Experiments and serving for Multi-label Text Classification Model
- Project Overview
- Installation and Setup
- Project Structure
- Workflow and Experiments
- Results
- Discussion
- Conclusion and Future Work
- Contact Information
The objective of this project is to develop a robust multi-label text classification model capable of accurately categorizing text into three distinct categories: cyber security, environmental issues, and others. This model aims to assist in automatically sorting texts based on their content, enhancing efficiency in content management and monitoring.
This project sits at the intersection of Natural Language Processing (NLP) and machine learning, focusing on the challenge of classifying text data into multiple categories. Multi-label classification is a complex area in NLP because each text can belong to more than one category, differing from traditional single-label classification problems.
The task is further complicated by common issues in text data, such as class imbalance where some categories are significantly underrepresented compared to others, ambiguous or overlapping class definitions, and the high dimensionality of textual data. Addressing these challenges requires careful design of data preprocessing, feature engineering, and the selection of appropriate modeling techniques that can effectively handle the nuances of multi-label text datasets.
- Dependencies: Different tools were used on the way of exploring the best model to train, so, libraries like:
scikit-learn,lightgbm,transformersare included explicitly or implicitly in therequirements.txtfile. Environment is based on Python 3.11 inside an isolated conda environment. - Installation: It is enough to run the following command to install
make requirementsor if there's a different environment choice, then a regular pip install will work:
pip install -U pip setuptools wheel
pip3 install -r requirements.txt- Execution: To run any of the experiments, after the installation, and activating the right environment, then running the jupyter notebook:
jupyter notebookthis will open the window of the project in the browser, and find the related project folders there. Then you can find ipython notebooks under notebooks.
Last step before start running the project is to copy the datasets train.csv and test.csv under the ./data/raw/ folder.
data-processing.ipynb is the starting point to generate the cleaned data, it will process them and save under ./data/processed/ folder.
The development of the classification models involved a series of structured steps, each building upon the insights and results of the previous:
-
Exploratory Data Analysis (EDA):
- Performed initial EDA to understand data characteristics, trends, and challenges.
- Identified issues such as class imbalance and homogeneity in the data. Outliers were also handled at this stage.
- Relevant insights and trends are detailed in the respective EDA notebook.
-
Data Cleaning:
- Removed noisy and unnecessary data that could potentially impact learning algorithms negatively.
- Ensured the cleaning process did not affect the overall data accuracy.
-
Data Splitting:
- Executed a canonical split into training, validation, and test sets, preparing them for model training.
- Additionally, created an upsampled version of the training set to address class imbalance.
-
Initial Model Training with Scikit-Learn:
- Started with simple, fast-to-implement sklearn models to gauge the difficulty of the problem.
- Employed SVC with tf-idf vectorization, achieving an overall macro F1 score of approximately 0.54.
- Experimented with both single model and per-class model approaches, with maximum per-class F1 scores reaching up to 0.76.
-
Advanced Classifier with Gradient Boosting:
- Transitioned to gradient boosting classifiers using LightGBM, improving performance to 0.60 overall macro F1 score and approximately 0.77 macro F1 score per class, still using tf-idf vectorization.
-
Implementation of Sentence Transformers:
- Shifted vector representation to sentence transformers for more contextually aware embeddings.
- Utilized
BAAI/bge-small-en-v1.5embedding model from the MTEB leaderboard with sklearn's SVC, resulting in F1 macro scores of approximately 0.80 for both classes. - LightGBM with
BAAI/bge-small-en-v1.5embeddings achieved F1 macro scores of 0.75 (cyber) and 0.84 (environment).
-
Fine-tuning BERT for Multi-label Classification:
- Fine-tuned a BERT model with a classification head specifically designed for multi-label tasks.
- Achieved F1 macro scores of 0.71 and 0.81 for the individual classes and about 0.68 overall.
-
SetFit for Sentence Transformers:
- Employed SetFit to fine-tune sentence transformers using a contrastive learning method, reaching F1 scores of 0.74 and 0.81 for the classes.
-
Testing and Validation:
- Utilized the
classification_reportfrom Scikit-Learn to provide detailed insights into the performance of each model across different metrics such as precision, recall, and F1 score. - While overall accuracy is a commonly referenced metric, it does not always provide a complete picture, especially in the context of class imbalances and multi-label classification. Therefore, a more granular and per-class look at metrics like F1 score and recall is essential. These metrics offer a deeper understanding of model performance, particularly in how well the model handles each individual class.
- These enhanced metrics were critical for assessing the effectiveness of the models under conditions where class representation varies significantly, ensuring that the evaluation reflected both the overall and class-specific accuracy and robustness of the models.
- Utilized the
- The progression of model complexity and the shift from traditional vectorization to deep learning embeddings markedly improved classification performance.
- Although hyperparameter tuning was manually conducted based on prior experience, automating this process might offer marginal gains. Nonetheless, manual adjustments provided significant enhancements in model performance.
- The series of experiments underscore the importance of contextually rich representations and sophisticated model architectures in tackling multi-label classification challenges effectively.
- The use of sentence transformers, particularly with the
BAAI/bge-small-en-v1.5embedding model, consistently demonstrated the highest F1 macro scores, underscoring the effectiveness of advanced embedding techniques in improving the classification accuracy.
The results are presented as macro averages of precision, recall, and F1-score for each model and experiment. Here's a detailed breakdown:
| Experiment | Overall_F1_Score (mutual) |
Cyber_Label F1_Score |
Environmental_Issue F1_Score |
|---|---|---|---|
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced | 0.630 | 0.746 | 0.840 |
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced-dart-100estm | 0.589 | 0.706 | 0.833 |
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced-dart-400estm | 0.608 | 0.738 | 0.825 |
| lightgbm-bge-small-default | 0.588 | 0.726 | 0.816 |
| lightgbm-bge-small-upsampled-dataset-default | 0.572 | 0.684 | 0.843 |
| lightgbm-tfidf-class-weight-balanced | 0.599 | 0.779 | 0.760 |
| lightgbm-tfidf-class-weight-balanced-dart | 0.513 | 0.724 | 0.724 |
| lightgbm-tfidf-class-weight-balanced-high-lr | 0.600 | 0.777 | 0.764 |
| lightgbm-tfidf-default | 0.494 | 0.726 | 0.704 |
| lr-bge-small-upsampled-dataset-default | 0.566 | 0.689 | 0.791 |
| rf-bge-small-upsampled-dataset-default | 0.372 | 0.590 | 0.726 |
| svc-bge-small-cleaned-dataset-default-prob | 0.587 | 0.738 | 0.804 |
| svc-bge-small-upsampled-dataset-c0.5 | 0.608 | 0.744 | 0.792 |
| svc-bge-small-upsampled-dataset-c0.8 | 0.655 | 0.792 | 0.801 |
| svc-bge-small-upsampled-dataset-default-prob | 0.672 | 0.801 | 0.814 |
| Experiment | Precision | Recall | F1_Score |
|---|---|---|---|
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced | 0.829 | 0.699 | 0.746 |
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced-dart-100estm | 0.777 | 0.668 | 0.706 |
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced-dart-400estm | 0.906 | 0.674 | 0.738 |
| lightgbm-bge-small-default | 0.852 | 0.672 | 0.726 |
| lightgbm-bge-small-upsampled-dataset-default | 0.788 | 0.641 | 0.684 |
| lightgbm-tfidf-class-weight-balanced | 0.779 | 0.779 | 0.779 |
| lightgbm-tfidf-class-weight-balanced-dart | 0.731 | 0.718 | 0.724 |
| lightgbm-tfidf-class-weight-balanced-high-lr | 0.805 | 0.754 | 0.777 |
| lightgbm-tfidf-default | 0.771 | 0.695 | 0.726 |
| lr-bge-small-upsampled-dataset-default | 0.651 | 0.800 | 0.689 |
| rf-bge-small-upsampled-dataset-default | 0.970 | 0.559 | 0.590 |
| svc-bge-small-cleaned-dataset-default-prob | 0.906 | 0.674 | 0.738 |
| svc-bge-small-upsampled-dataset-c0.5 | 0.703 | 0.819 | 0.744 |
| svc-bge-small-upsampled-dataset-c0.8 | 0.762 | 0.832 | 0.792 |
| svc-bge-small-upsampled-dataset-default-prob | 0.775 | 0.834 | 0.801 |
| setfit-bge-small | 0.730 | 0.750 | 0.740 |
| distilBERT | 0.780 | 0.780 | 0.780 |
| Experiment | Precision | Recall | F1_Score |
|---|---|---|---|
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced | 0.861 | 0.824 | 0.840 |
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced-dart-100estm | 0.841 | 0.826 | 0.833 |
| lightgbm-bge-small-cleaned-dataset-class-weight-balanced-dart-400estm | 0.852 | 0.804 | 0.825 |
| lightgbm-bge-small-default | 0.870 | 0.783 | 0.816 |
| lightgbm-bge-small-upsampled-dataset-default | 0.876 | 0.819 | 0.843 |
| lightgbm-tfidf-class-weight-balanced | 0.782 | 0.744 | 0.760 |
| lightgbm-tfidf-class-weight-balanced-dart | 0.782 | 0.696 | 0.724 |
| lightgbm-tfidf-class-weight-balanced-high-lr | 0.780 | 0.751 | 0.764 |
| lightgbm-tfidf-default | 0.769 | 0.677 | 0.704 |
| lr-bge-small-upsampled-dataset-default | 0.767 | 0.843 | 0.791 |
| rf-bge-small-upsampled-dataset-default | 0.865 | 0.685 | 0.726 |
| svc-bge-small-cleaned-dataset-default-prob | 0.874 | 0.766 | 0.804 |
| svc-bge-small-upsampled-dataset-c0.5 | 0.772 | 0.827 | 0.792 |
| svc-bge-small-upsampled-dataset-c0.8 | 0.781 | 0.832 | 0.801 |
| svc-bge-small-upsampled-dataset-default-prob | 0.796 | 0.839 | 0.814 |
| setfit-bge-small | 0.800 | 0.820 | 0.810 |
| distilBERT | 0.800 | 0.830 | 0.810 |
This tabulated data provides a clear and concise comparison of model performances across different experiments, highlighting the effectiveness of different approaches in tackling the complexities of multi-label text classification.
The results demonstrate that models employing sentence transformers generally outperform those using tf-idf vectorization, with notable improvements in both precision and recall, particularly for environmental issues.
Note: There are more experiments done, but failing ones weren't reported or shared.
The script used to produce these result tables can rerun with
python src/reporting/compile_experiment_report.pyIn text classification, especially multi-label classification, precision, recall, and F1-score are crucial for evaluating model performance:
-
Precision measures the accuracy of positive predictions—important when false positives are costly, e.g., marking important emails as spam.
-
Recall (Sensitivity) assesses the model's ability to identify all relevant instances. It is critical where missing a positive instance has significant consequences, such as failing to identify a document with crucial information.
-
F1-Score is the harmonic mean of precision and recall, providing a balance between them. It's particularly useful in scenarios with imbalanced classes, where accuracy alone can be misleading.
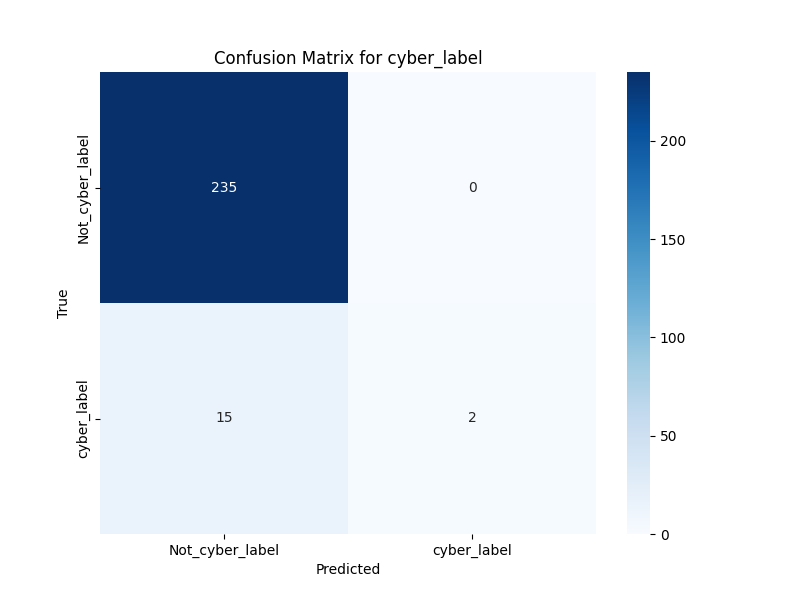
🏳 Important: Depending on the importance of the labels provided in the dataset, namely cyber security or not and environmental issue or not, given that consideration, one of these metrics will gain importance to maximize on the way to find the best model.
In multi-label scenarios, metrics are calculated for each label independently and then averaged (macro-average) or weighted by label frequency (micro-average). This approach ensures comprehensive performance assessment across all labels, highlighting the model's effectiveness and areas needing improvement.
Recall and F1-score are emphasized both overall and per label to ensure the model effectively identifies most positive instances while maintaining a balance between not missing critical labels (high recall) and minimizing incorrect label assignments (high F1-score). This dual focus helps in tuning the model to perform well across diverse and possibly imbalanced datasets.
The predictions are extracted from the best performing model (according to the table above) and can be found and downloaded from here test set predictions
The experiments reveal that advanced NLP techniques, especially those using sentence transformers and BERT fine-tuning, consistently deliver superior F1 scores. This underscores their capacity to effectively manage the complexities associated with multi-label text classification. Notably, the LightGBM model augmented with sentence transformer embeddings proved especially effective, achieving the highest F1 score of 0.84 for environmental issues. These findings highlight the crucial role that cutting-edge NLP technologies play in addressing common challenges such as class imbalance and in boosting the overall performance of classification models.
The project demonstrated the effectiveness of advanced NLP techniques, particularly sentence transformers and BERT fine-tuning, in enhancing multi-label text classification. The LightGBM model using sentence transformer embeddings performed exceptionally well, especially in classifying environmental issues.
Efforts to further improve the model will focus on the following technical objectives:
- Explore Advanced Ensemble Methods: Combine different models to leverage their strengths and improve accuracy.
- Implement AUC-ROC Analysis: Use AUC-ROC curves to assess model performance in distinguishing between classes. Set different thresholds if that works well with a certain model.
- Conduct Detailed Error Analysis: Identify and address specific weaknesses in the model.
- Evaluate Feature Importance: Analyze which features most significantly impact model predictions.
- Expand Cross-Validation: Ensure the model’s effectiveness across various data segments.
- Test Additional Deep Learning Architectures: Experiment with newer architectures to compare improvements.
- Utilize Data Augmentation: Increase training data variety to enhance model robustness.
- Integrate Multi-Modal Data: Incorporate different data types for a more comprehensive analysis.
- Apply Domain Adaptation Techniques: Adapt the model to perform well across varying data distributions.
- Serving and Deployment: The MLOps part of the model continuous modelling, evaluation, monitoring and iterating is important aspect in shipped ML model applications.
These steps are designed to refine the model’s predictive capabilities and ensure its practical applicability across different scenarios.
├── LICENSE
├── Makefile <- Makefile with commands like `make data` or `make train`
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── docs <- A default Sphinx project; see sphinx-doc.org for details
│
├── models <- Trained and serialized models, model predictions, or model summaries
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ `1.0-jqp-initial-data-exploration`.
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g.
│ generated with `pip freeze > requirements.txt`
│
├── setup.py <- makes project pip installable (pip install -e .) so src can be imported
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ │
│ ├── data <- Scripts to download or generate data
│ │ └── make_dataset.py
│ │
│ │ └── build_features.py
│ │
│ ├── models <- Scripts to train models and then use trained models to make
│ │ │ predictions
│ │ ├── predict_model.py
│ │ └── train_model.py
│ │
│ └── reporting <- Scripts to create exploratory and results oriented reporting
│ └── visualize.py
│
└── tox.ini <- tox file with settings for running tox; see tox.readthedocs.io
Project based on the cookiecutter data science project template. #cookiecutterdatascience

{kind=link}