forever-z-133 / blogs Goto Github PK
View Code? Open in Web Editor NEW已转移到 https://www.forever-z.cn/
Home Page: https://www.forever-z.cn/
已转移到 https://www.forever-z.cn/
Home Page: https://www.forever-z.cn/



































数学概念较多,开发中有些不一定常有遇到,请酌情浏览。
所有的方法都会先进行数据类型 Number 强制转换,所以传入 '-1' / [0] / null 也是可以的。
Math.PI
圆周率 π,一个圆的周长和直径之比,约等于 3.14159。
可用于计算弧度转角度,求轨迹角度等等。
Math.E
欧拉常数 e,也是自然对数的底数,约等于 2.718。
Math.LN2 / Math.Ln10
ln(2) 和 ln(10),即 loge(2) / loge(10),分别约等于 0.693 / 2.303。
Math.SQRT2/ Math.SQRT1_2
Math.aqrt(2) 和 Math.aqrt(1/2),即根号二 / 根号二分之一,分别约等于 1.414 / 0.707。
Math.abs(x)
取绝对值,即取正数。类型转换问题也略作演示:
Math.abs([1]); // 1
Math.abs('-1'); // 1
Math.abs('-1s'); // NaN
Math.abs(null); // 0
Math.abs(); // NaN
Math.min(...x) / Math.max(...x)
返回传入参数中最小 / 最大的那个值。
如果 Math.min() 没有参数,返回 Infinity,Math.max() 返回 -Infinity。
如果有参数不能转化为数值,将返回 NaN。
var x = Math.min(0, Math.max(++x, 10)); // 用以将 x 的值限定在 0-10
Math.max.apply(null, arr); // 返回数组中值最大的值,如果有值不能被转化,返回 NaN
Math.max(...arr); // 同上
Math.pow(x, y)
返回基数 x 的指数 y 次幂,即 xy 。
Math.random()
返回一个浮点,伪随机数在范围 [0, 1),左闭右开区间。
// 获取范围 `[min, max)` 的浮点数
function Random(min, max) {
return Math.random() * (max - min) + min;
}
// 获取范围 `[min, max)` 的整数
// `includeMax` 为 `true` 获取范围 `[min, max]` 的整数
function RandomInt(min, max, includeMax) {
min = Math.ceil(min);
max = Math.floor(max);
return Math.floor(Math.random() * (max - min + (includeMax?1:0))) + min;
}
// 据说直接 `Math.floor` 的没有上式分布均匀,暂时感觉不出来
Math.ceil() / Math.floor() / Math.round() / Math.trunc()
Math.ceil(x) 向上取整。Math.ceil(6.4); // 7 | Math.ceil(-6.5); // -6
Math.floor(x) 小于或等于 x 的最大整数。Math.floor(6.4); // 6 | Math.floor(-6.5); // -7
Math.round(x) 四舍五入后的整数(比 .5 大一丢才能五入,.5 是属于四舍的)。
Math.trunc(x) 直接去掉小数部分。还有如下几种方法能达到 Math.trunc 的效果:
parseInt(2.35); //(当然这个需要同正或同负咯)
~~2.35;
2.35 | 0;
2.35 >> 0;
Math.sqrt(x) / Math.cbrt(x)
Math.sqrt(x) 返回 x 的平方根。x 小于 0 则返回 NaN。
Math.cbrt(x) 返回 x 的立方根。草案中。
但并不存在 x 的 y 方根这种方法。
Math.hypot(...x)
平方和的立方根。如今 兼容 还是不错的。
可传多个值,不传参时返回 0,传负数时返回正数。
暂时就发现可以拿来求三角形的第三边长,或者方差。
各种三角函数
Math.sin() / Math.cos() / Math.tan()

Math.asin() / Math.acos() / Math.atan()

注:Math.atan(x) 的是 x/y 的正切函数,参数是比值的结果;
Math.atan2(y, x) 是 y/x 的反正切函数,参数是 y 轴坐标与 x 轴坐标。
传参需要符合数学规则,比如 Math.asin 的参数得在 [-1, 1] 区间内否则返回 NaN。
tan(90°) 在数学意义上是不存在的,但 JS 给出了一个较大数,个人推荐提前进行判断避免这个数值的出现。
注意:除了 Math.atan2() 参数都是弧度值,弧度除以 (Math.PI / 180) 则为角度,角度乘以 (Math.PI / 180) 则为弧度。
反曲线三角函数
(以后还是做成图比较直观,公式+曲线图)
Math.sinh = Math.sinh || function() {
return (Math.exp(x) - Math.exp(-x)) / 2);
}
Math.cosh = Math.cosh || function() {
return (Math.exp(x) + Math.exp(-x)) / 2;
}
Math.tanh = Math.tanh || function() {
return (Math.exp(x) - Math.exp(-x)) / (Math.exp(x) + Math.exp(-x));
}
Math.asinh = Math.asinh || function() {
return Math.log(x + Math.sqrt(x * x + 1));
}
Math.acosh = Math.acosh || function() {
return Math.log(x + Math.sqrt(x * x - 1));
}
Math.atanh = Math.atanh || function() {
return Math.log((1+x)/(1-x)) / 2;
}
现在还不知道它会有什么用。另外都还是草案阶段。
Math.exp(x)
即 ex。e 是欧拉常数 2.718(Math.E)。
Math.log(x) / Math.log2(x) / Math.log10(x) / Math.log1p(x)
自然对数 log(x) / log2(x) / log10(x)。
x 小于 0 返回 NaN,等于 0 返回 -Infinity。
Math.log1p(x) 相当于 log(x-1)。x 的范围相应 -1。
Math.clz32(x)
返回一个数字在转换成 32 无符号整形数字的二进制形式后, 开头的 0 的个数,。
比如 1000000 转为二进制为 00000000000011110100001001000000,前面有 12 个 0,
所以 Math.clz32(1000000) == 12。
Math.fround(x)
返回离它最近的单精度浮点数形式的数字。草案中。
Math.fround = Math.fround || function(x) {
return new Float32Array([x])[0];
};
Math.imul(x, y)
返回进行快速的类C语义的32位整数乘法后的结果。草案中。
无话可说,又不做引擎我能拿他做什么......
在学习 CSS 的之初就怀有疑惑,
横排布局干嘛要用 float 这种属性,
用了还会高度塌陷,怎么不发明些高级点的属性来完成横排布局呢。
以前我是没得选,
现在想想,都过去这么多年了,
也许我们可以重头来看看。
其实当时制定 CSS 的人也许就没想过会用 float 来布局,
最多来个 word 的那种文本环绕就不错了,
或者说布局本来不是 float 的本职工作,
你听过建房子有可能用左右浮动这种办法的吗...
虽然有多种方法去解决高度塌陷,
比如 overflow: hidden,但等到你遇到想露出的部分露不出来的时候,那就尴尬了。
另一方面,个人认为随着时代变化,网页的交互需求会翻倍增加,
不只停留在搭建和布局上,还将有更多动效/微数据上的突破,
所以 :before 和 :after 将会有更多应用,拿来清除浮动实在是大材小用了些。
而相对而言,inline-block 仿佛更像是为横排布局而设计的,
inline 是行,block 是块,一行里的方块。
可惜的是,它的兼容性实在不忍吐槽,IE8 都不支持,
要么底部有缝隙,需要 vertical-align:middle,
要么左右有缝隙,而 font-size:0 并不适用 chrome,
letter-spacing: -2px 的数值其实也并不稳定,有时候还会需要 -4px。
浮动布局就像是先伤己后伤人,
一挥刀自宫把自己脱离文档流,
再一反手影响别人,而且出招别扭。
浮动时我们多半要使用定宽,
虽然后来有诸如 bootstrap 的栅栏布局,但还是不够灵活,
稍微改大号字体都可能让整个布局崩坏。
曾经试着写类库的时候,希望做到三栏且居中的样式,
却最终我放弃了 float 动用了 absolute 来实现垂直居中,
而后发现甚至还不如 table-cell 方便。
这也许就是为什么 twitter 等公司互联网老大哥还在使用表格布局的部分原因吧。
另一方面,float 与 absolute 同是脱离文档流,
但 flost 还是能影响其他元素,所以说 float 脱离得并不彻底,
因此在重绘和回流时 float 将比 absolute 更烧。
其次由于浮动的效果,很多效果也就难以同时产生了,比如垂直居中/子级等高/元素排序等等...
不知是不是幸运降临,float 难得的很容易理解,兼容又不错,
有类库后使用也变得非常方便,深受后端人士喜爱。
但不管怎样,布局终究不是它的本质工作,
甚至让它成为了这个时代的主流,回头想想还是有些可怕的。
或许你没有体会过 表格布局/定位布局/浮动布局/栅栏布局 的优劣不同,
不知道他们在开发和维护上所消耗的成本精力的差别;
有些人也知道浮动这个属性能不用就不用,但是由于找不到更好的替代方法。
想来 CSS3 的开发者也发现了这个问题,
而推出了 flexbox 这种布局方式,很大程度上完善了布局功能。
它分三个阶段:
box(最老,如今兼容不怎么好),
flexbox(过渡,流传不广),
flex(最新),
及其 inline 形态(即 inline-box/inline-flex 等)。
flex 布局的中文名称十分的美妙:
自动布局/弹性布局/伸缩容器,
光看这名字就已经觉得超屌了。
它确实拥有以往布局难以企及的灵活性,
在它的领域里基本就可以完全抛弃 float 和 table 了,
因为它们能做的(单指布局),flex 肯定能做。
而且现在(20160815)兼容性还出乎意料地好,
基本本人接触到的设备都兼容了 flex,较大部分兼容 box。
flex 是 display 的属性值,这才是行块布局的正统啊,
它规定了该元素就是一个伸缩盒,是不是相比 float 更语义了呢。
就如同 display 其他属性值一样,
每个盒模式都有其特殊的样式效果,
如 inline 会失去高度,tabel-cell 会拥有一部分表格的特性,
display: flex 伸缩容器使其子级变成了伸缩项目,
拥有了直接横排布局,抢占空隙/自动宽度,自动高度,可排序,可靠齐等功能,
在此就不赘述各个属性的样式效果了,随便搜搜都能比我讲的好,比如我就爱看 这篇。
再说 flex 的弊端方面:
想将 flex 布局像栅栏布局那样类化,个人认为难度很大,
比如 .flex-row {dispaly:flex} .flex-row>*{flex-grow:1}
能产生横排子级全等宽的效果,
但当遇上需要一个定宽值得时候,这又得加上 flex-shrink:0。
有时加上超出显示省略号时父级得再加一个 overflow:hidden 等。
设为Flex布局以后,子元素的 float / clear 和 vertical-align 属性将失效,
这会使得与其他布局方式/类库冲突,请提前考量。
其次 CSS3 新属性对旧属性的影响也偶尔发生,
比如层叠上下文的影响,鄙人正在收罗中...
float 是一种流传很广的布局方式,
栅栏布局也是非常适用于快速的结构开发,
但随着我们对更多布局样式的需要、了解和实践,
总有一天,我们将选择更好的,比如 disaply: grid
Number.EPSILON
两个可表示(representable)数之间的最小间隔。主要用于以下情况的判断:
0.1 + 0.2; // 0.30000000000000004
0.1 + 0.2 - 0.3 < Number.EPSILON // ture
小于 Number.EPSILON 这个偏离值,就可以认为是相等的。
Number.NaN
特殊的“非数字”值。但并不等于 NaN,所以一般不用。
Number.MAX_SAFE_INTEGER
在 JavaScript 中最大的安全整数(253 - 1)。(反正我感觉没用)
Number.MAX_VALUE / Number.MIN_VALUE
最大的正数(1.7976931348623157e+308),
最小正数即最接近 0 的正数(5e-324)(也感觉没用)
Number.POSITIVE_INFINITY / Number.NEGATIVE_INFINITY
特殊的正无穷大值 / 特殊的负无穷大值。
在溢出时返回该值。与 Infinity / -Infinity 相等。
其具有数学特性,任何值与无穷大相乘还是无穷大,非无穷大的值除以无穷大等于 0。
Math.pow(10, 1000); // Infinity
Math.log(0); // -Infinity
500 / Infinity; // 0
-Infinity + Infinity; // NaN
Number.isNaN()
确定传递的值是否是 NaN。但并不等于 isNaN()。因更具语义且不会先进行 Number() 转化,个人推荐 Number.isNaN()。属于 ES6。
Number.isFinite()
确定传递的值类型及本身是否是有限数。属于 ES6。
这里的有限数并非 1/3 这种,而是判断 Infinity 的。
与 isFinite() 不相等,Number.isFinite('0') == isFinite('0') 也为 false,个人更推荐 Number.isFinite()。
Number.isInteger()
确定传递的值类型是 "number",且是整数。属于 ES6。注: 2 和 2.0 都会返回 true。
Number.isSafeInteger()
确定传递的值是否为安全整数 ( -(253 - 1) 至 253 - 1之间)。
parseInt(string, radix) / Number.parseInt()
两个 parseInt() 完全相等。
可以这样来理解它的转化规则就比较好记了,
(纯用于方便记忆,非真实代码逻辑)
radix 进制,'F',否则返回 NaN,所以大致有以下效果:
parseInt('1a'); \\ 1
parseInt(' 2a'); \\ 2
parseInt('a3'); \\ NaN
parseInt('24c', 8); \\ 20
parseInt('211', 2); \\ NaN(字符串首位没有符合 2 进制的数)
parseInt('34fas', 16); \\ 13562(获取到 16 进制的 '34fa' 再转 10 进制)
同时,它在判定是什么进制时是有些搞人的,举个栗子:
在不传入 radix 参数时,会默认认为 '0' 开头的为 8 进制,'0x' 开头的为 16 进制。
备注:ES6 提供了 '0b' 表示 2 进制,'0o' 表示 8 进制这种更好的写法
为了尽可能避免这样的错误,强烈推荐所有 parseInt() 指明 radix 参数。
parseInt('023s'); // 23
parseInt('023s', 8); // 19
parseFloat(string) / Number.parseFloat()
转化规则与 parseInt() 基本类似,但少了 radix 进制转化,都是 10 进制。
值得注意,parseFloat() 是支持 parseFloat('.23d') 这类无零小数的格式的。
再者,有个科学表达式方面的问题,但应该很少会出现。
parseFloat('.02e-10as'); // 2e-11
toFixed(digits)
返回带有小数点后 digits 位数字的字符串,digits 默认为 0,且必须小于 21 否则会报错。
(2.23121).toFixed(); // "2"
(12).toFixed(2); // "12.00"
(.9512).toFixed(2); // "0.95"
(-26.6e-3).toFixed(2); // "-0.03"
(1/3).toFixed(20); // "0.33333333333333331483"
toPrecision(precision)
precision 如果不传则直接转为字符串,也必须小于 21。
与 toFixed() 略有不同,以有效数字开始截取,且会四舍五入。
(9.87651).toPrecision(3); // "9.88"
(0.00123).toPrecision(5); // "0.0012300"
(0.00012309).toPrecision(4); // "0.0001231"
(1234.5).toPrecision(2); // "1.2e+3"
实验中有个让人无法理解的结果,希望有大佬能帮助解答
(0.012345).toPrecision(4); // "0.01235"
(0.0012345).toPrecision(4); // "0.001234"(就这个不按规矩来)
(0.0012346).toPrecision(4); // "0.001235"
(0.00123454).toPrecision(4); // "0.001235"
toString(radix)
将数字转为 radix 进制字符串,默认为 10 进制。
(17.2).toString(); // "17.2"
(254).toString(16); // "fe"
(-0x1f).toString(2); // "-11111"
toLocaleString()
所及概念有些多,个人也未用过,还是浏览 官方文档 吧。
valueOf()
表示指定 Number 对象的原始值的数字。开发中用的极少。
比如 var obj = new Number(10) 是一个对象,obj.valueOf() 才能拿到 10。
toExponential(fractionDigits)
转为科学计数法的字符串,并进行 fractionDigits 长度的截取和四舍五入,参数也不得大于 21。
0.07734.toExponential(); // "7.734e-2"
0.07735.toExponential(2); // "7.74e-2"
以后会有专题讨论此方面的问题,在此仅举几个例子:
Number(''); // 0
Number('0x12'); // 18
Number(new Date()); // 1504336166079
Number([1]); // 1
Number('100a'); // NaN
比 iframe 实现异步更新网页局部,ajax 要优异很多,但两者都有一个问题,就是失去了浏览器的前进后退的跳页功能。使用修改 hash 能弥补该效果,再配合下 history API 那就更棒了。
字面意思,向 history 历史记录中加入一个声明。
state 表示前往新页面时带上的数据,title 指定新页面的页面标题,url 就是新页面的链接了。
history.pushState({from: 'xx'}, null, 'to.html');张鑫旭大神的案例:http://www.zhangxinxu.com/study/201306/ajax-page-html5-history-api.html
PS:可以传 JSON 序列化了的 state,所以其实是可以传普通字符串数字等类型的参数的。
PS:state 传递后可以在当前页通过 histroy.state 来获取,比如 pushState({a:1},'','#main'),只有在 #main 这条记录中才能获取到,切换或者后退了就获取的是其他的 state 了。
PS:state 大小不得大于 640K,否则会报错。如果非要传递较大的数据,还是选用 sessionStorage 或者 localStorage 吧。
PPS:title 在如今(20171118) 好像依旧没有实现,但并没有被移除,也获取不到,还是得写上这个参数。如果确实需要这个功能,可以用 document.title = "xx"。
插个楼,document.title 用 setInterval 频繁修改在移动端效果不佳,需使用 requestAnimationFrame。
DEMO:https://foreverz133.github.io/demos/single/PageTitle.html
也是字面意思,把本页的历史记录替换掉,相当于不刷新页面的 location.replace。
参数和 history.pushState 一致。
// 地址栏:index.html
history.pushState({}, 'page2', '#main'); // index.html#main
history.replaceState({}, 'page2', '#detail'); // index.html#detail
history.back(); // index.html,效果上跳过了 #mainpopstate 事件可以监听本页无刷新跳链的变化
但 pushState 和 replaceState 不会触发 popstate,其他 history 操作(如 go/back/forword)和浏览器前进后退操作才会触发,鸡肋呀。
且 pushState 和 replaceState 的 hash 操作也是不触发 hashchange 的,但回退时触发,这就更心酸了。
再者,location.hash 的改变是会触发 popstate 事件的,且在 hashchange 之前,两者关系真是纠葛呀。
整理一下,这意味着,使用 popstate 无法得知主动跳页,使用 hashchange 就不便用 popstate(因为会触发两次),非常尴尬有木有。
至于 location.search 方面的问题,也是有些尴尬的,在 下文 还会细讲。
为了解决这些问题,有两条路可走:
一、要么保持原生的跳转方法不变,不断改进监听机制,尽量解决上述问题。
// 解决 pushState 不触发 popstate 问题
var oldPushState = history.pushState;
history.pushState = function(state, title, url) {
oldPushState.call(history, state, title, url);
// 运行一次 popstate 对应的 function 当做触发
popStateFunction();
};
// 解决 location.hash 的改变既触发 popstate 也触发 hashchange 的问题(不完美)
if (e && e.type == 'popstate') this.skip = true;
if (e && e.type == 'hashchange' && this.skip) return;
setTimeout(function(){ this.skip = false; }.bind(this), 1);详细代码可见:https://foreverz133.github.io/demos/single/router2.html
二、要么直接另写一套跳转机制,那么跳转监听自然也全权掌握。
$(window).on('linkchange', function(e, state, title){
console.log(state, title);
});
$.hrefTo = function(state, title, url) {
history.pushState(state, title, url);
$(window).trigger('linkchange', state, title);
}PS:pushState 等触发的 popstate 比 load 更快,虽然意料之中,但很容易被忽视。
PS:写在全局下直接运行的 location.hash = 'xx',有可能 会不创建历史记录哟。
PS:location.hash = 'xx' 多次那也还是一条记录,返回一次就行,但 pushState 就是每运行一次加一条记录,多点几下就麻烦了。
只出现一次的欢迎页
假设我们把 index.html 作为欢迎页,main.html 为主页面。
在 index.html 中延时 3s 然后 replaceState 到 main.html。
只有通过主入口进来的就欢迎一下,放完就消失,不管怎么 F5 刷新还是 main.html。
它相比 location.replace 没有刷新的感觉,相比在同一页操作要省去了好些是首次访问还是刷新的判断。
location.search
我们都知道不管是 href 里写 search 还是直接修改 location.search,页面都将刷新。
虽然可以像 vue-router 等单页面应用一样,把 hash 和 search 写在一块,比如 #/detail?id=xxx,这样只监听 hashchange 要方便很多。
但 search 放在 hash 前面才是 search,放在后面是合并了的 hash,用 location.search 是获取不到的。
而为了让 search 和 hash 能分离,这里恐怕需要绕个大圈...
不管怎样,我们肯定要使用 pushState 才能不刷新,但 pushState 不触发 popstate 事件,所以这需要上面那个 oldPushState 式的改写。
或者,索性不监听 popstate 了,全靠 hashchange,先 location.hash = '#page',然后再 replaceState({}, '', '?id=xx#page') 也算是跳页了。
合并还是分离哪种更好呢,真的没有定数。
我个人更偏好 hash 与 search 分离的这种,可能我是个比较喜欢强调尊重原生和语义的程序员吧。
再者,还可以使用 CSS3 的 :target 伪类,在 hash 变化时添加动画非常方便,而如果 hash 和 search 合并了,元素所需的 id 就变得很难书写了。
不过 :target 只知道有无 hash,同个元素无法分辨 #main 和 #page,这个有点不美妙。
<style>
.box { width:100px; height: 100px; background: pink; }
.box:target { background: red; transition: 1s; } /* 当链接有 #detail 的 hash 时,方块变红 */
</style>
<div class="box" id="detail"></div>再者,就是 search 键值对的获取可以改造一下了:
function getQueryString(name, str) {
var reg = new RegExp('(^|\\?|&)' + name + '=([^&#$]*)', 'i');
var r = (str || location.search || location.hash).match(reg);
return r != null ? decodeURIComponent(r[2]) : null;
}function locationConvert(str) {
var str = str || (location.search + location.hash) || '';
var hash = str.match(/#[^\?&$]*/);
hash = hash ? hash[0] : '#';
var search = str.replace(hash, '').split(/\?|&/);
search = search.reduce(function(re,b){
var x = b.split('=');
if (!b || x.length < 2) return re;
re[x[0]] = decodeURIComponent(x[1]);
return re;
}, {});
return { hash: hash, search: search }
}pjax
那么基于以上这些,我们其实可以做些可能的封装,也就是 pushState + ajax,所谓 pjax。
https://github.com/search?q=pjax&type=Repositories&utf8=%E2%9C%93
想象一下,<a href="#detail?id=xxx"> 再指定一个放内容的 div,屏蔽原生跳链进行点击监听,每次点击变成 pushState 跳链,再直接(或监听 popstate)进行 ajax 请求和绘制操作。
单页面应用实现起来是不是就无比简单了呢,这个过程中再加上动画和结果缓存,棒棒哒。
SEO(Search Engine Optimization)搜索引擎优化
搜索引擎优化是一种利用搜索引擎的搜索规则来提高目前网站在有关搜索引擎内的自然排名的方式。SEO是指为了从搜索引擎中获得更多的免费流量,从网站结构、内容建设方案、用户互动传播、页面等角度进行合理规划,使网站更适合搜索引擎的索引原则的行为。
存在的意义:为了提升网页在搜索引擎自然搜索结果中的收录数量以及排序位置而做的优化行为。简言之,就是希望百度等搜索引擎能多多收录我们精心制作后的网站,并且在别人访问时网站能排在前面。
SEO可以靠下面的这些指标来衡量:
Pr、收录量、快照日期、搜索流量、关键词排名数量
其实搜索引擎做的工作是相当复杂的,这里简单说一下大致的过程:
白帽SEO是业内公认的SEO手法,也是SEOer的道德标准,是采用正当、公平公正的手法进行操作的。白帽SEO需要对网站进行长期的维护,seo觉得虽然优化的周期过长,但网站更加稳定,后期效果比较明显。
灰帽SEO介于白帽与黑帽之间,与白帽SEO相比,它会采取一些取巧的操作方式,却又不像黑帽一样不遵守规则。
黑帽SEO则与白帽SEO恰恰相反,它是利用作弊、取巧的手段进行操作的,这种方式能够为网站在短时间内带来大量的排名与流量,但稳定性差,但大多逃不过被K的后果。
以我理解的话,SEO三大分类就如同原创、伪原创与抄袭之分
人们最为普遍用的一种手法。很多人在优化关键字的时候,堆积了关键字,目的只有一个,只是为了增加关键词的出现频次,增加关键词的密度,使劲的在网页代码中,meta标签,title, 注释, 图片alt中重复某个关键字,使这个关键字的密度非常的高,但是要是不被发现,会有很好的效果。被k率80%
这种方法是使用刷新标记,在网页代码里是metarefresh还有java还有js技术。当用户进入一个页面后,用这些功能使他迅速跳转到其他页面,这样,重定向使搜索引擎和用户所访问的页面不统一,这个一定要注意,这个笔者曾经有一个站点就是因为而被降权的,好久没有上来。被k率80%
刚做seo的新手往往认为,注册很多个域名,同时连到主站,以提高主站的PR!如果这些域名有各自的网站,则没有问题!但如果这些域名都只有很少的内容,或指向主站的某个页面,这样,搜索引擎会认为这是一种作弊行为!被k率70%!
很多的站点会把许多与本站并不相关的关键字加入到自己网站中,通过在META中设置与网站内容根本不相关的关键字,以骗取搜索引擎的收录与用户的点击,在这里算是一个不太正规的优化方式,但笔者说的是过多的虚假关键字,还有经常为了增加此关键字更改网页titile,这样两种方式都极有可能受到处罚降低排名(后者更为严重)。被k率60%
这个是违反网站提交纪律的一种比较卑鄙的作弊手段。他突破时间的限制,将一个网页在短时间内反复提交给同一个搜索引擎。被K率60%
为了增加关键词的出现频次,故意在网页中放一段与背景颜色相同的、包含密集关键字的文本。访客看不到,搜索引擎却能找到。类似方法还包括超小号文字、文字隐藏层等手段。这也是网站被降权的一个比较常见的原因,其实很多的并非自己放入的,而是一些出售黑链的人偷偷的给你加上的,这个就是要站长加强防范的意识了。被k率50%
加入大量链接机制,大量链接机制的意思是由大量网页交叉连接构成的一个网络系统这些作弊手段,一旦被搜索引擎发觉马上就有被K站的可能,希望seoer们在平时做优化时有意的无意的都要注意一下有没触犯到这些作弊手段,为提高搜索排行,吸引人点击,重复堆砌关键字,在博客和论坛大量发布与无关内容的链接,同称为垃圾链接。被k率50%
也就是诱饵行为,SEO中所使用的一种欺骗性技术。指创建两个网页,一个优化页和一个普通页,然后把优化页提交给搜索引擎,当优化页被搜索引擎收录后再以普通页取代该网页的行为。以长期的利益来考虑,不要尝试。被k率40%
大部的桥页,这些桥页都是由软件生成的。你可以想象,生成的文字是杂乱无章,没有什么的。如果是由人写出来的真正包含关键词的文章,就不是桥页了。
黑帽寄生代码快速排名,域名能够有很大的区别,但它们的IP地址能够是类似的。
为了便于寻址和层次化的布局网络,IP地址被分为A、B、C、D、E五类,商业运用中只用到A、B、C三类。
既然是优化,那我们就得遵循SEO的原理来做
网站首页是权重最高的地方,如果首页链接太少,没有“桥”,蜘蛛不能继续往下爬到内页,直接影响网站收录数量。但是首页链接也不能太多,一旦太多,没有实质性的链接,很容易影响用户体验,也会降低网站首页的权重,收录效果也不好。
因此对于中小型企业网站,建议首页链接在100个以内,链接的性质可以包含页面导航、底部导航、锚文字链接等等,注意链接要建立在用户的良好体验和引导用户获取信息的基础之上。
尽量让蜘蛛只要跳转3次,就能到达网站内的任何一个内页。扁平化的目录结构,比如:
通过3级就能找到苹果了。
导航应该尽量采用文字方式,也可以搭配图片导航,但是图片代码一定要进行优化,标签必须添加“alt”和“title”属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字。
其次,在网页上加上面包屑导航。好处:用户体验的提高;对蜘蛛而言,能够清楚的了解网站结构,同时还增加了大量的内部链接,方便抓取,降低跳出率。其实,面包屑导航每个层级的名称是一个潜在的关键词布局的好地方,多使用关键字,都可以实现SEO优化。
但是并不是所有的网站都适合用面包屑导航。有以下条件可以做:
网站层次不较多,机构目录比较深的网站适合做面包屑。那如果你的网站是个单页面或者网站只有一个分层,做了也没有意义。
网站结构相互独立不交叉的(重要),网站内容存在很多交叉的话,那么必然就会使达到网站内容页面的路径不统一,多用户体验也不好,这样会使搜索引擎认为网站结构混乱的不良状态。
logo 及主导航,以及用户的信息。通常网站 logo 应该处于最左上角,在代码中比主导航还更靠前。而图片 alt 文字大致相当于文字链接的锚文字效果。
左边正文,包括面包屑导航及正文;右边放热门文章及相关文章,好处:留住访客,让访客多停留,对蜘蛛而言,这些文章属于相关链接,增强了页面相关性,也能增强页面的权重。
次导航、版权信息和友情链接。
分页导航写法,推荐写法:“首页 1 2 3 4 5 6 7 8 9 下拉框”,这样蜘蛛能够根据相应页码直接跳转,下拉框直接选择页面跳转。而下面的写法是不推荐的,“首页 下一页 尾页”,特别是当分页数量特别多时,蜘蛛需要经过很多次往下爬,才能抓取,会很累、会容易放弃。
一个页面最好不要超过 100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,留不住访客,并且一旦超时,蜘蛛也会离开。
<title> 标题:只强调重点就行,尽量把重要的关键词放在前面,关键词不要重复出现,尽量做到每个页面的 <title> 标题中不要设置相同的内容。
<title>学邦技术-培训学校管理系统_教育机构管理软件_排课软件_艺术中心教务系统</title>
<meta name="description" > 标签:网页描述,需要高度概括网页内容,切记不能太长,过分堆砌关键词,每个页面也要有所不同。
<meta name="description" content="学邦技术以为教育培训学校提供高效运营管理SaaS服务为核心,提供培训机构管理系统,排课软件,学校管理软件等——BOSS校长、微秀、电服宝、教学易、学讯通等,从市场-咨询-教务-教研-服务全业务专业支撑,让学校运营管理更简单。">
<meta name="keywords" > 标签:关键词,列举出几个页面的重要关键字即可,切记过分堆砌。百度蜘蛛抓去网站时首先从最左边的开始,因此第一个关键词会被认为是最主要的
<meta name="keywords" content="学邦,BOSS校长,培训机构管理系统,排课软件,学校管理软件,培训班管理软件,培训学校管理软件">
对于关键词的选取要从网站的定位、竞争的热度与搜索指数以及借助一些相关的工具来分析数据,挖掘相关的关键词。当然这些需要 seoer 们经过实践,不断地积累经验,才能准确定位网站关键词。
需要注意的点是:a. 应将title中的关键词,包括长尾词中的短关键词,全部罗列出;b. 每一个页面的目标关键词限制在 2-3 个;c. 一般建议用英文 , 号做分隔符,否则设置会出现混乱,达不到很好的收录效果的。
<body> 中的标签:尽量让代码语义化,在适当的位置使用适当的标签,用正确的标签做正确的事。让阅读源码者和蜘蛛都一目了然。如:h1-h6 是用于标题类的,<nav> 标签是用来设置页面主导航的等。
<a> 标签:页内链接,要加 “title” 属性加以说明,让访客和蜘蛛知道。而外部链接,链接到其他网站的,则需要加上 rel="nofollow" 属性, 告诉蜘蛛不要爬,因为一旦蜘蛛爬了外部链接之后,就不会再回来了。
正文标题要用 <h1> 标签:蜘蛛 认为它最重要,若不喜欢 <h1> 的默认样式可以通过 CSS 设置。尽量做到正文标题用 <h1> 标签,副标题用 <h2> 标签, 而其它地方不应该随便乱用 h 标题标签。
<br> 标签:只用于文本内容的换行
表格应该使用 <caption> 表格标题标签
<img>应使用 "alt" 属性加以说明
<strong>、<em> 标签 : 需要强调时使用。<strong> 标签在搜索引擎中能够得到高度的重视,它能突出关键词,表现重要的内容,<em> 标签强调效果仅次于 <strong> 标签。 <b>、<i> 标签: 只是用于显示效果时使用,在 SEO 中不会起任何效果。
文本缩进不要使用特殊符号 应当使用 CSS 进行设置。版权符号不要使用特殊符号 © 可以直接使用输入法,拼 “banquan”,能打出版权符号 ©。
巧妙利用 CSS 布局,将重要内容的 HTML 代码放在最前面,最前面的内容被认为是最重要的,优先让蜘蛛读取,进行内容关键词抓取。
重要内容不要用 JS 输出,因为蜘蛛不认识
尽量少使用 iframe 框架,因为蜘蛛一般不会读取其中的内容
谨慎使用 display:none 对于不想显示的文字内容,应当设置 z-index 或设置到浏览器显示器之外。因为搜索引擎会过滤掉 display:none 其中的内容。
不断精简代码
js 代码如果是操作 DOM 操作,应尽量放在 body 结束标签之前,html 代码之后。
抛开网站开发注意的优化点之外,可以从以下几点着手优化
借助站长工具、爱站网或者各种站长后台我们可以分析出ip来路,以及关键词的搜索热度和相关词,我们再把这些词以一定的密度添加到页面中,以此来提升命中率。
写软文也是外链的一种重要推广方式,可以在知乎、豆瓣、博客、新浪、网易等地发文,不但可以与友情链接循环爬取,也可以让除本网站外有更多其他途径的搜索结果,哪怕知乎答案活了网站还没火也是可以的。
在更新文章的时候需要注意尽量原创,当然这也是所有SEO人员不管是内链还是外链都要想做到的效果,如果实在不能原创那就伪原创
软文的关键词一定要加上链接,或者加粗、下划线,不要小看这些细节,当客户在百度搜索关键词的时候百度很容易能抓取到。
还有就是网站文章的更新是需要有一定的规律性的,这样当蜘蛛爬行网站时就会出现规律性的爬行,这样搜索引擎抓取网站就是更容易、更方便。更新网站文章最忌讳的就是三天打鱼两天晒网的方式、想起更新文章就去更新、一次性更新n多篇文章等
我们经常会在页面底部看到友情链接。友情链接是作为网站之间相互交换流量,互惠互利的合作形式。事实上,友情链接对网站权重提升有着至关重要的作用。友链不仅可以引导用户浏览,而且搜索引擎也会顺着链接形成循环爬取,可以有效提升网站流量和快照的更新速度。
利用好分析工具
我们要在自己的站点安装百度统计代码,这样就可以分析出站点内用户的关注度和浏览流程,以此来不断优化站点结构,提升用户的留存率。同时也可以做用户画像,分析用户数据等等。
想要做好SEO并不是一件简单的事,需要持之以恒,面面俱到。对网站持续关注,并保持更新。
以上观点只是我最近学习的一些总结,只是简单的扫个盲,有错误的地方,还请各位指正与补充
本文不涉及 模板语法/列表渲染 等 MVVM 基本操作,仅对组件相关的知识进行梳理。
页面中调用一下文件就可以使用 Vue 了。
<script src="https://cdn.bootcss.com/vue/2.5.13/vue.min.js"></script>
Vue.extend()Vue.component()Vue 实例 的作用范围中使用组件注意:前两者必须放在 new Vue() 前面
<div id="app">
<my-component></my-component>
</div>
<!-- 下面这个组件不在 Vue 实例内,不会被渲染 -->
<my-component></my-component>
<script>
// 创建一个组件构造器
// 之后还可以包含组件所需的模板数据/事件/引用/等
var myComponent = Vue.extend({
template: '<p>this is my first test</p>',
});
// 注册组件,将 myComponent 构造器注册在 <my-component> 上
// 且为全局组件,所有 vue 实例下的 <my-component> 都将被渲染
Vue.component('my-component', myComponent);
// 创建 Vue 实例里面,HTML 中的 <my-component> 将生效
new Vue({
el: '#app',
});
</script>
注意:template 的值只能有一个父节点:
template: '<div></div><span></span>' // 将只渲染 <div>
注意:组件的命名,不能为1个字符,不能有2个大写,最终都会转为小写。
如果你的组件叫做 <Header> 也是不会被渲染的,因为它变成 HTML5 标签 <header> 了。
将第 2 步注册组件放在 Vue 实例内部 则为局部注册。
上一案例就是全局组件,所有 vue 实例下的 都将被渲染。
下面的案例是局部组件,仅该 vue 实例下的 会被渲染
<div id="app">
<my-component></my-component>
</div>
<div id="app2">
<my-component></my-component>
</div>
var myComponent = Vue.extend({
template: '<p>this is my first test</p>',
});
var a = new Vue({
el: '#app',
components: {
// 局部组件,仅 #app 下的 <my-component> 会被渲染
'my-component': myComponent,
}
});
// 全局注册,创建和注册 2 个过程合并为 1 个
Vue.component('my-component', {
template: '<div>This is the first component!</div>',
});
var vm1 = new Vue({
el: '#app1',
});
// 局部注册
var vm2 = new Vue({
el: '#app2',
components: {
'my-component': {
template: '<div>This is the second component!</div>',
},
}
});
<template> 或 <script><div id="app"><my-component></my-component></div>
<div id="app2"><my-component></my-component></div>
<!-- script 写法 -->
<script type="text/x-template" id="tpl_first">
<div>This is a component!</div>
</script>
<!-- template 写法 -->
<template id="tpl_first">
<div>This is a component, too!</div>
</template>
<template id="tpl_second">
<div>This is a component, too!</div>
</template>
Vue.component('my-component',{
template: '#tpl_first',
});
new Vue({
el: '#app',
});
new Vue({
el: '#app2',
components: {
'my-component': {
template: '#tpl_second',
},
},
});
当然,使用 .vue 文件方式来编写组件和项目就是另一套方案了,未来将在 vue-cli 的教程中涉及
基本也只有父子关系值得一提了。
<div id="app">
<parent>
<child>asda</child>
</parent>
</div>
var child = Vue.extend({
template: '<p>我是儿子呀</p>',
});
// 方案1,child 为 parent 的局部组件,解析成功
new Vue({
el: '#app',
components: {
'parent': {
template: '<div>我是父组件 <child></child> </div>',
components: {
'child': child
}
}
}
});
// 方案2,child 与 parent 同级,结果 <child> 未解析
new Vue({
el: '#app',
components: {
'child': child
'parent': {
template: '<div>我是父组件 <child></child> </div>',
}
}
});
// 方案3,child 为全局组件,解析成功
Vue.component('child', child);
new Vue({
el: '#app',
components: {
'parent': {
template: '<div>我是父组件 <child></child> </div>',
}
}
});
<parent> 套 <child> 这种写法是没用的template 中才有用,因为就算 HTML 中 <child> 被解析也会被 <parent> 的解析给替代。<div id="app">
<div>{{text}}</div>
<App></App>
</div>
new Vue({
el: '#app',
data: {
text: '随便来段文字',
},
components: {
'App': {
template: '<div>{{mine}}</div>',
data: function() {
return {
mine: '我自己内部的一些数据',
}
},
}
}
});
注意:在 Vue 实例 中,data 属性是个 对象,组件 中,data 是个 方法 返回一个对象。
(因为,如果组件中的 data 为对象,将只获得引用指针,多个该组件的操作,将使用同一个对象数据源)
双向绑定的概念是超简单也超诱人的,绑定同一个数据,只要数据变,所有节点的值都变。
表单上写有 v-model="x" 自动绑定了表单数据更改的监听事件。
<div id="app">
<input v-model="name"><br>
<span>我也要跟着改:{{name}}</span>
</div>
new Vue({
el: '#app',
data: {
name: '',
},
});
除了 {{x}} 这类数据定义,表单上的数据定义大有不同
<div id="app">
<p><input type="text" value="xxx"></p>
<p><input type="text" :value="text"></p>
<p><input type="text" v-model="text">{{text}}</p>
</div>
new Vue({
el: '#app',
data: {
text: 'input text',
},
});
分清以上三者的区别后,我们再往下走。
Vue 使得 HTML 的属性具有变量功能,比如 :value="my_data" :style="my_style + 'font-size: center;'"。
本文篇幅已过长,:style 等其实还可以传数组对象等来更简化的操作,感兴趣请前往 官方文档。
<p><input type="text" v-model="text"></p>
<textarea>{{text}}</textarea> <!-- 1 -->
<textarea :value="text"></textarea> <!-- 2 -->
上面这个略有不同,1 修改后就失去了双向绑定的特性,2 始终有,所以推荐使用 2
<div id="app">
<p><label><input type="checkbox" v-model="checked">{{checked}},{{type()}}</label></p>
<p>
<label><input type="checkbox" value="one" v-model="check">1</label>
<label><input type="checkbox" value="two" v-model="check">2</label>
—— {{check}}
</p>
</div>
new Vue({
el: '#app',
data: {
checked: 'input checkbox',
type: function() {
return typeof this.checked;
},
check: [],
},
});

效果如上,当数据的类型为数组时,它将获取表单的 value,即案例中的 check;
非数组(字符串数字等)时,它将获取正负逻辑值,即案例中的 checked。
PS:数据非数组时,v-model 才会影响默认选中状态,比如数据为 [1] 复选框为已选状态
PPS:如果数据数组中已有值,如 check: ['x'],将会保留,点击 1 得到 check: ['x', 'one']
<div id="app">
<label><input type="radio" name="chooseWaht" value="one" v-model="radio">One</label>
<label><input type="radio" name="chooseWaht" :value="three" v-model="radio">Two</label>
<p>{{radio}},{{type()}}</p>
</div>
new Vue({
el: '#app',
data: {
three: 'two',
radio: true,
type: function() {
return typeof this.radio;
},
},
});
单选框就只能返回 value 值了,是字符串,所以请注意该如何判断选中。
因此也影响不了单选框是否默认选中,只能自己写 checked 了。
注意:为了让 radio 真正能够单选,不要忘了加 name 属性哈。
<div id="app">
<select v-model="selected">
<option v-for="(option, i) in options" :value="value[i]">{{option}}</option>
</select>
<p>{{selected}}</p>
</div>
new Vue({
el: '#app',
data: {
value: ['1'],
options: ['one', 'two', 'three'],
selected: '',
},
});
如果 HTML 没有 value,就选则 <option> 里的文本;如果文本也没有,则是 "" 咯。
当 select 有 multiple 属性,即按住 Ctrl 多选时,数据(即上面案例中的 selected)需为数组。
形式非常多,Vue 实例下的数据最好改了。
var app = new Vue({
el: '#app',
data: { x: 1 },
});
console.log(++app.x);
或者新建新的数据,即数据渲染之前
<div id="app">{{x2}}</div>
new Vue({
el: '#app',
data: { x: 1 },
computed: {
x2: function(){
return this.x + 1
}
}
});
或者监听数据变化,即数据修改的同时。
但不推荐此法,用上面的 computed 会更好。
不过官网给出的 案例 中,watch 用以异步回调前的文本替换是不错的。
<div id="app">{{x}},{{x2}}</div>
new Vue({
el: '#app',
data: { x: 1, x2: 0 },
watch: {
x: function(){
this.x2 = this.x + 1
}
}
});
或者方法修改,即运行该方法时。而还有个过滤器 Vue.filter 。
<div id="app">{{x}},{{type1(x)}},{{type2(x)}},{{x | type3}}</div>
Vue.filter('type3', function (who) {
return typeof who
});
new Vue({
el: '#app',
data: {
x: 1,
type1: function(who) {
return typeof who
}
},
methods: {
type2: function(who) {
return typeof who
}
}
});
<div id="app">
<!-- transmit[0].text 将以 what 为名称传给 parent 组件 -->
<parent v-bind:what="transmit[0].text"></parent>
</div>
new Vue({
el: '#app',
data: {
transmit: [{
text: '把这个值传递下去',
}],
},
components: {
'parent': {
props: ['what'], // what 是被传过来的数据
data: function(){return { what: '我自己' }},
template: '<div>{{what}}</div>',
}
}
});
父组件 v-bind:x 中的 x 就是子组件要接受的数据的键名,
子组件定义 props 数组来监听键对应的值。
(所有的 v-bind 都可以省写,如 v-bind:x="" 省写为 :x="")
如果你写的是 what 而不是 :what 那传的是个字符串,而不是变量数据。
如果,props 的值与内部变量的名称相同,则使用 props 的值。
另外,传参参数的命名有些需要注意
v-bind:myData="" 视为无效v-bind:my-data="",props: ['my-data'] 是可行的v-bind:my-data="",props: ['myData'] 是可行的v-bind:my-data="",props: ['my-data'],<div>{{myData}}</div> 是可行的,<div>{{my-data}}</div> 会报错my_data 下划线式的命名,这个故事就长了,暂不推荐new Vue({
el: '#app',
components: {
'parent': {
data: function(){return { result: '我自己' }},
// 父级中指定 child-change 事件对应 change 方法,子级中触发则运行 change
template: `<div>
<child @child-change="change"></child>
机器外部显示:{{result}}</div>
</div>`,
methods: {
change: function(data) {
this.result = data.value;
}
},
components: {
'child': {
data: function() { return {word: ''} },
template: `<div>机器内部说:<input v-model="word"></div>`,
watch: {
'word': function(){
// 监听 word 变化然后 $emit 触发 child-change 事件并传值
this.$emit('child-change', {value: this.word});
},
}
}
}
}
}
});
子级在需要回传时(比如 watch 或 methods)中,$emit 一个事件名和数据,
在父级 template 中 @ 绑定该事件的监听,设置 methods 对应方法进行事件触发后的处理。
曾和同事讨论过一种,兄弟A先传给父级再传给兄弟B这样的办法,也算是一种思路吧。
当然使用 VueX 是最棒的方案咯,将在以后的教程中另行梳理。
本文则使用空的 vue 实例作为事件调度器。
var Event = new Vue(); // 事件调度器
new Vue({
el: '#app',
components: {
'Child': {
data: function() { return {word: ''} },
template: `<div>我说:<input v-model="word"></div>`,
watch: { word: function(){ Event.$emit('say-somthing', this.word) } },
},
'Childtwo': {
data: function(){ return {text: ''} },
template: `<div>复读机:{{text}}</div>`,
mounted: function() {
Event.$on('say-somthing', function(data) {
this.text = data;
}.bind(this)); // 特别注意此处的 this 本来指向 Event 哟
},
}
}
});
但上面的例子还只是单反面的兄弟间传递,非双向的。那么我们再举个栗子:

本文将梳理描述一些 异步程序开发方面的流派。
也不见得是异步的,回调很多的程序来开发的话也是这一套
function fn1(callback) {
setTimeout(function(){
callback && callback();
}, 100);
}
fn1(function(){ alert(); });
回调函数的优点是 简单、容易理解和部署。
缺点是不利于代码的阅读和维护,各个部分之间 高度耦合,流程会很混乱,而且每个任务只能指定一个回调函数。
比如 fn1(fn2(fn3)) 既不好看,改为 fn3(fn2) 也不见得很方便(比如未封装成方法的时候),绑两个回调比较麻烦等问题。
未封装时候写回调,形象可以戏称未“回调金字塔”,尖角向右的那个样子
我们就用 jquery 的 on + trigger 也是非常漂亮的。
function fn1() {
setTimeout(function(){
$('.my-list').triggle('done')
}, 100);
}
$('.my-list').on('done', f2).on('done', f3);
事件驱动模式,任务的执行不取决于代码的顺序,而取决于某个事件是否发生。
优点是比较容易理解,可以绑定多个事件,每个事件可以指定多个回调函数,而且可以去耦合,有利于实现模块化。
缺点是整个程序都要变成事件驱动型,运行流程会变得很 不清晰。
其实你把它叫做“观察者模式”或者“订阅发布模式”也是可以的,只是把 $('x') 改成了别的。
比如 var Event = new Vue(); Event.$on('xx'); Event.$emit('xx') 这种事件调度器。
原生如何写观察者模式呢,可见 这里
当时初次接触到 $.Deferred 时惊叹不已,这世间竟还有如此*的操作。
$.ajax("test.html")
.done(function(){ alert('哈哈,成功了!'); })
.done(function(){ alert('我还能再运行一次'); })
.fail(function(){ alert('出错啦!'); });
// 或者多个 ajax 一起玩耍
$.when($.ajax('test1.html'), $.ajax('test2.html'))
.done(function(){ alert('哈哈,成功了!'); })
基于 $.Deferred 自定义的异步就按下面这样写
var dtd = $.Deferred();
function wait(dtd){
setTimeout(function() {
dtd.resolve('finish');
}, 500);
return dtd;
};
$.when(wait(dtd))
.done(function(text){ alert(text); })
.done(function(text){ alert(text); })
jQuery 源码:https://github.com/jquery/jquery/blob/master/src/deferred.js
原理大致为,
function fn1(){
return new Promise(function(resolve, reject){
setTimeout(function(){
alert('');
}, 500);
})
}
ES6 标准化了的 Promise 相比
兼容代码:https://www.promisejs.org/polyfills/promise-7.0.4.js
虽然不是源码,但可以大致一窥 Promise 的实现原理。
GitHub:https://github.com/BYVoid/continuation
其实还不理解它的原理,但它确实做到了,有兴趣的可以研究一番,在此只作拓展阅读了。
function textProcessing(ret) {
fs.readFile('somefile.txt', 'utf-8', cont(err, contents));
if (err) return ret(err);
contents = contents.toUpperCase();
fs.readFile('somefile2.txt', 'utf-8', cont(err, contents2));
if (err) return ret(err);
contents += contents2;
fs.writeFile('somefile_concat_uppercase.txt', contents, cont(err));
if (err) return ret(err);
ret(null, contents);
}
textProcessing(cont(err, contents));
if (err) console.error(err);
Tween.js 只有 5.6k,拿来做动画是一个不错的选择。
是 CreateJS(神器)旗下的一个子项目,受众庞大,值得一学。
<script src="https://cdn.bootcss.com/tween.js/r14/Tween.min.js"></script>
以下代码请注意 TWEEN / Tween / tween 三者的区别
写个小 demo 先来感受一下 Tween.js 的魅力:
就是以下这样简单的 4 步完成值的匀速变化。
// 指定动画对象
var pos = {x: 0, y: 0};
var tween = new TWEEN.Tween(pos);
// 指定动画目标 和 运行时间
tween.to({x: 200}, 1000);
// 启动 tween
tween.start();
// 动画不断更新
animate();
function animate() {
TWEEN.update();
requestAnimationFrame(animate);
}
// 监听动画变动
tween.onUpdate(function(){
console.log(this.x)
});
update 即更新一次,如果传入某毫秒值作为参数,则一直更新该时间对应的动画值,试一次就懂了。
stop 即可暂停动画,再次 start 则从暂停处继续动画。
start 传入某毫秒值作为参数的话,代表动画将从该时间开始。
TWEEN.getAll() 获取动画队列,数组类型,动画完成就会清出队列。
TWEEN.removeALL() 清空队列。
TWEEN.add(B) 添加一个队列,与 chain 不同在于 add 是同时运行的。
TWEEN.remove(B) 把 B 从队列中清除。
A.chain(B) 可以连接多个动画,B 将在 A 结束之后运行。
repeat 循环动画,且 chain 还是跟在 repeat 最终结束之后。
yoyo 需与 repeat 合用,且需传入非 0 参数,偶数次动画会反向运行。
tween.repeat(1); // 将运行总共 2 次
tween.repeat(Infinity); // 无限循环
tween.yoyo(1); // 一次正序一次倒序的运行
delay 延迟运行。概念比较好理解,但眉头一皱,发现此事并不简单。
TWEEN.Easing 下有 Linear, Quadratic, Cubic, Quartic, Quintic, Sinusoidal, Exponential, Circular, Elastic, Back, Bounce 这 11 种类型的缓动类型。
除 Linear 只有 None 外,其他都含有 In, Out, InOut 3 种缓动效果。所以共计 31 种。
easing 方法传入以上参数,即可实现各种节奏效果。
tween.easing(TWEEN.Easing.Linear.None);
tween.easing(TWEEN.Easing.Bounce.InOut);
自定义缓动函数则传入一个方法,返回该时间帧应该改用的时间帧即可
tween.easing(function(k){
console.log(k); // k 为时间进度,范围 [0, 1)
return Math.floor(k * 10) / 10;
});
具体的效果区别,可参见此 DEMO,右键在新标签打开连接
曾经为了简化写动画的过程,也搞过一个这样的动画类工具,发出来缅怀一下。
!(function(){
// 判断类型
window.Type = function(obj) {
var typeStr = Object.prototype.toString.call(obj).split(" ")[1];
return typeStr.substr(0, typeStr.length - 1).toLowerCase();
}
// 区间内持续时间的变化
window.smooth = function(fn, duration, option, finish) {
var type, per, now = Date.now(), Timer, count = 0;
var _optionType = Type(option);
if (_optionType === 'boolean') { // 循环模式
type = 'infinite';
duration = duration || 25;
} else if (_optionType === 'number') { // 限定次数
type = 'remain';
duration = duration || 25;
var remain = option;
} else { // 运行一次,但 duration 期间按设备性能持续运行 fn
type = 'animate';
duration = duration || 1000;
if (option) finish = option;
}
_run();
function _run() {
per = Math.min(1, (Date.now() - now) / duration);
if (per < 1) {
if (type === 'animate') fn(per, ++count);
Timer = requestAnimationFrame(_run);
} else {
if (type === 'animate' && finish) finish();
if (type === 'infinite' || count < remain) {
now = Date.now();
fn(++count);
if (count === remain && finish) finish()
Timer = requestAnimationFrame(_run);
} else {
cancelAnimationFrame(Timer);
}
}
}
return {
stop: function() {
cancelAnimationFrame(Timer);
}
}
}
})()
个人觉得写的还是不错的,我也在经常使用,
只比 Tween.js 少了两个回调和 easing 而已。
之后如何使用,就看你的项目需求咯,加油大宝贝。
触底加载是非常场景的列表交互之一,但随着加载的元素越来越多就开始面临性能问题了;
想象一下微信信息列表中的数据,为何可以那么快速稳定的呈现;
再例如,在一次性生成 <select> 内容时也有可能一下加入了上千条数据,这都是很可怕的。
比如在使用 jquery.select2 插件的过程中,当行数达到 3000 时就开始有明显页面卡顿出现了。

虽然将其转为分页的触底加载交互在有一定的辅助,但依旧想寻找更多的优化方案。
在 无尽滚动的复杂度 此文中受到启迪,虽然改动 dom 好像更耗性能,但也许值的尝试。
singleton,产生一个类的唯一实例。
可以减少全局变量,且保证该实例的唯一性。
但会有闭包的毛病(占用内存),再者想创建另一个相似实例有悖于此模式。
var singleton = function( fn ){
var result;
return function(){
return result || ( result = fn .apply( this, arguments ) );
}
}
// 伪代码,不管运行几次 createGame,都只有一个 Game 实例
var createGame = singleton(function() {
return new Game();
})
// 或者这样,只会新建一个元素
var num = 0;
var createMask = singleton(function(){
var $d = document.createElement('div');
$d.className = 'x' + ++num;
return document.body.appendChild($d);
});
var mask1 = createMask();
var mask2 = createMask();
console.log(mask1, mask2); // <div class="x1"></div> <div class="x1"></div>
即 on 绑定回调,trigger 触发回调
var Events = function() {
var listen, log, obj, one, remove, trigger, __this;
var obj = {}, __this = this;
listen = function( key, eventfn ) {
var stack, _ref;
stack = ( _ref = obj[key] ) != null ? _ref : obj[ key ] = [];
return stack.push( eventfn );
};
one = function( key, eventfn ) {
remove( key );
return listen( key, eventfn );
};
remove = function( key ) {
var _ref;
return ( _ref = obj[key] ) != null ? _ref.length = 0 : void 0;
};
trigger = function() { //面试官打电话通知面试者
var fn, stack, _i, _len, _ref, key;
key = Array.prototype.shift.call( arguments );
stack = ( _ref = obj[ key ] ) != null ? _ref : obj[ key ] = [];
for ( _i = 0, _len = stack.length; _i < _len; _i++ ) {
fn = stack[ _i ];
if ( fn.apply( __this, arguments ) === false)
return false;
}
}
return {
on: listen,
one: one,
remove: remove,
trigger: trigger
}
}
// 例子
var eee = new Events;
eee.on('end', function(){ console.log('2s 后') });
setTimeout(function(){ eee.trigger('end'); }, 2000);
adapter,类似于USB转接口,也就是中间加一个过程,让参数得以匹配
// 例子1:改变函数参数传递
var something = { x: 1, y: 2, z: 3 };
var myfun = function(a, b, c) {
console.log(a, b, c);
}
var _myfun = function(obj) { // 这就是适配器
obj.x = Math.max(0, Math.min(obj.x, 5));
myfun(obj.x, obj.y, obj.z);
}
console.log(_myfun(something));
proxy,把对一个对象的访问, 交给另一个代理对象来操作。
比如进行允许/拒绝/缓存/合并等操作。
// 例子
var plus = function () {
var args = [].slice.call(arguments, 0);
return args.reduce((x, y) => x + y);
}
var proxy = function (fn) {
var cache = {};
return function(){
var args = Array.prototype.join.call(arguments, "-");
if( args in cache ){ // 判断是否被计算过
console.log( "从缓存中拿取" );
return cache[args];
}
return cache[args] = fn.apply(null, arguments);
}
}
var add = proxy(plus);
console.log(add(1, 2, 3, 4)); // 10
console.log(add(1, 2, 3, 4)); // 从缓存中拿取 10
//
decorator,为对象动态加入行为,都是不改变原来的对象添加功能。
包装模式与代理模式的不同,在于代理模式返回的结果会不变,包装模式则可能不会。
delegater,接收多个对象,将请求委托给另一个对象统一处理请求。
// 比如,事件冒泡和事件委托
function clicked() {}
var $li = document.querySelecterAll('li');
for (var i=0,len=$li.length; i<len; i++) {
$li.onclick = clicked
}
var $ul = document.querySelecterAll('ul');
$ul.onclick = function(e){
var el = e.target;
if (el.tagName.toLowerCase() == 'li') {
clicked.call(el, e)
}
}
复制一个或多个对象来创建一个新的对象。(为方便,下文操作均简称为拷贝)
普遍有两种用法,浅拷贝 和 合并对象。
有几点需要特别注意:
浅拷贝,只拷贝了引用的指针
原始类型会被包装为对象来处理
出现异常是中断拷贝,而不会重置
可访问性和可枚举性直接影响拷贝
单这一个要写的就好多,下次吧
微信小程序的小型专题研究,至于 案例 可前往 我的仓库 查看
在 app.json 的 window 选项中或页面配置中开启 enablePullDownRefresh;
在页面中写上 onPullDownRefresh 监听下拉刷新的触发;
当处理完数据刷新后,wx.stopPullDownRefresh 可以停止当前页面的下拉刷新。
注意事项
简单的美化
app.wxss 里 page { background: #e5e5e5 } 让背景色偏灰
app.json 里 "backgroundTextStyle": "dark" 让三个点变成黑色

感谢:http://www.wxappclub.com/topic/935
自写下拉刷新
除开配置中的 tabBar 的 position 为 top 这种样式外,可能你还会遇上超坑比的产品跟你说,顶部还得再加个搜索,或者顶部导航换个样式,那样我们就无法使用小程序自带的下拉刷新了。
而在小程序中,fixed 慢慢得到了比较好的支持,不会像 H5 那样特别不听话。
所以直接将顶部元素 fixed 一下,本页设为可下拉刷新,效果也是很棒的。
// page.json
{
"enablePullDownRefresh": true
}
// page.wxml
<view class="top-bar">顶部导航</view>
<view class="section others">test</view>
// page.wxss
.top-bar {
position: fixed;
top: 0; left: 0; right: 0;
z-index: 2;
background: #fff;
box-shadow: 0 2rpx 5rpx rgba(0,0,0,.1);
}
// page.js
Page({
onPullDownRefresh: function () {
wx.stopPullDownRefresh();
},
})
但需求往往无穷无尽,当遇到页面需要不同滑动区域时,比如 tabs 对应多个 scroll-view。
那么上面方案就会遇到一个问题,它们的滚动条是同一个呀,切换时滚动到的位置是一致的。
当然,用数组去记录切换前的已滑动位置,也是个不错的办法。
而不死心的我还是想试试有没有更直接的办法,实则是有的,只是不太妙而已。
原理:当 scroll-view 有高度时会使用 scroll-view 的滚动条,无高度时会使用全局的滚动条。
这样的话,我们只需监听 scroll 判断滑到顶了则去掉高度,那不就可以用全局的下拉刷新了吗。
方法是可行,方案也很*,但苹果机上有问题,下拉刷新时的三个点是在 web-view 外面。
// page.wxml
<scroll-view
style='height:{{listHeight}}px'
scroll-y
enable-back-to-top
bindscrolltolower='onReachBottom'
bindscroll='scroll'>
<view>列表内容</view
</scroll-view>
// page.js
let listHeight = 0;
Page({
onLoad: function() {
// 计算列表高度,这里的 50 为 .top-bar 高度,因为我设了 100rpx 的定值
wx.getSystemInfo({success: res => {
listHeight = res.windowHeight - 50;
this.setData({ listHeight: res.windowHeight - 50 });
}})
},
scroll: function(e) {
var st = e.detail.scrollTop
if (st < 1) this.setData({ listHeight: NaN })
},
onPullDownRefresh: function () {
setTimeout(() => {
this.setData({ listHeight: listHeight })
wx.stopPullDownRefresh();
}, 1000);
},
})
真的去自己重构 scroll-view 的话,我个人觉得是不必的。
只使用 scroll-view 的 bindscrolltoupper 触顶刷新其实是最好的,
让用户不用非要进行下拉刷新的操作,无意识滑回顶部时发现数据变了可能更令人开心。
CSS3 的 column 众所周知,用起来非常舒爽,但有顺序问题(会先把第一栏填满再填后面的)。
而更多 jquery 插件,不能引用是一回事,其算法在小程序中也比较难实现(宽高位置获取太麻烦)。
相对而言,花瓣网 的这种分栏式瀑布流要更容易实现一些。
布局和结构不难理解,分为 cols 个数的栏目,分别有自己的数组 list[col]。
<view class="list-box">
<block wx:for="{{cols}}" wx:key="*this" wx:for-item='col'>
<view class='list list{{col}}'> <!-- 单个栏目 -->
<block wx:for="{{list[col]}}" wx:key="unique" wx:for-index='i' wx:for-item='one'>
<view class='item'> <!-- 栏目中的一项 -->
<!-- 图片 -->
<image src='{{one.img}}' style='width:{{one.width}}px;height:{{one.height}}px'></image>
<!-- 文字,可多行 -->
<view class='desc'>{{one.text}}</view>
</view>
</block>
</view>
</block>
</view>
// index.js
data: {
cols: 2,
list: [[], []],
}
然后将新数据插入到栏目中最矮的一个栏目中去,那么我们就需要知道图片高度和文本高度。
获取图片高度可通过 wx.getImageInfo,用 bindload 也可以。
获取文本高度可通过 wx.createSelectorQuery().select('.desc').boundingClientRect。
// 返回单个列表项的高度,obj 为数据,index 为数据索引
getHeight: function(obj, index, callback) {
// 获取图片信息
wx.getImageInfo({
src: obj.img,
success: img => {
// 修改图片尺寸,宽度等于 col 宽,高度自适应
var ratio = img.width / img.height
obj.width = img.width = this.colWidth; // 这个 col 宽度需要另外获取
obj.height = img.height = obj.width / ratio;
// 获取文字高度
var $dom = wx.createSelectorQuery().select('#text_' + index);
$dom.boundingClientRect(rect => {
var height = img.height + rect.height;
obj.itemHeight = height;
callback && callback(height);
}).exec();
},
});
},
看到网上大多实现下来,最终列表项的顺序可能是无序的,所以我们最好是所有高度获取完了再计算。
// 传入新数据,计算列表分布,更新列表
update_list: function (r) { // r 为新数据
var total = r.reduce(x => ++x, 0);
r.forEach((item, i) => {
// 获取每个列表项的高度
this.getHeight(item, i, (height) => {
if (--total < 1) { // 高度全部获取完毕,开始计算
this.data.list = this.theNewList(r, this.data.list);
this.setData({ list: this.data.list });
}
})
})
},
// 根据后加入的列表,产生新的列表
theNewList: function (temp, list) { // temp 即 r,为新数据
temp.forEach(item => {
// 选出当前 col 高度最小值,_height 存储着各栏目的当前高度
var min = Math.min.apply(null, _height);
// 选出当前 col 高度最小值的索引
min = _height.indexOf(min);
// 进行赋值,这样做才是有顺序的列表
_height[min] += item.itemHeight;
list[min].push(item);
})
return this.data.list;
},

其实写轮播并不是件难事,小程序的轮播也是如此。
需处理的几个方面即可:拖拽操作,防止事件混淆,回调与自定义项。
另一方面,轮播的样式和场景处理也有不同流派
小程序的轮播是以父级高度为主,子级是 absolute 的,所以还可以完成 重叠/3d 等形式的动画切换。
而 swiper 的轮播是以 flex 布局为主,子级撑起父级高度的样式方案,只有单轴向的动画切换。
本案采用后者。当然这是由项目需求决定的,但其中大多流程不会改变。
// ... 代码整理中
步骤说清楚是简单的,但不得不说,小程序的坑能把人脚给崴了。
大致列举一下,后期会不断更新:
// ... 代码整理中
大致介绍一下,就是打开了摄像头,进行现实场景的识别,然后给予虚拟场景下的反馈。比如扫个图形出来个三维小萝莉什么的。
真 AR 能识别到视频流的每一帧,对小萝莉还能进行三维场景下的定位处理,这必然是很烧的事情,涉及到截图效率/场景识别/三维定位计算/三维绘制几个比较头疼的事情。
所以小程序能做的还是伪 AR,定时截个图,识别成功出结果,放个三维动画结束。
// ... 代码整理中
是 transition-timing-function 的值的一种。
四个参数的关系式如下(t 代表时间,取值范围 [0, 1]):
P0(1-t)3 + 3P1t(1-t)2 + 3P2t2(1-t)1 + P3t3
快捷工具:http://7xpdkf.com1.z0.glb.clouddn.com/bezier.html
也是 transition-timing-function 的值的一种。
steps 其实可以有两个参数。
第一个参数表示把动画分割成几次;
第二个参数该参数可选,默认是 end,表示开始值保持一次,若参数为 start,表示开始不保持。
具体效果如下图:

另外,transition-timing-function 的值还有一种为关键字,
共 7 种:ease 先快后慢,linear 匀速,
ease-in 开始较慢,ease-out 结束较慢,ease-in-out 比 ease 幅度更大,
step-start 相当于 steps(1, start),step-end 相当于 steps(1, end)
| 属性 | 默认值 |
|---|---|
| transition-property | all |
| transition-duration | 0s |
| transition-delay | 0s |
| transition-timing-function | ease |
注意:此处的 0 不能省掉 s,也算是特例了。
这也意味着,你只需要修改 transition-duration: 1s 其实就已经拥有 transition: all 1s 0 ease 了。
传入多个值,逗号隔开。
property 多于其他值的个数时,多出的默认为第一个
.box {
transition-property: width, background, opacity;
transition-duration: 2s, 500ms;
transition-timing-function: linear, ease;
transition-delay: 200ms, 0s;
}
/*类似于*/
.box:hover {
transition: width 2s linear 200ms, background 500ms ease 0s, opacity 2s linear 200ms;
}
property 少于其他值的个数时,多余的无效
.box {
transition-property: width;
transition-duration: 2s,500ms;
transition-timing-function: linear,ease;
transition-delay: 200ms,0s;
}
/*类似于*/
.box:hover {
transition: width 2s linear 200ms;
}
这是一个很棒的技巧,正向时为一个动画,反向时为另一个动画。
其实正向反向这个名词并不官方也不准确,如果你有更好的诠释方式可在下方评论,谢谢。
.box {
width:100px; height:100px; background: pink;
transition-duration: 3s; /* 鼠标移出时动画 3s */
}
.box:hover {
width: 300px;
transition-duration: 500ms; /* 鼠标悬停时动画 .5s */
}
如果目标值为 auto 是不会有动画效果的。
这也是 CSS 为什么无法实现 slideDown 效果的一道坎。
据说低版本 webkit 在反向时有动画,但其实无所谓啦。
至于像 gradient 渐变之类的无法实现动画你想必是知道的。
哪些能有动画请见此文:http://oli.jp/2010/css-animatable-properties/
还有些问题,比如 clip 不会触发动画,但会触发 transitionEnd,还是项目中遇到了再说吧。
比如,当动画时 font-size 变化后,拥有 em 的值所对应的结果其实也是变化的。
.box {
width:100px; height:100px; background: pink;
transition-duration: 2s;
border-right: 1em solid;
}
.box:hover {
font-size: 30px; /* 鼠标悬停时边框宽度也变化了 */
}
同理,百分比,vw 等数值都可能有隐性过渡,因为他们都属于相对值。
至今(20171009)都还有很多浏览器不支持 tranistionEnd 而要使用 webkitTransitionEnd,所以请做好兼容哟。
再者,如果多个 transition-property 有动画,是会触发多次 tranistionEnd 的。
当 duration-delay 为负值时,情况会很特殊,所以非常不推荐这些写。
.box {
width:100px; height:100px; background: pink;
transition-duration: 1s;
}
.box:hover {
font-size: 30px;
border-right: 2em solid; /* 特别注意,如果修改的是 border 将触发 4 次哟 */
}
var transitionEnd = 'onwebkittransitionend' in window ? 'webkitTransitionEnd' : 'transitionEnd';
var $box = document.querySelector('.box');
$box.addEventListener(transitionEnd, function(e){
console.log(e); // 触发了两次
});
除了 border 会触发四次外,padding 也可以,还有哪些以后整理。
所以推荐你在知道要使用 transitionEnd 的情况下,尽量不用 transition-property: all。
在 transitionEnd 的回调参数 event 中有些属性可能值得了解一下:
visibility 是可以有动画效果的。
举个栗子,在动画完成后加一个 visibility:hidden 的动画,能起到类似 display:none 的效果。
opacity: 0;
visibility: hidden;
transition: opacity 1s, visibility 0s 1s;
同理,在新建删除元素前添加动画,用 visibility 来实现也是非常爽的。
最近公司项目使用小程序做序列帧动画,大概有 116 张图,共 7.4M。
比较闲的日子里实验了一番,主要有以下几种方法,
结果当然是 canvas 性能最优咯,不会出现掉帧和卡屏的情况,其中最不推荐第一种
所以这次项目也就准备尝试下微信小程序的 canvas 会不会有别样的风味。
基本上和 html 的 canvas 区别不大,方法名略有不同,
canvas.getContext('2d') 等于 wx.createCanvasContext(canvas)。
再就是需要一个 draw() 方法才会绘制(经常容易忘记)。
至于 wx.createCanvasContext 放在 onReady 还是 onShow,以及重复新建等问题上,由于项目紧凑,手里机型太少,没试太多
接着就开始了填坑之路:
官方案例用的是 wx.chooseImage 返回缓存文件,但我们的是116张图呀。
真是的,也不多给几个案例,还得自己来尝试。
在 HTML 中如果想 drawImage 那就需要一个 Image 对象,
需要先 new Image() 或者获取到 DOM 中的 <img>,那么小程序该怎么办呢。
我略一沉凝,准备试它一试,直接使用了图片绝对路径,
ctx = ctx ? ctx : wx.createCanvasContext('imgs');
url = 'https://sum.kdcer.com/test/sw_shake/0/0 (1).jpg';
ctx.drawImage(url, 0, 0, 300, 500); // 直接使用图片路径
ctx.darw()
调试器上正常(后面证明,预览时也是正常的)。url 为相对路径也是可以的。
但,这个时候预加载就是个问题,图片加载比 draw 慢时就很尴尬了。
只能在 wxml 中去 bindload 或者 wx.downloadFile 来进行是否加载完成的处理咯。
上面的情况虽然调试器中可看,但手机预览时图片却没有绘制(其他点线图形绘制了),
唔,不妙。然后去论坛博客寻找了番,不禁感叹资料可真少啊。相当不妙。
换个方向,我再试试 wx.downloadFile 这种方法,用缓存文件该是符合官方案例的吧。
wx.downloadFile({
url: url,
success: function (res) {
ctx.drawImage(res.tempFilePath, 0, 0, 300, 500);
ctx.draw();
}
})
还好能看到些反馈,算是找到了错误原因。
返回给我的 res.tempFilePath 是个 .htm 结尾的文件,并报出 http 400(请求无效)。
我怀疑问题出在了文件本身,于是我改了下文件名,由 0 (1).jpg 改为 1.jpg,就能正常访问了。
再后来进行了一些实验,暂时还只发现了 空格+括号 这一种命名会失败。
返回去再试一次, drawImage 直接使用命名正确的图片绝对路径其实也是可以的。
比较坑的是,downloadFile 不能下载相对路径的图片,
这让我想优化把一部分图片放进小程序变得无比麻烦。
(其实 2M 资源放进去小程序就会变得非常卡,不推荐)
官方表示,downloadFile 最大并发限制为 10 个,
意味着直接 for 个 116 下是会报错的。
因此需要换用为递归的方式去预加载图片。
我写的递归不见得都适用,就不放出来了,应该没什么难点的。
(推荐先用 .html 写通递归,不然小程序编辑器死循环了很扎心)
初次开发时出现了小程序仅有打开了调试工具才能正常运行(预览时未下载图片)的情况,
后来经过同事点拨,原来还要设置 downloadFile 的合法域名。
合法域名每个月只能修改 5 次的限制应该不是什么大问题。
为了更好的动画优化,当然少不了 requestAnimationFrame 的存在。
然而,安卓机的小程序是有的,苹果机小程序却根本没有这个方法。
好在我们可以写段回退兼容:
if (typeof requestAnimationFrame == 'undefined') {
var lastTime = 0;
var requestAnimationFrame = function (callback) {
var currTime = new Date().getTime();
var timeToCall = Math.max(0, 16 - (currTime - lastTime));
var id = setTimeout(function () { callback(currTime + timeToCall); }, timeToCall);
lastTime = currTime + timeToCall;
return id;
};
}
if (typeof cancelAnimationFrame == 'undefined') {
var cancelAnimationFrame = function (id) {
clearTimeout(id);
};
}
小程序一直吹嘘着接近原生的流畅体验,但这次帧动画的项目中显然打脸了。
html 版的 canvas 每 15ms 绘制一次都是小 case,
但小程序则需要 50ms 以上的间隔。否则会出现间断性白屏。
60fps 和 20fps 虽然在 html 中有很大差距,
但在小程序中 20fps 并没有太影响用户的浏览体验。
毕竟 js 的运算和 webview 的通信本身就不是多快的一件事。
如果单单只考虑 webview 和 html 不带 JS 一起玩耍的话那当然小程序会流畅些。
canvas / video / map 在小程序中的 z 轴层级非常高,甚至能盖过调试工具。
所以我们想在他们上面再叠一些元素就只能靠 cover-view 了。
但是,cover-view 只支持基本的定位、布局、文本样式,
不支持设置单边的 border、opacity、background-image 等。
我觉得不能叠图这个问题还是有些麻烦的,至少操作起来是这样。
而且,cover-view 暂不支持 css 动画。
项目中还遇到过 cover-view 高度丢失等问题,玩耍得实在不畅快。
稍提一下,canvas 绑定的事件自带不冒泡,知道就行,影响不大。
不过有人去改了编辑器源码,见 we_flappybird,
测了可行,但并不推荐,编辑器下次更新又要改。
总的来说,填坑的路是比较烦人的,
后一个问题解决了又开始想,是不是前一个问题其实本来是对的,然后又回去重来一遍,
最后的最后,来来回回,才能彻底填平这个坑。
本文无需说明理论知识,纯简化实操的代码,直接来看吧:
Date 传入的参数需符合标准,请见 IETF-compliant RFC 2822 timestamps 或 version of ISO8601。
PS:传入的参数 date 需为 Date 对象的实例,请先行转化。
PPS:比如改变了天数,其实 时分秒并未改变,使用时请注意。(划重点)
PPPS:修改的是对象,为了避免操作的是同一个对象的数据栈,可以再 new Date() 一下。
function changeDate(datetime) {
return new Date(parseInt(datetime.replace("/Date(", "").replace(")/", ""), 10));
}
function day_offset(date, days) {
var date = new Date(date);
return new Date(date.setDate(date.getDate() + days));
}
function first_day_this_month(date) {
var date = new Date(date);
return new Date(date.setDate(1));
}
function monday_this_week(date) {
var date = new Date(date);
return DateAddDay(date, 1 - date.getDay());
}
function how_much_day(date, month) {
var date = new Date(date);
var year = date.getFullYear();
var m = [31, null, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31];
m[1] = (year % 4 == 0 && year % 100 != 0 || year % 400 == 0) ? 29 : 28;
return m[month - 1];
}
function two_date_minus_for_day(date1, date2) {
return Math.abs(Math.floor((date2 - date1) / (24 * 60 * 60 * 1000)));
}
// yyyy = 年 mm = 月 dd = 日 hh = 小时 nn = 分 ss = 秒
function date2str(date, pattern) {
var str = pattern;
str = str.replace(/y{4}/i, date.getFullYear());
str = str.replace(/m{2}/i, (date.getMonth()+1));
str = str.replace(/d{2}/i, date.getDate());
str = str.replace(/h{2}/i, date.getHours());
str = str.replace(/n{2}/i, date.getMinutes());
str = str.replace(/s{2}/i, date.getSeconds());
return str;
}
// 需要补零的
function date2str(date, pattern = 'yyyy-mm-dd', zero = false) {
var str = pattern;
str = str.replace(/y{4}/i, zero ? addZero(date.getFullYear()) : date.getFullYear());
str = str.replace(/m{2}/i, zero ? addZero((date.getMonth() + 1)) : (date.getMonth() + 1));
str = str.replace(/d{2}/i, zero ? addZero(date.getDate()) : date.getDate());
str = str.replace(/h{2}/i, zero ? addZero(date.getHours()) : date.getHours());
str = str.replace(/n{2}/i, zero ? addZero(date.getMinutes()) : date.getMinutes());
str = str.replace(/s{2}/i, zero ? addZero(date.getSeconds()) : date.getSeconds());
return str;
}
function addZero(num, n = 2) {
var len = num.toString().length;
while (len++ < n) num = "0" + num;
return num;
}
function addZero2(num, n = 2) {
if (Math.pow(10,n)<num) return num+'';
return (Array(n).join(0) + num).slice(-n);
}
var end = new Date(2017, (9-1), 8, 20, 0, 0);
var d = new Date(end - new Date());
setInterval(function(){
d = new Date(d.setSeconds(d.getSeconds() - 1));
if (d.getTime() > 0) console.log(d);
else console.log(end);
}, 1000);
本身理论并不难,但需要注意以下几点:
new 出来的时间是有时差的,比如最后一秒 getHours() 会为 8,所以如果有天数和小时级别的倒计时要特别注意这个坑(划重点)d 最后一秒 getTime() 为 0,去掉了时差会为负数哟所以我只能进行了下面这种性能实在不佳的封装
function dateAddSecond(date, second) {
return new Date(date.setSeconds(date.getSeconds() + second));
}
function timecount(start, end, fn, cb) {
var offset = end - start, Timer = null;
var d = new Date(offset);
var dd = new Date(offset); // 处理时区问题
dd = new Date(dd.setHours(dd.getHours() + dd.getTimezoneOffset() / 60));
// 正式开始
if (d.getTime() > -1) _begin();
else { fn && fn(end, d); cb && cb(); }
// 内部方法
function _begin() {
fn && fn(dd, d);
Timer = setInterval(_run, 1000);
}
function _run() {
d = dateAddSecond(d, -1);
dd = dateAddSecond(dd, -1);
fn && fn(dd, d);
if (d.getTime() < 1000) {
_stop(); cb && cb();
}
}
function _stop() {
clearInterval(Timer);
}
return {
start: _begin,
stop: _stop,
}
}
// ------ 倒计时运行
var endTime = new Date(2017, (9-1), 6, 13, 35, 0); // 这里修改结束时间
timecount(new Date(), endTime, function(left, raw){
// left 为真实剩余时间,raw 为时间相减本来得到的值
console.log(left, raw.getTime());
});
以下代码实现的是,从本月到往后五个月所有日期形成的二维数组。
其中 month_offset 和 day_offset 是类似的方法,就不再复写了。
var result = [];
var now = new Date();
var temp = first_day_this_month(now); // 先求取本月第一天,因为 31 号时的月份加减很容易出错咯
for (var i=0; i<6; i++) {
result[i] = [];
var month = month_offset(temp, i); // 六个月第一天的日期
var days = how_much_day(month.getMonth(), month.getFullYear()); // 当月有多少天
for (var j=0; j<days; j++) {
result[i].push(day_offset(month, j)); // 当月每一天放入数组中
}
}
console.log(result);
现在去做前端面试题都是心虚的,
本来可以做对的题,想想好像有坑,然后答错了。举个例子:
Number([0]); // 0
[0] == true; // false
if ([0]) alert('ok'); // "ok" // 恩? 不都是 false 吗所以本文将尽可能多的去试图挖一下 javascript 数据类型方面的蹊跷。
这张图大伙应该很熟悉了,但其实这里面有些很诡异的问题,很迷很迷。
0 == '0'; // true
0 == []; // true
'0' == []; // false双等时也许是进行了类型转换的,
比如都转为数字或字符串后再进行的比较。
个人猜测转换的顺序 可能 如下:
undefined < null < Boolean < Number < String < Array它是一层层向下进行转换后进行比较的。
'0' == true // false
// 实则是 0 == true 的比较再比如
Boolean([0]); // true
[0] == true; // false
// 实际是 '0' == true 最后 0 == true 的比较<= 这类数值判断,也是类似的,但很快就发现,
以上猜测并不完善,还有更多一步前置的 Number 转换。
2 > true; // true
'1' > '2'; // falseundefined == undefined; // true
undefined <= undefined; // false
// 因为 Number(undefined) 的结果是 NaN注意 [2] == [2] 当然是为 false 啦,
这个可 别混淆 了,以为也要去转化。
此处稍微提一下 -0 的存在,会造成 Infinity 与 -Infinity 的不同。
但我们多半会做分母不为零的判断的,恩大概会的吧。
0 === -0; // true
(1/-0) === (1/0); // false一般使用 if 大致会有以下五种情况,三目判断 和 并或非 也包含其中。
if (a <= b)
if (a)
if (a())
if (a = 1)
if (!a)
如图所示,if 中结果即是 Boolean() 转化后的结果。
请再回味一番,切实记住 if 判断与等于判断的不同哟。
也许更多是在 es5 默认值的时候会有丢丢问题吧。
NaN || 0; // 0还以为 !a 的判断会有坑,试验下来舒了口气,并没有什么特别之处。
这章好像要记住的和留意的东西也并不多,
typeof [] === 'object';
typeof NaN === 'number'
typeof null === 'object'却也是判断中稍有点难判的,所以才出现了 Array.isArray 和 isNaN 这样的方法存在。
为啥我试不出 typeof 为 array 的情况呀,很奇怪耶,是我记错了咩
还有像 Date RegExp arguments 等自然就是对象了,typeof 的坑相对要少很多。
用 [] instanceof Array 判数组真的很方便,但这块也还是有坑的。
'a' instanceof String // false
(new String('a')) instanceof String // true除此之外,还有原型链上的一点问题:
function Foo(){}
var foo = new Foo();
console.log(foo instanceof Foo); //true
Foo.prototype = new Aoo();
var foo2 = new Foo();
console.log(foo2 instanceof Foo) // true
console.log(foo2 instanceof Aoo) // true说实话,除了几个特例,用这个来判原型其实并不是很好的方法。
参考:https://www.ibm.com/developerworks/cn/web/1306_jiangjj_jsinstanceof/
constructor 相比 instanceof 有一点优势,就是它不随 __proto__ 的改变
function A(){};
var a = new A();
var b = new A();
a.__proto__ = {};
a instanceof A // false
b.constructor === A // true以往 es5 做继承时还要自己给 A.prototype.constructor 设新值,
有了 es6 的 class 后已经很简单了,用 constructor 来判原型也稳妥了起来。
至于基础数据类型嘛,也不太推荐用此方法。
isFinite();
isNaN();
Number.isNaN();
Array.isArray();其实 Object.is() 是类似 === 的,但又有点不一样,它是真真正正的绝对相等。
+0 === -0 // true
Object.is(+0, -0) // false
NaN === NaN // false
Object.is(NaN, NaN) // true还需稍微分清一下原型与实例即可,即 for-in 和 for-of 的区别。
'0' in [1, 2]; // true
'now' in Date; // true
'getFullYear' in Date; // false至于项目是使用以下哪种判断就见仁见智了。
if (Array.prototype.includes) {}
'includes' in [];obj.hasOwnProperty(key) 和 obj.isPrototypeOf(obj2) 等相关方法,整理中
+' 014' // 14
+'0x12' // 18
1 + '14' // '114'
1 + '0x12' // '10x12'
1 + +'14' // 15
'14' + 1 // '141'
1 + [1, 1]; // '11,1'
1 + {}; // '1[object Object]'
1 + null; // 1
1 +undefined; // NaN很鲜明,当有单独的运算符存在时(单加括号是不行滴),
会帮忙 Number 转换,否则 String 转换。
还请注意上例中后 4 种特殊的情况。
进行 ++ 运算时并不会帮忙转换为数字,还容易报错。
所以使用时这里得留个心眼哟。
++'14' // ReferenceError还有两个特立独行的数字运算,即 Infinity 和 0 的正负号。
Infinity+Infinity; // Infinity
-Infinity+(-Infinity); // -Infinity
Infinity+(-Infinity); // NaN
+0+(+0); // 0
(-0)+(-0); // -0
(+0)+(-0); // 0再看一个绝对不会遇到的特例,
{} + [] 理论上应该是 '[object Object]' + '' 才对,
就算不是也应该是 NaN + 0 吧,结果我又猜错了。
遇事不决问百度,结果震惊了,这里的 {} 被当成空代码块了,+[] 自然就是 0 了。
[] + {}; // '[object Object]'
{} + []; // 0Number 与 parseInt 的不同,将于下文 parseInt 系列方法 讲述
探讨一下 String 和 toString 的不同吧。
一方面是部分数据类型没有 toString 方法:
String(null); // 'null'
(null).toString(); // Uncaught TypeError
(undefined).toString(); // Uncaught TypeError另一方面是 toString 可以传个进制数的参(仅对数字类型有用)
(30).toString(16); // "1e"
('30').toString(16); // "30"至于 Date Error RegRxp 的字符串化,基本不会出啥幺蛾子。
用原型的 toString 来判数据类型也是种很巧妙常用的方法。
function typeOf(obj) {
var typeStr = Object.prototype.toString.call(obj).split(" ")[1];
return typeStr.substr(0, typeStr.length - 1).toLowerCase();
}
typeOf([]); // 'array'toString 在上文已有介绍,但还得再区分一下数组的。
[1,[2,"abc","",0,null,undefined,false,NaN],3].toString();
// "1,2,abc,,0,,,false,NaN,3"也即是下例想表达的意思:
(null).toString(); // Uncaught TypeError
[null].toString(); // ''toString 与 valueOf 大致是相同的,但是否有不同,整理中...
再则 (1).toFixed Date.parse 等,应该不会有啥常见错误。
只需注意那些是会 对入参进行隐形转换 的,下文 参数的隐形转换 将介绍
window.parseInt 和 Number.parseInt 是全等的,即完全相同。
主要来看 Number 与 parseInt 的不同,挺迷的,
它们并不是单纯的数据类型转化那么简单,举个例子:
Number(''); // 0
parseInt(''); // NaNparseInt 就很花哨,还会再多进行一些暗箱操作来判断和适配成数字。
可见,用 Number 转非整数时会是更好的选择。
parseInt(' 10 '); // 10 // 自动去空格,通用
parseInt('10.2'); // 10 // 数字后的全剔除,Number 和 parseFloat 没问题
parseInt('1e2'); // 1 // 区分不出科学计数法,Number 和 parseFloat 没问题
parseFloat('0x5'); // 0 // 区分不出进制,Number 和 parseInt 没问题当参数为数组时,当然也是先转 String 的咯,
而 parseInt 又能去除 , 后的字符,所以就有下面的情况。
Number([1, 2]); // NaN
parseInt([1, 2]); // 1比较典型的 isNaN 是先用 Number 转了一次,但 Number.isNaN 就没有。
isNaN('1x'); // true
Number.isNaN('1x'); // false这方面没做什么整理,遇到了再补吧。
'12'.replace(1, ''); // "2"
Math.max(0, '1.'); // '1'JSON.parse(JSON.strigify()) 深拷贝时可得注意了哟。
其实递归加对象解构来做深拷贝要更好一些哟。
JSON.stringify(Infinity); // 'null'
JSON.stringify(NaN); // 'null'
JSON.stringify(undefined); // undefined (注:非字符串)
JSON.stringify([undefined]); // '[null]'
JSON.stringify({a: undefined}); // '{}'
JSON.stringify({a: null}); // '{"a":null}'
JSON.stringify(() => {}); // 'undefined'encodeURI 方法不会对下列字符编码 ASCII字母、数字、~!@#$&*()=:/,;?+'
encodeURIComponent 方法不会对下列字符编码 ASCII字母、数字、~!*()'
所以 encodeURIComponent 比 encodeURI 编码的范围更大。
Array.from('foo'); // ["f", "o", "o"]
Object.assign([1], [2,3]); // [2, 3]大致就是这些了,写完要自闭一会,整个过程充满了怀疑与揣测。
虽然做了较为系统的拆分,但还是得承认没写好,敬请期待后续吧。
我还有一个 BUG 库,不妨也分享出来一起看看吧。
偏函数和科里化其实挺像的,同样是为了让前一次的入参得到保存,
var sumAll = (...args) => args.reduce((re, x) => re + x, 0);
var sum1 = curry(sumAll)(1); // 科里化
var sum2 = partial(sumAll, 1); // 偏函数
// 两者都存下了一些入参,只是科里化更轻巧拓展更多而已
var sum11 = sum1(2);
var sum22 = partial(sum2 , 2);
function partial(fn) {
var slice = Array.prototype.slice;
var _args = slice.call(arguments, 1);
return function() {
var args = slice.call(arguments, 0);
args = _args.concat(args);
return fn.apply(this, args);
}
}
CSS3 的 flex 布局已经路人皆知了,理论知识就不提了,不会的可看教程。
后来看到一篇关于 flex 内部渲染机制的 文章,
总结下来其实就是个很清晰的渲染流程:
width 或 flex-basis。flex-shrink 压缩。flex-grow 按比例分配空隙。而往复杂了看,flex-wrap 时又会是怎样的表现呢?
再回想起以往遇到过的样式 BUG,感觉应该是有些东西可以去探究的。
.item.image-left {
display: flex;
align-items: flex-start;
}
.item.image-left > :not(:last-child) {
margin-right: 10px;
}
.item.image-left .image {
width: 30%;
flex-shrink: 0;
}
.item.image-left .shrink{
flex-shrink: 0;
}
.item.image-left .contnet {
flex-grow: 1;
overflow: hidden;
}
其中,有几个要点需要了解一下:
.image 的 flex-shrink: 0 防止图片宽度被压缩,其他更多元素最好也都加上 .shrink。.content 的 overflow: hidden 防止子元素撑破 .item(重要)。.item 的 align-items 依需求改动,最好带上,不然可能造成纵向拉伸。flex-grow: 1,不然会平分空隙。以上皆为必须条件,最终我们可以得到这样的样式:
.tab-box {
overflow-x: auto;
overflow-y: hidden;
-webkit-overflow-scrolling: touch;
display: flex;
}
.tab-box .tab {
flex: 1 0 20%;
text-align: center;
}
.tab-box .tab .image {
width: 4em;
max-width: 80%;
margin: 0 auto;
}
flex: 1 0 20% 与 min-width: 20%; flex-grow: 1 是一个效果。.tab 的范围不那么大,则需摈弃 flex-grow: 1 而用 margin 居中替代。.image 的左右要贴边的话,用 margin 会更好,但需要一定计算量。其实看规则也很容易发现,当有多个需扩展或需压缩项时,是要按比例计算的。
全景效果,即在浏览器浏览 3d 实景的一个体验。
如今其实已经十分常见了,全景相机乃至全景地图都已经普及。
而我是个很笨的程序员,喜欢重复造轮子,
别人会做并不等于自己会做,插件能做并不代表我能做,
所以在这条路上也走过一段时间,在此稍作整理。
我更喜欢把它按形状来进行区分:方形全景,桶形全景,球形全景。
以下案例可能因为 GitHub 带宽的原因会加载比较慢,我也很绝望。
DEMO:https://foreverz133.github.io/demos/works/3Dview/
最火的鼻祖:http://show.im20.com.cn/zwj/pc.html
DEMO:https://foreverz133.github.io/demos/works/3Dview2/
主要基于 three.js + PhotoSphereViewer
【pano.js】http://www.expozeroquindici.it/pano/examples/css3d.html
【krpano】https://krpano.com/examples/
像 webpack 一直没怎么去弄懂它,因为觉得它太繁琐,依赖包太多了,
但不去熟悉依赖包又无法深入了解 webpack,这个死循环真是令人尴尬。
而这道坎终究是要过的,于是我重新从 node 开始学起。
node 上期已讲,有很棒的文件和网络处理,
但我个人还是留下了一些细节问题,比如:
require 引入的,那打包时干了什么之类的,所以后面花了较长的时间去研究这些。
学习 node 的过程并不太复杂,npm 或者原生的包可以用得超爽的,
甚至上述的所有需求都有了相应的包可以来完成,但具体怎么实现的呢。
拿 log 着色这个需求来讲, colors 也有着诸如 chalk 或 tfunk 等竞品,
但实际完成的都是 console.log('\x1B[1m文字\x1B[22m') 这个加粗效果的简化工作。
但依旧有着 '文字'.bold 或 chalk.bold('文字') 或 '{bold 文字}' 好几种不同的写法。
去阅读其源码的过程非常令人开心,
比如 fn() 和 fn.x() 怎么都能运行, str.bold 没有运行函数但起效了。
在学习中我深切地感受到,node 里的奇思妙想可能远比我看到的要多得多。
回到主题,先撇开 webpack 和网页应用不谈,我们只看 node 应用先。
假如我写了个通过链接下载文件的包,那怎么让别人用起来呢。
如果我已经完成了 download 的核心功能编写。
function download(url, output, fileName, callback) {
fileName = fileName || url.slice(url.lastIndexOf('/') + 1);
if (!fileName) throw new Error('没找到文件名');
const filePath = path.join(output, fileName);
const stream = fs.createWriteStream(filePath);
https.get(url, (res) => {
res.on('data', (chunk) => {
stream.write(chunk);
});
res.on('end', () => {
stream.end();
callback && callback(filePath);
});
});
}那么我就需要用户提供入参给我了,这里会有几种方案:
比如 node a.js url: 或 npm run xx -- url 这类直接写进命令行的(利用 node 全局的 process),
const args = process.argv.slice(2);
const url = args[0];或者通过 cmd 交互来等待用户输入的(利用 node 模块的 readline 和 util)。
(async () => {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const questionAsync = require('util').promisify((txt, next) => rl.question(txt, next));
const url = await questionAsync('请输入下载链接');
})();当然这两种需求,都有更方便的包已帮忙实现,请见 附录1 和 附录2。
现在只需要别人拿到我的 index.js 然后 cmd 跑下 node 命令就可以下载了,
但更多时候,我们会选择发布到 npm 上,然别人直接 install 下来,那么就需要使用 npm 了。
npm 都需要现有个 package.json,可以直接自己新建文件,也可以找个文件夹 cmd 跑 npm init。
其中,name 为 npm i name 时的包名,如果你想发布,得去 npmjs.com 上看看有没有同名的。
main 为 require 或 import 时返回的东西,bin 为全局使用该包时运行的代码。
// 假如 "name": "zyh-node", "main": "./index.js"
// index.js
modules.exports = { log: console.log }
// 假设包已上线,有人开始下载
npm i zyh-node
// 然后开始使用
const { log } = require('zyh-node');// 假如 "name": "zyh-node", "bin": { "zyh": "./cli/index.js" }
// cli/index.js
#!/usr/bin/env node
const args = process.argv.slice(2);
console.log(args[0]);
// 假设包已上线,有人开始下载
npm i -g zyh-node
// 然后开始使用(直接 cmd)
zyh hello
// 将在 cmd 打印出 hello其中 #!/usr/bin/env node 是告诉机器,需要用 node 来执行这个文件
npm login 和 npm publish 即可其他教程:https://www.jianshu.com/p/078acd2fe5e1 (包括可能会出现的报错)
首先,不管是写插件还是写网站,最好都得有个打包工具,毕竟要模块化组件化嘛。
这时又有 gulp webpack rollup parcel 等可供选择了,但其实应用场景是不同的。
拿 gulp 和 webpack 比较,webpack 就无法单独为 css 打包,得先有个 js 才行。
而 rollup 没有 webpack 那么多 loader,却很轻量,拿来只是写插件绝对够了。
而 parcel 直接入口就是 html,如何代码拆分合并会更黑盒,搭建网页应用也就更无脑了。
据说 Backpack 还适合 node 应用的打包,还有还有 Browserify Fusebox 等等。
一般来讲,网页应用还可能会有以下打包需求:
知道了以上这些,我们开始用 rollup 做个专门写插件的脚手架。
{
"name": "xb-builder",
"version": "1.0.0",
"description": "",
"bin": { "xb-builder": "./cli/index.js" } }
"scripts": {
"start": "cross-env NODE_ENV=development rollup --config -watch",
"build": "cross-env NODE_ENV=production rollup --config"
},
"author": "",
"license": "ISC",
"devDependencies": {
"cross-env": "^5.2.1",
"rollup": "^1.21.2",
"rollup-plugin-commonjs": "^10.1.0",
"rollup-plugin-json": "^4.0.0",
"rollup-plugin-node-resolve": "^5.2.0"
}
}// cli/index.js
#!/usr/bin/env node
const fs = require('fs');
const inquirer = require('inquirer');
const program = require('commander');
const spawn = require('cross-spawn');
const cliPath = require('path').resolve(__dirname, '../');
const packageJson = require('../package')
program.version(packageJson.version);
program.option('i, init <string>', '初始化项目').parse(process.argv);
if (program.init) {
const dir = process.cwd() + '/' + program.init;
!fs.existsSync(dir) && fs.mkdirSync(dir);
inquirer.prompt([
{ type: 'confirm', name: 'babel', message: '要不要 babel' },
]).then(answer => {
const command = ['i', '-D'];
// 是否加入 babel
if (answer.babel) {
command.push('@babel/core', '@babel/preset-env', 'rollup-plugin-babel'); // 还有一些 babel 改配置的操作就不写了
}
// 然后做代码搬运或下载
copyDir(cliPath, dir);
// 安装 node_modules,也可以缓成修改 package.json 让用户自己安装
spawn('npm', command, { stdio: 'inherit' });
});
}// rollup.config.js
import json from 'rollup-plugin-json'; /* 支持 json 文件引用 */
import resolve from 'rollup-plugin-node-resolve'; /* 支持 exports default */
import commonjs from 'rollup-plugin-commonjs'; /* 支持 module.exports */
import babel from "rollup-plugin-babel"; /* 支持 babel 转化 */
const env = process.env.NODE_ENV;
const isProduction = env === 'production';
const babelConfig = isProduction ? [babel({
exclude: 'node_modules/**' // 只编译我们的源代码
})] : [];
export default {
input: {
index: 'src/app.js'
},
output: [{
dir: 'dist',
format: 'umd',
name: 'app'
}],
plugins: [
json(),
commonjs(),
resolve({
// 将自定义选项传递给解析插件
customResolveOptions: {
moduleDirectory: 'node_modules'
}
}),
...babelConfig
],
};这时,我们 npm 发布后,被别人 npm i -g xb-builder 然后 xb-builder init name,
就可以有一个以 name 命名的文件夹,里面有着一堆基础代码咯。
比较推荐 commander 这个 npm 包。还有 meow yargs-parser 等其他可供学习。
较推荐 inquirer 这个 npm 包。还有 prompt souffleur 等其他可供学习。
未完成,敬请期待
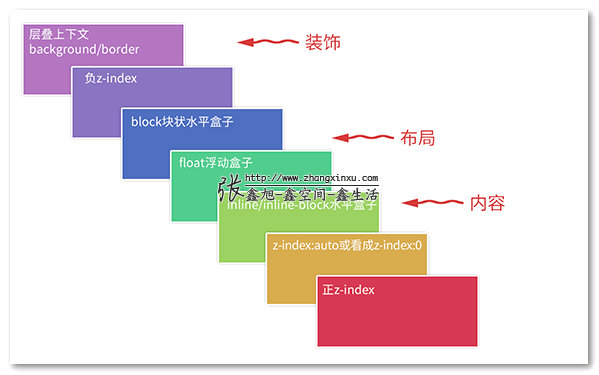
研究层叠样式表中的层叠,也即研究 CSS 的权重/级联/优先级。
由于翻译问题,层叠样式表其实更希望被叫作级联样式表,避免与层叠上下文混淆。
如何覆盖 inline style 的 !important 呢
<div id="app" style="color: red !important">嘤</div>
<style>
#app { animation: colorful 1s infinite }
@keyframes colorful {
0%, 100% { color: black; }
}
</style>
曾经遇到一个需求,用户拍身份证上传验证,
然后我卡在了拍照这个点上。
最初采用的是微信的 api 接口:wx.chooseImage,
既有选择相册又有拍照这个选项按钮,所有手机都兼容。
但随后发现,返回的是一种只有微信才能预览的 url 格式,也就是微信图片的缓存文件。
这样的 url 真是无奈(当然微信这样做是对的),
别的设备看不成,存了也没用,
canvas 又不识别,转不了 base64,
但验证身份证是要在 PC 端上看图人工审核的。
然后详细看了遍文档,
看上去好像是说可以先上传到微信然后就可以下载到本地了,
于是带着吐槽启用了另两个微信 api 接口:wx.uploadImage 和 wx.dowmloadImage。
万万没想到,结局是,
chooseImage 获得 localIds,
然后 uploadImage 得到 serverId,
再 downloadImage 又变成了 localId。
思索了一下,也许这不是浏览器权限的问题,
因此我找上了后端的小伙伴一起讨论下这个问题。
才知,downloadImage 得后台人员去下,具体原因他也没说明白...
好吧,稀里糊涂算是走通了这个流程。
然而... 正当我准备高兴一下的时候,对桌的同事跟我说,
刚才我试了下,input[type="file"] 好像选择相册时候就有一个拍照的按钮耶。
然后我试了一下,好像是的耶,
心中有句 MMP 不知当讲不当讲,上面走微信 api 这条路又坑又麻烦好伐。
然而... 正当我又准备高兴一下的时候,又一个同事跟我说,
刚才试了下,好像我的手机不行耶,
然后搜刮了八部手机试了一圈,
确实有部分手机只有选取图片没有拍照这个选项,比如小米3/华为mate7等。
拔凉拔凉的,web 标准是多么重要呀...
所以该项目只得还是选用了微信 api 接口这种方法,
小小庆幸一下客户群还好都是基于微信平台,不然还得改成 webapp 了。
随着时间流逝,后来有在研究另一个做假 AR 的需求,
寻找苹果机兼容 getUserMedia 打开手机摄像头的办法。
一直无果,于是向大佬汇报请求帮忙,
之后他给我找来了一个 camera api。
但其实是个打开拍照功能,没法加东西弄成 AR 呀。
但猛然想到,这不正好可以解决本篇的问题吗,就去看了下源码。
一切的一切只因为 accept="image/*" 这个属性!
<input type="file"> <!-- 部分手机没有拍照选项 -->
<input type="file" accept="image/*"> <!-- 都有了 -->
有个小插曲,accept="image/*" 会启动得特别慢嘛,有时候 5 秒无反应这完全不能忍。
第二天刚好就看到了类似的推文,解决了这个问题,
也就是把 image/* 改为 image/gif,image/jpeg,image/jpg,image/png,capture=camera。
有点偷懒的是,当时(20170418)测试时,
带有 accept="image/*" 属性没法使用 fileReader,具体情况我忘了。
只能使用 window.URL 的 createObjectURL,返回的是 blob 类型,
而 blob 类型和微信缓存图片也是一样的不能在其他设备使用的,
所以后续就没有再研究了。
而有网友加我好友来咨询我这个问题时,我又重新实验了一下,
accept="image/*" 属性和 fileReader 是可以一起用的,
但当时要下班了,没有实验太多的机型,我想这肯定不是一个严谨的结论。
好吧,结局是我又忘记试了,
总的来说,如果这条路也不通的话,怕是只能走微信 api 这条路了,
非微信浏览器则只能砍掉拍照这个需求了,仅能选择图片。
来来回回走了很多弯路,希望与君共勉
当某个函数我只想处理一次,然后下次直接拿实例;
当某个判断我只想处理一次,然后下次直接往下走;
当某个变量我只想是临时的,然后不用到处是全局变量......
遇到这些问题,已经有各式各样的答案,甚至设计模式,
那么,今天就来盘点这些偷懒的操作。
function func() {
/* 运算/判断/变量 都可以加进来 */
func = function() {
/* 然后使用上面结果,又覆盖掉同名函数,来达到无需再进行上面计算的功能 */
}
}可见,惰性函数充分利用了 js 的动态性,
众所周知,使用非 var 变量运行到才赋值定义,
使得函数在运行后被同名函数覆盖,
但原函数的上下文又得以保存在新函数的上下文中,
以此来到达去除重复运算,返回单例,保留公用变量的功能。
举个市面上常见的例子,很好理解
这样下次再运行 addEvent 时就不会再进行判断了。
function addEvent(type, element, fun) {
if (document.addEventListener) {
addEvent = function (type, element, fun) {
element.addEventListener(type, fun, false);
}
} else if(document.attachEvent){
addEvent = function (type, element, fun) {
element.attachEvent('on' + type, fun);
}
} else{
addEvent = function (type, element, fun) {
element['on' + type] = fun;
}
}
}同步运算,或者缓存结果,或者某公用但不想全局的变量,也可以用惰性函数来完成。
function getParams(moreParams) {
const user = { userId: 1 }; // 这是个某不变的量或运行结果
getParams = function(moreParams) {
return Object.assign({}, user, moreParams);
}
return getParams(moreParams);
}很容易发现,这样的使用场景和科里化与偏函数的使用场景有很多相似之处,也有明显的不同之处。
function partial(func, ...rawArgs) {
return function(...args) {
return func.call(this, ...rawArgs, ...args);
}
}// 原方法
let greet = (x, y) => return `${x} ${y}`;
// 偏函数改造
greet = partial(greet, 'hello');
console.log(greet('xb')); // "hello xb"const addEvent = (function() {
if (document.addEventListener) {
return function (type, element, fun) {
element.addEventListener(type, fun, false);
}
} else if(document.attachEvent){
return function (type, element, fun) {
element.attachEvent('on' + type, fun);
}
} else{
return function (type, element, fun) {
element['on' + type] = fun;
}
}
})();非常适用于存储变量和计算。
也可以再写个 partialAfter 之类的公共方法。
市面上的例子常常把前两者都算作科里化的一种实现,
但其实 addEnvet 和 addMore 都更像是偏函数,而科里化是偏函数的进一步包装。
function currying(fn, ...rawArgs) {
return function(...args) {
args = rawArgs.concat(args);
return fn.apply(this, newArgs)
}
}function curry(func) {
return function curried(...args) {
if (args.length >= func.length) {
return func.apply(this, args);
} else {
return function(...args2) {
return curried.call(this, ...args, ...args2);
}
}
}
}// 原方法
let log = (date, type, message) => console.log(date, type, message);
// 科里化改造
log = curry(log);
const todayLog = log(new Date());
todayLog('ERROR', 'xxx');
const todayTimeoutLog = log(new Date(), 'TIMEOUT');
todayTimeoutLog('某 api 请求超时');可见,科里化与偏函数根本的区别就是,
科里化使得变量可以更便捷地分批传入,而并不是说偏函数不能够,
所以至于实际情况用哪个,见仁见智,都是很不错的。
todayLog = partial(log, new Date());
todayTimeoutLog = partial(todayLog, 'TIMEOUT');面试题中常见的,可以无限加下去的科里化,add(1)(2, 3)...
这就只能靠修改函数的 toString 方法来实现了。
function curry2(func) {
let allArgs = [];
return function curried(...args) {
allArgs = allArgs.concat(args);
curried.toString = function() {
return func.call(this, ...allArgs);
}
return curried;
}
}
var addInfinity = curry2(add);
console.log(addInfinity(1, 2)(3)(4));众所周知,不想存全局变量时,存在 function 变量上也是可以的。
function getData() {
if (getData.loading) return;
getData.loading = true;
setTimeout(() => {
delete getData.loading;
}, 1e3);
}柯里化就是传递参数进行部分操作,又返回一个函数继续接受参数。
柯里化的过程是逐步传参的,逐步缩小函数的适用范围,逐步求解的过程。
它也是函数式编程(FP)**的一大组成部分,代表着过程抽象的高阶函数。
按张鑫旭大神的 总结,柯里化在实际应用中大致有三种:提前返回,延迟计算,参数复用
可以非常方便的减少变量和减少判断。
// 提前判断掉兼容性
var on = (function(){
if (window.addEventListener) {
return function(el, sType, fn, capture) {
el.addEventListener(sType, fn, (capture));
};
} else if (window.attachEvent) {
return function(el, sType, fn, capture) {
el.attachEvent("on" + sType, fn);
};
}
})();
// 节约不需要的变量,倒计时
var timecount = (function(){
var timer = null;
return function(times, fn, cb) {
clearInterval(timer);
timer = setInterval(function(){
if (--times > 0) fn && fn(times);
else clearInterval(timer), cb && cb();
}, 1000);
}
})()
科里化函数内有个变量,能保存传入的参数,以便返回的函数以后能用上。
function chechPhone(str) {
return /1\d{10}/.test(str);
}
// 科里化一下,复用性更高
function check(rule) {
return function(str) {
return rule.test(str);
}
}
var checkPhone = check(/1\d{10}/);
var checkNumber = check(/-?(\d+|\d+\.\d+|\.\d+)([eE][-+]?\d+)?/);
console.log(checkPhone('15972921527')); // true
也可以把方法传入后存下来,以后复用
function mapElement(fn) {
return function(query) {
var $elems = [].slice.call(document.querySelectorAll(query), 0);
return $elems.map(fn);
}
}
function _getValue(dom) {
switch (dom.tagName.toLowerCase()) {
case 'input': return dom.value;
case 'div': return dom.innerHTML;
}
}
var getValue = mapElement(_getValue);
console.log(getValue('.one'));
console.log(getValue('.two'));
将传入的参数仅做保存,待到获取时才进行计算
function createCurry(fn) {
var _args = [].slice.call(arguments, 1);
return function() {
if (arguments.length < 1) { // 不传参时才开始计算
return fn.apply(fn, _args);
} else {
_args = _args.concat([].slice.call(arguments));
}
}
}
function sum() {
var arr = [].slice.call(arguments, 0);
return arr.reduce((x, y) => x + y);
}
var _sum = createCurry(sum);
_sum(1, 2); _sum(3); _sum(4);
var result = _sum();
console.log(result); // 10
而实际传入一次算一次也是一种不错的体验,每次都能取到结果
function createCurry2(fn) {
var _args = [].slice.call(arguments, 1);
return function() {
_args = _args.concat([].slice.call(arguments));
return fn.apply(fn, _args);
}
}
function manyPeople() {
return [].slice.call(arguments).join(',');
}
var add = createCurry2(manyPeople, '默认');
console.log(add('我')); // '默认,我'
console.log(add('小王')); // '默认,我,小王'
上面那个 createCurry 和 createCurry2 都是很实用的封装,
其中 createCurry2 可以再封装得更复杂强大一些。
function curry(fn, args) {
var arity = fn.length; // 待运行函数参数的个数
var _args = [].slice.call(arguments, 1);
return function() {
_args = _args.concat([].slice.call(arguments));
if (_args.length < arity) {
return curry.call(this, fn, _args);
}
return fn.apply(this, _args);
}
}
而每次都计算也还有另一种操作,即重写函数的 toString 方法。
Function.prototype.currying = function() {
var fn = this, _args = [];
var _temp = function() {
_args = _args.concat([].slice.call(arguments));
return _temp;
}
_temp.toString = _temp.valueOf =function(){
return fn.apply(fn, _args);
}
return _temp;
}
function adder() { // 每次传入参数都计算结果并返回本身
return [].slice.call(arguments).reduce(function(a,b){return a+b});
}
var sum = adder.currying();
console.log(sum(2,4)(3)); // ƒ 9
// 这里的 ƒ 9 虽然 typeof 出来是 function,但算术加减什么的还是会按数字来算。
// 如果你觉得不保险,也可以再加上 sum(3).toString()
举几个例子,更深入地感受一下函数科里化的魅力吧。
比如,当页面中运行着多个倒计时,每个都来个 setInterval 是很烧的,
那么我们就可以利用函数科里化的来优化一下性能咯。
可以用来减少变量,也可以用来共用定时方法。
Function.prototype.currying = function() {
var _args = [].slice.call(arguments, 1), fn = this;
return function() {
_args = _args.concat([].slice.call(arguments));
return fn.apply(fn, _args);
}
}
如果上面的程序代表函数科里化,那下面的就是反科里化
Function.prototype.uncurrying = function() {
var _this = this
return function() {
return Function.prototype.call.apply(_this, arguments)
}
}
Date 对象的实例方法超级多,所有有些东西要写在前面。
一般使用中是用到 Date 的方法和实例方法,比如 Date.now() 和 new Date().getTime(),
所以这里我们先用 var d = new Date(); 来进行简单代替。
另一方面,在传时间参数方面,需遵循规范标准。(后者比较好理解)
如 IETF-compliant RFC 2822 timestamps 或 version of ISO8601
| 函数名 | 描述 |
|---|---|
| Date.now() | 返回 1970 年 1 月 1 日至今的毫秒数,相当于 new Date().getTime() |
| Date.parse(datestr) | 返回 1970 年 1 月 1 日至 datestr 代表时间的毫秒数 |
| Date.parse(...dateArr) | 返回 1970 年 1 月 1 日至 dateArr 代表时间的毫秒数 |
| Date.prototype.valueOf() | 基本没卵用 |
注意 datestr 的 规则:
'Dec 25, 1995' / 'Mon, 25 Dec 1995 13:30:00 +0430' /
'2011-10-10' / '2011-10-10T14:48:00' / '10 06 2014' 是可以的;
| 函数名 | 描述 |
|---|---|
| Date.prototype.getDate() | 日期 (1 ~ 31) |
| Date.prototype.getDay() | 星期几 (0 ~ 6) |
| Date.prototype.getMonth() | 月份 (0 ~ 11) |
| Date.prototype.getFullYear() | 年份,四位数字 |
| Date.prototype.getHours() | 小时 (0 ~ 23) |
| Date.prototype.getMinutes() | 分钟 (0 ~ 59) |
| Date.prototype.getSeconds() | 秒数 (0 ~ 59) |
| Date.prototype.getMilliseconds() | 毫秒 (0 ~ 999) |
| Date.prototype.getTime() | 返回 1970 年 1 月 1 日至今的毫秒数 |
| Date.prototype.getTimezoneOffset() | 时差,单位为分钟 |
| Date.prototype.getUTCDate() | 世界时,日期 (1 ~ 31) |
| Date.prototype.getUTCDay() | 世界时,星期几 (0 ~ 6) |
| Date.prototype.getUTCMonth() | 世界时,月份 (0 ~ 11) |
| Date.prototype.getUTCFullYear() | 世界时,年份,四位数字 |
| Date.prototype.getUTCHours() | 世界时,小时 (0 ~ 23) |
| Date.prototype.getUTCMinutes() | 世界时,分钟 (0 ~ 59) |
| Date.prototype.getUTCSeconds() | 世界时,秒数 (0 ~ 59) |
| Date.prototype.getUTCMilliseconds() | 世界时,毫秒 (0 ~ 999) |
与 get 类基本一致,传入数字类型参数即可。
注意返回值为 1970 年 1 月 1 日至今的毫秒数哟。
假使传入的数值超出了赋值范围,比如在二月 setDate(31) 则将累加返回三月的日期
| 函数名 | 描述 |
|---|---|
| Date.prototype.toSource() | 返回该对象的源代码。 |
| Date.prototype.toString() | 把 Date 对象转换为字符串。 |
| Date.prototype.toTimeString() | 把 Date 对象的时间部分转换为字符串。 |
| Date.prototype.toDateString() | 把 Date 对象的日期部分转换为字符串。 |
| Date.prototype.toUTCString() | 根据世界时,把 Date 对象转换为字符串。 |
| Date.prototype.toLocaleString() | 根据本地时间格式,把 Date 对象转换为字符串。 |
| Date.prototype.toLocaleTimeString() | 根据本地时间格式,把 Date 对象的时间部分转换为字符串。 |
| Date.prototype.toLocaleDateString() | 根据本地时间格式,把 Date 对象的日期部分转换为字符串。 |
为了方便,以下内容被我简写:后台=微信公众号文章编辑器,编辑器=第三方排版工具
以下限制请铭记在心,然后泡杯枸杞,千万不可暴躁,切记切记。
<span style>class 也会被清除,可以用 label 来标记这块是什么内容section 别用 divbackground,不能用 position<use> 使用无效(开通支付了的服务号能跳页,可能会有所不同)<rect /> 要改为 <rect></rect>实验出来的几条发布途径,都各有优点和缺点:
一般可分为两种,自动动画型和点击触发型。
var fn = [];
for (var i=0; i<10; i++) {
fn[i] = function(){ console.log(i); }
}
fn[2](); // 10
// for 运行完后的结果其实是:
i = 10;
fn[2] = function() {
console.log(i);
}
// 所以 fn[2]() 的结果自然是 10 了。
// 除非有办法让 i 成为其局部变量,比如闭包或 let 什么的。
面试题中常见而经典的 for 里的异步问题(或 for 里绑 onclick 等),
实为闭包问题,而 闭包问题本质是作用域和作用域链的问题,两者关系十分紧密。
为了更好的理解作用域,这可能需要更清晰地了解代码运行的真正内核,
去了解函数声明过程,作用域如何限定,局部变量如何来的等问题。
代码的执行会经过 编译和运行两个过程:
编译包括:词法语法分析、作用域规则确定和可运行代码生成。
运行包括:创建执行上下文,代码执行和垃圾回收。
创建执行上下文又包括:生成变量对象,建立作用域链,确定 this 指向。
代码执行又包括:变量赋值,函数引用,执行其他代码。
这其中也能看到变量声明和函数声明提前的本质:
// 程序在初始时,先进行了各种声明,运行到赋值时才赋值
console.log(a); // undefined
console.log(b); // Error: b is not defined
console.log(c); // ƒ c() {}
console.log(d); // undefined
var a = 1;
b = 2;
function c() {}
var c = 5;
var d = function(){}
全局和局部作用域的概念挺好理解,感觉无需赘述。
var a = 1;
xx();
function xx() {
console.log(a); // undefined,因为 a 在 xx 的作用域内被声明
var a = 2;
console.log(a); // 2
}
console.log(a); // 1
函数内部是局部作用域,那函数的参数属于外部还是内部呢?当然是内部啦。
很好用的 es6 的函数参数默认值,也是在声明之后赋值,先于函数内代码运行。
var a = 1;
fn();
function fn(a) { // 声明了局部变量 a,
console.log(a); // 未传值也无默认值,所以 undefined
a = 2;
console.log(a); // 2
}
console.log(a); // 1
const 相比 let 多一个不可更改的特性,所以作用域方面我们只论 let 即可,const 是一样的。
console.log(a); // a is not defined
let a = 1;
let b = 2;
function b() {} // 'b' has already been declared
for (let i=0; i<1; i++) {}
console.log(i); // i is not defined
if (true) { let x = 3; }
console.log(x); // x is not defined
function fn(k) {
let k = 11; // 'k' has already been declared
}; fn();
本节内容我无法去验证引擎内部运转机制是否如此,仅总结与自己的理解,可能有误,还请大佬点拨。
--------------------- 从此处分割,重写中
http://www.jianshu.com/p/9ecb728c5db9
https://www.cnblogs.com/wangfupeng1988/p/3986420.html
http://web.jobbole.com/92769/
函数声明时,是新建了一个变量指向这个函数(到被调用时才创建执行上下文);还是把函数内部也解析了一遍并早已确定了内部变量等(意淫个名字叫函数上下文)直到调用时再赋给执行上下文。
唔,我找到的资料大多没有提及这个先后问题,但字面意思上来看,应该是 前者更准确 些。
好的,忽略上面这个小插曲,回到作用域这个问题上来。
此外,每个函数还会产生一个 arguments 的局部变量,存入传入的值
本节内容我无法认证引擎内部运转机制,可能有误,还请大佬点拨。
每个区块都会创建运行上下文,这是代码运行最初就干了的事(eval 除外)。
创建运行上下文时(假设为 EO),就包含了 函数的局部变量、命名参数、参数集合以及 this;
当区块被运行到时,它们会新建成活动对象(假设为 AO),放进函数调用栈;
在 AO 对象中有个 scopeChain 的键值对代表作用域链,用数组保存着,最前端为本身 EO 的变量对象,最末端为全局 EO 的变量对象。
然后进行变量赋值,函数引用,执行其它代码,最终从函数调用栈中出栈。
// 因此本例中,f1 中的 a 在函数声明时就已经确认为是全局的 a 了
// f2 的作用域链中,保存的是 f1 的 EO,运行到 f3 新建 AO 时也是由 f1 的 EO 而来
var a = 1;
function f1() {
console.log(a);
}
function f2(f3) {
var a = 2;
f3();
}
f2(f1); // 1;
本文结构有些松散,实在抱歉,往后在更深地理解 JS 引擎后会不断完善。
在最新项目中,由于要频繁使用艺术字,
而用户设备没有此字体,因此以往的都是使用图片的...
所以在同事的瞩目期许之下,我开始实验研究这个问题的解决方案
也就是的 CSS3 中超屌的 @font-face;
@font-face {
font-family: 'xxxx';
src: url('../img/汉仪秀英体简.TTF');
}
.font {
font-family: 'xxxx', Arial, sans-serif;
}
该方案是能用的,非常符合标准,兼容性如今也完全没问题。
但是随着项目发布,还是出现了问题,
由于字体文件过大(3.8M),文件较小(300k)的字体文件没有出现此情况。
文字会出现了先不显示再显示默认字体再变为艺术字的过程,视觉效果相当不妙。
说到底是字体文件的这个坑还在研究中,阻塞什么的问题标准还未能解决。
font-display 有望解决这个问题,但现在(20170823)才刚刚开始被浏览器支持。
其次,用函数回调式方法加载字体也是个方案,比如 font face observer。
再或者使用 preload 提高加载的优先级
<link rel="preload" as="font" href="font.woff" crossorigin />
但是对于大文件和多文件时,这个方案还是十分不佳的。
第三方字体库还是挺多的,我暂时接触到的还不多,
大致可以分为两种,生成型和获取型。
比如阿里的 iconFont,
http://www.iconfont.cn/webfont/#!/webfont/index
属于生成型,输入文字,然后复制所给的代码即可。(下载文件按钮是失效的)
但所给字体相当的少,仅思源系列的 7 种字体。
唔当然,iconfont.cn 本身也确实不是为了提供字体而存在的,把 svg 做的图标导入然后生成类似 font awesome 字体文件才是它的核心
再比如 有字库,属于获取型。
https://www.youziku.com/onlinefont/index
调取 api,然后按照 文档 进行 js 书写,最后可实现 demo 所示的效果。
其实源码我没看太懂,原理猜测是传字给后端进行会员判断返回 css 和文件引用。
特别注意,你需要在个人中心设置域名白名单,
其次有库币的概念,每字每次耗 1 币,免费 10 万币,后续收费,暂时觉得还挺便宜。
如果你有更多的发现,不妨分享出来,感激不尽。
java 版的,得安一个 java sdk,效果非常好
https://github.com/forJrking/FontZip (下载 FontZip.jar 那个)
输入保留的文字然后点击OK,就生成了压缩后的字体文件。
基于 nodeJS,个人觉得要方便很多。http://font-spider.org/
书写的时候直接使用源字体文件,待发布时压缩一下,一气呵成。
该 font-family 下的字都被压到字体文件里了。
它还提供了 grunt 和 glup 的解决方案,但没有 webpack 的。
仅推荐个人用过且觉得还不错的工具:
全格式转换:https://www.fontke.com/tool/convfont/
Font-Spider 的依赖:http://ecomfe.github.io/fontmin/ (仅支持 ttf 转其他)
这是在小程序项目中想加入艺术字时发现的,无法引入字体文件。
那么引入 base64 好了,依赖工具 https://transfonter.org/ (访问有点慢)
还可以输入部分字符,只压缩这些字符。
正如上图,字体 A 中包含 大 字,字体 B 中包含 佬 字,
然后使用 font-family: A B 那么两个字都可以是艺术字了。
将同个字体文件拆成多份,最后合并到一起用,此方案是可行的。
比方说,某字体文件压缩后还有 1M,
那么拆成常用的 6000 个汉字,和可异步加载的其余汉字。
如果觉得以上压缩都比较烦,就是想用大文件,那就走优化加载这条路吧。
大字体文件的主要问题是字体未加载完前会隐藏文字,1s 后显示默认字体,字体加载完才正常显示。
虽然不知道 CSS 字体的渲染规则是什么,
但好像对异步问题并没有比较好的解决办法,唯有优化体验而已。
正如文首所写,用 rel="preload" 进行预加载:
<link rel="preload" href="font.woff2" as="font" type="font/woff2" crossorigin>
字体加载完成才进行字体渲染:
<style>
h1 { font-family: Arial, serif; }
.xxx h1 { font-family: 'MySpecialFont', serif; }
</style>
<link href="fonts.css" onload="document.body.className+=' xxx';" rel="stylesheet" type="text/css" >
后期有出现几次部分字体压缩后报错的情况,
都是 OTS parsing error,已遇到的主要报错有以下几种:
1) Failed to parse metrics in vhea
2) cmap: Failed to parse format 4 cmap subtable 0
3) invalid version tag
一般直接调用文件是没问题的,但压缩后才开始报错。
说明这类字体本身就有问题,不标准或已压缩(具体实际原因不了解)。
有去查找些资料,但情况太过复杂,
解决方案有改写 gulp 的,改写 IIS 的,实在不好总结。
所以最终只得和设计达成一致,
使用什么字体先让前端试试能不能压缩。
讲道理,现在字体版权也越来越重要,
可能以后能用的字体也越来越少,所以这样的工作量也不大,
而如果设计师自己设计字体了,那转成 SVG 或 iconfont 要更佳。
在使用 bootstrap 的模态框时,出现了半透明遮罩始终盖住模态框的情况,
只有把模态框的 HTML 写到 body 之下才恢复正常,
当时郁闷得对着屏幕举了半分钟的中指。(程序员最好看看佛经,学会清心寡欲)
后来有幸看到了张鑫旭在慕课网 CSS深入理解之 relative 的视频,
才算真正知晓了层叠上下文在 CSS 中的规则和运用技巧。
还有些名称比较类似的学术语言和概念,格式化上下文、执行上下文、音频上下文、2D上下文等,感兴趣地可以去搜一下玩玩。
废话有些多,下面就正式开始吧!
层叠上下文其实把它理解为 z 轴也没有问题,屏幕上面叠着一层层图层(不是所有的元素都是)。
层叠水平则表示同一层层叠上下文对应的图层。
那么怎样才能产生层叠上下文,让它的 z 轴不一样呢?
以下情况会创建层叠上下文(随着 CSS3 属性还在增加,本表不全):
<style>
.box {
width: 100px;
height: 100px;
margin: 0 auto -50px;
}
.box1 {background: pink}
.box2 {background: grey}
.box1 {left: 10px}
.box1 { transform: translate(0,0) }
</style>
<div class="box box1"></div> <!-- 粉色 -->
<div class="box box2"></div> <!-- 灰色 -->

此例中 .box1 创建了层叠上下文,z 轴上就比普通元素层级更高了,因此覆盖了 .box2。
而当有两个层叠上下文时,它们就有了兄弟和父子关系(假设现在都处于同级层叠水平)。
当为兄弟关系时(层叠上下文的兄弟关系,非 DOM 的兄弟),它们总是 后者居上 的。
<style>
.box {
width: 100px;
height: 100px;
margin: 0 auto -50px;
}
.item {
/* 两个 dom 中子级创建层叠上下文,构成兄弟关系的层叠水平 */
transform: translate(0,0);
width: 90px;
height: 90px;
top: -10px;
}
.box1 {background: pink}
.box2 {background: grey}
.item1 {background: red}
.item2 {background: green}
.item1 {left: -10px;}
.item2 {left: -20px;}
</style>
<div class="box box1"> <!-- 粉色 -->
<div class="item item1">item1</div> <!-- 红色 -->
</div>
<div class="box box2"> <!-- 灰色 -->
<div class="item item2">item2</div> <!-- 绿色 -->
</div>
<!-- .item 变为层叠上下文,所以比 .box 这种普通元素层级更高. -->
<!-- 且 .item 遵循后者居上,所以 .item2 覆盖了 .item1 -->

当为父子关系时,子级就存在父级的“作用域”内了,父级高我才高,不然我再高也没用。
<style>
.box { position: relative; z-index: 0 }
.item1 { z-index: 999; }
/* 紧跟上例,本来 .item2 由谁后谁上的原则位于上面。 */
/* 当现在其父级 .box 也创建的层叠上下文,且遵循谁后谁上,因此 .box2 要高于 .box1。 */
/* 此处 .item1 的父级已经低于 .box2 了,本身层级再高也还是在 .box1 的范围内而已。 */
</style>

注:此处 position: relative; 但不写 z-index: 0(即 z-index: auto),它会覆盖普通元素,但并不会创建层叠上下文。 下面这个也是类似的例子,
.box {
position: relative;
margin: 0 0 10px;
}
.box2 { z-index: 0; }
/* 只有 z-index 不为 auto 才创建层叠上下文,所以 .box2 创了,.box1 没创 */
.item {
position: relative;
z-index: -1;
}

既 z-index 不为 auto 的情况,这时它们总是 谁大谁上 的。
<style>
.box1 { z-index: 2; }
/* 这个就很好理解了,.box 现在是兄弟关系,.box1 的 z-index 更大,那么它就更高 */
</style>

回到最初那个 bootstrap 内容框在黑底下的问题,就很方便理解了。
<div class="content">
<div class="modal"></div> <!-- modal 内容框 -->
</div>
<div class="modal-backdrop"></div> <!-- 黑色半透明底 -->
.modal 和 .modal-backdrop 都定位了,成为了层叠上下文,而如果 .content 由于需要或误操作也创建了层叠上下文,那么 .content 和 .modal 就有了兄弟关系,谁后谁上+谁大谁上,最终造成黑底的层级高于了 .content 的层级,而 .modal 作为 .content 范围内子级也就因此被覆盖住了。
最终,要么我们把 .modal 从 .content 拿出放置于与 .modal-backdrop 同级,要么把 .content 的层级提高得比 .modal-backdrop 更大(如果 .content 还有背景色那就是另一回事了)。
所以个人认为 bootstrap 这样写是不好的,要遇上一个不懂层叠上下文的,想破头也不知道为什么。
我推荐下面的这种写法:(自创的,后来看 layui 等框架也是这样写的,看来我没做错)
<style>
.modal {
position: absolute;
top: 0; bottom: 0;
left: 0; right: 0;
opacity: 0;
z-index: -1;
overflow: hidden;
transition: opacity .3s, z-index 0s .3s;
}
.modal-bg {
position: absolute;
top: 0; bottom: 0;
left: 0; right: 0;
opacity: 0;
transition: opacity .15s;
background: rgba(0,0,0,.8);
}
.modal.in {
opacity: 1;
z-index: 1;
transition: opacity .3s, z-index 0s;
}
.modal.in .modal-bg {
opacity: 1;
}
.modal-box {
transform: translate3d(0,0,0);
}
</style>
<div class="modal">
<div class="modal-bg bg"></div> <!-- 黑底 -->
<div class="modal-box">内容</div>
</div>
就像张鑫旭大神所说,如果你理解了层叠上下文,那么就根本不需要把 z-index 设得很大了,1-2 足矣。
在张大神的 此文 中存在着这样一张图,一直让我产生着奇怪的误解。
后来才想通,这是非层叠上下文时的覆盖关系,但很容易让我们产生混淆。
比如 float / inline 等,和 relative 下 z-index 非 auto 一样,都是会产生覆盖,但不会创建层叠上下文。
里面的 background 和 z-index 真的实在是蛊惑人心,个人认为大可忽略不论。
在 旧博客 中不断有人来咨询,但一直没能很好的解答。
毕竟已经过去了快两年,应该可以重新开坑研究了。
首先有两大前提得讲清楚:

上图是serverless 这个词最近5年在 google 的搜索趋势,可以看到最近半年已经达到巅峰。
插播:链接
FAAS(函数即服务) + BAAS(后台即服务) 可以称为一个完整的 Serverless 的实现。
参考链接:
https://myslide.cn/slides/18364(阿里云前端分享)
https://yq.aliyun.com/articles/165104?spm=5176.162838.846423.1.35222a14ltnN0G(阿里云服务实例)
https://juejin.im/post/5d1c9380f265da1bc94f098e#heading-1(腾讯团队分享)
https://segmentfault.com/a/1190000018455041#articleHeader2(时间同步例子)
https://www.yunforum.net/group-topic-id-2725.html(鉴黄系统)
片外:https://weibo.com/tv/v/HBNP8CtOh?fid=1034:4390096124722903

https://juejin.im/post/5e0abd926fb9a04825712e3f#heading-4
input:-webkit-autofill{
box-shadow: 0 0 0px 1000px white inset !important;
}
就这两种,使用和记忆都非常方便。
var reg = /xx/gi;
var reg = new RegExp('xx', 'gi');
// new RegExp() 用在拼接正则表达式上也是一把好手
var y = 'any string';
var reg = new RegExp('x' + y + 'x', 'gi');
PS:new 形式的声明要转义哟,比如 new RegExp('\\d') 等同于 /\d/
普通的字符串匹配就不说了,'abc'.search(/a/) 这样用基本和 indexOf 差不多。
而正则高明之处就在于,有各种可以简化和分类来匹配字符的手段,比如元字符限定符等。
| 元字符 | 说明 |
|---|---|
. |
匹配除换行符以外的任意字符 |
\w |
匹配字母或数字或下划线或汉字 |
\s |
匹配任意的空白符,比如空格或TAB |
\d |
匹配数字 |
\W |
非 \w 的其他字符,\S \D 等同理 |
\b |
匹配单词的开始或结束,不适用于中文 |
^ |
匹配字符串的开始 |
$ |
匹配字符串结束 |
比如 /\d\d\d\d/ 即可匹配四个连续数字了。
而按上面的写法很重复呀,于是便有了重复限定符的存在,直接 /\d{4}/ 即可。
| 语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
/a(b|c)/ 即可匹配到 ab 或 ac 啦。
注意,并非到处都能用或,比如 \d{2|3} 或者 \d{2}|{3} 就不能,只能 \d{2}|\d{3}
全都用 | 来也还是太累了,于是就有了 /a[bcd]/ 来匹配 ab,ac,ad,甚至 /a[b-d]/ 更方便。
其中 [b-d] 即某 ascii 字符到另个字符间的所有,常见的 [0-9a-zA-z] 即是如此了。
如果区间中加上 ^ 则表示排除,[^8] 代表着除了 8 以外的其他任意字符。
但是吧,区间操作有它复杂的一面。
比如此时的 /[a|b]/ 中的 | 不再具有功能性,仅仅是个字符而已了。
还有 /[^$.]/ 等也是如此了,所以更为推荐此处的符号字符最好加上转义。
使用区间还是条件或,功能上是很相像的,但区间仅能处理单个字符,
如 /(hello)|(world)/ 的多字符匹配还是只能用条件或的。
上文中的多字符匹配即是分组,字面意思。
其次,'ab'.match(/(a)b/) 还会将分组的结果也进行导出,非常实用。
var htmlReg = /<([^\s>]+)(\s*[^>]*\s*)>([^<]*)<\/\s*([^>]+)\s*>/
'<div class="x">内容</div>'.match(htmlReg);
// ["<div class="x">内容</div>", "div", " class="x"", "内容", "div"]
另外分组还会产生 $1 这样的存在,与 replace 合用有不一样的火花。
'abc'.replace(/(a)bc/, '$1ed'); // 'aed'
如果分组后用 replace 遍历也是相当有趣的东西
'xyz'.replace(/(x)(y)c?/, function (a,b,c,d,e,f){
// a 代表匹配到的结果,即 'xy'
// b,c 代表括号内的匹配,更多分组会产生更多参数,即 'x' 'y'
// d 代表第一个被匹配的字符从源字符串的第几位开始,即 0
// e 代表源字符串,即 'xyz',再后面的参数就没有意义了
});
有时候你只想进行分组,但不想导出分组的内容,则有了 (?:) 的存在。
'abc'.match(/a(b)/); // ['ab'. 'b']
'abc'.match(/a(?:b)/); // ['ab']
但好像并不存在 (?!:) 这样的效果,不等于某字符组的其他就匹配。
但可以用 split(/a[bc]/).filter(item => !!item) 来匹配 a 后面不是 b 或 c 的其他所有匹配。
继续将上面的分组的需求进行延伸,
如果只想匹配前者但又必须存在后者进行条件约束,那就该零宽断言登场了。
即分组匹配,但导出时不加入结果。
'abc'.match(/a(?=b)/); // ['a']
加上 ! 代表不为该内容则匹配。
加上 < 代表匹配前面的内容,比较不好解释,以后再说。
| 零宽断言 | 说明 |
|---|---|
(?=pattern) |
'abac'.match(/a(?=b)/); // ["a", index: 0] |
(?<=pattern) |
'abac'.match(/(?<=b)a/); // ["a", index: 2] |
(?!pattern) |
'abac'.match(/a(?!b)/); // ["a", index: 2] |
(?<!pattern) |
以此类推 |
再举个例子,我只想匹配 hash 而不是 #hash 就需要用到。
'x.html#hash?id=2'.match(/(?<=#)[^?]*/)[0]; // 'hash'
此处比较容易与 (?:) 混淆,但其实也好理解,需要多加练习。
即想匹配 ( 字符时,会容易与分组混淆,所以用 \( 来转义为字符而非功能符号。
也就是 new RegExp 时的第二个参数,或者 /xx/gi 中尾斜杠之后字符,
它们可以用来规定和扩展正则的效果,比如常见的 i 则是忽视大小写都进行匹配。
在 replaceAll 方法并不存在的时候,正则的 g 也是匹配多个结果最好的办法。
| 修饰符 | 功能 |
|---|---|
| i | 忽略大小写,/a/i.test('A') == true |
| m | 匹配多行(\n 或模板字符串换行即为多行),常与行首 /^/ 和行尾 /$/ 合用 |
| g | 全局匹配,匹配多个结果,'aba'.replace(/a/g, 'x') == 'xbx' |
| u | 正确处理四个字节的 UTF-16 编码(比如 𠮷 为两个字符,用 . 匹配不了等问题) |
| y | 粘连模式,默认从首位开始,匹配一个随后紧接着的字符串,不明白可查 文档 |
注意,有些教程会有 s 这个修饰符,兼容性是不一致的哟。
| 方法 | 功能 |
|---|---|
| str.search(reg) | 高级版的 indexOf |
| reg.test(str) | 验证是否有匹配 |
| str.match(reg) | 返回匹配结果的数组 |
| str.split(reg) | 按匹配去拆分字符成数组 |
| str.replace(reg, fn) | 拆成数组并可进行替换 |
| reg.exec(str) | 较复杂,推荐多谷歌一下 |
// 获取 location.search 中 name 对应的值
function getHrefQuery(name, str) {
var reg = new RegExp('(^|\\?|&)' + name + '=([^&]*)(&|\"|\'|$)');
var r = (str || window.location.search).match(reg);
if (r != null) return decodeURIComponent(r[2]); return null;
}
getHrefQuery('id', 'x.html?id=1'); // '1'
// 1234.00 转为 1,234.00 金钱模式,注意小数不得超过三位
function money(val, fixed = '2', unit = ',') {
return (Number(val) || 0).toFixed(fixed).replace(/\B(?=(\d{3})+(?!\d))/g, unit);
}
字面量,匹配一个具体字符。比如a匹配字符"a",又比如 \n匹配换行符,又比如 \.匹配小数点。
字符组,匹配一个字符,可以是多种可能之一,比如 [0-9],表示匹配一个数字。也有 \d的简写形式。另外还有反义字符组,比如 [^0-9]和 \D等。
量词,表示一个字符连续出现,比如 a{1,3}表示"a"字符连续出现3次。还有 + ? * 的简写
锚点,匹配一个位置,而不是字符。比如^匹配字符串的开头,还有 \b 和 和 (?=a)
分组,用括号表示一个整体,比如 (ab)+,表示"ab"两个字符连续出现多次,也可以使用非捕获分组(?:ab)+。
分支,多个子表达式多选一,比如 abc|bcd,表达式匹配"abc"或者"bcd"字符子串。
反向引用,比如 \2,表示引用第2个分组。
正则引擎与优化:https://mp.weixin.qq.com/s/OtVRL37CNt_d5yEJPzzBzg
详细教程:https://juejin.im/post/5965943ff265da6c30653879
速查表:https://www.94xh.com/regexp.html
可视化正则:https://jex.im/regulex/
https://alf.nu/RegexGolf
https://regexone.com/lesson/introduction_abcs
https://regexcrossword.com/
http://callumacrae.github.io/regex-tuesday/
判断类(返回 boolean)
查找类(返回索引或值)
数组改造类(增删数组项)
遍历类
其他
Array.from(arrayLike, mapFn, thisArg)
将类数组对象或可遍历对象(arrayLike)转化为真实数组。
其实它更像是 Array.from(obj).map(mapFn, thisArg)。
而 arrayLike 到底是种怎样的概念呢。blabla...
// 生成连续数字数组的6种方法
var temp1 = (new Array(3*4)).join(' ').split(' ').map((v, i) => i);
var temp2 = Array.apply(null, {length: 4*3}).map((v, i) => i);
var temp3 = Array.from(new Array(3*4), (v, i) => i);
var temp4 = Array(3*4).fill(1).map((v, i) => i);
var temp5 = []; for (var i=0; i<3*4; i++) temp5.push(i);
var temp6 = new Array(3*4); for (var i=0; i<temp6.length; i++) temp6[i] = i;
console.log(temp1, temp2, temp3, temp4, temp5, temp6)
小程序在 本地资源 还是 远程资源、相对路径 还是 绝对路径 上与常规开发有所不同,
经验不足的话,会在这方面大大拉低开发进度和流畅感,
所以在此罗列一下小程序图片资源相关的坑眼,与君共鉴。
import 和 require 的区别
既然 import 是静态导入,那 import 就不能放在 block 中,例如
{
import xxx from "xxx";
}
// 会抛出一个受检异常再例如:
if (localStorage.getItem("random")) {
import xxx from "xxx";
}
// 会抛出一个受检异常同样会抛出一个受检异常,第二个例子是不是更好理解呢。
因为 import 是静态导入,所谓的静态就是在 buildtime 完成文件解析处理,那么由于 buildtime 并不会执行 runtime js 代码,更没有 localStorage 这个东东,怎么知道该不该导入xxx这个依赖呢,所以 import 不能放在 block 中。
相反,require 是 commonjs 中的动态导入,可以放在代码块中。
webpack 对 import 和 require 都做了支持,那么如果 webpack 碰到动态加载的 require 会怎么样呢。
例子:
教学易中有个场景是通过指定编译需要注册三个不同的登录页路由。
const loginPath = "xxx"; // 登录页路径
const loginRoute = (
<Route path={loginPath} component={require(`./routes/${loginPath}/`)} />
);假设routes下面有login.js, zxLogin.js, sklLogin.js三个登录页,项目运行时loginPath变量才会有值,其值为三个登录页中的一个。
打包好后,系统运行正常,路由正常,也实现了登录页的按需注册。那么问题来了,webpack 打包时loginPath变量还没有值呢,他怎么知道该帮我打哪个包呢。(我们都知道 webpack 是根据 entry 来打包的,没有 import 或 require 的文件是不会打包进来的)
好奇心驱使看了下打包后的 index.js 文件,原来 webpack 在解析require时把所有routes路径下的文件都给我打包进来了,buildtime 不知道变量 loginPath 的值干脆全给你打包进来吧。
需求是不想把所有文件都打包进来的,那怎么办呢,那就试试异步加载吧。
import 和 require 都有对应的异步加载方式,分别为:
// import() 提案
import("xxx").then(() => {});
// require.ensure
require.ensure([], function(require) {
var xxx = require("./xxx");
});其中require.ensure已经被 webpack 所支持,import()则需要借助 babel 插件babel-plugin-syntax-dynamic-import
react-router 结合异步加载的代码:
const loginPath = "xxx"; // 登录页路径
<Route
path={loginPath}
getComponent={(nextState, callback) => {
import(`./routes/${loginPath}/`).then(res => callback(null, res));
}}
/>;经过上述改良后,webpack 会帮你打包 4 份文件,分别为index.js, 0.js, 1.js, 2.js。其中数字是 webpack 默认的 chunk 命名方式,分别就是三个登录页 js,这样就能在 runtime 中根据需要去异步加载对应的 js。
require.ensure 虽然也能实现异步加载,但是最终还是要在函数中同步使用require引用,结果跟没优化前差不多,只是将三个登录页文件打包到了一个
0.js文件中。
项目中,150条数据进行4列同名单元格合并,结果耗时 10s 以上;
极大的开销都在前端部分,因此对其进行优化。
项目表格要依赖于 jquery.jqGrid 插件的部分功能,所以暂时放弃了拼 table 字符串的考虑。
// 【旧】jqgrid 合并单元格
function Merger($grid, CellName) {
var mya = $grid.getDataIDs();
var length = mya.length;
for (var i = 0; i < length; i++) {
var before = $grid.jqGrid('getRowData', mya[i]);
var rowSpanTaxCount = 1;
for (j = i + 1; j <= length; j++) {
var end = $grid.jqGrid('getRowData', mya[j]);
if (before[CellName] == end[CellName]) {
rowSpanTaxCount++;
$grid.setCell(mya[j], CellName, '', { display: 'none' });
} else {
rowSpanTaxCount = 1;
break;
}
$grid.find("#" + CellName + "" + mya[i] + "").attr("rowspan", rowSpanTaxCount);
}
}
}
var arr = ['brenchName','campusName','teacherName','workTypeName'];
for(var i = 0;i<arr.length;i++) Merger(grid ,arr[i]);以上是老版本的代码,以下是优化途径与优化比例。
首先看到两个 for 里套 attr 就有点方了,100 的 100 次方了解一下。
但为了合并同名单元格,无法避免地每列都要从头到尾进行对比。
而其实可以让后端先进行排序,
然后再改为复杂度只有 O(n) 的算法,只有 1比2,2比3 这样子,
就可以避免必须每列的每行都得从头再比一次了。
/* 最初可能是因为怕数据是无序的,所以才选用了这样的算法 */
for (var i=0; i<length; i++) {
for (var j=i+1; e<length; j++) {}
}/* 需基于数据本身是有序(类似按文件名排序)的,后端开销其实不大 */
for (var i=0,j=i+1; i<length; i++,j++) {}在 chrome 开发工具的 performance 中也能看到 scripting 的比例要比 rendering 的要高,
但好像一时也想不到更优的算法了。
for 里套 dom 操作是同步过程,意味着 dom 比较慢的话运算也会跟着慢,
所以就带着尝试的心态试了下,结果效果让人惊讶,莫名其妙会快 2s。
没有去做控制变量法来做更系统的测验,此条可能不准确。
这让我开始思索 js 与 dom 操作时更内核的原理,是因为有沟通成本吗。此处开坑留眼。
以前写过一篇提及选择器速度的 博客,可以看看。
所以对 $('[id^="' + name + '"]') 这样的列选择,改为 $('.' + name + ' td') 可能会更佳。
对项选择,当然是 id 选择器最佳咯,$('#' + name + id) 为现在采用的方法。
再者,其实 $.fn.data 方法在源码中实则为普通的对象赋值,并非 dom 中的 data-*,
将数据存在其中,可能要比放在 attr 中要更快捷检索到哟。
这个方面其实还可以有很多研究,再开一坑。
也就是先 fragment 或克隆到文档外,进行操作,再一次性替换。
这样可以避免每次修改带来的回流和重绘,合并为一次回流。
而从 $.fn.clone 的 源码 来看,它并不是件简单的事。
分别试了下 4 与 5 两种方法,理论上好像是一致的,
但结果 5 的效果要更为明显一些,更多地减少了 rendering 的开销,嘴角逐渐上扬。
但随即笑容逐渐消失,一时也想不到为何出现了这样的差异,
难道克隆的 dom 不仅仅是节点数据那么简单,还和样式树保持着关系?
hide(0) 方法(5%)hide 方法会经过 queen、animate 等一系列过程,还不如用 'css('display', 'none')' 来得直接。
如果你愿意的话,其实可以写一个专门用于进行 0s 显隐操作的方法。
这个方法只是还得思考下 show 时的 display 是什么。
$.fn.show0 = function(){
this.css('display', this.data('rawDisplay') || 'block');
}
$.fn.hide0 = function() {
this.data('rawDisplay', window.getComputedStyle(this[0])['display']);
this.css('display', 'none');
}当然啦,其实用 CSS 要更为简单得多,直接一个 .hide 类的增删即可。
PS:强制重绘问题可以附带了解,毕竟 display:none 也不是万无一失的。
这个嘛,也是心血来潮,GPU 加速在一定程度上也是层叠上下文所特有的优势,
相当于在文档上有新的一层,受影响较小,可以加快重绘的计算。
但不得不承认,除了 CSS 动画与 DOM 动画,在 CSS 方面的优化真的很难看出差别。
以下为新版代码,
还顺带处理了下原方法第二列同名但第一列不同的错误合并问题。
// 【新】合并 jqgrid 的单元格
function mergerCell($grid, keys) {
var data = $grid.jqGrid("getRowData");
var ids = $grid.getDataIDs();
// 获取每列的合并信息
var divideData = {};
keys.forEach(function(key, i){
divideData[key] = divideWithKeyValue(data, key, null, except(keys.slice(0, i)));
});
// 统一操作 DOM
$grid.addClass('hide');
for (var key in divideData) {
if (!divideData.hasOwnProperty(key)) continue;
var divide = divideData[key];
$grid.find('[id^="'+key+'"]').addClass('hide');
divide.forEach(function(d) {
var id = '#' + key + ids[d.index];
$grid.find(id).attr('rowspan', d.span).removeClass('hide');
});
}
$grid.removeClass('hide');
}
// 前一项与后一项进行对比,相比 reduce 多个最后项的对比,且可异步
function oneByOne(json, fn) {
for (var i=0,j=1,len=json.length; i<len; i++,j++) {
var me = json[i], next = json[j] ? json[j] : me;
fn && fn(me, next, i, Math.min(j, len-1));
}
}
// 将 json 以 key 的值进行拆分
// 返回:拆分开始的索引,拆分包含多少个,这是第几次拆分
function divideWithKeyValue(json, key, fn, except) {
var startIndex = 0, rowSpan = 1, times = 0, rowSpanData = [];
oneByOne(json.slice(0), function(me, next, i, j){
if (me[key] !== next[key] || i===j || (except && except(me, next))) {
var data = { start: startIndex, span: rowSpan, times: ++times };
rowSpanData.push(data);
fn && fn(data);
startIndex = j;
rowSpan = 1;
} else {
rowSpan++;
}
});
return rowSpanData;
}
// 排除兄弟列不同名的情况
function except(keys) {
return function(me, next) {
return keys.some(function(key){ return me[key] !== next[key] });
}
}
var arr = ['brenchName','campusName','teacherName','workTypeName'];
mergerCell(grid, arr);
(此图有可能名称反了,但不重要,我个人更偏向于 bootstrap 被叫作响应式的)
本文旨在罗列实现响应式或自适应布局的几种方案。
四种设备:移动端、PC 端、超大屏、高清屏
两种环境:没 device-width、有 device-width
其他注意事项:毛细线、多端兼容、设计稿还原精度
在 @media 出现之前,大家是怎么过的呢?
PC 页面大多是给容器定宽的,手机上屏宽等于定宽,想看清内容就得靠缩放拖拽。
弊端在哪呢,每进一页就要放大一次,PC 端与移动端设计必然多套。
随后 @media 和 viewport device-width 的组合拳之下,偷懒的方案栅栏布局横空出世。
如果将元素或内容看作是一个个的区块,那么搬运一下位置岂不是挺方便的嘛,
将宽度分为 12 栏,左边占 3 栏,中间占 7 栏,右边占 2 栏;
当宽度变小时,左边占 12 栏跑到上面去,中间占 9 栏,右边占 3 栏,相应变化。
且 device-width 自动会让文字跟随屏幕放大,
原本 PC 端 3 栏的内容,到移动端看到 12 栏的内容,一眼所能看到的信息量是相近的。
很明显,栅栏布局能非常方便且粗浅的处理 PC 端与移动端的样式调整,
字体大小会变大,适合小屏设备阅读,多端简单地适配操作非常简单。
但依旧有着问题,比如专注于小屏设备的话误差很大,专注于超大屏的话还缺些火候。
本方案算是优化的一类,可以稍稍弥补上述所说的大小屏问题。
虽然有着 device-width 文字得到了放大,
但 320px 小屏中的 12px 与 414px 小屏中的 12px 视觉上还是有较大差异的。
那么,用 em 去跟随这些细小的适配粒度,再放大一次呢。
html { font-size: 10px; }
@media screen and (min-width:321px) and (max-width:375px){
html { font-size:11px; }
}
@media screen and (min-width: 376px) and (max-width: 414px) {
html { font-size: 12px; }
}
@media screen and (min-width: 415px) and (max-width: 639px) {
html { font-size: 15px; }
}
@media screen and (min-width: 640px) and (max-width: 719px) {
html { font-size: 20px; }
}
@media screen and (min-width: 720px) and (max-width: 749px) {
html { font-size: 22.5px; }
}
@media screen and (min-width: 750px) and (max-width: 799px) {
html { font-size: 23.5px; }
}说实话,设定字体大小、边距间隙、定宽定高、动画位移,需要用到 px 的场景并不太多,
前两者甚至可以统一公共类来完成,所以随着 em 缩放一些,能够比较粗浅轻易的适配更小的粒度。
还带来了一个蛮有意思的效果,在只有 px 的时候,宽度变化想要高度也变化是困难的,
而宽度随 em 变化时,如果高度也写成 em 那就很妙了。
但这也有点小问题,就是 em 中的 em 其实是翻倍,这计算量可就哦豁了。
如果 em 会面临嵌套后多倍计算的话,直接用 rem 不就好了吗。
再进一步,em 方案中根节点的字体大小能否直接不用 @media 而用 js 来实现,
这也便造就了 lib-flexible 等插件的出现。
而 px2rem 或 postcss-pxtorem 等工具也让开发不用侧重于写 rem 而是写 px 了。
function flexable(remRatio = 75) {
function setRem() {
var winW = docEl.getBoundingClientRect().width;
$style.innerText = "html{font-size:" + (docEl.style.fontSize = winW / remRatio + "px") + " !important;}"
}
var win = window,
doc = document,
docEl = doc.documentElement,
$style = doc.createElement("style");
doc.head.appendChild($style);
setRem();
win.addEventListener("resize", setRem, !1);
}
flexable(7.5); // 7.5rem = 100vwhttps://foreverz133.github.io/demos/works/lib-flexible/js/lib-flexible.js
众所周知,小数和单数的尺寸数值其实并不精准,甚至 1px 就能造成 float 布局的错位,
而 rem 方案中转化为实际 px 其实相当多情况都是小数,所以会更注重毛细线效果的结果。
而 initial-scale 一定程度上可以稍稍减小误差的概率。
也能让高清屏得到 initial-scale 放大,显得更清晰细致(不包括图片)。
var isAndroid = win.navigator.appVersion.match(/android/gi);
var isIPhone = win.navigator.appVersion.match(/iphone/gi);
var devicePixelRatio = win.devicePixelRatio;
if (isIPhone) {
// iOS下,对于2和3的屏,用2倍的方案,其余的用1倍方案
if (devicePixelRatio >= 3 && (!dpr || dpr >= 3)) {
dpr = 3;
} else if (devicePixelRatio >= 2 && (!dpr || dpr >= 2)){
dpr = 2;
} else {
dpr = 1;
}
} else {
// 其他设备下,仍旧使用1倍的方案
dpr = 1;
}
scale = 1 / dpr;
metaEl.setAttribute('content', 'initial-scale=' + scale + ', maximum-scale=' + scale + ', minimum-scale=' + scale + ', user-scalable=no');在很多插件中,body 的 font-size 会被设置为 12 * dpr 的大小。
而如果将其设为 12rem 的话将出现一种很优秀的效果。
就是 Ctrl + 加号 去缩放屏幕时,并不会改变视图。
然而当开始使用 rem 后你会发现一个问题, @media 不再那么有效了,
那么我想用 @media(min-height: 414px) 或 @media(min-height: 414rem) 去调整些什么都是不可行的。
vw 方案则比较好地能部分解决这个问题,毕竟它并没有改变什么比例基准。
而 initial-scale 也可以靠 @media(min-device-pixel-ratio) 来搞搞。
可以说 vw 方案其实要比 rem 方案更应该被推崇,至少大漠也这么认为。
但是吧,rem 方案 和 vw 方案,在非全屏宽布局中其实都不太 OK。
.container {
width: 1280px;
margin-left: auto;
margin-right: auto;
}以上方案,都用到了 viewport 的 device-width 来进行屏幕宽度的响应,而 pt 方案则不然。
<meta name="viewport" content="user-scalable=no" />@function px($px, $designWidth: 750) {
return (735 / $designWidth) * $px * 1pt;
}它有着 rem 方案类似的效果,但不需要修改根节点字体大小。
比如:此处的 px(375, 750) 相当于 50vw。
不过,此方案在屏宽大于 980px 后就没用了,因此只适用于手机端。
以前有试用过三个月,没有出现过纰漏,感觉也是个非常有效的方案。
具体原理不详,原文来自于 移动端HTML响应式布局之神奇的pt。
其实这和流行 viewport 前的原始形态很相似,也是字体大小会随屏幕缩放,
但有个比例尺后,就和设计稿尺寸对应上了,妙哉妙哉。
<meta name="viewport" content="width=750,user-scalable=no" />此方案就很*了,直接改 viewport 其他都按 px 来。
不搞什么自动间隙,什么左右靠齐,就是固定宽,开发起来贼舒服。
以前试用了半年多,用于移动端也完全没问题,PC 端有极少设备不能用。
其实这是最常见的响应式方案了,只是并不处理文字而已。
所以仅有图片等元素的很多活动 H5 就直接用百分比绝对定位来实现自适应了。
以上方案都是根据屏宽来产生响应的,那么有没有办法以容器宽度来响应的呢。
很遗憾,要么 iframe 要么 transform 的 scale 来实现了。
比如一个游戏界面,只要固定的宽高不超出屏幕,居中就完事了。
function initWindowSize(designWidth = 750, designHeight = 1334) {
var winW = window.innerWidth;
var winH = window.innerHeight;
var $body = $('.container');
var ww, hh
if (winW / winH < designWidth / designHeight) {
ww = winW;
hh = designWidth / designHeight * ww;
} else {
hh = winH;
ww = designWidth / designHeight * hh;
}
var scale = ww / designWidth;
$body.css('transform', 'scale(' + scale + ')')
}而且此方案特别适合横屏应用,是改造量最少的方案。
String.raw()
模板字符串转为普通字符串。
昨天(20171102)小程序开发团队又失去了夜生活,
发布了振奋人心的新功能,小程序内打开网页。
老大们激动得像个两百斤的孩子,一波唱衰 APP 的浪潮怕是又要沸腾吧。
无论是不是公司要求,这种*操作必然是需要体验一下的。
再者如果能利用这个新功能实现热更新,省去频繁提交小程序审核的麻烦也是不错的。
所以进行了一次公司官网(包含案例库)的小程序化搬迁,主要罗列一下我的流程和坑眼。
官方表示:个人类型与海外类型的小程序暂不支持使用。
意味着你绑定的公众号需要公司认证。
否则会报错 {"base_resp":{"ret":-1}},绑了 AppID 的报错会显示公众号信息,没绑就没有。
注:记得将基础库版本改为 1.6.4 以上哟。
在有公司认证的小程序管理后台中,找到 设置 -> 开发设置 -> 业务域名。
然后就可以添加了,只是有些次数限制。
1)每个小程序帐号仅支持配置最多20个域名;
2)每个域名仅支持绑定最多20个小程序;
3)每个小程序一年内最多支持修改域名50次。
访问非白名单域名下的资源或接口,会报 {"base_resp":{"ret":-1}} 错误。
在论坛中看到一些无法配置或配置无效的问题,很偶现,重复操作几次吧。
有大神发现一个应该算是 bug 的情况,
在网页内写 iframe 然后链跨域网页竟然是可行的。
比如以往微信不能打开的淘宝网在非 ios 的小程序中可以被打开。
当 iframe 的链接为非 https 时不会报错,会不显示。
网页本身,网页内接口,页面内跳转的链接
以上三者(划重点)都需要 https,且满足域名白名单,
否则也会报 {"base_resp":{"ret":-1}} 错误。
图片等资源的链接和 iframe 一样有些特别,非 https 非白名单也可以显示,不知以后会不会修正这个。
单个页面中只会有一个 web-view,以先写的显示。
本页不管写了什么内容,web-view 都将全屏,即使有底部菜单。
且层级超高,高过了 canvas 等原生组件。但比 wx.showLoading 等要低。
再者,它是设不了样式的,用 boundingClientRect 也得不到宽高,虽然没人会这样搞。
如果小程序没有改动,只改动了网页,可能小程序会一直访问未改动前的网页。
所以在网页链接加上一个随机的 search 字符串,可以避免这种问题。
<web-view src="https://xx.com#wechat_redirect?temp={{webId}}"></web-view>
onReady: function() {
this.setData({ webId: Math.random().toString(36).substring(2, 7) });
}
跳转后的网页也会被缓存,这其实就很尴尬了,我也没想到什么比较简单的解决方案。
按照官方文档,需要再 web-view 的链接中加上 #wechat_redirect。
注:hash 要放在 search 前面哟,不然会不显示。这个和 HTML 的 hash 规则有点不一样。
在网页内想改变小程序的链接,是可以的。
现在只开放了 wx.miniProgram.navigateTo 和 wx.miniProgram.navigateBack 两个。
wx.miniProgram.navigateTo({ url: '/pages/index/index' });
注: 网页中需要引入 <script src="https://res.wx.qq.com/open/js/jweixin-1.3.0.js"></script>。
想想都有点小激动,往后有望使用 wx.miniProgram 让网页就有现在小程序的 API 功能,也就是快捷开发混合应用(当然网页还是得在微信内部,但如果我们假设,以后所有的浏览器都是小程序浏览器呢)
但 wx.miniProgram 并没有开放那么多功能,所以原本 JSSDK 的那套要更佳。
原本的那套嘛,可以单独写新的文章了,还是先看 JS-SDK说明文档 吧,以后我会补一篇。
然而,小程序内网页的 JSSDK 还是有丢丢限制的,
没有分享,支付,界面操作(比如隐藏右上角菜单)。
支付嘛,你觉得可以先 wx.miniProgram.navigateTo 到小程序中,完成了再跳回网页来。
以前网页直接能进行授权申请,但现在多了个小程序在中间,
等于我得先小程序获得授权拿到身份,再传给网页。
由于我司在这方面可能会带来较大改动,所以有丢丢怀疑这样是否正确,希望大佬们指点。
这方面微信那边应该也会有所调整,期待更新。
小程序的用户授权嘛,主要要用 wx.login 和 wx.getUserInfo 这两个方法,
后端所需要的加密解密什么的我就不知道了,可见 官方文档。
需要的话,可以看看之前项目中实践过的前端 代码
在 PC 上,video 标签是有默认封面图 poster 的,播放暂停也没啥毛病。

但移动端没有封面图,播放时会自动全屏(非所有手机),退出全屏会存在封面图但却是铺满 video 的。

所以本文主要探讨就是这个了,如何让移动端的视频有封面图,并顺带解决一些移动端视频播放的问题。
PC 上,可以用 canvas 来画视频,注意需要 loadeddata 事件之后。
$video.addEventListener('loadeddata', () => {
createVideoPoster(this)
});
function createVideoPoster($video) {
var oldCanvas = $video.parentNode.appendChild(canvas);
oldCanvas && oldCanvas.remove();
$video.setAttribute('crossOrigin', 'Anonymous');
var canvas = document.createElement('canvas');
var winW = canvas.width = $video.parentNode.offsetWidth;
var winH = canvas.height = $video.parentNode.offsetHeight;
var w = $video.clientWidth;
var h = $video.clientHeight;
if (winW / winH > w / h) {
hh = winH; ww = w / h * winH;
} else {
ww = winW; hh = h / w * winW;
}
canvas.getContext('2d').drawImage($video, winW/2-ww/2, winH/2-hh/2, ww, hh);
$video.parentNode.appendChild(canvas);
}crossOrigin 效果并不绝对正确,如果出现也没法 catch 到,感觉只能初始前弄个默认图。
跨域还会无法使用 canvas.toDataUrl,当然也可以不转图片咯,看需求吧。
这里 $video.setAttribute('crossOrigin', 'Anonymous') 有点迷,大小写都可以,
$video.crossorigin = 'anonymous' 必须小写。
然而较多移动端上依旧是无效的,无论延时多久都没用,就跟 autoplay 那样你体会一下。
获取视频时间的 video.duration 也是同理,移动端浏览器对这类限制真是强硬。
用 poster 属性搞张默认图呀,当然是可以的。因为这个锅直接就甩给后端/原生开发咯。
在视频保存前或显示前,把视频地址发给后端,后端帮我截屏返回图片地址。
看搜到的资料,是 streamReader 还是 ffmpeg 应该都不难。
这时候只管嘤嘤嘤感觉是没错的,但还是有不美好的地方。
因为播放后暂停,poster 就不显示了,暂停画面又变成铺满 video 了。
只需要在视频链接后面加上 ?x-oss-process=video/snapshot,t_500 即可。
还可以加上 f_jpg,w_800,h_600,m_fast 几个参数,除了高清需求好像不咋用不上。
很简单有木有,诚恳地感谢大佬和开源服务。
当然,仅放在阿里云上的资源才享有这样的功能。
但在之后的测试中,仅 mkv/mov/mp4 可以用该方法获取截图,其他会报 not supported format 错误。
还有另一个无关问题,项目中是把视频上传到阿里 OSS,
这个操作后,原本在 PC 上的 avi/mpeg/wmv 莫名不能播放了,移动端没事。
为了解决上面的问题,video 不可避免的要隐藏起来,不然用默认样式产品也不会催了我一周。
用弄好的封面图替代 video 原来的位置,video 隐藏起来,点击图片就 video.play()。
<div class="video-box">
<video src preload controls></video>
<div class="poster" style="background-image: url()">
</div>.video-box {
position: relative;
overflow: hidden;
}
.video-box:before {
content: '';
display: block;
padding-top: 50.67%;
}
.video-box > video {
position: fixed;
z-index: -1;
top: 0;
left: -999em;
object-fit: contain;
background: rgba(0,0,0,.8);
}
.video-box > .poster{
position: absolute;
top: 0; left: 0;
right: 0; bottom: 0;
background-size: contain;
background-position: center;
background-repeat: no-repeat;
}var isMobile = window.innerWidth < 768;
$('body').on('click', '.video-box', function () {
var $video = this.querySelector('video');
playVideo($video);
});
if (isMobile) {
$(window).on('hashchange', function() {
if (!location.hash || location.hash === '#') {
$('video').each(function(){ stopVideo(this); });
}
});
}
function playVideo($video) {
if (isMobile) {
location.hash = "videoPlay" + Math.random().toString(16).slice(2,6);
$($video).off().on('pause', function(){ history.back(); });
} else {
$($video).off().on('ended', function(){ stopVideo($video); });
}
$video.play();
$video.style.zIndex = 1;
$video.style.left = '0';
}
function stopVideo($video) {
$video.pause();
$video.currentTime = 0;
$video.style.zIndex = -1;
$video.style.left = '-999em';
}注意此处用的偏移式的隐藏方法,因为 display:none 的话 preload 是不起效的。
另外就是如何监听暂停问题,说实话这里我也没找到完全之策,只得用 hash 和 onpause 来了。
这个问题只需几个属性即可解决,看到 x5-video 前缀你是不是懂了什么。
但加与不加的样式是不同的,这就由产品去判断吧。
x5-video-player-type="h5" x5-video-player-fullscreen webkit-playsinline playsinline
另外,加上这个还有个好处,就是元素能覆盖在 video 之上了。
其他
https://help.aliyun.com/document_detail/66804.html?spm=a2c4g.11186623.6.613.nw5D3m
各家大厂的开放服务随便翻翻感觉都是惊喜呀,比如文件转码、直播、视频上传等等。
起初我以为视频不能播放是因为文件格式问题,但后来测试中还是遇上了播放 MP4 有声音没画面的情况,才算理解为何大多教材只说支持某编码格式而非文件格式。

概念上两者非常容易混淆,但完成的效果是一样的,需记住哪个是无色抠取,哪个是黑色抠除。
再者还有个裁剪,只是做裁切,没有对半透明情况的处理。
这样一说就知道,本文阅读起来可能是会有点乱的。
那么前端方法中 如何实现,又各 有哪些应用场景 呢?
比较容易搜到的,也是用得最多的,强得一批。
现在是只有遮罩功能的,mask 指定的是下层形状,本元素及其所有子级为上层图案。
以后的发展可能会通过 mask-composite 实现蒙版,小期待一下吧。
遮罩嘛,即有色就显示,无色则隐藏。
rgba(0,0,0,0)、tranpsarent,png 图片中的透明 或 无色 就抠除。
mask 和 background 的设置非常类似,也可以缩写:
mask-image / mask-repeat / mask-position / mask-size / mask-origin / mask-clip
mask-image 也和 background-image 一样支持 url, gradient,image-set,element 等等。
举几个栗子:
/* 滚动容器底部带点效果 */
.scroller-mask {
-webkit-mask: linear-gradient(#000 calc(100% - 5em), transparent);
mask: linear-gradient(#000 calc(100% - 5em), transparent);
}
/* 当然用 linear-gradient + pointer-events:none 也是不错的方法 */
/* 这个难理解一点,你看哪个有遮罩,哪块是透明的,唔,最好手写一下试试 */
.mask {
-webkit-mask-image: url(img/flower.png) center / 0 0 no-repeat;
mask-image: url(img/flower.png) center / 0 0 no-repeat;
animation: mask 2s;
}
@keyframes mask {
0% {-webkit-mask-size: 0 0;mask-size: 0 0}
100% {-webkit-mask-size: 100% 100%;mask-size: 100% 100%}
}
DEMO:https://foreverz133.github.io/demos/works/mask/ (网速有点慢)
至于剩下的 mask-mode / mask-type / mask-composite 浏览器支持还不太妙,暂可以不考虑。
但功能上却是强大,需要更多了解还请自行翻阅 文档。
PS:兼容性 方面虽然一片红,IE 什么的抛弃掉,实验下来其实还不错。写上 -webkit-mask 基本都能用。
PPS:firefox 中动画时 mask-size 小于 100% 会不显示,但定值可以,原因不知。
个人有点莫名的习惯,不管做什么效果,都会往 SVG 上想一想,可能源于它强大的功能吧。
相比 html+css 多了很多特性,如路径/线条的设置/诸多滤镜/视图限定等;
相比 canvas 多了一些 dom 上的便捷操作,如事件。
SVG 可以用 mask 来实现 蒙版,用 clipPath 来实现 裁剪(下文 会讲)。
区分一下,svg mask 为蒙版,白色为显示;css mask 为遮罩,有色为显示。
<svg width="300" height="250" viewBox="0 0 300 250" xmlns="http://www.w3.org/2000/svg">
<defs>
<path id="triangle" d="M50 0 L100 100 L0 100 Z" />
<rect id="rect" width="100" height="100" fill="red" />
<mask id="mask">
<use xlink:href="#triangle" fill="rgba(255,255,255,0.5)" />
<!-- 白色半透明的三角形蒙版 -->
</mask>
</defs>
<use xlink:href="#rect" x="10" y="10" mask="url(#mask)" />
<!-- 本来是方形,显示出来是粉色半透明的三角 -->
</svg>mask 蒙版内可以包裹透明图片或文字。
但使用蒙版的元素,却莫名不能是 image,这就很完蛋呀,有待研究。
如果 css 的 mask 适用于图片和渐变等的话,那 background-clip:text 就适用于文字。
字面意思,将背景裁切成文字范围。
另外,background-clip 还可以设 content-box,也是不错的功能,
默认 padding-box,border-box 有上边框不被修改的 BUG。
注:兼容性 上,明文规定要加 -webkit-。顺便抛弃 IE。
.demo {
background-image: linear-gradient(red, #000);
-webkit-background-clip: text;
color: transparent; /* 不见得非要用 text-fill-color */
}很多文章误以为是 text-fill-color 实现了遮罩功能,其实是 background-clip:text 呀!
clip 在 canvas 中本来的作用是切一块画布独立出来。
拿来做遮罩效果也是可以的,但并非真的遮罩,只是裁剪,因为它不是按有色无色来判断显示的。
var cv = document.querySelector('#canvas');
var img = document.querySelector('img');
var w = cv.width = window.innerWidth, h = cv.height = window.innerHeight;
var ctx = cv.getContext('2d');
ctx.save();
ctx.arc(60, 60, 50, 0, 2*Math.PI);
ctx.clip(); // 切一个圆形画布出来
ctx.drawImage(img, 0, 0, img.width, img.height);
ctx.restore();还可以用 beginPath, lineTo 等线条操作来形成图形。
注:fillRect 和 strokeRect 是无法被切出来的,要用 rect。
注:为了避免影响其他地方,用 save 和 restore 包起来就行了。
注:文字遮罩用 clip 是无法实现的。
修改 canvas 的渲染规则。比如后写的盖住前面的,改成后写的放到低层之类的。
这些规则中有一个 source-in,就能实现 遮罩(按黑白色来判断显隐)。
ctx.fillRect(10, 10, 200, 200);
ctx.globalCompositeOperation = "source-atop"; // 改为前者区域绘制后者
ctx.drawImage(img, 50, 50, img.width, img.height);
ctx.globalCompositeOperation = "source-out";如果你用的 strokeRect 和 fillText 那绘制出来的也是相应效果哟。
如果前者是半透明的,覆盖的后者渲染出来也会是半透明的。
如果前者是半透明的 PNG 图片,覆盖的后者出来的也会是半透明,强无敌。
注:globalCompositeOperation 的默认值是 source-over,用完了别忘了改回来,不然会影响后续操作。
全部规则效果一览:https://foreverz133.github.io/demos/single/globalCompositeOperation.html
其中有一些可以拿出来提一下,挺好玩的。
source-in:交叉的部分渲染后者
destination-in:交叉的部分渲染前者
destination-out:去掉交叉的部分
destination-over:后者放至下层
主要还是以裁剪为主,裁剪当然是不会根据形状的颜色什么的来判断显隐的咯。
<svg width="300" height="200" viewBox="0 0 300 200" xmlns="http://www.w3.org/2000/svg">
<defs>
<path id="triangle" d="M50 0 L100 100 L0 100 Z" />
<rect id="rect" width="100" height="100" fill="red" />
<clipPath id="clip">
<use xlink:href="#triangle" />
</clipPath>
</defs>
<use xlink:href="#rect" x="10" y="10" clip-path="url(#clip)" />
</svg>
css 的 clip-path 是老版属性 clip 的改良版,clip 必须绝对定位,且只有矩形还只能 px。
clip-path 则支持方形/圆形/椭圆形/多边形,单位也更丰富。
// 方形,上右下左距边框距离 round 圆角
clip-path: inset(1px 10% 1em 1vw round 2px 4px 6px 8px);
// 圆形,半径 at 位置
clip-path: circle(15px at 20px 20px);
// 椭圆,半轴长 at 位置
clip-path: ellipse(50% 30% at 50% 50%);
// 多边形
clip-path: polygon(50% 0%, 100% 50%, 50% 100%, 0% 50%);我觉得 clip-path 和 border-radius 一样,改个图片或者盒子的样式又方便又爽。
但也不一样,因为是裁剪,像 border 呀子级内容呀什么的也是会被剪掉的,hover 也还是原来的尺寸,
background
比如盖一层镂空的五角星显示背景色呀,盖一层镂空的字呀什么的
假 DEMO:https://foreverz133.github.io/demos/single/star.html
border
这应该就是名副其实的遮挡层了吧,与本文其实毫无关系。
但可能你会在你不了解 mask 或需要兼容时用到。
例子:http://www.zhangxinxu.com/wordpress/2016/03/better-black-mask-guide-overlay-method/
除此之外,radial-gradient 可以完成部分类似功能,比如圆形的镂空,位置和大小设置相较也更方便。
shape-outside
shape-outside 仅能算作是高级版 float 扩展,也与本文毫无关系。
只是因为既然写了 clip-path 那 shape-outside 就提一下,避免有理解错误。
注:shape-outside 得是浮动元素时才有效。
注:它能设的值和 clip-path 基本一致
它并不会改变本身什么东西,形状不会变,border 等也还是原来的样子,还得结合 clip-path 来用。
它只是让其他与其贴边的元素有了一个不一样的贴边效果。
.box {
width: 100px;
height: 100px;
float: left;
background: pink;
border: 3px solid #333;
box-shadow: 0 0 10px;
margin-right: 20px;
clip-path: polygon(50% 0%, 100% 50%, 50% 100%, 0% 50%);
shape-outside: polygon(50% 0%, 100% 50%, 50% 100%, 0% 50%);
}
PS:兼容性 吧,怎么说呢,回退到方形影响应该不大。
虽然 clip-path 又不像 border-radius 可以加边框阴影什么的,但其实 polygon 多边形可以有高级玩法,
比如:https://codepen.io/airen/pen/VPKQxb
文档 显示以后会支持 url 和 element 等,那就很方便了呀。顺便再期待一下 shape-inside 的出现。
你思考一下 css 的 mask / background-clip / clip-path 和 shape-outside 的使用场景,这其实很有意思。
遮罩是有色的部分显示图案,蒙版是白色的部分显示图案,裁剪只是裁成这个形状,三者的实际妙用在本文中并没有深入书写,仅算是梳理其功能和明确其区别。
还请大佬们多多分享此方面的巧妙案例咯,让小弟也开开眼。
撇开技术去理解前端,前端实际为布局、行为/交互、资源和数据、跨端和兼容这四大类。
所以心血来潮之下想另开几个大坑,去整理和表述出自己现在所能构想到的前端蓝图。
本系列包含动画、布局、交互、媒介四个方面,分别梳理我所理解的前端。
在 Behance 2020 设计趋势中有描述,2020 年度趋势为 Motion Design & Animations。
原文:https://mp.weixin.qq.com/s/EvtTSCkN6IxcY1nw1oePRA
伴随 5G 的来临,前端也需要更多思考交互响应与性能问题,
低延时下能解决大多数加载问题,就算本机性能差,也有云设备同步方案。
当不再有 loading 时,突然地数据显示变化是否会显得突兀呢。
在 imgCook 这类弱 AI 应用崛起时,网站开发者可以如何突围。
本文以动画为切入点,尝试探究整理其概念与意义。
首先,我想先理清交互的含义,它的概念很大,也可能存在些误解。
理清它有助于理解动画在交互中的作用。
交互,即人机交互,不同于机器反馈的单方面运行,
就好比输入输出中的输入不只有函数的变量传入,还有用户的操作行为带来的输入。
其实可见,交互设计并不是艺术设计,美感那是界面设计的事情(即下篇布局)。
交互更侧重于用户行为上的考量,通常也是分析大于设计,其实非常工程学。
而动画一定程度上是同时为美感和行为赋能,
你可以给按钮加上小动效,让画面更灵动,也可以为交互服务引导用户操作。
这是我理解的前端做动画的价值。
程序员通常是一个差的设计师和差的管理者。
—— 交互设计之父:Alan cooper
之后将介绍动画类型分类、如何实现动画、以及动画设计原则,与君共勉。
最基本的动画构成,只需要 起始态,结束态,时长 和 节奏
function anim(start, target, duration, options = {}) {
let time = +new Date();
const every = options.every;
const cubicBezier = options.cubicBezier;
const finish = options.finish;
(function loop() {
const t = +new Date() - time;
let per = cubicBezier ? cubicBezier(t, duration) : (t / duration);
const res = start + per * (target - start);
every && every(res, per);
if (per >= 1) return finish && finish();
requestAnimationFrame(loop);
})();
}示例:https://codepen.io/foreverZ133/pen/QWwWRVY
假如结束态如果是跳跃式的怎么办,比如从屏幕右侧滑出,却从屏幕左侧出现。这是我没有整理进去的。
可见这确实只是我个人的动画观,并不见得正确,所以过程中有其他想法可以随时说出来。
其实这也能看出动画的两种思维方式,
起止数值与业务有明确关系,从何开始从何结束即为元素实际表现;
起止数值只与时间有关,其实只是想获得已运动的百分比,与元素现有状态无关。
普通的起点到终点用目标思维会很简便,只需要把 now 值赋上去就行了,
但如果要实现跳跃式动画,如下,从 50-250 重复 5 次的效果
(先不管写进 finish 回调的拓展性功能哈)
示例:https://codepen.io/foreverZ133/pen/eYmmjNm
// 基于目标值的运算
var every = (now) => ($el.style.left = 50 + (now - 50) % ((1050 - 50) / 5) + 'px');
anim(50, 1050, 3e3, { every });
// 基于运动过程的运算
var every = (now, per) => ($el.style.left = 50 + (per % 0.2) * 1000 + 'px');
anim(0, 1000, 3e3, { every });TweenJS:http://www.createjs.cc/tweenjs/docs/modules/TweenJS.html
jquery.transit:http://www.jq22.com/demo/jquery.transit-master20161220/
对比两类插件的使用,目标思维使用更为便捷,过程思维更为灵活。
cubicBezier(t, start, changeBy, duration, a, b, c, d)
其中,t 为 nowDate - startDate,changeBy 为 target - start,abcd 为两个曲线句柄。
曲线句柄即为两个曲率标记点,可见下方 CSS 式节奏 的效果。
而 js 式的就是其曲线函数。至于两者怎么转换,我还暂时没研究。
CSS 式节奏:http://yisibl.github.io/cubic-bezier/
JS 式节奏:https://cdn.bootcss.com/jquery-easing/1.4.1/jquery.easing.js
https://codepen.io/foreverZ133/pen/NWPPzvY
可见,节奏实则为时间与变化量的关系,在数学的坐标系中即为各种曲线。
动画链包含:间隔/延时、暂停、反转、重复 和 同时动画/动画组
示例:https://codepen.io/foreverZ133/pen/LYEYKEj
这里不加入线条动画的讨论哈,我个人感觉会比较难讲,仅论述图形就好。
图形动画的本质其实就是多个单点动画,只是点的存储方式可以有些不同。
这个过程其实非常复杂,比如从三角形变四边形从三个点出发会有三种不同的动画。
暂且不论这种,单说图形就是一个整体元素的类型。
CSS 是一个 transform 怼上去就行了,让人觉得很简单,但其实这其中还能有些思考。
比如之前分享的 FLIP.js,或者 rotate 180° 后再 scale 的诡异表现。
https://forever-z-133.github.io/demos/single/edit-size-box2.html
而旋转到颠倒后再缩放的诡异表现,则是原本的对称中心变更了。
对称中心在图形动画中会产生相当大程度的影响,所以动画过程中不容忽视。
其实也很容易发现,图形每多一维就会多一个对称中心。
比如三维世界里,除了物体本身的对称中心,还会多一个世界中心,也就是摄像机视点。
FLIP 动画与传统 transition 动画的区别就在于,
举个栗子,transition 式的动画,是先计算该帧的 rotate 值,再反推该帧各点的位置。
而 FLIP 动画则是先得到最终 rotate 值对应的 matrix 值,然后每帧只需要乘以 matrix 相关值就行了。
很明显,FLIP 动画性能会更佳,但需要一点数字知识才能完成改造。
另一方面,FLIP.js 将动画从 css 中抽离到 js 中,css 只管状态结果,动画由 js 补充_(与上文的 Tween 也不同)_。
这也还是目标思维与过程思维的不同,在这个对比中得到充分的展现。你品,你细品。
(当然,现阶段并不支持反推旋转/斜切过程哈)
当图形动画作为单动画时,以上概念就都会演变成某个起始值,
其实这合并了计算过程,比如四个点旋转 30 度,实则是将旋转角度进行动画,再计算点的位置;
当然也有另一种方式,直接计算旋转结果时点的位置,然后对点位进行动画。
可能用惯了 css 动画,方法二相对较少地被认知,
但相对来说性能更佳,也是 matrix 性能更佳的原因之一。
其他的动画也是相似的,图形动画中会被抽象成某个特定的值去进行动画,
比如渐变肯定不能由我们去处理每个点的动画吧。有利有弊,仅思维上要认知到还有第二种方式。
然后再进一步合并动画类型,就会出现大家熟悉的名词了,
比如:晃动、闪烁、翻转、弹簧 等等。
当查看其他动画效果的源码时,你会很容易发现还有很多变量来影响动画节奏。
比如:摩擦(friction),节制(dampening),重力(gravity),惯性(inertia) 等等。
示例:https://forever-z-133.github.io/demos/single/coolHover.html
在淘宝大佬 winter 的图形三部曲的 bindingX 中,有着 手势、动画、滚动、陀螺仪 这种类型。
https://alibaba.github.io/bindingx/guide/cn_guide_base
仔细回忆一下,关于动画的触发应该会分为两种,即时反馈式动画 和 播放式动画。
其实还有 条件式动画,实为反馈过程中满足某条件产生的,也算是及时性动画的一种。
播放式动画也算是一劳永逸,未来应该还会有更多的及时性动画出现,比如视频播放/VR等 。
即多个元素都要进行动画,但它们之间就会有着一定的规律。
比如,拖动 A 则 B 也动,或者拖动 A 则 B稍后再动 之类的。
可以总结为 相似、相反、延时、减弱、**其他 ** 这几类联动形式。
https://mp.weixin.qq.com/s/54acdnB6QQltm9vMcKpYpw
什么样的动画才算是好动画呢,虽然 UX 设计并不属于前端范畴,但我个人一直很想探讨这方面。
很多时候都是别人想好了效果丢给前端去实现,但大多公司都不见得有 UX 设计这个岗位或概念,
或者当在做个人项目的时候,干巴巴的跳转和框架默认动画,都不够酷炫不够装逼,
想做类似 https://www.figma.com/ 这样的 IDE 的话。
国内可借鉴的案例并不多,那动画思路从哪来,怎么做好动画,这便是设计原则。
或者说,已成文的规律性总结,能帮我们更好地去理解自己正在做的事情。
迪斯尼工作室的电脑角色动画 12 原则
其实没啥关系,看着乐下吧
Material Design,谷歌对操作系统制定的设计语言
相关视频:https://www.youtube.com/watch?v=rrT6v5sOwJg&list=PL8PWUWLnnIXPD3UjX931fFhn3_U5_2uZG
主要文档:https://www.material.io/design/motion/understanding-motion.html
Informative(内容丰富) & Focused(有主体的) & Expressive(富有表现力的)
有反馈 & 有提示 & 表达有连续性的 & 有个性符号 & 运行是一致的
iOS design,美学完整性,一致性,直接操作,隐喻,用户控制
相关视频:https://b23.tv/av66343171
主要文档:https://developer.apple.com/design/human-interface-guidelines/ios/overview/themes/
非线性动画,可交互的 & 可中断的 & 可重新定向的 & 可随时响应的
播放式动画,可以逐步积累动画模板,后期要考虑的就只是节奏和触发实际了,
同时也有着 FLIP.js 这类工具的存在,播放式动画也有不同的思维方式来制作播放式动画。
而即使反馈式动画则要考虑得多一点,如何抽象动画变量,如何计算或反推关键点结果,
比如像做个滚动回弹,行为上有点像甩溜溜球,那么就有甩力/拉力,然后反推加速度,再反推位移 之类的。
再往后,像 anim 方法可以按已有逻辑进行拓展到很美妙咯,
其次 bindingX 的模式也可以很好的借鉴过来,
再者哪怕不做前端,玩玩抖音,玩玩视频特性,也是很棒的。
哪怕这些都并不见得真的会用,但却让我有了很多奇思妙想。
在 imgcook 基础上,有两版设计稿,绑定上对应关系,结合 FLIP 和 bindingX,连动画也能 AI 做了。
在 vue 中有个 Transition 组件,非常棒,但 react 的现在还不太 OK。
vue 的 transition-group 是真的很棒,查看文档。
有张鑫旭老师的阅文前端团队就是不一样,在 CSS 方面总是使人炫目:
理论:https://mp.weixin.qq.com/s/FQHOyiTxWtsAV1W8pn5xrw
实践:ziven27/blog#21
哲学:https://mp.weixin.qq.com/s/OrKw9guYNiu2cMinVAcU2w
文中讲述了 最佳主字号,最佳字阶,最佳字距 三个方面。
搭配 AntDesign 设计时的推导公式,和鑫旭老师常用的“感性理性认识法”,这是非常适合研究的系列。
////// 最佳主字号 //////////////////////////////
毋庸置疑,想要呼吸感就用 16px ,想要紧凑一点就 14px。
PC 端上可能不太一样,14-18px 都有,也牵扯太多移动端与PC适配方案异同的问题,暂不深究。
////// 最佳字阶 ////////////////////////////////
在当年毕设做 UI 库的时候就比较浅显地认识到了这个问题。
比如 h3 比 h4 大 1.2 倍的话 h1 会超大,而递增 4px 又感到好小,
再者当时采用的多半是文章排班所需的 1.67 的行高设置,递增的行高间隙也成了问题。
而经过文中稀奇古怪的推演之后,事情变得很是明朗 (果然固定 px 布局才是王道)。
按黄金分割比基本原则来划分,12、16、20、28、40、60 即为最佳字阶。

////// 多行布局时的最佳行高 ////////////////
这个问题是我开发中遇到相当频繁的问题。
一方面是普通排版时行高基本只有固定高度居中时有点用,
另一方面是文章排版时,行高的紧凑与否非常直接的影响着感官。
首先是多行文本排版时 (比如标题简介这样的场景),
行高绝不能是 1.4 或 2em 这样的设置,计算起来相当麻烦,相对值改起来也很麻烦;
或者此处全部行高设为 1,全凭自写间距来还原设计,显然复用性方面不太美妙。
所以文中给出了一个较好的通用方案,在给 h1 系列定值时,行高等于字号 + 8px。

举个简单的例子,原方案中字号越大则上下间距越大,
这就会造成 padding 的二次计算,而固定 4px 上间距的话就不会有这个问题

对设计师来说,带行高标注的事情依旧不麻烦,且对简单布局即使不标注也很精确的是 4px。
////// 文章中的最佳行高 ////////////////////
其实这个问题也不简单,核心区分点是中英文。
按当初借鉴了众多 UI 库的数据和个人审美后,1.48(英) 和 1.6(中) 是比较好的状态。

可见我的另个博客 关于间距规范的两点建议
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.