乐高框架是一个基于Spark的模块化计算框架,每个模块都是一个实现了框架接口的独立jar包,通过配置文件将模块链接成一个流程图,框架会执行流程图,得到最终结果。
框架名称之所以叫乐高,是因为乐高是目前市面上很牛逼的积木品牌,积木可以充分体现模块化的设计思路,所以使用lego命名新一代框架,彰显框架的高度模块化与灵活扩展。
乐高框架包含四种抽象概念,System(系统)、Application(应用)、Module(模块)和Assembly(部件)。
他们存在包含关系,左侧会包含右侧,如下:
System(系统)》Application(应用)》Module(模块)》Assembly(部件)。
Assembly(部件)通过实现框架的接口被开发出来,
System(系统)、Application(应用)和Module(模块)通过配置得到,无需额外开发。
其中System(系统)、Application(应用)、Module(模块)都可以独立执行。
使用akka和scaldi重构框架,支持并行的流程,
支持Spark 2.1.1版本。
框架会通过3步获取流程并执行出结果:
第1步是通过配置解析出逻辑执行计划
第2步是通过逻辑执行计划解析出物理执行计划,生成流程图
第3步是执行流程图,最后通过邮件或微信的方式通知用户流程图执行结果
- 框架进程中执行的每个部件都共用一个SparkContext
- 通过配置文件可灵活配置执行流程,支持
并行流程 - 每个部件都是一个独立的jar包,部件之间高度解耦,可复用
- 每个部件的参数可独立配置
- 流程中每个部件可以获取上一步中n(n >= 1)个部件的执行结果,再加工处理生成新的结果
- 支持local、yarn-client和yarn-cluster模式执行
- lego-common,包含一些共通的工具类和框架的接口规则
- lego-graph,包含逻辑执行计划的解析逻辑和物理执行计划的解析与运行逻辑
- lego-core,包含框架的运行入口
- 进行Assembly(部件)的开发
- 通过编写配置文件,配置出自己喜欢的流程
- 按照框架的规则部署
- 按照启动脚本模板,修改最多4个参数,完成启动脚本开发
- 执行启动脚本,执行任务流程
- 部件分为两类,数据清洗类和模型类,Assembly的项目需要导入lego-common的package后的jar包引入接口
- 数据清洗类部件需要实现CleanerAssembly接口的clean和succeed方法
- 模型类部件需要实现PredictModelAssembly接口的predict和succeed方法
- 两个接口中的clean和predict方法是部件的处理逻辑,succeed方法是部件的执行状态,框架需要通过该方法判断执行状态
- clean和predict方法包含3个输入参数
- sc:执行Spark任务所需的SparkContext
- config:当前这个部件的参数配置,对应部件配置文件conf/application.conf中parameters数组中的一个节点
- prevStepRDD:包含上一步执行结果的键值对,因为上一步可能是并行流程,所以有可能会传来n个结果,使用上一步部件的name提取结果
- clean和predict方法的返回参数是当前部件的执行结果,会传给下一步的部件
- 部件开发完成后,使用sbt assembly命令生成jar文件
CleanerAssembly接口:
trait CleanerAssembly extends Component{
/**
* Clean data
* @param sc SparkContext object on framework
* @param config Config object, can get assembly parameters by config
* @param prevStepRDD Data set Map of previous job
* @return Data set RDD[String] of current job
*/
def clean(sc: SparkContext, config: Config,
prevStepRDD: Option[Map[String, RDD[String]]] = None): Option[RDD[String]]
/***
* If job succeed
* @return (Boolean, String), 1st: will be true or false, true means succeed, false means failed; 2nd: will be "" if 1st is true, will be error message if 1st is false
*/
def succeed: (Boolean, String)
override def run(sc: SparkContext, config: Option[Config] = None,
prevStepRDD: Option[Map[String, RDD[String]]] = None): Option[ComponentResult] = {
val resultOpt = clean(sc, config.get, prevStepRDD)
val (succd, message) = succeed
val name = config.get.getString("name")
val result = resultOpt.map(r => Option(Map(name -> r))).getOrElse(None)
Some(ComponentResult(name, succd, message, result))
}
}PredictModelAssembly接口:
trait PredictModelAssembly extends Component{
/**
*
* @param sc SparkContext object on framework
* @param config Config object, can get assembly parameters by config
* @param prevStepRDD Data set Map of previous job
* @return Data set RDD[String] of current job
*/
def accuracy(sc: SparkContext, config: Config,
prevStepRDD: Option[Map[String, RDD[String]]] = None ): String
/**
*
* @param sc SparkContext object on framework
* @param config Config object, can get assembly parameters by config
* @param prevStepRDD Data set RDD[String] of previous job
* @return Data set RDD[String] of current job
*/
def predict(sc: SparkContext, config: Config,
prevStepRDD: Option[Map[String, RDD[String]]] = None): Option[RDD[String]]
/***
* If job succeed
* @return (Boolean, String), 1st: will be true or false, true means succeed, false means failed; 2nd: will be "" if 1st is true, will be error message if 1st is false
*/
def succeed: (Boolean, String)
override def run(sc: SparkContext, config: Option[Config] = None,
prevStepRDD: Option[Map[String, RDD[String]]] = None): Option[ComponentResult] = {
val resultOpt = predict(sc, config.get, prevStepRDD)
val (succd, message) = succeed
val name = config.get.getString("name")
val result = resultOpt.map(r => Option(Map(name -> r))).getOrElse(None)
Some(ComponentResult(name, succd, message, result))
}
}框架中配置解析使用https://github.com/typesafehub/config 实现
- 配置类型
system:标识该配置描述的是一个system(系统)
application:标识该配置描述的是一个application(应用)
module:标识该配置描述的是一个module(模块)
#system or application or module
type = "module"- 全局参数配置
出现在该配置中的键值对,会替换assembly下conf/application.conf中的相应键的值。
在最上层配置中的全局参数配置才可生效
举例1:你配置了一个system,那么只有在system的application.conf中的该配置才会生效;
举例2:你配置了一个application,那么只有在application的application.conf中的该配置才会生效。
context.parameters = [
{
key = "start-date"
value = "2017-01-01"
}
]- 日志目录
日志目录可配置本地目录或hdfs目录
log.dir = "/Users/deanzhang/work/code/github/lego-framework/sample/s1/log/"- 邮件相关配置(待完善)
- 微信相关配置(待完善)
- assemblies-dir
assembly的存放目录的绝对路径,该参数用于local运行模式下,查找存放assembly jar包的目录 - assemblies
包含所有部件配置信息的一个数组,每个部件配置包含如下字段-
name:部件的名称,用于记录日志,也用于查找对应的参数配置
-
index:部件的执行顺序,该参数可配置并行流程 配置并行流程的方法:
设置conf/application.conf中的index字段,其值存在".",则表示有一层并行流程。
比如,
assembly [a]的index = 1
assembly [b]的index = 1.1
assembly [c]的index = 1.2
assembly [d]的index = 2
则b和c为一个并行流程,即整体执行流程图如下:|-> b -| | | a - -> d | | |-> c -|具体可参加sample/s1中的实例(可本地执行)。
-
type:部件的类型,cleaner为数据清洗类部件,model为模型类部件
-
jar-name:部件jar文件的名称
-
class-name:部件实现框架接口(CleanerAssembly或PredictModelAssembly)的子类全路径
-
enable:标识该部件是否被执行,true为执行,false为不执行
-
- parameters
包含所有部件参数的一个数组,
每个部件参数配置必须包含一个name字段,对应assemblies中的name字段,用于部件与其参数配置的关联,
其他参数,使用者根据自己需求,随意配置。
参见sample/s1/s1.ap1/s1.ap1.m1/conf/application.conf
- parts
包含所有下级结构(application或module)配置的数组,每个结构配置包含如下字段- name:下级结构名称
- dir:下级结构所在目录
- index:下级结构的执行顺序,同assembly中index字段,同样可配置并行流程
- enable:标识该下级结构是否被执行,true为执行,false为不执行
参见 sample/s1/conf/application.conf 或 sample/s1/s1.ap1/conf/application.conf
sample/s1目录为一个部署完成的实例,使用者需修改其中与路径相关的配置,即整体替换s1目录下"/Users/deanzhang/work/code/github"为你本地lego-framework的目录,即可运行。
部署实例sample/s1概览:
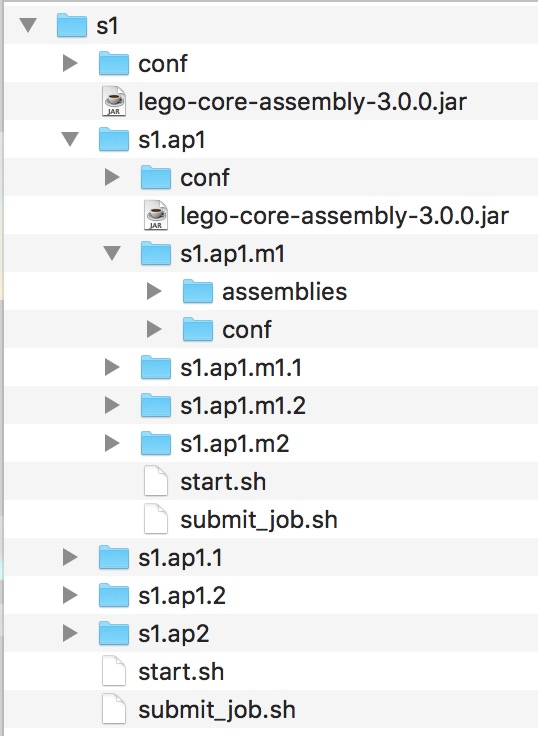
- 严格按照层级关系(System 》Application 》Module)的目录结构进行部署
比如,system s1下配置了application s1.ap1和s1.ap2;application s1.ap1下又配置了module s1.ap1.m1和sq.ap1.m2;
则s1.ap1.m1和sq.ap1.m2目录在s1.ap1下,s1.ap1和s1.ap2目录在s1下。
目录结构如下:
|s1-|
|-s1.ap1|
|-s1.ap1.m1
|-s1.ap1.m2
|-s1.ap2|
|-...
-
module目录包含如下内容
- assemblies文件夹:放置模块需要执行的所有部件jar包
- conf文件夹:放置模块需要的配置文件application.conf
- lego-core-assembly-x.x.x.jar:框架的jar文件,包含框架的主要处理逻辑,若想模块单独运行需添加该jar包
- submit_job.sh:提交任务的脚本
- start.sh:启动脚本,其中会调用submit_job.sh
-
application目录包含如下内容
- conf文件夹:放置应用需要的配置文件application.conf
- lego-core-assembly-x.x.x.jar:框架的jar文件,包含框架的主要处理逻辑,若想应用单独运行需添加该jar包
- submit_job.sh:提交任务的脚本
- start.sh:启动脚本,其中会调用submit_job.sh
- 其下的所有module的目录
-
system目录包含如下内容
- conf文件夹:放置系统需要的配置文件application.conf
- lego-core-assembly-x.x.x.jar:框架的jar文件,包含框架的主要处理逻辑
- submit_job.sh:提交任务的脚本
- start.sh:启动脚本,其中会调用submit_job.sh
- 其下的所有application的目录
-
提交任务脚本submit_job.sh
该文件一般情况不做任何修改,用start.sh传入正确的参数直接调用- 执行模板:
./submit_job.sh {deploy_mode(client/cluster)} {local_root_dir} {spark_parameters} {hdfs_models_root_dir}- 参数说明:
- deploy_mode
运行模式,有两个可选值:
local:表示以local模式提交spark任务
client:表示以yarn-client模式提交spark任务
cluster:表示以yarn-cluster模式提交spark任务 - local_root_dir
本地的模型根目录,填绝对路径 - spark_parameters
spark的参数,主要是spark的性能参数,
所有参数需要用双引号括起来,
比如 "--executor-memory 4G --conf spark.shuffle.consolidateFiles=true --conf spark.rdd.compress=true" - hdfs_models_root_dir
hdfs中模型的根目录的父级目录,该参数只针对cluster模式,client模式填写无效
比如规定所有需要使用yarn-cluster模式运行的模型,都要将模型存入hdfs://hadoop1:8020/models目录,那么该参数就填hdfs://hadoop1:8020/models,
比如本地模型目录为dove_pred,那么模型上传到hdfs后目录会在hdfs://hadoop1:8020/models/dove_pred
- deploy_mode
- 执行模板:
-
启动脚本start.sh
- local模式
#!/bin/bash DEPLOY_MODE=local LOCAL_ROOT_DIR=/Users/deanzhang/work/code/github/lego-framework/sample/s1 SPARK_PARAMTERS="--conf spark.shuffle.consolidateFiles=true --executor-memory 1500m --conf spark.rdd.compress=true" ./submit_job.sh $DEPLOY_MODE $LOCAL_ROOT_DIR "$SPARK_PARAMTERS"
- client模式
#!/bin/bash DEPLOY_MODE=client LOCAL_ROOT_DIR=/Users/deanzhang/work/code/github/lego-framework/sample/s1 SPARK_PARAMTERS="--conf spark.shuffle.consolidateFiles=true --executor-memory 1500m --conf spark.rdd.compress=true" ./submit_job.sh $DEPLOY_MODE $LOCAL_ROOT_DIR "$SPARK_PARAMTERS"
- cluster模式
#!/bin/bash DEPLOY_MODE=cluster LOCAL_ROOT_DIR=/home/sa/app/models/appB SPARK_PARAMETERS="--conf spark.shuffle.consolidateFiles=true --executor-memory 1500m --conf spark.rdd.compress=true" HDFS_MODELS_ROOT_DIR=hdfs://hadoop1:8020/models/ ./submit_job.sh $DEPLOY_MODE $LOCAL_ROOT_DIR "$SPARK_PARAMETERS" $HDFS_MODELS_ROOT_DIR
目前只支持通过一种内部的http邮件API或http微信API发送预警信息,下一步框架会提供更灵活的配置,可以向自定义邮件或微信API发送预警信息。
[ProjectName][[email protected]] System[s1] execute succeed
System[s1] start at 2017-10-16 16:46:15, finished at 2017-10-16 16:46:23, total elapsed time = 7586ms.
s1.ap1.m1.a1: execute succeed. started at 2017-10-16 16:46:15; finished at 2017-10-16 16:46:16, elapsed time = 284ms.
None
s1.ap1.m1.a1.1: execute succeed. started at 2017-10-16 16:46:16; finished at 2017-10-16 16:46:17, elapsed time = 1013ms.
a#b#c
s1.ap1.m1.a1.2: execute succeed. started at 2017-10-16 16:46:17; finished at 2017-10-16 16:46:17, elapsed time = 103ms.
a#b#c
s1.ap1.m1.a2: execute succeed. started at 2017-10-16 16:46:17; finished at 2017-10-16 16:46:17, elapsed time = 155ms.
a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a3: execute succeed. started at 2017-10-16 16:46:17; finished at 2017-10-16 16:46:17, elapsed time = 159ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a4: execute succeed. started at 2017-10-16 16:46:17; finished at 2017-10-16 16:46:17, elapsed time = 138ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a4.1: execute succeed. started at 2017-10-16 16:46:17; finished at 2017-10-16 16:46:17, elapsed time = 166ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a4.2: execute succeed. started at 2017-10-16 16:46:17; finished at 2017-10-16 16:46:18, elapsed time = 136ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.1.a1: execute succeed. started at 2017-10-16 16:46:18; finished at 2017-10-16 16:46:18, elapsed time = 231ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
...
[ProjectName][WARN!!][[email protected]] System[s1] execute failed
System[s1] start at 2017-10-16 17:00:18, finished at 2017-10-16 17:00:19, total elapsed time = 1763ms.
s1.ap1.m1.a1: execute succeed. started at 2017-10-16 17:00:18; finished at 2017-10-16 17:00:18, elapsed time = 278ms.
None
s1.ap1.m1.a1.1: execute succeed. started at 2017-10-16 17:00:18; finished at 2017-10-16 17:00:19, elapsed time = 879ms.
a#b#c
s1.ap1.m1.a1.2: execute succeed. started at 2017-10-16 17:00:19; finished at 2017-10-16 17:00:19, elapsed time = 68ms.
a#b#c
s1.ap1.m1.a2: execute succeed. started at 2017-10-16 17:00:19; finished at 2017-10-16 17:00:19, elapsed time = 156ms.
a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a3: execute succeed. started at 2017-10-16 17:00:19; finished at 2017-10-16 17:00:19, elapsed time = 158ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a4: execute succeed. started at 2017-10-16 17:00:19; finished at 2017-10-16 17:00:19, elapsed time = 135ms.
a#b#c#a#b#c#a#b#c#a#b#c#a#b#c#a#b#c
s1.ap1.m1.a4.1: execute failed!!!!! started at 2017-10-16 17:00:19; finished at 2017-10-16 17:00:19, elapsed time = 4ms.
java.lang.Exception: Throw a test exception



