huliyou / maoni Goto Github PK
View Code? Open in Web Editor NEWblog
blog




Intersection Observer API 提供给web开发者,一种异步查询元素相对于其他元素或窗口位置的能力。它常用于追踪一个元素在窗口的可视问题,比如下图,滚动页面,顶部会提示绿色方块的可视性。

在 Intersection Observer 出来之前,传统位置计算的方式,依赖于对DOM状态的轮询计算,然而这种方式会在主线程里密集执行从而造成页面性能问题,getBoundingClientRect()的频繁调用也可能引发浏览器的样式重计算和布局。如果是在iframe里,因为同源策略,我们不能直接访问元素,也就很难用传统方式去处理iframe里的元素。
Intersection Observer 的设计,就是为了更方便的处理元素的可视问题。使用 Intersection Observer 我们可以很容易的监控元素进入和离开可视窗口,实现节点的预加载和延迟加载。Intersection Observer 并不是基于像素变化的实时计算,它的反馈会有一定的延时,这种异步的方式减少了对DOM和style查询的昂贵计算和持续轮询,相比传统方式降低了CPU、GPU的消耗。
// 定义相交监视器
var observer = new IntersectionObserver(changes => {
for (const change of changes) {
console.log(change.time); // 发生变化的时间
console.log(change.rootBounds); // 根元素的矩形区域的信息
console.log(change.boundingClientRect); // 目标元素的矩形区域的信息
console.log(change.intersectionRect); // 目标元素与视口(或根元素)的交叉区域的信息
console.log(change.intersectionRatio); // 目标元素与视口(或根元素)的相交比例
console.log(change.target); // 被观察的目标元素
}
}, {});
// 开始观察某个目标元素
observer.observe(target);
// 停止观察某个目标元素
observer.unobserve(target);
// 关闭监视器
observer.disconnect();当目标元素和根元素相交发生改变时,会触发监视器的回调。
callback IntersectionObserverCallback = void (
sequence<IntersectionObserverEntry> entries,
IntersectionObserver observer
);回调的参数,entries 是一个IntersectionObserverEntry数组,数组的长度是我们监控目标元素的个数,另一个参数是 IntersectionObserver 对象。
IntersectionObserverEntry 对象提供了目标元素与跟元素相交的详细信息。他有如下几个属性。
interface IntersectionObserverEntry {
readonly attribute DOMHighResTimeStamp time;
readonly attribute DOMRectReadOnly? rootBounds;
readonly attribute DOMRectReadOnly boundingClientRect;
readonly attribute DOMRectReadOnly intersectionRect;
readonly attribute boolean isIntersecting;
readonly attribute double intersectionRatio;
readonly attribute Element target;
};
IntersectionObserver Option 是 IntersectionObserver 构造函数的第二个参数,用来配置监视器的部分信息。
dictionary IntersectionObserverInit {
Element? root = null;
DOMString rootMargin = "0px";
(double or sequence<double>) threshold = 0;
};
比如说我们可以用 Intersection Observer 实现图片的懒加载,当图片达到用户可视区的时候再进行加载。
优化大型网站性能,优先渲染用户可视的视图,根据用户页面滚动,按需加载视图。
实现列表的上拉加载,减少长列表的滑动卡顿。
优化广告推广的有效性,只有广告进入用户可视区,才算是有效的广告计数。
实现用户把播放器移除可视区时的自动暂停,进入可视区再进行播放。
还可以高效的实现视差动画。

IntersectionObserver 目前已经被主流的浏览器支持,我们可以使用渐进支持的方式使用它。对于目前浏览器的生态,我们也要做好向下降级的措施。
我们也可以使用 IntersectionObserver polyfill 增加浏览器的兼容,具体可以查看 polyfill.io。

2018混的这么差,所以要写一篇文章mark一下🤔。2018年,一定会在我的记忆中占有极大的重量,雄心满满的出发,而既疲倦又麻木的坐下来开始写失败感言。
2017年我成立了新蜂工作室,新蜂工作室是一个产品研发设计工作室,最初由我业余时间所创,想去连接更多的独立且各具技能的自由职业者组成一个团队。组合我们个体的技能实现更大的社会价值,也放大了每个个体的技能价值。
当时我们都还是兼职状态,合作过的工程师大概已经有20多人。那段时间真的是很疯狂,我上班的时候要联系客户,进行团队沟通,下班的时候还要赶项目。每谈成一个项目就屁颠屁颠高兴的不成,项目快交付出了很多bug又关心则乱,就这样兼职干了五个月,做了6个项目,盈利70万左右。当时我感觉挺有戏的,一帮人业余时间居然能搞出这么多事情,一定是有市场的。
之后成立友萌公司,则是有三点原因:
离开了待了三年的北京,终于可以做个断舍离的人,想走就走,不被任何事情牵绊。北京是个好城市但不是我的家。
回到了老家,自己喜欢的人却不常在,那便就成了冰冷的城市,一个我不喜欢的地方。
杭州是个精致的城市,房价相对很低,是个可以长期宅的城市。
新加坡,超级美丽的城市,我喜欢日落,我喜欢看海,我喜欢半夜在酒吧调酒,喜欢听别人自说自话。但我不喜欢短暂,总有一天我会回去。
无论从北向南,还是一路向北,我心无所属。难道这是宅的最高境界,有电有网就是世界😁。
我几乎没有想过死亡这个主题,一旦遇到,我就选择了逃避,逃避心里会好受很多。我的猫🐈叫小七,一只可爱的猫,一只粘人的猫,一只好吃的猫。因为肝脏问题,10月份离开了,而我至今都很难接受。死亡意味着,一旦离开,就是永远。永远也听不到它打呼噜,永远也不能给它挠痒,永远也不能给它铲屎。死亡是生命的轮回,尊重它便是对生命的认识。
17年许下一个愿望,如果盈利能超200万,工作室的人就新年一起去美国🇺🇸,现在只能呵呵的破产了。做黄了一个又一个产品,我对失败已经麻木了。现在我已经放弃再去接项目了,不是因为气垒,而是我做什么都会失败,投给我多少资金都会失败,已经不好意思再坑项目方了。
产品失败我并不难受,而那些信任我,而我又做出许诺没有兑现的队友,就真的真的不好意思。他们本可以继续自己安稳的人生路线,本可以不用在项目失败后听我乱bb,本可以一年拿着40w工资,现在估计都腰斩了。现在才懂得,能力不足,千万别承诺。
我是个失败者?生活没有那么容易的事情,没有重复练习的事情,没有答案的习题。想做成一件事情,真的很难很难,做成了是幸运。失败又不是错误,失败了又能怎样,世界不是依旧运转。反正失败不是我的错,可能是别人的,可能是世界的,反正不是我的。成功的对面不是失败,而是平庸。无论是成功亦或失败,都是努力争取过。让我喝茶看报,我做不到,我有我想要的,翻越这座山,世界会听到我的声音。
野心,能力不足以实现,所有的路都是弯路。出来一年我也看到了自己很多的不足,19年我已经看到自己要走的路,即使是弯路,我也要边走边试。
如果真的再给一次机会,我还是会这样,但不会再拉朋友一起做。毕竟人人都喜欢分享成功,而不是失败。
18年不悔也不爽,滚出,不送。
周末北京细雨绵绵,宅在家里看《人人都是产品经理》,里面一幅幅的思维导图着实吸引了我。如果当初没有放弃画画,我也能画出这样的思维导图。此时不禁想起大学里的P神,手绘1000多张图层的精美画作。
小学的时候我想用彩笔去画奥特曼,我爸给我报了画画班。虽然十五年过去了,我仍记得第一节课的题目:”画一个苹果“。下课结束后,我看着我那扭曲的非圆,就知道画画不适合我,这不是我想要的,我和我的绘画一样,然后都没了然后。
大一的时候,同学开始学吉他,花了半个月就已经能弹的很好了。和他一起买了吉他,每天他都会教我。但我实在乐律全无,一个月留下的只有手茧,然后就默默自我否定和放弃了。
看《中华小当家》,作为一个热爱生活追求美食的人,我也想做一个更厉害的厨师。用认真的美食表达态度,用料理让食客感到幸福。但我却无法去分配更多的时间和精力在这方面。
来到外面的花花世界,我们好奇不曾所见,我们想经历远方。我们会对很多事情,很多人感兴趣,我们希望它们在我们的世界留下倒影,留下痕迹。它们有光鲜的外表,它们会多彩我们的世界,它们,我们不曾拥有。而人的一生不是静止的,有太多太多的插曲,很多事情我们都浅尝辄止,不是因为入门遇到麻烦,就是岁月磨平了激情,最终只是我们世界的一个过客。
记得有一个对万科之争的评论:”你抢了年轻人的女朋友,年轻人抢了你的公司,时间花在哪里,成就就在哪里。“ 人的时间和精力有限,我们很难爱上一件事情又能很好的办好其他的事情,时间花在哪里,成就就在哪里。把时间和精力分散到很多兴趣上只会让人一事无成。
后来恍然大悟,我们对很多事情都会感兴趣,但是我们不一定热爱它们,至少不都是一生所爱。
感兴趣和热爱差别真的很大。我朋友老唐曾说过,”我干技术十几年了,虽然不能说非常热爱技术,我也对游戏很感兴趣,但是除了技术没有什么更适合我的。不是我选择了技术,而是技术选择了我“。不知道是不是十几年的光阴磨平了老唐对技术的激情,但是朴素的话是他对技术最好的表白。
罗永浩在陌陌直播的时候说过,若你在人生二十几岁的时候就知道自己热爱什么,那么非常恭喜你真的很幸运。如果三十几岁才明白一生所爱,那么也恭喜你。如果四十几岁才有所悟,那么也恭喜你,不晚。能发现自己一生所爱,而且能全身心的投入,真的很幸福。不论早晚,你所热爱的终将在你的世界停留。
愿幸运的人,能早日发现一生所求,遇见一生所爱。Good time, hard time, never bad time.
基于fastlane的移动运用部署
在程序的世界里,一切重复性的,流程化的工作都可以交给自动化去完成。
在移动开发中也是如此:其实写代码只是我们开发过程中的一部分,除此之外我们还需要进行编译,打包,上传,部署,库管理,版本控制等等Coding之外的杂事,而正是这些乏味而重复的工作占用了我们宝贵的时间。
所以在“懒人”遍布的工程师世界中,总会有人想尽办法做出改变,于是这些“懒人”们乐此不疲的造出许多美妙的轮子,既方便了自己,又帮助了他人,让这个世界变得更加美好。
这篇文章介绍其中一个轮子:Fastlane,这个Github上的明星项目截止到目前共获得1万多个Star,并且还有2000多个Fork。
大家都知道,最近几年,随着智能手机的普及,移动端不仅要承载更多业务场景的实现,并且还要应对不断变化业务需求。这就要求我们移动团队能够迅速响应变化,快速的迭代。那么随之而来的问题就是如何保障在不牺牲质量的前提下,尽可能的提升速度,我认为这一切需要建立在高质量的持续测试和持续交付体系之上。
但是移动端本身兴起的时间就比较短,各方面的成熟度也有所欠缺,能够拿来用的工具更是少之又少,随着业务深度广度的增加,迭代速度的加快,诸如证书管理,打包,上传,发布这类重复而毫无技术含量的工作逐渐占用了大家的时间,团队内部对此诟病不已。
所以我们一直在寻求一种工具,一种解决方案,旨在彻底解放工程师的“双手”。
Fastlane 是用 Ruby 语言编写的一套自动化工具集和框架,每一个工具实际都对应一个 Ruby 脚本,用来执行某一个特定的任务,而 Fastlane 核心框架则允许使用者通过类似配置文件的形式,将不同的工具有机而灵活的结合在一起,从而形成一个个完整的自动化流程。
到目前为止,Fastlane 的工具集大约包含170多个小工具,基本上涵盖了打包,签名,测试,部署,发布,库管理等等移动开发中涉及到的内容。
关于这些工具的描述和使用可以看这里:
https://docs.fastlane.tools/actions/Actions/
如果这些工具仍然没有符合你需求的,没有关系,得益于Fastlane本身强大的Action和Plugin机制,如果你恰好懂一些Ruby开发的话,可以很轻易的编写出自己想要的工具。
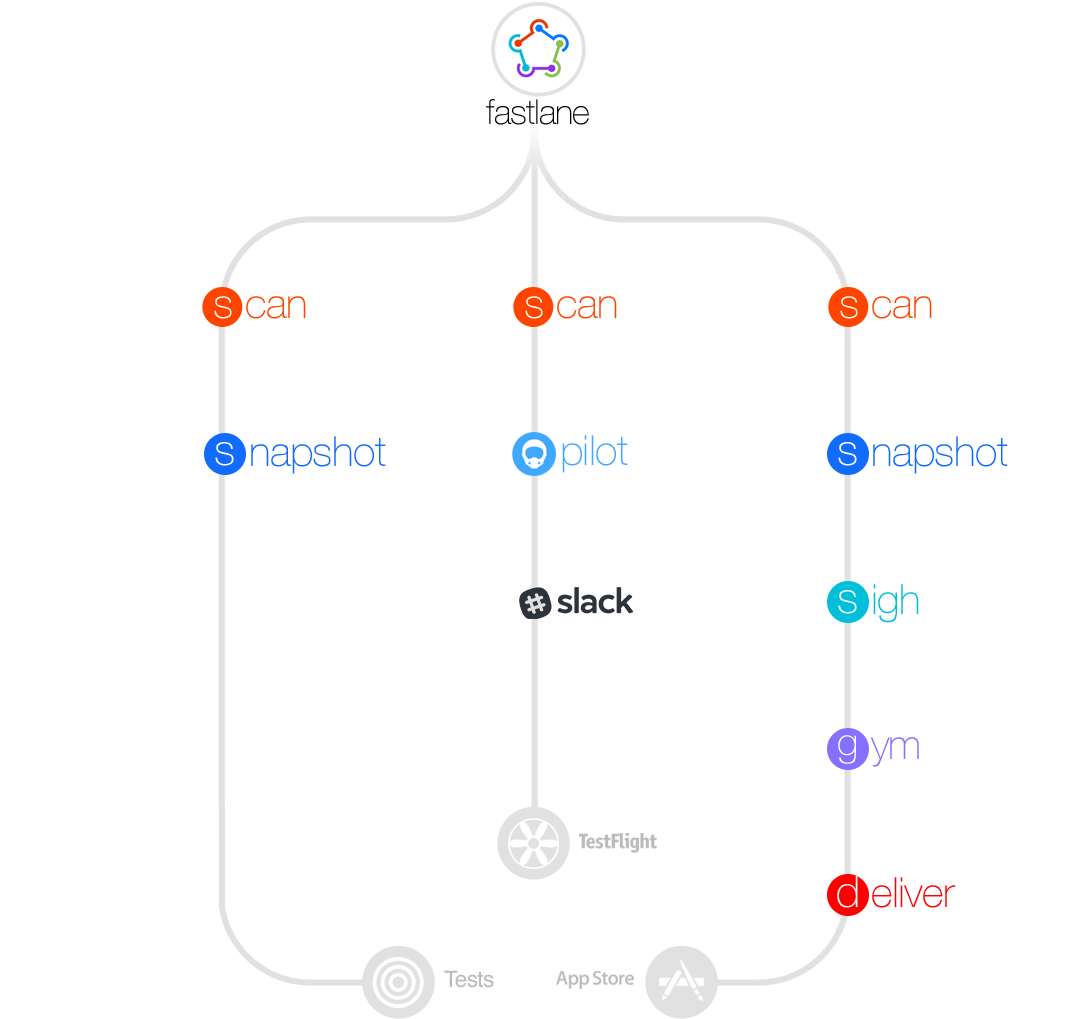
在 开发 -> 测试 -> 上线 的流程中,移动端一般会经过以下步骤:
手动部署流程 。。。
如果线上跟测发现有问题,那么需要修复完毕后重复上面的8个步骤。
其实做过这件事的同学应该都有体会,顺利的话差不多一次得30分钟吧,如果某一次Build Version忘记增加了,那么前面的工作就白做了。
而 Fastlane 则可以帮我们从以上步骤中解脱出来,真正专注于解决问题本身。使用了Fastlane这么长的时间,我最深的感受就是:Fastlane真正的将工程师从各种无聊而又必须要做的重复性劳动和流程化工作中解放出来,专注于业务或架构本身,使得整个开发效率,测试效率,运维效率大大提升。
以下将持续交付的流程拆分细说。
fastlane init
然后跟随配置引导,填写App和ITC相关信息,然后Fastlane会在项目目录下创建一个fastlane目录,里面包含所有和此项目相关的配置,剩下要做的就是将以上的流程配置在fastlane目录下的Fastfile中。
具体参考:
https://fabric.io/features/distribution?utm_campaign=fastlane.tools
关于 iOS 的开发证书等相关内容,请先阅读:Maintaining Your Signing Identities and Certificates
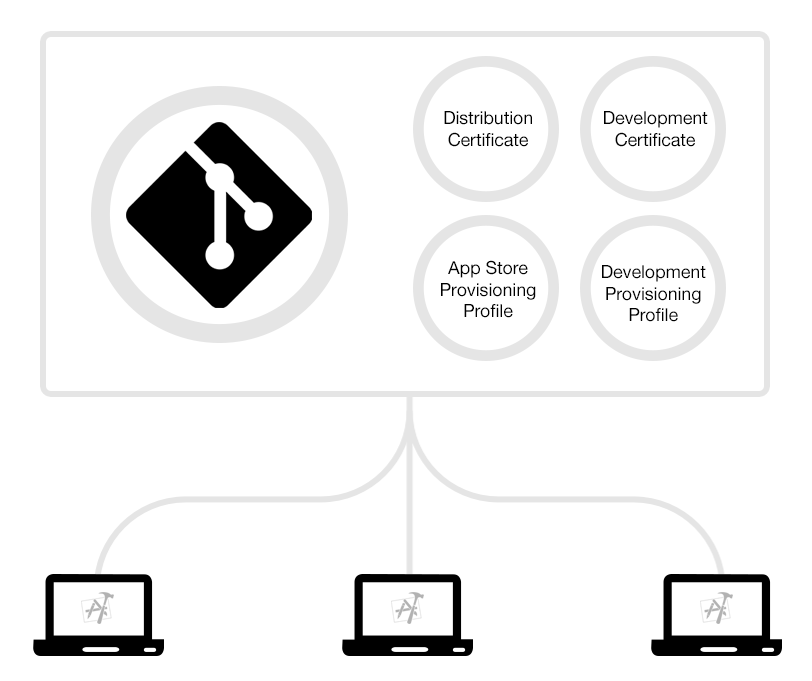
多人团队开发带来的问题:
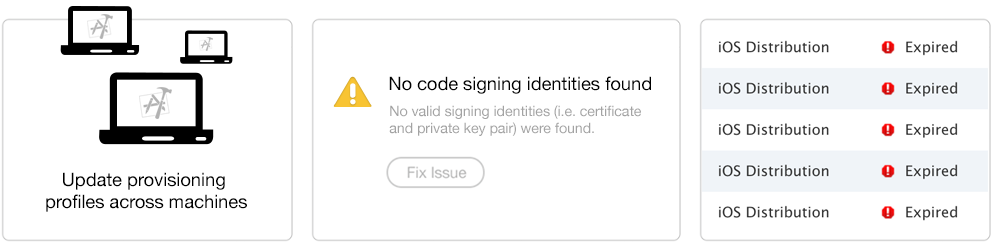
fastlane match 提供一种基于 git 的团队开发证书的管理方案
通过私有仓库存储 cer 证书 和 pp 文件,并自动更新过期证书和对应的pp文件。
fastlane match init
填写相关app信息和私有 git repo 地址。
match 使用请参考: https://github.com/fastlane/fastlane/tree/master/match#readme
具体可参考:
cert 是用来自动创建维护 iOS 证书的 fastlane action。
fastlane cert
具体使用参考: https://github.com/fastlane/fastlane/tree/master/cert#readme
sigh 是用来创建,更新,下载,匹配 pp文件的 fastlane action。
fastlane sigh
具体使用参考: https://github.com/fastlane/fastlane/tree/master/sigh#readme
gym 是用来打包的 fastlane action。
fastlane gym
具体使用参考:https://github.com/fastlane/fastlane/tree/master/gym
testflight
也可以使用pilot 进行 testflight 的管理
snapshot 配合 frameit 使用,来生成 app 截图
将 ipa,metadata,屏幕截图发布到ITC上
平心而论,Fastlane本身对Android平台的支持力度确实有限,15个核心工具中仅有2个是用于Android平台的,其中:
Supply是用于上传APK文件和同步Meta信息到Google Play商店(类似iOS的Deliver)
Screengrab是用于生成各种屏幕尺寸的截屏,然后上传这些截屏到Google Play商店
好吧,看上去这两个工具都和Google Play相关,这个对于国内大部分Android开发者来说,似乎都派不上用场。
当然这也不能怪Fastlane重iOS,轻Android。和iOS不同,Android本身就没有那么多琐碎的事情,比如:证书管理,Provisioning文件管理,推送证书管理,签名等等,也不需要专门使用一个类似Testflight的测试平台来分发测试包,基本上一个APK打包出来,就能随便安装了。
不过俗话说得好:“家家有本难念的经”,如果从开发复杂度来比较,Android平台其实是有过之而无不及的。功能开发完毕只是一切的开始,多系统,多屏幕,多厂商的适配,五花八门的市场分发才是真正的难题。如何快速,低成本的解决这些难题,将成为Andriod工程师们所面临的挑战。
我相信每个公司的市场部门都希望精确的统计到各个投放渠道的安装,激活,注册,留存,变现等数据,从而能够有的放矢。这一切的数据统计都来源于渠道包的生成。由于国内Android市场众多,所以在最终发版的时候,我们需要提供多个渠道包给市场同学,如果手动处理的话,那么步骤大概如下:
执行Git Pull命令,拉最新的代码到本地
修改渠道标识,如:在APK的META-INFO目录增加一个空的文件,文件名为渠道名
执行./gradlew clean命令清理环境
执行./gradlew assembleRelease打包Release版本
将生成的APK文件重新命名为改渠道对应的名字
然后以上步骤重复N次,N=渠道数,如果N>=3,我相信无论是多么有耐心的人,经过两三次下来,结果都会崩溃,尤其是万一上线前发现版本中包含Bug,那么只能重来一遍,此时N=渠道数x重来的次数。
其实我这里描述的场景可能稍显夸张,我相信大部分公司都会或多或少使用一些自动化的方式来处理,比如通过Shell命令等等。这里我们可以看看使用Fastlane如何进行处理:
首先,我们自定义一个Action:add_channels_to_apk,这个Action的作用就是:
拷贝最终打包生成的apk文件,并修改文件名为渠道名,如gengmei_qq_630.apk
然后将一个渠道名写入到apk文件的META-INFO目录中
其次,新建一个txt文件,里面写入所有需要打包的渠道名,如:QQ,360,Baidu...等等,渠道名之间用逗号隔开。
最后,在Fastfile中定义一个Lane来进行最终的集成处理:
desc "Package a new app version with different channels"
lane :do_package_apk do |options|
project = "#{options[:project]}"
target_version = options[:version]
hipchat(message: "Start package #{project} at version #{target_version}")
git_pull
gradle(task: "clean")
gradle(task: "assembleRelease")
add_channels_to_apk(channels: './channels.txt')
hipchat(message: "Deliver app #{project} successfully!")
end接下来的事就简单多了,每次需要打包的时候,只要执行如下的命令即可:
fastlane do_package_apk project:hso version:6.3.0
无论是5个渠道,还是50个渠道,1分钟内全部搞定,非常的方便。
JS 异步模型
Javascript 除了代码其余全是并行。 这句话说明了JavaScript最大的特点,本文将从JS的单线程,常见的并发模型,事件轮询并发模型等讲解JS的异步模型。
Javascript 语言的一个特点就是单线程,也就是说,同一时间只能做一件事。这么一听好像在效率上比其他语言有很大的劣势。那么Javascript 为什么还是单线程的? 这跟历史有关系。JavaScript从诞生起就是单线程。原因大概是不想让浏览器变得太复杂,因为多线程需要共享资源、且有可能修改彼此的运行结果 (比如一个线程要修改一个页面节点,一个线程要删除该节点),对于一种网页脚本语言来说,这就太复杂了。后来就约定俗成,JavaScript为一种单线程语言。(HTML5 Worker API可以实现多线程,但是子线程是不能修改 DOM 的,只有通过 postMessage 方法进行通信,所以 JavaScript 本身始终是单线程的。)。
那么 JavaScript 一开始的宿主是浏览器并采用了单线程的方式运行,那么为什么设计 Node.js 的时候依旧保留单线程的运行方式?
node.js中的第一个基本论点是I/O是昂贵的,第二个基本的论点是「每个连接一个线程」的模式是很耗内存的。

所以 node.js 采用了单线程的异步事件和单线程的非阻塞I/O。
如果某个任务很耗时,比如涉及很多I/O(输入/输出)操作,那么单线程的运行大概是下面的样子。线程同一时间只处理一个任务,每次一个。
上图的绿色部分是程序的运行时间,红色部分是等待时间。可以看到,由于I/O操作很慢,所以这个线程的大部分运行时间都在空等I/O操作的返回结果。这种运行方式称为"同步模式"(synchronous I/O)或"堵塞模式"(blocking I/O)。
这种方式的优点是简单,缺点是任何一个异步都将挂起其他任务。
对于单线程的JS如果以这种并发模型来运行,那web体验将是灾难的。
如果采用多线程,同时运行多个任务,那很可能就是下面这样。
上图表明,多线程不仅占用多倍的系统资源,也闲置多倍的资源,这显然不合理。
这种方式的优点是简单,比使用fork进程对内核更加友好,因为线程占用更少的系统开销,比单线程阻塞时能响应其他事物;缺点:你的机器可能没有线程,而且面向线程的编程由于担心对共享资源的访问控制,可能会很快地变得非常复杂。
Apache 就是用这种方式实现并发的,它的一个请求产生一个线程(或者进程,取决于配置文件)。随着并发连接数的增加以及为了服务更多的并发客户端而对更多线程的需求,你可以看见系统统开销是如何吃掉内存的。
单线程非阻塞的并发模型就是为了解决以上并发模型的缺点,以最小资源效率最大化。单线程遇到耗时I/O时将向任务队列发送I/O命令并挂起I/O完成的回调,并继续执行其他任务,当I/O完成时,任务队列会插入I/O完成事件,执行线程响应事件并执行返回的I/O。如下图:
上图主线程的绿色部分,还是表示运行时间,而橙色部分表示空闲时间。每当遇到I/O的时候,主线程就让Event Loop线程去通知相应的I/O程序,然后接着往后运行,所以不存在红色的等待时间。等到I/O程序完成操作,Event Loop线程再把结果返回主线程。主线程就调用事先设定的回调函数,完成整个任务。
可以看到,由于多出了橙色的空闲时间,所以主线程得以运行更多的任务,这就提高了效率。这种运行方式称为"异步模式"(asynchronous I/O)或"非堵塞模式"(non-blocking mode)。
Nginx和Node.js不是多线程,因为多个线程和多个进程会需要大量的内存。它们都是单线程的,但是是事件驱动。通过在一个线程中处理多个连接,这消除了由上千个线程/进程所产生的系统消耗。
Event Loop 是一个很重要的概念,指的是计算机系统的一种运行机制。JavaScript语言就采用这种机制,来解决单线程运行带来的一些问题。
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。
我们举一个打印的例子
setTimeout(() => console.log('one'), 0);
Promise.resolve().then(() => console.log('two'));
console.log('three');
上面的代码都想表达立即打印的意思,那么他们又是以怎样的顺序就行输出的呢?
运行到第一行代码时,我们遇到的是一个定时器,执行栈将向消息队列发送定时器事件,将在下一轮事件循环中将计时器回调放入执行栈中执行。
运行到第二行代码时,Promise.resolve() 将立刻返回一个 resolve 状态的 Promise,触发 then 的回调函数将放入本轮事件循环的末尾等待执行。
运行到第三行代码时,执行栈会执行代码并打印。输出 "three"。执行栈所有任务执行完成后,执行本轮消息队列内的事件,打印 "two", 下个事件轮询将打印 "one"。所以输出的顺序是 three -> two -> one。
所谓"异步",简单说就是一个任务不是连续完成的,可以理解成该任务被人为分成两段,先执行第一段,然后转而执行其他任务,等做好了准备,再回过头执行第二段。
比如,有一个任务是读取文件进行处理,任务的第一段是向操作系统发出请求,要求读取文件。然后,程序执行其他任务,等到操作系统返回文件,再接着执行任务的第二段(处理文件)。这种不连续的执行,就叫做异步。
相应地,连续的执行就叫做同步。由于是连续执行,不能插入其他任务,所以操作系统从硬盘读取文件的这段时间,程序只能干等着。
常见的异步场景有:
单个异步: 一个异步任务执行完成后,执行某些任务。
A --> S
多个异步继发:只有当前一个异步完成后,才会开始下一个异步。
A1 -->
--> A2
--> A3
多个异步并发:多个异步同时发生。
A1 -->
A2 -->
A3 -->
多个异步并发,所有异步完成后汇总:
A1 --> |
A2 --> | --> A4
A3 --> |
多个异步并发竞争,最先完成的执行:
A1 ----> |
A2 -> | --> A2
A3 ------> |
更复杂的便是以上情况的组合。
所谓回调函数,就是把任务的第二段单独写在一个函数里面,等到重新执行这个任务的时候,就直接调用这个函数。
读取文件进行处理,是这样写的。
fs.readFile('/etc/passwd', 'utf-8', function (err, data) {
if (err) throw err;
console.log(data);
});上面代码中,readFile函数的第三个参数,就是回调函数,也就是任务的第二段。等到操作系统返回了/etc/passwd这个文件以后,回调函数才会执行。
一个有趣的问题是,为什么 Node 约定,回调函数的第一个参数,必须是错误对象err(如果没有错误,该参数就是null)?
原因是执行分成两段,第一段执行完以后,任务所在的上下文环境就已经结束了。在这以后抛出的错误,原来的上下文环境已经无法捕捉,只能当作参数,传入第二段。
回调函数的优点是简单、容易理解和部署,缺点是不利于代码的阅读和维护,各个部分之间高度耦合(Coupling),流程会很混乱,而且每个任务只能指定一个回调函数。
比如用回调函数的方式实现多异步继发:
A(
B(
C(
...
)
)
)多个异步继发就会出现我们不想见到的 callback hell。
对于多个异步并发,所有异步完成后汇总和多个异步并发竞争,最先完成的执行,我们可以通过计数器去控制。
回调函数本身并没有问题,它的问题出现在多个回调函数嵌套。假定读取A文件之后,再读取B文件,代码如下。
fs.readFile(fileA, 'utf-8', function (err, data) {
fs.readFile(fileB, 'utf-8', function (err, data) {
// ...
});
});不难想象,如果依次读取两个以上的文件,就会出现多重嵌套。代码不是纵向发展,而是横向发展,很快就会乱成一团,无法管理。因为多个异步操作形成了强耦合,只要有一个操作需要修改,它的上层回调函数和下层回调函数,可能都要跟着修改。这种情况就称为"回调函数地狱"(callback hell)。
Promise 对象就是为了解决这个问题而提出的。它不是新的语法功能,而是一种新的写法,允许将回调函数的嵌套,改成链式调用。采用 Promise,连续读取多个文件,写法如下。
var readFile = require('fs-readfile-promise');
readFile(fileA)
.then(function (data) {
console.log(data.toString());
})
.then(function () {
return readFile(fileB);
})
.then(function (data) {
console.log(data.toString());
})
.catch(function (err) {
console.log(err);
});上面代码中,我使用了fs-readfile-promise模块,它的作用就是返回一个 Promise 版本的readFile函数。Promise 提供then方法加载回调函数,catch方法捕捉执行过程中抛出的错误。
可以看到,Promise 的写法只是回调函数的改进,使用then方法以后,异步任务的两段执行看得更清楚了,除此以外,并无新意。
Promise 的最大问题是代码冗余,原来的任务被 Promise 包装了一下,不管什么操作,一眼看去都是一堆then,原来的语义变得很不清楚。
从惰性计算说起 -> 惰性计算 -> thunk -> 协程 -> 外部迭代器 -> 幂等性
官网:mitmproxy.org
文档:https://docs.mitmproxy.org/stable/
at-rule-name-case: "lower", @命名规则:小写at-rule-name-space-after: "always-single-line", 这里必须始终在单行声明块在规则名称后面有一个空格。at-rule-semicolon-newline-after: "always" 有必须始终是分号后换行符block-closing-brace-empty-line-before: "never", {闭合前不许有空行}block-closing-brace-newline-after: "always" 有必须始终是右括号之后换行。block-closing-brace-newline-before: "always-multi-line" 这里必须始终在多行块右括号之前有一个换行符。block-closing-brace-space-before: "always-single-line" 这里必须始终在单行块右括号前一个空格。block-no-empty: true 不允许空块block-opening-brace-newline-after: "always-multi-line" 这里必须始终在多行块开括号后换行block-opening-brace-space-after: "always-single-line", 这里必须始终在单行块开括号后有一个空格。block-opening-brace-space-before: "always",有必须是开括号前一个空格color-hex-case: "lower", 颜色编码小写color-hex-length: "short", 短(速记变种:3、4个字符)color-no-invalid-hex: true, 禁止无效的16进制色码 如位数错误,或数字错误comment-empty-line-before: [ "always", {comment-no-empty: true, 注释不能为空comment-whitespace-inside: "always", 注释符号与内容间有空格custom-property-empty-line-before: [ "always", {declaration-bang-space-after: "never", 生命时!后不许空格declaration-bang-space-before: "always", !前有且仅有一个空格declaration-block-no-duplicate-properties: [ true, {declaration-block-no-redundant-longhand-properties: true, 禁止可以组合成一个速记属性普通写法的属性。如 padding-anydeclaration-block-no-shorthand-property-overrides: true, 禁止重写相关的手写速记的属性的属性。declaration-block-semicolon-newline-after: "always-multi-line",多行规则时,分号后必须换行符。declaration-block-semicolon-space-after: "always-single-line", 单行声明块是,分号后面必须有一个空格。declaration-block-semicolon-space-before: "never",分号前禁止空格declaration-block-single-line-max-declarations: 1, 限制单行声明块内声明的数量。declaration-block-trailing-semicolon: "always",有必须是一个尾随分号declaration-colon-newline-after: "always-multi-line", 生命属性值较多时,冒号后必须换行declaration-colon-space-after: "always-single-line", 单行是冒号后必须空格declaration-colon-space-before: "never", 冒号前禁止空格declaration-empty-line-before: [ "always", {font-family-no-duplicate-names: true, 禁止重复的字体系列名称。function-calc-no-unspaced-operator: true,function-comma-newline-after: "always-multi-line", 函数多行数在逗号后换行 translate(a, b)function-comma-space-after: "always-single-line", 函数单行是逗号后空一格function-comma-space-before: "never", 逗号前不空格function-linear-gradient-no-nonstandard-direction: true,function-max-empty-lines: 0,函数内不允许有空航function-name-case: "lower",function-parentheses-newline-inside: "always-multi-line", 有必须始终是多线功能的括号内换行。function-parentheses-space-inside: "never-single-line", 单行是空号和内容不得有空格function-whitespace-after: "always",keyframe-declaration-no-important: true, !important 单独一个声明块length-zero-no-unit: true, 0后无长度单位max-empty-lines: 1,media-feature-colon-space-after: "always",冒号后有且只有一个空格media-feature-colon-space-before: "never",冒号前无空格 如: @media (max-width: 600px) {};media-feature-name-case: "lower", 媒体功能名小写media-feature-name-no-unknown: true,media-feature-parentheses-space-inside: "never", 括号与内容家不许有空格media-feature-range-operator-space-after: "always", 运算符后有空格media-feature-range-operator-space-before: "always", 运算符前有空格 如:@media (max-width >= 600px) {}media-query-list-comma-newline-after: "always-multi-line", 这里必须始终在多行媒体查询列表中的逗号后换行。media-query-list-comma-space-after: "always-single-line", 这里必须始终在单行媒体查询列表中的逗号后空格。media-query-list-comma-space-before: "never",no-empty-source: true, 资源禁止为空no-eol-whitespace: true, 尾部不能为空no-extra-semicolons: true,no-invalid-double-slash-comments: true, no //no-missing-end-of-source-newline: true, 结束时空一行number-leading-zero: "always", .5 ❌; 0.5 ✔️number-no-trailing-zeros: true, 1.0 ❌; 1 ✔️property-case: "lower", 属性名称小写property-no-unknown: true,rule-nested-empty-line-before: [ "always-multi-line", {rule-non-nested-empty-line-before: [ "always-multi-line", {selector-attribute-brackets-space-inside: "never", [禁止空白] 如:[target] {}
selector-attribute-operator-space-after: "never", []选择器中的运算符前后不允许有空格
selector-attribute-operator-space-before: "never",
selector-combinator-space-after: "always",
selector-combinator-space-before: "always",
组合选择器如:~ > + 前后必须有空格
selector-descendant-combinator-no-non-space: true, .foo .bar {} 有且只有一个空格
selector-list-comma-newline-after: "always", 有必须始终是逗号后换行。如:
a,
b {}
selector-list-comma-space-before: "never", 逗号前不允许有空行
selector-max-empty-lines: 0,
selector-pseudo-class-case: "lower", 伪类名称小写
selector-pseudo-class-no-unknown: true,
selector-pseudo-class-parentheses-space-inside: "never", 如:input:not([type="submit"]) {}
selector-pseudo-element-case: "lower",
selector-pseudo-element-colon-notation: "double", ::
selector-pseudo-element-no-unknown: true,
selector-type-case: "lower",
selector-type-no-unknown: true,
shorthand-property-no-redundant-values: true, 在简写属性不允许重复值。string-no-newline: true,unit-case: "lower",unit-no-unknown: true,value-list-comma-newline-after: "always-multi-line", 属性值多行是可用逗号后换行value-list-comma-space-after: "always-single-line",value-list-comma-space-before: "never",value-list-max-empty-lines: 0,算是最合理的React/JSX编码规范之一了
react/no-multi-comp.React.createElement,除非从一个非JSX的文件中初始化你的app.Class vs React.createClass vs stateless
如果你的模块有内部状态或者是refs, 推荐使用 class extends React.Component 而不是 React.createClass ,除非你有充足的理由来使用这些方法.
eslint: react/prefer-es6-class react/prefer-stateless-function
// bad
const Listing = React.createClass({
// ...
render() {
return <div>{this.state.hello}</div>;
}
});
// good
class Listing extends React.Component {
// ...
render() {
return <div>{this.state.hello}</div>;
}
}如果你的模块没有状态或是没有引用refs, 推荐使用普通函数(非箭头函数)而不是类:
// bad
class Listing extends React.Component {
render() {
return <div>{this.props.hello}</div>;
}
}
// bad (relying on function name inference is discouraged)
const Listing = ({ hello }) => (
<div>{hello}</div>
);
// good
function Listing({ hello }) {
return <div>{hello}</div>;
}扩展名: React模块使用 .jsx 扩展名.
文件名: 文件名使用驼峰式. 如, ReservationCard.jsx.
引用命名: React模块名使用驼峰式命名,实例使用骆驼式命名. eslint: react/jsx-pascal-case
// bad
import reservationCard from './ReservationCard';
// good
import ReservationCard from './ReservationCard';
// bad
const ReservationItem = <ReservationCard />;
// good
const reservationItem = <ReservationCard />;模块命名: 模块使用当前文件名一样的名称. 比如 ReservationCard.jsx 应该包含名为 ReservationCard的模块. 但是,如果整个文件夹是一个模块,使用 index.js作为入口文件,然后直接使用 index.js 或者文件夹名作为模块的名称:
// bad
import Footer from './Footer/Footer';
// bad
import Footer from './Footer/index';
// good
import Footer from './Footer';高阶模块命名: 对于生成一个新的模块,其中的模块名 displayName 应该为高阶模块名和传入模块名的组合. 例如, 高阶模块 withFoo(), 当传入一个 Bar 模块的时候, 生成的模块名 displayName 应该为 withFoo(Bar).
为什么?一个模块的
displayName可能会在开发者工具或者错误信息中使用到,因此有一个能清楚的表达这层关系的值能帮助我们更好的理解模块发生了什么,更好的Debug.
```jsx
// bad
export default function withFoo(WrappedComponent) {
return function WithFoo(props) {
return <WrappedComponent {...props} foo />;
}
}
// good
export default function withFoo(WrappedComponent) {
function WithFoo(props) {
return <WrappedComponent {...props} foo />;
}
const wrappedComponentName = WrappedComponent.displayName
|| WrappedComponent.name
|| 'Component';
WithFoo.displayName = `withFoo(${wrappedComponentName})`;
return WithFoo;
}
```
为什么?对于
style和className这样的属性名,我们都会默认它们代表一些特殊的含义,如元素的样式,CSS class的名称。在你的应用中使用这些属性来表示其他的含义会使你的代码更难阅读,更难维护,并且可能会引起bug。
```jsx
// bad
<MyComponent style="fancy" />
// good
<MyComponent variant="fancy" />
```
不要使用 displayName 来命名React模块,而是使用引用来命名模块, 如 class 名称.
// bad
export default React.createClass({
displayName: 'ReservationCard',
// stuff goes here
});
// good
export default class ReservationCard extends React.Component {
}遵循以下的JSX语法缩进/格式. eslint: react/jsx-closing-bracket-location
// bad
<Foo superLongParam="bar"
anotherSuperLongParam="baz" />
// good, 有多行属性的话, 新建一行关闭标签
<Foo
superLongParam="bar"
anotherSuperLongParam="baz"
/>
// 若能在一行中显示, 直接写成一行
<Foo bar="bar" />
// 子元素按照常规方式缩进
<Foo
superLongParam="bar"
anotherSuperLongParam="baz"
>
<Quux />
</Foo>"), 其他均使用单引号. eslint: jsx-quotes为什么? JSX属性 不能包括转译的引号, 因此在双引号里包括像
"don't"的属性值更容易输入.
HTML属性也是用双引号,所以JSX属性也遵循同样的语法.
```jsx
// bad
<Foo bar='bar' />
// good
<Foo bar="bar" />
// bad
<Foo style={{ left: "20px" }} />
// good
<Foo style={{ left: '20px' }} />
```
总是在自动关闭的标签前加一个空格,正常情况下也不需要换行. eslint: no-multi-spaces, react/jsx-space-before-closing
// bad
<Foo/>
// very bad
<Foo />
// bad
<Foo
/>
// good
<Foo />不要在JSX {} 引用括号里两边加空格. eslint: react/jsx-curly-spacing
// bad
<Foo bar={ baz } />
// good
<Foo bar={baz} />JSX属性名使用骆驼式风格camelCase.
// bad
<Foo
UserName="hello"
phone_number={12345678}
/>
// good
<Foo
userName="hello"
phoneNumber={12345678}
/>如果属性值为 true, 可以直接省略. eslint: react/jsx-boolean-value
// bad
<Foo
hidden={true}
/>
// good
<Foo
hidden
/><img> 标签总是添加 alt 属性. 如果图片以presentation(感觉是以类似PPT方式显示?)方式显示,alt 可为空, 或者<img> 要包含role="presentation". eslint: jsx-a11y/img-has-alt
// bad
<img src="hello.jpg" />
// good
<img src="hello.jpg" alt="Me waving hello" />
// good
<img src="hello.jpg" alt="" />
// good
<img src="hello.jpg" role="presentation" />不要在 alt 值里使用如 "image", "photo", or "picture"包括图片含义这样的词, 中文也一样. eslint: jsx-a11y/img-redundant-alt
为什么? 屏幕助读器已经把
img标签标注为图片了, 所以没有必要再在alt里说明了.
```jsx
// bad
<img src="hello.jpg" alt="Picture of me waving hello" />
// good
<img src="hello.jpg" alt="Me waving hello" />
```
使用有效正确的 aria role属性值 ARIA roles. eslint: jsx-a11y/aria-role
// bad - not an ARIA role
<div role="datepicker" />
// bad - abstract ARIA role
<div role="range" />
// good
<div role="button" />不要在标签上使用 accessKey 属性. eslint: jsx-a11y/no-access-key
为什么? 屏幕助读器在键盘快捷键与键盘命令时造成的不统一性会导致阅读性更加复杂.
// bad
<div accessKey="h" />
// good
<div />key的值,推荐使用唯一ID. (为什么?)// bad
{todos.map((todo, index) =>
<Todo
{...todo}
key={index}
/>
)}
// good
{todos.map(todo => (
<Todo
{...todo}
key={todo.id}
/>
))}总是在Refs里使用回调函数. eslint: react/no-string-refs
// bad
<Foo
ref="myRef"
/>
// good
<Foo
ref={ref => { this.myRef = ref; }}
/>将多行的JSX标签写在 ()里. eslint: react/wrap-multilines
// bad
render() {
return <MyComponent className="long body" foo="bar">
<MyChild />
</MyComponent>;
}
// good
render() {
return (
<MyComponent className="long body" foo="bar">
<MyChild />
</MyComponent>
);
}
// good, 单行可以不需要
render() {
const body = <div>hello</div>;
return <MyComponent>{body}</MyComponent>;
}对于没有子元素的标签来说总是自己关闭标签. eslint: react/self-closing-comp
// bad
<Foo className="stuff"></Foo>
// good
<Foo className="stuff" />如果模块有多行的属性, 关闭标签时新建一行. eslint: react/jsx-closing-bracket-location
// bad
<Foo
bar="bar"
baz="baz" />
// good
<Foo
bar="bar"
baz="baz"
/>使用箭头函数来获取本地变量.
function ItemList(props) {
return (
<ul>
{props.items.map((item, index) => (
<Item
key={item.key}
onClick={() => doSomethingWith(item.name, index)}
/>
))}
</ul>
);
}当在 render() 里使用事件处理方法时,提前在构造函数里把 this 绑定上去. eslint: react/jsx-no-bind
为什么? 在每次
render过程中, 再调用bind都会新建一个新的函数,浪费资源.
```jsx
// bad
class extends React.Component {
onClickDiv() {
// do stuff
}
render() {
return <div onClick={this.onClickDiv.bind(this)} />
}
}
// good
class extends React.Component {
constructor(props) {
super(props);
this.onClickDiv = this.onClickDiv.bind(this);
}
onClickDiv() {
// do stuff
}
render() {
return <div onClick={this.onClickDiv} />
}
}
```
_ 前缀,本质上它并不是私有的.为什么?
_下划线前缀在某些语言中通常被用来表示私有变量或者函数。但是不像其他的一些语言,在JS中没有原生支持所谓的私有变量,所有的变量函数都是共有的。尽管你的意图是使它私有化,在之前加上下划线并不会使这些变量私有化,并且所有的属性(包括有下划线前缀及没有前缀的)都应该被视为是共有的。了解更多详情请查看Issue #1024, 和 #490 。
```jsx
// bad
React.createClass({
_onClickSubmit() {
// do stuff
},
// other stuff
});
// good
class extends React.Component {
onClickSubmit() {
// do stuff
}
// other stuff
}
```
在 render 方法中总是确保 return 返回值. eslint: react/require-render-return
// bad
render() {
(<div />);
}
// good
render() {
return (<div />);
}class extends React.Component 的生命周期函数:static 方法constructor 构造函数getChildContext 获取子元素内容componentWillMount 模块渲染前componentDidMount 模块渲染后componentWillReceiveProps 模块将接受新的数据shouldComponentUpdate 判断模块需不需要重新渲染componentWillUpdate 上面的方法返回 true, 模块将重新渲染componentDidUpdate 模块渲染结束componentWillUnmount 模块将从DOM中清除, 做一些清理任务onClickSubmit() 或 onChangeDescription()render 里的 getter 方法 如 getSelectReason() 或 getFooterContent()renderNavigation() 或 renderProfilePicture()render render() 方法如何定义 propTypes, defaultProps, contextTypes, 等等其他属性...
import React, { PropTypes } from 'react';
const propTypes = {
id: PropTypes.number.isRequired,
url: PropTypes.string.isRequired,
text: PropTypes.string,
};
const defaultProps = {
text: 'Hello World',
};
class Link extends React.Component {
static methodsAreOk() {
return true;
}
render() {
return <a href={this.props.url} data-id={this.props.id}>{this.props.text}</a>
}
}
Link.propTypes = propTypes;
Link.defaultProps = defaultProps;
export default Link;React.createClass 的生命周期函数,与使用class稍有不同: eslint: react/sort-comp
displayName 设定模块名称propTypes 设置属性的类型contextTypes 设置上下文类型childContextTypes 设置子元素上下文类型mixins 添加一些mixinsstaticsdefaultProps 设置默认的属性值getDefaultProps 获取默认属性值getInitialState 或者初始状态getChildContextcomponentWillMountcomponentDidMountcomponentWillReceivePropsshouldComponentUpdatecomponentWillUpdatecomponentDidUpdatecomponentWillUnmountonClickSubmit() or onChangeDescription()render like getSelectReason() or getFooterContent()renderNavigation() or renderProfilePicture()renderisMounted. eslint: react/no-is-mounted为什么?
isMounted反人类设计模式:(), 在 ES6 classes 中无法使用, 官方将在未来的版本里删除此方法.
程序的运行需要内存,而计算机的内存资源是有限的,所以我们要对内存资源进行合理有效的管理。对于持续运行的程序,我们除了要分配内存运行,也要及时的回收不再使用内存,否则内存占用会越来越高,导致系统性能问题或程序崩溃。内存泄漏就是不再使用的内存而没有及时回收。
对于一些语言(比如C语言),为开发者提供了malloc(),free()方法进行管理内存。开发者可以根据自身的需要进行分配内存,同时也要手动处理内存回收,对内存的管理具有很高的灵活性,当然也增加了额外的管理工作。
现代的一些语言,增加了垃圾回收机制,提供托管内存管理,减轻开发者的负担。

2019年,充满无数可能的一年,列了一下自己19年能够想到的事情,年中可能会调整,完成70%就算是满意。
iOS app 发布流
iOS app 发布流程大致归纳有以下几点:
打开 Xcode 账户设置
在第一栏的证书中的 iOS Distribution, 点击创建。本地就会生成开发所需要的发布证书。
在本地运用 Keychain 中,可以查看下载的证书。
确认证书是包含私钥的,发布证书缺少私钥就无法使用,所以要对证书进行备份。
也可以登录 developer.apple.com/account,进行发布证书的创建


在 Xcode > Preferences 中的 Accouts 里添加开发者账号
点击开发者账号,下载所需的证书和 pp文件
也可以去 developer.apple.com/account 进行下载
在该界面配置 bundleid, version, build, team。 配置项需和证书,pp文件一致。
选择通用设备,点击 Product > Archive 进行打包
打包后,点击 Upload to App Store
登录 iTunes Connect, 对上传的app 进行提交,待苹果审核通过后便可以进行发布。
css父块级元素透明,子级元素不透明的方法
web 开发流程
关于web的开发流程大家在工作中都有自己的一套工作流,这里简单讲一下前端组sona的开发工作流。
明确需求
拿到产品经理需求后一定要仔细阅读,主要注意需求的数据流、逻辑、交互。
数据流:根据页面承载的信息的数据流来确定Reducer的数据结构,要分析数据的流向,常常会发现需求有些数据无源而来,无源而去。
逻辑:整个业务流的逻辑是否合理,逻辑能否完全控制数据加工、流向。
交互:分析页面交互合理性,具体设备展现合理性。
技术评估
评估技术实现难度,是否需要先进行调研。开发工期较紧时,能否简化实现。
工期评估
确定业务的特性分支,写ROADMAP.md文档
最好对所做的业务能有工期的估计
一般一个后台的页面,列表展示一般为(2个小时)
一般一个具体页面平均工时为半天,组件无法复用复杂度再另估
一般一个微信页面工时为半天,组件无法复用复杂度另估
对接资源
跟UI设计对接UI素材
将素材上传OSS,cdn加速
跟后端开发对接rap,并根据rap确定reducer数据结构
基于master分支创建特性分支
联调
提测
merge to test
envoyer自动部署
envoyer有时可能因为网络抖动的原因无法部署,可以登录envoyer.io检查和手动部署
上线
merge to master
去envoyer.io手动部署上线
web 上线流程
把特性分支merge到dev分支上解决冲突
把特性分支merge到test分支上提测
把特性分支merge到master分支上上线
关于上线部署操作参考 web开发流程第6,7点
CLI命令
npm run dev 本地开发
npm run test 生成提测环境资源
npm run build 生成生产资源
在计算机科学中,lint是一种工具程序的名称,它用来标记源代码中,某些可疑的、不具结构性(可能造成bug)的段落。它是一种静态程序分析工具,最早适用于C语言,在UNIX平台上开发出来。后来它成为通用术语,可用于描述在任何一种计算机程序语言中,用来标记源代码中有疑义段落的工具。
对于个人而言,Lint 可以帮助开发者避免部分错误。
对于大型多人开发的项目,Lint 可以帮助团队统一编程风格,增加工程健壮性。
关于这几种 Lint 工具的对比可参考 JavaScript 代码静态质量检查
关于 JavaScript 编程规范可参考 JavaScript 编写规范
关于这几种 Lint 工具的对比可参考 CSS 代码静态质量检查
关于 CSS 编程规范可参考 CSS 编写规范
我写了一个前端基础设施的CLI工具,lint工具选取的是 ESLint + styleLint + flow
详细使用请见 rrn-cli
命令行程序开发教程
一种编程语言是否易用,很大程度上,取决于开发命令行程序的能力。
Node.js 作为目前最热门的开发工具之一,怎样使用它开发命令行程序,是 Web 开发者应该掌握的技能。
本文同过四个方面讲解命令行程序开发,它们各有长短,使用者应根据自身环境选择合适的方式。
There must have a "Hello World" way to program.
hello.js
#!/usr/bin/env node
console.log('hello world');现在 hello 就可以执行了。
node ./hello.js如果想把前面的 node 去掉,修改 hello.js 文件权限再执行
chmod 755 hello.js
./hello.js如果想把 hello 前面的路径去除,可以将 hello 的路径加入环境变量 PATH
系统参数可以通过 process.argv 来获取。
argvs.js
#!/usr/bin/env node
console.log(process.argv[2]);执行 node ./argvs.js hello 将打印出 "hello"
详
细可参考 doc
脚本可以通过 child_process 模块新建子进程,从而执行 Unix 系统命令。
child-porcess.js
#!/usr/bin/env node
var name = process.argv[2];
var exec = require('child_process').exec;
var child = exec('echo hello ' + name, function(err, stdout, stderr) {
if (err) throw err;
console.log(stdout);
});为了提高开发效率,我们可以使用一些封装的现有工具。
shelljs 模块重新包装了 child_process,调用系统命令更加方便。
ShellJS is a portable (Windows/Linux/OS X) implementation of Unix shell commands on top of the Node.js API. You can use it to eliminate your shell script's dependency on Unix while still keeping its familiar and powerful commands. You can also install it globally so you can run it from outside Node projects - say goodbye to those gnarly Bash scripts!
commander.js 是 node.js 命令行开发的完整解决方案,TJ 大神出品。
#!/usr/bin/env node
/**
* Module dependencies.
*/
var program = require('commander');
program
.version('0.0.1')
.option('-p, --peppers', 'Add peppers')
.option('-P, --pineapple', 'Add pineapple')
.option('-b, --bbq-sauce', 'Add bbq sauce')
.option('-c, --cheese [type]', 'Add the specified type of cheese [marble]', 'marble')
.parse(process.argv);
console.log('you ordered a pizza with:');
if (program.peppers) console.log(' - peppers');
if (program.pineapple) console.log(' - pineapple');
if (program.bbqSauce) console.log(' - bbq');
console.log(' - %s cheese', program.cheese);选项通过optin()函数定义。
当定义.command() 却没有对应的.action(callback), 就会由子命令进行处理
// file: ./examples/pm
var program = require('..');
program
.version('0.0.1')
.command('install [name]', 'install one or more packages')
.command('search [query]', 'search with optional query')
.command('list', 'list packages installed', {isDefault: true})
.parse(process.argv);子命令应该在该目录下,命名为"program-command"
此例 ./examples/pm 目录下应该有 pm-install pm-search pm-list
commander 会根据 option 自动生成文档
更多请参考 commander.js 文档
#!/usr/bin/env node
var argv = require('yargs').argv;
console.log('hello ', argv.name);
使用下面两种方式都可以
$ hello --name=tom
hello tom
$ hello --name tom
hello tom
#!/usr/bin/env node
var argv = require('yargs')
.option('n', {
alias : 'name',
demand: true,
default: 'tom',
describe: 'your name',
type: 'string'
})
.argv;
console.log('hello ', argv.n);上面代码指定 -n / --name 不可省略, 默认值是 tom, 并给出一行提示。
根据option() describe 生成
#!/usr/bin/env node
var argv = require('yargs')
.command("morning", "good morning", function (yargs) {
console.log("Good Morning");
})
.command("evening", "good evening", function (yargs) {
console.log("Good Evening");
})
.argv;
console.log('hello ', argv.n);用法:
$ hello morning -n tom
Good Morning
hello tom
根据 Unix 传统,程序执行成功返回 0,否则返回 1 。
Unix 允许程序之间使用管道重定向数据。
$ ps aux | grep 'node'脚本可以通过监听标准输入的data 事件,获取重定向的数据。
process.stdin.resume();
process.stdin.setEncoding('utf8');
process.stdin.on('data', function(data) {
process.stdout.write(data);
});操作系统可以向执行中的进程发送信号,process 对象能够监听信号事件。
process.on('SIGINT', function () {
console.log('Got a SIGINT');
process.exit(0);
});Node 开发离不开 npm,而脚本功能是 npm 最强大、最常用的功能之一,如果对上面的脚本编写有所了解,下面我们可以通过 npm script 对脚本进行组合和执行。
npm 使用 scripts 字段定义命令。
{
// ...
"scripts": {
"hello": "node ./scripts/hello.js",
}
}通过 npm run 执行命令
npm run hello === node ./hello.js
npm 脚本的原理非常简单。每当执行 npm run,就会自动新建一个 Shell,在这个 Shell 里面执行指定的脚本命令。因此,只要是 Shell(一般是 Bash)可以运行的命令,就可以写在 npm 脚本里面。
比较特别的是,npm run新建的这个 Shell,会将当前目录的node_modules/.bin子目录加入PATH变量,执行结束后,再将PATH变量恢复原样。
这意味着,当前目录的node_modules/.bin子目录里面的所有脚本,都可以直接用脚本名调用,而不必加上路径。比如,当前项目的依赖里面有 eslint,只要直接写eslint **.js 就可以了。
"lint": "eslint **.js"而不用写成下面这样。
"lint": "node_modules/.bin/eslint **.*js"我们也可以通过 package.json 中的 bin 字段定义可执行脚本的路径。
{
// ...
"bin": {
"hello": "./scripts/hello.js"
},
"scripts": {
"hello": "node hello",
}
}执行 npm link 可以把 hello 的路径加入环境变量PATH, 直接执行$ hello, 就不用输入路径了。
* 表示任意文件名,** 表示任意一层子目录
通过 -- 向 npm 脚本传入参数。
"lint": "eslint **.js"向上面的 npm run lint 命令传入参数,必须写成下面这样。
$ npm run lint -- --reporter checkstyle > checkstyle.xmlnpm 脚本有 pre 和 post 两个钩子。举例来说,build 脚本命令的钩子就是 prebuild 和 postbuild。
"prebuild": "echo I run before the build script",
"build": "cross-env NODE_ENV=production webpack",
"postbuild": "echo I run after the build script"通过 npm_package_ 前缀,npm 脚本可以拿到 package.json 里面的字段。比如,下面是一个 package.json。
{
"name": "hello",
"version": "1.0.0"
}那么,变量 npm_package_name 返回 hello,变量 npm_package_version 返回 1.0.0
console.log(process.env.npm_package_name); // hello
console.log(process.env.npm_package_version); // 1.0.0如果是 Bash 脚本,可以用 $npm_package_name 和 $npm_package_version 取到这两个值。
一句话:自动化。
对于需要反复重复的任务,例如压缩(minification)、编译、单元测试、linting等,自动化工具可以减轻你的劳动,简化你的工作。
当你配置好项目构建工具,任务运行器就会自动帮你或你的小组完成大部分无聊的工作。
npm install -g grunt-cli一般需要在你的项目中添加两份文件:package.json 和 Gruntfile。
package.json: 此文件被npm用于存储项目的元数据,以便将此项目发布为npm模块。你可以在此文件中列出项目依赖的grunt和Grunt插件,放置于devDependencies配置段内。
Gruntfile: 此文件被命名为 Gruntfile.js 或 Gruntfile.coffee,用来配置或定义任务(task)并加载Grunt插件的。 此文档中提到的 Gruntfile 其实说的是一个文件,文件名是 Gruntfile.js 或 Gruntfile.coffee。
Gruntfile由以下几部分构成:
通过一个简单的 Gruntfile.js 来讲解
module.exports = function(grunt) {
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("yyyy-mm-dd") %> */\n'
},
build: {
src: 'src/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
}
});
// 加载包含 "uglify" 任务的插件。
grunt.loadNpmTasks('grunt-contrib-uglify');
// 自定义 任务 "hello"
grunt.registerTask('hello', 'Log hello.', function() {
grunt.log.write('Logging hello...').ok();
});
// 默认被执行的任务列表。
grunt.registerTask('default', ['uglify', 'hello']);
};每一份 Gruntfile (和grunt插件)都遵循同样的格式,你所书写的Grunt代码必须放在此函数内:
module.exports = function(grunt) {
// Do grunt-related things in here
};大部分的Grunt任务都依赖某些配置数据,这些数据被定义在一个object内,并传递给 grunt.initConfig 方法。
在下面的案例中,grunt.file.readJSON('package.json') 将存储在package.json文件中的JSON元数据引入到grunt config中。 由于<% %>模板字符串可以引用任意的配置属性,因此可以通过这种方式来指定诸如文件路径和文件列表类型的配置数据,从而减少一些重复的工作。
你可以在这个配置对象中(传递给initConfig()方法的对象)存储任意的数据,只要它不与你任务配置所需的属性冲突,否则会被忽略。此外,由于这本身就是JavaScript,你不仅限于使用JSON;你可以在这里使用任意的有效的JS代码。如果有必要,你甚至可以以编程的方式生成配置。
与大多数task一样,grunt-contrib-uglify 插件中的uglify 任务要求它的配置被指定在一个同名属性中。在这里有一个例子, 我们指定了一个banner选项(用于在文件顶部生成一个注释),紧接着是一个单一的名为build的uglify目标,用于将一个js文件压缩为一个目标文件。
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("yyyy-mm-dd") %> */\n'
},
build: {
src: 'src/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
}
});像 concatenation、[minification]、grunt-contrib-uglify 和 linting这些常用的任务(task)都已经以grunt插件的形式被开发出来了。只要在 package.json 文件中被列为dependency(依赖)的包,并通过npm install安装之后,都可以在Gruntfile中以简单命令的形式使用:
// 加载能够提供"uglify"任务的插件。
grunt.loadNpmTasks('grunt-contrib-uglify');// 自定义 任务 "hello"
grunt.registerTask('hello', 'Log hello.', function() {
grunt.log.write('Logging hello...').ok();
});此为前端开发团队遵循和约定的开源项目目录规范,意在实现开源项目目录结构的一致性。
文档中使用的关键字「MUST」,「MUST NOT」,「REQUIRED」,「SHALL」,「SHALL
NOT」,「SHOULD」,「SHOULD NOT」,「RECOMMENDED」,「MAY」和「OPTIONAL」在RFC2119中被说明。
还未定稿,对规范中提及的点有不赞同的欢迎提出 issues 讨论。
参加的目录结构为:
.
├── .editorconfig
├── .travis.yml
├── dist
├── doc
├── README.md
├── src
每个项目都必须「MUST」包含一个README.md文件,此文件中应当「SHOULD」概要描述此项目的功能和特点等信息。
每个项目应当「SHOULD」包含.editorconfig,用来统一配置编辑器的换行、缩进存储格式,使用方式请参考editorconfig是什么?。
项目中所有 JS 源码应当「SHOULD」存放在此目录下,且所有JS文件编写应当「SHOULD」遵循Javascript 编码规范。
样式类文件存放应当「SHOULD」遵循以下规律,且文件编写应当「SHOULD」遵循CSS 编码规范。
css/images 目录下面。default 作为主题名称,且应当「SHOULD」默认提供,样式中对应图片文件应当「SHOULD」存放在样式文件所在的主题目录下的 images 目录下。less 目录下面。sass 目录下面。所有项目应当「SHOULD」包含一个 doc 目录,用来存放详细的 API 使用文档。
dist 作为项目输出目录,所有编译生成、提供给用户使用的文件应当「SHOULD」存放在此目录。
为了让不太擅长 node.js 的用户可以正常使用编译后的代码,dist 目录应当「SHOULD」包含基本输出结果并提交在 github 中。
所有工具类脚本应当「SHOULD」放在此目录。
所有测试相关代码应当「SHOULD」放在此目录。
为了测试代码覆盖率,所有为测试覆盖率生成的新 JS 文件应当「SHOULD」存放在此目录下面。
这部分要在三月份完成这部分内容要在四月份完成十一:新西兰🇳🇿 或者 日本🇯🇵 设计只有心没有能力,自学感觉也是弱鸡,估计会报培训,同道之人可以走起~图片压缩 -> 唯一编码 -> cdn加速
此为前端开发团队遵循和约定的 Markdown 编写规范,意在提高文档的可读性。
文档中使用的关键字「MUST」,「MUST NOT」,「REQUIRED」,「SHALL」,「SHALL
NOT」,「SHOULD」,「SHOULD NOT」,「RECOMMENDED」,「MAY」和「OPTIONAL」在 RFC2119 中有说明。
还未定稿,对规范中提及的点有不赞同的欢迎提出 issues(请添加 markdown 标签)讨论。
后缀必须「MUST」使用 .md。
文件名必须「MUST」使用小写,多个单词之间使用-分隔。
文件编码必须「MUST」用 UTF-8。
文档标题应该「SHOULD」这样写。
Markdown 编写规范
==========================
章节标题必须「MUST」以 ## 开始,而不是 #。
章节标题必须「MUST」在 # 后加一个空格,且后面没有 #。
// bad
##章节1
// bad
## 章节1 ##
// good
## 章节1
章节标题和内容间必须「MUST」有一个空行。
// bad
## 章节1
内容
## 章节2
// good
## 章节1
内容
## 章节2
代码段的必须「MUST」使用 Fenced code blocks 风格,如下所示:
```
console.log("");
```
表格的写法应该「SHOULD」参考 GFM,如下所示:
First Header | Second Header
------------- | -------------
Content Cell | Content Cell
Content Cell | Content Cell
| Left-Aligned | Center Aligned | Right Aligned |
| :------------ |:---------------:| -----:|
| col 3 is | some wordy text | $1600 |
| col 2 is | centered | $12 |
| zebra stripes | are neat | $1 |
中英文混排应该「SHOULD」采用如下规则:
中文符号应该「SHOULD」使用如下写法:
表达方式,应当「SHOULD」遵循《The Element of Style》:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.