hello2dj / blog Goto Github PK
View Code? Open in Web Editor NEW一些总结文章
一些总结文章






























Data visualization refers to the techniques used to communicate data or information by encoding it as visual objects (e.g., points, lines or bars) contained in graphics.
就是研究如何更好的使用可视化图形显示数据
使我们更好的洞悉数据
(svg 1000个左右dom元素就太多了,canvas 1000~5000左右,webGL数据量太大,有个信息密度问题太多密集恐惧症啊,太少不够显示信息)
关于CPS 原文地址
暂时理解为callback(比较直观一些), 当然也不能等同, 因为在cps的世界中所有的都是callback形式。试想一下一个语言里只有回调没有return,没有for,没有异常,没有throw, 没有break, 没有你所见过的各种语言的功能。因为通过cps他们都可以被实现。
state = (Store, Continuation, Env) 计算机计算 == 状态转换 == (存储, Continuation(后续,当前执行的计算的剩余计算过程), 环境)
cps是在1970s出现的一种编程风格,在1980s和1990s作为高级语言编译器的中间展示形式有着突出的表现
如今他作为非阻塞系统的编程风格再次被提起(通常是分布式)
cps在我的心中始终战友一席之地,因为他是我在Ph.D时期的秘密武器,他缩短了我取得Ph.D的时间,并且减少很多痛苦(agnoy)
这片文章介绍了cps的两个方面,一是在js中的异步编程风格,二是简单的介绍一下他在函数式语言中的中间(intermediate)形式
文章的主题:
What are continuations?
Concretely, a continuation is a procedure that represents the remaining steps in a computation. For the expression 3 * (f() + 8), think about the remaining steps in the compuation after evaluating the expression f(). For example, in C/Java, the procedure current_continuation is the continuation of the call to f():
void current_continuation(int result) {
result += 8 ;
result *= 3 ;
(continuation of 3 * (f() + 8))(result) ;
}
The value passed to the continuation is the return value of the call.
上面这段解释在说continuation 就是当前计算(computation)所剩余的其他计算,这也就解释continuation为什么叫continuation了,因为他就是当前计算的'后续'(后续过程):即后续的计算, 比如: let a = 3; let b = 4; 那么’let a = 3;‘的 continuation 就是 ’let b = 4;‘等后续计算步骤。对于上面的f(), 他的continutation就是 ’( + 8) * 3‘
如果一个语言支持continuation, 那么编程者就可以添加�一些控制结构好比异常处理,回溯(backtracking),线程和生成器
不幸的是,许多关于continuations的解释让人感到模糊和不解,(Such power deserves a solid pedagogical foundation.Continuation-passing style is that foundation)这样强大的工具应当有一个坚实的教学基础,而cps就是那个基础(可以简单的理解为callback)。
cps通过�代码给出了continuation的意义
有一个更好的方式可以让编程者自己了解cps,那就是通过遵守下面的一个限制或者约定:�任何一段程序都禁止向他的调用者返回
//意味着调用a,是用不会返回的
function a () {...}
a()
这里有另一个对cps说法, cps�使得控制流显示化-�---你不需要return,throw, break, continue, 不允许任意的跳转,甚至不允许在async function中使用for,while, 一般来说,手动编写cps是不直观并且容易出错的
正常来写的话如下
function id(x) {
return x ;
}
``�`
如果是cps
function id(x,cc) {
cc(x) ;
}
function fact(n) {
if (n == 0)
return 1 ;
else
return n * fact(n-1) ;
}
cps模式
function fact(n,ret) {
if (n == 0)
ret(1);
else
fact(n-1, function (t0) {
ret(n * t0);
});
}
我们来用一下
fact (5, function (n) {
console.log(n) ; // Prints 120 in Firebug.
})
function fact(n) {
return tail_fact(n,1) ;
}
function tail_fact(n,a) {
if (n == 0)
return a ;
else
return tail_fact(n-1,n*a) ;
}
cps的栗子
function fact(n,ret) {
tail_fact(n,1,ret) ;
}
function tail_fact(n,a,ret) {
if (n == 0)
ret(a) ;
else
tail_fact(n-1,n*a,ret) ;
}
一个简单的fetch实现
/*
fetch is an optionally-blocking
procedure for client->server requests.
If only a url is given, the procedure
blocks and returns the contents of the url.
If an onSuccess callback is provided,
the procedure is non-blocking, and the
callback is invoked with the contents
of the file.
If an onFail callback is also provided,
the procedure calls onFail in the event of
a failure.
*/
function fetch (url, onSuccess, onFail) {
// Async only if a callback is defined:
var async = onSuccess ? true : false ;
// (Don't complain about the inefficiency
// of this line; you're missing the point.)
var req ; // XMLHttpRequest object.
// The XMLHttpRequest callback:
function processReqChange() {
if (req.readyState == 4) {
if (req.status == 200) {
if (onSuccess)
onSuccess(req.responseText, url, req) ;
} else {
if (onFail)
onFail(url, req) ;
}
}
}
// Create the XMLHttpRequest object:
if (window.XMLHttpRequest)
req = new XMLHttpRequest();
else if (window.ActiveXObject)
req = new ActiveXObject("Microsoft.XMLHTTP");
// If asynchronous, set the callback:
if (async)
req.onreadystatechange = processReqChange;
// Fire off the request:
req.open("GET", url, async);
req.send(null);
// If asynchronous,
// return request object; or else
// return the response.
if (async)
return req ;
else
return req.responseText ;
}
一部分的cps编程对于nodejs来说是自然的
var sys = require('sys') ;
var http = require('http') ;
var url = require('url') ;
var fs = require('fs') ;
// Web server root:
var DocRoot = "./www/" ;
// Create the web server with a handler callback:
var httpd = http.createServer(function (req, res) {
sys.puts(" request: " + req.url) ;
// Parse the url:
var u = url.parse(req.url,true) ;
var path = u.pathname.split("/") ;
// Strip out .. in the path:
var localPath = u.pathname ;
// "<dir>/.." => ""
var localPath =
localPath.replace(/[^/]+\/+[.][.]/g,"") ;
// ".." => "."
var localPath = DocRoot +
localPath.replace(/[.][.]/g,".") ;
sys.puts(" local path: " + localPath) ;
// Read in the requested file, and send it back.
// Note: readFile takes the current continuation:
fs.readFile(localPath, function (err,data) {
var headers = {} ;
if (err) {
headers["Content-Type"] = "text/plain" ;
res.writeHead(404, headers);
res.write("404 File Not Found\n") ;
res.end() ;
} else {
var mimetype = MIMEType(u.pathname) ;
// If we can't find a content type,
// let the client guess.
if (mimetype)
headers["Content-Type"] = mimetype ;
res.writeHead(200, headers) ;
res.write(data) ;
res.end() ;
}
}) ;
}) ;
// Map extensions to MIME Types:
var MIMETypes = {
"html" : "text/html" ,
"js" : "text/javascript" ,
"css" : "text/css" ,
"txt" : "text/plain"
} ;
function MIMEType(filename) {
var parsed = filename.match(/[.](.*)$/) ;
if (!parsed)
return false ;
var ext = parsed[1] ;
return MIMETypes[ext] ;
}
// Start the server, listening to port 8000:
httpd.listen(8000) ;
假设你写了一个组合的choose函数,正常的写法:
function choose (n, k) {
return fact(n) / (fact(k) * fact(n-k));
}
现在假设你想�要�再一个server上计算�阶乘而不是在本地
你�可能会重写fact来等待server的响应,那是不好的,�相应的如果你使用cps来书写:
function choose(n, k, ret) {
fact(n, function (factn) {
fact(n - k, function (factnk) {
fact(k, function (factk) {
return (factn / (factnk * factk));
});
});
});
}
现在可以很直观的重写server上的异步阶乘计算
function fact(n, ret) {
fetch("./fact/" + n, function (res) {
ret(eval(res));
});
}
一旦程序使用cps,他就打破了语言本身的标准异常原理,但幸运的是,使用cps可以很简单的实现异常处理
异常�是�一个特殊的continuation
通过沿着current continuation传递current exceptional continuation,可以替换try/catch 语法糖
可以看下面的栗子
function fact (n) {
if (n < 0)
throw "n < 0" ;
else if (n == 0)
return 1 ;
else
return n * fact(n-1) ;
}
function total_fact (n) {
try {
return fact(n) ;
} catch (ex) {
return false ;
}
}
document.write("total_fact(10): " + total_fact(10)) ;
document.write("total_fact(-1): " + total_fact(-1)) ;
通过添加exceptional continuation, 见下
//与node不同,node只是部分cps,而这中处理就是完全的cps
function fact (n,ret,thro) {
if (n < 0)
thro("n < 0")
else if (n == 0)
ret(1)
else
fact(n-1,
function (t0) {
ret(n*t0) ;
},
thro)
}
function total_fact (n,ret) {
fact (n,ret,
function (ex) {
ret(false) ;
}) ;
}
total_fact(10, function (res) {
document.write("total_fact(10): " + res)
}) ;
total_fact(-1, function (res) {
document.write("total_fact(-1): " + res)
}) ;
再过去的几十年里,cps在�函数式�语言的编译器中是�中间显示的重要�工具
cps 去掉了retrun, 异常和first-class continuations(将continuation作为编程语言的一等公民)的语法糖
总之一句话,cps在编译领域起了很大的作用
接下来的就是Lisp语言的一些东西了,暂时还不懂,等看懂了再说吧流泪啊啊啊啊啊
如果上面没有看明白的话,请移步这篇文章如何写一个支持CPS的语言,英文版有时间我再翻译一下。
上次我们谈论协变和逆变时提到了 typescript, ts 本身是 js 的超集,从名字就可以看出来 ts 为 js 带来了类型,那么如何能写好 typescript?答案是从声明文件开始,若是能写的一手好的 ts 的声明文件,那 ts 的书写必然是手到擒来啊!2333333(我们就不在这里再做 ts 的基本语法的普及了详见handbook)
为什么?我们知道 ts 是 js 的超集也是会编译成 js 的,那么已有的 js 代码怎么和现有的 ts 项目融合呢(即在 ts 中引用 js)?因为 js 是弱类型的,是无法推导出变量的类型的,那么 ts 的编译器自然就无法集成 js 的代码了?此时声明文件就起到作用了,声明文件的目的就是告诉 ts 的编译器,我要引用 js 文件了,js 文件的内容有啥,暴露出来的变量叫啥,类型是啥等等,听着怎么那么像是 C/C++的头文件呢?ts 是强类型语言了,每个变量就都会有自己的类型(类型是不可变得哦),这些类型都是要声明的,还有接口也是要声明的,而 js 代码是没有这些的,所以就需要声明文件了
// 1
interface Dog {
bark: (world: string) => void;
}
const tuDog: Dog = {
bark: (world: string) {
console.log('bark');
}
}
// 2
interface TextSpan {
start: number;
end: number;
}
// 3
type Test = (version: number) => void;
上面的代码我们定义了两个接口类型,和一个 Test 的函数类型,当我们把这些类型定义都放到一个文件里时就成了一个‘声明文件’了,这里打引号的意思是,正常 ts 之间引用是不用专门抽出来写一成一个文件的(当然你要是乐意那也是可以的),这个例子就是在说声明文件就是一堆’类型声明‘(这里打引号是因为正式的声明文件里也是会声明变量的),就好比的 C/C++的头文件
// foo.js
module.exports.say = require('./say');
// say.js 我们在此假设 o 是string
module.exports = function say(o) {
return o;
}
// index.ts
import * as a from '../foo'; //此时是会报错的,因为没有foo.ts
a.say('123')
// 但若是 再加一个foo.d.ts文件
export function say(o: string): string;
// foo.js 我们在此假设 o 是string
global.say = function(o) {
return o;
};
// index.ts
import * as a from '../foo'; //此时是会报错的,因为没有foo.ts, 并且也没有bark
bark('123')
// 但若是 再加一个foo.d.ts文件
delcare function say(o: string): string;
// delcare var say: (o: string) => string;
总的来说就是 declare 使声明引用那些已经在代码执行环境中存在的 变量,函数,类,枚举,命名空间,或者 modules, 例如通过 script 标签引入的包。在 declare 命名空间和 modules 时应注意,只能在顶层是使用 declare, 命名空间内部是不允许使用的,命名空间内部的可访问情况可由 export 控制(想让谁可访问就 export 谁)
npm install --save-dev @types/node(package-name)
可以在这里搜索.d.ts
当然这里仅仅是简单的做了介绍,通过这个简单的介绍我们可以发现,当我们把声明文件写的完整的时候,基本就是 ts 出师的时候了。(举的栗子是两种分开的,那么在我的 node 项目的某个文件中既有 global 形式又有包的导出形式该怎么做呢?我还没写对,有待努力!各位看官要是知道的话忘不吝赐教([email protected]))
块即可,不可作为类型,以及值,只是用来分隔代码
推到出 函数返回值类型
type ReturnType<T> = T extends (...args: any[]) => infer R ? R : any;
普通类型定义 使用infer会报错
type ReturnType<T extends (...args: any[]) => infer R> = R; // Error, not supported
参考:
相机默认是朝向z负轴的,改变相机位置,并不改变镜头朝向,若不改变镜头朝向,则镜头仍然是朝向负轴的即使改变了相机位置(可以使用lookAt设置镜头朝向)
signature: three.OrthographicCamera(left, right, top, bottom, near, far)
这6个参数代表了相机拍摄到的空间的6个面的位置,这6个面正好围成一个长方体,称为视景体(视锥)(—Frustum—)
只有在视锥内的物体才会显示在屏幕上,而视锥之外的物体会被裁剪掉。
为了保持相机的��横竖比例,需要保证right-left 与top-bottom的比值与canvas的横竖比值相同(很明显若不一致会产生视觉�问题待贴图)
signature: three.PerspectiveCamera(fov, aspect(width/height), near, far)
fov: 控制了上下的张角, aspect: 控制了水平的张角,near和far控制了Z轴纵深显示的范围
这4个参数代表了相机拍摄到的空间体,称为视景体(视锥)(—Frustum—)
只有在视锥内的物体才会显示在屏幕上,而视锥之外的物体会被裁剪掉。
几何形状的主要作用是存储物体的顶点信息,通过指定几何形状的特征来创建例如球体,需要半径
signature: three.CubeGeometry(width, height, depth, widthSegments, heightSegments, depthSegments);
前三个是�在x,y, z上的长度,后三个代表在�三个轴上分段数(可不设,�默认是1, )真的是分段,把相应的长度分为指定段然后标明)
长方形
signature: three.PlaneGeometry(width, height, widhtSegments, heightSegments)
signature: three.SphereGeometry(radius, segmentsWdith, segmentsHeight, phiStart, phiLength, thetaStart, thetaLength)
phiStart表示经度开始的弧度(画半球的利器)
phiLength表示经度跨过得弧度
thetaStart表示纬度开始的弧度
thetaLength表示纬度�跨过得弧度
signature: three.CircleGeometry(radius, segments, thetaStart, thetaLength)
可以做很多东如: 圆台,无顶面底面
https://threejs.org/docs/index.html#api/geometries/CylinderGeometry
https://threejs.org/docs/index.html#api/geometries/TorusGeometry
https://threejs.org/docs/index.html#manual/introduction/Creating-a-scene
后续详述
材质是独立与物体空间信息之外的渲染效果信息,通过材质可以改变物体的颜色,纹理贴图,光照模式等
�使用基本材质渲染的物体颜色为纯色,不会由于光照产生敏感,阴影等效果,颜色若未指定则随机
signature: three.MeshBasicMaterial(opt)
opt可省略太多了,见文档,基础的有color颜色,opacity透明度等
visible: 是否可见
side: 渲染物体的正面还是反面(FrontSide or BackSide or DoubleSide)
wireframe: �是否渲染线而非面
map: 使用文理贴图
如:创建一个�不透明度为0.75的黄色材质
�这是符合Lambert光照模型的材质,特点是只考虑光照的漫反射而不考虑镜面反射,对于金属,镜子等物体就不合适了
我又要先上图了:
| Producer | Consumer | |
|---|---|---|
| Pull | Passive: produces data when requested. | Active: decides when data is requested. |
|
| Push | Active: produces data at its own pace. | Passive: reacts to received data. |
我们可以看到,在push系统中,consumer要做的就是要决定对接受到的数据做出如何的响应。而在pull系统中consumer要做的是决定什么时候去获取数据。可能ractive programming 就是从消费者的角度来定义的吧。消费者只需要对数据做出响应即可。
显然在pull的系统中,我们需要确定什么时候获取到数据,producer端是被动的,就好比前端和后端,后端就是被动。
那么push系统呢?是有producer来决定什么时候产生数据给Consumer的,而consumer是不关心什么时候拿到数据(典型的订阅模式啊)。
其实前端后端是pull,但我们也在经常性的使用push,那就是promise,当你调用promise后你是不知道什么时候才会拿得到数据的。可是promise是单值的push系统。
而rxjs带来了一个新的push系统,多值可取消的push系统(但rxjs不像promise那样全是异步的,rxjs可异步可同步)。
push 也有push的弊端,那就是backpressure问题
// Inside module Foo
function onNetworkRequest() {
// ...
// 此时Foo玩去可以好好
CCTV.incrementCounter();
// ...
}
此时箭头的生命是由箭尾决定的
是由Foo来控制什么时候调用Bar,此时控制权在Foo,我们需要向Foo提供对外响应, Bar的内部状态是由外部来修改的
Foo.addOnNetworkRequestListener(() => { // 事件一来我大CCTV就可以主动控制了, Foo也不知道
// 我大CCTV
self.incrementCounter(); // self is CCTV
});
可事实是Bar的状态完全可以是一个内部状态,而这个内部状态只需要根据外部事件的来决定做出如何的响应(reactive 的Bar)。
换句话说就是Bar的内部状态是要随着外部状态的改变而做出响应,但是什么响应就是Bar内部状态的实现了,若是按照第一种方式来看,我们就把Bar对事件的实现暴露给了Foo(举个栗子好比是新闻联播,他要去记录老外那里发生了啥事儿,但我们的新闻联播的播放室会告诉老外我们要怎么播放,要播放什么了么?这就是典型响应式啊,老外发生了事情,cctv收到了事件,然后播放给国内人民),当我们这么做了以后,Bar只需要关心自己的实现就好了,完全对自己负责就可以了
另一个好处就是关注点分离,各自关心自己的该关心的事情就好了。
也是,因为props是提前定义的也好比是监听机制只不过是没有起一个on....Listener罢了
单一责任原则:尽量保证一个类只会因为一个原因发生变化,当变化多于一个时,就需要分解这个类。否则将会因为内部存在过多的依赖而变得难以维护。
开放封闭原则:这个是我们最常使用的,具体可以体现在属性私有、方法公开这一点上。开放封闭原则讲究拥抱扩展、封闭修改。
里氏替换原则:保证每一个子类都能够直接替换其父类,满足is-A的关系。
依赖倒置原则:高层次的模块不应该依赖于低层次的模块,二者应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
接口分离原则:当一个用户需要多个接口的时候,尽量将每一个接口分离出来,而不是将多个接口放在一个类中,包含所有的接口
迪米特法则:如果两个类之间并不需要直接通信,那么就不应该让这两个类相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过另外的类来转发调用,降低类与类之间的耦合。
参考:
从响应式宣言中我们可以看到,不仅编程是可以响应式的,整个系统都应该是响应式的。
setImmediate 一定会在本轮event loop内的check 阶段执行,若是check阶段已经错过了,那就只能在下一轮的check阶段执行了。
参见上篇文章,见下图
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
可以看出来在同一次event loop内,timers阶段是在check阶段之前的,也就是说若是在同一个event loop内既有定时器到期又有setImmediate那肯定是setTimeout先执行。若不在一个event loop内那就不好说了,要具体情况具体分析了。
那么setTimeout(n) 和 setImmediate的执行顺序到底是啥?
// test.js
setTimeout(() => {
console.log('setTimeout');
}, 1)
setImmediate(() => {
console.log('setImmediate');
});
// 假设我的t 是2,那么输出就是
# setTimeout
# setImmediate
t的抉择就完全取决于机器的性能了
而且在此处还有一个问题就是node中setTimeout最小时间1毫秒,见源码如下
//lib/internal/timers.js~line#34
after *= 1; // coalesce to number or NaN
if (!(after >= 1 && after <= TIMEOUT_MAX)) {
if (after > TIMEOUT_MAX) {
process.emitWarning(`${after} does not fit into` +
' a 32-bit signed integer.' +
'\nTimeout duration was set to 1.',
'TimeoutOverflowWarning');
}
after = 1; // schedule on next tick, follows browser behavior
}
也就是说你设置0,最下也是1,那么就是说若你的机器性能很好,在1毫秒之前就开始执行event loop了,那么将会永远只看到setImmediate在setTimeout之前执行了。
前面说的都是在event loop之前设置,那么在event loop的期间执行js代码时设置的呢(我们只说同时设置的执行顺序)?(参见我前面的关于js代码的执行时机解释)
setTimeout(() => { // 1
console.log('外层timeout');
setTimeout(() => { // 2
console.log('set timeout in timeout');
});
setImmediate(() => { // 3
console.log('set immediate in timeout');
});
});
1的回调是在timers阶段执行的,而setTimeout内部的定时器一定是不可能在本次event loop的timers阶段执行的(分析后面再说),那就是说2的回调一定是在本次event loop之后的某次loop中的timers阶段执行的,可我们也要注意,本次loop的check阶段还没执行,因此就很明显了,3的回调会在本次loop的check阶段执行,因此得到总结在timer阶段设置的setTimeout和setImmediate一定是setImmediate先执行。
const fs = require('fs');
fs.readFile('./test.js', () => {
setTimeout(() => {
console.log('set timeout in poll phase');
});
setImmediate(() => {
console.log('set immediate in poll phase');
});
});
总的可以用一个流程图来概括
{% asset_img timerheimmediate.png timer & check phase %}
事实上这两者是没有可比的
setImmediate(() => {
console.log('immediate');
});
function a() {
process.nextTick(() => {
console.log('set nextTick');
a();
});
}
a();
可以试一下上面的代码, 你会发现这就是无限调用了。还有我们所熟知的promise也走的是v8 microtask机制(并且Promise使用时v8实现的promise)。那么同理,promise的then的回调和nextTick中的回调也是由v8 microtask机制来确定执行的,也是与event loop 无关的。当然这在promiseA+规范里面也是有相应描述的。为了测试我们可以执行以下代码
const promise = Promise.resolve(234)
setImmediate(() => {
console.log('immediate');
});
testPromise();
function testPromise() {
promise = promise.then(() => {
console.log('promise');
testPromise();
});
}
是的结果和执行pross.nextTick是一样的event loop被阻塞了。
在源代码里我们也可以看到见下
主要代码在/lib/internal/procss/next_tick.js(这里有太多的逻辑没搞明白只是知道了一个大概)
{% asset_img tickQueue.png tick queue %}
我们所创建的nextTick都是由这个全局的NextTickQueue来管理的,当我们执行nextTick,就push进去一个TickObject
{% asset_img tickObject.png tick object %}
执行nextTick的逻辑如下
{% asset_img nextTick.png nextTick %}
接下来就是触发nextTickQueue里面的tickObject的执行了
{% asset_img tickCb.png tick queue handle %}
在接下来就是设置_tickCallback(_tickDomainCallback是使用了Domain的版本)这个回调的执行时机了
{% asset_img setUpNextTick.png setUpNextTick %}
失败的地方就来了,我跟到C++代码里面后就完全没找到_tickCallback的具体执行时机的设置了,而且这里面也有太多的逻辑了,完全不知道是在干啥,还有待慢慢揭秘求高手。
到了这里我可以知道了nextTick一定是先执行的(同时设置)
Timeout具体属性见下
{% asset_img timeoutobj.png Timeout %}
其中_idleStart很重要,是指这个定时器的起始时间,比如在10秒的时候设置了一个40秒的定时器,那么到期的时候就检查这个now - _idleStart 是否大于定时的40秒,而这个时间应当是程序启动后经过的毫秒数。(纯属个人猜测)
生成了定时器对象后,怎么组织管理就是个问题了,定时器在node中是以对象加链表来组织的,相同时间的定时器会被放到同一个链表中,如都是定时的40毫秒,但设置的时间不同,那么他们就会被放到同一个list中,见下图
// ╔════ > Object Map
// ║
// ╠══
// ║ refedLists: { '40': { }, '320': { etc } } (keys of millisecond duration)
// ╚══ ┌─────────┘
// │
// ╔══ │
// ║ TimersList { _idleNext: { }, _idlePrev: (self), _timer: (TimerWrap) }
// ║ ┌────────────────┘
// ║ ╔══ │ ^
// ║ ║ { _idleNext: { }, _idlePrev: { }, _onTimeout: (callback) }
// ║ ║ ┌───────────┘
// ║ ║ │ ^
// ║ ║ { _idleNext: { etc }, _idlePrev: { }, _onTimeout: (callback) }
// ╠══ ╠══
// ║ ║
// ║ ╚════ > Actual JavaScript timeouts
// ║
// ╚════ > Linked List
插入的流程如下
{% asset_img insert.png insert %}
初始化TimerList的如下
{% asset_img timerlist.png timer list %}
在初始化一个TimersList时就会以他所属的过期的时间设置一个libuv的定时器,到期后处理自己这个list中node定时器,若是,还有未到期的,那么就继续设置libuv的定时器
接下来就是定时器到期后怎么处理了
{% asset_img timeouecb.png timer outdate %}
上面我的截图里说的语句不通了激动了,从上面可以看到,我们新设置的相同的定时器尤其是针对setTimeout(0)(虽然我们不可能有零这种情况),其实我想说的是,假设我们设置了两个1msecs的定时器,见代码吧
setTimeout(() => { // 1
console.log(1);
setTimeout(() => { // 2
console.log(2);
});
setImmediate(() => { // 3
console.log(3);
})
})
上述代码1,2的过期时间都是1,所以他们在同一个timerList中,还有我们看到前面的描述,当我们是while去处理timerlist的,根据前面的讲述我们知道3一定比2先输出,但是我们是while处理timerlist的,为什么没有判断2过期呢,我就发现了,因为判断过期取的是now - timer._idleStart, 而这个now是在定时器cb执之前取的,而timer._idleStart是在setTimeout时设置的,那就意味着,2的_idleStart 一定比1的到期是去的now 大,那就很明显了,无论如何都是是无法判断2过期(在本次loop期间判断2过期)了,即使是下面的代码也不行
setTimeout(() => { // 1
console.log(1);
setTimeout(() => { // 2
console.log(2);
});
for(let i = 0; i < 100e100; i ++) { // 1msec的时间绝对有了,那么是不是在本轮loop就可以判断timer过期呢,不会
let c = 0;
}
setImmediate(() => { // 3
console.log(3);
})
})
定时器的整体组织方式就是为了方便管理,减少底层真实定时器的使用。
调用setImmediate
{% asset_img newimme.png Immediate %}
Immediate构造函数的处理
{% asset_img appendimme.png append Immediate %}
加下来就是处理 check阶段处理immediate了
{% asset_img processimme.png 才处理immediate list %}
上图解释的很清楚了,这就告诉了我们另一个问题,在同一时期设置的setImmeidate会放到同一个队列,并且在一次loop check阶段就把所有的immediate回调给执行了。
setTimeout(() => { // 1
console.log(1);
setTimeout(() => { // 2
console.log(2);
});
for(let i = 0; i < 10e10; i++) {
let c = 0;
} // 上面的那个肯定过期了
for(let i = 0; i < 100; i++>) {
setImmediate(() => { // 3
console.log(3);
})
}
})
上面的代码我们的2在1的回调执行之后一定是过期的,那么若是同一时间设置的setImmediate不会在同一个loop的check阶段那么,我们的2输出之后就一定会有3,可以执行一下是没有的,也就证明了我们上面的源码分析是正确的。
打完收工,源码阅读很考验啊,应当先知道代码的最终功能是什么?你想要知道的问题是什么?然后再去跟代码,一定要先找到函数入口,在就是一步一步调试是很有用的,等着看看怎么调试v8以及node的c++代码势要把microtasks也高明白了。
看到了一篇列举程序员最常说的10句话
code reviews时最常听到的
当我们因为某一个问题被责怪时...
hi boy,你把debug代码从生产环境去掉了么?
明日复明日
这是电视的话题,却被It人员搞火了
为什么我们总是在问为什么?
所有的代码都像屎一样,哦,当然只有我的不是
快来干活,我的代码在编译呢。。好吧,加油
这里有的是实话,有的是玩笑话,有的自嘲话,可这些话是不是值得我们反思呢?
要务实,不能盲目,要考虑成本以及效率而不是一拍脑袋
造轮子的痛点是啥,一定要了解痛点是啥,一定说3遍
用轮子的瓶颈在哪,就像上面的图,你拿了个轮子给人用,这里就有两个问题
...
依赖库不是说加就加了,增加了一个就意味着增加不可预知的问题,依赖的崩溃往往是难以发现以及debug的,切记不要轻易hack以及使用私有的api即未公开的api(因为这类api极易发生改变)
* #### 避重趋轻,避繁趋简,避虚就实(奥卡姆原理:如无必要,勿增实体)
库的轻重不是以size来决定的,而应当是api简洁型的,易于使用,易于调试,易于发现以及解决问题的,典型的就是tj的作品, 简洁易于稳定,使用
轻量的库要好过于大而重的库,若没有必须的理由就不要新增库
* #### 可替代性
库的使用易于被替换,而不是说一定会被绑死的除非你确定你非此库不用,但应当尽量做到库的易替代性,随时可以更换,而且库的引入有时会引入一些无形的机制,因此应当尽量避免这种无形的机制的引入,这种说法又叫抽象渗透,就是说你依赖的库的某些抽象,渗透入了你的代码中,导致你也必须使用,举栗子就是async/await就是一种抽象渗透的典型,污染范围扩展到了你的整个代码中,一旦底层库使用了async/await你的代码就必须使用,否则就会出现代码执行顺序混乱的情况。这是时候就要用到solid中的一个原则了,叫做依赖反转,
从上述图中可以看出,高层不在依赖底层,他们都依赖接口(好比图IOC容器,关于IOC又可以讲很多了),总之这样做了以后可以让我们的代码与底层库解耦,就是说我们在引入库的时候是可以适当的包裹一下,使得库代码的污染区降到最低
再此有一句话(原作者说的就是李安在选演员时,还没确定时就已经然演员在脑中表演了,然后看效果)那么对于代码来说选择库或者框架时,没确定前就应当在脑中运行了,看看会是什么样,能是什么样,有什么好的效果,有什么弊端等等(这个得修炼)
###选择的原则(新手版)
前面有讲
通俗的说就是一个系统的混乱程度,而有一个定理就是一个系统的熵一定是越来越大(没有外部能量干扰),若是想要维持熵值就一定得有外部能量注入
看下面两个图
架构良好的系统
反之没有人维护
这是在说什么?架构的重要性以及优势,自行领悟吧!改天继续说说这个(这也是原作者讲的一个哦,只不过是捎带了一下)
:(){ :|:& };:
注解如下:
:() # 定义函数,函数名为":",即每当输入":"时就会自动调用{}内代码
{ # ":"函數起始字元
: # 用递归方式调用":"函数本身
| # 並用管線(pipe)將其輸出引至...(因为有一个管線操作字元,因此會生成一個新的進程)
: # 另一次递归调用的":"函数
# 综上,":|:"表示的即是每次調用函数":"的時候就會產生兩份拷貝
& # 調用間脱鉤,以使最初的":"函数被關閉後為其所調用的兩個":"函數還能繼續執行
} # ":"函數終止字元
; # ":"函数定义结束后将要进行的操作...
: # 调用":"函数,"引爆"fork炸弹
为了兼具移植性和性能,聪明的工程师们发明了 JIT 这个东西,所谓的 JIT 就是说在解释型语言中,对于经常用到的或者说有较大性能提升的代码在解释的时候编译成机器码,其他一次性或者说没有太大性能提升的代码还是以字节码的方式执行
大多数开发人员都是知道JIT编译器的(解释执行,比如ruby JIT, lua JIT- openresty就是集成lua JIT的nginx), JIT可以让我们的解释性语言(一般都比较慢)快如闪电,甚者可以和native code一较高下(当然这有写夸张),但JIT确实是可以让解释性语言跑的飞快。然后很少人知道JIT到底是如何运行的,甚着如何编写一个属于自己的JIT编译器。
掌握一些编译器的基本知识可以帮助我们更好的理解代码的运行原理。
在这篇文章里我们会去揭露一些JIT的原理,甚至实现一个我们自己的JIT编译器。
先确定一个编译器的基本知识点,就是我们可以认为编译器就是把一定格式的输入(通常就是源代码)转换到其他格式或者是相同格式的输出(通常是机器码)。JIT 编译器也不例外。
那是什么让JIT编译器与众不同的呢?那就是JIT并不是提前进行编译的(就是再运行之前编译的,想想我们的golang你想运行golang就得先编译再运行,再比如gcc, clang 或者其他这些都是提前编译的),JIT是在运行时进行编译的(Just-In-Time, 当然也是在执行编译器的输出之前,这句话很怪吧)。
在开始开发我们的JIT compiler之前我们得先选择一个输入语言。我选择的是JavaScript, 他的语法很简单。甚至我会使用JavaScript本身来实现一个JavaScript的JIT。你可以叫他 META-META!
总结一下我们要做的JIT就是从 source code -> IR(AST)-> machine code
我们的编译器可以接收JavaScript的源代码做为输入,然后生成X64架构的机器码(并且立即执行)。虽然人类更乐意使用文本表示,但是在生成机器码之前编译器的开发者则更倾向于使用多种IR(Intermediate Representations)来表示程序。
因为我们写的是一个简化版的编译器,所以我们只有一种IR, 当然这对我们来说足够了。我在这里会采用AST(Abstract Syntax Tree) 来作为我们唯一的IR。
从js的源代码中获取AST很简单,因为有很多现成的js parser他们都可以输出AST。 比如:esprima, acornjs等等。在本文中我推荐使用esprima, 因为他有很好的输出格式(MDN定义的一种AST格式)。
举个🌰, 我们看这句话: obj.method(42) 。 使用esprima.parse(...), 会生成如下的AST
{
type: 'Program',
body: [ {
type: 'ExpressionStatement',
expression: {
type: 'CallExpression',
callee: {
type: 'MemberExpression',
computed: false,
object: { type: 'Identifier', name: 'obj' },
property: { type: 'Identifier', name: 'method' }
},
arguments: [ { type: 'Literal', value: 42 } ]
}
}]
}我们先总结一下目前的情况:js源码(ok), AST生成(ok),机器码(待完成)
接下来我们会将一些汇编的基础知识,当然如果你对汇编有所了解的话,就直接跳到下一章吧。
汇编语言其实就是机器或者说CPU能够执行的二进制代码的近文本表示, 考虑到处理器是一行一行的读取并且执行指令的,因此我们把汇编的每一行都看作是一条指令也是合理的,如下:
mov rax, 1 ; 把 ‘1’ 放到 rax寄存器中
mov rbx, 2 ; 把 ‘2’ 放到 rbx寄存器中
add rax, rbx ; 计算rax和rbx的和然后放到rax中这个段汇编代码的执行结果是3(你可以从寄存器rax中拿到结果)。通过这个也可以看出来处理器的工作方式:1.把数据放到CPU的(寄存器)里面 2.通知CPU进行计算
通常来说CPU有足够多的寄存器来存放中间结果, 但是在某些情况下你可能也需要使用计算机的内存来存储或读取数据(一股计算机组成原理的味道):
mov rax, 1
mov [rbp-8], rbx ; 把rbx的数据存到内存中(栈内存)
mov rbx, 2
add rax, rbx
mov rbx, [rbp-8] ; 从内存读取数据到rbx中寄存器使用名字来标识(rax, rbx),内存使用地址来标识。地址的标识方式通常是[…]的形式。举个🌰,[rbp-8] 的意思是:从寄存器rbp中取出数据,然后减8,把这个结果作为内存的地址,通过这个值就可以对内存中[rbp-8]这个地址进行读写操作了。
rbp这个寄存器是用来存储当前栈的起始地址的,由于栈地址是从大到小,所以起始地址最大,依次相减就能获取可用的栈空间地址。
在往下讲就会牵扯更多的相关的知识了,我们就此打住。
实现一个完整的js JIT太复杂了,我们先挑点儿简单的操作一下,就是实现简单的js的加减乘除。
实现js的加减乘除最简单也是最好的办法就是使用深度遍历遍历AST,然后给每个节点生成机器码。那么怎么使用js来生成机器码呢?毕竟使用js时没有办法直接操作内存。
给大家介绍一下jit.js。 这是一个node.js的包(实际上是一个C++的扩展)。这个包可以生成并且执行机器码:
var jit = require('jit.js');
var fn = jit.compile(function() {
this.Proc(function() {
this.mov('rax', 42); // ‘move rax, 42’
this.Return();
});
});
console.log(fn()); // 42X86 机器码的转换 参见
按照上面的方式书写汇编语言,然后转成x86对应机器码, 比如:mov => 0xb3 (这只是个例子映射对错不论)
使用mmap在内存中开辟一段空间设置为 可执行 状态,然后把上面x86机器码数据写入(然后将起始地址强制转换为 函数指针,接着调用执行就好了)
var jit = require('jit.js');
var fn = jit.compile(function() {
this.Proc(function() {
this.mov('rax', 42);
this.Return();
});
});
console.log(fn.toString()); // function () { [native code] }这里fn调用toString显示的是native code,原因就是上述所描述的,这个fn的执行体并不是js写的,而是从汇编直接转换成机器码然后写入内存强制执行的。
最后只剩下遍历AST tree的工作了,不过由于我们只是要实现加减乘除,因此遍历很容易实现。
我会支持一下几种:
数字字面量({ type: 'Literal', value: 123 })
二元操作符:+ - * % ({ type: 'BinaryExpression', operator: '+', left: ... , right: .... })
一元操作符:- ({ type: 'UnaryExpression', operator: '-', argument: ... })
我们只支持整数暂不支持浮点数。
我们需要处理表达式时会遍历我们所支持的AST node, 生成能够返回rax中的结果的代码。听起来很简单?在动手之前有一件事需要我们谨记:在我们离开一个AST node时我们需要保证所有的寄存器都是干净的(不能污染其他程序),也就是说我们需要保存我们使用过的寄存并且在再次进入时能够恢复他们以前的数据(因为寄存器不是只有我们在使用,而是所有使用cpu的程序都有可能在使用,因此必须保存现场(即保存执行的上下文),否则再次进入就会丢失状态)。不过这个问题CPU已经替我们想好了就是 'pop'和 'push' 两个命令。
下面就是我们的最终的 js 加减乘除版 JIT了:
// main.js
var jit = require('jit.js'),
esprima = require('esprima'),
assert = require('assert');
var ast = esprima.parse(process.argv[2]);
// Compile
var fn = jit.compile(function() {
// This will generate default entry boilerplate
this.Proc(function() {
visit.call(this, ast);
// The result should be in 'rax' at this point
// This will generate default exit boilerplate
this.Return();
});
});
// Execute
console.log(fn());
function visit(ast) {
if (ast.type === 'Program')
visitProgram.call(this, ast);
else if (ast.type === 'Literal')
visitLiteral.call(this, ast);
else if (ast.type === 'UnaryExpression')
visitUnary.call(this, ast);
else if (ast.type === 'BinaryExpression')
visitBinary.call(this, ast);
else
throw new Error('Unknown ast node: ' + ast.type);
}
function visitProgram(ast) {
assert.equal(ast.body.length,
1,
'Only one statement programs are supported');
assert.equal(ast.body[0].type, 'ExpressionStatement');
visit.call(this, ast.body[0].expression);
}
function visitLiteral(ast) {
assert.equal(typeof ast.value, 'number');
assert.equal(ast.value | 0,
ast.value,
'Only integer numbers are supported');
this.mov('rax', ast.value);
}
function visitBinary(ast) {
// Preserve 'rbx' after leaving the AST node
this.push('rbx');
// Visit right side of expresion
visit.call(this, ast.right);
// Move it to 'rbx'
this.mov('rbx', 'rax');
// Visit left side of expression (the result is in 'rax')
visit.call(this, ast.left);
//
// So, to conclude, we've left side in 'rax' and right in 'rbx'
//
// Execute binary operation
if (ast.operator === '+') {
this.add('rax', 'rbx');
} else if (ast.operator === '-') {
this.sub('rax', 'rbx');
} else if (ast.operator === '*') {
// Signed multiplication
// rax = rax * rbx
this.imul('rbx');
} else if (ast.operator === '/') {
// Preserve 'rdx'
this.push('rdx');
// idiv is dividing rdx:rax by rbx, therefore we need to clear rdx
// before running it
this.xor('rdx', 'rdx');
// Signed division, rax = rax / rbx
this.idiv('rbx');
// Restore 'rdx'
this.pop('rdx');
} else if (ast.operator === '%') {
// Preserve 'rdx'
this.push('rdx');
// Prepare to execute idiv
this.xor('rdx', 'rdx');
this.idiv('rbx');
// idiv puts remainder in 'rdx'
this.mov('rax', 'rdx');
// Restore 'rdx'
this.pop('rdx');
} else {
throw new Error('Unsupported binary operator: ' + ast.operator);
}
// Restore 'rbx'
this.pop('rbx');
// The result is in 'rax'
}
function visitUnary(ast) {
// Visit argument and put result into 'rax'
visit.call(this, ast.argument);
if (ast.operator === '-') {
// Negate argument
this.neg('rax');
} else {
throw new Error('Unsupported unary operator: ' + ast.operator);
}
}好了,我们可以运行我们自己的JIT了,原版正装JIT(简陋版) voila(瞧):
$ node ./main.js '1 + 2 * 3'
7嗯,打完收工,往后出去可以吹牛了。接下来的文章我们会讲讲如何使用堆内存以及浮点数的支持!
let mut x = 123;
let mut y = &mut x;
// &mut x中的mut标志的是x对应的内存区域是否可变,mut y 标志的是 y对应的内存区域是否可变,y的内存区域存储的是x对应内存的地址
#[derive(Debug)]
struct MoveStruct {
x: Box<i32>,
y: Box<i64>,
}
fn main() {
let moveTest = MoveStruct{ x: Box::new(23), y: Box::new(43) };
let d = moveTest.x;
let x = moveTest;
// let c = moveTest.y;
println!("hello2dj {:?}", x);
}
// 报错
src/main.rs:64:7
|
63 | let d = moveTest.x;
| - value moved here
64 | let x = moveTest;
| ^ value used here after move
|
= note: move occurs because `moveTest.x` has type `std::boxed::Box<i32>`, which does not implement the `Copy` trait
但若是不在使用moveTest就可以了
let d = moveTest.x;
// let x = moveTest;
let c = moveTest.y;
ok
{integer} cannot be dereferencedlet mut a = 23;
let c = &mut a;
*c = 234;
println!("{}", a)
// 这是会报错的,因为a已经被可变借用了。
let mut a = 23;
let c = &a;
println!("{}", a)
#[derive(Debug)]
struct A {
a: i32,
b: B
}
#[derive(Debug)]
struct B {
c: i32,
d: i32
}
fn main() {
let pair = (0, -2);
let pa = A{a: 2, b: B {c: 23, d:23}};
// 试一试 ^ 将不同的值赋给 `pair`
let A { a:_, b: d } = pa; // 此处相当于move pa.b 给了d
println!("Tell me about {:?}", pair);
// match 可以解构一个元组
match pa {
// 绑定到第二个元素, 此处也是如此把 pa.d move给了 d
A{ a: _, b: d} => println!("First is `0` and `y` is `{:?}`", d),
_ => println!("It doesn't matter what they are"),
// `_` 表示不将值绑定到变量
}
println!("Tell me about {:?}", pa);
}
// 上面编译是会报错的
use partially moved value: pa
let c : i32 = match result {
Err(err) => {
2
}
Ok(record) => {
1
}
};
// 都带上分号则c的类型是();
let c : () = match result {
Err(err) => {
2;
}
Ok(record) => {
1;
}
};
impl<'a, E: Error + 'a> From<E> for Box<Error + 'a>
这意味着我们都可以把Error类型转换到Box
// my.rs
// main.rs
mod my;
....
fn return_closure(idx: Arc<AtomicUsize>) -> Box<FnOnce() -> () + Send + Sized> { // Sized 报错 因为Sized 不是auto traits
Box::new(move|| {
idx.fetch_add(10, Ordering::SeqCst);
})
}
fn foo<'a>(x: &'a i32)
fn foo<'a, 'b>(x: &'a i32, y: &'b i32)
fn foo<'a>(x: &'a i32) -> &'a i32
fn foo<'a>(x: &'a i32, x: &'b i32) -> &'a i32
fn foo(&'a self) -> &'a str
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str
where T: Display
{
println!("Announcement! {}", ann);
if x.len() > y.len() {
x
} else {
y
}
}
struct A<T> { // T可以是&类型,就相当于&'a SomeType,不需要在另外声明
a: T,
}
cannot move out of borrowed content
use std::sync::Arc;
struct A<T> {
it: Arc<T>, // 这里的T可以是引用那么他的生命周期是如何确定的
ie: B<T>,
}
struct B<T> {
it: Arc<T>,
}
fn main() {
let c = 32;
let d = &A{
it: Arc::new(23),
ie: B { it: Arc::new(23) },
};
let e = d.it;
// 会报错的
| let e = d.it;
| ^---
| |
| cannot move out of borrowed content
| help: consider using a reference instead: `&d.it`
error: aborting due to previous error
error: Could not compile `playground`.
}
见上面的代码,若d不是引用则可以move,但是move过后的d是不允许在使用,只能再move出去其他字段,若是再使用的话回报use of partially moved value: d,这个错。
解决引用无法move字段的方法
通过他我们知道了,当我们的trait写是self时,那我们的self的类型就是实现的self,比如我们的trait A接收的是self参数,然后我们给i32实现了trait A, 那么接收者就必须得是i32, 再好比我们给&'a i32实现了trait A,那么接收者就的是& i32。总结就是:trait 给谁实现了比如B, 那么方法的self的类型就是B。
trait Operation {
fn operation(self);
}
impl Operation for u32 {
fn operation(&self){ // 这里就会报错因为接受者参数写成了&self, 而不是self,这里的self就是u32
self;
}
}
// 调用的时候就可以使用
let a = 32u32;
a.operation();
// 甚至使用&来调用
let a = 32u32;
let d = &a;
d.operation();
通过上面的栗子,我们可以看到,rust在我们进行方法的调用的时候回自动给我们解引用,但当我们的类型是不可copy的时候,自动解引用就会触发move,那么就会报错了,见下
trait Operation {
fn operation(self);
}
struct Container<T> {
x:T
}
impl<T> Operation for Container<T> {
fn operation(self){
println!("dengjie");
self;
}
}
fn main() {
let a = Container {
x: 32u32,
};
let d = &a;
d.operation(); // 报错我们不可以把借用的内容move出去, 除非我们Container实现了Copy.
// cannot move out of borrowed content
}
原因是 Box是分配在堆上的空间,若是分别move,会造成堆空间的重复释放,而struct的栈上空间就不存在这个问题
https://joshleeb.com/posts/rust-traits-and-trait-objects/
https://stackoverflow.com/questions/28519997/what-are-rusts-exact-auto-dereferencing-rules/28552082
定义方法实现时 方噶的receiver只能是self, &self, &mut self, 若是其他的没有self receiver 则没有限制, 含有self的只能是上面三种形式
调用时rust会自动添加ref或者dref来进行适配
struct A {
a: i32
}
impl A {
fn say(&self) {
println!("{:?}", self.a);
}
}
fn main() {
let c = &&&A {a : 234};
c.say();
}
如上我们给A 定义了一个&self,但我们的调用确是&&&A, rust 会自行derf到&A
当然 A和会继承Deref的方法,因为rust在调用方法时会自动去适配Deref A的
对一个不能copy的Struct既有self又有&self调用是会报错的
struct A {
a: Box<i32>,
b: Box<String>,
}
fn test() {
let a = A{a..., b...};
let d = a.a; // ok
let e = &a; // error
let c = a.b; // ok
let a = Box::new(A{a.., b...});
let d = a.a; // ok; a partial moved
let e = a.b; // used moved value a;
}
struct A {
a: Box<i32>,
}
fn (c: &mut A) {
let e = mem::replace(&mut c.a, Box::new(0)) // error, 不允许move 借用的content
}
struct A {
a: Box<i32>,
}
fn (c: &A) {
let e = c.a // error, 不允许move 借用的content
}
https://zhuanlan.zhihu.com/p/24486743
不写这些getter,直接访问field。
这种办法是可以通过的。原因在于:Rust对于内部不同的访问路径是会分开记录borrow的,所以不会有任何问题。
证明move是copy的代码
https://play.rust-lang.org/?gist=2aafa34d69af1bdb04b0299d2dfb4f87&version=stable&mode=debug&edition=2015
#[derive(Debug)]
struct A<'a> {
array: [i32; 4],
a: &'a i32,
}
fn main() {
let c = [2i32, 3,4,5];
let mut a = A{array: c, a: &c[0]};
let mut d = a;
d.array[0] = 1234;
// *(d.a) = 12455;
println!("{:?}, {:?}", d.a, d);
}
// 结果
// 2, A { array: [1234, 3, 4, 5], a: 2 }
recap
Whew! As we can see, almost all of these rules talk about Self. A good intuition is “except in special circumstances, if your trait’s method uses Self, it is not object-safe.”
trait object's default lifetime is 'static, the captures must be 'static, otherwise there will be invalidate reference.
fn crash_rust() {
let mut p = Processor::new();
{
let s = "hi".to_string();
p.set_callback(|| println!("{}", s.len()));
}
// access to destroyed "s"!
p.invoke();
}
when we call invoke, the s has alreay been release.
match a {
1 => { 32; }
_ => { false }
// _ => { return flase; }
}
此时就会报错因为1对应的分支match返回 (),而_对应的分支返回false; 是编译不过的。
As previously mentioned, macro processing in Rust happens after the construction of the AST. As such, the syntax used to invoke a macro must be a proper part of the language's syntax.
ident: 标识符,用来表示函数或变量名 如 a, b, foo等等 'an identifier. Examples: x; foo.'
expr: 表达式 a + b, a * b, foo(23)等, '2 + 2; if true then { 1 } else { 2 }; f(42)' 'an expression. Examples: 2 + 2; if true then { 1 } else { 2 }; f(42).'
block: 代码块,用花括号包起来的多个语句 {}, () 'a brace-delimited sequence of statements. Example: { log(error, "hi"); return 12; }.'
pat: 模式,普通模式匹配(非宏本身的模式)中的模式,例如 Some(t), (3, 'a', _), let, match, 'Some(t); (17, 'a'); _.' 'a pattern. Examples: Some(t); (17, 'a'); _.'
path: 路径,注意这里不是操作系统中的文件路径,而是用双冒号分隔的限定名(qualified name),如 std::cmp::PartialOrd 'a qualified name. Example: T::SpecialA.'
tt(token tree): 单个语法树 (可以是任意的rust语法)'a single token tree.'
ty(type): 类型,语义层面的类型,如 i32, char 'a type. Examples: i32; Vec<(char, String)>; &T.'
item: 条目,function, struct, module, 'fn foo() { }; struct Bar;' 'an item. Examples: fn foo() { }; struct Bar;.'
meta: 元条目 如#[...] and #![...], 'cfg(target_os = "windows")' 'a "meta item", as found in attributes. Example: cfg(target_os = "windows").'
stmt: 单条语句,如 let a = 42; 'a single statement. Example: let x = 3.'
expr: variables must be followed by one of: => , ;
ty and path variables must be followed by one of: => , : = > as
pat variables must be followed by one of: => , =
Other variables may be followed by any token.
item: anything.
block: anything.
stmt: => , ;
pat: => , = if in
expr: => , ;
ty: , => : = > ; as
ident: anything.
path: , => : = > ; as
meta: anything.
tt: anything.
recognise_tree!(expand_to_larch!());
这里expand_to_larch也是个宏 可是对于宏来书输入就是token tree, 因此是不会展开expand_to_larch的;
https://danielkeep.github.io/tlborm/book/mbe-min-captures-and-expansion-redux.html
By parsing the input into an AST node, the substituted result becomes un-destructible
当我们把token tree 解析成AST node以后就无法再结构进行匹配了,因为AST node是个完整的语法,破坏了就没有语义了, 而token 还没有进行语义分析呢
词法解析器 -> token tree
语法解析器 -> AST node
macro_rules! capture_then_what_is {
(#[$m:meta]) => {what_is!(#[$m])};
}
macro_rules! what_is {
(#[no_mangle]) => {"no_mangle attribute"};
(#[inline]) => {"inline attribute"};
($($tts:tt)*) => {concat!("something else (", stringify!($($tts)*), ")")};
}
fn main() {
println!(
"{}\n{}\n{}\n{}",
what_is!(#[no_mangle]),
what_is!(#[inline]),
capture_then_what_is!(#[no_mangle]),
capture_then_what_is!(#[inline]),
);
}
就好比 下面的 '3 + 5', 再直接用match_tokens 匹配,那还能拆开为a + b, 但经过 capture_then_match_tokens 匹配后就是个整体的expr,再去用match_tokens进行匹配也是不行的。
macro_rules! capture_then_match_tokens {
($e:expr) => {match_tokens!($e)};
}
macro_rules! match_tokens {
($a:tt + $b:tt) => { {println!("{:}, {:}", stringify!($a), stringify!($b)); "got an addition"} };
(($i:ident)) => { { println!("{:}", stringify!($i)); "got an identifier" }};
($($other:tt)*) => { { println!("{:}", stringify!($($other)*)); "got something else"} };
}
fn main() {
println!("{}\n{}\n{}\n",
match_tokens!((caravan)),
match_tokens!(3 + 6),
match_tokens!(5));
println!("{}\n{}\n{}",
capture_then_match_tokens!((caravan)),
capture_then_match_tokens!(3 + 6),
capture_then_match_tokens!(5));
}
#[derive(Clone)]
pub enum Entry<K,V> {
Empty,
Full(K, V, u64),
Ghost(K, u64),
}
impl<K,V> Entry<K,V> {
#[inline]
#[allow(dead_code)]
pub fn is_empty(&self) -> bool {
match *self {
Entry::Empty => true,
_ => false
}
}
pub fn is_full(&self) -> bool {
match *self {
Entry::Full(..) => true,
_ => false
}
}
pub fn is_ghost(&self) -> bool {
match *self {
Entry::Ghost(..) => true,
_ => false
}
}
pub fn matches<Q: PartialEq<K>>(&self, key: &Q, hash: u64) -> bool {
match *self {
Entry::Empty => true,
Entry::Full(ref k, _, h) | Entry::Ghost(ref k, h) => hash == h && key == k,
}
}
pub fn key(&self) -> Option<&K> {
match *self {
Entry::Full(ref k, _, _) => Some(k),
_ => None,
}
}
pub fn value(&self) -> Option<&V> {
match *self {
Entry::Full(_, ref v, _) => Some(v),
_ => None,
}
}
}
当我们调用is_empty, self并不会move因为他只是匹配看看self是不是Entry::Empty类型,is_full也是,他是匹配的Entry::Full(..)类型,并没有move,等, Entry::Full(..) === Entry::Full(,,_),一个都不move或者引用,只有使用了self里的字段才会move或者引用
macro_rules! dead_rule {
($e:expr) => { ... };
($i:ident +) => { ... };
}
考虑当以dead_rule!(x+)形式调用此宏时,将会发生什么。解析器将从第一条规则开始试图进行匹配:它试图将输入解析为一个表达式;第一个标记(x)作为表达式是有效的,第二个标记——作为二元加的节点——在表达式中也是有效的。
至此,由于输入中并不包含二元加的右手侧元素,你可能会以为,分析器将会放弃尝试这一规则,转而尝试下一条规则。实则不然:分析器将会panic并终止整个编译过程,返回一个语法错误。
由于分析器的这一特点,下面这点尤为重要:一般而言,在书写宏规则时,应从最具体的开始写起,依次写至最不具体的。
macro_rules! capture_expr_then_stringify {
($e:expr) => {
stringify!($e)
};
}
fn main() {
println!("{:?}", stringify!(dummy(2 * (1 + (3)))));
println!("{:?}", capture_expr_then_stringify!(dummy(2 * (1 + (3)))));
}
> "dummy ( 2 * ( 1 + ( 3 ) ) )"
> "dummy(2 * (1 + (3)))"
个人理解token tree的解析是中序 而 AST的解析是先序
«a» «+» «b» «+» «( )» «+» «e»
╭────────┴──────────╮
«c» «+» «d» «[ ]»
╭─┴─╮
«0»
┌─────────┐
│ BinOp │
│ op: Add │
┌╴│ lhs: ◌ │
┌─────────┐ │ │ rhs: ◌ │╶┐ ┌─────────┐
│ Var │╶┘ └─────────┘ └╴│ BinOp │
│ name: a │ │ op: Add │
└─────────┘ ┌╴│ lhs: ◌ │
┌─────────┐ │ │ rhs: ◌ │╶┐ ┌─────────┐
│ Var │╶┘ └─────────┘ └╴│ BinOp │
│ name: b │ │ op: Add │
└─────────┘ ┌╴│ lhs: ◌ │
┌─────────┐ │ │ rhs: ◌ │╶┐ ┌─────────┐
│ BinOp │╶┘ └─────────┘ └╴│ Var │
│ op: Add │ │ name: e │
┌╴│ lhs: ◌ │ └─────────┘
┌─────────┐ │ │ rhs: ◌ │╶┐ ┌─────────┐
│ Var │╶┘ └─────────┘ └╴│ Index │
│ name: c │ ┌╴│ arr: ◌ │
└─────────┘ ┌─────────┐ │ │ ind: ◌ │╶┐ ┌─────────┐
│ Var │╶┘ └─────────┘ └╴│ LitInt │
│ name: d │ │ val: 0 │
└─────────┘ └─────────┘
从上面可以看出token自左向右中序,AST先根 先序
当出现在表达式中时,macro展开也必须是表达式,若是单个表达式则一层{} or [] 即可,若是多个则必须再嵌套一层{} 来表明是表达式
macro_rules! foo {
() => {{
...
}}
}
macro的输入是single token tree即匹配的也是single token tree, 输出是AST, 也就是说不可以把一个一个宏的展开结果输入给另一个宏
如书中的例子
e, init_array!(@accum 2, e) // 这就是个残缺的 因此不合法, e, 加个啥?
The only basic tokens that are not leaves are the "grouping" tokens: (...), [...], and {...}. These three are the interior nodes of token trees, and what give them their structure. To give a concrete example, this sequence of tokens:
a + b + (c + d[0]) + e
按照上面所说的 所有的tokens都是token trees 大部分也都是叶子,只有 (). {}. []不是,因此 上面的那个表达式一共有 7 个 single token tree;
a, +, b, +, (c + d[0]), +, e
怎么推断的呢? $(($t:tt)*) 有多少个$t就有多少个 single token tree
让机器懂的代码很简单,让人懂的代码就很难了。 其实代码也是在写作(虽然也大不相同),我现在发现能将自然科学和人文科学完美结合的就是计算机科学了。因为一段正确的代码需要正确的算法逻辑甚至是数学证明,事实上计算机科学发展的基础就是数。可是代码追求的不仅仅是正确,还得是可维护的,就是说是人可以读懂的。那么这时候就要看你的英语功底了,其实也不尽然,但是良好英语功底得是有的,只要你想写出大家可以看懂的代码(此处省略一万字别较真...)。
关于代码写作,大部分不是在写完整的句子,反而大部分是在写短语,是在给事物进行命名处理。而是否写的好,这里有两方面的问题:
看了上面两个问题就会发现,你写了一个正确代码,但却不一定写得出可读的代码。接下给大家看一些关于命名原则
好的栗子:daysDateRange, flightNumber, carColor
坏的栗子:days,dRange,temp,data, aux
关于这个原则,是视具体环境而变化的,比如data这个命名,有的时候我需要的就是data啊,越往底层走就越会出现像data这种抽象的命名,越往业务逻辑层走就越会出现像carColor这种具体的命名
坏的栗子:howLonDoesItTakeToOpenTheDoor, howBigIsTheMaterial...
好的栗子:timeToOpenTheDoor, MaterialSize
用缩写没问题,关键得有注释,或者是大家都知道的通用缩写
在需要的时候适当使用匈牙利标记法。
举个栗子: 你需要根据苹果的颜色来区分是否成熟 你可这么来命名
red_apples, yellow_apples ...
这条待定
保持一致性
如果采用驼峰式就都使用驼峰式
把业务领域的术语对应到你所熟知的命名上去
栗子: If your customer just considers “order” an “order” that has been approved, don’t call “order” to a non approved one in your code, call it “nonApprovedOrder” 同上
黄金条例: 花一些时间再命名上(我觉得这条是最靠谱的,我也要贯彻执行)
当你近乎不加思索的使用一个变量命名的时候,你基本上就已经选择了一个不好的命名。
反之,你总是在向着好的命名前进
一句话对我们的代码持续性重构,以及持续性的测试。因此我们需要大量的测试用例,是的,测试用例。
-----------------------------------------------(华丽的分割线)
在元素面板中我们是可以拖拽任意元素到页面中其他位置的(这个大家应该都知道。。。)
在元素面板中选中元素,然后就可以在控制台中使用 $0 引用它,神奇了
大吃一惊还有这等操作(管用)
在控制台中输入 $_ 引用上次操作结果
他要$?就更神奇了(管用)
这个大家都知道,直接截图就好了
在看下一个
使用 cmd-click(ctrl-click on windows) 组合点击一个元素面板中的 css 属性就会跳转到 Source panel 中(连续两连点击才可以哦)
不错不错(管用)
在元素面板右侧修改样式,然后使用上面方法跳 source panel 中,就会看到 css 源文件,右击文件名字,save as 保存到本地
选中一个元素然后按组合键 cmd-shift-p(or crtl-shift-p on windows)打开命令菜单(command menu), 接着输入 screenshot 选择 Capture node screenshot
有意思的功能, 可惜我试验失败了。。。(66.0.3359.139chrome 版本,大家可以试试),其实里面的 screenshot 还有另外两个 capture full siz screenshot(全截,我也失败了), capture screenshot 接的是当文档展示的区域我成功了
多行输入执行,啥也不说了,有用(管用)
每次换行使用 shit+enter 哦
清理使用 ctrl-l or cmd-k(管用)
在 source panel 中
cmd-o(ctrl-o on windows) 展示当前页面加载的所有文件
cmd-shift-o(ctrl-shift-o in windows) 展示当前文件的符号表(属性,函数以及类)
ctrl-g 调到当前文件的指定行
亲测管用
添加一个表达式到 debug session 中,不用手动计算了
管用, 在 source panel 中,若是没有 consle 面板,右键-> evaluate in console 即可
可以在 source panel 中的右侧看到 XHR/FETCH breakpoints 中添加断点,不知道请 ajax 啥时候发的,没问题,他可以帮你。。。
并且我还在下面发现了 Event Listener Breakpoint,而它可以带来的断点位置是在是太多了,比如: 动画(animation), Canvas, Clipboard, DOM Mutaion, keyboard, 哎呀太多了,大家可以亲自试一试
右键选中的元素,选择 break on 展开后会有 subtree modifications, 就是说如果有脚本修改了子元素,断点就会触发,还有 atrribute modification, 以及 node removal
cmd-shfit-p 打开的命令行里面的有用命令(还有更多的等待大家一起探索)
开发之前,要保证产品逻辑是通路,断路的产品逻辑是无法讲究体验的,即使上了线也是要打补丁,但很难补出一个apache。
出了问题,打补丁也只是hack, 产品逻辑通路的捋顺才是根本。
bug总是根源,要么是技术,要是产品。不但要捋清楚bug来源,还捋清楚服务边界,捋清楚边界不是为了找出背锅侠,根本目的是杜绝出现无人维护以及无人负责的项目。
我又要先上图了:
很多时候大家都在问我"hot" 和 "cold" observables的区别到底是啥?,或者是一个observable到底是单播还是多播?人们对于’Rx.Observable‘的内部工作原理似乎是非常迷惑的。当被问到如何描述一个observable的时候,人们经常说的就是这样的, “他是流(streams)”或者是“他是个类似promises的东西”。但事实上,我在很多场合以及一些公开演讲上都有讲过这些东西。
和promise作比较是有必要的,但不幸的是,恐怕不会有太大的用处。这两者都是异步原语,并且promises已经被js社区广泛接受和使用了,总体来说这是个好的开始。通过对比promise的‘then’和observable的’subscribe‘,我们可以看到两者在立即执行和延时执行上的区别,还可以看到observable的取消执行和可重用性,当然还有其他很多的东西。通过这种比较的方式学习对于observable的初学者来说是很容易接受的。但是这里有一个问题:就是这两者的不同之处远远大于类似之处。Promises都是多播的,Promise的resolve和reject都是异步的。当大家以处理promise的方式处理observables的时候,大家会发现有时候结果并不像预期的那样。Observables有时候是多播的,有时候又不是,并且通常是异步的。真的,有时候我也在责备自己,因为我有可能再使这种误解被延续。
若果你想彻底搞懂observable,你可以自己实现一个简单的observable。真的,这并没有听起来那么难。对于一个observable, 当我们去观察他的最小实现时会发现他只是一个拥有特定(specific,具体,指定,特定)目的的函数,而这个函数又有自己特定的类型。(就是一个具有特定目的的特定类型的函数)
/**
* 一个虚假的data source
*/
class DataSource {
constructor() {
let i = 0;
this._id = setInterval(() => this.emit(i++), 200);
}
emit(n) {
const limit = 10;
if (this.ondata) {
this.ondata(n);
}
if (n === limit) {
if (this.oncomplete) {
this.oncomplete();
}
this.destroy();
}
}
destroy() {
clearInterval(this._id);
}
}
/**
* 我们的 observable
*/
function MyObservable(observer) {
const datasource = new DatSource();
datasource.ondata = (e) => observer.next(e);
datasource.onerror = (e) => observer.error(err);
datasource.oncomplete = () => observer.complete();
return () => {
datasource.destroy();
}
}
/**
* 接下来我们可以使用上面的observable
*/
const unsub = myObservable({
next(x) { console.log(x); },
error(err) { console.error(err); },
complete() { console.log('done'); }
});
正如你看到的一样,他并不复杂,他只是一个简单的契约
当我们谈论Rxjs或者响应式编程的时候,我们大部分时间把observables放在首位,但事实上observer的实现才是这类响应式编程的核心工作者(workhorse驮马驮东西的马)。Observables是惰性的(inert)他们仅仅是函数,他们就在那里不动一直到你’订阅‘他们,’订阅‘后他就会建立你的observer(就是把observer与producer连接在一起),至此他们的活就干完了,然后就又变回了原始的状态等着被其他人再次调用, 另一方面observers则是保持在活跃状态,监听着producer的事件。
你可以用一个带有’next‘, 'error'以及’complete‘等方法的js 对象来订阅observable,但实际上这仅仅是个开始。在rxjs5我们提供了一些保证,下面是一些非常重要的保证:
为了达到以上目的,我们需要把你的observer包裹到一个SafeObserver中,这个SafeOberver会强制实现以上保证。为了实现2, 我们需要跟踪是否发生了complete 或者 error。为了实现3,我们需要让我们的SafeObserver知道消费者在什么时候调用了unsubscribe, 等等。
因此如果我们真的想要实现完整的SafeObserver,那将是很庞大的,因此在此文章中就不在具体详述,简要写一下怎么用。具体的实现可以看一下
jsbin
/**
* A contrived data source to use in our "observable"
* NOTE: this will clearly never error
*/
class DataSource {
constructor() {
let i = 0;
this._id = setInterval(() => this.emit(i++), 200);
}
emit(n) {
const limit = 10;
if (this.ondata) {
this.ondata(n);
}
if (n === limit) {
if (this.oncomplete) {
this.oncomplete();
}
this.destroy();
}
}
destroy() {
clearInterval(this._id);
}
}
/**
* Safe Observer
*/
class SafeObserver {
constructor(destination) {
this.destination = destination;
}
next(value) {
// only try to next if you're subscribed have a handler
if (!this.isUnsubscribed && this.destination.next) {
try {
this.destination.next(value);
} catch (err) {
// if the provided handler errors, teardown resources, then throw
this.unsubscribe();
throw err;
}
}
}
error(err) {
// only try to emit error if you're subscribed and have a handler
if (!this.isUnsubscribed && this.destination.error) {
try {
this.destination.error(err);
} catch (e2) {
// if the provided handler errors, teardown resources, then throw
this.unsubscribe();
throw e2;
}
this.unsubscribe();
}
}
complete() {
// only try to emit completion if you're subscribed and have a handler
if (!this.isUnsubscribed && this.destination.complete) {
try {
this.destination.complete();
} catch (err) {
// if the provided handler errors, teardown resources, then throw
this.unsubscribe();
throw err;
}
this.unsubscribe();
}
}
unsubscribe() {
this.isUnsubscribed = true;
if (this.unsub) {
this.unsub();
}
}
}
/**
* our observable
*/
function myObservable(observer) {
const safeObserver = new SafeObserver(observer);
const datasource = new DataSource();
datasource.ondata = (e) => safeObserver.next(e);
datasource.onerror = (err) => safeObserver.error(err);
datasource.oncomplete = () => safeObserver.complete();
safeObserver.unsub = () => {
datasource.destroy();
};
return safeObserver.unsubscribe.bind(safeObserver);
}
/**
* now let's use it
*/
const unsub = myObservable({
next(x) { console.log(x); },
error(err) { console.error(err); },
complete() { console.log('done')}
});
/**
* uncomment to try out unsubscription
*/
// setTimeout(unsub, 500);
若是我们把observables封装成一个class或者 一个对象,那么我们就可以很方便的把SafeObserver当做匿名的obserers传入(或者是函数就好像rxjs里的签名似的subscribe(fn, fn, fn))并且以更好的符合人体工程学的方式提供给开发者。通过在Observable的’subscribe‘中把SafeObserver以内在的形式创建, Observables 又可以以一种简单的方式来使用了:
const myObservable = new Observable((observer) => {
const datasource = new DataSource();
datasource.ondata = (e) => observer.next(e);
datasource.onerror = (err) => observer.error(err);
datasource.oncomplete = () => observer.complete();
return () => {
datasource.destroy();
};
});
你可能已经注意到了这个例子和我们的第一个例子是类似的。但是他更容易阅读和理解。具体实现可见jsbin但在jsbin里面我们可以看到在 new Observable的时候他把 observable又用safeObservable包裹了一下显然是没有必要的,因为我们在调用myObserable的subscribe的时候已经把observer用safeObservable包装过了
class Observable {
constructor(_subscribe) { // 我们在new Observable的时候传递的函数其实才是真正的
// subscribe
this._subscribe = _subscribe; // 保存起来当我们调用subscribe的时候回来调用他的
}
subscribe(observer) { // 你看包装过了
const safeObserver = new SafeObserver(observer);
return this._subscribe(safeObserver);
}
}
Rxjs中操作就是一个接收源observable,然后返回一个新的observable, 并且在你订阅他(指新的observable)的时候,他(操作符)会去订阅源observable。我们可以实现一个简单的如下:jsbin
function map(source, project) {
return new Observable(observer) => {
const mapObserver = {
next: (x) => observer.next(project(x)),
error: (err) => observer.error(err),
complete: () => observer.complete()
};
return source.subscribe(mapObserver);
}
}
这里最重要的地方是这个操作符做了什么: 当你订阅他所返回的observable的时候,他创建了一个’mapObserver‘去执行工作,并且把'observer'和mapObserver连在了一起。构造操作符的链式调用仅仅是创建了一个模板,用于在订阅时把observes连接在一起。
如果我们把所有的操作符都实现为独立的函数,那么我们的操作符链式调用会很丑陋
map(map(myObservable,(x) => x + 1), (x => x + 2)
那么我们可以想象一下如果我们来个5,6操作符,那个咋办?基本上时没法使用的了。
我们还可以使用reduce来简化一下具体实现参考jsbin
pipe(myObservable, map(x => x + 1), map(x => x + 2));
理想情况下,我们希望能够使用如下的方式进行链式调用
myObservable.map(x => x + 1).map(x => x + 2);
幸运的是,我们已经把Observable包装成了一个class, 因此我们可以把操作符作为class的方法实现:jsbin
/**
* Observable basic implementation
*/
class Observable {
constructor(_subscribe) {
this._subscribe = _subscribe;
}
subscribe(observer) {
const safeObserver = new SafeObserver(observer);
safeObserver.unsub = this._subscribe(safeObserver);
return safeObserver.unsubscribe.bind(safeObserver);
}
}
// 在此看到了map的实现
Observable.prototype.map = function (project) {
return new Observable((observer) => {
const mapObserver = {
next: (x) => observer.next(project(x)),
error: (err) => observer.error(err),
complete: () => observer.complete()
};
return this.subscribe(mapObserver);
});
}
现在我们就得到了我们想要的语法了。这样做还有一个好处,就是我们子类化一些特定Observable(好比包裹Promise或者需要一些静态数值时)
牢记此话,Observables are a function that take an observer and return a function. 不多也不少。如果你写了一个函数接收一个observer然后返回一个函数,那么他是同步的还是异步的呢?都有可能,他是一个函数,任何函数的行为都取决与他是如何实现的。因此在处理Observable时,就把他看作是一个你传入的函数的引用, 没有什么魔法,stateful alien type(有状态的外部类型)。当你在使用操作符的链式调用的时候,你所做的其实就是组合一个函数,建立observers的连接,并将它们连接在一起,以及将数据传递给你的observer。
本文中Observable返回都是一个函数,而在Rxjs回哦在那个以及es-observable规范中返回都是Subscription对象,他有一个更好的设计。但在这里这么写保持了文章的简洁性。
// This is going to behave strangely
const source$ = Observable.interval(1000).share();
const mapped$ = source$.map(x => {
if (x === 1) {
throw new Error('oops');
}
return x;
});
source$.subscribe(x => console.log('A', x));
mapped$.subscribe(x => console.log('B', x));
source$.subscribe(x => console.log('C', x));
// "A" 0
// "B" 0
// "C" 0
// "A" 1
// Uncaught Error: "oops"
另一个解决的办法就是使用observeOn
const source$ = Observable.interval(1000)
.share()
.observeOn(Rx.Scheduler.asap); // magic here
从subject下游抛出的同步错误会杀掉整个subject(尚未验证,不太明白说的是啥 // TODO: 验证 )
大神说他自己错了,Promise的错误处理才是个好主意。
将来的版本或许会支持error trap(但目前我是5.5.5了,也没支持)
有图有真相,最近的rxjs的一个issue的讨论

可能像promise那样全是异步的也不是必须的(shrug耸一下肩)。
只要有个统一意见就好,不要太多样化,以防可读性太差
每个项目无论大小,都有自己的约定俗称,这个一定是要统一,比如:更新时间是交给人,还是ORM,还是数据库默认值,一定要有统一。
type A interface {
Read(p []byte) (n int, err error)
_XXXAA@@()
}
这个位置我觉得可以学习一下pony语言增加结构型接口和命名接口 参见, 就是即有像go的interface又有rust的traits。
package main
import (
"fmt"
)
func main() {
pase_student()
}
type student struct {
Name string
Age int
}
func pase_student() {
m := make(map[string]*student)
stus := []student{
{Name: "zhou", Age: 24},
{Name: "li", Age: 23},
{Name: "wang", Age: 22},
}
for i, stu := range stus {
m[stu.Name] = &stu; // 应该改为m[stu.Name] = &stus[i]
}
for _, va := range m {
fmt.Printf("%p \n", va)
}
}
stus 是个 map, stu 并不会每次新生成一个, 其实循环时每次都是相同的 stu, 而且 golang 每次都是 copy 语义,你再看一眼会发现,给 map 赋值的是指针,那就意味着无论你如何改变 map 都会是相同的值。:= 多次声明不会重新定义新的变量, 可见规范
见下:
field1, offset := nextField(str, 0)
field2, offset := nextField(str, offset) // redeclares offset
a, a := 1, 2 // illegal: double declaration of a or no new variable if a was declared elsewhere
select {
case <- stopCh:
fmt.Println("go")
default:
fmt.Println("come")
}
channel 的使用,当 channel 是非缓冲的时候他就是阻塞读与写的, 所以使用 channel 的时候要小心同步阻塞,导致死锁 game over
ch := make(chan string)
ch <- "23" // 此时就会阻塞
// a <- ch 单写他也是会阻塞的
所以要小心不要出现只有读或者只有写的 channel 若是出现的话,分布在不同 goroutine 中时就会导致 golang 死锁,主在等子完成可是子阻塞在了 channel 读或者写上了。
package main
import (
"time"
"math/rand"
"sync"
"log"
"strconv"
)
func main() {
rand.Seed(time.Now().UnixNano())
log.SetFlags(0)
// ...
const MaxRandomNumber = 100000
const NumReceivers = 10
const NumSenders = 1000
wgReceivers := sync.WaitGroup{}
wgReceivers.Add(NumReceivers)
// ...
dataCh := make(chan int, 100)
stopCh := make(chan struct{})
// stopCh is an additional signal channel.
// Its sender is the moderator goroutine shown below.
// Its reveivers are all senders and receivers of dataCh.
toStop := make(chan string, 1)
// 设为缓冲1是为了防止moderator还未准备好就停止了
// the channel toStop is used to notify the moderator
// to close the additional signal channel (stopCh).
// Its senders are any senders and receivers of dataCh.
// Its reveiver is the moderator goroutine shown below.
var stoppedBy string
// moderator
go func() {
stoppedBy = <- toStop // part of the trick used to notify the moderator
// to close the additional signal channel.
close(stopCh)
}()
// senders
for i := 0; i < NumSenders; i++ {
go func(id string) {
for {
value := rand.Intn(MaxRandomNumber)
if value == 0 {
// here, a trick is used to notify the moderator
// to close the additional signal channel.
select {
case toStop <- "sender#" + id:
default:
}
return
}
// the first select here is to try to exit the
// goroutine as early as possible.
select {
case <- stopCh:
return
default:
}
// 为什么要在前面在加一个select stopCh呢? 因为若是到了这一步由于select的随机性(此时stopCh和dataCh都处于活跃状态select是随机选取的),有可能会继续发送,而没有选择stopCh
select {
case <- stopCh:
return
case dataCh <- value:
}
}
}(strconv.Itoa(i))
}
// receivers
for i := 0; i < NumReceivers; i++ {
go func(id string) {
defer wgReceivers.Done()
for {
// same as senders, the first select here is to
// try to exit the goroutine as early as possible.
select {
case <- stopCh:
return
default:
}
select {
case <- stopCh:
return
case value := <-dataCh:
if value == MaxRandomNumber-1 {
// the same trick is used to notify the moderator
// to close the additional signal channel.
select {
case toStop <- "receiver#" + id:
default:
}
return
}
log.Println(value)
}
}
}(strconv.Itoa(i))
}
// ...
wgReceivers.Wait()
log.Println("stopped by", stoppedBy)
}
a = [1,2,34]
t := a[1:3] // ok
c := (&a)[1:2] // ok
func main() {
runtime.GOMAXPROCS(1)
wg := sync.WaitGroup{}
wg.Add(20)
for i := 0; i < 10; i++ {
go func() {
fmt.Println("i: ", i)
wg.Done()
}()
}
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Println("i: ", i)
wg.Done()
}(i)
}
wg.Wait()
}
第一个打印的 i 都是 10, 因为他们打印的都是同一个变量 i。
先来假设出结论,帮助大家理解原因:
多个 defer 的执行顺序为“后进先出”;
defer、return、返回值三者的执行逻辑应该是:return 最先执行,return 负责将结果写入返回值中;接着 defer 开始执行一些收尾工作;最后函数携带当前返回值退出。
如何解释两种结果的不同:
上面两段代码的返回结果之所以不同,其实从上面第 2 条结论很好理解。
a()int 函数的返回值没有被提前声名,其值来自于其他变量的赋值,而 defer 中修改的也是其他变量,而非返回值本身,因此函数退出时返回值并没有被改变。
b()(i int) 函数的返回值被提前声名,也就意味着 defer 中是可以调用到真实返回值的,因此 defer 在 return 赋值返回值 i 之后,再一次地修改了 i 的值,最终函数退出后的返回值才会是 defer 修改过的值。
defer 是在函数结束前执行的,当返回值的临时变量赋给外部时才算调用结束吧!a = fn(2) 当把值给了 a 才算结束
我们可以这么理解 return 肯定先执行执行的结果就是把返回值计算出来并且赋值给返回值所存在的临时变量, 但我们命名返回值的时候,返回值并不是临时变量而是函数中声明的变量
参见签名
func append(slice []Type, elems ...Type) []Type
错误的栗子
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3}
s2 := []int{4, 5}
s1 = append(s1, s2)
fmt.Println(s1)
} // 错误因为 append接下来的参数是以一个一个传递的切片中的元素,而不是切片 正确的是 s1 = append(s1, ...s2)
就是说属性名字不同,类型不同或者顺序不同都是不能比较的
func main() {
sn1 := struct {
age int
name string
}{age: 11, name: "qq"}
sn2 := struct {
age int
name string
}{age: 11, name: "qq"}
if sn1 == sn2 {
fmt.Println("sn1 == sn2")
}
sm1 := struct {
age int
m map[string]string
}{age: 11, m: map[string]string{"a": "1"}}
sm2 := struct {
age int
m map[string]string
}{age: 11, m: map[string]string{"a": "1"}}
if sm1 == sm2 {
fmt.Println("sm1 == sm2")
}
}
此处 sn1 可以和 sn2 使用==比较但是如下
sn3:= struct {
name string
age int
}{age:11,name:"qq"}
sn3 就不能比较了
还有上例中,含有不可比较的 map,slice,func 等,所以 sm1 和 sm2 是不可比较的但是我们可以使用 deepEqual 来进行比较
if reflect.DeepEqual(sn1, sm) {
fmt.Println("sn1 ==sm")
}else {
fmt.Println("sn1 !=sm")
}
定义变量同时显式初始化不能提供数据类型只能在函数内部使用
var a chan int
// a 是空值nil
// chan的初始化一定是用make
var a map[int]string
// a 是空值nil
// map初始化一定使用make
// 使用new 生成的map也是nil的map
const (
x = iota
y
z = "zz"
k
p = iota
)
func main() {
fmt.Println(x,y,z,k,p)
}
// 结果
0
1
zz
zz
4(直接计算当前的值)
若是自定义类型类似于枚举,当我们传递字面量(如:2,3)时也是可以被识别为枚举值的。
const (
Apple, Banana = iota + 1, iota + 2
Cherimoya, Durian
Elderberry, Fig
)
// 输出
// Apple: 1
// Banana: 2
// Cherimoya: 2
// Durian: 3
// Elderberry: 3
// Fig: 4
const (
a = "1"
b
c
d
)
下面的就是错的
package main
func main() {
for i:=0;i<10 ;i++ {
loop:
println(i)
}
goto loop
}
package main
import "fmt"
func main() {
type MyInt1 int
type MyInt2 = int
var i int =9
var i1 MyInt1 = i // 错误 MyInt1是个新类型
var i2 MyInt2 = i // yes 是个别名
fmt.Println(i1,i2)
}
package main
import (
"errors"
"fmt"
)
var ErrDidNotWork = errors.New("did not work")
func DoTheThing(reallyDoIt bool) (err error) {
if reallyDoIt {
result, err := tryTheThing()
if err != nil || result != "it worked" {
err = ErrDidNotWork
}
fmt.Println(err)
}
return err
}
func tryTheThing() (string,error) {
return "",ErrDidNotWork
}
func main() {
fmt.Println(DoTheThing(true))
fmt.Println(DoTheThing(false))
}
// 输出两个
<nil>
<nil>
改为
func DoTheThing(reallyDoIt bool) (err error) {
var result string
if reallyDoIt {
result, err = tryTheThing() // 不要新定义变量
if err != nil || result != "it worked" {
err = ErrDidNotWork
}
}
return err
}
func main() {
defer func() {
if err:=recover();err!=nil{
fmt.Println("++++")
f:=err.(func()string)
fmt.Println(err,f(),reflect.TypeOf(err).Kind().String())
}else {
fmt.Println("fatal")
}
}()
defer func() {
// 这里就recover是捕获不到err的,所以这里的err是nil
if err:=recover();err!=nil{
fmt.Println("++++")
f:=err.(func()string)
fmt.Println(err,f(),reflect.TypeOf(err).Kind().String())
}else {
fmt.Println("fatal")
}
}()
defer func() {
panic(func() string {
return "defer panic"
})
}()
panic("panic")
}
package main
import "sync"
type A struct {
sync.Mutex
}
func main() {
a := A{}
a.Lock()
a.Unlock()
fmt.Println("Mutex a ", a)
}
上面代码运行是 ok 的。
下载放到 src 下的 golang/x/下
下载放到 src 下的 golang/x/下
如果你觉得方便,直接使用 http.Get 或者类似的方法发送请求,可能会导致一些问题, 因为这默认是使用 DefaultClient 作为 client:
if err, ok := err.(net.Error); ok && err.Timeout() {
……
}
func test()(a int) {
return
}
实际上 a 相当于已经命名了,相当于
func test() int {
var a int
return a
}
reflect.TypeOf(i).Elem().Field(0).Tag //获取定义在struct里面的标签
reflect.ValueOf(i).Elem().Field(0).String() //获取存储在第一个字段里面的值
最后再次重复一遍反射三定律:
一旦你理解了这些定律,使用反射将会是一件非常简单的事情。它是一件强大的工具,使用时务必谨慎使用,更不要滥用。
wrong
var x float64 = 3.4
v := reflect.ValueOf(x)
v.SetFloat(7.1) // Error: will panic.
yes
var x float64 = 3.4
p := reflect.ValueOf(&x) // Note: take the address of x.
fmt.Println("type of p:", p.Type())
fmt.Println("settability of p:", p.CanSet())
存入 map 的是值是不可以 addressable 的 a = map [string]int; &a["s"], 这个很好理解因为,map 回去做冲突处理,地址有可能发生变化。
Shared dependencies are fields of the structure
通过结构体的字段共享依赖,而不是到处引入(适用于所有的)
I have a single file inside every component called routes.go where all the routing can live:
package app
func (s *server) routes() {
s.router.HandleFunc("/api/", s.handleAPI())
s.router.HandleFunc("/about", s.handleAbout())
s.router.HandleFunc("/", s.handleIndex())
}
This is handy because most code maintenance starts with a URL and an error report — so one glance at routes.go will direct us where to look.
If a particular handler has a dependency, take it as an argument. 若是有特殊依赖则作为参数传入
s := make([]byte, 10)
n, err := os.Stdin.Read(s)
var firstname, secondname string
fmt.Scanln(&FirstName, &SecondNames) //Scanln 扫描来自标准输入的文本,将空格分隔的值依次存放到后续的参数内,直到碰到换行。
fmt.Scanf("%s %s", &firstName, &lastName) //Scanf与其类似,除了 Scanf 的第一个参数用作格式字符串,用来决定如何读取。
inputReader := bufio.NewReader(os.Stdin)
for {
input, _ := inputReader.ReadString('\n')
fmt.Println(input)
}
Slice, map, and function values are not comparable
如下若是使用指针作为receiver,则print 值时无法调用到String
type A struct {
c int
}
func (a A) String() string {
return "dj"
}
func format() {
a := &A{c: 22}
fmt.Println(a)
}
一般的reader都是没有缓冲的,bufio就是给reader加缓冲的
func readSlice() {
reader := bufio.NewReader(strings.NewReader("http://studygolang.com.\nIt is the home of gophers"))
line, _ := reader.ReadSlice('\n')
fmt.Println("the line is ", string(line))
n, _ := reader.ReadSlice('\n')
fmt.Println(string(n), string(line))
}
最后n和slice的值相同
而ReadBytes和ReadString就不会出现这个问题了,他们都新开辟的空间
如果ReadSlice在找到界定符之前遇到了error,
它就会返回缓存中所有的数据和错误本身(经常是 io.EOF)。
如果在找到界定符之前缓存已经满了,ReadSlice会返回bufio.ErrBufferFull错误。
当且仅当返回的结果(line)没有以界定符结束的时候,ReadSlice返回err != nil,
也就是说,如果ReadSlice返回的结果line不是以界定符delim结尾,那么返回的err也一定不等于nil
(可能是bufio.ErrBufferFull或io.EOF)。
并且当下次在读取时会继续向前
func ReadSliceSize() {
reader := bufio.NewReaderSize(strings.NewReader("http://studygolang.com.\nIt is the home of gophers"), 10)
line, _ := reader.ReadSlice('\n')
fmt.Println("the line is ", string(line))
n, _ := reader.ReadSlice('\n')
fmt.Println(string(n), string(line))
}
然而使用ReadBytes和ReadString就没有这个问题了,bufio.reader会自动为我们处理。
对基本类型排序
程序中应使用 Time 类型值来保存和传递时间,而不是指针。就是说,表示时间的变量和字段,应为time.Time类型,而不是*time.Time.类型。一个Time类型值可以被多个go程同时使用
这是实际开发中常用到的。
t, _ := time.Parse("2006-01-02 15:04:05", "2016-06-13 09:14:00")
fmt.Println(time.Now().Sub(t).Hours())
2016-06-13 09:14:00 这个时间可能是参数传递过来的。这段代码的结果跟预期的不一样。
原因是 time.Now() 的时区是 time.Local,而 time.Parse 解析出来的时区却是 time.UTC(可以通过 Time.Location() 函数知道是哪个时区)。在**,它们相差 8 小时。
所以,一般的,我们应该总是使用 time.ParseInLocation 来解析时间,并给第三个参数传递 time.Local。
bts := [5]byte{2, 3, 4, 5, 6}
fmt.Println(bts)
c := (*[4]byte)(unsafe.Pointer((uintptr(unsafe.Pointer(&bts)) + uintptr(1))))[:]
fmt.Println(c)
输出正确,直接使用 slice就错误(bts := []byte{2,3,4,5,6})
原因是:bts为slice的时候 bts的内部结构是
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
也就是说转化为[]byte以后 只有Data的地址,Len和Cap的值被转化为了字节
// reflect.SliceHeader and reflect.StringHeader
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
type StringHeader struct {
Data uintptr
Len int
}
/*
struct string{
uint8 *str;
int len;
}
struct []uint8{
uint8 *array;
int len;
int cap;
}
uintptr是golang的内置类型,是能存储指针的整型,uintptr的底层类型是int,它和unsafe.Pointer可相互转换。
但是转换后的string与[]byte共享底层空间,如果修改了[]byte那么string的值也会改变,就违背了string应该是只读的规范了,可能会造成难以预期的影响。
*/
func str2byte(s string) []byte {
x := (*[2]uintptr)unsafe.Pointer(&s)
h := [3]uintptr{x[0],x[1],x[1]}
return *(*[]byte)(unsafe.Pointer(&h))
}
func byte2str(b []byte) string{
return *(*string)(unsafe.Pointer(&b))
}
json:"name,omitempty,type" json: "name,[option]"type Test struct {
String *string `json:"string,omitempty"`
Integer *int `json:"integer,omitempty"`
}
type CA struct {
List []uint8
}
func main() {
ca := CA{[]uint8{1,2,3,4,5,6,7,8,9,0}}
r, _ := json.Marshal(ca)
fmt.Println(string(r)) //{"List":"AQIDBAUGBwgJAA=="}
}
package main
import "fmt"
type Param map[string]int
type Show struct {
Param
}
func main() {
s := new(Show)
fmt.Println("dj ", s.Param)
s.Param["dengjie"] = 123
}
// 报错
type People struct {
name string `json:"name"`
}
func main() {
js := `{
"name":"11"
}`
var p People
err := json.Unmarshal([]byte(js), &p)
if err != nil {
fmt.Println("err: ", err)
return
}
fmt.Println("people: ", p)
}
// {} 因为name是小写开头未暴露
type People struct {
Name string
}
func (p *People) String() string {
return fmt.Sprintf("print: %v", p)
}
func main() {
p := &People{}
p.String()
}
func main() {
ch := make(chan int, 1000)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
go func() {
for {
a, ok := <-ch
if !ok {
fmt.Println("close")
return
}
fmt.Println("a: ", a)
}
}()
close(ch)
fmt.Println("ok")
time.Sleep(time.Second * 100)
}
type student struct {
Name string
}
func zhoujielun(v interface{}) {
switch msg := v.(type) {
case *student, student:
msg.Name
}
}
// 错误 因为 v.(type)返回的是v的类型,是interface{}, 不能操作,v.(student).Name才可以
time.Sleep(time.Second * 100000000000000)
// 一乘就超出了int64的范围
Tx和statement不能分离,在DB中创建的statement也不能在Tx中使用,因为他们必定不是使用同一个连接使用Tx必须十分小心,例如下面的代码:
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
defer tx.Rollback()
stmt, err := tx.Prepare("INSERT INTO foo VALUES (?)")
if err != nil {
log.Fatal(err)
}
defer stmt.Close() // danger!
for i := 0; i < 10; i++ {
_, err = stmt.Exec(i)
if err != nil {
log.Fatal(err)
}
}
err = tx.Commit()
if err != nil {
log.Fatal(err)
}
// stmt.Close() runs here!
*sql.Tx一旦释放,连接就回到连接池中,这里stmt在关闭时就无法找到连接。所以必须在Tx commit或rollback之前关闭statement。
当使用tx时所有的操作必须在commit或者rollback之前关闭
type ExecuterList struct {
sync.Map
length int
}
func (e ExecuterList) Get(key string) IExecuter {
value, ok := e.Load(key)
if !ok {
return nil
}
if value == nil {
return nil
}
res, _ := value.(IExecuter)
return res
}
使用 go tool vet ,出现“Get passes lock by value: ExecuterList contains sync.Map contains sync.Mutex”, 解决方案有两种:
1,sync.Map用指针
type X struct {
*sync.Map
}
2, 也可以用 (e *ExecutorList) ,避免锁的复制。
var _ HelloServiceInterface = (*HelloServiceClient)(nil) // 确保 HelloServiceClient 实现了 HelloServiceInterface
不用但声明,若没有实现编译时就会报错
副本(replica/copy)指在分布式系统中为数据或服务提供的冗余。
系统通过副本控制协议,是得从系统外部读取内部各个副本的数据在一定条件下,读到的数据相同称之为副本一致性(consistency)。
哈希方式
按数据范围分布,比如用户 id[0-100],30 个一分区,工程中,为了数据迁移等负载均衡操作的方便, 往往利用动态划分区间的技术,使得每个区间中服务的数据量尽量的一样多。一般的,往往需要使用专门的服务器在内存中维护数据分布信息, 称这种数据的分布信息为一种元信息。实际工程中,一般也不按照某一维度划分数据范围,而是使用全部数据划分范围,从而避免数 据倾斜的问题。
按数据量分布,就是把固定大小的数据放在一起,好比 linux 中的 page,一个 page 一管理
一致性哈希,一致性哈希的基本方式是使用一个哈希函数计算数据或数据特征的哈希值,令该哈希函数的输出值域为一个封闭的环,即哈希 函数输出的最大值是最小值的前序。将节点随机分布到这个环上,每个节点负责处理从自己开始顺 时针至下一个节点的全部哈希值域上的数据。一致性哈希 的优点在于可以任意动态添加、删除节点,每次添加、删除一个节点仅影响一致性哈希环上相邻的 节点。
为此一种常见的改进算法是引入虚节点(virtual node)的概念,系统初始时就创建许多虚节点, 虚节点的个数一般远大于未来集群中机器的个数,将虚节点均匀分布到一致性哈希值域环上,其功能与基本一致性哈希算法中的节点相同。为每个节点分配若干虚节点。操作数据时,首先通过数据 的哈希值在环上找到对应的虚节点,进而查找元数据找到对应的真实节点。使用虚节点改进有多个 优点。首先,一旦某个节点不可用,该节点将使得多个虚节点不可用,从而使得多个相邻的真实节 点负载失效节点的压里。同理,一旦加入一个新节点,可以分配多个虚节点,从而使得新节点可以 负载多个原有节点的压力,从全局看,较容易实现扩容时的负载均衡。(原理是增加很多的虚拟节点,再将虚拟节点对应到真实节点参见)
移动数据不如移动计算lease 机 制最重要的应用:判定节点状态。
基本的问题背景如下:在一个分布式系统中,有一个中心服务器节点,中心服务器存储、维护 着一些数据,这些数据是系统的元数据。系统中其他的节点通过访问中心服务器节点读取、修改其 上的元数据。由于系统中各种操作都依赖于元数据,如果每次读取元数据的操作都访问中心服务器 节点,那么中心服务器节点的性能成为系统的瓶颈。为此,设计一种元数据 cache,在各个节点上 cache 元数据信息,从而减少对中心服务器节点的访问,提高性能。另一方面,系统的正确运行严 格依赖于元数据的正确,这就要求各个节点上 cache 的数据始终与中心服务器上的数据一致,cache 中的数据不能是旧的脏数据。最后,设计的 cache 系统要能最大可能的处理节点宕机、网络中断等 异常,最大程度的提高系统的可用性。
首先假设中心服务器与节点之间的时间同步。中心服务器向 cache 节点发送数据的同时下发一个 lease,每个 lease 都一个过期时间,并且这个过期时间是一个明确的时间点,例如 12:00 一旦过了这个时间,那么所有的缓存数据都将过期,lease 失效。这也意味着 lease 的过期时间与发放时间无关,也就是说有可能节点收到数据时 lease 就已经过期了。中心发出的 lease 的含义是:在 lease 时间内服务器保证不修改数据。
读流程:判断元数据是否已经处于本地 cache 且 lease 处于有效期内
1.1 是:直接返回 cache 中的元数据
1.2 否:向中心服务器节点请求读取元数据信息
1.2.1 服务器收到读取请求后,返回元数据及一个对应的 lease
1.2.2 客户端是否成功收到服务器返回的数据
1.2.2.1 失败或超时:退出流程,读取失败,可重试
1.2.2.2 成功:将元数据与该元数据的 lease 记录到内存中,返回元数据
修改流程:
首先给出本文对 lease 的定义:Lease 是由颁发者授予的在某一有效期内的承诺。颁发者一旦发 出 lease,则无论接受方是否收到,也无论后续接收方处于何种状态,只要 lease 不过期,颁发者一 定严守承诺;另一方面,接收方在 lease 的有效期内可以使用颁发者的承诺,但一旦 lease 过期,接 收方一定不能继续使用颁发者的承诺。
由于 lease 是一种承诺,具体的承诺内容可以非常宽泛,可以是上节的例子中数据的正确性;也 可以是某种权限,例如当需要做并发控制时,同一时刻只给某一个节点颁发 lease,只有持有 lease 的节点才可以修改数据;也可以是某种身份,例如在 primary-secondary(2.2.2 )架构中,给节点颁发 lease,只有持有 lease 的节点才具有 primary 身份。Lease 的承诺的内涵还可以非常宽泛,这里不再 一一列举。
关于时钟同步问题可以让 client 在申请 lease 时带上自己的时间戳,server 判断若是相差太大就不允许接入
是指分布式系统的状态,点对点的还是可以使用的
Lease 的有效期虽然是一个确定的时间点,当颁发者在发布 lease 时通常都是将当前时间加上一 个固定的时长从而计算出 lease 的有效期。如何选择 Lease 的时长在工程实践中是一个值得讨论的问 题。如果 lease 的时长太短,例如 1s,一旦出现网络抖动 lease 很容易丢失,从而造成节点失去 lease, 使得依赖 lease 的服务停止;如果 lease 的时长太大,例如 1 分钟,则一旦接受者异常,颁发者需要 过长的时间收回 lease 承诺。例如,使用 lease 确定节点状态时,若 lease 时间过短,有可能造成网络 瞬断时节点收不到 lease 从而引起服务不稳定,若 lease 时间过长,则一旦某节点宕机异常,需要较 大的时间等待 lease 过期才能发现节点异常。工程中,常选择的 lease 时长是 10 秒级别,这是一个经 过验证的经验值,实践中可以作为参考并综合选择合适的时长。
于是就有人提出相对弱一点的一致性模型,这些模型包括:线性一致性,原子一致性,顺序一致性,缓存一致性,静态一致性,处理器一致性,PRAM一致性,释放一致性,因果一致性,TSO一致性,PSO一致性,弱序一致性,本地一致性,连续一致性等等,当然,也包括我们要详细介绍的最终一致性。
https://pure-earth-7284.herokuapp.com/2016/02/14/talk-about-consistency/
Does JSON.stringify be fast enough? Can we improve the speed of it? The first idea comes into my mind is whether I can use C/C++ rewrite it? Cause there may be many redundant checks in V8 of it, whether I can discard them. But it may be wrong, stringify JSON object needs read it to judge the type of the JSON primitive type, may string, object or array etc.
Yeah, we must do that to analyze its typed to transform it to JSON string. But if we know the type, in another way that we have known the structure of the object. That means we don't need to analyze the type one by one anymore. Assume that we have a schema like below
{
type: 'object',
properties: {
firstName: {
type: 'string'
},
lastName: {
type: 'string'
},
age: {
description: 'Age in years',
type: 'integer'
},
reg: {
type: 'string'
}
}
}
so we must know the JSON object of this schema is an object having a property of string named firstName. so when we stringify it, we only add "{" at the start and "}" at the end, and also can add ' "fisrtName": ' follow the "{" according to the schema. Analyze the schema is cheap. Analyzing the object without knowing anything is difficult. Oh yeah, that's amazing.
The main principle of this package is the seem as we are talking above.
const fastJson = require('fast-json-stringify')
const stringify = fastJson({
title: 'Example Schema',
type: 'object',
properties: {
firstName: {
type: 'string'
},
lastName: {
type: 'string'
},
age: {
description: 'Age in years',
type: 'integer'
},
reg: {
type: 'string'
}
}
})
console.log(stringify({
firstName: 'Matteo',
lastName: 'Collina',
age: 32,
reg: /"([^"]|\\")*"/
}))
we can dig into the generated ‘stringify’ function
function $main(input) {
var obj = typeof input.toJSON === 'function'
? input.toJSON()
: input
// it's object we can add '{' directly
var json = '{'
var addComma = false
// whether has fisrtName
if (obj[ 'firstName' ] !== undefined) {
if (addComma) {
json += ','
}
addComma = true
json += '"firstName":'
json += $asString(obj[ 'firstName' ])
}
// whether has lastName
if (obj[ 'lastName' ] !== undefined) {
if (addComma) {
json += ','
}
addComma = true
json += '"lastName":'
json += $asString(obj[ 'lastName' ])
}
var rendered = false
// whether has age
var t = Number(obj[ 'age' ])
if (!isNaN(t)) {
if (addComma) {
json += ','
}
addComma = true
json += '"age":' + t
rendered = true
}
if (rendered) {
}
// where has reg
if (obj[ 'reg' ] !== undefined) {
if (addComma) {
json += ','
}
addComma = true
json += '"reg":'
json += $asString(obj[ 'reg' ])
}
json += '}'
return json
}
// {"firstName":"Matteo","lastName":"Collina","age":32,"reg":"\"([^\"]|\\\\\")*\""}
As shown above, that's so simple. There is a benchmark on Node 10.4.0:
JSON.stringify array x 3,269 ops/sec ±1.48% (86 runs sampled)
fast-json-stringify array x 5,945 ops/sec ±1.51% (87 runs sampled)
fast-json-stringify-uglified array x 5,720 ops/sec ±1.18% (89 runs sampled)
JSON.stringify long string x 9,325 ops/sec ±1.22% (88 runs sampled)
fast-json-stringify long string x 9,678 ops/sec ±0.99% (92 runs sampled)
fast-json-stringify-uglified long string x 9,578 ops/sec ±1.12% (92 runs sampled)
JSON.stringify short string x 3,307,218 ops/sec ±1.54% (92 runs sampled)
fast-json-stringify short string x 28,213,341 ops/sec ±1.72% (83 runs sampled)
fast-json-stringify-uglified short string x 29,130,846 ops/sec ±1.34% (87 runs sampled)
JSON.stringify obj x 1,441,648 ops/sec ±2.14% (87 runs sampled)
fast-json-stringify obj x 5,345,003 ops/sec ±1.02% (91 runs sampled)
fast-json-stringify-uglified obj x 5,331,581 ops/sec ±0.73% (91 runs sampled)
It's extremely fast. The last question is where fastify use it. Obviously using it in validation and reply.
flatstr is a package that makes some string's operation so fast. The homepage's section 'how it works' has explained it very clear in English.
Next is Chinese translation:
v8里面有两种处理字符串的方式
当我们处理字符串连接的时候,v8使用的是树结构。对于连接操作(concat), 构造一棵树明显比重新分配一块大的内存来的划算(大家可以思考一下为什么)。但是有一些其他操作树结构反而会带来更多的损耗(比如大量的字符串连接操作,大家又可以思考一下为什么了)。
V8里面有个内置函数叫String::Flatten, 它能够把树状的字符串结构再转化为C的数组形式。这个方法通常会在遍历字符串这个操作之前被调用(比如:测试一个正则表达式)。 在多次使用一个字符串时也会调用这个方法来作为优化。但这个方法并不是在所有的字符串操作时都会调用,比如我们传递一个字符串给WriteStream这个方法,此时字符串会被转为buffer, 但如果字符串的底层结构是树的话,这个转换操作就会很昂贵(至于为什么昂贵?留待下次探查,或者你们谁来追查一下?)。
关键在于String::Flatten并不是js的内置方法其实是v8独有的,但我们还是有办法触发这个方法的。
在(alt-benchmark.js)里面列举了一些可以触发这个方法的调用。其中转换成Number是代价最小的了。
但是自从Node10开始刚才我们所说的那些能触发Flatten的调用的操作V8都不会再去调用Flatten了。但没关系我们还可以通过'--allow-natives-syntax'这个flag来手动调用
'use strict'
if (!process.versions || !process.versions.node || parseInt(process.versions.node.split('.')[0]) >= 10) {
try {
var flatstr = Function('s', 'return typeof s === "string" ? %FlattenString(s) : s')
} catch (e) {
try {
// who can tell me why write 'v' + '8'?
var v8 = require('v' + '8')
v8.setFlagsFromString('--allow-natives-syntax')
var flatstr = Function('s', 'return typeof s === "string" ? %FlattenString(s) : s')
v8.setFlagsFromString('--no-allow-natives-syntax')
} catch (e) {
var flatstr = function flatstr(s) {
Number(s)
return s
}
}
}
} else flatstr = function flatstr(s) {
Number(s)
return s
}
module.exports = flatstr
如上就是Flatten的调用方式以及Node10以下的触发方式。其实这也是这个包的所有代码(不含测试等其他)。。。(求解释上面那个v8的引用方式。。。)
benchmark (fs.WriteStream)
unflattenedManySmallConcats*10000: 147.540ms
flattenedManySmallConcats*10000: 105.994ms
unflattenedSeveralLargeConcats*10000: 287.901ms
flattenedSeveralLargeConcats*10000: 226.121ms
unflattenedExponentialSmallConcats*10000: 410.533ms
flattenedExponentialSmallConcats*10000: 219.973ms
unflattenedExponentialLargeConcats*10000: 2774.230ms
flattenedExponentialLargeConcats*10000: 1862.815ms
可以看出基本都是flatstr 胜出的
ManySmallConcats: 28%
SeveralLargeConcats: 21%
ExponentialSmallConcats: 46%
ExponentialLargeConcats: 33%
最后需要注意的就是,物极必反,也不要太过于频繁的调用Flatten。毕竟他也是有性能损耗的。V8已经替我们做了很多的优化,我们就不要随便插手了。因此Flatten的正确使用方式应该是在传递字符串给非V8的代码:比如fs.WriteStream, xhr, DOM api等等。
So where fastify use flatstr? in the http reply, cause the data will be passed to WriteSteam
Fastify's router package is find-my-way based on radix tree akka compact Prefix Tree
Three picture explains radix clearly
Yeah every route path is mapped to a branch of the tree.
Insert 'water' at the root
Insert 'slower' while keeping 'slow'
insert 'tester' which is a prefix of 'tester'
Insert 'team' while splitting 'test' and creating a new edge label 'st'
Insert 'toast' while splitting 'te' and moving previous strings a level lower
Search for 'toasting'
Clearly radix tree is not a balanced trees so the cost is O(k) rather then O(log n), an K >= log n and K <= M(total of words or routes)
Compared to Array[M] (koa-router & express-router) it will be more efficient. Cause it needs lower comparison.
Compared to hash router it will be efficient too, even though hash time is O(1). Cause we need compute hash of the routes when use it. The most drawbacks of hash are that it does not support params and any (*) matches.
Another radix-router impletion in go echo
That's all? no
Far from enough. We still need to dig into fastify deeper
废话不说先上图
代码的质量可以被看作是上图的金字塔,每个顶点都代表这代码质量的一个特点。但总体来说一共包含两方面,基础和顶点(base and apex)
基础是什么呢? 基础是那些让我们的代码可靠,可面向未来的特点的集合。而顶点则是代码的功能和可靠性。 你想让你的顶点越高,那么基础就应当越大。
这个特征代表了代码是否易于阅读,是否易于理解代码的内容及其目的。他又包括以下几个特征:
好的注释,注意不是过多的注释,过多的注释可不是什么好事儿
好的命名无论是类,函数,变量等, 见我的这篇文章
一致的代码规范
干净的逻辑,说白了就是没有废话
这个特征代表了是否易于添加功能(对产品来说做减法的太少,做加法的太多了),好的设计应当具有高扩展性。扩展越高意味添加功能就越轻松,改动也越少。
这个特征代表了我们的功能模块之间是否低耦合,高内聚,模块内修改不影响其他模块。
这里有一些好的原则:
这个特征代表了我们的代码覆盖度有多少,我们的自动化程度有多少。还有单元测试,集成测试以及e2e测试的情况。
顶点代表了,我们的代码做了多少事,以及他的可靠程度
要让我们的基础足够大,整体机构自然就会很好。
不幸的是目前还没有什么具体的方法能够测量代码的可测试性,可读性,可扩展性,以及原子性,我们只能靠经验来判断。这是个悲哀。
无数先贤都在探索怎么才能把软件工程化做的更好,我也希望会做的更好,我也会为此做出努力。可这里隐含着一个问题,就好建筑业,他的工程化很成熟,因此带了无数的建筑工人,拿着微薄的工资,做着最累的工作。希望我们这里没有。
golang 的错误处理方式一直是他遭受抨击的一个原因之一。探查每一个的错误然后处理确实是一个艰巨的任务,这里有几招可以让你减少错误的处理方式(处理错误的方法)。
当我们写golang的时候倾向于
f, err := os.Open(path)
if err != nil {
// handle error
}
// do stuff
而不是
f, err := os.Open(path)
if err == nil {
// do stuff
}
// handle error
这种方式可以让我们的正常处理方式一路看到底,而不是if之后是错误
处理错误的第一步得是知道错误是啥,如果你的package发生了错误,那么你的用户一定对错误的原因很感兴趣。要做到让你的user知道错误是啥,你只需要实现error interface, 如下就可以了
type Error string
func (e Error) Error() string { return string(e) }
这样你的用户就可以通过类型断言来判断是否是你的错误
result, err := yourpackage.Foo()
if err, ok := err.(yourpackage.Error); ok {
// use tp to handle err
}
你也可以暴露一个结构体的error给你的用户
type OpenError struct {
File *File
Error string
}
func (oe *OpenError) Error() string {
// format error string here
}
func ParseFiles(files []*File) error {
for _, f := range files {
err := f.parse()
if err != nil {
return &OpenError{
File: f,
Error: err.Error(),
}
}
}
}
通过这种方式,你的用户就可以分辨具体是哪个文件解析失败了
但是当你包裹错误的时候你也应当注意,因为包裹一个error,会丢失一些信息,就好比上面那个你已经丢失了err的类型而只剩下了err里的信息
var c net.Conn
f, err := DownloadFile(e, path)
switch e := err.(type) {
default:
// this will get executed if err == nil
case net.Error:
// close connection, not valid anymore
c.Close()
return e
case error:
// if err is non-nil
return err
}
// do other things
见上如果此时你包裹了net.Error, 那么这段代码就不会看到net.Error这个错误了,而只能是一段错误信息,此时就无法具体区分错误了(见前一段的包裹方式丢失了具体的错误类型)
一个好的处理方式是尽量不要包裹你调用的其他包自己产生的错误,因为用户可能更关心他们产生的错误而不是你的。
有时候你可能想要持有一个错误而不是抛出,不管你是打算随后上报或者是你知道这个错误很快就会再次出现
这种情况的一个栗子就是bufio这个包。当bufio.Reader遇到一个错误,他会持有这个错误一直到buffer空为止,只有此时他才会上报这个错误。
另一种栗子就是使用go/loader。当使用参数调用遇到错误时,他会持有这个错误,因为有很大的概率他会再次使用相同的参数又调用一遍
如果你有一段错误处理的代码是重复的,你可以把他提出来做一个函数
func handleError(c net.Conn, err error){
// repeated error handling
}
func DoStuff(c net.Conn) error{
f, err := downloadFile(c, path)
if err != nil {
handeError(c, err)
return err
}
f, err := doOtherThing(c)
if err != nil {
handleError(c, err)
return err
}
}
一个替换方案是
func handeError(c net.Conn, err error) {
if err == nil {
return
}
// repeat err handling
}
func DoStuff(c net.Conn) error {
// defer func(){ handleError(c, err) }()
// 这是原文在的位置,但明显有错误啊,err未定义啊
f, err := downloadFile(c, path)
defer func(){ handleError(c, err) }()// 所以我挪到这里了,但效果是否ok,暂未验证
if err != nil {
return err
}
f, err := doOtherThing(c)
if err != nil
}
ps: 一个golang官网的一段翻译
先上代码
func returnError() error{
var p *MyError = nil
if bad() {
p = ErrBad
}
return p // Will always return a non-nil error
}
如上这里的p明明是nil值为啥返回后就不是了呢?这里涉及到另外一个问题就是�interface值,我们知道error是一个interface,而MyError是一个struct, 就是要把struct值赋值给interface,在golang里interface值是包括两个的一个type值,一个value值,只有当两者都是nil的时候interface值才是nil, 上述代码,很明显虽然value是nil,可是类型还在啊,就是说type不是你nil而是MyError, �改进如下
func returnsError() error {
if bad() {
return ErrBad
}
return nil
}
简介
在cs中hash table是一种经常使用的数据结构。许多hash table的实现都拥有很多的属性。但总的来说,他们都会提供快速查询,添加以及删除等功能。go 提供了一个内置的实现了hash table的map 类型。
声明和初始化
go map类型的签名如下
map[KeyType]ValueType
KeyType要求是能够comparable的类型, 而ValueType则可以是任意的类型,甚至是另一个map
如下一个key为string,value是int的map
var m map[string]int
map类型也是引用类型,就像指针或者切片一样,因此上面的声明的m是nil;我们还没有实例化map。一个值是nil的map再读取的时候就像是个空map你啥都读不到
value, ok := m["c"]
// value is 0, ok is false
但是写入nil map是会报错的。千万记得不要这么做要记得初始化map,请使用内置的make function(make 专门用来分配内存,初始化map, slice, channel)
m = make(map[string]int)
make会分配内存并且初始化然后返回一个map值,注意make不生成指针new才是返回指针但是new只分配内存,而不初始化。make的实现底层是基于的c的实现,本文只关注怎么使用,就不分析他的实现了。
m["route"] = 66
加下来取值
i := m["route"]
若是我们取得值不存在那么我们取到的会是值相应类型的默认值(zero value)。在我们的例子中我们读到的就是0:
j := m["root"]
// j == 0
内置的len函数可以得到map中的元素个数
n := len(m)
// n == 1
内置的delete函数是用来删除map中的元素
delete(m, "route")
delete没有返回值,并且若是删除的key不存在则啥都不处理
还有一种读取的语法如下
i, ok := m["route"]
这个语法是:i取得是m中route对应的数据,若是不存在route对应的数据则i会是对应类型的零值,而ok代表的是route在m是否存在,false即是不存在也就是说没有读到i值。
当我们只是为了验证是否存在相应的key时可以使用下划线来忽略key对应的数据
_, ok := m["route"]
为了遍历map,我们可以使用range关键字
for key, value := range m {
fmt.Println("Key:", key, "Value:", value)
}
若是不使用make,我们也可以使用map的字面量来初始化一个map
commits := map[string]int {
"rsc": 3711,
"r", 2138,
}
我们还可以初始化一个空map,和使用make是一样的
var m = map[string]int{}
比如,一个值为bool类型的map就可以看做是一个set类型的数据结构(要知道,布尔类型的默认值是false)。这个例子遍历一个linked list of nodes, 并且打印他们的值。他使用值类型是Node 指针的map来检测list是否有环。
type Node struct {
Next *Node
Value interface{}
}
var first *Node
visited := make(map[*Node]bool)
for n := first; n != nil; n = n.Next {
if visited[n] {
fmt.Println("cycle detected")
break
}
visited[n] = true
fmt.Println(n.Value)
}
若Node n已经被访问过了,则visited[n]的值是true, 若值是false则说明Node n没有被访问过。我们不需要再用其他数据来判断node在map中的存在性,map默认值已经帮我们处理了。
另一个有用的例子是slices的map, 我们知道当我们想一个nil slice append数据的时候是会分配新的内存的。因此当我们向slice的map中append 数据的时候,是不需要检查key是否存在的。可以看看下面的例子
type Person struct {
Name string
Likes []string
}
var people []*Person
likes := make(map[string][]*Person)
for _, p := range people {
for _, l := range p.Likes {
likes[l] = append(likes[l], p)
}
}
我们开一个打印出喜欢cheese的人:
for _, p := range likes["cheese"] {
fmt.Println(p.Name, "likes cheese.")
}
打印出有多少人喜欢bacon
fmt.Println(len(likes["bacon"]), " people like bacon.")
range 和 len都把nil slice当做长度是0的slice, 因此我们最后两个数据是不会出错的。
很明显strings, ints, 以及一些其他的类型可以做key,但是结构体就有点而出乎意料了。
让我们看这个
hits := make(map[string]map[string]int)
这是一个页面访问的次数的map,key对应二级url
n := hits["/doc/"]["au"]
但我们这么访问是错的,因为map是需要实例化的,我们可以这么读,但是当我们添加的时就会有问题,我们需要去初始化内部的map。如下
func add(m map[string]map[string]int, path, country string) {
mm, ok := m[path]
if !ok {
mm = make(map[string]int)
m[path] = mm
}
mm[country]++
}
add(hits, "/doc/", "au")
但是我们可以采用另一种设计如下
type Key struct {
Path, Country string
}
hits := make(map[Key]int)
此时我们可以一步添加
hits[Key{"/", "vn"}]++
另外读取也是非常方便的
n := hits[Key{"/ref/spec/", "ch"}]
看个例子
var counter = struct {
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}
读取的时候就可以使用读锁
couter.RLock()
n := counter.m["some_key"]
counter.RUnlock()
fmt.Println("some_key:", n)
写时用写锁
couter.Lock()
counter.m["some_key"]++
counter.Unlock()
sync.Mutex第一次被使用后,千万不可以复制,要传指针。因为sync.Mutex是结构体而非指针数据,接下来回来一篇文章分析一下的。
import "sort"
var m map[int]string
var keys []int
for k := range m {
keys = append(keys, k)
}
sort.Ints(keys)
for _, k := range keys {
fmt.Println("Key:", k, "value:", m[k])
}
type data struct {
name string
}
var a = map[string]data {"x": {"one"}}
m["x"].name = "two" // error
错误的,除非他的类型是指针
type data struct {
name string
}
func main() {
m := map[string]*data {"x":{"one"}}
m["x"].name = "two" //ok
fmt.Println(m["x"]) //prints: &{two}
}
但是要注意不要写入空的了指针,是会panic的
package main
type data struct {
name string
}
func main() {
m := map[string]*data {"x":{"one"}}
m["z"].name = "what?" //???
}
很显然,指针的默认值是nil,当然无法访问nil的name了。
但是slice element就可以addressable
type data struct {
name string
}
func main() {
s := []data {{"one"}}
s[0].name = "two" //ok
fmt.Println(s) //prints: [{two}]
}
// m是个map
h := handlers.m[c]
if h == nil {
if handlers.m == nil {
handlers.m = make(map[chan<- os.Signal]*handler)
}
h = new(handler)
handlers.m[c] = h
}
我又要先上图了:
// COLD
const cold = new Observable((observer) => {
const producer = new Producer();
// have observer listen to producer here
});
// HOT
const producer = new Producer();
cosnt hot = new Observable((observer) => {
// have observer listen to producer here
})
我的上篇文章介绍了observables就是函数。那篇文章的目的是解开observerable的神秘,但是没有深入那个困扰大家的问题:HOT VS COLD
Observables 就是一个绑定observer和producer的函数。是的,那就是全部。他其实不需要创建producer,他们仅仅是建立observer对producer的监听,并且返回一个函数可以用来移除监听器。对obserable的调用就好像是在调用一个函数,并且传递一个observer
生产者就是你的observable的数据来源。他可能是一个web socket, 或者是一个DOM event, 又或者是一个迭代器,甚至有可能是对一个数组的循环。总之,他可以是任何东西,可以用来获取数据并且传递给observer.next(value)。
如果一个observable的producer是在subscribe时创建并且激活的那么他就是 ‘cold’。这意味着,如果observables是函数,那么生产者就是在调用这个函数是创建和激活的。
下面这个栗子就是‘cold’, 因为他对websocket的监听是在你subscribe observable时建立的:
const source = new Observable((observer) => {
const socket = new WebSocket('ws://someurl');
socket.addEventListener('message', (e) => observer.next(e));
return () => socket.close();
});
因此任何subscribe source的对象,都会有自己的WebSocket的实例,并且当他unsubscribe的时候,他将会关闭那个socket。这意味着我们source仅仅只是unicast,因为这个生产者仅仅只能给一个监听者发送数据。这里有一个简单的栗子jsbin
如果一个observable的生产者是在订阅之外(就是不是在订阅时产生的行为)创建或者是激活的那么他就是'hot'。
const socket = new WebSocket('ws://someurl');
const source = new Observable((observer) => {
socket.addEventListener('message', (e) => observer.next(e));
});
现在任何订阅source的对象都共享一个相同的WebSocket实例。他将会高效的多播数据到所有的订阅者。但是这里还有个小问题:我们的obserable没有了对socket的取消逻辑。这意味着一旦发生了错误或者结束后,甚至是取消订阅,我们都无法关闭socket。所以我们真正想要的是让我们的'cold' observable 变成hot。这里有个例子就没有取消的逻辑[jsbin](Here is a JSBin showing this basic concept.)
从第一个cold observable的列子我可以看到如果所有的observable都是cold是会有一些问题的。比如,你不止一次的订阅一个observable,但是他有可能每次都创建了一些稀缺资源,好比 web socket connection, 可事实是你并不想创建很多的web socket连接。事实上你可能很容易的对一个observable创建很多的订阅,并且是在你没意识的情况下。假设我们需要从web socket的订阅中过滤出奇数和偶数,于是最终我们可能写出如下的代码:
source.filter(x => x % 2 === 0)
.subscribe(x => console.log('even', x));
source.filter(x => x % 2 ==== 1)
.subscribe(x => console.log('odd', x));
在我们把'cold' observable 变得 ’hot‘之前,我们需要先介绍一个新的类型:Rx Subject。他有如下特性:
// The death of a Subject
const subject = new Subject();
subject.subscribe(x => console.log(x));
subject.next(1); // 1
subject.next(2); // 2
subject.complete();
subject.next(3); // silently ignored
subject.unsubscribe();
subject.next(4); // Unhandled ObjectUnsubscribedError
之所以称之为’subject‘是因为上述第三点。 在四人帮的设计模式里,’Subjects‘是一个拥有’addObserver‘方法的类。在这个例子里面,’addObserver‘方法是’subscribe‘,这里有一个jsbin的例子:
const { Subject } = Rx;
const subject = new Subject();
// you can subscribe to them like any other observable
subject.subscribe(x => console.log('one', x), err => console.error('one', err));
subject.subscribe(x => console.log('two', x), err => console.error('two', err));
subject.subscribe(x => console.log('three', x), err => console.error('three', err));
// and you can next values into subjects.
// NOTICE: each value is sent to *all* subscribers. This is the multicast nature of subjects.
subject.next(1);
subject.next(2);
subject.next(3);
// An error will also be sent to all subscribers
subject.error(new Error('bad'));
// NOTICE: once it's errored or completed, you can't send new values into it
try {
subject.next(4); //throws ObjectUnsubscribedError
} catch (err) {
console.error('oops', err);
}
当我们使用了Subject,我们可以使用一些函数式编程方法来使一个 ’cold‘ Observable 'hot':
function makeHot(cold) {
const subject = new Subject();
cold.subscribe(subject);
return new Observable((observer) => subject.subscribe(observer));
}
// 整体流程就是:observer -> subject -> cold(依次订阅下一个observable)
我们的makeHot方法可以接收任何的cold observable并且可以通过创建一个共享的subject。这里有个例子jsbin
但是我们仍然有一些小的问题,因为,我们仍然没有跟踪我们源observable的subscription(就是cancel函数),因此当我们想要取消的时候,我们该怎么取消呢?我们可以通过添加引用计数来解决这个问题:
function makeHotRefCounted(cold) {
const subject = new Subject();
const mainSub = cold.subscribe(subject);
let refs = 0;
return new Observable((observer) => {
refs++;
let sub = subject.subscribe(observer);
return () => {
refs--;
if (refs === 0) mainSub.unsubscribe();
sub.unsubscribe();
}
});
}
这样我们就有了unsubscribe函数了。jsbin
你应当使用publish或者share而不是上面造的makeHot。 有很多种方法可以是cold变为hot, 并且在Rx中有很多种高效简洁的方法来实现。
在rxjs 5中,share操作符,可以是cold变成hot,以及使用引用计数的observable。并且这个observable还可以重试当他失败或者成功。因为当他错误,完成或者取消订阅以后,subjects就不可以重新使用了,于是share()操作符会重新回收死掉的subjects并且在生成一个新的subject,使得我们可以重新订阅。
这里有一个栗子jsbin
经过尝试错误,取消订阅是可以的重新订阅的。
Given everything stated above, one might be able to see how an Observable, being that it’s just a function, could actually be both “hot” and “cold”. Perhaps it observes two producers? One it creates and one it closes over? That’s probably bad juju, but there are rare cases where it might be necessary. A multiplexed web socket for example, must share a socket, but send its own subscription and filter out a data stream.
当你是用shared 引用来关闭producer,那么他是hot。 如果你是在你的observable中创建生产者那么他是cold,若是两者都做,那么我猜他是’warm‘吧!
hot Observable通常是多播的,但若是producer一次只提供一个监听器数据,此时再说他是多播的就会有些模糊了。
>>> x = new Array(3)
[undefined, undefined, undefined]
>>> y = [undefined, undefined, undefined]
[undefined, undefined, undefined]
>>> x.constructor == y.constructor
true
>>> x.map(function(){ return 0; })
[undefined, undefined, undefined]
>>> y.map(function(){ return 0; })
[0, 0, 0]
上述结果的原因是啥呢?MDN上有详细描述,当然es6规范也有详细规范接下来,我来翻译一下:
这是MDN种给的一个map的实现方式
// Production steps of ECMA-262, Edition 5, 15.4.4.19
// Reference: http://es5.github.io/#x15.4.4.19
if (!Array.prototype.map) {
Array.prototype.map = function(callback/*, thisArg*/) {
var T, A, k;
if (this == null) {
throw new TypeError('this is null or not defined');
}
// 1. Let O be the result of calling ToObject passing the |this|
// value as the argument.
var O = Object(this);
// 2. Let lenValue be the result of calling the Get internal
// method of O with the argument "length".
// 3. Let len be ToUint32(lenValue).
var len = O.length >>> 0;
// 4. If IsCallable(callback) is false, throw a TypeError exception.
// See: http://es5.github.com/#x9.11
if (typeof callback !== 'function') {
throw new TypeError(callback + ' is not a function');
}
// 5. If thisArg was supplied, let T be thisArg; else let T be undefined.
if (arguments.length > 1) {
T = arguments[1];
}
// 6. Let A be a new array created as if by the expression new Array(len)
// where Array is the standard built-in constructor with that name and
// len is the value of len.
A = new Array(len);
// 7. Let k be 0
k = 0;
// 8. Repeat, while k < len
while (k < len) {
var kValue, mappedValue;
// a. Let Pk be ToString(k).
// This is implicit for LHS operands of the in operator
// b. Let kPresent be the result of calling the HasProperty internal
// method of O with argument Pk.
// This step can be combined with c
// c. If kPresent is true, then
if (k in O) {
// i. Let kValue be the result of calling the Get internal
// method of O with argument Pk.
kValue = O[k];
// ii. Let mappedValue be the result of calling the Call internal
// method of callback with T as the this value and argument
// list containing kValue, k, and O.
mappedValue = callback.call(T, kValue, k, O);
// iii. Call the DefineOwnProperty internal method of A with arguments
// Pk, Property Descriptor
// { Value: mappedValue,
// Writable: true,
// Enumerable: true,
// Configurable: true },
// and false.
// In browsers that support Object.defineProperty, use the following:
// Object.defineProperty(A, k, {
// value: mappedValue,
// writable: true,
// enumerable: true,
// configurable: true
// });
// For best browser support, use the following:
A[k] = mappedValue;
}
// d. Increase k by 1.
k++;
}
// 9. return A
return A;
};
}
这是lodash中的map的实现
/**
* Creates an array of values by running each element of `array` thru `iteratee`.
* The iteratee is invoked with three arguments: (value, index, array).
*
* @since 5.0.0
* @category Array
* @param {Array} array The array to iterate over.
* @param {Function} iteratee The function invoked per iteration.
* @returns {Array} Returns the new mapped array.
* @example
*
* function square(n) {
* return n * n
* }
*
* map([4, 8], square)
* // => [16, 64]
*/
function map(array, iteratee) {
let index = -1
const length = array == null ? 0 : array.length
const result = new Array(length)
while (++index < length) {
result[index] = iteratee(array[index], index, array)
}
return result
}
export default map
源码面前了无秘密,规范面前也一样啊!
今天在jjc的群里正美大大抛出了一个问题

答案全是false
我很郁闷了,我觉得按照instanceof的执行过程应该是true啊!
为啥呢?因为一下两点
证明如下

(2).\__proto\__ === Number.prototype
// true
那么为啥 2 instanceof Number 是false呢
下面的es规范是基于ecma-262/5.1的,es6的规范有了一些变化,有了更多的新东西,更加严谨,但原理是一致的。
我们知道js中的原始类型(primitive) 只有如下几种
Undefined, Null, Boolean, String, Number
es6中多了一个原始类型 Symbol
要注意,Number是指原始类型而不是内置的Number对象, 其他类似
因此 3, '123', true, false, null, undefined等是原始类型,不是对象(Object)哦。
也就是说3 和 new Number(3)或者Number(3)不是一个类型哦,后两者是对象
参见下图

各位看官有没有看到里面的另一句话啊: Number object 可以通过是用Number函数方式的调用在转换为Number value。 Number(new Number(3)) instanceof Number === false
剩下的就是对象了Object,各种对象,就不缺对象
例子
3 instanceof Number
我们一步一步讲来
The production RelationalExpression : RelationalExpression instanceof ShiftExpression is evaluated as follows:
计算左侧 为3
GetValue 调用返回值�赋值给lval(此处我们只要知道GetValue(3) === 3就好了,后面会细讲)
计算Number ,那就是Number
同2 这里rval = Number
Type 调用会返回rval的类型,此处是对象Object[1]。
判断rval 是否有HasInstance 方法
接下来就该[[HasInstance]]了
Assume F is a Function object.
假设F是一个函数对象
When the [[HasInstance]] internal method of F is called with value V, the following steps are taken:
当我们调用F的[[HasInstance�]]方法时走如下步骤
如果v不是对象,返回false
很明显我们上面的调用就结束了。。。因为3不是个对象,而是个Number value
获取� F的prototype 给 O
找到V的原型�链,然后依次向上查找,直到结束,若�O与其中一个原型是同一个对象返回�true, 否则false
NOTE Function objects created using Function.prototype.bind have a different implementation of [[HasInstance]] defined in 15.3.4.5.3.
还有一个Symbol啊,在此有个很魔性的地方,我上面引入的ecma262/5.1是没有Symbol的,我们去看ecma262/6.0,里面是有Symbol的,可是在�那里我们可以看到Symbol也进级为了原始类型,因此Symbol('a') instanceof Symbol自然也是 false了,你说魔性不魔性。
官方解释如下
The Reference type is used to explain the behaviour of such operators
as delete, typeof, the assignment operators, the super keyword and
other language features. For example, the left-hand operand of an
assignment is expected to produce a reference.
我只看明白是为了解释某些操作而存在的,例如delete, typeof, super, left-hand operand等等,还有super keyword等等
Reference 含有3个component
identifier reference expressions, that resolve the identifier in the current lexical environment (or one of its parents)
标识符,解析标识符时会创建一个reference, base value is envRec, referenced name is identifier
property accessor expressions, i.e. the .… and […] operators
属性获取时会创建一个reference(这个就是我们后面要用到的哦)
function calls to host functions are permitted to return them, but such don't exist.
这个在es5规范里有说,是可以返回,但没有规定一定返回
(2).\__proto\__
// [Number: 0]
上面的转换�很显然是获取属性发生的转换,我们一步一步解析,请看下面
11 Expressions
11.1 Primary Expressions
Syntax
PrimaryExpression :
this
Identifier
Literal
ArrayLiteral
ObjectLiteral
( Expression )
参见上面,我们"(2)"是PrimaryExpression, 再来看看 (Expression)是啥
11.1.6 The Grouping Operator
The production PrimaryExpression : ( Expression ) is evaluated as follows:
1. Return the result of evaluating Expression. This may be of type Reference.
NOTE This algorithm does not apply GetValue to the result of evaluating Expression. The principal motivation for this is so that operators such as delete and typeof may be applied to parenthesised expressions.
很显然我们"(2)"是group expression,按照规范的描述,group expression返回的有可能是Reference
看了上面我们知道了"(2)"是啥,那按照规范所说的,"(2)"属于Express, 也可以看出来"2" 属于PrimaryExpression 中的Literal, 于是就有了下面的
11.1.3 Literal Reference
A Literal is evaluated as described in 7.8.
看到了Literal 参见7.8 具体就是规定了Number literal的语法
The production MemberExpression : MemberExpression [ Expression ] is evaluated as follows:
左侧计算 得到 2 赋值给baseReference
调用GetValue, 对2 ,依然返回2
计算属性Expression 赋值给 propertyNameReference, 对于'.'调用会变为'[]' 于是 就是"_proto_"字符串
调用GetValue, 对于propertyNameReference ,依然返回"_proto_"字符串
判断baseValue不是Null或者Undefined
转为String
If the syntactic production that is being evaluated is contained in strict mode code, let strict be true, else let strict be false.
Return a value of type Reference whose base value is baseValue and whose referenced name is propertyNameString, and whose strict mode flag is strict.
返回 Reference, base value是baseValue,对于我们的baseValue就是2,referenced name 是 propertyNameString,对于我们就是"_proto_"
The production CallExpression : CallExpression [ Expression ] is evaluated in exactly the same manner, except that the contained CallExpression is evaluated in step 1.
这句话的意思就是 CallExpress和属性获取类似。
到这里我们就完成了 "(2)._proto_"的完整解析,这个完整解析返回了一个Reference, 可是类型转换呢?
上面的步骤我们是完成了整个表达式的解析,但还没有使用表达式返回的结果,那我们来使用一下,比如 "(2)._proto_ === 2"
11.9.4 The Strict Equals Operator ( === )
The production EqualityExpression : EqualityExpression === RelationalExpression is evaluated as follows:
解析 EqualityExpression ,我们从前面可以得知,"(2)._proto_", 解析之后是一个Reference, 类似于 {baseValue: 2, referencedName: "_proto_", strict:...}
重头戏来了 把我们上一步得到的Reference 作为参数调用 GetValue会返回什么呢? 见下
上面的严格等于我们就不分析了,不是重点,来看看GetValue吧。很长很高能
8.7.1 GetValue (V)
判断V是不是一个Reference,不是直接返回V, 现在明白了GetValue(2)为啥返回2了吧。
获取base value, 对我们的Ref 就是2
这是用来判断base value为非null和undefined的
base value 不是原始类型,则让get为base的内部[[Get]]方法,若是原始类型则参见下面的internal [[GET]]方法的逻辑,嗯,我们的base value是2,于是就得走下面的internal [[GET]]方法了
调用get,使用referenceName作为参数, base value作为this
判断V的base value是不是object, number, string, Boolean
不是 上面列举的几类,那就一定是environment record
1. Return the result of calling the GetBindingValue (see 10.2.1) concrete method of base passing GetReferencedName(V) and IsStrictReference(V) as arguments.
The following [[Get]] internal method is used by GetValue when V is a property reference with a primitive base value. It is called using base as its this value and with property P as its argument. The following steps are taken:
internal [[GET]]method
我的神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊,神啊, 终于看到了类型转换啊!!! ToObject(base), 这个很简单了,把原始类型转换为对应Object类型,比如2(Number Value), 转换为Number Object, 其他类似 参见
...不解释了,往下就很容易理解了
NOTE The object that may be created in step 1 is not accessible outside of the above method. An implementation might choose to avoid the actual creation of the object. The only situation where such an actual property access that uses this internal method can have visible effect is when it invokes an accessor function. 这些说的就是step 1创建的object,不应当被外部访问到。
源码面前了无秘密,规范面前也一样啊!其实但我们理解了Reference 类型,那么this绑定的问题也就迎刃而解了,大家可以再去看看this的绑定问题也是基于Reference的
注
[1]Type(v)解释
根据具体的内容返回相应的类型,如字面3,返回�Number Type,new Number(3) 返回Object 类型
Fundamentally, JSX just provides syntactic sugar for the React.createElement(component, props, ...children) function. The JSX code:
Simply put, a React element describes what you want to see on the screen. Not so simply put, a React element is an object representation of a DOM node.’
In order to create our object representation of a DOM node (aka React element), we can use React’s createElement method.
const element = React.createElement(
'div',
{id: 'login-btn'},
'Login'
)
React.createElement(Icon, null)
So finally, what do we call it when we write out our component like this, ? We can call it “creating an element” because after the JSX is transpiled, that’s exactly what’s happening.
也就是我们在 jsx 文件里的所有的类似的写法都是在写 createElement()方法(jsx 会被 babel 转义)
function Button ({ addFriend }) {
return (
<button onClick={addFriend}>Add Friend</button>
)
}
function User ({ name, addFriend }) {
return (
<div>
<p>{name}</p>
<Button addFriend={addFriend}/>
</div>
)
}
function Button ({ addFriend }) {
return React.createElement(
"button",
{ onClick: addFriend },
"Add Friend"
)
}
function User({ name, addFriend }) {
return React.createElement(
"div",
null,
React.createElement(
"p",
null,
name
),
React.createElement(Button, { addFriend })
)
}
“Components are the building blocks of React”. Notice, however, that we started this post with elements. The reason for this is because once you understand elements, understanding components is a smooth transition. A component is a function or a Class which optionally accepts input and returns a React element.
createElement -> 解析props, 生成key或者ref, ->生成vnode
这个生命周期函数是在 render 之后 DOM 更新之前调用的
若是想要获取 DOM 更新之前的 DOM 数据可以在这个函数里获取
static defaultProps = {} // 默认属性
getDefaultProps , 函数的形式获取默认属性
getInitialState , 函数的形式获取初始state
keyof {a: 3} // a
type Partial<T> = {
[P in keyof T]?: T[P]; // P是T中的key, 且加了? 就是可选的意思
};
type Required<T> = {
[P in keyof T]-?: T[P]; // -? 就是去掉 ? 去掉可选性, 也可以使+?添加可选属性
};
type Readonly<T> = {
readonly [P in keyof T]: T[P]; // 全部加上readonly属性
};
最近在进行web端的一些性能调优,看到了taobaoFED的一篇文章(这是google chrome自己写的),里面讲到了利用合成层(compositing layers)来加速动画性能,其实就是在利用GPU加速,而合成层都会有单独的GraphicsLayer
这里先说几个概念
描述了某个dom对象的渲染方式,他和Dom node是一一对应的,这些RenderObjects保持了树结构,一个RenderObjects知道如何绘制一个node的内容, 他通过向一个绘图上下文(GraphicsContext)发出必要的绘制调用来绘制nodes。绘图上下文的责任就是向屏幕进行像素绘制(这个过程是先把像素级的数据写入位图中,然后再显示到显示器),在chrome里,绘图上下文是包裹了的Skia, 一个chrome自己的2d图形绘制库。
Each node in the DOM tree that produces visual output has a corresponding RenderObject. RenderObjects are stored in a parallel tree structure, called the Render Tree. A RenderObject knows how to paint the contents of the Node on a display surface. It does so by issuing the necessary draw calls to a GraphicsContext. A GraphicsContext is responsible for writing the pixels into a bitmap that eventually get displayed to the screen. In Chrome, the GraphicsContext wraps Skia, our 2D drawing library.
Each node in the DOM tree that produces visual output has a corresponding RenderObject
Each renderer represents a rectangular area usually corresponding to the node's CSS box, as described by the CSS spec. It contains geometric information like width, height and position.
一般来说,拥有相同的坐标空间的 RenderObjects,属于同一个渲染层(PaintLayer), 这个和RenderObjects是一对多的,RenderLayers的存在就是为了,保证页面元素以正确的顺序合成(composite),这样才能正确的展示元素的重叠以及半透明元素等等,并且,RenderLayer也是以树的形式来组织结构的,一个RenderLayer节点的children是被存储在两个有序list中的,一个负Z值的有序list,另一个是正Z值的有序list
为了充分利用(compositor,待解释)某些特殊的渲染层会被认为是合成层(Compositing Layers),合成层拥有单独的 GraphicsLayer,而其他不是合成层的渲染层,则和其第一个拥有 GraphicsLayer 父层公用一个。
每个 GraphicsLayer 都有一个 GraphicsContext,GraphicsContext 会负责输出该层的位图,位图是存储在共享内存中,作为纹理上传到 GPU 中,最后由 GPU 将多个位图进行合成,然后 draw 到屏幕上,此时,我们的页面也就展现到了屏幕上。
这里是有一个顺序的见图:
按照google的文章里还有一些其他的layer
From GraphicsLayers to WebLayers to CC Layers, Only a couple more layers of abstraction to go before we get to Chrome’s compositor implementation! GraphicsLayers can represent their content via one or more WebLayers. These are interfaces that WebKit ports needed to implement;
当我们实现compositor时只需要几层抽象即可,GraphicsLayers可以通过一个或者多个Weblayers就可以展现他的内容,比如WebContentsLayer.h 或者 WebScrollbarLayer.h.
这个就是google文章里介绍 compositor的:
Chrome’s compositor is a software library for managing GraphicsLayer trees and coordinating frame lifecycles. Code for it lives in the src/cc directory, outside of Blink.
Introducing the Compositor
Recall that rendering occurs in two phases: first paint, then composite. This allows the compositor to perform additional work on a per-compositing-layer basis. For instance, the compositor is responsible for applying the necessary transformations (as specified by the layer's CSS transform properties) to each compositing layer’s bitmap before compositing it. Further, since painting of the layers is decoupled from compositing, invalidating one of these layers only results in repainting the contents of that layer alone and recompositing.
Every time the browser needs to make a new frame, the compositor draws. Note this (confusing) terminology distinction: drawing is the compositor combining layers into the final screen image; while painting is the population of layers’ backings (bitmaps with software rasterization; textures in hardware rasterization).
Whither the GPU?
So how does the GPU come into play? The compositor can use the GPU to perform its drawing step. This is a significant departure from the old software rendering model in which the Renderer process passes (via IPC and shared memory) a bitmap with the page's contents over to the Browser process for display (see “The Legacy Software Rendering Path” appendix for more on how that works).
In the hardware accelerated architecture, compositing happens on the GPU via calls to the platform specific 3D APIs (D3D on Windows; GL everywhere else). The Renderer’s compositor is essentially using the GPU to draw rectangular areas of the page (i.e. all those compositing layers, positioned relative to the viewport according to the layer tree’s transform hierarchy) into a single bitmap, which is the final page image.
其实上面这些有些就是单纯的从taobaoFED那篇文章中copy来,但我也看了一下google的那篇文章,我发现其实淘宝的那篇文章关于术语概念的描述就是google文章的翻译,但淘宝的栗子举的很详细,值得一看,里面提到了一旦renderLayer提升为了合成层就会有自己的绘图上下文,并且会开启硬件加速,有利于性能提升,里面列举了一些特点
有几个问题我们需要注意一下:
Each GraphicsLayer has a GraphicsContext for the associated RenderLayers to paint into. The compositor is ultimately responsible for combining the bitmap output of GraphicsContexts together into a final screen image in a subsequent compositing pass. , 请注意这句话,说的是没个GraphicsLayer有自己的绘图上下文去绘制关联的RenderLayers,而 compositor是负责把绘图上下文的位图输出进行组合,那么组合这件事是交给了GPU,但是绘图上下文的工作依然是CPU啊,这里可以看一张google里的关于GPU的架构图

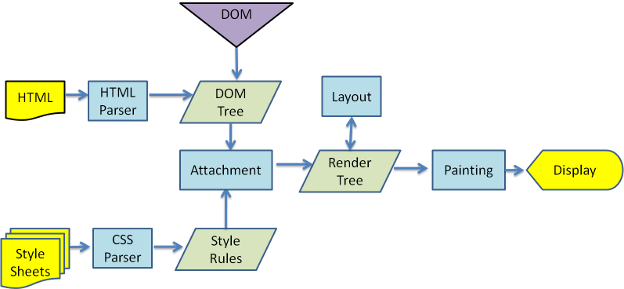
然后淘宝的文章又举了几个具体的栗子来说明合成层优点:
提升合成层的最好方式是使用 CSS 的 will-change 属性。从上一节合成层产生原因中,可以知道 will-change 设置为 opacity、transform、top、left、bottom、right 可以将元素提升为合成层。
而对于固定不变的区域,我们期望其并不会被重绘,因此可以通过之前的方法,将其提升为独立的合成层。
减少绘制区域,需要仔细分析页面,区分绘制区域,减少重绘区域甚至避免重绘。
接下来文章又提到了,合成层的一些问题
看完上面的文章,你会发现提升合成层会达到更好的性能。这看上去非常诱人,但是问题是,创建一个新的合成层并不是免费的,它得消耗额外的内存和管理资源。实际上,在内存资源有限的设备上,合成层带来的性能改善,可能远远赶不上过多合成层开销给页面性能带来的负面影响。同时,由于每个渲染层的纹理都需要上传到 GPU 处理,因此我们还需要考虑 CPU 和 GPU 之间的带宽问题、以及有多大内存供 GPU 处理这些纹理的问题。
demo 1 和 demo 2 中,会创建 2000 个同样的 div 元素,不同的是 demo 2 中的元素通过 will-change 都提升为了合成层,而两个 demo 页面的内存消耗却有很明显的差别。
之前无线开发时,大多数人都很喜欢使用 translateZ(0) 来进行所谓的硬件加速,以提升性能,但是性能优化并没有所谓的“银弹”,translateZ(0) 不是,本文列出的优化建议也不是。抛开了对页面的具体分析,任何的性能优化都是站不住脚的,盲目的使用一些优化措施,结果可能会适得其反。因此切实的去分析页面的实际性能表现,不断的改进测试,才是正确的优化途径。
接下来我也说一点其他的,当我们提升到合成层以后,也不是说可以为所欲为的,意味全都是GPU处理了,其实GPU只是在处理合成层的组合而已, 就像上面我提到的那样,接下来举个栗子大家就知道了
<style>
#a, #b {
position: absolute;
width: 100px;
height: 100px;
transform: translateZ(0);
}
#a {
background-color: blue;
left: 10px;
top: 10px;
z-index: 2;
animation: move 1s infinite linear;
}
#b {
background-color: red;
left: 50px;
top: 50px;
z-index: 1;
}
@keyframes move {
to { left: 100px; }
from { left: 30px; }
}
</style>
<div id="a">A</div>
<div id="b">B</div>
看上述代码,我把a,b都用translateZ提升到了合成层,然后加了个动画,但是我是直接改变left来实现动画的,此通过performance截图可以看到如下:
动画依然在触发restyle, layout, update layer tree, GPU也是用了但是是在Composite阶段使用的
在来看看绘制区域以及合成层的情况
会发现他连重绘的区域都没有。。。,后来在performance中一看,发现这货根本就没有paint的阶段,其实在上图中也可以看出来,有些阶段确实是没有paint的
那么接下来我直接把a,b 的translateZ去掉此时a,b就不再是合成层了,又会是如何呢见下图
从上面两张图可以看出若是没有提升到合成层,他是会有paint的操作的,那么这两次操作我只是为了说一件事,那就是如果你的动画本身就触发了reflow等操作,那么即使提升至合成层,空也无法最大限度的优化,甚至没啥提升
那么我们来看看,若是我们把动画改为使用translate来进行,就是把
@keyframes move {
from { left: 30px; }
to { left: 100px; }
}
//换成
@keyframes move {
from { transform: translateX(0); }
to { transform: translateX(70px); }
}
接下来看看我们改动后的效果
很显然效果很明显,几乎全是GPU操作了,而cpu的操作几乎只有GC了,可对于我们上面看到的chrome的GPU架构,GPU是单独的进程,那若是全交给GPU了,那么GPU进程的资源消耗是否又会过高了呢?(如 cpu, memory等等);
说了这么多,总结就是要合理的利用合成层,无论是否提升至合成层都应当注意reflow以及repaint的触发,上面的栗子出自
CSS GPU Animation: Doing It Right
先上图:
无论何时我都会被问到一个问题那就是如何再使用rxjs的时候使用promise和async和await呢?或者什么时候不能混合使用?我也说过几个不要同时使用的栗子。rxjs从一开始就可以很好的和promise一起使用。希望这篇文章能够很好的阐述一下。
举个栗子,假如你在使用switchMap, 那么你就可以像返回一个Observable一样返回一个Promise。就像下面这样 jsbin:
// An observable that emits 10 multiples of 100 every 1 second
const source$ = Observable.interval(1000)
.take(10)
.map(x => x * 100);
/**
* returns a promise that waits `ms` milliseconds and emits "done"
*/
function promiseDelay(ms) {
return new Promise(resolve => {
setTimeout(() => resolve('done'), ms);
});
}
// using it in a switchMap
source$.switchMap(x => promiseDelay(x)) // works
.subscribe(x => console.log(x));
source$.switchMap(promiseDelay) // just a little more terse
.subscribe(x => console.log(x));
// or takeUntil
source$.takeUntil(doAsyncThing('hi')) // totally works
.subscribe(x => console.log(x))
// or weird stuff you want to do like
Observable.of(promiseDelay(100), promiseDelay(10000)).mergeAll()
.subscribe(x => console.log(x))
经验证确实工作的很好
如果你的函数返回一个promise你可以使用Observable.defer包裹他,就可以使得他在发生错误是可以进行重试jsbin。
Observable.defer: Returns an observable sequence that invokes the specified factory function whenever a new observer subscribes.
function getErroringPromise() {
console.log('getErroringPromise called');
return Promise.reject(new Error('sad'));
}
Observable.defer(getErroringPromise)
.retry(3)
.subscribe(x => console.log);
// logs "getErroringPromise called" 4 times (once + 3 retries), then errors
经验证确实工作的很好
defer是一个强有力的工具,你也可以用它来封装async-await函数
Observable.defer(async function() {
const a = await promiseDelay(1000).then(() => 1);
const b = a + await promiseDelay(1000).then(() => 2);
return a + b + await promiseDelay(1000).then(() => 3);
})
.subscribe(x => console.log(x)) // logs 7
这个没有jsbin尝试失败了呃,因为不支持async-await,估计是我的姿势错了,但我在本地试了ok。
forEach 介绍:

const click$ = Observable.fromEvent(button, 'clicks');
/**
* Waits for 10 clicks of the button
* then posts a timestamp of the tenth click to an endpoint
* using fetch
*/
async function doWork() {
await click$.take(10)
.forEach((_, i) => console.log(`click ${i + 1}`));
return await fetch(
'notify/tenclicks',
{ method: 'POST', body: Date.now() }
);
}
经本地验证很ok
事实上toPromise比较怪异因为他并不是rxjs规范所定义的操作符,只是我们提供了而已。而且toPromise只会把最后一个值使用promise进行包装,那就意味着,若是Observable一直不触发complete那么这个promise就永远不会resolve。
toPromise是一个反模式,只有在需要promise的时候才使用,不要乱用,比如await
const source$ = Observable.interval(1000).take(3); // 0, 1, 2
// waits 3 seconds, then logs "2".
// because the observable takes 3 seconds to complete, and
// the interval emits incremented numbers starting at 0
async function test() {
console.log(await source$.toPromise());
}
经本地验证很ok。
基本上如果你的目的就是active programming那么就应当使用Rxjs.Observable。但为了符合人体工程学,我们还是提供了和Promise的互操作,谁让他这么流行呢!其实当我们在async/await中使用forEach的是后会带来更多的可能性。
今天看了一篇很棒的文章似是而非的JS - 异步调用可以转化为同步调用吗?
里面讲解了很多知识点,写篇文章总结总结,其实所有所有的就是想把异步代码调用,串行化执行(async, promise, co,async/await等等方法,而这片文章就是讲讲里面到底是啥)
人来说完全不知道这是什么鬼,只能靠猜...),查阅文档,当async
设置为true时异步调用,设为false时,则是同步调用
By default, all requests are sent asynchronously (i.e. this is set to true by default). If you need synchronous requests, set this option to false. Cross-domain requests and dataType: "jsonp" requests do not support synchronous operation. Note that synchronous requests may temporarily lock the browser, disabling any actions while the request is active. As of jQuery 1.8, the use of async: false with jqXHR ($.Deferred) is deprecated; you must use the success/error/complete callback options instead of the corresponding methods of the jqXHR object such as jqXHR.done().
可问题就来了,就像文章里说的,为啥jquery 对于jsonp的实现不允许async: false呢,在上述片段理由一句话Note that synchronous requests may temporarily lock the browser, disabling any actions while the request is active.,同不调用会阻塞browser的其他处理,而jsonp的实现是基于script标签实现的,就是因为这个么?不知道了,ok我们来继续, 我看到stackoverflow上有这么一段回答
It is completely impossible to do synchronous
JSONP. JSONP works by creating a <script> tag;
the browser does not expose any way to wait for
a <script> tag. In addition, SJAX is never a good idea; it will freeze the browser until the server replies.
You need to correctly use asynchrony. Consider using promises.
按照这段回答呢是说没办法,显然这是洪荒年代了,我来看看
文中提到的async属性caniuse 显然使用这个属性,我们是有办法的。我们再来看看文中提到的实现
export const loadJsonpSync = (url) => {
var result;
window.callback1 = (data) => (result = data)
let head = window.document.getElementsByTagName('head')[0];
let js = window.document.createElement('script');
js.setAttribute('type', 'text/javascript');
js.setAttribute('async', 'sync');
// 这句显式声明强调src不是按照异步方式调用的
js.setAttribute('src', url);
head.appendChild(js);
return result
}
上面这段代码其实不难理解,主要是要设置script标签的
async属性为sync,
window.callback1 = (data) => (result = data)
这是个jsonp实现,callback1显然就是, 要执行的回调, 可是作者说拿到的却是undefined,解释一下为什么jsonp中的async没有生效,现在解释起来真的是相当轻松,即document.appendChild的动作是交由dom渲染线程完成的,所谓的async阻塞的是dom的解析(关于dom解析请大家参考webkit技术内幕第九章资源加载部分),而非js引擎的阻塞。实际上,在async获取资源后,与js引擎的交互依旧是push taskQueue的动作,也就是我们所说的async call, 就是说async其实是阻塞dom解析线程,而非js执行线程,这就意味着,dom渲染就不进行了,一直到script加载完成,而js线程没有被阻塞,所以在dom线程阻塞等待的时候,js线程已经在执行了就直接反回result,所以很明显是undefined
先看一段文中提到的异步与同步定义
同步(英语:Synchronization),指对在一个系统中所发生的事件(event)之间进行协调,在时间上出现一致性与统一化的现象。在系统中进行同步,也被称为及时(in time)、同步化的(synchronous、in sync)。--摘自百度百科
异步的概念和同步相对。即时间不一致,不统一
(确定百度不会死人么2333333),还可以借助甘特图来表达一下
显然, t1,t2是同步,t1,t3是异步
作者提了一个实现例子
spinLock() {
// 自旋锁
fork Wait 3000 unlock()//开启一个异步线程,等待三秒后执行解锁动作
//本来新生成的线程与主线程的执行时不相关的,
//两者异步主线程的执行与新生成的线程不同步
loop until unlock
Put
‘unlock’
}
//pv原语,当信号量为假时立即执行下一步,同时将信号量置真
//反之将当前执行栈挂起,置入等待唤醒队列
//uv原语,将信号量置为假,并从等待唤醒队列中唤醒一个执行栈
Semaphore() {
pv()
fork Wait 3000 uv()
pv() //这一步是为了争夺信号量,因为虽然新生成的线程uv释放了信号量,但不一定就是主线程执行
uv()
Put 'unlock'
}
对于这段的解读,注释已经很详细了,这时候作者就继续追问了,那么js可以么?作者查看了,jquery,node的底层实现,都是使用的原生代码实现的,并没有使用js, 那么可以使用setTimeout来模拟fork么?
作者实现了第一个版本如下
var lock = true;
setTimeout(() => {
lock = false;
}, 5000);
while(lock);
console.log('unlock')
显然这段代码,肯定是不行的,因为大家都知道,js是单线程的,一旦执行了while(lock)就不可能再执行其他代码了,setTimeout的执行也是由于事件循环的调度执行的,但执行体仍然是同一个线程,作者按照理论模拟实现了一个eventloop,关于这个话题可以在写篇文章,坐等吧
接下来我们继续改进我们上面的代码片段
var lock = true
setTimeout(() => {
lock = false
console.log('unlock')
}, 5000)
function sleep() {
var i = 5000
while(i--);
}
var foo = () => setTimeout(() => {
sleep()
lock && foo()
});
foo()
作者说了,这是对while(true)做了切块处理(显然这又是可以讲解的一个话题),其实就是估计一下结束时间,不让while(true)阻塞了所有的代码,使用sleep估计一下运行时间,是有偏差的
可是,如果把代码最后的foo() 变成 foo() && console.log('wait5sdo'),显然wait5sdo依然没有在foo中的sleep执行完成以后在执行,是直接输出了,在js代码中,
========同步执行代码必然是在异步代码之前执行的=======
所以,无论从理论还是实际出发,我们都不得不承认,在js中,把异步方法改成同步方法这个命题是水月镜花.
async function () {
var data = await getAjax1()
console.log(data);
}
我去这段代码亲手推翻了==同步执行的代码片段必然在异步之前。== 的黄金定律!借助作者话就是意不意外,惊不惊喜,
相信很多人都会说,async/await是CO的语法糖,CO又是generator/promise的语法糖,好的,那我们不妨去掉这层语法糖,来看看这种代码的本质, 关于CO,读的人太多了,我实在不好老生常谈,可以看看这篇文章,咱们就直接绕过去了,这里给出一个简易的实现
http://www.cnblogs.com/jiasm/p/5800210.html
function wrap(wait) {
var iter;
iter = wait() //生成generator对象
const f = () => { //就是一个递归
const { value } = iter.next(); //这里调用generator的next方法移交执行权, 执行wait里的yield
value && value.then(f) //yield的返回值若是存在是promise,则继续执行,显然这里可以做thunk函数的适配
}
f()
}
function * wait() {
var p = () => new Promise(resolve => {
setTimeout(() => resolve(), 3000)
});
yield p();
console.log('unlock');
yield p();
console.log('unlock2');
console.log('it\'s sync');
}
显然这里的yield是个黑魔法啊,其实我们完全可以使用cb,来实现一个generator,见下
//显然要实现generator,我们就得关注生成器函数的返回,是一个可迭代的状态机,就是要实现这个状态机
function wait() {
const p = () => (value: new Promise(resolve => setTimeout(() => resolve(), 3000)));
//很显然这个状态机,每次都把next函数给替换掉
let state = {
next: () => {
state.next = programPart
return p()
}
function programPart() {
console.log('unlocked1')
state.next = programPart2
return p()
}
function programPart2() {
console.log('unlocked')
console.log('it\'s sync!')
retturn {value: void 0}
}
return state;
}
}
接下来是作者原话了
到此我们就完成了generator到function的转换,,这段代码本身也解释清楚了generator的本质,高阶函数,片段生成器,或者直接叫做函数生成器
(这一部分有很多可以聊得,再聊)
来补债了
这个原因经过作者的指导问题是这么来的
function* g() {
yield var a = 123
yield console.log(a);
}
function g() {
let state = {
next: () => {
state.next = f1
}
}
function f1() {
var a = 123
state.next = f2
}
function f2() { console.log(a) } }
就好比上面代码的转换过程,由于有变量提升的问题, generator中的console.log(a)是有输出的,而转换过后的是没有的,这就是其中作用域的坑
其实这个东西,如果把代码写出来估计大家都能看出问题来,可若是没有的话,会有点儿没注意这个代码的转换问题,我还以为是之前的转换代码本身有问题,其实是这种转换,本身对于js作用域的割裂(**************)
其实,在不知不觉中,我们已经重新发明了计算机科学中大名鼎鼎的CPS变换https://en.wikipedia.org/wiki/Continuation-passing_style
最后的最后,容我向大家介绍一下facebook的CPS自动变换工具--regenerator。他在我们的基础上修正了作用域的缺陷,让generator在es5的世界里自然优雅。我们向facebook脱帽致敬!!https://github.com/facebook/regenerator
推荐阅读 计算机程序的构造和解释 第一章generator部分实际上我们提供的解决方式存在缺陷,请从作用域角度谈谈(没有搞懂。。。还是菜啊,真是没看出来)
(API 设计是需要反馈的)[https://mp.weixin.qq.com/s/2SHUBIOH77ZTDbeuLV-VLw]
what do you want when to be a leader?
how rust solve dependency hell
es proxy 使用实例
1. proxy 断言
2. 10 use case
IT架构的思考 非常棒
misunderstanding fsync in Postgresql
code split in react with webpack4
cocepts you should know in react
write a redux(待译)
Accelerated Rendering in Chrome
How (not) to trigger a layout in WebKit
Rendering: repaint, reflow/relayout, restyle
提升性能的一些方法论,benchmark,analyse data
chrome performance
避免大型、复杂的布局和布局抖动
understanding-the-nodejs-event-loop
反脆弱性系统,可以错,要拥抱错误,但不能因为错误就崩溃性完全无法运行
同时由于考虑到庞大的 HTTP1.1 协议用户,所以 HTTP 方法、状态码、URI 及首部字段,等核心概念保持不变,也就是当前正在运行的网站不用做任何改变即可在 HTTP2 协议上运行。
二进制分帧机制改变了客户端与服务器之间交互数据的方式,涉及到以下几个重要的概念:
流:已建立的 TCP 连接上的双向字节流,逻辑上可看做一个较为完整的交互处理单元,即表达一次完整的资源请求-响应数据交换流程;一个业务处理单元,在一个流内进行处理完毕,这个流生命周期完结。
消息:由一个或多个帧组合而成,例如请求和响应。
帧:HTTP2 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流。所有 HTTP2 通信都在一个连接上完成,此连接理论上可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。图示如下:
HTTP2 的所有帧都采用二进制编码,所有首部数据都会被压缩。上图只是演示数据流、消息和帧之间的关系,而非实际传输时的编码结果。
二进制分帧层实现了多向请求和响应,客户端和服务器可以把 HTTP 消息分解为互不依赖的帧,然后乱序发送,最后再在另一端把它们重新组合起来。图示如下:
由上图可以看出,同一个 TCP 连接可以传输多个数据流,并且服务器到客户端方向有多个数据流,流是一个逻辑信道,所以属于它的帧可以乱序发送,最后再根据标记组合起来即可。把 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装是 HTTP2 最重要的改进,带来了巨大的性能提升,主要因为如下几个原因:
二进制分帧机制解决了 HTTP1.1 队头阻塞问题,也消除了并行处理和发送请求及响应时对多个 TCP 连接的依赖
每个流都包含一个优先级,用来告诉对端哪个流更重要,当资源有限的时候,服务器会根据优先级来选择应该先发送哪些流。HTTP2 中,每个请求都可以带一个 31bit 的优先值,0 表示最高优先级。数值越大优先级越低。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。
当前 web 页面的功能越来越强大,排版越来越精美,所以需要引用的 js 文件、css 文件或者图片等内容也越来越多,对每一个资源的外部引用,都是一次 request 请求。在 HTTP1.1 中,由于不具有多向请求与响应,所以可能需要额外的 TCP 连接,甚至导致队头堵塞,HTTP1.1 对此问题的解决方案可以参阅 HTTP 请求延迟解决方案一章节。当客户端获取服务器发送来的文档之后,通过分析获知需要引入额外的资源,然后再向服务器发送请求获取这些资源,如此大费周章,倒不如服务器主动推送这些额外资源。推送资源的特点如下:
在 HTTP1.1 中,每次请求或者响应都会发送一组首部信息,同时这些信息都是以文本形式发送,如果带有 cookie 信息的话,那么发送首部信息就是一份相当大的额外开销。为减少这些开销并提升性能,HTTP2 会压缩首部元数据,HTTP2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键/值对,对于相同的数据,不再通过每次请求和响应发送,首部表在 HTTP2 的连接存续期内始终存在,由客户端和服务器共同渐进地更新。
我希望这篇文章能够清晰的描述一下如何镜像 git 仓库---即我有一个 github 仓库 example.git, 还有一个 sourceforge 仓库 example.git, 我希望这两个仓库的代码可以镜像同步,就是我无论更新哪一个都会同步到另一个仓库上去。
cd /srv/gitsync
git clone --bare [email protected]:[account]/[repository].git
mv [repository].git [repository]
接下来,我们删除 origin 'remote',并且配置两个远程仓库为 upstream 就是添加 remote,看代码更详细:
cd [repository]
git remote remove origin
git remote add github [email protected]:[account]/[repository].git
git remote add sourceforge ssh://[account]@git.code.sf.net/p/[repository]/code
镜像意味着无论哪个仓库有更新都会同步到另外一个仓库上去。因此我们应当有个 webhook 来触发我们镜像脚本。每个代码管理都会提供这样的 hook 的。
#!/bin/bash
function sync_repo {
cd /srv/gitsync
cd $1
echo $1
# fetch all known remotes 获取所有remote的代码更新
git fetch --all -p
# 我们可以看同步就在下面进行
# push branches from sourceforge to github and via versa. 先同步sourceforge 到github. 注意 push的目的remote是github, 源remote是在refs/remote中指定的sourcefore
git push github "refs/remotes/sourceforge/*:refs/heads/*"
# 同理推送 github上的代码更新到sourceforge
git push sourceforge "refs/remotes/github/*:refs/heads/*"
}
# 处理参数,进入指定的bare仓库进行推送
cd /srv/gitsync
if [ "$1" == "" ]; then
# no command line parameters, print help message
echo "gitsync [report]|--all"
elif [ "$1" == "--all" ]; then
# "--all": for all known repositories
for D in *; do
if [ -d "${D}" ]; then
sync_repo $D
cd /srv/gitsync
fi
done
elif [ -d "$1" ]; then
# sync only the specified repository
sync_repo $1
else echo "gitsync [report]|--all"
fi
我们可以看到在 sync_repo 函数中我们把 github 和 sourceforge 进行了互相推送。当然你还可以进行更多的映射。
就像我们上面讨论的,我门使用 webhooks 来触发我们的 mirror 行为。可以使用如下的 php 脚本
if ($_SERVER['REQUEST_METHOD'] !== 'POST') {
die('POST required');
}
if (!isset($_REQUEST['repository'])) {
die('repository not specified');
}
// validate repository name to prevent injection and traversing attacks
$repo = $_REQUEST['repository'];
if (!preg_match('/^[a-zA-Z0-9]+$/', $repo)) {
die('invalid repository name');
}
header('HTTP/1.0 204 Found');
system('sudo -Hu gitsync /usr/local/bin/gitsync '.$repo);
我们必须的校验仓库名称,以防止 shell 命令注入,git 命令注入,以及目录遍历等非法行为。
上面的代码使用了 sudo 的权限,显然 webserver 不应该拥有可访问仓库的权限。
大部分代码管理都支持 webhook 验证,但是我么上面的例子没有使用验证,那意味着任何人都可以触发我们的同步行为。
git branch -d [branchName]
git push github --delete [branchName]
git push sourceforge --delete [branchName]
虽然麻烦但是我们还是实现了:)。
因为我们在把头尾index往里缩时我们判断的是小于和不小于(大于同理),比如我们把pivot 5 放在中间,当我们的头index判断不小于时,若是到了pivot条件也是成立的就跳到了pivot右侧,此时若是尾index也在右边发现了小于pivot的值在交换时就会出现,小于pivot的值出现在pivot的右侧,当然我们也可以做额外操作,判断若是头index到了pivot的位置时则不再继续
1.
| |
V V
4, 5, 8, 2
头 尾
2.
| |
V V
4, 5, 2, 8
头 尾
3. 此时找到了大于以及小于的pivot的值交换
4,5,2,8, 显然出问题了
、、、、、、
但是若是5在头部
5,4,8,2, 交换就没事了,因为接下来会有把pivot和low或者high交换的过程
2,1,2,1,3,4,5
上述3已经在正确位置了,再接下来的排序应当是4,5和2,1,2,1两组进行排序而不是3,4,5和2,1,2,1或者4,5和2,1,2,1, 3进行排序, 因为3已经是在正确位置了,没必要再排一次。
解析:元素较少时,大家都差不多,反而是希尔排序这样的好一些,好在哪啊?
我们都知道快排在元素基本有序时是最慢的最坏能达到o(n^2),所以当序列基本有序时我们可以采用堆排序
package main
import (
"fmt"
)
// threads 线程标识创建线程的个数
func quicksort(nums []int, length int) {
if length <= 1 {
return
}
left := 1
right := length - 1
pivot := nums[0]
for{
for; left < right && nums[right] > pivot; right--{ }
for; left < right && nums[left] <= pivot; left++ { }
if left >= right {
break
}
nums[left], nums[right] = nums[right], nums[left]
}
nums[0], nums[left] = nums[left], nums[0]
quicksort(nums[0:left], left) //分任务
temp := nums[left + 1: length]
quicksort(temp, len(temp))
return
}
func main() {
x := []int{3, 41, 24, 76, 11, 45, 3, 3, 64, 21, 69, 19, 36}
quicksort(x[:], len(x))
fmt.Println(x);
}
quicksort([]) -> [];
quicksort([Pivot|Rest]) ->
{Smaller, Larger} = partition(Pivot, Rest, [], []),
quicksort(Smaller) ++ [Pivot] ++ quicksort(Larger).
partition(_, [], Smaller, Larger) -> {Smaller, Larger};
partition(Pivot, [H|T], Smaller, Larger) ->
if H =< Pivot -> partition(Pivot, T, [H|Smaller], Larger);
H > Pivot -> partition(Pivot, T, Smaller, [H|Larger])
end.
erlang版的快排,很清晰的告诉了我们快排的核心**~一次确定一个数字的位置
每种语言总是有自己发光的地方,就好比普通的你我
js对于二进制数据的处理很弱,因此才会有了ArratBuffer。
ArrayBuffer使用来处理二进制数据的,并且有一些新的就API依赖于ArrayBuffer,例如websockets, web intents, XMLHttpRequest version 2 以及webworkers.
从语义上讲,ArrayBuffer就是一个通过一定的视窗去操作的简单字节数组,这个视窗就是一个ArrayBufferView的实例,定义了里面的字节数据是如何按照预期的数据结构进行组织的,举个栗子:如果你知道一个ArrayBuffer里面的字节数据是以16位的无符号整数展示的话,你就可以直接把ArrayBuffer用一个Uint16Array的视窗包裹起来,然后就可以通过Uint16Array所定义的有关Uint16方法来操作这些数据,就好像这个ArrayBuffer就是一个整数数组一样, ArrayBuffer的构造只有一个参数就是字节长度有且只有这一个
//例如 buf 包含了字节数据[0x02, 0x01, 0x03, 0x07]
//这里一定要注意硬件的大端与小端模式,x86就是小端模式
//对ArrayBuffer的读写操作其实都是同过TypedArray以及DataView操作的,也就是往里存数据也是一样的
let bufView = new Uint16Array(buf);
if (bufView[0] === 258) {
console.log("ok");
}
bufView[0] = 255 //buf现在存贮的就是[0xFF, 0x00, 0x03, 0x07]
bufView[0] = 0xff05 //现在就是 [0x05, 0xFF, 0x03, 0x07]
bufView[1] = 0x0210 //现在就是 [0x05, 0xFF, 0x10, 0x02]
/******** 再举一个写入的栗子*******/
//比如我声明一个2字节长的ArrayBuffer
let arr = new ArrayBuffer(2);
//然后通过Uint8来观察以及操作ArrayBuffer
let view = new Uint8Array(arr);
// log view : Uint8Array [ 0, 0 ]
// 然后 设置0
view[0] = 255;
// log view : Uint8Array [ 255, 0 ]
//在设置为256,注意溢出8位无符号整形最大值就是255,溢出以后就是0了
view[0] = 256;
// log view : Uint8Array [ 0, 0 ]
//等等。。。
BLOB (binary large object),二进制大对象
经常会遇到的一个很常见的实用性的问题就是如何把String转化到ArrayBuffer以及反转回来,但实际上ArrayBuffer是一个字节数组,这种转换需要两端都有一个统一的认识就是如何把string显示为字节,你可能已经看过这种协议了:字符串的编码(比如Unicode UTF-16和iso8859-1),因此,假设你和其他参与者都认同UTF-16编码,这样转换就像下面了:
function ab2str(buf) {
return String.fromCharCode.apply(null, new Uint16Array(buf));
}
function str2ab(str) {
let buf = new ArrayBuffer(str.length * 2); //bytes for each
let bufView = new Uint16Array(buf);
for (let i = 0; strLen = str.length; i < strLen; i++) {
bufView[i] = str.charCodeAt(i);
}
return buf;
}
注意点,当我们使用Uint16Array的时候,他仅仅是ArrayBuffer的一个视窗层,只是在这个视窗层看来数据都是16位的元素,他并不处理字符编码本身,编码自身的处理依然需要String.fromCharCode和str.CahrCodeAt来处理
接下来,继续深入看看吧,译文到此就结束了
先总结一下ArrayBuffer的构造方法吧
let u8a = new Uint8Array.from([1,2,3,5])
//bufferView的from方法接受一个array-like的对象,可以构造出一个bufferView,当然底层还得new 一个ArrayBuffer
//所以我们就拿到了ArrayBuffer咯
let ab = u8a.buffer //只读属性
//画蛇添足,为什么就是为了告诉你,我们可以这么做,并且也是为了说明这些bufferView使用了共同的ArrayBuffer,意味着你修改了其中的一个另一个的展现方式也会改变
let u16a = new Uint16Array(ab);
//log u16a Uint16Array [ 513, 1027 ]
u16a[0] = 1234;
//log u16a Uint16Array [ 1234, 1027 ]
//log u8a Uint8Array [ 210, 4, 3, 4 ]
到底是什么是TypedBuffer呢,其实就是下面所列举的
那么他们和ArrayBuffer又是什么关系呢? 引用两张图来说明一下,图中的01数据呢,就是ArrayBuffer
继续go on
go go go
最后一张一看你就会更清楚了
这个时候估计就会有疑问了,若是搞过多线程的话,就会问了,两个同时访问同一�内存区域,不会出问题么?答案是在js里不会,因为js是单线程啊,但又有来了,那webworkers呢,根据一些文章解读当把ArrayBuffer传递以后是没有办法在访问到了(暂时未实验见文章), 那就没办法了么?有的,方法总比问题多?那就是SharedArrayBuffer,和他配套的就是Aomtic的�一些操作详见也是上篇文章,至于TypedArray的操作已经在上面又说了,大部分都类似
最后在说一下DataView
DataView的签名 :new DataView(buffer [, byteOffset [, byteLength]])
签名的参数很明显就不解释了,DataView给了我们对ArrayBuffer更多的�操作空间,他可以让我们有选择性的操作某一范围的ArrayBuffer的数据
这里是DataView的方法列表
从这些方法我们可以看出我可以以多种的方式操作这段范围的ArrayBuffer,例如以int8, int16都可以,但是当我们使用Uint8Array操作时就只能以uint8的方式操作,而DataView就不一样了,可以多种多样,注意大端小端模式,�下列操作的参数是offset, value, littelEndianAble(false or true)
Read
DataView.prototype.getInt8()
DataView.prototype.getUint8()
DataView.prototype.getInt16()
DataView.prototype.getUint16()
DataView.prototype.getInt32()
DataView.prototype.getUint32()
DataView.prototype.getFloat32()
DataView.prototype.getFloat64()
Write
DataView.prototype.setInt8()
DataView.prototype.setUint8()
DataView.prototype.setInt16()
DataView.prototype.setUint16()
DataView.prototype.setInt32()
DataView.prototype.setUint32()
DataView.prototype.setFloat32()
DataView.prototype.setFloat64()
具体使用哪种方式还是要看具体的使用场景,大家自行发现吧,打完收工,下次写写Blob以及nodej�s的buffer对象
本篇大部分(出了最后的总结)是从一个大神哪里学习时总结的但忘了是哪个大神,若是引得不悦,果断删除([email protected])
Python3 支持 int、float、bool、complex(复数)。
在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
像大多数语言一样,数值类型的赋值和计算都是很直观的。
内置的 type() 函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
此外还可以用 isinstance 来判断:
>>> a = 111
>>> isinstance(a, int)
True
>>>
isinstance 和 type 的区别在于:
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False
区别就是:
type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型。
注意:在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
数值的除法(/)总是返回一个浮点数,要获取整数使用//操作符
#!/usr/bin/python3
str = 'Runoob'
print (str) # 输出字符串
print (str[0:-1]) # 输出第一个个到倒数第二个的所有字符
print (str[0]) # 输出字符串第一个字符
print (str[2:5]) # 输出从第三个开始到第五个的字符
print (str[2:]) # 输出从第三个开始的后的所有字符
print (str * 2) # 输出字符串两次
print (str + "TEST") # 连接字符串
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0] = 'm'会导致错误。
注意:
1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变。
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
#!/usr/bin/python3
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
tinylist = [123, 'runoob']
print (list) # 输出完整列表
print (list[0]) # 输出列表第一个元素
print (list[1:3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素
print (tinylist * 2) # 输出两次列表
print (list + tinylist) # 连接列表
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号(())里,元素之间用逗号隔开。
元组中的元素类型也可以不相同。
#!/usr/bin/python3
tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 )
tinytuple = (123, 'runoob')
print (tuple) # 输出完整元组
print (tuple[0]) # 输出元组的第一个元素
print (tuple[1:3]) # 输出从第二个元素开始到第三个元素
print (tuple[2:]) # 输出从第三个元素开始的所有元素
print (tinytuple * 2) # 输出两次元组
print (tuple + tinytuple) # 连接元组
注意:
集合(set)是一个无序不重复元素的序列。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号({})或者 set()函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
#!/usr/bin/python3
student = ({'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'})
print(student) # 输出集合,重复的元素被自动去掉
# 成员测试
if('Rose' in student) :
print('Rose 在集合中')
else :
print('Rose 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a和b的差集
print(a | b) # a和b的并集
print(a & b) # a和b的交集
print(a ^ b) # a和b中不同时存在的元素
以上实例输出结果:
{'Mary', 'Jim', 'Rose', 'Jack', 'Tom'}
Rose 在集合中
{'b', 'a', 'c', 'r', 'd'}
{'b', 'd', 'r'}
{'l', 'r', 'a', 'c', 'z', 'm', 'b', 'd'}
{'a', 'c'}
{'l', 'r', 'z', 'm', 'b', 'd'}
re.sub(r'(\b[a-z]+) \1', r'adfasdf', 'cat in the the hat') ->
\1 是第一个捕获 就是(\b[a-z]+),所以整个正则的意思就是匹配两个相同的单词,然后用r'adfasdf'替换
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class '__main__.Hello'>
要创建一个class类型,type()函数依次传入3个参数:
class的名称;
继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
通过type()函数创建的类和直接写class是完全一样的,因为Python解释器遇到class定义时,仅仅是扫描一下class定义的语法,然后调用type()函数创建出class。
正常情况下,我们都用class Xxx...来定义类,但是,type()函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。
连接起来就是:先定义metaclass,就可以创建类,最后创建实例。
所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。
metaclass是Python面向对象里最难理解,也是最难使用的魔术代码。正常情况下,你不会碰到需要使用metaclass的情况,所以,以下内容看不懂也没关系,因为基本上你不会用到。
我们先看一个简单的例子,这个metaclass可以给我们自定义的MyList增加一个add方法:
定义ListMetaclass,按照默认习惯,metaclass的类名总是以Metaclass结尾,以便清楚地表示这是一个metaclass:
# metaclass是类的模板,所以必须从`type`类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
有了ListMetaclass,我们在定义类的时候还要指示使用ListMetaclass来定制类,传入关键字参数metaclass:
class MyList(list, metaclass=ListMetaclass):
pass
当我们传入关键字参数metaclass时,魔术就生效了,它指示Python解释器在创建MyList时,要通过ListMetaclass.new()来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
new()方法接收到的参数依次是:
当前准备创建的类的对象;
类的名字;
类继承的父类集合;
类的方法集合。
测试一下MyList是否可以调用add()方法:
>>> L = MyList()
>>> L.add(1)
>> L
[1]
而普通的list没有add()方法:
>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'
动态修改有什么意义?直接在MyList定义中写上add()方法不是更简单吗?正常情况下,确实应该直接写,通过metaclass修改纯属变态。
但是,总会遇到需要通过metaclass修改类定义的。ORM就是一个典型的例子。
ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
要编写一个ORM框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类来。
让我们来尝试编写一个ORM框架。
编写底层模块的第一步,就是先把调用接口写出来。比如,使用者如果使用这个ORM框架,想定义一个User类来操作对应的数据库表User,我们期待他写出这样的代码:
class User(Model):
# 定义类的属性到列的映射:
id = IntegerField('id')
name = StringField('username')
email = StringField('email')
password = StringField('password')
# 创建一个实例:
u = User(id=12345, name='Michael', email='[email protected]', password='my-pwd')
# 保存到数据库:
u.save()
其中,父类Model和属性类型StringField、IntegerField是由ORM框架提供的,剩下的魔术方法比如save()全部由metaclass自动完成。虽然metaclass的编写会比较复杂,但ORM的使用者用起来却异常简单。
现在,我们就按上面的接口来实现该ORM。
首先来定义Field类,它负责保存数据库表的字段名和字段类型:
class Field(object):
def __init__(self, name, column_type):
self.name = name
self.column_type = column_type
def __str__(self):
return '<%s:%s>' % (self.__class__.__name__, self.name)
在Field的基础上,进一步定义各种类型的Field,比如StringField,IntegerField等等:
class StringField(Field):
def __init__(self, name):
super(StringField, self).__init__(name, 'varchar(100)')
class IntegerField(Field):
def __init__(self, name):
super(IntegerField, self).__init__(name, 'bigint')
下一步,就是编写最复杂的ModelMetaclass了:
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
if name=='Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
mappings = dict()
for k, v in attrs.items():
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys():
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
以及基类Model:
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
def save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items():
fields.append(v.name)
params.append('?')
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))
当用户定义一个class User(Model)时,Python解释器首先在当前类User的定义中查找metaclass,如果没有找到,就继续在父类Model中查找metaclass,找到了,就使用Model中定义的metaclass的ModelMetaclass来创建User类,也就是说,metaclass可以隐式地继承到子类,但子类自己却感觉不到。
在ModelMetaclass中,一共做了几件事情:
排除掉对Model类的修改;
在当前类(比如User)中查找定义的类的所有属性,如果找到一个Field属性,就把它保存到一个__mappings__的dict中,同时从类属性中删除该Field属性,否则,容易造成运行时错误(实例的属性会遮盖类的同名属性);
把表名保存到__table__中,这里简化为表名默认为类名。
在Model类中,就可以定义各种操作数据库的方法,比如save(),delete(),find(),update等等。
我们实现了save()方法,把一个实例保存到数据库中。因为有表名,属性到字段的映射和属性值的集合,就可以构造出INSERT语句。
编写代码试试:
u = User(id=12345, name='Michael', email='[email protected]', password='my-pwd')
u.save()
输出如下:
Found model: User
Found mapping: email ==> <StringField:email>
Found mapping: password ==> <StringField:password>
Found mapping: id ==> <IntegerField:uid>
Found mapping: name ==> <StringField:username>
SQL: insert into User (password,email,username,id) values (?,?,?,?)
ARGS: ['my-pwd', '[email protected]', 'Michael', 12345]
可以看到,save()方法已经打印出了可执行的SQL语句,以及参数列表,只需要真正连接到数据库,执行该SQL语句,就可以完成真正的功能。
不到100行代码,我们就通过metaclass实现了一个精简的ORM框架。
因此利用type就可以动态创建类型,利用object就可以动态实例化对象
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<type 'type'>
>>> print(type(h))
<class '__main__.Hello'>
# metaclass是创建类,所以必须从`type`类型派生:这是python2的写法
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
print(cls, name, bases, attrs)
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
class MyList(list):
__metaclass__ = ListMetaclass # 指示使用ListMetaclass来定制类
# python3的写法
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
c.append((cls, name, bases, attrs))
attrs['des'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
class MyList(list, metaclass = ListMetaclass):
pass
函数定义带星意味着强制使用命名参数
继承内置类型时调用父类型的初始化方法要注意传递self, 还有关于super的使用和其他language不同
List.__init__(self, [1,2,3])
#Create options
Libs = "-L $ pkglibdir "
Libs = " $ libs -l"
> change into:
#Create options
Libs = "- L $ pkglibdir"
Libs = "$ libs -lmysqlclient -lssl -lcrypto"
metaclass是Python中非常具有魔术性的对象,它可以改变类创建时的行为。这种强大的功能使用起来务必小心。
一些开发者经常会问我一个问题:页面到像素渲染的流程到底是啥?以及什么时候发生渲染以及为啥。所以啊我就发现好好的解释一下渲染像素到屏幕的过程是很有必要滴,且听我细细道来
本文是从chrome/Blink的角度来谈的。其中大部分对于其他浏览器来说也是大同小异的,好比layout 或者stlye calcs, 但是总体架构可能不太一样。
确实如此,那我们也从一副图开始说起吧
上图就是从得到像素到绘制到屏幕的整个完整过程
图里面有太多的东西了,所以我在下面进行了更详细的介绍,对于我们的理解来说这是很有帮助的
render process. 一个tab页就是会有一个render process, 他包含了很对的thread, 他负责对我们的操作做出回应。 这些thread 包括 Compositor, Tile Worker, 以及main threads
GPU process. 这个是单一的进程(就是说无论你打开多少个tab都只有这一个GPU process),他服务于所有的tab。实际渲染到屏幕的像素数据都是由那些提交到GPU process的帧中的tile数据(贴图)以及其他一些数据(例如顶点数据,矩阵数据),GPU就包含了一个thread, 而这个GPU thread才是实际干活的。
接下来让我们看看render process中的threads
Compositor thread. 当产生vsync event(vsync是指os告诉浏览器如何产生新的一帧)时这个thread是第一个被通知的。同时也会接受所有的input事件,Compositor会尽量避免打扰main thread, 他会尝试处理输入,例如处理滚动(这可不代表滚动就有compositor处理的哦)。如果他能处理,那么他会直接去更改layer的位置然后吧frames同过GPU thread 提交大GPU去, 但是如果要处理输入的事件,或者其他一个可视化的工作,那么他就会把这些交给main thread
Main Thread. 这个是浏览器处理任务的thread,包括我们所熟知的和喜爱的js, styles, layout 以及 paint(这些在将来有可能会因为Houdini而发生改变,通过使用Houdini我们可以在Compositor Thread中run一些code).这个thread也或得了一个荣耀“最能引起卡顿的家伙”, 很大一部分原因是因为有太多的东西在这里运行了
Compositor Tile Worker(s).这些都是由Compositor Thread启动的,是用来处理光栅化任务的(栅格化这个术语可以用于任何将向量图形转换成位图的过程)。
我们可以把Compositor Thread 当做“大boss”。因为他不去运行js,不去布局,不去paint,或者其他事情。他所要做的事情除了启动main thread, 就是把frames传输给screen. 而且如果他没有在等待input event, 他就可以在等待main thread完成任务的同时传输frames
你也可已设想 Serviec Workers 和 Web Workers 运行在this process(应该是指render process),但是我把他们放到后面在说,因为他们会使事情变得太复杂。
oftentimes the best way to improve performance is simply to remove the need for parts of the flow to be fired!
让我们逐步介绍从vsync到像素的流程。 值得记住的是,浏览器不需要执行所有这些步骤,这取决于哪些是需要进行的。 例如,如果没有新的HTML解析,那么解析HTML将不会触发。 事实上,提高性能的最佳方法通常是简单地避免整个流程中某些部分的触发例如layout或者其他!
同样值得注意的是,在样式和布局下的那些红色箭头似乎指向了requestAnimationFrame。 在代码中偶然触发是完全可能的。 这称为强制同步布局(或样式),它往往不利于性能。
Frame start. Vsync事件触发,一帧开始
输入事件。 输入数据同过compositor传递给main thread中相应的handler。每帧当中,首先触发的是事件处理的函数(如touchmove, scroll, click),但这不是必须的,因为有些没有事件发生。调度程序会尽力而为的尝试,成功性在不同操作系统之间有所不同。 在用户交互和事件之间还有一些延迟(making its way to the main thread to be handled 不会翻译了。。。)
requestAnimationFrame. 这里是进行屏幕元素更新的理想场所,你可以在这里刷新数据,并且这里是离最近一次Vsync最近的时机。其他视觉或者可视化任务(visual tasks),例如style calcs,将在这个task之后进行,因此这里是更改元素的理想时机,如果你进行了更改了-100个classes, 将不会导致100 style calcs, 他们将会被延时批量处理。这里有一个要注意的地方就是不要在这里访问computed styles 或者是布局属性(例如el.style.backgroundImage or el.style.offsetWidth). 如果你这么做了,那么你将会引起样式的重新计算,或者是重新布局或者是全部,更甚至引起强制同步布局或者更甚至是布局恶化
Parse HTML. 任何新加入的HTML都会被处理,并且创建DOM, 你经常会在页面加载时或者在类似于appendChild这样的操作后看到他
Recalc Styles. 所有新加入或者改变过的样式都会被计算。这可能是整棵树,或者可以缩小范围,取决于更改的内容。 例如,更改body上的类可能是整体的,但值得注意的是,浏览器已经非常聪明地自动限制了样式计算的范围。
Layout. 计算每个可见元素的几何信息(每个元素的位置和大小)。 它通常是为整个文档计算的,通常计算成本与DOM大小成比例。
Update Layer Tree. 这个是给排序元素(z-index相关,overlap相关)创建层叠上下文以及深度信息的过程
(The process of creating the stacking contexts and depth sorting elements.)
Paint. 这是两部分过程中的第一个:paint是draw调用的记录(填充矩形,写入文本),以查看任何新的或视觉上已经改变的元素。 第二部分是光栅化(参见下面),绘制调用被执行,纹理被填充。这部分是绘制调用的记录,通常比光栅化要快得多,但是这两个部分通常统称为“painting”。
Composite. the layer 和贴图信息被计算出来并且传递回来给compositor thread 进行处理。这是因为要处理will-chandge, 相互遮挡的元素,或者是开启了硬件加速的元素。
Raster Scheduled and Rasterize: The draw calls recorded in the Paint task are now executed. This is done in Compositor Tile Workers, the number of which depends on the platform and device capabilities. For example, on Android you typically find one worker, on desktop you can sometimes find four. The rasterization is done in terms of layers, each of which is made up of tiles.
Frame End: With the tiles for the various layers all rasterized, any new tiles are committed, along with input data (which may have been changed in the event handlers), to the GPU Thread.
Frame Ships: Last, but by no means least, the tiles are uploaded to the GPU by the GPU Thread. The GPU, using quads and matrices (all the usual GL goodness) will draw the tiles to the screen.
There are two versions of depth sorting that crop up in the workflow.
Firstly, there’s the Stacking Contexts, like if you have two absolutely positioned divs that overlap. Update Layer Tree is the part of the process that ensures that z-index and the like is heeded.
Secondly, there’s the Compositor Layers, which is later in the process, and applies more to the idea of painted elements. An element can be promoted to a Compositor Layer with the null transform hack, or will-change: transform, which can then be transformed around the place cheaply (good for animation!). But the browser may also have to create additional Compositor Layers to preserve the depth order specified by z-index and the like if there are overlapping elements. Fun stuff!
Virtually all of the process outlined above is done on the CPU. Only the last part, where tiles are uploaded and moved, is done on the GPU.
On Android, however, the pixel flow is a little different when it comes to Rasterization: the GPU is used far more. Instead of Compositor Tile Workers doing the rasterization, the draw calls are executed as GL commands on the GPU in shaders.
This is known as GPU Rasterization, and it’s one way to reduce the cost of paint. You can find out if your page is GPU rasterized by enabling the FPS Meter in Chrome DevTools:
There’s a ton of other stuff that you might want to dive into, like how to avoid work on the Main Thread, or how this stuff works at a deeper level. Hopefully these will help you out:
这篇文章会从字体相关的各个维度去探讨如何在Mobile Web上显示最佳的字体、行高、字重,以及如何实现精确到1px的文字垂直居中。
文章很长,这里直接给出几个核心的结论:
移动端字体设置,全局按如下方式:
font-family: system-ui, -apple-system, BlinkMacSystemFont, Helvetica Neue, Helvetica, sans-serif
解决中文网站在Android下文字垂直居中问题:
字重设置:Android下自带中文思源黑体只有一个字重normal,加一个伪粗体bold,iOS下自带中文苹方有100~600六个字重,所以跨端的中文加粗使用bold或者700,700以下的字重在Android下会直接fallback到normal
PS:这篇文章的所有探讨限于iOS & Android,并且Android Rom众多,厂商又可以修改字体配置,甚至增删字体,所以大部分测试和结论都针对原生ROM。
文字的对齐、渲染都和字体有关,所以在讨论任何文字排版优化之前,我们先来认识几个移动端的重要字体:
-apple-system、BlinkMacSystemFont:-apple-system是Apple在iOS 9,OSX 10.11中引入,通过它可以声明使用系统最新的San Francisco字体,并且未来系统更新字体后也可以自动指向新的字体,而BlinkMacSystemFont是Chrome针对-apple-system的类似实现
system-ui:是针对-apple-system和BlinkMacSystemFont的标准实现,Chrome 56+、Safari 10+开始支持,所以类似场景可以这样声明:font-family: system-ui, -apple-system, BlinkMacSystemFont, sans-serif
Noto Sans CJK SC:即思源黑体 - 简体中文,思源黑体是Google和Adobe合作开发的开源字体,是Android 5.0以后的默认中文字体,也是唯一的中文字体,该字体本身包含7种字重,而Android只安装了Regular这一个字重,Chrome开发者工具里显示:Noto Sans CJK SC Regular,因为Android里没有针对该字体设置family name,所以无法直接通过font-family指定,只能作为fallback来使用
Roboto:这是Google专门为Android开发的开源字体,Android 4.0以后的默认英文字体,无法直接通过font-family指定,使用:font-family: system-ui
San Francisco:最早是Apple为watchOS设计的字体,后来在OS X 10.11 El Capitan和iOS 9中取代了Helvetica Neue,成为默认的英文字体,该字体在Chrome开发者工具里查看的话会显示成.SF NS Text(包含6种字重)和.SF NS Display(包含9种字重),字号小于20px时使用.SF NS Text,20px以上时使用.SF NS Display,可以使用font-family: system-ui, -apple-system, BlinkMacSystemFont来声明,如果你非要手动声明,字号20px以上时使用:.SFNSDisplay-Black、.SFNSDisplay-Bold、.SFNSDisplay-Heavy、.SFNSDisplay-Light、.SFNSDisplay-Medium、.SFNSDisplay-Regular、.SFNSDisplay-Semibold、.SFNSDisplay-Thin、.SFNSDisplay-Ultralight,字号小于20px时可以用:.SFNSText-Bold、.SFNSText-Heavy、.SFNSText-Light、.SFNSText-Medium、.SFNSText-Regular、.SFNSText-Semibold
PingFang SC:即苹方 - 简体中文,这是Apple在iOS 9时专门设计的中文字体,和英文字体San Francisco配合非常协调,对应的font-family名字是:PingFang SC,包含6种字重
从以上组合进一步总结:
当前语言是zh且不声明英文字体族时,Android Chrome对英文也会fallback到Noto Sans CJK SC,所以声明英文字体族是有必要的,思源黑体+Roboto的搭配也还算和谐,但下文讲文字垂直居中时会提到这种设置导致的问题
当不声明英文字体族时,iOS Safari会将英文fallback到Helvetica,甚至不是上一代的系统默认字体Helvetica Neue,所以声明英文字体族是有必要的,可以保证使用最佳的英文字体San Francisco,中英混排时中文会fallback到苹方,苹方和San Francisco是同时随iOS 9发布的,2者配合非常和谐,也不需要担心2者混排会存在对齐问题
移动端世界没有中文衬线字体(font-family: serif),所以不要在中英混排的场景下设置衬线字体,否则衬线、非衬线在一起显示很不协调
如何设置line-height
对于行高的设置建议直接阅读@大貘 翻译的深入了解CSS字体度量,行高和vertical-align,总结几点:
字体的font-size不等于最终显示的大小,取决于字体设计师的定义,以Catamaran字体为例,当我们设置100px的字号时,大写字母的高度(Capital Height)是68px,小写字母的高度(X-Hegiht)是49px,整体的高度是164px(Ascender 1100 + Descender 540),要了解任意字体的相关属性可以使用(fontforge)[https://fontforge.github.io/en-US/]
我们日常使用的CSS单位em对应font-size本身,ex对应小写字母的高度(中文字体对应的也是该字体下英文小写字母的高度)
正因为第一点,为了不截掉文字,最小行高的设置需要依据字体来,以Arial为例,设置line-height: 1时就会造成文字下面被截掉的问题:
你可能并没有注意到过这个问题,用Android Chrome打开你的页面,仔细观察页面上需要文字垂直居中的元素,你会发现文字要么偏上要么偏下,不管是Google、Facebook、Twitter等国际一线公司(Apple没有问题,原因是通过Web Font使用了PingFang SC),还是国内的BAT都一样(包括专门搞内容的知乎、简书等)
这个问题无论你是用flex、行高、表格+vertical-align等都无法解决,因为文字在content-area内部渲染的时候已经偏上了,CSS的各种居中方案都是针对整个content-area内容。
结合前面的分析,移动端最佳的字体设置如下:
结论
font-family: system-ui, -apple-system, BlinkMacSystemFont, Helvetica Neue, Helvetica, sans-serif;
system-ui, -apple-system, BlinkMacSystemFont:这3个关键字都用来选择当前系统的最佳英文字体
Helvetica Neue:用于让不支持第一条且没有San Francisco字体的iOS 8以下环境使用最佳的英文字体Helvetica Neue
Helvetica:针对不支持第一条的Chrome 56以下端,设置成Helvetica的原因是Android的字体配置文件里会将Helvetica字体alias到sans-serif,而sans-serif对应当前版本下的最佳英文字体(Android 5.0以上就是Roboto)
我想判断一个变量 a 是什么类型,那么我们会怎么做? typeof a? ok,我们来看看
let a = 2;
typeof a; // 'number'
let c = 'as';
typeof c; // 'string'
嗯 :),看着不错哦!似乎我们是解决了,可惜啊,让我们来看一张表
| Type of val | result |
|---|---|
| Undefined | “undefined“ |
| Null | “object“ |
| Boolean | “boolean“ |
| Number | “number“ |
| NaN | “object“ |
| String | “string“ |
| Object (native and not callable) | “object“ |
| Object (native or host and callable) | “function“ |
| Object (host and not callable) | 不同实现有不同表现 |
额 :( 看完是不是就有一丝丝不高兴了,因为他并不是很好,因为有些类型他也没办法区分比如 null, Array 他都识别为对象了,不高兴啊!总之在 js 里面进行类型判断是一件很不爽的事情,不像 java 和 golang 这种强类型的语言,他们总是有很明确的方法来判断自己是啥类型因为他们都有自己的反射机制。
[[class]]是什么呢? es5 规范里面规定的所有的 js 对象都有的一个内部属性(es 规范使用[[]]表示内部属性),用来表明对象分类的字符串属性,就是说他是用来表示对象类型。对于我们来说,这意味着,所有的内置对象类型都有一个唯一的不可修改的,规范强制规定的值,很明显要是咱们能拿到这个值,对象类型识别问题就解决了。。。
此时 Object.prototype.toString 就要登场了。让我们看看 es5 规范里对于他的描述
ToObject 就是把 this 转换为对象,比如 4-> Number, '' -> String 等等
简单描述一下就是 toString 的调用会返回如下的格式
[object [[class]]]
看到没,通过他就可以拿到对象的内部[[class]]属性了。但这是时候有人就会说了,你瞅瞅下面的
[1,2,3].toString(); //"1, 2, 3"
(new Date).toString(); //"Sat Aug 06 2011 16:29:13 GMT-0700 (PDT)"
/a-z/.toString(); //"/a-z/"
你看,你看,还是不行啊!
上面现象的原因在于,打部分的内置对象都重写了 Object.prototype.toString 函数。比如Number。
显然直接调用时不行的,但坏就坏在我们在用 js, 好也好在我们在用 js, 估计大家都想到了,我们还有两个方法 call 和 apply, 如下
Object.prototype.toString.call([1,2,3]); //"[object Array]"
Object.prototype.toString.call(new Date); //"[object Date]"
Object.prototype.toString.call(/a-z/); //"[object RegExp]"
js 这门语言本身就积累了太多的弊端了,好好在用的人多,坏也坏在用的人多 用的人多语言本身才能发展的好,用的人多反而也会让 js 本身的发展瞻前顾后,就好比 c++似的。就 cs 发展到现在,我觉得其实是需要新的 GUI 语言的出现或者说专注于 application 的语言,比如我最近看了 Dart 就不错,语法合适,没有很多奇怪的问题,可惜也没有太好的发展,这个可以再开一篇来讲了。(劣币驱逐良币么?)
来,咱们封装一个 toType 吧!
const toType = function(obj) {
return ({}).toString.call(obj).match(/\s([a-zA-Z]+)/)[1].toLowerCase()
}
为什么要用({}).toString.call,在我看了就是少写几个字符而已,但其实若是我调用 toType 的次数太多,({})这种方式我觉得也不行啊,因为每次调用都要再创建一个对象啊!
我们来试试这个函数吧
toType({a: 4}); //"object"
toType([1, 2, 3]); //"array"
(function() {console.log(toType(arguments))})(); //arguments
toType(new ReferenceError); //"error"
toType(new Date); //"date"
toType(/a-z/); //"regexp"
toType(Math); //"math"
toType(JSON); //"json"
toType(new Number(4)); //"number"
toType(new String("abc")); //"string"
toType(new Boolean(true)); //"boolean"
我们再来看看 typeof
typeof {a: 4}; //"object"
typeof [1, 2, 3]; //"object"
(function() {console.log(typeof arguments)})(); //object
typeof new ReferenceError; //"object"
typeof new Date; //"object"
typeof /a-z/; //"object"
typeof Math; //"object"
typeof JSON; //"object"
typeof new Number(4); //"object"
typeof new String("abc"); //"object"
typeof new Boolean(true); //"object"
其实 typeof 也可以用函数调用的方法来书写, typeof(a),大家可以试试是 ok 的。
instanceof 又是什么呢?简单的说是用来测试一个对象是否是一个类的是实例(按照面向对象的说法)。他的实现方式是检测第二个输入参数的 prototype 是否在第一个输入参数的原型链上出现过(第二个参数必须是一个 constructor),比如:
let a = [1,2,3];
a.__proto__; // []
Array.prototype; // []和上面的那个是同一个对象
a instanceof Array; // true
a.__proto__ = {}
a instanceof Array; // false
有几个关于 instanceof 的点需要我们注意
const iFrame = document.createElement('IFRAME');
document.body.appendChild(iFrame);
const IFrameArray = window.frames[1].Array;
const array = new IFrameArray();
array instanceof Array; //false
array instanceof IFrameArray; //true;
很可惜的是我们的 toType 对他们并不管用:(, 比如:
toType(window);
//"global" (Chrome) "domwindow" (Safari) "window" (FF/IE9) "object" (IE7/IE8)
toType(document);
//"htmldocument" (Chrome/FF/Safari) "document" (IE9) "object" (IE7/IE8)
toType(document.createElement('a'));
//"htmlanchorelement" (Chrome/FF/Safari/IE) "object" (IE7/IE8)
toType(alert);
//"function" (Chrome/FF/Safari/IE9) "object" (IE7/IE8)
其实对于 Dom 对象来说使用 nodeType 来判断是最好的了,兼容性也 ok。
function isElement(obj) {
return obj.nodeType;
}
但这其实是一个 duck-typing, 因此也是没有保证的。
即使我们做了上面那么多的是事情依然不能够保证完美,因为 js 太灵活了。比如我们可以重写了 Object.prototype.toString 的实现,那么我们所提供的稍微靠谱的解决方案就 GG 了,因此我们最好不要随意去重写原生的 prototype 的方法。请避免把 toType 用到 host object 的判断以及要检查是否传入了未定义的变量。
说到抽象语法树就得说到具体语法树,具体差异,这个答案就很棒。
module.exports = (sequelize, DataTypes) =>
sequelize.define(
'answer',
{...}
)
而我想要的是
module.exports = app => {
const { DataTypes } = app.Sequelize;
const Answer = app.model.define(
'answer',
{...}
);
return Answer;
}
js的AST的parser有很多,但他们基本都遵循MDN给出的parser API
> var program = 'const answer = 42';
> esprima.tokenize(program);
[
{ type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' }
]
> var program = 'const answer = 42';
> esprima.parse(program);
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "answer"
},
"init": {
"type": "Literal",
"value": 42,
"raw": "42"
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
如上图,我们要是想替换answer这个名字怎么办呢?或者就像是替换为parseInt(2,10), 1: 想美团的那个根据position替换,还有就是直接替换 AST
> var program = 'const answer = 42';
> const ast = esprima.parse(program);
> ast.body[0].declarations[0].id.name = '替换掉了';
> var addon = 'const stentence = '你个坏人';
> ast.body.unshift(esprima.parse(addon).body[0])
> {
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "sentence"
},
"init": {
"type": "Literal",
"value": "你个坏人",
"raw": "'你个坏人'"
}
}
],
"kind": "const"
},
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "answer"
},
"init": {
"type": "Literal",
"value": 42,
"raw": "42"
}
}
],
"kind": "const"
}
]
"sourceType": "script"
}
问题来了我们生成新的AST,那怎么在转换为代码呢?escodegen
escodegen.generate(AST) // string
到此我们可以发现,我可以找到任何语句,进行任何合法的修改,uglify2还提供了一些便利的方法,比如TreeWalker 遍历语法树,很方便,但还未实操过,有待使用。
---------------------------------------------- 华丽分割线-------------------------------------------
我的好友也有一篇关于js ast的文章里面还介绍了babel插件的写法推荐一下(他可是高质量博主)
在上次写完后我就一直在思考一个问题,如何使用AST来编写DSL,js的表现力来说我觉得和那些有macro的语言还是差很多,不是不能做而是不优雅,比如:
crystal-lang 用宏定义方法
macro define_method(name, content)
def {{name}}
{{content}}
end
end
define_method dj, { puts 2 }
但用js的话就是
function define_method(body) {
new Function('a', 'b', body); // 此处body是字符串, 'a + b; return a + b'
}
const a = define_method('a + b; return a + b')
可以看出来,js的元编程其实就是字符串拼接,那么macro 和AST又有什么关系呢?关系就是:macro匹配的参数会转化为AST,然后进行操作。向上面的crystal-lang的define_method的name和content,在宏内部就是AST节点。可以看出来使用macro编写DSL是很方便的。即使像C/C++那样简陋的macro都很有用 就不用说rust,crystal中那么强大的宏了。 js目前不支持macro。
我想写个DSL语法 就叫 '||='
a ||= b; 若a为空 赋值为b
我看了js AST以后就在想esprima可以么?Babel可以么?
答: 目前不可以
原因:这些都只支持js的语法or Next JS的语法比如class, ArrowFuction等等, 你写个 '||=' babel也是识别不了的,肯定会报语法错误(不行你试试,要是真试了的话就别回来了。。。),也就是说你写的babel可以转换的那都是babel支持的语法,也可以说是js的语法或者是即将支持的语法。
问:此时就有人要问了,那JSX呢这可不是js的语法
答:这个是babel/parser内部就支持JSX
扩展: 那是不是就是说只要babel/parser能支持就好了
答:是的
举例:https://github.com/babel/babel/tree/master/packages/babel-parser/src/plugins 在这个文件夹下我们可以看到babel/parser支持的一些js语法之外的一些插件。
问:那接下该怎么做呢?
答:先看两张图

从这两个图我们可以看出 babel的工作原理就是 parse 源文件 到AST 再transform一下到 AST再从AST生成代码
接下来再看一篇关于babel plugin(注意是babel 的plugin不是babel/parser的plugin)的文章从零开始编写一个babel插件
这个文章实现了一个很简单的babel plugin插件干的事儿就是
import {uniq, extend, flatten, cloneDeep } from "lodash"
// convert to
import uniq from "lodash/uniq";
import extend from "lodash/extend";
import flatten from "lodash/flatten";
import cloneDeep from "lodash/cloneDeep";
那么babel plugin和上面的图是什么关系呢? babel plugin就是就是图中AST -> AST的transform过程。也就是说我们想要使用babel plugin,第一步我们写的源文件得能parse到AST。其实我们可以看出来我们使用balbel/plugin能做的也就是 babel支持的语法的替换,删减或者增加。上例就是替换使用一大坨来替换。
我们可以从这里学到一些东西,那就是旧项目的改造,怎么样?或者不合理语法的改造,不想一个一个手动改,那就AST来改造
回到我们的DSL 'a ||= b' 上来,怎么办?就问怎么办?显然在transform 这个阶段是不行的
问:又问了,那JSX是咋弄的?
答:可以看上面的回答,是babel/parser就支持,也就是说如果我们可以写个babel/parser的plugin就好了
问: 怎么给babel/parser写个plugin呢?
答:你去babel的主库里提pr(233333), 是的目前babel不支持给babel/parser写plugin, 但相信未来不会太遥远的。 #1351 被关闭了,但在很久以前的babel版本中我们是可以的详见adding-custom-syntax-to-babel
问:真的没办法了?
答:babel的parser是从acorn 来的,其实acorn是支持plugin的,炫酷,也就是说只要我们想实现总是可以的。关于他的扩展方式没看到文档有时间在继续吧,acorn。但我们找到了出路,我们也可以随心所欲的写一个新的DSL language了,然后转到JS。
Code -> (1)Token -> AST ->(2) AST -> CODE
再总结一下,babel plugin的作用域是在(2),他做的是把合法的babel语法AST(都不敢说是js语法了...)转换为合法的JS的AST。 babel/parser plugin的作用域是在(1),他做的是把不合法的源码转换为合法的babel AST。分清babel plugin 和 babel/parser plugin我们就更能理解babel plugin到底是在做啥,他又能做啥。
总归我们是可以用优雅的方式在js中来编写DSL, 但不使用acorn等parser是不行的,其实我们在做前端基础工具时是可以做这些的,采用js的语法,加入合理的DSL 非js 语法使用 acorn转换。(使用decorator和proxy也是可以大大增强js的表现力的)
用大白话来说其实我们就是想要一个其他语言到js的transformer。Typescirpt, PureScirpt, CoffeScript...
这类场景,在物理形态上类似前后端分离,此时的Web App已经不是全功能的Web App,而是根据场景定制、场景化的App。
这类场景,移动App是后端Service的使用者,此时的API GW还需要承担一部分MDM(此处是指移动设备管理,不是主数据管理)的职能。
这类场景,主要为了满足业务形态对外开放,与企业外部合作伙伴建立生态圈,此时的API GW需要增加配额、流控、令牌等一系列安全管控功能。
这类场景,业界提的比较少,很多时候系统的建设,都是为了满足企业自身业务的需要,实现对企业自有业务的映射。当互联网形态逐渐影响传统企业时,很多系统都会为了导入流量或者内容,依赖外部合作伙伴的能力,一些典型的例子就是使用「合作方账号登录」、「使用第三方支付平台支付」等等,这些对于企业内部来说,都是一些外部能力。此时的API GW就需要在边界上,为企业内部Service 统一调用外部的API做统一的认证、(多租户形式的)授权、以及访问控制。
这类场景,业界就提的更少了,但在传统企业,尤其是工业企业,传感器、物理设备从工业控制协议向IP转换,导致具备信息处理能力的「智能产品」在被客户激活使用直至报废过程中,信息的传输不能再基于VPN或者企业内部专线,导致物理链路上会存在一部分公网链路。此时的API GW所需要满足的,就是不是前三种单向的由外而内的数据流,也不是第四种由内而外的数据流,「内外兼修」的双向数据流,对于企业的系统来说终端设备很多情况下都不是直连网关,而是进过一个「客户侧」的集中网关在和企业的接入网关进行通信。
能和原子业务能力找到映射最好,一定要避免「万能接口」的出现。
尽可能的在报文头里面存放业务路由所需要的信息,避免对报文体进行解析。
API GW上线后,面临的很大问题都是后端服务如何自助发布到外部,同时不能重启网关服务,以保障业务的连续。在此过程中,如果涉及到报文格式的转换,那对API网关实现的技术要求比较高。如果让网关完成报文转换,第一种方案,网关需要知道报文的具体格式(也就是报文的元数据,或者是类定义),这部分要支持热更新。第二种方案,需要客户端在报文内另外附加元数据,网关通过运行期加载元数据对报文进行解析在进行报文的转换,这种方案性能不会很好。第三种方案,就是在运行期首次报文转换的时候,根据元数据生成报文转换代码并加载,这种方案对技术实现要求比较高,对网关外围平台支撑力度要求也不低。
先来普及一下
抽象漏洞wiki
抽象漏洞
总结一小下:抽象漏洞告诉我们出来混早晚要还的,无论你怎么去屏蔽复杂,怎么去抽象,总是不完整的总是会有漏洞的。
在js中,迭代器和可迭代对象是顺序访问数据的抽象层接口。我们可以在数组或者优先级队列中看到他们。
一个迭代器就是一个拥有next方法的对象。当你调用next()的时候,他会返回一个Plain Old Javascript Object。 这个返回值拥有done属性,当done值是false的时候,这个返回值还会有个value属性,数据就是value属性中的值。反而如果done是true,那么就应该不会有value属性。
迭代器不可以是async/await等异步方法
迭代器被设计为一个有状态的对象:重复调用next方法通常能获取到一系列的数据直到done为止。
这里有一个栗子: jsbin
const iCountdown = {
value: 10,
done: false,
next() {
this.done = this.done || this.value < 0;
if (this.done) {
return { done: true };
} else {
return { done: false, value: this.value-- };
}
}
};
iCountdown.next()
//=> { done: false, value: 10 }
iCountdown.next()
//=> { done: false, value: 9 }
iCountdown.next()
//=> { done: false, value: 8 }
// ...
iCountdown.next()
//=> { done: false, value: 1 }
iCountdown.next()
//=> { done: true }
可迭代对象是一个拥有[Symbol.iterator]方法的对象。当调用这个方法的时候他会返回一个迭代器。
举个栗子:jsbin
const countdown = {
[Symbol.iterator]() {
const iterator = {
value: 10,
done: false,
next() {
this.done = this.done || this.value < 0;
if (this.done) {
return { done: true };
} else {
return { done: false, value: this.value-- };
}
}
};
return iterator;
}
};
我们可以使用for ... of 来对这个对象进行迭代
for (const count of countdown) {
console.log(count);
}
或者我们还可以对他进行解构
const [ten, nine, eight, ...rest] = countdown;
ten
//=> 10
nine
//=> 9
eight
//=> 8
rest
//=> [7, 6, 5, 4, 3, 2, 1]
接下来让我们看看如何对一个文件进行迭代?
在看之前我们得先想想node有对文件有按行读的同步方法(上面我们提过了,迭代器只能使用同步方法)么?我找了一圈发现了一个异步读的方法,readline,这个包可以对文件流进行异步按行读取。
const readline = require('readline');
const fs = require('fs');
const rl = readline.createInterface({
input: fs.createReadStream('sample.txt'),
crlfDelay: Infinity
});
rl.on('line', (line) => {
console.log(`Line from file: ${line}`);
});
可以肯定的是node本身没有提供同步的按行读取文件的方法,那么我们就只能利用node的同步读方法来模拟按行读取了。每次读取一部分然后检查换行符,fs.readSync(fd, buffer, offset, length, position)。当然这里已然有一个包了‘n-readlines’。参见
好了这下我们可以看看对文件的按行迭代了
const fs = require('fs');
const lineByLine = require('n-readlines');
function lines (path) {
return {
[Symbol.iterator]() {
return {
done: false,
fileDescriptor: new lineByLine(path),
next() {
if (this.done) return { done: true };
const line = this.fileDescriptor.next();
this.done = !line;
if (this.done) {
this.fileDescriptor.fd && fs.closeSync(this.fileDescriptor.fd);
return { done: true };
} else {
return { done: false, value: line };
}
}
};
}
};
}
当我们想要对一个文件进行按行迭代时,我们就可以这么使用lines('./README.md');
当我们调用了Symbol.iterator我们就会得到一个文件的迭代器。
如下
for (const line of lines('./iter.js')) {
console.log(line.toString());
}
当我们把文件内容都迭代的读取完了以后,我们自然会关闭了文件。
可是若是我们只想读取第一行呢?
for (const line of lines('./iter.js')) {
console.log(line.toString());
break;
}
这样我们就会有一个问题了,就是该如何关闭文件。我们上面的代码是在读完以后回去检查文件是否关闭然后关闭。可是当我们只读取了一行就退出时,我们的文件时未关闭的。。。
这肯定是不好的。并且上面也不是唯一的情况,有时我们可能使用迭代器去管理我们的异步任务,比如我们通过指定端口和其他进程交互,很显然当我们完成了交互时我们会显式的去关闭指定的端口,我们可不想在使用中却被gc给收集了。
通过上面的描述,很明显我们需要一个能显式关闭迭代器的方法,以便迭代器能够释放他们所占用的资源。接下来让我们做一些尝试。
幸运的是,这里确实有这么一种机制来关闭迭代器。他设计的意图就是用来处理那些拥有各种各样的资源的迭代器,好比是文件描述符,一个打开的端口,大量的内存等等。
迭代器需要释放资源这是个问题,js为我们提供的机制来解决这些问题。但是我们依然先采用自己的方式来试试。
我们来看看
const countdown = {
[Symbol.iterator]() {
const iterator = {
value: 10,
done: false,
next() {
this.done = this.done || this.value < 0;
if (this.done) {
return { done: true };
} else {
return { done: false, value: this.value-- };
}
},
return(value) {
this.done = true;
if (arguments.length === 1) {
return { done: true, value };
} else {
return { done: true };
}
}
};
return iterator;
}
};
我们在前面看到了迭代器的主要方法next,其实这里还有一个return方法,它的签名时return(optionalValue),它的使用如下
我们再回头看看我们的countdown,来实现一下.return
const countdown = {
[Symbol.iterator]() {
const iterator = {
value: 10,
done: false,
next() {
this.done = this.done || this.value < 0;
if (this.done) {
return { done: true };
} else {
return { done: false, value: this.value-- };
}
},
return(value) {
this.done = true;
if (arguments.length === 1) {
return { done: true, value };
} else {
return { done: true };
}
}
};
return iterator;
}
};
这里我们看到了一些重复的逻辑,但他们是有用的,尤其是释放资源时,让我们再整理一下
const countdown = {
[Symbol.iterator]() {
const iterator = {
value: 10,
done: false,
next() {
if (this.done) {
return { done: true };
} else if (this.value < 0) {
return this.return();
} else {
return { done: false, value: this.value-- };
}
},
return(value) {
this.done = true;
if (arguments.length === 1) {
return { done: true, value };
} else {
return { done: true };
}
}
};
return iterator;
}
};
现在我们可以看到如何编写一个在耗尽整个迭代器之前打破的循环:
count iCountdown = countdown[Symbol.iterator]();
while (true) {
const { done, value: count } = iCountdown.next();
if (done) break;
console.log(count);
if (count === 6) {
iCountdown.return();
break;
}
}
调用return可以保证我们的iCountdown能够释放资源。那么如果for...of也是这么做的话(先调用next,最后调用return)那就完美了。
我们可以加一个输出
return(value) {
if (!this.done) {
console.log('Return to Forever');
this.done = true;
}
if (arguments.length === 1) {
return { done: true, value };
} else {
return { done: true };
}
}
接着可以尝试
for (const count of countdown) {
console.log(count);
if (count === 6) break;
}
//=>
10
9
8
7
6
Return to Forever
并且
const [ten, nine, eight] = countdown;
//=> Return to Forever
整体jsbin
当我们没有消费整个迭代器时,就是说中途break,js会自动调用return方法jsbin
我们也可以看出来return方法是可选的,若是实现了js就会去自动调用,没有则不回去调用。
看了上面,我们就会为我们的可迭代对象实现return方法尤其是那些需要释放资源的迭代对象,以便js为我们自动调用。
来看一个比较棘手的问题,若是我们就像构造一个函数来返回迭代对象的第一个元素(如果有的话),如下
function first (iterable) {
const [value] = iterable;
return value;
}
解构会替我们把迭代对象的迭代器给关掉。当然如果我们高兴我们也可以自己来手动实现
function first (iterable) {
const iterator = iterable[Symbol.iterator]();
const { done, value } = iterator.next();
if (!done) return value;
}
但我们可能会忽略了关闭我们所提取的迭代器,所以我们又必须得这么做:
function first (iterable) {
const iterator = iterable[Symbol.iterator]();
const { done, value } = iterator.next();
if (typeof iterator.return === 'function') {
iterator.return();
}
if (!done) return value;
}
一个很好的启发是,我们可以使用JavaScript的内置功能来关闭从可迭代对象中提取的迭代器。
而我们也知道解构会为我们关闭迭代器。我们也知道打断for ... of 循环也会关闭迭代器, 不管我们是否消费了整个迭代器。
还有上面所说的对于在一个生成器内从for ... of 中yield数据也是成立的。举个栗子,我们可以看看下面的函数mapWith
function * mapWith (mapFn, iterable) {
for (const value of iterable) {
yield mapFn(value);
}
}
这是个generator函数接收了一个迭代对象作为参数,并且返回一个可迭代对象。当我消耗了返回的迭代对象,那么内部的迭代对象也会被消耗掉,可若是我们中途断了,又会如何呢?jsbin
const countdownInWords = mapWith(n => words[n], countdown);
for (const word of countdownInWords) {
break;
}
//=> Return to Forever
是的完全ok js的内置功能又帮了我们, 而且在这里我们也看到了,生成器的返回值是可以和for...of一起使用的。
但不幸的是我们也不能总是成功
zipWith 函数会接受多个可迭代对象,并且把他们'zip'到一起返回,若是把他也写成一个生成器函数,我们是无法依靠js的内置功能去关闭所有的迭代器的。
来看
function * zipWith (zipper, ...iterables) {
const iterators = iterables.map(i => i[Symbol.iterator]());
while (true) {
const pairs = iterators.map(j => j.next()),
dones = pairs.map(p => p.done),
values = pairs.map(p => p.value);
if (dones.indexOf(true) >= 0) {
for (const iterator of iterators) {
if (typeof iterator.return === 'function') {
iterator.return();
}
}
return;
}
yield zipper(...values);
}
}
const fewWords = ['alper', 'bethe', 'gamow'];
for (const pair of zipWith((l, r) => [l, r], countdown, fewWords)) {
//... diddley
}
//=> Return to Forever
这段代码我们使用了显式关闭的方法,当所有迭代对象中的任何一个消耗尽了我们就显示关闭所有的迭代器(jsbin)。但是若是我们提前终止了外部循环,sorry是没人来擦屁股的(jsbin)。
const [[firstCount, firstWord]] = zipWith((l, r) => [l, r], countdown, fewWords);
//=>
试过栗子就知道了,没有Return to Forever输出,尽管js的内置功能帮我们把generator返回的迭代器关闭了,但其他的都没有关闭。但是也很明显,我们的迭代器和generator返回的迭代器毛关系都没有,他哪知道啥时候关闭啊。
根据 jaffathecake的建议,我们可以这么来
function * zipWith (zipper, ...iterables) {
const iterators = iterables.map(i => i[Symbol.iterator]());
try {
while (true) {
const pairs = iterators.map(j => j.next()),
dones = pairs.map(p => p.done),
values = pairs.map(p => p.value);
if (dones.indexOf(true) >= 0) {
for (const iterator of iterators) {
if (typeof iterator.return === 'function') {
iterator.return();
}
}
return;
}
yield zipper(...values);
}
}
finally {
for (const iterator of iterators) {
if (typeof iterator.return === 'function') {
iterator.return();
}
}
}
}
这个时候我们要是关闭了那肯定可以啊,这就是借助了,try/catch/finally, 就不试了,大家可以试试
还有另外一招我们也可以实现上述目的
function zipWith (zipper, ...iterables) {
return {
[Symbol.iterator]() {
return {
done: false,
iterators: iterables.map(i => i[Symbol.iterator]()),
zipper,
next() {
const pairs = this.iterators.map(j => j.next()),
dones = pairs.map(p => p.done),
values = pairs.map(p => p.value);
if (dones.indexOf(true) >= 0) {
return this.return();
} else {
return { done: false, value: this.zipper(...values) };
}
},
return(optionalValue) {
if (!this.done) {
this.done = true;
for (const iterable of this.iterators) {
if (typeof iterable.return === 'function') {
iterable.return();
}
}
}
if (arguments.length === 1) {
return { done: true, value:optionalValue };
} else {
return { done: true };
}
}
};
}
};
}
jsbin, 这相当于显示实现了一个可迭代对象。
无论哪种方式,我们都必须明确地安排这样的事情,当它自己的迭代器关闭时,zipWith关闭所有的迭代器。
那么什么语法可以用于迭代器呢?
const a = { ...iterable }
function* gen() {
yield* ['a', 'b', 'c'];
}
gen().next(); // { value: "a", done: false }
怎么样突然发现可迭代对象居然这么厉害了吧
总结一小下生成器就是coder友好版的迭代器,而可迭代对象则是实现了Symbol.iterator方法的对象且该方法返回一个迭代器。而且迭代器可以使用的语法,显然生成器的返回值当然也可以哦。
好了我们言归正传,接上话。
我们已经看到了,迭代器需要关闭。我们还知道迭代器的关闭是不可见的。有个return 方法需要我们去实现,并且需要被调用。但通常我们都是把迭代器和生成器,for ... of循环或者解构一起使用,他们把调用return这件事给我们隐藏了。
这种有意识的设计让我们对迭代器的学习和使用变得容易。当我们看到下面的代码
function * take (numberToTake, iterable) {
const iterator = iterable[Symbol.iterator]();
for (let i = 0; i < numberToTake; ++i) {
const { done, value } = iterator.next();
if (!done) yield value;
}
}
我们可以很快的明白这段代码是要干啥了,但是下面这段代码是不是更好呢:
function * take (numberToTake, iterable) {
let i = 0;
for (const value of iterable) {
if (i++ === numberToTake) {
return;
} else {
yield value;
}
}
}
但这里有一个关于显式还是隐式的永恒争论点
function * take (numberToTake, iterable) {
const iterator = iterable[Symbol.iterator]();
try {
for (let i = 0; i < numberToTake; ++i) {
const { done, value } = iterator.next();
if (!done) yield value;
}
}
finally {
if (typeof iterator.return === 'function') {
iterator.return();
}
}
}
for ... of 是不是更优雅?若是for(let i = 0; i < numberToTake; ++i)更快呢? try...finally是不是更好呢?因为他显式的关闭了迭代器。又或者他是不好的因为他引进了额外的代码?
所有的所有我觉得又回到了那句话:写代码写程序没有最好的,都是取舍问题。你们觉得呢?虽然我还做不到,因为取舍很难确定,因为有的时候是自己写的代码总想找点儿理由来维护他。
在改造事物方面,不同于改变事物,有一个简单朴素的原则;这个原则我们或许可以称之为悖论。在这种情况下存在某种制度或定理;为了简单起见,我们可以这么举例,有一个围栏或者大门设置在了路上。更现代的改革者到了这里并且说“我看不见他的作用,把他清理了吧”,对于更有智慧的改革者会说“如果你看不见他的用处,我是不会让你清理的,再去想想吧,等你想明白了,并且告诉我你看到了他的用处,那么我就会允许你把他彻底毁了。” - G.K.Chesterton
...省略一万字看原文吧
总结一小下就是:无论我们是函数式或者是OO,还是其他的,我们都会有像迭代器一样的抽象漏洞。当我们在大多数情况下使用他是好的,当我们到达使用的边缘的时候就会出问题。因此我们需要了解他的底层原理,若是不了解就不会知道到底除了啥问题。
我们有时候还是需要去了解一些底层的问题,否则有时候会真的很无能为力,尤其是出错的时候,我们可以使用抽象去减少一些复杂度,但这不代表我们完全不需要去了解抽象。
第一次听说抽象漏洞,学习了,非不证自明的东西总是会存在漏洞的。也加深了对迭代器,迭代对象,生成器的理解。其实还有一个更重要的就是,资源的关闭,我们的资源是有限的,一定要有收尾操作。
再来列举一下迭代对象可以使用的语法,生成器(准确说他的返回值)也可以哦
迭代对象的三个方法
js 会在for... of, 解构赋值,之后为我们自动调用return,当然是在没有完全消费掉数据的时候才会为我们调用。注意释放资源。我们可以利用这个功能。
在使用generator和迭代器的过程中要注意释放资源。能用js内置的最好不能就try/catch/finally
先上图
这几年前端发展的很快,出现了很多优秀的框架。例如Angular2, React, Vue等他们大大提升了开发者的生产效率,以及快速创建可测试化,可扩展的前端应用。但是在server端nodejs到没有出现如此的框架都是一些基础的框架,工具等等,虽然目前有eggjs,thinkjs,私以为他们架构成熟性还有待进步,他依然也只是提供了一些工具和方法等,不过egg还是要胜think一筹的(都是我瞎掰的),当然他们也都在不同程度上的解决了一些初步的架构问题。
这里我看到了一个新近的框架nestjs(基于express),他提供了一个开箱即用的架构体系,是啥样的架构体系呢?angular2的架构体系,可以说几乎是一样的架构体系,照着搬过来了,不过可以想一想用angular2的前端架构来写后端代码,也是一种酸爽!(typescript)在我看看来就是一个nodejs中ROR,flask或者是django。
{
provide: 'PhotoRepositoryToken',
useFactory: (connection: Connection) => connection.getRepository(Photo),
inject: ['DbConnectionToken'],
}
其中inject是这个注入值要使用的依赖注入,provide是提供给其他人要使用的注入标识符,useFactory代表要执行的方法,也可以是useValue,此时是一个普通对象即可。还有循环依赖,此时就要使用forwardRef了,就不细讲了,大家可以具体[参见](https://docs.nestjs.com/fundamentals/dependency-injection)
@Controller('cats')
export class CatsController {
@Get()
findAll(@Req() user) {
return [];
}
}
@Component()
export class CatsService {
private readonly cats: Cat[] = [];
create(cat: Cat) {
this.cats.push(cat);
}
}
// 使用
export class CatsController {
constructor(private readonly catsService: CatsService) {} // 注入
@Post()
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
}
@Module({
imports: [CatsModule, OrderModule, ReportModule, UserModule],
})
export class ApplicationModule {}
@Middleware()
export class LoggerMiddleware implements NestMiddleware {
resolve(...args: any[]): ExpressMiddleware {
return (req, res, next) => {
console.log('Request...');
next();
};
}
}
@Post()
async create(@Body() createCatDto: CreateCatDto) {
throw new HttpException({
status: HttpStatus.FORBIDDEN,
error: 'This is a custom message',
});
}
/**
{
"status": 403,
"error": "This is a custom message"
}
*/
expecptions的体系是可以扩展的,当然nest还提供很多的类型,如BadRequestExceptio, UnauthorizedExceptio等等
export class ForbiddenException extends HttpException {
constructor() {
super('Forbidden', HttpStatus.FORBIDDEN);
}
}
@Filter的正式称呼应当是Exception Filters。这次望文生义是正确的。是的就是处理Exception的。
@Catch(HttpException)
export class HttpExceptionFilter implements ExceptionFilter {
catch(exception: HttpException, response) {
const status = exception.getStatus();
response
.status(status)
.json({
statusCode: status,
message: `It's a message from the exception filter`,
});
}
}
// 使用
@Post()
@UseFilters(new HttpExceptionFilter())
async create(@Body() createCatDto: CreateCatDto) {
throw new ForbiddenException();
}
// 全局的
async function bootstrap() {
const app = await NestFactory.create(ApplicationModule);
app.useGlobalFilters(new HttpExceptionFilter());
await app.listen(3000);
}
bootstrap();
@Guard()
export class RolesGuard implements CanActivate {
canActivate(dataOrRequest, context: ExecutionContext): boolean | Promise<boolean> | Observable<boolean> {
return true;
}
}
// 使用
@Controller('cats')
@UseGuards(RolesGuard)
export class CatsController {}
我们可以自定义一些装饰器,给controller添加必要属性以供guard来使用
// roles Deacator
export const Roles = (...roles: string[]) => ReflectMetadata('roles', roles);
// 使用
@Post()
@Roles('admin')
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
// Roles guards 改写
@Guard()
export class RolesGuard implements CanActivate {
constructor(private readonly reflector: Reflector) {}
canActivate(req, context: ExecutionContext): boolean {
const { parent, handler } = context;
const roles = this.reflector.get<string[]>('roles', handler);
if (!roles) {
return true;
}
const user = req.user;
const hasRole = () => !!user.roles.find((role) => !!roles.find((item) => item === role));
return user && user.roles && hasRole();
}
}
// 使用同上
@Pipe()
export class ValidationPipe implements PipeTransform<any> {
transform(value: any, metadata: ArgumentMetadata) {
return value;
}
}
// 使用
@Post()
// @UsePipes(new ValidationPipe())
async create(@Body(new ValidationPipe()) createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
可以自定义装饰器,在guard里面我们已经见到过了。
nest还集成了graphql, websockets, microservice, 微服务这部分他提供两种通信方式,redis(pub/sub), tcp等等
app
-- modules
-- reports
-- report.controller.ts
-- report.service.ts
-- report.entity.ts
-- report.interface.ts
-- dto(data transfer object)
-- report.dto.ts(推荐class)
-- orders
...
-- common
-- db.provice.ts
...
nest项目也提供了很多的example, 总体来看写起来也还是很舒服的。集成了很多东西,点赞,希望下一个项目可以使用。
总会觉得自己不知道该怎么去更进一步的学习,一开始使用就觉得纯用express有很多问题,可是没有去思考怎么才能更好,总觉得见见世面,看看优秀的人都是怎么写的,可是,看完就完了,却没有想本项目做一样把看到的总结起来。不想动手写业余项目,因为就是觉得自己懂的太少了,还是得多看看,可是只看又有什么用呢?ps: 看的结果就是写出了屎一样的代码,还得努力啊!(有看的欢迎多多交流[email protected])
子类型(subtyping)在编程语言理论中一直是个复杂的话题。对协变和逆变的误解是造成这个问题的一个主要原因。这篇文章就是来说明这两个术语的。
接下来我们将会使用以下符号:
假设我们有这么三个类型
Greyhoud <: Dog <: Animal
可以看出Greyhound 是Dog的子类型,并且Dog 是Animal的子类型。通常来说,子类型是具有传递性的,因此Greyhound也是Animal的子类型。
问题: 下面那个类型是Dog -> Dog的子类型
我们如何回答这个问题呢?假设f是一个接收Dog -> Dog 函数类型作为参数的函数。此时我们并不关心f的返回值类型,举个栗子吧,假设:
f: (Dog -> Dog) -> String
现在我想用g作为参数来调用f,接下来我们一一看一下当g是上述类型时会是什么情况:
假设g: Grehound -> Grehound, 那个f(g)是否是类型安全的呢?
不是的,因为f有可能会用其他的Dog的子类型来调用g,比如:GemanShepherd
假设g: Geryhound -> Animal, 那个f(g)是否是类型安全的呢?
不是的,原因同上
假设g: Animal -> Animal, 那个f(g)是否是类型安全的呢?
不是的,因为f有可能调用了g,然后使用它的返回值让他吠,但并不是所有的动物都会吠。
假设g: Animal -> Greyhound, 那个f(g)是否是类型安全的呢?
是的,这个是安全的,f可以使用任意类型的Dog调用g,因为所有的Dog都是Animal,并且,f可以假设g的返回值就是Dog,因为所有的Greyhound都是Dog。
可以看出这个是类型安全的:
(Animal -> Greyhound) <: (Dog -> Dog)
返回值的类型很直接可以看出: Greyhound 是Dog的子类型。但是参数的类型有点儿炸: Animal是Dog的祖(super)类型啊!
为了用我们的行话(jargon)来解释这个奇怪的原因,我们规定参数的返回值类型是协变的,然而参数类型是逆变的。返回值是协变的意味着:A <: B暗指(T -> A) <: (T -> B)(A是B的子类就是说(T -> A)是 (T -> B)的子类型)。参数类型的逆变意味着: A <: B 暗指(B -> T)<: (A -T)(A和B交换位置)
有趣的事实是:在Typescript中,参数类型是双变的(即可以是逆变又可以是协变),很显然这是不合理(unsound)的表现(但是在2.6中可以使用--strictFunctionTypes来修正)
问题: 那么List是List的子类型么?
这问题的答案不是那么好说明的?如果list是不可变的,那么他就是类型安全的,但如果list是可变的,那么他就肯定不是安全的!
为什么呢?假设我需要一个List然后你给我传了一个List,然而我认为你给我传的就是List,那么我就有可能往list中再插入一个Cat, 那么你的List里面就有了一个Cat!显然类型系统是不允许你这么做的。
正式说明: 当我们的list是不可变(数据是否可变)的时候我们是允许类型是可协变的,但是若是可变(数据是否可变)得list那么list类型必须是不可变的(是指类型是否可变,无论是协变还是逆变都是不可以的)。
有趣的事实: 在Java里面,数组即是可变(是指数据是否可变)的又是类型可协变。显然这是不合理的(unsound)
libuv是一个跨平台的异步事件库。
libuv对于不同的I/O轮询机制提供了很多的抽象。例如:handle和stream是对socket和其他实体的高等抽象。还提供了跨平台的文件I / O和线程功能。以及一些其他的功能。
此处图一张:
libuv给用户提供了两个抽象用于和事件循环进行交互: handle和request。
handle表示长期存在的对象,当它激活时,它是用来处理特定的操作。例如:
request是用来表示短期存在的操作。这些操作可以通过一个handle来执行:写request通常是用来在一个handle上写数据;或者是独立于handle的: getaddrinfo rquest就不需要一个handle可以直接在事件循环上执行。
I/O(或者)循环是libuv的核心。它用来建立所有的I/O操作的内容,并且这意味着I/O 循环是一个单线程的。当然当我们在多个线程上运行的时候就可以跑多个事件循环了。libuv事件循环(或涉及循环或handle的任何其他API)就不是线程安全的,除非另有说明。事件循环遵循常见的单线程异步I/O方法:所有(网络)I/O在非阻塞套接字上执行,使用给定平台上可用的最佳机制:epoll on linux, kqueue on OSX其他等等。作为循环迭代的一部分,循环将阻塞等待已经添加到轮询器的套接字上的I/O活动,并且将触发回调来指示套接字条件(可读,可写的挂断),因此句柄可以读,写或执行期望的I/O操作。
见图
loop的now会被更新,在循环开始前,循环会缓存当前的时间以减少和和时间相关的系统调用。
如果循环处于活动状态,则开始迭代,否则循环将立即退出。 那么,什么时候循环被认为是活着的呢? 如果一个循环有处于激活状态或者被ref的handle,或者活动的请求或者正在被关闭的句柄,它就被认为是活着的。
运行(due)到期的定时器。所有活跃的的定时器如果他们的时间在now之前就会运行他们的cb。
处于等待的回调被调用。虽然所有的I/O回调都会在循环之后立即调用,但是还有这样的一些例子,比如一个回调被延迟到下一此循环了。因此如果上次循环有延时的I/O回调会在这个时间点调用。
Idle handle callbacks are called. Despite the unfortunate name, idle handles are run on every loop iteration, if they are active.
prepare handle 回调被调用。在循环被I/O阻塞之前(right before the loop will block for I/O)prepare回调就会立即被调用。
轮询超时时间计算。在循环被阻塞之前计算他会被阻塞多久。这里有一些计算的规则:
重要提示:libuv使用线程池来使异步文件I/O操作成为可能,但是网络I/O总是在单个线程(每个循环的线程)中执行。
与网络I/O不同,没有libuv可以依赖的特定于平台的文件I/O原语,因此当前的方法是在线程池中运行阻塞文件I/O操作。
libuv目前使用一个全局的线程池,所有的循环都可以和其交互。有如下3种操作使用的是线程池:
线程池的大小是相当受限制的。
** 2. 定义基本操作 **
#define QUEUE_NEXT(q) (*(QUEUE **) &((*(q))[0]))
#define QUEUE_PREV(q) (*(QUEUE **) &((*(q))[1]))
数组的第0个表示下一个,1表示上一个。
这里使用((QUEUE **) &(((q))[0]))这么复杂的表达是有两个原因。一个是转成左值(这里指的左值是指从数组元素的赋值的角度去看,就是指能不能给数组元素赋值),另一个是保存类型信息。
这样会丢失类型信息
#define QUEUE_NEXT(q) ((*(q))[0]) // 这个是数组的0号元素
这样不是左值
#define QUEUE_PREV(q) ((QUEUE *) ((*(q))[1])) // QUEUE* 是个数组指针非左值
q是 QUEUE * 这个是数组指针非左值
*(q) 是QUEUE
(*(q))[0]是数组第一个元素的值
&((*(q))[0])第一个元素的地址 (非左值)
(QUEUE **) &((*(q))[0]) 还是数组第一个元素之的地址但是这次保存了类型
* (QUEUE **) &((*(q))[0]) 是第一个元素的值得地址即保存了类型又是左值
** 3. 取值 **
这个队列的实现和数据无关,所以宏里面看不到data的定义,是不是很神奇,像在c++这种面向对象的语言中,我们一般通过迭代器来实现操作和数据的分离,而c语言可以用很巧妙的方式去高效的实现哦。
#define QUEUE_DATA(ptr, type, field) \
((type *) ((char *) (ptr) - ((char *) &((type *) 0)->field)))
((char *) &((type *) 0)->field))是拿到偏移量。为什么这样就可以拿到偏移量?其实很好理解,把0当做其实地址,取field的地址,就是偏移量啦。
cat /etc/group | grep docker
sudo gpasswd -a ${USER} docker
sudo service docker restart
比如 docker push docker.sensoro.com/library/ai-server,那么推送的地址是 docker.sensoro.com/library/ 我们的镜像想要叫 ai-server。 但是本地在 build 时,要用 docker build ./ -t docker.sensoro.com/library/ai-server tag 必须是这个。
host 模式
众所周知,Docker 使用了 Linux 的 Namespaces 技术来进行资源隔离,如 PID Namespace 隔离进程,Mount Namespace 隔离文件系统,Network Namespace 隔离网络等。一个 Network Namespace 提供了一份独立的网络环境,包括网卡、路由、Iptable 规则等都与其他的 Network Namespace 隔离。一个 Docker 容器一般会分配一个独立的 Network Namespace。但如果启动容器的时候使用 host 模式,那么这个容器将不会获得一个独立的 Network Namespace,而是和宿主机共用一个 Network Namespace。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。例如,我们在 10.10.101.105/24 的机器上用 host 模式启动一个含有 web 应用的 Docker 容器,监听 tcp80 端口。当我们在容器中执行任何类似 ifconfig 命令查看网络环境时,看到的都是宿主机上的信息。而外界访问容器中的应用,则直接使用 10.10.101.105:80 即可,不用任何 NAT 转换,就如直接跑在宿主机中一样。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
container 模式
在理解了 host 模式后,这个模式也就好理解了。这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
none 模式
这个模式和前两个不同。在这种模式下,Docker 容器拥有自己的 Network Namespace,但是,并不为 Docker 容器进行任何网络配置。也就是说,这个 Docker 容器没有网卡、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。
bridge 模式
bridge 模式是 Docker 默认的网络设置,此模式会为每一个容器分配 Network Namespace、设置 IP 等,并将一个主机上的 Docker 容器连接到一个虚拟网桥上。下面着重介绍一下此模式。
class A {
a() {}
}
那么展示就是 A - a(边) -> Function
此图是snapshot的json格式图

此图中的索引都是从零开始的
// 对应snapshot中的字段, 查找节点i的信息
var i_type = nodes[i];
var i_name = strings[nodes[i + 1]];
var i_id = nodes[i + 2];
var i_size = nodes[i + 3]
var i_edge_count = nodes[i + 4];
再具体的解释如下:




从上图我们可以清晰节点的类型一共有13种,hidden类型可能不展示

从上图可以看出共有7种
* map, array, symbol, object, regexp, number, boolean, string, date,typedarray...这些常见的内建对象我就不解释了,大家都知道
* 我们在sanpshot中还会经常看见两类string比较生疏的两个(这两类算在pimitive中), sliced string和 concatenated string
* 那我们就来看看string,在v8里的形式

在这里我们可以清晰的看出来,�v8的字符串类型,里面有sliced的解释,是其他字符串的部分引用(因为字面量字符串是不可变的so可以这么办。。),而cons的就是(a, b),�或者嵌套似的((a,b),c)这样的pairs(同样是因为�字面量的字符串是不可变的)
const parent = {
a: 23,
child: child,
}
const child = {
a: 23,
c: 12,
};
/**
child的大小就是8B(32为机器),parent大小就有得讨论了,若不算引用的具体内容大小,parent的大小也是8,而此时就是shallow size。那么包含引用内容呢?
*/
是指不但包含对象自身,还包含该对象所能引用的或者间接引用(parent.child, parent.child.child)
GC roots的概念来自与垃圾回收算法,js的垃圾回收�算法是基于根不可达来回收不使用的内存的,就选取某个对象作为初始点,沿着这个对象的引用链往下走,凡是通过这个对象无法访问到(是指通过引用可以获取到对象)的对象就认为是可以被回收的。
如上图5,6,7就无法被访问到,此时就可以认为5,6,7可以被回收了
�
从上面我们可以看出来,所有的对象是以树的形式展示的,devtools中如何显示对象�树的?
对象的保留树
就像我们前面所说的,堆就是由相互连接的对象构成的网络。在数学的世界中,这种结构称作图或者内存图。一个图是由节点和边构成的,而节点又是由边连接起来的,其中节点和边都有相应的标签。
这里问题�就来了那么js中的对象的构造函数都是啥呢
const a = 'hello2dj';
// a 的构造函数是 String, 但对于字面量来说还会有具体的展示类型,这与v8的内部实现相关
Object count 挡在summary视图模式下查看时,会有这个,按照上述来说对象树的节点是constructor, 属性是边,那么object count 就是�通过这个constructor 构造出来的对象实例数量
巧了还有一个我们可以在devtools里经常看到的就是有些对象是黄颜色标识的有些是�红色标识的,见图, 图中很明显标识�红色和黄色的�原因


在summary视图下第一栏是从constructor而这一栏是分两类的

见上图,他管()的行为叫tag,那就很明显了,在括号()下面的对象�就是全部的这种对象了。

我错了
* (string, regexp) 显示的是literal string 即 a='234'中的'23', regexp类似
* (num) 显示的�是以number�对象展示的对象
* (array) 那些通过数组�引用的对象,说白了就是数组对象
* (code deopt data)[]: v8去优化时的数据
* []:就是纯数组
* (object properties)[]:通过对象属性引用的对象
* (map descriptors)[]: map类型相关,暂时搁置
* (object elements)[]: �暂时未知
* (function scope info)[]: 暂时未知
* (system) 那就是原生代码了
* (compiled code) 编译过后的代码
* (closure) 通过闭包引用的对象,但感觉更像是闭包自己
* (sliced string): 搁置
* (undefined): 搁置
* (concatenated string): 搁置
代码如下,num2是一个Number对象,不知道为啥,我以字面量分配的num1,我没找到。。。(有待继续)
num2 = new Number(234);
接下来的图示顺序分析的

function globalLeak() {
bar = 'hello2dj';
}
这里bar没有生命就意味着他被global引用了,那么他就不会被回收
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) {
// 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);
此例说明:与节点或数据关联的计时器不再需要,node 对象可以删除,整个回调函数也不需要了。可是,计时器回调函数仍然没被回收(计时器停止才会被回收)。同时,someResource 如果存储了大量的数据,也是无法被回收的。
还有时间监听:
var element = document.getElementById('button');
function onClick(event) {
element.innerHTML = 'text';
}
element.addEventListener('click', onClick);
有时,保存 DOM 节点内部数据结构很有用。假如你想快速更新表格的几行内容,把每一行 DOM 存成字典(JSON 键值对)或者数组很有意义。此时,同样的 DOM 元素存在两个引用:一个在 DOM 树中,另一个在字典中。将来你决定删除这些行时,需要把两个引用都清除。
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image'),
text: document.getElementById('text')
};
function doStuff() {
image.src = 'http://some.url/image';
button.click();
console.log(text.innerHTML);
// 更多逻辑
}
function removeButton() {
// 按钮是 body 的后代元素
document.body.removeChild(document.getElementById('button'));
// 此时,仍旧存在一个全局的 #button 的引用
// elements 字典。button 元素仍旧在内存中,不能被 GC 回收。
}
此外还要考虑 DOM 树内部或子节点的引用问题。假如你的 JavaScript 代码中保存了表格某一个 的引用。将来决定删除整个表格的时候,直觉认为 GC 会回收除了已保存的 以外的其它节点。实际情况并非如此:此 是表格的子节点,子元素与父元素是引用关系。由于代码保留了 的引用,导致整个表格仍待在内存中。保存 DOM 元素引用的时候,要小心谨慎。
这段代码被引用了无数次了来自meteor
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing)
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log(someMessage);
}
};
};
setInterval(replaceThing, 1000);
代码片段做了一件事情:每次调用 replaceThing ,theThing 得到一个包含一个大数组和一个新闭包(someMethod)的新对象。同时,变量 unused 是一个引用 originalThing 的闭包(先前的 replaceThing 又调用了 theThing )。思绪混乱了吗?最重要的事情是,闭包的作用域一旦创建,它们有同样的父级作用域,作用域是共享的。someMethod 可以通过 theThing 使用,someMethod 与 unused 分享闭包作用域,尽管 unused 从未使用,它引用的 originalThing 迫使它保留在内存中(防止被回收)。当这段代码反复运行,就会看到内存占用不断上升,垃圾回收器(GC)并无法降低内存占用。本质上,闭包的链表已经创建,每一个闭包作用域携带一个指向大数组的间接的引用,造成严重的内存泄漏。
Meteor 的博文 解释了如何修复此种问题。在 replaceThing 的最后添加 originalThing = null 。

从obj1入手,上图中蓝色节点代表仅仅只有通过obj1才能直接或间接访问的对象。因为可以通过GC Roots访问,所以左图的obj3不是蓝色节点;而在右图却是蓝色,因为它已经被包含在retained集合内。
所以对于左图,obj1的retained size是obj1、obj2、obj4的shallow size总和;右图的retained size是obj1、obj2、obj3、obj4的shallow size总和。
对于obj2,它的retained size是:在左图中,是obj2和obj4的shallow size的和;在右图中,是obj2、obj3和obj4的shallow size的和。
还有一些全局变量
built-in object maps: 内建的对象
symbol table: 符号表(没搞明白这是个啥子鬼)
stacks of VM threads;(这个应该是指栈中的 变量)
compilation cache;(编译的缓存)
handle scopes;(v8中的属�术语,v8中每个对象都是被封在handle中的,句柄的scope)
global handles;(全局的句柄)
先来一个snapshot1
执行一些能够进行分配的动作再来一个snapshot2
再执行以下相同的操作来一个snapshot3
最后在snapshot3的summary下查看在1和2之间分配的对象
#include <unistd.h>
int pipe(int fd[2]); // 返回值:若成功返回0,失败返回-1

单个进程中的管道几乎没有任何用处。所以,通常调用 pipe 的进程接着调用 fork,这样就创建了父进程与子进程之间的 IPC 通道。如下图所示:
若要数据流从父进程流向子进程,则关闭父进程的读端(fd[0])与子进程的写端(fd[1]);反之,则可以使数据流从子进程流向父进程。
#include<stdio.h>
#include<unistd.h>
int main() {
int fd[2]; //两个文件描述符
pid_t pid;
char buff[20];
if(pipe(fd) < 0) //创建管道
printf("Create Pipe Error!\n");
if ((pid = fork()) < 0>) //创建子进程
printf("Fork Error!\n");
else if (pid > 0) // 父进程
{
close(fd[0]); //关闭读端
write(fd[1], "hello world\n", 12);
} else {
close(fd[1]); //关闭写端
read(fd[0], buf, 20);
printf("%s", buff);
}
}
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.











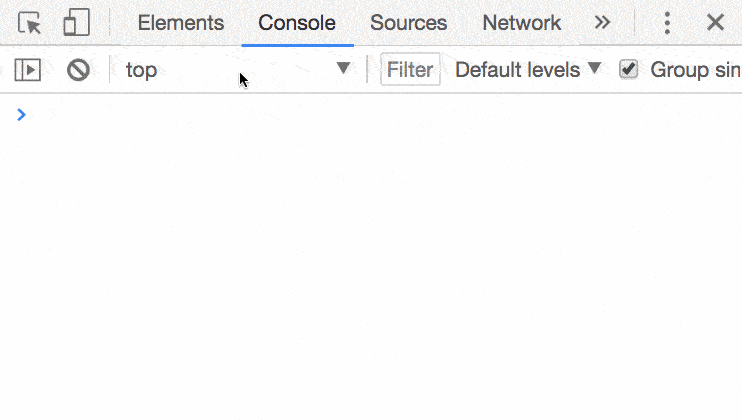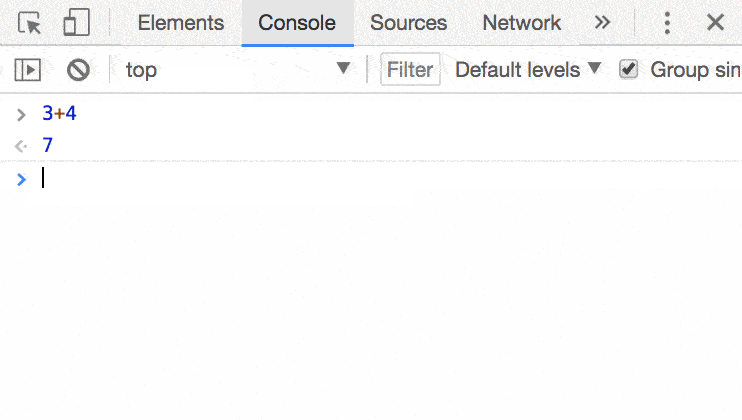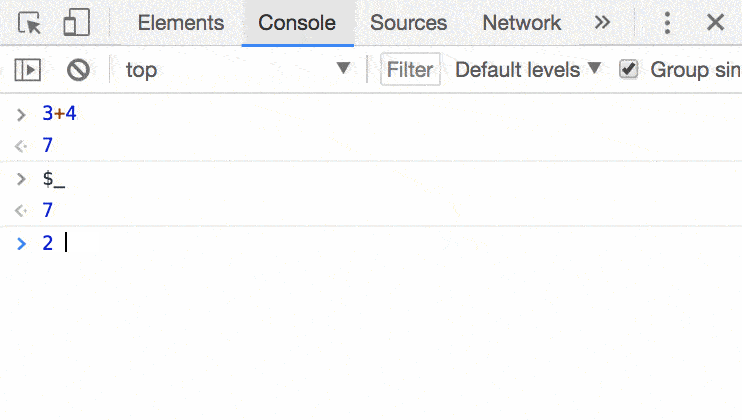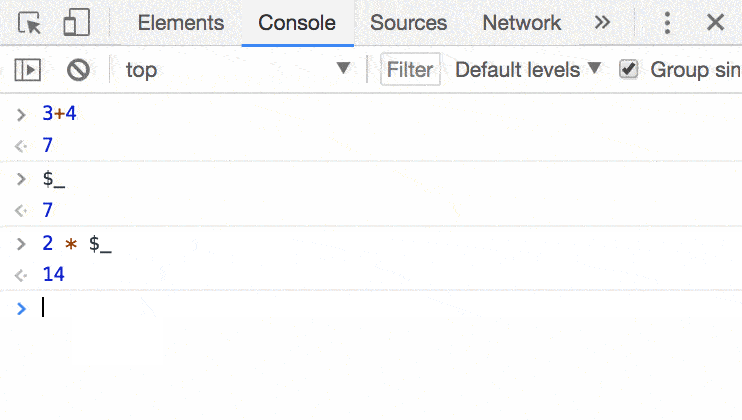
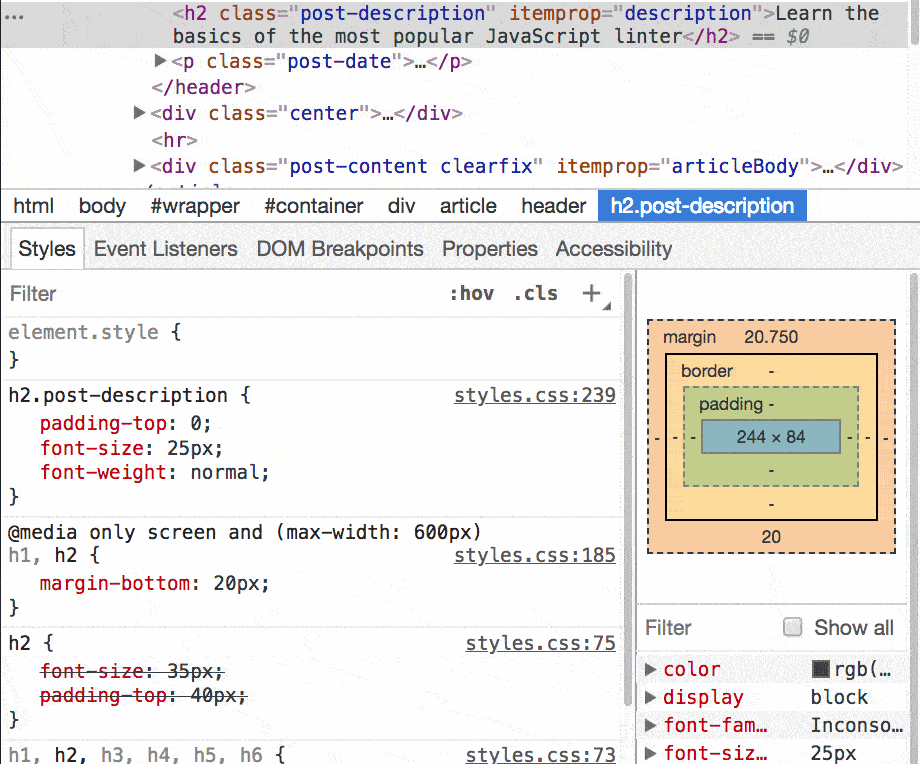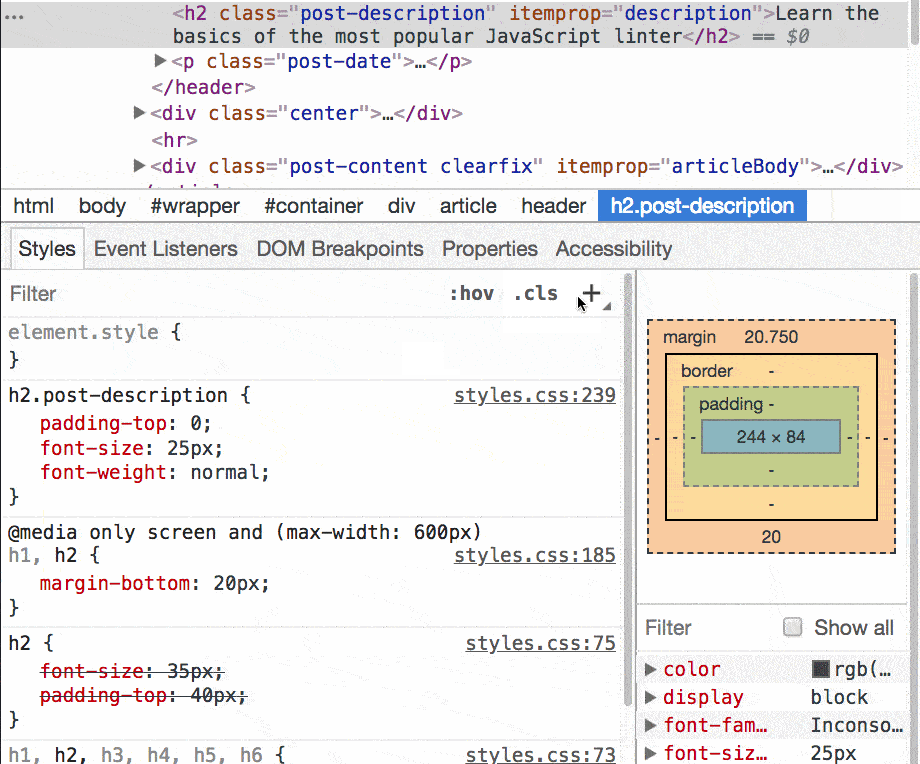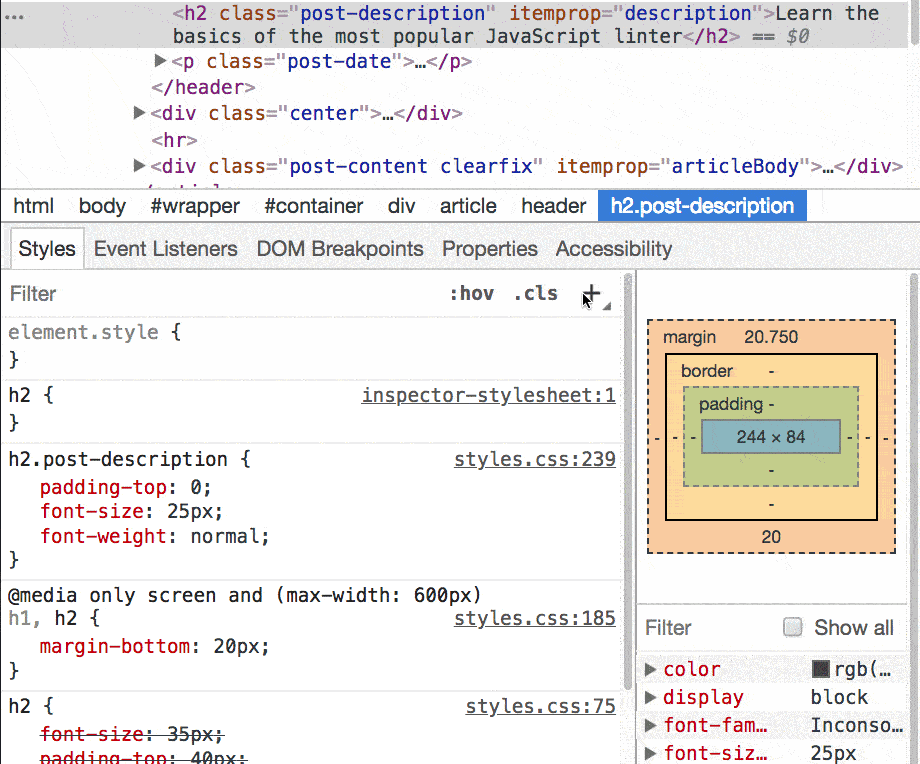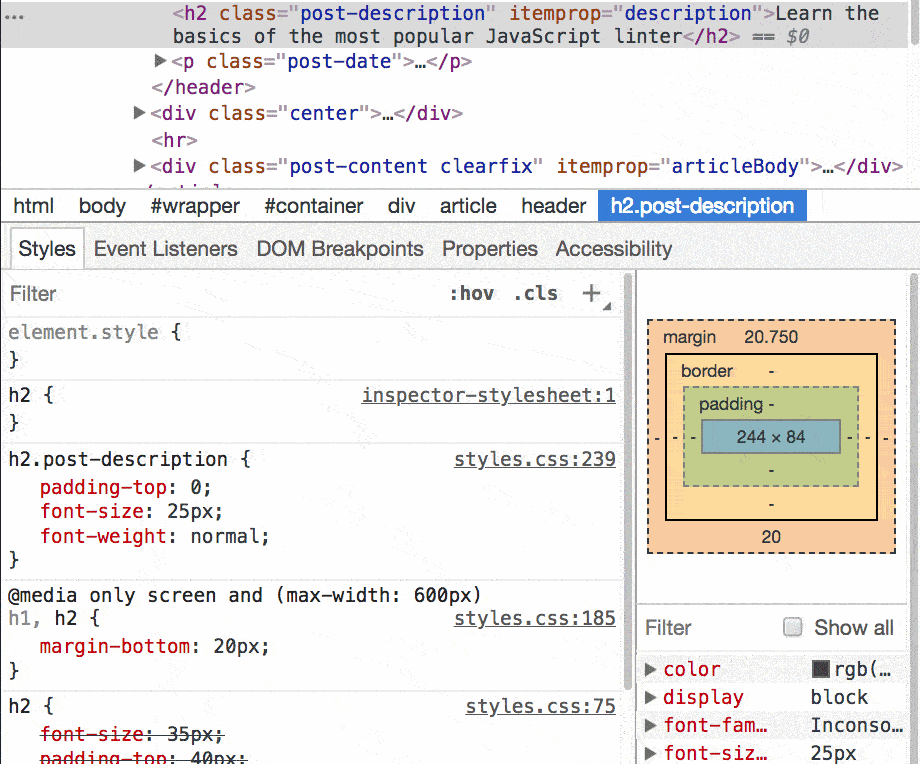
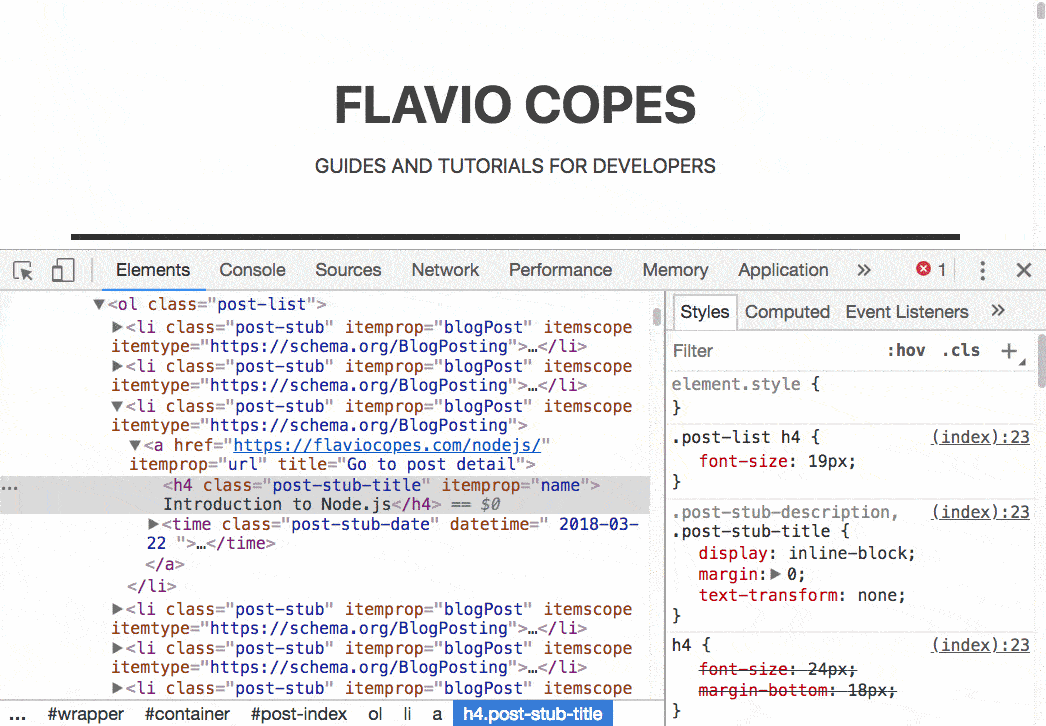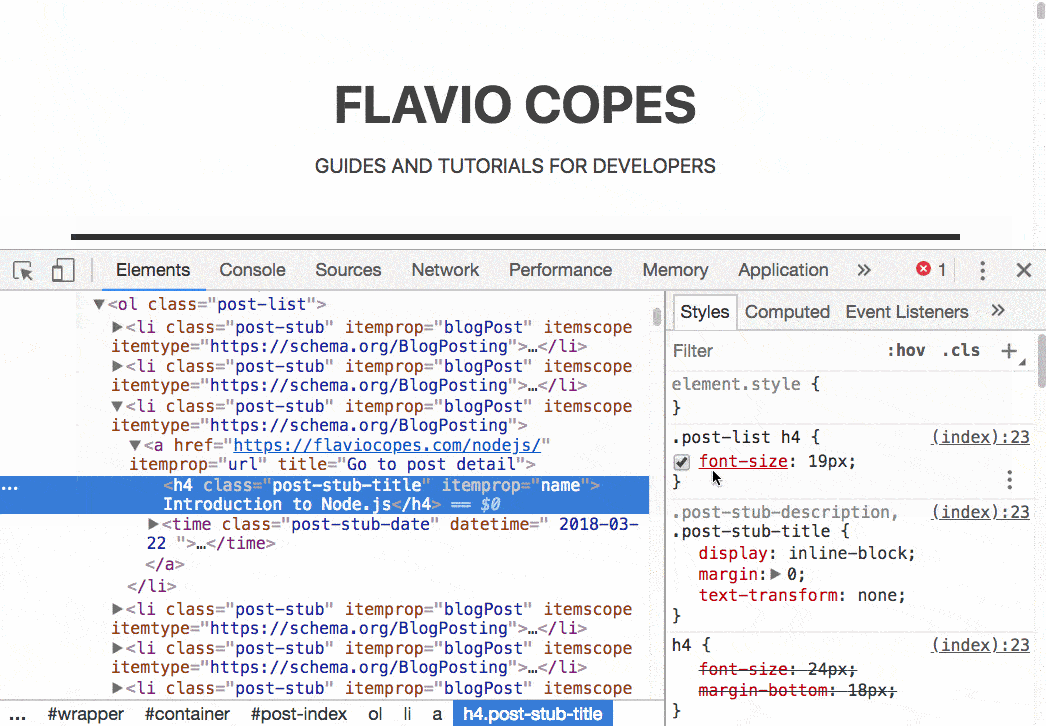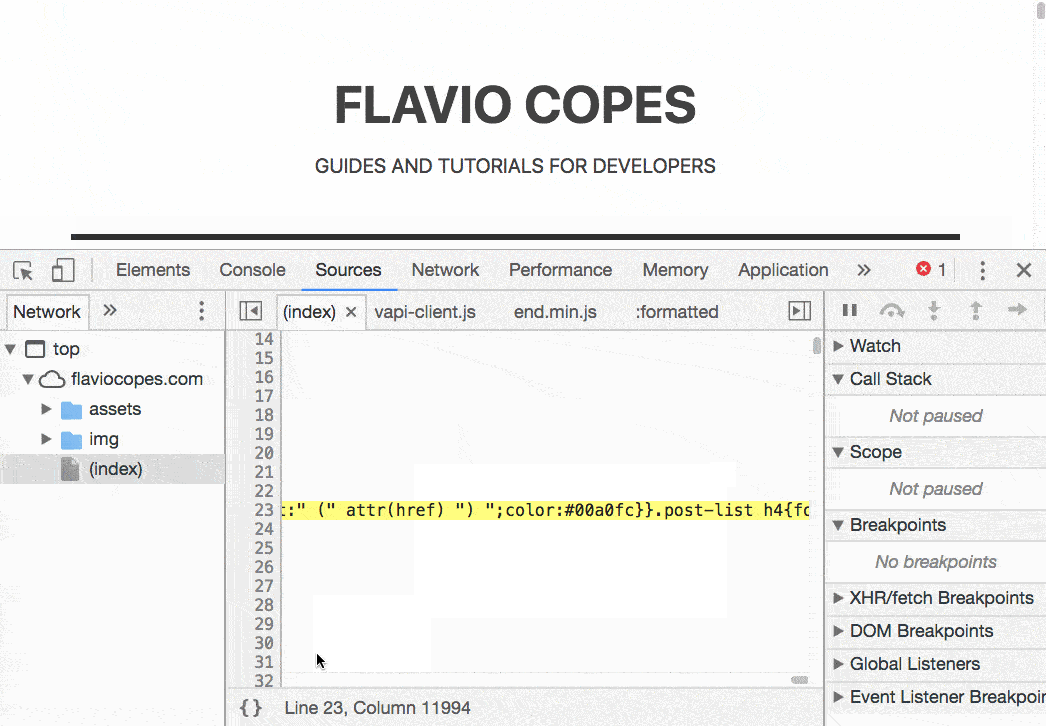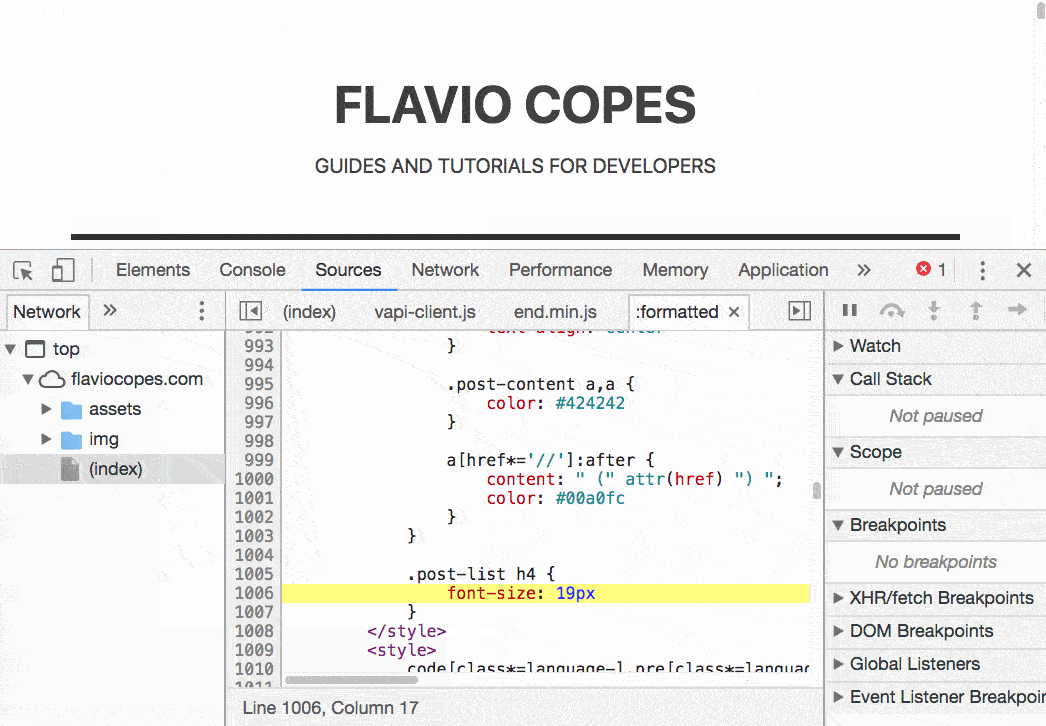
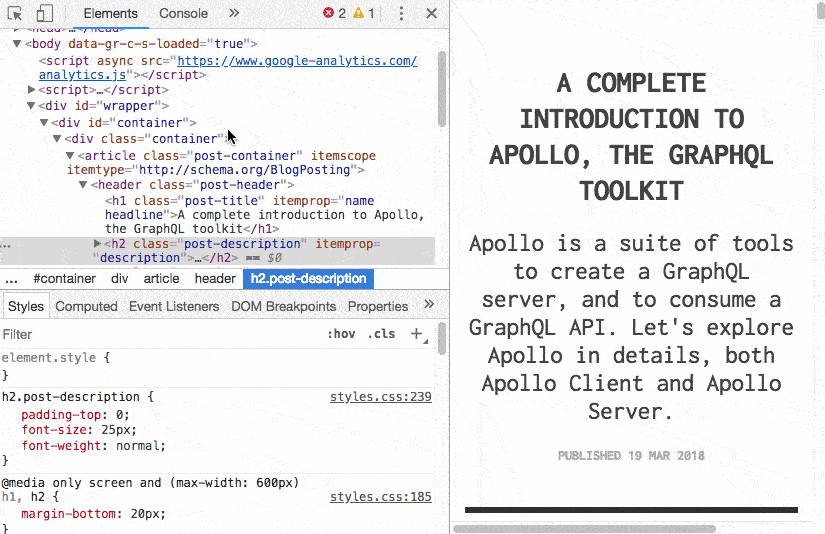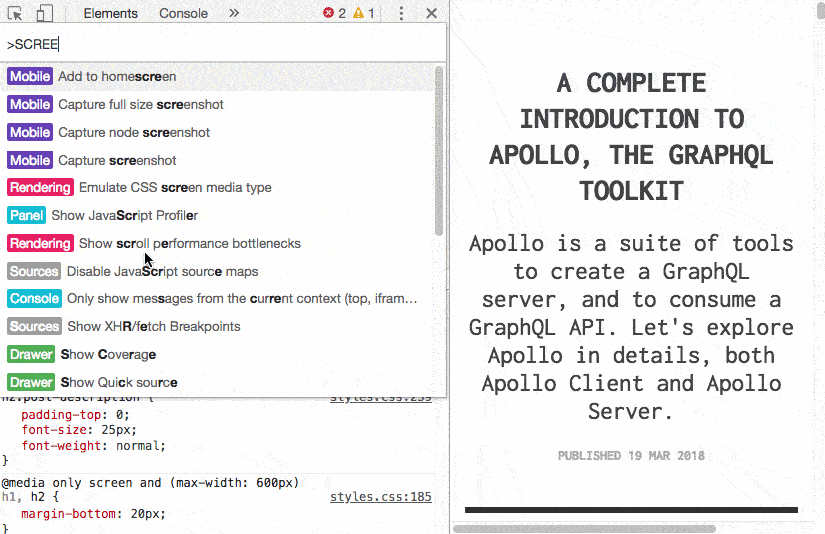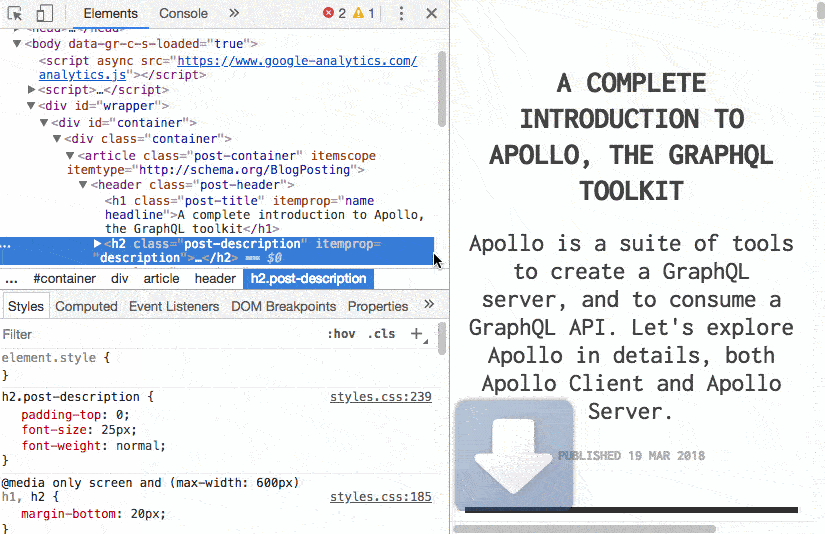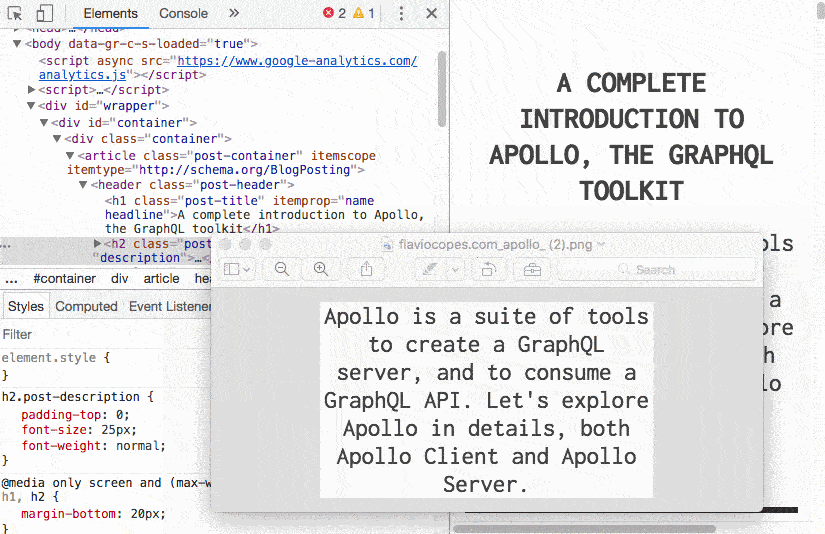
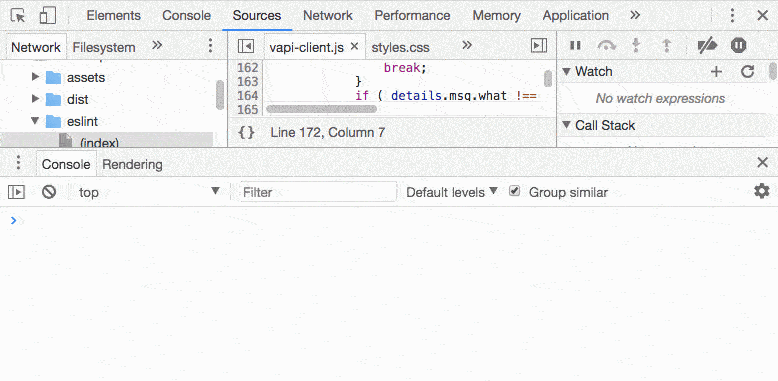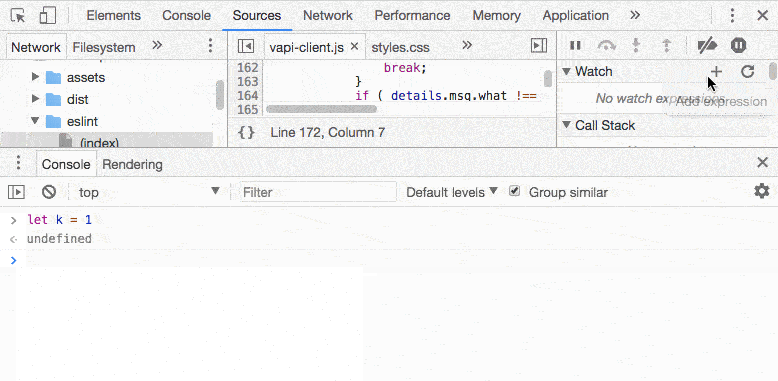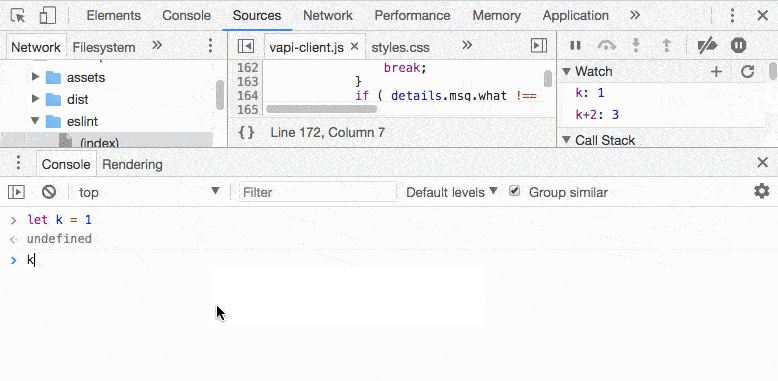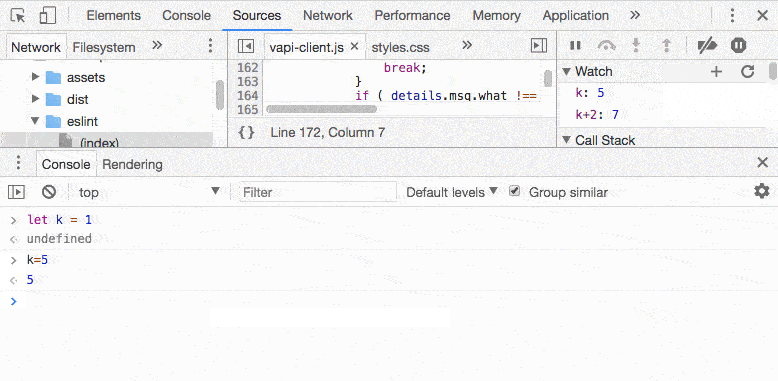
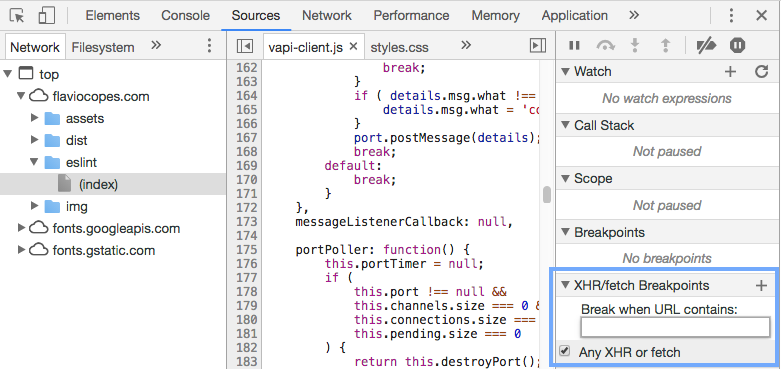
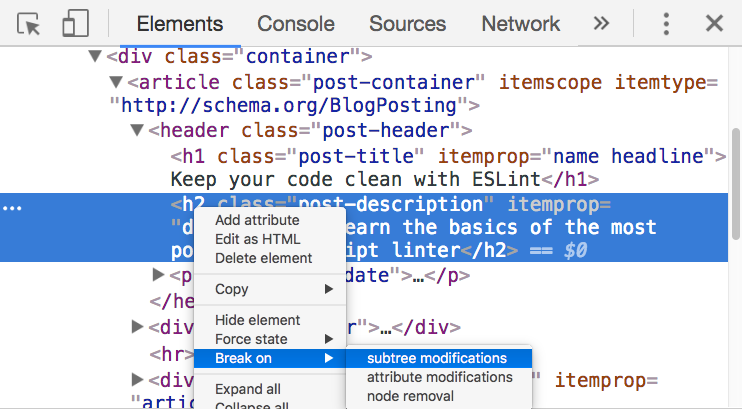



















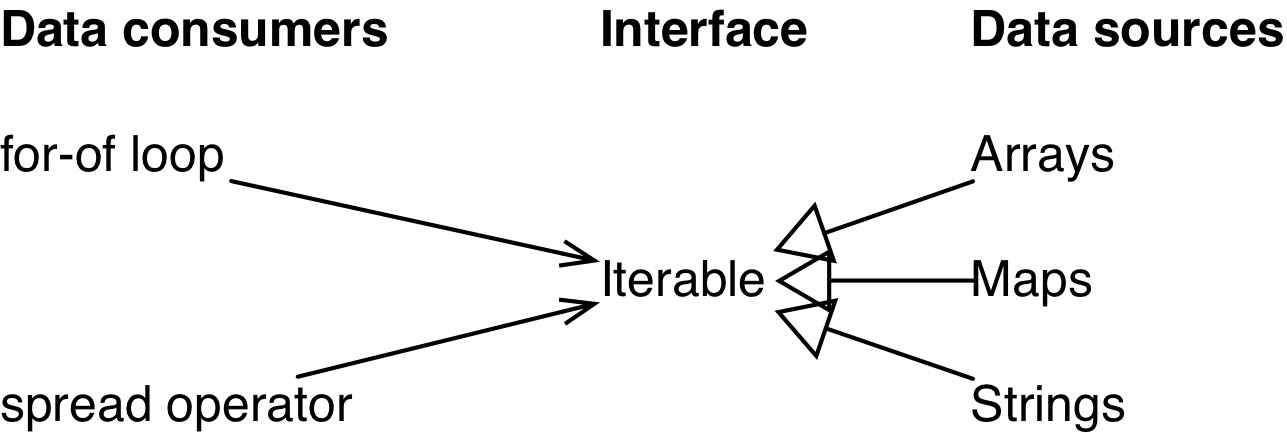


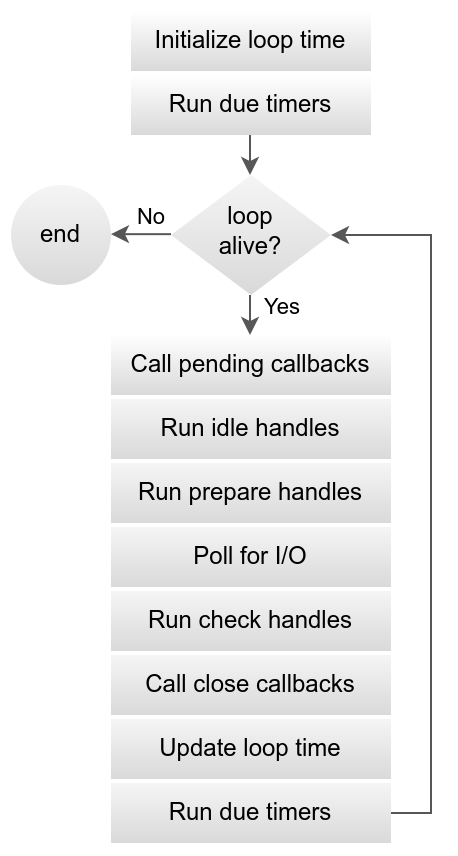




{kind=link}