Before we define the nodes and relationships we create a few CSV files to make the process easier.
Firstly, we create a file called 'students.csv' containing the firstName, lastName, id, gender, address, city, state, zipCode, and phone number for each student. This file is a subset of the provided 'data-students-and-housing.csv'
Secondly, we create a file called 'courses.csv' containing the department, number, and title of each distinct course. This file is derived from the provided 'data-courses.csv' file.
Thirdly, we create a file called 'dormitory.csv' containing the name for each distinct dormitory. This file is derived from the provided 'data-students-and-housing.csv'.
Fourthly, we create a file called 'enrolled.csv' containing the id, firstName, lastName, department, number, title, grade, section, and instructor for all of the records containing 'IP' for the field grade. The remaining records are used to create the final file, called 'completed.csv'.
We begin by clearing the database:
match (n) optional match (n)-[r]-() delete n,r
We load the CSV to create the student nodes in batch as follows:
load csv with headers from "file:C:/Users/DerekG/Documents/R/IS607/Assignment_13/students.csv" as students create (s:Student {firstName: students.firstName, lastName: students.lastName, id: students.id, gender: students.gender, address: students.address,city: students.city, state: students.state, zipCode: students.zipCode, phone: students.phone})
We load the CSV to create the course nodes as follows:
load csv with headers from "file:C:/Users/DerekG/Documents/R/IS607/Assignment_13/courses.csv" as courses create (c:Course {department: courses.department, number: courses.number, title: courses.title})
We load the CSV to create the dormitory nodes as follows:
load csv with headers from "file:C:/Users/DerekG/Documents/R/IS607/Assignment_13/dormitory.csv" as dormitory create (d:Dormitory {name: dormitory.name})
We load the CSV to define the 'enrolled' relationship as follows:
load csv with headers from "file:C:/Users/DerekG/Documents/R/IS607/Assignment_13/enrolled.csv" as courses match (a: Student {id: courses.id}), (c: Course {number: courses.number}) create (a) - [r:Enrolled {section: courses.section, instructor: courses.instructor, grade: courses.grade}] -> (c)
We load the CSV to define the 'completed' relationship as follows:
load csv with headers from "file:C:/Users/DerekG/Documents/R/IS607/Assignment_13/completed.csv" as courses match (a: Student {id: courses.id}), (c: Course {number: courses.number}) create (a) - [r:Completed {section: courses.section, instructor: courses.instructor, grade: courses.grade}] -> (c)
We load the CSV to define the 'housed' relationship as follows:
load csv with headers from "file:C:/Users/DerekG/Documents/R/IS607/Assignment_13/data-students-and-housing.csv" as housing match (a: Student {id: housing.id}), (b: Dormitory {name: housing.dormitory}) create (a) - [r:Housed {room: housing.room}] -> (b)
Although we can use a relational database to model the relationships represented in the graph database above, a relational database requires JOIN statements that slow performance considerably as we scale our application (as compared to a graph database). Given that graph databases can be implemented in a fully ACID-compliant manner, a graph database is a better choice than a relational database for this application, providing significantly improved query performance as we scale the application and a more parsimonious model that can easily be understood and discussed not only within the technology function, but also across the entire business.
This query will find all of the roommates of the student Richard Kowalski:
match (a: Student {firstName: "Richard", lastName: "Kowalski"}) - [r1:Housed] -> (b: Dormitory) <- [r2:Housed] - (c: Student) where r1.room = r2.room return c;
We update the graph database to reflect that fact that Richard Kowalski has completed section 12136 of Math 120: Finite Mathematics with a grade of B:
First, we can query the information before we make the update:
match (s:Student{firstName: "Richard",lastName: "Kowalski"})-[r]->(c:Course) return s.firstName,s.lastName,c.title,r
We make the update:
match (a: Student {firstName: "Richard", lastName: "Kowalski"}) - [r:Enrolled] -> (b: Course {number : '120'} ) CREATE (a) - [r2:Completed{grade:"B"}] -> (b) DELETE r
We double-check following the update:
match (s:Student{firstName: "Richard",lastName: "Kowalski"})-[r]->(c:Course) return s.firstName,s.lastName,c.title,r
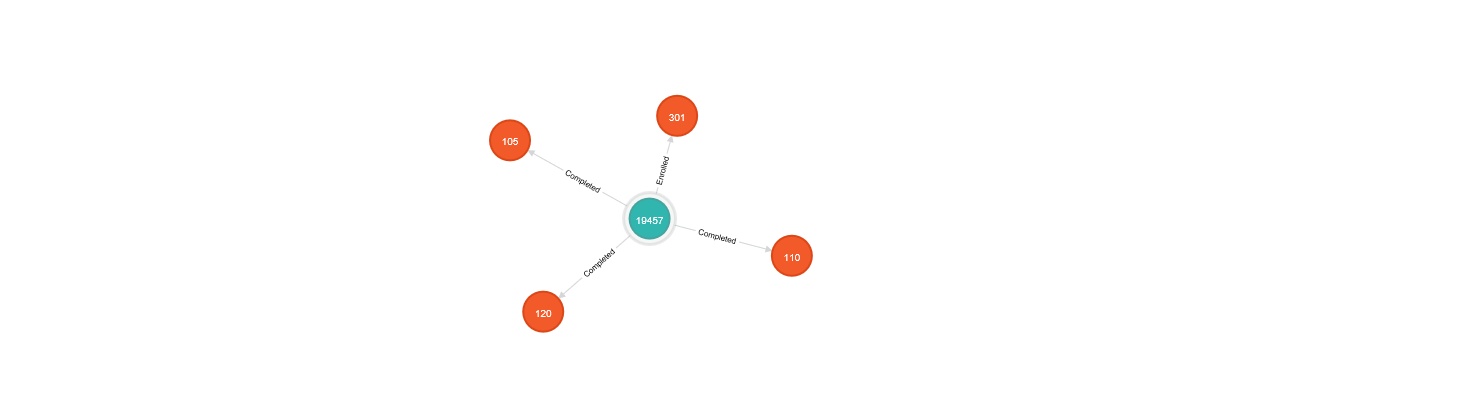
We finish by clearing the database:
match (n) optional match (n)-[r]-() delete n,r

