




A Python Package for the Google Chrome Dev Protocol, more document
To install pychrome, simply:
$ pip install -U pychrome
or from GitHub:
$ pip install -U git+https://github.com/fate0/pychrome.git
or from source:
$ python setup.py install
simply:
$ google-chrome --remote-debugging-port=9222
or headless mode (chrome version >= 59):
$ google-chrome --headless --disable-gpu --remote-debugging-port=9222
or use docker:
$ docker pull fate0/headless-chrome
$ docker run -it --rm --cap-add=SYS_ADMIN -p9222:9222 fate0/headless-chrome
import pychrome
# create a browser instance
browser = pychrome.Browser(url="http://127.0.0.1:9222")
# create a tab
tab = browser.new_tab()
# register callback if you want
def request_will_be_sent(**kwargs):
print("loading: %s" % kwargs.get('request').get('url'))
tab.Network.requestWillBeSent = request_will_be_sent
# start the tab
tab.start()
# call method
tab.Network.enable()
# call method with timeout
tab.Page.navigate(url="https://github.com/fate0/pychrome", _timeout=5)
# wait for loading
tab.wait(5)
# stop the tab (stop handle events and stop recv message from chrome)
tab.stop()
# close tab
browser.close_tab(tab)or (alternate syntax)
import pychrome
browser = pychrome.Browser(url="http://127.0.0.1:9222")
tab = browser.new_tab()
def request_will_be_sent(**kwargs):
print("loading: %s" % kwargs.get('request').get('url'))
tab.set_listener("Network.requestWillBeSent", request_will_be_sent)
tab.start()
tab.call_method("Network.enable")
tab.call_method("Page.navigate", url="https://github.com/fate0/pychrome", _timeout=5)
tab.wait(5)
tab.stop()
browser.close_tab(tab)more methods or events could be found in Chrome DevTools Protocol
set DEBUG env variable:
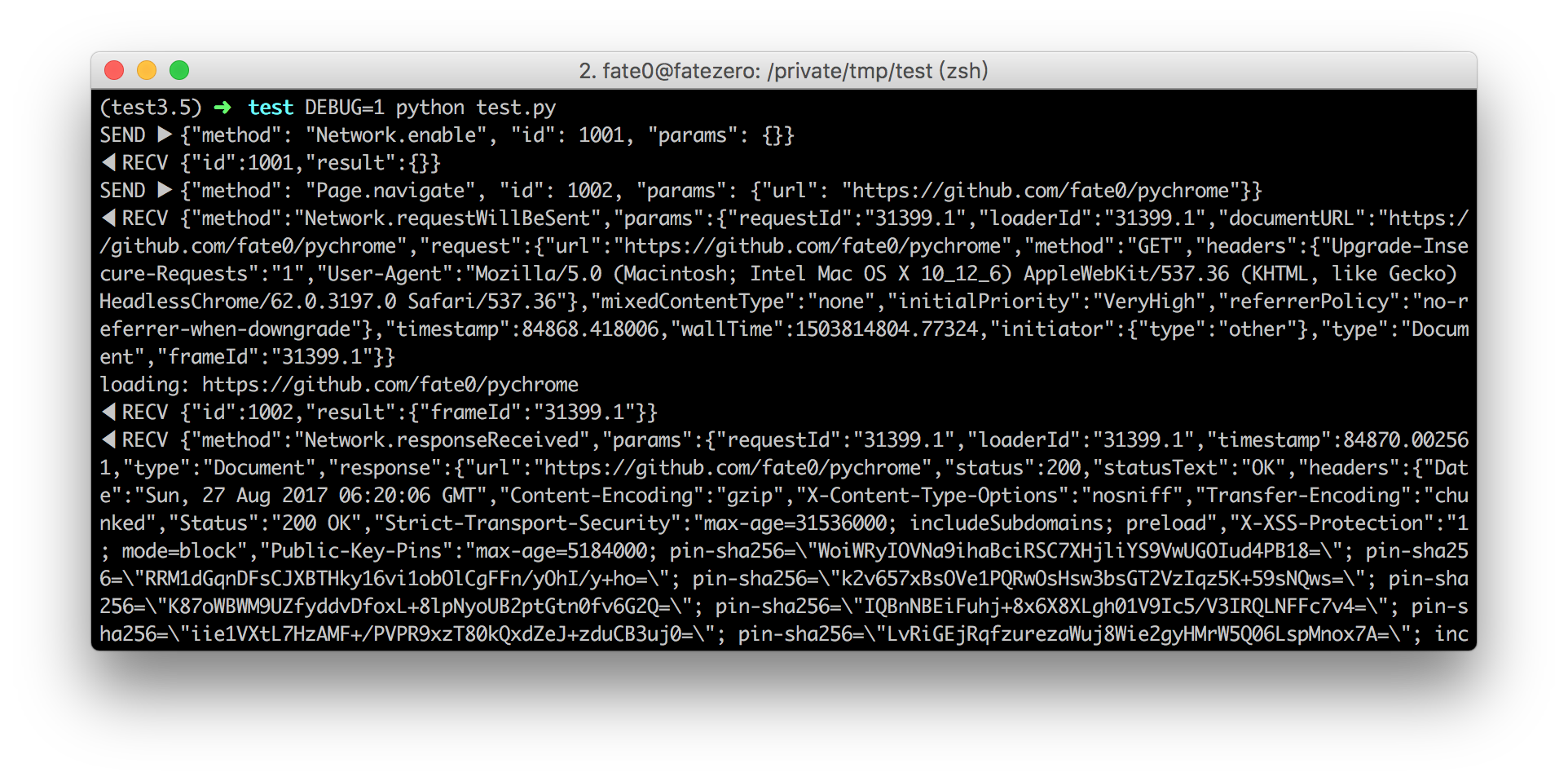
run pychrome -h for more info
example:
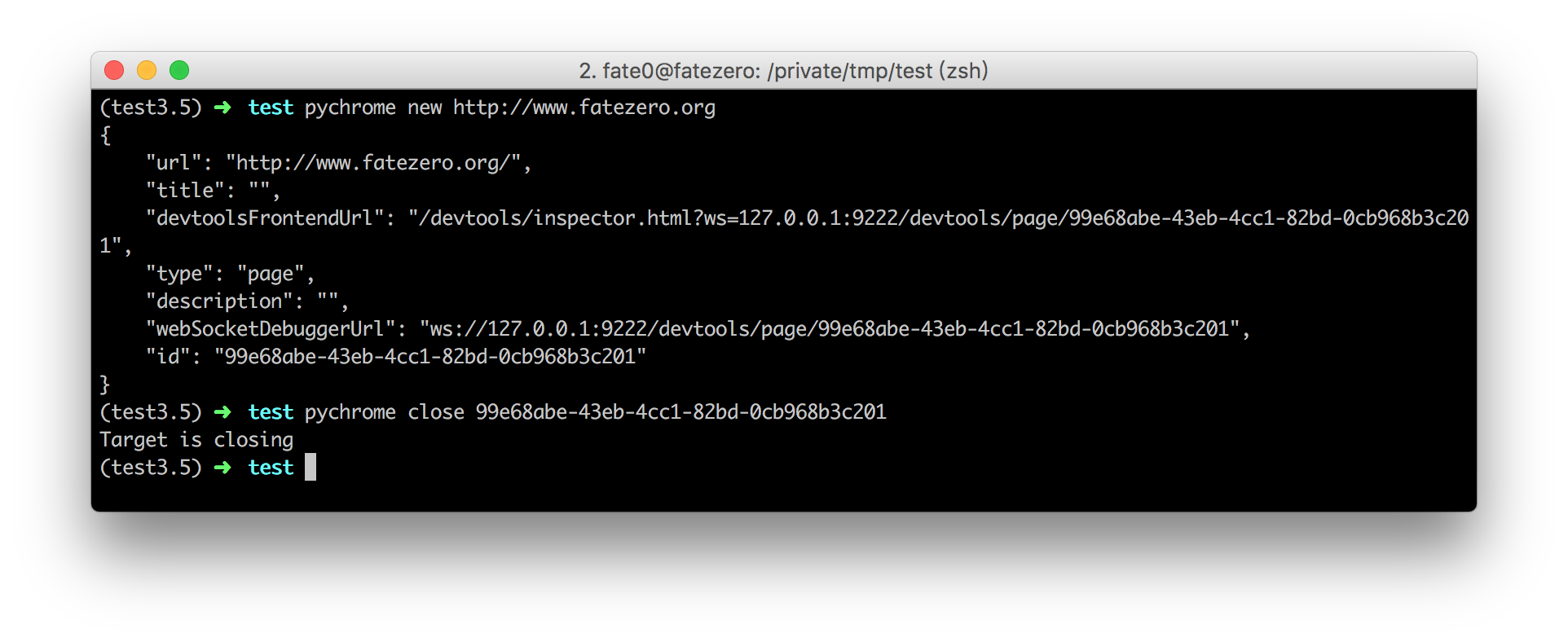
please see the examples directory for more examples

















































































































