요리 사진을 공유하고 이야기할 수 있는 소셜 미디어 서비스입니다.

Spring-bootVersion 2.6.2JavaVersion SE 11GradleSpring FrameworkVersion 5.3.14ThymeleafVersion 3.0.4JUnitVersion 5.8.2MybatisVersion 3.5.9MysqlVersion 8.0.27LombokVersion 1.18.22Spring Data JPAVersion 2.6.0Spring Data RedisVersion 2.6.0RedisVersion 7.0.0
JavascriptBootstrapVersion 5.1.3jQueryVersion 3.6.0
AWS S3AWS CloudFront
Github
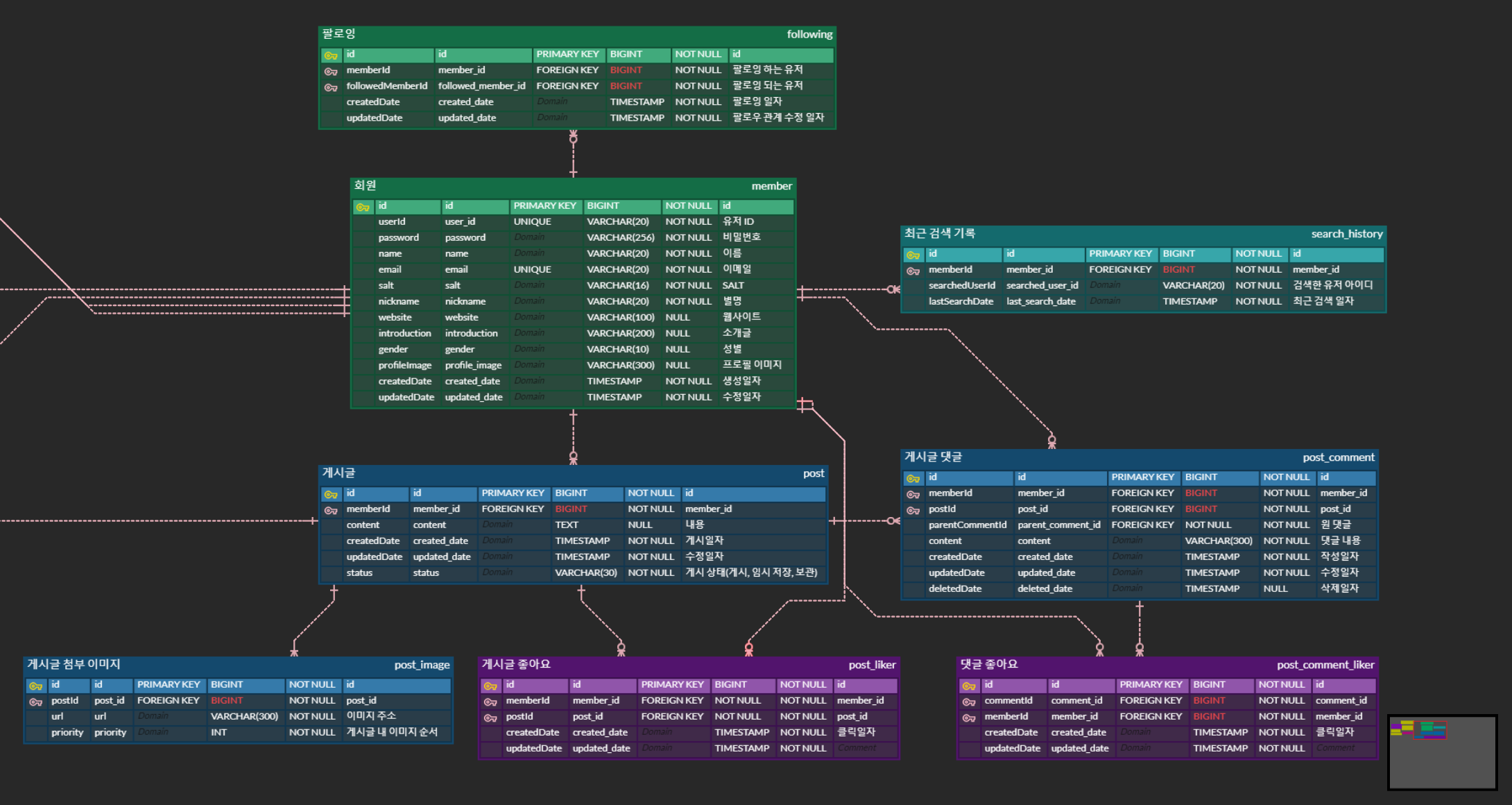
회원 정보 중 패스워드를 데이터베이스에 원문 그대로 직접 저장하는 것은 굉장히 위험하기 때문에 해싱하여 저장하였습니다.
SHA-256해시 알고리즘을 사용하였습니다.SHA-256는 동일한 패스워드에 대해 동일한 해시값을 반환한다는 문제가 있었습니다. 따라서salt라는 난수를 생성하여 패스워드에 더한 값을SHA-256으로 해싱하여 동일한 패스워드에 대해 다른 해시값을 가질 수 있도록 개발했습니다.
이미지 저장소는 1차 개발 단계에서 로컬 디스크를 사용하는 방식으로 구현하였으나, 이후 AWS S3를 사용하는 것으로 리팩토링을 진행하였습니다. 이미지 업로드는 비동기로 이루어지며, 과정은 아래와 같습니다.
- 클라이언트가 서버에 이미지 파일을 전송합니다.
- 서버는 클라이언트로부터 받은 이미지 파일명을 별도의 알고리즘을 통해
고유한 이름으로 변경하여 S3에 저장하고, 변경된 고유한 파일명을URI로 한 이미지 파일의URL을 클라이언트에 전달합니다.
서버 안정성 및 응답 속도 개선을 고려하여 변경하였습니다.
로컬 저장소를 사용하는 것은 서버가 클라이언트에게 크기가 큰 이미지 파일을 직접 전송하는 것이기 때문에 서버에 큰 부하를 야기한다고 판단했습니다. 수많은 이미지 요청을 처리하는 과정에서 병목이 발생할 수 있으며, 또한, 서버 네트워크 대역폭 이슈를 유발할 가능성이 높기 때문입니다.
로컬 저장소를 사용하는 것은 저장소로부터 물리적 거리가 멀어질수록 서비스 품질 저하를 피할 수 없기 때문에 CDN 기술이 필요했습니다. AWS S3는 원격 저장소 제공과 함께 AWS CloudFront라는 CDN 서비스를 연동할 수 있는 등의 장점이 있기에 적합한 선택이었습니다. Cloudfront는 S3에 대한 원본 파일 캐싱뿐만 아니라 브라우저 캐시 설정도 가능합니다. 현재 프로젝트 정책 상 이미지 수정은 허용하지 않기에 Cache의 기간을 충분히 크게 설정하여 응답 속도를 개선하였습니다.
1차 개발 단계에서는 Mybatis를 사용하여 개발하였으나 이후 JPA로 전환을 결정했습니다. JPA로 전환하면서 Entity, Repository, Service, Controller Layer 전반에 걸쳐 리팩토링을 진행하였습니다.
Mybatis를 사용하여 개발하는 것 자체에는 아무런 문제가 없었으나 사용하면서 몇 가지 불편함을 느꼈습니다.
- DB 테이블 생성 시마다 반복적인 SQL 쿼리 작성이 불가피한 점.
- 엔티티 필드에 변경 사항이 생길 시, 관련된 SQL 쿼리를 전부 수정해야 하는 점.
- mapper에서 각 쿼리마다 resultType/parameterType을 정의해야 하고, 파라미터를 하나하나 매핑해 주어야 하는 점.
JPA를 공부하면서, 개발 과정에서 막연하게 느꼈던 불편함이 어디에서 기인한 것인지 확실히 알게 되었습니다. 그리고 SQL Mapper와 ORM 기술 두 가지를 모두 경험해 보는 것이 개발자로서의 시야를 넓힐 수 있는 방법이 될 것이라는 확신이 들어 전환을 결정하였습니다. JPA를 적용하기 위해 기존 코드를 모두 리팩토링하였고, 훗날 프로젝트 규모가 커지고 복잡한 쿼리들이 많아지면 Mybatis와 함께 사용하는 것이 유리할 수 있다고 판단하여 Mybatis 코드는 삭제하지 않고 따로 모아두었습니다.
마이 페이지와 유저 페이지에서 해당 계정으로 게시한 전체 게시물을 조회할 수 있습니다. 이미지 기반의 소셜 미디어이기 때문에 게시물 노출 방식을 무한 스크롤 페이징 방식으로 구현하였습니다. 조회 결과, 다음 페이지의 존재 여부만 알면 다음 조회 요청 여부를 결정할 수 있기 때문에 Slice 객체를 사용하였습니다. 클라이언트의 비동기 요청은 async/await, fetch를 이용하여 구현하였습니다.
무한 스크롤 페이징은 팔로워 목록과 팔로우 목록을 확인할 때에도 사용하였습니다.
게시물은 게시("POSTING"), 임시저장("TEMPORARY_STORAGE"), 보관("PRIVATE"), 삭제("DELETED") 이렇게 네 가지 Status로 구분됩니다.
게시 상태
신규 포스팅 페이지에서 게시 버튼을 누르면 status 속성은 "POSTING"으로 저장되며, 생성된 Post의 상세 페이지로 이동합니다.
임시 저장 상태
임시저장 버튼을 누르면 해당 status 속성이 "TEMPORARY_STORAGE"로 저장되며, 이 경우 마이페이지로 이동됩니다. 임시 저장 게시물은 상단 네비게이션 바의 '임시 저장 목록' 버튼을 클릭하여 비동기 조회가 가능합니다.
보관 상태
게시물 수정 페이지에서 보관 버튼을 누르면 status 속성이 "PRIVATE"으로 변경되며 게시물 노출 영역에 노출되지 않습니다. 보관 게시물은 마이페이지의 '보관함' 탭에서 따로 확인할 수 있습니다.
삭제 상태
게시물을 삭제한 경우, 해당 게시물은 바로 "DELETED" 상태로 변경되어 게시물 목록에서 조회되지 않습니다. 관련 데이터는 "DELETED" 상태로 변경된 이후 비동기적으로 삭제됩니다.
async/await, fetch를 이용하여 댓글과 좋아요 기능을 구현하였습니다. 게시물 상세 페이지에서 댓글 작성을 할 수 있으며, 게시물에 대한 '좋아요'와 댓글에 대한 '좋아요' 모두 구현하였습니다.
기능 상세
댓글
- 게시물의 글 영역 아래에 바로 댓글이 작성일자 순으로 노출됩니다.
- 지나친 댓글 노출을 막기 위해 '댓글 더보기' 버튼을 클릭 시 다음 페이지를 불러옵니다.
- 게시글 상세 페이지 하단의 댓글 입력란을 통해 댓글을 등록할 수 있으며, 댓글이 입력되면 게시 버튼이 활성화 됩니다.
- 댓글 게시 버튼을 누르면 해당 댓글은 댓글 영역 최상단에 노출됩니다. 최상단에 노출된 댓글은 '댓글 더보기' 버튼으로 조회되지 않습니다. (중복 노출 방지)
- 댓글 작성자는 자신의 댓글의
...버튼을 통해 댓글 삭제가 가능합니다. - 댓글 작성자의 아이디를 클릭하면 해당 유저의 페이지로 이동합니다.
※댓글의 Entity는 대댓글 기능 구현을 고려하여 ParentComment와 연관관계 매핑이 되어 있지만, 대댓글 구현은 아직 진행하지 않은 상태입니다.
좋아요
- 유저가 게시물 또는 댓글의
좋아요버튼을 클릭하면 '좋아요' 개수가 갱신되고, 취소 시에도 갱신됩니다. - 또한 '좋아요' 버튼 클릭 시 '좋아요' 클릭한 유저 목록에서 조회가 가능합니다. 목록 내 유저 아이디를 클릭하면 해당 유저의 페이지로 이동합니다.
- 게시물에 대한 '좋아요' 현황은 댓글 입력 창 바로 위에 위치하고 있으며, 댓글에 대한 좋아요는 각 댓글 하단 영역에 위치합니다.
async/await, fetch를 이용하여 팔로우 기능을 구현했습니다. 다른 유저의 페이지에 방문하여 팔로우/언팔로우 할 수 있습니다. 유저 페이지 상단의 팔로워, 팔로우 영역을 클릭하면 팔로워, 팔로잉 목록을 확인할 수 있으며 목록에 노출된 유저들에 대해서도 팔로우/언팔로우가 가능합니다.
상세 기능
다른 유저 페이지에서의 팔로우 기능
- 다른 유저의 페이지 방문 후, 유저ID 우측
팔로우버튼을 클릭하면 팔로우 가능합니다. - 팔로우 버튼을 클릭하면
팔로우버튼은 사람 아이콘으로 바뀌고, 해당 유저의 팔로워 수가 갱신됩니다. - 해당 유저는 나를 팔로우 하지만, 나는 팔로우 하지 않는 상태일 때에는
맞팔로우버튼으로 노출됩니다. - 다른 유저의 페이지에서
팔로워,팔로우영역을 클릭하면 팔로워, 팔로잉 목록을 확인할 수 있으며 목록에 노출된 유저들에 대해서도 팔로우/언팔로우가 가능합니다. - 목록 내 유저 아이디를 클릭하면 해당 유저의 페이지로 이동합니다.
마이 페이지의 팔로워 목록
팔로워영역을 클릭하면 나를 팔로우 하는 유저 목록을 확인할 수 있습니다.- 팔로워 목록 우측의
삭제버튼을 클릭하면 해당 유저의 팔로우를 강제로 끊을 수 있으며, 삭제 시 팔로워 수가 갱신됩니다. - 팔로워 목록의 유저들 중에서 내가 팔로우 하지 않는 유저의 아이디 옆에는
팔로우버튼이 나타납니다. 이 버튼을 클릭하여 팔로우할 수 있습니다. 팔로우 버튼 클릭 시, 팔로워 수가 갱신됩니다. - 목록 내 유저 아이디를 클릭하면 해당 유저의 페이지로 이동합니다.
마이 페이지의 팔로우 목록
팔로우영역을 클릭하면 내가 팔로우 하는 유저 목록을 확인할 수 있습니다.- 팔로잉 목록 우측의
팔로잉버튼을 클릭하면팔로우버튼으로 변경되고언팔로우됩니다.팔로우버튼을 다시 클릭하면팔로잉버튼으로 변경되고팔로우가 됩니다. 단,팔로우버튼으로 바뀐 뒤 모달창을 벗어나면 해당 유저는 언팔로우 상태이기 때문에 팔로잉 목록에 노출되지 않습니다. 클릭 결과에 따라서 팔로우 수가 실시간으로 갱신됩니다. - 목록 내 유저 아이디를 클릭하면 해당 유저의 페이지로 이동합니다.
async/await, fetch를 이용하여 구현하였습니다. 상단 네비게이션바의 검색창을 통해 유저를 검색할 수 있으며, 최근 검색 기록을 확인할 수 있습니다.
기능 상세
유저 검색
검색창에 키워드를 입력하면, 유저ID 또는 닉네임에 해당 키워드가 포함된 유저들이 조회됩니다. 키워드가 변경되면 변경된 키워드에 맞춰 실시간으로 조회 결과를 불러옵니다. 조회 결과에 나타난 유저를 클릭하면 해당 유저의 페이지로 이동하며, 해당 유저는 최근 검색 기록에 저장됩니다.
최근 검색 기록
- 검색창을 클릭하고 아무런 키워드도 입력하지 않으면
최근 검색 기록을 보여줍니다. 가장 최근에 검색했던 순으로 정렬됩니다. - 최근 검색 목록의 유저를 클릭하면 해당 유저의 페이지로 방문하며, 최근 검색 날짜가 갱신됩니다.
- 유저 목록의 X 버튼을 클릭하면 해당 유저에 대한 검색 기록이 삭제되며,
모두 지우기버튼을 클릭하면 최근 검색 기록이 모두 삭제됩니다.
이 유저 검색 기능은 SQL의 LIKE문을 이용하여 구현하였고, 개발 단계에서 아무런 문제 없이 잘 동작했습니다. 하지만 프로젝트에 사용한 모든 쿼리들에 대해 실행계획을 확인하는 과정에서 성능 이슈로 이어질 수 있는 부분을 확인하였습니다.
LIKE %Keyword% 쿼리는 인덱스를 활용하지 못 하고 Full Table Scan을 하기 때문입니다. 이와 같은 쿼리는 유저 수가 많아지면 장애로 이어질 가능성이 높기에 수정이 필요하다고 판단했습니다. 이에 대한 내용은 개발 이슈 항목에서 자세히 다루고자 합니다.
'마이 페이지/유저 페이지'의 '유저 게시물 목록' 응답속도 향상을 위해 Redis Cache를 적용했습니다.
특정 유저의 게시물 목록에 대한 캐시는 다소 애매하게 보일 수 있습니다. 일반적인 유저의 게시물 목록이라면 Cache Hit Rate는 매우 낮을 수 밖에 없기 때문입니다. 그러나 방문자가 매우 많은 인플루언서의 게시물 목록이라면 충분히 의미 있는 Cache Hit Rate을 얻을 수 있다고 판단하여 적용하였습니다.
본 프로젝트에서 설정한 캐시의 TTL은 5분입니다. 캐시 히트율을 높이기 위해서는 TTL을 길게 설정하는 것이 좋을 수 있지만, 캐시 히트율이 낮은 일반 유저들에 대한 캐시가 오랜 시간 유지되는 것은 메모리 효율을 저하시키기 때문에 너무 길게 설정하는 것은 좋지 않다고 판단했습니다. 또한, 인플루언서의 경우 캐시가 만료되더라도 곧 다시 캐싱될 확률이 높기 때문에 적당한 시간이라고 생각합니다.
새로운 게시글이 업로드 되거나, 목록 내 게시물 상태가 변경(비공개 또는 삭제)되는 경우, 실제 데이터와 캐시 데이터가 다를 수 있습니다. 하지만 너무 잦은 동기화는 캐시 성능을 저하시키기 때문에 캐시 삭제의 기준을 정했습니다. 캐시 삭제는 자신의 게시글 목록에 대해서만 이루어집니다.
로그인 유저가 자신의 게시물 목록을 조회하는 경우
- 캐싱 : 초기 조회 목록(첫 페이지)만 캐싱
- 삭제 : 신규 포스팅 또는 게시물 상태 변경이 있을 때 캐시 삭제
로그인 유저가 타인의 게시물 목록을 조회하는 경우
- 캐싱 : 게시물 목록의 모든 페이지를 캐싱
- 삭제 : 별도의 삭제 명령 없음
타인의 게시물 목록에서 상태가 변경되어 접근할 수 없는 게시물에 대해서는 '관련 에러 페이지'로 이동하고, TTL 시간(5분)이 지나면 갱신되기 때문에 큰 문제는 되지 않는다고 판단했습니다. 다만, 신규 포스팅이나 게시물 상태 변경이 자신의 게시물 목록에 바로 반영되지 않는 것은 문제가 있다고 판단했습니다. 따라서 자신의 게시물 목록을 조회하는 경우에는 첫 페이지만 캐싱하도록 하고, 목록에 변경이 있을 때는 캐시를 삭제하도록 구현하였습니다.
개발 과정에서 중요도가 높다고 판단한 이슈들에 대해서는 보다 자세히 기술하였습니다.
기능 개발 항목의 유저 검색 파트에서 작성한 바와 같이 LIKE %Keyword% 쿼리의 Explain 결과, Full Table Scan으로 조회하고 있음을 확인하였습니다. 유저 데이터 수가 십만 단위, 백만 단위를 넘기는 환경에서 풀 테이블 스캔은 이슈를 야기할 수 있기에, 이에 대한 해결책으로 MySQL의 Full Text Search를 도입하였습니다.
Full Text Search를 적용하고 대용량 데이터에 대한 성능 테스트를 진행했으며, 검색어에 따른 성능 편차를 확인하였습니다. 그리고 성능 테스트 결과, FTS는 LIKE문에 비하여 빠른 검색 성능을 보이기는 하지만 대용량 데이터에 대해서는 성능적 한계로 사용하기 어렵다는 결론을 내렸습니다. 특히 동일한 인덱스를 갖는 데이터가 많거나, 길이가 긴 검색어에 대한 성능은 LIKE문에 비해 빠르지도 않으며 응답을 받을 수 없는 현상이 나타나기 때문입니다.
Full Text Search
MySQL에서 사용 가능한 FTS의 인덱싱 기법으로는 크게 Stopword 방식과 N-gram 방식이 있는데, 일부 키워드만 입력해도 검색 결과를 보여 주어야 하기에 N-gram 인덱싱 방식을 선택했습니다. N-gram token size는 2로 설정하였고, Fulltext Index는 'user_id' 컬럼과 'nickname' 컬럼을 묶어서 생성하였습니다.
Boolean Mode
Natural Language Mode는 검색어에서 추추한 키워드(토큰)들의 조회 결과를 합집합으로 구성하여 최종 결과를 도출하는 한편, Boolean Mode는 거기에 키워드(토큰)들의 Sequence까지 고려하여 최종 일치 여부를 검증합니다.
Natural Language Mode는 검색어에서 추출한 각각의 토큰과 일치하는 인덱스를 갖는 레코드를 모두 조회해 오기 때문에 Boolean Mode를 적용하여 검색의 정확성을 높힐 수 있었습니다. 이제 Fulltext Search를 통해 어느 정도 기대했던 결과를 얻을 수 있게 되어, 'Member' 테이블에 더미 데이터를 삽입하며 LIKE %Keyword% 쿼리와의 성능 비교 테스트를 진행하였습니다.
MySQL의 Procedure를 이용하여 더미 데이터를 삽입하며 테이블의 레코드 수에 따라 검색 성능이 어떠한 차이를 보이는지 테스트를 진행했습니다. 테스트는 데이터가 1만 개, 10만 개, 20만 개, 50만 개, 70만 개, 110만 개 일 때 LIKE 쿼리와 FTS 쿼리의 조회 속도를 측정하는 방식으로 진행하였습니다. 또한, 테스트는 각각 10회를 연속 조회한 뒤 초반 2회의 조회 결과를 제외한 8회 분의 결과입니다. 즉, 3회차를 1회차로 간주하여 총 8회의 시행 결과를 얻었습니다. 테스트 결과는 아래와 같습니다.
0. 테스트 검색어: 'er57'
1. LIKE 쿼리 속도
| LIKE %word% | 1만 개 | 10만 개 | 20만 개 | 50만 개 | 70만 개 | 110만 개 |
|---|---|---|---|---|---|---|
| 1회차 | 13ms | 151ms | 253ms | 449ms | 783ms | 989ms |
| 2회차 | 12ms | 154ms | 238ms | 451ms | 744ms | 981ms |
| 3회차 | 11ms | 162ms | 244ms | 445ms | 746ms | 982ms |
| 4회차 | 11ms | 151ms | 268ms | 442ms | 737ms | 979ms |
| 5회차 | 11ms | 151ms | 240ms | 432ms | 728ms | 988ms |
| 6회차 | 10ms | 160ms | 243ms | 432ms | 725ms | 981ms |
| 7회차 | 10ms | 160ms | 218ms | 436ms | 737ms | 992ms |
| 8회차 | 11ms | 160ms | 215ms | 436ms | 722ms | 992ms |
| 평균 | 11ms | 155ms | 240ms | 440ms | 740ms | 986ms |
2. Fulltext Search 속도
| Full Text Search | 1만 개 | 10만 개 | 20만 개 | 50만 개 | 70만 개 | 110만 개 |
|---|---|---|---|---|---|---|
| 1회차 | 15ms | 95ms | 180ms | 193ms | 197ms | 199ms |
| 2회차 | 15ms | 89ms | 177ms | 199ms | 192ms | 213ms |
| 3회차 | 16ms | 88ms | 184ms | 195ms | 193ms | 197ms |
| 4회차 | 14ms | 88ms | 186ms | 191ms | 193ms | 201ms |
| 5회차 | 13ms | 99ms | 182ms | 186ms | 193ms | 199ms |
| 6회차 | 14ms | 99ms | 180ms | 189ms | 197ms | 202ms |
| 7회차 | 13ms | 99ms | 179ms | 184ms | 200ms | 196ms |
| 8회차 | 13ms | 99ms | 188ms | 182ms | 193ms | 199ms |
| 평균 | 14ms | 88ms | 182ms | 190ms | 195ms | 201ms |
3. LIKE 문 vs Fulltext Search
| 검색 방법 | 1만 개 | 10만 개 | 20만 개 | 50만 개 | 70만 개 | 110만 개 |
|---|---|---|---|---|---|---|
| LIKE %word% | 11ms | 155ms | 240ms | 440ms | 740ms | 986ms |
| Full Text Search | 14ms | 88ms | 182ms | 190ms | 195ms | 201ms |
기대했던 대로 테이블의 레코드 수가 많아질수록 Fulltext Search의 속도가 압도적으로 빠르다는 결과를 도출할 수 있었습니다. 하나의 검색어에 대해 테이블 크기와 조회 속도의 연관성을 테스트한 것이므로, 이후 FTS가 검색어와 무관하게 일정한 성능을 유지할 수 있는지 검증을 시도했습니다. 그러나 여기서 더 큰 이슈가 발생했습니다.
Fulltext Search가 앞선 테스트에서는 준수한 성능을 보이는듯 하였으나 어떤 키워드들에 대해서는 Full Table Scan을 하는 LIKE문보다도 성능이 현저히 떨어지는 현상이 발생하였습니다. 예를 들어, faker라는 키워드로 조회했을 때 결과를 응답하기까지의 시간은 4000 ms을 넘겼고, chihiro 또는 neighbor 등 키워드 길이가 긴 검색어에 대해서는 분 단위를 넘어 아무리 기다려도 조회 결과를 응답하지 않는 현상까지 발생하였습니다. 특히, 조회 결과를 응답하지 못하는 쿼리에 대해서는 Explain 쿼리에 대해서도 응답하지 않았습니다.
이슈의 원인을 파악하기 위해 가장 먼저 아래 사항들을 체크해 보았습니다.
-
MySQL의 Fulltext Search와 Boolean 모드를 잘못 사용한 부분은 없는지 MySQL 8.0 공식 매뉴얼을 확인하였고, 필요한 기능들이 어떻게 동작하는지 꼼꼼히 확인해 보았으나, 잘못 사용하고 있거나 의도와 다르게 사용하고 있는 부분은 없었습니다.
-
어떠한 이유로 Fulltext Index 자체에 문제가 생긴 것은 아닌지 Fulltext Index를 삭제 후 재생성하기도 하고, 테이블을 새로 만들어 데이터 삽입부터 다시 진행하여 테스트해 보았으나 동일한 현상이 발생했습니다.
-
InnoDB의 Default Stopword로 인덱스가 적절하게 생성되지 못한 것은 아닌지 Stopword 설정을 Off 하고 Index를 재생성하였으나 동일한 현상이 발생했습니다.
-
두 개의 컬럼(user_id, nickname)에 대해 Fulltext Index를 생성하는 것이 성능 저하를 일으키지는 않는지 개별 컬럼에 대해 Fulltext Index를 생성하여 조회해 보았으나 동일한 현상이 발생했습니다.
여러 방면으로 테스트를 진행해 보면서 Boolean Mode의 Syntax를 적절하게 이용하여 조회 성능을 개선할 수는 있었으나 서비스에 적용할 수 있을 수준은 되지 못했습니다. 결정적으로 조회 결과를 응답 받지 못했던 키워드들에 대해서는 여전히 같은 현상이 발생했기 때문입니다. 하지만 문제가 발생하는 키워드의 공통점은 명확하게 알 수 있었습니다.
문제 발생 키워드의 공통점
- 검색어로부터 추출한 토큰과 동일한 인덱스를 갖는 레코드가 많은 경우
- 검색어의 길이가 긴 경우 (6자 이상의 검색어)
이번 테스트를 통해서 MySQL의 Fulltext Search는 데이터 테이블의 크기가 그리 크지 않은 경우에는 잘 동작하지만, 데이터 테이블의 크기가 커질수록 키워드에 따라 성능의 차이가 크게 나타남을 알 수 있었습니다. 다른 사례들을 찾아 보았으나 MySQL의 Fulltext Search에 대한 긍정적인 국내 후기들은 대체로 학습용으로만 사용해 본 사례들이 많았던 것 같습니다. MySQL 공식 문서에서도 길이가 긴 검색어에 대해서 Boolean Mode의 성능이 저하될 수 있음을 언급한 바가 있고, 해외 사용자들의 사례를 통해서도 100만 건 이상의 대용량 데이터에 대해 심각한 성능 이슈를 경험한 내용을 찾아볼 수 있었습니다. 이는 MySQL FTS가 가지는 성능적 한계라고 생각합니다.
MySQL의 Fulltext Search는 분명 성능적 이슈가 존재하지만, 소규모 서비스에 대해서는 LIKE문에 비해 준수한 성능을 보이는 것이 사실이기 때문에 서비스 규모와 상황에 따라서는 적절한 선택일 수 있다고 생각합니다.
현재 저의 프로젝트에서는 다시 LIKE문을 이용하여 검색 기능을 구현해놓았으나, 시간적 여유가 있었다면 다른 검색엔진과 연동하여 검색 성능을 개선해 보았을 것 같습니다. 물론, 다른 검색 엔진을 연동하는 것은 러닝 커브 문제와 동기화 문제 등 또다른 고려 사항이 발생할 수 있기 때문에 상황에 따라 적절한 선택을 해야 한다고 생각합니다.
검색 성능 이슈는 이번 프로젝트를 진행하며 가장 힘들었던 경험이었지만 그만큼 값진 경험이었습니다. 안정적인 서비스를 제공하기 위해서 개발자는 어떤 고민을 하고, 어떤 선택을 해야 하는지 배울 수 있었던 계기가 되었기 때문입니다.
게시물 정보를 담고 있는 Post 엔티티는 총 4개의 다른 엔티티와 연관 관계를 맺고 있습니다.
- PostImage
- PostLiker
- PostComment
- PostCommentLiker
위 네 개의 엔티티는 모두 Post 엔티티에 종속적인 엔티티이기 때문에 Post 삭제 시, 관련 데이터 또한 일괄적으로 삭제하고자 했습니다. 이를 위해 JPA의 orphanRemoval 속성을 이용하였으나, 쿼리가 지나치게 많이 나가는 이슈가 발생하였습니다. orphanRemoval = true로 설정하는 경우, orphan 객체들이 일괄적으로 삭제 되는 것이 아니라 단건으로 삭제되어 orphan 객체의 수만큼 삭제 쿼리가 발생하기 때문입니다. 아래는 Post 객체 하나를 삭제 할 때 발생하는 삭제 쿼리의 수입니다.
- PostImage 삭제 쿼리 (최대 10번)
- PostCommentLiker 삭제 쿼리 (PostComment 1개 당 N번)
- PostComment 삭제 쿼리 (M번)
- PostLiker 삭제 쿼리 (K번)
- Post 삭제 쿼리 (1번)
- 전체 쿼리 수 = N X M + M + K + 1 (최대 개수가 고정되어 있는 PostImage 제외)
이러한 방식은 유명 인플루언서의 인기 게시글을 삭제하는 것처럼 수십만 개 이상의 게시글 좋아요, 댓글, 댓글 좋아요를 보유하고 있는 게시글을 삭제하는 상황에서 장애로 이어질 수 있다고 판단하였습니다.
삭제할 Post 객체와 연관된 데이터를 Bulk Delete 하기 위해 Spring Data Jpa의 @Query 애너테이션 기능을 이용했습니다. parameter로 Post 객체를 넘겨주었고, Bulk 연산은 Persistence Context를 무시하고 진행되기 때문에 @Modifying 애너테이션의 clearAutomatically, flushAutomatically 속성을 true로 설정하였습니다.
//PostImageRepository
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query("delete from PostComment c where c.post = :post")
void deleteAllByPost(@Param("post") Post post);
//PostCommentLikerRepository
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query("delete from PostCommentLiker l where l.postComment.id in :commentIds")
void deleteInCommentIds(@Param("commentIds") List<Long> commentIds);이와 같은 방법을 통해 각 Entity에 대해 Bulk Delete를 구현하였습니다.
Bulk Delete를 하더라도 유저 참여도가 높은 게시글(매우 많은 수의 댓글, 좋아요)을 삭제하는 경우에는 여전히 문제가 남아있었습니다. 모든 데이터의 삭제가 완료될 때까지 유저에게 응답을 주지 못하기 때문입니다. 이를 해소하기 위해 이 모든 삭제 로직은 비동기로 처리하였습니다.
Spring Framework의 ThreadPoolTaskExecuter로 게시글 삭제 전용 Thread Pool을 생성하였고, 삭제 메서드에 @Async 애너테이션을 통해 해당 Therad Pool을 설정했습니다.
Service Layer의 로직은 아래와 같이 구현하였습니다.
@Transactional
@Async(value = "postAsyncThreadPool")
public void deletePost(Long loginMemberId, Long postId) throws Exception {
Member member = memberRepository.findById(loginMemberId).orElseThrow(IllegalArgumentException::new);
Post post = postRepository.findById(postId).orElseThrow(IllegalArgumentException::new);
//1. PostImage 삭제
postImageRepository.deleteAllByPost(post);
Pageable pageable = PageRequest.of(0, 1000);
int numberOfComments = postCommentRepository.countByPost(post);
//2. PostCommentLiker 삭제
for (int i = 0; i < numberOfComments / 1000 + 1; i++) {
//PostComment Id 리스트를 이용하여 PostCommentLiker 삭제
List<Long> commentIdList = postCommentRepository.findByPost(post, pageable).stream()
.map(PostComment::getId)
.collect(Collectors.toList());
postCommentLikerRepository.deleteInCommentIds(commentIdList);
}
//3. PostComment 삭제
postCommentRepository.deleteAllByPost(post);
//4. PostLiker 삭제
postLikerRepository.deleteAllByPost(post);
//5. Post 삭제
postRepository.delete(post);
log.info("DELETE POST: userId=[{}], deletedPostId=[{}]", member.getUserId(), postId);
}비동기 처리를 통해 Client에 빠르게 응답이 가능하게 되었지만, 모든 데이터의 삭제가 완료되기 전까지는 게시글 목록에서 삭제가 진행 중인 게시글이 노출되고 있었습니다. 따라서 게시글의 상태를 나타내는 Enum인 StatusType에 'DELETED' 상태를 추가하고, Client에서 게시글 삭제 요청이 오면 데이터 삭제를 진행하기 전에 게시글의 status를 DELETED로 변경하여 게시글 목록의 노출을 방지하였습니다.
위와 같은 방법을 통해 삭제 쿼리 수를 다음과 같이 개선할 수 있었습니다.
- PostImage 삭제 쿼리: 1회
- PostCommentLiker 삭제 쿼리: N / 1000 회; N은 PostComment 개수
- PostComment 삭제 쿼리: 1회
- PostLiker 삭제 쿼리: 1회
- Post 삭제 쿼리: 1회
- 전체 쿼리 수: n + 4
현재 프로젝트에서는 Hard Delete 방식을 사용하였으나, 실무에서는 대부분 Soft Delete 방식을 사용하는 것으로 알고 있습니다. 저 역시도 삭제한 데이터를 복원할 경우를 대비하여 Soft Delete 방식으로 구현하는 것을 염두에 두고 있었습니다. 그러나 부득이하게 Hard Delete를 사용해야 하는 경우가 생긴다면 어떤 식으로 이슈를 해결할 수 있을지 고민하는 과정에서 배울 수 있는 부분들이 있다고 판단하였기에 Hard Delete 방식을 선택하였습니다.
첫 프로젝트였기 때문에 개발 시점에는 멀티 쓰레드 환경에 대한 이해가 부족했고, 동시성 이슈를 고려하지 않은 채 개발을 진행했었습니다.
실제로 개발 시점에는 Transaction만 걸어 두면 동시성 이슈가 발생하지 않을 것이라고 낙관적으로 생각했었습니다. 그러나 이후에 진행한 API 개발 과제에서 동시성 이슈를 경험하였고, 이를 해결하는 과정에서 제가 잘못 알고 있던 부분에 대해 정확하게 이해할 수 있었습니다.
예외 처리를 해야한다는 것은 이해하고 있었지만, 그 필요성을 정확하게 이해하지는 못했었습니다. 또한, 예외 처리 방법에 대한 이해도 부족했습니다. 그렇기 때문에 모든 예외 상황을 하나의 에러페이지로 해결하고자 하였고, 예외 케이스도 제대로 잡아내지 못했습니다. 예외 상황에 대해 깊게 고민하지 않은 결과, 프로젝트가 종료 후 자잘한 버그들이 발견되었습니다.
이를 교훈으로 삼아 이후에 진행한 API 개발 과제에서는 Custom Response와 Custom Exception을 만들어 모든 예외 케이스들을 꼼꼼하게 처리할 수 있었습니다. 또한, 부족했던 테스트 코드 역시 개선하여 계층별 단위 테스트 및 통합 테스트를 진행하였습니다.
첫 프로젝트였기 때문에 부족한 점은 많았지만, 웹 개발의 전반적인 과정에 대한 이해도를 높일 수 있었다는 점에서 좋은 경험이었습니다.
유저의 요청을 받아서 처리하는 일련의 과정을 개발하면서, 프로젝트 전에 학습했던 Controller/Service/Repository 각 계층의 역할과 Spring MVC의 동작 원리를 직접적으로 경험함으로써 확실하게 이해할 수 있었습니다. 또한, Spring Framework에 대해서도 좀 더 잘 이해할 수 있게 되었습니다.
가장 좋았던 것은 책이나 강의로 공부할 때는 이해할 수 없었던 많은 부분들을 이해할 수 있게 되었다는 것입니다.
프로젝트를 마무리하는 시점에서 더욱 크게 체감했던 부분이지만, 배운 점 중에서 가장 중요한 부분이라고 생각합니다.
서버 개발자에게 특히 중요한 부분이 바로 퍼포먼스와 관련된 부분이라는 것을 배울 수 있었습니다. 프로젝트 초반에는 배운 내용을 적용하고 기능을 구현하는 것에 집중했다면, 후반부로 갈수록 실 배포 환경에서 성능 이슈가 발생하지 않도록 하려면 어떻게 해야 할까를 고민하려고 노력했습니다. 실제로 그 과정에서 이미지 파일의 응답 속도를 개선하기 위해 AWS S3와 CloudFront를 연동하기도 했고, Redis Cache를 통해서 일부 데이터에 대해 캐시를 적용하기도 하였습니다. 또한, MySQL 실행 계획을 통해 쿼리의 성능을 확인할 수 있었으며, 검색 성능 이슈 해결을 위한 다양한 고민과 시도를 해볼 수 있었습니다.
이렇듯 이번 프로젝트를 통해 안정적인 서비스를 만들고 성능을 개선하기 위해 어떤 고민을 해야 하는지, 개발 중 맞닥뜨린 이슈를 해결하기 위해 어떤 고민을 해야 하는지 배울 수 있었습니다. 이런 경험은 제가 서버 개발자로서 한 단계 더 성장할 수 있는 발판이 되었다고 생각합니다.
퍼포먼스 테스트와 함께 프로젝트 마무리 시점에 크게 체감했던 부분입니다. 그리고 동시에 아쉬움이 많은 부분이기도 합니다.
테스트 코드를 통해서 미처 생각하지 못했던 버그를 찾아낼 수 있었고, 제가 생각한 방향대로 잘 동작하는지 검증하는 과정을 경험함으로써 테스트 코드가 왜 중요한지 몸소 배울 수 있었습니다. 다만, 당시에는 확실하게 이해하고 작성하지 못했기 때문에 테스트 코드 자체에 부족한 점이 많았으리라 생각됩니다. 따라서 이 부분에 대해서는 이후에 진행한 API 개발 토이 프로젝트를 통해 보완하였습니다.
