最近启动了一个新项目 eyasliu/electron-startkit,在打包构建上有一些研究,主要是针对于 windows 程序的打包,其他平台的构建方式没有深入
试过了两个打包工具,
- electron-packager
- electron-builder
另外对优化打包后的体积优化有一些研究
这个工具做的事情很单一:构建好之后把程序放在一个文件夹下,文件夹的 [应用名].exe 就是应用启动入口,我们写的代码都被放到了 resource/app[.asar] 里面。这就是这个工具做的全部事情。
尽管做的事情单一,但是其提供了很多可选项
正是因为它的功能比较单一,所以用法也很简单,而且构建好的包很通用,可以配合其他工具一起使用,比如 electron-winstaller 或者 electron-wix-msi 进一步的打包成为 msi 安装包, 单个 exe 执行文件等等
使用方法:
# 命令行形式:
# electron-packager <sourcedir> <appname> --platform=<platform> --arch=<arch> [optional flags...]
electron-packager . DesktopApp --platform=win32 --arch=x64 --out=build --icon=icons/icon --asar
// 使用 js api
const packager = require('electron-packager')
packager({
arch: process.env.ARCH_TARGET || 'x64',
asar: true,
dir: path.join(__dirname, './'),
icon: path.join(__dirname, './icons/icon'),
out: path.join(__dirname, './build'),
overwrite: true,
platform: process.env.BUILD_TARGET || 'all'packager({
}).then(() => {
console.log('build done!')
}).catch(err => {
console.error('build error!!!')
})这里给出一点配置的建议:
- asar: true 设置为 true 可以使自己写的代码经过加密并打包到一个app.asar 文件中
- prune: true 设置为 true,只会将 package.json 的 dependencies 依赖包复制到 resources/app, 否则会将devDependencies 的依赖包也放进 resources/app 下面。当然,在最新版它默认就是 true[/斜眼笑]
配合其他工具二次打包
配合 electron-winstaller 打包成 msi
更多更详细配置见:https://github.com/electron/windows-installer#usage
const packager = require('electron-packager')
const electronInstaller = require('electron-winstaller');
packager({ /*上一步的配置*/}).then(() => {
appDirectory: './build/[your app name]-[platform]-[arch]', // 上一步使用 packager 打包好的目录
outputDirectory: './build/msi-installer',
authors: 'My App Inc.',
msi: true // 指定要 msi
}).then(() => {
console.log('build msi installer done')
})这样打包好之后 setup.exe 就是单个 exe 执行文件,setup.msi 就是windows 安装文件。
配合 electron-wix-msi 几乎和 electron-winstaller 一模一样,只是配置项有些不太一样。
官方网站与官方文档:https://www.electron.build/
electron-builder 这个工具就很强大了,几乎涵盖了构建所需要的大部分功能。官方的描述
A complete solution to package and build a ready for distribution Electron, Proton Native or Muon app for macOS, Windows and Linux with “auto update” support out of the box.
一个完整的解决方案,可以为macOS,Windows和Linux打包并构建一个可供分发的 Electron,Proton Native 或Muon应用程序,并提供开箱即用的“自动更新”支持。
所以它不但提供了构建功能,还提供了自动更新的功能。下面先看看它的构建功能
构建包
相关链接:
- https://www.electron.build/configuration/configuration
- https://www.electron.build/configuration/win
- https://www.electron.build/configuration/nsis
使用步骤:
- 编写配置文件:
- 在
package.json 中加一个 build 字段,里面就是放它的配置项
- 或者通过指定
--config <path/to/yml-or-json5-or-toml> 使用对应的配置文件,如果不指定,默认是 electron-builder.json
- 编写配置,请点击上方的相关链接查看,贴出一份我的配置
{
"productName": "Desktop APP",
"appId": "Personal.DesktopApp.Startkit.1.0.0",
"copyright": "Copyright © 2018 ${author}",
"directories": {
"output": "build"
},
"asar": true,
"artifactName": "${productName}-${version}.${ext}",
"compression": "maximum",
"files": [
"dist/electron/**/*"
],
"dmg": {
"contents": [
{
"x": 410,
"y": 150,
"type": "link",
"path": "/Applications"
},
{
"x": 130,
"y": 150,
"type": "file"
}
]
},
"mac": {
"icon": "build/icons/icon.icns"
},
"win": {
"icon": "build/icons/icon.ico",
"target": "nsis",
"legalTrademarks": "Eyas Personal"
},
"nsis": {
"allowToChangeInstallationDirectory": true,
"oneClick": false,
"menuCategory": true,
"allowElevation": false
},
"linux": {
"icon": "build/icons"
},
"electronDownload": {
"mirror": "http://npm.taobao.org/mirrors/electron/"
}
}部分配置项解读
配置项分为 公共部分 和 特定平台部分,公共部分主要是设置程序通用的选项
公共部分
- appId 必须要设置,是一个程序的唯一标识符,还与后面的程序自动更新有关
- asar 设置为 true 可以把自己的代码合并并加密
- productName 指定一下程序名称,这个对于后面创建桌面快捷方式和开始菜单都有关系
- compression 压缩级别,如果要打包成安装包的话建议设为 maximum 可以使安装包体积更小,当然打包时间会长一点点
win 特定部分
这里只讲 windows 相关的构建,特地说下windows的配置
- target 打包的类型,决定了打包后的文件类型
- nsis 打包成一个独立的 exe 安装程序,下方会详细说nsis配置
- nsis-web web安装程序(其实我还有些懵这是什么),总之打包之后生成一个 exe 文件和一个 7z 压缩包,双击 exe 会直接启动应用
- portable 打包成单个 exe 独立执行程序,双击该 exe 直接启用应用,如果要用这个,请将 compression 设置为 store,不然你的应该会启动的非常慢
- appx 打包成 Windows Store(windows 应用商店)的程序,只有 windows 10 才可用
- msi 打包成 msi 安装程序
- squirrel 使用 squirrel 打包,该工具已不再维护,但是还可用,建议使用nsis替代
- 7z 压缩成 7z 文件,解压后可双击打开
- zip 压缩成 zip 文件,解压后可双击打开
- tar.xz 压缩成 tar.xz 文件,解压后可双击打开
- legalTrademarks 公司名称
所以如果想要程序可以安装,请选择 msi 或者 nsis,如果想要作为独立执行程序,使用选择 portable
下面说下nsis的配置
nsis
对于打包 windows 程序来说,nsis这个配置是最主要的,nsis 本身是一个 Windows 系统下安装程序制作程序 http://nsis.sourceforge.net
这里对于它的一些配置特地说明
- oneClick 建议为 false,可以让用户点击下一步、下一步、下一步的形式安装程序,如果为true,当用户双击构建好的程序,自动安装程序并打开,即:一键安装(one-click installer)
- perMachine 安装的时候是否为所有用户安装
- allowToChangeInstallationDirectory 建议为 true,是否允许用户改变安装目录,默认是不允许
- installerIcon uninstallerIcon installerHeader installerHeaderIcon installerSidebar uninstallerSidebaruninstallDisplayName 定制安装与卸载的图标和界面
- displayLanguageSelector 安装的时候是否让用户选择语言
- createDesktopShortcut 是否创建桌面图标
- createStartMenuShortcut 是否在开始菜单创建入口
- menuCategory 是否在开始菜单创建一个分类入口
- include 指定要包含 nsis 的脚本,基于内置的nsis脚本进一步扩展
- script 指定自定义使用 nsis 的脚本,完全自己控制nsis 的打包
include nsis
相关文档:
- nsis 官网 http://nsis.sourceforge.net/Main_Page
- electron-builder 的内置nsis 脚本 https://github.com/electron-userland/electron-builder/tree/master/packages/app-builder-lib/templates/nsis
- electron-builder 自定义 nsis 说明: https://www.electron.build/configuration/nsis#custom-nsis-script
如果你要自己完全自定义 nsis 脚本,那么你应该并不需要 electron-builder,所以这里只接受自定义部分 nsis 脚本,首先将 nsis 配置的 include 指定脚本
{
"nsis": {
"oneClick": false,
"include": "./builder.nsi",
}
}
以下是对官方文档简单表达
- electron-builder 暴露 customHeader, preInit, customInit, customUnInit, customInstall, customUnInstall, customRemoveFiles,这几个区块
- customHeader 自定义安装、卸载界面的头部
- preInit 在安装前会执行脚本
- customInit 安装初始化
- customUnInit 卸载初始化
- customInstall 安装脚本
- customUnInstall 卸载脚本
- customRemoveFiles 重写卸载的时候要移除哪些文件
- 定义了 BUILD_RESOURCES_DIR 和 PROJECT_DIR 这两个变量
MUI2.nsh Modern UI 2.0
中文文档:http://www.ccav1.com/mui2/
其实electron-builder 内部引入了 mui2 作为定制安装界面,如果我们要定制安装界面,自然离不开它,比如要加个欢迎步骤和许可协议不走,只需要声明一下
!include "MUI2.nsh"
; 欢迎页面
!insertmacro MUI_PAGE_WELCOME
; 许可协议页面
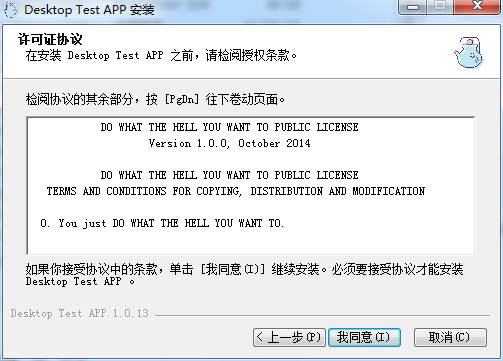
!insertmacro MUI_PAGE_LICENSE "${BUILD_RESOURCES_DIR}\resources\LICENCE.txt"然后就有欢迎界面也协议页面了
示例
贴出一份我的nsi脚本作为例子
; 引入 Modern UI 2.0
!include "MUI2.nsh"
; ; MUI Settings
!define MUI_ABORTWARNING
; 欢迎页面
!insertmacro MUI_PAGE_WELCOME
; 许可协议页面
!insertmacro MUI_PAGE_LICENSE "${BUILD_RESOURCES_DIR}\resources\LICENCE.txt"
; 初始化开始菜单
!define PRODUCT_STARTMENU_REGVAL "NSIS:StartMenuDir"
!define MUI_STARTMENUPAGE_NODISABLE
Var StartMenuFolder
!insertmacro MUI_PAGE_STARTMENU Application $StartMenuFolder
ShowInstDetails show
ShowUnInstDetails show
SpaceTexts show
; 安装脚本
!macro customInstall
; 写入开始菜单
CreateDirectory "$SMPROGRAMS\$StartMenuFolder"
!insertmacro MUI_STARTMENU_WRITE_BEGIN Application
CreateShortCut "$SMPROGRAMS\$StartMenuFolder\${PRODUCT_NAME}.lnk" "$INSTDIR\${PRODUCT_NAME}.exe"
CreateShortCut "$SMPROGRAMS\$StartMenuFolder\卸载 ${PRODUCT_NAME}.lnk" "$INSTDIR\Uninstall ${PRODUCT_NAME}.exe"
!insertmacro MUI_STARTMENU_WRITE_END
!macroend
; 卸载脚本
!macro customUnInstall
; 删除开始菜单
!insertmacro MUI_STARTMENU_GETFOLDER Application $StartMenuFolder
Delete "$SMPROGRAMS\$StartMenuFolder\${PRODUCT_NAME}.lnk"
Delete "$SMPROGRAMS\$StartMenuFolder\卸载 ${PRODUCT_NAME}.lnk"
RMDir "$SMPROGRAMS\$StartMenuFolder"
!macroend
命令行的使用
先去这里看看命令行的所有选项 https://www.electron.build/cli
在使用命令行工具的时候必须要指定 平台(platform) 和 架构(arch),它还提供了快捷选项,比如 --linux --win --x64 --ia32 等等,这里我建议再指定一下 --config 使用对应的构建配置文件
# 默认就是 build 命令
electron-builder --config scripts/builder.json --win --64
#等价于
electron-builder build --config scripts/builder.json --win --64
js API
尚不明确,无文档
构建包体积优化
包体积的优化有以下几点:
package.json
在打包的过程中,electron 会读取package.json 的 dependencies 依赖列表,并使用该列表重新解析依赖,将解析到的依赖复制到 resources/app 中,也就是我们的代码资源包,所以优化体积最主要就是减小 node_modules 的体积,那么 dependencies 的依赖尽量少,那么 node_modules 体积就会小,所以尽可能的把不必要的依赖包不要放到 dependencies,而是放到 devDependencies. 尤其安装的时候注意
npm install -D xxx
npm install --save-dev xxx
yarn add --dev xxx
webpack
使用 webpack 合并压缩代码,可以混淆代码并减小代码体积,在webpack的 externals 配置设置为 package.json 的 dependencies。在以后的编码中如果一个包你能确定它只有 js 文件用上了,就把它放到 devDependencies ,如果出了js 文件外还有其他二进制文件,就放到 dependencies。
比如 lodash 放到 devDependencies, sqlite3 因为包含有二进制文件就放到 dependencies。
// weback.config.js
const npmPackage = require('./package.json')
module.exports = {
// ...
externals: [ ...Object.keys(npmPackage.dependencies) ],
// ...
}至此,node_modules 的体积应该是大幅度减少了。
yarn autoclean
因为在构建过程中,解析好依赖后是直接复制当前目录的 node_modules 下面的包,那么用 yarn autoclean 命令自动清理掉 node_modules 下面没用的文件,比如 .md, .txt, doc/ 等等文件全清理掉,进一步优化 node_modules 体积
yarn autoclean --init
yarn autoclean
自动更新
官方文档: https://www.electron.build/auto-update
要使用自定更新功能,那么首先在配置文件中要配置一下 publish,你需要准备好一个静态服务器,你要有权限往静态服务器的目录上传文件,就这样
{
"publish": [
{
"provider": "generic",
"url": "http://localhost:8888/download/",
"channel": "latest"
}
],
}
- provider 使用哪种策略作为更新服务,这里指定用 generic,因为这是最简单最通用的
- url 静态服务器的url
- channel 频道,会决定检查更新的时候请求哪个文件,如果是 latest,就会请求 latest.yml
然后在main进程的入口文件加上代码
require("electron-updater").autoUpdater.checkForUpdatesAndNotify()如果按照上面的配置,那么更新流程是:
- 请求
${url}/${channel}.yml 文件,对比本地的客户端版本,如果没有新版本,什么都不做,否则下一步
- 请求
${url}/${latest.yml中定义的文件名} 下载好安装包
- 提醒用户新安装包下载好了,下次重启更新,或者立即更新
- 自动安装更新
每当构建好一个版本,把构建完后生成的 latest.yml 和安装包上传到那个静态服务器的目录,就可以实现版本更新了,如果你有兴趣,完全可以自己动手写个后端服务基于这个流程解锁更多姿势
其中上面的更新流程,你应该留意到了一切都是自动完成,如果想要自定义这些规则,可以这样
- 监听autoUpdater的事件,一有更新状态变化就会发事件
- error 检查更新错误
- checking-for-update 正在检查更新
- update-available 有新的可用更新
- update-not-available 没有可用的更新,也就是当前是最新版本
- download-progress 正在下载更新版,会有更新进度对象
- update-downloaded 新安装包下载完成
- 还有一些 api 可以控制流程
- .checkForUpdates() 执行一次检查更新
- .checkForUpdatesAndNotify() 执行一次检查更新,如果有新的可用更新,还会自定弹出一个自带的通知提示告诉用户有新的更新
- .downloadUpdate(cancellationToken) 执行下载安装包
- .quitAndInstall(isSilent, isForceRunAfter) 退出应用并安装更新, isSilent 是否静默更新,isForceRunAfter更新完后是否立即运行
- 还有一些配置项
- autoDownload = true 有可用更新时是否自动下载
- autoInstallOnAppQuit = true 如果安装包下载好了,那么当应用退出后是否自动安装更新
- allowPrerelease = false 是否接受开发版,测试版之类的版本号
- allowDowngrade = false 是否可以回退版本,比如从开发版降到旧的稳定版
更优雅的更新
其实有个更好的更新方案,每次安装更新的时候都是全量下载安装包更新,但是electron的应用呢,通常只会更新 resources/app.asar 这个文件,但是这个文件是非常小的,在更新的时候可以只更新这一个文件,这样更轻量,更可控,这就需要自己动手写个后端服务配合了,当然这里只是给出一个方案并没有demo。
展示
以下是最终配置后的安装过程截图
项目地址 https://github.com/eyasliu/electron-startkit