This is a prototype for an algorithm that modifies C# code in order to minimize the number of warnings caused by enabling C# 8.0 nullable reference types. If this ever gets out of the prototype stage, this might be a useful tool when migrate existing C# code to C# 8.0.
Note: this is a work in progress. Many C# constructs will trigger a NotImplementedException.
- Update your project to use C# 8.0:
<LangVersion>8.0</LangVersion> - Enable nullable reference types:
<Nullable>enable</Nullable> - If possible, update referenced libraries to newer versions that have nullability annotations.
- Compile the project and notice that you get a huge bunch of nullability warnings.
- Run
InferNull myproject.csproj. This modifies your code by inserting?in various places. - Compile your project again. You should get a smaller (and hopefully manageable) number of nullability warnings.
- The inference tool will only add/remove
?annotations on nullable reference types. It can also add the[NotNullWhen]attribute. It will never touch your code in any other way.- Existing
?annotations on nullable reference types are discarded and inferred again from scratch.
- Existing
- Unconstrained generic types are not reference types, and thus will never be annotated by the tool.
- The inference tool will not introduce any of the advanced nullability attributes.
- However, if these attributes are used in the input code, the tool will in some cases use them for better inference results.
- It can be useful to annotate generic code with these attributes before running the inference tool.
- The inference tool acts on one project (
.csproj) at a time. For best results, any referenced assemblies should already use nullability annotations.- If using the tool on multiple projects; apply the tool in the build order.
- For the .NET base class library, use .NET Core 3 (or later), or use ReferenceAssemblyAnnotator.
- For third-party libraries, consider upgrading to a newer version of the library if that adds nullability annotations.
- You can use
#nullable enableto mark code that you have finished manually reviewing.- The tool will never touch any code after
#nullable enableor#nullable disable. It only modifies code prior to those directives and code after#nullable restore. - You can use this to add nullability annotations to your project file-by-file:
- Don't use
<Nullable>enable</Nullable>on the project level - Use the
InferNull --add-nullable-enablecommand-line option to let the inference tool add the directive to all files - Use git to revert all changes made by the tool except those to a subset of the files.
- Make code changes to that subset of files to fix the remaining warnings.
- Commit, then later re-run
InferNull --add-nullable-enableto work on the next batch of files.
- Don't use
- The tool will never touch any code after
Let's start with a simple example:
1: class C
2: {
3: string key; // #1
4: string value; // #2
5:
6: public C(string key, string value) // key#3, value#4
7: {
8: this.key = key;
9: this.value = value;
10: }
11:
12: public override int GetHashCode()
13: {
14: return key.GetHashCode();
15: }
16:
17: public static int Main()
18: {
19: C c = new C("abc", null); // #5
20: return c.GetHashCode();
21: }
22: }We will construct a global "nullability flow graph".
For each appearance of a reference type in the source code that could be made nullable, we create a node in the graph.
If there's an assignment a = b, we create an edge from b's type to a's type.
If there's an assignment b = null, we create an edge from a special nullable node to b's type.
On a dereference a.M();, we create an edge from a's type to a special nonnull node (unless the dereference is protected by if (a != null)).

Clearly, everything reachable from the nullable node should be marked as nullable.
Similarly, everything that can reach the nonnull node should be marked as non-nullable.
Thus, in the example, key is inferred to be non-nullable, while value is inferred to be nullable.
Nullability inference works essentially in these steps:
- Initially, modify the program to mark every reference type as nullable. (
AllNullableSyntaxRewriter) - Create nodes for the nullability flow graph. (
NodeBuildingSyntaxVisitor) - Create edges for the nullability flow graph. (
EdgeBuildingSyntaxVisitor+EdgeBuildingOperationVisitor) - Assign nullabilities to nodes in the graph. (
NullCheckingEngine) - Modify the program to mark reference types with the inferred nullabilities. (
InferredNullabilitySyntaxRewriter)
The fundamental idea is to do something similar to C#'s nullability checks.
The C# compiler deals with types annotated with concrete nullabilities and emits a warning when a nullable type is used where a non-nullable type is expected.
The EdgeBuildingOperationVisitor instead annotates types with nullability nodes, and creates an edge when node#1 is used where node#2 is expected.
While in simple examples the resulting graphs can look like data flow graphs, that's not always an accurate view. An edge from node#1 to node#2 really only represents a constraint "if node#1 is nullable, then node#2 must also be nullable".
To build this graph, the EdgeBuildingOperationVisitor assign a TypeWithNode to every expression in the program.
For example, the field access this.key has the type-with-node string#1, where #1 is the node that was constructed for the declaration of the key field.
The TypeWithNode can also represent generic types like IEnumerable#x<string#1>. With generics, there's a top-level node #x for the generic type, but there's also a
separate node for each type argument.
If the graph contains a path from the nullable node to the nonnull node, we will be unable to create nullability annotations that allow compiling the code without warning:
no matter how we assign nullabilities to nodes along the path, there will be at least one edge where a nullable node points to a non-nullable node.
This violates the constraint represented by the edge, and thus causes a compiler warning.
If we cannot assign nullabilities perfectly (without causing any compiler warnings), we would like to minimize the number of warnings instead.
We do this by using the Ford-Fulkerson algorithm to compute the minimum cut (=minimum set of edges to be removed from the graph) so
that the nonnull node is no longer reachable from the nullable node.
This separates the graph into essentially three parts:
- nodes reachable from
nullable--> must be made nullable - nodes that reach
nonnull--> must not be made nullable - remaining nodes --> either choice would work
The removed edges correspond to the constraints that will produce warnings after we insert ? for the types inferred as nullable.
Thus the minimum cut ends up finding a solution that minimizes the number of constraints violated. If the constraints represented in our graph accurately model the
C# compiler, this minimizes the number of compiler warnings.
For the remaining nodes where either choice would work, we mark all nodes occurring in "input positions" (e.g. parameters) as nullable. Then we propagate this nullability along the outgoing edges. Any nodes that still remain indeterminate after that, are marked as non-nullable.
Consider this program:
1: class Program
2: {
3: public static int Test(string input) // input#1
4: {
5: if (input == null)
6: {
7: return -1;
8: }
9: return input.Length;
10: }
11: }input has the type-with-node string#1. A member access like .Length normally causes us to generate an edge to the special nonnull node, to encode that the
C# compiler will emit a "Dereference of a possibly null reference." warning.
However, in this example the static type-based view is not appropriate: the C# compiler performs control flow analysis, and notices that input cannot be
null at the dereference due to the null test earlier.
So for this example, we must not generate any edges, so that the input parameter can be made nullable.
Instead of re-implementing the whole C# nullability analysis, we solve this problem by simply asking Microsoft.CodeAnalysis for the NullableFlowState
of the expression we are analyzing. This works because prior to our analysis, we used the AllNullableSyntaxRewriter to mark everything as nullable --
if despite that the C# compiler still thinks something is non-nullable, it must be protected by a null check.
For the use of input in line 9, it has NullableFlowState.NotNull, so we represent its type-with-node as string#nonnull instead of string#1.
This way the dereference due to the .Length member access creates a harmless edge nonnull->nonnull. This edge is then discarded because it is not a useful constraint.
Thus this method does not result in any edges being added to the graph. Without any edge constraining input, it will be inferred as nullable due to occurring in input position.
1: class Program
2: {
3: public static void Main()
4: {
5: string n = null; // n#1
6: string a = Identity<string>(n); // a#3, type argument is #2
7: string b = Identity<string>("abc"); // b#5, type argument is #4
8: }
9: public static T Identity<T>(T input) => input;
10: }With generic methods, we do not create nodes for the type T, as that cannot be marked nullable without additional constraints
("CS8627: A nullable type parameter must be known to be a value type or non-nullable reference type. Consider adding a 'class', 'struct', or type constraint.").
Instead, any occurrences of T in the method signature are replaced with the type-with-node of the type arguments used to call the method.
Thus, the example above results in the following graph:

Thus, n#1, the type argument #2 and a#3 are all marked as nullable. But b#5 and the type argument #4 can remain non-nullable.
If the type arguments are not explicitly specified but inferred by the compiler, nullability inference will create additional "helper nodes" for the graph that are not associated with any syntax. This allows us to construct the edges for the calls in the same way.
1: using System.Collections.Generic;
2: class Program
3: {
4: List<string> list = new List<string>();
5:
6: public void Add(string name) => list.Add(name);
7: public string Get(int i) => list[i];
8: }
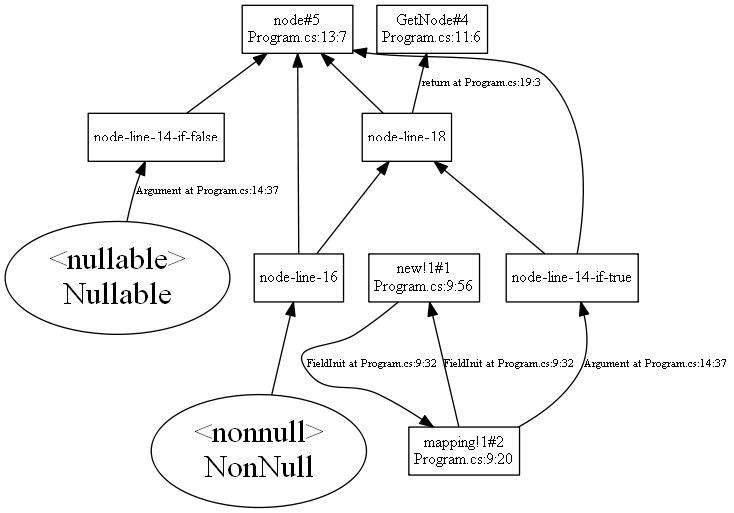
In this graph, you can see how generic types are handled:
The type of the list field generates two nodes:
list#3represents the nullability of the list itself.list!0#2represents the nullability of the strings within the list. Similarly,new!0#1represents the nullability of the string type argument in thenew List<string>expression. Because the type parameter ofListis invariant, the field initialization in line 4 creates a pair of edges (in both directions) between thenew!0#1andlist!0#2nodes. This forces both type arguments to have the same nullability.
The resulting graph expresses that the nullability of the return type of Get (represented by Get#5) depends on the nullability
of the name parameter in the Add method (node name#4).
Whether these types will be inferred as nullable or non-nullable will depend on whether the remainder of the program passes a nullable type to Add,
and on the existance of code that uses the return value of Get without null checks.
01: using System.Collections.Generic;
02:
03: class Program
04: {
05: public string someString = "hello";
06:
07: public bool TryGet(int i, out string name)
08: {
09: if (i > 0)
10: {
11: name = someString;
12: return true;
13: }
14: name = null;
15: return false;
16: }
17:
18: public int Use(int i)
19: {
20: if (TryGet(i, out string x))
21: {
22: return x.Length;
23: }
24: else
25: {
26: return 0;
27: }
28: }
29: }The TryGet function involves a common C# code pattern: the nullability of an out parameter depends on the boolean return value.
If the function returns true, callers can assume the out variable was assigned a non-null value.
But if the function returns false, the value might be null.
Using our own flow-analysis, the InferNull tool can handle this case
and automatically infer the [NotNullWhen(true)] attribute!

For the name parameter (in general: for any out-parameters in functions returning bool), we create not only the declared type name#2,
but also the name_when_true and name_when_false nodes. These extra helper nodes represent the nullability of out string name in the cases
where TryGet returns true/false.
Within the body of TryGet, we track the nullability of name based on the previous assignment as the "flow-state".
After the assignment name = someString; in line 11, the nullability of name is the same as the nullability of someString.
We represent this by saving the nullability node someString#1 as the flow-state of name.
On the return true; statement in line 12, we connect the current flow-state of the out parameters with the when_true helper nodes,
resulting in the someString#1-><name_when_true#1> edge.
Similarly, the return false; statement in line 15 results in an edge from <nullable> to <name_when_false#2>, because the name = null; assignment
has set the flow-state of name to <nullable>.
In the Use method, we also employ flow-state: even though x itself needs to be nullable, the then-branch of the if uses the <name_when_true#1> node
as flow-state for the x variable.
This causes the x.Length dereference to create an edge starting at <name_when_true#1>, rather than x's declared type (x#3).
This allows inference to success (no path from <nullable> to <nonnull>. In the inference result, name#2 and <name_when_false#2> are nullable,
but <name_when_true#1> is non-nullable. The difference in nullabilities between the when_false and when_true cases causes the tool to emit a [NotNullWhen(true)]
attribute:
using System.Collections.Generic;
using System.Diagnostics.CodeAnalysis;
class Program
{
public string someString = "hello";
public bool TryGet(int i, [NotNullWhen(true)] out string? name)
{
if (i > 0)
{
name = someString;
return true;
}
name = null;
return false;
}
public int Use(int i)
{
if (TryGet(i, out string? x))
{
return x.Length;
}
else
{
return 0;
}
}
}