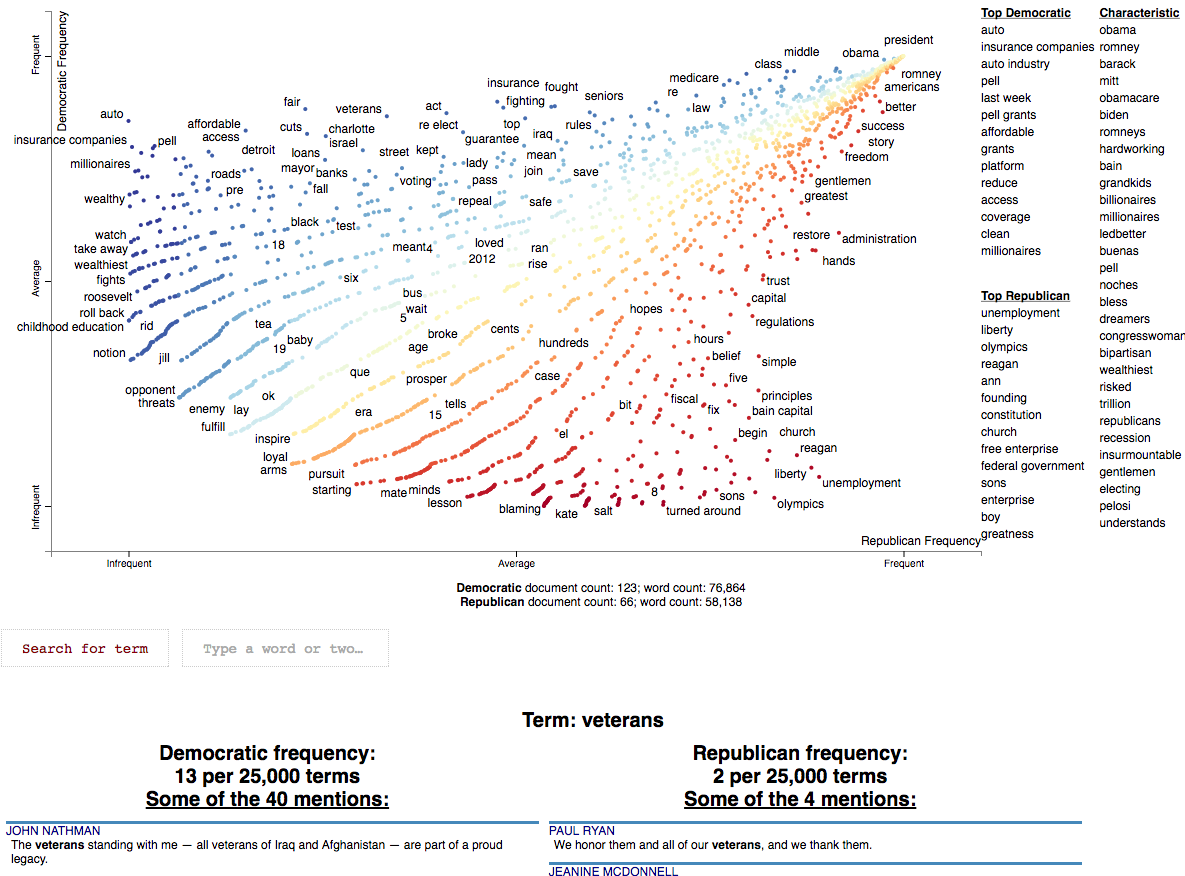
Notebooks for the Seattle PyData 2017 talk on Scattertext
A guide to using the python package Scattertext. If you feel so moved, please star it, fork it, or even contribute!
Check out the introductory presentation here.
The notebooks look best in Chrome.
In order to use these notebooks, please execute the following commands, please clone this repo and run (in Python 3):
$ git clone https://github.com/JasonKessler/Scattertext-PyData
$ pip3 install scattertext agefromname
$ cd Scattertext-PyData
$ jupyter notebook
- First Notebook how to use Scattertext to visualize differences in document types.
- Second Notebook how to use Scattertext and AgeFromName to understand how lanugage, gender and political party intersect.

- Third Notebook how to use Scattertext to visualize how the same word or semantic type is discussed different between document categories. In this case, we explore how "jobs" is discussed differently by Republicans and Democrats.