guevara / read-it-later Goto Github PK
View Code? Open in Web Editor NEWread it later
read it later

















































































































How to teach yourself hard things
https://ift.tt/2MILkGU
This blog is mostly about learning computer programming / systems. Probably 70% of these posts are in one way or another about things I’ve learned and why they’re exciting.
But how do you teach yourself hard things? I’ve talked before about having a growth mindset, which is about replacing the belief “I’m bad at X” with “I haven’t learned about X yet”.
Having a positive attitude is really important, but IMO by itself it’s not enough to learn hard things. Learning is a skill which takes a lot of work to get better at. So this blog post is about specific learning skills that I’ve worked on over time. They are:
Before we start, I want to talk a bit about what learning how to learn can look like. I’m not a teacher or anything, but here are a few things that I think helped me:
I think other ways people frequently get better at teaching themselves are:
It seems a bit weird to put “learn some math independently when you’re 8” alongside “do a PhD” but to me figuring out fractions on your own feels like the same kind of mental discipline that’s useful as an adult researcher exploring new ideas.
I’m going to avoid talking about math for the rest of this post because today I spend most of my time learning programming ideas, not math ideas. So let’s talk about some learning skills!
I think this is the most important learning skill. This is the skill of translating “I’m confused, I don’t get it” to “I have a specific question about X”.
For example, when I was learning Rust last winter, I felt really confused about references & borrowing. It took me a while to figure out why, but eventually I realized that I didn’t know the answers to the following questions: (answered in What’s a reference in Rust?)
& symbol in Rust actually mean?Once I understood the answers to these, I had a MUCH stronger understanding of how to use references and borrowing and was permanently less confused about how to write Rust code.
Being good at this is a HUGE DEAL! If I weren’t good at figuring out what I’m confused about, then I’d either need to:
Even though I think I’m pretty good at it now, I still find breaking down “I’m confused about X” into specific questions about X takes work. For example, I only came up with those questions about Rust references 3 years after I’d first used Rust. The reason it took so long is that I had to decide to actually sit down, notice what I found confusing, and focus on figuring out what I was confused about. That takes time!
But I do think that this is something that you can get better at over time. I’m much better at breaking down what’s confusing to me about a programming thing than I was and much more able to unstick myself.
Identifying what you do understand is IMO just as important as identifying what you don’t understand. For example, I don’t know everything about networking. One thing I do 100% know is that there are 65535 TCP ports. That is definitely true. The src/dest port fields in the TCP header are 16 bits (2^16=65536), so there is no room for more ports.
Having pieces of knowledge that I’m really confident about is really important when trying to figure out a tricky problem. For example, imagine a program printed out “port 1823832” in a log. That is not because there are secretly port numbers can be bigger than 65535 and I’ve just misunderstood! That’s because there’s a bug in the program, there’s no port 1823832. That’s kind of a silly example, but I need to debug complicated issues all the time and it would be a huge waste of time to second guess things that I do actually know.
Taking a bit of extra time to take a piece of knowledge that you’re pretty sure of (“there are 65535 ports, Wikipedia said so”) and make it totally ironclad (“that’s because the port field in the TCP header is only 16 bits”) is super useful because there is a big difference between “I’m 97% sure this is true” and “I am 100% sure about this and I never need to question it again”. Things I know are 100% true are way easier to rely on.
The next skill is “ask questions”. This is about taking the things you’ve identified that you’re confused about (“what’s the difference between TLS 1.3 and 1.2?”) and turning them into questions to ask a person.
Here I’m just going to link to a post I previously wrote called How to ask good questions.
The hardest part of asking questions for me is actually figuring out what I do and don’t know. I think there are also some interesting skills here about:
This is about:
I’m not aware of any good guides to doing tech research, though I think that could be a really interesting thing to write up – information about different areas is available in dramatically different places (man pages? books? mailing lists?) and some documentation is MUCH better than other than other documentation. How do you figure out the landscape of where information is in your area?
One last thing that has been important for me is to recognize when I’m confused about something and, instead of feeling bad (“oh no! I don’t know this thing! disaster!”), recognize that it’s a normal feeling and that it just means I’m about to learn something!
I like learning! It’s fun! So if I’m confused, that’s usually a good thing because it means I’m not stagnating. Here’s how I approach it:
Of course, I don’t do that every time I’m confused about something – sometimes I just note “ah, I’m confused about X, maybe I will figure that out someday but not today”. That’s okay too! Learning is a lifetime project :)
I don’t really think I could have a career as a programmer if I didn’t invest in learning new things. Almost everything I do in my job day-to-day is something I learned on my own, and most of it is stuff that I learned recently (in the last 2-3 years). So it makes sense for me to continue working on getting better at learning. Some learning skills I’d like to be better at are:
软技能——一本写给程序员的生存指南
https://ift.tt/2rZPSMy
也谈钱
这是一位在 33 岁实现财务自由的程序员的个人奋斗史,也是他对于生活和事业的全面总结以及留给后辈的指导。
作者(John Z.Sonmez)写作的初衷是希望告诉广大程序员,其实除了编程(职业本身)还有很多应该掌握、能够显著改善生活的「软技能」。通读下来,这本书的内容不仅仅适合程序员,也适合每个人。
这是一本真正从「人」(而非技术也非管理)的角度关注软件开发人员自身发展的书。
 软技能
软技能
前段时间桥水基金创始人雷·达里奥的《原则》可以说是红遍了大江南北,网上的解读可谓是铺天盖地,而且惊人的一致好评,甚至将其奉为圣经。我读完两遍以后,惊讶于达里奥深刻的见解的同时,也不免有点小小的遗憾。
也许是作者本人的地位和眼界的缘故,《原则》的内容极为精炼,非常高屋建瓴,但是少了那么一点点亲和力,很多大道理大家也懂,可是知易行难,即使是知道了依然感觉无从下手。原则更像是给了你种种目标,「你应该做到 XX」,但是我们知道 「目标 → 行动」其实还需要非常多的实践、思考和试错。
相比之下,软技能则是提供了各种行动清单,书中的每条建议,都是放下书本以后,可以立刻开始实践执行的,少了很多的转换成本。
不过,但凡是内容涉及很多领域的书籍,必然是广而不深的。这类书的目的更多是为了向你介绍那些你未曾想到过的可能性和方法,而难以让你深入精通。大家不要走入骂书的陷阱了,觉得书中内容太过泛泛而谈(如果有类似冲动,强烈建议看看 Hum 的读后感《一流的人讀書,都在哪裡畫線?》读书笔记)。
总了来说,这本书更像是一个聚合清单,涵盖了关于求职、工作、自我营销、生产力、理财、健身等等很多方向,很适合帮助我们发现认知的盲点,扩展边界,让我们找到被我们忽视的可能性。
读这本书的时候,总感觉是在刷少数派的首页文章,而且作者和少数派的写作方向及理念重合度很高。
《软技能》的内容主要划分为下面几个篇幅:
乍一看内容好像很散,什么都要讲,其实书中的主线非常清晰——认真地经营自己的生活。
由于全书内容很多、很杂,不太合适全面介绍,所以主要选择目前对我影响最大的生产力这一篇来切入,而且生产力也最符合少数派的主要定位。
如果说要请教关于工作效率的问题,我一定会优先向自由职业者或者长期在家办公的人士请教。因为在这类工作环境中,没有一套完整有效的工作方法很难保证任务有序进行。作者做过一段时间的自由职业,如今财务自由也算是自由职业的一种吧,在这方面还是相当有发言权的。
读完生产力这一章,我大致总结了两个核心观点:
为了满足这两个要求,作者介绍了 看板 + 番茄钟 的组合模式。
相信大家对于番茄钟都不陌生,也一定有很多朋友和我一样,尝试过一段时间后,因为不喜欢这个节奏就放弃了。其实作者也有同样的经历,最终还是在朋友的建议下重新开始尝试。他总结的一句话非常精辟,醍醐灌顶:
(番茄钟的精髓不是 25/5 的节奏,而是)给事前任务规划和事后回顾提供了一个量化指标。
番茄钟的节奏其实只是一种表面的形式,核心在于有意识的专注和量化时间。专注的时间原本是很难量化的,如果单纯只是统计工作时间很难知道自己当时的工作状态,而借助番茄钟可以把事后统计专注时间变为主动尝试专注。
 看板
看板
作者会每个星期使用看板进行一周的规划,每天一列,「今天」和「已完成」单独放一列,每天规划 9~10 个番茄钟。(这点很重要!其实能够坚持每天执行 10 个严格的番茄钟,就已经可以说是效率飞起了)
先说规划,很多时候,低效是由于把喜欢做的简单的事情放在前面做,而奢望进入状态以后,再来完成重要且有难度的工作。但是,任务却常常被一拖拖到晚上,一天的时间就这么混过去了。
如果我们明确每天只能专注 10 个番茄钟,由于时间的限制,就会很自然的把重要的事情放到前面做。使用看板和番茄钟搭配可以很直观的显示出时间的规划和限制。
再说回顾,其实很多时候并不是我们懒、不愿意做事,而是因为我们没有一个清晰的量化指标,不知道自己这一天到底做了多少工作。这个方法也同样提供了非常明确的量化指标,通过完成番茄钟的数量可以快速准确的评估自己一天的工作状况。
根据自己的情况,我进行了适当的调整,把 GTD 融合进来。
在使用 GTD 的过程中,我常常会遇到这样的烦恼,在「随时」清单中,总有那么几项重要但是不紧急的任务不想碰,在执行清单的时候总是会选择性的绕开这些项目。最终清单中常年驻守一些「钉子户」,最终总是不了了之藏进其他清单或者干脆删除了。
在使用看板做计划以后,我开始针对性的找到这些任务,把它们排到一天的开始,并在当天配合上其他我愿意做的任务,稍作缓解。
我打造的任务流程是这样的:GTD(Things)→ 看板(Notion)→ 番茄钟(Forest/JustFocus)
看板软件之所以选择 Notion 而不是大家熟知的 Trello,主要是因为 Notion 的自定义和透视功能非常强大,可以自己设计看板属性和透视图,而不仅仅局限在预设的几个功能上。大家也可以看看这篇介绍:加入表格、看板和日历,更全能的数字笔记工具:Notion 2.0。
最终两个星期执行下来,效果确实很给力,可以有效地干掉很多「老大难」。
记得 N 年前,多任务处理还是个流行词汇,被大家视为职场必备素质,不能多任务处理往往会被贴上低效的标签。结果现在情况基本又反过来了,多任务处理又被「证伪」,反倒成了低效的源头。
其实,这个问题不在于多任务处理本身,而是由于错误的理解和定义。对于多任务处理,作者是持支持态度的,但是前提是真正的多任务并行处理。
很多人以为的多任务处理,其实只是任务切换而已。
真正导致低效的其实是任务的不断切换,导致注意力反复被打断。其实,这些任务本质上是不可能同时执行的,比如,你不可能同时回复工作邮件 + 写个人博客。而真正的多任务,应该是确确实实的并行进行,并且通常满足如下组合:
一个需要相对高注意力的任务 + 一个几乎不需要注意力的任务
对应的例子也不少,比如一边健身一边聊天、一边做饭一边听得到、一边吃饭一边看电视(不过从健康角度还是不推荐的),对于效率是实打实的提升。
如果由于惰性不愿意开始工作,可以先试着硬着头皮开始工作 15 分钟。
专注状态存在一种明显的动量效应,我们专注 15 分钟以后,就比专注以前更容易进入和保持专注状态。
对此,我最深刻的印象是来自中学时的记忆。周末真心不想写作业,看见作业本就心烦。但是如果「机缘巧合」坐在了桌子前,开始写几分钟,就很容易一直坚持写下去了。类似的方法其实应用也不少,比如不想出门运动,可以试着先把运动服换上,就会发现出门变得容易多了。
注:原书为「冲量」,但是我觉得「动量」更恰当。
这本书可以说是给了我一个全面的启发,内容密度很大。仅凭这篇笔记也不过是管中窥豹,如果感兴趣,强烈建议购买全书。再简单摘录一些我的其他收获(不完整):
这篇读书笔记的写作过程和我其他笔记很不一样,以前的笔记基本上都是一边翻书一边写,想到什么内容总要回书中找到对应的部分验证一下,摘抄下来再继续。而这一次几乎没有翻书,大部分的引用都是写完之后才去贴上去的。
我自己的理解是,这本书的内容真的非常实用,很容易尝试并内化到自己的理解和实践中。这也是我对这本书推崇之极的主要原因,我甚至认为这是我过去几年读过的所有书中,最好的一本(比《原则》要好)!
能够读到《软技能》,还要感谢 @forecho ,半年前给我留言推荐了这本书。当时我简单的翻了翻书评,感觉不错就记下了。时隔半年之后,翻开这本书,真的有被惊艳到。
作者真人照片和书中的感觉以及程序员的普遍印象完全不同(兼职过模特和演员的程序员也是没谁了),故放一张作者的照片作为收尾。
 博客照片
博客照片
5 Easy Ways to Save an Article – Feedly Blog
https://ift.tt/2naBhwM
We’ve found that saving and organizing content around our most important goals is a great way to feed your team with high-value information. Plus, sharing smart, relevant articles with your team or professional network bolsters your status as a visible expert.
Sometimes you might feel overwhelmed by the volume of new content in your feeds. There are important updates coming in, but it can be hard to keep up.
In this post, we’ve shared the five easy ways to save articles and feed your team with only the most high-value, relevant information.
Find out more about Boards in this big announcement post.
If you find an important article while reading in Feedly on your desktop, click the “Save to Board” icon:
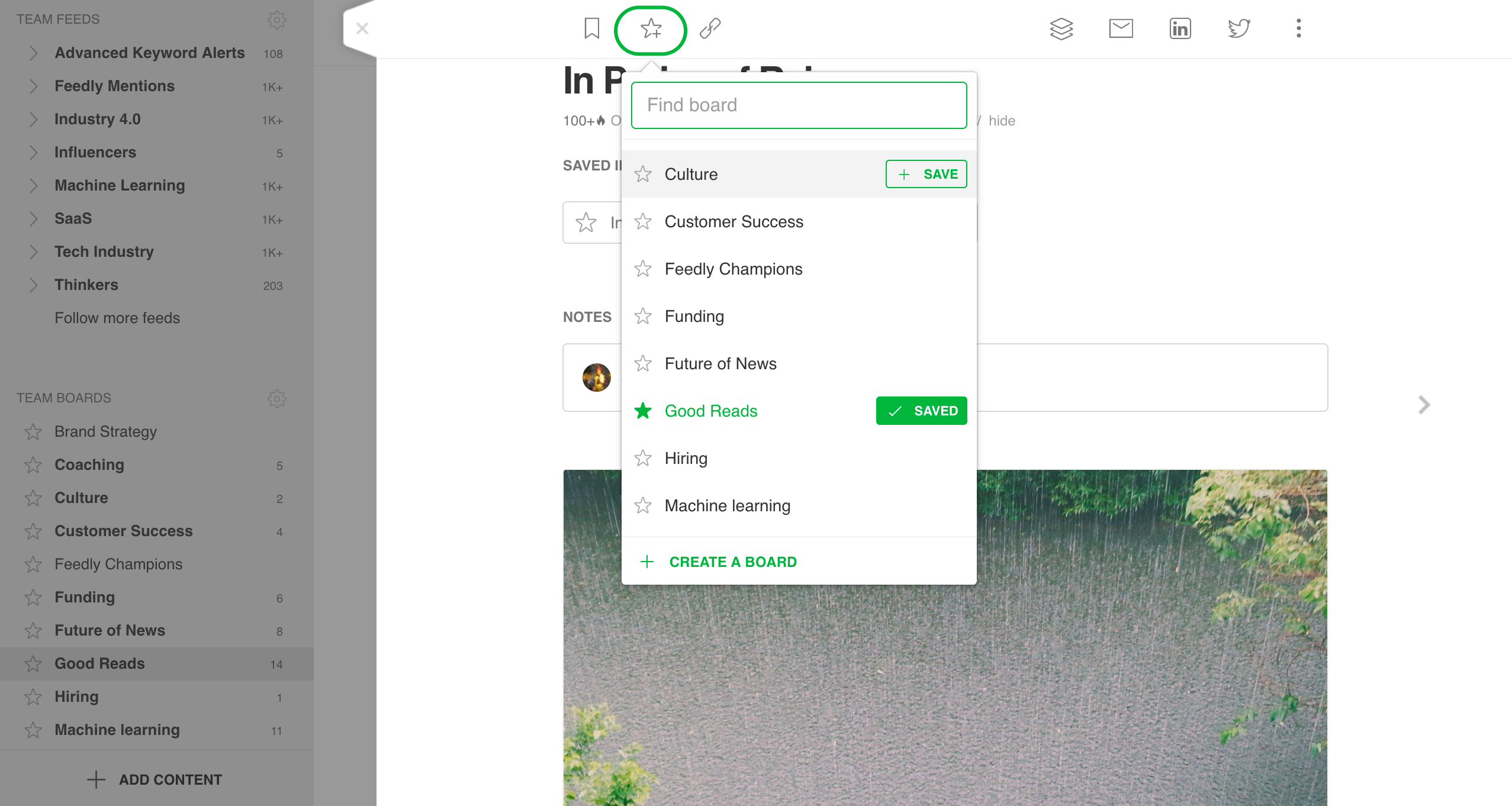 If you don’t have any Boards yet, we’ll prompt you to create one.
If you don’t have any Boards yet, we’ll prompt you to create one.
Click on the board icon to open your list of Boards. If this is your first one, take a moment to give it a name. You can save an article to multiple Boards.
We find that the best Board names are specific and related to a project or task. For example, a “Competitors” board just for articles about product launches in your market; or a “Client X” board dedicated to each client’s brand, executives, etc.
There is a vast (and expanding) ocean of content on the web. Instead of copy-pasting links between tabs or into a spreadsheet, the Feedly browser extension makes it easy and quick to save any article to your Feedly Boards.
Add the extension for Chrome, Firefox, and Safari, and you can save an article in two clicks. When you go back to your Boards on Feedly, the article will be right where you saved it.
 You can even create a new Board right from this extension.
You can even create a new Board right from this extension.
Links come at you from friends and colleagues too. There’s another quick way to save to Boards by pasting in a URL. Copy the article URL, then open one of your Boards. Click the star icon at the top right of a Board, paste the URL in the box, and click “Save to Board.”
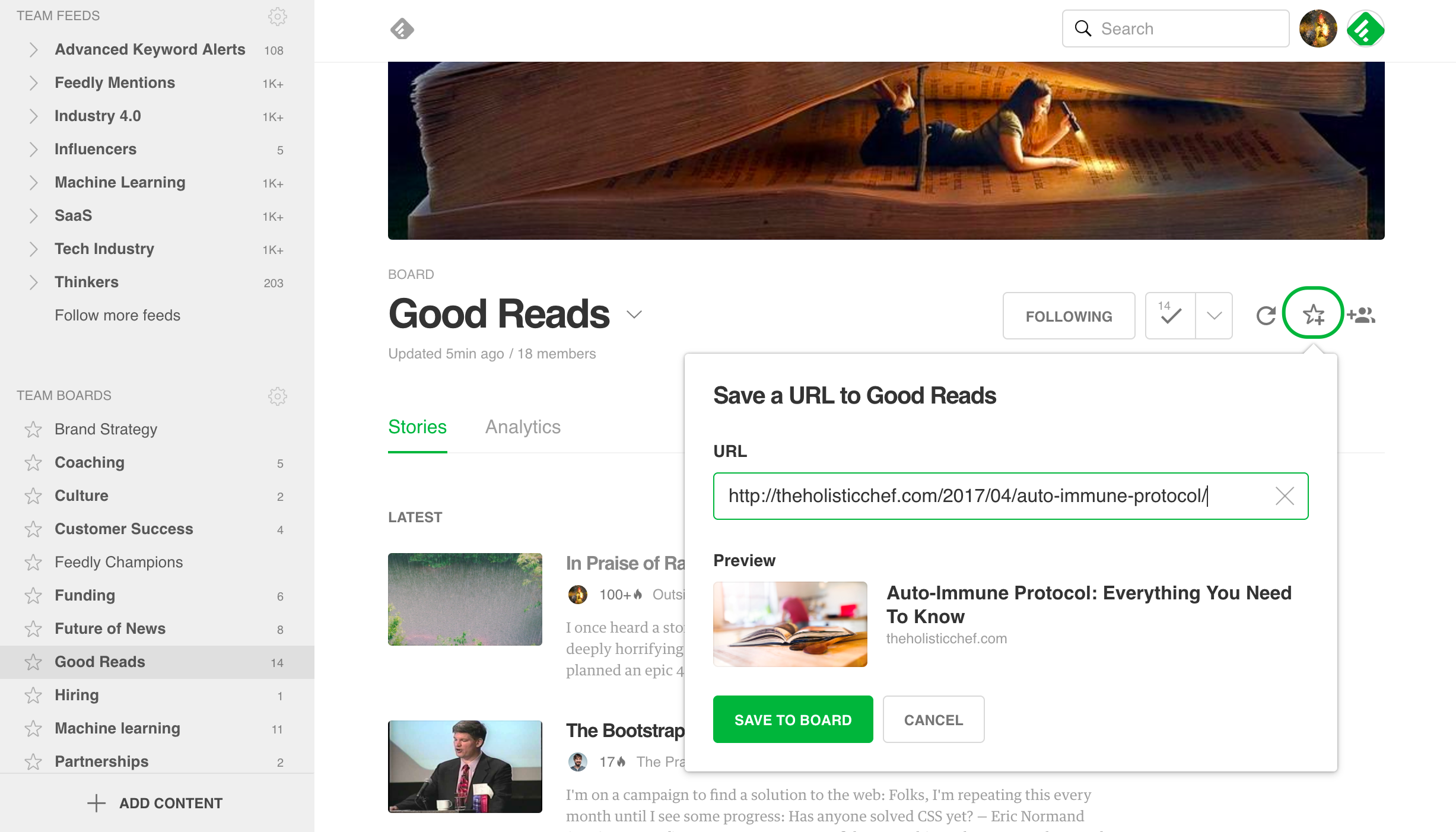 When you paste the article URL in the box, we’ll show you a snippet.
When you paste the article URL in the box, we’ll show you a snippet.
If you’re reading on the Feedly mobile app, tap the icon to save. You’ll be able to save the current article to one or more of your Personal and Team Boards.
Your content syncs automatically across all your devices.
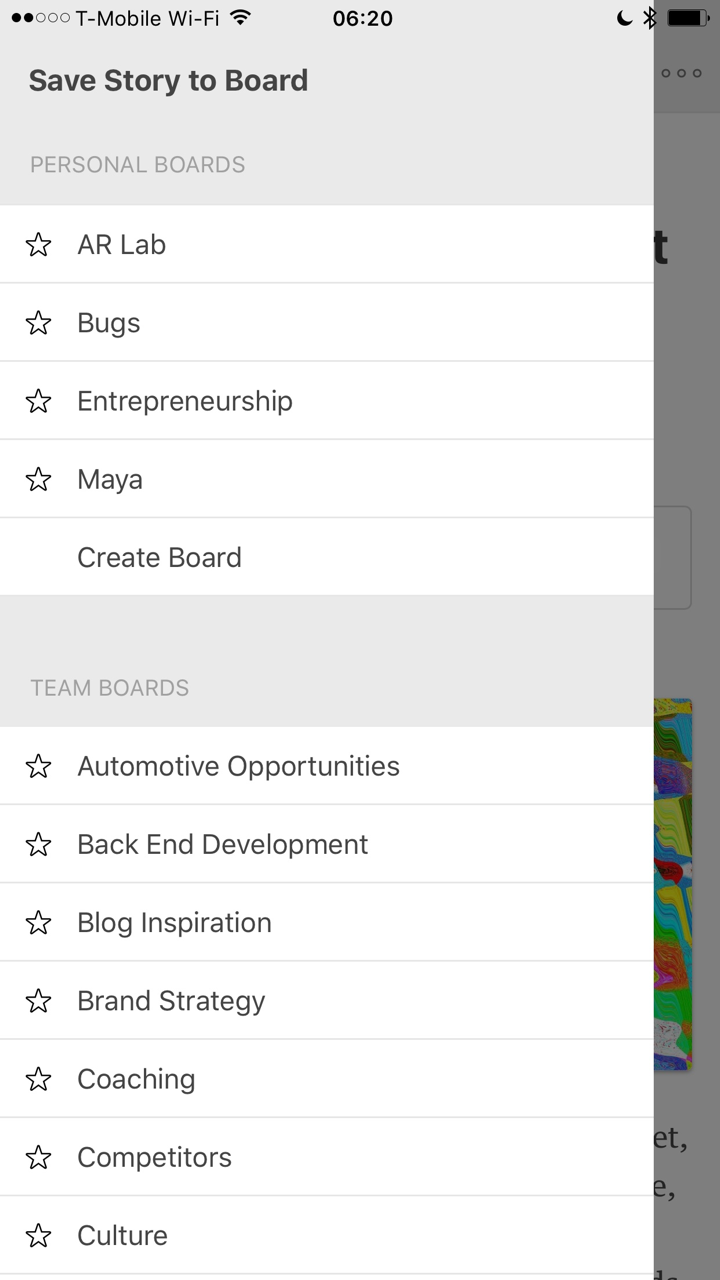 Tap on the star icon at the top of the article to show your list of Boards. Save it to as many Boards as you like.
Tap on the star icon at the top of the article to show your list of Boards. Save it to as many Boards as you like.
Similar to #2 above, it’s easy to save to Feedly from other apps on your phone or tablet. Open your device’s share menu, choose Feedly, and select the Boards where you want to put the article. This option requires that you have the Feedly mobile app installed.
If you have the Feedly app installed on mobile (Android or iPhone), the “Save to Feedly” option is automatically available in your device’s share menu.
That’s all for now! Thanks for using Feedly. We hope you enjoy Boards as much as we do.
</div><br>
动物界的强奸亚文化|大象公会
https://ift.tt/2DgC9ZO
如果在生活中留心观察,你不难发现这样的场景:树林间,一只鸟对另一只鸟穷追不舍;厨房里,一只苍蝇紧跟着另一只苍蝇不放;公园里,一只狗追着另一只狗试图强行骑跨。
这时响起的画外音,很可能是「万物复苏,又到了求偶交配的季节」,但鲜有人意识到,这些动物活动不是求偶,而是求偶失败后的霸王硬上弓。
● 鸭
强奸亚文化存在于几乎所有物种中。所有个体都抗拒强奸,但在绝大部分物种中,雄性的交配欲望高于雌性,雌性往往不成比例地沦为强奸受害者。
学界研究的强奸行为集中在雄性对雌性的强奸,这不意味着雄性强奸雄性或雌性强奸雌性不存在,只不过它们不如雄性强奸雌性那么随处可见而已。
说回原题。强奸之所以在动物界广泛存在,是因为它确实对雄性有好处,哪怕雌性承受了极高的代价。
由于雌性承担了绝大部分生育责任,她在择偶游戏中是权力上位者,雄性只能以极低的姿态去迎合雌性:
有的雌性喜欢漂亮的,那我长帅一点,有的雌性喜欢会打架的,那我能打一点,有的雌性喜欢跳舞好的,那我就去练跳舞,有的雌性是吃货,我就跋山涉水去给她找吃的[1]。
但雄性自然不满足于做被挑选者。
在他们的内部争斗中,胜利者会大大限制失败者的交配权,极端情况下,他们会咬掉失败者的生殖器,这和杀了他们没什么两样。但这仍然无法改变他们在面对雌性时的下位者姿态。
雄性体制内的蛋糕分完了,如果还想要更多,只能去抢雌性的蛋糕。最有利于个体的生存策略是,我想干什么就可以干什么,想和谁交配就和谁交配。你不愿意,那我就强迫你。
雄性的最佳强奸策略是,我可以强奸别人老婆,别人不能强奸我老婆。
可这种策略用脚趾头想都是很难成功的。雄性分配在生殖上的能量有限,却需要操心三件事,第一,正大光明地娶老婆,第二,保护老婆不受性*扰,第三,强奸别人的老婆。
不是所有雄性都迷恋强奸。强奸对于整个种群而言是不好的,因为雌性选择有助于整个种群筛选优质基因,强奸行为破坏了规则。
同时,强奸可能会带来雌性的器质性损伤,导致种群内可繁殖的雌性数量减少。蜘蛛在强奸时,毒牙会伤害雌性[2],龟(Testudo hermanni)会用自己的尾巴硬插雌性,造成生殖器损伤[3]。
● 象海豹
强奸率的升高还会导致娶妻成本和保护老婆的成本上升。进一步推理,桃花多的雄性利益增长,要小于没有桃花的雄性利益增长。虽然对于没有桃花的雄性,强奸带来的是从无到有的质变,但优质雄性把妹相对轻松,强奸的边际收益较低。
因此,处于权力上层的雄性经常会公开表示,为了种族的繁荣,不能强奸,并惩戒那些越轨的下层雄性。但很难说,私下里,他们自己是否同样严于律己。
如果强奸发生成本过低,阻止它的发生就变得极为困难。在这种条件下,雌性进化出了一整套防止强奸产子的系统。
第一招:把有强奸意图的雄性往死里打,必要时可以把它吃掉。
生物学第一定律:多挨几次打就老实了,但这只适用于雌性比雄性大的生物,雌性可以暴力反抗,或者存在于由雌性长者领导的母系社会,敢强奸,就会被族长驱逐出境。但道高一尺魔高一丈,雌蝎子喜食雄蝎子,雄蝎子无法抑制交配冲动,只能以身犯险,为了降低被吃掉的风险,雄蝎子会给雌蝎子注射小剂量的毒液(Sexual sting),这种毒液通常用来麻醉小型猎物[4]。
● 蝎
第二招:关闭生殖器
一种水里的小虫子(Gerris gracilicornis),雄性趴在雌性背上交配,雌性的生殖器有一扇小门,不愿意交配的时候不会开门,而且会使劲把雄性甩下去。
雄性破门而入的技巧不够高深,竟然想出杀敌一千自损八百的阴招,他们爬到雌性背上疯狂地性*扰,用脚在水面上荡起波纹,捕食者感知到了信号,就会快速过来捕食,如果悲剧真的发生,雄性会率先逃走,留雌性挡刀,所以雌性一旦觉察到他的小心思,为了防止丢命,便会妥协与其交配[5]。
● Water strider
第三招:雇个保镖
如果自己的身体不够强壮,家族中的雌性也不够有权力,就只能雇一个保镖,这个保镖通常是自己的老公,他天然地不愿意别人强奸自己的老婆,在这一点上是利益共同体,母鸡在被性*扰的时候就会主动寻求老公的帮助[6]。
但把自己的安危寄托在别人身上,终究是不牢靠的,即使防得了外人强奸,也防不了婚内强奸。再者说,保护老婆并不是雄性唯一感兴趣的事情,它们时常消极怠工,或跑去追求其他雌性,或贪吃误事。
雇保镖的初衷是用交配权换保护,你不保护我,我就不和你交配,主动权掌握在雌性手中,但雄性可以采取固定策略——强奸落单的雌性,如此一来,雌性不得不寻求雄性保护,保护变成刚需,雄性就有了更多讨价还价的筹码。
第四招:强奸了也不让你精子成功
靠别人不如靠自己,如果强奸很难避免,那么就把强奸带来的伤害降到最低,雌性形成了体内的精子筛选通道,可以把不喜欢的雄性精子从阴道里挤出去,把喜欢的雄性精子存起来慢慢用。
● 母鸡的储精管
喜欢的雄性更有可能当爹。如果雌性喜欢更长的精子,体内就会形成细长的储精管,雄性不得不努力制造更大的精子,果蝇也因此拥有了巨大的精子[8]。为了帮助雌性吸收精子,雄性不得不努力提高床上技巧,把雌性伺候舒服[9]。但雄性同样有对策,使用精液蛋白提高自己的精子储存率。
● 取悦雌性
第五招:选择性堕胎
雌性并不是一交配完就可以让卵子受精,她会让精子长时间地在生殖道内游荡,即使最后哪个幸运的冲破重重阻碍依旧和卵子结合了,雌性也可以根据自己的偏好选择性堕胎,可怜的受精卵无法着床,还面临被母体重吸收的风险,这种特殊的流产机制在蝙蝠中被发现过[10]。但雄性却利用了雌性的流产机制,会强迫再婚的雌性流掉前夫的孩子,尽快进入生育期[11]。
第六招:遗弃孩子
越往后,对雌性的伤害越大,如果之前的重重保护都不能让雌性捍卫自己的生育权,雌性在生产之后更有可能遗弃和自己不喜欢的雄性生的孩子[12],但雌性的生育代价远大于雄性,遗弃在大多数情况下不是最优解。
争夺交配权和生育权为什么这么重要?
因为,生殖权的背后是生存权——优先享用资源的权力。两性谁在其中发挥的作用更大,谁掌握主动权,对应的权力则更大。
或许更值得注意的是,它还很大程度地影响了进化方向和未来的权力格局。
选对象和家畜育种一个道理,雌性如果有权力,她可以持续选择顺从、爱带娃的雄性,经过多代的培育,雄性会变得越来越任劳任怨,雌性的权力就越来越大。相反,雄性如果有权力,他可以持续选择顺从、忠贞的雌性,经过多代的选择,雌性会以夫为纲,争立贞节牌坊,雄性的权力就越来越大[13]。
个体的暴力,让体型小的雌性无力反抗强奸,进化产生的制度的暴力,则能让母系氏族的强奸者无处遁逃。性暴力的背后是性别权力失衡,近年来学者提出观点,暴力不是获得权力的唯一途径,不可被掠夺的资源和知识在其中也起到至关重要的作用,设想一雌一雄生活在孤岛,只有雌性知道哪里可以找到食物和水源,尽管雄性从力量上远胜于雌性,他也无法轻易侵犯[14]。
性是权力的原因,也是权力的结果。基于上一代的两性权力,他们争夺交配权和生育权,争夺的结果又导致了后代的性别权力格局。
参考文献
1. Gwynne, D.T., Sexual conflict over nuptial gifts in insects.Annu. Rev. Entomol., 2008. 53: p. 83-101.
2. Johns, J.L., et al., Love bites: male fang use during coercive mating in wolf spiders.Behavioral ecology and sociobiology, 2009. 64(1): p. 13.
3. Golubović, A., et al., Is sexual brutality maladaptive under high population density?Biological Journal of the Linnean Society, 2018. 124(3): p. 394-402.
4. Inceoglu, B., et al., One scorpion, two venoms: prevenom of Parabuthus transvaalicus acts as an alternative type of venom with distinct mechanism of action.Proceedings of the National Academy of Sciences, 2003. 100(3): p. 922-927.
5. Han, C.S. and P.G. Jablonski, Male water striders attract predators to intimidate females into copulation.Nature communications, 2010. 1: p. 52.
6. Løvlie, H., J. Zidar, and C. Berneheim, A cry for help: female distress calling during copulation is context dependent.Animal behaviour, 2014. 92: p. 151-157.
7. King, L.M., et al., Segregation of spermatozoa within sperm storage tubules of fowl and turkey hens.Reproduction, 2002. 123(1): p. 79-86.
8. Miller, G.T. and S. Pitnick, Sperm-female coevolution in Drosophila.Science, 2002. 298(5596): p. 1230-1233.
9. Wulff, N.C., et al., Copulatory courtship by internal genitalia in bushcrickets.Scientific reports, 2017. 7: p. 42345.
10. Orr, T.J. and M. Zuk, Reproductive delays in mammals: an unexplored avenue for post‐copulatory sexual selection.Biological Reviews, 2014. 89(4): p. 889-912.
11. Berger, J., Induced abortion and social factors in wild horses.Nature, 1983. 303(5912): p. 59.
12. Crawford, C. and B.M.F. Galdikas, Rape in non-human animals: An evolutionary perspective.Canadian Psychology/Psychologie canadienne, 1986. 27(3): p. 215.
13. Lewis, R.J., Female Power in Primates and the Phenomenon of Female Dominance.Annual Review of Anthropology, 2018(0).
14. Lewis, R.J., Beyond dominance: the importance of leverage.The Quarterly review of biology, 2002. 77(2): p. 149-164.
哪些书该读?哪些地方该划线?《一流的人讀書,都在哪裡畫線?》读书笔记
https://ift.tt/2jpB0lZ
Hum
读书,如果是以学习为目的,如果不能过目不忘,就需要划线。
而划线,有两个重点:一是在哪划,换句话说是什么东西值得「划」;二是怎么划,一水儿的下划线?还是用虚线、波浪线?怎么用不同的颜色?书签怎么用?
这两个问题我一直在思考和总结,也在寻找别人的执行方法,看看是否有值得借鉴的内容。
正好,最近 Readmoo 这个**电子书平台上架了一本译书《一流的人讀書,都在哪裡畫線?》,作者是土井英司,日本的一位书评家与畅销书作家。
 《一流的人讀書,都在哪裡畫線?》封面
《一流的人讀書,都在哪裡畫線?》封面
买来一翻,发现这本书和此前想的不大一样:
所谓商业书,内容主要包括管理、生产力、运营、销售、经济等领域,形式上可以是畅销书,也可以是经典甚至教材。不过,这本书谈论的划线、选书、读书方法,适用于各类以「学习」为目的的书。
在这本书里,我认为最奠基的观点,是「不该因为从书中获得自己已经知道了的东西而喜悦」,而应该重视自己忽视了的、没意识到的、甚至不同意的观点与证据。
换言之,读书是为了「见己之小」而不是「见己之大」,是为了从中学东西,而不是读完以后更加自我感觉良好。
这和要警惕「回声效应」类似,我们在摄取信息时太容易选择已经认可的,它的问题是:如果这些信息是没问题的,那么你已经知道了,再巩固也没有多少益处;而如果这些信息有偏见的成分,那继续选择这些信息就是在加深偏见了。
从这个思路出发,作者认为在做读书笔记时,不该以做出「全书内容梳理列表」为目的,而应该主要记录自己学到了什么。我比较同意这个观点。因此,这篇笔记,我也将主要记录那些和我观点并不完全一致的地方,并在中和了双方观点之后,记下我新的想法。
人物传记,一直是我以为特别不值得一读的一个类别,原因是我认为:
这些理由我现在仍然保留,但是书中有一句话我也非常同意:
拓展視野最好的方法,就是與大人物當面聊天。
阿里巴巴的伯乐、日本软银孙正义,在去年 Bloomberg 的访问里分享过他在高中时,百折不挠地要见日本麦当劳社长面谈的经历(视频片段:3 分钟)。
在打了很多长途,被秘书搪塞多次无果之后,孙正义飞往东京。他把要求降低到,「我不要求说话,我只要求见他一面,不会打扰他,看他工作 3 分钟就行。」对方从来没见过这样的孩子,答应见孙正义一面。
在对话中,孙正义问自己将来应该做什么,对方回答:「计算机!」,并说「不要关注业界的过去,要思考业界的未来。」
所以,如果我们有自己敬佩的人,想要知道他的**,能做好准备、见一面,是最理想的。但如果没办法,也就只有通过他的传记、自传去了解他的一些想法了。
现在,我仍然不认为传记是特别值得阅读的,但是我也同意作者土井英司的观点。
看了前面我对传记类作品的态度,大概就能知道我选书很严。严到什么地步呢?比如《时间简史》这类的书,大概是过去的我会推荐的最好读的书了。我觉得值得读的书,是不能随手翻翻就能读完的书,而这种书大多都是教科书,还得是翻印多次的经典教科书。这本《一流的人讀書,都在哪裡畫線?》,如果不是我对「应该在哪划线」这个点特别感兴趣,我也是不会去看的。
为什么呢?我钻了一个牛角尖,叫做知识密度。这是我中学的时候,为了「不看坏书」想的办法。
打个比方,看一集肥皂剧要 40 分钟,看一集纪录片也是 40 分钟,但两者的知识密度完全不同。书更是如此,看一本坏书,问题不光是占用了看好书的时间,还会影响你对书的整体口味与判断能力。
如果我是抱着学习的心情去看书,我就希望它里面的知识密度高一些。因此我会很排斥「把几条核心内容不断用例子稀释成为一本书的篇幅」这样的「畅销书」思维。
这本书呢,也提出 11 个标准,其中有 10 个跟我思路类似,都是从各方面判断书籍的可信度,而且都很严格。但唯有一点,是让我感到震惊然而有道理的:
第八条:如果前幾頁就值得畫線,買了。
作者在全书都表示出了一个观点:商业类的书籍,不是为了看全书,而是一种投资。只要你能学到对当下的你有用的技能点、知识点,就是划算。他提到一个例子:
曾有讀者因閱讀拙作《成功讀書術》,而向我表達感謝。我在書中提到傳奇估價師是川銀藏的故事,並由此提出一個定律,那就是景氣循環與鋼鐵產能的時間差如何影響鋼鐵股價波動。後來某位讀者告訴我,這個定律給了他靈感,幫助他大賺一筆,令我欣喜不已。
这个例子是真金白银的情况,但不必非得如此现实,「学到」并不只是一个短期利益。作者在后文又举了让他看了就买书的两个句子:
「今天的商業環境不是『大欺小』,而是『快欺慢』。」——《嬌聯式栽培自我的技術》
「品牌就是顧客對你的評價,光做表面功夫是不夠的。」——《成城石井的創業》
至于其它 10 条选书的方法,网上可以搜得到,在此考虑到版权问题,不再讨论。
读书要读完,是大多数人的执念。但如果不是为了丰富自己而读书,大可不必把书从头到尾地读完。
这与前面的选书理由也颇一致,作者写道:
閱讀商業書就像在挖掘鑽石,只要挖到鑽石,其他砂石都不重要。
而读一些技巧性更强的书(比如本书),则完全可以把它当成工具书去读。你想知道作者眼中选书的 11 个方法?直接跳到那个位置看就可以了。
一些书甚至可以翻了目录,知道里面大概内容之后就放下,等到用得到的时候再看不迟。
我猜没人会说「我读书是为了追求速度和数量」。
但在社交网站上,常见有人「立帖为证」,定下「一年内读 100 本书」的目标,很强调数量。还有一种常见的是「一年内读 52 本书」,看起来稍微理性了点,实际上是把要求改成了一周一本,数量之外也规定了速度。
但读书快,肯定是不少人的目标。作者本人读书速度也是「1 天 3 本」,但是作者认为:
讀到不擅長或不熟悉的內容,讀得慢是理所當然,因為你不懂,慢慢讀才會懂,才會理解,才會吸收。這段過程是何等愉悅?由「不知」邁向「知之」是一件大工程,千萬不要把它想得像微波爐熱菜一樣簡單。
写毕业论文的时候,我大学时期的教授给我推荐了两本很深的书,在他读研期间,这两本书分别用一个月才读完。
读书速度,首先是和书籍的知识密度有关。这本《一流的人讀書,都在哪裡畫線?》,我读了 1 天就读完了,相信各位也可以做到差不多的进度。但是侯世达的《集异璧》,认真读完少说恐怕也要半个月往上。罗素和怀特海还写过一本《数学原理(Principia Mathematica)》,这本书全世界读完的人都没几个。
读书速度,和读书的态度、目的,也有一定的关联。作者读商业书的态度是「沙中淘金」那么对于他来说,淘金完毕就算读完。做学者的读亚里士多德,那一定得好几本字典来回对译,一字一句都不得出错,当然也就慢。
不一样态度和目的的人,用不同的时间和速度,来读不一样质量和内容含量的书,太理所当然不过了。实在不必成为操弄「xx 内读完 xx 本书」句式的人。
关于阅读作用,实际上要问的问题是:阅读=学习吗?
答案是:不完全等于。
作者说:
閱讀本身不會讓你獲得競爭優勢。閱讀只是一種「工具」或「契機」,讓你懂得發問,問出你的競爭優勢,並引發你的行為。我小時候讀了昆蟲圖鑑就跑去山裡抓蟲子,這個昆蟲男孩的競爭優勢在於「親眼見證實物」。把昆蟲圖鑑翻到爛,只是為了獲得親眼驗證所需的基礎知識。一定要親自接觸過昆蟲,才能長出智慧。
我们的知识,有太多是无法通过文字传达的。譬如游泳,没有人是看书学会游泳的。
哪怕 Step by Step 地写出每一个步骤,从软件使用技巧到高级物理实验,都仍然不可能做到让每一个阅读的人,都能复原同样的结果。这其中都需要实践,才能习得其中的「默会知识(Tatic Knowledge)」。
所以阅读不完全等于学习,读懂不完全等于学到。
这是这本书最后一个让我有自我反省的点。
骂书,是自诩会读书的人的一个通病,特别是对于科普类的读物来说,当把专业知识转为面向大众的词汇,就容易被相关从业者批判。
但作者提供了一个为这些图书辩解的思路:
正因為這本書不是給專業會計看的書,而是將專業知識一般化,寫給普羅大眾,才會成為暢銷書。再者,作者何時說過要寫給「專業會計」看?會寫這種書評的人,就是看了暢銷書才恍然大悟自己擅長的領域竟然還有金礦可以淘,淘金的人卻不是自己,才會眼紅批評。而這些人既然沒發現自己的嫉妒心,也就不會繼續成長了。
这个说法里有两个点:
第一个是人身攻击,即眼红别人淘到金而批评别人,见不得别人好。这个推论有些靠不住了,虽然确实有这样的人在,但肯定也有因为严谨性而批判的人。
第二个点更有价值,涉及到批评的人实际上选错了书。物理学家或者物理学的学生,买了一本市面上量子力学科普的畅销书,看完了去骂,实际上耽误了他自己的时间。
我也是稍前一段时间悟到了这点,还发了一条微博:
当你买了一个东西,发现它非常不适合你,你忍无可忍打了差评的时候,这个差评是打给你自己的。那个星级、分数代表了你对自己的了解程度和辨别力。
以上就是书中令我感到有所成长之处,但全书也有不少我已经知道的,也许能为各位提供价值的内容。譬如划线方法,作者有这 2 个提倡,在目录中就有体现:
如最开始所说,这本书并不完全,或者完全不是教我们「在哪划线」的书,很「标题党」。书名改为《如何读商业书,及优秀商业书推荐》,大概更恰当。
但这不影响书籍的价值,特别是作者在其中,对于「经营」这一领域,提出了一个架构:
并且针对每一个部分,提到了相应的重点,并提供了四五本按照作者选书标准,严选出来的的书。
这本书有一句书评是:「我在讀完這本書後,立刻上網買了許多作者推薦的好書。」这很符合我的心态。
好书还有一个评价的侧面,就是通过这本书你又知道了多少好书。在这个侧面,《一流的人讀書,都在哪裡畫線?》这本书应该能得高分。
贯穿你我一生的基因之谜
https://ift.tt/2OL4JDU
思考问题的熊
作为一名生物信息学在读博士,我每天的工作都在和基因打交道。但当有非专业内的朋友问起我正在做的事情,我却很难用只言片语解释清楚。
因为每说一句话都要涉及三五个专业的概念,而解释任何一个概念又需要再引入几个全新概念,所有的讨论不管从那个起点开始,最后都会归结到“基因”上来。
例如:基因是什么,基因怎么遗传,基因怎么发挥作用,我们能对基因做什么,这样做真的合适么等等。
这些问题有过高中生物基础的人基本上就可以回答,但回答通常又都不准确;而对于一个博士来说也可以回答,但往往却不太敢说。一方面是因为如果你在一个领域中陷入太久就会发现每当自以为了解一个东西后立刻又会冒出一个不了解的东西等待你;另一方面长期专注于某一个过于细分的领域往往会限制我们对于一个事物整体的理解。
此刻,如果有一本优秀的科普通识读物能够带你由浅入深的了解和理解一个行业或者学科,那无疑是幸运和幸福的,《基因传:众生之源》就是这样一本书。
接下来,从四个角度和你分享《基因传:众生之源》是一本怎样的书?
 封面
封面
这可能是最无聊的一个特点,但也是对一本科普读物最高的评价,意味着准确,严谨以及尊重事实。
如果你是有生命科学相关学科背景的读者,在本科或者读研读博时感觉自己专业基础并不扎实,这本书完全可以当做一本复习教材。从达尔文进化论开始,到高中生物里的孟德尔遗传定律和摩尔根遗传定律,再到肺炎链球菌试验,再到大学里学到的基因组学知识。在权威教科书《基因 X 》中提到的重点概念在《基因传:众生之源》中都有涉及而且解释通俗易懂。在书的最后还配有名词解释附录,可以说完全没毛病。
下面是这本书中关于“基因连锁交换定律”的解释和应用,嗯,非常教科书但是又通俗于教科书。
由于某些基因之间的连接十分紧密,以至于它们从不发生互换。摩尔根的学生认为,这些基因在染色体上的物理位置可能最为接近。而其他位置相距较远的连锁基因则更容易解离。但是无论如何连锁基因都不会出现在完全不同的染色体上。简而言之,遗传连锁的紧密程度反映了染色体上基因物理位置的远近:通过观测两种遗传性状(例如,金发与蓝眼)连锁或者解离的时间,就可以判断控制这些性状的基因在染色体上的距离。
如果稍微转化一下视角,把基因人格化(这没有任何问题,比如里查德·道金斯笔下自私的基因),那么《基因传:众生之源》绝对是一部优秀的名人传记。这本书按照时间顺序和故事情节,完整地讲述了基因理论的起源、发展和未来,以及这个过程中遇到的种种问题和麻烦。
在读某几个章节时,我仿佛有一种读《史蒂夫·乔布斯传》和《硅谷钢铁侠》的感觉。基因从不为人所知,到被极少数人接受,再到彻底改写生命科学的研究方法和历史。有所成就之前一定会经历各种意想不到的困难和误解,虽然成绩显著但是必然也存在着各种缺陷和问题。这就是生命科学圈的乔布斯和埃隆马斯克啊,再一次,没毛病。
在介绍基因研究困境时,你可以读到如下内容:
阿瑟·科恩伯格(Arthur Kornberg)曾经这样说过:“细胞生物学家凭借观察,遗传学家仰仗统计,生化学家依靠提纯。” 实际上,在显微镜的帮助下,细胞生物学家们已经习惯于在细胞水平观察可见结构执行的可识别功能。但是迄今为止,基因只是在统计学意义上“可见”。
在介绍基因给社会带来的影响时,下面两段描述让我震撼:
从孟德尔开始进行豌豆实验,再到卡丽·巴克被法院强制执行绝育手术,这中间只经历了短短的62年。就在这稍纵即逝的60多年间,基因已经从一种植物学实验中的抽象概念演变为操纵社会发展的强大工具。就像1927年在最高法院进行辩论的“巴克诉贝尔案”一样,遗传学和优生学领域也是鱼龙混杂,可是其影响力已经渗透到美国社会、政治和个人生活中。
将基因作为解决这些生物学核心问题答案的认识姗姗来迟,而这种滞后导致了一种奇怪的现象:作为事后出现的学科,遗传学将被迫与生物学其他主要领域的观点和解。如果基因是代表生物信息的通用货币,那么它将不仅局限于诠释遗传规律,而且还可以用来解释生物界的主要特征。
首先,基因需要解释变异现象:众所周知,人眼的形态不只六种,甚至可以出现60亿种连续的突变体,那么这些离散的遗传单位对此如何解释呢?
其次,基因需要解释进化过程:随着时间延长,生物体的特征和形态均会发生巨大改变,那么这些遗传单位又该如何作答呢?
第三,基因需要解释发育问题:这些指令由独立单位组成,那么它们该如何编码才能让胚胎发育成熟呢?
基因理论的发展史就是人类文化与伦理的进化史。作者以基因理论的发展为线索,为我们讲述了基因理论与俄国十月革命,第二次世界大战等众多历史事件背后的隐秘关联。也为我们清晰地描述了极端种族主义如何以基因学说为借口,逐步使科学完全论为政治工具。
到了20世纪中叶,无论基因学说被接受与否,它已经成为某种潜在的政治与文化工具,并且跻身历史上最危险的**之一。希特勒的种族净化政策基础来自于优生学和社会达尔文主义。优生学这一概念在纳粹德国得到全面推展,他们将不具生产力的人口以各种方法处理掉,从而阻止他们繁衍后代。
从强制绝育,到秘密屠杀,再到种族清洗。纳粹希望通过此举,实现创造一个优等民族的梦想。
纳粹主义盗用了基因与遗传学的名义为延续其罪恶进行宣传与辩解,同时还驾轻就熟地将遗传歧视整合到种族灭绝的行动中。从肉体上消灭精神病与残疾人(“他们的思维或行为不能和我们保持一致”)的行为只是大规模屠杀犹太人之前的热身运动。基因就这样史无前例地在悄无声息中与身份混为一谈,然后这些带有缺陷的身份被纳粹主义利用,并且成为他们实施种族灭绝的借口。
截至1941年,T4行动已经屠杀了将近25万的成人与儿童。此外,在1933年到1943年间,大约有40万人根据绝育法接受了强制绝育手术
德国纳粹坚信人的基因不可改变,因此低等人种必须被清除,而与德国纳粹行径遥相呼应的是苏联“大清洗运动”。
大清洗运动完全不科学的“科学”依据来自李森科的“新拉马克主义”,与德国纳粹不同,李森科认为一个事物本身的特性是怎样不重要,可以通过人为使其得到获得性遗传。对作物而言,它能够在短期内培育出更抗寒、更高产的品种;对人而言,社会革命(环境)能够有目的地塑造和改变人性(遗传)。
当科学沦为政治,政治干涉科学的时候,很难说谁是最大的受害者。
永远不要相信哪里还是一片净土,有人的地方就有江湖。
《基因传:众生之源》这本书之所以能让人读起来完全不觉乏味,是因为除了讲述科学问题以外还有大量的人性与道德参杂其中。
在发现问题和解决问题的过程中,合作是科学家们之间永远绕不开的话题,而只要涉及到利益也绝对绕不开斗争。在这你来我往之间,有人成功就有人失败,有人被铭记也就有人被遗忘。
达尔文同时期的另一位科学家华莱士几乎是同时和达尔文得出完全一致的结论并提前发表。不过两人的家庭背景和个人地位当时并不相同,达尔文高富帅出身,华莱士只能在图书馆长椅上读书。
达尔文看到华莱士寄给自己的手稿时发现“丫的,我文章被抢发了(还好没有我名气大)”,于是赶紧去找另一个圈中大佬求助,那个大佬建议他“要不就来一个背靠背文章发表”,但是文章发表后却没有引起太大波澜。
到了第二年达尔文感觉不能再等下去,于是放弃了整理好所有结果再出书的计划,匆忙将《物种起源》交给出版社并请求出版社尽快出版。他在给出版商的信中写到:“我衷心希望这本书能够在您的大力支持下旗开得胜”。从此以后人们记住了达尔文,至于华莱士……
1858年6月,华莱士将自己概括的自然选择理论初稿寄给了达尔文。达尔文对华莱士理论与自身观点的相似性感到震惊,而他在惊慌失措之余匆忙带着自己的手稿找到好友赖尔。赖尔巧妙地建议达尔文将两篇论文同时提交给即将于夏季召开的林奈学会会议,这样可以让达尔文与华莱士共同分享此项发现带来的荣誉。1858年7月1日,达尔文与华莱士的论文在伦敦被广泛传阅和公开讨论。但是听众对于他们二人的研究均不感兴趣。次年5月,林奈学会主席在总结的时候顺便说到,去年没有任何重要发现。
 物种起源
物种起源
哲学家路德维希·维特根斯坦(Ludwig Wittgenstein)写道:“一个微不足道的想法,就足以占据某个人的一生。” 确实,一眼看去孟德尔的人生充满了繁杂琐碎的念头。他整天周而复始地沉浸在播种、授粉、开花、采摘、剥壳与计数的工作里。尽管整个过程极度枯燥乏味,但是孟德尔却深信天下大事必作于细。
深信天下大事必作于细的孟德尔,1866年将自己的论文发表在年度《布尔诺自然科学协会学报》上,平日里少言寡语的孟德尔仅用44页纸就总结了自己将近10年的研究成果。
1866年至1900年,孟德尔的文章仅被引用了4次,几乎从科学文献的领域中消失。1890年至1900年的100年里,尽管关于人类遗传及其操纵的问题和顾虑已成为重点议题,但是孟德尔的名字与他的成果依然不为世界所知。而这也被称为“生物学史上最为怪异的沉默事件之一”
究其原因或许是因为缺乏权威性的协会期刊没有名气,没有人注意到那篇几十页的文章。总之,现代生物学的立足之本就这样被长期埋没。更可笑的事,直到1900年,有三篇完全独立的文章结果同时指向孟德尔的豌豆杂交实验,人们才想起40年前的他。
正如书中所写:研究成果被重新发现一次可以反映科学家的先见之明,而被重新发现三次则着实是对原创者的一种鄙夷不屑。
研究成果被重新发现一次可以反映科学家的先见之明,而被重新发现三次则着实是对原创者的一种鄙夷不屑。1900年,有3篇独立发表的论文在3个月内相继问世,而所有研究成果均指向孟德尔的豌豆杂交实验,当然这也暴露了某些生物学家目光短浅的事实,正是他们将孟德尔的成果尘封长达40年。
 孟德尔
孟德尔
DNA 双螺旋结构的解析无疑是近代生命科学发展史最重要的一件事。提到这件事,你最先想到的一定是沃森和克里克以及高中生物教材上的那张插图,如果你对生物还有多一点了解,可能会知道和这两个人共同分享诺贝尔奖的还有一位叫威尔金斯的科学家。
 教材配图
教材配图
其实,在这三个男人的背后,还有一位叫做罗莎琳德·富兰克林的女科学家被人们遗忘了。
罗莎琳德·富兰克林使用X射线的方式经过很长时间终于得到了一张极为清晰的 B 型 DNA 照片,并标记为“51号”。作为富兰克林同事的威尔金斯把这一消息告诉沃森后亲自从富兰克林的抽屉里取出这张关键的照片展示给他。另一边,富兰克林则完全不知道自己最珍贵的数据就这样被公开。
更神奇的是,后期在沃森和克里克因为一个关键问题而一筹莫展时,一份富兰克林提交给政府官员的详细工作报告印本又一次为他们提供了灵感。
或许我应该先得到罗莎琳德的许可,但是我没有这样做,”威尔金斯后来对此深感内疚,“那时的情形一言难尽……如果在正常情况下,那么我自然会先征得她的允许,可是即使当时大家相处融洽,她也不会允许别人这样做……虽然我先看到了这张照片,但是相信没有人会忽略其中的螺旋结构。”
1962年,沃森、克里克与威尔金斯凭借他们的发现荣获了诺贝尔奖,而富兰克林在1958年死于卵巢癌广泛转移,当时年仅37岁。
以上,就是如何从四个角度阅读《基因传:众生之源》这本书,我也把这本书推荐给你。
附:基因理论发展历程
 发展历程
发展历程
 发展历程
发展历程
注:文章所有引用均摘录于原书内容。
PHP的依赖管理工具Composer(1) - Chen Yuan's Blog
https://ift.tt/2ObIFFA
无论是在系统中,还是在高级编程语言中,依赖管理工具都扮演着重要的角色,因为它极大地提高了我们的开发效率。
Ubuntu有apt-get,Python有pip,Node.js有npm,PHP呢?
PHP有Composer。 最近一个项目需要,重新拿起PHP来编写程序开发。为了提高开发效率,尝试用Laravel框架进行开发,学一下新东西。近期应该会整理多一些文章。
Composer是 PHP 用来管理依赖(dependency)关系的工具。你可以在自己的项目中声明所依赖的外部工具库(libraries),Composer 会帮你安装这些依赖的库文件。
Laravel框架的功能部分是基于Composer,了解一下Composer对框架的学习与使用有一定的帮助。
总结一下自己使用Composer的过程与查阅的参考资料。
一种工具能解决某些具体的问题的属性。比如尺子能解决测量长度的问题。Composer将这样为你解决问题:
a)问题:你有一个项目依赖于若干个库,其中一些库依赖于其他库。
b)方法:你声明你所依赖的东西。
c)解决:Composer 会根据你的声明,找出哪个版本的包需要安装,并安装它们(将它们下载到你的项目中)。
测试环境:Ubuntu-14.04 + LAMP
全局安装,把composer.phar放在PATH中,这样就可以全局访问它了,在类Unix系统中,在使用时可以不加php前缀。
执行下面两条命令即可:
$ curl -sS https://getcomposer.org/installer | php
$ sudo mv composer.phar /usr/local/bin/composer
查看Composer版本号:
$ composer -V
Composer version 1.1.1 2016-05-17 12:25:44
Composer工具安装完成!
上面提到Composer解决问题的步骤abc,细化这些步骤:
a)问题:你正在创建一个项目,你需要一个库来做日志记录。你决定使用monolog第三方库,将它添加到你的项目中。
$ mkdir MyProject
$ cd MyProject/
b)方法:创建一个 composer.json 文件,其中描述了项目的依赖关系。
$ vim composer.json
{
"require": {
"monolog/monolog": "1.2.*"
}
}
composer.json指出项目需要一些monolog/monolog的包,从 1.2 开始的任何版本。
c)解决:使用composer install命令,解决和下载依赖。
$ composer install
$ ls
composer.json composer.lock vendor
可以看到,MyProject的文件中多了一个文件composer.lock和一个文件夹vendor。composer.lock文件的作用是锁定项目的版本。
vendor文件夹中包含了composer.json中指定的依赖monolog库文件和自动加载这些库文件的自动加载文件。依赖关系解决了,下面来看看具体如何在程序中使用monolog的功能。
在MyProject文件夹下新建app.php文件。里面的代码如下:
<?php
require 'vendor/autoload.php';
$log = new Monolog\Logger('name');
$log->pushHandler(new Monolog\Handler\StreamHandler('app.log', Monolog\Logger::WARNING));
$log->addWarning('Foo');
执行这段代码
$ php app.php
没有报错,产生一个app.log的文件,这样,第三方库引用就成功了。
清空环境,清空杂念——《断舍离》读书笔记
https://ift.tt/2ObrLE4
暗樱花
身边的杂物越多越多,却怎么也丢不掉,“舍不得”、“太可惜”;不断地买新东西,怎么都停不了手,因为“总有一天会用到”,“万一没有呢”;想把屋子收拾干净缺迟迟不行动,因为收拾“很麻烦”、“费时间”;......
说起以上的情景我相信很多人都会和我一样讪讪一笑,这说的不就是我嘛。总是忍不住剁手买东西,买回家也就冲着新鲜劲用两次,之后就再也不会宠幸它。
下定决心整理房间的时候也会因为“以后应该用得上”、“丢了很可惜“之类的理由来安慰自己,然后把这些东西换个地方放,久而久之干净舒适的房间就成为了一个物品泛滥的杂货铺。
断舍离就是通过收拾物品来了解自己,整理自己内心的混沌,让人生更舒适的行为技术。
翻译成人话就是通过收拾家里的破烂,也整理内心中的破烂,让人生变得开心的方法。
断舍离通篇强调要以自己为中心来考虑与物品的关系,不以“丢了很可惜”、“还能用”等为重点,而要以“这东西在当下是否适合自己”来考虑。
通过不断的对物品的断舍离,来实现对自己人生的断舍离,换工作、辞职、搬家、结婚.......
如果只是把不需要的东西扔到储物室或者某个柜子里,那不叫收拾,那只是叫移动,必须切实的做到把东西装进垃圾袋,扔出家门。
我曾经非常热衷于收集电子产品的包装盒,甚至专门准备了一个收纳箱来放这些空盒子,每次整理房间的时候看着那大大的箱子很是无奈,扔了又觉得可惜。
看了断舍离后咬着牙把它们扔了,带来的好处不仅仅是房间变空,也让我对待其他物品的时候能快速的抉择我是否需要。
长此以往就会自然而然的考虑这些东西是不是对自己真的有用,然后做出正确的选择。让你有限的精力更多的关注那些刚需,拒绝非刚需。
说到这里就不得不提前在少数派一个老生常谈的问题,APP泛滥,原本安装APP是想提高效率的我们却被无数的APP所绑架。断舍离的技能在此也是能发挥作用的,对于当下的你没有用的APP,请彻底卸载掉它吧。
推荐两篇相关文章
不做好应用推送管理,你每周可能会收到 700 多条「垃圾」信息
对于下定决心要扔掉的东西,但要在扔之前又心生怜悯“还是别扔了吧,万一啥时候用得上呢。”
因为迷茫,所以总是不能把身边的东西干脆利落的处理掉,身边的东西依然很多,很乱。
但即便如此,也要不断的实施断舍离来克服它。
这样,判断物品是否需要的速度就会越来越快,慢慢地,人就不会再以可惜为借口,把用不着的东西留在身边了。
渐渐地,你对于事情的判断也会越来越快,越来越果断。
作者在文中以两个例子为例,一个是自己的母亲,平时需要蛋黄酱,普通大小的蛋黄酱需要300日元,大号蛋黄酱原价500日元,打折后只需要350日元。
作者母亲和大多数人一样毫不犹豫的选择了大号蛋黄酱,即使吃不完会坏掉。还白白损失了50日元。
另一个则是原本只打算买一件T恤,却看到打折的西装,即使自己不需要,即使它的价格是T恤的5倍以上,但依旧会买下它。
我们总是不知不觉中就一头扎进商家的陷阱,做出这种看着是占便宜其实是吃亏的傻事。
扪心自问,我们很多时候添加一堆其实没啥用的商品到购物车,一看到降价便不考虑后果的买了下来。
很多人包括我父母会为了几年才来一次的亲戚朋友准备餐具、寝具甚至单独的房间,以我家的情况来看,近3年都没有亲戚朋友来我家过夜,几乎就可以认为是闲置占地方的一堆破烂。
为一年一次,甚至几年一次的事情花钱,说到底不过是虚荣罢了。
不喜欢待在家里,也就不会收拾屋子了。这种人都是对家庭有所不满,不愿意待在家里,所以就找各种各样的理由,让自己忙碌起来。再加上家里乱七八糟的,所以就更不想呆在家里了。慢慢地,在这样的恶心循环里越陷越深。
即便是现在已经不会再用的过去的东西,也会非得收着不可。相册、奖杯等等,统统当做命根子似的保管起来。他们多半隐含了对过去幸福时光的留恋。从不面对现实这一层意义上来看,与逃避现实型也有相通之处。
过分的囤积纸巾等日用品,某些东西没有了就回非常困扰、焦躁不安。这类人是最多的。
我是一个典型的担忧未来型,很多东西我都会准备双份甚至三份才会有安全感,虽然在不停的扔东西,但是还是会囤积一些诸如餐巾纸,文具,本子之类的东西。
集中收拾一点,即使只是一个抽屉,不要被收拾房间这几个字吓到,没有必要遵循传统意义的收拾房间就是把整个屋子都打扫一遍。那样太费时间,会极大的打击收拾的热情。
每天收拾一点,一周就能把一个房间收拾完,这样能给自己极大的信心,我也是能做到的。
优先从最影响健康的地方开始收拾,比如冰箱、洗漱台等地方。
一定要扔东西,优先从怎么看都没什么用的东西开始扔,在意的东西留到以后再说;不在意的东西扔的时候不会太犹豫,省时间的同时也在给自己信心,我也是能扔东西的。
当你再次回头看那些已经收拾过的地方的时候,会发现当初犹豫要不要扔的东西现在也能很心平气和的考虑扔掉它了。
对于别人送的很难丢掉的东西在扔的时候说“对不起”和“谢谢”,想想你送别人的东西,很多时候其实你已经忘记了,反之对方送你也是如此。
既然如此,那就抱着感激之情扔掉它吧。
看不见的收纳空间放七成,这样能让人有整理的欲望,如我家塞得满满当当的柜子我都没有打开它的欲望,后来知道真空压缩袋这神器后鼓起勇气给自家的柜子来了一个大扫除,现在每次打开柜子看着里面叠得整整齐齐的衣物,心情都是很愉悦的。
看得见的收纳空间放五成 ,就如同精品店里一样,货架上零零散散放着少量的东西,这样才会显得漂亮。
展示给别人看的收纳空间,这种收纳空间放一成即可。
这些所有的原则都要遵循一个大原则,那就是物品的总数量不变
当你使用贵重的物品的时候总会觉得很别扭,“万一坏了怎么办”、“给我这种人用是不是太浪费了?”
当你有这种念头的时候就说明这东西超过你的自我形象了,不过人类是很容易调节适应的,当你习惯了以后,潜意识里的自我形象也就跟着提高了。
一切有形的东西都是虚幻的,我们的心也是不断变化的。尽情的享受与物品难能可贵的短暂相遇,这一切就是我们所追求的幸福本身。当缘尽了,就潇洒的放手。不仅是对物品,对一切的一切都能做到这样,这就是断舍离的愿望。
物品要用才有价值。物品在此时、当下,应当出现在需要它的地方。
其实很早以前就听说过断舍离这个词语了,不过真正系统的通读全文也就是7月12号而已,读完第二天就看到少数派的征文活动了。
这也是我第一次使用Markdown格式写文章,一边写一边查询少数派文章和百度也是很开心。很感谢这篇文章,全程都在反复的看它。
已经很久很久没有这么认真的对待一件事情了,上一次这么认真是什么时候呢,应该还是在读书的时候吧。
这也是我少数派的第一篇文章,谢谢你能看到这里。Thanks♪(・ω・)ノ
Belpahar English Medium School - Wikipedia
https://ift.tt/2zsZnYO
| Belpahar English Medium School(BEMS) | |
|---|---|
| Location | |
|
Belpahar, Jharsuguda, Odisha Odisha, 768218 India |
|
| Information | |
| Type | Primary, Middle, Higher, 10+2 |
| Motto | Labour to Learn and Lead with Love |
| Established | 1968 |
| Status | Running |
| School district | Jharsuguda |
| School code | OR038 |
| Principal | Mrs. Rama Karthik |
| Staff | 55 |
| Gender | Both Male and Female |
| Number of students | 1325 |
| Classes | Class I to Class XII |
| Campus | TRL Krosaki Township, Belpahar |
| Houses | Gandhi, Radhakrishnan, Tagore, Tata |
| Affiliation | CISCE |
Belpahar English Medium School (School Code OR038) is a co-educational Higher Secondary School (HSC) of Belpahar region in Odisha affiliated to CISCECouncil for the Indian School Certificate Examinations, New Delhi for ICSE (Class X) and ISC (Class XII).[1] As of 2016, BEMS is headed by Mrs. Rama Karthik, principal, who currently holds the post of the vice president of both Orissa Associations of ICSE Schools (OAICSE) and All India Associations of ICSE Schools (ASISC).
The school started as a kindergarten School in the year 1968 by The Hand Maids of Mary, Sundergarh with the objective of offering primary education to the children of the officers of Tata Refractories Limited, now known as TRL Krosaki Refractories Limited. In 1977, it was taken over by the company. As of 2016 this school is under the aegis of Belpahar Educational Society (BEST).
The students of the school wear uniform. White half sleeved shirt, house T-Shirt, belt, school tie, white socks, white canvas shoes, navy blue socks and navy blue blazer for winter are common for all classes. Boys of Classes I to V must have white shorts, steel grey shorts, black laced boots, while those from Classes VI to XII must wear white trousers, steel grey trousers, black laced boots.
Girls irrespective of their classes must wear white knee length box pleaded skirts, steel grey neck pinafore, navy blue and white winter stockings and black buckled shoes.
Students after their admissions are horizontally divided into houses. The four houses are Gandhi with red colour, Radhakrishnan with green colour, Tagore with yellow colour and Tata with blue colour. These houses are named after great Indian leaders - Gandhi standing for Mohandas Karamchand Gandhi, Radhakrishnan for Dr. Sarvepalli Radhakrishnan, Tagore for Rabindranath Tagore and Tata for J. R. D. Tata.
The school is represented every year in various district, state and national level competitions. It also holds competitive examinations like Talent Search Competition (TSE), National Olympiads and quizzes headed by the principal of the school. It has also got awards for doing well in NCC, tennikoit, football, cricket, badminton, chess and kick boxing.[citation needed] Sambalpur NCC Group secured an overall first position in the Odisha directorate inter-group competition for boys at Thal Sainik Camp (TSC) in Puri. Cadets from the school performed well in both senior and junior categories. The cadets were selected in the Odisha Directed team.[2] The school also represented the BOURNVITA Quiz competition. Chiranjibi Pradhan and Vedaansh Pradhan became the champions of TCS IT Wiz, Bhubaneshwar in 2018.
姜鸣: 李鸿章最后岁月的新考证
https://ift.tt/2NpezxI
我曾经有个误解,认为李鸿章去世的地点是在北京贤良寺。这个说法,最初是读大学时从梁启超所著传记《李鸿章》一书中看来的。贤良寺位于东城的核心地段,北面是金鱼胡同,西面是校尉胡同,与王府井大街仅隔着东安市场。清末,贤良寺西跨院对外出租,类似高级招待所,进京觐见的大员清晨从东华门入宫,这里是个便捷的居停之处。李鸿章到京出差办事都借寓此处。
出发去议和谈判") 李鸿章(从贤良寺)出发去议和谈判
李鸿章(从贤良寺)出发去议和谈判
三十年前,1988年,我到贤良寺去踏访,当时住在西跨院的八旬老人王懋章先生,也说李鸿章死在这个院子。他说他父亲1916年就搬进西跨院住了,对院子的前后变迁和掌故极为熟悉。1990年,我写了《踏访贤良寺》,发表在《解放日报》的“朝花”副刊上。后来扩充、修订成《半生名节:贤良寺・李鸿章》,都介绍了这个观点。
 李鸿章在贤良寺西院内与随从及俄军军官合影
李鸿章在贤良寺西院内与随从及俄军军官合影
加深我对于李鸿章住在贤良寺印象的,是曾国藩孙女婿吴永的晚年回忆《庚子西狩丛谈》。吴永用了很多生动笔墨,描绘李鸿章1895年签订《马关条约》之后,被免去直隶总督、北洋大臣的职务,挂着大学士和总理衙门大臣的头衔,在北京工作和生活。“久居散地,终岁僦居贤良寺。”他描述说:
公每日起居饮食,均有常度。早间六七钟起,稍进餐点,即检阅公事;或随意看《通鉴》数页,临王圣教一纸。午间饭量颇佳,饭后更进浓粥一碗,鸡汁一杯。少停,更服铁水一盅,即脱去长袍,短衣负手,出廊下散步,非严寒冰雪,不御长衣。予即于屋内伺之,看其沿廊下从彼端至此端,往复约数十次。一家人伺门外,大声报曰:“够矣!”即牵帘而入,瞑坐皮椅上,更进铁酒一盅。一侍者为之扑捏两腿;良久,始徐徐启目曰:“请君自便,予将就息矣,然且勿去。”时幕中尚有于公式枚等数人,予乃就往坐谈。约一二钟,侍者报中堂已起,予等乃复入室;稍谈数语,晚餐已具。晚间进食已少。饭罢后,予即乘间退出,公亦不复相留,稍稍看书作信,随即就寝。凡历数十百日,皆一无更变。
吴永虽然没说李鸿章死于贤良寺,但他对李鸿章在贤良寺居住时栩栩如生的细节描绘,给我带来联想上的误导,一些李鸿章传记的作者恐怕也是如此。一直记得拜访王懋章先生的那个夜晚,我站在西跨院,想象着李鸿章背负双手,在屋檐下从东厢房到西厢房之间往复散步的情景。西跨院一年之后拆除了,空地上盖起了校尉小学,我多次拍过照,收录在《天公不语对枯棋》一书中。
此外,李鸿章的老部下,四川总督刘秉璋之子刘体信在《苌楚斋三笔》中也记录:
光绪庚辛之间,合肥李文忠公鸿章以议和居京,气体已衰,而饮啖甚豪。其家中虑其食多,恒量为裁制,文忠转不悦,常因食多致疾。西医属其不必多食,不听,属其不必食某物,亦不听。又属其万不可食糯米物,本日即饱食,次日仍自告西医。时合肥郑魁士总戎国俊亦在京,时至贤良寺行馆,文忠尝属其私购食物,藏于袖管带来。每总戎来见,文忠必尽逐诸客,幕客多戏谓之袖筒相会。……病故之前十日,因食多,致疾甚厉。西医因屡进忠言不听,直告之曰:“中堂再如是乱吃,必须死矣。”文忠不听而去,语人曰:“西医之言何戆也。”又逾七日,西医已谓万不能治。文忠之如夫人莫氏,即季皋侍郎经迈之生母,犹日求单方服之,未二日即病故。
最近,我阅读张佩纶家藏信札,却发现这些颇有背景的作者多年之后的回忆,远不如李鸿章去世前后当事人所写的信件来得准切。最近首次披露的张佩纶致侄子张人骏(时任山东巡抚)函,十分明确地地指出:李鸿章“殁于总部第中,盖七月病后销假,亦眠食需人,不能回贤良寺矣”。所谓“总部第”,即现在西总布胡同的宅第。
 张佩纶致张人骏亲笔信
张佩纶致张人骏亲笔信
这带来了新结论。
总部胡同,因明朝的总捕衙门设在此地而称作总捕胡同。乾隆年间改作总部胡同,至清末改称总布胡同,且以朝阳门内南小街为界,分称东、西总布胡同。
再查史料,光绪二十四年九月初二日(1898年10月16日)李鸿章致李经方函,落款处即写“仪翁书于总布胡同寓”。说明早在戊戌年间李鸿章即已入住,并非一直住在贤良寺的。光绪二十五年四月十二日致李经方函,又作“仪翁书于总布胡同寓斋”。同年十一月二十六日,他约德国驻华公使克林德二十八日上午“惠临贤良寺敝寓面谈一切。”接着,李鸿章出任两广总督,离京南下广州。北京爆发义和团事变和八国联军的进攻。
闰八月十八日(1900年10月11日),李鸿章以议和全权大臣的身份,在俄国军队护送下,从天津重返满目疮痍的北京,住在贤良寺,也在这里接待访客。联军宣布,在北京城被占领的情况下,另一位议和大臣庆亲王奕�的住地和贤良寺,为联军仅承认的“清国政府管辖的两个小院”。九月初六日,女儿鞠耦给他写信,信封地址是“速寄都城贤良寺”。以后家信,也都寄往贤良寺。
我所见到写有贤良寺的最后一个信封,是光绪二十七年八月十三日。九月十八日张佩纶致李鸿章家信,出现了“都城总部胡同”地址。这个实寄封,与他致张人骏信件的内容,可以相互印证,说明两处居所,李鸿章都在使用。从某种程度上是否可以说,贤良寺更像是李的行辕,既具有办公见客的功能,又可以住宿,而为世人熟悉。总布胡同则是私宅,李鸿章生命的最后岁月,按照传统习惯,应当在家中寿终正寝,所以病重之后,他转回到总布胡同了。
 张佩纶寄李鸿章,分别写有贤良寺和总部胡同地址的实寄封
张佩纶寄李鸿章,分别写有贤良寺和总部胡同地址的实寄封
我们知道,《辛丑条约》是**近代史上空前屈辱、赔款最大的一个不平等条约,庆亲王奕�和李鸿章作为全权大臣,代表清政府在条约上签字,李鸿章为此背负卖国贼的恶名。其实,《辛丑条约》源于八国联军占领北京,慈禧、光绪两宫逃亡,**面临被占领和瓜分的民族危机。八国联军入京,源于义和团攻打使馆,各地滥杀教民,清政府还向西方各国宣战。义和团源于山东教案引起的瓜分危机,和戊戌变法失败后洋人同情光绪皇帝,引起慈禧太后的怨恨。而戊戌变法,源于甲午战争失败后社会各阶层力图改革振兴改革的努力。这是一场绵延半个世纪的历史变迁,**第一次现代化进程失败后所面临的深刻危机,以一种扭曲和愚昧排外的形式表现出来。
对于现代化进程失败,李鸿章当然有不可逃避的历史责任。李鸿章很早认识到中西方的实力差距,主张学习西方先进军事装备和技术,但在每一场对外危机来临之时,他又认为既然打不过列强,就要避免决战,主张妥协。第一次现代化失败的转折点,是**军队在甲午战争中的全军覆没,其中重要原因,是与贪腐、军事技能低劣和望风而逃、毫无必胜的信念直接相连。李鸿章后来在贤良寺里对吴永说,我办了一辈子的事,练兵也,海军也,都是纸糊的老虎,何尝能实在放手办理?不过勉强涂饰,虚有其表,不揭破犹可敷衍一时。如一间破屋,由裱糊匠东补西贴,居然成一净室。乃必欲爽手扯破,自然真相破露,不可收拾,但裱糊匠有何术能负其责?这是自我开脱,作为洋务运动的最高负责人,花费了巨大的国帑资源后,怎么能用一句轻飘飘的“裱糊匠”,就把自己的历史责任开脱掉呢?
但就事论事地说,李鸿章庚子年奉诏入京,是为了解决当时最严重的国家困境,通过谈判和妥协,让两宫平安回京,恢复主权和秩序。此时,清政府极度虚弱、首都被敌占领,从高级官员到普通百姓毫无颜面,军队也不具备抵抗的斗志。从下图李鸿章衣衫褴褛的轿夫随从,即可透射出大清帝国奄奄一息的惨状。
 李鸿章从贤良寺乘轿出发,去进行议和谈判
李鸿章从贤良寺乘轿出发,去进行议和谈判
梁启超在《李鸿章传》中曾经设想:
当是时,为李鸿章计者曰,拥两广自立,为亚细亚洲开一新政体,上也;督兵北上,勤王剿拳,以谢万国,中也;受命入京,投身虎口,行将为顽固党所甘心,下也。虽然第一义者,惟有非常之学识,非常之气魄,乃能行之,李鸿章非其人也。彼当四十年前方壮之时,尚不敢有破格之举,况八十老翁安能语此?故为此言者,非能知李鸿章之为人也。第二义近似矣,然其时广东实无一兵可用,且此举亦涉嫌疑,万一廷臣与李不相能者,加以称兵犯厥之名,是骑虎而不能下也,李之衰甚矣!方日思苟且迁就,以保全身名,斯亦非其所能及也。虽然,彼固曾熟审于第三义,而有以自择。
从后来披露的史料看,英国驻香港总督卜力曾经谋划过“两广独立”,拥李鸿章为王或总统,联络流亡日本的孙中山来施行新政。孙中山在日本友人宫崎寅藏的陪同下已经乘船到达香港外海,但李鸿章最终选择第三策,北上与各国谈判和约。这是一项极为艰难的使命。
但在当时特定的环境下,却得到朝野的普遍赞扬,与后来史书中千夫所指的气氛完全不同。时人说他“晚年因中日一役,未免为舆论所集矢,然自此番再起,全国人士皆知扶危定倾,拯此大难,毕竟非公莫属,渐觉誉多而毁少,黄花晚节,重见芬香,此亦公之返照也。” 梁启超也说,“天下唯庸人无咎无誉”,他对李鸿章,总体上说佩服的,而非简单地斥之“卖国”。
 庆亲王奕�和李鸿章在签署《辛丑条约》时与各国公使合影
庆亲王奕�和李鸿章在签署《辛丑条约》时与各国公使合影
前些年有部流行的电视剧,说在《辛丑条约》签字时,庆亲王奕�踌躇不定,手一直发抖,几次拿笔又放下。李鸿章对庆王说的“人最难写的就是自己的名字,签在这卖国条约上,就是千古骂名,王爷还年轻,路还长着呢,还是由我来吧”。这显然是令人惊讶的胡编乱造。若无流亡西安的清政府批准,若无首席全权王大臣签字,列强能够承认条约的合法性吗?
在京期间,李鸿章承担巨大压力与列强周旋谈判,筋疲力尽、身心憔悴,最后抑郁而亡。若说他私下还有什么个人快感,恐怕是借洋人之口,迫使朝廷诛杀和放逐了官场中几个最顽固保守、盲目排外的政治对手,同时保全慈禧太后本人不被追究。他是老谋深算的政治家,岂会主动代庆王背锅,去独自签订什么“卖国条约”?
关于李鸿章临终的情形,在前述张佩纶致张人骏的信中透露了重要信息:
傅相八月初赏假,老怀甚喜。至廿日假满,仍是委顿。闺人(即张佩纶夫人李经�)电请续假而傅相不许,然久坐即腰酸,动即遗矢满�,心以为危。销假后,尚是季皋(李经迈)之生母(即李鸿章妾莫氏)与长孙国杰分班守下半夜。庆邸赴豫,行留部分,未免过劳。兼之俄约棘手,心中更多郁闷。十九夜陡然吐血,洋医以为胃血,吾谓直是肝郁所致耳,痛哉痛哉!
此前,七月二十三日,李鸿章已患感冒,鼻塞声重,精神困倦。但由于二十五日(1901年9月7日)为签订和约的日子,他还是抱病前往西班牙公使馆画押,回来后病情加重,寒热间作,痰咳不止,饮食不进,心中满是悲愤和无奈。八月一日,慈禧太后懿旨赏假二十天。在此期间,八国联军开始从北京撤退,太后、光绪两宫从西安准备回京,李鸿章和庆王继续就相关事项与外国公使洽谈。二十一日,李鸿章电奏:“静养两旬,诸病痊愈,惟身体软弱,腰腿酸痛,尚可力疾从公,应请销假。” 二十九日,庆亲王奉旨前往河南迎銮,北京的局面和剩下的交涉就交李鸿章一人承担。
这一时期,李与俄国谈判俄军从东北撤退极不顺利,俄国人还增加了要求中方向华俄道胜银行转让路矿权益的内容。他的健康继续恶化。用张佩纶的话,久坐腰酸,稍动则大便失禁。这样的衰弱状态下,九月十九日仍去俄国使馆谈判和争吵,回来后呕血一碗,医生说是胃血管破裂,必须静养,只能服食鸡汤、牛奶、参汤等流汁。李的病症加剧,绝非刘体信所述“贪食”引起。
此后还有随员记录,说他语多舌强,所论皆公事时事,心神似觉恍惚。但在对俄交涉上,始终没有退让。吴汝纶说:“傅相遍体皆老,独脑气不老。此公关国休戚,祝其长生者。殆遍天下也。”二十五日,李鸿章之子经述、经迈致电盛宣怀,说父亲以庆王不在,恐怕事情延搁,总是不尊医嘱,起床办事,而身体难以支撑。请他密电枢府,将病情如实报告以争取假期休息。“中外以此老为孤注,亦宜加以护惜,留以有待。”
也在这个时候,盛宣怀忙不迭地为太后回銮的专车采购各色器物和食品。本来下令向洋人宣战,又被洋人打得逃往太原、西安的太后,现在乘坐的御用火车车厢里,要配置镀金钢丝外国铜床,御床用洋绸枕头,红外国缎黑缎镶褥。黄、红绒背垫外国单靠椅,大餐陈设用五色玻璃插花大花瓶,镀银西式刀叉,高脚玻璃酒杯,细洋瓷咖啡具,甚至还有进口葡萄酒、咖啡、外国辣子、外国酱油,香水、牙刷和肥皂盒。
李鸿章于九月二十七日(1901年11月7日)上午11时去世。西医说他违背医嘱坐起来工作,所以身体迅速恶化。“出血已经基本得到控制。”美国医生满乐道说,“慢性胃炎和持续恶心造成的情况,病人只能服用最温和的流质食物。昨天李鸿章很愉快且不再疼痛,但今天早上2点他失去意识,并且不再能够吐痰。”留京办事大臣那桐则记录,他在二十六日已经觉得李鸿章危在旦夕,遂致电行在军机处,请朝廷预备重臣接替李鸿章;给庆王发电,向他通报情况;又给布政使周馥发电,要他迅速来京照料。
老部下周馥赶到时,李鸿章已身着殓衣,处于呼之能应口不能语的状态。延至次日中午,目犹瞠视不瞑。周馥哭号着说:
老夫子有何心思放不下,不忍去耶?公所经手未了事,我辈可以办了,请放心去吧!
李鸿章忽然目张口动,欲语泪流。周馥一面哭号,一面用手抚其眼睑,李鸿章的双眼方才合上,须臾气绝。(见《周馥自定年谱》)他的遗诗吟到:
劳劳车马未离鞍,临事方知一死难。
三百年来伤国步,八千里外吊民残。
秋风宝剑孤臣泪,落日旌旗大将坛。
海外尘氛犹未息,请君莫作等闲看。
李鸿章死了,次日,上海《申报》在第二版上发出一条简讯:
昨日午后四下钟越三十分时,京师飞传专电到来,译悉:本日午刻,李傅相开缺。因患呕血。电文甚简,余未及详。(见《译电传合肥傅相开缺事》,《申报》,1901年11月8日)
万里之外,《纽约时报》的消息则详细得多:
北京11月7日消息。李鸿章今天上午11时去世。他的身体状况从昨天(周三)上午开始恶化。
美国记者的报道还写道:
前一天晚上9时,李鸿章已经穿上了寿衣。衙门的院子里放满了实物大小的纸马纸椅、纸扎的苦力挑夫,这些是李的朋友赠送的。根据**风俗,纸人纸马将被焚烧,以随他的灵魂去天堂。
李鸿章去世时,他的夫人和两个儿子以及女儿和他在一起。
衙门挤满了**官员。召唤庆亲王的电报已经发出,他现在正在觐见朝廷的路上。庆亲王被认为将总体负责政府事务。电报还自保定府召唤布政使周馥前来,他将在李的继任者被任命之前护理直隶总督,继任者可能是袁世凯。
**官员有些难以料想李鸿章去世对大众的影响。为防止潜在的反对外国人的示威,**将军们已在城里布置军队以控制局面。不过出现问题的可能性非常小。
 外国公使吊唁李鸿章
外国公使吊唁李鸿章
还有外国画报配上插图,并对驻京外国公使的吊唁做了介绍:
外交团在李鸿章去世后第三天拜访李鸿章的家人并表示哀悼。他们受到了北京高级官员的接待。外交团首席,奥地利公使齐干作为发言人向死者的儿子作了简短致辞。李的两个儿子穿着白色的丧服,戴着模样古怪、似乎是用玉米杆编成的皇冠式帽子。在死者遗体供人瞻仰期间,房屋前搭了一座亭阁,亭阁**有个祭坛,上面有个香炉用来盛放香灰。祭坛脚下堆着供品,背后有一块碑,记载着死者的荣誉和美德。吊唁结束时,公使们来到祭坛前逐一鞠躬。
二十七日这天,慈禧、光绪两宫从河南汜水启銮,下午到达开封府荥阳县。这时接到电报,获悉李鸿章于午刻逝世。随行的吴永写道:“闻两宫并震悼失次;随扈人员,乃至宫监卫士,无不相顾错愕,如梁倾栋折、骤失倚侍者。”随即公布上谕,赐谥号文忠,追赠太傅,晋封一等侯爵,入祀贤良祠。后来还追加了多项恩赐,其中有一项,是在他立功省份,建立专祠,进行纪念。可见在当时,享受到极高规格的哀荣。
关于李鸿章临终前的两个住地的细微之别,目前除张佩纶、李鸿章的信件提到之外,我们所知甚少。外国公使吊唁的灵堂,《纽约时报》称作“李鸿章最后的衙门”(the late Li-Hung-Chang's yamen),估计是在贤良寺。其实这两处地方距离甚近,沿贤良寺正门所在的煤渣胡同东行至西单北大街,路对面就是东堂子胡同,总理衙门设在这里。向南折拐,是石大人胡同(今外交部街),再往南,就是西总布胡同。八国联军攻打北京的重要导火线,德国公使克林德(Baron Clemens Ketteler)是在胡同口被神机营章京恩海击毙的。《辛丑条约》第一款,就是在此建一座纪念牌坊。第一次世界大战德国战败后,牌坊被拆迁到中山公园。
 贤良寺和总布胡同示意图
贤良寺和总布胡同示意图
由于后来李鸿章祠堂设在西总布胡同27号,我们由此确定这座宅第的确切地址。至于产权是租赁还是自购,目前还见到光绪二十六年正月二十九日李鸿章致盛宣怀电报中提及:“总布胡同住宅既有成说,务勿为浮言所惑。”这个新课题的诸多细节,尚待继续考证。
据记载 李鸿章祠堂旧时门牌15号,在西总布胡同中段北侧,坐北朝南,后墙至外交部街南侧。祠堂名“表忠祠”,光绪二十八年(1902年)由李鸿章寓所改建而成。祠堂长144米,宽58米,占地面积八千多平方米。主体建筑为大门、仪门、前殿、享堂及东西配殿、碑亭等建筑构成的二进四合院,主要建筑顶部均覆黑琉璃瓦。享堂三楹,为歇山顶斗拱式样,前有月台三出陛。院墙砖砌,外抹红垩土,顶部覆灰色筒瓦,显然是在民居基础上做了改造,以符合祠堂的规范。
刘秉璋的另一位儿子刘体智说,慈禧太后本来想让李鸿章配享太庙,被军机大臣鹿传霖的一句话搅黄了。当时鹿传麟65岁,拙于言论,耳已重听,但在关键场合、关键岗位,“为福不足,为害有余。”当时枢臣代拟懿旨,鹿传麟突然问道:“祀于何处?”即跟在哪位先帝的排位之后?各位同僚便掐指盘算:若配享文宗,则咸丰朝时李鸿章刚刚入仕,未立功勋;配享穆宗,则同治朝中兴勋业,不乏其人,未可显分厚薄;至于当下,光绪帝活得好好的,更不可行。这样便觉得懿旨难于措词。事情就搁置下来。
配享未成,便建祠堂。李鸿章有多个祠堂,按照以往“立功”的省份,分别设在上海、天津、保定、南京等地。北京则显得特别,大官们都在这里上班,谁有特别的功劳呢?然而李鸿章可以,他凭着庚子议和,成为清代唯一在京师建立专祠的汉人官吏。
 李鸿章祠堂落成后迎神牌进入
李鸿章祠堂落成后迎神牌进入
1949年以后,李鸿章祠堂被改为北京市第一人民文化馆分馆、东单区文化馆、东城区文化馆。1978年拆除前院建筑及大门,建成两层的东城区文化办公室的办公楼。1991年拆除后院享堂、配殿,建成四层楼房,东城区档案局和档案馆迁入,大门改向北开,门牌为外交部街甲28号。整个李鸿章祠堂,目前仅剩余一段红色的院墙。
 目前李鸿章祠堂仅剩的一段红色围墙
目前李鸿章祠堂仅剩的一段红色围墙
踏人字拖去小吃摊,穿西装去牛排馆。用合适的方法读适合的书 ——《越读者》读书笔记
https://ift.tt/2KLCvWV
BravoCiao
本文是「少数派读书笔记征文活动」的第 4 篇入围作品。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。
《越读者》是一本有关阅读的文章集,作者是在**从事出版工作的韩裔华侨郝明义。书籍的英文名叫 《Reading in the Internet Age》,可见讨论范围并不限于纸质印刷物的阅读,内容涵盖了网络、科技带给我们的全新阅读体验和操作可能。阅读这件事,也不狭隘地单指「消化文字」,对网络时代,其他种信息传递方式的思考,是这本书独特的关照。
全书囊括了**应试教育对阅读兴趣的伤害及后坐力,对小说、诗歌、哲学甚至漫画等不同类型书籍的思考,网络带来的机遇,阅读的方法、工具和理念等等。文中不乏有洞见的金句和实用数据库清单,可那不是读书笔记需要罗列的。我试图整理出一套人人可上手的阅读流程,以求对大多数人有助益,但各人关注点不一,有兴趣的读者可自行阅读原书。
 越读者
越读者
牛津词典对文盲(Illiteracy)的解释是:The inability to read or write,根据韦氏大辞典(Marriam-Webster)网站,Illiteracy 最早出现于 1660 年,那时连第一次工业革命都没发生。
在科技发展如此迅猛的时代,2016 年 AlphaGo 打败李世石的新闻读起来都如同上个世纪般怀旧。
随着教育水平的普遍提高、新增知识量大爆炸、能说至少一门外语的人数不断增加,我们也应该自问,自己的信息处理能力是不是跟得上这个时代的要求:善用搜索引擎和庞大的网络资源吗?用一种以上的语言搜索资料吗?信息源够优质吗?读书有没有用对方法?
谨慎:是不是一不留神,成了个现代文盲。
我是一位文字与书籍爱好者,也在家庭与社会的影响下,在很长的一段时间里,认为文字比别种媒介更优越、承载了更多的真知灼见,但《越读者》里的一句话点醒了我:
书籍出现的好处是,把文字的传播力量做到最大化的扩散;坏处是,我们容易疏忽,甚至贬低书籍以外的知识来源。
用合适的媒介传播适合的信息,用合适的方法吸收适合的内容,这就是我读完这本书最大的收获。
文字自有其优点:是单位面积里信息浓缩度最高的媒介,又能够根据关键词快速搜索定位。
但也有其局限:需要展示操作流程、科技、生物相关的信息时,用文字会过分啰嗦,例如:心脏解剖图用文字描述自然不如图片一目了然。更重要的是,抑制了我们对其他感官的开发和重视。
文字本不天然处于上位。如果我们把文字、书籍放置于历史的长河中检阅,会发现文字的发明使用只有五千多年,人类拥有纸张,是距今大约两千年的事;有印刷术,**大约一千三百年,西方大约五百年。而在中文世界,我们以常见的书籍形式来阅读,不过一百多年的事情。和人类四百万年的进化史比起来,实在是简短一瞬。
人类对世界的观察并不是从文字开始,而是经历了图像、肢体、音乐、口语再落到文字这样的转变,文字书并不是一开始就成为社会中有为人士的标配。

郝明义把不同书籍比作四种食物:主食、美食、蔬果和甜食。
 主食 & 美食
主食 & 美食 蔬果 & 甜食
蔬果 & 甜食
给我最大启发的,倒是对甜食阅读的评述,如果一味禁止接触甜食,一来容易形成压抑过度后的反弹,嗜甜耽误吃正餐,二来也锻炼不出品鉴高质量甜点的舌头和味蕾。
阅读食物有四种,可按照划分标准放进不同盘子。
如果我们用理财类比阅读,能赋予阅读食物储蓄/消费的性质,储蓄类阅读包括主食、美食和蔬果,甜食阅读属于消费,应时时保证收支平衡。
 灵魂小猪
灵魂小猪
阅读时间也如同账户里的零钱 & 整款,现代社会的节奏越来越快,似乎我们只剩下零碎时间吸收知识,较轻松的主食、蔬果和甜食或许可以见缝插针消化完,可不受打扰的整块时间才能让我们有足够铺垫,进入深度工作状态咀嚼难啃的美食类资料。
 零钱 & 整款
零钱 & 整款
由于作者郝明义是出版界人士,平常没有太多时间阅读工作以外的书籍。他的方法是,四五点早起后的三小时,拿整块时间进行自己感兴趣的阅读,在此期间不受干扰。
有如此多事情抢夺我们注意力的时代,做到这一点显得越来越难也越来越有必要了。
搭配这四类食物,四位伟大的历史人物教会我们这些食用姿势:
 不求甚解、观其大略
不求甚解、观其大略 熟读精思、八面受敌
熟读精思、八面受敌
应对不同书、甚至不同书里的不同章节,要根据情况,混合使用前三种技法,举个例子:
面对某畅销书,作者介绍的部分,「观其大略」看看大学主修专业、过往工作背景这些重要信息,其余信息跳过;书里讲述的一个原理搭配了 A、B、C、D 四个例子,选择最感兴趣的一个「熟读精思」,其余「不求甚解」即可。
「八面受敌」是最厉害的武功招式,通常被拿来做主题阅读,或处理讨论了许多复杂问题、深奥难懂的书。并不是每一本书的每一个部分都是我们当前迫切需要的,它要求你破除「书必须被整本阅读完」的迷思,把书和资料打碎成片段,心中带着问题去找资料。当你对某一个主题抱有强烈好奇心,这套「批量处理」的方法是最有效的。
开出了第一条路,自己的专门阅读兴趣才算是可进可退,在开出第一条路之前,「博」,可能只是散漫;「专」,可能只是狭隘。
最理想的阅读路径是由泛读到选定一个专精的门类,再由这条专精的小道通往广阔的知识森林。由一门专门学问 → 直接相关学科 → 间接相关学科 → 不很相关学科 → 毫不相关的各科泛览。
理财高手们都是在攒到了第一桶金之后,才手握了让钱滚钱的入场券,读书也是如此,没有攒到第一张入场券的人,还没有资格说自己是在探索深邃的知识密林。
一开始的泛读是为了让人尽可能多地接触到不同知识门类、开眼界,领略到知识之海的广阔瑰丽,再选择一门专精、变为大学的专业,投入大量精力。
 理想的阅读路径
理想的阅读路径
可先行教育制度或许没办法让广大中学生有时间、机会自主探索,应试教育让人厌倦了被限定的阅读,到大学有了自由就容易演变成这样。
 大多数人的阅读路径
大多数人的阅读路径
我在来到英国上学之前,经历了一段 Gap,拿这个时间进行泛读,小说、诗歌、历史、管理、心理学等等各读了一点,来了英国之后就要开始面对繁重的专业阅读,如果想取得还不错的成绩,就要投入大量心力和时间,泛读的自由度不免下降。另外,在英国转专业也没那么容易,国内估计更是困难,如果一开始没有想清楚就选了专业,喜欢还好,不喜欢就难免要面对:「不喜欢我的专业,没热情念好书,但转系好难,即使不喜欢还要顾及 GPA。」这样的矛盾心态了。无法撼动体制还是早做打算吧。
 我的阅读路径
我的阅读路径
根据我自己的理解、整合,进行了如下汇总:
看完一本书后问自己这些问题:
另外提一些实用方法,都是阅读时实操性强、好上手的行动指南。
每个人可以有自己的标记方式,但是这个方式要能成体系、一以贯之。下面是书中的举例:
!:书中对自己有启发的地方口:需要后续追踪的地方?:看不明白、标记一下供日后回顾X:不同意作者观点的地方搭配如今的电子设备,传播和吸收信息这件事已经呈现出了更多元的生态,例如有用小动画讲解历史和金融知识的 YouTuber、少数派用视频演示 App 操作方式。未来文字不会再一家独大,被长久忽略的其他感官会逐渐复苏。
但就像 1545 年,德国铁匠古腾堡为欧洲带来了活字印刷,印刷书籍仍然花了 100 年才取代了手抄书。多媒体阅读的普及如今还面临技术、支付手段和阅读惯性的重重障碍,书籍在很长一段时间里,仍会是传播知识的重要载体,学会正确阅读文字书是不会亏的技能投资。
注:图标来自 Noun Project
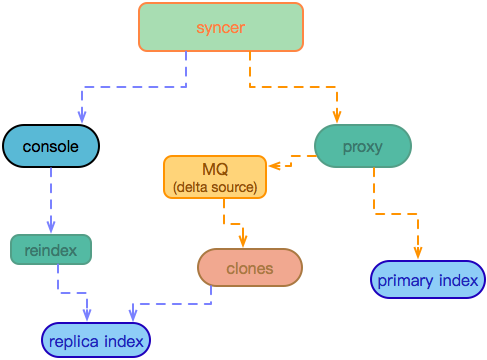
有赞搜索系统的架构演进
https://ift.tt/2zs8eKm
hehua
有赞搜索平台是一个面向公司内部各项搜索应用以及部分 NoSQL 存储应用的 PaaS 产品,帮助应用合理高效的支持检索和多维过滤功能,有赞搜索平台目前支持了大大小小一百多个检索业务,服务于近百亿数据。
在为传统的搜索应用提供高级检索和大数据交互能力的同时,有赞搜索平台还需要为其他比如商品管理、订单检索、粉丝筛选等海量数据过滤提供支持,从工程的角度看,如何扩展平台以支持多样的检索需求是一个巨大的挑战。
我是有赞搜索团队的第一位员工,也有幸负责设计开发了有赞搜索平台到目前为止的大部分功能特性,我们搜索团队目前主要负责平台的性能、可扩展性和可靠性方面的问题,并尽可能降低平台的运维成本以及业务的开发成本。
Elasticsearch 是一个高可用分布式搜索引擎,一方面技术相对成熟稳定,另一方面社区也比较活跃,因此我们在搭建搜索系统过程中也是选择了 Elasticsearch 作为我们的基础引擎。
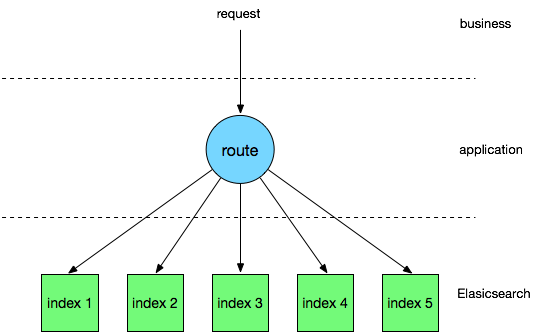
时间回到 2015 年,彼时运行在生产环境的有赞搜索系统是一个由几台高配虚拟机组成的 Elasticsearch 集群,主要运行商品和粉丝索引,数据通过 Canal 从 DB 同步到 Elasticsearch,大致架构如下:
通过这种方式,在业务量较小时,可以低成本的快速为不同业务索引创建同步应用,适合业务快速发展时期,但相对的每个同步程序都是单体应用,不仅与业务库地址耦合,需要适应业务库快速的变化,如迁库、分库分表等,而且多个 canal 同时订阅同一个库,也会造成数据库性能的下降。 另外 Elasticsearch 集群也没有做物理隔离,有一次促销活动就因为粉丝数据量过于庞大导致 Elasticsearch 进程 heap 内存耗尽而 OOM,使得集群内全部索引都无法正常工作,这给我上了深深的一课。
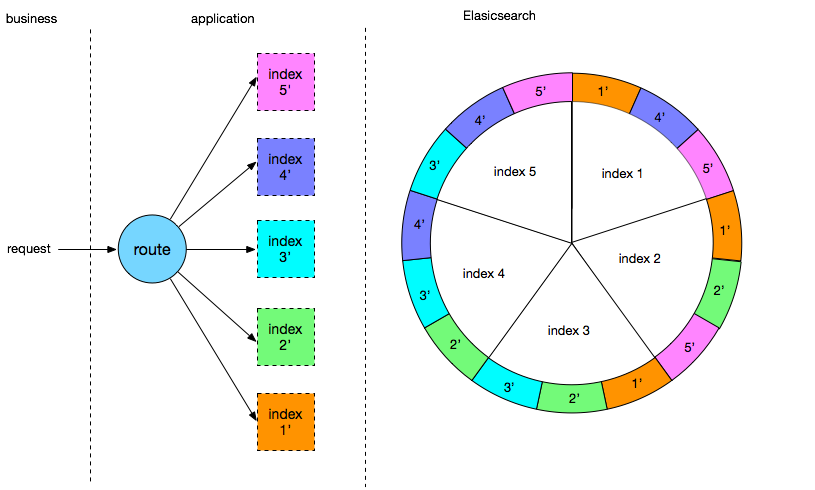
我们在解决以上问题的过程中,也自然的沉淀出了有赞搜索的 2.0 版架构,大致架构如下:
首先数据总线将数据变更消息同步到 mq,同步应用通过消费 mq 消息来同步业务库数据,借数据总线实现与业务库的解耦,引入数据总线也可以避免多个 canal 监听消费同一张表 binlog 的虚耗。
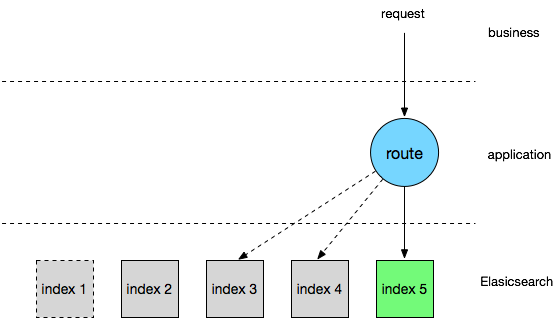
随着业务发展,我们也逐渐出现了一些比较中心化的流量入口,比如分销、精选等,这时普通的 bool 查询并不能满足我们对搜索结果的细粒率排序控制需求,将复杂的 function_score 之类专业性较强的高级查询编写和优化工作交给业务开发负责显然是个不可取的选项,这里我们考虑的是通过一个高级查询中间件拦截业务查询请求,在解析出必要的条件后重新组装为高级查询交给引擎执行,大致架构如下:
这里另外做的一点优化是加入了搜索结果缓存,常规的文本检索查询 match 每次执行都需要实时计算,在实际的应用场景中这并不是必须的,用户在一定时间段内(比如 15 或 30 分钟)通过同样的请求访问到同样的搜索结果是完全可以接受的,在中间件做一次结果缓存可以避免重复查询反复执行的虚耗,同时提升中间件响应速度,对高级搜索比较感兴趣的同学可以阅读另外一篇文章《有赞搜索引擎实践(工程篇)》,这里不再细述。
搜索应用和大数据密不可分,除了通过日志分析来挖掘用户行为的更多价值之外,离线计算排序综合得分也是优化搜索应用体验不可缺少的一环,在 2.0 阶段我们通过开源的 es-hadoop 组件搭建 hive 与 Elasticsearch 之间的交互通道,大致架构如下:
通过 flume 收集搜索日志存储到 hdfs 供后续分析,也可以在通过 hive 分析后导出作为搜索提示词,当然大数据为搜索业务提供的远不止于此,这里只是简单列举了几项功能。
这样的架构支撑了搜索系统一年多的运行,但是也暴露出了许多问题,首当其冲的是越发高昂的维护成本,除去 Elasticsearch 集群维护和索引本身的配置、字段变更,虽然已经通过数据总线与业务库解耦,但是耦合在同步程序中的业务代码依旧为团队带来了极大的维护负担。消息队列虽然一定程序上减轻了我们与业务的耦合,但是带来的消息顺序问题也让不熟悉业务数据状态的我们很难处理。这些问题我总结在之前写过的一篇文章。 除此之外,流经 Elasticsearch 集群的业务流量对我们来说呈半黑盒状态,可以感知,但不可预测,也因此出现过线上集群被内部大流量错误调用压到CPU占满不可服务的故障。
针对 2.0 时代的问题,我们在 3.0 架构中做了一些针对性调整,列举主要的几点:
1. 通过开放接口接收用户调用,与业务代码完全解耦;
2. 增加 proxy 用来对外服务,预处理用户请求并执行必要的流控、缓存等操作;
3. 提供管理平台简化索引变更和集群管理
这样的演变让有赞搜索系统逐渐的平台化,已经初具了一个搜索平台的架构:
作为对外服务的出入口,proxy 除了通过 ESLoader 提供兼容不同版本 Elasticsearch 调用的标准化接口之外,也内嵌了请求校验、缓存、模板查询等功能模块。 请求校验主要是对用户的写入、查询请求进行预处理,如果发现字段不符、类型错误、查询语法错误、疑似慢查询等操作后以 fast fail 的方式拒绝请求或者以较低的流控水平执行,避免无效或低效能操作对整个 Elasticsearch 集群的影响。 缓存和 ESLoader 主要是将原先高级搜索中的通用功能集成进来,使得高级搜索可以专注于搜索自身的查询分析和重写排序功能,更加内聚。我们在缓存上做了一点小小的优化,由于查询结果缓存通常来说带有源文档内容会比较大,为了避免流量高峰频繁访问导致 codis 集群网络拥堵,我们在 proxy 上实现了一个简单的本地缓存,在流量高峰时自动降级。
这里提一下模板查询,在查询结构(DSL)相对固定又比较冗长的情况下,比如商品类目筛选、订单筛选等,可以通过模板查询(search template)来实现,一方面简化业务编排DSL的负担,另一方面还可以通过编辑查询模板 template,利用默认值、可选条件等手段在服务端进行线上查询性能调优。
为了降低日常的索引增删、字段修改、配置同步上的维护成本,我们基于 Django 实现了最初版本的搜索管理平台,主要提供一套索引变更的审批流以及向不同集群同步索引配置的功能,以可视化的方式实现索引元数据的管理,减少我们在平台日常维护上的时间成本。 由于开源 head 插件在效果展示上的不友好,以及暴露了部分粗暴功能:
如图,可以通过点按字段使得索引按指定字段排序展示结果,在早期版本 Elasticsearch 会通过 fielddata 加载需要排序的字段内容,如果字段数据量比较大,很容易导致 heap 内存占满引发 full gc 甚至 OOM,为了避免重复出现此类问题,我们也提供了定制的可视化查询组件以支持用户浏览数据的需求。
由于 es-hadoop 仅能通过控制 map-reduce 个数来调整读写流量,实际上 es-hadoop 是以 Elasticsearch 是否拒绝请求来调整自身行为,对线上工作的集群相当不友好。为了解决这种离线读写流量上的不可控,我们在现有的 DataX 基础上开发了一个 ESWriter 插件,能够实现记录条数或者流量大小的秒级控制。
平台化以及配套的文档体系完善降低了用户的接入门槛,随着业务的快速增长,Elasticsearch 集群本身的运维成本也让我们逐渐不堪,虽然有物理隔离的多个集群,但不可避免的会有多个业务索引共享同一个物理集群,在不同业务间各有出入的生产标准上支持不佳,在同一个集群内部署过多的索引也是生产环境稳定运行的一个隐患。 另外集群服务能力的弹性伸缩相对困难,水平扩容一个节点都需要经历机器申请、环境初始化、软件安装等步骤,如果是物理机还需要更长时间的机器采购过程,不能及时响应服务能力的不足。
当前架构通过开放接口接受用户的数据同步需求,虽然实现了与业务解耦,降低了我们团队自身的开发成本,但是相对的用户开发成本也变高了,数据从数据库到索引需要经历从数据总线获取数据、同步应用处理数据、调用搜索平台开放接口写入数据三个步骤,其中从数据总线获取数据与写入搜索平台这两个步骤在多个业务的同步程序中都会被重复开发,造成资源浪费。这里我们目前也准备与 PaaS 团队内自研的DTS(Data Transporter,数据同步服务)进行集成,通过配置化的方式实现 Elasticsearch 与多种数据源之间的自动化数据同步。
要解决共享集群应对不同生产标准应用的问题,我们希望进一步将平台化的搜索服务提升为云化的服务申请机制,配合对业务的等级划分,将核心应用独立部署为相互隔离的物理集群,而非核心应用通过不同的应用模板申请基于 k8s 运行的 Elasticsearch 云服务。应用模板中会定义不同应用场景下的服务配置,从而解决不同应用的生产标准差异问题,而且云服务可以根据应用运行状况及时进行服务的伸缩容。
本文从架构上介绍了有赞搜索系统演进产生的背景以及希望解决的问题,涉及具体技术细节的内容我们将会在本系列的下一篇文章中更新。
欢迎关注我们的公众号

</div><br>
如何让「说走就走的旅行」更有价值——《旅行的艺术》读书笔记
https://ift.tt/2ArFnIH
微雨
忘了从什么时候开始,我们就被输入了一种「读万卷书,行万里路」的观念。而后,这个观念又衍生出了不同的说法,有人说「读万卷书不如行万里路」,强调的是「行路」;也有人说「行万里路不如读万卷书」,强调的是「读书」;还有人说这两者没有轻重之分,两手抓才是正解。
「来一场说走就走的旅行」、「灵魂和身体,总有一个在路上」是当下最时新的旅行语录了。旅行自然是必要的,但说走就走不一定是有价值的。因此我的观点是偏向于两手抓的,但要补充的是这两者的先后顺序:行路之前还是先读书为好。如果不读书便行上万里路,结果可能只是锻炼了身体开阔了眼界,却无法产生更多价值,比如说真正内化到精神内涵层面。所以,在旅行之前,至少得提前做点什么,比如读一读阿兰·德波顿的《旅行的艺术》。
于我个人而言,旅行的意义不仅在于放松身心、开阔眼界,更在于观察和感受,并引发自身的思考和改变。而德波顿作为一个哲学家,一个知识渊厚且富有逻辑思辨能力的作者,他笔下的《旅行的艺术》让我原本的观念得到了更深层次的升华。
这是怎样的一本书?
余秋雨在《推荐序》里说:
这本书不是游记散文,不是导游手册,也不是论述旅行历史和意义的常识读本。我们读到的,很像是用小说笔法写出来的人物传记片断。
译者南治国也在其《译者序》里说道:
结合福楼拜、波德莱尔等文学家的创作,参照凡·高、爱德华·霍珀等画家的作品,多方位地观照‘旅行’、剖析‘旅行’。
当我刚开始读这本书的时候,以为这会是一部游记,但深入阅读后发觉这更像是一本艺术史。而直到最后合上书本,才发现这其实是一本写在旅行路上的哲学思考随笔文集。
《旅行的艺术》分为五个部分:出发——动机——风景——艺术——回归,每部分有一至两篇文章。不过对于为什么旅行?如何更好地旅行?作者似乎不打算直接告诉我们,也不热心去考求。但看完整本书后,相信每个读者都会得到一种既思辩又感性的答案。这将影响甚至改变个人对旅行的看法,并有可能改变日后的旅行心态和旅行方式。
「诗意的远方」与「眼前的苟且」在细致的观察和感受中都有着美的可能。那么就跟随作者的脚步:
让我们在前往远方之前,先关注一下我们已经看到的东西。
作者每到一个地方,他的向导都不是一个专业导游,而是一个历史人物(作家、旅行家等)甚至只是圣经中一个小故事,像是旅行心灵导师一般的存在。

第一部分「出发」共有两个章节:「对旅行的期待」与「旅行中的特定场所」。开篇部分,作者便通过法国作家于斯曼的小说《逆流》中夸张的小故事,给读者抛出了一个值得思考的问题:
既然一个人能做在椅子上优哉游哉捧书漫游,又何苦要真的出行?
这个问题看似对旅行的怀着刁钻与不屑的态度,其实不然,作者在接下来的章节中,不仅通过各位名家的作品、经历和自己的旅行体验,阐明了自己对旅行的态度,还留下了很多发人深省的旅行哲思语录:
读完第一部分的内容后,我是很惊喜的,因为德波顿独特的写作手法和细腻的笔触,更是因为那大量引发个人思考的言论,让我对为什么去旅行,去哪里旅行等问题有了不一样的看法。于是,我又迫不及待地在第二部分「动机」中的两个章节「异国情调」与「好奇心」中发掘,发掘关于旅行在思维与心灵之间的碰撞。
在一场回归大自然的旅程中,风景是最强烈的存在,德波顿将风景这一主题分成了「乡村与城市」和「壮阔」两个章节,引导我们发现乡村与城市的差异,带领我们如何去发现自然的壮阔。
大自然中的各种现象,包括小鸟、小溪、水仙和绵羊,都是不可或缺的,因为它们能矫正和治疗城市人倍感困顿的心灵。
人类属于自然界,存在于自然界,人与自然是相互依存且相互制约的。也就是说,如果我们对大自然心存敬畏并心存谦卑地活着,这样我们会更容易找到自身存活于这个世界上的方式。
似乎对一个地方的感觉已经被这些地方的气质或是我们心中根深蒂固的思维模式所决定。因此,当我们力图改变对于这些美丽风景的感觉时,会觉得很无助,像是力图改变自己对已经觉得味美的冰淇淋的感觉一样。
于是,我们只是看到我们已经看到的,旅行中那种发现的乐趣荡然无存,毫无疑问,这趟旅行的价值便大打折扣了。那么,有没有办法可以提升我们欣赏风景的能力呢?作者给出的答案是:艺术。
那些伟大的艺术家们是我们的向导,因为有些旅游胜地,最初可能是因为艺术的呈现而得以成为众人旅行的目的地。所以,在关于艺术的这一部分内容里,「令人眼界大开的艺术」与「对美的拥有」这两章内容,作者以画家梵高和艺术家罗斯金为向导,向我们展示了如何通过艺术欣赏提升旅行体验,如何更好地去拥有旅行的美。
看着朋友圈里刷屏的旅游照片,就知道越来越多的人在享受难得的假期旅行。但其中一部分旅游者的确如作者所说的「因匆忙和随意变得麻木」,因此并不能真正去理解一趟旅行的意义。他们只是把逃离自己的所在地,到达别人的所在地看做某种胜利,接下来的行程中忙着拍照记录下这些短暂拥有的美色,而忽略了很多细节,比如自身的感受。
不过,比起拍照,德波顿与罗金斯更鼓励我们在旅途中绘画和写作:
正如作者所说,绘画和写作都是一个再创造的过程,不仅仅是在描绘我们所看到的的景物,而是加入我们个人的理解与情感的产物,我想,这样细心获取到的「美」才真正为我们所有吧!
在最后一章「习惯」里,作者德波顿通过梅伊斯特的《我的卧室之旅》为我们提供了另一种旅行方式——室内旅行,即以一种发现的眼光重新审视日常生活里的一切,撼动让我们麻木的习惯。这种独特的回归方式,我们明白了旅行的乐趣取决于旅行的心境,而感受力是旅行心境的最主要特征。
我想,如果我们可以带着一种发现的眼光,一种旅游的心境去感受生活的周遭,那么我们或许会发现常去的公园、超市、街巷等场所的有趣程度,可能并不亚于朋友圈里别人晒出的旅游美景,不亚于洪堡在南美之旅中所经过的高山和蝴蝶漫舞的丛林。
《旅行的艺术》不是一本旅行指南,而是一本非常有深度的读本。作者在结尾中这样写道:
穿着粉红色和蓝色相间的睡衣,心满意足的待在自己房间里的塞维尔·德·梅伊斯特正在悄悄提醒我们,让我们在前往远方之前,先关注一下我们已经看到的东西。
这是我在整本书里印象最深的一段。这最后一句话就足以作为阿兰·德波顿《旅行的艺术》这本书的缩写,也足以引发我关于旅行意义的深层思考:我们为什么要离开熟悉的地方去远方旅行?我们走过千山万水,领略到真正的精彩了吗?德波顿没有给我们一个准确的答案,但是合上书本以后,我们的内心早已有了自己的答案。
旅行,绝不凌驾于现实生活之上。这本书中的旅行日常看似啰嗦,却更加真实随性。经验感悟看似一碗心灵鸡汤,实质上却是最实用的方法论。这本书,会增加你很多知识的储备量,整体读下来让人感觉充实却不失轻盈。然后带着哲思的眼光来一场「说走就走的旅行」才会更有意义吧!
深度工作-碎片化时代中成功的良方
https://ift.tt/2n2nE0Q
JasperJia
本文字数:3133 字,阅读时间大约为:7-10分钟
首先, 让我们回到本次少数派读书笔记征文活动的第一句话:
碎片信息时代,我们因知识焦虑而不断摄取碎片信息,然而不系统不深入的碎片信息却又助长了这种焦虑。
碎片化时代下,我们的时间被邮件,电话,微信,微博,临时会议,甚至少数派😅 等切割成零碎的时间块。为了在快节奏的碎片化时代中保持高效率,人们选择使用各种 GTD 软件来整合和管理自己的零碎任务,减少任务切换频率和时间来更快速地完成工作。
然而, 如果你想快速掌握一门编程语言,通过一门高难度的考试,创作一本新书或者一首新歌,或许高效率地完成碎片化任务并不能(或者并不完全能)实现你的目标。本书就提供了一个反其道而行之的办法——深度工作(Deep Work)。
作者卡尔·纽波特(Cal Newport)现为乔治城大学计算机科学专业副教授,是麻省理工学院计算机科学博士。卡尔不仅自己成为了优秀的计算机科学的学者(曾一年发表9篇顶级期刊文章),他也希望更多人能成为优秀的学习者。除开这本《深度工作》,他还撰写了《如何成为尖子生》、《优秀到不能被忽视》、《深度职场力》等成功学书籍。
 本书封面及作者
本书封面及作者信息化时代的当下,卡尔认为有以下三类人可以成功:
 三类成功人士:高级技术工人,超级明星和财富所有者
三类成功人士:高级技术工人,超级明星和财富所有者高级技术工人(The High-Skilled Workers):能够快速学习和掌握智能机器,并很好地利用这些工具进行创造性工作;🔑
超级明星(The Superstars):行业内最顶尖人才或者具备特殊才能的专家。🏆
财富所有者(The Owners):拥有大量财富,可以进行投资的富有者。💰
卡尔认为深度工作是成长为上述三种成功人士的标配,是碎片化时代自控力和时间管理的良方,是迈向非凡成功不可缺少的技能。
One of the most valuable skills in our economy is becoming increasingly rare. If you master this skill, you’ll achieve extraordinary results.
这项我们经济时代最有价值的技能正在变得越来越稀缺。如果你掌握了这项技能,你将取得非凡的成就。
本书强调了深度工作这项技能的稀缺性以及重要性,并且系统地介绍了践行深度工作的策略和方法。丰富的例子和切实可行的方法让本书成为最权威的深度工作行动指南。
卡尔认为深度工作并不适合每个人,在结论部分他说道:
The deep life, of course, is not for everybody. It requires hard work and drastic changes to your habits. For many, there’s a comfort in the artificial busyness of rapid e mail messaging and social media posturing, while the deep life demands that you leave much of that behind.
当然,深度工作(生活)并不适用于每个人。它需要刻苦努力并且根本上改变你的习惯。对于大多数人来说,沉浸在快速收发电子邮件和社交媒体的慰藉。然而深度工作(工作)则是要摈弃这些。
如果你只是想追求知识的广度,并不在意内容的深度。如果你需要时刻保持社交的纽带,排斥反感远离尘嚣的孤独。那么本书并不适合你。相反,如果你需要集中精力并且夜以继日地完成一件事情,深度工作就是你最好的方舟。
对于正在攻读信息安全博士的我而言,常常陷入花大量时间去完成学习任务的困境 ,更糟糕的是周遭的人似乎也以工作时间多为光荣。作者卡尔很少工作超过晚上六点或者在周末加班,阅读此书也让我重新审视我的时间规划和管理,与其无休止地延长工作时间,不如尽最大可能提高工作深度和效率。
卡尔对“深度工作“进行了这样的描述:
Deep Work: Professional activities performed in a state of distraction free concentration that push your cognitive capabilities to their limit. These efforts create new value, improve your skill, and are hard to replicate.
深度工作:在无干扰的状态下集中注意力进行职业活动,将个人的认知能力达到极限。这种努力能够创造新价值,提升技能,并且难以复制。
与深度工作相反的,则是我们通常的碎片化工作方式。 在本书中,作者使用了”浮浅工作(Shallow Work)“ 来描述这种工作方式。
Shallow Work: Noncognitively demanding, logistical style tasks, often performed while distracted. These efforts tend to not create much new value in the world and are easy to replicate.
浮浅工作:是非认知性要求的,逻辑型工作并且常常在受到干扰的情况下执行。这项工作倾向于不会为世界产生太多价值,并且容易复制。
当我读完这两种工作方式的定义,我联想到了企业管理学中常常提到的一个术语”资源基础理论(Resource-based view,RBV)“。深度工作正好符合 RBV 所包含的四个显著特质:
V = Valuable 价值
R = Rare 稀缺
I = Imperfectly Imitable 难以完美复制
N = (Non) Substitutability 可持续的
资源基础理论的核心价值在于创造核心竞争力,这种核心竞争力可以在较长时间内持续下去,直至公司能够防止资源的模仿、转移或替代。深度工作的核心也正是如此。
最直接的回答是:深度工作能让你成为上文提到的三类成功人士(可能对于大多数来说,更倾向于前两种)。当今信息化时代,有两样核心能力不能忽视:
1. The ability to quickly master hard things.
1. 快速学习困难事务的能力。
2. The ability to produce at an elite level, in terms of both quality and speed.
2. 能创造出精英级别的价值,不论从质量还是速度上来说的能力。
深度工作就是能帮助你达成这两样核心能力的基础。无论是学习困难的新技能还是创造精英级别的价值,你都需要在没有干扰地情况下集中注意力。如果你认同下面的等式,你就应该掌握这项技能。
 生产力原理
生产力原理深度工作本质上是一种技能,你需要不断强化、学习以及训练。深度工作需要你保持专注,避免干扰,并且高强度地持续工作一段时间。以健身为例,大脑就是我们的肌肉,而深度工作就像我们做超级组,拼到力竭。
 深度工作就像健身
深度工作就像健身
深度工作总是在挑战你的认知极限,健身则是在挑战你的身体极限。当你还未习惯它们时,都会让你感到痛苦和难熬。你很容易被妹子给你发的微信所分心,很想拿起手机回复 “约一波?”;你也会被上司给你发的邮件所打扰,不知道是不是周末又得加班;你更会被少数派更新的文章所吸引,迫不及待地想了解新知识。
人们在浮浅工作的繁忙中寻找慰藉和舒适,往往抗拒深度工作的疲惫。你需要的是不停地训练,直到你能自由切换工作模式并高效率地完成任务。
深度工作中最为核心的一点是切忌分散注意力(distraction free concentration)。分散注意力会让你的执行力降低,效率下降,最终导致深度工作的流产。
别再信奉 deadline 是第一生产力。人们总是习惯于拖延,很多工作都在截止日期前一天或几个小时加班加点赶出来。我们需要将深度工作加入到我们日常例行任务里,每日留出2个小时或者每周挪出一个下午进行深度工作。高效率高强度地深度工作,能让你保质保量地完成任务。
在我博士学习的第一学期,我常常在截止日前一天开始赶课业,每次都是通宵达旦。后来导师给我讲,每天留出时间认认真真做作业,即使你每天只写了一页的论文,也比你在截止日前赶出来的质量好很多,自己也会轻松许多。其实,每次深度工作的时间不会太长,你需要的只是足够专注。
现在有许多帮助人们提高专注力的应用,比如:Forest,番茄钟,潮汐等。以我个人为例,只要我在图书馆学习,就会打开 Forest 帮助我管好自己焦躁的手。我并没有无安全地遵循番茄钟,每次设置的分钟数并不一定,一般是35-45分钟。种好一棵树,正好可以提醒我该起来喝水和走动。
 上周的森林种植情况(还是有两天偷懒了)😂
上周的森林种植情况(还是有两天偷懒了)😂《深度工作》为我们提供了一套提高专注度,对抗浮浅工作的方法。所有工作都会消耗你的精力和注意力,减少浮浅工作的时间,更多地投入到深度工作中,是我们能立足于当今社会的基础技能。
其实,一切效率低下(时间/专注力管理)的问题,都源自于你内心的懒😔。勤奋决定了你人生的下限,如果想把自己的底子垛高一点,那就积极地践行深度工作吧。
Newport, Cal. Deep work: Rules for focused success in a distracted world. Hachette UK, 2016.
Arin Basu (2017, Jan 11). Notes from my reading: Deep Work by Cal Newport [Medium log post]. Retrieved July 29, 2018, from https://medium.com/@arinbasu/notes-from-my-reading-deep-work-by-cal-newport-9299dc761f4e
Fahim Kadhi (2017, Feb 24). Book Notes: Deep Work by Cal Newport [Medium log post]. Retrieved July 29, 2018, from https://medium.com/@heemslife/book-notes-deep-work-by-cal-newport-be582cf40873
Marlo Yonocruz (2017, Oct 14). Book notes: Deep Work [Personal log post]. Retrieved July 29, 2018, from https://marloyonocruz.com/2017/10/14/book-notes-deep-work/
豆瓣读书 深度工作 https://book.douban.com/subject/27056409/
人口列车是怎样失控的|大象公会
https://ift.tt/2MwFRxR
PyCharm远程调试 - Chen Yuan's Blog
https://ift.tt/1XWDyrH
PyCharm提供两种远程调试(Remote Debugging)的方式:
本文主要介绍Python Debug Server配置与使用。
(上图为Python Debug Server模型,仅供参考)
如上图所示,PyCharm远程调试方式的模型其实就是一个典型的Server/Client模型。模型左侧,Server服务运行在本地主机PyCharm中。配置Debug Server完成后就可以启动这个服务器。服务器启动后,就是等待Client客户端的接入。模型右侧,需要调试的Python程序通过调用pycharm-debug提供的pydevd库,然后连接到服务端。这样,本地主机就可以使用PyCharm调试远程主机运行的Python程序了,调试的方法与直接调试本地Python程序一样。
首先在Run/Debug Configuration中添加Python Remote Debug服务。
(上图为Python Debug Server配置流程)
注:服务器命名和IP地址是必须配置的。若端口没有配置,则在服务器启动时随机分配;若路径映射没有配置,则在客户端连接服务端成功后PyCharm再提示选择配置。
服务器启动后会提示以下信息:
Starting debug server at port 51234
Use the following code to connect to the debugger:
import pydevd
pydevd.settrace('192.168.27.1', port=51234, stdoutToServer=True, stderrToServer=True)
Waiting for process connection...
其中,这两行代码需要嵌入到远程调试的Python代码中,这两行代码包含了服务器监听的IP地址和端口等信息。
import pydevd pydevd.settrace('192.168.27.1', port=51234, stdoutToServer=True, stderrToServer=True)
参考模型中提到,远程主机需要配置pydev库。而提供库的源文件在PyCharm安装路径下的debug-eggs目录中,其中pycharm-debug.egg对应的是版本2,pycharm-debug-py3k.egg对应的是版本3。
把pycharm-debug.egg文件复制到远程主机,然后通过easy_install命令安装。
PS:复制的方法有多种,通过ssh可以传输文件,注意权限问题。
$ sudo easy_install pycharm-debug.egg
然后把上面提及的两行代码嵌入到需要调试的Python程序中。
#demo.py print "remote debug" #嵌入服务器信息的代码,进入调试状态 import pydevd pydevd.settrace('192.168.27.1', port=51234, stdoutToServer=True, stderrToServer=True)print "code need to debug"
#离开调试模式
pydevd.stoptrace()
调试方式比较简单,首先启动远程主机的程序,进入调试状态。然后返回本地主机的PyCharm界面进行调试。
$ python demo.py remote debug
(上图为本地主机PyCharm调试界面说明)
此步骤之前需要配置路径映射关系,即远程主机中的代码如何映射到本地主机中,本文用到的是win-sshfs工具,工具的使用方式就有时间再介绍。
如何收集竞争情报——财报解读
https://ift.tt/2MWdUke
蓝鲸
竞争情报及数据收集,分析及解读是数据分析中的一个重要环节。获取竞争情报及数据的方法有很多种,常见的方法如爬虫数据抓取,官方披露文件,第三方调研机构研报等。从获取难度,数据时效性,数据颗粒度,可用维度及靠谱程度上对比来看每种方法各有利弊。本篇文章介绍如果通过解读公司财报获取竞争情报,这种方法的优势在于数据相对比较靠谱,毕竟数据经过了专业的财务审计,并且有来自证券交易所和做空机构的监管。缺点则在于时效性较差,季报和年报都是对过去的解读。此外只有上市公司才会发布财报信息,因此如果目标公司还没有上市则无法使用这个方法。
通过财务报表获取竞争情报的第一步是如何找到这些公司的财报。根据公司上市地点的不同我们可以在四个地方找到所需的财报文件。
第一种获得财报的方法是通过目标公司的官网获取,通常在上市公司的官网中都会包含一个投资人关系页面。这个页面中会包含公司的各种 财务报表信息。以下是京东的投资者关系页面。
不过,官网中的投资人页面入口通常比较隐蔽,有些官网则很难找到。同时对于获取多家公司的财报来说,这种方法也比较麻烦。因此我们 可以根据公司的上市地点通过交易所网站来获取财报信息。
美国证券交易委员会(SEC –the U.S. Securities and Exchange Commission)简称SEC。所有在美国上市的公司无论是纳斯达克证券市场 (NASDAQ)还是纽约证券交易所(NYSE)上市的公司都可以在SEC中找到。
SEC中查找公司财报的方法比较简单,在主导航FILINGS下选择Company Filing Search就可以到达搜索页面。在搜索页面中输入公司的名称,可以看到该公司的财务报表,根据上市时间的不同可以看到包括IPO初始上市文件(招股说明书),年报,季报及重大事项报告等内容。SEC中的所有文件都是英文版的,所以如果你的英文水平有限可以结合Google Translate来查看。
香港交易所,全称“香港交易及结算所有限公司”(Hong Kong Exchanges and Clearing Limited,英文简称HKEx)。所有在香港上市的公司财务文件都可以在这里找到,例如最近新上市的平安好医生,以及即将上市的海底捞等。
HKEx中查找公司财报的方法和SEC类似,在HKEx首页主导航的”市场数据”下选择”披露易”,然后在顶部”上市公司公告”区域选择”进阶搜寻”。输入股份代码或股份名称就可以找到目标公司的财务文件了。
在大陆地区上市的公司和回归A股的互联网中概股,如”三六零安全”等分别可以在上海证券交易所,和深圳证券交易所的网站上通过搜索找到。方法和HKEx类似,这里不再赘述。
上市公司的财报类型种类繁多,不同的时间节点及事件会发布不同的文件,例如IPO上市时会首先发布招股说明书,每个季度会发布季度财报,财年结束会发布年度财报,发生重大事件时还会发布重大事项报告(如并购和重大人事变更等)。因此,以SEC为例,我们搜索到的公司财报可能会是这样一个很长的,包含不同类型的文档列表。(公司官网会对财报进行分类展示,交易所网站支持按类型筛选及搜索)
在这些文档中,我们重点关注三类,第一是招股说明书(FormS-1/F-1),第二是公司的季度财报(Form10-Q),第三是公司的年度财报(From10-K)这三类文档从内容的详细程度来看招股说明书的内容最为全面,动辄三五百页。其次是季度财报和年度财报文档。我们可以利用SEC网站中的分类搜索功能筛选出这些文档。
在筛选结果中点击Documents可以查看该文档的结构目录,这里显示了文档中所包含的图片等信息。选择并点击类型为F-1/A的htm文件,就可以查看文档中的详细信息了。这里以alibaba的招股说明书为例,


公司的财报和招股说明书中包含了大量的信息,按类别来分的话我觉得有三大类,第一大类内容信息量较低,主要是一些模板式的标准化文字。第二大类是专业的财务报表。第三大类是公司的运营信息。从竞争情报分析的角度来看,对我们最有价值的是后两类内容。因此建议重点关注财报中的下面几部分内容。
第一个要关注的内容是目录中的“风险(Risk Factors)”部分,这部分根据不同公司主营业务和行业背景从产业链及上下游供应商关系,用户偏好,政策法规,行业竞争及内外部因素等几个维度介绍了影响公司运营及营收的主要风险因素。
第二个要关注的内容是目录中的“行业(INDUSTRY)”部分,这部分会从非常宏观的行业角度说明一下整个行业的增长驱动因素,互联网公司大部分的驱动因素都会包括互联网及移动互联网的普及率,以及国家重大政策带来变化。例如房屋中介的主要驱动力为移动互联网普及率提升及人口城镇化,金融类为消费金融市场发展及移动互联网普及率的提升。同时引用一下世界银行的数据或GDP规模占比,将**的情况和美国的情况进行对比,展望下潜在的市场营收规模。(关于潜在市场规模的坑,我们会在后面的文章中单独介绍)。
第四部分公司“业务(Business)”详细的介绍了公司的主营业务及流程,分别从用户,产品,渠道和竞争优势和技术能力的角度介绍了公司的商业模式,包括我们的用户是谁,我们提供什么样的产品和服务,以何种方式获得收入,未来的业务成长策略及路径,以及公司所特有的优势及创新能力创造的差异化和低成本的竞争壁垒。
第三个要关注的内容是”财务状况与经营成果的管理探讨与分析(Management’s Discussion and Analysis of Financial Condition and Results of Operations)”,简称(MD&A)。这部分内容从管理者的角度解读公司最近一段时间的运营情况,主要包括公司规模,收入及变现能力,业务成果,关键驱动因素等。并详细说明了一些关键业务指标(MAU,GMV等)的变化原因和战略动作。以及成本和收入的数字及分布。如不同业务及产品线带来的收入占比,毛利率以及市场投放,运营和人员在成本中的占比等等。
以上是财报中需要关注的主要信息部分,除此之外还可以通过其他财报解读媒体或财报电话会议中高管对财报的解读和与分析师的提问互动中获取信息。
我常使用的财报解读媒体主要是新浪科技和网易科技的上市公司财报解读,这两个媒体包含了主要的互联网中概股的信息,并按年份对财报信息和解读进行进行了整理和分类。 这两个的地址你可以在我博客网站分析库页面中的财务及运营数据分析部分找到入口链接。
财报电话会议中公司高管对财报要点的解读,以及与分析师的提问互动内容则主要包含在财报解读部分中。在财报电话会议中会包含很多财报文档以外的信息,如2017年的京东财报电话会议中花旗集团分析师关注了京东在印度尼西亚的业务发展及市场战略目标,刘强东就分享了京东在东南亚及印尼前五年的市场战略。这些信息可能并不会包含在财报文档中。
以上是公司层面的竞争情报及数据收集,欢迎朋友们拍砖及留言分享经验。后续将持续更新行业情报及数据收集的内容及方法。请继续关注 。
—【所有文章及图片版权归 蓝鲸(王彦平)所有。欢迎转载,但请注明转自“蓝鲸网站分析博客”。】—
打造移动创作工作室:Affinity Designer for iPad 入门指南
https://ift.tt/2LgeUTh
王禹效
在 iPad 拥有一个专业矢量绘图工具是很多人长期梦寐以求的。这样的工具出现了,它的名字叫 Affinity Designer,下文简称 Designer。
Designer 是一款矢量图及像素图创作软件。无论你是业余爱好者,还是专业设计师,都可以用它找到属于你的功能。其 iPad 版是与电脑版功能完全相同。从像素草稿,矢量绘图,到无比全面的文件格式导出等,它都可以专业应对。
 @Minja 使用 iPad 版 Designer 创作的花店 LOGO
@Minja 使用 iPad 版 Designer 创作的花店 LOGO
本文我将从 Designer 的核心功能以及对不同用户群支持的特有功能开始,首先介绍软件界面,触摸手势;接着谈谈部分高级功能及矢量,像素,导出,文本四大工具,结尾处我将给出购买建议及学习资源。
Designer 的最核心功能正是满足对矢量图和像素图创作需求。本节将从宏观角度简谈矢量图及像素图混合编辑及对比查看。
有人将 Designer 和 illustrator 类比,其实不全对。若你了解矢量图和像素图,会发现这两者各具优劣,矢量图由路径及锚点构成,无论放大多少倍依旧清晰顺滑;像素图由每一个像素点构成,放大后画面会变成一个个纯色的小格子。
 矢量图对比像素图
矢量图对比像素图
你可能经历过先在电脑上先用 PS 画像素稿,接着用 illustrator 补充矢量图形的情况,这种持续打断思路的工作流一直很不理想。矢量绘图一定程度上的限制了作品自由洒脱的感觉,而像素图很难实现清晰平顺的边缘棱角。
Designer 允许你将二者结合,各自利用其优势处理不同部分。它不但支持矢量绘图,也同时支持像素绘图,你可以充分利用两者的特性根据需要即使切换模式。
在下图的狮子脸部图中,狮子脸颊的轮廓是矢量勾勒,保证了轮廓的清晰分明;而脸颊内的细节则是用像素笔刷绘制,充分利用了像素笔刷带来的朦胧与无序感。
 矢量 + 像素组合使用
矢量 + 像素组合使用
在矢量工作中,您可能常会想,我的作品如果打印出来放在海报上是什么样,放在一般显示器上呢?这时候你可以更改视图模式进行查看,在导航器中根据需要选择矢量,标准像素,高清像素,轮廓稿即可。你还以如下图中将两种模式放在同一屏上对比,做到心中有数。
 双视图查看
双视图查看
介绍完了像素图和矢量图的混合编辑及对比查看,接着我们来看看在不同使用情景下 Designer 有什么特色功能。
Designer 对于创作者的实际需求考虑十分全面。对于平面设计,绘图,UI 设计,文本设计等工作常见需求均有支持。下面我将对每一种需求下常用的功能一一简述。
 易用的矢量笔刷
易用的矢量笔刷
 丰富的预设笔刷
丰富的预设笔刷
 内置 UI 库
内置 UI 库
 全面的文本支持
全面的文本支持
以上介绍的几种使用场景及部分功能只是几个典型的例子,并不代表着 Designer 只被局限在这些场景中。你可以把它们当作参考,按自己实际所需打造自己的工作流
若这是你第一次接触 Affinity 系列软件,你可能会在众多按钮和模式切换中迷茫,因此我们先来它界面的交互逻辑。
本节将完整介绍一个完整工作流中最常使用的功能。包括文件的创建,导航,图层编辑,复制,历史记录,保存及导出。
创建一个新画布很简单,点击主界面上的巨大「➕」并点击「新建文档」即可。若你想要新建文件夹,可以点击下方的「新建项目」按钮。
值得注意的是下图界面中的「从云端打开和从云端导入」,这两个选项的区别是从云打开后,保存的文件会存回云端本身的文件中,比较适合与电脑版联动编辑同一个文件。而从云端导入是将文件提取出来,并另存一个新文件。
 创建文件
创建文件
打开一个文件后,你会看到下图中的界面。它由顶部的核心模式切换,文档设置;左侧的当前模式下所有工具,快速选项;右侧的通用工具及注释;底部的所选工具设置组成。
 主界面
主界面
其中最为重要的当属核心模式切换。顶部的三个选项分别为矢量绘图,像素绘图及导出。你可以根据当前创作需要随时切换。以一副简笔画为例,你可以先在像素绘图模式下用像素笔刷快速打草稿,接着切换回矢量绘图进行润色,最后切换到导出模式选择所需区域及格式导出。
 模式切换
模式切换
当画面过大,或你希望避免误选取画面中物件的时候,可以使用通用工具中的「导航器」导航。除控制大小外,你还可以用它控制画面旋转锁定,调节视图模式等。
 导航器
导航器
当你选择一个物体时,常见的复制粘贴几何处理等操作在左上角的控制区。旋转,尺寸,对齐,锚点等选项在右下角的「变换」工具中。
 变换
变换
接着上面的选择物件继续说。有时当你想要创建一组图案时,针对每一个新复制的图案调整变换是非常困难且不现实的,这时候你可以使用记忆复制。复制完一次物体并修改变换后,才次点击「复制」则会触发相对于上一次位置的记忆复制。
 记忆轨迹复制
记忆轨迹复制
当你需要管理图层时,可以点击通用工具中的「图层」。涂层选项中第一排第三个那个不明所以的图标其实是「成组」,第四个图标加号允许你创建矢量,像素或蒙版图层。当你需要快速导航到某个图层时,只需双击该图层前面的小图案即可。
 图层
图层
总有一些操作你会不想要,那么该如何回到之前的某个时间点呢?点击通用工具中的「历史记录」即可。Designer 默认只会记录最近一百步操作,这经常不够用。你可以在「设置 - 常规中」将记录的步骤提高到最多 2048 步。
 历史记录
历史记录
Designer 中的所有文件均会默认保存在本机软件文件夹中,很难被找到。若你希望将它们存在 iCloud 中或其它位置,可以在「设置 - 常规」中更改默认保存位置。更改完成后点击待保存文件右下角的「三道杠 - 保存」。
 保存
保存
当你需要将文件分享给其他人时,只需点击「导出」,选择需要的格式并拖动到待分享的位置即可。
 快速导出到其它应用
快速导出到其它应用
基本操作到这里就介绍完了,接下来我们来看看具体操作中最重要的手势及其它进阶功能。
手势姿势在 Designer 的操作中所占比重太大,几乎可以说用 iPad 版的 Designer 却不知道手势操作会寸步难行。学好了手势,可以大幅提高你的工作效率。本节我会从基础的撤销与选择开始,依次介绍 Designer 所需要学习的手势操作。
注意:以下手势操作对任何模式均有用。
 基本手势
基本手势
 对物体操作
对物体操作
 整体控制
整体控制
 颜色控制
颜色控制
 图层控制
图层控制
 矢量笔刷
矢量笔刷
 像素笔刷
像素笔刷
Designer 的手势操作基本就是这些,学会并灵活运用,会让你的创作快人一步。
掌握了基础的界面,文件存取,基本手势,你基本已经可以在 Designer 中自由行动了。但它能为你提供的远不止这些,接下来我们看一些针对性更强但非常实用的功能。
你可以创建不同大小的画板来满足设计需求,也可以使用内置的不同设备画板。若你想要以当前选取的内容创建一个新画板,则可以选择「画板 - 从选取项 - 新建」。
 画板
画板
若你习惯用 Sketch,可能已经离不开同步符号了,Designer 也支持这一功能。与 Sketch 不同的是,你不需要指定更新主体,同步符号允许你选定任意一个对象,对其作出的更改会同步在其它所有对象中。你也可以根据实际需求断开或暂停同步。
 符号
符号
当你希望对所选对象添加阴影,高光等特效时,可以点击「图层 FX」选项进行设置。设置好后,你可以点击「粘贴图层特效」按钮来将此特效应用在其它图层上。
 图层特效
图层特效
Designer 的图层调整是非破坏性的,它以一个调整图层的形式存在,这意味着它不会直接覆盖在待修改的文件上,你可以随时根据需要进行调整。其调整选项非常丰富,如色彩平衡,滤镜,LUT 等。
 图层调整
图层调整
Designer 中的第一个模式为矢量模式。它包含了矢量画笔,节点,拐角,铅笔,钢笔,填充,透明度,拾色器等常用工具。本节我将介绍 Designer 有特色的几个功能。
矢量画笔和像素画笔类似,但其只能在矢量模式下使用。同理,像素笔刷只能在像素模式下使用。矢量笔刷的优势是放大不会失真,而且绘制完成后可以编辑节点来做调整。矢量笔刷所绘制的部分会出现在线稿视图中。
 线稿视图
线稿视图
透明度工具和渐变工具类似,但是调整的是选中图像的透明度,你同样可以指定线性透明度渐变,椭圆形渐变等方式。点击「透明度工具」,在想要施加透明度变化的物件上拖动即可。
 透明度工具
透明度工具
边角工具允许你精确控制任何拐角,将其转为圆角凸出或凹陷。点击任意一个拐角并向中心拖动即可,你可以在底下的控制栏中更改拐角类型。
 边角工具
边角工具
Designer 中的第三个模式为像素模式。它包含了像素画笔,笔擦,涂抹,填充等常用工具。本节我将介绍 Designer 有特色的几个功能。
Designer 让矢量与像素的合作更密切,你可以用矢量图形充当绘图的边界,在矢量区中使用像素笔刷绘制。切换至像素模式,选择一个喜欢的笔刷,在矢量图形中绘制即可,你的笔刷不会刷出矢量图的边界。这是因为在你绘制时,Designer 会自动帮你在矢量图中添加一个像素图层。
 在矢量图中绘制像素图
在矢量图中绘制像素图
有时非常精确的切边也许不一定是你想要的。这时候你可以考虑像素工具「羽化/外形/增大选取工具」,他们的作用是根据不同规则扩大当前选区,以便实现不同效果。在下图中,我希望给车的边沿加上一些泥土的痕迹,这时可以在智能选取车架后,点击外形选区工具,以轮廓为中心创建一个边沿选区,在这里面涂刷泥土色即可。
 选择轮廓
选择轮廓
当你需要非常精确的提取选取时,可以使用「优化选取区域」, Designer 会自动判断所选区域与背景之间的关系并优化选区细节。当然,你也可以手动指定某些区域为前景,某些为背景,某些为模糊区来加强 Designer 判断的准确性。
 优化选区
优化选区
Designer 中的第三个模式为导出模式。导出在不同工作流中有不同的需求,本节我们来看看如何满足这些需求。
Affinity Designer 在 iPad 上拥有非常全面的导出功能。无论是基础的 JPEG、PNG、GIF,还是全面分层的 PSD、SVG EPS 都可以轻松处理。对于导入来说,它也支持导入 AI、BMP、HEIF、RAW 等文件格式。想要直接全局导出只需点击「文档 - 导出」并选择格式即可。
 直接导出
直接导出
你可以手动选择需要导出的切片区域,也可以根据现有图层或画板自动生成切片。先用导出模式下的「切片选择工具」选中所需区域,接着点击图层中的「创建切片」即可。
 创建切片
创建切片
在切片管理器中根据需要选择格式,更高分辨率,JSON 文件后点击「全部导出」即可。这里值得注意的是连续自动更新的功能,有时候你希望自己做出更改会直接同步到导出文件中,这时候你可以开启「连续导出」,Designer 会根据你的更改自动更新导出的文件。
 切片导出
切片导出
优秀的设计离不开对细节的专注,以及对文本创作的巧思。本节将简介几个处理文本时的常用功能。
当你需要大段文字时,可以点击「框架文本」,它的功用和文本框类似,但又非常丰富的可控性。在选择并编辑完成后,你可以点开右侧的「文本通用工具」,在里面进一步调整基线,缩进,字形,排版等设置。文本框的右下角有两个点。内点调节大小时会文字重排,但不会调整字体大小;外点会直接调整字体大小以匹配文本框架。
 框架文本缩放
框架文本缩放
若你想为路径上添加文本,点击「艺术字工具」,并点击任意路径并输入文字即可。若你希望调节文字在路径上的位置,可以拖动文字左侧的绿色小箭头。
 路径文本
路径文本
当你需要导入外来字体时,需先将字体存放到 iOS「文件」应用内。打开 Designer,点击右上角「设置 - 字体 - 云导入」,选择待安装的字体点击「打开」即可安装。
 导入字体
导入字体
你可能需要更多的学习资源来熟练掌握 Designer。目前官方共提供四种教学资源,分别是软件自带的提醒,自带的说明文档,实体纸质书,和网页版视频教程。
 自带的提醒
自带的提醒
 自带的说明文档
自带的说明文档
 实体纸质书
实体纸质书
 视频教程
视频教程
使用费用: 若你订阅过 Adobe CC,可能会被动辄其数千元的订阅年费所震惊。Designer 采用一次性付费机制,这点要比 Adobe 良心许多。
支持的 iPad 版本:Designer 需要可观的运算量,因此对设备硬件有一定要求。它仅支持所有版本的 iPad Pro, 二代之后的 iPad Air,2017 年之后的 iPad,其它机型一律不支持,购买前务必需确认自己的 iPad 处在支持型号中。
触控笔及键盘:Designer 本身对于手势支持极好,若非重度用户不需要触控笔和键盘也完全没问题,所有操作都可以用多指手势完成。若你希望在手绘精准性和操作效率上有所提升,可以考虑搭配 Apple Pencil 和 Smart Keyboard 使用。若你想使用 Apple Pencil 绘画的话,建议在「首选项 - 工具」中开启「仅限手势触摸」以明确分工,避免发生误操作。
简单来说,我很喜欢 Affinity Designer。我认为这是一款针对设计者实际需求认真思考优化后的软件,大到矢量与像素模式的同步使用,无限的画布大小,小到专为 iPad 优化的每一个手势操作,丰富的导出格式等,每一个细节 Designer 都致力于解决创作过程与用户体验中的痛点。
而这一切美好的事物,都在你手边的 iPad 上,它能跟着你随时,随地创作。若你有需要就买吧,这是个不必犹豫的软件。
数字时代高效生活的底层逻辑|《用系统来工作》读书笔记
https://ift.tt/2LpvhwX
西门江雪
本文是「少数派读书笔记征文活动」的第 10 篇入围作品。征文投稿已截止,我们会陆续将入围作品刊载在首页上,刊载完毕后再发布评选结果。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。
记得我刚接触少数派的时候,如获至宝。可看久了,问题也来了:
答案可以很简单:看需求。不过,我的需求是什么?
在我看来,需求不是孤立存在的,一定和工作、生活的方方面面联系在一起,这些方方面面构成了一个系统。要了解需求,就得从整个系统的角度下手。
另一方面,我也摸索出了一套数字时代的生存经验,大概可以分为两类:一类是流程(workflow),一类是清单(checklist)。少数派上也有不少文章实际上是致力于改进流程的:workflow 本身就不用说了,URL Schemes 可以让应用衔接更便捷, todolist 类让任务管理流程更顺畅,写作类工具让写作这件事儿更趁手。凡此种种,有一个最重要的目的,用我的话讲就是:「让整个流程如丝般顺滑。」
不论是想分析和评估各种工具和应用,还是想创造和改进我自己的系统,都得琢磨一下作为「系统」的工作或者生活本身是如何运作的。
想借助前人的智慧,恰好发现了这本《用系统来工作》。
《用系统来工作》的英文原版曾经获得过纽约图书节非小说类最佳图书。原标题是「Work the System」, 副标题是「The Simple Mechanics of Making More and Working Less」,说白了就是事半功倍。实际上这套逻辑除了可以应用到工作上,还可以推广到生活中,work 还有「使……运转」的意思,所以其实我更喜欢把题目理解成「让系统运转起来」,讨论也就可以不限于工作了。
作者是一个叫 Sam Carpenter 的美国人。从前习惯性混吃等死,有一天灵光乍现,想到从另一个视角审视自己的生活,于是白手起家披荆斩棘创建了自己的公司。他用亲身经历阐释这种「系统」的视角,写成此书。
用系统来工作:是指设立目标进而完善系统的机械过程,会确保这些目标的实现。
步骤看起来非常简单:
指的是将看上去一体化的过程拆分为若干环节,把处理各种事务时的过程、步骤掰开了、揉碎了分析。
将设计的系统落实到纸面上,撰写系统三大文件:战略目标、经营总则、工作程序。作者说:
未被写下来的指令是风中羽毛。
区别于系统优化,这里的维护主要指保证系统运转、防止系统崩溃的行为。情绪或体力低潮期更容易意志薄弱,导致个人系统崩溃。
比如作者的个人维护系统之一是每天至少阅读一小时以安抚情绪。我理解的系统维护也可以是设计一种预防系统,就像取票处把验证身份证的平面设计成倾斜的,或者国外 ATM 机设定得先退出银行卡才能取现一样。如果可以借助预防机制强化习惯,便有助于系统的持续运转。
这一步的关键是行动,通过实践反馈来不断调整系统的小细节,提升效能。有个小问题:什么时候是个头?可参考回答:
系统就是标准化程序、项目清单和文件管理吗?
不是。
这本书其实和很多写「掌握工作和生活成功的 5 个秘诀 /10 个步骤」的文章不同,它的主要价值是提供一种世界观,一种看待问题的视角和方式。
我提炼了一下,它的基础是几种思维方式,可以启发我们站在不同角度看世界,也是拯救混乱人生的药方。
每个庞大复杂的系统都是由一个个零碎的部件组成的。因此,如果遇到新问题,或是工作、生活混乱失调,不用眉毛胡子一把抓,只需要做自己的项目工程师,耐心分析一下系统各个环节存在什么问题,然后分而治之、逐个击破。
好的产品经理要对产品和需求保持高度敏感,好的自我管理者也需要对自己的工作和生活保持高度觉知。就像禅宗所说的内观心法,即是将自己当做一个旁观者,细细观察自己的情绪与状态变化。2017 年诺贝尔经济学奖获得者泰勒在《助推》一书里曾经说过,我们有直觉和理性两种思维系统。很多时候我们大脑开启了直觉思维的自动导航系统,才恰恰给了我们冲动鲁莽懒惰等直觉本能趁虚而入的机会1 。因此,将自己当做一个旁观者有利于做出更理智的选择。
基于长年自我观察,我发现:过得去的坎儿就是挑战,过不去的坎儿才是困难;有所得的坎儿是挫折,无所得的坎儿才是失败。如果将工作和生活系统化了,那么所有的挑战和挫折都可以视为优化系统的契机,以这种心态看待遇到的难题,也会豁达许多。搞不好遇到挑战还有点兴奋——优化升级系统的机会来了。
作者认为,多任务处理是机器的事情,人就要按照单一顺序、线性执行。我最近也读到,认知心理学认为大脑更倾向于接受那些明确清晰完整的指令。这还与 GTD 里将事项分解为「下一步行动」一脉相承。因此,不必总时刻想着怎么盖一座完整的大楼,在用设计思维画出图纸后,专注于一砖一瓦就好了。
专注当下并不意味着执迷于碎片,相反,从系统角度审视工作和生活还可以开启上帝视角,在每一个当下都能看到未来。佛谚有云:「做一事成一习,以一习成一性,以一性成一命」2 ,亦同此理。
生活没有快捷键。
放慢节奏,条理生活,培养耐心,以冷静、理智的心态面对和处理各种事务,不仅是「用系统来工作」世界观的基础,也是它的表现。它将潜移默化地影响我们的思维,而我们也将在这不断的系统完善和迭代中打怪升级。
将工作和生活系统化,喜欢条理的人可能很赞同,随性的人可能会反对,觉得这样太无趣了,活得像一台机器一样。我之前一直没想明白这个问题,直到从书中获得了启发。作者反对将系统必然视为僵硬机械的框架,提出了「从刚性框架出发去冒险」的说法:
你的框架应该是一个安全港,便于日后由此产生疯狂怪诞的新想法,以进一步推动你实现理想人生。现在,放慢速度,开始建立秩序和结构。然后,从这个框架出发去冒险。
这个思路让我耳目一新,我知道了系统并不等于机器化,两者可以和谐共处,但也有了两个新疑问:
我想,系统的非僵化应该体现在两个方面:一是创新,也就是这里说的冒险;二是机动,也就是灵活的空间和余地。
作者只是提到了系统和冒险的关系,没有进一步阐释它的实现基础。自己挖坑自己填坑,我姑且推测有这么两方面。一方面,系统文件里的战略目标和经营总则为创新提供了底线。无论形式如何创新,目标和原则仍给人以可靠的安全感,因此创新不意味着偏离方向,只是寻找另外的航线而已。另一方面,拆分环节和程序部件有利于创新。有的时候创新只是不同的元素的不同组合,因此,试着调换一下元素或者组合方式就可以给人新鲜感。
例如,我是一个喜欢以不同姿势写字的人。在将程序部件拆分为写作场景、环境类型、工具、姿势等等后,就可以玩出不同花样。坐着在房间里写乏了,可以出去散步用手机边想边写,还可以带着平板去户外写等等,不一而足,可以不断解锁。
这一点作者没提,于是我继续填坑。机动灵活与创新相比,更倾向于留出顺其自然的余地,而不是自发设计的要素重组。我一直没想明白这点是怎么实现的,直到上周末去逛街。朋友知道,我设计了一套自我管理系统,奖励以积分兑换的方式存在,预先写在清单里,以奖励激励工作。逛街时,我发现了喜欢的耳钉,毫不犹豫地买了。
朋友大吃一惊,问我:「这耳钉没有在你计划之内的奖励清单上啊,为什么你还会买呢?」我说:「这是一种不期而遇的惊喜,完全可以属于奖励的一部分;虽然并未发挥平日里激励的功能,但我只要根据奖励的兑换原则在系统里扣除相应分数就可以了呀。」这样,就既可以维持系统运作,又留有空间和余地,给自己一个惊喜的可能。更何况,根据丹尼尔·平克在《驱动力》里对外在驱动的分析,这种未经计划的惊喜可以给人更大的幸福感3 。
作者没有明确提出系统化的适用范围,我却对这个问题很感兴趣。那么就要回答:
系统化并不是提倡我们要变成一个控制狂。
适度的控制才是获得幸福的关键。
他进一步说明,适度控制的前提是区分可控和不可控因素。可控的,专注处理、积极应对;不受控的,顺其自然。不过,我觉得防止变身控制狂还有另一个维度,那就是清楚群己边界,控制自己的系统,尊重别人的系统,不把个人意志强加于人。
作者自己也说了,不要制定程序处理很少发生的问题。道理很简单,犯不着,浪费时间和精力成本。
作者在这个问题上有前后矛盾之嫌:前面说也适用于个人生活,后面又说用于个人生活写下怎么保养体型这些太傻了。我倒觉得,兴许很多人还不能天然地有序安排好所有工作和生活事宜,用系统来设计生活并无不妥。
比如我虽然喜欢练瑜伽,但有时候还是会犯懒。我分析了去上瑜伽课过程的主要环节是:约课 → 带瑜伽服 → 上课。那么更好地保证上课频率的方式就是,提前准备好瑜伽服,一次课程结束后,趁着酸爽的感觉还在,迅速约好下次上课时间,绝不等到临时才约课。提前约课其实就是利用了行为经济学中的「默认选项」操作,利用自己懒得取消课来保障约好的课这个默认选项。类似的还有利用 Mac 开机时自动启动应用的功能,一开机就打开工作相关应用,缩短热机时间。
作者承认对「整体解决方案」不以为然,提倡分离法和简单机械论。这种说法很容易把自己树成一个靶子。其实,他提倡的不过是「把世界看成一个有序的过程组合,而不是大量景象、声音和事件的混合体」。在我看来,他反对的只是想一口吃个胖子那种生吞活剥的「整体方案」,所以才要庖丁解牛。我理解他的看法,但对作者鼓励多开发循环封闭系统的说法持保留意见。
毕竟,单单声称反对整体观念会有一个隐患:很多问题无法通过一个小系统的自我迭代解决。当我们真的面对类似问题时,或许还要考虑:这个小系统的输入是由什么驱动的?这个小系统的输出又能驱动什么?这些都要与单一系统之外的事物和人关联。我们要做的只不过是先从一个小系统入手,再在迭代过程中发现系统缺陷,在更大的系统中改进罢了。
回到开头的问题,这本书对我分析和评估各种工具和应用,或者创造和改进自我系统有没有帮助呢?
有。
教育心理学中有一个布鲁姆分类(Bloom’s Taronomy),说的正是学习程度的测量维度:回忆、理解、应用、分析、评估、创造4 。先有理解,才能分析、评估,进而创造。思考系统的构建和运作逻辑,对更新自我系统的作用自不必说,而对工具分析的作用则可以体现在我对数字时代人器关系的反思上。
数字时代人和工具的关系应该是怎样的?
如果把人的工作和生活看作一个系统,站在工具的角度可以帮我们:
而从系统角度来看工具,则可以帮我们:
平心而论,从行文表达和逻辑组织上看,这本书并不能称得上是一本优秀的书,以经历和故事为主,结构非常松散,表达中还有重复和矛盾之处;但这丝毫不妨碍它的启发性。至少这次它帮助我又一次优化了我的系统,而且是底层系统,也算值回时间。写到这里,我想到,或许系统的世界观还可以帮我们树立一种新的价值意识,不利于系统优化的无论看出来多么高大上都不应该占用太多精力,而有利于系统优化的不论看起来多么不起眼也不应该忽略。
事物本身的价值应该由自己判断,不同人对同一事物有不同的打开方式,同一人对同一事物在不同时期也会有不同认识——或许是一个彩蛋了。
阅读,时间交易的艺术(一):不要在阅读中浪费生命
https://ift.tt/2N7W51l
蔽锥
阅读是一场花自己的时间去交换别人的时间的交易,虽然看起来人人都会阅读,但你是否考虑过,在这场交易中你做也许是亏本买卖?你读的是什么?「读别人的书,是浪费你自己的生命」,茫茫书海中,你抄起来的那本书值得你浪费你的生命么?你怎么读的?你看完一本书之后再想引用书中的理论或事例时,能很快地想起或找到么,你对得起你付出的时间么?
「读什么」和「怎么读」这两个基本问题有很多大牛都分享过观点,我想介绍的是从时间交易的维度思考模式。在交易思维中,由于涉及盈亏,容不下各类模糊的马虎眼。精明的商人不是用格言警句来优化交易的,优化中最重要的是清晰界定标准,确定限制条件,再谈优化的方式。在阅读这场时间交易中,做一个精明的商人,也就是要精打细算地思考「读什么才值得浪费自己生命」以及「怎样读才对得起自己的时间」。
谈阅读方法的文章首次出现不会比文字首次出现晚太多,不过详细地从时间交易的角度「鸡贼」地讨论这个方法,这也许算第一次。我将综合介绍我从万维钢以及阳志平处学习到的阅读经验,结合我的切身阅读感受,介绍我摸索到的,阅读这门交易中交易的艺术。
") 特朗普大统领《交易的艺术》 (大误)
特朗普大统领《交易的艺术》 (大误)
我最早是从万维钢的《万万没想到》中,学到如何优化阅读方法的。这是一本 2014 年出版的老书,里面集结的是万维钢(网名:同人于野 微博)早年的博客 学而时嘻之 的部分文章,讲的都是从当时前沿的文章中得出的理工科思维方式如何认识世界的,「优化」正是这种思维方式的一大特色。书中有几篇关于阅读的讨论,其中提倡的「强力研读」方法对我影响很深,更重要的是其中围绕「强力研读」对阅读过程进行优化的整套方法论,让我领略了「对得起时间」的阅读方式。
 《万万没想到》封面
《万万没想到》封面
帮助我清晰思考这场时间交易的,影响我阅读方法更多的,是阳志平的一系列文章 (文章目录),可惜其文章尚未结集出版,故而本文算是对万维钢《万万没想到》一书的书评。阳志平老师的论述尽管更宏大和系统,但基于自我决定论的底色让这一切稍微不那么「理工科」,而是融入了人文情怀:阅读是你自己的事情。你可以,甚至应该和其他人不一样。这就是我说这门交易是艺术,而不是技术的最重要原因。
本文分为两篇,分别从「读什么」和「怎么读」的角度分享我所知的阅读交易技巧,此篇先从「读什么」开始,思考如何优化这场交易。
首先,既然是要换回来些什么,人生有限,而知也无涯,无法尽取,一生有限的交易中不浪费,首先要挑选好到底「读什么」。除了珍惜有限的生命外,甄选「读什么」还是在保护你的大脑,因为你通过阅读换回来的东西是放在脑袋里,读一本劣作,既浪费时间又在脑中平添糟粕,简直是双重打击。
无论是经典的《如何阅读一本书》、《如何读,为什么读》,还是街谈巷议,都会教你在书籍的汪洋中甄别该读的内容。一种常见的论调是,多读,你很快就会找到读的办法了,话是没错,却缺乏洞见,还不如介绍具体的标准。另一种常见的方法是开始凭借审美取向开列书单,天知道世上这样粗暴的判断的清单有多少。
一个精明的时间交易商,解决「读什么」的问题,需要一个清晰的判断好书的标准。《万万没想到》中处理这个问题非常的「理工科思维」,和断言警句不同,所谓理工科思维就是要摆事实讲道理,尽量让这个过程可测度,能操作。在书中,万维钢找到的标准是时间的「密度」,即花费单位时间换取到的时间量。第一次发现这个思路时,犹如一股清流涌入脑中,让我们从这个标准看起,逐渐深入思考怎么从时间交易的维度来选择「读什么」。
既然是换时间,那最直接的想法就是:同样的付出下换来尽量多的时间。《万万没想到》里就是这么考虑的,在讨论如何甄别阅读对象时,万维钢提出了一个思维密集度的概念,即
思维密集度 = 准备这个读物需要的时间/阅读这个读物需要的时间
一次阅读的思维密集度越高,也就是你花去的单位时间换来更多别人的时间,这是很划算的。比如万维钢十分喜欢非虚构作品,因为其中凝结的时间非常多:非虚构作品后面往往附着很长的注记和参考文献,其中凝结了作者巨量的时间,包括原作者阅读十倍的材料、采访相关人员、前往世界各地调查的时间;更进一步,书中关键的研究可能是数个团队花费无数的时间和金钱取得的。
沿着思维密集度这个概念,考虑「读什么」时,可以先判断其中凝结了多少的时间。万维钢提到新闻巨头默多克每天只看纽约时报和华尔街时报的头版,《黑天鹅》的作者塔勒布几乎不再看报纸和杂志,只读书。我们也许不用如此极端,但单从这个角度思考,同样阅读时间,该看普通的新闻、公众号文章、报刊、一线报刊、一线报刊的封面新闻、成功学书籍还是非虚构类专著,答案就十分明显了。
如果用书中凝结的时间「量」作为标准,你也许会疑问,所有人的时间是一样的么?的确,书籍中凝结的时间价值并不是简单计算「无差别的人类劳动」。笨人花笨功夫堆积半天猜笨迷,或者民科连知识的底板都没扎牢靠就要改天换地,这些情况下尽管也许他们倾注毕生心血,但也没有凝结出什么有益的东西,根本不值得换。
「单位时间内换取的时间量」并不是个完美的标准,但可以沿着这条路进行改良。《万万没想到》中也意识到不同人的时间是不同的,牛人在创作时会撬动他人的力量,同一本书的创作时间里时间的不同。一本书中最关键的 20% 核心内容一般由作者完成,而案例的补入、文辞的润色等时间是由助手等提供的。
格林斯潘写《动荡的世界》(The Age of Turbulence),据说基本是在浴缸里用铅笔在卡片上完成,手稿都是湿漉漉的。马布巴尼(Mahbubani)在《新亚洲半球》(The New Asian Hemisphere)这本书的感谢部分透露了牛人写书的写法:他写的时候只提供**,句子中有大量的空白,留给秘书去补充具体数字和细节。托马斯·弗里德曼(Thomas Friedman)写《世界是平的》,有一个秘书团队支持。就连娱乐人物艾尔·弗兰肯(Al Franken)写书讽刺美国政治,都有一个哈佛大学的研究生团队为他工作。
虽然万维钢本人并没有继续修正时间「密度」的标准,但如果加上这个补丁的话,从《万万没想到》里,我学到的「读什么」的标准是:「单位时间内换取的Σ(时间量*时间重要性)」。由此,可以得到一个优化方案:单位时间内要尽量多地换取书中最重要的人的时间。万维钢提供了判断一本书中内容重要性的洞见:重要的内容经常凝结在书本的框架脉络中,所以万维钢的建议是,在阅读时要尽量多地关注书中的框架脉络。某种程度上这是反直觉的,阅读时我经常记住并广为转述的是书中的案例,而不是框架。我相信你比我强,读到此处时,还记得我们旅程是从标准入手,逐渐确定我们要优化的目标。
顺着这个思路,既然同一本书中不同人的时间质量是不同的,不同的书之间的时间的质量如何衡量呢?《万万没想到》中对此没有答案,尽管万维钢喜爱非虚构类读物,但并没阐述他是如何在众多非虚构书籍中进行的。用「密度」框架思考「读什么」并不不完美,但是它让我意识到「读什么」的标准是可以更清晰的。最终解决我这个疑问是阳志平。
在思考「读什么」时,我们有了「单位时间内换取尽量多的重要的时间」的优化方案,但要在不同的书之间判定重要性,需要一个更宏大的价值系统。这并不意味着我们要进入价值判断「萝卜青菜」的窠臼,因为我见过一套非常理性的判断标准,来自阳志平。
沿用「密度」框架,可以冒昧将阳志平对书的价值判断概括为:单位时间内要尽量多地学习时代里最本源的学科中的最本源的知识。此处所指的本源并不是单单指「早期」,而是指他们在知识网络中处在的源头位置,即开一派之先的地位。本源之所以重要是演绎法的体现,所有的演绎都可以回归几个基本的源头,掌握源头强于掌握演绎,就如欧氏几何凭借极少的公理和定义就演绎出煌煌巨著。我将从三个关键词出发,对此做进一步解释:
第一个关键词是:时代。每个时代有不同的母题(motif),一个时代的母题是这个时代最主线的搏动,是时代的挑战、机遇以及认知边界最根本的体现,贴近时代母题比远离时代母题的知识更重要。不同的时代里,最主线的母题是不同的,阳志平对当下以及未来时代母题的判断是:「21 世纪是以建设虚拟世界为时代母题的计算机科学与网络科学; 22 世纪极有可能是宇宙学,那时人类已经步入太空时代。」查理·芒格曾经提出,要学习重要学科的重要模型,阳志平学习了芒格的思路但加入了时代的维度。在芒格的时代,时代认知科学、网络科学等尚未发端,这些当今显学的重要模型,在芒格已经出版的著作中难觅踪迹。
第二个关键是:最本源的学科。不同的学科之间的重要性,可以通过它们的本源程度来判断,更本源的学科包含着下游学科的基础。阳志平提供的方法是:将时代中的学科,按诞生历史进行排序,把里面偏一级的学科找到,然后通过科学期刊上的论文引用率排序,同时将相似的学科合并同类项,得出大致范围,综合考虑时代的母题,思考这些学科之间哪些更为本源和基础。一些不可化约的学科,如数学,则是任何时代都最本源的来源。综合判断后,阳志平提出了「五大元学科」的概念,即网络科学、认知&神经&心理科学、编程、数学与诗歌,进而还编列了开智正典(书单地址)。阳志平坦承,「五大元学科」的提法并不是精准,是一个「美学近似值」。你可以不同意这个结论,但是依旧可以照此方法判断时代里的重要学科是什么,你可以设置不同的标准,同时你也得为你的选择负起责任。
第三个关键是:学科中的本源知识。就像不同的学科在知识网络中的重要性上有差别一样,同一个学科内的一些知识也会比另一些更加的源头,掌握更源头的知识能够辐射更多下游知识。找到这些源头的方法与找到源头学科类似,即找到知识网络中更基础的那些知识,不过对于知识很少有严谨的引用排行。一个取巧方式是,学科内最本源的重要知识都是由少数这个学科内的天才创造的,可以通过学科文献引用率很快地找到这些天才,他们的作品中最重要的知识也在他们的少数作品中,找到他们最高引的几个重要内容即可找到那些知识的源头。阳志平借鉴马奇《经验的疆界》的说法,将知识分为了三类:模型,故事和行动,而找到各个学科中最本源的知识,就是不断地去找到抽象级别更高的高阶模型,找到更广为流传的故事内核,找到更新的「第二序改变」。
以人类误判心理学为例,畅销书《清醒思考的艺术》中总结了 52 种认知偏差,阳志平认为这是本书不够本源,因为「你把这 52 种认知偏差背得滚瓜烂熟,但只要有一个文笔更好的作者写了一本新书,假设这本新书只写了 36 种或者 42 种认知偏差,你又得将所有的知识体系推翻重来。无论最初的 52 种认知偏差,还是之后的 36 种或 42 种,最核心的源头知识来自少数研究者的贡献。你需要回到知识源头,掌握这些深层次的原理,并且创造足够多的练习机会,让它内化成你的本能。」
这套判断阅读对象价值重要性的标准,建立在网络分析以及现行学科体系的基础之上,借用了网络分析中分析源头的方法,在现行学科体系中找到最重要的本源的知识节点,而不单单是审美取向。在具体的判断中,阳志平加入了自己的取舍方案,对于结论不必照单全收,更重要的是这整套的分析方法。从现行科学体系中利用网络分析找到重要节点,需要对现行学科体系的认识以及网络分析的方法:
由此,思考「读什么」时,我们有了更好的优化方案:「单位时间内换取尽量多的时代本源学科内的本源知识」。在做阅读这场时间交易中,有了一个清晰、可实践的基础。
确定了标准,就可以筛选书了,凡选择必有代价,利用标准筛选掉的资源里的价值就是这套标准的机会成本,一个精明的商人除了做到利益最大化,也要做到损失最小化,在阅读中不够本源的内容该怎么办呢?
之前讨论了时间总量有限的情况下,优化「读什么」的方案。其实每个人遇到的限制还包括精力有限,每天的精力的总量是有限制的,而能够聚精会神的时间则更少。所以利用稍差一些的精力去减少损失,是完全划算的,也就是可以为不同的价值密度的读物分级,然后分级处理。
阳志平则将书分为了坏书、可用的书、力作、杰作与神作。对不同等级的图书,可以分配不同的时间,按不同的方式去阅读。《万万没想到》中,万维钢延续《如何阅读一本书》中对消遣阅读、以理解为目的阅读的分类,认为只有在以理解为目的的阅读中是最高级的阅读需要倾注最多的努力。
对于其他等级的信息,比如报刊、公众号文章等,阳志平是嗤之以鼻的,而万维钢则建议参考纽约书评对书的分级,把信息分为 toss skim read 三类,对它们采取先收集再处理的方式。我认为,在损失最小化的意义上,我更认同万维钢的处理模式,各个不同的媒介都不应该轻言放弃,而应该管理好,毕竟我个人对万维钢以及阳志平的学习,就是通过他们的博客、公众号等逐步入门的。我关于碎片阅读如何处理,我近期也将有文章出炉,欢迎关注。
有了标准,有了分级,在「读什么」上,我们的优化方案就呼之欲出了:
在阅读这场时间交易中,本文处理了如何筛选才能换回来不浪费生命的作品的方法,这只是一个初步的开始,交易的另一部分是,如何才能有一种配得上你时间的阅读方法呢?我们下回再说。
读《你要如何衡量你的人生》
https://ift.tt/2Q4bv7Q
forecho
本书有三个作者,但是最主要作者还是克里斯坦森,之后我才发现原来我买过他写的《创新者的窘境》这本书,虽然那本书我还没看(捂脸.gif)。
本书起源于2010年春,哈佛大学邀请克里斯坦森为毕业班的学生做演讲的内容。书中最主要讲述的三个主题,分别是:
下面我会分别来讲讲自己的收获与理解。但是在这之前需要说明的是,下面的内容有可能是带有偏见的,有可能是不够全面的,想要了解全部内容,还是推荐大家亲自去看书。
真正激励你的是什么?
想知道『如何获取事业上的成功?』之前,你要先思考一下『真正激励你的是什么?』。
作者给出了评判标准,将所有因素分两种,分别是:动力因素和基础因素,具体情况是:
克里斯坦森在序章明确指出『授人以鱼不如授人以渔』的观点。所以本书并不会直接回答你以上几个问题,而是告诉你怎么去思考。
基础因素只是幸福的副产品,让你不讨厌工作,但是一般不会让你爱上工作。而真正让你非常满意并且能爱上工作的是动力因素。那么现在你就要问问自己一下几个问题了:
如何找到自己事业呢?
你需要周密计划和偶然计划。你的人生是需要有规划的,但是我们也要抓住偶然获得的机会(这个机会是计划之外的)。
很多时候成功往往在你意料之外的地方。如果你还没有找到一个你热爱的事业,周密计划就代表着你现在的工作,但是我们也要时常去关注偶然的机会。
这里克里斯坦森提出了一个『发现 - 驱动计划』来帮你做出最佳的选择,你可以把这计划理解为『哪些假设条件需要得到验证,才能说明这个战略有效』。我的理解是这样的:
资源分配
我们拥有的资源包括:
因为资源的分配和回报永远成正比,那么如何来分配这些资源是非常重要的。如果说我想学英语我想健身。但是我从来不花时间和精力在学英语和健身上,我怎么可能会学到英语和拥有强壮的身体?
生活中你的每一次资源的分配,都表明了你真正在乎的是什么。你可以尝试在笔记本里面记录下你每天分配这些资源的情况。不用记录多久,一个星期就足够了。然后你会发现你花在看电视或者游戏上的时间远比你花上看书或者学习的时间要多得多。
不要只做立即获取回报的事情,事业可能算是一个立即获取资源的事情,但是你不能因为整天忙着工作,却不花时间来陪伴伴侣、教育孩子,最后下来,你的事业成功了,但是你的家庭却不幸福,你赚那么多钱有什么用。
投资资源
建立牢固的朋友和家庭关系,最重要的是投资时间。多留点时间给朋友和家庭,这部分会给我们带来永久的幸福。
不要因为孩子还小,就想着现在去忙事业,不花时间来陪孩子,时光不会倒流。研究表明孩子在出生头几个月的情况下对其智力发展非常重要,孩子听人说话最重要的时候就是刚出生的第一年,接触大量谈话的孩子拥有不可估量的认知优势。
如果你总是延后投资时间和精力,直到你感觉需要进行投资的时候就表示已经没机会了。
改变看问题的角度
这点对于改善你的人际关系非常有效。我们不能总是考虑自己需要什么,而不考虑对他人而言什么事情是最重要的。
要设身处地的站在她(也可以是他,以下都适用)的角度为她着想。不要只做正确的事情,而是做对方最需要我们做的事情。通往幸福婚姻的道路是找到你想让她幸福的那个人,她的幸福值得你付出。
孩子教育的问题
在讲这个之前克里斯坦森先讲了企业发展的问题,还拿戴尔做了案例。戴尔曾经是令人看好的电脑企业公司之一,却逐渐因为外包而使自己走上平庸的道路。文中有介绍华硕是怎么通过一步一步去『诱惑』戴尔外包给他,然后成长,最后独立的故事。
为了避免这种情况的出现我们先要了解自己的能力,知道什么能力不重要,什么能力是自己未来的核心。从而不要把自己的未来外包出去。
然后回到教育孩子的问题上来,同样我们也不要把教育孩子的机会外包出去。搞清楚你带孩子去参加各种活动真正的意图,是你想让他参加这个活动还是他想参加这些活动。也不要随便的给孩子报各种课外班,最好亲自去教导他们,而不是把他们丢给别人来教,孩子是在自己准备好时才能学到东西,而不是在我们准备好教导他们的时候。
克里斯坦森提到有三大能力决定一家企业能做什么不能做什么:
然后我们再回到孩子的教育问题上,同样使用『资源、应用流程和行为价值取向』模型来评估:
在『资源、应用流程和行为价值取向』模型中,三个能力才是决定一个孩子能变成什么样人,资源不是最重要的。
父母需要注意
写这一章节是因为克里斯坦森发现自己身边的同学或者朋友,以前是个好男人 - 聪明,事业成功,有责任心,但是最后却变成婚姻不幸福,甚至犯罪的道路。
克里斯坦森提到一下注意点:
由于篇幅和我的组织能力有限,我没有把书中所有的内容都整理出来,我推荐大家亲自去读这本书,书中克里斯坦森用到了很多公司的案例来我们讲解,而且会把公司的管理方式套用在家庭上,非常的有趣。
看完书之后,我要好好思考一下几个问题:
说了这么多,如果你对本书感兴趣,可以点击这里去**亚马逊购买,不到23块钱,两顿饭的钱,非常值。
PS:这是我第一次尝试写这么长的读书分享,欢迎大家多给点反馈。我打算以后每个月至少写一篇这样的读书分享,欢迎大家支持我和我一起读书。
本文写于 2017年04月11日,首发于我的个人博客:https://blog.forecho.com/how-will-you-measure-your-life.html

利用标签来整理阅读内容——《会读才会写》的读书笔记
https://ift.tt/2vj8MP8
SpecialK
本文是「少数派读书笔记征文活动」的第 2 篇入围作品,参与本次征文,将有机会赢取 Kindle Oasis 等丰厚奖品,你可以 点此查看 活动规则和奖品清单。
本文仅代表作者本人观点,少数派仅对标题和排版略作调整。
社会科学的写作,一直都有相对固定的「范式」。彭玉生在《“洋八股”与社会科学规范》将其划分为:问题、文献、假设、测量、数据、方法、分析、结论。
 “洋八股”与社会科学规范
“洋八股”与社会科学规范
对于社会科学类专业的学生来说,这些内容应该再熟悉不过了。面对这样泾渭分明的文章结构,需要从何处着手呢?
打表格是多数老师会建议你去做的方式。打表其实是在让你去筛选阅读中的关键信息。这些信息对于某一类文章都是普遍适用的,而如何选择需要的关键信息的类别,师门不同,就会有不同的方式。

《会读才会写》中提供了一个非常有意思的思路——利用「阅读密码」来做文献阅读的技巧,并且基于这些「密码」,来整理你的文献。作为读书笔记,本文会先介绍这本书的关键内容,再结合自身的使用,谈谈适用于日常阅读如何结合书中的方法。
 《会读才会写》
《会读才会写》
本书中的介绍的核心方法,就是添加「阅读密码」的方式,来标记文献的内容。将书中的「阅读密码」,所谓的阅读密码,其实就是将一些常用的标注简化为缩写的字母。将密码理解为「标签」更符合少数派读者的习惯,也更利于将这种方法扩展,所以下文我用标签来代指书中的阅读密码。
关于文献阅读,书中其实总结了两大类标签,首先是基于文献内容的标签,包括了:
其次是读者需要评注的部分的标签:POC (批评点 :Point of Critique)、MOP(明显的遗漏点:Missed Obvious Point)、RPP(待探讨的相关问题 :Relevant Point to Pursue) 、WIL (能否:Will)。书中将这些标签称为阅读策略。
每个标签(密码)对应的更具体含义在下表中给出 [1]:

需要注意的是,所谓「洋八股」的社会科学范式,每个部分所侧重的内容其实各有不同,在实际标注中也没有必要每一句话都要套用一个密码。标注标签的目的对于社会科学的文献研究来说,主要还是为了厘清文章的脉络,理解作者的逻辑,并为后续处理做准备。所以如何打标签,应当着重以目的为导向。书中有表格给出,用以识别文本的功能,表格如下 [2]:

现在,知道了这些密码就好像是知道了某张考卷的答案,只知道答案,却不解其缘由,显然是不行。
作者两个维度的分类,其实既满足了文献阅读中划出重点的需求也实现了简单的批注。并且,还一个极大的优势是后期的整理:

通过两个维度的整理,即对文章内容有了梳理,也为后续可能会用到的引用文献做了准备。
书中给出的标签,在我实际使用中的感受是十分适用的。可能是因为自己也是社科类的学生,所以基本上的标签在社科类的文献中都很适用。对于如何学习和习惯这种方法,结合我自己的实际使用,我给出一下几点建议:
针对一个问题,每一次密集阅读在整理文献时,反思一下此前的标签体系,做一些修改,这样在后续的使用中就能够更加习惯和自如了。
除了重点介绍的「阅读密码」,其实书中开始就提到另一套标签。以往每年整理学生的论文,为论文打分都是一件让作者感到头疼的事。因为经常会有人不满于自己的成绩,要与作者理论,这极大的消耗了作者的精力。于是,作者开始使用各种标签标记学生的文章,如:
通过这些标签,作者可以指出学生的问题所在,并为每个错误设置扣分值,加之全文的总体感受打上分数。这样做免除了不必要的麻烦的同时节省了宝贵的时间,也帮助学生认识到了自己文章的问题。
作者文中提到的这件事,其实正是验证了通过为文章内容打标签的方式,能够在某些方面实现意想不到的便利。书中提及的上述两套标签,分别帮助作者优雅的解决了文献阅读与文献批改的种种问题。第一套标签,作者利用两个维度设计了用于整理文章内容和用于标记批注类型的两个类型的标签。第二套标签,作者为不同标签赋予权重,为文章打分提供了依据。
对于有相同或者相近需求的学者们来说,上述内容是可以直接参考的。作者在书中通过大段的文本验证了即便是对于哲学研究,本书所设置的标签也是适用的。所以如果从事科学研究,是可以好好看看这本书的。书中其实有较多内容像是作者的碎碎念,如果身在学术共同体,一定会有更深的感受,对于作者的吐槽也会会心一笑。
其实这种方法也能很便捷的融入到自己的阅读体系中。为文章做标记或者高亮(highlight)某一段文字,其实也可以看作是一个标签。这个标签的作用是,提醒自己关注这段文字。这就好像任务管理中的优先级一般,是否高亮其实就是「优先」与「一般」的区别。构建自己的标签(密码)体系,利用诸如 Instapaper、Bear、Kindle 等软硬件的标注功能,来为自己阅读流打上标签(密码),实现自己对于阅读摄入的某种需求。
我为自己的日常阅读设计了以下的一些标签,希望能够提供各位参考:
在手机、iPad 上的阅读,我一般分两种情况处理。首先是利用 Instapaper 中直接标注法。之后再利用 Workflow 发送到印象笔记,进行归档 [3]。出现的 Instapaper 中的文章都是经过筛选的,都会有一定的标注的必要。其次是第二种情况,来自诸如 微信公众号、知乎、微博等等地方的文章,我一般的做法是通过发送到 Drafts 标注,再定期处理 Drafts 的 inbox ,发送到印象笔记归档。 Drafts 可以通过 Workflow 、Pin 等等工具实现快速、统一的抓取文字片段,并且添加标注。而在 Kindle 上看时,使用简短的标记,能够实现更为便利的标注体验。标注后再利用 Klib 导出到印象笔记归档即可。

最后,愿本文能够为大家提供有益的参考。
[1]: 见原书前言,表1 。
[2]: 见原书第 85 页,表 7.3 。原表还有一列是用来统计页数的,这里将其略去了。
[3]: Workflow 使用的是 Power+ 中的方法。
> 在 8 月 13 日前,参与读书笔记征文活动,赢取我们为你准备的丰厚大奖。你可以 点此 了解详细的征文规则。
卢小波: 难吃的月饼,勾画出了**的人际关系
https://ift.tt/2MWKh19
我有个朋友,88岁,有钱,银行理财每一笔都是上千万。前几天,他兴高采烈说:“我把一套房子卖掉了,又赚了420万!”
他走路已不太稳了,不说是颤颤巍巍,也算步履蹒跚。他赚钱还有意义吗?当然有,肯定有。我常在旁人议论时,为他辩护。
还有个广州朋友,也有钱。有钱人往往有收集癖。比如这几天,他就在热衷于收集各种月饼,一会儿惋惜,一会儿惊喜,一会儿愤怒:
“淘宝买不到恩平德发的豆沙月饼,唉唉。”
“哇,新会的陈皮豆沙和陈皮冬蓉,啊啊啊!”
“大班冰皮天下第一不接受任何质疑,哼哼!”
就这样,他还让太太另做三五十个豆沙月饼,在朋友圈里狂晒。除此以外,依他的人缘,起码还会收到个五六个礼盒月饼。
如此多的月饼,吃得完吗?这跟质疑开头那个老爷子一样,问题表面蠢萌,但还是值得一答。
节日就像时间的驿站,我们身为旅客,每到一站就得到一种标志性食品。春节是饺子,清明是团子,端午是粽子,中秋是月饼。
月饼的古怪在于,全世界没有哪一种食品像它这样,在短期内大规模迅速生产而又大量抛弃的。
如果你上网搜一搜“月饼喂猪”,百度的相关结果约为285,000个。“月饼喂猪”多到什么程度呢?很多养猪网站兽医网站,都有这种问答:“用月饼喂猪应该注意什么?”
 网络截图
网络截图
大规模生产,当然是刚需。天心月圆,桌面没有月饼,那还叫中秋吗?
更有意思的在于,它是一种泛社交产品。如果哪家主人,中秋时节没收个三盒两盒,他一定会感叹世态炎凉。如果桌上只孤零零一盒,还是主人自己买的,把他定位为社会边缘群体,基本不会冤枉。
我有时幻想,如果能在月饼盒里安装上GPS,观察记录它的轨迹,可以描出一幅最壮观的人类社交图。同一盒月饼,往往是你送给我,我再转送给别人,别人再转送给第三人。在不同的人家,转手两三次是常态。
所以,月饼在一定时期内,是具有金融属性的。它像是人情硬通货,流动性极大。
前几天看上海媒体报道说,22家高校食堂制作校徽校训月饼。有两位朋友就告诉我,主要不是学生自己吃,好多本地家长都让孩子多买些,送给长辈朋友。特别是名校月饼,饼皮上印着显赫校徽,简直可以光宗耀祖。作为人情硬通货,它的面值比较特殊,有金银纪念币的作用。
还有媒体报道说,这几天,上海的大妈爷叔“轧闹猛”,在老字号月饼铺外边,大排长队买月饼。队伍有多长?要排10小时以上。有些人甚至带来硬纸板、凉席等,其中还有些人直接打地铺睡路上。
 新闻图片:排队买月饼
新闻图片:排队买月饼
排队购物,当然是因为供应短缺。为什么会供应短缺呢?不是月饼少,而是好吃的月饼太少。有不少网友在新闻下留言:“吃月饼的人不会去排队的,排队的人都不是自己吃的。”送人当然要送好吃的。在这个意义上,要赞扬这些排队的人,他们送月饼送得比较真诚。
月饼最为人诟病的,是严重的高糖高油。每到中秋,就不断有医生出来呼吁,每人每天吃月饼,最好不要超过一个。特别是老人和孩子,尽量少吃。打开媒体,触目皆是“月饼吃多了会怎样”“怎样健康吃月饼”。反正,没人有办法放开肚皮吃月饼。试问,你可以一天三顿吃面条,但你敢一天三顿吃月饼吗?
所以,吃月饼基本是个体力活儿。
有个同事在办公室里说,他一天能吃4块月饼,立即收到大面积钦佩的目光,引来无数真诚赞叹。我猜,广州那个有钱朋友,狂晒他如何大吃月饼,应该是不方便夸耀自己肾好胃好,只好通过表态大吃月饼,暗示自己各方面身体指标好。
每家都有摞得很高的月饼,而且不能多吃。厂家商家的月饼,只要过了中秋这一天,就再也没人买,那只好喂猪了。可是猪也无辜啊。有人为猪打抱不平:“古人云,己所不欲,勿施于猪。人吃了会致病,猪吃了同样会致病。在这一点上,猪与人是一样的啊。”
月饼是人情硬通货,可是流通性再强,也会贬值。在治理月饼“通货膨胀”上,大家各有高招。最普遍的方式,是在礼盒里塞进茶叶、名酒,甚至手表。这就像金融衍生品,它有杠杆效应,能够最大力度撬动人情与社交。
在运营月饼“金融衍生品”上,全国再没有任何一个创意,能超过厦门人。
此地有“中秋博饼”的习俗,传说是郑成功发明的。早前是这么玩的:桌子摆放着一盒“会饼”,月饼从大到小,依次有32个。设状元1个,对堂2个,三红4个,四进8个,二举16个,一秀32个。大家围着一盒月饼,把六粒骰子掷到大碗里,以骰子点数的大小,决定你抢到月饼的大小。通过博饼,来预测你未来一年内的运气。
") 博饼习俗雕塑(来自网络)
博饼习俗雕塑(来自网络)
骰子在大碗里叮叮当当,很像一场赌博。专家学者评价,这是科举文化与博弈文化的优质组合,是有情感寄托的欢乐民俗。
在物质短缺时代,抢个大月饼回家蛮好。1995年我来厦门时,在单位里还博了一个状元大月饼。
时间飞快,就到了“月饼喂猪”的年代。厦门人的“博饼”习俗,也在慢慢地演变。开头,是在“博饼”时,添加了牙刷、肥皂之类的日用品,既有月饼也有衍生品。到了后来,所谓“博饼”,桌上完全没有月饼。就如同金融衍生品,完全看不到钞票。“博饼”的衍生物,从牙刷、酱油、大米,到化妆品、高压锅、羽绒被、电冰箱,应有尽有。最后,“博饼”现场来了最高奖品――汽车。
一把骰子掷下,状元可以当场开走汽车。
到了此时,“博饼”就成了全民狂欢。这个以月饼为名但不见月饼的活动,从农历八月初一起延续到农历九月初。如果是社交达人,一晚上要参加两三场博饼,一个多月参加个三五十场活动,这是基本常态。商场的日用品销售之旺,比春节只赢不输。晚上走进任何一个小区,都能听到窗口传来叮叮当当的掷骰子之声。
官方和商家,当然要与民同乐。全市要举办博饼大赛,各小区推出状元,状元与状元再PK,逐级比拼运气,最后比出总状元。
有那么几年,“博饼”的决赛现场,摆放在鼓浪屿的日光岩顶。巅峰之上,众人屏声敛气。全市十大高手,在天风海涛之中,对着一个巨大的红色瓷碗,掷下他的运气。
从月饼出发的活动,最终走至巅峰,厦门人也算是天涯若比邻,海内无知己了。拔剑四顾,治理“月饼通货膨胀”,谁能比得过厦门人?
月饼的正途,当然不在衍生品上。厦门“博饼”习俗终于式微。无论怎样,月饼的终极指向,仍要回归味之道。
作家桑格格说:“月饼什么时候能像是肉包子那么好吃,就算攻克难关了。”
月饼就是“国饼”啊。月饼界举四海之力,把你能够想象的所有食材,都往月饼里面放,麻辣龙虾、藤椒牛肉、韭菜鸡蛋、松露鹅肝、梅菜扣肉、酸菜带鱼……最后,把方便面、金嗓子喉片,都塞进月饼了。
 “五仁”月饼是网友投票选出的最难吃月饼,但是还有人独爱五仁
“五仁”月饼是网友投票选出的最难吃月饼,但是还有人独爱五仁
月饼界的长期攻关,终有回报。上天派来了拯救月饼的使者。今年中秋期间,高档月饼、新派月饼,全面进入爆发式增长。
一位广告界朋友举例说,一个没有任何宣传的冰淇淋新品牌,改做月饼。需在零下18到22度保存的月饼,突然爆销一时。好几种低温月饼,也同样不需要广告宣传,都生产来不及。原来计划宣传的,也全都置换档期,改成节后宣传其它产品。
 冰淇淋月饼
冰淇淋月饼
年轻人回到了月饼制造和消费主场。月饼这个社交产品,发生了核聚变。
让人惊奇的是,所有业者的主产品,原来都不是月饼。大的是和利、星巴克、哈根达斯,小的是甜品店和咖啡馆。对于他们来说,月饼就是一种季节限定款甜品。
月饼界忽然变得面目全非。拿冰淇淋做月饼,它还叫月饼吗,月饼的概念要重新定义吗?吃着冰激凌月饼,还会遥想唐诗宋词中的月亮吗?这种月饼还有没有原来的文化含量?
月饼起自唐朝的“胡饼”,到宋朝始有“月饼”之称。**人中秋吃月饼习俗,是从明朝开始的。唐朝的“胡饼”,跟传统月饼的差距,应该是大过传统月饼与冰淇淋月饼的差距。
一位行家说,在做西点的年轻人看来,月饼是一种很容易理解的糕点。月饼市场的洗牌,一直在进行中。月饼的突变,早有基础。
难道,月饼不是让年轻人热烈喜欢,才更强大更有生命力吗?
一位中年人说,他今年还是收到了一堆月饼,还是吃不过来。但他把传统月饼都送出去了,年轻人送的低温月饼,都保存在冰箱了。年轻人让月饼辗转于冰箱之间,正在逐步切断月饼走向猪圈的道路。
日本的正冈子规改良了俳句,到今天日本人都能自然地用传统诗歌表达情感。他说,和歌的用词不需要“拟古”,俳句用现代语、汉语、外来语都可以。**没有正冈子规这种人,来改良传统诗词,但至少现代诗抒写月亮,也一样动人。
赫尔岑说:“反复的节奏,重现的旋律,人生对此是有所偏爱的。”月亮每日两次带来潮水,每29.5天一次盈亏,每年呈现一次大圆满。而月饼,每年只吃那么几口,味道怎么样,真的很重要。
世界上,再无一种食品能像月饼那样,承载如此多的文化符号。它是诗意,是习俗,是伦常,是人情,是排场,是单位福利,更是民族性格。
感谢年轻人拯救了“国饼”。
原标题:《上天派来了拯救月饼界的使者》
维舟: 从戊戌变法的失败说起
https://ift.tt/2xvkxEe
1898年9月21日,戊戌变法宣告失败。**在原有制度框架内的维新运动不仅比日本晚了三十年,而且还失败了,这自此决定了清王朝的命运,在很大程度上甚至还决定了**在近代历史上的走向。创巨痛深之下,这场“百日维新”的失败在那之后就一直是**人念兹在兹的重要历史主题之一。
 光绪于1898年起用康、梁两人等推行新政
光绪于1898年起用康、梁两人等推行新政
在通行的近代史论述中,这场变法维新经常被描述为维新与守旧“两条路线”的斗争,而最终的失败则是因为守旧的反对势力比维新派强大得多。这乍看不无道理,但其实却似是而非,因为在几乎任何一场改革运动中,守旧的势力差不多都是更强大的――有时这正是进行改革的目的,因为这种弥漫于全社会的守旧已经带来了严重的危机。借用卡夫卡那句绕口令般的格言:“相信进步意味着进步已经出现,而这就谈不上是相信了。”如果当时的**站在维新派一边的已经是多数,那这就意味着已经相当进步,维新变法恐怕也没那么迫切了。
更重要的一点是:在历史上,尽管面临强大的守旧势力,但很多改革仍然成功推行了。赵武灵王胡服骑射、北魏孝文帝改革、甚至被戊戌变法中的维新派视为楷模的明治维新与俄国彼得大帝改革,哪一个不是这样?先秦的吴起在楚国、商鞅在秦国的变法,甚至在成功推行之后,仍遭守旧势力反扑而使改革者惨死。就现代史而言,1789年的法国大革命、1917年的俄国十月革命,革命派的力量在起初也都不及旧势力强大。当成功时就惊叹他们创造了历史,而失败时则归结为敌人力量太强,但问题的关键恐怕并不在此。
那些成功的改革都有一个特点:尽管改革派或许属于那个社会中极小一部分有危机感的精英,但却掌握了推行改革措施所必须的权威。秦国之所以能在战国七雄中最顺利地推行变法,与其说是商鞅多有远见,倒不如说是因为在秦国的权力结构中,国君就拥有更大的权威来确保变法的有效执行 。从这一点来看,戊戌变法在一开始就是不可能成功的,因为当时光绪帝名义上已经“亲政”,但实权仍在慈禧太后手里。变法若要成功,要么说服慈禧赞成,(至少获得她的默许),要么就是光绪帝得实际掌握权威。这就像明治维新时如果大权仍掌握在反对变革的德川幕府手中,也是不可能成功的。因此,戊戌变法失败的根本原因恐怕在于康有为、梁启超这些维新派可说弄错了顺序:他们应当先夺权,再推行改革。
 康有为和梁启超
康有为和梁启超
从奥斯曼帝国的近代史也能看出这一点:这个当时被讥为“欧洲病夫”的老大帝国,在面临近代西方压力时的处境与**十分相似,历任苏丹也曾多次想推行改革,但每次都相当艰难。改革派的塞利姆三世苏丹(1789-1807年在位)开明、真诚,但行事草率、热情过头,结果仓促之间引起近卫军暴动而被废黜;继承其遗志的马哈茂德二世苏丹(1808-1839年在位)虽然矢志变革,但一直等待了17年,才取得了推行改革政策所需的权威。两人所面对的守旧派反对势力其实同样强大,只不过后者在做好准备之前更能隐忍蛰伏。这意味着在形势不利时隐藏自己的真实意图,难免带上宫廷权力斗争和密室政治的色彩,很难像西方那种制度化的选举政治一样公开――但话说回来,如果是那样,这些改革派也极有可能是少数派而无法坚决推行自己的措施。正是因为变动时代的内忧外患引起了君主传统合法性的危机,他们才成为推行自上而下的宫廷革命的倡导者 。
 服饰改革后的马哈茂德二世
服饰改革后的马哈茂德二世
就光绪帝当时的处境来说,他显然还无法摆脱慈禧太后的阴影。实际上,慈禧当初之所以选择不足四周岁的光绪为帝,原本就是为了更便于继续掌权。1887年光绪帝年满十七岁,已到了亲政的年龄,慈禧虽然表示要让皇帝亲政,但却迟迟不愿交权。据《光绪朝东华录》记载,当时的帝师翁同�察言观色,以圣学未成,上折希望太后继续听政:“皇太后体祖宗之心为心,二十余年忧劳如一日,倘俟一二年后圣学大成,春秋鼎盛,从容授政,以弼我丕基,非特臣民之福,亦宗社之庆事。”并示意光绪帝在宫中求请,此举深得慈禧欢心。光绪生父醇亲王奕�也向慈禧表示:“亲政后,永照现在规矩,有凡宫内一切事宜,先请懿旨,再于皇帝前奏闻。”翁同�在受慈禧召见时则表示:皇上“亲政后断不改章程,书房随时提拨”。但这仍未能使慈禧就此放手 。即使在光绪帝大婚之后,慈禧仍然长期掌权,“光绪帝的奏折处理,须由慈禧太后进行事后监督,重大人事任命,则须由慈禧太后复核方为有效” 。
事实证明,慈禧对于光绪帝表现出任何独立倾向均极为敏感。1889年,河东河道总督吴大�奏请光绪帝生父醇亲王典礼,他原是想以此澄清朝政,不料慈禧震怒,认为其真实目的是为了“倾己势”,意在离间帝后,严斥吴大�“阚名邀宠”、“议礼梯荣”,对之大加折辱 。由此可见此事之敏感。光绪帝本人对慈禧也一直极为恭谨,直至慈禧发动政变扑灭百日维新前夕,他仍然连续四天陪慈禧太后看戏 。
在这种情况下,也难怪维新派想拉拢、争取袁世凯了,甚至有策划兵围颐和园的传闻 ,显然,此事若成,就能像康熙擒鳌拜那样,扫清亲政的最后障碍。类似的事历史上确实也有成功的,如武则天病危之际,张柬之等说服右羽林卫大将军李多祚,一举扫除张易之、张昌宗兄弟及武氏势力 。但其前提是武则天已经难以掌控局势,而张柬之等老臣在关键时刻比张氏兄弟这类宠幸老到得多,而在这方面,康有为、梁启超等人显然远非老谋深算。缺乏政治经验却又试图做风险巨大的一搏,失败是在所难免的。也难怪有美国历史学者认为戊戌变法仅是“一位年轻鲁莽的皇帝所领导的一次不智的、狂乱的‘百日’维新” 。
在一般人印象中,慈禧太后在“百日维新”中是守旧派的代表,因为正是她镇压了维新运动。但慈禧真的一味守旧、反对变法吗?且不论此前变革自强的洋务运动就靠慈禧在背后推动,即便是戊戌变法,如果得不到慈禧的默许,只怕别说“百日”,连一天都维持不下去。在辛亥革命百年纪念时,历史学家袁伟时曾接受采访,也强调“其实慈禧在戊戌变法期间是支持改革的”。不仅如此,在戊戌变法失败不到三年后,由慈禧本人主导推动的“新政”,实际上步子还迈得更大。金观涛、刘青峰所著《开放中的变迁:再论**社会超稳定结构》对**传统社会持明显的批判态度,但也承认:戊戌变法的失败导致意识形态认同危机更大范围涌现,而“自1901年局部意识形态认同危机加剧后,清廷所实行的改革比戊戌变法时的方法要大胆激进得多” 。
 慈禧太后
慈禧太后
仅仅三年时间里,一个人是怎么从“顽固守旧”忽然变得比维新派还更大胆激进的?那些原本反对维新变法的“强大”守旧势力,又为何忽然之间都不再是新政变革的阻碍了?
当然,这部分可归结于义和团事变引发八国联军入侵的巨大刺激,像徐桐等守旧派也死于此难,但这也表明:包括慈禧在内的这些所谓“守旧派”,其实并非不能转变自己的观点立场,必要时她甚至可以180度地大转弯。这导致后世学者对她往往有着截然不同的评价,例如《告别皇帝的**》一书中,对话的历史学者对她的评价相去甚远:
朱维铮:(戊戌变法时)慈禧是非常糟糕的一个人物,她对周围的那批人说,让他去闹,闹几天再说。
章开沅:慈禧这个人有魄力,有多年威权的积累,做事比较果断,所以推动了一些重大改革 。
袁伟时:慈禧是个没有远见的女人。
许倬云:慈禧是一个有手腕有权谋的女人,但是没有见识,热衷权力。
他们对慈禧推动的晚清十年新政,评价也十分悬殊:许倬云认为“改革成果很有限”,余英时干脆说“没有什么‘清末新政’,清王朝只是做了一些行政上的调整来缓和危机而已”。萧功秦则认为正是清末新政才推动了辛亥革命的爆发,因为咨议局、新军等在辛亥革命中起重要作用的力量其实都是新政的产物。袁伟时认为晚清新政“并不是流于字面,而是引发了非常了不起的社会变革”,从教育制度、法律体系到政治体制,其改革程度都是革命性的,然而与此同时,他却又对推动新政的慈禧本人持否定态度。问题在于:如果改革力度更大的新政都不算什么,那么戊戌变法就算成功恐怕取得的成果也有限,那我们又为何对它的失败如此介意呢?
为什么历史学家对这些人物和事件的评价出现这么大的分歧?这折射出那个酝酿变化的大时代本身充满着矛盾、动荡和不确定,而这些又集中在慈禧这类重要历史人物身上。尽管如今很多人对她并无好感,但据金启�所说,满族对她“很爱戴”,“甚至与康熙、乾隆并提” 。简单地把她说成是守旧派(甚至顽固派)或改革派都无助于我们理解这个人物的复杂性,倒不如说她是根据具体情形权衡判断来灵活决定自己的立场。
现在的历史论述给人的印象,仿佛守旧与维新两派人物的立场是固定不变、也不可调和的,但实际上,真正从意识形态层面反对变法的人恐怕是极少的 。英国学者William G. Beasley在《明治维新》一针见血地指出,明治维新有两个特征值得强调:“其一,它们的运作方式是封建性的,并充满个人色彩:表现为那些最终都可诉诸其私家军队的雄藩大名之间的争斗。其二,它们代表的是为权力而进行的斗争,而非意识形态之战。” 戊戌变法也是如此,尤其是第二点,甚至更有过之而无不及。
![《明治维新》-[英]威廉・G.比斯利 著-江苏人民出版社 2017年版](http://img1.gtimg.com/ninja/1/2018/09/ninja153758661939760.jpg "《明治维新》-[英]威廉・G.比斯利 著-江苏人民出版社 2017年版") 《明治维新》-[英]威廉・G.比斯利 著-江苏人民出版社 2017年版
《明治维新》-[英]威廉・G.比斯利 著-江苏人民出版社 2017年版
在先秦的吴起、商鞅变法中就有这样值得注意的一点:两人推行变法激起守旧派的不满,以至于他们后来都遭报复而惨死,然而在他们死后,变法措施并未被废除。且不说秦国后来就是靠商鞅变法的成效壮大,“没有哪部史书提到吴起之法被废,相反,吴起很多的政策,倒也延续下来了”(刘勃《战国歧途》)。这意味着,这些所谓守旧派不满的与其说是变法本身,倒不如说是因为自己的利益受到了触犯。
在戊戌变法中也是如此。维新派原本就多系来自边缘的南方知识分子,对权力核心而言乃是异类,本就容易引起排斥 ;但正如袁伟时所言:“当时认同国家富强的人很多,你要是不触犯他的利益,不随便很粗鲁去触犯一些符号性的东西,改革会比较顺利。康有为登上政治舞台,得到光绪皇帝的信任以后,他上奏的那些奏章,他提出的那些建议,很多都是很鲁莽的,而且不是当务之急,搞形式主义。”这其中导致很多人反对他的,便是1898年2月康有为第六次上书光绪帝,建议设制度局,这一建议一旦落实,将架空现行军机处及各部院,结果举朝“震愕”,群起反对,荣禄公开大骂:“开制度局是废我军机、内阁、六部,决不能答应。”刚毅等也散布说康有为要尽废所有衙门。甚至原本赞同变法的翁同�,其权力也会受到削弱乃至剥夺,因而他都开始怀疑康有为的变法动机,转而认为康氏“居心叵测”,不可不防,由此疏远康有为,并公开表示不赞同开设制度局 。1904年翁同�去世时,康有为作《哀词》十四首,自序“戊戌为**第一大变,翁公为**维新第一导师”,连翁同�这样同情变法者尚且如此,那么其他人就更不用说了。
 翁同�
翁同�
实际上,就算在西方的代议制政治中,引起太多人不适的全面变革也是很难吸引到足够多同盟者的。在这种情况下,要使人们赞同变革,必须尽可能地推进不那么容易遭致反对的渐进变革,而一项制度的变革牵涉的方面越多,实现变革的可能性越小,此时就只能期待下一个“重大历史机遇”的时刻到来。
在**传统政治中如果说有什么不一样,那就是:很多人反对的并不是变革本身。在权力斗争中,具体的主张是并不太重要的。如果他认定你是想要搞破坏,无论你说要变法还是守旧,在他眼里都没本质区别,那都不过是你在权力博弈中所使用的说辞,以掩盖你的真实意图罢了。与此同时,所谓“政治派别”本身也不是以政治主张来划分的,内部往往容纳极为庞杂的各色人等,即便观念根本不同都不妨碍他们为了权力斗争而结合起来。
这是传统政治在向现代政党政治转型时常能见到的现象。马尔克斯在《百年孤独》中嘲讽说,在哥伦比亚,“如今自由派和保守派的唯一区别就是,自由派去做五点的弥撒,而保守派去做八点的”。也就是说,不同党派其实极为相似,但仍然斗得不可开交,只是因为他们那不是为了意识形态,而是谁能上台。这也不仅是在上层政治中如此,19世纪早期的工业革命时代,由于蒸汽机取代工人而导致许多人失业,英国卢德分子大范围捣毁纺织机械,但其实,“他们只为保住饭碗,绝无反对技术进步之意” 。
以慈禧为首的晚清守旧派在很大程度上也是如此:与其说他们是从意识形态理念上反对变法维新,倒不如说他们只是害怕变法损害了自己的既得利益。正如《剑桥**史》中所说的,在戊戌变法中,“起初,问题不在于维新本身,而在于追求什么样的维新,以及这个官僚政治的君主国能否接受来自其结构以外的政治上的创新活动。” 也就是说,慈禧可以接受维新,但对她来说关键的是,这个维新不能威胁到自己的地位和满清王朝的**。因而三年后他们自己推行新政、未必危及自身权位时,原先对维新的那些阻碍忽然之间都消失不见了。当然长远来说,新政引发的后果对清王朝而言几乎是“毁灭性”或“自杀性”的,但对于错过了时机的慈禧来说,已经没有更好的选择了:与其等着人来革自己的命,不如自己主动发起革命。
这些都表明,当时的**政治仍未现代化,人们的政治主张很大程度上受到个人权力地位和利益的影响。事实上直至民国初年,很多政治乱象的症结仍然是“一切为个人私利,所有结合都是出于个人的关系利害” ,因而造成很多人的失望。1913年梁启超撰文《敬告政党及政党员》说到传统的“朋党”特征有五,第一条即是“以人为结合之中心,不以主义为结合之中心”,而现代的政团是有主义的。梁氏在《政闻社宣言书》中说:“政治团体之起,必有其所自信之主义,谓此主义确有裨于国利民福而欲实行之也,而凡反对此主义之政治,则排斥之也。故凡为政治团体者,既有政友,同时亦必有政敌。友也敌也,皆非徇个人之感情,而惟以主义相竞胜。”
王�森注意到在民国初年、尤其是1920年代之后“主义时代”的降临,到此时**人才开始突出“非人格化”(impersonal)的理念,强调对主义的坚守,而不像传统政治那样斤斤于个人利害(personal) 。德国社会学家马克斯・韦伯在《**的宗教》一书中就曾反复批评**文化最大的病症之一就是无法摆脱个人利害的网络,使得人们行事没有真正的信念与原则――当然,值得补充的是,这带来的一个好处是人们可以非常灵活,因为只要对个人有利,他可以随时从“守旧”摇身一变而为“维新”甚至“革命”;也正因此,**传统时代并不存在像西方那样为了不可妥协的理念而爆发的宗教战争。
 《**的宗教》-马克斯・韦伯 著-广西师范大学出版社2010年版
《**的宗教》-马克斯・韦伯 著-广西师范大学出版社2010年版
从某种程度上甚至可以说,我们现在将前现代**的很多改革中的人物划分为“改革”与“守旧”两派的观点是时代错置的,是我们将现代观念投射到历史中所产生的结果。历史学家黄永年在其论文《所谓“永贞革新”》中曾说到,唐代历次内部斗争(哪怕是牛李党争)本质上都不是施政理念、政策措施甚至社会集团的差异,而是一种人事为中心的权力斗争:“这些集团都得找一个皇帝或皇子为集团的核心,而参加的成员多数是皇帝或皇子的旧人,是以人事关系结集而并非以士族、庶族来区分。而且在政策上各集团之间也没有太大的差别。因为施点仁政之类本是**儒家的传统**,一般来讲无论哪个集团得势登上政治舞台总得多少做一点。”
在戊戌变法的时代也还是如此。翁同�虽然原本倾向维新派,但却未必是对其政治主张的认同,倒不如说是因为他自己和康有为一样对公羊学感兴趣 ,当其门人、军机处章京陈炽在《庸书》中主张**改行君主立宪时,翁同�无法接受,并强调“西法不可不讲,但中法尤不可忘”。甚至在维新派核心的康有为、梁启超、谭嗣同等人中,彼此理念也相去甚远。林少阳在《鼎革以文》一书中指出,历史论述中对很多人的“定性”无法说明当事人的复杂性,“后来被追认为‘改良派’的谭嗣同,就其**理路而言,无疑应该是革命派,但是一般来说他却被归类为改良派。实际上,从其个人的任侠气质、学术等观之,谭嗣同是典型的革命者,李泽厚先生甚至视其为**近代激进主义思潮的源头,不无道理。”
 谭嗣同
谭嗣同
实际上,袁世凯称帝时也一样。长久以来,袁世凯所获得的支持多来自其个人追随者,彼此之间是靠个人忠诚结合在一起的,袁世凯练兵时就亲自给将士发饷,注重灌输向他个人效忠,他的部下除了他谁都指挥不了,而可以跟任何人开战,不管他的对手是谁都一样。这在派系斗争中有用,但正如列文森在《儒家**及其现代命运》中所指出的,他的这些支持者即便在其称帝期间都未必支持君主制,“他们中许多人在袁世凯称帝时支持他,只是因为袁想称帝,而不是因为他们支持帝制。有一小部分人在袁世凯身上投资是因为他们各有私心,而其他一些人甚至就是对袁世凯本人有信心,无论袁去哪里都愿意跟随他。”
当时所谓的“集团”并不是像现代政党那样有着明确政治纲领的群体,人们之间的联结也不纯然是以政治理念为纽带,而往往与亲属、师生、门徒、同乡、同僚之类的社会关系网络有着千丝万缕的瓜葛。这是传统政治转向时无法摆脱的状况,日本近代的首届政党内阁仅维持了四个月就崩塌了,因为各政党内部存在诸多政策分歧,它们并非在一个伟大政治理念下集结的团体,而是不可避免地夹杂着个人和小团体私利的藩阀。确实,即便是在现代政治中,不同群体之间的联盟往往也不是仅靠理念内在的共通性就可以维持的,但**传统政治特别强调“以人为中心”。钱穆一生都在主张中西之分,认为“人中心”与“事中心”是中西史学最大差异,他反复强调“人”才是历史的发动者,“人”才是世运兴衰的关键,没有“人”便没有“事”,而非没有“事”便没有“人” 。
当然钱穆所说的“人”是“人本”,而传统**政治中的“人”其实是“人事”,但他的观点确实更贴近**传统的论调。晚清时翁同�有一次和慈禧太后谈到人治与法治的问题,认为任法不如任人,理由是:法律就算再完备,但如果没有贤臣良吏,这样的法律又有什么用呢?所以“法备不如任人”。这番见解给慈禧留下深刻印象,由此对他加以擢拔任用 。**传统的史论注重的往往也是“人”而非“事”,仿佛某一改革的成败,往往只是因为用人是否得当。戊戌变法失败之后不久,李鸿章在北京会见伊藤博文,认为其失败原因在于“变法太急,用人不当” ,便是这种观念的典型写照。
在这种视角之下,历史上的变革就不是两群人在政治理念上的差异,而变成了所谓“君子”与“小人”之争。不要以为这样的时代已经远去,实际上迄今为止,很多人在潜意识里所看到的与其说是“一种理念”,倒不如说是“一群人”。社会学家郭于华曾说过,**在好多议题上没必要分左派和右派,要分也只能分好派和坏派。这也许是一个尚未完全现代化的社会所不可避免的社会现象,但历史也已告诉我们:“制度”还是比“人”要更能提供稳定、可预期、有保障的条件,就像任何一家麦当劳餐馆的汉堡质量都差不多,而不会像很多中餐馆那样,换了个厨师后立刻连口味都不一样了。不管我们是否喜欢,现代化本身就意味着逐步的“非人格化”,使整个社会的运行摆脱个人利害的算计。
Analysis of Global 5G Development (1) - 5G Standardization so far
https://ift.tt/2zsNVwt
While 2G still has the biggest share in the global market, 4G LTE has certainly been up and running in most countries (186 countries as of January 2017. Source: GSA). As of Q3 2016, the global LTE subscription rate reached 22.4% (source: OVUM) and it is still going up. Especially, global LTE leaders have reported 70~80% of LTE penetration. Those with matured LTE markets, like South Korean big 3 telcos and Verizon in the USA, have been seeing stagnant profits for years, and anxiously looking to switch to 5G quickly.
Traditionally, mobile communication technologies had been categorized into ‘generations’. So, every time a new generation evolved into the next generation, new frequency, new radio access technology (RAT), and new network (RAN/Core) were defined and introduced, offering faster speeds and new services. But then there came 4G (LTE), which brought an integrated Core network to the world, allowing different RANs (2G/3G/4G/non-3GPP) to work together on it. 5G went even one step further, introducing a brilliant technology, ‘virtualization’, which makes it possible for different RAT, RAN and Core to be implemented as software on a universal server. This enabled telcos to adopt IT technologies that leverage open source SW/HW, making the communication infrastructure even more IT-based. As a result, the 5G ecosystem can extend its boundary to embrace ICT such as IT and IoT in addition to communication. This is why all telcos are aggressively seeking ways to transform into a platform provider, media service provider, solution provider or more.
5G global standardization has been driven by ITU and 3GPP. 3GPP aims to make technical reports (TRs) on 5G study items in Release 14 (scheduled to be finalized in June 2017), and develop 5G technical specifications (TSs) in Releases 15 and 16. When Release 14 is finalized and Release 15 begins in June 2017, a global race to take the lead in standardization, system development, and commercialization of 5G will begin in earnest.
5G commercialization has been mostly driven by telcos whose LTE has already reached the level of maturity or those who are in desperate need of increasing network capacities, and also by three nations in East Asia (South Korea, Japan and China) who are eager to develop and present 5G services during the Olympics games they are respectively hosting in 2018 (Winter), 2020 (Summer) and 2022 (Winter).
Although 3GPP 5G standard specifications, including supports for high-mobility, are not expected to be finalized before 2020, telcos like Verizon and AT&T are acting proactively. They aim to present broadband Internet that leverages pre-5G specifications, mmWave-based fixed wireless access (FWA), in 2017 in order to replace narrowband Internet and expand broadband service coverage. There certainly is a risk that such investment can fail if the actual 5G specifications end up being substantially different from the pre-5G specifications. Despite such risk, the two telcos are so determined as they need to expand broadband service coverage quick, and want to make 5G's standards resemble pre-5G's as much as possible.
Most active global leaders in 5G development include South Korean big 3 telcos (KT, SK Telecom and LG U+), and Verizon and AT&T in the USA, NTT DoCoMo in Japan, and China Mobile in China. We will look into 5G standardizations so far first, and analyze 5G strategies and developments by some of these 5G players.
|
|
|
Table of Contents
I. 5G Standardization so far II. 5G Developments in Leading Countries 1-2. SK Telecom 1-3. LG U+
2. U.S. 2-1. Verizon 2-1. AT&T
3. Japan 3-1. NTT DoCoMo
4. China 4-1. China Mobile |
I. 5G standardization so far
5G standardizations are led by two major standardization agencies: ITU and 3GPP.
Figure 1-1. Timeline for 5G in ITU-R (WP5D) and 3GPP
1. ITU
Most 5G standardization initiatives by ITU are carried out by two different groups: SG5 Working Party 5D (WP5D) for NITU-R and SG13 Focus Group IMT-2020 (FG IMT-2020) for ITU-T. In 2015, ITU-R WP5D defined 5G communication as 'IMT-2020', presenting the following 5G usage scenarios:
ITU-R WP5D plans to have 5G technical performance requirements, and evaluation criteria and method finalized in June 2017 (at the 27th meeting), and begin to collect 5G proposals starting October 2017 (the 28th meeting) to present the final 5G standard specifications in October 2020 (the 36th meeting). Allocations of 5G frequency bands are to be announced in the 2019 World Radiocommunication Conferences (WRC-19).
Figure 1-2. ITU-R: Detailed timeline of IMT-2020 (5G)
<Table 1-1> 5G performance index (as reported in the 25th WP5D meeting in October 2016)
2. 3GPP
3GPP is set to conduct a preliminary study on 5G specifications in Release 14, and, based on the findings, begin to develop 5G specifications in Releases 15 and 16. Release 15 will release 5G Phase 1 specifications that define basic features of 5G, and Release 16 will release 5G Phase 2 specifications defining additional features of 5G. 5G specifications will be finalized through two phases - Phases 1 and 2 ending in September 2018 and March 2020, respectively, but Stage 3 will end in June 2018 and December 2019.
Figure 2-1. 3GPP: Detailed Timeline of 5G (as of Dec. 2016)
■ Release 14
The purpose of Release 14, a preliminary study phase needed to establish technical specifications (TSs), is to write technical reports (TRs) of 5G. Two of the most representative study items of 5G are 'Requirements for 5G access technology' by TSG (Technical Specification Group) RAN and 'Architecture for 5G system' by TSG SA (Service & System Aspects), which are defined in TR 38.913 and TR 23.799, respectively.
<Table 2-1> 5G technical reports in Release 14
Below, we will briefly see some key 5G TRs prepared in Release 14 so far.
TR 38.913: Defines key performance indicators of 5G new radio (NR).
<Table 2-2> Key performance indicators for 5G new radio (TR 38.913 [V14.0.0])
22.891: In March 2016, 3GPP SA1 released TR 22.891 which outlined SMARTER (New Services and Markets Technology Enablers), one of the 5G study items (SI).
|
TR 22.891 defines over 70 use cases classified in five categories (See <Table 2-3> below). SA1 is currently finalizing separate SI works in these five categories, and has already conducted studies on the following four SIs in Release 14, completing the relevant technical reports (TR 22.861, TR 22.862, TR 22.863, and TR 22.864): |
sp |
|
||
A TR about Enhancement of V2X is scheduled to be completed in Release 15.
<Table 2-3> Use case categories (TR 22.891 [V14.0.0])
TR 23.799: 3GPP SA2 released TR 23.799 in last December which outlined the results of 'NextGen' study for 5G network architecture carried out in Release 14. In TR 23.799, key features relating to 5G network architecture are defined. <Table 2-4> shows what features are included and in which phases their technical specifications will be determined.
In 5G, eMBB service requires ultra-fast speeds (20 Gbps), mission-critical IoT service requires excellent latency (<5ms) and reliability (99.999%), and massive IoT service requires massive connectivity (106 devices/Km2). To meet all these requirements in various services, a 5G network should be versatile to offer an optimized and tailored solution for each service. One of the candidate technologies for that purpose is network slicing, which will be standardized in Release 15. Network slicing is one of the most essential technologies that 5G can probably rely on as it allows operators to split one physical network into multiple logically-independent networks.
<Table 2-4> Key issues for 5G system architecture (TR 23.799 [V14.0.0]) and phase of 5G system architecture work
■ Release 15
The scope of NR to be standardized in Release 15 include both non-standalone (NSA) and standalone (SA) operations. In NSA mode, both 5G NR and LTE can work together because the mode allows 5G NR to use LTE as an anchor on the control plane. Also, SA mode lets 5G NR work independently by supporting it with full control plane capability. While focusing on eMBB-type services, one of the 5G usage scenarios defined in ITU (eMBB, mMTC, URLLC), it also provides support for some URLLC-type services.
PHP的依赖管理工具Composer(2) - Chen Yuan's Blog
https://ift.tt/2Q2mG0U
之前介绍过如何安装Composer和简单使用,出门左拐能找到。
PHP的依赖管理工具Composer(1)
现在更深入地学习Composer。在上一篇MyProject的app.php中
<?php require 'vendor/autoload.php'; $log = new Monolog\Logger('name');...
上面的代码是为了 new Monolog\Logger('name') ,所以require 'vendor/autoload.php',作用是为了找到Monolog\Logger类的实现代码,然后require。
这应该很好理解,因为假如不用require 'vendor/autoload.php',那就必须require Logger.php源码。
在深入学习Composer的之前,了解一下Composer实现自动加载功能所参考的标准规范PSR。
FIG 制定的PHP规范,简称PSR,是PHP开发的事实标准。
PSR现在有6个规范,分别是:
PSR-4可以说是PSR-0的演进版本吧,PSR-4和PSR-0最大的区别是对下划线(underscore)的定义不同。PSR-4中,在类名中使用下划线没有任何特殊含义。而PSR-0则规定类名中的下划线 _ 会被转化成目录分隔符。
PHP的包管理系统Composer已经支持PSR-4,同时也允许在 composer.json 中定义不同的prefix使用不同的自动加载机制。
Composer使用PSR-0风格
vendor/
vendor_name/
package_name/
src/
Vendor_Name/
Package_Name/
ClassName.php # Vendor_Name\Package_Name\ClassName
tests/
Vendor_Name/
Package_Name/
ClassNameTest.php # Vendor_Name\Package_Name\ClassName
Composer使用PSR-4风格
vendor/
vendor_name/
package_name/
src/
ClassName.php # Vendor_Name\Package_Name\ClassName
tests/
ClassNameTest.php # Vendor_Name\Package_Name\ClassNameTest
对比以上两种结构,明显可以看出PSR-4带来更简洁的文件结构。
class的说明包括class、interface、traint或其他相似的结构。
一个规范的class命名如下面所示:
\<NamespaceName>(\<SubNamespaceNames>)*\<ClassName>
a.规范的命名必须指定一个最上层的NamespaceName名字,比如vendor的名字。
b.规范的命名可能有一个或多个SubNamespaceNames名字。
c.规范的命名必须指定一个类名。
d.下划线在命名的任一部分都没有特别的意义。(我的理解是不对下划线进行处理)
e.可以由任意大小写字母组合。
f.字母大小写敏感。
下面的表展示了对一个完全合规的类名, 命名空间前缀以及base目录对应的文件路径。
仔细分析一下所示的例子:
当加载完全合规的类名对应的文件时…
a.在完全合规的类名中, 不包含前面的命名空间分隔符,由一个顶级命名空间与一个或多个二级命名空间名称组成的命名空间前缀,对应于至少一个Base目录。
b.基目录之后的子目录名字必须(MUST)与命名空间前缀后的子命名空间名字匹配。
c.后面的类名对应于以.php为后缀的文件名,这个文件名必须(MUST)匹配到后面的类名。
d.自动加载实现一定不能(MUST NOT)抛出异常,一定不能(MUST NOT)引发任何级别的错误, 并且不应当(SHOULD NOT)返回值。
分析require 'vendor/autoload.php'源码。
<?php /* autoload.php 中require了autoload_real.php,然后 调用ComposerAutoloaderInit::getLoader()静态方法。 */ // autoload.php @generated by Composerrequire_once DIR . '/composer' . '/autoload_real.php';
return ComposerAutoloaderInitcc5afff809d01782ea6cfda49dba67db::getLoader();
ComposerAutoloaderInit的实现。
<?php
// autoload_real.php @generated by Composer
class ComposerAutoloaderInitcc5afff809d01782ea6cfda49dba67db
{
private static $loader;
public static function loadClassLoader($class)
{
if ('Composer\Autoload\ClassLoader' === $class) {
require __DIR__ . '/ClassLoader.php';
}
}
public static function getLoader()
{
if (null !== self::$loader) {
return self::$loader;
}
/*注册给定的函数作为 __autoload 的实现,
ComposerAutoloaderInit::loadClassLoader()
主要是为了调用上面的loadClassLoader()函数,
require ClassLoader.php,实例化一个$loader。*/
spl_autoload_register(array('ComposerAutoloaderInitcc5afff809d01782ea6cfda49dba67db', 'loadClassLoader'), true, true);
self::$loader = $loader = new \Composer\Autoload\ClassLoader();
spl_autoload_unregister(array('ComposerAutoloaderInitcc5afff809d01782ea6cfda49dba67db', 'loadClassLoader'));
$useStaticLoader = PHP_VERSION_ID >= 50600 && !defined('HHVM_VERSION');
if ($useStaticLoader) {
require_once __DIR__ . '/autoload_static.php';
call_user_func(\Composer\Autoload\ComposerStaticInitcc5afff809d01782ea6cfda49dba67db::getInitializer($loader));
} else {
/*然后就是通过$loader的方法,遍历autoload_namespaces.php/
autoload_psr4.php/autoload_classmap.php中的数组变量
以PSR-0为例,看看autoload_namespaces.php中具体的值
'Monolog' => array($vendorDir . '/monolog/monolog/src')
再看看$loader->set(Monolog,array($vendorDir . '/monolog/monolog/src'))
$this->fallbackDirsPsr0 = (array) $paths;
即$loader->fallbackDirsPsr0 = array($vendorDir . '/monolog/monolog/src')*/
$map = require __DIR__ . '/autoload_namespaces.php';
foreach ($map as $namespace => $path) {
$loader->set($namespace, $path);
}
$map = require __DIR__ . '/autoload_psr4.php';
foreach ($map as $namespace => $path) {
$loader->setPsr4($namespace, $path);
}
$classMap = require __DIR__ . '/autoload_classmap.php';
if ($classMap) {
$loader->addClassMap($classMap);
}
}
// activate the autoloader
// 调用$loader->register(true),执行autoloader
$loader->register(true);
return $loader;
}
}
// autoload_namespaces.php @generated by Composer
$vendorDir = dirname(dirname(__FILE__));
$baseDir = dirname($vendorDir);
return array(
'Monolog' => array($vendorDir . '/monolog/monolog/src'),
);
//ClassLoader.php
/**
* Registers a set of PSR-0 directories for a given prefix,
* replacing any others previously set for this prefix.
*
* @param string $prefix The prefix
* @param array|string $paths The PSR-0 base directories
*/
public function set($prefix, $paths)
{
if (!$prefix) {
$this->fallbackDirsPsr0 = (array) $paths;
} else {
$this->prefixesPsr0[$prefix[0]][$prefix] = (array) $paths;
}
}
/**
* Registers this instance as an autoloader.
*
* @param bool $prepend Whether to prepend the autoloader or not
*/
public function register($prepend = false)
{
//当找不到类抛出异常前,会调用$loader->loadClass()
//即进行$log = new Monolog\Logger('name');时,
//不知道Monolog\Logger在哪,就去调用这个函数取寻找,然后再include
//当然,再找不到就会抛出异常了。
spl_autoload_register(array($this, 'loadClass'), true, $prepend);
}
/**
* Loads the given class or interface.
*
* @param string $class The name of the class
* @return bool|null True if loaded, null otherwise
*/
public function loadClass($class)
{
if ($file = $this->findFile($class)) {
includeFile($file);
return true;
}
}
下面的代码就是寻找Monolog\Logger类源码的实现,简单分析一下。
//ClassLoader.php
/**
* Finds the path to the file where the class is defined.
*
* @param string $class The name of the class
*
* @return string|false The path if found, false otherwise
*/
public function findFile($class)
{
// work around for PHP 5.3.0 - 5.3.2 https://bugs.php.net/50731
//去掉命名空间前的斜杠,即如果是\Monolog\Logger,那么就变成Monolog\Logger
if ('\\' == $class[0]) {
$class = substr($class, 1);
}
// class map lookup
if (isset($this->classMap[$class])) {
return $this->classMap[$class];
}
if ($this->classMapAuthoritative) {
return false;
}
//找到Monolog\Logger的完整路径,包括php后缀名
$file = $this->findFileWithExtension($class, '.php');
// Search for Hack files if we are running on HHVM
if ($file === null && defined('HHVM_VERSION')) {
$file = $this->findFileWithExtension($class, '.hh');
}
if ($file === null) {
// Remember that this class does not exist.
return $this->classMap[$class] = false;
}
return $file;
}
private function findFileWithExtension($class, $ext)
{
// PSR-4 lookup
$logicalPathPsr4 = strtr($class, '\\', DIRECTORY_SEPARATOR) . $ext;
$first = $class[0];
if (isset($this->prefixLengthsPsr4[$first])) {
foreach ($this->prefixLengthsPsr4[$first] as $prefix => $length) {
if (0 === strpos($class, $prefix)) {
foreach ($this->prefixDirsPsr4[$prefix] as $dir) {
if (file_exists($file = $dir . DIRECTORY_SEPARATOR . substr($logicalPathPsr4, $length))) {
return $file;
}
}
}
}
}
// PSR-4 fallback dirs
foreach ($this->fallbackDirsPsr4 as $dir) {
if (file_exists($file = $dir . DIRECTORY_SEPARATOR . $logicalPathPsr4)) {
return $file;
}
}
// PSR-0 lookup
if (false !== $pos = strrpos($class, '\\')) {
// namespaced class name
$logicalPathPsr0 = substr($logicalPathPsr4, 0, $pos + 1)
. strtr(substr($logicalPathPsr4, $pos + 1), '_', DIRECTORY_SEPARATOR);
} else {
// PEAR-like class name
$logicalPathPsr0 = strtr($class, '_', DIRECTORY_SEPARATOR) . $ext;
}
//执行这一段程序
if (isset($this->prefixesPsr0[$first])) {
foreach ($this->prefixesPsr0[$first] as $prefix => $dirs) {
if (0 === strpos($class, $prefix)) {
foreach ($dirs as $dir) {
if (file_exists($file = $dir . DIRECTORY_SEPARATOR . $logicalPathPsr0)) {
return $file;
//$file = __DIR__."\vendor\monolog\monolog\src\Monolog\Logger.php"
}
}
}
}
}
// PSR-0 fallback dirs
foreach ($this->fallbackDirsPsr0 as $dir) {
if (file_exists($file = $dir . DIRECTORY_SEPARATOR . $logicalPathPsr0)) {
return $file;
}
}
// PSR-0 include paths.
if ($this->useIncludePath && $file = stream_resolve_include_path($logicalPathPsr0)) {
return $file;
}
}
找到$file = DIR.”\vendor\monolog\monolog\src\Monolog\Logger.php”之后include执行,然后就是Logger实例化的过程了。
Composer的运行过程就是酱紫了。
4、还有一个问题
autoload_namespaces.php、autoload_psr4.php、autoload_classmap.php中的数组变量怎么来的?
Monolog库中也有一个composer.json文件。
"autoload": {
"psr-0": {"Monolog": "src/"}
},
再看看autoload_namespaces.php文件,存在映射关系的。
'Monolog' => array($vendorDir . '/monolog/monolog/src')
Composer的学习目前就先到这里了,往后如果需要制作一个库,再往更深一层学习吧。
参考
via
September 25, 2018 at 08:08PM
把握知识的脾气,迈向学习的新途——《失实,为什么我们所知道的一切有一半都将是错的》 读书笔记
https://ift.tt/2zLWXqh
稀客sheek
这是一本书名耸人听闻的书,这是一本内容详实严谨的书。这是一本颠覆传统认识的书,这是一本启迪创新思维的书。
很少有一本书能将观念冲突演绎的如此淋漓尽致,《失实》做到了。纵观全书,作者塞缪尔 阿贝斯曼利用他在科学计量学方面的高深造诣,将塔勒布的“黑天鹅效应”和查布利斯的“看不见的大猩猩效应”进一步拓展到知识层面,向读者阐释了一个有关事实本身的事实——也许就在下一秒,我们习以为常的事实与知识就将有半数过期。这本书用详实的数据和精彩的实例告诫世界,知识和事实已经脱离了几个世纪前的线性发展,转为爆炸式的指数发展,只有掌握了知识的“脾气”和“秉性”,才能在不断提速的学习和创新过程中掌握先机。
就像人们每天使用的信用卡会有到期日一样,知识同样会在某个时间节点“到期”。关心科学发展的人会发现,2008年8月24日,冥王星从行星名单上消失,也从人们惯有的太阳系“九大行星”观念中消失;同时关心金融学和心理学的人会发现,金融心理学正在成为一门更具影响力的交叉学科,并对国家、企业的金融决策产生越来越积极的影响。在《失实》中,阿贝斯曼论述了知识到期的两个主要原因,类似冥王星变成矮行星的事例,代表了知识的“衰变”;类似金融心理学的出现,代表了知识的“相变”。正是“衰变”和“相变”的综合作用,造成了传统知识的加速到期。
在书中,阿贝斯曼借用基本粒子衰变的概念,提出了知识的半衰期。作为一名科学计量学专家,他论述衰变概念的工具自然是这门测量和分析科学本身的新兴学科。科学计量学诞生于1947年,当时,数学家普赖斯家里寄存了一套完整的《皇家学会哲学学报》,他把它们按照年份分批堆了起来,结果发现书堆的高度呈指数函数曲线增长。于是,普赖斯便开始分析各种其他的科学数据,最后于1960年得出结论——自17世纪起,科学知识便以每年4.7%的速度稳定增长着。这意味着科学数据的数量每15年就要翻一番。
基于普赖斯发现的这一规律,阿贝斯曼对多个学科进行了跟踪统计,发现现有的知识,甚至是那些人人都深信不疑的知识,正在以一种容易理解的,系统的方式发生改变。人们所知的绝大多数知识都是“**事实”(mesofacts),即变化速率位于中间的事实,但即便是**事实也在加速变化。如果一名上世纪七八十年代出生的人现在还在关注化学,会惊奇的发现,当前的元素周期表已经比高中时期多出了12个元素,也就是说,短短的30年间,元素总数增长了十分之一,高中的知识已经“衰变”过时。除了化学领域,其他领域的知识也在加速“衰变”,重大发现的倍增时间变为20年,医药领域的事实半衰期为45年,而经济学领域的知识半衰期更是短短的9.38年。这意味着,现代人要时刻做好心理和行动上的准备,以迎接随时可能到来的新旧知识交替。
《失控》一书的作者凯文凯利提出了“生物长尾”理论,即在超级丰富但种群稀少的物种中存在着生物的长尾现象,在长尾末端,可能存在10亿个微小物种,其总和超过了那些最普遍的物种总和。阿贝斯曼发现,知识和事实同样适用于长尾理论。任何重大发现和技术的突变,都必然是无数处于长尾末端看似平凡的知识累积质变的结果。也就是说,在认识世界可能性的过程中,每一个新的小发现都能教给我们一些东西,逐渐对所处环境有了更完整的了解。
摩尔定律在知识更迭过程中更是展露的淋漓尽致。在书中,阿贝斯曼不仅针对知识的指数增长进行了论述,更进一步指出摩尔定律适用于万事万物。当事物积累发展到一定阶段后,其发展趋势必然会呈现出指数特征。近一个世纪以来,现代人越来越深刻的感受到科学技术的迅猛发展,那些几年前还停留在小说和电影中的技术,很快就变成了现实。例如上世纪七八十年代风靡世界的漫画作品《机器猫》,启迪了一代人对未来世界的想象,但仅仅过了30年,随着3D打印技术、数码摄影技术的出现,漫画中的高科技道具已经有至少31种成为了现实。1994年,美国华尔街的专家读邮箱地址“@”的时候只会说“a在圈的外面”,而现在,中老年人和儿童都已经会正确读出这个符号。再如便携存储介质的发展,从5寸盘到3.5寸盘再到光盘、u盘和现在的云存储,时间跨度也只有30年。计算机技术的年均增长率已接近200%,处理器能力的指数型进化催生出相机像素等其他领域的跨越式进步。
这一切无不意味着,现在已经不是人类“创造”知识的年代,而是人类“追赶”知识的时代。知识的井喷已经成为非常现实的问题,正如威廉 迪克逊所说,“现实不会静静地坐等你为它画像。它们不断振动,满是混乱和困惑。”
参加过晚会的人都玩过传话游戏,游戏组织者将完整信息告诉第一个人,然后依次传递下去,最后一个人说出来的信息往往和最初的信息大相径庭。传话游戏显示了错误信息传播的特点,信息科学将之称为“噪声信道”,除非有一整套错误检查机制,否则信息在人与人的传播过程中可能会失真。不幸的是,知识在传播过程中,恰恰时刻遭遇“噪声信道”的阻击。统计证明,即便在美国这样具有较高科研水平的国家,也只有20%的科学家在引用文章时亲自阅读过,即4/5的科学家在引用论据时没有检验真实性。这样的信息谬误甚至会从科学界影响到人们的日常生活。例如一位科学家在研究菠菜中的含铁量时,误将每100克含铁量3.5毫克抄成了35毫克,相当于每吃100克菠菜就能吃下一个回形针。这个抄录失误直接导致了著名动画片《大力水手》的出现,更导致了欧美世界延续时间颇长的“菠菜热”,甚至在现在,仍有大批民众坚信菠菜的神奇疗效。
知识传播的另一个特征就是它的“隐身功能”。从广义上来说,知识对大半个世界成功隐身,而重复是自然而然的结果。很多领先于时代的研究直到多年以后有人再次开始做的时候才被发现已经有前人在做,比如现代遗传学之父孟德尔在死去后多年,才有科学家在重复他的研究时发现这名牧师是这门学科的先驱者。即便是在同一时代,知识也对不同的人隐身,造成了无数同步创新的例子,例如冷战时期美国和苏联的研究经常重复、格雷和贝尔在同一天申请了电话发明专利、达尔文和华莱士同时提出自然选择说等等。
这表明,现代人在研究的时候更需要具备勘误能力和回溯能力,避免让“噪声信道”和“隐身的知识”影响真正的创新。
相变是物理学术语,意指物质在不同状态间的跃迁,例如水在固态、液态、气态之间的转变。如果将这一概念应用在知识领域,则表示知识累积到一定程度后的质变,或交叉学科的出现。
在研究知识的指数型增长的同时,阿贝斯曼发现了知识质变的规律。在数学界,两个连续创新之间的改进增长期以及瓶颈期被称为一系列稳步上升的逻辑曲线,它是一种指数曲线的变体。在现有技术存活的空间被限定的前提下,技术本身会抑制自己的生长,增长速度会在指数增长后减缓,并保持一段时间的稳定,这一数量被称为承载能力。统计说明,一项技术在达到极限并超过承载能力后,会出现一个引进新技术的机会。知识正是在这样不断叠加的过程中完成了从量到质的跃迁。这表明,人们需要引导原有的知识来创造新的知识,所以必须积累一定的知识才能学习新的东西。技术知识的基石越多,新技术提高的速度就越快。但在这一发展过程中,人们很容易出现“塞麦尔维斯反射”现象,即基于个人的世界观和兴趣点而漠视周围的变化。这也是为什么很多精英在互联网金融异军突起的时候才意识到互联网的巨大潜力。
阿贝斯曼通过研究发现,人口的数量和质量同样影响了知识的“相变”。知识的维护和创造在大型群体中更容易实现,人口增长与创新和新事实的发展是携手并进的。理论上,人口较多的国家的科学、技术和文化创新比人口较少的国家来的多。不光国家,城市人口同样影响知识的质变。城市符合生产力和创新能力的报酬递增数学关系,大城市年人均专利数量比小城市更多,并且存在一种很精确的数学关系,这种比例叫超线性,即事物的发展速度比线性速度要快。这意味着,如果城市人口翻倍,那么生产力并不是简单翻倍,而是一倍以上。专利、城市生产总值、科研预算很多领域都存在这种关系。
知识的增长在人口世代更替中得到了鲜明的体现,200年间人类的日均行程上限都在呈现指数增长,这从侧面表明,每一代人比上一代人的视野都相对更开阔。正因为创新速度不断加快,剧烈的创新重置愈加频繁。我们都已经有直接的体验,即在短短的一世代要经历多重快速变化,这在历史上前所未有,且这一趋势没有放缓的迹象。之前重大进步深入人心大约需要十年,但在最近几年这个时间已经明显缩短。
这一切都说明,知识的“相变”是必然和持续的,且这种质变会给人类生活和社会模式带来巨大影响。人们思考问题已不能仅仅着眼于未来几年,而要以几十年为基本时间跨度来思考,并随时准备好迎接知识发展的“奇点”到来。
10年前,我们用的是拨号网络;而今天,我们用的是迅捷的4G甚至5G高速网络。20年前,我们认为人工智能只会出现在科幻作品中;而今天,人工智能已经通过了图灵测试,并在围棋、国际象棋等领域中秒杀人类智能。30年前,我们认为兜里揣着百元大钞就能横行天下;而今天,我们已经被手机绑架,忘记了钱包放在哪里。也许我们无法直观感受到每一门知识的具体改变,但科学技术的加速发展已经渗透到了生活的方方面面。
世界处在不断的变化中,知识日新月异,最见多识广的人也无法跟上变化的脚步。在这样的大趋势下,学习已不再是口号,已不再是任务,已不再是负担,而是工作、生活中实实在在的一部分。对于新生代的孩子来说,新的技术已经成为他们理所应当的生活习惯。对于初入职场的年轻人来说,知识的加速“衰变”会让他们不得不时刻保持学习的斗志。对于耄耋的老者来说,掌握新知识已不再是单纯的赶时髦,而是重新融入社会的必要条件。
“一招鲜吃遍天”的观念已经和冥王星的身份一样,在指数型发展的今天,不知不觉的走到了自己的知识半衰期。国家想要富强、社会想要发展、个人想要成长,已经和学习密不可分。只有真正将学习融入个人“血液”,才能具备在知识更新大潮中的生存资格。
前几天刚刚读完丹布朗的新作——《本源》,书中提出了一个有趣的观点(这里可能有剧透):生命的进化方向并非单纯的人工智能或者硅基生物,而是人类与技术的结合体。如此看来,《攻壳机动队》里拥有机械义体和人类大脑的素子还有《PSYCHO-PASS》里拥有血肉之躯和人工智能的反派才是人类进化的形态。但无论如何,人类与技术的高度融合已经是大势所趋。
学习也是如此。
现在的学习已经不是单纯的看书、听课,而是多平台、多工具的学习活动的总和。常看“少数派”的读者,对于利用印象笔记、draft打造个人知识库,用kindle作为随时随地的高效学习工具,用多种app打造学习工作流等技术并不会陌生。而这些新型的学习工具和学习技术,就是帮助我们在奇点临近的大时代做到“百尺竿头更进一步”的利器和法宝。不要抗拒技术,才是将学习进化到下一个形态的前提。
这与上一点并不矛盾,因为我们毕竟还是单纯的“人”,不是机械人或者在网络里永生的虚拟人。即便技术再怎么发展,我们也必须尊重生命个体的客观规律。看过豆瓣国产第一神剧《大明王朝1566》的朋友们都会有同样的想法——如果换做我,可能活不过主题曲。为什么?这是因为在古代,人们在学习的时候没有太多的辅助技术,只能博闻强记,将知识在自己脑子里打上“钢印”,这样在面对嘉靖这种爱玩文字游戏的变态上司时,才能依靠渊博的知识和海量的典故活命。所以,即便现在我们有少数派、kindle这些优秀的辅助手段作为“第二大脑”,也要时刻牢记,知识刻进脑子,才真正属于自己。
《失实》一书中的数据表明,每个人负责一小块区域的知识,专精某项业务,并成为行家里手,更有利于单项知识的传播。我们已经拥有了最新的学习技术,人人都可以成为博学家,但当汽车抛锚的时候,专业的赛车手和现查知乎的普通司机的表现将有天壤之别。按照目前的技术发展趋势,社会分工会越来越细,专精型的技术匠人将越来越被社会需要。
阿贝斯曼在书中论证,基于六度人脉理论,信息和知识的传播与社交圈紧密相关,也就是说,信息的传播靠的是社会空间而不是物理空间。知识在亲密社交圈(4人左右)的传播的认同率更高,但在弱纽带关系的社交群体中传播效率将更高。因此,不妨开拓“社交化学习”的新途径,增加自己获取知识的效率和能力。
在传播信息和学习知识之前,应该先进行批判性的思考,检验其真实性,在能力允许的范围内,尽可能避免“噪声信道”和“隐身知识”的出现。
即关注专业内、行业内、社会上的微小变化和新生知识,避免自我欺骗式的“塞麦尔维斯反射”效应。只有将自己的“正确”知识积累到一定程度,才能在未来社会提高自己做出正确判断的概率。
C++11多线程编程(1) - Chen Yuan's Blog
https://ift.tt/2xQHxwD
前段时间,我在Google std::thread时,读到了网站thispointer.com的多线程入门教程,该教程通俗易懂,但又不缺乏深度,其示例代码结合了许多C++11的新的特性,比如匿名函数等(第4部分进行拓展说明)。
下面,我就按照这个教程,介绍C++11 Multithreading。
C++11已经支持多线程,但编译时需要添加-std=c++11和 -pthread选项:
g++ -std=c++11 sample.cpp -pthread
如果使用CMake编译:
//CMakeLists.txt 中添加
set(CMAKE_CXX_FLAGS ${CMAKE_CXX_FLAGS} "-std=c++11 -pthread")
头文件:<thread>
在C++11中,我们使用std::thread类创建子线程,一个std::thread对象管理一个新的进程。
std::thread thObj(<CALLBACK>);
新建thObj对象后,子线程将执行对象绑定的回调函数CALLBACK,父线程仍然继续执行。
回调函数可以写成以下3种形式:
(1)Function Pointer 函数指针
(2)Function Objects 函数对象
(3)Lambda functions 匿名函数
#include <iostream> #include <thread>void thread_function()
{
for(int i = 0; i < 10000; i++);
std::cout<<"thread function Executing"<<std::endl;
}
int main()
{
std::thread threadObj(thread_function);
for(int i = 0; i < 10000; i++);
std::cout<<"Display From MainThread"<<std::endl;
threadObj.join();
std::cout<<"Exit of Main function"<<std::endl;
return 0;
}
#include <iostream> #include <thread> class DisplayThread { public: void operator()() { for(int i = 0; i < 10000; i++) std::cout<<"Display Thread Executing"<<std::endl; } };
int main()
{
std::thread threadObj( (DisplayThread()) );
for(int i = 0; i < 10000; i++)
std::cout<<"Display From Main Thread "<<std::endl;
std::cout<<"Waiting For Thread to complete"<<std::endl;
threadObj.join();
std::cout<<"Exiting from Main Thread"<<std::endl;
return 0;
}
#include <iostream>
#include <thread>
int main()
{
int x = 9;
std::thread threadObj([]{
for(int i = 0; i < 10000; i++)
std::cout<<"Display Thread Executing"<<std::endl;
});
for(int i = 0; i < 10000; i++)
std::cout<<"Display From Main Thread"<<std::endl;
threadObj.join();
std::cout<<"Exiting from Main Thread"<<std::endl;
return 0;
}
1.2 get_id()获取线程标识
std::thread::get_id()用于获取线程对象的标识,若线程对象没有绑定回调函数,返回a non-executing thread。 std::this_thread::get_id()用于获取当前线程标识。
#include <iostream>
#include <thread>
void thread_function()
{
std::cout<<"Inside Thread :: ID = "<<std::this_thread::get_id()<<std::endl;
}
int main()
{
std::thread threadObj1(thread_function);
std::thread threadObj2(thread_function);
if(threadObj1.get_id() != threadObj2.get_id())
std::cout<<"Both Threads have different IDs"<<std::endl;
std::cout<<"From Main Thread :: ID of Thread 1 = "<<threadObj1.get_id()<<std::endl;
std::cout<<"From Main Thread :: ID of Thread 2 = "<<threadObj2.get_id()<<std::endl;
threadObj1.join();
threadObj2.join();
return 0;
}
Output:
Inside Thread :: ID = 3083496256
Both Threads have different IDs
From Main Thread :: ID of Thread 1 = 3083496256
From Main Thread :: ID of Thread 2 = 3075103552
Inside Thread :: ID = 3075103552
1.3 join()线程结合
join()顾名思义指把threadObj线程加入到当前线程,这时原来两个交替执行的线程合并为顺序执行了。比如父线程A调用了子线程B的join()方法后,那么子线程B执行完毕后再执行父线程A。
#include <iostream>
#include <thread>
#include <algorithm>//std::for_each
class WorkerThread
{
public:
void operator()()
{
std::cout<<"Worker Thread "<<std::this_thread::get_id()<<" is Executing"<<std::endl;
}
};
int main()
{
std::vector<std::thread> threadList;
for(int i = 0; i < 10; i++)
{
threadList.push_back( std::thread( WorkerThread() ) );
}
// Now wait for all the worker thread to finish i.e.
// Call join() function on each of the std::thread object
std::cout<<"wait for all the worker thread to finish"<<std::endl;
std::for_each(threadList.begin(),threadList.end(), std::mem_fn(&std::thread::join));
std::cout<<"Exiting from Main Thread"<<std::endl;
return 0;
}
1.4 detach()线程分离
detach()方法使得父线程不再管理子线程。detached 线程也称为守护线程或后台线程。
std::thread th(funcPtr);
th.detach();
需要仔细处理线程的detach()和join()方法,使用joinable()方法检查线程对象是否可以join/detach.
准则1:Never call join() or detach() on std::thread object with no associated executing thread.
std::thread threadObj( (WorkerThread()) );
threadObj.join();
threadObj.join(); // It will cause Program to Terminate
std::thread threadObj( (WorkerThread()) );
threadObj.detach();
threadObj.detach(); // It will cause Program to Terminate
准则2: Never forget to call either join or detach on a std::thread object with associated executing thread.
RESOURCE ACQUISITION IS INITIALIZATION (RAII)可以有效帮助我们解决忘记join/detach的情况。
#include <iostream>
#include <thread>
class ThreadRAII
{
std::thread & m_thread;
public:
ThreadRAII(std::thread & threadObj) : m_thread(threadObj)
{
}
~ThreadRAII()
{
// Check if thread is joinable then detach the thread
if(m_thread.joinable())
{
m_thread.detach();
}
}
};
void thread_function()
{
for(int i = 0; i < 10000; i++);
std::cout<<"thread_function Executing"<<std::endl;
}
int main()
{
std::thread threadObj(thread_function);
// If we comment this Line, then program will crash
ThreadRAII wrapperObj(threadObj);
return 0;
}
1.5 子线程参数的传递
参数在std::thread的构造方法时以拷贝的方式进行传递。
1.5.1 引用作为参数传递
#include <iostream>
#include <thread>
void threadCallback(int const & x)
{
int & y = const_cast<int &>(x);
y++;
std::cout<<"Inside Thread x = "<<x<<std::endl;
}
int main()
{
int x = 9;
std::cout<<"In Main Thread : Before Thread Start x = "<<x<<std::endl;
std::thread threadObj(threadCallback, x);
threadObj.join();
std::cout<<"In Main Thread : After Thread Joins x = "<<x<<std::endl;
return 0;
}
Output:
In Main Thread : Before Thread Start x = 9
Inside Thread x = 10
In Main Thread : After Thread Joins x = 9
什么原因?Its because x in the thread function threadCallback is reference to the temporary value copied* at the new thread’s stack.
可以用std::ref()来解决这一问题。
#include <iostream>
#include <thread>
void threadCallback(int const & x)
{
int & y = const_cast<int &>(x);
y++;
std::cout<<"Inside Thread x = "<<x<<std::endl;
}
int main()
{
int x = 9;
std::cout<<"In Main Thread : Before Thread Start x = "<<x<<std::endl;
std::thread threadObj(threadCallback,std::ref(x));
threadObj.join();
std::cout<<"In Main Thread : After Thread Joins x = "<<x<<std::endl;
return 0;
}
1.5.2 成员函数指针作为回调函数时的参数传递
#include <iostream>
#include <thread>
class DummyClass {
public:
DummyClass()
{}
DummyClass(const DummyClass & obj)
{}
void sampleMemberFunction(int x)
{
std::cout<<"Inside sampleMemberFunction "<<x<<std::endl;
}
};
int main() {
DummyClass dummyObj;
int x = 10;
std::thread threadObj(&DummyClass::sampleMemberFunction,&dummyObj, x);
threadObj.join();
return 0;
}
从第1部分的参数传递可以看出,线程间的数据共享方式很简单,但这种简单的方式容易导致很多问题,其中常见的一个就是:竞争条件。
第2部分将介绍竞争条件产生及如何解决竞争条件导致的异常。
2. 多线程条件竞争及其解决方法
2.1 竞争条件异常的产生
下面将以钱包为例说明竞争条件导致异常的产生,假设testMultithreadedWallet产生5个线程同时调用addMoney()方法。
#include <iostream>
#include <thread>
#include <vector>
class Wallet
{
int mMoney;
public:
Wallet() :mMoney(0){}
int getMoney() { return mMoney; }
void addMoney(int money)
{
for(int i = 0; i < money; ++i)
{
mMoney++;
}
}
};
int testMultithreadedWallet()
{
Wallet walletObject;
std::vector<std::thread> threads;
for(int i = 0; i < 5; ++i){
threads.push_back(std::thread(&Wallet::addMoney, &walletObject, 1000));
}
for(int i = 0; i < threads.size() ; i++)
{
threads.at(i).join();
}
return walletObject.getMoney();
}
int main()
{
int val = 0;
for(int k = 0; k < 1000; k++)
{
if((val = testMultithreadedWallet()) != 5000)
{
std::cout << "Error at count = "<<k<<" Money in Wallet = "<<val << std::endl;
}
}
return 0;
}
Outputs:
...
Error at count = 971 Money in Wallet = 4568
Error at count = 972 Money in Wallet = 4260
Error at count = 972 Money in Wallet = 4260
Error at count = 973 Money in Wallet = 4976
Error at count = 973 Money in Wallet = 4976
...
这就是竞争条件产生异常的示例,当多个线程同时改变同一地址指向的变量时,异常将会出现。
异常产生的原因分析
每一个线程同时对mMoney变量递增,虽然mMoney++看起来是一条命令,但底层可以细分为3个命令:
(1)加载mMoney变量至寄存器;
(2)寄存器递增+1;
(3)更新寄存器值到mMenoy变量。
假设线程1和线程2”mMoney++“操作的底层命令执行顺序如下:
Thread 1 Thread 2
加载mMoney变量至寄存器
加载mMoney变量至寄存器
寄存器递增+1
寄存器递增+1
更新寄存器值到mMenoy变量
更新寄存器值到mMenoy变量
如果这两个线程执行之前mMoney=46,那么经过线程1和线程2的递增,mMoney应该为48。但是由于出现上面的执行顺序,mMoney=46被加载至不同的寄存器后递增为mMoney=47,这是因为寄存器不同,最后更新mMenoy值时有一次递增被忽略了。
2.2 互斥锁解决竞争条件异常
互斥锁可以有效解决竞争条件导致的异常,仍以上面的为例子。互斥锁的使用很简单,在需要加锁的代码之前调用lock()加锁,代码之后再调用unlock()解锁。
C++11的互斥锁std::mutex在头文件<mutex>文件中。
#include<iostream>
#include<thread>
#include<vector>
#include<mutex>
class Wallet
{
int mMoney;
std::mutex mutex;
public:
Wallet() :mMoney(0){}
int getMoney() { return mMoney; }
void addMoney(int money)
{
mutex.lock();
for(int i = 0; i < money; ++i)
{
mMoney++;
}
mutex.unlock();
}
};
为了避免忘记调用unlock()方法导致的阻塞,可以使用std::lock_guard互斥锁。
class Wallet
{
int mMoney;
std::mutex mutex;
public:
Wallet() :mMoney(0){}
int getMoney() { return mMoney; }
void addMoney(int money)
{
std::lock_guard<std::mutex> lockGuard(mutex);
// In constructor it locks the mutex
for(int i = 0; i < money; ++i)
{
// If some exception occurs at this
// poin then destructor of lockGuard
// will be called due to stack unwinding.
//
mMoney++;
}
// Once function exits, then destructor
// of lockGuard Object will be called.
// In destructor it unlocks the mutex.
}
};
参考资料
via
September 25, 2018 at 07:56PM
探寻你分心的原因学会控制注意力的方法丨注意力曲线读书笔记
探寻你分心的原因,学会控制注意力的方法丨《注意力曲线》读书笔记
https://ift.tt/2vI5sNN
ElijahLee
本文是「少数派读书笔记征文活动」的第 6 篇入围作品。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。
当你在阅读这篇文章时,是不是正身处于嘈杂的地铁中?你的脑海里回想起同事还没给你材料?邮件没有回复?手机快没电了?刚收到一条微信消息,该怎么回复?数字时代出现的短暂注意力现象已经比比皆是了。我们正准备进行一项重要的任务,但是电话铃声或者智能设备的噪音很快将你的注意力转移到别处。
《注意力曲线:打败分心与焦虑》一书探讨的就是在数字时代注意力如何集中、丧失后如何重获的方法和步骤。作者是露西·乔·帕拉迪诺,她有 30 年的注意力研究生涯。但就我个人而言,这本书最重要的价值是揭示了大脑受到的外界刺激和注意力水平的基本关系,而从该基本关系引申的实践方法论,也有普适价值。

核心收获:倒 U 形注意力曲线
我们可以说出很多通过切换注意力来提升工作效率的方法,例如劳逸结合、番茄工作法等等。但这些方法的原理,似乎并不广为人知。看完《注意力曲线》一书,我获得的核心收获便是倒 U 形的注意力曲线。这条原理般的曲线是如此的基础简洁,以至于相比之下,书中大量可用于实操的方法论显得相形见绌。
人对事物的注意力和该事物对大脑的刺激,呈现出一条山形或者倒 U 形的曲线。当事物引起的刺激不足时,我们会感觉到无聊而容易分心;当刺激过度时,疲惫、紧张、害怕、焦虑的情绪也会让注意力不集中。而在适当、稳定的刺激下,大脑可以保持对事物持续的注意力,这时候我们会感觉到富有成效,进展顺利。

劳逸结合、番茄工作法等等方法的科学性,都可以从注意力曲线中找到依据。维持 25~45 分钟的番茄钟,可以让你的注意力从刺激较少的初期过渡到注意力专区中。劳逸结合也可以理解为持续注意力过长的情况下,通过减少当前刺激来转移注意力。
重获失去的注意力
学习了倒 U 形注意力曲线之后,重获失去的注意力就变得简单了。作者提到的两个步骤浅显易懂:
-
自我观察:停下来并注意到自己不在注意力专区;
-
改变状态:选择一种方法让自己恢复或平静下来。
自我观察非常容易实现。当你的注意力不在专区中时,要么是刺激不足外化为感觉到无聊、懈怠等情绪,要么是刺激过度外化为感觉到紧张、焦虑等情绪,这些情绪都是很容易被你察觉到的。当你在注意力高度集中时,也就是所谓的心流状态,你会全身心投入,甚至毫无感觉,废寝忘食。你不需要开启注意力雷达检测系统,刻意停下来并使自己注意到注意力离开专区了,因为你的情绪、行为等都会自然反映它的变化。
改变状态则有更多复杂的情形和方法。《注意力曲线》这本书的大量篇幅都在介绍各种普适性方法,说实话我认为它们缺乏条理,没有系统逻辑,缺乏深度以及行文分散。作者提到的注意力丧失时通过心理暗示、自我激励、四角呼吸等方法来重获注意力等,似乎是适用于各类情绪管理、心理健康养成法等放之四海皆准的法则。以至于我颇为认同某位读者的点评:
明明一百个字能说清的事情,作者却写了一本书,太浪费纸了。
 图片来自申龙斌的博客
图片来自申龙斌的博客当你明白自我观察和改变状态两个步骤后,完全可以自行探索总结出适合自己的方法。当你觉得工作无聊(这很容易被你察觉到)不想干活时,可以通过和同事领导针对这项任务进行交流,听听他的想法和建议,用这些信息作为新的刺激,来帮助你进入注意力专区。而在刺激过度时,你会感觉到疲惫、紧张、或者是害怕,这时起身走走,找几个调皮逗逼的同事开开玩笑,把过度的刺激分散掉,更有利于让你回过头来进入注意力专区中。
其他收获
当然,除了倒 U 形的注意力曲线之外,《注意力曲线》一书剩余的内容也不全是毫无价值。以下一些观点要么让我倍感新奇,要么让我感同身受。
环境免疫
想让一个孩子保持注意力,应该让他的兄弟姐妹跟他在同一间屋子里。
数字时代下,一个安静无纷扰的环境越来越难能可贵,这也使得「只能在安静环境下才能保持注意力」成了一种疾病。要习得保持注意力的能力,就要在注意力容易分散的环境下进行。
2016 年我开始尝试在上下学的公交车上写稿。最近搬家后我又开始在拥挤的地铁通勤时写稿了。你可能会觉得不可思议,公交地铁嘈杂的环境与需要集中精神理顺思路的写作状态相互冲突。至少在我通勤写稿的初期,我也遇到难以集中注意力困境。但适当的心理暗示、自我激励,都有助于在复杂环境下保持注意力,而一旦养成习惯后,在任何环境下快速进入注意力专区就变得容易了。乘坐交通工具时写稿,走路运动时构思文章,洗澡时思考选题,这既是身体与思维运动的结合,也得益于注意力快速集中的能力。
在逆境中困苦,顺境就会常在。

关于拖延的另一种解读
如果你总是拖延, 那么回头看一下你的拖延战术的根源。你是不是曾经把拖延法作为一种抗争的方法?
作者把一部分拖延症现象解读为在缺乏有效抗议时引发的抗争行为,我觉得十分新奇。书中以儿童用拖延写作业为例,因为他们缺乏有效的手段来向家长教师表达抗争,于是采取拖延策略。而在实际工作中,对于别人交付的工作比如上司领导等,都可能是「我不想做,你硬要交给我的」。在没有有效抗争手段时,拖延就成为了唯一的选择,作者赞同防拖延专家简伯卡博士的分类,这是由于「害怕被控制」用不作为来表达抗争的拖延行为。
拖延症和注意力集中之间存在什么关系呢?作者提到的孩子害怕写功课的例子也让人豁然开朗。孩子外在表现为反抗和拖延来与父母对抗,但在潜意识里,他们是担心的。他们害怕不会做功课、犯错误,因此分泌了过多的肾上腺素也就是过多的刺激,从而使大脑离开了注意力专区,向右偏移进入过度刺激的注意力低下的阶段。在成人工作中,拖延也有出于对工作的害怕、恐惧而引发。你害怕面临无休无止的设计改稿、害怕领导同事对报告材料的批评。作者认为在这些情况下你还没有机会体会到即将开始的工作是无聊的,肾上腺素分泌带来的恐惧就已经把你拉向了注意力低下的右侧。
我个人认为,作者将拖延症和注意力相互关联的论述似乎有些牵强,但将拖延症解读为抗争的手段和害怕的外在表现,甚为新奇有趣。
利用碎片化时间高效产出是伪命题
利用碎片化时间一直被视为节约时间高效产出的重要手段。但从注意力曲线的角度来看,短期刺激引发的注意力效果是低下的。
首先,碎片化时间的环境是复杂的。你可能正在等公交地铁、开会间隙、等待咖啡,你想利用这些时间有所产出是非常困难的。这些时候刺激水平不足,没有经过长时间的训练尝试,注意力较难集中。其次,即使在碎片化时间内你进入了注意力专区,也会因为短时间内的结束,让区区几分钟的心流变得作用寥寥。
因此正如 JmPotato 在《碎片化还是沉浸式?关于阅读的一些思考》 一文中探讨碎片化阅读和沉浸式阅读两种方式时提到的:
通过碎片化阅读获得信息固然及时且便利,但大多数内容的长久价值却十分的小。
小结
如果以 10 分标准评价一本书,我会给《注意力曲线》打 7 分,最实用的知识是在于产生对注意力曲线的基本认知,而引申出来的方法和技巧,可能有助于注意力集中的训练,但它们的实用性见仁见智。
via 少数派 - 高品质数字消费指南
September 26, 2018 at 12:01AM
有赞线上拨测系统实践一
有赞线上拨测系统实践(一)
https://ift.tt/2zsprTN
zhangshilong
前言
一直以来,作为互联网软件工程师接触最多的事务之一便是持续集成(Continuous integration,简称 CI)。持续集成俨然已成为主流互联网软件开发流程中一个重要的环节。现今有赞内部在实践持续交付(Continuous delivery,简称 CD),它可以被看成是后持续集成时代的产物。需要强调的是,不管是 CI 还是 CD,更多的是强调作为软件开发交付过程中的实践,而一旦交付到生产环境CI和CD就无能为力了。有赞线上拨测系统正是为了弥补这一不足。现有的线上保障手段可分为运维层面、产品层面、安全层面、服务层面和测试层面等维度。本文重点介绍我们在测试层面的实践。
基于测试脚本的线上监控产生
我们做测试线上拨测系统的初衷有以下几点:
1. 主动预警线上问题。有赞有很多个业务线,各个业务线有不同的开发测试同学对接,我们很难做到每次发布都把影响面评估得十分准确。运维层面的监控更多的是被动告警,即用户流量触发了线上 bug,我们才会收到报警,用户体验不够好。我们需要在线上 bug 预警方面变被动为主动,周期性地知晓各个业务线的健康状况。
2. 小流量下敏捷发现线上问题。通常我们软件的发布都是在凌晨流量非常低的时候进行。发布完成后,回归时间长(靠手动),测试面有限(无法做到次次发布全量回归)。此时需要敏捷构造一波覆盖面全的流量,在小流量背景下,敏捷发现线上问题。
3. 知晓紧急情况下业务的受影响范围以及后续收敛情况。例如当生产环境出现网络异常等非软件故障时,需要清楚业务层面的影响;当网络恢复后,需要知道业务影响是否都已经收敛。
在此之前这些场景都需要测试人员手工介入,灵活度敏捷度都非常差。有了这套系统后,测试人员可以增加自己关注的场景,场景可以通过主动触发和定时触发来执行,通过告警系统通知到有关人员,做到第一时间排查问题,减少故障影响,降低故障时长。
基础版
1.0 版本我们使用通用的 SpringWeb 搭建,有赞内部称为线上机器人检查。系统结构如下

1.0 版系统架构图
系统主要为三个模块:
1. 任务调度模块。该模块将用例执行封装成系统任务,使用 Spring Quartz 来定时触发。对外提供 API 对接有赞发布平台,每当系统发布上线完成后主动触发用例执行。
2. 测试用例模块。包括业务访问,断言和告警。测试场景需要各个业务线的测试同学投入开发。
3. 告警模块。对接有赞内部告警平台。

1.0版流程图
系统将用例分为基础用例和场景用例,支持场景并发或者顺序同步执行。具体执行策略由用例设计者结合具体情况在用例开发过程中设定。
存在的问题
基础版满足了最小可用,这种方式优点在于前期能够快速投入使用,且对于经常写集成用例的人来说成本不高,但对其他人(测试新人、开发、运维等)则不然。概括而言,其缺点主要集中在以下几点:
- 业务线一旦多起来,用例代码开发成本提高;
- 随着用例数量增加,后期用例维护成本很大;
- 用例上线不灵活,每次用例改动需要重新发布;
- 无法直观看到运行情况和业务覆盖情况;
- 每次执行不区分业务,全量执行;
- 用例代码存在冗余,效率比较低。
配置化和可视化
由于这些不可规避的问题,我们重新设计并发布了 2.0 版本。对应解决以上问题:
- 测试用例和测试场景支持配置化,可以从管理平台上配置;
- 用例配置标准化,给定标准用例结构和断言策略;
- 通过管理平台来管理自己的用例,用例改动实时生效,无需发布;
- 增加前端展示,通过图表直观展示运行情况和业务覆盖情况,方便不同人群查阅;
- 对接发布平台,按照指定的应用名来区分跑哪些用例;
- 设计用例执行框架,实现核心代码复用。
新版系统架构图如下

2.0版系统架构图
用例模型如下:
字段
是否必填
说明
用例名称
是
建议命名格式:“用例类型:服务:方法”
用例类型
是
两种类型可选http或dubbo
用例描述
是
场景描述
所属业务
是
用例所属业务阈
请求url
否
http协议调用的url
请求头
否
http header
请求参数
否
http或dubbo的请求入参。支持动态参数注入实现用例间依赖
服务名称
否
对应请求dubbo协议的接口名(包名+类名)
请求方法
是
http协议:GET、POST、PUT等;dubbo协议:方法名
断言
是
支持多个
是否开启
否
控制开关,关闭后不再运行。默认开启
是否登录
否
开启后,使用默认账号进行登录操作。默认不开启
是否重试
否
开启后,⽤例失败重试1次。默认否
前/后置检查
否
执行⽤例前/后,先执行前/后置检查,失败则中断
*此处略去了部分有赞内部使用的字段
为了更直观展示线上业务的健康状况我们增加了丰富前端报表

数据展示
新版本与老版本的主要区别在于:
- 将执行流和数据流进行了分离,测试用例设计无需编码,支持配置化,用例作为数据存放到 DB 中重复使用,用例的执行引擎管理用例的执行流。
- 对通用的事务进行了封装,比如登录、切换店铺等操作,通过统一的线程池进行管理。
- 支持动态参数注入,实现了用例间的相互依赖,后面再单独介绍这块内容。
任务执行流程图如下:

2.0版流程图
任务执行引擎通过不同的工作线程实现。不同业务用例并发执行,业务内部用例串行执行。系统根据不同的用例的类型(http/dubbo)分发到具体任务流中。

核心类设计
用例间依赖的实现
从用例的复杂度上讲,我们的用例主要分为两大类:单一场景的基础用例和复杂场景的组合用例。组合用例是在基础用例的基础上进行一定的集成,用例的输入输出存在一定的依赖。我们实现用例依赖的方式有两种:
- 通过配置用例的前置后置关系。
- 通过参数注入。
第一种方式,在配置用例的时候,给它一个前置用例,当然前置用例也是在平台中管理的。这样当执行到该用例的时候,执行引擎会先去执行前置用例。
第二种方式,针对 Json 格式的入参,我们定义如下格式进行参数注入:
$#a,b,c#$
各个字段分别代表的含义为:
a:被依赖用例的ID
b:被依赖用例响应的字段(key值),比如:name
c:可选字段,当被依赖值位于 array 里面时,取其 index 下标
举例:{"code":"$#8,data,0#$","type":"$#10,type#$"}
参数注入的流程如下:

参数注入流程图
断言模块设计
在新版系统里面,我们设计了四种类型的通用断言,几乎可以满足我们自己的所有应用场景。这四种类型分别是:
1. 是否包含。
响应内容包含指定内容为 true,反之为 false。
非空/null。
响应内容非空/null为 true,为空/null为 false。
-
JSON 特定位置的值的“相等”判断。
这种情况系统首先会将响应内容转换成 json,添加断言时需要指定待比较对象在 json 串中的坐标。如果该坐标上的值与指定的值相等则为 true,反之为 false。
那么如何给一个 json 串的每个值设置一个独一无二的坐标呢?考虑到 json 存在嵌套关系且 key 可能重复,我们通过一种复合 key 的来表示这个坐标,例如有如下 json:
{
"data": {
"list": [
"1",
"2"
],
"info": {
"name": "张三",
"age": 18
}
},
"code": 200
}
对标红的值的断言可以这样表示:{"data":{"info":{"name":"张三"}}},如果返回的位置的值为"张三"则判断结果为 true,否则为 false。
- 面向 JSON 的伪代码表达式判断
前面三种类型的断言仅满足了部分场景,对于一些复杂的断言仍然无法满足,比如上文 json 中 list size 的断言。为此,我们引入第四种断言方式---伪代码断言。针对 list size 的断言我们可以这样写:
getJSONObject("data")getJSONObject("list").size() > 0
代码在处理的时候会将该表达式拼接在 json 对象后进行执行。整段代码执行的结果为真断言为 true,否则为 false。
伪代码的动态编译、加载和调用,采用 GroovyShell 来实现。该部分代码实现如下:
public Result compare(String response) {
Result result = new Result();
// 单例获取GroovyShell
GroovyShell shell = SingleGroovyUtil.getGroovyShell();
Binding binding = null;
JSONObject jsonObject = new JSONObject();
JSONArray jsonArray = new JSONArray();
Object value = null;
try {
if (response.startsWith("[")){
jsonArray = JSON.parseArray(response);
binding = new Binding();
binding.setVariable("data", jsonArray);
value = InvokerHelper.createScript(shell.getClass(), binding).evaluate("data." + textStatement);
}else {
jsonObject = JSON.parseObject(response);
binding = new Binding();
binding.setVariable("data", jsonObject);
value = InvokerHelper.createScript(shell.getClass(), binding).evaluate("data." + textStatement);
}
if((Boolean)value) {
result.setSuccess(true);
}else {
result.setSuccess(false);
String msg = JsonUtil.findErrMsgByJsonObject(jsonObject);
result.setMsg(String.format("断言失败。断言的内容[%s], 错误描述[%s]", this.textStatement, msg.length()>0?msg:response));
}
} catch (Exception e) {
result.setSuccess(false);
String msg = JsonUtil.findErrMsgByJsonObject(jsonObject);
result.setMsg(String.format("断言时发生异常。ErrMsg=[%s],actual=[%s]", e.getMessage(), msg.length()>0?msg:response));
} finally { // 处理完后,主动将对象置为null
binding = null;
}
return result;
}
插件化
新版系统满足了用例的可配置化以及可视化的要求,同时也牺牲了一部分的灵活性。例如一些复杂断言的伪代码会非常长,且可读性不高,一不留神就会出错;简单的用例依赖可以满足,复杂的用例依赖却很难满足。比如用例 A 在某些条件下依赖用例 B,其他条件下依赖用例 C,这种复杂依赖关系走配置化并不合适。基于以上考虑,我们在现有的系统的基础上又增加了插件化的特性,来支持复杂用例的接入。

3.0 版系统架构图
插件化的设计**如下:
- 平台对外提供一套用例标准,测试同学开发符合标准的用例添加到平台即可运行。
- 用例与平台完全解耦,用例在平台可配置。
- 用例支持热插拔,平台无需重启。
用例标准通过接口的形式对外提供,封装成jar包暴露出来。用例设计者直接依赖该jar包并实现指定接口即可。用例接口定义如下:
public interface AbstractTestCase {
CaseResult before();
CaseResult run();
void after();
}
用例开发完成后打包成 jar 包上传到平台,一个 jar 包中可包含一个用例也可以包含多个用例。
jar 包上传后平台要做的事情如下:
- 动态把 jar load 进 JVM
- 解析实现了 AbstractTestCase 接口的类
- 按照指定策略调用类中的方法
- 上报并展示结果数据
获取 jar 包中实现了 AbstractTestCase 接口的代码如下:
/**
* 获取jar包中某接口的实现类
*/
public static List<Class<?>> getAllImplClassesByInterface(Class c) {
List<Class<?>> filteredList = new ArrayList<Class<?>>();
//判断是否是接口
if (c.isInterface()) {
try {
//获取jar包中的所有类
List<Class> allClass = getClassesByPackageName();
allClass.forEach(clazz -> {
if (c.isAssignableFrom(clazz)) {
if (!c.equals(clazz)) {
filteredList.add(clazz);
}
}
});
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
return filteredList;
}
未来
未来有赞线上拨测系统会提供更丰富的功能,例如更灵活的用例执行策略,核心用例执行频率更高,边缘业务执行频率降低;更全面的报警策略,各个业务方可以自由定制关心的用例,线上问题第一时间触达;支持多机房,目前该系统只在单机房进行部署,有赞核心业务已完成多机房部署,拨测系统也会随之调整;系统支持分布式,为了防范系统单点故障,未来还会考虑进行分布式部署。
目前这套系统可以保障测试同学第一时间知晓有赞线上核心业务异常,将来保障的业务广度和深度会进一步提高,成为有赞线上质量保障至关重要的一环。
欢迎关注我们的公众号

</div><br>
技术
via 有赞技术团队 https://ift.tt/2lOIVul
September 10, 2018 at 03:43PM
企業復盤SLOW之O 青蛙加復盤等於閉環Closed Loop
企業復盤SLOW之O 青蛙加復盤等於閉環(Closed Loop)
https://ift.tt/2rZNYLR

「我来讲我们企业理一位芳芳的复盘故事…」這是長帆第三次培训,餐饮业的陈总之前和我說了,他要來分享幾個他們企業復盤及青蛙的例子。
前幾天晚上我们深圳益田假日广场店的生意很火爆,当天接了很多尾牙的单子,店里面热闹得很。
时间快要关门了,却看到一位女客户到柜台求救
原来是当晚有一位老板款待全公司同仁尾牙,自己喝开了,醉得睡著了,同仁陆续离去,剩下老婆。可是老婆死活叫不醒,老板体重有点重,家虽然在走路可以到的华侨城,但老板娘也搬不动,于是和我们的柜台同仁求援。
我立刻带了前台的小崔、厨房的老向过去协助,没想到人喝醉了特别重,抬起来又滑下去。我灵机一动,想楼下超市拿了买菜的手推车。三个同仁七手八脚把客人搬到手推车上。
老板娘说他们家就在隔壁华侨园,所以也不叫车了,我们三个同事就陪著老板娘一路推到他家楼下。再搬到三楼,放到老板家里客厅沙发,临走时老板娘还不断道谢,大家一身是汗,回到餐厅也已经十二点。
隔天,老板娘亲自送了两瓶红酒过来,说要送给昨天帮忙的同仁,实在推不过,我们只好收下来。
「復盤提供了我們企業很多有溫度的案例,現在我們公司兩千個員工,每週挑出三個案例各店微信分享,一年就有一百五十六個案例,我們會印出一本千悅服務手冊,送到各店手中。」陳總本身是個很有溫度的人,因此他們的企業,就藉由復盤,累積了大量的案例。

「我們第一、二堂課教了大家復盤及青蛙。」這是我在長帆第三堂課程的破題「今天我們要教的是閉環(Closed Loop)」
「每天我們數百位在不同微信群裡面復盤,每天青蛙打卡,形成了整個企業的訊息流。」我微微頓了一下,特意放慢速度解釋今天課程的主題「整個訊息流系統,當然不能有漏洞(Open Loop),要靠大家做好復盤及青蛙,團隊協力,才能達到最大效益。」
我用中階幹部褚晶(黃總的秘書)一天的工作來解釋閉環的運作。
「褚晶經過一天的工作後,自然會在腦內有些想法或念頭(這些就是雜事)」我慢慢地解釋「這些想法經過沈澱,就是她在回家路上寫在滴答清單,發到微信群中的復盤。」
「當褚晶回家後,休息一夜醒來,很自然地又沈澱出工作新想法,一早她寫下今天的青蛙到滴答清單,並發送到群裡」我細細解說褚晶寫出的復盤及青蛙,是整個公司訊息流的一部分
「於是,褚晶到了辦公室就依照自己的青蛙去工作,當然會有很多的突發狀況,但是她知道今天的青蛙是什麼,會儘量努力”先吃下那隻青蛙”」我慢慢講出第三部分「這樣認真吃青蛙、蝌蚪,處理突發狀況到晚上,很自然很多想法或念頭(這個狀況是雜事,還沒理清成下一步行動),就又寫下一天的復盤。」
「…」全場很安靜,講完閉環後,彷彿重新喚醒他們對復盤及青蛙打卡的認識。
企業全體復盤及青蛙打卡的訊息,以滴答清單還有微信為容器,每天吃青蛙,每天復盤,形成每天閉環(Closed Loop),這樣的培訓要進行100天。
要的就是長帆物流的中高階幹部,自己做好閉環,進而協助他們下屬同仁做好閉環。
這樣企業的訊息流(Workflow)系統得以無聲、自動化地運轉。絕大部分的企業訊息流都無法順利運作起來,因為管理人員需要投入大量的管理,才能維持系統的運作。
要系統的破綻,長期運作訊息流系統,做好每日閉環,我給了褚晶一些建議。
1. 建立好每天吃青蛙及復盤系統,讓同仁熟悉滴答清單及微信打卡的工具。
2. 建立任務清單,把手上專案列表追蹤,並且每週檢視一次。
3. 善用番茄工作法(設定25分鐘專注工作時間,五分鐘休息時間),並列出一個兩小時內要做的事情小清單,配合番茄鐘使用。
4. 整理好自己工作的桌面,設定一個實體的收件匣,建立一個桌面工作流系統,處理實體的文件及紙張。
褚晶是一個年輕有為的中階幹部,只要一個企業的中階幹部學習好青蛙打卡,做好復盤,建立閉環,對她一輩子的職業生涯一定會有很深的影響,讓我們為她加油。

快思慢想(Thinking. Fast and Slow)是著名行為心理學家 丹尼爾‧卡內曼(Daniel Kahneman)的重要著作,作者把大腦運行系統分為系統一及系統二。
系統一(Fast),反應直覺,容易被旁邊有趣的東西吸引,好處是可以瞬間找到最適合的下一步行動。
系統二(Slow),理性思考,在正式的場合,忍耐控制自己不看旁邊正妹,好處是可以處理複雜的事情,例如寫一份訴訟案件的文件草稿。
快思慢想這個概念,也可以套用我們在閉環時的先吃青蛙及復盤打卡上,幫助我們的工作流程更加順暢,時間管理能力更好。我們分別用FAST及SLOW八個角度來思考如何做好更好的閉環。
快思,每天快速規劃青蛙,瞭解一天重點,用FAST法則,吃完今天青蛙。
F:青蛙,每天花五分鐘列出1-3隻青蛙;5-7隻蝌蚪,發到群組裡面,接著九點半時看一下團隊所有人的青蛙,接著決定當下要花時間去做的最重要的事情,持續推進,直到吃完第一隻青蛙。
永錫老師的用法:我自己會維持一個今日工作清單,先吃青蛙,後吃蝌蚪,搭配番茄工作法推進。
A:行動,問自己下一步行動是什麼?
首先瞭解目前手上的大小事情,大事情是專案,小事情是雜事,問自己「下一步行動是什麼?問自己「預期的結果是什麼?」。把雜事理清,決定下一步行動,找出預期結果,就能管好一個專案。
永錫老師的用法:我會把手上的專案列成任務清單,每週理清,隨時掌控各個專案的進行狀況。
S:切小,把吃不完的青蛙切小,找到下一步行動
我們在吃青蛙時,常常遇到一個狀況就是青蛙太大隻,你可以利用條列法、心智圖或九宮格法,一隻大青蛙分成,頭部、兩隻前腳、兩隻後腳、青蛙身體等部分,分析一下吃青蛙的方式,這樣可以有效幫助我們找到吃青蛙的下一步行動。
永錫老師的用法:我比較喜歡的是日本松村寧雄先生的曼陀羅九宮格法,我會把複雜的專案(例如寫書,我的近期任務清單),在紙本或電腦上,用九宮格的方式來梳理,先切成九部分,就各自的部分,列出思考要點,找出下一步行動。
T:時間,番茄工作法,幫助我們更加專注
番茄工作法和吃青蛙是天造地設的一對,每天的青蛙,通常需要1.5-2.5個小時才能完成,也就是要花三到五個番茄鐘,當我們需要專注工作前,設個番茄鐘,就能讓我們的工作效率大增。
永錫老師的用法:我使用好友5S生活開發的實體番茄鐘,25分鐘專注一件事情,休息5分鐘時,離開座位兩公尺以上,徹底休息。
慢想,如果我們希望復盤寫得更好,每天花個五分鐘,慢下來寫日記,以下介紹永錫老師寫好日記的SLOW法則
S:成功日記(慢想),寫下自己的成功日記。
寫在群裡的日記時,初期要多寫自己成功的事情,也多稱讚團隊寫的內容,這樣能夠促成團隊寫衝越來越多的成功日記,還有人會為了寫日記,特別去做出好的行為。
永錫老師的用法:滴答清單中使用 #人名,這樣子人名會變色,打到微信時也更容易閱讀姓名。
L:槓桿,讓青蛙及復盤發揮更大效果
一個好的槓桿工具,可以穿梭在不同場景,滴答清單及微信,可以在不同平台上手機使用,也可以在任何桌機操作。不僅如此,微信可以發紅包,一種是群體搶紅包,這對沒有遵守規則者是懲罰,遵守規則的他人是獎勵,讓整個復盤及青蛙打卡的過程更具遊戲性。
除此,我們建議復盤不要超過140字,寫的內容要分點、分段、有人名,都可以讓彼此閱讀復盤的體驗更好
永錫老師的用法:每個人都喜歡聽到自己的姓名,寫復盤時多寫人名,整個微信群中會建立越來越好的氛圍。
O:閉環,把握青蛙及復盤的連續技,建立好的閉環
褚晶每天晚上工作完成後,寫下自己的復盤;隔天上班前列出自己每日工作計畫(青蛙);經過一天的行動,有些想法,寫下第二天的復盤,就這樣日復一日,週復一週,形成閉環。
在一百天中,雕琢這閉環,思考如何寫出更好的復盤,並閱讀同伴的復盤,寫好更好的青蛙,並閱讀伙伴的每日計劃,根據時間管理的方法,做出更多好的行動,這樣讓自己青蛙、復盤、行動形成連續技,做出更好的閉環。
永錫老師的用法:每天早上寫復盤,接著規劃自己一天的計畫發到群裡面,並且做好每週檢視工作,掌握自己任務清單的狀況。
W:檢視青蛙及復盤
每天發出復盤後,在群裡面看復盤,發出青蛙後,在群裡面看彼此青蛙(看同事是否需要自己協作),想好需要協作時的處理狀況;每七天團隊一起來做分享七天日記的心得,也等於是檢視上週團隊的專案推進狀況;每個月召開會議檢視整個團隊打卡狀況(MS Excel打卡統計表格),一起討論團隊下個月前進方向。
永錫老師的用法:每天寫日記,每週會閱讀一週來的日記,分享給團隊有意思的體會。
快思FAST,慢想SLOW,用八個方法來做好吃青蛙及復盤,就是做好復盤(Clossed Loop)
講完芳芳的案例,全場居然響起了一片掌聲,陳總和大家微微一鞠躬
「永錫老師今天幫大家講了閉環,讓企業的訊息流更加順暢。這兩年,我們整個企業比較順利地完成了日閉環(每日青蛙+每日復盤),現在正在努力做好第二個周閉環(周計劃及每周復盤)。」陳總沒有投影片,就用他的真誠,和長帆物流的幹部們說著「每天發青蛙和蝌蚪,每天寫復盤,感覺好像成了自己血液里的東西,好像變成了自己的DNA。 」
我沒有講話,全場的同仁也沒有講話。
「每天看同事們復盤,我覺得對他們的**和行為,感同身受,這是一個分享,吸收和享受的過程,感覺很幸福,感覺跟小夥伴們更緊密了。」陳總一面說,一面踱步,慢慢走到課堂中間「有點不能想象,如果每天不做的話會有什麼感受。以前我們公司老是出去學習別人的經驗,學習別人的方法和系統。現在,我們很快就會擁有一套千悅特色的系統了,這在全國餐飲企業裡面,絕對是第一個。 」
最後的尾音高揚,分享結束,全場掌聲
「陳總,如果有人每天復盤及青蛙打卡只是寫流水帳怎麼辦?」曼麗非常認真,立刻舉手,說出她想請教的問題
「是的,總會有人因為自己能力的問題,意願的問題,打出來的結果不如人意。我們會有高階主管去現場瞭解他打卡的狀況,先予以輔導。」帶領員工的陳總經驗豐富,緩緩回答「如果是他學不會,那主管必須再教導,給同仁時間空間;如果是意願甚至態度的問題,主管要說明這是公司制度,必須即時做到賞罰分明,不能打迷糊帳,讓同仁有偷懶空間。」
「陳總,請教一下,公司如果有部分同仁不打卡怎麼辦?」快芳問到她自己團隊的問題,有一位同是很排斥打卡,甚至威脅要退群。
「我們公司也有這樣的案例,有位廚師叫做光頭,剛剛打卡沒多久,就因為被罰了紅包,和她主管吵著要退群,說是不想要受到限制,結果他真的推群了。大家也不理他,過了半年,光頭來找我,偷偷要我請他主管讓他進群」陳總笑瞇瞇地說「因為他發現公司裡所有的訊息都在復盤及青蛙打卡裡面,不在群裡看不到,大家也想看群就知道了,為什麼光頭不知道。
「所以如果人拍斥打卡,想要退群」陳總眼睛望向快芳座椅的方向「一開始就是勸導,但是他還是堅持要退群,我們也沒辦法,但是除非他不想待在公司了,最後我相信他還是想回到群裡面的。」

「陳總,這個打卡系統可以找出人才嗎?」HR小羅問起了她職責相關的問題
「我發一個我們HR高級主管的復盤到群裡面吧。」陳總拿起手機來操作,把他今天收到的一個復盤發到群裡。
「今天對倉庫管理進行了訪談式調查,以前常常聽多位領導表樣說倉庫5S(日本一種管理手法),
主動幫助店裡其他崗位的員工,從復盤看到很多案例。今天和他所在的樓面主管及廚師長溝通,發現店裡同仁對他評價非常高,幾乎沒有缺點,唯一可惜的是年紀稍微大了點。像這種員工,我們必須主動發現並放對崗位善加運用,不然就埋沒了。我們應該要通過各種渠道挖掘人才並主動培養。人才庫的建立不是一朝一夕的事,必須設成青蛙,主動行動」
「我們的HR可以透過復盤寫出她找尋人才的方法,其他的高階決策幹部看到了,就可以進而學習。」陳總對長帆的同仁說著,HR小羅拼命點頭,手則是不停做筆記
「最後,我想送大家八個字”由形入型,由型盡心”,這也是我們企業打卡的心路歷程。」分享的最後,陳總說「一開始打卡,大家總是心不甘情不願,像是我們光頭,就退群不打了,這個階段就是”形”,形狀的形。」
「接著我們的中高階幹部把打卡推廣到第一線員工,所以第一線員工,和他們主管一樣處在”形”,形狀的形。」陳總慢慢說著,像是把這一路上的心得都和長帆同仁述說「但這中高階主管警覺到,他們必須認真打,要做到更高層次,也就是”型”,成了一種典型,第一線員工的模範。」
「而我們這些高階決策群,看著下面第一線同仁是”形”,中高階主管是”型”」陳總語速增快了,但是他似乎沒有知覺「這個復盤及青蛙打卡的習慣,成了自己血液里的東西,好像變成了自己的DNA,這就進心了。”由形入型,由型盡心”這八個字,送給大家。」
「感謝陳總,我們長帆一定會吸收陳總公司經驗,持續復盤及青蛙打卡。」黃總接著上了講台,和陳總深深握了手。「我們掌聲感謝陳總的分享」
全場鼓掌,陳總鞠躬下台,”由形入型,由型盡心”,真是精彩。
via twhsi的BLOG :: 隨意窩 Xuite :: https://ift.tt/LaHq4h
May 22, 2018 at 06:27PM
这些在线工具让你打开浏览器就能写作
这些在线工具,让你打开浏览器就能写作
https://ift.tt/2QEywjd
Hover
虽然在线工具的完整性与流畅度往往无法与客户端应用相比,但便捷的使用与同步体验却远在后者之上。如果你有时不时地在一个陌生的电脑上写作的需求,或是和我一样已经懒到不愿意安装本地应用了,那么在线工具会是你不二的选择。
接下来我将从以下 5 个方向来推荐一些好用的在线工具,给有同样需求的写作爱好者们提供一些参考:
-
Markdown 编辑器
-
作图工具
-
表格工具
-
信息图工具
-
图床工具
Markdown 编辑器
StackEdit
这是一款老牌的开源在线 Markdown 编辑器,并且还完整地支持 HTML 语法。StackEdit 至今已经经历了 5 个大版本更新,所以不管是书写还是预览的流畅度都与客户端应用无二,可以说是最优秀的在线编辑器之一了,我的数篇文章(包括这一篇)也都是在 StackEdit 上完成的。
 StackEdit 的主界面,左右分别是文档与设置界面,都可关闭,中间的编辑界面可在阅读、纯编辑与实时预览三个状态中切换
StackEdit 的主界面,左右分别是文档与设置界面,都可关闭,中间的编辑界面可在阅读、纯编辑与实时预览三个状态中切换
StackEdit 默认将文件与设置存储在本地,在登录谷歌账号之后,可以同步自定义设置,除此之外 StackEdit 也支持与 Google Drive(以后要叫 Google One 了)、 Dropbox 和 GitHub 中的文件同步。
 自定义选项众多,我只将字号调小了0.1,默认字号对中文来说偏大
自定义选项众多,我只将字号调小了0.1,默认字号对中文来说偏大
如果你经营着自己的博客,你还可以直接在 StackEdit 上将文章推送到 WordPress 或是 Blogger 上。
版本控制(这一功能开启需要登录谷歌账号)与实时保存对于写作工具来说也是必不可少的,我不止一次在关闭素材时顺手把浏览器也关闭了,而我的亲身体验可以保证,StackEdit 是一个不需要保存键也不会丢失任何内容的编辑器。
写完稿件以后自然要导出,StackEdit 默认支持导出为 Markdown 和 HTML 文件,如果你需要 PDF 或是使用内置的 PanDoc,就得先要为这个开源项目给予 5 美元的赞助。
StackEdit 唯一的遗憾是,最新版本不支持通过 CSS 自定义预览界面的样式(可以自定义导出的 HTML 文件的样式),从 GitHub 上 Issues 里的回答来看,作者似乎很满意目前的默认样式,并不打算在后续的版本中添加支持。
Dillinger
要说 Dillinger 在功能上有什么超越 StackEdit 之处的话,大概只有可以实时显示转换后的 HTML 代码这一点了(点击预览窗口上方的「</>」按钮,即在预览窗显示 HTML 代码)。如果你是用英文写作的话,不用付费即可导出 PDF 勉强也能算是一个优点(中文会显示为乱码)。
而说起缺点的话,同步滚动有位置差,编辑界面没有任何自定义选项,无法建立文件夹只能扎堆排列文档,沉浸模式下怪异的界面…… Dillinger 的功能简陋得像一个半成品。
但就像猫咪们的糟糕性格总能获得铲屎官的原谅一样,Dillinger 优雅的字体与配色,恰当好处的 UI 界面,总能让我忽略其内里的缺陷,毕竟写作的热情要比任何外部的功能都重要。
 编辑界面简洁优雅,无可挑剔
编辑界面简洁优雅,无可挑剔
作图工具
如果你需要在文章中加入脑图、流程图或者信息图来更好地解释一些概念或者想法,你也可以通过下面这些在线作图工具实现。当然你在上传这些图片至编辑器时,还是需要从本地中转一下。
ProcessOn
ProcessOn 是一款免费的在线制图工具(模版收费),所支持的原型设计、实时协作这些不合这次的主题就不做讨论了,主要要介绍的是它在思维导图和流程图两个方面的应用。
ProcessOn 的思维导图界面上只有一些调整和辅助按钮,因为它是通过快捷键操作的,新人拿到会有点懵,好在按键并不复杂,点看 说明 就能快速了解。
的大纲") ProcessOn 思维导图的主界面,在编辑的是这篇文章(第一版)的大纲
ProcessOn 思维导图的主界面,在编辑的是这篇文章(第一版)的大纲
ProcessOn 的流程图界面相比思维导图就直观很多了,只是比一般的绘图工具多了一个导航窗口,中规中矩的界面,相比之下更像是一个客户端的产品,当然它并没有丢掉在线工具实时保存的特性。
 ProcessOn 的流程图主界面
ProcessOn 的流程图主界面
不管是思维导图还是流程图,制作完成后都可以导出成常见的图片或是 PDF 格式,如果付费会员,还可以将思维导图导出为 Word 或是 PPT 格式。
Draw.io
Draw.io 真正体现了在线工具的精髓——随取随用,不需要注册账号,不用新建文件,没有欢迎界面,没有模版选择,打开即是一个 A4 画幅的编辑界面。
因为不区分图形类型,所以 Draw.io 会一股脑得把所有图形选项塞给你,看起来不太友好,但这也意味着只要上手,你可以用它完成任何复杂的图形。更强大的地方在于,完成的图形可以以 HTML 和 XML 的形式导出,摆脱图片的限制,直接嵌入到网页之中。
Draw.io 的缺点也很明显,编辑界面上显眼的「修改未保存」时刻提醒我们,只要这页面一关闭,后果难以想象。
 相比 ProcessOn,文本与图形选项放在了右侧,更为方便
相比 ProcessOn,文本与图形选项放在了右侧,更为方便
如果碰到一直加载的情况,不用担心是网站关闭了,和 Slack 一样 Draw.io 偶尔也会抽风。
表格工具
如前文所说,表格在所有标记语言中都表现得极为繁琐,我们在表格标记书写上花费的时间往往超过内容本身,这个时候难免怀念起富文本编辑器简单的表格插入,如果你想在 Markdown 中获得同样的体验,那么可以试试这两款工具
Tables Generator
Tables Generator 是一款在线的表格生成工具,使用的方法非常简单,你只需要在其中像富文本一样编辑表格,他就会自动把表格的内容转换相应的标记语法,目前 Tables Generator 支持 LaTex、HTML、Markdown 和 MediaWiki 四种语法,基本涵盖了主流需求。
 工具的上半部分是编辑区,编辑完成后点击一下「Generate」,就会自动转换成标记语言显示在下半区
工具的上半部分是编辑区,编辑完成后点击一下「Generate」,就会自动转换成标记语言显示在下半区
值得一提的是 Tables Generator 还支持一种纯文本格式的表格,通过一定的符号、空格和换行,让表格得以在纯文本下展现。
 Tables Generator 生成的纯文本格式表格,非常有创意
Tables Generator 生成的纯文本格式表格,非常有创意
this DaveJ
this DaveJ 的功能与 Tables Generator 有所不同,通过这个工具你可以将 Excel 表格里复制出来的内容转换为 Markdown 格式显示出来。
网站声明支持 Google Sheets 和 Excel,经过测试 WPS 也可以完美使用,而 Numbers 的内容复制进去就完全没有反应了。
 this DaveJ 的表格转换界面,其本身是一个物联网向的教程网站,表格转换工具只是其中的一部分
this DaveJ 的表格转换界面,其本身是一个物联网向的教程网站,表格转换工具只是其中的一部分
信息图工具
数据可视化,这是信息图的根本目的,但在插一个饼状图都要考虑配色的今天,好看显然已经是必要要求之一。一张制作精良的信息图既能展示复杂的数据,又能为冗长的文章增色不少。
Infogram
不过作为非专业人士,让我用 Adobe 全家桶凭空制作一张信息图是不现实的,所以我所推荐的 Infogram 自然是提供了大量现成模版的。Infogram 的模版涉及广泛,但大部分都要收费,最低可以以 19 美元的价格使用 100 套,在我看来只要能在关键时刻用上一套,这 100 多人民币的投入就物超所值。
 Infogram 上精美的模版
Infogram 上精美的模版
Infogram 的编辑界面非常简单,重要功能是插入图标、地图、文字、图片、图形和视频,对模版的编辑只要点击相应位置即可。编辑完成的信息图可以以图片或 PDF 的形式输出。
 Infogram 的编辑界面
Infogram 的编辑界面
发现**
这个算是我的一点私货,地图本是较少用到的一类信息图,但我偏好历史,尤其喜欢以地图为基础写作,发现** 就是我最常用的网站。
在发现**上,可以以各类卫星、地形、街道、历史或 地图云集 的地图为底图,辅以文字数据和线条图形,定制自己专需的地图。
不过发现**本身不是一个在线应用,它所导出的 .geojson 和 .ageeye 格式必须使用 GIS 软件打开,所以我每次都选择直接截图使用。
 地图编辑界面
地图编辑界面
图床
现在的网站不再吝啬于图片占用的那一点空间,图片直传已经成了所有内容分发网站的必然方式,除了自建博客,应该很少还有用户在接触「图床」这么一个古老的事物,但随着 Markdown 的兴起,老古董也焕发了新的生机。
介于 Markdown 的纯文本属性,其本身无法保存任何媒体文件,本地的 Markdown 编辑器多选择将图片副本与文本保存在同一目录下以方便调用,而在线编辑器则多支持以 Google Drive 为存储盘。显然,在国内图床是一个更好的手段。
SM.MS
国内外大大小小的图床不少,甚至不少云服务商都提供有免费的空间,但作为一个图床应用,像SM.MS 如此直白的,倒是凤毛麟角了。
没有社交,没有水印,它能做的就是接受你上传来的图片然后给出一个链接,而你能做的也就是选择复制何种格式的链接。
 SM.MS 的主页
SM.MS 的主页
路过图床
路过图床 的功能和 SM.MS 十分接近,你只需在网页中上传一张图片,就可以在下方获得它的专有链接。
另外,路过图床非常贴心地提供了不同尺寸的图片的链接,并且用户也可以直接复制 HTML、BBCode、Markdown 代码,方便了不少。

希望我推荐的这些在线工具可以帮助到想要随时随地写作的你,也欢迎大家分享更多使用的在线工具。
Lifehacker
via 少数派 http://sspai.com
September 17, 2018 at 03:10PM
维多利亚时代的性高潮及同行评议的危机大象文摘
维多利亚时代的性高潮及同行评议的危机|大象文摘
https://ift.tt/2NsVtru
文章来源: Robinson Meyer|利维坦(ID: liweitan2014)

利维坦按:在维多利亚时期或 “电气时代”,正如那个时期的很多广告里所提到的一样,诸如电报和电灯一类的新发明快速改变了普通大众的日常生活。但在这些实用的居家设备之外,衍生出更多不可靠的电疗发明,比如本文中所提及的振动器,试图利用激烈的振动来保有美丽和增进健康。另外,当时还一度非常流行电疗腰带,这个奇妙的装置由镀银的锌、铜线圈和电线构成,能产生微量的电流,对人体产生刺激。

一些腰带和此广告中展示的波斯顿腰带一样,据称能帮助获得更好的性体验。

一则1900年刊登的麦克劳克林医生的电腰带广告,称这款腰带可治疗疼痛和神经系统疾病。
这个装备意在治疗所有已知的不适与疾病包括疲劳、阳萎、胃病(消化不良)、肝病、神经紊乱、心脏病、疝气以及令人不够满意的性爱表现——当然,这种万能神器,99%都是骗人的。
本文中的振动器声名远播,这要归结到雷切尔·梅恩斯在那本书中的描述——但她的描述有多少是基于历史事实的?有人对此提出了质疑。当然,我相信,即便是在证据面前,大众仍旧会对这个虚构的故事(起码偏离了基本事实)深以为然——男性对女性性欲的普遍偏见和妄想,会让这个故事继续下去。
文/Robinson Meyer、Ashley Fetters
译/清清
校对/老房
原文/https://ift.tt/2DgC4oY
本文基于创作共同协议(BY-NC),由清清在利维坦发布

图源:Cultura Colectiva
这是医学史上最有吸引力的丑闻之一:在维多利亚时代的鼎盛时期,医生们经常通过唤起性高潮的方式来治疗女性患者。这种大规模的治疗——专治现已不存在的“癔症”(hysteria,又名歇斯底里症)——是通过振动器这项技术实现的。医生使用振动器能够快速有效地按摩女性的阴蒂,并且手和手腕不会太累。
这样的解释真让人不安,如此一来,振动器之所以成功,并不是因为它们提高了女性的快感,而是因为它们为男性医生节省了体力。在过去的几年时间里,这个故事迅速演变成了主流文化。随之出现了获得托尼奖提名的戏剧,由玛吉·吉伦哈尔(Maggie Gyllenhaal)主演的浪漫喜剧,甚至还有一系列品牌振动器。萨曼莎·比(Samantha Bee)在3月份时以此为素材编了一部滑稽短剧。这些层出不穷的离奇新闻故事,包括VICE、《琼斯妈妈》和《今日心理》,让读者们在惊喜和真实中受到了教益。

电影《歇斯底里》(Hysteria)剧照。图源:YAM Magazine
总之,这已经成了人们看待维多利亚时代性生活的经典故事。根据一篇有争议的新论文,这则故事也有可能是纯属虚构的。
(journalofpositivesexuality.org/wp-content/uploads/2018/08/Failure-of-Academic-Quality-Control-Technology-of-Orgasm-Lieberman-Schatzberg.pdf)
佐治亚理工学院(Georgia Tech)的两位历史学家在论文指出,没有证据表明维多利亚时代的医生曾使用振动器作为医疗技术来刺激女性产生性高潮。他们这样写道:“对女性生殖器进行人工按摩,从来都不是对癔病的常规治疗方法。”该文章的作者以及性玩具历史畅销书Buzz的作者哈莉·利伯曼(Hallie Lieberman)说:“这故事无从考证,因此并不属实。”

《性高潮技术》封面,雷切尔·梅恩斯著。图源:Snapdeal
要找到这则传闻的来源也不是难事,维多利亚式振动器的整个故事源于雷切尔·梅恩斯(Rachel Maines)这位学者的文章,他是一位历史学家和康奈尔大学(Cornell University)的前访问科学家。她1999年的著作《性高潮技术》(The Technology of Orgasm)在当时被描述为“女性性唤起的秘密历史”,书中写道,从希波克拉底到现代,阴蒂按摩作为一门医疗技术已经有了几百年的历史。
(courses.cit.cornell.edu/rpm24/technologyOfOrgasm.html)
但是,根据乔治亚理工学院历史与社会学学院的主席利伯曼和埃里克·沙茨伯格(Eric Schatzberg)的说法,这并不属实。他们说,能表明性高潮被广泛认为是治疗女性癔症的一种方法的证据并不充足,而能证明维多利亚时代的人使用振动器来诱导性高潮作为一种医学技术的证据就更少了。他们在文章中写道,“梅恩斯并没有引用到任何有关公开描述使用振动器来按摩阴蒂区域的内容。她的英文资料中甚至没有提及过通过按摩或者其他远程来唤起性高潮的‘性兴奋’产品。”
相反,他们认为梅恩斯对初始资料持“睁只眼闭只眼”的态度来掩饰证据的不足,并引用了一大堆不相关的内容来作论据。

1910年某振动器广告:“振动可以保持健康。它可以锻炼肌肉,促进血液循环,并激活神经系统。人们可以在自己的房间内自我治疗,或者治疗其他家庭成员。其中经常在家治疗的有:耳聋,头痛,失眠,腰痛,神经紧张,神经痛,神经衰弱,瘫痪,扭伤等。”图源:Internet Archive/Flickr Commons
在一次采访中,梅恩斯表示,她听到了关于这篇文章的各种批评,但其实她在《性高潮技术》中的论点只是一个“假设”。她说:“我从来没有说过有证据证明这是真的。我只是说,这是一个有趣的假设,正如利伯曼所指出的,准确来说,是人们对此事非常关注。并且,以某种方式将其转变为神话形式的时机已经成熟。我并没有把它当成真的来写,但是人们确实喜欢,并传播开来了。”
梅恩斯补充说道,她在《性高潮技术》中的论据非常的“薄弱”,但其他学者竟然过了那么长时间才对她的论据提出质疑,这让她感到有点惊讶。“我原以为人们会立即对我的论据进行攻击,但却是等了20年,人们甚至不想去怀疑此事,因为他们非常喜欢这个故事,所以不想去攻击它。”

1891年有关振动器在腹部的操作演示图。图源:Mashable
虽然梅恩斯现在声称自己的论据只是一个“假设”,但是她当时在《性高潮技术》这篇文章中并不是用这样的假设口吻来写的。在书中的前几页,她这样写道:“在西方医学传统中,医生或助产士对生殖器进行按摩致性高潮是对癔症的一种标准疗法。当时振动器在19世纪末成为了一种机电医疗仪器,从之前的按摩技术演变成了医生需要的快捷有效的物理疗法,尤其是对癔症的治疗。”
当被问及这本书的陈述性语气时,梅恩斯说:“我的本意就是把它作为一种假设,但也许我表达的方式并没有传达出这样的信息。对历史数据的解读一向都是开放性的。”
沙茨伯格说:“实际上,在这本书中,她根本不是把它作为一种假设,而是声称这是事实。我认为,梅恩斯当时就知道自己的论据站不住脚,只是后来遭到的议论太多,她才出尔反尔的。”

图为各种用于振动按摩的器械:圆形或方形的振荡板、振荡辊(带有能转动的圆柱形机件的机器)、带旋转圆筒和硬质橡胶的辊、旋转锤和离心振动器,1906年。图源:伦敦惠康图书馆
当利伯曼第一次看到《性高潮技术》时,她确实没有想到这竟会是假设的。她和沙茨伯格研究新论文是在2010年的一次课堂上,当时利伯曼正在准备关于性玩具历史的论文。她的导师说过,有时候查看学者的引文会对理解他们的论文有帮助。利伯曼说:“于是我就开始研究这本书的引文,发现是假的。”
沙茨伯格当时是威斯康星大学的教授,利伯曼拿这本书给他看,征求他的意见。他们开始逐个翻看这本书里的引文,发现这些引文存在严重造假。在一篇文章中,梅恩斯提到了1660年英国外科医生纳萨尼尔·海默尔(Nathaniel Highmore)所描述的一项技术。最初的引文是从拉丁语翻译过来的,描述了一种运动“这就正如同小男孩玩的一种游戏,一只手摩擦胃,同时用另一只手拍打头”。梅恩斯说,这是作为 “外阴按摩”引起性高潮难度的一种参考。
利伯曼和沙茨伯格说,事实并非如此。他们这样写道:“这个关于男孩游戏的引用是在对手指的复杂动作的讨论中出现的,尤其是在演奏弦乐器的时候。这样的讨论跟外阴的按摩一点关系也没有。” (当梅恩斯被问及此说法时,她仍然坚信海默尔描述的就是外阴的按摩。)
在另一篇文章中,梅恩斯引用了一位19世纪的医生对振动器如何加速按摩过程的描述。医生若不使用振动器,引文这样写道:“要经过一个小时的辛苦努力才能完成任务,但效果却远不如振动器在5到10分钟内就能轻松完成的好。”
利伯曼说,但这并不是对外阴按摩的描述。她告诉我说,“振动器是专利产品。” 它们被用作一种省力的装置,用于许多不同类型的不那么刺激的按摩。她说,这位医生实际上是在提倡用振动按摩器来按摩“肠道,肾脏,肺和皮肤”。

1891年振动器广告:“它可以消除疲劳,缓解神经紧张,同时也可以消除脸上的皱纹。”图源:Internet Archive/Flickr Commons
虽然利伯曼和沙茨伯格已经发现了这些问题,但是却没人愿意出版。起初,利伯曼想要发表一篇文章,里面结合了她对性玩具历史的研究成果和对梅恩斯论文的反驳。但是她里面的《性高潮技术》框架却遭到了一位匿名审稿人的反对。最终,利伯曼将所有关于梅恩斯的批评从文章中剔除,文章才得以发表。
利伯曼与沙茨伯格合作,把对梅恩斯的批评整合成了一篇完整的期刊文章,并再次努力寻找一本能出版该文章的杂志。据《大西洋月刊》查阅的电子邮件显示,编辑们现在觉得,他们的批评范围不应该局限在这一本书上,而且对梅恩斯的政治性文章应该要多些宽容。一位编辑表示,他们不应该把梅恩斯的主张视为错误的事实,而应视为过时的历史解读。那位评论者写道:“这只不过是一种解读,而你们偏要把“事实”扯到其中。这不就和我们一直在回顾工业革命发生的‘事实’以及是如何发生的是一样的吗?”
这篇文章发表在《积极性行为杂志》的八月期刊上。
(journalofpositivesexuality.org/)
利伯曼说:“有些人说‘噢,你这是在攻击梅恩斯。’但是如果她的文章没有这些错误,我也不会自寻烦恼。我没有想批评她,也不想去攻击她,我对她没有成见。我只是想把他人的成果作为立论基础,可一旦这个成果是错误的,那就会给性历史研究领域的学者带来麻烦。”
沙茨伯格说:“假如你是一个正在写论文的毕业生,遇到这种看似在研究领域内已被广泛认可,但却又考证不了的事情时,真的是件麻烦事。”

1913年,一名女子在使用Sanofix牌振动器。它可用于按摩前额,面部,颈部和胸部。图源:惠康图书馆
其他历史学家之前也有发现梅恩斯的文章有问题。一位研究维多利亚时代性别的著名历史学家费恩·里德尔(Fern Riddell),曾在2014年英国《卫报》的一篇文章中对“维多利亚人发明振动器”这一说法作出反驳。(里德尔当时并没有回复通过她的出版商发送的电子邮件。)
此外,英国开放大学的古典文学教授海伦·金(Helen King),在2011年写了一篇很长的学术论文来反驳梅恩斯对希腊语和拉丁语资源的使用。金在邮件中说道,梅恩斯“故意歪曲”她引用的古代文本的翻译,比如把医学文本“下背部的按摩翻译为‘手淫’”。“她任意玩弄翻译过来的文本;例如,她引用了一篇普通的关于罗马洗浴的文章来支撑她的假设,即浴室里的自来水是用来自慰的,然而那篇文章并没有提到水的压力或女性,更不用说自慰了!”
读了这篇新论文,金说她有一个想法:“令人惊讶的是,梅恩斯的书比我想象中的还要糟糕......我很好奇,出版社是否曾派人对此进行过审阅。”
这个出版社叫约翰·霍普金斯大学出版社(Johns Hopkins University Press),19年前出版了《性高潮技术》这本书。出版社的编辑部主任格雷格·布里顿(Greg Britton)说:“大多数资深学者都知道,大学出版社在对他们的书进行同行评审时会以其他资深学者对作品质量的评价作为参考。20年前,这本书在出版之前被编辑选中,经历了一轮严格的单盲同行评审,然后得到教师编辑委员会的批准。”
雷格·布里顿还说道:“但是出版社不会像利伯曼和沙茨伯格所说的那样,对他们的书进行事实核查。重点是,梅恩斯教授一直认为,她的论断只是一个有待进一步探索的假设。”

话剧《在隔壁房间》剧照。图源:The Telegraph
梅恩斯认同金的文章给利伯曼和沙茨伯格的论文开了先例。她声称自己从没想过要把维多利亚时期用振动器做癔症治疗这个想法充当历史事实。确切地说,她只不过是想通过这种可能性的呈现,来引起人们思考和谈论除了传统上更熟悉的男性性高潮之外的“相互性高潮”或者女性性高潮。考虑到它在流行文化中的巨大影响,尤其是对戏剧作品的影响,例如莎拉·鲁尔(Sarah Ruhl),她的戏剧《在隔壁房间》(也叫《振动器戏剧》)获得了普利策奖提名。她说,“就这方面而言我认为我是成功的。”
沙茨伯格和利伯曼说,他们意识到性别和性快乐的研究的重要性和合法性的同时,也很看重事实。沙茨伯格说,“在这个后事实的时代,在学术的堡垒中,我们应该保持对事实的热爱、尊敬和重视,并使之成为永恒不懈的追求。”
近些年来,社会科学面临着“复现性危机”(reproducibility crisis)的挑战,以往的基本发现,到了心理学、营养科学和其他学科那里就行不通了,无法再次运用。利伯曼和沙茨伯格认为,同样的“出版或作废”这些推动危机的诱因也能解释振动器的故事:他们写道,它的成功“是一个警示故事,说明谎言可以轻易地嵌入到人文学科中”。
沙茨伯格说:“人们不会因为检查之前的工作而得到奖励,他们会因为在性别研究中有了新发现而得到奖励。在科学领域如此,在人文学科中也是如此。”
利伯曼说,从整件事情中可以看出研究院倾向于证实误差。她说:“这是个淫秽、性感的故事,听起来像色情故事。我们认为维多利亚时代的人所知道的性知识和受到的性教育没有如今的我们多——我们逐渐对性有了更多的了解,而那段历史也顺着这段故事不断向前发展。这样理解最合理。这与人们所认为的在那个年代没有女性性快感这个概念的看法是一致的。”
她补充说道:“对我来说,最大的收获之一是同行评审的过程是有缺陷的。同行审查不能代替事实核查。我们需要解决这个问题,我们需要开始检查其他人的文章,尤其是在历史方面。”
利伯曼说,对于金而言,这收获就更明显了,那就是“人们喜欢听这个故事”以及“振动器的故事深受人们喜欢”。
在这个话题无孔不入且热爱阅读的新媒体编辑部,我们经常在各种五花八门的公众号上,遇到或曲高和寡或趣味小众、但非常有意思的新鲜玩意儿。
现在,它们都将一一出现在这个栏目里。
我们也随时欢迎您的参与,留言向我们推荐您读到的低调好文。
本文由公众号「利维坦」(ID:liweitan2014)授权转载,欢迎点击「阅读原文」访问关注。
原文
kindle4rss
via 大象公会 https://ift.tt/2DryWqo
September 21, 2018 at 12:25PM
魏阳
**人的月亮崇拜史
魏阳: **人的月亮崇拜史
https://ift.tt/2DrqGGW
中秋将至,全家在一起做月饼。儿女们欢欣雀跃,乐此不疲。
女儿问:“为什么每年到了中秋节,人们总是要赏月,为什么不去”赏日“呢?”
说实话,我还真没想过这个问题。我沉默了一下回答:“因为……我们是一个崇拜月亮的民族吧。”
传统**似乎是一个属于月亮的国度。不过,中秋节赏月的传统,其实是从唐宋年间才开始。
对于上古**人来说,日与月似乎同等重要。先秦的典籍《周易・系辞上》中有“悬象著明,莫大乎日月”的说法。《礼记》记载,上古的贵族“祭日於�,祭月於西,以端其位。”汉代的郑玄解释说:“日出�方,月在西方……大明生於�,月生於西,此��之分,夫�之位也”。日与月成为阴阳的代表,规范了君臣、夫妇、父子等社会礼节。所以后世的朝廷总要在春分时节祭拜太阳,秋分祭拜月亮。南朝时期“以春分朝於殿庭之西,�向而拜日,秋分於殿庭之�,西向而拜月”。这种对日月的平等的崇拜,一直延续到明清北京的日坛与月坛。
最早提到中秋的,是战国时期成书的《礼记》。其中记载:“仲秋之月�衰老,行糜粥�食。” 古人相信,秋天是万物凋零的开始,所以提醒老年人要注意身体,多喝粥。上古典籍中虽然提到“中秋”这个词,但是我们并不知道是不是指阴历八月十五,或者是泛指秋季的中期。这时的“中秋(仲秋)”似乎还不是十分特别的节日。先秦时,也没有月饼。――据研究,月饼的名字,要到宋代才出现。吃月饼,要到明代才开始流行。
中秋赏月成为一个传统节日,要到唐宋年间才开始流行的。唐代开始出现中秋赏月宴饮的习俗。到了宋代,发展为全民通宵达旦的狂欢。从唐宋开始,最美的传说,总是属于月亮。最美的诗句,是在赞美月亮。人们在月下思索历史、感悟人生、探索宇宙,千般思绪,都化作对月亮的崇拜和感激。
虽然在政治领域,日月显得同等重要,但是从传世诗歌的数量来看,自唐宋时代开始,日月对**人的美学意义开始发生变化。现存的《唐诗三百首》中,咏叹太阳的不过数首,而与月亮有关却超过一百首。《全唐诗》中,仅以八月十五赏月为主题的就有共111首,出自65位诗人之手。宋词中中秋词更为壮观,共达210首之多,多以“中秋”、 “月夕”为题,内容描写月色、思乡、思亲;高频词有嫦娥、玉兔、蟾蜍、桂树、月宫、琼楼等等。可以说,自唐宋以来,中秋是**诗人的狂欢节。
传统历法虽然是阳历与阴历的合体,但是大体上,是根据月亮的盈亏变化而定的“月历”。 春节,元宵、清明、中秋、重阳、腊八,七夕和除夕,这些重要节日,无一例外按照阴历来计算。
写“月有阴晴圆缺”的苏轼,曾经记载过这样一个故事。说唐朝时候的洛阳,有个官二代叫做李源。他有一个好基友,是个庙里的和尚,叫做圆泽。常常在一起聊天。一天,他们约好了自驾游去青城峨眉山。圆泽想要从长安走,但是李源坚持要从荆州做船去。圆泽拗不过朋友,只好说:“那真是没办法了。”
船行到荆州的南浦,看到一个妇人在水边汲水,圆泽就流下泪来,说:“我不肯走这条路,就是因为怕见到她!”李源吃惊的问。圆泽说:“这位妇人,我注定要投生做她的儿子。因为我不肯来,她怀孕了三年还生不下来。现在既然遇见,无法再逃了。我很快会死去,投生在她家。三天以后你来见我,我会向你微笑。十三年后的中秋之夜,你到杭州的天竺寺,我再与你一见。“
李源十分为自己的路径选择后悔。他为朋友洗澡更衣念咒语。很快,圆泽就去世了。妇人同时生下了一个孩子。三天后,李源去看这个孩子。果然,孩子对着他灿烂地微笑。李源埋葬了朋友,回到圆泽的庙里一问才知道。圆泽在旅行之前,就已经向庙里交代过后世了。
十三年后的中秋之夜,李源如约来到杭州的天竺寺,忽然听到有一个牧童敲着牛角在月光下唱歌。
歌词唱到:“三生石上旧精魂,赏月吟风莫要论;惭愧情人远相访,此身虽异性长存。“
李源很激动,这就是他的好基友!牧童却对他说:“好兄弟,你真讲信用!可是,我俗缘未了,咱们还不能在一起玩。我要勤加修炼,咱们后会有期哦!“说完就走了,李源再也没有找到他的好基友。
李源从此看破红尘,有人推荐他去朝廷当官也不去。一直住在寺庙里,八十岁才去世。
两人在杭州相见的地方,后来被叫做“三生石”。到今天还是著名旅游景点。去年热播的剧集《三生三世十里桃花》,用的就是这个传说的梗。
苏轼记载的这个故事,有几个地方很有趣。第一,中秋赏月,是到了宋代才开始流行起来的。第二,月下的“情人”,指的是一对好基友,而不是恋爱的男女。“三生石”的故事,最初指的是男人之间的友情。这种友情,让他们成为月光下的“情人”,即使身体变化了,情谊却长存。第三,秋月之美,在古代,常常与佛教对人事无常、茫茫轮回的感叹,联系在一起。月亮,让古人们对于世俗的压力和生活的焦虑,保持了一种诗意的距离。
面对生活的苟且,古人追求的不是“诗与远方“,而是“诗与月光”。
宋代另一个赏月的例子,来自与南宋时成书的《大宋宣和遗事》。说一年中秋,月色如画。宋徽宗与道士林灵素,宠妃明妃三人赏月。徽宗突发奇想,想去月亮上的广寒宫,林灵素用法术招来两只青鸾,带着徽宗去了月宫。却在那里见到了后来入主中原,俘虏徽宗的女真人首领。中秋的月亮,以神秘的方式,向一代昏君预示了未来,却让他在这之后更加醉生梦死。这里,月亮代表了无法逃避的宿命,映照着人类的渺小与脆弱。
明清时期,中秋节已经成为一大传统节日。这时的**社会,出现了更大的地域流动性。军人,商人,僧侣,官员似乎总是背井离乡,正旅行在四通八达的路上。这时的中秋,也渐渐被赋予了“团圆”的含义。《正德江宁县志》记载:“中秋夜,南京人必赏月,合家赏月称为‘庆团圆‘,团坐聚饮称为’圆月‘,出游待市称为’走月‘”。中秋,是必须要和家人在一起度过的时光――甚至,连非人类也不能免俗。
清代纪晓岚的《阅微草堂笔记》记载了一个故事,说有个姓郭的人,中秋节和朋友聚会,聊到鬼神。郭生说,我从来不怕鬼。大家就起哄说,你可能不敢去一个传说中的凶宅吧。郭生说“有啥不敢的”!一个人带着把剑,去了凶宅。凶宅有数十件房间,“秋草满庭,荒芜蒙翳”,吓人得很。郭生抱剑独坐。半夜,果然有个人影飘来门前。郭生拿着剑要跳起来。那人影把袖子一挥,郭生全身立刻僵住,动弹不得。那人说:“你也算条汉子,只是有点争强好胜而已。今天大过节的,本来应该招待你一下,只是,有女眷要出来赏月,不方便见面。夜已深了,只好委屈你到大缸里呆一下。”
说罢,几个人把郭生抬到了一个大荷花缸里,上面压了一块大石头。很快,郭生在缸里听到阵阵笑语,数十名男女,在一起喝酒聊天赏月。突然,郭生闻到了缸中有酒香,一摸才发现,手边就有酒菜,于是大吃大喝起来。还有几个小孩子,围着缸唱着歌,说主人交代来给客人娱乐,好不热闹。许久,有人敲着缸说:“郭先生,别怪罪。今天大家都喝高了,没劲把压住缸的大石头移开了,对不住哦!不过,你的朋友就快来了。” 第二天早上,郭生的朋友们翻墙进了凶宅找郭。听到他在缸内大叫,把石头移开让他出来。这时才发现,缸内的酒具和杯盘,都是郭生自己家的用具,昨晚就丢了,现在才找到。
明清的**,无论是贵是贱,是人是鬼,中秋佳节,总要合家团聚,在一起赏月宴饮。这月光似水的夜晚,就连鬼故事,也让人在好笑之余,觉得挺温馨。
有趣的是,如此崇拜月亮的传统文化,对于太阳,似乎没有说过什么好话。
**最古老的文献《尚书》中提到:夏代有个暴君叫做桀,作恶多端。老百姓忿忿不平地说:“时日曷丧,予及汝皆亡!” 翻译成现代汉语,就是说:你这个混球太阳啥时候死翘翘啊?我宁愿跟你一起完蛋!“
上古传说中有十个太阳一起出现,祸害人间的故事。这时,必须有盖世大英雄,比如后羿,出来用弓箭把肆虐的太阳一个一个消灭掉。
登高观日,诗人李白写下的诗句是:“总为浮云能蔽日,长安不见使人愁。”太阳,代表被小人愚弄操纵的君主。不能见到太阳――无法接近帝国的权力中心,让诗人产生了巨大的焦虑和挫败感。
在传统文化中,太阳常常是一个暴虐昏聩的存在,象征了一个个滥用权力、任性胡为、傲慢愚蠢的男性帝王。而追逐太阳的人,一般也没什么好下场。《山海经》中的巨人夸父,终于在奔跑中力竭渴死――和战国时期法家权臣商鞅、韩非一样,成为了自己追逐的虚幻权力的牺牲品。
太阳成为歌颂的对象,要在激烈反传统的五四运动之后才出现。只有当传统文化被当作“四旧”遭到彻底批判的年代,太阳才会成为一个独一无二的正面比喻。
月亮则不同,这是一个充满了女性温柔,温婉娴静,多愁善感的意象。这里,没有对于权力的滥用和崇拜,只有对于人性的怜悯和世事的伤感。月亮,是传统**人的精神家园。毫不奇怪,**历代以来,数量最多的,便是咏叹月亮的名句。
一旦面对月亮,那些世俗的焦虑、权力的纷扰,瞬间不见了踪影。月亮,净化了**人的心灵,给了他最澄静豁达的胸怀;让他在面对历史的沧桑,人事的变幻,和世界的孤独时,永远以一种审美而超脱的心态,感受一切。
这种审美的心态,让张九龄写出“海上生明月,天涯共此时”的感叹,让张若虚写出“春江潮水连海平,海上明月共潮生”的美景,让李白写出“长安一片月,万户捣衣声”的寂寥,让苏轼写出“但愿人长久,千里共婵娟”的祝愿……
在传统文化中,如果太阳是力量与征服,月亮则是超脱与宁静。如果太阳是短暂与泛滥,月亮则是永恒与智慧。如果太阳象征着政治的粗暴,月亮则代表着人世的善良。如果太阳是真理和绝对,月亮则是虚幻与怀疑。如果太阳是炙热的权力,那么月亮则是远离权力后,对人性的一点伤感和怜悯。
月亮,是**文化那个永远微笑、宽容、美好的母亲;是那一个永远温柔、恬静、冰雪聪明的情人。
我想对女儿说,这也许就是为什么,**没有“赏日”的节日。
传统**人的灵魂,也许就是夜空那片皓月。
然而,月亮在近代却经历了文化上的“去魅”,随着传统文化凋零。
民国时期,当传统文化经历了五四新文化运动的洗礼,月亮渐渐失去神秘美好的象征力量。家庭的团圆和佛教的感悟,都不再重要;新时期的作家开始探讨传统对于人性的意义,理想与社会经济结构的关系。鲁迅《故事新编》中的《奔月》是其中的代表。故事用一种近乎无厘头的态度,解构了古典传说中嫦娥奔月的传说。
故事里后羿,曾经是一位射九日,斩长蛇的英雄。只是随着经济情况的窘迫,他越来越无法打到大猎物,每天只能射到一些乌鸦麻雀之类的小动物。老婆嫦娥只能吃到炸酱面,消费降级,满腹怨言,无聊得天天打麻将。往昔辉煌不再,家庭琐事却一地鸡毛。这对盖世英雄和绝世美女的组合,没有如童话般“永远幸福下去”。在经济的巨大压力下,爱情产生了悲剧性的异化。
有一天,后羿要跋涉七十多里去寻找猎物,半路却碰到小人(逢蒙)的伏击,险些丢了性命。回到家才发现,妻子嫦娥已经彻底厌倦了这萎靡的生活,吞食了仙药,独自去了月亮。后羿听到后大怒,要用弓箭将月亮射下来。
鲁迅写到:“他一手拈弓,一手捏着三枝箭,都搭上去,拉了一个满弓,正对着月亮。身子是岩石一般挺立着,眼光直射,闪闪如岩下电,须发开张飘动,像黑色火,这一瞬息,使人仿佛想见他当年射日的雄姿。”
然而,这时的月亮,已经今非昔比。中了三箭的月亮,竟“还是安然地悬着,发出和悦的更大的光辉,似乎毫无伤损。”后羿朝着月亮大吼。“他前进三步,月亮便退了三步;他退三步,月亮却又照数前进了。”
这里,月亮变成了保守势力中最不可抗拒的力量,无论向月亮射去多少弓箭,那邪恶而黑暗的势力,却发出“和悦的更大的光辉”,让这位当年的文化英雄无计可施,无能为力,让他失去了爱人,让他失去了力量。
被生活操皮实了后羿,精疲力尽,只得回头对佣人说:“我实在饿极了,还是赶快去做一盘辣子鸡,烙五斤饼来,给我吃了好睡觉。”
正如鲁迅在另一篇小说《伤逝》中所描写的。五四的狂飙突进精神,很快在二十年代的逆流中消退。没有经济和社会结构的支持,无论是英雄还是爱人,无论是理想还是爱情,都终将被内心的黑暗吞没,向生活的萎靡妥协,沦为时代的牺牲品。如卡夫卡笔下“城堡”一样不可理喻的月亮,此刻成了保守文化最坚固堡垒的象征,摧毁了一切美好和理想,最终让英雄向生活的平庸低头。
当月光凋零的时候,也是传统文化凋零的时候。
原标题:《千年的婵娟,**人崇拜月亮的历史》
kindle4rss
via 腾讯·大家 https://ift.tt/2kVSmsD
September 24, 2018 at 12:21PM
泛读从读书到读人再到读己
泛读,从读书到读人,再到读己
https://ift.tt/2nZJ5zS
哪里来的小熊猫
最近放在泛读上的时间明显少了,时间主要花在精读上,豆瓣「在读」里有几本书齐头并进,《编码》、《原则》、《论语》和《曾国藩的正侧面》。前两本最需要用心,边读、边反思、边实践;纸本的《论语》用来睡前催眠;最后一本则是为找理想人格,在精力次一等的时候随手翻阅。
 因为一段时间中精力、思维状态的不同,我更倾向于同时读多本书,以便刚日读经、柔日读史。
因为一段时间中精力、思维状态的不同,我更倾向于同时读多本书,以便刚日读经、柔日读史。
泛读虽少,仍有需求。人对于「新奇」有着很本能的渴求。刷社交媒体或浏览网页,是一种客观需要,我总得安抚自己的这点欲望。但哪怕是闲读,我也有着自己的原则。
不论何时何地,以何种形式,我总是希望,当新信息流过我的时候,能留下点什么。
从精读到泛读
落到实践上,就是摘抄。摘抄分在两端。在手机上,是通过 Workflow 在印象笔记里建立文档,综合起相关话题。暂时分得很粗略,除了经济金融,就是其他。相比较下电脑端的摘抄就好了许多。用的是系统自带的 Stickies,平时先往里边倒,到周末再梳理分类。
 手机端的摘录形式由 Workflow 自动生成。可由上边的链接下载并配置。
手机端的摘录形式由 Workflow 自动生成。可由上边的链接下载并配置。
分类,就是关键词合并。分得很潦草,只求一眼扫过去,知道关注点在哪。这主要是方便我事后反思,看时间有没有用对地方。理想状态是扫一眼关键词还能对其观点有粗略印象,并看最近有没有因为这些新观点,在行为处事上起些变化,有些长进。如有,那这点泛读的时间花得就很值得。
 这点刚开始做,也是相当粗疏。名称为 Stickies&Drafts 的缩写,甜甜圈提醒我,这不是正餐:)
这点刚开始做,也是相当粗疏。名称为 Stickies&Drafts 的缩写,甜甜圈提醒我,这不是正餐:)
举例而言,我在七月头的那周看了些「社群与信息源」的文章,里边有些文句我咀嚼至今,仍是常读常新:
不定期检查自己的核心信息源来自哪里,它到底是不是足够好。具体就是:
- 搞明白这个行业里最厉害的人是谁?他们在哪里做什么?他们有没有公开的内容输出?开始尝试用他们做的东西;
- 观察身边有哪些人也在关注这群人,想办法和他们混在一起。
这寥寥几行字,足以成为我在筛选信息源上的指导方针。摘下这段话,就已经拿到了原文的精华。现在我泛读常常是这样的,带着目的去抓取信息,只要脑子还够用,我就必须明确:哪些文章、甚至哪些字句最值得我的时间;哪些草草翻一遍,乃至直接关掉就算了。
本质上,所有的信息都是在帮我克服不确定性。于我而言,信息中的不确定性越大,需要的时间就越多,今后也能产生越大的收益。这不限于阅读,看视频、听音频都是如此。对于视觉思维的我来说,音频是典型的泛读(听),通常我是边跑步边听,但听到赞叹处,我一定会按下暂停键,然后跑慢几步,琢磨琢磨。有时候思索一会,能明显感到头脑中打一个激灵,仿佛一条通路在那一瞬间接上,爽得很。
 六月读《倚天屠龙记》,很受郭襄感动,多读了一点相关,也多留下一点痕迹。
六月读《倚天屠龙记》,很受郭襄感动,多读了一点相关,也多留下一点痕迹。
但若是信息里边没新东西(不确定性太少),那就直接关掉。比如现在读理财,一谈到财富自由,核心往往是那几条:增加被动收入、关注复利与成长。这我都会背,在我眼里也就没什么新奇,不会再看。
从读书到读人
跟人聊天也是一样。只要这人的言语能给我启发,我一样会掏出手机,打开 Drafts,开始做笔记。这情景很能够增加对方的虚荣心,使他更加「好为人师」,也就能够带给我更多收获。这样的姿态看似「低下」,但我想明白了:
很多时候,我只是误以为自己能与人平等沟通、辩驳,而其实因为在相关话题上对方掌握的信息量、历经的思考要远远多过我,我根本就没资格与他平等对话。我就是他的学生。我只有听和问的资格。
但这也不是说受着耳提面命,然后唯唯诺诺,我总会提问题,他是否答得好,我心里也有杆秤。再说得有野心一点,通过这样的问与答,我是想「吞吃」下他的视角。比如我一直看好某人的穿着打扮与沟通技巧,前阵子和他吃饭,席间摆着学生姿态向他讨教,边听边记,一点一滴都是收益。他聊得开心,我记得也不亦乐乎,并且我知道,以后我若是再有相关困惑,他就是我的信息源。
 梳理得很粗疏,但是两小时谈话中的核心,我觉得是自己抓住了的。
梳理得很粗疏,但是两小时谈话中的核心,我觉得是自己抓住了的。
当然,人各有所长,所以这类面向人的「泛读」从来都是组合化的。跟不同的人,我从来都能学到不同的东西。微信里我会用心维护的一些核心朋友,身上都有着至少一条值得我学习的优点。它们有的很具体,比如有人是律师、有人是交易员、有人是会计,这是我学习专业知识的渠道;有的人本硕博是相关专业,比如历史、政治、数学,有些事我懵懵懂懂,但经他一讲,豁然开朗;有的甚至是一些看似很虚的性格,比如勇气,再比如最近我很想学到的执行力。
其实性格上的事,看着玄乎,实际上仍有很大学习空间。这个人你与他近距离相处,就很可以揣摩他的那点勇猛究竟从何而来。过往我曾是很懦弱的人,甚至还在钱包上烙了「勇气长随」几个字,但在这一年半载,我能看到自身的「刚猛」,正在缓缓育成。有时我反思来由,觉得这与我跟某个室友的长久相处关系密切。他是直爽而豪杰的人,凡事总将「不要怂,就是干」挂在嘴边,在这潜移默化中,我受到他很积极的影响。
 傻我知道,但据我实践,确实是很不错的心理暗示:)
傻我知道,但据我实践,确实是很不错的心理暗示:)
这就是我关于泛读所想额外表述的一点。泛读,不但是读书,更是在读人。读人也分精读和泛读,上述那本《曾国藩的正侧面》是精读,我读心中所仰的苏轼、织田信长或《谍影重重》里的波恩,也都是精读。但他们毕竟离我远。从身边的人,从这些还没有「发育」完全,但相关优秀品质已经有模有样的人身上,我同样能够得到想要的东西。这点和《创造101》之类不无类似。只是粉丝在养成别人,我在养成我自己。
这很有趣。
从读人到读己
最后再想提的一点,是我在读以外,也在不断与自己对话。每天,每时每刻,我都会冒出许多稀奇古怪的念头,甚至我还刻意记录过一段时间的梦境。它们统统都会被我先收集在Drafts里,然后再往印象笔记中整理。只是他们确实太潦草了。我曾以为这些闪逝的念头都是财宝,事实上记下后过一段时间再看,往往会发现:都是什么呀。不仅是不成体系,连通过关键词分类都做不到。
 回头看去,废话连篇,用语粗俗。但好歹是我自己下的仔。
回头看去,废话连篇,用语粗俗。但好歹是我自己下的仔。
但我还是尽量选择记录,因为它们都是我生命中某段思绪的切片。印象笔记的检索功能做得很好,所以有事通过搜索重现几年前的一段话,看到那时的焦灼与踌躇,再回到当下,面对同样的问题已有成竹,这里边确实会有着隐隐的感动。
因而我把读几年前的日记也当作泛读。这点日记对其他任何人都没啥大用,但对我自己而言,它比我读过的任何书都重要。这是我这一路缓缓走来的写照。心里想到有这近两千篇日记,就很踏实,因为回首其中的每一字句,都是我的来时路。
 软件叫作 Day One。内容因为太私人,没有展开。但关于思路,我以后会试着分享。
软件叫作 Day One。内容因为太私人,没有展开。但关于思路,我以后会试着分享。
这篇如果要总结,那只有一句话,已经写在了前边。那便是我很贪婪,我总是希望,流过我的每一点信息,不论是以文字、语音、视频还是现场交谈的形式,都能够为我产生一点价值。一点能够长久的价值。
不论是精读泛读,这都是我的遴选标准。至少到目前为止,它运行得好像还不错:)
via 少数派 - 高品质数字消费指南
September 26, 2018 at 12:05AM
离开书本读人与读己
离开书本,读人与读己
https://ift.tt/2C3hw2v
哪里来的小熊猫
生活不顺,遇上烦恼,似乎总有一张万能的药方——多读书。
读书、健身与旅行,已是新时代青年的三项「非处方药」。但作为在本科读了四年哲学的人,我有时常常会想,比起康德黑格尔维特根斯坦,维修冰箱和洗衣机的说明书和现实之间的联系更直接。
各人有各人的难处,作者不是我肚子里的蛔虫,不知我正面临着怎样的境遇。开出来的药方,也未必对得上我的症状。搞得我往往是听了一肚子道理,却还是过不好日子,很是憋屈。
我想走出这困局。于是我决定换个维度,去获取信息。
读人
我开始更多地从人的维度,获取反馈与建议。
近来我时常觉得,一些人聊天中给到我的启发,有时不亚于读书。仔细想想,这当中的缘故其实自然,因为这个人不仅是说,他还做到了;他不仅做到了,他还就在我面前,供我问询。对于想解决有关问题却始终在原地打转的我来讲,这可真是一座宝矿。
好比我聊天掌握不好节奏,这问题我隐约知道,却始终难改。直到前一阵有朋友要去海外读书,临别吃饭。也许是想到此后有一年半载不会相见,他上来就将我一通批,「我觉得你说话有料,但是讲话的方式总叫人想睡觉。」
我脸一红,还是问了下去,「那你说怎么改?」
他娓娓道来。
很多话因为讲很针对,算是直接扎在了我的病灶上,可以说又痛又爽。仿若我在读一本书,他直接红笔加粗给我划了重点,逐字逐句地告诉我,我天天都在哪犯错。
脸上是火辣辣地疼,但心里其实很过瘾。
其实从内心抵触到虚心接受,这一步我也是花了好久才跨过去。别的不说,因为怕被人挑错,在香港七年,直到毕业我都讲不好广东话。这问题那朋友当年也与我提过。过去我和他吃饭,点菜甚至加汤都要请他喊服务员,就怕念错音漏了怯。他那天就跟我说,「别怕,大胆讲。」还反问我,「到底是念错音丢脸,还是四五年了都讲不好广东话丢脸?」
我觉得他讲得有理,但练厚这点面皮,花了我整整五年。等我终于克服这点心理障碍,接受了这种负反馈调节,那我之后在粤语上的进步,可以说是突飞猛进。
 粤语学习记录
粤语学习记录
我的「听讲笔记」
别人讲得精彩,光听可是不够。言语间的重点我得记下来日后揣摩。
过往我读书会做笔记,现在别人讲到精彩处,我同样会掏出手机,做「听讲笔记」。这事儿其实挺能增强对方的虚荣心。他一高兴,更加「好为人师」,我正好能收获更多。这样的姿态看似「低下」,但我现在想明白了,有时觉得能与对方平等沟通甚而辩驳,是一种错觉。
在我所咨询的话题上,对方掌握的信息量、经过的思考要远多过我,所以我本来就更应当认真听和问。
而提问的过程,也是在读他。对于我提出的问题,他是否答得好,我心里也有杆秤。再说得有野心一点,通过这样的问与答,我是想「吞吃」下他的视角。随着提问,他能给我远比书本要针对的答案;随着提问,他会告诉我他是怎样走到这一步的;也随着提问,我能够接近他解决问题的思路。
在我的核心朋友圈里,每个朋友都至少一个标签。有的关于职业,比如律师、交易员、会计;有的关于本硕专业,比如历史、政治、数学;有的甚至是一些看似很虚的东西,比如勇气和执行力。
我提炼出这些关键词,就是想在遇到相关问题时,直接想起这个人。通过这个人的桥接,我能更快地获得更高质量的信息。如我最近对太平天国感兴趣,马上就可以找本科学历史的老友荐书,看到相关文章也可转发给他,他也乐意讨论这些;再比如我有做不出的会计题,都可以转给在四大干这行的老友求教。他也不会?不存在的,毕竟他背后还连着几十上百个会计。
许多时候,人是比谷歌更好用的搜索工具。特别是当这个人在这个话题上浸润已久,那他能给出的答案,往往比搜索引擎还要好,还要实际。因为里边不仅有他的体会,还有他曾经犯过的错。
只是看他愿不愿意告诉你。
当然,只是在微信里打标签实在过于潦草。现在,我已在印象笔记里建档人际笔记本。每个朋友都有单独一篇,记录点滴。这不全然是我问他答,他的爱好,他的苦恼,以及有什么我能帮到他的地方,都值得思考与记录。
友情需要维护,从来不该是单方面的索取。
我的「性格篮子」
我是内向的人,凡事不敢争取。内向固然给了我极珍贵的内省品质,但很多时候,在需要我外向、需要我站出来的时刻,我做不到。这阻碍了我的成长,更使我丧失了许多机会。我一直想要突破这点性格上的局限。
都说江山易改、本性难移,但我一直不信这邪。我始终觉得,性格不过是人在一系列情境下的习惯反应,只要我能逐个雕琢这些反应,再把它们综合起来,我就相当于拥有了那种性格。外向的人或许天生外向,而经过后天训练,我也同样可以。只不过我要走更远的路。
曾经我的办法是读文艺作品。织田信长的洒脱不羁、曹操的枭雄之性、邓公的实在与坚毅,都曾深深打动我,那都是我想成为的模样。只是想学到这点性格特质,又远远难于学具体知识。因为他们离我太远。我只能远观到他的勇气,却无法看到勇气下他强行按住的恐惧;只能看到他酾酒临江横槊赋诗,却无法将他的痛苦与无奈细瞧。
人一旦离得远,就会被神化,就不真实。而不真实的东西,通常是没法学的。你只会赞叹他怎么做到的那些,却对他的来时路一无所知。或许好的传记可以,但又往往受限于虚美与隐恶。
后来我慢慢发现,许多品质,身边的人就有,从身边的人身上,我就可有的学。
好比我将自己的内向剖开,里边其实是胆小懦弱,而不敢争,其实是输不起。我很瞧不起自己这点怂劲,乃至在钱包上烙了「勇气长随」四个字,下定决心要改。这一年多里,我很欣喜地看到,属于我的一点刚猛,正在缓缓育成。
 傻吗?挺傻的。但是还算有用,挺不错的心理暗示。
傻吗?挺傻的。但是还算有用,挺不错的心理暗示。决心是有帮助的,但与我的室友关系也挺大。他北方人,直爽豪迈,遇到事总将「别怂」挂在嘴边,然后猛冲猛打。和这样的人长久相处,我逐渐看懂,他为何会有这样豪爽直接的性格。好像主要是因为……家里有钱。有底气所以不用讨好别人。
说正经的。事实上,他看待许多问题的思路,确实很影响到我。敢爱敢恨,想赢,也不怕输,在某些方面,我能感到自己的取舍在向他靠近,吸收他的视角,化为我用。勇敢这项品质一点点被复刻到我自己身上,这感觉好像是在自我养成。
还有许多好品质,我都想学。同上边建立「咨询小队」一样,我也想建立属于我的性格篮子,它们都来自于我的身边人。等到这一篮子的性格一件一件发展成熟,那性格就不再成为我的阻碍。我只要考虑在不同的情境下,应该拿出什么样的性格就好。
 会实现吗?但愿我不是全然痴人说梦:)
会实现吗?但愿我不是全然痴人说梦:)读己
知识与性格上的信息,别人都可以带给我。但要说谁最清楚我是什么样的人,那一定是我自己;要弄清楚今后往什么方向走,那一定也是我自己的责任。
只是这种对自己的探索,往往不能够一蹴而就。过去几年里,我以为自己做得最值的事情,就是写了一千七百多篇日记。这些字句,铺就了我的来时路。
 到外地时我很爱在当地打多两篇,很多记忆,就不会随风散去。
到外地时我很爱在当地打多两篇,很多记忆,就不会随风散去。来时路
一千七百多个日日夜夜里,是一千七百多个迥异的我。因为是日记,我尽可以对自己无比坦诚。坦诚到我再读及当年的文字时,都特别想抱抱那时的自己。
高考后的迷茫,进大学时的无措,毕业前的焦虑,一点一滴,都在纸上。我想隔着屏幕你也能感受到我当时的心绪:
高中时还有理想有抱负,现在只是麻木,只想逃避。每次走在路上,都只想快点回宿舍,不想给人瞧见。我很自卑,而可怕之处在于,我还认为我自由。(2012.2.4)
没有什么比我自己的文字,更能牵动我的心绪。那时候的我确实挺没用挺无能,但那就是我的来时路。每当我现在取得一点小成绩,心情过于亢奋,我都会回头看一看。记忆会美化自身,而白纸黑字永远在那里。它使我从躁动恢复平静,也使我更加包容,因为它告诉我,每个人想逃出他自己的肖申克,都不容易。
当然不可能每个点都那么丧。日记里有专门的「开心」标签,现在看来有的很呆萌,因为根本不会再像那样弱弱地思考了:
到组爸妈快毕业时才开始喜欢组聚。平时和组兄弟也不联系。真希望你能慢慢打开自己,多去和人交流,其实没什么不好的,是不是呢?加油,阿童。(2014.1.18)
Day One 有个功能叫「去年今日」,会在每早推给你这一天的每个过去。每早我都会打开看看,一年前的我,两年前三年前和八年前的我,每个我都在诉说他的故事。这就是我的历史。尽管在这些历史里,不如意固十之八九,但就算有的苦涩有的难受,有的甚至不忍回顾,但只要它们在那里,我心里就很踏实。因为正是那每一个过去,汇成了今天这个我。
不煽情了。我最想说的是,这些文字比我更懂我自己:我的优势何来,我的弱点何在。别的不说,仅是上文里所说的勇气,我就在日记里不知把自己批判了多少回。一件事一件事地反思,尝试在相同情境下,找出更好的选项。正是靠这样一遍遍的洗刷,我才能够积蓄到足够力量,尝试冲破这性格上的囚笼。
换言之,每篇日记,其实都是我与自己反复的对话与反复拉锯。有时候回头再看,才发现我已经走出了好远的路。
朝前看
最近在日记里开展了些新活动。说是新,其实是我在小学三年级就开始干的事。
三年级时的我特别喜欢在墙上乱涂乱画,写给一年后的自己,问他那时候多高。现在我又开始了类似的期许。我想写给一年后、两年后甚至五年十年后的自己,我想知道那时候的他会怎么样,过得还好吗。
这倒不是纯粹地遐想与空想。而是我发觉,只有当真正对未来怀有切实的期许,我才真正会去把握每个当下。就如同数千个过去汇成了今天的我,每个现在的我汇到一起,就构成了我的未来。
我想要做很多很多事,有的很常规,比如成家立业;有的很遥远,比如下深海、上太空;还有的相当扯淡,比如能和鬼神沟通(其实我觉得这是叶公好龙)。而它们有个共同点,都在未来。每每想到这点,生活就有了盼头。有盼头就不容易无聊,而无聊恰恰是人生的大敌。
不煽情了。这事儿说穿了就是列计划而已。计划真要落实,那也不是只在日记草草记两笔的事。现在我的做法是放进印象笔记,而后一点点推进,从年到月到周,再到一周每天,安排事项,项项落实。这是在以终为始。是我读完《高效能人士的七个习惯》后,印象很深的一条好习惯。
 周计划
周计划
总而言之,通过日记,我正在把自己的过去、现在与将来给拴在一起。
这事儿的感觉特别好,仿若是在时间的长河上,我有了一台时光机。虽然时间事实上没法回头,但日记多少能使我保留自己的过去;虽然前方仍旧是迷雾重重,但随着一项项期许的落笔,梳理着梳理着,我至少更知道自己要些什么了。那就不会「越过山丘,却发现无人等候」。
很奇妙。从别人口中,从自己笔下,我正把自己一点点抽丝剥茧。过去、现在与未来连成一体,他者与自我重新联系。慢慢,迷茫从我身上剥去;慢慢,笃定在我身上显现。我好像终于找到了属于我的那点为什么。这也是我在读了四年哲学后,所没有找到的,那点人生的意义。
后记
文中所有表格,都是使用印象笔记自身所附带的表格。这里 有一些模板可供参考。
文题中说是要离开书本,实际上写完我才发现,我的许多思路,仍自书本而来。这一篇的想法许多承袭自《原则》一书,比如怎样放下由 Ego(我执)造成的自我设限,多听取他人意见,从而找到最合理的道路。达里奥的想法改变我很多,事实上,我在上一篇讲精读的 文章 里,说要接纳反驳,运用的是同样的思路。
这篇文里的许多都很虚。但就像我在开篇所说,谁也无法全然对别人感同身受。每个人都面临着他特有的艰难,理论与现实的鸿沟,需要他自己去跨越。在每个十字路口,都要他自己作选择。选择固然不易,也需要他承担所有责任与后果。但这恰恰是身而为人的自由所在:你有自由意志。
最后用梁任公的话收尾吧:
天戴其苍,地履其黄,前途似海,来日方长。
via 少数派 - 高品质数字消费指南
September 25, 2018 at 11:56PM
Analysis of Global 5G Development (2) - Korea: KT
Analysis of Global 5G Development (2) - Korea: KT
https://ift.tt/2zt6Qap
Table of Contents
II. 5G Developments in Leading Countries
1. Korea
1-1. KT
1-2. SK Telecom
1-3. LG U+
2. U.S.
2-1. Verizon
2-1. AT&T
3. Japan
3-1. NTT DoCoMo
4. China
4-1. China Mobile
II. 5G Developments in Leading Countries
1. Korea
As the average rates of their LTE subscription have stagnated (at 82.9% as of Q3 2016), South Korea's big 3 telcos are all aggressively seeking ways to develop new services and move forwards 5G.

Figure 1-1. Number of mobile connections in Korea (Q3 2016)
KT, as a sponsoring telco of the PyeongChang Winter Olympic in 2018, is aiming to launch 5G trial service in time before the event begins, and then ultimately commercial 5G services in 2019. The telco developed 5G RAT common specifications with Verizon, a USA telco who is almost ready to present commercial 5G FWA services in 2017, while driving many global partnerships for 5G standardization. SK Telecom (SK Telecom), the strongest rival of KT, also introduced Quantum, its 5G brand, to the world in last November, taking the lead in global efforts for 5G development through conducting a demonstration of 'Connected Car', one of its new Quantum solutions, and more. SK Telecom also declared that it would begin 5G trial service in the second half of the year and make itself ready to launch 5G commercial service by 2019. LG U+ is gearing up for 5G commercialization by 2020.
1-1. KT
■ What's planned
KT aims to launch 5G trial service during the 2018 PyeongChang Olympic Games. With the experience to be gained from the service, the telco hopes to move forwards to present the world's first commercial, mobile 5G service in 2019, positioning itself as a leader in 5G standardization. The 5G trial service in 2018 will be based on the pre-standard specification because 5G global standards will not be available around 2020. As all the 5G systems that KT is currently developing for the 5G trial service are technically and fundamentally based on the pre-standard specifications, KT is working closely with global leading players in the field like global manufacturers and telcos to ensure that this specification is reflected in the final 5G standards as much as possible.
Simply put, KT's ultimate 5G strategy is to make the PyeongChang 5G technology a global and commercial 5G technology by:
- [2016] Develop a set of 5G common specifications (KT 5G-SIG specifications*) in partnership with global vendors
- [2018] Present commercial-level 5G trial service based on the KT 5G-SIG specification during the PyeongChang Winter Olympics
- [2017-2019] Have the KT 5G-SIG specification to be reflected in the 3GPP 5G standards as much as possible
- [2019] Upgrade 5G trial network to a commercial network that comply with 3GPP 5G NR standards
- [2019] Launch the world's first commercial 5G service
* Commonly known as, KT 5G specifications or PyeongChang 5G specifications
■ Progresses made and to be made
We will see 5G development made by KT so far as categorized in Figure 1-2 below.

Figure 1-2. KT 5G progress
KT 5G Specifications
KT formed 'KT 5G-SIG' with global vendors (Samsung, Ericsson, Nokia, Intel and Qualcomm) in November 2015 and finalized the 'KT 5G-SIG’ specifications, the world’s first common specifications for 5G, in June 2016 (Figure 1-3). 5G.201 and 5G.211 - 5G.214 define RF/physical layer specifications while 5G.300, 5G.321 - 5G.323 and 5G.331 define higher layer protocol specifications.
The telco, collaboratively with Verizon, completed development of common specifications for mmWave-based 5G RAT, and is also cooperating for SDN/NFV and GiGA Wire technologies. mmWave-based 5G and GiGA Wire will be adopted to be used for fixed wireless access and existing coaxial cable, respectively, to help deploy broadband Internet.

Figure 1-3. KT 5G-SIG members and KT 5G-SIG specifications
The KT 5G specifications, while primarily based on LTE specification and EPC, were designed to be 3GPP forward-compatible. <Table 1-1> and <Table 1-2> show key items defined in the KT 5G-SIG specifications.
RF/Physical layer: The operating frequency band of KT 5G is 28 GHz (27.5 - 28.35 GHz) with up to 800 MHz bandwidth using 8x100 MHz carrier aggregation. A radio frame duration is 10 ms and each subframe period (or TTI) is 0.2 ms which consists of 14 OFDM symbols. KT 5G frame structure supports i) self-contained subframe which enables a DL data transmission and UL ACK in the same subframe and ii) dynamic TDD assignment which can dynamically change the UL and DL subframe ratios to cope with instantaneous traffic conditions. In the self-contained structure, each subframe keeps DL data in the front symbols and UL ACK in the back symbol. KT 5G radio supports hybrid beamforming which can combine the advantage of both analog and digital beamforming. 8 MIMO streams per cell and 2 MIMO streams per UE are supported.
<Table 1-1> KT 5G-SIG specifications: RF/Physical layer

(source: KT, presented at Mobile Communication Technology Workshop by KICS, February 2017)
Network/Protocol: KT's transition to 5G network will be made based on EPC, in a way that minimize changes required in the core network. The KT's 5G network can be SW upgraded to reflect the updates/changes once 3GPP 5G standards are finalized in the future. It will be able to support both Non-standalone (NSA) and Standalone (SA) modes as being discussed in 3GPP (Currently, only SA mode is supported in Verizon network). The network, consisting of EPC and PyeongChang trial base station (P5G RAN), to be composed of LTE base stations (eNBs) and 5G base stations, will ensure seamless interworking between LTE and 5G.
<Table 1-2> KT 5G-SIG specifications: Network/Protocol

(source: KT, presented at Mobile Communication Technology Workshop by KICS, February 2017)
Development/Test
Based on the specifications, KT built a 5G network testbed and completed mmWave channel modeling and field tests in 2015. In the second half of 2016, it introduced 5G systems and devices (in partnership with Samsung, Ericsson, Nokia and Intel) based on the KT 5G specifications. Then, it performed a 5G e2e First Call test using the same specifications in October 2016, followed by interworking tests between base stations and devices a month later. Starting from October 2016, the telco has been conducting fields tests in select areas in Seoul and PyeongChang using the '5G test network' configured based on the KT 5G specifications. In the field tests conducted in Seoul in December 2016, inbuilding, handover, multi-vendor interoperability and more were tested, and inbuilding tests showed averages of 2.3 Gbps download speeds. Now it is carrying out field tests in PyeongChang.
- Oct. 2016: Performed, jointly with Samsung, 5G e2e First Call test based on the 'KT 5G-SIG' specifications
- Oct. 2016: Began 5G virtualized core network verification process with Samsung and Nokia
- Nov. 2016: Developed KT 5G-SIG base station with Ericsson and Nokia
- Nov. 2016: Performed first interworking tests between 5G base stations and 5G devices
- Dec. 2016: Conducted field tests in downtown Seoul, supporting 5G indoor 2.3 Gbps (DL) and testing handovers
- Feb. 2017 ~ : Currently conducting field tests in the PyeongChang Olympic arena and village

(a) 5G e2e First Call Test (KT - Samsung)

(b) Ericsson 5G UE and BBU (left) and Nokia RFU (right)
Figure 1-4. KT 5G-SIG based 5G system

Figure 1-5. KT 5G BUS: handover test
5G Network Deployment
In November 2016, a test event titled 'Hello PyeongChang' started as a part of preparation efforts for the sport event and it will go on until April 2017. From the end of 2016 to March 2017, KT conducted a range of field tests in downtown Seoul (e.g. indoor performance and handover tests in last December) and PyeongChang (e.g. immersive services in actual sports events during February and March 2017). After that, the 5G trial network for the PyeongChang Olympic 5G trial service will be deployed in Pyeongchang, Jeongseon, Gangneung and other select areas in Seoul by September 2017. After the sports event, the 5G trial network will be upgraded and expanded to reflect the 3GPP Release 15 specifications, making it possible to deploy a real 5G commercial network in 2019.
- March 2017: KT 5G test network deployed in PyeongChang
- September 2017: KT 5G trial network deployment to be completed
5G Service Demonstration
To demonstrate 5G trial service in preparation, KT conducted the 1st test event in February 2016, and the 2nd test event in February and March 2017 in PyeongChang. In December, 2016, a field test to demonstrate the upgraded service presented in the first test event was carried out as well.
1) 1st test event (in February 2016): Sync view, 360° VR, Hologram live, 5G Safety, Interactive multi-view (time slice), etc.
- Sync view - Streaming events from the perspectives of players
- 360° VR - Live streaming of events in real time through multi-channel
- Interactive multi-view - e.g. Can be used in video replay by referees
- Hologram live
- 5G safety - Drone featuring face recognition solution integrated with AI system

Figure 1-6. 5G services demonstrated in the 1st test event (February 2016)
2) 5G field test demonstration (December 2016): Upgraded services tested in the 1st test event were demonstrated.
- Sync view - Live streaming from the perspective of a bobsleigh player running at the average speeds of 120-150 Km/hour
- Hologram - World's first multi-party hologram
- 360° VR - Offers upgraded views of arenas, waiting rooms and interview rooms
- Interactive multi-view - Provides views of each player, allowing viewers to keep tracks of their movement individually in a team sports game like ice hockey

Figure 1-7. 5G Field test demonstration (Upgraded services tested in the 1st test event, December 2016)
3) 2nd test event (in March 2017)
In the ‘Hello PyeongChang’ event, various services including four key 5G immersive services, Sync View service, 360º VR service, Interactive Multi-View service, and Omni Point View service, were actually offered and tested in real games. In addition, 5G converged services, like Mixed Reality (MR)/Virtual Reality) (VR) service, 5G autonomous driving bus, drone delivery, were also demonstrated.
- Sync view – technically verified in actual games during the Bobsleigh World Cup held by International Bobsleigh Skeleton Federation (IBSF)
- 360° VR – technically verified in actual games during the Four Continents Figure Skating Championships held by International Skating Union (ISU)
- Interactive multi-view - technically verified in actual games during the Four Continents Figure Skating Championships held by International Skating Union (ISU)
- Omni point view - technically verified in actual games during the Cross Country World Cup held by International Ski Federation (FIS)
- Demonstration of MR torch relay and VR Walk Through
- Demonstration of 5G autonomous driving bus and drone delivery
- Demonstration of hologram live in 5G autonomous driving bus

Figure 1-8. Verification of four key 5G immersive services and demonstration of 5G converged services during the 2nd test event (February and March 2017)
■ Key radio access technologies
Some of KT’s key radio access technologies based on the KT 5G-SIG specifications are outlined below.
- mmWave - 5G-SIG system operates in 28GHz mmWave band using up to 800MHz bandwidth (through CA of eight (8) 100MHz channels). mmWave band has smaller cell coverage, but shorter wave length. This makes it possible to mount more antennas in the same footprint, allowing multiple antenna solutions to be adopted.
- Hybrid beamforming - Can support both analog and digital beamforming
- Lean Design - More efficient in minimizing control signals than LTE. Can improve data transmission speeds by fully utilizing radio resources. Reference signals and system information that are kept "always on" in LTE can be minimized.
- Self-contained structure - Radio frame that can process downlink data and uplink response in less than 1 ms is supported to meet the relevant 5G requirement.
- Dynamic TDD - Utilize radio resources in more efficient ways by adjusting UL/DL link rates in real-time depending on the amount of traffic or the nature of service being offered.
- 4G-5G interworking - The KT 5G-SIG specifications had it mandatory for devices to have dual connectivity that offers both LTE and 5G connections at the same time, and offer uninterrupted service through handovers between LTE and 5G. By default, control signals are transmitted via LTE and data are delivered via 5G.

Figure 1-9. Key radio access technologies
■ Key infrastructure technologies
Some of the key infrastructure technologies are:
- Network Virtualization - In KT's 5G system, mobile network/service functions run as SW on universal-purpose servers. Dedicated networks such as disaster network, IoT network, and traffic network are virtualized as SW solutions on universal, common HW equipment. This means a new network can be easily deployed through modifying the configuration of the network using SW on the existing network, and even customized as a dedicated network that meets an operator's business needs and facilitate introduction of application services.
- Network distribution and SW-based control architecture - In 5G where capacity per cell reaches 20 Gbps, traffic must be distributed before they can be processed. Servers (i.e. edge clouds) are distributed across the nation through SW virtualization, and network functions are placed on to the servers, effectively distributing traffic data. Resource allocation for virtualized network functions on the edge clouds are controlled by the orchestrator in the central location through SW.
■ 5G global collaboration activity
KT have been aggressively working with 5G standardization organizations, such as 3GPP and ITU, and 5G leading companies for establishment of KT 5G specifications. It has also teamed up with global leading vendors through 5G-SIG, 5G DF, NFV Open Lab, SDI Open Eco Alliance, etc. to pave ways to develop 5G system and deploy software-based networks.
<Table 1-3> 5G global collaboration activity

■ Other 5G services
Although, for now, KT's main focus is on successful launch of 5G trial service, the telco has showed keen interests in artificial intelligence and autonomous driving service technologies.
- Artificial Intelligence (AI) Service: In January 2017, KT launched an IPTV-based AI service with 'GiGA Genie', an voice/video-based AI set-top box (see Netmanias's blog).
- Autonomous driving service: Infrastructure for autonomous driving services requires high data throughput in order to link transmit data on road conditions in real time. KT has been taking the lead in building nationwide wired/wireless networks across the nation to realize the vision of 'GiGATopia' it had declared, and now with its strong wired infrastructure, it has secured competitive advantage in terms of infrastructure environment needed for autonomous driving service. Some of the technologies that it is currently investing are ITS/vehicle control, next generation telematics based on high precision position measurement, and eco-drive/electric car, vehicle entertainment based on 5G ultra-wideband network.
■ 5G roadmap

Figure 1-10. KT 5G roadmap
via Network Manias https://ift.tt/2ORhYmr
September 25, 2018 at 09:17PM
李岩
纹枰论道四十年从官方棋圣聂卫平到罗德学者侯逸凡
李岩: 纹枰论道四十年:从官方棋圣聂卫平,到罗德学者侯逸凡
https://ift.tt/2OajTW4
 左起:柯洁、古力、聂卫平、谷歌CEO皮查伊
左起:柯洁、古力、聂卫平、谷歌CEO皮查伊
如今提到围棋,人们更多会谈论年少轻狂的柯洁,战胜人类的谷歌阿尔法狗等等。90后、00后们可能很难想象,围棋这项形式简单的对弈项目,曾在一段时间内承载了厚重的民族感情,延续了很多国人的“抗日”情结,有人因它封圣,也有人因它疯掉,更多人因它疯狂。小小的棋盘,曾连着每一个**人的心。
而今,棋类项目已褪去它过于沉重的民族主义光环,回归到益智类体育项目的本质,还诞生了侯逸凡这样的优质偶像――不仅是国际象棋的世界“棋后”,也是世界级的“学霸”。四十年来,棋类项目卸下民族大义重担的过程,也是**人自信心提升的过程。
一、1970年代之前:日本对**围棋的“扶贫”,对中日民间外交有破冰的作用
关于中日两国各自在围棋历史上的地位,有人有过一个形象的比喻:**是围棋的生母,日本是围棋的养母。顾名思义,**人最先发明了围棋这项运动,也在古代取得过很高的成就;但在近代上百年的时间里,日本人把围棋这项运动推向了高峰。也有人说,日本人重新发明了围棋。直到现在,英语中几乎所有涉及围棋的术语,用的都是日语转译词。
其实日本围棋超越我国的时间点,可能早在几百年前,但真正让**人意识到有这么回事,是大概一百年前。1909年时,有位日本四段棋手高部道平来**巡游,谈笑风生间灭掉了当时**所有高手。而围棋最高是九段,四段在职业棋手里算很一般的。高部道平四段让**人明白,中日围棋早已拉开档次上的差距。
在那之后,段祺瑞、陈毅这两位身为政治人物的棋迷,客观上推动了中日围棋交流。段祺瑞资助了当时**围棋第一人吴清源赴日本学棋,为他成为现代围棋第一人奠定了基础。当然这事一直有争议,前几年吴老去世时,依然有很多人对他赴日这点耿耿于怀。
而另一位棋迷+外交家陈毅元帅,则巧妙地用围棋为中日邦交正常化铺了一段路。
 陈毅与日本友人下围棋
陈毅与日本友人下围棋
1960年6月,在时任副总理陈毅的邀请下,首次中日友谊赛在北京、上海、杭州三地举行,来访的日本代表团以濑越宪作名誉九段为团长,团员包括当时日本棋界的两位高手――桥本宇太郎九段和坂田荣男九段。
其实,派这样的高手对付**棋手,更多是外交层面的重视,而非竞技上的考虑。当时不要说九段高手,就是业余高手,对战**高手也是占上风的。这样的交流活动,名为友谊赛,实则是扶贫团。这样的访华交流团,日本一共组织了五次,**还在1962年回访过日本。这一系列活动为新**培养了第一批优秀的围棋专业人士,后来担任**棋院首任院长的陈祖德,就是在访日交流中战胜日本棋手而脱颖而出的。
1972年,中日邦交正常化。围棋在其中起到的作用,虽没有乒乓球在中美关系上的影响力大,但它提供了一种思路,即用民间体育交流融冰两国关系,这种范式对今后的外交活动都有不可低估的试水意义。
二、1980年代:聂卫平围棋“抗日”,被官方授予“棋圣”称号,有证书的那种
**和日本的历史积怨,以及日本围棋不可战胜的神话,使得围棋天然被赋予了一种悲壮色彩。上文提到的陈祖德在10岁时,获得了与时任上海市市长陈毅下棋的机会,当时陈毅就勉励他:“陈祖德,你要把老前辈的本事都学过来,要超过他们(日本棋手)。”
后来他真的做到了。19岁时,他战胜了访华的日本九段棋手杉内雅男。其实一盘棋很难说明问题,那盘棋日本九段也对陈祖德进行了“让先”,并不是实打实的公平对垒。但在1960年代,这一盘棋还是在民间掀起了一股“围棋热”,很多十来岁的孩子都开始学习围棋,因为“学了围棋就可以战胜日本了”。
后来因为政治运动,围棋队暂停,很多棋手都去干了其他事,再度恢复已经是1970年代的事,而且棋手们久疏战阵,如果说十年前他们还能看到一点日本围棋的车尾灯,那此时,已经又拉开了巨大的差距。
这种背景下,一项本着在**普及围棋,在日本拯救收视率(老是赢,日本人也渐渐对围棋兴趣减退了)的比赛,在1984年举行,这就是后来诞生过奇迹的中日围棋擂台赛。
 首届中日围棋擂台赛聂卫平胜藤泽秀行
首届中日围棋擂台赛聂卫平胜藤泽秀行
所谓的奇迹,其实也简单,就是**队赢了。首届比赛之前,日本《棋》周刊公布了一项民意测试,结果在三千多名投票者中,只有27个人认为**队会胜。而这27个人中24人是在日的**留学生,可以理解为投的是“爱国票”。也就是说,当时中日围棋的差距不仅是肉眼可见,简直是有理智的人都明白的。
就是在这种情况下,**队赢了,而且连赢了三届。对于之前赢一次日本人就举国欢腾的**围棋界,连续三届,每届干掉七八个日本最厉害的棋手,放现在基本是**男足把巴西、德国、英格兰、意大利、西班牙……转着圈赢了好几遍的意思。当时国内的舆论就不仅仅是轰动了,简直就是炸了。
这都是因为一个人――聂卫平。
简述一下聂老(围棋迷对聂卫平的尊称,从他四十多岁就这么叫)的光辉战绩:
第一届擂台赛,他上场前**队以5:7落后,他连赢三盘,最终8:7战胜日本队;
第二届擂台赛,他上场前**队以4:8落后,他连赢五盘,最终9:8战胜日本队;
第三届擂台赛,他上场前**队以8:8与日本对打平,他战胜对方擂主,最终9:8战胜日本队。
以上战绩中可以看出两点:一是聂老作为最后出场的擂主,三次扮演孤胆英雄,绝地反击逆转日本队,赢得荡气回肠;二是在他的带动下,**围棋整体实力在那几年突飞猛进,到了第三届时(1988年)已经可以与日本队分庭抗礼了。
在聂老第三次战胜日本队后,1988年3月26日,由时任国务院副总理、**围棋协会名誉主席方毅亲自向聂卫平颁发了**围棋棋圣证书。方毅还称赞聂卫平是**围棋界的“孔夫子”。
那时,**体育已经初步崛起,拥有了十几块奥运金牌,还有**女排这样缔造五连冠辉煌的队伍,但因围棋与日本的渊源,以及聂老孤胆英雄绝地反击的过程太有戏剧性,多重因素堆叠,将聂卫平推到了棋圣的高度。由**围棋协会授予,副总理亲自颁发证书,是现代以来绝无仅有的官方封圣行为,是空前的,也很可能是绝后的。
三、1990年代:钱宇平因一盘棋的压力,彻底退出棋坛
从常识判断,出圣人的领域,通常是不好混的。一个圣人当“面子”,就得有一批高手当“里子”。在1990年代,就有这样一位棋手,充当了围棋光环的“里子”。
 1980-90年代,围棋热最疯狂的时候,聂卫平出门是这样的
1980-90年代,围棋热最疯狂的时候,聂卫平出门是这样的
聂卫平职业生涯的巅峰就是他封圣的那刻,之后几年虽还保持一线水准,但已经不是杀神模式了,截止到目前,聂老也没有获得过一次世界冠军。**人第一次获得围棋世界冠军是1995年的事,马晓春在那一年连获东洋证券杯和富士通杯两项冠军,距离聂老封圣已经过去了七年。
而在1995年之前,**人曾有一次非常接近世界冠军的机会,但“第一个获世界冠军的**棋手”这个头衔所带来的压力,却把当事人压垮了。
1991年,**棋手钱宇平打进了第四届富士通杯的决赛,对手是日籍韩裔棋手赵治勋。当时钱宇平25岁,正在当打之年,而赵治勋比他大十岁,那年已经35岁,对于围棋手来讲算是巅峰已过了,从精力来讲,钱宇平占优;当时他们俩都没拿过世界冠军,理论上“世界冠军”的头衔对他们的诱惑和压力是相似的。
然而,钱宇平还有另外一大压力来源,即**人的围棋情结。赵治勋虽祖籍韩国,但已代表日本出战多年,所以这场比赛很容易被定义为中日PK。当时还有一个时代背景,即聂卫平的不败神话已破灭,第四届中日围棋擂台赛以**队失败告终。而第五届中日围棋擂台赛上,**又赢了回来,终结比赛的正是钱宇平,这也是**队第一次由聂老之外的人终结擂台赛。
胜石田芳夫,这也是他最后一次出现在国际赛场上") 1991年富士通杯上,钱宇平(左)胜石田芳夫,这也是他最后一次出现在国际赛场上
1991年富士通杯上,钱宇平(左)胜石田芳夫,这也是他最后一次出现在国际赛场上
再加上钱宇平闯进富士通杯――这一世界上最重要围棋比赛的决赛,使得钱宇平有隐隐取代已年近四十的聂老,成为**围棋第一人的趋势。重重压力下,钱宇平扛不住了。
钱宇平原患有“青春期精神综合症”,在备战富士通杯决赛的过程中,病情加剧,难以控制情绪,最终在决战前夜选择了弃权。此后他进入了漫长的养病过程,虽偶有复出,但再也难以跻身一线棋手,没过几年便销声匿迹了。
,此时他已因病退隐多年") 2007年,来到研究室摆棋的钱宇平(右),此时他已因病退隐多年
2007年,来到研究室摆棋的钱宇平(右),此时他已因病退隐多年
钱宇平的悲剧,是**围棋不堪其重的一个缩影。一项棋类运动,因缘际会,承载了过重的国仇家恨,虽然在某一个时段获得了全民的热捧,但不得不说这种热度是有些畸形的,一盘棋的压力竟至于压垮一个人。经过了钱宇平这道坎,更重要的是,随着**国力的提升,**的棋类运动在逐渐走向正常。
四、2000年代:棋后、博士、局级干部,谢军让顶尖棋手“正常”起来
国际象棋(以下简称国象)在**的发展,有点弯道超车的意思。从历史上来说,国象跟围棋、**象棋完全不能比,无论群众基础还是历史战绩,国象都是棋类运动中垫底的存在,甚至不如跳棋。从领导来源也可以看出:**棋院和体育总局棋牌运动管理中心的历任领导,基本都是从围棋国手里出,陈祖德作为**棋院的院长,就曾为国象的发展提出过指导性意见。
然而不得不说,国象棋手真争气,截至目前,**有四五位女棋手获得过世界“棋后”头衔,在世界最高水平的奥赛团体赛上,**男女团也都斩获过冠军,战绩上完全不输早早起步的围棋。
不仅如此,国象棋手里还诞生过很多“学霸”,上清华北大,读博士,考取外国大学教职等,在棋盘外的生活也丰富多彩,一改围棋手给老百姓留下的呆头呆脑,高智商低情商等印象。
国象棋手这一系列的清新之风,始于谢军。
1991年,正当钱宇平因压力过大,放弃富士通杯决赛之时,在另一条战线上,谢军为**棋类项目带来了意外之喜。先是在那一年年初,她获得了女子世界冠军挑战权;随后在那年秋天,她以8.5:6.5战胜了当时的世界棋后,格鲁吉亚棋手齐布尔达尼泽,成为了新一届的世界棋后。那一年她只有21岁,而她的对手则已经把持了棋后荣誉长达13年之久。
战胜老棋后齐布尔达尼泽,获得女子世界冠军") 1991年,谢军(右)战胜老棋后齐布尔达尼泽,获得女子世界冠军
1991年,谢军(右)战胜老棋后齐布尔达尼泽,获得女子世界冠军
说这是意外之喜,是因为谢军不仅是第一位来自**的棋后,也是史上第一位欧洲以外的棋后,在她之前,**的国际象棋运动基本处在萌芽状态,全民关注度跟围棋完全不是一个数量级的,谢军的这个棋后桂冠,无异于从天而降,横空出世,石头缝里蹦出来的。对于很多**人来说,都是在谢军这个世界冠军之后,才开始注意到还有国际象棋这么个玩意。
也就是在谢军获得棋后之后,时任**棋院院长的陈祖德给**国象事业定了四步走的基调:先拿女子个人冠军(谢军已经拿了),再拿女子团体冠军,第三步拿男子团体冠军,第四步拿男子个人冠军。
当时这个四步走的论调一出,很多人都在背后揶揄陈祖德是外行领导内行,下围棋的懂什么国象。然后事后看,这四步走真是无比正确,**国象事业完全按照他的预测走完了前三步,即拿到了男子团体世界冠军,目前正冲着男子个人世界冠军努力着。
具体到谢军个人,则堪称棋手的典范。在1991年夺冠后,她又在1993、1999、2000年三次获得女子国象世界冠军,获得了棋后称号,并率领**女队在1998、2000、2004年三夺团体世界冠军。
下棋之外,人家个人生活一点没放下,跟普通女人一样结婚生子,在北师大从本科读起,花了十四年时间(毕竟要边下棋边读书),拿了法学学士、体育学硕士和心理学博士三个学位,拿到博士还不满足,接着进行了教育专业的博士后研究。
棋后、博士后,这也并不是她的全部。体育项目取得成功后,她跟很多**体育界的人一样,选择了赛而优则仕,32岁就当上了北京棋院的院长。后来,她又分别担任西城区教委副主任、首都体育学院副院长等职务,官至副局级。
 2017年,当年的对手谢军和齐布尔达尼泽,早已一笑泯恩仇
2017年,当年的对手谢军和齐布尔达尼泽,早已一笑泯恩仇
一般的运动员当官,碍于文化水平不高等问题,通常是对口解决,在家乡体育局里,自己从事的项目里谋一份副职或闲职。像谢军这样获得了博士学位,跳脱开自己的棋类项目,进入教育口、高校口任职,并获得升迁,这就不仅仅凭借她的运动成绩,而是靠实打实的能力了。
这里还有个小插曲,谢军曾至少两次参加北京市体育局公开选拔副局长的考试,但都被“刷下去”了。这也从侧面反映,她的官职不只是靠运动成绩搏来的。
谢军能够比较轻松地规划自己的人生,一方面是她的确优秀,另一方面也有棋类项目渐渐摆脱了民族情感的捆绑,还原为一项普通竞技项目的原因。
五、2010年代:棋后、90后、罗德学者,侯逸凡让顶尖棋手“酷”起来
如果说谢军的出现,让**的棋手看起来“正常”多了,不再背负那么大的压力,那在她之后的另一位棋后,则让**棋手看起来特别“酷”。她就是比谢军小整整两轮,同样属狗的90后棋手侯逸凡。
谢军21岁获得棋后桂冠,已经很年轻了,但侯逸凡更年轻,2010年第一次获女子世界冠军时,刚刚16岁,一脸青春痘,头上别着两根小发卡就去加冕棋后桂冠了。随后,她又在2011、2013、2016年三夺棋后桂冠,跟谢军一样,共获得四次世界冠军。
 少女时期的侯逸凡,头上两根小发卡是标配
少女时期的侯逸凡,头上两根小发卡是标配
与谢军稍有不同的是,谢军在同时代女棋手中,是属于稍稍领先一筹,但差距不明显,跟高手过招互有胜负的状态;而侯逸凡在同代棋手当中则是一骑绝尘,难有对手,以至于22岁拿下第四个棋后之后,她已经“不稀得”跟女棋手玩了。如今,她基本只参加男子比赛,虽然已不是棋后,但她后面的每一个棋后都明白,自己虽为名义上的世界冠军,但还有一个水平远超自己的侯逸凡,在远远地俯视自己。
从谢军延续下来的一个国象优良传统,则在之后的棋手身上发扬光大,那就是学霸传统。**另外两位棋后诸宸、许昱华,分别是清华国际关系硕士和北大中文系硕士,2010年跟侯逸凡争夺棋后的棋手阮露斐,从清华经管学院本科毕业后,考取了美国卡耐基梅隆大学商学院的全额奖学金直读博士,目前已基本放弃国象,转行成为旧金山州立大学的一名助理教授。
而侯逸凡在打遍女子国象界无敌手的同时,学业也没放下,18岁时跟着同龄人一起入读北大国际关系学院,本科期间拿了两次世界棋后之余,同学还是经常能在课堂里见到她。23岁时,她更是得到了号称世界上竞争最激烈的奖学金之一的罗德奖学金,得以获得每年3万英镑的费用,去牛津大学攻读硕士学位。全**只有4位获选者,她是其中之一。据说她在牛津的学科与谢军相似,也是教育学方向,主攻儿童发展。
 2017年获得罗德奖学金的侯逸凡,已出落得亭亭玉立
2017年获得罗德奖学金的侯逸凡,已出落得亭亭玉立
罗德奖学金有“全球本科生诺贝尔奖”的美誉,得奖者被称为“罗德学者”(Rhodes Scholars)。而在此之前,她其实就干过一件有学者气,甚至有女王气的事:对抗国际棋联,全面退出女子棋后争夺战。
前面说过,侯逸凡如今只参加男子比赛,这一方面是她水平超出女棋手一截,“不稀得”参加女子比赛了,但更重要的是,如今的女子棋后产生方法无比复杂,远没有男子棋王的产生方法那样清晰。侯逸凡认为,这种赛制上的男女不平等,是对女棋手的不尊重,如果赛制一天不改,她一天不回归女子比赛。
这种不听话的孩子,在**体育界,乃至**教育界,都太罕见了!
可以说,罗德学者能落到侯逸凡身上,她的国象成绩,北大背景当然是一方面,但勇于据理力争,怒怼国际棋联,展现出的勇气、智慧、自我管理能力,或整体概括为,那股酷劲儿,也是罗德奖学金选拔评委非常中意的。
结语:
从聂卫平赢了几盘棋被授予“棋圣”称号;到钱宇平因为不敢下一盘棋而导致精神崩溃;再到谢军自如地穿梭在下棋、生活、工作当中;直到侯逸凡因为“不听话”而获得国际奖学金的青睐。四十年来,**棋手在棋盘内外,展现出了不同的精神风貌,而在这些个体的背后,是国人对于棋类运动越来越不纠结的过程。这个过程,某种程度上说,就是**日渐强大的过程。
kindle4rss
via 腾讯·大家 https://ift.tt/2kVSmsD
September 25, 2018 at 10:54AM
学会好好睡觉 | 睡眠革命的读书笔记
学会好好睡觉 | 睡眠革命的读书笔记
https://ift.tt/2FfpZgc
也谈钱
良好的睡眠是工作生活的基础,我们都知道睡眠很重要,却很少真的花时间思考怎样睡眠。
最近刚读完一本名叫《睡眠革命》的书,看完之后,即使是我这样「沾枕头就睡着」类型的人,也一样能有满满的收获,并更正了很多睡眠的误区。
 睡眠革命
睡眠革命
书中的主要内容包括昼夜节律、睡眠类型、睡眠周期、睡前醒后、日间小睡和睡眠环境改造等几个部分。我把书里边一些重要的内容进行了整理,做成了这样一份读书笔记。在笔记中,我把顺序按照自己认为的重要程度稍作了调整。
核心收获
对我而言,读完这本书最大的收获是:
- 睡前、醒后的一段时间(大约 90 分钟)和睡眠本身一样重要,会有效影响睡眠质量和自己第二天的状态;
- 早睡早起其实并不适合每个人;
- 睡眠的质量应该以「周」为单位统计,不要因为一天的睡眠质量而过早判断;
- 失眠的一个重要原因是「担心自己会失眠」,听起来很无厘头,但却是事实;
睡眠前后
对于睡眠而言,重要的不只是床上的那段时间,睡眠前的准备和醒后的「仪式」也非常重要。对于晚睡晚起类型,醒后的仪式更加重要,会直接影响一天的效率,应该好好利用这段时间有效的唤醒自己。
我常常有这样的感觉,生活中突然出现一点变化,本来很习以为常的小事被跳过(比如停水不能洗漱,放假在家比较懒散),会觉得一天都昏昏沉沉的不精神。突然放假在家的前几天,也会觉得效率超级低下。其原因,很大程度上就是起床后的「唤醒仪式」发生了变化,导致没有把自己完全唤醒。
我们平时上班的时候,起床后要很认真的洗漱穿戴、吃早饭,其实这就是一种唤醒活动。而突然放假在家,起床后这些活动被省略或者简化,就会导致唤醒不彻底、白天不精神。
睡眠前后的例行程序其实也是睡眠的重要组成部分,建议各安排 90 分钟左右的时间帮助自己进入状态;
睡眠以前
- 调整灯光,调低亮度,改为暖色;
- 关闭各种电子产品;
- 调整温度,适当降低温度,16~18 度最佳;
- 「下载」自己的一天(作者的独创方法,在纸上写下一天的重要事项。防止自己在床上还是翻来覆去的想);
- 可以用这段时间做做家务,整理文档这样的琐事;
- 用鼻子呼吸很重要,必要的话,可以用鼻贴扩张鼻腔,封住嘴巴。很多睡眠不佳的情况都是由于用嘴呼吸引起的。
睡醒以后
- 不要立刻开始使用电子产品;
- 整个过程可以尽可能的慢下来,让身体渐渐适应(如果时间不够就早起一点);
- 好好享受早餐;
- 可以适量轻微运动;
- 可以利用灯光调节自己,早点清醒过来;
昼夜节律

 昼夜节律
昼夜节律
- 昼夜的更替节律是人体生物调节的根基,调节人体的节律要顺势而为;
- 光线是昼夜节律中影响最大的因素,蓝光不宜在晚上出现;
人体生理状态在一天内随时间的周期变化就是——昼夜节律,是了解睡眠的基础。想要获得良好的睡眠,必须顺势而为,对着干不会有好结果的。
最典型的应用就是光线,我们都知道睡眠的时候应该关灯、拉上窗帘,就是对于昼夜节律的应用。如果晚上点亮 200W 的大灯泡,能睡好觉才怪。
其他的应用还有:
- 人在睡眠中,体温会渐渐降低。如果卧室的温度太高,就很容易影响睡眠质量。
- 从傍晚到早上的这个过程,人的血压是渐渐下降的,如果在睡前进行剧烈运动(散步等简单的有氧运动没有问题)就会导致血压升高,同样会影响睡眠。
如果你的健身计划中包括傍晚去健身房做剧烈运动,可要注意了,这个时间人的血压是一天中最高的。你要知道,剧烈运动会引起血压飙升,特别是如果你上了一点年纪的话。
两种睡眠类型
睡眠类型是遗传的,我往往能在一公里之外就觉察出所遇到的那些人各自属于哪种睡眠类型。你喜欢熬夜和晚睡吗?早晨需要闹钟叫你起床吗?你想不想在白天午睡一会儿?你是否常常不吃早餐?在不用上班的日子里,你喜欢多睡一会儿吗?如果答案为是,那么你很可能是一个晚睡星人。
- 早睡类型、晚睡类型,早睡早起并不适合所有人;
- 不要在周末睡懒觉,来回调节颠倒会很痛苦;
常言道「早睡早起身体好」,但是事实上,这句话并不适合所有人。人的睡眠类型是由基因决定的,分为 早睡早起类型 和 晚睡晚起类型。如果强硬的要求晚睡晚起的人,每天早睡早起,常常是费力不讨好。这也是为什么我们早早起床,有的人一天精神抖擞,而有的人却昏昏沉沉。
另外,尽量保证固定时间起床,即使是周末也是如此。如果周末恶补睡眠,只会导致周期节律被打乱,周一上班的时候就容易频频点头。
R90 睡眠周期
- 在固定的时间起床,这个整个计划的基础;
- 不同人对于睡眠的周期数量要求是不同的,不要以小时为统计单位,而是以周期数;
- 睡眠周期应该以周为单位统计,而不是每天;
- 每周 35 个睡眠周期比较常见,午休 30 分钟也能算是一个周期;
- 尽量不要连续三天睡眠不足;
人的一般睡眠周期为 90 分钟,睡眠的过程就是浅度睡眠到深度睡眠再到浅度睡眠的不断循环。计算睡眠时间,最好以周期的倍数计算,而不是简单的「N 小时」,所谓的「每天 8 小时」,其实应该是每天 5 个周期(7.5 小时)。
用上床睡觉的时间,而不是起床的时间,来调节睡眠的长度。起床的时间要尽可能固定。
一般而言,我们通常需要每周 35 个睡眠周期,平均下来每天 5 个。可以用一个星期来实验一下,看看自己到底需要多少个睡眠周期,有的人可能只要 28 个,而有的人可能需要 40 多个,还是因人而异。如果白天精神抖擞,说明睡眠周期足够;如果觉得很困倦,可能是因为睡眠不足。
日间小睡
日间小睡(中午或者傍晚)可以最为一周睡眠周期的有效补充。30 分钟的小睡甚至可以媲美晚上的一整个睡眠周期的效果。如果晚上睡眠不足,那么千万不要忽视日间小睡。如果晚上睡眠充足,没有午睡也无需太担心。
- 小睡可以用来弥补晚上睡眠周期的不足,计入每周睡眠的周期数;
- 小睡要么短点 30 分钟左右,要么就一个完整的周期;
- 傍晚也是一个有效的小睡时机,适合晚睡晚起类型;
- 即使是 30 分钟的小睡,也可以作为一个完整睡眠周期来统计;
睡眠环境
作者比较提倡纯粹的睡眠环境,在卧室除了睡觉,什么也不做。其他活动尽可能的搬到卧室以外的空间。
另外,床垫的作用远远高于床架本身,我们应该尽可能把资金花在床垫本身。如果预算有限,可以考虑只买床垫。
作者专门提到,睡眠过程中其实不需要喝水,也不建议在卧室放一杯水。会口渴的醒来,往往是因为睡觉时用嘴呼吸,喝水只是治标不治本的方法。
- 睡姿:建议胎儿型睡姿,面向非重要的一侧(惯用右手则面向左侧);
- 床垫的选择:侧卧时,从侧面看头、腰、髋部成一条直线(没有枕头的情况下)。其实,一个合适的床垫可以不用枕头(不过枕头已经成为一种习惯,没那么容易放弃)
- 床垫只选合适的(以上面一条为标准),不一定贵的就合适;
- 床垫的选择应该按照身材最魁梧的那一方为标准;
- 床垫远比床架重要;
- 床垫建议 7 年左右换一次床垫;
- 半夜其实并不需要喝水,口渴是因为用嘴呼吸了;
- 营造安全感可以改善睡眠,睡觉以前检查一下全部门窗;
其他
- 每天咖啡因摄入量不要超过 400 mg;
- 失眠的一个重要原因是「担心自己失眠」,把晚上的睡眠看得太重,反而导致睡不好。其实日间小睡、睡前醒后的准备、卧室的布置,都是睡眠的重要环节,与其担心晚上睡不好,不如从其他方面来下手。
想了解更多有关「睡觉」的知识,欢迎阅读少数派「助你睡个好觉」专题。
via 少数派 - 高品质数字消费指南
September 25, 2018 at 11:58PM
有赞搜索系统的技术内幕
有赞搜索系统的技术内幕
https://ift.tt/2OPtXAY
hehua
上文说到有赞搜索系统的架构演进,为了支撑不断演进的技术架构,除了 Elasticsearch 的维护优化之外,我们也开发了上层的中间件来应对不断提高的稳定性和性能要求。
Elasticsearch 的检索执行效率可以表示为:
O(num_of_files * logN)
其中 numoffiles 表示索引文件段的个数,N 表示需要遍历的数据量,从这里我们可以总结出提升查询性能可以考虑的两点:
- 减少遍历的索引文件数量
- 减少遍历的索引文档总数
从 Elasticsearch 自身来说,减少索引文件数量方面可以参考几点:
- 通过 optimize 接口强制合并段
- 增大 index buffer/refresh_interval,减少小段生成,控制相同数量的文档生成的新段个数
不论是强制合并或者 index buffer/refreshinterval,都有其应用场景的限制,比如调整 index buffer / refreshinterval 会相应的延长数据可见时间;optimize 对冷数据集比较适用,如果数据在不断变化过程中,除了新段的生成,老数据可能因为旧段过大而得不到物理删除,反而造成较大的负担。
而减少文档总数方面,也可以做相应的优化:
- 减少文档更新
- 指定 _routing 来路由查询到指定的 shard
- 通过 rollover 接口进行冷热隔离
这里尤其需要注意的是减少文档更新,由于 LSM 追加写的数据组织方式,更新数据其实是新增数据+标记老数据为删除状态的组合,真实参与计算的数据量是有效数据和标记删除的数据量之和,减少文档更新次数除了减少标记删除数据之外,还可以降低段 merge 以及索引刷新的消耗。
考虑到实际的业务场景,如果将海量数据存储于单个索引,由于 shard 个数不可变,一方面会使得索引分配大量的 shard,数据量持续增长会逐渐拖慢索引访问性能,另一方面想要通过扩展 shard 提高读写性能需要重建海量数据,成本相当高昂。
索引拆分
为了增强索引的横向扩容能力,我们在中间件层面进行了索引拆分,参考实际的业务场景将大索引拆分为若干个小索引。
在索引拆分前,首先需要检查索引对应业务是否满足拆分的三个必要条件:
- 读写操作必定会带入固定条件
- 读写操作维度唯一
- 用户不关心全局的搜索结果
比较典型的比如店铺内商品搜索,不论买卖家都只关心固定店铺内的商品检索结果,没有跨店铺检索需求,后台店铺与商品也有固定的映射关系,这样就可以在中间件层面对读写请求进行解析,并路由到对应的子索引中,减少遍历的文档总量,可以在性能上获得明显的提升。

相对 Elasticsearch 自带的 _routing,这个方案具备更加灵活的控制粒度,比如可以配置白名单,将部分店铺数据路由到其他不同 SLA 级别的索引或集群,当然可以配合 _routing 以获得更好的表现。
索引拆分首先会带来全局索引文件数据上升的问题,不过因为没有全局搜索需求,所以不会带来实质的影响;其次比较需要注意的是数据倾斜问题,在拆分前需要先通过离线计算模拟索引拆分效果,如果发现数据倾斜严重,就可以考虑将子索引数据进行重平衡。

如图所示,数据重平衡在原有的拆分基础上加入一个逻辑拆分步骤:
- 数据首先拆分为 5 个逻辑索引
- 设定重平衡因子,假设为 N
- 根据重平衡因子将逻辑索引数据顺序哈希到N个连续的物理索引中

如图,按平衡因子3重平衡之后文档数据量的最大差值从 510 降为了 160,单索引占全局数据量比例从之前的 53% 降低为 26%,能够起到不错的数据平衡效果。
冷热隔离
在查询维度不唯一的场景下,索引拆分就不适用了,为了解决此类场景下的性能问题,可以考虑对索引进行冷热隔离。
比如日志/订单类型的数据,具备比较明显的时间特征,大量的操作都集中在近期的一段时间内,这时就可以考虑依据时间字段对其拆分为冷热索引。

Elasticsearch 自带有 rollover 接口供索引进行自动轮转,通过索引存活时间和保存的文档数量作为轮转条件,满足其中之一即可创建一个新索引并将其作为当前的活跃索引。
在实际应用过程中,rollover 接口需要用户感知活跃索引的变更,且自行计算查询需要访问的索引范围,为了对用户屏蔽底层这些复杂操作的细节,我们在中间件封装了索引的冷热隔离特性,从用户视角只须访问固定索引并带入固定字段即可。

首先配置路由表,根据不同的时间跨度划定不同的路由规则,比如业务初期数据增量并不大,可以用50的时间跨度创建子索引,后期业务增量变大后逐渐缩短时间跨度至 10 来创建子索引。
通过查询条件的起止时间点分别从路由表中计算对应的子索引偏移量,得到起止范围,以上图为例,连续的子索引范围为 index2~index14,也就是该条件将命中此区间内的全部子索引,写操作也类似,区别在于写数据只会落到一个子索引,一般是当前的活跃索引。
这样冷热隔离的方式拆分可以兼容多维度的查询需求,比如订单的买卖家查询维度,而且拆分规则比较灵活,可以动态调整,另外删除数据只需要删除整个过期索引,而不必通过 deletebyquery 的方式缓慢删除索引数据。
除此之外,为了更好的配合用户使用,我们还对此开发了索引的自动轮转/定时清理等辅助功能。
HA
随着搜索系统的广泛使用,用户对系统的稳定性也提出了更高的要求,比如在机房发生断电等故障情况下,依然能够保证服务可用,这就需要我们能够将数据进行跨机房复制同步。
首先考虑的方案是跨机房组建 Elasticsearch 集群,这样实现非常简单,但是问题是机房的网络交互是走专线的,在集群宕机恢复数据过程中会有很大的带宽消耗,可能引起机房间的网络拥堵,因此这个方案并不可行。
Elasticsearch 本身也在开发 Changes API 特性,可以用于跨集群的数据同步,但可惜的是该特性仍然在开发中,在参考了主流的数据同步方法后,我们在中间件层开发了一套异步数据复制系统。

在确认索引开启多机房复制后,首先在 proxy 侧启动增量同步,发送同步消息给 mq 作为同步程序 clones 的增量数据源,然后通过 reindex 功能从主索引全量复制数据到从索引。
在跨机房同步过程中,数据容易因为 MQ、proxy 异步发送等影响而乱序,Elasticsearch 可以通过乐观锁来保证数据变更的一致性,避免乱序的影响,前提是 version 能够一直保持在索引中。
但是在物理删除模式下,由于数据被物理清理,无法继续保持版本号的延续,这就有可能导致跨机房数据同步的脏写。

为了避免乐观锁失效,我们的解决方法是软删除的方式:
- delete 操作在中间件转换为 index 操作,文档内容仅包含一个特殊字段,不会命中正常的搜索条件,也就是正常情况下无法搜索得到该文档,达到实际的删除效果
- 在中间件将 create/get/update/delete 等操作转换为 script 请求,保持原有语义不变
- 通过软删除文档中特殊字段记录的时间戳定时清理数据(可选)
为了能够感知到主从索引间的数据一致性和同步延迟,还有一套辅助的数据对账系统实时运行,可以用于主从索引数据的校验、修复并通过 MQ 消费延时计算主从数据的延迟。
小结
到这里有赞搜索系统的大致框架已经介绍完毕,因为篇幅的原因还有很多细节的功能设计并没有完整表述,也欢迎有兴趣的同学联系我们一起探讨,有表述错误的地方也欢迎大家联系我们纠正。
关于 Elasticsearch 方面本次的两篇文章都没有太多涉及,后续待我们整理完善之后会作为一个扩展阅读奉送给大家。
欢迎关注我们的公众号
</div><br>
技术
via 有赞技术团队 https://ift.tt/2lOIVul
September 14, 2018 at 06:21PM
不要相信一个熬夜的人说的每一句话
不要相信一个熬夜的人说的每一句话
https://ift.tt/2xQLLEy
对于人类来说,让人感到愉悦欣快的因素或多或少都与多巴胺有关,具体到短暂 / 低强度的熬夜这件事上,其情况如下:
使用正电子发射断层成像技术(positron emission tomography, PET)研究同一组人在短期熬夜和正常休息之后的脑功能情况,观察对象是放射性标定[11C]raclopride([11C]雷氯必利). 它是中枢多巴胺 D2 受体特异性拮抗剂. 短期熬夜之后,人脑中这种拮抗剂跟多巴胺受体的结合降低[1]:

这预示这多巴胺水平在短期熬夜之后增加了——如果多巴胺受体没有因为熬夜而减少的话(服用安非他命之后会导致这种情况,这是服用毒品导致毒品效力递减的机制之一)。
在短期熬夜之后多巴胺水平的增加可以保持神经系统的情形,从而弥补睡眠剥夺导致的损失。但伴随的是认知能力的降低,并且多巴胺水平的增加度跟认知能力的降低度正相关:

也就是说,短暂熬夜虽然会让人有欣快感,但这种欣快感只是一种“假象”:一则,它并不伴随认知能力的增加,不会提高工作效率,而是对工作有害;二则,这种欣快感有可能是熬夜之后的认知错乱导致的对自身精神状态的错误感知[2].
这种熬夜之后认知功能的紊乱表现在多个方面:
1) 对事物的情绪感知变得更加积极和正面

这种情绪认知偏移是中脑边缘通路(Mesolimbic Pathway)的兴奋增加导致的。其兴奋增加还会导致大脑神经系统的警觉层度上升[3], 让神经更加紧张。
2) 短期熬夜之后,前额叶跟杏仁核的功能协同(连接)水平降低[2, 4]:

这也就是说,在短暂熬夜之后,人的理性情绪(前额叶主导)变得薄弱了,而人的本能性情绪(杏仁核)凸显出来。在这种情况下,人做决定会变得更加冒险,更加极端并且不着实际。具体表现为:对“得”更加敏感,同时对“失”更加迟钝。


不难理解,在这种“得失”认知失调的情况下,我们会做出多么愚蠢的决定。
总结:
- 短期 / 低强度失眠 / 熬夜之后的欣快感是神经系统的 代偿机制 的表现
- “代偿”的作用不会使得人脑功能达到正常休息情况下的水平
- 短期 / 低强度失眠 / 熬夜之后人的情绪认知发生变化,对自身情绪感知变得更加积极,这种情况下人对自己精神状态的评估是不可信的
- 短期 / 低强度失眠 / 熬夜之后人的决策变得更加极端,更加冒险,对潜在的损失视而不见,对可能的获益又估计过高。(更加放飞自我)
5. 不要相信一个失眠 / 熬夜的人说的每一句话
[1] Volkow, Nora D., Gene-Jack Wang, Frank Telang, Joanna S. Fowler, Jean Logan, Christopher Wong, Jim Ma et al. "Sleep deprivation decreases binding of [11C] raclopride to dopamine D2/D3 receptors in the human brain."Journal of Neuroscience 28, no. 34 (2008): 8454-8461.
[2] Gujar, Ninad, Seung-Schik Yoo, Peter Hu, and Matthew P. Walker. "Sleep deprivation amplifies reactivity of brain reward networks, biasing the appraisal of positive emotional experiences."Journal of Neuroscience 31, no. 12 (2011): 4466-4474.
[3] Pezze, Marie A., and Joram Feldon. "Mesolimbic dopaminergic pathways in fear conditioning."Progress in neurobiology 74, no. 5 (2004): 301-320.
[4] Yoo, Seung-Schik, Ninad Gujar, Peter Hu, Ferenc A. Jolesz, and Matthew P. Walker. "The human emotional brain without sleep—a prefrontal amygdala disconnect."Current Biology 17, no. 20 (2007): R877-R878.
[5] Venkatraman, Vinod, Scott A. Huettel, Lisa YM Chuah, John W. Payne, and Michael WL Chee. "Sleep deprivation biases the neural mechanisms underlying economic preferences."Journal of Neuroscience31, no. 10 (2011): 3712-3718.
kindle4rss
via 知乎日报 https://ift.tt/2yVSp04
September 25, 2018 at 08:47AM
200年来科学家最接近万有引力常数G的一次Nature自然科研
200年来,科学家最接近万有引力常数G的一次|Nature自然科研
https://ift.tt/2I5iefh
本文由《Nature 自然科研》授权转载,欢迎访问关注。
原文以Gravity measured with record precision为标题
发布在2018年8月29日的《自然》新闻与观点上
原文作者:美国国家标准技术研究所Stephan Schlamminger
控制引力相互作用强度的万有引力常数G很难准确测量。现在,一支研究团队采用两种独立方法测出了截至目前常数G的最精确值。
虽然引力在我们的日常生活中似乎很强,例如在举起重物时,但是它是四种基本力中最弱的一种。两个物体之间的引力与它们的质量成正比。如果其中一个物体是地球,引力则可能相当大。但如果是实验室中的物体,引力则可能太小而无法准确测量。例如,两个相隔1米的1千克物体之间的引力相当于少量生物细胞的重量。
因此,万有引力常数G是测量精度最差的物理常数之一。现在,华中科技大学物理学院引力中心团队的杨山清教授,邵成刚教授和罗俊院士为通讯作者,物理学院博士后黎卿,中山大学天琴中心副研究员薛超及物理学院博士生刘建平,邬俊飞为共同第一作者的研究团队使用两种独立方法精确测量了G值,相关结果发表在了《自然》期刊上(DOI:10.1038/s41586-018-0431-5)。

研究的实验设置。
来源:Li et al.
1798年,科学家卡文迪许使用扭秤在实验室中第一次确定了G值。该扭秤由一个哑铃组成,哑铃中间系了一条细丝。引力作用于哑铃末端,方向垂直于哑铃的杆和细丝的轴线。该力导致哑铃围绕该轴旋转,导致细丝发生扭曲。
最终,哑铃达到细丝的扭转力与引力平衡的位置。哑铃在该位置的旋转角度被记录下来。接着,沿相反方向施加引力并第二次测量旋转角度。利用这两个角度之间的差异可以计算出引力的大小。
在扭秤实验中,引力由特定的外部质量源提供。这些质量源在两个或两个以上不同位置之间移动以改变力的方向和大小。因为哑铃在水平面上旋转,所以原本会对实验产生重大影响的地球引力可以忽略不计。
多年来,人们研发出了许多技术以通过扭秤来测量G值。2000年,通过用一块薄板(也称为板摆)代替哑铃,实验精度得到了显著提升。
研究团队依据不同的测量技术——扭秤周期法(TOS)和扭秤角加速度反馈法(AAF),构建了两个含板扭秤。在TOS方法中,板的旋转是振荡的。通过计算外部质量源处于两种不同配置时的振荡速度变化,计算G值。在AAF方法中,研究人员使用两个转盘分别旋转扭秤和外部质量源。当细丝的扭曲量减小到零时,G由与扭秤相关联的转盘的角加速度来确定。
作者使用TOS方法和AAF方法得到的G值分别为6.674184×10^-11和6.674484×10^-11立方米每千克每平方秒。其相对不确定度是截至目前为止最小的:大约为11.6 ppm(ppm:百万分之一),而先前使用AAF方法得到的G值不确定度是13.7 ppm。
研究团队非常仔细地进行了实验,并详细描述了他们的工作。该研究是精准测量领域卓越工艺的典范。然而,G值的真值仍然不清楚。在过去40年中对G值进行的各种测定结果不尽相同(图1)。虽然个别结果的相对不确定度大约为10 ppm,但最小值和最大值之间的差异约为500 ppm。

图1 | 万有引力常数的测量。两个物体之间的引力强度由万有引力常数G描述,G值以立方米每千克每平方秒为单位表示。该图显示了过去40年中G值的高精度测量结果,误差条表示不确定度。红色方块表示本论文作者团队的最新测量结果,紫色方块表示他们过去的测量结果。竖直灰线表示科学技术数据委员采纳的G值,阴影区域表示不确定度。
这种差异至少有两种可能的解释。第一种可能性是,一个或多个实验的技术细节并没有完全被理解,这可能导致测量的G值出现系统误差或者未完全反映测量所存在的不确定度。举例来说,细丝的滞弹性可能导致TOS方法得到的结果出现偏差——该效应在1995年被首次指出。
第二种可能性是,某些未知的物理机制导致测量结果分散。虽然后一种可能性更令人兴奋,但可能性也更低。尽管如此,不应该无视这种可能。
目前,尝试理解不同结果之间的差异与进行新测量同样重要,甚至研究团队得到的前后结果也不一致:最新两个实验确定的G值与同一实验室之前得到的测量结果,在统计学上并不吻合。作者推测原因可能在于细丝滞弹性,但他们没有给出明确的解释。
因为所有这四个实验都是在同一个机构进行的,所以比较它们应该比比较世界各地不同研究组的不同实验更为直接。因此,可以借此机会揭示出现测量差异的原因,进而更进一步地了解G值的真值。应该鼓励研究团队接受这一挑战。最后,如果我们想要理解G值的测量,就必须找出各种测量结果不相一致的原因。ⓝ
Nature|doi:10.1038/d41586-018-06028-6
版权声明:
本文由施普林格·自然上海办公室负责翻译。中文内容仅供参考,一切内容以英文原版为准。欢迎转发至朋友圈,如需转载,请邮件 [email protected]。未经授权的翻译是侵权行为,版权方将保留追究法律责任的权利。
© 2018 Macmillan Publishers Limited, part of Springer Nature. All Rights Reserved
本文由《Nature 自然科研》授权转载,欢迎长按下方二维码访问关注。点击「阅读原文」获取英文原文。

原文
kindle4rss
via 大象公会 https://ift.tt/2DryWqo
September 22, 2018 at 03:28PM
如何写好一个非虚构故事
如何写好一个非虚构故事?
https://ift.tt/2Pi3eOk
四旬
本文是「少数派读书笔记征文活动」的第 7 篇入围作品。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。

什么是非虚构?怎么找选题?采访时需要注意什么?怎么用现有素材拼凑出一个故事?诸如此类问题,都是本文尝试解决的,无论你是否从事写作行业,或是根本就没有想过这件事,相信这篇文章都会对你有所帮助。
什么是非虚构?
非虚构(non-fiction),从字面意思上看便很清楚了,「非」+「虚构」。不同于小说,非虚构是以「真实」为内核的,就像是影视作品里的「纪录片」,2015 年,非虚构作家斯维特兰娜·阿列克谢耶维奇获得诺贝尔文学奖,标志着此题材在社会意义和文学价值两个方面都得到了空前的承认。
完成一部非虚构作品需要一段时间的观察,采访,素材的收集,这种题材也通常以历史、时代、社会、人性的深度挖掘为己任。

而《哈佛非虚构写作课:怎样讲好一个故事》——这本名字听起来有点野鸡的书,含括了 51 位非虚构从业者的经验之谈,为读者打开了非虚构的大门。
本文主要以此为基础,主要从选题,采访,写作,技巧,四个方面来介绍非虚构的创作流程,即:如何写好一个非虚构故事?
选题的寻找

没有选题,何谈写作?非虚构写作虽然可以揭示时代、社会,但这并不意味着我们一定要找大人物,相反,倘若用心观察起身边的人物,往往会找到被我们忽视的温情。
下面有一些从日常寻找故事的技巧:
- 和陌生人交谈
- 不时打破自己的规律路线
- 读墙上的文字
- 到酒吧逛逛
- 单独吃午饭,听周围的对话,若遇到有趣的事情,就和对方聊聊,人们通常都抱有善意
- 琢磨「谁去」?比如:谁去清理移动厕所的化粪箱,比赛结束后,谁去清理座位底下的垃圾
- 不要忽视失败者,比如一场比赛后,失败者的更衣室往往比胜利者的更有意思
正如普利策特写报道奖获得者莱恩·德格雷戈所说:
我们睁开眼睛,竖起耳朵,不再势利,见识到以前我们没听全的事, 凭诚实的好奇去见识更广阔的世界——这时故事涌现了。有时,就像快乐的蓝鸲鸟,最好的故事落在自家的后院。

Tips
找到选题之后,得弄清楚自己打算用这个选题来干什么:你需要从哪些方面讲述一个怎样的故事——试着向别人讲述你的观察,根据别人的回应,来确定哪个地方能吸引别人,哪些地方可以再挖掘一下,或是从回应里看到之前没有发现的视角。

采访
在找到选题到真正写作这段过程中,还有尤为重要的一步——采访:你得开始为你的故事收集素材了,在这过程中,我们需要注意什么?
做足功课
你得事先在家里做好功课:你知道得越多,你就越能享受「圈内人」的待遇。
这个没得说,当你随着受访者/潜在受访者进入他们的世界时,所获得的东西能丰富到那种程度,完全取决于你自己的功课,如果你经验不足,你很容易只得到一些浮于表面的东西。

录音/不录?
面对一次采访,你会选择录音吗?大多数人也许都是「yes」,理由是它比记笔记精确得多,也能确保后期写上去的句子采访对象确实有说过,除此之外,能让你在采访时抽出空来和他们的视线接触,观察他们说话时的表情,姿态手势,动作(此处暗藏采访要点)。
但也有人不赞成录音,并且觉得用录音来确认采访对象话语的这件事根本就不靠谱——人们在说话的时候,往往「嗯」又「啊」,有时还会扔掉主语和代词。
并且,录音会使自己大脑偷懒——从而走神,随后的重听也会让人落入大片琐碎信息中。

所以到底录?还是不录?笔者筛选了一个中肯的回复:录,但是作为备选项——并不能只依靠它,从而对采访本身进行限制。采访时更重要的是:
- 耐心听,努力从那个人的角度去看世界
- 用自己的语言记下对方的意思,而不是在意于他们嘴里的每一个字
同样,要大概清楚自己的想要一个怎样到故事,并对信息过滤,直走故事核心。而录音,则作为事后不确定信息的补充(不一定去听)。
不止采访一个人

如果条件允许的话,不要只采访你的故事主角。即使你和你的采访对象待了很长一段时间,你看到的也只是组成他们一生的千千万万个小时中很小的一部分。我们假装了解了他们,但是并非如此,人们往往比描写出来的更为复杂。
普利策奖得主戴维·哈伯斯塔姆说,每次采访结束时,他一定要问这个问题:「我还应该去找谁?」这样到手的观点就越多,视角就越丰富,效果越好。
就算这个故事最后没有用到这些素材,它们也在无形之中让你更客观,成为你故事中看不见的「冰山」。

避免只有采访
除了采访,还要记得观察:观察场景、观察人物,人物往往在场景中会展现出更真实的自我。正如普利策特写报道奖得主莱恩·德格雷戈里所言:
一般来说,如果做访谈,我会把时间安排在事件之前或之后, 不会让访谈打断情节。如果我的受访者有某种定例式的日程安排, 我也会随着这个定例走。我会看着那个人去做事,有些事情我本来绝对想不到去问他的。

经过观察之后的作品应该是怎样的?或许如下例子:
整个房间都是粉色的,一种浅浅的、像新开的桃花一样的粉色。这是这个 15 岁女孩最喜欢的颜色,她有时把嘴唇和指甲涂成这种颜色,用这种颜色装饰右脚的鞋子,或者涂抹最心爱的笔记本扉页。现在,人们只能凭借房间里不多的展品,来想象这个女孩。这些展品,包括一条绣满了小草莓的粉色围巾,一面粉色的小镜子, 和一个画着小猫的粉色水杯,被随意摆放在这间只有 19 平方米的纪念馆里,讲述一场短暂的生命过程。——《最具体的纪念》
好的观察应该不限于视觉,也可以打开你的五官,比如我们都熟知的这篇:
我们沿着小路散步到井房,房顶上盛开的金银花芬芳扑鼻。莎莉文老师把我的一只手放在喷水口下,一股清凉的水在我手上流过。她在我的另一只手上拼写「WN」
——「水」字,起先写得很慢,第二遍就写得快一些。我静静地站着,注意她手指的动作。突然间,我恍然大悟,有股神奇的感觉在我脑中激荡,我一下子理解了语言文字的奥秘了,知道了「水」这个字就是正在我手上流过的这种清凉而奇妙的东西。
——《假如我有三天光明》
Tips: 前期沟通
这是一个关于采访伦理的问题,与你的潜在采访对象沟通时,可以告知你的采访对象你将会做什么,会有怎样的结果,你们甚至可以谈论酬劳等问题——这可以免掉之后的许多麻烦。国家图书奖得主特蕾西·基德尔是这样做的:
我试着回答他们所有问题,酬劳也几乎总是被提及,如果没有, 我则会告诉他们:「我不能为此付你钱。这必须是你出于自愿做的事」。
那时我还不怎么介意他们是否答应(我当然也希望他们同意),但知道自己可以在那个时间点就选择离开这个选题,也是件好事。我会在最开始自己还没任何投入的情况下就把这些问题处理掉。
写作
当当当!终于到了写作环节!采访观察之后,我们需要挑选素材,「拼」出一个好的非虚构故事。这时,需要注意些什么呢?

细节
引导读者入戏是写作者的义务,这时细节便起到了很大的作用。初学者通常会忽略掉细节的描写,如果你写「她出了一场小事故」,读者什么也感受不到,但换成「她踏空了,一脚栽倒楼下」,读者们就全明白了
但细节并不是越多越好,也要防止堆积太多,让整篇文章显得拖沓而散漫。就像一部纪录片,如果夹杂了过多旁白的——会毁掉观众们「发现」的感觉,从而抛弃你的故事。
细节太多也不行,太少也不可?到底应该怎样筛选细节呢?如下例:
如果故事是关于一位音乐老师及她对学生的教导,那么这位老师的个人生活在这里就不是那么重要。
但如果这个故事是讲她每周有六个晚上流连于酒吧的生活,那辅导学生的情节大可不必在此出现。
简而言之,只有能解释「动机」的信息才可以写入稿件,除此以外的其他东西都没有必要。准确的细节选择可以刻画出鲜活人物:
她 35 岁,穿着凉鞋勉强有一米六高。臀部逐渐变得像盛满粉蒸肉的平底锅。作为一个八个孩子的妈妈,她有着不寻常的温和性格。母鸡落在她手里,安静地要睡着了,这时她却操起斧头砍断了它的脖子。
四句话,描写了数量惊人的画面:这个女人的身高、年龄、体型、孩子的数量、穿什么鞋、她的家庭饮食、食物来源,甚至对他们的乡下生活做了匆忙的一瞥。至关重要的是,女人的温柔、果断和坚定都恰到好处地体现在她的行为举止当中。
结构

好的非虚构作品,就像在讲一个笑话,你必须把叙事主线里的每一部分都精准安排好,否则笑点就会失效。在非虚构作品中,我们要想好怎么安排结构,可以是这样:
开头是人物即将要开展的一个决定性行动,再及时回溯,解释他如何走到了这一点。
通常大多数作品都有一个潜在的内核,而各色作品都是这个内核下的包装:
中心人物遇到了困难——与之斗争——克服了困难/被它击败。

此处奥义需读者自行体会。
往上走
好的故事是往上走的
故事第一段需要仔细打磨,它肩负着吸引读者注意力的任务,但如果你在开头就把最好的材料交出去了,你就无法创造张力——读者可能在第一段段尾就停下来。
因此,文章必须提供一种体验,驱动读者往下读完你的故事。如果读者不能坚持到最后,不管你想表达的内容是什么,都亳无意义了。
所以,怎么做呢?
先设置小的冲突,留下一些线索

我们需要冲突去创造故事张力,吸引读者眼球,通常会选择先设置小的冲突,比如:
黎明即临的黑暗里,丹妮尔·赫弗恩的闹钟再一次响了。她进了卫生间,洗脸,刷牙,穿好衣服。像往常一样,她穿上那件蓝色米老鼠的套头衫。屋子里很安静。其他人都还没起床。
她每天早上重复着同样的事。自己做早餐,装好要带去学校的午餐盒,去等巴士。但这天早上有些不同。丹妮尔并不想装午餐。她想买点什么,比如布鲁克林咖啡馆的芝士比萨。昨晩,她问父母能否给她些钱。但他们拒绝了。丹妮尔下了楼。穿过客厅时,她注意到桌子尾端有些多余的零钱。
她数了数那些硬币:1.55 美元。
她拿起这些钱,放进自己的钱包。背上包,离开家,在身后锁上门。
这个场景交待了状况,并且让观众好奇:「她父母会发现吗?他们会作何反应?」这是一个很小的冲突,但是足够引起读者们的兴趣读下去。
放慢最好的材料
在建立某种紧张感之后,我们要学会松弛有度。
学会在何处加快或放慢速度便是关键:当你解释枯燥(但是重要)的背景信息时,加快速度;当行动进入关键节点的时候——放慢速度。
你只有慢下来,读者才能跟你进入正在发生的世界。
你需要让读者屏息不动,看到所有你想要他们看的东西。
怎么做?
在纸上留出更多空间。多分段。找出场景内自然的停顿(你可能会倾向于直接跳过它们,但事实上它们会帮你减慢步伐)。举个例子:
我曾经写过一个关于谋杀的故事,其中有一场警察追逐战。警察朝逃逸车辆的轮胎开枪。
当车开始原地打转的时候,车载CD播放器传出的音乐停了。我写下了这个音乐的停顿,好拉长那个充满悬念的时刻。
结尾

结尾是什么?布鲁斯·德席尔瓦说:「结尾是你把故事主旨钉在读者记忆中并回响数天的最后一次机会」,通常来说,你应该筛选你的素材,选择有意思的部分当作结尾。
你甚至可以尝试先写结尾。
结尾是你的目的地,当你已经知道你去往何处,剩下的文章就好写多了。
结尾往往需要需要强化文章主题,引起读者共鸣。也可以选择留白,让读者有思考的空间。一个好的结尾可以是:
- 一个生动的场景
- 一个生动的细节,暗示着比自身更强大的东西,或是暗示故事可能发展的方向。举个不恰当的例子,比如哥斯拉中人们在为打败怪兽欢呼时,镜头却拉到了海底——一颗怪兽的蛋。
- 令人难忘的奇闻逸事,却阐明了文章的主要观点
转一个《人物》的例子:一篇写李志的稿子,需要表现出他是一个严守规则的人。结尾便用了记者在李志车上所经历的小故事:
采访结束已经是晚上8点多,李志给工作室的植物都浇了一遍水,把桌上散落的杯子收纳到水池边,锁好工作室的门,开车回家。创意园区里的路七拐八弯,绕过一幢房子后,迎面有车灯射来,他与一辆车狭路相逢。
「(这是)单行线啊大哥!」李志有些无奈地脱口而出。他轻轻踩下油门,车向前驶去——行驶在正确道路上的车无需避让,对面那辆闯上单行线的车被逼得不断倒退。这条单行线不长,开过这一段路,李志就拐出了创意园区,到达了宽阔的大马路上。
结尾用了一个有意思的小故事来阐明主题:李志在单行道上逼退别人的车。这个小故事也成了文章的标题——《行驶在正确道路上的汽车无需避让》。
非虚构小贴士
上文已经介绍了完成一部非虚构作品所需的大部分流程,然而实际操作中我们往往被一些意料之外的点困扰到,我们或许可以利用美国小说家斯图尔特·奥南的小贴士来应对他们:
谈论
写,不要聊。刚开始写一个东西时,忍住不要对之谈论太多。有时, 聊着聊着作品的神秘性就没了,结果你失去了热情。
视角转变
带上你的人物。我常常变身为笔下的主要人物,努力钻进那个人的视角。我会整天想象,那个人如何看待我看到的事情。如果主要人物是一个等丈夫出狱等了25年的女人,我会走进一个监狱大堂,看每一个人都像看一个享受自由的人。
梦
记下你的梦。我曾经半夜醒来,然后得到了完整的短故事。
黄金时间
仔细为时间做预算。弄清楚你的黄金时间段是什么,规划日程表,把黄金时间用于你最在意的工作。

连续性
永远不要把稿子扔开太长时间。如果好几个星期不去写,你就永远写不完。
小注脚
永远不要迫使自己从写停了的地方开始写。这会使得接下来的写作很难,每次停笔时,写一个小注或提醒,帮你第二天往下写。
绑在椅子上
采取极端手段。以前我真的用尼龙绳把自己绑在椅子上,强迫自己盯着光标。修改时,我发现自己保留的句子里,感觉糟糕的日子写的,和轻易顺畅的日子写的,数量一样多。
罗伯特·弗罗斯特( Robert Frost)说得最好:「写作的艺术,就是把裤子放进椅子的艺术。」如果你被绑在椅子上,就会容易不少。
叙事的引诱

时常听到新闻工作者们抱怨「新闻已死」——在互联网冲击下的今天,人们的注意力越来越涣散,新闻也逐渐碎片化,浅薄化。作为非虚构这样的深度新闻的似乎已经没有了出路。
然而情况并非如此,人类对于「故事」的需求是永恒存在的,只是会在互联网上换种形式出现。对于非虚构写作本身,你既可以功利一点(此处就不举例了,笑),也可以单纯地探索这个时代的苦乐与温情,展现其应有的价值。
当然,于个人而言,「开始写」才是最重要的。看完这篇文章的你,不妨跟着它的脚步,留心起周围的生活,在日渐浮躁的今天,尝试写出属于你的自己,独一无二的「非虚构」。
图文/四旬
via 少数派 - 高品质数字消费指南
September 26, 2018 at 12:04AM
读书 | 漫步华尔街一本很新的老书告诉你为什么个人投资者也有能力做好理财投资
读书 | 《漫步华尔街》一本很新的老书告诉你,为什么个人投资者也有能力做好理财投资
https://ift.tt/2BtQVeY
也谈钱
本文是「少数派读书笔记征文活动」的第 9 篇入围作品。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。
 漫步华尔街
漫步华尔街
对于投资而言,相比于新书、热门书,我更喜欢经过时间检验的老书和经典。而首版发行于 40 年前的《漫步华尔街》无疑是符合这一标准的。而且难能可贵的是,在过去的几十年,《漫步华尔街》经过了 11 次再版,不断的加入时代最近的变化,称之为年轻的老书也不为过。
道理我们都懂,但是……
其实《漫步华尔街》并没有什么高深的新奇道理,只要一句话就可以简单概括——投资指数基金优于投资主动管理的基金。曾经的责编 Hum 更是对我直言,作为作者应该更多的学习新内容,我这样不断的巩固已有的认知是一种危险的行为。我当时真的惊出一身冷汗,但是转念一想,又想通了,我是作者,但我更是一名投资者。
一位我很尊敬的投资前辈常把一个词挂在嘴边——「保持浓度」。投资的重点不是研究多少新奇的内容、方法,而是能把简单、正确的常识和道理不断加深,直到入地三尺的程度。
为什么简单但是有效的投资方法,能够坚持并盈利的投资者实际上寥寥无几?为什么知易行难?无非是认知的浓度还不够。尤其当熊市到来时,人心惶惶,更是需要这些经典老书来帮助我们巩固认知,保持浓度。
「太阳底下没有新鲜事」,投资要的是简单、正确的不断重复,而不是新奇刺激的方法与逻辑。这一点在书中也得到了完美的体现,金融机构不断的创新,不断的推出新的工具,却始终难以打败市场,指数基金依然是个人投资者最有效的投资方式。
《漫步华尔街》全书可以分成两大部分。前三章通过回顾历史上的泡沫事件、定量回测各种新老投资方法的业绩和对比,论证了指数基金投资的有效性;最后一章则是作者给广大读者提供的投资建议和指南。
作者在引言中这样写道:
本书是一部简明扼要的个人投资指南,涵盖了从保险到个人所得税的所有内容。主要观点很简单:倘若投资者买入并持有指数基金,而不是勉为其难地买卖个股或主动管理型基金,那么他们的财务境遇就会好得多。
贪婪催生泡沫周而复始
泡沫的一再出现,再到一地鸡毛,其实反应一个投资的悖论——越是大家认可大家相信的东西,越是危险,越是濒临崩溃。虽然历史上著名的郁金香泡沫、科技股泡沫已经被不断重复得遭人厌烦,但是依然挡不住新版的郁(qu)金(kuai)香(lian)的一再出现。
这整个循环机制就如同「庞氏骗局」,在这种骗局中,必须找到越来越多易于轻信的投资者,让他们从先前已买入股票的投资者手中买入股票。最终,「博傻」骗局再也找不到更傻的傻瓜参与进来。
作者在分析房地产泡沫时,放上了一张图,我的印象很深——美国经通货膨胀调整后的房价。在很长的历史回溯中,房价的上涨速度都和通货膨胀基本保持一致。在 2007 年前后,房价的涨幅大幅度偏离了通货膨胀,最后导致了经济危机。
 经通胀调整后房价
经通胀调整后房价
从这个角度来看,当房价大幅度偏离后,只有两种结局,要么房价降下来,要么通货膨胀跟上去。但是,无论哪种情况发生,对于经济来说都会是一种打击。
为什么主动管理难以跑赢市场
在第二篇,作者详细论述了对于基本面分析和技术分析两大方法的观点并分析其优劣。对于基本面分析而言,其难点在于预测未来收益,这几乎是一个不可能完成的任务。而对于技术分析,根据各种技术分析策略的回测,考虑交易的损耗(费用和纳税)以后,这些方法并不能带来正回报。
主动管理难以跑赢市场的内在逻辑在于:
- 市场的有效性
- 频繁交易的佣金和税款造成的损耗
- 主动管理基金的高收费
市场的有效性导致了主动交易难以打败市场,而主动交易产生的交易成本和高收费更是让一切雪上加霜。
总而言之,不管是基本面还是技术分析,都不能保证跑赢市场。诚然,在任何群体中都存在能够持续跑赢的个体,比如巴菲特、芒格、达里奥,但是这些个体的方法往往都不能复制,存在特殊性,个例并不能代表整体。
除了投资方法的局限,作者作为金融从业人员,还揭露了很多行业内幕。由于利益的不一致,金融行业一直存在投资人和管理人以及上市公司间的冲突和博弈。这些因素也进一步加剧了主动管理的难度。
在一起很知名的事件中,有位分析师斗胆建议投资者卖掉川普泰姬玛哈尔赌场债券( Trump’ s Taj Mahal bonds),因为这只债券不太可能支付利息。大名鼎鼎的川普本人便威胁要以法律手段报复分析师所在的公司,公司二话没说立即开除了分析师(后来,债券果真违约了)。
读老书除了内容更可靠,还有一种意外惊喜,能够看到一些名人的历史和过去大家对他的评价。再同时对照现在的最新情况,有种隐隐的上帝视角。作者写书时,川普还不是总统,却已然有了如今的 Twitter 风范。
新投资理论不能带来新的收益
在分析传统投资方法的基础上,新版《漫步华尔街》增加了很多对新投资方法的论证和回测,保持和时代同步(希望作者能长命百岁 😊)。
不过,这部分的阅读需要一定的投资经验,会出现一些术语。简单转述几个结论,感兴趣的话推荐看原书。内容稍微有些干,用一句话概括,作者再次证明,个人投资的最佳方法是使用指数基金的简单被动投资。如果实在无感也可以跳过本节。
你应当了解新投资技术中现代投资技巧的精华,它们有时可能会提供有用的帮助,但永远也不会出现一个俊美的精灵来解决我们的所有投资难题。退一步说,即使他现身了,大概我们也会把事情弄糟,
现代投资理论用 α 和 β 来衡量投资的超额收益和面临的风险。但是,在实际操作阶段,获得准确的数字却成为了一大难题。所以,这些数字更多的只能在一定程度上衡量结果,而不能衡量收益产生的原因。而且历史没法预测未来,过去的数字不一定能够延续到未来。
结构性风险靠分散投资来进行规避,但是系统性风险则不能。在一定范围内,承担更多的系统性风险(不可分散的风险),才可能提高回报,比如使用杠杆。同一品种的投资,当投资标的数量超过 50 以后,结构性风险就基本抵消了。
行为金融学对人性的分析大致可以整理为四种因素:过度自信、判断偏差、羊群效应和风险厌恶。不仅仅是个人投资者,机构投资者也一样会受到影响。行为金融学的研究,进一步证明了战胜市场的困难。
Smart-β 其实并不聪明,其背后的逻辑既然是主动管理。而且,不同策略有各自不同的适用环境,既存在跑赢的时候,也有跑输的时候,依然逃不过均值回归的道理。
A 股的特殊性
对于国内的应用,我们也需要注意,被动投资逻辑的一大根基在于市场的有效性。所以,这个方法直接搬到国内会存在一定的缺陷。
一方面,**市场是一个弱有效市场,过去十年间主动基金的平均收益是跑赢被动基金的。另一方面,最为深入人心的「上证综指」存在很严重的缺陷,非上市交易部分所占权重过高,导致不能正确反映真实市场行情。而国际常用的指数编制方式是需要剔除非流通股份的。
不过,从大方向上来看,国内市场的有效性一定是不断提高的,在未来指数基金投资一定会成为主流。
我的建议是,核心投资以指数基金的被动投资为主,在非核心部分适度配置部分主动基金作为补充。
个人投资者如何更务实
个人投资其实也可以表现很好,不是因为个人投资者比专业投资者有什么优势,而是因为绝大部分的专业投资实在是名不副实。经过作者的量化分析,很多看起来专业、高大上的工具,往往都经不起推敲。
作者在这个部分,通过 10 个小节,说明了个人投资者从无到有构建起自己的投资组合的原则:
-
开始储蓄:要赚钱,先 省钱,通过储蓄积累本金。
-
备好保险:准备好现金储备,使用 紧急备用金 和 保险 来保护自己。
-
强化现金管理:通过现金管理,避免现金储备的贬值,国内的余额宝做得很好。
-
学会避税:这里指的是合法合理的避税,而不是建议大家偷漏税。
-
确定目标:确定自己的投资目标和投资期限。
-
拥有恒产:在合理的范围内,拥有一个自己的房产。
-
从债券入手:使用较低风险的债券开始构建投资组合。
-
规避高投机品种:非专业投资者不建议投资黄金、收藏品、期货等投资品。
-
降低佣金:选择佣金更低的券商和交易途径。
-
多元化:使用多元化投资组合,避免结构性风险。
在这十条中,对于保险、房产和避税三个方面,我的感触颇深。
关于保险,作者强调,「请记住高于一切的规矩是:保持简单。避免购买任何综合性的金融产品,也要避开那些极力想把这类产品推销给你的如饥似渴的代理人。」返还型保险就是一个反例,同时具备保险和投资的属性,最后的结果是不上不下。根据 我的计算,返还型保险既不能起到很好的保护效果,也不能获得很好的投资收益。
关于房产,除了「有恒产者有恒心」以外,自有房产还能提供很多税收优势。但是,我们也要做好区分。在我看来,虽然自主的房子同时涵盖消费和部分的投资属性,但是很多购房者完全是以投资为名,行消费之实。
关于避税,国外的读者在这一点上感触应该是很深的。国内目前由于税收体质还不完善,影响不大。但是,国内以后也一定会向发达国家靠拢。
此外,作者并没有理想化的建议个人完全不炒股,只通过指数基金进行投资。因为,想要获得超额收益的想法是深植于人性的。对于想要自行操作的投资者,作者建议则是通过指数基金构建核心资产,而非核心资产作为个人主动管理的部分,兼顾风险和收益。
最后,我再唠叨一句:投资的核心不是选择收益,而是选择风险。投资风险必须和自己的风险承受能力相匹配。一般而言,年轻人的风险承受能力高于中年人,有车有房无贷款投资者的风险承受能力高于需要还贷的投资者。
决定未来收益的三大因素
未来收益率 = 初始股息率 + 增长率 - 估值变化
虽然长期来看,估值的水平趋向于一个平均值,但是在一个较短周期(10 年以下)内,估值变化实际上是收益率的主导因素。在历史上的很多经济繁荣时期,增长率表现很好,但是由于初始估值过高、初始股息率过低,导致后期的收益表现很糟糕。
作者对比了 1947~2009 年的四个时期,进行了论证。最终的结论是,投资的首选起点是估值低、股息率高的时期,而不是繁荣和高增长时期。从投资收益的角度来看,便宜比繁荣更重要。
总结
作者用很大的篇幅论述了主动管理、打败市场的困难现实,不管是传统的投资思路,还是新兴的投资逻辑,在实际应用中都难以打败市场。
市场的有效性证实了被动指数投资的可行和优势。所以,作者鼓励个人投资者优先考虑指数基金投资,规避主动管理类的资管服务。
总的来说,《漫步华尔街》非常值得有一定经验的大众投资者阅读。帮助自己跳出打败市场的思维框架,以中庸的思路重新审视市场,并打造一个并不平庸的投资结果。一句话总结——个人投资者应该优先考虑使用被动指数基金来配置投资组合。
对读者的经验还是有点要求。虽然全书的专业术语并不多,但是很多观点比较浓缩。如果完全没有投资经验,可能会缺乏代入感。
via 少数派 - 高品质数字消费指南
September 26, 2018 at 12:01AM
如何创造源源不断的销售力 | 读书笔记征文
如何创造源源不断的销售力 | 读书笔记征文
https://ift.tt/2wdbXIZ
cooabyli

本文是「少数派读书笔记征文活动」的第 8 篇入围作品。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。
如何提升卖方的销售力
在喜剧界,搞笑艺人创作的笑料可以分为「普遍适用性」和「容易厌倦型」。所谓容易厌倦型,就是我们常见的「俏皮话」,或者说是现在的突然流行的网络流行语,这些流行语刚出来的时候可以使观众十分有新鲜感,也很容易逗笑观众,但是来的快去的也快,很容易被消费者厌倦。拿我们的春晚举例子,每年春晚也有大量的小品、相声使用了网络流行语,但是电视机前的观众,尤其是年轻人根本不觉得好笑,就是因为网络流行语就是「俏皮话」似的笑料,已经被观众厌倦了。
不过还有另外一种笑料,叫「普遍适用型」笑料。这些笑料有固定的铺垫、陈述、反转等方法、套路,我们**的相声界对这种笑料的创作方式炉火纯青,如说相声常见的手法:「抖包袱」。抖包袱的方法大概有三翻四抖、违反常规、阴错阳差等 20 多种,但是创作的笑料却不计其数,不为观众厌倦。
比较高超的相声演员,如郭德纲,则是能同时把「俏皮话」型的笑料和「普遍适用型」的笑料结合起来,在经典相声的基础上,加入现在流行的「俏皮话」,通过演员深厚的表演、语言能力表述出来,不仅能取得观众的欢心,也不容易被观众厌倦。
在现在的消费者市场中,企业的经营主们,也面临着和喜剧界一样的问题。消费者就像观众厌倦了老旧的笑料一样,也厌倦了企业的老产品。产品变得不被消费者认可,自然也不会被消费者购买。在这种情况下,企业的生命力逐渐衰减,急需开发出新的、被消费者喜欢的新产品,但是却没有开发方向。
企业主该怎么做,才能像源源不断创造出被观众喜爱的笑料的相声演员一样,开发持续被消费者喜欢、也就是具有销售力的产品呢?
7–11 的经营者在《零售心理战》中告诉了我们两个创造销售力的企业经营原则:
「应对变化」与「贯彻基本」
- 应对变化:紧跟消费者的变化,满足消费者需求
- 贯彻基本:始终站在消费者角度思考问题
应对变化
如何应对时刻在变的消费者需求呢?
如果你告诉一家被消费者抛弃了的企业,它被市场淘汰的原因是因循守旧,不懂得保持变化以应对消费者需求,它的企业主可能会十分困惑的回应你:我就是在一直保持变化啊!
是啊,每个企业主都知道要保持变化以应对消费者,也在兢兢业业的工作,那么他为什么还是被消费者抛弃了呢?
因为人们总是受制于过去的经验,尤其是过去的成功经验。人们总是习惯总结学习成功的经验,这些经验中克服困难的自信和努力奋斗的精神会始终被铭记于心。但是,这些成功经验也是驱使这些企业主在面对未来的变化中,继续使用同一种方法,最为关键的是,这些方法在潜意识里被运用,当局者甚至全然注意不到这一点。事实证明,无法忘记历史成功经验的人,极少具有应对市场变化的能力。越有过成功历史的人,越是如此。这被叫做「被成功复仇」。
这就是应对变化最大的敌人:思维定势。
有这么一个潜水员的故事:有一名潜水员在下潜到 50 米深的海底时,不小心掉落了一罐百威啤酒。但是由于百威的鲜艳的红色瓶身,这名潜水员立即发现了这件事。而事实上,在这种程度的水深之下,光线几乎无法到达,潜水员不可能分辨出百威瓶身的颜色。这是由于它脑海中「百威=红色」的固定认知,导致它看到了理应无法看到的红色。
可见思维定势对人的影响有多大。
如果把这个红色的瓶身比喻为消费者需求大的变化,就不难理解企业主们受制于历史经验时的判断和想法了。无法应对变化的人,并不是不愿意去观察变化,也不是看不到变化,而是即使仔细观察了,也看不到变化的真正模样。
如何应对变化呢?7–11 的经营者铃木敏文提供了这样的一个方法,叫做:「打破前定和谐」。
前定和谐是哲学概念,基本含义是:上帝在创造时间万物时,预先让万物的发展变化保持和谐,以此保证世界运行的秩序。在日本,前定和谐也被引申为:
任何人都按照预定的进程发展,所有行动的结果也皆与预期无异。
世间的万物按照前定和谐的方式稳定运行,而在没有竞争的市场中,各个企业也在按照它过往的成功经验,良好的经营着。但是现在的市场充分竞争,没有企业是「前定和谐」的,都必须打破以往的成功经验,以应对竞争的市场、变化的消费者需求。
打破以往的成功经验,就必须要有新的经营方法、新的产品来对企业进行革新,这也就是创新。创新很难,创新不足,可能仅仅是从「A」到「A+」的小变化,并没有给消费者多么耳目一新的感觉,消费者也许并不买账,创新太过,可能又过犹不及,风险极高。
那么企业该如果做到恰到好处的创新呢?答案就是使用「打破前定和谐」的方法。
有这么一个例子:在欧洲的冬季,人们喜欢在可可中加入少许黄油,这样可以让可可的又味变得更加浓郁香甜。而在日本却鲜有人知道这一方法。本书作者的朋友秋元康想到,如果提出「从秋天到冬天的漫漫长夜中,一首拿着加入些许黄油的温可可,一手捧着文库本(一种 A6 大小的书)阅读的概念,这前所未有的新鲜感必定让很多人感兴趣。
可可是常见的饮品,黄油、文库本同样也不新奇。但是在三者搭配后,却产生了全新的创意,这个创意不是「A」到「A+」的小变化,却也不是让消费者完全不理解的陌生概念,它就是非常恰到好处的创新,是从「A」到「B」的突破。
7–11 做了很多类似于「可可、黄油、与文库本」类似的打破前定和谐的事情。
7–11 作为现在最大的连锁便利店,深受消费者的喜欢。不过在 7–11 创办时,日本社会正处于大型超市蓬勃发展的时期,社会并不看好便利店模式。当时因为受到大型超市的挤压,不少便利店纷纷关门,在这种形式下,7–11 打算进入便利店市场,在当时来看,并不是一个明智的举动。
但是 7–11 的经营着铃木敏文通过「打破前定和谐」的方式,将便利店的「便利」与「三餐购物」结合起来,创造了便利店全新的业态,正是这一个创新举动,使得便利店整个行业的业绩触底回升,开启了「便利店的复兴」时代。
此后的经营中,7–11 做了大量的工作,将「便利」与「三餐购物」这一定位贯彻到底。比如开启便民送货服务、代客交水电费服务、便民 ATM 取款机等各种工作;同时开发大量的高品质便当、快餐、速食等等,这些工作成果让专家都惊叹:便利店竟然可以做到如此地步!
不仅如此,7–11 在新产品开发的原则上,也进行了「打破前定和谐」的思考。
企业主在开发产品时,通常会面临着一个「高品质」与「便利性」的权衡,到底是应该开发品质较低、面向与大众市场的产品,还是应该开发高品质、面向高收入人群的产品呢?
企业主在这两个选项中纠结的不知所措,但是却从来没有考虑过还有第三个选项:开发高品质、面向大众的产品。
第一种和第二种选项是大量企业中的思考方式,这也带来了在这两个选项中,有着大量的竞争,而第三种方式这是一个新的空白市场,对于顾客而言,这正好抓住了他们的潜在需求。
7–11 在第三种选项的指导下,不断的开发新产品,不断的带给消费者惊喜。靠着这些,7–11 甚至超过了星巴克,成了日本最大的咖啡零售商。
我们身边就有类似于 7–11 的一家企业:小米。
7–11 是传统的便利店吗?并不是,它什么都卖,甚至还开银行,在每个店里面装上了 ATM 机。那小米是一家手机制造公司吗?当然也不是,小米也什么都卖,电视机、净水机,路由器、充电宝,什么都有。
同样的,小米也遵循着和 7–11 同样的产品开发理念:开发高品质,面向大众的产品。7–11 便利店的关东煮、咖啡称霸日本,小米公司的充电宝、手环也是做到了**市场销量第一,而且和 7–11 一样,产品品质都远远超过了同类产品。
某种层面上讲,「开发面向大众的高品质产品」模式,正是现在我们一直在说的「消费升级」。
贯彻基本:始终站在消费者角度思考问题
像应对变化总会面临」思维定势「这个敌人一样,站在消费者角度思考,同样面临者一个巨大的敌人:为顾客着想。
有一个笑话,大家也许都听过:一对情侣晚上河边散步,清凉的风吹来,女生说:我有点冷。男生听到后,马上说:那我们跑步吧,跑一跑就不冷了。
这里的男生有什么问题呢?
也许在男生看来,的确没有问题,你说冷,那就跑一跑,这样就不冷了嘛。
但是其实男生是有问题的,问题出在了他是在用「为顾客考虑」在想问题,而不是「站在顾客角度」想问题,如果站在女生角度思考,就明白,女生自己知道怎么解决冷的问题,甚至可能她都不冷,她是在想要你给他关心。比如说抱一抱。
「为顾客考虑」和「站在顾客角度思考」看起来好像没什么区别,但实际上是两个完全不同的思考模式。一种是站在自己的立场,给企业要给消费者的产品,而第二种是站在消费者立场,给消费者自己要的产品。
企业开发产品如果陷入了「为顾客考虑」模式,就会有一大堆为顾客考虑的理由,比如要为了消费者安全、为了更方便的提供售后服务、为了保证产品稳定运行,等等等,但却没有考虑,消费者最简单的需求其实就是是使用这个产品,而这些考虑,全部变成了消费者使用这个产品的阻碍。
这两种模式最大的区别,就是前一种模式脱离了消费者,没有满足消费者真正的需求。
便利店在做促销的时候,经常有一种促销方法,比如买一送一、加量不加价等。但在当今日本,随着少子化情况的加剧,家庭人又在逐步降低,加量不加价已经不是消费者的真正需求了。商家一味的认为加量不加价是在为顾客考虑,多实惠啊。但是站在消费者角度:这是企业强加给我的实惠,我家里人又不多,根本不需要一次买这么多量。
现在的**,同样面临这样的问题。消费者不缺企业促销赠送的东西,但想着反正是送的,也许就接受了。这种促销,能达到企业预想的效果吗?
「为顾客考虑」,根本上是卖方优先的思考模式「以顾客的角度思考问题」,是将顾客的需求放在第一位,以满足顾客的需求为目的。但如果是「为顾客考虑」,其实说的是「企业在为顾客考虑」,企业是站在自己的立场上,去满足消费者需求。
前面有说,7–11 通过「打破前定和谐」的方式将自己定位为「便利+三餐购物」的新型便利店,也为此做了很多努力。其中有一项努力,就恰好说明了「为顾客考虑」和「以顾客的角度思考问题」两种模式下企业做事的不同。
7–11 曾经开发过一款「红小豆糯米」的饭团,在这款产品上市前的品尝会上,董事们发现,这个饭团并没有迟到平常的香糯又感。
于是铃木敏文叫出负责人,问怎么回事。原来传统的「红小豆糯米饭团」中的糯米是蒸出来的,但是 7–11 的工厂中没有蒸红豆的器具,便用了煮的方式。同时负责人表示,他们在煮红豆的水量、温度、时间、压力、火候上做了大量的实验工作,现在的又感,已经是最接近蒸出来的红豆的结果了。
这位负责人其实就是站在「为顾客考虑」的角度在思考问题。尽管他实验了各种方法,做出来最好的又感,但是却没有以「站在消费者的角度思考」的方式想问题。因为当消费者吃到这个「红小豆糯米」时,只有一个感觉:不好吃。
消费者可不会管你到底付出了多少努力。
铃木敏文当即要求负责人,「红小豆糯米」必须用蒸的方式制作,同时为分散在全国各地的加工厂都配备了专用于「红小豆糯米」的新设备,这些投资不是小数目,但是站在消费者角度考虑,却也是很值得。
只需要「站在消费者角度考虑」,不需要考虑竞争对手有人说,要取得市场,光「站在消费者角度思考」是不行的,还要观察竞争对手,把竞争对手打败才行。
铃木敏文认为:与其关注横向的同行,不如一心一意的面对消费者需求,真正的竞争对手恰恰是瞬息万变的消费者需求。
同时铃木敏文也提到了一个「跨界打劫」的概念。即使把竞争对手都打败了也没有,也许突然一天,你就会被某个不相关的行业颠覆。拿报纸举例,也许你把其他的报纸都打败了,但是突然一天,智能手机把你整个行业掀翻了。
在这种情况下,就需要重新建立「以消费者为出发点,思考新事业连锁」的概念。所以,报纸业也需要去开发手机 APP,哪怕将来你的报纸一张也卖不出去了,你要你能在手机上满足消费者看新闻的需求,你一样能好好活着。
同样的你可以发现,小米正是遵循者这一概念,以消费者为出发点,建立了围绕着手机电子产品的事业连锁。
如何站在消费者角度思考问题?
说了这么多,该怎么站在消费者角度思考问题呢?
这个问题的答案十分的简单:每个人自己都是消费者,多观察自己就可以了。
如果你是一个产品的生产者,想一想当你走到超市的时候,你是如何选择别家的产品的呢?可能你会发现一些显而易见不符合消费者需求的产品,甚至你都会想,难道这些产品的生产者就不会站在消费者角度想一想、亲自用一用这些产品吗?
其实别人用你生产的产品,何尝又没有这样的想法呢。
可以尝试观察自己,把头脑恢复成空白模式,自己就是消费者,重新审查你眼前的产品,这样就能站在消费者角度考虑了。
via 少数派 - 高品质数字消费指南
September 26, 2018 at 12:04AM
将知识种进脑子像读教材那样读书
将知识种进脑子——像读教材那样读书
https://ift.tt/2Oq61DA
哪里来的小熊猫
本文是「少数派读书笔记征文活动」的第 5 篇入围作品。
文章仅代表作者本人观点,少数派仅对标题和排版略作调整。
读书,常常是书读一遍,过后脑子却空白一片。旁人问起感受,只能以不错、很好作答。更有甚者,有时翻阅豆瓣才发现一本书竟早已「读过」,这事儿可真叫尴尬。为了对付这症状,我笔记也做过,思维导图也画过,奈何只是把书中内容摘进印象笔记,它们还是没种在我脑子里。旁人叫我简单讲讲,我兴许能说出个一二三四,但往往乱而无章,甚至是篡改作者原意,到头来讲的都是自己的粗浅理解。
这不是自欺欺人吗?
读书绝不仅是做笔记的事。就像当年在学校,学神也往往不是笔记做得最勤快的。如何尽快消化所学并善加运用,才是核心所在。泛言之,所有知识向(叫功利向也可)的阅读,都应该抱住这个鹄的,并且心中至少常系两条问题:
- 这事儿的本质是什么?
- 它的知识结构是怎样的?
从我最近的阅读体会讲讲。
阅读强度
最近是在啃书,但啃的是教材。年底要考 CFA,我又没什么金融基础,所以这条路走得比较艰辛。六月看完一本会计,七月看完数理方法,每周花在上边的时间大概八小时。多不算多,但极耗脑力,小说我大可以没日没夜地读,但读教材,往往两三小时便使我脑子停转,一段时间里,不想再做任何事。
阅读效果却十分显著。这种高强度的阅读迅速在我脑海里搭建出金融框架,而且在生成框架的同时,许多过往的行为方式已被优化。举例而言,学完会计里「库存」一章,我便开始着手调整自己的书影音管理。过去的库存积压得多,过上一年都未必消化,而不消化,就不产生收益。联系上会计的上下文,你要不抓紧消化库存(卖出),要不就「勾销」(直接删除),至少要「调低账面价值」(并入「真的不想读啊」文件夹)。单纯放在那里,没有用。
这样的阅读使我感到自己真在吃进信息,并不断将它们化为己用。换言之,我能感到自己正在生长出一重经济、金融的视角。那它们的本质是什么?在我看,金融即是讲收益与风险如何平衡,到经济,则是讲供与求这组关系。那结构是什么?CFA 的教案已写得相当清楚,除了会计、数理,还有就是公司金融、股与债、衍生品、多元投资、道德等等,通过五六本书的合力,金融的世界得到了恰如其分的描绘。
这种感觉,宛如看见一个新世界徐徐铺展在你眼前。而这,才是我的阅读目的。
不管是书、影、音还是与人辩论、请教,都是使我接近真实的方式。我越接近真实,我就越能做对决策。当然这种过程很累、非常累,我想任何经历过司法考试、注册会计考试等的人都有体会,这与读闲书不同,与泛读也不同,这是精读、是高强度的阅读。在过程中,你会不止一次地感觉到头脑耗尽。你想放弃。
所以在开启这样的阅读以前,请务必找准自己的热情。我是真的想要理解经济金融世界的运行,才会心甘情愿地承受这样的阅读强度,以及随之而来的煎熬与痛苦。不然,我当然更是想继续抱着我的《倚天屠龙记》读了,多美好啊,左拥右抱,四女同舟何所望。
 这张图很羞耻,很乱,也很贪心,但还是放上来,为说明我热情的来由
这张图很羞耻,很乱,也很贪心,但还是放上来,为说明我热情的来由但如果你也愿意尝试这样高强度的阅读,那我愿意继续分享一点我的心得与体会给你。
必须试错
想要真正学点东西,读书就不能停留在信手翻阅的程度。仅做摘录也不够,因为你不知道自己是否理解正确,也很难将书上的道理与现实情况相关联。于是读到的很多道理就成了空中楼阁,然后被人批评作:鸡汤。
但书上写的和现实里运行的,中间就是有着一道深深的鸿沟哇。譬如最近学蛙泳,颠来倒去其实就那几个动作,教练反反复复就那几句话:身体放松、双腿打开、脚腕锁住、并腿排水,但我就是做不到啊。我知道蛙泳的道理还背得滚瓜烂熟,但就是游不动,又呛水。
好在我有教练。教练不仅示范给我看,还手把手帮我矫正动作。我终于慢慢知道该如何做。
那阅读中的教练在哪里?把书中的道理,如何化为实践?在题目里。这同样是别人给我的反馈。
教材的优势,就在于它常配有习题。而习题的本质,就是告诉你哪里理解错了,必须重新来过。一遍遍地刷习题,就是使思维自洽的过程。
这个过程相当痛苦。今年早些时候学写代码,有时明明觉得逻辑没错,测试却总跑不对,简直抓狂。但每当当我苦想、查 Stack Overflow、问码农,终于抓住 bug 后,那一瞬脑袋里仿若绽开烟花,一扇新的窗户从此推开。并且我深深知道,这个位置我再也不会犯错了。
从编程到金融,这点**得以继承:做题不仅不是畏途,相反,这是必备过程,且往往比单纯阅读更行之有效。因为它更主动。读书有时还会读着走神,小说翻过两三页,才发现一字都没读进脑袋。但做题则要求我必须思考。而这正是痛苦所在。但它值得。
如果说什么时候知识最能种进我的脑海,那就是在这样不断试错的过程里。我能够做对这件事,是因为可能出现的很多其他错误,我都犯过。比如在 Python 里把 while 的首字母 w 大写:)
假设你同意我的结论,把做题放入阅读的重要一环。那现在,你又会遇到问题。问题是,不是所有好书,都配有习题。那我该如何校验自己的思考,确保我能领会到作者原意,并且尽可能地能将书中的道理,拖入实践当中?
简单,和懂的人交流。
接纳反驳
别人的反驳就是我的良药。这和做题一样,可以迅速帮我纠正思维中的偏误。只是这更不舒服。每个人心底都有「ego」,总觉得自己才是对的,遇到批评,总想反驳。我明明知道这是「我执」,要放下,奈何这过程简直剜心。
举个例子。我是文科生,最近学 CFA 中的数理,每每觉得自己遇上了新概念。正态分布、自由度、假设检验、贝叶斯公式,这些东西我都想与学统计、数学的俩室友讨论。问题是这些东西我觉得新鲜,他们却觉得再入门不过,偏偏理工男又都直白,于是我连续被吊打了一个月:
- 「这你都不会。」
- 「不是积个分就有了吗?」
- 「Stochastic 怎么都不认识?」
这一个月,我自以为的高中数学基础,一路被他们说到了小学水平。好在他们嘴巴毒心却软,一句刻薄话过后,往往会长篇累牍加以解释,往往点中关窍,胜我摸黑走路一整晚。不过尽管我很感谢他们,却也在默默等待时机,期待将来谈到文史哲,我能抛出一句:
「Mesopotamia 怎么都不认识?」
总而言之,读书这事虽然静,虽然很可以一个人做,但尽量不要单打独斗。读书的本质是接受作者单方向的灌输,然而听着听着,你心底总有问题想问,又或在潜意识里形成理解偏误。这时,有题做题,有人问人,而这些都是消化书里内容的必由之路。
全面铺开
上文的读书思路主要是关于说理书,而不是故事书;读的是议论文,而不是记叙文。目的在于掌握某一块的知识。往小了说,是一项技巧;往中间说是技能;往大说则是形成一项思维方式。
若想形成思维方式,那就更不是读一本书便够的事。你得比较着读、铺开来读。同一门类下的许多本书,许多个作者,互相间都在交叉印证。这点我也是刚刚开始,只能简单分享。
 近年想要进行的专题阅读
近年想要进行的专题阅读如上图,我现在的兴趣围绕在经济金融、人际关系、神经科学与计算机科学上。但编程主要靠练不靠读,人际靠的也是多见、多说,而不是多读、多写。所以我将阅读重点放在另外两项。而这里我想说的是,当将阅读具体到某一专题,便请不要再被信息的「传播介质」所影响,换言之,当你想搞明白什么,不必把信息来源局限于书。
如我学CFA,主教材自然是课本,但除了读书做题,我还在「得到」上订阅了「香帅的北大金融课」,从另一角度构建金融世界观。对会计,则打算另读《手把手教你读财报》,看看如何分析现实中茅台财报;数理,尤其是统计,则观看 YouTube上的 jbstatistics 加以辅助,原因无他,作为金融课里讲的数理实在太浅,没头没尾地抛个公式,然后叫你记住,叫人恼火。比较有意思的是学公司金融一章,我在看《公司的力量》这部纪录片,和《大国崛起》是同班制作人马。
这些东西都是我自己找来读的、看的、听的。我非常高兴,它们之间互有补充,交叉印证,大大强化了我的理解。再举例,仅是 YouTube 上 IFT 提供的章节视频解读,就已经帮到我太多,要知教材往往一章便是三四十页的英文,看久了真让人吐血,那先听几段老师的讲解,至少我能在截图的闲暇中吃两根香蕉一颗橙,补一补消耗的脑力。
再者,我最近见人都有意无意地与之相关,比如你找交易员同学见一面,问一问涡轮(Warrants)到底怎样发、怎样做、赚钱的模型是怎样的,很多就很清楚了,同时清楚的,还有课本与实际间到底存在多少出入。
总而言之,我最后是要搞明白问题,是要对某一块形成真实的理解,这才是最终的目的,而不是具体读完某一本书。大言不惭地讲,书也都是人写的,只是暂时他们掌握的信息量远远高过我。我总是在提醒自己,只要握住求知这个最终目的,那手段尽可以丰富多彩。
无非是搞明白这件事而已。
 学习 CFA 的框架图
学习 CFA 的框架图一点废话
老实说,很多场景下我觉得读书未必是最好的方式。从根本上讲,有的人擅长看文字,也有的人擅长听语音、记动作。我擅长阅读,不擅长记动作,所以游泳学得艰难,读书却可以很投入。凡事想着充分发挥所长,才是高效的路。比如听觉思维的人,就该多听少看。另外,因技术进步而引入的新鲜路径,则是人人都应当把握的好处,这是时代带给我们的红利。
比如利用「扇贝」,我已背了一万五千单词;比如在 edX 上我进行了 Python 入门,非常喜欢,最后还买了证书,当作给挚爱的老师刷了大火箭。再有我正给自己建立归档及检索系统,很多东西从此毋需过多记忆。博闻强识是上个时代的优点,现在既然印象笔记随身携带,还记那么多做什么?观其大略即可,最要紧的是记逻辑关系。
而这正是开篇我提出的那两条:
- 这事儿的本质是什么?
- 它的知识结构是怎样的?
只有当我时刻保有这样的问题意识,才不会迷失在「要抓紧读完,快点快点,还剩几页」里。我才能够承受痛苦,不断头疼着思考,直到收获破晓般的领悟。
再多讲一点废话,读书读书,关键还是你到底想在书里找什么。过去我读网文,找的实际上是「扮猪吃老虎」、是「妻妾成群」,以填补现实中的虚空。现在回顾,当时的我好可怜。因为幻觉永远是幻觉,我只会越来越沉浸在假象里,与现实中的斑斓多姿只会越隔越远。而现在,即使我念兹在兹的还是窈窕淑女,却再也不是从种马文中寻觅了。我找的是穿衣打扮、健身护肤、谈吐举止,以及其他一切现实可行的种种。
长久看,这注定是一条痛苦的路。《闻香识女人》里的一句台词代表了我曾经的选择:如今我走到人生十字路口,我知道哪条路是对的,毫无例外,我就知道,但我从不走,为什么?因为妈的太苦了。然而现在,我终于逐渐在理解《少有人走的路》里的这几句:
I shall be telling this with a sigh
Somewhere ages and ages hence:
Two roads diverged in a wood, and I--
I took the one less traveled by,
And that has made all the difference.
希望大家都能够变得更好,既能够在书海里遨游,也能在现实里驰骋。本来还有挺多想要分享,但这篇文已经写得太长,资不赘述。
via 少数派 - 高品质数字消费指南
September 26, 2018 at 12:04AM
看书十倍速速读真的这么神奇雪球速读法读书笔记
看书十倍速?速读真的这么神奇?——《雪球速读法》读书笔记
https://ift.tt/2LiziCk
陈宇浩
本文是「少数派读书笔记征文活动」的第 1 篇入围作品,参与本次征文,将有机会赢取 Kindle Oasis 等丰厚奖品,你可以 点此查看 活动规则和奖品清单。
本文仅代表作者本人观点,少数派仅对标题和排版略作调整。
人们常说「书中自有黄金屋」,加之各种资讯都告诉我们要多读书,各种书单也层出不穷,但真正的大量阅读好像并不是那么容易。不知你有没有如下问题:
-
读得慢:读书有时候特别慢,可能花一下午认真地看书也才看了不到1/4;或者读书卡到一般,中途读不下去,又搁置了很久,导致书没有读完。
-
读不透:书硬着头皮读完了,感觉收获很多,但到需要用的时候或者向别人介绍的时候又不能想出清晰的思路。
-
读不多:想要读的书买了很多,但无奈很少有时间或看的太慢,导致书都在堆着。
如果你都不幸中招了,恭喜你,这本书就是为解决这些问题而来。这本书虽然名字非常的功利,长得就像一本畅销书,但绝不是简单地罗列速读的技术列表让你去执行,而是介绍了一种全新的阅读**。或者说,书中所说的「速读」,和你想象的速读完全不一样。
本文主要介绍雪球速读法,在介绍一些原理后解决「读得慢」的问题。接下来,我会结合书里一些**和我本人的经验,解决「读不透」和「读不多」的问题。
 《雪球速读法》
《雪球速读法》
我们到底在速读什么
引用书中的例子,我们先来看一句话,请快速的扫一眼:
事者竟志有成
是不是一秒钟就知道是什么意思,但细心的你有没有发现这句话顺序全是乱的呢,甚至本来第一个字都挪到了第五个字,我们还是能轻松地看出来。你可能会想,我早就知道啦,中文母语者可以看快速看懂打乱顺序的句子,那请你看看接下来的句子,请快速的扫一眼
产无者心恒无恒1
阖之寸制开五之键门2
吹于齑羹者而惩3
你可能会说,这是什么鬼?其实这也是打乱顺序的句子,只不过我们看不出来是因为:我们缺少了关于这些句子的「杂学资料库」,也就是相关的知识、资讯、经验等。对于「有志者事竟成」,我们可能小学就知道了,然后在人生中不断的看见、朗读,在积累关于这个句子的杂学资料库,所以无论这六个字怎么看,只用扫一眼就「速读」完成了。所以说,我们能够扫一眼就看出打乱的句子,并不是因为我们真的有这种能力,而是我们具备与之相关的资料库,才能一看就懂。我们读书或者速读,都是在讲所看内容与资料库相匹配,然后生成化学反应。
在《雪球速读法》这本书中,作者提出了一个核心公式:
速读能力 = 速读技巧 × 杂学资料库(知识、资讯、经验等)
如果你读一本书,没有与之相关的资料库,哪怕你学习了那种「一目十行」、「不在内心里读出来」的速读技巧,碰到上面的三句古语,你的阅读速度照样上不去;相反,如果你已经积累了资料库,只要很简单的传统速读技巧(如看书不在内心读出来),读书速读都会大大增加。
解决「读得慢」—— 雪球速读法
在书中,作者从两大原则入手,介绍了什么是雪球速读法,而后提供了一种可操作的执行方案。
雪球速读法两大原则
在正式介绍雪球速读法之前,先让我们看看作者推出雪球速读法的两大原则:
一、读的快,更容易理解内容
这里的读的快,不是说那种一定要几秒看完一页的快,而是说不要把看一本书的周期拉的太长。很多人(包括我自己)都可能有这种经历,用一周或者一个月看一本书,每次只看了一点点,到看到最后一章节的时候已经记不清前面在讲什么了,因为周期拉的太长。这里的快讲求的是一个整体性,用一天两天快速看完,反而可能能记住大部分而能回忆出整本书的整体结构,以至于更容易理解内容。若周期拉的太长,每天只深入一小节,有可能会陷入「见木不见林」的陷阱里。
二、第二次读的时候,会比第一次读的更快
这条原则看上去符合直觉多了。作为学生,复习考试的时候可能更能体会到这点,复习的时候基本都是第二次看书,看的肯定比第一次快很多,因为基本的知识点已经知晓,只用再温习一下并将知识结构串起来,所以可能原来花几小时学的书本内容再画花半个小时就能再看一遍。其实这也反映了资料库的重要性,当我们已经学过书本内容时,就已经积累好了资料库,当我们再看书时,自然就会看的很快。
滚雪球 = 高速 × 大量循环
我们终于要将雪球滚起来了,其实雪球速读法的核心**就是:
利用极短的时间快速「看」完一本书,积累这本书的杂学资料库,然后再重复阅读一遍,这样又在短时间内积累了更多资料,然后再重复阅读,周而复始。
作者将这里的「看」定义为:「阅读时不转换成声音」,「阅读时不求甚解」。「阅读时不转换成声音」的意思是不要将文字在心里默念出来,而是单纯用眼睛去读,比如打乱的「有志者事竟成」你是不会一个字一个字念的;「阅读时不求甚解」的意思是不要费力地去理解每一句话的意思,而是带着轻松的心情去扫读。
怎么样,是不是跟我们想像中的速读不太一样,我们可能一直以为速读就是那种想扫描仪那样几秒翻一页,然后浏览书籍达到过目不忘。其实这种阅读方式可能和我们传统阅读方式也不太一样,至少对我来说,我原来认为应该尽力按顺序读懂书中的每一个章节。但《雪球速读法》倡导的是,第一遍根本不用去完全看懂,只要快速浏览完掌握基本的关于本书的资料库就好,因为没关系我们还会阅读第二遍,第三遍,且遍数越多,阅读会越快而且理解的更好。
其实作者也借鉴了传统速读法的招式,比如只用眼睛而不要默念。但我觉得更新颖的是作者打破了我原有的「看书就要一次读懂、读明白」的固有观念。在固有观念里,因为一般只会读一遍,所以要逐字细读,力求每个都搞懂了再去读下一章,所以在固有观念里,「阅读时不求甚解」是荒谬的,这也导致我们不太可能一目十行快速扫完全书,所以阅读速度不会太快。但正是在「雪球速读法」这种观念下,正是因为我们放下了「一定要一次读懂」的执念,我们才有可能做到不卡在某一章节上、不去放缓阅读速度来理解,因为我们知道在第二遍读时会理解的更好。
利用这种**,我们便可以在每次看书时都能快速阅读而没有心理负担,然后因为第一次读的快,便能进行第二次,又因为读过一次了所以第二次更快,在这种复利效应中,我们的雪球就滚起来了。这也是「雪球速读法」名字的由来。
 高速与大量循环的滚雪球模式
高速与大量循环的滚雪球模式上图也比较好地诠释了为什么高速 × 大量循环是一种滚雪球的方式。
相比之下,我以前的读书方式可能是低速 × 少量循环:因为想要全部理解便要慢慢读,如果卡在了某一个地方上,因为第一次读也没有积累杂学资料库,便读的更慢,读的慢就没时间读第二遍,然后没有书中相关的知识信息就读的更慢,就造成了一个恶性循环。这点在阅读自己不熟悉领域上的书中体现的尤为严重。
雪球速读法的具体技巧:三十分钟看一本书
书中提供了一种能够具体操作的技巧:
- 在 2-3 分钟内把目录反复看十遍;
- 在 5-6 分钟内把前言和后记反复看 5 遍以上;
- 在 5-6 分钟内像看报纸一样浏览全书文本,基本只看标题 经过以上三步,其实你在 15 分钟内就把全书浏览了一遍,且其实能够说出基本大纲;
- 在剩下的 15 分钟内反复看文本,逐步扩大阅读范围,比如第二次只阅读标题+副标题+感兴趣的部分,再接着重复「高速大量循环」。
解决「读不透」—— 到底怎样才算读过一本书
有人可能会觉得读得快以后会不会反而「读不透」书,速读一本书不算是很正式的读过一本书。书中关于「怎样才算读过一本书」给出了自己的观点,来证明或许使用雪球速读法更能算是「读过一本书」。同时我也会结合个人的经验谈谈我自己的理解。
书中解答
书中这样写道:
然而齊藤孝先生在《閱讀力》這本書中寫道:“要能夠‘闡述內容大綱’,才算是讀完一本書”。一這種方式定義“讀完”,較容易被大多數人接受。
所以说,当我们花很长读完一本书时,我们可能真的觉得书讲的很好,道理都很对,但是具体哪些章节好、哪些观点统领了全书,已然因为阅读周期太长而想不起来了。相比之下,「雪球速读法」能让我们短时间内把握全书架构,再深入理解每一个细节,这样回想起来,能准确的定位每一个观点,从而更好的把控全书。
个人经验:到底怎样才算旅游了一次?
我高三暑假去土耳其旅游和大二暑假去日本旅游的经历之间的对比,可能真的很像传统阅读法与雪球速读法之间的对比。去土耳其那次是我小姨全程当导游的,所以从机票到目的地我都不用担心,只要跟着她玩就好了,十几天玩下来真的非常开心。但我玩完回来就发现,尽管我们从土耳其东边一路开车到西边,经历了好多个城市,我并不能完全回想起整个路线图,城市名字我就能记得个伊斯坦布尔和卡帕多西亚(事实上卡帕多西亚还是之前我去看《花儿与少年》看到过才印象比较深)。虽然玩的非常开心我也能记住有趣景点和片段,但整个记忆是零散的,一直把景点和地方都对不上,一直都不知道棉花堡具体在哪里。
等到大二暑假去日本的时候,因为自由行带着妈妈去玩,从签证到规划路线都是我一个人完成的,所以在去之前就知道基本路线是怎么样,哪个景点在哪个城市,京都离大阪有多远。而在玩的过程中,又一次加深了这种印象,然后回来整理照片又相当于将整个行程又过了一次,所以过了一年多我也能清晰地讲出我们第几天在哪个城市,去了哪些景点。
其实这两次经历特别像传统阅读方法 vs 雪球速读法,也像是线性 vs 结构俯瞰。在线性阅读中,我们跟着书本的逻辑走,可能会深刻体味到作者的**,但有时只读一遍便很容易陷入「见木不见林」的陷阱中,然后想着读一遍都这么累了,还是不要读第二遍了吧,于是根本不能整体把控这本书,要阐述大纲也阐述不出来。而雪球速读法更像是结构化地俯瞰这本书,第一遍只求看出大概结构,后面就可以深入了解每一块的内容,内容的串联也会非常紧密。当要阐述大纲时,很容易就阐述出来了。
解决「读不多」—— 怎样看待未读的书
解决了「读得慢」和「读不透」的问题后,也许有人还有「读不多」的问题:自己想看的书太多了,纵使读得很快也赶不上买书剁手的速度。对于这点,在书中作者提出了一种方法:积读法。其实原来我也是囤积了很多书但没读几本的人,但现在我慢慢地改正了这点,而我觉得最重要的是:放下读书的执念。
积读法
这是书中一种推荐的方法,用于读掉自己买了但一直未读的书。
积读法是指将书堆在自己的面前,对,就那样堆着,然后利用零碎的时间来快速扫过标题,像积累资料库那样看过书名。时间长了以后,就像速读那样对此产生一种熟悉感,就会有兴趣阅读它,只翻过几页没有关系,再放回去堆着并继续利用空闲时间看它的书名,久而久之就会更容易读完书。对于这种方法我还抱有疑问的态度。我猜背后的逻辑一是和书产生亲近感;二是把书堆着总会比看不见它更容易读完,因为至少你每天看着书名就会产生兴趣。关于积读法有兴趣的读者可以深入本书并看看自己的理解。
虽然对积读法这种方法本身有一定疑问,但我对其**还是持赞同态度的,其实就是和书产生亲近感,我觉得更重要的是放下本身的执念。
放下读书的执念
我原来觉得,读书是这么一种活动:一定要在一个风和日丽的下午,坐在一个咖啡馆的窗边,心情是无忧无虑的,精神是充沛的,然后选一本有趣的书,一口气读完,在黄昏中合上最后一页。然而……大学三年过去了,我从没有找到这么一个下午。要么是天气不太好、要么是比较忙碌,要么是书刚读了几页感觉意思不大,总之有各种各样的借口搁浅读书计划。后来我觉得是把读书想的太神圣了,觉得一定要全身心地投入看书而不被打扰,但是这种「黄金时间」,很难找出来,一旦被中断,便觉得特别的丧气,下次就不想读书了,便进入了一个恶性循环。以前读书还必须旁边放一个本子记录每章节的纲要,所以速度也是惨不忍睹。
但自从我放下了这种执念后,有点进入像「不太求甚解」的状态,反而在最近一个月里看了大概十本书:我在高铁上看完了《断舍离》,又在飞机上看完了《雪球速读法》,在实习接送的大巴车上看完了《智能时代》。当我开始允许环境有点嘈杂、允许被中断、允许精神状态不是最佳后,我不再把看书当做一种神圣且沉重的任务,通过这样一种状态,我看完了更多的书;相比之前,说不定我还留有时间再看一遍。这种状态总比买了好多书不看要强太多了吧。
借用《断舍离》把物品当拟人化的比喻,我也想将书比喻为人。那些买来却放着不读的书就像一位位我们仰慕已久的人物,我们总在找一个「黄金时间」与之问候,着装要好、时间要刚合适、问候语不能太差,可是在生活中,我们总找不到这样的时间。纵使那位人物再**深邃,我们也只能远观而不得交谈。所以最重要的不是等那一个时机,而是主动上前握手问候。更何况书籍是这样一位朋友,只要你上前握手,他必定欣然接受,然后对你倾囊相授。
后记 —— 为什么买《雪球速读法》
《雪球速读法》其实是一本**出版的书,原书是日本作者,**译版,也就是说书中基本都是繁体字、竖排印,而且它是从右往左翻的。
在**做交换生的时候,偶然在学校的一个讲座上听说「囧星人」这个 YouTuber,似乎在 YouTube 上很火。然后就搜索了一下这个频道随便看看,由于「看书十倍速」这个标题实在是非常的标题党,就点进去看了看顺便买了下来,因为我觉得对于看书来讲,可能学会怎么看书会更加重要。比较有趣的是,这个频道同样推荐了 Hum 推荐过的书:哪些书该读?哪些地方该划线?《一流的人讀書,都在哪裡畫線?》读书笔记。有兴趣的读者可以在 YouTube 上搜索「囧星人」了解一下。
鉴于《雪球速读法》是**出版,国内书店可能不太好买,不过我查了一下淘宝上似乎都能买到。本文写的简单,想真正了解这种速读方法的读者还是买一本书自己阅读。书不太厚,而且**排版每页字也少,不难阅读,也许你看完本文,通过所介绍的简单的「雪球速读法」读《雪球速读法》呢,算是一种奇妙的体验吧。
最后,希望《雪球速读法》这本书能够解决你「读得慢」、「读不透」、「读不多」的问题,让你更轻松地读完自己想要读的书。
via 少数派 - 高品质数字消费指南
September 25, 2018 at 11:59PM
C11多线程编程(2) - Chen Yuan's Blog
C++11多线程编程(2) - Chen Yuan's Blog
https://ift.tt/2zrz3y3
目录
- 多线程创建和参数传递
- 多线程条件竞争及其解决方法
- 多线程事件处理、条件变量
- 多线程返回值
- 线程池
3.1 多线程事件处理
在第1部分中对多线程的创建、参数传递的使用作了说明,另外对线程间数据共享导致竞争条件异常进行了分析,并给出互斥锁的解决方式。我继续参考thisPointer的教程,深入多线程的事件处理。
什么是多线程的事件处理?有时候,线程往往需要等待类似于条件为真或另一个线程任务完成的事件,这就是多线程的事件处理。先来看一个程序需求。
3.1.1 功能分析
现在我们需要实现一个网络编程的客户端程序,这个程序的任务如下:
- 连接服务器
- 从XML文件加载数据
- 发送加载的数据
分析易知任务1与其他两个任务是独立的,但任务3依赖于任务2。任务1和任务2可以设计在两个平行执行的线程上实现,从而提升程序的性能。
下面我们将使用多线程的方式设计客户端程序。这个程序包含两个线程,线程1需要完成的任务是:
- 连接服务器
- 等待线程2加载XML文件的数据
- 发送加载的数据
线程2需要完成的任务是:

3.1.2 方式1:共享变量
定义一个默认值为false的全局布尔变量isDataLoaded,在Thread 2中设置为真,Thread 1中轮询该布尔变量是否为true,若为true则执行发送数据。显然,需要一个互斥锁来保证isDataLoaded的同步。
#include<iostream>
#include<thread>
#include<mutex>
class Application
{
std::mutex m_mutex;
bool m_bDataLoaded;
public:
Application()
{
m_bDataLoaded = false;
}
void loadData()
{
// Make This Thread sleep for 1 Second
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
std::cout<<"Loading Data from XML"<<std::endl;
// Lock The Data structure
std::lock_guard<std::mutex> guard(m_mutex);
// Set the flag to true, means data is loaded
m_bDataLoaded = true;
}
void mainTask()
{
std::cout<<"Do Some Handshaking"<<std::endl;
// Acquire the Lock
m_mutex.lock();
// Check if flag is set to true or not
while(m_bDataLoaded != true)
{
// Release the lock
m_mutex.unlock();
//sleep for 100 milli seconds
std::this_thread::sleep_for(std::chrono::milliseconds(100));
// Acquire the lock
m_mutex.lock();
}
// Release the lock
m_mutex.unlock();
//Doc processing on loaded Data
std::cout<<"Do Processing On loaded Data"<<std::endl;
}
};
int main()
{
Application app;
std::thread thread_1(&Application::mainTask, &app);
std::thread thread_2(&Application::loadData, &app);
thread_2.join();
thread_1.join();
return 0;
}
方式1的实现存在一个很严重的问题就是Thread 1 在轮询isDataLoaded时需要占用CPU的资源。另外,程序功能越复杂时,需要共享的全局变量就可能越多,就越容易产生Bugs。最好的方式是Thread 2完成加载数据的任务后通知Thread 1,数据准备好了,可以发送了。那么这这么实现呢?
3.1.3 方式2:条件变量
头文件#include<condition_variable>
条件变量也是需要互斥变量来配合使用。
#include <iostream>
#include <thread>
#include <functional>
#include <mutex>
#include <condition_variable>
//using namespace std::placeholders;
class Application
{
std::mutex m_mutex;
std::condition_variable m_condVar;
bool m_bDataLoaded;
public:
Application()
{
m_bDataLoaded = false;
}
void loadData()
{
// Make This Thread sleep for 1 Second
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
std::cout<<"Loading Data from XML"<<std::endl;
// Lock The Data structure
std::lock_guard<std::mutex> guard(m_mutex);
// Set the flag to true, means data is loaded
m_bDataLoaded = true;
// Notify the condition variable
m_condVar.notify_one();
}
bool isDataLoaded()
{
return m_bDataLoaded;
}
void mainTask()
{
std::cout<<"Do Some Handshaking"<<std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(3000));
// Acquire the lock
std::unique_lock<std::mutex> mlock(m_mutex);
// Start waiting for the Condition Variable to get signaled
// Wait() will internally release the lock and make the thread to block
// As soon as condition variable get signaled, resume the thread and
// again acquire the lock. Then check if condition is met or not
// If condition is met then continue else again go in wait.
m_condVar.wait(mlock, std::bind(&Application::isDataLoaded, this));
std::cout<<"Do Processing On loaded Data"<<std::endl;
}
};
int main()
{
Application app;
std::thread thread_1(&Application::mainTask, &app);
std::thread thread_2(&Application::loadData, &app);
thread_2.join();
thread_1.join();
return 0;
}
4.1 多线程返回值std::future
在许多场景下,我们想从线程的处理中返回需要的值。接下来还是通过一个假设的场景来说明std::future的使用方法。
假设在我们的程序中,一个线程的任务是压缩指定文件夹,我们需要这个线程返回压缩后的文件名和文件大小。
我们先来看看按照前面教程的内容怎么来说实现它。
4.1.1 常规的方法:使用指针共享线程间数据
传递一个指针到任务线程,通过它来保存数据。主线程使用条件变量等待指针指向的值是否改变。当任务线程设置好数据好,主线程将会唤醒并从指针中获取到数据。这种常规的方法,我们需要使用的一个条件变量、一个互斥锁和一个指针变量。3个变量去一个获取线程返回值。若我们需要获取多个返回值呢?程序设计的复杂度越来越大了。有没有简单的方式?
4.1.2 C++11的方法:std::future和std::promise
std::future是一个模版类,它的实例用于保存”未来”值。换句话说,std::future的实例保存的值会在未来设置。另外,std::future提供了一个获取这个”未来”值的成员方法get()。若这个”未来”值还没有被设置,线程调用get()去获取值时将会被阻塞,直到这个值被设置了。
std::promise也是一个模版类,它的实例用于许诺说未来一定会设置一个”未来”值,它是与std::future的实例结合使用的。也即是说std::promise实例与结合的std::future实例共享数据。
下面一步一步来说明它们俩是如何结合使用的。
首先,在Thread 1创建一个std::promise实例
std::promise<int> promiseObj;
现在promiseObj没有设置好值,但它许诺将来别人会设置某个值,一旦设置完成,我们就可以通过关联std::future实例来获取到。
假设Thread 1传递这个promiseObj给Thread 2,那么Thread 1怎么知道Thread 2 设置好值了呢?
很简单,通过关联的std::future实例。每一个std::promise实例都有一个相关联的std::future实例。 在promiseObj传递给Thread 2之前时,保存std::future实例。
std::future<int> futureObj = promiseObj.get_future();
然后Thread 1就可以使用futureObj来获取Thread 2返回的值了。
int val = futureObj.get();
Thread 1会一直阻塞,直到Thread 2 设置了promiseObj的值。
promiseObj.set_value(45);

#include <iostream>
#include <thread>
#include <future>
void initiazer(std::promise<int> * promObj)
{
std::cout<<"Inside Thread"<<std::endl; promObj->set_value(35);
}
int main()
{
std::promise<int> promiseObj;
std::future<int> futureObj = promiseObj.get_future();
std::thread th(initiazer, &promiseObj);
std::cout<<futureObj.get()<<std::endl;
th.join();
return 0;
}
有一种情况是”promObj”在没有设置值之前就已经被销毁了,那么调用get()这个方法会抛出异常。
回到这一部分刚开始提出的问题,如果要从线程返回多个值怎么办。现在很简单就能解决了,你需要返回多少个值就传递多少个std::promise实例给其他线程。
参考资料
</div><br>
cpp,Concurrency
via dasheyuan.com http://dasheyuan.com
September 25, 2018 at 06:10PM
GitHub上删不掉的issues - Chen Yuan's Blog
GitHub上删不掉的issues - Chen Yuan's Blog
https://ift.tt/2O8C92g
小结一下GitHub上的issues功能,很有意思。
今天发现Yikun的博客中的图床地址很特别:cloud.githubusercontent.com。探究了一番之后发现他是用GitHub的issues的功能来写的博客,图片可以直接拖拽到issues的编辑框中,然后自动上传github的服务器,生成图床地址的。
测试issues中上传图片的功能之后想删除测试的issue,但发现是删不掉的!!!如同版本提交commits,也是删不掉的。另外,对应issues的每一个操作都会记录下来。
这样的设计应该是有原因的,现在想不明白,以后再探究吧。
今天也大概了解了一下GitHub的API,也挺好玩的。
issues的属性
GitHub中每一个仓库都会有对应的一个issues的功能,issues中可以新建多个issue,每一个issue就像一篇文章,有标题和内容,还有评论。另外,每个issue都有唯一的编号“#n”。
issue可以设置:Opened和Closed两种状态。
issue 还可以有额外的属性:
Labels,标签。包括bug、invalid等,可以自定义。表示issue的类型,解决的方式。
Milestone,里程碑。通常用来做版本管理,v0.1、v1.0之类的,也可以是任意自定义字符串。一个里程碑对应的所有 issue 都被关闭后,这个里程碑会被自动认为已经达成。
Assignee,责任人。指定这个issue由谁负责来解决。
个人如何利用issues的功能?
GitHub 的issue功能,对个人而言,就如同 TODO list。
可以把所有想要在下一步完成的工作,如 feature 添加、bug 修复等,都写成一个个的 issue ,放在上面。既可以作为提醒,也可以统一管理。
另外,每一次 commit 都可以选择性的与某个 issue 关联。比如在 message 中添加 #n,就可以与第 n 个 issue 进行关联。
commit message title, #1
这个提交会作为一个 comment ,出现在编号为1的 issue 记录中。
如果添加:
- fix #n
- fixes #n
- fixed #n
- close #n
- closes #n
- closed #n
比如
commit message title, fix #n
则可以自动关闭第 n 个 issue,即issue的状态从Opened变成了Closed。
充分利用这些功能,让每一个 commit 的意义更加明确,可以起到了良好的过程管理作用,使得这个Git库的项目进度更加显然。而且,这也是项目后期,写文档的绝佳素材。
团队如何利用issues的功能?
对团队而言,这就是一个协作系统。
现在,很多大公司的软件研发团队协作,都是通过JIRA来实现的。
目前也流行很多非代码的团队协作,比如teambition、Tower.im、Worktile、trello等。
其实,GitHub 的issues,就是一个轻量级协作系统。它的comment支持 GitHub Flavored Markdown,可以进行内容丰富的交流。
Git本身就是分布式的代码版本控制软件,是为了程序员的协作而设计的。而 issues 的 Assignee 功能,就是这个在线协作系统的核心,足以让一群线上的开发者,一起完成一个软件项目。
最后,作为一个路人,也可以通过 issues 给别人的项目提 bug。
参考
</div><br>
via dasheyuan.com http://dasheyuan.com
September 25, 2018 at 08:33PM
Mirror - 基于 issues 的博客工具
Mirror - 基于 issues 的博客工具
https://ift.tt/2xRi0n0
Mirror 是一个简单的博客工具,基于 GitHub API 获取 issues 数据,然后展示在页面上。
该工具的方便之处在于只需要在 issue 上写你的博客文章,你的网站会自动更新博客内容。
借助 GitHub,你可以轻松的用 markdown 书写你的博客内容,永久保存,不用担心数据丢失问题。还可以非常方便上传博客图片,拖入编辑器即可。
该博客工具非常适合以 issue 作为自己博客的用户,无痛生成博客网站,对原来内容毫无影响
Mirror 还支持多用户协作,你可以方便的设置哪些用户写的内容可以显示在博客网站上,避免无关内容
Mirror 在移动端同时有很好的浏览体验
预览地址
项目地址
https://github.com/LoeiFy/Mirror
新版本使用 GitHub GraphQL API
REST API 版本:https://github.com/LoeiFy/Mirror/tree/rest-api
Demo:http://mirror.am0200.com/rest-api/
更详细的介绍可以看项目说明
如何安装
安装很简单,需要一个 nodejs 环境,一个简单的命令即可,如果没有 nodejs 环境,可以直接下载资源包自己配置,后面会有说明
1
$ sudo npm install Mirror -g
使用
新建
1
2
$ cd newblog
$ mirror init
或者
完成后你的 blog 就在 newblog 这里
配置你的 blog
首先需要获取你的 access token,这个 token 只要只读权限
https://github.com/settings/tokens
只需要勾选两个选择,其他不要勾选
- read:user Read all user profile data
- user:email Access user email addresses (read-only)
修改 config.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 标题
title: Mirror
# github 用户名
user: LoeiFy
# blog 内容来源 repo
repo: Recordum
# 多用户,设定哪些用户写的 issue 内容可以展示出来,项目的用户名会自动包括进来
# 多个用户用逗号(英文逗号)隔开,例如:user0,user1
authors:
# token
# token 需要用 `#` 符号分割
# 例子: 5#c31bffc137f44faf7efc4a84da827g7ca2cfeaa
token:
# 分页
per_page: 10
生成博客
发布你的 blog
你可以添加域名到 CNAME
push 文件到一个 repo 的 gh-pages 分支
参考例子:https://github.com/LoeiFy/Mirror/tree/gh-pages
最后
现在你可以在 github issue 上写博客了,内容会同步更新。一个例子
在 https://github.com/LoeiFy/Recordum/issues 这个 issue 上写博客内容,对应网站 https://mirror.am0200.com/ 会自动同步更新内容
另一种安装方式
你可以直接下载资源包,下载最新的 release,然后打开 index.html 进行配置,按照例子进行配置即可
https://github.com/LoeiFy/Mirror/raw/master/mirror.zip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<!-- index.html -->
<script>
/*
**
** blog config here
** token should be separated by '#'.
** example: 5#c31bffc137f44faf7efcs4544da827g7ca2cfeaa
** muti-authors should be separated by ','. and the user is included in.
** example: 'LoeiFy, author0'
**
*/
window.config = {"title":"","user":"","repository":"","authors":"","perpage":"","token":""}
</script>
配置好后,可以先尝试本地预览,需要一个本地服务器,放上去访问 index.html 即可,测试没问题就可以把全部文件上传到对应地址即可,也可以放到 GitHub pages 上
名字来源
Mirror 是 DJ Okawari 所作的专辑

via acyort.am0200.com https://ift.tt/2QRxAYC
September 25, 2018 at 08:22PM
Recommend Projects
-
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
 Vue.js
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
 TensorFlow
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
 Django
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
 D3
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
-
Recommend Org
-
 Facebook
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
 Microsoft
Microsoft
Open source projects and samples from Microsoft.
-
 Google
Google
Google ❤️ Open Source for everyone.
-
 Alibaba
Alibaba
Alibaba Open Source for everyone
-
 D3
D3
Data-Driven Documents codes.
-
 Tencent
Tencent
China tencent open source team.
-
Jobs
Jooble














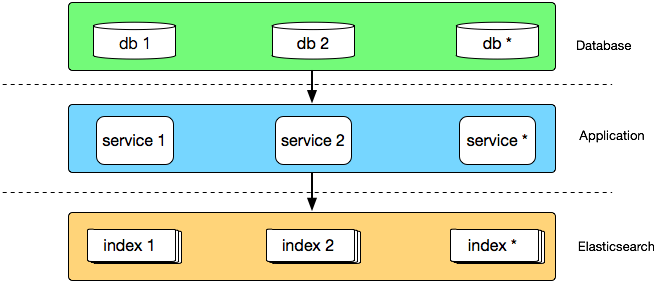
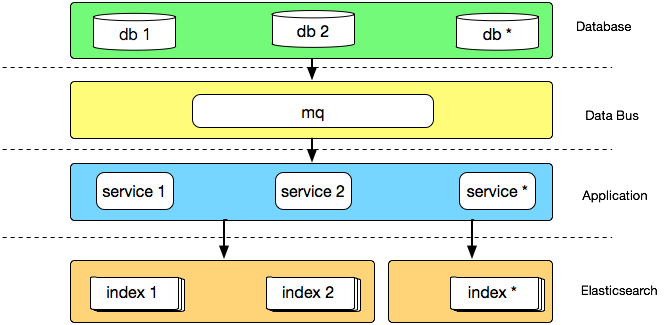
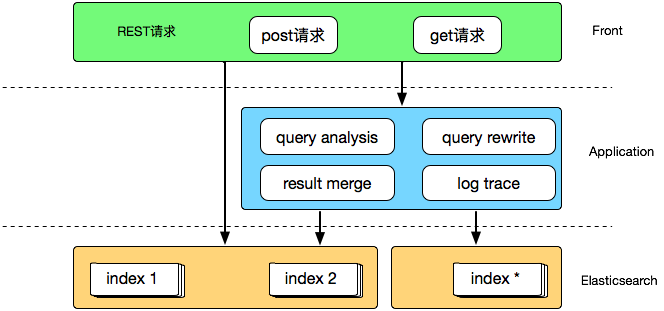
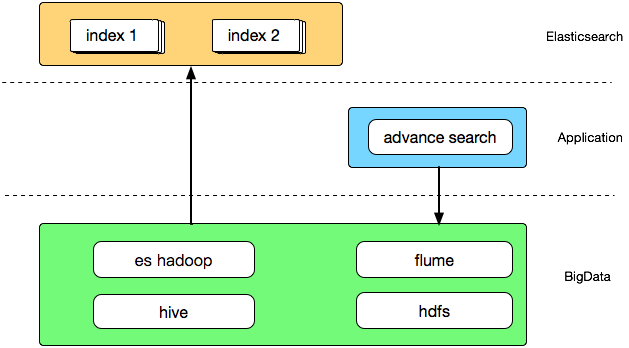
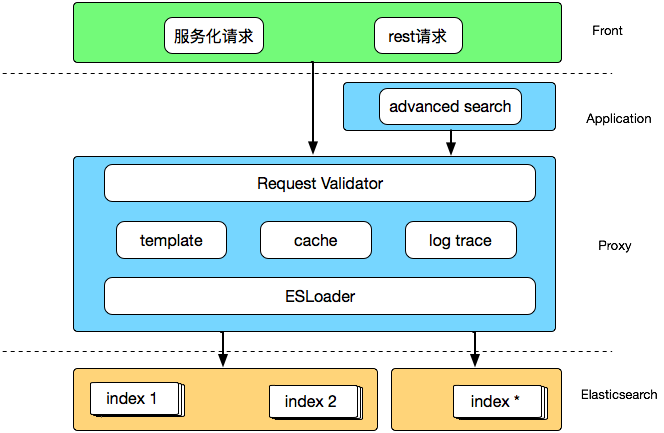



















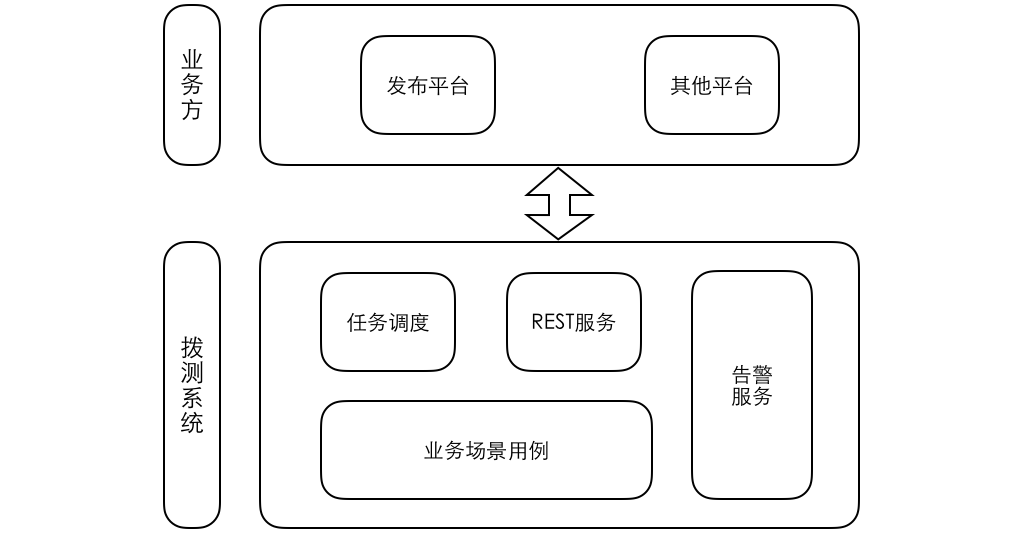
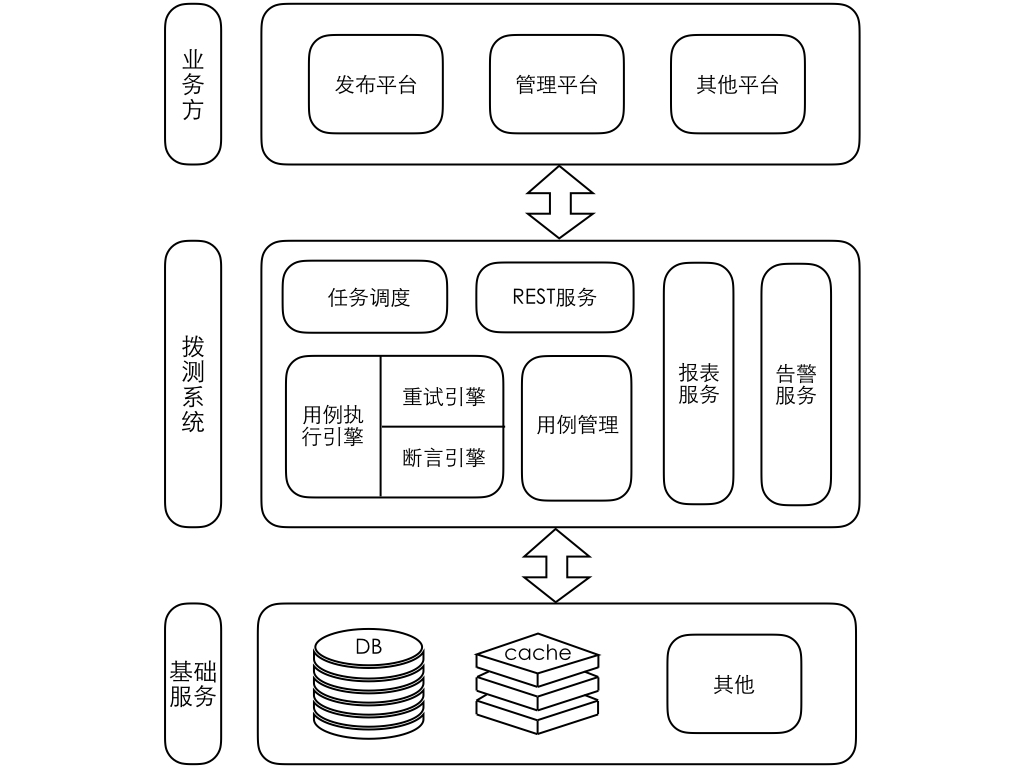
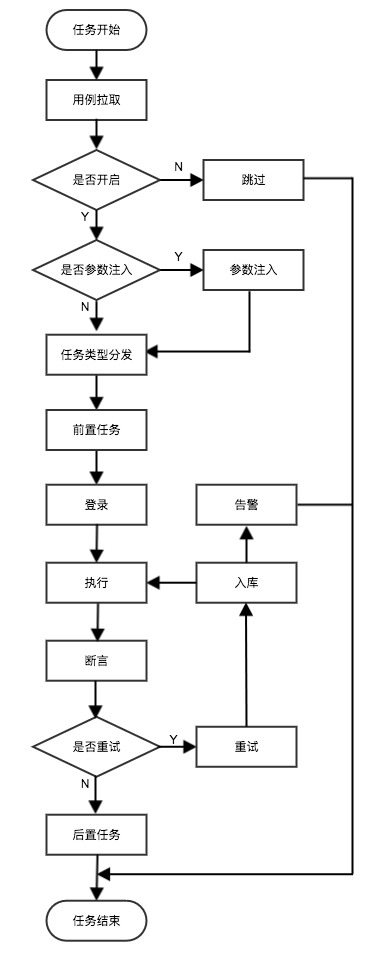

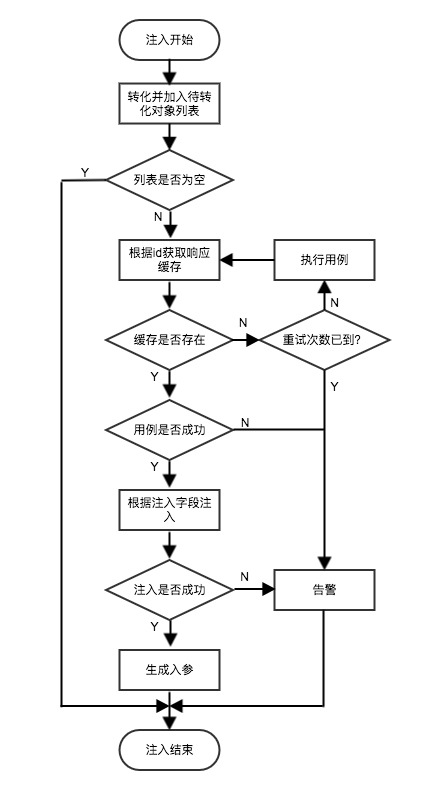
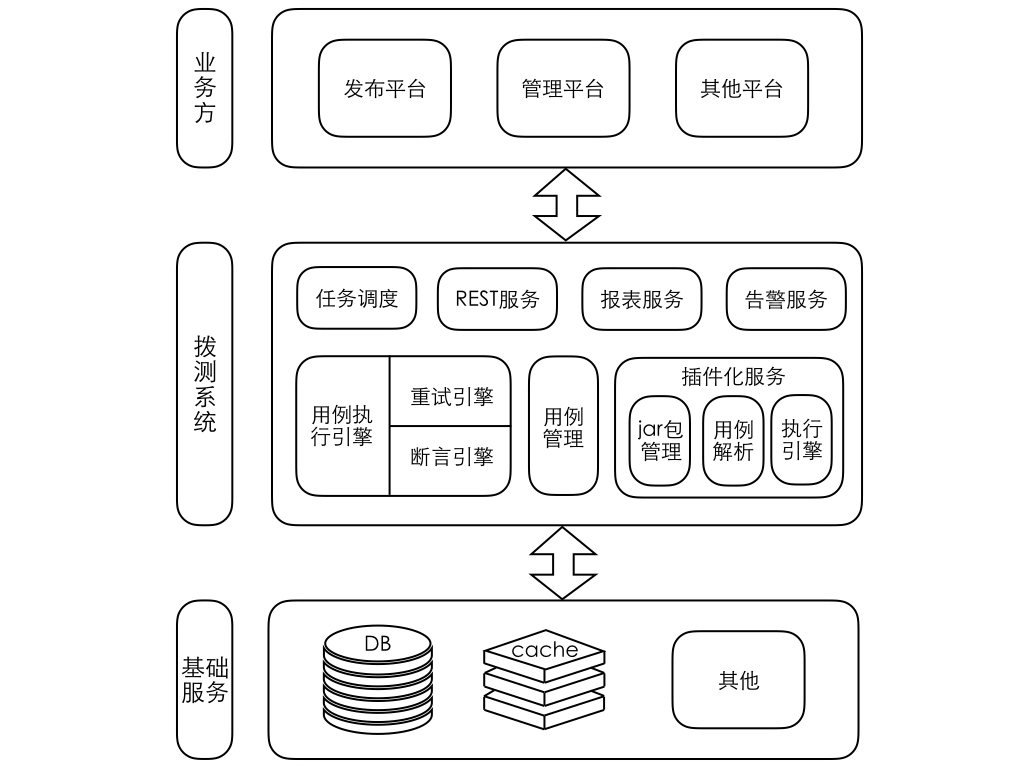





的大纲")







































胜石田芳夫,这也是他最后一次出现在国际赛场上")
,此时他已因病退隐多年")
战胜老棋后齐布尔达尼泽,获得女子世界冠军")