Libre collaborative resource mapper powered by open-knowledge


This repository hosts Inventaire.io source code. Its a collaborative resources mapper project, while yet only focused on exploring books mapping with wikidata and ISBNs
This repository tracks server-side developments, while the (heavy) client-side can be found here. Client-related technical issues should go in the client repo, while this repo gathers all other technical issues. Non-technical discussions, such as feature requests, should preferably happen in the chat.
This is the installation documentation for a developement environment. For production setup, see: inventaire-deploy
- git, curl (used in some installation scripts), graphicsmagick (used to resize images), inotify-tools (used in API tests scripts):
- NodeJS (>=10, using the latest LTS is recommended), NVM (allows greater version update flexibility)
- a CouchDB (>=3.1) instance (on port 5984 for default config)
- an Elasticsearch (>=7.10) instance (on port 9200 for default config)
To install all this those dependencies on Ubuntu 20.04:
For packages available in Ubuntu default repositories:
sudo apt-get update
sudo apt-get install git curl wget graphicsmagick inotify-toolsFor packages that need a more elaborated installation, see their own documentation:
Alternatively, CouchDB and Elasticsearch could be run in Docker, see docker-inventaire
Whatever the way you installed CouchDB and Elasticsearch, you should now be able to get a response from them:
# Verify that CouchDB is up
curl http://localhost:5984
# Verify that Elasticsearch is up
curl http://localhost:9200git clone https://github.com/inventaire/inventaire.git
cd inventaire
npm install --global tsx
npm installThis should have installed:
- the server (this git repository) in the current directory
- the client (inventaire-client) in the
clientdirectory - i18n strings (inventaire-i18n) in the
inventaire-i18ndirectory
The installation step above should have triggered the creation of a ./config/local.cjs file, in which you can override all present in ./config/default.cjs: make sure to set db username and password to your CouchDB username and password.
And now you should be all set! You can now start the server (on port 3006 by default)
# Starting the server in watch mode so that it reboots on file changes
npm run watchTo debug emails in the browser:
- Get some username and password at https://ethereal.email/create and set the following values in config:
mailer.nodemailer.userandmailer.nodemailer.pass. - Make an action that triggers the email you would like to work on on the local server (ex: send a friend request)
- Open https://ethereal.email/messages to see the generated email
Note that, while convenient, debugging emails in the browser is quite an approximation, as some email clients are antiquated, and, sadly, modern CSS can't be used.
If you want to work on the client, you need to start the webpack watcher and dev server (on port 3005 by default)
# In another terminal
cd inventaire/client
npm run watch- To use executable that are used by the project (such as
mocha), you can either find them in./node_modules/.binor install them globally with npm:npm install -g tsx mocha lev2etc.
- main: the stable branch. Unstable work should happen in feature-specific branches and trigger pull requests when ready to be merged in the main branch. See Code Contributor Guidelines.
- main: the stable branch. Unstable work should happen in feature-specific branches and trigger pull requests when ready to be merged in the main branch. See Code Contributor Guidelines.
The repository tracking strings used in the server (for emails, activitypub) and client (for the web UI) in all the supported languages. For helping to translate, see the Inventaire Weblate project
tracking installation scripts and documentation to run inventaire in production
- main: the main implementation targeting Ubuntu 16.04. Additional branches can be started to document installation on other environments
- main: tracking docker installation files for development and testing use
This repository correspond to the the "Server" section in the stack map
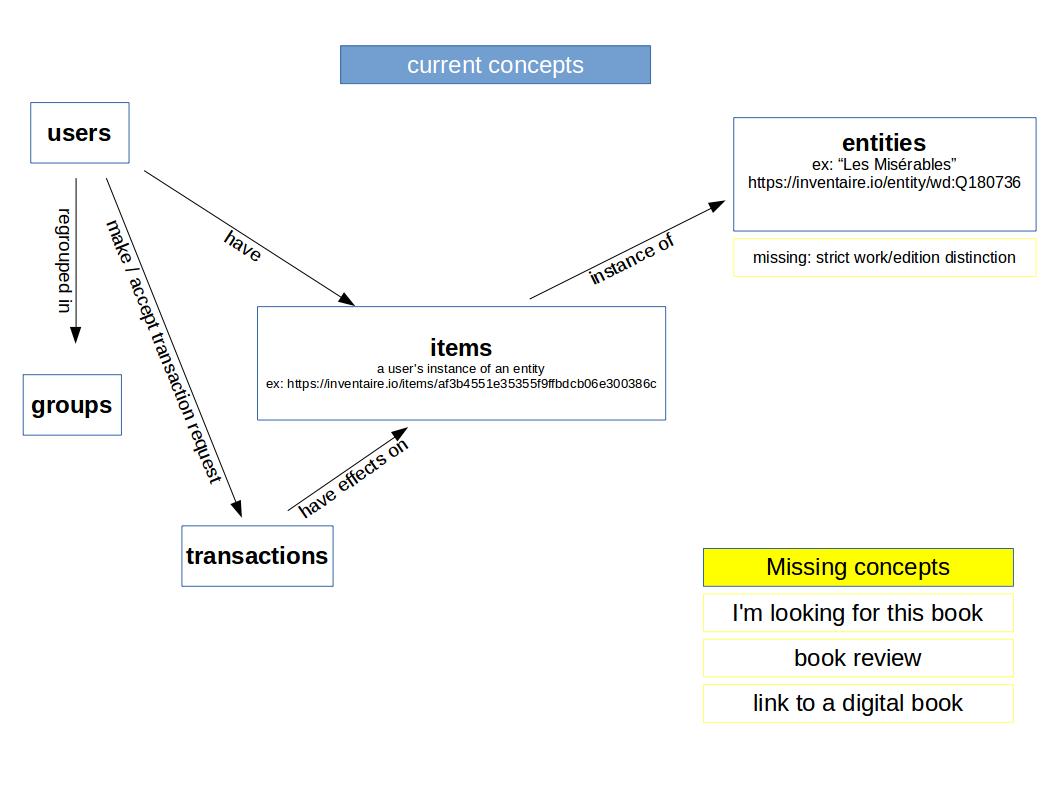
the app has a few core concepts:
- Users
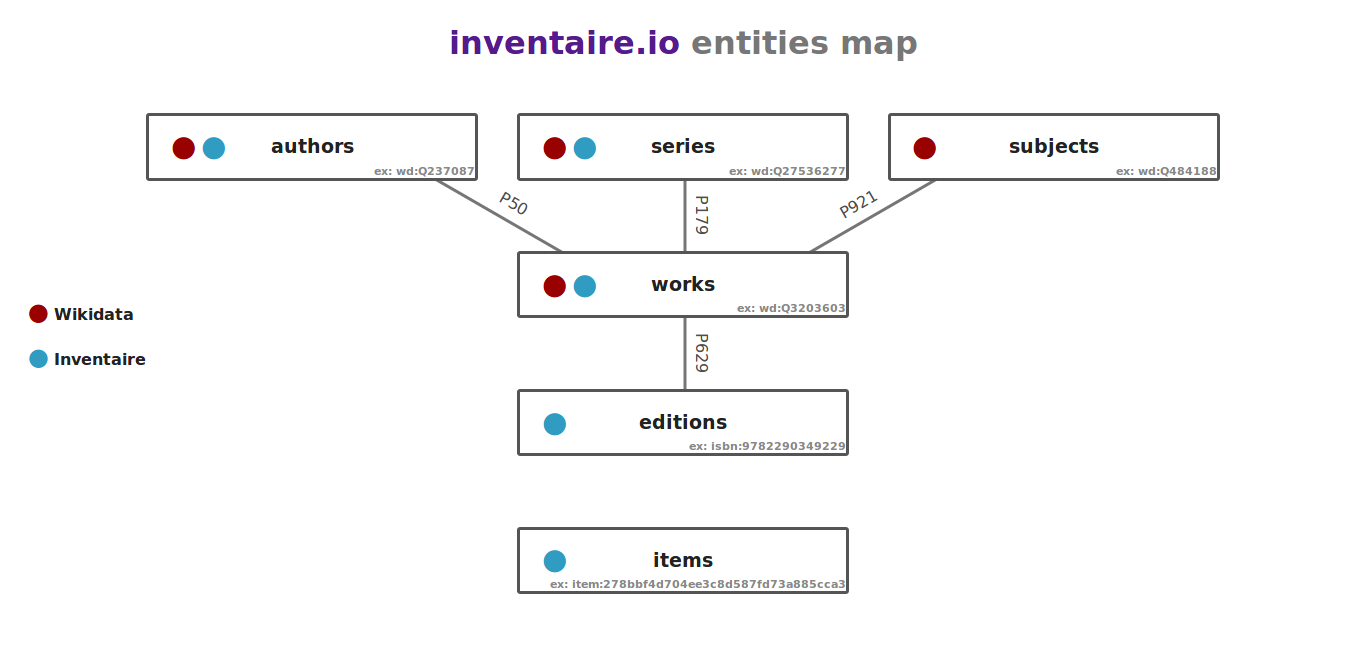
- Entities : which can be authors (ex: wd:Q353), books (ex: wd:Q393018) and books' specific editions (ex: isbn:9782070389162). The term entities comes from wikidata terminology. See the entities map.
- Items : instances of book entities that a user says they have. It can be an instance of a work or a specific edition of a work.
- Transactions : discussion between two users about a specific item with an open transaction mode (giving, lending, selling). Transactions have effects on items: giving and selling an item make it move from the owner to the requester inventory; lending an item shows it as unavailable.
- Groups: groups of users with one or more admins
For code-related contributions, see How to contribute on wiki.inventaire.io.
see docs
see wiki.inventaire.io You may want to directly go to the technical wiki page
see wiki: API
see Administration
Inventaire is an open-sourced project licensed under AGPLv3.














































