jawil / blog Goto Github PK
View Code? Open in Web Editor NEWToo young, too simple. Sometimes, naive & stupid 🐌
Too young, too simple. Sometimes, naive & stupid 🐌









































































































































































































之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西,算是对自己学习的一点总结),对DOM的理解又具体了一步,因为DOM本来就是一个抽象和概念性的东西,每深入一步了解,在脑中就会稍微具体一点,通过这次的对DOM的系统学习,对DOM有一个比较深刻的理解,明白了DOM在JavaScript这门语言中举足轻重的地位,了解了DOm的发展历史,也让我明白了存在浏览器浏览器兼容性的历史原因,对DOM的结构有了进一步的认知,对DOM的一些API也更加熟悉,对比较抽象和概念性的DOM认知稍微具体了一些。下面就是自己深入学习DOM这门课程整理的一些笔记,大部分来自学习中查阅的资料以及视频中老师讲的一些关键性知识点,当然也不可或缺的有自己的一些记录和理解。
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
文章稍长,本文只论述DOM基础概念,不涉及DOM的一些事件原理机制,页面元素的操作和常用API的讲解以及兼容性事项,所以概念性东西比较多,稍微有点抽象,其中有笔记来大部分来自老师的口述,还有一部分是查阅的文档,最后有一部分是自己的记录和理解。
通过document.createElement("p")创建一个p元素一共溯寻了7层原型链,你知道吗?
学习视频地址:DOM探索之基础详解篇,老师讲的很好,有兴趣的可以结合视频学习一下,建议看完视频再看笔记,加深印象,你会受益匪浅。
DOM,文档对象模型(Document Object Model)。DOM是 W3C(万维网联盟)的标准,DOM定义了访问HTML和XML文档的标准。在W3C的标准中,DOM是独于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。
W3C DOM由以下三部分组成:
DOM(文档对象模型)是针对xml经过扩展用于html的应用程序编程接口,我们又叫API。DOM把整个页面映射为一个多层的节点结构,html或xml页面中的每个组成部分都是某种类型的节点,这些节点又包含着不同类型的数据。
我们知道,一个网页是由html来搭建结构的,通过css来定义网页的样式,而JavaScript赋予了页面的行为,通过它我们可以与页面进行交互,实现页面的动画效果等等。那javascript究竟通过什么来实现的呢?通过ECMAScript这个标准,我们可以编写程序让浏览器来解析,利用ECMAScript,我们可以通过BOM对象(即browser object model)来操作浏览器窗口、浏览器导航对象(navigator)、屏幕分辨率(screen)、浏览器历史(history)、cookie等等。但这个通过BOM来实现的交互远远不够。要实现页面的动态交互和效果,操作html才是核心。那如何操作html呢?对,就是DOM,简单的说,DOM给我们提供了用程序来动态控制html的接口,也就是早期的DHTMl的概念。因此,DOM处在javascript赋予html具备动态交互和效果的能力的核心地位上。
JavaScript在早期版本中提供了查询和操作Web文档的内容API(如:图像和表单),在JavaScript中定义了定义了'images'、'forms'等,因此我们可以像下这样访问第一张图片或名为“user”的表单:
document.images[0]document.forms['user']
这实际上是未形成标准的试验性质的初级阶段的DOM,现在习惯上被称为DOM0,即:第0级DOM。由于DOM0在W3C进行标准备化之前出现,还处于未形成标准的初期阶段,这时Netscape和Microsoft各自推出自己的第四代浏览器,自此DOM遍开始出各种问题。
Netscape Navigator 4和IE4分别发布于1997年的6月和10月,这两种浏览器都大幅扩展了DOM,使JavaScript的功能大大增加,而此时也开始出现一个新名词:DHTML。
DHTML是Dynamic HTML(动态HTML)的简称。DHTML并不是一项新技术,而是将HTML、CSS、JavaScript技术组合的一种描述。即:
利用DHTML,看起来可以很容易的控制页面元素,并实现一此原本很复杂的效果(如:通过改变元素位置实现动画)。但事实并非如此,因为没有规范和标准,两种浏览器对相同功能的实现确完全不一样。为了保持程序的兼容性,程序员必须写一些探查代码以检测JavaScript是运行于哪种浏览器之下,并提供与之对应的脚本。JavaScript陷入了前所未有的混乱,DHTML也因此在人们心中留下了很差的印象。
我们在阅读DOM标准的时候,经常会看到DOM0级这样的字眼,实际上DOM0级这个标准是不存在的。所谓DOM0级只是DOM
历史坐标系中的一个参照点而已,具体地说DOM0级就是指IE4.0和Netscape navigator4.0最初支持的那个DHTML。
在浏览器厂商进行浏览器大站的同时,W3C结合大家的优点推出了一个标准化的DOM,并于1998年10月完成了第一级 DOM,即:DOM1。W3C将DOM定义为一个与平台和编程语言无关的接口,通过这个接口程序和脚本可以动态的访问和修改文档的内容、结构和样式。
DOM1级主要定义了HTML和XML文档的底层结构。在DOM1中,DOM由两个模块组成:DOM Core(DOM核心)和DOM HTML。其中,DOM Core规定了基于XML的文档结构标准,通过这个标准简化了对文档中任意部分的访问和操作。DOM HTML则在DOM核心的基础上加以扩展,添加了针对HTML的对象和方法,如:JavaScript中的Document对象.
在DOM1的基础上DOM2引入了更多的交互能力,也支持了更高级的XML特性。DOM2将DOM分为更多具有联系的模块。DOM2级在原来DOM的基础上又扩充了鼠标、用户界面事件、范围、遍历等细分模块,而且通过对象接口增加了对CSS的支持。DOM1级中的DOM核心模块也经过扩展开始支持XML命名空间。在DOM2中引入了下列模块,在模块包含了众多新类型和新接口:

完整的DOM2标准(图片来自百度百科):

DOM3级:进一步扩展了DOM,引入了以统一方式加载和保存文档的方法,它在DOM Load And Save这个模块中定义;同时新增了验证文档的方法,是在DOM Validation这个模块中定义的。
DOM3进一步扩展了DOM,在DOM3中引入了以下模块:
DOM可以将任何HTML描绘成一个由多层节点构成的结构。节点分为12种不同类型,每种类型分别表示文档中不同的信息及标记。每个节点都拥有各自的特点、数据和方法,也与其他节点存在某种关系。节点之间的关系构成了层次,而所有页面标记则表现为一个以特定节点为根节点的树形结构。
先看一张w3school上面的一张图:
先来看看下面代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>DOM</title>
</head>
<body>
<h2><a href="http://www.baidu.com">javascript DOM</a></h2>
<p>对HTML元素进行操作,可添加、改变或移除css样式等</p>
<ul>
<li>Javascript</li>
<li>DOM</li>
<li>CSS</li>
</ul>
</body>
</html>将HTML代码分解为DOM节点层次图:
HTML文档可以说由节点构成的集合,DOM节点有:
我们说DOM文档对象模型是从文档中抽象出来的,DOM操作的对象也是文档,因此我们有必要了解一下文档的类型。文档随着历史的发展演变为多种类型,如下:
GML(Generalized Markup Language, 通用标记语言)是1960年代的一种IBM文档格式化语言,用于描述文档的组织结构、各部件及其相互关系。GML在文档具体格式方面,为文档员提供了一些方便,他们不必再为IBM的打印机格式化语言SCRIPT要求的字体规范、行距以及页面设计等浪费精力。这个IBM的GML包括1960年代的GML和1980年代的ISIL。
SGML(Standard Generalized Markup Language, 标准通用标记语言)是1986年基于IBM的GML制定ISO标准(ISO 8879)。SGML是现时常用的超文本格式的最高层次标准,是可以定义标记语言的元语言,甚至可以定义不必采用"<>"的常规方式。由于SGML的复杂,因而难以普及。HTML和XML同样衍生于SGML,XML可以被认为是SGML的一个子集,而HTML是SGML的一个应用。
HTML(HyperText Markup Language, 超文本标记语言)是为“网页创建和其它可在网页浏览器中看到的信息”设计的一种标记语言。HTML被用来结构化信息——例如标题、段落和列表等等,也可用来在一定程度上描述文档的外观和语义。1982年,蒂姆·伯纳斯-李为使世界各地的物理学家能够方便的进行合作研究,创建了使用于其系统的HTML。之后HTML又不断地扩充和发展,成为国际标准,由万维网联盟(W3C)维护。第一个正式标准是1995年发布的RFC 1866(HTML 2.0)。
XML(eXtensible Markup Language, 可扩展标记语言)是专家们使用SGML精简制作,并依照HTML的发展经验,产生出一套使用上规则严谨,但是简单的描述数据语言。XML在1995年开始有雏形,在1998二月发布为W3C的标准(XML1.0)
XHTML(eXtensible HyperText Markup Language, 可扩展超文本标记语言)的表现方式与超文本标记语言(HTML)类似,不过语法上更加严格。从继承关系上讲,HTML是一种基于标准通用标记语言(SGML)的应用,是一种非常灵活的置标语言,而XHTML则基于可扩展标记语言(XML),XML是SGML的一个子集。XHTML 1.0在2000年1月26日成为W3C的推荐标准。
DOM1级定义了一个Node接口,这个Node接口在javascript中是作为Node类型来实现的。除了IE以外,其他所有浏览器都可以访问这个类型。每个节点都有一个nodeType属性,用于表明节点的类型。节点类型通过定义数值常量和字符常量两种方式来表示,IE只支持数值常量。节点类型一共有12种,这里介绍常用的7种类型。如下图:
看下面这个例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>DocumentFragment文档片段节点</title>
</head>
<body>
<!-- tip区域 -->
<div id="tip">test1</div>
<ul class="list-node">
<li>test2<li>
</ul>
<script>
var frag = document.createDocumentFragment();
for (var i = 0; i < 10; i++) {
var li = document.createElement("li");
li.innerHTML = "List item" + i;
frag.appendChild(li);
}
document.getElementById("list-node").appendChild(frag);
</script>
</body>
</html> 以下引用均来自老师说的话,感觉每句话都很重要,所以就写下来了。
是组成文档树的重要部分,它表示了html、xml文档中的元素。通常元素因为有子元素、文本节点或者两者的结合,元素节点是唯一能够拥有属性的节点类型。
例子中的:html、heade、meta、title、body、div、ul、li、script都属于Element(元素节点);
代表了元素中的属性,因为属性实际上是附属于元素的,因此属性节点不能被看做是元素的子节点。因而在DOM中属性没有被认为是文档树的一部分。换句话说,属性节点其实被看做是包含它的元素节点的一部分,它并不作为单独的一个节点在文档树中出现。
例子中的:lang、charset、id、class都属于Attr(属性节点);
是只包含文本内容的节点,在xml中称为字符数据,它可以由更多的信息组成,也可以只包含空白。在文档树中元素的文本内容和属性的文本内容都是由文本节点来表示的。
例子中的:DocumentFragment文档片段节点、test1、test2、元素节点之后的空白区域都属于Text(文本节点);
表示注释的内容
例子中的:<!-- tip区域 -->都属于Comment(注释节点);
是文档树的根节点,它是文档中其他所有节点的父节点。要注意的是,文档节点并不是html、xml文档的根元素,因为在xml文档中,处理指令、注释等内容可以出现在根元素之外,所以我们在构造DOM树的时候,根元素并不适合作为根节点,因此就有了文档节点,而根元素是作为文档节点的子节点出现的。
例子中的:<!DOCTYPE html>、html作为Document(文档节点)的子节点出现;
每一个Document都有一个DocumentType属性,它的值或者是null,或者是DocumentType对象。比如声明文档类型时<!doctype html>就是文档类型节点。
例子中的:<!DOCTYPE html> 就属于DocumentType(文档类型节点);
是轻量级的或最小的Document对象,它表示文档的一部分或者是一段,不属于文档树。不过它有一种特殊的行为,该行为使得它非常有用。比如:当请求把一个DocumentFragment节点插入到文档的时候,插入的不是DocumentFragment自身,而是它的所有的子孙节点。这使得DocumentFragment成了有用的占位符,暂时存放那些一次插入文档的节点,同时它还有利于实现文档的剪切、复制和粘贴等操作。
例子中的:var frag = document.createDocumentFragment(); 就属于DocumentFragment(文档片段节点);
通过DOM节点类型,我们可知,可以通过某个节点的nodeType属性来获得节点的类型,节点的类型可以是数值常量或者字符常量。示例代码如下:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>nodeType</title>
</head>
<body>
<div id="container">这是一个元素节点</div>
<script>
var divNode = document.getElementById('container');
/*
IE中只支持数值常量,因为低版本IE浏览器没有内置Node对象,其他浏览器数值常量和字符常量都支持,因此可
以直接用数值常量判断,这里为了比较两种写法,便都写在了这里
*/
if (divNode.nodeType == Node.ELEMENT_NODE || divNode.nodeType === 1) {
alert("Node is an element.");
}
</script>
</body>
</html> 先看示例代码:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>nodeName,nodeValue</title>
</head>
<body>
<!--nodeName,nodeValue实验-->
<div id="container">这是一个元素节点</div>
<script>
var divNode = document.getElementById('container');
console.log(divNode.nodeName + "/" + divNode.nodeValue);
//结果: DIV/null
var attrNode = divNode.attributes[0];
console.log(attrNode.nodeName + "/" + attrNode.nodeValue);
//结果: id/container
var textNode = divNode.childNodes[0];
console.log(textNode.nodeName + "/" + textNode.nodeValue);
//结果: #text/这是一个元素节点
var commentNode = document.body.childNodes[1];
//表示取第二个注释节点,因为body下面的第一个注释节点为空白符。
console.log(commentNode.nodeName + "/" +commentNode.nodeValue);
//结果: #comment/nodeName,nodeValue实验
console.log(document.doctype.nodeName + "/" + document.doctype.nodeValue);
//结果: html/null
var frag = document.createDocumentFragment();
console.log(frag.nodeName + "/" + frag.nodeValue);
//结果: #document-fragment/null
</script>
</body>
</html> 根据实验,得出以下汇总表格:
还记得刚开始学习JavaScript时候,经常会犯这样的错误:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Dom not ready</title>
<script>
document.getElementById("header").style.color = "red";
</script>
</head>
<body>
<h1 id="header">这里是h1元素包含的内容</h1>
</body>
</html>最后发现结果并不是我们想要的,文字并没有变成红色,我想最先入门学习JavaScript操作DOM时候多多少少会遇到这种困惑和错误,其实出现这种问题的原因就是我们没有区分HTML标签和DOM节点的区别的缘故了,由这个问题就引出下面要说的domReady和浏览器渲染解析原理了。
html是一种标记语言,它告诉我们这个页面有什么内容,但行为交互是需要通过DOM操作来实现的。我们不要以为有两个尖括号就以为它是一个DOM了,html标签要通过浏览器解析才会变成DOM节点,当我们向地址栏传入一个url的时候,我们开始加载页面,就能看到内容,在这期间就有一个DOM节点构建的过程。节点是以树的形式组织的,当页面上所有的html都转换为节点以后,就叫做DOM树构建完毕,简称为domReady。
实际上浏览器是通过渲染引擎来实现的。渲染引擎的职责就是把请求的内容显示到浏览器屏幕上。默认情况下渲染引擎可以显示html、xml文档及图片。通过插件(浏览器扩展)它可以显示其他类型的文档,比如我们安装pdf viewer插件,我们就可以显示pdf文档。这里专注渲染引擎的主要用途,即是将css格式化的html和图片在浏览器上进行显示。
浏览器渲染要做的事就是把CSS,HTML,图片等静态资源展示到用户眼前。
渲染引擎首先通过网络获得所请求文档的内容,通常以8k分块的方法来完成:
上图就是html渲染的基本过程,但这并不包含解析过程中浏览器加载外部资源,比如图片、脚本、iframe等的一些过程。说白了,上面的4步仅仅是html结构的渲染过程。而外部资源的加载在html结构的渲染过程中是贯彻始终的,即便绘制DOM节点已经完成,而外部资源仍然可能正在加载或者尚未加载。
Firefox浏览器Gecko渲染流程跟Webkit内核渲染类似,大同小异,WebKit 和 Gecko 使用的术语略有不同,但整体流程是基本相同的。这里以Webkit内核作为例子来说明浏览器渲染的主要流程。
浏览器的渲染原理并非三言两语,几个图就能说明白的,上图说的只是介绍一个大环节的过程和步骤,这里抛砖引玉象征性说个大概,更多关于浏览器内部工作原理的文章,请阅读:浏览器的工作原理:新式网络浏览器幕后揭秘
上面的各个代码实例中,并没有考虑domReady,程序也能正常运行,因为我们把javascript代码写在了body元素最后的位置。因为浏览器是从上到下,从左向右渲染元素的,这样实例中的js代码一定在domReady之后去执行的。那为什么还要用domReady呢?事实上,我们在编写大型项目的时候,js文件往往非常多,而且之间会相互调用,大多数都是外部引用的,不把js代码直接写在页面上。这样的话,如果有个domReady这个方法,我们想用它就调用,不管逻辑代码写在哪里,都是等到domReady之后去执行的。
window.onload方法,表示当页面所有的元素都加载完毕,并且所有要请求的资源也加载完毕才触发执行function这个匿名函数里边的具体内容。这样肯定保证了代码在domReady之后执行。使用window.onload方法在文档外部资源不多的情况下不会有什么问题,但是当页面中有大量远程图片或要请求的远程资源时,我们需要让js在点击每张图片时,进行相应的操作,如果此时外部资源还没有加载完毕,点击图片是不会有任何反应的,大大降低了用户体验。那既然window.onload方法不可行,又该怎么做呢?
你肯定想到了jquery中的$(document).ready(function(){})方法了,其实jquery中的domReady应该和window.onload的实现原理是大同小异的。为了解决window.onload的短板,w3c 新增了一个 DOMContentLoaded 事件。
这里提到了DOMContentLoaded事件,这里由于篇幅有限,就不多做介绍,这里面也有很多细节可以学习,有兴趣的童鞋,可以看看我之前收藏的两篇文章:
你不知道的 DOMContentLoaded
浅谈DOMContentLoaded事件及其封装方法
学习就是一个无底洞,因为深不可测,才让人不断探索。
参考jquery中domReady的实现原理,来看一下javascript中domReady的实现策略。
在页面的DOM树创建完成后(也就是HTML解析第一步完成)即触发,而无需等待其他资源的加载。即domReady实现策略:
1. 支持DOMContentLoaded事件的,就使用DOMContentLoaded事件。
2. 不支持的就用来自Diego Perini发现的著名Hack兼容。兼容原理大概就是通过IE中的document,
documentElement.doScroll('left')来判断DOM树是否创建完毕。
JavaScript实现domReady,【domReady.js】
function myReady(fn){
//对于现代浏览器,对DOMContentLoaded事件的处理采用标准的事件绑定方式
if ( document.addEventListener ) {
document.addEventListener("DOMContentLoaded", fn, false);
} else {
IEContentLoaded(fn);
}
//IE模拟DOMContentLoaded
function IEContentLoaded (fn) {
var d = window.document;
var done = false;
//只执行一次用户的回调函数init()
var init = function () {
if (!done) {
done = true;
fn();
}
};
(function () {
try {
// DOM树未创建完之前调用doScroll会抛出错误
d.documentElement.doScroll('left');
} catch (e) {
//延迟再试一次~
setTimeout(arguments.callee, 50);
return;
}
// 没有错误就表示DOM树创建完毕,然后立马执行用户回调
init();
})();
//监听document的加载状态
d.onreadystatechange = function() {
// 如果用户是在domReady之后绑定的函数,就立马执行
if (d.readyState == 'complete') {
d.onreadystatechange = null;
init();
}
}
}
} 在页面中引入donReady.js文件,引用myReady(回调函数)方法即可。
感兴趣的童鞋可以看看各个主流框架domReady的实现:点击我查看
下面通过一个案例,来比较domReady与window.onload实现的不同,很明显,onload事件是要在所有请求都完成之后才执行,而domReady利用hack技术,在加载完dom树之后就能执行,所以domReady比onload执行时间更早,建议采用domReady。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>domReady与window.onload</title>
<script src="domReady.js"></script>
</head>
<body>
<div id="showMsg"></div>
<div>
<img src="http://ww1.sinaimg.cn/large/ae49ba57gy1fe9zofelhdj20xc0xc42s.jpg" alt="">
<img src="http://ww1.sinaimg.cn/large/ae49ba57gy1fe9zofahw3j20m80etq4a.jpg" alt="">
<img src="http://ww1.sinaimg.cn/large/ae49ba57gy1fe9zoi3ny6j20l20dw4gd.jpg" alt="">
<img src="http://ww1.sinaimg.cn/large/ae49ba57gy1fe9zog3tauj20m80et0uw.jpg" alt="">
<img src="http://ww1.sinaimg.cn/large/ae49ba57gy1fe9zofi2o5j20m80ettaq.jpg" alt="">
<img src="http://ww1.sinaimg.cn/large/ae49ba57gy1fe9zohjuvhj20tb0cdwvp.jpg" alt="">
</div>
<script>
var d = document;
var msgBox = d.getElementById("showMsg");
var imgs = d.getElementsByTagName("img");
var time1 = null,
time2 = null;
myReady(function() {
msgBox.innerHTML += "dom已加载!<br>";
time1 = new Date().getTime();
msgBox.innerHTML += "时间戳:" + time1 + "<br>";
});
window.onload = function() {
msgBox.innerHTML += "onload已加载!<br>";
time2 = new Date().getTime();
msgBox.innerHTML += "时间戳:" + time2 + "<br>";
msgBox.innerHTML += "domReady比onload快:" + (time2 - time1) + "ms<br>";
};
</script>
</body>
</html>执行结果对比,发现DomReady比onload快乐2秒多。
为什么要判断元素的节点?
因为要判断元素节点类型,因为属性的一系列操作与元素的节点类型息息相关,如果我们不区分它们,我们就不知道用元素的直接属性操作(例如:ele.xxx=yyy)还是用一个方法操作(el.setAttribute(xxx,yyy))。
设计元素类型的判定,这里给出有4个方法:
(1). isElement :判定某个节点是否为元素节点
(2). isHTML :判定某个节点是否为html文档的元素节点
(3). isXML : 判定某个节点是否为xml文档的元素节点
(4). contains :用来判定两个节点的包含关系
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isElement</title>
</head>
<body>
<div id="test">aaa</div>
<!--这是一个注释节点-->
<script>
var isElement = function (el){
return !!el && el.nodeType === 1;
}
var a = { //随意定义一个变量,设置nodeType为1
nodeType: 1
}
console.log(isElement(document.getElementById("test")));
//结果: true
console.log(isElement(document.getElementById("test").nextSibling));
//这里的nextSibling属性查找下一个相邻节点,即注释节点
//结果: false
console.log(isElement(a));
//结果: true
</script>
</body>
</html> 注意代码中的!!用法:!!一般用来将后面的表达式转换为布尔型的数据(boolean).
因为javascript是弱类型的语言(变量没有固定的数据类型)所以有时需要强制转换为相应的类型,关于JavaScript的隐式转换,可以看看之前我写的一篇博客,这篇文章几乎分析到了所有的转换规则,感兴趣的童鞋可以点击查阅,学习了解一下。
从++[[]][+[]]+[+[]]==10?深入浅出弱类型JS的隐式转换
注意:上面的代码定义了一个变量a,将它的nodeType的值设为1,由于元素节点的节点类型的数值常量为1,所以这里在打印的的时候,会将a认为是元素节点,所以打印true。这种结果明显不是我们想要的,即使这种情况很少出现。下面给出解决方案:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isElement</title>
</head>
<body>
<div id="test">aaa</div>
<!--这是一个注释节点-->
<script>
var testDiv = document.createElement('div');
var isElement = function (obj) {
if (obj && obj.nodeType === 1) {//先过滤最简单的
if( window.Node && (obj instanceof Node )){
//如果是IE9,则判定其是否Node的实例
return true; //由于obj可能是来自另一个文档对象,因此不能轻易返回false
}
try {//最后以这种效率非常差但肯定可行的方案进行判定
testDiv.appendChild(obj);
testDiv.removeChild(obj);
} catch (e) {
return false;
}
return true;
}
return false;
}
var a = {
nodeType: 1
}
console.log(isElement(document.getElementById("test")));
//结果: true
console.log(isElement(document.getElementById("test").nextSibling));
//结果: false
console.log(isElement(a));
//结果: false
</script>
</body>
</html> 这样,在判断a是否是元素节点时,结果就是false了。
更多关于元素节点的判断请参考:How do you check if a JavaScript Object is a DOM Object?
我们可以简单的将所有的元素节点化为两类:一类是HTML,一类是XML。不过从严格意义上来说,HTML只是XML的一个子集,它拥有更多的特性,而XML在矢量绘图的处理上又派生出了两大类:SVG和VML。那么按照这种方法,我们可以简单的认为如果不是HTML,就是XML的元素节点了。而HTML是比较容易识别的,因为它有更多的特性。比如说,XML是没有className的,或者我们通过一个元素的ownerDocument得到它的文档对象,XML是没有document.getElementById()和document.getElementsByTagName()这些方法的.此外,最大的区别是HTML元素的nodeName总是大写的,当你使用createElement()方法创建HTML元素的时候,无论你传入的字母是大写还是小写,最后得到的都是大写。
接下来就看看各大类库是怎么实现HTML和XML文档的元素节点的判定的。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isXML</title>
</head>
<body>
<script>
//Sizzle, jQuery自带的选择器引擎
var isXML = function(elem) {
var documentElement = elem && (elem.ownerDocument || elem).documentElement;
return documentElement ? documentElement.nodeName !== "HTML" : false;
};
console.log(isXML(document.getElementById("test")));
//但这样不严谨,因为XML的根节点,也可能是HTML标签,比如这样创建一个XML文档
try {
var doc = document.implementation.createDocument(null, 'HTML', null);
console.log(doc.documentElement);
console.log(isXML(doc));
} catch (e) {
console.log("不支持creatDocument方法");
}
</script>
</body>
</html> 浏览器随便找个HTML页面验证一下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isXML</title>
</head>
<body>
<script>
//我们看看mootools的slick选择器引擎的源码:
var isXML = function(document) {
return (!!document.xmlVersion) || (!!document.xml) || (toString.call(document) == '[object XMLDocument]')
|| (document.nodeType == 9 && document.documentElement.nodeName != 'HTML');
};
//精简版
var isXML = window.HTMLDocument ? function(doc) {
return !(doc instanceof HTMLDocument);
} : function(doc) {
return "selectNodes" in doc;
}
</script>
</body>
</html> 不过,这些方法都只是规范,javascript对象是可以随意添加的,属性法很容易被攻破,最好是使用功能法。功能法的实现代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isXML</title>
</head>
<body>
<script>
var isXML = function(doc) {
return doc.createElement("p").nodeName !== doc.createElement("P").nodeName;
}
</script>
</body>
</html> 我们知道,无论是HTML文档,还是XML文档都支持createELement()方法,我们判定创建的元素的nodeName是区分大小写的还是不区分大小写的,我们就知道是XML还是HTML文档,这个方法是目前给出的最严谨的函数了。
判断是不是HTML文档的方法如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isHTML</title>
</head>
<body>
<script>
var isHTML = function(doc) {
return doc.createElement("p").nodeName === doc.createElement("P").nodeName;
}
console.log(isHTML(document));
</script>
</body>
</html> 有了以上判断XML和HTML文档的方法,我们就可以实现一个元素节点属于HTML还是XML文档的方法了,实现代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>isHTMLElement</title>
</head>
<body>
<script>
var testDiv = document.createElement('div');
var isElement = function (obj) {
if (obj && obj.nodeType === 1) {//先过滤最简单的
if( window.Node && (obj instanceof Node )){
//如果是IE9,则判定其是否Node的实例
return true; //由于obj可能是来自另一个文档对象,因此不能轻易返回false
}
try {//最后以这种效率非常差但肯定可行的方案进行判定
testDiv.appendChild(obj);
testDiv.removeChild(obj);
} catch (e) {
return false;
}
return true;
}
return false;
}
var isHTML = function(doc) {
return doc.createElement("p").nodeName === doc.createElement("P").nodeName;
}
var isHTMLElement = function(el){
if(isElement){
return isHTML(el.ownerDocument);
}
return false;
}
console.log(isHTMLElement(testDiv));
</script>
</body>
</html> DOM可以将任何HTML描绘成一个由多层节点构成的结构。节点分为12种不同类型,每种类型分别表示文档中不同的信息及标记。每个节点都拥有各自的特点、数据和方法,也与其他节点存在某种关系。节点之间的关系构成了层次,而所有页面标记则表现为一个以特定节点为根节点的树形结构。DOM间的节点关系大致如下。
节点关系不仅仅指元素节点的关系,document文档节点也包含在内。在最新的浏览器中,所有的节点都已经装备了contains()方法,
元素之间的包含关系,用自带的contains方法,只有两个都是元素节点,才能兼容各个浏览器,否则ie浏览器有的版本是不支持的,可以采用hack技术,自己写一个contains方法去兼容。
元素之间的包含关系:contains()方法.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>contains</title>
</head>
<body>
<div id="p-node">
<div id="c-node">子节点内容</div>
</div>
<script>
var pNode = document.getElementById("p-node");
var cNode = document.getElementById("c-node").childNodes[0];
alert(pNode.contains(cNode)); //true
</script>
</body>
</html> 兼容各浏览器的contains()方法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>contains</title>
</head>
<body>
<div id="p-node">
<div id="c-node">子节点内容</div>
</div>
<script>
//兼容的contains方法
function fixContains(a, b) {
try {
while ((b = b.parentNode)){
if (b === a){
return true;
}
}
return false;
} catch (e) {
return false;
}
}
var pNode = document.getElementById("p-node");
var cNode = document.getElementById("c-node").childNodes[0];
alert(fixContains(pNode, cNode)); //true
alert(fixContains(document, cNode)); //true
</script>
</body>
</html>
DOM节点是一个非常复杂的东西,对它的每一个属性的访问,不走运的话,就可能会向上溯寻到N多个原型链,因此DOM操作是个非常耗性能的操作。风头正盛的react为了解决这个问题,提出了虚拟DOM的概念,合并和屏蔽了很多无效的DOM操作,效果非常惊人。接下来看看DOM节点究竟是如何继承的。
使用document.createElement("p")创建p元素,其实document.createElement("p")是HTMLParagraphElement的一个实例,而HTMLParagraphElement的父类是HTMLElement,HTMLElement的父类是Element,Element的父类是Node,Node的父类是EventTarget,EventTarget的父类是Function,Function的父类是Object。
创建一个p元素一共溯寻了7层原型链:
下面我们来分析一下创建一个元素所继承的属性分别是啥。
document.createElement("p")首先就是一个实例对象,它是由构造函数HTMLParagraphElement产生的,你可以这么看这个问题:
function HTMLParagraphElement() {
[native code]
}
document.createElement("p")=new HTMLParagraphElement('p');由以上继承关系可以看出来:
document.createElement("p").constructor===HTMLParagraphElement document.createElement("p").__proto__===HTMLParagraphElement.prototype
对实例对象,构造函数,以及JavaScript原型链和继承不太熟悉的童鞋,该补习一下基础看看了。
我们先来看看document.createElement("p")自身有哪些属性,遍历对象属性方法一般有三种:
先来讲一讲遍历对象属性三种方法的差异性,当做补充复习。
遍历数组属性目前我知道的有:for-in循环、Object.keys()和Object.getOwnPropertyNames(),那么三种到底有啥区别呢?
for-in循环:会遍历对象自身的属性,以及原型属性,包括enumerable 为 false(不可枚举属性);
Object.keys():可以得到自身可枚举的属性,但得不到原型链上的属性;
Object.getOwnPropertyNames():可以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性,Symbols属性
也得不到.
Object.defineProperty顾名思义,就是用来定义对象属性的,vue.js的双向数据绑定主要在getter和setter函数里面插入一些处理方法,当对象被读写的时候处理方法就会被执行了。 关于这些方法和属性的更具体解释,可以看MDN上的解释(戳我);
简单看一个小demo例子加深理解,对于Object.defineProperty属性不太明白,可以看看上面介绍的文档学习补充一下.
'use strict';
class A {
constructor() {
this.name = 'jawil';
}
getName() {}
}
class B extends A {
constructor() {
super();
this.age = 22;
}
//getAge不可枚举
getAge() {}
[Symbol('fullName')]() {
}
}
B.prototype.get = function() {
}
var b = new B();
//设置b对象的info属性的enumerable: false,让其不能枚举.
Object.defineProperty(b, 'info', {
value: 7,
writable: true,
configurable: true,
enumerable: false
});
//Object可以得到自身可枚举的属性,但得不到原型链上的属性
console.log(Object.keys(b)); //[ 'name', 'age' ]
//Object可A以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性,Symbols属性也得不到
console.log(Object.getOwnPropertyNames(b)); //[ 'name', 'age', 'info' ]
for (var attr in b) {
console.log(attr);//name,age,get
}
//in会遍历对象自身的属性,以及原型属性
console.log('getName' in b); //true
有了上面的知识作为扩充,我们就可以清晰明了的知道,创建元素P标签每一步都继承了哪些属性,继承对象自身有哪些属性,由于篇幅有限,大家可以自行子在浏览器测试,看看这些对象的一些属性和方法,便于我们理解。
例如我们想看:HTMLElement对象有哪些自身属性,我们可以这么查看:
Object.getOwnPropertyNames(HTMLElement)我们想看:HTMLElement的原型对象有哪些自身属性,我们可以这么查看:
Object.getOwnPropertyNames(HTMLElement.prototype)HTMLElement的原型对象有哪些自身属性,根据原型链,我们也可以这么查看:
因为:document.createElement("p").__proto__.__proto__===HTMLElement.prototype
Object.getOwnPropertyNames(document.createElement("p").__proto__.__proto__)
使用document.createTextNode("xxx")创建文本节点,其实document.createTextNode("xxx")是Text的一个实例,而Text的父类是CharactorData,CharactorData的父类是Node,Node的父类是EventTarget,EventTarget的父类是Function,Function的父类是Object。
创建一个文本节点一共溯寻了6层原型链。
因此,所有节点的继承层次都不简单,但相比较而言,元素节点是更可怕的。从HTML1升级到HTML3.2,再升级到HTML4.1,再到HTML5,除了不断地增加新类型、新的嵌套规则以外,每个元素也不断的添加新属性。
下面看一个例子:创建一个p元素,打印它第一层原型的固有的属性的名字,通过Object的getOwnPropertyNames()获取当前元素的一些属性,这些属性都是他的原始属性,不包含用户自定义的属性。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>DOM inheritance hierarchy</title>
</head>
<body>
<script>
console.log(Object.getOwnPropertyNames(document.createElement("p").__proto__));
//访问p元素上一层原型控制台打印: ["align","constructor"]
console.log(
Object.getOwnPropertyNames(document.createElement("p").__proto__.__proto__)
);
/*访问p元素上一层原型的再上一层原型,控制台会打印很多属性,感兴趣的伙伴可以自己贴代码到控制台看
一下,它要比访*问第一层原型的属性多得多。这也就是说,每往上一层,原型链就为它添加一些属性。
*/
</script>
</body>
</html> 下面看一个空的div元素,并且没有插入到DOM里边,看它有多少自有属性(不包括原型链继承来的属性)
在新的HTML规范中,许多元素的固有属性(比如value)都放到了原型链当中,数量就更加庞大了。因此,未来的发展方向是尽量使用现成的框架来实现,比如MVVM框架,将所有的DOM操作都转交给框架内部做精细处理,这些实现方案当然就包括了虚拟DOM的技术了。但是在使用MVVM框架之前,掌握底层知识是非常重要的,明白为什么这样做,为什么不这样做的目的。这也是为什么要理解DOM节点继承层次的目的。
HTML存在许多种类型的标签,有的标签下面只允许特定的标签存在,这就叫HTML嵌套规则。
不按HTML嵌套规则写,浏览器就不会正确解析,会将不符合嵌套规则的节点放到目标节点的下面,或者变成纯文本。
关于HTML嵌套规则,一定要掌握块状元素和内联元素的区别。
块状元素:一般是其他元素的容器,可容纳内联元素和其他块状元素,块状元素排斥其他元素与其位于同一行,宽度(width)高度(height)起作用。常见块状元素为div和p
内联元素:内联元素只能容纳文本或者其他内联元素,它允许其他内联元素与其位于同一行,但宽度(width)高度(height)不起作用。常见内联元素为a.
块状元素与内联元素嵌套规则:
(1).块元素可以包含内联元素或某些块元素,但内联元素却不能包含块元素,它只能包含其他的内联元素
例:
<div><h1></h1><p></p></div>
<a href="#"><span></span></a>
(2).块级元素不能放在
里面
例:<p><ol><li></li></ol></p><p><div></div></p>
(3).有几个特殊的块级元素提倡只能包含内联元素,不能再包含块级元素,这几个特殊的标签是:
h1、h2、 h3、h4、 h5、 h6、 p 、dt
(4).li标签可以包含div标签
例:
<li><div></div></li>
(5).块级元素与块级元素并列,内联元素与内联元素并列
例:
<div><h2></h2><p></p></div>
<div><a href="#"></a><span></span></div>
有些东西很好用,但是你未必知道;有些东西你可能用过,但是你未必知道原理。
实现一个目的有多种途径,俗话说,条条大路通罗马。很多内容来自平时的一些收集以及过往博客文章底下的精彩评论,收集整理拓展一波,发散一下大家的思维以及拓展一下知识面。
茴字有四种写法,233333..., 文末有彩蛋有惊喜。
很多语言都有 sleep 函数,显然 js 没有,那么如何能简短优雅地实现这个方法?
function sleep(sleepTime) {
for(var start = +new Date; +new Date - start <= sleepTime;) {}
}
var t1 = +new Date()
sleep(3000)
var t2 = +new Date()
console.log(t2 - t1)优点:简单粗暴,通俗易懂。
缺点:这是最简单粗暴的实现,确实 sleep 了,也确实卡死了,CPU 会飙升,无论你的服务器 CPU 有多么 Niubility。
function sleep(time) {
return new Promise(resolve => setTimeout(resolve, time))
}
const t1 = +new Date()
sleep(3000).then(() => {
const t2 = +new Date()
console.log(t2 - t1)
})优点:这种方式实际上是用了 setTimeout,没有形成进程阻塞,不会造成性能和负载问题。
缺点:虽然不像 callback 套那么多层,但仍不怎么美观,而且当我们需要在某过程中需要停止执行(或者在中途返回了错误的值),还必须得层层判断后跳出,非常麻烦,而且这种异步并不是那么彻底,还是看起来别扭。
function sleep(delay) {
return function(cb) {
setTimeout(cb.bind(this), delay)
};
}
function* genSleep() {
const t1 = +new Date()
yield sleep(3000)
const t2 = +new Date()
console.log(t2 - t1)
}
async(genSleep)
function async(gen) {
const iter = gen()
function nextStep(it) {
if (it.done) return
if (typeof it.value === "function") {
it.value(function(ret) {
nextStep(iter.next(ret))
})
} else {
nextStep(iter.next(it.value))
}
}
nextStep(iter.next())
}优点:同 Promise 优点,另外代码就变得非常简单干净,没有 then 那么生硬和恶心。
缺点:但不足也很明显,就是每次都要执行 next() 显得很麻烦,虽然有 co(第三方包)可以解决,但就多包了一层,不好看,错误也必须按 co 的逻辑来处理,不爽。
co 之所以这么火并不是没有原因的,当然不是仅仅实现 sleep 这么无聊的事情,而是它活生生的借着generator/yield 实现了很类似 async/await 的效果!这一点真是让我三观尽毁刮目相看。
const co = require("co")
function sleep(delay) {
return function(cb) {
setTimeout(cb.bind(this), delay)
}
}
co(function*() {
const t1 = +new Date()
yield sleep(3000)
const t2 = +new Date()
console.log(t2 - t1)
})function sleep(delay) {
return new Promise(reslove => {
setTimeout(reslove, delay)
})
}
!async function test() {
const t1 = +new Date()
await sleep(3000)
const t2 = +new Date()
console.log(t2 - t1)
}()优点:同 Promise 和 Generator 优点。 Async/Await 可以看做是 Generator 的语法糖,Async 和 Await 相较于 * 和 yield 更加语义,另外各个函数都是扁平的,不会产生多余的嵌套,代码更加清爽易读。
缺点: ES7 语法存在兼容性问题,有 babel 一切兼容性都不是问题
至于 Async/Await 比 Promise 和 Generator 的好处可以参考这两篇文章:
Async/Await 比 Generator 的四个改进点
关于Async/Await替代Promise的6个理由
在 javascript 优雅的写 sleep 等于如何优雅的不优雅,2333
这里有 C++ 实现的模块:https://github.com/ErikDubbelboer/node-sleep
const sleep = require("sleep")
const t1 = +new Date()
sleep.msleep(3000)
const t2 = +new Date()
console.log(t2 - t1)优点:能够实现更加精细的时间精确度,而且看起来就是真的 sleep 函数,清晰直白。
缺点:缺点需要安装这个模块,^_^,这也许算不上什么缺点。
从一个间简简单单的 sleep 函数我们就就可以管中窥豹,看见 JavaScript 近几年来不断快速的发展,不单单是异步编程这一块,还有各种各样的新技术和新框架,见证了 JavaScript 的繁荣。
你可能不知道的前端知识点:Async/Await是目前前端异步书写最优雅的一种方式
上面第一个用多种方式实现 sleep 函数,我们可以发现代码有 +new Date()获取时间戳的用法,这只是其中的一种,下面就说一下其他两种以及 +new Date()的原理。
var timestamp=new Date().getTime()优点:具有普遍性,大家都用这个
缺点:目前没有发现
var timestamp = (new Date()).valueOf()valueOf 方法返回对象的原始值(Primitive,'Null','Undefined','String','Boolean','Number'五种基本数据类型之一),可能是字符串、数值或 bool 值等,看具体的对象。
优点:说明开发者原始值有一个具体的认知,让人眼前一亮。
缺点: 目前没有发现
var timestamp = +new Date()优点:对 JavaScript 隐式转换掌握的比较牢固的一个表现
缺点:目前没有发现
现在就简单分析一下为什么 +new Date() 拿到的是时间戳。
一言以蔽之,这是隐式转换的玄学,实质还是调用了 valueOf() 的方法。
我们先看看 ECMAScript 规范对一元运算符的规范:
一元+ 运算符
一元 + 运算符将其操作数转换为 Number 类型并反转其正负。注意负的 +0 产生 -0,负的 -0 产生 +0。产生式 UnaryExpression : - UnaryExpression 按照下面的过程执行。
- 令 expr 为解释执行 UnaryExpression 的结果 .
- 令 oldValue 为 ToNumber(GetValue(expr)).
- 如果 oldValue is NaN ,return NaN.
- 返回 oldValue 取负(即,算出一个数字相同但是符号相反的值)的结果。
+new Date() 相当于 ToNumber(new Date())
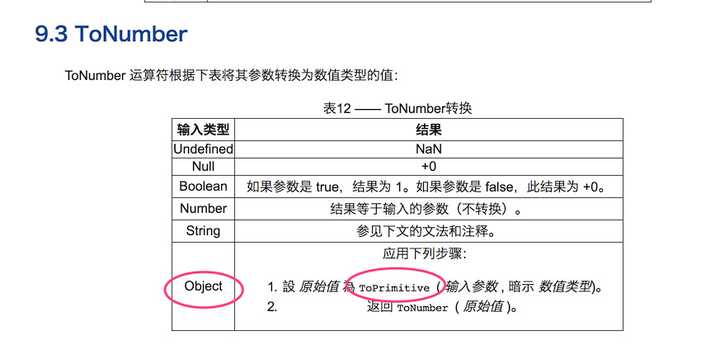
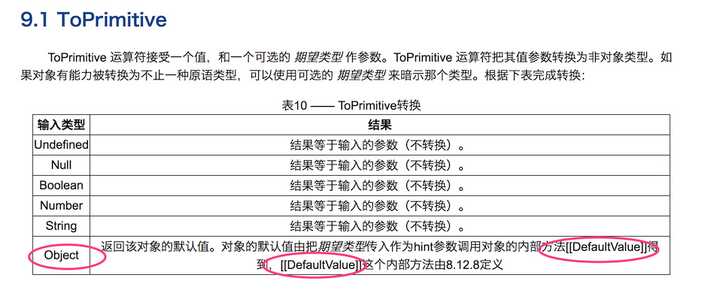
我们再来看看 ECMAScript 规范对 ToNumber 的定义:
我们知道 new Date() 是个对象,满足上面的 ToPrimitive(),所以进而成了 ToPrimitive(new Date())。
接着我们再来看看 ECMAScript 规范对 ToPrimitive 的定义,一层一层来,抽丝剥茧。
这个 ToPrimitive 刚开始可能不太好懂,我来大致解释一下吧:
ToPrimitive(obj,preferredType)
JavaScript 引擎内部转换为原始值 ToPrimitive(obj,preferredType) 函数接受两个参数,第一个 obj 为被转换的对象,第二个preferredType 为希望转换成的类型(默认为空,接受的值为 Number 或 String)
在执行 ToPrimitive(obj,preferredType) 时如果第二个参数为空并且 obj 为 Date 的实例时,此时 preferredType 会被设置为 String,其他情况下 preferredType 都会被设置为Number 如果 preferredType 为 Number,ToPrimitive 执行过程如下:
- 如果obj为原始值,直接返回;
- 否则调用 obj.valueOf(),如果执行结果是原始值,返回之;
- 否则调用 obj.toString(),如果执行结果是原始值,返回之;
- 否则抛异常。
如果 preferredType 为 String,将上面的第2步和第3步调换,即:
- 如果obj为原始值,直接返回;
- 否则调用 obj.toString(),如果执行结果是原始值,返回之;
- 否则调用 obj.valueOf(),如果执行结果是原始值,返回之;
- 否则抛异常。
首先我们要明白 obj.valueOf() 和 obj.toString() 还有原始值分别是什么意思,这是弄懂上面描述的前提之一:
toString 用来返回对象的字符串表示。
var obj = {};
console.log(obj.toString());//[object Object]
var arr2 = [];
console.log(arr2.toString());//""空字符串
var date = new Date();
console.log(date.toString());//Sun Feb 28 2016 13:40:36 GMT+0800 (**标准时间)valueOf 方法返回对象的原始值,可能是字符串、数值或 bool 值等,看具体的对象。
var obj = {
name: "obj"
}
console.log(obj.valueOf()) //Object {name: "obj"}
var arr1 = [1]
console.log(arr1.valueOf()) //[1]
var date = new Date()
console.log(date.valueOf())//1456638436303
如代码所示,三个不同的对象实例调用valueOf返回不同的数据原始值指的是 'Null','Undefined','String','Boolean','Number','Symbol' 6种基本数据类型之一,上面已经提到过这个概念,这里再次申明一下。
最后分解一下其中的过程:+new Date():
- 运算符
new的优先级高于一元运算符+,所以过程可以分解为:
var time=new Date();
+time- 根据上面提到的规则相当于:
ToNumber(time)time是个日期对象,根据ToNumber的转换规则,所以相当于:ToNumber(ToPrimitive(time))- 根据
ToPrimitive的转换规则:ToNumber(time.valueOf()),time.valueOf()就是 原始值 得到的是个时间戳,假设time.valueOf()=1503479124652- 所以
ToNumber(1503479124652)返回值是1503479124652这个数字。- 分析完毕
你可能不知道的前端知识点:隐式转换的妙用
注:暂不考虑对象字面量,函数等引用类型的去重,也不考虑 NaN, undefined, null等特殊类型情况。
数组样本:[1, 1, '1', '2', 1]
无需思考,我们可以得到 O(n^2) 复杂度的解法。定义一个变量数组 res 保存结果,遍历需要去重的数组,如果该元素已经存在在 res 中了,则说明是重复的元素,如果没有,则放入 res 中。
var a = [1, 1, '1', '2', 1]
function unique(arr) {
var res = []
for (var i = 0, len = arr.length; i < len; i++) {
var item = arr[i]
for (var j = 0, len = res.length; j < jlen; j++) {
if (item === res[j]) //arr数组的item在res已经存在,就跳出循环
break
}
if (j === jlen) //循环完毕,arr数组的item在res找不到,就push到res数组中
res.push(item)
}
return res
}
console.log(unique(a)) // [1, 2, "1"]优点: 没有任何兼容性问题,通俗易懂,没有任何理解成本
缺点: 看起来比较臃肿比较繁琐,时间复杂度比较高O(n^2)
var a = [1, 1, '1', '2', 1]
function unique(arr) {
return arr.filter(function(ele,index,array){
return array.indexOf(ele) === index//很巧妙,这样筛选一对一的,过滤掉重复的
})
}
console.log(unique(a)) // [1, 2, "1"]优点:很简洁,思维也比较巧妙,直观易懂。
缺点:不支持 IE9 以下的浏览器,时间复杂度还是O(n^2)
var a = [1, 1, '1', '2', 1]
function unique(arr) {
var obj = {}
return arr.filter(function(item, index, array){
return obj.hasOwnProperty(typeof item + item) ?
false :
(obj[typeof item + item] = true)
})
}
console.log(unique(a)) // [1, 2, "1"]优点:hasOwnProperty 是对象的属性(名称)存在性检查方法。对象的属性可以基于 Hash 表实现,因此对属性进行访问的时间复杂度可以达到O(1);
filter 是数组迭代的方法,内部还是一个 for 循环,所以时间复杂度是 O(n)。
缺点:不兼容 IE9 以下浏览器,其实也好解决,把 filter 方法用 for 循环代替或者自己模拟一个 filter 方法。
以 Set 为例,ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
const unique = a => [...new Set(a)]优点:ES6 语法,简洁高效,我们可以看到,去重方法从原始的 14 行代码到 ES6 的 1 行代码,其实也说明了 JavaScript 这门语言在不停的进步,相信以后的开发也会越来越高效。
缺点:兼容性问题,现代浏览器才支持,有 babel 这些都不是问题。
你可能不知道的前端知识点:ES6 新的数据结构 Set 去重
function formatNumber(str) {
let arr = [],
count = str.length
while (count >= 3) {
arr.unshift(str.slice(count - 3, count))
count -= 3
}
// 如果是不是3的倍数就另外追加到上去
str.length % 3 && arr.unshift(str.slice(0, str.length % 3))
return arr.toString()
}
console.log(formatNumber("1234567890")) // 1,234,567,890优点:自我感觉比网上写的一堆 for循环 还有 if-else 判断的逻辑更加清晰直白。
缺点:太普通
function formatNumber(str) {
// ["0", "9", "8", "7", "6", "5", "4", "3", "2", "1"]
return str.split("").reverse().reduce((prev, next, index) => {
return ((index % 3) ? next : (next + ',')) + prev
})
}
console.log(formatNumber("1234567890")) // 1,234,567,890优点:把 JS 的 API 玩的了如指掌
缺点:可能没那么好懂,不过读懂之后就会发出我怎么没想到的感觉
function formatNumber(str) {
return str.replace(/\B(?=(\d{3})+(?!\d))/g, ',')
}
console.log(formatNumber("123456789")) // 1,234,567,890下面简单分析下正则/\B(?=(\d{3})+(?!\d))/g:
/\B(?=(\d{3})+(?!\d))/g:正则匹配边界\B,边界后面必须跟着(\d{3})+(?!\d);(\d{3})+:必须是1个或多个的3个连续数字;(?!\d):第2步中的3个数字不允许后面跟着数字;(\d{3})+(?!\d):所以匹配的边界后面必须跟着3*n(n>=1)的数字。
最终把匹配到的所有边界换成,即可达成目标。
优点:代码少,浓缩的就是精华
缺点:需要对正则表达式的位置匹配有一个较深的认识,门槛大一点
(123456789).toLocaleString('en-US') // 1,234,567,890如图,你可能还不知道 JavaScript 的 toLocaleString 还可以这么玩。
还可以使用 Intl对象 - MDN
Intl 对象是 ECMAScript 国际化 API 的一个命名空间,它提供了精确的字符串对比,数字格式化,日期和时间格式化。Collator,NumberFormat 和 DateTimeFormat 对象的构造函数是 Intl 对象的属性。
new Intl.NumberFormat().format(1234567890) // 1,234,567,890优点:简单粗暴,直接调用 API
缺点:Intl兼容性不太好,不过 toLocaleString的话 IE6 都支持
你可能不知道的前端知识点:Intl对象 和 toLocaleString的方法。
let a = 3,b = 4 变成 a = 4, b = 3
首先最常规的办法,引入一个 temp 中间变量
let a = 3,b = 4
let temp = a
a = b
b = temp
console.log(a, b)优点:一眼能看懂就是最好的优点
缺点:硬说缺点就是引入了一个多余的变量
在不引入中间变量的情况下也能交互两个变量
let a = 3,b = 4
a += b
b = a - b
a -= b
console.log(a, b)优点:比起楼上那种没有引入多余的变量,比上面那一种稍微巧妙一点
缺点:当然缺点也很明显,整型数据溢出,比如说对于32位字符最大表示有符号数字是2147483647,也就是Math.pow(2,31)-1,如果是2147483645和2147483646交换就失败了。
利用一个数异或本身等于0和异或运算符合交换率。
let a = 3,b = 4
a ^= b
b ^= a
a ^= b
console.log(a, b)下面用竖式进行简单说明:(10进制化为二进制)
a = 011
(^) b = 100
则 a = 111(a ^ b的结果赋值给a,a已变成了7)
(^) b = 100
则 b = 011(b^a的结果赋给b,b已经变成了3)
(^) a = 111
则 a = 100(a^b的结果赋给a,a已经变成了4)从上面的竖式可以清楚的看到利用异或运算实现两个值交换的基本过程。
下面从深层次剖析一下:
1.对于开始的两个赋值语句,a = a ^ b,b = b ^ a,相当于b = b ^ (a ^ b) = a ^ b ^ b,而b ^ b 显然等于0。因此b = a ^ 0,显然结果为a。
2. 同理可以分析第三个赋值语句,a = a ^ b = (a ^ b) ^ a = b
注:
它的意思是判断两个相应的位值是否为”异“,为”异"(值不同)就取真(1);否则为假(0)。
优点:不存在引入中间变量,不存在整数溢出
缺点:前端对位操作这一块可能了解不深,不容易理解
熟悉 ES6 语法的人当然不会对解构陌生
var a = 3,b = 4;
[b, a] = [a, b]其中的解构的原理,我暂时还没读过 ES6的规范,不知道具体的细则,不过我们可以看看 babel 是自己编译的,我们可以看出点门路。
哈哈,简单粗暴,不知道有没有按照 ES 的规范,其实可以扒一扒 v8的源码,chrome 已经实现这种解构用法。
这个例子和前面的例子编写风格有何不同,你如果细心的话就会发现这两行代码多了一个分号,对于我这种编码不写分号的洁癖者,为什么加一个分号在这里,其实是有原因的,这里就简单普及一下,建议大家还是写代码写上分号。
尽管 JavaScript 有 C 的代码风格,但是它不强制要求在代码中使用分号,实际上可以省略它们。
JavaScript 不是一个没有分号的语言,恰恰相反上它需要分号来就解析源代码。 因此 JavaScript 解析器在遇到由于缺少分号导致的解析错误时,会自动在源代码中插入分号。
var foo = function() {
} // 解析错误,分号丢失
test()自动插入分号,解析器重新解析。
var foo = function() {
}; // 没有错误,解析继续
test()下面的代码没有分号,因此解析器需要自己判断需要在哪些地方插入分号。
(function(window, undefined) {
function test(options) {
log('testing!')
(options.list || []).forEach(function(i) {
})
options.value.test(
'long string to pass here',
'and another long string to pass'
)
return
{
foo: function() {}
}
}
window.test = test
})(window)
(function(window) {
window.someLibrary = {}
})(window)下面是解析器"猜测"的结果。
(function(window, undefined) {
function test(options) {
// 没有插入分号,两行被合并为一行
log('testing!')(options.list || []).forEach(function(i) {
}); // <- 插入分号
options.value.test(
'long string to pass here',
'and another long string to pass'
); // <- 插入分号
return; // <- 插入分号, 改变了 return 表达式的行为
{ // 作为一个代码段处理
foo: function() {}
}; // <- 插入分号
}
window.test = test; // <- 插入分号
// 两行又被合并了
})(window)(function(window) {
window.someLibrary = {}; // <- 插入分号
})(window); //<- 插入分号解析器显著改变了上面代码的行为,在另外一些情况下也会做出错误的处理。
我们翻到7.9章节,看看其中插入分号的机制和原理,清楚只写以后就可以尽量以后少踩坑
**必须用分号终止某些 ECMAScript 语句 ( 空语句 , 变量声明语句 , 表达式语句 , do-while 语句 , continue 语句 , break 语句 , return 语句 ,throw 语句 )。这些分号总是明确的显示在源文本里。然而,为了方便起见,某些情况下这些分号可以在源文本里省略。描述这种情况会说:这种情况下给源代码的 token 流自动插入分号。**
还是比较抽象,看不太懂是不是,不要紧,我们看看实际例子,总结出几个规律就行,我们先不看抽象的,看着头晕,看看具体的总结说明, 化抽象为具体 。
首先这些规则是基于两点:
1. 新行并入当前行将构成非法语句,自动插入分号。
if(1 < 10) a = 1
console.log(a)
// 等价于
if(1 < 10) a = 1;
console.log(a);2. 在continue,return,break,throw后自动插入分号
return
{a: 1}
// 等价于
return;
{a: 1};3. ++、--后缀表达式作为新行的开始,在行首自动插入分号
a
++
c
// 等价于
a;
++c;4. 代码块的最后一个语句会自动插入分号
function(){ a = 1 }
// 等价于
function(){ a = 1; }1. 新行以 ( 开始
var a = 1
var b = a
(a+b).toString()
// 会被解析为以a+b为入参调用函数a,然后调用函数返回值的toString函数
var a = 1
var b =a(a+b).toString()2. 新行以 [ 开始
var a = ['a1', 'a2']
var b = a
[0,1].slice(1)
// 会被解析先获取a[1],然后调用a[1].slice(1)。
// 由于逗号位于[]内,且不被解析为数组字面量,而被解析为运算符,而逗号运算符会先执
行左侧表达式,然后执行右侧表达式并且以右侧表达式的计算结果作为返回值
var a = ['a1', 'a2']
var b = a[0,1].slice(1)3. 新行以 / 开始
var a = 1
var b = a
/test/.test(b)
// /会被解析为整除运算符,而不是正则表达式字面量的起始符号。浏览器中会报test前多了个.号
var a = 1
var b = a / test / .test(b)4. 新行以 + 、 - 、 % 和 * 开始
var a = 2
var b = a
+a
// 会解析如下格式
var a = 2
var b = a + a5. 新行以 , 或 . 开始
var a = 2
var b = a
.toString()
console.log(typeof b)
// 会解析为
var a = 2
var b = a.toString()
console.log(typeof b)到这里我们已经对ASI的规则有一定的了解了,另外还有一样有趣的事情,就是“空语句”。
// 三个空语句
;;;
// 只有if条件语句,语句块为空语句。
// 可实现unless条件语句的效果
if(1>2);else
console.log('2 is greater than 1 always!');
// 只有while条件语句,循环体为空语句。
var a = 1
while(++a < 100);建议绝对不要省略分号,同时也提倡将花括号和相应的表达式放在一行, 对于只有一行代码的 if 或者 else 表达式,也不应该省略花括号。 这些良好的编程习惯不仅可以提到代码的一致性,而且可以防止解析器改变代码行为的错误处理。
关于JavaScript 语句后应该加分号么?(点我查看)我们可以看看知乎上大牛们对着个问题的看法。
你可能不知道的前端知识点:原来 JavaScript 还有位操作以及分号的使用细则
{0:1,1:2,2:3,length:3}这种形式的就属于类数组,就是按照数组下标排序的对象,还有一个 length 属性,有时候我们需要这种对象能调用数组下的一个方法,这时候就需要把把类数组转化成真正的数组。
var makeArray = function(array) {
var ret = []
if (array != null) {
var i = array.length
if (i == null || typeof array === "string") ret[0] = array
else while (i) ret[--i] = array[i];
}
return ret
}
makeArray({0:1,1:2,2:3,length:3}) //[1,2,3]优点:通用版本,没有任何兼容性问题
缺点:太普通
var arr = Array.prototype.slice.call(arguments);这种应该是大家用过最常用的方法,至于为什么可以这么用,很多人估计也是一知半解,反正我看见大家这么用我也这么用,要搞清为什么里面的原因,我们还是从规范和源码说起。
照着规范的流程,自己看看推演一下就明白了:
英文版15.4.4.10 Array.prototype.slice (start, end)
中文版15.4.4.10 Array.prototype.slice (start, end)
如果你想知道 JavaScript 的 sort 排序的机制,到底是哪种排序好,用的哪种,也可以从规范看出端倪。
在官方的解释中,如[mdn]
The slice() method returns a shallow copy of a portion of an array into a new array object.
简单的说就是根据参数,返回数组的一部分的 copy。所以了解其内部实现才能确定它是如何工作的。所以查看 V8 源码中的 Array.js 可以看到如下的代码:
方法 ArraySlice,源码地址,第 660 行,直接添加到 Array.prototype 上的“入口”,内部经过参数、类型等等的判断处理,分支为 SparseSlice 和 SimpleSlice 处理。
slice.call 的作用原理就是,利用 call,将 slice 的方法作用于 arrayLike,slice 的两个参数为空,slice 内部解析使得 arguments.lengt 等于0的时候 相当于处理 slice(0) : 即选择整个数组,slice 方法内部没有强制判断必须是 Array 类型,slice 返回的是新建的数组(使用循环取值)”,所以这样就实现了类数组到数组的转化,call 这个神奇的方法、slice 的处理缺一不可。
直接看 slice 怎么实现的吧。其实就是将 array-like 对象通过下标操作放进了新的 Array 里面:
// This will work for genuine arrays, array-like objects,
// NamedNodeMap (attributes, entities, notations),
// NodeList (e.g., getElementsByTagName), HTMLCollection (e.g., childNodes),
// and will not fail on other DOM objects (as do DOM elements in IE < 9)
Array.prototype.slice = function(begin, end) {
// IE < 9 gets unhappy with an undefined end argument
end = (typeof end !== 'undefined') ? end : this.length;
// For native Array objects, we use the native slice function
if (Object.prototype.toString.call(this) === '[object Array]'){
return _slice.call(this, begin, end);
}
// For array like object we handle it ourselves.
var i, cloned = [],
size, len = this.length;
// Handle negative value for "begin"
var start = begin || 0;
start = (start >= 0) ? start : Math.max(0, len + start);
// Handle negative value for "end"
var upTo = (typeof end == 'number') ? Math.min(end, len) : len;
if (end < 0) {
upTo = len + end;
}
// Actual expected size of the slice
size = upTo - start;
if (size > 0) {
cloned = new Array(size);
if (this.charAt) {
for (i = 0; i < size; i++) {
cloned[i] = this.charAt(start + i);
}
} else {
for (i = 0; i < size; i++) {
cloned[i] = this[start + i];
}
}
}
return cloned;
};优点:最常用的版本,兼容性较强
缺点:ie 低版本,无法处理 dom 集合的 slice call 转数组。(虽然具有数值键值、length 符合ArrayLike 的定义,却报错)搜索资料得到 :因为 ie 下的 dom 对象是以 com 对象的形式实现的,js 对象与com对象不能进行转换 。
使用 Array.from, 值需要对象有 length 属性, 就可以转换成数组
var arr = Array.from(arguments);扩展运算符
var args = [...arguments];ES6 中的扩展运算符...也能将某些数据结构转换成数组,这种数据结构必须有便利器接口。
优点:直接使用内置 API,简单易维护
缺点:兼容性,使用 babel 的 profill 转化可能使代码变多,文件包变大
你可能不知道的前端知识点:slice 方法的具体原理
const a = parseInt(2.33333)parseInt() 函数解析一个字符串参数,并返回一个指定基数的整数 (数学系统的基础)。这个估计是直接取整最常用的方法了。
更多关于 parseInt() 函数可以查看 MDN 文档
const a = Math.trunc(2.33333)Math.trunc() 方法会将数字的小数部分去掉,只保留整数部分。
特别要注意的是:Internet Explorer 不支持这个方法,不过写个 Polyfill 也很简单:
Math.trunc = Math.trunc || function(x) {
if (isNaN(x)) {
return NaN;
}
if (x > 0) {
return Math.floor(x);
}
return Math.ceil(x);
};数学的事情还是用数学方法来处理比较好。
双波浪线 ~~ 操作符也被称为“双按位非”操作符。你通常可以使用它作为代替 Math.trunc() 的更快的方法。
console.log(~~47.11) // -> 47
console.log(~~1.9999) // -> 1
console.log(~~3) // -> 3
console.log(~~[]) // -> 0
console.log(~~NaN) // -> 0
console.log(~~null) // -> 0失败时返回0,这可能在解决 Math.trunc() 转换错误返回 NaN 时是一个很好的替代。
但是当数字范围超出 ±2^31−1 即:2147483647 时,异常就出现了:
// 异常情况
console.log(~~2147493647.123) // -> -2147473649 🙁| (按位或) 对每一对比特位执行或(OR)操作。
console.log(20.15|0); // -> 20
console.log((-20.15)|0); // -> -20
console.log(3000000000.15|0); // -> -1294967296 🙁^ (按位异或),对每一对比特位执行异或(XOR)操作。
console.log(20.15^0); // -> 20
console.log((-20.15)^0); // -> -20
console.log(3000000000.15^0); // -> -1294967296 🙁<< (左移) 操作符会将第一个操作数向左移动指定的位数。向左被移出的位被丢弃,右侧用 0 补充。
console.log(20.15 < < 0); // -> 20
console.log((-20.15) < < 0); //-20
console.log(3000000000.15 << 0); // -> -1294967296 🙁上面这些按位运算符方法执行很快,当你执行数百万这样的操作非常适用,速度明显优于其他方法。但是代码的可读性比较差。还有一个特别要注意的地方,处理比较大的数字时(当数字范围超出 ±2^31−1 即:2147483647),会有一些异常情况。使用的时候明确的检查输入数值的范围。
let arr = [1, 2, 3, 4, 5]
function sum(arr){
let x = 0
for(let i = 0; i < arr.length; i++){
x += arr[i]
}
return x
}
sum(arr) // 15优点:通俗易懂,简单粗暴
缺点:没有亮点,太通俗
let arr = [1, 2, 3, 4, 5]
function sum(arr) {
return arr.reduce((a, b) => a + b)
}
sum(arr) //15优点:简单明了,数组迭代器方式清晰直观
缺点:不兼容 IE 9以下浏览器
let arr = [1, 2, 3, 4, 5]
function sum(arr) {
return eval(arr.join("+"))
}
sum(arr) //15优点:让人一时看不懂的就是"好方法"。
缺点:
eval 不容易调试。用 chromeDev 等调试工具无法打断点调试,所以麻烦的东西也是不推荐使用的…
性能问题,在旧的浏览器中如果你使用了eval,性能会下降10倍。在现代浏览器中有两种编译模式:fast path和slow path。fast path是编译那些稳定和可预测(stable and predictable)的代码。而明显的,eval 不可预测,所以将会使用 slow path ,所以会慢。
更多关于 eval 的探讨可以关注这篇文章: JavaScript 为什么不推荐使用 eval?
你可能不知道的前端知识点:eval的使用细则
祝大家圣诞快乐🎄,欢迎补充和交流。
觉得本人写的不算很烂的话,可以登录关注一下我的GitHub博客,新手写东西写的不好之处,还望见谅,毕竟水平有限,写东西只为交流提高,一起学习,还望大神多加指点,指出纰漏,和提出宝贵的意见,博客会坚持写下去。
今天同学去面试,做了两道面试题,全部做错了,发过来给我看,我一眼就看出来了,因为这种题我做过,至于为什么结果是那样,我也之前没有深究过,他问我为什么,我也是一脸的懵逼,不能从根源上解释问题的原因,所以并不能完全让他信服。今天就借着这个机会深扒一下,如果没有耐心可以点击右上角,以看小说的心态看技术文章,走马观花,不加思考,这样的量变并不能带来质的改变。花上10+分钟认真阅读我相信你会受益匪浅,没收获你买把武昌火车站同款菜刀砍我😄。因为我是写完这篇博客再回头写这段话的,在写的过程中也学到了很多,所以在此分享一下共同学习。
登高自卑,与君共勉。
下面一起看看这道题,同学微信发给我截图:
如果看的不太清楚,我把代码敲一遍,给大家看看:
var name = "jay"; //一看这二逼就是周杰伦的死忠粉
var person = {
name: "kang",
pro: {
name: "Michael",
getName: function() {
return this.name;
}
}
};
console.log(person.pro.getName());
var pepole = person.pro.getName;
console.log(pepole());这里我就不卖关子了,不少童鞋也应该遇到过做过类似的题目,就是考察this,我们先看看答案:
console.log(person.pro.getName());//Michael
console.log(pepole());//jay第一个很简单,this就是指向person.pro的引用,那么this.name就是person.pro.name,于是第一个就是输出Michael,再来看看第二个就蹊跷了,和第一个明明是一样的方法,为什么输出的结果是jay呢?
既然我们知道结果是jay了,反着推理一步步来,不难推出调用people()这个方法时候的this.name就相当于和var name = "jay",var声明的全局变量和全局环境下的this的变量有什么联系呢?;那么这个this到底是什么,总得是一个具体东西吧?
我们一步步分析,this.name这个this有一个name属性,很明显就是一个对象,那具体是什么对象呢?this的指向是在函数被调用的时候确定的,于是有人说就是Window对象,没错是没错,确实是Window对象,然后var name声明的全局变量name和window.name是相同的作用;但是你只只知其然,而不知其所以然,学深一门语言就是要有刨根问底的精神,打破砂锅问到底,知其然还要知其所以然。
我们就先验证一下,那个this到底是不是window对象吧。我们把代码稍微调整一下,输出this。
var name = "jay"; //一看这二逼就是周杰伦的死忠粉
var person = {
name: "kang",
pro: {
name: "Michael",
getName: function() {
console.log(this);
return this.name;
}
}
};
console.log(person.pro.getName());
var pepole = person.pro.getName;
console.log(pepole());看看控制台输出,确实没错就是window对象。
再来看看var name声明的name和window.name是否相等呢?
var name;
console.log(name===window.name)确实是一样的,类型和值没有任何的不同。
好滴,那么你说this就是window对象,至于为什么是这样你也不清楚,是否永远是这样呢?我们看看这段代码输出又会是咋样呢?
'use strict';
var name = "jay"; //一看这二逼就是周杰伦的死忠粉
var person = {
name: "kang",
pro: {
name: "Michael",
getName: function() {
console.log(this);
return this.name;
}
}
};
console.log(person.pro.getName());
var pepole = person.pro.getName;
console.log(pepole());还会是跟上面一样的结果吗?我们拭目以待.
看到结果没:Cannot read property 'name' of undefined,这是什么意**必大家已经很清楚了,此时的this成了undefined了,undefined当然也就没有name这个属性,所以浏览器报错了。那么为什么会这样呢?
同样换种写法再来看看这段代码输出什么呢?
var name = "jay";
var person = {
name : "kang",
getName : function(){
return function(){
return this.name;
};
}
};
console.log(person.getName()());控制台自己输出一下看看,我想此时你的心情一定是这样的:
在弄明白这些问题之前,我们先弄清楚全局环境下的this,var声明的全局变量和window对象之间的联系与区别:
先看四个简单的例子对比,均在js非严格模式测试,也就是没有声明'use strict':
demo1:
var name="jawil";
console.log(name);
console.log(window.name)
console.log(this.name)demo2:
name="jawil";
console.log(name);
console.log(window.name)
console.log(this.name)demo3:
window.name="jawil";
console.log(name);
console.log(window.name)
console.log(this.name)demo4:
this.name="jawil";
console.log(name);
console.log(window.name)
console.log(this.name)其实这四个demo是一个意思,输出的结果没有任何差别,为什么没有差别呢?因为他们在同一个环境,也就是全局环境下:
我们换一种在不同的环境下执行这段代码看一看结果:
demo5:
var name="jawil";
var test={
name:'jay',
getName:function(){
console.log(name);
console.log(window.name)
console.log(this.name)
}
}
test.getName();最后结果一次输出为:
console.log(name);//jawil
console.log(window.name)//jawil
console.log(this.name)//jay因为此处的this不再指向全局对象了,所以结果肯定不同,我们先来看看全局对象和全局环境下的this,暂不考虑其他环境下的this。
其实我们看技术文章,总觉得似懂非懂,一知半解,不是看不懂代码,而是因为很多时候我们对一些概念没有比较深入的了解,但是也没有去认真继续下去考究,这也不能怪我们,毕竟开发时候不太深入这些概念对我们业务也没啥影响,但是我发现我自己写东西时候,不把概念说清楚,总不能让人信服和彻底明白你讲的是什么玩意,我想写博客最大的好处可以让自己进一步提高,更深层次的理解你所学过的东西,你讲的别人都看不懂,你确认你真的懂了吗?
既然扯到这么深,就顺便扯扯执行环境和作用域,这些都是js这门语言的重点和难点,没有一定的沉淀很难去深入探讨这些东西的.
函数的每次调用都有与之紧密相关的作用域和执行环境。从根本上来说,作用域是基于函数的,而执行环境是基于对象的(例如:全局执行环境即全局对象window)。
全局属性和函数可用于所有内建的 JavaScript 对象。
- 全局对象是预定义的对象,作为 JavaScript 的全局函数和全局属性的占位符。通过使用全局对象,可以访问所有其他所有预定义的对象、函数和属性。全局对象不是任何对象的属性,所以它没有名称。
- 在顶层 JavaScript 代码中,可以用关键字 this 引用全局对象。但通常不必用这种方式引用全局对象,因为全局对象是作用域链的头,这意味着所有非限定性的变量和函数名都会作为该对象的属性来查询。例如,当JavaScript 代码引用 parseInt() 函数时,它引用的是全局对象的 parseInt 属性。全局对象是作用域链的头,还意味着在顶层 JavaScript 代码中声明的所有变量都将成为全局对象的属性。
- 全局对象只是一个对象,而不是类。既没有构造函数,也无法实例化一个新的全局对象。
- 在 JavaScript 代码嵌入一个特殊环境中时,全局对象通常具有环境特定的属性。实际上,ECMAScript 标准没有规定全局对象的类型,JavaScript 的实现或嵌入的 JavaScript 都可以把任意类型的对象作为全局对象,只要该对象定义了这里列出的基本属性和函数。例如,在允许通过 LiveConnect 或相关的技术来脚本化 Java 的 JavaScript 实现中,全局对象被赋予了这里列出的 java 和 Package 属性以及 getClass() 方法。而在客户端 JavaScript 中,全局对象就是 Window 对象,表示允许 JavaScript 代码的 Web 浏览器窗口。
在 JavaScript 核心语言中,全局对象的预定义属性都是不可枚举的,所有可以用 for/in 循环列出所有隐式或显式声明的全局变量,如下所示:
上一篇博客我就讲到遍历对象属性的三种方法:
for-in循环、Object.keys()以及Object.getOwnPropertyNames()不同的区别,想要了解可以细看我这篇博客:传送门
var variables = "";
for (var name in this)
{
variables += name + "<br />";
}
document.write(variables);首先来说说js中的执行环境,所谓执行环境(有时也称环境)它是JavaScript中最为重要的一个概念。执行环境定义了变量或函数有权访问的其他数据 ,决定了它们各自的行为。而每个执行环境都有一个与之相关的变量对象,环境中定义的所有变量和函数都保存在这个对象中。
当JavaScript解释器初始化执行代码时,它首先默认进入全局执行环境,从此刻开始,函数的每次调用都会创建一个新的执行环境。
每个函数都有自己的执行环境。当执行流进入一个函数时,函数的环境就会被推入一个环境栈中(execution stack)。在函数执行完后,栈将其环境弹出,把控制权返回给之前的执行环境。ECMAScript程序中的执行流正是由这个便利的机制控制着。执行环境可以分为创建和执行两个阶段。在创建阶段,解析器首先会创建一个变量对象(variable object,也称为活动对象activation object),它由定义在执行环境中的变量、函数声明、和参数组成。在这个阶段,作用域链会被初始化,this的值也会被最终确定。在执行阶段,代码被解释执行。
不同类型的JavaScript代码具有不同的Execution Context
Demo:
<script type="text/javascript">
function Fn1(){
function Fn2(){
alert(document.body.tagName);//BODY
//other code...
}
Fn2();
}
Fn1();
//code here
</script>
特别说明:图片来自于笨蛋的座右铭博客
当javascript代码被浏览器载入后,默认最先进入的是一个全局执行环境。当在全局执行环境中调用执行一个函数时,程序流就进入该被调用函数内,此时JS引擎就会为该函数创建一个新的执行环境,并且将其压入到执行环境堆栈的顶部。浏览器总是执行当前在堆栈顶部的执行环境,一旦执行完毕,该执行环境就会从堆栈顶部被弹出,然后,进入其下的执行环境执行代码。这样,堆栈中的执行环境就会被依次执行并且弹出堆栈,直到回到全局执行环境。
此外还要注意一下几点:
当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain。作用域链的用途是保证对执行环境有权访问的所有变量和函数的有序访问。
作用域链包含了执行环境栈中的每个执行环境对应的变量对象.
通过作用域链,可以决定变量的访问和标识符的解析。
注意:全局执行环境的变量对象始终都是作用域链的最后一个对象。
在访问变量时,就必须存在一个可见性的问题(内层环境可以访问外层中的变量和函数,而外层环境不能访问内层的变量和函数)。更深入的说,当访问一个变量或调用一个函数时,JavaScript引擎将不同执行环境中的变量对象按照规则构建一个链表,在访问一个变量时,先在链表的第一个变量对象上查找,如果没有找到则继续在第二个变量对象上查找,直到搜索到全局执行环境的变量对象即window对象。这也就形成了Scope Chain的概念。
特别说明:图片来自于笨蛋的座右铭博客
作用域链图,清楚的表达了执行环境与作用域的关系(一一对应的关系),作用域与作用域之间的关系(链表结构,由上至下的关系)。
Demo:
var color = "blue";
function changeColor(){
var anotherColor = "red";
function swapColors(){
var tempColor = anotherColor;
anotherColor = color;
color = tempColor;
// 这里可以访问color, anotherColor, 和 tempColor
}
// 这里可以访问color 和 anotherColor,但是不能访问 tempColor
swapColors();
}
changeColor();
// 这里只能访问color
console.log("Color is now " + color);上述代码一共包括三个执行环境:全局执行环境、changeColor()的局部执行环境、swapColors()的局部执行环境。
上述代码的作用域链如下图所示:
从上图发现。内部环境可以通过作用域链访问所有的外部环境,但是外部环境不能访问内部环境中的任何变量和函数。
标识符解析(变量名或函数名搜索)是沿着作用域链一级一级地搜索标识符的过程。搜索过程始终从作用域链的前端开始,然后逐级地向后(全局执行环境)回溯,直到找到标识符为止。
执行环境为全局执行环境和局部执行环境,局部执行环境是函数执行过程中创建的。
作用域链是基于执行环境的变量对象的,由所有执行环境的变量对象(对于函数而言是活动对象,因为在函数执行环境中,变量对象是不能直接访问的,此时由活动对象(activation object,缩写为AO)扮演VO(变量对象)的角色。)共同组成。
当代码在一个环境中执行时,会创建变量对象的一个作用域链。作用域链的用途:是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链的前端,始终都是当前执行的代码所在环境的变量对象。
<script type="text/javascript">
(function(){
a= 5;
console.log(window.a);//undefined
var a = 1;//这里会发生变量声明提升
console.log(a);//1
})();
</script>window.a之所以是undefined,是因为var a = 1;发生了变量声明提升。相当于如下代码:
<script type="text/javascript">
(function(){
var a;//a是局部变量
a = 5;//这里局部环境中有a,就不会找全局中的
console.log(window.a);//undefined
a = 1;//这里会发生变量声明提升
console.log(a);//1
})();
</script>更多关于变量提升和执行上下文详细解说这里就不多少了,不然越扯越深,有兴趣可以看看这篇图解,浅显易懂:
前端基础进阶(二):执行上下文详细图解
相信大家看到这里,也很累了,但是也有收获,大概有了一些深刻印象,对概念也有一些比较深入的理解了。
这里我就稍微总结一下,上面讲了一些什么,对接下来的解析应该有很大的帮助。
1. 浏览器的全局对象是window
2. 全局执行环境即window对象所创建的,局部执行环境是函数执行过程中创建的。
3. 全局对象,可以访问所有其他所有预定义的对象、函数和属性。
4. 当javascript代码被浏览器载入后,默认最先进入的是一个全局执行环境。
5. 明白了执行上下文和作用域的一些概念,知道其中的运行机制和原理。
我们再回头看看这两个demo比较,我们解释清楚这个demo执行的结果。
demo1:
var name="jawil";
console.log(name);//jawil
console.log(window.name)//jawil
console.log(this.name)//jawilldemo2:
name="jawil";
console.log(name);//jawil
console.log(window.name)//jawil
console.log(this.name)//jawil好,从例子看以看出,这两个name都是全局属性,未通过var声明的变量a和通过var声明的变量b,都可以通过this和window访问到.
我们可以在控制台打印出windowd对象,发现name成了window对象的一个属性:
var name="jawil";
console.log(window);
name2="test";
console.log(window);这是其实一个作用域和上下文的问题。在JavaScript中,this指向当前的上下文,而var定义的变量值在当前作用域中有效。JavaScript有两种作用域,全局作用域和局部作用域。局部作用域就是在一个函数里。var关键字使用来在当前作用于中创建局部变量的,而在浏览器中的JavaScript全局作用域中使用var语句时,会把申明的变量挂在window上,而全局作用域中的this上下文恰好指向的又是window,因此在全局作用域中var申明的变量和window上挂的变量,即this可访问的变量有间接的联系,但没有直接联系,更不是一样的。
上面的分析我们知道了,全局变量,全局环境下的this,还有全局对象之间的关系了,具体总结一下就是:
1. 全局环境的this会指向全局对象window,此时this===window;
2. 全局变量会挂载在window对象下,会成为window下的一个属性。
3. 如果你没有使用严格模式并给一个未声明的变量赋值的话,JS会自动创建一个全局变量。
那么用var声明的全局变量赋值和未声明的全局变量赋值到底有什么不同呢?这里不再是理解理解这道面试题的重点,想深入探究可以看看这篇文章:javascript中加var和不加var的区别 你真的懂吗.
该回头了,好累😫,再来看看这道面试题:
var name = "jay"; //一看这二逼就是周杰伦的死忠粉
var person = {
name: "kang",
pro: {
name: "Michael",
getName: function() {
return this.name;
}
}
};
console.log(person.pro.getName());
var pepole = person.pro.getName;
console.log(pepole());最后就成了为什么person.pro.getName()的this是person.pro而pepole()的this成了window对象。这里我们就要了解this的运行机制和原理。
在这里,我们需要得出一个非常重要一定要牢记于心的结论,this的指向,是在函数被调用的时候确定的。也就是执行上下文被创建时确定的。因此我们可以很容易就能理解到,一个函数中的this指向,可以是非常灵活的。
在一个函数上下文中,this由调用者提供,由调用函数的方式来决定。
如果调用者函数,被某一个对象所拥有,那么该函数在调用时,内部的this指向该对象。如果函数独立调用,那么该函数内部的this,则指向undefined。但是在非严格模式中,当this指向undefined时,它会被自动指向全局对象。
person.pro.getName()中,getName是调用者,他不是独立调用,被对象person.pro所拥有,因此它的this指向了person.pro。而pepole()作为调用者,尽管他与person.pro.getName的引用相同,但是它是独立调用的,因此this指向undefined,在非严格模式,自动转向全局window。
再来看一个例子,来加深理解这段话:
var a = 20;
function getA() {
return this.a;
}
var foo = {
a: 10,
getA: getA
}
console.log(foo.getA()); // 10灵机一动,再来一个。如下例子。
function foo() {
console.log(this.a)
}
function active(fn) {
fn(); // 真实调用者,为独立调用
}
var a = 20;
var obj = {
a: 10,
getA: foo
}
active(obj.getA);
这个例子提示一下,关于函数参数的传递赋值问题。
JS是按值传递还是按引用传递?
这里我就不多做解答了,大家自行揣摩。
以上关于this解答来自波同学的引用,我这里就偷了个懒在,直接拿来引用。
原文地址:前端基础进阶(五):全方位解读this
最后把知道面试题梳理一下:
console.log(person.pro.getName());//Michael
var pepole = person.pro.getName;
console.log(pepole());//jayperson.pro.getName()中,getName是调用者,他不是独立调用,被对象person.pro所拥有,因此它的this指向了person.pro,所以this.name=person.pro.name="Michael";
而pepole()作为调用者,尽管他与person.pro.getName的引用相同,但是它是独立调用的,因此this指向undefined,在非严格模式,自动转向全局window。
这道题实在非严格模式下,所以this指向了window,又因为全局变量挂载在window对象下,所以this.name=window.name=“jay”
完毕~写的有点啰嗦,只是尽量想说明白,讲清一些概念的东西,反正我是收获很多,你呢?
参考文章:
JavaScript 全局对象
原生JS执行环境与作用域深入理解
理解Javascript_12_执行模型浅析
前端基础进阶(二):执行上下文详细图解
前端基础进阶(五):全方位解读this
查看下吧
学习了!
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
按照格式推荐好用的插件有福利哦,说不定会送1024论坛邀请码,好自为之,你懂的,嘿嘿嘿。
由于github的issues没有TOC菜单栏导航,所以这里方便大家查看,先安利一款Chrome浏览器的插件,感谢github用户@BBcaptain 推荐。点击我呀,进入商店,自备梯子,如果不会翻墙,赶紧转行。。。
效果预览,是不是很方便,图片较多,建议等待一会或者多刷新几下:
github:https://github.com/toddmotto/echo
官方网站:https://toddmotto.com/echo-js-simple-javascript-image-lazy-loading/
star:3k+
Install:
npm:npm install echo-js
bower:bower install echojs
大小:2KB
功能介绍:
Echo.js 是一个独立的延迟加载图片的 JavaScript 插件。Echo.js 不依赖第三方库,压缩后不到1KB大小。 延迟加载是提高网页首屏显示速度的一种很有效的方法,当图片元素进入窗口可视区域的时候,它就会改变图像的 src 属性,从服务端加载所需的图片,这也是一个异步的过程。
Demo:
效果预览地址:https://jawil.github.io/demo/echo.js/
Demo源码:https://github.com/jawil/jawil.github.io/tree/master/demo/echo.js
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/callmecavs/layzr.js
官方网站:http://callmecavs.com/layzr.js/
star:5k+
Install:
npm:npm install layzr.js --save
大小:2.75 KB
功能介绍:
Lazyr.js 是一个小的、快速的、现代的、相互间无依赖的图片延迟加载库。通过延迟加载图片,让图片出现在(或接近))视窗才加载来提高页面打开速度。这个库通过保持最少选项并最大化速度。
Demo:
跟上面的Echo.js用法类似,喜欢的可以自行去尝试,这里就不再演示了,我一般用Echo.js。
github:https://github.com/ustbhuangyi/better-scroll
官方网站:https://ustbhuangyi.github.io/better-scroll/
star:300+
Install:
npm install better-scroll --save-dev
import BScroll from 'better-scroll';
大小:24 KB
功能介绍:
better-scroll 是一个只有24.8KB的 JavaScript 模拟浏览器自带滚动条的插件,是在**iscroll**开源的基础上进行优化的一款插件,简单好用,轻巧高性能,功能强大,API通俗易懂,是一款优秀的scroll插件,抛弃原生滚动条,从现在做起。
Demo:
效果预览地址:https://jawil.github.io/demo/eleme/ (PC端切换到移动模式)
Demo源码:https://github.com/jawil/webpack2
注:在ustbhuangyi的源码下改进了一下,做成多页面,技术栈:webpack2+vue.js2+sass+axios
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/ustbhuangyi/picker
官方网站:http://ustbhuangyi.github.io/picker/
star:200+
Install:
npm: npm install better-picker --save-dev
import Picker from 'better-picker'
大小:46.5 KB
功能介绍:
移动端最好用的的筛选器组件,高仿 ios 的 UIPickerView ,非常流畅的体验,原生 JS 实现,不依赖任何插件和第三方库。
Demo:
效果预览地址:http://ustbhuangyi.github.io/picker/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/RubaXa/Sortable
官方网站:http://rubaxa.github.io/Sortable/
star:9k+
Install:
Bower: bower install sortablejs --save
npm: npm install sortablejs
大小:5 KB
功能介绍:
Sortable:现代浏览器上用于实现元素拖拽排序的功能,支持 Meteor, AngularJS, React,不依赖 jQuery这玩意。
Demo:
效果预览地址:http://rubaxa.github.io/Sortable/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/kenwheeler/slick
官方网站:http://kenwheeler.github.io/slick/
star:17k+
Install:
Bower: bower install slick-carousel --save
npm: npm install slick-carousel
CDNs:
https://cdnjs.com/libraries/slick-carousel
https://www.jsdelivr.com/projects/jquery.slick
大小:40 KB
功能介绍:
slick 是一个功能异常强大的一个图片滑动切换效果库,接口丰富,支持各种动画和各种样式的切换滑动,唯一的缺点就是基于jQuery,基本废了,现在没人喜欢用jQuery,该淘汰了。。。支持 RequireJS 以及 Bower 安装。
Demo:
效果预览地址:http://kenwheeler.github.io/slick/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。

github:https://github.com/lyfeyaj/Swipe
官方网站:http://lyfeyaj.github.io/swipe/
star:200+
Install:
Bower: bower install swipe-js --save
npm: npm install swipe-js
大小:5 KB
功能介绍:
swipe:非常轻量级的一个图片滑动切换效果库, 性能良好, 尤其是对手机的支持, 压缩后的大小约 5kb。可以结合 jQuery、RequireJS 使用。
Demo:
效果预览地址:http://lyfeyaj.github.io/swipe/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/mango/slideout
star:6k+
Install:
npm:npm install slideout
spm:spm install slideout
bower:bower install slideout.js
component:component install mango/slideout
<script src="https://cdnjs.cloudflare.com/ajax/libs/slideout/1.0.1/slideout.min.js"></script>
大小:4 KB
功能介绍:
Slideout.js 是为您的移动 Web 应用开发的触摸滑出式的导航菜单。它没有依赖,自由搭配简单的标记,支持原生的滚动,您可以轻松地定制它。它支持不同的 CSS3 转换和过渡。最重要的是,它只是4KB 。
Demo:
效果预览地址:https://slideout.js.org/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/t4t5/sweetalert
官方网站:http://t4t5.github.io/sweetalert/
star:15k+
Install:
bower:bower install sweetalert
npm:npm install sweetalert
<script src="dist/sweetalert.min.js"></script>
<link rel="stylesheet" type="text/css" href="dist/sweetalert.css">
大小:16 KB
功能介绍:
Sweet Alert 是一个替代传统的 JavaScript Alert 的漂亮提示效果。SweetAlert 自动居中对齐在页面**,不管您使用的是台式电脑,手机或平板电脑看起来效果都很棒。另外提供了丰富的自定义配置选择,可以灵活控制。
Demo:
效果预览地址:http://t4t5.github.io/sweetalert/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
类似插件:limonte/sweetalert2,好像这个最近还在更新,这个感觉更漂亮,大同小异,这里不多做介绍。
github:https://github.com/limonte/sweetalert2
官方网站: https://limonte.github.io/sweetalert2/
github:https://github.com/leaverou/awesomplete/
官方网站:http://leaverou.github.io/awesomplete/
star:5k+
Install:
npm: npm install awesomplete
大小:5 KB
功能介绍:
Awesomplete 是一款超轻量级的,可定制的,简单的自动完成插件,零依赖,使用现代化标准构建。你可以简单地添加 awesomplete 样式,让它自动处理(你仍然可以通过指定 HTML 属性配置更多选项),您可以用几行 JS 代码,提供更多的自定义。
Demo:
效果预览地址:http://leaverou.github.io/awesomplete/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/nosir/cleave.js/
官方网站:http://nosir.github.io/cleave.js/
star:6k+
Install:
npm:npm install --save cleave.js
bower:bower install --save cleave.js
大小:11.1 KB
功能介绍:
Cleave.js 有一个简单的目的:帮助你自动格式输入的文本内容。 这个想法是提供一个简单的方法来格式化您的输入数据以增加输入字段的可读性。通过使用这个库,您不需要编写任何正则表达式来控制输入文本的格式。然而,这并不意味着取代任何验证或掩码库,你仍应在后端验证数据。它支持信用卡号码、电话号码格式(支持各个国家)、日期格式、数字格式、自定义分隔符,前缀和块模式等,提供 CommonJS/AMD 模式以及ReactJS 组件端口。
Demo:
效果预览地址:http://nosir.github.io/cleave.js/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
输入201748自动格式化成2017-04-08,是不是很方便
github:https://github.com/facebook/immutable-js
官方网站:http://facebook.github.io/immutable-js/
star:18k+
Install:
npm install immutable --S-D
大小:60 KB
功能介绍:
不可变数据是指一旦创建就不能被修改的数据,使得应用开发更简单,允许使用函数式编程技术,比如惰性评估。Immutable JS 提供一个惰性 Sequence,允许高效的队列方法链,类似 map 和 filter ,不用创建中间代表。Immutable.js 提供持久化的列表、堆栈、Map, 以及 OrderedMap 等,最大限度地减少需要复制或缓存数据。
Demo:
<script src="immutable.min.js"></script>
<script>
var map1 = Immutable.Map({a:1, b:2, c:3});
var map2 = map1.set('b', 50);
map1.get('b'); // 2
map2.get('b'); // 50
</script>更多信息和探讨请移步,这里不多做介绍:facebook immutable.js 意义何在,使用场景?
github:https://github.com/Popmotion/popmotion
star:3k+
Install:
npm install --save popmotion
import { tween } from 'popmotion';
大小:12 KB
功能介绍:
Popmotion 是一个只有12KB的 JavaScript 运动引擎,可以用来实现动画,物理效果和输入跟踪。原生的DOM支持:CSS,SVG,SVG路径和DOM属性的支持,开箱即用。Popmotion 网站上有很多很赞的效果,赶紧去体验一下。
Demo:
效果预览地址:http://codepen.io/popmotion/pen/egwMGQ
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/michaelvillar/dynamics.js
star:6k+
Install:
npm: npm install dynamics.js
bower: bower install dynamics.js
大小:20 KB
功能介绍:
Popmotion 是一个只有12KB的 JavaScript 运动引擎,可以用来实现动画,物理效果和输入跟踪。原生的DOM支持:CSS,SVG,SVG路径和DOM属性的支持,开箱即用。Popmotion 网站上有很多很赞的效果,赶紧去体验一下。
Demo:
效果预览地址:http://dynamicsjs.com/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/maroslaw/rainyday.js
官方网站:http://maroslaw.github.io/rainyday.js/
star:5k+
Install:
在github的dist目录下载rainyday.min.js
大小:10 KB
功能介绍:
Rainyday.js 背后的想法是创建一个 JavaScript 库,利用 HTML5 Canvas 渲染一个雨滴落在玻璃表面的动画。Rainyday.js 有功能可扩展的 API,例如碰撞检测和易于扩展自己的不同的动画组件的实现。它是一个使用 HTML5 特性纯 JavaScript 库,支持大部分现代浏览器。
Demo:
效果预览地址:http://maroslaw.github.io/rainyday.js/demo012_1.html
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/nolimits4web/Swiper
官方网站:http://idangero.us/swiper/
star:11.8k+
Install:
在github上下载
大小:暂不确定,按需引入
功能介绍:
Swiper 是移动 Web 开发中最常用的滑块插件,是一款免费的,最现代化的移动触摸滑块,支持硬件加速的转换和惊人的原生表现。它的目的是在移动网站,移动 Web 应用程序和 Hygrid 混合应用程序中使用。最初的设计主要是为 iOS,但同时也支持最新的 Android,Windows Phone 8 和现代的桌面浏览器。
Demo:
效果预览地址:http://idangero.us/swiper/#.WOik3l--uaW
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/daniel-lundin/snabbt.js
官方网站:http://daniel-lundin.github.io/snabbt.js/
star:5k+
Install:
bower:bower install snabbt.js
npm:npm install snabbt.js
CDNs:
https://cdnjs.com/libraries/snabbt.js
http://www.jsdelivr.com/#!snabbt
大小:16 KB
功能介绍:
Snabbt.js 是一个简约的 JavaScript 动画库。它会平移,旋转,缩放,倾斜和调整你的元素。通过矩阵乘法运算,变换等可以任何你想要的方式进行组合。最终的结果通过 CSS3 变换矩阵设置。
Demo:
效果预览地址:http://daniel-lundin.github.io/snabbt.js/periodic.html
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/desandro/imagesloaded
官方网站:http://imagesloaded.desandro.com/
star:6k+
Install:
Bower: bower install imagesloaded --save
npm: npm install imagesloaded
CDNs:
<script src="https://unpkg.com/[email protected]/imagesloaded.pkgd.min.js"></script>
<script src="https://unpkg.com/[email protected]/imagesloaded.pkgd.js"></script>
大小:5 KB
功能介绍:
imagesLoaded 是一个用于来检测网页中的图片是否载入完成的 JavaScript 工具库。支持回调的获取图片加载的进度,还可以绑定自定义事件。可以结合 jQuery、RequireJS 使用。
Demo:
效果预览地址:http://codepen.io/desandro/full/hlzaw/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/idriskhenchil/Fort.js
官方网站:https://github.com/idriskhenchil/Fort.js
star:800+
Install:
CDN:
css:
https://cdnjs.cloudflare.com/ajax/libs/Fort.js/2.0.0/fort.min.css
js:
https://cdnjs.cloudflare.com/ajax/libs/Fort.js/2.0.0/fort.min.js
大小:6 KB
功能介绍:
Fort.js 是一款用于时尚、现代的表单填写进度提示效果的 JavaScript 库,你需要做的就是添加表单,剩下的任务就交给 Fort.js 算法了,使用非常简单。提供了Default、Gradient、Sections 以及 Flash 四种效果,满足开发的各种场合需要。
Demo:
效果预览地址:http://idriskhenchil.github.io/default/index.html
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/nicolasbize/magicsuggest
官方网站:http://nicolasbize.com/magicsuggest/
star:1k+
Install:
github自行进行下载
大小:21.8 KB
功能介绍:
MagicSuggest 是专为 Bootstrap 主题开发的多选组合框。它支持自定义呈现,数据通过 Ajax 异步获取,使用组件自动过滤。它允许空间免费项目,也有动态加载固定的建议。
Demo:
效果预览地址:http://nicolasbize.com/magicsuggest/examples.html
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/adamwdraper/Numeral-js
star:4k+
Install:
npm: npm install numeral
CDNs:
<script src="//cdnjs.cloudflare.com/ajax/libs/numeral.js/2.0.6/numeral.min.js"></script>
大小:10 KB
功能介绍:
Numeral.js 是一个用于格式化和操作数字的 JavaScript 库。数字可以格式化为货币,百分比,时间,甚至是小数,千位,和缩写格式,功能十分强大。支持包括中文在内的17种语言。
Demo:
var myNumeral = numeral(1000);
var value = myNumeral.value();
// 1000
var myNumeral2 = numeral('1,000');
var value2 = myNumeral2.value();
// 1000
github:https://github.com/desandro/draggabilly
官方网站:http://draggabilly.desandro.com/
star:2k+
Install:
Bower: bower install draggabilly --save
npm: npm install draggabilly
CDNs:
<script src="https://npmcdn.com/[email protected]/dist/draggabilly.pkgd.min.js"></script>
<script src="https://npmcdn.com/[email protected]/dist/draggabilly.pkgd.js"></script>
大小:5 KB
功能介绍:
Draggabilly 是一个很小的 JavaScript 库,专注于拖放功能。只需要简单的设置参数就可以在你的网站用添加拖放功能。兼容 IE8+ 浏览器,支持多点触摸。可以灵活绑定事件,支持 RequireJS 以及 Bower 安装。
Demo:
效果预览地址:http://draggabilly.desandro.com/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/quilljs/quill/
官方网站:https://quilljs.com
star:12k+
Install:
npm: npm install quill
CDNs:
<!-- Main Quill library -->
<script src="//cdn.quilljs.com/1.0.0/quill.js" type="text/javascript"></script>
<script src="//cdn.quilljs.com/1.0.0/quill.min.js" type="text/javascript"></script>
<!-- Theme included stylesheets -->
<link href="//cdn.quilljs.com/1.0.0/quill.snow.css" rel="stylesheet">
<link href="//cdn.quilljs.com/1.0.0/quill.bubble.css" rel="stylesheet">
<!-- Core build with no theme, formatting, non-essential modules -->
<link href="//cdn.quilljs.com/1.0.0/quill.core.css" rel="stylesheet">
<script src="//cdn.quilljs.com/1.0.0/quill.core.js" type="text/javascript"></script>
大小:需求不同,大小不同
功能介绍:
Quill 的建立是为了解决现有的所见即所得(WYSIWYG)的编辑器本身就是所见即所得(指不能再扩张)的问题。如果编辑器不正是你想要的方式,这是很难或不可能对其进行自定义以满足您的需求。
Quill 旨在通过把自身组织成模块,并提供了强大的 API 来构建额外的模块来解决这个问题。它也并没有规定你用样式来定义编辑器皮肤。Quill 还提供了所有你希望富文本编辑器说用于的功能,包括轻量级封装,众多的格式化选项,以及广泛的跨平台支持。
Demo:
效果预览地址:https://quilljs.com/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/addyosmani/basket.js
官方网站:https://addyosmani.com/basket.js/
star:2k+
Install:
Bower: bower install basket.js --save
npm: npm install basket.js
大小:4 KB
功能介绍:
basket.js是一款基于 LocalStorage 的资源加载器,可以用来缓存 script 和 css, 手机端使用速度快于浏览器直接缓存。
Demo:
效果预览地址:https://addyosmani.com/basket.js/
更多示例请查看官方文档
github:https://github.com/jlmakes/scrollreveal
官方网站:https://scrollrevealjs.org/
star:12k+
Install:
Bower: bower install scrollreveal --save
npm: npm install scrollreveal
CDNs:
<script src="https://unpkg.com/scrollreveal/dist/scrollreveal.min.js"></script>
大小:8 KB
功能介绍:
scrollReveal.js 是一个用于使元素以非常酷帅的方式进入画布的 JavaScript 工具库。轻量级,高性能,无依赖的一个小巧酷炫的库。
Demo:
效果预览地址:https://scrollrevealjs.org/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
github:https://github.com/moment/moment/
官方网站:http://momentjs.com/
star:30k+
Install:
bower install moment --save # bower
npm install moment --save # npm
yarn add moment # Yarn
Install-Package Moment.js # NuGet
spm install moment --save # spm
meteor add momentjs:moment # meteor
大小:16.6 KB
功能介绍:
moment.js是一个轻量级的JavaScript库日期解析、验证操作,格式化日期的库。
Demo:
效果预览地址:http://momentjs.com/
Demo效果预览:
这是一个GIF动图,不信,你看第一行的日期,时间在走😄。
github:https://github.com/infinite-scroll/infinite-scroll
官方网站:http://www.infinite-scroll.com/
star:4k+
Install:
github自行下载
大小:20 KB
功能介绍:
infinite-scroll是一款滚动加载,滚动到最下到自动加载的轻量级JavaScript插件,简单实用,按需加载提高用户体验,非常适合移动端使用,配合上面的图片懒加载如虎添翼。
Demo:
效果预览地址:http://www.dazeddigital.com/
Demo效果预览:
图片有点大,稍等片刻。建议上面Demo效果预览地址进行预览。
推荐有福利,送1024论坛邀请码,嘿嘿嘿。
更多推荐请访问:github优秀前端项目分享(转)
var a = {};
var num = 0;
a.valueOf = function(){
return ++num
};
a == '1' && a == '2' && a == '3'Originally posted by @H246802 in #1 (comment)
一款强大的 GitHub 的 Chrome 扩展 —— GayHub,优化 GitHub 的阅读体验。
为了进一步提高 GitHub 阅览体验这个小目标 ,让大家更方便的畅游 Github,因此诞生了 GayHub。
请自行忽略下面截图书签栏等不健康网站,为了您的健康,请转移你犀利的目光。1024
给 github 插上翅膀,让你轻松切换文件,方便阅读,把 Vscode 的精美的侧边栏完美移植到 github 上,颜值颇高,100 多种精美图标完美移植,加上Pjax的无刷新切换文件,体验颇佳。
截图:对于微软的VScode和TypeScript这种大型开源,10000+文件的解析起来也毫无压力,稍等片刻即可打开,颜值与性能并存。
温馨提示:不要打开Linux这种巨无霸的开源,因为从GitHub接口拉取所有目录文件名数据都需要几分钟。。。
TOC导航:
为了清晰明了的概览整个GitHub文档、issue、wiki的结构层次,为此开发了这个强大的功能,支持任意层次嵌套,能完美解析内容的所有嵌套标题,性能优越,滑动起来如丝滑般流畅。
截图:不管你嵌套多少层,解析不出来算我输。
GitHub的白色主题在晚上稍微有些刺眼,就在stylish上找了一套暗色主题修改一下移植到了github上,喜欢暗色主题可以开启,默认不开启。
截图:透明加暗色,感觉颜值有个提升,因人而异,我还是喜欢亮色的主题,习惯了
图片全屏预览:
GitHub默认点击图片会跳转到另一个窗口,有时候无意点到也会跳转到另一个页面,体验稍差,为此添加了一个类似知乎点击图片全屏查看的功能
截图:
复制代码:
方便的帮助用户实现点击复制代码的功能,告别冗长的移动拖动选中再复制黏贴的繁琐步骤,轻轻一点,demo我有。
截图:
图像展示
进入首页,大佬图像一览无余,更清晰直观的看出大佬的各种动态,关注大佬的一举一动,时刻关心最新开源技术。
在大屏幕下,会展示所有的内容,在mac等小屏幕下默认只显示侧边栏目录树,而TOC默认是隐藏的。
截图:
如果对您有帮助,您可以点右上角 "Star" 支持一下 谢谢! ^_^
或者您可以 "follow" 一下,我会不断开源更多的有趣的项目
如有问题请直接在 Issues 中提,或者您发现问题并有非常好的解决方案,欢迎 PR 👍
github源码地址:https://github.com/jawil/GayHub
欢迎测bug和提出你认为需要改进的地方,送截图某论坛邀请码。😁
我们的项目是通过pm2来部署的一个nodejs应用。
最近发现,我们更新完应用文件,然后restart对应pm2应用之后,更新的内容未生效,还是原来的内容,这是pm2的缓存么,只有把pm2进程杀掉,然后重新部署才生效。求大神指点
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
工欲善其事,必先利其器。
前不久在 掘金 上看到一篇文章,前端 PS 切图方法,图文详细,相信每个前端都经过这种最原始的切图手法,不禁想起自己以前刚入门那会懒得切图,直接QQ截图,现在想起来真是初生牛犊不怕虎,怎么方便怎么来。。。
这种原始的PS切图,不能说不好,只能说太影响效率了,一直认为能用机器解决的事,就不要用人工操作,特别是切图这种体力活,不应该是由程序员来完成的,如果开发还停留在手工切图,没什么意义,只能说你的时间太廉价了。
这里切图推荐一个插件:Cutterman,更多切图工具介绍请移步:扶朕起来,朕还能切
Cutterman致力于改善设计师的工作效率,为设计师提供优秀、高效、实用的技术解决方案, 解放双手。让创意不再有界限, 让设计更专注!
Cutterman能够让你只需要点击一个按钮,就自动输出你需要的各种各样的图片,快到没有朋友!
将一个个标注手动画出来,耗时费力不说,画得两眼昏花,一不小心就会出现漏标的情况。而这些漏标的地方,攻城狮们往往在开发过程中才会发现,于是不得不一次又一次地找设计师进行确认。
切好图之后该怎么标注了,这是一个面临的问题,别告诉我你还在手动一个一个在那里测距离,我看见我同事之前就是用PS一个一个在那里量距离,看得我强迫症和尴尬症都犯了,记住,不要把时间浪费在体力活上,能用工具解决的事就不要用双手,你这么喜欢干这种测距离的体力活你咋不去搬砖呢😄,让别人用双手拯救你的双手。
有时候标注设计师会帮你做,但是也不是总能碰见这么善解人意的设计师,我方设计师VS别人设计师。
碰见这种我方设计师,没人替我们分担,这种低效的协作方式,造成了大多数互联网产品设计团队普遍的悲剧:明天要上线,通宵抠细节,吐血调界面,加班!!!
设计师不帮我们标注,咋们自己来,借助工具标注也是分分钟的事情,假如复杂的标注蹂躏了你,不要悲伤,不要哭泣。
如果有一天,设计师只需专注界面设计,不需再做切图和标注的工作;如果有一天,工程师只需专注功能框架建设,不需再花太多心思在标注UI上面;没有如果,这一天真的来了。。。
工以利器为助,人以贤友为助。有了这些工具的辅佐,让我们开发的效率又快又好,简直如虎添翼,爽到不行。
以下是一些能够让程序员与设计师 相爱 的软件
对!就!是!相!爱!
你耕田来我织布
你设计来我开发
天天让我标注测距离,标你妹啊,作为射击狮,却干着死美工的活,每天要为程序猿同学标注PSD有木有?但我却憧憬着成为逼格很高的射击狮。为了能够早点下班泡妹子看电影。标你妹啊帮你解放你的双手…
一款全中文免费的自动标注的神器!彻底解放设计师的双手,上传文件就能蹭蹭蹭的自动标注!什么?你还想自动作图?冷静点冷静点…万一失业了呢?
现在,这款叫蓝湖的设计师标注神器,最新版开始支持“自动标注”的功能(目前仅支持.Sketch,Psd版本即将上线)
只需下载“蓝湖”Mac端App,即可实现:从Sketch一键导出设计图→自动生成标注→自动共享给团队→团队相关成员自动收到提醒等一系列自动化功能。
蓝湖是一款产品设计师的协作平台,帮助设计师更快地完成工作。蓝湖通过帮助设计师更好地向团队展示设计图,描述页面之间的跳转关系。蓝湖还支持从Sketch一键分享、在线协作…
“自动标注”功能可以完整而清晰地将Sketch设计图中每个元素的尺寸、位置、颜色、间距、字号 等样式信息自动同步到蓝湖,团队内的工程师等同事可以随时查看。
如果设计图出现改动和更新,蓝湖也能自动添加新版本。
如今设计师的工具那么多,这一款工具的优势在哪里呢
1.所有功能完全免费,没有任何项目或团队成员数量限制。
2.中文的!中文的!中文的!
3.无与伦比的快!在国内的服务器+蓝湖工程师呕心沥血优化的算法,使蓝湖的“自动标注”的速度嗖嗖的!
4.蓝湖还整合了设计图流程的展示,设计图历史版本管理,多种情况和状态的设计图管理等功能。
5.设计师不但可以为每张设计图添加备注文档,其他团队成员还可以针对设计图发表评论,方便团队在线高效沟通。(内心竟有点小小的惶恐…)
6.在蓝湖上,还可以基于设计图快速制作一个高保真的交互原型,让工程师不用再跑来问你“这个按钮跳到哪啊”,该原型还可以在蓝湖手机端App和微信上进行操作和预览。
美团,网易,面包旅行等等国内知名互联网公司都参与了蓝湖的早期内测,为 “蓝湖”提出了很多专业的建议。“蓝湖”基于这些反馈快速迭代,而“自动标注”功能就是其中一项。
由于是国内的团队,沟通起来非常方便!所以如果设计师们有痛点或是需求,可以积极讨论!没准下版本的蓝湖就能直接自动作图了呢!!!
对惹,蓝湖主体功能是Web端网页平台,不需要下载,直接注册就可以免费使用。
来源:你丫才美工(Ymeigong),之前今日头条看到的推荐,不知道网址。。。
随着sketch的普及(sketch是啥,能吃吗?自行谷歌、必应),国内外很多项目团队都陆续用起了sketch+zeplin的开发模式。不过话说回来,sketch真的有那么好用吗?很多小伙伴们表示用ps好几年了,要我重新学一个软件,臣妾做不到啊!~
其实刚进公司的时候也是这种心情的,没用过mac更没用过sketch,完全的小白用户,当时内心几乎是奔溃的。但是自从接触sketch后,真的是爱不释手,都不想用回ps了。
在使用 Zeplin 之前,最早是使用马克曼(手动标注,这里不做推荐)进行标注的,也就是直接在输出效果图上量尺寸;使用 Sketch 插件 Measure 之后,可以在画板中生成尺寸标注信息,导出标注图提供给开发同学使用。无论是马克曼还是 Measure,最后的交付物是一致的,马克曼和接下来要介绍的Measure这种原始的标准就是已经破坏了原本的视觉效果图,标注的信息一定会对原设计稿形成遮挡,因此一般效果图和标注图要分开给,开发也经常需要在两个图之间切换,图片管理不太方便。
zeplin 主要就是为了解决上述问题的,使用它之后,可以在 Sketch 中一键导入 Artboard,在设计师做好图层管理(命名、分组)的前提下,它可以自动生成标注信息(并且可以标注为 pt 或 dp),允许添加注释形成类 prd 文档,并且自动提取 Style Guide,同时还允许添加项目组成员,提供给团队组查看项目。
介绍之后回答两个基本问题
答:不好意思,目前没有!设计师为了提升工作效率,就算吃土一两个月也要买台mac。不过windows用户除了装mac虚拟机外,现在ps也支持zeplin插件了,只要安装个插件,没有mac也照样可以任性的告别切图和标注。
答:真够意思,这个必须有!不久前只有mac版,不过zeplin团队怎么会放弃windows那么大块的市场呢。真是喜大普奔,现在zeplin也支持windows了,从此开发哥哥再也不会抱怨网页端的zeplin打开速度超级慢了。
好了,废话不多说,直接进正题。
1、sketch支持多画板,便于同时预览,占用内存较ps小很多;
2、sketch支持导出flinto,便于制作交互动效原型;
3、zeplin解放设计师的双手,从此告别切图和标注;
4、zeplin降低工程师的沟通成本,提高设计还原度。
更多细节已经安装方法导出技巧请移步:APP标注无烦恼!告别切图标注-Sketch/PS+Zeplin
这里这介绍工具,由于篇幅有限,并不详细教你怎么用,工具多用用就会了,熟能生巧。
更多关于Zeplin的体验和细节请移步:Zeplin 的使用体验如何?
Sketch Measure是一款可用于标注和设计规范的工具,支持Sketch 3.5版以上。Measure帮你解放你的双手…
1.创建叠加
2.度量尺寸
3.度量边距
4.获取属性
5.添加注释
关于Sketch Measure的使用教程,这里也不多细说,这里抛砖引玉的介绍一下,想要了解和使用请移步:
Sketch Measure切图标注插件使用教程
下面谈一谈Zeplin和Sketch Measure的区别,纯属引用,表示没用过Sketch Measure:
①Zeplin注册免费,只能保留一个Active项目,“STARTER”17刀/月,3个Active项目,“GROWING BUSINESS”26刀/月,12个Active项目。“ORGANIZATION”每个用户6.75刀/月。
②支持MAC的Sketch和PS,以及PC的PS。(最大的优点)
③数据必须上传到网络上,可以用客户端查看也可以网页查看,必须是注册用户。(很麻烦,有些公司不允许上传就没办法了)
④自动生成styleguide。(非常棒)
⑤切图需要查看相应页面时,从切图栏下载。(我用的并不多,也可能有其他方式)
①完全免费。
②只支持MAC Sketch,但查看不受限制。
③数据保存在本地(html文件),方便打包后发邮件,缺点是每次更新都要再发一遍,管理麻烦。
④没有Zeplin智能,没有自动styleguide,但是有类似AssistorPS一样的手动标注。
⑤有“颜色命名”但比styleguide差很多,希望以后能更新类似功能。自动打包输出切图,支持iOS和Android的命名方式。
标你妹适合小型的个人的一些项目,对于新手来说,学习成本基本为0,非常方便,web端没有平台限制;
蓝湖Mac端APP首先你得有一台Mac,其次是OSX系统,国内的良心之作,速度很快,适合个人和企业协同合作开发;
Zeplin适合小型的团队,还带有一部分协作办公的功能(留言和更新状况),要求前端也能适应这种新的方式;
Sketch Measure更传统一些,本地文档、打包切图等等,更适合有自己办公流程的大公司,仅仅支持Mac。
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
在一个
Web项目中,注册,登录,修改用户信息,下订单等功能的实现都离不开提交表单。这篇文章就阐述了如何编写相对看着舒服的表单验证代码。
假设我们正在编写一个注册的页面,在点击注册按钮之前,有如下几条校验逻辑。
注:为简单起见,以下例子以传统的浏览器表单验证,Ajax异步请求不做探讨,浏览器端验证原理图:
简要说明:
这里我们前端只做浏览器端的校验。很多工具可以在表单检验过后、浏览器发送请求前截取表单数据,攻击者可以修改请求中的数据,从而绕过
JavaScript,将恶意数据注入服务器,这样会增加XSS(全称 Cross Site Scripting)攻击的机率。对于一般的网站,都不赞成采用浏览器端的表单验证方法。浏览器端和服务器端双重验证方法在浏览器端验证方法基础上增加服务器端的验证,其原理如图所示,该方法增加服务器端的验证,弥补了传统浏览器端验证的缺点。若表单输入不符合要求,浏览器端的Javascript验证能很快地给出响应,而服务器端的验证则可以防止恶意用户绕过Javascript验证,保证最终数据的准确性。
HTML代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>探索几种表单验证最佳实践方式</title>
</head>
<body>
<form action="http://xxx.com/register" id="registerForm" method="post">
<div class="form-group">
<label for="user">请输入用户名:</label>
<input type="text" class="form-control" id="user" name="userName">
</div>
<div class="form-group">
<label for="pwd">请输入密码:</label>
<input type="password" class="form-control" id="pwd" name="passWord">
</div>
<div class="form-group">
<label for="phone">请输入手机号码:</label>
<input type="tel" class="form-control" id="phone" name="phoneNumber">
</div>
<div class="form-group">
<label for="email">请输入邮箱:</label>
<input type="text" class="form-control" id="email" name="emailAddress">
</div>
<button type="button" class="btn btn-default">Submit</button>
</form>
</body>
</html>JavaScript代码:
let registerForm = document.querySelector('#registerForm')
registerForm.addEventListener('submit', function() {
if (registerForm.userName.value === '') {
alert('用户名不能为空!')
return false
}
if (registerForm.userName.length < 6) {
alert('用户名长度不能少于6位!')
return false
}
if (registerForm.passWord.value === '') {
alert('密码不能为空!')
return false
}
if (registerForm.passWord.value.length < 6) {
alert('密码长度不能少于6位!')
return false
}
if (registerForm.phoneNumber.value === '') {
alert('手机号码不能为空!')
return false
}
if (!/^1(3|5|7|8|9)[0-9]{9}$/.test(registerForm.phoneNumber.value)) {
alert('手机号码格式不正确!')
return false
}
if (registerForm.emailAddress.value === '') {
alert('邮箱地址不能为空!')
return false
}
if (!/^\w+([+-.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
$/.test(registerForm.emailAddress.value)) {
alert('邮箱地址格式不正确!')
return false
}
}, false)这样编写代码,的确能够完成业务的需求,能够完成表单的验证,但是存在很多问题,比如:
registerForm.addEventListener绑定的函数比较庞大,包含了很多的if-else语句,看着都恶心,这些语句需要覆盖所有的校验规则。registerForm.addEventListener绑定的函数缺乏弹性,如果增加了一种新的校验规则,或者想要把密码的长度校验从6改成8,我们都必须深入registerForm.addEventListener绑定的函数的内部实现,这是违反了开放-封闭原则的。- 算法的复用性差,如果程序中增加了另一个表单,这个表单也需要进行一些类似的校验,那我们很可能将这些校验逻辑复制得漫天遍野。
所谓办法总比问题多,办法是有的,比如马上要讲解的使用 策略模式 使表单验证更优雅更完美,我相信很多人很抵触设计模式,一听设计模式就觉得很遥远,觉得自己在工作中很少用到设计模式,那么你就错了,特别是JavaScript这种灵活的语言,有的时候你已经在你的代码中使用了设计模式,只是你不知道而已。更多关于设计模式的东西,以后会陆续写博客描述,这里只希望大家抛弃设计模式神秘的感觉,通俗的讲,它无非就是完成一件事情通用的办法而已。
回到正题,假如我们不想使用过多的 if - else 语句,那么我们心中比较理想的代码编写方式是什么呢?我们能不能像编写配置一样的去做表单验证呢?再来一个”一键验证“的功能,是不是很爽?答案是肯定的,所以我们心中理想的编写代码的方式如下:
// 获取表单form元素
let registerForm = document.querySelector('#registerForm')
// 创建表单校验实例
let validator = new Validator();
// 编写校验配置
validator.add(registerForm.userName, 'isNonEmpty', '用户名不能为空')
validator.add(registerForm.userName, 'minLength:6', '用户名长度不能小于6')
// 开始校验,并接收错误信息
let errorMsg = validator.start()
// 如果有错误信息输出,说明校验未通过
if(errorMsg){
alert(errorMsg)
return false//阻止表单提交
}怎么样?感受感受,是不是看上去优雅多了?好了,有了这些思路,我们就可以向目标迈进了,下一步就要了解了解什么事策略模式了。
策略模式,单纯的看它的名字”策略“,指的是做事情的方法,比如我们想到某个地方旅游,你可以有几种策略供选择:
1、飞机,嗖嗖嗖直接就到了,节省时间。
2、火车,可以选择高铁出行,专为飞机恐惧症者提供。
3、徒步,不失为一个锻炼身体的选择。
4、other method……
在程序设计中,我们也经常遇到类似的情况,要实现一种方案有多种方案可以选择,比如,一个压缩文件的程序,即可选择zip算法,也可以选择gzip算法。
所以,做一件事你会有很多方法,也就是所谓的策略,而我们今天要讲的策略模式也就是这个意思,它的核心**是,将做什么和谁去做相分离。所以,一个完整的策略模式要有两个类,一个是策略类,一个是环境类(主要类),环境类接收请求,但不处理请求,它会把请求委托给策略类,让策略类去处理,而策略类的扩展是很容易的,这样,使得我们的代码易于扩展。
在表单验证的例子中,各种验证的方法组成了策略类,比如:判断是否为空的方法(如:isNonEmpty),判断最小长度的方法(如:minLength),判断是否为手机号的方法(isMoblie)等等,他们组成了策略类,供给环境类去委托请求。下面,我们就来实战一下。
策略模式的组成
抽象策略角色:策略类,通常由一个接口或者抽象类实现。
具体策略角色:包装了相关的算法和行为。
环境角色:持有一个策略类的引用,最终给客户端用的。
策略类很简单,它是由一组验证方法组成的对象,即策略对象,重构表单校验的代码,很显然第一步我们要把这些校验逻辑都封装成策略对象:
/*策略对象*/
const strategies = {
isNonEmpty(value, errorMsg) {
return value === '' ?
errorMsg : void 0
},
minLength(value, length, errorMsg) {
return value.length < length ?
errorMsg : void 0
},
isMoblie(value, errorMsg) {
return !/^1(3|5|7|8|9)[0-9]{9}$/.test(value) ?
errorMsg : void 0
},
isEmail(value, errorMsg) {
return !/^\w+([+-.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/.test(value) ?
errorMsg : void 0
}
}根据我们的思考,我们使用add方法添加验证配置,如下:
validator.add(registerForm.userName, 'isNonEmpty', '用户名不能为空')
validator.add(registerForm.userName, 'minLength:6', '用户名长度不能小于6')add方法接受三个参数,第一个参数是表单字段,第二个参数是策略对象中策略方法的名字,第三个参数是验证未通过的错误信息。
然后使用 start 方法开始验证,若验证未通过,返回验证错误信息,如下:
let errorMsg = validator.start()
另外,再解释一下下面这句代码:
add方法第一个参数我们说过了,是要验证的表单元素,第二个参数是一个字符串,使用 冒号(:) 分割,前面是策略方法名称,后面是传给这个方法的参数,第三个参数仍然是错误信息。
但是这种参数配置还是有问题,我们的要求是多种校验规则,比如用户名既不能为空,又要满足用户名长度不小于6,并不是单一的,上面的为什么要写两次,这种看着就不舒服,这时候我就需要对配置参数做一点小小的改动,我们用数组来传递多个校验规则:
validator.add(registerForm.userName, [{
strategy: 'isNonEmpty',
errorMsg: '用户名不能为空!'
}, {
strategy: 'minLength:6',
errorMsg: '用户名长度不能小于6位!'
}])最后是Validator类的实现:
/*Validator类*/
class Validator {
constructor() {
this.cache = [] //保存校验规则
}
add(dom, rules) {
for (let rule of rules) {
let strategyAry = rule.strategy.split(':') //例如['minLength',6]
let errorMsg = rule.errorMsg //'用户名不能为空'
this.cache.push(() => {
let strategy = strategyAry.shift() //用户挑选的strategy
strategyAry.unshift(dom.value) //把input的value添加进参数列表
strategyAry.push(errorMsg) //把errorMsg添加进参数列表,[dom.value,6,errorMsg]
return strategies[strategy].apply(dom, strategyAry)
})
}
}
start() {
for (let validatorFunc of this.cache) {
let errorMsg = validatorFunc()//开始校验,并取得校验后的返回信息
if (errorMsg) {//r如果有确切返回值,说明校验没有通过
return errorMsg
}
}
}
}使用策略模式重构代码以后,我们仅仅通过‘配置’的方式就可以完成一个表单的校验,这些校验规则也可以复用在程序的任何地方,还能作为插件的形式,方便地被移植到其他项目中。
/*客户端调用代码*/
let registerForm = document.querySelector('#registerForm')
const validatorFunc = () => {
let validator = new Validator()
validator.add(registerForm.userName, [{
strategy: 'isNonEmpty',
errorMsg: '用户名不能为空!'
}, {
strategy: 'minLength:6',
errorMsg: '用户名长度不能小于6位!'
}])
validator.add(registerForm.passWord, [{
strategy: 'isNonEmpty',
errorMsg: '密码不能为空!'
}, {
strategy: 'minLength:',
errorMsg: '密码长度不能小于6位!'
}])
validator.add(registerForm.phoneNumber, [{
strategy: 'isNonEmpty',
errorMsg: '手机号码不能为空!'
}, {
strategy: 'isMoblie',
errorMsg: '手机号码格式不正确!'
}])
validator.add(registerForm.emailAddress, [{
strategy: 'isNonEmpty',
errorMsg: '邮箱地址不能为空!'
}, {
strategy: 'isEmail',
errorMsg: '邮箱地址格式不正确!'
}])
let errorMsg = validator.start()
return errorMsg
}
registerForm.addEventListener('submit', function() {
let errorMsg = validatorFunc()
if (errorMsg) {
alert(errorMsg)
return false
}
}, false)在修改某个校验规则的时候,只需要编写或者改写少量的代码。比如我们想要将用户名输入框的校验规则改成用户名不能少于4个字符。可以看到,这时候的修改是毫不费力的。代码如下:
validator.add(registerForm.userName, [{
strategy: 'isNonEmpty',
errorMsg: '用户名不能为空!'
}, {
strategy: 'minLength:4',
errorMsg: '用户名长度不能小于4位!'
}])当然,策略模式也有一些缺点,但掌握了策略模式,这些缺点并不严重。
策略模式使开发人员能够开发出由许多可替换的部分组成的软件,并且各个部分之间是弱连接的关系。
弱连接的特性使软件具有更强的可扩展性,易于维护;更重要的是,它大大提高了软件的可重用性。
策略模式固然可行,但是包装的有点多了,而且不便于书写,代码书写量增加了不少,也就是有一定门槛,那有没有更好的实现方式呢?我们能不能通过一层代理,在设置属性时候就去拦截它呢?这就是今天要讲到的ES6的Proxy对象。
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming),即对编程语言进行编程。
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
let obj = new Proxy({}, {
get (target, key, receiver) {
console.log(`getting ${key}!`)
return Reflect.get(target, key, receiver)
},
set (target, key, value, receiver) {
console.log(`setting ${key}!`)
return Reflect.set(target, key, value, receiver)
}
})上面代码对一个空对象架设了一层拦截,重定义了属性的读取(get)和设置(set)行为。这里暂时先不解释具体的语法,只看运行结果。对设置了拦截行为的对象obj,去读写它的属性,就会得到下面的结果。
obj.count = 1
// setting count!
++obj.count
// getting count!
// setting count!
// 2上面代码说明,Proxy 实际上重载(overload)了点运算符,即用自己的定义覆盖了语言的原始定义。
ES6 原生提供 Proxy 构造函数,用来生成 Proxy 实例。
let proxy = new Proxy(target, handler);Proxy 对象的所有用法,都是上面这种形式,不同的只是handler参数的写法。其中,new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为。
下面是另一个拦截读取属性行为的例子。
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35上面代码中,作为构造函数,Proxy接受两个参数。第一个参数是所要代理的目标对象(上例是一个空对象),即如果没有Proxy的介入,操作原来要访问的就是这个对象;第二个参数是一个配置对象,对于每一个被代理的操作,需要提供一个对应的处理函数,该函数将拦截对应的操作。比如,上面代码中,配置对象有一个get方法,用来拦截对目标对象属性的访问请求。get方法的两个参数分别是目标对象和所要访问的属性。可以看到,由于拦截函数总是返回35,所以访问任何属性都得到35。
注意,要使得Proxy起作用,必须针对Proxy实例(上例是proxy对象)进行操作,而不是针对目标对象(上例是空对象)进行操作。
利用proxy拦截不符合要求的数据
function validator(target, validator, errorMsg) {
return new Proxy(target, {
_validator: validator,
set(target, key, value, proxy) {
let errMsg = errorMsg
if (value == '') {
alert(`${errMsg[key]}不能为空!`)
return target[key] = false
}
let va = this._validator[key]
if (!!va(value)) {
return Reflect.set(target, key, value, proxy)
} else {
alert(`${errMsg[key]}格式不正确`)
return target[key] = false
}
}
})
}负责校验的逻辑代码
const validators = {
name(value) {
return value.length > 6
},
passwd(value) {
return value.length > 6
},
moblie(value) {
return /^1(3|5|7|8|9)[0-9]{9}$/.test(value)
},
email(value) {
return /^\w+([+-.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/.test(value)
}
}客户端调用代码
const errorMsg = { name: '用户名', passwd: '密码', moblie: '手机号码', email: '邮箱地址' }
const vali = validator({}, validators, errorMsg)
let registerForm = document.querySelector('#registerForm')
registerForm.addEventListener('submit', function() {
let validatorNext = function*() {
yield vali.name = registerForm.userName.value
yield vali.passwd = registerForm.passWord.value
yield vali.moblie = registerForm.phoneNumber.value
yield vali.email = registerForm.emailAddress.value
}
let validator = validatorNext()
validator.next();
!vali.name || validator.next(); //上一步的校验通过才执行下一步
!vali.passwd || validator.next();
!vali.moblie || validator.next();
}, false)优点:条件和对象本身完全隔离开,后续代码的维护,代码整洁度,以及代码健壮性和复用性变得非常强。
缺点:兼容性不好,有babel怕啥,粗糙版,很多细节其实还可以优化,这里只提供一种思路。
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
有些童鞋肯定有所疑惑,花了大量时间学习正则表达式,却发现没有用武之地,正则不就是验证个邮箱嘛,其他地方基本用不上,其实,大部分人都是这种感觉,所以有些人干脆不学,觉得又难又没多大用处。殊不知,想要成为编程大牛,正则表达式必须玩转,GitHub上优秀的开源库和框架里面到处都是强大的正则匹配,当年jQuery作者也被称为正则小王子。这里分享一些工作中用到的和自己收集的一些正则表达式的妙用,到处闪耀着开发者智慧的火花。
实现一个需求的方法很多种,哪种更好,仁者见仁智者见智,这里只提供一种对比的思维来激发大家学习正则的兴趣和养成活用正则的思维。
作为前端开发人员,总会有点自己的奇技淫巧,毕竟前端开发不同于后端,代码全部暴漏给用户不说,代码冗余了少则影响带宽,多则效率降低。正则表达式(Regular Expression),这是一块硬骨头,很难啃,但是啃着又很香。所以今天我也来爆一些正则表达式的奇技淫巧。
正则大法好,正则大法好,正则大法好,重要的事情说三遍。
https://www.baidu.com?name=jawil&age=23 name的value值非正则实现:
function getParamName(attr) {
let search = window.location.search // "?name=jawil&age=23"
let param_str = search.split('?')[1] // "name=jawil&age=23"
let param_arr = param_str.split('&') // ["name=jawil", "age=23"]
let filter_arr = param_arr.filter(ele => { // ["name=jawil"]
return ele.split('=')[0] === attr
})
return decodeURIComponent(filter_arr[0].split('=')[1])
}
console.log(getParamName('name')) // "jawil"用正则实现:
function getParamName(attr) {
let match = RegExp(`[?&]${attr}=([^&]*)`) //分组运算符是为了把结果存到exec函数返回的结果里
.exec(window.location.search)
//["?name=jawil", "jawil", index: 0, input: "?name=jawil&age=23"]
return match && decodeURIComponent(match[1].replace(/\+/g, ' ')) // url中+号表示空格,要替换掉
}
console.log(getParamName('name')) // "jawil"看不太懂先学习一下这篇文章:[ JS 进阶 ] test, exec, match, replace
非正则实现:
let test = '1234567890'
function formatCash(str) {
let arr = []
for (let i = 1; i < str.length; i++) {
if (str.length % 3 && i == 1)
arr.push(str.substr(0, str.length % 3))
if (i % 3 === 0)
arr.push(str.substr(i - 2, 3))
}
return arr.join(',')
}
console.log(formatCash(test)) // 1,234,567,890用正则实现:
let test1 = '1234567890'
let format = test1.replace(/\B(?=(\d{3})+(?!\d))/g, ',')
console.log(format) // 1,234,567,890下面简单分析下正则/\B(?=(\d{3})+(?!\d))/g:
/\B(?=(\d{3})+(?!\d))/g:正则匹配边界\B,边界后面必须跟着(\d{3})+(?!\d);(\d{3})+:必须是1个或多个的3个连续数字;(?!\d):第2步中的3个数字不允许后面跟着数字;(\d{3})+(?!\d):所以匹配的边界后面必须跟着3*n(n>=1)的数字。最终把匹配到的所有边界换成,即可达成目标。
非正则实现:
function trim(str) {
let start, end
for (let i = 0; i < str.length; i++) {
if (str[i] !== ' ') {
start = i
break
}
}
for (let i = str.length - 1; i > 0; i--) {
if (str[i] !== ' ') {
end = i
break
}
}
return str.substring(start, end + 1)
}
let str = " jaw il "
console.log(trim(str)) // "jaw il"用正则实现:
function trim(str) {
return str.replace(/(^\s*)|(\s*$)/g, "")
}
let str = " jaw il "
console.log(trim(str)) // "jaw il"质数又称素数。指在一个大于1的自然数中,除了1和此整数自身外,没法被其他自然数整除的数。
非正则实现:
function isPrime(num){
// 不是数字或者数字小于2
if(typeof num !== "number" || !Number.isInteger(num)){
// Number.isInterget 判断是否为整数
return false
}
//2是质数
if(num == 2){
return true
}else if(num % 2 == 0){ //排除偶数
return false
}
//依次判断是否能被奇数整除,最大循环为数值的开方
let squareRoot = Math.sqrt(num)
//因为2已经验证过,所以从3开始;且已经排除偶数,所以每次加2
for(let i = 3; i <= squareRoot; i += 2) {
if (num % i === 0) {
return false
}
}
return true
}
console.log(isPrime(19)) // true用正则实现:
function isPrime(num) {
return !/^1?$|^(11+?)\1+$/.test(Array(num+1).join('1'))
}
console.log(isPrime(19)) // true要使用这个正规则表达式,你需要把自然数转成多个1的字符串,如:2 要写成 “11”, 3 要写成 “111”, 17 要写成“11111111111111111”,这种工作使用一些脚本语言可以轻松的完成,JS实现也很简单,我用Array(num+1).join('1')这种方式实现了一下。
一开始我对这个表达式持怀疑态度,但仔细研究了一下这个表达式,发现是非常合理的,下面,让我带你来细细剖析一下是这个表达式的工作原理。
首先,我们看到这个表达式中有“|”,也就是说这个表达式可以分成两个部分:/^1?$/ 和 /^(11+?)\1+$/
可见这个正规则表达式是取非素数,要得到素数还得要对整个表达式求反。通过上面的分析,我们知道,第二部分是最重要的,对于第二部分,举几个例子,
示例一:判断自然数8。我们可以知道,8转成我们的格式就是“11111111”,对于 (11+?) ,其匹配了“11”,于是还剩下“111111”,而 \1+$ 正好匹配了剩下的“111111”,因为,“11”这个模式在“111111”出现了三次,符合模式匹配,返回true。所以,匹配成功,于是这个数不是质数。
示例二:判断自然数11。转成我们需要的格式是“11111111111”(11个1),对于 (11+?) ,其匹配了“11”(前两个1),还剩下“111111111”(九个1),而 \1+$ 无法为“11”匹配那“九个1”,因为“11”这个模式并没有在“九个1”这个串中正好出现N次。于是,我们的正则表达式引擎会尝试下一种方法,先匹配“111”(前三个1),然后把“111”作为模式去匹配剩下的“11111111”(八个1),很明显,那“八个1”并没有匹配“三个1”多次。所以,引擎会继续向下尝试……直至尝试所有可能都无法匹配成功。所以11是素数。
通过示例二,我们可以得到这样的等价数算算法,正则表达式会匹配这若干个1中有没有出现“二个1”的整数倍,“三个1”的整数倍,“四个1”的整数倍……,而,这正好是我们需要的算素数的算法。现在大家明白了吧。
这里只考虑最简单字符串的数组去重,暂不考虑,对象,函数,NaN等情况,这种用正则实现起来就吃力不讨好了。
非正则实现:
①ES6实现
let str_arr=["a","b","c","a","b","c"]
function unique(arr){
return [...new Set(arr)]
}
console.log(unique(str_arr)) // ["a","b","c"]②ES5实现
var str_arr = ["a", "b", "c", "a", "b", "c"]
function unique(arr) {
return arr.filter(function(ele, index, array) {
return array.indexOf(ele) === index
})
}
console.log(unique(str_arr)) // ["a","b","c"]③ES3实现
var str_arr = ["a", "b", "c", "a", "b", "c"]
function unique(arr) {
var obj = {},
array = []
for (var i = 0, len = arr.length; i < len; i++) {
var key = arr[i] + typeof arr[i]
if (!obj[key]) {
obj[key] = true
array.push(arr[i])
}
}
return array
}
console.log(unique(str_arr)) // ["a","b","c"]额,ES4呢。。。对不起,由于历史原因,ES4改动太大,所以被废弃了。
可以看到从ES3到ES6,代码越来越简洁,JavaScript也越来越强大。
用正则实现:
var str_arr = ["a", "b", "c", "a", "b", "c"]
function unique(arr) {
return arr.sort().join(",,").
replace(/(,|^)([^,]+)(,,\2)+(,|$)/g, "$1$2$4").
replace(/,,+/g, ",").
replace(/,$/, "").
split(",")
}
console.log(unique(str_arr)) // ["a","b","c"]这里我只是抛砖引玉的利用几个例子对比来展现正则表达式的强大,其实正则表达式的应用远远不止这些,这里列出的只是冰山一角,更多的奇淫技巧需要你们来创造,知识点API是有限的,技巧和创造却是无限的,欢迎大家开动脑门,创造或分享自己的奇淫技巧。
如果还没有系统学习正则表达式,这里提供一些网上经典的教程供大家学习。
正则表达式(Regular Expression),这是一块硬骨头,很难啃,但是啃着又很香。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。很多地方我们都需要使用正则,所以今天就将一些优秀的教程,工具总结起来。
https://en.wikipedia.org/wiki/Regular_expression 了解一样东西,当然先从WIKI开始最好了。
// Regular Expression examples
I had a \S+ day today
[A-Za-z0-9\-_]{3,16}
\d\d\d\d-\d\d-\d\d
v(\d+)(\.\d+)*
TotalMessages="(.*?)"
<[^<>]>http://deerchao.net/tutorials/regex/regex.htm 30分钟入门教程,网上流传甚广
https://qntm.org/files/re/re.html 55分钟教程【英文】,
http://regex.learncodethehardway.org/book/ 一本简单的书,每一节就是一块内容
https://swtch.com/~rsc/regexp/regexp1.html 正则匹配原理解析
http://stackoverflow.com/tags/regex/info stackoverflow 正则标签,标签下有值得点击的链接,一些典型的问题
http://regexr.com/ 正则学习测试于一身
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions MDN出品,JavaScript方面内容
https://regex101.com/ in JavaScript, Python, PCRE 16-bit, generates explanation of pattern
https://www.debuggex.com/ 正则验证测试,清晰明了
https://mengzhuo.org/regex/ 中文版正则验证测试
http://refiddle.com/ 测试工具
http://myregexp.com/ 也是测试工具,都可以试一试
http://regex.alf.nu 闯关模式练习正则表达式,完成一个个正则匹配的测验
http://regexone.com/ 通过实际练习掌握正则表达式
https://regexcrossword.com/ 正则挑战,有不同难度,很丰富
http://callumacrae.github.io/regex-tuesday/ 正则挑战,完成正则匹配要求
https://msdn.microsoft.com/zh-cn/library/az24scfc.aspx MSDN 微软出品
http://www.jb51.net/tools/regex.htm 常用正则表达式,如匹配网址、日期啊这种,这个谷歌一搜很多的
https://www.cheatography.com/davechild/cheat-sheets/regular-expressions/ 速查表地址,如下图

一般阿里社招都是招3-5年的P6+高级工程师,当初自己一年经验也没有想过有这个面试机会。
虽然没想着换工作,但是经常关注一些招聘网站的信息,某一天,在某boss上有个人找我,叫我发一下简历,我一看是阿里的某技术专家,虽然之前也有阿里的在某boss上给我要简历,但是我深知自己经验不足,然后给boss说我是16届的,只有一年经验,然后就没有然后了。这次我依然这么回复,但是这boss说,没关系,他喜欢基础好的,让我可以试一试,于是我也抱着试一试的心态发了简历。
简历发过去之后,boss就给我打了电话,让我简单的介绍一下自己,我就噼里啪啦说了一些,还说了一些题外话。然后boss就开始问我问题。
由于面了四轮,所以最开始的面试记忆有点模糊了,细细回想,又感觉记忆犹新。
我就说了一下IE的怪异盒模型和标注浏览器的盒模型,然后可以通过box-sizing属性控制两种盒模型的变换。
这个也不难,简单说了一两个应用场景,具体就不一一细说了。
这个我也比较了解,各种概念和属性能想到的说了一大堆,也扯到了Grid布局,基本这个也没啥问题。
说了一下flex弹性布局的实现,说了一下兼容性,扯到了postcss的一些东西,然后说了一下常规的兼容性比较好的实现。
这个我之前写过相关的文章,自己也有比较深入的理解,所以这个也不在话下,噼里啪啦说了一大堆,也不知道面试官听得咋样。
说了三种,然后说了一些冒泡,默认事件,以及DOM2,DOM3级的一些标准。
这个因人而异,开放性问题,主要考察平时项目的一些积累吧,这个我回答感觉也比较ok。
这个我看过一些文章,但是没有什么印象,扯了一些概念,但是回答的不是很深。
第一轮电话初探,大约面了50分钟,就记起来这么多,还有一些细节问题可能淡忘了,总体来说,面的都是以基础为主,然后boss说把我简历推荐给内部,进行正式的社招流程。
然后当天晚上一个女的面试官就给我打电话了,说八点半进行下一轮技术面试,没想到效率这么快,我都没怎么准备。
这次就直接省略自我介绍了。
这个自己就说了一下自己的理解,以及自己用node写的多入口怎么配置,然后面试官说不是多入口配置,然后我又说了一下自己的理解,然后这题就过了。
这个我也还算比较了解,就说了一下ES的一些API,比如generator啥的默认不转换,只转换语法,需要这个来转换,然后说profill啥的,扯了一下stage-1,stage-2,stage-3,这个问题回答还算清楚。
这个我主要回答了一下,我之前也没怎么了解,一个想到是缓存原理,压缩只重新压缩改变的,还有就是减少冗余的代码,压缩只用于生产阶段,然后面试官问还有呢?我就说,还可以从硬件上提升,可以得到质的飞跃,比如换台I9处理器的电脑。。。。
这个噼里啪啦说了一堆,协商缓存和强制缓存的区别,流程,还有一些细节,提到了expires,Cache-Control,If-none-match,Etag,last-Modified的匹配和特征,这一块之前有过比较详细的了解,所以还是应答如流。
这个没答上来。。。
我就说了一下Jason和cors,然后问我JSONP的原理以及cors怎么设置,这一块自己也实践过,所以还是对答如流的。
这个也还好,就是考虑的细节不是很周全,先是说了一种JSON.stringify和JSON.parse的实现,以及这种实现的缺点,主要就是非标准JSOn格式无法拷贝以及兼容性问题,然后问了我有么有用过IE8的一个什么JSON框架,我也不记得是什么了,因为我压根没听过,然后说了一下尾递归实现深拷贝的原理,还问了我typeof null是啥,这个当然是Object。。。
这个也是因人而异,开放性问题,大致扯了一下自己的经历,也还OK。
最后问了有什么需要问的地方,面试到这里基本就结束了,大约面了一个多钟头,还是蛮累的。总体来说,回答的广度和深度以及细节都还算OK,觉得这轮面试基本没什么悬念。
过了几天,接到阿里另一个面试官的电话,上一轮面试通过了,这次是二轮技术面,说估计一个钟头。这次依然跳过自我介绍之类的,直奔主题。
这个我就说了一下,然后loader配置啥的,也还ok。
这个我简单说了一下我自己了解的,因为这一块我也没深入去研究,所以说的应该比较浅。
这一块我说了一下自己的思路,大致也还OK,我也没去深入研究怎么转换的,之前好像看过类似的文章,自己也只观察过转换之后的代码是啥样的,至于怎么转换的规则,真的没去深入观察。
这里我就说了一下自己了解的git flow方面的东西,因为没有实战经验,所以我就选择性说明了这一块的不熟练,然后面试官也没细问。
这个我就说了一下函数柯里化一些了解,以及在函数式编程的应用,最后说了一下JS中bind函数和数组的reduce方法用到了函数柯里化。
这一块主要是API和概念的问题,扯了一些规范以及严格模式下其他情况this只想问题。
这个也是说了一下自己的理解和认知,自己对模块化历史以及一些规范都有所涉猎,这一块也还凑合。
主要是发布订阅的设计模式,还有就是ES5的Object.defineProperty的getter和setter机制,然后顺便扯了一下Angular的脏检测,以及alvon.js最先用到这种方式。然后扯了一下vue.js和react.js异同点,权衡框架选择,调研分析之类,噼里啪啦说了一大堆。
这一款就按照自己用过简书或者掘金,SG这类草稿的体验,详细说了一下,这个开放性问题,说到点基本就OK。
最后面试官问我有什么想问的吗,面试到这里基本就结束了,差不多面了一个小时,说过几天就会给答复,如果过了就会去阿里园区进行下一轮的技术面。
上一轮发挥感觉没前两轮发挥好,所以还是有点不自信的,没想到第三天后,就来电话了,通知我去阿里园区面试。
因为阿里西溪园区距离我不到十公里,我就踩着共享单车一点钟就出发了,天气比较热,飘在路上,百感交集,身边一辆法拉利轰鸣而过,又一辆兰博基尼呼啸而过,我心里一万头草泥马奔腾,MLGB,心里暗想,为神马开这车的人不是此刻看文章的你?
走到半路了,面试官给我打电话了,说我怎么还没到,说约定的是两点钟,我一下子就懵逼了,短信只有一个游客访问ID,并没有通知我具体时间,反正不管谁的疏忽,我肯定是要迟到了,于是我快马加鞭,踩着贼难骑的共享单车,背着微风,一路狂奔,到阿里园区已是汗流浃背,油光满面,气喘乎乎。。。
面试迟到了,印象肯定不好,加上满头大汗的形象也不太好,加上自己饥渴难耐,这面是估计要GG了,一进来就直奔主题,这次是两个大Boss面试我。
这个问题就是个开场白,简要说明一下,问题都不大,这个面试官就是第一次打电话给我面试的那个boss,所以技术那块boss心里也有个底细,所以没再问技术问题。
具体业务场景,我就不一一描述,Boss在白板上画了一个大致的模块图,然后做了一些需求描述。
然后需求一层一层的改变,然后往下挖,主要是考察应对产品能力,以及对代码的可维护性和可拓展性这些考察,开放性问题,我觉得还考察一些沟通交流方面的能力,因为有些地方面试官故意说得很含糊,反正就是一个综合能力,以及对产品的理解,中间谈到怎么实现,也问到了一些具体的点,记得问到的有一下几个。
① 怎么获取一个元素到视图顶部的距离。
② getBoundingClientRect获取的top和offsetTop获取的top区别
③事件委托
主要是考察http协议头Referer,然后怎么判断是阿里的ip或者啥的,我也不太清楚。
。。。排序的还算清楚一点,查找真的不知所措,没回答上来,也没猜,意义不大,不会就是不会。
这个很简单,跨站脚本攻击XSS(cross site scripting),攻击类型主要有两种:反射型和存储型,简单说了一下如何防御:
①转义
②DOM解析白名单
③第三方库
④CSP
自己对web安全这块系统学习过,前前后后大约了解了很多,对于XSS,CSRF,点击劫持,Cookie安全,HTTP窃听篡改,密码安全,SQL注入,社会工程学都有一定了解,所以这个自然也不在话下。
我是类比JS数组和对象来回答的,反正还算凑合吧,自己都数据结构这块多少还是有些印象,所以入了前端,对数据结构和算法确实一直淡忘了。
这个我能想到的大致都说了一遍,不同的场景交互和细节以及功能都有所偏差,以及功能的侧重都可能不同。
我写了两种实现方式:
ES6实现:
[...new Set([1,2,3,1,'a',1,'a'])]ES5实现:
[1,2,3,1,'a',1,'a'].filter(function(ele,index,array){
return index===array.indexOf(ele)
})这个回答的不算好,本来也想到类比git的处理方式,但是说的时候往另外一个方面说了,导致与面试官想要的结果不一样。
最后说目前的工作经验达不到P6水平,业务类稍弱,阿里现在社招只要P6的高级工程师,但是可以以第二梯队进去,就是以第三方签署就业协议,一年后可以转正,就是俗称的外包。多少还是有点遗憾,面了四轮面了个外包,最后放弃这份工作了。
最后,感谢boss一直以来的关照和器重。
Javascript是一门很吊的语言,我可能学了假的JavaScript,哈哈,大家还有什么推荐的,补充送那啥邀请码。
本文秉承着:你看不懂是你SB,我写的代码就要牛逼。
"★★★★★☆☆☆☆☆".slice(5 - rate, 10 - rate);定义一个变量rate是1到5的值,然后执行上面代码,看图
才发现插件什么的都弱爆了
(!(~+[])+{})[--[~+""][+[]]*[~+[]] + ~~!+[]]+({}+[])[[~!+[]]*~+[]]
了解为什么请移步:一行能装逼的JavaScript代码
这个牛逼了
console.log(([][[]]+[])[+!![]]+([]+{})[!+[]+!![]])😂😂😂,舅服你
try {
something
} catch (e) {
window.location.href =
"http://stackoverflow.com/search?q=[js]+" +
e.message;
}[].forEach.call($$("*"),function(a){
a.style.outline="1px solid #"+(~~(Math.random()*(1<<24))).toString(16)
})翻译成正常语言就是这样的
Array.prototype.forEach.call(document.querySelectorAll('*'),
dom => dom.style.outline = `1px solid #${parseInt(Math.random() *
Math.pow(2,24)).toString(16)}`)接下来在浏览器控制看看:something magic happens
具体分析请参见这篇文章:从一行代码里面学点JavaScript
Math.random().toString(16).substring(2)
Math.random().toString(36).substring(2)
解析请移步:js奇淫技巧1
这么多写法你选择哪一种?我选择死亡。
( function() {}() );
( function() {} )();
[ function() {}() ];
~ function() {}();
! function() {}();
+ function() {}();
- function() {}();
delete function() {}();
typeof function() {}();
void function() {}();
new function() {}();
new function() {};
var f = function() {}();
1, function() {}();
1 ^ function() {}();
1 > function() {}();
// ...从来不需要声明一个变量的值是undefined,因为JavaScript会自动把一个未赋值的变量置为undefined。所有如果你在代码里这么写,会被鄙视的
var data = undefined;但是如果你就是强迫症发作,一定要再声明一个暂时没有值的变量的时候赋上一个undefined。那你可以考虑这么做:
var data = void 0; // undefinedvoid在JavaScript中是一个操作符,对传入的操作不执行并且返回undefined。void后面可以跟()来用,例如void(0),看起来是不是很熟悉?没错,在HTML里阻止带href的默认点击操作时,都喜欢把href写成javascript:void(0),实际上也是依靠void操作不执行的意思。
当然,除了出于装逼的原因外,实际用途上不太赞成使用void,因为void的出现是为了兼容早起ECMAScript标准中没有undefined属性。void 0的写法让代码晦涩难懂。
var a = ~~2.33
var b= 2.33 | 0
var c= 2.33 >> 0用正则魔法实现:
var test1 = '1234567890'
var format = test1.replace(/\B(?=(\d{3})+(?!\d))/g, ',')
console.log(format) // 1,234,567,890非正则的优雅实现:
function formatCash(str) {
return str.split('').reverse().reduce((prev, next, index) => {
return ((index % 3) ? next : (next + ',')) + prev
})
}
console.log(formatCash('1234567890')) // 1,234,567,890我服
while (1) {
alert('牛逼你把我关了啊')
}你很机智,好一个障眼法
清除缓存: <a href="javascript:alert('清除成功');">清除缓存</a>var a = 0;
var b = ( a++, 99 );
console.log(a); // 1
console.log(b); // 99常规办法:
var a=1,b=2;
a += b;
b = a - b;
a -= b;缺点也很明显,整型数据溢出,对于32位字符最大表示数字是2147483647,如果是2147483645和2147483646交换就失败了。
黑科技办法:
a ^= b;
b ^= a;
a ^= b;哈哈😄,看不懂的童鞋建议去补习一下C语言的位操作,我就不去复习了,以前学嵌入式时候学的位操作都忘了
var a = {
a: 1,
b: { c: 1, d: 2 }
}
var b=JSON.parse(JSON.stringify(a))不考虑IE的情况下,标准JSON格式的对象蛮实用,不过对于undefined和function的会忽略掉。
哈哈,不准用强制类型转换,那么就想到了强大了隐式转换
var a =1
+a滚动条很长哦😯
([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[+[]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[+[]]+([][[]]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()([][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()(([]+{})[+[]])[+[]]+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]+[]))+([]+{})[+!![]]+(!![]+[])[+!![]]+(![]+[])[!+[]+!![]]+([][[]]+[])[!+[]+!![]]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[+[]]+([][[]]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()([][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()(([]+{})[+[]])[+[]]+(!+[]+!![]+[])+(+!![]+[]))居然能运行,牛逼的隐式转换
强大的隐式转换,23333
0.1 +0.2 == 0.3 竟然是不成立的。。。。所以这就是为什么数据库存储对于货币的最小单位都是分。
简单说,0.1和0.2的二进制浮点表示都不是精确的,所以相加后不是0.3,接近(不等于)
0.30000000000000004。
所以,比较数字时,应该有个宽容值。ES6中这个宽容值被预定义了:Number.EPSILON。
[...new Set([1, "1", 2, 1, 1, 3])]前不久面试阿里就问了这道题,哈哈,所以也写上一下
Array(6).fill(8)这个够短了吧,好像是当初哪里看到的一个面试题,就自己想到了ES6的一些API
条件判断
var a = b && 1
// 相当于
if (b) {
a = 1
} else {
a = b
}
var a = b || 1
// 相当于
if (b) {
a = b
} else {
a = 1
}
逃出迷宫,2333
var numbers = [5, 458 , 120 , -215 , 228 , 400 , 122205, -85411];
var maxInNumbers = Math.max.apply(Math, numbers);
var minInNumbers = Math.min.apply(Math, numbers);var argArray = Array.prototype.slice.call(arguments);
或者ES6:
var argArray = Array.from(arguments)很多JavaScript教程都告诉我们,不要直接用内置对象的构造函数来创建基本变量,例如var arr = new Array(2); 的写法就应该用var arr = [1, 2];的写法来取代。
但是,Function构造函数(注意是大写的Function)有点特别。Function构造函数接受的参数中,第一个是要传入的参数名,第二个是函数内的代码(用字符串来表示)。
var f = new Function('a', 'alert(a)');
f('jawil'); // 将会弹出窗口显示jawil这种方式可以根据传入字符串内容来创建一个函数 是不是高大上?!
正常的版本:
function find (x, y) {
for ( let i = 0; i < x.length; i++ ) {
if ( x[i] == y ) return i;
}
return null;
}
let arr = [0,1,2,3,4,5]
console.log(find(arr, 2))
console.log(find(arr, 8))结果到了函数式成了下面这个样子(好像上面的那些代码在下面若影若现,不过又有点不太一样,为了消掉if语言,让其看上去更像一个表达式,动用了 ? 号表达式):
//函数式的版本
const find = ( f => f(f) ) ( f =>
(next => (x, y, i = 0) =>
( i >= x.length) ? null :
( x[i] == y ) ? i :
next(x, y, i+1))((...args) =>
(f(f))(...args)))
let arr = [0,1,2,3,4,5]
console.log(find(arr, 2))
console.log(find(arr, 8))最后奉劝大家一句:莫装逼、白了少年头,2333。。。原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
世间万物,为我所用。
掘金不仅是一个很好的在线同性交友平台,也是一个学习交流和分享技术场所,更是程序猿和程序媛获取养料的精神家园。
分享是一个杂乱无章的环节,这无可厚非,因为在这里人人平等,每个人都可以分享自己看到的精品文章,也可以创作记录分享自己的成果,这是平台带给大家的优势,同时,面对零零散散的文章,对于我们来说,很困惑,我到底该学什么,从入门到精通的过程是怎样的?我该如何系统的学习这门语言?
汪洋大海,我该如何探寻所需的宝藏?
学习路途,我该如何寻找最佳的曲线?
去年开始看掘金,收藏了很多文章,也收获了很多知识,但是对于上面的疑问一直也在摸索当中,这里先感谢掘金这个平台,让我能学习到很多新的未知的东西,但在用掘金的这段时间内,也发现看的东西虽然很多,但是很杂,没有系统化的去深入了解一个东西,于是诞生了把自己看到过的,错过的,还有将要发表的,一起做一个整理和集合。
看见好的文章就收藏,后来发现收藏了几百篇,很多都是重复的,也不够系统化,资源如浩瀚大海,找起来也麻烦,无疑给自己增加了负担,在此,为了方便大家系统的学习前端这门课程,找准自己的定位,我利用空余时间,把掘金有屎以来分享的前端文章做了一个归类,方便掘金的朋友学习和收藏,喜欢的朋友可以收藏一下,这篇文章会持续更新,也欢迎关注【我的GitHub博客】获取最新动态。
贵有恒何必三更眠五更起,最无益只怕一日曝十日寒。 一天更新一点,每天看一点,坚持就是胜利,如果只整理和收藏不花时间看,一切都是徒劳。✌️
没有规矩,无以成方圆。
为什么把这个放在首位呢?好的代码规范不仅自己看起来赏心悦目,心情舒畅,我怎么就这么牛逼写出这么好看的代码(熏疼自己三秒钟,这往往只是错觉),别人看起来也直观一目了然,后来接手维护的人看了这种高逼格的代码也不会出现这种情况:这尼玛什么几把玩意,简直一坨翔,坑死劳资了(反正我走了也听不到🙉,你就骂吧)
《JavaScript风格指南》
《JavaScript 代码整洁之道》
《Airbnb 的 JavaScript 编程规范》
国学大师王国维自己的著作《人间词话》中说:
古今之成大事业、大学问者,必经过三重境界:
第一境界:昨夜西风凋碧树,独上高楼,望尽天涯路。
第二境界:衣带渐宽终不悔,为伊消得人憔悴。
第三境界:众里寻他千百度,蓦然回首,那人却在灯火阑珊处。
其实我觉得学习JavaScript也要经历类似的三种阶段:
第一境界:看山是山,看水是水。
第二境界:看山不是山,看水不是水。
第三境界:看山还是山,看水还是水。
国学大师王国维精妙地以三句词道破人生之路:起初的迷惘,继而的执着和最终的顿悟。
我以瞎几把乱扯三句词道破学习JavaScript之路:起初的表象,继而的本质和最终的本质回归到现象。
看是是山,看水是水。
万丈高楼平地起,胸有丘壑宏图画。
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。任何事情都要从基础做起,打好基础,不浮躁,才能做好一件事,学习一门语言也是一样,从“Hello World!"开始,踏踏实实,夯实基础,基础知识是整个学习体系的根本,没有牢固的基础知识作为根基,我们的学习和努力必将事倍功半,学习提纲是巩固基础知识的一种有效手段.
《思维导图来学习Javascript基础知识》
《多年 JavaScript 学习笔记整理》
《javascript 基础小结篇》
《前端开发基础 - JavaScript》
《你不知道的 Javascript》
看山不是山,看水不是水。
其实地上本没有坑,踩的人多了,于是就有了。
JS是一门玄学,是一门很灵活的语言,当然里面有很多不好懂的概念,尤其是学完基础之后,对执行环境、this、类型转换、作用域链、闭包、原型链、继承、eval、JS左值与引用、浅复制与深复制、IIFE、模块化、函数式编程等等都有着这样或那样的不解之惑,想要成为JS大神这些门槛和坑不得不踩。
因为JavaScript具有自动垃圾回收机制,所以对于前端开发来说,内存空间并不是一个经常被提及的概念,很容易被大家忽视。特别是很多不是计算机专业的朋友在进入到前端之后,会对内存空间,内存管理,内存释放的认知比较模糊,甚至有些人干脆就是一无所知。
《前端基础进阶:详细图解 JavaScript 内存空间》
《JavaScript 内存管理》
《JavaScript 中的内存释放》
首先来说说js中的执行环境,所谓执行环境(也称执行上下文–execution context)它是JavaScript中最为重要的一个概念。执行环境定义了变量或函数有权访问的其他数据 ,决定了它们各自的行为。而每个执行环境都有一个与之相关的变量对象,环境中定义的所有变量和函数都保存在这个对象中。
当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain)。作用域链的用途是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链包含了执行环境栈中的每个执行环境对应的变量对象.通过作用域链,可以决定变量的访问和标识符的解析。
《前端基础进阶:详细图解 JavaScript 执行上下文》
《深入探讨 JavaScript 的执行环境和栈》
《图解 JS 上下文与作用域》
深入理解执行上下文中的变量对象,从原理上解释变量提升,为接下来理解作用域链,闭包,原型打下坚实的理论基础,值得基础知识不牢固的盆友一阅。
当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain)。作用域链的用途是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链包含了执行环境栈中的每个执行环境对应的变量对象.通过作用域链,可以决定变量的访问和标识符的解析。
关于闭包的概念,是婆说婆有理。因而,我就翻阅了**红皮书(p178)**上对于闭包的陈述:
闭包是指有权访问另外一个函数作用域中的变量的函数
这概念有点绕,拆分一下。从概念上说,闭包有两个特点:
在ES 6之前,Javascript只有函数作用域的概念,没有块级作用域(但catch捕获的异常 只能在catch块中访问)的概念(IIFE可以创建局部作用域)。每个函数作用域都是封闭的,即外部是访问不到函数作用域中的变量。
《前端基础进阶:详细图解,彻底搞懂闭包与作用域链》
《JavaScript 闯关记之作用域和闭包》
《你想知道的关于 JavaScript 作用域的一切 (译)》
《弄懂 JavaScript 的作用域和闭包》
This,传说中的天使还是魔鬼?对于新手来说,this的指向一直是很头疼的地方,用的好就是天使,用的差就是魔鬼了,人人都想成为代码中的天使,为了避免成为魔鬼,我们必须好好深入学习一下this的作用机理和一些常见的坑。
《前端基础进阶:全方位解读 this》
《JavaScript 中的 this 陷阱的最全收集 -- 没有之一》
《Javascript 深入浅出 this》
《从 ECMA 规范深入理解 js 中的 this》
在JS里,万物皆对象。方法(Function)是对象,方法的原型(Function.prototype)是对象。因此,它们都会具有对 象共有的特点。 即:对象具有属性__proto__,可称为隐式原型,一个对象的隐式原型指向构造该对象的构造函数的原型,这也保证了实例 能够访问在构造函数原型中定义的属性和方法。
《JavaScript原型详解》
《三张图搞懂JavaScript的原型对象与原型链》
《JavaScript 原型中的哲学**》
《一张图搞懂 Javascript 中的原型链、prototype、__proto__的关系》
Javascript 这门语言对于习惯了众多传统 OOP 语言 (c++,Java 等) 的 coder 来说其实是一门很奇怪的语言, 因为 Javascript 的 OOP 方式是基于原型的, 而非传统的类继承,主要有原型链继承,借用构造函数继承,组合继承,寄生式继承,寄生组合继承。
《js 原型链继承,借用构造函数继承, 组合继承,寄生式继承,寄生组合继承》
《Javascript 三招两式之对象继承 (上)》
《JavaScript 三招两式之对象继承 (下)》
《征服 JavaScript 面试系列:类继承和原型继承的区别》
《谈一谈 JavaScript 继承》
每个函数都会有一个 Arguments 对象实例 arguments,它引用着函数的实参,可以用数组下标的方式”[]” 引用 arguments 的元素。arguments.length 为函数实参个数,arguments.callee 引用函数自身。
《Arguments 对象深入了解》
《javascript arguments(callee、caller) 详解》
《Javascript 中的 arguments 对象》
如果把通过函数或方法调用,明确的将某种类型转换成另一种类型称为显示转换 ,相反则称为隐式类型转换 。google和维基百科中没有找到“显示类型转换”,“隐式类型转换”的字眼。暂且这么称呼。 JavaScript的数据类型是非常弱的(不然不会叫它做弱类型语言了)!在使用算术运算符时,运算符两边的数据类型可以是任意的,比如,一个字符串可和数字相加。之所以不同的数据类型之间可以做运算,是因为JavaScript引擎在运算之前会悄悄的把他们进行了隐式类型转换的,如下是数值类型和布尔类型的相加:
3 + true; // 4
结果是一个数值型!如果是在C或者Java环境的话,上面的运算肯定会因为运算符两边的数据类型不一致而导致报错的!但
是,在JavaScript中,只有少数情况下,错误类型才会导致出错,比如调用非函数,或者读取null或者undefined的属
性时。
《从 []==![] 为 true 来剖析 JavaScript 各种蛋疼的类型转换》
《一篇文章搞定 JS 类型转换》
《聊一聊 JS 中的『隐式类型转换』》
全拼Imdiately Invoked Function Expression,立即执行的函数表达式。立即执行函数在模块化中也大有用处。用立即执行函数处理模块化可以减少全局变量造成的空间污染,构造更多的私有变量。
立即执行函数写法大全:
// 最常用的两种写法
(function(){ /* code */ }()); // 老道推荐写法
(function(){ /* code */ })(); // 当然这种也可以
// 括号和JS的一些操作符(如 = && || ,等)可以在函数表达式和函数声明上消除歧义
// 如下代码中,解析器已经知道一个是表达式了,于是也会把另一个默认为表达式
// 但是两者交换则会报错
var i = function(){ return 10; }();
true && function(){ /* code */ }();
0, function(){ /* code */ }();
// 如果你不怕代码晦涩难读,也可以选择一元运算符
!function(){ /* code */ }();
~function(){ /* code */ }();
-function(){ /* code */ }();
+function(){ /* code */ }();
// 你也可以这样
new function(){ /* code */ }
new function(){ /* code */ }() // 带参数
《javascript模块化编程-详解立即执行函数表达式IIFE》
《Javascript 的匿名函数与自执行》
《js 匿名自执行函数中闭包的高级使用(前端必看)》
这一篇掘金没有推荐过,不过我认为真的写的很全很详细,这里也推荐一下:
《详解javascript立即执行函数表达式(IIFE)》
平时的工作中,也许你会经常用到setTimeout这个方法,可是你真的了解setTimeout吗?本系列想通过总结setTimeout的用法,顺便来探索javascript里面的事件执行机制。在一个基础阶段,理解JavaScript定时器的工作原理的是非常重要的。通常它们看起来不那么直观,因为它们处于单线程中。
《[译] JavaScript 中的定时器是如何工作的?》
《关于 JavaScript 定时器我的一些小理解》
《JavaScript 定时器及相关面试题》
《【原】以 setTimeout 来聊聊 Event Loop》
该方法允许精确添加或修改对象的属性。一般情况下,我们为对象添加属性是通过赋值来创建并显示在属性枚举中(for...in 或 Object.keys 方法), 但这种方式添加的属性值可以被改变,也可以被删除。而使用 Object.defineProperty() 则允许改变这些额外细节的默认设置。例如,默认情况下,使用 Object.defineProperty() 增加的属性值是不可改变的。 对象里目前存在的属性描述符有两种主要形式:数据描述符和存取描述符。数据描述符是一个拥有可写或不可写值的属性。存取描述符是由一对 getter-setter 函数功能来描述的属性。描述符必须是两种形式之一;不能同时是两者。
《理解 JavaScript 的 Object.defineProperty() 函数》
《解析神奇的 Object.defineProperty》
《双向绑定的简单实现 - 基于 ES5 对象的 getter/setter 机制》
今天看博客时,看到了这样的一段js代码: var bind = Function.prototype.call.bind(Function.prototype.bind); 上面那段代码涉及到了call、bind,所以我想先区别一下call、apply、bind的用法。这三个方法的用法非常相似,将函数绑定到上下文中,即用来改变函数中this的指向。这个系列就是让大家深入理解其中的差异。
《JS 中 call、apply、bind 那些事》
《JavaScript 中的 call、apply、bind 深入理解》
《回味JS基础:call apply 与 bind》
《深入浅出妙用 Javascript 中 apply、call、bind》
eg:有A、B两个对象,且都有子对象
深拷贝:将B对象拷贝到A对象中,包括B里面的子对象;
浅拷贝:将B对象拷贝到A对象中,但不包括B里面的子对象;
首先深复制和浅复制只针对像 Object, Array 这样的复杂对象的。简单来说,浅复制只复制一层对象的属性,而深复制则递归复制了所有层级。
《JavaScript 深拷贝》
《javaScript 中的浅拷贝和深拷贝》
《深入剖析 JavaScript 的深复制》
还记得被称为正则小王子的jQuery作者吗?但正则表达式对于我来说一直像黑暗魔法一样的存在。手机正则去网上搜,邮箱正则去网上搜,复杂点的看看文档拼凑一下,再复杂只能厚着脸皮让其他同事给写一个。从来没有系统的学习过,搞完这个系列是不是准备拿下它。
《正则表达式 - 理论基础篇》
《正则表达式学习笔记》
《正则表达式实践篇》
《常见的正则表达式可视化描述》
《最全面的常用正则表达式大全》
直接来个
JavaScript 程序采用了异步事件驱动编程(Event-driven programming)模型,维基百科对它的解释是:
事件驱动程序设计(英语:Event-driven programming)是一种电脑程序设计模型。这种模型的程序运行流程是由用户的动作(如鼠标的按键,键盘的按键动作)或者是由其他程序的消息来决定的。相对于批处理程序设计(batch programming)而言,程序运行的流程是由程序员来决定。批量的程序设计在初级程序设计教学课程上是一种方式。然而,事件驱动程序设计这种设计模型是在交互程序(Interactive program)的情况下孕育而生的
《JavaScript 浏览器事件解析》
《深入理解 - 事件委托》
《我也来说说 JS 的事件机制》
《DOM 事件深入浅出(一)》
《DOM 事件深入浅出(二)》
《JS 中的事件绑定、事件监听、事件委托是什么?》
其他一些容易混淆的难点就不单独开一个类型,这里就统一做一个系列说明,也是平时经常遇到的一些痛点和难点吧,主要是区分一些概念,知道彼此之间的异同,以下简称一张图系列。
《一张图看懂JavaScript中数组的迭代方法:forEach、map、filter、reduce、every、some》
《一张图看懂encodeURI、encodeURIComponent、decodeURI、decodeURIComponent的区别》
《一张图彻底掌握 scrollTop, offsetTop, scrollLeft, offsetLeft......》
《一张图看懂 Function 和 Object 的关系及简述 instanceof 运算符》
看山还是山,看水还是水。
如果学习JavaScript不是为了成为高手,那将毫无意义。
其实,高手有一颗寂寞的心,因为高手的造就本就是用寂寞堆积而成。
程序设计=数据结构+算法
《学习JavaScript数据结构(一)——栈和队列》
《学习 JavaScript 数据结构(二)——链表》
《学习 JavaScript 数据结构(三)——集合》
《学习 javascript 数据结构 (四)——树》
《javaScript的数据结构与算法(五)——字典和散列表》
《前端面试中常见的算法问题读后整理》
《常见数据结构 (一)- 栈, 队列, 堆, 哈希表》
《常见数据结构 (二)- 树 (二叉树,红黑树,B 树)》
《算法学习笔记》
《javascript array js 缓存算法、数组随机抽取、字母串转数字,数字转字符串》
《JavaScript 算法练习》
** 由于浏览器同源策略,凡是发送请求url的协议、域名、端口三者之间任意一与当前页面地址不同即为跨域。具体可以查看下表(来源)**
《前端跨域问题及解决方案》
《直白的话告诉你在 javascript 中如何用 jsonp 实现跨域请求》
《前端 Ajax 跨域请求方案沙里淘金》
《你所不知道的跨域资源共享(CORS)》
《带你一步一步的理解前端跨域的原理及实践》
《HTML5 跨域通信 API - window.postMessage》
《前端跨域整理》
《跨域问题,解决之道》
为什么要学习设计模式? 做事情之前问个为什么总是好的。关于设计模式的好坏,我在知乎上也看过一些讨论,有知友对其提出过一些疑问,里面有一些关于设计模式的观点:
任何事物的出现都有其道理,任何语言都有其不足之处,设计模式是对语言不足的补充(Peter Norvig)。设计模式也是编程经验的总结,我想学习它对像我这样的前端新手的能力会有很大的提升。
细说说它的好处:
设计模式能让你用更少的词汇做更充分的沟通;
谈话在模式层次时,不会被压低到对象和类这种琐碎的事情上;
懂设计模式的团队,彼此之间对于设计的看法不容易产生误解;
共享词汇能帮助初级人员快速成长。
《学习设计模式前需要知道的事情》
《常用的 JavaScript 设计模式》
《JavaScript 设计模式》读后感觉很复杂
《JavaScript 设计模式》
《听飞狐聊 JavaScript 设计模式系列 13》
什么是函数式编程?
《函数式编程入门教程》
《想学函数式编程?》
《给 JavaScript 开发者讲讲函数式编程》
《前端基础进阶(七):函数与函数式编程》
《『翻译』JavaScript 函数式编程》
《JavaScript 函数式编程》
具体来说,在 JavaScript 中,我们可以将一个函数 A 作为参数传给另一个函数 B,或者,在函数 B 中将函数 A 作为返回值返回。那么这里的函数 B 就是上面所说的高阶函数。 在《javascript设计模式和开发实践》中是这样定义的。 函数可以作为参数被传递; 函数可以作为返回值输出。
《javascript 高阶函数介绍》
《程序媛学 JS 小记一笔——高阶函数》
《高阶函数对系统的 “提纯”》
《JavaScript 之闭包与高阶函数(一)》
天下武功,无坚不摧,唯快不破。
Javascript是一门非常灵活的语言,我们可以随心所欲的书写各种风格的代码,不同风格的代码也必然也会导致执行效率的差异,作用域链、闭包、原型继承、eval等特性,在提供各种神奇功能的同时也带来了各种效率问题,用之不慎就会导致执行效率低下,开发过程中零零散散地接触到许多提高代码性能的方法,整理一下平时比较常见并且容易规避的问题。
《吹毛求疵的追求优雅高性能JavaScript》
《天生就慢的 DOM 如何优化?》
《Javascript 高性能动画与页面渲染》
《一个关于 js 线程和性能优化的文档,有例子哦!》
《合理使用 IIFE 优化 JS 引擎的性能》
《高性能 JavaScript》读书笔记
就像最早听到斐波拉切数列一样,第一次听到柯里化我也是懵逼的
柯里化又称部分求值,字面意思就是不会立刻求值,而是到了需要的时候再去求值。如果看的懵逼,没事,看完整篇文章再回过头来看这里你就会豁然开朗。 反柯里化的作用是,当我们调用某个方法,不用考虑这个对象在被设计时,是否拥有这个方法,只要这个方法适用于它,我们就可以对这个对象使用它。
《前端高手必备:详解 JavaScript 柯里化》
《简单理解JavaScript中的柯里化和反柯里化》
《浅谈函数式编程柯里化的魔法》
《从一道面试题谈谈函数柯里化 (Currying)》
《掌握 JavaScript 函数的柯里化》
如今 Chrome 浏览器无疑是最受前端青睐的工具,原因除了界面简洁、大量的应用插件,良好的代码规范支持、强大的 V8 解释器之外,还因为 Chrome 开发者工具提供了大量的便捷功能,方便我们前端调试代码,我们在日常开发中是越来越离不开 Chrome,是否熟练掌握 Chrome 调试技巧恐怕也会成为考量前端技术水平的标杆。 介绍 Chrome 调试技巧的文章很多,本文结合我自己的开发经验,希望从实际运用的角度为大家再一次谈一谈这些功能,也希望对大家都有所帮助和启发。 在chrome的开发者工具中,通过断点调试,我们能够非常方便的一步一步的观察JavaScript的执行过程,直观感知函数调用栈,作用域链,变量对象,闭包,this等关键信息的变化。因此,断点调试对于快速定位代码错误,快速了解代码的执行过程有着非常重要的作用,这也是我们前端开发者必不可少的一个高级技能。
《前端高手必备技能:如何在 chrome 开发者工具中观察函数调用栈、作用域链与闭包》
《比 console.log 更多-chrome 调试命令》
《JavaScript30 中文指南 - 09 Console 调试技巧指南》
《聊一聊移动端调试那些事》
《前端 chrome 浏览器调试总结》
《我的职业是前端工程师【五】: 前端工程师必会的六个调试技能》
《九个 Console 命令,让 js 调试更简单》
《再谈 Chrome 实用调试技巧》
《调试 CSS 的方法》
《前端调试效率低?试试这 10 个 Chrome 开发者工具 使用技巧》
《前端开发中的 JS 调试技巧》
天下武功,唯快不破。算法越快,越容易破。
《如何让前端更安全?——XSS 攻击和防御详解》
《HTTPS 互联网世界的安全基础》
《关于 Web 安全,99% 的网站都忽略了这些》
《Web 前端慢加密》
技巧恰似黑魔法,效率堪比加速器,都是开发过程中不可或缺的一部分,善用技巧,提高效率。
高手之所以高,很大一部分在于技巧巧妙,效率高,让人自愧不如,所以成了我们眼中的高手,其实高手也是从菜鸟过来的,由于长期的学习和经验的积累,再加上善于总结,自然一步步成长成为高手,为了加速自己成为高手,我们可以向高手取经,学习他们分享的一些技巧和解决问题思维方式。
《34 个实用的 webAPP 开发技巧分享,值得收藏》
《不造个轮子,你还真以为你会写代码了? | 掘金技术征文》
《【译】帮助你更快学习 JavaScript 的六个思维技巧》
《提升效率黑科技》
《【译】六个漂亮的 ES6 技巧》
《【译】45种 Javascript 技巧大全》
《程序员应该掌握的 10 个搜索技巧》
《你必须『收藏』的Github技巧》
《老司机教你更好的进行 CSS 编程 70 个技巧》
《聊一聊这些常见而且实用的 css 技巧》
青,取之于蓝而青于蓝;冰水为之而寒于水。
jQuery:一年没写链式JQ了,在这个人手一个MVVM框架的年代,JQuery就不做推荐,想要了解可以自行学习。
vue.js react.js,angularjs···此处省略一万篇文章和略干文字。
关于框架的学习,最好多看看官方文档,多多实践,我这里就不多做介绍了,框架太多,我用的也不多,这里也就不献丑推荐什么的,自己对框架也一知半解,没有深入去研究底层的实现,仅仅停留在够用就行没去深究的层面,大家想学什么框架可以自己去搜索相关资料和教程。
解放双手,成就你的梦想。
简历好比人的一张脸,不能丑了别人,爽了自己。
对于开发者与设计师们,一封好的的简历会让自己的面试增色不少。本次分享的简历简介精致,而且样式多种多样。包含 INDD、IDML、PDF、PSD、DOCX 等格式,方便自由修改和学习。
《Talk is cheap, show me the code - 用 github 数据辅助你完善简历》
《27 款优质简洁的个人简历打包下载》
《10+ 优秀简洁的个人简历下载(五)》
《15 款优质实用简洁的个人简历模板打包下载 (一)》
《5 款精致简洁求职简历》
任凭风吹雨打,胜似闲庭信步。
首先我希望表达的一点,就是面试的评判跟学校里的考试完全是两回事,太多的人把面试当做考试而把注意力放在题目上。 事实上面试中未必是所有题目全都回答"正确"就一定会通过或者较高评价。面试是面试官和面试者双方"挖掘与展示才能"的过程,参考前面提到的面试过程,全部回答正确的情况很可能是因为面试官不感兴趣懒得追问。 对于面试官而言,基本评判原则就是"我要不要这个人做我的同事?",多数情况下,这个答案会非常清楚。一些题目是充分的,也就是"回答对了说明这个人具有可以依靠的才能",一些题目则是必要的,也就是"回答错了说明这个人无法胜任我们的工作"。
《最近遇到的前端面试题》
《大厂前端面试题汇总》
《前端面试集合》
《前端面试题精选》
《一道 JS 面试题所引发的 "血案",透过现象寻本质,再从本质看现象》
他山之石,可以攻玉。
经验犹如一所大学校,它能使你认识到自己是个什么样的傻瓜。
人生就是不断的推销自己,不停的面试,狭义的面试我们认为就是工作上的面试,而广义的面试就是做人的面试,到处就是展示推销自己。看看别人面试心得,取经一下,避免别人已经犯过的错误,也是一种进步。
《面试感悟:一名 3 年工作经验的程序员应该具备的技能》
《我的 web 前端面试经历 - 百度》
《1月前端面试记》
《关于前端面试》
《迟来的面试总结》
积土成山,风雨兴焉;积水成渊,蛟龙生焉。
善于积累,善于总结,也是学习的一门功课,积累是一个循序渐进的过程,搜集总结同时也是一个费时费力的过程,看看别人的积累和总结,不禁感叹于别人的知识面和认真的态度,自己会觉得有压力从而产生动力,此时的自己会不会蠢蠢欲动,给自己所学所看来一个强势的总结呢?
《也许是史上最全的前端资源大汇总》
《JavaScript 开发者必备的资源合集》
《前端知识点大百科全书》
《100+ 超全的 web 开发工具和资源整理》
《Web 前端从入门菜鸟到实践老司机所需要的资料与指南合集》
《GitHub 上最全的前端入门资源汇总 快速入门前端》
《前端教程 & 开发模块化 / 规范化 / 工程化 / 优化 & 工具 / 调试 & 值得关注的博客 / Git & 面试 - 资源汇总》
《送给前端的你,推荐几篇前端汇总文章。 - 学习编程 - 知乎专栏》
《前端学习资源汇总——前端收藏夹》
《最全前端资源汇集》
插件是我们开发时候的左膀右臂。
平时自己写插件主要有下面几个问题:
(1)开发插件需要时间,可能拖延项目工期,如果工期紧急不建议选用这种方式
(2)自己造的轮子未必有现有轮子的好用,要考虑到队友是否适用
(3)需要比较高的开发水平
这里搜集一些常用的插件供大家参考使用。
工欲善其事,必先利其器。
张三和李四都要上山砍柴,但他们的斧头都有点钝了,张三没有理会,拿着斧头就上山了,因为他的斧头不利,砍的都是比较细的树柴……李四就不同了,他拿来磨刀石,用劲地把斧头先磨好,虽然他比张三慢了起步,但是他的准备工夫做到家了,砍柴砍得很快。到太阳下山了,张三只背了小小的一捆柴下来,但是李四,背着一大捆的柴下来…… 由此可见,准备工夫做好了,可以事半功倍!
《超全面 + 最流行的「前端速查表」高清版大全》
《成为专业程序员路上用到的各种优秀资料、神器及框架》
《前端切图神器 avocode》
《2015 年末必备前端工具集》
《【译】2016 年我最喜欢的前端工》
《前端新手可以浏览的网站》
《收集非常好用的 Mac 应用程序、软件以及工具,主要面向开发者和设计师。》
《工具武装的前端开发工程师》
《一个前端程序猿的 Sublime Text3 的自我修养》
《前端工程师的工具包》
本文分享首发【掘金】,同时收录在【我的GitHub博客】,觉得本文写的不算烂的,可以点击【我的GitHub博客】顺便登录一下账号给个星星✨鼓励一下,关注最新更新动态,大家一起多交流学习,欢迎随意转载交流,不要钱,文末有福利哦😯,你懂的😉。
登高自卑,与君共勉。
文武之道,一张一弛,要劳逸结合,是不是?
老司机镇楼,投币上车。*年,看了这么多这么累,是不是该撸一发呢😄,我好想射点什么,先撸一盘LOL去了,哈哈,大家别想歪了。
待续的今后继续更新完善。
同许多初学 Javascript 的菜鸟一样,起初,我也是采用拼接字符串的形式,将 JSON 数据嵌入 HTML 中。开始时代码量较少,暂时还可以接受。但当页面结构复杂起来后,其弱点开始变得无法忍受起来:
HTML 片段都是离散化的数据,难以对其中重复的部分进行提取。<template> 标签。这是 HTML5 中新增的一个标签,标准极力推荐将 HTML 模板放入 <template> 标签中,使代码更简洁。当时我的心情就是这样的:
这TMD是在逗我吗。
于是出来了后来的 ES6,ES6的模板字符串用起来着实方便,对于比较老的项目,项目没webpack,gulp 等构建工具,无法使用 ES6 的语法,但是想也借鉴这种优秀的处理字符串拼接的方式,我们不妨可以试着自己写一个,主要是思路,可以使用 ES6 语法模拟 ES6的模板字符串的这个功能。
后端返回的一般都是 JSON 的数据格式,所以我们按照下面的规则进行模拟。
实现一个 render(template, context) 方法,将 template 中的占位符用 context 填充。
不需要有控制流成分(如 循环、条件 等等),只要有变量替换功能即可
级联的变量也可以展开
被转义的的分隔符 { 和 } 不应该被渲染,分隔符与变量之间允许有空白字符
var obj = {name:"二月",age:"15"};
var str = "{{name}}很厉害,才{{age}}岁";
输出:二月很厉害,才15岁。PS:本文需要对正则表达式有一定的了解,如果还不了解正则表达式,建议先去学习一下,正则也是面试笔试必备的技能,上面链接末尾有不少正则学习的链接。
如果是你,你会怎么实现?可以先尝试自己写写,实现也不难。
先不说我的实现,我把这个题给其他好友做的时候,实现的不尽相同,我们先看几位童鞋的实现,然后在他们的基础上找到常见的误区以及实现不够优雅的地方。
let str = "{{name}}很厉害,才{{age}}岁"
let obj = {name: '二月', age: 15}
function test(str, obj){
let _s = str.replace(/\{\{(\w+)\}\}/g, '$1')
let result
for(let k in obj) {
_s = _s.replace(new RegExp(k, 'g'), obj[k])
}
return _s
}
const s = test(str, obj)最基本的是实现了,但是代码还是有很多问题没考虑到,首先 Object 的 key 值不一定只是 \w,
还有就是如果字符串是这种的:
let str = "{{name}}很name厉害,才{{age}}岁"`
会输出 :二月很厉害二月害,才15岁此处你需要了解正则的分组才会明白 $1 的含义,错误很明显,把本来就是字符串不要替换的 name 也给替换了,从代码我们可以看出二月的思路。
str,先用正则匹配出 {{name}} 和 {{age}},然后用分组获取括号的 name,age,最后用 replace 方法把 {{name}} 和 {{age}} 替换成 name 和 age,最后字符串就成了 name很name厉害,才age岁,最后 for in 循环的时候才导致一起都被替换掉了。for in 循环完全没必要,能不用 for in 尽量不要用 for in,for in 会遍历自身以及原型链所有的属性。var str = "{{name}}很厉害,才{{age}}岁";
var str2 = "{{name}}很厉name害,才{{age}}岁{{name}}";
var obj = {name: '周杰伦', age: 15};
function fun(str, obj) {
var arr;
arr = str.match(/{{[a-zA-Z\d]+}}/g);
for(var i=0;i<arr.length;i++){
arr[i] = arr[i].replace(/{{|}}/g,'');
str = str.replace('{{'+arr[i]+'}}',obj[arr[i]]);
}
return str;
}
console.log(fun(str,obj));
console.log(fun(str2,obj));思路是正确的,知道最后要替换的是 {{name}} 和 {{age}} 整体,而不是像二月童鞋那样最后去替换 name,所有跑起来肯定没问题,实现是实现了但是感觉有点那个,我们要探讨的是一行代码也就是代码越少越好。
function a(str, obj) {
var str1 = str;
for (var key in obj) {
var re = new RegExp("{{" + key + "}}", "g");
str1 = str1.replace(re, obj[key]);
}
console.log(str1);
}
const str = "{{name}}很厉name害{{name}},才{{age}}岁";
const obj = { name: "jawil", age: "15" };
a(str, obj);实现的已经简单明了了,就是把 obj 的 key 值遍历,然后拼成 {{key}},最后用 obj[key] 也就是 value 把 {{key}} 整个给替换了,思路很好,跟我最初的版本一个样。
function parseString(str, obj) {
Object.keys(obj).forEach(key => {
str = str.replace(new RegExp(`{{${key}}}`,'g'), obj[key]);
});
return str;
}
const str = "{{name}}很厉name害{{name}},才{{age}}岁";
const obj = { name: "jawil", age: "15" };
console.log(parseString(str, obj));其实这里还是有些问题的,首先我没用 for...in 循环就是为了考虑不必要的循环,因为 for...in 循环会遍历原型链所有的可枚举属性,造成不必要的循环。
我们可以简单看一个例子,看看 for...in的可怕性。
// Chrome v63
const div = document.createElement('div');
let m = 0;
for (let k in div) {
m++;
}
let n = 0;
console.log(m); // 231
console.log(Object.keys(div).length); // 0一个 DOM 节点属性竟然有这么多的属性,列举这个例子只是让大家看到 for in 遍历的效率问题,不要轻易用 for in循环,通过这个 DOM 节点之多也可以一定程度了解到 React 的 Virtual DOM 的**和优越性。
除了用 for in 循环获取 obj 的 key 值,还可以用 Object.key() 获取,Object.getOwnPropertyNames() 以及 Reflect.ownKeys()也可以获取,那么这几种有啥区别呢?这里就简单说一下他们的一些区别。
for...in循环:会遍历对象自身的属性,以及原型属性,for...in循环只遍历可枚举(不包括enumerable为false)属性。像Array和Object使用内置构造函数所创建的对象都会继承自Object.prototype和String.prototype的不可枚举属性;
Object.key():可以得到自身可枚举的属性,但得不到原型链上的属性;
Object.getOwnPropertyNames():可以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性, Symbols 属性也得不到.
Reflect.ownKeys:该方法用于返回对象的所有属性,基本等同于Object.getOwnPropertyNames()与Object.getOwnPropertySymbols之和。
上面说的可能比较抽象,不够直观。可以看个我写的 DEMO,一切简单明鸟。
const parent = {
a: 1,
b: 2,
c: 3
};
const child = {
d: 4,
e: 5,
[Symbol()]: 6
};
child.__proto__ = parent;
Object.defineProperty(child, "d", { enumerable: false });
for (var attr in child) {
console.log("for...in:", attr);// a,b,c,e
}
console.log("Object.keys:", Object.keys(child));// [ 'e' ]
console.log("Object.getOwnPropertyNames:", Object.getOwnPropertyNames(child)); // [ 'd', 'e' ]
console.log("Reflect.ownKeys:", Reflect.ownKeys(child)); // [ 'd', 'e', Symbol() ]上面的实现其实已经很简洁了,但是还是有些不完美的地方,通过 MDN 首先我们先了解一下 replace 的用法。
通过文档里面写的 str.replace(regexp|substr, newSubStr|function) ,我们可以发现 replace 方法可以传入 function 回调函数,
function (replacement) 一个用来创建新子字符串的函数,该函数的返回值将替换掉第一个参数匹配到的结果。参考这个指定一个函数作为参数。
有了这句话,其实就很好实现了,先看看具体代码再做下一步分析。
function render(template, context) {
return template.replace(/\{\{(.*?)\}\}/g, (match, key) => context[key]);
}
const template = "{{name}}很厉name害,才{{age}}岁";
const context = { name: "jawil", age: "15" };
console.log(render(template, context));可以对照上面文档的话来做分析:该函数的返回值(obj[key]=jawil)将替换掉第一个参数(match=={{name}})匹配到的结果。
简单分析一下:.*? 是正则固定搭配用法,表示非贪婪匹配模式,尽可能匹配少的,什么意思呢?举个简单的例子。
先看一个例子:
源字符串:aa<div>test1</div>bb<div>test2</div>cc
正则表达式一:<div>.*</div>
匹配结果一:<div>test1</div>bb<div>test2</div>
正则表达式二:<div>.*?</div>
匹配结果二:<div>test1</div>(这里指的是一次匹配结果,不使用/g,所以没包括<div>test2</div>)
根据上面的例子,从匹配行为上分析一下,什是贪婪与非贪婪匹配模式。
利用非贪婪匹配模就能匹配到所有的{{name}},{{age}},上面的也说到过正则分组,分组匹配到的就是 name,也就是 function 的第二个参数 key。
所以这行代码的意思就很清楚,正则匹配到{{name}},分组获取 name,然后把 {{name}} 替换成 obj[name](jawil)。
当然后来发现还有一个小问题,如果有空格的话就会匹配失败,类似这种写法:
const template = "{{name }}很厉name害,才{{age }}岁";所以在上面的基础上还要去掉空格,其实也很简单,用正则或者 String.prototype.trim() 方法都行。
function render(template, context) {
return template.replace(/\{\{(.*?)\}\}/g, (match, key) => context[key.trim()]);
}
const template = "{{name }}很厉name害,才{{age }}岁";
const context = { name: "jawil", age: "15" };
console.log(render(template, context));将函数挂到 String 的原型链,得到最终版本
甚至,我们可以通过修改原型链,实现一些很酷的效果:
String.prototype.render = function (context) {
return this.replace(/\{\{(.*?)\}\}/g, (match, key) => context[key.trim()]);
};如果{}中间不是数字,则{}本身不需要转义,所以最终最简洁的代码:
String.prototype.render = function (context) {
return this.replace(/{{(.*?)}}/g, (match, key) => context[key.trim()]);
};之后,我们便可以这样调用啦:
"{{name}}很厉name害,才{{ age }}岁".render({ name: "jawil", age: "15" });通过一个小小的模板字符串的实现,领悟到要把一个功能实现不难,要把做到完美真是难上加难,需要对基础掌握牢固,有一定的沉淀,然后不断地打磨才能比较优雅的实现,通过由一个很小的点往往可以拓展出很多的知识点。
在引出下面要阐述的问题答案之前,先深入了解几个重要慨念,之前这些概念也是模模糊糊,从最原始的一步步搞清楚。
解释定义最好的地方就是它的起源,这里便是ECMAScript规范,我们看看规范怎么定义函数(function)的。
摘录来自ECMAScript 5.1规范的4.3.24小节:
对象类型的成员,标准内置构造器
Function的一个实例,并且可做为子程序被调用。注: 函数除了拥有命名的属性,还包含可执行代码、状态,用来确定被调用时的行为。函数的代码不限于 ECMAScript。
至于什么是实例对象,什么构造器(构造函数)下面的会详细讲,这里我们只引用定义,知道有这么个东西它叫这个名字就够了。
函数使用function 关键字来定义,其后跟随,函数名称标识符、 一对圆括号、一对花括号。
结合一个栗子理解这句话:
function demo(){
console.log('jawil');
}上面这几行代码就是一个函数,这个函数是标准内置构造器 Function的一个实例,因此函数是一个对象。demo就是这个函数的名字,对象是保存在内存中的,函数名demo则是指向这个对象的指针。console.log('jawil')则是可执行代码。
对于内存,引用,指针不太明白,没有任何认知的童鞋可以去尝试搜索补习一下这些概念,其实都是一些概念,花点时间理解一下就好了。
在浏览器我们也可以检验一下:
demo instanceof Function
//true上面只是创建函数的一种方式, JavaScript 中有三种创建形式,分别是:
①声明式
function fn(){ }; //这种定义的方式,无论在哪儿定义,别处都可以调用 ;②函数的字面量或叫直接量或称表达式
var fn=function () { }; //此时函数作为表达式存在,调用只能在定义的后面;
//解释一下表达式:凡是将数据和运算符等联系起来有值得式子就是表达式。③以new Function 的形式
var fn = new Function (arg1 , arg2 ,arg3 ,…, argN , body)
/*Function 构造函数所有的参数都是字符串类型。除了最后一个参数, 其余的参数都作为生成函数的参数即形参。
这里可以没有参数。最后一个参数, 表示的是要创建函数的函数体。
使用Function构造器生成的Function对象是在函数创建时解析的。这比你使用函数声明或者函数表达式(function)
并在你的代码中调用更为低效,因为使用后者创建的函数是跟其他代码一起解析的。
*/上面三种创建方式,第三种var fn = new Function (arg1 , arg2 ,arg3 ,…, argN , body)是最直观的,
很容易就联想到fn instanceof Function,fn一眼就看出来就是Function的实例,但是为什么JavaScript还要创造用function来创建一个函数呢?
答案显而易见,用function创建一个函数更优雅,灵活,书写方便,浏览器看到function时候其实已经帮你做了new Function()这一步了,function和new Function()创建的函数都是Function的一个实例,只是方式不一样,其实本质都是一样。就如同创建一个对象一样,我们可以var obj=new Object(),当然我们也可以var obj={};
我觉得function创建函数只是new Function()创建函数的一个语法糖,不对之处还望指出,反正我是这么理解的。
我们看看ECMAScript规范怎么定义构造函数(constructor)的。
创建和初始化对象的函数对象。
注:构造器的“prototype”属性值是一个原型对象,它用来实现继承和共享属性。
构造函数就是初始化一个实例对象,对象的prototype属性是继承一个实例对象。
这些抽象的东西其实不好讲,不好写,讲一个抽象的概念,又引出好几个抽象的概念,情何以堪,实例对象和原型prototype下一节讲,了解概念尽量多结合栗子加深理解,理解构造函数,首先就要理解上面函数的一个概念和定义。
这种抽象的东西不是很好记忆,我们通过一个示例来说明可能更好了解。
function Person(name){
this.name=name;
}在javascript中,你可以把上面的代码看做一个函数,一个类,一个方法,都没有问题。
其实,在JavaScript中,首先,它是函数,任何一个函数你都可以把它看做是构造函数,它没有明显的特征。那什么时候它就明显了呢?实例化的时候。
var jawil=new Person('微醺岁月');当这一句代码结束,你就可以肯定的认为 Person 函数是一个构造函数,因为它 new 了"微醺岁月"。
那么,"微醺岁月" 是什么?"微醺岁月"是一个人,一个实实在在的人,是被构造函数初始化出来的。所以 var jawil 就变成了一个实例。
我们看看ECMAScript规范怎么定义构造函数(constructor)的。
为其他对象提供共享属性的对象。
当构造器创建一个对象,为了解决对象的属性引用,该对象会隐式引用构造器的“prototype”属性。通过程序表达式 constructor.prototype 可以引用到构造器的“prototype”属性,并且添加到对象原型里的属性,会通过继承与所有共享此原型的对象共享。另外,可使用 Object.create 内置函数,通过明确指定原型来创建一个新对象。
首先说一下,只有函数才有prototype(原型)属性。为什么只有函数才有prototype属性?ECMAScript规范就这么定的。
但是不是所有的函数都有prototype属性呢?答案是否定的,这可不一定。我们看个简单的栗子:
用 Function.prototype.bind 创建的函数对象没有 prototype 属性。
那么prototype(原型)到底有啥作用呢?
prototype对象是实现面向对象的一个重要机制。每个函数也是一个对象,它们对应的类就是Function,每个函数对象都具有一个子对象prototype。Prototype 表示了该函数的原型,prototype表示了一个类的属性的集合。当通过new来生成一个类的对象时,prototype对象的属性就会成为实例化对象的属性。
这些概念简单了解一下,这不是本人要讲的重点,这里一笔带过,不太懂的可以自己去查相关资料补习一下基础。
引用《JavaScript权威指南》的一段描述:
Every JavaScript object has a second JavaScript object (or null ,
but this is rare) associated with it. This second object is known as a prototype, and the first object inherits properties from the prototype.
翻译出来就是每个JS对象一定对应一个原型对象,并从原型对象继承属性和方法。好啦,既然有这么一个原型对象,那么对象怎么和它对应的?
对象__proto__属性的值就是它所对应的原型对象:
var one = {x: 1};
var two = new Object();
one.__proto__ === Object.prototype // true
two.__proto__ === Object.prototype // true
one.toString === one.__proto__.toString // true上面的代码应该已经足够解释清楚__proto__了。
把实例和对象对比来看,或许更容易理解。
实例对象和对象的区别,从定义上来讲:
1、实例是类的具象化产品,
2、而对象是一个具有多种属性的内容结构。
3、实例都是对象,而对象(比如说Object.prototype)不全是实例。
实例是相对而言,这话怎么理解了,我们看下面两个小栗子比如说:
var a=new Array();
a instanceof Array//true我们可以说a是Array数组的一个实例;
function Array(){
[native code]
}
Array instanceof Function//true我们知道Array也是一个函数,虽然他是一个构造函数,只要是函数,从上面的知识点可以知道,Array是Function的一个实例。
通俗的理解这几个的关系:
JavaScript引擎是个工厂。
最初,工厂做了一个最原始的产品原型。
这个原型叫Object.prototype,本质上就是一组无序key-value存储({})之后,工厂在Object.prototype的基础上,研发出了可以保存一段“指令”并“生产产品”的原型产品,叫函数。
起名为Function.prototype,本质上就是[Function: Empty](空函数)为了规模化生产,工厂在函数的基础上,生产出了两个构造器:
生产函数的构造器叫Function,生产kv存储的构造器叫Object。你在工厂定制了一个产品,工厂根据Object.prototype给你做了一个Foo.prototype。
然后工厂发现你定制的产品很不错。就在Function.prototype的基础上做了一个Foo的构造器,叫Foo。工厂在每个产品上打了个标签__proto__,以标明这个产品是从哪个原型生产的。
为原型打了个标签constructor,标明哪个构造器可以依照这个原型生产产品。
为构造器打了标签prototype,标明这个构造器可以从哪个原型生产产品。所以,我觉得先有Function还是Object,就看工厂先造谁了。其实先做哪个都无所谓。因为在你定制之前,他们都做好了。
我们知道,Array,Date,Number,String,Boolean,Error甚至Object都是Function的一个实例,那么Function是谁的实例呢?
先看一个简单的小栗子:
function Person(){
...一些自定义的code
}
Person.__proto__ === Function.prototype;//true
Person.prototype instanceof Object;//true再来看看这个:Function
也就是浏览器显示的这个,我们暂且这么类比:
function Person(){
...一些自定义的code
}
function Function(){
[native code]//系统帮我们写的code
}我们再来看看,先暂时忽略后面的:
Person.__proto__=== Function.prototype;//true
Person函数是Function的一个实例。
Function.__proto__=== Function.prototype;//true
上面说了,Person函数是Function的一个实例,这没有争议,那么这行代码是否可以说Function函数对象是由Function构造函数创建的一个实例?
因为我们普遍的认知就是:实例对象(A)的__proto__属性指向它的构造函数(B)的原型对象(prototype)。
大白话就是:A(儿子)继承了B(父母)的一些特性(prototype)才有了A。所以问题就来了,当A===B的时候,该怎么理解了?这就是今天问题的引出了,下面就要探讨这个问题了。
再来看:
Person.__proto__=== Person.prototype;//false
这个显而易见可以看出,Person函数不是由Person的实例,因为Person是Function的一个实例。
Function构造函数的prototype属性和__proto__属性都指向同一个原型,是否可以说Function对象是由Function构造函数创建的一个实例?
Function.prototype和Function.__proto__都指向Function.prototype,这就是鸡和蛋的问题怎么出现的一样。
在这之前,我一直有个误解就是,认为所有对象就是Object的实例,现在想起来真是Too young,Too simple.
Object.prototype 是对象吗?
当然是。
An object is a collection of properties and has a single prototype object. The prototype may be the null value.
这是object的定义,Object.prototype显然是符合这个定义的。但是,Object.prototype并不是Object的实例。 这也很好理解Object.prototype.__proto__是null。
就如同刚才上面区分实例和对象一样,实例都是对象,而对象(比如说Object.prototype)不全是实例。
这已经某种程度上解开了鸡和蛋的问题:Object.prototype是对象,但它不是通过Object函数创建的。Object.prototype谁创建的,它是v8引擎(假设用的都是chrome浏览器)按照ECMAScript规范创造的一个对象。我只能这么给你解释。
未完待续,好累,歇一会儿~
关于这个问题也困扰了我很久,功力不够,无法详细回答,但是经过一番查找和探究,在知乎上看到了这篇回答,引用一下,与大家共同学习。
在JavaScript中,Function构造函数本身也算是Function类型的实例吗?Function构造函数的prototype属性和__proto__属性都指向同一个原型,是否可以说Function对象是由Function构造函数创建的一个实例?
Yes and No.
Yes 的部分:
按照JS中“实例”的定义,a 是 b 的实例即 a instanceof b 为 true,默认判断条件就是 b.prototype 在 a 的原型链上。而 Function instanceof Function 为 true,本质上即 Object.getPrototypeOf(Function) === Function.prototype,正符合此定义。
No 的部分:
Function 是 built-in 的对象,也就是并不存在“Function对象由Function构造函数创建”这样显然会造成鸡生蛋蛋生鸡的问题。实际上,当你直接写一个函数时(如 function f() {} 或 x => x),也不存在调用 Function 构造器,只有在你显式调用 Function 构造器时(如 new Function('x', 'return x') )才有。
注意,本质上,a instanceof b 只是一个运算,即满足某种条件就返回 true/false,当我们说 a 是 b 的实例时,也只是表示他们符合某种关系。JS 是一门强大的动态语言,你甚至可以在运行时改变这种关系,比如修改对象的原型从而改变 instanceof 运算的结果。此外,ES6+ 已允许通过 Symbol.hasInstance 来自定义 instanceof 运算。
我知道很多 JS 学习者会迷恋于对象和函数之间的 instanceof 关系,并希望探究到底谁更本源?我当初也在这个问题上浪费了很多时间。但这是一个伪问题。参见:JavaScript 里 Function 也算一种基本类型?以上。
对JavaScript的原型和原型链相比以前有了一个更深刻的认识,同时也对函数,构造函数,实例对象的一些概念有了一个更具体的认知,以前对这些概念都是模模糊糊,没有一个明确的概念,导致在理解一些问题上出现盲点,比如说:function和Function的问题,现在总是认知清楚了,也了解到没有十全十美的语言,任何语言也有它的一些缺陷和漏洞,比如说Function对象是由Function构造函数创建的一个实例?typeof null的返回值是Object的问题,历史的车轮滚滚向前,语言也是向前发展,但愿JavaScript发展越来越好,越来越完善,一统天下😄。
结论:先有 Object.prototype(原型链顶端),Function.prototype 继承 Object.prototype 而产生,最后,Function 和 Object 和其它构造函数继承 Function.prototype 而产生。
- 先有 Object.prototype,再有 Object,那么先有 Object.prototype 里面的这个 Object 代表的是什么呢?
- Function.proto=== Function.prototype;
Function 构造函数的 prototype 属性和__proto__属性都指向同一个原型,是否可以说 Function 对象是由 Function 构造函数创建的一个实例?
- Object instanceof Function // true
Function instanceof Object // true
Object 本身是构造函数,继承了 Function.prototype;Function 也是对象,继承了 Object.prototype。感觉成了鸡和蛋的问题了。
- 比如说:
function Person(){}
Person.prototype 是一个对象,为什么 Function.prototype 却是一个函数呢,当然函数也是一个对象,为什么要这么设计呢?
JavaScript 的语言设计有哪些缺陷?
JS 的 new 到底是干什么的?
从__proto__和prototype来深入理解JS对象和原型链
在JavaScript中,Function构造函数本身也算是Function类型的实例吗?
JS中先有Object还是先有Function?
JavaScript 世界万物诞生记
test
停更了?
你是否在面试中遇到过各种奇葩和比较细节的问题?
[]==[]
//false
[]==![]
//true
{}==!{}
//false
{}==![]
//VM1896:1 Uncaught SyntaxError: Unexpected token ==
![]=={}
//false
[]==!{}
//true
undefined==null
//true看了这种题目,是不是想抽面试官几耳光呢?哈哈,是不是看了之后一脸懵逼,两脸茫然呢?心想这什么玩意
其实这些都是纸老虎,知道原理和转换规则,理解明白这些很容易的,炒鸡容易的,真的一点都不难,我们要打到一切纸老虎,不信?
我们就从[] == []和[] == ![]例子切入分析一下为什么输出的结果是true而不是其它的呢?
有点js基础应该知道对象是引用类型,就会一眼看出来[] == []会输出false,因为左边的[]和右边的[]看起来长的一样,但是他们引用的地址并不同,这个是同一类型的比较,所以相对没那么麻烦,暂时不理解[] == []为false的童鞋这里就不细说,想要弄清楚可以通过这篇文章来了解JavaScript的内存空间详解.
变量对象与堆内存
简单类型都放在栈(stack)里
对象类型都放在堆(heap)里
var a = 20;
var b = 'abc';
var c = true;
var d = { m: 20 }//地址假设为0x0012ff7c
var e = { m: 20 }//重新开辟一段内存空间假设为0x0012ff8f
console.log(e==d);//false
首先,我们来看一下代码:
function Person(id,name,age){
this.id = id;
this.name = name;
this.age = age;
}
var num = 10;
var bol = true;
var str = "abc";
var obj = new Object();
var arr = ['a','b','c'];
var person = new Person(100,"笨蛋的座右铭",25); 然后我们来看一下内存分析图:
变量num,bol,str为基本数据类型,它们的值,直接存放在栈中,obj,person,arr为复合数据类型,他们的引用变量存储在栈中,指向于存储在堆中的实际对象。 由上图可知,我们无法直接操纵堆中的数据,也就是说我们无法直接操纵对象,但我们可以通过栈中对对象的引用来操作对象,就像我们通过遥控机操作电视机一样,区别在于这个电视机本身并没有控制按钮。
记住一句话:能量是守衡的,无非是时间换空间,空间换时间的问题 堆比栈大,栈比堆的运算速度快,对象是一个复杂的结构,并且可以自由扩展,如:数组可以无限扩充,对象可以自由添加属性。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。相对于简单数据类型而言,简单数据类型就比较稳定,并且它只占据很小的内存。不将简单数据类型放在堆是因为通过引用到堆中查找实际对象是要花费时间的,而这个综合成本远大于直接从栈中取得实际值的成本。所以简单数据类型的值直接存放在栈中。
搬运文章:理解js内存分配
首先第一步:你要明白ECMAScript规范里面==的真正含义
GetValue 会获取一个子表达式的值(消除掉左值引用),在表达式 [] == ![] 中,[] 的结果就是一个空数组的引用(上文已经介绍到数组是引用类型),而 ![] 就有意思了,它会按照 11.4.9 和 9.2 节的要求得到 false。
首先我们了解一下运算符的优先级:
刚看到这里是不是就咬牙切齿了,好戏还在后头呢,哈哈
!取反运算符的优先级会高于==,所以我们先看看!在ECAMScript是怎么定义的?
所以![]最后会是一个Boolean类型的值(这点很关键,涉及到下面的匹配选择).
两者比较的行为在 11.9.3 节里,所以翻到 11.9.3:
在这段算法里,[]是Object,![]是Boolean,两者的类型不同,y是Boolean类型,由此可知[] == ![]匹配的是条件 8,所以会递归地调用[] == ToNumber(Boolean)进行比较。
[]空数组转化成Boolean,那么这个结果到底是true还是false呢,这个当然不是你说了算,也不是我说了算,ECMAScript定义的规范说了算:我们来看看规范:
[]是一个对象,所以对应转换成Boolean对象的值为true;那么**![]对应的Boolean值就是false
进而就成了比较[] == ToNumber(false)**了
再来看看ECMAScipt规范中对于Number的转换
由此可以得出此时的比较成了**[]==0**;
在此处因为 [] 是对象,0是数字Number,比较过程走分支 10(若Type(x)为Object且Type(y)为String或Number, 返回比较ToPrimitive(x) == y的结果。),可以对比上面那张图.
ToPrimitive 默认是调用 toString 方法的(依 8.2.8),于是 ToPrimitice([]) 等于空字符串。
再来看看ECMAScript标准怎么定义ToPrimitice方法的:
是不是看了这个定义,还是一脸懵逼,ToPrimitive这尼玛什么玩意啊?这不是等于没说吗?
再来看看火狐MDN上面文档的介绍:
JS::ToPrimitive
查了一下资料,上面要说的可以概括成:
ToPrimitive(obj,preferredType)
JS引擎内部转换为原始值ToPrimitive(obj,preferredType)函数接受两个参数,第一个obj为被转换的对象,第二个
preferredType为希望转换成的类型(默认为空,接受的值为Number或String)
在执行ToPrimitive(obj,preferredType)时如果第二个参数为空并且obj为Date的事例时,此时preferredType会
被设置为String,其他情况下preferredType都会被设置为Number如果preferredType为Number,ToPrimitive执
行过程如
下:
1. 如果obj为原始值,直接返回;
2. 否则调用 obj.valueOf(),如果执行结果是原始值,返回之;
3. 否则调用 obj.toString(),如果执行结果是原始值,返回之;
4. 否则抛异常。
如果preferredType为String,将上面的第2步和第3步调换,即:
1. 如果obj为原始值,直接返回;
2. 否则调用 obj.toString(),如果执行结果是原始值,返回之;
3. 否则调用 obj.valueOf(),如果执行结果是原始值,返回之;
4. 否则抛异常。
首先我们要明白**obj.valueOf()**和 **obj.toString()**还有原始值分别是什么意思,这是弄懂上面描述的前提之一:
toString用来返回对象的字符串表示。
var obj = {};
console.log(obj.toString());//[object Object]
var arr2 = [];
console.log(arr2.toString());//""空字符串
var date = new Date();
console.log(date.toString());//Sun Feb 28 2016 13:40:36 GMT+0800 (**标准时间)valueOf方法返回对象的原始值,可能是字符串、数值或bool值等,看具体的对象。
var obj = {
name: "obj"
};
console.log(obj.valueOf());//Object {name: "obj"}
var arr1 = [1];
console.log(arr1.valueOf());//[1]
var date = new Date();
console.log(date.valueOf());//1456638436303
如代码所示,三个不同的对象实例调用valueOf返回不同的数据
原始值指的是['Null','Undefined','String','Boolean','Number']五种基本数据类型之一(我猜的,查了一下
确实是这样的)
弄清楚这些以后,举个简单的例子:
var a={};
ToPrimitive(a)
分析:a是对象类型但不是Date实例对象,所以preferredType默认是Number,先调用a.valueOf()不是原始值,继续来调
用a.toString()得到string字符串,此时为原始值,返回之.所以最后ToPrimitive(a)得到就是"[object Object]".
如果觉得描述还不好明白,一大堆描述晦涩又难懂,我们用代码说话:
const toPrimitive = (obj, preferredType='Number') => {
let Utils = {
typeOf: function(obj) {
return Object.prototype.toString.call(obj).slice(8, -1);
},
isPrimitive: function(obj) {
let types = ['Null', 'String', 'Boolean', 'Undefined', 'Number'];
return types.indexOf(this.typeOf(obj)) !== -1;
}
};
if (Utils.isPrimitive(obj)) {
return obj;
}
preferredType = (preferredType === 'String' || Utils.typeOf(obj) === 'Date') ?
'String' : 'Number';
if (preferredType === 'Number') {
if (Utils.isPrimitive(obj.valueOf())) {
return obj.valueOf()
};
if (Utils.isPrimitive(obj.toString())) {
return obj.toString()
};
} else {
if (Utils.isPrimitive(obj.toString())) {
return obj.toString()
};
if (Utils.isPrimitive(obj.valueOf())) {
return obj.valueOf()
};
}
}
var a={};
ToPrimitive(a);//"[object Object]",与上面文字分析的一致分析了这么多,刚才分析到哪里了,好像到了比较ToPrimitive([]) == 0现在我们知道ToPrimitive([])="",也就是空字符串;
那么最后就变成了**""==0**这种状态,继续看和比较这张图
发现typeof("")为string,0为number,发现第5条满足规则,最后就成了toNumber("")==0的比较了,根据toNumber的转换规则:
所以toNumber("")=0,最后也就成了0 == 0的问题,于是[]==![]最后成了0 == 0的问题,答案显而易见为true,一波三折
==运算规则的图形化表示
前面说得很乱,根据我们得到的最终的图3,我们总结一下==运算的规则:
1. undefined == null,结果是true。且它俩与所有其他值比较的结果都是false。
2. String == Boolean,需要两个操作数同时转为Number。
3. String/Boolean == Number,需要String/Boolean转为Number。
4. Object == Primitive,需要Object转为Primitive(具体通过valueOf和toString方法)。
瞧见没有,一共只有4条规则!是不是很清晰、很简单。
喜欢我总结的文章对你有帮助有收获的话麻烦点个star
我的github博客地址,总结的第一篇,不好之处和借鉴不得到之处还望见谅,您的支持就是我的动力!
本文首发我的个人博客:前端小密圈,评论交流送1024邀请码,嘿嘿嘿😄。
来自朋友去某信用卡管家的做的一道面试题,用原生JavaScript模拟ES5的bind方法,不准用call和bind方法。
至于结果嘛。。。那个人当然是没写出来,我就自己尝试研究了一番,其实早就写了,一直没有组织好语言发出来。
额。。。这个题有点刁钻,这是对JavaScript基本功很好的一个检测,看你JavaScript掌握的怎么样以及平时有没有去深入研究一些方法的实现,简而言之,就是有没有折腾精神。
不准用不用call和apply方法,这个没啥好说的,不准用我们就用原生JavaScript先来模拟一个apply方法,感兴趣的童鞋也可以看看chrome的v8怎么实现这个方法的,这里我只按照自己的思维实现,在模拟之前我们先要明白和了解原生call和apply方法是什么。
简单粗暴地来说,call,apply,bind是用于绑定this指向的。(如果你还不了解JS中this的指向问题,以及执行环境上下文的奥秘,这篇文章暂时就不太适合阅读)。
我们单独看看ECMAScript规范对apply的定义,看个大概就行:
15.3.4.3 Function.prototype.apply (thisArg, argArray)
顺便贴一贴中文版,免得翻译一下,中文版地址:
通过定义简单说一下call和apply方法,他们就是参数不同,作用基本相同。
1、每个函数都包含两个非继承而来的方法:apply()和call()。
2、他们的用途相同,都是在特定的作用域中调用函数。
3、接收参数方面不同,apply()接收两个参数,一个是函数运行的作用域(this),另一个是参数数组。
4、call()方法第一个参数与apply()方法相同,但传递给函数的参数必须列举出来。
知道定义然后,直接看个简单的demo
var jawil = {
name: "jawil",
sayHello: function (age) {
console.log("hello, i am ", this.name + " " + age + " years old");
}
};
var lulin = {
name: "lulin",
};
jawil.sayHello(24);
// hello, i am jawil 24 years old然后看看使用apply和call之后的输出:
jawil.sayHello.call(lulin, 24);// hello, i am lulin 24 years old
jawil.sayHello.apply(lulin, [24]);// hello, i am lulin 24 years old结果都相同。从写法上我们就能看出二者之间的异同。相同之处在于,第一个参数都是要绑定的上下文,后面的参数是要传递给调用该方法的函数的。不同之处在于,call方法传递给调用函数的参数是逐个列出的,而apply则是要写在数组中。
总结一句话介绍call和apply
call()方法在使用一个指定的this值和若干个指定的参数值的前提下调用某个函数或方法。
apply()方法在使用一个指定的this值和参数值必须是数组类型的前提下调用某个函数或方法。
上面代码,我们注意到了两点:
call和apply改变了this的指向,指向到lulinsayHello函数执行了这里默认大家都对this有一个基本的了解,知道什么时候this该指向谁,我们结合这两句话来分析这个通用函数:f.apply(o),我们直接看一本书对其中原理的解读,具体什么书,我也不知道,参数我们先不管,先了解其中的大致原理。
注意红色框中的部分,f.call(o)其原理就是先通过 o.m = f 将 f作为o的某个临时属性m存储,然后执行m,执行完毕后将m属性删除。
知道了这个基本原来我们再来看看刚才jawil.sayHello.call(lulin, 24)执行的过程:
// 第一步
lulin.fn = jawil.sayHello
// 第二步
lulin.fn()
// 第三步
delete lulin.fn上面的说的是原理,可能你看的还有点抽象,下面我们用代码模拟实现apply一下。
根据这个思路,我们可以尝试着去写第一版的 applyOne 函数:
// 第一版
Function.prototype.applyOne = function(context) {
// 首先要获取调用call的函数,用this可以获取
context.fn = this;
context.fn();
delete context.fn;
}
//简单写一个不带参数的demo
var jawil = {
name: "jawil",
sayHello: function (age) {
console.log(this.name);
}
};
var lulin = {
name: "lulin",
};
//看看结果:
jawil.sayHello.applyOne(lulin)//lulin正好可以打印lulin而不是之前的jawil了,哎,不容易啊!😄
最一开始也讲了,apply函数还能给定参数执行函数。举个例子:
var jawil = {
name: "jawil",
sayHello: function (age) {
console.log(this.name,age);
}
};
var lulin = {
name: "lulin",
};
jawil.sayHello.apply(lulin,[24])//lulin 24注意:传入的参数就是一个数组,很简单,我们可以从Arguments对象中取值,Arguments不知道是何物,赶紧补习,此文也不太适合初学者,第二个参数就是数组对象,但是执行的时候要把数组数值传递给函数当参数,然后执行,这就需要一点小技巧。
参数问题其实很简单,我们先偷个懒,我们接着要把这个参数数组放到要执行的函数的参数里面去。
Function.prototype.applyTwo = function(context) {
// 首先要获取调用call的函数,用this可以获取
context.fn = this;
var args = arguments[1] //获取传入的数组参数
context.fn(args.join(',');
delete context.fn;
}很简单是不是,那你就错了,数组join方法返回的是啥?
typeof [1,2,3,4].join(',')//string
Too young,too simple啊,最后是一个 "1,2,3,4" 的字符串,其实就是一个参数,肯定不行啦。
也许有人会想到用ES6的一些奇淫方法,不过apply是ES3的方法,我们为了模拟实现一个ES3的方法,要用到ES6的方法,反正面试官也没说不准这样。但是我们这次用eval方法拼成一个函数,类似于这样:
eval('context.fn(' + args +')')
先简单了解一下eval函数吧
定义和用法
eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
语法:
eval(string)
string必需。要计算的字符串,其中含有要计算的 JavaScript 表达式或要执行的语句。该方法只接受原始字符串作为参数,如果 string 参数不是原始字符串,那么该方法将不作任何改变地返回。因此请不要为 eval() 函数传递 String 对象来作为参数。
简单来说吧,就是用JavaScript的解析引擎来解析这一堆字符串里面的内容,这么说吧,你可以这么理解,你把eval看成是<script>标签。
eval('function Test(a,b,c,d){console.log(a,b,c,d)};Test(1,2,3,4)')
就是相当于这样
<script>
function Test(a,b,c,d){
console.log(a,b,c,d)
};
Test(1,2,3,4)
</script>第二版代码大致如下:
Function.prototype.applyTwo = function(context) {
var args = arguments[1]; //获取传入的数组参数
context.fn = this; //假想context对象预先不存在名为fn的属性
var fnStr = 'context.fn(';
for (var i = 0; i < args.length; i++) {
fnStr += i == args.length - 1 ? args[i] : args[i] + ',';
}
fnStr += ')';//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
eval(fnStr); //还是eval强大
delete context.fn; //执行完毕之后删除这个属性
}
//测试一下
var jawil = {
name: "jawil",
sayHello: function (age) {
console.log(this.name,age);
}
};
var lulin = {
name: "lulin",
};
jawil.sayHello.applyTwo(lulin,[24])//lulin 24好像就行了是不是,其实这只是最粗糙的版本,能用,但是不完善,完成了大约百分之六七十了。
其实还有几个小地方需要注意:
1.this参数可以传null或者不传,当为null的时候,视为指向window
举个两个简单栗子栗子🌰:
demo1:
var name = 'jawil';
function sayHello() {
console.log(this.name);
}
sayHello.apply(null); // 'jawil'demo2:
var name = 'jawil';
function sayHello() {
console.log(this.name);
}
sayHello.apply(); // 'jawil'2.函数是可以有返回值的.
举个简单栗子🌰:
var obj = {
name: 'jawil'
}
function sayHello(age) {
return {
name: this.name,
age: age
}
}
console.log(sayHello.apply(obj,[24]));// {name: "jawil", age: 24}这些都是小问题,想到了,就很好解决。我们来看看此时的第三版apply模拟方法。
//原生JavaScript封装apply方法,第三版
Function.prototype.applyThree = function(context) {
var context = context || window
var args = arguments[1] //获取传入的数组参数
context.fn = this //假想context对象预先不存在名为fn的属性
if (args == void 0) { //没有传入参数直接执行
return context.fn()
}
var fnStr = 'context.fn('
for (var i = 0; i < args.length; i++) {
//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
fnStr += i == args.length - 1 ? args[i] : args[i] + ','
}
fnStr += ')'
var returnValue = eval(fnStr) //还是eval强大
delete context.fn //执行完毕之后删除这个属性
return returnValue
}好紧张,再来做个小测试,demo,应该不会出问题:
var obj = {
name: 'jawil'
}
function sayHello(age) {
return {
name: this.name,
age: age
}
}
console.log(sayHello.applyThree(obj,[24]));// 完美输出{name: "jawil", age: 24}完美?perfact?这就好了,不存在的,我们来看看第四步的实现。
其实一开始就埋下了一个隐患,我们看看这段代码:
Function.prototype.applyThree = function(context) {
var context = context || window
var args = arguments[1] //获取传入的数组参数
context.fn = this //假想context对象预先不存在名为fn的属性
......
}就是这句话, context.fn = this //假想context对象预先不存在名为fn的属性,这就是一开始的隐患,我们只是假设,但是并不能防止contenx对象一开始就没有这个属性,要想做到完美,就要保证这个context.fn中的fn的唯一性。
于是我自然而然的想到了强大的ES6,这玩意还是好用啊,幸好早就了解并一直在使用ES6,还没有学习过ES6的童鞋赶紧学习一下,没有坏处的。
重新复习下新知识:
基本数据类型有6种:Undefined、Null、布尔值(Boolean)、字符串(String)、数值(Number)、对象(Object)。
ES5对象属性名都是字符串容易造成属性名的冲突。
举个栗子🌰:
var a = { name: 'jawil'};
a.name = 'lulin';
//这样就会重写属性ES6引入了一种新的原始数据类型Symbol,表示独一无二的值。
注意,Symbol函数前不能使用new命令,否则会报错。这是因为生成的Symbol是一个原始类型的值,不是对象
Symbol函数可以接受一个字符串作为参数,表示对Symbol实例的描述,主要是为了在控制台显示,或者转为字符串时,比较容易区分。
// 没有参数的情况
var s1 = Symbol();
var s2 = Symbol();
s1 === s2 // false
// 有参数的情况
var s1 = Symbol("foo");
var s2 = Symbol("foo");
s1 === s2 // false注意:
Symbol值不能与其他类型的值进行运算。
作为属性名的Symbol
var mySymbol = Symbol();
// 第一种写法
var a = {};
a[mySymbol] = 'Hello!';
// 第二种写法
var a = {
[mySymbol]: 'Hello!'
};
// 第三种写法
var a = {};
Object.defineProperty(a, mySymbol, { value: 'Hello!' });
// 以上写法都得到同样结果
a[mySymbol] // "Hello!"注意,Symbol值作为对象属性名时,不能用点运算符。
看看下面这个栗子🌰:
var a = {};
var name = Symbol();
a.name = 'jawil';
a[name] = 'lulin';
console.log(a.name,a[name]); //jawil,lulinSymbol值作为属性名时,该属性还是公开属性,不是私有属性。
这个有点类似于java中的protected属性(protected和private的区别:在类的外部都是不可以访问的,在类内的子类可以继承protected不可以继承private)
但是这里的Symbol在类外部也是可以访问的,只是不会出现在for...in、for...of循环中,也不会被Object.keys()、Object.getOwnPropertyNames()返回。但有一个Object.getOwnPropertySymbols方法,可以获取指定对象的所有Symbol属性名。
看看第四版的实现demo,想必大家了解上面知识已经猜得到怎么写了,很简单。
直接加个var fn = Symbol()就行了,,,
//原生JavaScript封装apply方法,第四版
Function.prototype.applyFour = function(context) {
var context = context || window
var args = arguments[1] //获取传入的数组参数
var fn = Symbol()
context[fn] = this //假想context对象预先不存在名为fn的属性
if (args == void 0) { //没有传入参数直接执行
return context[fn]()
}
var fnStr = 'context[fn]('
for (var i = 0; i < args.length; i++) {
//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
fnStr += i == args.length - 1 ? args[i] : args[i] + ','
}
fnStr += ')'
var returnValue = eval(fnStr) //还是eval强大
delete context[fn] //执行完毕之后删除这个属性
return returnValue
}呃呃呃额额,慢着,ES3就出现的方法,你用ES6来实现,你好意思么?你可能会说,不管黑猫白猫,只要能抓住老鼠的猫就是好猫,面试官直说不准用call和apply方法但是没说不准用ES6语法啊。
反正公说公有理婆说婆有理,这里还是不用Symbol方法实现一下,我们知道,ES6其实都是语法糖,ES6能写的,咋们ES5都能实现,这就导致了babel这类把ES6语法转化成ES5的代码了。
至于babel把Symbol属性转换成啥代码了,我也没去看,有兴趣的可以看一下稍微研究一下,这里我说一下简单的模拟。
ES5 没有 Sybmol,属性名称只可能是一个字符串,如果我们能做到这个字符串不可预料,那么就基本达到目标。要达到不可预期,一个随机数基本上就解决了。
//简单模拟Symbol属性
function jawilSymbol(obj) {
var unique_proper = "00" + Math.random();
if (obj.hasOwnProperty(unique_proper)) {
arguments.callee(obj)//如果obj已经有了这个属性,递归调用,直到没有这个属性
} else {
return unique_proper;
}
}
//原生JavaScript封装apply方法,第五版
Function.prototype.applyFive = function(context) {
var context = context || window
var args = arguments[1] //获取传入的数组参数
var fn = jawilSymbol(context);
context[fn] = this //假想context对象预先不存在名为fn的属性
if (args == void 0) { //没有传入参数直接执行
return context[fn]()
}
var fnStr = 'context[fn]('
for (var i = 0; i < args.length; i++) {
//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
fnStr += i == args.length - 1 ? args[i] : args[i] + ','
}
fnStr += ')'
var returnValue = eval(fnStr) //还是eval强大
delete context[fn] //执行完毕之后删除这个属性
return returnValue
}好紧张,再来做个小测试,demo,应该不会出问题:
var obj = {
name: 'jawil'
}
function sayHello(age) {
return {
name: this.name,
age: age
}
}
console.log(sayHello.applyFive(obj,[24]));// 完美输出{name: "jawil", age: 24}到此,我们完成了apply的模拟实现,给自己一个赞 b( ̄▽ ̄)d
这个不需要讲了吧,道理都一样,就是参数一样,这里我给出我实现的一种方式,看不懂,自己写一个去。
//原生JavaScript封装call方法
Function.prototype.callOne = function(context) {
return this.applyFive(([].shift.applyFive(arguments), arguments)
//巧妙地运用上面已经实现的applyFive函数
}看不太明白也不能怪我咯,我就不细讲了,看个demo证明一下,这个写法没问题。
Function.prototype.applyFive = function(context) {//刚才写的一大串}
Function.prototype.callOne = function(context) {
return this.applyFive(([].shift.applyFive(arguments)), arguments)
//巧妙地运用上面已经实现的applyFive函数
}
//测试一下
var obj = {
name: 'jawil'
}
function sayHello(age) {
return {
name: this.name,
age: age
}
}
console.log(sayHello.callOne(obj,24));// 完美输出{name: "jawil", age: 24}养兵千日,用兵一时。
如果掌握了上面实现apply的方法,我想理解起来模拟实现bind方法也是轻而易举,原理都差不多,我们还是来看看bind方法的定义。
我们还是简单的看下ECMAScript规范对bind方法的定义,暂时看不懂不要紧,获取几个关键信息就行。
15.3.4.5 Function.prototype.bind (thisArg [, arg1 [, arg2, …]])
注意一点,ECMAScript规范提到: Function.prototype.bind 创建的函数对象不包含 prototype 属性或 [[Code]], [[FormalParameters]], [[Scope]] 内部属性。
bind() 方法会创建一个新函数,当这个新函数被调用时,它的
this值是传递给bind()的第一个参数, 它的参数是bind()的其他参数和其原本的参数,bind返回的绑定函数也能使用new操作符创建对象:这种行为就像把原函数当成构造器。提供的this值被忽略,同时调用时的参数被提供给模拟函数。。
语法是这样样子的:fun.bind(thisArg[, arg1[, arg2[, ...]]])
呃呃呃,是不是似曾相识,这不是call方法的语法一个样子么,,,但它们是一样的吗?
bind方法传递给调用函数的参数可以逐个列出,也可以写在数组中。bind方法与call、apply最大的不同就是前者返回一个绑定上下文的函数,而后两者是直接执行了函数。由于这个原因,上面的代码也可以这样写:
jawil.sayHello.bind(lulin)(24); //hello, i am lulin 24 years old
jawil.sayHello.bind(lulin)([24]); //hello, i am lulin 24 years oldbind方法还可以这样写 fn.bind(obj, arg1)(arg2).
用一句话总结bind的用法:该方法创建一个新函数,称为绑定函数,绑定函数会以创建它时传入bind方法的第一个参数作为this,传入bind方法的第二个以及以后的参数加上绑定函数运行时本身的参数按照顺序作为原函数的参数来调用原函数。
实际使用中我们经常会碰到这样的问题:
function Person(name){
this.nickname = name;
this.distractedGreeting = function() {
setTimeout(function(){
console.log("Hello, my name is " + this.nickname);
}, 500);
}
}
var alice = new Person('jawil');
alice.distractedGreeting();
//Hello, my name is undefined这个时候输出的this.nickname是undefined,原因是this指向是在运行函数时确定的,而不是定义函数时候确定的,再因为setTimeout在全局环境下执行,所以this指向setTimeout的上下文:window。关于this指向问题,这里就不细扯
以前解决这个问题的办法通常是缓存this,例如:
function Person(name){
this.nickname = name;
this.distractedGreeting = function() {
var self = this; // <-- 注意这一行!
setTimeout(function(){
console.log("Hello, my name is " + self.nickname); // <-- 还有这一行!
}, 500);
}
}
var alice = new Person('jawil');
alice.distractedGreeting();
// after 500ms logs "Hello, my name is jawil"这样就解决了这个问题,非常方便,因为它使得setTimeout函数中可以访问Person的上下文。但是看起来稍微一种蛋蛋的忧伤。
但是现在有一个更好的办法!您可以使用bind。上面的例子中被更新为:
function Person(name){
this.nickname = name;
this.distractedGreeting = function() {
setTimeout(function(){
console.log("Hello, my name is " + this.nickname);
}.bind(this), 500); // <-- this line!
}
}
var alice = new Person('jawil');
alice.distractedGreeting();
// after 500ms logs "Hello, my name is jawil"bind() 最简单的用法是创建一个函数,使这个函数不论怎么调用都有同样的 this 值。JavaScript新手经常犯的一个错误是将一个方法从对象中拿出来,然后再调用,希望方法中的 this 是原来的对象。(比如在回调中传入这个方法。)如果不做特殊处理的话,一般会丢失原来的对象。从原来的函数和原来的对象创建一个绑定函数,则能很漂亮地解决这个问题:
this.x = 9;
var module = {
x: 81,
getX: function() { return this.x; }
};
module.getX(); // 81
var getX = module.getX;
getX(); // 9, 因为在这个例子中,"this"指向全局对象
// 创建一个'this'绑定到module的函数
var boundGetX = getX.bind(module);
boundGetX(); // 81很不幸,Function.prototype.bind 在IE8及以下的版本中不被支持,所以如果你没有一个备用方案的话,可能在运行时会出现问题。bind 函数在 ECMA-262 第五版才被加入;它可能无法在所有浏览器上运行。你可以部份地在脚本开头加入以下代码,就能使它运作,让不支持的浏览器也能使用 bind() 功能。
幸运的是,我们可以自己来模拟bind功能:
了解了以上内容,我们来实现一个初级的bind函数Polyfill:
Function.prototype.bind = function (context) {
var me = this;
var argsArray = Array.prototype.slice.callOne(arguments);
return function () {
return me.applyFive(context, argsArray.slice(1))
}
}我们先简要解读一下:
基本原理是使用apply进行模拟。函数体内的this,就是需要绑定this的实例函数,或者说是原函数。最后我们使用apply来进行参数(context)绑定,并返回。
同时,将第一个参数(context)以外的其他参数,作为提供给原函数的预设参数,这也是基本的“颗粒化(curring)”基础。
上面的实现(包括后面的实现),其实是一个典型的“Monkey patching(猴子补丁)”,即“给内置对象扩展方法”。所以,如果面试者能进行一下“嗅探”,进行兼容处理,就是锦上添花了。
Function.prototype.bind = Function.prototype.bind || function (context) {
...
}对于函数的柯里化不太了解的童鞋,可以先尝试读读这篇文章:前端基础进阶(八):深入详解函数的柯里化。
上述的实现方式中,我们返回的参数列表里包含:atgsArray.slice(1),他的问题在于存在预置参数功能丢失的现象。
想象我们返回的绑定函数中,如果想实现预设传参(就像bind所实现的那样),就面临尴尬的局面。真正实现颗粒化的“完美方式”是:
Function.prototype.bind = Function.prototype.bind || function (context) {
var me = this;
var args = Array.prototype.slice.callOne(arguments, 1);
return function () {
var innerArgs = Array.prototype.slice.callOne(arguments);
var finalArgs = args.concat(innerArgs);
return me.applyFive(context, finalArgs);
}
}上面什么是bind函数还介绍到:bind返回的函数如果作为构造函数,搭配new关键字出现的话,我们的绑定this就需要“被忽略”。
有了上边的讲解,不难理解需要兼容构造函数场景的实现:
Function.prototype.bind = Function.prototype.bind || function (context) {
var me = this;
var args = Array.prototype.slice.callOne(arguments, 1);
var F = function () {};
F.prototype = this.prototype;
var bound = function () {
var innerArgs = Array.prototype.slice.callOne(arguments);
var finalArgs = args.concat(innerArgs);
return me.apply(this instanceof F ? this : context || this, finalArgs);
}
bound.prototype = new F();
return bound;
}我们需要调用bind方法的一定要是一个函数,所以可以在函数体内做一个判断:
if (typeof this !== "function") {
throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable");
}做到所有这一切,基本算是完成了。其实MDN上有个自己实现的polyfill,就是如此实现的。
另外,《JavaScript Web Application》一书中对bind()的实现,也是如此。
//简单模拟Symbol属性
function jawilSymbol(obj) {
var unique_proper = "00" + Math.random();
if (obj.hasOwnProperty(unique_proper)) {
arguments.callee(obj)//如果obj已经有了这个属性,递归调用,直到没有这个属性
} else {
return unique_proper;
}
}
//原生JavaScript封装apply方法,第五版
Function.prototype.applyFive = function(context) {
var context = context || window
var args = arguments[1] //获取传入的数组参数
var fn = jawilSymbol(context);
context[fn] = this //假想context对象预先不存在名为fn的属性
if (args == void 0) { //没有传入参数直接执行
return context[fn]()
}
var fnStr = 'context[fn]('
for (var i = 0; i < args.length; i++) {
//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
fnStr += i == args.length - 1 ? args[i] : args[i] + ','
}
fnStr += ')'
var returnValue = eval(fnStr) //还是eval强大
delete context[fn] //执行完毕之后删除这个属性
return returnValue
}
//简单模拟call函数
Function.prototype.callOne = function(context) {
return this.applyFive(([].shift.applyFive(arguments)), arguments)
//巧妙地运用上面已经实现的applyFive函数
}
//简单模拟bind函数
Function.prototype.bind = Function.prototype.bind || function (context) {
var me = this;
var args = Array.prototype.slice.callOne(arguments, 1);
var F = function () {};
F.prototype = this.prototype;
var bound = function () {
var innerArgs = Array.prototype.slice.callOne(arguments);
var finalArgs = args.concat(innerArgs);
return me.applyFive(this instanceof F ? this : context || this, finalArgs);
}
bound.prototype = new F();
return bound;
}好紧张,最后来做个小测试,demo,应该不会出问题:
var obj = {
name: 'jawil'
}
function sayHello(age) {
return {
name: this.name,
age: age
}
}
console.log(sayHello.bind(obj,24)());// 完美输出{name: "jawil", age: 24}看了这篇文章,以后再遇到类似的问题,应该能够顺利通过吧~
#-------------------------------------------------
#-------------------------------------------------
QT += core gui
QT += serialport
greaterThan(QT_MAJOR_VERSION, 4): QT += widgets
TARGET = COMTOOLV2
TEMPLATE = app
RC_FILE =main.rc
DEFINES += QT_DEPRECATED_WARNINGS
#DEFINES += QT_DISABLE_DEPRECATED_BEFORE=0x060000 # disables all the APIs deprecated before Qt 6.0.0
CONFIG += c++11
SOURCES +=
main.cpp
mainwindow.cpp
about.cpp
HEADERS +=
mainwindow.h
hexascii.h
about.h
FORMS +=
mainwindow.ui
about.ui
qnx: target.path = /tmp/$${TARGET}/bin
else: unix:!android: target.path = /opt/$${TARGET}/bin
!isEmpty(target.path): INSTALLS += target
RESOURCES +=
res.qrc
strategy: 'isPhone',
errMsg: '电话格式不正确'
比如独立一个Js出来管理这些配置字段
Hey there! Nice repo you got here. Could someone who knows English and Chinese translate what's going on?
之前不久,由于自己平时涉猎还算广泛,总结了一篇博客:这些JavaScript编程黑科技,装逼指南,高逼格代码,让你惊叹不已,没想到受到了大家的欢迎,有人希望能博主还能整理个 CSS 的一些黑魔法小技巧,无奈我 CSS 一直很渣,没什么干货,最近写了一个 Chrome 插件 GayHub,算是把 GitHub 的样式审查了个变,在写的过程中,也收获了很多关于 CSS 的小技巧,尤其是开始的第一个技巧,学习到了很多,于是再加上一波搜集,就诞生这篇博文,欢迎补充~~~😂。
CSS 的 content 属性 attr 抓取资料鼠标悬浮实现一个提示的文字,类似github的这种,如图:
想必大家都想到了伪元素 after,但是文字怎么获得呢,又不能用 JavaScript。
CSS 的伪元素是个很強大的东西,我们可以利用他做很多运用,通常为了做一些效果,content:" " 多半会留空,但其实可以在里面写上 attr 抓资料哦!
<div data-msg="Open this file in Github Desktop">
hover
</div>div{
width:100px;
border:1px solid red;
position:relative;
}
div:hover:after{
content:attr(data-msg);
position:absolute;
font-size: 12px;
width:200%;
line-height:30px;
text-align:center;
left:0;
top:25px;
border:1px solid green;
}在 attr 里面塞入我们在 html 新增的 data-msg 属性,这样伪元素 (:after) 就会得到该值。
同样的,你还可以结合其他强大的选择器使用,例如:使用属性选择器选择空链接
显示没有文本值但是 href 属性具有链接的 a 元素的链接:
a[href^="http"]:empty::before {
content: attr(href);
}这样做很方便。
:valid 和 :invalid 来做表单即时校验让表单检验变得简单优雅,不需要写冗长的 JS 代码来校验设置样式
html5 丰富了表单元素,提供了类似 required,email,tel 等表单元素属性。同样的,我们可以利用 :valid 和 :invalid 来做针对html5表单属性的校验。
:required 伪类指定具有required 属性的表单元素:valid 伪类指定一个通过匹配正确的所要求的表单元素:invalid 伪类指定一个不匹配指定要求的表单元素 <div class="container">
<div class="row" style="margin-top: 2rem;">
<form>
<div class="form-group">
<label>name</label>
<input type="text" required placeholder="请输入名称">
</div>
<div class="form-group">
<label>email</label>
<input type="email" required placeholder="请输入邮箱">
</div>
<div class="form-group">
<label>homepage</label>
<input type="url" placeholder="请输入博客url">
</div>
<div class="form-group">
<label>Comments</label>
<textarea required></textarea>
</div>
</form>
</div>
</div>.valid {
border-color: #429032;
box-shadow: inset 5px 0 0 #429032;
}
.invalid {
border-color: #D61D1D;
box-shadow: inset 5px 0 0 #D61D1D;
}
.form-group {
width: 32rem;
padding: 1rem;
border: 1px solid transparent;
&:hover {
border-color: #eee;
transition: border .2s;
}
label {
display: block;
font-weight: normal;
}
input,
textarea {
display: block;
width: 100%;
line-height: 2rem;
padding: .5rem .5rem .5rem 1rem;
border: 1px solid #ccc;
outline: none;
&:valid {
@extend .valid;
}
&:invalid {
@extend .invalid;
}
}
}更多伪元素技巧可以参看这篇文章:你不知道的CSS
nth-of-type 选择某范围内的子元素table表格红绿相间,显示的更加直观
<table>
<tbody>
<tr>
<td>1</td>
</tr>
<tr>
<td>2</td>
</tr>
<tr>
<td>3</td>
</tr>
<tr>
<td>4</td>
</tr>
<tr>
<td>5</td>
</tr>
<tr>
<td>6</td>
</tr>
</tbody>
</table>tbody tr:nth-of-type(2n){
background-color: red;
}
tbody tr:nth-of-type(2n+1){
background-color: green;
}你也这样来做,选择5-10的子元素。
table tr:nth-child(n+5):nth-child(-n+10) {
background-color: red;
}有时候,需要容器的文字从上到下排列,而不是从左往右排列,如图所示:
这是segmentfault的回到顶部,他的实现很简单,就是设置一定宽度让其折行,如果我要实现这种需求呢?
writing-mode 这个 CSS 属性,我们是不是很少见到,很少用到!我们往往称不常见的东西为“生僻”,就像是不常见的文字我们叫“生僻字”,因此不常见的 CSS 属性,我们可以叫做“生僻属性”,writing-mode 给我们的感觉就是一个“生僻属性”,很弱,可有可无。这个属性可以追溯到 IE 5.5 时代,兼容性是相当好的。
<h4>咏柳</h4>
<p>碧玉妆成一树高,<br>万条垂下绿丝绦。<br>不知细叶谁裁出,<br>二月春风似剪刀。</p>
<div class="verticle-mode">
<h4>咏柳</h4>
<p>碧玉妆成一树高,<br>万条垂下绿丝绦。<br>不知细叶谁裁出,<br>二月春风似剪刀。</p>.verticle-mode {
writing-mode: tb-rl;
-webkit-writing-mode: vertical-rl;
writing-mode: vertical-rl;
}
/* IE7比较弱,需要做点额外的动作 */
.verticle-mode {
*width: 120px;
}
.verticle-mode h4,
.verticle-mode p {
*display: inline;
*writing-mode: tb-rl;
}
.verticle-mode h4 {
*float:right;
}更多细节与讨论请移步张鑫旭老师的这篇文章:改变CSS世界纵横规则的writing-mode属性
需要为一个列表添加个动画,容器的高度是不确定的,也就是高度为
auto,悬浮时候撑开内容有个过渡动画
如下图所示:
而用 CSS3 实现的话,由于高度的不确定,而 transtion 是需要具体的树枝,所以设置 height:auto 是无法实现效果的,可以通过 max-height 这个属性间接的实现这么个效果,css 样式是这样的:
<ul>
<li>
<div class="hd"> 列表1 </div>
<div class="bd">列表内容<br>内容列表内容<br>内容列表内容<br>内容</div>
</li>
<li>
<div class="hd"> 列表1 </div>
<div class="bd">列表内容<br>内容列表内容<br>内容列表内容<br>内容</div>
</li>
<li>
<div class="hd"> 列表1 </div>
<div class="bd">列表内容<br>内容列表内容<br>内容列表内容<br>内容</div>
</li>
</ul>.bd {
max-height:0;
overflow:hidden;
transition: all 1s ease-out;
}
li:hover .bd {
max-height: 600px;
transition-timing-function: ease-in;
}跟前面 GIF 差不多,这里就不录 GIF 了,有兴趣的可以自己尝试感受一下
pointer-events 禁用 a 标签事件效果在做
tab切换的时候,当选中当前项,禁用当前标签的事件,只有切换其他tab的时候,才重新请求新的数据。
pointer-events 是一个用于 HTML 指针事件的属性。
pointer-events 可以禁用 HTML 元素的 hover/focus/active 等动态效果。
默认值为 auto,语法:pointer-events: auto | none | visiblepainted | visiblefill | visiblestroke | visible | painted | fill | stroke | all;
<ul>
<li>
<a class="tab" href="https://google.com">aaa</a>
</li>
<li>
<a class="tab active" href="https://facebook.com">bbb</a>
</li>
<li>
<a class="tab" href="https://stackoverflow.com">ccc</a>
</li>
</ul> .active{
pointer-events: none;
}好像没什么效果😂
CSS 如何实现文字两端对齐红框所在的文字有四个字的、三个字的、两个字的,如果不两端对齐可以选择居中对齐,或者右对齐。但是如果要想文字两端对齐呢?
<div>姓名</div>
<div>手机号码</div>
<div>验证码</div>
<div>账号</div>
<div>密码</div>div{
margin:10px 0;
width:100px;
border:1px solid red;
text-align-last: justify;
}:not() 去除导航上不需要的属性有时候导航栏需要之间需要用逗号,进行隔离,但是最后一个不需要
<ul class="nav">
<li>a</li>
<li>b</li>
<li>c</li>
<li>d</li>
<li>e</li>
</ul>li{
list-style:none;
margin-bottom:10px;
display:inline-block;
}
ul > li:not(:last-child)::after {
content: ",";
}当然,你可以使用 .nav li + li(不包括第一个li) 或者 .nav li:first-child ~ li(不包括最后一个li), 但是使用 :not() 的意图特别清晰,CSS选择器按照人类描述它的方式定义边框。
或者,你已经学习了一些关于 使用 :not(),你还可以尝试:
/* 选择1到3的元素并显示 */
li:not(:nth-child(-n+3)){
display: none;
}在IOS机型中,非body元素的滚动条会非常不流畅,又不想用JS模拟滚动条。
传统 pc 端中,子容器高度超出父容器高度,通常使用 overflow:auto 可出现滚动条拖动显示溢出的内容,而移动web开发中,由于浏览器厂商的系统不同、版本不同,导致有部分机型尤其是 IOS 机型不支持弹性滚动,从而在开发中制造了所谓的 BUG。
body{
-webkit-overflow-scrolling: touch; /* ios5+ */
}
ele{
overflow:auto;
}-webkit-overflow-scrolling属性具有继承效果,所以在 body 上设置即可,这样局部滚动条就非常的流畅了。
所有滚动条都相当的流畅了
radio ,checkbox 属性设计师:你那个单选框按钮好丑啊,跟我的设计稿差好远。程序员:我有什么办法,浏览器就是这样的。。。
记得刚开始写页面时候,被浏览器各种默认的 UI 样式恶心到了,当初确实也没啥办法,反正也不影响功能,就那样吧。
先讲一下原理:checkbox hack技术
我们使用
CSS一些特殊的选择器,然后配合单选框以及复选框自带的一些特性,可以实现元素的显示隐藏效果。然后通过一些简单的扩展,我们可以不使用任何JavaScript代码实现类似:自定义的单复选框,“更多”展开与收起效果,选项卡切换效果,或是多级下拉列表效果等等。
相信很多前端开发人员都会遇到
boss让修改checkbox和radio样式,毕竟自带的样式太丑了。后来我们发现修改自带样式并不是那么容易,最后直接使出杀手锏——点击之后替换图片。
今天教大家一种方法,不用替换图片,随意修改样式。
先讲一下原理:两个关键东东,一是伪类选择器
:checked,表示对应控件元素(单选框或是复选框)选中时的样式;二就是加号+相邻兄弟选择器,这个符号表示选择后面的兄弟节点。于是,两者配合,就可以轻松自如控制后面元素的显示或者隐藏,或是其他样式了。
而如何让单复选框选中和不选中了,那就是
label标签了哈,for属性锚定对应的单选框或是复选框,然后点击这里的label标签元素的时候,对应的单复选框就会选中或是取消选中。然后,就有上面的效果啦!
这里只给一个 radio 单选框的代码,仅供参考:
<div class="radio-beauty-container">
<label>
<span class="radio-name">前端工程师</span>
<input type="radio" name="radioName" id="radioName1" hidden/>
<label for="radioName1" class="radio-beauty"></label>
</label>
<label>
<span class="radio-name">后端工程师</span>
<input type="radio" name="radioName" id="radioName2" hidden/>
<label for="radioName2" class="radio-beauty"></label>
</label>
<label>
<span class="radio-name">全栈工程师</span>
<input type="radio" name="radioName" id="radioName3" hidden/>
<label for="radioName3" class="radio-beauty"></label>
</label>
</div>.radio-beauty-container {
font-size: 0;
$bgc: green;
%common {
padding: 2px;
background-color: $bgc;
background-clip: content-box;
}
.radio-name {
vertical-align: middle;
font-size: 16px;
}
.radio-beauty {
width: 18px;
height: 18px;
box-sizing: border-box;
display: inline-block;
border: 1px solid $bgc;
vertical-align: middle;
margin: 0 15px 0 3px;
border-radius: 50%;
&:hover {
box-shadow: 0 0 7px $bgc;
@extend %common;
}
}
input[type="radio"]:checked+.radio-beauty {
@extend %common;
}
}
美化radio单选框在线预览地址:点击我呀
美化checkbox复选框在线预览地址:点击我呀
更多关于这方面的介绍和例子可以参看张鑫旭大神的这篇文章:CSS radio/checkbox单复选框元素显隐技术
input 焦点光标的颜色设计师觉得默认的光标颜色有点与整体设计风格不符合,有点突兀,想换成红色的
<input value="This field uses a default caret." />
<input class="custom" value="I have a custom caret color!" />input {
caret-color: auto;
display: block;
margin-bottom: .5em;
}
input.custom {
caret-color: red;
}rem 布局不再使用 JavaScript 设置这里不探讨 rem 的原理以及细节,还不熟悉的童鞋建议去恶补一下。
有时候,移动端用
rem布局时候,根据不同的屏幕宽度要设置不同的font-size来做到适配,要写一坨JS来设置,能不能不用JS呢?
例如:以 750px 设计稿作为基准,根节点设置 font-size 为 100px ,只考虑 DPR 为 2 的情况,只考虑最简单的情况
document.querySelector('html').style.fontSize = `${window.innerWidth / 7.5 }px`;现在移动端 css3 单位 vw ,wh 兼容性已经很不错了,在不需要兼容太低版本的安卓机情况下可以这样来:
html{
font-size: calc(100vw / 7.5)
}就这么简单的设置,rem 就可以使用了
transparent 属性实现各种三角形,提示框在不使用图片的情况,实现一个简单的三角形箭头
#triangle-right {
width: 0;
height: 0;
border-top: 50px solid transparent;
border-left: 100px solid red;
border-bottom: 50px solid transparent;
}复杂点的话,同样的原理还可以实现一个五角星,原理都是利用 transparent 的透明属性。
记得2008年时候汶川大地震时候,很多网站图片都变成黑白色彩悼念逝者
<img src="https://user-gold-cdn.xitu.io/2017/9/25/0844cf44a8d8c4ed026d6c488a6e9b80?
imageView2/1/w/500/h/200/q/85/interlace/1" alt="" class="desaturate">img.desaturate {
filter: grayscale(100%);
-webkit-filter: grayscale(100%);
-moz-filter: grayscale(100%);
-ms-filter: grayscale(100%);
-o-filter: grayscale(100%);
}实现文字波浪线的强调效果,如图所示
相信大家对于 text-decoration 这个属性并不陌生,在重置 a 标签的默认样式时,我们经常要这样写:text-decoration: none; 可能对它了解的人也很少,实际上 text-decoration 是一个复合属性,由 line、style 和 color 组成。
所以我们可以实现这样的效果:
可惜的是 line 只有 underline (下划线)、overline (上划线)和 line-through (删除线)。如果突然需要下划波浪线,怎么办呢?不要急,神奇的 CSS 会帮你做到的。首先,你需要先了解一下渐变的使用技巧。
说一下这里的思路,我们首先要用两段渐变构造一个基本元素:'X'(这里我就不放图了),下一步就比较重要了,我们要截取'X'的上半部分,得到一个'V',从而结合 repeat 形成波浪线。下面是用 scss 写的一个 mixin ,方便以后使用。
@mixin waveline($color,$h) {
position: relative;
&::after {
content: '';
display: block;
position: absolute;
top: 100%;
left: 0;
width: 100%;
height: $h;
background: linear-gradient(135deg, transparent, transparent 45%, $color, transparent 55%, transparent 100%),
linear-gradient(45deg, transparent, transparent 45%, $color, transparent 55%, transparent 100%);
background-size: $h * 2 $h * 2;
}
}这些技巧在当前版本的Chrome,Firefox, Safari, 以及Edge, 和IE11可以工作,移动端基本都没问题,IE 重度开发者慎用。
相关兼容性自行查找:https://caniuse.com/
国服第一切图仔的 CSS 仓库:你想知道的 CSS 奇技淫巧,在这里,都有。iCSS -- interesting css
受益颇多,所以推荐一波。😂
PM2是一个带有负载均衡功能的Node应用的进程管理器。PM2可以利用服务器上的所有CPU,并保证进程永远都活着,0秒的重载,部署管理多个Node项目。PM2是Node线上部署完美的管理工具。
npm install pm2 -g : 全局安装。
pm2 start app.js : 启动服务,入口文件是app.js。
pm2 start app.js -i [n] --name [name] : 启动n个进程,名字命名为name。
npm restart [name or id] : 重启服务。
npm reload [name or id] : 和rastart功能相同,但是可以实现0s的无缝衔接;如果有nginx的使用经验,可以
对比nginx reload指令。
pm2 start app.js --max_memory_restart 1024M : 当内存超过1024M时自动重启。 如果工程中有比较棘手的内
存泄露问题,这个算是一个折中方案。
pm2 monit : 对服务进行监控。
至于要启动几个进程,可以通过服务器的内核数进行确定,几个内核就启动几个服务。指令如下:
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id" | sort| uniq | wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
当然可以启动多个端口,一个端口号对应一个服务,这样的话就需要nignx来做负载均衡了。
nginx可以做的事情主要有两个:
- 反向代理,实现简单的负载均衡: 如果有多台服务器或者一台服务器多个端口,可以考虑用nginx。
- 静态资源缓存:把一些静态资源(如静态页面,js等资源文件)放到nginx里,可以极大的提高服务的性能。
开发环境中多以fork的方式启动,生产环境中多用cluster方式启动
上面的示例图中可以看一“watching”一项,这个项默认是disabled,可以通过如下命令开启
pm2 start app.js --name m --watch建议:这个适合在开发时用,可以省不少时间,生产环境下最好不要用
cluster是fork的派生,cluster支持所有cluster拥有的特性;
fork不支持socket地址端口复用,cluster支持地址端口复用。因为只有node的cluster模块支持socket选项SO_REUSEADDR;
fork不可以启动多个实例进程,cluster可以启动多个实例。但node的child_process.fork是可以实现启动多个进程的,但是为什么没有实现呢?就个人理解,node多为提供网络服务,启动多个实例需要地址端口复用,此时便可使用cluster模式实现,但fork模式并不支持地址端口复用,多实例进程启动会产生异常错误。但对于常驻任务脚本而言,不需要提供网络服务,此时多进程启动可以实现,同时也提高了任务处理效率。对于上述需求,可以两种方式实现,一是配置app0,app1,app2方式启动多个进程,二是通过应用实例自身调用child_process.fork多进程编程实现;
fork模式可以应用于其他语言,如php,python,perl,ruby,bash,coffee, 而cluster只能应用于node;
fork不支持定时重启,cluster支持定时重启。定时重启也就是配置中的cron_restart配置项。
pm2的监控有两种方式:
pm2 monit是专门用来监控的命令,监控项包括cpu与内存
缺点monit展示内容太过粗糙,不够详细
可以查看出每个进程的运行状态。
如果需要更详细的监控内容,对于cli而言一般都是可以实现的。
这种监控方式的缺点:
a. 不够直观,需要自己去执行命令并分析结果;
b. 不便于多台服务器的应用监控管理;
日志系统对于任意应用而言,通常都是必不可少的一个辅助功能。pm2的相关文件默认存放于$HOME/.pm2/目录下,其日志主要有两类:
a. pm2自身的日志,存放于$HOME/.pm2/pm2.log;
b. pm2所管理的应用的日志,存放于$HOME/.pm2/logs/目录下,标准谁出日志存放于${APP_NAME}_out.log,标准错误日志存放于${APP_NAME}_error.log;
这里之所以把日志单独说明一下是因为,如果程序开发不严谨,为了调试程序,导致应用产生大量标准输出,使服务器本身记录大量的日志,导致服务磁盘满载问题。一般而言,pm2管理的应用本身都有自己日志系统,所以对于这种不必要的输出内容需禁用日志,重定向到/dev/null。
与crontab比较,也有类似情况,crontab自身日志,与其管理的应用本身的输出。应用脚本输出一定需要重定向到/dev/null,因为该输出内容会以邮件的形式发送给用户,内容存储在邮件文件,会产生意向不到的结果,或会导致脚本压根不被执行;
pm2支持配置文件启动:
pm2 ecosystem: 生成配置文件ecosystem.json
pm2 startOrRestart /file/path/ecosystem.json : 通过配置文件启动服务
如下是开发时ecosystem.json的内容:
{
/**
* Application configuration section
* http://pm2.keymetrics.io/docs/usage/application-declaration/
* 多个服务,依次放到apps对应的数组里
*/
apps : [
// First application
{
name : "nova",
max_memory_restart: "300M",
script : "/root/nova/app.js",
out_file : "/logs/nova_out.log",
error_file : "/logs/nova_error.log",
instances : 4,
exec_mode : "cluster",
env: {
NODE_ENV: "production"
}
}
]
}
上述采用cluster模式启动了4个服务进程;如果服务占用的内存超过300M,会自动进行重启。
配置项
name 应用进程名称;
script 启动脚本路径;
cwd 应用启动的路径,关于script与cwd的区别举例说明:在/home/polo/目录下运行/data/release/node/
index.js,此处script为/data/release/node/index.js,cwd为/home/polo/;
args 传递给脚本的参数;
interpreter 指定的脚本解释器;
interpreter_args 传递给解释器的参数;
instances 应用启动实例个数,仅在cluster模式有效,默认为fork;
exec_mode 应用启动模式,支持fork和cluster模式;
watch 监听重启,启用情况下,文件夹或子文件夹下变化应用自动重启;
ignore_watch 忽略监听的文件夹,支持正则表达式;
max_memory_restart 最大内存限制数,超出自动重启;
env 环境变量,object类型,如{"NODE_ENV":"production", "ID": "42"};
log_date_format 指定日志日期格式,如YYYY-MM-DD HH:mm:ss;
error_file 记录标准错误流,$HOME/.pm2/logs/XXXerr.log),代码错误可在此文件查找;
out_file 记录标准输出流,$HOME/.pm2/logs/XXXout.log),如应用打印大量的标准输出,会导致pm2日志过大;
min_uptime 应用运行少于时间被认为是异常启动;
max_restarts 最大异常重启次数,即小于min_uptime运行时间重启次数;
autorestart 默认为true, 发生异常的情况下自动重启;
cron_restart crontab时间格式重启应用,目前只支持cluster模式;
force 默认false,如果true,可以重复启动一个脚本。pm2不建议这么做;
restart_delay 异常重启情况下,延时重启时间;
PM2是一款非常优秀的Node进程管理工具,它有着丰富的特性:能够充分利用多核CPU且能够负载均衡、能够帮助应用在崩溃后、指定时间(cluster model)和超出最大内存限制等情况下实现自动重启。
个人几点看法保证常驻应用进程稳定运行:
定时重启,应用进程运行时间久了或许总会产生一些意料之外的问题,定时可以规避一些不可测的情况;
最大内存限制,根据观察设定合理内存限制,保证应用异常运行;
合理min_uptime,min_uptime是应用正常启动的最小持续运行时长,超出此时间则被判定为异常启动;
设定异常重启延时restart_delay,对于异常情况导致应用停止,设定异常重启延迟可防止应用在不可测情况下不断重启的导致重启次数过多等问题;
设置异常重启次数,如果应用不断异常重启,并超过一定的限制次数,说明此时的环境长时间处于不可控状态,服务器异常。此时便可停止尝试,发出错误警告通知等。
关于pm2的使用,主要还是运用于常驻脚本。
通过shell脚本实现资源拉取、服务重启、nginx缓存更新等操作,再配合pm2的监控功能,就初步达到了一个后端工程部署的标配了。
最近在恶补计算机网络方面的知识,之前对于TCP的三次握手和四次分手也是模模糊糊,对于其中的细节更是浑然不知,最近看了很多这方面的知识,也在系统的学习计算机网络,加深自己的CS功底,就把看过的一些比较好的东西和自己的一些理解二次加工组织一下然后交流分享,一起学习进步,对了这个面试好像经常问到。
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
但是为什么一定要进行三次握手来保证连接是双工的呢,一次不行么?两次不行么?我们举一个现实生活中两个人进行语言沟通的例子来模拟三次握手。
引用网上的一些通俗易懂的例子,虽然不太正确,后面会指出,但是不妨碍我们理解,大体就是这么个理解法。
老婆让甲出去打酱油,半路碰到一个朋友乙,甲问了一句:哥们你吃饭了么?
结果乙带着耳机听歌呢,根本没听到,没反应。甲心里想:跟你说话也没个音,不跟你说了,沟通失败。说明乙接受不到甲传过来的信息的情况下沟通肯定是失败的。
如果乙听到了甲说的话,那么第一次对话成功,接下来进行第二次对话。
乙听到了甲说的话,但是他是老外,中文不好,不知道甲说的啥意思也不知道怎样回答,于是随便回答了一句学过的中文 :我去厕所了。甲一听立刻笑喷了,“去厕所吃饭”?道不同不相为谋,离你远点吧,沟通失败。说明乙无法做出正确应答的情况下沟通失败。
如果乙听到了甲的话,做出了正确的应答,并且还进行了反问:我吃饭了,你呢?那么第二次握手成功。
通过前两次对话证明了乙能够听懂甲说的话,并且能做出正确的应答。 接下来进行第三次对话。
甲刚和乙打了个招呼,突然老婆喊他,“你个死鬼,打个酱油咋这么半天,看我回家咋收拾你”,甲是个妻管严,听完吓得二话不说就跑回家了,把乙自己晾那了。乙心想:这什么人啊,得,我也回家吧,沟通失败。说明甲无法做出应答的情况下沟通失败。
如果甲也做出了正确的应答:我也吃了。那么第三次对话成功,两人已经建立起了顺畅的沟通渠道,接下来开始持续的聊天。
通过第二次和第三次的对话证明了甲能够听懂乙说的话,并且能做出正确的应答。
可见,两个人进行有效的语言沟通,这三次对话的过程是必须的。
为了保证服务端能收接受到客户端的信息并能做出正确的应答而进行前两次(第一次和第二次)握手,为了保证客户端能够接收到服务端的信息并能做出正确的应答而进行后两次(第二次和第三次)握手。
这个例子举得挺好的。不过个人感觉为什么是三次而不是二次,不是因为为了证明甲能听懂乙并回应(第二次乙能正确的响应甲说明俩人之间沟通已无障碍了),而是怕出现以下情况而浪费感情。这个情景是这样的(例子有点不实际意会就好):甲在路上跟乙打招呼,由于刮风什么的这句活被吹跑了,然后甲又跟打了个招呼,乙听到了并作出了回应。此时不管是三次握手还是两次握手两个人都能愉快的沟通。0.1秒后俩人四次挥手告别了。此时被风刮跑的那句话又传到了乙的耳朵里,乙认为甲又要跟他沟通,所以做出了响应的回应。(问题出现了)假如采用2次握手,乙就认定了甲要跟他沟通,于是就不停的等,浪费感情。可如果是采用3次握手,乙等了一会后发现甲没有回应他就认为甲走了然后自己也就走了!
这就很明白了,其实第三步是防止了乙的一直等待而浪费自己的时间,而不是为了保证甲能够正确回应乙的信息。。。后面的也会讲到。
引用知乎上的别人引用的一个回答,从另外一个角度阐释:
在Google Groups的TopLanguage中看到一帖讨论TCP“三次握手”觉得很有意思。贴主提出“TCP建立连接为什么是三次握手?”的问题,在众多回复中,有一条回复写道:“这个问题的本质是, 信道不可靠, 但是通信双发需要就某个问题达成一致. 而要解决这个问题, 无论你在消息中包含什么信息, 三次通信是理论上的最小值. 所以三次握手不是TCP本身的要求, 而是为了满足"在不可靠信道上可靠地传输信息"这一需求所导致的. 请注意这里的本质需求,信道不可靠, 数据传输要可靠. 三次达到了, 那后面你想接着握手也好, 发数据也好, 跟进行可靠信息传输的需求就没关系了. 因此,如果信道是可靠的, 即无论什么时候发出消息, 对方一定能收到, 或者你不关心是否要保证对方收到你的消息, 那就能像UDP那样直接发送消息就可以了.”。这可视为对“三次握手”目的的另一种解答思路。
上面的纯属大白话娱乐讲解,可能还有偏差,例子可能有点不得体。在我们真正了解TCP的三次握手和四次分手之前,必须了解一些基本的概念,最后和这大白话例子对比结合一下理解,说不定就会顿时融会贯通。
HTTP协议即超文本传送协议(Hypertext Transfer Protocol ),是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。
HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
1)在HTTP 1.0中,客户端的每次请求都要求建立一次单独的连接,在处理完本次请求后,就自动释放连接。
2)在HTTP 1.1中则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
由于HTTP在每次请求结束后都会主动释放连接,因此HTTP连接是一种“短连接”,要保持客户端程序的在线状态,需要不断地向服务器发起连接请求。通常 的做法是即时不需要获得任何数据,客户端也保持每隔一段固定的时间向服务器发送一次“保持连接”的请求,服务器在收到该请求后对客户端进行回复,表明知道 客户端“在线”。若服务器长时间无法收到客户端的请求,则认为客户端“下线”,若客户端长时间无法收到服务器的回复,则认为网络已经断开。
套接字(socket)是通信的基石,是支持TCP/IP协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序进程提供并发服务的问题。多个TCP连接或多个应用程序进程可能需要通过同一个 TCP协议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应 用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket 。
套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。
服务器监听:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态,等待客户端的连接请求。
客户端请求:指客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。
连接确认:当服务器端套接字监听到或者说接收到客户端套接字的连接请求时,就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发 给客户端,一旦客户端确认了此描述,双方就正式建立连接。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
创建Socket连接时,可以指定使用的传输层协议,Socket可以支持不同的传输层协议(TCP或UDP),当使用TCP协议进行连接时,该Socket连接就是一个TCP连接。
由于通常情况下Socket连接就是TCP连接,因此Socket连接一旦建立,通信双方即可开始相互发送数据内容,直到双方连接断开。但在实际网 络应用中,客户端到服务器之间的通信往往需要穿越多个中间节点,例如路由器、网关、防火墙等,大部分防火墙默认会关闭长时间处于非活跃状态的连接而导致 Socket 连接断连,因此需要通过轮询告诉网络,该连接处于活跃状态。
而HTTP连接使用的是“请求—响应”的方式,不仅在请求时需要先建立连接,而且需要客户端向服务器发出请求后,服务器端才能回复数据。
很多情况下,需要服务器端主动向客户端推送数据,保持客户端与服务器数据的实时与同步。此时若双方建立的是Socket连接,服务器就可以直接将数 据传送给客户端;若双方建立的是HTTP连接,则服务器需要等到客户端发送一次请求后才能将数据传回给客户端,因此,客户端定时向服务器端发送连接请求, 不仅可以保持在线,同时也是在“询问”服务器是否有新的数据,如果有就将数据传给客户端。TCP(Transmission Control Protocol) 传输控制协议
TCP是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接:
位码即tcp标志位,有6种标示:SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) RST(reset重置) URG(urgent紧急)
Sequence number(顺序号码) Acknowledge number(确认号码)
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。
具体的关于TCP是什么,我不打算详细的说了;当你看到这篇文章时,我想你也知道TCP的概念了,想要更深入的了解TCP的工作,我们就继续。它只是一个超级麻烦的协议,而它又是互联网的基础,也是每个程序员必备的基本功。首先来看看OSI的七层模型:
我们需要知道TCP工作在网络OSI的七层模型中的第四层——Transport层,IP在第三层——Network层,ARP在第二层——Data Link层;在第二层上的数据,我们把它叫Frame,在第三层上的数据叫Packet,第四层的数据叫Segment。 同时,我们需要简单的知道,数据从应用层发下来,会在每一层都会加上头部信息,进行封装,然后再发送到数据接收端。这个基本的流程你需要知道,就是每个数据都会经过数据的封装和解封装的过程。 在OSI七层模型中,每一层的作用和对应的协议如下:
TCP是一个协议,那这个协议是如何定义的,它的数据格式是什么样子的呢?要进行更深层次的剖析,就需要了解,甚至是熟记TCP协议中每个字段的含义。哦,来吧。
其中 ACK SYN 序号 这三个部分在以下会用到,它们的介绍也在下面。
上面就是TCP协议头部的格式,由于它太重要了,是理解其它内容的基础,下面就将每个字段的信息都详细的说明一下。
Source Port和Destination Port:分别占用16位,表示源端口号和目的端口号;用于区别主机中的不同进程,而IP地址是用来区分不同的主机的,源端口号和目的端口号配合上IP首部中的源IP地址和目的IP地址就能唯一的确定一个TCP连接;
Sequence Number:用来标识从TCP发端向TCP收端发送的数据字节流,它表示在这个报文段中的的第一个数据字节在数据流中的序号;主要用来解决网络报乱序的问题;
Acknowledgment Number:32位确认序列号包含发送确认的一端所期望收到的下一个序号,因此,确认序号应当是上次已成功收到数据字节序号加1。不过,只有当标志位中的ACK标志(下面介绍)为1时该确认序列号的字段才有效。主要用来解决不丢包的问题;
Offset:给出首部中32 bit字的数目,需要这个值是因为任选字段的长度是可变的。这个字段占4bit(最多能表示15个32bit的的字,即4*15=60个字节的首部长度),因此TCP最多有60字节的首部。然而,没有任选字段,正常的长度是20字节;
TCP Flags:TCP首部中有6个标志比特,它们中的多个可同时被设置为1,主要是用于操控TCP的状态机的,依次为URG,ACK,PSH,RST,SYN,FIN。每个标志位的意思如下:
URG:此标志表示TCP包的紧急指针域(后面马上就要说到)有效,用来保证TCP连接不被中断,并且督促中间层设备要尽快处理这些数据;
ACK:此标志表示应答域有效,就是说前面所说的TCP应答号将会包含在TCP数据包中;有两个取值:0和1,为1的时候表示应答域有效,反之为0;
PSH:这个标志位表示Push操作。所谓Push操作就是指在数据包到达接收端以后,立即传送给应用程序,而不是在缓冲区中排队;
RST:这个标志表示连接复位请求。用来复位那些产生错误的连接,也被用来拒绝错误和非法的数据包;
SYN:表示同步序号,用来建立连接。SYN标志位和ACK标志位搭配使用,当连接请求的时候,SYN=1,ACK=0;连接被响应的时候,SYN=1,ACK=1;这个标志的数据包经常被用来进行端口扫描。扫描者发送一个只有SYN的数据包,如果对方主机响应了一个数据包回来 ,就表明这台主机存在这个端口;但是由于这种扫描方式只是进行TCP三次握手的第一次握手,因此这种扫描的成功表示被扫描的机器不很安全,一台安全的主机将会强制要求一个连接严格的进行TCP的三次握手;
FIN: 表示发送端已经达到数据末尾,也就是说双方的数据传送完成,没有数据可以传送了,发送FIN标志位的TCP数据包后,连接将被断开。这个标志的数据包也经常被用于进行端口扫描。
暂时需要的信息有:
ACK : TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1
SYN(SYNchronization) : 在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
FIN (finis)即完,终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
多么清晰的一张图,当然了,也不是我画的,我也只是引用过来说明问题了。
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了神秘的“四次分手”。
至此,TCP的四次分手就这么愉快的完成了。当你看到这里,你的脑子里会有很多的疑问,很多的不懂,感觉很凌乱;没事,我们继续总结。
在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。在另一部经典的《计算机网络》一书中讲“三次握手”的目的是为了解决“网络中存在延迟的重复分组”的问题。
在谢希仁著《计算机网络》书中同时举了一个例子,如下:
“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
这就很明白了,防止了服务器端的一直等待而浪费资源。
那四次分手又是为何呢?TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。如果要正确的理解四次分手的原理,就需要了解四次分手过程中的状态变化。
TCP的作用是流量控制,主要是控制数据流的传输。下面以浏览网页为例,根据自身理解来解释一下这个过程。(注:第二个ack属于代码段ack位)
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。
第一次握手:客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主 动关闭连接之前,TCP 连接都将被一直保持下去。断开连接时服务器和客户端均可以主动发起断开TCP连接的请求,断开过程需要经过“四次握手”(过程就不细写了,就是服务器和客 户端交互,最终确定断开)
IP 192.168.1.116.3337 > 192.168.1.123.7788: S 3626544836:3626544836
IP 192.168.1.123.7788 > 192.168.1.116.3337: S 1739326486:1739326486 ack 3626544837
IP 192.168.1.116.3337 > 192.168.1.123.7788: ack 1739326487,ack 1
第一次握手:192.168.1.116发送位码syn=1,随机产生seq number=3626544836的数据包到192.168.1.123,192.168.1.123由SYN=1知道192.168.1.116要求建立联机;
第二次握手:192.168.1.123收到请求后要确认联机信息,向192.168.1.116发送ack number=3626544837,syn=1,ack=1,随机产生seq=1739326486的包;
第三次握手:192.168.1.116收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,192.168.1.116会再发送ack number=1739326487,ack=1,192.168.1.123收到后确认seq=seq+1,ack=1则连接建立成功。
总结到这里,也该结束了,但是对于TCP的学习远还没有结束。TCP是一个非常复杂的协议,这里稍微总结了一下TCP的连接与断开连接是发生的事情,其中还有很多的“坑”,让我们后续有时间再继续填吧。好了,完毕!
TCP三次握手详解及释放连接过程
首先简单介绍一下TCP三次握手
TCP 为什么是三次握手,为什么不是两次或四次?
最后推荐一个学习HTTP的github项目地址:我自己提炼的关于《HTTP权威指南》每章的知识点总结!
最近看了很多这方面的文章,能搜到的基本看了个遍,但感觉还是似懂非懂,知道这个东西,很难说出这是个什么东西,先整理一些概念,慢慢消化,以后慢慢探索其中的原因。
虚拟像素,可以理解为“直觉”像素,
CSS和JS使用的抽象单位,浏览器内的一切长度都是以CSS像素为单位的,CSS像素的单位是px。
在CSS规范中,长度单位可以分为两类,绝对(absolute)单位以及相对(relative)单位。px是一个相对单位,相对的是设备像素(device pixel)。
在同样一个设备上,每1个CSS像素所代表的物理像素是可以变化的(即CSS像素的第一方面的相对性);
在不同的设备之间,每1个CSS像素所代表的物理像素是可以变化的(即CSS像素的第二方面的相对性);
px实际是pixel(像素)的缩写,根据 维基百科的解释,它是图像显示的基本单元,既不是一个确定的物理量,也不是一个点或者小方块,而是一个抽象概念。所以在谈论像素时一定要清楚它的上下文!一定要清楚它的上下文!一定要清楚它的上下文!
不同的设备,图像基本采样单元是不同的,显示器上的物理像素等于显示器的点距,而打印机的物理像素等于打印机的墨点。而衡量点距大小和打印机墨点大小的单位分别称为ppi和dpi:
ppi:每英寸多少像素数,放到显示器上说的是每英寸多少物理像素及显示器设备的点距。
dpi:每英寸多少点。
关于打印机的点距我们不去关心,只要知道 当用于描述显示器设备时ppi与dpi是同一个概念 。
由于不同的物理设备的物理像素的大小是不一样的,所以css认为浏览器应该对css中的像素进行调节,使得浏览器中 1css像素的大小在不同物理设备上看上去大小总是差不多 ,目的是为了保证阅读体验一致。为了达到这一点浏览器可以直接按照设备的物理像素大小进行换算,而css规范中使用**"参考像素"**来进行换算。
1参考像素即为从一臂之遥看解析度为96DPI的设备输出(即1英寸96点)时,1点(即1/96英寸)的视角。它并不是1/96英寸长度,而是从一臂之遥的距离处看解析度为96DPI的设备输出一单位(即1/96英寸)时视线与水平线的夹角。通常认为常人臂长为28英寸,所以它的视角是:
(1/96)in / (28in * 2 * PI / 360deg) = 0.0213度。
由于css像素是一个视角单位,所以在真正实现时,为了方便基本都是根据设备像素换算的。浏览器根据硬件设备能够直接获取css像素
作为Web开发者,我们接触的更多的是用于控制元素样式的样式单位像素。这里的像素我们称之为CSS像素。
CSS像素有什么特别的地方?我们可以借用quirksmode中的这个例子:
假设我们用PC浏览器打开一个页面,浏览器此时的宽度为800px,页面上同时有一个400px宽的块级元素容器。很明显此时块状容器应该占页面的一半。
但如果我们把页面放大(通过“Ctrl键”加上“+号键”),放大为200%,也就是原来的两倍。此时块状容器则横向占满了整个浏览器。
吊诡的是此时我们既没有调整浏览器窗口大小,也没有改变块状元素的css宽度,但是它看上去却变大了一倍——这是因为我们把CSS像素放大为了原来的两倍。
CSS像素与屏幕像素1:1同样大小时:
CSS像素(黑色边框)开始被拉伸,此时1个CSS像素大于1个屏幕像素
也就是说默认情况下一个CSS像素应该是等于一个物理像素的宽度的,但是浏览器的放大操作让一个CSS像素等于了两个设备像素宽度。在后面你会看到更复杂的情况,在高PPI的设备上,CSS像素甚至在默认状态下就相当于多个物理像素的尺寸。
从上面的例子可以看出,CSS像素从来都只是一个相对值。
设备像素(物理像素),顾名思义,显示屏是由一个个物理像素点组成的,通过控制每个像素点的颜色,使屏幕显示出不同的图像,屏幕从工厂出来那天起,它上面的物理像素点就固定不变了,单位pt。
pt在css单位中属于真正的绝对单位,1pt = 1/72(inch),inch及英寸,而1英寸等于2.54厘米。
不同的设备,其图像基本单位是不同的,比如显示器的点距,可以认为是显示器的物理像素。现在的液晶显示器的点距一般在0.25mm到0.29mm之间。而打印机的墨点,也可以认为是打印机的物理像素,300DPI就是0.085mm,600DPI就是0.042mm。
注意,我们通常所说的显示器分辨率,其实是指桌面设定的分辨率,而不是显示器的物理分辨率。只不过现在液晶显示器成为主流,由于液晶的显示原理与CRT不同,只有在桌面分辨率与物理分辨率一致的情况下,显示效果最佳,所以现在我们的桌面分辨率几乎总是与显示器的物理分辨率一致了。
小知识:屏幕普遍采用RGB色域(红、绿、蓝三个子像素构成),而印刷行业普遍使用CMYK色域(青、品红、黄和黑)
获得设备像素比(dpr)后,便可得知设备像素与CSS像素之间的比例。当这个比率为1:1时,使用1个设备像素显示1个CSS像素。当这个比率为2:1时,使用4个设备像素显示1个CSS像素,当这个比率为3:1时,使用9(3*3)个设备像素显示1个CSS像素。
所以,有如下公式:
DPR = 设备像素/CSS像素
设备独立像素,也称为逻辑像素,简称dip。
根据上述设备像素与CSS像素之间的关系、及DPR的官方定义,我们可以推断出:
CSS像素 =设备独立像素 = 逻辑像素
下面,还是引用 http://www.cnblogs.com/2050/p/3877280.html 文中的内容说明:
在移动端浏览器中以及某些桌面浏览器中,window对象有一个devicePixelRatio属性,它的官方的定义为:设备物理像素和设备独立像素的比例,也就是 devicePixelRatio = 物理像素 / 独立像素。
CSS像素就可以看做是设备的独立像素,所以通过devicePixelRatio,我们可以知道该设备上一个css像素代表多少个物理像素。例如,在Retina屏的iphone上,devicePixelRatio的值为2,也就是说1个css像素相当于2个物理像素。但是要注意的是,devicePixelRato在不同的浏览器中还存在些许的兼容性问题,所以我们现在还并不能完全信赖这个东西,具体的情况可以看下这篇文章。
为什么是“每四个一组”?而且要让这四个一组来显示“原来屏幕的一个像素”?这大概就是 Retina 显示技术的一种表现吧。而这“每四个一组”的“大像素”,可以被称作“设备独立像素”,device independent pixel ,或者 density-independentpixel ,它可以是系统中的一个点,这个点代表一个可以由程序使用的虚拟像素,然后由相关系统转换为物理像素。
“设备独立像素”也有人称为“CSS像素”,一种形象的说法,更倾向于表明与 CSS 中尺寸的对应。
设备独立像素与物理像素的对应关系,可以这样看:
类似的每四个一组的对应关系,也许正是 Retina 显示技术所做的。
设备像素比(dpr 描述的是未缩放状态下,
物理像素和CSS像素的初始比例关系,计算方法如下图。
设备像素比(dpr) 是指在移动开发中1个css像素占用多少设备像素,如2代表1个css像素用2x2个设备像素来绘制。
设备像素比(dpr),公式为1px = (dpr)^2 * 1dp,可以理解为1px由多少个设备像素组成;
每英寸像素取值,更确切的说法应该是像素密度,也就是衡量单位物理面积内拥有像素值的情况。
顾名思义,每英寸的像素点(设备像素),已知屏幕分辨率和主对角线的尺寸,则ppi等于
以爱疯6为例:
var 斜边尺寸 = V(1920^2+1080^2) V代表开根号
var ppi = 斜边尺寸/5.5
ppi = 401ppi
我们知道,ppi越高,每英寸像素点越多,图像越清晰;我们可以类比物体的密度,密度越大,单位体积的质量就越大,ppi越高,单位面积的像素越多。
毕竟这些参数是外国人先发明的,他们会优先选择自己熟悉的计量单位作为显示设备的工厂标准参数,因此ppi就用作显示设备的工业标准;
告诉业界人士,ppi达到多少是高清屏,此时对应的dpr是多少,而不直接告诉你我现在的显示设备dpr是多少,毕竟人们直接听到像素分辨率会更加有反应。
设备像素比与ppi相关,一般是ppi/160的整数倍:
用iPhone 3gs和4s来举例。假设有个邮件列表界面,我们不妨按照PC端网页设计的思维来想象。3gs上大概只能显示4-5行,4s就能显示9-10行,而且每行会变得特别宽。但两款手机其实是一样大的。如果照这种方式显示,3gs上刚刚好的效果,在4s上就会小到根本看不清字。
在现实中,这两者效果却是一样的。这是因为Retina屏幕把2x2个像素当1个像素使用。比如原本44像素高的顶部导航栏,在Retina屏上用了88个像素的高度来显示。导致界面元素都变成2倍大小,反而和3gs效果一样了。画质却更清晰。
在以前,iOS应用的资源图片中,同一张图通常有两个尺寸。你会看到文件名有的带@2x字样,有的不带。其中不带@2x的用在普通屏上,带@2x的用在Retina屏上。只要图片准备好,iOS会自己判断用哪张,Android道理也一样。
由此可以看出,苹果以普通屏为基准,给Retina屏定义了一个2倍的倍率(iPhone 6plus除外,它达到了3倍)。实际像素除以倍率,就得到逻辑像素尺寸。只要两个屏幕逻辑像素相同,它们的显示效果就是相同的。
这是一种显示技术,可以将把更多的像素点压缩至一块屏幕里,从而达到更高的分辨率并提高屏幕显示的细腻程度,这种分辨率在正常观看距离下足以使人肉眼无法分辨其中的单独像素。
最先使用retina屏幕是iphone 4,屏幕分辨率为960 * 640(326ppi)。
对比如下两幅图,可以清晰地看出是否 Retina 屏的显示差异:
图2 iPhone 3GS
图3 iPhone 4
两代iPhone 的物理尺寸(屏幕宽高有多少英寸)是一样的,从上图可以看出,iphone 4的显示效果要明显好于iphone 3GS,虽然 iPhone 4 分辨率提高了,但它不同于普通的电脑显示器那样为了显示更多的内容,而是提升显示相同内容时的画面精细程度。这种提升方式是靠提升单位面积屏幕的像素数量,即像素密度来提升分辨率,这样做的主要目的是为了提高屏幕显示画面的精细程度。以第三代 MacBook Pro with Retina Display为例, 工作时显卡渲染出的2880x1880个像素每四个一组,输出原来屏幕的一个像素显示的大小区域内的图像。这样一来,用户所看到的图标与文字的大小与原来的1440x900分辨率显示屏相同,但精细度是原来的4倍。
注意:在桌面显示器中,我们调整了显示分辨率,比如从 800 * 600 调整到 1024 * 768 时,屏幕的文字图标会变小,显示的内容更多了。但 Retina 显示方式不会产生这样的问题,或者说, Retina 显示技术解决的是显示画面精细程度的问题,而不是解决显示内容容量的问题。
PPI 说的是像素密度,而分辨率说的是块屏幕的像素尺寸,譬如说 1334*750 就是 iPhone(6~7)的分辨率,说 iPhone(6~7)的分辨率是 326 是错误的表述,326 是它的像素密度,单位是 PPI。
询问别人一粒像素有多大是一个非常鸡贼的问题(小心面试遇到这样的题),虽然我们说像素是构成屏幕的发光的点,是物理的,但是像素在脱离了屏幕尺寸之后是没有大小可言的,你可以将 1920 * 1080 颗像素放到一台 40 寸的小米电视机里面,也可以将同样多的像素全部塞到一台 5.5 寸的 iPhone7 Plus 手机里面去,那么对于 40 寸的电视而言,每个像素颗粒当然会大于 5.5 寸的手机的像素。
所以光看屏幕的分辨率对于设计师来说是不具备多少实际意义的,通过分辨率计算得出的像素密度(PPI)才是设计师要关心的问题,我们通过屏幕分辨率和屏幕尺寸就能计算出屏幕的像素密度的。
再次使用 iPhone(6~7)作为例子。我们知道该屏幕的横向物理尺寸为 2.3 英寸 ,且横向具有 750 颗像素,根据下面的公式,我们能够算出 iPhone(6~7)的屏幕是 326 PPI,意为每寸存在 326 颗像素。
其实不论我们怎么除,计算得出来的像素密度(PPI)都会是这个数,宽存在像素除以宽物理长度,高存在像素除以高物理长度,得数都接近于 326。
ppk大神对于移动设备上的viewport有着非常多的研究(第一篇,第二篇,第三篇),有兴趣的同学可以去看一下,本文中有很多数据和观点也是出自那里。ppk认为,移动设备上有三个viewport。
首先,移动设备上的浏览器认为自己必须能让所有的网站都正常显示,即使是那些不是为移动设备设计的网站。但如果以浏览器的可视区域作为viewport的话,因为移动设备的屏幕都不是很宽,所以那些为桌面浏览器设计的网站放到移动设备上显示时,必然会因为移动设备的viewport太窄,而挤作一团,甚至布局什么的都会乱掉。也许有人会问,现在不是有很多手机分辨率都非常大吗,比如768x1024,或者1080x1920这样,那这样的手机用来显示为桌面浏览器设计的网站是没问题的吧?前面我们已经说了,css中的1px并不是代表屏幕上的1px,你分辨率越大,css中1px代表的物理像素就越多,devicePixelRatio的值也越大,这很好理解,因为你分辨率增大了,但屏幕尺寸并没有变大多少,必须让css中的1px代表更多的物理像素,才能让1px的东西在屏幕上的大小与那些低分辨率的设备差不多,不然就会因为太小而看不清。所以在1080x1920这样的设备上,在默认情况下,也许你只要把一个div的宽度设为300多px(视devicePixelRatio的值而定),就是满屏的宽度了。回到正题上来,如果把移动设备上浏览器的可视区域设为viewport的话,某些网站就会因为viewport太窄而显示错乱,所以这些浏览器就决定默认情况下把viewport设为一个较宽的值,比如980px,这样的话即使是那些为桌面设计的网站也能在移动浏览器上正常显示了。ppk把这个浏览器默认的viewport叫做 layout viewport。
这个layout viewport的宽度可以通过document.documentElement.clientWidth 来获取。
然而,layout viewport 的宽度是大于浏览器可视区域的宽度的,所以我们还需要一个viewport来代表 浏览器可视区域的大小,ppk把这个viewport叫做 visual viewport 。visual viewport的宽度可以通过window.innerWidth 来获取,但在Android 2, Oprea mini 和 UC 8中无法正确获取。
现在我们已经有两个viewport了:layout viewport 和 visual viewport。但浏览器觉得还不够,因为现在越来越多的网站都会为移动设备进行单独的设计,所以必须还要有一个能完美适配移动设备的viewport。所谓的完美适配指的是,首先不需要用户缩放和横向滚动条就能正常的查看网站的所有内容;第二,显示的文字的大小是合适,比如一段14px大小的文字,不会因为在一个高密度像素的屏幕里显示得太小而无法看清,理想的情况是这段14px的文字无论是在何种密度屏幕,何种分辨率下,显示出来的大小都是差不多的。当然,不只是文字,其他元素像图片什么的也是这个道理。ppk把这个viewport叫做 ideal viewport,也就是第三个viewport——移动设备的理想viewport。
ideal viewport并没有一个固定的尺寸,不同的设备拥有有不同的ideal viewport。所有的iphone的ideal viewport宽度都是320px,无论它的屏幕宽度是320还是640,也就是说,在iphone中,css中的320px就代表iphone屏幕的宽度。
但是安卓设备就比较复杂了,有320px的,有360px的,有384px的等等,关于不同的设备ideal viewport的宽度都为多少,可以到http://viewportsizes.com去查看一下,里面收集了众多设备的理想宽度。
再总结一下:ppk把移动设备上的viewport分为 layout viewport 、 visual viewport 和 ideal viewport 三类,其中的ideal viewport是最适合移动设备的viewport,ideal viewport的宽度等于移动设备的屏幕宽度,只要在css中把某一元素的宽度设为ideal viewport的宽度(单位用px),那么这个元素的宽度就是设备屏幕的宽度了,也就是宽度为100%的效果。ideal viewport 的意义在于,无论在何种分辨率的屏幕下,那些针对ideal viewport 而设计的网站,不需要用户手动缩放,也不需要出现横向滚动条,都可以完美的呈现给用户。
移动设备默认的viewport是layout viewport,也就是那个比屏幕要宽的viewport,但在进行移动设备网站的开发时,我们需要的是ideal viewport。那么怎么才能得到ideal viewport呢?这就该轮到meta标签出场了。
我们在开发移动设备的网站时,最常见的的一个动作就是把下面这个东西复制到我们的head标签中:
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0">
该meta标签的作用是让当前viewport的宽度等于设备的宽度,同时不允许用户手动缩放。也许允不允许用户缩放不同的网站有不同的要求,但让viewport的宽度等于设备的宽度,这个应该是大家都想要的效果,如果你不这样的设定的话,那就会使用那个比屏幕宽的默认viewport,也就是说会出现横向滚动条。
这个name为viewport的meta标签到底有哪些东西呢,又都有什么作用呢?
meta viewport 标签首先是由苹果公司在其safari浏览器中引入的,目的就是解决移动设备的viewport问题。后来安卓以及各大浏览器厂商也都纷纷效仿,引入对meta viewport的支持,事实也证明这个东西还是非常有用的。
在苹果的规范中,meta viewport 有6个属性(暂且把content中的那些东西称为一个个属性和值),如下:
这些属性可以同时使用,也可以单独使用或混合使用,多个属性同时使用时用逗号隔开就行了。
此外,在安卓中还支持 target-densitydpi 这个私有属性,它表示目标设备的密度等级,作用是决定css中的1px代表多少物理像素
特别说明的是,当 target-densitydpi=device-dpi 时, css中的1px会等于物理像素中的1px。
因为这个属性只有安卓支持,并且安卓已经决定要废弃<strike>target-densitydpi</strike> 这个属性了,所以这个属性我们要避免进行使用 。
要得到ideal viewport就必须把默认的layout viewport的宽度设为移动设备的屏幕宽度。因为meta viewport中的width能控制layout viewport的宽度,所以我们只需要把width设为width-device这个特殊的值就行了。
<meta name="viewport" content="width=device-width">
下图是这句代码在各大移动端浏览器上的测试结果:
可以看到通过width=device-width,所有浏览器都能把当前的viewport宽度变成ideal viewport的宽度,但要注意的是,在iphone和ipad上,无论是竖屏还是横屏,宽度都是竖屏时ideal viewport的宽度。
这样的写法看起来谁都会做,没吃过猪肉,谁还没见过猪跑啊~,确实,我们在开发移动设备上的网页时,不管你明不明白什么是viewport,可能你只需要这么一句代码就够了。
可是你肯定不知道
<meta name="viewport" content="initial-scale=1">
这句代码也能达到和前一句代码一样的效果,也可以把当前的的viewport变为 ideal viewport。
呵呵,傻眼了吧,因为从理论上来讲,这句代码的作用只是不对当前的页面进行缩放,也就是页面本该是多大就是多大。那为什么会有 width=device-width 的效果呢?
要想清楚这件事情,首先你得弄明白这个缩放是相对于什么来缩放的,因为这里的缩放值是1,也就是没缩放,但却达到了 ideal viewport 的效果,所以,那答案就只有一个了,缩放是相对于 ideal viewport来进行缩放的,当对ideal viewport进行100%的缩放,也就是缩放值为1的时候,不就得到了 ideal viewport 吗?事实证明,的确是这样的。下图是各大移动端的浏览器当设置了<meta name="viewport" content="initial-scale=1"> 后是否能把当前的viewport 宽度变成 ideal viewport 的宽度的测试结果。
测试结果表明 initial-scale=1 也能把当前的 viewport 宽度变成 ideal viewport 的宽度,但这次轮到了windows phone 上的IE 无论是竖屏还是横屏都把宽度设为竖屏时 ideal viewport 的宽度。但这点小瑕疵已经无关紧要了。
但如果 width 和 initial-scale=1 同时出现,并且还出现了冲突呢?比如:
<meta name="viewport" content="width=400, initial-scale=1">
width=400 表示把当前 viewport 的宽度设为400px,initial-scale=1 则表示把当前 viewport 的宽度设为ideal viewport的宽度,那么浏览器到底该服从哪个命令呢?是书写顺序在后面的那个吗?不是。当遇到这种情况时,浏览器会取它们两个中较大的那个值。例如,当width=400,ideal viewport 的宽度为320时,取的是400;当width=400, ideal viewport的宽度为480时,取的是ideal viewport的宽度。(ps:在uc9浏览器中,当initial-scale=1时,无论width属性的值为多少,此时viewport的宽度永远都是ideal viewport的宽度)
最后,总结一下,要把当前的viewport宽度设为ideal viewport的宽度,既可以设置 width=device-width,也可以设置 initial-scale=1,但这两者各有一个小缺陷,就是iphone、ipad以及IE 会横竖屏不分,通通以竖屏的ideal viewport宽度为准。所以,最完美的写法应该是,两者都写上去,这样就 initial-scale=1 解决了 iphone、ipad的毛病,width=device-width则解决了IE的毛病:
<meta name="viewport" content="width=device-width, initial-scale=1">
首先我们先来讨论一下缩放的问题,前面已经提到过,缩放是相对于 ideal viewport 缩放的,缩放值越大,当前viewport的宽度就会越小,反之亦然。例如在iphone中,ideal viewport 的宽度是320px,如果我们设置 initial-scale=2 ,此时 viewport 的宽度会变为只有160px了,这也好理解,放大了一倍嘛,就是原来1px的东西变成2px了,但是1px变为2px并不是把原来的320px变为640px了,而是在实际宽度不变的情况下,1px变得跟原来的2px的长度一样了,所以放大2倍后原来需要320px才能填满的宽度现在只需要160px就做到了。因此,我们可以得出一个公式:
visual viewport宽度 = ideal viewport宽度 / 当前缩放值
当前缩放值 = ideal viewport宽度 / visual viewport宽度
ps: visual viewport 的宽度指的是浏览器可视区域的宽度。
大多数浏览器都符合这个理论,但是安卓上的原生浏览器以及IE有些问题。安卓自带的webkit浏览器只有在 initial-scale = 1 以及没有设置width属性时才是表现正常的,也就相当于这理论在它身上基本没用;而IE则根本不甩initial-scale这个属性,无论你给他设置什么,initial-scale表现出来的效果永远是1。
好了,现在再来说下 initial-scale 的默认值问题,就是不写这个属性的时候,它的默认值会是多少呢?很显然不会是1,因为当 initial-scale = 1 时,当前的 layout viewport 宽度会被设为 ideal viewport 的宽度,但前面说了,各浏览器默认的 layout viewport 宽度一般都是980啊,1024啊,800啊等等这些个值,没有一开始就是 ideal viewport 的宽度的,所以 initial-scale 的默认值肯定不是1。安卓设备上的 initial-scale 默认值好像没有方法能够得到,或者就是干脆它就没有默认值,一定要你显示的写出来这个东西才会起作用,我们不管它了,这里我们重点说一下iphone和ipad上的 initial-scale 默认值。
根据测试,我们可以在iphone和ipad上得到一个结论,就是无论你给 layout viewpor 设置的宽度是多少,而又没有指定初始的缩放值的话,那么iphone和ipad会自动计算 initial-scale 这个值,以保证当前 layout viewport 的宽度在缩放后就是浏览器可视区域的宽度,也就是说不会出现横向滚动条。比如说,在iphone上,我们不设置任何的 viewport meta 标签,此时 layout viewport 的宽度为980px,但我们可以看到浏览器并没有出现横向滚动条,浏览器默认的把页面缩小了。根据上面的公式,当前缩放值 = ideal viewport宽度 / visual viewport宽度,我们可以得出:
当前缩放值 = 320 / 980
也就是当前的 initial-scale 默认值应该是 0.33这样子。当你指定了 initial-scale 的值后,这个默认值就不起作用了。
总之记住这个结论就行了:在iphone和ipad上,无论你给viewport设的宽的是多少,如果没有指定默认的缩放值,则iphone和ipad会自动计算这个缩放值,以达到当前页面不会出现横向滚动条(或者说viewport的宽度就是屏幕的宽度)的目的。
第一种方法
可以使用 document.write 来动态输出 meta viewport 标签,例如:
document.write('<meta name="viewport" content="width=device-width,initial-scale=1">')第二种方法
通过 setAttribute 来改变
<meta id="testViewport" name="viewport" content="width = 380">
<script>
var mvp = document.getElementById('testViewport');
mvp.setAttribute('content','width=480');
</script>安卓2.3自带浏览器上的一个 bug
<meta name="viewport" content="width=device-width">
<script type="text/javascript">
alert(document.documentElement.clientWidth); //弹出600,正常情况应该弹出320
</script>
<meta name="viewport" content="width=600">
<script type="text/javascript">
alert(document.documentElement.clientWidth); //弹出320,正常情况应该弹出600
</script>测试的手机 ideal viewport 宽度为320px,第一次弹出的值是600,但这个值应该是第行meta标签的结果啊,然后第二次弹出的值是320,这才是第一行meta标签所达到的效果啊,所以在安卓2.3(或许是所有2.x版本中)的自带浏览器中,对 meta viewport 标签进行覆盖或更改,会出现让人非常迷糊的结果。
一只笔的像素如下:
这只笔在屏幕c,d,e下的显示效果如下:
看到同一张图片在各屏幕显示大小不一。
我们希望不同屏幕显示图片的大小要一致。
我们要计算图片缩放比例。
计算公式:
(图片逻辑像素大小px1) / (图片缩放后实际像素大小px2) = (设备像素dp) / (设备独立像素dips)
px2 = px1 * (dp / dips)
px2 = px1 * dpr
此时,这只笔在屏幕c,d,e下的显示效果如下:
通过上面的我们可以看到,不同的
DPR(设备像素比)要想显示大小一样,必须准备三张不同分辨率的图片,那么,我想一张图片就在三种不同的屏幕下显示一样的大小,能做到吗?当然能做到,这就需要缩放了,要自己计算缩放多麻烦,那有没有一种简单的方式呢?当然有,那就是你在熟悉不过的px,你会发现设置图片宽度为50px以后,在各个移动终端的大小看起来都一样,这是什么原因呢。
按照 CSS 规范的定义,CSS 中的 px 是一个相对长度,它相对的,是 viewing device 的分辨率。这个viewing device,通常就是电脑显示器。典型的电脑显示器的分辨率是96DPI,也就是1像素为1/96英寸(实际上,假设我们的显示器分辨率都与物理分辨率一致,而液晶点距其实是0.25mm到0.29mm之间,所以不太可能是正好1/96英寸,而只是接近)。
一般来说,px 就是对应设备的物理像素,然而如果输出设备的解析度与电脑显示器大不相同,输出效果就会有问题。例如打印机输出到纸张上,其解析度比电脑屏幕要高许多,如果不缩放,直接使用设备的物理像素,那电脑上的照片由 600DPI 的打印机打出来就比用显示器看小了约6倍。
所以 CSS 规定,在这种情况下,浏览器应该对像素值进行缩放调节,以保持阅读体验的大体一致。也就是要保持一定像素的长度在不同设备输出上看上去的大小总是差不多。
怎样确保这一点呢?直接按照设备物理像素的大小进行换算当然是一个方式,但是CSS考虑得更多,它建议,转换应按照“参考像素”(reference pixel)来进行。
眼睛看到的大小,取决于可视角度。而可视角度取决于物体的实际大小以及物体与眼睛的距离。10米远处一个1米见方的东西,与1米远处的10厘米见方的东西,看上去的大小差不多是一样的,所谓一叶障目不见泰山,讲的就是这个常识。
因此CSS规范使用视角来定义“参考像素”,1参考像素即为从一臂之遥看解析度为96DPI的设备输出(即1英寸96点)时,1点(即1/96英寸)的视角。
请注意这个差别——CSS规范定义的参考像素并不是1/96英寸,而是1/96英寸在一臂之遥的看起来的视角。通常认为常人臂长为28英寸,所以其视角可以计算出来是0.0213度。(即(1/96)in / (28in * 2 * PI / 360deg) )
我们在使用不同设备输出时,眼睛与设备输出的典型距离是不同的。比如电脑显示器,通常是一臂之距,而看书和纸张时(对应于打印机的设备输出),则通常会更近一些。看电视时则会更远,比如一般建议是电视机屏幕对角线的2.5到3倍长——如果你是个42'彩电,那就差不多是3米远。看电影的话……我就不知道多远了,您自己量吧。
因此,1参考像素:
对于电脑显示器是0.26mm(即1/96英寸);
对于激光打印机是0.20mm(假设阅读距离通常为55cm,即21英寸);
而换算时,对于300DPI的打印机(即每个点是1/300英寸),1px通常会四舍五入到3dots,也就是0.25mm左右;而对于600DPI的打印机,则可能四舍五入到5dots,也就是0.21mm。
上图中,左边的屏幕(可以认为是电脑屏幕)的典型视觉距离是71厘米即28英寸,其1px对应了0.28mm;
而右边的屏幕(可以认为是你的42寸高清电视)的典型视觉距离是3.5米即120英寸,其1px对应1.3mm。42寸的1080p电视,分辨率是1920*1080,则其物理像素只有0.5mm左右,可见确实是高清哦。
综上,px 是一个相对单位,而且在特定设备上总是一个近似值(原则是尽量接近参考像素)。
然而,如果你把绝对单位理解为对输出效果的绝对掌控,事情却大相径庭。就网页输出的最主要对象——电脑屏幕来说,px 可被视为一个基准单位——与桌面分辨率一致,如果是液晶屏,则几乎总是与液晶屏物理分辨率一致——也就是说网页设计者设定的1px,就是“最终看到这个网页的用户的显示器上的1个点距”!反倒是那些绝对单位,其实一点也不绝对。
深入理解移动端像素知识与Viewport知识
移动端H5页面的设计稿尺寸(上)
移动端H5页面的设计稿尺寸(下)
你真的了解像素吗
移动前端开发之viewport的深入理解
设备像素,设备独立像素,CSS像素
移动端开发系列——像素与viewport
移动端高清、多屏适配方案
像素(px)到底是个什么单位
CSS 长度单位
彻底理解 UI 及 Web 的尺寸单位:基本概念
针对iPhone的pt、Android的dp、HTML的css像素与dpr、设计尺寸和物理像素的浅分析
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
最近在学习Node.js里面的fs模块,遇到了一个比较诡异的现象,踩到了坑,就是读取当前目录下的一个文件,死活读取不到,由于之前对于Node.js里面的path模块也不太熟悉,也没系统研究过,所以今天就踩了这个坑,记录踩坑的过程,防止以后踩坑和大家也踩坑。
说一下当时的情形:
我纳闷的很半天,我明明就是读取当前目录下的1.findLargest.js,为什么提示找不到这个文件,运行了几遍,死活找不到1.findLargest.js这个文件。
后来才发现是因为运行这个文件不是从当前目录运行了,从图中可以看出,当前的目录是/Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs,而我运行这个脚本的目录是/Users/jawil/Desktop/nodejs/demo/ES6-lottery;这就是问题的所在了。不过为什么运行脚本的位置也会影响这个路径呢,且往下看。
计算机不会欺骗人,一切按照规则执行,说找不到这个文件,那肯定就是真的找不到,至于为什么找不到,那就是因为我们理解有偏差,我最初理解的'./'是当前执行js文件所在的文件夹的绝对路径,然后Node.js的理解却不是这样的,我们慢慢往下看。
Node.js中的文件路径大概有 __dirname, __filename, process.cwd(), ./ 或者 ../,前三个都是绝对路径,为了便于比较,./ 和 ../ 我们通过 path.resolve('./')来转换为绝对路径。
简单说一下这几个路径的意思,:
__dirname: 获得当前执行文件所在目录的完整目录名
__filename: 获得当前执行文件的带有完整绝对路径的文件名
process.cwd():获得当前执行node命令时候的文件夹目录名
./: 文件所在目录
先看一看我电脑当前的目录结构:
syntax/
-nodejs/
-1.findLargest.js
-2.path.js
-3.fs.js
-regs
-regx.js
-test.txt
在 path.js 里面我们写这些代码,看看输出是什么:
const path = require('path')
console.log('__dirname:', __dirname)
console.log('__filename:', __filename)
console.log('process.cwd():', process.cwd())
console.log('./:', path.resolve('./'))在当前目录下也就是nodejs目录运行 node path.js,我们看看输出结果:
__dirname: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs
__filename: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs/2.path.js
process.cwd(): /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs
./: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs然后在 项目根目录ES6-lottery 目录下运行 node syntax/nodejs/2.path.js,我们再来看看输出结果:
__dirname: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs
__filename: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs/2.path.js
process.cwd(): /Users/jawil/Desktop/nodejs/demo/ES6-lottery
./: /Users/jawil/Desktop/nodejs/demo/ES6-lottery答案显而易见?我们可以通过上面的例子对比,暂时得出表面的结论:
- __dirname: 总是返回被执行的 js 所在文件夹的绝对路径
- __filename: 总是返回被执行的 js 的绝对路径
- process.cwd(): 总是返回运行 node 命令时所在的文件夹的绝对路径
- ./: 跟 process.cwd() 一样,返回 node 命令时所在的文件夹的绝对路径
但是,我们再来看看这个例子,我们在上面的例子加几句代码,然后:
我们在1.findLargest.js先加这句代码
exports.A = 1;再来在刚才报错的3.fs.js里面加这两句代码看看:
const test = require('./1.findLargest.js');
console.log(test)运行node syntax/nodejs/3.fs.js,最后看看结果:
为什么都是读取./1.findLargest.js文件,一样的路径,为什么require能获取到,而readFile读取不到呢?
于是查了不少资料,看到了一些关于require引入模块的机制,从中学到了不少,也明白了为什么是这样。
我们先了解一下require() 的基本用法:
下面的内容来自require() 源码解读,由阮一峰翻译自《Node使用手册》。
我们从第(2)小条的a部分可以看出:
(2)如果 X 以 "./" 或者 "/" 或者 "../" 开头
a. 根据 X 所在的父模块,确定 X 的绝对路径。
b. 将 X 当成文件,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
const test = require('./1.findLargest.js')按照上面规则翻译一遍就是:
根据1.findLargest.js所在的父模块,确定1.findLargest.js的绝对路径为/Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs,关于其中的寻找细节这里不做探讨。
先把1.findLargest.js当成文件,依次查找当前目录下的1.findLargest.js,找到了,就返回该文件,不再继续执行。
根据require的基本规则,对于上面出现的情形也就不足为奇了,更多require的机制和源码解读,请移步:
require() 源码解读。
那么关于 ./ 正确的结论是:
在 require() 中使用是跟 __dirname 的效果相同,不会因为启动脚本的目录不一样而改变,在其他情况下跟 process.cwd() 效果相同,是相对于启动脚本所在目录的路径。
- __dirname: 获得当前执行文件所在目录的完整目录名
- __filename: 获得当前执行文件的带有完整绝对路径的文件名
- process.cwd():获得当前执行node命令时候的文件夹目录名
- ./: 不使用require时候,./与process.cwd()一样,使用require时候,与__dirname一样
只有在 require() 时才使用相对路径(./, ../) 的写法,其他地方一律使用绝对路径,如下:
// 当前目录下
path.dirname(__filename) + '/path.js';
// 相邻目录下
path.resolve(__dirname, '../regx/regx.js');最后看看改过之后的结果,不会报错找不到文件了,不管在哪里执行这个脚本文件,都不会出错了,防止以后踩坑。
blog搬家了?请放出地址呦
赶紧续费啦
博主你真的是草榴社区的程序猿? 辣么6
李小龙说过:"天下武功,无坚不摧,唯快不破".(真的说过吗?)
我想说的是:"世间网站,完美体验,唯快不破".(这个我承认我说过.)
俗话说,时间就是生命,时间就是金钱,时间就是一切,人人都不想把时间白白浪费,一个网站,最重要的就是体验,而网站好不好最直观的感受就是这个网站打开速度快不快,卡不卡.
当打开一个购物网站卡出翔,慢的要死,是不是如同心塞一样的感受,蓝瘦香菇,想买个心爱的宝贝都不能买,心里想这尼玛什么玩意.
那么如何让我们的网站给用户最佳的体验呢?大环境我们不说,什么网络啊,浏览器性能啊,这些我们无法改变,我们能改变的就是我们码农能创造的,那就是代码的性能.代码精简,执行速度快,嵌套层数少等等都是我们可以着手优化注意的地方.
恰巧最近刚看完**《高性能JavaScript》收获颇丰,今天就以点带面从追求高性能JavaScript的目的书写的代码来感受一下速度提升带来的体验,从编程实践,代码优化的角度总结一下自己平时遇到、书中以及其他地方看到有关提高JavaScript性能的例子,其他关于加载和执行,数据存取,浏览器中的DOM,算法和流程控制,字符串和正则表达式,快速响应的用户界面,Ajax**这些大范围的方向这里就不多加阐述.我们从代码本身出发,用数据说话,挖掘那些细思极恐的效率.有的提升可能微不足道,但是所有的微不足道聚集在一起就是一个从量到质变.
比较宽泛的阐释高性能JavaScript,从大体上了解提高JavaScript性能的有几个大方面,可以阅读这两篇文章作详细了解:
本文只从代码和数据上阐述具体说明如何一步步提高JavaScript的性能.
Javascript是一门非常灵活的语言,我们可以随心所欲的书写各种风格的代码,不同风格的代码也必然也会导致执行效率的差异,作用域链、闭包、原型继承、eval等特性,在提供各种神奇功能的同时也带来了各种效率问题,用之不慎就会导致执行效率低下,开发过程中零零散散地接触到许多提高代码性能的方法,整理一下平时比较常见并且容易规避的问题。
你一天(一周)内写了多少个循环了?
我们先以最简单的循环入手作为切入点,这里我们只考虑单层循环以及比较不同循环种类和不同流程控制的效率.
测试数据:[1,2,3,...,10000000]
测试依据:数组[1,2,3,''',10000000]的累加所需要的时间
测试环境:node版本v6.9.4环境的v8引擎
为什么不在浏览器控制台测试?
首先不同浏览器的不同版本性能可能就不一样,这里为了统一,我选择了node环境,为什么不选择浏览器而选择了node环境测试,这是因为浏览器的一部分原因.
因为用控制台是测不出性能的,因为控制台本质上是个套了一大堆安全机制的eval,它的沙盒化程度很高。这里我们就一个简单的例子来对比一下,浏览器和node环境同样的代码的执行效率.
测试的数组代码:
var n = 10000000;
// 准备待测数组
var arr = [];
for(var count=0;count<n;count++){
arr[count] = 1;
}
// for 测试
console.time('for');
for(var i=0;i<arr.length;i++){
arr[i];
}
console.timeEnd('for');就想简单测试一下这段生成待测数组所消耗时间的对比:
这是最新谷歌浏览器控制台的执行结果:
时间大约在28ms左右.
我们再来在node环境下测试一下所需要的时间:
时间稳定在7ms左右,大约3倍的差距,同样都是v8引擎,浏览器就存在很明显的差距,这是由于浏览器的机制有关,浏览器要处理的事情远远比单纯在node环境下执行代码处理的事情多,所以用浏览器测试性能没有在单纯地node环境下靠谱.
具体细节和讨论可以参看知乎上的这篇RednaxelaFX的回答:
为何浏览器控制台的JavaScript引擎性能这么差?
各个循环实现的测试代码,每个方法都会单独执行,一起执行会有所偏差.
// for 测试(for和while其实差不多,这里我们只测试for循环)
console.time('for');
for (var i = 0; i < arr.length; i++) {
arr[i];
}
console.timeEnd('for');
// for loop测试
console.time('for');
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
console.timeEnd('for');
// for loop缓存测试
console.time('for cache');
var sum = 0;
var len = arr.length;
for (var i = 0; i < len; i++) {
sum += arr[i];
}
console.timeEnd('for cache');
// for loop倒序测试
console.time('for reverse');
var sum = 0;
var len = arr.length;
for (i = len-1;i>0; i--) {
sum += arr[i];
}
console.timeEnd('for reverse');
//forEach测试
console.time('forEach');
var sum = 0;
arr.forEach(function(ele) {
sum += ele;
})
//这段代码看起来更加简洁,但这种方法也有一个小缺陷:你不能使用break语句中断循环,也不能使用return语句返回
到外层函数。
console.timeEnd('forEach');
//ES6的for of测试
console.time('for of');
var sum = 0;
for (let i of arr) {
sum += i;
}
console.timeEnd('for of');
//这是最简洁、最直接的遍历数组元素的语法
//这个方法避开了for-in循环的所有缺陷
//与forEach()不同的是,它可以正确响应break、continue和return语句
// for in 测试
console.time('for in');
var sum=0;
for(var i in arr){
sum+=arr[i];
}
console.timeEnd('for in');最后在node环境下各自所花费的不同时间:
| 循环类型 | 耗费时间(ms) |
|---|---|
| for | 约11.998 |
| for cache | 约10.866 |
| for 倒序 | 约11.230 |
| forEach | 约400.245 |
| for in | 约2930.118 |
| for of | 约320.921 |
从上面的表格统计比较可以看出,前三种原始的for循坏一个档次,然后forEach和for of也基本属于一个档次,for of的执行速度稍微高于forEach,最后最慢的就是for in循环了,差的不是几十倍的关系了.
看起来好像是那么回事哦!
同样是循坏为什么会有如此大的悬殊呢?我们来稍微分析一下其中的个别缘由导致这样的差异.
for in 一般是用在对象属性名的遍历上的,由于每次迭代操作会同时搜索实例本身的属性以及原型链上的属性,所以效率肯定低下.
for...in 实际上效率是最低的。这是因为 for...in 有一些特殊的要求,具体包括:
1. 遍历所有属性,不仅是 ownproperties 也包括原型链上的所有属性。
2. 忽略 enumerable 为 false 的属性。
3. 必须按特定顺序遍历,先遍历所有数字键,然后按照创建属性的顺序遍历剩下的。
这里既然扯到对象的遍历属性,就顺便扯一扯几种对象遍历属性不同区别,为什么for...in性能这么差,算是一个延伸吧,反正我发现写一篇博客可以延伸很多东西,自己也可以学到很多,还可以巩固自己之前学过但是遗忘的一些东西,算是温故而知新.
遍历数组属性目前我知道的有:for-in循环、Object.keys()和Object.getOwnPropertyNames(),那么三种到底有啥区别呢?
for-in循环:会遍历对象自身的属性,以及原型属性,包括enumerable 为 false(不可枚举属性);
Object.keys():可以得到自身可枚举的属性,但得不到原型链上的属性;
Object.getOwnPropertyNames():可以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性,Symbols属性
也得不到.
Object.defineProperty顾名思义,就是用来定义对象属性的,vue.js的双向数据绑定主要在getter和setter函数里面插入一些处理方法,当对象被读写的时候处理方法就会被执行了。 关于这些方法和属性的更具体解释,可以看MDN上的解释(戳我);
简单看一个小demo例子加深理解,对于Object.defineProperty属性不太明白,可以看看上面介绍的文档学习补充一下.
'use strict';
class A {
constructor() {
this.name = 'jawil';
}
getName() {}
}
class B extends A {
constructor() {
super();
this.age = 22;
}
//getAge不可枚举
getAge() {}
[Symbol('fullName')]() {
}
}
B.prototype.get = function() {
}
var b = new B();
//设置b对象的info属性的enumerable: false,让其不能枚举.
Object.defineProperty(b, 'info', {
value: 7,
writable: true,
configurable: true,
enumerable: false
});
//Object可以得到自身可枚举的属性,但得不到原型链上的属性
console.log(Object.keys(b)); //[ 'name', 'age' ]
//Object可A以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性,Symbols属性也得不到
console.log(Object.getOwnPropertyNames(b)); //[ 'name', 'age', 'info' ]
for (var attr in b) {
console.log(attr);//name,age,get
}
//in会遍历对象自身的属性,以及原型属性
console.log('getName' in b); //true从这里也可以看出为什么for...in性能这么慢,因为它要遍历自身的属性和原型链上的属性,这无疑就增加了所有不必要的额外开销.
目前绝大部分开源软件都会在for loop中缓存数组长度,因为普通观点认为某些浏览器Array.length每次都会重新计算数组长度,因此通常用临时变量来事先存储数组长度,以此来提高性能.
而forEach是基于函数的迭代(需要特别注意的是所有版本的ie都不支持,如果需要可以用JQuery等库),对每个数组项调用外部方法所带来的开销是速度慢的主要原因.
总结:
1.能用for缓存的方法循环就用for循坏,性能最高,写起来繁杂;
2.不追求极致性能的情况下,建议使用forEach方法,干净,简单,易读,短,没有中间变量,没有成堆的分号,简单非常
优雅;
3.想尝鲜使用ES6语法的话,不考虑兼容性情况下,推荐使用for of方法,这是最简洁、最直接的遍历数组元素的语法,该方
法避开了for-in;循环的所有缺陷与forEach()不同的是,它可以正确响应break、continue和return语句.
4.能避免for in循环尽量避免,太消费性能,太费时间,数组循环不推荐使用.
常见的条件语句有if-else和switch-case,那么什么时候用if-else,什么时候用switch-case语句呢?
我们先来看个简单的if-else语句的代码:
if (value == 0){
return result0;
} else if (value == 1){
return result1;
} else if (value == 2){
return result2;
} else if (value == 3){
return result3;
} else if (value == 4){
return result4;
} else if (value == 5){
return result5;
} else if (value == 6){
return result6;
} else if (value == 7){
return result7;
} else if (value == 8){
return result8;
} else if (value == 9){
return result9;
} else {
return result10;
}最坏的情况下(value=10)我们可能要做10次判断才能返回正确的结果,那么我们怎么优化这段代码呢?一个显而易见的优化策略是将最可能的取值提前判断,比如value最可能等于5或者10,那么将这两条判断提前。但是通常情况下我们并不知道(最可能的选择),这时我们可以采取二叉树查找策略进行性能优化。
if (value < 6){
if (value < 3){
if (value == 0){
return result0;
} else if (value == 1){
return result1;
} else {
return result2;
}
} else {
if (value == 3){
return result3;
} else if (value == 4){
return result4;
} else {
return result5;
}
}
} else {
if (value < 8){
if (value == 6){
return result6;
} else {
return result7;
}
} else {
if (value == 8){
return result8;
} else if (value == 9){
return result9;
} else {
return result10;
}
}
}这样优化后我们最多进行4次判断即可,大大提高了代码的性能。这样的优化**有点类似二分查找,和二分查找相似的是,只有value值是连续的数字时才能进行这样的优化。但是代码这样写的话不利于维护,如果要增加一个条件,或者多个条件,就要重写很多代码,这时switch-case语句就有了用武之地。
将以上代码用switch-case语句重写:
switch(value){
case 0:
return result0;
case 1:
return result1;
case 2:
return result2;
case 3:
return result3;
case 4:
return result4;
case 5:
return result5;
case 6:
return result6;
case 7:
return result7;
case 8:
return result8;
case 9:
return result9;
default:
return result10;
}swtich-case语句让代码显得可读性更强,而且swtich-case语句还有一个好处是如果多个value值返回同一个结果,就不用重写return那部分的代码。一般来说,当case数达到一定数量时,swtich-case语句的效率是比if-else高的,因为switch-case采用了branch table(分支表)索引来进行优化,当然各浏览器的优化程度也不一样。
相对来说,下面几种情况更适合使用switch结构:
枚举表达式的值。这种枚举是可以期望的、平行逻辑关系的。
表达式的值具有离散性,不具有线性的非连续的区间值。
表达式的值是固定的,不是动态变化的。
表达式的值是有限的,而不是无限的,一般情况下表达式应该比较少。
表达式的值一般为整数、字符串等类型的数据。
而if结构则更适合下面的一些情况:
具有复杂的逻辑关系。
表达式的值具有线性特征,如对连续的区间值进行判断。
表达式的值是动态的。
测试任意类型的数据。
除了if-else和swtich-case外,我们还可以采用查找表。
var results = [result0, result1, result2, result3, result4, result5, result6, result7,
result8, result9, result10];
//return the correct result
return results[value]; 当数据量很大的时候,查找表的效率通常要比if-else语句和swtich-case语句高,查找表能用数字和字符串作为索引,而如果是字符串的情况下,最好用对象来代替数组。当然查找表的使用是有局限性的,每个case对应的结果只能是一个取值而不能是一系列的操作。
从根源上分析if else 和 switch的效率,之前只知道if else 和switch算法实现不同,但具体怎么样就不清楚了,为了刨根问底,翻阅了很多资料,但无奈找到了原因我还是不太懂,只知道就是这么回事,不懂汇编,懂底层汇编的大神还望多加指点.
想要深入从汇编的角度了解可以看看这篇文章:switch...case和if...else效率比较
学前端的我想问你汇编是啥?能吃吗?
在选择分支较多时,选用switch...case结构会提高程序的效率,但switch不足的地方在于只能处理字符或者数字类型的变量,if...else结构更加灵活一些,if...else结构可以用于判断表达式是否成立,比如if(a+b>c),if...else的应用范围更广,switch...case结构在某些情况下可以替代if...else结构。
小结:
1. 当只有两个case或者case的value取值是一段连续的数字的时候,我们可以选择if-else语句;
2. 当有3~10个case数并且case的value取值非线性的时候,我们可以选择switch-case语句;
3. 当case数达到10个以上并且每次的结果只是一个取值而不是额外的JavaScript语句的时候,我们可以选择查找表.
什么是事件委托:通俗的讲,事件就是onclick,onmouseover,onmouseout,等就是事件,委托呢,就是让别人来做,这个事件本来是加在某些元素上的,然而你却加到别人身上来做,完成这个事件。
也就是:利用冒泡的原理,把事件加到父级上,触发执行效果。
好处呢:
1.提高性能。
2.新添加的元素还会有之前的事件。
试想一下,一个页面上ul的每一个li标签添加一个事件,我们会不会给每一个标签都添加一个onclick呢。 当页面中存在大量元素都需要绑定同一个事件处理的时候,这种情况可能会影响性能,不仅消耗了内存,还多循环时间。每绑定一个事件都加重了页面或者是运行期间的负担。对于一个富前端的应用,交互重的页面上,过多的绑定会占用过多内存。 一个简单优雅的方式就是事件委托。它是基于事件的工作流:逐层捕获,到达目标,逐层冒泡。既然事件存在冒泡机制,那么我们可以通过给外层绑定事件,来处理所有的子元素出发的事件。
一个事件委托的简单实现:
document.getElementById('ulId').onclick = function(e) {
var e = e || window.event;
var target = e.target || e.srcElement; //兼容旧版本IE和现代浏览器
if (target.nodeName.toLowerCase() !== 'ul') {
return;
}
console.log(target.innerHTML);
}我们可以看一个例子:需要触发每个li来改变他们的背景颜色。
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
首先想到最直接的实现:
window.onload = () => {
let oUl = document.querySelector("#ul");
let aLi = oUl.querySelectorAll("li");
Array.from(aLi).forEach(ele => {
ele.onmouseover = function() {
this.style.background = "red";
}
ele.onmouseout = function() {
this.style.background = "";
}
})
}这样我们就可以做到li上面添加鼠标事件。
但是如果说我们可能有很多个li用for循环的话就比较影响性能。
下面我们可以用事件委托的方式来实现这样的效果。html不变
window.onload = () => {
let oUl = document.querySelector("#ul");
/*
这里要用到事件源:event 对象,事件源,不管在哪个事件中,只要你操作的那个元素就是事件源。
ie:window.event.srcElement
标准下:event.target
nodeName:找到元素的标签名
*/
//虽然习惯用ES6语法写代码,这里事件还是兼容一下IE吧
oUl.onmouseover = ev => {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
//console.log(target.innerHTML);
if (target.nodeName.toLowerCase() === "li") {
target.style.background = "red";
}
}
oUl.onmouseout = ev=> {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
//console.log(target.innerHTML);
if (target.nodeName.toLowerCase() == "li") {
target.style.background = "";
}
}
}好处2,新添加的元素还会有之前的事件。
我们还拿这个例子看,但是我们要做动态的添加li。点击button动态添加li
<input type="button" id="btn" />
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>不用事件委托我们会这样做:
window.onload = () => {
let oUl = document.querySelector("#ul");
let aLi = oUl.querySelectorAll("li");
let oBtn = document.querySelector("#btn");
let iNow = 4;
//刚才用forEach实现,现在就用性能最高的for实现,把刚才学的温习一下
for (let i = 0, len = aLi.length; i < len; i++) {
aLi[i].onmouseover = function() {
this.style.background = "red";
}
aLi[i].onmouseout = function() {
this.style.background = "";
}
}
oBtn.onclick = function() {
iNow++;
let oLi = document.createElement("li");
oLi.innerHTML = 1* iNow;
oUl.appendChild(oLi);
}
}这样做我们可以看到点击按钮新加的li上面没有鼠标移入事件来改变他们的背景颜色。
因为点击添加的时候for循环已经执行完毕。
那么我们用事件委托的方式来做。就是html不变
window.onload = () => {
let oUl = document.querySelector("#ul");
let oBtn = document.querySelector("#btn");
let iNow = 4;
oUl.onmouseover = ev => {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
if (target.nodeName.toLowerCase() === "li") {
target.style.background = "red";
}
}
oUl.onmouseout = ev => {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
if (target.nodeName.toLowerCase() == "li") {
target.style.background = "";
}
}
oBtn.onclick = function() {
iNow++;
let oLi = document.createElement("li");
oLi.innerHTML = 1111 * iNow;
oUl.appendChild(oLi);
}
}对于浏览器来说,一个标识符所处的位置越深,去读写他的速度也就越慢(对于这点,原型链亦是如此)。这个应该不难理解,简单比喻就是:杂货店离你家越远,你去打酱油所花的时间就越长... 熊孩子,打个酱油那么久,菜早烧焦了 -.-~
我们在编码过程中多多少少会使用到一些全局变量(window,document,自定义全局变量等等),了解javascript作用域链的人都知道,在局部作用域中访问全局变量需要一层一层遍历整个作用域链直至顶级作用域,而局部变量的访问效率则会更快更高,因此在局部作用域中高频率使用一些全局对象时可以将其导入到局部作用域中,例如:
对比看看:
//修改前
function showLi(){
var i = 0;
for(;i<document.getElementsByTagName("li").length;i++){ //一次访问document
console.log(i,document.getElementsByTagName("li")[i]); //三次访问document
};
};
//修改后
function showLi(){
var li_s = document.getElementsByTagName("li"); //一次访问document
var i = 0;
for(;i<li_s.length;i++){
console.log(i,li_s[i]); //三次访问局部变量li_s
};
};再来看看两个简单的例子;
//1、作为参数传入模块
(function(window,$){
var xxx = window.xxx;
$("#xxx1").xxx();
$("#xxx2").xxx();
})(window,jQuery);
//2、暂存到局部变量
function(){
var doc = document;
var global = window.global;
} 我们都知道eval可以将一段字符串当做js代码来执行处理,据说使用eval执行的代码比不使用eval的代码慢100倍以上(具体效率我没有测试,有兴趣同学可以测试一下),前面的浏览器控制台效率低下也提到eval这个问题.
JavaScript 代码在执行前会进行类似“预编译”的操作:首先会创建一个当前执行环境下的活动对象,并将那些用 var
申明的变量设置为活动对象的属性,但是此时这些变量的赋值都是 undefined,并将那些以 function 定义的函数也
添加为活动对象的属性,而且它们的值正是函数的定义。但是,如果你使用了“eval”,则“eval”中的代码(实际上为字
符串)无法预先识别其上下文,无法被提前解析和优化,即无法进行预编译的操作。所以,其性能也会大幅度降低
对上面js的预编译,活动对象等一些列不太明白的童鞋.看完这篇文章恶补一下,我想你会收获很多:前端基础进阶(三):变量对象详解
其实现在大家一般都很少会用eval了,这里我想说的是两个类eval的场景(new Function{},setTimeout,
setInterver)
setTimtout("alert(1)",1000);
setInterver("alert(1)",1000);
(new Function("alert(1)"))(); 上述几种类型代码执行效率都会比较低,因此建议直接传入匿名方法、或者方法的引用给setTimeout方法.
众所周知的,DOM操作远比javascript的执行耗性能,虽然我们避免不了对DOM进行操作,但我们可以尽量去减少该操作对性能的消耗。
为什么操作DOM这么耗费性能呢?
浏览器通常会把js和DOM分开来分别独立实现。
举个栗子冷知识,在IE中,js的实现名为JScript,位于jscript.dll文件中;DOM的实现则存在另一个库中,名为mshtml.dll(Trident)。
Chrome中的DOM实现为webkit中的webCore,但js引擎是Google自己研发的V8。
Firefox中的js引擎是SpiderMonkey,渲染引擎(DOM)则是Gecko。
DOM,天生就慢
前面的小知识中说过,浏览器把实现页面渲染的部分和解析js的部分分开来实现,既然是分开的,一旦两者需要产生连接,就要付出代价。
两个例子:
- 小明和小红是两个不同学校的学生,两个人家里经济条件都不太好,买不起手机(好尴尬的设定Orz...),所以只能通过写信来互相交流,这样的过程肯定比他俩面对面交谈时所需要花费的代价大(额外的事件、写信的成本等)。
- 官方例子:把DOM和js(ECMAScript)各自想象为一座岛屿,它们之间用收费桥进行连接。ECMAScript每次访问DOM,都要途径这座桥,并交纳“过桥费”。访问DOM的次数越多,费用也就越高。
因此,推荐的做法是:尽可能的减少过桥的次数,努力待在ECMAScript岛上。
让我们通过一个最简单的代码解释这个问题:
function innerLi_s(){
var i = 0;
for(;i<20;i++){
document.getElementById("Num").innerHTML="A";
//进行了20次循环,每次又有2次DOM元素访问:一次读取innerHTML的值,一次写入值
};
};针对以上方法进行一次改写:
function innerLi_s(){
var content ="";
var i = 0;
for(;i<20;i++){
content += "A"; //这里只对js的变量循环了20次
};
document.getElementById("Num").innerHTML += content;
//这里值进行了一次DOM操作,又分2次DOM访问:一次读取innerHTML的值,一次写入值
};简单说下什么是重排和重绘:
浏览器下载完HTMl,CSS,JS后会生成两棵树:DOM树和渲染树。 当Dom的几何属性发生变化时,比如Dom的宽高,或者颜色,position,浏览器需要重新计算元素的几何属性,并且重新构建渲染树,这个过程称之为重绘重排。
元素布局的改变或内容的增删改或者浏览器窗口尺寸改变都将会导致重排,而字体颜色或者背景色的修改则将导致重绘。
对于类似以下代码的操作,据说现代浏览器大多进行了优化(将其优化成1次重排版):
//修改前
var el = document.getElementById("div");
el.style.borderLeft = "1px"; //1次重排版
el.style.borderRight = "2px"; //又1次重排版
el.style.padding = "5px"; //还有1次重排版
//修改后
var el = document.getElementById("div");
el.style.cssText = "border-left:1px;border-right:2px;padding:5px"; //1次重排版针对多重操作,以下三种方法也可以减少重排版和重绘的次数:
更多DOM优化的细节以及关于浏览器页面的**重排(Reflows)和重绘(Repaints)**的概念和优化请参考:天生就慢的DOM如何优化?,花10+分钟阅读,你会受益匪浅.
我了解到的JavaScript中改变作用域链的方式只有两种1)使用with表达式 2)通过捕获异常try catch来实现
但是with是大家都深恶痛绝的影响性能的表达式,因为我们完全可以通过使用一个局部变量的方式来取代它(因为with的原理是它的改变作用域链的同时需要保存很多信息以保证完成当前操作后恢复之前的作用域链,这些就明显的影响到了性能)
try catch中的catch子句同样可以改变作用域链。当try块发生错误时,程序自动转入catch块并将异常对象推入作用域链前端的一个可变对象中,也就是说在catch块中,函数所有的局部变量已经被放在第二个作用域链对象中,但是catch子句执行完成之后,作用域链就会返回到原来的状态。应该最小化catch子句来保证代码性能,如果知道错误的概念很高,我们应该尽量修正错误而不是使用try catch.
虽说现代浏览器都已经做的很好了,但是本兽觉得这是自己对代码质量的一个追求。并且可能一个点或者两个点不注意是不会产生多大性能影响,但是从多个点进行优化后,可能产生的就会质的飞跃了
JavaScript 总结的这几个提高性能知识点,希望大家牢牢掌握。
高性能JavaScript循环语句和流程控制
if else 和 switch的效率
switch...case和if...else效率比较
JavaScript提高性能知识点汇总
JavaScript执行效率小结
天生就慢的DOM如何优化?
编写高性能的JavaScript代码
我的github博客,喜欢的朋友可以点个star,你的支持就是我学习、搬运、总结和拓展的动力.
本文纯属原创? 如有雷同? 纯属抄袭? 不甚荣幸! 欢迎转载!
原文收录在【我的GitHub博客】,觉得本文写的不算烂的,可以点击【我的GitHub博客】顺便登录一下账号给个星星✨鼓励一下,关注最新更新动态,大家一起多交流学习,欢迎随意转载交流,不要钱,文末没有福利哦😯,你懂的😉。
如果你很直接,就是直白想看我的结果分析,请直接跳到第六章,只要你看的懂,前面的知识点可以忽略。
凡是都有一个来源和起因,这个题不是我哪篇文章看到的,也不是我瞎几把乱造出来的,我也没这个天赋和能力,是我同事之前丢到群里,叫我们在浏览器输出一下,对结果出乎意料,本着实事求是的精神,探寻事物的本质,不断努力追根溯源,总算弄明白了最后的结果,最后的收获总算把js的隐式类型转换刨根问底的搞清楚了,也更加深入的明白了为什么JS是弱类型语言了。
一看就看出答案的大神可以跳过,鄙文会浪费你宝贵的时间,因为此文会很长,涉及到知识点很多很杂很细,以及对js源码的解读,而且很抽象,如果没有耐心,也可以直接跳过,本文记录本人探索这道问题所有的过程,会很长。
可能写的不太清楚,逻辑不太严密,存在些许错误,还望批评指正,我会及时更正。去年毕业入坑前端一年,并不是什么老鸟,所以我也是以一个学习者的身份来写这篇文章,逆向的记录自己学习探索的过程,并不是指点江山,挥斥方遒,目空一切的大神,如果写的不好,还望见谅。
首先对于这种问题,有人说是闲的蛋疼,整天研究这些无聊的,有啥用,开发谁会这么写,你钻牛角尖搞这些有意思吗?
对于这种质疑,我只能说:爱看不看,反正不是写给你看。
当然,这话也没错,开发过程中确实不会这么写,但是我们要把开发和学习区分开来,很多人开发只为完成事情,不求最好,但求最快,能用就行😊。学习也是这样,停留在表面,会用API就行,不会去深层次思考原理,因此很难进一步提升,就是因为这样的态度才诞生了一大批一年经验重复三五年的API大神😄。
但是学习就不同,学习本生就是一个慢慢深入,寻根问底,追根溯源的过程,如果对于探寻问题的本质追求都没有,我只能说做做外包就好,探究这种问题对于开发确实没什么卵用,但是对我们了解JavaScript这门语言却有极大的帮助,可以让我们对这门语言的了解更上一个台阶。JavaScript为什么是弱类型语言,主要体现在哪里,弱类型转换的机制又是什么?
有人还是觉得其实这对学习JS也没什么多大卵用,我只能说:我就喜欢折腾,你管得着?反正我收获巨多就够了。
++[[]][+[]]+[+[]]===10?这个对不对,我们先不管,先来看几个稍微简单的例子,当做练习入手。
这几个是留给大家的作业,涉及到的知识点下面我会先一一写出来,为什么涉及这些知识点,因为我自己一步步踩坑踩过来的,所以知道涉及哪些坑,大家最后按照知识点一步一步分析,一定可以得出 答案来,列出知识点之后,我们再来一起分析++[[]][+[]]+[+[]]===10?的正确性。
- {}+{}//chrome:"[object Object][object Object]",Firfox:NaN
- {}+[]//0
- []+{}//"[object Object]"
首先,关于1、2和3这三个的答案我是有一些疑惑,先给出答案,希望大家看完这篇文章能和我讨论一下自己的想法,求同存异。
4.{}+1
5.({}+1)
6.1+{}
7.[]+1
8.1+[]
9.1-[]
10.1-{}
11.1-!{}
12.1+!{}
13.1+"2"+"2"
14.1+ +"2"+"2"
15.1++"2"+"2"
16.[]==![]
17.[]===![]这几个例子是我随便写的,几乎包含了所有弱类型转换所遇到的坑,为什么会出现这种情况,就不得不从JS这门语言的特性讲起,大家都知道JS是一门动态的弱类型语言,那么你有没有想过什么叫做弱类型?什么叫做动态?大家都知道这个概念,但有没有进一步思考呢?
今天通过这几个例子就来了解一下JS的弱类型,什么是动态暂时不做探讨。
按照计算机语言的类型系统的设计方式,可以分为强类型和弱类型两种。二者之间的区别,就在于计算时是否可以不同类型之间对使用者透明地隐式转换。从使用者的角度来看,如果一个语言可以隐式转换它的所有类型,那么它的变量、表达式等在参与运算时,即使类型不正确,也能通过隐式转换来得到正确地类型,这对使用者而言,就好像所有类型都能进行所有运算一样,所以这样的语言被称作弱类型。与此相对,强类型语言的类型之间不一定有隐式转换。
弱类型相对于强类型来说类型检查更不严格,比如说允许变量类型的隐式转换,允许强制类型转换等等。强类型语言一般不允许这么做。具体说明请看维基百科的说明。
根据强弱类型的判别定义,和上面的十几个例子已经充分说明JavaScript 是一门弱类型语言了。
先讲一讲一些概念,要想弄懂上面题目答案的原理,首先你要彻底弄懂以下的概念,有些时候对一些东西似懂非懂,其实就是对概念和规则没有弄透,弄透之后等会回过头对照就不难理解,不先了解透这些后面的真的不好理解,花点耐心看看,消化一下,最后串通梳理一下,一层一层的往下剥,答案迎刃而解。
为了能够弄明白这种隐式转换是如何进行的,我们首先需要搞懂如下一些基础知识。如果没有耐心,直接跳到后面第四章4.8 小结我总结的几条结论,这里仅给想要一步步通过过程探寻结果的人看。
| 运算符 | 描述 |
|---|---|
| . [] () | 字段访问、数组下标、函数调用以及表达式分组 |
| ++ — - + ~ ! delete new typeof void | 一元运算符、返回数据类型、对象创建、未定义值 |
| * / % | 乘法、除法、取模 |
| + - + | 加法、减法、字符串连接 |
| << >> >>> | 移位 |
| < <= > >= instanceof | 小于、小于等于、大于、大于等于、instanceof |
| == != === !== | 等于、不等于、严格相等、非严格相等 |
| & | 按位与 |
| ^ | 按位异或 |
| && | 逻辑与 |
| ?: | 条件 |
| = oP= | 赋值、运算赋值 |
| , | 多重求值 |
一元运算符只有一个参数,即要操作的对象或值。它们是 ECMAScript 中最简单的运算符。
delete,void,--,++这里我们先不扯,免得越扯越多,防止之前博文的啰嗦,这里咋们只讲重点,有兴趣的可以看看w3school(点我查看)对这几个的详细讲解。
上面的例子我们一个一个看,看一个总结一个规则,基本规则上面例子几乎都包含了,如有遗漏,还望反馈补上。
这里我们只讲 一元加法 和 一元减法 :
我们先看看ECMAScript5规范(熟读规范,你会学到很多很多)对一元加法和一元减法的解读,我们翻到11.4.6和11.4.7。
其中涉及到几个ECMAScript定义的抽象操作,ToNumber(x),ToPrimitive(x)等等 下一章详细解答,下面出现的抽象定义也同理,先不管这个,有基础想深入了解可以提前熟读ECMAScript5规范(点击查看)。
规范本来就是抽象的东西,不太好懂不要紧,我们看看例子,这里的规范我们只当做一种依据来证明这些现象。
大多数人都熟悉一元加法和一元减法,它们在 ECMAScript 中的用法与您高中数学中学到的用法相同。
一元加法本质上对数字无任何影响:
var iNum = 20;
iNum = +iNum;//注意不要和iNum += iNum搞混淆了;
alert(iNum); //输出 "20"尽管一元加法对数字无作用,但对字符串却有有趣的效果,会把字符串转换成数字。
var sNum = "20";
alert(typeof sNum); //输出 "string"
var iNum = +sNum;
alert(typeof iNum); //输出 "number"这段代码把字符串 "20" 转换成真正的数字。当一元加法运算符对字符串进行操作时,它计算字符串的方式与 parseInt() 相似,主要的不同是只有对以 "0x" 开头的字符串(表示十六进制数字),一元运算符才能把它转换成十进制的值。因此,用一元加法转换 "010",得到的总是 10,而 "0xB" 将被转换成 11。
另一方面,一元减法就是对数值求负(例如把 20 转换成 -20):
var iNum = 20;
iNum = -iNum;
alert(iNum); //输出 "-20"与一元加法运算符相似,一元减法运算符也会把字符串转换成近似的数字,此外还会对该值求负。例如:
var sNum = "20";
alert(typeof sNum); //输出 "string"
var iNum = -sNum;
alert(iNum); //输出 "-20"
alert(typeof iNum); //输出 "number"在上面的代码中,一元减法运算符将把字符串 "-20" 转换成 -20(一元减法运算符对十六进制和十进制的处理方式与一元加法运算符相似,只是它还会对该值求负)。
在多数程序设计语言中,加性运算符(即加号或减号)通常是最简单的数学运算符。
在 ECMAScript 中,加性运算符有大量的特殊行为。
我们还是先看看ECMAScript5规范(熟读规范,你会学到很多很多)对加号运算符 ( + )解读,我们翻到11.6.1。
前面读不懂不要紧,下一章节会为大家解读这些抽象词汇,大家不要慌,但是第七条看的懂吧, 这就是为什么1+"1"="11"而不等于2的原因 ,因为规范就是这样的,浏览器没有思维只会按部就班的执行规则,所以规则是这样定义的,所以最后的结果就是规则规定的结果,知道规则之后,对浏览器一切运行的结果都会豁然开朗,哦,原来是这样的啊。
在处理特殊值时,ECMAScript 中的加法也有一些特殊行为:
不过,如果某个运算数是字符串,那么采用下列规则:
例如:
var result = 5 + 5; //两个数字
alert(result); //输出 "10"
var result2 = 5 + "5"; //一个数字和一个字符串
alert(result); //输出 "55"这段代码说明了加法运算符的两种模式之间的差别。正常情况下,5+5 等于 10(原始数值),如上述代码中前两行所示。不过,如果把一个运算数改为字符串 "5",那么结果将变为 "55"(原始的字符串值),因为另一个运算数也会被转换为字符串。
注意:为了避免 JavaScript 中的一种常见错误,在使用加法运算符时,一定要仔细检查运算数的数据类型
减法运算符(-),也是一个常用的运算符:
var iResult = 2 - 1;减、乘和除没有加法特殊,都是一个性质,这里我们就单独解读减法运算符(-)
我们还是先看看ECMAScript5规范(熟读规范,你会学到很多很多)对减号运算符 ( - )解读,我们翻到11.6.2。
与加法运算符一样,在处理特殊值时,减法运算符也有一些特殊行为:
注释:如果运算数都是数字,那么执行常规的减法运算,并返回结果。
直接从 C(和 Java)借用的两个运算符是前增量运算符和前减量运算符。
所谓前增量运算符,就是数值上加 1,形式是在变量前放两个加号(++):
var iNum = 10;
++iNum;第二行代码把 iNum 增加到了 11,它实质上等价于:
var iNum = 10;
iNum = iNum + 1;我们还是先看看ECMAScript5规范(熟读规范,你会学到很多很多)对前自增运算符 ( ++ )解读,我们翻到11.4.4。
此图有坑,后面会说到,坑了我很久。。。
看不懂这些抽象函数和词汇也不要紧,想要深入了解可以通读ECMAScript5规范中文版,看几遍就熟悉了,第一次看见这些肯定一脸懵逼,这是什么玩意,我们只要明白++是干什么就行,这里不必去深究v8引擎怎么实现这个规范的。
至于
var a=1;
console.log(a++);//1
var b=1;
cosole.log(++b);//2还弄不明白的该好好补习了,这里不在本文的知识点,也不去花篇幅讲解这些,这里我们只要明白一点: 所谓前增量运算符,就是数值上加 1 。
尽管 JavaScript 有 C 的代码风格,但是它不强制要求在代码中使用分号,实际上可以省略它们。
JavaScript 不是一个没有分号的语言,恰恰相反上它需要分号来就解析源代码。 因此 JavaScript 解析器在遇到由于缺少分号导致的解析错误时,会自动在源代码中插入分号。
var foo = function() {
} // 解析错误,分号丢失
test()自动插入分号,解析器重新解析。
var foo = function() {
}; // 没有错误,解析继续
test()下面的代码没有分号,因此解析器需要自己判断需要在哪些地方插入分号。
(function(window, undefined) {
function test(options) {
log('testing!')
(options.list || []).forEach(function(i) {
})
options.value.test(
'long string to pass here',
'and another long string to pass'
)
return
{
foo: function() {}
}
}
window.test = test
})(window)
(function(window) {
window.someLibrary = {}
})(window)下面是解析器"猜测"的结果。
(function(window, undefined) {
function test(options) {
// 没有插入分号,两行被合并为一行
log('testing!')(options.list || []).forEach(function(i) {
}); // <- 插入分号
options.value.test(
'long string to pass here',
'and another long string to pass'
); // <- 插入分号
return; // <- 插入分号, 改变了 return 表达式的行为
{ // 作为一个代码段处理
foo: function() {}
}; // <- 插入分号
}
window.test = test; // <- 插入分号
// 两行又被合并了
})(window)(function(window) {
window.someLibrary = {}; // <- 插入分号
})(window); //<- 插入分号解析器显著改变了上面代码的行为,在另外一些情况下也会做出错误的处理。
我们翻到7.9章节,看看其中插入分号的机制和原理,清楚只写以后就可以尽量以后少踩坑
**必须用分号终止某些 ECMAScript 语句 ( 空语句 , 变量声明语句 , 表达式语句 , do-while 语句 , continue 语句 , break 语句 , return 语句 ,throw 语句 )。这些分号总是明确的显示在源文本里。然而,为了方便起见,某些情况下这些分号可以在源文本里省略。描述这种情况会说:这种情况下给源代码的 token 流自动插入分号。**
还是比较抽象,看不太懂是不是,不要紧,我们看看实际例子,总结出几个规律就行,我们先不看抽象的,看着头晕,看看具体的总结说明, 化抽象为具体 。
首先这些规则是基于两点:
1. 新行并入当前行将构成非法语句,自动插入分号。
if(1 < 10) a = 1
console.log(a)
// 等价于
if(1 < 10) a = 1;
console.log(a);2. 在continue,return,break,throw后自动插入分号
return
{a: 1}
// 等价于
return;
{a: 1};3. ++、--后缀表达式作为新行的开始,在行首自动插入分号
a
++
c
// 等价于
a;
++c;4. 代码块的最后一个语句会自动插入分号
function(){ a = 1 }
// 等价于
function(){ a = 1; }1. 新行以 ( 开始
var a = 1
var b = a
(a+b).toString()
// 会被解析为以a+b为入参调用函数a,然后调用函数返回值的toString函数
var a = 1
var b =a(a+b).toString()2. 新行以 [ 开始
var a = ['a1', 'a2']
var b = a
[0,1].slice(1)
// 会被解析先获取a[1],然后调用a[1].slice(1)。
// 由于逗号位于[]内,且不被解析为数组字面量,而被解析为运算符,而逗号运算符会先执
行左侧表达式,然后执行右侧表达式并且以右侧表达式的计算结果作为返回值
var a = ['a1', 'a2']
var b = a[0,1].slice(1)3. 新行以 / 开始
var a = 1
var b = a
/test/.test(b)
// /会被解析为整除运算符,而不是正则表达式字面量的起始符号。浏览器中会报test前多了个.号
var a = 1
var b = a / test / .test(b)4. 新行以 + 、 - 、 % 和 * 开始
var a = 2
var b = a
+a
// 会解析如下格式
var a = 2
var b = a + a5. 新行以 , 或 . 开始
var a = 2
var b = a
.toString()
console.log(typeof b)
// 会解析为
var a = 2
var b = a.toString()
console.log(typeof b)到这里我们已经对ASI的规则有一定的了解了,另外还有一样有趣的事情,就是“空语句”。
// 三个空语句
;;;
// 只有if条件语句,语句块为空语句。
// 可实现unless条件语句的效果
if(1>2);else
console.log('2 is greater than 1 always!');
// 只有while条件语句,循环体为空语句。
var a = 1
while(++a < 100);建议绝对不要省略分号,同时也提倡将花括号和相应的表达式放在一行, 对于只有一行代码的 if 或者 else 表达式,也不应该省略花括号。 这些良好的编程习惯不仅可以提到代码的一致性,而且可以防止解析器改变代码行为的错误处理。
关于JavaScript 语句后应该加分号么?(点我查看)我们可以看看知乎上大牛们对着个问题的看法。
js引擎是如何判断{}是代码块还是对象的?
这个问题不知道大家有没有想过,先看看几个例子吧?
首先要深入明白的概念:
原始表达式是表达式的最小单位——它不再包含其他表达式。javascript中的原始表达式包括this关键字、标识符引用、字面量引用、数组初始化、对象初始化和分组表达式,复杂表达式暂不做讨论。
语句没有返回值,而表达式都有返回值的,表达式没有设置返回值的话默认返回都是undefined。
在 javascript 里面满足这个条件的就函数声明、变量声明(var a=10是声明和赋值)、for语句、if语句、while语句、switch语句、return、try catch。
但是 javascript 还有一种函数表达式,它的形式跟函数声明一模一样。如果写 function fn() { return 0;} 是函数声明而写var a = function fn(){ return 0;} 等号后面的就是函数表达式。
1.{a:1}
2.{a:1};
3.{a:1}+1我们直接在chrome看看结果:
很奇怪是吧:
再来看看在Firefox下面的情况:
其他IE没测,我Mac没法装IE,大家自行测试。
第二个很好理解,在有;的情况下,chrome和Firefox一致的把{a:1}解析为代码块,那么{a:1}怎么理解这个代码块,为什么不报错,还记得goto语句吗,JavaScript保留了goto的语法,我最先也半天没缓过神来,还好记得c语言里面的这个语法,没白学,其实可以这么理解:
{
a:
1;
};关于第二个{a:1}+1的答案,chrome和Firefox接过也一致,两个浏览器都会把这段代码解析成:
{
a:
1;
};
+1;其中关于{a:1}两个浏览器就达成了不一样的意见,只要{}前面没有任何运算符号,Firefox始终如一的把{}解析成{};也就是我们熟知的代码块,而不是对象字面量。
而chrome就不同了,如果{a:1}后面和前面啥也没有,{a:1}在chrome浏览器会首先检查这个是不是标准对象格式,如果是返回这个对象,如果不是,则当做代码块执行代码。当然这种情况基本可以不考虑,你写代码就写个{a:1}然后就完了?
共同的特点:
如果{}前面什么运算符都没有,{}后面也没有分号(;)结尾,Firefox会始终如一的解析为代码块,而chrome有细微的差别,chrome会解析为对象字面量。
这里也是我通过浏览器输出结果进行的一种归纳,当然可能还有没有总结到位的地方,也可能还有错误,发现ECMAScript规范对于{}何时解析为对象何时解析为代码块也没有找到比较详细的解答,有可能也是我看的不仔细,遗漏了这块,还望大家能解答一下这块。
如果你觉得以上的很繁琐,我是新手,也看不太懂,不要紧,不要慌,循序渐进,以后会懂的,这里我就直接总结出几个结论,总结的不对的地方,还望反馈指出,对照着结论来验证上面的十几个例子:
- 数组下标([])优先级最高, 一元运算符(--,++,+,-)的优先级高于加法或减法运算符(+,-);
- ++前增量运算符,就是数值上加 1;
- 一元运算符(+,-)的后面如果不是数字,会调用 ToNumber 方法按照规则转化成数字类型。
- 对于加号运算符(+)
首先执行代码,调用 ToPrimitive 方法得到原始值
①如果原始值是两个数字,则直接相加得出结果。
②如果两个原始值都是字符串,把第二个字符串连接到第一个上,也就是相当于调用 concat 方法。
③如果只有一个原始值是字符串,调用 ToString 方法把另一个运算数转换成字符串,结果是两个字符串连接成的字符串。- 对于减号运算符(-)
不知道大家有没有看到ECMAScript规范,这里比+少了一步 ToPrimitive ,所以 - 相对容易理解。
①如果是两个数字,则直接相减得出结果。
②如果有一个不是数字,会调用 ToNumber 方法按照规则转化成数字类型,然后进行相减。- 分号的插入
①新行并入当前行将构成非法语句,自动插入分号。
②在continue,return,break,throw后自动插入分号
③++、--后缀表达式作为新行的开始,在行首自动插入分号
④代码块的最后一个语句会自动插入分号
⑤新行以 ( 、[、\、+ 、 - 、,、. % 和 *开始都不会插入分号- {}的两种解读
①当{}的前面有运算符号的时候,+,-,*,/,()等等,{}都会被解析成对象字面量,这无可争议。
②当{}前面没有运算符时候但有;结尾的时候,或者浏览器的自动分号插入机制给{}后面插入分号(;)时候,此时{}都会被解析成代码块。
③如果{}前面什么运算符都没有,{}后面也没有分号(;)结尾,Firefox会始终如一的解析为代码块,而chrome有细微的差别,chrome会解析为对象字面量。
前面关于ECMAScript规范的解读,涉及到几个重要的抽象操作:
首先,让我们快速的复习一下。 在 JavaScript 中,一共有两种类型的值(ES6的 symbol 暂不做讨论):
原始值(primitives)
1. undefined
2. null
3. boolean
4. number
5. string
对象值(objects)。
除了原始值外,其他的所有值都是对象类型的值,包括数组(array)和函数(function)等。
这里的每个操作都有其严格并复杂的定义,可以直接查阅ECMA规范文档对其的详细说明。
附上在线中文文档地址:ECMAScript
我们先看看GetValue(v) : 引用规范类型,下面是ECMAScript规范的解读:
这什么鬼,我也不太懂,反正就是关于引用规范的一些抽象描述,鄙人才疏学浅,也不能化抽象为具体的解释一番,太抽象了,好难啊,功力还不够,不懂但对我们解决上面的问题也没有什么影响,我们只看关键的几个:
这里我们先看下SameValue()和ToPrimitive()两个操作。
我们还是先看看ECMAScript5规范(熟读规范,你会学到很多很多)对 SameValue 方法解读,我们翻到9.12。
这个SameValue操作说的就是,如果x,y两个值类型相同,但又不同时是Number类型时的比较是否相等的操作。
ToPrimitive() 方法
转换成原始类型方法。
还是来看看 ECMAScript 标准怎么定义 ToPrimitice 方法的:
是不是看了这个定义,还是一脸懵逼,ToPrimitive这尼玛什么玩意啊?这不是等于没说吗?
再来看看火狐MDN上面文档的介绍:
JS::ToPrimitive
查了一下资料,上面要说的可以概括成:
ToPrimitive(obj,preferredType)
JS引擎内部转换为原始值ToPrimitive(obj,preferredType)函数接受两个参数,第一个obj为被转换的对象,第二个
preferredType为希望转换成的类型(默认为空,接受的值为Number或String)
在执行ToPrimitive(obj,preferredType)时如果第二个参数为空并且obj为Date的事例时,此时preferredType会
被设置为String,其他情况下preferredType都会被设置为Number如果preferredType为Number,ToPrimitive执
行过程如
下:
1. 如果obj为原始值,直接返回;
2. 否则调用 obj.valueOf(),如果执行结果是原始值,返回之;
3. 否则调用 obj.toString(),如果执行结果是原始值,返回之;
4. 否则抛异常。
如果preferredType为String,将上面的第2步和第3步调换,即:
1. 如果obj为原始值,直接返回;
2. 否则调用 obj.toString(),如果执行结果是原始值,返回之;
3. 否则调用 obj.valueOf(),如果执行结果是原始值,返回之;
4. 否则抛异常。首先我们要明白 obj.valueOf() 和 obj.toString() 还有原始值分别是什么意思,这是弄懂上面描述的前提之一:
toString用来返回对象的字符串表示。
var obj = {};
console.log(obj.toString());//[object Object]
var arr2 = [];
console.log(arr2.toString());//""空字符串
var date = new Date();
console.log(date.toString());//Sun Feb 28 2016 13:40:36 GMT+0800 (**标准时间)valueOf方法返回对象的原始值,可能是字符串、数值或bool值等,看具体的对象。
var obj = {
name: "obj"
};
console.log(obj.valueOf());//Object {name: "obj"}
var arr1 = [1];
console.log(arr1.valueOf());//[1]
var date = new Date();
console.log(date.valueOf());//1456638436303
如代码所示,三个不同的对象实例调用valueOf返回不同的数据原始值指的是['Null','Undefined','String','Boolean','Number']五种基本数据类型之一,一开始就提到过。
弄清楚这些以后,举个简单的例子:
var a={};
ToPrimitive(a)
分析:a是对象类型但不是Date实例对象,所以preferredType默认是Number,先调用a.valueOf()不是原始值,继续来调
用a.toString()得到string字符串,此时为原始值,返回之.所以最后ToPrimitive(a)得到就是"[object Object]".如果觉得描述还不好明白,一大堆描述晦涩又难懂,我们用代码说话:
const toPrimitive = (obj, preferredType='Number') => {
let Utils = {
typeOf: function(obj) {
return Object.prototype.toString.call(obj).slice(8, -1);
},
isPrimitive: function(obj) {
let types = ['Null', 'String', 'Boolean', 'Undefined', 'Number'];
return types.indexOf(this.typeOf(obj)) !== -1;
}
};
if (Utils.isPrimitive(obj)) {
return obj;
}
preferredType = (preferredType === 'String' || Utils.typeOf(obj) === 'Date') ?
'String' : 'Number';
if (preferredType === 'Number') {
if (Utils.isPrimitive(obj.valueOf())) {
return obj.valueOf()
};
if (Utils.isPrimitive(obj.toString())) {
return obj.toString()
};
} else {
if (Utils.isPrimitive(obj.toString())) {
return obj.toString()
};
if (Utils.isPrimitive(obj.valueOf())) {
return obj.valueOf()
};
}
}
var a={};
ToPrimitive(a);//"[object Object]",与上面文字分析的一致
这个就比ToPrimitive() 方法好理解多了,就是把其他类型按照一定的规则转化成数字类型,也就是类似Number()和parseInt()的方法。
还是继续看看ECMAScipt规范中对于Number的转换
是不是又看到 ToPrimitive() 方法了,是不是看了上面的就好理解多了,如果ToNumber(x)这个x是对象就要调用ToPrimitive方法返回x的原始值,是不是一下子就串起来了。
这个理解起来跟 ToNumber 方法大同小异,还是继续看看ECMAScipt规范中对于String的转换.
对数值类型应用 ToString
ToString 运算符将数字 m 转换为字符串格式的给出如下所示:
养兵千日,用兵一时。
了解了这么多深入的基础知识,该发挥用武之地了,我已经用完洪荒之力了,是时候表演真正的技术了。
好像前面忘记讲 == 符号了,不要紧,之前这个我的上一篇博文已经非常详细的分析过了,可以看看我的这篇博文(点击查看)。这里就不花篇幅介绍了,感觉越来越坑,越写越多。
这里就简单说一下,总结一下==转换规则:
==运算规则的图形化表示
1. undefined == null,结果是true。且它俩与所有其他值比较的结果都是false。
2. String == Boolean,需要两个操作数同时转为Number。
3. String/Boolean == Number,需要String/Boolean转为Number。
4. Object == Primitive,需要Object转为Primitive(具体通过valueOf和toString方法)。
瞧见没有,一共只有4条规则!是不是很清晰、很简单。
根据 4.1 ECMAScript 运算符优先级 可以这样拆分:
相当于这样:
(++[[]][+[]])
+
([+[]])①先看里面的+[]
根据 4.2 ECMAScript 一元运算符(+、-) 可以知道,一元运算符会调用 ToNumber 方法把 ToNumber([]) 转化成数字。
根据 5.5 ToNumber(x) 的转换规则,x为[]是数组对象,因此会调用 ToPrimitive 方法。
根据 5.4 ToPrimitive(input [ , PreferredType]) 的转换规则,空数组先调用 valueOf() 方法,得到[]不是原始值,继续调用 toString() 方法,得到 ""空字符串 。
递归的调用之后成了 ToNumber("") ,答案显而易见,根据 5.5 ToNumber(x) 的转换规则对照图片可以看出ToNumber("")===0。 那么[+[]]就变相的成了[0] 。
此时成了(++[[]][+[]])+[0]
+[]上面已经分析出来了,结果为0,那么此时就成了++[[]][0]
根据 4.2 ECMAScript 一元运算符(+、-) 可以知道,数组下标的优先级高于一元运算符++,那么理所当然成了这样 ++([[]][0]) ,而[[]][0]可以看出数组下标为0也就是第一个元素,此时为[],那么最后成了++[].
++[]这是什么鬼👻,根据 4.5 ECMAScript 前自增运算符(++) 没有发现任何有调用 ToNumber 的方法,浏览器试了一下,果然有问题,报错啦,到底哪里出问题了呢,为什么走着走着就走偏了。问题出在哪一步呢?
为什么++([[]][0])在浏览器不报错,而++[]报错,我知道问题就出在这一步,但是一直相不出原因,光瞎想是没用的,没事继续读读ECMAScript规范,然后中文版的并没有看出什么玩意,最后在github英文版找到原因了。
首先我们在浏览器输出一下++[]
无意之中照着错误搜,搜到了这个后缀自增++:
顺便看看大同小异的前缀自增++
Increment Operator_操作的第5步PutValue(expr, newValue)要求expr是引用。这就是问题的关键,为什么之前我没发现,因为之前我一直看的是中文版,来看看中文版的截图对比一下
发现后面的3,4,5都没有,我一度以为自己理解错了,为什么这个规则没有调ToNumber()却也能得到数字,原来是翻译中这块内容遗漏了,我该好好补习英语了,尽量多看英文文档。
看到第五条大大的 Call PutValue(expr, newValue). ,
阅读es5英文文档,可以看到_Prefix Increment Operator_操作的第5步PutValue(expr, newValue)要求expr是引用。
我们还是来看看 PutValue 到底是什么定义,这里我们只需要知道++a,这个a是引用类型才不会报Uncaught ReferenceError: Invalid left-hand side expression in postfix operation这个错误。
而我们知道[[]][0]是对象的属性访问,而我们知道对象的属性访问返回的是引用,所以可以正确执行。
++[[]][0]可以这么拆分,只要保持引用关系就行:
var refence=[[]][0];
++refence;再来进一步拆分
var refence=[];
refence=refence+1;最后就成了
refence=[]+1;根据 4.3 ECMAScript 加法运算符(+) ,[]+1可以看成是ToPrimitive([])+ToPrimitive(1),根据 5.4 ToPrimitive(input [ , PreferredType]) 的转换规则,空数组先调用 valueOf() 方法,得到[]不是原始值,继续调用 toString() 方法,得到 "" 空字符串。
于是就成了 ""+1 ,根据 4.3 ECMAScript 加法运算符(+) ,有一个字符串,另外一个也会变成字符串,所以""+1==="1"。所以 ++[[]][0] === "1" ;
好像分析的是这么回事,其实错了,大家不要跟着我错误的步骤走,我其实忽略了很重要的一点。
看看规范有一点遗漏了,就是 Let oldValue be ToNumber(GetValue(expr)).
就是++时候旧的值要进行 ToNumber() 运算,最后最后一步应该是这样子的:
refence=ToNumber([])+1;ToNumber([])===0,别问我为什么,照着我上面的分析自己分析一遍,不难,我因为分析多了,所以一眼就看出来了,所以最后成了0+1=1的问题,所以 ++[[]][0] === 1 。
左边++[[]][0] === 1;
右边[+[]]的值为[0];
所以最后成了1+[0]的问题了。
根据 5.4 ToPrimitive(input [ , PreferredType]) 的转换规则,[0]数组先调用 valueOf() 方法,得到[0]不是原始值,继续调用 toString() 方法,得到 “0” 的字符串。
所以最后就成了 1+"0"==="10" 。
于是最后就成了 "10" == 10 的问题,根据ECMAScript规范==的对应法则:
对比第5条,可以发现最后成了ToNumber("10")与10的比较,而ToNumber("10") === 10,
左边最后 === 10,
右边最后 === 10。
10 === 10为true.
所以 ++[[]][+[]]+[+[]]==10 为true,大功告成,可喜可贺,实力分析了一波,有错误还望批评指正。
1. {}+{}//chrome:"[object Object][object Object]",Firfox:NaN
2. {}+[]//0
3. []+{}//"[object Object]"通过这个例子,我发现刚才4.7 ECMAScript 对{}的解读还不够彻底,首先我们按照前面常规的思维来解答:
第一例子: {}+{} 首先左边{}和右边{}会调用 ToPrimitive 两边都会得到:"[object Object]",所以最后就是这两个相同的字符串相加,得到: "[object Object][object Object]" ,chrome符合,Firefox不符合。
第二个例子: {}+[] 按照这种思维首先左边{}和右边[]会调用 ToPrimitive ,分别得到"[object Object]"和""空字符串,那么相加结果应该是 "[object Object]" ,为什么结果成了 0 ,而且在 chrome 和 Firfox 都是0?
第三个例子: []+{} 按照这种思维首先左边[]和右边{}会调用 ToPrimitive ,分别得到""空字符串和"[object Object]",最后相加结果 "[object Object]" ,这个没有任何疑惑,chrome和Firefox都符合。
第一例子: {}+{} 浏览器这么解析,把{}不解析为对象字面量而是代码块,也就是let a={}这种块,代码可以看成是这样 {};+{} ,那么{};执行啥也没有,接下来就是 +{} ,+是一元运算符,上面讲到了,这里+{}执行时候首先会调用ToNumber(),参数{}是object会首先调用 ToPrimitive 得到原始值: "[object Object]" ,这时候就可以发现ToNumber("[object Object]")转化的就是 NaN 了,chrome不符合,Firefox符合。
第二个例子: {}+[] 按照这种思维,最后解析成 {};+[] ,+是一元运算符,上面讲到了,这里+[]执行时候首先会调用ToNumber(),参数[]是object会首先调用 ToPrimitive 得到原始值: ""空字符串 ,最后根据规则ToNumber("")得到数字0.这种思维下没有任何疑惑,chrome和Firefox都符合。
第三个例子: []+{} 首先左边[]和右边{}会调用 ToPrimitive ,分别得到""空字符串和"[object Object]",最后相加结果 "[object Object]" ,这个没有任何疑惑,chrome和Firefox都符合。
那么问题来了?问题的矛盾就在于第一条和第二条,chrome和Firefox对于{}+{}解析是不一样的,对于第一个{}chrome解析为对象字面量,而Firefox解析为代码块,这无可厚非, 关键是第二个例子{}+[] ,既然第一个例子 {}+{} 的第一个{}chrome解析为对象字面量而第二个例子 {}+[] 中,chrome却解析为代码块,匪夷所思,有谁能扒一扒源码分析一下,chrome对{}的详细解析,到底什么时候解析为代码块,什么时候解析为对象字面量?有点想不明白为什么这么不一致,而 Firefox始终如一,第一个{}一直解析为代码块,运算符号后面{}解析为对象字面量。
Firefox的我能理解,开头{}一律解析为代码块(block),而chrome却让人捉摸不透。。。
前面的十几个例子,大家有兴趣对照着规则自己一个一个做做,看看自己是否真的理解了,理解了也再熟悉一遍,学习本来就是一个重复的过程。
突然灵机一动:
var obj = {
valueOf: function() {
return 18;
}
};
console.log(
1 <= "2",
"1" <= "a",
obj >= "17"
);这个答案又是多少呢?
var obj = {
valueOf: function() {
return {a:1};
},
toString:function(){
return 0;
}
};
console.log(obj==[]);最后这个呢?
var obj = {
valueOf: function() {
return {a:1};
},
toString:function(){
return "0";
}
};
console.log(obj==[]);
从 []==![] 为 true 来剖析 JavaScript 各种蛋疼的类型转换(厚颜无耻的也参考一下自己文章)
ECMAScript5.1中文版
Annotated ECMAScript 5.1
JavaScript 秘密花园
w3school中文文档
JS魔法堂:ASI(自动分号插入机制)和前置分号
JavaScript中,{}+{}等于多少?
前端可以看看这篇文章:前端基础进阶(十二):深入核心,详解事件循环机制
下面这篇文章基本和前端知识没多大关系,不过了解下没有坏处
从输入 URL 到页面加载完成的过程中都发生了什么事情?
下面这篇文章结合一个实例来分析地址栏输入URL之后到底发生了哪些事情
地址栏输入URL之后到底发生了哪些事情?
这个从面试的角度分析就蛮好,太底层了毕竟太晦涩,这个就刚刚好
前端经典面试题: 从输入URL到页面加载发生了什么?
发现每一篇的侧重点都不同,这个也记录一下吧,学习之路,任重而道远
从一道百度面试题到分析输入url到页面返回的过程(或者查询返回过程)
还有一篇文章其实也不错,从前后端分离的切入点分析CSRF的防范之道。前后端分离架构下CSRF防御机制
这篇也不错:浅谈CSRF攻击方式
「每日一题」MVC 是什么?
「每日一题」MVC 是什么?(续1)
「每日一题」什么是 API?
「每日一题」什么是异步?
「每日一题」Callback(回调)是什么?
「每日一题」CSRF 是什么?
「每日一题」XSS 是什么?
「每日一题」什么是响应式页面?
谷歌出品的这篇好像也不错:HTTP 缓存
good
最近做的一个项目涉及到评分和展示分数的模块,UI设计师也给了几个切好的图片,实现五角星评分方式很多,本质爱折腾的精神和对性能追求以及便于维护的考虑,搜集和尝试了很多方式,最终采用了纯css驱动的实现方式完成评分和展示分数的功能,没有js,也就意味着没判断逻辑,代码出错的几率更少,也更便于维护,在此,把这个功能的实现的过程记录和分享一下,一起学习交流。
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步。
不极致追求性能的话,直接利用设计师给的png或者jpg啥的,或者直接转成base64.
HTML:
<div class="icon"></div>CSS:
@import url(http://netdna.bootstrapcdn.com/font-awesome/3.2.1/css/font-awesome.css);
.icon:before {
content: '\f005';
font-family: FontAwesome;
}基本原理:利用transparent的透明不可见和transform转换拼接一个正五角星。
HTML:
<div class="star-five"></div>CSS:
.star-five{
width: 0;
height: 0;
color: red;
margin: 50px 0;
position: relative;
display: block;
border-left: 100px solid transparent;
border-right: 100px solid transparent;
border-bottom: 70px solid red;
transform:rotate(35deg);
}
.star-five:before{
width: 0;
height: 0;
border-left: 30px solid transparent;
border-right: 30px solid transparent;
border-bottom: 80px solid red;
position: absolute;
top: -45px;
left: -65px;
color: white;
display: block;
content: "";
transform:rotate(-35deg);
}
.star-five:after{
width: 0;
height: 0;
display: block;
position: absolute;
color: red;
top: 3px;
left: -105px;
border-left: 100px solid transparent;
border-right: 100px solid transparent;
border-bottom: 70px solid red;
content: "";
transform:rotate(-70deg);
}不建议使用这种,因为选择之后改变颜色状态比较麻烦,改起来很不方便,不如前面几种方便好维护。
★😄
简单粗暴,容易控制,品相协调,下面实现方式以★为准。
不用js来控制评分,当然不能错过强大的css选择器,这里就先介绍一下关于实现这个功能要用到的一些css选择器。
在介绍css强大的选择器之前,先普及一下“CSS radio/checkbox单复选框元素显隐技术”,又称“checkbox hack技术”。
我们使用CSS一些特殊的选择器,然后配合单选框以及复选框自带的一些特性,可以实现元素的显示隐藏效果。然后通过一
些简单的扩展,我们可以不使用任何JavaScript代码实现类似:自定义的单复选框,“更多”展开与收起效果,选项卡切换
效果,或是多级下拉列表效果等等。
相信很多前端开发人员都会遇到boss让修改checkbox和radio样式,毕竟自带的样式太丑了。后来我们发现修改自带样式
并不是那么容易,最后直接使出杀手锏——点击之后替换图片。
今天教大家一种方法,不用替换图片,随意修改样式。还是先看效果图:
先讲一下原理:两个关键东东,一是伪类选择器:checked,表示对应控件元素(单选框或是复选框)选中时的样式;二就是加号+ 相邻兄弟选择器,这个符号表示选择后面的兄弟节点。于是,两者配合,就可以轻松自如控制后面元素的显示或者隐藏,或是其他样式了。 而如何让单复选框选中和不选中了,那就是label标签了哈,for属性锚定对应的单选框或是复选框,然后点击这里的label标签元素的时候,对应的单复选框就会选中或是取消选中。然后,就有上面的效果啦!
这里只给一个radio单选框的代码,仅供参考:
HTML:
<div class="radio-beauty-container">
<label>
<span class="radio-name">前端工程师</span>
<input type="radio" name="radioName" id="radioName1" hidden/>
<label for="radioName1" class="radio-beauty"></label>
</label>
<label>
<span class="radio-name">后端工程师</span>
<input type="radio" name="radioName" id="radioName2" hidden/>
<label for="radioName2" class="radio-beauty"></label>
</label>
<label>
<span class="radio-name">全栈工程师</span>
<input type="radio" name="radioName" id="radioName3" hidden/>
<label for="radioName3" class="radio-beauty"></label>
</label>
</div>SCSS:
.radio-beauty-container {
font-size: 0;
$bgc: green;
%common {
padding: 2px;
background-color: $bgc;
background-clip: content-box;
}
.radio-name {
vertical-align: middle;
font-size: 16px;
}
.radio-beauty {
width: 18px;
height: 18px;
box-sizing: border-box;
display: inline-block;
border: 1px solid $bgc;
vertical-align: middle;
margin: 0 15px 0 3px;
border-radius: 50%;
&:hover {
box-shadow: 0 0 7px $bgc;
@extend %common;
}
}
input[type="radio"]:checked+.radio-beauty {
@extend %common;
}
}美化radio单选框在线预览地址:点击我呀
美化checkbox复选框在线预览地址:点击我呀
更多关于这方面的介绍和例子可以参看张鑫旭大神的这篇文章:CSS radio/checkbox单复选框元素显隐技术
HTML:
<div class="wrapper">
<p class="test1">1</p>
<p class="test2">2</p>
<p class="test3">3</p>
<p class="test4">4</p>
<p class="test5">5</p>
</div>CSS:
p{
width:20px;
line-height:20px;
border:1px solid gray;
text-align:center;
font-weight: 700;
}.test1+p{
background-color:green;
}.wrapper>p{
background-color:green;
}.test2~p{
background-color:green;
}.test2::before{
background-color:green;
content:"前"
}
.test2::after{
background-color:green;
content:"后"
}.wrapper>:not(.test2){
background-color:green;
}HTML:
<input type="radio" name="" id="" />
<span>3333</span>
CSS:
input:checked+span{
border:10px solid red;
}
这里只提一下本文要用到的CSS选择器,更多关于CSS3强大的选择器请移步这里:全面整理 CSS3 选择器的用法
HTML:
<div class="rating">
<input type="radio" id="star5" name="rating" value="5" hidden/>
<label for="star5"></label>
<input type="radio" id="star4" name="rating" value="4" hidden/>
<label for="star4"></label>
<input type="radio" id="star3" name="rating" value="3" hidden/>
<label for="star3"></label>
<input type="radio" id="star2" name="rating" value="2" hidden/>
<label for="star2"></label>
<input type="radio" id="star1" name="rating" value="1" hidden/>
<label for="star1"></label>
</div>关于input标签的隐藏,我这里只要用hidden属性实现隐藏,当然还有很多实现方式,只要input不占据文档的位置但是看不见就OK,我们需要隐藏单选框,且为可用性隐藏。这里还有几种方式仅供大家参考:
.rating >input {
display: none;
} .rating >input {
position: absolute;
clip: rect(0 0 0 0);
}.rating >input {
position: absolute;
opacity: 0;
}CSS:
.rating {
font-size: 0;
display: table;
}
.rating > label {
color: #ddd;
float: right;
}
.rating > label:before {
padding: 5px;
font-size: 24px;
line-height: 1em;
display: inline-block;
content: "★";
}
.rating > input:checked ~ label,
.rating:not(:checked) > label:hover,
.rating:not(:checked) > label:hover ~ label {
color: #FFD700;
}
.rating > input:checked ~ label:hover,
.rating > label:hover ~ input:checked ~ label,
.rating > input:checked ~ label:hover ~ label {
opacity: 0.5;
}用户评完分之后,会看到展示的分数,假设五个星星,满分10分。
展示评分就比较简单,放两个一模一样的html,五角星颜色不同,灰色的放在下面,评分的亮色放在上面,然后按照百分比显示分数。
HTML:
<div class="star-rating">
<div class="star-rating-top" style="width:50%">
<span></span>
<span></span>
<span></span>
<span></span>
<span></span>
</div>
<div class="star-rating-bottom">
<span></span>
<span></span>
<span></span>
<span></span>
<span></span>
</div>
</div>CSS:
.star-rating {
unicode-bidi: bidi-override;
color: #ddd;
font-size: 0;
height: 25px;
margin: 0 auto;
position: relative;
display: table;
padding: 0;
text-shadow: 0px 1px 0 #a2a2a2;
}
.star-rating span {
padding: 5px;
font-size: 20px;
}
.star-rating span:after {
content: "★";
}
.star-rating-top {
color: #FFD700;
padding: 0;
position: absolute;
z-index: 1;
display: block;
top: 0;
left: 0;
overflow: hidden;
white-space: nowrap;
}
.star-rating-bottom {
padding: 0;
display: block;
z-index: 0;
}当接口返回的分数是5分的时候,刚好占据一半的星星,2星半,只要计算出百分比就行,只用管数据,用上vue.js数据驱动的特点来动态展示样式这个简直不要太容易。
本文方法好处在于,纯CSS驱动,各种切换根本不需要JS,省了不少JS,对于类似这种需求大家也可以举一反三,这里只提供一些思路,没有细说;同时图片背景比较小或者可以直接不使用图片,比起使用图片节省不少资源,和提高些许性能。但是,学习以及理解成本稍高,可能并不适用于所有同行,因此,此文适合喜欢“折腾”的童鞋。
Is there a way for an English explaining what's going on?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.