immuni-app / immuni-documentation Goto Github PK
View Code? Open in Web Editor NEWRepo for Immuni's documentation.
License: Other
Repo for Immuni's documentation.
License: Other














































































































































































































Up to now there has been a lack of moderation of the issue section which, in my opinion, generates so much confusion and noise. It is not clear who is speaking on behalf of whom and who are the team members. Probably, it is written somewhere, but you should make it more explicit. In this way, when one reads the issues, he can easily discriminate who is a team member and who is not. Also, you should start putting labels to the issues, and clearly state what is the action you are going to take about them.
Thank you
Hi,
I just read this article https://www.huffingtonpost.it/entry/dentro-immuni_it_5ec3d79fc5b61dc1549dd87c where the author states:
Secondo quanto appreso da Huffpost, il download dovrebbe essere disponibile ai cittadini nella prima settimana di giugno e tra gli step preliminari per il suo utilizzo le stesse fonti parlano di un questionario che l’utente dovrà compilare con i suoi dati anagrafici e i dettagli del suo stato di salute, comprese informazioni relative a eventuali familiari contagiati, tamponi effettuati o test sierologici, così da avere un quadro completo della propria condizione come si farebbe di fronte a un medico.
From Google Translate
According to what has been learned from Huffpost, the download should be available to citizens in the first week of June and among the preliminary steps for its use the same sources speak of a questionnaire that the user will have to fill in with his personal data and details of his status health, including information relating to any infected family members, swabs or serological tests, so as to have a complete picture of your condition as you would do in front of a doctor.
Could you please confirm or deny the aforementioned statement?
Is it true? is it false?
Nowhere and nobody has ever been talked about collecting Immuni users' health records and I think this would be a tremendous and unacceptable privacy issue.
Would you care to clarify please?
Thank you in advance, I look forward to reading a statement and a reply from you soon.
While skimming the documentation, I noticed that no statement has been made about the app user interface accessibility, i.e. its ability to be used by people with disabilities who leverage assistive technologies in order to interact with their smartphones.
Other than a law requirement, making the app accessible will ensure that people with disabilities can use it. Both on iOS and Android assistive technology exist that allow people with disabilities to interact with their device: screen reader (talkback on Android, VoiceOver on iOS) for blind people, screen magnifying, switch control for people with motor impairments, etc.
Having more details on which frameworks/technologies will be employed to create the app's user interface would help provide more recommendations in this regard.
Google Play Services is closed-source non-free software, as stated by the Free Software Foundation:
If an app's own code is free software but it depends on Google Play Services, that app as a whole is effectively nonfree; it can't run on a free version of Android, such as Replicant.
As it may not be a problem for people having Google Play Services installed on their devices, this may have strong implications if the app were to be made mandatory, in fact it would risk creating a precedent for our state to forcedly require us citizens to install closed-source non-transparent software on their smartphones.
Moreover, Google Play Services is not available on recent Huawei and Honor devices if not through unofficial installation methods.
I see you are using MongoDB as database backend. I wonder why PostgreSQL was not used, considering also the more favourable licensing model and the fact that you are using Python as a language, which fits very well with Postgres.
Thanks and good luck!
Hello!
In the Open Points section you mention:
Dummy traffic. We would like to minimise the information that an attacker could gain by analysing network traffic. We are finalising decisions on sampling rules and dummy uploads.
Is this kind of measure necessary? From my point of view, Immuni should never be able to communicate the health status of the user; instead, it should be the responsibility of hospitals or family doctors. If this is unavoidable, just send a single message every day, regardless of the positivity. Dummy traffic should be avoided and used only as a last resort, as it will cause unnecessary network pressure and opens the possibility of unforeseen attacks.
I have no doubt that there is a good reason behind this decision, but nonetheless it's quite rare to see this kind of measure taken. From my experience, I've only seen it implemented in:
Without seeing the rationale —and possibly the analysis— behind this point, I'm worried that it might cause more problems than the one that it's trying to solve.
Thanks!
First of all, thanks for making this available - it's a great contribution to the community.
Related to Privacy, I find the documentation a bit lacking.
Few examples:
Are you planning to details those parts?
Are you considering adopting TCN protocols and the (specification)[https://www.apple.com/covid19/contacttracing/] provided by Apple and Google.
Thanks!
API specs to conform Interoperability rules.
Immuni #38) Fixed: #78You can use the online checker for further hints.
Hi,
Are you aware of the Paparazzi attack?
See these papers:
https://eprint.iacr.org/2020/399.pdf
https://eprint.iacr.org/2020/493.pdf
https://eprint.iacr.org/2020/531.pdf
and also this recent presentation: https://youtu.be/XVXKLOWxw7c?t=4664
These attacks have been practically implemented and simulated: https://github.com/oseiskar/corona-sniffer
Any attacker with very low capabilities (that is, just placing bluetooth passive sniffers that are very cheap, small and undetectable) can trace infected users and draw on a map all their movements.
This is an high risk for the citizens' privacy as well as for the National security since a foreign country can perform surveillance of targeted people very easily.
Do you have some countermeasures to this attack?
Did you inform the authorities that your system is subject to this attack?
Many more attacks do exist, the documentation has no discussion about them.
Indeed, the documentation is really scarce and "How it works" does not describe technical details, this is not professional, we hope you can give us a White Paper with an analysis.
I have waited for over a week, but feel compelled to open this issue now:
where is the DPIA?
It is already incredible that no code whatsoever has been released.
It is doubly incredible that the folder "Design" contains a handful of screenprints: no user stories, no use cases, no personas, no usability assessments, no nothing.
But if design has somehow been settled then a DPIA should be promptly executed and be subject (at least in an edited form) to public scrutiny.
The same holds for a reasonable ISO31000-based risk assessment.
Let me remind you that a DPIA is a legal requirement, and a proper risk assessment is a must-have to demonstrate proper accountability.
Thank you
Walter Vannini
The app mockups are referring multiple times to the person using the app as a Male.
Please rephrase the occurrences to acknowledge the existence of women and non-binary people.
I.E.
Benvenuto
Ciao
Rilevato contatto con un positivo al COVID-19
Rilevato contatto con una persona positiva al COVID-19
Android version of Immuni app will depend on Google Play Services, which contains the implementation of Exposure Notification service.
As a consequence:
An up-to-date version of Google Play Services package is required; the only officially supported method for updating this package is through Google Play Store, which in turn requires the user to connect its phone to a Google account, which is related to user identity.
Generation of temporary IDs, advertisement, recording of contacts, exposure detection and notification is managed by closed source code in the Google Play Services executable, which is aware of the user's Google account and maintains network connections to overseas servers.
There is no verifiable segregation between code implementing the Exposure Notification service and code implementing other untelated services provided by Google Play Services.
The user has no practical way to restrict unnecessary permissions to the code managing the Exposure Notication service, as this service is provided by Google Play Services, which requires ample permissions above those required by the majority of apps and restricting them will almost always result in limited/erratic phone operation, which discourages the user from limiting them.
Therefore:
a. having a Google account is a precondition in order to install and use the app, as well as to keep it up-to-date;
b. the executable providing the Exposure Notification is aware of real user identify (through his/her account), temporary IDs advertised by the user, contacts recorded and exposures;
c. the same executable is closed-source and maintains encrypted network connections to overseas servers which cannot be audited, so that it cannot be ruled out that data described in item b could potentially be disclosed to one or more overseas centralised entities, which could record and correlate massively data from users.
In addition to the above privacy and security concerns, it must be also noted that obliging the user of a government-supported app to subscribe for a Google account (which means establishing a contractual agreement with a private entity) in order to install and use the app could be a well founded subject for anti-trust claims.
Personal thought: it seems that we are putting more trust in private overseas corporations than in legitimate governments; the fact that the app will actually be actually privacy-friendly and decentralized as advertised relies only on blindly trusting these corporations to behave rightfully.
What kind of random generator is used?
Is it based on a Cryptographically_secure_pseudorandom_number_generator ?
If not, which one? Reference?
If yes, could you provide a dataset of generated keys?
This expands on #22.
Failure in understanding that public digital services' inclusiveness is an absolute priority is a huge telltale mark.
Contact tracing must be non-discriminatory in every aspect, as stressed multiple times by EU-level policymakers (not earlier than two days ago by the European Parliament), and this includes a number of topics such as accessibility (#8), multilingual support (#13), privacy by design even in the documentation (#16), using a gender-neutral language (#22), and avoiding ableisms.
I will go to such lengths as to claim that a failure in delivering a thoroughly inclusive digital or service is tantamount to a failure of the whole project, as it would pave the way for a less fair society. And that is true regardless of whether the service were elsewise successful in fighting the pandemics or not.
Come on: inclusiveness is no unattainable goal even with such hectic time constraints as we all are facing. A good starting point are Google's guidelines on writing inclusive documentation.
@eutopian-eu
Hello,
I think app name is dangerously misleading, giving a false security feeling of immunization.
Contact tracing apps are use to track infected people.
Please remember to submit informations on compliance with AGID guidelines on secure software
https://www.agid.gov.it/it/sicurezza/cert-pa/linee-guida-sviluppo-del-software-sicuro
A Privacy Policy is still missing from the documentation.
I understand that development is still ongoing, but if design has been settled upon, then there's nothing to keep you from releasing a comprehensive Privacy Policy.
Also, once the application is release, the Privacy Policy will be necessary to determine if and how the application Behaves As Advertised or not.
In short, code does things, and there will be enought discussion on how it does them.
The Privacy Policy tells us what the code should do, so I see the Privacy Policy as (one) essential tool in analysing your app.
Oh, by the way: a Privacy Policy is also a legal requirement.
Thank you
Walter Vannini
Citizens should freely decide to upload or not their TEKs once they discover to be infected. Moreover, their decision should remain private. As far as I understand (please correct me in case I'm wrong), the procedure proposed by Immuni violates this freedom/privacy. Indeed the infected citizen when asked by the Healthcare Operator might feel under a psychological pressure due to so called "civic sense" and could be afraid that the Healthcare Operator would then gossip about her/his decision. After accepting to do it, there is an OTP generated by the app and validated by the Healthcare Operator. If the user decides to abort (i.e., the user does not complete the upload), its decision would not remain private since the server will not receive the TEKs from the specific citizen that corresponds to the OTP validated by the Healthcare Operator, and that knows the identity of the citizen. This is not acceptable.
Currently there are many other things that I dislike of Immuni but I would like to at least propose a fix to this problem. After the validation of the OTP, the app should offer to the citizen the possibility to opt among two options: 1) upload of the real TEKs or 2) upload of randomly generated TEKs (that have never been sent as identifier beacons). In this way the citizen can freely decide not to send the real TEAKs and still this decision remains known uniquely to him. This is privacy by design (FYI).
Please let me know if my analysis is correct, and in the affirmative case please explain if you are going to update Immuni implementing the fix that I've just suggested (otherwise, explain why you're not protecting the privacy of the citizens).
Additionally, the citizen might want to prefer a mixed solution. Consider for example a citizen that 3 days before the test was in some risky situation so that communicating the TEK corresponding to that day might be harmful (e.g., the citizen could be fired), while there is no problem to communicate the TEKs corresponding to all other days. An even better solution, therefore, consists of offering to the citizen the possibility of selectively choosing the reak TEKs to upload, so that the discarded ones will be replaced by randomly chosen TEKs. Basically the citizen will have a form with the last X days (I don't know if X=14 or some other number) and day by day the citizen will select or not a checkbox in order to send the real TEK or the fake TEK. From a usability point of view I think the user should have 3 options: 1) upload all real; 2) upload all fake; 3) mixed upload. Only in case the 3rd option is selected, then the citizen should receive a form with a day-by-day checkbox. It's certainly beneficial that the citizen can perform this action far from the Healthcare Operator so that the time spent to choose the favorite option does not leak any information on her/his decision.
Hi,
the documentation says:
"Upon assessing transmission risk. The upload may happen after the app has downloaded new keys from the server and assessed the transmission risk for the user, based on their recent contacts with SARS-CoV-2 positive users. In this case, the ensuing epidemiological data are uploaded automatically".
So the epidemiological data are AUTOMATICALLY uploaded without user's consent.
You cite some Ministerial decree.
Can you point us the precise decree and article within that would prescribe users to automatically upload their epidemiological data without consent?
That in conformity with the Italian API Guidelines, the spec details the usage of the cache header.
Especially the usage of Cache-Control and Vary header (eg. Cache-Control: private, max-age, no-store, ...).
Cache-Control is correctly mentioned but its usage is not detailed.
to consider URIs (e.g https://immuni.example/errors/1004) instead of error-codes (eg. 1004) to describe errors. See https://tools.ietf.org/html/rfc7807#section-4.
The app can still process the response, thus deriving the error code.
This simplifies the evolution of the API interface and better guides the client in resolving possible errors conditions without filing issues or even contacting the support.
In the issues and in some documents it is mentioned that the app will be under MPL (https://innovazione.gov.it/app_Immuni_risposte_quesiti_anorc/). In the README, in the context section, the license is specified as GNU AGPL 3 (https://github.com/immuni-app/documentation#context). In the AGID guide lines the license is specified as EUPL (https://www.agid.gov.it/it/agenzia/stampa-e-comunicazione/notizie/2019/05/13/pubblicate-linee-guida-agid-sullacquisizione-il-riuso-del-software-nella-pa).
At the moment, it is not possible to understand which (if any) of these licenses will be adopted.
Similarly, the context document, there's a reference to a Terms of Service and a Privacy Notice document. Both of them are missing.
The use of the word "Protezione attiva/non attiva" should be avoided.
The risk is to give a false sense of security to the user.
Better use the word "Applicazione attiva" or "Tracking" or "Exposure tracking".
This is very important, because the app doesn't provide ANY protection, but only a monitoring of the exposure.
Quoting from the readme file:
"To make sure only users who actually tested positive for SARS-CoV-2 upload their keys to the server, the upload procedure can only be performed with the cooperation of an authenticated healthcare operator. The operator asks the user to provide a code generated by the app and inputs it into a back-office tool. The upload can succeed only if the code used by the app to authenticate the data corresponds to that entered in the system by the healthcare operator."
Please make it explicit that by doing that you have to trust the provider of the service (the government) to not collude with the health authority in order to not link the uploaded data with the user's real identity. The attack is really easy: the health authority who is aware of the real identity of user U, can forward the mapping between the activation code and the real identity of U to the server, which can in turn derive the mapping between this code and data uploaded by U.
If coupled with Paparazzi attack, this can lead to undetectable fine-grained tracing of targeted individuals.
Note that de-anonymization of uploaded data is also possible via IP address, so some mechanism to ensure anonymity while uploading data is also necessary, but this does not seem to be mentioned either. Please Clarify.
This may sound like a petty issue, but I am writing it for the sake of clarity. Feel free to close it if you find it irrelevant
In the Glossary, you define:
The duration of the Exposure (measured in five-minute increments and capped at 30 minutes)
and then
Rolling Proximity Identifier (RPI). A 16-byte identifier generated from a TEK, broadcast via BLE by a Mobile Client, and stored locally by the nearby Mobile Clients. The RPI being broadcast changes multiple times an hour to prevent wireless tracking of the Mobile Client.
Assuming that the RPI changes n times an hour, it means that it changes every 60/n minutes on average.
Multiple times an hour implies that the RPI changes at least 2 times per hour.
Now, if n > 2, the time between two changes is less than 30. What is the point of capping the duration of the Exposure at 30 minutes then?
Please, be sure to set a reasonable number of changes per hour (less than 12 on average!).
Thank you and good work.
Edit:
I found this document from Google's blog The Keyword. On page 3, it states
Rolling Proximity Identifier - A privacy preserving identifier derived from the Daily Tracing Key and sent in the bluetooth advertisements. It changes every ~15 minutes to prevent wireless tracking of the device.
This confirms my understanding that the Duration of the Exposure can never be measured as more than ~15 minutes, so capping it a 30 minutes is useless since the number of changes per hours is greater than 2 (around 4).
Bare in mind that the linked document is labelled as Preliminary - Subject to Modification and Extension, so clarification from your part is still needed.
Edit 2:
Your own Privacy Policy states:
"Ogni 10 minuti Immuni genera un codice casuale (Rolling Proximity Identifier - RPI) a partire dalla chiave di esposizione giornaliera (Temporary Exposure Key - TEK) e lo invia ai dispositivi vicini"
So the number of changes n appear to be 6.
How is this coherent with the idea that a contact is at risk if longer than 15 minutes?
See here or here for example.
Location (Android only). On Android devices, Location needs to be on to detect nearby devices, although the A/G Framework’s documentation explicitly states that it does not actually use location data. This may be quite confusing for the user, but unfortunately it is outside of the Android App’s control. Please note that this does not mean that the Android App will request the Location permission, but only that Location needs to be activated at system level in order for the A/G Framework to work properly.
This doesn't seem what Google is stating . And that can potentially kill the usage as we have 75% of Android in Italy. I would strongly recommend to verify and double check.
Missing information on accessible development for people with disabilities, ensuring "accessibility by default". Accessibility as indicated by the Minister of Innovation must be an integral part of the project which must also include tests with people with different types of disabilities.
Hi all,
As described in the public documentation, the google APIs give a way to calculate what they call "RiskScore" that is a number used to express the overall level of risk of a given contact happened between users.
In my opinion this is the key feature of the app: the app, "by definition", must provide the best way to automatically detect a contact between different subjects while minimizing the number of false positive and false negative. Otherwise, if this will be not true, there would be an high risk of having a counterproductive effect instead of having a real help in fighting the virus with the only result of making higher the level of overall confusion.
Said that, I see that with reference to the all the exposure configuration parameters (see for example the ConfigurationSettingsService.kt class) the code reports, I hope, some "dummy" values for these key parameters.
For example, with reference to the paramter "attenuationScores", that is the fundamental parameter that regulates how the bluetooth signal is taken in consideration in the overall Risk equation, I see in the code the values "(1, 2, 3, 4, 5, 6, 7, 8)".
My question is: how the overall parameters, not only the "attenuationScores" but also the "daysSinceLastExposureScore", "durationScore", "transmissionRiskScore", will be determined? On which scientific/experimental basis they will be built/calculated to ensure the overall system functionality avoiding or keeping low the false positive and false negative detections?
Thanks in advance for any answer.
Here and everywhere: information is a collective noun, so you don't expect to use it with plural (eg. infos).
In the tek upload section of https://github.com/immuni-app/immuni-documentation/blob/master/Technology%20Description.md#backend-services-technologies, it seems that when uploading the TEKs, it includes exposure summary info. Is this to do analytics of who is infected AND has seen an notification before? Does this mean the App remembers the notification?
An implementation of the app not relying on Google Play Services should be provided for users of AOSP-based devices.
Such implementation of the app, not depending on closed source components, should be made available through open source repositories such as F-Droid.
In the documentation you announce that:
"The app is available in Italian, German, and British English".
The choice seems (1) arbitrary and (2) discriminatory. Without an adequate multilingual coverage, the app would not reach a large part of the Italian population, especially in particularly vulnerable sector of society, and thus jeopardize its efficiency. Looking at the linguistic composition of the migrant population in Italy, at least Arabic and Chinese should be prioritized.
Custom HTTP headers to have a scope. See https://tools.ietf.org/html/rfc6648
They have not: Exp-Dummy-Data & co should be Immuni-Exp-Dummy-Data
Fix it after merging #33 and #34
See https://github.com/immuni-app/documentation/blob/master/API.yaml#L82
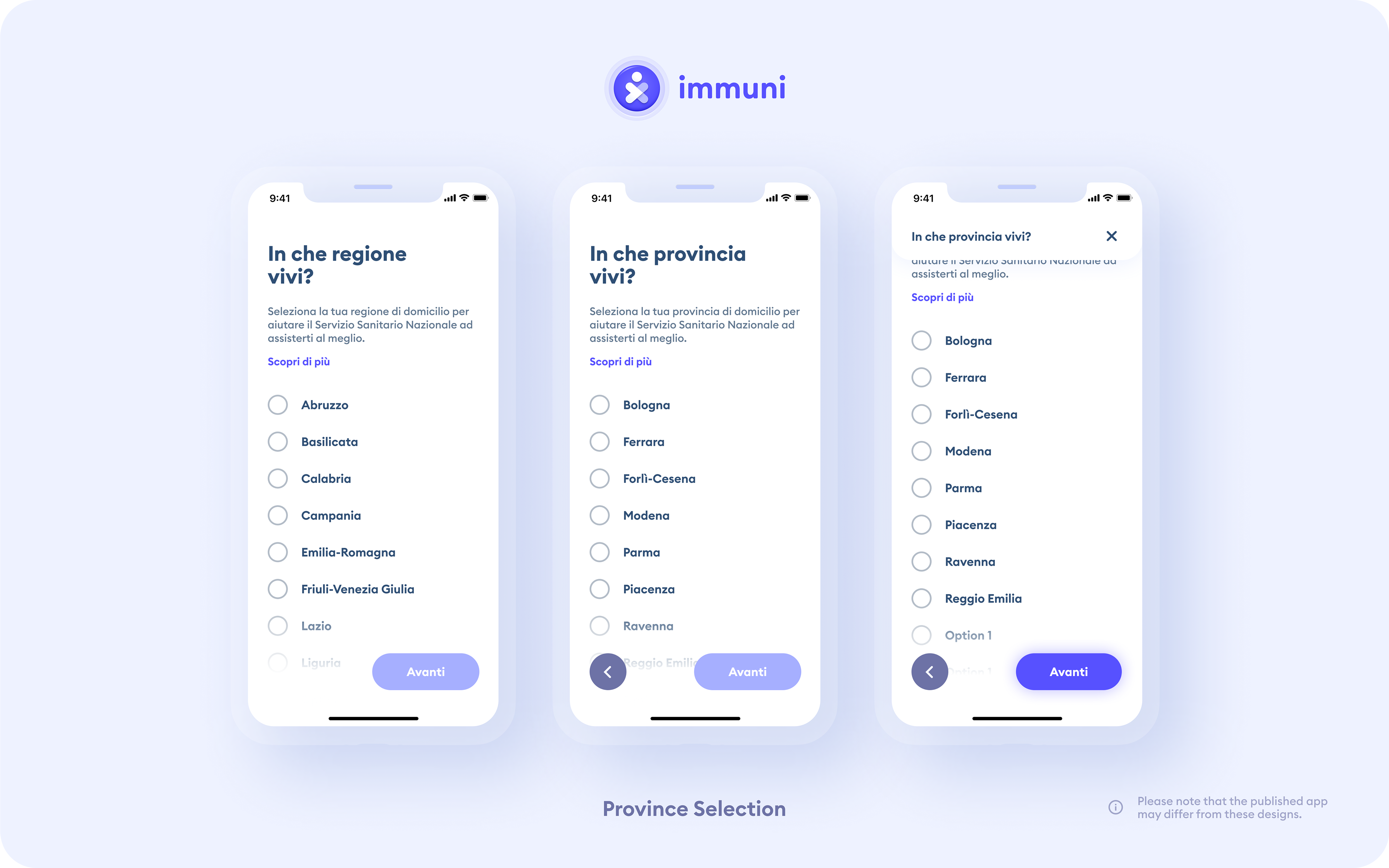
From a usability prospective the province list is lacking a search interaction pattern. Searching in a list of +20 element can be frustrating for the user.
The verb in the API endpoint should be only the HTTP/HTTPS verbs.
For example:
Resource path
POST /v1/authorise-otp (this is a service not a resource)
Maybe you can consider to refactor them to
POST /v1/authorizations
Hi, thanks for the documentation. It is, however, useless unless you also share the source code. What is your plan to release it openly?
It is important to release all the code, and not just a selection as suggested by the documentation, and to release it as soon as possible so to allow the whole community to assess it before the app is launched. Ideally, as the decisions you are taking now have a strong impact on delicate societal dynamics, the development of the app should be openly accessible: don't wait to have the definitive version running to share the code, start now.
PS This involve the code both on the device side and on the server side.
Sarebbe auspicabile che i repository del progetto Immuni avessero dei README ( non il codice ) in italiano, così da facilitarne la comprensione anche a noi non tecnici o ai curiosi ( soprattutto visto il tema in oggetto)
The app should provide the user with a live counter of contacts recorded.
While the number itself is of no real significance (it would not count unique subjects but just ephemeral IDs), the counter would serve as a "hearthbeat", providing the user confidence that the app is actually doing its job. People is going to install this app and, if everything goes well, they will see no feedback at all for months: this could create the false sensation that the app is doing nothing and is not useful. Showing some kind of "progress" can create a sense of community involvement ("See how many! Everybody is using it!").
Of course the UI has to be well thought, so that number of contacts cannot be mistaken as an indication of dangerous contacts.
See for similarity: DP-3T/dp3t-app-android-demo#3
I see no reference to interoperability with foreign systems using the same A&G protocol or other systems. This is essential to make the app effective upon substantial reopening of EU internal borders.
In-depth discussion here:
https://drive.google.com/file/d/1mGfE7rMKNmc51TG4ceE9PHEggN8rHOXk/edit
Dalla documentazione
In the case that the Mobile Client is stolen, an attacker may gain access to the data Immuni stored on it by accessing raw data from the device storage. To prevent this, all data stored by the App are encrypted using AES. The AES decryption keys are stored in the OS-specific native key storage databases (Keychain on iOS and Keystore on Android).
Per accedere all’applicazione non vi è nessuna fase di autenticazione, così che un soggetto, se entra in possesso del terminale anche per pochi minuti, può vedere tranquillamente tutti i dati registrati dall’APP e/o interagire con l’APP. In particolare, può essere visto se un soggetto è risultato positivo al COVID oppure se ha ricevuto una notifica di rischio esposizione.
Si dovrebbe prevedere un livello di autenticazione all’app in locale, per esempio come viene comunemente fatto per i client del banking on line, magari con l’autenticazione tramite impronta digitale, riconoscimento facciale o password
AS A researcher I MIGHT WANT TO process a N-degree exposure graph SO THAT:
(
The point 3 is crucial: centralizing data is risky from both the privacy-preserving and security point of view, but at the same time a centralized data graph could potentially be a useful resource for research.
The following proposal suggests an approach which may allow researchers to process data and retrieve results without having direct access to data, thus shielding citizens from feature creeps or other types of privacy erosions.
The proposal might require a certain complexity, but it could be useful to:
PROPOSAL:
A. Build a secondary and fully separated Ingestion Service to automatically gather the minimum appropriate set of TEKs/RPIs from users (all users or sub-sets of users like, for example, the ones specifically opting-in or belonging to a specific province/zip-code), so that a N-degree exposure graph can be available for research purpose (to selectively limit the degree, if required, the N+ degree data will be canceled or not stored at all). This graph will be managed through a Trusted Execution Environment (or an OPAL*-like environment) in a way that authorised researchers could process data through vetted queries or vetted algorithms so that they can get answers without direct access to data (making algorithms go to data, not viceversa). As an alternative to vetted processes, the system could either (1) limit the results of processing so that it is not possible to query a narrow set of users and/or retrieve granular results or (2) provide an interface for querying/processing so that only pre-defined processing options are available. This could potentially open significant research opportunities without lowering the privacy-preserving value of the architecture.
B. The control of this secondary Ingestion Service and of the related TEE / OPAL architecture will be given to a trusted, transparent and accountable third party who will represent the highest level of data protection and trust (i.e. the Italian Data Protection Authority). An appropriate control dashboard to manage authorisations and prior analysis/approval of queries/algorithms will be available for the team of experts managing this Service within the trusted authority.
C. Authorization to submit processes/queries/algorithms on data will be given to research centers/authorities upon acceptance of research guidelines and ethical code of conduct; the results of processing should, whenever possible, publicly released.
D. The proposal does not erode privacy with respect to the current implementation, provided that the third party managing the TEE is trusted and accountable (this is a reasonably feasible trade-off), while researchers and research centers can be authorised with a zero-trust approach because (1) they cannot access data and (2) the processes (queries/algorithms) they submit for vetting can be pre-examined before execution (the vetting process will be held by field experts and, preferably, made public).
EXAMPLES:
Suppose there is a large amount of tests to allocate and that a team of experts wants to simulate the potential impact of different allocation options
Suppose researchers want to predict the impact of local temporary red zones according to the graph of contact/exposure of users in the specific area.
In a recent interview , Innovation Minister Pisano declared
«Grazie alle elaborazioni fatte sul server di Sogei sapremo in forma anonima e aggregata quanti soggetti sono stati allertati in ogni provincia, quanti poi effettivamente si ammalano, dopo quanto tempo e a quale distanza e in che giorno sono stati a contatto con un infetto».
It seems then that the server will contain information about both the infected user and his/her contacts. Even if the information is read in anonymized and aggregated form, the detailed contacts will be on the server.
Could you please clarify how this guarantees decentralization?
Thank you.
This issue has the only purpose to check whether the team members of Immuni-app are still interested in discussing issues and the development of the Immuni-app is still in progress.
User (utente) is a very common expression to refer to the person using any app.
However I would suggest to call the word person (persona) as it is more inclusive and has a strong relations with real life contacts.
Furthermore, as in the future the Immuni backend should be able to fetch positive contacts from other app backends (used in other countries), the Immuni user could be notified of contacts occurred with people that are not Immuni users themselves, but are still people.
You are a bounch of idiots.
This endpoint returns x-protobuf media-type. Is that correct?
Dalla documentazione
Without appropriate countermeasures, even if the data in transit are encrypted, an attacker could still infer sensitive information by analysing the communication between the Mobile Client and Backend Services. For example, an exchange of information between the Mobile Client and the Exposure Ingestion Service could reveal that the user is uploading their TEKs and has therefore tested positive for SARS-CoV-2. To minimise this risk, the following measures are in place:
Visto che è possibile un’analisi del traffico, la misura di pacchetti fasulli inviati al server non è idonea alla mitigazione del rischio, poichè tale misura ha un senso nel caso in cui l’upload dei dati avvenga sempre all’interno dello stesso network. Cosa che, invece, sarà improbabile. Infatti è altamente probabile che l’eventuale invio dei dati avvenga all’interno di una struttura sanitaria, una volta che è stato comunicata la positività al COVID. Ciò esporrà l’utente al fatto che, mediante l’analisi del traffico, sarà facilmente identificabile il soggetto che effettua l’upload dei dati connesso all’interno del network aziendale della struttura sanitaria.
Dovrebbe essere prevista un avviso, in modo da informare l’utente, per esempio, di effettuare l’upload solamente tramite la connessione dati e disconnettendo la connessione wireless.
I am sorry to open this issue in the documentation section, but there is no other section available, and also no security assessment has been provided yet. In any case, I think it is useful to supply a link to this new study that describes how tracing apps could be subject to replay attacks:
https://down.dsg.cs.tcd.ie/tact/replay.pdf
It is impossible to say if Immuni is also subject to this, given the lack of information, but it will be possible to address or close this issue once the source code is actually available.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.