ddpn08 / automatic1111-colab Goto Github PK
View Code? Open in Web Editor NEWUsing StableDiffusion webui on Colab
Using StableDiffusion webui on Colab


















































































































/content/stable-diffusion-webui
Already up to date.
Python 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0]
Commit hash: 828438b4a190759807f9054932cae3a8b880ddf1
Installing requirements for Web UI
Launching Web UI with arguments: --ckpt-dir /content/drive/MyDrive/AI/models --ui-config-file /content/drive/MyDrive/AI/automatic1111/config/ui-config.json --ui-settings-file /content/drive/MyDrive/AI/automatic1111/config/config.json --styles-file /content/drive/MyDrive/AI/automatic1111/config/styles.csv --deepdanbooru --xformers --share --enable-console-prompts
Traceback (most recent call last):
File "/content/stable-diffusion-webui/launch.py", line 251, in
start()
File "/content/stable-diffusion-webui/launch.py", line 242, in start
import webui
File "/content/stable-diffusion-webui/webui.py", line 13, in
from modules import devices, sd_samplers, upscaler, extensions, localization
File "/content/stable-diffusion-webui/modules/sd_samplers.py", line 11, in
from modules import prompt_parser, devices, processing, images
File "/content/stable-diffusion-webui/modules/processing.py", line 15, in
import modules.sd_hijack
File "/content/stable-diffusion-webui/modules/sd_hijack.py", line 10, in
import modules.textual_inversion.textual_inversion
File "/content/stable-diffusion-webui/modules/textual_inversion/textual_inversion.py", line 13, in
from modules import shared, devices, sd_hijack, processing, sd_models, images, sd_samplers
File "/content/stable-diffusion-webui/modules/shared.py", line 8, in
import gradio as gr
File "/usr/local/envs/automatic/lib/python3.10/site-packages/gradio/init.py", line 3, in
import gradio.components as components
File "/usr/local/envs/automatic/lib/python3.10/site-packages/gradio/components.py", line 32, in
from gradio.blocks import Block
File "/usr/local/envs/automatic/lib/python3.10/site-packages/gradio/blocks.py", line 32, in
from gradio import (
File "/usr/local/envs/automatic/lib/python3.10/site-packages/gradio/networking.py", line 19, in
from gradio.tunneling import create_tunnel
File "/usr/local/envs/automatic/lib/python3.10/site-packages/gradio/tunneling.py", line 17, in
import paramiko
File "/usr/local/envs/automatic/lib/python3.10/site-packages/paramiko/init.py", line 22, in
from paramiko.transport import SecurityOptions, Transport
File "/usr/local/envs/automatic/lib/python3.10/site-packages/paramiko/transport.py", line 92, in
from paramiko.ed25519key import Ed25519Key
File "/usr/local/envs/automatic/lib/python3.10/site-packages/paramiko/ed25519key.py", line 22, in
import nacl.signing
File "/usr/local/envs/automatic/lib/python3.10/site-packages/nacl/signing.py", line 16, in
import nacl.bindings
File "/usr/local/envs/automatic/lib/python3.10/site-packages/nacl/bindings/init.py", line 16, in
from nacl.bindings.crypto_aead import (
File "/usr/local/envs/automatic/lib/python3.10/site-packages/nacl/bindings/crypto_aead.py", line 17, in
from nacl._sodium import ffi, lib
ImportError: /usr/local/envs/automatic/lib/python3.10/site-packages/_cffi_backend.cpython-310-x86_64-linux-gnu.so: symbol ffi_type_uint32 version LIBFFI_BASE_7.0 not defined in file libffi.so.7 with link time reference
UPD: Error is gone with turned on gradio app authentication
Hello, Is it possible to install the extensions directly in my Google Drive instead of the SD copy in the virtual machine?, specially with the ControlNet extension that is the biggest one and is hardly difficult and heavy to install every time you start the SD repo.
Thanks in advance for your Good work ;-)
Must run in pc?
If it's possible then I could place checkpoints and loras in many different Google account drives and use short cut to load them.
hi I'm getting this error message ValueError: images do not match during inpainting
while using this auto photoshop stablediffusion plugin
API error: POST: https://d8e87081614310d5ae.gradio.live/sdapi/v1/img2img {'error': 'ValueError', 'detail': '', 'body': '', 'errors': 'images do not match'}
Traceback (most recent call last):
File "/usr/local/envs/automatic/lib/python3.10/site-packages/anyio/streams/memory.py", line 94, in receive
return self.receive_nowait()
File "/usr/local/envs/automatic/lib/python3.10/site-packages/anyio/streams/memory.py", line 89, in receive_nowait
raise WouldBlock
anyio.WouldBlock
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/base.py", line 78, in call_next
message = await recv_stream.receive()
File "/usr/local/envs/automatic/lib/python3.10/site-packages/anyio/streams/memory.py", line 114, in receive
raise EndOfStream
anyio.EndOfStream
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/api/api.py", line 144, in exception_handling
return await call_next(request)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/base.py", line 84, in call_next
raise app_exc
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/base.py", line 70, in coro
await self.app(scope, receive_or_disconnect, send_no_error)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/base.py", line 108, in call
response = await self.dispatch_func(request, call_next)
File "/content/stable-diffusion-webui/modules/api/api.py", line 109, in log_and_time
res: Response = await call_next(req)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/base.py", line 84, in call_next
raise app_exc
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/base.py", line 70, in coro
await self.app(scope, receive_or_disconnect, send_no_error)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/gzip.py", line 24, in call
await responder(scope, receive, send)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/gzip.py", line 44, in call
await self.app(scope, receive, self.send_with_gzip)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 79, in call
raise exc
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 68, in call
await self.app(scope, receive, sender)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 21, in call
raise e
File "/usr/local/envs/automatic/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 18, in call
await self.app(scope, receive, send)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/routing.py", line 718, in call
await route.handle(scope, receive, send)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/routing.py", line 276, in handle
await self.app(scope, receive, send)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/routing.py", line 66, in app
response = await func(request)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/fastapi/routing.py", line 237, in app
raw_response = await run_endpoint_function(
File "/usr/local/envs/automatic/lib/python3.10/site-packages/fastapi/routing.py", line 165, in run_endpoint_function
return await run_in_threadpool(dependant.call, **values)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/starlette/concurrency.py", line 41, in run_in_threadpool
return await anyio.to_thread.run_sync(func, *args)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/usr/local/envs/automatic/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "/usr/local/envs/automatic/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
File "/content/stable-diffusion-webui/modules/api/api.py", line 355, in img2imgapi
processed = process_images(p)
File "/content/stable-diffusion-webui/modules/processing.py", line 486, in process_images
res = process_images_inner(p)
File "/content/stable-diffusion-webui/modules/processing.py", line 694, in process_images_inner
image_mask_composite = Image.composite(image.convert('RGBA').convert('RGBa'), Image.new('RGBa', image.size), p.mask_for_overlay.convert('L')).convert('RGBA')
File "/usr/local/envs/automatic/lib/python3.10/site-packages/PIL/Image.py", line 3341, in composite
image.paste(image1, None, mask)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/PIL/Image.py", line 1731, in paste
self.im.paste(im, box, mask.im)
ValueError: images do not match
does anyone know what I can do?
Getting the following error in Step 3 - Launch WebUI
The extraction of xformers gets stuck and doesn't proceed
==> WARNING: A newer version of conda exists. <==
current version: 22.11.1
latest version: 23.1.0
Please update conda by running
$ conda update -n base -c defaults conda
Or to minimize the number of packages updated during conda update use
conda install conda=23.1.0
environment location: /usr/local/envs/automatic
added / updated specs:
- xformers
The following packages will be downloaded:
package | build
---------------------------|-----------------
xformers-0.0.16.dev432+git.bc08bbc|py310_cu11.3_pyt1.12.1 292.7 MB xformers/label/dev
------------------------------------------------------------
Total: 292.7 MB
The following NEW packages will be INSTALLED:
xformers xformers/label/dev/linux-64::xformers-0.0.16.dev432+git.bc08bbc-py310_cu11.3_pyt1.12.1
Downloading and Extracting Packages
xformers-0.0.16.dev4 | 292.7 MB | : 0% 0/1 [00:00<?, ?it/s]
Saving the Style updates the file /content/stable-diffusion-webui/styles.csv. But that change in not reflected in /content/data/configs/styles.csv.
I like this repo for automatic1111 ui. I see now dreambooth is added, which is cool. I want to use it. But is there an option to just use the automatic111 ui? I just need to make something very basic and don't need any extra training
Greetings!
After running the Google Colab notebook mounting my Google Drive, I generate an image but the image is saved on the outputs folder of the automatic1111 folder on Google Colab.
/content
Local Path Variables:
Mounted at /content/drive
Model already downloaded, moving to next step
/content/stable-diffusion-webui
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 332M 100 332M 0 0 224M 0 0:00:01 0:00:01 --:--:-- 359M
curl: Saved to filename 'GFPGANv1.3.pth'
models_path: /content/drive/MyDrive/AI/models
output_path: /content/drive/MyDrive/AI/automatic1111/outputs
config_path: /content/drive/MyDrive/AI/automatic1111/config
This is the output of the "1.2 setup models" cell, it seems that the Google Drive output folder path is correct, and the model and configuration files seem to be saved correctly in Google Drive. so I don't know what could be causing the error or if this is the expected behavior and I have to manually save the images to the /outputs folder in Google Drive
Check "mount_google_drive" checkbox on "1.2 setup models" cell, Run Google Colab notebook, generate an image
The images should be saved on the /content/drive/MyDrive/AI/automatic1111/outputs folder inside Google Drive if "mount_google_drive" checkbox is checked
I managed to get the images saved in Google Drive by editing the AI/automatic1111/config/config.json file in Google Drive as follows
...
"outdir_txt2img_samples": "../drive/MyDrive/AI/automatic1111/outputs/txt2img-images",
"outdir_img2img_samples": "../drive/MyDrive/AI/automatic1111/outputs/img2img-images",
"outdir_extras_samples": "../drive/MyDrive/AI/automatic1111/outputs/extras-images",
"outdir_grids": "",
"outdir_txt2img_grids": "../drive/MyDrive/AI/automatic1111/outputs/txt2img-grids",
"outdir_img2img_grids": "../drive/MyDrive/AI/automatic1111/outputs/img2img-grids",
...
It seems that just editing the file once is enough to make the configuration last every time you run Google Colab, but it is a manual process, I don't know if there is a solution that could be added to the Google Colab notebook to do this automatically when it is used for the first time.

I'm attempting to mount my google drive, and keep getting this error. I attempted to create the folder, however the error still occurs. Any suggestions would be greatly appreciated. Thank you!
Hi, I have set up the notebook to use conda that is stored on Google Drive in the following folder:
/content/drive/MyDrive/conda/bin/conda
The first install of the script works fine and it uses conda. But when I restart colab and the script tries to load from conda, it cannot initialize conda and shows this error:
/bin/bash: /content/drive/MyDrive/conda/bin/conda: /content/drive/MyDrive/conda/bin/python: bad interpreter: Permission denied
It still goes on to install everything, but it is not doing that in the conda environment and therefore it is only using python version 3.8.10
Somehow this has to do with the permissions in the conda folder. I tried to change the permissions in the conda/bin folder to +x but that isn't enough.
Add civitai exrension? is it possible ?
As the title stated. I wanted to install extensions, specifically DreamArtist to try that one out, but I wasn't able to use it because it released an error that extensions are not allowed because of permissions.
Is there a way for me to use extensions here?
Hi
I encountered this issue when running the notebook:
Already up to date.
Python 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0]
Commit hash: 29fb5327640465fc83111e2170c5d8aa2b15266c
Installing requirements for Web UI
Launching Web UI with arguments: --xformers --share
No checkpoints found. When searching for checkpoints, looked at:
- file /content/stable-diffusion-webui/model.ckpt
- directory /content/stable-diffusion-webui/models/Stable-diffusion
Can't run without a checkpoint. Find and place a .ckpt file into any of those locations. The program will exit.
I know I could probably fix this just by changing the model directory, but what I don't understand and it frustrates me is that these same directory (AI/models) worked a few months ago. It's the default directory for Deforum Stable Diffusion, for example. Can anyone tell me why the MyDrive/AI/models directory is no longer recognized by default?
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "/content/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/content/stable-diffusion-webui/modules/textual_inversion/ui.py", line 33, in train_embedding
embedding, filename = modules.textual_inversion.textual_inversion.train_embedding(*args)
File "/content/stable-diffusion-webui/modules/textual_inversion/textual_inversion.py", line 413, in train_embedding
ds = modules.textual_inversion.dataset.PersonalizedBase(data_root=data_root, width=training_width, height=training_height, repeats=shared.opts.training_image_repeats_per_epoch, placeholder_token=embedding_name, model=shared.sd_model, cond_model=shared.sd_model.cond_stage_model, device=devices.device, template_file=template_file, batch_size=batch_size, gradient_step=gradient_step, shuffle_tags=shuffle_tags, tag_drop_out=tag_drop_out, latent_sampling_method=latent_sampling_method, varsize=varsize, use_weight=use_weight)
File "/content/stable-diffusion-webui/modules/textual_inversion/dataset.py", line 128, in init
entry.cond_text = self.create_text(filename_text)
File "/content/stable-diffusion-webui/modules/textual_inversion/dataset.py", line 154, in create_text
text = random.choice(self.lines)
File "/opt/conda/lib/python3.10/random.py", line 378, in choice
return seq[self._randbelow(len(seq))]
IndexError: list index out of range
it was fine but stop working today.
in the final cell i get:
/content/stable-diffusion-webui
Already up to date.
Python 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0]
Commit hash: a1cf55a9d1c82f8e56c00d549bca5c8fa069f412
Installing xformers
Traceback (most recent call last):
File "/content/stable-diffusion-webui/launch.py", line 294, in
prepare_environment()
File "/content/stable-diffusion-webui/launch.py", line 230, in prepare_environment
run_pip("install xformers", "xformers")
File "/content/stable-diffusion-webui/launch.py", line 78, in run_pip
return run(f'"{python}" -m pip {args} --prefer-binary{index_url_line}', desc=f"Installing {desc}", errdesc=f"Couldn't install {desc}")
File "/content/stable-diffusion-webui/launch.py", line 49, in run
raise RuntimeError(message)
RuntimeError: Couldn't install xformers.
Command: "/usr/local/envs/automatic/bin/python" -m pip install xformers --prefer-binary
Error code: 1
stdout: Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting xformers
Using cached xformers-0.0.13.tar.gz (292 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'error'
stderr: error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
I didn't change any settings,
I am having a weird bug where the colab deletes my current data folder and replaces it with a new (but mostly empty) folder of the same name. I have my data_dir set as "/content/drive/MyDrive/sd/" which contains a folder by the name of "models" as specified by the colab UI. Then I have the data_dir_gdrive set as "/content/drive/MyDrive/sd/automatic1111". After running step 1.2 - step 3, my original "sd" folder has been moved to the trash, along with everything inside of it, including models, outputs, and settings. I am left with a fresh new "sd" folder that only contains the folders 'Conda-env', 'scripts', 'config', 'outputs', and 'models'.
I was able to use Stable Diffusion by 16:00 Japan time (UCT+9), but when I did a RUN according to the wiki, the UI address was not displayed and I could not access the UI although it was running.
I initialized all the contents of my Google Drive, etc., and installed the UI using "Setup environment" in "3 - Launch WebUI". content/stable-diffusion-webui/models/Stable-diffusion", but there was no sd-v1-4.ckpt in the path /content/stable-diffusion-webui/models/Stable-diffusion, and I could not start it.
I downloaded various files with sd-v1-4.ckpt in the path of /content/stable-diffusion-webui/models/Stable-diffusion, but only the UI address was not shown and I could not access it.
What can I do to fix the problem of the UI address not being displayed?

Hi,
Great stuff everything is working fine right now except VAE. I placed them in the same folder as the model and it does not load them.
After the image is generated, in colab, you can see that there is a product under the outputs folder, and the location is located in the driver, that is, on Google Cloud Disk, but there is no product when I log in from Google Cloud Disk. After I log out, got nothing
イメージが生成された後、colab では、outputs フォルダーの下に製品があり、場所はドライバー、つまり Google Cloud Disk にありますが、Google からログインすると製品がありません。 Cloud Disk. ログアウトしても何も表示されない
/content/stable-diffusion-webui
Already up to date.
The following values were not passed to accelerate launch and had defaults used instead:
--num_processes was set to a value of 1
--num_machines was set to a value of 1
--mixed_precision was set to a value of 'no'
To avoid this warning pass in values for each of the problematic parameters or run accelerate config.
Python 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0]
Commit hash: a9fed7c364061ae6efb37f797b6b522cb3cf7aa2
Installing requirements for Web UI
Launching Web UI with arguments: --no-half-vae --xformers --share --gradio-queue --styles-file /content/data/config/styles.csv
Loading weights [e1441589a6] from /content/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned.ckpt
Creating model from config: /content/stable-diffusion-webui/configs/v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Traceback (most recent call last):
File "/opt/conda/bin/accelerate", line 8, in
sys.exit(main())
File "/opt/conda/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 43, in main
args.func(args)
File "/opt/conda/lib/python3.10/site-packages/accelerate/commands/launch.py", line 837, in launch_command
simple_launcher(args)
File "/opt/conda/lib/python3.10/site-packages/accelerate/commands/launch.py", line 354, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['/opt/conda/bin/python', 'launch.py']' died with <Signals.SIGKILL: 9>.
I think it would be pretty cool to add SD Dynamic Prompts to the predefined extensions as its really powerful and useful imo (https://github.com/adieyal/sd-dynamic-prompts) so new users can play around with this fancy extension
Is it possible to mount the extensions directory in Google Drive? I would like to use the [Dynamic Prompts}(https://github.com/adieyal/sd-dynamic-prompts) extension, however since the extensions directory is not mapped, I'm unable to create the wildcard files. They are normally put in automatic1111\extensions\wildcards however even if I create that directory in google drive it doesn't work.
Thank you for this colab, it's amazing.
Issue:
At Run Script step, the following error occurs:
Running on local URL: http://127.0.0.1:7860/
Running on public URL: https://c52af886-9da1-47f6.gradio.live/
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
Traceback (most recent call last):
File "/content/stable-diffusion-webui/launch.py", line 361, in
start()
File "/content/stable-diffusion-webui/launch.py", line 356, in start
webui.webui()
File "/content/stable-diffusion-webui/webui.py", line 232, in webui
app.add_middleware(GZipMiddleware, minimum_size=1000)
File "/opt/conda/lib/python3.10/site-packages/starlette/applications.py", line 135, in add_middleware
raise RuntimeError("Cannot add middleware after an application has started")
RuntimeError: Cannot add middleware after an application has started
Killing tunnel 127.0.0.1:7860 <> https://c52af886-9da1-47f6.gradio.live/
Traceback (most recent call last):
File "/opt/conda/bin/accelerate", line 8, in
sys.exit(main())
File "/opt/conda/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 43, in main
args.func(args)
File "/opt/conda/lib/python3.10/site-packages/accelerate/commands/launch.py", line 837, in launch_command
simple_launcher(args)
File "/opt/conda/lib/python3.10/site-packages/accelerate/commands/launch.py", line 354, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['/opt/conda/bin/python', 'launch.py']' returned non-zero exit status 1.
Apparently this is fixed by adding to python script:
-m pip install --upgrade fastapi==0.90.1
but thats beyond me hence why I used a colab.
More details of other users with same error here:
https://www.reddit.com/r/StableDiffusion/comments/10yurxl/help_with_error_please/
The option can be toggled and directly beneath that toggle are two github links to extensions, So is it pulling them and storing them on gdrive. What does that toggle do?
Thanks.

If I run the "Setup enviroment" I get this error:
ERROR: HTTP error 404 while getting https://github.com/ddPn08/automatic1111-colab/blob/main/xformers/T4/xformers-0.0.13.dev0-py3-none-any.whl?raw=true
ERROR: Could not install requirement xformers==0.0.13.dev0 from https://github.com/ddPn08/automatic1111-colab/blob/main/xformers/T4/xformers-0.0.13.dev0-py3-none-any.whl?raw=true because of HTTP error 404 Client Error: Not Found for url: https://github.com/ddPn08/automatic1111-colab/blob/main/xformers/T4/xformers-0.0.13.dev0-py3-none-any.whl?raw=true for URL https://github.com/ddPn08/automatic1111-colab/blob/main/xformers/T4/xformers-0.0.13.dev0-py3-none-any.whl?raw=true
/content/stable-diffusion-webui
Python 3.10.8 (main, Oct 12 2022, 19:14:09) [GCC 7.5.0]
Commit hash: 1b91cbbc1163d3613aa329bed3aecd8e29ca52ca
Installing xformers
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/content/stable-diffusion-webui/launch.py", line 163, in prepare_enviroment
run_pip("install xformers", "xformers")
File "/content/stable-diffusion-webui/launch.py", line 62, in run_pip
return run(f'"{python}" -m pip {args} --prefer-binary{index_url_line}', desc=f"Installing {desc}", errdesc=f"Couldn't install {desc}")
File "/content/stable-diffusion-webui/launch.py", line 33, in run
raise RuntimeError(message)
RuntimeError: Couldn't install xformers.
Command: "/usr/bin/python3" -m pip install xformers --prefer-binary
Error code: 1
stdout: Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting xformers
Using cached xformers-0.0.13.tar.gz (292 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'error'
stderr: error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
Then, if I try running the "Run script" I get this:
Already up to date.
Python 3.10.8 (main, Oct 12 2022, 19:14:09) [GCC 7.5.0]
Commit hash: 1b91cbbc1163d3613aa329bed3aecd8e29ca52ca
Installing xformers
Traceback (most recent call last):
File "/content/stable-diffusion-webui/launch.py", line 199, in <module>
prepare_enviroment()
File "/content/stable-diffusion-webui/launch.py", line 163, in prepare_enviroment
run_pip("install xformers", "xformers")
File "/content/stable-diffusion-webui/launch.py", line 62, in run_pip
return run(f'"{python}" -m pip {args} --prefer-binary{index_url_line}', desc=f"Installing {desc}", errdesc=f"Couldn't install {desc}")
File "/content/stable-diffusion-webui/launch.py", line 33, in run
raise RuntimeError(message)
RuntimeError: Couldn't install xformers.
Command: "/usr/bin/python3" -m pip install xformers --prefer-binary
Error code: 1
stdout: Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting xformers
Using cached xformers-0.0.13.tar.gz (292 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'error'
stderr: error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
And then it stops the cell. What can it be? I'm using the colab notebook as it is on the repo.

The save button no longer saves the file to the outputs/Saved folder in data_dir_gdrive/AI/automatic1111/outputs/Saved nor /content/data/outputs/Saved. No error in the notebook or browser. I have the new directory structure setup.
In the Load model cell, I have specified path to my gdrive, where the checkpoint resides.
After cell execution, it outputs the paths correctly:
models_path: /content/drive/MyDrive/AI/models
output_path: /content/drive/MyDrive/AI/automatic1111/outputs
config_path: /content/drive/MyDrive/AI/automatic1111/config
However, when running the "Run script" cells, it complains that it could not find the checkpoint
/content/stable-diffusion-webui/model.ckpt
I can get around this by copying the checkpoint there, but is this expected behavior?
Hello! I'm using your collab note since yesterday and everything was okay. But now, while I'm running the note, I can't open public URL because of 504 Gateway Time-out problem. How can I solve it?


suggestion: Add Gradio username and password along with URLs on last cell, to make easy to find
It came as surprise when I opened WebUI, I didn't notice that need and can be changed, other people may not find as well...
As the title says. Crash at screenshot position.

Hello, I got this error for the first time. Do I need VAE file now? How do I set it up with custom models? Thank you.

Hi!
I'm launching it on a new and clean account. In paragraph 1.2, the same error always occurs.
All parameters are standard.
FileNotFoundError Traceback (most recent call last)
in
47 extensions_file_path = f"{data_dir}/extensions.txt"
48
---> 49 os.makedirs(models_path, exist_ok=True)
50 os.makedirs(output_path, exist_ok=True)
51 os.makedirs(config_path, exist_ok=True)
/usr/lib/python3.8/os.py in makedirs(name, mode, exist_ok)
221 return
222 try:
--> 223 mkdir(name, mode)
224 except OSError:
225 # Cannot rely on checking for EEXIST, since the operating system
FileNotFoundError: [Errno 2] No such file or directory: '/content/data/models'
I had pointed the colab to my AI folder and there was a symlink error. When I went to check Drive, the AI folder was trashed including all models and generated art, etc. I guess it would have been best to keep it in the /automatic1111 folder.
Hi, sorry if that is a stupid question, I am a complete beginner.
I used that code with colab an in general it works great - thank you very much!
However, I am not able to train an embedding.
There seems to be an issue with the file directories:
Can someone please advise?
Greetings, I have this problem when I load the "Running on public URL" no appears, any idea why it happens?

In what directory should I put Textual Inversions? I've tired all the obvious locations.
Unless I'm missing something, I think you may need to add something like:
embeddings_dir: /content/drive/MyDrive/AI/embeddings
It looks like the styles.csv file is being stored in the stable-diffusion-webui folder and not stored in google drive as it was before. This makes any changes to the file transient.
as the title says. May be related to AUTOMATIC1111/stable-diffusion-webui#2202
I don't know the cause myself, so I'd like some advice from an expert.
Thank you for doing a great job, but there is another issue after recent update:
/content/stable-diffusion-webui
Already up to date.
Python 3.10.8 (main, Nov 24 2022, 14:13:03) [GCC 11.2.0]
Commit hash: 685f9631b56ff8bd43bce24ff5ce0f9a0e9af490
Installing requirements for Web UI
Launching Web UI with arguments: --share
No module 'xformers'. Proceeding without it.
No checkpoints found. When searching for checkpoints, looked at:
Clearing folders in Google Drive did not help.
Or maybe i'm doing something wrong.
Hello, is there any chance to be available to save my Hype Net and Embeddings trainings into my Google Drive to not lose them, because now SD is only mounted in the virtual machine and every time the Google colab shuts down I lost everything I've done in the training.
Thanks in advance, great work.
;-)
I got the following error when running the script to launch WebUI:
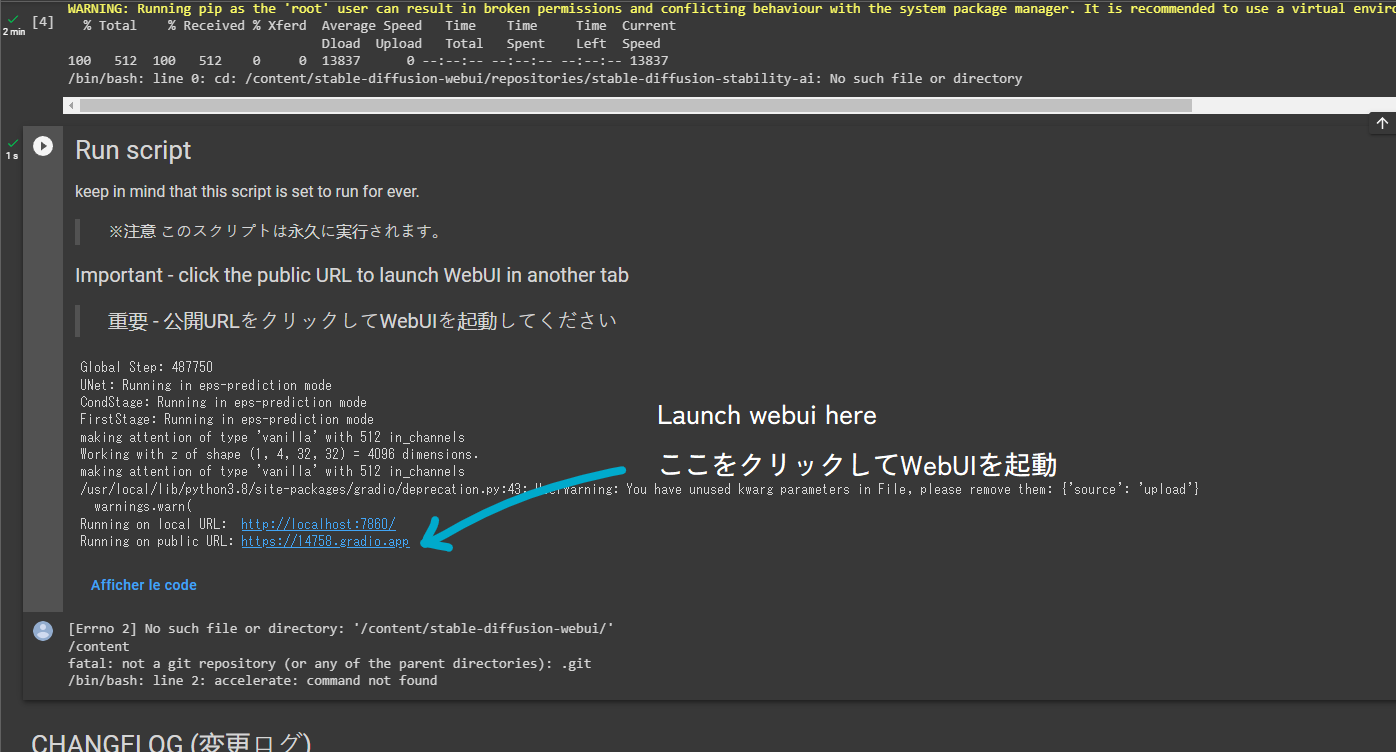
Any idea where the error could come from?
With default configuration, there are errors on txt2img and img2img:
FileNotFoundError: [Errno 2] No such file or directory: 'outputs/txt2img-images'
FileNotFoundError: [Errno 2] No such file or directory: 'outputs/img2img-images'
(Creatng of mentioned folders did not help)
I can only load it into the Model checkpoint folder. No Lora or embeddings folder is available!
First, I have to thank about all the good work that is this : it's ,amazing.
Now, the problem.
First, I initiate the Google Colab, step by step. Good, right, done, perfect. All works normally and the IA accepts good the Hypernetworks, the Lora, and all the add-on.
When I restart another day, appear this

And I say, well, maybe the set-up isn't neccesary, it's just run it again and all, but nope.

This won't be a very bad problem : install accelerate and it's done ¿right? .

And this, I haven't find anything .
Why , when I wanted to use it again , this happen? How I can solve?
Loading weights [2c02b20a] from /content/drive/MyDrive/AI/models/sd-v2-0.ckpt
Traceback (most recent call last):
File "/content/stable-diffusion-webui/launch.py", line 294, in <module>
start()
File "/content/stable-diffusion-webui/launch.py", line 289, in start
webui.webui()
File "/content/stable-diffusion-webui/webui.py", line 131, in webui
initialize()
File "/content/stable-diffusion-webui/webui.py", line 61, in initialize
modules.sd_models.load_model()
File "/content/stable-diffusion-webui/modules/sd_models.py", line 261, in load_model
load_model_weights(sd_model, checkpoint_info)
File "/content/stable-diffusion-webui/modules/sd_models.py", line 192, in load_model_weights
model.load_state_dict(sd, strict=False)
File "/usr/local/envs/automatic/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1604, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for LatentDiffusion:
size mismatch for model.diffusion_model.input_blocks.1.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.1.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.2.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.2.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.4.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.4.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.5.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.5.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.7.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.7.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.8.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.8.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.middle_block.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.middle_block.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.3.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.3.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.4.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.4.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.5.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.5.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.6.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.6.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.7.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.7.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.8.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.8.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.9.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.9.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.10.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.10.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.11.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.11.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.