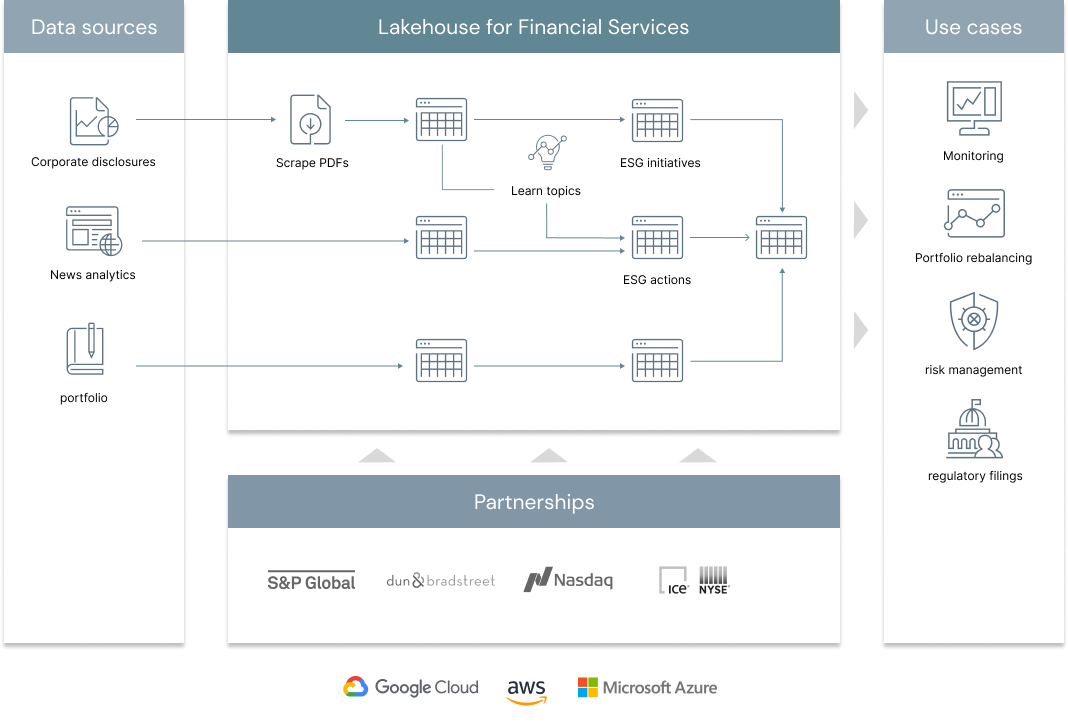
The future of finance goes hand in hand with social responsibility, environmental stewardship and corporate ethics. In order to stay competitive, Financial Services Institutions (FSI) are increasingly disclosing more information about their environmental, social and governance (ESG) performance. By better understanding and quantifying the sustainability and societal impact of any investment in a company or business, FSIs can mitigate reputation risk and maintain the trust with both their clients and shareholders. At Databricks, we increasingly hear from our customers that ESG has become a C-suite priority. This is not solely driven by altruism but also by economics: Higher ESG ratings are generally positively correlated with valuation and profitability while negatively correlated with volatility (source). In this solution, we offer a novel approach to sustainable finance by combining NLP techniques and news analytics to extract key strategic ESG initiatives and learn companies' commitments to corporate responsibility.
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| beautifulsoup4 | Web scraper | MIT | https://www.crummy.com/software/BeautifulSoup |
| PyPDF2 | PDF parser | BSD | https://pypi.org/project/PyPDF2 |
| NLTK | NLP toolkit | Apache2 | https://github.com/nltk/nltk |
| Spacy | NLP toolkit | MIT | https://spacy.io/ |
| Wordcloud | Visualization | MIT | https://github.com/amueller/word_cloud |
| PyYAML | Reading Yaml files | MIT | https://github.com/yaml/pyyaml |
| spark-gdelt | GDELT wrapper | Apache2 | https://github.com/aamend/spark-gdelt |
To run this accelerator, clone this repo into a Databricks workspace. Switch to the web-sync branch if you would like to run the version of notebooks currently published on the Databricks website. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs. The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.


