
Reusable Reproducible Composable Software

Fractalide is a free and open source service programming platform using dataflow graphs. Graph nodes represent computations, while graph edges represent typed data (may also describe tensors) communicated between them. This flexible architecture can be applied to many different computation problems, initially the focus will be Microservices to be expanded out into the Internet of Things.
Fractalide is in the same vein as the NSA’s Niagrafiles (now known as Apache-NiFi) or Google’s TensorFlow but stripped of all Java, Python and GUI bloat. Fractalide faces big corporate players like Ab Initio, a company that charges a lot of money for dataflow solutions.
Truly reusable and reproducible efficient nodes is what differentiates Fractalide from the others. It’s this feature that allows open communities to mix and match nodes quickly and easily.
Fractalide stands on the shoulders of giants by combining the strengths of each language into one programming model.
| Op | Technology | Safe | Zero-cost Abstractions | Reuse | Reproducible | Distributed Type System | Concurrent | Service Config Man. |
|---|---|---|---|---|---|---|---|---|
NixOS |
✔ |
|||||||
+ |
Nix Expr |
✔ |
||||||
+ |
Rust |
✔ |
✔ |
✔ |
||||
+ |
Flow-based Programming |
✔ |
✔ |
|||||
+ |
Cap’n Proto |
✔ |
||||||
= |
Fractalide Model |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
Fractalide brings safe, fast, reusable, black-box dataflow functions and a means to compose them.
Tagline: "Nixpkgs is not enough! Here, have 'Nixfuncs' too!"
Fractalide brings reproducible, reusable, black-box dataflow functions, a means to compose them and a congruent model of configuration management.
Tagline: Safety extended beyond the application boundary into infrastructure.
Fractalide brings safe fast reproducible classical Flow-based programming components, and a congruent model of configuration management.
Tagline: Reproducible components!
Fractalide brings safe, fast, reusable, reproducible, black-box dataflow functions, a means to compose them and a congruent model of configuration management.
Tagline: Here, have a beer!
Language level modules become tightly coupled with the rest of the code, moving around these modules also poses a problem.
An unanticipated outcome occurred when combining FBP and Nix. It’s become our peanut butter and jam combination, so to say, but requires a bit of explaining, so hang tight.
Nix is a content addressable store, so is git, so is docker, except that docker’s SHA resolution is at container level and git’s SHA resolution is at changeset level. Nix on the other hand has a SHA resolution at package level, and it’s known as a derivation. If you’re trying to create reproducible systems this is the correct resolution. Too big and you’re copying around large container sized images with multiple versions occupying gigabytes of space, too small and you run into problems of git not being able to scale to support thousands of binaries that build an operating system. Therefore Nix subsumes Docker.
Indeed it’s these simple derivations that allow python 2.7 and 3.0 to exist side-by-side without conflicts. It’s what allows the Nix community to compose an entire operating system, NixOS. These derivations are what makes NixOS a congruent configuration management system, and congruent systems are reproducible systems. They have to be.
Flow-based programming in our books has delivered on its promise. In our system FBP components are known as nodes and they are reusable, clean and composable. It’s a very nice way to program computers. Though, we’ve found, the larger the network of nodes, the more overhead required to build, manage, version, package, connect, test and distribute all these moving pieces. This really doesn’t weigh well against FBP’s advantages. Still, there is this beautiful reusable side that is highly advantageous! If only we could take the good parts?
When nix is assigned the responsibility of declaratively building fbp nodes, a magic thing happens. All that manual overhead of having to build, manage and package etc gets done once and only once by the node author, and completely disappears for everyone thereafter. We’re left with the reusable good parts that FBP has to offer. Indeed the greatest overhead a node user has, is typing the node's name. We’ve gone further and distilled the overhead to a few lines, no more intimidating than a typical config file such as Cargo.toml:
{ agent, edges, mods, pkgs }:
agent {
src = ./.;
edges = with edges; [ PrimText FsPath ];
mods = with mods.rs; [ rustfbp rusqlite ];
osdeps = with pkgs; [ sqlite pkgconfig ];
}Now just to be absolutely clear of the implications; it’s possible to call an extremely complex community developed hierarchy of potentially 1000+ nodes, where each node might have different https://crates.io dependencies, they might have OS level dependencies such as openssl etc and nix will ensure the entire hierarchy is correctly built and made available. All this is done by just typing the node name and issuing a build command.
It’s this feature that sets us apart from Google TensorFlow and Apache-NiFi. It contains the DNA to build a massive sprawling community of open source programmers, this and the C4, that is. It’s our hope anyway!
The vast majority of system configuration management solutions use either the divergent or convergent model.
We’re going to quote Steve Traugott’s excellent work verbatim.
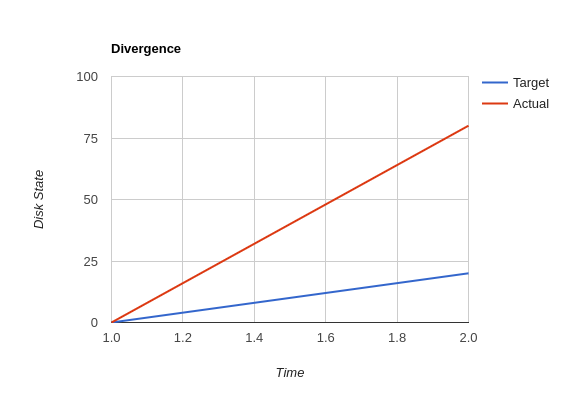
"One quick way to tell if a shop is divergent is to ask how changes are made on production hosts, how those same changes are incorporated into the baseline build for new or replacement hosts, and how they are made on hosts that were down at the time the change was first deployed. If you get different answers, then the shop is likely divergent.
The symptoms of divergence include unpredictable host behavior, unscheduled downtime, unexpected package and patch installation failure, unclosed security vulnerabilities, significant time spent "firefighting", and high troubleshooting and maintenance costs."
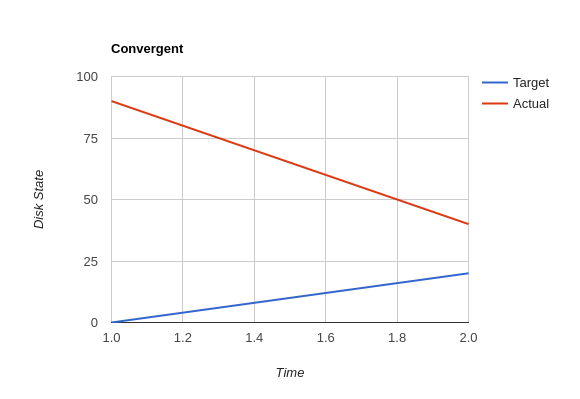
"The baseline description in a converging infrastructure is characteristically an incomplete description of machine state. You can quickly detect convergence in a shop by asking how many files are currently under management control. If an approximate answer is readily available and is on the order of a few hundred files or less, then the shop is likely converging legacy machines on a file-by-file basis.
A convergence tool is an excellent means of bringing some semblance of order to a chaotic infrastructure. Convergent tools typically work by sampling a small subset of the disk - via a checksum of one or more files, for example - and taking some action in response to what they find. The samples and actions are often defined in a declarative or descriptive language that is optimized for this use. This emulates and preempts the firefighting behavior of a reactive human systems administrator - "see a problem, fix it." Automating this process provides great economies of scale and speed over doing the same thing manually.
Because convergence typically includes an intentional process of managing a specific subset of files, there will always be unmanaged files on each host. Whether current differences between unmanaged files will have an impact on future changes is undecidable, because at any point in time we do not know the entire set of future changes, or what files they will depend on.
It appears that a central problem with convergent administration of an initially divergent infrastructure is that there is no documentation or knowledge as to when convergence is complete. One must treat the whole infrastructure as if the convergence is incomplete, whether it is or not. So without more information, an attempt to converge formerly divergent hosts to an ideal configuration is a never-ending process. By contrast, an infrastructure based upon first loading a known baseline configuration on all hosts, and limited to purely orthogonal and non-interacting sets of changes, implements congruence. Unfortunately, this is not the way most shops use convergent tools…"
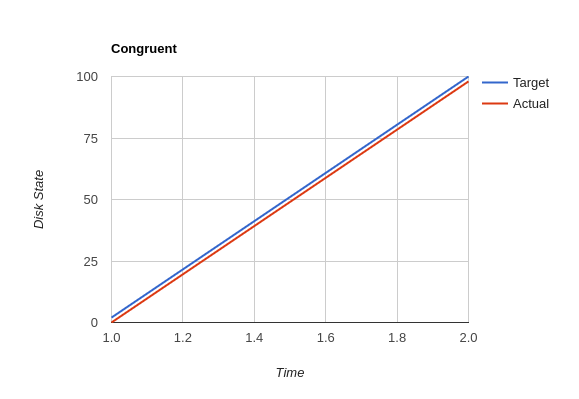
"By definition, divergence from baseline disk state in a congruent environment is symptomatic of a failure of code, administrative procedures, or security. In any of these three cases, we may not be able to assume that we know exactly which disk content was damaged. It is usually safe to handle all three cases as a security breach: correct the root cause, then rebuild.
You can detect congruence in a shop by asking how the oldest, most complex machine in the infrastructure would be rebuilt if destroyed. If years of sysadmin work can be replayed in an hour, unattended, without resorting to backups, and only user data need be restored from tape, then host management is likely congruent.
Rebuilds in a congruent infrastructure are completely unattended and generally faster than in any other; anywhere from ten minutes for a simple workstation to two hours for a node in a complex high-availability server cluster (most of that two hours is spent in blocking sleeps while meeting barrier conditions with other nodes).
Symptoms of a congruent infrastructure include rapid, predictable, "fire-and-forget" deployments and changes. Disaster recovery and production sites can be easily maintained or rebuilt on demand in a bit-for-bit identical state. Changes are not tested for the first time in production, and there are no unforeseen differences between hosts. Unscheduled production downtime is reduced to that caused by hardware and application problems; firefighting activities drop considerably. Old and new hosts are equally predictable and maintainable, and there are fewer host classes to maintain. There are no ad-hoc or manual changes. We have found that congruence makes cost of ownership much lower, and reliability much higher, than any other method."
Fractalide does not violate the congruent model of Nix, and it’s why NixOS is a dependency. Appreciation for safety has extended beyond the application boundary into infrastructure as a whole.
A language needed to be chosen to implement Fractalide. Now as Fractalide is primarily a Flow-based programming environment, it would be beneficial to choose a language that at least gets concurrency right.
Rust was a perfect fit. The concept of ownership is critical in Flow-based Programming. The Flow-based scheduler is typically responsible for tracking every Information Packet (IP) as it flows through the system. Fortunately Rust excels at getting the concept of ownership right. To the point of leveraging this concept that a garbage collector is not needed. Indeed, different forms of concurrency can be layered on Rust’s ownership concept. One very neat advantage Rust gives us is that we can very elegantly implement Flow-based Programming’s idea of concurrency. This makes our scheduler extremely lightweight as it doesn’t need to track IPs at all. Once an IP isn’t owned by any component, Rust makes it wink out of existence, no harm to anyone.
It’s easy to disrespect API contracts in a distributed services setup.
We wanted to ensure there was no ambiguity about the shape of the data a node receives. Also if the shape of data changes, the error must be caught at compile time. Cap’n Proto schema fits these requirements, and fits them perfectly when nix builds the nodes calling the Cap’n Proto schema. Because, if a schema changes, nix will register the change and will rebuild everything (nodes and subgraphs) that depends on that schema, thus catching the error. We’ve also made it such, during graph load time agents cannot connect their ports unless they use the same Cap’n Proto schema. This is a very nice safety property.
From a fresh install of NixOS (using the nixos-unstable channel) we’ll build the fractalide virtual machine (fvm) and execute the humble NAND logic gate on it.
$ git clone https://github.com/fractalide/fractalide.git
$ cd fractalide
$ nix-build --argstr node test_nand
...
$ ./result
boolean : false-
Contributors are listed in AUTHORS. Copyright is distributed throughout the community to protect contributors from having their work used unethically.
-
Our contribution policy is the C4.2 (Collective Code Construction Contract).
-
Read the C4.2 (Collective Code Construction Contract) and the line by line explanation of the protocol.
-
Fork this github repository under your own github account.
-
Clone your fork locally on your development machine.
-
Choose one problem to solve. If you aren’t solving a problem that’s already in the issue tracker you should describe the problem there (and your idea of the solution) first to see if anyone else has something to say about it (maybe someone is already working on a solution, or maybe you’re doing something wrong). If the issue is in the issue tracker, you should comment on the issue to say you’re working on the solution so that other people don’t work on the same thing.
-
Add the Fractalide repository as an upstream source and pull any changes:
$ git remote add upstream git://github.com/fractalide/fractalide //only needs to be done once $ git checkout master //just to make sure you're on the correct branch $ git pull upstream master //this grabs any code that has changed, you want to be working on the latest 'version' $ git push //update your remote fork with the changes you just pulled from upstream master
-
Create a local branch on your machine
git checkout -b branch_name(it’s usually a good idea to call the branch something that describes the problem you are solving). -
Solve the problem in the absolute most simple and fastest possible way with the smallest number of changes humanly possible. Tell other people what you’re doing by putting very clear and descriptive comments in your code every 2-3 lines. Add your name to the AUTHORS file so that you become a part owner of Fractalide.
-
Commit your changes to your own fork: Before you commit changes, you should check if you are working on the latest version (again). Go to the github website and open your fork of Fractalide, it should say This branch is even with Fractalide:master. If not, you need to pull the latest changes from the upstream Fractalide repository and replay your changes on top of the latest version:
$ git stash //save your work locally $ git checkout master $ git pull upstream master $ git push $ git checkout -b branch_name_stash $ git stash pop //_replay_ your work on the new branch which is now fully up to date with the fractalide repository
Now you can add and commit your changes:
$ git add changed_file.js //repeat for each file you changed
$ git commit -m 'problem: very short description of problem //do not close the '', press ENTER two (2) times
>
>solution: short description of how you solved the problem.' //Now you can close the ''. Also mention the issue number if there is one (e.g. #6)
$ git push //this will send your changes to _your_ fork on Github-
Go to your fork on Github and select the branch you just worked on. Click "pull request" to send a pull request back to the Fractalide repository.
-
Send the pull request.
If your pull request contains a correct patch (read the C4) a maintainer should merge it. If you want to work on another problem in the meantime simply repeat the above steps starting at:
$ git checkout masterYes, this is sometimes possible. Your first step is to very carefully read and understand everything above, including the linked files, then start fixing problems and sending pull requests! If your code is amazing and brilliant but you don’t understand the contribution process we cannot consider you for a paid position. Make sure you follow the project on Github so you get updates. Contact Fractalide’s BDFL (Benevolent Dictator For Life): Stewart Mackenzie if you’ve been contributing code to Fractalide and want to keep doing it but you require financial assistance.
| Name | Info | Language |
|---|---|---|
Founder and maintainer of Fractalide |
English |
|
Founder and maintainer of Fractalide |
French |
The project license is specified in LICENSE. Fractalide is free software; you can redistribute it and/or modify it under the terms of the Mozilla Public License Version 2 as approved by the Free Software Foundation.
Follow us on twitter













































