Crowdsourcing sample quality scores for multimedia event detection
Gathering annotated data for machine learning applications can be very time consuming and expensive. Crowdsourcing is found to be an effective method to overcome this problem. CrowdTruth is an approach for crowdsourcing that utilizes disagreement between multiple annotators to determine the quality of workers, labels and data points. In this paper, we introduce a method based on the CrowdTruth approach to effectively gather annotations for events in videos by using multiple annotators per video. We analyze the effectiveness of increasing the amount of annotators and show how multiple annotators can be used to extract information about the quality of a worker, the ambiguity of a label and finally the quality score for each video. We show how these video quality scores can be utilized by a Support Vector Machine during training to improve the performance of the classifier. We compare our own crowd sourced annotations with the crowdsourcing method of Jiang et al. 2011. Results confirm that using exclusively high-quality data points as positives examples can improve results on both accuracy and ranking metrics significantly.
Robert Iepsma, Theo Gevers, Zoltan Szlavik and Lora Aroyo (2016)
Universiteit van Amsterdam
Crowdsourcing tasks used
Task 1: Annotate anything happening in the video
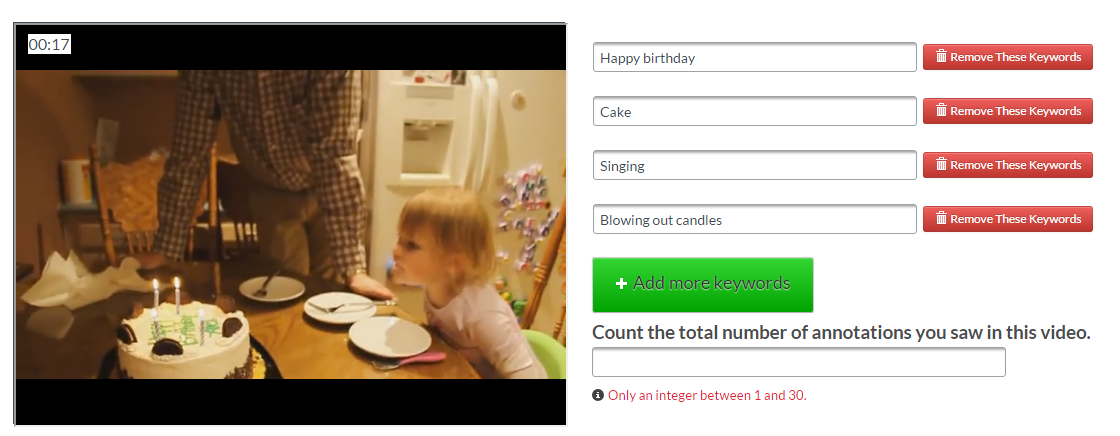
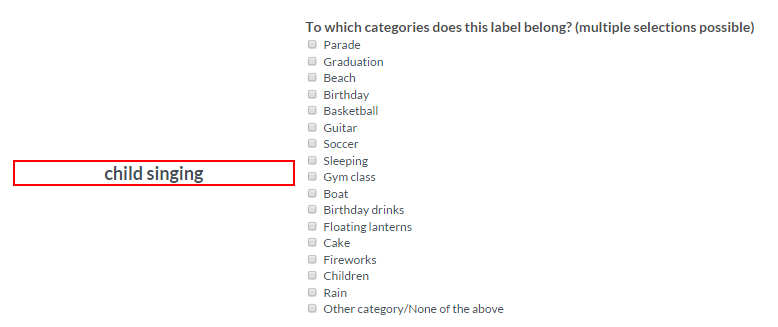
Task 2: To which categories does this label belong?
| Task | Workers/Unit | Payment/Unit |
|---|---|---|
| Task 1 | 15 | $0.02 |
| Task 2 | 15 | $0.002 |
Dataset files
Videos used in this research originate from the Columbia Consumer Video (CCV) Database, where all videos containing the events 'Birthday', 'Graduation' and 'Parade' aswell as 10 videos for both 'Soccer' and 'Basketball' are used during annotation.
This repository contains all the data and code that was used to annotate consumer videos from CCV aswell as all features and labels used during training and testing of the classifiers. We distinguish two different folders 'Code' and 'Data'. The folder 'Code' contains all python files used to compute Unit-Label scores for each video using the crowdsourcing task output. The 'Data' folder contains the input and output files from all crowdsourcing tasks together with all output files produced by the python files from 'Code'.
The data and results produced by this research have been achieved by following the following steps:
- Gather annotations about anything happening in a video with crowdsourcing task 1 using the input file Data/Task-1/_0_Task_1_input.csv, employing batches with a maximum size of 30 videos.
- Run python code 1 to 7 from /Code/Task-1 to obtain the task 2 input file (Data/Task-1/_7_Task_2_input.csv) and the file containing the labels with the highest Unit-Label score (Data/Task-1/_7_average_unit_label_scores.csv). Select labels to use during task 2 by using a Unit-Label score threshold based on the average and standard deviation returned by Code/Task-1/7. get_highest_unit_label_score.py or by manually selecting events.
- Gather annotations about which labels belong to which events with crowdsourcing task 2 using the generated input file Data/Task-1/_7_Task_2_input.csv.
- Run python code 1 to 4 from Code/Task-2 to obtain vectorized annotations (Data/Task-2/_4_keyword_labels.csv) for each input unit (Data/Task-2/_4_keywords.csv) used in task 2, where each column represents the selected event labels in step 2 (Data/Task-2/_4_categoryNames.csv).
- Merge the video worker annotations obtained from task 1 after removing spammers and writing style disagreement (output from Code/Task-1/6. translate_writing_style_disagreement.py) with the keywords and keyword labels obtained from task 2 in the previous step using Code/Merge-Tasks/1. Get_Final_Annotations.py
- Run python code 1 to 3 from Code/Calc-Unit-Label-Scores to compute the Unit-Label scores for each video (Data/Calc-Unit-Label-Scores/_3_unit_label_scores.csv).
**Note that during the original research, at first only 380 videos were annotated, and additional resources were aquired in a later stage to annotate another 516 videos. Therefore, different event labels were selected to use during task 2, since the latter 516 videos had to use the same high-level event labels in task 2 as the first 380 videos, resulting in slightly different output files. The files that were used during the original research are included in the 'Data' folder, identified with 'ACTUALUSED' in their name.
The datasets used to train and test our Support Vector Machines can be found at Data/Datasets, where each combination of train and test set contains:
- Features of train and test set
- Test set labels:
- CCV
- CT@t
- Train set labels:
- CCV
- CCVeq
- CT@t
- CTmv
- Video ids of train and test set
CCV labels are the original labels from Columbia Consumer Video (CCV) Database.
CCVeq labels are the original CCV labels, where some positive labels are set to negative to match the number of positive labels for each event used in the CT@t label set with a threshold of 0.86.
CT@t labels are the Unit-Label Scores, with the value -1 for videos that were not used in during annotation gathering.
CTmv labels are the event labels calculated Majority Voting over the annotations gathered via CrowdTruth.
Multimedia event detection
The feature sets together with the label sets were used to train a Support Vector Machine and a Weighted Support Vector Machine for event detection. For this, LIBSVM -- A Library for Support Vector Machines was used.
