架源码的研究前,首先了解他们的使用场景、官网文档等;然后一定要用他,至少也要写几个小 demo,达到熟练掌握的程度;最后再从入口、API、使用方法等等多个维度去了解他内部的实现细节。如果这个库过于庞大,那就先按模块和功能拆分,一点点地消化。
最后还有一个问题,有些同学会问,源码那么枯燥,我们分析学习它的有什么好处呢?首先,学习源码有助于我们更深入掌握和应用这个库或者框架;其次,我们还可以学习到源码中很多编程技巧,可以迁移到我们平时的开发工作中;最后,对于一些高级开发工程师而言,我们可以学习到它的设计**,对将来有一天我们也去设计一个库或者框架是非常有帮助的,这也是提升自身能力水平的非常好的途径。
VueJS 有新的版本推出,在这里可以看到所有的变化。这里有一个使用新版本开发的工作示例的应用程序,代码可以在 Github 上找到,去那里做一些很棒的事情吧。
VueJS 推出了一个新的版本。对于不知道 VueJS 为何物的同学,可以去他们的官网看看。VueJS 是一个融合了 AngularJS 和 React 一些特性的前端框架。第一版的 VueJS 可以被称作 “AgularJS lite”,它有类似 Angular 的模板系统,也用到了“脏检查”技术(原文这里有误,在Vue中,实际上用的是 es5 的 Object.defineProperty)去监测那些需要在 DOM 中变化的数据。然而,VueJS 的API 很小巧,因为它不会包含一些额外的工具库如 AJAX,这点和 React 很像。 然而,在下一个版本中,一些事情改变了。它像 React 一样使用了 “Virtual DOM” 模型,同时允许开发者选择任意类型的模板。因此,VueJS 的作者也实现了流式服务端渲染技术,这个技术在今天的 Web 开发中总是受欢迎的。幸运的是,API 接口本身没有多少改变。VueJS 的周边的开发工具需要更新去兼容新的版本,不过我们仍然可以使用 .vue 单文件去开发组件。想要好好的看一下新版本的实现和一些 API 的改变的话,仔细阅读 VueJS 这个Github issue。
VueJS 2.0,像 React 一样,使用了 “Virtual DOM” 并且允许你使用任意的模板系统。
让我们用 Express,PassportJS,VueJS 2.0 开发一个简单的应用,来演示一下如何在应用程序中设置身份验证以及服务端和客户端是如何通信的。这个应用可以让用户去查看、添加和删除 exclamation。你可以查看任意用户的 exclamation,可以添加 exclamation,也可以随时删除自己的 exclamation 。你甚至可以删除其它用户的 exclamation,如果你有删除权限的话。
第一件事,让我们创建一个目录来保存我们的代码,然后引入初始依赖关系,我们使用 npm 进行安装。
mkdir vuejs2-authentication
cd vuejs2-authentication
npm init -y
npm install --save-dev nodemon
npm install --save express body-parser express-session connect-mongo flash node-uuid passport passport-local pug
这些将被用来创建我们的服务器。接下来,让我们创建一些虚拟的数据并存放在 data.json 文件中。
{
"users": [
{
"username": "[email protected]",
"password": "green",
"scopes": ["read", "add", "delete"]
},
{
"username": "[email protected]",
"password": "geller",
"scopes": ["read"]
}
],
"exclamations": [
{
"id": "10ed2d7b-4a6c-4dad-ac25-d0a56c697753",
"text": "I'm the holiday armadillo!",
"user": "[email protected]"
},
{
"id": "c03b65c8-477b-4814-aed0-b090d51e4ca0",
"text": "It's like...all my life, everyone has always told me: \"You're a shoe!\"",
"user": "[email protected]"
},
{
"id": "911327fa-c6fc-467f-8138-debedaa6d3ce",
"text": "I...am over...YOU.",
"user": "[email protected]"
},
{
"id": "ede699aa-9459-4feb-b95e-db1271ab41b7",
"text": "Imagine the worst things you think about yourself. Now, how would you feel if the one person that you trusted the most in the world not only thinks them too, but actually uses them as reasons not to be with you.",
"user": "[email protected]"
},
{
"id": "c58741cf-22fd-4036-88de-fe51fd006cfc",
"text": "You threw my sandwich away?",
"user": "[email protected]"
},
{
"id": "dc8016e0-5d91-45c4-b4fa-48cecee11842",
"text": "I grew up with Monica. If you didn't eat fast, you didn't eat!",
"user": "[email protected]"
},
{
"id": "87ba7f3a-2ce7-4aa0-9827-28261735f518",
"text": "I'm gonna go get one of those job things.",
"user": "[email protected]"
},
{
"id": "9aad4cbc-7fff-45b3-8373-a64d3fdb239b",
"text": "Ross, I am a human doodle!",
"user": "[email protected]"
}
]
}
另外,确保添加了如下脚本到package.json文件中。我们稍后会在写VueJS部分时添加更多的脚本。
"start": "node server.js",
"serve": "nodemon server.js"
接着创建server.js文件,添加如下代码:
// Import needed modules
const express = require('express');
const bodyParser = require('body-parser');
const session = require('express-session');
const MongoStore = require('connect-mongo')(session);
const flash = require('flash');
const passport = require('passport');
const LocalStrategy = require('passport-local');
const uuid = require('node-uuid');
const appData = require('./data.json');
// Create app data (mimics a DB)
const userData = appData.users;
const exclamationData = appData.exclamations;
function getUser(username) {
const user = userData.find(u => u.username === username);
return Object.assign({}, user);
}
// Create default port
const PORT = process.env.PORT || 3000;
// Create a new server
const server = express();
// Configure server
server.use(bodyParser.json());
server.use(bodyParser.urlencoded({ extended: false }));
server.use(session({
secret: process.env.SESSION_SECRET || 'awesomecookiesecret',
resave: false,
saveUninitialized: false,
store: new MongoStore({
url: process.env.MONGO_URL || 'mongodb://localhost/vue2-auth',
}),
}));
server.use(flash());
server.use(express.static('public'));
server.use(passport.initialize());
server.use(passport.session());
server.set('views', './views');
server.set('view engine', 'pug');
让我们过一下这部分代码。首先,我们引入了依赖库。接下来,我们引入了应用所需的数据文件,通常你会使用一些数据库,不过对于我们这个应用这样就足够了。最后,我们创建了一个 Express 的服务器并且用 session 和 body parser 模块对它配置。我们还开启了flash消息模块以及静态资源模块,这样我们可以通过 Node 服务器提供对Javascript文件的访问的服务。然后我们把Pug作为我们的模板引擎,我们将会在 home 页和 dashboard 页使用。
接下来,我们配置 Passport 来提供一些本地的身份验证。稍后我们会创建与它交互的页面。
// Configure Passport
passport.use(new LocalStrategy(
(username, password, done) => {
const user = getUser(username);
if (!user || user.password !== password) {
return done(null, false, { message: 'Username and password combination is wrong' });
}
delete user.password;
return done(null, user);
}
));
// Serialize user in session
passport.serializeUser((user, done) => {
done(null, user.username);
});
passport.deserializeUser((username, done) => {
const user = getUser(username);
delete user.password;
done(null, user);
});
这是一段相当标准的 Passport 代码。我们会告诉 Passport 我们本地的策略,当它尝试验证,我们会从用户数据中找到该用户,如果该用户存在且密码正确,那么我们继续前进,否则我们会返回一条消息给用户。同时我们也会把用户的名称放到session中,当我们需要获取用户消息的时候,我们可以直接通过 session 中的用户名查找到用户。
接下来部分的代码,我们将编写一些自定义的中间件功能应用到我们的路由上,去确保用户可以做某些事情。
// Create custom middleware functions
function hasScope(scope) {
return (req, res, next) => {
const { scopes } = req.user;
if (!scopes.includes(scope)) {
req.flash('error', 'The username and password are not valid.');
return res.redirect('/');
}
return next();
};
}
function canDelete(req, res, next) {
const { scopes, username } = req.user;
const { id } = req.params;
const exclamation = exclamationData.find(exc => exc.id === id);
if (!exclamation) {
return res.sendStatus(404);
}
if (exclamation.user !== username && !scopes.includes('delete')) {
return res.status(403).json({ message: "You can't delete that exclamation." });
}
return next();
}
function isAuthenticated(req, res, next) {
if (!req.user) {
req.flash('error', 'You must be logged in.');
return res.redirect('/');
}
return next();
}
让我们过一下这段代码。hasScope 方法检查请求中的用户是否有所需的特定权限,我们通过传入一个字符串去调用该方法,它会返回一个服务端使用的中间件。canDelete 方法是类似的,不过它同时检查用户是否拥有这个 exclamation 以及是否拥有删除权限,如果都没有的话用户就不能删除这条 exclamation。这些方法稍后会被用到一个简单的路由上。最后,我们实现了 isAuthenticated,它仅仅是检查这个请求中是否包含用户字段来判断用户是否登录。
接下来,让我们创建2个主要的路由:home 路由和 dashboard 路由。
// Create home route
server.get('/', (req, res) => {
if (req.user) {
return res.redirect('/dashboard');
}
return res.render('index');
});
server.get('/dashboard',
isAuthenticated,
(req, res) => {
res.render('dashboard');
}
);
这里,我们创建了 home 路由。我们检查用户是否登录,如果登录,则把请求重定向到 dashborad 页面。同时我们创建了 dashborad 路由,我们先使用 isAuthenticated 中间件去确保用户已经登录,然后渲染 dashborad 页面模板。
现在我们需要去创建身份验证的路由。
// Create auth routes
const authRoutes = express.Router();
authRoutes.post('/login',
passport.authenticate('local', {
failureRedirect: '/',
successRedirect: '/dashboard',
failureFlash: true,
})
);
server.use('/auth', authRoutes);
我们创建了路由安装在 /auth 路径上,它提供了一个简单路由 /login,这些我们稍后会在页面的表单提交时用到。
接下来,我们将会创建一些 API 的路由。这些 API 会允许我们获取所有的 exclamation,添加一条 exclamation,删除一条 exclamation。还有一个路由 /api/me 去获取当前登录用户的信息。为了保持结构统一,我们创建一个新的路由,把我们的路由添加上去,通过 /api 安装到服务中。
// Create API routes
const apiRoutes = express.Router();
apiRoutes.use(isAuthenticated);
apiRoutes.get('/me', (req, res) => {
res.json({ user: req.user });
});
// Get all of a user's exclamations
apiRoutes.get('/exclamations',
hasScope('read'),
(req, res) => {
const exclamations = exclamationData;
res.json({ exclamations });
}
);
// Add an exclamation
apiRoutes.post('/exclamations',
hasScope('add'),
(req, res) => {
const { username } = req.user;
const { text } = req.body;
const exclamation = {
id: uuid.v4(),
text,
user: username,
};
exclamationData.unshift(exclamation);
res.status(201).json({ exclamation });
}
);
// Delete an exclamation
apiRoutes.delete('/exclamations/:id',
canDelete,
(req, res) => {
const { id } = req.params;
const exclamationIndex = exclamationData.findIndex(exc => exc.id === id);
exclamationData.splice(exclamationIndex, 1);
res.sendStatus(204);
}
);
server.use('/api', apiRoutes);
现在我们只需要启动服务。
// Start the server
server.listen(PORT, () => {
console.log(`The API is listening on port ${PORT}`);
});
以上就是服务端我们需要的代码!我们仍然要创建模板。创建 views/index.pug 文件,添加以下代码。
doctype html
html(lang='en')
head
title Exclamations!
link(rel='stylesheet' href='https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css' integrity='sha384-1q8mTJOASx8j1Au+a5WDVnPi2lkFfwwEAa8hDDdjZlpLegxhjVME1fgjWPGmkzs7' crossorigin='anonymous')
style.
h1 {
margin-bottom: 20px;
}
body
.container-fluid
.row
.col-md-4.col-md-offset-4
while message = flash.shift()
.alert.alert-danger
p= message.message
h1.text-center Exclamations!
form(action='/auth/login' method='POST')
.form-group
label(for='username') Email Address
input.form-control(name='username')
.form-group
label(for='password') Password
input.form-control(name='password' type='password')
button.btn.btn-primary(type='submit') Login
这是一个基本的 HTML 页面,我们使用 bootstrap 去添加一些基本的样式。我们创建一个简单的表单,它用来提交数据到我们的服务器。我们还把从服务端输出的错误消息打印在页面中。
现在,通过执行 npm run serve 命令启动服务然后在浏览器中输入 localhost:3000,可以看到这个 login 页面。
然后从 data.json 文件里找到一条邮箱地址和密码的数据登录。一旦你登录,你会得到一条消息说我们没有 dashborad 模板。所以我们来现在来创建它。
doctype html
html(lang='en')
head
title Dashboard
link(rel='stylesheet' href='https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css' integrity='sha384-1q8mTJOASx8j1Au+a5WDVnPi2lkFfwwEAa8hDDdjZlpLegxhjVME1fgjWPGmkzs7' crossorigin='anonymous')
link(rel='stylesheet' href='/styles.bundle.css')
body
#app-container
script(src='app.bundle.js')
这代码也太少了,这一切都是在哪里?其实我们要做的就是给 VueJS 一个位置去安装它的初始化组件。这就是为什么我们只需要一个 app-container 和一个包含我们代码 script 文件就足够了。
这里并不会做任何事情,除非我们创建了这些文件并且建立一个开发管道让我们的代码工作起来。让我们创建这些文件并且下载所需的依赖。
mkdir public
touch public/app.bundle.js public/styles.bundle.css
npm install --save vue@next axios
npm install --save-dev babel-core babel-runtime babel-plugin-transform-runtime babel-preset-es2015 browserify babelify vueify@next browserify-hmr vue-hot-reload-api watchify concurrently
虽然需要安装很多依赖,但是这些都很简单。它能允许我们使用 Babel 和它的所有能力。我们通过 browersify 去打包代码,还可以使用 vueify 把组件放在一个文件中。注意到我们把 next 版本放在了 vue 和 vueify 后,这样可以安装到最新的 alpha 版本的 VueJS 和配合这个 VueJS 版本的 vueify。让我们给 package.json 文件添加一些脚本,来让我们的应用编译变得更加容易。
"prestart": "npm run build:js",
"build:js": "browserify src/app.js -t vueify -p [ vueify/plugins/extract-css -o public/styles.bundle.css ] -t babelify -o public/app.bundle.js",
"watch:js": "watchify src/app.js -t vueify -t babelify -p browserify-hmr -p [ vueify/plugins/extract-css -o public/styles.bundle.css ] -o public/app.bundle.js",
"dev": "concurrently \"npm run serve\" \"npm run watch:js\""
我们还需要对 Babel 做配置,创建一个 .babelrc 文件,添加如下代码:
{
"presets": [
"es2015"
],
"plugins": [
"transform-runtime"
]
}
我们已经做好了管道配置,在命令行运行 npm run dev 。它将启动我们的服务器,编译静态资源,同时监听我们 JavaScript 文件的变化。一切就绪,让我们去编写 Vue 应用吧。创建 src/app.js 文件,添加如下代码:
import Vue from 'vue';
import ExclamationsViewer from './exclamations_viewer.vue';
new Vue({
el: '#app-container',
render(createElement) {
return createElement(ExclamationsViewer);
},
});
这里我们依赖了 Vue 和 ExclamationsViewer 组件,稍后我们会创建它。然后我们创建了一个 Vue 实例。我们在实例化的时候会传入一个配置对象,它包含一个 el 属性,它是我们应用容器的一个选择器,在这个例子中它是 id 为 app-container 选择器。我们还会传入一个 render 方法,这是 Vue 创建模板的新方式。在以前,我们会传入 template 属性,值为模板字符串。现在,我们可以通过编程方式创建模板就像在 React 里用 React.createElment 方法一样。render 方法传入父组件的 createElement 方法,我们使用它去在父组件里创建子组件。在这个例子中我们要实例化一个 ExclamationsViewer 。
现在让我们来创建 ExclamationsViewer 组件。创建 src/exclamations_viewer.vue 文件,添加如下代码:
<style>
.exclamations-viewer,
.add-form-container {
margin-top: 20px;
}
</style>
<template>
<div class="container">
<div class="row exclamations-viewer">
<div class="col-md-4">
<Exclamation-List :user='user' title='All Exclamations' :exclamations='exclamations'></Exclamation-List>
</div>
</div>
</div>
</template>
<script>
import axios from 'axios';
import ExclamationList from './exclamation_list.vue';
export default {
name: 'ExclamationsViewer',
data: () => ({
user: {
scopes: [],
},
exclamations: [],
}),
beforeMount() {
axios.all([
axios.get('/api/me'),
axios.get('/api/exclamations'),
]).then(([{ data: meData }, { data: exclamationData }]) => {
this.user = meData.user;
this.exclamations = exclamationData.exclamations;
});
},
components: {
ExclamationList,
},
};
</script>
这里我们创建一个简单的 Vue 组件。因为我们用了 vueify ,我们可以在一个 vue 文件中把组件分离成 CSS,template,scrip t代码 3 个部分。CSS 被 <style></style> 标签包围。我们没有写太多 CSS 代码,只设置了一些间距。在模板中,我们设置了一个经典的 bootstrap 栅格布局并且添加了一个自定义组件 Exclamation-List,稍后我们会创建它。为了给组件传入 props 我们在属性前面加上了冒号,然后我们传入一个字符串,它表示我们要传递给子组件的一段数据。例如,:user='user' 表示我们把当前组件 data 中的 user 作为属性传入 Exclamation-List。接下来,在我们的 script 标签中,我们引入了 axios 库和 ExclamationList 库。我们通过设置 data 属性为一个 function 并调用它去实例化和组件的数据。这里,我们仅仅返回一个对象包一个拥有空 scopes 数组的 user 对象和一个空 exclamations 数组。任何将要被使用的数据需要在 data 对象里做初始化,这点很重要。否则,Vue 可能不能有效的监测到这部分数据的变化。
接下来,在 Vue 生命周期的 beforeMount 方法中去调用 API 请求当前登录用户和所有 exclamation 信息。然后我们把数据保存在组件中,它会替换掉我们在 data 方法里创建的数据,Vue 会完美实现这一点。最后,我们通过把 ExclamationList 组件添加到当前组件的 components 属性来局部注册。如果不添加的话,VueJS是不知道任何关于 ExclamationList 组件的。注意:我们添加组件的时候可以用 PascalCase(ExclamationList) 命名法,也可以用 camelCase(exclamationList) 命名法,但是在模板中引用组件的时候,必须用 list-case(Exclamation-List) 命名法。
接下来我们要做的事情就是创建 ExclamationList 组件。创建 src/exclamation_list.vue,然后添加如下代码:
<style scoped>
.exclamation-list {
background-color: #FAFAFA;
border: 2px solid #222;
border-radius: 7px;
}
.exclamation-list h1 {
font-size: 1.5em;
text-align: center;
}
.exclamation:nth-child(2) {
border-top: 1px solid #222;
}
.exclamation {
padding: 5px;
border-bottom: 1px solid #222;
}
.user {
font-weight: bold;
margin-top: 10px;
margin-bottom: 5px;
}
</style>
<template>
<div class="exclamation-list">
<h1></h1>
<div class="exclamation" v-for='exclamation in exclamations' :key='exclamation.id'>
<p class="user"></p>
<p class="text"></p>
<button v-if='canDelete(exclamation.user)' class="btn btn-danger">Remove</button>
</div>
</div>
</template>
<script>
export default {
props: {
title: {
type: String,
default: '',
},
exclamations: {
type: Array,
default: () => ([]),
},
user: {
default: {},
},
},
methods: {
canDelete(user) {
return this.user.scopes.includes('delete') || this.user.username === user;
},
},
};
</script>
在这个组件中,我们写了更多的 CSS 代码,但没有什么疯狂的地方。在我们的模板中,我们遍历了从属性传入的 exclamations 。v-for 指令会遍历获得到每一个 exclamation 并且可以提供 exclamation 的属性给该 div 的内部元素使用。这里我们打印出用户名称和exclamation的文本。注意我们给 div 传入了一个 key 属性,它替代了早起版本 Vue 的 track-by 属性。它可以帮助 Vue 去优化 DOM 的修改,尽可能去复用已有示例。组件有一个 delete 按钮,只有当 user 拥有delete scope的时候才会显示出来。我们通过 v-if 指令去依据条件现实或者隐藏 delete 按钮。这个条件就是 canDelete 方法的的返回值,它接收 exclamation 的 user 属性作为参数。我们接下来把这个方法添加到组件中。
在组件的脚本部分,我们导出了一个对象并指出了 props 属性接收从父组件传来 props。我们期望 title 是字符串类型,exclamtions 是数组类型,user 是对象类型。接下来,我们创建一个 methods 对象,上面有 canDelete 方法,该方法检查当前用户是否含有 delete scope 或者拥有这个 exclamation。
如果我们打开浏览器,会看到所有 exclamation 。如果我们用 Rachel 这个用户登录,会显示所有 exclamation 删除按钮,但是用 Ross 这个用户登录,只能在他自己的 exclamation 显示删除按钮。
既然我们有了删除按钮,接下来实现它的功能。因为是父组件拥有所有的数据,我们会传入子组件一个方法去从 API 层面和本地数据层面去删除父组件的 exclamation。
在 ExclamationsViewer 组件中,添加如下代码:
methods: {
onExclamationRemoved(id) {
axios.delete(`/api/exclamations/${id}`)
.then(() => {
this.exclamations = this.exclamations.filter(e => e.id !== id);
});
},
},
我们给 methods 对象添加了 onExclamationRemoved 方法,接收 exclamation 的 ID。该方法会发送一个 delete 请求到后端 API,然后过滤掉本地数据中被删除的 exclamation。所有使用这块数据的组件都会被更新。现在,我们需要把这个方法传入到子组件中,更新模板如下所示:
<Exclamation-List :user='user' :onRemove='onExclamationRemoved' title='All Exclamations' :exclamations='exclamations'></Exclamation-List>
我们通过 onRmove 属性把方法传入子组件。现在我们在 ExclamationList 组件添加这个属性。
props: {
...
onRemove: {
default: () => {},
},
...
},
我们还添加了一个方法到 methods 对象中
methods: {
onRemoveClicked(id) {
this.onRemove(id);
},
...
}
这个方法对 onRemove 属性做了简单的封装,传入 exclamation 的 ID。现在我们就可以在 ExclamationList 模板中使用这个方法了。
<button v-on:click='onRemoveClicked(exclamation.id)' v-if='canDelete(exclamation.user)' class="btn btn-danger">Remove</button>
这里我们添加了带有 click 的 v-on 指令。这是一个很好的方式当元素被点击时告诉 Vue 去执行该表达式。我们通过传入 exclamation 的 ID 去运行 onRemovedClicked 方法,这会反过来让父组件通过 API 层面和本地数据层面删除该 exclamation。
现在如果你尝试删除一条 exclamation,它会从列表中删除。如果你刷新页面,它也不会再回来!
为了看更多酷炫的功能,让我们创建另一个列表只显示用户自己的 exclamation。在 ExclamationsViewer 组件添加如下代码:
<div class="col-md-4">
<Exclamation-List :user='user' :onRemove='onExclamationRemoved' title='Your Exclamations' :exclamations='userExclamations'></Exclamation-List>
</div>
这里,我们添加了另一个列表,不过注意到我们只把 userExclamations 作为属性。userExclamations 是一个计算属性。这是 Vue 的一个概念,它会执行一个方法,在模板中可以当做一个普通变使用。它只会计算一次,除非当它依赖的数据发生变化。我们会通过过滤当前的 exclamation 列表计算出 userExclamations。这样让我们可以单独处理两个列表,我们不必改变原来的列表。给 ExclamationsViewer 组件添加如下代码:
computed: {
userExclamations() {
return this.exclamations.filter(exc => exc.user === this.user.username);
},
},
现在当你打开浏览器,你会看到两个列表。新的列表只会显示当前登录用户的 exclamations。
这就是在我们组件代码背后的力量,我们可以在很多地方轻松的复用各个组件。
一旦我们有非常多的 exclamations,我们就很难找出特定的一条。我们可以给列表添加一个搜索框,我们将用一个新组件实现。这个新组件会复用当前的 ExclamationList 组件。创建 src/exclamation_search_list.vue,添加如下代码:
<template>
<div>
<div class="input-container">
<div class="form-group">
<label for='searchTerm'>Search:</label>
<input v-model='searchTerm' type="text" class='form-control' placeholder="Search term">
</div>
</div>
<Exclamation-List :user='user' :onRemove='onRemove' title='Filtered Exclamations' :exclamations='exclamationsToShow'></Exclamation-List>
</div>
</template>
<script>
import ExclamationList from './exclamation_list.vue';
export default {
data() {
return {
searchTerm: '',
};
},
props: {
exclamations: {
type: Array,
default: () => ([]),
},
onRemove: {
default: () => {},
},
user: {
default: {},
},
},
computed: {
exclamationsToShow() {
let filteredExclamations = this.exclamations;
this.searchTerm.split(' ')
.map(t => t.split(':'))
.forEach(([type, query]) => {
if (!query) return;
if (type === 'user') {
filteredExclamations = filteredExclamations.filter(e => e.user.match(query));
} else if (type === 'contains') {
filteredExclamations = filteredExclamations.filter(e => e.text.match(query));
}
});
return filteredExclamations;
},
},
components: {
ExclamationList,
},
};
</script>
这里我们有一个由表单和 ExclamationList 组成的模板。表单没有什么特别的地方,它由一个 label 和一个 text input 构成。然而,注意到 input 上有一个 v-model 属性。传入该属性的字符串(本例是 ’searchForm’ )和我们想要同步给 input 的 value 上的 data 是相关联的。如果我们在input框输入改变它的 value, Vue 会更新组件中的 data 数据,这样我们就可以用这部分数据去过滤显示的 exclamations。
为了过滤 exclamations,我们将使用另一个计算属性。这个过滤规则允许我们按照 user 过滤或者按照文本内容过滤。如果我们想根据 user 过滤,我们输入 user:searchTerm,这个 searchTerm 就是我们要过滤的的 user。如果我们想根据文本内容过滤,我们输入 contains:searchTerm。如果我们同时想要 2 种过滤规则,我们可以设置空格分隔2种规则,然后分别获得 2 种规则的 type 和 query。最终,我们遍历这 2 种规则去过滤,拿到最终的过滤结果。
看一下我们在模板中 ExclamationList 部分添加的代码。注意到当前组件传递到子组件的属性和从父组件传来的属性名称相同,不同的是传入子组件的 exclamations 的值是 exclamationsToShow。一旦我们会当前组件中过滤它的值,那么它将会在ExclamationList组件中改变。
这是我们打开浏览器,它并没有任何显示,当然不会显示了!我们创建了组件,但我们并没有把它添加到 ExclamationsViewer 组件中。打开那个文件,把 ExclamationSearchList 添加到模板中,导入到 script 的依赖中,然后添加到 components 对象里。
<template>
...
<div class="col-md-4">
<Exclamation-Search-List :user='user' :onRemove='onExclamationRemoved' :exclamations='exclamations'></Exclamation-Search-List>
</div>
...
</template>
<script>
...
import ExclamationSearchList from './exclamation_search_list.vue';
...
components: {
ExclamationList,
ExclamationSearchList,
},
...
</script>
现在我们打开浏览器,我们有了第三列列表,它可以根据 input 输入的文本过滤相关的 exclamations 显示。尝试输入 user:rac,它应该只会显示 Rachel 的 exclamations。
我们还剩最后一件事,添加表单。创建 src/exclamation_add_form.vue 文件,添加如下代码:
<template>
<form class="form-inline" v-on:submit.prevent='onFormSubmit'>
<div class="form-group">
<label for='exclamationText'>Exclamation</label>
<textarea cols="30" rows="2" class="form-control" placeholder="Enter exclamation here." v-model='exclamationText'></textarea>
</div>
<input type="submit" value="Submit" class="btn btn-success">
</form>
</template>
<script>
export default {
data() {
return {
exclamationText: '',
};
},
props: ['onAdd'],
methods: {
onFormSubmit() {
this.onAdd(this.exclamationText);
this.exclamationText = '';
},
},
};
</script>
这是一个相当简单的组件。模板部分只有一个 textarea 和一个提交 button 构成的表单。表单上有 v-on 指令,v-on 指令是 Vue 中我们给DOM 元素添加事件的一种途径。我们使用 :submit 去表达我们要监听的是 submit 事件。.prevent 修饰符表示我们会在事件处理函数的最后自动调用 preventDefault 方法。在我们的 script 代码中,我们只需要通过 data 中的 exclamationText 跟踪 texteara 文本的变化。我们接收父组件传递的 onAdd 方法,当表单提交的时候会调用 onAdd 方法,传入 exclamationText,然后把 exclamationText 清空。
我们需要把这些添加到 ExclamationsViewer 组件中。
<template>
<div class="container">
<div class="row add-form-container" v-if='canAdd()'>
<div class="col-md-12">
<Exclamation-Add-Form :onAdd='onExclamationAdded'></Exclamation-Add-Form>
</div>
</div>
<div class="row exclamations-viewer">
...
</template>
<script>
import ExclamationAddForm from './exclamation_add_form.vue';
...
methods: {
onExclamationAdded(text) {
axios.post('/api/exclamations', { text }).then(({ data }) => {
this.exclamations = [data.exclamation].concat(this.exclamations);
});
},
canAdd() {
return this.user.scopes.includes('add');
},
onExclamationRemoved(id) {
...
components: {
...
ExclamationAddForm,
...
},
</script>
我们把 add 表单添加到模板中并传递一个 onAdd 属性。我们用v-if去条件显示这个表单,只有当用户拥有 add scope 的时候显示。我们添加了 onExclamationAdded 和 canAdd 方法到当前组件对象中,也把表单组件添加到 components 属性中。onExclamationAdded 把文本作为 post 请求发送到 API 接口,接着在把接口的返回值添加到我们的 exclamations 数组中。幸运的是,所有的列表都更新并显示我们新的 exclamation。
如果我们打开浏览器,我们可以添加一条 exclamation。如果我们添加一条后刷新浏览器,它仍然在那儿。
本文来自《Vue.js 权威指南》源码篇的一个章节,现在分享出来给大家
Vue.js 最显著的功能就是响应式系统,它是一个典型的 MVVM 框架,模型(Model)只是普通的 JavaScript 对象,修改它则视图(View)会自动更新。这种设计让状态管理变得非常简单而直观,不过理解它的原理也很重要,可以避免一些常见问题。下面让我们深挖 Vue.js 响应式系统的细节,来看一看 Vue.js 是如何把模型和视图建立起关联关系的。
我们先来看一个简单的例子。代码示例如下:
<div id="main">
<h1>count: {{times}}</h1>
</div>
<script src="vue.js"></script>
<script>
var vm = new Vue({
el: '#main',
data: function () {
return {
times: 1
};
},
created: function () {
var me = this;
setInterval(function () {
me.times++;
}, 1000);
}
});
</script>运行后,我们可以从页面中看到,count 后面的 times 每隔 1s 递增 1,视图一直在更新。在代码中仅仅是通过 setInterval 方法每隔 1s 来修改 vm.times 的值,并没有任何 DOM 操作。那么 Vue.js 是如何实现这个过程的呢?我们可以通过一张图来看一下,如下图所示:
图中的模型(Model)就是 data 方法返回的{times:1},视图(View)是最终在浏览器中显示的DOM。模型通过Observer、Dep、Watcher、Directive等一系列对象的关联,最终和视图建立起关系。归纳起来,Vue.js在这里主要做了三件事:
接下来我们就结合 Vue.js 的源码来详细介绍这三个过程。
首先来看一下 Vue.js 是如何给 data 对象添加 Observer 的。我们知道,Vue 实例创建的过程会有一个生命周期,其中有一个过程就是调用 vm.initData 方法处理 data 选项。initData 方法的源码定义如下:
<!-源码目录:src/instance/internal/state.js-->
Vue.prototype._initData = function () {
var dataFn = this.$options.data
var data = this._data = dataFn ? dataFn() : {}
if (!isPlainObject(data)) {
data = {}
process.env.NODE_ENV !== 'production' && warn(
'data functions should return an object.',
this
)
}
var props = this._props
// proxy data on instance
var keys = Object.keys(data)
var i, key
i = keys.length
while (i--) {
key = keys[i]
// there are two scenarios where we can proxy a data key:
// 1. it's not already defined as a prop
// 2. it's provided via a instantiation option AND there are no
// template prop present
if (!props || !hasOwn(props, key)) {
this._proxy(key)
} else if (process.env.NODE_ENV !== 'production') {
warn(
'Data field "' + key + '" is already defined ' +
'as a prop. To provide default value for a prop, use the "default" ' +
'prop option; if you want to pass prop values to an instantiation ' +
'call, use the "propsData" option.',
this
)
}
}
// observe data
observe(data, this)
}在 initData 中我们要特别注意 proxy 方法,它的功能就是遍历 data 的 key,把 data 上的属性代理到 vm 实例上。_proxy 方法的源码定义如下:
<!-源码目录:src/instance/internal/state.js-->
Vue.prototype._proxy = function (key) {
if (!isReserved(key)) {
// need to store ref to self here
// because these getter/setters might
// be called by child scopes via
// prototype inheritance.
var self = this
Object.defineProperty(self, key, {
configurable: true,
enumerable: true,
get: function proxyGetter () {
return self._data[key]
},
set: function proxySetter (val) {
self._data[key] = val
}
})
}
}proxy 方法主要通过 Object.defineProperty 的 getter 和 setter 方法实现了代理。在前面的例子中,我们调用 vm.times 就相当于访问了 vm.data.times。
在 _initData 方法的最后,我们调用了 observe(data, this) 方法来对 data 做监听。observe 方法的源码定义如下:
<!-源码目录:src/observer/index.js-->
export function observe (value, vm) {
if (!value || typeof value !== 'object') {
return
}
var ob
if (
hasOwn(value, '__ob__') &&
value.__ob__ instanceof Observer
) {
ob = value.__ob__
} else if (
shouldConvert &&
(isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
ob = new Observer(value)
}
if (ob && vm) {
ob.addVm(vm)
}
return ob
}observe 方法首先判断 value 是否已经添加了 ob 属性,它是一个 Observer 对象的实例。如果是就直接用,否则在 value 满足一些条件(数组或对象、可扩展、非 vue 组件等)的情况下创建一个 Observer 对象。接下来我们看一下 Observer 这个类,它的源码定义如下:
<!-源码目录:src/observer/index.js-->
export function Observer (value) {
this.value = value
this.dep = new Dep()
def(value, '__ob__', this)
if (isArray(value)) {
var augment = hasProto
? protoAugment
: copyAugment
augment(value, arrayMethods, arrayKeys)
this.observeArray(value)
} else {
this.walk(value)
}
}Observer 类的构造函数主要做了这么几件事:首先创建了一个 Dep 对象实例(关于 Dep 对象我们稍后作介绍);然后把自身 this 添加到 value 的 ob 属性上;最后对 value 的类型进行判断,如果是数组则观察数组,否则观察单个元素。其实 observeArray 方法就是对数组进行遍历,递归调用 observe 方法,最终都会调用 walk 方法观察单个元素。接下来我们看一下 walk 方法,它的源码定义如下:
<!-源码目录:src/observer/index.js-->
Observer.prototype.walk = function (obj) {
var keys = Object.keys(obj)
for (var i = 0, l = keys.length; i < l; i++) {
this.convert(keys[i], obj[keys[i]])
}
}walk 方法是对 obj 的 key 进行遍历,依次调用 convert 方法,对 obj 的每一个属性进行转换,让它们拥有 getter、setter 方法。只有当 obj 是一个对象时,这个方法才能被调用。接下来我们看一下 convert 方法,它的源码定义如下:
<!-源码目录:src/observer/index.js-->
Observer.prototype.convert = function (key, val) {
defineReactive(this.value, key, val)
}convert 方法很简单,它调用了 defineReactive 方法。这里 this.value 就是要观察的 data 对象,key 是 data 对象的某个属性,val 则是这个属性的值。defineReactive 的功能是把要观察的 data 对象的每个属性都赋予 getter 和 setter 方法。这样一旦属性被访问或者更新,我们就可以追踪到这些变化。接下来我们看一下 defineReactive 方法,它的源码定义如下:
<!-源码目录:src/observer/index.js-->
export function defineReactive (obj, key, val) {
var dep = new Dep()
var property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
var getter = property && property.get
var setter = property && property.set
var childOb = observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
var value = getter ? getter.call(obj) : val
if (Dep.target) {
dep.depend()
if (childOb) {
childOb.dep.depend()
}
if (isArray(value)) {
for (var e, i = 0, l = value.length; i < l; i++) {
e = value[i]
e && e.__ob__ && e.__ob__.dep.depend()
}
}
}
return value
},
set: function reactiveSetter (newVal) {
var value = getter ? getter.call(obj) : val
if (newVal === value) {
return
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = observe(newVal)
dep.notify()
}
})
}defineReactive 方法最核心的部分就是通过调用 Object.defineProperty 给 data 的每个属性添加 getter 和setter 方法。当 data 的某个属性被访问时,则会调用 getter 方法,判断当 Dep.target 不为空时调用 dep.depend 和 childObj.dep.depend 方法做依赖收集。如果访问的属性是一个数组,则会遍历这个数组收集数组元素的依赖。当改变 data 的属性时,则会调用 setter 方法,这时调用 dep.notify 方法进行通知。这里我们提到了 dep,它是 Dep 对象的实例。接下来我们看一下 Dep 这个类,它的源码定义如下:
<!-源码目录:src/observer/dep.js-->
export default function Dep () {
this.id = uid++
this.subs = []
}
// the current target watcher being evaluated.
// this is globally unique because there could be only one
// watcher being evaluated at any time.
Dep.target = nullDep 类是一个简单的观察者模式的实现。它的构造函数非常简单,初始化了 id 和 subs。其中 subs 用来存储所有订阅它的 Watcher,Watcher 的实现稍后我们会介绍。Dep.target 表示当前正在计算的 Watcher,它是全局唯一的,因为在同一时间只能有一个 Watcher 被计算。
前面提到了在 getter 和 setter 方法调用时会分别调用 dep.depend 方法和 dep.notify 方法,接下来依次介绍这两个方法。depend 方法的源码定义如下:
<!-源码目录:src/observer/dep.js-->
Dep.prototype.depend = function () {
Dep.target.addDep(this)
}depend 方法很简单,它通过 Dep.target.addDep(this) 方法把当前 Dep 的实例添加到当前正在计算的Watcher 的依赖中。接下来我们看一下 notify 方法,它的源码定义如下:
<!-源码目录:src/observer/dep.js-->
Dep.prototype.notify = function () {
// stablize the subscriber list first
var subs = toArray(this.subs)
for (var i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}notify 方法也很简单,它遍历了所有的订阅 Watcher,调用它们的 update 方法。
至此,vm 实例中给 data 对象添加 Observer 的过程就结束了。接下来我们看一下 Vue.js 是如何进行指令解析的。
Vue 指令类型很多,限于篇幅,我们不会把所有指令的解析过程都介绍一遍,这里结合前面的例子只介绍 v-text 指令的解析过程,其他指令的解析过程也大同小异。
前面我们提到了 Vue 实例创建的生命周期,在给 data 添加 Observer 之后,有一个过程是调用 vm.compile 方法对模板进行编译。compile 方法的源码定义如下:
<!-源码目录:src/instance/internal/lifecycle.js-->
Vue.prototype._compile = function (el) {
var options = this.$options
// transclude and init element
// transclude can potentially replace original
// so we need to keep reference; this step also injects
// the template and caches the original attributes
// on the container node and replacer node.
var original = el
el = transclude(el, options)
this._initElement(el)
// handle v-pre on root node (#2026)
if (el.nodeType === 1 && getAttr(el, 'v-pre') !== null) {
return
}
// root is always compiled per-instance, because
// container attrs and props can be different every time.
var contextOptions = this._context && this._context.$options
var rootLinker = compileRoot(el, options, contextOptions)
// resolve slot distribution
resolveSlots(this, options._content)
// compile and link the rest
var contentLinkFn
var ctor = this.constructor
// component compilation can be cached
// as long as it's not using inline-template
if (options._linkerCachable) {
contentLinkFn = ctor.linker
if (!contentLinkFn) {
contentLinkFn = ctor.linker = compile(el, options)
}
}
// link phase
// make sure to link root with prop scope!
var rootUnlinkFn = rootLinker(this, el, this._scope)
var contentUnlinkFn = contentLinkFn
? contentLinkFn(this, el)
: compile(el, options)(this, el)
// register composite unlink function
// to be called during instance destruction
this._unlinkFn = function () {
rootUnlinkFn()
// passing destroying: true to avoid searching and
// splicing the directives
contentUnlinkFn(true)
}
// finally replace original
if (options.replace) {
replace(original, el)
}
this._isCompiled = true
this._callHook('compiled')
}我们可以通过下图来看一下这个方法编译的主要流程:
这个过程通过 el = transclude(el, option) 方法把 template 编译成一段 document fragment,拿到 el 对象。而指令解析部分就是通过 compile(el, options) 方法实现的。接下来我们看一下 compile 方法的实现,它的源码定义如下:
<!-源码目录:src/compiler/compile.js-->
export function compile (el, options, partial) {
// link function for the node itself.
var nodeLinkFn = partial || !options._asComponent
? compileNode(el, options)
: null
// link function for the childNodes
var childLinkFn =
!(nodeLinkFn && nodeLinkFn.terminal) &&
!isScript(el) &&
el.hasChildNodes()
? compileNodeList(el.childNodes, options)
: null
/**
* A composite linker function to be called on a already
* compiled piece of DOM, which instantiates all directive
* instances.
*
* @param {Vue} vm
* @param {Element|DocumentFragment} el
* @param {Vue} [host] - host vm of transcluded content
* @param {Object} [scope] - v-for scope
* @param {Fragment} [frag] - link context fragment
* @return {Function|undefined}
*/
return function compositeLinkFn (vm, el, host, scope, frag) {
// cache childNodes before linking parent, fix #657
var childNodes = toArray(el.childNodes)
// link
var dirs = linkAndCapture(function compositeLinkCapturer () {
if (nodeLinkFn) nodeLinkFn(vm, el, host, scope, frag)
if (childLinkFn) childLinkFn(vm, childNodes, host, scope, frag)
}, vm)
return makeUnlinkFn(vm, dirs)
}
}compile 方法主要通过 compileNode(el, options) 方法完成节点的解析,如果节点拥有子节点,则调用 compileNodeList(el.childNodes, options) 方法完成子节点的解析。compileNodeList 方法其实就是遍历子节点,递归调用 compileNode 方法。因为 DOM 元素本身就是树结构,这种递归方法也就是常见的树的深度遍历方法,这样就可以完成整个 DOM 树节点的解析。接下来我们看一下 compileNode 方法的实现,它的源码定义如下:
<!-源码目录:src/compiler/compile.js-->
function compileNode (node, options) {
var type = node.nodeType
if (type === 1 && !isScript(node)) {
return compileElement(node, options)
} else if (type === 3 && node.data.trim()) {
return compileTextNode(node, options)
} else {
return null
}
}compileNode 方法对节点的 nodeType 做判断,如果是一个非 script 普通的元素(div、p等);则调用 compileElement(node, options) 方法解析;如果是一个非空的文本节点,则调用 compileTextNode(node, options) 方法解析。我们在前面的例子中解析的是非空文本节点 count: {{times}},这实际上是 v-text 指令,它的解析是通过 compileTextNode 方法实现的。接下来我们看一下 compileTextNode 方法,它的源码定义如下:
<!-源码目录:src/compiler/compile.js-->
function compileTextNode (node, options) {
// skip marked text nodes
if (node._skip) {
return removeText
}
var tokens = parseText(node.wholeText)
if (!tokens) {
return null
}
// mark adjacent text nodes as skipped,
// because we are using node.wholeText to compile
// all adjacent text nodes together. This fixes
// issues in IE where sometimes it splits up a single
// text node into multiple ones.
var next = node.nextSibling
while (next && next.nodeType === 3) {
next._skip = true
next = next.nextSibling
}
var frag = document.createDocumentFragment()
var el, token
for (var i = 0, l = tokens.length; i < l; i++) {
token = tokens[i]
el = token.tag
? processTextToken(token, options)
: document.createTextNode(token.value)
frag.appendChild(el)
}
return makeTextNodeLinkFn(tokens, frag, options)
}compileTextNode 方法首先调用了 parseText 方法对 node.wholeText 做解析。主要通过正则表达式解析 count: {{times}} 部分,我们看一下解析结果,如下图所示:
解析后的 tokens 是一个数组,数组的每个元素则是一个 Object。如果是 count: 这样的普通文本,则返回的对象只有 value 字段;如果是 {{times}} 这样的插值,则返回的对象包含 html、onTime、tag、value 等字段。
接下来创建 document fragment,遍历 tokens 创建 DOM 节点插入到这个 fragment 中。在遍历过程中,如果 token 无 tag 字段,则调用 document.createTextNode(token.value) 方法创建 DOM 节点;否则调用processTextToken(token, options) 方法创建 DOM 节点和扩展 token 对象。我们看一下调用后的结果,如下图所示:
可以看到,token 字段多了一个 descriptor 属性。这个属性包含了几个字段,其中 def 表示指令相关操作的对象,expression 为解析后的表达式,filters 为过滤器,name 为指令的名称。
在compileTextNode 方法的最后,调用 makeTextNodeLinkFn(tokens, frag, options) 并返回该方法执行的结果。接下来我们看一下 makeTextNodeLinkFn 方法,它的源码定义如下:
<!-源码目录:src/compiler/compile.js-->
function makeTextNodeLinkFn (tokens, frag) {
return function textNodeLinkFn (vm, el, host, scope) {
var fragClone = frag.cloneNode(true)
var childNodes = toArray(fragClone.childNodes)
var token, value, node
for (var i = 0, l = tokens.length; i < l; i++) {
token = tokens[i]
value = token.value
if (token.tag) {
node = childNodes[i]
if (token.oneTime) {
value = (scope || vm).$eval(value)
if (token.html) {
replace(node, parseTemplate(value, true))
} else {
node.data = _toString(value)
}
} else {
vm._bindDir(token.descriptor, node, host, scope)
}
}
}
replace(el, fragClone)
}
}makeTextNodeLinkFn 这个方法什么也没做,它仅仅是返回了一个新的方法 textNodeLinkFn。往前回溯,这个方法最终作为 compileNode 的返回值,被添加到 compile 方法生成的 childLinkFn 中。
我们回到 compile 方法,在 compile 方法的最后有这样一段代码:
<!-源码目录:src/compiler/compile.js-->
return function compositeLinkFn (vm, el, host, scope, frag) {
// cache childNodes before linking parent, fix #657
var childNodes = toArray(el.childNodes)
// link
var dirs = linkAndCapture(function compositeLinkCapturer () {
if (nodeLinkFn) nodeLinkFn(vm, el, host, scope, frag)
if (childLinkFn) childLinkFn(vm, childNodes, host, scope, frag)
}, vm)
return makeUnlinkFn(vm, dirs)
}compile 方法返回了 compositeLinkFn,它在 Vue.prototype._compile 方法执行时,是通过 compile(el, options)(this, el) 调用的。compositeLinkFn 方法执行了 linkAndCapture 方法,它的功能是通过调用 compile 过程中生成的 link 方法创建指令对象,再对指令对象做一些绑定操作。linkAndCapture 方法的源码定义如下:
<!-源码目录:src/compiler/compile.js-->
function linkAndCapture (linker, vm) {
/* istanbul ignore if */
if (process.env.NODE_ENV === 'production') {
// reset directives before every capture in production
// mode, so that when unlinking we don't need to splice
// them out (which turns out to be a perf hit).
// they are kept in development mode because they are
// useful for Vue's own tests.
vm._directives = []
}
var originalDirCount = vm._directives.length
linker()
var dirs = vm._directives.slice(originalDirCount)
dirs.sort(directiveComparator)
for (var i = 0, l = dirs.length; i < l; i++) {
dirs[i]._bind()
}
return dirs
}linkAndCapture 方法首先调用了 linker 方法,它会遍历 compile 过程中生成的所有 linkFn 并调用,本例中会调用到之前定义的 textNodeLinkFn。这个方法会遍历 tokens,判断如果 token 的 tag 属性值为 true 且 oneTime 属性值为 false,则调用 vm.bindDir(token.descriptor, node, host, scope) 方法创建指令对象。 vm._bindDir 方法的源码定义如下:
<!-源码目录:src/instance/internal/lifecycle.js-->
Vue.prototype._bindDir = function (descriptor, node, host, scope, frag) {
this._directives.push(
new Directive(descriptor, this, node, host, scope, frag)
)
}Vue.prototype._bindDir 方法就是根据 descriptor 实例化不同的 Directive 对象,并添加到 vm 实例 directives 数组中的。到这一步,Vue.js 从解析模板到生成 Directive 对象的步骤就完成了。接下来回到 linkAndCapture 方法,它对创建好的 directives 进行排序,然后遍历 directives 调用 dirs[i]._bind 方法对单个directive做一些绑定操作。dirs[i]._bind方法的源码定义如下:
<!-源码目录:src/directive.js-->
Directive.prototype._bind = function () {
var name = this.name
var descriptor = this.descriptor
// remove attribute
if (
(name !== 'cloak' || this.vm._isCompiled) &&
this.el && this.el.removeAttribute
) {
var attr = descriptor.attr || ('v-' + name)
this.el.removeAttribute(attr)
}
// copy def properties
var def = descriptor.def
if (typeof def === 'function') {
this.update = def
} else {
extend(this, def)
}
// setup directive params
this._setupParams()
// initial bind
if (this.bind) {
this.bind()
}
this._bound = true
if (this.literal) {
this.update && this.update(descriptor.raw)
} else if (
(this.expression || this.modifiers) &&
(this.update || this.twoWay) &&
!this._checkStatement()
) {
// wrapped updater for context
var dir = this
if (this.update) {
this._update = function (val, oldVal) {
if (!dir._locked) {
dir.update(val, oldVal)
}
}
} else {
this._update = noop
}
var preProcess = this._preProcess
? bind(this._preProcess, this)
: null
var postProcess = this._postProcess
? bind(this._postProcess, this)
: null
var watcher = this._watcher = new Watcher(
this.vm,
this.expression,
this._update, // callback
{
filters: this.filters,
twoWay: this.twoWay,
deep: this.deep,
preProcess: preProcess,
postProcess: postProcess,
scope: this._scope
}
)
// v-model with inital inline value need to sync back to
// model instead of update to DOM on init. They would
// set the afterBind hook to indicate that.
if (this.afterBind) {
this.afterBind()
} else if (this.update) {
this.update(watcher.value)
}
}
}Directive.prototype._bind 方法的主要功能就是做一些指令的初始化操作,如混合 def 属性。def 是通过 this.descriptor.def 获得的,this.descriptor 是对指令进行相关描述的对象,而 this.descriptor.def 则是包含指令相关操作的对象。比如对于 v-text 指令,我们可以看一下它的相关操作,源码定义如下:
<!-源码目录:src/directives/public/text.js-->
export default {
bind () {
this.attr = this.el.nodeType === 3
? 'data'
: 'textContent'
},
update (value) {
this.el[this.attr] = _toString(value)
}
}v-text 的 def 包含了 bind 和 update 方法,Directive 在初始化时通过 extend(this, def) 方法可以对实例扩展这两个方法。Directive 在初始化时还定义了 this.update 方法,并创建了 Watcher,把 this.update 方法作为 Watcher 的回调函数。这里把 Directive 和 Watcher 做了关联,当 Watcher 观察到指令表达式值变化时,会调用 Directive 实例的 _update 方法,最终调用 v-text 的 update 方法更新 DOM 节点。
至此,vm 实例中编译模板、解析指令、绑定 Watcher 的过程就结束了。接下来我们看一下 Watcher 的实现,了解 Directive 和 Observer 之间是如何通过 Watcher 关联的。
我们先来看一下 Watcher 类的实现,它的源码定义如下:
<!-源码目录:src/watcher.js-->
export default function Watcher (vm, expOrFn, cb, options) {
// mix in options
if (options) {
extend(this, options)
}
var isFn = typeof expOrFn === 'function'
this.vm = vm
vm._watchers.push(this)
this.expression = expOrFn
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
this.deps = []
this.newDeps = []
this.depIds = new Set()
this.newDepIds = new Set()
this.prevError = null // for async error stacks
// parse expression for getter/setter
if (isFn) {
this.getter = expOrFn
this.setter = undefined
} else {
var res = parseExpression(expOrFn, this.twoWay)
this.getter = res.get
this.setter = res.set
}
this.value = this.lazy
? undefined
: this.get()
// state for avoiding false triggers for deep and Array
// watchers during vm._digest()
this.queued = this.shallow = false
}Directive 实例在初始化 Watche r时,会传入指令的 expression。Watcher 构造函数会通过 parseExpression(expOrFn, this.twoWay) 方法对 expression 做进一步的解析。在前面的例子中, expression 是times,passExpression 方法的功能是把 expression 转换成一个对象,如下图所示:
可以看到 res 有两个属性,其中 exp 为表达式字符串;get 是通过 new Function 生成的匿名方法,可以把它打印出来,如下图所示:
可以看到 res.get 方法很简单,它接受传入一个 scope 变量,返回 scope.times。对于传入的 scope 值,稍后我们会进行介绍。在 Watcher 构造函数的最后调用了 this.get 方法,它的源码定义如下:
<!-源码目录:src/watcher.js-->
Watcher.prototype.get = function () {
this.beforeGet()
var scope = this.scope || this.vm
var value
try {
value = this.getter.call(scope, scope)
} catch (e) {
if (
process.env.NODE_ENV !== 'production' &&
config.warnExpressionErrors
) {
warn(
'Error when evaluating expression ' +
'"' + this.expression + '": ' + e.toString(),
this.vm
)
}
}
// "touch" every property so they are all tracked as
// dependencies for deep watching
if (this.deep) {
traverse(value)
}
if (this.preProcess) {
value = this.preProcess(value)
}
if (this.filters) {
value = scope._applyFilters(value, null, this.filters, false)
}
if (this.postProcess) {
value = this.postProcess(value)
}
this.afterGet()
return value
}Watcher.prototype.get 方法的功能就是对当前 Watcher 进行求值,收集依赖关系。它首先执行 this.beforeGet 方法,源码定义如下:
<!-源码目录:src/watcher.js-->
Watcher.prototype.beforeGet = function () {
Dep.target = this
}Watcher.prototype.beforeGet 很简单,设置 Dep.target 为当前 Watcher 实例,为接下来的依赖收集做准备。我们回到 get 方法,接下来执行 this.getter.call(scope, scope) 方法,这里的 scope 是 this.vm,也就是当前 Vue 实例。这个方法实际上相当于获取 vm.times,这样就触发了对象的 getter。在第一小节我们给 data 添加 Observer 时,通过 Object.defineProperty 给 data 对象的每一个属性添加 getter 和 setter。回顾一下代码:
<!-源码目录:src/observer/index.js-->
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
var value = getter ? getter.call(obj) : val
if (Dep.target) {
dep.depend()
if (childOb) {
childOb.dep.depend()
}
if (isArray(value)) {
for (var e, i = 0, l = value.length; i < l; i++) {
e = value[i]
e && e.__ob__ && e.__ob__.dep.depend()
}
}
}
return value
},
…
})当获取 vm.times 时,会执行到 get 方法体内。由于我们在之前已经设置了 Dep.target 为当前 Watcher 实例,所以接下来就调用 dep.depend() 方法完成依赖收集。它实际上是执行了 Dep.target.addDep(this),相当于执行了 Watcher 实例的 addDep 方法,把 Dep 实例添加到 Watcher 实例的依赖中。addDep 方法的源码定义如下:
<!-源码目录:src/watcher.js-->
Watcher.prototype.addDep = function (dep) {
var id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}Watcher.prototype.addDep 方法就是把 dep 添加到 Watcher 实例的依赖中,同时又通过 dep.addSub(this) 把 Watcher 实例添加到 dep 的订阅者中。addSub 方法的源码定义如下:
<!-源码目录:src/observer/dep.js-->
Dep.prototype.addSub = function (sub) {
this.subs.push(sub)
}至此,指令完成了依赖收集,并且通过 Watcher 完成了对数据变化的订阅。
接下来我们看一下,当 data 发生变化时,视图是如何自动更新的。在前面的例子中,我们通过 setInterval 每隔 1s 执行一次 vm.times++,数据改变会触发对象的 setter,执行 set 方法体的代码。回顾一下代码:
<!-源码目录:src/observer/index.js-->
Object.defineProperty(obj, key, {
…
set: function reactiveSetter (newVal) {
var value = getter ? getter.call(obj) : val
if (newVal === value) {
return
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = observe(newVal)
dep.notify()
}
})这里会调用 dep.notify() 方法,它会遍历所有的订阅者,也就是 Watcher 实例。然后调用 Watcher 实例的 update 方法,源码定义如下:
<!-源码目录:src/watcher.js-->
Watcher.prototype.update = function (shallow) {
if (this.lazy) {
this.dirty = true
} else if (this.sync || !config.async) {
this.run()
} else {
// if queued, only overwrite shallow with non-shallow,
// but not the other way around.
this.shallow = this.queued
? shallow
? this.shallow
: false
: !!shallow
this.queued = true
// record before-push error stack in debug mode
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.debug) {
this.prevError = new Error('[vue] async stack trace')
}
pushWatcher(this)
}
}Watcher.prototype.update 方法在满足某些条件下会直接调用 this.run 方法。在多数情况下会调用 pushWatcher(this) 方法把 Watcher 实例推入队列中,延迟 this.run 调用的时机。pushWatcher 方法的源码定义如下:
<!-源码目录:src/batcher.js-->
export function pushWatcher (watcher) {
const id = watcher.id
if (has[id] == null) {
// push watcher into appropriate queue
const q = watcher.user
? userQueue
: queue
has[id] = q.length
q.push(watcher)
// queue the flush
if (!waiting) {
waiting = true
nextTick(flushBatcherQueue)
}
}
}pushWatcher 方法把 Watcher 推入队列中,通过 nextTick 方法在下一个事件循环周期处理 Watcher 队列,这是 Vue.j s的一种性能优化手段。因为如果同时观察的数据多次变化,比如同步执行 3 次 vm.time++,同步调用 watcher.run 就会触发 3 次 DOM 操作。而推入队列中等待下一个事件循环周期再操作队列里的 Watcher,因为是同一个 Watcher,它只会调用一次 watcher.run,从而只触发一次 DOM 操作。接下来我们看一下 flushBatcherQueue 方法,它的源码定义如下:
<!-源码目录:src/batcher.js-->
function flushBatcherQueue () {
runBatcherQueue(queue)
runBatcherQueue(userQueue)
// user watchers triggered more watchers,
// keep flushing until it depletes
if (queue.length) {
return flushBatcherQueue()
}
// dev tool hook
/* istanbul ignore if */
if (devtools && config.devtools) {
devtools.emit('flush')
}
resetBatcherState()
}flushBatcherQueue 方法通过调用 runBatcherQueue 来 run Watcher。这里我们看到 Watcher 队列分为内部 queue 和 userQueue,其中 userQueue 是通过 $watch() 方法注册的 Watcher。我们优先 run 内部queue 来保证指令和 DOM 节点优先更新,这样当用户自定义的 Watcher 的回调函数触发时 DOM 已更新完毕。接下来我们看一下 runBatcherQueue 方法,它的源码定义如下:
<!-源码目录:src/batcher.js-->
function runBatcherQueue (queue) {
// do not cache length because more watchers might be pushed
// as we run existing watchers
for (let i = 0; i < queue.length; i++) {
var watcher = queue[i]
var id = watcher.id
has[id] = null
watcher.run()
// in dev build, check and stop circular updates.
if (process.env.NODE_ENV !== 'production' && has[id] != null) {
circular[id] = (circular[id] || 0) + 1
if (circular[id] > config._maxUpdateCount) {
warn(
'You may have an infinite update loop for watcher ' +
'with expression "' + watcher.expression + '"',
watcher.vm
)
break
}
}
}
queue.length = 0
}runBatcherQueued 的功能就是遍历 queue 中 Watcher 的 run 方法。接下来我们看一下 Watcher 的 run 方法,它的源码定义如下:
<!-源码目录:src/watcher.js-->
Watcher.prototype.run = function () {
if (this.active) {
var value = this.get()
if (
value !== this.value ||
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated; but only do so if this is a
// non-shallow update (caused by a vm digest).
((isObject(value) || this.deep) && !this.shallow)
) {
// set new value
var oldValue = this.value
this.value = value
// in debug + async mode, when a watcher callbacks
// throws, we also throw the saved before-push error
// so the full cross-tick stack trace is available.
var prevError = this.prevError
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' &&
config.debug && prevError) {
this.prevError = null
try {
this.cb.call(this.vm, value, oldValue)
} catch (e) {
nextTick(function () {
throw prevError
}, 0)
throw e
}
} else {
this.cb.call(this.vm, value, oldValue)
}
}
this.queued = this.shallow = false
}
}Watcher.prototype.run 方法再次对 Watcher 求值,重新收集依赖。接下来判断求值结果和之前 value 的关系。如果不变则什么也不做,如果变了则调用 this.cb.call(this.vm, value, oldValue) 方法。这个方法是 Directive 实例创建 Watcher 时传入的,它对应相关指令的 update 方法来真实更新 DOM。这样就完成了数据更新到对应视图的变化过程。 Watcher 巧妙地把 Observer 和 Directive 关联起来,实现了数据一旦更新,视图就会自动变化的效果。尽管 Vue.js 利用 Object.defineProperty 这个核心技术实现了数据和视图的绑定,但仍然会存在一些数据变化检测不到的问题,接下来我们看一下这部分内容。
今天我们就讲到这里,更多精彩内容关注我们的书籍《Vue.js 权威指南》
作者:嵇智
最近在用 Vue 重构一个历史项目,一个考试系统,题目量很大,所以核心组件的性能成为了关注点。先来两张图看下最核心的组件 Paper 的样式。
从图中来看,分为答题区与选择面板区。
稍微对交互逻辑进行下拆解:
基于以上考虑,我觉得我必须有三个响应式的数据:
currentIndex: 当前选中题目的序号。questions:所有题目的信息,是个数组,里面维护了每道题的问题、选项、正确与否等信息。cardData:题目分组的信息,也是个数组,按章节名称对不同的题目进行了分类。数组每一项数据结构如下:
currentIndex = 0 // 用来标记当前选中题目的索引
questions = [{
secId: 1, // 所属章节的 id
tid: 1, // 题目 id
content: '题目内容' // 题目描述
type: 1, // 题型,1 ~ 3 (单选,多选,判断)
options: ['选项1', '选项2', '选项3', '选项4',] // 每个选项的描述
choose: [1, 2, 4], // 多选——记录用户未提交前的选项
done: true, // 标记当前题目是否已做
answerIsTrue: undefined // 标记当前题目的正确与否
}]
cardData = [{
startIndex: 0, // 用来记录循环该分组数据的起始索引,这个值等于前面数据的长度累加。
secName: '章节名称',
secId: '章节id',
tids: [1, 2, 3, 11] // 该章节下面的所有题目的 id
}]由于题目可以左右滑动切换,所以我每次从 questions 取了三个数据去渲染,用的是 cube-ui 的 Slide 组件,只要自己根据 this.currentIndex 结合 computed 特性去动态的切割三个数据就行。
这一切都显得很美好,尤其是即将结束了一个历史项目的核心组件的编写之前,心情特别的舒畅。
然而转折点出现在了渲染选择面板样式这一步
代码逻辑很简单,但是发生了让我懵逼的事情。
<div class="card-content">
<div class="block" v-for="item in cardData" :key="item.secName">
<div class="sub-title">{{item.secName}}</div>
<div class="group">
<span
@click="cardClick(index + item.startIndex)"
class="item"
:class="getItemClass(index + item.startIndex)"
v-for="(subItem, index) in item.secTids"
:key="subItem">{{index + item.startIndex + 1}}</span>
</div>
</div>
</div>其实就是利用 cardData 去生成 DOM 元素,这是个分组数据(先是以章节为维度,章节下面还有对应的题目),上面的代码其实是一个循环里面嵌套了另一个循环。
但是,只要我切换题目或者点击面板,抑或是触发任意响应式数据的改变,都会让页面卡死!!
当下的第一反应,肯定是 js 在某一步的执行时间过长,所以利用 Chrome 自带的 Performance 工具 追踪了一下,发现问题出在 getItemClass 这个函数调用,占据了 99% 的时间,而且时间都超过 1s 了。瞅了眼自己的代码:
getItemClass (index) {
const ret = {}
// 如果是做对的题目,但并不是当前选中
ret['item_true'] = this.questions[index]......
// 如果是做对的题目,并且是当前选中
ret['item_true_active'] = this.questions[index]......
// 如果是做错的题目,但并不是当前选中
ret['item_false'] = this.questions[index]......
// 如果是做错的题目,并且是当前选中
ret['item_false_active'] = this.questions[index]......
// 如果是未做的题目,但不是当前选中
ret['item_undo'] = this.questions[index]......
// 如果是未做的题目,并且是当前选中
ret['item_undo_active'] = this.questions[index]......
return ret
},这个函数主要是用来计算选择面板每一个小圆圈该有的样式。每一步都是对 questions 进行了 getter 操作。初看,好像没什么问题,但是由于之前看过 Vue 的源码,细想之下,觉得不对。
首先,webpack 会将 .vue 文件的 template 转换成 render 函数,也就是实例化组件的时候,其实是对响应式属性求值的过程,这样响应式属性就能将 renderWatcher 加入依赖当中,所以当响应式属性改变的时候,能触发组件重新渲染。
我们先来了解下 renderWatcher 是什么概念,首先在 Vue 的源码里面是有三种 watcher 的。我们只看 renderWatcher 的定义。
// 位于 vue/src/core/instance/lifecycle.js
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
// 位于 vue/src/core/instance/render.js
Vue.prototype._render = function (): VNode {
......
const { render, _parentVnode } = vm.$options
try {
vnode = render.call(vm._renderProxy, vm.$createElement)
} catch (e) {
......
}
return vnode
}稍微分析下流程:实例化 Vue 实例的时候会走到 $mount,即走到上述的 new Watcher,这个就是 renderWatcher,之后走到 updateComponent 函数,也就是会执行 _render,函数内部会通过 vm.$options 取到由 template 编译生成的 render 函数,进而执行 renderWatcher 收集依赖。_render 返回的是组件的 vnode,传入 _update 函数从而执行组件的 patch,最终生成视图。
其次,从我写的 template 来分析,为了渲染选择面板的 DOM,是有两层 for 循环的,内部每次循环都会执行 getItemClass 函数,而函数的内部又是对 questions 这个响应式数组进行了 getter 求值,从目前来看,时间复杂度是 O(n²),如上图所示,我们大概有 2000 多道题目,我们假设有 10 个章节,每个章节有 200 道题目,getItemClass 内部是对 questions 进行了 6 次求值,这样一算,粗略也是 12000 左右,按 js 的执行速度,是不可能这么慢的。
那么问题是不是出现在对 questions 进行 getter 的过程中,出现了 O(n³) 的复杂度呢?
于是,我打开了 Vue 的源码,由于之前深入研究过源码,所以轻车熟路地找到了 vue/src/core/instance/state.js 里面将 data 转换成 getter/setter 的部分。
function initData (vm: Component) {
......
// observe data
observe(data, true /* asRootData */)
}定义一个组件的 data 的响应式,都是从 observe 函数开始,它的定义是位于 vue/src/core/observer/index.js。
export function observe (value: any, asRootData: ?boolean): Observer | void {
if (!isObject(value) || value instanceof VNode) {
return
}
let ob: Observer | void
if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) {
ob = value.__ob__
} else if (
shouldObserve &&
!isServerRendering() &&
(Array.isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
ob = new Observer(value)
}
if (asRootData && ob) {
ob.vmCount++
}
return ob
}observe 函数接受对象或者数组,内部会实例化 Observer 类。
export class Observer {
value: any;
dep: Dep;
vmCount: number;
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {
this.walk(value)
}
}
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i])
}
}
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}Observer 的构造函数很简单,就是声明了 dep、value 属性,并且将 value 的 _ob_ 属性指向当前实例。举个栗子:
// 刚开始的 options
export default {
data : {
msg: '消息',
arr: [1],
item: {
text: '文本'
}
}
}
// 实例化 vm 的时候,变成了以下
data: {
msg: '消息',
arr: [1, __ob__: {
value: ...,
dep: new Dep(),
vmCount: ...
}],
item: {
text: '文本',
__ob__: {
value: ...,
dep: new Dep(),
vmCount: ...
}
},
__ob__: {
value: ...,
dep: new Dep(),
vmCount: ...
}
}也就是每个对象或者数组被 observe 之后,多了一个 _ob_ 属性,它是 Observer 的实例。那么这么做的意义何在呢,稍后分析。
继续分析 Observer 构造函数的下面部分:
// 如果是数组,先篡改数组的一些方法(push,splice,shift等等),使其能够支持响应式
if (Array.isArray(value)) {
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
// 数组里面的元素还是数组或者对象,递归地调用 observe 函数,使其成为响应式数据
this.observeArray(value)
} else {
// 遍历对象,使其每个键值也能成为响应式数据
this.walk(value)
}
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
// 将对象的键值转换成 getter / setter,
// getter 收集依赖
// setter 通知 watcher 更新
defineReactive(obj, keys[i])
}
}
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}我们再捋一下思路,首先在 initState 里面调用 initData,initData 得到用户配置的 data 对象后调用了 observe,observe 函数里面会实例化 Observer 类,在其构造函数里面,首先将对象的 _ob_ 属性指向 Observer 实例(这一步是为了检测到对象添加或者删除属性之后,能触发响应式的伏笔),之后遍历当前对象的键值,调用 defineReactive 去转换成 getter / setter。
所以,来分析下 defineReactive。
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
// 每个属性收集 watcher 的管理器
const dep = new Dep()
......
// 递归地去将属性值变成响应式
let childOb = !shallow && observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
// 当前属性收集 watcher
dep.depend() // 语句1
if (childOb) {
// 如果当前属性对应的属性值是对象,将当前 watcher 加入 val.__ob__.dep当中去,为什么要这么做呢?先思考一下
childOb.dep.depend() // 语句2
// 如果当前属性对应的属性值是数组,递归地将当前 watcher 加入数组每一项,item.__ob__.dep当中去,为什么要这么做呢?
if (Array.isArray(value)) { // 语句3
dependArray(value)
}
}
}
return value
},
set: function reactiveSetter (newVal) {
.....
childOb = !shallow && observe(newVal)
dep.notify()
}
})
}
function dependArray (value: Array<any>) {
for (let e, i = 0, l = value.length; i < l; i++) {
e = value[i]
e && e.__ob__ && e.__ob__.dep.depend()
if (Array.isArray(e)) {
dependArray(e)
}
}
}首先,我们从 defineReactive 可以看出,每个响应式属性都有一个 Dep 实例,这个是用来收集 watcher 的。由于 getter 与 setter 都是函数,并且引用了 dep,所以形成了闭包,dep 一直存在于内存当中。因此,假如在渲染组件的时候,如果使用了响应式属性 a,就会走到上述的语句1,dep 实例就会收集组件这个 renderWatcher,因为在对 a 进行 setter 赋值操作的时候,会调用 dep.notify() 去 通知 renderWatcher 去更新,进而触发响应式数据收集新一轮的 watcher。
那么语句2与3,到底是什么作用呢
我们举个栗子分析
<div>{{person}}<div>export default {
data () {
return {
person: {
name: '张三',
age: 18
}
}
}
}
this.person.gender = '男' // 组件视图不会更新因为 Vue 是无法探测到对象增添属性,所以也没有一个时机去触发 renderWatcher 的更新。
为此, Vue 提供了一个 API,this.$set,它是 Vue.set 的别名。
export function set (target: Array<any> | Object, key: any, val: any): any {
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key)
target.splice(key, 1, val)
return val
}
if (key in target && !(key in Object.prototype)) {
target[key] = val
return val
}
const ob = (target: any).__ob__
if (target._isVue || (ob && ob.vmCount)) {
process.env.NODE_ENV !== 'production' && warn(
'Avoid adding reactive properties to a Vue instance or its root $data ' +
'at runtime - declare it upfront in the data option.'
)
return val
}
if (!ob) {
target[key] = val
return val
}
defineReactive(ob.value, key, val)
ob.dep.notify()
return val
}set 函数接受三个参数,第一个参数可以是 Object 或者 Array,其余的参数分别为 key, value。如果利用这个 API 给 person 增加一个属性呢?
this.$set(this.person, 'gender', '男') // 组件视图重新渲染为什么通过 set 函数又能触发重新渲染呢?注意到这一句, ob.dep.notify(),ob怎么来的呢,那就得回到之前的 observe 函数了,其实 data 经过 observe 处理之后变成下面这样。
{
person: {
name: '张三',
age: 18,
__ob__: {
value: ...,
dep: new Dep()
}
},
__ob__: {
value: ...,
dep: new Dep()
}
}
// 只要是对象,都定义了 __ob__ 属性,它是 Observer 类的实例从 template 来看,视图依赖了 person 这个属性值,renderWatcher 被收集到了 person 属性的 Dep 实例当中,对应 defineReactive 函数定义的语句1,同时,语句2的作用就是将 renderWatcher 收集到 person._ob_.dep 当中去,因此在给 person 增加属性的时候,调用 set 方法才能获取到 person._ob_.dep,进而触发 renderWatcher 更新。
那么得出结论,语句2的作用是为了能够探测到响应式数据是对象的情况下增删属性而引发重新渲染的。
再举个栗子解释下语句3的作用。
<div>{{books}}<div>export default {
data () {
return {
books: [
{
id: 1,
name: 'js'
}
]
}
}
}因为组件对 books 进行求值,而它是一个数组,所以会走到语句3的逻辑。
if (Array.isArray(value)) { // 语句3
dependArray(value)
}
function dependArray (value: Array<any>) {
for (let e, i = 0, l = value.length; i < l; i++) {
e = value[i]
e && e.__ob__ && e.__ob__.dep.depend()
if (Array.isArray(e)) {
dependArray(e)
}
}
}从逻辑上来看,就是循环 books 的每一项 item,如果 item 是一个数组或者对象,就会获取到 item._ob_.dep,并且将当前 renderWatcher 收集到 dep 当中去。
如果没有这一句,会发生什么情况?考虑下如下的情况:
this.$set(this.books[0], 'comment', '棒极了') // 并不会触发组件更新如果理解成 renderWatch 并没有对 this.books[0] 进行求值,所以改变它并不需要造成组件更新,那么这个理解是有误的。正确的是因为数组是元素的集合,内部的任何修改是需要反映出来的,所以语句3就是为了在 renderWatcher 对数组求值的时候,将 renderWatcher 收集到数组内部每一项 item._ob_.dep 当中去,这样只要内部发生变化,就能通过 dep 获取到 renderWatcher,通知它更新。
那么结合我的业务代码,就分析出来问题出现在语句3当中。
<div class="card-content">
<div class="block" v-for="item in cardData" :key="item.secName">
<div class="sub-title">{{item.secName}}</div>
<div class="group">
<span
@click="cardClick(index + item.startIndex)"
class="item"
:class="getItemClass(index + item.startIndex)"
v-for="(subItem, index) in item.secTids"
:key="subItem">{{index + item.startIndex + 1}}</span>
</div>
</div>
</div>getItemClass (index) {
const ret = {}
// 如果是做对的题目,但并不是当前选中
ret['item_true'] = this.questions[index]......
// 如果是做对的题目,并且是当前选中
ret['item_true_active'] = this.questions[index]......
// 如果是做错的题目,但并不是当前选中
ret['item_false'] = this.questions[index]......
// 如果是做错的题目,并且是当前选中
ret['item_false_active'] = this.questions[index]......
// 如果是未做的题目,但不是当前选中
ret['item_undo'] = this.questions[index]......
// 如果是未做的题目,并且是当前选中
ret['item_undo_active'] = this.questions[index]......
return ret
},首先 cardData 是一个分组数据,循环里面套循环,假设有 10 个章节, 每个章节有 200 道题目,那么其实会执行 2000 次 getItemClass 函数,getItemClass 内部会有 6 次对 questions 进行求值,每次都会走到 dependArray,每次执行 dependArray 都会循环 2000 次,所以粗略估计 2000 * 6 * 2000 = 2400 万次,如果假设一次执行的语句是 4 条,那么也会执行接近一亿次的语句,性能自然是原地爆炸!
既然从源头分析出了原因,那么就要找出方法从源头上去解决。
拆分组件
很多人理解拆分组件是为了复用,当然作用不止是这些,拆分组件更多的是为了可维护性,可以更语义化,在同事看到你的组件名的时候,大概能猜出里面的功能。而我这里拆分组件,是为了隔离无关的响应式数据造成的组件渲染。从上图可以看出,只要任何一个响应式数据改变,Paper 都会重新渲染,比如我点击收藏按钮,Paper 组件会重新渲染,按道理只要收藏按钮这个 DOM 重新渲染即可。
在嵌套循环中,不要用函数
性能出现问题的原因是在于我用了 getItemClass 去计算每一个小圆圈的样式,而且在函数里面还对 questions 进行了求值,这样时间复杂度从 O(n²) 变成了 O(n³)(由于源码的 dependArray也会循环)。最后的解决方案,我是弃用了 getItemClass 这个函数,直接更改了 cardData 的 tids 的数据结构,变成了 tInfo,也就是在构造数据的时候,计算好样式。
this.cardData = [{
startIndex: 0,
secName: '章节名称',
secId: '章节id',
tInfo: [
{
id: 1,
klass: 'item_false'
},
{
id: 2,
klass: 'item_false_active'
}]
}]如此一来,就不会出现 O(n³) 时间复杂度的问题了。
善用缓存
我发现 getItemClass 里面自己写的很不好,其实应该用个变量去缓存 quesions,这样就不会造成对 questions 多次求值,进而多次走到源码的 dependArray 当中去。
const questions = this.questions
// good // bad
// questions[0] this.questions[0]
// questions[1] this.questions[1]
// questions[2] this.questions[2]
......
// 前者只会对 this.questions 一次求值,后者会三次求值从这次教训,自己也学到了也很多。
代码:
<scroll class="wrapper" :data="dataObj" ref="scroll"></scroll>
this.$http.get(url, {})
.then((res) => {
this.html = res.data;
this.$nextTick(() => {
this.$refs.scroll.scrollTo(0,0);
this.$refs.scroll.refresh();
})
})
参考了你的文章,这里仅仅是一个获取数据,确认渲染之后refresh的动作,为什么有时候可以拖动,有时候无法拖动,在scroll组件设置refreshDelay为2s又可以滚动了,是我刷新的时机不对吗
本文并不是什么高深的技术文章,只是记录我最近遇到一个因为 Vue 升级导致我的一个项目踩坑以及我解决问题的过程。文章虽长但不水,写下来的目的是想和大家分享一下我遇到问题时候一个思考的方法和态度。
背景:去年我在慕课网推出了一门 Vue.js 的入门实战课程——Vue.js 高仿饿了么外卖 App ,这门课程收到了非常不错的反响,于是今年又在慕课网上继续推出了 Vue.js 的高级进阶实战课程——Vue.js 音乐 App,同样反馈不错。每天晚上下班回家,我会去问答区看一下学生们的问题,发现近期有不少同学反馈了同样的问题,iOS 微信里点击不能播放歌曲了,PC 可以。通常遇到这种问题我会让学生先去访问我的项目的线上地址,看看我的代码会不会有问题,得到的结论是我的线上代码没问题,但他们自己写就不行,并且说已经完全和我的代码做了对比,这就让我觉得十分诡异。没过多久,有些学生就想出了一个办法,在全局 document 绑定一个同步的 click 事件,在 click 事件的回调函数中同步触发一次 audio 的 play 方法,似乎解决了问题,也得到了一些同学的采纳,但是我看到以后的第一反应是不能用这种太 hack 的方式去解决问题,必须找到问题的本质,于是乎我开始了一段很有意思的找问题的过程。
先看现象:同学们写的代码在 iOS 微信浏览器下不能播放,PC 是可以的;我线上的代码是都可以。了解现象后我开始排查问题:
同学们的代码写的有问题?
虽然会有这种可能性,但从 2 个维度被我否决了:1. 同学们也都对比过我的源码的,而且出问题的同学也不是个别现象;2. 如果是代码问题,那么大多可能性是 PC 和移动端都不能播放。
找不同?
这个问题是最新才出现的,同学们开始学习编写课程代码都也是通过 vue-cli 脚手架先初始化代码。接着我大概看了一下新版的脚手架初始化的代码,果然是大不同,webpack 升级到 3+,配置发生了很大的变化。不过依据我的经验,构建工具的升级是不会影响业务代码的,一定还有别的原因。
Vue.js 升级?
除了 webpack 配置的不同,最新脚手架初始化的代码用的 Vue.js 版本是 2.5+,而我线上代码的 Vue.js 版本是 2.3+,难道是 Vue.js 导致的问题吗?带着这个疑问我去翻阅了 Vue.js 的 release log,发现 Vue.js 大大小小版本发布了十几次。如果每个都仔细查看也会很耗时,于是我采用了一个经典的 2 分法的思路去定位,我先把 Vue.js 升级到 2.4.0,发现竟然安装不了(这是 Vue.js 刚升到 2.4 npm 发布的 bug),于是又升级到 2.4.1,然后拿我的手机试了一下,还是可以播放的。接着我把 Vue.js 升级到 2.5.0,手机一试果然不能播放了,(擦。。)我心里默念一句,总算找到问题所在了。
以上定位到问题大概花了我半小时时间,但是我并没有找到问题的根本原因,于是我翻阅了 Vue.js 2.5 的 release log,由于很长就不列了。Vue.js 每次升级主要分成 2 大类,Features & Improvements 和 Bug Fixes。我从上往下依次扫了一遍,把一些关于它核心的改动都点进去看了一下代码的修改,最终锁定了这一条:
use MessageChannel for nextTick 6e41679, closes #6566 #6690
接着我点进去看了一下改动,我滴天,改动很大呀,nextTick 的核心实现变了,MutationObserver 不见了,改成了 MessageChannel 的实现。等等,有些同学看到这里,可能会懵,这都是些啥呀。不急,我先简单解释一下 Vue 的 nextTick。
介绍 Vue 的 nextTick 之前,我先简单介绍一下 JS 的运行机制:JS 执行是单线程的,它是基于事件循环的。对于事件循环的理解,阮老师有一篇文章写的很清楚,大致分为以下几个步骤:
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度被调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要清空所有的 micro task。
关于 macro task 和 micro task 的概念,这里不会细讲,简单通过一段代码演示他们的执行顺序:
for (macroTask of macroTaskQueue) {
// 1. Handle current MACRO-TASK
handleMacroTask();
// 2. Handle all MICRO-TASK
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}在浏览器环境中,常见的 macro task 有 setTimeout、MessageChannel、postMessage、setImmediate;常见的 micro task 有 MutationObsever 和 Promise.then。对于它们更多的了解,感兴趣的同学可以看这篇文章。
回到 Vue 的 nextTick,nextTick 顾名思义,就是下一个 tick,Vue 内部实现了 nextTick,并把它作为一个全局 API 暴露出来,它支持传入一个回调函数,保证回调函数的执行时机是在下一个 tick。官网文档介绍了 Vue.nextTick 的使用场景:
Usage: Defer the callback to be executed after the next DOM update cycle. Use it immediately after you’ve changed some data to wait for the DOM update.
使用:在下次 DOM 更新循环结束之后执行延迟回调,在修改数据之后立即使用这个方法,获取更新后的 DOM。
在 Vue.js 里是数据驱动视图变化,由于 JS 执行是单线程的,在一个 tick 的过程中,它可能会多次修改数据,但 Vue.js 并不会傻到每修改一次数据就去驱动一次视图变化,它会把这些数据的修改全部 push 到一个队列里,然后内部调用 一次 nextTick 去更新视图,所以数据到 DOM 视图的变化是需要在下一个 tick 才能完成。
接下来,我们来看一下 Vue 的 nextTick 的实现,在 Vue.js 2.5+ 的版本,抽出来一个单独的 next-tick.js 文件去实现它,
/* @flow */
/* globals MessageChannel */
import { noop } from 'shared/util'
import { handleError } from './error'
import { isIOS, isNative } from './env'
const callbacks = []
let pending = false
function flushCallbacks () {
pending = false
const copies = callbacks.slice(0)
callbacks.length = 0
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
// Here we have async deferring wrappers using both micro and macro tasks.
// In < 2.4 we used micro tasks everywhere, but there are some scenarios where
// micro tasks have too high a priority and fires in between supposedly
// sequential events (e.g. #4521, #6690) or even between bubbling of the same
// event (#6566). However, using macro tasks everywhere also has subtle problems
// when state is changed right before repaint (e.g. #6813, out-in transitions).
// Here we use micro task by default, but expose a way to force macro task when
// needed (e.g. in event handlers attached by v-on).
let microTimerFunc
let macroTimerFunc
let useMacroTask = false
// Determine (macro) Task defer implementation.
// Technically setImmediate should be the ideal choice, but it's only available
// in IE. The only polyfill that consistently queues the callback after all DOM
// events triggered in the same loop is by using MessageChannel.
/* istanbul ignore if */
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
// Determine MicroTask defer implementation.
/* istanbul ignore next, $flow-disable-line */
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
// in problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) setTimeout(noop)
}
} else {
// fallback to macro
microTimerFunc = macroTimerFunc
}
/**
* Wrap a function so that if any code inside triggers state change,
* the changes are queued using a Task instead of a MicroTask.
*/
export function withMacroTask (fn: Function): Function {
return fn._withTask || (fn._withTask = function () {
useMacroTask = true
const res = fn.apply(null, arguments)
useMacroTask = false
return res
})
}
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}我们在有之前的知识背景,再理解 nextTick 的实现就不难了,这里有一段很关键的注释:在 Vue 2.4 之前的版本,nextTick 几乎都是基于 micro task 实现的,但由于 micro task 的执行优先级非常高,在某些场景下它甚至要比事件冒泡还要快,就会导致一些诡异的问题,如 issue #4521、#6690、#6566;但是如果全部都改成 macro task,对一些有重绘和动画的场景也会有性能影响,如 issue #6813。所以最终 nextTick 采取的策略是默认走 micro task,对于一些 DOM 交互事件,如 v-on 绑定的事件回调函数的处理,会强制走 macro task。
这个强制是怎么做的呢,原来在 Vue.js 在绑定 DOM 事件的时候,默认会给回调的 handler 函数调用 withMacroTask 方法做一层包装,它保证整个回调函数执行过程中,遇到数据状态的改变,这些改变都会被推到 macro task 中。
对于 macro task 的执行,Vue.js 优先检测是否支持原生 setImmediate,这是一个高版本 IE 和 Edge 才支持的特性,不支持的话再去检测是否支持原生的 MessageChannel,如果也不支持的话就会降级为 setTimeout 0。
回到我们的问题,iOS 微信浏览器不能播放歌曲和 nextTick 有什么关系呢?先来看一下我们的歌曲播放这个功能的实现方法。
我们的代码会有一个播放器组件 player.vue,在这个组件中我们会持有一个 html5 的 audio 标签。由于可调用播放的地方很多,比如在歌曲列表组件、榜单组件、搜索结果组件等等,因此我们用 vuex 对播放相关的数据进行管理。我们把正在播放的列表 playlist 和当前播放索引 currentIndex 用 state 维护,当前播放的歌曲 currentSong 通过它们计算而来:
// state.js
const state = {
playlist: [],
currentIndex:0
}
// getters.js
export const currentSong = (state) => {
return state.playlist[state.currentIndex] || {}
}然后我们在 player.vue 组件里 watch currentSong 的变化去播放歌曲:
// player.vue
watch : {
currentSong(newSong,oldSong) {
if (!newSong.id || !newSong.url || newSong.id === oldSong.id) {
return
}
this.$refs.audio.src = newSong.url
this.$refs.audio.play()
}
}这样我们就可以在任何组件中提交对 playlist 和 currentIndex 的修改来达到播放不同歌曲的目的。那么这么写和 nextTick 有什么关系呢?
因为在 Vue.js 中,watcher 的回调函数执行默认是异步的,当我们提交对 playlist 或者 currenIndex 的修改,都会触发 currentSong 的变化,但是由于是异步,并不会立刻执行 watcher 的回调函数,而会在 nextTick 后执行。所以当我们点击歌曲列表中的歌曲后,在 click 的事件回调函数中会提交对 playlist 和 currentIndex 的修改, 经过一系列同步的逻辑执行,最终是在 nextTick 后才会执行 wathcer 的回调,也就是调用 audio 的 play。
所以本质上,就是用户点击到 audio 的 play 并不是在一个 tick 中完成,并且前面提到 Vue.js 中对 v-on 绑定事件执行的 nextTick 过程会强制使用 macro task。那么到底是不是由于 nextTick 影响了 audio 在 iOS 微信浏览器中的播放呢,
我们就来把化繁为简,写一个简单 demo 来验证这个问题,用的 Vue.js 版本是 2.5+ 的。
<template>
<div id="app">
<audio ref="audio"></audio>
<button @click="changeUrl">click me</button>
</div>
</template>
<script>
const musicList = [
'http://ws.stream.qqmusic.qq.com/108756223.m4a?fromtag=46',
'http://ws.stream.qqmusic.qq.com/101787871.m4a?fromtag=46',
'http://ws.stream.qqmusic.qq.com/718475.m4a?fromtag=46'
]
export default {
name: 'app',
data() {
return {
index: 0,
url: ''
}
},
methods: {
changeUrl() {
this.index = (this.index + 1) % musicList.length
this.url = musicList[this.index]
}
},
watch: {
url(newUrl) {
this.$refs.audio.src = newUrl
this.$refs.audio.play()
}
}
}
</script>
这段代码的逻辑非常简单,我们会添加一个 watcher 监听 url 变化,当点击按钮的时候,会调用 changeUrl 方法,修改 url,然后 watcher 的回调函数执行,并调用 audio 的 play 方法。这段代码在 PC 浏览器是可以正常播放歌曲的,但是在 iOS 微信浏览器里却不能播放,这就证实了我们之前的猜想——在用户点击事件的回调函数到 audio 的播放如果经历了 nextTick 在 iOS 微信浏览器下不能播放。
有些同学可能会认为,当用户点击了按钮到播放的过程在 iOS 微信浏览器或者是 iOS safari 浏览器应该需要在同一个 tick 才能执行,果真需要这样吗?我们把上述代码做一个简单的修改:
changeUrl() {
this.index = (this.index + 1) % musicList.length
this.url = musicList[this.index]
setTimeout(()=>{
this.$refs.audio.src = this.url
this.$refs.audio.play()
}, 0)
}我们现在不利用 Vue.js 的 nextTick 了,直接来模拟 nextTick 的过程,发现使用 setTimeout 0 是可以在 iOS 微信浏览器器、包括 iOS safari 下播放的,然而实际上我们只要在 1000ms 内的延时时间播放都是可以的,但是超过 1000ms,比如 setTimeout 1001 又不能播放了,感兴趣的同学可以试试,这个现象的理论依据我还没找到,如果知道理论的同学也非常欢迎留言告诉我。
所以通过上述的实验,我们发现并不一定要在同一个 tick 执行播放,那么为啥 Vue.js 的 nextTick 是不可以的呢?回到 nextTick 的 macro task 的实现,它优先 setImmediate、然后 MessageChannel,最后才是 setTimeout 0。我们知道,除了高版本 IE 和 Edge,setImmediate 是没有原生支持的,除非一些工具对它进行了重新改写。而 MessageChannel 的浏览器支持程度还是非常高的,那么我把这段 demo 的异步过程改成用 MessageChannel 实现。
changeUrl() {
this.index = (this.index + 1) % musicList.length
this.url = musicList[this.index]
let channel = new MessageChannel()
let port = channel.port2
channel.port1.onmessage = () => {
this.$refs.audio.src = this.url
this.$refs.audio.play()
}
port.postMessage(1)
}这段代码在 PC 浏览器是可以播放的,而在 iOS 微信浏览器又不能播放了,调试后发现 this.$refs.audio.play() 的逻辑也是可以执行到的,但是歌曲并不能播放,应该是浏览器对 audio 播放在使用 MessageChannel 做异步的一种限制。
前面提到实现 macro task 还有一种方法是利用 postMessage,它的浏览器支持程度也很好,我们来把 demo 改成利用它来实现。
changeUrl() {
this.index = (this.index + 1) % musicList.length
this.url = musicList[this.index]
addEventListener('message', () => {
this.$refs.audio.src = this.url
this.$refs.audio.play()
}, false);
postMessage(1, '*')
}这段代码在 PC 浏览器和 iOS 微信浏览器以及 iOS safari 都可以播放的,说明并不是 macro task 的锅,而是 MessageChannel 的锅。其实 macro task 还有很多实现方式,感兴趣的同学可以看看 core-js 中对于 macro task 的几种实现方式。
现在我们定位到问题的本质是因为 Vue.js 的 nextTick 中优先使用了 MessageChannel,它会影响 iOS 微信浏览器的播放,那么我们如何用最小成本来解决这个问题呢?
如果是真实运行在生产环境中的项目,毫无疑问这肯定是优先解决问题的首选,因为确实也是因为 Vue.js 的升级才造成这个 bug 的。在我们的实际项目中,我们都是锁死某个 Vue.js 的版本的,除非我们想使用某个 Vue.js 新版的 feature 或者是当前版本遇到了一个严重 bug 而新版已经修复的情况,我们才会考虑升级 Vue.js,并且每次升级都需要经过完整的功能测试。
为何把 Vue.js 降级到 2.4+ 就没问题呢,因为 Vue.js 2.5 之前的 nextTick 都是优先使用 microtask 的,那么 audio 播放的时机实际上还是在当前 tick,所以当然不会有问题。
说到版本问题,其实这也是 Vue.js 的一点瑕疵吧,升版本的时候有时候改动过于激进了,比如这次关于 nextTick 的升级,它其实是 Vue.js 一个非常核心的功能,但是它只有单元测试,并没有大量的功能测试 case 覆盖,也只能通过社区帮助反馈问题做改进了。
Vue.js 的 watcher 默认是异步的,当然它也提供了同步的 watcher,这样 watcher 的回调函数执行就不需要经历了 nextTick,这样确实可以修复这个 bug,但又会引起别的问题。因为我们的音乐播放器有一个 feature 是可以在播放的过程中切换播放模式,我们支持顺序播放、随机播放、单曲循环三种播放模式,当我们从顺序播放切到随机播放模式的时候,实际上是对播放列表 playlist 做了修改,同时也修改了 currentIndex,这样可以保证我们在切换模式的时候并不会修改当前歌曲。那么问题来了,由于 currentSong 是由 playlist 和 currentIndex 计算而来的,对它们任何一个修改,都会触发 currentSong 的变化,由于我们现在改成同步的 watcher,那么 currentSong 的回调会执行 2 次,这样第一次的修改导致计算出来的歌曲就变成了另外一首了,这个显然也不是我们期望的。所以同步 watcher 也是不可行的。
其实还有很多方式都能“修复”这个问题,比如我们不通过 watcher,改成每次点击通过 event bus 去通知;比如仍然使用同步 watcher,但 currentSong 不通过计算,直接用 state 保留;比如每次点击事件不通过 v-on 绑定,我们直接在 mounted 的钩子函数里利用原生的 addEventListener 去绑定 click 事件。
当然,上述几个方式都是可行的,但是我并不推荐这么去改,因为这样对业务代码的改动实在太大了,如果我们本身的写法如果是合理的,却要强行改成这些方式,就好像是:我知道了框架的某一个坑,我用一些奇技淫巧绕过了这些坑,这样做也是不合理的。
框架产生的意义是什么:制定一种友好的开发规范,提升开发效率,让开发人员更加专注业务逻辑的开发。所以优秀的框架不应该限制开发人员对于一些场景下功能的实现方式,仅仅是因为这种实现方式虽然本身合理但可能会触发框架某个坑。
由于不想动业务代码,所以我就想了一些比较 hack 的办法,因为是 MessageChannel 的锅,所以我就在 Vue.js 的初始化前,引入了一段 hack.js
// hack for global nextTick
function noop() {
}
window.MessageChannel = noop
window.setImmediate = noop这样的话 Vue.js 在初始化 nextTick 的时候,发现全局的 setImmediate 和 MessageChannel 被改写了,就自动降级为 setTimeout 0 的实现,这样就可以规避掉我们的问题了。当然,这种 hack 方式算是没有办法的办法了,我并不推荐。
所以这种情况最合理的就是给 Vue.js 提 issue,我确实也是这么做了,去 Github 上提了一个 issue,第一次给 Vue.js 提 issue,发现 Vue 官方这块做的还是蛮人性化的,直接给一个提 issue 的链接,通过填写一些表单来描述这个 issue,并且推荐了一个很好的复现问题的工具 CodeSandbox 。这个 issue 当天就收到了尤大的回复,他表示 Vue.js 的 nextTick 确实会造成这个问题,但是我应该在同一个 tick 完成歌曲的播放,而不应该使用 watcher,接着就 close 了 issue。因为我提 issue 为了更直观的演示核心问题,用的就是上面提到的非常简单的 demo,所以在这种场景下,他说的也没问题,确实没有必要使用 watcher,于是我赶紧又回复了 issue,说明了一下我的真实使用场景,并表明希望从 Vue.js 内核去修复这个问题。可惜的是,尤大目前也并没有再回复这个 issue。
通过记录我这一次发现问题——定位问题——解决问题的过程,我想给同学带来的思考不仅仅是这个问题本身,还有我们遇到问题后的一些态度。发现问题并不难,很多人在写代码中都会发现问题,那么发现问题后你的第一反应是尝试自己解决,还是去求助,我相信前者肯定更好。那么在解决之前需要定位问题,这里我要提到一个词,叫“面向巧合编程”,很多人遇到问题后会不断尝试这种办法,很可能某个办法就从表象上“解决”了这个问题,却不知道为什么,这种解决问题的方式是很不靠谱的,你可能并没有根本上解决问题,又可能解决了这个问题却又引发另一个问题。所以定位问题的本质就非常关键了,其实这是一个能力,一个好的工程师不仅会写代码,也要会查问题,能快速定位到问题的本质,是一个优秀的工程师的必要条件,这一点不容易,需要平时不断地的积累。在定位到问题的本质后,就要解决问题了,一道题往往有多解,但每种解法是否合理,这也是一个需要思考的过程,多和一些比你厉害的人交流,多积攒一些这方面的经验,这也是一个积累的过程。如果以后你再遇到问题,也用这样的态度去面对的问题,那么你也会很快的成长。
很多同学学习我的音乐课程后,会问:“黄老师,你什么时候再出新视频呀?”,其实我想说这门课程你真的学完了吗?因为它的定位是一门 Vue.js 的进阶课程,不仅仅是因为课程的项目本身比较复杂,而且项目中很多知识点都可以做延伸的学习,另外项目难免会有一些小 bug 和一些由于接口改动引发的功能不可用的情况,遇到这些问题除了给我提 issue,尝试自己去解决然后给我提 pull request 的方式是不是对自己的提升更大呢?所以这门课程还是值得多去挖掘的,如果真正榨干了这门课的价值再来问我也不迟,当然我也会给你们带来更多干货的课程。
最后也来小小安利我的这门 Vue.js 进阶课程吧(慕课网地址),感兴趣的同学可以点进去看看课程介绍。课程的项目是托管在我的 Github 私服的,并不开源,所以外面的一切和这个课程相关的代码都是盗版的。这个源码我是一直维护的,包括最近 Vue.js 的脚手架的升级,以及依赖方接口的一些改造造成的功能不可用问题,都已经得到了解决。简单地截几张截图:
这一张是对 issue 的处理,我们在课程推出来后解决了几十个 issue,如果有同学在学习过程中遇到问题建议去翻阅 issue 寻找答案。有一些版本的升级的 issue 我不会关,为了让同学们可以更方便的找到。
这一张是代码提交记录,可以看到除了我还是有一些很不错的同学在一起维护这个项目,这其中有一个同学学习非常主动,自驱力很强,常与我探讨技术问题,最近他也加入了滴滴,在我们部门做了很多的产出。
更直观的感受这个项目,可以扫描下方的二维码,体验一下接近原生 App 的感觉:
我们有一个官方的课程交流群,如果购买了这门课程,欢迎与其它同学一起交流学习,也可以加我的 qq 和微信,交流技术问问题都可以,不过我一般白天很忙,晚上才有时间。
当然,想关注我的一些动态,也欢迎 follow 我的 Github。
希望同学们一起来支持正版,抵制盗版,我会为大家带来更多优质的课程以及其它的一些形式的技术方向的分享。
本文参考的一些值得延伸学习的文章:
作者:崔静
虽然现在有各种前端框架来提高开发效率,但是在某些情况下,原生 JavaScript 实现的组件也是不可或缺的。例如在我们的项目中,需要给业务方提供一个通用的支付组件,但是业务方使用的技术栈可能是 Vue、React 等,甚至是原生的 JavaScript。那么为了实现通用性,同时保证组件的可维护性,实现一个原生 JavaScript 的组件也就显得很有必要了。
下面左图为我们的 Panel 组件的大概样子,右图则为我们项目的大概目录结构:
我们将一个组件拆分为 .html、.js、.css 三种文件,例如 Panel 组件,包含 panel.html、panel.js、panel.css 三个文件,这样可以将视图、逻辑和样式拆解开来便于维护。为了提升组件灵活性,我们 Panel 中的标题,button 的文案,以及中间 item 的个数、内容等均由配置数据来控制,这样,我们就可以根据配置数据动态渲染组件。这个过程中,为了使数据、事件流向更为清晰,参考 Vue 的设计,我们引入了数据处理中心 data center 的概念,组件需要的数据统一存放在 data center 中。data center 数据改变会触发组件的更新,而这个更新的过程,就是根据不同的数据对视图进行重新渲染。
panel.html 就是我们常说的“字符串模板”,而对其进行解析变成可执行的 JavaScript 代码的过程则是“模板引擎”所做的事情。目前有很多的模板引擎供选择,且一般都提供了丰富的功能。但是在很多情况下,我们可能只是处理一个简单的模板,没有太复杂的逻辑,那么简单的字符串模板已足够我们使用。
主要分为以下几类:
简单粗暴——正则替换
最简单粗暴的方式,直接使用字符串进行正则替换。但是无法处理循环语句和 if / else 判断这些。
a. 定义一个字符串变量的写法,比如用 <%%> 包裹
const template = (
'<div class="toast_wrap">' +
'<div class="msg"><%text%></div>' +
'<div class="tips_icon <%iconClass%>"></div>' +
'</div>'
)b. 然后通过正则匹配,找出所有的 <%%>, 对里面的变量进行替换
function templateEngine(source, data) {
if (!data) {
return source
}
return source.replace(/<%([^%>]+)?%>/g, function (match, key) {
return data[key] ? data[key] : ''
})
}
templateEngine(template, {
text: 'hello',
iconClass: 'warn'
})简单优雅——ES6 的模板语法
使用 ES6 语法中的模板字符串,上面的通过正则表达式实现的全局替换,我们可以简单的写成
const data = {
text: 'hello',
iconClass: 'warn'
}
const template = `
<div class="toast_wrap">
<div class="msg">${data.text}</div>
<div class="tips_icon ${data.iconClass}"></div>
</div>
`在模板字符串的 ${} 中可以写任意表达式,但是同样的,对 if / else 判断、循环语句无法处理。
简易模板引擎
很多情况下,我们渲染 HTML 模板时,尤其是渲染 ul 元素时, 一个 for 循环显得尤为必要。那么就需要在上面简单逻辑的基础上加入逻辑处理语句。
例如我们有如下一个模板:
var template = (
'I hava some menu lists:' +
'<% if (lists) { %>' +
'<ul>' +
'<% for (var index in lists) { %>' +
'<li><% lists[i].text %></li>' +
'<% } %>' +
'</ul>' +
'<% } else { %>' +
'<p>list is empty</p>' +
'<% } %>'
)直观的想,我们希望模板能转化成下面的样子:
'I hava some menu lists:'
if (lists) {
'<ul>'
for (var index in lists) {
'<li>'
lists[i].text
'</li>'
}
'</ul>'
} else {
'<p>list is empty</p>'
}为了得到最后的模板,我们将散在各处的 HTML 片段 push 到一个数组 html 中,最后通过 html.join('') 拼接成最终的模板。
const html = []
html.push('I hava some menu lists:')
if (lists) {
html.push('<ul>')
for (var index in lists) {
html.push('<li>')
html.push(lists[i].text)
html.push('</li>')
}
html.push('</ul>')
} else {
html.push('<p>list is empty</p>')
}
return html.join('')如此,我们就得到了可以执行的 JavaScript 代码。对比一下,容易看出从模板到 JavaScript 代码,经历了几个转换:
<%%> 中如果是逻辑语句(if/else/for/switch/case/break),那么中间的内容直接转成 JavaScript 代码。通过正则表达式 /(^( )?(var|if|for|else|switch|case|break|;))(.*)?/g 将要处理的逻辑表达式过滤出来。<% xxx %> 中如果是非逻辑语句,那么我们替换成 html.push(xxx) 的语句<%%> 之外的内容,我们替换成 html.push(字符串)const re = /<%(.+?)%>/g
const reExp = /(^( )?(var|if|for|else|switch|case|break|;))(.*)?/g
let code = 'var r=[];\n'
let cursor = 0
let result
let match
const add = (line, js) => {
if (js) { // 处理 `<%%>` 中的内容,
code += line.match(reExp) ? line + '\n' : 'r.push(' + line + ');\n'
} else { // 处理 `<%%>` 外的内容
code += line !== '' ? 'r.push("' + line.replace(/"/g, '\\"') + '");\n' : ''
}
return add
}
while (match = re.exec(template)) { // 循环找出所有的 <%%>
add(template.slice(cursor, match.index))(match[1], true)
cursor = match.index + match[0].length
}
// 处理最后一个<%%>之后的内容
add(template.substr(cursor, template.length - cursor))
// 最后返回
code = (code + 'return r.join(""); }').replace(/[\r\t\n]/g, ' ')到此我们得到了“文本”版本的 JavaScript 代码,利用 new Function 可以将“文本”代码转化为真正的可执行代码。
最后还剩一件事——传入参数,执行该函数。
方式一:可以把模板中所有的参数统一封装在一个对象 (data) 中,然后利用 apply 绑定函数的 this 到这个对象。这样在模板中,我们便可通过 this.xx 获取到数据。
new Function(code).apply(data)方式二:总是写 this. 会感觉略麻烦。可以把函数包裹在 with(obj) 中来运行,然后把模板用到的数据当做 obj 参数传入函数。这样一来,可以像前文例子中的模板写法一样,直接在模板中使用变量。
let code = 'with (obj) { ...'
...
new Function('obj', code).apply(data, [data])但是需要注意,with 语法本身是存在一些弊端的。
到此我们就得到了一个简单的模板引擎。
在此基础上,可以进行一些包装,拓展一下功能。比如可以增加一个 i18n 多语言处理方法。这样可以把语言的文案从模板中单独抽离出来,在全局进行一次语言设置之后,在后期的渲染中,直接使用即可。
基本思路:对传入模板的数据进行包装,在其中增加一个 $i18n 函数。然后当我们在模板中写 <p><%$i18n("something")%></p> 时,将会被解析为 push($i18n("something"))
具体代码如下:
// template-engine.js
import parse from './parse' // 前面实现的简单的模板引擎
class TemplateEngine {
constructor() {
this.localeContent = {}
}
// 参数 parentEl, tpl, data = {} 或者 tpl, data = {}
renderI18nTpl(tpl, data) {
const html = this.render(tpl, data)
const el = createDom(`<div>${html}</div>`)
const childrenNode = children(el)
// 多个元素则用<div></div>包裹起来,单个元素则直接返回
const dom = childrenNode.length > 1 ? el : childrenNode[0]
return dom
}
setGlobalContent(content) {
this.localeContent = content
}
// 在传入模板的数据中多增加一个$i18n的函数。
render(tpl, data = {}) {
return parse(tpl, {
...data,
$i18n: (key) => {
return this.i18n(key)
}
})
}
i18n(key) {
if (!this.localeContent) {
return ''
}
return this.localeContent[key]
}
}
export default new TemplateEngine()通过 setGlobalContent 方法,设置全局的文案。然后在模板中可以通过<%$i18n("contentKey")%>来直接使用
import TemplateEngine from './template-engine'
const content = {
something: 'zh-CN'
}
TemplateEngine.setGlobalContent(content)
const template = '<p><%$i18n("something")%></p>'
const divDom = TemplateEngine.renderI18nTpl(template)在我们介绍的方法中使用 '<%%>' 的来包裹逻辑语块和变量,此外还有一种更为常见的方式——使用双大括号 {{}},也叫 mustache 标记。在 Vue, Angular 以及微信小程序的模板语法中都使用了这种标记,一般也叫做插值表达式。下面我们来看一个简单的 mustache 语法模板引擎的实现。
模板引擎 mustache.js 的原理
有了方法3的基础,我们理解其他的模板引擎原理就稍微容易点了。我们来看一个使用广泛的轻量级模板 mustache 的原理。
简单的例子如下:
var source = `
<div class="entry">
{{#author}}
<h1>{{name.first}}</h1>
{{/author}}
</div>
`
var rendered = Mustache.render(source, {
author: true,
name: {
first: 'ana'
}
})模板解析
模板引擎首先要对模板进行解析。mustache 的模板解析大概流程如下:
tokens = []
while (!剩余要处理的模板字符串是否为空) {
value = scanner.scanUntil(openingTagRe);
value = 模板字符串中第一个 {{ 之前所有的内容
if (value) {
处理value,按字符拆分,存入tokens中。例如 <div class="entry">
tokens = [
{'text', "<", 0, 1},
{'text', "d"< 1, 2},
...
]
}
if (!匹配{{) break;
type = 匹配开始符 {{ 之后的第一个字符,得到类型,如{{#tag}},{{/tag}}, {{tag}}, {{>tag}}等
value = 匹配结束符之前的内容 }},value中的内容则是 tag
匹配结束符 }}
token = [ type, value, start, end ]
tokens.push(token)
}
然后通过遍历 tokens,将连续的 text 类型的数组合并。
遍历 tokens,处理 section 类型(即模板中的 {{#tag}}{{/tag}},{{^tag}}{{/tag}})。section 在模板中是成对儿出现的,需要根据 section 进行嵌套,最后和我们的模板嵌套类型达到一致。
渲染
解析完模板之后,就是进行渲染了:根据传入的数据,得到最终的 HTML 字符串。渲染的大致过程如下:
首先将渲染模板的数据存入一个变量 context 中。由于在模板中,变量是字符串形式表示的,如 'name.first'。在获取的时候首先通过 . 来分割得到 'name' 和 'first' 然后通过 trueValue = context['name']['first'] 设值。为了提高性能,可以增加一个 cache 将该次获取到的结果保存起来,cache['name.first'] = trueValue 以便于下次使用。
渲染的核心过程就是遍历 tokens,获取到类型,和变量 (value) 的正真的值,然后根据类型、值进行渲染,最后将得到的结果拼接起来,即得到了最终的结果。
众多模板引擎中,如何锁定哪个是我们所需的呢?下面提供几个可以考虑的方向,希望可以帮助大家来选择:
功能
选择一个工具,最主要的是看它能否满足我们所需。比如,是否支持变量、逻辑表达式,是否支持子模板,是否会对 HTML 标签进行转义等。下面表格仅仅做几个模板引擎的简单对比。
不同模板引擎除了基本功能外,还提供了自己的特有的功能,比如 artTemplate 支持在模板文件上打断点,使用时方便调试,还有一些辅助方法;handlesbars 还提供一个 runtime 的版本,可以对模板进行预编译;ejs 逻辑表达式写法和 JavaScript 相同;等等在此就不一一例举了。
大小
对于一个轻量级组件来说,我们会格外在意组件最终的大小。功能丰富的模板引擎便会意味着体积较大,所以在功能和大小上我们需要进行一定的衡量。artTemplate 和 doT 较小,压缩后仅几 KB,而 handlebars 就较大,4.0.11 版本压缩后依然有 70+KB。
(注:上图部分数据来源于 https://cdnjs.com/ 上 min.js 的大小,部分来源于 git 上大小。大小为非 gzip 的大小)
性能
如果有非常多的频繁 DOM 更新或者需要渲染的 DOM 数量很多,渲染时,我们就需要关注一下模板引擎的性能了。
最后,以我们的项目为例子,我们要实现的组件是一个轻量级的组件(主要为一个浮层界面,两个页面级的全覆盖界面)同时用户的交互也很简单,组件不会进行频繁重新渲染。但是对组件的整体大小会很在意,而且还有一点特殊的是,在组件的文案我们需要支持多语言。所以最终我们选定了上文介绍的第三种方案。
最近的工作当中有个任务是做国际化。这篇文章也是做个简单的总结。
url进行区分,需要维护多份代码。IP去下发语言标识字段(前端根据下发的表示字段切换语言环境)useragent.lang浏览器环境语言进行设定lang字段去做语言标识,在页面渲染出来前,前端来决定使用的语言包。语言包是在本地编译的过程中就将语言包编译进了代码当中,没有采用异步加载的方式。vue-i18n这个插件来进行。插件提供了单复数,中文转英文的方法。a下文有对vue-i18n的源码进行分析。因为英文的阅读方向也是从左到右,因此语言展示的方向不予考虑。但是在一些阿拉伯地区国家的语言是从右到左进行阅读的。中文转英文后部分文案过长
图片
第三方插件(地图,SDK等)
a.中文转英文后肯定会遇到文案过长的情况。那么可能需要精简翻译,使文案保持在一定的可接受的长度范围内。但是大部分的情况都是文案在保持原意的情况下无法再进行精简。这时必须要前端来进行样式上的调整,那么可能还需要设计的同学参与进来,对一些文案过多出现折行的情况再单独做样式的定义。在细调样式这块,主要还是通过不同的语言标识去控制不同标签的class,来单独定义样式。

b. 此外,还有部分图片也是需要做调整,在C端中,大部分由产品方去输出内容,那么图片这块的话,还需要设计同学单独出图。c. 在第三方插件中这个环节当中,因为使用了腾讯地图插件,由于腾讯地图并未推出国内地图的英文版,所以整个页面的地图部分暂时无法做到国际化。由此联想到,你应用当中使用的其他一些第三方插件或者SDK。

货币及支付方式
时间的格式
在一些支付场景下,货币符号,单位及价格的转化等。不同国家地区在时间的格式显示上有差异。
翻译工作
map表的维护
当前翻译的工作流程是拆页面,每拆一个页面,FE同学整理好可能会出现的中文文案,再交由翻译的同学去完成翻译的工作。负责不同页面的同学维护着不同的map表,在当前的整体页面架构中,不同功能模块和页面被拆分出去交由不同的同学去做,那么通过跳页面的方式去暂时缓解map表的维护问题。如果哪一天页面需要收敛,这也是一个需要去考虑的问题。如果从整个项目的一开始就考虑到国际化的问题并采取相关的措施都能减轻后期的工作量及维护成本。同时以后一旦map表内容过多,是否需要考虑需要将map表进行异步加载。
// 入口main.js文件
import VueI18n from 'vue-i18n'
Vue.use(VueI18n) // 通过插件的形式挂载
const i18n = new VueI18n({
locale: CONFIG.lang, // 语言标识
messages: {
'zh-CN': require('./common/lang/zh'), // 中文语言包
'en-US': require('./common/lang/en') // 英文语言包
}
})
const app = new Vue({
i18n,
...App
}).$mout('#root')
// 单vue文件
<template>
<span>{{$t('你好')}}</span>
</template>Vue-i18n是以插件的形式配合Vue进行工作的。通过全局的mixin的方式将插件提供的方法挂载到Vue的实例上。
其中install.jsVue的挂载函数,主要是为了将mixin.js里面的提供的方法挂载到Vue实例当中:
import { warn } from './util'
import mixin from './mixin'
import Asset from './asset'
export let Vue
// 注入root Vue
export function install (_Vue) {
Vue = _Vue
const version = (Vue.version && Number(Vue.version.split('.')[0])) || -1
if (process.env.NODE_ENV !== 'production' && install.installed) {
warn('already installed.')
return
}
install.installed = true
if (process.env.NODE_ENV !== 'production' && version < 2) {
warn(`vue-i18n (${install.version}) need to use Vue 2.0 or later (Vue: ${Vue.version}).`)
return
}
// 通过mixin的方式,将插件提供的methods,钩子函数等注入到全局,之后每次创建的vue实例都用拥有这些methods或者钩子函数
Vue.mixin(mixin)
Asset(Vue)
}接下来就看下在Vue上混合了哪些methods或者钩子函数. 在mixin.js文件中:
/* @flow */
// VueI18n构造函数
import VueI18n from './index'
import { isPlainObject, warn } from './util'
// $i18n 是每创建一个Vue实例都会产生的实例对象
// 调用以下方法前都会判断实例上是否挂载了$i18n这个属性
// 最后实际调用的方法是插件内部定义的方法
export default {
// 这里混合了computed计算属性, 注意这里计算属性返回的都是函数,这样就可以在vue模板里面使用{{ $t('hello') }}, 或者其他方法当中使用 this.$t('hello')。这种函数接收参数的方式
computed: {
// 翻译函数, 调用的是VueI18n实例上提供的方法
$t () {
if (!this.$i18n) {
throw Error(`Failed in $t due to not find VueI18n instance`)
}
// add dependency tracking !!
const locale: string = this.$i18n.locale // 语言配置
const messages: Messages = this.$i18n.messages // 语言包
// 返回一个函数. 接受一个key值. 即在map文件中定义的key值, 在模板中进行使用 {{ $t('你好') }}
// ...args是传入的参数, 例如在模板中定义的一些替换符, 具体的支持的形式可翻阅文档https://kazupon.github.io/vue-i18n/formatting.html
return (key: string, ...args: any): string => {
return this.$i18n._t(key, locale, messages, this, ...args)
}
},
// tc方法可以单独定义组件内部语言设置选项, 如果没有定义组件内部语言,则还是使用global的配置
$tc () {
if (!this.$i18n) {
throw Error(`Failed in $tc due to not find VueI18n instance`)
}
// add dependency tracking !!
const locale: string = this.$i18n.locale
const messages: Messages = this.$i18n.messages
return (key: string, choice?: number, ...args: any): string => {
return this.$i18n._tc(key, locale, messages, this, choice, ...args)
}
},
// te方法
$te () {
if (!this.$i18n) {
throw Error(`Failed in $te due to not find VueI18n instance`)
}
// add dependency tracking !!
const locale: string = this.$i18n.locale
const messages: Messages = this.$i18n.messages
return (key: string, ...args: any): boolean => {
return this.$i18n._te(key, locale, messages, ...args)
}
}
},
// 钩子函数
// 被渲染前,在vue实例上添加$i18n属性
// 在根组件初始化的过程中:
/**
* new Vue({
* i18n // 这里是提供了自定义的属性 那么实例当中可以通过this.$option.i18n去访问这个属性
* // xxxx
* })
*/
beforeCreate () {
const options: any = this.$options
// 如果有i18n这个属性. 根实例化的时候传入了这个参数
if (options.i18n) {
if (options.i18n instanceof VueI18n) {
// 如果是VueI18n的实例,那么挂载在Vue实例的$i18n属性上
this.$i18n = options.i18n
// 如果是个object
} else if (isPlainObject(options.i18n)) { // 如果是一个pobj
// component local i18n
// 访问root vue实例。
if (this.$root && this.$root.$i18n && this.$root.$i18n instanceof VueI18n) {
options.i18n.root = this.$root.$i18n
}
this.$i18n = new VueI18n(options.i18n) // 创建属于component的local i18n
if (options.i18n.sync) {
this._localeWatcher = this.$i18n.watchLocale()
}
} else {
if (process.env.NODE_ENV !== 'production') {
warn(`Cannot be interpreted 'i18n' option.`)
}
}
} else if (this.$root && this.$root.$i18n && this.$root.$i18n instanceof VueI18n) {
// root i18n
// 如果子Vue实例没有传入$i18n方法,且root挂载了$i18n,那么子实例也会使用root i18n
this.$i18n = this.$root.$i18n
}
},
// 实例被销毁的回调函数
destroyed () {
if (this._localeWatcher) {
this.$i18n.unwatchLocale()
delete this._localeWatcher
}
// 组件销毁后,同时也销毁实例上的$i18n方法
this.$i18n = null
}
}这里注意下这几个方法的区别:
$tc这个方法可以用以返回翻译的复数字符串, 及一个key可以对应的翻译文本,通过|进行连接:
例如:
// main.js
new VueI18n({
messages: {
car: 'car | cars'
}
})
// template
<span>{{$tc('car', 1)}}</span> ===>>> <span>car</span>
<span>{{$tc('car', 2)}}</span> ===>>> <span>cars</span>$te这个方法用以判断需要翻译的key在你提供的语言包(messages)中是否存在.
接下来就看看VueI18n构造函数及原型上提供了哪些可以被实例继承的属性或者方法
/* @flow */
import { install, Vue } from './install'
import { warn, isNull, parseArgs, fetchChoice } from './util'
import BaseFormatter from './format' // 转化函数 封装了format, 里面包含了template模板替换的方法
import getPathValue from './path'
import type { PathValue } from './path'
// VueI18n构造函数
export default class VueI18n {
static install: () => void
static version: string
_vm: any
_formatter: Formatter
_root: ?I18n
_sync: ?boolean
_fallbackRoot: boolean
_fallbackLocale: string
_missing: ?MissingHandler
_exist: Function
_watcher: any
// 实例化参数配置
constructor (options: I18nOptions = {}) {
const locale: string = options.locale || 'en-US' // vue-i18n初始化的时候语言参数配置
const messages: Messages = options.messages || {} // 本地配置的所有语言环境都是挂载到了messages这个属性上
this._vm = null // ViewModel
this._fallbackLocale = options.fallbackLocale || 'en-US' // 缺省语言配置
this._formatter = options.formatter || new BaseFormatter() // 翻译函数
this._missing = options.missing
this._root = options.root || null
this._sync = options.sync || false
this._fallbackRoot = options.fallbackRoot || false
this._exist = (message: Object, key: string): boolean => {
if (!message || !key) { return false }
return !isNull(getPathValue(message, key))
}
this._resetVM({ locale, messages })
}
// VM
// 重置viewModel
_resetVM (data: { locale: string, messages: Messages }): void {
const silent = Vue.config.silent
Vue.config.silent = true
this._vm = new Vue({ data })
Vue.config.silent = silent
}
// 根实例的vm监听locale这个属性
watchLocale (): any {
if (!this._sync || !this._root) { return null }
const target: any = this._vm
// vm.$watch返回的是一个取消观察的函数,用来停止触发回调
this._watcher = this._root.vm.$watch('locale', (val) => {
target.$set(target, 'locale', val)
}, { immediate: true })
return this._watcher
}
// 停止触发vm.$watch观察函数
unwatchLocale (): boolean {
if (!this._sync || !this._watcher) { return false }
if (this._watcher) {
this._watcher()
delete this._watcher
}
return true
}
get vm (): any { return this._vm }
get messages (): Messages { return this._vm.$data.messages } // get 获取messages参数
set messages (messages: Messages): void { this._vm.$set(this._vm, 'messages', messages) } // set 设置messages参数
get locale (): string { return this._vm.$data.locale } // get 获取语言配置参数
set locale (locale: string): void { this._vm.$set(this._vm, 'locale', locale) } // set 重置语言配置参数
get fallbackLocale (): string { return this._fallbackLocale } // fallbackLocale 是什么?
set fallbackLocale (locale: string): void { this._fallbackLocale = locale }
get missing (): ?MissingHandler { return this._missing }
set missing (handler: MissingHandler): void { this._missing = handler }
get formatter (): Formatter { return this._formatter } // get 转换函数
set formatter (formatter: Formatter): void { this._formatter = formatter } // set 转换函数
_warnDefault (locale: string, key: string, result: ?any, vm: ?any): ?string {
if (!isNull(result)) { return result }
if (this.missing) {
this.missing.apply(null, [locale, key, vm])
} else {
if (process.env.NODE_ENV !== 'production') {
warn(
`Cannot translate the value of keypath '${key}'. ` +
'Use the value of keypath as default.'
)
}
}
return key
}
_isFallbackRoot (val: any): boolean {
return !val && !isNull(this._root) && this._fallbackRoot
}
// 插入函数
_interpolate (message: Messages, key: string, args: any): any {
if (!message) { return null }
// 获取key对应的字符串
let val: PathValue = getPathValue(message, key)
if (Array.isArray(val)) { return val }
if (isNull(val)) { val = message[key] }
if (isNull(val)) { return null }
if (typeof val !== 'string') {
warn(`Value of key '${key}' is not a string!`)
return null
}
// TODO ?? 这里的links是干什么的?
// Check for the existance of links within the translated string
if (val.indexOf('@:') >= 0) {
// Match all the links within the local
// We are going to replace each of
// them with its translation
const matches: any = val.match(/(@:[\w|.]+)/g)
for (const idx in matches) {
const link = matches[idx]
// Remove the leading @:
const linkPlaceholder = link.substr(2)
// Translate the link
const translatedstring = this._interpolate(message, linkPlaceholder, args)
// Replace the link with the translated string
val = val.replace(link, translatedstring)
}
}
// 如果没有传入需要替换的obj, 那么直接返回字符串, 否则调用this._format进行变量等的替换
return !args ? val : this._format(val, args) // 获取替换后的字符
}
_format (val: any, ...args: any): any {
return this._formatter.format(val, ...args)
}
// 翻译函数
_translate (messages: Messages, locale: string, fallback: string, key: string, args: any): any {
let res: any = null
/**
* messages[locale] 使用哪个语言包
* key 语言映射表的key
* args 映射替换关系
*/
res = this._interpolate(messages[locale], key, args)
if (!isNull(res)) { return res }
res = this._interpolate(messages[fallback], key, args)
if (!isNull(res)) {
if (process.env.NODE_ENV !== 'production') {
warn(`Fall back to translate the keypath '${key}' with '${fallback}' locale.`)
}
return res
} else {
return null
}
}
// 翻译的核心函数
/**
* 这里的方法传入的参数参照mixin.js里面的定义的方法
* key map的key值 (为接受的外部参数)
* _locale 语言配置选项: 'zh-CN' | 'en-US' (内部变量)
* messages 映射表 (内部变量)
* host为这个i18n的实例 (内部变量)
*
*/
_t (key: string, _locale: string, messages: Messages, host: any, ...args: any): any {
if (!key) { return '' }
// parseArgs函数用以返回传入的局部语言配置, 及映射表
const parsedArgs = parseArgs(...args) // 接收的参数{ locale, params(映射表) }
const locale = parsedArgs.locale || _locale // 语言配置
// 字符串替换
/**
* @params messages 语言包
* @params locale 语言配置
* @params fallbackLocale 缺省语言配置
* @params key 替换的key值
* @params parsedArgs.params 需要被替换的参数map表
*/
const ret: any = this._translate(messages, locale, this.fallbackLocale, key, parsedArgs.params)
if (this._isFallbackRoot(ret)) {
if (process.env.NODE_ENV !== 'production') {
warn(`Fall back to translate the keypath '${key}' with root locale.`)
}
if (!this._root) { throw Error('unexpected error') }
return this._root.t(key, ...args)
} else {
return this._warnDefault(locale, key, ret, host)
}
}
// 转化函数
t (key: string, ...args: any): string {
return this._t(key, this.locale, this.messages, null, ...args)
}
_tc (key: string, _locale: string, messages: Messages, host: any, choice?: number, ...args: any): any {
if (!key) { return '' }
if (choice !== undefined) {
return fetchChoice(this._t(key, _locale, messages, host, ...args), choice)
} else {
return this._t(key, _locale, messages, host, ...args)
}
}
tc (key: string, choice?: number, ...args: any): any {
return this._tc(key, this.locale, this.messages, null, choice, ...args)
}
_te (key: string, _locale: string, messages: Messages, ...args: any): boolean {
const locale = parseArgs(...args).locale || _locale
return this._exist(messages[locale], key)
}
te (key: string, ...args: any): boolean {
return this._te(key, this.locale, this.messages, ...args)
}
}
VueI18n.install = install
VueI18n.version = '__VERSION__'
// 如果是通过CDN或者外链的形式引入的Vue
if (typeof window !== 'undefined' && window.Vue) {
window.Vue.use(VueI18n)
}另外还有一个比较重要的库函数format.js:
/**
* String format template
* - Inspired:
* https://github.com/Matt-Esch/string-template/index.js
*/
// 变量的替换, 在字符串模板中写的站位符 {xxx} 进行替换
const RE_NARGS: RegExp = /(%|)\{([0-9a-zA-Z_]+)\}/g
/**
* template
*
* @param {String} string
* @param {Array} ...args
* @return {String}
*/
// 模板替换函数
export function template (str: string, ...args: any): string {
// 如果第一个参数是一个obj
if (args.length === 1 && typeof args[0] === 'object') {
args = args[0]
} else {
args = {}
}
if (!args || !args.hasOwnProperty) {
args = {}
}
// str.prototype.replace(substr/regexp, newSubStr/function) 第二个参数如果是个函数的话,每次匹配都会调用这个函数
// match 为匹配的子串
return str.replace(RE_NARGS, (match, prefix, i, index) => {
let result: string
// match是匹配到的字符串
// prefix ???
// i 括号中需要替换的字符换
// index是偏移量
// 字符串中如果出现{xxx}不需要被替换。那么应该写成{{xxx}}
if (str[index - 1] === '{' &&
str[index + match.length] === '}') {
return i
} else {
// 判断args obj是否包含这个key值
// 返回替换值, 或者被匹配上的字符串的值
result = hasOwn(args, i) ? args[i] : match
if (isNull(result)) {
return ''
}
return result
}
})
}本项目是使用vue作为前端框架,使用vue-i18n作为国际化的工具。
vue-i18n进行替换body上添加多语言的标识class属性SDK或插件的国际化推动Vue版本: 2.3.2
virtual-dom(后文简称vdom)的概念大规模的推广还是得益于react出现,virtual-dom也是react这个框架的非常重要的特性之一。相比于频繁的手动去操作dom而带来性能问题,vdom很好的将dom做了一层映射关系,进而将在我们本需要直接进行dom的一系列操作,映射到了操作vdom,而vdom上定义了关于真实dom的一些关键的信息,vdom完全是用js去实现,和宿主浏览器没有任何联系,此外得益于js的执行速度,将原本需要在真实dom进行的创建节点,删除节点,添加节点等一系列复杂的dom操作全部放到vdom中进行,这样就通过操作vdom来提高直接操作的dom的效率和性能。
Vue在2.0版本也引入了vdom。其vdom算法是基于snabbdom算法所做的修改。
在Vue的整个应用生命周期当中,每次需要更新视图的时候便会使用vdom。那么在Vue当中,vdom是如何和Vue这个框架融合在一起工作的呢?以及大家常常提到的vdom的diff算法又是怎样的呢?接下来就通过这篇文章简单的向大家介绍下Vue当中的vdom是如何去工作的。
首先,我们还是来看下Vue生命周期当中初始化的最后阶段:将vm实例挂载到dom上,源码在src/core/instance/init.js
Vue.prototype._init = function () {
...
vm.$mount(vm.$options.el)
...
} 实际上是调用了src/core/instance/lifecycle.js中的mountComponent方法,
mountComponent函数的定义是:
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
// vm.$el为真实的node
vm.$el = el
// 如果vm上没有挂载render函数
if (!vm.$options.render) {
// 空节点
vm.$options.render = createEmptyVNode
}
// 钩子函数
callHook(vm, 'beforeMount')
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
...
} else {
// updateComponent为监听函数, new Watcher(vm, updateComponent, noop)
updateComponent = () => {
// Vue.prototype._render 渲染函数
// vm._render() 返回一个VNode
// 更新dom
// vm._render()调用render函数,会返回一个VNode,在生成VNode的过程中,会动态计算getter,同时推入到dep里面
vm._update(vm._render(), hydrating)
}
}
// 新建一个_watcher对象
// vm实例上挂载的_watcher主要是为了更新DOM
// vm/expression/cb
vm._watcher = new Watcher(vm, updateComponent, noop)
hydrating = false
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
return vm
}注意上面的代码中定义了一个updateComponent函数,这个函数执行的时候内部会调用vm._update(vm._render(), hyddrating)方法,其中vm._render方法会返回一个新的vnode,(关于vm_render是如何生成vnode的建议大家看看vue的关于compile阶段的代码),然后传入vm._update方法后,就用这个新的vnode和老的vnode进行diff,最后完成dom的更新工作。那么updateComponent都是在什么时候去进行调用呢?
vm._watcher = new Watcher(vm, updateComponent, noop)实例化一个watcher,在求值的过程中this.value = this.lazy ? undefined : this.get(),会调用this.get()方法,因此在实例化的过程当中Dep.target会被设为这个watcher,通过调用vm._render()方法生成新的Vnode并进行diff的过程中完成了模板当中变量依赖收集工作。即这个watcher被添加到了在模板当中所绑定变量的依赖当中。一旦model中的响应式的数据发生了变化,这些响应式的数据所维护的dep数组便会调用dep.notify()方法完成所有依赖遍历执行的工作,这里面就包括了视图的更新即updateComponent方法,它是在mountComponent中的定义的。
updateComponent方法的定义是:
updateComponent = () => {
vm._update(vm._render(), hydrating)
}完成视图的更新工作事实上就是调用了vm._update方法,这个方法接收的第一个参数是刚生成的Vnode,调用的vm._update方法(src/core/instance/lifecycle.js)的定义是
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
const vm: Component = this
if (vm._isMounted) {
callHook(vm, 'beforeUpdate')
}
const prevEl = vm.$el
const prevVnode = vm._vnode
const prevActiveInstance = activeInstance
activeInstance = vm
// 新的vnode
vm._vnode = vnode
// Vue.prototype.__patch__ is injected in entry points
// based on the rendering backend used.
// 如果需要diff的prevVnode不存在,那么就用新的vnode创建一个真实dom节点
if (!prevVnode) {
// initial render
// 第一个参数为真实的node节点
vm.$el = vm.__patch__(
vm.$el, vnode, hydrating, false /* removeOnly */,
vm.$options._parentElm,
vm.$options._refElm
)
} else {
// updates
// 如果需要diff的prevVnode存在,那么首先对prevVnode和vnode进行diff,并将需要的更新的dom操作已patch的形式打到prevVnode上,并完成真实dom的更新工作
vm.$el = vm.__patch__(prevVnode, vnode)
}
activeInstance = prevActiveInstance
// update __vue__ reference
if (prevEl) {
prevEl.__vue__ = null
}
if (vm.$el) {
vm.$el.__vue__ = vm
}
// if parent is an HOC, update its $el as well
if (vm.$vnode && vm.$parent && vm.$vnode === vm.$parent._vnode) {
vm.$parent.$el = vm.$el
}
}在这个方法当中最为关键的就是vm.__patch__方法,这也是整个virtaul-dom当中最为核心的方法,主要完成了prevVnode和vnode的diff过程并根据需要操作的vdom节点打patch,最后生成新的真实dom节点并完成视图的更新工作。
接下来就让我们看下vm.__patch__里面到底发生了什么:
function patch (oldVnode, vnode, hydrating, removeOnly, parentElm, refElm) {
// 当oldVnode不存在时
if (isUndef(oldVnode)) {
// 创建新的节点
createElm(vnode, insertedVnodeQueue, parentElm, refElm)
} else {
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
// 对oldVnode和vnode进行diff,并对oldVnode打patch
patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly)
}
}
}在对oldVnode和vnode类型判断中有个sameVnode方法,这个方法决定了是否需要对oldVnode和vnode进行diff及patch的过程。
function sameVnode (a, b) {
return (
a.key === b.key &&
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
)
}sameVnode会对传入的2个vnode进行基本属性的比较,只有当基本属性相同的情况下才认为这个2个vnode只是局部发生了更新,然后才会对这2个vnode进行diff,如果2个vnode的基本属性存在不一致的情况,那么就会直接跳过diff的过程,进而依据vnode新建一个真实的dom,同时删除老的dom节点。
vnode基本属性的定义可以参见源码:src/vdom/vnode.js里面对于vnode的定义。
constructor (
tag?: string,
data?: VNodeData, // 关于这个节点的data值,包括attrs,style,hook等
children?: ?Array<VNode>, // 子vdom节点
text?: string, // 文本内容
elm?: Node, // 真实的dom节点
context?: Component, // 创建这个vdom的上下文
componentOptions?: VNodeComponentOptions
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = undefined
this.context = context
this.functionalContext = undefined
this.key = data && data.key
this.componentOptions = componentOptions
this.componentInstance = undefined
this.parent = undefined
this.raw = false
this.isStatic = false
this.isRootInsert = true
this.isComment = false
this.isCloned = false
this.isOnce = false
}
// DEPRECATED: alias for componentInstance for backwards compat.
/* istanbul ignore next */
get child (): Component | void {
return this.componentInstance
}
}每一个vnode都映射到一个真实的dom节点上。其中几个比较重要的属性:
tag 属性即这个vnode的标签属性data 属性包含了最后渲染成真实dom节点后,节点上的class,attribute,style以及绑定的事件children 属性是vnode的子节点text 属性是文本属性elm 属性为这个vnode对应的真实dom节点key 属性是vnode的标记,在diff过程中可以提高diff的效率,后文有讲解比如,我定义了一个vnode,它的数据结构是:
{
tag: 'div'
data: {
id: 'app',
class: 'page-box'
},
children: [
{
tag: 'p',
text: 'this is demo'
}
]
}最后渲染出的实际的dom结构就是:
<div id="app" class="page-box">
<p>this is demo</p>
</div>让我们再回到patch函数当中,在当oldVnode不存在的时候,这个时候是root节点初始化的过程,因此调用了createElm(vnode, insertedVnodeQueue, parentElm, refElm)方法去创建一个新的节点。而当oldVnode是vnode且sameVnode(oldVnode, vnode)2个节点的基本属性相同,那么就进入了2个节点的diff过程。
diff的过程主要是通过调用patchVnode(src/core/vdom/patch.js)方法进行的:
function patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly) {
...
}if (isDef(data) && isPatchable(vnode)) {
// cbs保存了hooks钩子函数: 'create', 'activate', 'update', 'remove', 'destroy'
// 取出cbs保存的update钩子函数,依次调用,更新attrs/style/class/events/directives/refs等属性
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode)
}更新真实dom节点的data属性,相当于对dom节点进行了预处理的操作
接下来:
...
const elm = vnode.elm = oldVnode.elm
const oldCh = oldVnode.children
const ch = vnode.children
// 如果vnode没有文本节点
if (isUndef(vnode.text)) {
// 如果oldVnode的children属性存在且vnode的属性也存在
if (isDef(oldCh) && isDef(ch)) {
// updateChildren,对子节点进行diff
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
// 如果oldVnode的text存在,那么首先清空text的内容
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
// 然后将vnode的children添加进去
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 删除elm下的oldchildren
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// oldVnode有子节点,而vnode没有,那么就清空这个节点
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
// 如果oldVnode和vnode文本属性不同,那么直接更新真是dom节点的文本元素
nodeOps.setTextContent(elm, vnode.text)
}这其中的diff过程中又分了好几种情况,oldCh为oldVnode的子节点,ch为Vnode的子节点:
oldVnode.text !== vnode.text,那么就会直接进行文本节点的替换;vnode没有文本节点的情况下,进入子节点的diff;oldCh和ch都存在且不相同的情况下,调用updateChildren对子节点进行diff;oldCh不存在,ch存在,首先清空oldVnode的文本节点,同时调用addVnodes方法将ch添加到elm真实dom节点当中;oldCh存在,ch不存在,则删除elm真实节点下的oldCh子节点;oldVnode有文本节点,而vnode没有,那么就清空这个文本节点。这里着重分析下updateChildren(src/core/vdom/patch.js)方法,它也是整个diff过程中最重要的环节:
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
// 为oldCh和newCh分别建立索引,为之后遍历的依据
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, elmToMove, refElm
// 直到oldCh或者newCh被遍历完后跳出循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
// 插入到老的开始节点的前面
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 如果以上条件都不满足,那么这个时候开始比较key值,首先建立key和index索引的对应关系
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : null
// 如果idxInOld不存在
// 1. newStartVnode上存在这个key,但是oldKeyToIdx中不存在
// 2. newStartVnode上并没有设置key属性
if (isUndef(idxInOld)) { // New element
// 创建新的dom节点
// 插入到oldStartVnode.elm前面
// 参见createElm方法
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
elmToMove = oldCh[idxInOld]
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && !elmToMove) {
warn(
'It seems there are duplicate keys that is causing an update error. ' +
'Make sure each v-for item has a unique key.'
)
// 将找到的key一致的oldVnode再和newStartVnode进行diff
if (sameVnode(elmToMove, newStartVnode)) {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined
// 移动node节点
canMove && nodeOps.insertBefore(parentElm, newStartVnode.elm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
// same key but different element. treat as new element
// 创建新的dom节点
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}
}
}
}
// 如果最后遍历的oldStartIdx大于oldEndIdx的话
if (oldStartIdx > oldEndIdx) { // 如果是老的vdom先被遍历完
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
// 添加newVnode中剩余的节点到parentElm中
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) { // 如果是新的vdom先被遍历完,则删除oldVnode里面所有的节点
// 删除剩余的节点
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}在开始遍历diff前,首先给oldCh和newCh分别分配一个startIndex和endIndex来作为遍历的索引,当oldCh或者newCh遍历完后(遍历完的条件就是oldCh或者newCh的startIndex >= endIndex),就停止oldCh和newCh的diff过程。接下来通过实例来看下整个diff的过程(节点属性中不带key的情况):
首先从第一个节点开始比较,不管是oldCh还是newCh的起始或者终止节点都不存在sameVnode,同时节点属性中是不带key标记的,因此第一轮的diff完后,newCh的startVnode被添加到oldStartVnode的前面,同时newStartIndex前移一位;

第二轮的diff中,满足sameVnode(oldStartVnode, newStartVnode),因此对这2个vnode进行diff,最后将patch打到oldStartVnode上,同时oldStartVnode和newStartIndex都向前移动一位

第三轮的diff中,满足sameVnode(oldEndVnode, newStartVnode),那么首先对oldEndVnode和newStartVnode进行diff,并对oldEndVnode进行patch,并完成oldEndVnode移位的操作,最后newStartIndex前移一位,oldStartVnode后移一位;

第四轮的diff中,过程同步骤3;

第五轮的diff中,同过程1;
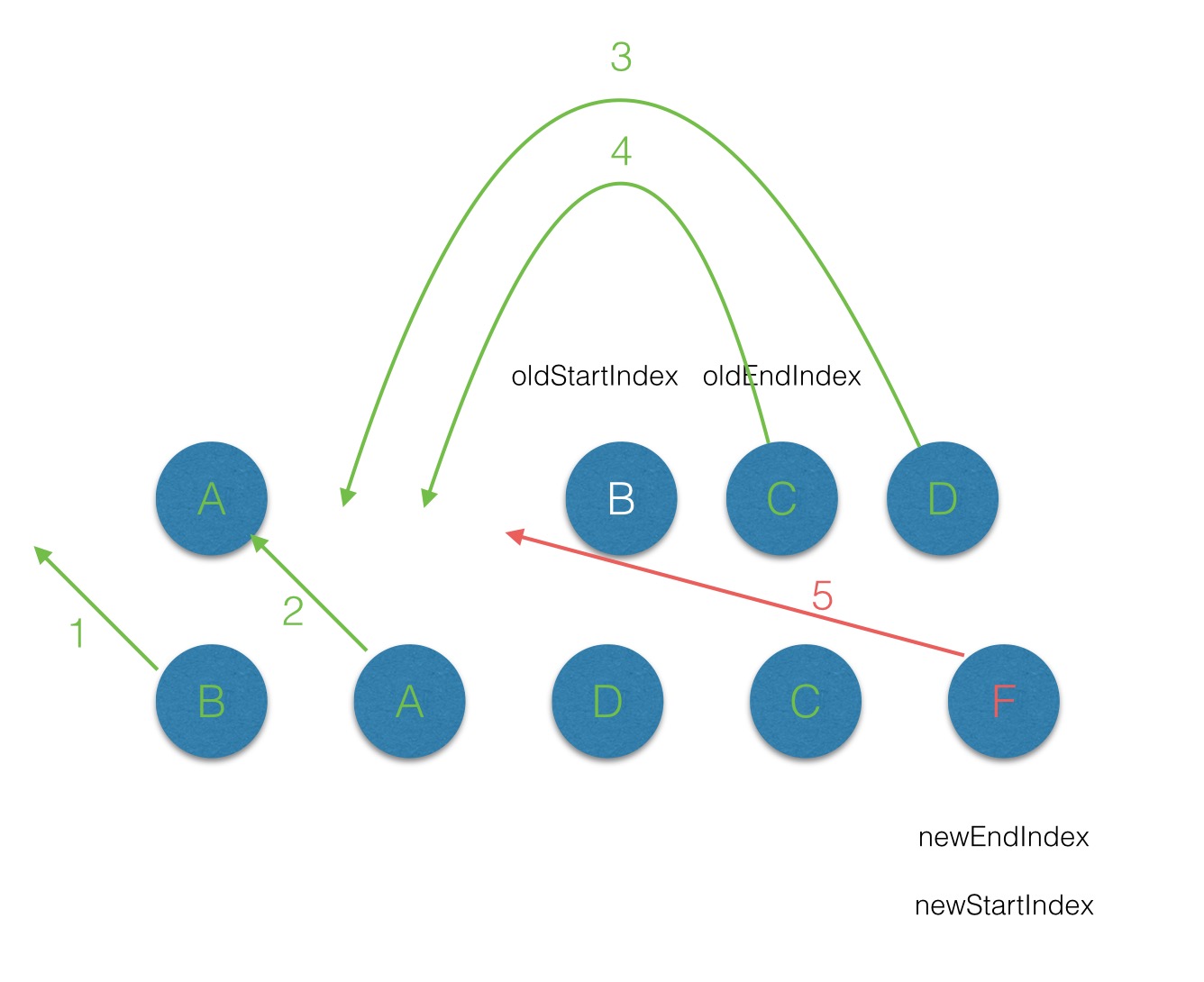
遍历的过程结束后,newStartIdx > newEndIdx,说明此时oldCh存在多余的节点,那么最后就需要将这些多余的节点删除。
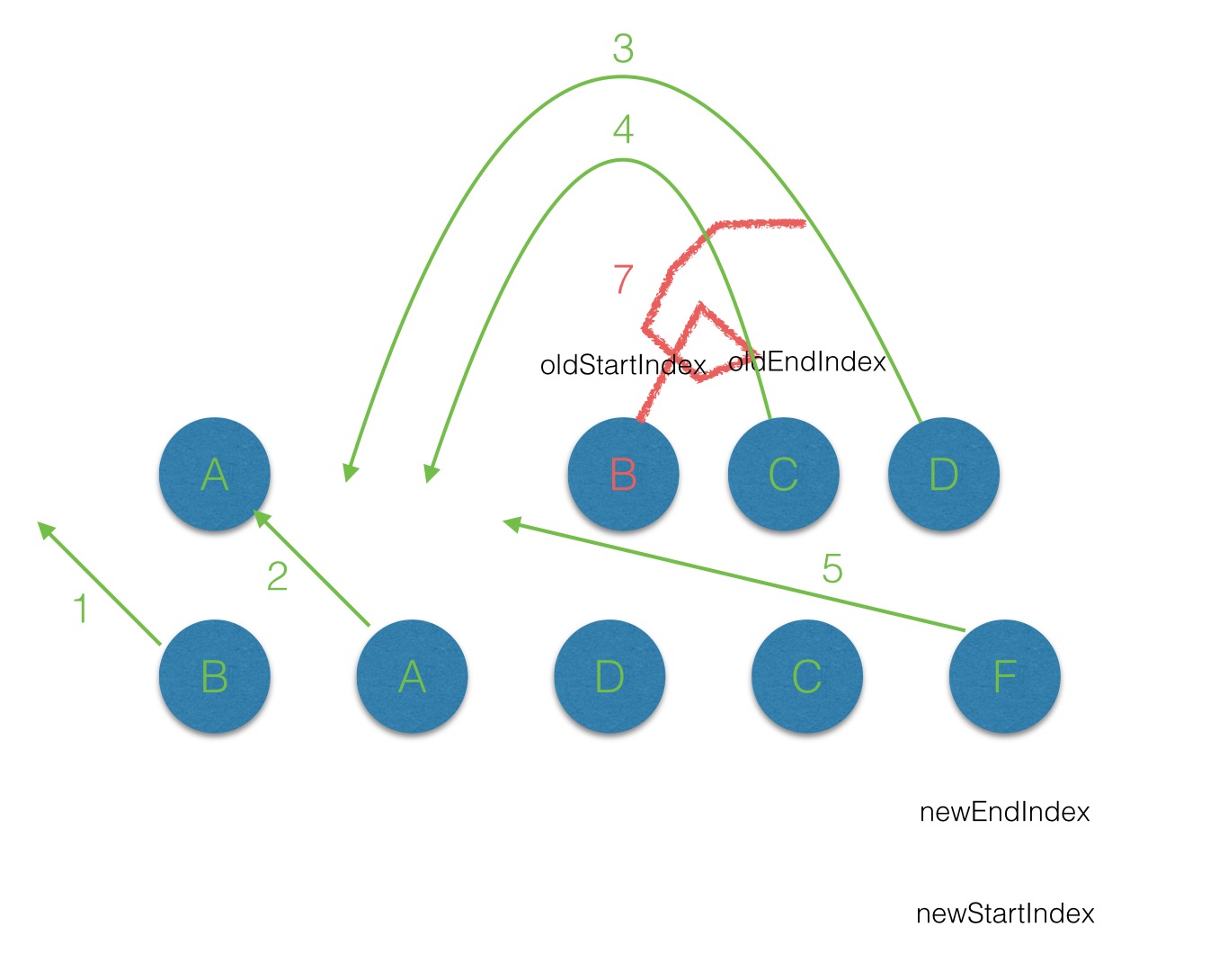
在vnode不带key的情况下,每一轮的diff过程当中都是起始和结束节点进行比较,直到oldCh或者newCh被遍历完。而当为vnode引入key属性后,在每一轮的diff过程中,当起始和结束节点都没有找到sameVnode时,首先对oldCh中进行key值与索引的映射:
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : nullcreateKeyToOldIdx(src/core/vdom/patch.js)方法,用以将oldCh中的key属性作为键,而对应的节点的索引作为值。然后再判断在newStartVnode的属性中是否有key,且是否在oldKeyToIndx中找到对应的节点。
key,那么就将这个newStartVnode作为新的节点创建且插入到原有的root的子节点中:if (isUndef(idxInOld)) { // New element
// 创建新的dom节点
// 插入到oldStartVnode.elm前面
// 参见createElm方法
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} key,那么就取出oldCh中的存在这个key的vnode,然后再进行diff的过程: elmToMove = oldCh[idxInOld]
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && !elmToMove) {
// 将找到的key一致的oldVnode再和newStartVnode进行diff
if (sameVnode(elmToMove, newStartVnode)) {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
// 清空这个节点
oldCh[idxInOld] = undefined
// 移动node节点
canMove && nodeOps.insertBefore(parentElm, newStartVnode.elm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
// same key but different element. treat as new element
// 创建新的dom节点
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}通过以上分析,给vdom上添加key属性后,遍历diff的过程中,当起始点, 结束点的搜寻及diff出现还是无法匹配的情况下时,就会用key来作为唯一标识,来进行diff,这样就可以提高diff效率。
带有Key属性的vnode的diff过程可见下图:
注意在第一轮的diff过后oldCh上的B节点被删除了,但是newCh上的B节点上elm属性保持对oldCh上B节点的elm引用。



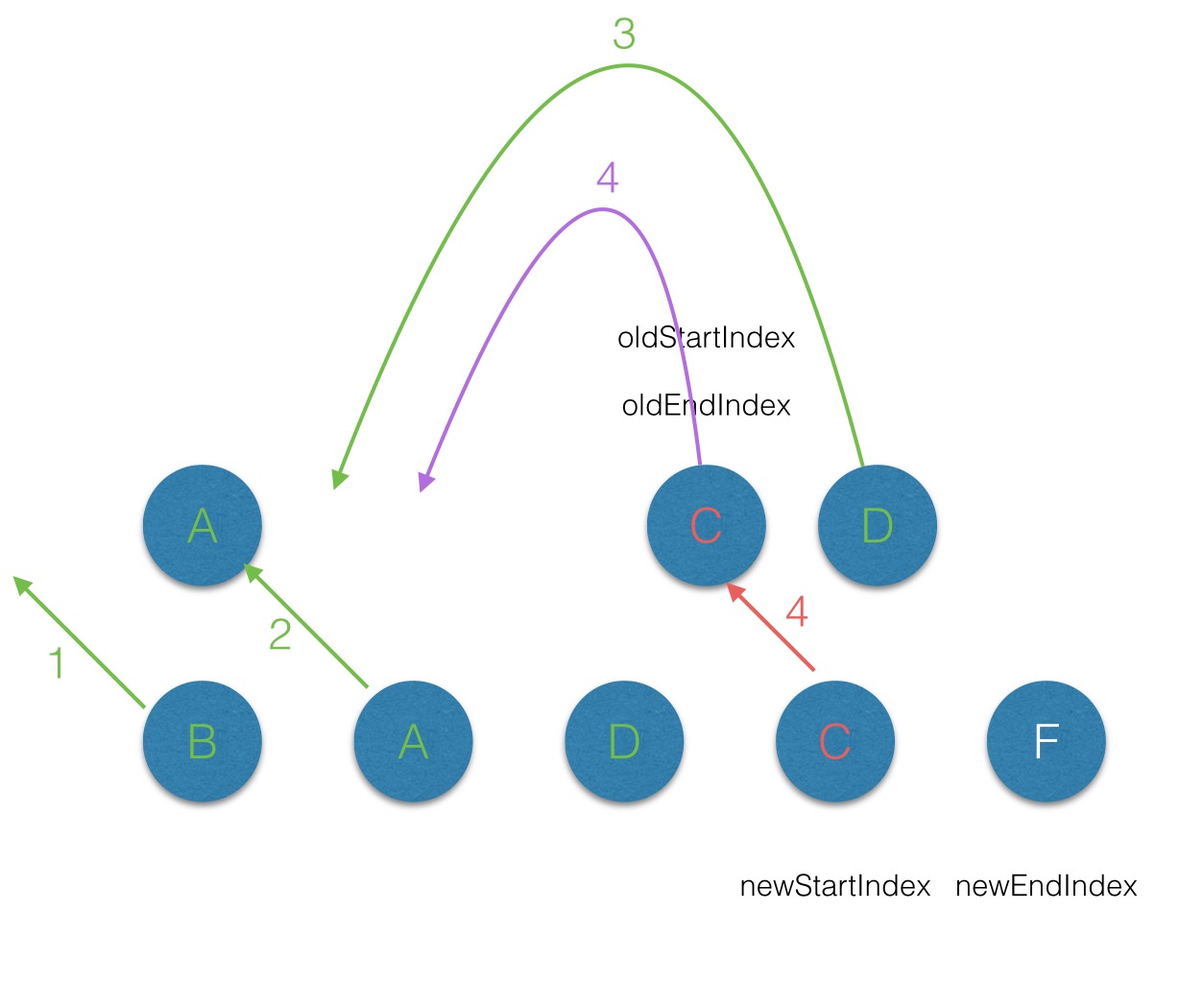

滴滴公共FE团队现在有十多个小伙伴,男女比例为 1: 1。
主要包含以下几大职能方向:
团队职责:
简单先介绍对外的我们做的比较大的一些事情
全局类:
1、公司统一权限登录移动化和PC改版
2、移动端用户统一登录SDK
**可视化方向:**滴滴国内央视曝光10多次春运迁徙可视化。
**组件化方向:**公司级组件库 - 魔方。
通用服务:
1、TMS 运营和模板平台
2、NPM Private
用户类:
滴滴公共FE团队做的实践还是很多的,现列举几个比较重大且应用度广的实践。
痛点:
每一个系统UI、交互规范、组件技术都不一样,复用性低,依赖第三方开源但技术支持不到位,遇到问题没人服务。
途径:
展示:
技术:
关于魔方 PC 端构建流程介绍:
]由于 PC 我们全部依托 Angular 指令来编写,在 WebPack 采用了 ngtemplate-loader
不同环境 2 套配置文件:
webpack.config.js // 开发环境
webpack.min.js // 生产环境打包
区别:
//webpack.min.js
output: {
path: __dirname + '/dist/mofang-widget/' + version,
filename: '[name].min.js',
library: 'mofang',
libraryTarget: 'umd'
},
我们打包之后的目录:
dist/mofang-widget/0.1.1/mofang-widget.min.js
如何配置第三方依赖:
resolve: {
root: path.join(__dirname, 'src'),
alias: {
components: path.join(__dirname, 'src', 'components'),
vendor_a: path.join(__dirname, 'src', 'vendor'),
ui_bootstrap_a: path.join(__dirname, 'src', 'vendor', 'angular-ui-bootstrap'),
ui_select_a: path.join(__dirname, 'src', 'vendor', 'angular-ui-select'),
resource_a: path.join(__dirname, 'src', 'vendor', 'angular-resource'),
sanitize_a: path.join(__dirname, 'src', 'vendor', 'angular-sanitize')
}
}
如何处理 directory 里面的 template:
// 目录结构
components
didi-list
didi-list.html
didi-list.js
// bn-list.js
var templateListUrl = require('./bn-list.html');
// 指令代码:
{
templateUrl: templateListUrl
}
module: {
loaders: [
{
test: /\.html$/,
loader: 'ngtemplate!html'
}
]
}
如何按版本发布:
整体我们依赖 pkg.json 的 version:
var version = require('./package.json').version;
// 方案一:
plugins: [
new webpack.DefinePlugin({
__VERSION__: JSON.stringify(version)
})
]
// 方案二:
callbackLoader: {
getVersion: function () {
return "'" + version + "'";
}
}
关于 iOS 9 Safari iframe src with scheme not working:
具体可以参阅:
http://stackoverflow.com/questions/31891777/ios-9-safari-iframe-src-with-custom-url-scheme-not-working
Webpack 动态加载:
require.ensure([], function (require) {
var qqmap = require('./qq/qqmap');
callback && callback(qqmap);
}, 'qqmap');
require.ensure([], function (require) {
var alimap = require('./ali/alimap');
callback && callback(alimap);
}, 'alimap');
痛点:
途径:
技术:
我们采用更定制化的Nodejs服务框架(从 Sailsjs 参考了很多) + mongo + pm2
结合公司发布系统、定制日志监控和脚本化运维规范
架构图:
遇到的技术问题:
1、如何灵活地进行线上线下配置
我们的 DNode 系统里面,默认支持 2 个配置文件
config/env/dev.js
config/env/prod.js
// config/env/dev.js
{
port: 1234
}
// config/env/prod.js
{
port: 8000
}
启动服务的时候,控制参数:
默认走的是 dev 的所有配置
dnode app.js --prod
这样默认就执行了所有 prod 的配置参数
2、脚本化运维 DNode 服务:
整体我们还是依托公司的发布系统,设置后置脚本来部署和安装部分依赖:
build.sh --- 部分安装,配置等
control.sh --- 提供一些方法来控制服务,启动 pm2 的参数和日志路径等
* `./control.sh start`:启动服务,如果服务已经启动会报错。
* `./control.sh restart`:重启服务,要求服务已经启动才能正确执行。
* `./control.sh reload`:优雅重启服务,要求服务已经启动才能正确执行。
* `./control.sh stop`:停止服务
日志监控:
设置固定的日志,依托公司统一日志监控,设置拉取策略和一些采集匹配规则
3、如何处理不同类型的文件上传?
在 DNode 里面我们所有的请求都会安装配置的 middleware 数组顺序,进行流转:
这样的优势:
我们可以在一开始设置一些 requestTimer 的监控 middleware
首先我们检查 request 头是:
if (req.is('multipart/form-data')) {
}
然后我们会通过 formidable的 2 个方法:
var formObj = new formidable.IncomingForm({
uploadDir: uploadPath,
keepExtensions: true,
multiples: false
});
formObj.parse(req, function(err, fields, files) {
// 这里面我们可以 check file.type 来对不同类型的文件进行不一样的处理:
// 比如 css 文件:
if (files.file.type == 'text/css') {
minCssCode = new CleanCss().minify(cssCode).styles;
}
// 比如 js 文件:
if (files.file.type == 'text/javascript') {
minJsCode = UglifyJS.minify(jsCode, {fromString: true}).code;
}
// 比如 zip 文件:
if (files.file.type == 'application/zip' || files.file.type == 'application/octet-stream') {
}
}
如何限制体积:
我们这边采用的是 skipper 在 bodyParser 的 middleware 里面做了一次过滤。
痛点:
途径:
技术:
Nodejs + 数据存储 + 各种配置系统 + 脚本
痛点:
滴滴早期WebApp首页是由业务线同学维护,与业务线有一定程度耦合,新业务线接入相对比较困难。
途径:
技术:
痛点:
滴滴早期的登录每个业务线都会做一套,有开发成本。不利于账号部门收敛和管理各业务线账号,不利于做一些账号安全和组件升级;登录没有打通,新业务线或运营活动接入登录成本高。
途径:
展示:
技术:
痛点:
前端项目越来越多,内部产出的工具包也比较多,如何自建一个私有库。
途径:
技术:
最近新技术的落地:
这个问题其实我每天都在思考,好像一直没有太明确的答案,这里也只是分享一些我个人的见解:
下面我从几个方面具体来谈一谈。
团队永远和人有关系,下面我从几个简单的维度,通过我对几个游戏的理解来分享一下我认为公共团队的人所需要的气质。
1.“飙车”
**敢于超越,专业性要求高:**赛车手和我们一般的开车的同学相比:更专业、对车子的熟悉度更高、追求超越和不愿意被超越。我很多时候推荐团建都是去玩室内卡丁车,而且每次都发现:有一些同学愿意最后和一些跑圈快的一组再比一轮,即使最后,那可能也是其他圈里面最快的。
2.乐高拼图
**能够沉浸在技术里面,去思考问题,最终产出:**乐高一般有几千块零散的拼图、需要沉下心来、而且在脑海中大概有一个架子,不断地去尝试和调整,最终完成一个作品时候,你会很自豪。
3.潜水
**敢于挑战自己惧怕的东西,克服困难,战胜自己:**潜水是我开始最惧怕的一项运动,很早前我不会游泳,但我又渴望翱翔大海,在一段比较长的震痛期后,我完成了浮浅和深浅,看到了很多常人看不到的美丽景色:大海龟、大鲸鲨、暴风鱼群等。
4.写作&分享
**沟通和沉淀才能让知识更记忆深刻:**我自己喜欢翻译和写一写技术总结的文章,已经成为生活中一个不可或缺的习惯。然后再分享出来,得到一些批评和反馈。
作为公共团队的 FE Leader,其实我的压力还是比较大的,除了满足业务需求外,你更多还需要告诉团队方向在哪里、我们的计划是否是可以落地的。
我自身也折腾过各种机器和环境部署、数据库,也接触过后端和安卓开发,在研究跨端体验的时候,花了 2 个月看了 iOS 相关的基础书籍和代码。
很多时候解决方案的合理性和全局观,不只是你熟悉业务就可以了,我更倾向让团队的很多同学熟悉前端独立部署、如何和不同的端交互以及他们内部相关的技术组成。而且大部分时候不敢于技术革新的一个很大原因:不了解、不熟悉、没把握。
很多时候时间确实是不够用的,而且有时候会参加很多会议和培训等。我管理时间一般的方式如下:
在很多时候,永远需要一个带头人跑的快一点,积极一点,在技术上鼓励创新和不断打磨沉淀优化,鼓励团队的小伙伴通过一些工具和技术手段来解决一些重复性的事情。
除了利用合理、稳定、高效的技术解决方案来服务日常的业务支撑外,考虑到前端技术的日新月异,我们也沉淀和创造一个统一的技术氛围:
公共 FE 团队在任何一个大公司都离不开业务线小伙伴的支持和厚爱,领导的认可和关注。
要感谢的人很多,有很多可能我自己都叫不上名字,不管怎样,真心感谢所有帮助过以及信任着公共 FE 团队的同学,
同样地也再次特别感谢我们团队的每一个亲爱的小伙伴。
一路同行,只因为有你们:huangyi、wangjing、wangjin、suwei、shumei、xiaoqi、yanfen、miaodian、cuijing、yufei、huan总
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.