dwqs / blog Goto Github PK
View Code? Open in Web Editor NEW:dog: :clap: :star2: Welcome to star
License: MIT License
:dog: :clap: :star2: Welcome to star
License: MIT License








































































































































































































在JavaScript中,创建数组可以使用Array构造函数,或者使用数组直接量[],后者是首选方法。Array对象继承自Object.prototype,对数组执行typeof操作符返回object而不是array。然而,[] instanceof Array也返回true。也就是说,类数组对象的实现更复杂,例如strings对象、arguments对象,arguments对象不是Array的实例,但有length属性,并能通过索引取值,所以能像数组一样进行循环操作。
在本文中,我将复习一些数组原型的方法,并探索这些方法的用法。

这是JavaScript中最简单的方法,但是IE7和IE8不支持此方法。
.forEach 有一个回调函数作为参数,遍历数组时,每个数组元素均会调用它,回调函数接受三个参数:
此外,可以传递可选的第二个参数,作为每次函数调用的上下文(this).
['_', 't', 'a', 'n', 'i', 'f', ']'].forEach(function (value, index, array) {
this.push(String.fromCharCode(value.charCodeAt() + index + 2))
}, out = [])
out.join('')
// <- 'awesome'
后文会提及.join,在这个示例中,它用于拼接数组中的不同元素,效果类似于out[0] + '' + out[1] + '' + out[2] + '' + out[n]。
不能中断.forEach循环,并且抛出异常也是不明智的选择。幸运的事我们有另外的方式来中断操作。
如果你用过.NET中的枚举,这两个方法和.Any(x => x.IsAwesome) 、 .All(x => x.IsAwesome)类似。
和.forEach的参数类似,需要一个包含value,index,和array三个参数的回调函数,并且也有一个可选的第二个上下文参数。MDN对.some的描述如下:
some将会给数组里的每一个元素执行一遍回调函数,直到回调函数返回true。如果找到目标元素,some立即返回true,否则some返回false。回调函数只对已经指定值的数组索引执行;它不会对已删除的或未指定值的元素调用。
max = -Infinity
satisfied = [10, 12, 10, 8, 5, 23].some(function (value, index, array) {
if (value > max) max = value
return value < 10
})
console.log(max)
// <- 12
satisfied
// <- true
注意,当回调函数的value < 10时,中断函数循环。.every的运行原理和.some类似,但回调函数是返回false而不是true。
.join和.concat 经常混淆。.join(separator)以separator作为分隔符拼接数组元素,并返回字符串形式,如果没有提供separator,将使用默认的,。.concat会创建一个新数组,作为源数组的浅拷贝。
浅拷贝意味着新数组和原数组保持相同的对象引用,这通常是好事。例如:
var a = { foo: 'bar' }
var b = [1, 2, 3, a]
var c = b.concat()
console.log(b === c)
// <- false
b[3] === a && c[3] === a
// <- true
每个人都知道.push可以再数组末尾添加元素,但是你知道可以使用[].push('a', 'b', 'c', 'd', 'z')一次性添加多个元素吗?
.pop 方法是.push 的反操作,它返回被删除的数组末尾元素。如果数组为空,将返回void 0 (undefined),使用.pop和.push可以创建LIFO (last in first out)栈。
function Stack () {
this._stack = []
}
Stack.prototype.next = function () {
return this._stack.pop()
}
Stack.prototype.add = function () {
return this._stack.push.apply(this._stack, arguments)
}
stack = new Stack()
stack.add(1,2,3)
stack.next()
// <- 3
相反,可以使用.shift和 .unshift创建FIFO (first in first out)队列。
function Queue () {
this._queue = []
}
Queue.prototype.next = function () {
return this._queue.shift()
}
Queue.prototype.add = function () {
return this._queue.unshift.apply(this._queue, arguments)
}
queue = new Queue()
queue.add(1,2,3)
queue.next()
// <- 1
Using .shift (or .pop) is an easy way to loop through a set of array elements, while draining the array in the process.
list = [1,2,3,4,5,6,7,8,9,10]
while (item = list.shift()) {
console.log(item)
}
list
// <- []
.map为数组中的每个元素提供了一个回调方法,并返回有调用结果构成的新数组。回调函数只对已经指定值的数组索引执行;它不会对已删除的或未指定值的元素调用。
Array.prototype.map 和上面提到的.forEach、.some和 .every有相同的参数格式:.map(fn(value, index, array), thisArgument)
values = [void 0, null, false, '']
values[7] = void 0
result = values.map(function(value, index, array){
console.log(value)
return value
})
// <- [undefined, null, false, '', undefined × 3, undefined]
undefined × 3很好地解释了.map不会对已删除的或未指定值的元素调用,但仍然会被包含在结果数组中。.map在创建或改变数组时非常有用,看下面的示例:
// casting
[1, '2', '30', '9'].map(function (value) {
return parseInt(value, 10)
})
// 1, 2, 30, 9
[97, 119, 101, 115, 111, 109, 101].map(String.fromCharCode).join('')
// <- 'awesome'
// a commonly used pattern is mapping to new objects
items.map(function (item) {
return {
id: item.id,
name: computeName(item)
}
})
filter对每个数组元素执行一次回调函数,并返回一个由回调函数返回true的元素组成的新数组。回调函数只会对已经指定值的数组项调用。
通常用法:.filter(fn(value, index, array), thisArgument),跟C#中的LINQ表达式和SQL中的where语句类似,.filter只返回在回调函数中返回true值的元素。
[void 0, null, false, '', 1].filter(function (value) {
return value
})
// <- [1]
[void 0, null, false, '', 1].filter(function (value) {
return !value
})
// <- [void 0, null, false, '']
如果没有提供compareFunction,元素会被转换成字符串并按照字典排序。例如,”80″排在”9″之前,而不是在其后。
跟大多数排序函数类似,Array.prototype.sort(fn(a,b))需要一个包含两个测试参数的回调函数,其返回值如下:
[9,80,3,10,5,6].sort()
// <- [10, 3, 5, 6, 80, 9]
[9,80,3,10,5,6].sort(function (a, b) {
return a - b
})
// <- [3, 5, 6, 9, 10, 80]
这两个函数比较难理解,.reduce会从左往右遍历数组,而.reduceRight则从右往左遍历数组,二者典型用法:.reduce(callback(previousValue,currentValue, index, array), initialValue)。
previousValue 是最后一次调用回调函数的返回值,initialValue则是其初始值,currentValue是当前元素值,index是当前元素索引,array是调用.reduce的数组。
一个典型的用例,使用.reduce的求和函数。
Array.prototype.sum = function () {
return this.reduce(function (partial, value) {
return partial + value
}, 0)
};
[3,4,5,6,10].sum()
// <- 28
如果想把数组拼接成一个字符串,可以用.join实现。然而,若数组值是对象,.join就不会按照我们的期望返回值了,除非对象有合理的valueOf或toString方法,在这种情况下,可以用.reduce实现:
function concat (input) {
return input.reduce(function (partial, value) {
if (partial) {
partial += ', '
}
return partial + value
}, '')
}
concat([
{ name: 'George' },
{ name: 'Sam' },
{ name: 'Pear' }
])
// <- 'George, Sam, Pear'
和.concat类似,调用没有参数的.slice()方法会返回源数组的一个浅拷贝。.slice有两个参数:一个是开始位置和一个结束位置。
Array.prototype.slice 能被用来将类数组对象转换为真正的数组。
Array.prototype.slice.call({ 0: 'a', 1: 'b', length: 2 })
// <- ['a', 'b']
这对.concat不适用,因为它会用数组包裹类数组对象。
Array.prototype.concat.call({ 0: 'a', 1: 'b', length: 2 })
// <- [{ 0: 'a', 1: 'b', length: 2 }]
此外,.slice的另一个通常用法是从一个参数列表中删除一些元素,这可以将类数组对象转换为真正的数组。
function format (text, bold) {
if (bold) {
text = '<b>' + text + '</b>'
}
var values = Array.prototype.slice.call(arguments, 2)
values.forEach(function (value) {
text = text.replace('%s', value)
})
return text
}
format('some%sthing%s %s', true, 'some', 'other', 'things')
.splice 是我最喜欢的原生数组函数,只需要调用一次,就允许你删除元素、插入新的元素,并能同时进行删除、插入操作。需要注意的是,不同于`.concat和.slice,这个函数会改变源数组。
var source = [1,2,3,8,8,8,8,8,9,10,11,12,13]
var spliced = source.splice(3, 4, 4, 5, 6, 7)
console.log(source)
// <- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 ,13]
spliced
// <- [8, 8, 8, 8]
正如你看到的,.splice会返回删除的元素。如果你想遍历已经删除的数组时,这会非常方便。
var source = [1,2,3,8,8,8,8,8,9,10,11,12,13]
var spliced = source.splice(9)
spliced.forEach(function (value) {
console.log('removed', value)
})
// <- removed 10
// <- removed 11
// <- removed 12
// <- removed 13
console.log(source)
// <- [1, 2, 3, 8, 8, 8, 8, 8, 9]
利用.indexOf 可以在数组中查找一个元素的位置,没有匹配元素则返回-1。我经常使用.indexOf的情况是当我有比较时,例如:a === 'a' || a === 'b' || a === 'c',或者只有两个比较,此时,可以使用.indexOf:['a', 'b', 'c'].indexOf(a) !== -1。
注意,如果提供的引用相同,.indexOf也能查找对象。第二个可选参数用于指定开始查找的位置。
var a = { foo: 'bar' }
var b = [a, 2]
console.log(b.indexOf(1))
// <- -1
console.log(b.indexOf({ foo: 'bar' }))
// <- -1
console.log(b.indexOf(a))
// <- 0
console.log(b.indexOf(a, 1))
// <- -1
b.indexOf(2, 1)
// <- 1
如果你想从后向前搜索,可以使用.lastIndexOf。
在面试中新手容易犯的错误是混淆.indexOf和in操作符:
var a = [1, 2, 5]
1 in a
// <- true, but because of the 2!
5 in a
// <- false
问题是in操作符是检索对象的键而非值。当然,这在性能上比.indexOf快得多。
var a = [3, 7, 6]
1 in a === !!a[1]
// <- true
该方法将数组中的元素倒置。
var a = [1, 1, 7, 8]
a.reverse()
// [8, 7, 1, 1]
.reverse 会修改数组本身。
在浅说Flux开发中,简单介绍了Flux及其开发方式。Flux可以说是一个框架,其有本身的 Dispatcher 接口供开发者;也可以说是一种数据流单向控制的架构设计,围绕单向数据流的核心,其定义了一套行为规范,如下图:
Redux的设计就继承了Flux的架构,并将其完善,提供了多个API供开发者调用。借着react-redux,可以很好的与React结合,开发组件化程度极高的现代Web应用。本文是笔者近半年使用react+redux组合的一些总结,不当之处,敬请谅解。
Action是数据从应用传递到 store/state 的载体,也是开启一次完成数据流的开始。
以添加一个todo的Action为例:
{
type:'add_todo',
data:'我要去跑步'
}
这样就定义了一个添加一条todo的Action,然后就能通过某个行为去触发这个Action,由这个Action携带的数据(data)去更新store(state/reducer):
store.dispatch({
type:'add_todo',
data:'your data'
})
type 是一个常量,Action必备一个字段,用于标识该Action的类型。在项目初期,这样定义Action也能愉快的撸码,但是随着项目的复杂度增加,这种方式会让代码显得冗余,因为如果有多个行为触发同一个Action,则这个Action要写多次;同时,也会造成代码结构不清晰。因而,得更改创建Action的方式:
const ADD_TODO = 'add_todo';
let addTodo = (data='default data') => {
return {
type: ADD_TODO,
data: data
}
}
//触发action
store.dispatch(addTodo());
更改之后,代码清晰多了,如果有多个行为触发同一个Action,只要调用一下函数 addTodo 就行,并将Action要携带的数据传递给该函数。类似 addTodo 这样的函数,称之为 Action Creator。Action Creator 的唯一功能就是返回一个Action供 dispatch 进行调用。
但是,这样的Action Creator 返回的Action 并不是一个标准的Action。在Flux的架构中,一个Action要符合 FSA(Flux Standard Action) 规范,需要满足如下条件:
type 、payload、error 和 meta 中的一个或者多个属性。type 字段不可缺省,其它字段可缺省error 字段不可缺省,切必须为 truepayload 是一个对象,用作Action携带数据的载体。所以,上述的写法可以更改为:
let addTodo = (data='default data') => {
return {
type: ADD_TODO,
payload: {
data
}
}
}
在 redux 全家桶中,可以利用 redux-actions 来创建符合 FSA 规范的Action:
import {creatAction} from 'redux-actions';
let addTodo = creatAction(ADD_TODO)
//same as
let addTodo = creatAction(ADD_TODO,data=>data)
可以采用如下一个简单的方式检验一个Action是否符合FSA标准:
let isFSA = Object.keys(action).every((item)=>{
return ['payload','type','error','meta'].indexOf(item) > -1
})
在我看来,Redux提高了两个非常重要的功能,一是 Reducer 拆分,二是中间件。Reducer 拆分可以使组件获取其最小属性(state),而不需要整个Store。中间件则可以在 Action Creator 返回最终可供 dispatch 调用的 action 之前处理各种事情,如异步API调用、日志记录等,是扩展 Redux 功能的一种推荐方式。
Redux 提供了 applyMiddleware(...middlewares) 来将中间件应用到 createStore。applyMiddleware 会返回一个函数,该函数接收原来的 createStore 作为参数,返回一个应用了 middlewares 的增强后的 createStore。
export default function applyMiddleware(...middlewares) {
return (createStore) => (reducer, preloadedState, enhancer) => {
//接收createStore参数
var store = createStore(reducer, preloadedState, enhancer)
var dispatch = store.dispatch
var chain = []
//传递给中间件的参数
var middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action)
}
//注册中间件调用链
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
//返回经middlewares增强后的createStore
return {
...store,
dispatch
}
}
}
创建 store 的方式也会因是否使用中间件而略有区别。未应用中间价之前,创建 store 的方式如下:
import {createStore} from 'redux';
import reducers from './reducers/index';
export let store = createStore(reducers);
应用中间价之后,创建 store 的方式如下:
import {createStore,applyMiddleware} from 'redux';
import reducers from './reducers/index';
let createStoreWithMiddleware = applyMiddleware(...middleware)(createStore);
export let store = createStoreWithMiddleware(reducers);
那么怎么自定义一个中间件呢?
根据 redux 文档,中间件的签名如下:
({ getState, dispatch }) => next => action
根据上文的 applyMiddleware 源码,每个中间件接收 getState & dispatch 作为参数,并返回一个函数,该函数会被传入下一个中间件的 dispatch 方法,并返回一个接收 action 的新函数。
以一个打印 dispatch action 前后的 state 为例,创建一个中间件示例:
export default function({getState,dispatch}) {
return (next) => (action) => {
console.log('pre state', getState());
// 调用 middleware 链中下一个 middleware 的 dispatch。
next(action);
console.log('after dispatch', getState());
}
}
在创建 store 的文件中调用该中间件:
import {createStore,applyMiddleware} from 'redux';
import reducers from './reducers/index';
import log from '../lib/log';
//export let store = createStore(reducers);
//应用中间件log
let createStoreWithLog = applyMiddleware(log)(createStore);
export let store = createStoreWithLog(reducers);
可以在控制台看到输出:
可以对 store 应用多个中间件:
import log from '../lib/log';
import log2 from '../lib/log2';
let createStoreWithLog = applyMiddleware(log,log2)(createStore);
export let store = createStoreWithLog(reducers);
log2 也是一个简单的输出:
export default function({getState,dispatch}) {
return (next) => (action) => {
console.log('我是第二个中间件1');
next(action);
console.log('我是第二个中间件2');
}
}
看控制台的输出:
应用多个中间件时,中间件调用链中任何一个缺少 next(action) 的调用,都会导致 action 执行失败
Redux 本身不处理异步行为,需要依赖中间件。结合 redux-actions 使用,Redux 有两个推荐的异步中间件:
两个中间件的源码都是非常简单的,redux-thunk 的源码如下:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
从源码可知,action creator 需要返回一个函数给 redux-thunk 进行调用,示例如下:
export let addTodoWithThunk = (val) => async (dispatch, getState)=>{
//请求之前的一些处理
let value = await Promise.resolve(val + ' thunk');
dispatch({
type:CONSTANT.ADD_TO_DO_THUNK,
payload:{
value
}
});
};
效果如下:
这里之所以不用 createAction,如前文所说,因为 createAction 会返回一个 FSA 规范的 action,该 action 会是一个对象,而不是一个 function:
{
type: "add_to_do_thunk",
payload: function(){}
}
如果要使用 createAction,则要自定义一个异步中间件。
export let addTodoWithCustom = createAction(CONSTANT.ADD_TO_DO_CUSTOM, (val) => async (dispatch, getState)=>{
let value = await Promise.resolve(val + ' custom');
return {
value
};
});
在经过中间件处理时,先判断 action.payload 是否是一个函数,是则执行函数,否则交给 next 处理:
if(typeof action.payload === 'function'){
let res = action.payload(dispatch, getState);
} else {
next(action);
}
而 async 函数返回一个 Promise,因而需要作进一步处理:
res.then(
(result) => {
dispatch({...action, payload: result});
},
(error) => {
dispatch({...action, payload: error, error: true});
}
);
这样就自定义了一个异步中间件,效果如下:
当然,我们可以对函数执行后的结果是否是Promise作一个判断:
function isPromise (val) {
return val && typeof val.then === 'function';
}
//对执行结果是否是Promise
if (isPromise(res)){
//处理
} else {
dispatch({...action, payload: res});
}
那么,怎么利用 redux-promise 呢?redux-promise 是能处理符合 FSA 规范的 action 的,其对异步处理的关键源码如下:
action.payload.then(
result => dispatch({ ...action, payload: result }),
error => {
dispatch({ ...action, payload: error, error: true });
return Promise.reject(error);
}
)
因而,返回的 payload 不再是一个函数,而是一个 Promise。而 async 函数执行后就是返回一个 Promise,所以,让上文定义的 async 函数自执行一次就可以:
export let addTodoWithPromise = createAction(CONSTANT.ADD_TO_DO_PROMISE, (val) =>
(async (dispatch, getState)=>{
let value = await Promise.resolve(val + ' promise');
return {
value
};
})()
);
结果如下图:
示例源码:redux-demo
收藏!
我一般都喜欢去一些技术类博客社区或者 UGC 社区浏览文章,相信与我同类的你应该也有这爱好。为了方便自己的阅读,而不用一个一个打开目标网站的地址,就基于 Node+React 写了一个小爬虫: Tech-Read,用于抓取常去的 UGC 社区的文章摘要。目前的版本大概样子如下:
在线地址:Tech-Read
github 地址:tech-read
Tech-Read 是个人的一个业余项目,初衷是方便自己阅读,实在是懒于去社区网站阅读,其次用于练手喽,毕竟最近在学点新东西。
在工作上,接触的技术栈是 Node + React,所以 TR 也采用了 Node + React 的技术栈。React 用于前端界面渲染,Node 用于抓取网页,并将解析后的 DOM 数据返回给前端调用。
前端的请求是用 fetch 发起的,由于部分社区做了跨域设置,So 用 Node 能帮我解决一些跨域的问题:
以及在 fetch 中解析 DOM 时碰到的诸如 Uncaught (in promise) TypeError: unexpected token <... 等杂七杂八的错误。
并且 Node 端提供了直接操作 DOM 节点的 cheerio,它是 jQuery 的一个子集实现,能非常方便的操作 DOM 元素。所以,目前我把 DOM 解析放在了 Node 端,前端只负责渲染。
所以,现在的处理流程如下:
由于目前业务比较简单,前端的状态管理就用 Flux。Node 使用 Koa,匹配到 fetch 发起的路由后,通过 request 向目标网站发起请求,然后通过 cheerio 解析 body,获取 DOM 元素数据,以 json 形式返回给前端进行展示。
request 发起的异步请求的返回对象不带 Promise/Generator 等特性,所以不能同步写,但利用 Promise 简单封装下:
exports.parseBody = function (url) {
return new Promise(function (resolve, reject) {
request(url, (error, res, body) => {
if(!error && res.statusCode === 200) {
resolve(body);
} else {
reject(error);
}
});
});
};
就能同步的来写异步请求了:
let resBody = yield lib.parseBody('http://toutiao.io/').then((body) => {
return body;
});
另外一个选择是,利用 co-request,基于 generator 的一个网络请求库。
我个人很喜欢开发者头条,所以第一个抓取的也是开发者头条。由于我想在 TR 上直接看原文,就像这样子:
所以我需要拿到原文链接,插入到 Iframe 里面去。抓取其它社区时,能在抓取首页时顺便拿到原文链接,但是抓取开发者头条的时候,并不能,因为它的 DOM 结构是这样的:
这个 a 的 href 属性并不是原文的链接,要想拿到原文链接,还需要再向 http://toutiao.io/r/b04ku7/r/b04ku7 发起一次 get 请求:
但这个 Location 是不能直接拿到的,因为返回的状态码是 302,页面会被直接跳转到了 Location 指向的页面。但是,request 发起请求后的 response 中则包含了 host 和 path 信息:
req.on('response', (res) => {
if(res.statusCode === 200) {
urlPath = res.client._httpMessage._headers.host + res.client._httpMessage.path;
resolve(urlPath);
}
});
将二者拼接,就能得到原文的 URL 了。
开发者头条部分实现了无限加载:
let contents = document.getElementsByClassName('toutiao-contents')[0];
let contentsHeight = contents.getBoundingClientRect().height;
contents.addEventListener('scroll', (e) => {
let triggerNextMinHeight = e.target.scrollHeight - e.target.scrollTop - contentsHeight;
if(triggerNextMinHeight < 22) {
//fetch data & update component state
}
},false);
无限加载调用的接口是:
http://toutiao.io/prev/date //date 形如 2016-04-26
前文以抓取开发者头条为例,简单讲述了爬虫的实现思路,接下来就简单说说怎么部署 Node 服务。
由于服务器上已经跑了自己的博客,端口 80 已经被Apache 监听了,所以,你看到的 TR 的线上端口就是奇怪的 8080 了,这是 Nginx 监听的,然后被代理到本地的 9000 端口,这也是开发用的端口。
部署之前,先安装下 Node(系统是 CentOS 6.5 64bit)。
1、安装nvm
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bash
或者:
wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bash
建议使用 nvm 安装 Node,因为 nvm 会安装到用户的目录,而 n 会安装到全局的 /usr/ 目录下去。
2、安装 Node
nvm install 4.4.2
如果安装了多版本,则可以将默认的 Node 版本设置成 4.4.2:
nvm alias default 4.4.2
3、安装Nginx
切换到 /etc/yum.repos.d/ 创建文件 nginx.repo ,将下面的粘贴到文件中:
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=0
enabled=1
然后安装 Nginx:
yum install nginx
另一种安装方式是开启 epel-source( epel.repo 中需要有这个配置项)。
首先切换到 /etc/yum.repos.d,运行 cat epel.repo:
// ...
[epel]
// ...
enabled=1
// ...
[epel-source]
// ...
enabled=0
// ...
// ...[epel] 里面的 enabled 是 1(如果是0要改为1), [epel-source] 里面的 enabled 是 0,将其改为1,退出保存。
运行 yum repolist 查看是否添加了 epel-source:
// ...
epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 12299
epel-source Extra Packages for Enterprise Linux 7 - x86_64 - Source 0然后运行 yum install -y nginx 安装 nginx,安装完成之后可运行 nginx -v 查看 nginx 的版本。
EPEL的全称叫 Extra Packages for Enterprise Linux 。EPEL是由 Fedora 社区打造,为 RHEL 及衍生发行版如 CentOS、Scientific Linux 等提供高质量软件包的项目
Nginx 的相关配置:
/etc/init.d/nginx start/restart # 启动/重启Nginx服务
/etc/init.d/nginx stop # 停止Nginx服务
/etc/nginx/nginx.conf # Nginx配置文件位置
4、配置 Nginx
切换到 /etc/nginx/conf.d ,复制 default.conf 文件,按照需要配置新的 conf 文件:
techread.conf 配置文件如下:
listen: 监听的线上端口
server_name: 访问的域名
root: 根目录
index: 默认访问的文件
nginx 可以有多个虚拟主机,每个虚拟主机一个对应的server配置项。
红框部分是 Nginx 的反向代理配置,常见的配置项如下:
location / {
# 被代理的服务器IP
proxy_pass http://10.0.0.137; # 必需 也可以是本机上的一个 node 服务地址,如127.0.0.1
# 以下是一些反向代理的配置(非必需)
proxy_redirect off;
# 后端的Web服务器可以通过 X-Forwarded-For 获取用户真实IP
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 允许客户端请求的最大单文件字节数
client_max_body_size 10m;
# 缓冲区代理缓冲用户端请求的最大字节数
client_body_buffer_size 128k;
# nginx跟后端服务器连接超时时间(代理连接超时)
proxy_connect_timeout 300;
# 后端服务器数据回传时间(代理发送超时)
proxy_send_timeout 300;
# 连接成功后,后端服务器响应时间(代理接收超时)
proxy_read_timeout 300;
# 设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffer_size 4k;
#proxy_buffers缓冲区,网页平均在32k以下的话,这样设置
proxy_buffers 4 32k;
#高负荷下缓冲大小(proxy_buffers*2)
proxy_busy_buffers_size 64k;
#设定缓存文件夹大小,大于这个值,将从upstream服务器传
proxy_temp_file_write_size 64k;
}
proxy_pass 是必备项,表示要被代理的服务地址,其它可有可无。
安利一份关于解读 Nginx 源码的资源:Nginx 福利
启动 Nginx 时,默认是读取 default.conf,现在需要将其更改为读取 techread.conf。 回到 /etc/nginx 下,修改 nginx.conf 文件, 将 include 的引用改为新建的文件:techread.conf:
重启 nginx,线上部署就 OK 了。
在 Web 应用中,JavaScript 通过 XMLHttpRequest (XHR)来执行异步请求,这是一种有效改进页面通信的技术,当我们谈及Ajax技术的时候,通常意思就是基于 XMLHttpRequest 的 Ajax。虽说 Ajax 很有用,但它不是最佳 API,它在设计上不符合职责分离原则,将输入、输出和用事件来跟踪的状态混杂在一个对象里。而且,基于事件的模型与现在 JavaScript 流行的 Promise 以及基于生成器的异步编程模型相背驰。本文将要介绍的内容则是XMLHttpRequest 的最新替代技术—— Fetch API, 它是 W3C 的正式标准。
在介绍之前,先看看目前主流浏览器对 Fetch API 的支持情况:

Fetch 的支持目前还处于早期的阶段,在 Firefox 39 以上,和 Chrome 42 以上都被支持了。
如果你现在就想使用它,还可以用 Fetch Polyfil,用于支持那些还未支持 Fetch 的浏览器。
在使用 Fetch 之前,也可以对其进行功能性检测:
if(self.fetch) {
// run my fetch request here
} else {
// do something with XMLHttpRequest?
}
在 Fetch API 中,最常用的就是 fetch() 函数。它接收一个URL参数,返回一个 promise 来处理 response。response 是一个 Response 对象:
fetch("/data.json").then(function(res) {
// res instanceof Response == true.
if (res.ok) {
res.json().then(function(data) {
console.log(data.entries);
});
} else {
console.log("Looks like the response wasn't perfect, got status", res.status);
}
}, function(e) {
console.log("Fetch failed!", e);
});
fetch() 接受第二个可选参数,一个可以控制不同配置的 init 对象。如果是提交一个 POST 请求,代码如下:
fetch("http://www.example.org/submit.php", {
method: "POST",
headers: {
"Content-Type": "application/x-www-form-urlencoded"
},
body: "firstName=Nikhil&favColor=blue&password=easytoguess"
}).then(function(res) {
if (res.ok) {
//res.ok用于检测请求是否成功
console.log("Perfect! Your settings are saved.");
} else if (res.status == 401) {
console.log("Oops! You are not authorized.");
}
}, function(e) {
console.log("Error submitting form!");
});
如果遇到网络故障,fetch() promise 将会 reject,带上一个 TypeError 对象。想要精确的判断 fetch() 是否成功,需要包含 promise resolved 的情况,此时再判断 Response.ok 是不是为 true。
Fetch 实现了四个接口:GlobalFetch、Headers、Request 和 Response。GloabaFetch 就只包含了一个 fetch 方法用于获取网络资源,其它三个直接对应了相应的 HTTP 概念。此外,在 request/reponse 中,还混淆了 Body。
Headers 接口允许定义 HTTP 的请求头(Request.headers)和响应头(Response.headers)。一个 Headers 对象是一个简单的多名值对:
var content = "Hello World";
var myHeaders = new Headers();
myHeaders.append("Content-Type", "text/plain");
myHeaders.append("Content-Length", content.length.toString());
myHeaders.append("X-Custom-Header", "ProcessThisImmediately");
也可以传一个多维数组或者对象字面量:
myHeaders = new Headers({
"Content-Type": "text/plain",
"Content-Length": content.length.toString(),
"X-Custom-Header": "ProcessThisImmediately",
});
此外,Headers 接口提供了 set ,delete 等 API 用于检索其内容:
console.log(reqHeaders.has("Content-Type")); // true
console.log(reqHeaders.has("Set-Cookie")); // false
reqHeaders.set("Content-Type", "text/html");
reqHeaders.append("X-Custom-Header", "AnotherValue");
console.log(reqHeaders.get("Content-Length")); // 11
console.log(reqHeaders.getAll("X-Custom-Header")); // ["ProcessThisImmediately", "AnotherValue"]
reqHeaders.delete("X-Custom-Header");
console.log(reqHeaders.getAll("X-Custom-Header")); // []
虽然有些操作仅在 ServiceWorkers 中使用,但相对于 XHR,其本身提供了非常方便的操作 Headers 的 API。
出于安全原因,有些 header 字段的设置仅能通过 User Agent 实现,不能通过编程设置:请求头禁置字段 和 响应头禁置字段。
如果使用了一个不合法的 HTTP Header 属性名或者写入一个不可写的属性,Headers 的方法通常都抛出 TypeError 异常:
var myResponse = Response.error();
try {
myResponse.headers.set("Origin", "http://mybank.com");
} catch(e) {
console.log("Cannot pretend to be a bank!");
}
最佳实践是在使用之前检查 content type 是否正确,比如:
fetch(myRequest).then(function(response) {
if(response.headers.get("content-type") === "application/json") {
return response.json().then(function(json) {
// process your JSON further
});
} else {
console.log("Oops, we haven't got JSON!");
}
});
由于 Headers 可以在 request 请求中被发送或者在 response 请求中被接收,并且规定了哪些参数是可写的,Headers 对象有一个特殊的 guard 属性。这个属性没有暴露给 Web,但是它影响到哪些内容可以在 Headers 对象中被改变。
可能的值如下:
Request 接口定义了通过HTTP请求资源的request格式,一个简单请求构造如下:
var req = new Request("/index.html");
console.log(req.method); // "GET"
console.log(req.url); // "http://example.com/index.html"
console.log(req.headers); //请求头
和 fetch() 一样,Request 接受第二个可选参数,一个可以控制不同配置的 init 对象:
var myHeaders = new Headers();
var myInit = { method: 'GET',
headers: myHeaders,
mode: 'cors',
cache: 'default' ,
credentials: true,
body: "image data"};
var myRequest = new Request('flowers.jpg',myInit);
fetch(myRequest,myInit)
.then(function(response) {
return response.blob();
})
.then(function(myBlob) {
var objectURL = URL.createObjectURL(myBlob);
myImage.src = objectURL;
});
mode 属性用来决定是否允许跨域请求,以及哪些response 属性可读。mode 可选的属性值:
credentials 枚举属性决定了cookies 是否能跨域得到,这与 XHR 的 withCredentials 标志相同,但是只有三个值,分别是"omit"(默认),"same-origin"以及"include"。
Response 实例是在 fentch() 处理完 promises 之后返回的,它的实例也可用通过 JavaScript 来创建, 但只有在 ServiceWorkers 中才真正有用。当使用 respondWith() 方法并提供了一个自定义的response来接受request时:
var myBody = new Blob();
addEventListener('fetch', function(event) {
event.respondWith(new Response(myBody, {
headers: { "Content-Type" : "text/plain" }
});
});
Response() 构造方法接受两个可选参数—response的数据体和一个初始化对象(与 Request() 所接受的init参数类似.)
最常见的response属性有:
Request 和 Response 都实现了 Body 接口,在请求过程中,二者都会携带 Body,其可以是以下任何一种类型的实例:
此外,Request 和 Response 都为他们的body提供了以下方法,这些方法都返回一个Promise对象:
Using Fetch
Asynchronous APIs Using the Fetch API and ES6 Generators
This API is so fetching
git 是一个非常棒的源代码管理工具,它的使用已经完全整合到开发的工作流当中;同时,git 还是一个 review/OTAP/deployment 工具。
当在 CLI 中使用 git 时,有时必须输入很多比较长的命令来完成一些事情。尽管大部分 git 命令是很简单的,但是也有一些非常复杂并难以输入的命令。而开发人员是比较懒的,并会尽可能的少输入命令。
因为上述情况很符合我,所以对于我经常使用的 git 命令,我会使用其别名来代替,并会改进命令的返回信息。在这篇文章中,我会介绍一些简单但非常有用的 git 别名。
一些 git 别名非常简单,用这些别名替换原始的 git 命令也意味着减少你的输入,这有一个别名列表:
co = checkout # Checkout a branch
cob = checkout -b # Checkout a new not yet existing branch
f = fetch -p # Fetch from a repository and prune any remote-tracking references that no longer exist on the remote.
c = commit # Commit you changes
p = push # Push you changes to a remote
ba = branch -a # List both remote-tracking branches and local branches.
bd = branch -d # Delete a branch only if it has been merged
bD = branch -D # Force delete a branch
dc = diff --cached # Display the staged changes
查看当前工作目录的提交状态是大多数开发者的一项日常工作。我们会分段查看自己对哪些文件做了改变,并判断我们是否改变了原本不打算改变的文件。
将命令简化,并让其显示更多的信息:
st = status -sb
例如:
我喜欢在添加改变之前进行 review,或许你也这么做。git diff 是能实现这个需求的一个不错的工具。但如果你只想添加你改变的那部分,或者每次只想 review 一小部分,你可以将你改变的那部分分多次提交。
在这种情况下,git add -p 能解决你的需求:
a = add -p
例如:
git 日志能帮助我们查看在工作目录下对代码做了哪些改变,日志不仅记录了代码的提交历史,而且会记录分支的合并情况。当我们 输入规范的提交信息 时,git 日志就成为一个查看代码变更和为什么变更的重要工具。
改善 git 日志的输出能快速定位这些改变:
plog = log --graph --pretty='format:%C(red)%d%C(reset) %C(yellow)%h%C(reset) %ar %C(green)%aN%C(reset) %s'
例如:
lg = log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit
例如:
tlog = log --stat --since='1 Day Ago' --graph --pretty=oneline --abbrev-commit --date=relative
例如:
当你对某个 project 有问题并想找一个人说明时,怎么找到这个 project 的第一贡献者就非常有必要了。
rank = shortlog -sn --no-merges
例如:
在提交 PR 之前,我们需要创建一个本地分支来提交代码,时间久了之后,你就会发现有很多已经合并到 master 上的分支,一个一个删除这些分支是比较麻烦的事。
当这些已经合并的分支的数量很大时,用一个简单的别名来删除这些分时是很方便的。这个别名会删除所有已经合并到你当前所在分支的分支:
bdm = "!git branch --merged | grep -v '*' | xargs -n 1 git branch -d"
例如:
[alias]
# Shortening aliases
co = checkout
cob = checkout -b
f = fetch -p
c = commit
p = push
ba = branch -a
bd = branch -d
bD = branch -D
dc = diff --cached
# Feature improving aliases
st = status -sb
a = add -p
# Complex aliases
plog = log --graph --pretty='format:%C(red)%d%C(reset) %C(yellow)%h%C(reset) %ar %C(green)%aN%C(reset) %s'
tlog = log --stat --since='1 Day Ago' --graph --pretty=oneline --abbrev-commit --date=relative
lg = log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit
rank = shortlog -sn --no-merges
bdm = "!git branch --merged | grep -v '*' | xargs -n 1 git branch -d"
在做项目的对外分享时,分享有两种:一种是公开的,一种是私密的。私密的需要提取码,需要提取码就需要输入框。正常的输入框是这样的:
不正常的输入框就是这样子的:
后面的这种方式在手机端比较常见的,譬如支付宝和微信支付的密码输入。
有两种实现方式,先说简单的。
简单的实现思路是设置一个等大的 input 框和 div,然后通过设置 z-index,将 input 置于 div 上面,同时将 input 框的 opacity 设置趋近于 0,所以 HTML 结构应该是类似酱紫的:
<input type="text" value='提取码' maxLength="6" autoComplete="off"/>
<div id='pwd'>
<span>宫格1</span>
<span>宫格2</span>
<span>宫格3</span>
<span>宫格4</span>
<span>宫格5</span>
<span>宫格6</span>
<span class='custom-cursor'></span>
</div>
CSS :
input {
position: absolute;
z-index: 10;
top: 0;
left: 50%;
transform: translateX(-50%);
opacity: 0.01;
height: 34px;
width: 232px;
box-sizing: border-box;
}
#pwd{
position: absolute;
top: 0;
left: 50%;
height: 34px;
width: 232px;
overflow: hidden;
color: #0d9aff;
box-sizing: border-box;
transform: translateX(-50%);
}
.custom-cursor{
position: absolute;
top: 5px;
left: 2px;
width: 1px;
height: 22px;
border: 1px solid black;
animation:mymove .3s infinite;
}
@keyframes mymove {
0%{
opacity: 0;
}
100%{
opacity: 1;
}
}
因为 input 框是不可见的,所以要模拟一个光标,作为一个输入的提示。光标的偏移距离要根据输入自动去计算。
另一种实现方式比较复杂,不仅需要根据输入来计算 input 框自身的偏移距离,还需要计算所用字体的宽高,因为 input 框的偏移距离和所用的字体是相关的。部分在线编辑器就采用类似的方式来实现的,但取而代之的是 textarea 。
Shift 多选在文件管理器或资源管理器中是很常见的操作,OS X 和 Windows 对 shift 多选的实现方式也不尽相同。
在我看来,shift 多选的有两个比较难的点:一是怎么确定边界,二是怎么确定选择的方式。相对来说,后者比较容易实现。
确定边界的情况和操作比较复杂,如下图:

在我们自身的项目中,对 shift多选采取的是比较简单的实现方式,所以图示是针对我们自身的业务场景来实现的,不具遍普遍性,但可以提供参考的思路。
Linux一般将文件可存取访问的身份分为3个类别:owner、group、others,且3种身份各有read、write、execute等权限。
由于Linux是多用户、多任务的操作系统,因此可能常常有多人同时在某台主机上工作,但每个人均可在主机上设置文件的权限,让其成为个人的“私密文件”,即个人所有者。因为设置了适当的文件权限,除本人(文件所有者)之外的用户无法查看文件内容。
例如某个MM给你发了一封Email情书,你将情书转为文件之后存档在自己的主文件夹中。为了不让别人看到情书的内容,你就能利用所有者的身份去设置文件的适当权限,这样,即使你的情敌想偷看你的情书内容也是做不到的。
用户组最有用的功能就体现在多个团队在同一台主机上开发资源的时候。例如主机上有A、B两个团体,A中有a1,a2,a3三个成员,B中有b1,b2两个成员,这两个团体要共同完成一份报告F。由于设置了适当的权限,A、B团体中的成员都能互相修改对方的数据,但是团体C的成员则不能修改F的内容,甚至连查看的权限都没有。同时,团体的成员也能设置自己的私密文件,让团队的其它成员也读取不了文件数据。在Linux中,每个账户支持多个用户组。如用户ab1即可属于A用户组,也能属于B用户组。
这个是个相对概念。打个比方,大明、二明、小明一家三兄弟住在一间房,房产证上的登记者是大明,那么,大明一家就是一个用户组,这个组有大明、二明、小明三个成员;另外有个人交张三,和他们三没有关系,那么这个张三就是其他人了。
同时,大明、二明、小明有各自的房间,三者虽然能自由进出各自的房间,但是小明不能让大明看到自己的情书、日记等,这就是文件所有者(用户)的意义。
在Linux中,还有一个神一样存在的用户,就是root。之所以称为超级用户,因为在所有用户中它拥有最大的权限 ,也管理着普通用户。
在Linux系统中,默认的系统账户和普通账户信息记录在/etc/passwd文件中,个人密码在/etc/shadow文件下,用户组名称记录在/etc/group,所以,这三个文件是不能随便删的。
要设置权限,就需要知道文件的一些基本属性和权限的分配规则。在Linux中,ls命令常用来查看文件的属性,ls是list的缩写,用于显示文件的文件名和相关属性。
[root@www ~]# ls -al
total 45
drwxr-x--- 4 root root 4096 Sep 8 14:06
-rw-r--r-- 1 root root 43043 Sep 4 18:34 test.txt
含义如下:

第一个字符[d]代表该文件是一个目录,[-]代表该文件是一个普通文件,test.txt是文件名,[l]是连接文件,[b]是设备文件等。
如前文所说,Linux中存在用户、用户组和其他人概念,各自有不同的权限,对于一个文件来说,其权限具体分配如下:

权限分配中,均是rwx的三个参数组合,且位置顺序不会变化。没有对应权限就用 – 代替。
Linux中有几个常用于用户组、所有者和各种身份的权限的修改的命令:
chgrp:改变文件所属用户组
chown:改变文件所有者
chmod:改变文件权限
直接用chgrp就行,它是change group是缩写。不过,要被改变的组名必须在/etc/group文件内存在才行,否则出错。
[root@www ~]# chgrp [-R] 文件名/目录名
—R:进行递归,可修改子目录下的文件
change owner 的缩写是chown,用于改变所有者。不过,用户名必须存在于/etc/passwd文件内。
[root@www ~]# chown [-R] 账号名称 文件名/目录名
[root@www ~]# chown [-R] 账号名称:组名 文件名/目录名
—R:进行递归,可修改子目录下的文件
文件权限的改变一般是用chmod命令,权限的设置方法有两种:
Linux的基本权限有9个,即owner、group、others三种身份各有自己的r/w/x权限,三个为一组。各权限对应的数字是:r—>4,w—>2,x—>1.
每种身份(owner、group、others)的三个权限(r/w/x)分数是累加的,如-rw-r–r–转换数字是:
owner=rw-=4+2+0=6 group=r–=4+0+0=4 others=r–=4+0+0=4
所以该文件的权限数字是644
[root@www ~]# chmod [-R] xyz 文件名/目录名
xyz:数字类型的权限属性,为rwx属性数值的相加
—R:进行递归,可修改子目录下的文件
##修改test.txt的权限为777
[root@www ~]# chmod 777 test.txt
这种方式就是用u,g,o来代表三种身份的权限,此外a代表all,即全部身份(owner、group、others)
##修改test.txt的权限为rwxr-xr-x
[root@www ~]# chmod u=rwx,go=rx test.txt
##去掉test.txt所有身份的x权限
[root@www ~]# chmod a-x test.txt
##再添加test.txt所有身份的x权限
[root@www ~]# chmod a+x test.txt
在 Webpack 2 的文档 完成之后,就会推出 Webpack 2 的 beta 版本, 但这并不意味着你知道怎么配置 Webpack 2, 却不能在项目中使用 Webpack 2.
简单来说, Webpack 是一个针对 JavaScript 的打包工具. 然而, 随着 Webpack 日渐流行, 它逐渐演变成了前端代码的管理工具(不论是人为故意还是社区推动的).
之前的任务管理方式是: HTML文件、样式和JavaScript是各自独立的, 你必须分开地管理每一个文件, 并确保一切能正常运行.
类似Gulp的任务管理工具能处理多个不同的预处理器和编译器, 但是在所有情况下, 这都是将一个文件作为源输入, 经过处理后输出编译后的文件. 然而, Gulp 完成这些工作就像是一个任务接一个任务进行的, 没有从系统(或全局)的角度考虑如何完成任务的输入和输出. 这成了开发者的负担: 在生产环境下, 开发者需要找到任务结束的地方, 并通过合理地方式将所有的任务有序地组装在一起.
而Webpack则尝试询问一个大胆的问题来减轻开发者的负担: 假如在开发过程中的某一个部分能处理其所有的依赖会怎么样呢? 假如我们可以简单地用某种方式去写代码, 而构建程序去管理最终所必需使用到的代码又会怎么样呢?
Webpack的方式是: 如果webpack知道依赖的资源, 它就会将项目实际用到的资源构建到生产环境中.
如果过去几年你都混迹在 web 社区中, 你应该知道解决这个问题的更好方式是: 用 JavaScript 去构建. 而 Webpack 尝试通过JavaScript来解析依赖, 让构建过程变得更加简单. 但仅用于管理代码并不是Webpack设计的厉害之处, 其厉害之处在于Webpack的任务管路方式 100% 由JavaScript来完成的(利用了 Node 特性). Webpack 使你在写 JavaScript 时, 有能力从(项目的)全局角度掌控和把握整个项目.
换句话说: 你不是为Webpack写代码, 而是为你的项目写代码. 同时, webpack会自动运行(当然, 你需要写一些配置文件).
简而言之, 如果你曾经纠结过下面的任何一个问题:
那么, 你会从Webpack中收益, 因为 Webpack 能轻易地处理上述问题, 它会通过 JavaScript 来管理模块依赖和加载顺序而不是你的开发头脑. 此外, Webpack 能在服务端运行, 这意味着你能创建渐进增强的网站.
在这篇文章中, 我们将使用Yarn(brew install yarn)而不是npm, 但这完全取决于你, 因为它们做的是同样的事. 在项目目录, 将运行下面的命令将 Webpack 2 添加到全局和本地项目中:
npm i -g webpack@beta webpack-dev-server@beta
yarn add --dev webpack@beta webpack-dev-server@beta
注: 在本文中, 我们用简单的方式全局安装了 Webpack 2, 而不是通过被推荐的 NPM 脚本. 两种方式都行, 文档 说明了二者的区别.
安装了 Webpack 2之后, 我们需要在项目的根目录下创建一个 webpack.config.js 文件:
const path = require('path');
const webpack = require('webpack');
module.exports = {
context: path.resolve(__dirname, './src'),
entry: {
app: './app.js',
},
output: {
path: path.resolve(__dirname, './dist'),
filename: '[name].bundle.js',
},
};
注意:
__dirname是指你的项目根目录.
还记得 Webpack 是怎么知道项目如何运行的吗? 它是通过读取你的代码来获知这一信息的. Webpack 的工作流如下:
context 文件夹开始entry 对应的文件import (ES6) 或者 require() (Node) 依赖项时, 它会解析这些代码, 并且打包到最终构建里. 接着它会不断递归搜索实际需要的依赖项, 直到它到达了“树”的底部.output.path 对应的目录, 并将 output.filename 的值作为最终的资源名([name] 表示使用 entry 项的 key).如果 src/app.js 看起来像下面的样子(假设之前已运行了 yarn add moment):
import moment from 'moment';
var rightNow = moment().format('MMMM Do YYYY, h:mm:ss a');
console.log(rightNow);
// "October 23rd 2016, 9:30:24 pm"
(在项目的根目录下)运行:
webpack -p
p表示'生产'模式, 输出文件会被 混淆/压缩.
运行命令之后, Webpack 会输出一个 dist/app.bundle.js 文件, 同时在控制台输出当前日期. 需要注意的是, Webpack 会自动找到 moment 的指向(即使你有一个 moment.js 存在于目录中, 但 Webpack 默认会优先去寻找 moment 的Node模块).
你可以修改 entry 对象, 指定任意数量的入口文件和输出文件.
const path = require('path');
const webpack = require('webpack');
module.exports = {
context: path.resolve(__dirname, './src'),
entry: {
app: ['./home.js', './events.js', './vendor.js'],
},
output: {
path: path.resolve(__dirname, './dist'),
filename: '[name].bundle.js',
},
};
按照入口文件在数组中的顺序, 所有文件会被打包在一个 dist/app.bundle.js 里.
const path = require('path');
const webpack = require('webpack');
module.exports = {
context: path.resolve(__dirname, './src'),
entry: {
home: './home.js',
events: './events.js',
contact: './contact.js',
},
output: {
path: path.resolve(__dirname, './dist'),
filename: '[name].bundle.js',
},
};
如果不想把所有打包在一个文件中, 你可以选择将多个文件打包在多个文件中. 上述例子会输出三个文件: dist/home.bundle.js, dist/events.bundle.js 和 dist/contact.bundle.js.
如果你将应用分开打包到多个 output 文件里(如果你的应用有非常多的 JavaScript 文件不需要在前期加载, 这样做是非常有效的), 有可能会出现很多冗余的代码, 因为 Webpack 是独立解析每个文件的依赖的. 幸运的是, Webpack 已经内置了 CommonsChunk 插件来处理这个问题:
module.exports = {
// …
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: 'commons',
filename: 'commons.js',
minChunks: 2,
}),
],
// …
};
加上 CommonsChunk 插件后, 任何一个模块在你的 output 文件中被加载 2 次(该值由 minChunks 设置)及以上, 该模块就会被打包在 common.js 中, 你可以在客户端缓存这些模块. 虽然这会增加额外的请求, 但这能防止客户端多次下载同一个模块.
在开发环境中, Webpack 可以提供一个开发服务器, 因为无论是你正在开发一个静态网站还是仅用于项目的前端原型设计, 它都能满足你的需要. 为启动服务器, 仅需要在 webpack.config.js 中添加一个 devServer 对象:
module.exports = {
context: path.resolve(__dirname, './src'),
entry: {
app: './app.js',
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, './dist/assets'),
publicPath: '/assets', // New
},
devServer: {
contentBase: path.resolve(__dirname, './src'), // New
},
};
在 src 目录下创建一个带如下标签的 index.html 文件:
<script src="/assets/app.bundle.js"></script>
在终端运行如下命令:
webpack-dev-server
开发服务器会运行在 localhost:8080(打开你的浏览器访问该地址就能看到你的页面). 需要注意的是 script 标签里的 /assets 是和 output.publicPath 匹配的--你可以把它命名成任何你想要的名字(如果你使用CDN, 这会很有用).
Webpack 提供了热加载功能. 当你修改了 JavaScript 文件后, Webpack 会自动重新加载资源, 而不需要你手动去刷新浏览器. 但是, 任何对 webpack.config.js 文件的改变都需要重启服务器才会生效.
需要使用在全局作用域下的函数? 只需在 output.library 进行简单的设置就行:
module.exports = {
output: {
library: 'myClassName',
}
};
它会把你的打包文件捆绑在 window.myClassName 实例上. 设置了作用域之后, 你可以在文件的入口处进行调用(更多设置可以查阅文档).
到目前为止, 我只介绍了怎么使用 Webpack 处理 JavaScript 文件. 从处理 JavaScript 文件开始是非常重要的, 因为这是 Webpack 唯一能识别的语言. 实际上, Webpack 可以使用 Loaders 来处理各种通过 JavaScript 传递的任何类型的文件.
loader 可以是像 Sass 这样的预处理器, 也可以是像 Babel 这样的编译器. 在 NPM 里, 它们通常被命名为 *-loader, 例如: sass-loader 或者 babel-loader.
如果你想在项目里通过 Babel 使用 ES6, 首先需要安装合适的loader来编译 es6:
yarn add --dev babel-loader babel-core babel-preset-es2015
然后, 将loader添加到 webpack.config.js 中, 告诉 Webpack 在何处使用该loader:
module.exports = {
// …
module: {
rules: [
{
test: /\.js$/,
use: [{
loader: 'babel-loader',
options: { presets: ['es2015'] }
}],
},
// Loaders for other file types can go here
],
},
// …
};
Webpack 1.x 的用户需要注意: Loaders 的核心理念和Webpack 2是保持一致的, 但是它的语法在Webpack 2中有所改善. 最终准确的语法需要等到 Webpack 2的文档完成之后才知道.
正则表达式 /\.js$/ 会去搜索任何 .js 后缀的文件, 然后通过 Babel 来加载这些文件. Webpack 依赖正则表达式来给你(对文件处理的)完全控制权---它不会限制你需要处理的文件扩展或者让你按照一定的方式来组织代码. 例如: 可能 /my_legacy_code/ 目录下的文件不是 ES6 写的, 你可以修改上面的 test 字段为 /^((?!my_legacy_code).)*\.js$/, 这样就能排除指定的文件目录里的js文件, 剩余的(js文件)则由 Babel 处理.
如果你的应用只需要加载 CSS, Webpack 也能满足需要. 创建一个 index.js 文件, 然后引入需要的 CSS 文件:
import styles from './assets/stylesheets/application.css';
然后会报错: You may need an appropriate loader to handle this file type. 在上文说过, Webpack 仅能识别 JavaScript. 因此, 需要安装合适的loader来处理 CSS 文件:
yarn add --dev css-loader style-loader
然后在 webpack.config.js 中添加一条规则:
module.exports = {
// …
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader'],
},
// …
],
},
};
Loaders会按照数组的逆序运行, 也就是说, 会先运行 css-loader, 后运行 style-loader.
你可能会注意到, 在生产环境下, CSS 会被打包到 JavaScript 文件里, style-loader 则会把样式写在 style 标签中. 此外, Webpack 通过将这些文件打包成一个文件来自动地解析所有的 @import 查询(而不是依赖 CSS 的默认 import 功能, 这会导致额外的 header 请求, 并且加载资源非常慢).
从 JavaScript 中加载 CSS 是非常神奇的, 因为这样你可以用新的方式将 CSS 模块化. 也就是说, 可以仅通过 button.js 来加载 button.css, 这意味着如果 button.js 没有用到, 其对应的 CSS 也不会被构建到生产环境中.
我们可以使用 Webpack 里的 ~ 前缀来引入 Node 模块. 假如我们执行了 yarn add normalize.css, 那么就可以这么用:
@import "~normalize.css";
这样就可以充分利用 NPM 管理第三方样式库的优点---版本更新和避免复制和粘贴. 更近一步, 和 CSS 默认的 import 功能相比, 用 Webpack 打包 CSS 有明显的优势, 因为它可以为客户端减少头部请求以及缓慢的加载时间.
你可能已经听过 CSS 模块. 如果你通过 JavaScript 来构建 DOM 节点, 它能运行的很好. 从本质上来说, 它将你的CSS类扩展到加载它的JavaScript文件中了(了解更多).
如果你要使用 CSS模块, 可以用 css-loader 来打包 CSS 文件(yarn add --dev css-loader):
module.exports = {
// …
module: {
rules: [
{
test: /\.css$/,
use: [
'style-loader',
{ loader: 'css-loader', options: { modules: true } }
],
},
// …
],
},
};
当启用了 CSS 的模块功能, 在 Node中引入CSS时去掉 ~ 前缀是没有任何意义的(例如: @import "normalize.css";). 然而在你通过 @import 引入自己的 CSS 文件时会碰到类似 can’t find ___ 的构建错误, 解决方式是在 webpack.config.js 中添加一个 resolve 对象, 让 Webpack 对预定的模块顺序有更好的理解.
module.exports = {
//…
resolve: {
modules: [path.resolve(__dirname, './src'), 'node_modules']
},
};
首先指定了源文件目录, 然后添加了 node_modules 目录. 这样, Webpack 在查找模块时, 会首先从源目录开始查找, (如果没找到)然后从已安装的 Node 模块中查找(你使用时, 要分别将 "src" 和 "node_modules" 目录替换成你的项目的源目录和Node模块目录).
需要Sass? 没问题, 首先安装loader:
yarn add --dev sass-loader node-sass
然后加一条规则:
module.exports = {
// …
module: {
rules: [
{
test: /\.(sass|scss)$/,
use: [
"style-loader",
"css-loader",
"sass-loader",
]
}
// …
],
},
};
这样你就能在 JavaScript 文件里通过 import 来引用 .scss 或者 .sass 文件, 剩下的事情交给 Webpack 来处理.
你可能需要处理渐进增强的情况, 也可能因某些原因需要分离 CSS 文件. 这个也很简单, 只需将配置文件中的 style-loader 用 extract-text-webpack-plugin 代替就行. 例如:
import styles from './assets/stylesheets/application.css';
在本地安装该插件(需要安装2016年10月的Beta版本):
yarn add --dev [email protected]
然后修改下配置文件:
const ExtractTextPlugin = require('extract-text-webpack-plugin');
module.exports = {
// …
module: {
rules: [
{
test: /\.css$/,
loader: ExtractTextPlugin.extract({
loader: 'css-loader?importLoaders=1',
}),
},
// …
]
},
plugins: [
new ExtractTextPlugin({
filename: '[name].bundle.css',
allChunks: true,
}),
],
};
运行 webpack -p 之后, 你会发现在 output 指定的目录中会有一个 app.bundle.css 文件. 最后, 在 HTML 文件中通过 <link> 标签正常引用.
为了最大程度的使用 Webpack, 你必须用模块化、可复用性以及可独立处理的思维方式去思考, 让每个模块把各自负责的事情做好. 这意味着类似下面这样的文件:
└── js/
└── application.js // 300KB of spaghetti code
会变成这样:
└── js/
├── components/
│ ├── button.js
│ ├── calendar.js
│ ├── comment.js
│ ├── modal.js
│ ├── tab.js
│ ├── timer.js
│ ├── video.js
│ └── wysiwyg.js
│
└── application.js // ~ 1KB of code; imports from ./components/
最后编译的结果是非常简洁且可复用的代码. 每个独立的组件通过 import 来引入依赖, 再通过 export 来暴露公共接口给其他模块. Babel + ES6就提供了上述特性, 并且你可以使用 JavaScript Classes 来实现更好的模块化, 而且不需要考虑运行作用域.
Getting Started with Webpack 2
Webpack2 升级指南和特性摘要
A Detailed Introduction To Webpack
构造函数也是函数,用new创建对象时调用的函数,与普通函数的一个区别是,其首字母应该大写。但如果将构造函数当作普通函数调用(缺少new关键字),则应该注意this指向的问题。
var name = "Pomy";
function Per(){
console.log("Hello "+this.name);
}
var per1 = new Per(); //"Hello undefined"
var per2 = Per(); //"Hello Pomy"
使用new时,会自动创建this对象,其类型为构造函数类型,指向对象实例;缺少new关键字,this指向全局对象。
可以用instanceof来检测对象类型,同时每个对象在创建时都自动拥有一个constructor属性,指向其构造函数(字面量形式或Object构造函数创建的对象,指向Object,自定义构造函数创建的对象则指向它的构造函数)。
console.log(per1 instanceof Per); //true
console.log(per1.constructor === Per); //true
每个对象实例都有一个内部属性:[[Prototype]],其指向该对象的原型对象。构造函数本身也具有prototype 属性指向原型对象。所有创建的对象都共享该原型对象的属性和方法。
function Person(){}
Person.prototype.name="dwqs";
Person.prototype.age=20;
Person.prototype.sayName=function()
{
alert(this.name);
};
var per1 = new Person();
per1.sayName(); //dwqs
var per2 = new Person();
per2.sayName(); //dwqs
alert(per1.sayName == per2.sayName); //true

所以,实例中的指针仅指向原型,而不指向构造函数。 ES5提供了hasOwnProperty()和isPropertyOf()方法来反应原型对象和实例之间的关系
alert(Person.prototype.isPrototypeOf(per2)); //true
per1.blog = "www.ido321.com";
alert(per1.hasOwnProperty("blog")); //true
alert(Person.prototype.hasOwnProperty("blog")); //false
alert(per1.hasOwnProperty("name")); //false
alert(Person.prototype.hasOwnProperty("name")); //true
因为原型对象的constructor属性是指向构造函数本身,所以在重写原型时,需要注意constructor属性的指向问题。
function Hello(name){
this.name = name;
}
//重写原型
Hello.prototype = {
sayHi:function(){
console.log(this.name);
}
};
var hi = new Hello("Pomy");
console.log(hi instanceof Hello); //true
console.log(hi.constructor === Hello); //false
console.log(hi.constructor === Object); //true
使用对象字面量形式改写原型对象改变了构造函数的属性,因此constructor指向Object,而不是Hello。如果constructor指向很重要,则需要在改写原型对象时手动重置其constructor属性
Hello.prototype = {
constructor:Hello,
sayHi:function(){
console.log(this.name);
}
};
console.log(hi.constructor === Hello); //true
console.log(hi.constructor === Object); //false
利用原型对象的特性,我们可以很方便的在JavaScript的内建原型对象上添加自定义方法:
Array.prototype.sum=function(){
return this.reduce(function(prev,cur){
return prev+cur;
});
};
var num = [1,2,3,4,5,6];
var res = num.sum();
console.log(res); //21
String.prototype.capit = function(){
return this.charAt(0).toUpperCase()+this.substring(1);
};
var msg = "hello world";
console.log(msg.capit()); //"Hello World"
利用[[Prototype]]特性,可以实现原型继承;对于字面量形式的对象,会隐式指定Object.prototype为其[[Prototype]],也可以通过Object.create()显示指定,其接受两个参数:第一个是[[Prototype]]指向的对象(原型对象),第二个是可选的属性描述符对象。
var book = {
title:"这是书名";
};
//和下面的方式一样
var book = Object.create(Object.prototype,{
title:{
configurable:true,
enumerable:true,
value:"这是书名",
wratable:true
}
});
字面量对象会默认继承自Object,更有趣的用法是,在自定义对象之间实现继承。
var book1 = {
title:"JS高级程序设计",
getTitle:function(){
console.log(this.title);
}
};
var book2 = Object.create(book1,{
title:{
configurable:true,
enumerable:true,
value:"JS权威指南",
wratable:true
}
});
book1.getTitle(); //"JS高级程序设计"
book2.getTitle(); //"JS权威指南"
console.log(book1.hasOwnProperty("getTitle")); //true
console.log(book1.isPrototypeOf("book2")); //false
console.log(book2.hasOwnProperty("getTitle")); //false
当访问book2的getTitle属性时,JavaScript引擎会执行一个搜索过程:现在book2的自有属性中寻找,找到则使用,若没有找到,则搜索[[Prototype]],若没有找到,则继续搜索原型对象的[[Prototype]],直到继承链末端。末端通常是Object.prototype,其[[Prototype]]被设置为null。
实现继承的另外一种方式是利用构造函数。每个函数都具有可写的prototype属性,默认被自懂设置为继承自Object.prototype,可以通过改写它来改变原型链。
function Rect(length,width){
this.length = length;
this.width = width;
}
Rect.prototype.getArea = function(){
return this.width * this.length;
};
Rect.prototype.toString = function(){
return "[Rect"+this.length+"*"+this.width+"]";
};
function Square(size){
this.length = size;
this.width = size;
}
//修改prototype属性
Square.prototype = new Rect();
Square.prototype.constructor = Square;
Square.prototype.toString = function(){
return "[Square"+this.length+"*"+this.width+"]";
};
var rect = new Rect(5,10);
var square = new Square(6);
console.log(rect.getArea()); //50
console.log(square.getArea()); //36
如果要访问父类的toString(),可以这样做:
Square.prototype.toString = function(){
var text = Rect.prototype.toString.call(this);
return text.replace("Rect","Square");
}
在Web开发者中,Google Chrome是使用最广泛的浏览器。六周一次的发布周期和一套强大的不断扩大开发功能,使其成为了web开发者必备的工具。你可能已经熟悉了它的部分功能,如使用console和debugger在线编辑CSS。在这篇文章中,我们将分享15个有助于改进你的开发流程的技巧。
如果你使用过sublime text,那么你可能不习惯没有Go to anything这个功能的覆盖。你会很高兴听到chrome开发者功能也有这个功能,当DevTools被打开的时候,按Ctrl+P(cmd+p on mac),就能快速搜寻和打开你项目的文件。
如果你希望在源代码中搜索要怎么办呢?在页面已经加载的文件中搜寻一个特定的字符串,快捷键是Ctrl + Shift + F (Cmd + Opt + F),这种搜寻方式还支持正则表达式哦
在Sources标签中打开一个文件之后,在Windows和Linux中,按Ctrl + G,(or Cmd + L for Mac),然后输入行号,DevTools就会允许你跳转到文件中的任意一行。
另外一种方式是按Ctrl + O,输入:和行数,而不用去寻找一个文件。
DevTools控制台支持一些变量和函数来选择DOM元素:
想要了解更多控制台命令,戳这里:Command Line API
当编辑一个文件的时候,你可以按住Ctrl(cmd for mac),在你要编辑的地方点击鼠标,可以设置多个插入符,这样可以一次在多个地方编辑。
勾选在Console标签下的保存记录选项,你可以使DevTools的console继续保存记录而不会在每个页面加载之后清除记录。当你想要研究在页面还没加载完之前出现的bug时,这会是一个很方便的方法。

Chrome’s Developer Tools有内建的美化代码,可以返回一段最小化且格式易读的代码。Pretty Print的按钮在Sources标签的左下角。
对于开发移动友好页面,DevTools包含了一个非常强大的模式,这个谷歌视频介绍了其主要特点,如调整屏幕大小、触摸仿真和模拟糟糕的网络连接。

设备模式的另一个很酷的功能是模拟移动设备的传感器,例如触摸屏幕和加速计。你甚至可以恶搞你的地理位置。这个功能位于元素标签的底部,点击“show drawer”按钮,就可看见Emulation标签 --> Sensors.
当在样式编辑中选择了一个颜色属性时,你可以点击颜色预览,就会弹出一个颜色选择器。当选择器开启时,如果你停留在页面,鼠标指针会变成一个放大镜,让你去选择像素精度的颜色。
DevTools有一个可以模拟CSS状态的功能,例如元素的hover和focus,可以很容易的改变元素样式。在CSS编辑器中可以利用这个功能
Web浏览器在构建如文本框、按钮和输入框一类元素时,其它基本元素的视图是隐藏的。不过,你可以在Settings -> General 中切换成Show user agent shadow DOM,这样就会在元素标签页中显示被隐藏的代码。甚至还能单独设计他们的样式,这给你了很大的控制权。
当在Sources标签下编辑文件时,按下Ctrl + D (Cmd + D) ,当前选中的单词的下一个匹配也会被选中,有利于你同时对它们进行编辑。
在颜色预览功能使用快捷键Shift + Click,可以在rgba、hsl和hexadecimal来回切换颜色的格式
Workspaces是Chrome DevTools的一个强大功能,这使DevTools变成了一个真正的IDE。Workspaces会将Sources选项卡中的文件和本地项目中的文件进行匹配,所以你可以直接编辑和保存,而不必复制/粘贴外部改变的文件到编辑器。
为了配置Workspaces,只需打开Sources选项,然后右击左边面板的任何一个地方,选择Add Folder To Worskpace,或者只是把你的整个工程文件夹拖放入Developer Tool。现在,无论在哪一个文件夹,被选中的文件夹,包括其子目录和所有文件都可以被编辑。为了让Workspaces更高效,你可以将页面中用到的文件映射到相应的文件夹,允许在线编辑和简单的保存。
了解更多关于Workspaces的使用,戳这里:Workspaces
大多数情况下,在 React Native 中创建动画是推荐使用 Animated API 的,其提供了三个主要的方法用于创建动画:
Easing 模块定义了很多缓冲曲线函数。toValue 值更新的同时跟踪当前的速度状态,以确保动画连贯。译者注:React Native(0.37) 目前只支持Animated.Text/Animated.View/Animated.Image
以我的经验来看,Animated.timing() 和 Animated.spring() 在创建动画方面是非常有效的。
除了这三个创建动画的方法,对于每个独立的方法都有三种调用该动画的方式:
stopTogether 选项来改变这个效果。第一个要创建的动画是使用 Animated.timing 创建的旋转动画。
// Example implementation:
Animated.timing(
someValue,
{
toValue: number,
duration: number,
easing: easingFunction,
delay: number
}
)
这种方式常用于创建需要loading指示的动画,在我使用React Native的项目中,这也是创建动画最有效的方式。这个理念也可以用于其它诸如按比例放大和缩小类型的指示动画。
开始之前,我们需要创建一个新的React Native 项目或者一个空的React Native项目。创建新项目之前,需要输入 react-native init 来初始化一个项目,并切换到该项目目录:
react-native init animations
cd animations
然后打开 index.android.js 和 index.ios.js。
现在已经创建了一个新项目,则第一件事是在已经引入的 View 之后从 react native 中引入 Animated,Image 和 Easing:
import {
AppRegistry,
StyleSheet,
Text,
View,
Animated,
Image,
Easing
} from 'react-native'
Animated 是我们将用于创建动画的库,和React Native交互的载体。
Image 用于在UI中显示图片。
Easing 也是用React Native创建动画的载体,它允许我们使用已经定义好的各种缓冲函数,例如:linear, ease, quad, cubic, sin, elastic, bounce, back, bezier, in, out, inout 。由于有直线运动,我们将使用 linear。在这节(阅读)完成之后,对于实现直线运动的动画,你或许会有更好的实现方式。
接下来,需要在构造函数中初始化一个带动画属性的值用于旋转动画的初始值:
constructor () {
super()
this.spinValue = new Animated.Value(0)
}
我们使用 ** Animated.Value** 声明了一个 spinValue 变量,并传了一个 0 作为初始值。
然后创建了一个名为 spin 的方法,并在 componentDidMount 中调用它,目的是在 app 加载之后运行动画:
componentDidMount () {
this.spin()
}
spin () {
this.spinValue.setValue(0)
Animated.timing(
this.spinValue,
{
toValue: 1,
duration: 4000,
easing: Easing.linear
}
).start(() => this.spin())
}
spin() 方法的作用如下:
this.spinValue 的值以 Easing.linear 的动画方式在 4000 毫秒从 0 变成 1。Animated.timing 需要两个参数,一个要变化的值(本文中是 this.spinValue) 和一个可配置对象。这个配置对象有四个属性:toValue(终值)、duration(一次动画的持续时间)、easing(缓存函数)和delay(延迟执行的时间)start,它将在(一次)动画完成之后调用,这也是创建无穷动画的一种基本方式。start() 需要一个完成回调,该回调在动画正常的运行完成之后会被调用,并有一个参数是 {finished: true},但如果动画是在它正常运行完成之前而被停止了(如:被手势动作或者其它动画中断),则回调函数的参数变为 {finished: false}。译者注:如果在回调中将动画的初始值设置成其终值,该动画就不会再执行。如将 this.spinValue.setValue(0) 改为 this.spinValue.setValue(1),spin动画不会执行了
现在方法已经创建好了,接下来就是在UI中渲染动画了。为了渲染动画,需要更新 render 方法:
render () {
const spin = this.spinValue.interpolate({
inputRange: [0, 1],
outputRange: ['0deg', '360deg']
})
return (
<View style={styles.container}>
<Animated.Image
style={{
width: 227,
height: 200,
transform: [{rotate: spin}] }}
source={{uri: 'https://s3.amazonaws.com/media-p.slid.es/uploads/alexanderfarennikov/images/1198519/reactjs.png'}}
/>
</View>
)
}
render 方法中,创建了一个 spin 变量,并调用了 this.spinValue 的 interpolate 方法。interpolate 方法可以在任何一个 Animated.Value 返回的实例上调用,该方法会在属性更新之前插入一个新值,如将 0inputRange 和 outputRange 参数给interpolate 方法,并分别赋值为 [0,1] 和 &[‘0deg’, ‘360deg’]。container 样式值的 View和 带 height, width和 transform 属性的Animated.Image,并将 spin 的值赋给 transform 的 rotate 属性,这也是动画发生的地方:transform: [{rotate: spin}]
最后,在 container 样式中,使所有元素都居中:
const styles = StyleSheet.create({
container: {
flex: 1,
justifyContent: 'center',
alignItems: 'center'
}
})
这个示例动画的最终代码在这里。
这是 Easing 模块的源码链接,从源码中可以看到每一个 easing 方法。
我创建了另外一个示例项目,里面包含了大部分 easing 动画的实现,可以供你参考,链接在这里。(项目的运行截图)依据在下面:
该项目实现的 easing 动画在 RNPlay 的地址在这里。
上文已经说过了 Animated.timing 的基础知识,这一节会例举更多使用 Animated.timing 与 interpolate 结合实现的动画示例。
下一个示例中,会声明一个单一的动画值, this.animatedValue ,然后将该值和 interpolate 一起使用来驱动下列属性值的变化来创建复杂动画:
在开始之前,可以创建一个新分支或者清除上一个项目的旧代码。
第一件事是在构造函数中初始化一个需要用到的动画属性值:
constructor () {
super()
this.animatedValue = new Animated.Value(0)
}
接下来,创建一个名为animate的方法,并在 componentDidMount() 中调用该方法:
componentDidMount () {
this.animate()
}
animate () {
this.animatedValue.setValue(0)
Animated.timing(
this.animatedValue,
{
toValue: 1,
duration: 2000,
easing: Easing.linear
}
).start(() => this.animate())
}
在 render 方法中,我们创建 5 个不同的插值变量:
render () {
const marginLeft = this.animatedValue.interpolate({
inputRange: [0, 1],
outputRange: [0, 300]
})
const opacity = this.animatedValue.interpolate({
inputRange: [0, 0.5, 1],
outputRange: [0, 1, 0]
})
const movingMargin = this.animatedValue.interpolate({
inputRange: [0, 0.5, 1],
outputRange: [0, 300, 0]
})
const textSize = this.animatedValue.interpolate({
inputRange: [0, 0.5, 1],
outputRange: [18, 32, 18]
})
const rotateX = this.animatedValue.interpolate({
inputRange: [0, 0.5, 1],
outputRange: ['0deg', '180deg', '0deg']
})
...
}
interpolate 是一个很强大的方法,允许我们用多种方式来使用单一的动画属性值:this.animatedValue。因为 this.animatedValue 只是简单的从0变到1,因而我们能将这个值插入到 opacity、margins、text sizes 和 rotation 等样式属性中。
最后,返回实现了上述变量的 Animated.View 和 Animated.Text 组件:
return (
<View style={styles.container}>
<Animated.View
style={{
marginLeft,
height: 30,
width: 40,
backgroundColor: 'red'}} />
<Animated.View
style={{
opacity,
marginTop: 10,
height: 30,
width: 40,
backgroundColor: 'blue'}} />
<Animated.View
style={{
marginLeft: movingMargin,
marginTop: 10,
height: 30,
width: 40,
backgroundColor: 'orange'}} />
<Animated.Text
style={{
fontSize: textSize,
marginTop: 10,
color: 'green'}} >
Animated Text!
</Animated.Text>
<Animated.View
style={{
transform: [{rotateX}],
marginTop: 50,
height: 30,
width: 40,
backgroundColor: 'black'}}>
<Text style={{color: 'white'}}>Hello from TransformX</Text>
</Animated.View>
</View>
)
当然,也需要更新下 container 样式:
const styles = StyleSheet.create({
container: {
flex: 1,
paddingTop: 150
}
})
这个示例动画的最终代码在这里。
接下来,我们将会使用 Animated.spring() 方法创建动画。
// Example implementation:
Animated.spring(
someValue,
{
toValue: number,
friction: number
}
)
我们继续使用上一个项目,并只需要更新少量代码就行。在构造函数中,创建一个 springValue 变量,初始化其值为0.3:
constructor () {
super()
this.springValue = new Animated.Value(0.3)
}
然后,删除 animated 方法和componentDidMount方法,创建一个新的 spring 方法:
spring () {
this.springValue.setValue(0.3)
Animated.spring(
this.springValue,
{
toValue: 1,
friction: 1
}
).start()
}
springValue 的值重置为 0.3Animated.spring 方法,并传递两个参数:一个要变化的值和一个可配置对象。可配置对象的属性可以是下列的任何值:toValue (number), overshootClamping (boolean), restDisplacementThreshold (number), restSpeedThreshold (number), velocity (number), bounciness (number), speed (number), tension(number), 和 friction (number)。除了 toValue 是必须的,其他值都是可选的,但 friction 和 tension 能帮你更好地控制 spring 动画。start() 启动动画动画已经设置好了,我们将其放在 View 的click事件中,动画元素依然是之前使用过的 React logo 图片:
<View style={styles.container}>
<Text
style={{marginBottom: 100}}
onPress={this.spring.bind(this)}>Spring</Text>
<Animated.Image
style={{ width: 227, height: 200, transform: [{scale: this.springValue}] }}
source={{uri: 'https://s3.amazonaws.com/media-p.slid.es/uploads/alexanderfarennikov/images/1198519/reactjs.png'}}/>
</View>
Animated.Image,并为其 scale 属性添加 this.springValue这个示例动画的最终代码在这里。
Animated.parallel() 会同时开始一个动画数组里的全部动画。
先看一下这个api是怎么调用的:
// API
Animated.parallel(arrayOfAnimations)
// In use:
Animated.parallel([
Animated.spring(
animatedValue,
{
//config options
}
),
Animated.timing(
animatedValue2,
{
//config options
}
)
])
开始之前,我们先直接创建三个我们需要的动画属性值:
constructor () {
super()
this.animatedValue1 = new Animated.Value(0)
this.animatedValue2 = new Animated.Value(0)
this.animatedValue3 = new Animated.Value(0)
}
然后,创建一个 animate 方法并在 componendDidMount() 中调用它:
componentDidMount () {
this.animate()
}
animate () {
this.animatedValue1.setValue(0)
this.animatedValue2.setValue(0)
this.animatedValue3.setValue(0)
const createAnimation = function (value, duration, easing, delay = 0) {
return Animated.timing(
value,
{
toValue: 1,
duration,
easing,
delay
}
)
}
Animated.parallel([
createAnimation(this.animatedValue1, 2000, Easing.ease),
createAnimation(this.animatedValue2, 1000, Easing.ease, 1000),
createAnimation(this.animatedValue3, 1000, Easing.ease, 2000)
]).start()
}
在 animate 方法中,我们将三个动画属性值重置为0。此外,还创建了一个 createAnimation 方法,该方法接受四个参数:value, duration, easing, delay(默认值是0),返回一个新的动画。
然后,调用 Animated.parallel(),并将三个使用 createAnimation 创建的动画作为参数传递给它。
在 render 方法中,我们需要设置插值:
render () {
const scaleText = this.animatedValue1.interpolate({
inputRange: [0, 1],
outputRange: [0.5, 2]
})
const spinText = this.animatedValue2.interpolate({
inputRange: [0, 1],
outputRange: ['0deg', '720deg']
})
const introButton = this.animatedValue3.interpolate({
inputRange: [0, 1],
outputRange: [-100, 400]
})
...
}
最后,我们用一个主 View 包裹三个 Animated.Views:
<View style={[styles.container]}>
<Animated.View
style={{ transform: [{scale: scaleText}] }}>
<Text>Welcome</Text>
</Animated.View>
<Animated.View
style={{ marginTop: 20, transform: [{rotate: spinText}] }}>
<Text
style={{fontSize: 20}}>
to the App!
</Text>
</Animated.View>
<Animated.View
style={{top: introButton, position: 'absolute'}}>
<TouchableHighlight
onPress={this.animate.bind(this)}
style={styles.button}>
<Text
style={{color: 'white', fontSize: 20}}>
Click Here To Start
</Text>
</TouchableHighlight>
</Animated.View>
</View>
当 animate() 被调用时,三个动画会同时执行。
这个示例动画的最终代码在这里。
先看一下这个api是怎么调用的:
// API
Animated.sequence(arrayOfAnimations)
// In use
Animated.sequence([
Animated.timing(
animatedValue,
{
//config options
}
),
Animated.spring(
animatedValue2,
{
//config options
}
)
])
和 Animated.parallel() 一样, Animated.sequence() 接受一个动画数组。但不同的是,Animated.sequence() 是按顺序执行一个动画数组里的动画,等待一个完成后再执行下一个。
import React, { Component } from 'react';
import {
AppRegistry,
StyleSheet,
Text,
View,
Animated
} from 'react-native'
const arr = []
for (var i = 0; i < 500; i++) {
arr.push(i)
}
class animations extends Component {
constructor () {
super()
this.animatedValue = []
arr.forEach((value) => {
this.animatedValue[value] = new Animated.Value(0)
})
}
componentDidMount () {
this.animate()
}
animate () {
const animations = arr.map((item) => {
return Animated.timing(
this.animatedValue[item],
{
toValue: 1,
duration: 50
}
)
})
Animated.sequence(animations).start()
}
render () {
const animations = arr.map((a, i) => {
return <Animated.View key={i} style={{opacity: this.animatedValue[a], height: 20, width: 20, backgroundColor: 'red', marginLeft: 3, marginTop: 3}} />
})
return (
<View style={styles.container}>
{animations}
</View>
)
}
}
const styles = StyleSheet.create({
container: {
flex: 1,
flexDirection: 'row',
flexWrap: 'wrap'
}
})
AppRegistry.registerComponent('animations', () => animations);
由于 Animated.sequence() 和 Animated.parallel() 很相似,因而对 Animated.sequence() 就不多作介绍了。主要不同的一点是我们是使用循环创建 Animated.Values。
这个示例动画的最终代码在这里。
(图片太大,上传不了) gif动态图
先看一下这个api是怎么调用的:
// API
Animated.stagger(delay, arrayOfAnimations)
// In use:
Animated.stagger(1000, [
Animated.timing(
animatedValue,
{
//config options
}
),
Animated.spring(
animatedValue2,
{
//config options
}
)
])
和 Animated.parallel() 和 Animated.sequence() 一样, Animated.Stagger 接受一个动画数组。但不同的是,Animated.Stagger 里面的动画有可能会同时执行(重叠),不过会以指定的延迟来开始。
与上述两个动画主要的不同点是 Animated.Stagger 的第一个参数,delay 会被应用到每一个动画:
import React, { Component } from 'react';
import {
AppRegistry,
StyleSheet,
Text,
View,
Animated
} from 'react-native'
const arr = []
for (var i = 0; i < 500; i++) {
arr.push(i)
}
class animations extends Component {
constructor () {
super()
this.animatedValue = []
arr.forEach((value) => {
this.animatedValue[value] = new Animated.Value(0)
})
}
componentDidMount () {
this.animate()
}
animate () {
const animations = arr.map((item) => {
return Animated.timing(
this.animatedValue[item],
{
toValue: 1,
duration: 4000
}
)
})
Animated.stagger(10, animations).start()
}
render () {
const animations = arr.map((a, i) => {
return <Animated.View key={i} style={{opacity: this.animatedValue[a], height: 20, width: 20, backgroundColor: 'red', marginLeft: 3, marginTop: 3}} />
})
return (
<View style={styles.container}>
{animations}
</View>
)
}
}
const styles = StyleSheet.create({
container: {
flex: 1,
flexDirection: 'row',
flexWrap: 'wrap'
}
})
AppRegistry.registerComponent('SampleApp', () => animations);
这个示例动画的最终代码在这里。
文中使用的demo repo: react native animations
React Native Animations Using the Animated API
Animated Docs
Promise 是一个非常简单的概念,即使你没有机会使用 Promise,你也可能阅读过一些关于 Promise 的文章。
Promise 的价值在于使得异步代码以一个更可读的风格结构化,而不是因异步函数嵌套显得混乱不堪。这篇文章会接触到 6 个你可能不知道的关于 Promise 的事。
开始列举之前,先看看怎么创建 Promise:
var p = new Promise(function(resolve, reject) {
resolve("hello world");
});
p.then(function(str) {
alert(str);
});
then() 返回一个 forked Promise(分叉的 Promise)下面两段代码有什么不同?
// Exhibit A
var p = new Promise(/*...*/);
p.then(func1);
p.then(func2);
// Exhibit B
var p = new Promise(/*...*/);
p.then(func1)
.then(func2);
如果你认为两段代码等价,那么你可能认为 promise 仅仅就是一维回调函数的数组。然而,这两段代码并不等价。p 每次调用 then() 都会返回一个 forked promise。因此,在A中,如果 func1 抛出一个异常,func2 依然能执行,而在B中,func2 不会被执行,因为第一次调用返回了一个新的 promise,由于 func1 中抛出异常,这个 promise 被 rejected了,结果 func2 被跳过不执行了。
下面的代码会 alert 什么?
var p = new Promise(function(resolve, reject) {
resolve("hello world");
});
p.then(function(str) {})
.then(function(str) {
alert(str);
});
第二个 then() 中的alert不是显示任何东西,因为在 promise 的上下文中,回调函数像普通的回调函数一样传递结果。promise 期望你的回调函数或者返回同一个结果,或者返回其它结果,返回的结果会被传给下一个回调。
这和适配器传递结果的**一样,看下面的示例:
var feetToMetres = function(ft) { return ft*12*0.0254 };
var p = new Promise(/*...*/);
p.then(feetToMetres)
.then(function(metres) {
alert(metres);
});
下面的两段代码有什么不同:
// Exhibit A
new Promise(function(resolve, reject) {
resolve("hello world");
})
.then(
function(str) {
throw new Error("uh oh");
},
undefined
)
.then(
undefined,
function(error) {
alert(error);
}
);
// Exhibit B
new Promise(function(resolve, reject) {
resolve("hello world");
})
.then(
function(str) {
throw new Error("uh oh");
},
function(error) {
alert(error);
}
);
在A中,当第一个 then 抛出异常时,第二个 then 能捕获到该异常,并会弹出 'uh oh'。这符合只捕获来自上一级异常的规则。
在B中,正确的回调函数和错误的回调函数在同一级,也就是说,尽管在回调中抛出了异常,但是这个异常不会被捕获。事实上,B中的错误回调只有在 promise 被 rejected 或者 promise 自身抛出一个异常时才会被执行。
在一个错误回调中,如果没有重新抛出错误,promise 会认为你已经恢复了该错误,promise 的状态会转变为 resolved。在下面的例子中,会弹出’I am saved’ 是因为第一个 then() 中的错误回调函数并没有重新抛出异常。
var p = new Promise(function(resolve,reject){
reject(new Error('pebkac'));
});
p.then(
undefined,
function(error){ }
)
.then(
function(str){
alert('I am saved!');
},
function(error){
alert('Bad computer!');
}
);
Promise 可被视为洋葱的皮层,每一次调用 then 都会被添加一层皮层,每一个皮层表示一个能被处理的状态,在皮层被处理之后,promise 会认为已经修复了错误,并准备进入下一个皮层。
仅仅因为你已经在一个 then() 函数中执行过代码,并不意味着你不能够暂停 promise 去做其他事情。为了暂停当前的 promise,或者要它等待另一个 promise 完成,只需要简单地在 then() 函数中返回另一个 promise。
var p = new Promise(/*...*/);
p.then(function(str){
if(!loggedIn){
return new Promise(/*...*/);
}
})
.then(function(str){
alert("Done!");
});
在上面的代码中,直到新的 promise 的状态是 resolved解析后,alert 才会显示。如果要在已经存在的异步代码中引入更多的依赖,这是一个很便利的方式。例如,你发现用户会话已经超时了,因此,你可能想要在继续执行后面的代码之前发起第二次登录。
运行下面的代码会弹出什么呢?
function runme() {
var i = 0;
new Promise(function(resolve) {
resolve();
})
.then(function() {
i += 2;
});
alert(i);
}
你可能会认为弹出2,因为 promise 已经是 resolved ,then() 会立即执行(同步)。然而,promise 规范要求所有回调都是异步的,因此,alert 执行时 i 的值还没有被修改。
原文:Six Things You Might Not Know About Promises
Promise 的正确打开方式
Promise/A+
Promise 教程
JavaScript Promises 102 - The 4 Promise Methods
Koa 是一个类似于 Express 的Web开发框架,创始人也都是TJ。Koa 的主要特点是,使用了 ES6 的 Generator 函数,进行了架构的重新设计。Koa 的原理和内部结构很像 Express,但是语法和内部结构进行了升级。
创建一个 koa 非常简单:
var koa = require('koa');
var app = koa();
app.listen(3000);
或者可以酱紫:
var koa = require('koa');
var http = require('http');
var app = koa();
http.createServer(app.callback()).listen(4000);
这两种方式在 koa 内部是等价的,在 Application 模块中, listen 就会调用自身的 callback:
//listen的实现
app.listen = function(){
debug('listen');
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};
callback 返回的函数会作为 server 的回调:
app.callback = function(){
/**
* 省略的代码
**/
return function(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}
};
callback 也会将多个中间件转成了一个 fn,在构建服务器函数时方便调用。状态码默认是 404,即没有任何中间件修改过就是 404。
每个请求都会通过 createContext 创建一个上下文对象,其参数则分别是 Node 的 request 对象和 response 对象:
app.createContext = function(req, res){
var context = Object.create(this.context);
var request = context.request = Object.create(this.request);
var response = context.response = Object.create(this.response);
context.app = request.app = response.app = this;
context.req = request.req = response.req = req;
context.res = request.res = response.res = res;
request.ctx = response.ctx = context;
request.response = response;
response.request = request;
context.onerror = context.onerror.bind(context);
context.originalUrl = request.originalUrl = req.url;
context.cookies = new Cookies(req, res, {
keys: this.keys,
secure: request.secure
});
context.accept = request.accept = accepts(req);
context.state = {};
return context;
};
对于接收的参数,在返回上下文 context 之前,koa 会将参数注入到自身的 request 对象和 response 对象上,ctx.request 和 ctx.response 返回的是 koa 的对应对象,ctx.req 和 ctx.res 返回的是 Node 的对应对象;同时也会将 app 注册到 context/respose/request 对象上,方便在各自的模块中调用:
var app = Application.prototype;
module.exports = Application;
function Application() {
if (!(this instanceof Application)) return new Application;
this.env = process.env.NODE_ENV || 'development'; //环境变量
this.subdomainOffset = 2; //子域偏移量
this.middleware = []; //中间件数组
this.proxy = false; //是否信任头字段 proxy
this.context = Object.create(context); // koa的上下文(this)
this.request = Object.create(request); //koa的request对象
this.response = Object.create(response); //koa 的reponse对象
}
context 对象是 Koa context 模块扩展出来的,添加了诸如 state、cookie、req、res 等属性。
onFinished 是一个第三方函数,用于监听 http response 的结束事件,执行回调。如果找到 context.onerror 方法,这是 koa默认的错误处理函数,它处理的是错误导致的异常结束。错误的处理是在 callback 中监听的:
// callback
if (!this.listeners('error').length) this.on('error', this.onerror);
koa 本身是没有定义事件处理机制的,其事件处理机制继承自 Node 的 events:
var Emitter = require('events').EventEmitter;
Object.setPrototypeOf(Application.prototype, Emitter.prototype);
默认的错误分发是在 Context 模块中:
onerror : function(err){
//some code
this.app.emit('error', err, this);
//some code
}
此外,在 Context 模块中,还将 request 对象和 response 对象的一些方法和属性委托给了 context 对象:
//response委托
delegate(proto, 'response')
.method('attachment')
.method('append')
.access('status')
.access('body')
.getter('headerSent')
.getter('writable');
.....
//request委托
delegate(proto, 'request')
.method('acceptsLanguages')
.method('get')
.method('is')
.access('querystring')
.access('url')
.getter('origin')
.getter('href')
.getter('subdomains')
.getter('protocol')
.getter('host')
....
通过第三方模块 delegate 将 koa 在 Response 模块和 Request 模块中定义的方法委托到了 context 对象上,所以以下的一些写法是等价的:
//在每次请求中,this 用于指代此次请求创建的上下文 context(ctx)
this.body ==> this.response.body
this.status ==> this.response.status
this.href ==> this.request.href
this.host ==> this.request.host
.....
在 createContext 方法中,还给 context 定义了重要属性 state
context.state = {}
这个属性可以被各个中间件共享,用于在中间件之间传递数据,这也是 koa 推荐的方式:
this.state.user = yield User.find(id);
中间件是对 HTTP 请求进行处理的函数,对于每一个请求,都会通过中间件进行处理。在 koa 中,中间件通过 use 进行注册,且必须是一个 Generator 函数(未开启 this.experimental):
app.use(function* f1(next) {
console.log('f1: pre next');
yield next;
this.body = 'hello koa';
console.log('f1: post next');
});
app.use(function* f2(next) {
console.log(' f2: pre next');
console.log(' f2: post next');
});
输出如下:
f1: pre next
f2: pre next
f2: post next
f1: post next
与 Express 的中间件顺序执行不同,在koa中,中间件是所谓的“洋葱模型”或级联式(Cascading)的结构,也就是说,属于是层层调用,第一个中间件调用第二个中间件,第二个调用第三个,以此类推。上游的中间件必须等到下游的中间件返回结果,才会继续执行。
koa 对中间件的数量并没有限制,可以随意注册多个中间件。但如果有多个中间件,只要有一个中间件缺少 yield next 语句,后面的中间件都不会执行:
app.use(function *(next){
console.log('>> one');
yield next;
console.log('<< one');
});
app.use(function *(next){
console.log('>> two');
this.body = 'two';
console.log('<< two');
});
app.use(function *(next){
console.log('>> three');
yield next;
console.log('<< three');
});
上面代码中,因为第二个中间件少了yield next语句,第三个中间件并不会执行。
如果想跳过一个中间件,可以直接在该中间件的第一行语句写上return yield next:
app.use(function* (next) {
if (skip) return yield next;
})
koa中,中间件唯一的参数就是 next。如果要传入其他参数,必须另外写一个返回 Generator 函数的函数。
this.experimental 是为了判断是否支持es7,开启这个属性之后,中间件可以传入async函数:
app.use(async function (next){
await next;
this.body = body;
});
但 koa 默认是不支持 es7 的,如果想支持,需要在代码中明确指定 this.experimental = true
app.use = function(fn){
if (!this.experimental) {
// es7 async functions are not allowed,
// so we have to make sure that `fn` is a generator function
assert(fn && 'GeneratorFunction' == fn.constructor.name, 'app.use() requires a generator function');
}
debug('use %s', fn._name || fn.name || '-');
this.middleware.push(fn);
return this;
};
在 callback 中输出错误信息:
app.callback = function(){
if (this.experimental) {
console.error('Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.')
}
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
//省略
};
compose 的全名叫 koa-compose,它的作用是把一个个不相干的中间件串联在一起:
// 有3个中间件
this.middlewares = [function *m1() {}, function *m2() {}, function *m3() {}];
// 通过compose转换
var middleware = compose(this.middlewares);
// 转换后得到的middleware是这个样子的
function *() {
yield *m1(m2(m3(noop())))
}
从上述的 use 的实现可知,由于 use 的每次调用均会返回 this,因而可以进行链式调用:
app.use(function *m1() {}).use(function *m2() {}).use(function *m3() {})
koa自身有 request 对象和 response 对象来处理路由,一个简单的路由处理如下:
app.use(function* () {
if(this.path == '/'){
this.body = 'hello koa';
} else if(this.path == '/get'){
this.body = 'get';
} else {
this.body = '404';
}
});
也可以通过 this.request.headers 来获取请求头。由于没有对响应头做设置,默认响应头类型是 text/plain,可以通过 response.set来设置:
app.use(function* (next) {
if(this.path == '/'){
this.body = 'hello koa';
} else if(this.path == '/get'){
this.body = 'get';
} else {
yield next;
}
});
app.use(function* () {
this.response.set('content-type', 'application/json;charset=utf-8');
return this.body = {message: 'ok', statusCode: 200};
});
上面代码中,每一个中间件负责部分路径,如果路径不符合,就传递给下一个中间件。
复杂的路由需要安装 koa-router:
var app = require('koa')();
var Router = require('koa-router');
var myRouter = new Router();
myRouter.get('/', function *(next) {
this.response.body = 'Hello World!';
});
app.use(myRouter.routes());
app.listen(4000);
由于 koa 使用 generator 作为中间件,所以 myRouter.routes() 返回的是一个 generator,并等同于 myRouter.middleware:
Router.prototype.routes = Router.prototype.middleware = function () {
var router = this;
var dispatch = function *dispatch(next) {
//code
}
//省略
return dispatch;
};
koa-router 提供了一系列于 HTTP 动词对应的方法:
router.get()
router.post()
router.put()
router.del()
router.patch()
del 是 delete 的别名:
// Alias for `router.delete()` because delete is a reserved word
Router.prototype.del = Router.prototype['delete'];
这些动词方法可以接受两个参数,第一个是路径模式,第二个是对应的控制器方法(中间件),定义用户请求该路径时服务器行为。
注意,路径匹配的时候,不会把查询字符串考虑在内。比如,/index?param=xyz 匹配路径 /index。
关于 koa-router 的更多细节,且听下回分解。
最近阅读了《精通CSS: 高级Web标准解决方案》,书的内容不错,初学者可以用来入门,有经验的人也可以用来查漏补缺,上面对于浏览器兼容和常见bug的解决方案值得参考。
对于同一个元素,可能会有多个规则,为了解决规则之间的冲突,CSS 会利用 层叠 给每个规则分配一个重要度:
层叠优先级依次降低,优先级相同的规则,后定义的规则优先。为了计算规则的特殊性,可以给每种选择器分配一个数值,然后,将规则的每个选择器的值加在一起,计算出规则的特殊性。
对于一个选择器,其特殊性分为4个成分等级:a, b, c 和 d
通配符和继承得到的CSS属性对特殊性没有影响。看一个 demo:选择器规则
h2的最终颜色是灰色的,从规则的特殊性分析一下(从左至右依次是abcd的值)
| 选择器 | 特殊性 | 以10为基数的特殊性 |
|---|---|---|
| #content div#main-content h2 | 0,2,0,2 | 202 |
| #content #main-content>h2 | 0,2,0,1 | 201 |
| body #content div[id='main-content'] h2 | 0,1,1,3 | 113 |
| #main-content div.news-story h2 | 0,1,1,2 | 112 |
| #main-content [class='news-story'] h2 | 0,1,1,1 | 111 |
| div#main-content div.news-story h2.first-child | 0,1,2,3 | 123 |
从上表可知,第一个选择器的特殊性最高,所以h2的颜色最终为灰色(gray)。
当块元素的 Top 和 Bottom 外边距相遇时,它们将形成一个外边距。合并后的外边距的高度等于两个发生合并的外边距的高度中的较大者,称为 Margin Collapsing(Margin 塌陷)。
Margin Collapsing 基于三种情况:
上一个块元素出现在另一个块元素之上时,如果设置了 margin,二者的 margin-bottom 和 margin-top 会发生叠加:
如果父块元素和第一个子元素之间没有边框、内边距、内联内容和 间距 分开,若设置了 margin,则二者的 margin-top 会叠加;或者父块元素和最后一个子元素之间没有边框、内边距、内联内容和高度设置(height/min-height/max-height),若设置了 margin,则二者的 margin-bottom 会叠加。
可以给父元素增加 border、设置 padding、填充内容等方式来解决,还可以通过 overflow:hidden 来解决:
<div>
/**填充内容**/
<p>margin-top</p>
</div>
div{
overflow:hidden;
//padding:10px;
//border:1px solid transparent;
}
对于没有边框、内边距、内联内容和高度设置(height/min-height)的空块元素,如果设置了 margin,则顶底外边距会发生叠加:
如果这个外边距碰到另一个空元素的外边距,则还会发生叠加,合并成一个外边距。但是 浮动和绝对定位的元素是不会发生 Margin Collapse 现象的。
荐读:深入理解BFC和Margin Collapse Mastering margin collapsing
CSS 中的定位主要跟 position 属性有关,MDN 上关于 position 的语法如下:
/* Keyword values */
position: static;
position: relative;
position: absolute;
position: fixed;
position: sticky;
/* Global values */
position: inherit;
position: initial;
position: unset;
静态定位,position 的默认值,各元素的位置由元素在 HTML 的位置决定
相对定位的元素会根据 top,left,bottom,right 的值相对于该元素处于静态定位时(普通文档流)的位置进行偏移。
相对定位的元素仍会占据原来的空间,因而,该元素偏移会覆盖其它框。
绝对定位的元素会脱离文档流,是相对于距离它最近的那个已经定位(非 static)的祖先元素确定的,如果没有已定位的祖先元素,则相对于初始的包含块定位。绝对定位的元素不会产生 Margin Collapse 现象。
Demo1:相对于最初包含块偏移
Demo2:相对于定位的祖先元素定位
因为绝对定位的元素与文档流无关,所以会覆盖页面的其它元素,并可以通过 z-index 属性来控制元素的堆叠顺序,其值越大,元素越在上层。z-index 只再非静态定位的元素中有效。
另外,对于绝对定位的行内元素,会改变其显示形态,变成“块元素”,能对其设置宽高、外边距、边框等属性。
固定定位是绝对定位的一种,差异在于固定定位的元素的包含块是视口(viewport),这使得改元素总是出现在窗口中的相同位置。
这是 CSS3 的一个新属性,它的表现类似 position:relative 和 position:fixed 的合体,在目标区域在屏幕中可见时,它的行为就像 position:relative; 而当页面滚动超出目标区域时,它的表现就像 position:fixed,它会固定在目标位置。其兼容性如下:
在 Firefox 或 Safari 中查看 sticky 的 Demo
荐读:CSS position
与浮动相关的属性是 float。浮动元素和绝对定位元素一样,也会脱离文档流,不会占据空间:
<div class='news'>
<img src='http://ww3.sinaimg.cn/bmiddle/8d522661gw1ey1rotf8t6j205k03hjr9.jpg' />
<p>some text</p>
<div>
//css
.news{
border:1px solid red;
}
img{
float: left;
}
p{
float: right;
}
由于图片和文本都不占空间,所以 div 并没有被撑开,就看到了图示的效果。那么,如何让包围元素再视觉上包围浮动元素呢?
<p>some text</p>
<br class='clear' />
//css
.clear{
clear: both;
}
这种方式不会受到子元素大小的限制,但会增加额外的标签和代码。
.news:after{
display: block;
height: 125px;
content: '';
}
这种方式不用增加额外的标签和代码,但是会受子元素大小的限制。
.news{
float: left;
}
.news{
border:1px solid red;
overflow: hidden;
}
这种方式会自动清理包含的任何浮动元素,但在某些情况下,会影响盒子的显示,产生滚动条或者阶段内容。
雪碧图(CSS Sprite)是网站优化的一种方式,将多张背景图合并到一张大图上,从而减少 HTTP 请求数。对雪碧图进行定位的相关属性是 background-position。
背景图片被放置在元素的背景放置区(background positioning area)内,放置区指定了背景图片将被放置的区域,用一套坐标体系来控制位置。因为默认的放置区是在填充框内,所以默认情况放置区的坐标原点在填充框左上角。这意味着当你为元素应用背景图片的时候,浏览器从填充框的左上角开始放置第一张以及随后的图片。
background-position 有两个值:第一个值表示水平位置,第二个值表示垂直位置。位置的值可以用关键字(top/left/right/bottom/center)、百分比和像素表示,也可以混合,但规范不建议这么做。
当使用关键字的时候,若只指定了一个值,则另一个值默认是 center。
如果使用像素设置背景位置,则是图像左上角到背景放置区左上角的距离;
如果使用百分比设置背景位置,则是相对于图像上的定点进行定位。
使用像素,则图像出现在放置区的左上角下面20px,左边20px;使用百分比,则是图像上相对于图像左上角20%的定点到放置区左上角20%的位置。
荐读:CSS中的background-position 《CSS: Using Percent for Margin and Padding》
JavaScript不仅门槛低,而且是一门有趣、功能强大和非常重要的语言。各行各业的人发现自己最混乱的选择是JavaSscript编程语言。由于有着各种各样的背景,所以不是每个人都对JavaScript及其基本原理有广泛的认识。通常来书,除非你去参加工作面试才会去思考为什么或者怎么做,否则JavaScript只是你工作的内容。
这个系类的目标是深入探讨JavaScript的一些概念和理论。主题来自于 Darcy Clarke的JavaScript典型面试问题列表。希望你不仅仅是为了答案而阅读完这篇文章,每一篇文章会让对过去学过的知识有一个新的理解,或者重温你学习的东西,这有利于你用JavaScript实现所有交互。
事件委托是一种由其它元素而非事件目标元素来响应事件产生的行为的**。用document元素来处理按钮的点击行为就是事件委托的一个例子,另一种常见情况是,用ul元素来处理其子元素li的事件。
有多种方法来处理事件委托。标准方法来源于原生浏览器的功能。浏览器以一种特定的工作流程来处理事件,并支持事件捕获和事件冒泡。W3C关于浏览器怎么支持事件的文档:W3C DOM Level 3 Events。一些JS库和框架公开了其它方式,如发布/订阅模型(将在后文提及)。
事件捕获和事件冒泡是事件流中的两个阶段,任何事件产生时,如点击一个按钮,将从最顶端的容器开始(一般是html的根节点)。浏览器会向下遍历DOM树直到找到触发事件的元素,一旦浏览器找到该元素,事件流就进入事件目标阶段,该阶段完成后,浏览器会沿DOM树向上冒泡直到最顶层容器,看看是否有其它元素需要使用同一个事件。
下面的示例说明了这个过程。点击按钮会导致事件流识别本身在容器下面的文本,每一个元素都接收同样的点击监听代码,由于事件捕获,点击事件会首先触发HTML节点绑定的点击处理程序,然后在事件冒泡阶段的末尾返回到最顶层元素。
大多数现代库使用冒泡监听,而在捕获阶段处理。浏览器包含一个方法来管理事件冒泡。事件处理程序可以调用stopPropagation告诉DOM事件停止冒泡,第二个方式是调用stopImmediatePropagation,它不仅停止冒泡,也会阻止这个元素上其它监听当前事件的处理程序触发。然而,停止传播事件时要小心,因为你不知道是否有其它上层的DOM元素可能需要知道当前事件。
还有第三个可以控制元素如何对事件作出回应的方法。所有现代浏览器支持preventDefault方法,这个方法会阻止浏览器处理事件的默认行为。一个常见示例就是链接,使用链接执行UI操作是一种常见的做法。然而,当我们不希望链接跟普通被激活的链接一样会在新标签页打开一个新页面,就可以使用preventDefault方法来阻止这个默认行为。
还有其它实现事件委托的方法可以考虑,其中值得一提的就是发布/订阅模型。发布/订阅模型也称为了广播模型,牵涉到两个参与者。通常,两个参与者在DOM中并没有紧密的联系,而且可能是来自兄弟的容器。可以给它们共同的祖先元素设置监听处理程序,但是如果共同的祖先元素在DOM树中处于较高层次(离根节点比较近),就会监听很多同辈元素的事件,会造成意想不到的结果;当然,也可能存在逻辑或结构原因要分开这两个元素。
发布/订阅模型也能自定义事件。发布/订阅模型从一个元素发送消息后并向上遍历,有时也向下遍历,DOM会通知遍历路径上的所有元素事件发生了。在下面的示例中,JQuery通过trigger方法传递事件。
使用事件委托来管理事件流有很多优点,其中最大的优点是改善性能。元素绑定的每一个监听器都会占用一些内存,如果页面上只有少数几个监听器,我们也不会注意到它们之间的区别,然后,如果要监听一个50行5列的表格中的每个单元格,你的Web应用会开始变慢,为了使应用程序最快运行的最好方式是保持尽可能低的内存使用。
使用事件委托能减少监听器数量,在元素的容器上绑定事件意味着只需要一个监听器。这种方法的缺点是,父容器的侦听器可能需要检查事件来选择正确的操作,而元素本身不会是一个监听器。额外处理带来的影响远低于许多存在内存中的监听器。
更少的监听器和更少的DOM交互也易于维护。父容器层次的监听器能处理多种不同的事件操作,这是一种简单的方法来管理相关的事件操作,这些事件通常需要执行相关功能或需要共享数据。
如果父容器是监听器,然后要执行独立的内部操作而并不需要添加或者移除本身的监听器。元素操作在单页应用中是极其常见的,为某部分添加一个按钮这样简单的事情也会为应用程序创建一个潜在的性能块,没有合适的事件委托,就必须手动为每一个按钮添加监听,如果每个侦听器不清理干净,它可能会导致内存泄漏。浏览器不会清理页面,因此在单页应用中,所有从内存中清理不当的碎片都会留在内存中,这些碎片会降低程序性能。
当在页面中添加交互时,仔细考虑一下,是否真的需要去监听元素。
另一篇值得一读的文章:Event Delegation In JavaScript
this 关键字在JavaScript中的一种常用方法是指代码当前上下文。
操作this的另一种方式是通过call、apply和bind。三种方法都被用于调用一个函数,并能指定this的上下文,你可以让代码使用你规定的对象,而不是依靠浏览器去计算出this指向什么。Call、apply和bind本身是相当复杂的,应该有自己的文档记录,我们会把这当做未来待解决问题的一部分。下面是一个改变this指向方法的示例:
不错,好文收藏。
在组件的整个生命周期中,随着该组件的props或者state发生改变,其DOM表现也会有相应的变化。一个组件就是一个状态机,对于特定地输入,它总返回一致的输出。
一个React组件的生命周期分为三个部分:实例化、存在期和销毁时。
当组件在客户端被实例化,第一次被创建时,以下方法依次被调用:
1、getDefaultProps
2、getInitialState
3、componentWillMount
4、render
5、componentDidMount
当组件在服务端被实例化,首次被创建时,以下方法依次被调用:
1、getDefaultProps
2、getInitialState
3、componentWillMount
4、render
componentDidMount 不会在服务端被渲染的过程中调用。
对于每个组件实例来讲,这个方法只会调用一次,该组件类的所有后续应用,getDefaultPops 将不会再被调用,其返回的对象可以用于设置默认的 props(properties的缩写) 值。
var Hello = React.creatClass({
getDefaultProps: function(){
return {
name: 'pomy',
git: 'dwqs'
}
},
render: function(){
return (
<div>Hello,{this.props.name},git username is {this.props.dwqs}</div>
)
}
});
ReactDOM.render(<Hello />, document.body);
也可以在挂载组件的时候设置 props:
var data = [{title: 'Hello'}];
<Hello data={data} />
或者调用 setProps (一般不需要调用)来设置其 props:
var data = [{title: 'Hello'}];
var Hello = React.render(<Demo />, document.body);
Hello.setProps({data:data});
但只能在子组件或组件树上调用 setProps。别调用 this.setProps 或者 直接修改 this.props。将其当做只读数据。
React通过 propTypes 提供了一种验证 props 的方式,propTypes 是一个配置对象,用于定义属性类型:
var survey = React.createClass({
propTypes: {
survey: React.PropTypes.shape({
id: React.PropTypes.number.isRequired
}).isRequired,
onClick: React.PropTypes.func,
name: React.PropTypes.string,
score: React.PropTypes.array
...
},
//...
})
组件初始化时,如果传递的属性和 propTypes 不匹配,则会打印一个 console.warn 日志。如果是可选配置,可以去掉.isRequired。propTypes 的详解可戳此
对于组件的每个实例来说,这个方法的调用**有且只有一次,**用来初始化每个实例的 state,在这个方法里,可以访问组件的 props。每一个React组件都有自己的 state,其与 props 的区别在于 state只存在组件的内部,props 在所有实例**享。
getInitialState 和 getDefaultPops 的调用是有区别的,getDefaultPops 是对于组件类来说只调用一次,后续该类的应用都不会被调用,而 getInitialState 是对于每个组件实例来讲都会调用,并且只调一次。
var LikeButton = React.createClass({
getInitialState: function() {
return {liked: false};
},
handleClick: function(event) {
this.setState({liked: !this.state.liked});
},
render: function() {
var text = this.state.liked ? 'like' : 'haven\'t liked';
return (
<p onClick={this.handleClick}>
You {text} this. Click to toggle.
</p>
);
}
});
ReactDOM.render(
<LikeButton />,
document.getElementById('example')
);
每次修改 state,都会重新渲染组件,实例化后通过 state 更新组件,会依次调用下列方法:
1、shouldComponentUpdate
2、conponentWillUpdate
3、render
4、conponentDidUpdate
但是不要直接修改 this.state,要通过 this.setState 方法来修改。
在首次渲染执行前立即调用且仅调用一次。如果在这个方法内部调用 setState 并不会触发重新渲染,这也是在 render 方法调用之前修改 state 的最后一次机会。
该方法会创建一个虚拟DOM,用来表示组件的输出。对于一个组件来讲,render方法是唯一一个必需的方法。render方法需要满足下面几点:
render方法返回的结果并不是真正的DOM元素,而是一个虚拟的表现,类似于一个DOM tree的结构的对象。react之所以效率高,就是这个原因。
该方法不会在服务端被渲染的过程中调用。该方法被调用时,已经渲染出真实的 DOM,可以再该方法中通过 this.getDOMNode() 访问到真实的 DOM(推荐使用 ReactDOM.findDOMNode())。
var data = [..];
var comp = React.createClass({
render: function(){
return <imput .. />
},
conponentDidMount: function(){
$(this.getDOMNode()).autoComplete({
src: data
})
}
})
由于组件并不是真实的 DOM 节点,而是存在于内存之中的一种数据结构,叫做虚拟 DOM (virtual DOM)。只有当它插入文档以后,才会变成真实的 DOM 。有时需要从组件获取真实 DOM 的节点,这时就要用到 ref 属性:
var Area = React.createClass({
render: function(){
this.getDOMNode(); //render调用时,组件未挂载,这里将报错
return <canvas ref='mainCanvas'>
},
componentDidMount: function(){
var canvas = this.refs.mainCanvas.getDOMNode();
//这是有效的,可以访问到 Canvas 节点
}
})
需要注意的是,由于 this.refs.[refName] 属性获取的是真实 DOM ,所以必须等到虚拟 DOM 插入文档以后,才能使用这个属性,否则会报错。
此时组件已经渲染好并且用户可以与它进行交互,比如鼠标点击,手指点按,或者其它的一些事件,导致应用状态的改变,你将会看到下面的方法依次被调用
1、componentWillReceiveProps
2、shouldComponentUpdate
3、componentWillUpdate
4、render
5、componentDidUpdate
组件的 props 属性可以通过父组件来更改,这时,componentWillReceiveProps 将来被调用。可以在这个方法里更新 state,以触发 render 方法重新渲染组件。
componentWillReceiveProps: function(nextProps){
if(nextProps.checked !== undefined){
this.setState({
checked: nextProps.checked
})
}
}
如果你确定组件的 props 或者 state 的改变不需要重新渲染,可以通过在这个方法里通过返回 false 来阻止组件的重新渲染,返回 `false 则不会执行 render 以及后面的 componentWillUpdate,componentDidUpdate 方法。
该方法是非必须的,并且大多数情况下没有在开发中使用。
shouldComponentUpdate: function(nextProps, nextState){
return this.state.checked === nextState.checked;
//return false 则不更新组件
}
这个方法和 componentWillMount 类似,在组件接收到了新的 props 或者 state 即将进行重新渲染前,componentWillUpdate(object nextProps, object nextState) 会被调用,注意不要在此方面里再去更新 props 或者 state。
这个方法和 componentDidMount 类似,在组件重新被渲染之后,componentDidUpdate(object prevProps, object prevState) 会被调用。可以在这里访问并修改 DOM。
每当React使用完一个组件,这个组件必须从 DOM 中卸载后被销毁,此时 componentWillUnmout 会被执行,完成所有的清理和销毁工作,在 conponentDidMount 中添加的任务都需要再该方法中撤销,如创建的定时器或事件监听器。
当再次装载组件时,以下方法会被依次调用:
1、getInitialState
2、componentWillMount
3、render
4、componentDidMount
在 getInitialState 方法中,尝试通过 this.props 来创建 state 的做法是一种反模式。
//反模式
getDefaultProps: function(){
return {
data: new Date()
}
},
getInitialState: function(){
return {
day: this.props.date - new Date()
}
},
render: function(){
return <div>Day:{this.state.day}</div>
}
经过计算后的值不应该赋给 state,正确的模式应该是在渲染时计算这些值。这样保证了计算后的值永远不会与派生出它的 props 值不同步。
//正确模式
getDefaultProps: function(){
return {
data: new Date()
}
},
render: function(){
var day = this.props.date - new Date();
return <div>Day:{day}</div>
}
如果只是简单的初始化 state,那么应用反模式是没有问题的。
以下面的一张图总结组件的生命周期:

1: <!DOCTYPE html>
2: <html>
3: <head>
4: <title>常用console命令</title>
5: <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
6: </head>
7: <body>
8: <script type="text/javascript">
9: console.log('hello');
10: console.info('信息');
11: console.error('错误');
12: console.warn('警告');
13: </script>
14: </body>
15: </html>
最常用的就是console.log了。
console上述的集中度支持printf的占位符格式,支持的占位符有:字符(%s)、整数(%d或%i)、浮点数(%f)和对象(%o):
| 占位符 | 作用 |
|---|---|
| %s | 字符串 |
| %d or %i | 整数 |
| %f | 浮点数 |
| %o | 可展开的DOM |
| %O | 列出DOM的属性 |
| %c | 根据提供的css样式格式化字符串 |
1: <script type="text/javascript">
2: console.log("%d年%d月%d日",2011,3,26);
3: </script>
效果:

%o、%O都是用来输出Object对象的,对普通的Object对象,两者没区别,但是打印dom节点时就不一样了:
// 格式成可展开的的DOM,像在开发者工具Element面板那样可展开
console.log('%o',document.body.firstElementChild);
// 像JS对象那样访问DOM元素,可查看DOM元素的属性
// 等同于console.dir(document.body.firstElementChild)
console.log('%O',document.body.firstElementChild);
%c占位符是最常用的。使用%c占位符时,对应的后面的参数必须是CSS语句,用来对输出内容进行CSS渲染。常见的输出方式有两种:文字样式、图片输出。
文字输出
console.log("%cHello world,欢迎您!","color: red; font-size: 20px");
//输出红色的、20px大小的字符串:Hello world,欢迎您!
除了普通文本,还能输出如知乎的console面板一样的字符画。这些字符画是可以在线生成的:
大概方法:使用在线工具生成字符画,然后复制到sublime中,将每行开头的换行删除,且替换成\n。最后只有一行代码,即保证没有换行,最后再丢到console.log("")代码中即可,当然,也可以添加结合%c做出更酷炫的效果(console输出默认是不换行的)。
图片输出

由于 console不能定义img,因此用背景图片代替。此外,console不支持width和height,利用空格和font-size代替;还可以使用padding和line-height代替宽高。
不想这么麻烦,可以试试console-image这个插件。
1: <!DOCTYPE html>
2: <html>
3: <head>
4: <title>常用console命令</title>
5: <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
6: </head>
7: <body>
8: <script type="text/javascript">
9: console.group("第一组信息");
10:
11: console.log("第一组第一条:我的博客(http://www.ido321.com)");
12:
13: console.log("第一组第二条:CSDN(http://blog.csdn.net/u011043843)");
14:
15: console.groupEnd();
16:
17: console.group("第二组信息");
18:
19: console.log("第二组第一条:程序爱好者QQ群: 259280570");
20:
21: console.log("第二组第二条:欢迎你加入");
22:
23: console.groupEnd();
24: </script>
25: </body>
26: </html>
效果:

console.dir()可以显示一个对象所有的属性和方法。
1: <script type="text/javascript">
2: var info = {
3: blog:"http://www.ido321.com",
4: QQGroup:259280570,
5: message:"程序爱好者欢迎你的加入"
6: };
7: console.dir(info);
8: </script>
效果:

console.dirxml()用来显示网页的某个节点(node)所包含的html/xml代码。
1: <!DOCTYPE html>
2: <html>
3: <head>
4: <title>常用console命令</title>
5: <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
6: </head>
7: <body>
8: <div id="info">
9: <h3>我的博客:www.ido321.com</h3>
10: <p>程序爱好者:259280570,欢迎你的加入</p>
11: </div>
12: <script type="text/javascript">
13: var info = document.getElementById('info');
14: console.dirxml(info);
15: </script>
16: </body>
17: </html>
效果:

console.assert()用来判断一个表达式或变量是否为真。如果结果为否,则在控制台输出一条相应信息,并且抛出一个异常。
1: <script type="text/javascript">
2: var result = 1;
3: console.assert( result );
4: var year = 2014;
5: console.assert(year == 2018 );
6: </script>
1是非0值,是真;而第二个判断是假,在控制台显示错误信息

console.trace()用来追踪函数的调用轨迹。
1: <script type="text/javascript">
2: /*函数是如何被调用的,在其中加入console.trace()方法就可以了*/
3: function add(a,b){
4: console.trace();
5: return a+b;
6: }
7: var x = add3(1,1);
8: function add3(a,b){return add2(a,b);}
9: function add2(a,b){return add1(a,b);}
10: function add1(a,b){return add(a,b);}
11: </script>
控制台输出信息:

console.time()和console.timeEnd(),用来显示代码的运行时间。
1: <script type="text/javascript">
2: console.time("控制台计时器一");
3: for(var i=0;i<1000;i++){
4: for(var j=0;j<1000;j++){}
5: }
6: console.timeEnd("控制台计时器一");
7: </script>
运行时间是38.84ms

性能分析(Profiler)就是分析程序各个部分的运行时间,找出瓶颈所在,使用的方法是console.profile()。
1: <script type="text/javascript">
2: function All(){
3: alert(11);
4: for(var i=0;i<10;i++){
5: funcA(1000);
6: }
7: funcB(10000);
8: }
9:
10: function funcA(count){
11: for(var i=0;i<count;i++){}
12: }
13:
14: function funcB(count){
15: for(var i=0;i<count;i++){}
16: }
17:
18: console.profile('性能分析器');
19: All();
20: console.profileEnd();
21: </script>
输出如图:

Search engines are pretty good at finding what you’re looking for these days, but sometimes they still come up short. For those occasions there are a few little known tricks which come in handy.
目前来说,搜索引擎 很擅长找到你需要的信息,但有时搜索结果并不如人意。在这种场合下,知道一些鲜为人知的小技巧是很有用的。
So here are some tips for better googling (as it’s the most popular search engine) but many will work on other search engines too.
下面会介绍 10 个谷歌(最受欢迎的搜索引擎)搜索技巧,当然,这10 个技巧也可以用于其它搜索引擎。
The simplest and most effective way to search for something specific is to use quote marks around a phrase or name to search for those exact words in that exact order.
最简单和最有效的搜索方式是给关键词加上双引号,这样搜索引擎会反馈和关键词完全吻合的搜索结果。
For instance, searching for Joe Bloggs will show results with both Joe and Bloggs but not necessarily placed sequentially. Searching for “Joe Bloggs” will surface only those that specifically have the name Joe Bloggs somewhere on the page.
例如,搜索 Joe Bloggs 时,搜索引擎会返回同时跟 Joe 和 Bloggs 相关的结果,而搜索 "Joe Bloggs" 时,搜索引擎只返回跟 "Joe Bloggs" 相关的结果。
The exact or explicit phrase search is very useful for excluding more common but less relevant results.
准确搜索会排除常见但相关度偏低的信息,会提高搜索的精确性。
If exact phrase doesn’t get you what you need, you can specifically exclude certain words using the minus symbol.
A search for “Joe Bloggs” -jeans will find results for Joe Bloggs, but it will exclude those results for the Joe Bloggs brand of jeans.
如果准确搜索不能得到想要的结果,你可以通过使用减号的方式来排除特定词汇。
例如搜索 Joe Bloggs -jeans 时,搜索引擎会返回与 Joe Bloggs 匹配但已经排除关键字 jeans 的信息。
Default text searches find results with all the words of the query. By using the OR term you can search for one or another term, not just all the terms. OR searches can be useful for finding things that you’re not sure which term will be used from a known list.
默认的文本搜索会返回所有和关键字相关的信息,通过使用 OR,不仅能返回和关键字都相关的信息,还能返回和两个关键字分别相关的信息。在不确定哪个哪个关键字对搜索结果起决定作用时,OR 搜索是很有用的。
Sometimes it’s useful to search for a less specific term. If you’re not sure which term will be used you can use synonym search.
Searching for plumbing ~university will bring up results for plumbing from colleges as well as universities, for example.
有时使用不确定的关键词进行搜索反而更有用。如果你不确定使用哪个关键词,可以试试使用同义词搜索。
例如,你搜索 plumbing ~university,则搜索引擎会返回包含 plumbing universities 和 plumbing colleges 的信息。
The search engines of most websites are poor. You can search using Google instead by using the site or domain limiter.
Searching with site:theguardian.com followed by a search term, will find results from only theguardian.com. Combining with explicit search terms makes it even more powerful.
很多网站缺乏搜索功能,但你可以通过谷歌等搜索引擎对站内进行搜索。
在搜索引擎上输入 site:theguardian.com 和搜索关键字,搜索引擎会返回网站 theguardian.com 内和关键词相关的信息。结合准确搜索,能使这项功能更强大。
Like the blank tile in Scrabble, the asterisk works as a wild card within searches. It can be used in place of a missing word or part of a word, which is useful for completing phrases, but also when you’re trying to search for a less definite article.
A search for architect* will search for architect, but also architectural, architecture, architected, architecting and any other word which starts with architect.
类似拼图游戏 Scrabble 的空白方块,在搜索引擎中,不管关键字缺失的是一连串单词中的其中一个还是一个单词的某一部分,都可以使用星号来填补缺失的部分,这同样适用于搜索一篇确定性偏低的文章。
例如,在搜索引擎输入 architect*,则会得到所有包含 architect、architectural、architecture、architected、architecting 以及其他所有以architect 作为开头的词汇的信息。
Searching for something with a qualifier between two ranges is a good way of answering questions. For instance, if you’re looking for the who were the British prime ministers between 1920 and 1950 a search using british prime minister 1920.. 1950 will bring up results with dates ranging between 1920 and 1950.
That’s your search term followed by two full stops and a space.
在一定范围内使用限定词来搜索某些东西是一个不错的方法。例如想要找出 1920 至 1950 年间的英国首相,直接在搜索引擎中输入 英国首相 1920.. 1950 即可得出想要的结果。
记住,数值之间的符号是两个英文句号加一个空格键。
Sometimes you only want to find text either within the URL, body or title of a page. Using the qualifier inurl: will search just within the url. The qualifier intext: will search within the body, while intitle: will search only within a page title.
For example, intitle:review will bring up all the articles with “review” in the page title.
有时,你只想找出所有和关键词相关的网页链接、网页主体(内容)和标题,这时,就可以使用对应的限定词:inurl: 、intext 和 intitle。
例如,在搜索引擎中输入 intitle: 评测 会得到所有和关键词 评测 相关的网页标题。
The related qualifier is useful for finding similar sites. Searching for related:theguardian.com for instance, will bring up the websites of other news organisations that Google deems the most similar to the Guardian.
相关的限定词可用于搜索相关网站时使用。例如,你仅需在搜索引擎中输入 **related:**theguardian.com 即可得到所有和 theguardian.com 相关的网站的搜索结果。
All these search tools can be combined to narrow down or expand searches. While some of them may be used only rarely, some such as explicit phrase searches are useful in almost all cases.
As Google and other search engines improve their understanding of the way people naturally type or say search queries, these power tools will likely become less and less useful – at least that’s the goal that search engines are working towards – but that’s certainly not the case at the moment.
你可以组合使用上述的搜索技巧来缩小或扩大搜索范围。尽管一些搜索技巧不常使用,但是准确搜索和站内搜索的使用范围是很广的。
随着 Google 等搜索引擎对用户自然语言理解程度的提高,这些搜索技能的适用场景会越来越少,至少这是搜索引擎的共同追求目标。但是在当下,掌握这些搜索技巧还是非常有用的。
(但是在天朝,你懂的~~)
原文:How to use search like a pro: 10 tips and tricks for Google and beyond
先看看下面的程序:
var sum = 0;
for(var i = 0; i < 10; i++) {
sum += 0.1;
}
console.log(sum);
上面的程序会输出1吗?
在 你有必要知道的 25 个 JavaScript 面试题 一文中,第 8 个题浅显的说了下 js 为什么不能正确处理小数运算的问题。今天重拾旧题,更深层次的剖析下这个问题。
但要先说明的是,不能正确处理小数的运算并不是 JavaScript 语言本身的设计错误,其它高级编程语言,如C,Java等,也是不能正确处理小数运算的:
#include <stdio.h>
void main(){
float sum;
int i;
sum = 0;
for(i = 0; i < 100; i++) {
sum += 0.1;
}
printf('%f\n', sum); //10.000002
}
我们都知道,用高级编程语言编写的程序需要经过解释、编译等操作转变成 CPU(Central Processing Unit) 可以识别的机器语言才能运行,而对 CPU 来说,它不识别数的十进制、八进制和十六进制等,我们在程序中声明的这些进制数都会被转成二进制数进行运算。
为什么不是转换成三进制数进行运算呢?
计算机内部是由很多的 IC (Integrated Circuit: 集成电路) 这种电子部件构成的,它的长相大概是这样子:
IC 有很多种形状,在其两侧或内部并排排列着很多引脚(图示只画出了一侧)。IC 的所有引脚,只有直流电压 0V 或 5V 两个状态,即一个 IC 引脚只能表示两个状态。IC 的这个特性就决定了计算机内部的数据只能用二进制数处理。
由于 1 位(一个引脚)只能表示两个状态,所以二进制的计算方式就变成了 0、1、10、11、100....这种形式:
所以,在数的运算中,所有操作数都会被转成二进制数参与运算,如39,会被转换成二进制 00100111
如前文所说,程序中的数据都会被转换成二进制数,小数参与运算时,也会被转成二进制,如十进制的11.1875 会被转换成1101.0010。
小数点后 4 位用二进制数表示的数值范围是 0.0000~0.1111,因此,这只能表示 0.5、0.25、0.125、0.0625 这四个十进制数以及小数点后面的位权组合(相加)而成的小数:
| 二进制数 | 对应的十进制数 |
|---|---|
| 0.0000 | 0 |
| 0.0001 | 0.0625 |
| 0.0010 | 0.125 |
| 0.0011 | 0.1875 |
| 0.0100 | 0.25 |
| 0.1000 | 0.5 |
| 0.1001 | 0.5625 |
| 0.1010 | 0.625 |
| 0.1011 | 0.6875 |
| 0.1111 | 0.9375 |
从上表可以看出,十进制数 0 的下一位是 0.0625,所以,0~0.0625 之间的小数,就无法用小数点后 4 位数的二进制数表示;如果增加二进制数小数点后面的位数,与其相对应的十进制数的个数也会增加,但无论增加多少位,都无法得到 0.1 这个结果。实际上,0.1 转换成二进制是 0.00110011001100110011…… 注意 0011 是无限重复的:
console.log(0.2+0.1);
//操作数的二进制表示
0.1 => 0.0001 1001 1001 1001…(无限循环)
0.2 => 0.0011 0011 0011 0011…(无限循环)
js 的 Number 类型并没有像 C / Java 等分整型、单精度、双精度等,而是统一表现为双精度浮点型。按照 IEEE 的规定,单精度浮点数用 32 位表示全体小数,而双精度浮点数用 64 位表示全体小数,而浮点数由符号、尾数、指数和基数组成,所以并不是所有的位数都用来表示小数,符号、指数等也要占据位数,基数不占据位数:
双精度浮点数的小数部分最多支持 52 位,所以两者相加之后得到这么一串 0.0100110011001100110011001100110011001100…因浮点数小数位的限制而截断的二进制数字,这时候,再把它转换为十进制,就成了 0.30000000000000004。
js 不能正确处理小数运算,包括其它高级编程语言一样,这不是语言本身的设计错误,而是计算机内部本身就不能正确处理小数的运算,对小数的运算往往会得到意想不到的结果,因为并不是所有的十进制小数能被二进制表示。
《程序是怎么跑起来的》
虽然Linux发行版支持各种各样的饿GUI(graphical user interfaces),但在某些情况下,Linux的命令行接口(bash)仍然是简单快速的。Bash和 Linux Shell 需要输入命令来完成任务,因而被称为 命令行 接口。
命令是计算机执行任务的指令。可以使用命令去关闭计算机,或者列出当前目录的文件列表,或当前文本的内容,或者屏幕显示一条消息。
如果你是一个新手,并尝试使用命令行接口,我们收集了各种基本的Linux命令来供你学习,帮你在各种Linux发行版中完成各种任务。虽然不是很详细,但是对Linux初学者,或普通用火,或管理员都是很有用的。
ls会列举出当前工作目录的内容(文件或文件夹),就跟你在GUI中打开一个文件夹去看里面的内容一样。

mkdir 用于新建一个新目录

pwd显示当前工作目录

对于当前在终端运行的会中中,cd 将给定的文件夹(或目录)设置成当前工作目录。

rmdir 删除给定的目录。

rm 会删除给定的文件或文件夹,可以使用rm -r 递归删除文件夹

cp 命令对文件或文件夹进行复制,可以使用cp -r 选项来递归复制文件夹。
mv
cat 用于在标准输出(监控器或屏幕)上查看文件内容
tail 默认在标准输出上显示给定文件的最后10行内容,可以使用tail -n N 指定在标准输出上显示文件的最后N行内容。
less 按页或按窗口打印文件内容。在查看包含大量文本数据的大文件时是非常有用和高效的。你可以使用Ctrl+F向前翻页,Ctrl+B向后翻页。

grep "" 在给定的文件中搜寻指定的字符串。grep -i "" 在搜寻时会忽略字符串的大小写,而grep -r "" 则会在当前工作目录的文件中递归搜寻指定的字符串。

这个命令会在给定位置搜寻与条件匹配的文件。你可以使用find -name 的-name选项来进行区分大小写的搜寻,find -iname 来进行不区分大小写的搜寻。
find <folder-to-search> -iname <file-name>

tar命令能创建、查看和提取tar压缩文件。tar -cvf <archive-name.tar> 是创建对应压缩文件,tar -tvf <archive-to-view.tar> 来查看对应压缩文件,tar -xvf <archive-to-extract.tar>来提取对应压缩文件。

gzip 命令创建和提取gzip压缩文件,还可以用gzip -d 来提取压缩文件。

unzip <archive-to-extract.zip>对gzip文档进行解压。在解压之前,可以使用unzip -l <archive-to-extract.zip>命令查看文件内容。

--help会在终端列出所有可用的命令,可以使用任何命令的-h或-help选项来查看该命令的具体用法。

whatis 会用单行来描述给定的命令。
man 会为给定的命令显示一个手册页面。

exit用于结束当前的终端会话。

ping 通过发送数据包ping远程主机(服务器),常用与检测网络连接和服务器状态。

who能列出当前登录的用户名。

su 用于切换不同的用户。即使没有使用密码,超级用户也能切换到其它用户。

uname会显示出关于系统的重要信息,如内核名称、主机名、内核版本、处理机类型等等,使用uname -a可以查看所有信息。

free会显示出系统的空闲内存、已经占用内存、可利用的交换内存等信息,free -m将结果中的单位转换成KB,而free –g则转换成GB。

df查看文件系统中磁盘的使用情况–硬盘已用和可用的存储空间以及其它存储设备。你可以使用df -h将结果以人类可读的方式显示。

ps显示系统的运行进程。

top命令会默认按照CPU的占用情况,显示占用量较大的进程,可以使用top -u 查看某个用户的CPU使用排名情况。

shutdown用于关闭计算机,而shutdown -r用于重启计算机。
9 Linux Commands & Codes to be Wary of
实用linux命令(一)
实用Linux命令(二)
fork
对于大多数开发者来说,JavaScript 的 this 关键字会造成诸多困扰。由于 JavaScript 不具备如 Java 等语言的严格类模型,因而除非是在处理回调,否则代码中的 this 指向并不清晰。
一般来说,对于部分运行中的代码(非回调)会通过 new 关键字和 Function.prototype 提供的一些方法,如 call/apply 等来绑定函数的上下文。
在每个 class 中,React 使用 this 指向组件本身,这会给开发者造成一些困扰。如在 React 组件中,可能会经常看到类似如下的代码:
this.setState({ loading: true });
fetch('/').then(function loaded() {
this.setState({ loading: false });
});
上述代码会造成 TypeError ,因为 this.setState 不是一个函数。抛出 TypeError 的原因是当 promise 的回调被调用时,内部的上下文已经改变了,this 指向了错误的对象。
那么,怎么正确绑定代码中的 this 呢?
本文提供的 6 种方式中,有一些是比较老的技术,另一些是针对 React 的,还有一些可能浏览器也不支持,但还是值得探讨一下。
这种方式就是在 React 组件的作用域顶端创建一个指向 this 的变量:
var component = this;
component.setState({ loading: true });
fetch('/').then(function loaded() {
component.setState({ loading: false });
});
这种方式方便,易于理解,并能保证 this 会指向正确的上下文。
这种方式是在函数运行时将 this 注入到回调中,使回调中的 this 能指向正确的上下文:
this.setState({ loading: true });
fetch('/').then(function loaded() {
this.setState({ loading: false });
}.bind(this));
在 JavaScript 中,所有函数都有 bind 方法,其允许你为 this 指定特定值。一旦函数被绑定,上下文就不能被覆盖,也就意味着 this 会指向正确的上下文。
当使用 React.createClass 来定义组件时,React 允许你随意在此组件的类中定义方法,而在方法中调用的 this 会自动绑定到组件自身:
React.createClass({
componentWillMount: function() {
this.setState({ loading: true });
fetch('/').then(this.loaded);
},
loaded: function loaded() {
this.setState({ loading: false });
}
});
对于不是非常复杂的组件来说,这是一种非常不错的解决 this 指向问题的方式。而事实上呢,如果在组件的方法中使用 .bind(this),React 会抛出一个警告:
bind(): You are binding a component method to the component. React does this for you automatically in a high-performance way, so you can safely remove this call.
但对于 ES2015 的类 来说,自动绑定并不适用。
ES2015 规范引入了箭头函数,使函数的定义更加简洁。箭头函数会隐式返回一个值,但更重要的是,它是在一个封闭的作用域中使用 this:
this.setState({ loading: true });
fetch('/').then(() => {
this.setState({ loading: false });
});
不管嵌套多少层,箭头函数中的 this 总能指向正确的上下文,因为函数体内的 this 指向的对象,就是定义时所在的对象,而不是使用时所在的对象。但缺点就是,由于箭头函数不能命名,因而在调试时,堆栈信息给的标签是 anonymous function。
如果你用 Babel 将 ES6 的代码转换成 ES5 的代码,就会发现两个有趣的现象:
在某些情况下,编译器能判断函数名是否被赋值给了某个变量
编译器使用 别名 来维护上下文
const loaded = () => {
this.setState({ loading: false });
};
// will be compiled to
var _this = this;
var loaded = function loaded() {
_this.setState({ loading: false });
};
在 ES7 中,有一个关于 bind 语法 的提议,提议将 :: 作为一个新的绑定操作符,该操作符会将左值和右值(一个函数)进行绑定。
以 map 的实现为例:
function map(f) {
var mapped = new Array(this.length);
for(var i = 0; i < this.length; i++) {
mapped[i] = f(this[i], i);
}
return mapped;
}
与 lodash 不同,我们不需要传递数据给 map 作为参数:
[1, 2, 3]::map(x => x * 2)
// [2, 4, 6]
对下面的代码熟悉吗?
[].map.call(someNodeList, myFn);
// or
Array.from(someNodeList).map(myFn);
ES7 的绑定语法允许你像使用箭头函数一样使用 map:
someNodeList::map(myFn);
在 React 中也是可以使用的:
this.setState({ loading: true });
fetch('/').then(this::() => {
this.setState({ loading: false });
});
一些函数允许为 this 传递一个明确的值,保证其指向正确的上下文,例如 map 函数则将 this 作为最后一个参数:
items.map(function(x) {
return <a onClick={this.clicked}>x</a>;
}, this);
虽然代码能运行,但这不是函数的一致实现。大部分函数并不接受 this 参数,所以最好还是采用上文中的其它方式来绑定 this 。
CSS中主要的伪元素有四个:before/after/first-letter/first-line,在before/after伪元素选择器中,有一个content属性,能够实现页面中的内容插入。
content : ”插入的文章”,或者 content:none 不插入内容
#html
<h1>这是h1</h1>
<h2>这是h2</h2>
#css
h1::after{
content:"h1后插入内容"
}
h2::after{
content:none
}
运行结果:https://jsfiddle.net/dwqs/Lmm1r08x/
可以使用content属性的 open-quote 属性值和 close-quote 属性值在字符串两边添加诸如括号、单引号、双引号之类的嵌套文字符号。open-quote 用于添加开始的文字符号,close-quote 用于添加结束的文字符号。修改上述的css:
h1{
quotes:"(" ")"; /*利用元素的quotes属性指定文字符号*/
}
h1::before{
content:open-quote;
}
h1::after{
content:close-quote;
}
h2{
quotes:"\"" "\""; /*添加双引号要转义*/
}
h2::before{
content:open-quote;
}
h2::after{
content:close-quote;
}
运行结果:https://jsfiddle.net/dwqs/p8e3qvv4/
content属性也可以直接在元素前/后插入图片
#html
<h3>这是h3</h3>
#css
h3::after{
content:url(http://ido321.qiniudn.com/wp-content/themes/yusi1.0/img/new.gif)
}
运行结果:https://jsfiddle.net/dwqs/c6qk6pkv/
content属性可以直接利用attr获取元素的属性,将其插入到对应位置。
#html
<a href="http:///www.ido321.com">这是链接</a>
#css
a:after{
content:attr(href);
}
运行结果:https://jsfiddle.net/dwqs/m220nzan/
利用content的counter属性针对多个项目追加连续编号.
#html
<h1>大标题</h1>
<p>文字</p>
<h1>大标题</h1>
<p>文字</p>
<h1>大标题</h1>
<p>文字</p>
<h1>大标题</h1>
<p>文字</p>
#css
h1:before{
content:counter(my)'.';
}
h1{
counter-increment:my;
}
运行结果:https://jsfiddle.net/dwqs/2ueLg3uj/
默认插入的项目编号是数字型的,1,2,3.。。。自动递增,也能给项目编号追加文字和样式,依旧利用上面的html,css修改如下:
h1:before{
content:'第'counter(my)'章';
color:red;
font-size:42px;
}
h1{
counter-increment:my;
}
运行结果:https://jsfiddle.net/dwqs/17hqznca/
利用content(计数器名,编号种类)格式的语法指定编号种类,编号种类的参考可以依据ul的list-style-type属性值。利用上述的html,css修改如下:
h1:before{
content:counter(my,upper-alpha);
color:red;
font-size:42px;
}
h1{
counter-increment:my;
}
运行结果:https://jsfiddle.net/dwqs/4nsrtxup/
大编号中嵌套中编号,中编号中嵌套小编号。
#html
<h1>大标题</h1>
<p>文字1</p>
<p>文字2</p>
<p>文字3</p>
<h1>大标题</h1>
<p>文字1</p>
<p>文字2</p>
<p>文字3</p>
<h1>大标题</h1>
<p>文字1</p>
<p>文字2</p>
<p>文字3</p>
#css
h1::before{
content:counter(h)'.';
}
h1{
counter-increment:h;
}
p::before{
content:counter(p)'.';
margin-left:40px;
}
p{
counter-increment:p;
}
运行结果:https://jsfiddle.net/dwqs/2k5qbz51/
在示例的输出中可以发现,p的编号是连续的。如果对于每一个h1后的三个p重新编号的话,可以使用counter-reset属性重置,修改上述h1的css:
h1{
counter-increment:h;
counter-reset:p;
}
这样,编号就重置了,看看结果:https://jsfiddle.net/dwqs/hfutu4Lq/
还可以实现更复杂的嵌套,例如三层嵌套。
#html
<h1>大标题</h1>
<h2>中标题</h2>
<h3>小标题</h3>
<h3>小标题</h3>
<h2>中标题</h2>
<h3>小标题</h3>
<h3>小标题</h3>
<h1>大标题</h1>
<h2>中标题</h2>
<h3>小标题</h3>
<h3>小标题</h3>
<h2>中标题</h2>
<h3>小标题</h3>
<h3>小标题</h3>
#css
h1::before{
content:counter(h1)'.';
}
h1{
counter-increment:h1;
counter-reset:h2;
}
h2::before{
content:counter(h1) '-' counter(h2);
}
h2{
counter-increment:h2;
counter-reset:h3;
margin-left:40px;
}
h3::before{
content:counter(h1) '-' counter(h2) '-' counter(h3);
}
h3{
counter-increment:h3;
margin-left:80px;
}
运行结果:https://jsfiddle.net/dwqs/wuuckquy/
张大大有一篇利用counter实现计数的文章:小tip:CSS计数器+伪类实现数值动态计算与呈现
在0.28版rn中,如果textinput的位置在靠近底部的位置,在textinput获取焦点后,ios上弹出的键盘会遮住textinput,导致用户无法输入;android上弹出键盘时,整个界面会被网上顶,textinput不会被遮住。
在0.28中,解决ios上该问题的方式是利用 ScrollView contentInset 属性,监听键盘的弹出和隐藏事件(keyboardWillShow/keyboardWillHide),获取键盘的高度,动态设置成 contentInset 的值。
将rn升级成0.33后,android和ios上都会出现TextInput 被键盘遮挡的问题,ios上原来的方式也不能解决此问题了。
在 ios 上,textinput 未获取焦点前:

获取焦点后:

textinput被键盘挡住了。android上有同样的问题。
解决这种情况的一种方式,监听键盘的弹出和隐藏事件,在ScrollView底部设置一个占位符组件,将占位符的高度设置成键盘的高度。
监听键盘事件:
this.keyboardShow = Platform.OS === 'ios' ?
Keyboard.addListener('keyboardWillShow',this.updateKeyboardSpace.bind(this)) : Keyboard.addListener('keyboardDidShow',this.updateKeyboardSpace.bind(this));
this.keyboardHide = Platform.OS === 'ios' ?
Keyboard.addListener('keyboardWillHide',this.resetKeyboardSpace.bind(this)) : Keyboard.addListener('keyboardDidHide',this.resetKeyboardSpace.bind(this));
在事件处理程序中,获取键盘高度:
updateKeyboardSpace(frames){
if(!frames.endCoordinates){
return;
}
let keyboardSpace = frames.endCoordinates.height;//获取键盘高度
this.setState({
keyboardSpace: keyboardSpace
})
}
最后将高度传递给占位符组件:
<ScrollView>
//其他元素
<KeyboardSpacer keyboardSpace={this.state.keyboardSpace}/>
</ScrollView>
KeyboardSpacer组件实现如下:
const styles = StyleSheet.create({
container: {
left: 0,
right: 0,
bottom: 0
}
});
export default class KeyboardSpacer extends Component {
constructor(){
super();
}
static propTypes = {
keyboardSpace: PropTypes.number
};
static defaultProps = {
keyboardSpace: 0
};
render() {
let {keyboardSpace} = this.props;
return (
<View style={[styles.container, { height: ~~keyboardSpace }]} />
);
}
}
效果如下:

这样子能解决部分场景,例如textInput的位置是靠近底部的。如果textinput框的位置是靠近页面上部的,那么textinput框会被顶上去,就会因超出ScrollView的视口范围而被“遮住”。
这时,就不能单纯的将键盘的高度给 KeyboardSpacer 了,而应该根据textinput在ScrollView视口的位置进行 KeyboardSpacer 高度的计算了。
在页面加载之后,能获取到 ScrollView的视口高度ViewportHeight,这个值是保持不变的。此外,也能拿到textinput距离ScrollViewd顶边的垂直距离InputY,这个值是固定的,不会随着页面的滚动而变化页面示意如下:
在界面滚动一定距离之后,页面示意如下:
红边表示此时ScrollView的顶边位置,虚线框表示textInput框的原位置,实体框表示textInput在页面滚动之后的位置。
页面滚动时,能获取到ScrollView已经滚动的偏移量 scrollY,此时,就能计算出此时 textInput 距离ScrollView视口底部的距离 InputToBottom:
InputToBottom = ViewportHeight - (InputY - scrollY + textInput的高度)
此时,应该根据InputToBottom与键盘高度的大小比较来设置 keyboardSpace:
keyboardHeight = frames.endCoordinates.height; //键盘高度
keyboardSpace = InputToBottom >= keyboardHeight ? 0 : keyboardHeight - InputToBottom;
在图示页面的布局中,还有一个底部元素,因而在计算 keyboardHeight 时,因考虑下实际情况是否需要减去底部元素的高度或者ScrollView的marginBottom值。
对于一个项目,常用的一些npm简单命令包含的功能有:初始化一个文件夹( npm init ),下载npm模块( npm install ),创建测试( npm test ) 和自定义脚本( npm run )。但是,进一步了解一些 npm 的使用技巧可以彻底改变你的日常开发任务。
注: 如果你需要关于初学npm的参考,可以参阅我们的初学者指南。如果你对 npm 和 Yarn 之间的差异感到困扰,可以参阅我们发表的文章:Yarn vs npm:你需要知道的一切
npm 文档 和 CLI 命令行文档 是非常不错地的学习资料,但需要通过浏览器访问,这并不是很方便。因而可以通过命令行快速获取所有可选项:
npm help
此外,还能获取特定 npm 命令的使用帮助:
npm help <command>
例如:npm help install
另一种方式是通过下面的命令:
npm <command> -h
npm 通过bash提供了命令自动完成功能(包括 Bash for Windows 10 ):
npm completion >> ~/.bashrc
//or Z shell
npm completion >> ~/.zshrc
重新加载shell配置文件:
source ~/.bashrc
现在,在终端注入 npm ins ,然后按下 tab 键就会出现 install 了,不会再浪费时间去全部输入了。
当你试图安装全部模块时,类 Linux 系统可能会抛出权限错误,可以在npm命令之前添加 sudo 来执行,但这是一个较危险的选择。一个更高的解决方式是改变 npm 默认的模块安装目录:
mkdir ~/.npm-global
npm config set prefix '~/.npm-global'
使用适当的文本编辑器将下面的一行添加到 ~/.bashrc 或者 ~/.zshrc 文件中:
export PATH="$HOME/.npm-global/bin:$PATH"
重新加载配置文件(source ~/.bashrc),然后重新安装npm到用户所属路径:
npm install -g npm
这也会更新npm。
你可以通过下面的命令显示npm当前的版本:
npm -v
如果有需要,可以通过下面的命令更新npm:
npm install -g npm
当 Node 的主版本 released 之后,你也可能需要重新构建 C++ 扩展:
npm rebuild
如果你需要管理多个版本的node.js和npm,可以考虑使用 n 或者 nvm。这有一篇关于 nvm 的文章:使用 nvm 安装多版本的Node.js
使用 npm init 初始化一个新的项目,这会提示你关于项目的更多细节,并创建一个 package.json 文件。
如果你厌倦了每次开始一个新的项目都需要重新输入同样的信息,可以使用 -y 标记表示你能接受 package.json 文件的一堆默认值:
npm init -y
或者你可以设置一些语义化的默认值:
npm config set init.author.name <name>
npm config set init.author.email <email>
到目前为止,npm上已经有超过350000个模块了,并且每天还在持续增长。尽管有很多非常棒的模块,但是你还是想避免使用一些不受欢迎的、存在bug的或者无人维护的模块。在 npmjs 和 Github 上搜索npm模块是很实用但这还有一些其它选择:
npms
npms 根据一个基于项目版本、模块下载次数、最新更新日期、提交频率、测试覆盖率、文档、贡献者数量、issues数、star数、forks数和作者在社区的地位的综合测量分数进行模块排名。
npm Discover
npm Discover 定位于快速搜索和其它模块通常一起使用的模块,如 body-parser 通常和Express一起使用。
Packages by PageRank
Packages by PageRank 按照模块的谷歌排名进行搜索和排序。
Curated npm Lists
还一个选择就是利用别人的搜索结果。当需要一个健壮的解决方案时,我经常会参考 sindresorhus 的 Awesome Node.js。
你已经安装了一些模块,看看都有啥:
npm list
(ls、la & ll 可以用作 list 的别名)
该命令会显示所有模块:(安装的)模块,子模块以及子模块的子模块等。可以限制输出的模块层级:
npm list --depth=0
打开一个模块的主页:
npm home <package>
这只有在你的系统能打开浏览器时有用--在服务端的系统上会失败。同样,可以打开一个模块的 Github 仓库:
npm repo <package>
或者它的文档:
npm docs <package>
或者它目前的bugs列表:
npm bugs <package>
npm list 会显示和你已经安装地模块的关联模块---这些没有在 package.json文件中被引用。你可以单独 npm uninstall 每一个模块或者全部移除它们:
npm prune
如果安装模块时你添加了 --production 标记或者 NODE_ENV 被设置成 production,package.json 文件中被指定为 devDependencies 的模块也会被移除。
默认情况下,当用 --save/-S 或者 --save-dev/-D 安装一个模块时,npm 通过脱字符(^)来限定所安装模块的主版本号。例如,当运行 npm update 时, ^1.5.1 允许安装版本号大于 1.5.1 但小于 2.0.0 版本的模块。
波浪号(~)字符是限定模块的次要版本。例如,当运行 npm update 时, ~1.5.1 允许安装版本号大于 1.5.1 但小于 1.6.0 版本的模块。可以将需要安装的模块版本前缀默认设置成波浪号(~):
npm config set save-prefix="~"
对于那些偏执的认为任何更新(模块的行为)会破坏系统的人,可以配置npm仅安装精确版本号的模块:
npm config set save-exact true
另一个选择是,可以在项目中使用 shrinkwrap:
npm shrinkwrap
这会生成一个 shrinkwrap.json 文件,该文件包含了你正在使用的模块的指定版本。当运行 npm install 时,该文件所指定的模块版本会覆盖 package.json 文件中所指定的版本。
怎么知道一个模块已经更新了呢?我之前的方式是先列举出项目所依赖的模块(npm list --depth=0),然后在 npmjs.com 上找到该模块,手动检查该模块的版本是否已经更新。这非常费时。幸运的是,有一个更简单的方式:
npm outdated
或者 npm outdated -g 来查找全局模块。
你也可以查看一个独立模块的当前版本:
npm list <package>
也可以查看检验当前和历史版本:
npm view <package> versions
npm view <package> 会显示一个独立模块的所有信息,包括它的依赖、关键字、更新日期、贡献者、仓库地址和许可证等。
当你正在开发一个模块时,会经常想在其它项目中尝试使用或者在任何一个目录运行它(如果你的应用支持),这时没必要将其发布到 npm,并全局安装---仅需在该模块所在目录使用下面的命令:
npn list
该命令会为模块在全局目录下创建一个符号链接。可以通过下面的命令查看模块引用:
npm list -g --depth=0
或者:
npm outdated -g
现在,就可以从命令行运行模块或者通过 require 在任何项目中引入该模块。
另一个选择是,可以通过文件路径在 package.json 文件中声明对该模块的依赖:
"dependencies": {
"myproject": "file:../myproject/"
}
10 Tips and Tricks That Will Make You an npm Ninja
在一个Web页面的CSS渲染中,块级格式化上下文 (Block Fromatting Context)是按照块级盒子布局的。W3C对BFC的定义如下:
浮动元素和绝对定位元素,非块级盒子的块级容器(例如 inline-blocks, table-cells, 和 table-captions),以及overflow值不为“visiable”的块级盒子,都会为他们的内容创建新的BFC(块级格式上下文)。
为了便于理解,我们换一种方式来重新定义BFC。一个HTML元素要创建BFC,则满足下列的任意一个或多个条件即可:
1、float的值不是none。
2、position的值不是static或者relative。
3、display的值是inline-block、table-cell、flex、table-caption或者inline-flex
4、overflow的值不是visible
BFC是一个独立的布局环境,其中的元素布局是不受外界的影响,并且在一个BFC中,块盒与行盒(行盒由一行中所有的内联元素所组成)都会垂直的沿着其父元素的边框排列。
要显示的创建一个BFC是非常简单的,只要满足上述4个CSS条件之一就行。例如:
<div class="container">
你的内容
</div>
在类container中添加类似 overflow: scroll,overflow: hidden,display: flex,float: left,或 display: table 的规则来显示创建BFC。虽然添加上述的任意一条都能创建BFC,但会有一些副作用:
1、display: table 可能引发响应性问题
2、overflow: scroll 可能产生多余的滚动条
3、float: left 将把元素移至左侧,并被其他元素环绕
4、overflow: hidden 将裁切溢出元素
因而无论什么时候需要创建BFC,都要基于自身的需要来考虑。对于本文,将采用 overflow: hidden 方式:
.container {
overflow: hidden;
}
如前文所说,在一个BFC中,块盒与行盒(行盒由一行中所有的内联元素所组成)都会垂直的沿着其父元素的边框排列。W3C给出得规范是:
在BFC中,每一个盒子的左外边缘(margin-left)会触碰到容器的左边缘(border-left)(对于从右到左的格式来说,则触碰到右边缘)。浮动也是如此(尽管盒子里的行盒子 Line Box 可能由于浮动而变窄),除非盒子创建了一个新的BFC(在这种情况下盒子本身可能由于浮动而变窄)。
常规流布局时,盒子都是垂直排列,两者之间的间距由各自的外边距所决定,但不是二者外边距之和。
<div class="container">
<p>Sibling 1</p>
<p>Sibling 2</p>
</div>
对应的CSS:
.container {
background-color: red;
overflow: hidden; /* creates a block formatting context */
}
p {
background-color: lightgreen;
margin: 10px 0;
}
渲染结果如图:
在上图中,一个红盒子(div)包含着两个兄弟元素(p),一个BFC已经创建了出来。
理论上,两个p元素之间的外边距应当是二者外边距之和(20px)但实际上却是10px,这是外边距折叠(Collapsing Margins)的结果。
在CSS当中,相邻的两个盒子(可能是兄弟关系也可能是祖先关系)的外边距可以结合成一个单独的外边距。这种合并外边距的方式被称为折叠,并且因而所结合成的外边距称为折叠外边距。折叠的结果按照如下规则计算:
1、两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
2、两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
3、两个外边距一正一负时,折叠结果是两者的相加的和。
产生折叠的必备条件:margin必须是邻接的! (对于不产生折叠的情况,见参考文章的链接)
BFC可能造成外边距折叠,也可以利用它来避免这种情况。BFC产生外边距折叠要满足一个条件:两个相邻元素要处于同一个BFC中。所以,若两个相邻元素在不同的BFC中,就能避免外边距折叠。
改进前面的例子:
<div class="container">
<p>Sibling 1</p>
<p>Sibling 2</p>
<p>Sibling 3</p>
</div>
对应的CSS:
.container {
background-color: red;
overflow: hidden; /* creates a block formatting context */
}
p {
background-color: lightgreen;
margin: 10px 0;
}
结果和上面一样,由于外边距折叠,三个相邻P元素之间的垂直距离是10px,这是因为三个 p 标签都从属于同一个BFC。
修改第三个P元素,使之创建一个新的BFC:
<div class="container">
<p>Sibling 1</p>
<p>Sibling 2</p>
<div class="newBFC">
<p>Sibling 3</p>
</div>
</div>
对应的CSS:
.container {
background-color: red;
overflow: hidden; /* creates a block formatting context */
}
p {
margin: 10px 0;
background-color: lightgreen;
}
.newBFC {
overflow: hidden; /* creates new block formatting context */
}
现在的结果如图:
因为第二个和第三个P元素现在分属于不同的BFC,它们之间就不会发生外边距折叠了。
浮动元素是会脱离文档流的(绝对定位元素会脱离文档流)。如果一个没有高度或者height是auto的容器的子元素是浮动元素,则该容器的高度是不会被撑开的。我们通常会利用伪元素(:after或者:before)来解决这个问题。BFC能包含浮动,也能解决容器高度不会被撑开的问题。
看个例子:
<div class="container">
<div>Sibling</div>
<div>Sibling</div>
</div>
CSS:
.container {
background-color: green;
}
.container div {
float: left;
background-color: lightgreen;
margin: 10px;
}
在上面这个例子中,容器没有任何高度,并且它包不住浮动子元素,容器的高度并不会被撑开。为解决这个问题,可以在容器中创建一个BFC:
.container {
overflow: hidden; /* creates block formatting context */
background-color: green;
}
.container div {
float: left;
background-color: lightgreen;
margin: 10px;
}
现在容器可以包住浮动子元素,并且其高度会扩展至包住其子元素,在这个新的BFC中浮动元素又回归到页面的常规流之中了。
如上图所示,对于浮动元素,可能会造成文字环绕的情况(Figure1),但这并不是我们想要的布局(Figure2才是想要的)。要解决这个问题,我们可以用外边距,但也可以用BFC。
First let us understand why the text wraps. For this we have to understand how the box model works when an element is floated. This is the part I left earlier while discussing the alignment in a block formatting context. Let us understand what is happening in Figure 1 in the diagram below:
假设HTML是:
<div class="container">
<div class="floated">
Floated div
</div>
<p>
Quae hic ut ab perferendis sit quod architecto,
dolor debitis quam rem provident aspernatur tempora
expedita.
</p>
</div>
上图整个黑色区域表示 p 元素。p 元素没有移位但它叠在了浮动元素之下,而p元素的文本(行盒子)却移位了,行盒子水平变窄来给浮动元素腾出了空间。随着文本的增加,最后文本将环绕在浮动元素之下,因为那时候行盒子不再需要移位,也就成了图Figure1的样子。
再回顾一下W3C的描述:
在BFC上下文中,每个盒子的左外侧紧贴包含块的左侧(从右到左的格式里,则为盒子右外侧紧贴包含块右侧),甚至有浮动也是如此(尽管盒子里的行盒子 Line Box 可能由于浮动而变窄),除非盒子创建了一个新的BFC(在这种情况下盒子本身可能由于浮动而变窄)。
因而,如果p元素创建一个新的BFC那它就不会再紧贴包含块的左侧了。
如果我们创建一个占满整个容器宽度的多列布局,在某些浏览器中最后一列有时候会掉到下一行。这可能是因为浏览器四舍五入了列宽从而所有列的总宽度会超出容器。但如果我们在多列布局中的最后一列里创建一个新的BFC,它将总是占据其他列先占位完毕后剩下的空间。
例如:
<div class="container">
<div class="column">column 1</div>
<div class="column">column 2</div>
<div class="column">column 3</div>
</div>
对应的CSS:
.column {
width: 31.33%;
background-color: green;
float: left;
margin: 0 1%;
}
/* Establishing a new block formatting
context in the last column */
.column:last-child {
float: none;
overflow: hidden;
}
现在尽管盒子的宽度稍有改变,但布局不会打破。当然,对多列布局来说这不一定是个好办法,但能避免最后一列下掉。这个问题上弹性盒或许是个更好的解决方案,但这个办法可以用来说明元素在这些环境下的行为。
Understanding Block Formatting Contexts in CSS
深入理解BFC和Margin Collapse
gulp 是基于 Nodejs 的自动任务运行器,能自动化地完成javascript/coffee/sass/less/html/image/css等文件的的测试、检查、合并、压缩、格式化、浏览器自动刷新、部署文件生成,并监听文件在改动后重复指定的这些步骤。在实现上,gulp 借鉴了Unix操作系统的管道(pipe)**,前一级的输出,直接变成后一级的输入,使得在操作上非常简单.
安装 gulp 之前,先安装 Node.js,然后全局安装gulp:
npm install -g gulp
安装完之后,可以检测gulp的版本:
全局安装gulp后,还需要在每个要使用gulp的项目中都单独安装一次。把目录切换到你的项目文件夹中,然后在命令行中执行:
npm install gulp
如果想在安装的时候把gulp写进项目package.json文件的依赖中,则可以加上–save-dev:
npm install gulp --save-dev
--save:将保存配置信息至 package.json(package.json是nodejs项目配置文件。package.json是一个普通json文件,不能添加任何注释。参看 http://www.zhihu.com/question/23004511 );
-dev/-dep:保存至package.json的devDependencies节点,不指定-dev/dep将保存至dependencies节点。
安装Gulp之后,可以运行npm init初始化package.json文件:

需要注意的是,name是不能包含大写字母的:

初始化之后,需要在项目的根目录下建立gulpfile.js文件,文件名不能更改:
var gulp = require('gulp');
gulp.task('default', function() {
console.log('hello gulp');
});

默认任务将被运行,向控制台输出hello gulp。如果需要运行单个任务, 使用 gulp taskname命令(上述等效于gulp default)。
gulp在git上只介绍了四个API:task、dest、src、watch,除此之外,gulp还提供了一个run方法。
src()方法是指定需要处理的源文件的路径,gulp借鉴了Unix操作系统的管道(pipe)**,前一级的输出,直接变成后一级的输入,gulp.src返回当前文件流至可用插件.
| 参数 | 说明 |
|---|---|
| globs | 需要处理的源文件匹配符路径 |
| options | 有3个属性buffer、read、base |
globs的文件匹配说明:
“src/a.js”:指定具体文件;
“”:匹配所有文件 例:src/.js(包含src下的所有js文件);
“”:匹配0个或多个子文件夹 例:src//.js(包含src的0个或多个子文件夹下的js文件);
“{}”:匹配多个属性 例:src/{a,b}.js(包含a.js和b.js文件) src/.{jpg,png,gif}(src下的所有jpg/png/gif文件);
“!”:排除文件 例:!src/a.js(不包含src下的a.js文件);
var gulp = require('gulp'),
gulp.task('test', function () {
//gulp.src('test/style.css')
gulp.src(['css/**/*.css','!css/{extend,page}/*.css'])
.pipe(gulp.dest('./css'));
});
options的三个属性说明:
options.buffer: 类型:Boolean 默认:true 设置为false,将返回file.content的流并且不缓冲文件,处理大文件时非常有用;
options.read: 类型:Boolean 默认:true 设置false,将不执行读取文件操作,返回null;
options.base: 类型:String 设置输出路径以某个路径的某个组成部分为基础向后拼接
dest()方法是指定处理完后文件输出的路径;
| 参数 | 说明 |
|---|---|
| path | 指定文件输出路径,或者定义函数返回文件输出路径亦可 |
| options | 有2个属性cwd、mode |
options.cwd
Type: String Default: process.cwd()
cwd for the output folder, only has an effect if provided output folder is relative.
options.mode
Type: String Default: 0777
Octal permission string specifying mode for any folders that need to be created for output folder.
修改之前的gulpfile.js的内容如下:
var gulp = require('gulp');
gulp.task('testtask', function() {
gulp.src('./js/test.js')
.pipe(gulp.dest('./build'));
});
运行结果如下图:

利用gulp.dest('./build')将新建的test.js文件移动到了build目录,对比前后两次的ls -al命令,dest()会自动创建目录。
该方法用于定义一个gulp任务。
| 参数 | 说明 |
|---|---|
| name | 任务名称,不能包含空格 |
| deps | 该任务依赖的任务,依赖任务的执行顺序跟在deps中声明的顺序一致 |
| fn | 该任务调用的插件操作 |
再次修改gulpfile.js文件,定义一个任务列表
var gulp = require('gulp');
gulp.task('task1',function(){
console.log('task1 done');
});
gulp.task('task2',function(){
console.log('task2 done!');
});
gulp.task('task3',function(){
console.log('task3 done');
});
gulp.task('end',['task1','task3','task2'],function(){
console.log('end done');
});
运行结果:

watch()方法是用于监听文件变化,文件一修改就会执行指定的任务.
| 参数 | 说明 |
|---|---|
| glob | 需要处理的源文件匹配符路径 |
| opts | 具体参看https://github.com/shama/gaze; |
| tasks | 需要执行的任务的名称数组 |
| cb(event) | 每个文件变化执行的回调函数 |
每当监视的文件发生变化时,就会调用cb函数,并且会给它传入一个对象,该对象包含了文件变化的一些信息:
type: 属性为变化的类型,可以是 added,changed,deleted
path: 属性为发生变化的文件的路径
gulp.task('uglify',function(){
//do something
});
gulp.task('reload',function(){
//do something
});
gulp.watch('js/**/*.js', ['uglify','reload']);
watcher.on('change', function(event) {
console.log('File ' + event.path + ' was ' + event.type + ', running tasks...');
});
// same as
gulp.watch('js/**/*.js', function(event){
//变化类型 added为新增,deleted为删除,changed为改变
console.log(event.type);
//变化的文件的路径
console.log(event.path);
});
gulp模块的run()方法,表示要执行的任务。可能会使用单个参数的形式传递多个任务。注意:任务是尽可能多的并行执行的,并且可能不会按照指定的顺序运行.
修改之前的gulpfile.js文件中的end任务:
gulp.task('end',function(){
gulp.run('task1','task3','task2');
});
运行结果:

使用gulp-uglify压缩javascript文件,减小文件大小。利用npm先安装gulp-uglify:
npm install --save-dev gulp-uglify
安装之后,在gulpfile.js中引入:
var gulp = require('gulp'),
uglify = require("gulp-uglify");
gulp.task('minify-js', function () {
gulp.src('js/*.js') // 要压缩的js文件
.pipe(uglify())
.pipe(gulp.dest('dist/js')); //压缩后的路径
});
###压缩多个文件
var gulp = require('gulp'),
uglify = require('gulp-uglify');
gulp.task('jsmin', function () {
//多个文件以数组形式传入
gulp.src(['src/js/index.js','src/js/detail.js'])
.pipe(uglify())
.pipe(gulp.dest('dist/js'));
});
var gulp = require('gulp'),
uglify= require('gulp-uglify');
##匹配符“!”,“*”,“**”,“{}”
gulp.task('jsmin', function () {
//压缩src/js目录下的所有js文件
//除了test1.js和test2.js(**匹配src/js的0个或多个子文件夹)
gulp.src(['src/js/*.js', '!src/js/**/{test1,test2}.js'])
.pipe(uglify())
.pipe(gulp.dest('dist/js'));
});
用来重命名文件流中的文件。用gulp.dest()方法写入文件时,文件名使用的是文件流中的文件名,如果要想改变文件名,那可以在之前用gulp-rename插件来改变文件流中的文件名。
npm install --save-dev gulp-rename
简单运用:
var gulp = require('gulp'),
rename = require('gulp-rename'),
uglify = require("gulp-uglify");
gulp.task('rename', function () {
gulp.src('js/jquery.js')
.pipe(uglify()) //压缩
//会将jquery.js重命名为jquery.min.js
.pipe(rename('jquery.min.js'))
.pipe(gulp.dest('js'));
});
压缩css文件时并给引用url添加版本号避免缓存:
npm install --save-dev gulp-minify-css
简单运用:
var gulp = require('gulp'),
cssmin = require('gulp-minify-css');
//确保已本地安装gulp-make-css-url-version [npm install gulp-make-css-url-version --save-dev]
cssver = require('gulp-make-css-url-version');
gulp.task('testCssmin', function () {
gulp.src('src/css/*.css')
.pipe(cssver()) //给css文件里引用文件加版本号(文件MD5)
.pipe(cssmin())
.pipe(gulp.dest('dist/css'));
});
使用gulp-htmlmin压缩html,可以压缩页面javascript、css,去除页面空格、注释,删除多余属性等操作。
npm install --save-dev gulp-htmlmin
简单使用:
var gulp = require('gulp'),
htmlmin = require('gulp-htmlmin');
gulp.task('testHtmlmin', function () {
var options = {
removeComments: true,//清除HTML注释
collapseWhitespace: true,//压缩HTML
//省略布尔属性的值 <input checked="true"/> ==> <input />
collapseBooleanAttributes: true,
//删除所有空格作属性值 <input id="" /> ==> <input />
removeEmptyAttributes: true,
//删除<script>的type="text/javascript"
removeScriptTypeAttributes: true,
//删除<style>和<link>的type="text/css"
removeStyleLinkTypeAttributes: true,
minifyJS: true,//压缩页面JS
minifyCSS: true//压缩页面CSS
};
gulp.src('src/html/*.html')
.pipe(htmlmin(options))
.pipe(gulp.dest('dist/html'));
});
用来把多个文件合并为一个文件,我们可以用它来合并js或css文件等,这样就能减少页面的http请求数了.
npm install --save-dev gulp-concat
简单使用:
var gulp = require('gulp'),
concat = require("gulp-concat");
gulp.task('concat', function () {
gulp.src('js/*.js') //要合并的文件
.pipe(concat('all.js')) // 合并匹配到的js文件并命名为 "all.js"
.pipe(gulp.dest('dist/js'));
});
其它常用插件:
gulp-imagemin: 压缩图片文件
gulp-jshint: 侦测javascript代码中错误和潜在问题的工具
前段时间,写了篇关于React的文件:React:组件的生命周期,比较详细的说了下React组件的生命周期。
说道 React,很容易可以联想到 Flux。今天以 React 介绍及实践教程 一文中的demo为示例,简单说说 Flux 的开发方式。
Flux 是 Facebook 用户建立客户端 Web 应用的前端架构, 它通过利用一个单向的数据流补充了 React 的组合视图组件。
Flux 的设计架构如图:
Flux 架构有三个主要部分:Dispatcher 、Store 和View(React 组件)。Store 包含了应用的所有数据,Dispatcher 负责调度,替换了 MVC中 的Controller,当 Action 触发时,决定了 Store 如何更新。当 Store变化后,View 同时被更新,还可以生成一个由Dispatcher 处理的Action。这确保了数据在系统组件间单向流动。当系统有多个 Store 和 View 时,仍可视为只有一个 Store 和一个 View,因为数据只朝一个方向流动,并且不同的 Store 和 View 之间不会直接影响彼此。
在颜色盘的demo中,对界面的组件划分是这样的:
用户在 ColorPanel(View) 上产生一个 Action,Action 将数据流转到 Dispatcher,Dispatcher 根据 Action 传递的数据更新 Store,当 Store变化后,View 同时被更新。
(若你要获取本文的源代码,可以戳此:Flux-Demo)
Store 包含了应用的所有数据,并负责更新 View(ColorPanel),为简单,简化 Store 的定义:
let EventEmitter = require('events').EventEmitter;
let emitter = new EventEmitter();
export let colorStore = {
colorId: 1,
listenChange(callback){
emitter.on('colorChange', callback);
},
getColorId(){
return this.colorId
},
setColorId(colorId){
this.colorId = colorId;
emitter.emit('colorChange');
}
};
Action 要靠 Dispatcher 去调度,才能更新 Store,并有 Store 去更新对应的 View 组件。定义一个 colorDispatcher 用于调度:
import {Dispatcher} from 'flux';
import {colorStore} from './colorStore';
export let colorDispatcher = new Dispatcher();
colorDispatcher.register((payload) => {
switch (payload.action){
case 'CHANGE_COLOR_ID':
colorStore.setColorId(payload.colorId);
break;
}
});
当鼠标悬浮在 ColorBar 中的一个颜色框时,根据颜色框 ID 的变化,ColorDisplay 显示对应的颜色。我们定义一个 Action 为 CHANGE_COLOR_ID:
import {colorDispatcher} from './colorDispatcher';
export let colorAction = {
changeColorId(colorId){
colorDispatcher.dispatch({
action: 'CHANGE_COLOR_ID',
colorId: colorId
})
}
};
建议定义的 Action 符合 FSA 规范。
按照上图的组件划分,我们渲染出界面:
ColorDisplay:
import React, {Component} from 'react';
class ColorDisplay extends Component {
shouldComponentUpdate(nextProps, nextState){
return this.props.selectedColor.id !== nextProps.selectedColor.id;
}
render(){
return (
<div className = 'color-display'>
<div className = {this.props.selectedColor.value}>
{this.props.selectedColor.title}
</div>
</div>
)
}
}
export default ColorDisplay;
ColorBar:
import React, {Component} from 'react';
import {colorAction} from '../flux/colorAction';
import {colorStore} from '../flux/colorStore';
class ColorBar extends Component {
handleHover(colorId){
let preColorId = colorStore.getColorId();
if(preColorId != colorId){
colorAction.changeColorId(colorId);
}
}
render(){
return (
<ul>
{/* Reaact中循环渲染元素时, 需要用key属性确保正确渲染, key值唯一*/}
{this.props.colors.map(function(color){
return (
<li key = {color.id}
onMouseOver = {this.handleHover.bind(this, color.id)}
className = {color.value}>
</li>
)
}, this)}
</ul>
)
}
}
export default ColorBar;
ColorPanel:
import React, {Component} from 'react';
import ColorDisplay from './colorDisplay';
import ColorBar from './colorBar';
import {colorStore} from '../flux/colorStore'
class ColorPanel extends Component {
constructor(props){
super(props);
this.state = {
selectedColor: this.getSelectedColor(colorStore.getColorId())
};
colorStore.listenChange(this.onColorHover.bind(this));
}
getSelectedColor(colorId){
if(! colorId){
return null
}
let length = this.props.colors.length;
let i;
for(i = 0; i < length; i++) {
if(this.props.colors[i].id === colorId){
break;
}
}
return this.props.colors[i];
}
shouldComponentUpdate(nextProps, nextState){
return this.state.selectedColor.id !== nextState.selectedColor.id;
}
render(){
return (
<div>
<ColorDisplay selectedColor = {this.state.selectedColor} />
<ColorBar colors = {this.props.colors} />
</div>
)
}
onColorHover(){
let colorId = colorStore.getColorId();
this.setState({
selectedColor: this.getSelectedColor(colorId)
})
}
}
ColorPanel.defaultProps = {
colors: [
{id: 1, value: 'red', title: 'red'},
{id: 2, value: 'blue', title: 'blue'},
{id: 3, value: 'green', title: 'green'},
{id: 4, value: 'yellow', title: 'yellow'},
{id: 5, value: 'pink', title: 'pink'},
{id: 6, value: 'black', title: 'black'}
]
};
export default ColorPanel;
App:
var ReactDom = require('react-dom');
import React from 'react';
import ColorPanel from './panel/colorPanel';
require('./app.css');
window.onload = function () {
ReactDom.render(<ColorPanel />, document.getElementById('demos'));
}
最终的的界面如下:
本文简单的说了下如何利用 Flux 去开发实际应用,对于负载要求不高的应用,Flux 是完全可以使用的,复杂的富应用则可以借助 Redux + React 构建,Redux 负责数据分发和管理,其数据流的可控性比 Flux 更强,React 则依旧负责 View,但二者并不能直接连接,需要依赖 react-redux。
若你要获取本文的源代码,可以戳此:Flux-Demo
感谢辛勤的工作;
readme.md文档,标题部分加个空格方能正确达到可能想要的效果。例如
持续关注!
7.15,我拿到了我的工牌。那是中午12点了,去三楼办理入职时还要一张电子照片,但身上没带,于是凯哥直接用手机当场帮我照了一张,背景是公司的墙。现在想想,我应该带一张帅气的电子照片在身上的~~~~
1.15,掐指一算,快要发工资了(钱包早已经空了),也刚好来美团半年了。这半年,是我大学四年成长最快、见识最多和认识自己的半年,也是认识你们的半年。选择忘记一些人和事,因为碰到了新的人和事。
或许是保持一个平衡吧,想到了未命铭(很牛的人,神一样的存在,哈哈~~美团到处是牛人)说的一句话:事物的复杂度不会凭空消失,只会从一个事物转移到另一个事物。
2015 已经过去了,我觉得这一年对我还是有很多影响的,所以我觉得需要好好总结一下,因为有可能这会是我写的最认真的一份年度总结了~~~以后也是老油条了,哈哈O(∩_∩)O,你懂的。
我发现,15是一个有趣的数字。7.15 发生了很多事,如我入职美团(2015),江南Style发布(2012),澳门历史城区被列入《世界遗产名录》,优衣库上头条(2015),七一五政变(1927)等,但是我和优衣库是无关的。
我的适应能力还是很强的,来北京并没有感觉什么不适应,除了要天天上班,哈哈~~~。
北京地铁线很多,纵横交错,一不留心就找不着北了,三番五次坐错地铁或者坐过了,不知道要在哪一站下,北京太大了,经常找不到地===
北京有多大呢?不在一个区的恋人都是异地恋!!!
帝都除了空气质量,什么都比妖都高多了:地铁比妖都贵,房租比妖都贵,吃饭比妖都贵,水果比妖都贵,总感觉喝矿泉水都比妖都贵。但三天有2.8天是雾霾!!!好想念妖都的蓝天白云,青色的春坪,妖艳的夏花,清爽的秋风,温暖的冬阳。
刚来那一两个月,周末没什么活动,就呆在住房里,或看书,或睡觉,或玩电脑,或写代码。没有出去玩,怕出去玩一趟就不知道回来了,其实重点是No Money!!! 而那时也没有房补,正正经经的白领一个。
九月份有了房补,周末也能出去耍耍了,更多的是去书店。九月份有一场的 SegmentFault Day 的活动,在中关村那边,去玩了下,但中途退场了,就去了创业大街的言几又书店,待了一个下午,看了成龙大哥的自传。
从那以后,我每周末都会去书店,如:三联(文艺青年好去处)、北京图书大夏(技术书籍很多)、王府井书店(没有北图好看)、外文书店(略古典,书籍以英文版的外国文学偏多)、万圣书园(隔壁就是咖啡馆,装逼好去处)等。
现在也是定期去书店,还是喜欢三联,无论是手机还是电脑,都能自动连上其wifi,哈哈~~
读书,新知,生活。这难道就是文艺青年的生活吗?
2015年,学习和了解的东西还真不少 ,但悲哀的是,我也不知道有多少。或许你懂的,有很多东西只能意会不能言全吧,但我能感觉到我的变化,有些很微妙,有些很明显。从下面几个方面来概括一下吧:
My goal for 2016 is to accomplish the goals of 2015 which I should have done in 2014 because I made a promise in 2013 and planned in 2012.
1、使用 typeof bar === "object" 判断 bar 是不是一个对象有神马潜在的弊端?如何避免这种弊端?
使用 typeof 的弊端是显而易见的(这种弊端同使用 instanceof):
let obj = {};
let arr = [];
console.log(typeof obj === 'object'); //true
console.log(typeof arr === 'object'); //true
console.log(typeof null === 'object'); //true
从上面的输出结果可知,typeof bar === "object" 并不能准确判断 bar 就是一个 Object。可以通过 Object.prototype.toString.call(bar) === "[object Object]" 来避免这种弊端:
let obj = {};
let arr = [];
console.log(Object.prototype.toString.call(obj)); //[object Object]
console.log(Object.prototype.toString.call(arr)); //[object Array]
console.log(Object.prototype.toString.call(null)); //[object Null]
而 [] === false 是返回 false 的。
2、下面的代码会在 console 输出神马?为什么?
(function(){
var a = b = 3;
})();
console.log("a defined? " + (typeof a !== 'undefined'));
console.log("b defined? " + (typeof b !== 'undefined'));
这跟变量作用域有关,输出换成下面的:
console.log(b); //3
console,log(typeof a); //undefined
拆解一下自执行函数中的变量赋值:
b = 3;
var a = b;
所以 b 成了全局变量,而 a 是自执行函数的一个局部变量。
3、下面的代码会在 console 输出神马?为什么?
var myObject = {
foo: "bar",
func: function() {
var self = this;
console.log("outer func: this.foo = " + this.foo);
console.log("outer func: self.foo = " + self.foo);
(function() {
console.log("inner func: this.foo = " + this.foo);
console.log("inner func: self.foo = " + self.foo);
}());
}
};
myObject.func();
第一个和第二个的输出不难判断,在 ES6 之前,JavaScript 只有函数作用域,所以 func 中的 IIFE 有自己的独立作用域,并且它能访问到外部作用域中的 self,所以第三个输出会报错,因为 this 在可访问到的作用域内是 undefined,第四个输出是 bar。如果你知道闭包,也很容易解决的:
(function(test) {
console.log("inner func: this.foo = " + test.foo); //'bar'
console.log("inner func: self.foo = " + self.foo);
}(self));
4、将 JavaScript 代码包含在一个函数块中有神马意思呢?为什么要这么做?
换句话说,为什么要用立即执行函数表达式(Immediately-Invoked Function Expression)。
IIFE 有两个比较经典的使用场景,一是类似于在循环中定时输出数据项,二是类似于 JQuery/Node 的插件和模块开发。
for(var i = 0; i < 5; i++) {
setTimeout(function() {
console.log(i);
}, 1000);
}
上面的输出并不是你以为的0,1,2,3,4,而输出的全部是5,这时 IIFE 就能有用了:
for(var i = 0; i < 5; i++) {
(function(i) {
setTimeout(function() {
console.log(i);
}, 1000);
})(i)
}
而在 JQuery/Node 的插件和模块开发中,为避免变量污染,也是一个大大的 IIFE:
(function($) {
//代码
} )(jQuery);
5、在严格模式('use strict')下进行 JavaScript 开发有神马好处?
6、下面两个函数的返回值是一样的吗?为什么?
function foo1()
{
return {
bar: "hello"
};
}
function foo2()
{
return
{
bar: "hello"
};
}
在编程语言中,基本都是使用分号(;)将语句分隔开,这可以增加代码的可读性和整洁性。而在JS中,如若语句各占独立一行,通常可以省略语句间的分号(;),JS 解析器会根据能否正常编译来决定是否自动填充分号:
var test = 1 +
2
console.log(test); //3
在上述情况下,为了正确解析代码,就不会自动填充分号了,但是对于 return 、break、continue 等语句,如果后面紧跟换行,解析器一定会自动在后面填充分号(;),所以上面的第二个函数就变成了这样:
function foo2()
{
return;
{
bar: "hello"
};
}
所以第二个函数是返回 undefined。
7、神马是 NaN,它的类型是神马?怎么测试一个值是否等于 NaN?
NaN 是 Not a Number 的缩写,JavaScript 的一种特殊数值,其类型是 Number,可以通过 isNaN(param) 来判断一个值是否是 NaN:
console.log(isNaN(NaN)); //true
console.log(isNaN(23)); //false
console.log(isNaN('ds')); //true
console.log(isNaN('32131sdasd')); //true
console.log(NaN === NaN); //false
console.log(NaN === undefined); //false
console.log(undefined === undefined); //false
console.log(typeof NaN); //number
console.log(Object.prototype.toString.call(NaN)); //[object Number]
ES6 中,isNaN() 成为了 Number 的静态方法:Number.isNaN().
8、解释一下下面代码的输出
console.log(0.1 + 0.2); //0.30000000000000004
console.log(0.1 + 0.2 == 0.3); //false
JavaScript 中的 number 类型就是浮点型,JavaScript 中的浮点数采用IEEE-754 格式的规定,这是一种二进制表示法,可以精确地表示分数,比如1/2,1/8,1/1024,每个浮点数占64位。但是,二进制浮点数表示法并不能精确的表示类似0.1这样 的简单的数字,会有舍入误差。
由于采用二进制,JavaScript 也不能有限表示 1/10、1/2 等这样的分数。在二进制中,1/10(0.1)被表示为 0.00110011001100110011…… 注意 0011 是无限重复的,这是舍入误差造成的,所以对于 0.1 + 0.2 这样的运算,操作数会先被转成二进制,然后再计算:
0.1 => 0.0001 1001 1001 1001…(无限循环)
0.2 => 0.0011 0011 0011 0011…(无限循环)
双精度浮点数的小数部分最多支持 52 位,所以两者相加之后得到这么一串 0.0100110011001100110011001100110011001100...因浮点数小数位的限制而截断的二进制数字,这时候,再把它转换为十进制,就成了 0.30000000000000004。
对于保证浮点数计算的正确性,有两种常见方式。
一是先升幂再降幂:
function add(num1, num2){
let r1, r2, m;
r1 = (''+num1).split('.')[1].length;
r2 = (''+num2).split('.')[1].length;
m = Math.pow(10,Math.max(r1,r2));
return (num1 * m + num2 * m) / m;
}
console.log(add(0.1,0.2)); //0.3
console.log(add(0.15,0.2256)); //0.3756
二是是使用内置的 toPrecision() 和 toFixed() 方法,注意,方法的返回值字符串。
function add(x, y) {
return x.toPrecision() + y.toPrecision()
}
console.log(add(0.1,0.2)); //"0.10.2"
9、实现函数 isInteger(x) 来判断 x 是否是整数
可以将 x 转换成10进制,判断和本身是不是相等即可:
function isInteger(x) {
return parseInt(x, 10) === x;
}
ES6 对数值进行了扩展,提供了静态方法 isInteger() 来判断参数是否是整数:
Number.isInteger(25) // true
Number.isInteger(25.0) // true
Number.isInteger(25.1) // false
Number.isInteger("15") // false
Number.isInteger(true) // false
JavaScript能够准确表示的整数范围在 -2^53 到 2^53 之间(不含两个端点),超过这个范围,无法精确表示这个值。ES6 引入了Number.MAX_SAFE_INTEGER 和 Number.MIN_SAFE_INTEGER这两个常量,用来表示这个范围的上下限,并提供了 Number.isSafeInteger() 来判断整数是否是安全型整数。
10、在下面的代码中,数字 1-4 会以什么顺序输出?为什么会这样输出?
(function() {
console.log(1);
setTimeout(function(){console.log(2)}, 1000);
setTimeout(function(){console.log(3)}, 0);
console.log(4);
})();
这个就不多解释了,主要是 JavaScript 的定时机制和时间循环,不要忘了,JavaScript 是单线程的。详解可以参考 从setTimeout谈JavaScript运行机制。
11、写一个少于 80 字符的函数,判断一个字符串是不是回文字符串
function isPalindrome(str) {
str = str.replace(/\W/g, '').toLowerCase();
return (str == str.split('').reverse().join(''));
}
这个题我在 codewars 上碰到过,并收录了一些不错的解决方式,可以戳这里:Palindrome For Your Dome
12、写一个按照下面方式调用都能正常工作的 sum 方法
console.log(sum(2,3)); // Outputs 5
console.log(sum(2)(3)); // Outputs 5
针对这个题,可以判断参数个数来实现:
function sum() {
var fir = arguments[0];
if(arguments.length === 2) {
return arguments[0] + arguments[1]
} else {
return function(sec) {
return fir + sec;
}
}
}
13、根据下面的代码片段回答后面的问题
for (var i = 0; i < 5; i++) {
var btn = document.createElement('button');
btn.appendChild(document.createTextNode('Button ' + i));
btn.addEventListener('click', function(){ console.log(i); });
document.body.appendChild(btn);
}
1、点击 Button 4,会在控制台输出什么?
2、给出一种符合预期的实现方式
1、点击5个按钮中的任意一个,都是输出5
2、参考 IIFE。
14、下面的代码会输出什么?为什么?
var arr1 = "john".split(''); j o h n
var arr2 = arr1.reverse(); n h o j
var arr3 = "jones".split(''); j o n e s
arr2.push(arr3);
console.log("array 1: length=" + arr1.length + " last=" + arr1.slice(-1));
console.log("array 2: length=" + arr2.length + " last=" + arr2.slice(-1));
会输出什么呢?你运行下就知道了,可能会在你的意料之外。
MDN 上对于 reverse() 的描述是酱紫的:
Description
The reverse method transposes the elements of the calling array object in place, mutating the array, and returning a reference to the array.
reverse() 会改变数组本身,并返回原数组的引用。
slice 的用法请参考:slice
15、下面的代码会输出什么?为什么?
console.log(1 + "2" + "2");
console.log(1 + +"2" + "2");
console.log(1 + -"1" + "2");
console.log(+"1" + "1" + "2");
console.log( "A" - "B" + "2");
console.log( "A" - "B" + 2);
输出什么,自己去运行吧,需要注意三个点:
console.log(2 + 1 + '3'); / /‘33’
console.log('3' + 2 + 1); //'321'
console.log(typeof '3'); // string
console.log(typeof +'3'); //number
同样,可以在数字前添加 '',将数字转为字符串
console.log(typeof 3); // number
console.log(typeof (''+3)); //string
NaNconsole.log('a' * 'sd'); //NaN
console.log('A' - 'B'); // NaN
这张图是运算转换的规则
16、如果 list 很大,下面的这段递归代码会造成堆栈溢出。如果在不改变递归模式的前提下修善这段代码?
var list = readHugeList();
var nextListItem = function() {
var item = list.pop();
if (item) {
// process the list item...
nextListItem();
}
};
原文上的解决方式是加个定时器:
var list = readHugeList();
var nextListItem = function() {
var item = list.pop();
if (item) {
// process the list item...
setTimeout( nextListItem, 0);
}
};
解决方式的原理请参考第10题。
17、什么是闭包?举例说明
可以参考此篇:从作用域链谈闭包
18、下面的代码会输出什么?为啥?
for (var i = 0; i < 5; i++) {
setTimeout(function() { console.log(i); }, i * 1000 );
}
请往前面翻,参考第4题,解决方式已经在上面了
19、解释下列代码的输出
console.log("0 || 1 = "+(0 || 1));
console.log("1 || 2 = "+(1 || 2));
console.log("0 && 1 = "+(0 && 1));
console.log("1 && 2 = "+(1 && 2));
逻辑与和逻辑或运算符会返回一个值,并且二者都是短路运算符:
false 的操作数 或者 最后一个是 true的操作数console.log(1 && 2 && 0); //0
console.log(1 && 0 && 1); //0
console.log(1 && 2 && 3); //3
如果某个操作数为 false,则该操作数之后的操作数都不会被计算
true 的操作数 或者 最后一个是 false的操作数console.log(1 || 2 || 0); //1
console.log(0 || 2 || 1); //2
console.log(0 || 0 || false); //false
如果某个操作数为 true,则该操作数之后的操作数都不会被计算
如果逻辑与和逻辑或作混合运算,则逻辑与的优先级高:
console.log(1 && 2 || 0); //2
console.log(0 || 2 && 1); //1
console.log(0 && 2 || 1); //1
在 JavaScript,常见的 false 值:
0, '0', +0, -0, false, '',null,undefined,null,NaN
要注意空数组([])和空对象({}):
console.log([] == false) //true
console.log({} == false) //false
console.log(Boolean([])) //true
console.log(Boolean({})) //true
所以在 if 中,[] 和 {} 都表现为 true:
20、解释下面代码的输出
console.log(false == '0')
console.log(false === '0')
请参考前面第14题运算符转换规则的图。
21、解释下面代码的输出
var a={},
b={key:'b'},
c={key:'c'};
a[b]=123;
a[c]=456;
console.log(a[b]);
输出是 456,参考原文的解释:
The reason for this is as follows: When setting an object property, JavaScript will implicitly stringify the parameter value. In this case, since b and c are both objects, they will both be converted to "[object Object]". As a result, a[b] anda[c] are both equivalent to a["[object Object]"] and can be used interchangeably. Therefore, setting or referencing a[c] is precisely the same as setting or referencing a[b].
22、解释下面代码的输出
console.log((function f(n){return ((n > 1) ? n * f(n-1) : n)})(10));
结果是10的阶乘。这是一个递归调用,为了简化,我初始化 n=5,则调用链和返回链如下:
23、解释下面代码的输出
(function(x) {
return (function(y) {
console.log(x);
})(2)
})(1);
输出1,闭包能够访问外部作用域的变量或参数。
24、解释下面代码的输出,并修复存在的问题
var hero = {
_name: 'John Doe',
getSecretIdentity: function (){
return this._name;
}
};
var stoleSecretIdentity = hero.getSecretIdentity;
console.log(stoleSecretIdentity());
console.log(hero.getSecretIdentity());
将 getSecretIdentity 赋给 stoleSecretIdentity,等价于定义了 stoleSecretIdentity 函数:
var stoleSecretIdentity = function (){
return this._name;
}
stoleSecretIdentity 的上下文是全局环境,所以第一个输出 undefined。若要输出 John Doe,则要通过 call 、apply 和 bind 等方式改变 stoleSecretIdentity 的this 指向(hero)。
第二个是调用对象的方法,输出 John Doe。
25、给你一个 DOM 元素,创建一个能访问该元素所有子元素的函数,并且要将每个子元素传递给指定的回调函数。
函数接受两个参数:
原文利用 深度优先搜索(Depth-First-Search) 给了一个实现:
function Traverse(p_element,p_callback) {
p_callback(p_element);
var list = p_element.children;
for (var i = 0; i < list.length; i++) {
Traverse(list[i],p_callback); // recursive call
}
}
文章参考:
25 Essential JavaScript Interview Questions
JavaScript中的立即执行函数表达式
Javascript 严格模式详解
声明:文中对问题的回答仅代表博主个人观点
如果你正在规划一个新的前端项目或者重构现有的项目,可能就会发现,你已经跟不上前端生态的变化了,因为现在有太多的技术栈供你选择:React、Flux、Angular、Aurelia、Mocha、Jasmine、Babel、TypeScript,、Flow......这些技术栈的出现试图开发变得简单,但有一部分却增加了学习成本和项目维护的不稳定性,因为技术栈的变化速度太快了。
尽管这样,但是好消息是,前端生态的技术栈开始变得稳定了,部分项目进行了合并,技术的最佳实践也越来越清晰了,有人已经开始基于上述的技术栈而不是新框架来规划项目了。
本文主要介绍一些我在 Web 应用中所涉及和推崇的技术,由于一些技术还存在争议,所以基于个人所见和经验,对每一项技术只做简单的介绍和分析。
React 提供了视图和组件层,但还需要某个东西来管理应用的状态和生命周期。Redux 则成为首选。
和 React 一起,Facebook 提供了一种被称为 Flux 的单向数据流设计模式。Flux 基本实现了简化组件状态管理的承诺,但也带来了新的问题,如怎么存储状态、发送 Ajax 请求等。
为了解决上述两个问题,社区产生了大量基于 Flux 模式的框架:Fluxible, Reflux, Alt, Flummox, Lux, Nuclear, Fluxxor 等等。
最终,一个类 flux 的实现成功吸引了社区的注意,它就是 Redux。在 Redux 中,只有一个集中的 store(这个 store 可以由多个组件的子 store 组成) 和资源中心,组件状态的所有变化都由 纯函数 作控制,Reducer 则负责维护组成 store 的数据。相比 Flux 来说,Redux 的数据流向和控制更加清晰。
可以抛弃 CoffeeScript,因为 ES6 拥有了它的大多数优良特性,而作为标准,ES6 已经被大多数新版本的浏览器支持。Babel 则能将 ES6 转为 ES5 ,让 Web 应用能得到更多稍低版本浏览器的支持。TypeScript 和 Flow 都为 JavaScript 提供了静态类型系统,使用静态类型检查,可以有效捕获错误,减少测试工作量。
ESLint 不仅是一个代码检查工具,还完美支持 ES6,并提供了 React 插件。JSLint 已经过时,ESLint 是可以取代 JSHint 和 JSCS 的组合的工具。
你可以按照你的代码风格来配置 ESLint,而我则强烈推荐 Airbnb 的 JavaScript 开发规范,而这规范中的大部分能通过 ESLint airbnb config 强制执行。
现在应该用 npm 来接管 web 应用的一切!类似 Browserify 和 Webpack 的构建工具为 NPM 在 Web 领域注入了强大的动力。NPM 使应用的版本管理变得非常容易,也将更多地与 Node.js 生态系统接触,但目前 NPM 对于 CSS 的处理尚不足够完善。
使用 npm时,可能需要考虑怎么在应用要部署的服务器上处理构建问题。与 Ruby 的 Bundler 不同,对于依赖的版本,npm 是通过通配符来管理,并且依赖包可以在你完成编码和开始部署之间的任何时刻被改变,但能通过 shrinkwrap 来冻结依赖(建议使用 Uber 的 shrinkwrap 来获取更好的一致性输出),也可以使用类似 Sinopia 的工具来托管自己的私有 npm 服务器。
除非你喜欢在页面添加数百个脚本标签,否则,你需要使用构建工具来打包页面资源。此外,还需要某些工具让浏览器支持 NPM 包。这就是 Webpack 应该干的事:
相对于 Gulp or Grunt,Webpack 能更好地处理各种资源,但 Gulp or Grunt 在执行其它类型的构建任务时还是很有用的。对于基本任务(如 运行 webpack 或者 eslint),推荐使用 NPM Script
对于 JavaScript 的单元测试,有很多框架可以选择,如 Jasmine,Mocha,Tape,AVA 和 Jest,我个人对于测试框架有如下要求:
第一条标准就排除了 Ava 和 Jest。
我个人喜欢断言库 Chai(插件丰富)和 Mocha(对异步支持友好) 。此外,推荐使用 Chai as promise 和 Dirty Chai 来避免一些不必要的问题。Webpack 的 mocha-leader 插件允许开发者自动执行测试。
对于 React 而言,开发者可以参考一下 Airbnb 的 Enzyme 和 Teaspoon。
JavaScript 不像 Java 或者 .NET 有自身的核心工具库,因而开发者都需要从外面引入工具库。Lodash 就是一个功能非常齐全的工具库,并且由于惰性执行 等特性,其性能很优越。此外,Lodash 支持开发按需引用资源。在 4.x 版本中,Lodash 为偏爱函数式编程的开发者提供了一个“函数式开发”模式。
许多基于 React 的应用已经不需要 jQuery 了,除非是接收一个旧有项目或者第三库依赖 jQuery,否则就找不到使用 jQuery 的理由了,也以为能取代 $.ajax 了。
Fetch 基于 promise,使用 fetch 能使项目保持简单,但目前只有 Firefox 和 Chrome 支持,对于其他浏览器,需要引入 polyfill,个人推荐使用 isomorphic-fetch 来确保能覆盖各浏览器端,也包括服务端。
关于更多为什么 promise 很重要的细节,可以戳: asynchronous programming
CSS 模块化是比较滞后的领域,SASS 目前朝着这个方向发展。在 JavaScript 项目中,node-sass 是实现 CSS 模块化的一种不错的方式,它是一个会和 Node 版本保持同步更新的 C 语言库。
目前的 CSS 模块化方案缺少一些最佳实践,如引用导入(reference import)和本地 URL 重写(native URL rewriting)。LESS 是不错的 CSS 预处理器,但由于缺少 SASS 的许多功能而不受追捧。PostCSS 是很有希望实现 CSS 模块化的。CSS 模块 是一件值得考虑的事情,它会阻止 CSS 的部分“重叠”和冲突,保持 CSS 代码的干净和独立性,不用担心类名会被覆盖或者必须为类名指定“非常明确”的名称。
通用或同构的 JavaScript 是指能同时运行在客户端和服务端。出于性能考虑和 SEO 的目的,JavaScript 同构最初用于服务端的预渲染。使用 React 可以实现同构 JavaScript,但是并不简单,它提高了程序的复杂度,限制了开发者可选的工具和第三方库。
如果你正在构建一个 B2C(Business to Customer) 网站,如电商网站,可以考虑 JavaScript 同构,因为除了去到指定路由别无选择,对于内部网站或 B2B(Business to Business) 应用,性能就显得不重要了。
最近,总有人问要怎么去设计 API,每个人都钻进了 RESTFul API 的“万花筒“,认为 SOAP 过时了。在业界有很多关于 API 设计的协议和规范,如 HATEOAS,JSON API,HAL,GraphQL 等。
GraphQL 赋予了客户端进行任意查询的能力。搭配 Relay,可以更好地处理客户端的状态和缓存。不过,创建 GraphQL 的服务端接口的难度还较大,且大多数的文档都是面向 Node.js 的。
尽管业界有诸多协议,但我并不认为有一个完美的解决方案,对 API 设计,我有自己的认知:
如果你正在使用 RESTful,可以参考 Swagger 文档来编写 API。
Electron 是 Atom 编辑器的基础,能够使用前端技术来构建桌面应用,其核心就是能在 Chrome 窗口中渲染 GUI 的 Node.js。Electron 可以操作系统本地 API,并且不受浏览器的沙盒安全限制。跟其它桌面应用一样,Electron 能帮开发者完成应用的打包、发布、安装和自动更新,这是创建跨平台软件最简单的方式,并且 Electron 有完整的文档和活跃的开发社区。
尽管 nw.js 已经存在多年,但是 Electron 比它更稳定和易于使用。
文章最后,提供一个基于 Electron、React 和热加载的 demo:Boilerplate。
本文参照 @Francois Ward 的文章翻译,有增删)
在客户端(浏览器端)存储数据有诸多益处,最主要的一点是能快速访问(网页)数据。(以往)在客户端有五种数据存储方法,而目前就只有四种常用方法了(其中一种被废弃了):
Cookies 是一种在文档内存储字符串数据最典型的方式。一般而言,cookies 会由服务端发送给客户端,客户端存储下来,然后在随后让请求中再发回给服务端。这可以用于诸如管理用户会话,追踪用户信息等事情。
此外,客户端也用使用 cookies 存储数据。因而,cookies 常被用于存储一些通用的数据,如用户的首选项设置。
通过下面的语法,我们可以创建,读取,更新和删除 cookies:
// Create
document.cookie = "user_name=Ire Aderinokun";
document.cookie = "user_age=25;max-age=31536000;secure";
// Read (All)
console.log( document.cookie );
// Update
document.cookie = "user_age=24;max-age=31536000;secure";
// Delete
document.cookie = "user_name=Ire Aderinokun;expires=Thu, 01 Jan 1970 00:00:01 GMT";
所有主流浏览器均支持 Cookies.
Local Storage 是 Web Storage API 的一种类型,能在浏览器端存储键值对数据。Local Storage 因提供了更直观和安全的API来存储简单的数据,被视为替代 Cookies 的一种解决方案。
从技术上说,尽管 Local Storage 只能存储字符串,但是它也是可以存储字符串化的JSON数据。这就意味着,Local Storage 能比 Cookies 存储更复杂的数据。
通过下面的语法,我们可以创建,读取,更新和删除 Local Storage:
// Create
const user = { name: 'Ire Aderinokun', age: 25 }
localStorage.setItem('user', JSON.stringify(user));
// Read (Single)
console.log( JSON.parse(localStorage.getItem('user')) )
// Update
const updatedUser = { name: 'Ire Aderinokun', age: 24 }
localStorage.setItem('user', JSON.stringify(updatedUser));
// Delete
localStorage.removeItem('user');
相比于Cookies:
localStorage.setItem('test',1);
console.log(typeof localStorage.getItem('test')) //"string"
localStorage.setItem('test2',[1,2,3]);
console.log(typeof localStorage.getItem('test2')) //"string"
console.log(localStorage.getItem('test2')) //"1,2,3"
localStorage.setItem('test3',{a:1,b:2});
console.log(typeof localStorage.getItem('test3')) //"string"
console.log(localStorage.getItem('test3')) //"[object object]"
//为避免存取数据不一致的情形,存储复合数据类型时进行序列化,读取时进行反序列化
localStorage.setItem('test4', JSON.stringify({a:1,b:2}));
console.log(typeof localStorage.getItem('test4')) //"string"
console.log(JSON.parse(localStorage.getItem('test4'))) //{a:1,b:2}
IE8+/Edge/Firefox 2+/Chrome/Safari 4+/Opera 11.5+(caniuse)
Session Storage 是 Web Storage API 的另一种类型。和 Local Storage 非常类似,区别是 Session Storage 只存储当前会话页(tab页)的数据,一旦用户关闭当前页或者浏览器,数据就自动被清除掉了。
通过下面的语法,我们可以创建,读取,更新和删除 Session Storage:
// Create
const user = { name: 'Ire Aderinokun', age: 25 }
sessionStorage.setItem('user', JSON.stringify(user));
// Read (Single)
console.log( JSON.parse(sessionStorage.getItem('user')) )
// Update
const updatedUser = { name: 'Ire Aderinokun', age: 24 }
sessionStorage.setItem('user', JSON.stringify(updatedUser));
// Delete
sessionStorage.removeItem('user');
和 Local Storage 一样
IndexedDB 是一种更复杂和全面地客户端数据存储方案,它是基于 JavaScript、面向对象的和数据库的,能非常容易地存储数据和检索已经建立关键字索引的数据。
在构建渐进式Web应用一文中,我已经介绍了怎么使用 IndexedDB 来创建一个离线优先的应用。
注:在示例中,我使用了 Jake's Archibald 的 IndexedDB Promised library, 它提供了 Promise 风格的IndexedDB方法
使用 IndexedDB 在浏览器端存储数据比上述其它方法更复杂。在我们能创建/读取/更新/删除任何数据之前,首先需要先打开数据库,创建我们需要的stores(类似于在数据库中创建一个表)。
function OpenIDB() {
return idb.open('SampleDB', 1, function(upgradeDb) {
const users = upgradeDb.createObjectStore('users', {
keyPath: 'name'
});
});
}
创建或者更新store中的数据:
// 1. Open up the database
OpenIDB().then((db) => {
const dbStore = 'users';
// 2. Open a new read/write transaction with the store within the database
const transaction = db.transaction(dbStore, 'readwrite');
const store = transaction.objectStore(dbStore);
// 3. Add the data to the store
store.put({
name: 'Ire Aderinokun',
age: 25
});
// 4. Complete the transaction
return transaction.complete;
});
检索数据:
// 1. Open up the database
OpenIDB().then((db) => {
const dbStore = 'users';
// 2. Open a new read-only transaction with the store within the database
const transaction = db.transaction(dbStore);
const store = transaction.objectStore(dbStore);
// 3. Return the data
return store.get('Ire Aderinokun');
}).then((item) => {
console.log(item);
})
删除数据:
// 1. Open up the database
OpenIDB().then((db) => {
const dbStore = 'users';
// 2. Open a new read/write transaction with the store within the database
const transaction = db.transaction(dbStore, 'readwrite');
const store = transaction.objectStore(dbStore);
// 3. Delete the data corresponding to the passed key
store.delete('Ire Aderinokun');
// 4. Complete the transaction
return transaction.complete;
})
如果你有兴趣了解更多关于IndexedDB的使用,可以阅读我的这篇关于怎么在渐进式Web应用(PWA)使用IndexedD。
IE10+/Edge12+/Firefox 4+/Chrome 11+/Safari 7.1+/Opera 15+(caniuse)
| Feature | Cookies | Local Storage | Session Storage | IndexedDB |
|---|---|---|---|---|
| Storage Limit | ~4KB | ~5MB | ~5MB | Up to half of hard drive |
| Persistent Data? | Yes | Yes | No | Yes |
| Data Value Type | String | String | String | Any structured data |
| Indexable ? | No | No | No | Yes |
sdasd
React自发布以来吸引了越来越多的开发者,React开发和模块管理的主流工具webpack也被大家所熟知。那么webpack有哪些优势,可以成为最主流的React开发工具呢?
CommonJS和AMD是用于JavaScript模块管理的两大规范,前者定义的是模块的同步加载,主要用于NodeJS;而后者则是异步加载,通过requirejs等工具适用于前端。随着npm成为主流的JavaScript组件发布平台,越来越多的前端项目也依赖于npm上的项目,或者自身就会发布到npm平台。因此,让前端项目更方便的使用npm上的资源成为一大需求。
web开发中常用到的静态资源主要有JavaScript、CSS、图片、Jade等文件,webpack中将静态资源文件称之为模块。webpack是一个module bundler(模块打包工具),其可以兼容多种js书写规范,且可以处理模块间的依赖关系,具有更强大的js模块化的功能。Webpack对它们进行统一的管理以及打包发布,其官方主页用下面这张图来说明Webpack的作用:
Webpack具有requireJs和browserify的功能,但仍有很多自己的新特性:
1. 对 CommonJS 、 AMD 、ES6的语法做了兼容
2. 对js、css、图片等资源文件都支持打包
3. 串联式模块加载器以及插件机制,让其具有更好的灵活性和扩展性,例如提供对CoffeeScript、ES6的支持
4. 有独立的配置文件webpack.config.js
5. 可以将代码切割成不同的chunk,实现按需加载,降低了初始化时间
6. 支持 SourceUrls 和 SourceMaps,易于调试
7. 具有强大的Plugin接口,大多是内部插件,使用起来比较灵活
8.webpack 使用异步 IO 并具有多级缓存。这使得 webpack 很快且在增量编译上更加快
以 react-sample 为例,简单说明 Webpack 如何打包一个 React 组件,其目录结构如下:
其中Hello.js定义了一个简单的React组件,使用ES6语法:
/**
* Created by pomy on 15/11/4.
*/
import React, {Component} from 'react';
class Hello extends Component {
render(){
return (
<div>Hello, {this.props.name}!</div>
);
}
}
entry.js是入口文件,将一个Hello组件输出到界面:
/**
* Created by pomy on 15/11/4.
*/
import React from 'react';
import Hello from './hello';
React.render(<Hello name="Nate" />, document.body);
index.html的内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>React Sample</title>
</head>
<body>
<script src="./assets/bundle.js"></script>
</body>
</html>
webpack.config.js文件通常放在项目的根目录中,它本身也是一个标准的Commonjs规范的模块:
var path = require('path');
module.exports = {
entry: path.resolve(__dirname, './src/entry.js'),
output: {
path: path.resolve(__dirname, './assets'),
filename: 'bundle.js'
},
module: {
loaders: [
{ test: /\.js?$/, loaders: ['babel'], exclude: /node_modules/ },
{ test: /\.js$/, loader: 'babel-loader', exclude: /node_modules/}
]
},
resolve:{
extensions:['','.js','.json']
},
};
整个代码在 这里,clone之后,切换到react-sample目录下,在终端运行 npm i && npm run build 进行打包,打包后的文件名是 bundle.js, 所在相对目录是 /assets。至此,webpack打包过程就ok了。
webpack 可以作为全局的npm模块安装,也可以在当前项目中安装。
npm install -g webpack
npm install --save-dev webpack
对于全局安装的webpack,直接执行此命令会默认使用当前目录的webpack.config.js作为配置文件。如果要指定另外的配置文件,可以执行:
webpack —config webpack.custom.config.js
每个项目下都必须配置有一个 webpack.config.js ,它的作用如同常规的 gulpfile.js/Gruntfile.js ,就是一个配置项,告诉 webpack 它需要做什么。
前文说了,webpack.config.js文件通常放在项目的根目录中,它本身也是一个标准的Commonjs规范的模块。在导出的配置对象中有几个关键的参数:
entry
entry 参数定义了打包后的入口文件,可以是个字符串或数组或者是对象;如果是数组,数组中的所有文件会打包生成一个filename文件;如果是对象,可以将不同的文件构建成不同的文件:
{
entry: {
page1: "./page1",
//支持数组形式,将加载数组中的所有模块,但以最后一个模块作为输出
page2: ["./entry1", "./entry2"]
},
output: {
path: "dist/js/page",
publicPath: "/output/",
filename: "[name].bundle.js"
}
}
该段代码最终会生成一个 page1.bundle.js 和 page2.bundle.js,并存放到 ./dist/js/page 文件夹下
output
output参数是个对象,定义了输出文件的位置及名字:
output: {
path: "dist/js/page",
publicPath: "/output/",
filename: "[name].bundle.js"
}
path: 打包文件存放的绝对路径
publicPath: 网站运行时的访问路径
filename:打包后的文件名
当我们在entry中定义构建多个文件时,filename可以对应的更改为[name].js用于定义不同文件构建后的名字。
module
在webpack中JavaScript,CSS,LESS,TypeScript,JSX,CoffeeScript,图片等静态文件都是模块,不同模块的加载是通过模块加载器(webpack-loader)来统一管理的。loaders之间是可以串联的,一个加载器的输出可以作为下一个加载器的输入,最终返回到JavaScript上:
module: {
//加载器配置
loaders: [
//.css 文件使用 style-loader 和 css-loader 来处理
{ test: /\.css$/, loader: 'style-loader!css-loader' },
//.js 文件使用 jsx-loader 来编译处理
{ test: /\.js$/, loader: 'jsx-loader?harmony' },
//.scss 文件使用 style-loader、css-loader 和 sass-loader 来编译处理
{ test: /\.scss$/, loader: 'style!css!sass?sourceMap'},
//图片文件使用 url-loader 来处理,小于8kb的直接转为base64
{ test: /\.(png|jpg)$/, loader: 'url-loader?limit=8192'}
]
}
test 项表示匹配的资源类型,loader或loaders 项表示用来加载这种类型的资源的loader,loader的使用可以参考 using loaders,更多的loader可以参考 list of loaders。
! 用来定义loader的串联关系,”-loader”是可以省略不写的,多个loader之间用“!”连接起来,但所有的加载器都需要通过npm来加载。
此外,还可以添加用来定义png、jpg这样的图片资源在小于10k时自动处理为base64图片的加载器:
{
test: /\.(png|jpg)$/,
loader: 'url-loader?limit=10000'
}
给css和less还有图片添加了loader之后,我们不仅可以像在node中那样require js文件了,我们还可以require css、less甚至图片文件:
require('./bootstrap.css');
require('./myapp.less');
var img = document.createElement('img');
img.src = require('./glyph.png');
注意,require()还支持在资源path前面指定loader,即require(![loaders list]![source path])形式:
require("!style!css!less!bootstrap/less/bootstrap.less");
// “bootstrap.less”这个资源会先被"less-loader"处理,
// 其结果又会被"css-loader"处理,接着是"style-loader"
// 可类比pipe操作
require() 时指定的loader会覆盖配置文件里对应的loader配置项。
resolve
webpack在构建包的时候会按目录的进行文件的查找,resolve属性中的extensions数组中用于配置程序可以自行补全哪些文件后缀:
resolve: {
//查找module的话从这里开始查找
root: '/pomy/github/flux-example/src', //绝对路径
//自动扩展文件后缀名,意味着我们require模块可以省略不写后缀名
extensions: ['', '.js', '.json', '.scss'],
//模块别名定义,方便后续直接引用别名,无须多写长长的地址
alias: {
AppStore : 'js/stores/AppStores.js',//后续直接 require('AppStore') 即可
ActionType : 'js/actions/ActionType.js',
AppAction : 'js/actions/AppAction.js'
}
}
然后我们想要加载一个js文件时,只要 require(‘common’)就可以加载common.js文件了。
注意一下, extensions 第一个是空字符串 ! 对应不需要后缀的情况.
plugin
webpack提供了[丰富的组件]用来满足不同的需求,当然我们也可以自行实现一个组件来满足自己的需求:
plugins: [
//your plugins list
]
在webpack中编写js文件时,可以通过require的方式引入其他的静态资源,可通过loader对文件自动解析并打包文件。通常会将js文件打包合并,css文件会在页面的header中嵌入style的方式载入页面。但开发过程中我们并不想将样式打在脚本中,最好可以独立生成css文件,以外链的形式加载。这时extract-text-webpack-plugin插件可以帮我们达到想要的效果。需要使用npm的方式加载插件,然后参见下面的配置,就可以将js中的css文件提取,并以指定的文件名来进行加载。
npm install extract-text-webpack-plugin –save-dev
plugins: [
new ExtractTextPlugin('styles.css')
]
externals
当我们想在项目中require一些其他的类库或者API,而又不想让这些类库的源码被构建到运行时文件中,这在实际开发中很有必要。此时我们就可以通过配置externals参数来解决这个问题:
externals: {
"jquery": "jQuery"
}
这样我们就可以放心的在项目中使用这些API了:var jQuery = require(“jquery”);
context
当我们在require一个模块的时候,如果在require中包含变量,像这样:
require("./mods/" + name + ".js");
那么在编译的时候我们是不能知道具体的模块的。但这个时候,webpack也会为我们做些分析工作:
于是这个时候为了更好地配合wenpack进行编译,我们可以给它指明路径,像在cake-webpack-config中所做的那样(我们在这里先忽略abcoption的作用):
var currentBase = process.cwd();
var context = abcOptions.options.context ? abcOptions.options.context :
path.isAbsolute(entryDir) ? entryDir : path.join(currentBase, entryDir);
关于 webpack.config.js 更详尽的配置可以参考 这里
webpack的使用通常有三种方式:
1、命令行使用:webpack 其中entry.js是入口文件,result.js是打包后的输出文件
2、node.js API使用:
var webpack = require('webpack');
webpack({
//configuration
}, function(err, stats){});
3、默认使用当前目录的 webpack.config.js 作为配置文件。如果要指定另外的配置文件,可以执行:webpack –config webpack.custom.config.js
webpack 的执行也很简单,直接执行
webpack --display-error-details
webpack的使用和browserify有些类似,下面列举几个常用命令:
webpack 最基本的启动webpack命令
webpack -w 提供watch方法,实时进行打包更新
webpack -p 对打包后的文件进行压缩
webpack -d 提供SourceMaps,方便调试
webpack --colors 输出结果带彩色,比如:会用红色显示耗时较长的步骤
webpack --profile 输出性能数据,可以看到每一步的耗时
webpack --display-modules 默认情况下 node_modules 下的模块会被隐藏,加上这个参数可以显示这些被隐藏的模块
React Webpack Cookbook
基于webpack的前端工程化探索
深入浅出React(二):React开发神器Webpack
webpack入门
webpack-howto
webpack docs
webpack优化基本篇
在之前的两篇关于构建模块化的文章中,谈到了 rem & em 和 响应式排版,而在文章的评论中,对基于视口单位的网页排版抱有很大的想象空间。
由于视口单位涉及到计算,有一段时间我是抵制在工作使用视口单位。但就在上周,我克服了心中的抵制情绪,开始去了解视口单位在网页排版中的使用。在深入介绍视口单位以及其在网页排版中的工作原理时,先了解下有哪些常见的视口单位。
在 CSS 规范中,有4种类型的可用视口单位:
vw --- 1vw 等于视口宽度的 1%vh --- 1vh 等于视口高度的 1%vmin --- vw 和 vh 中的较小值vmax --- vw 和 vh 中的较大值视口,即浏览器屏幕大小,1vw 等于浏览器宽度的 1%,100vw 即整个浏览器的宽度。
视口的单位大小会根据视口大小的改变自动计算,视口大小的改变常发生于页面加载、页面缩放或者屏幕方向的改变(横纵切换)。正因为如此,创建一个大小总为视口四分之一大小的容器是非常容易滴:
.component {
width: 50vw;
height: 50vh;
background: rgba(255, 0, 0, 0.25)
}
将视口单位用于网页排版的唯一理由就是视口的单位大小会根据客户端浏览器的视口大小自动计算。也就是说,我们不必明确地通过媒体查询来声明字体大小。举个demo来简要说明一下。
代码如下,将断点设置为 800px,字体大小从 16px 变为 20px:
// Note: CSS are all written in SCSS
html {
font-size: 16px;
@media (min-width: 800px) {
font-size: 20px;
}
}
对于上述代码,当视口大小是 800px 时,字体会从 16px "突变" 到 20px。在响应式排版中,这是经常采用的方式。有时,你会碰到在两个断点之间添加额外的媒体查询来确保页面排版适应所有设备:
html {
font-size: 16px;
@media (min-width: 600px) {
font-size: 18px;
}
@media (min-width: 800px) {
font-size: 20px;
}
}
尽管这样做能达到效果,但需要更多特定的媒体查询规则和字体大小。通常,会选择 3~4 中字体大小。
但是,如何不同媒体查询或字体大小的设置来达到同样的效果呢?
当然是有滴,这就是视口单位的用处了。你可以用视口单位来表示字体大小:
html { font-size: 3vw; }
是不是很棒?一段简短的代码就实现了适配。但也有明显的缺点,就是视口的单位大小是根据设备屏幕的视口大小计算的,对于小屏幕设备(如宽度 320px 的手机),字体太小,难以阅读;对于大屏幕设备(如宽度 1440px 的笔记本),字体会变的非常大,同样也会难以阅读。
所以,现在面临的一个有意思的挑战是---怎么解决不同设备的视口宽度对视口单位计算的影响?一种简单地方式是设置 font-size 的最小值,然后通过 calc() 属性来动态计算小屏幕设备上的字体大小值:
html { font-size: calc(18px + 0.25vw) }
参考 Mike Riethmuller 的 Precise control over responsive typography
但是,不是所有的浏览器都支持 calc() 的这种计算方式(px+vw)。解决方式也很简单,结合使用百分比和 vw 用于 calc 计算能获得更好地浏览器支持:
html { font-size: calc(112.5% + 0.5vw) }
下一个需要克服的挑战就是用视口单位来设置排版元素(h1-h6)的字体大小。
首先,我创建一个 <h1> 元素,将其字体大小设置为body 的两倍:
html { font-size: calc(112.5% + 0.25vw) }
h1 { font-size: calc((112.5% + 0.25vw) * 2); }
我试图将 html 元素的字体大小乘以2,但并不可行,对于 <h1>,字体大小是基于百分比计算的。在字体大小继承了 <html> 的大小之后,又重新计算了 <h1> 的字体大小。
现在假设视口宽度是 800px,默认的 font-size 是 16px:
html 元素,112.5% 意味着 font-size 是 18px(112.5/100 * 16px)html 的 font-size 的最终值是 20px(18px + 2px)按照同样的方法来计算 h1 元素的 font-size,但需要特别注意的是此时百分比(112.5%)的相对计算量值:
h1 元素,112.5% 意味着 font-size 是 22.5px(112.5/100 * 20px)h1 的 font-size 的最终值是 49px((22.5px + 2px) * 2)这与最初想把 h1 元素的 font-size 设置成 Body 的两倍大小的想法相违背。但我们知道了造成差异的原因是由于 h1 继承了 html 的 font-size,有两种方式来解决这个问题。
第一种方式就简单滴将 112.5% 改为 100%:
h1 { font-size: calc((100% + 0.25vw) * 2) }
第二种方式是确保 font-size 不被跨元素继承:
h1 { font-size: calc((100% + 0.25vw) * 2) }
p { font-size: calc((100% + 0.25vw)) }
这两种方式看起来有点 hack,看起来不爽,于是又继续尝试其它方法。最终,最干净的方式是使用 Rem & Em:
html { font-size: calc(112.5% + 0.25vw) }
h1 { font-size: 2em; }
既然讲到了字体大小的计算,那接下来的问题是:"视口单位的垂直和标准化计算是怎么样的?"
这个相对比较容易回答。不知是否注意到,视口单位常仅被用于 html 元素?其它元素仍用 rem 和 em 作为计算的单位。
这就意味着,你仍然能使用 rem 和 em 用于视口单位的垂直和标准化计算,这和我之前在 Everything I Know about Responsive Typography 一文中讨论的一样。
结束这篇文章之前,最后一个需要谈到的问题是:要怎么样去计算 vw 的值,才能在视口宽度是 800px 时,排版的字体大小为 20px?很多人问到了这个问题,因而,将这个问题简化成一个词就是---精确。换句话说,如何才能字体大小更加精确?
结果是,Mike 已经替我解决了这个问题,我只需要再简单解释下计算方式。
假设你要处理下面两种情况:
**首先,我们必须将较小的 font-size 值转为百分比。**第一部计算是:calc(18/16 * 100%) (或者 calc(112.5%))。**接下来,计算出 vw 值。**这部分的计算略繁琐:
最终,结果如下:
html {
font-size: calc(112.5% + 4 / 400 * (100vw - 600px) )
}
开始接触可能会比较复杂,但是熟悉之后,你可以把它简化成 Sass 混入(simple sass mixin)。
有时我们会忽略错误处理和堆栈追踪的一些细节, 但是这些细节对于写与测试或错误处理相关的库来说是非常有用的. 例如这周, 对于 Chai 就有一个非常棒的PR, 该PR极大地改善了我们处理堆栈的方式, 当用户的断言失败的时候, 我们会给予更多的提示信息(帮助用户进行定位).
合理地处理堆栈信息能使你清除无用的数据, 而只专注于有用的数据. 同时, 当更好地理解 Errors 对象及其相关属性之后, 能有助于你更充分地利用 Errors.
在谈论错误之前, 先要了解下(函数的)调用栈的原理:
当有一个函数被调用的时候, 它就被压入到堆栈的顶部, 该函数运行完成之后, 又会从堆栈的顶部被移除.
堆栈的数据结构就是后进先出, 以 LIFO (last in, first out) 著称.
例如:
function c() {
console.log('c');
}
function b() {
console.log('b');
c();
}
function a() {
console.log('a');
b();
}
a();
在上述的示例中, 当函数 a 运行时, 其会被添加到堆栈的顶部. 然后, 当函数 b 在函数 a 的内部被调用时, 函数 b 会被压入到堆栈的顶部. 当函数 c 在函数 b 的内部被调用时也会被压入到堆栈的顶部.
当函数 c 运行时, 堆栈中就包含了 a, b 和 c(按此顺序).
当函数 c 运行完毕之后, 就会从堆栈的顶部被移除, 然后函数调用的控制流就回到函数 b. 函数 b 运行完之后, 也会从堆栈的顶部被移除, 然后函数调用的控制流就回到函数 a. 最后, 函数 a 运行完成之后也会从堆栈的顶部被移除.
为了更好地在demo中演示堆栈的行为, 可以使用 console.trace() 在控制台输出当前的堆栈数据. 同时, 你要以从上至下的顺序阅读输出的堆栈数据.
function c() {
console.log('c');
console.trace();
}
function b() {
console.log('b');
c();
}
function a() {
console.log('a');
b();
}
a();
在 Node 的 REPL 模式中运行上述代码会得到如下输出:
Trace
at c (repl:3:9)
at b (repl:3:1)
at a (repl:3:1)
at repl:1:1 // <-- For now feel free to ignore anything below this point, these are Node's internals
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
正如所看到的, 当从函数 c 中输出时, 堆栈中包含了函数 a, b 以及c.
如果在函数 c 运行完成之后, 在函数 b 中输出当前的堆栈数据, 就会看到函数 c 已经从堆栈的顶部被移除, 此时堆栈中仅包括函数 a 和 b.
function c() {
console.log('c');
}
function b() {
console.log('b');
c();
console.trace();
}
function a() {
console.log('a');
b();
}
正如所看到的, 函数 c 运行完成之后, 已经从堆栈的顶部被移除.
Trace
at b (repl:4:9)
at a (repl:3:1)
at repl:1:1 // <-- For now feel free to ignore anything below this point, these are Node's internals
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:513:10)
当程序运行出现错误时, 通常会抛出一个 Error 对象. Error 对象可以作为用户自定义错误对象继承的原型.
Error.prototype 对象包含如下属性:
constructor--指向实例的构造函数message--错误信息name--错误的名字(类型)上述是 Error.prototype 的标准属性, 此外, 不同的运行环境都有其特定的属性. 在例如 Node, Firefox, Chrome, Edge, IE 10+, Opera 以及 Safari 6+ 这样的环境中, Error 对象具备 stack 属性, 该属性包含了错误的堆栈轨迹. 一个错误实例的堆栈轨迹包含了自构造函数之后的所有堆栈结构.
如果想了解更多关于 Error 对象的特定属性, 可以阅读 MDN 上的这篇文章.
为了抛出一个错误, 必须使用 throw 关键字. 为了 catch 一个抛出的错误, 必须使用 try...catch 包含可能跑出错误的代码. Catch的参数是被跑出的错误实例.
如 Java 一样, JavaScript 也允许在 try/catch 之后使用 finally 关键字. 在处理完错误之后, 可以在 finally 语句块作一些清除工作.
在语法上, 你可以使用 try 语句块而其后不必跟着 catch 语句块, 但必须跟着 finally 语句块. 这意味着有三种不同的 try 语句形式:
try...catchtry...finallytry...catch...finallyTry语句内还可以在嵌入 try 语句:
try {
try {
throw new Error('Nested error.'); // The error thrown here will be caught by its own `catch` clause
} catch (nestedErr) {
console.log('Nested catch'); // This runs
}
} catch (err) {
console.log('This will not run.');
}
也可以在 catch 或 finally 中嵌入 try 语句:
try {
throw new Error('First error');
} catch (err) {
console.log('First catch running');
try {
throw new Error('Second error');
} catch (nestedErr) {
console.log('Second catch running.');
}
}
try {
console.log('The try block is running...');
} finally {
try {
throw new Error('Error inside finally.');
} catch (err) {
console.log('Caught an error inside the finally block.');
}
}
需要重点说明一下的是在抛出错误时, 可以只抛出一个简单值而不是 Error 对象. 尽管这看起来看酷并且是允许的, 但这并不是一个推荐的做法, 尤其是对于一些需要处理他人代码的库和框架的开发者, 因为没有标准可以参考, 也无法得知会从用户那里得到什么. 你不能信任用户会抛出 Error 对象, 因为他们可能不会这么做, 而是简单的抛出一个字符串或者数值. 这也意味着很难去处理堆栈信息和其它元信息.
例如:
function runWithoutThrowing(func) {
try {
func();
} catch (e) {
console.log('There was an error, but I will not throw it.');
console.log('The error\'s message was: ' + e.message)
}
}
function funcThatThrowsError() {
throw new TypeError('I am a TypeError.');
}
runWithoutThrowing(funcThatThrowsError);
如果用户传递给函数 runWithoutThrowing 的参数抛出了一个错误对象, 上面的代码能正常捕获错误. 然后, 如果是抛出一个字符串, 就会碰到一些问题了:
function runWithoutThrowing(func) {
try {
func();
} catch (e) {
console.log('There was an error, but I will not throw it.');
console.log('The error\'s message was: ' + e.message)
}
}
function funcThatThrowsString() {
throw 'I am a String.';
}
runWithoutThrowing(funcThatThrowsString);
现在第二个 console.log 会输出undefined. 这看起来不是很重要, 但如果你需要确保 Error 对象有一个特定的属性或者用另一种方式来处理 Error 对象的特定属性(例如 Chai的throws断言的做法), 你就得做大量的工作来确保程序的正确运行.
同时, 如果抛出的不是 Error 对象, 也就获取不到 stack 属性.
Errors 也可以被作为其它对象, 你也不必抛出它们, 这也是为什么大多数回调函数把 Errors 作为第一个参数的原因. 例如:
const fs = require('fs');
fs.readdir('/example/i-do-not-exist', function callback(err, dirs) {
if (err instanceof Error) {
// `readdir` will throw an error because that directory does not exist
// We will now be able to use the error object passed by it in our callback function
console.log('Error Message: ' + err.message);
console.log('See? We can use Errors without using try statements.');
} else {
console.log(dirs);
}
});
最后, Error 对象也可以用于 rejected promise, 这使得很容易处理 rejected promise:
new Promise(function(resolve, reject) {
reject(new Error('The promise was rejected.'));
}).then(function() {
console.log('I am an error.');
}).catch(function(err) {
if (err instanceof Error) {
console.log('The promise was rejected with an error.');
console.log('Error Message: ' + err.message);
}
});
这一节是针对支持 Error.captureStackTrace的运行环境, 例如Nodejs.
Error.captureStackTrace 的第一个参数是 object, 第二个可选参数是一个 function. Error.captureStackTrace 会捕获堆栈信息, 并在第一个参数中创建 stack 属性来存储捕获到的堆栈信息. 如果提供了第二个参数, 该函数将作为堆栈调用的终点. 因此, 捕获到的堆栈信息将只显示该函数调用之前的信息.
用下面的两个demo来解释一下. 第一个, 仅将捕获到的堆栈信息存于一个普通的对象之中:
const myObj = {};
function c() {
}
function b() {
// Here we will store the current stack trace into myObj
Error.captureStackTrace(myObj);
c();
}
function a() {
b();
}
// First we will call these functions
a();
// Now let's see what is the stack trace stored into myObj.stack
console.log(myObj.stack);
// This will print the following stack to the console:
// at b (repl:3:7) <-- Since it was called inside B, the B call is the last entry in the stack
// at a (repl:2:1)
// at repl:1:1 <-- Node internals below this line
// at realRunInThisContextScript (vm.js:22:35)
// at sigintHandlersWrap (vm.js:98:12)
// at ContextifyScript.Script.runInThisContext (vm.js:24:12)
// at REPLServer.defaultEval (repl.js:313:29)
// at bound (domain.js:280:14)
// at REPLServer.runBound [as eval] (domain.js:293:12)
// at REPLServer.onLine (repl.js:513:10)
从上面的示例可以看出, 首先调用函数 a(被压入堆栈), 然后在 a 里面调用函数 b(被压入堆栈且在a之上), 然后在 b 中捕获到当前的堆栈信息, 并将其存储到 myObj 中. 所以, 在控制台输出的堆栈信息中仅包含了 a 和 b 的调用信息.
现在, 我们给 Error.captureStackTrace 传递一个函数作为第二个参数, 看下输出信息:
const myObj = {};
function d() {
// Here we will store the current stack trace into myObj
// This time we will hide all the frames after `b` and `b` itself
Error.captureStackTrace(myObj, b);
}
function c() {
d();
}
function b() {
c();
}
function a() {
b();
}
// First we will call these functions
a();
// Now let's see what is the stack trace stored into myObj.stack
console.log(myObj.stack);
// This will print the following stack to the console:
// at a (repl:2:1) <-- As you can see here we only get frames before `b` was called
// at repl:1:1 <-- Node internals below this line
// at realRunInThisContextScript (vm.js:22:35)
// at sigintHandlersWrap (vm.js:98:12)
// at ContextifyScript.Script.runInThisContext (vm.js:24:12)
// at REPLServer.defaultEval (repl.js:313:29)
// at bound (domain.js:280:14)
// at REPLServer.runBound [as eval] (domain.js:293:12)
// at REPLServer.onLine (repl.js:513:10)
// at emitOne (events.js:101:20)
当将函数 b 作为第二个参数传给 Error.captureStackTraceFunction 时, 输出的堆栈就只包含了函数 b 调用之前的信息(尽管 Error.captureStackTraceFunction 是在函数 d 中调用的), 这也就是为什么只在控制台输出了 a. 这样处理方式的好处就是用来隐藏一些与用户无关的内部实现细节.
在JavaScript中,数据类型分为两类:
保存一些简单数据,如true,5等。JavaScript共有5中原始类型:
var name = "Pomy";
var blog = "http://www.ido321.com";
var age = 22;
alert(typeof blog); //"string"
alert(typeof age); //"number"
原始类型的值是直接保存在变量中,并可以用 typeof 进行检测。但是typeof对null的检测是返回object,而不是返回null:
//弹出Not null
if(typeof null){
alert("Not null");
}else{
alert("null");
}
所以检测null时,最好用全等于(===),其还能避免强制类型转换:
console.log("21" === 21); //false
console.log("21" == 21); //true
console.log(undefined == null); //true
console.log(undefined === null); //false
对于字符串、数字或者布尔值,其都有对应的方法,这些方法来自于对应的原始封装类型:String、Number和Boolean。原始封装类型将被自动创建。
var name = "Pomy";
var char = name.charAt(0);
console.log(char); //"P"
在JavaScript引擎中发生的事情:
var name = "Pomy";
var temp = new String(name);
var char = temp.charAt(0);
temp = null;
console.log(char); //"P"
字符串对象的引用在用完之后立即被销毁,所以不能给字符串添加属性,并且instanceof检测对应类型时均返回false:
var name = "Pomy";
name.age = 21;
console.log(name.age); //undefined
console.log(name instanceof String); //false
保存为对象,实质是指向内存位置的引用,所以不在变量中保存对象。除了自定义的对象,JavaScript提供了6中内建类型:
可以用new来实例化每一个对象,或者用字面量形式来创建对象:
var obj = new Object;
var own = {
name:"Pomy",
blog:"http://www.ido321.com",
"my age":22
};
console.log(own.blog); //访问属性
console.log(own["my age"]);
obj = null; //解除引用
obj 并不包含对象实例,而是一个指向内存中实际对象所在位置的指针(或者说引用)。因为typeof对所有非函数的引用类型均返回object,所以需要用instanceof来检测引用类型。
在JavaScript中,函数就是对象。使函数不同于其他对象的决定性特性是函数存在一个被称为[[Call]]的内部属性。内部属性无法通过代码访问而是定义了代码执行时的行为。
1、函数声明:用function关键字,会被提升至上下文
2、函数表达式:不能被提升
3、实例化Function内建类型
sayHi(); //函数提升
function sayHi(){
console.log("Hello");
}
//其他等效等效方式
/*
var sayHi = function(){
console.log("Hello");
}
var sayHi = new Function(" console.log(\"Hello\");");
*/
JavaScript函数的另外一个独特之处在于可以给函数传递任意数量的参数。函数参数被保存在arguments类数组对象中,其自动存在函数中,能通过数字索引来引用参数,但它不是数组实例:
alert(Array.isArray(arguments)); //false
类数组对象arguments 保存的是函数的实参,但并不会忽略形参。因而,arguments.length返回实参列表的长度,arguments.callee.length返回形参列表的长度。
function ref(value){
return value;
}
console.log(ref("Hi"));
console.log(ref("Hi",22));
console.log(ref.length); //1
关于this的问题,可参考此文:JavaScript中的this。
JavaScript提供了三个方法用于改变this的指向:call、apply和bind。三个函数的第一个参数都是指定this的值,其他参数均作为参数传递给函数。
对象是一种引用类型,创建对象常见的两种方式:Object构造函数和对象字面量形式:
var per1 = {
name:"Pomy",
blog:"http://www.ido321.com"
};
var per2 = new Object;
per2.name = "不写代码的码农";
在JavaScript中,可以随时为对象添加属性:
per1.age = 0;
per1.sayName = function(){
alert(this.name); //"Pomy"
}
因而,在检测对象属性是否存在时,常犯的一个错误是:
//结果是false
if(per1.age){
alert(true)
}else{
alert(false);
}
per1.age 是存在的,但是其值是0,所以不能满足if条件。if判断中的值是一个对象、非空字符串、非零数字或true时,判断会评估为真;而当值是一个null、undefined、0、false、NaN或空字符串时评估为假。
因而,检测属性是否存在时,有另外的两种方式:in和hasOwnProperty(),前者会检测原型属性和自有(实例)属性,后者只检测自有(实例)属性。
console.log("age" in per1); //true
console.log(per1.hasOwnProperty("age")); //true
console.log("toString" in per1); //true
console.log(per1.hasOwnProperty("toString")); //false
对象per1并没有定义toString,该属性继承于Object.prototype,所以in和hasOwnProperty()检测该属性时出现差异。如果只想判断一个对象属性是不是原型,可以利用如下方法:
function isPrototypeProperty(obj,name){
return name in obj && !obj.hasOwnProperty(name);
}
若要删除一个属性,用delete操作符,用于删除自有属性,不能删除原型属性。
per1.toString = function(){
console.log("per1对象");
};
console.log(per1.hasOwnProperty("toString")); //true
per1.toString(); //"per1对象"
delete per1.toString;
console.log(per1.hasOwnProperty("toString")); //false
console.log(per1.toString()); //[object Object]
有时需要枚举对象的可枚举属性,也有两种方式:for-in循环和Object.keys(),前者依旧会遍历出原型属性,后者只返回自有属性。所有可枚举属性的内部属性[[Enumerable]]的值均为true。
var per3 = {
name:"Pomy",
blog:"http://www.ido321.com",
age:22,
getAge:function(){
return this.age;
}
};
实际上,大部分原生属性的[[Enumerable]]的值均为false,即该属性不能枚举。可以通过propertyIsEnumerable()检测属性是否可以枚举:
console.log(per3.propertyIsEnumerable("name")); //true
var pros = Object.keys(per3); //返回可枚举属性的名字数组
console.log("length" in pros); //true
console.log(pros.propertyIsEnumerable("length")); //false
属性name是自定义的,可枚举;属性length是Array.prototype的内建属性,不可枚举。
属性有两种类型:数据属性和访问器属性。二者均具有四个属性特征:
**[[Enumerable]] :**布尔值,属性是否可枚举,自定义属性默认是true。
**[[Configurable]] :**布尔值,属性是否可配置(可修改或可删除),自定义属性默认是true。它是不可逆的,即设置成false后,再设置成true会报错。
**[[Value]]:**保存属性的值。
**[[Writable]]:**布尔值,属性是否可写,所有属性默认可写。
**[[Get]]:**获取属性值。
**[[Set]]:**设置属性值。
ES 5提供了两个方法用于设置这些内部属性:
Object.defineProperty(obj,pro,desc_map) 和 Object.defineProperties(obj,pro_map)。利用这两个方法为per3添加一个属性和创建一个新对象per4:
Object.defineProperty(per3,"sex",{
value:"male",
enumerable:false,
configurable:false, //属性不能删除和修改,该值也不能被设置成true
});
console.log(per3.sex); //'male'
console.log(per3.propertyIsEnumerable("sex")); //false
delete per3.sex; //不能删除
per3.sex = "female"; //不能修改
console.log(per3.sex); //'male'
Object.defineProperty(per3,"sex",{
configurable:true, //报错
});
per4 = {};
Object.defineProperties(per4,{
name:{
value:"dwqs",
writable:true
},
blog:{
value:"http://blog.92fenxiang.com"
},
Name:{
get:function(){
return this.name;
},
set:function(value){
this.name = value;
},
enumerable:true,
configurable:true
}
});
console.log(per4.name); //dwqs
per4.Name = "Pomy";
console.log(per4.Name); //Pomy
需要注意的是,通过这两种方式来定义新属性时,如果不指定特征值,则默认是false,也不能创建同时具有数据特征和访问器特征的属性。可以通过Object.getOwnPropertyDescriptor()方法来获取属性特征的描述,接受两个参数:对象和属性名。若属性存在,则返回属性描述对象。
var desc = Object.getOwnPropertyDescriptor(per4,"name");
console.log(desc.enumerable); //false
console.log(desc.configurable); //false
console.log(desc.writable); //true
根据属性的属性类型,返回的属性描述对象包含其对应的四个属性特征。
对象和属性一样具有指导其行为的内部特征。其中,[[Extensible]]是一个布尔值,指明改对象本身是否可以被修改([[Extensible]]值为true)。创建的对象默认都是可以扩展的,可以随时添加新的属性。
ES5提供了三种方式:
"use strict";
var per5 = {
name:"Pomy"
};
console.log(Object.isExtensible(per5)); //true
console.log(Object.isSealed(per5)); //false
console.log(Object.isFrozen(per5)); //false
Object.freeze(per5);
console.log(Object.isExtensible(per5)); //false
console.log(Object.isSealed(per5)); //true
console.log(Object.isFrozen(per5)); //true
per5.name="dwqs";
console.log(per5.name); //"Pomy"
per5.Hi = function(){
console.log("Hi");
};
console.log("Hi" in per5); //false
delete per5.name;
console.log(per5.name); //"Pomy"
var desc = Object.getOwnPropertyDescriptor(per5,"name");
console.log(desc.configurable); //false
console.log(desc.writable); //false
注意,禁止修改对象的三个方法只对对象的自有属性有效,对原型对象的属性无效,仍然可以在原型上添加或修改属性。
function Person(name){
this.name = name;
}
var person1 = new Person("Pomy");
var person2 = new Person("dwqs");
Object.freeze(person1);
Person.prototype.Hi = function(){
console.log("Hi");
};
person1.Hi(); //"Hi";
person2.Hi(); //"Hi";
在 关于Redux的一些总结(一):Action & 中间件 & 异步 一文中,有提到可以根据 reducer 对组件进行拆分,而不必将 state 中的数据原封不动地传入组件,可以根据 state 中的数据,动态地输出组件需要的(最小)属性。
在常规的组件开发方式中,组件自身的数据和状态是耦合的,这种方式虽能简化开发流程,在短期内能提高开发效率,但只适用于小型且复杂度不高的SPA 应用开发,而对于复杂的 SPA 应用来说,这种开发方式不具备良好的扩展性。以开发一个评论组件 Comment 为例,常规的开发方式如下:
class CommentList extends Component {
constructor(){
super();
this.state = {commnets: []}
}
componentDidMount(){
$.ajax({
url:'/my-comments.json',
dataType:'json',
success:function(data){
this.setState({comments:data});
}.bind(this)
})
}
render(){
return <ul>{this.state.comments.map(renderComment)}</ul>;
}
renderComment({body,author}){
return <li>{body}-{author}</li>;
}
}
随着应用的复杂度和组件复杂度的双重增加,现有的组件开发方式已经无法满足需求,它会让组件变得不可控制和难以维护,极大增加后续功能扩展的难度。并且由于组件的状态和数据的高度耦合,这种组件是无法复用的,无法抽离出通用的业务无关性组件,这势必也会增加额外的工作量和开发时间。
在组件的开发过程中,从组件的职责角度上,将组件分为 容器类组件(Container Component) 和 展示类组件(Presentational Component)。前者主要从 state 获取组件需要的(最小)属性,后者主要负责界面渲染和自身的状态(state)控制,为容器组件提供样式。
按照上述的概念,Comment应该有两部分组成:CommentListContainer和CommentList。首先定义一个容器类组件(Container Component):
//CommentListContainer
class CommentListContainer extends Component {
constructor(){
super();
this.state = {commnets: []}
}
componentDidMount(){
$.ajax({
url:'/my-comments.json',
dataType:'json',
success:function(data){
this.setState({comments:data});
}.bind(this)
})
}
render(){
return <CommnetList comments={this.state.comments}/>;
}
}
容器组件CommentListContainer获取到数据之后,通过props传递给子组件CommentList进行界面渲染。CommentList是一个展示类组件:
//CommentList
class CommentList extends Component {
constructor(props){
super(props);
this.state = {commnets: []}
}
render(){
return <ul>{this.props.comments.map(renderComment)}</ul>;
}
renderComment({body,author}){
return <li>{body}-{author}</li>;
}
}
将Comment组件拆分后,组件的自身状态和异步数据被分离,界面样式由展示类组件提供。这样,对于后续的业务数据变化需求,只需要更改容器类组件或者增加新的展示类业务组件,极大提高了组件的扩展性。
容器类组件主要功能是获取 state 和提供 action,渲染各个子组件。各个子组件或是一个展示类组件,或是一个容器组件,其职责具体如下:
展示类组件自身的数据来自于父组件(容器类组件或展示类组件),组件自身提供样式和管理组件状态。展示类组件是状态化的,其主要职责如下:
react-redux 为 React 组件和 Redux 提供的 state 提供了连接。当然可以直接在 React 中使用 Redux:在最外层容器组件中初始化 store,然后将 state 上的属性作为 props 层层传递下去。
class App extends Component{
componentWillMount(){
store.subscribe((state)=>this.setState(state))
}
render(){
return <Comp state={this.state}
onIncrease={()=>store.dispatch(actions.increase())}
onDecrease={()=>store.dispatch(actions.decrease())}/>
}
}
但这并不是所推荐的方式,相比上述的方式,更好的一个写法是结合 react-redux。
首先在最外层容器中,把所有内容包裹在 Provider 组件中,将之前创建的 store 作为 prop 传给 Provider。
const App = () => {
return (
<Provider store={store}>
<Comp/>
</Provider>
)
};
Provider 内的任何一个组件(比如这里的 Comp),如果需要使用 state 中的数据,就必须是「被 connect 过的」组件——使用 connect 方法对「你编写的组件(MyComp)」进行包装后的产物。
class MyComp extends Component {
// content...
}
const Comp = connect(...args)(MyComp);
connect 会返回一个与 store 连接后的新组件。那么,我们就可以传一个 Presentational Component 给 connect,让 connect 返回一个与 store 连接后的 Container Component。
connect 接受四个参数,返回一个函数:
export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options = {}){
//code
return function wrapWithConnect(WrappedComponent){
//other code
....
//merge props
function computeMergedProps(stateProps, dispatchProps, parentProps) {
const mergedProps = finalMergeProps(stateProps, dispatchProps, parentProps)
if (process.env.NODE_ENV !== 'production') {
checkStateShape(mergedProps, 'mergeProps')
}
return mergedProps
}
....
render(){
//other code
....
if (withRef) {
this.renderedElement = createElement(
WrappedComponent, {
...this.mergedProps,
ref: 'wrappedInstance'
})
} else {
this.renderedElement = createElement(
WrappedComponent,
this.mergedProps
)
}
return this.renderedElement
}
}
}
wrapWithConnect 接受一个组件作为参数,在 render 会调用 React 的 createElement 基于传入的组件和新的 props 返回一个新的组件。
以 connect 的方式来改写Comment组件:
//CommentListContainer
import getCommentList '../actions/index'
import CommentList '../comment-list.js';
function mapStateToProps(state){
return {
comment: state.comment,
other: state.other
}
}
function mapDispatchToProps(dispatch) {
return {
getCommentList:()=>{
dispatch(getCommentList());
}
}
}
export default connect(mapStateToProps,mapDispatchToProps)(CommentList);
在Comment组件中,CommentListContainer 只作为一个连接器作用,连接
CommentList 和 state:
//CommentList
class CommentList extends Component {
constructor(props){
super(props);
}
componentWillMount(){
//获取数据
this.props.getCommentList();
}
render(){
let {comment} = this.props;
if(comment.fetching){
//正在加载
return <Loading />
}
//如果对CommentList item的操作比较复杂,也可以将item作为一个独立组件
return <ul>{this.props.comments.map(renderComment)}</ul>;
}
renderComment({body,author}){
return <li>{body}-{author}</li>;
}
}
关于 connect 比较详细的解释可以参考:React 实践心得:react-redux 之 connect 方法详解
在 关于Redux的一些总结(一):Action & 中间件 & 异步 一文中,有提到可以根据 reducer 对组件进行拆分,而不必将 state 中的数据原封不动地传入组件,可以根据 state 中的数据,动态地输出组件需要的(最小)属性。
在常规的组件开发方式中,组件自身的数据和状态是耦合的,这种方式虽能简化开发流程,在短期内能提高开发效率,但只适用于小型且复杂度不高的SPA 应用开发,而对于复杂的 SPA 应用来说,这种开发方式不具备良好的扩展性。以开发一个评论组件 Comment 为例,常规的开发方式如下:
class CommentList extends Component {
constructor(){
super();
this.state = {commnets: []}
}
componentDidMount(){
$.ajax({
url:'/my-comments.json',
dataType:'json',
success:function(data){
this.setState({comments:data});
}.bind(this)
})
}
render(){
return <ul>{this.state.comments.map(renderComment)}</ul>;
}
renderComment({body,author}){
return <li>{body}-{author}</li>;
}
}
随着应用的复杂度和组件复杂度的双重增加,现有的组件开发方式已经无法满足需求,它会让组件变得不可控制和难以维护,极大增加后续功能扩展的难度。并且由于组件的状态和数据的高度耦合,这种组件是无法复用的,无法抽离出通用的业务无关性组件,这势必也会增加额外的工作量和开发时间。
在组件的开发过程中,从组件的职责角度上,将组件分为 容器类组件(Container Component) 和 展示类组件(Presentational Component)。前者主要从 state 获取组件需要的(最小)属性,后者主要负责界面渲染和自身的状态(state)控制,为容器组件提供样式。
按照上述的概念,Comment应该有两部分组成:CommentListContainer和CommentList。首先定义一个容器类组件(Container Component):
//CommentListContainer
class CommentListContainer extends Component {
constructor(){
super();
this.state = {commnets: []}
}
componentDidMount(){
$.ajax({
url:'/my-comments.json',
dataType:'json',
success:function(data){
this.setState({comments:data});
}.bind(this)
})
}
render(){
return <CommnetList comments={this.state.comments}/>;
}
}
容器组件CommentListContainer获取到数据之后,通过props传递给子组件CommentList进行界面渲染。CommentList是一个展示类组件:
//CommentList
class CommentList extends Component {
constructor(props){
super(props);
this.state = {commnets: []}
}
render(){
return <ul>{this.props.comments.map(renderComment)}</ul>;
}
renderComment({body,author}){
return <li>{body}-{author}</li>;
}
}
将Comment组件拆分后,组件的自身状态和异步数据被分离,界面样式由展示类组件提供。这样,对于后续的业务数据变化需求,只需要更改容器类组件或者增加新的展示类业务组件,极大提高了组件的扩展性。
容器类组件主要功能是获取 state 和提供 action,渲染各个子组件。各个子组件或是一个展示类组件,或是一个容器组件,其职责具体如下:
展示类组件自身的数据来自于父组件(容器类组件或展示类组件),组件自身提供样式和管理组件状态。展示类组件是状态化的,其主要职责如下:
react-redux 为 React 组件和 Redux 提供的 state 提供了连接。当然可以直接在 React 中使用 Redux:在最外层容器组件中初始化 store,然后将 state 上的属性作为 props 层层传递下去。
class App extends Component{
componentWillMount(){
store.subscribe((state)=>this.setState(state))
}
render(){
return <Comp state={this.state}
onIncrease={()=>store.dispatch(actions.increase())}
onDecrease={()=>store.dispatch(actions.decrease())}/>
}
}
但这并不是所推荐的方式,相比上述的方式,更好的一个写法是结合 react-redux。
首先在最外层容器中,把所有内容包裹在 Provider 组件中,将之前创建的 store 作为 prop 传给 Provider。
const App = () => {
return (
<Provider store={store}>
<Comp/>
</Provider>
)
};
Provider 内的任何一个组件(比如这里的 Comp),如果需要使用 state 中的数据,就必须是「被 connect 过的」组件——使用 connect 方法对「你编写的组件(MyComp)」进行包装后的产物。
class MyComp extends Component {
// content...
}
const Comp = connect(...args)(MyComp);
connect 会返回一个与 store 连接后的新组件。那么,我们就可以传一个 Presentational Component 给 connect,让 connect 返回一个与 store 连接后的 Container Component。
connect 接受四个参数,返回一个函数:
export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options = {}){
//code
return function wrapWithConnect(WrappedComponent){
//other code
....
//merge props
function computeMergedProps(stateProps, dispatchProps, parentProps) {
const mergedProps = finalMergeProps(stateProps, dispatchProps, parentProps)
if (process.env.NODE_ENV !== 'production') {
checkStateShape(mergedProps, 'mergeProps')
}
return mergedProps
}
....
render(){
//other code
....
if (withRef) {
this.renderedElement = createElement(
WrappedComponent, {
...this.mergedProps,
ref: 'wrappedInstance'
})
} else {
this.renderedElement = createElement(
WrappedComponent,
this.mergedProps
)
}
return this.renderedElement
}
}
}
wrapWithConnect 接受一个组件作为参数,在 render 会调用 React 的 createElement 基于传入的组件和新的 props 返回一个新的组件。
以 connect 的方式来改写Comment组件:
//CommentListContainer
import getCommentList '../actions/index'
import CommentList '../comment-list.js';
function mapStateToProps(state){
return {
comment: state.comment,
other: state.other
}
}
function mapDispatchToProps(dispatch) {
return {
getCommentList:()=>{
dispatch(getCommentList());
}
}
}
export default connect(mapStateToProps,mapDispatchToProps)(CommentList);
在Comment组件中,CommentListContainer 只作为一个连接器作用,连接
CommentList 和 state:
//CommentList
class CommentList extends Component {
constructor(props){
super(props);
}
componentWillMount(){
//获取数据
this.props.getCommentList();
}
render(){
let {comment} = this.props;
if(comment.fetching){
//正在加载
return <Loading />
}
//如果对CommentList item的操作比较复杂,也可以将item作为一个独立组件
return <ul>{this.props.comments.map(renderComment)}</ul>;
}
renderComment({body,author}){
return <li>{body}-{author}</li>;
}
}
关于 connect 比较详细的解释可以参考:React 实践心得:react-redux 之 connect 方法详解
本文参考 Git - Useful Tips 一文翻译,不当之处,敬请谅解
这篇文章的目的是给经常使用git管理项目提供一个有益的提醒。如果你是git新手,可以先阅读文后的引用部分,然后在回头阅读此篇文章。在介绍git命令之前,你可以先看看来自 on-my-zsh 提供的别名。
git config --global user.name "Your Name"git config --global user.email "[email protected]"git config --global core.editor <your favorite editor here>
git config --global core.editor vimgit init:初始化一个repo。git status(gst):查看 repo 状态git add <filename>(ga):添加一个文件到暂存区git add .(gaa):添加所有文件到暂存区git add *.js:添加所有后缀为js的文件到暂存区git rm --cached <file>:从暂存区删除一个新文件git commit -m "My first commit"(gcmsg):创建一次带 message 的提交git commit -v -a(gca):
-v是 verbose 的缩写,会在底部显示差异信息和更多有意义的信息-a 类似于 git add .,会添加所有被修改和删除的文件,但会忽略新创建的文件git help <command>:查看对应命令的帮助手册git log(glg,glgg,glo, glog):查看项目的提交历史git reset HEAD <filename>(grh):从暂存区删除一个被修改的文件git reset HEAD(grh):从暂存区删除所有被修改的文件git checkout <filename>(gco):从暂存区删除一个被修改的文件,并撤销文件的更改git commit -m "My first commit" --amend:添加文件/更改在暂存区的最后一次提交git commit -v -a --amend(gca!):添加文件/更改在暂存区的最后一次提交.gitignore:告诉git,哪些文件不被加入版本跟踪
git add <filename> -f 命令添加一个不被版本跟踪的文件git diff <filename>(gd):查看基于当前文件的最后一次提交的更改差异git diff (gd):查看基于所有文件的最后一次提交的更改差异git reset HEAD~2 --soft:从项目提交历史中删除最近两次提交,但不丢弃文件的更改git reset HEAD~2 --hard:从项目提交历史中删除最近两次提交,但会丢弃文件的更改和在(最后两次)提交中创建的新文件git reset <commit> --soft --hard:
--soft:将所有被更改的文件回溯到“待提交”状态--hard:commit 之后,对被git追踪的文件的任何更改都被丢弃git reflog:显示包括"被撤销"在内的所有提交git merge <commit hash>:重新提交(restore the commit)git clean -f:删除工作目录中不被git进行版本追踪的文件git stash(gsta):将所有暂存区的文件移动到“储藏区”,类似于另一种类型的工作区git stash list:查看储藏队列(Stash lists)git stash apply:将最近一次储藏恢复到暂存区(可以用类似 git stash apply stash@{num}(num从0开始计数) 的命令来使用在队列中的任意一个储藏(stashes))git stash clear:清空储藏队列git stash save "name of the stash":为储藏设置命名git stash pop(gstp):将最近一次储藏恢复到暂存区并从储藏队列删除此储藏git stash drop(gstd):从储藏队列删除最近一次储藏(stash@{0})(git stash drop stash@{num} 从储藏队列删除指定储藏)git checkout -b dev(gco):创建 dev 分支并从当前分支切换到 dev 分支git branch(gb):查看所有分支git checkout master(gcm):切换到主分支git merge <branch>(gm):合并分支git rebase master:先将 master 上的更改合并到当前分支,再添加当前分支的更改。如果有冲突,解决冲突后加 --continue 参数继续合并git branch -d <branch>: 删除分支,-D 则强制删除分支git merge <branch> --squash:将多次提交合并成一个,其流程如下:# Go to the `master` branch
git checkout master
# Create a temp branch
git checkout -b temp
# Merge the feature/x branch into the temp using --squash
git merge feature/x --squash
# See the new modifications/files in the Staging Area
git status
# Create the unified commit
git commit -m "Add feature/x"
# Delete the feature/x branch
git branch -D feature/x
git remote add <name> <url>:添加一个将被追踪的远程仓库git remote rm <name>:移除一个远程仓库git push <remote> <remote-branch>(gp,ggp):将当前分支的本地 commit 推送到远程仓库git fetch <remote> <remote-branch>:拉取远程仓库的最新 commit 到当前(本地)分支(<remote>/<branch>),不会合并git pull <remote> <remote-branch>(gl,ggl):拉取远程仓库的最新 commit 到当前(本地)分支,并自动 merge
git pull --rebase(gup):以 rebase 的方式进行合并,而不是 mergegit tag <name>:创建一个 tag(如:v1.3)git push --tags:将本地 tags 推送到远程仓库git push <tag>:推送指定的本地 tag 到远程接着 koa源码解读 一文中的末尾接着唠嗑 koa-router。
在 koa 中,对中间件的使用是支持链接调用的。同样,
对于多个路径的请求,koa-router 也支持链式调用:
router
.get('/', function *(next) {
this.body = 'Hello World!';
})
.post('/users', function *(next) {
// ...
})
.put('/users/:id', function *(next) {
// ...
})
.del('/users/:id', function *(next) {
// ...
});
因为每个动词方法都会返回router本身:
methods.forEach(function (method) {
Router.prototype[method] = function (name, path, middleware) {
var middleware;
if (typeof path === 'string' || path instanceof RegExp) {
middleware = Array.prototype.slice.call(arguments, 2);
} else {
middleware = Array.prototype.slice.call(arguments, 1);
path = name;
name = null;
}
this.register(path, [method], middleware, {
name: name
});
return this;
};
});
Node 本身提供了数十个 HTTP 请求动词,koa-router 只是实现了部分常用的:
function Router(opts) {
if (!(this instanceof Router)) {
return new Router(opts);
}
this.opts = opts || {};
this.methods = this.opts.methods || [
'HEAD',
'OPTIONS',
'GET',
'PUT',
'PATCH',
'POST',
'DELETE'
];
//省略
};
这些请求动词的实现是通过第三方模块 methods 支持的,然后 koa-router 内部进行了注册处理:
methods.forEach(function (method) {
Router.prototype[method] = function (name, path, middleware) {
//见上述代码
this.register(path, [method], middleware, {
name: name
});
return this;
};
});
this.register 接受请求路径,方法,中间件作为参数,返回已经注册的路由:
Router.prototype.register = function (path, methods, middleware, opts) {
opts = opts || {};
var stack = this.stack;
// create route
var route = new Layer(path, methods, middleware, {
//Layer是具体实现,包括匹配、中间件处理等
end: opts.end === false ? opts.end : true,
name: opts.name,
sensitive: opts.sensitive || this.opts.sensitive || false,
strict: opts.strict || this.opts.strict || false,
prefix: opts.prefix || this.opts.prefix || "",
});
//other code
return route;
};
由上述代码可知,koa-router 是支持中间件来处理路由的:
myRouter.use(function* (next) {
console.log('aaaaaa');
yield next;
});
myRouter.use(function* (next) {
console.log('bbbbbb');
yield next;
});
myRouter.get('/', function *(next) {
console.log('ccccccc');
this.response.body = 'Hello World!';
});
myRouter.get('/test', function *(next) {
console.log('dddddd');
this.response.body = 'test router middleware';
});
通过 router.use 来注册中间件,中间件会按照顺序执行,并会在匹配的路由的回调之前调用:
对于不匹配的路由则不会调用。同时,如果注册的路由少了 yield next, 则之后的中间件以及被匹配的路由的回调就不会被调用;路由的中间件也是支持链接调用的:
Router.prototype.use = function () {
var router = this;
//other code
return this;
};
中间件也支持特定路由和数组路由:
// session middleware will run before authorize
router
.use(session())
.use(authorize());
// use middleware only with given path
router.use('/users', userAuth());
// or with an array of paths
router.use(['/users', '/admin'], userAuth());
从上述分析可知,对于同一个路由,能用多个中间件处理:
router.get(
'/users/:id',
function (ctx, next) {
return User.findOne(ctx.params.id).then(function(user) {
ctx.user = user;
return next();
});
},
function (ctx) {
console.log(ctx.user);
// => { id: 17, name: "Alex" }
}
);
这样的写法看起来会更紧凑。
Koa-router允许为路径统一添加前缀:
var myRouter = new Router({
prefix: '/koa'
});
// 等同于"/koa"
myRouter.get('/', function* () {
this.response.body = 'koa router';
});
// 等同于"/koa/:id"
myRouter.get('/:id', function* () {
this.response.body = 'koa router-1';
});
也可以在路由初始化后设置统一的前缀,koa-router 提供了 prefix 方法:
Router.prototype.prefix = function (prefix) {
prefix = prefix.replace(/\/$/, '');
this.opts.prefix = prefix;
this.stack.forEach(function (route) {
route.setPrefix(prefix);
});
return this;
};
所以,以下代码是和上述等价的:
var myRouter = new Router();
myRouter.prefix('/koa');
// 等同于"/koa"
myRouter.get('/', function* () {
this.response.body = 'koa router';
});
// 等同于"/koa/:id"
myRouter.get('/:id', function* () {
this.response.body = 'koa router-1';
});
路径的参数通过 this.params 属性获取,该属性返回一个对象,所有路径参数都是该对象的成员:
// 访问 /programming/how-to-node
router.get('/:category/:title', function *(next) {
console.log(this.params);
// => { category: 'programming', title: 'how-to-node' }
});
param 方法可以对参数设置条件,可用于常规验证和自动加载的验证:
router
.get('/users/:user', function *(next) {
this.body = this.user;
})
.param('user', function *(id, next) {
var users = [ '0号用户', '1号用户', '2号用户'];
this.user = users[id];
if (!this.user) return this.status = 404;
yield next;
})
param 接受两个参数:路由的参数和处理参数的中间件:
Router.prototype.param = function (param, middleware) {
this.params[param] = middleware;
this.stack.forEach(function (route) {
route.param(param, middleware);
});
return this;
};
如果 /users/:user 的参数 user 对应的不是有效用户(比如访问 /users/3),param 方法注册的中间件会查到,就会返回404错误。
也可以将参数验证不通过的路由通过 redirect 重定向到另一个路径,并返回301状态码:
router.redirect('/login', 'sign-in');
// 等同于
router.all('/login', function *() {
this.redirect('/sign-in');
this.status = 301;
});
all 是一个私有方法,会处理某路由的所有的动词请求,相当于一个中间件。如果在 all 之前或者之后出现了处理同一个路由的动词方法,则要调用 yield next,否则另一个就不会执行:
myRouter.get('/login',function* (next) {
this.body = 'login';
// 没有yield next,all不会执行
yield next;
}).get('/sign',function* () {
this.body = 'sign';
}).all('/login',function* () {
console.log('login');
});
myRouter.get('/sign2',function* () {
this.body = 'sign';
}).all('/login2',function* () {
console.log('login2');
//没有yield next,get不会执行
yield next;
}).get('/login2',function* (next) {
this.body = 'login';
});
redirect 方法的第一个参数是请求来源,第二个参数是目的地,两者都可以用路径模式的别名代替,还有第三个参数是状态码,默认是 301:
Router.prototype.redirect = function (source, destination, code) {
// lookup source route by name
if (source[0] !== '/') {
source = this.url(source);
}
// lookup destination route by name
if (destination[0] !== '/') {
destination = this.url(destination);
}
return this.all(source, function *() {
this.redirect(destination);
this.status = code || 301;
});
};
对于非常复杂的路由,koa-router 支持给复杂的路径模式起别名。别名作为第一个参数传递给动词方法:
router.get('user', '/users/:id', function *(next) {
// ...
});
然后可以通过 url 实例方法来生成路由:
router.url('user', 3);
// => "/users/3"
//等价于
router.url('user', { id: 3 });
//=> 'users/3'
该方法接收两个参数:路由别名和参数对象:
Router.prototype.url = function (name, params) {
var route = this.route(name);
if (route) {
var args = Array.prototype.slice.call(arguments, 1);
return route.url.apply(route, args);
}
return new Error("No route found for name: " + name);
};
第一个参数用于 route 方式查找匹配的别名,找到则返回 true,否则返回 false:
Router.prototype.route = function (name) {
var routes = this.stack; //路由别名
for (var len = routes.length, i=0; i<len; i++) {
if (routes[i].name && routes[i].name === name) {
return routes[i];
}
}
return false;
};
除了实例方法 url 外,koa-router 还提供一个静态的方法 url 生成路由:
var url = Router.url('/users/:id', {id: 1});
// => "/users/1"
第一个参数是路径模式,第二个参数是参数对象。
除了给路由命名,koa-router 还支持路由嵌套处理:
var forums = new Router();
var posts = new Router();
posts.get('/', function (ctx, next) {...});
posts.get('/:pid', function (ctx, next) {...});
forums.use('/forums/:fid/posts', posts.routes(), posts.allowedMethods());
// responds to "/forums/123/posts" and "/forums/123/posts/123"
app.use(forums.routes());
众所周知,当使用CSS技术的时候,很容被一些奇异问题给困住。而当我们面对新的问题时,这会让我们处于非常不利的位置。
但是,伴随着Web的发展,新的解决方案也在慢慢成熟。因此,作为一个Web设计和前端开发人员,除了对我们使用的工具或属性非常了解并能熟练运用,已经别无选择了。
这也意味着,对于那些特别的工具或属性,即使平常很少使用,但是当需要的时候,我们也能很好的把它运用到工作中。
今天,我就介绍一些你之前可能不知道的CSS 属性,是一些例如px和ems测量方面的单位,但是很有可能你之前都没听过这些。一起来看看吧。
从与我们已经熟悉的但很相似的单位开始介绍。em被定义为相对于当前对象内文本的字体大小。如果你给body元素设置了一个字体大小,那么body的任何子元素的em值都等于body设置的font-size。
<body>
<div class="test">Test</div>
</body>
body {
font-size: 14px;
}
div {
font-size: 1.2em; // calculated at 14px * 1.2, or 16.8px
}
div中的字体大小是1.2em,也就是div从父类元素继承的字体大小的1.2倍。在这里,body的字体是14px,那么div的字体大小是1.2*14=16.8px.
但是,如果你用em一层一层级联得定义嵌套元素的字体大小又会花生什么事情呢?在下面这一小段代码里我们应用了和上面一样一样的CSS,每一个div都从它上一级父元素继承了字体大小,并且逐渐得增加。
<body>
<div>
Test <!-- 14 * 1.2 = 16.8px -->
<div>
Test <!-- 16.8 * 1.2 = 20.16px -->
<div>
Test <!-- 20.16 * 1.2 = 24.192px -->
</div>
</div>
</div>
</body>
虽然在某些地方这正是我们想要的,但是通常情况下我们还是希望就依赖单一的相对度量单位就好。这时,就应该用rem了,rem中的r代表根元素,它的值就是根元素设置的字体大小。在大多数情况下,根元素就是html了。
html {
font-size: 14px;
}
div {
font-size: 1.2rem;
}
这样在上面的那三个嵌套的div娃们的字体大小都是 1.2*14px = 16.8px 了。
Rems不仅适用于字体大小,也用于网格布局。例如,你可以用基于html根元素字体大小的rem作为整个网格布局或者UI库的大小单位,然后在其他特定的地方用em单位。这样将会给你带来更多的字体大小和伸缩的可控性,
.container {
width: 70rem; // 70 * 14px = 980px
}
概念上来说,这个方法的**就是让你的界面根据你的内容进行缩放。但是,这样做并不是对所有的情况都有意义。
响应式Web设计对百分比规则有很大的依赖性。然而,对于每一个问题,CSS百分比并不是最好的解决方案。CSS宽度是相对于包含它的最近的父元素的宽度的。如果你想使用的是视口的高度或宽度,而不是父元素的,那要肿么办呢?vh和vw就能满足这个需求了。
1vh等于1%的视口高度。例如,浏览器高度是900px,那么1vh = 900*1%=9px,同理,若视口宽度是750px,则1vw是7.5px。
它们的用途很广泛。比如,我们用很简单的方法只用一行CSS代码就实现同屏幕等高的框。
.slide {
height: 100vh;
}
假设你要来一个和屏幕同宽的标题,你只要设置这个标题的font-size的单位为vm,那标题的字体大小就会自动根据浏览器的宽度进行缩放,以达到字体和viewport大小同步的效果,有木有?!
vh和vw是相对于视口的宽度和高度,而vmin和vmax则关于视口高度和宽度两者的最小或者最大值。例如,如果浏览器的高宽分别为700px和1100px,则1vmin=7px,1vmax=11px;如果高宽分别是1080px和800px,则1vmin=8px,1vmax=10.8px。
那么什么时候需要这些值呢?
假设有一个元素,你需要让它始终在屏幕上可见。只要对其高度和宽度使用vmin单位,并赋予其低于100的值就可以做到了。例如,可以这样定义一个至少有两个边触摸到屏幕的方形:
.box {
height: 100vmin;
width: 100vmin;
}

如果你要让这个方形框框始终铺满整个视口的可见区域(四边始终触摸到屏幕的四边):
.box {
height: 100vmax;
width: 100vmax;
}

结合使用这些单位可以为我们提供一个新颖有意思的方式来灵活地利用我们视口的大小。
单位ex和ch,就跟em和rem类似,取决于当前的字体和字体大小。然而,跟em和rem不同的是,ex和ch是基于字体的度量单位,依赖于设定的字体。
单位ch通常被定义为数字0的宽度。你可以在Eric Meyers的博客里找到关于它的一些有意思的讨论,例如将一个等宽字体的字母”N”的宽度设置为40ch,那么在另一种类型的字体里它却可以包含40个字母。这个单位的传统用途主要是盲文的排版,但是除此之外,肯定还有可以应用他的地方。
单位ex定义为当前字体的小写x的高度或者1/2的em。很多时候,它是字体的中间标志。

x-height; the height of the lower case x(read more about The Anatomy of Web Typography)
他们有很多的用途,但是大部分用于版式的微调。比如,sup元素(上角标字符),可以利用position:relative;bottom: 1ex;实现,同理,可以实现一个下角标文字。浏览器默认的处理方式是利用上标和下标特定垂直对齐规则,但是如果你想更细粒度更精确得控制,你可以像下面这样做:
sup {
position: relative;
bottom: 1ex;
}
sub {
position: relative;
bottom: -1ex;
}
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。
关于闭包的概念,是婆说婆有理。因而,我就翻阅了红皮书(p178)上对于闭包的陈述:
闭包是指有权访问另外一个函数作用域中的变量的函数
这概念有点绕,拆分一下。从概念上说,闭包有两个特点:
1、函数
2、能访问另外一个函数作用域中的变量
在ES 6之前,Javascript只有函数作用域的概念,没有块级作用域(但catch捕获的异常 只能在catch块中访问)的概念(IIFE可以创建局部作用域)。每个函数作用域都是封闭的,即外部是访问不到函数作用域中的变量。
function getName() {
var name = "美女的名字";
console.log(name); //"美女的名字"
}
function displayName() {
console.log(name); //报错
}
但是为了得到美女的名字,不死心的单身汪把代码改成了这样:
function getName() {
var name = "美女的名字";
function displayName() {
console.log(name);
}
return displayName;
}
var 美女 = getName();
美女() //"美女的名字"
这下,美女是一个闭包了,单身汪想怎么玩就怎么玩了。(但并不推荐单身汪用中文做变量名的写法,大家不要学)。
关于闭包呢,还想再说三点:
function getOuter(){
var date = '815';
function getDate(str){
console.log(str + date); //访问外部的date
}
return getDate('今天是:'); //"今天是:815"
}
getOuter();
getDate是一个闭包,该函数执行时,会形成一个作用域A,A中并没有定义变量date,但它能在父一级作用域中找到该变量的定义。
function getOuter(){
var date = '815';
function getDate(str){
console.log(str + date); //访问外部的date
}
return getDate; //外部函数返回
}
var today = getOuter();
today('今天是:'); //"今天是:815"
today('明天不是:'); //"明天不是:815"
function updateCount(){
var count = 0;
function getCount(val){
count = val;
console.log(count);
}
return getCount; //外部函数返回
}
var count = updateCount();
count(815); //815
count(816); //816
为毛闭包就能访问外部函数的变量呢?这就要说说Javascript中的作用域链了。
Javascript中有一个执行环境(execution context)的概念,它定义了变量或函数有权访问的其它数据,决定了他们各自的行为。每个执行环境都有一个与之关联的变量对象,环境中定义的所有变量和函数都保存在这个对象中。你可以把它当做Javascript的一个普通对象,但是你只能修改它的属性,却不能引用它。
变量对象也是有父作用域的。当访问一个变量时,解释器会首先在当前作用域查找标示符,如果没有找到,就去父作用域找,直到找到该变量的标示符或者不再存在父作用域了,这就是作用域链。
作用域链和原型继承有点类似,但又有点小区别:如果去查找一个普通对象的属性时,在当前对象和其原型中都找不到时,会返回undefined;但查找的属性在作用域链中不存在的话就会抛出ReferenceError。
作用域链的顶端是全局对象。对于全局环境中的代码,作用域链只包含一个元素:全局对象。所以,在全局环境中定义变量的时候,它们就会被定义到全局对象中。当函数被调用的时候,作用域链就会包含多个作用域对象。
关于作用域链讲得略多(红皮书上有关于作用域及执行环境的详细解释),看一个简单地例子:
// my_script.js
"use strict";
var foo = 1;
var bar = 2;
在全局环境中,创建了两个简单地变量。如前面所说,此时变量对象是全局对象:
执行上述代码,my_script.js本身会形成一个执行环境,以及它所引用的变量对象。
改动一下代码,创建一个没有函数嵌套的函数:
"use strict";
var foo = 1;
var bar = 2;
function myFunc() {
//-- define local-to-function variables
var a = 1;
var b = 2;
var foo = 3;
console.log("inside myFunc");
}
console.log("outside");
//-- and then, call it:
myFunc();
当myFunc被定义的时候,myFunc的标识符(identifier)就被加到了当前的作用域对象中(在这里就是全局对象),并且这个标识符所引用的是一个函数对象(function object)。函数对象中所包含的是函数的源代码以及其他的属性。其中一个我们所关心的属性就是内部属性[[scope]]。[[scope]]所指向的就是当前的作用域对象。也就是指的就是函数的标识符被创建的时候,我们所能够直接访问的那个作用域对象(在这里就是全局对象)。
比较重要的一点是:myFunc所引用的函数对象,其本身不仅仅含有函数的代码,并且还含有指向其被创建的时候的作用域对象。
当myFunc函数被调用的时候,一个新的作用域对象被创建了。新的作用域对象中包含myFunc函数所定义的本地变量,以及其参数(arguments)。这个新的作用域对象的父作用域对象就是在运行myFunc时我们所能直接访问的那个作用域对象。
所以,当 myFunc 被执行的时候,对象之间的关系如下图所示:
如前面所说,当函数返回没有被引用的时候,就会被垃圾回收器回收。但是对于闭包(函数嵌套是形成闭包的一种简单方式)呢,即使外部函数返回了,函数对象仍会引用它被创建时的作用域对象。
"use strict";
function createCounter(initial) {
var counter = initial;
function increment(value) {
counter += value;
}
function get() {
return counter;
}
return {
increment: increment,
get: get
};
}
var myCounter = createCounter(100);
console.log(myCounter.get()); // 返回 100
myCounter.increment(5);
console.log(myCounter.get()); // 返回 105
当调用 createCounter(100) 时,对象之间的关系如下图所示:
内嵌函数increment和get都有指向createCounter(100) scope的引用。如果createCounter(100)没有任何返回值,那么createCounter(100) scope不再被引用,于是就可以被垃圾回收。但是因为createCounter(100)实际上是有返回值的,并且返回值被存储在了myCounter中,所以对象之间的引用关系变成了如下图所示:
需要用点时间思考的是:即使createCounter(100)已经返回,但是其作用域仍在,并能且只能被内联函数访问。可以通过调用myCounter.increment() 或 myCounter.get()来直接访问createCounter(100)的作用域。
当myCounter.increment() 或 myCounter.get()被调用时,新的作用域对象会被创建,并且该作用域对象的父作用域对象会是当前可以直接访问的作用域对象。此时,引用关系如下:
当执行到return counter;时,在get()所在的作用域并没有找到对应的标示符,就会沿着作用域链往上找,直到找到变量counter,然后返回该变量。
调用increment(5)则会更有意思:
当单独调用increment(5)时,参数value会存贮在当前的作用域对象。函数要访问value,能马上在当前作用域找到该变量。但是当函数要访问counter时,并没有找到,于是沿着作用域链向上查找,在createCounter(100)的作用域找到了对应的标示符,increment()就会修改counter的值。除此之外,没有其他方式来修改这个变量。闭包的强大也在于此,能够存贮私有数据。
对于上面的counter示例,再说点扩展的事。看代码:
//myScript.js
"use strict";
function createCounter(initial) {
/* ... see the code from previous example ... */
}
//-- create counter objects
var myCounter1 = createCounter(100);
var myCounter2 = createCounter(200);
myCounter1 和 myCounter2创建之后,关系图是酱紫的:
在上面的例子中,myCounter1.increment和myCounter2.increment的函数对象拥有着一样的代码以及一样的属性值(name,length等等),但是它们的[[scope]]指向的是不一样的作用域对象。
这才有了下面的结果:
var a, b;
a = myCounter1.get(); // a 等于 100
b = myCounter2.get(); // b 等于 200
myCounter1.increment(1);
myCounter1.increment(2);
myCounter2.increment(5);
a = myCounter1.get(); // a 等于 103
b = myCounter2.get(); // b 等于 205
作用域会存储变量,但this并不是作用域的一部分,它取决于函数调用时的方式。关于this指向的总结,可以看这篇文章:JavaScript面试问题:事件委托和this
__dirname的值 根据我一般体验是获取当前模块的绝对路径吧 , 至少好像不是什么项目根目录的解释
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
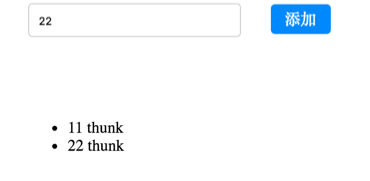
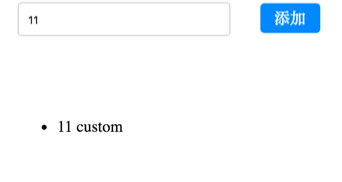

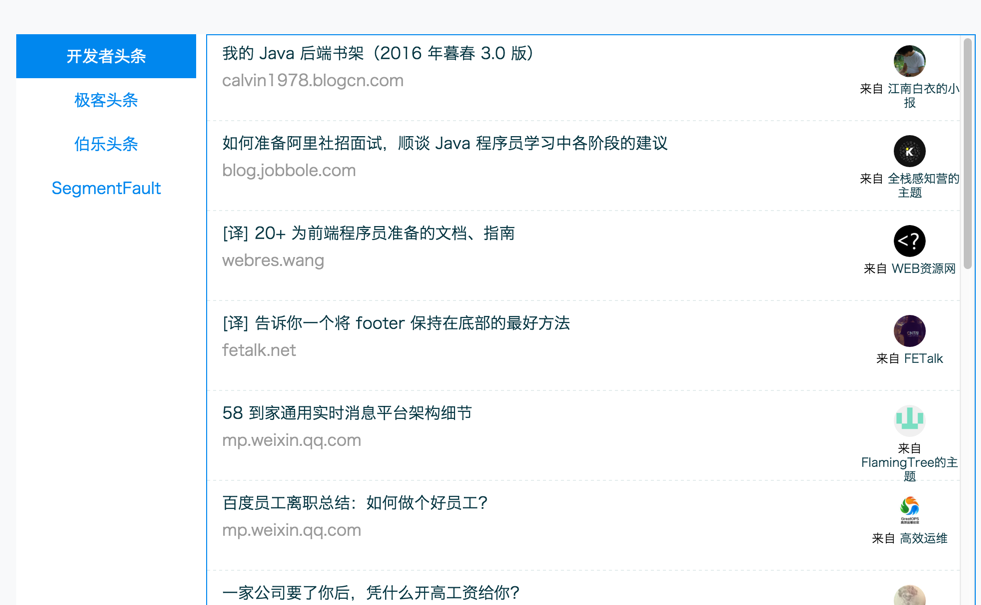

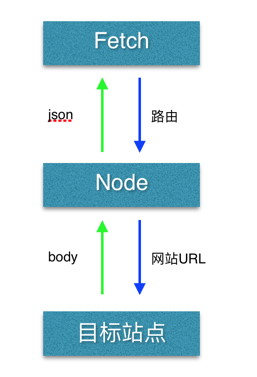

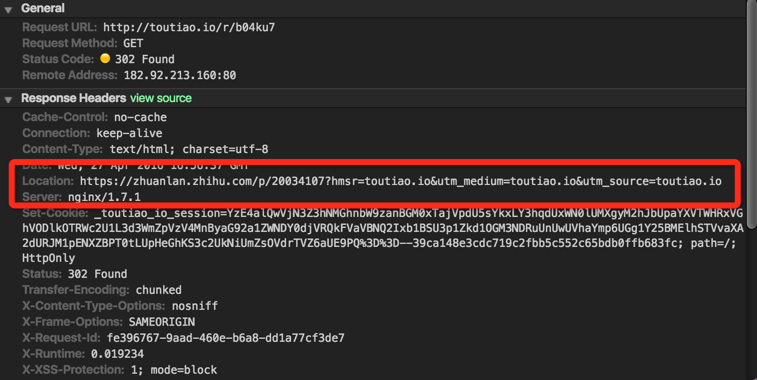























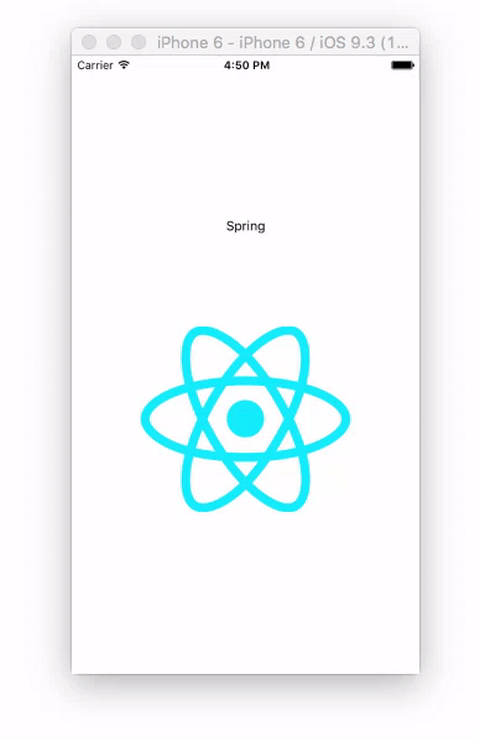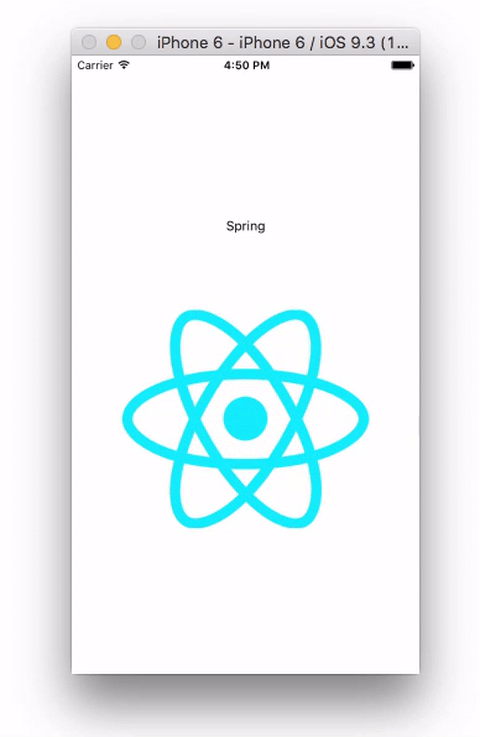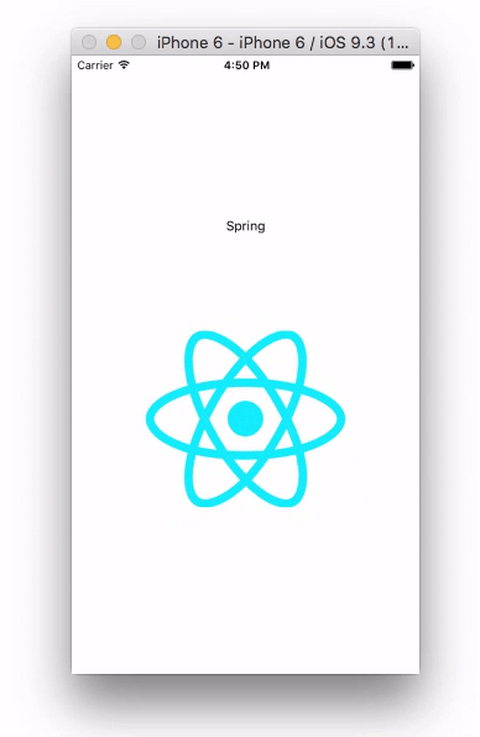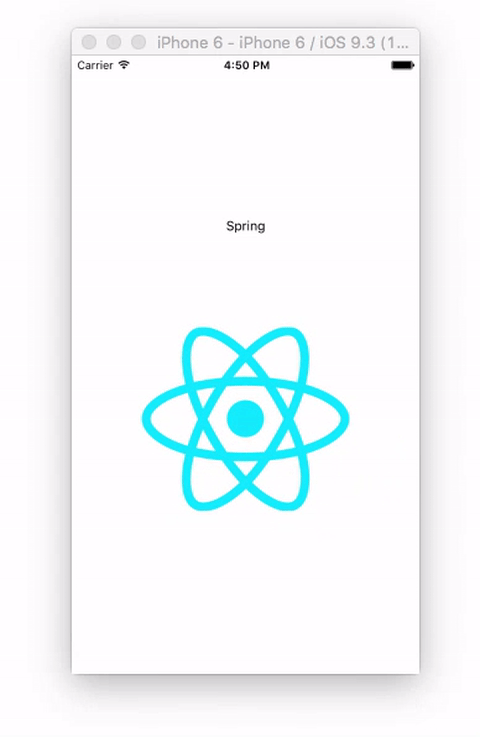




















































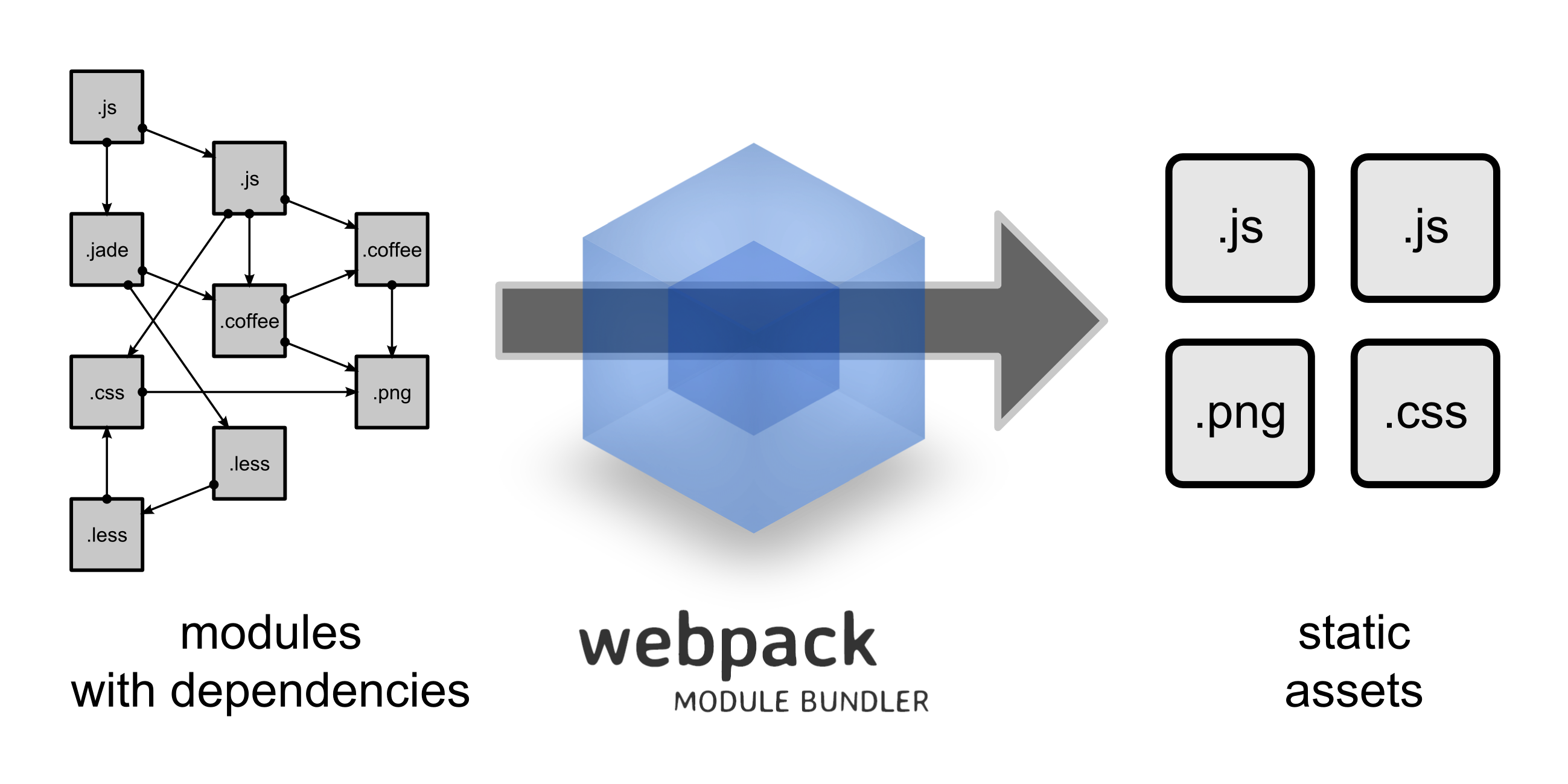










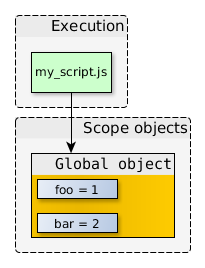
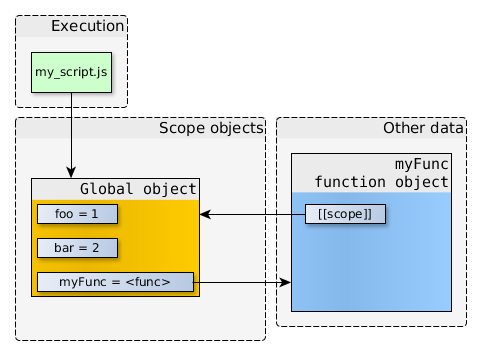
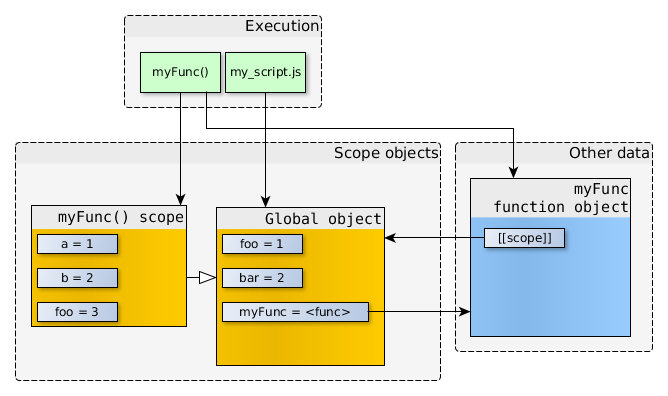
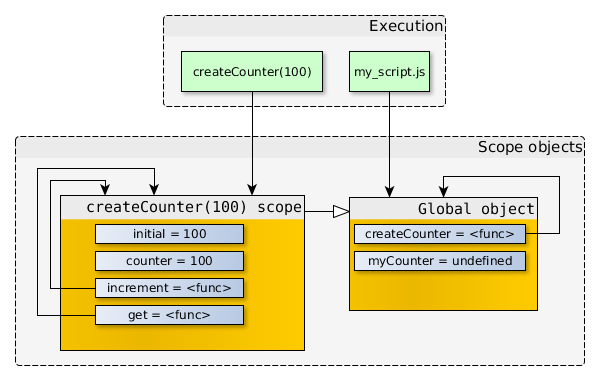
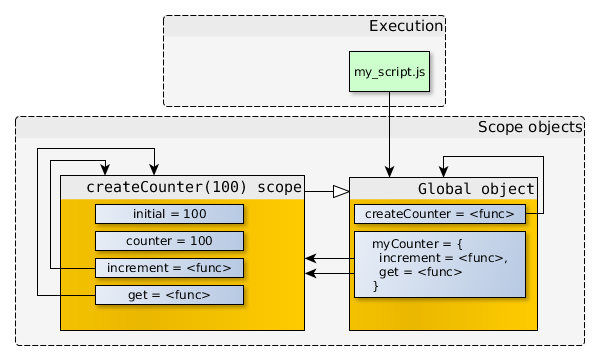
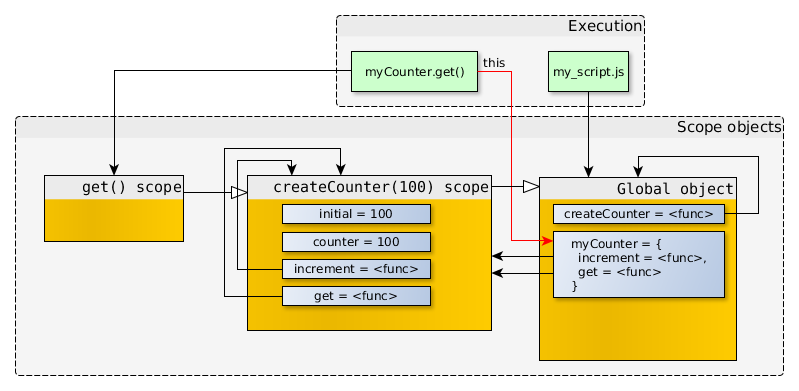
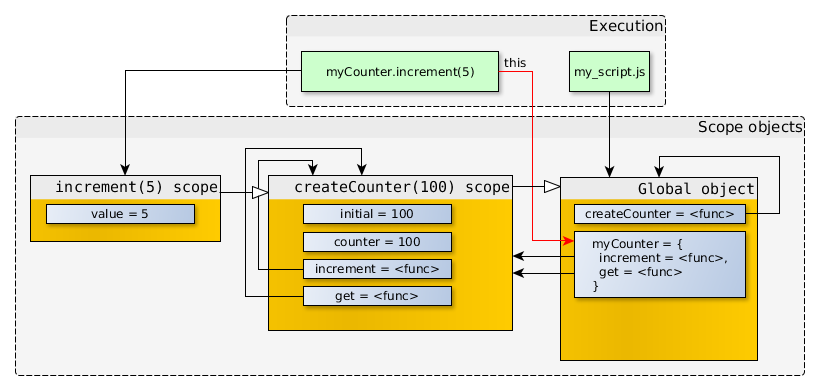
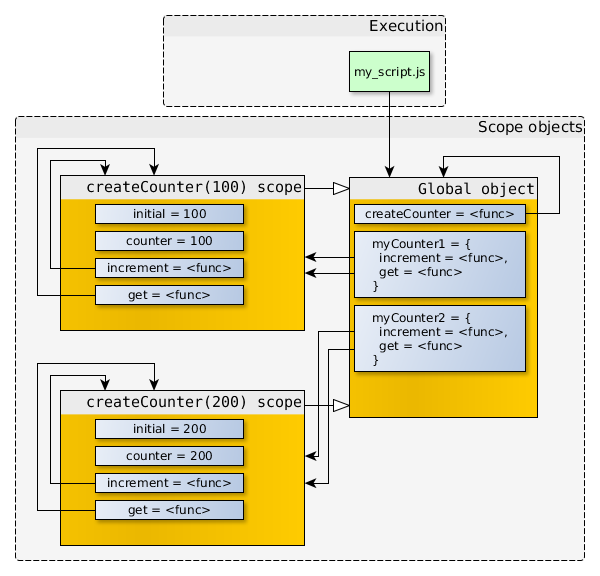
{kind=link}