Moving forward in the future this repository will be no longer supported and eventually lead to deprecation. Please use our latest versions of our products moving forward or alternatively you may fork the repository to continue use and development for your personal/business use.
This repo contains a set of modules for deploying a Nomad cluster on AWS using Terraform. Nomad is a distributed, highly-available data-center aware scheduler. A Nomad cluster typically includes a small number of server nodes, which are responsible for being part of the consensus protocol, and a larger number of client nodes, which are used for running jobs.
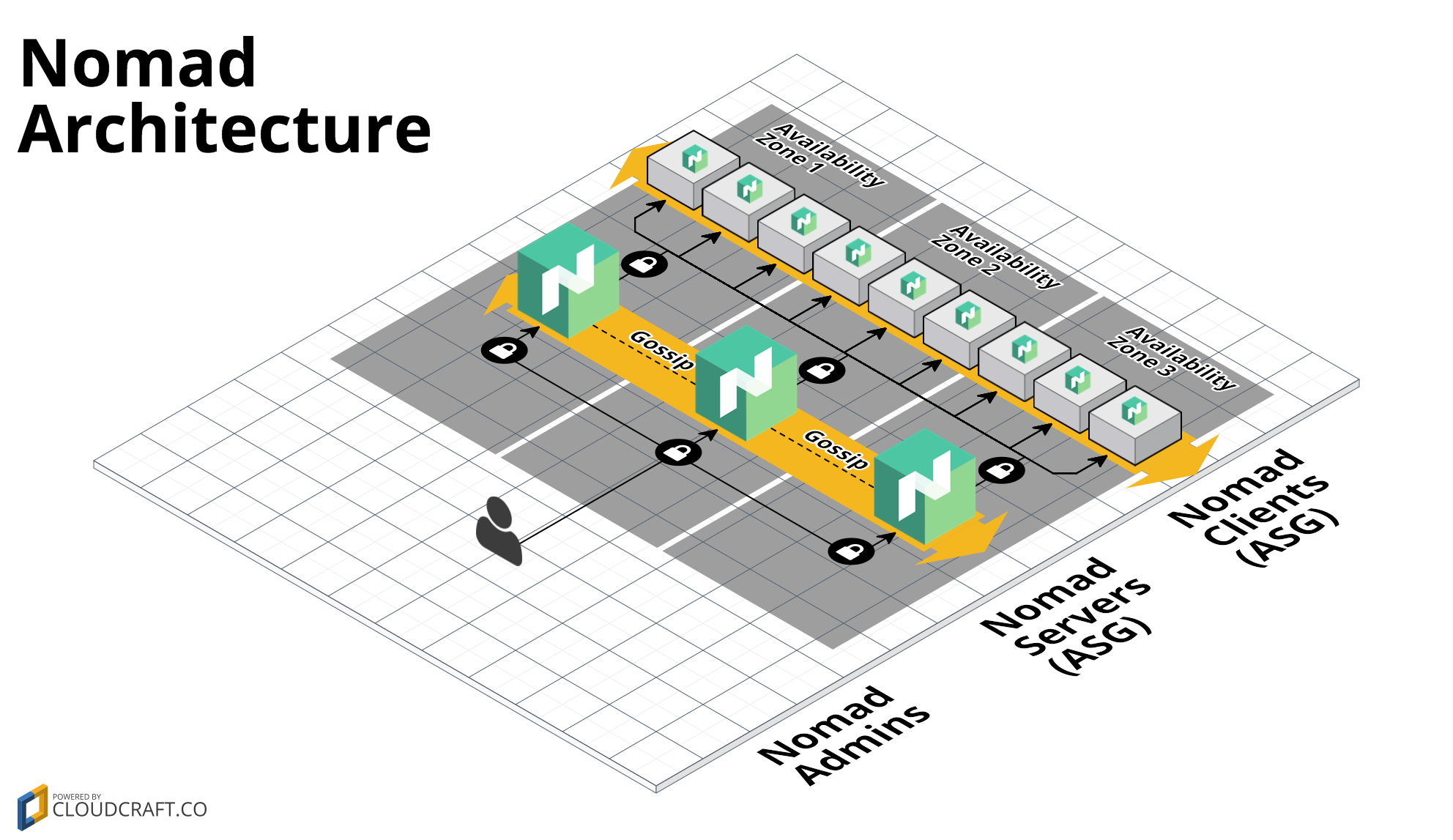
- Deploy server nodes for managing jobs and client nodes running jobs
- Supports colocated clusters and separate clusters
- Least privilege security group rules for servers
- Auto scaling and Auto healing
This repo was created by Gruntwork, and follows the same patterns as the Gruntwork Infrastructure as Code Library, a collection of reusable, battle-tested, production ready infrastructure code. You can read How to use the Gruntwork Infrastructure as Code Library for an overview of how to use modules maintained by Gruntwork!
- Nomad Use Cases: overview of various use cases that Nomad is optimized for.
- Nomad Guides: official guide on how to configure and setup Nomad clusters as well as how to use Nomad to schedule services on to the workers.
- Nomad Security: overview of how to secure your Nomad clusters.
- modules: the main implementation code for this repo, broken down into multiple standalone, orthogonal submodules.
- examples: This folder contains working examples of how to use the submodules.
- test: Automated tests for the modules and examples.
- root: The root folder is an example of how to use the nomad-cluster module module to deploy a Nomad cluster in AWS. The Terraform Registry requires the root of every repo to contain Terraform code, so we've put one of the examples there. This example is great for learning and experimenting, but for production use, please use the underlying modules in the modules folder directly.
If you just want to try this repo out for experimenting and learning, check out the following resources:
- examples folder: The
examplesfolder contains sample code optimized for learning, experimenting, and testing (but not production usage).
If you want to deploy this repo in production, check out the following resources:
- Nomad Production Setup Guide: detailed guide covering how to setup a production deployment of Nomad.
- How to deploy Nomad and Consul in the same cluster
- How to deploy Nomad and Consul in separate clusters
- How to connect to the Nomad cluster
- What happens if a node crashes
- How to connect load balancers to the ASG
These modules were created by Gruntwork, in partnership with HashiCorp, in 2017 and maintained through 2021. They were deprecated in 2022, see the top of the README for details.
Please see LICENSE for details on how the code in this repo is licensed.
Copyright © 2019 Gruntwork, Inc.













































































































































