


Warning! This software is in beta, it is extremely likely there'll be bugs, and some ugly things. Please report bugs, and make suggestions via the issues tab.
Documentation Index (DocDex) is a utility API which scans javadocs on the web, caches everything into a calculated mixture of memory, file, and database, then provides a JSON API to easily access the information. Warning, don't run this on remote sites, it probably won't work, and you probably won't be able to access that site afterwards.
./gradlew shadowJarArchives will be in app/build/libs/ and discord/build/libs/
- Java 11
I recommend using SDKMAN to install java
SDKMAN:
curl -s "https://get.sdkman.io" | bash
source "$HOME/.sdkman/bin/sdkman-init.sh" # run this if you don't want to open a new terminal
sdk install java 11.0.9.hs- MongoDB
https://docs.mongodb.com/manual/installation/#mongodb-community-edition-installation-tutorials
java -Xmx2G -jar docdex.jarThere are 3 main parts to the configuration, the HTTP settings, mongodb settings, and javadoc settings. The HTTP stuff is extremely self explanatory, with a host and a port. If this is confusing, there's honestly no point of going any further.
The Mongo section has some basic details, including the host & port, along with a database name. You do not need to create the database manually, docdex will do that for you. If you've never used mongo before and are only installing it for the purpose of using docdex, ignore the username and password. By default mongo is not authenticated, just make sure it's not also publicly accessible.
The javadocs section may be a bit more confusing, here's the basic schematic:
javadocs: array [
javadoc: object {
names: array [string "jdk", string "jdk11"],
link: string "http://localhost/docs/jdk11/index.html",
actual_link: string "https://docs.oracle.com/en/java/javase/11/docs/api"
}
]
- The names include anything that the javadoc should be referenced as in code. The usage
here would be in the index route, with the javadoc parameter. e.g.
javadoc=jdk, orjavadoc=jdk11. - The link should be a link to your locally hosted instance of the javadoc you're indexing. It's absolutely essential that you localhost the javadocs, otherwise your IP may be blacklisted for an attempted attack. It also probably straight up won't work. Additionally, the link needs to refer to a "no frames" version of the javadoc. If you're not sure how to achieve this, simply click the no frames button on the javadoc page. It'll be near the top, next to FRAMES, NEXT, and PREV.
- The actual link is a publicly accessible version of the same javadoc that'll be used when linking to the object in the api. This should not point to a particular index file, but rather the webroot directory of the javadoc, such as in the example above.
Make sure to populate the config.json with your javadocs. On first start, it'll crawl the sites (which can take a while), and then save the indexes to file & database. As mentioned earlier, you should only run this on local sites. Doing otherwise will result in extremely long crawl times, or your ip being banned from said site. Multiple javadoc sites are loaded concurrently to help with speed.
The idea is that after a crawl, the index will be saved into a file (json). This allows the index to easily be moved around. There's two population methods in DocDex, crawl, which scans the web javadocs, and flatfile, which loads from the json file(s). Flatfile is much faster than crawl, so you should always use prebuilt indexes if possible.
Once population has finished, there's two storage methods. DocDex will attempt to save the loaded objects into a flatfile (if one doesn't already exist). It'll then load them into the database (once again if the collection doesn't already exist). The database is where the actual index gets its data from, not the flatfile.
When running the jar, a web server will be spun up on the port & host specified in the config. The route /index will then be made available. Two parameters are required to receive a non-null response from this route, javadoc and query. Javadoc refers to one of the names inside your config.json, and the query is one of the objects from the javadoc (e.g. a class or method).
Both methods (methods, constructors) and types (classes, interfaces, enums, annotations) have two identifiers. The first is their name, e.g. CommandExecutor (name) or CommandExecutor#onCommand (method). Additionally, there's also FQN identifiers in the event of duplicate names, e.g. org.bukkit.command.CommandExecutor & org.bukkit.command.CommandExecutor#onCommand.
When requesting from the index with a query, it'll first attempt to find a perfect match for the query (two possible matches, name or fqn). If it can't find one, it'll use a ratio of the levenshtein distance of the algorithm, and either the name or fqn (determined by whether the query contains periods) of every object in that javadoc. e.g.
/index?javadoc=1.16.4&query=commandexecutor
/index?javadoc=1.16.4&query=commandexecutor~oncommand
/index?javadoc=jdk&query=map~getordefault(key, defaultvalue)
/index?javadoc=1.16.4&query=material-birch_log
- Queries are case insensitive.
- Use ~ instead of # for methods (including constructors)
- Parameters for methods are optional. If you include them, you can either use parameter names, parameter types, or the entire thing. (e.g.
key,string, orstring key)- Use - instead of % for fields (including enum constants)
In addition to the 2 required parameters (javadoc & query), there are 3 optional parameters.
- algorithm=ALGORITHM
- algorithm_option=ALGORITHM_OPTION
- limit=int
The algorithm/algorithm option refers to the searching algorithm used to
order results. The default algorithm is an implementation of the jaro winkler
algorithm, with algorithm option similarity. There are two options, distance
and similarity. These are currently only used for jaro winkler and
normalized_levenshtein. If an algorithm doesn't have a similarity implementation,
it'll default to distance regardless of what you put in. I recommend sticking to
the following algorithms:
- SIMPLE_RATIO_LEVENSHTEIN
- JARO_WINKLER (similarity or distance)
- NORMALIZED_LEVENSHTEIN (similarity or distance)
The limit parameter limits the maximum potential results to that number. Adding the limit parameter WILL NOT guarantee that a specific quantity is returned, merely a quantity within the bounds of the supplied limit.
/index?javadoc=1.16.4&query=playah&algorithm=normalized_levenshtein&algorithm_type=distance
/index?javadoc=1.16.4&query=playah&limit=3
In addition to the index, a second endpoint is exposed /javadocs, which provides a list of all the loaded javadocs.
- MySQL
https://opensource.com/article/20/10/mariadb-mysql-linux
Don't forget to secure the installation
This may be a bit of a hassle, but the bot requires MySQL as it's designed to be a public bot, and therefore stores individual server settings. Once MySQL (or a fork such as MariaDB) is installed, you'll need to create a database and user for it. To do so is relatively trivial, first start off with connecting to mysql.
mysql -u root -pYou'll then be prompted to enter the password you used when securing the installation. Don't be worried if you can't see the characters as you're typing them in, this is intentional.
You'll then want to run these commands individually, in order:
CREATE DATABASE docdex;
CREATE USER 'docdex'@'localhost' IDENTIFIED BY '{password}';
GRANT ALL PRIVILEGES ON docdex.* TO 'docdex'@'localhost';
FLUSH PRIVILEGES;
exit;This will create a database called docdex, create a user called docdex on the host localhost,
give all permissions to the user docdex on localhost to the database docdex,
and then it'll exit the connection.
Make sure to replace {password} with a secure, randomly generated password.
The bots config is split up into sections like the apps, with some basic bot details at the top, a section for mysql settings, and a section for the bots presence/activity settings. Here is the basic structure of the bot settings:
token: string "dsdjaklsdjkladj"
prefix: string "d;"
url: string "https://docdex.helpch.at"
default_javadoc: "jdk"
This is fairly self explanatory. The token refers to your bot's token, which can be fetched from your discord application. The prefix is the default prefix of the bot, however keep in mind it can be changed on a per server basis. The url refers to your docdex app instance. Do not append any of the routes onto the end, the bot will do that for you. The default javadoc is the default javadoc the search & metadata commands will use. I recommend leaving it as jdk.
The mysql settings structure is as follows:
host: string "127.0.0.1"
port: int 3306
username: string "docdex"
password: string "1234"
database: string "database"
table_prefix: string "docdex_"
pool_size: int 10
The first half is todo with your connection, and the second todo with the actual database
itself. The host should refer to whatever your mysql instance is being hosted on. If localhost,
use 127.0.0.1 or localhost. If you're using an external instance, use its public ip.
The username and password are the same that we used in the mysql setup earlier. If you left
it as is, the username should be docdex, and the password whatever you replaced {password}
with.
The database name, likewise, if left as is from the mysql setup above, should be docdex.
The table prefix refers to what all the tables in the database are prefixed with. You probably
don't need to change this. The pool size is how many connections to the database are actively
maintained at any one time. 10 is a very fair number, and it's unlikely you'll ever need to increase
it. You may actually want to consider decreasing it.
status: enum "online"
activity: enum "watching"
message: string "the docs (d;help)"
The status refers to the online status of your bot, e.g. online, offline, etc. The value
MUST be one of the values listed here.
It is case insensitive. The activity once again, is another enum value (also case insensitive),
and must be one of the values listed here.
Keep in mind, bots cannot have a custom status. DEFAULT refers to the
playing status. The message can be any string. This example presence would look like this:

You can either use the public instance (which uses https://docdex.helpch.at) or run your own. The public invite is https://piggypiglet.me/docdex.
java -Xmx1G -jar bot.jar
On first run, a config will generate, and then the application will immediately shut down. Populate the config with your token, along with your docdex link. The default prefix is d;, and you should familiarise yourself with the commands which are accessible via d;help.
- Paginations will cease to function after 15 minutes with no activity. i.e. if someone hasn't reacted to a pagination for 15 minutes, the pagination will no longer work.
- If you set your prefix to something stupid and can't use the bot anymore, simply send
@DocDex resetprefix. Removing the bot from your server will not remove its saved settings.
The bot currently has 7 commands, all of which can be viewed through the bot via d;help. However, heres a more detail description of each:
d;info:
Just shows some basic information about the bot, along with a description. Currently,
it provides a link to the api, github, and discord invite. It also has my name,
the amount of servers its in (and user count), and the javadoc count (along with
the default javadoc). There's also a version number.
d;docs / d;javadocs:
This command provides a list of all the javadocs which are accessible via the bot.
d; / d;search:
This is the default command, the search command, which allows you
to retrieve javadoc information. It's quite a complicated one, with 3 parameters. They're
explained below, in the next command.
d;sub_interfaces / d;super_interfaces / d;extensions /
d;implementing_classes / d;all_implementations / d;methods /
d;sub_classes / d;implementations / d;fields:
These are effectively all the same command, they just show a different metadata object.
The syntax is identical to the search command, having 3 parameters, which are:
[javadoc] [limit/$] <query>. As you can see, the only required parameter is query.
The javadoc refers to one of the possible javadoc names, for example jdk, or spigot.
In the docs menu, javadocs separated with / mean they're aliases. So for example, with
spigot/1.16.4, you could use either 1.16.4 or spigot with the search command, or any
of these metadata commands. The limit is a number, which you can use on fuzzy queries. It
dictates how many results are returned. By default, the limit is five. Alternatively, you
can use the symbol $ for your limit, which will simply return the first result. Here are some
examples:
d;map#getordefault- returns five suggestions.d;map#getordefault(key, defaultvalue)- returns information on Map#getOrDefault.d;$ map#getordefault- returns information on Map#getOrDefault.d;3 map#getordefault- returns 3 suggestions.d;implementing_classes collection- returns all implementations of java.util.Collection.d;spigot player- returns information on spigot's Player interface.d;spigot playah- returns 5 suggestions,playerbeing the first one.d;spigot 3 playah- returns 3 suggestions,playerstill being the first one.d;spigot $ playah- returns information on spigot's Player interface.d;spigot material%birch_log- returns information on spigot's Material.BIRCH_LOG
If a javadoc object is too big to be viewed in discord, a link will simply be sent to view it online.
Permission based commands are by default, limited to users with the ADMINISTRATOR permission. However, you can allow/disallow access to specific commands for role(s) via one of the commands below.
d;prefix:
This command sets the servers prefix, e.g. d;prefix d>. From there on out, you'd use d> instead
of d;.
d;algorithm:
This command sets the searching algorithm which will be used when requesting
from the api instance. It accepts two parameters (case insensitive), the algorithm type, and
the algorithm option. Usage: d;algorithm <algorithm> <algorithm option>.
Algorithms can be found here,
and algorithm options here.
By default, the jaro winkler algorithm is used, with the similarity algorithm
option. If searches aren't returning the correct result, try using a different
algorithm/option.
d;role:
This command allows you to declare whether a particular role can access permission based
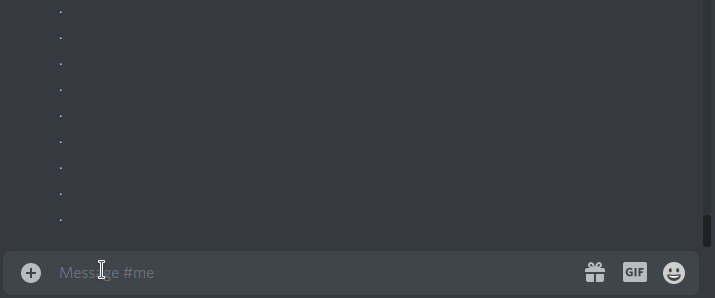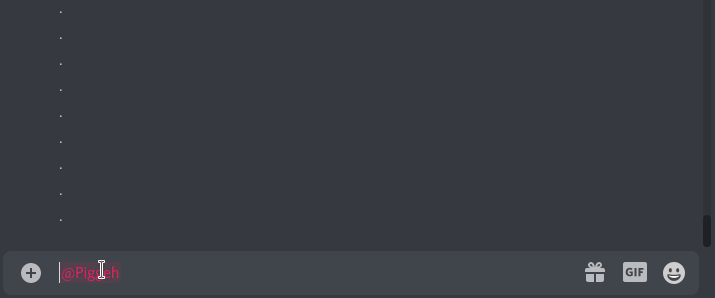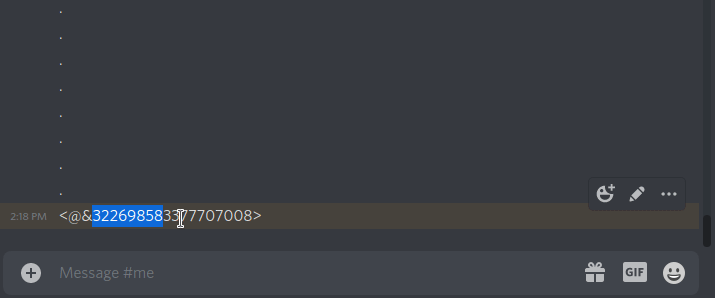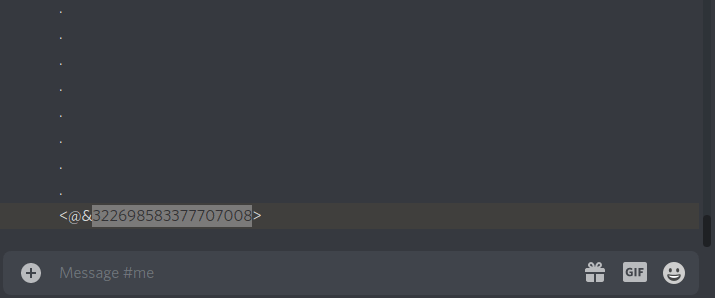
commands. Usage is d;role <add/remove> <role>. e.g. d;role add 322698583377707008. You can get
a role's id by tagging it, and putting a blackslash before the @ e.g.
d;command:
This command allows you to edit the "rules" for a command. Commands currently have 3
possible rules, "allow", "disallow", and "recommendation". Allow/disallow refers to
which channels the command can be used in, and the recommendation is a message which will
be sent if a user attempts to use a command in a channel which does not fall into the
constraints you set in allow/disallow. By default, any command can be used anywhere. If
you add an allow, the command can only be used in those channel(s). If you add a disallow,
the command can be used anywhere but the channels you have disallowed. The usage is
d;command <allow/disallow/recommendation> [add/remove] <command> <value> For example:
d;command allow add help 248724056692621313- Add248724056692621313tohelp's allowed channel list.d;command allow remove help 248724056692621313- Remove248724056692621313fromhelp's allowed channel list.d;command disallow add help 248724056692621313- Add248724056692621313tohelp's disallowed channel list.d;command recommendation help This command can only be used in #bot-commands.- Set the recommendation for "help" to "This command can only be used in #bot-commands.".
The auto updater subproject is for internal use only, to keep the public instance up to date. You're welcome to try use it, but you'd have to copy my exact setup. I will not provide support for attempts to use this.


