This repository houses source code, sample files, and associated documentation. Developers are welcome to fork the repository and contribute.
Programming Problem:
Our objective is to extract tabular data from a collection of diverse PDF documents and convert it into a structured format (CSV files) for further analysis.
The documents lack consistency in table placement and formatting. They originate from various organizations and potentially exhibit different layouts. A portion of the PDFs are scanned images, while others incorporated Optical Character Recognition (OCR) technology when scanned, and finally there are also electronically generated documents of text and markdown elements.
Solution Designed:
The data extraction process is implemented in a multi-step approach:
- File Indexing and Filtering: Documents are categorized and potentially filtered based on specific criteria.
- Text Extraction: The documents are converted into machine-readable text format using appropriate techniques.
- Text Analysis and Page Selection: Textual content is analyzed to identify pages containing relevant information. This may involve the identification of keywords and their concentrations to pinpoint pages requiring detailed parsing.
- Table Extraction and Conversion: Tables are extracted from the designated pages and formatted as CSV files, enabling further analysis.
Built using python. Utilized publicly available libraries detailed below and the Google Gemini LLM API.
A brownfield, as defined by the US Environmental Protection Agency (USEPA), “is a property the expansion, redevelopment, or reuse of which may be complicated by the presence or potential presence of a hazardous substance, pollutant, or contaminant.” Brownfields are often abandoned or underutilized sites due to the presence of contamination or suspected contamination.
This project and its associated code target the extraction of data from publicly available documents obtained through a collaborative effort with the Michigan Department of Environmental, Great Lakes, and Energy (EGLE). The documents encompass assessments of commercial properties within the Detroit area.
More information:
Note: this repository already contains and example of a run of two addresses. You can delete the existing files inside the directories and then follow instructions below to run it on your own. Be sure to have all required libraries installed prior to running the python scripts. Do not delete the directories themselves, only the files inside them (with exception of the results folder inside each address folder).
- all the ~/SRC_brownfield_pdfs/ADDRESS/results contents and the results folder itself. Leave the address folder intact.
- contents of ~/CompletedReport_pages/
- contents of ~/Gemini/textSource_Documents/
- contents of ~/Gemini/CSV_Results/
- Run script ==PRD_Processor_Brownfield.py== using python in Terminal/Command-Line. This will convert the PDFs to raw text.
- Run script ==FindReportPages.py== using python in Terminal/Command-Line. This will seperate only those pages which are considered relevant using the wordmaps and keyword set.
- Copy the files from ~/CompletedReport_pages/ to --> ~/Gemini/textSource_Documents/, this must be done manually before running the next steps using Gemini.
- Get an API key from Gemini console and copy it to the relevant variable in GeminiAPIQueryLib.py, you must acquire your own key for this script to work.
- Run script ==FindReportPages.py== using python in Terminal/Command-Line. This will iterate all text documents in the ~/Gemini/textSource_Documents/ and send them to LLM API for processing. The response will be saved under the directory ~/Gemini/CSV_Results/ as both a TXT file and a related CSV file.
Note: some additional cleaning and normalizing may be required before using the CSVs in SAS, R, or other software.
Download to local filesystem - PDF documents which were uploaded to cloud by partner.
-
Saved in folder named by Street Address of location.
-
Each folder contains multiple PDF documents associated. Note: not every document is important to extract textual/table data from like correspondence for example.
-
Included files in repository for two Brownfield locations. These can be used in your testing and development.
Will be collecting attribute information that is useful to categorization for targeting and assigning unique identifier to each document that will be used for later associations.
- Index files by name and location, generate filepath for later access.
- Get file sizes of each PDF.
- Hash filename as unique identifier going forward. Used MD5 for speed but still collision-resistant.
- Can at this point filter by filename attribute. In our example, I filtered to only filenames containing ‘BEA’ or ‘RI’ as the document type acronym.
- Check PDF attributes. We’ll get the number of pages and check the content of the first page for text to classify text/image type PDF.
- Save this information and index to a CSV in script directory. This result file is used as input for future steps, so you don’t need to pre-process every time or keep objects in memory forever.
Converting the pdf to text with script yields a standardized result. Python exports readable text to an array of plaintext files.
- The structure comprises all files under a hashed-filename titled folder.
- Inside this folder, there is an identifier file containing the title of the original document and other attributes.
- Multiple files per page are generated for each type of media result. The file named Page_xx_Content.txt for each page represents all text.
- For each page, there is a word-map file detailing the words on the content page and their locations.
Here is an example source folder with multiple reports per address. The results subdirectory here will contain the text extracted.
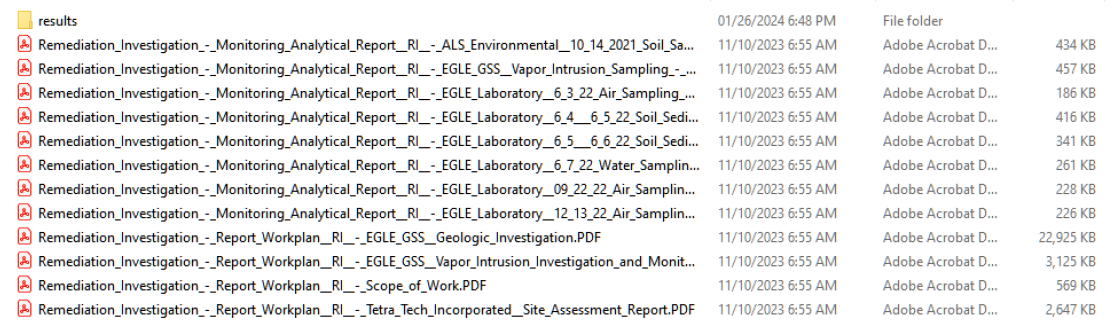
Here is the directory structure and the plaintext files generated per document. You can see the directory is the unique hash-name of the document and each page has associated text files labeled accordingly.
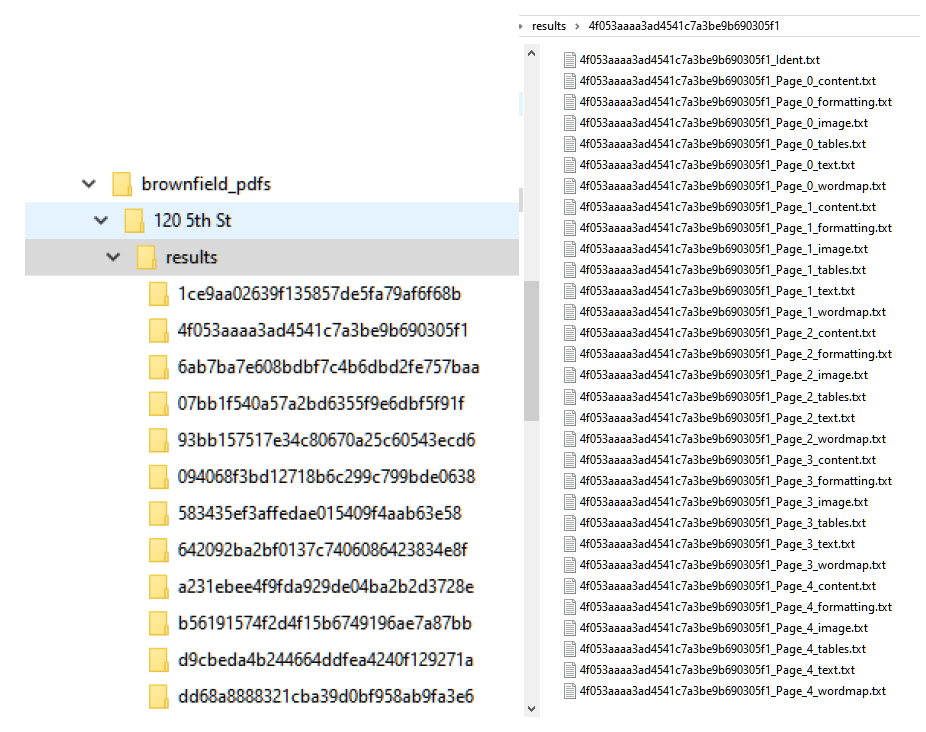
Here is the example of a single page of a PDF. The word-map is the frequency and location of each word in the page.
We need to find the pages in the documents which contain tables with relevant data. This will seperate these plaintext documents for further processing.
- Using wordmap from previous step, look for keywords that denote a page has relevant data in it.
- Python reads each wordmap and copies it to another directory if the page contains keywords from a user supplied set.
A trained Gemini LLM instance will be utilized to read the text files and parse out a table structure. This will be formatted as a CSV and output by the instance.
- using python, send requests with plaintext of each individual page in directories to the Gemini API for processing.
- API will respond with formatted text from the output. Python receives this and then writes a CSV file with the response.
We need to make sure the csv tables extracted by Gemini LLM adhere to a consistent structure and have the same variables.
- Using python, check header row and number of columns.
- If inconsistent then flag file for further review.
Copy checked result files to a directory that will be read by SAS program.
- adhere to shallow/wide directory structure that is easy to read into SAS
- seperate by report type and address
Note: this is slightly outdated and not totally accurate. But it does illustrate the overall concepts well. Update in future.
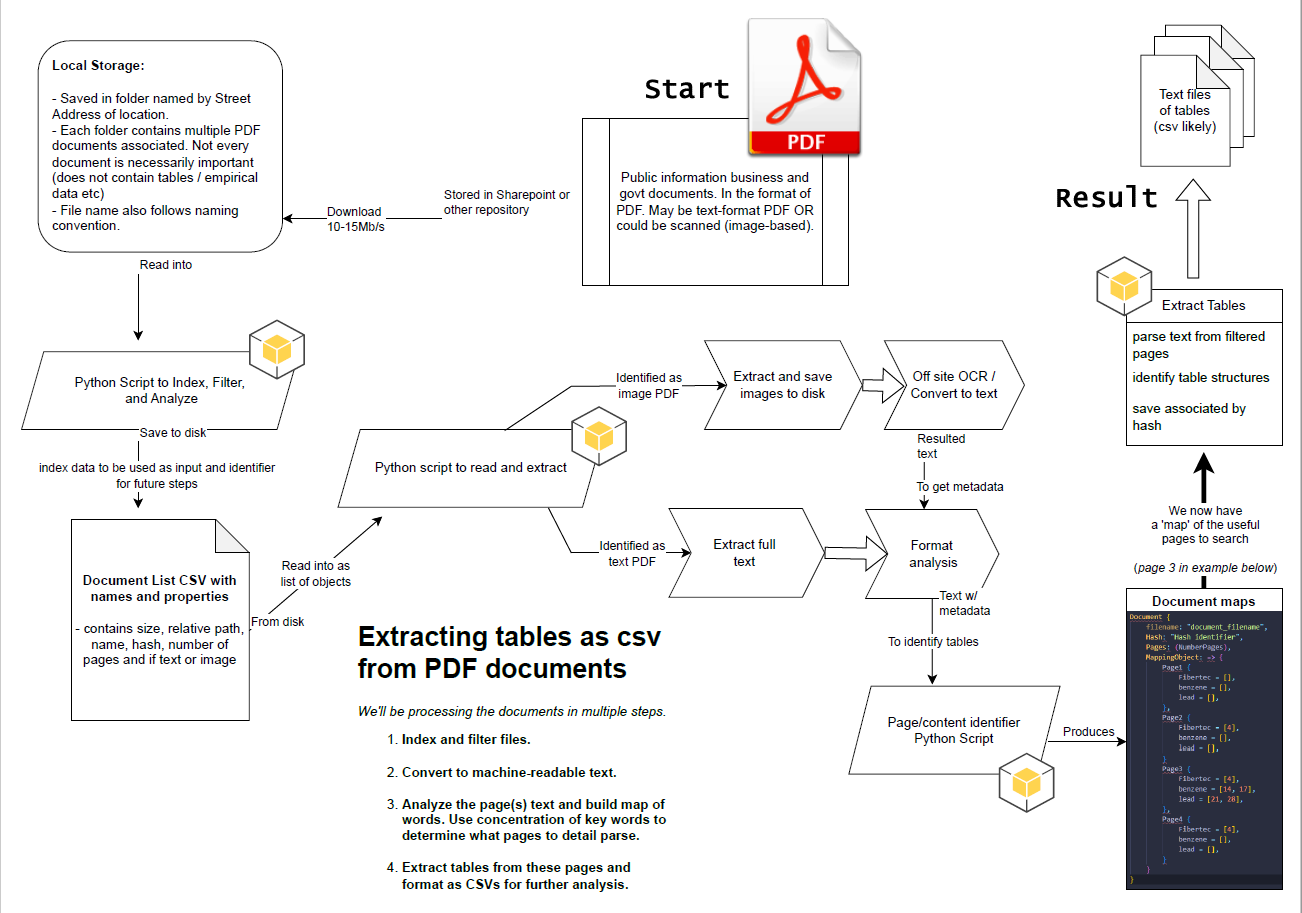
Python Libraries:
Special Thanks..
My HFH Colleagues:
Support, brainstorming, debugging help, and instrumental ideas.
George Stavrakis:
Heavily borrowed from George's code and tutorial when creating the text extraction page. Check out his Medium profile: https://medium.com/@george.stavrakis.1996
