面对的问题
在访问一些海外网站或者海外应用时,通常会遇到访问慢的情况,访问慢有两个原因,一个是丢包,一个是线路拥塞。当然还有其他一些原因,比如说运营商劫持或者防火墙拦截的情况。当你在跨国企业时,这种现象就特别严重,比方说,你们公司的数据中心在美国,而你的客户端在需要与数据中心交互获取最新的数据,这时候再丢包就影响心情了。所以,很多时候,我们会加个类似”跳板“之类的东西来加快我们与数据中心的交互速度。
加速器
很多人理解的加速器仅限于网游加速器,简单来说是玩外服游戏时特别卡,丢包严重,延时严重,需要一款加速器来让我们游戏数据走加速线路出去,而加速线路给他们解决来丢包和延时的问题。但是我认为加速器应该有更大的用途,可以加速应用,游戏也是应用的一种,当然也访问一些在国内无法访问的网站。
加速器原理
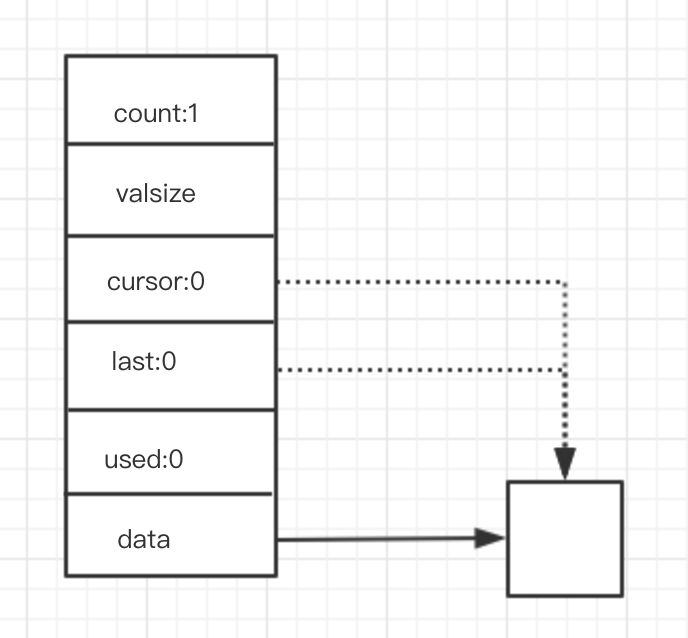
目前了解到的所有加速器基本都是一个原理,将客户数据通过一条高速通道把数据流引到某台服务器A,A与最终需要访问的应用应该足够稳定,丢包和延时都比较好,然后A再将用户的网络数据包发送给目的服务器,并且将结果原路返回,最终回到客户电脑,简单来说中间整个过程都是 代理,把数据送出去再送回来,参考下图。

这里面的难点都在tunnel上,而tunnel上又可以继续细分下来。
在了解tunnel之前,需要知道两点
1)tcp协议在长距离传输丢包会非常严重,从大陆地区到香港某些时刻会丢包丢到怀疑人生
2)运营商对udp数据有歧视,参考udp2raw
之前提到,tunnel的目的就是将数据送出去再送回来,那么会碰到第一个问题,数据从哪里来。
因此,我们需要采取一种措施将数据导向我们tunnel的入口。措施有很多种,每个系统都不太一样,我接触的大致会有一下几种方式
第一种,通过网关的方式,所有数据都会经过网关外出,如果你有一个硬件,可以是树莓派或者其他,接入正在使用的网络,然后开放ap或者手动设置网关或者dhcp的方式,接入的所有设备的网络数据包自然就会到达网关来。

这个图片非常抽象,我觉得需要加以说明。首先我们的设备gateway(这里假设是树莓派)和用户接入共同的网络,可以认为他们连上同一个热点,在一个局域网里面,但是,修改pc的网关指向我们的树莓派,这样pc上的网络数据就会经过我们的树莓派出去,我们就可以在树莓派上对数据包进行处理,决定哪些数据包应该进行何种操作。这是一种通过网关的方式。
第二种是编写客户端,这种很容易理解,每个pc上运行有一个客户端,客户端可以决定哪些数据包应该进行何种操作,实际上,第一种方式也可以认为是一种客户端,但是同时也是pc的接入点,他可以接入多个pc的请求,相当与路由器。具体如下图

这其中pc出口后面的线路省略。
还有第三种,不用编写客户端,也不用搞树莓派,通过vpn+接入程序。好处是不用额外的设备,也不用针对各个平台开发客户端,只有云服务器,缺点是如果vpn使用系统自带的,如果走的是udp协议,在运营商这块可能就会被卡住,还有就是可能会牺牲一点性能。

这三种引流方法相对比较容易实现的是第一种,当然第一种实现了之后,第三种基本上就实现了,第二种由于平台之间的差异性,实现难度不小的。还有其他方式可以进行引流,可以设置pac和一些类似socks之类的代理,但是无法做到全局代理,如果某个应用不走域名,直接走ip,而且走的是tcp或者udp协议,那么这类应用将无法加速。
接下来针对这三种方式的一些技术内部做一些描述
网关设备
既然我们已经在开发跑在设备之上的网络程序了,那我们在设备之上肯定会选择linux,一方面是Linux在网络方面能够进行更多的控制,还有就是用户态的工具和库比较多。
在pc配置了网关指向之后,我们需要在网关上做分流的工作,让部分流量走我们的tunnel方向出,部分流量走用户的正常网络出,有两种方法可以做到这种
首先第一种是非常普遍的做法,采用虚拟网卡的方式,也就是tun和tap两种类型的设备,关于tun和tap设备的基本原理也是需要很大篇幅才能够描述清楚,这里只需要知道,tun设备可以接收route过来的三层数据包,读取tab设备可以读取到二层数据帧,剩下的就是把三层包包装发送出去,走tunnel。这是目前大部分加速器都会采用的方式,简单,稳定。值得注意的是,windows平台下虚拟网卡设备是需要单独开发驱动程序的,所以相对来说windows下通过tun和tap实现加速器的难度要更大,linux内核已经有虚拟网卡驱动程序了。windows下还有其他更加恶心的机制也能够实现分流。关于tun设备,这里有个参考资源
第二种做法相对来说可能比较少见,通过NAT的方式,本地监听tcp和udp端口,符合条件的数据包将通过DNAT来将数据导向我们本地监听的端口,所有分流都是通过nat来实现,以tcp为例,也就是说用户实际上是和我们本地的程序建立三次握手和数据交互。我们程序可以读取用户的数据,将数据通过tunnel再发送出去,这里面有个问题,无论如何我们的A程序都需要知道这些数据该送去哪里,所以在网关这里需要把用户的这边原本想访问的真实地址发送给A,而问题就是网关这边是经过DNAT的,对这个tcp连接来说,他能拿到的目的地址就是他本身的ip以及端口。所以需要一种机制能够将用户真实想访问的地址和端口给查询出来,再发给A节点。
Linux内核里面有一个连接跟踪的概念,能够标示某个连接的双向五元祖,即是
原始五元祖
OriginSrcIP,OriginSrcPort,OriginDstIP,OriginDstPort,OriginProtocol
返回时候的五元祖
ReplySrcIP,ReplySrcPort,ReplyDstIP,ReplyDstPort,ReplyProtocol
我们需要的信息就是OriginDstIP和OriginDstPort,
接下来问题就是怎么查了,连接跟踪是存放在内核里面的,也就是说我们得想个办法和内核通信,于是就回到了用户态和内核态通信方式上。我了解的通信方式有几种
一种是netlink方式,很久之前的一段代码里面似乎有使用netlink往内核模块发送配置消息的
一种是设备文件方式,之前的tun和tap就属于设备文件的一种
当然还有其他方式,我用过的基本就这两种。
如果从内核到用户态的话,netlink就相当的挫,但是使用netlink给内核点消息这个完全是没问题的。netfilter有个工具可以查看连接跟踪的,叫conntrack,仔细琢磨netfilter的官网会发现conntrack用了他自己写的一个库,叫libnetfilter_conntrack,就我接触netfilter来看,netfilter用户态下所有的配置工具都是采用netlink的方式。但是在用这个之前得考虑性能上的问题。
设备文件基本上就是要写内核模块,然后把所有连接信息写入到某个文件里面去,然后用户进程在去读取这个文件,然后进行解析。
这是网关方式的基本流程,基本逻辑如下
func main() {
tcpAddr, udpAddr := ":2000",":2000"
ListenTCP(tcpAddr)
}
func ListenTCP(tcpAddr) {
listener, err := net.Listen("tcp", tcpAddr)
if err != nil {
return
}
for {
conn, err := listener.Accept()
if err != nil {
break
}
go handleTCPClient(conn)
}
}
func handleTCPClient(conn net.Conn) {
originDstAddr := getOriginAddr(conn.LocalAddr().String(), conn.RemoteAddr().String())
// forward to tunnel
// write back to client
}具体实现起来还是有一些难度的。
客户端
第二种客户端方式在Linux下实现难度相对比较小,其他平台具体实现的机制似乎都不太一样,以Windows平台下为例,windows平台也可以通过虚拟网卡+路由的方式实现,但是windows应该是没有实现虚拟网卡驱动,怎么办,估计得自己去写一个虚拟网卡驱动,人都不是万能的,我相信windows平台下这方面的人比Linux来说要少得多。我一开始了解windows平台下客户端的实现时,并没有从虚拟网卡的角度去实现,当时的基本思路如下:
根据在学校接触到的win32汇编的经验可以快速想到windows平台下是可以hook住某个api然后注入函数的,所以我想能不能hook住connect函数,然后把目的地址改成本地的地址,这样数据包出去的时候就会往本地走来,但是这种注入方式应该是需要知道进程id,不太友好,所以就不做细想,后面了解到windows平台下提供有一种叫做lsp的机制能够实现相关需求,再进一步了解,发现lsp机制已经让微软给淘汰来,取而代之的是一种叫wfp的技术,这块在网络安全方面用的应该是比较多,但是他们的对于我而言,缺点都是要写驱动相关的代码,所以就放到来待定的位置来,后面参考openvpn的实现方式,发现用的是虚拟网卡,ok,跟Linux下的实现类似,但是这个网卡驱动,估计得自己写。所以私以为客户端的方式不太适合linux程序员,当然如果本身是个开发团队的话,可以试一试。
vpn+云服务器
采用vpn+云服务器的方式最简单方便,通过vpn将流量导入到云服务器,然后再在云服务器上实现分流,这种方式基本综合了前面两种实现,并且服务器性能通常比设备性能要高,这里面有几个问题。
第一,如果vpn采用udp的方式运行,小心运营商阻断导致丢包,第二,客户电脑上可能运行了其他程序,特别是杀毒软件之类的,其他程序有可能会造成一些干扰,比如说,如果你需要加速dns,但是某些杀软可能非常“友好”的给你优化了dns,将DNS指向他们自己的DNS,这个就会有问题。第三,由于不在客户端进行分流,所以所有流量都会到服务器,这个就导致,如果服务器带宽比客户上的带宽要小,那么客户不经过加速的地址的下载速度可能就会因服务器带宽较低导致速度变慢,客户那边就会call你了。所以可能云服务器需要配置非常高的带宽,带宽通常都挺贵的。
tunnel广域网
再来研究研究广域网部分,也就是tunnel里面的技术,这块我目前涉及不深,以下面模型为例
大部分开发人员都知道,TCP协议本身很复杂,但是复杂说明他替你做了很多事,比如自动重传,拥塞控制以及滑动窗口等技术,但是tcp协议又太复杂了,长链路tcp丢包重传又很严重,UDP协议就比较简单,源端口目的端口各占两个字节,长度和校验和各占两个字节,就八个字节udp头,其他什么都没有,但是相对而言用udp实现一些需要可靠性的就会相对复杂,目前业界有两款用的应该是相对比较多的协议,一个是google涉及了quic协议,quic协议是基于UDP的,另外一款是kcp协议。当然还有其他的很多,我认为可以从学术的角度进行搜索,学术界肯定有过很多尝试和发表过的论文可以参考。解决的问题都是用udp实现相对可靠的传输。